TensorRT-LLM 后端#
用于 TensorRT-LLM 的 Triton 后端。您可以在 后端仓库 中了解有关 Triton 后端的更多信息。TensorRT-LLM 后端的目的是让您使用 Triton 推理服务器来服务 TensorRT-LLM 模型。inflight_batcher_llm 目录包含支持飞行中批处理、分页注意力等功能的后端的 C++ 实现。
在哪里可以询问有关 Triton 和 Triton 后端的一般问题?请务必阅读以下所有信息以及主 server 仓库中提供的 通用 Triton 文档。如果您在那里找不到答案,可以在 问题页面 上提问。
目录#
入门指南#
快速开始#
以下是如何在 4-GPU 环境中使用 Triton TensorRT-LLM 后端服务 TensorRT-LLM 模型的示例。该示例使用了来自 TensorRT-LLM 仓库 的 GPT 模型,以及 NGC Triton TensorRT-LLM 容器。请确保您克隆的 TensorRT-LLM 后端版本与容器中 TensorRT-LLM 的版本相同。请参阅支持矩阵以查看对齐的版本。
在本示例中,我们将使用 Triton 24.07 和 TensorRT-LLM v0.11.0。
启动 Triton TensorRT-LLM 容器#
启动带有 TensorRT-LLM 后端的 Triton Docker 容器 nvcr.io/nvidia/tritonserver:<xx.yy>-trtllm-python-py3。
在 Docker 外部创建一个 engines 文件夹,以便在以后的运行中重复使用引擎。请确保将 <xx.yy> 替换为您要使用的 Triton 版本。
docker run --rm -it --net host --shm-size=2g \
--ulimit memlock=-1 --ulimit stack=67108864 --gpus all \
-v </path/to/engines>:/engines \
nvcr.io/nvidia/tritonserver:24.07-trtllm-python-py3
准备 TensorRT-LLM 引擎#
如果您已经准备好引擎,则可以跳过此步骤。请按照 TensorRT-LLM 仓库中的 指南 了解有关如何为所有受支持模型准备引擎的更多详细信息。您还可以查看 教程,以查看更多使用 TensorRT-LLM 模型进行服务的示例。
cd /app/examples/gpt
# Download weights from HuggingFace Transformers
rm -rf gpt2 && git clone https://hugging-face.cn/gpt2-medium gpt2
pushd gpt2 && rm pytorch_model.bin model.safetensors && wget -q https://hugging-face.cn/gpt2-medium/resolve/main/pytorch_model.bin && popd
# Convert weights from HF Tranformers to TensorRT-LLM checkpoint
python3 convert_checkpoint.py --model_dir gpt2 \
--dtype float16 \
--tp_size 4 \
--output_dir ./c-model/gpt2/fp16/4-gpu
# Build TensorRT engines
trtllm-build --checkpoint_dir ./c-model/gpt2/fp16/4-gpu \
--gpt_attention_plugin float16 \
--remove_input_padding enable \
--kv_cache_type paged \
--gemm_plugin float16 \
--output_dir /engines/gpt/fp16/4-gpu
有关参数的更多详细信息,请参阅此处。
准备模型仓库#
接下来,创建 Triton 服务器将使用的模型仓库。可以在 all_models 文件夹中找到模型。该文件夹包含两组模型
gpt:使用 TensorRT-LLM 纯 Python 运行时。inflight_batcher_llm`:使用带有执行器 API 的 C++ TensorRT-LLM 后端,其中包括最新的功能,包括飞行中批处理。
all_models/inflight_batcher_llm 中有五个模型将在本示例中使用
模型 |
描述 |
|---|---|
|
此模型用于将预处理、tensorrt_llm 和后处理模型链接在一起。 |
|
此模型用于标记化,即将提示(字符串)转换为 input_ids(整数列表)。 |
|
此模型是您的 TensorRT-LLM 模型的包装器,用于推理。输入规范可以在此处找到 |
|
此模型用于反标记化,即将 output_ids(整数列表)转换为 outputs(字符串)。 |
|
此模型也可以用于将预处理、tensorrt_llm 和后处理模型链接在一起。 |
要了解有关集成和 BLS 模型的更多信息,请参阅集成模型和业务逻辑脚本文档。
要了解有关使用 BLS 模型的优势和局限性的更多信息,请参阅模型配置部分。
mkdir /triton_model_repo
cp -r /app/all_models/inflight_batcher_llm/* /triton_model_repo/
修改模型配置#
使用脚本填写模型配置文件中的参数。为了获得最佳性能或自定义参数,请参阅 perf_best_practices。有关模型配置和可以修改的参数的更多详细信息,请参阅模型配置部分。
ENGINE_DIR=/engines/gpt/fp16/4-gpu
TOKENIZER_DIR=/app/examples/gpt/gpt2
MODEL_FOLDER=/triton_model_repo
TRITON_MAX_BATCH_SIZE=4
INSTANCE_COUNT=1
MAX_QUEUE_DELAY_MS=0
MAX_QUEUE_SIZE=0
FILL_TEMPLATE_SCRIPT=/app/tools/fill_template.py
DECOUPLED_MODE=false
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/ensemble/config.pbtxt triton_max_batch_size:${TRITON_MAX_BATCH_SIZE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/preprocessing/config.pbtxt tokenizer_dir:${TOKENIZER_DIR},triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},preprocessing_instance_count:${INSTANCE_COUNT}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/tensorrt_llm/config.pbtxt triton_backend:tensorrtllm,triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},decoupled_mode:${DECOUPLED_MODE},engine_dir:${ENGINE_DIR},max_queue_delay_microseconds:${MAX_QUEUE_DELAY_MS},batching_strategy:inflight_fused_batching,max_queue_size:${MAX_QUEUE_SIZE},encoder_input_features_data_type:TYPE_FP16
