4. 集群用户指南#
欢迎使用您的 Run:ai on DGX Cloud 集群!本指南的这一部分面向希望在集群上运行工作负载的从业人员。有关完整的 Run:ai 文档,请参阅 Run:ai 文档库。
4.1. 登录您的集群#
有两种方法可以与 Run:ai on DGX Cloud 集群交互
使用 Run:ai UI:您的集群管理员应为您提供访问集群的 URL。使用此 URL 登录 Run:ai UI。
使用 Run:ai CLI:此选项仅限于某些用户类型。要使用 Run:ai CLI,您必须首先使用 UI 登录。要了解如何设置 CLI,请访问高级用法中的访问 Run:ai CLI。
4.1.1. 访问 Run:ai UI#
要在浏览器中访问 Run:ai 控制台,请按照以下步骤操作
转到您的集群管理员提供给您的集群 URL。
在登录对话框中,单击Continue with SSO(使用 SSO 继续)。您的 SSO 登录对话框将打开。
输入您的详细信息。登录后,您将被带到 Run:ai 集群概览页面。
4.2. 了解您的角色和范围#
在 Run:ai 中工作时,您的用户角色决定了您可以在集群中执行的操作。本节解释如何识别您的角色并了解您的权限。您可以在单个集群中被分配多个角色。
4.2.1. 了解您的用户角色#
当您首次收到集群 URL 时,您的集群管理员应已告知您分配的角色。如果您尚未收到此信息,请联系您的集群管理员。
要查看您的用户类型允许的权限和操作,请访问 Run:ai RBAC 文档。
4.3. 浏览您在 DGX Cloud 上的 Run:ai 环境#
本节介绍 Run:ai on DGX Cloud 的关键概念,重点介绍 DGX Cloud 集群特有的领域。有关更多信息,请参阅完整的 Run:ai 文档库。
4.3.1. 概述#
登录 Run:ai UI 后,您将被带到 Run:ai Overview(概览)页面。
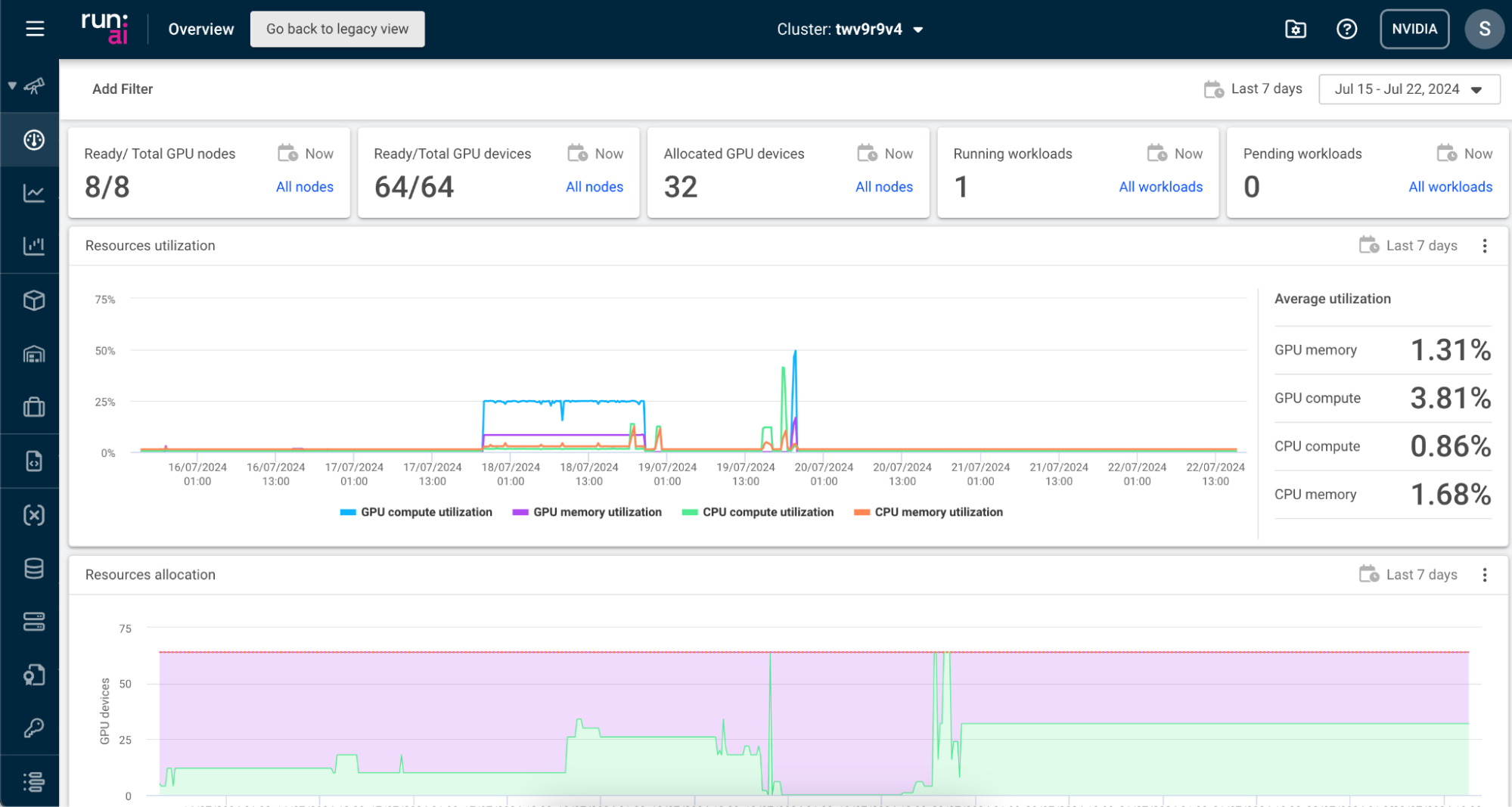
Overview(概览)页面显示有关您的集群的关键指标,包括资源利用率和已分配的 GPU 设备数量。您的集群名称列在顶部导航栏中。
左侧导航菜单提供对 UI 不同部分的快速访问。使用它可以导航到 Projects(项目)、Workloads(工作负载)、Departments(部门)和 Nodes(节点)页面等,如下所述。
有关分析、配额管理和节点的更多信息,请访问 Run AI 文档。
4.3.2. 部门和项目#
访问 Run:ai 部门 以获取有关部门和项目的详细介绍。
4.3.2.1. 部门#
部门允许您将配额与不同的团队和用户组关联。用户是部门的成员,所有项目都必须在部门内创建。
注意
只有角色为应用程序管理员和编辑者的用户才能创建部门。
4.3.2.1.1. 创建部门#
有关创建部门的说明,请参阅集群管理员指南的创建部门部分。
4.3.2.2. 项目#
项目用于分配资源,并在不同的研究计划之间定义明确的护栏。用户组(或在某些情况下为个人)与项目关联,并且可以在该项目内针对固定的项目分配运行工作负载。
所有项目都与部门关联。务必注意部门的配额限制,因为这些限制将影响与该部门关联的任何项目的分配和配额。
多个用户可以被纳入同一项目。项目级信息(包括凭据)对该项目中的所有用户可见。
4.3.2.2.1. 创建项目#
注意
