NVIDIA CUDA 编译器驱动程序 NVCC
关于 CUDA 编译器驱动程序 nvcc 的文档。
1. 简介
1.1. 概述
1.1.1. CUDA 编程模型
CUDA 工具包面向一类应用程序,这些应用程序的控制部分在通用计算设备上作为进程运行,并使用一个或多个 NVIDIA GPU 作为协处理器来加速单程序多数据 (SPMD) 并行作业。此类作业是自包含的,因为它们可以完全由一批 GPU 线程执行和完成,而无需主机进程的干预,从而从并行图形硬件中获得最佳收益。
GPU 代码以一种本质上是 C++ 的语言实现为函数集合,但带有一些注释以将其与主机代码区分开来,以及一些注释以区分 GPU 上存在的不同类型的数据内存。这些函数可能带有参数,并且可以使用非常类似于常规 C 函数调用的语法来调用它们,但略有扩展,以便能够指定必须执行被调用函数的 GPU 线程矩阵。在其生命周期内,主机进程可能会调度许多并行 GPU 任务。
有关 CUDA 编程模型的更多信息,请查阅 CUDA C++ 编程指南。
1.1.2. CUDA 源文件
CUDA 应用程序的源文件由传统的 C++ 主机代码和 GPU 设备函数混合组成。CUDA 编译轨迹将设备函数与主机代码分离,使用专有的 NVIDIA 编译器和汇编器编译设备函数,使用可用的 C++ 主机编译器编译主机代码,然后在主机目标文件中嵌入编译后的 GPU 函数作为 fatbinary 映像。在链接阶段,添加特定的 CUDA 运行时库以支持远程 SPMD 过程调用,并提供显式的 GPU 操作,例如 GPU 内存缓冲区的分配和主机-GPU 数据传输。
1.1.3. NVCC 的用途
编译轨迹涉及每个 CUDA 源文件的多个拆分、编译、预处理和合并步骤。 CUDA 编译器驱动程序 nvcc 的目的在于向开发人员隐藏 CUDA 编译的复杂细节。 它接受一系列传统的编译器选项,例如用于定义宏和包含/库路径,以及用于控制编译过程。 所有非 CUDA 编译步骤都转发到 nvcc 支持的 C++ 主机编译器,并且 nvcc 将其选项转换为适当的主机编译器命令行选项。
1.2. 支持的主机编译器
在以下情况下,nvcc 需要通用 C++ 主机编译器
在非 CUDA 阶段(运行阶段除外),因为这些阶段将由
nvcc转发到此编译器。在 CUDA 阶段,用于多个预处理阶段和主机代码编译(另请参见 CUDA 编译轨迹)。
nvcc 假定主机编译器是使用编译器提供商设计的标准方法安装的。 如果主机编译器安装是非标准的,则用户必须确保环境设置正确,并使用相关的 nvcc 编译选项。
以下文档提供了有关支持的主机编译器的详细信息
在所有平台上,将在当前执行搜索路径中找到的默认主机编译器可执行文件(Linux 上的 gcc 和 g++,Windows 上的 cl.exe)将被使用,除非使用适当的选项另行指定(请参阅文件和路径规范)。
请注意,nvcc 不支持编译超过主机系统最大路径长度限制的文件路径。 要支持编译长文件路径,请参阅您的系统文档。
2. 编译阶段
2.1. NVCC 标识宏
nvcc 预定义以下宏
__NVCC__编译 C/C++/CUDA 源文件时定义。
__CUDACC__编译 CUDA 源文件时定义。
__CUDACC_RDC__在可重定位设备代码模式下编译 CUDA 源文件时定义(请参阅用于单独编译的 NVCC 选项)。
__CUDACC_EWP__在可扩展的整体程序模式下编译 CUDA 源文件时定义(请参阅用于指定编译器/链接器行为的选项)。
__CUDACC_DEBUG__在设备调试模式下编译 CUDA 源文件时定义(请参阅用于指定编译器/链接器行为的选项)。
__CUDACC_RELAXED_CONSTEXPR__当在命令行上指定
--expt-relaxed-constexpr标志时定义。 有关更多详细信息,请参阅CUDA C++ 编程指南。__CUDACC_EXTENDED_LAMBDA__当在命令行上指定
--expt-extended-lambda或--extended-lambda标志时定义。 有关更多详细信息,请参阅CUDA C++ 编程指南。__CUDACC_VER_MAJOR__使用
nvcc的主版本号定义。__CUDACC_VER_MINOR__使用
nvcc的次版本号定义。__CUDACC_VER_BUILD__使用
nvcc的构建版本号定义。__NVCC_DIAG_PRAGMA_SUPPORT__当 CUDA 前端编译器支持使用
nv_diag_suppress、nv_diag_error、nv_diag_warning、nv_diag_default、nv_diag_once和nv_diagnostic编译指示进行诊断控制时定义。__CUDACC_DEVICE_ATOMIC_BUILTINS__当 CUDA 前端编译器支持设备原子编译器内置函数时定义。 有关更多详细信息,请参阅CUDA C++ 编程指南。
2.2. NVCC 阶段
编译阶段是可以由 nvcc 的命令行选项选择的逻辑转换步骤。 单个编译阶段仍然可以被 nvcc 分解为更小的步骤,但是这些更小的步骤只是阶段的实现:它们取决于 nvcc 使用的内部工具的表面上任意的能力,并且所有这些内部工具可能会随着 CUDA 工具包的新版本而更改。 因此,只有编译阶段在版本之间是稳定的,并且尽管 nvcc 提供了显示其执行的编译步骤的选项,但这些选项仅用于调试目的,不得在构建脚本中复制和使用。
nvcc 阶段由命令行选项和输入文件名后缀的组合选择,并且这些阶段的执行可以通过其他命令行选项进行修改。 在阶段选择中,输入文件后缀定义阶段输入,而命令行选项定义阶段的所需输出。
以下段落列出了已识别的文件名后缀和支持的编译阶段。 有关 nvcc 命令行选项的完整说明,请参见NVCC 命令行选项。
2.3. 支持的输入文件后缀
下表定义了 nvcc 如何解释其输入文件
输入文件后缀 |
描述 |
|---|---|
|
CUDA 源文件,包含主机代码和设备函数 |
|
C 源文件 |
|
C++ 源文件 |
|
PTX 中间汇编文件(请参阅图 1) |
|
单个 GPU 架构的 CUDA 设备代码二进制文件 (CUBIN)(请参阅图 1) |
|
CUDA fat 二进制文件,可能包含多个 PTX 和 CUBIN 文件(请参阅:ref: 图 1 <cuda-compilation-from-cu-to-executable-figure>) |
|
目标文件 |
|
库文件 |
|
资源文件 |
|
共享对象文件 |
请注意,nvcc 不区分目标文件、库文件或资源文件。 当执行链接阶段时,它只是将这些类型的文件传递给链接器。
2.4. 支持的阶段
下表指定了支持的编译阶段,以及启用每个阶段执行的 nvcc 选项。 它还列出了每个阶段生成的输出文件的默认名称,当未使用选项 --output-file 指定显式输出文件名时,该名称生效
阶段 |
|
默认输出文件名 |
|
|---|---|---|---|
长名称 |
短名称 |
||
CUDA 编译到 C/C++ 源文件 |
|
|
|
C/C++ 预处理 |
|
|
<标准输出上的结果> |
C/C++ 编译到目标文件 |
|
|
源文件名,后缀替换为 Linux 上的 |
从 CUDA 源文件生成 Cubin |
|
|
源文件名,后缀替换为 |
从 PTX 中间文件生成 Cubin。 |
|
|
源文件名,后缀替换为 |
从 CUDA 源文件生成 PTX |
|
|
源文件名,后缀替换为 |
从源文件、PTX 文件或 cubin 文件生成 Fatbinary |
|
|
源文件名,后缀替换为 |
链接可重定位设备代码。 |
|
|
Windows 上的 |
从链接的可重定位设备代码生成 Cubin。 |
|
|
|
从链接的可重定位设备代码生成 Fatbinary |
|
|
|
链接可执行文件 |
<无阶段选项> |
Windows 上的 |
|
构建目标文件存档或库 |
|
|
Windows 上的 |
|
|
|
<标准输出上的结果> |
|
|
|
<标准输出上的结果> |
将 CUDA 源编译为 OptiX IR 输出。 |
|
|
源文件名,后缀替换为 |
将 CUDA 源编译为 LTO IR 输出。 |
|
|
源文件名,后缀替换为 |
运行可执行文件 |
|
|
注释
此列表中的最后一个阶段更像是一个便利阶段。 它允许运行已编译和链接的可执行文件,而无需显式设置 CUDA 动态库的库路径。
除非指定了阶段选项,否则
nvcc将编译和链接其所有输入文件。
3. CUDA 编译轨迹
CUDA 编译的工作原理如下:输入程序针对设备编译进行预处理,并编译为 CUDA 二进制文件 (cubin) 和/或 PTX 中间代码,这些代码放置在 fatbinary 中。 输入程序再次针对主机编译进行预处理,并进行综合以嵌入 fatbinary 并将 CUDA 特定的 C++ 扩展转换为标准 C++ 构造。 然后,C++ 主机编译器将综合的主机代码与嵌入的 fatbinary 编译为主机对象。 实现此目的的确切步骤显示在图 1中。
每当主机程序启动设备代码时,CUDA 运行时系统都会检查嵌入的 fatbinary,以获取当前 GPU 的适当 fatbinary 映像。
默认情况下,CUDA 程序以整体程序编译模式编译,即设备代码无法引用来自单独文件的实体。 在整体程序编译模式下,设备链接步骤无效。 有关单独编译和整体程序编译的更多信息,请参阅在 CUDA 中使用单独编译。
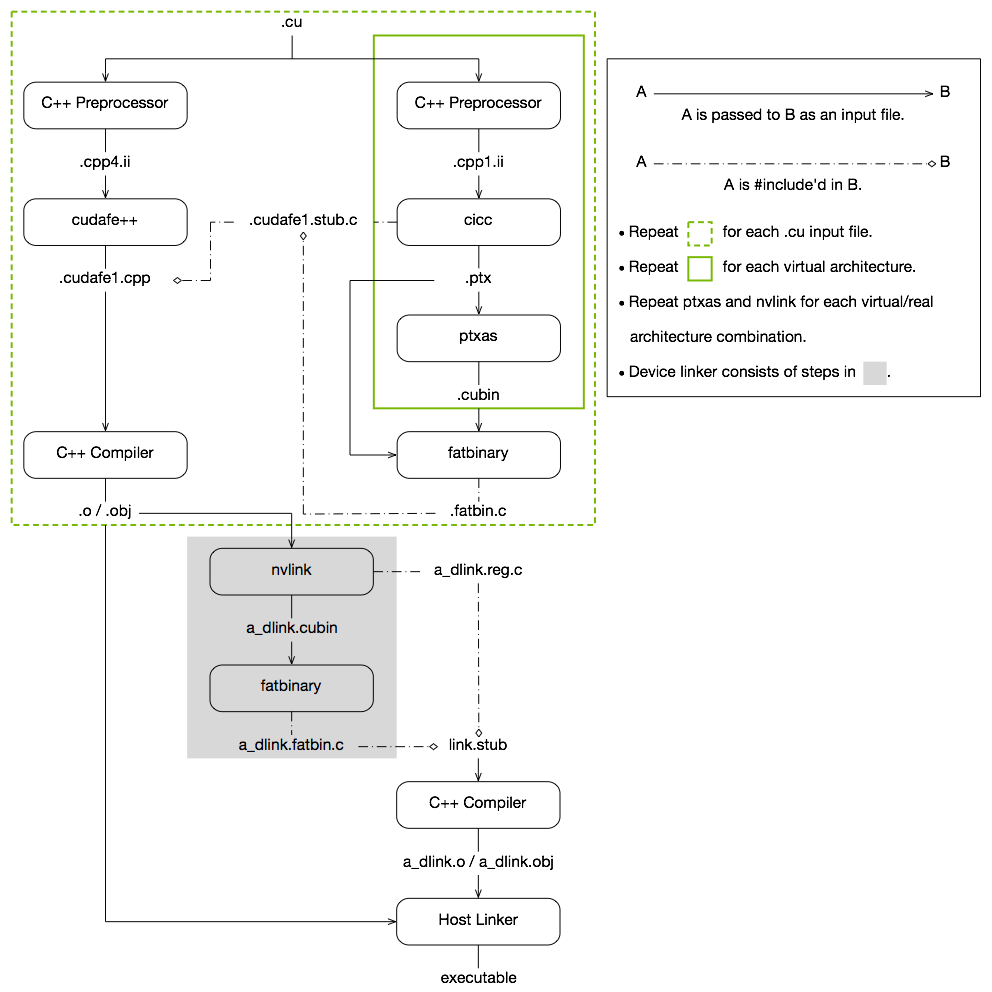
CUDA 编译轨迹
4. NVCC 命令行选项
4.1. 命令行选项类型和表示法
每个 nvcc 选项都有一个长名称和一个短名称,它们可以互换使用。 这两个变体通过必须在选项名称前加上的连字符数量来区分:长名称必须以两个连字符开头,而短名称必须以单个连字符开头。 例如,-I 是 --include-path 的短名称。 长选项旨在用于构建脚本中,其中选项的大小不如描述性值重要。 相比之下,短选项旨在用于交互式使用。
nvcc 识别三种类型的命令行选项:布尔选项、单值选项和列表选项。
布尔选项没有参数; 它们要么在命令行上指定,要么不指定。 单值选项最多只能指定一次,但列表选项可以重复。 这些选项类型的示例分别是:--verbose (切换到详细模式),--output-file (指定输出文件)和 --include-path (指定包含路径)。
单值选项和列表选项必须具有参数,这些参数必须在选项名称本身之后,后跟一个或多个空格或等号字符。 当使用一个字符的短名称(如 -I、-l 和 -L)时,选项的值也可以紧跟在选项本身之后,而无需用空格或等号字符分隔。 列表选项的各个值可以用逗号在选项的单个实例中分隔,或者可以重复该选项,或者可以组合这两种情况。
因此,对于上面提到的可能取值的两个示例选项,以下表示法是合法的
-o file
-o=file
-Idir1,dir2 -I=dir3 -I dir4,dir5
除非另有说明,否则本文档通篇使用长选项名称。 但是,短名称可以代替长名称使用,效果相同。
4.2. 命令行选项描述
本节介绍 nvcc 选项表。 表中的选项类型可以按如下方式识别:布尔选项在第一列中没有指定参数,而其他两种类型则有。 列表选项可以通过参数末尾的重复指示符 ,... 来识别。
长选项在选项表的第一列中描述,短选项占据第二列。
4.2.1. 文件和路径规范
4.2.1.1. --output-file file (-o)
指定输出文件的名称和位置。
4.2.1.2. --objdir-as-tempdir (-objtemp)
在与目标文件相同的目录中创建所有中间文件。 编译完成后,这些中间文件将被删除。 此选项仅在同时使用 -c、-dc 或 -dw 时才生效。 使用此选项将确保嵌入在目标文件中的中间文件名在同一文件的多次编译中不会更改。 但是,如果输入是 stdin,则不能保证这一点。 如果使用两个不同的选项编译同一个文件,例如“nvcc -c t.cu”和“nvcc -c -ptx t.cu”,则应在不同的目录中编译这些文件。 在同一目录中编译它们可能会导致编译失败或产生不正确的结果。
4.2.1.3. --pre-include file,... (-include)
指定在预处理期间必须预先包含的头文件。
4.2.1.4. --library library,... (-l)
指定要在链接阶段使用的库,不带库文件扩展名。
将在使用选项 --library-path 指定的库搜索路径上搜索库(请参阅库)。
4.2.1.5. --define-macro def,... (-D)
定义要在预处理期间使用的宏。
def 可以是 name 或 name=definition。
name - 将 name 预定义为宏。
name=definition - definition 的内容将被标记化和预处理,就像它们出现在
#define指令中的转换阶段 3 中一样。 定义将被嵌入的换行符截断。
4.2.1.6. --undefine-macro def,... (-U)
在预处理或编译期间取消定义现有宏。
4.2.1.7. --include-path path,... (-I)
指定包含搜索路径。
4.2.1.8. --system-include path,... (-isystem)
指定系统包含搜索路径。
4.2.1.9. --library-path path,... (-L)
指定库搜索路径(请参阅库)。
4.2.1.10. --output-directory directory (-odir)
