参考
NVIDIA Nsight VSE 的其他资源。
参考主题
本节提供 NVIDIA Nsight Visual Studio Edition 用户指南的附加信息和资源。
调试外部应用程序
早期版本的 NVIDIA Nsight™ VSE 只能调试在 Visual C++ 中构建的项目。但是,从 NVIDIA Nsight™ VSE 3.1 开始,CUDA 调试支持 C++ 和 C# 项目。
如果您想使用 NVIDIA Nsight™ VSE 调试在 C++ 或 C# 以外的环境中构建的应用程序,请使用下面概述的教程。
将 NVIDIA Nsight™ VSE 调试用于其他项目类型
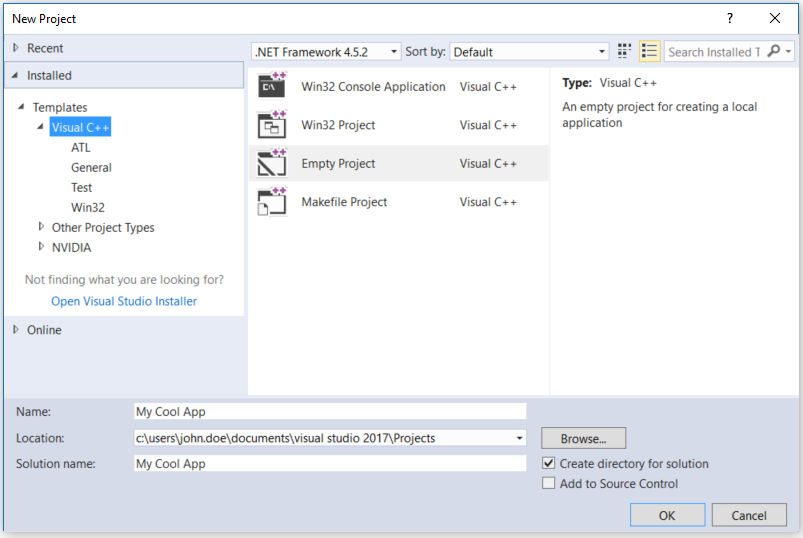
在 Visual Studio 中,通过转到“文件”>“新建”>“项目”来创建“虚拟”项目。
注意
对于 Visual Studio 2019 和 2022,新项目设置过程略有不同。请参阅 使用 Visual Studio 2019 或 2022。
在 Visual C++ 模板的节点上,选择“空项目”。
输入项目的名称,然后单击“确定”。
选择项目的“Nsight 用户属性”以编辑默认设置。
作为替代方法,您也可以转到“项目”菜单 >“Nsight 用户属性”。
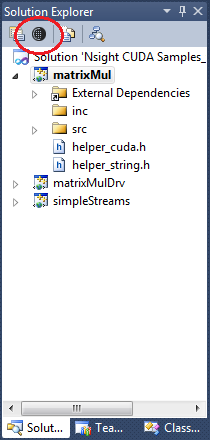
选择“启动外部程序”,然后输入要调试的外部应用程序的路径。
配置您的特定调试环境可能需要的任何其他启动选项或文件同步设置。
单击“确定”以保存您的设置。
您现在可以开始使用 NVIDIA Nsight™ VSE 调试您的应用程序。
为此,请转到“Nsight”菜单或右键单击您的项目,然后选择适当的活动 [启动 CUDA 调试(传统/下一代)、启动图形调试等]。
超时检测与恢复 (TDR)
TDR 代表超时检测和恢复。这是 Windows 操作系统的功能,用于检测显卡响应问题,并通过重置显卡恢复到功能正常的桌面。如果操作系统在一定时间内(默认值为 2 秒)未收到显卡的响应,则操作系统将重置显卡。
在 TDR 存在之前,此类问题会导致系统冻结,并且需要重新启动操作系统。如果启用了 TDR 并且您看到 TDR 错误消息“显示驱动程序停止响应并已恢复”,则表示 Windows 操作系统已重置显示驱动程序。
有三种不同的可能调试配置
使用单个 GPU 进行本地调试,
使用多个 GPU 进行本地调试,或
远程调试。
选择最能反映您的 NVIDIA Nsight™ VSE 设置的配置
使用单个 GPU 进行本地调试
禁用 TDR 会移除一层宝贵的保护,因此通常建议您保持启用状态。
但是,将 TDR 延迟设置得太低可能会导致调试器因以下两个原因之一而失败
在某些 GPU 上进行调试时,TDR 延迟小于 10 秒将失败。
