高级主题#
版本兼容性#
默认情况下,TensorRT 引擎仅与构建它们所用的 TensorRT 版本兼容。通过适当的构建时配置,可以构建与更高版本的 TensorRT 兼容的引擎。使用 TensorRT 8 构建的 TensorRT 引擎也与 TensorRT 9 和 TensorRT 10 运行时兼容,但反之则不然。但是,版本兼容引擎可能比为默认运行时构建的引擎慢。
版本兼容性从 8.6 版本开始支持;计划必须使用至少 8.6 或更高版本构建,并且运行时必须为 8.6 或更高版本。
当使用版本兼容性时,引擎在运行时支持的 API 是构建版本中支持的 API 与用于运行它的版本 API 的交集。TensorRT 仅在主要版本边界上删除 API,因此这在主要版本内不是问题。但是,希望将 TensorRT 8 或 TensorRT 9 引擎与 TensorRT 10 一起使用的用户必须迁移到已删除的 API 之外,并建议避免使用已弃用的 API。
创建版本兼容引擎的推荐方法是按如下方式构建
1builderConfig.setFlag(BuilderFlag::kVERSION_COMPATIBLE);
2IHostMemory* plan = builder->buildSerializedNetwork(network, config);
1builder_config.set_flag(tensorrt.BuilderFlag.VERSION_COMPATIBLE)
2plan = builder.build_serialized_network(network, config)
对版本兼容引擎的请求会导致精简运行时的副本添加到计划中。当您反序列化计划时,TensorRT 将识别出它包含运行时副本。它加载运行时以反序列化并执行计划的其余部分。由于这会导致代码在拥有进程的上下文中从计划中加载和运行,因此您应该仅以这种方式反序列化受信任的计划。要向 TensorRT 指示您信任该计划,请调用
1runtime->setEngineHostCodeAllowed(true);
1runtime.engine_host_code_allowed = True
如果您在计划中打包插件,则还需要受信任计划的标志。有关更多信息,请参阅 插件共享库 部分。
手动加载运行时#
以前的方法(版本兼容性)将运行时的副本与每个计划一起打包,如果您的应用程序使用许多模型,这可能会受到限制。另一种方法是自己管理运行时加载。对于这种方法,请按照上一节中的说明构建版本兼容计划,但也要设置一个额外的标志以排除精简运行时。
1builderConfig.setFlag(BuilderFlag::kVERSION_COMPATIBLE);
2builderConfig.setFlag(BuilderFlag::kEXCLUDE_LEAN_RUNTIME);
3IHostMemory* plan = builder->buildSerializedNetwork(network, config);
1builder_config.set_flag(tensorrt.BuilderFlag.VERSION_COMPATIBLE)
2builder_config.set_flag(tensorrt.BuilderFlag.EXCLUDE_LEAN_RUNTIME)
3plan = builder.build_serialized_network(network, config)
要运行此计划,您必须有权访问构建它所用的版本的精简运行时。假设您已使用 TensorRT 8.6 构建了计划,并且您的应用程序链接到 TensorRT 10。您可以按如下方式加载计划。
1IRuntime* v10Runtime = createInferRuntime(logger);
2IRuntime* v8ShimRuntime = v10Runtime->loadRuntime(v8RuntimePath);
3engine = v8ShimRuntime->deserializeCudaEngine(v8plan);
1v10_runtime = tensorrt.Runtime(logger)
2v8_shim_runtime = v10_runtime.load_runtime(v8_runtime_path)
3engine = v8_shim_runtime.deserialize_cuda_engine(v8_plan)
运行时将为 TensorRT 8.6 运行时转换 TensorRT 10 API 调用,检查以确保支持该调用并执行任何必要的参数重映射。
从存储加载#
在大多数操作系统上,TensorRT 可以直接从内存中加载共享运行时库。但是,在 3.17 之前的 Linux 内核上,需要一个临时目录。使用 IRuntime::setTempfileControlFlags 和 IRuntime::setTemporaryDirectory API 来控制 TensorRT 对这些机制的使用。
将版本兼容性与 ONNX 解析器结合使用#
当从使用 TensorRT 的 ONNX 解析器生成的 TensorRT 网络定义构建版本兼容引擎时,您必须指定解析器必须使用本机 InstanceNormalization 实现而不是插件实现。
为此,请使用 IParser::setFlag() API。
1auto *parser = nvonnxparser::createParser(network, logger);
2parser->setFlag(nvonnxparser::OnnxParserFlag::kNATIVE_INSTANCENORM);
1parser = trt.OnnxParser(network, logger)
2parser.set_flag(trt.OnnxParserFlag.NATIVE_INSTANCENORM)
此外,解析器可能需要插件来完全实现网络中使用的所有 ONNX 算子。特别是,如果网络用于构建版本兼容引擎,则可能需要包含某些插件(与引擎序列化或在外部提供并显式加载)。
要查询实现特定解析网络所需的插件库列表,请使用 IParser::getUsedVCPluginLibraries API
1auto *parser = nvonnxparser::createParser(network, logger);
2parser->setFlag(nvonnxparser::OnnxParserFlag::kNATIVE_INSTANCENORM);
3parser->parseFromFile(filename, static_cast<int>(ILogger::Severity::kINFO));
4int64_t nbPluginLibs;
5char const* const* pluginLibs = parser->getUsedVCPluginLibraries(nbPluginLibs);
1parser = trt.OnnxParser(network, logger)
2parser.set_flag(trt.OnnxParserFlag.NATIVE_INSTANCENORM)
3
4status = parser.parse_from_file(filename)
5plugin_libs = parser.get_used_vc_plugin_libraries()
有关使用生成的库列表来序列化插件或在外部打包插件的说明,请参阅 插件共享库 部分。
硬件兼容性#
默认情况下,TensorRT 引擎仅与构建它们的设备类型兼容。通过构建时配置,可以构建与其他类型设备兼容的引擎。目前,硬件兼容性仅支持 Ampere 及更高版本的设备架构,并且在 NVIDIA DRIVE OS 或 JetPack 上不受支持。
例如,要构建与所有 Ampere 及更新架构兼容的引擎,请按如下方式配置 IBuilderConfig
