5. CLI 高级用法#
在本节中,我们将提供关于您的 Run:ai 集群更高级用法的指导。
5.1. 访问 Run:ai CLI#
一旦您通过 Run:ai UI 登录集群,您就可以设置并通过 CLI 登录。
Run:ai on DGX Cloud 为 Linux、Mac 和 Windows 系统提供 CLI。只有管理员和具有 Researcher 角色的用户(L1 researchers、Research Managers 和 L2 researchers)才能使用 Run:ai CLI。
5.1.1. CLI 先决条件#
在设置 Run:ai CLI 之前,您必须拥有 NVIDIA 或您的集群管理员提供的 kubeconfig 文件。
重要提示
对于管理员,请使用您的 TAM 在集群交接期间提供的 kubeconfig 文件。安全地存储此原始文件,因为 Run:ai CLI 将在设置过程中修改您的 kubeconfig。请勿直接使用原始文件。对于用户,请使用您的集群管理员提供的 kubeconfig 文件。
您还需要安装 kubectl CLI 工具。如果尚未安装 kubectl,请导航到 kubectl 下载说明,并按照适用于您操作系统的正确说明进行操作。
一旦 kubectl 安装在您的系统上,您就可以继续进行设置。设置过程分为两个阶段
下载 Run:ai CLI
设置您的 kubeconfig 文件
请按照下面各节中每个阶段的说明进行操作。
5.1.2. 下载 Run:ai CLI#
登录 Run:ai UI 后,单击右上角的帮助图标 (?)。这将显示一个下拉菜单。
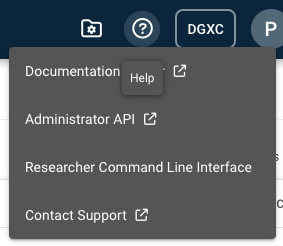
从菜单中选择 Researcher Command Line Interface。这将加载一个弹出菜单。
注意
如果 Researcher Command Line Interface 选项不可用,则表示您的用户角色不允许您使用 CLI。请联系您的集群管理员以获得帮助。
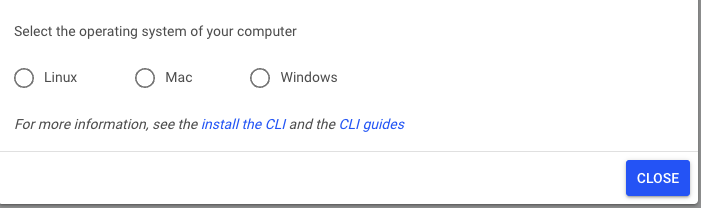
选择您的操作系统,并通过在您机器的终端中运行给定的代码行来下载安装程序文件。
如果您在 Linux 或 Mac 上工作
设置可执行位并将可执行文件放在典型的 PATH 位置。例如
chmod +x ./runai sudo cp ./runai /usr/local/bin
如果您在 Windows 系统上工作
您需要将下载的文件重命名为具有
.exe扩展名,并将其移动到$PATH$中的文件夹。
注意
客户端当前未签名或未被具有隐私和安全设置的平台识别。您可能需要先显式地转到这些设置,以允许 CLI 运行。
5.1.3. 设置您的 Kubernetes 配置文件#
您的 NVIDIA TAM 将在集群 onboarding 期间(如果您是集群管理员)或您的集群管理员(如果您是集群用户)为您提供 kubeconfig 文件。此文件特定于您的 Run:ai on DGX Cloud 集群,不应修改。
要设置您的 Kubernetes 配置文件
在安装 CLI 的系统上的主文件夹中创建一个名为 .kube 的目录。
将配置文件另存为
config在您刚刚创建的 .kube 文件夹中。您的文件现在应位于~/.kube/config。或者,通过运行export KUBECONFIG=</path/to/runai/config>将KUBECONFIG环境变量设置为您选择的任何位置。从终端窗口,使用 Run:ai 客户端通过键入
runai login登录。如果成功,CLI 将显示一个您必须点击的链接。在新浏览器中打开此链接。您将被带到浏览器中的 Run:ai 登录页面。单击 “CONTINUE WITH SSO” 按钮并登录。
登录后,您将看到一条消息,提示 “Login Successful”。将给定的文本复制并粘贴回终端,系统会提示您输入验证码。如果成功,您应该在终端中收到消息 “Logged in successfully”。
通过运行
kubectl get nodes测试连接。您应该看到集群上可用的节点集及其状态。
有关如何使用 Run:ai CLI 的完整详细信息,请访问 Run:ai CLI 文档。
5.2. 研究人员的 Kubernetes 用法#
Run:ai 在 Kubernetes 之上提供了 AI 作业调度、网络和存储结构,Kubernetes 是当今使用的主要容器编排平台。Kubernetes 平台为各种不同类型的工作负载提供所需的可扩展性和弹性,包括 Run:ai 提供的交互式工作负载(notebooks)和分布式训练作业。
本指南无法提供关于 Kubernetes 和 Kubernetes 生态系统相关各种主题的详尽解释。但是,重要的是要认识到,由于 Run:ai 基于 Kubernetes,因此它允许通过集群 API 与 Kubernetes 集群进行交互。因此,在 Researcher 命名空间中,无需使用 Run:ai UI 或 CLI 即可执行许多操作。
假设在 UI 中创建了一个名为 demo-project 的项目。该项目将通过 Kubernetes API 以名为 runai-demo-project 的命名空间可见。这将是 Researcher 项目命名空间的一个示例。Researcher 配置将使我们能够在该命名空间中创建 Kubernetes 资源。
kubectl config set-context --current --namespace=runai-demo-project
一旦确定了目标命名空间,就可以在其中创建 Kubernetes 资源,例如 PersistentVolumeClaim (PVC)。此 PVC 本质上是一个基本的 Kubernetes 存储资源,它定义了一个要挂载到作业 (pod) 的文件系统。此 PVC 资源可以表示为 YAML,并使用 Kubernetes kubectl CLI 工具应用于 Researcher 命名空间。
1 apiVersion: v1
2 kind: PersistentVolumeClaim
3 metadata:
4 name: demo-claim
5 namespace: runai-demo-project
6 spec:
7 storageClassName: zonal-rwx
8 accessModes:
9 - ReadWriteMany
10 resources:
11 requests:
12 storage: 100Gi
此 YAML 可以像这样应用
kubectl apply -n runai-demo-project -f demo-claim.yaml
5.3. 管理员的高级 Kubernetes 用法#
如果您是集群管理员,NVIDIA 可以为您的用户分配额外的集群角色,以便访问 Kubernetes 集群的更多部分,包括项目命名空间内外。这可以用于在集群中部署许多第三方 MLOps 工具、Helm charts、operators 等,以便在 AI 解决方案中与 Run:ai 一起使用。但是,为了保持集群的安全性和稳定性,无法修改在 onboarding 之前已部署的系统资源和组件。
