集成模型#
集成模型表示一个或多个模型的管道,以及这些模型之间输入和输出张量的连接。集成模型旨在用于封装涉及多个模型的过程,例如“数据预处理 -> 推理 -> 数据后处理”。为此目的使用集成模型可以避免传输中间张量的开销,并最大限度地减少必须发送到 Triton 的请求数量。
集成调度器必须用于集成模型,无论集成内部的模型使用哪个调度器。对于集成调度器,集成模型不是实际的模型。相反,它在模型配置中将集成内模型之间的数据流指定为 ModelEnsembling::Step 条目。调度器收集每个步骤中的输出张量,并根据规范将它们作为输入张量提供给其他步骤。尽管如此,从外部视图来看,集成模型仍然被视为单个模型。
请注意,集成模型将继承所涉及模型的特性,因此请求标头中的元数据必须符合集成内部的模型。例如,如果其中一个模型是有状态模型,则集成模型的推理请求应包含 有状态模型 中提到的信息,这些信息将由调度器提供给有状态模型。
例如,考虑一个用于图像分类和分割的集成模型,它具有以下模型配置
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [
{
name: "IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ 1000 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
ensemble_scheduling {
step [
{
model_name: "image_preprocess_model"
model_version: -1
input_map {
key: "RAW_IMAGE"
value: "IMAGE"
}
output_map {
key: "PREPROCESSED_OUTPUT"
value: "preprocessed_image"
}
},
{
model_name: "classification_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "segmentation_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
ensemble_scheduling 部分指示将使用集成调度器,并且集成模型由三个不同的模型组成。step 部分中的每个元素指定要使用的模型,以及模型的输入和输出如何映射到调度器识别的张量名称。例如,step 中的第一个元素指定应使用最新版本的 image_preprocess_model,其输入“RAW_IMAGE”的内容由“IMAGE”张量提供,其输出“PREPROCESSED_OUTPUT”的内容将映射到“preprocessed_image”张量以供以后使用。调度器识别的张量名称是集成输入、集成输出以及 input_map 和 output_map 中的所有值。
组成集成的模型也可能启用动态批处理。由于集成模型只是在组成模型之间路由数据,因此 Triton 可以将请求放入集成模型中,而无需修改集成的配置以利用组成模型的动态批处理。
假设仅服务于集成模型、预处理模型、分类模型和分割模型,客户端应用程序将把它们视为四个不同的模型,可以独立处理请求。但是,集成调度器会将集成模型视为如下所示。
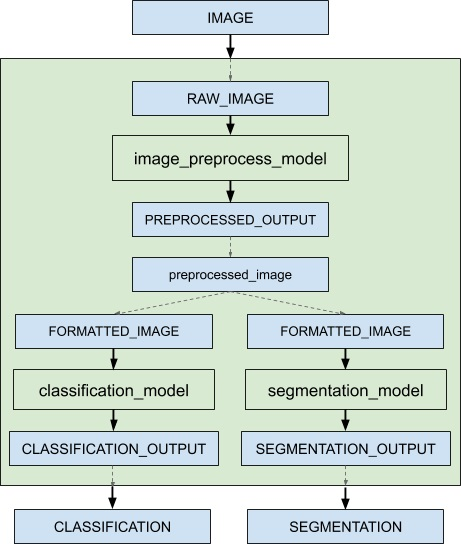
当收到集成模型的推理请求时,集成调度器将
识别请求中的“IMAGE”张量映射到预处理模型中的输入“RAW_IMAGE”。
检查集成内的模型,并向预处理模型发送内部请求,因为所需的所有输入张量都已准备就绪。
识别内部请求的完成,收集输出张量并将内容映射到“preprocessed_image”,这是集成内已知的唯一名称。
将新收集的张量映射到集成内模型的输入。在本例中,“classification_model”和“segmentation_model”的输入将被映射并标记为就绪。
检查需要新收集张量的模型,并向输入就绪的模型发送内部请求,在本例中为分类模型和分割模型。请注意,响应将以任意顺序排列,具体取决于各个模型的负载和计算时间。
重复步骤 3-5,直到不再应发送内部请求,然后使用映射到集成输出名称的张量响应推理请求。
与其他模型不同,集成模型不支持模型配置中的“instance_group”字段。原因是集成调度器本身主要是事件驱动的调度器,开销非常小,因此几乎永远不会成为管道的瓶颈。集成内部的组成模型可以使用各自的 instance_group 设置单独向上或向下扩展。为了优化您的模型管道性能,您可以使用 模型分析器 来查找最佳模型配置。
其他资源#
您可以在以下链接中找到其他端到端集成示例