1. 产品概述#
DGX Cloud 上的 Run:ai 是一个基于 Kubernetes 的 AI 工作负载管理平台,它使团队能够高效地调度和运行 AI 作业,并优化 GPU 资源分配,以支持其 AI 计划。
作为一种托管服务提供,此解决方案旨在帮助企业和机构快速启动并执行任何规模的数据科学和 AI 项目,而无需自行管理基础设施。GPU 集群由 NVIDIA 负责配置、管理和维护。

DGX Cloud 上的 Run:ai 提供:
计算集群:客户可以访问专用 AI 集群,该集群配备了由 NVIDIA 云服务提供商 (CSP) 合作伙伴提供的最先进的 NVIDIA GPU 容量,以及存储和网络,作为其 DGX Cloud 订阅的一部分。
用户界面:Run:ai 提供 UI 和 CLI 用于与集群交互。
AI 训练能力:DGX Cloud 上的 Run:ai 支持分布式 AI 训练工作负载,用于模型开发、微调和批处理作业,以及用于实验和数据科学工作流的交互式工作负载。
优化的资源利用率:DGX Cloud 上的 Run:ai 提供自动化的 GPU 集群管理、编排和作业排队,以实现高效的资源共享和优化的利用率。
用户和资源管理:最终用户可用的特性和功能通过基于角色的访问控制 (RBAC) 进行管理。Run:ai 使用项目和部门的概念来管理跨集群的资源访问。
集群和工作负载可观测性:Run:ai GUI 提供仪表板,用于监控和管理工作负载、用户和资源利用率。
NVIDIA AI Enterprise 订阅:所有 DGX Cloud 订阅均包含访问 NVIDIA AI Enterprise 的权限,该订阅提供对 NVIDIA 优化的 GPU 软件套件的访问。
支持:客户可以获得 NVIDIA 提供的 24/7 企业级支持。NVIDIA 将是客户的主要支持方。客户将可以联系到技术客户经理 (TAM)。
1.1. 集群架构#
架构堆栈由 CSP 上 NVIDIA 优化的 Kubernetes 集群组成,该集群连接到 Run:ai 软件即服务 (SaaS) 云控制平面。每个可用组件的确切配置和容量在 onboarding 过程中根据企业的需求进行定制。
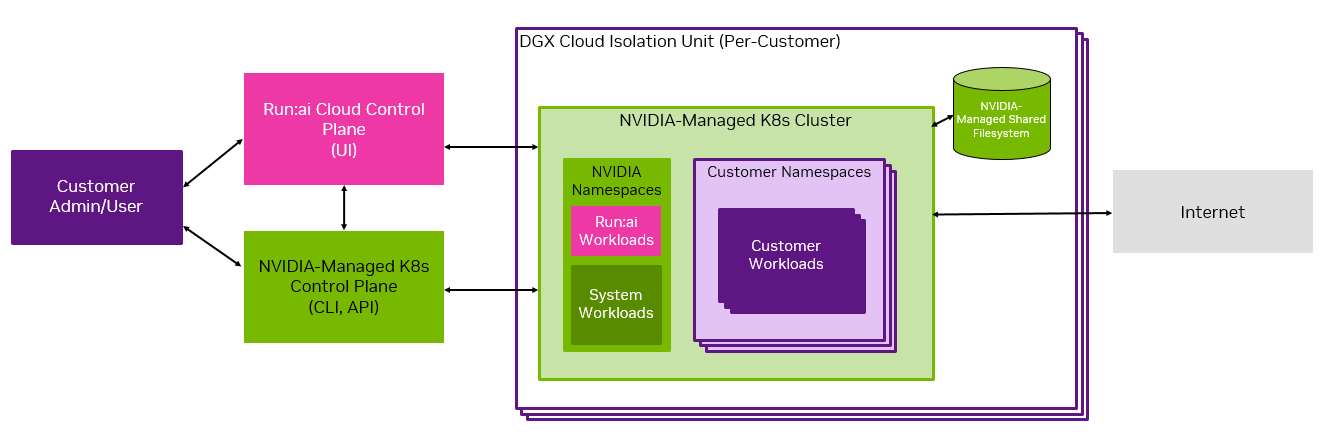
此图显示了高层集群架构,并指出了系统的共享管理。
集群配置了 CSP 特定的计算、存储和网络资源。每个 GPU 计算节点由八个 NVIDIA H100 GPU 组成。
在 Kubernetes 集群中,存在 NVIDIA 命名空间和客户命名空间。客户负责运营客户命名空间,而 NVIDIA 负责 NVIDIA 命名空间。
对于共享文件存储,DGX Cloud 上的 Run:ai 利用给定部署运行所在 CSP 提供的高性能存储。作为部署一部分提供的存储可以同时配置持久数据源和临时卷。DGX Cloud 不支持某些数据源。有关更多信息,请参阅《用户指南》的 存储 部分。
本地固态存储连接到每个使用 GPU 计算资源的工作负载中的节点。