指定输出文件的目录。
此选项旨在让依赖项生成步骤(请参阅 --generate-dependencies)生成一个规则,该规则在正确的目录中定义目标目标文件。
4.2.1.11. --dependency-output file (-MF)
指定依赖项输出文件。
此选项指定依赖项生成步骤的输出文件(请参阅 --generate-dependencies)。 如果设置了依赖项输出文件,则必须指定选项 --generate-dependencies 或 --generate-nonystem-dependencies。
4.2.1.12. --generate-dependency-targets (-MP)
为每个依赖项添加一个空目标。
此选项将伪目标添加到依赖项生成步骤(请参阅 --generate-dependencies),旨在避免在删除旧依赖项时出现 makefile 错误。 输入文件不会作为伪目标发出。
4.2.1.13. --compiler-bindir directory (-ccbin)
指定默认主机编译器可执行文件所在的目录。
还可以指定主机编译器可执行文件名,以确保选择正确的主机编译器。 此外,如果 nvcc 在 Windows 上的 Cygwin shell 或 MinGW shell 中执行,则可能需要指定驱动程序前缀选项(--input-drive-prefix、--dependency-drive-prefix 或 --drive-prefix)。
4.2.1.14. --allow-unsupported-compiler (-allow-unsupported-compiler)
禁用 nvcc 对支持的主机编译器版本的检查。
使用不支持的主机编译器可能会导致编译失败或运行时执行不正确。 使用风险自负。 此选项在 MacOS 上无效。
4.2.1.15. --archiver-binary executable (-arbin)
指定用于使用 --lib 创建静态库的 archiver 工具的路径。
4.2.1.17. --cudadevrt {none|static} (-cudadevrt)
指定要使用的 CUDA 设备运行时库的类型:无 CUDA 设备运行时库或静态 CUDA 设备运行时库。
允许值
nonestatic
默认值
默认使用静态 CUDA 设备运行时库。
4.2.1.18. --libdevice-directory directory (-ldir)
指定包含 libdevice 库文件的目录。
Libdevice 库文件位于 CUDA 工具包的 nvvm/libdevice 目录中。
4.2.1.19. --target-directory string (-target-dir)
指定目标目录中的子文件夹名称,默认的包含和库路径位于该子文件夹中。
4.2.2. 用于指定编译阶段的选项
此类别中的选项指定输入文件必须编译到的阶段。
4.2.2.1. --link (-link)
指定默认行为:编译和链接所有输入文件。
默认输出文件名
在 Windows 上使用 a.exe,在其他平台上使用 a.out 作为默认输出文件名。
4.2.2.2. --lib (-lib)
如有必要,将所有输入文件编译为目标文件,并将结果添加到指定的库输出文件中。
默认输出文件名
在 Windows 上使用 a.lib,在其他平台上使用 a.a 作为默认输出文件名。
4.2.2.3. --device-link (-dlink)
将包含可重定位设备代码的目标文件以及 .ptx、.cubin 和 .fatbin 文件链接到一个包含可执行设备代码的目标文件中,该文件可以传递给主机链接器。
默认输出文件名
在 Windows 上使用 a_dlink.obj,在其他平台上使用 a_dlink.o 作为默认输出文件名。当此选项与 --fatbin 结合使用时,使用 a_dlink.fatbin 作为默认输出文件名。当此选项与 --cubin 结合使用时,使用 a_dlink.cubin 作为默认输出文件名。
4.2.2.4. --device-c (-dc)
将每个 .c、.cc、.cpp、.cxx 和 .cu 输入文件编译为包含可重定位设备代码的目标文件。
它等效于 --relocatable-device-code=true --compile。
默认输出文件名
源文件扩展名在 Windows 上被替换为 .obj,在其他平台上被替换为 .o,以创建默认输出文件名。例如,x.cu 的默认输出文件名在 Windows 上为 x.obj,在其他平台上为 x.o。
4.2.2.5. --device-w (-dw)
将每个 .c、.cc、.cpp、.cxx 和 .cu 输入文件编译为包含可执行设备代码的目标文件。
它等效于 --relocatable-device-code=false --compile。
默认输出文件名
源文件扩展名在 Windows 上被替换为 .obj,在其他平台上被替换为 .o,以创建默认输出文件名。例如,x.cu 的默认输出文件名在 Windows 上为 x.obj,在其他平台上为 x.o。
4.2.2.6. --cuda (-cuda)
将每个 .cu 输入文件编译为 .cu.cpp.ii 文件。
默认输出文件名
.cu.cpp.ii 附加到源文件名的基本名称以创建默认输出文件名。例如,x.cu 的默认输出文件名是 x.cu.cpp.ii。
4.2.2.7. --compile (-c)
将每个 .c、.cc、.cpp、.cxx 和 .cu 输入文件编译为目标文件。
默认输出文件名
源文件扩展名在 Windows 上被替换为 .obj,在其他平台上被替换为 .o,以创建默认输出文件名。例如,x.cu 的默认输出文件名在 Windows 上为 x.obj,在其他平台上为 x.o。
4.2.2.8. --fatbin (-fatbin)
将所有 .cu、.ptx 和 .cubin 输入文件编译为仅设备 .fatbin 文件。
使用此选项,nvcc 将丢弃每个 .cu 输入文件的主机代码。
默认输出文件名
源文件扩展名被替换为 .fatbin 以创建默认输出文件名。例如,x.cu 的默认输出文件名是 x.fatbin。
4.2.2.9. --cubin (-cubin)
将所有 .cu 和 .ptx 输入文件编译为仅设备 .cubin 文件。
使用此选项,nvcc 将丢弃每个 .cu 输入文件的主机代码。
默认输出文件名
源文件扩展名被替换为 .cubin 以创建默认输出文件名。例如,x.cu 的默认输出文件名是 x.cubin。
4.2.2.10. --ptx (-ptx)
将所有 .cu 输入文件编译为仅设备 .ptx 文件。
使用此选项,nvcc 将丢弃每个 .cu 输入文件的主机代码。
默认输出文件名
源文件扩展名被替换为 .ptx 以创建默认输出文件名。例如,x.cu 的默认输出文件名是 x.ptx。
4.2.2.11. --preprocess (-E)
预处理所有 .c、.cc、.cpp、.cxx 和 .cu 输入文件。
默认输出文件名
默认情况下,输出在 stdout 中生成。
4.2.2.12. --generate-dependencies (-M)
生成一个依赖文件,该文件可以包含在 Makefile 中,用于 .c、.cc、.cpp、.cxx 和 .cu 输入文件。
nvcc 使用固定的前缀来标识预处理文件中的依赖项(在 Linux 上为 ‘#line 1’,在 Windows 上为 ‘# 1’)。以此前缀开头的源位置指令中提到的文件将包含在依赖项列表中。
默认输出文件名
默认情况下,输出在 stdout 中生成。
4.2.2.13. --generate-nonsystem-dependencies (-MM)
与 --generate-dependencies 相同,但跳过在系统目录中找到的头文件(仅限 Linux)。
默认输出文件名
默认情况下,输出在 stdout 中生成。
4.2.2.14. --generate-dependencies-with-compile (-MD)
生成依赖文件并编译输入文件。依赖文件可以包含在 Makefile 中,用于 .c、.cc、.cpp、.cxx 和 .cu 输入文件。
此选项不能与 -E 一起指定。依赖文件名的计算方式如下
如果指定了
-MF,则指定的文件将用作依赖文件名。如果指定了
-o,则通过将后缀替换为 ‘.d’,从指定的文件名计算依赖文件名。否则,通过将输入文件名的后缀替换为 ‘.d’ 来计算依赖文件名。
如果依赖文件名是基于 -MF 或 -o 计算的,则不支持多个输入文件。
4.2.2.15. --generate-nonsystem-dependencies-with-compile (-MMD)
与 --generate-dependencies-with-compile 相同,但跳过在系统目录中找到的头文件(仅限 Linux)。
4.2.2.16. --optix-ir (-optix-ir)
将 CUDA 源代码编译为 OptiX IR (.optixir) 输出。OptiX IR 仅供 OptiX 通过适当的 API 使用。此功能不支持链接时优化 (-dlto)、lto_NN -arch 目标或 -gencode。
默认输出文件名
源文件扩展名被替换为 .optixir 以创建默认输出文件名。例如,x.cu 的默认输出文件名是 x.optixir。
4.2.2.17. --ltoir (-ltoir)
将 CUDA 源代码编译为 LTO IR (.ltoir) 输出。此功能仅在链接时优化 (-dlto) 或 lto_NN -arch 目标中受支持。
默认输出文件名
源文件扩展名被替换为 .ltoir 以创建默认输出文件名。例如,x.cu 的默认输出文件名是 x.ltoir。
4.2.2.18. --run (-run)
编译和链接所有输入文件到一个可执行文件,并执行它。
当输入是单个可执行文件时,它将在没有任何编译或链接的情况下执行。此步骤旨在为不想费心设置必要环境变量的开发人员而设计;这些变量由 nvcc 临时设置。
4.2.3. 用于指定编译器/链接器行为的选项
4.2.3.1. --profile (-pg)
检测生成的代码/可执行文件,以供 gprof 使用。
4.2.3.2. --debug (-g)
为主机代码生成调试信息。
4.2.3.3. --device-debug (-G)
为设备代码生成调试信息。
如果未指定 --dopt,则此选项将关闭设备代码上的所有优化。它不适用于性能分析;请改用 --generate-line-info 进行性能分析。
4.2.3.4. --extensible-whole-program (-ewp)
生成可扩展的整体程序设备代码,允许某些调用在与 libcudadevrt 链接之前不被解析。
4.2.3.5. --no-compress (-no-compress)
不要在 fatbinary 中压缩设备代码。
4.2.3.6. --compress-mode {default|size|speed|balance|none} (-compress-mode)
选择 fatbinary 中的设备代码压缩行为。
允许值
default
使用默认压缩模式,就像未指定此模式一样。此模式的行为可能因版本而异。目前,它等效于
speed。
size
使用更侧重于减小二进制文件大小的压缩模式,但会牺牲压缩和解压缩时间。
speed
使用更侧重于减少解压缩时间的压缩模式,但最终二进制文件大小的减少较少。
balance
使用一种在二进制文件大小与压缩和解压缩时间之间取得平衡的压缩模式。
none
none
不执行压缩。等效于 --no-compress。
默认值
默认模式使用 default。
4.2.3.7. --generate-line-info (-lineinfo)
为设备代码生成行号信息。
4.2.3.8. --optimization-info kind,... (-opt-info)
为指定的优化种类提供优化报告。
支持以下标签
inline
发出与函数内联相关的备注。内联传递可能会被编译器多次调用,并且在早期传递中未内联的函数可能会在后续传递中内联。
4.2.3.9. --optimize level (-O)
指定主机代码的优化级别。
4.2.3.10. --dopt kind (-dopt)
允许值
启用设备代码优化。当与
-G一起指定时,为优化的设备代码启用有限的调试信息生成(目前,仅限行号信息)。当未指定-G时,隐式使用-dopt=on。
on:启用设备代码优化。
4.2.3.11. --dlink-time-opt (-dlto)
执行设备代码的链接时优化。选项 ‘-lto’ 也是 ‘-dlto’ 的别名。链接时优化必须在编译和链接时都指定;在编译时,它存储高级中间代码,然后在链接时,它链接在一起并优化中间代码。如果在链接时未找到该中间代码,则不会发生任何事情。中间代码也在编译时与 --gpu-code='lto_NN' 目标一起存储。选项 -dlto -arch=sm_NN 将添加一个 lto_NN 目标;如果您只想添加一个 lto_NN 目标,而不是 -arch=sm_NN 通常生成的 compute_NN,请使用 -arch=lto_NN。
4.2.3.12. --gen-opt-lto (-gen-opt-lto)
在生成 LTO IR 之前运行优化器传递。
4.2.3.13. --split-compile number (-split-compile)