只有角色为应用程序管理员、部门管理员、编辑者和研究经理的用户才能在其 Run:ai 集群上的范围内创建和管理项目。
按照集群管理员指南中的创建项目创建项目。
4.3.2.2.2. 编辑现有项目#
如果您的权限允许,您可以通过单击项目名称左侧的复选框,然后单击项目概览页面顶部菜单栏上的 Edit(编辑)来更新现有项目。这将带您返回项目创建页面,您可以在其中根据需要更新任何条目。
您可以通过单击项目名称左侧的复选框,然后单击项目概览页面顶部菜单栏上的 Access Rules(访问规则)来更新项目的用户访问权限。这将弹出一个弹出窗口,您可以在其中输入其他用户电子邮件地址以授予他们对项目的访问权限。
4.3.3. 工作负载#
工作负载是您提交到集群执行的计算作业或任务。您的 Run:ai on DGX Cloud 集群上启用了两种类型的工作负载
工作空间 - 最适合开发和探索数据和代码的交互式环境。
训练 - 非交互式的分布式训练作业。
注意
集群中未启用推理,并且已弃用的 Jobs 工作负载尚未经过验证。
工作负载在项目范围内运行,并且可以消耗各种资源。有关这些资源的详细信息,请参见本指南的下一节。以下是资源的简要概述
环境 - 工作负载必须具有环境。环境充当容器,包含库、需求以及可选的代码和数据。
计算资源 - 工作负载需要分配的计算资源,这些资源决定了它可以使用的 CPU 和 GPU 数量。
卷 - 卷可以与作业关联,从而可以访问您的数据。它们专用于特定的工作负载,并且无法传输。
数据源 - 您可以连接到各种数据源,包括 Git 和持久卷声明 (PVC)。数据源与工作负载分开创建,并且可以在不同的工作负载之间使用(如果需要)。
凭据 - 在项目级别作用域的凭据将自动注入到项目中运行的任何工作负载中。
模板 - 模板允许您预先填写工作负载创建表单,并将其保存以供项目中的用户稍后使用。这对于经常使用的工作负载非常有用。
在接下来的章节中,我们将更详细地介绍这些工作负载组件中的每一个。
我们还在交互式工作负载示例指南中提供了创建和启动各种工作负载的完整示例。
4.3.4. 环境#
Run:ai 环境指定容器 URL 以及容器的镜像拉取策略和入口命令。所有工作负载必须指定环境。
创建环境时,您可以指定范围,指示哪些部门和项目可以查看和使用它。
4.3.4.1. 创建新环境#
注意
只有角色为应用程序管理员、部门管理员、编辑者、环境管理员、L1 研究员和研究经理的用户才能创建环境。
要使用 Run:ai UI 创建新环境
在左侧导航菜单中,选择 Environments(环境)。您将被带到 Environments(环境)概览页面,该页面显示有关集群中现有环境的信息。
单击页面左上角的 + NEW ENVIRONMENT(+ 新环境)。您将被带到 New environment(新建环境)创建页面。
为环境选择一个 Scope(范围)。这决定了哪些集群、部门、组或项目可以部署该环境。
输入环境名称和描述。
插入容器镜像的 URL,然后选择镜像的拉取策略。
选择工作负载的架构和类型。
(可选)为您的工具选择连接。
(可选)在 Runtime settings(运行时设置)下拉菜单下,设置在 Pod 中运行容器的任何命令和参数。为容器添加任何环境变量和工作目录。
注意
使用容器镜像时,务必注意容器的启动命令或入口点。
(可选)在 Security(安全性)菜单下,为容器设置其他 Linux 功能,并指示是否应从镜像或自定义位置获取 UID、GID 和组。
