DALI TRITON 后端#
此仓库包含用于 Triton 推理服务器的 DALI 后端的代码。
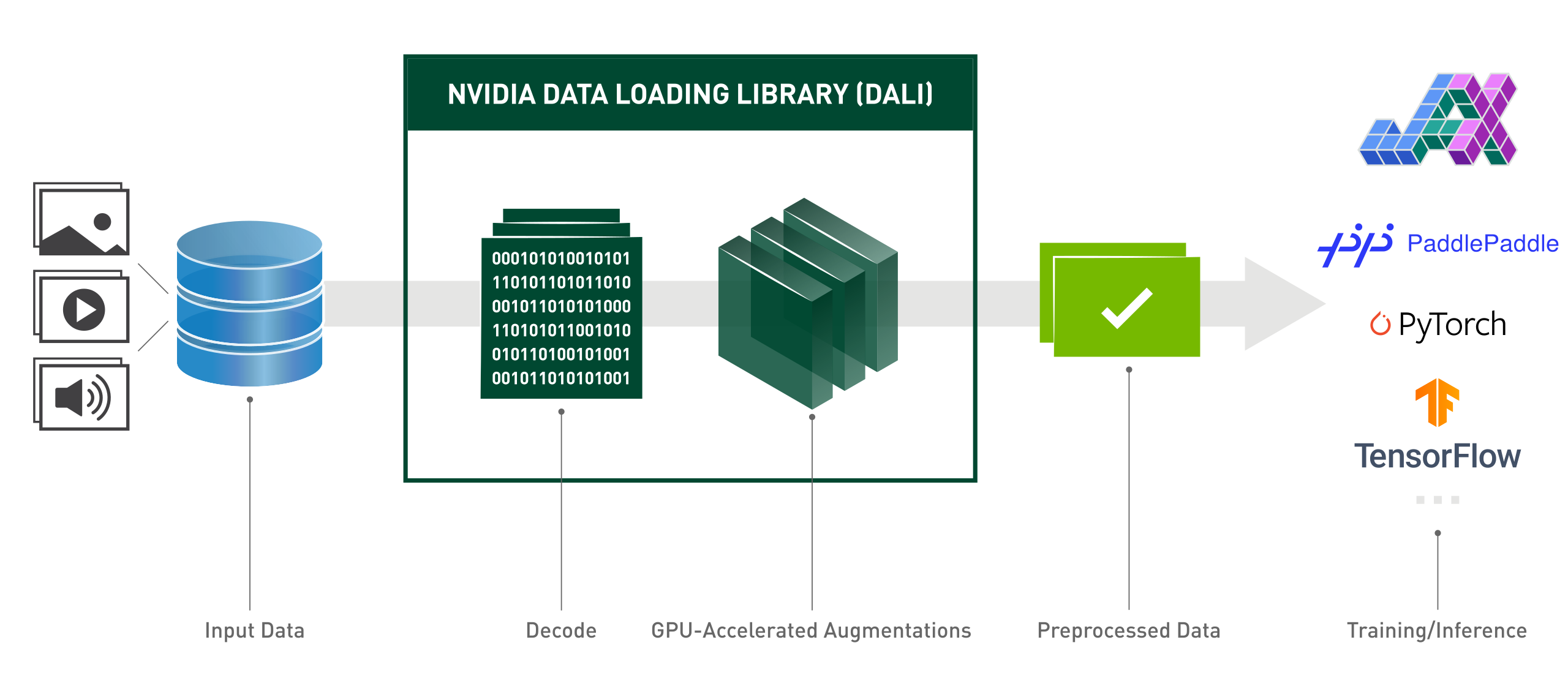
NVIDIA DALI ®,数据加载库,是一组高度优化的构建块和一个执行引擎,用于加速深度学习应用输入数据的预处理。DALI 既提供了性能,又提供了灵活性,可以作为一个库加速不同的数据管线。这个库可以轻松集成到不同的深度学习训练和推理应用中,而无需考虑使用的深度学习框架。
要了解更多关于 DALI 的信息,请参考我们的主页。入门指南 和 教程 将指导您完成最初的步骤,支持的操作 将帮助您构建由 GPU 驱动的数据处理管线。
发现任何错误?#
欢迎在此处或 DALI 的 github 仓库 中发布问题。
如何使用?#
DALI 数据管线在 Triton 中表示为一个 模型。要创建这样一个模型,您必须在 Python 中组合一个 DALI 管线。然后,您必须对其进行序列化(通过调用 Pipeline.serialize 方法)或使用 自动序列化 来生成模型文件。例如,我们将使用简单的调整大小管线
import nvidia.dali as dali from nvidia.dali.plugin.triton import autoserialize @autoserialize @dali.pipeline_def(batch_size=256, num_threads=4, device_id=0) def pipe(): images = dali.fn.external_source(device="cpu", name="DALI_INPUT_0") images = dali.fn.image_decoder(images, device="mixed") images = dali.fn.resize(images, resize_x=224, resize_y=224) return images模型文件应包含在 Triton 的 模型仓库 中。这是一个例子
model_repository └── dali ├── 1 │ └── model.dali └── config.pbtxt正如 Triton 中常见的做法,您的 DALI 模型文件应命名为
model.dali。您可以在模型配置中通过设置default_model_filename选项来覆盖此名称。这是我们用于ResizePipeline示例的完整config.pbtxtname: "dali" backend: "dali" max_batch_size: 256 input [ { name: "DALI_INPUT_0" data_type: TYPE_UINT8 dims: [ -1 ] } ] output [ { name: "DALI_OUTPUT_0" data_type: TYPE_UINT8 dims: [ 224, 224, 3 ] } ]
如果在管线定义中指定了关于输入、输出和最大批大小的信息,则可以省略编写大部分配置文件。有关此功能的详细信息,请参阅 配置自动补全。
配置自动补全#
为了简化模型部署,Triton 服务器可以从模型文件本身推断出配置文件的部分内容。对于 DALI 后端,关于输入、输出和最大批大小的信息可以在管线定义中指定,无需在配置文件中重复。下面您可以看到如何在 Python 管线定义中包含配置信息
import nvidia.dali as dali
from nvidia.dali.plugin.triton import autoserialize
import nvidia.dali.types as types
