最佳实践#
使用 trtexec 进行性能基准测试#
本节介绍如何使用命令行工具 trtexec 进行 TensorRT 性能基准测试,以获取深度学习模型的推理性能测量结果。
如果您使用 TensorRT NGC 容器,则 trtexec 安装在 /opt/tensorrt/bin/trtexec。
如果您手动安装了 TensorRT,则 trtexec 是安装的一部分。
或者,您可以从源代码使用 TensorRT OSS 仓库 构建 trtexec。
使用 ONNX 文件进行性能基准测试#
如果您的模型已经是 ONNX 格式,则 trtexec 工具可以直接测量其性能。在本示例中,我们将使用来自 ONNX 模型动物园的 ResNet-50 v1 ONNX 模型 来展示如何使用 trtexec 测量其性能。
例如,测量批大小为 4 的 ResNet-50 性能的 trtexec 命令是
trtexec --onnx=resnet50-v1-12.onnx --shapes=data:4x3x224x224 --fp16 --noDataTransfers --useCudaGraph --useSpinWait
其中
--onnx标志指定 ONNX 文件的路径。--shapes标志指定输入张量的形状。--fp16标志启用 FP16 策略。添加其他标志是为了使性能结果更稳定。
--shapes 标志的值格式为 name1:shape1,name2:shape2,..。假设您不知道输入张量的名称和形状。您可以使用 Netron 等工具可视化 ONNX 模型,或运行 Polygraphy 模型检查来获取信息。
例如,运行 polygraphy inspect model resnet50-v1-12.onnx 会打印出
[I] Loading model: /home/pohanh/trt/resnet50-v1-12.onnx [I] ==== ONNX Model ==== Name: mxnet_converted_model | ONNX Opset: 12 ---- 1 Graph Input(s) ---- {data [dtype=float32, shape=('N', 3, 224, 224)]} ---- 1 Graph Output(s) ---- {resnetv17_dense0_fwd [dtype=float32, shape=('N', 1000)]} ---- 299 Initializer(s) ---- ---- 175 Node(s) ----
它显示 ONNX 模型具有一个名为 data 的图输入张量,其形状为 ('N', 3, 224, 224),其中 'N' 表示维度可以是动态的。因此,指定批大小为 4 的输入形状的 trtexec 标志将是 --shapes=data:4x3x224x224。
运行 trtexec 命令后,trtexec 将解析您的 ONNX 文件,构建 TensorRT 计划文件,测量此计划文件的性能,然后打印性能摘要,如下所示
[04/25/2024-23:57:45] [I] === Performance summary === [04/25/2024-23:57:45] [I] Throughput: 507.399 qps [04/25/2024-23:57:45] [I] Latency: min = 1.96301 ms, max = 1.97534 ms, mean = 1.96921 ms, median = 1.96917 ms, percentile(90%) = 1.97122 ms, percentile(95%) = 1.97229 ms, percentile(99%) = 1.97424 ms [04/25/2024-23:57:45] [I] Enqueue Time: min = 0.0032959 ms, max = 0.0340576 ms, mean = 0.00421173 ms, median = 0.00415039 ms, percentile(90%) = 0.00463867 ms, percentile(95%) = 0.00476074 ms, percentile(99%) = 0.0057373 ms [04/25/2024-23:57:45] [I] H2D Latency: min = 0 ms, max = 0 ms, mean = 0 ms, median = 0 ms, percentile(90%) = 0 ms, percentile(95%) = 0 ms, percentile(99%) = 0 ms [04/25/2024-23:57:45] [I] GPU Compute Time: min = 1.96301 ms, max = 1.97534 ms, mean = 1.96921 ms, median = 1.96917 ms, percentile(90%) = 1.97122 ms, percentile(95%) = 1.97229 ms, percentile(99%) = 1.97424 ms [04/25/2024-23:57:45] [I] D2H Latency: min = 0 ms, max = 0 ms, mean = 0 ms, median = 0 ms, percentile(90%) = 0 ms, percentile(95%) = 0 ms, percentile(99%) = 0 ms [04/25/2024-23:57:45] [I] Total Host Walltime: 3.00355 s [04/25/2024-23:57:45] [I] Total GPU Compute Time: 3.00108 s [04/25/2024-23:57:45] [I] Explanations of the performance metrics are printed in the verbose logs.
它打印了许多性能指标,但最重要的是吞吐量和中位数延迟。在本例中,批大小为 4 的 ResNet-50 模型可以以 每秒 507 次推理 的吞吐量(每秒 2028 张图像,因为批大小为 4)和 1.969 毫秒 的中位数延迟运行。
有关 吞吐量 和 延迟 对您的深度学习推理应用程序的意义的解释,请参阅 高级性能测量技术 部分。有关其他 trtexec 标志和 trtexec 报告的其他性能指标的详细说明,请参阅 trtexec 部分。
使用 ONNX+量化进行性能基准测试#
为了享受量化带来的额外性能优势,需要在 ONNX 模型中插入 Quantize/Dequantize 操作,以告知 TensorRT 在何处量化/反量化张量以及使用哪些缩放因子。
我们推荐的 ONNX 量化工具是 ModelOptimizer 包。您可以通过运行以下命令安装它
pip3 install --no-cache-dir --extra-index-url https://pypi.nvidia.com nvidia-modelopt
使用 ModelOptimizer,您可以通过运行以下命令获得量化的 ONNX 模型
python3 -m modelopt.onnx.quantization --onnx_path resnet50-v1-12.onnx --quantize_mode int8 --output_path resnet50-v1-12-quantized.onnx
它从 resnet50-v1-12.onnx 加载原始 ONNX 模型,使用随机数据运行校准,将 Quantize/Dequantize 操作插入到图中,然后将带有 Quantize/Dequantize 操作的 ONNX 模型保存到 resnet50-v1-12-quantized.onnx。
现在新的 ONNX 模型包含 INT8 Quantize/Dequantize 操作,我们可以使用类似的命令再次运行 trtexec
trtexec --onnx=resnet50-v1-12-quantized.onnx --shapes=data:4x3x224x224 --stronglyTyped --noDataTransfers --useCudaGraph --useSpinWait
我们使用 --stronglyTyped 标志而不是 --fp16 标志来要求 TensorRT 严格遵循量化 ONNX 模型中的数据类型,包括所有 INT8 Quantize/Dequantize 操作。
以下是运行带有量化 ONNX 模型的 trtexec 命令后的示例输出
[04/26/2024-00:31:43] [I] === Performance summary === [04/26/2024-00:31:43] [I] Throughput: 811.74 qps [04/26/2024-00:31:43] [I] Latency: min = 1.22559 ms, max = 1.23608 ms, mean = 1.2303 ms, median = 1.22998 ms, percentile(90%) = 1.23193 ms, percentile(95%) = 1.23291 ms, percentile(99%) = 1.23395 ms [04/26/2024-00:31:43] [I] Enqueue Time: min = 0.00354004 ms, max = 0.00997925 ms, mean = 0.00431524 ms, median = 0.00439453 ms, percentile(90%) = 0.00463867 ms, percentile(95%) = 0.00476074 ms, percentile(99%) = 0.00512695 ms [04/26/2024-00:31:43] [I] H2D Latency: min = 0 ms, max = 0 ms, mean = 0 ms, median = 0 ms, percentile(90%) = 0 ms, percentile(95%) = 0 ms, percentile(99%) = 0 ms [04/26/2024-00:31:43] [I] GPU Compute Time: min = 1.22559 ms, max = 1.23608 ms, mean = 1.2303 ms, median = 1.22998 ms, percentile(90%) = 1.23193 ms, percentile(95%) = 1.23291 ms, percentile(99%) = 1.23395 ms [04/26/2024-00:31:43] [I] D2H Latency: min = 0 ms, max = 0 ms, mean = 0 ms, median = 0 ms, percentile(90%) = 0 ms, percentile(95%) = 0 ms, percentile(99%) = 0 ms [04/26/2024-00:31:43] [I] Total Host Walltime: 3.00219 s [04/26/2024-00:31:43] [I] Total GPU Compute Time: 2.99824 s [04/26/2024-00:31:43] [I] Explanations of the performance metrics are printed in the verbose logs.
