CUDA 调试器入门
NVIDIA Nsight VSE CUDA 调试器简介。
演练:调试 CUDA 应用程序
在以下演练中,我们将介绍您可能用于调试基于 CUDA 的应用程序的一些更常见步骤。我们使用名为 Matrix Multiply 的示例应用程序作为示例。NVIDIA CUDA 工具包 SDK 包含此示例应用程序。有关 NVIDIA CUDA 工具包和 NVIDIA GPU CUDA 示例的更多信息,包括许可信息,请访问:http://www.nvidia.com/getcuda
在本演练中,我们假设应用程序是远程调试的(NVIDIA Nsight™ VSE 主机软件在安装了 Visual Studio 的计算机上运行,Nsight Monitor 在另一台计算机上运行)。[1]
[1] 请注意,下一代 CUDA 调试器仅支持本地调试。目前不支持远程调试。
打开示例项目并设置断点
在 CUDA SDK 中打开名为 matrixMul 的示例项目。
有关查找示例应用程序的帮助,请参阅使用示例。
您可能会注意到还有其他名称相似的示例项目:matrixMul_nvrtc、matrixMul_CUBLAS、matrixMultDrv。本示例中使用的项目使用 CUDA 运行时 API。
注意
注意,此文件包含 CPU 代码(即
matrixMultiply())和 GPU 代码(即matrixMultiplyCUDA(),任何使用__global__或__device__关键字指定的函数)。旧版 CUDA 调试器仅支持调试 GPU CUDA 内核
下一代 CUDA 调试器允许您同时调试 CPU 和 GPU 代码。
首先,让我们在 GPU 代码中设置一些断点。
打开名为
matrixMul.cu的文件,并找到 CUDA 内核函数matrixMulCUDA()。在以下位置设置断点
int aStep = BLOCK_SIZE
在以下语句的开头设置另一个断点
for {int a = aBegin, b = bBegin;
现在,让我们在 CPU 代码中设置一些断点
在同一文件
matrixMul.cu中,找到 CPU 函数matrixMultiply()。在以下位置设置一个断点
if (block_size == 16)
在以下语句的开头设置另一个断点
printf("done\n");
在本演练的这一部分中,您打开了示例项目并设置了断点。接下来,我们构建示例项目并启动调试会话。
配置本地或远程调试
初始化目标计算机。
注意
如果您在单台计算机上使用旧版 CUDA 调试器
Nsight Monitor 将自动为您启动。您可以跳过此步骤。
如果您正在使用下一代 CUDA 调试器