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/postprocessing/config.pbtxt tokenizer_dir:${TOKENIZER_DIR},triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},postprocessing_instance_count:${INSTANCE_COUNT},max_queue_size:${MAX_QUEUE_SIZE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/tensorrt_llm_bls/config.pbtxt triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},decoupled_mode:${DECOUPLED_MODE},bls_instance_count:${INSTANCE_COUNT}
注意:建议将 pre/post_instance_counts 的数量与 triton_max_batch_size 匹配,以获得更好的性能。
使用 Triton 服务#
现在,您已准备好使用 TensorRT-LLM 模型启动 Triton 服务器。
使用 launch_triton_server.py 脚本。这将使用 MPI 启动多个 tritonserver 实例。
# 'world_size' is the number of GPUs you want to use for serving. This should
# be aligned with the number of GPUs used to build the TensorRT-LLM engine.
python3 /app/scripts/launch_triton_server.py --world_size=4 --model_repo=${MODEL_FOLDER}
当服务器成功部署时,您应该会看到以下日志。
...
I0503 22:01:25.210518 1175 grpc_server.cc:2463] Started GRPCInferenceService at 0.0.0.0:8001
I0503 22:01:25.211612 1175 http_server.cc:4692] Started HTTPService at 0.0.0.0:8000
I0503 22:01:25.254914 1175 http_server.cc:362] Started Metrics Service at 0.0.0.0:8002
要停止容器内的 Triton 服务器,请运行
pkill tritonserver
发送推理请求#
使用generate 端点#
generate 端点的一般格式
curl -X POST localhost:8000/v2/models/${MODEL_NAME}/generate -d '{"{PARAM1_KEY}": "{PARAM1_VALUE}", ... }'
在本示例中使用的模型的情况下,您可以将 MODEL_NAME 替换为 ensemble 或 tensorrt_llm_bls。检查集成模型和 tensorrt_llm_bls 模型的 config.pbtxt 文件,您可以看到生成此模型的响应需要 4 个参数
text_input:用于生成响应的输入文本
max_tokens:请求的输出令牌数
bad_words:(可以为空的)不良词语列表
stop_words:(可以为空的)停止词语列表
因此,我们可以通过以下方式查询服务器
如果使用集成模型
curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": "What is machine learning?", "max_tokens": 20, "bad_words": "", "stop_words": ""}'
如果使用 tensorrt_llm_bls 模型
curl -X POST localhost:8000/v2/models/tensorrt_llm_bls/generate -d '{"text_input": "What is machine learning?", "max_tokens": 20, "bad_words": "", "stop_words": ""}'
应该返回类似于以下内容的结果(为提高可读性而格式化)
{
"model_name": "ensemble",
"model_version": "1",
"sequence_end": false,
"sequence_id": 0,
"sequence_start": false,
"text_output": "What is machine learning?\n\nMachine learning is a method of learning by using machine learning algorithms to solve problems.\n\n"
}
使用客户端脚本#
您可以参考 inflight_batcher_llm/client 中的客户端脚本,了解如何通过 Python 脚本发送请求。
以下是使用 inflight_batcher_llm_client 向 tensorrt_llm 模型发送请求的示例。
pip3 install tritonclient[all]
INFLIGHT_BATCHER_LLM_CLIENT=/app/client/inflight_batcher_llm_client.py
python3 ${INFLIGHT_BATCHER_LLM_CLIENT} --request-output-len 200 --tokenizer-dir ${TOKENIZER_DIR}
结果应类似于以下内容
Using pad_id: 50256
Using end_id: 50256
Input sequence: [28524, 287, 5093, 12, 23316, 4881, 11, 30022, 263, 8776, 355, 257]
Got completed request
Input: Born in north-east France, Soyer trained as a
Output beam 0: chef before moving to London in the early 1990s. He has since worked in restaurants in London, Paris, Milan and New York.