吞吐量为 每秒 811 次推理,中位数延迟为 1.23 毫秒。与上一节中的 FP16 性能结果相比,吞吐量提高了 60%。
逐层运行时和层信息#
在前面的章节中,我们描述了使用 trtexec 测量端到端延迟。本节将展示使用 trtexec 的逐层运行时和逐层信息的示例。这将帮助您确定每层对端到端延迟的贡献量,以及性能瓶颈在哪一层。
以下是使用量化 ResNet-50 ONNX 模型打印逐层运行时和逐层信息的 trtexec 命令示例
trtexec --onnx=resnet50-v1-12-quantized.onnx --shapes=data:4x3x224x224 --stronglyTyped --noDataTransfers --useCudaGraph --useSpinWait --profilingVerbosity=detailed --dumpLayerInfo --dumpProfile --separateProfileRun
--profilingVerbosity=detailed 标志启用详细的层信息捕获,--dumpLayerInfo 标志在日志中显示逐层信息,--dumpProfile --separateProfileRun 标志在日志中显示逐层运行时延迟。
以下代码是量化 ResNet-50 模型中卷积层之一的逐层信息示例日志
Name: resnetv17_stage1_conv0_weight + resnetv17_stage1_conv0_weight_QuantizeLinear + resnetv17_stage1_conv0_fwd, LayerType: CaskConvolution, Inputs: [ { Name: resnetv17_pool0_fwd_QuantizeLinear_Output_1, Location: Device, Dimensions: [4,64,56,56], Format/Datatype: Thirty-two wide channel vectorized row major Int8 format }], Outputs: [ { Name: resnetv17_stage1_relu0_fwd_QuantizeLinear_Output, Location: Device, Dimensions: [4,64,56,56], Format/Datatype: Thirty-two wide channel vectorized row major Int8 format }], ParameterType: Convolution, Kernel: [1,1], PaddingMode: kEXPLICIT_ROUND_DOWN, PrePadding: [0,0], PostPadding: [0,0], Stride: [1,1], Dilation: [1,1], OutMaps: 64, Groups: 1, Weights: {"Type": "Int8", "Count": 4096}, Bias: {"Type": "Float", "Count": 64}, HasBias: 1, HasReLU: 1, HasSparseWeights: 0, HasDynamicFilter: 0, HasDynamicBias: 0, HasResidual: 0, ConvXAsActInputIdx: -1, BiasAsActInputIdx: -1, ResAsActInputIdx: -1, Activation: RELU, TacticName: sm80_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize96x64x64_stage3_warpsize2x2x1_g1_tensor16x8x32_simple_t1r1s1, TacticValue: 0x483ad1560c6e5e27, StreamId: 0, Metadata: [ONNX Layer: resnetv17_stage1_conv0_fwd]
日志显示层名称、输入和输出张量名称、张量形状、张量数据类型、卷积参数、策略名称和元数据。Metadata 字段显示此层对应的 ONNX 操作。由于 TensorRT 具有图融合优化,因此一个引擎层可能对应于原始模型中的多个 ONNX 操作。
以下代码是量化 ResNet-50 模型中最后几层的逐层运行时延迟示例日志
[04/26/2024-00:42:55] [I] Time(ms) Avg.(ms) Median(ms) Time(%) Layer [04/26/2024-00:42:55] [I] 56.57 0.0255 0.0256 1.8 resnetv17_stage4_conv7_weight + resnetv17_stage4_conv7_weight_QuantizeLinear + resnetv17_stage4_conv7_fwd [04/26/2024-00:42:55] [I] 103.86 0.0468 0.0471 3.3 resnetv17_stage4_conv8_weight + resnetv17_stage4_conv8_weight_QuantizeLinear + resnetv17_stage4_conv8_fwd [04/26/2024-00:42:55] [I] 46.93 0.0211 0.0215 1.5 resnetv17_stage4_conv9_weight + resnetv17_stage4_conv9_weight_QuantizeLinear + resnetv17_stage4_conv9_fwd + resnetv17_stage4__plus2 + resnetv17_stage4_activation2 [04/26/2024-00:42:55] [I] 34.64 0.0156 0.0154 1.1 resnetv17_pool1_fwd [04/26/2024-00:42:55] [I] 63.21 0.0285 0.0287 2.0 resnetv17_dense0_weight + resnetv17_dense0_weight_QuantizeLinear + transpose_before_resnetv17_dense0_fwd + resnetv17_dense0_fwd + resnetv17_dense0_bias + ONNXTRT_Broadcast + unsqueeze_node_after_resnetv17_dense0_bias + ONNXTRT_Broadcast_ONNXTRT_Broadcast_output + (Unnamed Layer* 851) [ElementWise] [04/26/2024-00:42:55] [I] 3142.40 1.4149 1.4162 100.0 Total
它显示 resnetv17_pool1_fwd 层的中位数延迟为 0.0154 毫秒,占端到端延迟的 1.1%。通过此日志,您可以识别哪些层占端到端延迟的最大部分,以及性能瓶颈。
逐层运行时日志中报告的 Total 延迟是逐层延迟的总和。由于测量逐层延迟造成的开销,它通常略长于报告的端到端延迟。例如,Total 中位数延迟为 1.4162 毫秒,但上一节中显示的端到端延迟为 1.23 毫秒。
使用 TensorRT 计划文件进行性能基准测试#
如果您使用 TensorRT API 构建 TensorRT INetworkDefinition 并在单独的脚本中构建计划文件,您仍然可以使用 trtexec 测量计划文件的性能。
例如,如果计划文件另存为 resnet50-v1-12-quantized.plan,那么您可以运行 trtexec 命令以使用此计划文件测量性能
trtexec --loadEngine=resnet50-v1-12-quantized.plan --shapes=data:4x3x224x224 --noDataTransfers --useCudaGraph --useSpinWait
性能摘要输出与前面章节中的类似。
持续时间和迭代次数#
默认情况下,trtexec 预热至少 200 毫秒,并运行推理至少 10 次迭代或至少 3 秒,以较长者为准。您可以通过添加 --warmUp=500、--iterations=100 和 --duration=60 标志来修改这些参数,这意味着预热运行至少 500 毫秒,推理运行至少 100 次迭代或至少 60 秒,以较长者为准。
有关其他 trtexec 标志的详细说明,请参阅 trtexec 部分或运行 trtexec --help。
高级性能测量技术#
在使用 TensorRT 进行任何优化工作之前,必须确定应该测量什么。没有测量,就不可能取得可靠的进展或衡量是否已取得成功。
延迟:网络推理的性能指标是从向网络呈现输入到输出可用之间经过的时间。这是单个推理的网络延迟。延迟越低越好。在某些应用中,低延迟是关键的安全要求。在其他应用中,延迟作为服务质量问题直接对用户可见。对于批量处理,延迟可能并不重要。
吞吐量:另一个性能指标是在固定时间内可以完成多少次推理。这是网络的吞吐量。吞吐量越高越好。更高的吞吐量表明更有效地利用了固定的计算资源。对于批量处理,所花费的总时间将由网络的吞吐量决定。
查看延迟和吞吐量的另一种方法是固定最大延迟,并在该延迟下测量吞吐量。像这样的服务质量测量可能是用户体验和系统效率之间的合理折衷。
在测量延迟和吞吐量之前,您必须选择开始和停止计时的确切点。不同的点对于网络和应用程序有不同的意义。
在许多应用程序中,存在一个处理管道,整个管道的延迟和吞吐量可以衡量整体系统性能。由于预处理和后处理步骤很大程度上取决于特定应用程序,因此本节仅考虑网络推理的延迟和吞吐量。
挂钟计时#
挂钟时间(计算开始到结束之间经过的时间)可用于测量应用程序的总体吞吐量和延迟,并将推理时间置于更大系统的上下文中。C++11 在 <chrono> 标准库中提供了高精度计时器。例如,std::chrono::system_clock 表示系统范围的挂钟时间,而 std::chrono::high_resolution_clock 以可用的最高精度测量时间。
以下示例代码片段显示了测量网络推理主机时间
1#include <chrono>
2
3auto startTime = std::chrono::high_resolution_clock::now();
