加速深度学习模型的推理#
模型加速是一个复杂且细致入微的主题。诸如图优化模型、剪枝、知识蒸馏、量化等技术的可行性,高度依赖于模型的结构。这些主题中的每一个都是其自身广阔的研究领域,构建自定义工具需要大量的工程投入。
为了简洁和客观,本文的讨论将侧重于在使用 Triton 推理服务器部署模型时建议使用的工具和功能,而不是对生态系统进行详尽的概述。
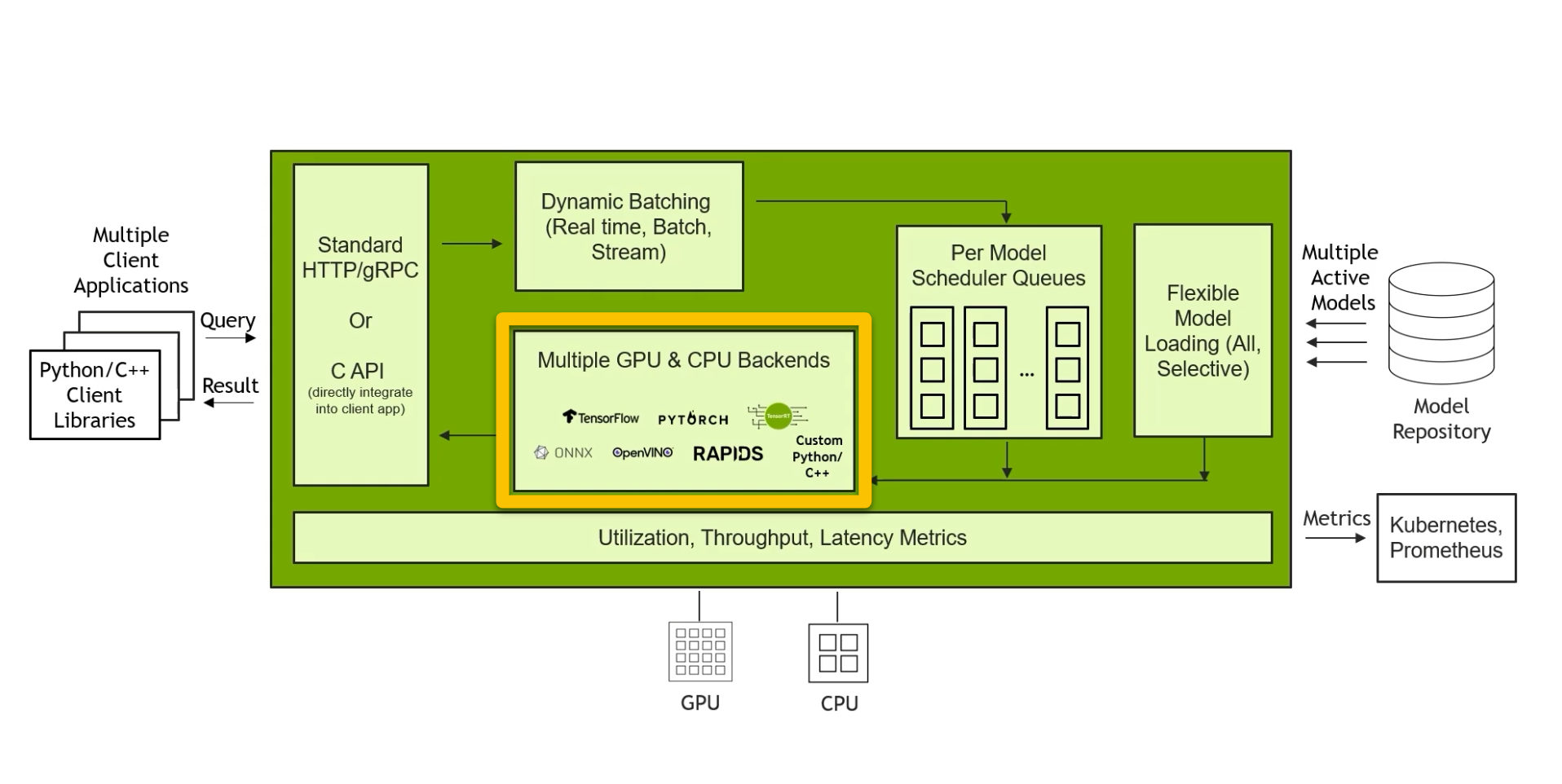
Triton 推理服务器有一个称为“Triton 后端”或 “后端” 的概念。后端本质上是执行模型的实现。后端可以是围绕流行的深度学习框架(如 PyTorch、TensorFlow、TensorRT 或 ONNX Runtime)的包装器,或者用户可以选择构建针对其模型和用例定制的后端。这些后端中的每一个都有其特定的加速选项。
Triton 模型的性能调优在 此处 进行了广泛讨论,但本文档将在下面更详细地介绍。
加速建议取决于两个主要因素
硬件类型:Triton 用户可以选择在 GPU 或 CPU 上运行模型。由于 GPU 提供的并行性,它们提供了许多性能加速途径。使用 PyTorch、TensorFlow、ONNX runtime 和 TensorRT 的模型可以利用这些优势。对于 CPU,Triton 用户可以利用 OpenVINO 后端进行加速。
模型类型:通常用户利用以下三种不同类型的模型中的一种或多种:
浅层模型(如随机森林)、神经网络(如 BERT 或 CNN),以及最后,大型 Transformer 模型,这些模型通常太大而无法放入单个 GPU 的内存中。每个模型类别都利用不同的优化来加速性能。
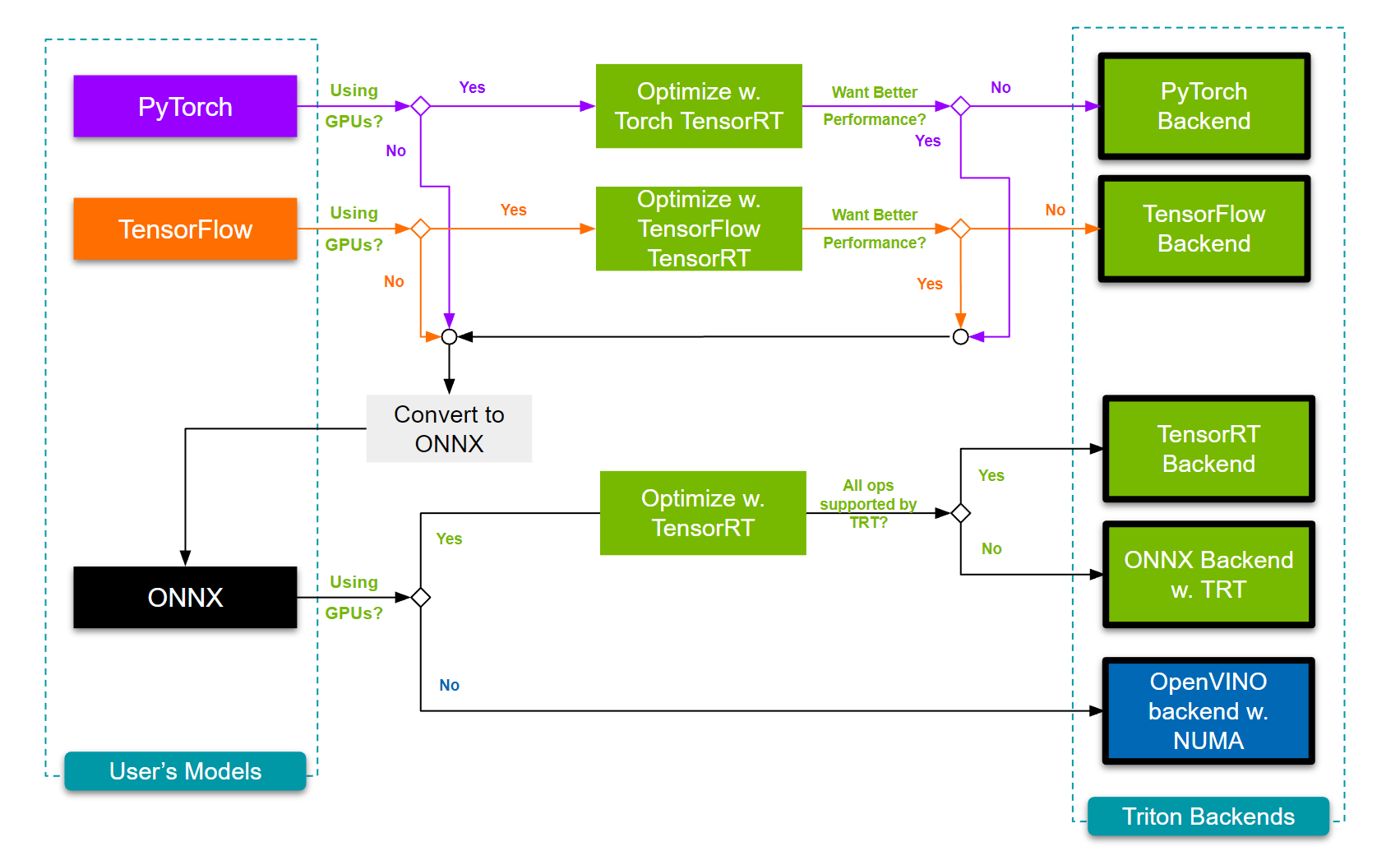