CUDA 内核的调试版本运行速度较慢,并且可能本质上需要更多时间才能完成。如果 TDR 延迟太低,内核可能没有足够的时间完成。
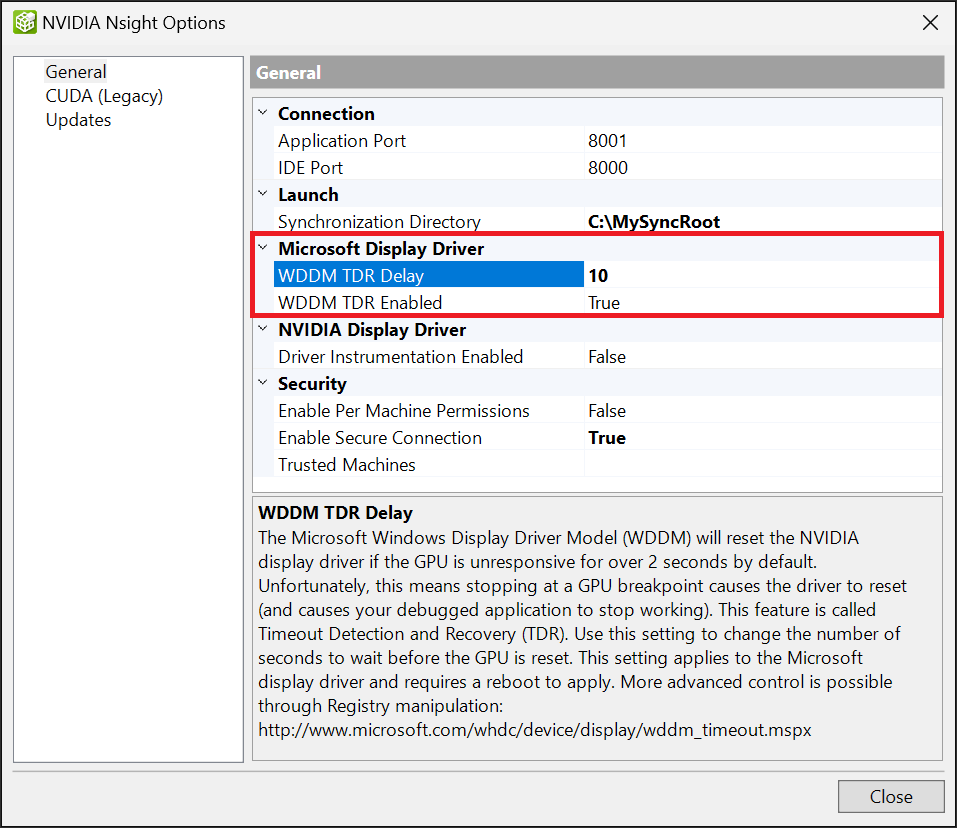
因此,如果您使用单个 GPU 进行本地调试,建议您保持启用 TDR,并将延迟设置为 10 秒。
要启用 TDR 并更改延迟,请执行以下操作
右键单击系统托盘中的“Nsight Monitor”图标。
选择“选项”。
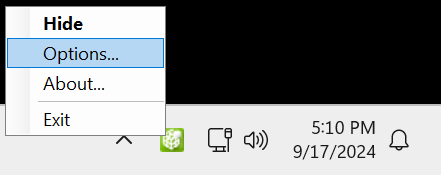
在“选项”窗口的“常规”选项卡上,将“WDDM TDR 已启用”设置为“True”。
将“WDDM TDR 延迟”从默认设置更改为“10”。
使用多个 GPU 进行本地调试或远程调试
当使用具有多个 GPU 的本地调试配置或远程调试配置时,禁用 TDR 非常重要。这是因为对于大多数 CUDA 应用程序,TDR 意味着 TDR 之后的任何调试操作都将失败。您将无法单步执行、设置断点、查看变量等。应用程序将收到网格启动失败,并且 CUcontext 将开始报告错误。
启用 TDR 可能会干扰 GPU 调试,因为当目标应用程序的执行暂停或调试器执行某些操作时,操作系统会将显卡视为无响应。
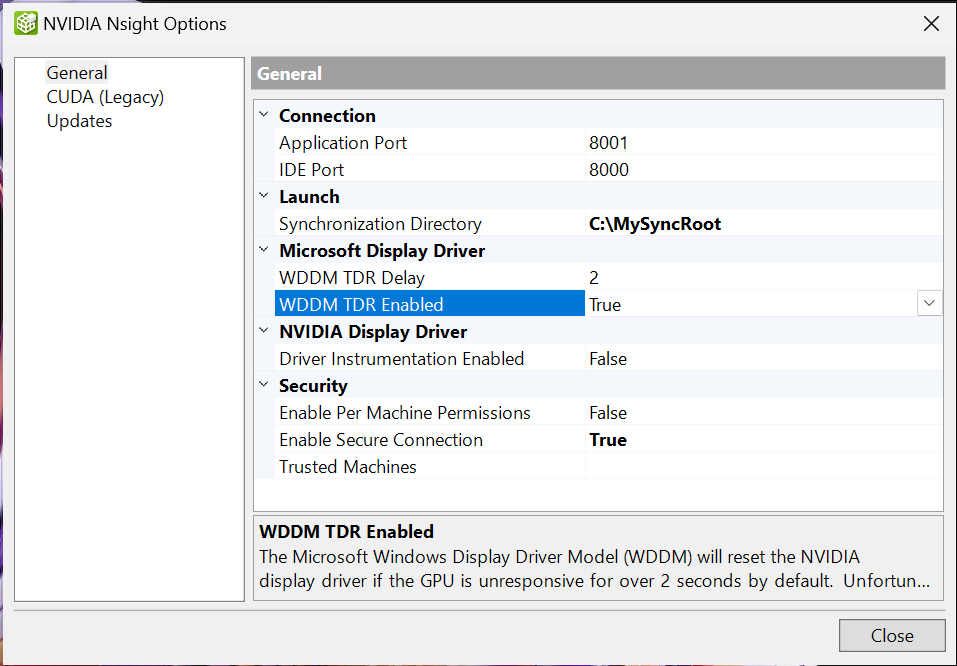
要禁用 TDR,请执行以下操作
右键单击系统托盘中的“Nsight Monitor”图标。
选择“选项”。
在“选项”窗口的“常规”选项卡上,将“WDDM TDR 已启用”设置为“False”。
有关 TDR 的更多信息,请参见
Tesla 计算集群 (TCC)
对于大多数 GPU,您无需在 NVIDIA Nsight™ VSE 中执行任何特定操作即可在 Tesla 计算集群 (TCC) 设备上启用调试。您无需修改 Visual Studio 项目或启用任何特定设置。TCC 设备只是显示为标准 CUDA 设备。对于某些 GPU,默认模式不是 TCC。有关更多信息,请参见下文。
注意
除非通过 Visual Studio 中的正常“停止调试”命令 (SHIFT+F5),否则不要终止在 TCC 设备上执行代码并在断点处暂停的进程。在 TCC 设备上的调试会话期间,异常终止暂停的目标应用程序会导致不可预测的行为。即使终止的进程看起来正常终止,也会导致将来对 cuCtxInit() 的调用无限期挂起。唯一的恢复方法是重新启动目标计算机。请参阅最新的发行说明,以了解此行为的任何更改。
局限性
在 TCC 设备上调试代码时,您会遇到 2 个主要限制
没有 Vulkan、OpenGL 或 Direct3D 互操作支持。
当底层设备在 TCC 模式下运行时,您不能将显示器连接到适配器。物理连接显示器会导致不可预测的行为。Windows 将 TCC 适配器检测为“标准 VGA”设备(实际上并非如此),连接到现有的 NVIDIA 设备。不可预测的行为会导致必须重新启动整个系统。
