1. Tegra 的 CUDA
本应用笔记概述了 NVIDIA® Tegra® 内存架构,以及将代码从连接到 x86 系统的独立 GPU (dGPU) 移植到 Tegra® 集成 GPU (iGPU) 的注意事项。它还讨论了 EGL 互操作性。
2. 概述
本文档概述了 NVIDIA® Tegra® 内存架构,以及将代码从连接到 x86 系统的独立 GPU (dGPU) 移植到 Tegra® 集成 GPU (iGPU) 的注意事项。它还讨论了 EGL 互操作性。
本指南适用于已经熟悉 CUDA® 和 C/C++ 编程,并希望为 Tegra® SoC 开发应用程序的开发人员。
《CUDA C++ 编程指南》和《CUDA C++ 最佳实践指南》中提供的性能指南、最佳实践、术语和一般信息适用于所有支持 CUDA 的 GPU 架构,包括 Tegra® 设备。
《CUDA C++ 编程指南》和《CUDA C 最佳实践指南》可在以下网站找到
CUDA C++ 编程指南
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html
CUDA C++ 最佳实践指南
https://docs.nvda.net.cn/cuda/cuda-c-best-practices-guide/index.html
3. 内存管理
在 Tegra® 设备中,CPU(主机)和 iGPU 共享 SoC DRAM 内存。具有独立 DRAM 内存的 dGPU 可以通过 PCIe 或 NVLink 连接到 Tegra 设备。目前仅 NVIDIA DRIVE 平台支持此功能。
连接 dGPU 的 Tegra® 内存系统的概述如 图 1 所示。
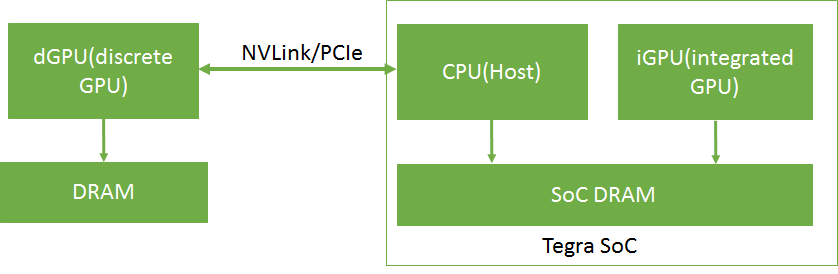
图 1 连接 dGPU 的 Tegra 内存系统
在 Tegra 中,设备内存、主机内存和统一内存都分配在同一物理 SoC DRAM 上。在 dGPU 上,设备内存分配在 dGPU DRAM 上。Tegra 系统中的缓存行为与带有 dGPU 的 x86 系统不同。Tegra 系统中不同内存类型的缓存和访问行为如 表 1 所示。
内存类型 |
CPU |
iGPU |
连接 Tegra 的 dGPU |
设备内存 |
无法直接访问 |
已缓存 |
已缓存 |
可分页主机内存 |
已缓存 |
无法直接访问 |
无法直接访问 |
钉页主机内存 |
当计算能力小于 7.2 时,未缓存。 当计算能力大于或等于 7.2 时,已缓存。 |
未缓存 |
未缓存 |
统一内存 |
已缓存 |
已缓存 |
不支持 |
在 Tegra 上,由于设备内存、主机内存和统一内存都分配在同一物理 SoC DRAM 上,因此可以避免重复的内存分配和数据传输。
3.1. I/O 一致性
I/O 一致性(也称为单向一致性)是一项功能,借助该功能,GPU 等 I/O 设备可以读取 CPU 缓存中的最新更新。当 CPU 和 GPU 之间共享同一物理内存时,它消除了执行 CPU 缓存管理操作的需要。GPU 缓存管理操作仍然需要执行,因为一致性是单向的。请注意,当使用托管内存或互操作内存时,CUDA 驱动程序会在内部执行 GPU 缓存管理操作。
Tegra 设备从 Xavier SOC 开始支持 I/O 一致性。应用程序应该从这项硬件功能中受益,而无需更改应用程序的代码(见下文第 2 点)。
以下功能依赖于 I/O 一致性支持
cudaHostRegister()/cuMemHostRegister()仅在 I/O 一致的平台上受支持。主机注册支持可以使用设备属性 cudaDevAttrHostRegisterSupported / CU_DEVICE_ATTRIBUTE_HOST_REGISTER_SUPPORTED 进行查询。使用
cudaMallocHost()/cuMemHostAlloc()/cuMemAllocHost()/cuMemAllocHost()分配的钉页内存的 CPU 缓存仅在 I/O 一致的平台上启用。
3.2. 估算集成 GPU 设备上的总可分配设备内存
cudaMemGetInfo() API 返回 GPU 可用于分配的可用内存快照和总量。如果任何其他客户端分配内存,可用内存可能会发生变化。
独立 GPU 具有专用的 DRAM,称为 VIDMEM,它与 CPU 内存分离。cudaMemGetInfo API 返回独立 GPU 中可用内存的快照。
Tegra SoC 上的集成 GPU 与 CPU 和其他 Tegra 引擎共享 DRAM。CPU 可以通过将 DRAM 的内容移动到 SWAP 区域或反之亦然来控制 DRAM 的内容并释放 DRAM 内存。cudaMemGetInfo API 目前不考虑 SWAP 内存区域。cudaMemGetInfo API 返回的大小可能小于实际可分配的内存,因为 CPU 可能能够通过将页面移动到 SWAP 区域来释放某些 DRAM 区域。为了估算可分配设备内存量,CUDA 应用程序开发人员应考虑以下几点
在 Linux 和 Android 平台上: Linux 和 Android 上的设备可分配内存主要取决于交换空间和主内存的总大小和可用大小。以下几点可以帮助用户估算各种情况下设备可分配内存的总量
主机分配内存 = 已用物理内存总量 – 设备分配内存
如果(主机分配内存 < 可用交换空间),则设备可分配内存 = 物理内存总量 – 已分配设备内存
如果(主机分配内存 > 可用交换空间),则设备可分配内存 = 物理内存总量 – (主机分配内存 - 可用交换空间)
其中,
设备分配内存是设备上已分配的内存。可以从
/proc/meminfo中的NvMapMemUsed字段或/sys/kernel/debug/nvmap/iovmm/clients的total字段中获取。已用物理内存总量可以使用
free -m命令获取。Mem行中的used字段表示此信息。物理内存总量从
/proc/meminfo中的MemTotal字段获取。可用交换空间可以使用
free -m命令找到。Swap行中的free字段表示此信息。-
如果
free命令不可用,则可以从/proc/meminfo中获取相同的信息,如下所示已用物理内存总量 =
MemTotal–MemFree可用交换空间 =
SwapFree
在 QNX 平台上: QNX 不使用交换空间,因此,cudaMemGetInfo.free 将是对可分配设备内存的合理估计,因为没有交换空间可以将内存页面移动到交换区域。
4. 移植注意事项
最初为连接到 x86 系统的 dGPU 开发的 CUDA 应用程序可能需要修改才能在 Tegra 系统上高效运行。本节介绍了将此类应用程序移植到 Tegra 系统的注意事项,例如选择合适的内存缓冲区类型(钉页内存、统一内存等)以及在 iGPU 和 dGPU 之间进行选择,以实现应用程序的高效性能。
4.1. 内存选择
CUDA 应用程序可以使用各种类型的内存缓冲区,例如设备内存、可分页主机内存、钉页内存和统一内存。即使这些内存缓冲区类型分配在同一物理设备上,但如 表 1 所示,每种内存缓冲区类型都具有不同的访问和缓存行为。为高效的应用程序执行选择最合适的内存缓冲区类型非常重要。
设备内存
对于可访问性仅限于 iGPU 的缓冲区,请使用设备内存。例如,在具有多个内核的应用程序中,可能存在一些缓冲区,这些缓冲区仅由应用程序的中间内核用作输入或输出。这些缓冲区仅由 iGPU 访问。此类缓冲区应使用设备内存分配。
可分页主机内存
对于可访问性仅限于 CPU 的缓冲区,请使用可分页主机内存。
钉页内存
具有不同计算能力的 Tegra 系统在 I/O 一致性方面表现出不同的行为。例如,计算能力大于或等于 7.2 的 Tegra 系统是 I/O 一致的,而其他系统则不是 I/O 一致的。在具有 I/O 一致性的 Tegra 系统上,钉页内存的 CPU 访问时间与可分页主机内存一样好,因为它缓存在 CPU 上。但是,在没有 I/O 一致性的 Tegra 系统上,钉页内存的 CPU 访问时间较长,因为它未缓存在 CPU 上。
建议对小型缓冲区使用钉页内存,因为缓存效应对于此类缓冲区可以忽略不计,并且钉页内存不像统一内存那样涉及任何额外的开销。在没有额外开销的情况下,如果访问模式在 iGPU 上不适合缓存,则钉页内存也更适合大型缓冲区。对于大型缓冲区,当缓冲区在 iGPU 上以合并方式仅访问一次时,iGPU 上的性能可以与 iGPU 上的统一内存一样好。
统一内存
统一内存缓存在 iGPU 和 CPU 上。在 Tegra 上,在应用程序中使用统一内存需要在内核启动、同步和预取提示调用期间执行额外的相干性和缓存维护操作。在计算能力小于 7.2 的 Tegra 系统上,这种相干性维护开销略高,因为它们缺乏 I/O 一致性。
在具有 I/O 一致性的 Tegra 设备(计算能力为 7.2 或更高)上,统一内存缓存在 CPU 和 iGPU 上,对于 iGPU 和 CPU 频繁访问的大型缓冲区,并且iGPU 上的访问是重复的,统一内存是首选,因为重复访问可以抵消缓存维护成本。在没有 I/O 一致性的 Tegra 设备(计算能力小于 7.2)上,对于 CPU 和 iGPU 频繁访问的大型缓冲区,并且iGPU 上的访问不是重复的,统一内存仍然比钉页内存更可取,因为钉页内存未在 CPU 和 iGPU 上缓存。这样,应用程序可以利用 CPU 上的统一内存缓存。
钉页内存或统一内存可用于减少 CPU 和 iGPU 之间的数据传输开销,因为这两种内存都可以从 CPU 和 iGPU 直接访问。在应用程序中,必须在主机和 iGPU 上都可访问的输入和输出缓冲区可以使用统一内存或钉页内存分配。
注意
统一内存模型要求驱动程序和系统软件在当前的 Tegra SOC 上管理相干性。软件管理的相干性本质上是不确定的,不建议在安全上下文中使用。在这些应用程序中,零拷贝内存(钉页内存)是首选。
评估应用程序中统一内存开销、钉页内存缓存未命中和设备内存数据传输的影响,以确定正确的内存选择。
4.2. 钉页内存
本节提供有关将 x86 系统中具有 dGPU 的系统中使用钉页内存分配的应用程序移植到 Tegra 的指南。为连接到 x86 系统的 dGPU 开发的 CUDA 应用程序使用钉页内存来减少数据传输时间,并将数据传输与内核执行时间重叠。有关此主题的特定信息,请参阅以下网站上的“主机和设备之间的数据传输”和“异步和重叠传输与计算”。
“主机和设备之间的数据传输”
“异步和重叠传输与计算”
在没有 I/O 一致性的 Tegra 系统上,重复访问钉页内存会降低应用程序性能,因为在此类系统中钉页内存未缓存在 CPU 上。
下面显示了一个示例应用程序,其中一组过滤器和操作(k1、k2 和 k3)应用于图像。分配钉页内存以减少 x86 系统上使用 dGPU 的数据传输时间,从而提高整体应用程序速度。但是,使用相同的代码定位 Tegra 设备会导致 readImage() 函数的执行时间急剧增加,因为它重复访问未缓存的缓冲区。这增加了整体应用程序时间。如果 readImage() 所花费的时间明显高于内核执行时间,建议使用统一内存来减少 readImage() 时间。否则,通过删除不必要的数据传输调用来评估具有钉页内存和统一内存的应用程序,以确定最合适的内存。
// Sample code for an x86 system with a discrete GPU
int main()
{
int *h_a,*d_a,*d_b,*d_c,*d_d,*h_d;
int height = 1024;
int width = 1024;
size_t sizeOfImage = width * height * sizeof(int); // 4MB image
//Pinned memory allocated to reduce data transfer time
cudaMallocHost(h_a, sizeOfImage);
cudaMallocHost(h_d, sizeOfImage);
//Allocate buffers on GPU
cudaMalloc(&d_a, sizeOfImage);
cudaMalloc(&d_b, sizeOfImage);
cudaMalloc(&d_c, sizeOfImage);
cudaMalloc(&d_d, sizeOfImage);
//CPU reads Image;
readImage(h_a); // Intialize the h_a buffer
// Transfer image to GPU
cudaMemcpy(d_a, h_a, sizeOfImage, cudaMemcpyHostToDevice);
// Data transfer is fast as we used pinned memory
// ----- CUDA Application pipeline start ----
k1<<<..>>>(d_a,d_b) // Apply filter 1
k2<<<..>>>(d_b,d_c)// Apply filter 2
k3<<<..>>>(d_c,d_d)// Some operation on image data
// ----- CUDA Application pipeline end ----
// Transfer processed image to CPU
cudaMemcpy(h_d, d_d, sizeOfImage, cudaMemcpyDeviceToHost);
// Data transfer is fast as we used pinned memory
// Use processed Image i.e h_d in later computations on CPU.
