3. 集群管理员指南#
恭喜您拥有新的 Run:ai on DGX Cloud 集群!
本节为集群管理员提供关于设置和管理 Run:ai on DGX Cloud 集群以及支持用户的基本信息。它涵盖了特定于 Run:ai on DGX Cloud 产品的设置过程。有关全面的管理细节,请参阅Run:ai 文档。
3.1. 集群交接#
为了准备您的入门,您应该已与您的 NVIDIA 技术客户经理 (TAM) 进行了沟通。您的 TAM 将提供所需文档,以便在入门呼叫之前完成以下操作
为 NGC 和 Run:ai 指定管理员
将您的 IdP 与 NVIDIA 身份联合联盟联合
指定允许列表无类别域间路由 (CIDR) 范围
在您的入门呼叫期间,将提供以下内容
用于访问 Run:ai 云控制平面的 URL 端点
您和 NVIDIA 之间的共享支持渠道(Slack 或 Teams)
kubeconfig 文件,设置 CLI 访问集群所需
集群的 URL(在 kubeconfig 文件中)
集群的 OIDC Issuer 的 URL(在 kubeconfig 文件中)
3.2. 访问您的集群#
管理员可以通过两种方式与 Run:ai on DGX Cloud 集群交互
使用 Run:ai UI:NVIDIA 将为您提供 URL 和集群的初始用户登录信息。此用户将被授予应用程序管理员角色。然后,该个人将能够创建部门和项目,邀请其他用户,并为他们分配访问规则。
使用 Run:ai CLI:要使用 Run:ai CLI,您必须首先使用 UI 登录。登录 UI 后,用户将能够设置 CLI。要了解如何设置 Run:ai CLI,请参阅访问 Run:ai CLI。
3.2.1. 访问 Run:ai UI#
要在浏览器中访问 Run:ai 控制台
转到集群 URL,如 TAM 在入门说明中给您的那样。
在登录对话框中,单击CONTINUE WITH SSO。您的 SSO 登录页面将作为弹出窗口打开。
输入您的详细信息。登录后,您将被带到 Run:ai 集群概览页面。
3.3. 管理用户#
Run:ai 使用基于角色的访问控制 (RBAC) 来确定用户的访问权限以及与集群组件交互的能力。每个用户可以分配多个角色。有关集群用户类型的更多详细信息,请参阅集群用户。
3.3.1. 创建用户#
Run:ai on DGX Cloud 的用户管理利用您现有的身份提供商 (IdP) 通过 NVIDIA 的身份联合服务进行身份验证。作为入门过程的一部分,您的 NVIDIA TAM 应该与您合作将您的 IdP 注册到该服务。
Run:ai 访问和角色分配在 Run:ai 平台内单独管理。
客户管理员无法在 Run:ai 中添加本地用户或更改 SSO 配置;他们只能分配和删除角色。
