1. 数据下载示例#
1.1. 在训练工作负载中从 S3 下载数据#
在此示例中,我们将创建一个新的工作负载,以从私有 S3 存储桶下载数据。由于此示例的非交互性质,我们将使用训练工作负载。我们将配置具有私有信息的工作负载,以访问 S3 存储桶并执行必要的命令来安装和运行 s5cmd 工具,以将数据从该存储桶下载到 PVC。
1.1.1. 先决条件和要求#
运行数据下载训练工作负载之前,需要满足以下条件
您必须具有用户角色L1 研究员、ML 工程师或系统管理员才能完成本教程的所有章节。
您的用户必须能够访问项目和部门。
您必须有权访问您范围内的计算资源才能使用——它可以是仅 CPU 的,这对于避免在不必要时使用 GPU 资源来说是理想的。
您必须拥有包含数据的私有 S3 存储桶。
您必须拥有通过访问密钥 ID 和秘密访问密钥从 S3 下载该数据的必要权限。
1.1.2. 创建凭据#
为了安全地将必要的密钥插入到工作负载中,我们将为访问密钥 ID 和秘密访问密钥创建一个凭据,从而允许访问我们的 S3 存储桶。
要创建新的凭据,请转到凭据页面。单击+ 新建凭据,然后单击访问密钥以打开访问密钥创建表单。
在表单上,设置所需的范围。范围应尽可能窄——在本例中,将范围设置为与您的工作负载的目标项目匹配。
为访问密钥指定一个描述性名称,例如
aws-access-keys,并根据需要添加描述。在密钥窗格中,选择新建密钥。将访问密钥字段设置为您的 AWS 访问密钥 ID,将访问密钥字段设置为您的 AWS 秘密访问密钥。
单击创建凭据以保存新的凭据。
1.1.3. 创建数据源#
我们将创建一个 PVC 数据源,以允许生成的数据集与未来的工作负载共享。
要创建新的 PVC,请转到数据源页面。单击新建数据源,然后单击 PVC 以打开 PVC 创建表单。
在新表单上,设置所需的范围。
重要提示
在集群或部门级别创建的 PVC 数据源不会跨项目或命名空间复制数据。每个项目或命名空间都将作为单独的 PVC 副本进行配置,并具有不同的底层 PV;因此,每个 PVC 中的数据不会被复制。
为 PVC 指定一个易于记忆的名称,例如
s3-dataset,并根据需要添加描述。对于数据选项,选择一个新的 PVC 存储类,该存储类根据PVC 推荐存储类满足您的需求。在本例中,
zonal-rwx就足够了。要允许所有节点从 PVC 读取和写入,请为访问模式选择多节点读写。输入适合您的目标数据集的容量——在本示例中,我们将指定10 TB。选择 Filesystem 作为卷模式。最后,将容器路径设置为/dataset,PVC 将挂载在容器内。表单完成后,单击页面底部的创建数据源按钮。
注意
首次使用新 PVC 启动作业时,启动时间会更长,因为存储仅在首次声明 PVC 时才会配置。
1.1.4. 创建训练工作负载#
转到工作负载概览页面,然后单击左上角的 + 新建工作负载按钮。将出现一个下拉菜单。从下拉菜单中,选择训练。您将进入新建训练创建页面。
选择要在其中运行作业的所需项目。
将表单的模板窗格设置为从头开始。
为您的工作负载输入一个描述性名称,例如
s3-download。单击继续。几秒钟后,创建过程的环境窗格将出现。要为工作负载创建新环境,请单击环境窗格右上角的 + 新建环境按钮。将打开环境创建表单。
在环境创建表单中,输入环境的名称,例如
s3-download-env,并可选择添加描述。在 Image URL 下,输入
nvcr.io/nvidia/pytorch:24.08-py3。如果需要,可以更改镜像拉取策略。建议在大多数情况下使用默认值“如果尚不存在”,但是如果您要将新容器与相同的标签推送到 NGC 组织,则应使用“始终从注册表拉取镜像”以检查镜像的更新。在工作负载架构 & 类型窗格下,选择标准和 训练(如果尚未选中)。这些选项可能已选中并灰显。
不要修改任何其他设置,包括运行时设置部分——我们将为特定的工作负载填写该部分,以使此环境在未来工作负载中保持多用途。
单击页面右下角的创建环境。您应该看到一个弹出窗口,提示您的环境已创建。页面将刷新,您将返回到新建训练创建页面的环境窗格顶部。您刚刚创建的环境现在应该被选中。
打开此训练工作负载的运行时设置部分。我们将在此工作负载中执行一系列命令。将命令字段设置为
bash -c,并将参数字段设置为"wget https://github.com/peak/s5cmd/releases/download/v2.2.2/s5cmd_2.2.2_Linux-64bit.tar.gz; tar -xf s5cmd_2.2.2_Linux-64bit.tar.gz; ./s5cmd cp s3://your-s3-bucket-name-here/* /dataset"要将凭据嵌入到工作负载中,请单击 + 环境变量按钮两次。
对于第一个条目的名称字段,输入
AWS_ACCESS_KEY_ID,将来源设置为Credentials,将凭据名称字段设置为aws-access-keys,并将密钥字段设置为AccessKeyId。对于第二个条目的名称字段,输入
AWS_SECRET_ACCESS_KEY,将来源设置为Credentials,将凭据名称字段设置为aws-access-keys,并将密钥字段设置为SecretKey。转到计算资源窗格并选择您所需的计算资源——理想情况下是仅 CPU 资源,以避免消耗 GPU 资源。
在数据源部分中,选择您的
s3-datasetPVC。转到页面底部,然后单击创建训练。这会将您的工作负载添加到队列中,并在集群资源可用后自动进行调度。
创建训练工作负载后,您将进入工作负载概览页面,您可以在其中查看工作负载的状态。一旦状态显示“运行中”,您的训练工作负载即在运行。如果您选择的容器以前未拉取到集群,则这可能需要一段时间。
一旦状态为“已完成”,您可以通过单击工作负载并选择蓝色横幅右侧的显示详细信息按钮来查看结果。在工作负载的详细信息窗格中选择 日志 选项卡——它应该指示数据正在从您的 S3 存储桶复制到您的新 PVC。
1.1.5. 清理环境#
作业完成后,可以将其删除以释放资源供其他作业使用。请注意,某些作业不会自行终止,应进行监控以确保已完成作业的资源不会处于空闲状态。
1.2. 使用来自 Google Cloud Storage 的数据#
有两种方法可以使用驻留在 Google 或其他云中的数据
将数据从 Google Cloud Storage (GCS) 或其他云复制到 DGX Cloud 环境中的共享存储 NFS 文件系统。
直接从云提供商内的服务访问数据。我们建议此时将此作业作为纯 Kubernetes 作业运行。
以下是以下场景的示例
1.2.1. 示例:使用 GCS 将数据复制到 Run:ai 内的 PVC#
在 GCP 中,创建一个具有所需权限的自定义 GCP 角色。
以下是最小权限集,可以通过克隆 Storage Object Viewer 角色并添加
storage.buckets.get权限来创建。1 storage.buckets.get 2 storage.buckets.getIamPolicy 3 storage.buckets.listEffectiveTags 4 storage.buckets.listTagBindings 5 storage.managedFolders.create 6 storage.managedFolders.get 7 storage.managedFolders.list 8 storage.objects.list
创建一个 GCP 服务帐户 (SA)。
在目标存储桶上将自定义角色分配给服务帐户。
为创建的 SA 创建一个服务帐户密钥,并下载 .json 密钥文件。保护密钥文件,因为它包含您的私钥。
使用以下命令在您的 Run:ai 项目(命名空间)中创建一个包含 SA 密钥的 Kubernetes 密钥。
注意
您必须将 kubeconfig 设置为 DGX Cloud 提供的 Run:ai 研究员配置。
kubectl create secret generic google-gcs-creds --from-file=key=projectID-deadbeef.json -n runai-<Run:ai projectName>
在 Run:ai 中,使用以下步骤创建数据源作为 PVC
指定 PVC 的范围、名称和可选描述。
在数据挂载部分中,选择新建 PVC。选择存储类、访问模式,并始终选择 Filesystem。然后,在任何容器中设置默认挂载路径。
注意
不支持块卷模式。选择它可能会在启动使用生成的 PVC 的工作负载时导致错误。
使用
kubectl get pvc命令来确定 Run:ai 控制台创建的 PVC 的实际名称。实际名称将类似于name-for-pvc-<cluster-identifier>-<digits>。在下一步中使用此名称。创建一个 Kubernetes 清单 YAML,利用 Google Cloud 命令行将数据从 GCS 复制到 PVC 中。下面的示例使用您创建的密钥和 PVC 作为挂载卷到容器。ProjectID 和存储桶名称通过环境变量传递给
