控制 GPU 执行
使用 NVIDIA Nsight VSE CUDA 调试器控制 GPU 执行
控制 GPU 执行
在本节中,了解更多关于如何控制 GPU 执行、设置 GPU 断点、使用全局冻结以及使用屏障/Warp-Exit 运行控制的信息。
控制执行
CUDA 调试器允许您在调试会话期间控制 CUDA 程序的执行。CUDA 调试器支持步进到一行代码,以及将程序运行到光标位置。
为了使用以下任何功能,被调试的 CUDA 程序必须由于在断点处停止或来自先前的执行控制语句而暂停。
先决条件
源代码应使用 nvcc 和 “-G”选项 进行编译,以便提供带有调试符号和行号信息的非优化代码。也可以使用 “-linetable” 进行编译以便使用符号进行调试;但是,这将优化 SASS 并导致不稳定的源步进和源断点行为。
注意
OptiX 应用程序通常使用 -linetable 构建,并可能受到此行为的影响。请参阅其他 OptiX 限制,特别是它们如何影响 GPU 断点。
步进行为
步进时,除了调试器焦点 Warp 之外的所有 Warp 都会被冻结。但是,当单步执行 __syncthreads() 时,当前块中的所有 Warp 都允许取得进展。这允许焦点 Warp 越过 __syncthreads() 函数。
步出全局函数将恢复应用程序(与按 F5 或选择菜单命令“调试 > 继续”的结果相同)。
单步执行内核函数的最后一行也将恢复应用程序执行。
单步执行内联函数的最后一行与步出内联函数的结果相同。
最佳实践
为了在调试时获得最佳步进行为,我们建议在代码中尽可能使用花括号。将花括号放在源代码的单独一行上。例如,由于编译器生成作用域信息的方式,以下编码风格会导致不同的步进行为。
这些代码片段会导致次优的步进行为
for () statement;
for () statement;
for () { statement;
}
此代码片段会产生最佳的步进行为
for ()
{
statement;
}
一般来说,通过声明临时变量来分解计算可以使代码更易于调试。变量在特定行集中“存活”的机会增加。这意味着当您单步执行代码时,变量的值将更容易识别。
避免在使用时终止调试监视器。如果在应用程序停止在 CUDA 断点时终止调试监视器进程,您将无法终止目标进程。
使用单独的 Visual Studio 实例来调试目标应用程序的主机部分。如果您希望在 CUDA 调试器附加时调试 CUDA 应用程序的主机部分,则必须使用不同的 Visual Studio 实例进行附加。将 Visual Studio 的同一实例同时附加为主机和 GPU 调试器将导致调试器挂起。
单步执行程序
启动调试会话。
使用 Nsight CUDA 调试位置工具栏选择要单步执行的线程。
有关更多信息,请参阅指定调试器上下文。
从“调试”菜单中,选择“步入”。
或者,按键盘上的 F11 键。
当前线程的程序计数器将前进一行源代码。
注意
使用“步入”会导致调试器执行当前选定线程的下一条指令。步进发生在当前焦点线程上。
运行到光标
要将目标应用程序运行到光标位置
在包含源代码的文档窗口中,右键单击所需的源代码行。
从上下文菜单中,选择运行到光标...
