使用 DLA#
NVIDIA DLA (深度学习加速器) 是一个针对深度学习操作的固定功能加速引擎。它旨在完全硬件加速卷积神经网络。DLA 支持各种层,例如卷积、反卷积、全连接、激活、池化、批归一化等。有关 TensorRT 层中 DLA 支持的更多信息,请参阅 DLA 支持的层和限制 部分。
DLA 适用于从 GPU 卸载 CNN 处理,并且对于这些工作负载而言,功耗效率更高。此外,在冗余非常重要的场合(例如任务关键型或安全应用)中,它可以提供独立的执行管线。
有关更多信息,请参阅 DLA 开发者页面和 DLA 教程 NVIDIA Jetson Orin 上的深度学习加速器入门。
在为 DLA 构建模型时,TensorRT 构建器会解析网络并调用 DLA 编译器将网络编译为 DLA 可加载项。请参阅 使用 trtexec,了解如何在 DLA 上构建和运行网络。
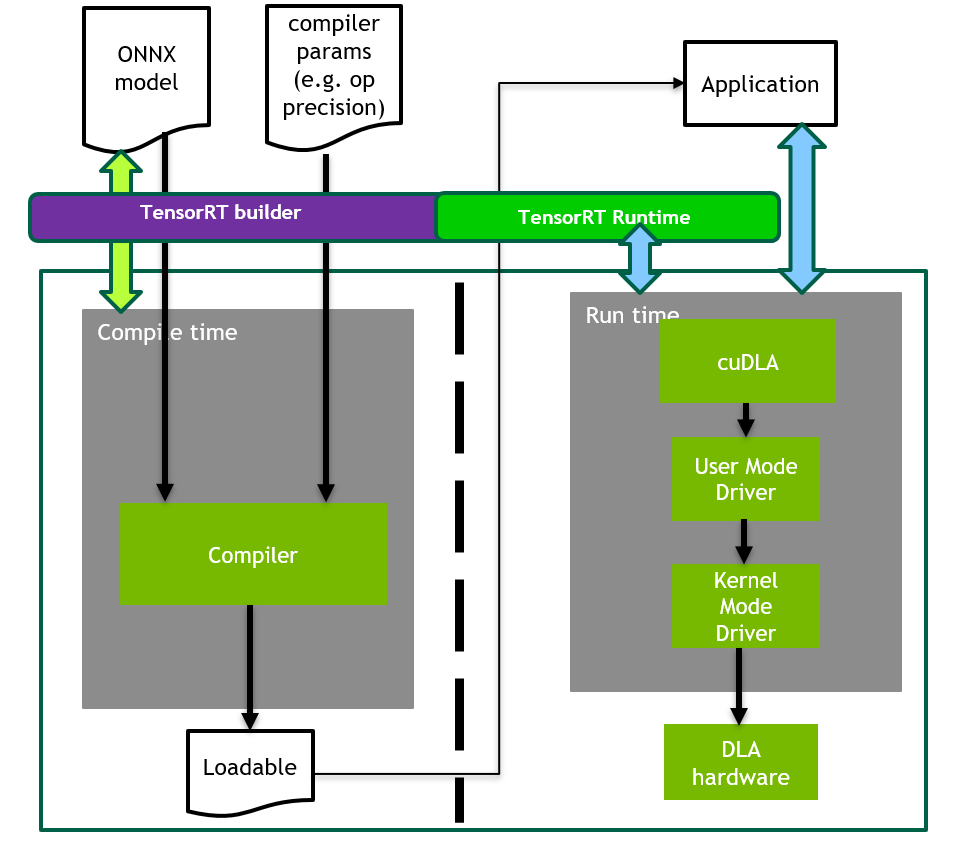
构建和启动可加载项#
有几种方法可以构建和启动 DLA 可加载项,可以嵌入在 TensorRT 引擎中,也可以采用独立形式。
请参阅 DLA 独立模式 部分,了解如何在 TensorRT 之外生成独立的 DLA 可加载项。
使用 trtexec#
要允许 trtexec 使用 DLA,您可以使用 –useDLACore 标志。例如,要在 FP16 模式下在 DLA 核心 0 上运行 ResNet-50 网络,并为不支持的层启用 GPU 回退模式,请运行
./trtexec --onnx=data/resnet50/ResNet50.onnx --useDLACore=0 --fp16 --allowGPUFallback
trtexec 工具具有用于在 DLA 上运行网络的其他参数。有关更多信息,请参阅 命令行程序 部分。
使用 TensorRT API#
您可以使用 TensorRT API 构建和运行 DLA 推理,并在层级别启用 DLA。以下部分提供了相关的 API 和示例。
在 TensorRT 推理期间在 DLA 上运行#
可以将 TensorRT 构建器配置为在 DLA 上启用推理。DLA 支持目前仅限于以 FP16 和 INT8 模式运行的网络。DeviceType 枚举用于指定网络或层在其上执行的设备。可以使用 IBuilderConfig 类中的以下 API 函数来配置网络以使用 DLA
setDeviceType(ILayer* layer, DeviceType deviceType):此函数设置层必须在其上执行的deviceType。getDeviceType(const ILayer* layer):此函数可用于返回此层在其上执行的deviceType。如果层在 GPU 上执行,则此函数返回DeviceType::kGPU。canRunOnDLA(const ILayer* layer):此函数检查层是否可以在 DLA 上运行。setDefaultDeviceType(DeviceType deviceType):此函数设置构建器的默认deviceType。它确保所有可以在 DLA 上运行的层都在 DLA 上运行,除非使用setDeviceType覆盖层的deviceType。getDefaultDeviceType():此函数返回由setDefaultDeviceType设置的默认deviceType。isDeviceTypeSet(const ILayer* layer):此函数检查是否已为此层显式设置deviceType。resetDeviceType(ILayer* layer):此函数重置此层的deviceType。该值将重置为setDefaultDeviceType指定的deviceType,如果未指定,则重置为DeviceType::kGPU。allowGPUFallback(bool setFallBackMode):此函数通知构建器,如果本应在 DLA 上运行的层无法在 DLA 上运行,则使用 GPU。有关更多信息,请参阅 GPU 回退模式 部分。reset():此函数可以重置IBuilderConfig状态,这将所有层的deviceType设置为DeviceType::kGPU。重置后,可以重复使用构建器来构建具有不同 DLA 配置的另一个网络。