gcloud rsync。1 apiVersion: v1 2 kind: Pod 3 metadata: 4 name: gcp-gcs-copy-2-pv-podd 5 namespace: runai-<Run:ai projectName> 6 spec: 7 volumes: 8 - name: pv-storage 9 persistentVolumeClaim: 10 claimName: name-for-pvc 11 - name: gcp-sa-credential 12 secret: 13 secretName: google-gcs-creds 14 restartPolicy: OnFailure 15 schedulerName: runai-scheduler 16 containers: 17 - name: gcp-cli-container 18 image: google/cloud-sdk 19 imagePullPolicy: IfNotPresent 20 env: 21 - name: PROJECTNAME 22 value: projectID 23 - name: BUCKET 24 value: bucket-name 25 volumeMounts: 26 - mountPath: "/data/shared" 27 name: pv-storage 28 - name: gcp-sa-credential 29 mountPath: /etc/gcp_cred 30 readOnly: true 31 command: ["sh","-c"] 32 args: 33 - gcloud auth activate-service-account --key-file=/etc/gcp_cred/key; 34 gcloud storage rsync -r gs://${BUCKET} /data/shared/ --project=${PROJECTNAME};
使用以下命令在 DGX Cloud 环境中提交 Kubernetes 清单以供执行:
kubectl apply -f mainifast.yaml -n runai-<Run:ai ProjectName>。使用
kubectl get pod gcp-gcs-copy-2-pv-podd监控作业完成情况
您现在可以在 Run:ai 作业中使用 PVC。
1.2.2. 示例:直接在 Google Cloud Services 内使用数据#
Run:ai 训练作业可以直接访问 Google Cloud Storage 中的数据。本节提供了一个如何在 Python 作业中执行此操作的示例,以及使其实现所需的小配置步骤。
以下 Python 代码演示了如何将存储桶中的所有文本文件读取到字符串列表中。虽然这种方法对于 AI 训练工作负载可能不实用,但它将有助于说明必要的配置。
1 from google.cloud import storage
2 import argparse
3 import os
4
5 def get_bucket_name():
6 parser = argparse.ArgumentParser(description="Read text files from a Google Cloud Storage bucket.")
7 parser.add_argument("bucket_name", help="The name of the bucket to read from.", nargs='?')
8 args = parser.parse_args()
9
10 if args.bucket_name:
11 return args.bucket_name
12 elif "BUCKET" in os.environ:
13 return os.environ["BUCKET"]
14 else:
15 print("Error: Bucket name not provided. Please provide it as a command line argument or set the BUCKET environment variable.")
16 return None
17
18 def read_bucket_files(bucket_name):
19 storage_client = storage.Client()
20 bucket = storage_client.bucket(bucket_name)
21
22 file_contents = []
23 blobs = bucket.list_blobs()
24 for blob in blobs:
25 if blob.name.endswith(".txt"):
26 # Download the file content
27 content = blob.download_as_string().decode("utf-8")
28 file_contents.append(content)
29
30 return file_contents
31
32 if __name__ == "__main__":
33 bucket_name = get_bucket_name()
34 if bucket_name:
35 file_contents = read_bucket_files(bucket_name)
36 else:
37 exit(1)
38
39 for content in file_contents:
40 print(content)
要在 Kubernetes 上的容器化训练作业中执行上述代码,您需要执行以下操作
将 Google Cloud Storage Python 库包含到容器中。
将密钥注入到容器中,以允许对 GCS API 进行适当的授权。
要安装 google-cloud-storage Python 库,请使用 pip 将其安装到容器镜像中。例如,使用以下 Dockerfile
1FROM python:3.12
2
3RUN pip install google-cloud-storage
4RUN mkdir /app
5COPY read.py /app/
6
7ENTRYPOINT ["python"]
8CMD ["/app/read.py"]
要将密钥注入到容器中,请使用 Kubernetes 密钥作为文件挂载,并将环境变量 GOOGLE_APPLICATION_CREDENTIALS 指向该文件。下面的示例使用与上面创建的密钥相同的密钥。
1 apiVersion: v1
2 kind: Pod
3 metadata:
4 name: gcs-reader
5 spec:
6 containers:
7 - name: gcs-reader
8 image: nvcr.io/<orgID>/gcs-read:latest
9 imagePullPolicy: IfNotPresent
10 command: ["python", "/app/read.py"]
11 env:
12 - name: BUCKET
13 value: bucket-name
14 - name: GOOGLE_APPLICATION_CREDENTIALS
15 value: /etc/gcp_cred/key
16 volumeMounts:
17 - name: gcs-creds
18 mountPath: /etc/gcp_cred
19 readOnly: true
20 imagePullSecrets:
21 - name: nvcr.io-creds
22 volumes:
23 - name: gcs-creds
24 secret:
25 secretName: google-gcs-creds
26 restartPolicy: OnFailure
注意
目前,Run:ai 作业中没有将 Kubernetes 密钥作为文件挂载的方法。Run.ai 仅支持环境变量。由于 Google 库需要令牌文件(应该是密钥),因此您需要使用变通方法才能将它们与 Run:ai 作业一起使用。推荐的变通方法是
仅将 Kubernetes 原生作业用于数据操作,或者
将 GCP 服务帐户密钥复制到共享存储中,并将
GOOGLE_APPLICATION_CREDENTIALS环境变量指向该共享存储位置。
1.2.3. 示例:从 Google BigQuery 读取数据#
您可以直接在 Run:ai 上的训练作业中使用来自 Google BigQuery 的数据。此示例显示了 Python 脚本和所需的小配置代码。
在 GCP 中,BigQuery Data Viewer 角色包含必要的权限,可以在 table、dataset 或 project 级别分配。遵循最小权限原则,NVIDIA 建议在 Table 级别分配角色,除非您需要从数据集或项目中读取多个表。以下是 BigQuery 读取器的 Python 代码示例。
1 import argparse
2 import os
3 from google.cloud import bigquery
4
5 def read_bigquery_table(project, dataset, table):
6 client = bigquery.Client()
7 table_ref = client.dataset(dataset).table(table)
8 table = client.get_table(table_ref)
9
10 rows = client.list_rows(table)
11 return rows
12
13 if __name__ == "__main__":
14 parser = argparse.ArgumentParser(description='Read a BigQuery table.')