4context->enqueueV3(stream);
5cudaStreamSynchronize(stream);
6auto endTime = std::chrono::high_resolution_clock::now();
7float totalTime = std::chrono::duration<float, std::milli>
8 (endTime - startTime).count();
1import time
2from cuda import cudart
3err, stream = cudart.cudaStreamCreate()
4start_time = time.time()
5context.execute_async_v3(stream)
6cudart.cudaStreamSynchronize(stream)
7total_time = time.time() - start_time
如果设备上一次只有一个推理发生,那么这可能是一种简单的分析各种操作耗时的方法。推理通常是异步的,因此请确保添加显式的 CUDA 流或设备同步来等待结果可用。
CUDA 事件#
仅在主机上计时的一个问题是它需要主机/设备同步。优化的应用程序可能在设备上并行运行许多推理,并具有重叠的数据移动。此外,同步会给计时测量增加一些噪声。
为了帮助解决这些问题,CUDA 提供了 Event API。此 API 允许您将事件放置到 CUDA 流中,GPU 将在遇到事件时对其进行时间戳记。然后,时间戳记的差异可以告诉您不同操作花费了多长时间。
以下示例代码片段显示了计算两个 CUDA 事件之间的时间
1cudaEvent_t start, end;
2cudaEventCreate(&start);
3cudaEventCreate(&end);
4
5cudaEventRecord(start, stream);
6context->(enqueueV3stream);
7cudaEventRecord(end, stream);
8
9cudaEventSynchronize(end);
10float totalTime;
11cudaEventElapsedTime(&totalTime, start, end);
1from cuda import cudart
2err, stream = cudart.cudaStreamCreate()
3err, start = cudart.cudaEventCreate()
4err, end = cudart.cudaEventCreate()
5cudart.cudaEventRecord(start, stream)
6context.execute_async_v3(stream)
7cudart.cudaEventRecord(end, stream)
8cudart.cudaEventSynchronize(end)
9err, total_time = cudart.cudaEventElapsedTime(start, end)
内置 TensorRT 分析#
深入研究推理性能需要在优化的网络中进行更精细的计时测量。
TensorRT 具有 Profiler (C++, Python) 接口,您可以实现该接口以使 TensorRT 将分析信息传递到您的应用程序。调用时,网络将在分析模式下运行。完成推理后,将调用您的类的分析器对象以报告网络中每层的计时。这些计时可用于定位瓶颈,比较序列化引擎的不同版本,以及调试性能问题。
分析信息可以从常规推理 enqueueV3() 启动或 CUDA 图启动中收集。有关更多信息,请参阅 IExecutionContext::setProfiler() 和 IExecutionContext::reportToProfiler() (C++, Python)。
循环内的层被编译成一个单一的单体层;因此,这些层的单独计时不可用。此外,某些子图(尤其是具有类似 Transformer 网络的子图)由下一代图形优化器处理,该优化器尚未与 Profiler API 集成。对于这些网络,请使用 CUDA 分析工具 分析逐层性能。
通用示例代码 (common.h) 中提供了一个显示如何使用 IProfiler 接口的示例。
给定输入网络或计划文件,您可以使用 trtexec 使用 TensorRT 分析网络。有关更多信息,请参阅 trtexec 部分。
ONNX 分析工具#
Nsight Deep Learning Designer 是 ONNX 模型的集成设计环境。它构建于 TensorRT 之上。其内置分析器通过 TensorRT 运行 ONNX 模型的推理,并根据 GPU 性能指标收集分析数据。Nsight Deep Learning Designer 生成的分析器报告提供了 ONNX 模型在 TensorRT 层级的推理性能的全面视图。其 GUI 还帮助开发人员将各个 TensorRT 层的性能与其原始 ONNX 运算符相关联。
Nsight Deep Learning Designer 分析通常从 GUI 开始。打开 Nsight Deep Learning Designer 应用程序,然后从欢迎屏幕单击 Start Activity。从列表中选择目标平台类型,如果您希望从远程计算机在 Linux 或 L4T 目标上进行分析,您还可以定义远程连接。选择 Profile TensorRT Model 作为活动类型。
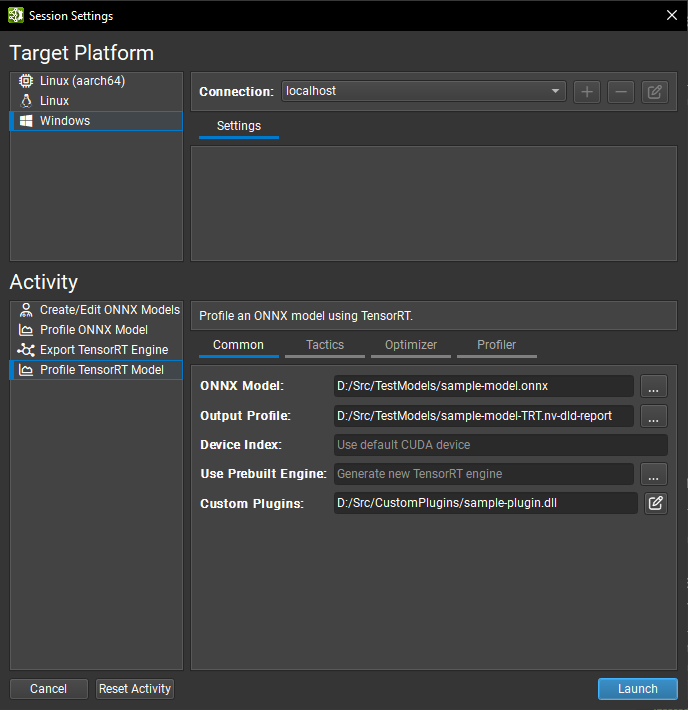
分析器活动设置通常在 trtexec 中具有类似项,并在 GUI 中的四个选项卡中拆分。有关每个设置的详细信息,请参阅 Nsight Deep Learning Designer 文档。此处列出了最常用的设置
Common:要分析的 ONNX 模型、其对应的 TensorRT 引擎(如果已构建)以及保存分析器报告的位置。
Tactics:类型模式(默认类型、类型约束 (层级权限控制) 或强类型 (强类型网络))以及弱类型网络中 FP16、BF16、TF32、INT8 和 FP8 精度 (网络级精度控制) 的开/关切换。
Optimizer:可重新拟合的权重 (重新拟合引擎)、INT8 量化缓存路径 (使用校准进行后训练量化)。
Profiler:将 GPU 时钟锁定到基本值 (GPU 时钟锁定和浮动时钟) 和 GPU 计数器采样率。
使用动态形状 (使用动态形状) 的网络应在分析之前指定优化配置文件。这可以通过在 Nsight Deep Learning Designer 中编辑 ONNX 网络、从命令行进行分析或(对于兼容网络)在“Optimizer”选项卡中设置 Inferred Batch 选项来完成。当提供批大小时,具有单个前导通配符的输入形状将自动填充批大小。此功能适用于任意秩的输入形状。
要启动 Nsight Deep Learning Designer 分析器,请单击 Launch 按钮。该工具将根据需要自动将 TensorRT 和 CUDA 运行时库部署到目标,然后生成分析报告
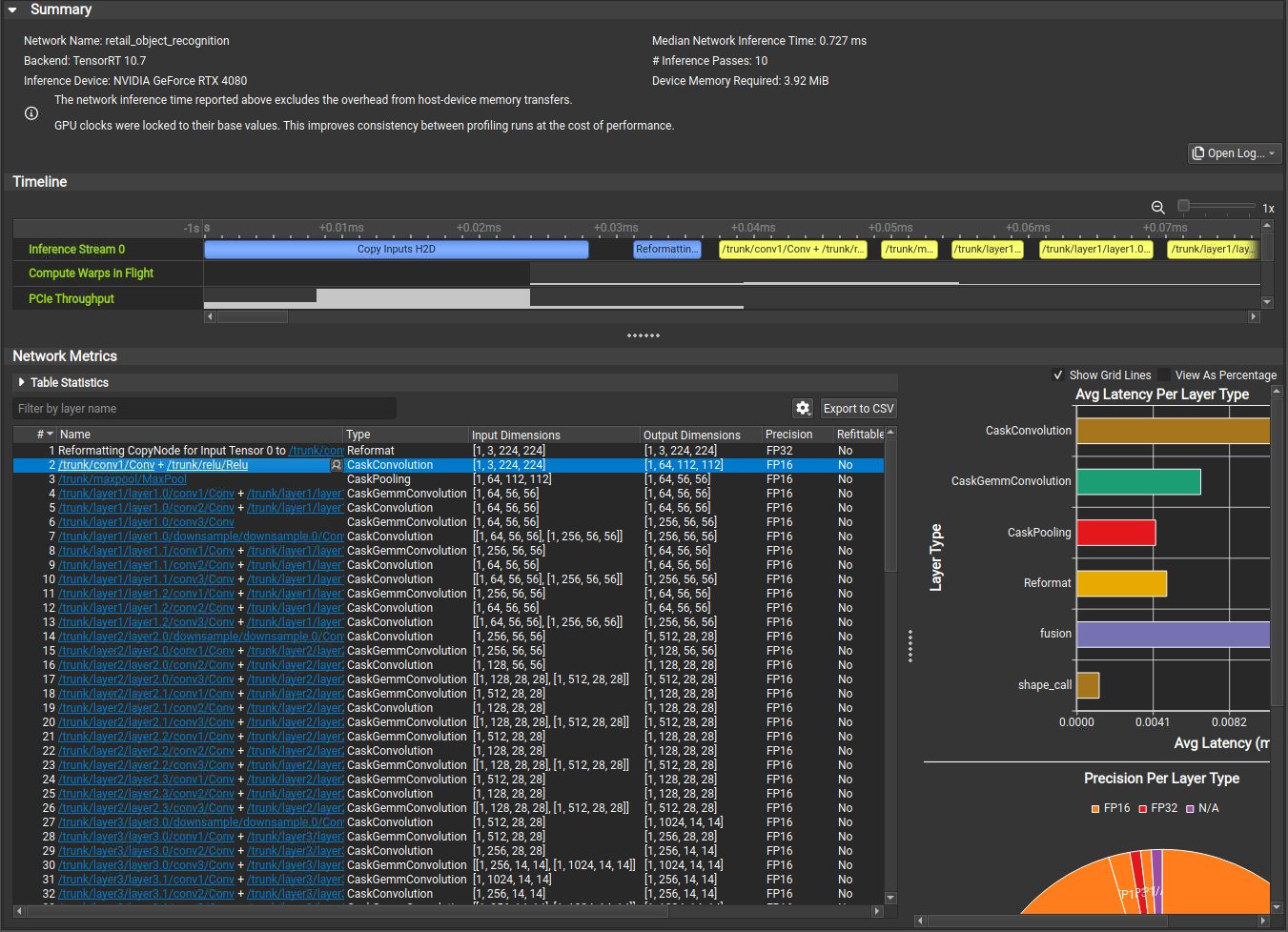
Nsight Deep Learning Designer 包括一个命令行分析器;有关使用说明,请参阅工具 文档。
了解 Nsight Deep Learning Designer 时间线视图

在 Nsight Deep Learning Designer 时间线视图中,每个网络推理流都显示为时间线的一行,以及收集的 GPU 指标,例如 SM 活动和 PCIe 吞吐量。在推理流上执行的每个层都显示为相应时间线视图上的一个范围。张量内存副本或重格式等开销源以蓝色突出显示。
了解 Nsight Deep Learning Designer 层表
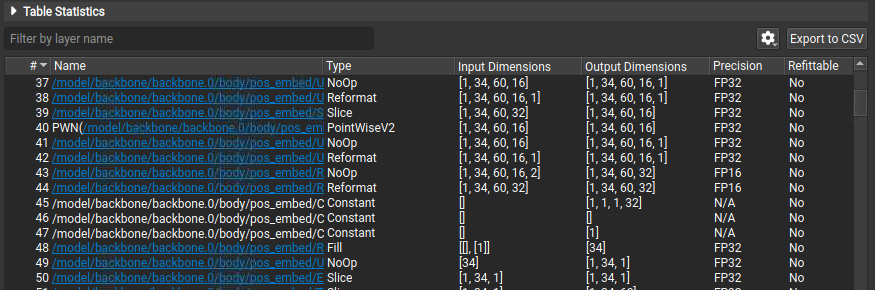
“Network Metrics”表视图显示网络执行的所有 TensorRT 层、它们的类型、维度、精度和推理时间。层推理时间在表中以原始时间测量值和推理过程的百分比形式提供。您可以按名称过滤表。表中的超链接指示层名称在原始 ONNX 源模型中引用节点的位置。单击超链接或使用所选层的 Name 列中的下拉菜单打开原始 ONNX 模型并在其上下文中突出显示该层。
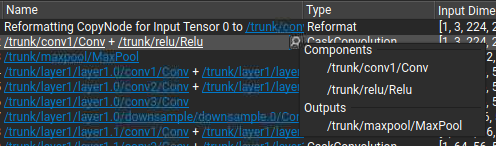
在表中选择一系列层会将它们的统计信息聚合到更高级别的摘要中。每个表列都在摘要区域中表示,其中包含选择中最常见的值,按频率排序。将鼠标光标悬停在信息图标上以查看值的完整列表和关联的频率。推理时间列以最小值、最大值、平均值和总计显示,使用绝对时间,推理过程百分比作为单位。在这种情况下,总时间可用于快速求和单个执行流中层的推理时间。选择中的层不需要是连续的。

了解 Nsight Deep Learning Designer 网络图
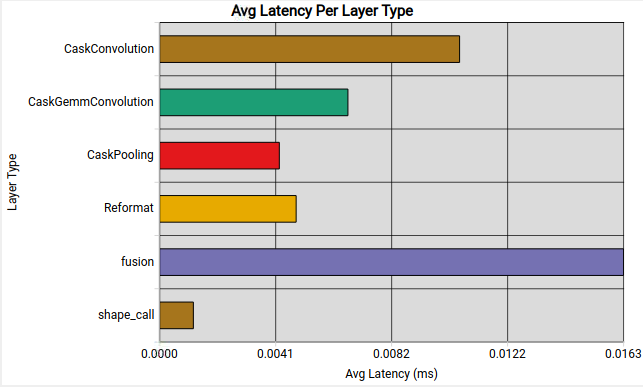
Nsight Deep Learning Designer 显示 TensorRT 引擎中每种类型的层的平均推理延迟。这可以突出显示网络在非关键计算上花费大量时间的区域。
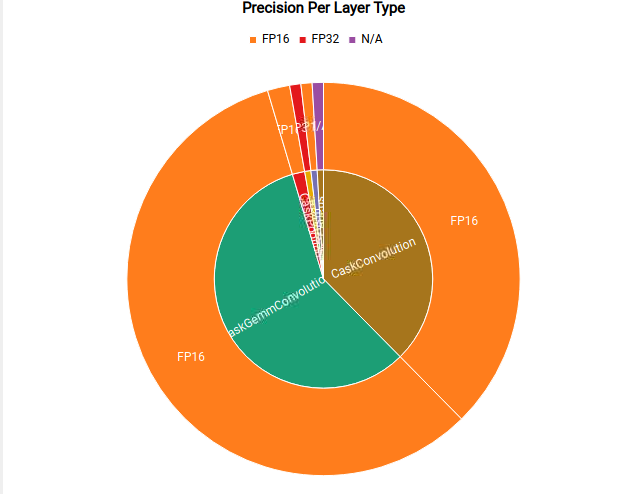
Nsight Deep Learning Designer 还显示 TensorRT 引擎中每种类型的层使用的精度。这可以突出显示网络量化的潜在机会,并可视化设置 TensorRT 的策略精度标志的效果。
CUDA 分析工具#
推荐的 CUDA 分析器是 NVIDIA Nsight Systems。一些 CUDA 开发人员可能更熟悉 nvprof 和 nvvp。但是,这些工具正在被弃用。这些分析器可用于任何 CUDA 程序,以报告有关执行期间启动的内核、主机和设备之间的数据移动以及使用的 CUDA API 调用的计时信息。
Nsight Systems 可以配置为仅报告程序执行的一部分的计时信息,或报告传统的 CPU 采样分析信息和 GPU 信息。
Nsight Systems 的基本用法是首先运行命令 nsys profile -o <OUTPUT> <INFERENCE_COMMAND>,然后在 Nsight Systems GUI 中打开生成的 <OUTPUT>.nsys-rep 文件以可视化捕获的分析结果。
仅分析推理阶段
在分析 TensorRT 应用程序时,您应该仅在引擎构建完成后启用分析。在构建阶段,会尝试所有可能的策略并计时。分析执行的这一部分不会显示任何有意义的性能测量结果,并且将包含所有可能的内核,而不是为推理选择的内核。限制分析范围的一种方法是
第一阶段:构建应用程序以在一个阶段中构建和然后序列化引擎。
第二阶段:加载序列化的引擎,在第二阶段运行推理,并仅分析第二阶段。
