高级主题
使用 NVIDIA Nsight VSE CUDA 调试器的高级主题。
在本节中,了解更多关于高级 CUDA 主题的信息,例如 PTX 和 SASS 汇编调试、如何使用 CUDA 内存检查器,以及调试 OptiX 应用程序时的限制。
PTX 和 SASS 汇编调试
PTX 是一种低级并行线程执行虚拟机和指令集架构 (ISA)。PTX 将 GPU 公开为并行计算设备。
此外,PTX 为通用并行编程提供了一个稳定的编程模型和指令集,并且旨在在 NVIDIA GPU 上高效运行。诸如 CUDA 和 C/C++ 之类的高级语言编译器生成 PTX 指令,这些指令经过优化并转换为本机目标架构指令。
SASS 是低级汇编语言,它编译为二进制微代码,该代码在本机 NVIDIA GPU 硬件上执行。
从 NVIDIA Nsight Visual Studio Edition 6.0 开始,PTX 和 SASS 汇编调试现已可用。要使用此功能,请使用以下教程。
注意
旧版 CUDA 调试器不支持使用 OptiX 应用程序进行调试,而新一代 CUDA 调试器有许多限制。
启用 PTX/SASS 汇编调试
在 Visual Studio 中,转到工具 > 选项 > 调试。
同时选中启用地址级调试以及子选项如果源不可用,则显示反汇编。
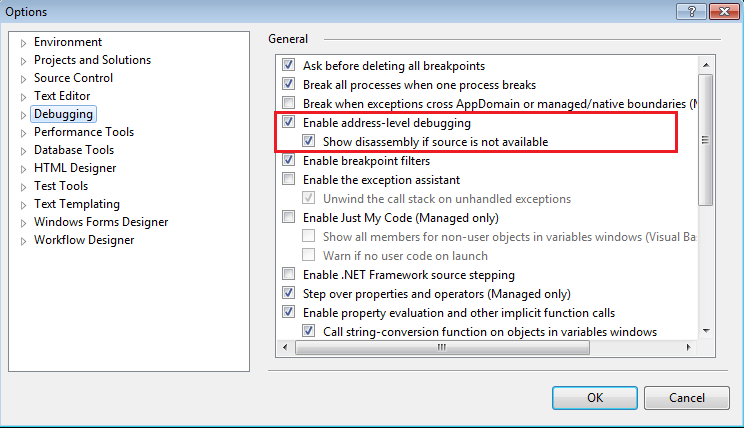
注意
目前,这仅适用于具有调试符号的 CUDA 应用程序(即,使用
–G0构建的应用程序)。如果应用程序未使用调试符号 (–G0) 构建,则 PTX 反汇编视图将为空白。此外,这仅显示当前停止的内核的一个 CUDA 函数。用户无法滚动到模块中的其他 CUDA 内核。 |
一旦 CUDA 调试器停止,您可以通过以下方法之一打开 Visual Studio 反汇编文档
Visual Studio 源代码视图的转到反汇编命令。
调用堆栈的转到反汇编命令。
断点视图的转到反汇编命令。
使用 Visual Studio 菜单 调试 > 窗口 > 反汇编。
注意
这只能在通过断点在 CUDA 内核中停止时工作。Visual Studio 反汇编视图中没有静态或离线反汇编。
当转到反汇编时,可能存在多个关联的地址。在这种情况下,Visual Studio 将弹出一个对话框,询问您要查看哪个地址。
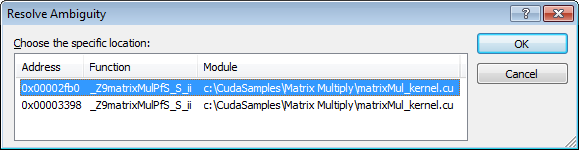
反汇编文档窗口中支持的 Visual Studio 选项包括以下内容
显示源代码;
显示代码字节;
显示行号;
显示工具栏;
显示地址.
