CUDA C++ 最佳实践指南
使用 CUDA 工具包从 NVIDIA GPU 获得最佳性能的编程指南。
1. 序言
本最佳实践指南旨在帮助开发人员从 NVIDIA® CUDA® GPU 获得最佳性能。它介绍了已建立的并行化和优化技术,并解释了可以大大简化 CUDA 功能 GPU 架构编程的编码隐喻和习惯用法。
虽然本指南的内容可以用作参考手册,但您应该意识到,随着对各种编程和配置主题的探索,某些主题会在不同的上下文中重新讨论。因此,建议初次阅读的读者按顺序阅读本指南。这种方法将大大提高您对有效编程实践的理解,并使您能够在以后更好地使用本指南作为参考。
1.1. 谁应该阅读本指南?
本指南中的讨论都使用 C++ 编程语言,因此您应该能够轻松阅读 C++ 代码。
本指南参考并依赖于其他几个文档,您应该手头备有这些文档以供参考,所有这些文档均可在 CUDA 网站 https://docs.nvda.net.cn/cuda/ 免费获得。以下文档是尤其重要的资源
CUDA 安装指南
CUDA C++ 编程指南
CUDA 工具包参考手册
特别是,本指南的优化部分假设您已成功下载并安装了 CUDA 工具包(如果尚未安装,请参阅适用于您平台的 CUDA 安装指南),并且您已基本熟悉 CUDA C++ 编程语言和环境(如果尚未熟悉,请参阅 CUDA C++ 编程指南)。
1.2. 评估、并行化、优化、部署
本指南介绍了评估、并行化、优化、部署 (APOD) 应用程序设计周期,旨在帮助应用程序开发人员快速识别代码中最容易从 GPU 加速中受益的部分,快速实现这种益处,并尽早开始在生产中利用由此产生的加速。
APOD 是一个循环过程:只需最少的初始时间投入即可实现、测试和部署初始加速,此时循环可以再次开始,方法是识别进一步的优化机会、看到额外的加速,然后将应用程序的更快版本部署到生产环境中。
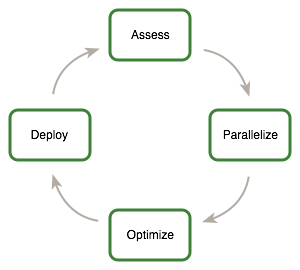
1.2.1. 评估
对于现有项目,第一步是评估应用程序,以找到代码中负责大部分执行时间的部分。掌握这些知识后,开发人员可以评估这些瓶颈以进行并行化,并开始研究 GPU 加速。
通过了解最终用户的需求和约束以及应用阿姆达尔定律和古斯塔夫森定律,开发人员可以确定通过加速应用程序的已识别部分所能获得的性能改进上限。
1.2.2. 并行化
在识别出热点并完成了设置目标和期望的基本练习之后,开发人员需要并行化代码。根据原始代码,这可以像调用现有的 GPU 优化库(如 cuBLAS、cuFFT 或 Thrust)一样简单,也可以像添加一些预处理器指令作为并行化编译器的提示一样简单。
另一方面,某些应用程序的设计将需要进行一些重构以展现其固有的并行性。由于即使是 CPU 架构也需要展现并行性才能提高或只是维持顺序应用程序的性能,因此 CUDA 系列并行编程语言(CUDA C++、CUDA Fortran 等)旨在尽可能简化这种并行性的表达,同时支持在专为最大并行吞吐量而设计的 CUDA 功能 GPU 上运行。
1.2.3. 优化
在完成每一轮应用程序并行化之后,开发人员可以转向优化实现以提高性能。由于有许多可能的优化可以考虑,因此充分了解应用程序的需求可以帮助使该过程尽可能顺利。但是,与整个 APOD 一样,程序优化是一个迭代过程(识别优化机会、应用和测试优化、验证实现的加速并重复),这意味着程序员不必花费大量时间来记忆所有可能的优化策略,然后才能看到良好的加速。相反,可以在学习优化策略时逐步应用它们。
优化可以在各个级别应用,从重叠数据传输与计算,一直到微调浮点运算序列。可用的性能分析工具对于指导此过程非常宝贵,因为它们可以帮助为开发人员的优化工作建议下一步最佳行动方案,并提供对本指南优化部分相关部分的参考。
1.2.4. 部署
在完成应用程序的一个或多个组件的 GPU 加速后,可以比较结果与原始期望。回想一下,最初的评估步骤允许开发人员确定通过加速给定热点可以达到的潜在加速上限。
在解决其他热点以提高总加速之前,开发人员应考虑采用部分并行化的实现并将其投入生产。这很重要,原因有很多;例如,它允许用户尽早从他们的投资中获利(加速可能是部分的,但仍然有价值),并且它通过为应用程序提供进化而非革命性的一组更改,最大限度地降低了开发人员和用户的风险。
1.3. 建议和最佳实践
在本指南中,针对 CUDA C++ 代码的设计和实现提出了具体建议。这些建议按优先级分类,优先级是建议的效果及其范围的混合。对于大多数 CUDA 应用程序来说,能够带来显著改进的操作具有最高优先级,而仅影响非常特定情况的小型优化则具有较低的优先级。
在实施较低优先级的建议之前,最好先确保已应用所有相关的高优先级建议。这种方法往往可以在投入的时间内提供最佳结果,并避免过早优化的陷阱。
建立优先级的益处和范围标准将根据程序的性质而有所不同。在本指南中,它们代表了一种典型情况。您的代码可能反映不同的优先级因素。无论这种可能性如何,最好先验证是否忽略了任何更高优先级的建议,然后再进行较低优先级的项目。
注意
为简洁起见,本指南中的代码示例省略了错误检查。但是,生产代码应系统地检查每个 API 调用返回的错误代码,并通过调用 cudaGetLastError() 检查内核启动是否失败。
1.4. 评估您的应用程序
从超级计算机到移动电话,现代处理器越来越依赖并行性来提供性能。核心计算单元(包括控制单元、算术单元、寄存器以及通常的一些缓存)被复制多次,并通过网络连接到内存。因此,所有现代处理器都需要并行代码才能充分利用其计算能力。
虽然处理器正在不断发展以向程序员公开更细粒度的并行性,但许多现有应用程序要么作为串行代码发展而来,要么作为粗粒度并行代码发展而来(例如,其中数据被分解为并行处理的区域,子区域使用 MPI 共享)。为了从任何现代处理器架构(包括 GPU)中获益,第一步是评估应用程序以识别热点,确定它们是否可以并行化,并了解现在和将来的相关工作负载。
2. 异构计算
CUDA 编程涉及在两个不同的平台上同时运行代码:具有一个或多个 CPU 的主机系统和一个或多个启用 CUDA 的 NVIDIA GPU 设备。
虽然 NVIDIA GPU 经常与图形相关联,但它们也是强大的算术引擎,能够并行运行数千个轻量级线程。这种能力使它们非常适合可以利用并行执行的计算。
但是,设备基于与主机系统截然不同的设计,并且了解这些差异以及它们如何决定 CUDA 应用程序的性能,对于有效地使用 CUDA 至关重要。
2.1. 主机和设备之间的差异
主要差异在于线程模型和独立的物理内存
- 线程资源
-
主机系统上的执行管道可以支持有限数量的并发线程。例如,具有两个 32 核处理器的服务器只能同时运行 64 个线程(如果 CPU 支持同时多线程,则可以运行略多于 64 个线程)。相比之下,CUDA 设备上最小的可执行并行单元包含 32 个线程(称为线程束)。现代 NVIDIA GPU 每个多处理器最多可支持 2048 个活动线程并发运行(请参阅 CUDA C++ 编程指南的功能和规格)在具有 80 个多处理器的 GPU 上,这将导致超过 160,000 个并发活动线程。
- 线程
-
CPU 上的线程通常是重量级实体。操作系统必须在 CPU 执行通道上交换线程以提供多线程功能。因此,上下文切换(当两个线程被交换时)速度慢且开销大。相比之下,GPU 上的线程非常轻量级。在典型的系统中,数千个线程排队等待工作(以每个 32 个线程的线程束为单位)。如果 GPU 必须等待一个线程束,它只需开始执行另一个线程束上的工作。由于单独的寄存器分配给所有活动线程,因此在 GPU 线程之间切换时,无需交换寄存器或其他状态。资源会一直分配给每个线程,直到它完成执行。简而言之,CPU 内核旨在最大限度地减少少量线程的延迟,而 GPU 旨在处理大量并发的轻量级线程,以最大限度地提高吞吐量。
- RAM
-
主机系统和设备各自具有其自己独立的物理内存 1。由于主机内存和设备内存是分开的,因此主机内存中的项目有时必须在设备内存和主机内存之间进行通信,如 什么是 CUDA 启用设备上运行的程序? 中所述。
这些是 CPU 主机和 GPU 设备在并行编程方面的主要硬件差异。其他差异将在本文档的其他地方讨论。考虑到这些差异而组成的应用程序可以将主机和设备一起视为一个有凝聚力的异构系统,其中每个处理单元都被利用来完成它最擅长的工作:主机上的顺序工作和设备上的并行工作。
2.2. 什么是 CUDA 启用设备上运行的程序?
在确定应用程序的哪些部分在设备上运行时,应考虑以下问题
设备非常适合可以在大量数据元素上同时并行运行的计算。这通常涉及对大型数据集(如矩阵)进行算术运算,其中相同的操作可以在数千个(如果不是数百万个)元素上同时执行。这是 CUDA 获得良好性能的要求:软件必须使用大量(通常是数千或数万个)并发线程。对并行运行大量线程的支持源于 CUDA 使用上述轻量级线程模型。
-
要使用 CUDA,必须将数据值从主机传输到设备。这些传输在性能方面代价高昂,应尽量减少。(请参阅 主机和设备之间的数据传输。)这种代价有几个影响
-
操作的复杂性应证明将数据移入和移出设备的成本是合理的。为少量线程短暂使用而传输数据的代码几乎看不到或看不到性能优势。理想的情况是许多线程执行大量工作。
例如,将两个矩阵传输到设备以执行矩阵加法,然后将结果传输回主机将不会实现太大的性能优势。这里的问题是每个传输的数据元素执行的操作数。对于前面的过程,假设大小为 NxN 的矩阵,有 N2 个运算(加法)和 3N2 个元素传输,因此运算与传输元素的比率为 1:3 或 O(1)。当此比率较高时,更容易获得性能优势。例如,相同矩阵的矩阵乘法需要 N3 个运算(乘加),因此运算与传输元素的比率为 O(N),在这种情况下,矩阵越大,性能优势越大。操作类型是另一个因素,因为加法比三角函数等具有不同的复杂性概况。在确定操作应在主机上还是在设备上执行时,务必包括将数据传输到设备和从设备传输数据的开销。
数据应尽可能长时间地保留在设备上。由于应尽量减少传输,因此在同一数据上运行多个内核的程序应倾向于将数据保留在设备上内核调用之间,而不是将中间结果传输到主机,然后再将它们发送回设备以进行后续计算。因此,在前面的示例中,如果要添加的两个矩阵由于之前的某些计算而已经位于设备上,或者如果加法的结果将在后续计算中使用,则矩阵加法应在设备上本地执行。即使计算序列中的一个步骤可以在主机上更快地执行,也应使用这种方法。如果它可以避免主机和设备内存之间的一个或多个传输,即使是相对较慢的内核也可能是有利的。 主机和设备之间的数据传输 提供了更多详细信息,包括主机和设备之间以及设备内部带宽的测量值。
-
为了获得最佳性能,在设备上运行的相邻线程的内存访问应具有一定的连贯性。某些内存访问模式使硬件能够将多个数据项的读取或写入组合到一个操作中。无法布局数据以实现合并,或者没有足够的局部性来有效利用 L1 或纹理缓存的数据,在 GPU 计算中使用时往往会看到较小的加速。一个值得注意的例外是完全随机的内存访问模式。一般来说,应避免这些模式,因为与峰值能力相比,任何架构都以较低的效率处理这些内存访问模式。但是,与基于缓存的架构(如 CPU)相比,延迟隐藏架构(如 GPU)往往能更好地应对完全随机的内存访问模式。
- 1
-
在具有集成 GPU 的片上系统中,例如 NVIDIA® Tegra®,主机内存和设备内存物理上是相同的,但主机内存和设备内存之间仍然存在逻辑区别。有关详细信息,请参阅 CUDA for Tegra 应用说明。
3. 应用程序性能分析
3.1. 性能分析
许多代码使用相对少量的代码完成大部分工作。使用性能分析器,开发人员可以识别此类热点,并开始编译并行化候选列表。
3.1.1. 创建性能分析
有许多可能的方法可以对代码进行性能分析,但在所有情况下,目标都是相同的:识别应用程序花费大部分执行时间的函数。
注意
高优先级: 为了最大限度地提高开发人员的工作效率,请对应用程序进行性能分析,以确定热点和瓶颈。
任何性能分析活动最重要的考虑因素是确保工作负载是真实的 - 即,从测试中获得的信息和基于该信息做出的决策与真实数据相关。使用不切实际的工作负载可能会导致次优结果和浪费精力,这既是因为导致开发人员针对不切实际的问题规模进行优化,又是因为导致开发人员专注于错误的函数。
有许多工具可以用来生成性能分析。以下示例基于 gprof,这是一个来自 GNU Binutils 集合的 Linux 平台的开源性能分析器。
$ gcc -O2 -g -pg myprog.c
$ gprof ./a.out > profile.txt
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
33.34 0.02 0.02 7208 0.00 0.00 genTimeStep
16.67 0.03 0.01 240 0.04 0.12 calcStats
16.67 0.04 0.01 8 1.25 1.25 calcSummaryData
16.67 0.05 0.01 7 1.43 1.43 write
16.67 0.06 0.01 mcount
0.00 0.06 0.00 236 0.00 0.00 tzset
0.00 0.06 0.00 192 0.00 0.00 tolower
0.00 0.06 0.00 47 0.00 0.00 strlen
0.00 0.06 0.00 45 0.00 0.00 strchr
0.00 0.06 0.00 1 0.00 50.00 main
0.00 0.06 0.00 1 0.00 0.00 memcpy
0.00 0.06 0.00 1 0.00 10.11 print
0.00 0.06 0.00 1 0.00 0.00 profil
0.00 0.06 0.00 1 0.00 50.00 report
3.1.2. 识别热点
在上面的示例中,我们可以清楚地看到函数 genTimeStep() 占应用程序总运行时间的三分之一。这应该是我们并行化的第一个候选函数。 理解扩展 讨论了我们可能期望从这种并行化中获得的潜在好处。
值得注意的是,上面示例中的其他几个函数也占用了总运行时间的很大一部分,例如 calcStats() 和 calcSummaryData()。并行化这些函数也应该提高我们的加速潜力。但是,由于 APOD 是一个循环过程,我们可能会选择在后续的 APOD 过程中并行化这些函数,从而将我们在任何给定过程中工作范围限制在一小组增量更改中。
3.1.3. 理解扩展
应用程序通过在 CUDA 上运行所能实现的性能优势完全取决于它可以并行化的程度。无法充分并行化的代码应在主机上运行,除非这样做会导致主机和设备之间过度传输。
注意
高优先级: 为了从 CUDA 中获得最大收益,请首先专注于寻找并行化顺序代码的方法。