并行执行编译器优化。
拆分编译尝试通过使编译器能够并发运行某些优化传递来减少编译时间。它通过将设备代码拆分为更小的转换单元来实现这一点,每个单元包含一个或多个设备函数,并在多个线程上并发运行每个单元的优化传递。然后,它将在代码生成之前链接回拆分的单元。该选项接受一个数值,用于指定编译器可以使用的最大线程数。也可以通过设置 --split-compile=0 来允许编译器使用系统上可用的最大线程数。设置 --split-compile=1 将导致此选项被忽略。此选项可以与设备链接时优化 (-dlto) 以及 --threads 结合使用。
4.2.3.14. --split-compile-extended number (-split-compile-extended)
更激进形式的 -split-compile。仅在 LTO 模式下可用。
扩展拆分编译尝试通过将并发编译扩展到后端来进一步减少编译时间。这种激进形式的拆分编译可能会影响已编译二进制文件的性能。该选项接受一个数值,用于指定编译器可以使用的最大线程数。也可以通过设置 --split-compile-extended=0 来允许编译器使用系统上可用的最大线程数。设置 --split-compile-extended=1 将导致此选项被忽略。此选项仅适用于设备链接时优化 (-dlto),并且可以与 --threads 结合使用。
4.2.3.15. --ftemplate-backtrace-limit limit (-ftemplate-backtrace-limit)
将单个警告或错误的模板实例化注释的最大数量设置为 limit。
允许值为 0,表示不应强制执行限制。如果主机编译器提供等效标志,则此值也会传递给主机编译器。
4.2.3.16. --ftemplate-depth limit (-ftemplate-depth)
将模板类的最大实例化深度设置为 limit。
如果主机编译器提供等效标志,则此值也会传递给主机编译器。
4.2.3.17. --no-exceptions (-noeh)
禁用主机代码的异常处理。
通过在主机编译器调用期间传递 “-EHs-c-” (对于 cl.exe) 和 “–fno-exceptions” (对于其他主机编译器) 来禁用主机代码的异常处理。这些标志在任何使用 “-Xcompiler” 直接传递给主机编译器的标志之前添加到主机编译器调用中
默认值(在 Windows 上)
在 Windows 上,默认情况下 nvcc 将 /EHsc 传递给主机编译器。
示例(在 Windows 上)
当需要其他链接器选项以进行更多控制时,请使用选项 --linker-options。
4.2.3.19. --x {c|c++|cu} (-x)
允许值
显式指定输入文件的语言,而不是让编译器根据文件名后缀选择默认语言。cc++
默认值
cu
源代码的语言根据文件名后缀确定。
4.2.3.20. --std {c++03|c++11|c++14|c++17|c++20} (-std)
允许值
选择特定的 C++ 方言。c++03c++11c++14c++17
默认值
c++20
默认 C++ 方言取决于主机编译器。nvcc 匹配主机编译器使用的默认 C++ 方言。
4.2.3.21. --no-host-device-initializer-list (-nohdinitlist)
不将 std::initializer_list 的成员函数隐式视为 __host__ __device__ 函数。
4.2.3.22. --expt-relaxed-constexpr (-expt-relaxed-constexpr)
实验性标志:允许主机代码调用 ``__device__ constexpr`` 函数,以及设备代码调用 ``__host__ constexpr`` 函数。
请注意,此标志的行为可能会在未来的编译器版本中发生更改。
4.2.3.23. --extended-lambda (-extended-lambda)
允许 lambda 声明中的 __host__、__device__ 注解。
4.2.3.24. --expt-extended-lambda (-expt-extended-lambda)
别名 --extended-lambda。
4.2.3.25. --machine {64} (-m)
允许值
64
默认值
指定 64 位架构。
此选项基于执行 nvcc 的主机平台设置。
4.2.3.26. --m64 (-m64)
别名 --machine=64
4.2.3.27. --host-linker-script {use-lcs|gen-lcs} (-hls)
允许值
使用主机链接器脚本(仅限 GNU/Linux)以在构建可执行文件或共享库时启用对某些 CUDA 特定要求的支持。
use-lcs
准备主机链接器脚本,并使主机链接器能够支持尺寸较大的可重定位设备目标文件,否则在某些情况下,会导致主机链接器因重定位截断错误而失败。
gen-lcs
生成一个主机链接器脚本,该脚本可以在主机链接器在 nvcc 之外单独调用时手动传递给主机链接器。此选项可以与
-shared或-r选项组合使用,以生成可在生成主机共享库或主机可重定位链接时使用的链接器脚本。使用此选项生成的文件必须作为主机链接器的最后一个输入文件提供。
链接器脚本可能已被使用,并通过主机链接器选项 --script (或 -T) 传递给主机链接器,那么生成的**主机**链接器脚本必须扩充现有的链接器脚本。在这种情况下,必须使用选项 -aug-hls 来生成仅包含扩充部分的链接器脚本。否则,主机链接器的行为是未定义的。
诸如带有非默认参数的 -z 之类的主机链接器选项,可能会在内部修改默认链接器脚本,这与此选项不兼容,并且任何此类用法的行为都是未定义的。
不执行压缩。等效于 --no-compress。
use-lcs 用作默认类型。
4.2.3.28. --augment-host-linker-script (-aug-hls)
启用生成扩充现有主机链接器脚本的主机链接器脚本(仅限 GNU/Linux)。有关更多详细信息,请参见选项 --host-linker-script。
4.2.3.29. --host-relocatable-link (-r)
当与 -hls=gen-lcs 结合使用时,控制 -hls=gen-lcs 的行为,并将其设置为生成可在主机可重定位链接 (ld -r 链接) 中使用的主机链接器脚本。有关更多信息,请参见选项 -hls=gen-lcs。
此选项目前仅在使用 -hls=gen-lcs 时有效;在所有其他情况下,此选项当前被忽略。
4.2.4. 用于传递特定阶段选项的选项
这些标志允许将特定选项直接传递给 nvcc 封装的内部编译工具,而无需让 nvcc 负担过多的关于这些工具的详细知识。
4.2.4.1. --compiler-options options,... (-Xcompiler)
直接为编译器/预处理器指定选项。
4.2.4.2. --linker-options options,... (-Xlinker)
直接为主机链接器指定选项。
4.2.4.3. --archive-options options,... (-Xarchive)
直接为库管理器指定选项。
4.2.4.4. --ptxas-options options,... (-Xptxas)
直接为 PTX 优化汇编器 ptxas 指定选项。
4.2.4.5. --nvlink-options options,... (-Xnvlink)
直接为设备链接器 nvlink 指定选项。
4.2.5. 用于指导编译器驱动程序的选项
4.2.5.1. --static-global-template-stub {true|false} (-static-global-template-stub)
在程序整体编译模式 (-rdc=false) 下,强制为为 __global__ 函数模板生成的主机端桩函数使用 static 链接。
__global__ 函数表示 GPU 代码执行的入口点,通常从主机代码引用。在程序整体编译模式(nvcc 默认)下,每个翻译单元中的设备代码形成一个独立的设备程序。在发送到主机编译器的代码中,CUDA 前端编译器会将原始 __global__ 函数或函数模板的主体内容替换为对 CUDA 运行时库的调用以启动内核(这些在下面被称为“桩”函数)。
当此标志为 false 时,模板桩函数将具有弱链接。如果两个不同的翻译单元 a.cu 和 b.cu 对 __global__ 模板 G 具有相同的实例化,则会产生问题。
例如
//common.h
template <typename T>
__global__ void G() { qqq = 4; }
//a.cu
static __device__ int qqq;
#include "common.h"
int main() { G<int><<<1,1>>>(); }
//b.cu
static __device__ int qqq;
#include "common.h"
int main() { G<int><<<1,1>>>(); }
当 a.cu 和 b.cu 在 nvcc 程序整体模式下编译时,为 a.cu 和 b.cu 生成的设备程序是单独的程序,但主机链接器将遇到 G<int> 桩实例化的多个弱定义,并在链接的主机程序中仅选择一个。因此,从 a.cu 或 b.cu 启动 G<int> 将错误地启动对应于 a.cu 或 b.cu 之一的设备程序;而正确的预期行为是,来自 a.cu 的 G<int> 启动为 a.cu 生成的设备程序,而来自 b.cu 的 G<int> 启动为 b.cu 生成的设备程序。
当标志为 true 时,CUDA 前端编译器将使所有桩函数在生成的主机代码中成为 static。这解决了上述问题,因为 a.cu 和 b.cu 中的 G<int> 现在引用主机目标代码中的不同符号,并且主机链接器不会合并这些符号。
注释
除非程序在程序整体编译模式 (
-rdc=false) 下编译,否则此选项将被忽略。在某些极端情况下(仅在程序整体编译模式下),启用此标志可能会破坏现有代码
如果
__global__函数模板被声明为友元,并且友元声明是实体的第一个声明。如果
__global__函数模板被引用,但在当前翻译单元中未定义。
默认值
false 。请注意,在未来的 CUDA 工具包主要版本中,默认值将更改为 true 。
4.2.5.3. --forward-unknown-to-host-compiler (-forward-unknown-to-host-compiler)
将未知选项转发到主机编译器。“未知选项”是以 - 开头后跟另一个字符的命令行参数,并且不是已识别的 nvcc 标志或已识别的 nvcc 标志的参数。
如果未知选项后跟一个单独的命令行参数,则该参数将不会被转发,除非它以 - 字符开头。
例如
nvcc -forward-unknown-to-host-compiler -foo=bar a.cu将-foo=bar转发到主机编译器。nvcc -forward-unknown-to-host-compiler -foo bar a.cu将报告bar参数的错误。nvcc -forward-unknown-to-host-compiler -foo -bar a.cu将-foo和-bar转发到主机编译器。
注意:在 Windows 上,另请参阅选项 -forward-slash-prefix-opts 以转发以 '/' 开头的选项。
4.2.5.4. --forward-unknown-to-host-linker (-forward-unknown-to-host-linker)
将未知选项转发到主机链接器。“未知选项”是以 - 开头后跟另一个字符的命令行参数,并且不是已识别的 nvcc 标志或已识别的 nvcc 标志的参数。
如果未知选项后跟一个单独的命令行参数,则该参数将不会被转发,除非它以 - 字符开头。
例如
nvcc -forward-unknown-to-host-linker -foo=bar a.cu将-foo=bar转发到主机链接器。nvcc -forward-unknown-to-host-linker -foo bar a.cu将报告bar参数的错误。nvcc -forward-unknown-to-host-linker -foo -bar a.cu将-foo和-bar转发到主机链接器。
注意:在 Windows 上,另请参阅选项 -forward-slash-prefix-opts 以转发以 '/' 开头的选项。
4.2.5.5. --forward-unknown-opts (-forward-unknown-opts)
暗示选项 -forward-unknown-to-host-linker 和 -forward-unknown-to-host-compiler 的组合。
例如
nvcc -forward-unknown-opts -foo=bar a.cu将-foo=bar转发到主机链接器和编译器。nvcc -forward-unknown-opts -foo bar a.cu将报告bar参数的错误。nvcc -forward-unknown-opts -foo -bar a.cu将-foo和-bar转发到主机链接器和编译器。
注意:在 Windows 上,另请参阅选项 -forward-slash-prefix-opts 以转发以 '/' 开头的选项。