为 Tesla 产品设置 TCC 模式
NVIDIA GPU 可以存在于三种模式之一:TCC、MCDM 或 WDDM。TCC 和 MCDM 模式禁用 Windows 图形,并在 无头 配置中使用,而 WDDM 模式是 Windows 图形所必需的。NVIDIA GPU 也分为三个类别
GeForce — 通常默认为 WDDM 模式;用于游戏图形。
Quadro — 通常默认为 WDDM 模式,但也经常用作 TCC 计算设备。
Tesla — 通常默认为 TCC 模式,但也提供 MCDM。当前的驱动程序需要 GRID 许可证才能在 Tesla 设备上启用 WDDM。
NVIDIA Nsight™ VSE 计算调试 不 需要特定的驱动程序模式。
NVIDIA 控制面板将显示您的 GPU 处于哪种模式;或者,您可以使用 nvidia-smi 命令生成一个表格,其中将显示您的 GPU 及其正在使用的模式。
要更改 TCC 模式,请使用 NVIDIA SMI 实用程序。默认情况下,它位于 C:\Program Files\NVIDIA Corporation\NVSMI。使用以下语法更改 TCC 模式
nvidia-smi -g {GPU_ID} -dm {0|1|2}
0 = WDDM
1 = TCC
2 = MCDM
注意
NVIDIA Nsight Visual Studio Edition 支持在以下模式下进行 CUDA 调试
MCDM 模式
在 Pascal 系列 GPU(及更高版本)上使用下一代 CUDA 调试器。
TCC 模式
在 Pascal 系列 GPU(及更高版本)上使用下一代 CUDA 调试器。
在 Kepler 系列 GPU(仅限 SM_50)上使用传统 CUDA 调试器。
WDDM 模式
在 Pascal 系列 GPU(及更高版本)上使用下一代 CUDA 调试器。
在 Kepler 系列 GPU(仅限 SM_50)上使用传统 CUDA 调试器。
有关更多详细信息,请参阅 计算调试器支持的配置。
关于 TCC
TCC(Tesla 计算集群)驱动程序是支持 CUDA C/C++ 应用程序的 Windows 驱动程序。该驱动程序启用远程桌面服务,并减少 Windows 上的 CUDA 内核启动开销。请注意,TCC 驱动程序禁用 Tesla 产品上的图形。
TCC 和 Tesla 产品的主要目的是帮助使用 CUDA 执行模拟和大规模计算(尤其是浮点计算)的应用程序,例如专业用途和科学研究领域的图像生成。
使用 Tesla 计算集群驱动程序包的好处
TCC 驱动程序使 NVIDIA GPU 可以在具有非 NVIDIA 集成显卡的节点中使用。
运行 TCC 驱动程序的系统上的 NVIDIA GPU 将通过远程桌面(直接和通过依赖于远程桌面的集群管理系统)可用。
运行 TCC 驱动程序的系统上的 Windows 服务(在会话 0 中)运行的应用程序可以使用 NVIDIA GPU。