注意
请注意,目前不支持显示符号选项。
您可以选择将 CUDA 反汇编视图显示为 PTX、SASS 或 PTX 和 SASS 的组合。这位于 Visual Studio 反汇编视图的右上角,并控制显示哪个反汇编。
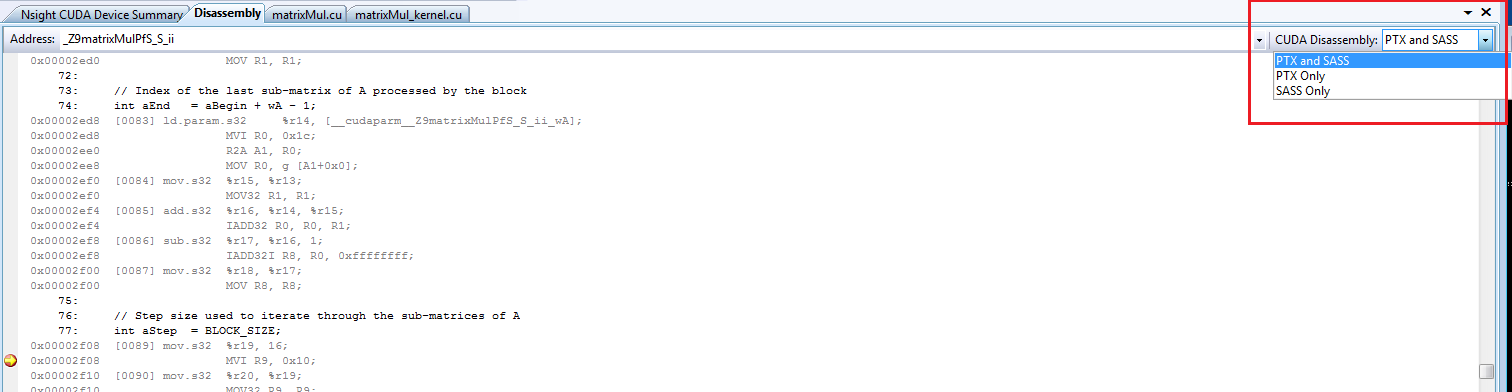
注意
Visual Studio 反汇编视图中方括号 [0090] 中的数字是 PTX 行号。
地址断点
使用旧版 CUDA 调试器 PTX 和 SASS 汇编调试功能,支持地址断点。可以在反汇编的断点列中看到用于添加和删除断点的标准 Visual Studio 控件。
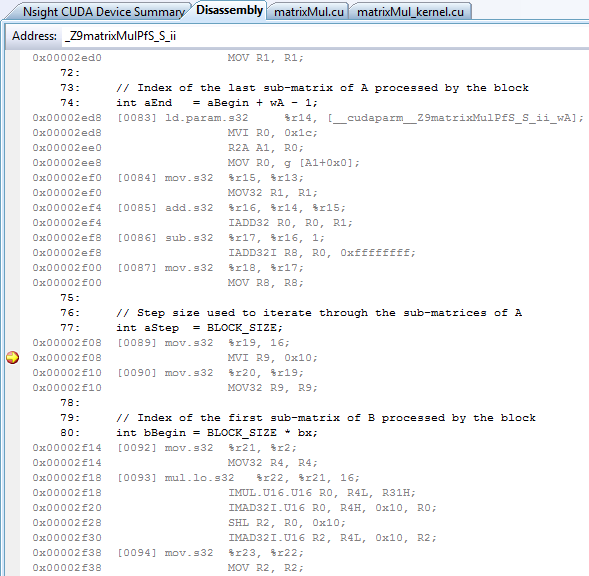
关于地址断点的一些注意事项
Visual Studio 在每个调试会话后禁用地址断点。
这些断点可以使用任何高级断点条件。
某些指令无法修补(即,无法在它们上面设置断点)。发生这种情况时,断点将移动到上一个可修补的断点指令。
可以在 Visual Studio 断点视图的“地址”列中看到源断点的地址。
地址断点始终设置在 SASS 地址处。
运行控制
将运行控制与旧版 CUDA 调试器 PTX 和 SASS 汇编调试一起使用时,单步跳入/跳出/跳过所有操作都按预期正常工作。这遵循 Visual Studio 源代码、语句和指令控制。在内核的最后一行单步执行将继续程序。
当单步执行指令(这是反汇编的默认设置)并且显示 SASS 时,旧版 CUDA 调试器将始终在 SASS 级别单步执行。
PTX > 仅单步执行 PTX 指令。
SASS > 仅单步执行 SASS 指令。
PTX + SASS > 也单步执行 SASS 指令。
注意
请注意,当显示 SASS 时,无法控制单步执行 PTX。
有关 PTX 的更多信息,请参见 CUDA 文档
NVIDIA GPU Computing Toolkit installation path\CUDA\<version number>\doc\