IBuilder 类中的以下 API 函数可用于帮助配置网络以使用 DLA
getMaxDLABatchSize():此函数返回 DLA 可以支持的最大批大小。注意
对于任何张量,索引维度总大小与请求的批大小的组合都不得超过此函数返回的值。
getNbDLACores():此函数返回用户可用的 DLA 核心数。
如果构建器不可访问,例如在推理应用程序中在线加载计划文件时,则可以使用 DLA 扩展以不同的方式指定要使用的 DLA IRuntime。IRuntime 类中的以下 API 函数可用于配置网络以使用 DLA
getNbDLACores():此函数返回用户可访问的 DLA 核心数。setDLACore(int dlaCore):要在其上执行的 DLA 核心。其中dlaCore是0和getNbDLACores() - 1之间的值。默认值为0。getDLACore():运行时执行分配到的 DLA 核心。默认值为0。
示例:使用 DLA 运行示例#
本节详细介绍如何使用启用的 DLA 运行 TensorRT 示例。
创建构建器。
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger)); if (!builder) return false; builder->setMaxBatchSize(batchSize); config->setMaxWorkspaceSize(16_MB);
启用
GPUFallback模式。config->setFlag(BuilderFlag::kGPU_FALLBACK); config->setFlag(BuilderFlag::kFP16); or config->setFlag(BuilderFlag::kINT8);
启用在 DLA 上的执行,其中
dlaCore指定要在其上执行的 DLA 核心。config->setDefaultDeviceType(DeviceType::kDLA); config->setDLACore(dlaCore);
通过这些额外的更改,sampleMNIST 已准备好在 DLA 上执行。要使用 DLA Core 1 运行示例,请将
--useDLACore=0附加到示例命令。
示例:在网络创建期间为层启用 DLA 模式#
在此示例中,让我们创建一个包含输入、卷积和输出的简单网络。
创建构建器、构建器配置和网络。
IBuilder* builder = createInferBuilder(gLogger); IBuilderConfig* config = builder.createBuilderConfig(); INetworkDefinition* network = builder->createNetworkV2(0U);
将输入层添加到具有输入维度的网络。
auto data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W});
添加卷积层,其中包含隐藏层输入节点、步幅以及滤波器和偏差的权重。
auto conv1 = network->addConvolution(*data->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]); conv1->setStride(DimsHW{1, 1});