假设应用程序无法序列化引擎或必须连续运行两个阶段。在这种情况下,您还可以在第二阶段周围添加 cudaProfilerStart() 和 cudaProfilerStop() CUDA API,并在 Nsight Systems 命令中添加 -c cudaProfilerApi 标志,以仅分析 cudaProfilerStart() 和 cudaProfilerStop() 之间的部分。
了解 Nsight Systems 时间线视图
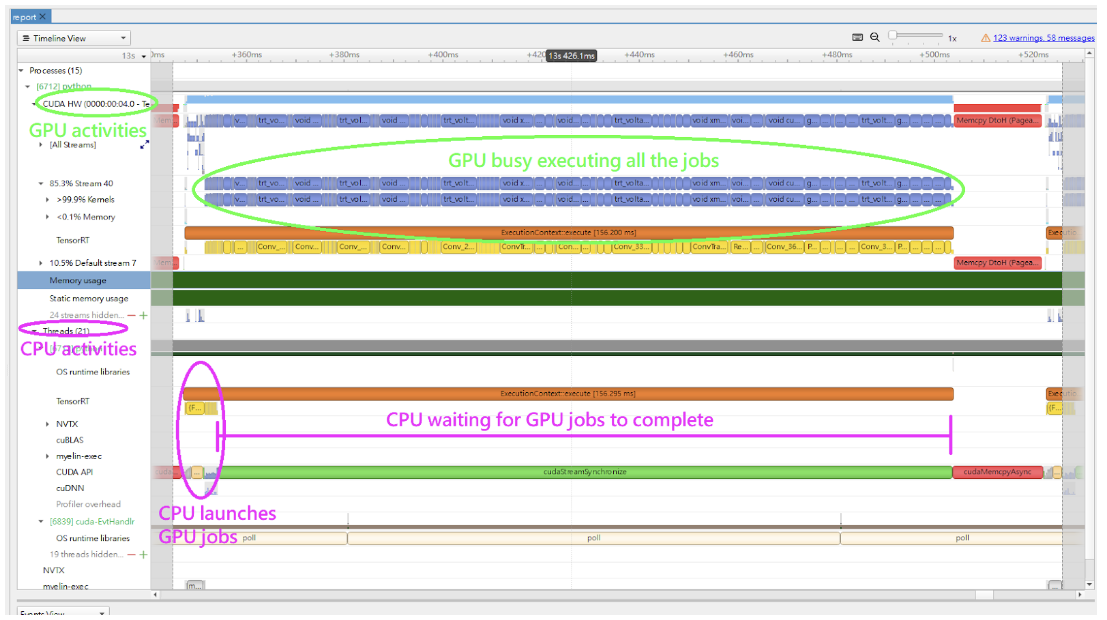
在 Nsight Systems 时间线视图中,GPU 活动显示在 CUDA HW 下的行中,CPU 活动显示在 Threads 下的行中。默认情况下,CUDA HW 下的行是折叠的。因此,您必须单击它以展开行。
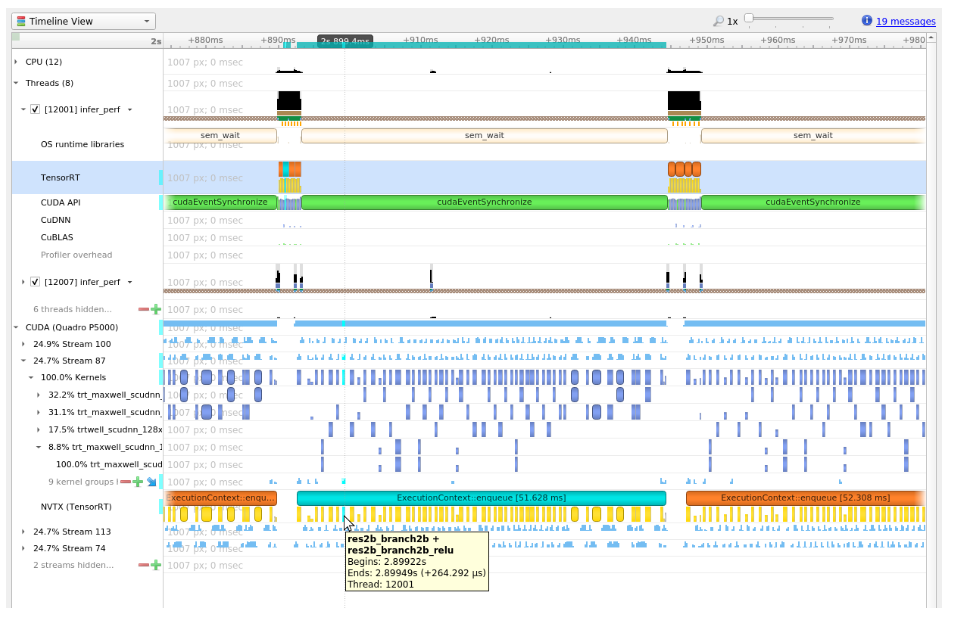
在典型的推理工作流程中,应用程序调用 context->enqueueV3() 或 context->executeV3() API 来排队作业,然后在流上同步以等待 GPU 完成作业。如果您只查看 CPU 活动,则在 cudaStreamSychronize() 调用中,系统似乎一段时间内什么也没做。当 CPU 等待时,GPU 可能正忙于执行排队的作业。下图显示了一个查询推理的示例时间线。
trtexec 工具使用稍微复杂的方法来排队作业。当 GPU 仍在执行来自上一个查询的作业时,它会排队下一个查询。有关更多信息,请参阅 trtexec 部分。
下图显示了 Nsight Systems 时间线视图中正常推理工作负载的典型视图,在不同的行上显示 CPU 和 GPU 活动。
在 Nsight Systems 中使用 NVTX 跟踪
跟踪启用 NVIDIA Tools Extension SDK (NVTX),这是一个基于 C 的 API,用于标记应用程序中的事件和范围。它允许 Nsight Compute 和 Nsight Systems 收集 TensorRT 应用程序生成的数据。
将内核名称解码回原始网络中的层可能很复杂。因此,TensorRT 使用 NVTX 为每一层标记一个范围,从而允许 CUDA 分析器将每一层与调用以实现它的内核相关联。在 TensorRT 中,NVTX 帮助将运行时引擎层执行与 CUDA 内核调用相关联。Nsight Systems 支持在时间线上收集和可视化这些事件和范围。当应用程序挂起时,Nsight Compute 还支持收集和显示给定线程中所有活动 NVTX 域和范围的状态。
在 TensorRT 中,每一层可能会启动一个或多个内核来执行其操作。启动的确切内核取决于优化的网络和存在的硬件。根据构建器的选择,可能会在层计算之间穿插多个重新排序数据的附加操作;这些重格式操作可以实现为设备到设备内存副本或自定义内核。
例如,以下屏幕截图来自 Nsight Systems。
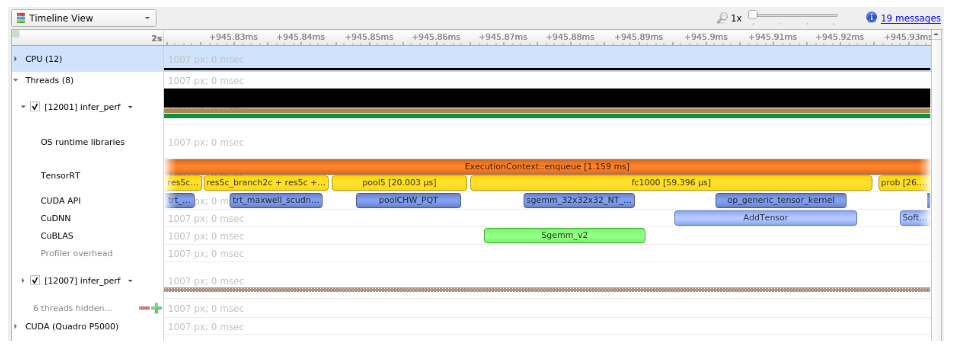
内核在 GPU 上运行;换句话说,下图显示了 CPU 端的层执行和内核启动及其在 GPU 端的执行之间的相关性。
控制 NVTX 跟踪中的详细程度
默认情况下,TensorRT 仅在 NVTX 标记中显示层名称。同时,用户可以通过在构建引擎时在 IBuilderConfig 中设置 ProfilingVerbosity 来控制详细程度。例如,要禁用 NVTX 跟踪,请将 ProfilingVerbosity 设置为 kNONE
1builderConfig->setProfilingVerbosity(ProfilingVerbosity::kNONE);
1builder_config.profilling_verbosity = trt.ProfilingVerbosity.NONE
另一方面,您可以选择允许 TensorRT 在 NVTX 标记中打印更详细的层信息,包括输入和输出维度、操作、参数、策略编号等,方法是将 ProfilingVerbosity 设置为 kDETAILED
1builderConfig->setProfilingVerbosity(ProfilingVerbosity::kDETAILED);
1builder_config.profilling_verbosity = trt.ProfilingVerbosity.DETAILED
注意
启用详细的 NVTX 标记会增加 enqueueV3() 调用的延迟,并且如果性能取决于 enqueueV3() 调用的延迟,则可能会导致性能下降。
使用 trtexec 运行 Nsight Systems
以下是使用 trtexec 工具收集 Nsight Systems 配置文件的命令示例
trtexec --onnx=foo.onnx --profilingVerbosity=detailed --saveEngine=foo.plan nsys profile -o foo_profile --capture-range cudaProfilerApi trtexec --profilingVerbosity=detailed --loadEngine=foo.plan --warmUp=0 --duration=0 --iterations=50
第一个命令构建引擎并将其序列化到 foo.plan,第二个命令使用 foo.plan 运行推理,并生成 foo_profile.nsys-rep 文件,该文件随后可以在 Nsight Systems 用户界面中打开以进行可视化。
--profilingVerbosity=detailed 标志允许 TensorRT 在 NVTX 标记中显示更详细的层信息,--warmUp=0、--duration=0 和 --iterations=50 标志允许您控制运行多少次推理迭代。默认情况下,trtexec 运行推理三秒钟,这可能会导致 nsys-rep 文件输出过大。
如果启用了 CUDA 图,请将 --cuda-graph-trace=node 标志添加到 nsys 命令,以查看每个内核的运行时信息
nsys profile -o foo_profile --capture-range cudaProfilerApi --cuda-graph-trace=node trtexec --profilingVerbosity=detailed --loadEngine=foo.plan --warmUp=0 --duration=0 --iterations=50 --useCudaGraph
(可选)在 Nsight Systems 中启用 GPU 指标采样
在独立 GPU 系统上,将 --gpu-metrics-device all 标志添加到 nsys 命令,以采样 GPU 指标,包括 GPU 时钟频率、DRAM 带宽、Tensor Core 利用率等。如果添加了该标志,这些 GPU 指标将显示在 Nsight Systems Web 界面中。
DLA 分析#
要分析 DLA,在使用 NVIDIA Nsight Systems CLI 时添加 --accelerator-trace nvmedia 标志,或在使用用户界面时启用 Collect other accelerators trace。例如,以下命令可以与 NVIDIA Nsight Systems CLI 一起使用
nsys profile -t cuda,nvtx,nvmedia,osrt --accelerator-trace=nvmedia --show-output=true trtexec --loadEngine=alexnet_int8.plan --warmUp=0 --duration=0 --iterations=20
这是一个示例报告
NvMediaDLASubmit为每个 DLA 子图提交一个 DLA 任务。任务的运行时可以在 Other accelerators trace 下的 DLA 时间轴中找到。由于允许 GPU 回退,TensorRT 自动添加了一些 CUDA 内核,例如
permutationKernelPLC3和copyPackedKernel,这些内核用于数据重格式化。由于 TensorRT 使用
EGLStream在 GPU 内存和 DLA 之间传输数据,因此执行了EGLStreamAPI。
为了最大化 GPU 利用率,trtexec 提前入队一个批次的查询。
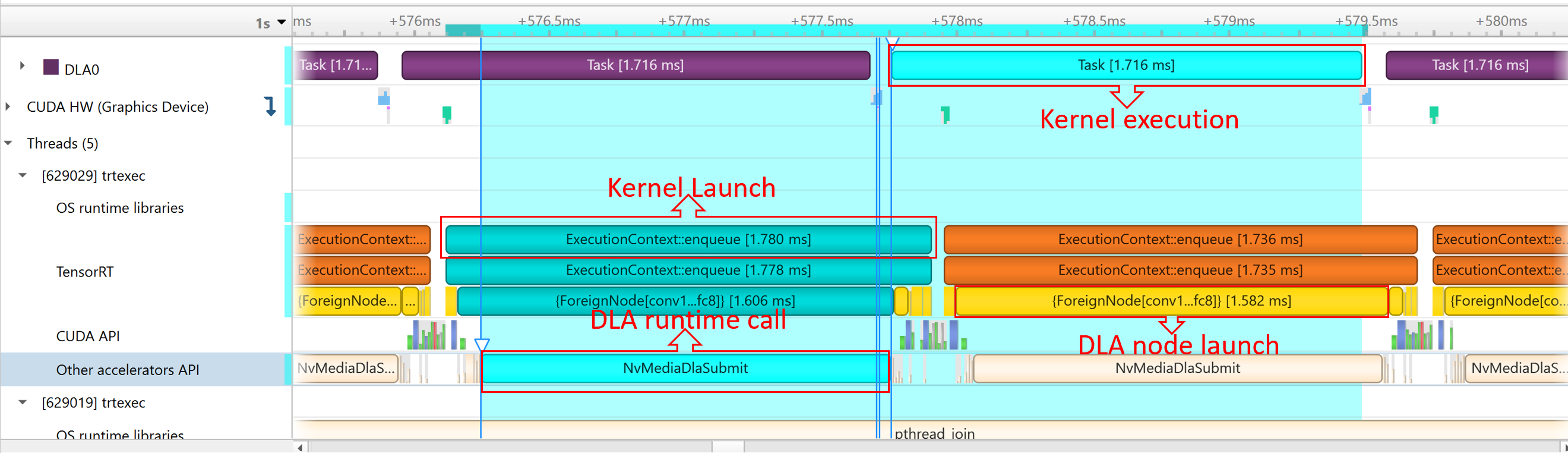
DLA 任务的运行时可以在 Other Accelerator API 下找到。一些 CUDA 内核和 EGLStream API 被调用,用于 GPU 和 DLA 之间的交互。
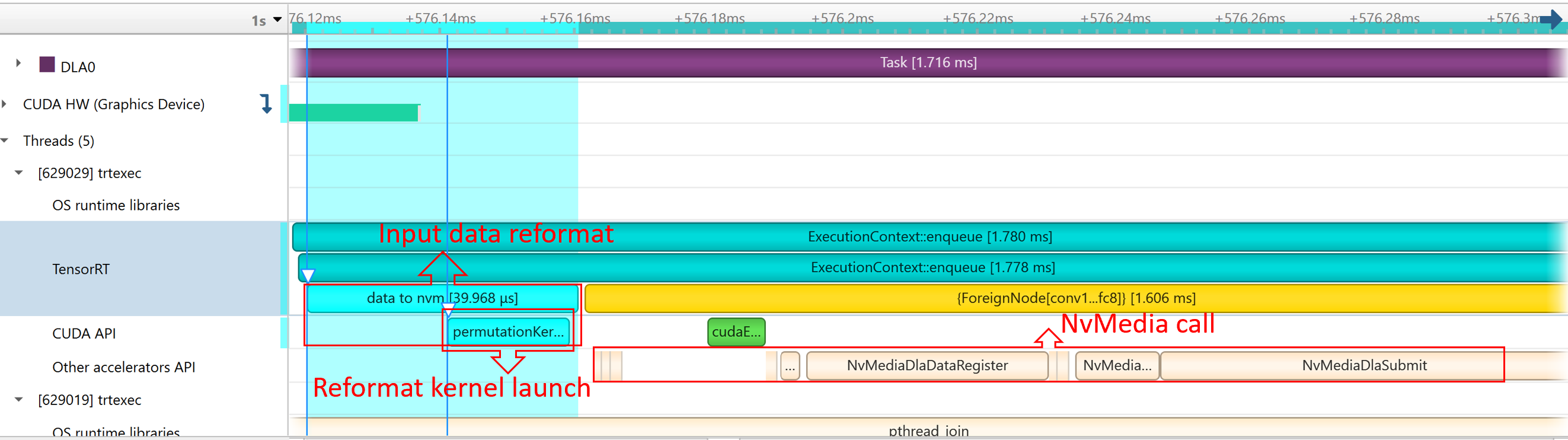
跟踪内存#
跟踪内存使用情况与执行性能同等重要。通常,设备的内存比主机的内存更受限。为了跟踪设备内存,推荐的机制是创建一个简单的自定义 GPU 分配器,该分配器在内部保留一些统计信息,然后使用常规的 CUDA 内存分配函数 cudaMalloc 和 cudaFree。
可以为构建器 IBuilder (用于网络优化)和 IRuntime (在反序列化引擎时)设置自定义 GPU 分配器,使用 IGpuAllocator API。自定义分配器的一个思路是跟踪当前已分配的内存量,并将带有时间戳和其他信息的分配事件推送到全局分配事件列表中。查看分配事件列表可以分析一段时间内的内存使用情况。
在移动平台上,GPU 内存和 CPU 内存共享系统内存。在内存大小非常有限的设备上(如 Nano),即使所需的 GPU 内存小于系统内存,系统内存也可能会耗尽。在这种情况下,增加系统交换空间可以解决一些问题。以下是一个示例脚本:
echo "######alloc swap######" if [ ! -e /swapfile ];then sudo fallocate -l 4G /swapfile sudo chmod 600 /swapfile sudo mkswap /swapfile sudo /bin/sh -c 'echo "/swapfile \t none \t swap \t defaults \t 0 \t 0" >> /etc/fstab' sudo swapon -a fi
性能测量的硬件/软件环境#
性能测量受多种因素影响,包括硬件环境差异(如机器的散热能力)和软件环境差异(如 GPU 时钟设置)。本节总结了一些可能影响性能测量的事项。
请注意,涉及 nvidia-smi 的项目仅在独立 GPU 系统上受支持,移动系统上不受支持。
GPU 信息查询和 GPU 监控#
在测量性能时,建议您并行记录和监控 GPU 状态以及推理工作负载。拥有监控数据可以帮助您在看到意外的性能测量结果时识别可能的根本原因。
在推理开始之前,调用 nvidia-smi -q 命令以获取有关 GPU 的详细信息,包括产品名称、功率上限、时钟设置等。然后,在推理工作负载运行时,并行运行 nvidia-smi dmon -s pcu -f <FILE> -c <COUNT> 命令,将 GPU 时钟频率、功耗、温度和利用率打印到文件中。调用 nvidia-smi dmon --help 以获取有关 nvidia-smi 设备监控工具的更多选项。