He is married to the former model and actress, Anna-Marie, and has two children, a daughter, Emma, and a son, Daniel.
Soyer's wife, Anna-Marie, is a former model and actress.
He is survived by his wife, Anna-Marie, and their two children, Daniel and Emma.
Soyer was born in the north-east of France, and moved to London in the early 1990s.
He was a chef at the London restaurant, The Bistro, before moving to New York in the early 2000s.
He was a regular at the restaurant, and was also a regular at the restaurant, The Bistro, before moving to London in the early 2000s.
Soyer was a regular at the restaurant, and was
Output sequence: [28524, 287, 5093, 12, 23316, 4881, 11, 30022, 263, 8776, 355, 257, 21221, 878, 3867, 284, 3576, 287, 262, 1903, 6303, 82, 13, 679, 468, 1201, 3111, 287, 10808, 287, 3576, 11, 6342, 11, 21574, 290, 968, 1971, 13, 198, 198, 1544, 318, 6405, 284, 262, 1966, 2746, 290, 14549, 11, 11735, 12, 44507, 11, 290, 468, 734, 1751, 11, 257, 4957, 11, 18966, 11, 290, 257, 3367, 11, 7806, 13, 198, 198, 50, 726, 263, 338, 3656, 11, 11735, 12, 44507, 11, 318, 257, 1966, 2746, 290, 14549, 13, 198, 198, 1544, 318, 11803, 416, 465, 3656, 11, 11735, 12, 44507, 11, 290, 511, 734, 1751, 11, 7806, 290, 18966, 13, 198, 198, 50, 726, 263, 373, 4642, 287, 262, 5093, 12, 23316, 286, 4881, 11, 290, 3888, 284, 3576, 287, 262, 1903, 6303, 82, 13, 198, 198, 1544, 373, 257, 21221, 379, 262, 3576, 7072, 11, 383, 347, 396, 305, 11, 878, 3867, 284, 968, 1971, 287, 262, 1903, 4751, 82, 13, 198, 198, 1544, 373, 257, 3218, 379, 262, 7072, 11, 290, 373, 635, 257, 3218, 379, 262, 7072, 11, 383, 347, 396, 305, 11, 878, 3867, 284, 3576, 287, 262, 1903, 4751, 82, 13, 198, 198, 50, 726, 263, 373, 257, 3218, 379, 262, 7072, 11, 290, 373]
提前停止#
您还可以通过使用 --stop-after-ms 选项在几毫秒后发送停止请求来提前停止生成过程
python3 ${INFLIGHT_BATCHER_LLM_CLIENT} --stop-after-ms 200 --request-output-len 200 --request-id 1 --tokenizer-dir ${TOKENIZER_DIR}
您会发现生成过程提前停止,因此生成的令牌数少于 200。您可以查看客户端代码,了解如何实现提前停止。
返回上下文 logits 和/或生成 logits#
如果您想获取上下文 logits 和/或生成 logits,则需要在构建引擎时启用 --gather_context_logits 和/或 --gather_generation_logits (或 --gather_all_token_logits 以同时启用两者)。有关这两个标志的更多设置详细信息,请参阅 build.py 或 gpt_runtime。
启动服务器后,您可以通过在客户端脚本中传递相应的参数 --return-context-logits 和/或 --return-generation-logits 来获取 logits 的输出(end_to_end_grpc_client.py 和 inflight_batcher_llm_client.py)。
例如
python3 ${INFLIGHT_BATCHER_LLM_CLIENT} --request-output-len 20 --tokenizer-dir ${TOKENIZER_DIR} --return-context-logits --return-generation-logits
结果应类似于以下内容
Input sequence: [28524, 287, 5093, 12, 23316, 4881, 11, 30022, 263, 8776, 355, 257]
Got completed request
Input: Born in north-east France, Soyer trained as a
Output beam 0: has since worked in restaurants in London,
Output sequence: [21221, 878, 3867, 284, 3576, 287, 262, 1903, 6303, 82, 13, 679, 468, 1201, 3111, 287, 10808, 287, 3576, 11]
context_logits.shape: (1, 12, 50257)
context_logits: [[[ -65.9822 -62.267445 -70.08991 ... -76.16964 -78.8893
-65.90678 ]
[-103.40278 -102.55243 -106.119026 ... -108.925415 -109.408585
-101.37687 ]
[ -63.971176 -64.03466 -67.58809 ... -72.141235 -71.16892
-64.23846 ]
...
