部署 HuggingFace 模型#
注意:如果您是 Triton 推理服务器的新用户,建议您查看概念指南的第 1 部分。本教程假设您对 Triton 推理服务器有基本的了解。
相关页面 |
HuggingFace 模型导出指南:ONNX, TorchScript |
|---|
开发人员经常使用开源模型。HuggingFace 是许多开源模型的流行来源。本指南中的讨论将侧重于用户如何使用 Triton 推理服务器部署几乎任何来自 HuggingFace 的模型。在此示例中,使用了 HuggingFace 上提供的 ViT 模型。
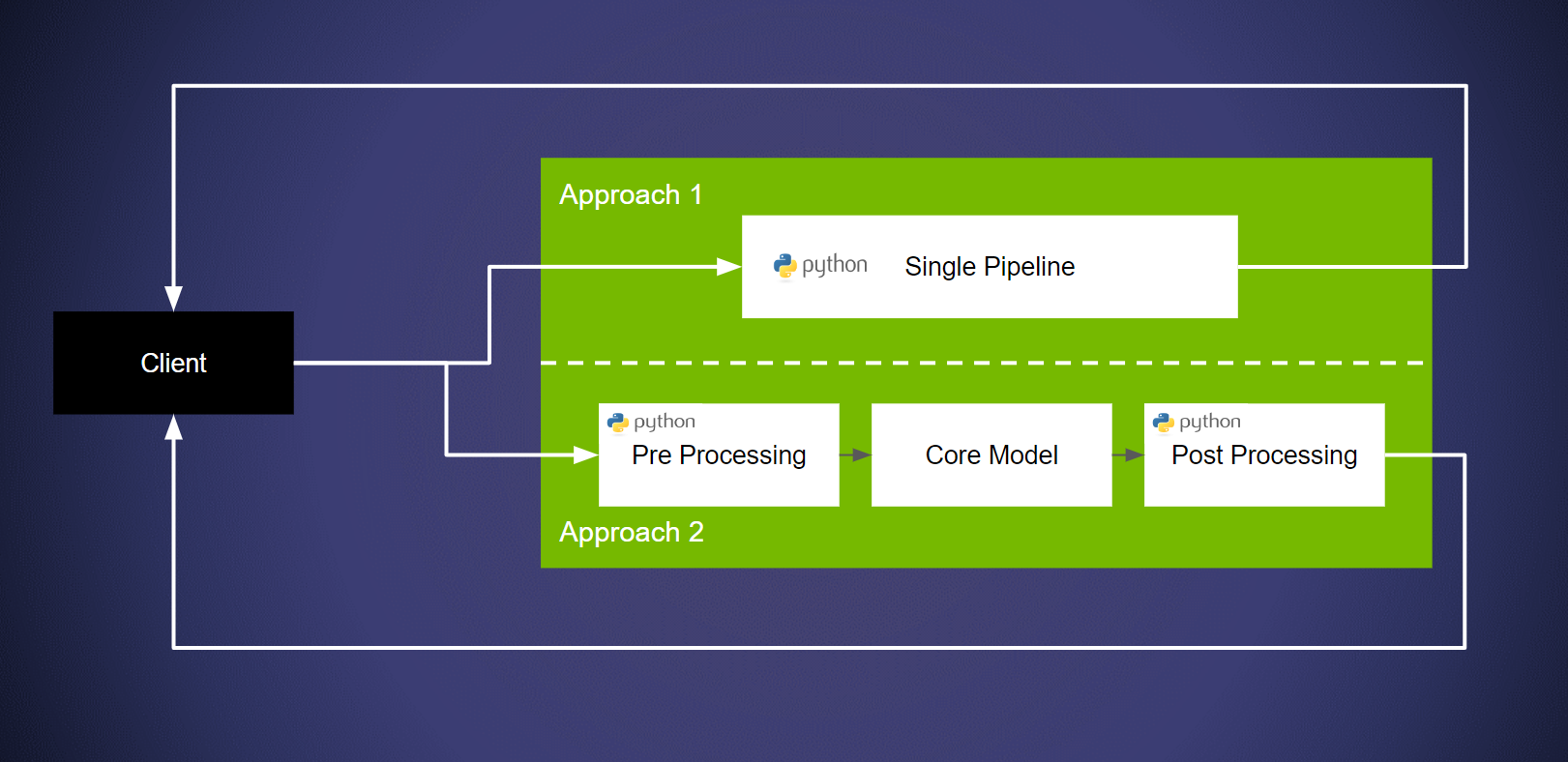
在 Triton 推理服务器上部署模型管线主要有两种方法
方法 1:部署管线而不显式地将模型从管线中分离出来。此方法的核心优势在于用户可以快速部署他们的管线。这可以通过使用 Triton 的 “Python 后端” 来实现。有关更多信息,请参阅此示例。总之,我们使用 Python 后端部署模型/管线。
方法 2:分解管线,使用不同的后端进行预处理/后处理,并在框架后端上部署核心模型。在这种情况下,优势在于在专用框架后端上运行核心网络可提供更高的性能。此外,还可以利用许多特定于框架的优化。有关更多信息,请参阅概念指南的第 4 部分。这可以通过 Triton 的集成来实现。有关此内容的说明可以在概念指南的第 5 部分中找到。有关更多信息,请参阅文档。总之,我们构建一个集成,其中包含预处理步骤和导出的模型。
示例#
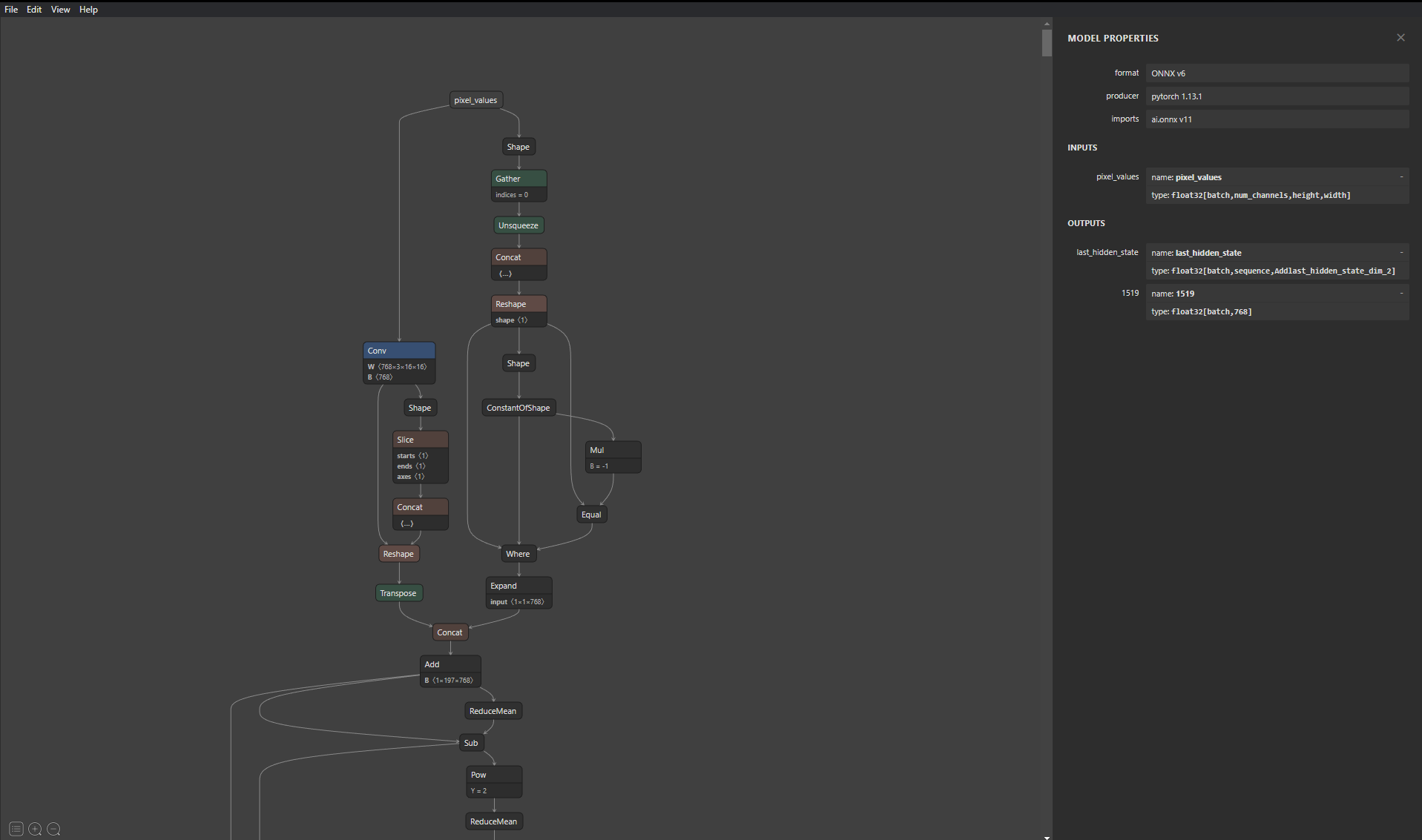
为了便于解释,这里使用了 ViT 模型(HuggingFace 链接)。这个特定的 ViT 模型没有应用头(如图像分类),但 HuggingFace 提供了 具有不同头的 ViT 模型,用户可以使用它们。部署模型时的一个良好实践是,如果您不熟悉模型结构,则应理解并探索模型的结构。使用 Netron 等工具,可以通过图形界面轻松查看结构。虽然 Triton 为模型自动生成配置文件,但用户可能仍然需要输入和输出层的名称来构建客户端/模型集成,为此我们可以使用此工具。
在 Python 后端上部署(方法 1)#
使用 Triton 的 python 后端需要用户定义 TritonPythonModel 类的最多三个函数
initialize():此函数在 Triton 加载模型时运行。建议使用此函数来初始化/加载任何模型和/或数据对象。定义此函数是可选的。
def initialize(self, args):
self.feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
self.model = ViTModel.from_pretrained("google/vit-base-patch16-224-in21k")
execute():此函数在每次请求时执行。它可用于容纳所有必需的管线逻辑。
def execute(self, requests):
responses = []
for request in requests:
inp = pb_utils.get_input_tensor_by_name(request, "image")
input_image = np.squeeze(inp.as_numpy()).transpose((2,0,1))