config->setHardwareCompatibilityLevel(nvinfer1::HardwareCompatibilityLevel::kAMPERE_PLUS);
在硬件兼容性模式下构建时,TensorRT 会排除不兼容硬件的策略,例如使用特定于架构的指令或需要比某些设备上可用的共享内存更多的策略。因此,硬件兼容引擎可能比其非硬件兼容的同类引擎具有更低的吞吐量和/或更高的延迟。这种性能影响的程度取决于网络架构和输入大小。
兼容性检查#
TensorRT 将用于创建计划的库的主要版本、次要版本、补丁版本和构建版本记录在计划中。如果这些版本与用于反序列化计划的运行时版本不匹配,则反序列化将失败。当使用版本兼容性时,检查将由反序列化计划数据的精简运行时执行。默认情况下,该精简运行时包含在计划中,并且保证匹配成功。
TensorRT 还在计划中记录计算能力(主要版本和次要版本),并针对计划加载到的 GPU 检查它。如果它们不匹配,计划将无法反序列化。这确保了在构建阶段选择的内核存在并且可以运行。当使用硬件兼容性时,检查会放宽;使用 HardwareCompatibilityLevel::kAMPERE_PLUS,检查将确保计算能力大于或等于 8.0,而不是检查精确匹配。
TensorRT 还会检查以下属性,如果它们不匹配,则会发出警告,除非使用硬件兼容性
全局内存总线宽度
L2 缓存大小
每个块和多处理器最大共享内存
纹理对齐要求
多处理器数量
GPU 设备是集成的还是离散的
如果 GPU 时钟速度在引擎序列化和运行时系统之间有所不同,则序列化系统选择的策略可能不是运行时系统的最佳策略,并且可能会导致一些性能下降。
如果无法为每种类型的 GPU 构建 TensorRT 引擎,您可以选择多个 GPU 来构建引擎,并在具有相同架构的不同 GPU 上运行引擎。例如,在 NVIDIA RTX 40xx GPU 中,您可以使用 RTX 4080 构建引擎,并使用 RTX 4060 构建引擎。在运行时,您可以在 RTX 4090 GPU 上使用 RTX 4080 引擎,并在 RTX 4070 GPU 上使用 4060 引擎。在大多数情况下,与运行使用相同 GPU 构建的引擎相比,引擎将运行而不会出现功能问题,并且性能下降很小。
但是,仅当引擎需要大量设备内存且可用内存小于构建引擎时,反序列化才可能成功。在这种情况下,建议在较小的 GPU 或计算资源有限的较大设备上构建引擎。
在某些情况下,安全运行时可以反序列化在 TensorRT 的主要版本、次要版本、补丁版本和构建版本不完全匹配的环境中生成的引擎。有关更多信息,请参阅 NVIDIA DRIVE OS 6.5 开发者指南。
重新拟合引擎#
TensorRT 可以使用新权重重新拟合引擎,而无需重建它。但是,必须在构建时指定执行此操作的选项
... config->setFlag(BuilderFlag::kREFIT) builder->buildSerializedNetwork(network, config);
稍后,您可以创建一个 Refitter 对象
ICudaEngine* engine = ...; IRefitter* refitter = createInferRefitter(*engine,gLogger)
然后,更新权重。例如,要更新一组名为 Conv Layer Kernel Weights 的权重
Weights newWeights = ...; refitter->setNamedWeights("Conv Layer Kernel Weight", newWeights);
新权重的计数应与用于构建引擎的原始权重相同。如果出现问题,例如权重名称错误或权重计数发生更改,setNamedWeights 将返回 false。
您可以使用 INetworkDefinition::setWeightsName() 在构建时命名权重 - ONNX 解析器使用此 API 将权重与 ONNX 模型中使用的名称关联起来。否则,TensorRT 将根据相关的层名称和权重角色在内部命名权重。
您还可以通过以下方式将 GPU 权重传递给 refitter
Weights newBiasWeights = ...; refitter->setNamedWeights("Conv Layer Bias Weight", newBiasWeights, TensorLocation::kDEVICE);
由于引擎的优化方式,如果您更改了一些权重,您可能还必须提供其他一些权重。该接口可以告诉您必须提供哪些额外的权重。
这通常需要两次调用 IRefitter::getMissingWeights,第一次是获取必须提供的权重对象数量,第二次是获取它们的层和角色。
int32_t const n = refitter->getMissingWeights(0, nullptr); std::vector<const char*> weightsNames(n); refitter->getMissingWeights(n, weightslayerNames.data());
您可以按任何顺序提供缺失的权重
for (int32_t i = 0; i < n; ++i) refitter->setNamedWeights(weightsNames[i], Weights{...});
返回的缺失权重集是完整的,因为仅提供缺失的权重不需要更多。
提供所有权重后,您可以更新引擎
bool success = refitter->refitCudaEngine(); assert(success);
如果重新拟合返回 false,请检查日志以获取诊断信息;也许问题是关于仍然缺失的权重。还有一个异步版本 refitCudaEngineAsync,它可以接受流参数。
您可以直接更新权重内存,然后在另一次迭代中调用 refitCudaEngine/ refitCudaEngineAsync。如果需要更改权重指针,请调用 setNamedWeights 以覆盖之前的设置。调用 unsetNamedWeights 以取消设置先前设置的权重,以便它们不会在以后的重新拟合中使用,并且可以安全地释放这些权重。
完成重新拟合后,您可以删除 refitter
delete refitter;
引擎的行为就像它是从使用新权重更新的网络构建的一样。重新拟合引擎后,先前创建的执行上下文可以继续使用。
要查看引擎中的所有可重新拟合的权重,请使用 refitter->getAllWeights(...),这类似于上面使用 getMissingWeights 的方式。
权重剥离#
启用重新拟合后,可以在构建引擎后更新网络中的所有常量权重。但是,使用新权重重新拟合引擎会带来成本和潜在的运行时影响。无法常量折叠权重可能会阻止构建器执行某些优化。
当构建时未知将用于重新拟合引擎的权重时,此成本是不可避免的。但是,在某些情况下,权重是已知的。例如,您可以将 TensorRT 用作多个后端之一来执行 ONNX 模型,并希望避免在 TensorRT 计划中额外复制权重。
权重剥离构建配置启用了这种情况;启用后,TensorRT 仅对不影响构建器优化能力并生成与不可拟合引擎具有相同运行时性能的引擎的常量权重启用重新拟合。然后,这些权重将从序列化引擎中省略,从而生成一个小的计划文件,可以在运行时使用 ONNX 模型中的权重重新拟合该文件。
trtexec 工具提供了用于构建权重剥离引擎的 -stripWeights 标志。有关更多信息,请参阅 trtexec 部分。
以下步骤说明如何重新拟合权重剥离引擎的权重。当使用 ONNX 模型时,ONNX 解析器库可以自动执行重新拟合。有关更多信息,请参阅 直接从 ONNX 重新拟合权重剥离引擎 部分。
设置相应的构建器标志以启用权重剥离构建。在此,
kSTRIP_PLAN标志与kREFIT或kREFIT_IDENTICAL配合使用。它默认为后者。REFIT_IDENTICAL标志指示 TensorRT 构建器在引擎将使用与构建时提供的权重相同的权重重新拟合的假设下进行优化。kSTRIP_PLAN标志通过剥离可重新拟合的权重来最大限度地减小计划大小。
1...