15 parser.add_argument('--project', help='The project ID.')
16 parser.add_argument('--dataset', help='The dataset ID.')
17 parser.add_argument('--table', help='The table ID.')
18
19 args = parser.parse_args()
20
21 project = args.project or os.environ.get('PROJECTNAME')
22 dataset = args.dataset or os.environ.get('DATASET')
23 table = args.table or os.environ.get('TABLENAME')
24
25 if not project or not dataset or not table:
26 print("Error: Missing project, dataset, or table name.")
27 exit(1)
28
29 rows = read_bigquery_table(project, dataset, table)
30
31 for row in rows:
32 print(row)
使用以下 Dockerfile 将上述代码包含在容器中
1 FROM python:3.12
2
3 RUN pip install google-cloud-bigquery
4 RUN mkdir /app
5 COPY read-bq.py /app/
6
7 ENTRYPOINT ["python"]
8 CMD ["/app/read-bq.py"]
最后,您可以使用以下 Kubernetes 清单启动作业/Pod
1 apiVersion: v1
2 kind: Pod
3 metadata:
4 name: read-bq
5 spec:
6 containers:
7 - name: read-bq
8 image: nvcr.io/<orgID>/read-from-bq:latest
9 imagePullPolicy: Always
10 command: ["python", "/app/read-bq.py"]
11 env:
12 - name: PROJECTNAME
13 value: project
14 - name: DATASET
15 value: austin_training
16 - name: TABLENAME
17 value: example
18 - name: GOOGLE_APPLICATION_CREDENTIALS
19 value: /etc/gcp_cred/key
20 volumeMounts:
21 - name: gcs-creds
22 mountPath: /etc/gcp_cred
23 readOnly: true
24 imagePullSecrets:
25 - name: nvcr.io-creds
26 volumes:
27 - name: gcs-creds
28 secret:
29 secretName: google-gcs-creds
30 restartPolicy: OnFailure
1.2.4. 使用服务帐户密钥的替代方案#
服务帐户密钥是强大的凭据,如果管理不当,可能会带来安全风险。Workload Identity Federation 消除了与服务帐户密钥相关的维护和安全负担。借助 Workload Identity Federation,您可以使用 Identity and Access Management (IAM) 向外部身份授予 IAM 角色,并直接访问 Google Cloud 资源。您还可以通过服务帐户模拟授予访问权限。