[ -80.776375 -79.1815 -85.50916 ... -87.07368 -88.02817
-79.28435 ]
[ -10.551408 -7.786484 -14.524468 ... -13.805856 -15.767286
-7.9322424]
[-106.33096 -105.58956 -111.44852 ... -111.04858 -111.994194
-105.40376 ]]]
generation_logits.shape: (1, 1, 20, 50257)
generation_logits: [[[[-106.33096 -105.58956 -111.44852 ... -111.04858 -111.994194
-105.40376 ]
[ -77.867424 -76.96638 -83.119095 ... -87.82542 -88.53957
-75.64877 ]
[-136.92282 -135.02484 -140.96051 ... -141.78284 -141.55045
-136.01668 ]
...
[-100.03721 -98.98237 -105.25507 ... -108.49254 -109.45882
-98.95136 ]
[-136.78777 -136.16165 -139.13437 ... -142.21495 -143.57468
-134.94667 ]
[ 19.222942 19.127287 14.804495 ... 10.556551 9.685863
19.625107]]]]
批大小 > 1 的请求#
TRT-LLM 后端支持批大小大于 1 的请求。当发送批大小大于 1 的请求时,TRT-LLM 后端将返回多个批大小为 1 的响应,其中每个响应都将与给定的批索引关联。名为 batch_index 的输出张量与每个响应关联,以指示此响应对应的批索引。
客户端脚本 end_to_end_grpc_client.py 演示了客户端如何发送批大小 > 1 的请求并使用 Triton 返回的响应。当将 --batch-inputs 传递给客户端脚本时,客户端将创建一个包含多个提示的请求,并使用 batch_index 输出张量将响应与原始提示关联。例如,可以运行
python3 /app/client/end_to_end_grpc_client.py -o 5 -p '["This is a test","I want you to","The cat is"]' --batch-inputs
以向 Triton 服务器发送批大小为 3 的请求。
从源代码构建#
有关如何从源代码构建 Triton TRT-LLM 容器的更多详细信息,请参阅build.md。
支持的模型#
此处仅列出了一些示例。有关所有受支持的模型,请参阅支持矩阵。
LLaMa
Gemma
Mistral
多模态
编码器-解码器
模型配置#
有关模型配置的更多详细信息,请参阅模型配置。
模型部署#
TRT-LLM 多实例支持#
TensorRT-LLM 后端依赖于 MPI 来协调模型在多个 GPU 和节点上的执行。目前,支持两种不同的模式来跨多个 GPU 运行模型:领导者模式和协调器模式。
注意:这与 Triton Server 的模型多实例支持不同,后者允许在相同或不同的 GPU 上运行模型的多个实例。有关 Triton Server 多实例支持的更多信息,请参阅Triton 模型配置文档。
领导者模式#
在领导者模式下,TensorRT-LLM 后端为每个 GPU 生成一个 Triton Server 进程。进程等级为 0 的进程是领导者进程。其他 Triton Server 进程不会从 TRITONBACKEND_ModelInstanceInitialize 调用返回,以避免端口冲突并允许其他进程接收请求。
下图描述了此模式的概述
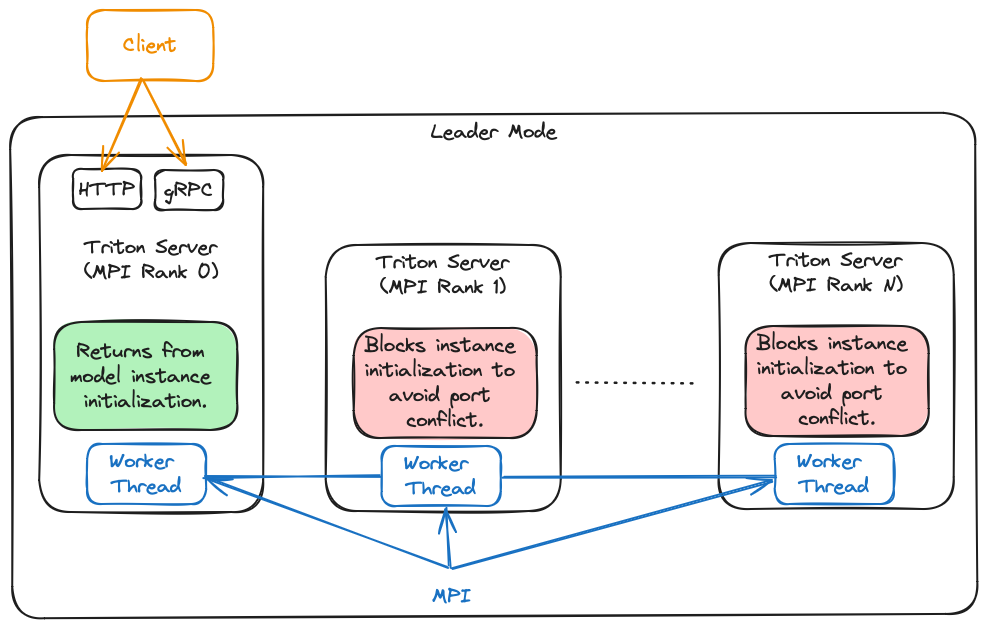
此模式对 slurm 部署友好,因为它不使用 MPI_Comm_spawn。
协调器模式#
在协调器模式下,TensorRT-LLM 后端生成一个充当协调器的 Triton Server 进程,并为每个模型所需的每个 GPU 生成一个 Triton Server 进程。此模式主要用于使用 TensorRT-LLM 后端服务多个模型。在此模式下,MPI 世界大小必须为 1,因为 TRT-LLM 后端将根据需要自动创建新的工作程序。下图描述了此模式的概述
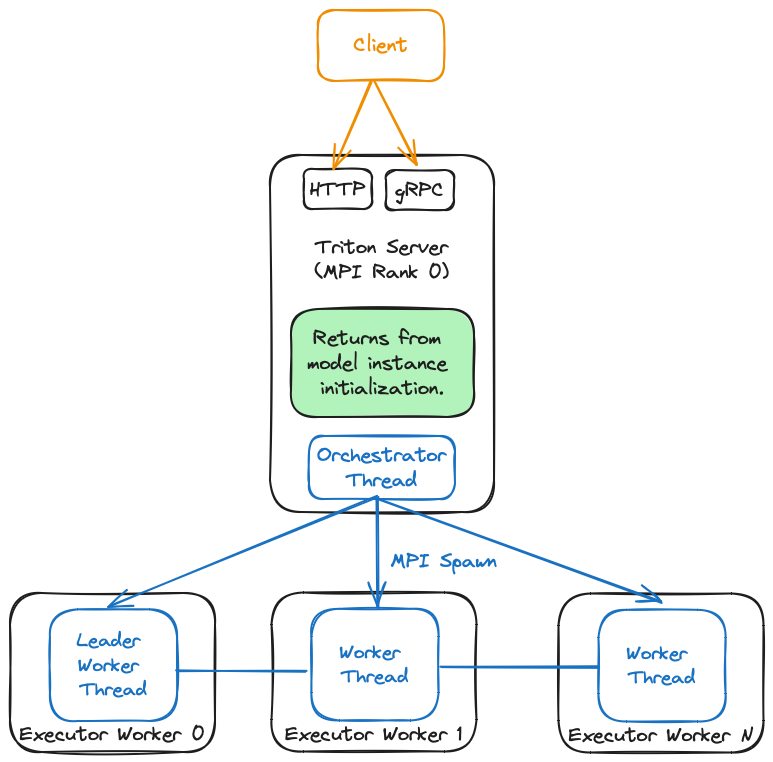
由于此模式使用 MPI_Comm_spawn,因此可能无法与 slurm 部署正常工作。此外,这目前仅适用于单节点部署。
运行 LLaMa 模型的多个实例#
有关在不同配置中运行 LLaMa 模型的多个实例的更多信息,请参阅运行 LLaMa 模型的多个实例。
多节点支持#
查看 多节点生成式 AI w/ Triton Server 和 TensorRT-LLM 教程,了解 Triton Server 和 TensorRT-LLM 多节点部署。
模型并行#
张量并行、流水线并行和专家并行#
TensorRT-LLM 支持张量并行、流水线并行和专家并行。
有关如何使用张量并行、流水线并行和专家并行构建引擎的更多详细信息,请参阅 examples 文件夹中的模型。
下面显示了一些示例
使用 4 路张量并行和 2 路流水线并行构建 LLaMA v3 70B。
python3 convert_checkpoint.py --model_dir ./tmp/llama/70B/hf/ \