UseImageonCPU(h_d);
}
// Porting the code on Tegra
int main()
{
int *h_a,*d_b,*d_c,*h_d;
int height = 1024;
int width = 1024;
size_t sizeOfImage = width * height * sizeof(int); // 4MB image
//Unified memory allocated for input and output
//buffer of application pipeline
cudaMallocManaged(h_a, sizeOfImage,cudaMemAttachHost);
cudaMallocManaged(h_d, sizeOfImage);
//Intermediate buffers not needed on CPU side.
//So allocate them on device memory
cudaMalloc(&d_b, sizeOfImage);
cudaMalloc(&d_c, sizeOfImage);
//CPU reads Image;
readImage (h_a); // Intialize the h_a buffer
// ----- CUDA Application pipeline start ----
// Prefetch input image data to GPU
cudaStreamAttachMemAsync(NULL, h_a, 0, cudaMemAttachGlobal);
k1<<<..>>>(h_a,d_b)
k2<<<..>>>(d_b,d_c)
k3<<<..>>>(d_c,h_d)
// Prefetch output image data to CPU
cudaStreamAttachMemAsync(NULL, h_d, 0, cudaMemAttachHost);
cudaStreamSynchronize(NULL);
// ----- CUDA Application pipeline end ----
// Use processed Image i.e h_d on CPU side.
UseImageonCPU(h_d);
}
ThecudaHostRegister() 函数
cudaHostRegister() 函数在计算能力小于 7.2 的 Tegra 设备上不受支持,因为这些设备没有 I/O 一致性。如果设备不支持 cudaHostRegister(),请使用其他钉页内存分配函数,例如 cudaMallocHost() 和 cudaHostAlloc()。
钉页内存上的 GNU 原子操作
Tegra CPU 不支持未缓存内存上的 GNU 原子操作。由于钉页内存未在计算能力小于 7.2 的 Tegra 设备上缓存,因此钉页内存不支持 GNU 原子操作。
4.3. 在 Tegra 上有效使用统一内存
在应用程序中使用统一内存需要在内核启动、同步和预取提示调用时执行额外的相干性和缓存维护操作。这些操作与其他 GPU 工作同步执行,这可能会导致应用程序中出现不可预测的延迟。
可以通过提供数据预取提示来提高 Tegra 上统一内存的性能。驱动程序可以使用这些预取提示来优化相干性操作。为了预取数据,除了《CUDA C 编程指南》的“相干性和并发性”部分中描述的技术外,还可以使用 cudaStreamAttachMemAsync() 函数,链接如下
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html#um-coherency-hd
来预取数据。统一内存的预取行为,由附件标志状态的更改触发,如 表 2 所示。
之前的标志 |
当前的标志 |
预取行为 |
cudaMemAttachGlobal/cudaMemAttachSingle |
cudaMemAttachHost |
导致预取到 CPU |
cudaMemAttachHost |
cudaMemAttachGlobal/ cudaMemAttachSingle |
导致预取到 GPU |
cudaMemAttachGlobal |
cudaMemAttachSingle |
没有预取到 GPU |
cudaMemAttachSingle |
cudaMemAttachGlobal |
没有预取到 GPU |
以下示例显示了 cudaStreamAttachMemAsync() 的用法,用于预取数据。
注意
但是,Tegra 设备不支持使用 cudaMemPrefetchAsync() 的数据预取技术,如《CUDA C++ 编程指南》的“性能调优”部分中所述,网址如下
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html#um-performance-tuning
注意
QNX 系统软件存在限制,这阻止了所有 UVM 优化的实施。因此,在 QNX 上使用 cudaStreamAttachMemAsync() 预取提示对性能没有好处。
__global__ void matrixMul(int *p, int *q, int*r, int hp, int hq, int wp, int wq)
{
// Matrix multiplication kernel code
}
void MatrixMul(int hp, int hq, int wp, int wq)
{
int *p,*q,*r;
int i;
size_t sizeP = hp*wp*sizeof(int);
size_t sizeQ = hq*wq*sizeof(int);
size_t sizeR = hp*wq*sizeof(int);
//Attach buffers 'p' and 'q' to CPU and buffer 'r' to GPU
cudaMallocManaged(&p, sizeP, cudaMemAttachHost);
cudaMallocManaged(&q, sizeQ, cudaMemAttachHost);
cudaMallocManaged(&r, sizeR);
//Intialize with random values
randFill(p,q,hp,wp,hq,wq);
// Prefetch p,q to GPU as they are needed in computation
cudaStreamAttachMemAsync(NULL, p, 0, cudaMemAttachGlobal);
cudaStreamAttachMemAsync(NULL, q, 0, cudaMemAttachGlobal);
matrixMul<<<....>>>(p,q,r, hp,hq,wp,wq);
// Prefetch 'r' to CPU as only 'r' is needed
cudaStreamAttachMemAsync(NULL, r, 0, cudaMemAttachHost);
cudaStreamSynchronize(NULL);
// Print buffer 'r' values
for(i = 0; i < hp*wq; i++)
printf("%d ", r[i]);
}
注意
可以在 matrixMul 内核代码之后添加额外的 cudaStreamSynchronize(NULL) 调用,以避免在 cudaStreamAttachMemAsync() 调用中引起不可预测性的回调线程。
4.4. GPU 选择
在具有 dGPU 的 Tegra 系统上,决定 CUDA 应用程序是在 iGPU 还是 dGPU 上运行可能会对应用程序的性能产生影响。在做出此类决定时需要考虑的一些因素是内核执行时间、数据传输时间、数据局部性和延迟。例如,要在 dGPU 上运行应用程序,必须在 SoC 和 dGPU 之间传输数据。如果应用程序在 iGPU 上运行,则可以避免这种数据传输。
4.5. 同步机制选择
cudaSetDeviceFlags API 用于控制 CPU 线程的同步行为。在 CUDA 10.1 之前,默认情况下,iGPU 上的同步机制使用 cudaDeviceBlockingSync 标志,当等待设备完成工作时,该标志会阻塞同步原语上的 CPU 线程。cudaDeviceBlockingSync 标志适用于具有功率限制的平台。但是在需要低延迟的平台上,需要手动设置 cudaDeviceScheduleSpin 标志。自 CUDA 10.1 以来,对于每个平台,默认同步标志是根据针对该平台优化的内容确定的。有关同步标志的更多信息,请参见 cudaSetDeviceFlags API 文档。
4.6. Tegra 上不支持的 CUDA 功能
Tegra 平台支持 CUDA 的所有核心功能。例外情况如下所示。
cudaHostRegister()函数在 QNX 系统上不受支持。这是由于 QNX OS 的限制。在计算能力大于或等于 7.2 的 Linux 系统中,此函数受支持。计算能力小于 7.2 的 Tegra 设备不支持系统范围的原子操作。
连接到 Tegra 的 dGPU 不支持统一内存。
由于 iGPU 上尚不支持具有并发访问的统一内存,因此不支持
cudaMemPrefetchAsync()函数。Tegra 不支持 NVIDIA 管理库 (NVML) 库。但是,作为监视资源利用率的替代方法,可以使用
tegrastats。自 CUDA 11.5 起,只有事件共享 IPC API 在计算能力为 7.x 和更高的 L4T 和嵌入式 Linux Tegra 设备上受支持。内存共享 IPC API 在 Tegra 平台上仍然不受支持。EGLStream、NvSci 或
cuMemExportToShareableHandle()/cuMemImportFromShareableHandle()API 可用于在两个进程中的 CUDA 上下文之间进行通信。远程直接内存访问 (RDMA) 仅在运行 L4T 或嵌入式 Linux 的 Tegra 设备上受支持。
JIT 编译可能需要大量的 CPU 和带宽资源,这可能会干扰系统中的其他工作负载。因此,不建议确定性嵌入式应用程序使用 PTX-JIT 和 NVRTC JIT 等 JIT 编译,并且可以通过为特定的 GPU 目标编译来完全绕过 JIT 编译。例如:如果要为 SM 版本 87 编译,请使用此 nvcc 标志
--generate-code arch=compute_87,code=sm_87为此设备创建 CUDA 二进制文件。这避免了首次运行期间的 JIT 编译,并提高了运行时性能。在安全上下文中,Tegra 设备不支持 JIT 编译。Tegra 不支持对等 (P2P) 通信调用。
运行 QNX 的 Tegra 系统不支持 cuSOLVER 库。
不支持 nvGRAPH 库。
CUB 在 Tegra 产品上是实验性的。
有关其中一些功能的更多信息,请访问以下网站
IPC
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html#interprocess-communication
NVSCI
RDMA
https://docs.nvda.net.cn/cuda/gpudirect-rdma/index.html
P2P
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html#peer-to-peer-memory-access
5. EGL 互操作性
互操作是一种在两个 API 之间共享资源的有效机制。要与多个 API 共享数据,API 必须为每个 API 实现单独的互操作。
EGL 提供了互操作扩展,使其可以充当连接 API 的枢纽,从而消除了对多个互操作的需求,并封装了共享资源。API 必须实现这些扩展才能通过 EGL 与任何其他 API 互操作。CUDA 支持的 EGL 互操作是 EGLStream、EGLImage 和 EGLSync。
EGL 互操作扩展允许应用程序在 API 之间切换,而无需重写代码。例如,NvMedia 是生产者,CUDA 是消费者的基于 EGLStream 的应用程序可以修改为使用 OpenGL 作为消费者,而无需修改生产者代码。
注意
在 DRIVE OS 平台上,NVSCI 作为 EGL 互操作性的替代方案提供,用于安全关键型应用程序。请参考 NVSCI 以获取更多详细信息。
5.1. EGLStream
EGLStream 互操作性有助于在 API 之间高效传输帧序列,从而允许使用多个 Tegra® 引擎,例如 CPU、GPU、ISP 和其他引擎。
考虑一个应用程序,其中摄像头连续捕获图像,与 CUDA 共享以进行处理,然后稍后使用 OpenGL 渲染这些图像。在此应用程序中,图像帧在 NvMedia、CUDA 和 OpenGL 之间共享。缺少 EGLStream 互操作性将要求应用程序包含多个互操作以及 API 之间冗余的数据传输。EGLStream 有一个生产者和一个消费者。
EGLStream 提供以下优势
生产者和消费者之间高效的帧传输。
隐式同步处理。
跨进程支持。
dGPU 和 iGPU 支持。
Linux、QNX 和 Android 操作系统支持。
5.1.1. EGLStream 流
EGLStream 流具有以下步骤
初始化生产者和消费者 API
-
创建 EGLStream 并连接消费者和生产者。
注意
EGLStream 使用
eglCreateStreamKHR()创建,使用eglDestroyStreamKHR()销毁。消费者应始终在生产者之前连接到 EGLStream。
有关更多信息,请参阅以下网站上的 EGLStream 规范: https://www.khronos.org/registry/EGL/extensions/KHR/EGL_KHR_stream.txt
分配用于 EGL 帧的内存。
生产者填充 EGL 帧并将其呈现给 EGLStream。
消费者从 EGLStream 获取帧并在处理后将其释放回 EGLStream。
生产者从 EGLStream 收集消费者释放的帧。
生产者将同一帧或新帧呈现给 EGLStream。
步骤 4-7 重复执行,直到任务完成,使用旧帧或新帧。
消费者和生产者与 EGLStream 断开连接。
释放用于 EGL 帧的内存。
反初始化生产者和消费者 API。
EGLStream 应用程序流程如图 2所示。
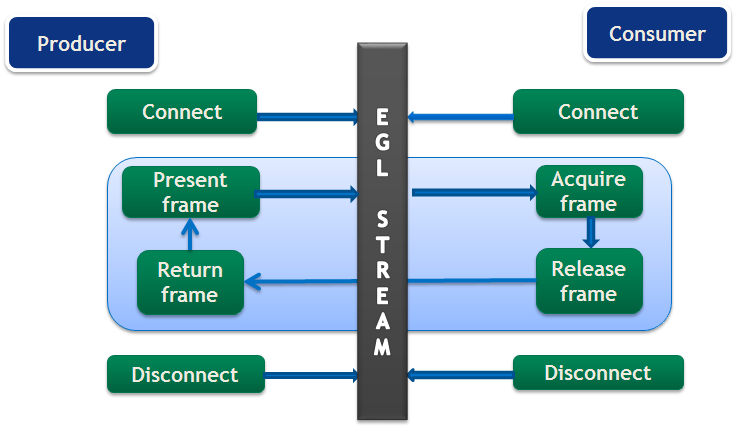
图 2 EGLStream 流
CUDA 生产者和消费者函数在表 3中列出。
角色 |
功能 |
API |
生产者 |
将生产者连接到 EGLStream |
|
将帧呈现给 EGLStream |
cuEGLStreamProducerPresentFrame() cudaEGLStreamProducerPresentFrame() |