考虑到这些广泛的类别,让我们深入研究具体场景和决策过程,以选择最合适的 Triton 后端用于用例,并简要讨论可能的优化。
基于 GPU 的加速#
如前所述,可以通过多种方式实现深度学习模型的加速。诸如融合层之类的图级优化可以减少执行所需的 GPU 内核数量。融合层使模型执行更节省内存并增加操作密度。一旦融合,内核自动调谐器可以选择正确的内核组合以最大化 GPU 资源的利用率。同样,使用较低精度(FP16、INT8 等)以及量化等技术可以大幅减少内存需求并提高吞吐量。
性能优化策略的确切性质因每个 GPU 的硬件设计而异。这些是我们使用 NVIDIA TensorRT 为深度学习从业者解决的众多挑战中的一小部分,TensorRT 是一个专注于深度学习推理优化的 SDK。
虽然 TensorRT 可以与流行的深度学习框架(如 PyTorch、TensorFlow、MxNET、ONNX Runtime 等)一起使用,但它也具有与 PyTorch(Torch-TensorRT) 和 TensorFlow(TensorFlow-TensorRT) 的框架级集成,以为其各自的开发人员提供灵活性和回退机制。
直接使用 TensorRT#
用户可以通过三种途径将其模型转换为 TensorRT:C++ API、Python API 和 trtexec/polygraphy(TensorRT 的命令行工具)。请参阅本指南以获取详细示例。
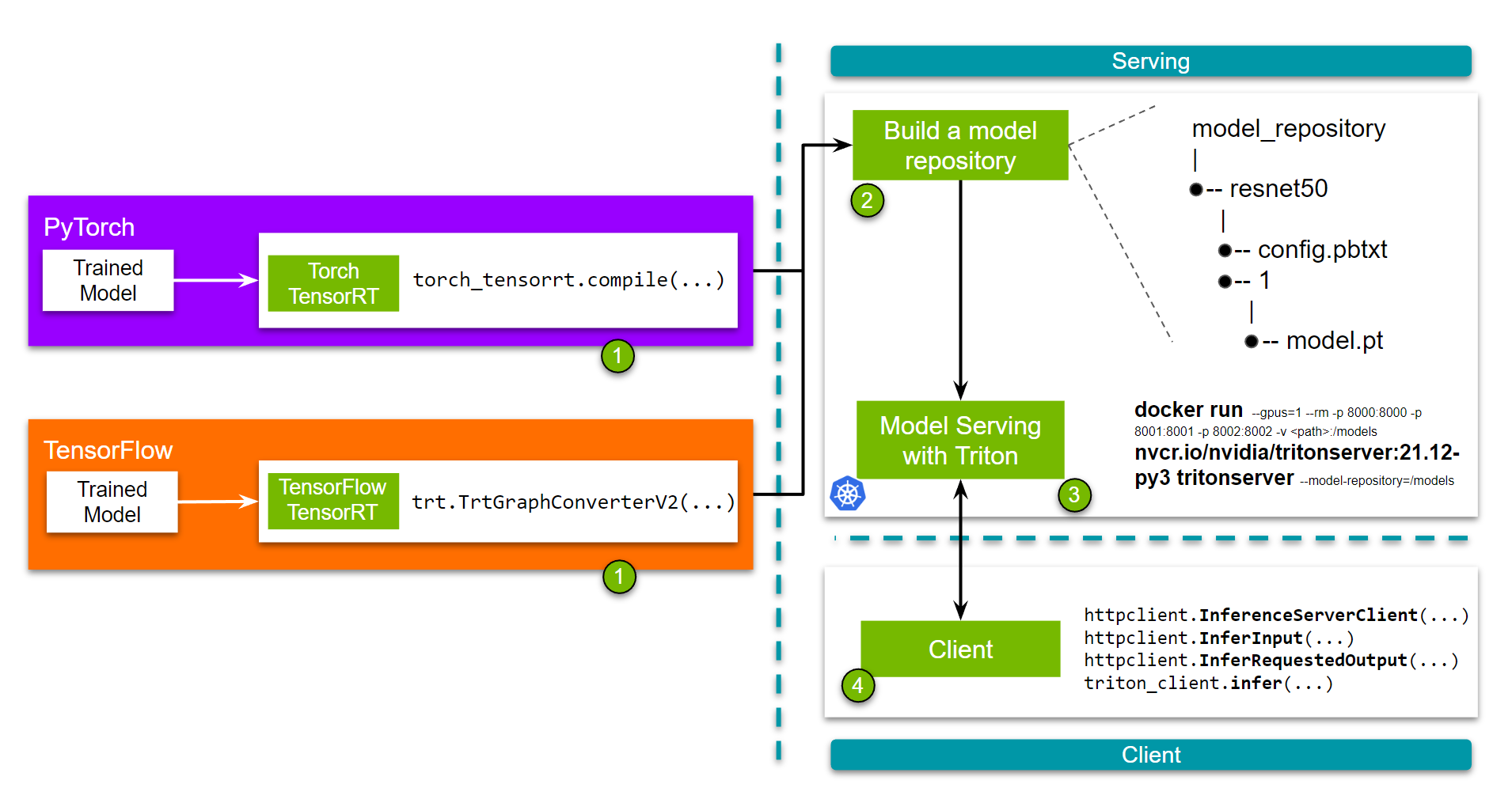
也就是说,需要两个主要步骤。首先,将模型转换为 TensorRT 引擎。建议使用 TensorRT 容器 运行命令。
trtexec --onnx=model.onnx \
--saveEngine=model.plan \
