3. 分布式训练工作负载示例#
在本节中,我们将提供有关在 DGX Cloud 上的 Run:ai 集群上运行多个训练工作负载的说明。这些示例并非详尽无遗,但可以针对您自己的工作负载进行调整。
3.1. 分布式 PyTorch 训练作业#
在本示例中,我们将演示如何使用 Kubeflow 的 PyTorch 训练运算符运行多节点训练作业。
3.1.1. 要求#
为了运行分布式 PyTorch 训练作业,需要构建自定义 Docker 容器。这是必要的,以便将相关代码放入容器中,该容器可以运行并为所有未来的作业共享。
要构建自定义 Docker 容器,需要在本地机器上安装 Docker 运行时,该本地机器的 CPU 架构应与 DGX Cloud 主机相同(也就是说,如果 DGX Cloud 主机具有基于 AMD64 的 CPU,则容器需要在 AMD64 机器上构建。如果 DGX Cloud 主机是基于 arm 的,则容器需要在 ARM CPU 上构建)。要在本地安装 Docker,请按照Docker Engine 安装指南进行操作。
此外,您需要使用在上面的“凭据”部分中创建的 NGC 密钥向 NGC 私有注册表进行身份验证。要使用 NGC 进行身份验证,请运行以下命令(注意,用户名必须完全是“$oauthtoken”)
1$ docker login nvcr.io 2Username: $oauthtoken 3Password: <NGC Key here>
3.1.2. 创建自定义 Docker 容器#
在安装了 Docker 的本地机器上,创建并导航到要保存 Dockerfile 的目录,例如
pytorch-distributed1$ mkdir -p pytorch-distributed 2$ cd pytorch-distributed
在新目录中,打开一个名为
run.sh的新文件,并将以下内容复制到该文件1#!/bin/bash 2 3torchrun multinode.py --batch_size 32 100 25 4cp snapshot.pt /checkpoints
这是一个非常简单的脚本,它使用
torchrun启动分布式训练作业,并将生成的检查点复制到容器内的/checkpoints目录,以便以后可以再次使用。保存并关闭文件。接下来,打开另一个名为
Dockerfile的新文件,并将以下内容复制到该文件1FROM nvcr.io/nvidia/pytorch:24.07-py3 2 3WORKDIR /runai-distributed 4RUN git clone https://github.com/pytorch/examples 5 6WORKDIR /runai-distributed/examples/distributed/ddp-tutorial-series 7COPY run.sh .
此 Dockerfile 使用 NGC 上托管的 24.07 PyTorch 容器作为基础,在容器内部克隆官方 PyTorch 示例存储库,并将之前创建的
run.sh文件复制到容器中。保存并关闭文件。本地保存这两个文件后,使用以下命令构建容器,将 <ORG ID> 替换为 NGC 上私有注册表的 ID
docker build -t nvcr.io/<ORG ID>/pytorch-ddp-example:24.07-py3 .
这将在本地构建自定义容器。
构建完成后,使用以下命令将镜像推送到 NGC 私有注册表
docker push nvcr.io/<ORG ID>/pytorch-ddp-example:24.07-py3
自定义容器将在您的私有 NGC 注册表中可用,并可以立即用于作业。
3.1.3. 创建数据源#
为了更轻松地在未来的作业中重用代码和检查点,创建了一个数据源,特别是 PVC。PVC 可以挂载在作业中,并且在作业完成后仍然存在,因此可以重用创建的任何数据。
要创建新的 PVC,请转到数据源页面。单击新建数据源,然后单击 PVC 以打开 PVC 创建表单。