单击 CREATE ENVIRONMENT(创建环境)。您将被带回到 Environments(环境)概览页面,您的环境将列在该页面的表格中。
4.3.4.2. 编辑环境#
注意
只有角色为应用程序管理员、部门管理员、编辑者、环境管理员、L1 研究员和研究经理的用户才能编辑环境。
您可以通过创建“编辑副本”来编辑现有环境。要编辑环境,请从 UI 中的 Environment(环境)概览页面
单击您要编辑的环境。菜单栏将出现在页面顶部。
单击 COPY & EDIT(复制和编辑)。您将被带到 New environment(新建环境)概览页面,该页面将预先填充所选环境的详细信息。
根据需要编辑环境,然后单击 CREATE ENVIRONMENT(创建环境)。
4.3.5. 计算资源#
在 Run:ai 中,计算资源是指由 CPU 设备和内存组成的资源请求,以及可选的 GPU 和 GPU 内存。当请求具有特定计算资源的工作空间时,调度程序会搜索这些资源。如果可用,工作空间将启动并访问它们。
注意
在您的 Run:ai on DGX Cloud 集群上,您不能使用部分 GPU。因此,请避免选择或创建使用部分 GPU 的计算资源。
4.3.5.1. 创建新的计算资源#
注意
只有角色为应用程序管理员、计算资源管理员、部门管理员、编辑者、L1 研究员和研究经理的用户才能创建新的计算资源。
要创建新的计算资源
使用左侧导航菜单导航到 Compute Resources(计算资源)概览页面。
单击 + NEW COMPUTE RESOURCE(+ 新建计算资源)。您将被带到 New compute resource(新建计算资源)创建页面。
为资源设置 Scope(范围)。有权在该范围内创建工作负载的所有用户都将能够使用该计算资源。
为您的计算资源命名并添加描述。
在页面的 Resources(资源)部分下,选择每个 Pod 的 CPU 和 GPU 设备数量,以及 CPU 和 GPU 设备的内存。
注意
您的 Run:ai on DGX Cloud 集群不支持部分 GPU。
填写完页面后,单击 CREATE COMPUTE RESOURCE(创建计算资源)。您将被带到 Compute resource(计算资源)概览页面,您的新计算资源将出现在资源列表中。
4.3.6. 存储#
在 Run:ai 中,有两种类型的存储
数据源 - 可以附加到工作负载的持久存储。
卷 - 在工作负载启动时创建的非持久存储,仅在工作负载运行时持续存在。
在接下来的章节中,我们将更详细地介绍数据源和卷,并提供使用这些存储类型访问和读取数据的示例。
DGX Cloud 在当前版本中为持久存储提供了 GCP Filestore。Filestore 为用户提供了多种存储类。
4.3.6.1. 数据源#
数据源是持久的通用存储或与外部数据(如 Git 存储库)的连接。
DGX Cloud 支持的数据源有
持久卷声明 (PVC)(请参阅下面的详细信息)
Git
ConfigMap
DGX Cloud 不支持以下数据源
NFS
S3 存储桶
主机路径
创建任何数据源时,都需要为其分配一个范围,定义哪些项目和部门可以使用数据源或连接到数据源。以下部分提供了有关支持的数据源的更多详细信息。
4.3.6.1.1. PVC#