--explicitBatch
转换完成后,将模型放入模型仓库(如第 1 部分所述)中的 model.plan 中,并在 config.pbtxt 中使用 tensorrt 作为 backend。
除了转换为 TensorRT 之外,用户还可以利用一些 cuda 特定优化。
如果用户遇到模型中的某些算子不受 TensorRT 支持的情况,则有三种可能的选择
使用框架集成之一:TensorRT 与框架有两个集成:Torch-TensorRT (PyTorch) 和 TensorFlow-TensorRT (TensorFlow)。这些集成内置了回退机制,以便在 TensorRT 不直接支持图的情况下使用框架后端。
将 ONNX Runtime 与 TensorRT 结合使用:Triton 用户还可以将此回退机制与 ONNX Runtime 结合使用(更多信息请参见以下部分)。
构建插件:TensorRT 允许构建插件并实现自定义操作。用户可以编写自己的 TensorRT 插件 来实现不受支持的操作(推荐给专家用户)。强烈建议报告所述操作,以便 TensorRT 本身支持它们。
使用 TensorRT 与 PyTorch/TensorFlow 的集成#
对于 PyTorch,Torch-TensorRT 是一个 Ahead of Time Compiler,它将 TorchScript/Torch FX 转换为以 TensorRT 引擎为目标的模块。编译后,用户可以像使用 TorchScript 模型一样使用优化后的模型。请查看 Torch TensorRT 入门指南 以了解更多信息。请参阅本指南以获取详细示例,演示如何使用 Torch TensorRT 编译 PyTorch 模型并将其部署在 Triton 上。