程序计数器将前进到指定的源代码行。
停止 CUDA 调试器
从“调试”菜单中,选择停止调试。
或者,您也可以按调试器工具栏上的停止图标,或键入 SHIFT+F5。
目标应用程序现在将停止。Visual Studio 停止调试会话并返回到编辑布局。
设置 GPU 断点
NVIDIA Nsight Visual Studio Edition 的下一代调试器和旧版调试器可以根据 GPU 断点控制执行。
先决条件
源代码应使用 nvcc 和 “‘-G’选项 进行编译,以便提供带有调试符号和行号信息的非优化代码。也可以使用 “-linetable” 进行编译以便使用符号进行调试;但是,这将优化 SASS 并导致不稳定的源步进和源断点行为。
注意
OptiX 应用程序通常使用 -linetable 构建,并可能受到此行为的影响。请参阅其他 OptiX 限制,特别是它们如何影响 GPU 断点。
GPU 断点
您可以使用 NVIDIA Nsight™ VSE 在 CUDA 代码中设置断点。开发工具支持两种类型的断点:源断点和数据断点。
源断点允许您在指定的 CUDA 源代码行处暂停应用程序。您还可以约束断点,使其仅在特定块和线程正在执行时中断。将断点约束到特定块和线程是在大规模并行环境中至关重要的功能,在这样的环境中,您可能有成百上千个线程同时运行。
数据断点会在下一个可执行代码行即将写入指定的 GPU 内存范围时暂停应用程序的执行。
您可以使用与其他 Visual Studio 支持的语言相同的熟悉的对话框、键盘快捷键和工具窗口来设置和配置 CUDA 断点。
注意
当代码行具有内联函数调用时,同一行代码可能会多次满足断点条件。例如,在以下代码行上设置断点:
x = cos() + sin()
将在该行生成 3 个断点:一个用于表达式的评估,以及该行上的每个函数各一个。
注意! 如果您正在执行本地调试,请确保在使用 CUDA 调试焦点选择器对话框之前禁用 WPF 硬件加速。有关禁用 WPF 硬件加速的更多信息,请参阅设置本地调试。
创建源断点
您可以在任何可执行的 CUDA 源代码行上设置断点。
要在源代码行上设置断点
在源代码窗口中,将插入点移动到您希望应用程序中断的行。
要在跨越两行或多行语句的语句中设置断点,请将插入点移动到语句的最后一行。
从调试菜单中,选择切换断点。
或者,按 F9 键,或在源代码文档的左边距中单击鼠标左键。
红色断点标志会出现在源代码文档的左边距中。
断点标志的颜色指示断点的状态。例如,红色填充的标志表示正常的、已启用的断点。白色填充的标志表示断点已禁用。断点标志内的 + 号表示断点至少有一个高级功能,例如条件、命中计数或筛选器附加到它。
有关断点的更多信息,请参阅 Microsoft 的 Visual Studio 文档:http://msdn.microsoft.com/en-us/library/5557y8b4.aspx
注意
如果您在无效的源位置(例如注释行)设置断点,则断点将“跳转”到 10 行范围内下一个可用的有效源代码行。
创建数据断点
您还可以在任何 GPU 内存地址设置数据断点,这将在即将向该地址写入数据之前暂停您的程序。
注意
数据断点目前仅在旧版调试器中受支持。
要在内存地址设置数据断点
在断点窗口中,单击新建菜单,然后选择新建数据断点。
在程序应在写入该内存空间时暂停的 GPU 内存空间中输入指针的名称或数值地址。
单击确定。
应用程序将在即将写入指定内存区域的下一个应用程序源代码行之前暂停。
管理断点
使用标准的 Visual Studio 断点工具窗口来启用、禁用、添加和删除断点。
从“调试”菜单中,选择“窗口 > 断点”,或使用 Ctrl+Alt+B 键盘快捷键。
通过标记断点旁边的复选框来启用或禁用断点。
通过选择一个断点,然后单击工具栏中的“删除”按钮来删除断点。
通过选择一个断点,然后单击工具栏中的“全部删除”按钮来删除所有断点。
通过选择工具栏中的“转到源”按钮导航到断点的源代码位置。
注意
调试器不支持 Visual Studio 断点工具窗口中的“转到反汇编”功能。
条件断点
在具有成百上千个线程的大规模并行环境中,能够将断点缩小到仅关注的区域至关重要。CUDA 调试器支持为 GPU 线程设置带有任意表达式的条件断点。表达式可以使用程序变量、内在函数 blockIdx 和 threadIdx,以及一些简写宏,以便更轻松地根据 blockIdx 和 threadIdx 设置条件。
从 NVIDIA Nsight Visual Studio Edition 2020.3.0 版本开始,Visual Studio 断点命中计数已受支持(请参阅 Microsoft 断点文档的“命中计数”部分)。请注意以下预期行为
随着评估断点条件和计数的线程和迭代次数的增加,Visual Studio 调试器和 NVIDIA 调试器都需要越来越多的时间来运行。在大量使用的代码中使用此断点功能时,应预期会出现明显的延迟。在具有数千个线程的 CUDA 内核中,这些延迟可能会被放大。
命中计数比较是在主机上而不是在本地 GPU 上评估的,这增加了 CUDA 代码中条件断点的评估时间。
在暂停事件(断点命中)期间,无论断点上有多少线程,命中计数都只递增一次。
要在 CUDA C 断点上设置块或线程条件
在源代码行上设置断点。
右键单击断点。
从下拉菜单中,选择“条件...”