@autoserialize
@dali.pipeline_def(batch_size=256, num_threads=4, device_id=0, output_dtype=[types.UINT8], output_ndim=[3])
def pipe():
images = dali.fn.external_source(device="cpu", name="DALI_INPUT_0", dtype=types.UINT8, ndim=1)
images = dali.fn.image_decoder(images, device="mixed")
images = dali.fn.resize(images, resize_x=224, resize_y=224)
return images
如您所见,我们向外部源算子添加了 dtype 和 ndim (维度数) 参数。它们提供了填写配置文件中 inputs 字段所需的信息。为了填写 outputs 字段,我们向管线定义添加了 output_dtype 和 output_ndim 参数。这些参数应该是列表,每个输出都有一个值。
这样,我们可以将配置文件限制为仅命名模型和指定 DALI 后端
name: "dali"
backend: "dali"
部分配置#
如果管线定义中不存在某些信息,或者要覆盖某些值,您仍然可以提供这些信息。例如,您可以使用配置文件为模型输出指定新名称,这在稍后在集成模型中使用它们时可能很有用。您还可以覆盖最大批大小。上面定义的管线的配置文件可能如下所示
name: "dali"
backend: "dali"
max_batch_size: 128
output [
{
name: "DALI_OUTPUT_0"
dims: [ 224, 224, 3 ]
}
]
这样的配置文件将最大批大小值覆盖为 128。它还将管线输出重命名为 "DALI_OUTPUT_0",并将其形状指定为 (224, 224, 3)。
有关可在配置文件中指定的模型参数的详细信息,请参阅 DALI 模型配置文件 文档。
自动序列化#
在 Triton 中使用 DALI 后端时,用户必须在模型仓库中提供 DALI 模型。表示模型的规范方法是在其中包含序列化的 DALI 模型文件,并正确命名文件(默认情况下为 model.dali)。将模型存储在序列化文件中产生的问题是,序列化后,模型变得晦涩难懂,几乎无法再读取。自动序列化功能允许用户在模型仓库中用 Python 代码表示模型。对于 Python 定义的模型,DALI 后端使用内部序列化机制,并免除用户手动序列化的操作。
要使用自动序列化功能,用户需要将 DALI 管线的 Python 定义放在模型文件内(默认情况下为 model.dali,但默认文件名可以在 config.pbtxt 中配置)。这样的管线定义必须用 @autoserialize 修饰,例如
import nvidia.dali as dali
@dali.plugin.triton.autoserialize
@dali.pipeline_def(batch_size=3, num_threads=1, device_id=0)
def pipe():
'''
An identity pipeline with autoserialization enabled
'''
data = dali.fn.external_source(device="cpu", name="DALI_INPUT_0")
return data
Python 中正确的 DALI 管线定义,以及自动序列化,应满足以下条件
只有