在新表单上,设置所需的范围。
重要提示
在集群或部门级别创建的 PVC 数据源不会跨项目或命名空间复制数据。每个项目或命名空间都将作为单独的 PVC 副本进行配置,并具有不同的底层 PV;因此,每个 PVC 中的数据都不会被复制。
为 PVC 指定一个易于记忆的名称,例如
distributed-pytorch-checkpoint,并根据需要添加描述。对于数据选项,请根据 PVC 建议此处选择适合您需求的新 PVC 存储类。在本示例中,
zonal-rwx就足够了。要允许所有节点从 PVC 读取和写入,请为访问模式选择多节点读写。输入10 TB作为大小,以确保我们有足够的容量用于未来的作业。选择文件系统作为卷模式。最后,将容器路径设置为/checkpoints,这是 PVC 将在容器内部挂载的位置。完成后的部分应如下图所示。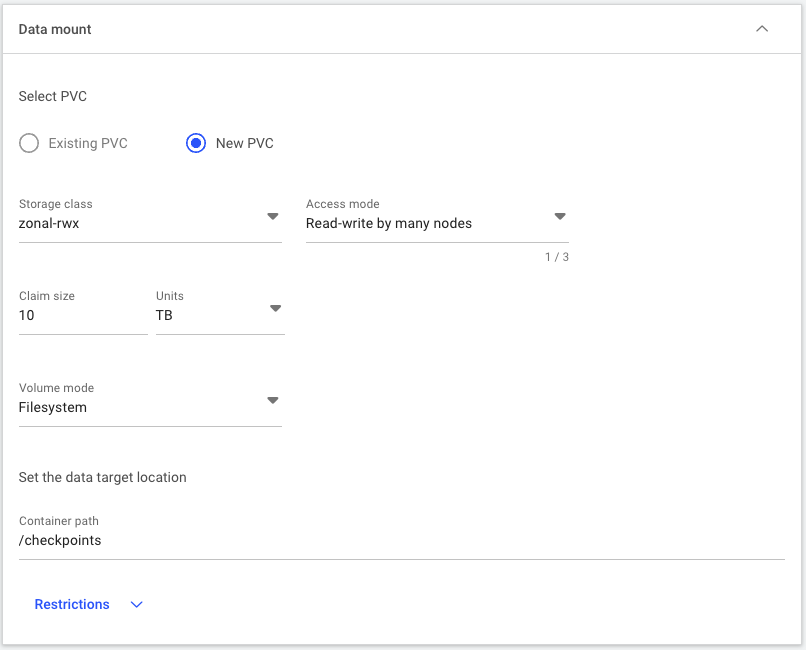
表单完成后,使用页面底部的按钮创建数据源。
注意
首次使用新 PVC 启动作业时,启动时间会更长,因为存储仅在首次声明 PVC 时才会配置。
3.1.4. 通过 UI 创建工作负载#
要创建训练作业,请导航到工作负载页面,然后单击新建工作负载 > 训练。
在项目创建表单页面上,选择要在其中运行作业的所需项目。
为工作负载架构选择分布式以运行多节点作业。这将添加一个下拉菜单,其中列出了用于运行分布式作业的可用框架。由于我们正在运行 PyTorch 作业,因此选择 PyTorch 框架。
分布式训练配置具有工作节点和主节点或仅工作节点选项。
注意
在本文档中,我们将使用术语“主节点”而不是“主节点”,以与现代术语保持一致。请注意,UI 和命令可能仍将其称为“主节点”。
通常,当运行需要彼此协调的多节点作业(例如执行 all_reduce 操作的作业)时,需要主节点。主节点可以与工作节点相同并运行训练过程,也可以是仅进行协调的轻量级 Pod。如果作业不需要进程之间的协调,则可以使用仅工作节点选项。对于我们的示例,我们希望 Pod 彼此协调。选择工作节点和主节点选项。
确保为模板选择从头开始选项。
为作业指定一个名称,例如“distributed-training-pytorch”,然后单击继续。
在打开的新环境表单中,选择新建环境。在新表单中,为环境提供一个名称,例如“distributed-pytorch-env”,并可选择添加描述。
在镜像 URL 中,提供在上面的创建自定义 Docker 容器部分中容器构建期间指定的镜像标签名称,例如
nvcr.io/<ORG ID>/pytorch-ddp-example:24.07-py3。这将使用已推送到您的私有 NGC 组织的容器来执行作业。如果需要,可以更改镜像拉取策略。对于大多数情况,建议使用默认值“如果本地不存在”,但如果您正在使用相同的标签将新容器推送到 NGC 组织,则应使用“始终从注册表拉取镜像”来检查镜像是否有更新。
表单上的大多数其余设置都可以保持默认值,但运行时设置除外。运行时设置指示要将 Pod 打开到的目录以及要在容器内部启动的命令(如果需要除默认容器值以外的其他值)。
在我们的示例中,我们希望使用
torchrun启动multinode.py脚本,该脚本运行多进程应用程序,其中每个进程都有其唯一的排名。PyTorch 训练运算符与 torchrun 协调,以根据为作业分配的 GPU 总数自动设置RANK、LOCAL_RANK和WORLD_SIZE以及其他环境变量。在命令和参数字段中,输入torchrun multinode.py --batch_size 32 100 25作为命令。这将使用 32 的批大小在所有分配的 GPU 上运行分布式训练作业 100 个总 epoch,并每 25 个 epoch 保存一个检查点。对于目录字段,填写