可以分配的集群角色如下
kubectl edit clusterrolebindings dgxc-customer-app-admin-access
一旦 NVIDIA 首先将此角色分配给集群管理员,集群管理员就有权将其他管理员用户绑定到此 dgxc-customer-app-admin-access 集群角色绑定。要绑定其他用户,请在编辑器中添加以下代码块以将用户分配给此集群角色绑定
- apiGroup: rbac.authorization.k8s.io
kind: User
name: sally@acme.com
此集群角色授予用户以下权限
资源 |
dgxc-customer-app-admin-access ClusterRole |
应用程序管理员/L1 Researcher |
|---|---|---|
accessrules |
get list create update patch delete |
none |
amljobs |
get list create update patch delete |
none |
bindings |
* |
none |
clusterpolicies |
get list create update patch delete |
none |
clusterrolebindings |
get list create update patch delete |
none |
clusterroles |
get list create update patch delete |
none |
componentstatuses |
* |
none |
configmaps |
get list create update patch delete |
none |
configurations |
get list create update patch delete |
none |
controllerrevisions |
get list create update patch delete |
none |
cronjobs |
get list create update patch delete |
none |
customresourcedefinitions |
get list create update patch delete |
none |
daemonsets |
get list create update patch delete |
none |
datavolumes |
get list create update patch delete |
none |
departments |
get list create update patch delete |
none |
deployments |
get list create update patch delete |
get list create update patch delete |
devworkspaces |
get list create update patch delete |
none |
distributedpolicies |
get list create update patch delete |
none |
distributedworkloads |
get list create update patch delete |
get list create update patch delete |
endpoints |
get list create update patch delete |
get list |
endpointslices |
get list |
get list |
eniconfigs |
get list create update patch delete |
none |
events |
get list create update patch delete |
get list |
eventsources |
get list create update patch delete |
none |
horizontalpodautoscalers |
get list create update patch delete |
none |
inferencepolicies |
get list create update patch delete |
none |
inferenceworkloads |
get list create update patch delete |
get list create update patch delete |
ingressclasses |
get list create update patch delete |
none |
ingresses |
get list create update patch delete |
none |
interactivepolicies |
get list create update patch delete |
none |
interactiveworkloads |
get list create update patch delete |
none |
jobs |
get list create update patch delete |
get list create update patch delete |
leases |
get list create update patch delete |
none |
limitranges |
* |
none |
localsubjectaccessreviews |
get list create update patch delete |
none |
mpijobs |
get list create update patch delete |
get list create update patch delete |
namespaces |
get list create update patch delete |
get list |
networkpolicies |
get list create update patch delete |
none |
nodepools |
get list |
get list |
nodes |
get list |
get list |
notebooks |
get list create update patch delete |
none |
persistentvolumeclaims |
get list create update patch delete |
get list create update patch delete |