键入您希望调试器在此断点处评估的表达式。例如,要仅在特定块或线程索引(例如块索引 (0,1) 和线程索引 (0,1,0))上中断,请键入
@blockIdx(0,1,0) && @threadIdx(0,1,0)
单击“确定”。断点标志显示加号。
当运行代码的 blockIdx 和 threadIdx 与条件断点中指定的 blockIdx 和 threadIdx 匹配时,调试器将暂停目标应用程序的执行。
支持的调试器宏
CUDA 调试器具有基本的宏展开器,可以按如下方式展开某些子表达式
宏 |
展开 |
注释 |
|---|---|---|
|
|
x、y 和 z 必须是十进制整数。 |
|
|
N 必须是十进制整数。 |
|
|
x、y 和 z 必须是十进制整数。 |
|
|
N 必须是十进制整数。 |
目前,用户无法添加任何额外的宏。
注意
如果表达式访问了错误的指针,则该表达式将被评估为 false,并且不会触发断点。作为一种解决方法,您可以使用表达式短路与 && 和 || 运算符来有条件地评估子表达式。例如,如果您使用以下表达式
p && (*p > 5)
那么如果 ‘p’ 设置为 NULL,则不会取消引用 ‘p’。
函数断点
NVIDIA Nsight™ VSE 支持函数断点。要设置函数断点,请使用以下方法之一
从 Visual Studio 断点窗口中,选择新建 > 在函数处中断。
从 Visual Studio 调试菜单中,选择新建断点 > 在函数处中断。
从 CUDA 信息窗口中,从下拉菜单中选择 函数 页面。从这里,您可以右键单击函数行以设置断点。

即使模块在构建时没有符号,函数断点也有效。但是,仅反汇编调试可用。
用户可以输入以下内容之一
函数的修饰名称。
函数的未修饰名称,不带任何函数签名。例如,
matrixMul将解析为matrixMul(int)和matrixMul(char)。如果指定了签名,CUDA 调试器将找不到该函数(例如,
matrixMul(int)或matrixMul<int>())。
或者,用户可以指定模块名称。语法如下:
[ModuleName!]FunctionName
如果 ModuleName 未指定,则断点将设置在所有已加载模块中具有该名称的每个函数中。模块名称在使用 CUDART 时效果最佳,因为它具有模块的 .cu 名称。例如:MyModule.cu!MyKernel