TensorFlow 用户可以利用 TensorFlow TensorRT,它将图分割为 TensorRT 支持和不支持的子图。然后,受支持的子图将替换为 TensorRT 优化的节点,从而生成一个同时具有 TensorFlow 和 TensorRT 组件的图。请参阅本教程,其中解释了使用 TensorFlow-TensorRT 加速模型并将其部署在 Triton 推理服务器上所需的确切步骤。
使用 TensorRT 与 ONNX RunTime 的集成#
有三种加速 ONNX runtime 的选项:使用 TensorRT 和 CUDA 执行提供程序用于 GPU,以及使用 OpenVINO(稍后部分讨论)用于 CPU。
通常,TensorRT 将提供比 CUDA 执行提供程序更好的优化,但这取决于模型的确切结构,更准确地说,它取决于正在加速的网络中使用的算子。如果支持所有算子,则转换为 TensorRT 将产生更好的性能。当选择 TensorRT 作为加速器时,所有受支持的子图都由 TensorRT 加速,而图的其余部分在 CUDA 执行提供程序上运行。用户可以通过在配置文件中添加以下内容来实现此目的。
TensorRT 加速
optimization {
execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" }
parameters { key: "max_workspace_size_bytes" value: "1073741824" }
}]
}
}
也就是说,用户也可以选择在不进行 TensorRT 优化的情况下运行模型,在这种情况下,CUDA EP 是默认的执行提供程序。更多详细信息请参见 此处。有关 文本识别 模型(在本系列第 1-3 部分中使用)的示例配置文件,请参阅此处的 onnx_tensorrt_config.pbtxt。