2config->setFlag(BuilderFlag::kSTRIP_PLAN);
3config->setFlag(BuilderFlag::kREFIT_IDENTICAL);
4builder->buildSerializedNetwork(network, config);
1config.flags |= 1 << int(trt.BuilderFlag.STRIP_PLAN)
2config.flags |= 1 << int(trt.BuilderFlag.REFIT_IDENTICAL)
3builder.build_serialized_network(network, config)
构建引擎后,保存计划文件并将其分发给安装程序。
在客户端,当您首次启动网络时,更新引擎中的所有权重。由于引擎计划中的所有权重都已删除,请使用
getAllWeightsAPI。
1int32_t const n = refitter->getAllWeights(0, nullptr);
1all_weights = refitter.get_all()
逐个更新权重。
1for (int32_t i = 0; i < n; ++i)
2 refitter->setNamedWeights(weightsNames[i], Weights{...});
1for name in wts_list:
2 refitter.set_named_weights(name, weights[name])
保存完整的引擎计划文件。
1auto serializationConfig = SampleUniquePtr<nvinfer1::ISerializationConfig>(cudaEngine->createSerializationConfig());
2auto serializationFlag = serializationConfig->getFlags()
3serializationFlag &= ~(1<< static_cast<uint32_t>(nvinfer1::SerializationFlag::kEXCLUDE_WEIGHTS));
4serializationConfig->setFlags(serializationFlag)
5auto hostMemory = SampleUniquePtr<nvinfer1::IHostMemory>(cudaEngine->serializeWithConfig(*serializationConfig));
1serialization_config = engine.create_serialization_config()
2serialization_config.flags &= ~(1 << int(trt.SerializationFlag.EXCLUDE_WEIGHTS))
3binary = engine.serialize_with_config(serialization_config)
应用程序现在可以使用新的完整引擎计划文件进行未来的推理。
直接从 ONNX 重新拟合权重剥离引擎#
当使用从 ONNX 模型创建的权重剥离引擎时,可以使用 ONNX 解析器库中的 IParserRefitter 类自动完成重新拟合过程。以下步骤说明如何创建类并运行重新拟合过程。
按照 权重剥离 中的描述创建您的引擎,并创建一个
IRefitter对象。
1IRefitter* refitter = createInferRefitter(*engine, gLogger);
1refitter = trt.Refitter(engine, TRT_LOGGER)
创建一个
IParserRefitter对象。
1IParserRefitter* parserRefitter = createParserRefitter(*refitter, gLogger);
1parser_refitter = trt.OnnxParserRefitter(refitter, TRT_LOGGER)
调用
IParserRefitter的refitFromFile()函数。确保 ONNX 模型与用于创建权重剥离引擎的模型相同。如果在 ONNX 模型中找到所有剥离的权重,此函数将返回true;否则,它将返回false。
1bool result = parserRefitter->refitFromFile(“path_to_onnx_model”);
1result = parser_refitter.refit_from_file(“path_to_onnx_model”)
调用 IRefitter 的
refit函数以完成重新拟合过程。
1refitSuccess = refitter->refitCudaEngine();
1refit_success = refitter.refit_cuda_engine()
权重剥离与精简运行时配合使用#
此外,我们可以进一步利用精简运行时来减小权重剥离引擎的包大小。精简运行时是版本兼容引擎中使用的同一运行时。最初的目的是允许您生成版本 X 的 TensorRT 引擎,并使用版本 Y 构建的应用程序加载它。精简运行时库相对较小,约为 40 MiB。因此,当目标客户机器上已提供权重时,TensorRT 之上的软件分发商只需要运送无权重引擎以及 40 MiB 精简运行时。
构建引擎的推荐方法如下
1builderConfig.setFlag(BuilderFlag::kVERSION_COMPATIBLE);
2builderConfig.setFlag(BuilderFlag::kEXCLUDE_LEAN_RUNTIME);
3builderConfig.setFlag(BuilderFlag::kSTRIP_PLAN);
4IHostMemory* plan = builder->buildSerializedNetwork(network, config);
1builder_config.set_flag(tensorrt.BuilderFlag.VERSION_COMPATIBLE)
2builder_config.set_flag(tensorrt.BuilderFlag.EXCLUDE_LEAN_RUNTIME)
3builder_config.set_flag(tensorrt.BuilderFlag.STRIP_PLAN)
4
5plan = builder.build_serialized_network(network, config)
使用共享精简运行时库路径加载引擎
1runtime->loadRuntime("your_lean_runtime_full_path")
1runtime.load_runtime("your_lean_runtime_full_path")
有关精简运行时的更多信息,请参阅 版本兼容性 部分。
细粒度重新拟合构建#
当使用 kREFIT 构建器配置时,所有权重都标记为可重新拟合。当难以区分可训练权重和不可训练权重时,这很有用。但是,将所有权重标记为可重新拟合可能会导致性能权衡。这是因为当权重标记为可重新拟合时,某些优化会被破坏。例如,在 GELU 表达式的情况下,TensorRT 可以将所有 GELU 系数编码到单个 CUDA 内核中。但是,如果所有系数都标记为可重新拟合,则 TensorRT 可能无法再将 Conv-GELU 操作融合到单个内核中。为了解决这个问题,我们引入了细粒度重新拟合 API。此 API 提供了对哪些权重标记为可重新拟合的精确控制,从而可以实现更有效的优化。
这是一个在 INetworkDefinition 中将权重标记为可重新拟合的示例
1...
2network->setWeightsName(Weights(weights), "conv1_filter"));
3network->markWeightsRefittable("conv1_filter");
4assert(network->areWeightsMarkedRefittable("conv1_filter"));
1...
2network.set_weights_name(conv_filter, "conv1_filter")
3network.mark_weights_refittable("conv1_filter")
4assert network.are_weights_marked_refittable("conv1_filter")
稍后,我们需要像这样更新构建器配置
1...
2config->setFlag(BuilderFlag::kREFIT_INDIVIDUAL)
3builder->buildSerializedNetwork(network, config);
1...
2config.set_flag(trt.BuilderFlag.REFIT_INDIVIDUAL)
3builder.build_serialized_network(network, config)
其余的重新拟合代码遵循与重新拟合所有权重工作流程相同的步骤。
使用细粒度重新拟合构建剥离权重#
细粒度重新拟合构建也适用于权重剥离标志。要运行此操作,我们必须在代码中启用两个构建器标志,并在将必要的权重标记为可重新拟合后启用。
这是一个示例
1...