通过了解应用程序如何扩展,可以设定期望并计划增量并行化策略。 强扩展和阿姆达尔定律 描述了强扩展,它允许我们为固定问题规模设置加速上限。 弱扩展和古斯塔夫森定律 描述了弱扩展,其中加速是通过增加问题规模来实现的。在许多应用程序中,强扩展和弱扩展的结合是可取的。
3.1.3.1. 强扩展和阿姆达尔定律
强扩展衡量的是,对于固定的总体问题规模,随着系统中添加更多处理器,解决问题的时间如何减少。表现出线性强扩展的应用程序的加速等于使用的处理器数量。
强扩展通常与阿姆达尔定律等同,阿姆达尔定律规定了通过并行化串行程序的部分可以预期的最大加速。本质上,它指出程序的最大加速 S 为
\(S = \frac{1}{(1 - P) + \frac{P}{N}}\)
其中 P 是可并行化的代码部分占总串行执行时间的比例,N 是并行代码部分运行的处理器数量。
N 越大(即,处理器数量越多),P/N 分数越小。将 N 视为一个非常大的数字可能更简单,这实际上将方程转换为 \(S = 1/(1 - P)\)。现在,如果串行程序运行时间的 3/4 被并行化,则相对于串行代码的最大加速为 1 / (1 - 3/4) = 4。
实际上,即使大多数应用程序表现出一定程度的强扩展,它们也不会表现出完全线性的强扩展。对于大多数目的而言,关键点是可并行化部分 P 越大,潜在的加速就越大。相反,如果 P 是一个小数(意味着应用程序基本上不可并行化),则增加处理器数量 N 对提高性能几乎没有作用。因此,为了获得固定问题规模的最大加速,值得花精力来增加 P,最大限度地增加可以并行化的代码量。
3.1.3.2. 弱扩展和古斯塔夫森定律
弱扩展衡量的是,随着系统中添加更多处理器,在每个处理器的问题规模固定的情况下,解决问题的时间如何变化;即,随着处理器数量的增加,总体问题规模也会增加。
弱扩展通常与古斯塔夫森定律等同,古斯塔夫森定律指出,在实践中,问题规模会随着处理器数量而扩展。因此,程序的最大加速 S 为
\(S = N + (1 - P)(1 - N)\)
其中 P 是可并行化的代码部分占总串行执行时间的比例,N 是并行代码部分运行的处理器数量。
看待古斯塔夫森定律的另一种方式是,当我们扩展系统时,保持不变的不是问题规模,而是执行时间。请注意,古斯塔夫森定律假设串行执行与并行执行的比率保持不变,反映了设置和处理更大问题的额外成本。
3.1.3.3. 应用强扩展和弱扩展
了解哪种类型的扩展最适用于应用程序是估计加速的重要组成部分。对于某些应用程序,问题规模将保持不变,因此仅强扩展适用。一个示例是模拟两个分子如何相互作用,其中分子大小是固定的。
对于其他应用程序,问题规模将增长以填充可用的处理器。示例包括将流体或结构建模为网格或栅格,以及一些蒙特卡罗模拟,其中增加问题规模可以提高精度。
在了解应用程序性能分析后,开发人员应了解如果计算性能发生变化,问题规模将如何变化,然后应用阿姆达尔定律或古斯塔夫森定律来确定加速上限。
4. 并行化您的应用程序
在识别出热点并完成了设置目标和期望的基本练习之后,开发人员需要并行化代码。根据原始代码,这可以像调用现有的 GPU 优化库(如 cuBLAS、cuFFT 或 Thrust)一样简单,也可以像添加一些预处理器指令作为并行化编译器的提示一样简单。
另一方面,某些应用程序的设计将需要进行一些重构以展现其固有的并行性。由于即使是 CPU 架构也需要展现这种并行性才能提高或只是维持顺序应用程序的性能,因此 CUDA 系列并行编程语言(CUDA C++、CUDA Fortran 等)旨在尽可能简化这种并行性的表达,同时支持在专为最大并行吞吐量而设计的 CUDA 功能 GPU 上运行。
5. 入门
并行化顺序代码有几种关键策略。虽然将这些策略应用于特定应用程序的细节是一个复杂且特定于问题的主题,但此处列出的一般主题普遍适用,无论我们是将代码并行化以在多核 CPU 上运行还是在 CUDA GPU 上使用。
5.1. 并行库
并行化应用程序最直接的方法是利用现有的库,这些库可以代表我们利用并行架构。CUDA 工具包包含许多此类库,这些库已针对 NVIDIA CUDA GPU 进行了微调,例如 cuBLAS、cuFFT 等。
这里的关键是,当库与应用程序的需求良好匹配时,它们最有用。例如,已经使用其他 BLAS 库的应用程序通常可以非常容易地切换到 cuBLAS,而几乎不使用线性代数的应用程序对 cuBLAS 没有什么用处。其他 CUDA 工具包库也是如此:cuFFT 具有类似于 FFTW 等的接口。
同样值得注意的是 Thrust 库,它是一个并行的 C++ 模板库,类似于 C++ 标准模板库。Thrust 提供了丰富的数据并行原语集合,例如 scan、sort 和 reduce,它们可以组合在一起,以简洁、可读的源代码实现复杂的算法。通过根据这些高级抽象描述您的计算,您可以让 Thrust 自由地自动选择最有效的实现。因此,Thrust 可用于 CUDA 应用程序的快速原型设计(程序员生产力至关重要),以及生产环境(鲁棒性和绝对性能至关重要)。
5.2. 并行化编译器
并行化顺序代码的另一种常用方法是使用并行化编译器。通常,这意味着使用基于指令的方法,程序员使用 pragma 或其他类似的符号向编译器提供关于可以在哪里找到并行性的提示,而无需修改或调整底层代码本身。通过向编译器公开并行性,指令允许编译器完成将计算映射到并行架构的详细工作。
OpenACC 标准提供了一组编译器指令,用于指定标准 C、C++ 和 Fortran 中的循环和代码区域,这些循环和代码区域应从主机 CPU 卸载到附加的加速器(例如 CUDA GPU)。加速器设备的管理细节由启用 OpenACC 的编译器和运行时隐式处理。
有关详细信息,请参阅 http://www.openacc.org/。
5.3. 编码以暴露并行性
对于需要超出现有并行库或并行化编译器所能提供的额外功能或性能的应用程序,与现有顺序代码无缝集成的并行编程语言(例如 CUDA C++)至关重要。
一旦我们定位了应用程序性能评估中的热点,并确定自定义代码是最佳方法,我们就可以使用 CUDA C++ 将代码该部分的并行性暴露为 CUDA 内核。然后,我们可以将此内核启动到 GPU 上并检索结果,而无需对应用程序的其余部分进行重大重写。
当应用程序的总运行时间的大部分花费在少数相对隔离的代码部分时,这种方法最直接。更难以并行化的是具有非常扁平的性能评估的应用程序——即,时间花费相对均匀地分布在大部分代码库中的应用程序。对于后一种应用程序,可能需要进行一定程度的代码重构以暴露应用程序中固有的并行性,但请记住,这种重构工作将倾向于使所有未来的架构(CPU 和 GPU)都受益,因此如果必要,这是非常值得努力的。
6. 获得正确答案
获得正确答案显然是所有计算的主要目标。在并行系统中,可能会遇到传统面向串行编程中通常不会遇到的困难。这些困难包括线程问题、由于浮点值的计算方式而导致的意外值,以及 CPU 和 GPU 处理器操作方式差异引起的挑战。本章 بررسی 可能影响返回数据正确性的问题,并指出适当的解决方案。
6.1. 验证
6.1.1. 参考比较
对于任何现有程序的修改,正确性验证的一个关键方面是建立某种机制,通过该机制可以将来自代表性输入的先前已知良好的参考输出与新结果进行比较。每次更改后,使用适用于特定算法的任何标准确保结果匹配。有些会期望按位相同的结果,但这并非总是可能的,尤其是在涉及浮点运算的情况下;有关数值精度,请参阅 数值精度。对于其他算法,如果实现与参考值在某个小 epsilon 范围内匹配,则可以认为实现是正确的。
请注意,用于验证数值结果的过程可以轻松扩展到验证性能结果。我们希望确保我们所做的每次更改都是正确的,并且它提高了性能(以及提高了多少)。作为我们循环 APOD 过程组成部分的频繁检查这些事项将有助于确保我们尽可能快地获得期望的结果。
6.1.2. 单元测试
上述参考比较的一个有用的对应物是以一种易于在单元级别验证的方式构建代码本身。例如,我们可以将 CUDA 内核编写为许多短的 __device__ 函数的集合,而不是一个大的单片 __global__ 函数;每个设备函数都可以在将它们全部连接在一起之前独立测试。
例如,许多内核除了实际计算之外,还具有用于访问内存的复杂寻址逻辑。如果我们在引入大部分计算之前单独验证我们的寻址逻辑,那么这将简化任何后续的调试工作。(请注意,CUDA 编译器认为任何不贡献于全局内存写入的设备代码都是死代码,可以消除,因此我们必须至少将某些内容写入全局内存作为我们寻址逻辑的结果,以便成功应用此策略。)
更进一步,如果大多数函数被定义为 __host__ __device__ 而不仅仅是 __device__ 函数,那么这些函数可以在 CPU 和 GPU 上进行测试,从而提高我们对函数正确性的信心,并且不会出现任何意外的结果差异。如果有差异,那么这些差异将尽早被发现,并且可以在简单函数的上下文中理解。
作为一个有用的副作用,如果我们希望在我们的应用程序中包含 CPU 和 GPU 执行路径,则此策略将为我们提供一种减少代码重复的方法:如果我们的 CUDA 内核的大部分工作是在 __host__ __device__ 函数中完成的,我们可以轻松地从主机代码和设备代码调用这些函数,而无需重复。
6.2. 调试
CUDA-GDB 是 GNU 调试器的端口,可在 Linux 和 Mac 上运行;请参阅:https://developer.nvidia.com/cuda-gdb。
NVIDIA Nsight Visual Studio Edition 可作为 Microsoft Visual Studio 的免费插件使用;请参阅:https://developer.nvidia.com/nsight-visual-studio-edition。
一些第三方调试器也支持 CUDA 调试;有关更多详细信息,请参阅:https://developer.nvidia.com/debugging-solutions。
6.3. 数值精度
不正确或意外的结果主要来自浮点精度的原因,这是由于浮点值的计算和存储方式造成的。以下各节解释了主要的关注点。CUDA C++ 编程指南的功能和技术规范以及关于浮点精度和性能的白皮书和随附的网络研讨会中介绍了浮点运算的其他特性,可从 https://developer.nvidia.com/content/precision-performance-floating-point-and-ieee-754-compliance-nvidia-gpus 获取。
6.3.1. 单精度与双精度
CUDA 计算能力 1.3 及更高的设备提供对双精度浮点值(即 64 位宽的值)的本机支持。由于前者的更高精度和舍入问题,使用双精度运算获得的结果通常与通过单精度运算执行的相同操作不同。因此,务必确保比较精度相同的值,并在一定容差范围内表达结果,而不是期望它们是完全相同的。
6.3.2. 浮点数学不具有结合律
每个浮点运算都涉及一定程度的舍入。因此,执行算术运算的顺序很重要。如果 A、B 和 C 是浮点值,则 (A+B)+C 不保证等于 A+(B+C),就像在符号数学中一样。当您并行化计算时,您可能会更改运算顺序,因此并行结果可能与顺序结果不匹配。此限制并非 CUDA 特有,而是浮点值并行计算的固有组成部分。
6.3.3. IEEE 754 合规性
所有 CUDA 计算设备都遵循 IEEE 754 二进制浮点表示标准,但有一些小的例外。这些例外在 CUDA C++ 编程指南的功能和技术规范中详细说明,可能会导致结果与主机系统上计算的 IEEE 754 值不同。
主要区别之一是融合乘加 (FMA) 指令,它将乘加运算组合成单个指令执行。其结果通常与分别执行两个运算获得的结果略有不同。
6.3.4. x86 80 位计算
x86 处理器在执行浮点计算时可以使用 80 位双精度扩展数学。这些计算的结果通常可能与 CUDA 设备上执行的纯 64 位运算不同。为了更接近地匹配值,请将 x86 主机处理器设置为使用常规双精度或单精度(分别为 64 位和 32 位)。这可以使用 FLDCW x86 汇编指令或等效的操作系统 API 完成。
7. 优化 CUDA 应用程序
在完成每一轮应用程序并行化之后,开发人员可以转向优化实现以提高性能。由于有许多可能的优化可以考虑,因此充分了解应用程序的需求可以帮助使该过程尽可能顺利。但是,与整个 APOD 一样,程序优化是一个迭代过程(识别优化机会、应用和测试优化、验证实现的加速并重复),这意味着程序员不必花费大量时间来记忆所有可能的优化策略,然后才能看到良好的加速。相反,可以在学习优化策略时逐步应用它们。
优化可以在各个级别应用,从重叠数据传输与计算,一直到微调浮点运算序列。可用的性能分析工具对于指导此过程非常宝贵,因为它们可以帮助为开发人员的优化工作建议下一步最佳行动方案,并提供对本指南优化部分相关部分的参考。
8. 性能指标
当尝试优化 CUDA 代码时,了解如何准确测量性能以及了解带宽在性能测量中的作用至关重要。本章讨论如何使用 CPU 计时器和 CUDA 事件正确测量性能。然后,它探讨带宽如何影响性能指标以及如何缓解它带来的一些挑战。
8.1. 计时
CUDA 调用和内核执行可以使用 CPU 或 GPU 计时器进行计时。本节 بررسی 两种方法的功能、优点和缺点。
8.1.1. 使用 CPU 计时器
任何 CPU 计时器都可用于测量 CUDA 调用或内核执行的经过时间。各种 CPU 计时方法的细节不在本文档的范围之内,但开发人员应始终注意其计时调用提供的分辨率。
使用 CPU 计时器时,至关重要的是要记住,许多 CUDA API 函数是异步的;也就是说,它们在完成工作之前将控制权返回给调用 CPU 线程。所有内核启动都是异步的,名称中带有 Async 后缀的内存复制函数也是如此。因此,为了准确测量特定调用或 CUDA 调用序列的经过时间,有必要通过在启动和停止 CPU 计时器之前立即调用 cudaDeviceSynchronize() 将 CPU 线程与 GPU 同步。cudaDeviceSynchronize() 会阻止调用 CPU 线程,直到线程先前发出的所有 CUDA 调用完成。
虽然也可以将 CPU 线程与 GPU 上的特定流或事件同步,但这些同步函数不适用于对默认流以外的流中的代码进行计时。cudaStreamSynchronize() 会阻止 CPU 线程,直到先前发出的给定流中的所有 CUDA 调用完成。cudaEventSynchronize() 会阻止,直到 GPU 记录了特定流中的给定事件。由于驱动程序可能会交错执行来自其他非默认流的 CUDA 调用,因此其他流中的调用可能会包含在计时中。
由于默认流(流 0)表现出设备上工作的序列化行为(只有在任何流中所有先前的调用都完成后,默认流中的操作才能开始;并且在完成之前,任何流中后续的操作都不能开始),因此这些函数可以可靠地用于默认流中的计时。
请注意,本节中提到的 CPU 到 GPU 同步点意味着 GPU 处理管道中的停顿,因此应谨慎使用以最大限度地减少其性能影响。