TCC 驱动程序专门设计用于 Microsoft 的 Windows HPC Server 2008。但是,NVIDIA 的 TCC 驱动程序可以与 Windows HPC Server 2008 以外的操作系统一起使用。NVIDIA TCC 驱动程序没有与 WDDM 相同的固定分配限制或内存碎片行为。您可以将 TCC 驱动程序与 XP 样式的显示驱动程序混合使用。
有关支持的操作系统以及与其他 NVIDIA 驱动程序的兼容性的更多信息,请参阅 NVIDIA Tesla 上的文档
http://www.nvidia.com/object/tesla_computing_solutions.html
有关 Windows HPC Server 2008 上 NVIDIA 硬件兼容性的更多信息,请参见
http://technet.microsoft.com/en-us/library/ff793340_ws.10_.aspx
要在 NVIDIA 网站上搜索 Tesla 驱动程序,请参见
环境变量
NVIDIA Nsight™ VSE 创建某些系统环境变量,这些变量在定义构建属性时很有用。这些变量与 Visual Studio 定义的构建宏是分开的。
有关构建命令(例如 $(OutDir) 和 $(TargetName))可用的宏列表的更多信息,请参阅 MSDN 上关于 构建命令和属性的宏 的文章。
要查看与 CUDA 路径相关的环境变量
打开控制面板中的“高级系统设置”面板。
开始 > 控制面板。
选择“系统和维护”。
选择“系统”。
在左侧窗格中,选择“高级系统设置”。
“系统属性”窗口打开。
单击“环境变量”按钮。
在“系统变量”下,滚动以查看名称中包含 CUDA 的变量。
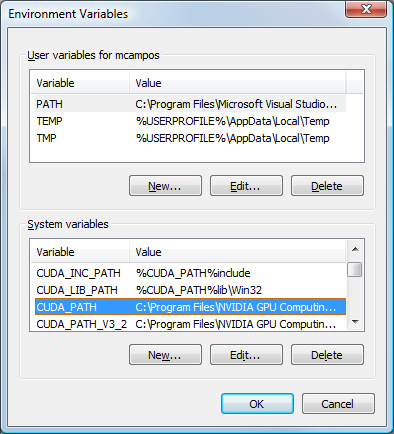
单击“确定”关闭窗口。
“环境变量”窗口列出了以 CUDA 开头的系统环境变量。这些变量可以在项目属性页中使用,以控制构建过程的各个方面。
DirectCompute
Microsoft DirectCompute 是一个应用程序编程接口 (API),它支持 Microsoft Windows 7 和 Windows 8 上图形处理单元上的通用计算。
NVIDIA 的 Direct3D 11 GPU 支持 DirectCompute。这使开发人员可以利用 NVIDIA GPU 的大规模并行计算能力,在消费者和专业市场中创建引人注目的计算应用程序。
另请参阅
NVIDIA Nsight Visual Studio Edition 故障排除
问题
当我将项目转换为较新版本的 Visual Studio 时,出现构建错误。
解决方法
有关如何转换项目的更多信息,请参阅 NVIDIA 开发者论坛。
问题
如何获取 NVIDIA Nsight™ VSE 主机和监视器的诊断日志,以进行故障排除?