inputs = self.feature_extractor(images=input_image, return_tensors="pt")
outputs = self.model(**inputs)
# Sending results
inference_response = pb_utils.InferenceResponse(output_tensors=[
pb_utils.Tensor(
"label",
outputs.last_hidden_state.numpy()
)
])
responses.append(inference_response)
return responses
finalize():此函数在 Triton 卸载模型时执行。它可用于释放任何内存,或安全卸载模型所需的任何其他操作。定义此函数是可选的。
要运行此示例,请打开两个终端并使用以下命令
终端 1:此终端将用于启动 Triton 推理服务器。
# Pick the pre-made model repository
mv python_model_repository model_repository
# Pull and run the Triton container & replace yy.mm
# with year and month of release. Eg. 23.05
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}:/workspace/ -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:yy.mm-py3 bash
# Install dependencies
pip install torch torchvision
pip install transformers
pip install Image
# Launch the server
tritonserver --model-repository=/models
终端 2:此终端将用于运行客户端。
# Pull & run the container
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:yy.mm-py3-sdk bash
# Run the client
python3 client.py --model_name "python_vit"
使用 Triton 集成部署(方法 2)#
在讨论围绕部署模型的细节之前,第一步是下载并导出模型。建议在 NGC 上提供的 PyTorch 容器内运行以下操作。如果这是您首次尝试在 Triton 中设置模型集成,强烈建议您在继续之前查看本指南。分解管线的关键优势是提高了性能并可以访问多种加速选项。有关模型加速的详细信息,请浏览概念指南的第 4 部分。
# Pull the PyTorch Container from NGC
docker run -it --gpus=all -v ${PWD}:/workspace nvcr.io/nvidia/pytorch:23.05-py3
# Install dependencies
pip install transformers
pip install transformers[onnx]