pipeline_def可以用autoserialize修饰。在给定的模型版本中,只能有一个管线定义可以用
autoserialize修饰。
加载模型文件时,DALI 后端遵循以下优先级
首先,DALI 后端尝试从用户在
default_model_filename属性中指定的模型位置加载序列化模型(如果未显式指定,则为model.dali);如果上一步失败,DALI 后端尝试从用户指定的模型位置加载并自动序列化 Python 管线定义。重要提示:在这种情况下,我们要求包含模型定义的文件名以
.py结尾,例如mymodel.py;如果上一步失败,DALI 后端尝试从给定模型版本中的
dali.py文件加载并自动序列化 Python 管线定义。
如果您没有在 config.pbtxt 文件中调整模型路径定义,则应遵循经验法则
如果您有一个序列化的管线,请将文件命名为
model.dali并将其放入模型仓库中,如果您有一个要自动序列化的管线的 python 定义,请将其命名为
dali.py。
提示和技巧:#
目前,从 Triton 向 DALI 管线传递输入的唯一方法是使用
fn.external_source算子。因此,您很可能希望使用它将编码后的图像(或任何其他数据)馈送到 DALI 中。给您的
fn.external_source算子与您在config.pbtxt中给 Input 的名称相同的名称。
已知限制:#
DALI 的
ImageDecoder仅接受来自 CPU 的数据 - 在组合您的 DALI 管线时请记住这一点。Triton 仅接受同构批处理形状。您可以随意用零填充您的编码图像批次
由于 DALI 的限制,当为
count大于 1 的 DALI 模型定义实例组时,您可能会观察到异常增加的内存消耗。我们建议为 DALI 模型使用默认实例组。
如何构建?#
Docker 构建 #
使用 docker 构建 DALI 后端非常简单,只需
git clone --recursive https://github.com/triton-inference-server/dali_backend.git
cd dali_backend
docker build -f docker/Dockerfile.release -t tritonserver:dali-latest .
并且 tritonserver:dali-latest 将成为您的新 tritonserver docker 镜像
裸机#
先决条件#
要构建 dali_backend,您需要 CMake 3.17+
使用最新的 DALI 版本#
如果您需要使用比 tritonserver 镜像中提供的 DALI 更新的版本,您可以使用 DALI 的 nightly builds。只需使用 pip 安装您喜欢的任何 DALI 版本(有关如何操作的更多信息,请参阅链接)。在这种情况下,在构建 dali_backend 时,您需要将 -D TRITON_SKIP_DALI_DOWNLOAD=ON 选项传递给您的 CMake 构建。dali_backend 将在您的系统中找到最新安装的 DALI 并使用此特定版本。
构建#
构建 DALI 后端非常简单。要记住的一件事是克隆包含所有子模块的 dali_backend 仓库
git clone --recursive https://github.com/triton-inference-server/dali_backend.git
cd dali_backend
mkdir build
cd build
cmake ..
make
构建过程将生成 unittest 可执行文件。您可以使用它为 DALI 后端运行单元测试