将卷积层设置为在 DLA 上运行。
if(canRunOnDLA(conv1)) { config->setFlag(BuilderFlag::kFP16); or config->setFlag(BuilderFlag::kINT8); builder->setDeviceType(conv1, DeviceType::kDLA); }
标记输出。
network->markOutput(*conv1->getOutput(0));
设置要在其上执行的 DLA 核心。
config->setDLACore(0)
使用 cuDLA API#
cuDLA 是 CUDA 编程模型的扩展,它将 DLA 运行时软件与 CUDA 集成在一起。这种集成使得可以使用 CUDA 编程结构(例如流和图)启动 DLA 可加载项。
CuDLA 透明地管理共享缓冲区并同步 GPU 和 DLA 之间的任务。请参阅 NVIDIA cuDLA 文档,了解如何在编写 cuDLA 应用程序时使用 cuDLA API 来实现这些用例。
有关使用 TensorRT 构建可与 cuDLA 一起使用的独立 DLA 可加载项的更多信息,请参阅 DLA 独立模式 部分。
DLA 支持的层和限制#
本节列出了 DLA 支持的层以及与每个层相关的约束。
一般限制#
以下限制适用于在 DLA 上运行时的所有层
最大支持批大小为 4096。
非批处理维度的最大支持大小为 8192。
DLA 不支持动态维度。因此,对于通配符维度,配置文件的
min、max和opt值必须相等。运行时维度必须与用于构建的维度相同。
如果任何中间层无法在 DLA 上运行并且启用了
GPUFallback,则 TensorRT 可能会将网络拆分为多个 DLA 可加载项。否则,TensorRT 可能会发出错误并回退。有关更多信息,请参阅 GPU 回退模式 部分。由于硬件和软件内存限制,每个核心最多只能同时加载 16 个 DLA 可加载项。
每个层在一个 DLA 可加载项中必须具有相同的批大小。具有不同批大小的层将划分为单独的 DLA 图。
注意
DLA 的批大小是除
CHW维度之外的所有索引维度的乘积。例如,如果输入维度为NPQRS,则有效批大小为N*P。
层支持和限制#
以下列表提供了在 DLA 上运行时指定层的层支持和限制
激活层
仅支持两个空间维度操作。
FP16 和 INT8 均受支持。
支持的函数:
ReLU、Sigmoid、TanH、Clipped ReLU和Leaky ReLU。不支持 ReLU 的负斜率。
Clipped ReLU仅支持范围[1, 127]内的值。TanH、SigmoidINT8 支持通过自动升级到 FP16 来实现。
比较操作(等于、大于、小于)
除了使用常量(应该是 FP32 类型并填充相同的值)外,它仅支持 INT8 层精度和 INT8 输入。
DLA 要求比较操作输出为 FP16 或 INT8 类型。因此,比较层之后必须紧跟一个 Cast 操作(
IIdentityLayer或ICastLayer)到 FP16 或 INT8,并且除了此 Cast 操作之外,不应有直接使用者。ElementWise比较层和上述后续的IIdentityLayer或ICastLayer显式地将您的设备类型设置为 DLA,将其精度设置为 INT8。否则,这些层将在 GPU 上运行。即使允许 GPU 回退,您也应该预料到在某些情况下引擎构建会失败,例如当 DLA 可加载项编译失败时。如果是这种情况,请取消设置
ElementWise比较层和IIdentityLayer或ICastLayer的设备类型和/或精度,以便将两者都卸载到 GPU。
连接层
DLA 仅支持沿通道轴的连接。
Concat 必须至少有两个输入。