8.1.2. 使用 CUDA GPU 计时器
CUDA 事件 API 提供了创建和销毁事件、记录事件(包括时间戳)以及将时间戳差异转换为毫秒浮点值的调用。如何使用 CUDA 事件计时代码 说明了它们的用法。
如何使用 CUDA 事件计时代码
cudaEvent_t start, stop;
float time;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord( start, 0 );
kernel<<<grid,threads>>> ( d_odata, d_idata, size_x, size_y,
NUM_REPS);
cudaEventRecord( stop, 0 );
cudaEventSynchronize( stop );
cudaEventElapsedTime( &time, start, stop );
cudaEventDestroy( start );
cudaEventDestroy( stop );
这里 cudaEventRecord() 用于将 start 和 stop 事件放入默认流(流 0)。当设备到达流中的该事件时,它将记录事件的时间戳。cudaEventElapsedTime() 函数返回 start 和 stop 事件记录之间经过的时间。此值以毫秒为单位表示,分辨率约为半微秒。与此列表中的其他调用一样,它们的具体操作、参数和返回值在CUDA 工具包参考手册中进行了描述。请注意,计时是在 GPU 时钟上测量的,因此计时分辨率与操作系统无关。
8.2. 带宽
带宽(数据可以传输的速率)是性能最重要的限制因素之一。几乎所有代码更改都应在它们如何影响带宽的上下文中进行。如本指南的 内存优化 中所述,带宽会受到数据存储在哪个内存中、数据布局方式和访问顺序以及其他因素的显着影响。
为了准确测量性能,计算理论带宽和有效带宽非常有用。当后者远低于前者时,设计或实现细节可能会降低带宽,而增加带宽应成为后续优化工作的主要目标。
注意
高优先级: 在测量性能和优化收益时,请使用计算的有效带宽作为指标。
8.2.1. 理论带宽计算
理论带宽可以使用产品文献中提供的硬件规格进行计算。例如,NVIDIA Tesla V100 使用 HBM2(双倍数据速率)RAM,其内存时钟速率为 877 MHz,内存接口宽度为 4096 位。
使用这些数据项,NVIDIA Tesla V100 的峰值理论内存带宽为 898 GB/s
\(\left. \left( 0.877 \times 10^{9} \right. \times (4096/8) \times 2 \right) \div 10^{9} = 898\text{GB/s}\)
在此计算中,内存时钟速率转换为 Hz,乘以接口宽度(除以 8,将位转换为字节),然后乘以 2,因为是双倍数据速率。最后,将该乘积除以 109 以将结果转换为 GB/s。
注意
某些计算使用 10243 而不是 109 进行最终计算。在这种情况下,带宽将为 836.4 GiB/s。在计算理论带宽和有效带宽时,重要的是使用相同的除数,以便比较有效。
注意
在启用 ECC 的 GDDR 内存的 GPU 上,可用的 DRAM 减少了 6.25%,以允许存储 ECC 位。与禁用 ECC 的相同 GPU 相比,为每个内存事务获取 ECC 位也会将有效带宽降低约 20%,尽管 ECC 对带宽的确切影响可能会更高,并且取决于内存访问模式。另一方面,HBM2 内存提供专用的 ECC 资源,允许免开销的 ECC 保护。2
8.2.2. 有效带宽计算
有效带宽是通过对特定程序活动进行计时并了解程序如何访问数据来计算的。为此,请使用以下公式
\(\text{有效带宽} = \left( {\left( B_{r} + B_{w} \right) \div 10^{9}} \right) \div \text{时间}\)
这里,有效带宽的单位为 GB/s,Br 是每个内核读取的字节数,Bw 是每个内核写入的字节数,时间以秒为单位。
例如,要计算 2048 x 2048 矩阵复制的有效带宽,可以使用以下公式
\(\text{有效带宽} = \left( {\left( 2048^{2} \times 4 \times 2 \right) \div 10^{9}} \right) \div \text{时间}\)
元素数乘以每个元素的大小(float 为 4 个字节),乘以 2(因为是读取和写入),除以 109(或 1,0243)以获得传输的 GB 内存。此数字除以秒为单位的时间以获得 GB/s。
8.2.3. Visual Profiler 报告的吞吐量
对于计算能力为 2.0 或更高的设备,Visual Profiler 可用于收集几种不同的内存吞吐量度量。以下吞吐量指标可以显示在“详细信息”或“详细信息图表”视图中
请求的全局加载吞吐量
请求的全局存储吞吐量
全局加载吞吐量
全局存储吞吐量
DRAM 读取吞吐量
DRAM 写入吞吐量
请求的全局加载吞吐量和请求的全局存储吞吐量值指示内核请求的全局内存吞吐量,因此对应于 有效带宽计算 下所示的计算获得的有效带宽。
由于最小内存事务大小大于大多数字大小,因此内核所需的实际内存吞吐量可能包括内核未使用的数据的传输。对于全局内存访问,此实际吞吐量由全局加载吞吐量和全局存储吞吐量值报告。
重要的是要注意,这两个数字都很有用。实际内存吞吐量显示代码与硬件限制的接近程度,而有效带宽或请求带宽与实际带宽的比较可以很好地估计由于内存访问的次优合并而浪费了多少带宽(请参阅 合并访问全局内存)。对于全局内存访问,请求的内存带宽与实际内存带宽的比较由全局内存加载效率和全局内存存储效率指标报告。
- 2
-
作为例外,分散写入 HBM2 会看到来自 ECC 的一些开销,但远低于在受 ECC 保护的 GDDR5 内存上使用类似访问模式的开销。
9. 内存优化
内存优化是性能最重要的领域。目标是通过最大化带宽来最大化硬件的使用。带宽最好通过尽可能多地使用快速内存和尽可能少地使用慢速访问内存来服务。本章讨论主机和设备上的各种内存类型,以及如何最好地设置数据项以有效使用内存。
9.1. 主机和设备之间的数据传输
设备内存和 GPU 之间的峰值理论带宽(例如,在 NVIDIA Tesla V100 上为 898 GB/s)远高于主机内存和设备内存之间的峰值理论带宽(在 PCIe x16 Gen3 上为 16 GB/s)。因此,为了获得最佳的整体应用程序性能,即使这意味着在 GPU 上运行与在主机 CPU 上运行相比没有显示任何加速的内核,也必须尽量减少主机和设备之间的数据传输。
注意
高优先级: 尽量减少主机和设备之间的数据传输,即使这意味着在设备上运行一些与在主机 CPU 上运行相比没有显示性能提升的内核。
中间数据结构应在设备内存中创建,由设备操作,并在不被主机映射或复制到主机内存的情况下销毁。
此外,由于与每次传输相关的开销,将许多小传输批处理为一个较大的传输比单独进行每次传输的性能要好得多,即使这样做需要将不连续的内存区域打包到连续缓冲区中,然后在传输后解包也是如此。
最后,当使用页锁定(或固定)内存时,可以实现主机和设备之间更高的带宽,如 CUDA C++ 编程指南和本文档的 固定内存 部分所述。
9.1.1. 固定内存
页锁定或固定内存传输实现了主机和设备之间最高的带宽。例如,在 PCIe x16 Gen3 卡上,固定内存可以达到大约 12 GB/s 的传输速率。
固定内存使用 Runtime API 中的 cudaHostAlloc() 函数分配。bandwidthTest CUDA 示例展示了如何使用这些函数以及如何测量内存传输性能。
对于已预先分配的系统内存区域,可以使用 cudaHostRegister() 动态固定内存,而无需分配单独的缓冲区并将数据复制到其中。
不应过度使用固定内存。过度使用会降低整体系统性能,因为固定内存是一种稀缺资源,但多少是太多很难预先知道。此外,与大多数正常的系统内存分配相比,系统内存的固定是一项重量级操作,因此与所有优化一样,测试应用程序及其运行的系统以获得最佳性能参数。
9.1.2. 异步传输和与计算的重叠
使用 cudaMemcpy() 的主机和设备之间的数据传输是阻塞传输;也就是说,仅在数据传输完成后才将控制权返回给主机线程。cudaMemcpyAsync() 函数是 cudaMemcpy() 的非阻塞变体,其中控制权立即返回给主机线程。与 cudaMemcpy() 相比,异步传输版本需要固定主机内存(请参阅 固定内存),并且它包含一个额外的参数,即流 ID。流只是在设备上按顺序执行的操作序列。不同流中的操作可以交错,在某些情况下可以重叠——此属性可用于隐藏主机和设备之间的数据传输。
异步传输使数据传输与计算在两个不同方面重叠成为可能。在所有启用 CUDA 的设备上,可以将主机计算与异步数据传输和设备计算重叠。例如,异步传输和与计算的重叠 演示了如何在例程 cpuFunction() 中的主机计算在数据传输到设备并且使用设备的内核执行时执行。
重叠计算和数据传输
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, 0);
kernel<<<grid, block>>>(a_d);
cpuFunction();
cudaMemcpyAsync() 函数的最后一个参数是流 ID,在本例中使用默认流(流 0)。内核也使用默认流,并且在内存复制完成之前不会开始执行;因此,不需要显式同步。由于内存复制和内核都立即将控制权返回给主机,因此主机函数 cpuFunction() 会重叠它们的执行。
在异步传输和计算重叠中,内存复制和内核执行是顺序发生的。在能够同时进行复制和计算的设备上,可以将设备上的内核执行与主机和设备之间的数据传输重叠。设备是否具有此能力由 cudaDeviceProp 结构的 asyncEngineCount 字段(或 deviceQuery CUDA 示例的输出中列出)指示。在具有此能力的设备上,重叠再次需要pinned host memory(固定主机内存),此外,数据传输和内核必须使用不同的非默认流(流 ID 非零的流)。之所以需要非默认流来实现重叠,是因为使用默认流的内存复制、内存设置函数和内核调用仅在设备上(任何流中)所有先前的调用完成后才开始,并且在它们完成之前,设备上(任何流中)不会开始任何操作。
异步传输和计算重叠 说明了基本技术。
并发复制和执行
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, stream1);
kernel<<<grid, block, 0, stream2>>>(otherData_d);
在此代码中,创建了两个流,并在数据传输和内核执行中使用,如 cudaMemcpyAsync 调用和内核的执行配置的最后一个参数中所指定的那样。
异步传输和计算重叠 演示了如何将内核执行与异步数据传输重叠。当数据依赖性使得数据可以分成块并在多个阶段传输时,可以使用此技术,启动多个内核来操作每个到达的块。顺序复制和执行 和 分阶段并发复制和执行 演示了这一点。它们产生等效的结果。第一段显示了参考的顺序实现,该实现传输并操作一个包含 N 个浮点数的数组(其中 N 假设可以被 nThreads 整除)。
顺序复制和执行
cudaMemcpy(a_d, a_h, N*sizeof(float), dir);
kernel<<<N/nThreads, nThreads>>>(a_d);
分阶段并发复制和执行 显示了如何将传输和内核执行分解为 nStreams 阶段。这种方法允许数据传输和执行之间的一些重叠。
分阶段并发复制和执行
size=N*sizeof(float)/nStreams;
for (i=0; i<nStreams; i++) {
offset = i*N/nStreams;
cudaMemcpyAsync(a_d+offset, a_h+offset, size, dir, stream[i]);
kernel<<<N/(nThreads*nStreams), nThreads, 0,
stream[i]>>>(a_d+offset);
}
(在 分阶段并发复制和执行 中,假设 N 可以被 nThreads*nStreams 整除。)由于流内的执行是顺序发生的,因此在各自流中的数据传输完成之前,任何内核都不会启动。当前的 GPU 可以同时处理异步数据传输和执行内核。具有单个复制引擎的 GPU 可以执行一个异步数据传输并执行内核,而具有两个复制引擎的 GPU 可以同时执行一个从主机到设备的异步数据传输、一个从设备到主机的异步数据传输,以及执行内核。GPU 上的复制引擎数量由 cudaDeviceProp 结构的 asyncEngineCount 字段给出,该字段也在 deviceQuery CUDA 示例的输出中列出。(应该提到的是,不可能将阻塞传输与异步传输重叠,因为阻塞传输发生在默认流中,因此它将在所有先前的 CUDA 调用完成后才开始。在它完成之前,它不允许任何其他 CUDA 调用开始。)图 1 中显示了两个代码段的执行时间线图,并且对于图下半部分的 分阶段并发复制和执行,nStreams 等于 4。
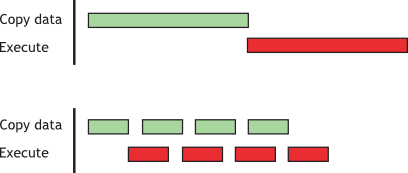
图 1 复制和内核执行的时间线比较
- 顶部
-
顺序
- 底部
-
并发
对于此示例,假设数据传输和内核执行时间相当。在这种情况下,以及当执行时间 (tE) 超过传输时间 (tT) 时,分阶段版本的总体时间粗略估计为 tE + tT/nStreams,而顺序版本的总体时间为 tE + tT。如果传输时间超过执行时间,则总体时间的粗略估计为 tT + tE/nStreams。
9.1.3. 零复制
零复制 是 CUDA 工具包 2.2 版本中添加的一项功能。它使 GPU 线程能够直接访问主机内存。为此,它需要映射的pinned (non-pageable) memory(非分页内存)。在集成 GPU 上(即,CUDA 设备属性结构的 integrated 字段设置为 1 的 GPU),映射的pinned memory始终是性能提升,因为它避免了多余的复制,因为集成 GPU 和 CPU 内存实际上是相同的物理内存。在独立 GPU 上,映射的pinned memory 仅在某些情况下才有利。由于数据未缓存在 GPU 上,因此映射的pinned memory 应仅读取或写入一次,并且读取和写入内存的全局加载和存储应合并。零复制可以代替流使用,因为内核发起的数据传输会自动与内核执行重叠,而无需设置和确定最佳流数量的开销。
注意
低优先级: 对于 CUDA 工具包 2.2 及更高版本,在集成 GPU 上使用零复制操作。
零复制主机代码 中的主机代码显示了零复制的典型设置方式。
零复制主机代码
float *a_h, *a_map;
...