2config->setFlag(BuilderFlag::kSTRIP_PLAN);
3config->setFlag(BuilderFlag::kREFIT_INDIVIDUAL);
4builder->buildSerializedNetwork(network, config);
1config.flags |= 1 << int(trt.BuilderFlag.STRIP_PLAN)
2config.flags |= 1 << int(trt.BuilderFlag.REFIT_INDIVIDUAL)
3builder.build_serialized_network(network, config)
其余的重新拟合和推理代码与 权重剥离 部分相同。
算法选择和可重现的构建#
TensorRT 优化器的默认行为是选择全局最小化引擎执行时间的算法。它通过对每个实现进行计时来实现这一点,有时,当实现具有相似的计时时,系统噪声可能会决定在构建器的任何特定运行中将选择哪个实现。不同的实现通常会使用不同的浮点值累积顺序,并且两个实现可能会使用不同的算法甚至以不同的精度运行。因此,构建器的不同调用通常不会导致返回位相同结果的引擎。
有时,拥有确定性构建或重新创建早期构建的算法选择非常重要。在 TensorRT 的先前版本中,通过实现 IAlgorithmSelector 来满足上述要求。在新版本中,使用了可编辑的计时缓存。
首次构建引擎时,您将 BuilderFlag::kEDITABLE_TIMING_CACHE 标志提供给 TensorRT 以启用可编辑缓存。同时,您启用并保留日志和缓存文件。日志将提供每个模型层的名称、键、可用策略和选定策略。缓存文件将记录 TensorRT 所做的决策。
下次构建同一引擎时,您将相同的标志提供给 TensorRT,并使用接口 ITimingCache::update 来更新缓存。具体来说,为某些层选择策略。然后,将缓存传递给 TensorRT。在构建过程中,TensorRT 将使用新分配的策略。与以前不同,在新版本中,每个层只能分配一个策略。
强类型网络#
默认情况下,TensorRT 自动调整张量类型以生成最快的引擎。当模型精度要求层以高于 TensorRT 选择的精度运行时,这可能会导致精度损失。一种方法是使用 ILayer::setPrecision 和 ILayer::setOutputType API 来控制层的 I/O 类型,从而控制其执行精度。这种方法有效,但弄清楚哪些层必须以高精度运行才能获得最佳精度可能具有挑战性。
另一种方法是在模型中指定低精度使用,例如 自动混合精度训练 或 量化感知训练,并让 TensorRT 遵循精度规范。TensorRT 仍将自动调整不同的数据布局,以找到网络的最佳内核集。
当您向 TensorRT 指定网络是强类型时,它会使用 算子类型规范 中的规则为每个中间和输出张量推断类型。在构建引擎时,会遵守推断的类型。由于类型未自动调整,因此从强类型网络构建的引擎可能比 TensorRT 选择张量类型的引擎慢。另一方面,由于评估的内核替代方案更少,因此构建时间可能会缩短。
DLA 不支持强类型网络。
您可以按如下方式创建强类型网络
1IBuilder* builder = ...;
2INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kSTRONGLY_TYPED)))
1builder = trt.Builder(...)
2builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.STRONGLY_TYPED))
对于强类型网络,不允许使用层 API setPrecision 和 setOutputType,也不允许使用构建器精度标志 kFP16、kBF16、kFP8、kINT8、kINT4 和 kFP4。kTF32 构建器标志是允许的,因为它控制 FP32 类型的 TF32 Tensor Core 使用,而不是控制 TF32 数据类型的使用。
弱类型网络中的降低精度#
网络级精度控制#
默认情况下,TensorRT 以 32 位精度工作,但也可以使用 16 位和 8 位量化浮点数执行操作。使用较低的精度需要更少的内存并能够实现更快的计算。
降低的精度支持取决于您的硬件(请参阅 硬件和精度)。您可以查询构建器以检查平台上支持的精度支持
1if (builder->platformHasFastFp16()) { … };
1if builder.platform_has_fp16:
在构建器配置中设置标志会通知 TensorRT 它可能会选择较低精度的实现
1config->setFlag(BuilderFlag::kFP16);
1config.set_flag(trt.BuilderFlag.FP16)
有三个精度标志:FP16、INT8 和 TF32,它们可以独立启用。如果较低的精度内核可以带来更短的运行时,或者如果不存在低精度实现,TensorRT 仍将选择更高精度的内核。
当 TensorRT 为层选择精度时,它会自动转换权重,以便层可以运行。
虽然使用 FP16 和 TF32 精度相对简单,但使用 INT8 会增加额外的复杂性。有关更多信息,请参阅 使用量化类型 部分。
请注意,即使启用了精度标志,引擎的输入/输出绑定也默认为 FP32。有关如何设置输入/输出绑定的数据类型和格式的信息,请参阅 I/O 格式 部分。
层级精度控制#
构建器标志提供宽松的、粗粒度的控制。但是,有时,网络的一部分需要更高的动态范围或对数值精度敏感。您可以按层约束输入和输出类型
1layer->setPrecision(DataType::kFP16)
1layer.precision = trt.fp16
这为输入和输出提供了一个首选类型(此处为 DataType::kFP16)。
您可以进一步为层的输出设置首选类型
1layer->setOutputType(out_tensor_index, DataType::kFLOAT)
1layer.set_output_type(out_tensor_index, trt.fp32)
计算将使用与输入相同的浮点类型。大多数 TensorRT 实现的输入和输出都具有相同的浮点类型;但是,Convolution、Deconvolution 和 FullyConnected 可以支持量化的 INT8 输入和非量化的 FP16 或 FP32 输出,因为有时使用来自量化输入的更高精度输出对于保持精度是必要的。
设置精度约束会向 TensorRT 提示它应选择层实现,该层实现的输入和输出与首选类型匹配,如果上一层的输出和下一层的输入与请求的类型不匹配,则插入重新格式化操作。请注意,TensorRT 只有在也使用构建器配置中的标志启用这些类型的情况下,才能选择具有这些类型的实现。
默认情况下,TensorRT 仅当这种实现可以带来更高性能的网络时才会选择它。如果另一种实现速度更快,TensorRT 将使用它并发出警告。您可以通过在构建器配置中首选类型约束来覆盖此行为。
1config->setFlag(BuilderFlag::kPREFER_PRECISION_CONSTRAINTS)
1config.set_flag(trt.BuilderFlag.PREFER_PRECISION_CONSTRAINTS)
如果首选约束,则 TensorRT 会遵守这些约束,除非没有具有首选精度约束的实现,在这种情况下,它会发出警告并使用最快的可用实现。
要将警告更改为错误,请使用 OBEY 而不是 PREFER
1config->setFlag(BuilderFlag::kOBEY_PRECISION_CONSTRAINTS);
1config.set_flag(trt.BuilderFlag.OBEY_PRECISION_CONSTRAINTS);
sampleINT8API 说明了如何使用这些 API 来降低精度。
精度约束是可选的 - 您可以使用 C++ 中的 layer->precisionIsSet() 或 Python 中的 layer.precision_is_set 查询是否已设置约束。如果未设置精度约束,则从 C++ 中的 layer->getPrecision() 返回的结果或读取 Python 中的 precision 属性是没有意义的。输出类型约束同样是可选的。