寄存器视图
可以通过右键单击视图并选择所需的寄存器集,将 Visual Studio 调试器 > 窗口 > 寄存器配置为显示 CPU、SASS 和 PTX 寄存器。
设备(在旧版调试器上)或 SASS(在新一代调试器上) — 显示 GPU 寄存器。
PTX — 显示 PTX 寄存器,假设应用程序是使用调试符号构建的。
SASS loc — 显示作用域内的 SASS 寄存器。
请注意,新一代调试器不提供 SASS loc 寄存器视图。
PTX loc — 显示作用域内的 GPU PTX 寄存器,假设应用程序是使用调试符号构建的。
注意
新一代调试器还通过 Nsight > 窗口 > GPU 寄存器提供格式化、可自定义的寄存器视图。
有关更多信息,请参见新一代 CUDA 调试器寄存器视图和如何评估表达式的值。
内存检查器
注意
此功能仅受旧版 CUDA 调试器支持。新一代 CUDA 调试器将在未来的版本中支持此功能。
CUDA 内存检查器检测全局和共享内存中的问题。如果 CUDA 调试器在运行内核时检测到 MMU 故障,则它将无法指定故障的确切位置。在这种情况下,启用 CUDA 内存检查器并重新启动调试,CUDA 内存检查器将精确指出触发故障的语句。
CUDA 内存检查器还将检测在发布模式下构建的代码中的问题。如果没有符号 (-G0),它将不显示任何关联的源代码。
注意
必须在开始调试之前启用 CUDA 内存检查器。
注意
请记住,启用 CUDA 内存检查器运行内核会产生性能损失。
使用内存检查器
在 Visual Studio 中,打开一个基于 CUDA 的项目。
使用以下三种方法之一启用内存检查器
从Nsight 菜单中,选择“选项”> CUDA。将启用内存检查器的设置从“False”(默认设置)更改为 True。
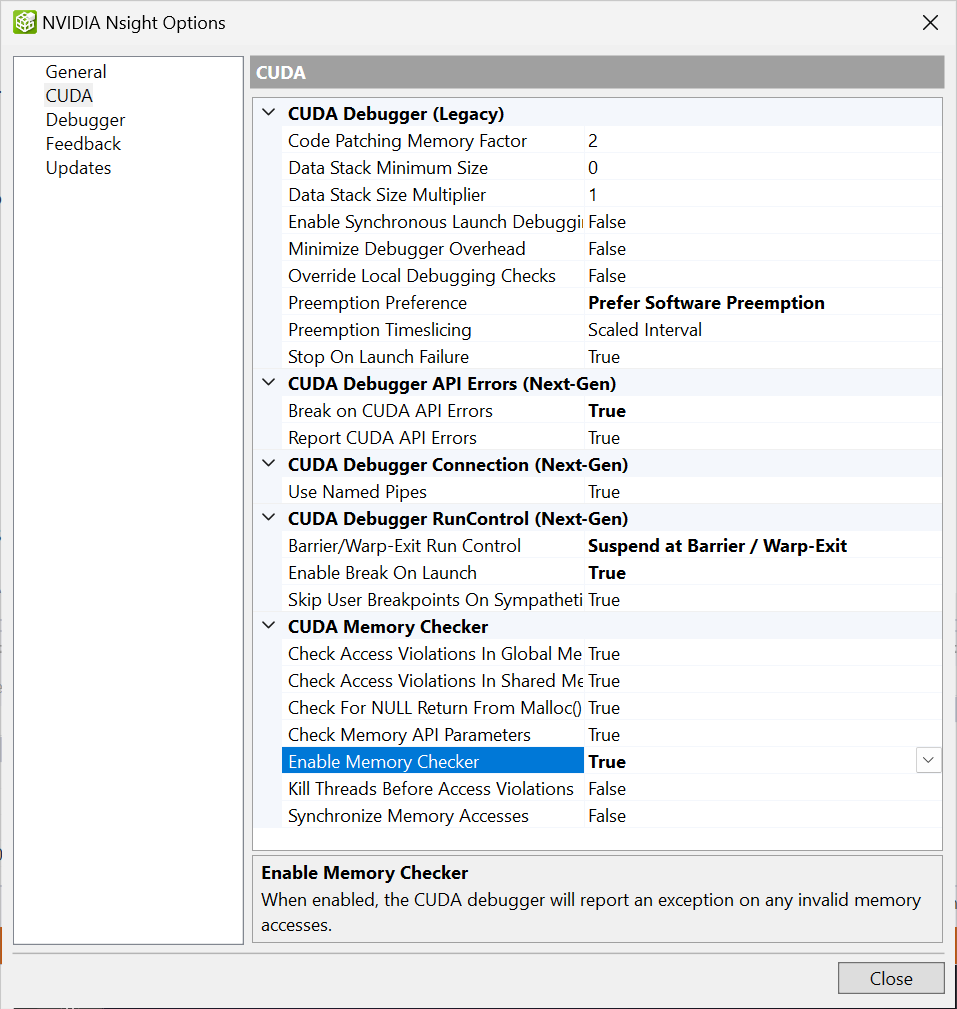
或者,您可以从 CUDA 工具栏中选择“内存检查器”图标以启用内存检查。