# Export the model
python -m transformers.onnx --model=google/vit-base-patch16-224 --atol=1e-3 onnx/vit
下载模型后,按照下面描述的结构设置模型仓库。模型仓库的基本结构以及所需的配置文件在 ensemble_model_repository 中提供。
model_repository/
|-- ensemble_model
| |-- 1
| `-- config.pbtxt
|-- preprocessing
| |-- 1
| | `-- model.py
| `-- config.pbtxt
`-- vit
`-- 1
`-- model.onnx
在这种方法中,有三点需要考虑。
预处理:ViT 的特征提取步骤在 python 后端完成。此步骤的实现细节与上面部分中遵循的过程相同。
ViT 模型:只需将模型放置在上面描述的仓库中即可。Triton 推理服务器将自动生成所需的配置文件。如果您希望查看生成的配置,请在启动服务器时附加
--log-verbose=1。集成配置:在此配置中,我们映射集成中两个部分的输入和输出层,即在 python 后端处理的
preprocessing和部署在 ONNX 后端的 ViT 模型。
要运行此示例,与之前的流程类似,请使用两个终端
终端 1:此终端将用于启动 Triton 推理服务器。
# Pick the pre-made model repository and add the model
mv ensemble_model_repository model_repository
mkdir -p model_repository/vit/1
mv vit/model.onnx model_repository/vit/1/
mkdir model_repository/ensemble_model/1
# Pull and run the Triton container & replace yy.mm
# with year and month of release. Eg. 23.05
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}:/workspace/ -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:yy.mm-py3 bash
# Install dependencies
pip install torch torchvision torchaudio
pip install transformers
pip install Image
# Launch the server
tritonserver --model-repository=/models
终端 2:此终端将用于运行客户端。
# Pull & run the container
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:yy.mm-py3-sdk bash
# Run the client
python3 client.py --model_name "ensemble_model"
总结#
总而言之,部署大多数 HuggingFace 模型有两种方法,要么在 python 后端上部署整个管线,要么构建集成。