作为快捷方式,函数页面具有为用户输入函数名称的功能。在这种情况下,使用修饰的函数名称,它将设置在包含指定函数名称的每个模块中。
全局冻结
NVIDIA Nsight™ VSE 主菜单具有全局冻结选项。这允许您在使用任何 CUDA 运行控制(例如步进、恢复或运行到光标)时控制哪些 Warp 将取得进展。例如,您可以确保在步进时只有一个 Warp 移动。
注意
请注意,如果其他 Warp 被冻结,代码中的屏障将阻止 Warp 取得任何进展。这是因为块中的所有 Warp 都需要越过屏障,如果其他 Warp 被冻结,它们将无法做到这一点。
有关如何在屏障处或内核末尾继续或步进时控制执行的更多详细信息,请参阅屏障步进。
此选项必须在每个调试会话中设置。它不会在会话之间持久存在。
使用全局冻结
启动 CUDA 调试器。
打开一个基于 CUDA 的项目。
在项目中设置断点。(有关如何设置断点的信息,请参阅演练:调试 CUDA 应用程序。)
确保 Nsight Monitor 在目标计算机上运行。
从扩展菜单的 Nsight 下,选择“启动 CUDA 调试”。
作为替代选项,您也可以在解决方案资源管理器中右键单击项目,然后选择“启动 CUDA 调试”。
CUDA 调试器启动并启动目标应用程序。
当应用程序在断点处暂停时,转到扩展菜单的 Nsight 下,然后选择“冻结”。选择您希望使用的冻结选项。
选择冻结首选项
设置 |
“运行”命令(继续、F5 或运行到光标)的操作 |
“步进”命令(步入、步出或单步跳过)的操作 |
|---|---|---|
调度器锁定恢复全部 |
没有冻结任何内容。 |
没有冻结任何内容。 |
调度器锁定恢复块 |
当前块之外的所有 Warp 都被冻结。 |
当前块之外的所有 Warp 都被冻结。 |
调度器锁定恢复 Warp |
除了当前 Warp 之外的所有 Warp 都被冻结。 |
除了当前 Warp 之外的所有 Warp 都被冻结。 |
调度器锁定步进块 |
没有冻结任何内容。 |
当前块之外的所有 Warp 都被冻结。 |
调度器锁定步进 Warp (默认) |
没有冻结任何内容。 |
除了当前 Warp 之外的所有 Warp 都被冻结。 |
屏障/Warp-Exit 运行控制