持久卷声明 (PVC) 是用户发起的 Kubernetes 存储容量请求。在 Run:ai 数据源的上下文中,PVC 是一个存储池,可以根据 DGX Cloud 部署中一组可用的存储类型进行配置,这些存储类型具有不同的功能和容量。
从概念上讲,PVC 数据源应被用作高性能共享目录,用于存储需要在每个项目或命名空间中访问的数据,以用于您的工作负载。
重要提示
创建 PVC 会计入集群可用的存储配额。应注意确保有效使用每个 PVC,以免过快耗尽您的总可用存储配额。
根据您的 DGX Cloud 集群部署在哪个 CSP 上,您将在创建 PVC 时有不同的存储类可供选择。如果您不知道您的集群在哪个 CSP 上,请联系您的集群管理员或 NVIDIA TAM 了解更多详细信息。
推荐的存储类
基于 GCP 的集群利用 Google Filestore 提供的共享存储。建议在 DGX Cloud 中使用以下来自 Filestore 的 PVC 存储类。它们的性能特征和功能在此处列出。
服务层级 |
GKE 存储类 |
GKE PVC 大小 |
部署 |
访问模式 |
|---|---|---|---|---|
区域 |
zonal-rwx |
10-100 TiB |
区域 |
read/write/many(多读/写) |
所有其他 PVC 存储类(none、standard、standard-rwo、standard-rwx、premium-rwo、premium-rwx、Enterprise-rwx、Enterprise-multishare-rwx)均不受支持,使用它们将导致作业失败。
推荐的存储类
基于 AWS 的集群利用 FSx Lustre 提供的共享存储。以下存储类可供使用
服务层级 |
存储类 |
PVC 大小 |
部署 |
访问模式 |
|---|---|---|---|---|
FSx Lustre (SSD) |
lustre-sc |
12-160 TiB |
PERSISTENT-1 |
read/write/many(多读/写) |
所有其他 PVC 存储类(none、gp2、ebs)均不受支持,使用它们将导致作业失败。
注意
有关每个存储类的总存储容量或当前存储利用率的信息,请参阅高级用法中的管理您的存储利用率。
创建 PVC
注意
只有角色为应用程序管理员、数据源管理员、部门管理员、编辑者、L1 研究员和研究经理的用户才能创建 PVC。
要从 Run:ai UI 创建 PVC
从 Data Sources(数据源)概览页面,单击 + NEW DATA SOURCES(+ 新建数据源)。将出现一个下拉菜单。
从下拉菜单中,选择 PVC。您将被带到 New data source(新建数据源)创建页面。
设置 PVC 的 Scope(范围),然后输入名称和描述。
重要提示
在集群或部门级别创建的 PVC 数据源不会跨项目或命名空间复制数据。每个项目或命名空间将配置为单独的 PVC 副本,具有不同的底层 PV;因此,每个 PVC 中的数据不会被复制。
填写表单的 Data mount(数据挂载)部分
选择 Storage(存储)类。请务必查看DGX Cloud 推荐的存储类。
选择 PVC 的访问模式配置 - 单节点读/写、多节点只读或多节点读/写。
指定声明大小以确保 PVC 的最小容量。
注意
PVC 可能大于实际需要,具体取决于底层存储的最小分区大小。在配置大于 1 TiB 的存储时,请参考上表以确保与目标存储类的兼容性。
