构建复杂管道:Stable Diffusion#
观看此解释视频,其中讨论了管道,然后再继续进行示例。此示例重点展示 Triton 推理服务器的两个功能
使用多个后端#
构建由深度学习模型驱动的管道是一项协作工作,通常涉及多个贡献者。贡献者通常具有不同的开发环境。这可能会导致在使用来自不同贡献者的工作构建单个管道时出现问题。Triton 用户可以使用 Python 或 C++ 后端以及业务逻辑脚本 API (BLS) API 来触发模型执行,从而解决此挑战。
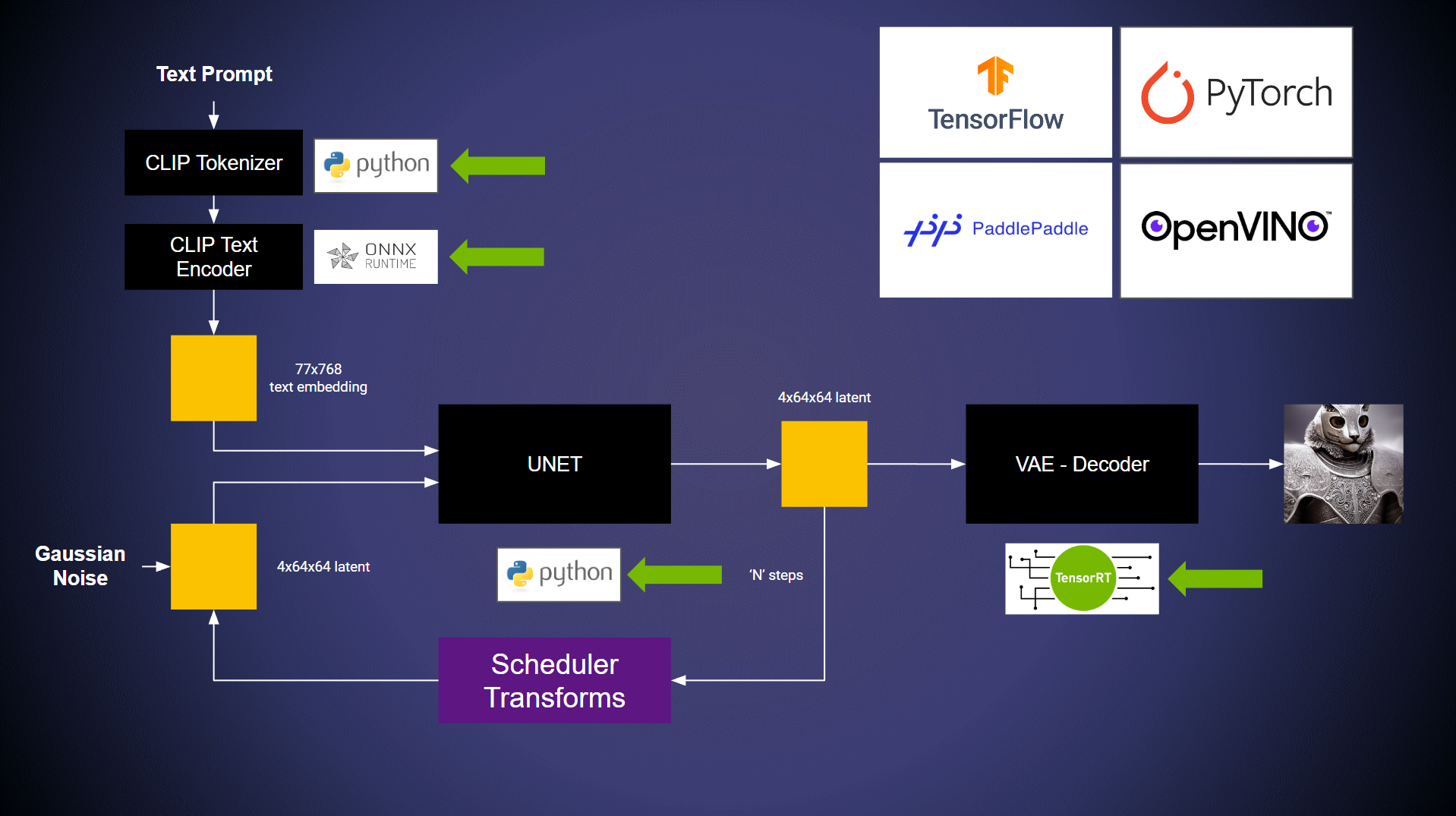
在此示例中,模型正在以下后端上运行:
ONNX 后端
TensorRT 后端
Python 后端
部署在框架后端上的模型都可以使用以下 API 触发:
encoding_request = pb_utils.InferenceRequest(
model_name="text_encoder",
requested_output_names=["last_hidden_state"],
inputs=[input_ids_1],
)
response = encoding_request.exec()
text_embeddings = pb_utils.get_output_tensor_by_name(response, "last_hidden_state")
有关完整示例,请参阅 pipeline 模型中的 model.py。
Stable Diffusion 示例#
在开始之前,请克隆此存储库并导航到根文件夹。为了获得更轻松的用户体验,请使用三个不同的终端。
步骤 1:准备服务器环境#
首先,运行 Triton 推理服务器容器。
# Replace yy.mm with year and month of release. Eg. 22.08
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}:/workspace/ -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:yy.mm-py3 bash
接下来,安装 python 后端中运行的模型所需的所有依赖项,并使用您的 huggingface 令牌登录(需要 HuggingFace 上的帐户)。
# PyTorch & Transformers Lib
pip install torch torchvision torchaudio
pip install transformers ftfy scipy accelerate
pip install diffusers==0.9.0
pip install transformers[onnxruntime]
huggingface-cli login
步骤 2:导出和转换模型#
使用 NGC PyTorch 容器导出和转换模型。
docker run -it --gpus all -p 8888:8888 -v ${PWD}:/mount nvcr.io/nvidia/pytorch:yy.mm-py3
pip install transformers ftfy scipy
pip install transformers[onnxruntime]
pip install diffusers==0.9.0
huggingface-cli login
cd /mount
python export.py
# Accelerating VAE with TensorRT
trtexec --onnx=vae.onnx --saveEngine=vae.plan --minShapes=latent_sample:1x4x64x64 --optShapes=latent_sample:4x4x64x64 --maxShapes=latent_sample:8x4x64x64 --fp16
# Place the models in the model repository
mkdir model_repository/vae/1
mkdir model_repository/text_encoder/1
mv vae.plan model_repository/vae/1/model.plan
mv encoder.onnx model_repository/text_encoder/1/model.onnx
步骤 3:启动服务器#
从服务器容器中,启动 Triton 推理服务器。
tritonserver --model-repository=/models
步骤 4:运行客户端#
使用客户端容器并运行客户端。
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:yy.mm-py3-sdk bash
# Client with no GUI
python3 client.py
# Client with GUI
pip install gradio packaging
python3 gui/client.py --triton_url="localhost:8001"
注意:首次推理查询可能比后续查询花费更多时间