解决方法
关闭 Visual Studio 和 Nsight Monitor。
在主机和目标计算机上,转到以下位置,并删除任何现有文件
%AppData%\NVIDIA Corporation\Nsight\Vsip\1.0\Logs %AppData%\NVIDIA Corporation\Nsight\Monitor\1.0\Logs
按如下方式编辑
Nvda.Diagnostics.nlog。在主机上
C:\Program Files (x86)\NVIDIA Corporation\Nsight Visual Studio Edition 2023.2\Host\Common\Configurations
在目标计算机上
C:\Program Files (x86)\NVIDIA Corporation\Nsight Visual Studio Edition 2023.2\Monitor\Common\Configurations
转到文件底部的最后一个记录器
<logger name="*" minlevel="Error" writeTo="file-high-severity" />.
将
minlevel属性值从"Error"更改为"Trace"。保存文件。
重现问题,并发送以下生成的日志
%AppData%\NVIDIA Corporation\Nsight\Vsip\1.0\Logs %AppData%\NVIDIA Corporation\Nsight\Monitor\1.0\Logs
问题
当在源代码中设置断点时,CUDA 调试器会在与断点无关的位置暂停执行。
当多个 __global__ 函数(内核)在单个模块中调用 __device__ 函数,并且以下两者都为真时,可能会发生这种情况
__device__函数未内联。不同的内核调用完全相同的
__device__函数。
解决方法
您可以采取几种方法来解决此问题
通过将
__forceinline__关键字应用于__device__函数,强制__device__函数内联。请注意,在调试版本中使用inline关键字不会强制内联。重新组织源代码,使每个
__device__函数只有一个__global__函数。这意味着每个使用 NVIDIA CUDA 编译器 (nvcc.exe) 编译的.cu文件应最多包含一个__global__函数。这适用于 Driver API 和 CUDART 应用程序。请注意,此方法还存在其他潜在问题推荐:将常用的
__device__函数移动到公共头文件。使用#include语句将__device__函数包含在每个包含__global__函数的.cu文件中。潜在问题:如果您的源代码包含以下样式的全局变量声明
__device__ int x;
并且该变量被多个
__global__函数使用,则使用多个文件多次调用__global__函数不是一个简单的解决方法。在这种情况下,我们建议从源代码中消除以该样式声明的全局变量,并将它们作为内核参数。潜在问题:每个
__constant__变量都与一个 CUDA 模块(已编译的.cu文件)相关联。如果您的源代码的编写方式是多个内核依赖于同一个
__constant__变量,并且应用程序的主机代码端动态更新该变量,那么您将需要对源代码进行更广泛的更改对于 CUDART 应用程序,在将
__constant__变量复制到每个.cu文件时,为每个变量指定不同的名称。任何更新先前单个变量实例的主机代码现在都必须更新所有实例。
问题
我收到警告,提示 64 位注入和/或 32 位注入不存在。
解决方法
Nsight Monitor 检查 64 位版本的 CUDA 注入。这意味着如果 64 位和/或 32 位注入不存在,您可能会收到警告。如果发生这种情况,请重新安装工具。
问题
当我在具有 2 个 GPU 的单台机器上本地使用 CUDA 调试器时,我的机器挂起。
解决方法
在具有 NVIDIA Nsight™ VSE 工具的两个 GPU 上进行本地调试时,有几个可能的问题可能导致机器挂起。
确保您的 TDR 设置已正确配置。有关更多信息,请参阅 超时检测和恢复。
我们建议不要在您调试 CUDA 代码的 GPU 上连接显示器或运行桌面,因为在 GPU 上同时进行活动可能会导致机器挂起。有关更多信息,请参阅 操作方法:设置本地无头 GPU 调试。
问题
当我同时使用 CPU 调试器时,GPU 调试器挂起。