4.2.5.6. --forward-slash-prefix-opts (-forward-slash-prefix-opts)
如果指定了此标志,并且启用了将未知选项转发到主机工具链 (-forward-unknown-opts 或 -forward-unknown-to-host-linker 或 -forward-unknown-to-host-compiler),则以 '/' 开头的命令行参数将转发到主机工具链。
例如
nvcc -forward-slash-prefix-opts -forward-unknown-opts /T foo.cu将标志/T转发到主机编译器和链接器。
如果未指定此标志,则以 '/' 开头的命令行参数将视为输入文件。
例如
nvcc /T foo.cu将 ‘/T’ 视为输入文件,并且 Windows API 函数GetFullPathName()用于确定完整路径名。
注意:此标志仅在 Windows 上受支持。
4.2.5.7. --dont-use-profile (-noprof)
在编译时不要使用 nvcc.profile 文件中的配置。
4.2.5.8. --threads number (-t)
指定用于并行执行编译步骤的最大线程数。
当为多个架构编译时,此选项可用于提高编译速度。编译器创建 number 个线程以并行执行编译步骤。如果 number 为 1,则忽略此选项。如果 number 为 0,则使用的线程数是机器上的 CPU 数量。
4.2.5.9. --dryrun (-dryrun)
列出编译子命令,但不执行它们。
4.2.5.10. --verbose (-v)
在执行编译子命令时列出它们。
4.2.5.11. --keep (-keep)
保留内部编译步骤期间生成的所有中间文件。
4.2.5.12. --keep-dir directory (-keep-dir)
将内部编译步骤期间生成的所有中间文件保留在此目录中。
4.2.5.13. --save-temps (-save-temps)
此选项是 --keep 的别名。
4.2.5.14. --clean-targets (-clean)
删除相同的 nvcc 命令在没有此选项的情况下将生成的所有非临时文件。
此选项反转 nvcc 的行为。指定后,将不执行任何编译阶段。相反,将删除 nvcc 否则会创建的所有非临时文件。
4.2.5.15. --run-args arguments,... (-run-args)
当与 --run 结合使用时,为可执行文件指定命令行参数。
4.2.5.16. --use-local-env (-use-local-env)
使用此标志强制 nvcc 假定 cl.exe 的环境已经设置好,并跳过运行来自 MSVC 安装的批处理文件,该批处理文件设置 cl.exe 的环境。这可以显着减少小型程序的整体编译时间。
4.2.5.17. --force-cl-env-setup (-force-cl-env-setup)
强制 nvcc 始终运行来自 MSVC 安装的批处理文件,以设置 cl.exe 的环境(匹配旧版 nvcc 行为)。
如果未指定此标志,则默认情况下,如果满足以下条件,nvcc 将跳过运行批处理文件:cl.exe 在 PATH 中,环境变量 VSCMD_VER 已设置,并且,如果指定了 -ccbin,则由 -ccbin 表示的编译器与 PATH 中的 cl.exe 匹配。跳过批处理文件执行可以显着减少小型程序的整体编译时间。
4.2.5.18. --input-drive-prefix prefix (-idp)
指定输入驱动器前缀。
在 Windows 上,所有引用文件名的命令行参数都必须转换为 Windows 本机格式,然后才能传递给纯 Windows 可执行文件。此选项指定当前开发环境如何表示绝对路径。对于 Cygwin 构建环境,使用 /cygwin/ 作为 prefix,对于 MinGW,使用 / 作为 prefix。
4.2.5.19. --dependency-drive-prefix prefix (-ddp)
指定依赖项驱动器前缀。
在 Windows 上,当生成依赖项文件时(请参阅 --generate-dependencies),所有文件名都必须为所使用的 make 实例进行适当的转换。某些 make 实例在原生 Windows 格式的绝对路径中处理冒号时会遇到问题,这取决于编译 make 实例的环境。对于 Cygwin make,使用 /cygwin/ 作为 prefix,对于 MinGW,使用 / 作为 prefix。或者,通过不指定任何内容,将这些文件名保留为原生 Windows 格式。
4.2.5.20. --drive-prefix prefix (-dp)
指定驱动器前缀。
此选项将 prefix 同时指定为 --input-drive-prefix 和 --dependency-drive-prefix。
4.2.5.21. --dependency-target-name target (-MT)
当生成依赖项文件时(请参阅 --generate-dependencies),指定生成的规则的目标名称。
4.2.5.22. --no-align-double
指定在 32 位平台上不应将 -malign-double 作为编译器参数传递。
警告: 这会使 ABI 与 CUDA 的内核 ABI 对于某些 64 位类型不兼容。
4.2.5.23. --no-device-link (-nodlink)
在链接目标文件时跳过设备链接步骤。
4.2.5.24. --allow-unsupported-compiler (-allow-unsupported-compiler)
禁用 nvcc 对支持的主机编译器版本的检查。
使用不支持的主机编译器可能会导致编译失败或运行时执行不正确。 使用风险自负。 此选项在 MacOS 上无效。
4.2.6. 用于控制 CUDA 编译的选项
4.2.6.1. --default-stream {legacy|null|per-thread} (-default-stream)
指定来自编译程序的 CUDA 命令默认发送到的流。
允许值
legacy
CUDA 传统流(每个上下文,与其他流隐式同步)
per-thread
普通 CUDA 流(每个线程,不与其他流隐式同步)
null
legacy的已弃用别名
默认值
legacy 用作默认流。
4.2.7. 用于控制 GPU 代码生成的选项
4.2.7.1. --gpu-architecture (-arch)
指定必须编译 CUDA 输入文件的 NVIDIA 虚拟 GPU 架构的类名。
除了下面针对简写描述的例外情况外,使用此选项指定的架构必须是虚拟架构(例如 compute_50)。通常,仅此选项不会触发为真实架构(那是 nvcc 选项 --gpu-code 的作用,请参见下文)汇编生成的 PTX;相反,它的目的是控制 PTX 输入的预处理和编译。
为了方便起见,在简单的 nvcc 编译的情况下,支持以下简写。如果未指定选项 --gpu-code 的值,则此选项的值默认为 --gpu-architecture 的值。在这种情况下,作为上述描述的唯一例外,为 --gpu-architecture 指定的值可以是真实架构(例如 sm_50),在这种情况下,nvcc 使用指定的真实架构及其最接近的虚拟架构作为有效的架构值。例如,nvcc --gpu-architecture=sm_50 等效于 nvcc --gpu-architecture=compute_50 --gpu-code=sm_50,compute_50。如果指定了加速真实 gpu(例如 -arch=sm_90a),则加速和非加速虚拟代码都将添加到代码列表中:--gpu-architecture=compute_90a --gpu-code=sm_90a,compute_90,compute_90a。
当指定 -arch=native 时,nvcc 检测系统上可见的 GPU 并为其生成代码,此选项不会生成 PTX 程序。如果系统上没有可见的受支持 GPU,则会发出警告,并将使用默认架构。
如果指定 -arch=all,nvcc 会嵌入所有受支持架构 (sm_*) 的编译代码映像,以及最高主要虚拟架构的 PTX 程序。对于 -arch=all-major,nvcc 会嵌入所有受支持的主要版本 (sm_*0) 的编译代码映像,以及最早受支持的版本,并添加最高主要虚拟架构的 PTX 程序。
有关受支持的虚拟架构列表,请参见 虚拟架构功能列表,有关受支持的真实架构列表,请参见 GPU 功能列表。
默认值
sm_52 用作默认值;PTX 是为 compute_52 生成的,然后为 sm_52 汇编和优化。
4.2.7.2. --gpu-code code,... (-code)
指定要为其汇编和优化 PTX 的 NVIDIA GPU 的名称。
nvcc 在结果可执行文件中嵌入每个指定的 code 架构的编译代码映像,对于每个真实架构(例如 sm_50),这是一个真正的二进制加载映像,对于虚拟架构(例如 compute_50),则是 PTX 代码。
在运行时,如果在当前 GPU 中未找到二进制加载映像,则 CUDA 运行时系统会动态编译此类嵌入的 PTX 代码。
为选项 --gpu-architecture 和 --gpu-code 指定的架构可以是虚拟的,也可以是真实的,但是 code 架构必须与 arch 架构兼容。当使用 --gpu-code 选项时,--gpu-architecture 选项的值必须是虚拟 PTX 架构。
例如,--gpu-architecture=compute_60 与 --gpu-code=sm_52 不兼容,因为早期的编译阶段将假定 sm_52 上不存在的 compute_60 功能的可用性。
4.2.7.3. --generate-code specification (-gencode)
此选项提供了 --gpu-architecture=arch --gpu-code=code,... 选项组合的概括,用于指定 nvcc 在代码生成方面的行为。
之前的选项组合为不同的真实架构生成代码,但为相同的虚拟架构生成 PTX,而 --generate-code 选项允许为不同的虚拟架构生成多个 PTX。实际上,--gpu-architecture=arch --gpu-code=code,... 等价于 --generate-code=arch=arch,code=code,...。
可以为不同的虚拟架构重复使用 --generate-code 选项。
4.2.7.4. --relocatable-device-code {true|false} (-rdc)
启用或禁用生成可重定位设备代码。
如果禁用,则生成可执行设备代码。可重定位设备代码必须先链接才能执行。
允许值
truefalse
默认值
禁用可重定位设备代码的生成。
4.2.7.5. --entries entry,... (-e)
指定必须为其生成代码的全局入口函数。
为所有入口函数生成 PTX,但仅汇编选定的入口函数。此选项的入口函数名称必须以 mangled name 形式指定。
默认值
nvcc 为所有入口函数生成代码。
4.2.7.6. --maxrregcount amount (-maxrregcount)
指定 GPU 函数可以使用的最大寄存器数量。
在达到函数特定限制之前,较高的值通常会提高执行此函数的单个 GPU 线程的性能。但是,由于线程寄存器是从每个 GPU 上的全局寄存器池分配的,因此此选项的较高值也会减少最大线程块大小,从而减少线程并行度。因此,良好的 maxrregcount 值是权衡的结果。
小于 ABI 所需最小寄存器的值将被编译器提升到 ABI 最小值限制。
用户程序可能无法使用所有寄存器,因为某些寄存器由编译器保留。
默认值
没有假定的最大值。
4.2.7.7. --use_fast_math (-use_fast_math)
使用快速数学库。
--use_fast_math 意味着 --ftz=true --prec-div=false --prec-sqrt=false --fmad=true。
4.2.7.8. --ftz {true|false} (-ftz)
控制单精度非规格化数支持。
--ftz=true 将非规格化值刷新为零,而 --ftz=false 保留非规格化值。
--use_fast_math 意味着 --ftz=true。
允许值
truefalse
默认值
此选项设置为 false,nvcc 保留非规格化值。
4.2.7.9. --prec-div {true|false} (-prec-div)
此选项控制单精度浮点除法和倒数。
--prec-div=true 启用 IEEE 最近舍入模式,而 --prec-div=false 启用快速近似模式。
--use_fast_math 意味着 --prec-div=false。
允许值
truefalse
默认值
此选项设置为 true,nvcc 启用 IEEE 最近舍入模式。
4.2.7.10. --prec-sqrt {true|false} (-prec-sqrt)
此选项控制单精度浮点平方根。
--prec-sqrt=true 启用 IEEE 最近舍入模式,而 --prec-sqrt=false 启用快速近似模式。
--use_fast_math 意味着 --prec-sqrt=false。
允许值
truefalse
默认值
此选项设置为 true,nvcc 启用 IEEE 最近舍入模式。