计算集群连接到 Run:ai SaaS 控制平面,用于资源管理、工作负载提交和集群监控。每个客户在 Run:ai 控制平面中都被分配一个Realm,每个 Realm 在多租户控制平面中被视为一个租户。
Run:ai 的 GUI 和 CLI 是用户与平台交互的主要界面。
1.3. 集群入口和出口#
如概述部分所示,每个 DGX Cloud 上的 Run:ai 集群都可以通过 Run:ai 云控制平面或 NVIDIA 管理的 Kubernetes 控制平面访问。
对 Run:ai 云控制平面的所有入口都通过单点登录 (SSO) 进行控制,单点登录 (SSO) 按照 管理员指南 中所述的 onboarding 过程中提供的说明进行配置。端口 443 可从外部访问。
对 NVIDIA 管理的 Kubernetes 控制平面的入口由客户指定的 CIDR 范围控制,该范围也在 onboarding 过程中通过您的 TAM 进行配置。端口 443 也可从外部访问。
默认情况下,出口仅受禁运限制。
客户可以使用 配置集群的入口/出口 CIDR 中提供的说明修改入口和出口限制。
重要提示
NVIDIA 建议不要将 Kubernetes API 暴露于互联网。这种暴露违反了 Kubernetes 最佳实践。但是,NVIDIA 允许客户按照上述说明配置入口规则。在这种情况下,NVIDIA 建议客户设置 VPN 或代理来限制入站 IP,并使用单个或有限的一组 IP 进行访问。虽然 NVIDIA 不会阻止 0.0.0.0/0,但在任何情况下都不能建议允许它。
1.4. 集群用户范围和用户角色#
本节旨在概述 DGX Cloud 上的 Run:ai 集群中的用户范围和角色。在后续章节中,我们将介绍如何创建和管理用户角色。
1.4.1. 用户范围#
Run:ai 使用范围的概念来定义每个用户可以访问集群的哪些组件,这基于其分配的角色。范围可以包括整个集群、部门和项目。在 Run:ai 集群中,每个工作负载都在一个项目中运行。项目是部门的一部分。
当用户添加到 Run:ai 集群时,可以将他们分配到部门和/或项目的任意组合中。

此图像提供了一个集群的示例,该集群有三个部门,部门 1 和部门 3 各有一个项目,而部门 2 包含两个项目。用户 X 可以访问项目 1-a 和项目 2-b。用户 Y 可以访问部门 1 和部门 2。用户 Z 可以访问部门 2 和项目 3-a。
1.4.1.1. Run:ai 部门#
每个 Run:ai 项目都与一个部门关联,并且多个项目可以与同一个部门关联。部门被分配资源配额,建议配额大于其所有关联项目的配额之和。
1.4.1.2. Run:ai 项目#
项目实施资源分配,并在不同的研究计划之间定义清晰的界限。用户组,或在某些情况下是个人,与项目关联,可以在其中运行工作负载,利用项目的资源分配。
1.4.2. 集群用户#
Run:ai 使用基于角色的访问控制 (RBAC) 来确定用户的访问权限以及与集群组件交互的能力。
注意
可以为每个用户分配多个角色。
Run:ai RBAC 文档详细介绍了 Run:ai 用户角色以及每个角色的权限。