GPU 时钟锁定和浮动时钟#
默认情况下,GPU 时钟频率是浮动的,这意味着在没有活动工作负载时它处于空闲状态,并在工作负载开始时提升到加速时钟频率。这通常是期望的行为,因为它允许 GPU 在空闲时产生更少的热量,并在有活动工作负载时以最大速度运行。
或者,您可以通过调用 sudo nvidia-smi -lgc <freq> 命令将时钟锁定在特定频率(反之,您可以使用 sudo nvidia-smi -rgc 命令再次让时钟浮动)。sudo nvidia-smi -q -d SUPPORTED_CLOCKS 命令可以找到支持的时钟频率。时钟频率锁定后,它应保持在该频率,除非发生功率或热节流,这将在接下来的章节中解释。当节流启动时,设备的行为类似于时钟浮动。
使用浮动时钟或正在进行节流的运行 TensorRT 工作负载可能会导致策略选择的更多不确定性以及跨推理的不稳定性能测量,因为每个 CUDA 内核可能以略微不同的时钟频率运行,具体取决于驱动程序在当时将时钟提升或节流到哪个频率。另一方面,使用锁定时钟运行 TensorRT 工作负载可以实现更确定的策略选择和一致的性能测量。尽管如此,平均性能不会像时钟浮动或锁定在最大频率并进行节流时那样好。
关于在运行 TensorRT 工作负载时是否应该锁定时钟或锁定哪个时钟频率,没有明确的建议。这取决于是否需要确定性和稳定的性能或最佳平均性能。
GPU 功耗和功率节流#
当平均 GPU 功耗达到功率限制时,就会发生功率节流,功率限制可以通过 sudo nvidia-smi -pl <power_cap> 命令设置。发生这种情况时,驱动程序必须将时钟节流到较低的频率,以使平均功耗保持在限制以下。如果测量是在短时间内(例如在 20 毫秒内)进行的,则不断变化的时钟频率可能会导致不稳定的性能测量。
功率节流是按设计发生的,并且是自然现象,当 GPU 时钟未锁定或锁定在较高频率时,尤其对于功率限制较低的 GPU(如 NVIDIA T4 和 NVIDIA A2 GPU)更是如此。为了避免功率节流引起的性能变化,您可以将 GPU 时钟锁定在较低的频率以稳定性能数据。但是,平均性能数据将低于浮动时钟或时钟锁定在较高频率时的数据,即使在这种情况下也会发生功率节流。
功率节流的另一个问题是,如果您的性能基准测试应用程序中推理之间存在间隙,则可能会扭曲性能数据。例如,如果应用程序在每次推理时同步,则在推理之间 GPU 会有一段空闲时间。这些间隙导致 GPU 平均功耗降低,因此时钟节流较少,并且 GPU 可以以更高的平均时钟频率运行。但是,以这种方式测量的吞吐量数据是不准确的,因为当 GPU 完全加载且推理之间没有间隙时,实际时钟频率会更低,并且实际吞吐量将达不到使用基准测试应用程序测量的吞吐量数据。
为了避免这种情况,trtexec 工具旨在通过在 GPU 内核执行之间几乎不留间隙来最大化 GPU 执行,以便它可以测量 TensorRT 工作负载的真实吞吐量。因此,如果您发现您的基准测试应用程序报告的性能与 trtexec 报告的性能之间存在差距,请检查功率节流和推理之间的间隙是否是原因。
最后,功耗可能取决于激活值,从而导致不同的输入性能测量。例如,如果所有网络输入值都设置为零或 NaN,则 GPU 的功耗低于输入为正常值时的功耗,因为 DRAM 和 L2 缓存中的位翻转更少。为了避免这种差异,在测量性能时,始终使用最能代表实际值分布的输入值。trtexec 工具默认使用随机输入值,但您可以使用 --loadInputs 标志指定输入。有关更多信息,请参阅 trtexec 部分。
GPU 温度和热节流#
当 GPU 温度达到预定义的阈值(对于大多数 GPU 约为 85 摄氏度)时,就会发生热节流,并且驱动程序必须将时钟节流到较低的频率,以防止 GPU 过热。您可以通过查看 nvidia-smi dmon 命令记录的温度在推理工作负载运行时逐渐升高,直到达到约 85°C 并且时钟频率下降来判断是否发生了这种情况。
如果热节流发生在主动散热 GPU(如 Quadro A8000)上,则可能是 GPU 上的风扇损坏或障碍物阻碍了气流。
如果热节流发生在被动散热 GPU(如 NVIDIA A10)上,则很可能是 GPU 没有得到适当的冷却。被动散热 GPU 需要外部风扇或空调来冷却 GPU,并且气流必须通过 GPU 才能有效冷却。常见的冷却问题包括在并非为 GPU 设计的服务器中安装 GPU,或在服务器中安装错误数量的 GPU。在某些情况下,气流绕过 GPU 而不是通过 GPU 流动“容易的路径”(摩擦最小的路径)。解决此问题需要检查服务器中的气流,并在必要时安装气流导向装置。
请注意,较高的 GPU 温度也会导致电路中更多的泄漏电流,从而增加 GPU 在特定时钟频率下的功耗。因此,对于更可能发生功率节流的 GPU(如 NVIDIA T4),即使 GPU 时钟尚未被热节流,散热不良也可能导致较低的稳定时钟频率(由于功率节流),从而导致更差的性能。
另一方面,只要 GPU 得到适当的冷却,环境温度(服务器周围环境的温度)通常不会影响 GPU 性能,功率限制较低的 GPU 的性能可能会略微受到影响。
H2D/D2H 数据传输和 PCIe 带宽#
在独立 GPU 系统上,输入数据通常必须在推理开始之前从主机内存复制到设备内存 (H2D),并且输出数据必须在推理之后从设备内存复制回主机内存 (D2H)。这些 H2D/D2H 数据传输通过 PCIe 总线进行,它们有时会影响推理性能,甚至成为性能瓶颈。H2D/D2H 复制也可以在 Nsight Systems 配置文件中看到,显示为 cudaMemcpy() 或 cudaMemcpyAsync() CUDA API 调用。
为了实现最大吞吐量,H2D/D2H 数据传输应与其他推理的 GPU 执行并行运行,以便在发生 H2D/D2H 复制时 GPU 不会空闲。这可以通过在并行流中运行多个推理,或在与用于 GPU 执行的流不同的流中启动 H2D/D2H 复制,并使用 CUDA 事件在流之间同步来完成。trtexec 工具显示了后一种实现的示例。
当 H2D/D2H 复制与 GPU 执行并行运行时,它们可能会干扰 GPU 执行,尤其是在主机内存是可分页的情况下(这是默认情况)。因此,建议您使用 cudaHostAlloc() 或 cudaMallocHost() CUDA API 为输入和输出数据分配锁页主机内存。
要检查 PCIe 带宽是否成为性能瓶颈,您可以检查 Nsight Systems 配置文件,查看推理查询的 H2D 或 D2H 复制的延迟是否比 GPU 执行部分长。如果 PCIe 带宽成为性能瓶颈,以下是一些可能的解决方案。
首先,检查 GPU 的 PCIe 总线配置是否正确,包括使用的代数(例如,Gen3 或 Gen4)和通道数(例如,x8 或 x16)。接下来,减少必须使用 PCIe 总线传输的数据量。例如,假设输入图像具有高分辨率,并且 H2D 复制成为瓶颈。在这种情况下,您可以将 JPEG 压缩图像通过 PCIe 总线传输,并在推理工作流程之前在 GPU 上解码图像,而不是传输原始像素。最后,考虑使用 NVIDIA GPUDirect 技术直接从/向网络或文件系统加载数据,而无需通过主机内存。
此外,如果您的系统具有 AMD x86_64 CPU,请使用 numactl --hardware 命令检查机器的 NUMA(非统一内存访问)配置。位于两个不同 NUMA 节点上的主机内存和设备内存之间的 PCIe 带宽远小于位于同一 NUMA 节点上的主机/设备内存之间的带宽。在数据将被复制到的 GPU 所在的 NUMA 节点上分配主机内存。此外,将触发 H2D/D2H 复制的 CPU 线程绑定到该特定 NUMA 节点。
请注意,在移动平台上,主机和设备共享相同的内存,因此如果主机内存是使用 CUDA API 分配的,并且是锁页内存而不是可分页内存,则不需要 H2D/D2H 数据传输。
默认情况下,trtexec 工具测量 H2D/D2H 数据传输的延迟,这会告诉用户 H2D/D2H 复制是否可能成为 TensorRT 工作负载的瓶颈。但是,H2D/D2H 复制会影响 GPU 计算时间的稳定性。在这种情况下,您可以添加 --noDataTransfers 标志以禁用 H2D/D2H 传输,并仅测量 GPU 执行部分的延迟。
TCC 模式和 WDDM 模式#
在 Windows 机器上,有两种驱动程序模式:您可以将 GPU 配置为 TCC 模式和 WDDM 模式。可以通过调用 sudo nvidia-smi -dm [0|1] 命令来指定模式,但是连接到显示器的 GPU 不应配置为 TCC 模式。有关更多信息,请参阅 TCC 模式文档。
在 TCC 模式下,GPU 配置为专注于计算工作,并且禁用了 OpenGL 或显示器显示等图形支持。对于运行 TensorRT 推理工作负载的 GPU,这是推荐的模式。另一方面,当使用 TensorRT 运行推理工作负载时,WDDM 模式往往会导致 GPU 的性能结果更差且不稳定。
这不适用于基于 Linux 的操作系统。
入队绑定工作负载和 CUDA 图#
IExecutionContext 的 enqueueV3() 函数是异步的。也就是说,它在所有 CUDA 内核启动后立即返回,而无需等待 CUDA 内核执行完成。但是,在某些情况下,enqueueV3() 时间可能比实际 GPU 执行时间长,从而导致 enqueueV3() 调用的延迟成为性能瓶颈。我们说这种类型的工作负载是“入队绑定”的。以下两个原因可能导致工作负载入队绑定。
首先,如果工作负载在计算量方面非常小,例如包含具有小 I/O 大小的卷积、具有小 GEMM 大小的矩阵乘法或整个网络中主要是逐元素操作,则工作负载往往是入队绑定的。这是因为大多数 CUDA 内核平均需要 CPU 和驱动程序大约 5-15 微秒才能启动每个内核,因此如果每个 CUDA 内核执行时间平均只有几微秒长,则内核启动时间将成为主要的性能瓶颈。
为了解决这个问题,请尝试通过增加批处理大小来增加每个 CUDA 内核的计算量。您还可以使用 CUDA 图 将内核启动捕获到图中,并启动该图而不是调用 enqueueV3()。
其次,如果工作负载包含需要设备同步的操作(例如循环或 if-else 条件),则自然会是队列绑定的。增加批处理大小可能有助于提高吞吐量,而不会增加延迟。
在 trtexec 中,如果报告的 Enqueue Time 接近或长于报告的 GPU Compute Time,您可以判断工作负载是入队绑定的。在这种情况下,建议您添加 --useCudaGraph 标志以在 trtexec 中启用 CUDA 图,这将减少 Enqueue Time,只要工作负载不包含任何同步操作。
BlockingSync 和 SpinWait 同步模式#
如果使用 cudaStreamSynchronize() 或 cudaEventSynchronize() 测量性能,同步开销变化可能会导致性能测量变化。本节介绍变化的原因以及如何避免这些变化。