或者,使用 Nsight 菜单并选择 启用 CUDA 内存检查器。
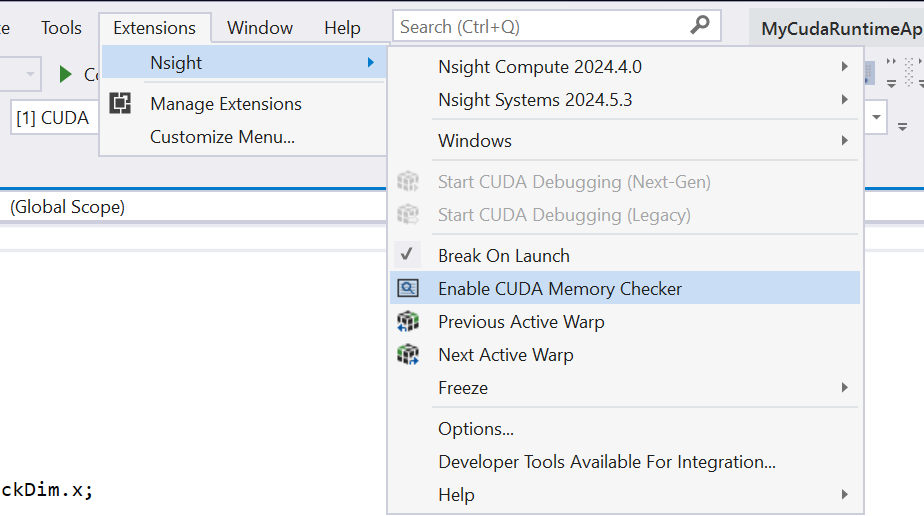
用户可以启用全局内存或共享内存中的检查,以及 CUDA 内存检查器的总体控制。
当全局内存空间启用时,NVIDIA Nsight™ VSE 还将检查通过设备代码使用
malloc和free分配的内存中的违规行为。启动 CUDA 调试器。
确保 Nsight Monitor 在目标系统上运行。
从 Nsight 菜单中,选择“启动 CUDA 调试(旧版)”。或者,您可以使用以下备用方法之一
右键单击解决方案资源管理器中的项目,然后选择调试 > 启动 CUDA 调试(旧版)
Nsight CUDA 调试工具栏 > 启动 CUDA 调试(旧版)
Nsight Connections 工具栏 > 启动 CUDA 调试(旧版)
旧版 CUDA 调试器启动并启动目标应用程序。
在调试会话期间,如果目标尝试写入无效的内存位置,调试器会在违规代码行上触发断点,从而停止执行。CUDA 调试器在执行将写入无效内存位置的指令之前停止。
CUDA 内存检查器将未对齐的指针和尝试写入无效地址视为两个单独的检查。这意味着对于相同的尝试内存访问,您可能会遇到两个单独的断点。
例如,以下语句将首先触发一个断点,因为指针未对齐,然后触发第二个断点,因为它尝试写入无效的内存地址
*(int*)0xffffffff = 0xbad;
补丁 RAM 空间不足错误
启用 CUDA 内存检查器后,它将消耗 GPU 上的额外内存。如果 CUDA 调试器的补丁 RAM 不足,则会给出以下错误
Internal debugger error occurred while attempting to launch
"KernelName - CUmodule 0x04e67f10: code patching failed due to lack of code patching memory.