|
获取已释放的帧 |
cuEGLStreamProducerReturnFrame() cudaEGLStreamProducerReturnFrame() |
|
断开与 EGLStream 的连接 |
||
消费者 |
将消费者连接到 EGLStream |
cuEGLStreamConsumerConnect() cuEGLStreamConsumeConnectWithFlags() cudaEGLStreamConsumerConnect() cudaEGLStreamConsumerConnectWithFlags() |
从 EGLStream 获取帧 |
cuEGLStreamConsumerAcquireFrame() |
|
释放已消耗的帧 |
cuEGLStreamConsumerReleaseFrame() cudaEGLStreamConsumerReleaseFrame() |
|
断开与 EGLStream 的连接 |
5.1.2. CUDA 作为生产者
当 CUDA 作为生产者时,支持的消费者是 CUDA、NvMedia 和 OpenGL。当 CUDA 作为生产者时要使用的 API 函数在表 3中列出。除了连接和断开与 EGLStream 的连接外,所有 API 调用都是非阻塞的。
以下生产者端步骤在下面的示例代码中显示
准备一个帧 (第 3-19 行)。
将生产者连接到 EGLStream (第 21 行)。
填充帧并呈现给 EGLStream (第 23-25 行)。
从 EGLStream 获取释放的帧 (第 27 行)。
在任务完成后断开消费者连接。(第 31 行)。
void ProducerThread(EGLStreamKHR eglStream) {
//Prepares frame
cudaEglFrame* cudaEgl = (cudaEglFrame *)malloc(sizeof(cudaEglFrame));
cudaEgl->planeDesc[0].width = WIDTH;
cudaEgl->planeDesc[0].depth = 0;
cudaEgl->planeDesc[0].height = HEIGHT;
cudaEgl->planeDesc[0].numChannels = 4;
cudaEgl->planeDesc[0].pitch = WIDTH * cudaEgl->planeDesc[0].numChannels;
cudaEgl->frameType = cudaEglFrameTypePitch;
cudaEgl->planeCount = 1;
cudaEgl->eglColorFormat = cudaEglColorFormatARGB;
cudaEgl->planeDesc[0].channelDesc.f=cudaChannelFormatKindUnsigned
cudaEgl->planeDesc[0].channelDesc.w = 8;
cudaEgl->planeDesc[0].channelDesc.x = 8;
cudaEgl->planeDesc[0].channelDesc.y = 8;
cudaEgl->planeDesc[0].channelDesc.z = 8;
size_t numElem = cudaEgl->planeDesc[0].pitch * cudaEgl->planeDesc[0].height;
// Buffer allocated by producer
cudaMalloc(&(cudaEgl->pPitch[0].ptr), numElem);
//CUDA producer connects to EGLStream
cudaEGLStreamProducerConnect(&conn, eglStream, WIDTH, HEIGHT))
// Sets all elements in the buffer to 1
K1<<<...>>>(cudaEgl->pPitch[0].ptr, 1, numElem);
// Present frame to EGLStream
cudaEGLStreamProducerPresentFrame(&conn, *cudaEgl, NULL);
cudaEGLStreamProducerReturnFrame(&conn, cudaEgl, eglStream);
.
.
//clean up
cudaEGLStreamProducerDisconnect(&conn);
.
}
帧表示为 cudaEglFramestructure。cudaEglFrame 中的 frameType 参数指示帧的内存布局。支持的内存布局是 CUDA 数组和设备指针。帧的宽度和高度值与 cudaEGLStreamProducerConnect() 中指定的值的任何不匹配都会导致未定义的行为。在示例中,CUDA 生产者正在发送单个帧,但它可以循环发送多个帧。CUDA 不能向 EGLStream 呈现超过 64 个活动帧。
cudaEGLStreamProducerReturnFrame() 调用会一直等待,直到它收到来自消费者的已释放帧。一旦 CUDA 生产者向 EGLstream 呈现第一个帧,至少会有一个帧始终可供消费者获取,直到生产者断开连接。 这可以防止从 EGLStream 中移除最后一个帧,这将阻止 cudaEGLStreamProducerReturnFrame()。
使用 EGL_NV_stream_reset 扩展将 EGLStream 属性 EGL_SUPPORT_REUSE_NV 设置为 false,以允许从 EGLStream 中移除最后一个帧。这允许从 EGLStream 中移除或返回最后一个帧。
5.1.3. CUDA 作为消费者
当 CUDA 作为消费者时,支持的生产者是 CUDA、OpenGL、NvMedia、Argus 和 Camera。当 CUDA 作为消费者时要使用的 API 函数在表 3 中列出。除了连接和断开与 EGLStream 的连接外,所有 API 调用都是非阻塞的。
以下消费者端步骤在下面的示例代码中显示
将消费者连接到 EGLStream (第 5 行)。
从 EGLStream 获取帧 (第 8-10 行)。
在消费者上处理帧 (第 16 行)。
将帧释放回 EGLStream (第 19 行)。
在任务完成后断开消费者连接 (第 22 行)。
void ConsumerThread(EGLStreamKHR eglStream) {
.
.
//Connect consumer to EGLStream
cudaEGLStreamConsumerConnect(&conn, eglStream);
// consumer acquires a frame
unsigned int timeout = 16000;
cudaEGLStreamConsumerAcquireFrame(& conn, &cudaResource, eglStream, timeout);
//consumer gets a cuda object pointer
cudaGraphicsResourceGetMappedEglFrame(&cudaEgl, cudaResource, 0, 0);
size_t numElem = cudaEgl->planeDesc[0].pitch * cudaEgl->planeDesc[0].height;
.
.
int checkIfOne = 1;
// Checks if each value in the buffer is 1, if any value is not 1, it sets checkIfOne = 0.
K2<<<...>>>(cudaEgl->pPitch[0].ptr, 1, numElem, checkIfOne);
.
.
cudaEGLStreamConsumerReleaseFrame(&conn, cudaResource, &eglStream);
.
.
cudaEGLStreamConsumerDisconnect(&conn);
.
}
在示例代码中,CUDA 消费者接收单个帧,但它也可以循环接收多个帧。如果 CUDA 消费者在指定的时间限制内未能使用 cudaEGLStreamConsumerAcquireFrame() 接收新帧,它会从 EGLStream 重新获取之前的帧。时间限制由超时参数指示。
应用程序可以使用 eglQueryStreamKHR() 查询新帧的可用性。如果消费者使用已释放的帧,则会导致未定义的行为。消费者行为仅针对读取操作定义。当消费者写入帧时,行为未定义。
如果在连接到 EGLStream 时销毁 CUDA 上下文,则流将置于 EGL_STREAM_STATE_DISCONNECTED_KHR 状态,并且连接句柄将失效。
5.1.4. 隐式同步
EGLStream 在应用程序中提供隐式同步。例如,在之前的代码示例中,生产者和消费者线程都在并行运行,并且 K1 和 K2 内核进程访问相同的帧,但消费者线程中的 K2 执行保证仅在生产者线程中的内核 K1 完成后发生。cudaEGLStreamConsumerAcquireFrame() 函数在 GPU 端等待直到 K1 完成,并确保生产者和消费者之间的同步。变量 checkIfOne 永远不会在消费者线程中的 K2 内核内设置为 0。
类似地,生产者线程中的 cudaEGLStreamProducerReturnFrame() 保证仅在 K2 完成且消费者释放帧后才获取帧。这些非阻塞调用允许 CPU 在两者之间执行其他计算,因为同步在 GPU 端处理。
EGLStreams_CUDA_Interop CUDA 示例代码详细展示了 EGLStream 的用法。
5.1.5. 生产者和消费者之间的数据传输
当生产者和消费者位于同一设备上时,可以避免生产者和消费者之间的数据传输。但是,在包含 dGPU 的 Tegra® 平台上(例如 NVIDIA DRIVE™ PX 2 中),生产者和消费者可能位于不同的设备上。 在这种情况下,内部需要额外的内存复制来在 Tegra® SoC DRAM 和 dGPU DRAM 之间移动帧。EGLStream 允许生产者和消费者在任何 GPU 上运行,而无需修改代码。
注意
在 Tegra® 设备连接到 dGPU 的系统上,如果生产者帧使用 CUDA 数组,则生产者和消费者都应位于同一 GPU 上。但是,如果生产者帧使用 CUDA 设备指针,则消费者可以位于任何 GPU 上。
5.1.6. EGLStream 管道
应用程序可以在管道中使用多个 EGL 流,以将帧从一个 API 传递到另一个 API。对于 NvMedia 向 CUDA 发送帧以进行计算的应用程序,CUDA 在计算后将同一帧发送到 OpenGL 进行渲染。
EGLStream 管道在图 3中示出。

图 3 EGLStream 管道
NvMedia 和 CUDA 分别作为生产者和消费者连接到一个 EGLStream。CUDA 和 OpenGL 分别作为生产者和消费者连接到另一个 EGLStream。
以管道方式使用多个 EGLStream 可以灵活地跨多个 API 发送帧,而无需分配额外的内存或需要显式数据传输。跨上述 EGLStream 管道发送帧涉及以下步骤。
NvMedia 向 CUDA 发送帧以进行处理。
CUDA 使用该帧进行计算,并发送到 OpenGL 进行渲染。
OpenGL 消耗该帧并将其释放回 CUDA。
CUDA 将该帧释放回 NvMedia。
可以在循环中执行上述步骤,以方便在 EGLStream 管道中传输多个帧。
5.2. EGLImage
EGLImage 互操作允许 EGL 客户端 API 与其他 EGL 客户端 API 共享图像数据。例如,应用程序可以使用 EGLImage 互操作来与 CUDA 共享 OpenGL 纹理,而无需分配任何额外的内存。单个 EGLImage 对象可以在多个客户端 API 之间共享以进行修改。
EGLImage 互操作不提供隐式同步。应用程序必须维护同步以避免竞争条件。
注意
EGLImage 使用 eglCreateImageKHR() 创建,并使用 eglDestroyImageKHR() 销毁。
有关更多信息,请参阅以下网站上的 EGLImage 规范
https://www.khronos.org/registry/EGL/extensions/KHR/EGL_KHR_image_base.txt
5.2.1. CUDA 与 EGLImage 的互操作
CUDA 支持与 EGLImage 的互操作,允许 CUDA 读取或修改 EGLImage 的数据。EGLImage 可以是单平面或多平面资源。在 CUDA 中,单平面 EGLImage 对象表示为 CUDA 数组或设备指针。类似地,多平面 EGLImage 对象表示为设备指针或 CUDA 数组的数组。Tegra® 设备在运行 Linux、QNX 或 Android 操作系统时支持 EGLImage。
使用 cudaGraphicsEGLRegisterImage() API 向 CUDA 注册 EGLImage 对象。向 CUDA 注册 EGLImage 会创建一个图形资源对象。应用程序可以使用 cudaGraphicsResourceGetMappedEglFrame() 从图形资源对象获取帧。在 CUDA 中,帧表示为 cudaEglFrame 结构。cudaEglFrame 中的 frameType 参数指示帧是 CUDA 设备指针还是 CUDA 数组。对于单平面图形资源,应用程序可以使用 cudaGraphicsResourceGetMappedPointer() 或 cudaGraphicsSubResourceGetMappedArray() 分别直接获取设备指针或 CUDA 数组。CUDA 数组可以绑定到纹理或表面引用,以便在内核内部访问。此外,可以通过 cudaMemcpy3D() 读取和写入多维 CUDA 数组。
注意
无法从 CUDA 对象创建 EGLImage。cudaGraphicsEGLRegisterImage() 函数仅在 Tegra® 设备上受支持。此外,cudaGraphicsEGLRegisterImage() 仅期望 ‘0’ 标志,因为其他 API 标志供将来使用。
以下示例代码展示了 EGLImage 互操作性。在代码中,EGLImage 对象 eglImage 是使用 OpenGL 纹理创建的。eglImage 对象在 CUDA 中映射为 CUDA 数组 pArray。pArray 数组绑定到表面对象,以允许在 changeTexture 中修改 OpenGL 纹理。函数 checkBuf() 检查纹理是否已使用新值更新。
int width = 256;
int height = 256;
int main()
{
.