作为环境入职的一部分,NVIDIA 将为您提供环境的 OIDC 颁发者 URL。导航到您组织的 Google Cloud Console,然后转到 IAM & 管理员 > Workload Identity Federation。单击创建池按钮继续。

在后续的工作流向导中,为池提供名称和可选描述,然后选择 OpenID Connect (OIDC) 作为提供商。
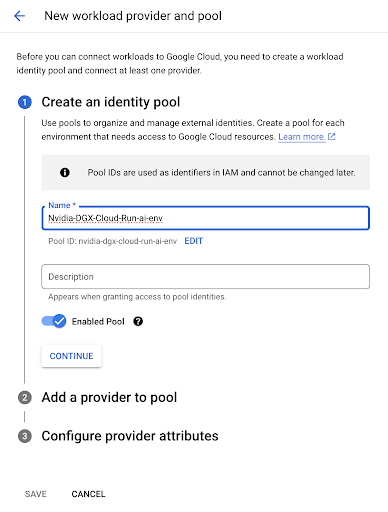
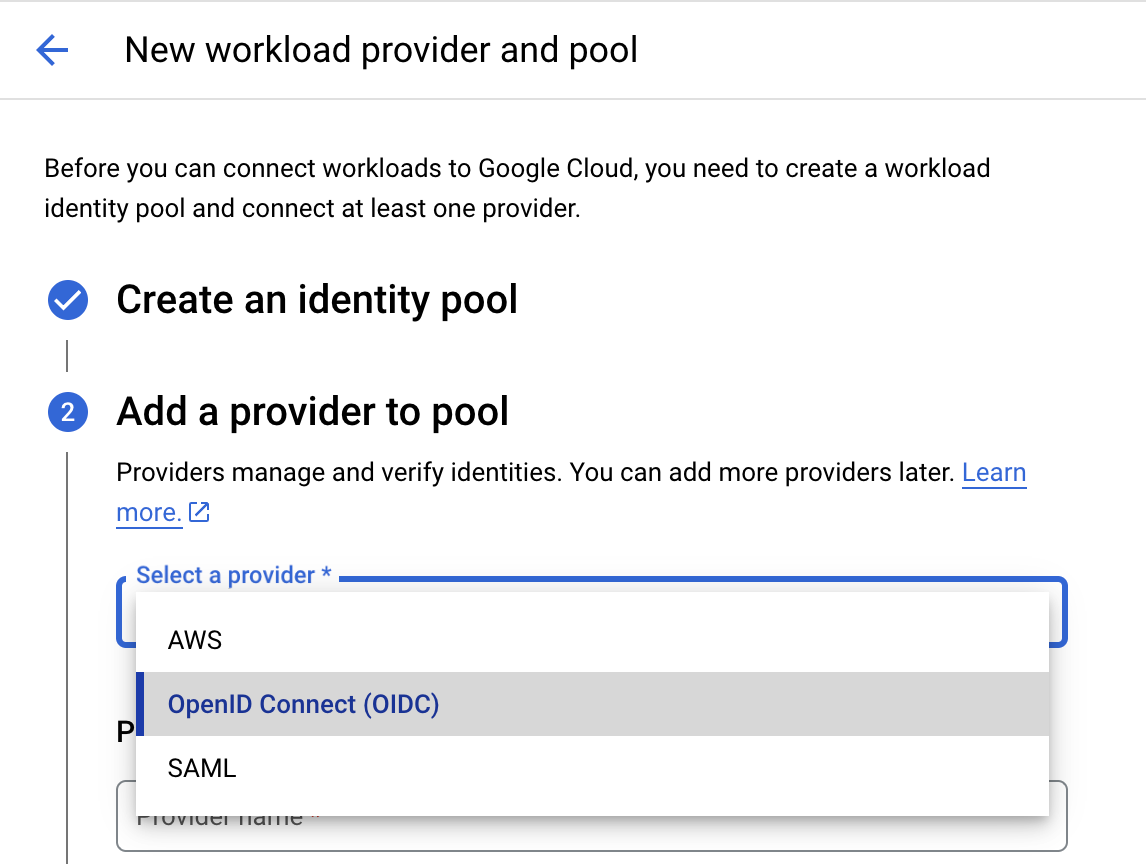
选择提供商类型后,输入 “dgx-cloud” 作为提供商名称,并将您的环境提供的颁发者 URL 粘贴到颁发者 (URL) 字段中。在 受众 下,选择默认受众。
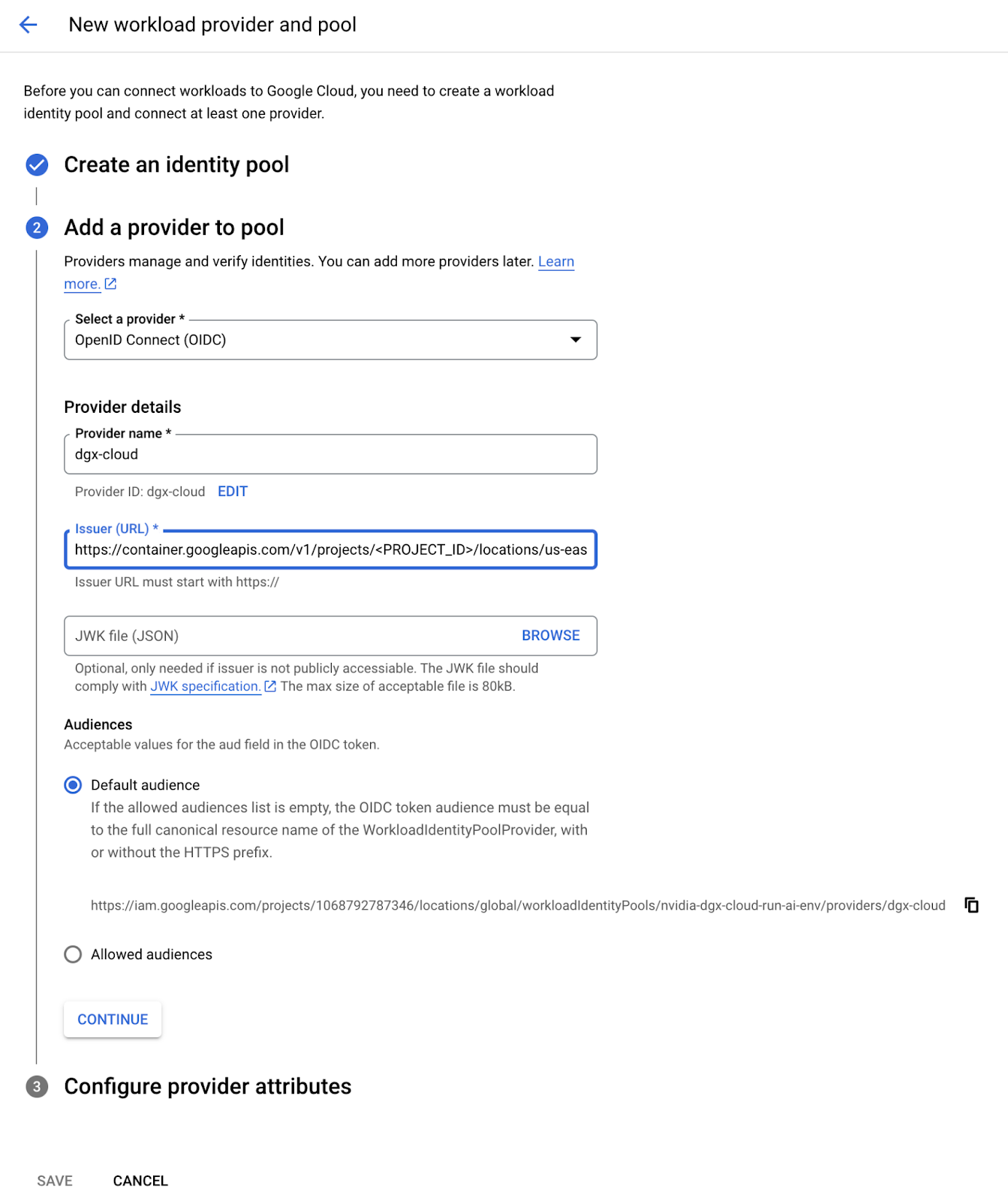
最后,在配置提供商属性步骤中添加映射 google.subject 到 assertion.sub。
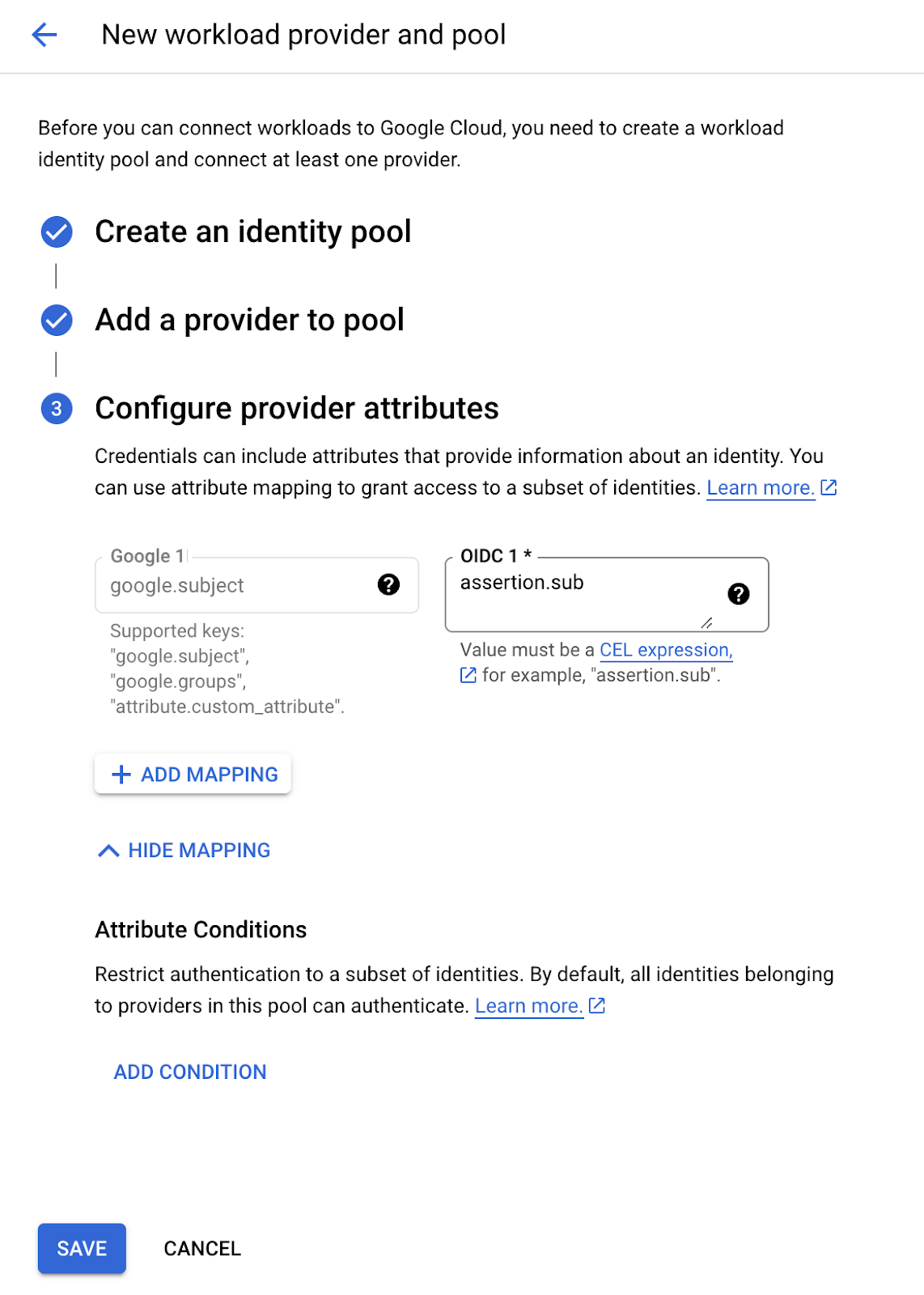
完成后,Workload Identity Pool 将确认它可以与 “dgx-cloud” Kubernetes 集群通信。您应该在您创建的提供商附近的左上角看到一个绿色复选标记,如下所示。
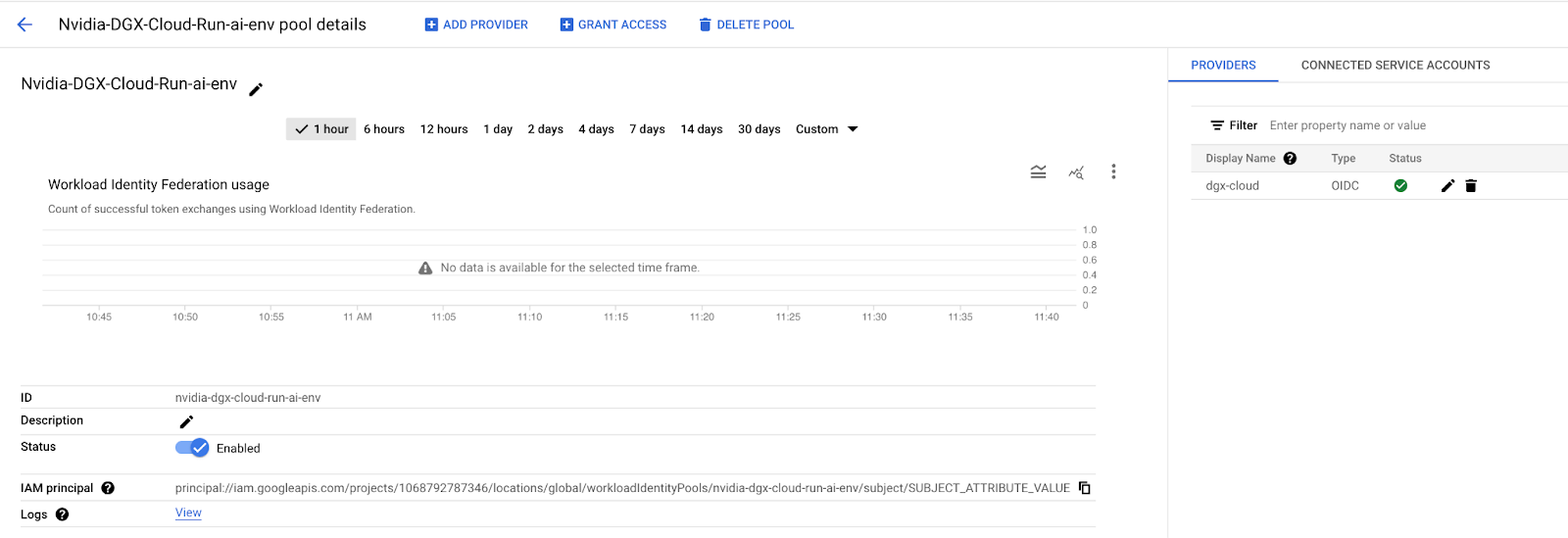
然后,单击右上角的连接的服务帐户,然后选择下载配置按钮。当配置您的应用程序对话框出现时,选择您创建的提供商,然后将路径 /var/run/service-account/token 粘贴到 OIDC ID 令牌路径字段中,将格式保留为 “text”,然后单击下载配置以下载所需的配置文件。
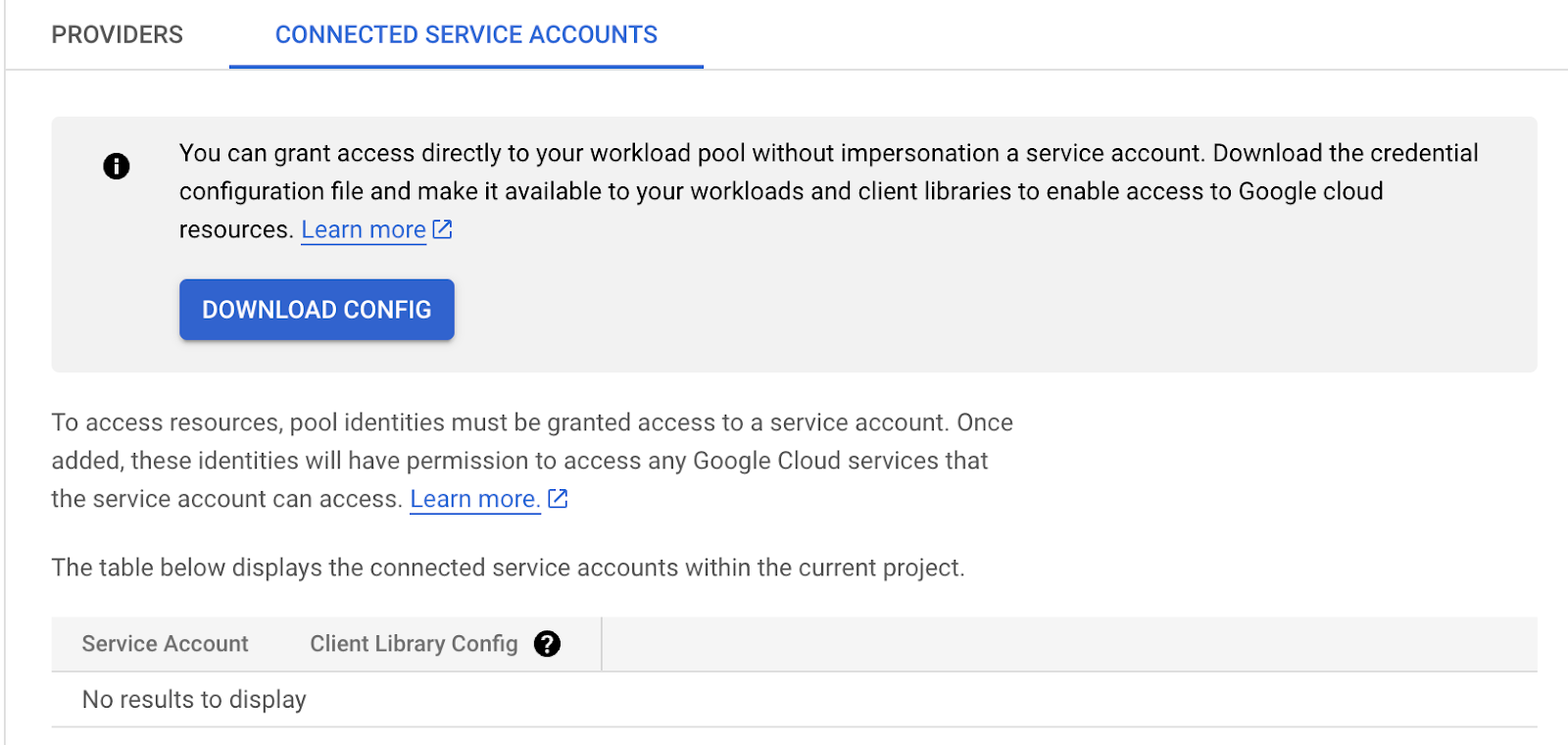
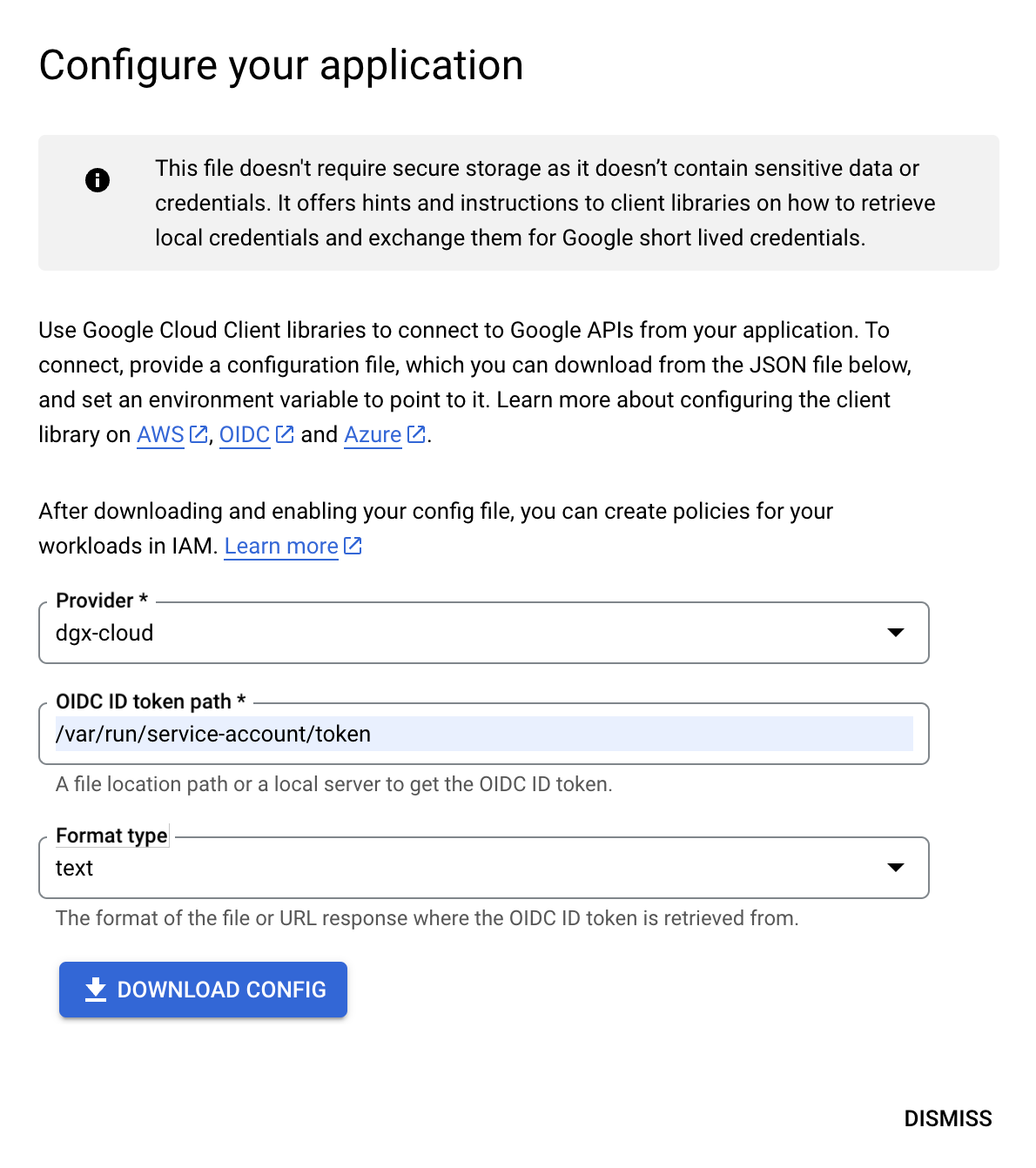
保存配置文件后,单击关闭。在主 Identity Federation Pool 页面上,找到并复制 IAM Principal 字段中的值。它看起来类似于
principal://iam.googleapis.com/projects/1091797687346/locations/global/workloadIdentityPools/nvidia-dgx-cloud-run-ai-env/subject/SUBJECT_ATTRIBUTE_VALUE
其中 SUBJECT_ATTRIBUTE_VALUE 表示 Kubernetes 标识符。
例如,如果服务帐户是 Run:ai 项目 runai-projectname 中的 default,并且我们将 system:serviceaccount:runai-projectname:default 替换为 SUBJECT_ATTRIBUTE_VALUE,则整体 IAM Principal 将为
principal://iam.googleapis.com/projects/1068792787346/locations/global/workloadIdentityPools/nvidia-dgx-cloud-run-ai-env/subject/system:serviceaccount:runai-projectname:default``
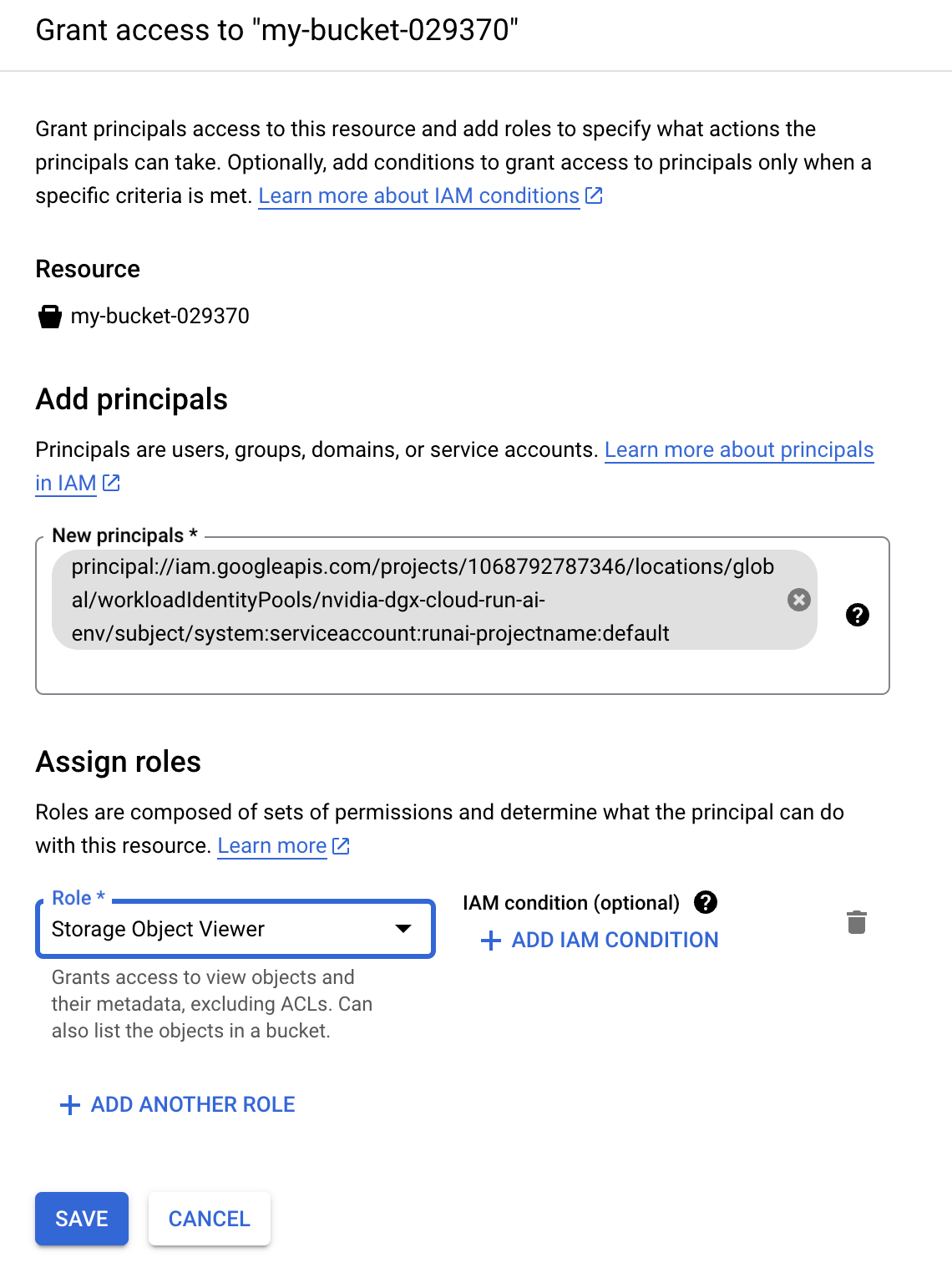
这是要在 GCP IAM 中使用的 IAM Principal,用于授予对该 Run:ai 项目中工作负载的访问权限,如下所示