目前不支持远程调试。目标计算机假定为 localhost。请转到构建示例并启动调试器。
在目标计算机上,启动 Nsight Monitor。
在目标计算机上,单击 Windows“开始”菜单。
向下滚动已安装的程序,然后选择:NVIDIA Corporation > Nsight Monitor。
Nsight Monitor 启动。Nsight Monitor 图标出现在系统托盘中。
在主机上,配置项目以进行本地或远程调试。
在解决方案资源管理器中,右键单击项目名称 matrixMul,然后选择“Nsight 用户属性”。(或者,您也可以转到“项目”菜单 >“Nsight 用户属性”。)
“用户设置”窗口出现。
在左侧窗格中,选择“启动”。
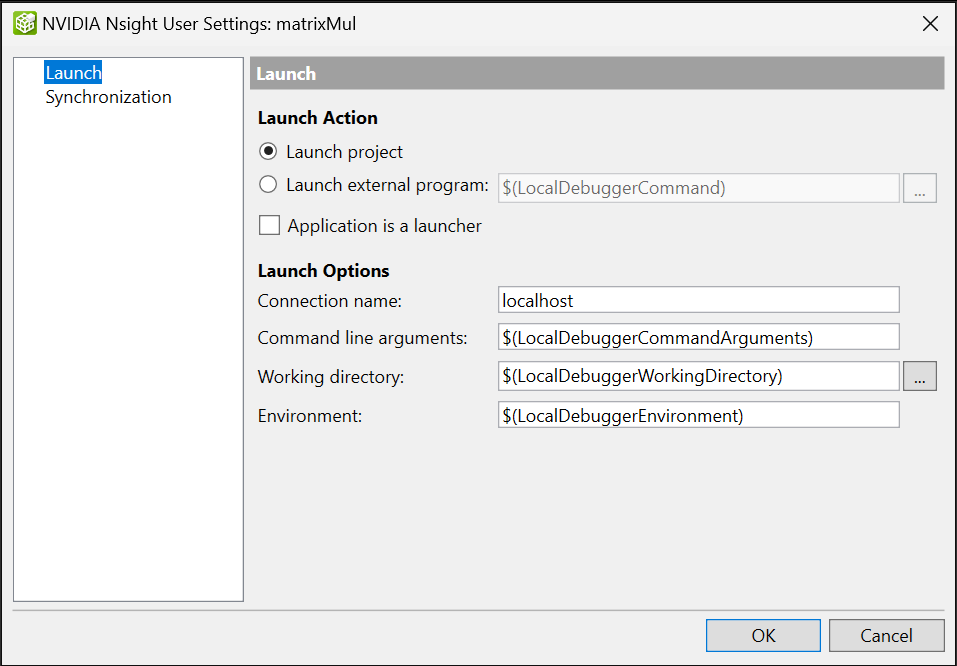
本地目标(默认)设置
对于远程调试,您可以通过将“连接名称”字段中的
localhost替换为目标计算机的地址(将在其上运行要调试的应用程序的远程计算机)来更改该字段。这可以是您本地网络中计算机的 IP 地址,也可以是您的网络上识别的计算机名称(有关更多信息,请参阅建议的 IP 地址格式)。重要提示:请勿使用映射驱动器来指定主机名。例如
错误:
M:\正确:jsmith.mydomain.com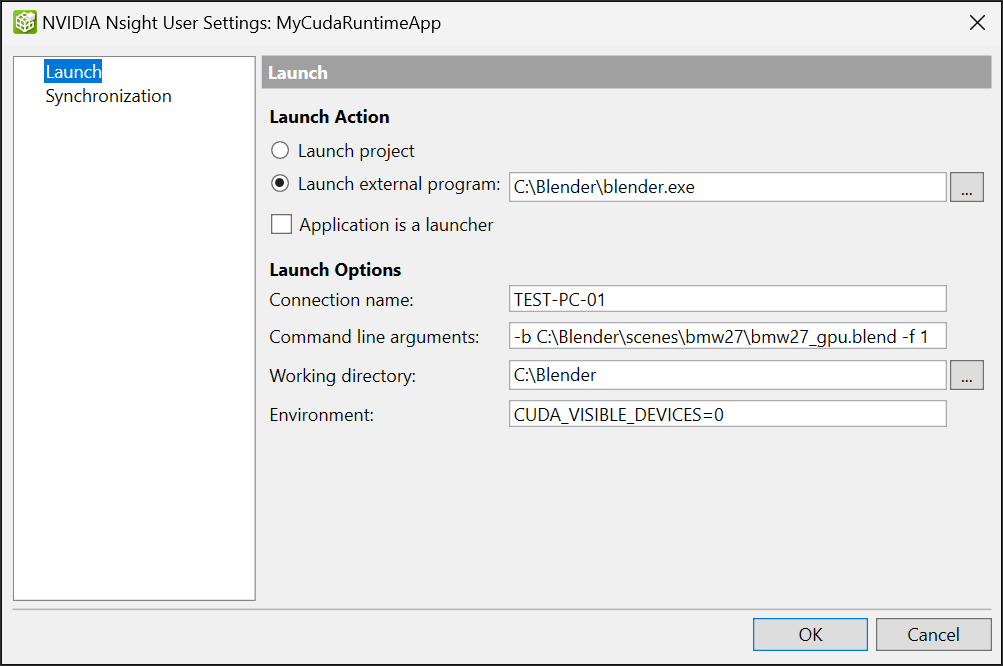
远程目标:TEST-PC-01
您可以选择更新默认值
工作目录— 您可以指定要目标应用程序用作其工作目录的目录。默认工作目录是项目目录
命令行参数— 使用工作目录中的文件指定,或直接在此字段中指定。
环境— 指定环境变量及其值。
当在环境字段中设置 $(Environment) 时,调试器将从 VS 属性中的本地调试选项中获取环境块。
启动操作
启动项目— 启动当前项目的可执行文件
启动外部程序— 用于后期调试器附加
注意:下一代 CUDA 调试器目前不支持后期附加。
应用程序是启动器— 用于后期调试器附加到由另一个程序(即游戏引擎)启动的程序。
注意:下一代 CUDA 调试器目前不支持后期附加。
单击“确定”
可选:在远程调试时,要在文件复制到远程系统失败时中止启动,请将“同步失败时中止”选项设置为“True”。
从Nsight 菜单中,选择“Nsight 选项”。“Nsight 选项”窗口打开。
在左侧窗格中,选择“常规”。
在“启动”部分下,将“同步失败时中止”设置为“True”。
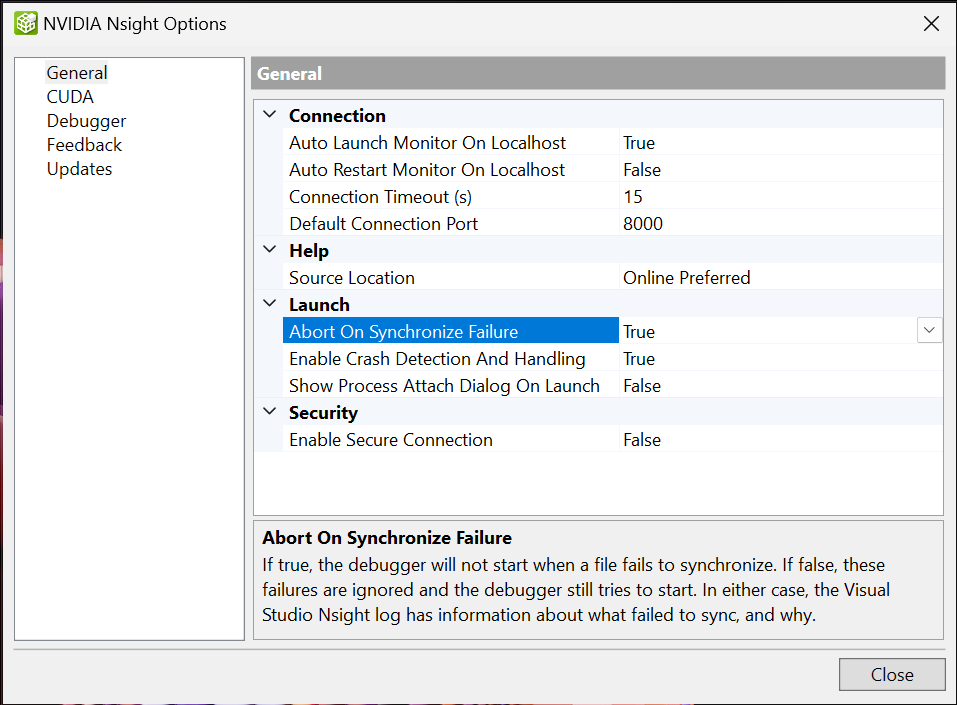
单击“确定”按钮。
配置旧版 CUDA 调试器和旧版 CUDA 内存检查器属性。
从 Nsight 菜单中选择“Nsight 选项”。“Nsight 选项”窗口打开。