在 Run:ai 中为用户分配角色后,用户可以使用其 IdP 帐户的电子邮件地址通过 SSO 登录 Run:ai。IdP 电子邮件地址必须与 Run:ai 中分配的角色关联的电子邮件地址匹配。
从您的 IdP 中删除用户不会自动撤销其 Run:ai 访问权限。要完全撤销用户的访问权限,必须在 Run:ai 平台内删除其角色。
3.3.1.1. 在 Run:ai 中分配角色#
注意
只有角色为应用程序管理员、编辑、部门管理员和研究经理的用户才能在集群内分配角色。
要分配角色
从 Run:ai 概览页面中,选择右上角的工具 & 设置菜单。
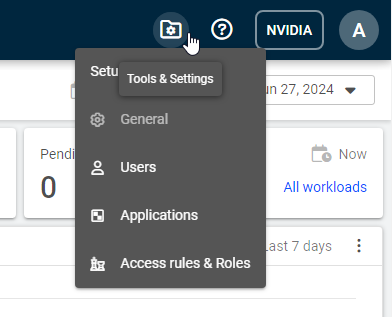
从菜单中,选择访问规则 & 角色。您将被带到访问规则 & 角色概览页面。
选择+ 新建访问规则以向用户分配新角色。将出现新建访问规则弹出窗口。

在主题下,选择用户。
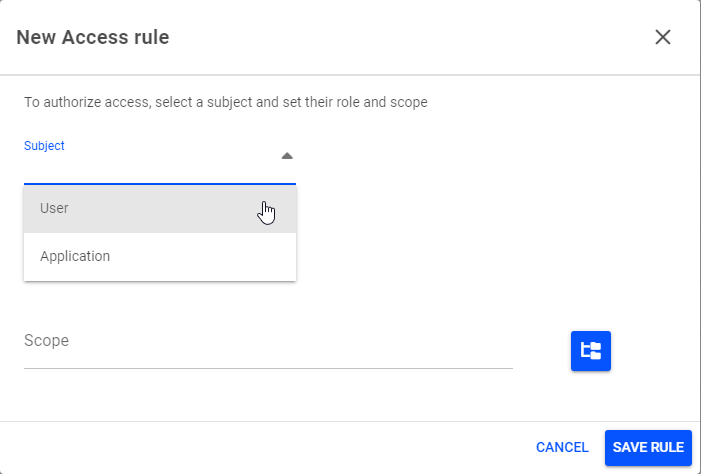
输入与其 SSO 用户帐户关联的用户电子邮件地址。
选择要邀请用户的角色和范围,如用户范围概述指南部分所述。
注意
您必须通知用户他们的角色和范围,因为这决定了他们可以在集群内做什么和不能做什么。
单击保存规则以保存规则。
现在,用户可以使用客户管理员或 NVIDIA TAM 提供的 URL,在登录屏幕上使用 SSO 选项登录 Run:ai 环境。
3.3.1.2. 在 Run:ai 中创建访问规则#
重要提示
在 Run:ai 集群中,任何对访问规则具有“CREATE”权限的用户都可以在他们所属的任何 SCOPE 中,在其 SCOPE 中的角色“级别”相等或更低的位置创建其他权限(访问规则)。
以下角色具有“创建”访问规则权限
应用程序管理员
部门管理员
编辑
研究经理
由于创建访问规则的能力不限于特定范围,因此管理和监控集群用户非常重要。
3.3.1.2.1. 示例:分配访问角色#
在此示例中,我们展示了所有 创建 访问规则权限即使在特定部门级别授予,也都在集群级别的后果。
Alice 在部门 1 中担任 编辑 角色,在部门 2 中担任 L1 研究员 角色。由于 Alice 从她在部门 1 中的角色获得了“CREATE”访问规则权限,Alice 可以向项目 2-A 添加其他用户,角色为 L1 研究员 或更低(包括 L2 研究员 和 查看者)。这些新用户可以在集群中运行作业并使用资源。他们还可以访问任何范围限定为项目 2-A 的凭据。
但是,部门 2 的管理部门可能不知道 Alice 在部门 1 中担任编辑角色。因此,不要假设 Alice 有权向项目 2-A 添加用户,尤其是在项目 2-A 包含专有信息的情况下。
3.4. 管理员集群设置#