当调用 cudaStreamSynchronize() 时,驱动程序有两种方式等待流完成。如果已使用 cudaSetDeviceFlags() 调用设置了 cudaDeviceScheduleBlockingSync 标志,则 cudaStreamSynchornize() 使用阻塞同步机制。否则,它使用自旋等待机制。
类似的想法适用于 CUDA 事件。如果使用 cudaEventDefault 标志创建 CUDA 事件,则 cudaEventSynchronize() 调用使用自旋等待机制。如果使用 cudaEventBlockingSync 标志创建 CUDA 事件,则 cudaEventSynchronize() 调用将使用阻塞同步机制。
当使用阻塞同步模式时,主机线程会屈服于另一个线程,直到设备工作完成。这允许 CPU 在设备仍在执行时保持空闲状态以节省功耗或供其他 CPU 工作负载使用。但是,阻塞同步模式往往会在某些操作系统中导致流/事件同步中相对不稳定的开销,从而导致延迟测量中的变化。
另一方面,当使用自旋等待模式时,主机线程会不断轮询,直到设备工作完成。由于流/事件同步中的开销更短且更稳定,因此使用自旋等待使延迟测量更加稳定。但是,它会消耗一些 CPU 计算资源并导致 CPU 功耗增加。
因此,如果您想降低 CPU 功耗或不希望流/事件同步消耗 CPU 资源(例如,您正在并行运行其他繁重的 CPU 工作负载),请使用阻塞同步模式。如果您更关心稳定的性能测量,请使用自旋等待模式。
在 trtexec 中,默认同步机制是阻塞同步模式。添加 --useSpinWait 标志以启用使用自旋等待模式的同步,从而以更高的 CPU 利用率和功耗为代价获得更稳定的延迟测量。
优化 TensorRT 性能#
以下各节重点介绍 GPU 上的通用推理流程以及一些提高性能的通用策略。这些想法适用于大多数 CUDA 程序员,但对于来自其他背景的开发人员来说可能不太明显。
批处理#
最重要的优化是使用批处理尽可能并行地计算更多结果。在 TensorRT 中,批次是可以统一处理的输入集合。批次中的每个实例都具有相同的形状,并以类似的方式流经网络。因此,可以轻松地并行计算每个实例。
每个网络层都将有一些开销和同步,以计算前向推理。通过并行计算更多结果,可以更有效地抵消此开销。此外,许多层的性能受限于输入中的最小维度。如果批处理大小为 1 或较小,则此大小通常可能是限制性能的维度。例如,具有 V 个输入和 K 个输出的全连接层可以针对一个批次实例实现为矩阵乘以具有 VxK 权重矩阵的 1xV 矩阵。如果批处理 N 个实例,则变为 NxV 乘以 VxK 矩阵。向量-矩阵乘法器变为矩阵-矩阵乘法器,效率更高。
较大的批处理大小在 GPU 上几乎总是更有效。极大的批次(例如 N > 2^16)有时可能需要扩展索引计算,如果可能,应避免使用。但通常,增加批处理大小会提高总吞吐量。此外,当网络包含 MatrixMultiply 层时,对于 FP16 和 INT8 推理,32 倍数的批处理大小往往具有最佳性能,因为利用了 Tensor Core(如果硬件支持它们)。
在 NVIDIA Ada Lovelace 或更高版本的 GPU 上,如果较小的批处理大小有助于 GPU 在 L2 缓存中缓存输入/输出值,则减小批处理大小可能会显着提高吞吐量。因此,应尝试各种批处理大小,以找到提供最佳性能的批处理大小。
有时,由于应用程序的组织方式,批处理推理工作是不可能的。在某些常见的应用程序中,例如每请求进行推理的服务器,可以实现机会性批处理。对于每个传入的请求,等待时间 T。如果有其他请求进来,则将它们批量处理在一起。否则,继续进行单实例推理。此策略会为每个请求增加固定的延迟,但可以大大提高系统的最大吞吐量。
NVIDIA Triton 推理服务器 提供了一种使用 TensorRT 引擎启用动态批处理的简单方法。
使用批处理
批处理维度是张量维度的一部分,您可以通过添加优化配置文件来指定批处理大小的范围和要优化的批处理大小。有关更多信息,请参阅 使用动态形状 部分。
推理内多流#
一般来说,CUDA 编程流是组织异步工作的一种方式。放入流中的异步命令保证按顺序运行,但可能相对于其他流无序执行。特别是,可以调度两个流中的异步命令并发运行(受硬件限制)。
在 TensorRT 和推理的上下文中,优化后的最终网络的每一层都需要在 GPU 上进行运算。然而,并非所有层都能充分利用硬件的计算能力。在单独的流中调度请求允许工作在硬件可用时立即被调度,而无需不必要的同步。即使只有部分层可以重叠,整体性能也会得到提升。
使用 IBuilderConfig::setMaxAuxStreams() API 来设置 TensorRT 可以用来并行运行多个层的最大辅助流数量。辅助流与 enqueueV3() 调用中提供的 “主流 (mainstream)” 形成对比。如果启用,TensorRT 将在辅助流上并行运行一些层,与在主流上运行的层并行。
例如,要在最多八个流(即七个辅助流和一个主流)上运行推理,
1config->setMaxAuxStreams(7)
1config.max_aux_streams = 7
请注意,这仅设置了辅助流的最大数量。但是,如果 TensorRT 确定使用更多流没有帮助,它可能会使用少于此数量的辅助流。
要获取 TensorRT 为引擎使用的实际辅助流数量,请运行以下命令
1int32_t nbAuxStreams = engine->getNbAuxStreams()
1num_aux_streams = engine.num_aux_streams
当从引擎创建执行上下文时,TensorRT 会自动创建运行推理所需的辅助流。但是,您也可以指定您希望 TensorRT 使用的辅助流
1int32_t nbAuxStreams = engine->getNbAuxStreams();
2std::vector<cudaStream_t> streams(nbAuxStreams);
3for (int32_t i = 0; i < nbAuxStreams; ++i)
4{
5 cudaStreamCreate(&streams[i]);
6}
7context->setAuxStreams(streams.data(), nbAuxStreams);
1from cuda import cudart
2num_aux_streams = engine.num_aux_streams
3streams = []
4for i in range(num_aux_streams):
5 err, stream = cudart.cudaStreamCreate()
6 streams.append(stream)
7context.set_aux_streams(streams)
TensorRT 始终会在使用 enqueueV3() 调用提供的主流和辅助流之间插入事件同步。
在
enqueueV3()调用的开始,TensorRT 将确保所有辅助流等待主流上的活动。在
enqueueV3()调用的结束,TensorRT 将确保主流等待所有辅助流上的活动。
启用辅助流可能会增加内存消耗,因为某些激活缓冲区可能无法再被重用。
跨推理多流#
除了推理内部流式处理之外,您还可以启用多个执行上下文之间的流式处理。例如,您可以构建一个具有多个优化配置文件的引擎,并为每个配置文件创建一个执行上下文。然后,在不同的流上调用执行上下文的 enqueueV3() 函数,以允许它们并行运行。
运行多个并发流通常会导致多个流同时共享计算资源。这意味着在推理期间,网络可用的计算资源可能比 TensorRT 引擎优化时更少。资源可用性的这种差异可能导致 TensorRT 为实际运行时条件选择次优内核。为了减轻这种影响,您可以在引擎创建期间限制可用计算资源的数量,使其更接近实际运行时条件。这种方法通常以牺牲延迟为代价来提高吞吐量。有关更多信息,请参阅 限制计算资源 部分。
也可以将多个主机线程与流一起使用。一种常见的模式是将传入的请求分派到等待工作的worker线程池。在这种情况下,worker线程池中的每个线程都将拥有一个执行上下文和一个 CUDA 流。每个线程将在其流中请求工作,一旦工作可用。每个线程将与其流同步以等待结果,而不会阻塞其他 worker 线程。
CUDA 图#
CUDA 图 以一种允许 CUDA 优化其调度的方式表示内核序列(或更一般地,图)。当您的应用程序性能对内核排队的 CPU 时间敏感时,这可能特别有用。
将 CUDA 图与 TensorRT 执行上下文一起使用#
TensorRT 的 enqueueV3() 方法支持 CUDA 图捕获,用于不需要管道中间 CPU 交互的模型。例如
1// Call enqueueV3() once after an input shape change to update internal state.
2context->enqueueV3(stream);
3
4// Capture a CUDA graph instance
5cudaGraph_t graph;
6cudaGraphExec_t instance;
7cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
8context->enqueueV3(stream);
9cudaStreamEndCapture(stream, &graph);
10cudaGraphInstantiate(&instance, graph, 0);
11
12// To run inferences, launch the graph instead of calling enqueueV3().
13for (int i = 0; i < iterations; ++i) {
14 cudaGraphLaunch(instance, stream);
15 cudaStreamSynchronize(stream);
16}
1from cuda import cudart
2err, stream = cudart.cudaStreamCreate()
3
4# Call execute_async_v3() once after an input shape change to update internal state.
5context.execute_async_v3(stream);
6
7# Capture a CUDA graph instance
8cudaStreamBeginCapture(stream, cudart.cudaStreamCaptureModeGlobal)
9context.execute_async_v3(stream)
10err, graph = cudart.cudaStreamEndCapture(stream)
11err, instance = cudart.cudaGraphInstantiate(graph, 0)
12
13# To run inferences, launch the graph instead of calling execute_async_v3().