在 NVIDIA Nsight Visual Studio Edition 2019.3 中,下一代调试器引入了选项来控制当活动 Warp 尝试移动到屏障上方或从 __global__ 内核退出(完成其执行)时的运行控制行为。
屏障/Warp-Exit 运行控制如何提供帮助
在 NVIDIA Nsight Visual Studio Edition 2019.3 之前,下一代调试器的全局冻结模式默认为“调度器锁定步进 Warp”(仅步进活动 Warp)。当遇到屏障或全局内核结束时,活动线程会步进,然后等待块中的其他 Warp 到达屏障,但它们都被冻结,因此没有 Warp 取得进展,并且内核看起来像是挂起了。为了重新获得执行的控制权,用户必须使用“调试 > 中断(暂停)”,并切换到另一个 Warp 和/或将冻结模式更改为按块恢复。
例如,此 Warp 信息页面显示活动 Warp 和线程(黄色箭头指示器)正在步进或处于断点(红色 - 请参阅 下一代调试器状态检查视图中的 Warp 信息),并且块中剩余的线程和 Warp 是活动的(绿色),但由于冻结模式设置为调度器锁定步进 Warp 而被冻结且没有取得进展。
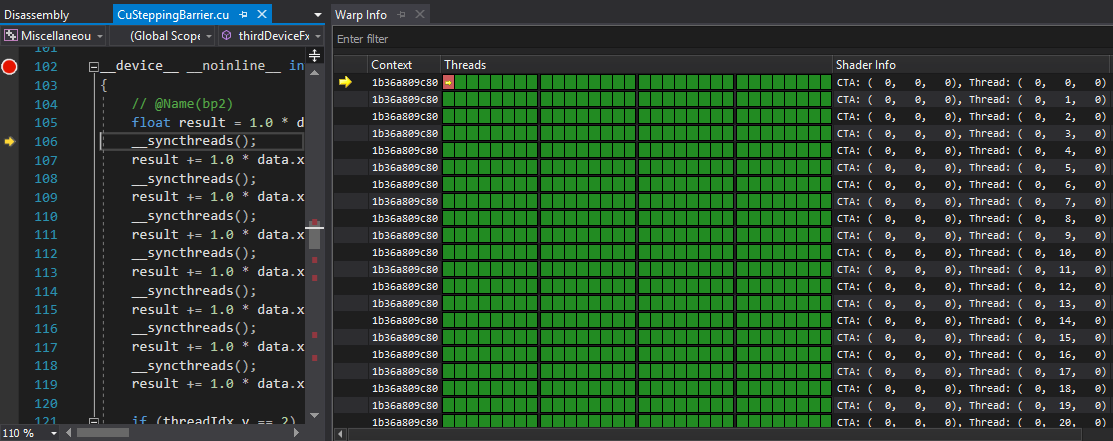
在 NVIDIA Nsight Visual Studio Edition 2019.2 及更早版本中,尝试单步跳过屏障(SASS BAR 命令或 SyncThreads CUDA 命令)会导致上述明显的挂起。
从 2019.3 版本开始,当屏障/Warp-Exit 模式设置为“暂停”时,当焦点线程尝试取得进展(通过步进、继续等)时,它会尝试越过屏障,但在其余线程和 Warp 到达屏障之前无法越过。请注意
指令指针已前进到
__syncthreads()屏障之后(但在块的其余部分赶上之前不会进一步前进)。Warp (0,0,0) 命中屏障(青色),并且块中剩余的 Warp 是活动的(绿色),但仍然没有取得进展。
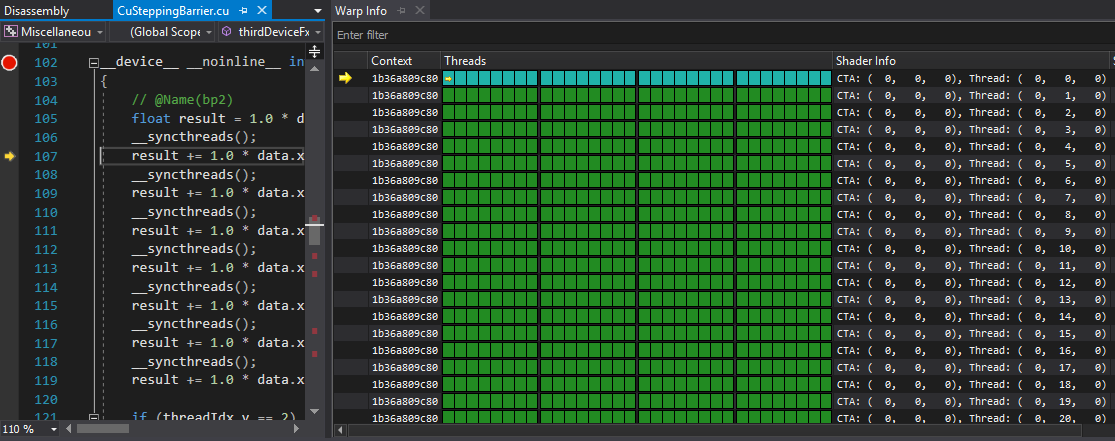
此时
步进活动 Warp 不会导致任何进一步的进展。
继续(F5)将允许所有 Warp 运行到完成或下一个断点。
将冻结模式更改为调度器锁定步进块并步进将允许块的其余部分到达屏障(并步进源代码程序计数器)。
将冻结模式更改为调度器锁定恢复全部将允许所有块取得进展(并步进源代码程序计数器)。
设置