如果发生这种情况,请通过转到 Nsight > 选项 > CUDA > 代码修补内存因子来增加补丁 RAM 因子。
这是内核指令大小的倍数,它被添加到 64k 的基本补丁 RAM 大小中。
另一种选择是禁用共享或全局内存检查,以便使用较少的补丁 RAM。
内存检查器结果
CUDA 内存检查器结果将转到“输出”窗口的“Nsight”页面,以及CUDA 信息工具窗口。

错误代码 |
含义 |
|---|---|
mis ld |
内存加载期间的未对齐访问 |
mis st |
内存存储期间的未对齐访问 |
mis atom |
原子内存事务处理期间的未对齐访问 - 原子函数传递了未对齐的地址 |
adr ld |
内存加载期间的无效地址 |
adr st |
内存存储期间的无效地址 - 尝试写入超出范围的内存位置,有时也称为限制违规。 |
adr atom |
原子内存事务处理期间的无效地址 - 原子函数尝试在无效地址进行内存访问。 |
示例 1
以下代码片段显示了一个尝试写入超出声明数组范围的内存地址的示例。
尝试写入超出数组索引范围
__device__ float globalArray[10]; __global__ void naughtyWriter () { int i; for (i = 0; i <=> 10; i++) //error: index will exceed array length globalArray[i] => 1; }
请注意,代码示例 1 将 globalArray[] 声明为数据类型为 float 的数组,位于全局内存 (__device__ 内存) 中。如果数组已在 CPU 执行的函数中声明,则该数组将放置在线程本地内存中,CUDA 内存检查器不会检查该内存。
示例 2
以下代码片段显示了尝试写入无效内存地址的示例。如果启用了 CUDA 内存检查器,则调试尝试执行此代码的应用程序将在执行将 0xd1e 分配给数组的语句之前触发断点。
尝试写入无效内存地址
__global__ void other NaughtyWriter(int * pValues, int numElements) { pValues[numElements] = 0xd1e; >//error: invalid memory address }
调试 OptiX 应用程序时的限制
概述
当使用 OptiX SDK 开发应用程序时,某些框架库被认为是专有的,并且具有调试和分析工具限制。对于许多 NVIDIA 工具,涉及这些库的调用堆栈完全受到限制。某些 NVIDIA 工具提供对使用框架库的用户代码的一些可见性。这些工具包括
Nsight Visual Studio Edition 的新一代 CUDA 调试器
Nsight Compute Profiler
cuda-gdb 调试器
NVIDIA Nsight Visual Studio Edition 的限制
旧版 CUDA 调试器
涉及这些库的调用堆栈和状态信息完全受到限制。
新一代 CUDA 调试器
常规
默认情况下,OptiX 应用程序使用 -lineinfo 构建,这通常是为了分析而优化 SASS。-linetable 选项与源代码不完全匹配,因此单步执行行为与您使用 -G(通常用于调试)获得的行为不同。优化的 SASS 使源代码单步执行和源代码断点设置充其量是随意性的。因此,建议您尽可能在 SASS 反汇编中设置断点和单步执行。
调用堆栈和 GPU 状态信息可能仅限于用户代码。调用堆栈的 OptiX 库部分将被标记为 [NVIDIA 内部],并且堆栈的这些部分的状态信息将受到限制。
断点
断点只能在不受限制的 OptiX 模块代码和用户代码中设置。更具体地说
函数断点
用户代码中的函数断点的工作方式与其他 CUDA 应用程序相同。
受限 OptiX 内部代码中的函数断点将无法解析。例如,如果您使用
.*,则调试器将仅解析用户和不受限制的 OptiX 函数中的断点。
源断点
如常规中所述,OptiX 代码通常是经过优化的。这可能会导致源断点解析为多个位置。相应地,断点视图可能会为给定的断点显示多个子实例。因此,建议您尽可能在 SASS 反汇编中设置断点和单步执行。