gcloud projects add-iam-policy-binding projects/PROJECT_ID \
--role=roles/container.clusterViewer \
--member=principal://iam.googleapis.com/projects/1068792787346/locations/global/workloadIdentityPools/nvidia-dgx-cloud-run-ai-env/subject/system:serviceaccount:runai-projectname:default \
--condition=None
或使用 Cloud Console UI
提供 IAM 权限后,应在 “dgx-cloud” Kubernetes 集群上构建 ConfigMap,其中包含您使用以下命令下载的配置文件。
kubectl create configmap google-wi --from-file clientLibraryConifg-dgx-cloud.json --namespace runai-projectname
创建 ConfigMap 后,每个工作负载都应使用三个项目进行扩充:投影 SA 令牌的卷、映射 ConfigMap 的卷以及指向 ConfigMap 投影的环境变量。以下示例清单显示了一个包含三个要求的简单容器。
注意
以下 serviceAccountToken 中的 audience 属性可以从 clientLibraryConifg 文件 audience 字段复制(请务必添加 https:)。
1 apiVersion: v1
2 kind: Pod
3 metadata:
4 name: oidc-example
5 spec:
6 containers:
7 - name: example
8 image: google/cloud-sdk
9 command: ["/bin/sh", "-c", "gcloud auth login --cred-file $GOOGLE_APPLICATION_CREDENTIALS && sleep infinity"]
10 volumeMounts:
11 - name: token
12 mountPath: "/var/run/service-account"
13 readOnly: true
14 - name: workload-identity-credential-configuration
15 mountPath: "/etc/workload-identity"
16 readOnly: true
17 env:
18 - name: GOOGLE_APPLICATION_CREDENTIALS
19 value: "/etc/workload-identity/clientLibraryConifg-dgx-cloud.json"
20 volumes:
21 - name: token
22 projected:
23 sources:
24 - serviceAccountToken:
25 audience: https://iam.googleapis.com/projects/<Your PROJECT_ID>/locations/global/workloadIdentityPools/<Your WORKLOAD_POOL>/providers/<Your WORKLOAD_PROVIDER>
26 expirationSeconds: 3600
27 path: token
28 - name: workload-identity-credential-configuration
29 configMap:
30 name: cloud-ce-config