.
unsigned char *hostSurf;
unsigned char *pSurf;
CUarray pArray;
unsigned int bufferSize = WIDTH * HEIGHT * 4;
pSurf= (unsigned char *)malloc(bufferSize); hostSurf = (unsigned char *)malloc(bufferSize);
// Initialize the buffer
for(int y = 0; y < HEIGHT; y++)
{
for(int x = 0; x < WIDTH; x++)
{
pSurf[(y*WIDTH + x) * 4 ] = 0; pSurf[(y*WIDTH + x) * 4 + 1] = 0;
pSurf[(y*WIDTH + x) * 4 + 2] = 0; pSurf[(y*WIDTH + x) * 4 + 3] = 0;
}
}
// NOP call to error-check the above glut calls
GL_SAFE_CALL({});
//Init texture
GL_SAFE_CALL(glGenTextures(1, &tex));
GL_SAFE_CALL(glBindTexture(GL_TEXTURE_2D, tex));
GL_SAFE_CALL(glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, WIDTH, HEIGHT, 0, GL_RGBA, GL_UNSIGNED_BYTE, pSurf));
EGLDisplay eglDisplayHandle = eglGetCurrentDisplay();
EGLContext eglCtx = eglGetCurrentContext();
// Create the EGL_Image
EGLint eglImgAttrs[] = { EGL_IMAGE_PRESERVED_KHR, EGL_FALSE, EGL_NONE, EGL_NONE };
EGLImageKHR eglImage = eglCreateImageKHR(eglDisplayHandle, eglCtx, EGL_GL_TEXTURE_2D_KHR, (EGLClientBuffer)(intptr_t)tex, eglImgAttrs);
glFinish();
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, WIDTH, HEIGHT, GL_RGBA, GL_UNSIGNED_BYTE, pSurf);
glFinish();
// Register buffer with CUDA
cuGraphicsEGLRegisterImage(&pResource, eglImage,0);
//Get CUDA array from graphics resource object
cuGraphicsSubResourceGetMappedArray( &pArray, pResource, 0, 0);
cuCtxSynchronize();
//Create a CUDA surface object from pArray
CUresult status = CUDA_SUCCESS;
CUDA_RESOURCE_DESC wdsc;
memset(&wdsc, 0, sizeof(wdsc));
wdsc.resType = CU_RESOURCE_TYPE_ARRAY; wdsc.res.array.hArray = pArray;
CUsurfObject writeSurface;
cuSurfObjectCreate(&writeSurface, &wdsc);
dim3 blockSize(32,32);
dim3 gridSize(width/blockSize.x,height/blockSize.y);
// Modifies the OpenGL texture using CUDA surface object
changeTexture<<<gridSize, blockSize>>>(writeSurface, width, height);
cuCtxSynchronize();
CUDA_MEMCPY3D cpdesc;
memset(&cpdesc, 0, sizeof(cpdesc));
cpdesc.srcXInBytes = cpdesc.srcY = cpdesc.srcZ = cpdesc.srcLOD = 0;
cpdesc.dstXInBytes = cpdesc.dstY = cpdesc.dstZ = cpdesc.dstLOD = 0;
cpdesc.srcMemoryType = CU_MEMORYTYPE_ARRAY; cpdesc.dstMemoryType = CU_MEMORYTYPE_HOST;
cpdesc.srcArray = pArray; cpdesc.dstHost = (void *)hostSurf;
cpdesc.WidthInBytes = WIDTH * 4; cpdesc.Height = HEIGHT; cpdesc.Depth = 1;
//Copy CUDA surface object values to hostSurf
cuMemcpy3D(&cpdesc);
cuCtxSynchronize();
unsigned char* temp = (unsigned char*)(malloc(bufferSize * sizeof(unsigned char)));
// Get the modified texture values as
GL_SAFE_CALL(glGetTexImage(GL_TEXTURE_2D, 0, GL_RGBA, GL_UNSIGNED_BYTE,(void*)temp));
glFinish();
// Check if the OpenGL texture got modified values
checkbuf(temp,hostSurf);
// Clean up CUDA
cuGraphicsUnregisterResource(pResource);
cuSurfObjectDestroy(writeSurface);
.
.
}
__global__ void changeTexture(cudaSurfaceObject_t arr, unsigned int width, unsigned int height){
unsigned int x = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int y = threadIdx.y + blockIdx.y * blockDim.y;
uchar4 data = make_uchar4(1, 2, 3, 4);
surf2Dwrite(data, arr, x * 4, y);
}
void checkbuf(unsigned char *ref, unsigned char *hostSurf) {
for(int y = 0; y < height*width*4; y++){
if (ref[y] != hostSurf[y])
printf("mis match at %d\n",y);
}
}
由于 EGLImage 不提供隐式同步,因此上述示例应用程序使用 glFinish() 和 cudaThreadSynchronize() 调用来实现同步。这两个调用都会阻塞 CPU 线程。为了避免阻塞 CPU 线程,请使用 EGLSync 提供同步。以下部分显示了使用 EGLImage 和 EGLSync 的示例。
5.3. EGLSync
EGLSync 是一种跨 API 同步原语。它允许 EGL 客户端 API 与其他 EGL 客户端 API 共享其同步对象。例如,应用程序可以使用 EGLSync 互操作来与 CUDA 共享 OpenGL 同步对象。
注意
EGLSync 对象使用 eglCreateSyncKHR() 创建,并使用 eglDestroySyncKHR() 销毁。
有关更多信息,请参阅以下网站上的 EGLSync 规范
https://www.khronos.org/registry/EGL/extensions/KHR/EGL_KHR_fence_sync.txt
5.3.1. CUDA 与 EGLSync 的互操作
在成像应用程序中,当两个客户端在 GPU 上运行并共享资源时,缺少跨 API GPU 同步对象会迫使客户端使用 CPU 端同步来避免竞争条件。CUDA 与 EGLSync 的互操作允许应用程序直接在 CUDA 和其他客户端 API 之间交换同步对象。 这避免了对 CPU 端同步的需求,并允许 CPU 完成其他任务。在 CUDA 中,EGLSync 对象映射为 CUDA 事件。
注意
目前,CUDA 与 EGLSync 的互操作仅在 Tegra® 设备上受支持。
5.3.2. 从 CUDA 事件创建 EGLSync
以下示例代码展示了如何从 CUDA 事件创建 EGLSync 对象。请注意,从 CUDA 事件创建 EGLSync 对象应在记录 CUDA 事件后立即进行。
EGLDisplay dpy = eglGetCurrentDisplay();
// Create CUDA event
cudaEvent_t event;
cudaStream_t *stream;
cudaEventCreate(&event);
cudaStreamCreate(&stream);
// Record the event with cuda event
cudaEventRecord(event, stream);
const EGLAttrib attribs[] = {
EGL_CUDA_EVENT_HANDLE_NV, (EGLAttrib )event,
EGL_NONE
};
//Create EGLSync from the cuda event
eglsync = eglCreateSync(dpy, EGL_NV_CUDA_EVENT_NV, attribs);
//Wait on the sync
eglWaitSyncKHR(...);
注意
在从 CUDA 事件创建 EGLSync 对象之前初始化 CUDA 事件,以避免未定义的行为。
5.3.3. 从 EGLSync 创建 CUDA 事件
以下示例代码展示了如何从 EGLSync 对象创建 CUDA 事件。
EGLSync eglsync;
EGLDisplay dpy = eglGetCurrentDisplay();
// Create an eglSync object from openGL fense sync object
eglsync = eglCreateSyncKHR(dpy, EGL_SYNC_FENCE_KHR, NULL);
cudaEvent_t event;
cudaStream_t* stream;
cudaStreamCreate(&stream);
// Create CUDA event from eglSync
cudaEventCreateFromEGLSync(&event, eglSync, cudaEventDefault);
// Wait on the cuda event. It waits on GPU till OpenGL finishes its
// task
cudaStreamWaitEvent(stream, event, 0);
注意
cudaEventRecord() 和 cudaEventElapsedTime() 函数不支持从 EGLSync 对象创建的事件。
下面重写了 EGLImage 部分中给出的相同示例,以说明 EGLSync 互操作的用法。在示例代码中,CPU 阻塞调用(例如 glFinish() 和 cudaThreadSynchronize())被 EGLSync 互操作调用替换。
int width = 256;
int height = 256;
int main()
{
.
.
unsigned char *hostSurf;
unsigned char *pSurf;
cudaArray_t pArray;
unsigned int bufferSize = WIDTH * HEIGHT * 4;
pSurf= (unsigned char *)malloc(bufferSize); hostSurf = (unsigned char *)malloc(bufferSize);
// Intialize the buffer
for(int y = 0; y < bufferSize; y++)
pSurf[y] = 0;
//Init texture
GL_SAFE_CALL(glGenTextures(1, &tex));
GL_SAFE_CALL(glBindTexture(GL_TEXTURE_2D, tex));
GL_SAFE_CALL(glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, WIDTH, HEIGHT, 0, GL_RGBA, GL_UNSIGNED_BYTE, pSurf));
EGLDisplay eglDisplayHandle = eglGetCurrentDisplay();
EGLContext eglCtx = eglGetCurrentContext();
cudaEvent_t cuda_event;
cudaEventCreateWithFlags(cuda_event, cudaEventDisableTiming);
EGLAttribKHR eglattrib[] = { EGL_CUDA_EVENT_HANDLE_NV, (EGLAttrib) cuda_event, EGL_NONE};
cudaStream_t* stream;
cudaStreamCreateWithFlags(&stream,cudaStreamDefault);
EGLSyncKHR eglsync1, eglsync2;
cudaEvent_t egl_event;
// Create the EGL_Image
EGLint eglImgAttrs[] = { EGL_IMAGE_PRESERVED_KHR, EGL_FALSE, EGL_NONE, EGL_NONE };
EGLImageKHR eglImage = eglCreateImageKHR(eglDisplayHandle, eglCtx, EGL_GL_TEXTURE_2D_KHR, (EGLClientBuffer)(intptr_t)tex, eglImgAttrs);
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, WIDTH, HEIGHT, GL_RGBA, GL_UNSIGNED_BYTE, pSurf);
//Creates an EGLSync object from GL Sync object to track
//finishing of copy.
eglsync1 = eglCreateSyncKHR(eglDisplayHandle, EGL_SYNC_FENCE_KHR, NULL);
//Create CUDA event object from EGLSync obejct
cuEventCreateFromEGLSync(&egl_event, eglsync1, cudaEventDefault);
//Waiting on GPU to finish GL copy
cuStreamWaitEvent(stream, egl_event, 0);
// Register buffer with CUDA
cudaGraphicsEGLRegisterImage(&pResource, eglImage, cudaGraphicsRegisterFlagsNone);
//Get CUDA array from graphics resource object
cudaGraphicsSubResourceGetMappedArray( &pArray, pResource, 0, 0);
.