您的 DGX Cloud 上的 Run:ai 集群支持 Run:ai 文档中列出的所有角色,除了 部门管理员 角色,该角色已针对 DGX Cloud 上的 Run:ai 集群进行了修改。有关更多详细信息,请参见下文。
1.4.2.1. 客户管理员角色和 NVIDIA 管理员角色#
客户和 NVIDIA 在 DGX Cloud 上的 Run:ai 集群中都拥有管理角色。角色权限之间存在差异。默认情况下,客户管理员将被授予部门管理员和应用程序管理员角色。NVIDIA 支持人员将被授予NVIDIA 云操作员和NVIDIA 云支持角色。所有 NVIDIA 角色仅用于集群管理和支持,无权访问客户数据集。
1.4.2.1.1. 客户管理员角色#
两个客户管理员角色是应用程序管理员和部门管理员。
注意
部门管理员角色存在于标准 Run:ai 角色中,但在 DGX Cloud 集群上,部门管理员的权限与 Run:ai 文档中列出的权限不同。
应用程序管理员
应用程序管理员可以:
创建和编辑部门和项目
管理和分配用户的访问角色
在集群中创建和编辑组件,包括计算资源、数据源和凭据
应用程序管理员不能:
编辑集群上的节点或节点池
部门管理员
部门管理员可以:
创建和编辑项目
管理和分配用户的访问角色
在集群中创建和编辑组件,包括计算资源、数据源和凭据
部门管理员不能:
创建部门
1.4.2.1.2. NVIDIA 管理员角色#
NVIDIA 支持人员将被授予NVIDIA 云操作员和NVIDIA 云支持角色。
注意
所有 NVIDIA 角色仅用于集群管理和支持,无权访问客户数据集或凭据。
NVIDIA 云操作员
NVIDIA 云操作员可以:
管理设置
管理 SSO
管理集群
管理节点池
查看节点
查看用户
查看访问规则
查看事件历史记录
NVIDIA 云操作员不能:
创建用户
分配角色
查看客户私有数据
NVIDIA 云支持
NVIDIA 云支持角色可以:
查看系统中的所有实体
NVIDIA 云支持角色不能:
在集群中执行任何操作
1.4.2.2. 客户用户角色#
在这里,我们详细介绍三个用户角色:L1-研究员、研究经理和ML 工程师。有关 Run:ai 角色的完整信息,包括编辑和查看者(此处未介绍),请参阅 Run:ai 文档 或访问 Run:ai UI 中集群工具和设置菜单下的 访问规则和角色 页面。角色选项卡提供了完整的角色和权限列表。
L1 研究员
Run:ai 平台中的 L1 研究员可以提交 ML 工作负载、查看概览仪表板,并查看集群级分析。研究员必须分配到特定项目,并且只能在这些项目中提交工作负载。
研究经理
研究经理可以查看集群上其范围内运行的工作负载。他们可以创建环境、资源、模板和数据源,但不能提交工作负载。
ML 工程师
ML 工程师可以查看集群内的部门、项目、节点池、节点和仪表板。他们可以查看工作负载,也可以管理推理工作负载。
1.5. 后续步骤#
要开始使用,请尝试我们的交互式工作负载示例。有关访问集群的更多信息,请参阅集群管理员指南或集群用户指南,以开始承担您在集群上的主要职责。
有关使用 Run:ai 的详细信息,请参见 Run:ai 文档。