如果未使用 ILayer::setPrecision 或 ILayer::setOutputType API 设置任何约束,则会忽略 BuilderFlag::kPREFER_PRECISION_CONSTRAINTS 或 BuilderFlag::kOBEY_PRECISION_CONSTRAINTS。层可以根据允许的构建器精度从精度或输出类型中进行选择。
请注意,除非张量是网络的输入/输出张量之一,否则 ITensor::setType() API 不会设置张量的精度约束。此外,layer->setOutputType() 和 layer->getOutput(i)->setType() 之间存在区别。前者是约束 TensorRT 将为层选择的实现的可选类型。后者指定网络输入/输出的类型,如果张量不是网络输入/输出,则忽略后者。如果它们不同,TensorRT 将插入强制转换以确保遵守两个规范。因此,如果您为生成网络输出的层调用 setOutputType(),则通常应将相应的网络输出配置为具有相同的类型。
TF32#
默认情况下,TensorRT 允许使用 TF32 Tensor Core。当计算内积时,例如在卷积或矩阵乘法期间,TF32 执行执行以下操作
将 FP32 被乘数四舍五入为 FP16 精度,但保留 FP32 动态范围。
计算舍入被乘数的精确乘积。
将乘积累积在 FP32 总和中。
TF32 Tensor Core 可以加速使用 FP32 的网络,通常不会损失精度。对于需要 HDR(高动态范围)用于权重或激活的模型,它比 FP16 更强大。
不能保证使用 TF32 Tensor Core,也没有办法强制实现使用它们 - TensorRT 可以随时回退到 FP32,并且如果平台不支持 TF32,则始终回退。但是,您可以通过清除 TF32 构建器标志来禁用它们的使用。
1config->clearFlag(BuilderFlag::kTF32);
1config.clear_flag(trt.BuilderFlag.TF32)
在构建引擎时,设置环境变量 NVIDIA_TF32_OVERRIDE=0 会禁用 TF32 的使用,即使设置了 BuilderFlag::kTF32。当设置为 0 时,此环境变量会覆盖 NVIDIA 库的任何默认设置或程序化配置,因此它们永远不会使用 TF32 Tensor Core 加速 FP32 计算。这仅用作调试工具,NVIDIA 库之外的任何代码都不应根据此环境变量更改行为。除 0 之外的任何其他设置都为将来使用而保留。
警告
在运行引擎时,将环境变量 NVIDIA_TF32_OVERRIDE 设置为不同的值可能会导致不可预测的精度/性能影响。在运行引擎时,最好保持未设置状态。
注意
除非您的应用程序需要 TF32 提供的更高动态范围,否则 FP16 将是更好的解决方案,因为它几乎总是能产生更快的性能。
BF16#
TensorRT 在 NVIDIA Ampere 及更高架构上支持 bfloat16 (brain float) 浮点格式。与其他精度一样,可以使用相应的构建器标志启用它
1config->setFlag(BuilderFlag::kBF16);
1config.set_flag(trt.BuilderFlag.BF16)
请注意,并非所有层都支持 bfloat16。有关更多信息,请参阅TensorRT 算子文档。
计算精度的控制#
有时,除了设置算子的输入和输出精度外,还希望控制计算的内部精度。TensorRT 默认根据层输入类型和全局性能考虑因素选择计算精度。
TensorRT 提供了两个额外的功能层来控制计算精度
INormalizationLayer 提供了一个 setPrecision 方法来控制累积的精度。默认情况下,为了避免溢出错误,即使在混合精度模式下,TensorRT 也会使用 FP32 进行累积,而与构建器标志无关。您可以使用此方法指定使用 FP16 累积。
对于 IMatrixMultiplyLayer,TensorRT 默认根据输入类型和性能考虑因素选择累积精度。但是,累积类型的范围保证至少与输入类型一样大。当使用强类型模式时,您可以通过将输入转换为 FP32 来强制 FP16 GEMM 使用 FP32 精度。TensorRT 识别此模式并将类型转换与 GEMM 融合,从而产生具有 FP16 输入和 FP32 累积的单个内核。

I/O 格式#
TensorRT 使用许多不同的数据格式优化网络。为了允许在 TensorRT 和客户端应用程序之间高效地传递数据,这些底层数据格式在网络 I/O 边界处公开,用于标记为网络输入或输出的张量,以及在插件之间传递数据时。对于其他张量,TensorRT 选择能够实现最快整体执行速度的格式,并且可能会插入重新格式化以提高性能。
您可以通过分析可用的 I/O 格式以及对于 TensorRT 之前和之后的运算最有效的格式,来组装最佳数据管道。
要指定 I/O 格式,您可以将一个或多个格式指定为位掩码。
以下示例将输入张量格式设置为 TensorFormat::kHWC8。请注意,此格式仅适用于 DataType::kHALF,因此必须相应地设置数据类型。
1auto formats = 1U << TensorFormat::kHWC8;
2network->getInput(0)->setAllowedFormats(formats);
3network->getInput(0)->setType(DataType::kHALF);
1formats = 1 << int(tensorrt.TensorFormat.HWC8)
2network.get_input(0).allowed_formats = formats
3network.get_input(0).dtype = tensorrt.DataType.HALF
请注意,在非网络输入/输出的张量上调用 setAllowedFormats() 或 setType() 没有效果,并且会被 TensorRT 忽略。
sampleIOFormats 演示了如何使用 C++ 指定 I/O 格式。
下表显示了支持的格式。
格式 |
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|
|
仅适用于 GPU |
是 |
是 |
是 |
是 |
是 |
是 |
是 |
是 |
是 |
|
否 |
否 |
仅适用于 GPU |
否 |
否 |
否 |
否 |
是 |
否 |
否 |
|
否 |
否 |
是 |
是 |
否 |
否 |
否 |
是 |
否 |
否 |
|
否 |
否 |
仅适用于 GPU |
否 |
否 |
否 |
否 |
仅适用于 GPU |
否 |
否 |
|
否 |
否 |
是 |
否 |
否 |
否 |
否 |
否 |
否 |
否 |
|
否 |
仅适用于 GPU |
仅适用于 GPU |
是 |
否 |
否 |
否 |
否 |
否 |
否 |
|
否 |
否 |
仅适用于 GPU |
否 |
否 |
否 |
否 |
仅适用于 GPU |
否 |
否 |
|
否 |
否 |
仅适用于 GPU |
仅适用于 GPU |
否 |
否 |
否 |
否 |
否 |
否 |
|
否 |
仅适用于 GPU |
否 |
否 |
否 |
是 |
否 |
否 |
否 |
否 |
|
否 |
否 |
仅适用于 DLA |
仅适用于 DLA |
否 |
否 |
否 |
否 |
否 |
否 |
|
否 |
否 |
仅适用于 DLA |
仅适用于 DLA |
否 |
否 |
否 |
否 |
否 |
否 |
|
否 |
否 |
仅适用于 NVIDIA Ampere GPU 及更高版本 |
仅适用于 GPU |
否 |
否 |
否 |
否 |
仅适用于 GPU |
否 |
|
否 |
仅适用于 GPU |
否 |
否 |
否 |
否 |
否 |
否 |
否 |
否 |
请注意,对于向量化格式,通道维度必须零填充到向量大小的倍数。例如,如果输入绑定具有维度 [16,3,224,224]、kHALF 数据类型和 kHWC8 格式,则绑定缓冲区的实际所需大小将为 16**224*224*sizeof(half) 字节,即使 engine->getBindingDimension() API 将张量维度返回为 [16,3,224,224]。填充部分中的值(即本示例中 C=3,4,…,7 的位置)必须填充为零。
有关这些格式的数据在内存中如何布局的信息,请参阅数据格式描述部分。
稀疏性#
NVIDIA Ampere 架构 GPU 支持结构化稀疏性。权重在每四个条目的向量中必须至少有两个零,才能使用此功能来获得更高的推理性能。对于 TensorRT,要求如下