要准备您的集群以供用户运行工作负载,您必须设置以下内容
部门
项目
计算资源
有关 部门 和 项目 的详细介绍,请参阅Run:ai 部门。
3.4.1. 部门#
部门 允许您将配额与不同的团队和用户组关联。用户是部门的成员,所有项目都必须在部门内创建。
注意
只有角色为应用程序管理员和编辑的用户才能创建和管理部门。
3.4.1.1. 修改默认部门#
当您的 Run:ai on DGX Cloud 集群配置好后,将创建一个“默认”部门。但是,该部门不会分配任何资源配额,因此无法在该部门内运行任何工作负载。
注意
只有角色为应用程序管理员和编辑的用户才能修改部门。
要向默认部门添加配额
在 Run:ai UI 中,使用左侧导航菜单导航到部门概览页面。
单击“default”部门条目。蓝色“已选择”菜单应出现在页面顶部。
单击编辑以访问编辑部门页面。
(可选)重命名部门。
在配额管理部分中,选择应为部门分配多少 GPU 设备、CPU 核心和多少 CPU 内存。
单击保存以更新部门。您将被带回到部门概览页面,新配额应显示在表中的值中。
3.4.1.2. 创建部门#
在您的集群中拥有多个部门允许您管理项目组并为不同的组设置配额。
注意
只有角色为应用程序管理员和编辑的用户才能创建部门。
您可以使用以下步骤创建部门
导航到部门概览页面。
单击+ 新建部门。您将被带到新建部门创建页面。
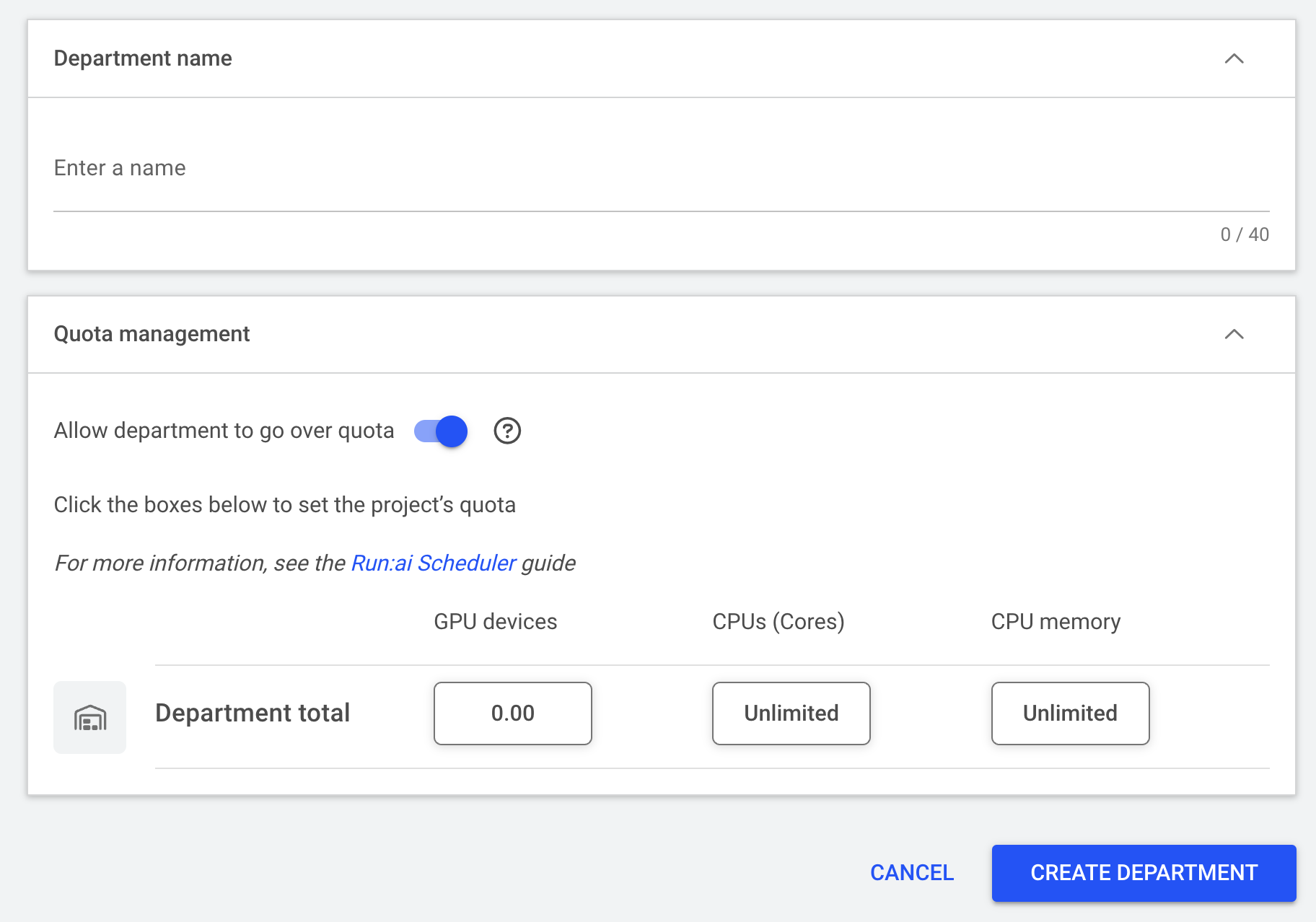
输入部门名称。
为部门选择配额。您还应为以下三个选项中的每一个选择配额:GPU 设备、CPU 核心和 CPU 内存。
选择是否允许部门超出配额。如果允许部门超出配额,它将使用集群中可用的备用 GPU(如果可用),超出列出的配额。
单击创建部门以保存。您将被带回到部门概览页面。
3.4.2. 项目#
项目 用于实施资源分配,并在不同的研究计划之间定义明确的护栏。用户组(或在某些情况下,个人)与项目关联,然后可以在该项目内针对固定的项目分配运行工作负载。
所有项目都与部门关联。务必注意部门的配额限制,因为这些限制将影响与该部门关联的任何项目的分配和配额。
多个用户可以限定在同一个项目中。项目级信息(包括凭据)对该项目中的所有用户可见。
3.4.2.1. 创建项目#
注意
只有角色为应用程序管理员、部门管理员、编辑和研究经理的用户才能创建项目。
要创建项目
导航到项目概览页面。
单击+ 新建项目。您将被带到新建项目创建页面。
选择将在其下创建项目的部门。项目将对该部门内的所有用户可见。
在项目名称部分中,输入项目的名称。
在配额管理部分中,选择项目可以使用的资源总数。
(可选)使用调度规则下拉菜单设置集群的任何规则。
单击创建项目。您将被带到项目概览页面,您可以在其中查看新创建项目的状态。
3.4.2.2. 编辑项目#