选择 Volume mode(卷模式)作为 Filesystem(文件系统)选项。
注意
不支持 Block(块)Volume mode(卷模式)。选择它可能会导致启动使用结果 PVC 的工作负载时出错。
指定 Container path(容器路径)以定义 PVC 在正在运行的作业中可访问的路径。
注意
如果您未指定
/scratch卷,则将使用临时存储为基于 GPU 的计算资源隐式配置一个卷。(可选)在 Restrictions(限制)窗格中,您可以根据需要使用切换开关将存储设置为只读。
注意
这是 PVC 访问模式配置的替代方案。
单击 CREATE DATA SOURCE(创建数据源)。您将被带到 Data sources(数据源)概览页面,您可以在其中查看新的 PVC 数据源。
注意
创建新数据源时,您还可以选择现有的 PVC。此 PVC 可以使用 K8s API 或集群上的 kubectl 直接创建。有关与 K8s 集群交互的更多信息,请参阅设置您的 Kubernetes 配置文件。
4.3.6.1.2. Git#
Git 是一种版本控制系统 (VCS),用于管理软件项目中的迭代代码修改和协作。作为 Run:ai 数据源,它获取公共或私有 Git 存储库,并使其作为文件系统路径在工作负载内部可用。
创建 Git 数据源
注意
只有角色为应用程序管理员、数据源管理员、部门管理员、编辑者、L1 研究员和研究经理的用户才能创建 Git 数据源。
要使用 UI 在您的 Run:ai 集群中创建 Git 数据源
从 Data sources(数据源)概览页面,单击 + NEW DATA SOURCE(+ 新建数据源)。将出现一个下拉菜单。
从下拉菜单中,选择 Git。您将被带到 New data source(新建数据源)创建页面。
设置 Git data source(Git 数据源)的范围。
在相关字段中输入名称和描述。
填写 Git 存储库的 URL,并可以选择指定分支。
为数据源选择相关的凭据。如果 Git 存储库是私有的,则需要这些凭据。(您可以在 Run:ai 凭据 Web 界面中创建必要的凭据)。
设置 Container path(容器路径)。这定义了 Git 数据源在正在运行的作业中可访问的路径。
注意
如果您未指定
/scratch卷,则将使用临时存储为基于 GPU 的计算资源隐式配置一个卷。单击 CREATE DATA SOURCE(创建数据源)。您将被带到 Data sources(数据源)概览页面,您的新数据源将显示在该页面的表格中。
4.3.6.1.3. ConfigMap#
ConfigMap 是一个 Kubernetes 对象,用于将非机密数据存储为键值对。作为 Run:ai 数据源,它获取 Run:ai Kubernetes 集群中存在的 ConfigMap,并使其作为文件在工作负载内部可用。
注意
只有角色为应用程序管理员、数据源管理员、部门管理员、编辑者、L1 研究员和研究经理的用户才能创建 Configmap。
要从 UI 在您的 Run:ai 集群中创建 Configmap
从 Data sources(数据源)概览页面,单击 NEW DATA SOURCE(新建数据源)。将出现一个下拉菜单。
从下拉菜单中,选择 ConfigMap。您将被带到 New data source(新建数据源)创建页面。