cudaGetDeviceProperties(&prop, 0);
if (!prop.canMapHostMemory)
exit(0);
cudaSetDeviceFlags(cudaDeviceMapHost);
cudaHostAlloc(&a_h, nBytes, cudaHostAllocMapped);
cudaHostGetDevicePointer(&a_map, a_h, 0);
kernel<<<gridSize, blockSize>>>(a_map);
在此代码中,使用 cudaGetDeviceProperties() 返回的结构的 canMapHostMemory 字段来检查设备是否支持将主机内存映射到设备的地址空间。通过调用 cudaSetDeviceFlags() 并使用 cudaDeviceMapHost 来启用页锁定内存映射。请注意,cudaSetDeviceFlags() 必须在设置设备或进行需要状态的 CUDA 调用之前调用(即,基本上在创建上下文之前)。页锁定的映射主机内存使用 cudaHostAlloc() 分配,并且通过函数 cudaHostGetDevicePointer() 获取映射的设备地址空间的指针。在 零复制主机代码 中的代码中,kernel() 可以使用指针 a_map 引用映射的pinned host memory,就像 a_map 指向设备内存中的位置一样。
注意
映射的pinned host memory 允许您将 CPU-GPU 内存传输与计算重叠,同时避免使用 CUDA 流。但是,由于对这些内存区域的任何重复访问都会导致重复的 CPU-GPU 传输,因此请考虑在设备内存中创建第二个区域,以手动缓存先前读取的主机内存数据。
9.1.4. 统一虚拟寻址
计算能力为 compute capability 2.0 及更高版本的设备在 64 位 Linux 和 Windows 上支持一种称为统一虚拟寻址 (UVA) 的特殊寻址模式。使用 UVA,主机内存和所有已安装的受支持设备的设备内存共享一个单一的虚拟地址空间。
在 UVA 之前,应用程序必须跟踪哪些指针指向设备内存(以及哪个设备的)以及哪些指向主机内存,作为每个指针的单独元数据(或程序中的硬编码信息)。另一方面,使用 UVA,可以通过使用 cudaPointerGetAttributes() 检查指针的值来简单地确定指针指向的物理内存空间。
在 UVA 下,使用 cudaHostAlloc() 分配的pinned host memory 将具有相同的主机和设备指针,因此对于此类分配,无需调用 cudaHostGetDevicePointer()。然而,通过 cudaHostRegister() 事后pinned的主机内存分配将继续具有与其主机指针不同的设备指针,因此在这种情况下,cudaHostGetDevicePointer() 仍然是必要的。
UVA 也是在受支持的配置中为受支持的 GPU 启用跨 PCIe 总线或 NVLink 直接对等 (P2P) 传输数据,绕过主机内存的必要前提。
有关 UVA 和 P2P 的更多解释和软件要求,请参阅 CUDA C++ 编程指南。
9.2. 设备内存空间
CUDA 设备使用多个内存空间,这些内存空间具有不同的特性,反映了它们在 CUDA 应用程序中的不同用途。这些内存空间包括全局内存、本地内存、共享内存、纹理内存和寄存器,如 图 2 所示。
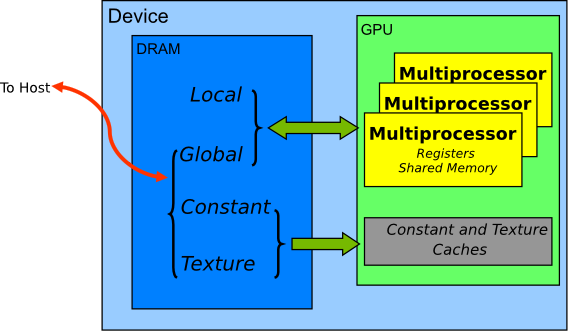
图 2 CUDA 设备上的内存空间
在这些不同的内存空间中,全局内存是最丰富的;有关每个 计算能力 级别中每个内存空间中可用内存量的信息,请参阅 CUDA C++ 编程指南的功能和技术规范。全局内存、本地内存和纹理内存具有最大的访问延迟,其次是常量内存、共享内存和寄存器文件。
内存类型的各种主要特征如 表 1 所示。
内存 |
芯片上/芯片外位置 |
是否缓存 |
访问 |
作用域 |
生命周期 |
|---|---|---|---|---|---|
寄存器 |
芯片上 |
不适用 |
读/写 |
1 个线程 |
线程 |
本地 |
芯片外 |
是†† |
读/写 |
1 个线程 |
线程 |
共享 |
芯片上 |
不适用 |
读/写 |
块中所有线程 |
块 |
全局 |
芯片外 |
† |
读/写 |
所有线程 + 主机 |
主机分配 |
常量 |
芯片外 |
是 |
只读 |
所有线程 + 主机 |
主机分配 |
纹理 |
芯片外 |
是 |
只读 |
所有线程 + 主机 |
主机分配 |
† 在计算能力为 6.0 和 7.x 的设备上,默认在 L1 和 L2 中缓存;在计算能力较低的设备上,默认仅在 L2 中缓存,尽管有些设备允许通过编译标志选择在 L1 中缓存。 |
|||||
†† 默认情况下在 L1 和 L2 中缓存,计算能力为 5.x 的设备除外;计算能力为 5.x 的设备仅在 L2 中缓存本地内存。 |
在纹理访问的情况下,如果纹理引用绑定到全局内存中的线性数组,则设备代码可以写入底层数组。绑定到 CUDA 数组的纹理引用可以通过表面写入操作写入(通过将表面绑定到相同的底层 CUDA 数组存储)。应避免在同一内核启动中从纹理读取数据,同时写入其底层全局内存数组,因为纹理缓存是只读的,并且在关联的全局内存被修改时不会失效。
9.2.1. 合并访问全局内存
在为支持 CUDA 的 GPU 架构编程时,一个非常重要的性能考虑因素是全局内存访问的合并。warp(线程束)中的线程对全局内存的加载和存储被设备合并为尽可能少的事务。
注意
高优先级: 尽可能确保全局内存访问被合并。
合并的访问要求取决于设备的计算能力,并在 CUDA C++ 编程指南中记录。
对于计算能力为 6.0 或更高的设备,要求可以很容易地总结:warp 中线程的并发访问将合并为等于服务 warp 中所有线程所需的 32 字节事务数量的事务数。
对于某些计算能力为 5.2 的设备,可以选择启用对全局内存访问的 L1 缓存。如果在这些设备上启用了 L1 缓存,则所需的事务数等于所需的 128 字节对齐段的数量。
注意
在计算能力为 6.0 或更高的设备上,L1 缓存是默认设置,但是,无论全局加载是否在 L1 中缓存,数据访问单元都是 32 字节。
在使用 GDDR 内存的设备上,当 ECC 开启时,以合并的方式访问内存更为重要。分散的访问会增加 ECC 内存传输开销,尤其是在将数据写入全局内存时。
以下简单示例说明了合并的概念。这些示例假设计算能力为 6.0 或更高,并且访问的是 4 字节字,除非另有说明。
9.2.1.1. 简单的访问模式
合并的第一个也是最简单的例子可以通过任何计算能力为 6.0 或更高的启用 CUDA 的设备实现:第 k 个线程访问 32 字节对齐数组中的第 k 个字。并非所有线程都需要参与。
例如,如果 warp 中的线程访问相邻的 4 字节字(例如,相邻的 float 值),则四个合并的 32 字节事务将服务于该内存访问。图 3 <coalesced-access-figure> 中显示了这种模式。
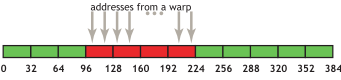
图 3 合并访问
此访问模式导致四个 32 字节事务,以红色矩形表示。
如果从四个 32 字节段中的任何一个仅请求了字的子集(例如,如果几个线程访问了同一个字,或者如果某些线程没有参与访问),则仍然会获取整个段。此外,如果 warp 中线程的访问在四个段内或跨段进行了置换,则计算能力为 compute capability 6.0 或更高的设备仍然只会执行四个 32 字节事务。
9.2.1.2. 顺序但未对齐的访问模式
如果 warp 中的顺序线程访问顺序但未与 32 字节段对齐的内存,则将请求五个 32 字节段,如 图 4 所示。

图 4 落在五个 32 字节段内的未对齐顺序地址
通过 CUDA 运行时 API 分配的内存(例如通过 cudaMalloc())保证至少对齐到 256 字节。因此,选择合理的线程块大小,例如 warp 大小的倍数(即,当前 GPU 上为 32),有助于 warp 进行正确对齐的内存访问。(考虑如果线程块大小不是 warp 大小的倍数,例如,第二个、第三个和后续线程块访问的内存地址会发生什么情况。)
9.2.1.3. 未对齐访问的影响
使用简单的复制内核(例如 演示未对齐访问的复制内核 中的内核)来探索未对齐访问的后果是容易且信息丰富的。
演示未对齐访问的复制内核
__global__ void offsetCopy(float *odata, float* idata, int offset)
{
int xid = blockIdx.x * blockDim.x + threadIdx.x + offset;
odata[xid] = idata[xid];
}
在 演示未对齐访问的复制内核 中,数据从输入数组 idata 复制到输出数组,这两个数组都存在于全局内存中。内核在主机代码的循环中执行,该循环改变参数 offset 从 0 到 32(例如,图 4 对应于这种未对齐)。在 NVIDIA Tesla V100(计算能力 7.0)上,具有各种偏移量的复制的有效带宽如 图 5 所示。
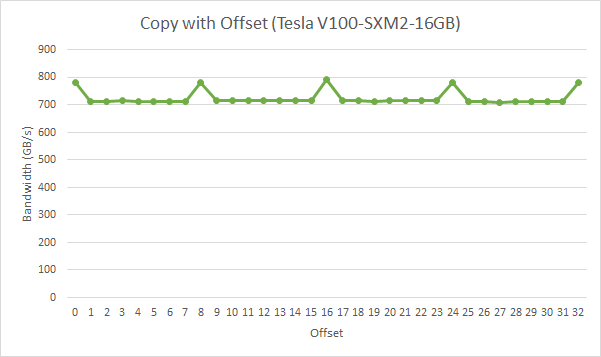
图 5 offsetCopy 内核的性能
对于 NVIDIA Tesla V100,没有偏移量或偏移量是 8 字倍数的全局内存访问导致四个 32 字节事务。实现的带宽约为 790 GB/s。否则,每个 warp 加载五个 32 字节段,我们预计内存吞吐量约为无偏移量时实现的 4/5th。
在这个特定的例子中,实现的偏移内存吞吐量约为 9/10th,因为相邻的 warp 重用了其邻居获取的缓存行。因此,虽然影响仍然很明显,但它不如我们可能预期的那么大。如果相邻的 warp 没有表现出如此高度的过度获取缓存行的重用,则影响会更大。
9.2.1.4. 跨步访问
如上所述,在未对齐的顺序访问的情况下,缓存有助于减轻性能影响。然而,对于非单位步幅访问,情况可能有所不同,这是一种在处理多维数据或矩阵时经常出现的模式。因此,确保尽可能多地利用每个获取的缓存行中的数据,是这些设备上内存访问性能优化的重要组成部分。
为了说明跨步访问对有效带宽的影响,请参阅 演示非单位步幅数据复制的内核 中的内核 strideCopy(),它以 stride 元素的步幅在线程之间从 idata 复制数据到 odata。
演示非单位步幅数据复制的内核
__global__ void strideCopy(float *odata, float* idata, int stride)
{
int xid = (blockIdx.x*blockDim.x + threadIdx.x)*stride;
odata[xid] = idata[xid];
}
图 6 说明了这种情况;在这种情况下,warp 中的线程以 2 的步幅访问内存中的字。此操作导致在 Tesla V100(计算能力 7.0)上每个 warp 加载八个 L2 缓存段。
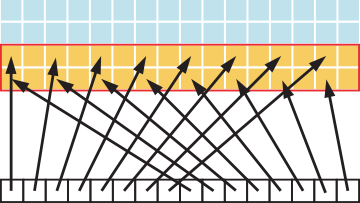
图 6 相邻线程以 2 的步幅访问内存
步幅为 2 会导致 50% 的加载/存储效率,因为事务中一半的元素未使用,并表示浪费的带宽。随着步幅的增加,有效带宽会降低,直到每个 warp 中的 32 个线程加载 32 个 32 字节段的点,如 图 7 所示。
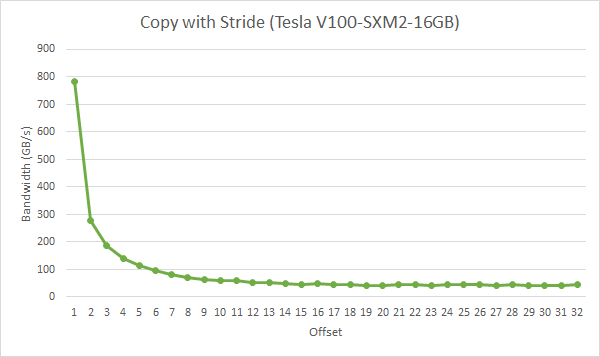
图 7 strideCopy 内核的性能
如 图 7 所示,应尽可能避免非单位步幅全局内存访问。一种这样做的方法是利用共享内存,这将在下一节中讨论。
9.2.2. L2 缓存
从 CUDA 11.0 开始,计算能力为 8.0 及以上的设备能够影响数据在 L2 缓存中的持久性。由于 L2 缓存是片上的,因此它可能为全局内存提供更高的带宽和更低的延迟访问。
有关更多详细信息,请参阅 CUDA C++ 编程指南 中的 L2 访问管理部分。
9.2.2.1. L2 缓存访问窗口
当 CUDA 内核重复访问全局内存中的数据区域时,可以将此类数据访问视为持久性访问。另一方面,如果数据仅访问一次,则可以将此类数据访问视为流式访问。L2 缓存的一部分可以预留出来,用于对全局内存中的数据区域进行持久性访问。如果预留部分未被持久性访问使用,则流式或正常数据访问可以使用它。
用于持久性访问的 L2 缓存预留大小可以在限制范围内调整
cudaGetDeviceProperties(&prop, device_id);
cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, prop.persistingL2CacheMaxSize); /* Set aside max possible size of L2 cache for persisting accesses */
可以使用 CUDA 流或 CUDA 图内核节点上的访问策略窗口来控制用户数据到 L2 预留部分的映射。下面的示例显示了如何在 CUDA 流上使用访问策略窗口。
cudaStreamAttrValue stream_attribute; // Stream level attributes data structure
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(ptr); // Global Memory data pointer
stream_attribute.accessPolicyWindow.num_bytes = num_bytes; // Number of bytes for persisting accesses.