4.2.7.11. --fmad {true|false} (-fmad)
此选项启用(禁用)将浮点乘法和加法/减法收缩为浮点乘加运算 (FMAD, FFMA, 或 DFMA)。
--use_fast_math 意味着 --fmad=true。
允许值
truefalse
默认值
此选项设置为 true,nvcc 启用将浮点乘法和加法/减法收缩为浮点乘加运算 (FMAD, FFMA, 或 DFMA)。
4.2.7.12. --extra-device-vectorization (-extra-device-vectorization)
此选项启用更激进的设备代码向量化。
4.2.7.13. --compile-as-tools-patch (-astoolspatch)
为 CUDA 工具编译补丁代码。暗示 --keep-device-functions。
只能与 --ptx 或 --cubin 或 --fatbin 结合使用。
不得与 -rdc=true 或 -ewp 结合使用。
某些 PTX ISA 功能可能在此编译模式下不可用。
4.2.7.14. --keep-device-functions (-keep-device-functions)
在整个程序编译模式下,保留用户定义的外部链接 __device__ 函数定义在生成的 PTX 中。
4.2.7.15. --jump-table-density percentage (-jtd)
指定 switch 语句中的 case 密度百分比,并将其用作确定是否使用跳转表(brx.idx 指令)来实现 switch 语句的最小阈值。
百分比范围从 0 到 101(含)。
默认值
此选项设置为 101,nvcc 禁用 switch 语句的跳转表生成。
4.2.8. 通用工具选项
4.2.8.1. --disable-warnings (-w)
禁止所有警告消息。
4.2.8.2. --source-in-ptx (-src-in-ptx)
在 PTX 中交错源代码。
只能与 --device-debug 或 --generate-line-info 结合使用。
4.2.8.3. --restrict (-restrict)
断言所有内核指针参数都是 restrict 指针。
4.2.8.4. --Wno-deprecated-gpu-targets (-Wno-deprecated-gpu-targets)
禁止关于已弃用的 GPU 目标架构的警告。
4.2.8.5. --Wno-deprecated-declarations (-Wno-deprecated-declarations)
禁止关于使用已弃用实体的警告。
4.2.8.6. --Wreorder (-Wreorder)
当成员初始化器重新排序时生成警告。
4.2.8.7. --Wdefault-stream-launch (-Wdefault-stream-launch)
当在 <<<...>>> 内核启动语法中未提供显式流参数时生成警告。
4.2.8.8. --Wmissing-launch-bounds (-Wmissing-launch-bounds)
当 __global__ 函数没有显式的 __launch_bounds__ 注解时生成警告。
4.2.8.9. --Wext-lambda-captures-this (-Wext-lambda-captures-this)
当扩展 lambda 隐式捕获 this 时生成警告。
4.2.8.10. --Werror kind,... (-Werror)
将指定类型的警告变为错误。
以下是此选项接受的警告类型列表
all-warnings
将所有警告视为错误。
cross-execution-space-call
对不支持的跨执行空间调用更加严格。对于从
__host____device__到__host__函数的调用,编译器将生成错误而不是警告。
reorder
当成员初始化器重新排序时生成错误。
default-stream-launch
当在
<<<...>>>内核启动语法中未提供显式流参数时生成错误。
missing-launch-bounds
当
__global__函数没有显式的__launch_bounds__注解时生成警告。
ext-lambda-captures-this
当扩展 lambda 隐式捕获
this时生成错误。
deprecated-declarations
对使用已弃用实体生成错误。
4.2.8.11. --display-error-number (-err-no)
此选项显示 CUDA 前端编译器生成的任何消息的诊断编号(注意:不是主机编译器)。
4.2.8.12. --no-display-error-number (-no-err-no)
此选项禁用显示 CUDA 前端编译器生成的任何消息的诊断编号(注意:不是主机编译器)。
4.2.8.13. --diag-error errNum,... (-diag-error)
为 CUDA 前端编译器生成的指定诊断消息发出错误(注意:不影响主机编译器/预处理器生成的诊断信息)。
4.2.8.14. --diag-suppress errNum,... (-diag-suppress)
禁止显示 CUDA 前端编译器生成的指定诊断消息(注意:不影响主机编译器/预处理器生成的诊断信息)。
4.2.8.15. --diag-warn errNum,... (-diag-warn)
为 CUDA 前端编译器生成的指定诊断消息发出警告(注意:不影响主机编译器/预处理器生成的诊断信息)。
4.2.8.16. --resource-usage (-res-usage)
显示 GPU 代码的资源使用情况,例如寄存器和内存。
当设置 --relocatable-device-code=true 时,此选项暗示 --nvlink-options=--verbose。否则,它暗示 --ptxas-options=--verbose。
4.2.8.17. --device-stack-protector {true|false} (-device-stack-protector)
启用或禁用在设备代码中生成堆栈金丝雀。
堆栈金丝雀使利用涉及堆栈局部变量的某些类型的内存安全漏洞变得更加困难。编译器使用启发式方法来评估每个函数中此类错误的风险。只有那些被认为高风险的函数才会使用堆栈金丝雀。
允许值
truefalse
默认值
设备代码中堆栈金丝雀的生成已禁用。
4.2.8.18. --help (-h)
打印关于此工具的帮助信息。
4.2.8.19. --version (-V)
打印关于此工具的版本信息。
4.2.8.20. --options-file file,... (-optf)
从指定文件中包含命令行选项。
4.2.8.21. --time filename (-time)
生成一个逗号分隔值表,其中包含每个编译阶段所花费的时间,并将其附加到作为选项参数给出的文件的末尾。如果文件为空,则在表格的第一行生成列标题。
如果文件名是 -,则定时数据在 stdout 中生成。
4.2.8.22. --qpp-config config (-qpp-config)
使用 q++ 主机编译器时,指定配置 ([[compiler/]version,][target])。该参数将使用其 -V 标志转发到 q++ 编译器。
4.2.8.23. --list-gpu-code (-code-ls)
列出该工具支持的非加速 GPU 架构 (sm_XX) 并退出。
如果同时设置了 --list-gpu-code 和 --list-gpu-arch,则列表将使用与 --generate-code 值相同的格式显示。
4.2.8.24. --list-gpu-arch (-arch-ls)
列出该工具支持的非加速虚拟设备架构 (compute_XX) 并退出。
如果同时设置了 --list-gpu-arch 和 --list-gpu-code,则列表将使用与 --generate-code 值相同的格式显示。
4.2.9. 阶段选项
以下章节列出了一些有用的选项,用于较低级别的编译工具。
4.2.9.1. Ptxas 选项
下表列出了一些有用的 ptxas 选项,可以使用 nvcc 选项 -Xptxas 指定。
4.2.9.1.1. --allow-expensive-optimizations (-allow-expensive-optimizations)
启用(禁用)允许编译器使用最大可用资源(内存和编译时间)执行昂贵的优化。
如果未指定,则默认行为是在优化级别 >= O2 时启用此功能。
4.2.9.1.2. --compile-only (-c)
生成可重定位对象。
4.2.9.1.3. --def-load-cache (-dlcm)
全局/通用加载的默认缓存修饰符。
4.2.9.1.4. --def-store-cache (-dscm)
全局/通用存储的默认缓存修饰符。
4.2.9.1.5. --device-debug (-g)
语义与 nvcc 选项 --device-debug 相同。
4.2.9.1.6. --disable-optimizer-constants (-disable-optimizer-consts)
禁用优化器常量库的使用。
4.2.9.1.7. --entry entry,... (-e)
语义与 nvcc 选项 --entries 相同。
4.2.9.1.8. --fmad (-fmad)
语义与 nvcc 选项 --fmad 相同。
4.2.9.1.9. --force-load-cache (-flcm)
在全局/通用加载上强制指定缓存修饰符。
4.2.9.1.10. --force-store-cache (-fscm)
在全局/通用存储上强制指定缓存修饰符。
4.2.9.1.11. --generate-line-info (-lineinfo)
语义与 nvcc 选项 --generate-line-info 相同。
4.2.9.1.12. --gpu-name gpuname (-arch)
指定要为其生成代码的 NVIDIA GPU 的名称。
此选项也接受虚拟计算架构,在这种情况下,代码生成将被抑制。这可以仅用于解析。
此选项的允许值:compute_50, compute_52, compute_53, compute_60, compute_61, compute_62, compute_70, compute_72, compute_75, compute_80, compute_86, compute_87, compute_89, compute_90, compute_90a, compute_100, compute_100a, compute_101, compute_101a, compute_120, compute_120a, lto_50, lto_52, lto_53, lto_60, lto_61, lto_62, lto_70, lto_72, lto_75, lto_80, lto_86, lto_87, lto_89, lto_90, lto_90a, lto_100, lto_100a, lto_101, lto_101a, sm_50, sm_52, sm_53, sm_60, sm_61, sm_62, sm_70, sm_72, sm_75, sm_80, sm_86, sm_87, sm_89, sm_90, sm_90a, sm_100, sm_100a, sm_101, sm_101a, sm_120, sm_120a
默认值:sm_52。
4.2.9.1.13. --help (-h)
语义与 nvcc 选项 --help 相同。
4.2.9.1.14. --machine (-m)
语义与 nvcc 选项 --machine 相同。
4.2.9.1.15. --maxrregcount amount (-maxrregcount)
语义与 nvcc 选项 --maxrregcount 相同。
4.2.9.1.16. --opt-level N (-O)
指定优化级别。
默认值:3。
4.2.9.1.17. --options-file file,... (-optf)
语义与 nvcc 选项 --options-file 相同。
4.2.9.1.18. --position-independent-code (-pic)
生成位置无关代码。
默认值
对于整个程序编译:true
否则:false
4.2.9.1.19. --preserve-relocs (-preserve-relocs)
此选项将使 ptxas 为变量生成可重定位引用,并在链接的可执行文件中保留为它们生成的重定位。
4.2.9.1.20. --sp-bounds-check (-sp-bounds-check)
生成堆栈指针边界检查代码序列。
当指定 --device-debug 或 --opt-level=0 时,此选项将自动开启。
4.2.9.1.21. --suppress-async-bulk-multicast-advisory-warning (-suppress-async-bulk-multicast-advisory-warning)
在使用 sm_90 的 cp.async.bulk{.tensor} 指令中使用 .multicast::cluster 修饰符时,禁止显示警告。
4.2.9.1.22. --verbose (-v)
启用详细模式,该模式会打印代码生成统计信息。