14for i in range(iterations):
15 cudart.cudaGraphLaunch(instance, stream)
16 cudart.cudaStreamSynchronize(stream)
CUDA 图的局限性#
CUDA 图无法处理某些操作,因此如果执行上下文包含此类操作,则图捕获可能会失败。CUDA 图不支持的典型深度学习算子包括循环、条件语句以及需要数据相关形状的层。在这些情况下,cudaStreamEndCapture() 将返回 cudaErrorStreamCapture* 错误,表明图捕获已失败,但上下文可以继续用于没有 CUDA 图的正常推理。有关 CUDA 图的局限性的更多信息,请参阅 CUDA 编程指南。
此外,在捕获图时,重要的是要考虑在存在动态形状时使用的两阶段执行策略。
更新模型的内部状态以考虑输入大小的任何更改。
将工作流式传输到 GPU。
对于在构建时输入大小固定的模型,第一阶段不需要每次调用都进行工作。否则,如果自上次调用以来输入大小已更改,则可能需要一些工作来更新派生属性。
第一阶段的工作不是为了被捕获而设计的,即使捕获成功,也可能会增加模型执行时间。因此,在更改输入形状或形状张量的值后,在捕获图之前,先调用一次 enqueueV3() 以刷新延迟更新。
使用 TensorRT 捕获的图特定于输入大小和执行上下文的状态。修改从中捕获图的上下文将在执行图时导致未定义的行为——特别是,如果应用程序正在使用 createExecutionContextWithoutDeviceMemory() 为激活提供其内存,则内存地址也会作为图的一部分被捕获。输入和输出缓冲区的位置也被捕获为图的一部分。
因此,最佳实践是每个捕获的图使用一个执行上下文,并使用 createExecutionContextWithoutDeviceMemory() 在上下文之间共享内存。
trtexec 允许您检查您构建的 TensorRT 引擎是否与 CUDA 图捕获兼容。有关更多信息,请参阅 trtexec 部分。
使用 CUDA 图捕获的并发 CUDA 活动#
在捕获 CUDA 图时,在 CUDA 传统默认流上启动 CUDA 内核或调用同步 CUDA API(如 cudaMemcpy())会失败,因为这些 CUDA 活动隐式地同步了 TensorRT 执行上下文使用的 CUDA 流。
为了避免破坏 CUDA 图捕获,请确保其他 CUDA 内核在非默认 CUDA 流上启动,并使用 CUDA API 的异步版本,如 cudaMemcpyAsync()。
或者,可以使用 cudaStreamNonBlocking 标志创建一个 CUDA 流,以捕获执行上下文的 CUDA 图。如果执行上下文使用辅助流,请确保您也使用使用 cudaStreamNonBlocking 标志创建的流调用 setAuxStreams() API。有关如何在 TensorRT 执行上下文中设置辅助流的信息,请参阅 推理内部多流式处理 部分。
启用融合#
层融合#
TensorRT 尝试在构建阶段对网络执行许多不同类型的优化。在第一阶段,尽可能融合层。融合将网络转换为更简单的形式,但保留相同的整体行为。在内部,许多层实现都有额外的参数和选项,这些参数和选项在创建网络时无法直接访问。相反,融合优化步骤检测受支持的操作模式,并将多个层融合为一个具有内部选项集的层。
考虑卷积后跟 ReLU 激活的常见情况。使用这些操作创建网络涉及使用 addConvolutionNd 添加一个 Convolution 层,然后使用 addActivation 添加一个 Activation 层,并将 ActivationType 设置为 kRELU。未优化的图将包含用于卷积和激活的单独层。卷积的内部实现支持直接从卷积核一步计算输出上的 ReLU 函数,而无需第二次内核调用。融合优化步骤将检测到卷积后跟 ReLU。验证实现是否支持这些操作,然后将它们融合到一个层中。
要调查发生了哪些融合,构建器会将其操作记录到构建期间提供的 logger 对象。优化步骤位于 kINFO 日志级别。要查看这些消息,请确保在 ILogger 回调中记录它们。
融合通常通过创建一个新层来处理,该层的名称包含被融合的两个层的名称。例如,一个名为 ip1 的 MatrixMultiply 层 (InnerProduct) 与一个名为 relu1 的 ReLU Activation 层融合,以创建一个名为 ip1 + relu1 的新层。
融合类型#
以下列表描述了支持的融合类型。
支持的层融合
ReLU 激活:单个激活层将替换执行 ReLU 的 Activation 层,后跟执行 ReLU 的激活。
卷积和 ReLU 激活:Convolution 层可以是任何类型,值不受限制。Activation 层必须是 ReLU 类型。
卷积和 GELU 激活:输入和输出精度应相同,均为 FP16 或 INT8。Activation 层必须是 GELU 类型。TensorRT 应在 NVIDIA Turing 或更高版本上运行,CUDA 版本为 10.0。
卷积和 Clip 激活:Convolution 层可以是任何类型,值不受限制。Activation 层必须是 Clip 类型。
Scale 和 Activation:Scale 层后跟一个 Activation 层,可以融合到一个 Activation 层中。
卷积和 ElementWise 操作:Convolution 层后跟 ElementWise 层中的简单
sum、min或max可以融合到 Convolution 层中。除非广播跨批次大小,否则 sum 不能使用广播。Padding 和卷积/反卷积:如果所有填充大小均为非负数,则 padding 后跟 Convolution 或 Deconvolution 可以融合到一个 Convolution/Deconvolution 层中。
Shuffle 和 Reduce:没有重塑的 Shuffle 层,后跟一个 Reduce 层,可以融合到一个 Reduce 层中。Shuffle 层可以执行置换,但不能执行任何重塑操作。Reduce 层必须具有一组
keepDimensions维度设置。Shuffle 和 Shuffle:每个 Shuffle 层都由一个转置、一个重塑和第二个转置组成。一个 Shuffle 层后跟另一个 Shuffle 层可以被替换为单个 Shuffle 层(或什么都不做)。如果两个 Shuffle 层都执行重塑操作,则只有当第一个 shuffle 的第二个转置是第二个 shuffle 的第一个转置的逆转置时,才允许此融合。
Scale:添加
0、乘以1或计算1次幂的 Scale 层可以被删除。卷积和 Scale:调整卷积权重可以将卷积层后跟一个
kUNIFORM或kCHANNEL的 Scale 层融合为单个卷积。如果 scale 具有非常量 power 参数,则禁用此融合。卷积和通用激活:此融合发生在下面提到的 pointwise 融合之后。具有一个输入和一个输出的 pointwise 可以称为通用激活层。卷积层后跟一个通用激活层可以融合到一个卷积层中。
Reduce:它执行平均池化,Pooling 层将替换它。Reduce 层必须具有
keepDimensions设置,并且在使用kAVG操作进行批处理之前,从 CHW 输入格式跨H和W维度进行缩减。卷积和池化:Convolution 层和 Pooling 层必须具有相同的精度。Convolution 层可能已经具有来自先前融合的融合激活操作。
深度可分离卷积:具有激活的深度卷积,后跟具有激活的卷积,有时可以融合为单个优化的
DepSepConvolution层。两个卷积的精度都必须为 INT8,并且设备的计算能力必须为 7.2 或更高版本。Softmax 和 Log:如果尚未与先前的 log 操作融合,则可以融合到单个 Softmax 层中。
Softmax 和 TopK:它可以融合到单个层中。Softmax 可能包含也可能不包含 Log 操作。
支持的缩减操作融合
GELU:表示以下方程的一组 Unary 和 ElementWise 层可以融合为单个
GELU缩减操作。\(0.5x\times \left( 1+\tanh\left( \frac{2}{π}\left( x+0.044715x^{3} \right) \right) \right)\)
或替代表示形式
\(0.5x \times \left( 1+erf\left( \frac{x}{\sqrt{2}} \right) \right)\)
L1Norm:Unary 层
kABS操作,后跟 Reduce 层kSUM操作,可以融合为单个L1Norm缩减操作。平方和:具有相同输入(平方运算)的 product ElementWise 层,后跟
kSUM缩减,可以融合为单个平方sum缩减操作。L2Norm:平方和运算,后跟
kSQRTUnaryOperation,可以融合为单个L2Norm缩减操作。LogSum:Reduce 层
kSUM,后跟kLOGUnaryOperation,可以融合为单个LogSum缩减操作。LogSumExp:Unary
kEXPElementWise 操作,后跟LogSum融合,可以融合为单个LogSumExp缩减操作。
Pointwise 融合#
多个相邻的 Pointwise 层可以融合为单个 Pointwise 层以提高性能。
支持以下类型的 Pointwise 层,但有一些限制
Activation: 支持每种ActivationType。Constant: 仅限具有单个值的常量 (size == 1)。ElementWise: 支持每种ElementWiseOperation。Pointwise:Pointwise本身也是一个 Pointwise 层。Scale: 仅支持ScaleMode::kUNIFORM。Unary: 支持每种UnaryOperation。
融合的 Pointwise 层的大小不是无限的,因此某些层可能不会被融合。
融合创建一个新层,其名称由两个融合层组成。例如,一个名为 add1 的 ElementWise 层与一个名为 relu1 的 ReLU Activation 层融合,创建一个名为 fusedPointwiseNode(add1, relu1) 的新层。
Q/DQ 融合#
有关优化包含 QuantizeLinear 和 DequantizeLinear 层的 INT8 和 FP8 网络的建议,请参阅 显式量化 部分。
多头注意力融合#
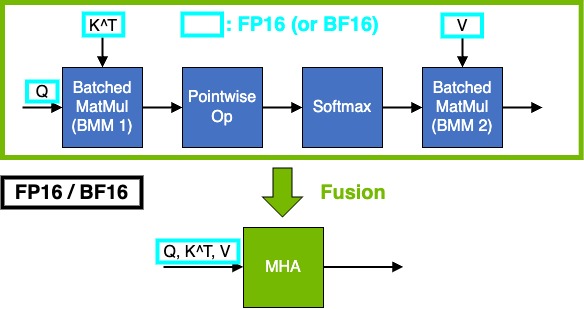
我们强烈建议您根据上述限制调整您的模型,以便发生多头注意力 (MHA) 融合。这很重要,因为它通过将内存占用从 O(S^2) 显着减少到 O(S) 来支持大序列长度,其中 S 是序列长度。最重要的是,它还共享算子融合的常见性能优势,即减少内存流量、更好地利用硬件、减少内核启动和同步开销。
多头注意力 (MHA) 计算 softmax(Q * K^T / scale + mask) * V,其中
Q是查询嵌入K是键嵌入V是值嵌入
Q 的形状是 [B, N, S_q, H],K 和 V 的形状是 [B, N, S_kv, H],其中
B是批次大小N是注意力头的数量H是头/隐藏大小S_q和S_kv分别是查询和键/值的序列长度。
TensorRT 默认根据输入类型和性能考虑因素选择累积精度。但是,您也可以控制累积精度(请参阅 控制计算精度)。
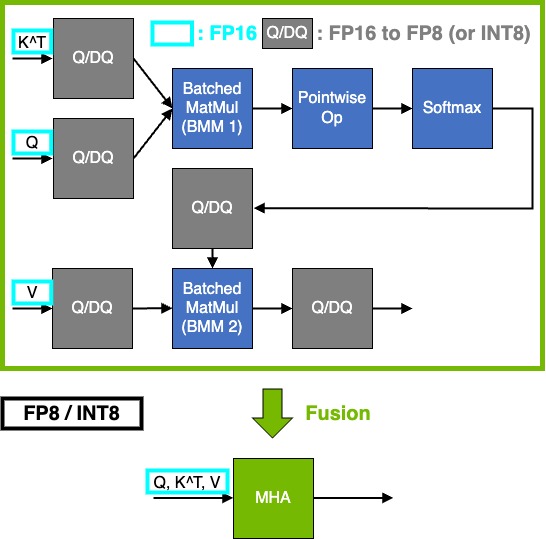
MHA 融合捕获 MHA 中串联的常见 pointwise 运算符。这些包括 pointwise 运算列表 中的缩放(pointwise 乘法)和掩码运算符(pointwise 加法和选择)。它还涵盖了 MHA 之后的 Q/DQ 融合,用于某些量化和架构(Ampere 上的 FP16/BF16 到 FP8/INT8)。
特性 |
FP16 |
BF16 |
INT8 |
FP8 |
|---|---|---|---|---|
SM 版本 ( |
|
|
|
|
头大小 ( |
|
|
|
|
序列长度 ( |
无限制 |
无限制 |
|
|
量化 |
非必需 |
非必需 |
在 MHA 模式中为 FP8 和 INT8 指定 Q/DQ 层。 |
在 MHA 模式中为 FP8 和 INT8 指定 Q/DQ 层。 |
累积精度 ( |
|
FP32 |
INT32 |
FP32 |
累积精度 ( |
|
FP32 |
INT32 |
FP32 |
支持的掩码类型 |
任何掩码 |
任何掩码 |
任何掩码 |
任何掩码 |
任何掩码 意味着掩码可以使用 TensorRT 中的 Select 运算符。TensorRT 可能会根据性能评估或其他约束条件决定不将 MHA 图融合到单个内核中。
特性 |
FP16 |
BF16 |
FP8 |
|---|---|---|---|
SM 版本 ( |
SM100 |
SM100 |
SM100 |
头大小 ( |
|
|
|
序列长度 ( |
无限制 |
无限制 |
无限制 |
量化 |
非必需 |
非必需 |
在 MHA 模式中为 FP8 和 INT8 指定 Q/DQ 层。 |
累积精度 ( |
FP32 |
FP32 |
FP32 |
累积精度 ( |
FP32 |
FP32 |
FP32 |
示例工作流程:FP8 MHA 融合#
假设您的本地计算机上有一个 ONNX 模型 vit_base_patch8_224_Opset17.onnx 和校准数据 calib.npy。
安装 TensorRT 模型优化器。
pip3 install --no-cache-dir --extra-index-url https://pypi.nvidia.com nvidia-modelop
使用 TensorRT 模型优化器量化模型。有关更多信息,请参阅这些 详细说明。
python3 -m modelopt.onnx.quantization \ --onnx_path=vit_base_patch8_224_Opset17.onnx \ --quantize_mode=<fp8|int8> \ --calibration_data=calib.npy \ --calibration_method=<max|entropy> \ --output_path=vit_base_patch8_224_Opset17.quant.onnx
使用 TensorRT 编译量化模型。
trtexec --onnx=vit_base_patch8_224_Opset17.quant.onnx \ --saveEngine=vit_base_patch8_224_Opset17.engine \ --stronglyTyped --skipInference --profilingVerbosity=detailed
使用 TensorRT 运行量化模型。
trtexec --loadEngine=vit_base_patch8_224_Opset17.engine \ --useCudaGraph --noDataTransfers --useSpinWait
如果您想检查 MHA 是否已融合,请添加以下选项。如果您在
output.log文件中找到mhaop,则 MHA 应该已融合。trtexec --loadEngine=vit_base_patch8_224_Opset17.engine \ --profilingVerbosity=detailed --dumpLayerInfo --skipInference &> output.log
