NVIDIA Triton 推理服务器#
Triton 推理服务器是一款开源推理服务软件,可简化 AI 推理。Triton 推理服务器使团队能够部署来自多种深度学习和机器学习框架的任何 AI 模型,包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL 等。Triton 支持在 NVIDIA GPU、x86 和 ARM CPU 或 AWS Inferentia 上的云、数据中心、边缘和嵌入式设备上进行推理。Triton 推理服务器为多种查询类型提供优化的性能,包括实时、批量、集成和音频/视频流。Triton 推理服务器是 NVIDIA AI Enterprise 的一部分,NVIDIA AI Enterprise 是一个软件平台,可加速数据科学流程并简化生产 AI 的开发和部署。
Triton 架构#
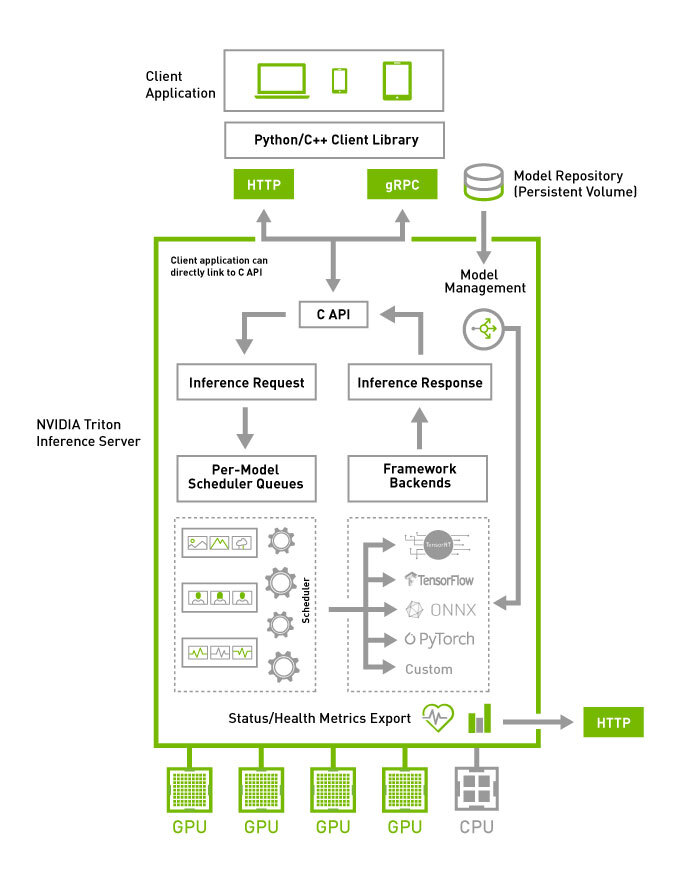
下图显示了 Triton 推理服务器的高级架构。模型仓库是一个基于文件系统的模型仓库,Triton 将使这些模型可用于推理。推理请求通过 HTTP/REST 或 GRPC 或 C API 到达服务器,然后路由到相应的每个模型调度器。Triton 实现了多种调度和批处理算法,这些算法可以在每个模型的基础上进行配置。每个模型的调度器可以选择执行推理请求的批处理,然后将请求传递给与模型类型对应的后端。后端使用批量请求中提供的输入执行推理,以生成请求的输出。然后返回输出。
Triton 支持 后端 C API,允许使用新功能扩展 Triton,例如自定义预处理和后处理操作,甚至新的深度学习框架。
可以通过专用的模型管理 API查询和控制 Triton 正在服务的模型,该 API 可通过 HTTP/REST 或 GRPC 协议或 C API 获得。
就绪和活跃状态健康端点以及利用率、吞吐量和延迟指标简化了 Triton 集成到 Kubernetes 等部署框架中。
Triton 主要特性#
主要特性包括
提供 后端 API,允许添加自定义后端和预处理/后处理操作
使用 集成 或 业务逻辑脚本 (BLS) 的模型管道
基于社区开发的 KServe 协议的 HTTP/REST 和 GRPC 推理协议
指标,指示 GPU 利用率、服务器吞吐量、服务器延迟等
加入 Triton 和 TensorRT 社区,及时了解最新的产品更新、错误修复、内容、最佳实践等。需要企业支持?NVIDIA 全球支持通过 NVIDIA AI Enterprise 软件套件 为 Triton 推理服务器提供。
请参阅最新发行说明,了解有关最新功能和错误修复的更新。