所有输入必须具有相同的空间维度。
FP16 和 INT8 均受支持。
在 INT8 模式下,输入的动态范围必须相同。
在 INT8 模式下,输出的动态范围必须等于每个输入。
卷积层和全连接层
仅支持两个空间维度操作。
FP16 和 INT8 均受支持。
内核大小的每个维度必须在
[1, 32]范围内。填充必须在
[0, 31]范围内。填充的维度必须小于相应的内核维度。
步幅的维度必须在
[1, 8]范围内。输出映射的数量必须在
[1, 8192]范围内。输入通道数
[1, 8192]。对于使用
TensorFormat::kDLA_LINEAR、TensorFormat::kCHW16和TensorFormat::kCHW32格式的操作,组数必须在[1, 8192]范围内。对于使用
TensorFormat::kDLA_HWC4格式的操作,组数必须在[1, 4]范围内。扩张卷积必须在
[1, 32]范围内。如果 CBUF 大小要求
wtBanksForOneKernel + minDataBanks超过numConvBufBankAllotted限制16,则不支持操作,其中 CBUF 是内部卷积缓存,用于在操作之前存储输入权重和激活,wtBanksForOneKernel是一个内核存储卷积所需的最小权重/内核元素的最小 bank 数,minDataBanks是存储卷积所需的最小激活数据的最小 bank 数。当卷积层由于 CBUF 约束而未能通过验证时,详细信息将显示在日志输出中。
反卷积层
仅支持两个空间维度。
FP16 和 INT8 均受支持。
内核维度和步幅必须在
[1, 32]范围内,或者必须为1x[64, 96, 128]和[64, 96, 128]x1。TensorRT 已禁用 DLA 上
[23 - 32]范围内的反卷积方形内核和步幅,因为它们会显着减慢编译速度。填充必须为
0。分组反卷积必须为
1。扩张反卷积必须为
1。输入通道数必须在
[1, 8192]范围内。输出通道数必须在
[1, 8192]范围内。
ElementWise 层
仅支持两个空间维度操作。
FP16 和 INT8 均受支持。
支持的操作:
Sum、Sub、Product、Max、Min、Div、Pow、Equal、Greater和Less(单独描述)。当操作数之一具有以下形状配置之一时,支持广播
NCHW(即,形状相等)
NC11(即,N 和 C 相等,H 和 W 为 1)
N111(即,N 相等,C、H 和 W 为 1)
Div操作第一个输入(被除数)可以是 INT8、FP16 或 FP32 常量。第二个输入(除数)必须是 INT8 或 FP32 常量。
如果输入之一是常量,则其所有权重的值必须相同。此外,另一个输入在 INT8 中必须是非常量。
Pow操作一个输入必须是用相同值填充的 FP32 常量;另一个必须是 INT8 非常量。
LRN(局部响应归一化)层
允许的窗口大小为
3、5、7或9。支持的归一化区域为
ACROSS_CHANNELS。LRN INT8 支持通过自动升级到 FP16 来实现。
参数 ReLU 层
Slope 输入必须是与输入张量具有相同秩的构建时常量。
池化层
仅支持两个空间维度操作。
FP16 和 INT8 均受支持。
支持的操作:
kMAX、kAVERAGE。窗口的维度必须在
[1, 8]范围内。填充的维度必须在
[0, 7]范围内。步幅的维度必须在
[1, 16]范围内。在 INT8 模式下,输入和输出张量比例必须相同。
Reduce 层
仅支持 4D 输入张量。
所有输入非批处理维度必须在
[1, 8192]范围内。FP16 和 INT8 均受支持。
仅支持 MAX 操作类型,其中 CHW 轴的任意组合都会被缩减。
Resize 层
比例的数量必须正好为
4。前两个比例元素必须正好为