--output_dir ./tllm_checkpoint_8gpu_tp4_pp2 \
--dtype float16 \
--tp_size 4 \
--pp_size 2
trtllm-build --checkpoint_dir ./tllm_checkpoint_8gpu_tp4_pp2 \
--output_dir ./tmp/llama/70B/trt_engines/fp16/8-gpu/ \
--gemm_plugin auto
使用张量并行和专家并行构建 Mixtral8x22B
python3 ../llama/convert_checkpoint.py --model_dir ./Mixtral-8x22B-v0.1 \
--output_dir ./tllm_checkpoint_mixtral_8gpu \
--dtype float16 \
--tp_size 8 \
--moe_tp_size 2 \
--moe_ep_size 4
trtllm-build --checkpoint_dir ./tllm_checkpoint_mixtral_8gpu \
--output_dir ./trt_engines/mixtral/tp2ep4 \
--gemm_plugin float16
请参阅 文档,详细了解 TensorRT-LLM 专家并行如何在专家混合 (MoE) 中工作。
MIG 支持#
有关如何使用 MIG 运行 TRT-LLM 模型和 Triton 的更多详细信息,请参阅 MIG 教程。
调度#
调度器策略帮助批处理管理器调整如何调度请求以供执行。TensorRT-LLM 中支持两种调度器策略:MAX_UTILIZATION 和 GUARANTEED_NO_EVICT。请参阅批处理管理器设计,详细了解调度器策略的工作原理。您可以通过 tensorrt_llm 模型的模型配置中的 batch_scheduler_policy 参数指定调度器策略。
键值缓存#
请参阅 KV 缓存部分,详细了解 TensorRT-LLM 如何支持 KV 缓存。此外,请查看 KV 缓存重用 文档,详细了解如何在构建 TRT-LLM 引擎时启用 KV 缓存重用。KV 缓存的参数可以在 tensorrt_llm 模型的模型配置中找到。
解码#
解码模式 - Top-k、Top-p、Top-k Top-p、集束搜索、Medusa、ReDrafter、Lookahead 和 Eagle#
TensorRT-LLM 支持各种解码模式,包括 top-k、top-p、top-k top-p、集束搜索 Medusa、ReDrafter、Lookahead 和 Eagle。请参阅采样参数部分,详细了解 top-k、top-p、top-k top-p 和集束搜索解码。有关 Medusa、ReDrafter、Lookahead 和 Eagle 的更多详细信息,请参阅推测性解码文档。
解码模式的参数可以在 tensorrt_llm 模型的模型配置中找到。
推测性解码#
请参阅推测性解码文档,详细了解 TensorRT-LLM 如何支持推测性解码以提高性能。推测性解码的参数可以在 tensorrt_llm_bls 模型的模型配置中找到。
分块上下文#
有关如何使用分块上下文的更多详细信息,请参阅 分块上下文部分。分块上下文的参数可以在 tensorrt_llm 模型的模型配置中找到。
量化#
查看 量化指南,详细了解如何安装量化工具包并量化 TensorRT-LLM 模型。此外,请查看博客文章 在 TRT-LLM 中使用 SOTA 量化技术加速推理,详细了解如何使用量化加速推理。
LoRa#
有关如何将 LoRa 与 TensorRT-LLM 和 Triton 结合使用的更多详细信息,请参阅lora.md。
在基于 Slurm 的集群中启动 Triton 服务器#
准备一些脚本#
tensorrt_llm_triton.sub
#!/bin/bash
#SBATCH -o logs/tensorrt_llm.out
#SBATCH -e logs/tensorrt_llm.error
#SBATCH -J <REPLACE WITH YOUR JOB's NAME>
#SBATCH -A <REPLACE WITH YOUR ACCOUNT's NAME>
#SBATCH -p <REPLACE WITH YOUR PARTITION's NAME>
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --time=00:30:00
sudo nvidia-smi -lgc 1410,1410
srun --mpi=pmix \
--container-image triton_trt_llm \
--container-workdir /tensorrtllm_backend \
--output logs/tensorrt_llm_%t.out \
bash /tensorrtllm_backend/tensorrt_llm_triton.sh
tensorrt_llm_triton.sh
TRITONSERVER="/opt/tritonserver/bin/tritonserver"
MODEL_REPO="/triton_model_repo"
${TRITONSERVER} --model-repository=${MODEL_REPO} --disable-auto-complete-config --backend-config=python,shm-region-prefix-name=prefix${SLURM_PROCID}_