// (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize)
stream_attribute.accessPolicyWindow.hitRatio = 1.0; // Hint for L2 cache hit ratio for persisting accesses in the num_bytes region
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss.
//Set the attributes to a CUDA stream of type cudaStream_t
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);
访问策略窗口需要 hitRatio 和 num_bytes 的值。根据 num_bytes 参数的值和 L2 缓存的大小,可能需要调整 hitRatio 的值,以避免 L2 缓存行的抖动。
9.2.2.2. 调整访问窗口命中率
hitRatio 参数可用于指定接收 hitProp 属性的访问比例。例如,如果 hitRatio 值为 0.6,则全局内存区域 [ptr..ptr+num_bytes) 中 60% 的内存访问具有持久性属性,而 40% 的内存访问具有流式属性。为了理解 hitRatio 和 num_bytes 的影响,我们使用滑动窗口微基准测试。
此微基准测试使用 GPU 全局内存中的 1024 MB 区域。首先,我们使用 cudaDeviceSetLimit() 为持久性访问预留 30 MB 的 L2 缓存,如上所述。然后,如下图所示,我们指定对内存区域的前 freqSize * sizeof(int) 字节的访问是持久性的。因此,这些数据将使用 L2 预留部分。在我们的实验中,我们改变此持久性数据区域的大小,从 10 MB 到 60 MB,以模拟数据适合或超出 30 MB 的可用 L2 预留部分的各种场景。请注意,NVIDIA Tesla A100 GPU 具有 40 MB 的总 L2 缓存容量。对内存区域的剩余数据(即,流式数据)的访问被视为正常或流式访问,因此将使用剩余的 10 MB 非预留 L2 部分(除非 L2 预留部分的一部分未使用)。
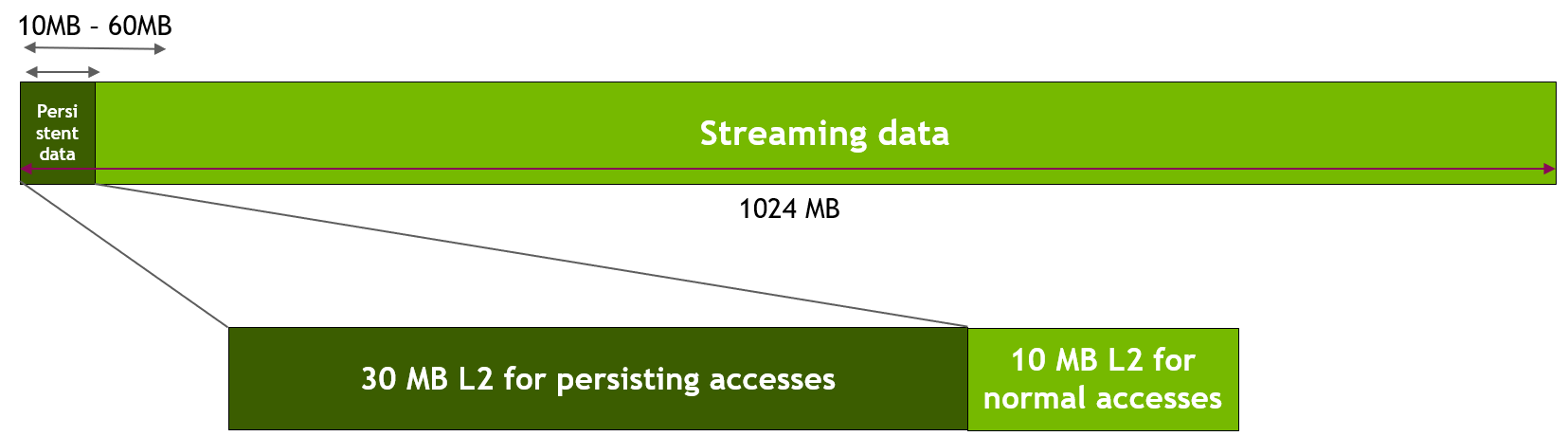
图 8 在滑动窗口实验中将持久性数据访问映射到预留的 L2
考虑以下内核代码和访问窗口参数,作为滑动窗口实验的实现。
__global__ void kernel(int *data_persistent, int *data_streaming, int dataSize, int freqSize) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
/*Each CUDA thread accesses one element in the persistent data section
and one element in the streaming data section.
Because the size of the persistent memory region (freqSize * sizeof(int) bytes) is much
smaller than the size of the streaming memory region (dataSize * sizeof(int) bytes), data
in the persistent region is accessed more frequently*/
data_persistent[tid % freqSize] = 2 * data_persistent[tid % freqSize];
data_streaming[tid % dataSize] = 2 * data_streaming[tid % dataSize];
}
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data_persistent);
stream_attribute.accessPolicyWindow.num_bytes = freqSize * sizeof(int); //Number of bytes for persisting accesses in range 10-60 MB
stream_attribute.accessPolicyWindow.hitRatio = 1.0; //Hint for cache hit ratio. Fixed value 1.0
下图显示了上述内核的性能。当持久性数据区域很好地适应 L2 缓存的 30 MB 预留部分时,观察到高达 50% 的性能提升。但是,一旦此持久性数据区域的大小超过 L2 预留缓存部分的大小,由于 L2 缓存行的抖动,观察到大约 10% 的性能下降。
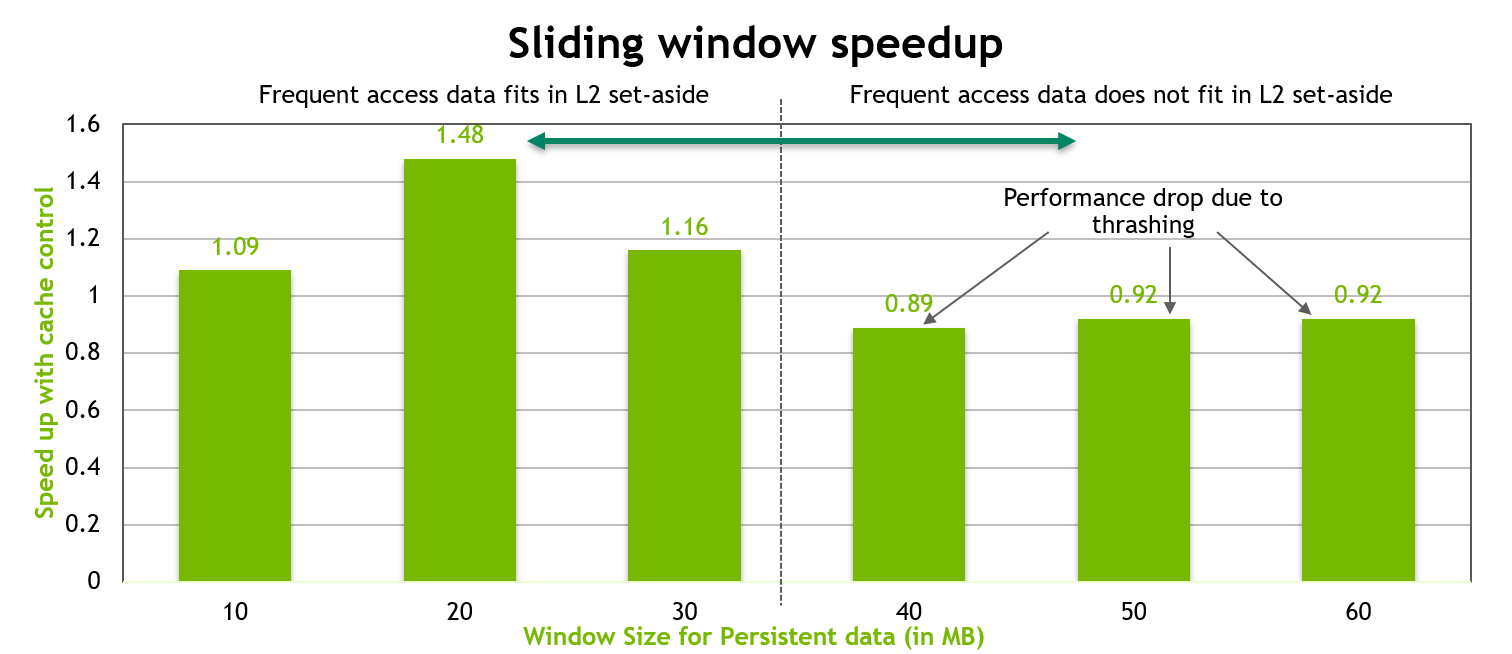
图 9 命中率为 1.0 的固定滑动窗口基准测试的性能
为了优化性能,当持久性数据的大小大于预留的 L2 缓存部分的大小时,我们在访问窗口中调整 num_bytes 和 hitRatio 参数,如下所示。
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data_persistent);
stream_attribute.accessPolicyWindow.num_bytes = 20*1024*1024; //20 MB
stream_attribute.accessPolicyWindow.hitRatio = (20*1024*1024)/((float)freqSize*sizeof(int)); //Such that up to 20MB of data is resident.
我们将访问窗口中的 num_bytes 固定为 20 MB,并调整 hitRatio,以便总持久性数据中的随机 20 MB 驻留在 L2 预留缓存部分中。此持久性数据的剩余部分将使用流式属性访问。这有助于减少缓存抖动。结果如下图所示,我们看到无论持久性数据是否适合 L2 预留部分,都具有良好的性能。
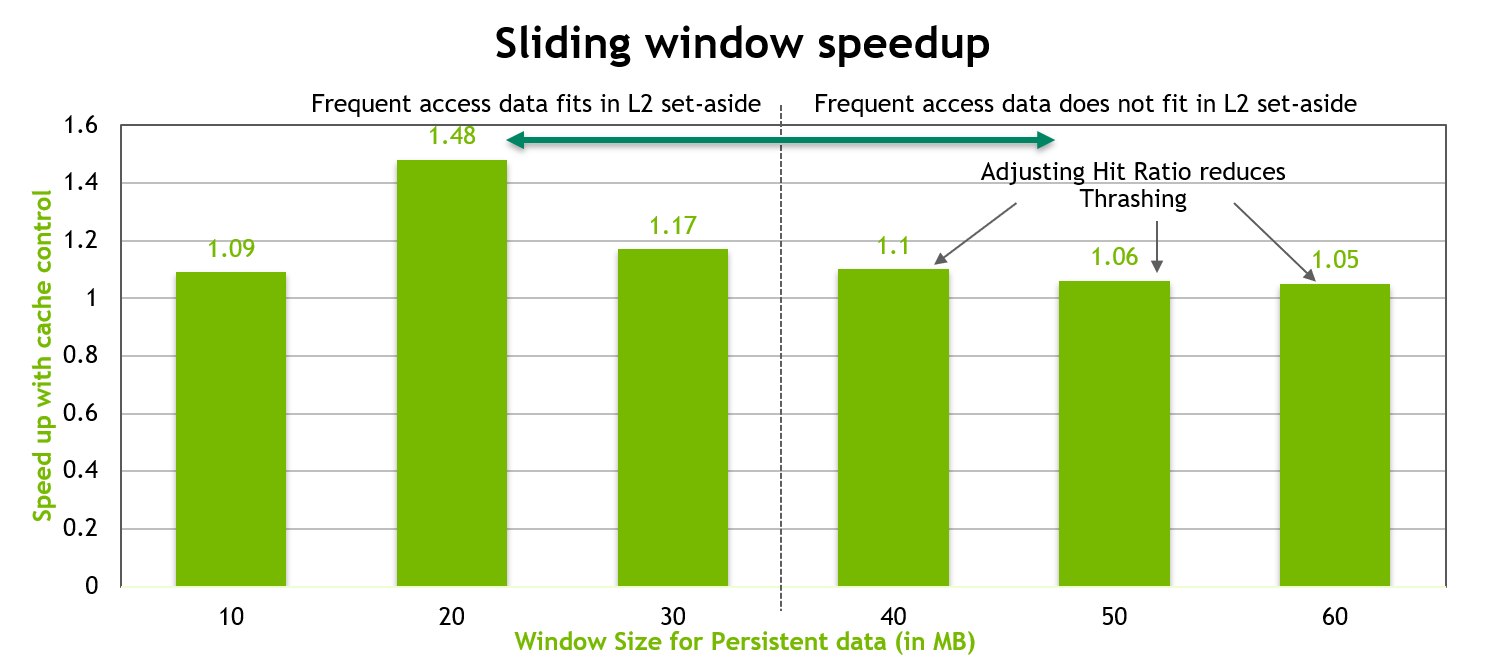
图 10 具有调整后的命中率的滑动窗口基准测试的性能
9.2.3. 共享内存
由于共享内存是片上的,因此它比本地内存和全局内存具有更高的带宽和更低的延迟 - 前提是线程之间没有bank conflicts(存储体冲突),如下节详述。
9.2.3.2. 矩阵乘法中的共享内存 (C=AB)
共享内存使块中的线程能够协同工作。当一个块中的多个线程使用来自全局内存的相同数据时,可以使用共享内存仅从全局内存访问一次数据。共享内存还可以用于避免非合并的内存访问,方法是从全局内存中以合并的模式加载和存储数据,然后在共享内存中重新排序数据。除了存储体冲突之外,warp 在共享内存中进行非顺序或未对齐访问不会受到任何性能损失。
通过矩阵乘法 C = AB 的简单示例来说明共享内存的使用,其中 A 的维度为 Mxw,B 的维度为 wxN,C 的维度为 MxN。为了保持内核的简单性,M 和 N 都是 32 的倍数,因为对于当前设备,warp 大小 (w) 为 32。
问题的一种自然分解是使用 wxw 线程的块和瓦片大小。因此,就 wxw 瓦片而言,A 是列矩阵,B 是行矩阵,C 是它们的外积;参见 图 11。启动一个 N/w 乘以 M/w 块的网格,其中每个线程块从 A 的单个瓦片和 B 的单个瓦片计算 C 中不同瓦片的元素。
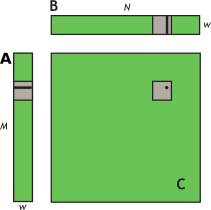
图 11 块列矩阵乘以块行矩阵。块列矩阵 (A) 乘以块行矩阵 (B),得到乘积矩阵 (C)。
为此,simpleMultiply 内核(未优化的矩阵乘法)计算矩阵 C 的瓦片的输出元素。
未优化的矩阵乘法
__global__ void simpleMultiply(float *a, float* b, float *c,
int N)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int i = 0; i < TILE_DIM; i++) {
sum += a[row*TILE_DIM+i] * b[i*N+col];
}
c[row*N+col] = sum;
}
在 未优化的矩阵乘法 中,a、b 和 c 分别是指向矩阵 A、B 和 C 的全局内存的指针;blockDim.x、blockDim.y 和 TILE_DIM 都等于 w。wxw 线程块中的每个线程计算 C 的瓦片中的一个元素。row 和 col 是特定线程正在计算的 C 中元素的行和列。for 循环(遍历 i)将 A 的一行乘以 B 的一列,然后将其写入 C。
此内核的有效带宽在 NVIDIA Tesla V100 上为 119.9 GB/s。为了分析性能,有必要考虑 warp 在 for 循环中如何访问全局内存。线程的每个 warp 计算 C 的瓦片的一行,这取决于 A 的单行和 B 的整个瓦片,如 图 12 所示。
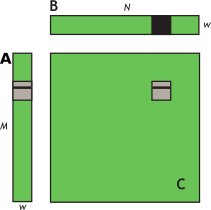
图 12 计算瓦片的一行。使用 A 的一行和 B 的整个瓦片计算 C 中瓦片的一行。
对于 for 循环的每次迭代 i,warp 中的线程读取 B 瓦片的一行,这对于所有计算能力来说都是顺序且合并的访问。
然而,对于每次迭代 i,一个 warp 中的所有线程从全局内存中读取矩阵 A 的相同值,因为索引 row*TILE_DIM+i 在一个 warp 内是常量。即使这样的访问在计算能力为 2.0 或更高的设备上只需要 1 次事务,事务中也存在带宽浪费,因为在 32 字节的缓存段中只使用了一个 4 字节的字。我们可以在循环的后续迭代中重用这个缓存行,并且最终会利用所有 8 个字;然而,当许多 warp 同时在同一个多处理器上执行时(通常情况下是这样),缓存行很容易在迭代 i 和 i+1 之间从缓存中被驱逐出去。
通过将 A 的 tile 读取到共享内存中,可以提高任何计算能力的设备的性能,如 使用共享内存提高矩阵乘法中的全局内存加载效率 所示。
__global__ void coalescedMultiply(float *a, float* b, float *c,
int N)
{
__shared__ float aTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x];
__syncwarp();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i]* b[i*N+col];
}
c[row*N+col] = sum;
}
在 使用共享内存提高矩阵乘法中的全局内存加载效率 中,A 的 tile 中的每个元素都只从全局内存读取一次,以完全合并的方式(没有带宽浪费)读取到共享内存。在 for 循环的每次迭代中,共享内存中的一个值被广播到 warp 中的所有线程。在将 A 的 tile 读取到共享内存后,使用 __syncwarp() 就足够了,而不需要 __syncthreads() 同步屏障调用,因为只有 warp 内将数据写入共享内存的线程读取这些数据。这个内核在 NVIDIA Tesla V100 上实现了 144.4 GB/s 的有效带宽。这说明了当硬件 L1 缓存驱逐策略与应用程序的需求不匹配,或者当 L1 缓存不用于从全局内存读取时,如何将共享内存用作用户管理的缓存。
可以进一步改进 使用共享内存提高矩阵乘法中的全局内存加载效率 处理矩阵 B 的方式。在计算矩阵 C 的 tile 的每一行时,会读取整个 B tile。通过将 B tile 一次性读取到共享内存中,可以消除重复读取 B tile 的情况(通过读取更多数据到共享内存进行改进)。
__global__ void sharedABMultiply(float *a, float* b, float *c,
int N)
{