在左侧窗格中,选择“CUDA”。
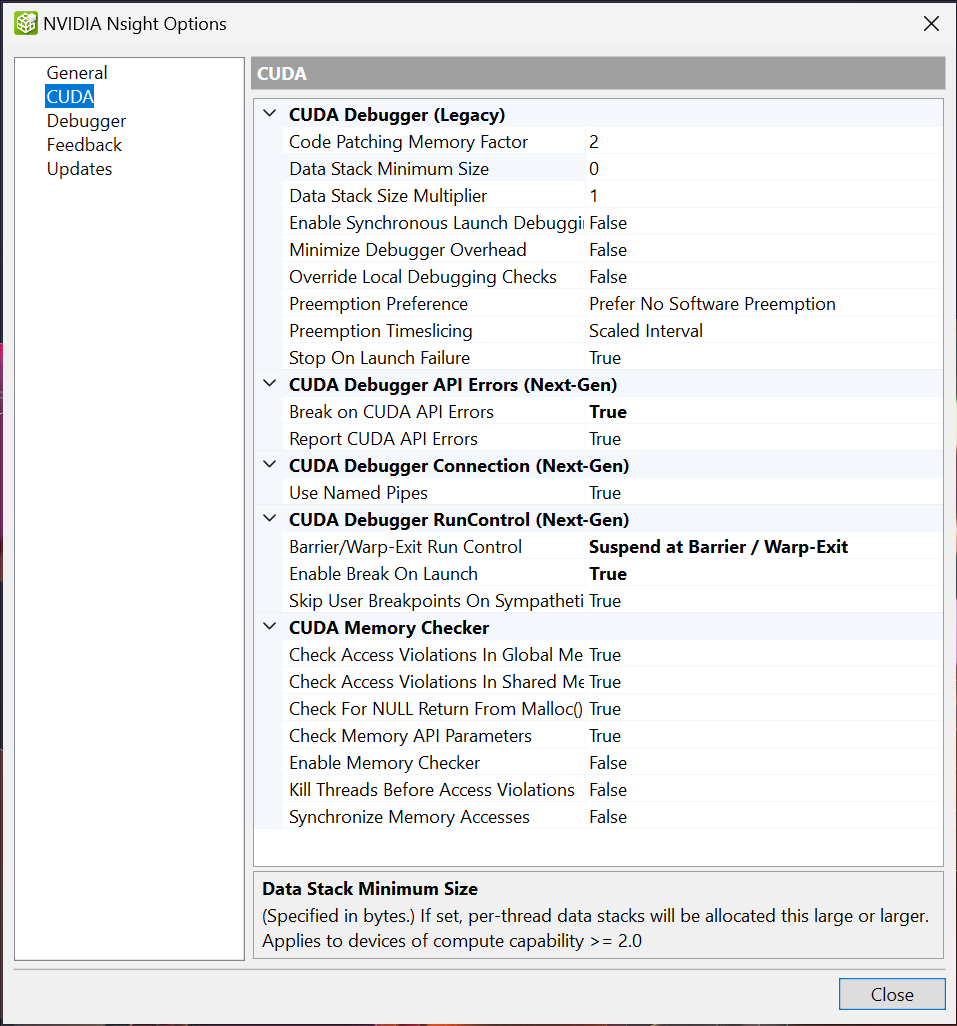
配置旧版 CUDA 设置以满足您的调试需求。
注意
关于 CUDA 数据堆栈功能的注意事项
在较新的架构上,每个 GPU 线程都有一个私有数据堆栈。通常,所需的数据堆栈大小由编译器确定,并且通常驱动程序的默认大小大于内核所需的大小。
但是,如果内核使用递归函数,则编译器无法静态确定数据堆栈大小。在这种情况下,应用程序必须使用
CU_LIMIT_STACK_SIZE调用cuCtxGetLimit()和cuCtxSetLimit(),以确保足够的堆栈空间。对于发布编译的内核,设置
CU_LIMIT_STACK_SIZE通常是应用程序的责任。由于调试编译的内核需要额外的堆栈空间,因此应用程序将需要针对调试和发布使用不同的堆栈大小设置。
为了方便起见,并避免使用特定于调试内核的代码污染应用程序代码,我们在 CUDA 调试器中添加了设置,这些设置将在调试时自动增加您的堆栈大小设置。
构建示例并启动调试器
在主机上,构建 matrixMul 项目。
从 Visual Studio“生成”菜单中,选择“重新生成 matrixMul”。
NVIDIA Nsight™ VSE 构建项目。
注意
您必须使用以下 nvcc 编译器开关来生成 CUDA 内核的符号信息
-G
调试本机 CPU 代码(需要下一代调试器)时,您还应使用
-g, -0nvcc 编译器标志来生成带有符号信息的未优化代码。查看输出窗口以查找错误消息。如果项目构建成功,请转到下一步。如果项目未构建,则需要先纠正问题,然后再转到下一步。
从 Nsight 菜单中,选择
启动 CUDA 调试(旧版)
启动 CUDA 调试(下一代)
有关为您的系统配置选择正确的调试器的信息,请参阅系统要求页面。
或者,您也可以选择
右键单击项目,然后选择“调试”>“启动 CUDA 调试(旧版)/(下一代)”
单击“启动 CUDA 调试(旧版)/(下一代)”工具栏图标。
通过右键单击 Visual Studio 工具栏并切换“Nsight CUDA 调试”来显示/隐藏此图标组。
单击“启动 CUDA 调试(旧版)/(下一代)”工具栏菜单项。
通过右键单击 Visual Studio 工具栏并切换“Nsight 连接”来显示/隐藏此图标组。
如果您启动了旧版 CUDA 调试
您会注意到,在主机上,弹出消息指示已建立连接。
请注意,使用远程调试配置时,必须在调试之前启动 Nsight Monitor。但是,在本地调试设置中,启动 CUDA 调试器时,Nsight Monitor 将自动启动。
您已启动调试会话。在本演练的下一节中,我们将查看您在调试会话期间通常会检查的一些窗口。