.
//Create a CUDA surface object from pArray
struct cudaResourceDesc resDesc;
memset(&resDesc, 0, sizeof(resDesc));
resDesc.resType = cudaResourceTypeArray; resDesc.res.array.array = pArray;
cudaSurfaceObject_t inputSurfObj = 0;
cudaCreateSurfaceObject(&inputSurfObj, &resDesc);
dim3 blockSize(32,32);
dim3 gridSize(width/blockSize.x,height/blockSize.y);
// Modifies the CUDA array using CUDA surface object
changeTexture<<<gridSize, blockSize>>>(inputSurfObj, width, height);
cuEventRecord(cuda_event, stream);
//Create EGLsync object from CUDA event cuda_event
eglsync2 = eglCreateSync64KHR(dpy, EGL_SYNC_CUDA_EVENT_NV, eglattrib);
//waits till kernel to finish
eglWaitSyncKHR(eglDisplayHandle, eglsync2, 0);
.
//Copy modified pArray values to hostSurf
.
unsigned char* temp = (unsigned char*)(malloc(bufferSize * sizeof(unsigned char)));
// Get the modified texture values
GL_SAFE_CALL(glGetTexImage(GL_TEXTURE_2D, 0, GL_RGBA, GL_UNSIGNED_BYTE,(void*)temp));
.
.
// This function check if the OpenGL texture got modified values
checkbuf(temp,hostSurf);
// Clean up CUDA
cudaGraphicsUnregisterResource(pResource);
cudaDestroySurfaceObject(inputSurfObj);
eglDestroySyncKHR(eglDisplayHandle, eglsync1);
eglDestroySyncKHR(eglDisplayHandle, eglsync2);
cudaEventDestroy(egl_event);
cudaEventDestroy(cuda_event);
.
.
}
6. Jetson 的 CUDA 可升级软件包
CUDA 从 JetPack SDK 5.0 开始引入了升级路径,该路径提供了一个选项来更新 CUDA 驱动程序和 CUDA 工具包到最新版本。
6.1. 安装 CUDA 升级软件包
6.1.1. 前提条件
Jetson 设备必须安装兼容的 NVIDIA JetPack 版本。有关更多信息,请参阅使用正确的升级包。
6.1.2. 从网络存储库或本地安装程序
CUDA 下载页面提供了关于如何下载和使用本地安装程序或 CUDA 网络存储库来安装最新工具包的分步说明。CUDA 升级软件包会与适用于 Linux-aarch64-jetson 设备的相应 CUDA 工具包一起下载和安装。
对于应用程序在主机上构建并且只需要在目标设备上独立安装 CUDA 升级软件包的用例,可以在 CUDA Repos 中找到相应的 Debians。以 11.8 为例,可以通过运行以下命令来安装它
$ sudo apt-get install -y cuda-compat-11-8
注意
这是具有磁盘空间(辅助存储)限制的设备的 CUDA 升级推荐路径。
已安装的升级软件包位于版本化的工具包位置。例如,对于 11.8,它位于 /usr/local/cuda-11.8/。
升级软件包包含以下文件
libcuda.so.*- CUDA 驱动程序libnvidia-nvvm.so.*- 即时 - 链接时优化(仅限 CUDA 11.8 及更高版本)libnvidia-ptxjitcompiler.so.*- PTX 文件的 JIT(即时)编译器nvidia-cuda-mps-control- CUDA MPS 控制可执行文件nvidia-cuda-mps-server- CUDA MPS 服务器可执行文件
这些文件共同实现了 CUDA 11.8 驱动程序接口。
注意
此软件包仅提供文件,而不配置系统。
示例
以下命令显示如何安装 CUDA 升级软件包并使用它来运行应用程序。
$ sudo apt-get -y install cuda
Reading package lists...
Building dependency tree...
Reading state information...
The following additional packages will be installed:
cuda-11-8 cuda-cccl-11-8 cuda-command-line-tools-11-8 cuda-compat-11-8
...<snip>...
The following NEW packages will be installed:
cuda cuda-11-8 cuda-cccl-11-8 cuda-command-line-tools-11-8 cuda-compat-11-8
...<snip>...
0 upgraded, 48 newly installed, 0 to remove and 38 not upgraded.
Need to get 15.7 MB/1,294 MB of archives.
After this operation, 4,375 MB of additional disk space will be used.
Get:1 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/arm64 cuda-compat-11-8 11.8.31339915-1 [15.8 MB]
Fetched 15.7 MB in 12s (1,338 kB/s)
Selecting previously unselected package cuda-compat-11-8.
(Reading database ...
...<snip>...
(Reading database ... 100%
(Reading database ... 148682 files and directories currently installed.)
Preparing to unpack .../00-cuda-compat-11-8_11.8.30682616-1_arm64.deb ...
Unpacking cuda-compat-11-8 (11.8.30682616-1) ...
...<snip>...
Unpacking cuda-11-8 (11.8.0-1) ...
Selecting previously unselected package cuda.
Preparing to unpack .../47-cuda_11.8.0-1_arm64.deb ...
Unpacking cuda (11.8.0-1) ...
Setting up cuda-toolkit-config-common (11.8.56-1) ...
Setting up cuda-nvml-dev-11-8 (11.8.56-1) ...
Setting up cuda-compat-11-8 (11.8.30682616-1) ...
...<snip>...
$ ls -l /usr/local/cuda-11.8/compat
total 55300
lrwxrwxrwx 1 root root 12 Jan 6 19:14 libcuda.so -> libcuda.so.1
lrwxrwxrwx 1 root root 14 Jan 6 19:14 libcuda.so.1 -> libcuda.so.1.1
-rw-r--r-- 1 root root 21702832 Jan 6 19:14 libcuda.so.1.1
lrwxrwxrwx 1 root root 19 Jan 6 19:14 libnvidia-nvvm.so -> libnvidia-nvvm.so.4
lrwxrwxrwx 1 root root 23 Jan 6 19:14 libnvidia-nvvm.so.4 -> libnvidia-nvvm.so.4.0.0
-rw-r--r-- 1 root root 24255256 Jan 6 19:14 libnvidia-nvvm.so.4.0.0
-rw-r--r-- 1 root root 10665608 Jan 6 19:14 libnvidia-ptxjitcompiler.so
lrwxrwxrwx 1 root root 27 Jan 6 19:14 libnvidia-ptxjitcompiler.so.1 -> libnvidia-ptxjitcompiler.so
$ export PATH=/usr/local/cuda-11.8/bin:$PATH
$ export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH
用户可以设置 LD_LIBRARY_PATH 以包含升级软件包安装的库,然后再运行 CUDA 11.8 应用程序
$ LD_LIBRARY_PATH=/usr/local/cuda-11.8/compat:$LD_LIBRARY_PATH ~/Samples/1_Utilities/deviceQuery
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Orin"
CUDA Driver Version / Runtime Version 11.8 / 11.8
CUDA Capability Major/Minor version number: 8.7
...<snip>...
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.8, CUDA Runtime Version = 11.8, NumDevs = 1
Result = PASS
在给定系统上的任何时间点只能安装一个 CUDA 升级软件包。在安装新的 CUDA 升级软件包时,将删除已安装的升级软件包的先前版本,并将其替换为新版本。默认驱动程序(最初随 NVIDIA JetPack 安装,并且是 L4T BSP 的一部分)将由安装程序保留。应用程序可以选择使用默认版本的 CUDA(最初随 NVIDIA JetPack 安装)或升级软件包安装的版本。LD_LIBRARY_PATH 变量可用于选择所需的版本。
除了 LD_LIBRARY_PATH 之外,CUDA MPS 用户还必须设置 PATH 变量,以便在使用 MPS 之前以及运行使用 MPS 的 CUDA 应用程序之前,使用升级软件包安装的 nvidia-cuda-mps-* 可执行文件。随升级软件包安装的 MPS 可执行文件仅与随同一升级软件包安装的 CUDA 驱动程序兼容,反之亦然,这可以使用版本信息进行检查。
如果升级软件包与 NVIDIA JetPack 版本不兼容,则安装将失败。
6.2. CUDA 升级软件包的部署注意事项
6.2.1. 使用正确的升级包
CUDA 升级软件包以它可以支持的最高工具包命名。例如,如果您使用的是 NVIDIA JetPack SDK 5.0 (11.4) 驱动程序,但需要 11.8 应用程序支持,请安装 11.8 的 CUDA 升级软件包。
每个 CUDA 版本将仅支持针对特定 NVIDIA JetPack 版本的升级。下表显示了每个 CUDA 版本支持的 NVIDIA JetPack SDK 版本。
JetPack SDK |
CUDA 11.4 |
CUDA 11.8 |
CUDA 12.0 |
CUDA 12.1 |
CUDA 12.2 |
CUDA 12.3 onwards |
|---|---|---|---|---|---|---|
5.x |
默认 |
C |
C |
C |
C |
X |
JetPack SDK |
CUDA 12.2 |
CUDA 12.3 |
CUDA 12.4 |
CUDA 12.5 |
CUDA 12.6 |
|---|---|---|---|---|---|
6.x |
默认 |
X |
C |
C |
C |
下表显示了 NVIDIA JetPack 5.x 版本上的 CUDA UMD 和 CUDA 工具包版本兼容性
CUDA UMD |
CUDA 工具包 |
||||
11.4(默认 - NVIDIA JetPack 的一部分) |
11.8 |
12.0 |
12.1 |
12.2 |
|
11.4(默认 - NVIDIA JetPack 的一部分) |
C |
C (次要版本兼容性) |
X |