解决方法
永远不要使用同一个 Visual Studio 实例同时运行 CUDA 调试器和 CPU 调试器。
通常,请确保仅使用 CUDA 调试器或 CPU 调试器,而不是两者都使用。在 CUDA 调试会话期间附加 CPU 调试器并命中 CPU 断点将导致 CUDA 调试器挂起(直到您恢复 CPU 进程)。
如果小心,您可以附加两个单独的 Visual Studio 实例(一个 CUDA,一个 CPU)。当您在 CPU 代码中停止时,CUDA 调试器将挂起。一旦您恢复 CPU 代码,CUDA 调试器将恢复正常。
问题
我无法在我的 CUDA 代码中设置和命中断点。
解决方法
确保使用发行说明中指定的驱动程序版本。这是断点不起作用的最常见原因。驱动程序必须安装在您的应用程序代码运行的计算机上。
另外,请确保您的项目使用兼容的 CUDA 工具包。兼容版本的 CUDA 工具包生成符号信息,使 CUDA 调试器在使用 -G0 标志在 nvcc 命令行上时能够正确调试您的代码。如果您正在使用 CUDA Driver API,请确保在项目的构建输出目录中,每个已编译的 .cubin 文件旁边都有 .cubin.elf.o 文件。使用 CUDA 运行时 API 的项目将符号信息嵌入到对象文件本身中。
问题
我收到以下错误消息
Local debugging failed. Nsight is incompatible with WPF acceleration.Please see documentation about WPF acceleration. Run theDisableWpfHardwareAcceleration.reg in your Nsight installation.
解决方法
禁用 WPF D3D 加速。有关更多信息,请参阅 设置本地调试。
如果一个或多个应用程序正在使用 WPF 硬件加速运行,并且您运行 .reg 文件,则在重新启动这些应用程序之前,您可能仍然会遇到问题。如果您正在执行本地调试,则包括 Nsight Monitor - 您需要重新启动它,因为它也是 WPF 应用程序。
问题
当我通过从“Nsight”菜单中选择“启动 CUDA 调试”来调试程序时,我的程序忽略在 CPU 代码中设置的断点。
解决方法
CUDA 调试器忽略在 CPU 代码中设置的断点,因为它目前不支持调试 x86 或其他 CPU 代码。
问题
当我命中 CUDA 断点时,我只在 CUDA 内核中的线程 (0, 0, 0) 上中断一次。如果我点击“继续 (F5)”,它永远不会再次中断,并且整个启动完成。
解决方法
CUDA 调试器的默认行为是在内核的第一个线程上无条件中断。之后,断点具有基于 CUDA 焦点选择器的隐式条件。如果您想在不同的线程上中断,请使用 CUDA 焦点选择器将焦点切换到所需的线程,或设置条件断点,以便调试器仅在您指定的线程上停止。有关设置条件断点的更多信息,请参阅 操作方法:指定调试器上下文 和 操作方法:设置 GPU 断点。切换焦点后,CUDA 调试器会在内核启动期间保持焦点,并且仅在该线程中的断点处中断。
问题
尝试复制和粘贴着色器代码时遇到错误。
解决方法
当使用 Productivity Power Tools 扩展时,这可能会在 Visual Studio 2012 中发生。禁用“HTML 复制”选项,您应该能够在着色器编辑器中正常复制和粘贴。
声明
声明
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 不对这些材料作出任何明示、暗示、法定或其他方面的保证,并且明确声明不承担所有关于不侵权、适销性和适用于特定用途的暗示保证。
提供的信息据信是准确可靠的。但是,NVIDIA Corporation 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果不承担任何责任。未通过暗示或其他方式授予 NVIDIA Corporation 任何专利权下的许可。本出版物中提及的规范如有更改,恕不另行通知。本出版物取代并替换以前提供的所有其他信息。未经 NVIDIA Corporation 明确书面批准,NVIDIA Corporation 产品不得用作生命支持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。