为 ConfigMap 选择 Scope(范围)。
注意
ConfigMap 只能在单个项目级别作用域。您不能选择整个集群或部门作为 ConfigMap 的范围。
输入名称和描述。
从 ConfigMap 名称下拉菜单中,选择 Run:ai Kubernetes 集群上存在的 ConfigMap。
设置 Container(容器)路径,该路径定义了 ConfigMap 在正在运行的作业中可访问的路径。
注意
如果您未指定
/scratch卷,则将使用临时存储为基于 GPU 的计算资源隐式配置一个卷。单击 CREATE DATA SOURCE(创建数据源)。您将被带到 Data sources(数据源)概览页面,新的 ConfigMap 将显示在该页面的表格中。
4.3.6.2. 卷#
卷是 Run:ai 中特定于工作负载的存储。在工作负载创建时,用户可以创建新卷。卷的大多数配置选择都镜像了PVC数据源部分中记录的那些。此外,用户可以将卷的内容指定为持久性或临时性。持久卷保留写入其中的所有数据,直到与其关联的工作负载被删除。临时卷的内容在每次工作负载停止时都会被删除。
工作负载可以使用临时本地存储作为暂存空间、缓存和日志。本地临时存储的生命周期不会超出单个 Pod 的生命周期。它通过容器的可写层、日志目录和 EmptyDir 卷暴露给 Pod。EmptyDir 卷中的数据在容器崩溃后仍然保留。
当用户提交需要 GPU 的作业时,节点本地 SSD 上的 EmptyDir 将作为暂存磁盘附加到 Pod。 /scratch 目录看起来有 6TiB,这是节点上的总存储空间;但是,每个 Pod 限制为 200 GiB。如果 Pod 超过此 200 GiB 限制,它将被从节点中驱逐(即终止)。仅 CPU 工作负载不会配置 /scratch 目录。
4.3.7. 凭据#
Run:ai UI 支持用于访问容器和应用程序的凭据,否则这些容器和应用程序将被门控。您的集群上支持的凭据类型有
Docker 注册表
访问密钥
用户名和密码
集群中未启用 Generic Secret 类型的凭据。
当您向集群添加凭据时,必须选择一个范围。然后,任何在该作用域级别部署的工作负载都可以使用这些凭据。可以应用的最小范围是项目级范围。凭据没有用户特定的作用域可用。
作为您订阅 Run:ai on DGX Cloud 的一部分,您被授予访问 NVIDIA GPU Cloud (NGC) 目录 的权限。 NGC 目录包含 GPU 加速的 AI 模型和 SDK,使您能够以光速将 AI 注入到您的应用程序中。
4.3.7.1. 访问您的 NGC 组织#
您的集群管理员可以邀请您加入 NVIDIA GPU Cloud (NGC)。收到邀请后,请按照电子邮件中的说明设置您的帐户。
4.3.7.2. 设置您的 NGC API 密钥#
要生成您的 NGC API 密钥,请按照以下步骤操作
登录 NGC。
单击屏幕右上角的用户帐户菜单,然后选择 Setup(设置)。
单击 Generate Personal Key(生成个人密钥),并在打开的新表单中生成密钥。将显示的密钥保存在安全的地方,因为该密钥只会显示一次,并且是后续步骤所必需的。
4.3.7.3. 将 NGC 凭据添加到 Run:ai 集群#
注意
只有角色为应用程序管理员、凭据管理员、部门管理员、编辑者和L1 研究员的用户才能向集群添加凭据。