1(对于未更改的批处理和通道维度)。比例中的最后两个元素分别表示沿高度和宽度维度的比例值,在最近邻模式下必须是
[1, 32]范围内的整数值,在双线性模式下必须是[1, 4]范围内的整数值。请注意,对于双线性调整大小 INT8 模式,当输入动态范围大于输出动态范围时,该层将升级到 FP16 以保持准确性。这可能会对延迟产生负面影响。
Scale 层
仅支持两个空间维度操作。
FP16 和 INT8 均受支持。
支持的模式:
Uniform、Per-Channel和ElementWise。仅支持
scale和shift操作。
Shuffle 层
仅支持 4D 输入张量。
所有输入非批处理维度必须在
[1, 8192]范围内。请注意,DLA 将该层分解为独立的转置和重塑操作。这意味着上述限制分别适用于每个分解的操作。
批处理维度不能参与重塑或转置。
Slice 层
FP16 和 INT8 均受支持。
它支持高达一般 DLA 最大值的批大小。
所有输入非批处理维度必须在
[1, 8192]范围内。仅支持 4D 输入和 CHW 维度切片。
仅支持静态切片,因此必须使用 TensorRT
ISliceLayer设置器 API 或作为常量输入张量静态提供切片参数。
Softmax 层
仅在 NVIDIA Orin 上受支持,在 Xavier 上不受支持。
所有输入非批处理维度必须在
[1, 8192]范围内。轴必须是非批处理维度之一。
支持 FP16 和 INT8 精度。
在内部,有两种模式,模式的选择基于给定的输入张量形状。
当所有非批处理、非轴维度均为
1时,将触发精确模式。优化模式允许非批处理、非轴维度大于
1,但将轴维度限制为 1024,并且涉及可能导致输出中出现小误差的近似值。误差的大小随着轴维度大小接近 1024 而增加。
Unary 层
DLA 支持
ABS、SIN、COS和ATAN操作类型。对于
SIN、COS和ATAN,输入精度必须为 INT8。所有输入非批处理维度必须在
[1, 8192]范围内。
在 NVIDIA Orin 上进行推理#
由于 NVIDIA Orin 和 Xavier DLA 之间的硬件规格差异,NVIDIA Orin 上的 FP16 卷积操作可能会导致延迟增加多达 2 倍。
在 NVIDIA Orin 上,DLA 将非卷积操作(FP16 和 INT8)的权重作为 FP19 值(使用 4 字节容器)存储在可加载项内部。对于这些 FP19 值,通道维度会填充为 16 (FP16) 或 32 (INT8) 的倍数。特别是在元素级 Scale、Add 或 Sub 操作较大的情况下,这会膨胀 DLA 可加载项的大小,从而膨胀包含此类可加载项的引擎。图优化可能会通过更改层的类型(例如,当权重为常量层的 ElementWise 乘法层融合到 scale 层中时)而无意中触发此行为。
GPU 回退模式#
GPUFallbackMode 将构建器设置为,如果标记为在 DLA 上运行的层无法在 DLA 上运行,则使用 GPU。由于以下原因,层无法在 DLA 上运行
DLA 不支持
layer操作。指定的参数超出 DLA 的支持范围。
给定的批大小超过了允许的最大 DLA 批大小。有关更多信息,请参阅 DLA 支持的层和限制 部分。
网络中层的组合导致内部状态超出 DLA 可以支持的范围。
平台上没有可用的 DLA 引擎。
当禁用 GPU 回退时,如果层无法在 DLA 上运行,则会发出错误。
DLA 上的 I/O 格式#
DLA 支持设备独有的格式,并且由于矢量宽度字节要求,这些格式对其布局有限制。
对于 DLA 输入张量,支持 kDLA_LINEAR(FP16, INT8)、kDLA_HWC4(FP16, INT8)、kCHW16(FP16) 和 kCHW32(INT8)。