persistentvolumes |
get list create update patch delete |
none |
pipelineruns |
get list create update patch delete |
none |
poddisruptionbudgets |
get list create update patch delete |
none |
podgroups |
get list create update patch delete |
get list create update patch delete |
pods |
get list create update patch delete |
get list create update patch delete |
podtemplates |
* |
none |
priorityclasses |
get list create update patch delete |
none |
projects |
get list |
get list |
pytorchjobs |
get list create update patch delete |
get list create update patch delete |
replicasets |
get list create update patch delete |
get list create update patch delete |
replicationcontrollers |
* |
none |
resourcequotas |
* |
none |
revisions |
get list create update patch delete |
none |
rolebindings |
get list create update patch delete |
none |
roles |
get list create update patch delete |
none |
routes |
get list create update patch delete |
get list create update patch delete |
runaidgxclogexporters |
get list create update patch delete |
none |
runaidgxcnetworkpolicies |
get list create update patch delete |
none |
runaidgxcstorages |
get list create update patch delete |
none |
runaijobs |
get list create update patch delete |
get list create update patch delete |
scheduledworkflows |
get list create update patch delete |
none |
secrets |
get list create update patch delete |
get list create update patch delete |
seldondeployments |
get list create update patch delete |
none |
selfsubjectaccessreviews |
get list create update patch delete |
none |
selfsubjectreviews |
get list create update patch delete |
none |
selfsubjectrulesreviews |
get list create update patch delete |
none |
sensors |
get list create update patch delete |
none |
serviceaccounts |
get list create update patch delete |
none |
services |
get list create update patch delete |
get list create update patch delete |
statefulsets |
get list create update patch delete |
get list create update patch delete |
storageclasses |
get list |
get list |
subjectaccessreviews |
get list create update patch delete |
none |
taskruns |
get list create update patch delete |
none |
tfjobs |
get list create update patch delete |
get list create update patch delete |
tokenreviews |
get list create update patch delete |
none |
trainingpolicies |
get list create update patch delete |
none |
trainingworkloads |
get list create update patch delete |
get list create update patch delete |
virtualmachineinstances |
get list create update patch delete |
none |
virtualmachines |
get list create update patch delete |
none |
workflows |
get list create update patch delete |
none |
xgboostjobs |
get list create update patch delete |
get list create update patch delete |
5.4. Kubernetes 的安全限制#
Run:ai on DGX Cloud 旨在确保客户工作负载遵守安全最佳实践。这既是为了客户的利益,也是为了平台本身的利益。请注意,Run:ai on DGX Cloud 中实施了一组策略,这些策略将阻止尝试使用以下 Kubernetes 功能的客户工作负载
访问容器运行时 Unix 套接字
访问主机网络
访问 sysctl
ClusterRoleBinding 修改
自定义 selinux 安全选项
HostPath 挂载
特权容器
特权提升