X |
X |
11.8(通过升级软件包) |
C (二进制兼容性) |
C |
X |
X |
X |
12.0(通过升级软件包) |
C (二进制兼容性) |
C (二进制兼容性) |
C |
C (次要版本兼容性) |
C (次要版本兼容性) |
12.1(通过升级软件包) |
C (二进制兼容性) |
C (二进制兼容性) |
C (二进制兼容性) |
C |
C (次要版本兼容性) |
12.2(通过升级软件包) |
C (二进制兼容性) |
C (二进制兼容性) |
C (二进制兼容性) |
C (二进制兼容性) |
C |
下表显示了 NVIDIA JetPack 6.x 版本上的 CUDA UMD 和 CUDA 工具包版本兼容性
CUDA UMD |
CUDA 工具包 |
|||||
12.2(默认 - NVIDIA JetPack 的一部分) |
12.4 |
12.5 |
12.6 |
12.7 |
12.8 |
|
12.2(默认 - NVIDIA JetPack 的一部分) |
C |
C (次要版本兼容性) |
C (次要版本兼容性) |
C (次要版本兼容性) |
X |
C (次要版本兼容性) |
12.4(通过升级软件包) |
C (二进制兼容性) |
C |
C (次要版本兼容性) |
C (次要版本兼容性) |
X |
C (次要版本兼容性) |
12.5(通过升级软件包) |
C (二进制兼容性) |
C (二进制兼容性) |
C |
C (次要版本兼容性) |
X |
C (次要版本兼容性) |
12.6(通过升级软件包) |
C (二进制兼容性) |
C (二进制兼容性) |
C (二进制兼容性) |
C |
X |
C (次要版本兼容性) |
12.7 |
X |
X |
X |
X |
X |
X |
12.8(通过升级软件包) |
C (二进制兼容性) |
C (二进制兼容性) |
C (二进制兼容性) |
C (二进制兼容性) |
X |
C |
C - 兼容
X – 不兼容
注意
NVIDIA JetPack SDK 5.x 上的 CUDA 升级软件包从 CUDA 11.8 开始提供。
6.2.2. 功能例外
CUDA 升级软件包仅更新 CUDA 驱动程序接口,同时保持 NVIDIA JetPack SDK 组件的其余部分不变。如果最新 CUDA 驱动程序中的新功能需要更新的 NVIDIA JetPack SDK 组件/接口,则在使用时可能无法工作并报错。
6.2.3. 检查兼容性支持
除了 CUDA 驱动程序和某些编译器组件外,NVIDIA JetPack 中的其他驱动程序仍保持默认版本。CUDA 升级路径仅适用于 CUDA。
编写良好的应用程序应使用以下错误代码来确定是否支持 CUDA 升级。系统管理员应注意这些错误代码,以确定部署中是否存在错误。
CUDA_ERROR_SYSTEM_DRIVER_MISMATCH = 803。此错误表示升级的 CUDA 驱动程序版本与系统上已安装的驱动程序版本之间存在不匹配。CUDA_ERROR_COMPAT_NOT_SUPPORTED_ON_DEVICE = 804。此错误表示系统已更新为使用 CUDA 升级软件包运行,但 CUDA 检测到的可见硬件不支持此配置。
7. cuDLA
DLA(深度学习加速器)是 NVIDIA Tegra SoC 上存在的固定功能加速器,用于推理应用程序。DLA HW 具有卓越的性能/W,并且可以原生运行现代神经网络中的许多层,因此使其成为嵌入式 AI 应用程序的有吸引力的价值主张。编程 DLA 通常包括离线和在线步骤:在离线步骤中,输入网络由 DLA 编译器解析和编译为可加载文件;在在线步骤中,该可加载文件由 DLA HW 执行以生成推理结果。NVIDIA 当前提供的用于执行在线或执行步骤的 SW 堆栈包括 NvMediaDla 和 DLA 运行时/KMD。这些 API 共同使用户能够将 DLA 任务提交到 DLA HW 以进行推理。主要功能路径如下图所示。
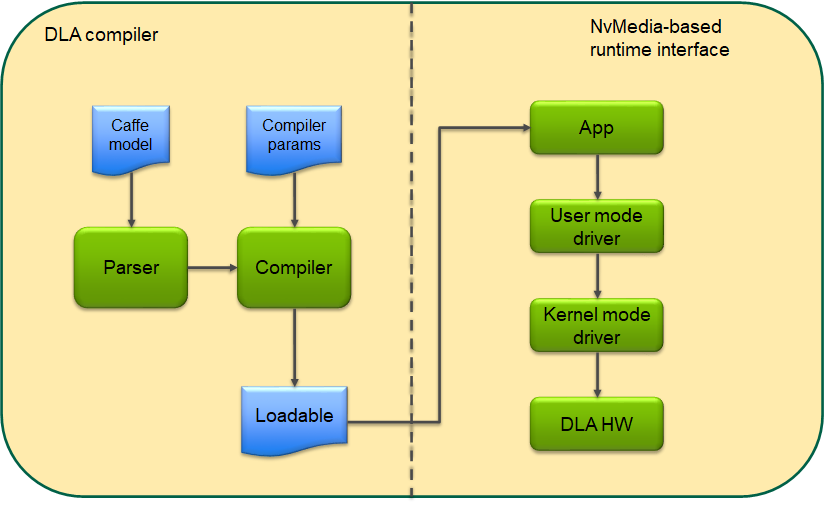
图 4 DLA SW 堆栈
从上面的模型可以看出,希望在应用程序中一起使用 GPU 和 DLA 的用户将不得不使用互操作机制(例如 EGLStreams/NvSci)来共享缓冲区以及 GPU 和 DLA 之间的同步原语。这些互操作机制通常涉及每个共享缓冲区的许多步骤,并且微调 GPU 和 DLA 之间任务调度的能力有限。cuDLA 是 CUDA 编程模型的扩展,它将 DLA(深度学习加速器)与 CUDA 集成在一起,从而可以使用 CUDA 编程构造(例如流和图)提交 DLA 任务。管理共享缓冲区以及同步 GPU 和 DLA 之间的任务由 cuDLA 透明地处理,从而使程序员可以专注于高级用例。
7.1. 开发者指南
本节介绍使用 cuDLA API 编程 DLA HW 所涉及的关键原则。cuDLA 接口公开了初始化设备、管理内存和提交 DLA 任务的机制。因此,本节讨论如何将 cuDLA API 用于这些用例。这些 API 的详细规范在 API 规范中描述,在编写 cuDLA 应用程序时应参考该规范。
由于 cuDLA 是 CUDA 的扩展,因此它被设计为与执行 CUDA 功能(例如 GPU 管理、上下文管理等)的 CUDA API 协同工作。因此,在评估 cuDLA API 的行为时,应用程序的当前状态(就选择哪个 GPU 以及当前活动上下文(及其生命周期)而言)都是重要的考虑因素。
7.1.1. 设备模型
要执行任何 DLA 操作,应用程序首先必须创建 cuDLA 设备句柄。cudlaCreateDevice() API 创建 cuDLA 设备的逻辑实例,其中选定的 DLA HW 实例与通过 CUDA 选择的当前活动 GPU 耦合。例如,以下代码片段将创建一个由当前 GPU(通过 cudaSetDevice() 设置)和 DLA HW 0 组成的逻辑实例。目前,cuDLA 仅支持 Tegra 上的 iGPU,并且尝试通过将当前 GPU 设置为 dGPU 来创建设备句柄将导致在 cudlaCreateDevice() 期间出现设备创建错误。
cudlaDevHandle devHandle;
cudlaStatus ret;
ret = cudlaCreateDevice(0, &devHandle, CUDLA_CUDA_DLA);
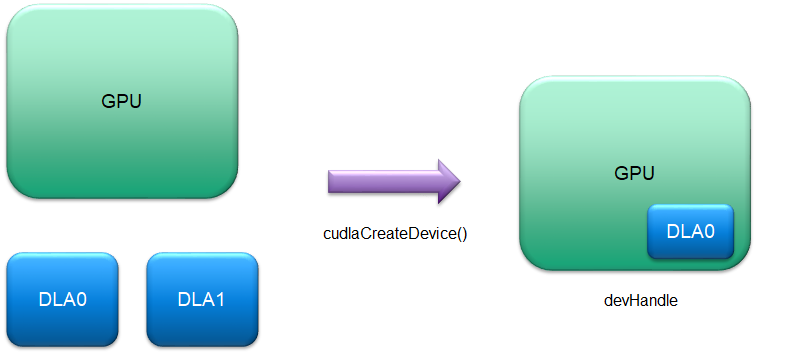
图 5 设备模型
用户可以使用 cudlaCreateDevice() 创建任意数量的此类逻辑实例,使用 GPU 和 DLA HW 实例的任何组合(取决于系统资源可用性)

图 6 设备模型 - 多个实例
此外,cudlaCreateDevice() 在设备创建期间支持备用标志 - CUDLA_STANDALONE。当应用程序希望在独立模式下创建 cuDLA 设备时,可以使用此标志,即不将其与 GPU 设备耦合。所有设备提交也可以使用独立模式下的 cuDLA 完成,但在此模式下,不支持 CUDA 交互。因此,在下文中,在描述特定 API 或特定用例时,考虑两种执行模式:混合模式和独立模式。API 规范包含有关哪些 API 在哪种模式下受支持的完整详细信息。
7.1.2. 加载和查询模块
cuDLA 设备句柄需要与它关联一个合适的 loadable,然后才能进行任何 DLA 任务提交。loadable 通常使用 TensorRT 离线创建。loadable 具有有关输入和输出张量数量及其各自元数据的信息,并且可以由应用程序查询以检索此信息。成功的 cuDLA 设备初始化后的典型应用程序流程如下所示(穿插一些调试日志)
DPRINTF("Device created successfully\n");
// Load the loadable from 'loadableData' in which the loadable binary has
// been copied from the location of the loadable - disk or otherwise.
err = cudlaModuleLoadFromMemory(devHandle, loadableData, file_size, &moduleHandle, 0);
if (err != cudlaSuccess)
{
// handle error
}
// Get tensor attributes.
uint32_t numInputTensors = 0;
uint32_t numOutputTensors = 0;
cudlaModuleAttribute attribute;
err = cudlaModuleGetAttributes(moduleHandle, CUDLA_NUM_INPUT_TENSORS, &attribute);
if (err != cudlaSuccess)
{
// handle error
}
numInputTensors = attribute.numInputTensors;
DPRINTF("numInputTensors = %d\n", numInputTensors);
err = cudlaModuleGetAttributes(moduleHandle, CUDLA_NUM_OUTPUT_TENSORS, &attribute);
if (err != cudlaSuccess)
{
// handle error
}
numOutputTensors = attribute.numOutputTensors;
DPRINTF("numOutputTensors = %d\n", numOutputTensors);
cudlaModuleTensorDescriptor* inputTensorDesc =
(cudlaModuleTensorDescriptor*)malloc(sizeof(cudlaModuleTensorDescriptor)
*numInputTensors);
cudlaModuleTensorDescriptor* outputTensorDesc =
(cudlaModuleTensorDescriptor*)malloc(sizeof(cudlaModuleTensorDescriptor)
*numOutputTensors);
if ((inputTensorDesc == NULL) || (outputTensorDesc == NULL))
{
// handle error
}
attribute.inputTensorDesc = inputTensorDesc;
err = cudlaModuleGetAttributes(moduleHandle,
CUDLA_INPUT_TENSOR_DESCRIPTORS,
&attribute);
if (err != cudlaSuccess)
{
// handle error
}
attribute.outputTensorDesc = outputTensorDesc;
err = cudlaModuleGetAttributes(moduleHandle,
CUDLA_OUTPUT_TENSOR_DESCRIPTORS,
&attribute);
if (err != cudlaSuccess)
{
// handle error
}
应用程序可以使用检索到的张量描述符来设置其数据缓冲区的大小和格式。有关张量描述符内容的详细信息,请参阅 API 规范部分中的 cudlaModuleGetAttributes()。
7.1.3. 内存模型
GPU 和 DLA 具有不同的 MMU,它们在执行各自的功能时管理 VA 到 PA 的转换。下图显示了一个示例,其中 GMMU 执行 GPU VA 的转换,而 SMMU 对来自 DLA 的 VA 执行类似的功能。
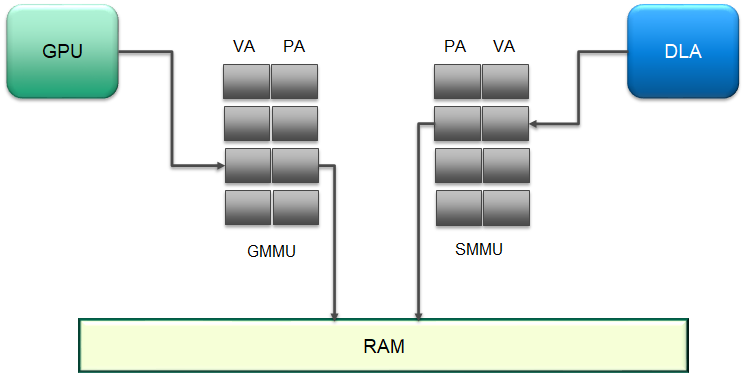
图 7 虚拟地址到物理地址转换
在混合模式下,在 DLA 可以访问 CUDA 指针之前,必须先向 DLA 注册 CUDA 指针。此注册步骤会在 SMMU 中创建一个条目,并返回相应的 VA 以用于任务提交。以下代码片段显示了使用标志 CUDLA_CUDA_DLA 创建的设备句柄的注册示例
// Allocate memory on GPU.
void* buffer;
uint32_t size = 100;
result = cudaMalloc(&inputBufferGPU, size);
if (result != cudaSuccess)
{
// handle error
}
// Register the CUDA-allocated buffers.
uint64_t* bufferRegisteredPtr = NULL;
err = cudlaMemRegister(devHandle,
(uint64_t* )inputBufferGPU,
size,
&bufferRegisteredPtr,
0);
if (err != cudlaSuccess)
{
// handle error
}
在独立模式下,cuDLA 的运行无需底层 CUDA 设备。因此,在此模式下,由应用程序执行的内存分配(需要随后注册)必须来自 CUDA 外部。在 Tegra 系统上,cuDLA 支持通过 cudlaImportExternalMemory() API 注册 NvSciBuf 分配,如下面的代码片段所示
// Allocate the NvSciBuf object.