提示
有两种方法可以将累积数据类型设置为 FP32
手动设置计算精度。有关更多信息,请参阅这些 详细说明。
使用 TensorRT 模型优化器 转换您的 ONNX 模型,它会自动添加 Cast ops。
如果 MHA 的头大小 (
H) 不是 16 的倍数,请不要在 MHA 中添加 Q/DQ ops 以回退到 FP16 MHA,从而获得更好的性能。考虑到这些限制,请比较 INT8 和 FP8 的 MHA 融合。
限制计算资源#
当减少的计算资源量更好地代表运行时期间的预期条件时,限制引擎创建期间 TensorRT 可用的计算资源数量是有益的。例如,当 GPU 预计将与 TensorRT 引擎并行执行额外工作,或者当引擎预计将在资源较少的不同 GPU 上运行时(请注意,推荐的方法是在将用于推理的 GPU 上构建引擎,但这可能并不总是可行的)。
您可以通过以下步骤限制可用计算资源的数量
启动 CUDA MPS 控制守护程序。
nvidia-cuda-mps-control -d
使用
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE环境变量设置要使用的计算资源数量。例如,export CUDA_MPS_ACTIVE_THREAD_PERCENTAGE=50。构建网络引擎。
停止 CUDA MPS 控制守护程序。
echo quit | nvidia-cuda-mps-control
生成的引擎针对减少的计算核心数量(在本例中为 50%)进行了优化,并且在推理期间使用类似条件时可提供更好的吞吐量。建议您尝试不同数量的流和不同的 MPS 值,以确定网络的最佳性能。
有关 nvidia-cuda-mps-control 的更多详细信息,请参阅 nvidia-cuda-mps-control 文档 和相关的 GPU 要求 此处。
确定性策略选择#
TensorRT 在引擎构建阶段遍历所有可能的策略,并选择最快的策略。由于选择是基于策略的延迟测量,因此如果某些策略具有相似的延迟,TensorRT 可能会在不同的运行中选择不同的策略。因此,从相同的 INetworkDefinition 构建的不同引擎在输出值和性能方面可能会略有不同。您可以使用 引擎检查器 API 或在构建引擎时启用详细日志记录来检查引擎的选定策略。
如果需要确定性策略选择,以下列出了一些可能有助于提高策略选择确定性的建议。
锁定 GPU 时钟频率
默认情况下,GPU 的时钟频率未锁定,这意味着 GPU 通常处于空闲时钟频率,并且仅在存在活动的 GPU 工作负载时才提升到最大时钟频率。但是,时钟从空闲频率提升到最大频率存在延迟,这可能会在 TensorRT 遍历策略并选择最佳策略时导致性能变化,从而导致非确定性策略选择。
因此,在构建 TensorRT 引擎之前锁定 GPU 时钟频率可能会提高策略选择的确定性。有关如何锁定和监视 GPU 时钟以及可能影响 GPU 时钟频率的因素的更多信息,请参阅 性能测量的硬件/软件环境 部分。
增加平均计时迭代次数
默认情况下,TensorRT 会为每个 tactic 运行至少四次迭代并取平均延迟。您可以通过调用 setAvgTimingIterations() API 来增加迭代次数
1builderConfig->setAvgTimingIterations(8);
1Builder_config.avg_timing_iterations = 8
增加平均计时迭代次数可能会提高 tactic 选择的确定性,但所需的引擎构建时间会变得更长。
使用 Timing Cache
Timing Cache 记录特定层配置的每个 tactic 的延迟。如果 TensorRT 遇到另一个具有相同配置的层,则会重用 tactic 延迟。因此,通过在具有相同 INetworkDefinition 和构建器配置的多个引擎构建运行中重用相同的 timing cache,您可以使 TensorRT 在生成的引擎中选择相同的 tactic 集。
形状更改和优化配置文件切换的开销#
在 IExecutionContext 切换到新的优化配置文件或输入绑定的形状更改后,TensorRT 必须重新计算整个网络中的张量形状,并为新形状重新计算某些 tactic 所需的资源,然后才能开始下一次推理。这意味着在形状/配置文件更改后的第一次 enqueueV3() 调用可能比后续的 enqueueV3() 调用更长。
优化形状/配置文件切换的成本是一个活跃的开发领域。但是,在某些情况下,这种开销仍然会影响推理应用程序的性能。例如,NVIDIA Volta GPU 或更旧 GPU 的一些卷积 tactic 具有更长的形状/配置文件切换开销,即使它们的推理性能在所有可用 tactic 中是最好的。在这种情况下,从构建引擎时的 tactic 源禁用 kEDGE_MASK_CONVOLUTIONS tactic 可能会减少形状/配置文件切换的开销。
优化层性能#
以下描述详细说明了如何优化列出的层。
Gather:使用轴 0 以最大化 Gather 层的性能。Gather 层没有可用的融合。
Reduce:为了最大限度地发挥 Reduce 层的性能,请跨最后一个维度(尾部 reduce)执行 reduce 操作。这允许通过顺序内存位置实现最佳的内存读/写模式。如果执行常见的 reduce 操作,请以一种方式表达 reduce,使其融合为单个操作。
RNN:基于循环的 API 为在循环中使用通用层提供了更灵活的机制。
ILoopLayer循环支持丰富的自动循环优化集,包括循环融合、展开和循环不变代码移动等等。例如,当正确组合同一 MatrixMultiply 层的多个实例以在沿序列维度展开循环后最大化机器利用率时,通常可以获得显着的性能提升。如果您可以避免具有沿序列维度的循环数据依赖的 MatrixMultiply 层,则效果最佳。Shuffle:如果输入张量仅在 shuffle 层中使用,并且该层的输入和输出张量不是网络的输入和输出张量,则会省略等效于底层数据的恒等操作的 Shuffle 操作。TensorRT 不会为此类操作执行额外的内核或内存复制。
TopK:为了最大限度地发挥 TopK 层的性能,请使用较小的
K值,减少数据的最后一个维度,以允许最佳的顺序内存访问。可以使用 Shuffle 层来重塑数据,然后适当地重新解释索引值,从而模拟一次沿多个维度的 reduce 操作。
有关层的更多信息,请参阅 TensorRT 算子文档。
优化 Tensor Core#
Tensor Core 是在 NVIDIA GPU 上实现高性能推理的关键技术。在 TensorRT 中,所有计算密集型层都支持 Tensor Core 操作:MatrixMultiply、Convolution 和 Deconvolution。
如果 I/O 张量维度与某个最小粒度对齐,则 Tensor Core 层往往会获得更好的性能
对齐要求适用于 Convolution 和 Deconvolution 层中的 I/O 通道维度。
在 MatrixMultiply 层中,对齐要求适用于
M x K乘以K x N的 MatrixMultiply 中的矩阵维度K和N。
下表捕获了建议的张量维度对齐,以获得更好的 Tensor Core 性能。
Tensor Core 操作类型 |
建议的张量维度对齐(以元素为单位) |
|---|---|
TF32 |
4 |
FP16 |
密集数学运算为 8,稀疏数学运算为 16 |
INT8 |
32 |
当在不满足这些要求的情况下使用 Tensor Core 实现时,TensorRT 会隐式地将张量填充到最接近的对齐倍数,向上舍入模型定义中的维度,以便在模型中留出额外的容量,而不会增加计算或内存流量。
TensorRT 始终为层使用最快的实现,因此,在某些情况下,即使 Tensor Core 实现可用,它也可能不使用它。
要检查层是否使用了 Tensor Core,请在使用 Nsight Systems 分析 TensorRT 应用程序时,使用 --gpu-metrics-device all 标志运行 Nsight Systems。Tensor Core 使用率可以在 Nsight Systems 用户界面中的SM 指令/Tensor 活动行下的分析结果中找到。有关使用 Nsight Systems 分析 TensorRT 应用程序的更多信息,请参阅 CUDA 分析工具。
期望 CUDA 内核达到 100% 的 Tensor Core 使用率是不切实际的,因为还存在其他开销,例如 DRAM 读/写、指令停顿、其他计算单元等。操作的计算密集程度越高,CUDA 内核可以实现的 Tensor Core 使用率就越高。
下图是 Nsight Systems 分析的示例。

优化插件#
TensorRT 提供了一种注册执行层操作的自定义插件的机制。注册插件创建器后,您可以搜索注册表以查找创建器,并在序列化/反序列化期间将相应的插件对象添加到网络。
加载插件库后,所有 TensorRT 插件都会自动注册。有关自定义插件的更多信息,请参阅 使用自定义层扩展 TensorRT。
插件性能取决于执行插件操作的 CUDA 代码。标准的 CUDA 最佳实践 适用。在开发插件时,从执行插件操作并验证正确性的简单独立 CUDA 应用程序开始可能会有所帮助。然后,可以使用性能测量、更多单元测试和备用实现来扩展插件程序。在代码工作并优化后,可以将其作为插件集成到 TensorRT 中。
在插件中支持尽可能多的格式对于获得最佳性能非常重要。这消除了在网络执行期间进行内部重新格式化操作的需要。有关示例,请参阅 使用自定义层扩展 TensorRT 部分。
优化 Python 性能#
使用 Python API 时,大多数相同的性能考虑因素都适用。在构建引擎时,构建器优化阶段通常是性能瓶颈,而不是用于构建网络的 API 调用。Python API 和 C++ API 之间的推理时间应该几乎相同。
在 Python API 中设置输入缓冲区涉及到使用 pycuda 或另一个 CUDA Python 库(如 cupy)将数据从主机传输到设备内存。这如何工作的细节将取决于主机数据来自何处。在内部,pycuda 支持 Python Buffer Protocol,允许高效访问内存区域。这意味着如果输入数据以 numpy 数组或另一种支持 buffer protocol 的类型以合适的格式提供,则可以高效访问并传输到 GPU。为了获得更好的性能,请使用 pycuda 分配一个页锁定缓冲区并写入最终的预处理输入。
有关使用 Python API 的更多信息,请参阅 Python API 文档。
提高模型精度#
根据构建器配置,TensorRT 可以以 FP32、FP16、BF16、FP8 或 INT8 精度执行层。默认情况下,TensorRT 选择以产生最佳性能的精度运行层。有时,这可能会导致精度不佳。通常,运行更高精度的层有助于提高精度,但会带来一些性能损失。
我们可以采取以下几个步骤来提高模型精度
验证层输出
使用 Polygraphy 转储层输出并验证没有 NaN 或 Inf。
--validate选项可以检查 NaN 和 Inf。此外,我们可以将层输出与来自 ONNX 运行时等的黄金值进行比较。对于 FP16 和 BF16,模型可能需要重新训练,以确保中间层输出可以用 FP16/BF16 精度表示,而不会溢出或下溢。
对于 INT8,请考虑使用更具代表性的校准数据集重新校准。如果您的模型来自 PyTorch,我们还提供了 NVIDIA 的 PyTorch 量化工具包,用于框架中的 QAT 以及 TensorRT 中的 PTQ。您可以尝试这两种方法,并选择精度更高的方法。
操作层精度
有时,以某种精度运行层会导致不正确的输出。这可能是由于固有的层约束(例如,LayerNorm 输出不应为 INT8)或模型约束(输出发散,导致精度不佳)。
您可以控制层执行精度和输出精度。
实验性的 debug precision 工具可以帮助自动查找要以高精度运行的层。
使用可编辑 Timing Cache 选择合适的 tactic。
当同一模型的两个构建引擎之间的精度发生变化时,可能是由于为某一层选择了错误的 tactic。
使用可编辑 Timing Cache 转储可用的 tactic。使用合适的 tactic 更新缓存。
运行到运行的精度变化不应改变;一旦为特定的 GPU 构建了引擎,它应该在多次运行中产生位精确的输出。如果不是,请提交 TensorRT 错误报告。
优化构建器性能#
TensorRT 构建器会分析每个层可用的 tactic,以搜索最快的推理引擎计划。如果模型具有许多层或复杂的拓扑结构,则构建器时间可能会很长。以下部分提供了减少构建器时间的选项。
Timing Cache#
TensorRT 创建了一个层计时缓存,以减少构建器时间并保留层分析信息。它包含的信息特定于目标设备、CUDA、TensorRT 版本以及可以更改层实现的 BuilderConfig 参数,例如 BuilderFlag::kTF32 或 BuilderFlag::kREFIT。
如果其他层具有相同的 IO 张量配置和层参数,则 TensorRT 构建器会跳过分析并重用缓存的结果。如果计时查询在缓存中未命中,则构建器会对层进行计时并更新缓存。
计时缓存可以序列化和反序列化。您可以使用 IBuilderConfig::createTimingCache 从缓冲区加载序列化的缓存
ITimingCache* cache = config->createTimingCache(cacheFile.data(), cacheFile.size());
将缓冲区大小设置为 0 会创建一个新的空计时缓存。
然后在构建之前将缓存附加到构建器配置。
config->setTimingCache(*cache, false);
由于缓存未命中,计时缓存可以在构建期间使用更多信息进行扩充。构建完成后,可以将其序列化以供另一个构建器使用。
IHostMemory* serializedCache = cache->serialize();
如果构建器没有附加计时缓存,它会创建其临时本地缓存并在完成后销毁它。
编译缓存是计时缓存的一部分,它缓存 JIT 编译的代码,默认情况下将作为计时缓存的一部分进行序列化。可以通过设置 BuildFlag 来禁用它。
config->setFlag(BuilderFlag::kDISABLE_COMPILATION_CACHE);
注意
计时缓存支持最常用的层类型:Convolution、Deconvolution、Pooling、SoftMax、MatrixMultiply、ElementWise、Shuffle 和张量内存布局转换。未来版本将添加更多层类型。
构建器优化级别#
在构建器配置中设置优化级别,以调整 TensorRT 应花费多长时间搜索可能具有更好性能的 tactic。默认情况下,优化级别为 3。将其设置为较小的值会导致引擎构建时间大大缩短,但引擎的性能可能会更差。另一方面,将其设置为较大的值会增加引擎构建时间,但如果 TensorRT 可以找到更好的 tactic,则生成的引擎可能会表现更好。
例如,要将优化级别设置为 0(最快)
1config->setOptimizationLevel(0);
1config.optimization_level = 0