要将 NGC 凭据添加到 Run:ai 集群
从 Run:ai 左侧导航菜单访问 Credentials(凭据)页面。
单击 + NEW CREDENTIALS(+ 新建凭据),然后从下拉菜单中选择 Docker registry(Docker 注册表)。您将被带到 New credential(新建凭据)创建页面。
为您的 NGC 凭据选择 Scope(范围)。该密钥可供任何在该范围内启动的工作负载使用。例如,如果您的范围设置为部门级别,则与该部门关联的任何项目中启动的所有工作负载都可以使用该密钥,无论哪个用户创建了凭据或启动了工作负载。
输入凭据的名称和描述。这对任何集群用户都是可见的。
选择 New secret(新建密钥)。
对于用户名,使用
$oauthtoken。对于密码,粘贴您的令牌。
在 Docker Registry URL(Docker 注册表 URL)下,输入
nvcr.io。单击 CREATE CREDENTIALS(创建凭据)。您的凭据现在将保存在集群中。
4.3.7.4. 添加 Git 凭据#
要将 Git 凭据添加到您的 Run:ai on DGX Cloud 集群,您必须首先从您的 Git 服务器创建一个个人访问令牌,并在创建过程中授予对所需存储库的访问权限。您可以通过按照 这些说明在 GitHub 上创建令牌,并通过按照 这些说明在 GitLab 上创建令牌。
注意
只有角色为应用程序管理员、凭据管理员、部门管理员、编辑者和L1 研究员的用户才能向集群添加凭据。
生成个人访问令牌后,按照以下说明将您的凭据添加到 Run:ai 集群
从 Run:ai 左侧导航菜单访问 Credentials(凭据)页面。
单击 + NEW CREDENTIALS(+ 新建凭据),然后从下拉菜单中选择 Username & password(用户名和密码)。您将被带到 New credential(新建凭据)创建页面。
为您的凭据选择 Scope(范围)。该密钥可供任何在该范围内启动的工作负载使用。
输入凭据的名称和描述。这对任何集群用户都是可见的。
选择 New secret(新建密钥)。
对于用户名,使用您的 Git 用户名。
对于密码,粘贴您的个人访问令牌。
单击 CREATE CREDENTIALS(创建凭据)。您的凭据现在将保存在集群中。
4.3.8. 模板#
模板用于预定义常用工作负载。它们使基于预设说明快速轻松地启动工作负载。
注意
只有角色为应用程序管理员、凭据管理员、部门管理员、编辑者、L1 研究员、研究经理和模板管理员的用户才能向集群添加凭据。
要创建模板,请从左侧导航菜单导航到 Templates(模板)概览页面,然后
单击 + NEW TEMPLATE(+ 新建模板)。将打开 New Template Creation(新建模板创建)页面。
为模板设置 Scope(范围)。这决定了哪些部门和项目可以使用此模板。
输入模板名称和描述。
为您的模板选择或创建要使用的 Environment(环境)。
选择计算资源。
(可选)为 Volumes(卷)和 Data Sources(数据源)选择值。
选择完模板的所有所需设置后,单击 CREATE TEMPLATE(创建模板)。您将被带回到 Templates(模板)概览页面。
创建后,可以在 New Workload(新建工作负载)创建过程中选择模板以供使用。