对于卷积,对于每个输出通道和内核权重中的每个空间像素,每四个输入通道必须至少有两个零。换句话说,假设内核权重的形状为
[K, C, R, S]并且C % 4 == 0,则使用以下算法验证要求hasSparseWeights = True for k in range(0, K): for r in range(0, R): for s in range(0, S): for c_packed in range(0, C // 4): if numpy.count_nonzero(weights[k, c_packed*4:(c_packed+1)*4, r, s]) > 2 : hasSparseWeights = False
对于矩阵乘法,其中常量产生输入,缩减轴 (
K) 的每四个元素必须至少有两个零。
Polygraphy (polygraphy inspect sparsity) 可以检测 ONNX 模型中的运算权重是否遵循 2:4 结构化稀疏模式。
要启用稀疏性功能,请在构建器配置中设置 kSPARSE_WEIGHTS 标志,并确保启用 kFP16 或 kINT8 模式。例如
1config->setFlag(BuilderFlag::kSPARSE_WEIGHTS);
2config->setFlag(BuilderFlag::kFP16);
3config->setFlag(BuilderFlag::kINT8);
1config.set_flag(trt.BuilderFlag.SPARSE_WEIGHTS)
2config.set_flag(trt.BuilderFlag.FP16)
3config.set_flag(trt.BuilderFlag.INT8)
在 TensorRT 日志的末尾,当 TensorRT 引擎构建完成时,TensorRT 会报告哪些层包含满足结构化稀疏性要求的权重,以及 TensorRT 选择哪些策略来使用结构化稀疏性。有时,具有结构化稀疏性的策略可能比正常策略慢,TensorRT 将选择正常策略。以下输出显示了 TensorRT 日志的示例,其中显示了有关稀疏性的信息
[03/23/2021-00:14:05] [I] [TRT] (Sparsity) Found 3 layer(s) eligible to use sparse tactics: conv1, conv2, conv3 [03/23/2021-00:14:05] [I] [TRT] (Sparsity) Chose 2 layer(s) using sparse tactics: conv2, conv3
强制内核权重具有结构化稀疏模式可能会导致精度损失。请参阅 PyTorch 中的自动稀疏性工具 部分,以通过进一步的微调来恢复丢失的精度。
要使用 trtexec 测量具有结构化稀疏性的推理性能,请参阅trtexec 部分。
空张量#
TensorRT 支持空张量。如果张量的一个或多个维度的长度为零,则该张量为空张量。零长度维度通常不会得到特殊处理。如果规则适用于长度为 L 的维度(对于 L 的任意正值),则通常也适用于 L=0。
例如,当沿最后一个轴连接维度为 [x,y,z] 和 [x,y,w] 的两个张量时,结果的维度为 [x,y,z+w],而与 x、y、z 或 w 是否为零无关。
隐式广播规则保持不变,因为只有单位长度维度对于广播是特殊的。例如,给定两个维度为 [1,y,z] 和 [x,1,z] 的张量,它们通过 IElementWiseLayer 计算的和的维度为 [x,y,z],而与 x、y 或 z 是否为零无关。
如果引擎绑定是空张量,它仍然需要一个非空内存地址,并且不同的张量应该具有不同的地址。这与 C++ 规则一致,即每个对象都有唯一的地址。例如,new float[0] 返回一个非空指针。如果使用可能为零字节返回空指针的内存分配器,请改为请求至少一个字节。
有关每个层对空张量的任何特殊处理,请参阅TensorRT 算子文档。
重用输入缓冲区#
TensorRT 允许指定 CUDA 事件,以便在输入缓冲区可以重用时发出信号。这允许应用程序在完成当前推理的同时立即重新填充输入缓冲区区域以进行下一次推理。例如
1context->setInputConsumedEvent(&inputReady);
1context.set_input_consumed_event(inputReady)
引擎检查器#
TensorRT 提供了 IEngineInspector API 来检查 TensorRT 引擎内部的信息。从反序列化的引擎调用 createEngineInspector() 以创建引擎检查器,然后调用 getLayerInformation() 或 getEngineInformation() 检查器 API 以分别获取引擎中特定层或整个引擎的信息。您可以打印给定引擎的第一层的信息以及引擎的整体信息,如下所示
1auto inspector = std::unique_ptr<IEngineInspector>(engine->createEngineInspector());
2inspector->setExecutionContext(context); // OPTIONAL
3std::cout << inspector->getLayerInformation(0, LayerInformationFormat::kJSON); // Print the information of the first layer in the engine.
4std::cout << inspector->getEngineInformation(LayerInformationFormat::kJSON); // Print the information of the entire engine.
1inspector = engine.create_engine_inspector()
2inspector.execution_context = context # OPTIONAL
3print(inspector.get_layer_information(0, LayerInformationFormat.JSON)) # Print the information of the first layer in the engine.
4print(inspector.get_engine_information(LayerInformationFormat.JSON)) # Print the information of the entire engine.
请注意,引擎/层信息中的详细程度取决于构建引擎时 ProfilingVerbosity 构建器配置设置。默认情况下,ProfilingVerbosity 设置为 kLAYER_NAMES_ONLY,因此只会打印层名称。如果 ProfilingVerbosity 设置为 kNONE,则不会打印任何信息;如果设置为 kDETAILED,则会打印详细信息。
以下是一些由 getLayerInformation() API 打印的层信息示例,具体取决于 ProfilingVerbosity 设置
1"node_of_gpu_0/res4_0_branch2a_1 + node_of_gpu_0/res4_0_branch2a_bn_1 + node_of_gpu_0/res4_0_branch2a_bn_2"
1{
2 "Name": "node_of_gpu_0/res4_0_branch2a_1 + node_of_gpu_0/res4_0_branch2a_bn_1 + node_of_gpu_0/res4_0_branch2a_bn_2",
3 "LayerType": "CaskConvolution",
4 "Inputs": [
5 {
6 "Name": "gpu_0/res3_3_branch2c_bn_3",
7 "Dimensions": [16,512,28,28],
8 "Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format."
9 }],
10 "Outputs": [
11 {
12 "Name": "gpu_0/res4_0_branch2a_bn_2",
13 "Dimensions": [16,256,28,28],
14 "Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format."