要确认配置,请运行 kubectl exec -it oidc-example -n runai-projectname -- bash 以访问容器,并运行 gcloud config list 以确认配置。
应可以使用 gcloud 或 gsutil 命令访问在 IAM 中配置的 GCP 资源。
1.3. 使用来自 Amazon S3 的数据#
有两种方法可以使用驻留在 AWS 或其他云中的数据
将数据从 Amazon S3 或其他云存储复制到 DGX Cloud 环境中的共享存储 NFS 文件系统。
直接从云提供商内的服务访问数据。我们建议此时将此作业作为纯 Kubernetes 作业运行。
以下是以下场景的示例
1.3.1. 示例:使用 S3 将数据复制到 Run:ai 内的 PVC#
在 AWS 中,创建一个具有所需权限的自定义 AWS IAM 角色。
以下是最小权限集,可以通过授予 S3 读取访问权限来创建。
1 s3:GetObject 2 s3:ListBucket 3 s3:GetBucketPolicy 4 s3:PutObject
创建一个 AWS IAM 用户或角色。
将自定义角色分配给 IAM 用户或角色,以允许访问目标 S3 存储桶。
为 IAM 用户创建一个访问密钥,并下载 .csv 密钥文件。保护密钥文件,因为它包含您的私有凭据。
使用以下命令在您的 Run:ai 项目(命名空间)中创建一个包含 IAM 访问密钥的 Kubernetes 密钥。
注意
您必须将 kubeconfig 设置为 DGX Cloud 提供的 Run:ai 研究员配置。
kubectl create secret generic aws-s3-creds --from-literal=aws_access_key_id=<ACCESS_KEY_ID> --from-literal=aws_secret_access_key=<SECRET_ACCESS_KEY> -n runai-<Run:ai projectName>
在 Run:ai 中,使用以下步骤创建数据源作为 PVC
指定 PVC 的范围、名称和可选描述。
在数据挂载部分中,选择新建 PVC。选择存储类、访问模式,并始终选择 Filesystem。然后,在任何容器中设置默认挂载路径。
注意
不支持块卷模式。选择它可能会在启动使用生成的 PVC 的工作负载时导致错误。
使用
kubectl get pvc命令来确定 Run:ai 控制台创建的 PVC 的实际名称。实际名称将类似于name-for-pvc-<cluster-identifier>-<digits>。在下一步中使用此名称。创建一个 Kubernetes 清单 YAML,利用 AWS CLI 将数据从 S3 复制到 PVC 中。下面的示例使用您创建的密钥和 PVC 作为挂载卷到容器。存储桶名称通过环境变量传递给
aws s3 sync命令。1 apiVersion: v1 2 kind: Pod 3 metadata: 4 name: aws-s3-copy-2-pv-pod 5 namespace: runai-<Run:ai projectName> 6 spec: 7 volumes: 8 - name: pv-storage 9 persistentVolumeClaim: 10 claimName: name-for-pvc 11 - name: aws-credential 12 secret: 13 secretName: aws-s3-creds 14 restartPolicy: OnFailure 15 schedulerName: runai-scheduler 16 containers: 17 - name: aws-cli-container 18 