精度考量#
降低的精度格式#
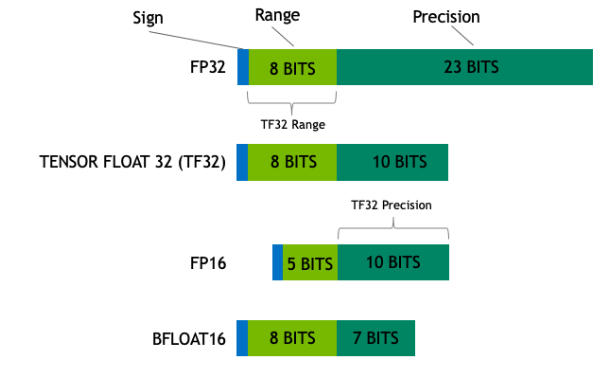
浮点精度的选择会显著影响性能和精度。除了标准单精度浮点 (FP32) 外,TensorRT 还支持三种降低的精度格式:TensorFloat-32 (TF32)、半精度浮点 (FP16) 和 Brain Floating Point (BF16)。
TF32 在 TensorRT 中默认启用,使用 8 位指数和 10 位尾数,将 FP32 的动态范围与 FP16 的计算效率相结合。FP16 具有 5 位指数和 10 位尾数,具有显著的速度和内存效率优势,但由于其有限的精度和范围,可能会表现出降低的精度。BF16 具有 8 位指数和 7 位尾数,提供比 FP16 更大的动态范围,但精度较低。较大的指数使 BF16 适用于溢出是一个问题的情况,但精度可以降低。每种格式都提供独特的权衡,选择取决于具体的任务要求,例如对速度、内存效率或数值精度的需求。
ULP 对大数值的影响#
ULP,“最后一位的单位”,衡量浮点运算的精度。它表示两个不同的浮点数之间的最小差异。ULP 量化了给定浮点格式中连续可表示数字之间的差距。此差距的大小取决于所表示数字的大小。
对于大数值,ULP 可能变得相当大。这意味着两个连续浮点数之间的差异变得显著。当数值计算涉及大数值时,高 ULP 可能导致显著的舍入误差。这些误差会累积并可能导致数值不稳定,最终降低计算的精度。
在某些模型中,数据的大小会随着其通过网络层而增加,尤其是在没有归一化层的情况下。例如,没有归一化的级联卷积层可以放大数值,使降低的精度格式难以保持精度。
FP16 溢出#
FP16 比 FP32、TF32 和 BF16 具有更窄的可表示值范围,使其更容易发生溢出。FP16 的 5 位指数将其最大值限制为 65,504,而 FP32、TF32 和 BF16 使用 8 位指数,提供更广泛的范围。FP16 中的溢出会导致 Inf(无穷大)值,这会传播错误并导致 NaN(非数字)值,严重降低模型精度。
例如,IReduceLayer 容易因累积沿某个轴的所有值(最小值归约和最大值归约除外)而溢出。
敏感计算#
某些模型计算对精度变化高度敏感。对这些计算使用降低的精度格式可能会因其降低的精度而导致显著的精度损失。
例如,Sigmoid 或 Softmax 由于其指数分量而放大小的数值差异。
缓解策略#
为了在推理期间使用降低的精度时减轻精度损失,请考虑以下策略
- 混合精度推理
结合 FP16、BF16、TF32 和 FP32 运算。以 FP32 执行关键的、对精度敏感的计算,并对不太敏感的运算使用降低的精度以获得性能优势。线性运算尤其适用于降低的精度,因为除了带宽降低外,它们的计算还通过 Tensor Core 加速。这可以通过在强类型模式下添加
ICastLayer或在弱类型模式下设置层精度约束来实现。有关更多信息,请参阅 强类型网络 和 弱类型网络中的降低精度 部分。- 控制计算精度
除了设置层的输入/输出精度外,有时还可以控制内部计算精度。有关更多信息,请参阅 计算精度控制 部分。
- 幅度调整
缩放输入数据以防止与高幅度数据相关的精度损失。
量化格式#
TensorRT 支持多种量化格式,用于压缩深度学习模型
INT8:8 位整数类型,范围为
[-128, 127]。INT4:4 位整数类型,范围为
[-8, 7]。FP8:浮点类型(1 位符号位、4 位指数、3 位尾数),范围
[-448, 448]。FP4:浮点类型(1 位符号位、2 位指数、1 位尾数),范围
[-6, 6]。
有关更多信息,请参阅 类型和精度 部分。
量化类型中的均匀和非均匀分布#
整数格式(如 INT8 和 INT4)使用均匀量化,这意味着值的范围被划分为大小相等的间隔。此方法简单高效,但可能无法最佳地捕获权重和激活的分布。
浮点格式(如 FP8E4M3 和 FP4E2M1)具有非均匀分布,更多值集中在 0 附近,这更好地对齐了神经网络权重和激活的典型分布。
量化误差#
量化引入了两种误差来源,可能会显著影响深度学习模型的精度:舍入误差和钳位误差。
舍入误差发生在连续值被近似为最接近的量化值时,导致信息丢失。TensorRT 使用四舍五入到最接近的偶数方法,在平局的情况下四舍五入到最接近的偶数值,有助于减少量化过程中的偏差。
钳位误差发生在值超出量化范围并被裁剪到最近边界时,导致动态范围丢失。钳位误差和舍入误差之间存在权衡,这在比例选择中体现出来:设置允许较少值被裁剪的比例意味着更高的舍入误差。