4.2.9.1.23. --version (-V)
语义与 nvcc 选项 --version 相同。
4.2.9.1.24. --warning-as-error (-Werror)
将所有警告变为错误。
4.2.9.1.25. --warn-on-double-precision-use (-warn-double-usage)
如果在指令中使用了 double 类型,则发出警告。
4.2.9.1.26. --warn-on-local-memory-usage (-warn-lmem-usage)
如果使用了本地内存,则发出警告。
4.2.9.1.27. --warn-on-spills (-warn-spills)
如果寄存器溢出到本地内存,则发出警告。
4.2.9.1.28. --compile-as-tools-patch (-astoolspatch)
为 CUDA 工具编译补丁代码。
不应与 -Xptxas -c 或 -ewp 结合使用。
某些 PTX ISA 功能可能在此编译模式下不可用。
4.2.9.1.29. --maxntid (-maxntid)
指定线程块可以拥有的最大线程数。
如果与 -maxrregcount 选项一起使用,则此选项将被忽略。对于指定了 .maxntid 指令的入口函数,此选项也会被忽略。
4.2.9.1.30. --minnctapersm (-minnctapersm)
指定要映射到 SM 的最小 CTA 数量。
如果与 -maxrregcount 选项一起使用,则此选项将被忽略。对于指定了 .minnctapersm 指令的入口函数,此选项也会被忽略。
4.2.9.1.31. --override-directive-values (-override-directive-values)
通过相应的选项值覆盖 PTX 指令值。
此选项仅对 -minnctapersm、-maxntid 和 -maxrregcount 选项有效。
4.2.9.1.32. --make-errors-visible-at-exit (-make-errors-visible-at-exit)
在退出点生成必要的指令,以使内存错误和故障在退出时可见。
4.2.9.1.33. --oFast-compile (-Ofc)
指定首选设备代码编译速度的级别。
默认值:0。
4.2.9.1.34. --device-stack-protector (-device-stack-protector)
启用或禁用在设备代码中生成堆栈金丝雀。
堆栈金丝雀使利用涉及堆栈局部变量的某些类型的内存安全漏洞变得更加困难。编译器使用启发式方法来评估每个函数中此类错误的风险。只有那些被认为高风险的函数才会使用堆栈金丝雀。
允许值
truefalse
默认值
设备代码中堆栈金丝雀的生成已禁用。
4.2.9.1.35. --g-tensor-memory-access-check (-g-tmem-access-check)
为 tcgen05 操作启用张量内存访问检查。
4.2.9.1.36. --split-compile (-split-compile)
指定运行编译器优化时要利用的最大并发线程数。
如果指定的值为 1,则选项将被忽略。如果指定的值为 0,则线程数将为底层机器上的 CPU 数量。
4.2.9.2. NVLINK 选项
以下是一些有用的 nvlink 选项列表,可以使用 nvcc 选项 --nvlink-options 指定。
4.2.9.2.1. --disable-warnings (-w)
禁止所有警告消息。
4.2.9.2.2. --preserve-relocs (-preserve-relocs)
在链接的可执行文件中保留已解析的重定位。
4.2.9.2.3. --verbose (-v)
启用详细模式,该模式会打印代码生成统计信息。
4.2.9.2.4. --warning-as-error (-Werror)
将所有警告变为错误。
4.2.9.2.5. --suppress-arch-warning (-suppress-arch-warning)
当对象不包含目标架构的代码时,禁止显示警告。
4.2.9.2.6. --suppress-stack-size-warning (-suppress-stack-size-warning)
当无法确定堆栈大小时,禁止显示警告。
4.2.9.2.7. --dump-callgraph (-dump-callgraph)
转储有关调用图和寄存器使用情况的信息。
4.2.9.2.8. --dump-callgraph-no-demangle (-dump-callgraph-no-demangle)
转储不进行名称修饰的调用图信息。
4.2.9.2.9. --Xptxas (-Xptxas)
Ptxas 选项(仅与 LTO 一起使用)。
4.2.9.2.10. --cpu-arch (-cpu-arch)
指定 CPU 目标架构的名称。
4.2.9.2.11. --extra-warnings (-extrawarn)
发出有关可能问题的额外警告。
4.2.9.2.12. --gen-host-linker-script (-ghls)
指定要生成的主机链接器脚本的类型。
4.2.9.2.13. --ignore-host-info (-ignore-host-info)
忽略有关主机引用的信息,因此不要删除可能被主机引用的设备代码。
4.2.9.2.14. --keep-system-libraries (-keep-system-libraries)
不要优化掉系统库(例如 cudadevrt)代码。
4.2.9.2.15. --kernels-used (-kernels-used)
指定正在使用的内核。可以是内核名称的一部分,因此任何名称中包含该字符串的内核都将被匹配。如果使用此选项,则任何其他内核都将被视作死代码并被删除。
4.2.9.2.16. --options-file (-optf)
从指定的文件中包含命令行选项。
4.2.9.2.17. --report-arch (-report-arch)
在错误消息中报告 SM 目标架构。
4.2.9.2.18. --suppress-debug-info (-suppress-debug-info)
不在输出中保留调试符号。如果未使用 –debug 选项,则此选项将被忽略。
4.2.9.2.19. --variables-used (-variables used)
指定正在使用的变量。可以是变量名称的一部分,因此任何名称中包含该字符串的变量都将被匹配。如果使用此选项,则任何其他变量都将被视作死代码并可能被删除,除非设备代码有其他访问。
4.2.9.2.20. --device-stack-protector {true|false} (-device-stack-protector)
启用或禁用在设备代码中生成堆栈金丝雀(stack canaries)(仅与 LTO 一起使用)。
堆栈金丝雀使利用涉及堆栈局部变量的某些类型的内存安全漏洞变得更加困难。编译器使用启发式方法来评估每个函数中此类错误的风险。只有那些被认为高风险的函数才会使用堆栈金丝雀。
允许值
truefalse
默认值
设备代码中堆栈金丝雀的生成已禁用。
4.3. NVCC 环境变量
NVCC_PREPEND_FLAGS 和 NVCC_APPEND_FLAGS
如果设置了以下环境变量,则可以使用它们来扩充 nvcc 命令行标志
NVCC_PREPEND_FLAGS
在普通 nvcc 命令行之前注入的标志。
NVCC_APPEND_FLAGS
在普通 nvcc 命令行之后注入的标志。
例如,在设置之后
export NVCC_PREPEND_FLAGS='-G -keep -arch=sm_60'
export NVCC_APPEND_FLAGS='-DNAME=" foo "'
以下调用
nvcc foo.cu -o foo
等效于
nvcc -G -keep -arch=sm_60 foo.cu -o foo -DNAME=" foo "
这些环境变量可用于全局注入 nvcc 标志,而无需修改构建脚本。
来自 NVCC_PREPEND_FLAGS 或 NVCC_APPEND_FLAGS 的附加标志将列在详细日志中(--verbose)。
NVCC_CCBIN
可以使用环境变量 NVCC_CCBIN 设置默认主机编译器。例如,在设置之后
export NVCC_CCBIN='gcc'
如果未设置 --compiler-bindir,nvcc 将选择 gcc 作为主机编译器。
NVCC_CCBIN 可用于全局控制默认主机编译器。如果 NVCC_CCBIN 和 --compiler-bindir 均已设置,则 nvcc 将选择由 --compiler-bindir 指定的主机编译器。例如
export NVCC_CCBIN='gcc'
nvcc foo.cu -ccbin='clang' -o foo
在这种情况下,nvcc 将选择 clang 作为主机编译器。
5. GPU 编译
本章介绍由 nvcc 与 CUDA 驱动程序协同维护的 GPU 编译模型。它将通过一些技术部分,并在最后提供具体示例。
5.1. GPU 代际
为了实现架构演进,NVIDIA GPU 以不同的代际发布。新一代产品引入了功能和/或芯片架构的重大改进,而同一代际内的 GPU 型号则显示出较小的配置差异,这些差异适度地影响功能、性能或两者兼而有之。
GPU 应用程序的二进制兼容性在不同代际之间无法保证。例如,为 Fermi GPU 编译的 CUDA 应用程序很可能无法在 Kepler GPU 上运行(反之亦然)。这是因为一个代际的指令集和指令编码与其他代际的不同。
在某些条件下,可以保证一个 GPU 代际内的二进制兼容性,因为它们共享基本的指令集。当两个 GPU 版本没有功能差异时(例如,当一个版本是另一个版本的缩小版时),或者当一个版本在功能上包含在另一个版本中时,就是这种情况。后者的一个例子是 base Maxwell 版本 sm_50,其功能是所有其他 Maxwell 版本的子集:为 sm_50 编译的任何代码都将在所有其他 Maxwell GPU 上运行。
5.2. GPU 功能列表
下表列出了当前 GPU 架构的名称,并注释了它们提供的功能。还有其他差异,例如寄存器和处理器集群的数量,这些差异仅影响执行性能。
在 CUDA 命名方案中,GPU 被命名为 sm_xy,其中 x 表示 GPU 代际号,y 表示该代际中的版本。此外,为了方便比较 GPU 功能,CUDA 尝试选择其 GPU 名称,使得如果 x1y1 <= x2y2,则 sm_x1y1 的所有非 ISA 相关功能都包含在 sm_x2y2 的功能中。由此可见,sm_50 确实是 base Maxwell 模型,这也解释了为什么表中较高的条目始终是较低条目的功能扩展。此外,如果我们从指令编码中抽象出来,这意味着 sm_50 的功能将继续包含在所有后续的 GPU 代际中。正如我们接下来将看到的,此属性将成为 nvcc 对应用程序兼容性支持的基础。
|
Maxwell 支持 |
|
Pascal 支持 |
|
Volta 支持 |
|
Turing 支持 |
|
NVIDIA Ampere GPU 架构支持 |
|
Ada 支持 |
|
Hopper 支持 |
|
Blackwell 支持 |
5.3. 应用程序兼容性
CPU 代际之间的二进制代码兼容性,以及发布的指令集架构,是确保在现场分发的应用程序在新版本的 CPU 成为主流时继续运行的常用机制。
GPU 的情况有所不同,因为 NVIDIA 无法在不牺牲 GPU 定期改进机会的情况下保证二进制兼容性。相反,正如图形编程领域中已经惯例的那样,nvcc 依赖于两阶段编译模型,以确保应用程序与未来 GPU 代际的兼容性。
5.4. 虚拟架构
GPU 编译通过中间表示 PTX 执行,PTX 可以被视为虚拟 GPU 架构的汇编语言。与实际的图形处理器相反,这样的虚拟 GPU 完全由它向应用程序提供的一组功能或特性定义。特别是,虚拟 GPU 架构提供(很大程度上)通用的指令集,并且二进制指令编码不是问题,因为 PTX 程序始终以文本格式表示。
因此,nvcc 编译命令始终使用两个架构:虚拟 中间架构,加上 真实 GPU 架构,以指定要执行的预期处理器。为了使这样的 nvcc 命令有效,真实 架构必须是 虚拟 架构的实现。这将在下面进一步解释。
选择的虚拟架构更像是对应用程序所需 GPU 功能的声明:使用 较小的 虚拟架构仍然允许在第二个 nvcc 阶段使用 更广泛的 实际架构。相反,指定提供应用程序未使用的功能的虚拟架构会不必要地限制可以在第二个 nvcc 阶段指定的可能 GPU 的集合。
由此可见,虚拟架构应始终选择 尽可能低 的级别,从而最大化可以运行的实际 GPU。真实 架构应选择 尽可能高 的级别(假设这总是生成更好的代码),但这只有在知道应用程序预期运行的实际 GPU 的情况下才有可能。正如我们稍后将在即时编译的情况下看到的那样,驱动程序确切地知道这一点,运行时 GPU 是程序即将启动/执行的 GPU。

使用虚拟和真实架构的两阶段编译
5.5. 虚拟架构功能列表
|
Maxwell 支持 |
|
Pascal 支持 |
|
Volta 支持 |
|
Turing 支持 |
|
NVIDIA Ampere GPU 架构支持 |
|
Ada 支持 |
|
Hopper 支持 |
|
Blackwell 支持 |
上表列出了当前定义的虚拟架构。虚拟架构命名方案与第 GPU 功能列表 节中显示的真实架构命名方案相同。