还有一些其他 ONNX runtime 特定的优化。有关更多信息,请参阅我们的 ONNX 后端文档 的这一部分。
基于 CPU 的加速#
Triton 推理服务器还支持仅 CPU 模型的加速,使用 OpenVINO。在配置文件中,用户可以添加以下内容来启用 CPU 加速。
optimization {
execution_accelerators {
cpu_execution_accelerator : [{
name : "openvino"
}]
}
}
虽然 OpenVINO 提供了软件级别的优化,但考虑所使用的 CPU 硬件也很重要。CPU 包括多个内核、内存资源和互连。对于多个 CPU,这些资源可以与 NUMA(非统一内存访问)共享。有关更多信息,请参阅 Triton 文档的此部分。
加速浅层模型#
浅层模型(如梯度提升决策树)通常用于许多管线中。这些模型通常使用 XGBoost、LightGBM、Scikit-learn、cuML 等库构建。这些模型可以通过 Forest Inference Library 后端部署在 Triton 推理服务器上。有关更多信息,请查看 这些示例。
加速大型 Transformer 模型#
在另一方面,深度学习从业者被具有数十亿参数的大型 Transformer 模型所吸引。对于如此规模的模型,通常需要不同类型的优化或跨 GPU 并行化。跨 GPU 的并行化(因为它们可能无法容纳在 1 个 GPU 上)可以通过张量并行或管线并行来实现。为了解决这个问题,用户可以使用 Faster Transformer Library 和 Triton 的 Faster Transformer 后端。请查看此博客 以获取更多信息!