15 }],
16 "ParameterType": "Convolution",
17 "Kernel": [1,1],
18 "PaddingMode": "kEXPLICIT_ROUND_DOWN",
19 "PrePadding": [0,0],
20 "PostPadding": [0,0],
21 "Stride": [1,1],
22 "Dilation": [1,1],
23 "OutMaps": 256,
24 "Groups": 1,
25 "Weights": {"Type": "Int8", "Count": 131072},
26 "Bias": {"Type": "Float", "Count": 256},
27 "AllowSparse": 0,
28 "Activation": "RELU",
29 "HasBias": 1,
30 "HasReLU": 1,
31 "TacticName": "sm80_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x128x64_stage4_warpsize4x2x1_g1_tensor16x8x32_simple_t1r1s1_epifadd",
32 "TacticValue": "0x11bde0e1d9f2f35d"
33 }
此外,当引擎使用动态形状构建时,引擎信息中的动态维度将显示为 -1,并且不会显示张量格式信息,因为这些字段取决于推理阶段的实际形状。要获取特定推理形状的引擎信息,请创建 IExecutionContext,将所有输入维度设置为所需的形状,然后调用 inspector->setExecutionContext(context)。设置上下文后,检查器将打印上下文中设置的特定形状的引擎信息。
trtexec 工具提供了 --profilingVerbosity、--dumpLayerInfo 和 --exportLayerInfo 标志,用于获取给定引擎的引擎信息。有关更多详细信息,请参阅trtexec 部分。
目前,引擎信息中仅包含绑定信息和层信息,包括中间张量的维度、精度、格式、策略索引、层类型和层参数。在未来的 TensorRT 版本中,可能会在引擎检查器输出中添加更多信息,作为输出 JSON 对象中的新键。还将提供有关检查器输出中键和字段的更多规范。
此外,某些子图由下一代图形优化器处理,该优化器仍需要与引擎检查器集成。因此,这些层中的层信息尚未显示。这将在 TensorRT 的未来版本中得到改进。
使用 Nsight Deep Learning Designer 进行引擎图形可视化
当使用 --exportLayerInfo 选项将详细的 TensorRT 引擎层信息导出到 JSON 文件时,可以使用 Nsight Deep Learning Designer 可视化引擎的计算图。打开应用程序,然后从文件菜单中,选择打开文件,然后选择包含导出的元数据的 .trt.json 文件。
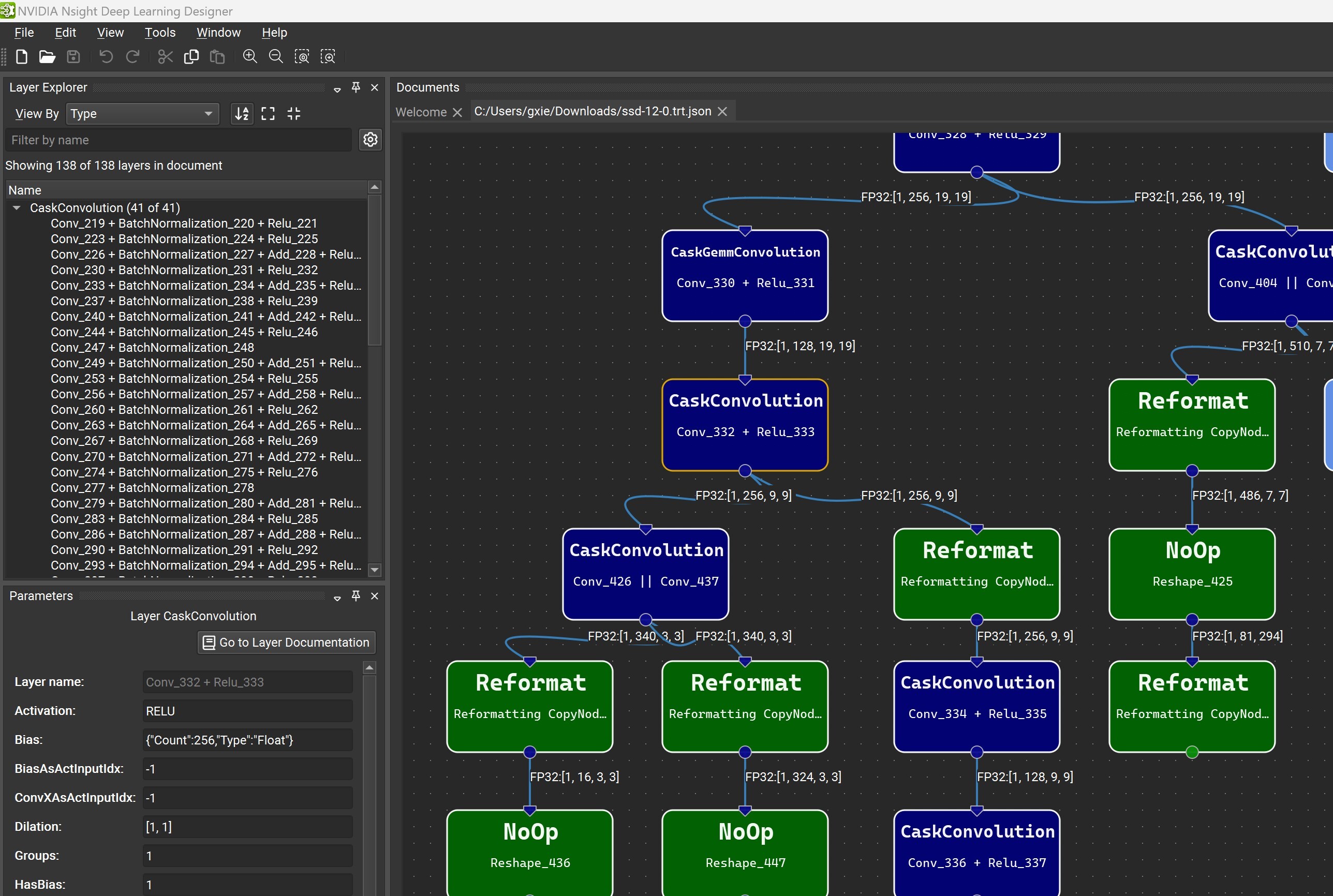
层浏览器窗口允许您搜索特定层或浏览网络中的层。参数编辑器窗口允许您查看所选层的元数据。
优化器回调#
优化器回调 API 功能允许您监视 TensorRT 构建过程的进度,例如,在交互式应用程序中提供用户反馈。要启用进度监视,请创建一个实现 IProgressMonitor 接口的对象,然后将其附加到 IBuilderConfig,例如
1builderConfig->setProgressMonitor(&monitor);
1context.set_progress_monitor(monitor)
优化分为分层嵌套的阶段,每个阶段都包含多个步骤。在每个阶段开始时,都会调用 IProgressMonitor 的 phaseStart() 方法,告知您阶段名称及其包含的步骤数。当每个步骤完成时,会调用 stepComplete() 函数,并在阶段完成时调用 phaseFinish()。
从 stepComplete() 返回 false 会干净利落地强制提前终止构建。
预览功能#
预览功能 API 是 IBuilderConfig 的扩展,允许逐步将新功能引入 TensorRT。选定的新功能在此 API 下公开,允许您选择加入或退出。预览功能保持预览状态一个或两个 TensorRT 发布周期,然后要么集成为主流功能,要么被删除。当预览功能完全集成到 TensorRT 中时,不再可以通过预览 API 控制它。
预览功能使用 32 位 PreviewFeature 枚举定义。功能名称和 TensorRT 版本连接功能标识符。
<FEATURE_NAME>_XXYY
XX 和 YY 分别是 TensorRT 发布的版本的主要版本和次要版本,它们首次引入了该功能。主要版本和次要版本使用两位数字指定,必要时使用前导零填充。
假设预览功能的语义从一个 TensorRT 版本更改为另一个版本。在这种情况下,较旧的预览功能将被弃用,修订后的功能将被分配新的枚举值和名称。
已弃用的预览功能根据弃用策略进行标记。
有关 C++ API 的更多信息,请参阅 nvinfer1::PreviewFeature、IBuilderConfig::setPreviewFeature 和 IBuilderConfig::getPreviewFeature。
Python API 使用 PreviewFeature 枚举 set_preview_feature 和 get_preview_feature 函数具有类似的语义。
调试张量#
调试张量功能允许您在网络执行时检查中间张量。使用调试张量和将所有必需的张量标记为输出之间存在一些关键区别
将所有张量标记为输出需要您预先提供内存来存储张量,而调试张量如果不需要,可以在运行时关闭。
当调试张量关闭时,对网络执行的性能影响将降至最低。
对于循环中的调试张量,每次写入时都会发出值。
要启用此功能,请执行以下步骤
在编译网络之前标记目标张量。
1networkDefinition->markDebug(&tensor);
1network.mark_debug(tensor)
定义一个从
IDebugListener派生的DebugListener类,并实现用于处理张量的虚函数。
1virtual void processDebugTensor(
2 void const* addr,
3 TensorLocation location,
4 DataType type,