__shared__ float aTile[TILE_DIM][TILE_DIM],
bTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x];
bTile[threadIdx.y][threadIdx.x] = b[threadIdx.y*N+col];
__syncthreads();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i]* bTile[i][threadIdx.x];
}
c[row*N+col] = sum;
}
请注意,在 通过读取更多数据到共享内存进行改进 中,读取 B tile 后需要调用 __syncthreads(),因为一个 warp 从共享内存中读取数据,而这些数据是由不同的 warp 写入共享内存的。这个例程在 NVIDIA Tesla V100 上的有效带宽为 195.5 GB/s。请注意,性能提升不是由于两种情况下的合并访问得到改善,而是由于避免了从全局内存的冗余传输。
各种优化的结果总结在 表 2 中。
优化 |
NVIDIA Tesla V100 |
|---|---|
无优化 |
119.9 GB/s |
合并访问,使用共享内存存储 A 的 tile |
144.4 GB/s |
使用共享内存消除 B 的 tile 的冗余读取 |
195.5 GB/s |
注意
中等优先级: 使用共享内存避免从全局内存进行冗余传输。
9.2.3.4. 从全局内存到共享内存的异步复制
CUDA 11.0 引入了异步复制功能,该功能可在设备代码中使用,以显式管理从全局内存到共享内存的数据异步复制。此功能使 CUDA 内核能够将从全局内存复制数据到共享内存与计算重叠。它还避免了传统上存在于全局内存读取和共享内存写入之间的中间寄存器文件访问。
有关更多详细信息,请参阅 CUDA C++ 编程指南 中的 memcpy_async 部分。
为了理解从全局内存到共享内存的同步复制和异步复制之间的性能差异,请考虑以下微基准 CUDA 内核,用于演示同步和异步方法。对于 NVIDIA A100 GPU,异步复制是硬件加速的。
template <typename T>
__global__ void pipeline_kernel_sync(T *global, uint64_t *clock, size_t copy_count) {
extern __shared__ char s[];
T *shared = reinterpret_cast<T *>(s);
uint64_t clock_start = clock64();
for (size_t i = 0; i < copy_count; ++i) {
shared[blockDim.x * i + threadIdx.x] = global[blockDim.x * i + threadIdx.x];
}
uint64_t clock_end = clock64();
atomicAdd(reinterpret_cast<unsigned long long *>(clock),
clock_end - clock_start);
}
template <typename T>
__global__ void pipeline_kernel_async(T *global, uint64_t *clock, size_t copy_count) {
extern __shared__ char s[];
T *shared = reinterpret_cast<T *>(s);
uint64_t clock_start = clock64();
//pipeline pipe;
for (size_t i = 0; i < copy_count; ++i) {
__pipeline_memcpy_async(&shared[blockDim.x * i + threadIdx.x],
&global[blockDim.x * i + threadIdx.x], sizeof(T));
}
__pipeline_commit();
__pipeline_wait_prior(0);
uint64_t clock_end = clock64();
atomicAdd(reinterpret_cast<unsigned long long *>(clock),
clock_end - clock_start);
}
内核的同步版本将元素从全局内存加载到中间寄存器,然后将中间寄存器值存储到共享内存。在内核的异步版本中,一旦调用 __pipeline_memcpy_async() 函数,就会发出从全局内存加载并直接存储到共享内存的指令。__pipeline_wait_prior(0) 将等待直到管道对象中的所有指令都已执行。使用异步复制不使用任何中间寄存器。不使用中间寄存器可以帮助减少寄存器压力并可以增加内核占用率。使用异步复制指令从全局内存复制到共享内存的数据可以缓存在 L1 缓存中,或者可以选择绕过 L1 缓存。如果各个 CUDA 线程正在复制 16 字节的元素,则可以绕过 L1 缓存。这种差异在 图 13 中说明。

图 13 比较从全局内存到共享内存的同步复制与异步复制
我们评估了两个内核的性能,每个线程使用 4B、8B 和 16B 大小的元素,即为模板参数使用 int、int2 和 int4。我们调整内核中的 copy_count,使每个线程块从 512 字节复制到 48 MB。内核的性能如图 图 14 所示。
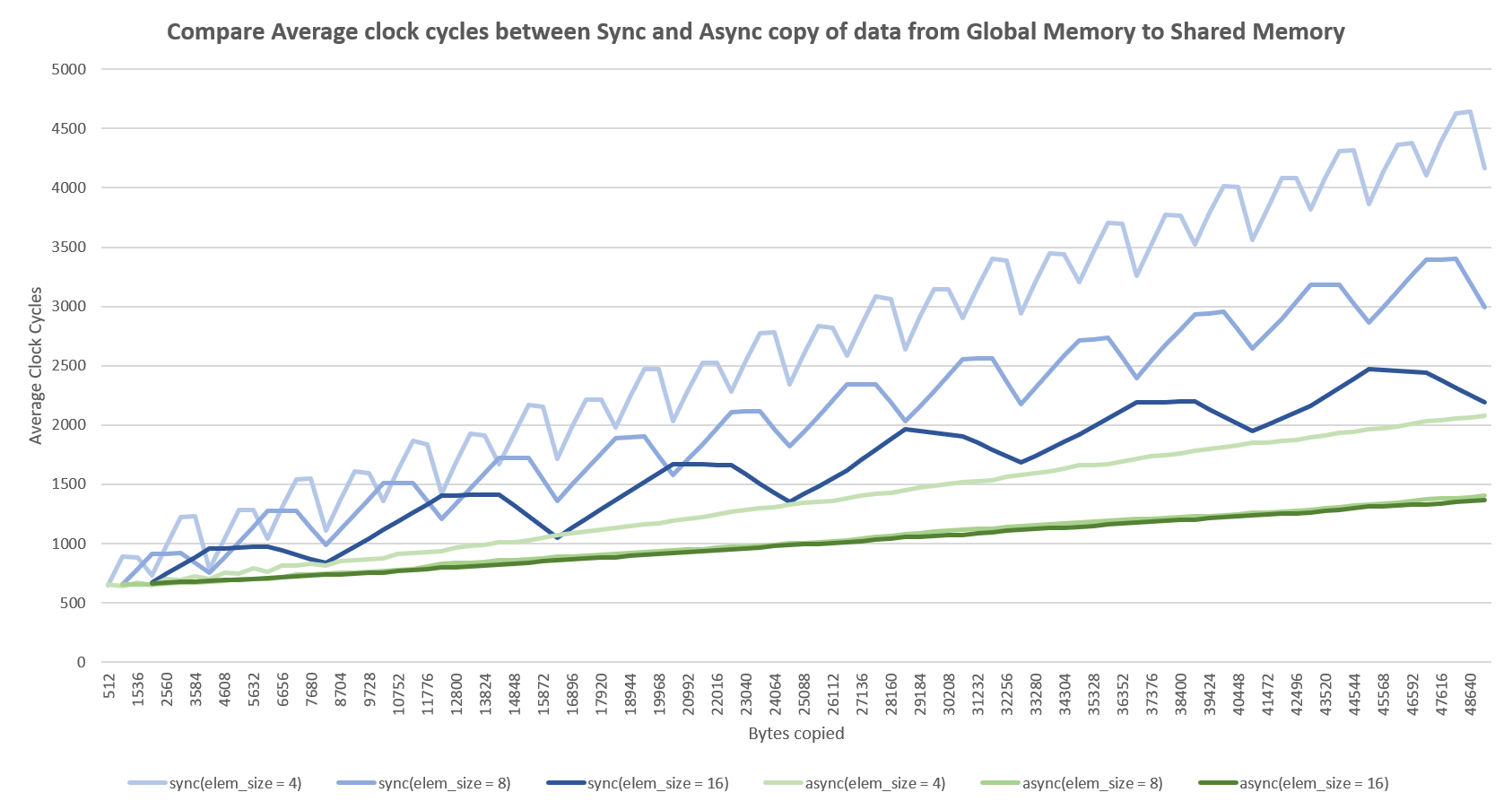
图 14 比较从全局内存到共享内存的同步复制与异步复制的性能
从性能图表中,可以对该实验进行以下观察。
当
copy_count参数是所有三种元素大小的 4 的倍数时,同步复制可实现最佳性能。编译器可以优化 4 个加载和存储指令的组。这从锯齿曲线中可以明显看出。在几乎所有情况下,异步复制都实现了更好的性能。
异步复制不需要
copy_count参数是 4 的倍数,即可通过编译器优化最大化性能。总的来说,当使用大小为 8 或 16 字节的元素进行异步复制时,可以获得最佳性能。
9.2.4. 本地内存
本地内存之所以如此命名,是因为它的作用域对于线程是本地的,而不是因为它的物理位置。实际上,本地内存是片外的。因此,访问本地内存与访问全局内存一样昂贵。换句话说,名称中的本地并不意味着更快的访问速度。
本地内存仅用于保存自动变量。nvcc 编译器在确定没有足够的寄存器空间来保存变量时会这样做。可能放置在本地内存中的自动变量是大型结构或数组(会占用过多的寄存器空间)以及编译器确定可能被动态索引的数组。
检查 PTX 汇编代码(通过使用 -ptx 或 -keep 命令行选项编译 nvcc 获得)可以揭示变量是否在第一编译阶段已放置在本地内存中。如果已放置,它将使用 .local 助记符声明,并使用 ld.local 和 st.local 助记符访问。如果未放置,则后续编译阶段可能仍然会另作决定,如果他们发现该变量为目标架构消耗了过多的寄存器空间。没有办法检查特定变量的情况,但是当使用 --ptxas-options=-v 选项运行时,编译器会报告每个内核的总本地内存使用量 (lmem)。
9.2.5. 纹理内存
只读纹理内存空间是缓存的。因此,纹理获取仅在缓存未命中时才花费一次设备内存读取;否则,它仅花费一次从纹理缓存读取。纹理缓存针对 2D 空间局部性进行了优化,因此读取彼此靠近的纹理地址的同一 warp 的线程将获得最佳性能。纹理内存也设计用于具有恒定延迟的流式获取;也就是说,缓存命中减少了 DRAM 带宽需求,但不会减少获取延迟。
在某些寻址情况下,通过纹理获取读取设备内存可能是从全局内存或常量内存读取设备内存的有利替代方案。
9.2.5.1. 额外的纹理功能
如果使用 tex1D()、tex2D() 或 tex3D() 而不是 tex1Dfetch() 获取纹理,则硬件提供其他功能,这些功能可能对某些应用程序(例如图像处理)有用,如 表 4 所示。
功能 |
用途 |
注意事项 |
|---|---|---|
过滤 |
texel 之间快速、低精度的插值 |
仅当纹理引用返回浮点数据时有效 |
归一化纹理坐标 |
与分辨率无关的编码 |
无 |
寻址模式 |
自动处理边界情况1 |
只能与归一化纹理坐标一起使用 |
1 表 4 底行中边界情况的自动处理是指纹理坐标落在有效寻址范围之外时如何解析纹理坐标。有两种选择:clamp 和 wrap。如果 x 是坐标,N 是一维纹理的 texel 数,则使用 clamp,如果 x < 0,则 x 替换为 0,如果 1 <x,则替换为 1-1/N。使用 wrap,x 替换为 frac(x),其中 frac(x) = x - floor(x)。Floor 返回小于或等于 x 的最大整数。因此,在 clamp 模式下,当 N = 1 时,1.3 的 x 被 clamp 到 1.0;而在 wrap 模式下,它被转换为 0.3 |
在内核调用中,纹理缓存与全局内存写入保持不一致,因此从同一内核调用中通过全局存储写入的地址进行纹理获取将返回未定义的数据。也就是说,如果内存位置已由先前的内核调用或内存复制更新,则线程可以安全地通过纹理读取内存位置,但如果它先前已由同一线程或同一内核调用中的另一个线程更新,则不能安全读取。
9.2.6. 常量内存
设备上总共有 64 KB 的常量内存。常量内存空间是缓存的。因此,从常量内存读取仅在缓存未命中时才花费一次从设备内存读取;否则,它仅花费一次从常量缓存读取。warp 内线程对不同地址的访问是串行化的,因此成本随 warp 内所有线程读取的唯一地址数量线性增加。因此,当同一 warp 中的线程仅访问少数不同的位置时,常量缓存是最佳的。如果一个 warp 的所有线程都访问相同的位置,那么常量内存可以像寄存器访问一样快。
9.2.7. 寄存器
通常,访问寄存器每个指令消耗零个额外的时钟周期,但由于寄存器写后读依赖关系和寄存器内存 bank 冲突,可能会发生延迟。
编译器和硬件线程调度器将尽可能最佳地调度指令,以避免寄存器内存 bank 冲突。应用程序无法直接控制这些 bank 冲突。特别是,没有与寄存器相关的原因将数据打包到向量数据类型中,例如 float4 或 int4 类型。
9.2.7.1. 寄存器压力
当没有足够的寄存器可用于给定任务时,会发生寄存器压力。即使每个多处理器包含数千个 32 位寄存器(请参阅 CUDA C++ 编程指南的功能和技术规格),这些寄存器也在并发线程之间进行分区。为防止编译器分配过多寄存器,请使用 -maxrregcount=N 编译器命令行选项或启动边界内核定义限定符(请参阅 CUDA C++ 编程指南的执行配置)来控制每个线程分配的最大寄存器数。
9.3. 分配
通过 cudaMalloc() 和 cudaFree() 进行设备内存分配和释放是昂贵的操作。建议使用 cudaMallocAsync() 和 cudaFreeAsync(),它们是流排序的池分配器,用于管理设备内存。
9.4. NUMA 最佳实践
一些最新的 Linux 发行版默认启用自动 NUMA 平衡(或“AutoNUMA”)。在某些情况下,自动 NUMA 平衡执行的操作可能会降低在 NVIDIA GPU 上运行的应用程序的性能。为了获得最佳性能,用户应手动调整其应用程序的 NUMA 特性。
最佳 NUMA 调整将取决于每个应用程序和节点的特性和所需的硬件关联性,但通常建议在 NVIDIA GPU 上计算的应用程序选择禁用自动 NUMA 平衡的策略。例如,在 IBM Newell POWER9 节点(其中 CPU 对应于 NUMA 节点 0 和 8)上,使用
numactl --membind=0,8
将内存分配绑定到 CPU。
10. 执行配置优化
良好性能的关键之一是保持设备上的多处理器尽可能繁忙。多处理器之间工作负载不平衡的设备将提供次优的性能。因此,设计应用程序以使用线程和 block,从而最大限度地提高硬件利用率并限制阻碍工作自由分配的做法非常重要。这项工作的关键概念是占用率,这将在以下各节中进行解释。
在某些情况下,还可以通过设计应用程序来改进硬件利用率,以便多个独立的内核可以同时执行。多个内核同时执行称为并发内核执行。并发内核执行将在下面描述。
另一个重要的概念是管理为特定任务分配的系统资源。如何管理这种资源利用率将在本章的最后几节中讨论。