NvSciBufObj inputBufObj;
sciError = NvSciBufObjAlloc(reconciledInputAttrList, &inputBufObj);
if (sciError != NvSciError_Success)
{
// handle error
}
uint64_t* inputBufObjRegPtr = NULL;
// importing external memory
cudlaExternalMemoryHandleDesc memDesc = { 0 };
memset(&memDesc, 0, sizeof(memDesc));
memDesc.extBufObject = (void *)inputBufObj;
memDesc.size = size;
err = cudlaImportExternalMemory(devHandle, &memDesc, &inputBufObjRegPtr, 0);
if (err != cudlaSuccess)
{
// handle error
}
7.1.4. 任务执行和同步模型
7.1.4.1. 任务执行
提交 DLA 任务以执行类似于将 CUDA 内核提交到 GPU。cuDLA 原生支持 CUDA 流,并与流语义无缝协作,以确保所有为 DLA 设计的任务仅在流上的先前任务执行完成后才由 DLA 硬件执行。这使应用程序能够使用熟悉的流语义在 GPU 和 DLA 之间设置复杂的处理工作流程,而无需管理 GPU 和 DLA 之间的内存一致性和执行依赖性。执行模型的直观说明如下图所示。DLA 任务可以与给定流或多个流中的 GPU 任务交错,并且 cudlaSubmitTask() 处理所有内存/执行依赖项。
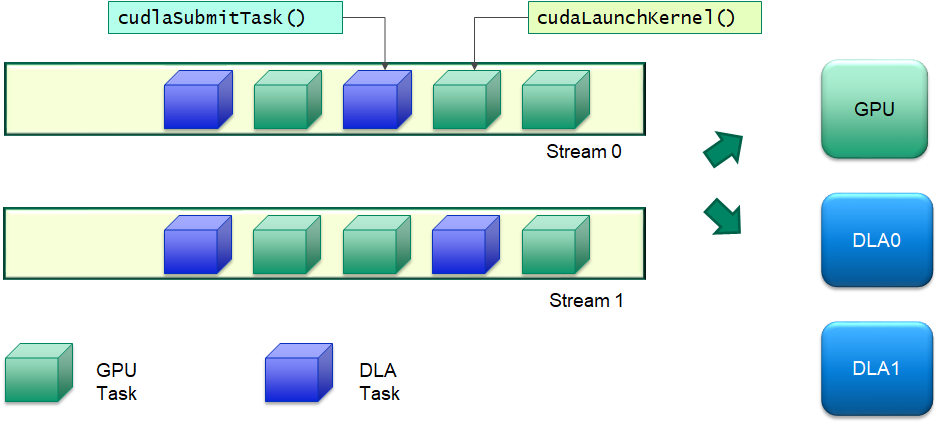
Figure 8 cuDLA 任务执行模型
提交任务 API 需要以在 DLA 中注册的地址形式的输入和输出张量(使用 cudlaMemRegister())。应用程序可以预先向 cuDLA 注册所有必需的指针,然后在 cudlaSubmitTask() 期间使用注册的指针。反过来,此 API 确保在 DLA 开始执行当前任务之前,与注册指针相对应的底层内存上先前操作的结果对 DLA 可见。下面的代码片段显示了一个由 CUDA 和 cuDLA 操作组成的典型应用程序代码
DPRINTF("ALL MEMORY REGISTERED SUCCESSFULLY\n");
// Copy data from CPU buffers to GPU buffers.
result = cudaMemcpyAsync(inputBufferGPU, inputBuffer, inputTensorDesc[0].size, cudaMemcpyHostToDevice, stream);
if (result != cudaSuccess)
{
// handle error
}
result = cudaMemsetAsync(outputBufferGPU, 0, outputTensorDesc[0].size, stream);
if (result != cudaSuccess)
{
// handle error
}
// Enqueue a cuDLA task.
cudlaTask task;
task.moduleHandle = moduleHandle;
task.outputTensor = &outputBufferRegisteredPtr;
task.numOutputTensors = 1;
task.numInputTensors = 1;
task.inputTensor = &inputBufferRegisteredPtr;
task.waitEvents = NULL;
task.signalEvents = NULL;
err = cudlaSubmitTask(devHandle, &task, 1, stream, 0);
if (err != cudlaSuccess)
{
// handle error
}
DPRINTF("SUBMIT IS DONE !!!\n");
result = cudaMemcpyAsync(outputBuffer, outputBufferGPU, outputTensorDesc[0].size, cudaMemcpyDeviceToHost, stream);
if (result != cudaSuccess)
{
// handle error
}
在独立模式下,cudlaSubmitTask() 中的 stream 参数必须指定为 NULL,因为 cuDLA 独立于 CUDA 运行。在这种情况下,提交到 DLA 的任务以 FIFO 顺序执行。
7.1.4.1.1. 多线程用户提交
如果用户确定提交到特定设备句柄仅在此线程中发生,并且此设备句柄与任何其他可能在并行线程中用于提交的设备句柄之间在应用程序级别没有共享数据,则用户可以在提交到特定设备句柄期间指定 CUDLA_SUBMIT_SKIP_LOCK_ACQUIRE 标志。此标志有助于提交路径中的一些优化,这可能会从应用程序的角度来看带来更好的提交时间。
7.1.4.2. 同步
混合模式下任务的同步不需要不同的 API。由于 DLA 任务被提交到 CUDA 流,因此只需等待流完成其工作,以确保在该流上提交的所有 DLA 任务都已完成。在这方面,DLA 任务同步与 CUDA 中可用的任何不同的同步机制(事件、流、设备)兼容,并且整个 CUDA 机制可供应用程序设置不同的流程和用例。
然而,在独立模式下,同步机制是不同的,因为 cuDLA 独立于 CUDA 运行。在此模式下,cudlaTask 结构提供了一个规定,用于指定 cuDLA 必须等待和分别发出信号的等待和信号事件,作为 cudlaSubmitTask() 的一部分。每个提交的任务都将等待其所有等待事件发出信号,然后再开始执行,并将提供一个信号事件(如果在 cudlaSubmitTask() 期间请求了一个信号事件),应用程序(或任何其他实体)可以等待该信号事件,以确保提交的任务已完成执行。在 cuDLA 1.0 中,仅支持 NvSciSync fences 作为等待事件的一部分。此外,只有 NvSciSync 对象可以注册并作为信号事件的一部分发出信号,并且与发出信号的事件相对应的 fence 作为 cudlaSubmitTask() 的一部分返回。
像所有内存操作一样,事件的底层后备存储(在本例中为 NvSciSync 对象)必须在任务提交中使用之前在 cuDLA 中注册。下面的代码片段显示了一个示例流程,其中应用程序创建输入和输出 NvSciSync 对象并注册它们,创建与它们对应的 fences,将相应的 fences 标记为等待/信号作为 cudlaSubmitTask() 的一部分,然后发出输入 fence 的信号并等待输出 fence。
7.1.4.2.1. 注册外部信号量:
sciError = NvSciSyncObjAlloc(nvSciSyncReconciledListObj1, &syncObj1);
if (sciError != NvSciError_Success)
{
// handle error
}
sciError = NvSciSyncObjAlloc(nvSciSyncReconciledListObj2, &syncObj2);
if (sciError != NvSciError_Success)
{
// handle error
}
// importing external semaphore
uint64_t* nvSciSyncObjRegPtr1 = NULL;
uint64_t* nvSciSyncObjRegPtr2 = NULL;
cudlaExternalSemaphoreHandleDesc semaMemDesc = { 0 };
memset(&semaMemDesc, 0, sizeof(semaMemDesc));
semaMemDesc.extSyncObject = syncObj1;
err = cudlaImportExternalSemaphore(devHandle,
&semaMemDesc,
&nvSciSyncObjRegPtr1,
0);
if (err != cudlaSuccess)
{
// handle error
}
memset(&semaMemDesc, 0, sizeof(semaMemDesc));
semaMemDesc.extSyncObject = syncObj2;
err = cudlaImportExternalSemaphore(devHandle,
&semaMemDesc,
&nvSciSyncObjRegPtr2,
0);
if (err != cudlaSuccess)
{
// handle error
}
DPRINTF("ALL EXTERNAL SEMAPHORES REGISTERED SUCCESSFULLY\n");
7.1.4.2.2. cudlaSubmitTask() 的事件设置
// Wait events
NvSciSyncFence preFence = NvSciSyncFenceInitializer;
sciError = NvSciSyncObjGenerateFence(syncObj1, &preFence);
if (sciError != NvSciError_Success)
{
// handle error
}
cudlaWaitEvents* waitEvents;
waitEvents = (cudlaWaitEvents *)malloc(sizeof(cudlaWaitEvents));
if (waitEvents == NULL)
{
// handle error
}
waitEvents->numEvents = 1;
CudlaFence* preFences = (CudlaFence *)malloc(waitEvents->numEvents *
sizeof(CudlaFence));
if (preFences == NULL)
{
// handle error
}
preFences[0].fence = &preFence;
preFences[0].type = CUDLA_NVSCISYNC_FENCE;
waitEvents->preFences = preFences;
// Signal Events
cudlaSignalEvents* signalEvents;
signalEvents = (cudlaSignalEvents *)malloc(sizeof(cudlaSignalEvents));
if (signalEvents == NULL)
{
// handle error
}
signalEvents->numEvents = 1;
uint64_t** devPtrs = (uint64_t **)malloc(signalEvents->numEvents *
sizeof(uint64_t *));
if (devPtrs == NULL)
{
// handle error
}
devPtrs[0] = nvSciSyncObjRegPtr2;
signalEvents->devPtrs = devPtrs;
signalEvents->eofFences = (CudlaFence *)malloc(signalEvents->numEvents *
sizeof(CudlaFence));
if (signalEvents->eofFences == NULL)
{
// handle error
}
NvSciSyncFence eofFence = NvSciSyncFenceInitializer;
signalEvents->eofFences[0].fence = &eofFence;
signalEvents->eofFences[0].type = CUDLA_NVSCISYNC_FENCE;
// Enqueue a cuDLA task.
cudlaTask task;
task.moduleHandle = moduleHandle;
task.outputTensor = &outputBufObjRegPtr;
task.numOutputTensors = 1;
task.numInputTensors = 1;
task.inputTensor = &inputBufObjRegPtr;
task.waitEvents = waitEvents;
task.signalEvents = signalEvents;
err = cudlaSubmitTask(devHandle, &task, 1, NULL, 0);
if (err != cudlaSuccess)
{
// handle error
}
DPRINTF("SUBMIT IS DONE !!!\n");
7.1.4.2.3. 等待信号事件
// Signal wait events.
// For illustration purposes only. In practice, this signal will be done by another
// entity or driver that provides the data input for this particular submitted task.
NvSciSyncObjSignal(syncObj1);
// Wait for operations to finish.
// For illustration purposes only. In practice, this wait will be done by
// another entity or driver that is waiting for the output of the submitted task.
sciError = NvSciSyncFenceWait(reinterpret_cast<NvSciSyncFence*>(signalEvents->eofFences[0].fence),
nvSciCtx, -1);
if (sciError != NvSciError_Success)
{
// handle error
}
7.1.4.2.4. cuDLA 中支持的同步原语
cuDLA 支持两种类型的 NvSciSync 对象原语。这些是同步点和确定性信号量。默认情况下,cuDLA 将同步点原语优先于确定性信号量原语,并在应用程序使用 cudlaGetNvSciSyncAttributes() 请求时在 NvSciSync 属性列表中设置这些优先级。
对于确定性信号量,用于创建 NvSciSync 对象的 NvSciSync 属性列表必须将 NvSciSyncAttrKey_RequireDeterministicFences 键的值设置为 true。确定性 fences 允许用户即使在相应的信号入队之前,也可以在信号量对象上排队等待。对于这样的信号量对象,cuDLA 保证每个信号操作都会将 fence 值增加 ‘1’。用户应跟踪在信号量对象上入队的信号并相应地插入等待。
7.1.4.2.5. 在 NvSciSyncAttrList 中设置 NvSciSyncAttrKey_RequireDeterministicFences 键
// Set NvSciSyncAttrKey_RequireDeterministicFences key to true in
// NvScisyncAtrrList that is used to create NvSciSync object with
// Deterministic Semaphore primitive.