如果 srun 初始化了 mpi 环境,您可以使用以下命令启动 Triton 服务器
srun --mpi pmix launch_triton_server.py --oversubscribe
提交 Slurm 作业#
sbatch tensorrt_llm_triton.sub
您可能需要联系集群的管理员以帮助您自定义上述脚本。
Triton 指标#
从 Triton 的 23.11 版本开始,用户现在可以通过查询 Triton 指标端点来获取 TRT LLM 批处理管理器统计信息。这可以通过以上述任何方式启动 Triton 服务器(确保构建代码/容器为 23.11 或更高版本)并查询服务器来完成。收到成功响应后,您可以通过输入以下内容来查询指标端点
curl localhost:8002/metrics
批处理管理器统计信息由指标端点在以 nv_trt_llm_ 为前缀的字段中报告。这些字段的输出应类似于以下内容(假设您的模型是飞行中批处理模型)
# HELP nv_trt_llm_request_metrics TRT LLM request metrics
# TYPE nv_trt_llm_request_metrics gauge
nv_trt_llm_request_metrics{model="tensorrt_llm",request_type="context",version="1"} 1
nv_trt_llm_request_metrics{model="tensorrt_llm",request_type="scheduled",version="1"} 1
nv_trt_llm_request_metrics{model="tensorrt_llm",request_type="max",version="1"} 512
nv_trt_llm_request_metrics{model="tensorrt_llm",request_type="active",version="1"} 0
# HELP nv_trt_llm_runtime_memory_metrics TRT LLM runtime memory metrics
# TYPE nv_trt_llm_runtime_memory_metrics gauge
nv_trt_llm_runtime_memory_metrics{memory_type="pinned",model="tensorrt_llm",version="1"} 0
nv_trt_llm_runtime_memory_metrics{memory_type="gpu",model="tensorrt_llm",version="1"} 1610236
nv_trt_llm_runtime_memory_metrics{memory_type="cpu",model="tensorrt_llm",version="1"} 0
# HELP nv_trt_llm_kv_cache_block_metrics TRT LLM KV cache block metrics
# TYPE nv_trt_llm_kv_cache_block_metrics gauge
nv_trt_llm_kv_cache_block_metrics{kv_cache_block_type="tokens_per",model="tensorrt_llm",version="1"} 64
nv_trt_llm_kv_cache_block_metrics{kv_cache_block_type="used",model="tensorrt_llm",version="1"} 1
nv_trt_llm_kv_cache_block_metrics{kv_cache_block_type="free",model="tensorrt_llm",version="1"} 6239
nv_trt_llm_kv_cache_block_metrics{kv_cache_block_type="max",model="tensorrt_llm",version="1"} 6239
# HELP nv_trt_llm_inflight_batcher_metrics TRT LLM inflight_batcher-specific metrics
# TYPE nv_trt_llm_inflight_batcher_metrics gauge
nv_trt_llm_inflight_batcher_metrics{inflight_batcher_specific_metric="micro_batch_id",model="tensorrt_llm",version="1"} 0
nv_trt_llm_inflight_batcher_metrics{inflight_batcher_specific_metric="generation_requests",model="tensorrt_llm",version="1"} 0
nv_trt_llm_inflight_batcher_metrics{inflight_batcher_specific_metric="total_context_tokens",model="tensorrt_llm",version="1"} 0