编辑 .cu 文件属性
在 Visual Studio 中,您可能会遇到依赖项失败,因为 .cu 文件的属性配置不正确。要解决此问题,请使用以下步骤。
右键单击包含的 .cu 文件,然后选择“属性”。
将“项类型”更改为“C/C++ 标头”。
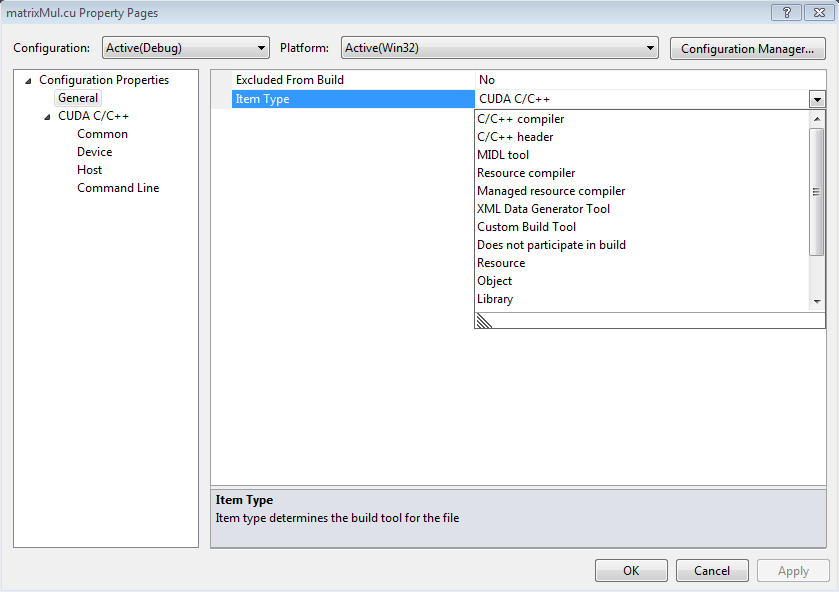
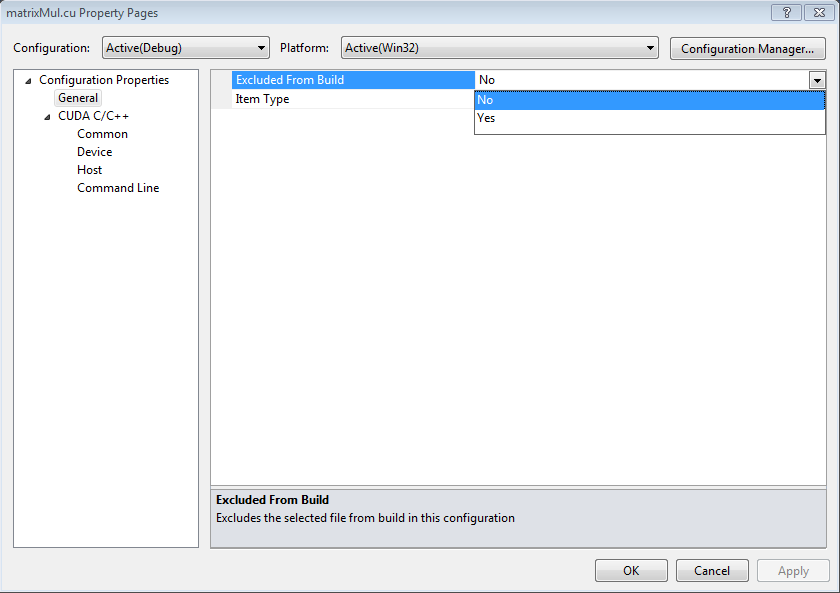
确保将“从生成中排除”属性设置为“否”。
检查变量的值
启动 CUDA 调试器。
从 Visual Studio 中的 Nsight 菜单中,选择以下任一项
启动 CUDA 调试(下一代)
启动 CUDA 调试(旧版)
有关为您的系统配置选择正确的调试器的信息,请参阅系统要求。
或者,您也可以选择
右键单击项目,然后选择“调试”>“启动 CUDA 调试(旧版)/(下一代)”
单击“启动 CUDA 调试(旧版)/(下一代)”工具栏图标。
通过右键单击 Visual Studio 工具栏并切换“Nsight CUDA 调试”来显示/隐藏此图标组。
单击“启动 CUDA 调试(旧版)/(下一代)”工具栏菜单项。
通过右键单击 Visual Studio 工具栏并切换“Nsight 连接”来显示/隐藏此图标组。
从“调试”菜单中,选择“窗口”>“局部变量”。
“局部变量”窗口打开。“局部变量”窗口显示当前词法范围内的变量及其值。
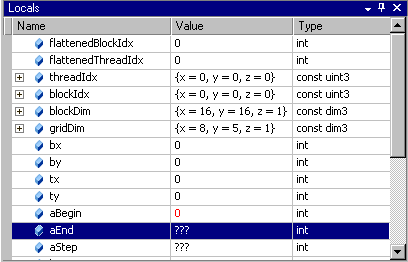
注意:您无法通过编辑“局部变量”窗口中的值来更改 GPU 内存中的值。
检查内存中的值
启动 CUDA 调试器。
从 Visual Studio 中的 Nsight 菜单中,选择以下任一项
启动 CUDA 调试(下一代)
启动 CUDA 调试(旧版)
有关为您的系统配置选择正确的调试器的信息,请参阅系统要求。
或者,您也可以选择
右键单击项目,然后选择“调试”>“启动 CUDA 调试(旧版)/(下一代)”
单击“启动 CUDA 调试(旧版)/(下一代)”工具栏图标。
通过右键单击 Visual Studio 工具栏并切换“Nsight CUDA 调试”来显示/隐藏此图标组。
单击“启动 CUDA 调试(旧版)/(下一代)”工具栏菜单项。
通过右键单击 Visual Studio 工具栏并切换“Nsight 连接。”来显示/隐藏此图标组。
从“调试”菜单中,选择“窗口”>“内存”>“内存窗口 1”。
“内存”窗口打开。
从“局部变量”窗口将变量拖动到“内存”窗口。
内存窗口显示与变量(或指针)对应的地址的值。
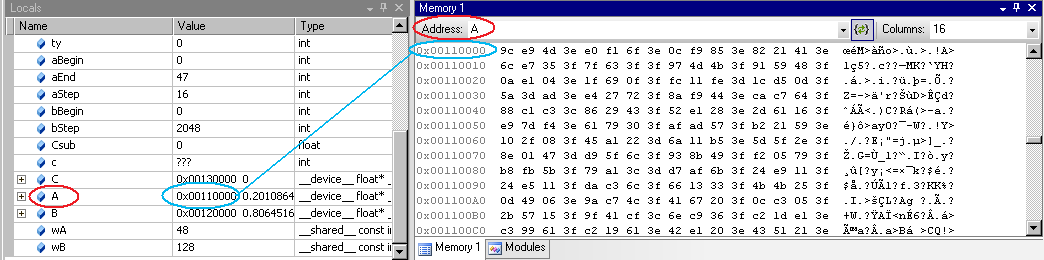