5.6. 更多机制
显然,编译分阶段本身无助于实现应用程序与未来 GPU 的兼容性目标。为此,我们需要另外两种机制:即时编译 (JIT) 和胖二进制文件 (fatbinaries)。
5.6.1. 即时编译
到实际 GPU 的编译步骤将代码绑定到一个 GPU 代际。在该代际内,它涉及 GPU 覆盖范围 和可能的性能之间的选择。例如,编译为 sm_50 允许代码在所有 Maxwell 代际 GPU 上运行,但如果 Maxwell GM206 及更高版本是唯一目标,则编译为 sm_53 可能会产生更好的代码。

设备代码的即时编译
通过指定虚拟代码架构而不是 真实 GPU,nvcc 将 PTX 代码的汇编推迟到应用程序运行时,此时目标 GPU 是确切已知的。例如,当应用程序在 sm_50 或更高架构上启动时,以下命令允许生成完全匹配的 GPU 二进制代码。
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50
即时编译的缺点是增加了应用程序启动延迟,但这可以通过让 CUDA 驱动程序使用编译缓存来缓解(请参阅 CUDA C++ 编程指南 的“第 3.1.1.2 节,即时编译”),该缓存在应用程序的多次运行中是持久的。
5.6.2. 胖二进制文件
克服 JIT 造成的启动延迟,同时仍然允许在新 GPU 上执行的另一种解决方案是指定多个代码实例,如
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_52
此命令为两个 Maxwell 变体生成精确代码,以及 PTX 代码,以便在新一代 GPU 出现时供 JIT 使用。nvcc 将其设备代码组织在胖二进制文件中,这些文件能够保存同一 GPU 源代码的多个翻译版本。在运行时,当设备函数启动时,CUDA 驱动程序将选择最合适的翻译版本。
5.7. NVCC 示例
5.7.1. 基本表示法
nvcc 提供了选项 --gpu-architecture 和 --gpu-code,用于指定两个翻译阶段的目标架构。除了下面描述的允许的简写形式外,--gpu-architecture 选项接受单个值,该值必须是虚拟计算架构的名称,而选项 --gpu-code 接受值列表,这些值都必须是实际 GPU 的名称。nvcc 为每个这些 GPU 执行阶段 2 翻译,并将结果嵌入到编译结果中(通常是主机目标文件或可执行文件)。
示例
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=sm_50,sm_52
5.7.2. 简写形式
nvcc 允许一些用于简单情况的简写形式。
5.7.2.1. 简写形式 1
--gpu-code 参数可以是虚拟架构。在这种情况下,将为这样的虚拟架构省略阶段 2 翻译,并且将嵌入阶段 1 PTX 结果。在应用程序启动时,如果驱动程序没有找到更好的替代方案,则驱动程序将使用 PTX 作为输入来调用阶段 2 编译。
示例
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_52
5.7.2.2. 简写形式 2
可以省略 --gpu-code 选项。仅在这种情况下,--gpu-architecture 值可以是非虚拟架构。--gpu-code 值默认为 --gpu-architecture 指定的 GPU 实现的 最接近 虚拟架构,加上 --gpu-architecture 值本身。最接近 的虚拟架构用作有效的 --gpu-architecture 值。如果 --gpu-architecture 值是虚拟架构,它也用作有效的 --gpu-code 值。
示例
nvcc x.cu --gpu-architecture=sm_52
nvcc x.cu --gpu-architecture=compute_50
等效于
nvcc x.cu --gpu-architecture=compute_52 --gpu-code=sm_52,compute_52
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50
5.7.2.3. 简写形式 3
可以同时省略 --gpu-architecture 和 --gpu-code 选项。
示例
nvcc x.cu
等效于
nvcc x.cu --gpu-architecture=compute_52 --gpu-code=sm_52,compute_52
5.7.3. 扩展表示法
在所有需要为一个或多个 GPU 生成代码的情况下,都可以使用选项 --gpu-architecture 和 --gpu-code,并使用通用的虚拟架构。这将导致对 nvcc 阶段 1 的单次调用(即,预处理和虚拟 PTX 汇编代码的生成),然后是针对每个指定的 GPU 重复的编译阶段 2(二进制代码生成)。
使用通用的虚拟架构意味着在整个 nvcc 编译过程中,所有假定的 GPU 功能都是固定的。例如,以下 nvcc 命令假定 sm_50 代码和 sm_53 代码均不支持半精度浮点运算。
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_53
有时,需要执行不同的 GPU 代码生成步骤,并跨不同的架构进行分区。这可以通过使用 nvcc 选项 --generate-code 来实现,此时必须使用该选项来代替 --gpu-architecture 和 --gpu-code 的组合。
与 --gpu-architecture 选项不同,--generate-code 选项可以在 nvcc 命令行中重复使用。它接受子选项 arch 和 code,这些子选项不得与其主选项等效项混淆,但行为类似。如果使用重复的架构编译,则设备代码必须使用基于架构标识宏 __CUDA_ARCH__ 值的条件编译,这将在下一节中描述。
例如,以下命令假定 sm_50 和 sm_52 代码不支持半精度浮点运算,但在 sm_53 上完全支持。
nvcc x.cu \
--generate-code arch=compute_50,code=sm_50 \
--generate-code arch=compute_50,code=sm_52 \
--generate-code arch=compute_53,code=sm_53
或者,将实际的 GPU 代码生成留给 CUDA 驱动程序中的 JIT 编译器。
nvcc x.cu \
--generate-code arch=compute_50,code=compute_50 \
--generate-code arch=compute_53,code=compute_53
代码子选项可以与稍微复杂的语法结合使用。
nvcc x.cu \
--generate-code arch=compute_50,code=[sm_50,sm_52] \
--generate-code arch=compute_53,code=sm_53
5.7.4. 虚拟架构宏
对于为 compute_xy 编译的每个阶段 1 nvcc 编译,架构标识宏 __CUDA_ARCH__ 被分配一个三位数值字符串 xy0(以字面量 0 结尾)。
此宏可用于 GPU 函数的实现中,以确定当前正在编译的虚拟架构。主机代码(非 GPU 代码)不得依赖于它。
架构列表宏 __CUDA_ARCH_LIST__ 是编译器调用中指定的每个虚拟架构的逗号分隔的 __CUDA_ARCH__ 值列表。该列表按数值升序排序。
在编译 C、C++ 和 CUDA 源文件时,会定义宏 __CUDA_ARCH_LIST__。
例如,以下 nvcc 编译命令行会将 __CUDA_ARCH_LIST__ 定义为 500,530,800。
nvcc x.cu \
--generate-code arch=compute_80,code=sm_80 \
--generate-code arch=compute_50,code=sm_52 \
--generate-code arch=compute_50,code=sm_50 \
--generate-code arch=compute_53,code=sm_53
6. 在 CUDA 中使用单独编译
在 5.0 版本之前,CUDA 不支持单独编译,因此 CUDA 代码无法跨文件调用设备函数或访问变量。这种编译被称为整体程序编译。我们一直支持主机代码的单独编译,只是 CUDA 设备代码需要全部在一个文件中。从 CUDA 5.0 开始,支持设备代码的单独编译,但旧的整体程序模式仍然是默认模式,因此有新的选项来调用单独编译。
6.1. 单独编译的代码更改
单独编译设备代码所需的代码更改与您已经为主机代码所做的更改相同,即使用 extern 和 static 来控制符号的可见性。请注意,以前 extern 在 CUDA 代码中被忽略;现在它将被遵循。通过使用 static,可以在不同的文件中拥有多个同名的设备符号。因此,引用字符串名称的符号的 CUDA API 调用已被弃用;相反,应通过其地址引用符号。
6.2. 用于单独编译的 NVCC 选项
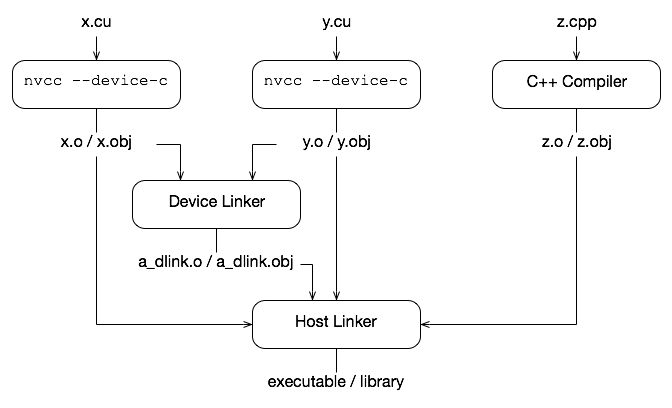
CUDA 的工作原理是将设备代码嵌入到主机对象中。在整体程序编译中,它将可执行的设备代码嵌入到主机对象中。在单独编译中,我们将可重定位的设备代码嵌入到主机对象中,并运行设备链接器 nvlink 以将所有设备代码链接在一起。nvlink 的输出然后与所有主机对象链接在一起,由主机链接器形成最终的可执行文件。
可重定位与可执行设备代码的生成由 --relocatable-device-code 选项控制。
--compile 选项已用于控制在主机对象处停止编译,因此添加了一个新选项 --device-c,它只是执行 --relocatable-device-code=true --compile。
要仅调用设备链接器,可以使用 --device-link 选项,该选项会发出一个包含嵌入式可执行设备代码的主机对象。然后,必须将该输出传递给主机链接器。或者
nvcc <objects>
可以用于隐式调用设备和主机链接器。这是可行的,因为如果设备链接器没有看到任何可重定位的代码,它将不会执行任何操作。
下图显示了流程。
CUDA 单独编译轨迹
6.3. 库
设备链接器能够读取静态主机库格式(Linux 和 Mac OS X 上的 .a,Windows 上的 .lib)。它忽略任何动态库(.so 或 .dll)。--library 和 --library-path 选项可用于将库传递给设备和主机链接器。当使用 --library 选项时,库名称的指定不带库文件扩展名。
nvcc --gpu-architecture=sm_50 a.o b.o --library-path=<path> --library=foo
或者,在 Windows 上,可以在不使用 --library 选项的情况下使用库名称,包括库文件扩展名。
nvcc --gpu-architecture=sm_50 a.obj b.obj foo.lib --library-path=<path>
请注意,设备链接器会忽略任何没有可重定位设备代码的对象。
6.4. 示例
假设我们有以下文件
//---------- b.h ----------
#define N 8
extern __device__ int g[N];
extern __device__ void bar(void);
//---------- b.cu ----------
#include "b.h"
__device__ int g[N];
__device__ void bar (void)
{
g[threadIdx.x]++;
}
//---------- a.cu ----------
#include <stdio.h>
#include "b.h"
__global__ void foo (void) {
__shared__ int a[N];
a[threadIdx.x] = threadIdx.x;
__syncthreads();
g[threadIdx.x] = a[blockDim.x - threadIdx.x - 1];
bar();
}
int main (void) {
unsigned int i;
int *dg, hg[N];
int sum = 0;
foo<<<1, N>>>();
if(cudaGetSymbolAddress((void**)&dg, g)){
printf("couldn't get the symbol addr\n");
return 1;
}
if(cudaMemcpy(hg, dg, N * sizeof(int), cudaMemcpyDeviceToHost)){
printf("couldn't memcpy\n");
return 1;
}
for (i = 0; i < N; i++) {
sum += hg[i];
}
if (sum == 36) {
printf("PASSED\n");
} else {
printf("FAILED (%d)\n", sum);
}
return 0;
}
这些文件可以使用以下命令进行编译(这些示例适用于 Linux)
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 a.o b.o
如果要分别调用设备和主机链接器,可以执行以下操作