# HELP nv_trt_llm_general_metrics General TRT LLM metrics
# TYPE nv_trt_llm_general_metrics gauge
nv_trt_llm_general_metrics{general_type="iteration_counter",model="tensorrt_llm",version="1"} 0
nv_trt_llm_general_metrics{general_type="timestamp",model="tensorrt_llm",version="1"} 1700074049
# HELP nv_trt_llm_disaggregated_serving_metrics TRT LLM disaggregated serving metrics
# TYPE nv_trt_llm_disaggregated_serving_metrics counter
nv_trt_llm_disaggregated_serving_metrics{disaggregated_serving_type="kv_cache_transfer_ms",model="tensorrt_llm",version="1"} 0
nv_trt_llm_disaggregated_serving_metrics{disaggregated_serving_type="request_count",model="tensorrt_llm",version="1"} 0
相反,如果您启动了 V1 模型,则您的输出将类似于上面的输出,但飞行中批处理相关的字段将被替换为类似于以下内容的内容
# HELP nv_trt_llm_v1_metrics TRT LLM v1-specific metrics
# TYPE nv_trt_llm_v1_metrics gauge
nv_trt_llm_v1_metrics{model="tensorrt_llm",v1_specific_metric="total_generation_tokens",version="1"} 20
nv_trt_llm_v1_metrics{model="tensorrt_llm",v1_specific_metric="empty_generation_slots",version="1"} 0
nv_trt_llm_v1_metrics{model="tensorrt_llm",v1_specific_metric="total_context_tokens",version="1"} 5
请注意,23.12 版本之前的 Triton 版本不支持基本 Triton 指标。因此,以下字段将报告 0
# HELP nv_inference_request_success Number of successful inference requests, all batch sizes
# TYPE nv_inference_request_success counter
nv_inference_request_success{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_request_failure Number of failed inference requests, all batch sizes
# TYPE nv_inference_request_failure counter
nv_inference_request_failure{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_count Number of inferences performed (does not include cached requests)
# TYPE nv_inference_count counter
nv_inference_count{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_exec_count Number of model executions performed (does not include cached requests)
# TYPE nv_inference_exec_count counter
nv_inference_exec_count{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_request_duration_us Cumulative inference request duration in microseconds (includes cached requests)
# TYPE nv_inference_request_duration_us counter
nv_inference_request_duration_us{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_queue_duration_us Cumulative inference queuing duration in microseconds (includes cached requests)
# TYPE nv_inference_queue_duration_us counter
nv_inference_queue_duration_us{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_compute_input_duration_us Cumulative compute input duration in microseconds (does not include cached requests)