image: amazon/aws-cli 19 imagePullPolicy: IfNotPresent 20 env: 21 - name: BUCKET 22 value: <bucket-name> 23 volumeMounts: 24 - mountPath: "/data/shared" 25 name: pv-storage 26 - name: aws-credential 27 mountPath: /root/.aws/ 28 readOnly: true 29 command: ["sh","-c"] 30 args: 31 - aws s3 sync s3://${BUCKET} /data/shared/;
使用以下命令在 DGX Cloud 环境中提交 Kubernetes 清单以供执行:
kubectl apply -f manifest.yaml -n runai-<Run:ai ProjectName>。使用
kubectl get pod aws-s3-copy-2-pv-pod监控作业完成情况。
您现在可以在 Run:ai 作业中使用 PVC。
1.3.2. 示例:直接在 AWS Services 内使用数据#
Run:ai 训练作业可以直接访问 Amazon S3 中的数据。本节提供了一个如何在 Python 作业中执行此操作的示例,以及使其实现所需的小配置步骤。
以下 Python 代码演示了如何将存储桶中的所有文本文件读取到字符串列表中。虽然这种方法对于 AI 训练工作负载可能不实用,但它将有助于说明必要的配置。
1 import boto3
2 import argparse
3 import os
4
5 def get_bucket_name():
6 parser = argparse.ArgumentParser(description="Read text files from an AWS S3 bucket.")
7 parser.add_argument("bucket_name", help="The name of the bucket to read from.", nargs='?')
8 args = parser.parse_args()
9
10 if args.bucket_name:
11 return args.bucket_name
12 elif "BUCKET" in os.environ:
13 return os.environ["BUCKET"]
14 else:
15 print("Error: Bucket name not provided. Please provide it as a command line argument or set the BUCKET environment variable.")
16 return None
17
18 def read_bucket_files(bucket_name):
19 s3_client = boto3.client('s3')
20 file_contents = []
21 response = s3_client.list_objects_v2(Bucket=bucket_name)
22 for obj in response.get('Contents', []):
23 if obj['Key'].endswith(".txt"):
24 file_obj = s3_client.get_object(Bucket=bucket_name, Key=obj['Key'])
25 content = file_obj['Body'].read().decode('utf-8')
26 file_contents.append(content)