10.1. 占用率
线程指令在 CUDA 中按顺序执行,因此,当一个 warp 暂停或停顿,执行其他 warp 是隐藏延迟并保持硬件繁忙的唯一方法。因此,与多处理器上活动 warp 数量相关的某些指标对于确定硬件保持繁忙的效率非常重要。此指标为占用率。
占用率是每个多处理器活动 warp 数量与最大可能活动 warp 数量的比率。(要确定后一个数字,请参阅 deviceQuery CUDA 示例或参考 计算能力。)查看占用率的另一种方法是硬件处理 warp 能力的百分比,该百分比正在积极使用中。
更高的占用率并不总是等同于更高的性能 - 存在一个点,超过该点额外的占用率不会提高性能。但是,低占用率始终会干扰隐藏内存延迟的能力,从而导致性能下降。
CUDA 内核所需的每个线程资源可能会以不希望的方式限制最大 block 大小。为了保持与未来硬件和工具包的向前兼容性,并确保至少一个线程 block 可以在 SM 上运行,开发人员应包含单个参数 __launch_bounds__(maxThreadsPerBlock),该参数指定内核将启动的最大 block 大小。否则可能导致“启动请求的资源过多”错误。提供两个参数版本的 __launch_bounds__(maxThreadsPerBlock,minBlocksPerMultiprocessor) 在某些情况下可以提高性能。minBlocksPerMultiprocessor 的正确值应使用详细的每个内核分析来确定。
10.1.1. 计算占用率
确定占用率的几个因素之一是寄存器可用性。寄存器存储使线程能够将局部变量保存在附近,以实现低延迟访问。但是,寄存器集合(称为寄存器文件)是一种有限的商品,驻留在多处理器上的所有线程都必须共享。寄存器一次性分配给整个 block。因此,如果每个线程 block 使用大量寄存器,则可以驻留在多处理器上的线程 block 数量会减少,从而降低多处理器的占用率。每个线程的最大寄存器数可以在编译时使用 -maxrregcount 选项按文件手动设置,或者使用 __launch_bounds__ 限定符按内核手动设置(请参阅 寄存器压力)。
为了计算占用率,每个线程使用的寄存器数是关键因素之一。例如,在 CUDA 计算能力 7.0 的设备上,每个多处理器有 65,536 个 32 位寄存器,最多可以同时驻留 2048 个线程(64 个 warp x 每个 warp 32 个线程)。这意味着在其中一个设备中,为了使多处理器具有 100% 的占用率,每个线程最多可以使用 32 个寄存器。但是,这种确定寄存器计数如何影响占用率的方法没有考虑寄存器分配粒度。例如,在计算能力为 7.0 的设备上,每个线程使用 37 个寄存器的 128 线程 block 内核在每个多处理器上有 12 个活动的 128 线程 block 时,占用率为 75%,而每个线程使用相同 37 个寄存器的 320 线程 block 内核占用率为 63%,因为每个多处理器只能驻留四个 320 线程 block。此外,寄存器分配向上舍入到每个 warp 最近的 256 个寄存器。
可用寄存器数量、每个多处理器上同时驻留的最大线程数以及寄存器分配粒度因不同的计算能力而异。由于寄存器分配中的这些细微差别,以及多处理器的共享内存也在驻留线程 block 之间进行分区,因此寄存器使用率和占用率之间的确切关系可能难以确定。nvcc 的 --ptxas options=v 选项详细说明了每个内核每个线程使用的寄存器数。有关各种计算能力的设备的寄存器分配公式,请参阅 CUDA C++ 编程指南的硬件多线程,有关这些设备上可用的寄存器总数,请参阅 CUDA C++ 编程指南的功能和技术规格。或者,NVIDIA 提供了一个占用率计算器,作为 Nsight Compute 的一部分;请参阅 https://docs.nvda.net.cn/nsight-compute/NsightCompute/index.html#occupancy-calculator。
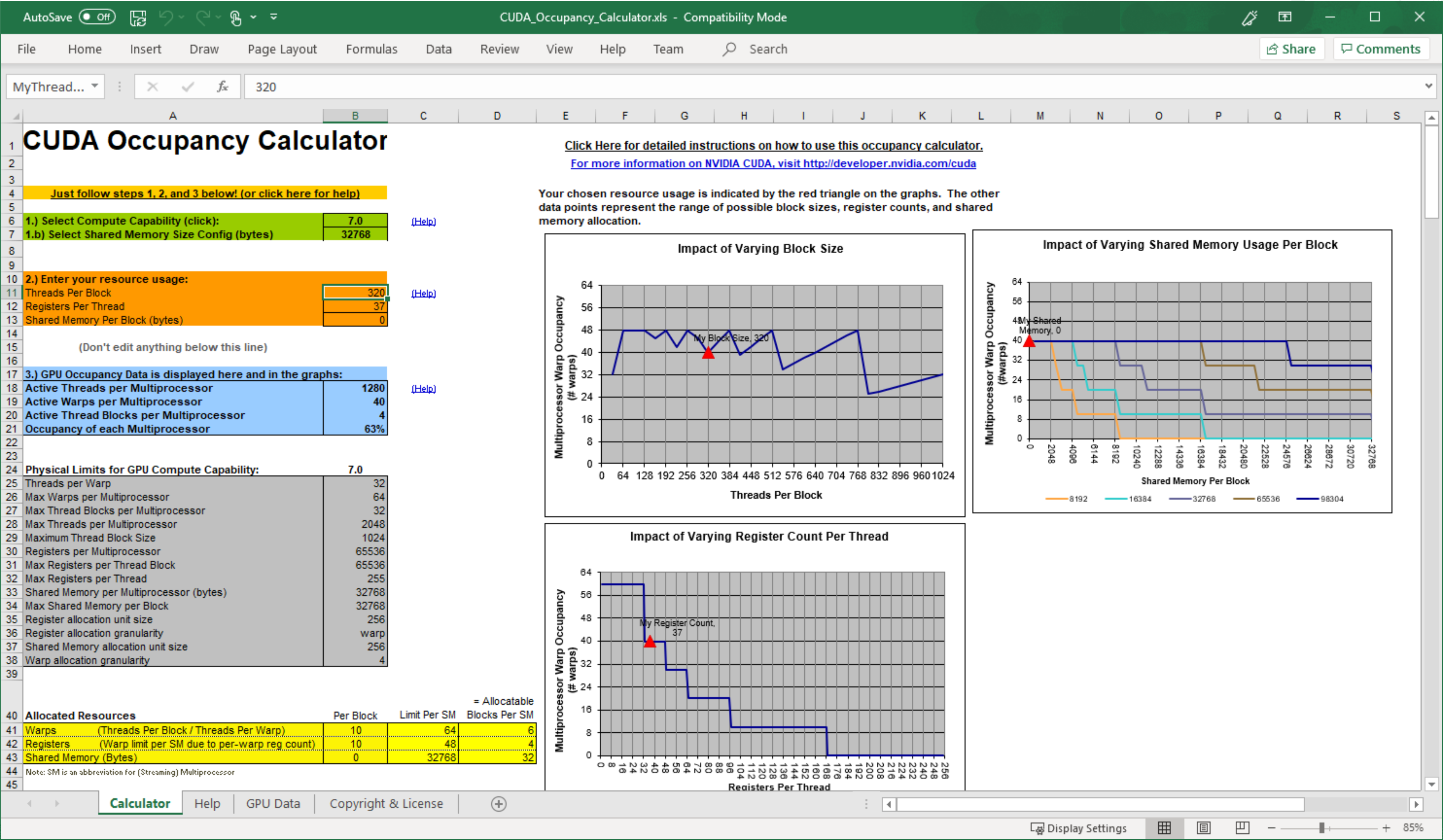
图 15 使用 CUDA 占用率计算器来预测 GPU 多处理器占用率
应用程序还可以使用 CUDA 运行时的占用率 API,例如 cudaOccupancyMaxActiveBlocksPerMultiprocessor,以根据运行时参数动态选择启动配置。
10.2. 隐藏寄存器依赖性
注意
中等优先级: 为了隐藏由寄存器依赖性引起的延迟,请保持每个多处理器有足够数量的活动线程(即,足够的占用率)。
当指令使用之前指令写入寄存器中存储的结果时,会发生寄存器依赖性。大多数算术指令的延迟在计算能力为 7.0 的设备上通常为 4 个周期。因此,线程必须等待大约 4 个周期才能使用算术结果。但是,这种延迟可以通过执行其他 warp 中的线程来完全隐藏。有关详细信息,请参阅 寄存器。
10.3. 线程和 Block 启发式方法
注意
中等优先级: 每个 block 的线程数应为 32 个线程的倍数,因为这提供了最佳的计算效率并有助于合并访问。
每个网格的 block 维度和大小以及每个 block 的线程维度和大小都是重要因素。这些参数的多维方面允许更轻松地将多维问题映射到 CUDA,并且在性能方面不起作用。因此,本节讨论大小,但不讨论维度。
延迟隐藏和占用率取决于每个多处理器的活动 warp 数量,这由执行参数以及资源(寄存器和共享内存)约束隐式确定。选择执行参数是在延迟隐藏(占用率)和资源利用率之间取得平衡的问题。
选择执行配置参数应同时进行;但是,某些启发式方法适用于每个参数。在选择第一个执行配置参数 - 每个网格的 block 数或网格大小时,主要考虑的是保持整个 GPU 繁忙。网格中的 block 数应大于多处理器的数量,以便所有多处理器至少有一个 block 可以执行。此外,每个多处理器应有多个活动 block,以便不等待 __syncthreads() 的 block 可以保持硬件繁忙。此建议受资源可用性的限制;因此,应在第二个执行参数(每个 block 的线程数或block 大小)以及共享内存使用情况的上下文中确定。为了扩展到未来的设备,每个内核启动的 block 数应为数千个。
在选择 block 大小时,重要的是要记住,多个并发 block 可以驻留在多处理器上,因此占用率不仅由 block 大小决定。特别是,更大的 block 大小并不意味着更高的占用率。
如 占用率 中所述,更高的占用率并不总是等同于更好的性能。例如,将占用率从 66% 提高到 100% 通常不会转化为性能的类似提升。较低占用率的内核将比较高占用率的内核具有更多的每个线程可用寄存器,这可能会减少寄存器溢出到本地内存;特别是,在高度暴露的指令级并行性 (ILP) 的情况下,在某些情况下,有可能以低占用率完全覆盖延迟。
选择 block 大小涉及许多此类因素,并且不可避免地需要进行一些实验。但是,应遵循一些经验法则
每个 block 的线程数应为 warp 大小的倍数,以避免在未充分填充的 warp 上浪费计算并促进合并访问。
应使用最少 64 个线程/block,并且仅当每个多处理器有多个并发 block 时才使用。
每个 block 128 到 256 个线程是尝试不同 block 大小的良好初始范围。
如果延迟影响性能,请使用多个较小的线程 block 而不是每个多处理器一个大的线程 block。这对于频繁调用
__syncthreads()的内核尤其有利。
请注意,当线程 block 分配的寄存器多于多处理器上可用的寄存器时,内核启动将失败,就像请求过多共享内存或过多线程时一样。
10.5. 并发内核执行
正如异步传输以及与计算的重叠传输中所述,CUDA 流 (streams) 可用于将内核执行与数据传输重叠。在能够进行并发内核执行的设备上,流 (streams) 也可用于同时执行多个内核,以更充分地利用设备的多处理器。设备是否具有此功能由 cudaDeviceProp 结构的 concurrentKernels 字段指示(或在 deviceQuery CUDA 示例的输出中列出)。并发执行需要非默认流 (streams)(stream 0 以外的流),因为使用默认流的内核调用仅在设备上(任何流中)所有先前的调用都已完成后才开始,并且在它们完成之前,设备上(任何流中)不会开始任何操作。
以下示例说明了基本技术。因为 kernel1 和 kernel2 在不同的非默认流 (streams) 中执行,所以有能力的设备可以同时执行这些内核。
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
kernel1<<<grid, block, 0, stream1>>>(data_1);
kernel2<<<grid, block, 0, stream2>>>(data_2);
10.6. 多上下文
CUDA 工作发生在特定 GPU 的进程空间内,称为上下文 (context)。上下文 (context) 封装了该 GPU 的内核启动和内存分配,以及诸如页表之类的支持结构。上下文 (context) 在 CUDA Driver API 中是显式的,但在 CUDA Runtime API 中是完全隐式的,后者会自动创建和管理上下文 (contexts)。
使用 CUDA Driver API,CUDA 应用程序进程可能会为给定的 GPU 创建多个上下文 (contexts)。如果多个 CUDA 应用程序进程并发访问同一 GPU,这几乎总是意味着多个上下文 (contexts),因为上下文 (context) 与特定的主机进程绑定,除非使用了多进程服务 (Multi-Process Service)。
虽然可以在给定的 GPU 上并发分配多个上下文 (contexts)(及其相关的资源,例如全局内存分配),但这些上下文 (contexts) 中只有一个可以在任何给定时刻在该 GPU 上执行工作;共享同一 GPU 的上下文 (contexts) 是时间分片的。创建额外的上下文 (contexts) 会产生每个上下文 (context) 数据的内存开销和上下文 (context) 切换的时间开销。此外,当来自多个上下文 (contexts) 的工作本来可以并发执行时,对上下文 (context) 切换的需求可能会降低利用率(另请参见并发内核执行)。
因此,最好避免在同一 CUDA 应用程序中每个 GPU 使用多个上下文 (contexts)。为了帮助实现这一点,CUDA Driver API 提供了访问和管理每个 GPU 上称为主上下文 (primary context) 的特殊上下文 (context) 的方法。这些是 CUDA Runtime 在线程还没有当前上下文 (context) 时隐式使用的相同上下文 (contexts)。
// When initializing the program/library
CUcontext ctx;
cuDevicePrimaryCtxRetain(&ctx, dev);
// When the program/library launches work
cuCtxPushCurrent(ctx);
kernel<<<...>>>(...);
cuCtxPopCurrent(&ctx);
// When the program/library is finished with the context
cuDevicePrimaryCtxRelease(dev);
注意
NVIDIA-SMI 可用于将 GPU 配置为独占进程模式 (exclusive process mode),这将每个 GPU 的上下文 (contexts) 数量限制为一个。此上下文 (context) 可以是创建进程中所需数量的线程的当前上下文 (context),并且如果使用 CUDA driver API 创建的非主上下文 (non-primary context) 已经存在于设备上,则 cuDevicePrimaryCtxRetain 将会失败。
11. 指令优化
了解指令的执行方式通常可以进行有用的低级优化,尤其是在频繁运行的代码(程序中的所谓热点)中。最佳实践建议在完成所有更高级别的优化之后再执行此优化。
11.1. 算术指令
单精度浮点数提供最佳性能,强烈建议使用。各个算术运算的吞吐量在CUDA C++ Programming Guide中详细说明。