# TYPE nv_inference_compute_input_duration_us counter
nv_inference_compute_input_duration_us{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_compute_infer_duration_us Cumulative compute inference duration in microseconds (does not include cached requests)
# TYPE nv_inference_compute_infer_duration_us counter
nv_inference_compute_infer_duration_us{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_compute_output_duration_us Cumulative inference compute output duration in microseconds (does not include cached requests)
# TYPE nv_inference_compute_output_duration_us counter
nv_inference_compute_output_duration_us{model="tensorrt_llm",version="1"} 0
# HELP nv_inference_pending_request_count Instantaneous number of pending requests awaiting execution per-model.
# TYPE nv_inference_pending_request_count gauge
nv_inference_pending_request_count{model="tensorrt_llm",version="1"} 0
基准测试#
查看 GenAI-Perf 工具,用于基准测试 TensorRT-LLM 模型。
您还可以使用 benchmark_core_model 脚本来基准测试核心模型 tensosrrt_llm。该脚本直接向部署的 tensorrt_llm 模型发送请求。基准核心模型延迟表示 TensorRT-LLM 的推理延迟,不包括通常由 HuggingFace 等第三方库处理的预处理/后处理延迟。
benchmark_core_model 可以从 2 个来源生成流量。1 - 数据集(包含提示和可选响应的 json 文件)2 - 令牌正态分布(用户指定的输入、输出 seqlen)
默认情况下,指数分布用于控制请求的到达率。可以将其更改为恒定到达时间。
cd tools/inflight_batcher_llm
示例:使用提供的分词器运行数据集,请求速率为 10 个请求/秒。
python3 benchmark_core_model.py -i grpc --request_rate 10 dataset --dataset <dataset path> --tokenizer_dir <> --num_requests 5000
示例:生成 I/O seqlen 令牌,输入正态分布,mean_seqlen=128,stdev=10。输出正态分布,mean_seqlen=20,stdev=2。设置 stdev=0 以获得恒定 seqlens。
python3 benchmark_core_model.py -i grpc --request_rate 10 token_norm_dist --input_mean 128 --input_stdev 5 --output_mean 20 --output_stdev 2 --num_requests 5000
预期输出
[INFO] Warm up for benchmarking.
[INFO] Start benchmarking on 5000 prompts.
[INFO] Total Latency: 26585.349 ms
[INFO] Total request latencies: 11569672.000999955 ms
+----------------------------+----------+
| Stat | Value |
+----------------------------+----------+
| Requests/Sec | 188.09 |
| OP tokens/sec | 3857.66 |
| Avg. latency (ms) | 2313.93 |
| P99 latency (ms) | 3624.95 |
| P90 latency (ms) | 3127.75 |
| Avg. IP tokens per request | 128.53 |
| Avg. OP tokens per request | 20.51 |
| Total latency (ms) | 26582.72 |
| Total requests | 5000.00 |
+----------------------------+----------+
请注意,该文档中的预期输出仅供参考,具体的性能数字取决于您使用的 GPU。
测试 TensorRT-LLM 后端#
请按照 ci/README.md 中的指南,了解如何运行 TensorRT-LLM 后端的测试。