对于 DLA 输出张量,仅支持 kDLA_LINEAR(FP16, INT8)、kCHW16(FP16) 和 kCHW32(INT8)。
对于 kCHW16 和 kCHW32 格式,如果 C 不是整数倍,则必须将其填充到下一个 32 字节边界。
对于 kDLA_LINEAR 格式,沿 W 维度的步幅必须填充到 64 字节。内存格式等效于维度为 [N][C][H][roundUp(W, 64/elementSize)] 的 C 数组,其中 elementSize 对于 FP16 为 2,对于 Int8 为 1,张量坐标 (n, c, h, w) 映射到数组下标 [n][c][h][w]。
对于 kDLA_HWC4 格式,沿 W 维度的步幅在 Xavier 上必须是 32 字节的倍数,在 NVIDIA Orin 上必须是 64 字节的倍数。
当
C == 1时,TensorRT 将格式映射到本机灰度图像格式。当
C == 3或C == 4时,它映射到本机彩色图像格式。如果C == 3,则沿 W 轴步进的步幅必须填充到4个元素。
在这种情况下,填充通道位于第 4 个索引处。理想情况下,填充值无关紧要,因为 DLA 编译器会将权重中的第 4 个通道填充为零;但是,应用程序可以安全地分配一个包含四个通道的零填充缓冲区并填充三个有效通道。
当
C为{1, 3, 4}时,则填充的C'分别为{1, 4, 4},内存布局等效于维度为[N][H][roundUp(W, 32/C'/elementSize)][C']的C数组,其中elementSize对于 FP16 为2,对于 Int8 为1。张量坐标(n, c, h, w)映射到数组下标[n][h][w][c],roundUp计算大于或等于W的64/elementSize的最小倍数。
当使用 kDLA_HWC4 作为 DLA 输入格式时,它具有以下要求
C必须为1、3或4第一层必须是卷积。
卷积参数必须满足 DLA 要求。有关更多信息,请参阅 DLA 支持的层和限制 部分。
启用 GPU 回退时,TensorRT 可能会插入重格式化层以满足 DLA 的要求。否则,输入和输出格式必须与 DLA 兼容。在所有情况下,TensorRT 期望数据采用的步幅可以通过查询 IExecutionContext::getStrides 获得。
DLA 独立模式#
如果需要在 TensorRT 之外运行推理,可以使用 EngineCapability::kDLA_STANDALONE 生成 DLA 可加载项,而不是 TensorRT 引擎。然后可以将此可加载项与 cuDLA API 一起使用。
使用 C++ 构建 DLA 可加载项#
将默认设备类型和引擎功能设置为 DLA 独立模式。
builderConfig->setDefaultDeviceType(DeviceType::kDLA); builderConfig->setEngineCapability(EngineCapability::kDLA_STANDALONE);
指定 FP16、INT8 或两者都指定。例如
builderConfig->setFlag(BuilderFlag::kFP16);
DLA 独立模式不允许重新格式化;因此,需要设置
BuilderFlag::kDIRECT_IO。builderConfig->setFlag(BuilderFlag::kDIRECT_IO);
将 I/O 张量的允许格式设置为 DLA 支持的一种或多种格式。
照常构建。
使用 trtexec 生成 DLA 可加载项#
trtexec 工具可以生成 DLA 可加载项,而不是 TensorRT 引擎。同时指定 --useDLACore 和 --safe 参数会将构建器功能设置为 EngineCapability::kDLA_STANDALONE。此外,指定 --inputIOFormats 和 --outputIOFormats 会限制 I/O 数据类型和内存布局。通过指定 --saveEngine 参数,DLA 可加载项将保存到文件中。