修改屏障和 Warp-Exit 运行控制行为的设置可以在 Nsight > 选项 > CUDA > CUDA 调试器运行控制(下一代)下找到。
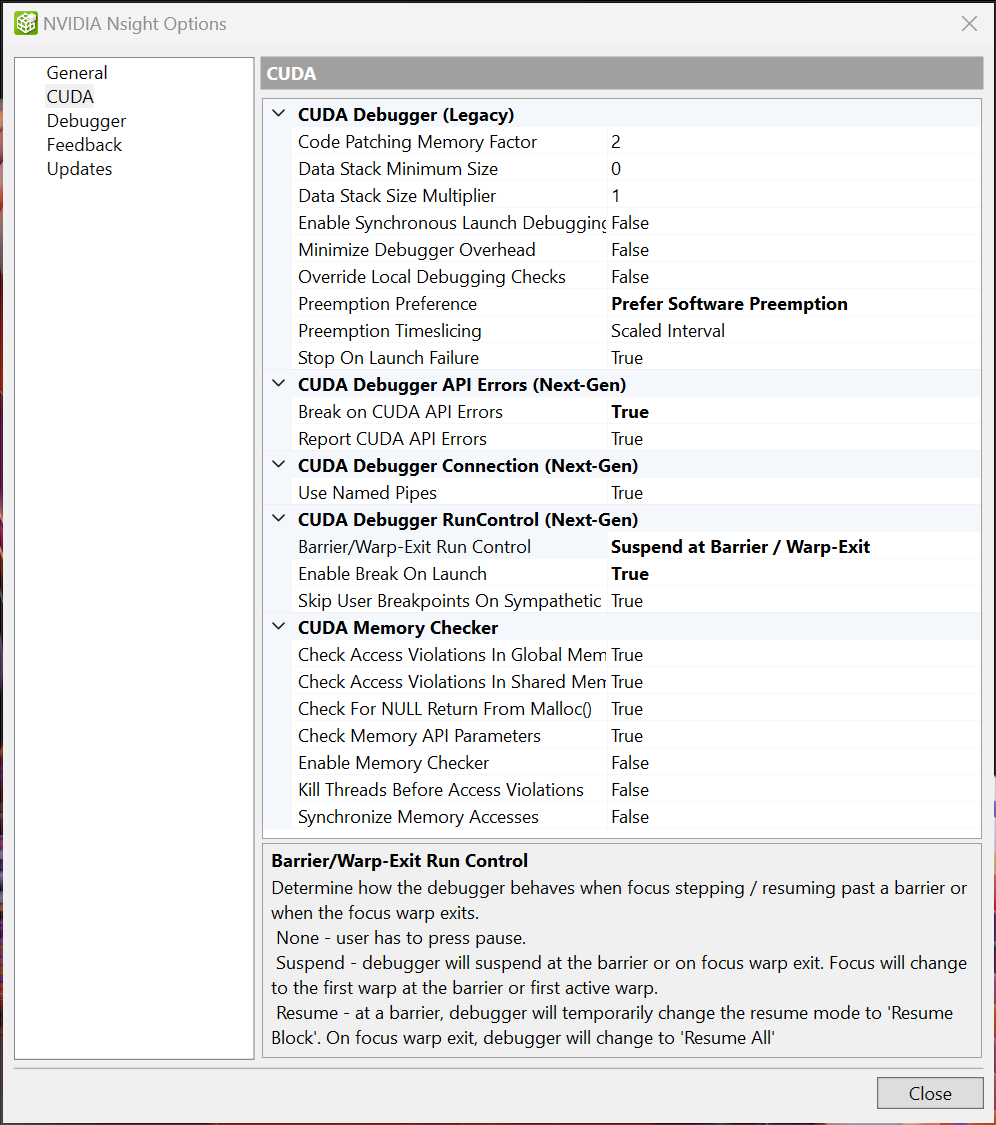
屏障/Warp-Exit 运行控制设置确定当焦点步进或恢复超过屏障,或者当焦点 Warp 退出时的调试器行为。选项包括:
无 - 活动 Warp 等待块中的其他 Warp。但是,其余 Warp 被冻结且没有取得进展。内核看起来像是挂起了。
建议使用“调试 > 中断(暂停)”来更改活动 Warp 和/或全局冻结模式。请注意,您最终可能会停留在 CPU 线程上。在这种情况下,您必须将线程更改回您的 CUDA 线程才能继续 GPU 调试。
在屏障/Warp-Exit 处恢复
在屏障处恢复 - 将出现警告通知
Warning: Scheduler Locking Warp has been temporarily changed to Scheduler Locking Block to step past a barrier.
步进允许整个块(包括活动 Warp)步进越过屏障,然后重新冻结非活动 Warp(如果调度器锁定步进 Warp)或其他块(如果调度器锁定步进块)。
注意
其他 Warp 可能比焦点 Warp 取得更多进展。
在退出
__global__函数时恢复 - 该行为与 恢复 模式匹配。将出现警告通知Warning: Focus warp exited. Debugger automatically suspended.
指示器根据当前的冻结模式自动落入下一个 Warp 或块。步进允许剩余的 Warp 取得进展,运行到完成或命中其他断点或屏障。
您可以将屏障/Warp-Exit 运行控制设置修改为 无 以手动控制步进 Warp。
在屏障/Warp-Exit 处暂停
在屏障处暂停 - 活动 Warp 保持暂停在屏障处,而其他 Warp 保持冻结(如果调度器锁定步进 Warp)或其他块保持冻结(如果调度器锁定步进块)。将出现警告通知
Warning: Focus warp hit a barrier. Debugger automatically suspended. Modify the 'Barrier/Warp-Exit Run Control' setting to change this behavior.