在
__local__、__const__或__shared__中查看内存时,请确保 Visual Studio 内存视图设置为“自动重新评估”。这将确保显示的内存是正确的内存空间。否则,显示可能会更改为默认为全局内存的地址。注意
您无法通过编辑“内存”窗口中的值来更改 GPU 内存中的值。
检查 SASS 索引常量的值
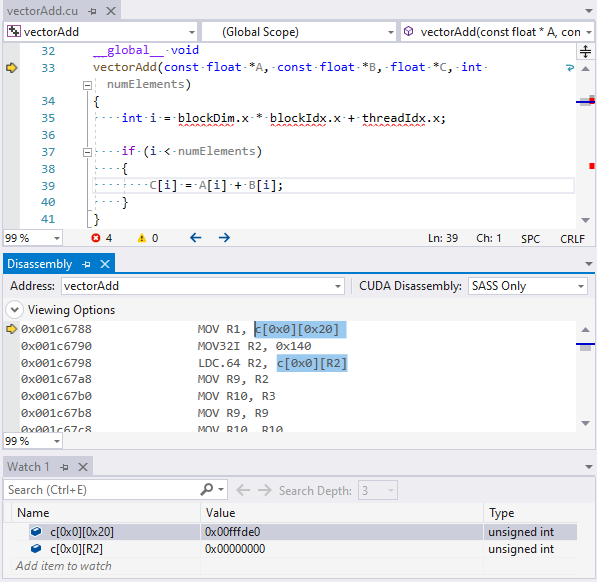
从“调试”菜单中,选择“窗口”>“反汇编”,并将 CUDA 反汇编设置为 SASS。
SASS 是特定于 GPU 架构的反汇编,其实施可能会发生变化,因此 NVIDIA 未对其进行文档化,尽管它类似于 PTX。
从 Nsight 菜单中,确保已设置“启动时中断”。
启动 CUDA 调试器
从 Visual Studio 中的 Nsight 菜单中,选择:“启动 CUDA 调试(下一代)”。
执行将在第一个内核启动时停止。
请注意,启动用户内核参数常量在反汇编视图中表示为 c[bank][offset]。
从“调试”菜单中,选择“窗口”>“监视”。
添加索引常量以查看其值。
c[bank][offset] 表示法指的是常量内存中的位置。
索引常量可能在其他地方找到,并且大量用于引用
每个模块的常量变量
每个模块的常量文字(const double = 1.0),无法直接编码到指令中
每个启动用户内核参数(最多 4KB)
每个启动驱动程序内核参数(本地内存基址、GridDim、BlockDim)
模块级常量的 bank 将与每个内核启动常量的 bank 不同。
bank 和偏移量在不同的 GPU 架构之间会有所不同。
下一代 CUDA 调试器还可以在内存视图中使用语法 (constant int*)0 读取模块常量(bank=0,c[0][#])。对于 c[0][0x100],请使用 (constant int*)0x100。
下一代 CUDA 调试器还可以使用 (params int*)0 查看 4KiB 的内核参数。这映射到 c[3][0x140] 或 c[3][0x160],具体取决于架构。
另请参阅
操作指南
参考
教程:使用 CUDA 调试器
在以下教程中,我们将介绍如何使用 CUDA 调试器的一些基本功能。在本教程中,我们使用名为 Matrix Multiply 的示例应用程序,但您可以使用自己的源代码遵循相同的步骤。
本教程介绍如何本地调试应用程序。这意味着您需要在安装了 Visual Studio 的计算机上运行 NVIDIA Nsight™ VSE 主机软件,并在同一台计算机上运行 Nsight Monitor。
确保您使用的计算机满足系统要求。有关更多信息,请参阅NVIDIA Nsight 软件的系统要求。