这些限制还假设与 Kubernetes 资源或 API 的任何交互都在授予每个用户的权限范围内执行,如研究人员的 Kubernetes 用法和管理员的高级 Kubernetes 用法中所述。不允许在系统命名空间中安装其他组件。
5.5. 管理您的存储利用率#
要检查当前存储利用率和可用配额,请使用前面提到的集群角色在集群上运行以下命令
注意
您首先需要按照 访问 Run:ai CLI 中的说明设置 Run:ai 和 Kubernetes CLI。
kubectl get runaidgxcstorages -n dgxc-tenant-cluster-policies
此命令将显示集群内已分配和已使用的存储配额的摘要。
NAME STORAGECLASSES QUOTAUSEDPCT QUOTA QUOTAUSED STORAGECONSUMED
amazon-fsx-for-lustre lustre-sc 82.14% 100800.000000Gi 82800Gi 55386.1928Gi
要获得更详细的存储分配列表,包括各个 PersistentVolume 存储,请运行以下命令
kubectl describe runaidgxcstorages -n dgxc-tenant-cluster-policies
此命令将生成更详细的输出,显示如下示例的详细信息
pvc-fb3366ff-e909-46b7-bbc5-bdab282037cc:
Capacity: 1200Gi
Creation Time: 2024-10-04T23:30:10Z
File Shares:
fs-09b5f2919e0eb7555:
Name: fs-09b5f2919e0eb7555
Orphaned: true
Values:
free_bytes: 1114.218994Gi
free_bytes_percent: 92.85
used_bytes: 85.781006Gi
used_bytes_percent: 7.15
Location: us-east-1
Name: pvc-fb3366ff-e909-46b7-bbc5-bdab282037cc
State: AVAILABLE
Tier: SSD
5.5.1. 卷保护#
为了数据保护,DGX Cloud 默认修改任何 PersistentVolume 请求,使其具有 “Retain” 的保留策略,无论底层 StorageClass 是否具有 “Delete” 的默认策略。这实际上意味着即使卷被 pod 释放后,所有卷仍将保留。这确保了重要数据不会因默认的 Kubernetes 集群存储策略而被意外丢失。但是,这也意味着这些卷可能会随着时间的推移而累积,并继续计入您的 CSP 项目存储配额。
您可以使用上面提到的 StorageClass API 来更改任何卷的保留策略。在您明确确定可以删除的卷之后,请使用以下命令
kubectl edit runaidgxcstorages -n dgxc-tenant-cluster-policies
此命令将启动您的编辑器,您可以在其中修改任何现有卷的保留策略。例如
spec:
instances:
pvc-0ffa54ec-049b-4ad8-847e-8476b44e18ca:
name: pvc-0ffa54ec-049b-4ad8-847e-8476b44e18ca
persistentVolumeReclaimPolicy: Retain
可以更改为
spec:
instances:
pvc-0ffa54ec-049b-4ad8-847e-8476b44e18ca:
name: pvc-0ffa54ec-049b-4ad8-847e-8476b44e18ca
persistentVolumeReclaimPolicy: Delete
保存更改后,卷将在不再使用时被删除。请注意,PersistentVolume 在其所有 pod 引用都消失之前不会被删除。换句话说,集群中不再有 pod 引用该卷。
5.6. 通过 CLI 检索 Kubernetes 配置文件#
如果您是集群管理员,并且已经通过 Run:ai 和 Kubernetes CLI 访问了 DGX Cloud 集群,则可以通过运行以下命令检索新的 kubeconfig
注意
要执行以下操作,您必须具有 管理员的高级 Kubernetes 用法 中描述的管理员集群角色。
kubectl get cm -n runai ssokubeconfig -o json | jq -r '.data.kubeconfig'
然后,您可以将此 kubeconfig 提供给新用户和研究人员,以便通过 CLI 访问集群。
5.7. 配置集群的 Ingress/Egress CIDR#
对于集群管理员,已提供 API,以便您可以更新已添加到 IP 允许列表以访问集群的 CIDR。这可以用于向集群添加其他用户及其网络。有关 IP 允许列表的更多信息,请参见此处:集群 Ingress 和 Egress。
要将其他 CIDR 添加到 IP 允许列表,请运行以下命令
注意
要执行以下操作,您必须具有 管理员的高级 Kubernetes 用法 中描述的集群角色。
kubectl edit runaidgxcnetworkpolicies -n dgxc-tenant-cluster-policies
这将打开您的编辑器,并显示您可以添加、删除或修改的任何现有 CIDR 范围。
apiGroup: runai.dgxc.nvidia.com/v1beta1
kind: RunaiDGXCNetworkPolicy
metadata:
name: dgxc-tenant-network-policy
namespace: dgxc-tenant-cluster-policies
spec:
egressPolicy:
permittedCIDR:
- 172.32.0.0/11
- 172.64.0.0/10
- 172.128.0.0/9
- 192.128.0.0/11
- 192.160.0.0/13
ingressPolicy:
permittedCIDR:
- 172.32.0.0/11
- 172.64.0.0/10
- 172.128.0.0/9
- 192.128.0.0/11
- 192.160.0.0/13
clusterAccessPolicy:
permittedCIDR:
- 172.32.0.0/11
- 172.64.0.0/10
- 172.128.0.0/9
- 192.128.0.0/11
- 192.160.0.0/13
请注意,在本示例中,我们使用了任意公共 CIDR 范围。作为 onboarding 过程的一部分,如果您想将访问限制在公司 VPN 内,则可以指定自己的 CIDR 范围。另请注意,我们指定了一个 egressPolicy 对象,该对象可能适用,也可能不适用于您的公司网络规则,并且可以被认为是可选的。换句话说,许多工作负载可能需要自由访问公共互联网位置,例如 NVIDIA 的 NGC 或 Hugging Face。