并发模型执行#
Triton 架构允许在同一系统上并行执行多个模型和/或同一模型的多个实例。系统可以有零个、一个或多个 GPU。下图显示了两个模型的示例:model0 和 model1。假设 Triton 当前未处理任何请求,当针对每个模型的两个请求同时到达时,Triton 会立即将它们都调度到 GPU 上,并且 GPU 的硬件调度器开始并行处理这两个计算。在系统 CPU 上执行的模型由 Triton 以类似方式处理,只是每个模型 CPU 线程执行的调度由系统的操作系统处理。

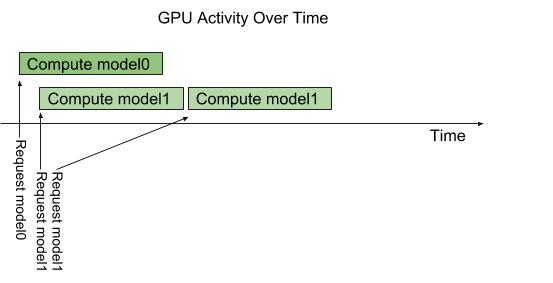
默认情况下,如果同一模型的多个请求同时到达,Triton 将通过在 GPU 上一次只调度一个请求来序列化它们的执行,如下图所示。
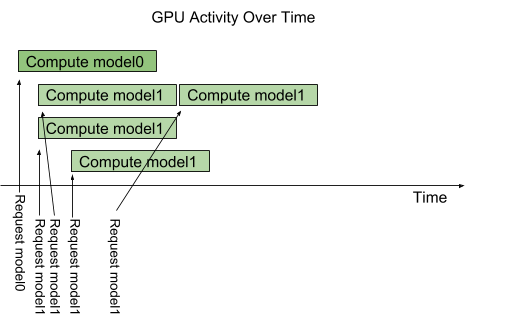
Triton 提供了一个 模型配置选项,称为 instance-group,允许每个模型指定应允许该模型的多少个并行执行。每个此类启用的并行执行都称为一个实例。默认情况下,Triton 为系统中每个可用的 GPU 为每个模型提供一个实例。通过使用模型配置中的 instance_group 字段,可以更改模型的执行实例数。下图显示了模型 1 配置为允许三个实例时的模型执行情况。如图所示,前三个模型 1 推理请求立即并行执行。第四个模型 1 推理请求必须等到前三个执行之一完成后才能开始。
模型和调度器#
Triton 支持多种调度和批处理算法,可以为每个模型独立选择。本节介绍无状态和有状态模型,以及 Triton 如何提供调度器来支持这些模型类型。对于给定的模型,调度器的选择和配置是通过 模型的配置文件 完成的。
无状态模型#
关于 Triton 的调度器,无状态模型在推理请求之间不维护状态。对无状态模型执行的每个推理都独立于使用该模型的所有其他推理。
无状态模型的示例是 CNN,例如图像分类和对象检测。默认调度器 或 动态批处理器 可用作这些无状态模型的调度器。
RNN 和类似的具有内部存储器的模型可以是无状态的,只要它们维护的状态不跨越推理请求。例如,如果内部状态不在推理请求批次之间传递,则迭代批次中所有元素的 RNN 被 Triton 视为无状态。默认调度器 可用于这些无状态模型。动态批处理器 不能使用,因为模型通常不期望批次代表多个推理请求。
有状态模型#
关于 Triton 的调度器,有状态模型在推理请求之间维护状态。该模型期望多个推理请求共同形成一个推理序列,这些请求必须路由到同一个模型实例,以便正确更新模型正在维护的状态。此外,模型可能需要 Triton 提供控制信号,例如,指示序列的开始和结束。
序列批处理器必须用于这些有状态模型。如下所述,序列批处理器确保序列中的所有推理请求都路由到同一个模型实例,以便模型可以正确地维护状态。序列批处理器还与模型通信,以指示序列何时开始、序列何时结束、序列何时有推理请求准备好执行,以及序列的关联 ID。
当为有状态模型发出推理请求时,客户端应用程序必须为序列中的所有请求提供相同的关联 ID,并且还必须标记序列的开始和结束。关联 ID 允许 Triton 识别请求属于同一序列。
控制输入#
为了使有状态模型能够与序列批处理器正确运行,模型通常必须接受一个或多个控制输入张量,Triton 使用这些张量与模型通信。模型配置 的 ModelSequenceBatching::Control 部分指示模型如何公开序列批处理器应用于这些控件的张量。所有控件都是可选的。以下是模型配置的一部分,显示了所有可用控制信号的示例配置。
sequence_batching {
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "END"
control [
{
kind: CONTROL_SEQUENCE_END
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "READY"
control [
{
kind: CONTROL_SEQUENCE_READY
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "CORRID"
control [
{
kind: CONTROL_SEQUENCE_CORRID
data_type: TYPE_UINT64
}
]
}
]
}
开始:开始输入张量使用配置中的 CONTROL_SEQUENCE_START 指定。示例配置表明模型有一个名为 START 的输入张量,其数据类型为 32 位浮点型。序列批处理器将在模型上执行推理时定义此张量。START 张量必须是一维的,大小等于批次大小。张量中的每个元素指示相应批次槽中的序列是否正在开始。在示例配置中,fp32_false_true 指示序列开始由等于 1 的张量元素指示,非开始由等于 0 的张量元素指示。
结束:结束输入张量使用配置中的 CONTROL_SEQUENCE_END 指定。示例配置表明模型有一个名为 END 的输入张量,其数据类型为 32 位浮点型。序列批处理器将在模型上执行推理时定义此张量。END 张量必须是一维的,大小等于批次大小。张量中的每个元素指示相应批次槽中的序列是否正在结束。在示例配置中,fp32_false_true 指示序列结束由等于 1 的张量元素指示,非结束由等于 0 的张量元素指示。
就绪:就绪输入张量使用配置中的 CONTROL_SEQUENCE_READY 指定。示例配置表明模型有一个名为 READY 的输入张量,其数据类型为 32 位浮点型。序列批处理器将在模型上执行推理时定义此张量。READY 张量必须是一维的,大小等于批次大小。张量中的每个元素指示相应批次槽中的序列是否具有准备好进行推理的推理请求。在示例配置中,fp32_false_true 指示序列就绪由等于 1 的张量元素指示,非就绪由等于 0 的张量元素指示。
关联 ID:关联 ID 输入张量使用配置中的 CONTROL_SEQUENCE_CORRID 指定。示例配置表明模型有一个名为 CORRID 的输入张量,其数据类型为无符号 64 位整数型。序列批处理器将在模型上执行推理时定义此张量。CORRID 张量必须是一维的,大小等于批次大小。张量中的每个元素指示相应批次槽中序列的关联 ID。