5 Dims const& shape,
6 char const* name,
7 cudaStream_t stream) = 0;
1process_debug_tensor(self, addr, location, type, shape, name, stream)
当在执行期间调用该函数时,调试张量将通过参数传递
location: TensorLocation of the tensor addr: pointer to buffer type: data Type of the tensor shape: shape of the tensor name: name of the tensor stream: Cuda stream object数据将采用线性格式。
将您的侦听器附加到
IExecutionContext。
1executionContext->setDebugListener(&debugListener);
1execution_context.set_debug_state(tensorName, flag)
权重流式传输#
权重流式传输功能允许您将某些权重从设备内存卸载到主机内存。在网络执行期间,这些权重根据需要从主机流式传输到设备。此技术可以释放设备内存,使您能够运行更大的模型或处理更大的批次大小。
要启用此功能,在引擎构建期间,使用 kSTRONGLY_TYPED 创建网络,并将 kWEIGHT_STREAMING 设置为构建器配置
1…
2builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kSTRONGLY_TYPED));
3config->setFlag(BuilderFlag::kWEIGHT_STREAMING);
1builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.STRONGLY_TYPED))
2config.set_flag(trt.BuilderFlag.WEIGHT_STREAMING)
在运行时,反序列化会分配一个主机缓冲区来存储所有权重,而不是直接将它们上传到设备。这会增加主机的峰值内存使用量。您可以使用 IStreamReaderV2 直接从引擎文件反序列化,避免需要临时缓冲区,这有助于减少峰值内存使用量。IStreamReaderV2 替换了现有的 IStreamReader 反序列化方法。
反序列化引擎后,通过以下方式设置权重的设备内存预算
1…
2engine->setWeightStreamingBudgetV2(size)
1…
2engine.weight_streaming_budget_v2 = size
以下 API 可以帮助确定预算
getStreamableWeightsSize()返回可流式传输权重的总大小。getWeightStreamingScratchMemorySize()返回启用权重流式传输时上下文的额外暂存内存大小。getDeviceMemorySizeV2()返回上下文所需的总暂存内存大小。如果在通过setWeightStreamingBudgetV2()启用权重流式传输之前调用此 API,则返回值将不包括权重流式传输所需的额外暂存内存大小,可以使用getWeightStreamingScratchMemorySize()获取。否则,它将包括此额外内存。
此外,您可以结合有关当前可用设备内存大小、上下文数量和其他分配需求的信息。
TensorRT 还可以通过 getWeightStreamingAutomaticBudget() 自动确定内存预算。但是,由于有关用户特定内存分配需求的信息有限,因此自动确定的预算可能不是最优的,并且可能导致内存不足错误。
如果 setWeightStreamingBudgetV2 设置的预算大于通过 getStreamableWeightsSize() 获取的可流式传输权重的总大小,则预算将被裁剪为总大小,从而有效地禁用权重流式传输。
您可以通过 getWeightStreamingBudgetV2() 查询设置的预算。
当引擎没有活动上下文时,可以通过再次设置预算来调整预算。
设置预算后,TensorRT 将自动确定要将哪些权重保留在设备内存上,以最大程度地重叠计算和权重提取。
跨平台兼容性#
默认情况下,TensorRT 引擎只能在构建它们的同一平台(操作系统和 CPU 架构)上执行。通过构建时配置,可以构建引擎以与其他类型的平台兼容。例如,要在 Linux x86_64 平台上构建引擎并期望该引擎在 Windows x86_64 平台上运行,请按如下方式配置 IBuilderConfig
config->setRuntimePlatform(nvinfer1::RuntimePlatform::kWINDOWS_AMD64);
跨平台引擎的性能可能与目标平台上本机构建的引擎存在差异。此外,它无法在其构建的主机平台上运行。
当构建也需要版本向前兼容性的跨平台引擎时,必须设置 kEXCLUDE_LEAN_RUNTIME 以排除目标平台精简运行时。
平铺优化#
平铺优化支持跨内核平铺推理。除了内核级平铺之外,此技术还利用片上缓存来实现连续内核。它可以显着提高受内存带宽限制的平台的性能。
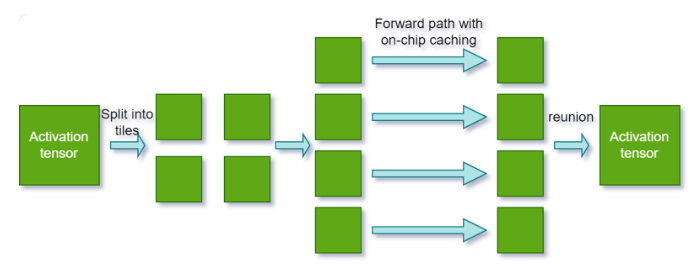
要激活平铺优化,请执行以下步骤
设置平铺优化级别。使用以下 API 指定 TensorRT 应该花费多少时间来搜索可能提高性能的更有效的平铺解决方案
builderConfig->setTilingOptimizationLevel(level)
默认情况下,优化级别设置为
0,这意味着 TensorRT 不会执行任何平铺优化。增加级别使 TensorRT 能够探索各种策略和更大的搜索空间,以提高性能。但是,请注意,这可能会显着增加引擎构建时间。
配置平铺的 L2 缓存限制。使用以下 API 向 TensorRT 提供运行时可以为当前引擎分配的 L2 缓存资源估算值
builderConfig->setL2LimitForTiling()
此 API 提示 TensorRT 可以考虑在运行时为当前 TensorRT 引擎专用多少 L2 缓存资源。这将帮助 TensorRT 为在单个 GPU 上并发运行的多个任务应用更好的平铺解决方案。请注意,L2 缓存的使用取决于工作负载和启发式方法;TensorRT 可能不会对所有层应用此限制。
TensorRT 管理默认值。