工作示例#
在继续之前,请为本系列第 1-3 部分中使用的文本识别模型设置模型仓库。然后,导航到模型仓库并启动两个容器
# Server Container
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v$(pwd):/workspace/ -v/$(pwd)/model_repository:/models nvcr.io/nvidia/tritonserver:22.11-py3 bash
# Client Container (on a different terminal)
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:22.11-py3-sdk bash
由于这是一个我们转换为 ONNX 的模型,并且 TensorRT 加速示例已链接在整个解释中,我们将探索 ONNX 途径。使用 ONNX 后端时,需要考虑三种情况
在 GPU 上使用 CUDA 执行提供程序加速 ONNX RT 执行:
ORT_cuda_ep_config.pbtxt在 GPU 上使用 TRT 加速 ONNX RT 执行:
ORT_TRT_config.pbtxt在 CPU 上使用 OpenVINO 加速 ONNX RT 执行:
ORT_openvino_config.pbtxt
在使用 ONNX RT 时,无论执行提供程序如何,都有一些 通用优化 需要考虑。这些可以是图级优化,或选择用于并行执行的线程的数量和行为,或一些内存使用优化。每种选项的使用高度依赖于要部署的模型。
有了这些背景知识,让我们使用适当的配置文件启动 Triton 推理服务器。
tritonserver --model-repository=/models
注意:这些基准测试仅用于说明性能提升的一般曲线。这不是通过 Triton 可获得的最高吞吐量,因为资源利用率功能尚未启用(例如,动态批处理)。有关模型优化完成后最佳部署配置,请参阅 Model Analyzer 教程。
注意:这些设置旨在最大化吞吐量。有关管理延迟要求,请参阅 Model Analyzer 教程。
作为参考,基线性能如下
Inferences/Second vs. Client Average Batch Latency
Concurrency: 2, throughput: 4191.7 infer/sec, latency 7633 usec
在 GPU 上使用 CUDA 执行提供程序加速 ONNX RT 执行#
对于此模型,启用了对最佳卷积算法的详尽搜索。了解更多选项。
## Additions to Config
parameters { key: "cudnn_conv_algo_search" value: { string_value: "0" } }
parameters { key: "gpu_mem_limit" value: { string_value: "4294967200" } }
## Perf Analyzer Query
perf_analyzer -m text_recognition -b 16 --shape input.1:1,32,100 --concurrency-range 64
...
Inferences/Second vs. Client Average Batch Latency
Concurrency: 2, throughput: 4257.9 infer/sec, latency 7672 usec
在 GPU 上使用 TRT 加速 ONNX RT 执行#
在指定使用 TensorRT 执行提供程序时,CUDA 执行提供程序用作 TensorRT 不支持的算子的回退。如果支持所有算子,建议原生使用 TensorRT,因为性能提升和优化选项明显更好。在本例中,TensorRT 加速器与较低的 FP16 精度一起使用。
## Additions to Config
optimization {
graph : {
level : 1
}
execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt",
parameters { key: "precision_mode" value: "FP16" },
parameters { key: "max_workspace_size_bytes" value: "1073741824" }
}]
}
}
## Perf Analyzer Query
perf_analyzer -m text_recognition -b 16 --shape input.1:1,32,100 --concurrency-range 2
...
Inferences/Second vs. Client Average Batch Latency
Concurrency: 2, throughput: 11820.2 infer/sec, latency 2706 usec
在 CPU 上使用 OpenVINO 加速 ONNX RT 执行#
Triton 用户还可以使用 OpenVINO 进行 CPU 部署。可以通过以下方式启用此功能
optimization { execution_accelerators {
cpu_execution_accelerator : [ {
name : "openvino"
} ]
}}
由于在大多数情况下,1 个 CPU 与 1 个 GPU 进行比较并不是完全公平的比较,我们鼓励在用户的本地 CPU 硬件上进行基准测试。了解更多
对于每个后端,还有许多其他功能可以启用,具体取决于特定模型的需求。有关可能的功能和优化的完整列表,请参阅 此 protobuf。
下一步是什么?#
在本教程中,我们介绍了使用 Triton 推理服务器时可用于加速模型的众多优化选项。这是由 6 部分组成的教程系列的第 4 部分,该系列涵盖了将深度学习模型部署到生产环境中所面临的挑战。第 5 部分涵盖 构建模型集成。第 3 部分和第 4 部分分别侧重于资源利用率和框架级模型加速这两个不同方面。结合使用这两种技术将实现可能的最佳性能。由于具体选择高度依赖于工作负载、模型、SLA 和硬件资源,因此此过程因用户而异。我们强烈鼓励用户尝试所有这些功能,以找到其用例的最佳部署配置。