SASS 断点
在大多数情况下,SASS 断点按预期工作,但有一个例外:Visual Studio 使用绝对地址保存 SASS 断点,因此地址在会话之间可能不同。(它们不是函数 + 偏移量,这将正确地重新定位。)
PTX 断点
PTX 断点的工作方式与其他 CUDA 应用程序相同。
活动时中断
启动时中断
无法在受限 OptiX 内部代码中设置启动函数内部断点。因此,“启动时中断”功能不能用于中断 Optix 对用户代码的回调。
反汇编
限制
反汇编视图不会显示受限的 OptiX 模块代码。
不允许单步执行受限的 OptiX 代码。
当滚动或以其他方式更改视图的反汇编位置时,不会显示受限函数或其文件名。
以下内容仅适用于不受限制的 OptiX 框架库代码和用户代码,但有上述例外
SASS 可以正常显示和单步执行。
PTX(如果存在)可以正常显示和单步执行。
OptiX 不受限制的代码可能显示为
/generated/generated。首次调试器查找 OptiX
/generated/generated文件时,可能会出现一个对话框。取消该对话框将确保它不再显示。还将显示相应的文件名。
调用堆栈
对于受限的 OptiX 函数,显示 [NVIDIA 内部]。
多个受限函数可能会折叠为一个 [NVIDIA 内部] 帧。
[NVIDIA 内部] 帧没有源代码或反汇编,以及其他受限状态信息。
可以正常查看和检查 [NVIDIA 内部] 帧下方和之间的用户代码,但某些寄存器可能不正确。
请注意,这在 cuda-gdb 中是不可能的。
可以正常查看和检查最顶层 [NVIDIA 内部] 帧上方的用户代码。
模块
受限模块将显示为
[CUDA]<module handle>
用户和不受限制的模块,其显示方式与其他 CUDA 应用程序相同。
运行控制
反汇编单步执行的行为与其他 CUDA 应用程序相同。
如常规中所述,OptiX 代码通常是经过优化的。这可能会导致不稳定的源代码单步执行。因此,建议您尽可能在 SASS 反汇编中设置断点和单步执行。
自动窗口
当调用堆栈涉及 [NVIDIA 内部] 帧时,不支持自动变量状态。
局部变量窗口
当调用堆栈涉及 [NVIDIA 内部] 帧时,局部变量状态视图仅显示启动信息。
监视窗口
当调用堆栈涉及 [NVIDIA 内部] 帧时,监视变量不会显示。
PTX 寄存器(例如,%r279 或 %r515)由于缺少设备调试信息 (
-G) 将无法解析,并将显示以下消息Unable to evaluate the expression.
内存
内存视图的行为与其他 CUDA 应用程序相同。
GPU 寄存器(Visual Studio 和 GPU 寄存器视图)
寄存器视图的行为与其他 CUDA 应用程序在最顶层 [NVIDIA 内部] 调用堆栈帧上方相同,但下方的寄存器值不可靠。
限制
PTX 寄存器由于缺少设备调试信息 (
-G) 而不显示。
Warp 信息
Warp 信息视图的行为与其他 CUDA 应用程序相同。
Lane 信息
Lane 信息视图的行为与其他 CUDA 应用程序相同。
符号
默认情况下,OptiX 框架模块没有符号。
API 跟踪
涉及受限 OptiX 库函数的 API 跟踪信息完全受到限制。
声明
声明
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“资料”)均按“原样”提供。NVIDIA 不对这些资料作任何明示、暗示、法定或其他方面的保证,并且明确声明不承担任何关于不侵权、适销性和针对特定用途的适用性的暗示保证。
所提供的信息据信是准确且可靠的。但是,NVIDIA 公司对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果不承担任何责任。未以暗示或其他方式授予 NVIDIA 公司专利权下的任何许可。本出版物中提及的规范如有更改,恕不另行通知。本出版物取代并替换以前提供的所有其他信息。未经 NVIDIA 公司的明确书面批准,NVIDIA 公司产品不得用作生命支持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。