在退出
__global__函数时暂停 - 该行为与 恢复 模式匹配。Warning: Focus warp exited. Debugger automatically suspended.
指示器根据当前的冻结模式自动落入下一个 Warp 或块。步进允许剩余的 Warp 取得进展,运行到完成或命中其他断点或屏障。
您可以将屏障/Warp-Exit 运行控制设置修改为 无 以手动控制步进 Warp。
跳过同情 Warp 上的用户断点 可以设置为以下两种方式之一
True - 同情 Warp 忽略屏障和非条件断点。这些 Warp 仅在焦点 Warp 命中断点或屏障时暂停。
False - 此设置适用于在屏障处步进,不建议用于具有大量线程的计算内核(例如,图形内核)。性能可能会受到严重影响。
活动时中断
在 NVIDIA Nsight Visual Studio Edition 2020.2.0 中,下一代调试器引入了选项,可以在发生某些运行时活动(例如内核启动)或发生 API 错误时暂停执行。
启动时中断
下一代调试器可以在启动函数上自动插入内部断点。
启用启动时中断功能,方法是将选项设置为“True”。
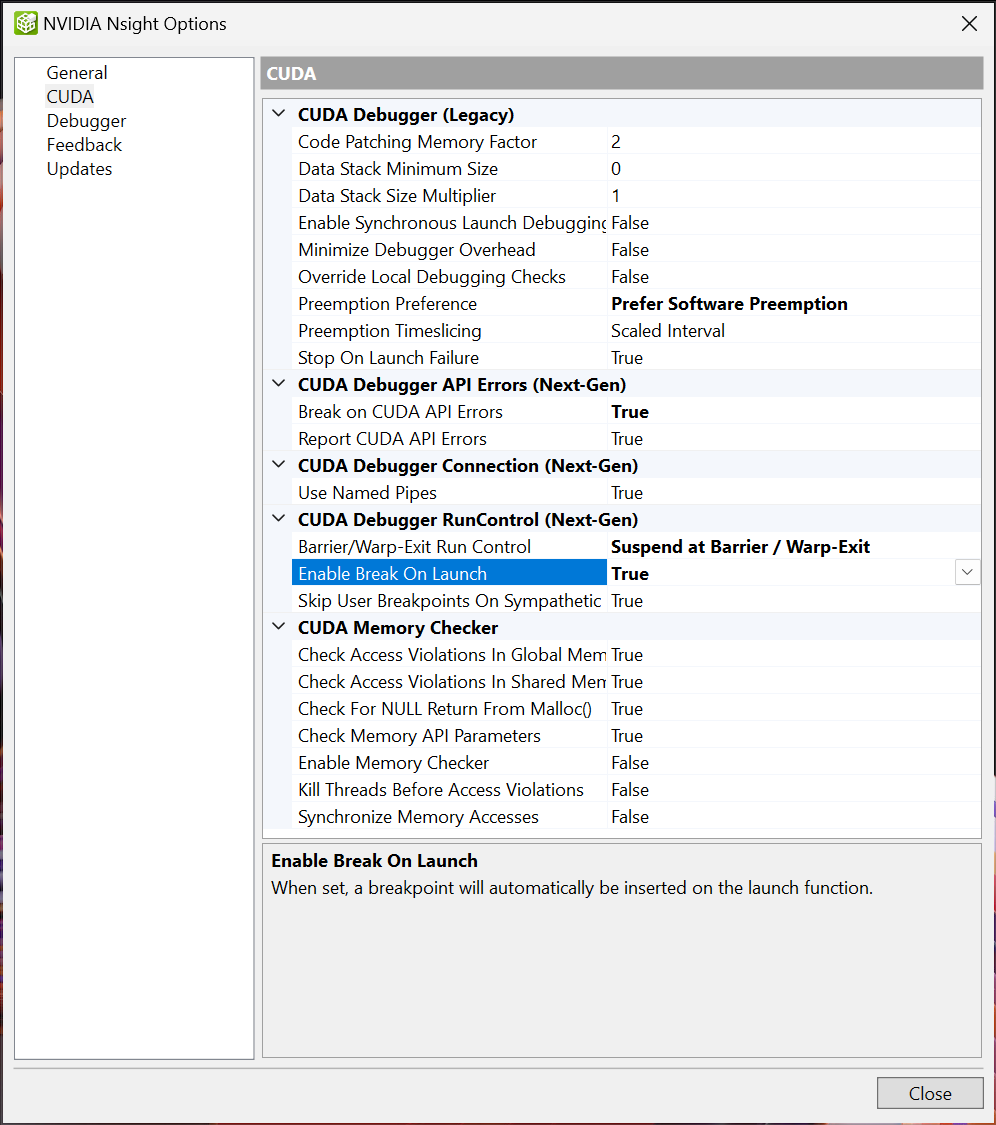
您可以使用扩展菜单下的 Nsight 部分轻松切换启动时中断行为
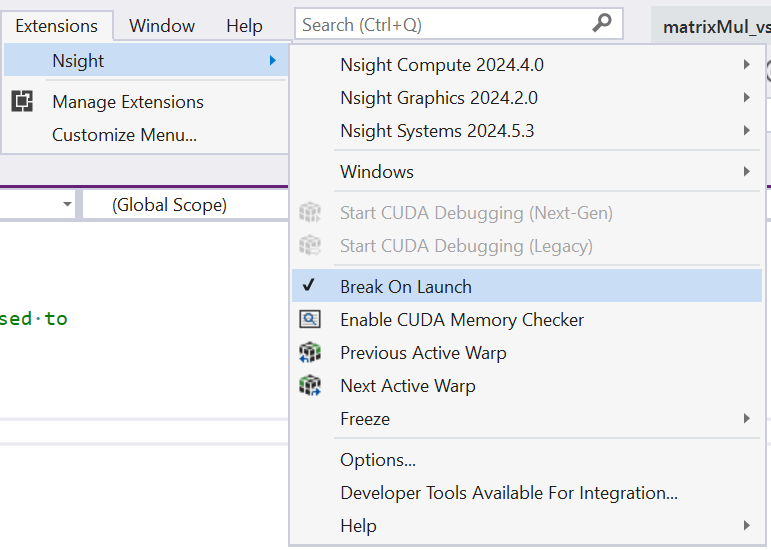
启用后,当任何 [1] __global__ 内核启动时,执行将暂停。当设置函数断点很繁琐时,这很有用。如下所示,没有显示用户断点,但执行在内核入口点暂停。
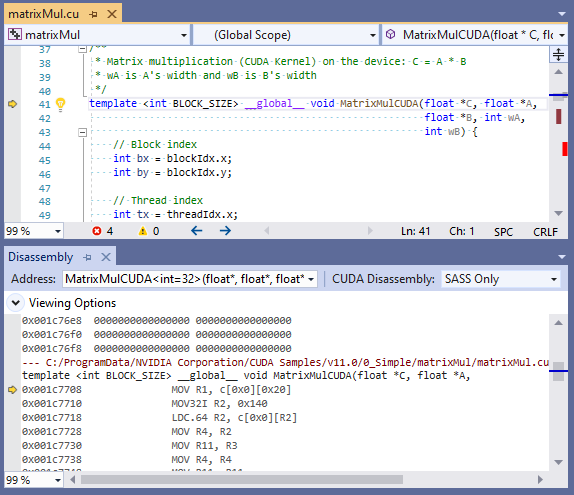
[1] 请注意,这不适用于 受限制的 Optix 代码。
API 错误时中断