这将是我们在本教程中的第一个练习:配置计算机以进行本地调试。在本教程中
练习 1:打开项目并构建可执行文件
让我们打开示例项目 matrixMul。这是一个简单的基于 CUDA 的应用程序,用于将 2 个矩阵相乘。源代码中的算法相对简单,但仍然可以让您了解 CUDA 调试器的工作原理。matrixMul 应用程序包含在 CUDA 工具包软件中(请参阅使用示例)。
确保您理解使用与 NVIDIA Nsight™ VSE 兼容的 CUDA 工具包的重要性。
注意
CUDA 工具包:为了将项目与 NVIDIA Nsight™ VSE 工具一起使用,我们建议您使用工具附带的编译器。此版本编译器的默认安装目录为
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
编译器位于按其版本标记的子目录中,例如
...\<version_number>\bin\nvcc.exe
NVIDIA Nsight™ VSE 工具与此版本的编译器配合使用效果最佳。但是,这些工具也适用于标准工具包。无论您使用哪个编译器,您用于编译 CUDA C 代码的 CUDA 工具包都必须支持以下开关,以生成 CUDA 内核的符号信息:-G。
还建议您在使用下一代调试器时使用 -g -0 nvcc 标志来生成带有本机主机端代码符号信息的未优化代码。
打开名为 matrixMul 的示例项目。
浏览到
C:\ProgramData\NVIDIA Corporation\CUDA Samples\<version_number>
在这里,您将找到许多示例项目,以及受支持的 Visual Studio 版本项目和解决方案。
浏览到
C:\ProgramData\NVIDIA Corporation\CUDA Samples\<version_number>\0_Simple\MatrixMul
双击
matrixMul_vs20YY.sln
适用于您的 Visual Studio 版本的 文件
Visual Studio 启动。matrixMul 项目打开。您可能会注意到 0_Simple 包含其他名称相似的示例项目,例如 matrixMulDrv。此项目使用 CUDA 驱动程序 API。本示例中使用的项目使用 CUDART(CUDA 运行时 API)。
构建 matrixMul 项目。
从 Visual Studio“生成”菜单中,选择“重新生成 matrixMul”。NVIDIA Nsight™ VSE 构建项目。
查看输出窗口以查找错误消息。如果项目构建成功,请转到下一步。如果项目未构建,则需要先纠正问题,然后再转到下一步。