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o
g++ a.o b.o link.o --library-path=<path> --library=cudart
请注意,所有期望的目标架构都必须传递给设备链接器,因为它指定了最终可执行文件中将包含的内容(某些对象或库可能包含针对多个架构的设备代码,链接步骤可以选择将哪些内容放入最终可执行文件中)。
如果要使用驱动程序 API 加载链接的 cubin,则可以仅请求 cubin
nvcc --gpu-architecture=sm_50 --device-link a.o b.o \
--cubin --output-file link.cubin
对象可以放入库中并与以下命令一起使用
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --lib a.o b.o --output-file test.a
nvcc --gpu-architecture=sm_50 test.a
请注意,设备链接器仅支持静态库。
PTX 文件可以编译为主机对象文件,然后使用以下命令链接
nvcc --gpu-architecture=sm_50 --device-c a.ptx
一个使用库、主机链接器和动态并行性的示例是
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o
nvcc --lib --output-file libgpu.a a.o b.o link.o
g++ host.o --library=gpu --library-path=<path> \
--library=cudadevrt --library=cudart
在一个主机可执行文件中执行多个设备链接是可能的,只要每个设备链接彼此独立即可。这种独立性的要求意味着它们不能跨设备可执行文件共享代码,也不能共享地址(例如,只有当设备链接同时看到调用者和潜在的回调被调用者时,才能将设备函数地址从主机传递到设备以进行回调;您不能将地址从一个设备可执行文件传递到另一个设备可执行文件,因为它们是单独的地址空间)。
6.5. 单独编译的优化
由于无法跨文件内联代码,单独编译的代码可能没有整体程序代码那么高的性能。获得最佳性能的一种方法是使用链接时优化,它存储中间代码,然后将这些代码链接在一起以执行高级优化。这可以使用 --dlink-time-opt 或 -dlto 选项来完成。必须在编译和链接时都指定此选项。如果只有部分文件使用 -dlto 编译,则这些文件将被链接和优化在一起,而其余文件则使用正常的单独编译。一个副作用是,这会将一些编译时间转移到链接阶段,并且对于非常大的代码可能存在一些可伸缩性问题。如果要使用 -gencode 进行编译以构建多个架构,请使用 -dc -gencode arch=compute_NN,code=lto_NN 来指定要存储的中间 IR(其中 NN 是 SM 架构版本)。然后使用 -dlto 选项链接到特定架构。
从 CUDA 12.0 开始,通过 nvJitLink 库支持运行时 LTO。
6.6. 潜在的单独编译问题
6.6.1. 对象兼容性
只有具有相同 ABI 版本、链接兼容的 SM 目标架构和相同指针大小(32 或 64)的可重定位设备代码才能链接在一起。链接器的工具包版本必须 >= 对象的工具包版本。不兼容的对象将产生链接错误。链接兼容的 SM 架构是指具有兼容的 SASS 二进制文件,这些二进制文件可以组合而无需转换,例如 sm_52 和 sm_50。对象可能已针对不同的架构进行了编译,但也有 PTX 可用,在这种情况下,设备链接器会将 PTX JIT 编译为 cubin 以用于所需的架构,然后再进行链接。可重定位的设备代码需要 CUDA 5.0 或更高版本的工具包。
如果将链接时优化与 -dlto 一起使用,则中间 LTOIR 仅保证在主要版本内兼容(例如,可以将 12.0 和 12.1 LTO 中间文件链接在一起,但不能将 12.1 和 11.6 链接在一起)。
如果使用 launch_bounds 属性或 --maxrregcount 选项将内核限制为一定数量的寄存器,则内核调用的所有函数都不得使用超过该数量的寄存器;如果它们超过限制,则将给出链接错误。
6.6.2. JIT 链接支持
JIT 链接意味着在加载时对代码进行隐式重新链接。如果 cubin 在加载时与目标架构不匹配,则驱动程序会重新调用设备链接器以生成目标架构的 cubin,方法是首先将每个对象的 PTX JIT 编译为相应的 cubin,然后将新的 cubin 链接在一起。如果找不到对象的 PTX 或 cubin 以用于目标架构,则链接将失败。目前不支持 LTO 中间文件的隐式 JIT 链接,但可以使用 nvJitLink 库显式链接它们。
6.6.3. 隐式 CUDA 主机代码
像上面的 b.cu 这样的文件仅包含 CUDA 设备代码,因此人们可能会认为 b.o 对象不需要传递给主机链接器。但实际上,每当可以从主机端访问设备符号时,都会生成隐式主机代码,无论是通过启动还是通过像 cudaGetSymbolAddress() 这样的 API 调用。此隐式主机代码被放入 b.o 中,并且需要传递给主机链接器。此外,为了使 JIT 链接工作,所有设备代码都必须传递给主机链接器,否则主机可执行文件将不包含 JIT 链接所需的设备代码。因此,一个通用规则是,设备链接器和主机链接器必须看到相同的主机对象文件(如果对象文件中有任何设备引用 - 如果文件是纯主机,则设备链接器不需要看到它)。如果包含设备代码的对象文件未传递给主机链接器,则您将看到有关函数 __cudaRegisterLinkedBinary_name 调用未定义或未解析的符号 __fatbinwrap_name 的错误消息。
6.6.4. 使用 __CUDA_ARCH__
在单独编译中,__CUDA_ARCH__ 不得在标头中使用,以致不同的对象可能包含不同的行为。或者,必须保证所有对象都将针对相同的 compute_arch 进行编译。如果弱函数或模板函数在标头中定义,并且其行为取决于 __CUDA_ARCH__,则如果对象针对不同的 compute arch 编译,则该函数在对象中的实例可能会冲突。例如,如果 a.h 包含
template<typename T>
__device__ T* getptr(void)
{
#if __CUDA_ARCH__ == 500
return NULL; /* no address */
#else
__shared__ T arr[256];
return arr;
#endif
}
然后,如果 a.cu 和 b.cu 都包含 a.h 并为同一类型实例化 getptr,并且 b.cu 期望非 NULL 地址,并使用以下命令编译
nvcc --gpu-architecture=compute_50 --device-c a.cu
nvcc --gpu-architecture=compute_52 --device-c b.cu
nvcc --gpu-architecture=sm_52 a.o b.o
在链接时,仅使用 getptr 的一个版本,因此行为将取决于选择哪个版本。为避免这种情况,a.cu 和 b.cu 必须针对相同的 compute arch 进行编译,或者 __CUDA_ARCH__ 不应在共享标头函数中使用。
6.6.5. 库中的设备代码
如果在库以及非库对象(或另一个库)中定义了具有非弱外部链接的设备函数,则设备链接器将抱怨多个定义(这与传统的可能忽略来自库对象的函数定义的宿主链接器不同,如果已在较早的对象中找到)。
7. NVCC 的其他用法
7.1. 交叉编译
交叉编译通过使用以下 nvcc 命令行选项来控制
--compiler-bindir用于交叉编译,其中底层主机编译器能够为目标平台生成对象。
在 x86 系统上,如果 CUDA 工具包安装已配置为支持交叉编译到 Tegra 和非 Tegra ARM 目标,则当指定 ARM 主机交叉编译器时,nvcc 将默认使用非 Tegra 配置。要改为使用 Tegra 配置,请将 “-target-dir aarch64-linux” 传递给 nvcc。
7.2. 保留中间阶段文件
nvcc 默认情况下将中间结果存储到临时文件中,这些文件在完成之前立即删除。使用的临时文件目录的位置取决于当前平台,如下所示
- Windows
使用环境变量
TEMP的值。如果未设置,则改用C:\Windows\temp。- 其他平台
使用环境变量
TMPDIR的值。如果未设置,则改用/tmp。
选项 --keep 使 nvcc 将这些中间文件存储在当前目录或 --keep-dir 指定的目录中,名称如支持的阶段中所述。
7.3. 清理生成的文件
通过重复该命令,但使用附加选项 --clean-targets,可以清理特定 nvcc 命令生成的所有文件。在使用 --keep 之后,此选项特别有用,因为 --keep 选项通常会留下相当数量的中间文件。
由于使用 --clean-targets 将删除原始 nvcc 命令创建的内容,因此准确重复原始命令中的所有选项非常重要。例如,在以下示例中,省略 --keep 或添加 --compile 将具有不同的清理效果。
nvcc acos.cu --keep
nvcc acos.cu --keep --clean-targets
7.4. 打印代码生成统计信息
可以通过将选项 --resource-usage 传递给 nvcc 来打印每个编译的设备函数使用的寄存器数量和所需的内存量摘要。
$ nvcc --resource-usage acos.cu -arch sm_80
ptxas info : 1536 bytes gmem
ptxas info : Compiling entry function 'acos_main' for 'sm_80'
ptxas info : Function properties for acos_main
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 6 registers, 1536 bytes smem, 32 bytes cmem[0]
如以上示例所示,列出了静态分配的全局内存 (gmem) 的量。
全局内存和一些常量库是模块范围的资源,而不是每个内核的资源。常量变量到常量库的分配是特定于配置文件的。
在此之后,打印每个内核的资源信息。
堆栈帧是此函数使用的每个线程的堆栈使用量。溢出存储和加载表示在堆栈内存上完成的存储和加载,这些堆栈内存用于存储无法分配给物理寄存器的变量。
类似地,显示了寄存器数量、共享内存量和常量库中分配的总空间。
8. 声明
8.1. 声明
本文档仅供参考,不得视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果或使用不承担任何责任。本文档不承诺开发、发布或交付任何材料(下文定义)、代码或功能。
NVIDIA 保留在不另行通知的情况下随时对本文档进行更正、修改、增强、改进和任何其他更改的权利。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、飞机、太空或生命支持设备,也不适用于 NVIDIA 产品的故障或 malfunction 可以合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在此类设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此此类包含和/或使用由客户自行承担风险。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每种产品的全部参数进行测试。评估和确定本文档中包含的任何信息的适用性、确保产品适合并符合客户计划的应用以及执行应用所需的测试以避免应用或产品的默认设置是客户的唯一责任。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的关于第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要从第三方获得其专利或其他知识产权下的许可,或从 NVIDIA 获得 NVIDIA 专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,并且在不经修改且完全符合所有适用的出口法律和法规的情况下,并附带所有相关的条件、限制和声明,才允许复制本文档中的信息。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 不对材料作出任何明示、暗示、法定或其他方面的保证,并明确声明不承担所有关于不侵权、适销性和适用于特定用途的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害)负责,无论其因何种原因引起,也无论其责任理论如何,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因而遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的总体和累积责任应根据产品的销售条款进行限制。
8.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
8.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。