控制遇到 CUDA API 错误时的行为的设置可以在 Nsight > 选项 > CUDA > 下找到
报告 CUDA API 错误.
当设置为“True”时,调试器将记录目标应用程序中发生的所有 CUDA API 错误。
CUDA API 错误时中断.
当设置为“True”时,只要 CUDA API 调用失败,调试器就会导致 CPU DebuggerBreak。
请注意,还必须启用“报告 CUDA API 错误”,CUDA API 错误才能触发 DebuggerBreak。
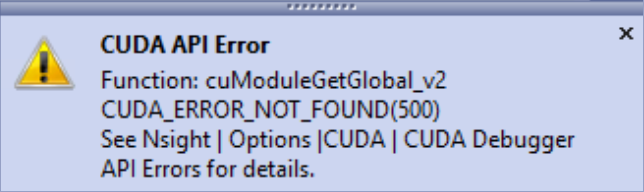
当CUDA API 错误时中断启用并且遇到 API 错误时,
将出现通知,提醒您注意 CUDA API 错误。
执行将暂停,允许您切换到 GPU 线程并检查堆栈、变量和 GPU 状态。
可以恢复执行(即 F5 继续)
声明
注意
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、清单和其他文档(统称为“材料”,单独或合并)均“按原样”提供。NVIDIA 不对这些材料做出任何明示、暗示、法定或其他方面的保证,并且明确声明不承担所有关于不侵权、适销性和特定用途适用性的默示保证。
所提供的信息据信是准确且可靠的。但是,NVIDIA 公司对使用此类信息造成的后果,或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。在 NVIDIA 公司的任何专利权项下,未通过暗示或其他方式授予任何许可。本出版物中提及的规格如有更改,恕不另行通知。本出版物取代并替换之前提供的所有其他信息。未经 NVIDIA 公司明确书面批准,NVIDIA 公司产品不得用作生命维持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。