您现在已成功打开项目并构建了 matrixMul 可执行文件。
练习 2:设置断点
在我们运行 matrixMul 应用程序之前,让我们在源代码的关键位置设置一些断点。这将导致 CUDA 调试器在这些点暂停目标应用程序的执行,并让我们有机会检查变量的值和每个线程的状态。
打开名为
matrixMul_kernel.cu的文件。在
matrixMul_kernel.cu中的语句处设置断点int aBegin = wA * BLOCK_SIZE * by;
您还可以使用 Visual Studio 提供的任何其他各种方法来设置断点。Visual Studio 使用红色圆圈(字形)标记断点的位置。
让我们设置另一个断点。在以下语句开头设置一个断点
int aStep = BLOCK_SIZE;
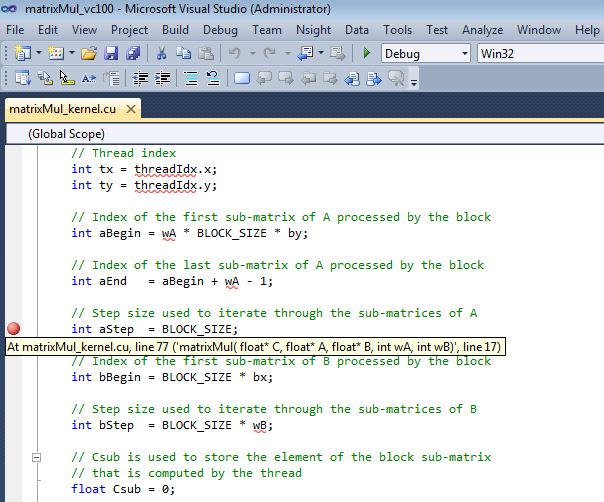
让我们在以下位置设置另一个断点
int BS(ty, tx) = B[b + wB * ty + tx];
这个特定的断点很有趣,因为它发生在紧邻
_synchthreads语句的源代码行上。
练习 3:运行 CUDA 调试器并检查变量
让我们启动 CUDA 调试器,并查看我们在断点处设置的变量和内存。
启动 Nsight Monitor。
在目标计算机上,单击 Windows“开始”菜单。
向下滚动已安装的程序,然后选择:NVIDIA Corporation > Nsight Monitor。
Nsight Monitor 启动。监视器图标出现在系统托盘中。
启动 CUDA 调试器。从 Visual Studio 中的 Nsight 菜单中,选择“启动 CUDA 调试”。(或者,您也可以右键单击项目并选择“启动 CUDA 调试”。)
CUDA 调试器启动。请注意,弹出消息指示已建立连接。调试器启动 matrixMul 应用程序。执行继续进行,直到调试器遇到第一个断点,此时调试器暂停执行。
除非您更改了键绑定,否则无法使用 F5 启动 CUDA 调试器。Visual Studio 中 F5 键的默认键绑定是启动本机调试器(CPU 调试器)。但是,一旦 CUDA 调试器启动,它将响应影响运行控制的其他键绑定(例如 F11 和 F12)。
从“调试”菜单中,选择“窗口”>“局部变量”。“局部变量”窗口打开。“局部变量”窗口显示当前词法范围内的变量及其值。注意“局部变量”窗口中变量 aBegin 的值。
单击“单步跳入”图标或按 F11。
注意,变量 aBegin 的值已更改。红色表示该值由于上次执行的指令而更改,在本例中,该指令是具有第一个断点的语句。
请记住,与在 CPU 代码上使用本机调试器不同,您无法通过编辑“局部变量”窗口中的值来更改 GPU 内存中的值。