注意
只有角色为应用程序管理员、部门管理员、编辑和研究经理的用户才能编辑项目。
您可以通过单击项目名称左侧的复选框来更新项目,然后单击项目概览页面顶部菜单栏上的编辑。这将使您返回到项目创建页面,您可以根据需要更新任何条目。
3.4.2.3. 更新对项目的访问权限#
注意
只有角色为应用程序管理员、部门管理员、编辑和研究经理的用户才能更新对项目的访问权限。
如果用户有权访问某个部门,并且在该部门内创建了一个新项目,则他们将自动被授予对该项目的访问权限。
要更新对项目的访问权限
在项目概览页面中,单击项目名称左侧的复选框。
单击项目概览页面顶部菜单栏上的访问规则。这将弹出一个弹出窗口,您可以在其中输入其他用户电子邮件地址以授予他们对项目的访问权限。
3.4.3. 计算资源#
在 Run:ai 中,计算资源 是一个资源请求,由 CPU 设备、内存和(可选)GPU 和 GPU 内存组成。当请求具有特定计算资源的工作区时,调度程序会查找那些请求的资源,如果这些资源可用,则将启动具有访问这些资源权限的工作区。
您可以通过从 Run:ai UI 的左侧导航菜单导航到计算资源来查看集群中可用的计算资源。
注意
只有角色为应用程序管理员、计算资源管理员、数据源管理员、部门管理员、编辑、L1 研究员和研究经理的用户才能创建和管理计算资源。
作为集群管理员,您应确保在首次获得集群时,集群中预加载的计算资源对您的用户及其用例是合理的。我们建议您
删除任何使用部分 GPU 的集群资源。GPU 拆分在您的 Run:ai on DGX Cloud 集群上是不可能的。
设置仅 CPU 计算资源。
设置 1 个(一个)和 8 个 GPU 计算资源。
这些建议仅为指南,您的团队可能需要替代计算资源。有关如何设置计算资源的说明,请参阅集群用户入门指南中的计算资源部分。
3.4.4. 集群更新和升级#
正如产品概述的共享责任部分所述,NVIDIA 负责作为 DGX Cloud 托管服务一部分提供的所有集群更新和升级。
这些更新和升级可能是中断性的或非中断性的。在进行更新或升级之前,您的 NVIDIA TAM 将与您联系,通知您即将进行的更新或升级。
对于非中断性更新或升级,TAM 将沟通工作的范围和预计时间窗口。
对于中断性更新或升级,TAM 将沟通工作的范围,并在可能的情况下,使您能够从一系列选项中选择一个时间窗口。根据工作范围,可能并非总是能够为维护时间窗口提供一系列选项。
对于导致停机的中断性更新或升级,NVIDIA 制定了以下规则
对于具有 20 个或更少 GPU 节点的集群,将执行 surge 升级,并将 maxUnavailable 属性设置为 100%。
对于具有超过 20 个 GPU 节点的集群,将拆除并使用自动化重新创建整个 GPU 节点池。