/runai-distributed/examples/distributed/ddp-tutorial-series。这是保存在我们构建的容器内部的脚本的位置,也是我们希望 Pod 在启动时打开到的容器内部的路径。选择创建环境按钮后,您将返回到作业创建页面,并选择了新环境。在计算资源窗格中,选择所需的工作节点数。请注意,由于我们正在使用主节点和工作节点配置,并且我们希望主节点参与训练,因此我们将指定的工作节点数比作业预期的总节点数少一个。换句话说,如果我们想要运行一个 8 节点作业,其中主节点将协调进程并进行训练,我们将指定 7 个工作节点和 1 个主节点(这是下一个表单)。在我们的示例中,我们将使用 2 个总节点进行训练。因此,在表单中选择 1 个工作节点。
对于计算资源,我们希望在具有所有可用 GPU 资源的完整 DGX 节点上进行训练。在您的项目中选择 GPU 容量为 8 的计算资源。
在数据源窗格中,选择在上一节中创建的 PVC 的名称。本示例中 PVC 的名称为“distributed-pytorch-checkpoints”。单击继续以导航到主节点配置页面。
如前所述,对于分布式 PyTorch 作业,主节点 Pod 可以具有与工作节点 Pod 不同的配置。对于我们的示例,我们希望对工作节点和主节点使用相同的设置,因此请确保取消选择允许主节点使用不同的设置单选按钮。
完成后,单击创建训练以将训练作业排队。
3.1.5. 监控作业#
提交作业后,可以在工作负载页面中查看状态。在列表中找到作业名称,例如上一个示例中的“distributed-training-pytorch”。单击作业将显示一个表单,其中包含有关作业的其他信息,包括事件历史记录、指标和日志。
事件历史记录选项卡显示作业的当前状态,例如“正在创建”、“正在初始化”、“待定”、“正在运行”等等。此外,它还显示一个日志,其中包含所有状态的时间戳,包括适用时的任何输出消息。这对于查看作业是否正在运行或是否因任何原因失败非常有用。
指标选项卡包含多个图表,显示 Pod 资源使用情况,包括 GPU、CPU 和内存利用率。这有助于确定作业对硬件资源的压力有多大,或者可能查看应用程序是否未充分利用资源。在选项卡的顶部,有一个下拉列表,用于选择特定 Pod 或所有 Pod 聚合的指标,以获得更精细的粒度。
最后,日志选项卡显示每个 Pod 的实时 STDOUT,包括聚合输出。在我们的示例应用程序中,将有输出显示训练进度,包括每个 GPU 的 epoch、批大小和步数。日志是查看训练进度或可能查看过程中是否存在任何错误的好地方。
3.1.6. 获取检查点#
我们创建的 run.sh 脚本的结尾将最新生成的检查点复制到附加到作业的 PVC。现在,任何使用同一 PVC 的作业都将能够加载作业内部 /checkpoints/snapshot.pt 处的检查点。同样,任何数据都可以保存到作业中指定的文件系统路径处的 PVC。这在生成长时间运行的训练作业中的检查点以继续未来作业的进度或更改作业之间的超参数时非常有用。
3.1.7. 清理环境#
作业完成后,可以将其删除以释放资源以供其他作业使用。请注意,某些作业不会自行终止,应监控作业以确保已完成作业的资源不会闲置。
3.2. 使用零配额项目处理较低优先级的工作负载#
在本示例中,我们将逐步介绍创建零配额项目以处理较低优先级工作负载的过程,确保它们始终是可抢占的。
本示例旨在供集群管理员管理集群的使用情况,并演示如何为集群的混合使用对某些工作负载和项目进行优先级排序。通过这种方式,当需要运行较高优先级的工作负载时,可以抢占较低优先级的工作负载,并在较高优先级的工作负载完成后恢复较低优先级的工作负载。
集群管理员完成项目和配额配置后,用户可以在分配的项目中运行符合较低或较高优先级用例的工作负载,并且它们的工作负载将按配置进行调度和抢占。
3.2.1. 要求#
3.2.2. 通过 UI 创建最大配额项目#
在本节中,我们将创建一个具有足够配额以使用整个集群计算资源的项目。
注意
这是一个只需执行一次的设置步骤。除非删除,否则最大配额项目将持续存在。
导航到项目页面,然后单击 + 新建项目按钮。
在范围字段中,确保选择了