27 return file_contents
28
29 if __name__ == "__main__":
30 bucket_name = get_bucket_name()
31 if bucket_name:
32 file_contents = read_bucket_files(bucket_name)
33 else:
34 exit(1)
35
36 for content in file_contents:
37 print(content)
要在 Kubernetes 上的容器化训练作业中执行上述代码,您需要执行以下操作
将 适用于 Python 的 AWS SDK (Boto3) 包含到容器中。
将密钥注入到容器中,以允许对 S3 API 进行适当的授权。
要安装 boto3 Python 库,请使用 pip 将其安装到容器镜像中。例如,使用以下 Dockerfile
1 FROM python:3.12
2
3 RUN pip install boto3
4 RUN mkdir /app
5 COPY read.py /app/
6
7 ENTRYPOINT ["python"]
8 CMD ["/app/read.py"]
要将密钥注入到容器中,请使用 Kubernetes 密钥作为文件挂载,并将环境变量 AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY。下面的示例使用与上面创建的密钥相同的密钥。
1apiVersion: v1
2kind: Pod
3metadata:
4 name: s3-reader
5spec:
6 containers:
7 - name: s3-reader
8 image: nvcr.io/<orgID>/s3-read:latest
9 imagePullPolicy: IfNotPresent
10 command: ["python", "/app/read.py"]
11 env:
12 - name: BUCKET
13 value: <bucket-name>
14 - name: AWS_ACCESS_KEY_ID
15 valueFrom:
16 secretKeyRef:
17 name: aws-s3-creds
18 key: aws_access_key_id
19 - name: AWS_SECRET_ACCESS_KEY
20 valueFrom:
21 secretKeyRef:
22 name: aws-s3-creds
23 key: aws_secret_access_key
24 volumeMounts:
25 - name: aws-credentials
26 mountPath: /root/.aws/
27 readOnly: true
28 imagePullSecrets:
29 - name: nvcr.io-creds
30 volumes:
31 - name: aws-credentials
32 secret:
33 secretName: aws-s3-creds
34 restartPolicy: OnFailure
注意
目前,Run:ai 作业中没有将 Kubernetes 密钥作为文件挂载的方法。Run:ai 仅支持环境变量。由于适用于 Python 的 AWS SDK 需要访问密钥(应作为密钥存储),因此您需要使用变通方法才能将它们与 Run:ai 作业一起使用。推荐的变通方法是
仅将 Kubernetes 原生作业用于数据操作,或者
将 AWS 凭据复制到共享存储中,并将
AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量指向该共享存储位置。