例如,要使用 trtexec 为 ONNX 模型生成 FP16 DLA 可加载项,请运行
./trtexec --onnx=model.onnx --saveEngine=model_loadable.bin --useDLACore=0 --fp16 --inputIOFormats=fp16:chw16 --outputIOFormats=fp16:chw16 --skipInference --safe
自定义 DLA 内存池#
您可以使用 IBuilderConfig::setMemoryPoolLimit (C++) 或 IBuilderConfig.set_memory_pool_limit (Python) 自定义分配给网络中每个 DLA 子网络的内存池大小。DLA 内存池有三种类型(有关详细信息,请参阅 MemoryPoolType 枚举)
托管 SRAM
行为类似于缓存,较大的值可能会提高性能。
如果没有可用的托管 SRAM,DLA 仍然可以通过回退到本地 DRAM 来运行。
在 Orin 上,每个 DLA 核心都有 1 MiB 的专用 SRAM。在 Xavier 上,4 MiB 的 SRAM 在多个核心(包括 2 个 DLA 核心)之间共享。
本地 DRAM
用于存储 DLA 子网络中的中间张量。较大的值可能允许将更大的子网络卸载到 DLA。
全局 DRAM
用于存储 DLA 子网络中的权重。较大的值可能允许将更大的子网络卸载到 DLA。
每个子网络所需的内存可能小于池大小,在这种情况下,将分配较小的量。池大小仅作为上限。
请注意,所有 DLA 内存池都需要 2 的幂的大小,最小为 4 KiB。违反此要求会导致 DLA 可加载项编译失败。
在多子网络情况下,重要的是要记住池大小适用于每个 DLA 子网络,而不是整个网络,因此有必要了解消耗的资源总量。特别是,您的网络聚合消耗的托管 SRAM 最多可以是池大小的两倍。
NVIDIA Orin 的默认托管 SRAM 池大小设置为 0.5 MiB,而 Xavier 的默认大小为 1 MiB。Orin 具有严格的每核限制,而 Xavier 具有一定的灵活性。此 Orin 默认设置保证在所有情况下,引擎的聚合托管 SRAM 消耗量将保持在硬件限制以下。不过,如果您的引擎只有一个 DLA 子网络,这将意味着您的引擎仅消耗一半的硬件限制,因此您可能会通过将池大小增加到 1 MiB 来提高性能。
确定 DLA 内存池使用情况#
从给定网络成功编译可加载项后,构建器会报告成功编译为可加载项的子网络候选对象的数量,以及这些可加载项每个池使用的总内存量。对于每个因内存不足而失败的子网络候选对象,将发出一条消息,指出哪个内存池不足。在详细日志中,构建器还会报告每个可加载项的内存池要求。
DLA 上的稀疏性#
NVIDIA Orin 平台上的 DLA 支持结构化稀疏性 (SS),这可以最大限度地减少延迟并最大限度地提高生产吞吐量。
结构化稀疏性#
结构化稀疏性 (SS) 加速了沿 C 维度的 2:4 稀疏模式。在每个由四个值组成的连续块中,沿 C 必须有两个值为零。通常,SS 为数学密集型且通道维度是 128 的倍数的 INT8 卷积提供最大的好处。”
SS 有几个要求和限制。
要求
仅适用于 NHWC 以外格式的 INT8 卷积。
通道大小必须大于 64。
限制
只有量化 INT8 权重最多为 256K 的卷积才能从 SS 中受益——实际上,限制可能更严格。
只有
K % 64在{0, 1, 2, 4, 8, 16, 32}中的卷积才能在此版本中从 SS 中受益,其中K是内核的数量(对应于输出通道的数量)。