单击“运行”图标或按 F5。
CUDA 调试器恢复执行 matrixMul 应用程序,并在执行下一断点处源代码行上的指令之前暂停。在我们继续执行之前,让我们看一下内存中的值。
从“调试”菜单中,选择“窗口”>“内存”>“内存窗口 1”。“内存”窗口打开。
从“局部变量”窗口将变量拖动到“内存”窗口。内存窗口显示与变量(或指针)对应的地址的值。
在 __local__、__const__ 或 __shared__ 中查看内存时,请确保 Visual Studio 内存视图设置为“自动重新评估”。这将确保显示的内存是正确的内存空间。否则,显示可能会更改为默认为全局内存的地址。
注意 |
您无法通过编辑“内存”窗口中的值来更改 GPU 内存中的值。 |
练习 4:运行内存检查器
CUDA 内存检查器跟踪所有内存分配。以确保目标应用程序不会访问无效的内存位置。
在 CUDA 内核启动中写入越界内存位置会导致 GPU 终止启动,并将 CUDA 上下文置于永久错误状态。这会导致所有 CUDA API 函数返回错误代码,例如 CUDA_ERROR_UNKNOWN。如果没有内存检查器,则可能难以调试导致无效内存访问的编码错误。
从 Nsight 菜单中,选择“启用 CUDA 内存检查器”。复选标记表示已启用内存检查器。
启动 CUDA 调试器。
确保 Nsight Monitor 在目标计算机(远程计算机或 localhost,具体取决于您的配置)上运行。
从 Nsight 菜单中,选择“启动 CUDA 调试”。(或右键单击项目并选择“启动 CUDA 调试”。)
CUDA 调试器启动并启动目标应用程序。
其他主题
CUDA 调试器 |
|---|
声明
声明
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“资料”)均按“原样”提供。NVIDIA 不对这些资料作任何明示、暗示、法定或其他方面的保证,并且明确声明不承担任何关于不侵权、适销性和适用于特定用途的暗示保证。
所提供的信息被认为是准确且可靠的。但是,NVIDIA Corporation 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果不承担任何责任。未通过暗示或其他方式授予 NVIDIA Corporation 专利权项下的任何许可。本出版物中提及的规格如有更改,恕不另行通知。本出版物取代并替换之前提供的所有其他信息。未经 NVIDIA Corporation 明确书面批准,NVIDIA Corporation 产品不得用作生命维持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。