default部门(或能够使用集群所有可用资源的备用部门)。在项目名称字段中输入一个名称,例如
full-quota-project。在配额管理下,将 GPU 设备字段设置为使用部门可用的所有 GPU,并将 CPU(核心)和 CPU 内存字段设置为
Unlimited。不要更改其他字段,然后单击创建项目按钮。
3.2.3. 通过 UI 创建零配额项目#
在本节中,我们将创建一个零配额项目。在此项目中运行的工作负载仍然可以使用计算资源,但将始终超出配额并容易被抢占。
注意
这是一个只需执行一次的设置步骤。除非删除,否则零配额项目将持续存在。
导航到项目页面,然后单击 + 新建项目按钮。
在范围字段中,确保选择与上一节中使用的部门相同的部门。
在项目名称字段中输入一个名称,例如
zero-quota-project。在配额管理下,将 GPU 设备、CPU(核心)和 CPU 内存字段设置为
0。不要更改其他字段,然后单击创建项目按钮。
3.2.4. 通过 UI 创建较低优先级的交互式工作负载#
在本节中,我们将在零配额项目中创建并启动一个工作空间。
注意
在零配额项目中使用训练工作负载时,也存在相同的调度行为。使用的一些确切步骤和环境会有所不同。
导航到工作负载页面,然后单击 + 新建工作负载按钮。选择 Workspace 选项。
在项目部分下选择
zero-quota-project选项。在模板部分下选择从头开始。
在工作空间名称部分下输入一个名称,例如
zero-quota-workspace,然后单击继续按钮。在环境部分下选择
jupyter-lab选项。在计算资源部分下选择
h100-1g选项。打开常规部分,然后将
允许工作空间超出项目配额开关切换为打开状态(打开时将显示为蓝色)。否则,工作空间将无法启动。单击创建工作空间按钮。
UI 将自动返回到工作负载页面 - 观察
zero-quota-workspace工作负载进入Running状态。
3.2.5. 通过 UI 创建较高优先级的训练工作负载#
在本节中,我们将在全配额项目中创建并启动训练工作负载。此训练工作负载将抢占在零配额项目中启动的工作负载。
导航到工作负载页面,然后单击 + 新建工作负载按钮。选择 Training 选项。
在项目部分下选择
full-quota-project选项。在工作负载架构部分下选择
Distributed选项。当设置分布式训练的框架下拉菜单出现在工作负载架构部分中时,选择
PyTorch选项。当设置分布式训练配置选项出现在工作负载架构部分中时,选择
Workers only选项。在模板部分下选择从头开始。
在训练名称部分下输入一个名称,例如
full-quota-training,然后单击继续按钮。单击环境部分下的 + 新建环境按钮。
在下一个屏幕中,在环境名称和描述部分下输入一个名称,例如
simple-pytorch-environment。在镜像部分下,将 Image URL 字段设置为
nvcr.io/nvidia/pytorch:24.07-py3。单击创建环境按钮。
返回到上一个屏幕后,确保在我们刚刚创建的
simple-pytorch-environment在环境部分中处于选中状态。单击运行时设置部分。
单击 + 命令和参数按钮。
在命令字段下输入
sleep 5m。在设置训练的工作节点数字段中,选择一个数字,该数字使用集群中的所有可用 GPU 节点。例如,在 32 个 GPU 的集群中,该数字将为
4(每个节点 8 个 GPU,8*4=32)。在计算资源部分下选择
h100-8g选项。单击创建训练按钮。
UI 将自动返回到工作负载页面 - 观察
zero-quota-workspace工作负载首先进入Pending状态,然后full-quota-training工作负载进入Running状态。如果
full-quota-training工作负载已完成或已停止,则zero-quota-workspace工作负载将在集群中存在可用资源时恢复。
3.2.6. 清理环境#
可以安全地删除本示例中使用的所有测试工作负载和项目。