NvSciSyncAccessPerm cpuPerm = NvSciSyncAccessPerm_SignalOnly;
keyValue[0].attrKey = NvSciSyncAttrKey_RequiredPerm;
keyValue[0].value = (void*) &cpuPerm;
keyValue[0].len = sizeof(cpuPerm);
bool detFenceReq = true;
keyValue[1].attrKey = NvSciSyncAttrKey_RequireDeterministicFences;
keyValue[1].value = (const void*)&detFenceReq;
keyValue[1].len = sizeof(detFenceReq);
return NvSciSyncAttrListSetAttrs(list, keyValue, 2);
7.1.4.2.6. NvSciFence 的时间戳支持
cuDLA 在 cuDLA 独立模式下支持 NvSci 的时间戳功能。
时间戳支持使用户能够获得特定 fence 发出信号的时间。此时间值是以微秒为单位的 DLA 时钟的快照。
cuDLA 用户可以通过在填写 NvSci waiter 属性列表时将 NvSciSyncAttrKey_WaiterRequireTimestamps 键的值设置为 true 来请求时间戳支持。
用户可以将此时间戳与 SOF(帧开始)fence 和 EOF(帧结束)fence 一起使用,以分别获得任务开始前和任务完成后 DLA 时钟的快照。这使使用者能够计算 DLA 执行提交任务所花费的时间。
7.1.4.2.7. 请求 NvSciSync 对象的时间戳支持
sciError fillCpuWaiterAttrList(NvSciSyncAttrList list)
{
bool cpuWaiter = true;
NvSciSyncAttrKeyValuePair keyValue[3];
memset(keyValue, 0, sizeof(keyValue));
keyValue[0].attrKey = NvSciSyncAttrKey_NeedCpuAccess;
keyValue[0].value = (void*) &cpuWaiter;
keyValue[0].len = sizeof(cpuWaiter);
NvSciSyncAccessPerm cpuPerm = NvSciSyncAccessPerm_WaitOnly;
keyValue[1].attrKey = NvSciSyncAttrKey_RequiredPerm;
keyValue[1].value = (void*) &cpuPerm;
keyValue[1].len = sizeof(cpuPerm);
bool cpuRequiresTimeStamp = true;
keyValue[2].attrKey = NvSciSyncAttrKey_WaiterRequireTimestamps;
keyValue[2].value = (void*) &cpuRequiresTimeStamp;
keyValue[2].len = sizeof(cpuRequiresTimeStamp);
return NvSciSyncAttrListSetAttrs(list, keyValue, 3);
}
NvSciSyncCpuWaitContext nvSciCtx;
NvSciSyncModule syncModule;
NvSciSyncAttrList waiterAttrListObj = nullptr;
NvSciSyncAttrList signalerAttrListObj = nullptr;
NvSciSyncAttrList syncAttrListObj[2];
NvSciSyncAttrList nvSciSyncConflictListObj;
NvSciSyncAttrList nvSciSyncReconciledListObj;
sciError = NvSciSyncModuleOpen(&syncModule);
if (sciError != NvSciError_Success) {
//handle error
}
sciError = NvSciSyncAttrListCreate(syncModule, &signalerAttrListObj);
if (sciError != NvSciError_Success) {
//handle error
}
sciError = NvSciSyncAttrListCreate(syncModule, &waiterAttrListObj);
if (sciError != NvSciError_Success) {
//handle error
}
err = cudlaGetNvSciSyncAttributes(reinterpret_cast<uint64_t*>(signalerAttrListObj),
CUDLA_NVSCISYNC_ATTR_SIGNAL);
if (err != cudlaSuccess) {
//handle error
}
sciError = fillCpuWaiterAttrList(waiterAttrListObj);
if (sciError != NvSciError_Success) {
//handle error
}
syncAttrListObj[0] = signalerAttrListObj;
syncAttrListObj[1] = waiterAttrListObj;
sciError = NvSciSyncAttrListReconcile(syncAttrListObj,
2,
&nvSciSyncReconciledListObj,
&nvSciSyncConflictListObj3);
if (sciError != NvSciError_Success) {
//handle error
}
sciError = NvSciSyncObjAlloc(nvSciSyncReconciledListObj, &syncObj);
if (sciError != NvSciError_Success) {
//handle error
}
sciError = NvSciSyncCpuWaitContextAlloc(syncModule, &nvSciCtx);
if (sciError != NvSciError_Success) {
//handle error
}
7.1.4.2.8. 从 Fence 中提取时间戳值
有关更多信息,请参阅这些章节
// To extract Timestamp of the fence
// Timestamp will be valid only after fence is signaled
// hence Fence must be waited up on before extracting timestamp value
uint64_t eofTimestampUS = 0UL;
sciError = NvSciSyncFenceGetTimestamp(reinterpret_cast<NvSciSyncFence*>(signalEvents->eofFences.fence), &(eofTimestampUS));
if ((sciError != NvSciError_Success) || (eofTimestampUS == 0UL)) {
//handle error
}
7.1.4.3. 故障诊断
为了对 DLA 硬件执行故障诊断,用户应指定 CUDLA_MODULE_ENABLE_FAULT_DIAGNOSTICS 标志以加载模块,并在任务提交期间指定 CUDLA_SUBMIT_DIAGNOSTICS_TASK。此任务可用于探测 DLA 硬件的状态。设置此标志后,在独立模式下,不允许用户执行仅事件提交,其中张量信息为 NULL,并且任务中仅存在事件(等待/信号或两者)。这是因为该任务始终在内部加载的诊断模块上运行。此诊断模块不期望任何输入张量,因此不需要输入张量内存。但是,用户应查询输出张量的数量,分配输出张量内存,并在使用提交任务时传递相同的内存。
7.1.4.4. NOOP 提交
用户可以在调用 cudlaSubmitTask() 时将某些任务标记为 noop 任务。
这是通过在 cudlaSubmitTask() 的 flags 参数中传递 CUDLA_SUBMIT_NOOP 来完成的。noop 提交意味着所有其他提交语义都得到维护。具体而言,任务被提交到 DLA,等待/信号事件在前后都被考虑,并且流语义得到尊重。关键的区别在于任务被 DLA 跳过执行。这在混合模式和独立模式下都受支持。
7.1.5. 错误报告模型
任务执行的异步性质导致两种可以通过 cuDLA API 报告的错误
同步错误
异步错误
同步错误是指当 cuDLA API 在应用程序中被调用时,作为其返回代码的一部分报告的错误。异步错误是指与顺序程序执行相比,稍后检测到的错误。这里的典型场景是,提交给 DLA 硬件的每个任务都在特定的持续时间后执行。因此,如果任务执行中存在错误,则无法将其作为任务提交 API 的一部分报告。根据错误的时间,它们会在后续的 cuDLA API 调用期间或同步操作之后报告。作为 cuDLA API 一部分报告的硬件执行错误在应用程序级别很容易处理。但是,如果当前没有 cuDLA API 调用正在执行或即将在应用程序中执行,则应用程序需要执行额外的步骤来处理异步错误。
在混合模式下,DLA 硬件错误可以通过 CUDA 同步操作报告。正如设备模型部分所述,cuDLA 在逻辑上将 DLA 与 GPU 关联以用于执行。因此,任何 DLA 硬件错误都通过 CUDA 传播给用户。用户需要从 CUDA 同步操作中检查特定于 DLA 的错误,然后使用 cudlaGetLastError() 检查 cuDLA 设备句柄以获取确切的错误。如果应用程序中有多个 cuDLA 设备句柄,并且每个句柄都在混合模式下向 cuDLA 提交了一些任务,则必须检查每个设备句柄是否存在错误。这里的底层模型是使用 CUDA 检测 DLA 硬件错误,然后在相关句柄上使用 cudlaGetLastError() 报告确切的错误。下面的代码片段显示了一个示例
result = cudaStreamSynchronize(stream);
if (result != cudaSuccess)
{
DPRINTF("Error in synchronizing stream = %s\n", cudaGetErrorName(result));
if (result == cudaErrorExternalDevice)
{
cudlaStatus hwStatus = cudlaGetLastError(devHandle);
if (hwStatus != cudlaSuccess)
{
DPRINTF("Asynchronous error in HW = %u\n", hwStatus);
}
}
}
此错误报告模型也与 CUDA Driver API 兼容,因此,如果应用程序使用 CUDA Driver API 进行同步,则类似的错误代码和错误处理流程也适用。
在独立模式下,该模型类似,但例外的是,没有相应的机制来检测作为同步操作一部分的错误。在此模式下,应用程序等待提交任务的唯一选项是等待最新提交返回的 NvSciSync fence。截至撰写本文时,NvSciSync 不支持报告 DLA 硬件错误,因此应用程序应等待 fence,然后查询 cudlaGetLastError() 以查找执行期间的任何错误。
7.2. 从 NvMediaDla 迁移到 cuDLA
NvMediaDla 和 cuDLA 具有不同的编程模型,各自 API 公开的功能在某种程度上重叠。下表提供了从 NvMediaDla API 到等效 cuDLA API 或功能的映射。这旨在用作将 NvMediaDla 应用程序迁移到 cuDLA 应用程序时的参考。
NvMediaDla |
cuDLA |
|---|---|
|
|
|
不需要,因为 ping 在 |
|
|
|
|
|
不可用 |
|
|
|
不可用 |
|
|
|
不可用 |
|
不可用 |
|
不需要,因为声明 |
|
不需要,因为 cuDLA 模块被声明为 |
|
不需要,因为这在 |
|
不需要,因为这在 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不可用 |
|
|
|
|
|
|
|
不需要,因为 |
|
不需要,因为 |
|
不需要,因为 |
7.3. 分析 cuDLA 应用程序
cuDLA API 可以使用 NVIDIA Nsight Systems 进行分析。以下命令可用于生成 cuDLA API 的跟踪。这些跟踪可以在 Nsight 中查看。
$ nsys profile --trace nvtx -e CUDLA_NVTX_LEVEL=1 --output <file> <cudla_App>
7.4. cuDLA 发行说明
cuDLA 1.2.1 中的已知问题
在混合模式下,cuDLA 在内部使用主上下文通过 CUDA 分配内存。因此,在销毁/重置 CUDA 主上下文之前,必须销毁所有 cuDLA 设备初始化。
在销毁 cuDLA 设备句柄之前,务必确保先前提交给设备的所有任务都已完成。否则可能会导致应用程序崩溃,因为内部内存分配仍在使用中。
应用程序进行的 NvSciBuf 缓冲区分配必须遵守 DLA 对齐约束。
应用程序有责任确保在提交任务时,作为等待事件一部分指定的 fence 没有重复。
通常,cuDLA API 返回的任何同步或异步错误都必须被视为不可恢复的错误。在这种情况下,应用程序应重新启动并再次初始化 cuDLA 以提交 DLA 任务。此规则的例外是
cudlaErrorMemoryRegistered,当应用程序尝试再次注册特定内存而不取消注册时,cuDLA 会返回该错误。cuDLA 不支持 CUDA 和 DLA 之间的 UVM。
cuDLA 不支持 CUDA Graph。
cuDLA 不支持每个线程的默认流。
cuDLA 不支持 CNP(DLA 函数不能与 CNP 一起使用)。
cuDLA 不支持块线性内存。
cuDLA 目前不支持 CUDA VMM API。
cuDLA 不支持 dGPU。
在某些条件下,DLA 固件可能会因某些任务而挂起。这可能导致应用程序在混合模式和独立模式下都挂起。应用程序应检测到这些情况并做出相应的响应。
支持加载多个模块。
加载多个模块时,不支持逐层统计功能。
当加载单个模块并且同一模块用于任务提交以及统计信息转换时,支持逐层统计。
8. 通知
8.1. 通知
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。NVIDIA 公司(“NVIDIA”)对本文档中包含信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息而造成的后果或使用,或因使用此类信息而可能导致的侵犯专利或第三方其他权利的行为不承担任何责任。本文档不承诺开发、发布或交付任何材料(如下定义)、代码或功能。
NVIDIA 保留随时修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是当前和完整的。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的单独销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在此类设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的故障。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。NVIDIA 对基于或归因于以下原因的任何故障、损坏、成本或问题不承担任何责任:(i)以违反本文档的任何方式使用 NVIDIA 产品或(ii)客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的关于第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方专利或其他知识产权下的第三方许可,或获得 NVIDIA 专利或其他知识产权下的 NVIDIA 许可。
只有在事先获得 NVIDIA 书面批准的情况下,才能复制本文档中的信息,复制时不得进行更改,并且必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和通知。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他方面的保证,并明确否认所有关于不侵权、适销性和特定用途适用性的默示保证。在法律允许的最大范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害负责,包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论损害是如何造成的,也无论责任理论如何,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,NVIDIA 对此处描述的产品的客户的累计责任应根据产品的销售条款进行限制。
8.2. OpenCL
OpenCL 是 Apple Inc. 的商标,经 Khronos Group Inc. 许可使用。
8.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。