11.1.1. 除法和取模运算
注意
低优先级: 使用移位运算来避免昂贵的除法和取模计算。
整数除法和取模运算尤其耗费资源,应尽可能避免或替换为按位运算:如果 \(n\) 是 2 的幂,则 ( \(i/n\) ) 等价于 ( \(i \gg {log2}(n)\) ),并且 ( \(i\% n\) ) 等价于 ( \(i\&\left( {n - 1} \right)\) )。
如果 n 是字面量,编译器将执行这些转换。(有关更多信息,请参阅CUDA C++ Programming Guide中的性能指南)。
11.1.2. 循环计数器:有符号与无符号
注意
中低优先级: 循环计数器应使用有符号整数而不是无符号整数。
在 C 语言标准中,无符号整数溢出语义是明确定义的,而有符号整数溢出会导致未定义的结果。因此,编译器可以对有符号算术进行比无符号算术更积极的优化。这在循环计数器中尤其值得注意:由于循环计数器的值通常总是正数,因此可能很想将计数器声明为无符号。但是,为了获得稍微好一点的性能,应该将它们声明为有符号的。
例如,考虑以下代码
for (i = 0; i < n; i++) {
out[i] = in[offset + stride*i];
}
在此,子表达式 stride*i 可能会使 32 位整数溢出,因此如果 i 被声明为无符号,则溢出语义会阻止编译器使用某些可能原本适用的优化,例如强度缩减 (strength reduction)。相反,如果 i 被声明为有符号,其中溢出语义未定义,则编译器有更大的自由度来使用这些优化。
11.1.3. 倒数平方根
对于单精度,倒数平方根应始终显式调用为 rsqrtf(),对于双精度,则调用为 rsqrt()。仅当不违反 IEEE-754 语义时,编译器才会将 1.0f/sqrtf(x) 优化为 rsqrtf()。
11.1.4. 其他算术指令
注意
低优先级: 避免将双精度数自动转换为单精度数。
编译器有时必须插入转换指令,从而引入额外的执行周期。以下情况就是如此:
对
char或short进行操作的函数,其操作数通常需要转换为int用作单精度浮点计算输入的双精度浮点常量(在定义时没有任何类型后缀)
后一种情况可以通过使用单精度浮点常量来避免,单精度浮点常量使用 f 后缀定义,例如 3.141592653589793f、1.0f、0.5f。
对于单精度代码,强烈建议使用 float 类型和单精度数学函数。
还应注意,CUDA 数学库的互补误差函数 erfcf() 特别快,并且具有完整的单精度精度。
11.1.5. 小分数指数的指数运算
对于某些分数指数,与使用 pow() 相比,通过使用平方根、立方根及其倒数可以显著加速指数运算。对于那些指数不能完全表示为浮点数的指数运算(例如 1/3),这也可能提供更准确的结果,因为使用 pow() 会放大初始表示误差。
下表中的公式对于 x >= 0, x != -0,即 signbit(x) == 0 有效。
计算 |
公式 |
|---|---|
x1/9 |
|
x-1/9 |
|
x1/6 |
|
x-1/6 |
|
x1/4 |
|
x-1/4 |
|
x1/3 |
|
x-1/3 |
|
x1/2 |
|
x-1/2 |
|
x2/3 |
|
x-2/3 |
|
x3/4 |
|
x-3/4 |
|
x7/6 |
|
x-7/6 |
|
x5/4 |
|
x-5/4 |
|
x4/3 |
|
x-4/3 |
|
x3/2 |
|
x-3/2 |
|
11.1.6. 数学库
注意
中优先级: 当速度比精度更重要时,请使用快速数学库。
支持两种类型的运行时数学运算。可以通过它们的名称来区分它们:一些名称带有前导下划线,而另一些则没有(例如,__functionName() 与 functionName())。遵循 __functionName() 命名约定的函数直接映射到硬件级别。它们速度更快,但精度略低(例如,__sinf(x) 和 __expf(x))。遵循 functionName() 命名约定的函数速度较慢,但精度较高(例如,sinf(x) 和 expf(x))。__sinf(x)、__cosf(x) 和 __expf(x) 的吞吐量远大于 sinf(x)、cosf(x) 和 expf(x) 的吞吐量。如果需要减小参数 x 的幅度,则后者会变得更加昂贵(慢大约一个数量级)。此外,在这种情况下,参数缩减代码使用本地内存,由于本地内存的高延迟,这甚至会更影响性能。《CUDA C++ Programming Guide》中提供了更多详细信息。
另请注意,每当计算同一参数的正弦和余弦时,都应使用 sincos 指令系列来优化性能
__sincosf()用于单精度快速数学运算(见下一段)sincosf()用于常规单精度sincos()用于双精度
nvcc 的 -use_fast_math 编译器选项会将每个 functionName() 调用强制转换为等效的 __functionName() 调用。它还会禁用单精度反常数支持,并降低单精度除法的一般精度。这是一种激进的优化,可能会降低数值精度并改变特殊情况处理。更稳健的方法是仅在性能提升值得且可以容忍更改后的行为时,有选择地引入对快速内在函数的调用。请注意,此开关仅对单精度浮点数有效。
注意
中优先级: 如果可能,首选更快、更专业的数学函数,而不是更慢、更通用的数学函数。
对于小的整数幂(例如,x2 或 x3),显式乘法几乎肯定比使用通用指数例程(如 pow())更快。虽然编译器优化改进不断寻求缩小这种差距,但显式乘法(或使用等效的专用内联函数或宏)可能具有显著的优势。当需要同一底数的多个幂时(例如,在 x2 和 x5 都非常接近地计算时),这种优势会增加,因为这有助于编译器进行公共子表达式消除 (CSE) 优化。
对于使用基数 2 或 10 的指数运算,请使用函数 exp2() 或 expf2() 和 exp10() 或 expf10(),而不是函数 pow() 或 powf()。pow() 和 powf() 在寄存器压力和指令计数方面都是重量级函数,这是因为通用指数运算中出现大量特殊情况以及在基数和指数的整个范围内实现良好精度的难度。exp2()、exp2f()、exp10() 和 exp10f() 函数在性能方面与 exp() 和 expf() 类似,并且可能比它们的 pow()/powf() 等效函数快十倍。
对于指数为 1/3 的指数运算,请使用 cbrt() 或 cbrtf() 函数,而不是通用指数函数 pow() 或 powf(),因为前者比后者快得多。同样,对于指数为 -1/3 的指数运算,请使用 rcbrt() 或 rcbrtf()。
将 sin(π*<expr>) 替换为 sinpi(<expr>),将 cos(π*<expr>) 替换为 cospi(<expr>),并将 sincos(π*<expr>) 替换为 sincospi(<expr>)。这在精度和性能方面都很有优势。作为一个具体的例子,要以度而不是弧度评估正弦函数,请使用 sinpi(x/180.0)。同样,当函数参数的形式为 π*<expr> 时,单精度函数 sinpif()、cospif() 和 sincospif() 应替换对 sinf()、cosf() 和 sincosf() 的调用。(sinpi() 比 sin() 具有的性能优势是由于简化的参数缩减;精度优势是因为 sinpi() 仅隐式地乘以 π,有效地使用了无限精确的数学 π,而不是单精度或双精度近似值。)
11.2. 内存指令
注意
高优先级: 尽量减少全局内存的使用。尽可能首选共享内存访问。
内存指令包括任何从共享内存、本地内存或全局内存读取或写入的指令。当访问未缓存的本地或全局内存时,存在数百个时钟周期的内存延迟。
例如,以下示例代码中的赋值运算符具有高吞吐量,但至关重要的是,从全局内存读取数据存在数百个时钟周期的延迟
__shared__ float shared[32];
__device__ float device[32];
shared[threadIdx.x] = device[threadIdx.x];
如果存在足够的独立算术指令可以在等待全局内存访问完成时发出,则线程调度器可以隐藏大部分全局内存延迟。但是,最好尽可能避免访问全局内存。
12. 控制流
12.1. 分支和发散
注意
高优先级: 避免同一 warp (线程束) 内的不同执行路径。
流控制指令(if、switch、do、for、while)可能会导致同一 warp (线程束) 中的线程发散,即遵循不同的执行路径,从而显著影响指令吞吐量。如果发生这种情况,则必须单独执行不同的执行路径;这会增加此 warp (线程束) 执行的指令总数。
为了在控制流取决于线程 ID 的情况下获得最佳性能,应编写控制条件,以最大限度地减少发散 warp (线程束) 的数量。
这是可能的,因为 warp (线程束) 在 block (块) 中的分布是确定性的,如《CUDA C++ Programming Guide》的 SIMT 架构中所述。一个简单的示例是当控制条件仅取决于 (threadIdx / WSIZE) 时,其中 WSIZE 是 warp (线程束) 大小。
在这种情况下,没有 warp (线程束) 发散,因为控制条件与 warp (线程束) 完全对齐。
对于仅包含少量指令的分支,warp (线程束) 发散通常会导致边际性能损失。例如,编译器可以使用谓词来避免实际分支。相反,所有指令都被调度,但每个线程的条件代码或谓词控制哪些线程执行指令。具有错误谓词的线程不写入结果,也不评估地址或读取操作数。
从 Volta 架构开始,独立线程调度 (Independent Thread Scheduling) 允许 warp (线程束) 在数据相关的条件块外部保持发散状态。显式的 __syncwarp() 可用于保证 warp (线程束) 已为后续指令重新收敛。
12.2. 分支预测
注意
低优先级: 使编译器易于使用分支预测来代替循环或控制语句。
有时,编译器可能会通过使用分支预测来展开循环或优化掉 if 或 switch 语句。在这些情况下,没有 warp (线程束) 会发散。程序员还可以使用以下方法控制循环展开
#pragma unroll
有关此编译指示的更多信息,请参阅《CUDA C++ Programming Guide》。
当使用分支预测时,不会跳过任何执行取决于控制条件的指令。相反,每个这样的指令都与每个线程的条件代码或谓词相关联,该条件代码或谓词根据控制条件设置为 true 或 false。虽然每个这些指令都被调度为执行,但实际上只执行具有 true 谓词的指令。具有 false 谓词的指令不写入结果,它们也不评估地址或读取操作数。
仅当分支条件控制的指令数小于或等于某个阈值时,编译器才会用预测指令替换分支指令。
13. 部署 CUDA 应用程序
在完成应用程序的一个或多个组件的 GPU 加速后,可以比较结果与原始期望。回想一下,最初的评估步骤允许开发人员确定通过加速给定热点可以达到的潜在加速上限。
在解决其他热点以提高总加速之前,开发人员应考虑采用部分并行化的实现并将其投入生产。这很重要,原因有很多;例如,它允许用户尽早从他们的投资中获利(加速可能是部分的,但仍然有价值),并且它通过为应用程序提供进化而非革命性的一组更改,最大限度地降低了开发人员和用户的风险。
14. 了解编程环境
随着每一代 NVIDIA 处理器的发展,新的功能被添加到 GPU 中,CUDA 可以利用这些功能。因此,了解架构的特性非常重要。
程序员应该注意两个版本号。第一个是计算能力,第二个是 CUDA Runtime 和 CUDA Driver API 的版本号。
14.1. CUDA 计算能力
计算能力 (compute capability) 描述了硬件的特性,并反映了设备支持的指令集以及其他规范,例如每个 block (块) 的最大线程数和每个多处理器的寄存器数。较高的计算能力 (compute capability) 版本是较低(即较早)版本的超集,因此它们是向后兼容的。
可以通过编程方式查询设备中 GPU 的计算能力 (compute capability),如 deviceQuery CUDA 示例所示。该程序的输出显示在图 16中。此信息是通过调用 cudaGetDeviceProperties() 并访问其返回的结构中的信息获得的。
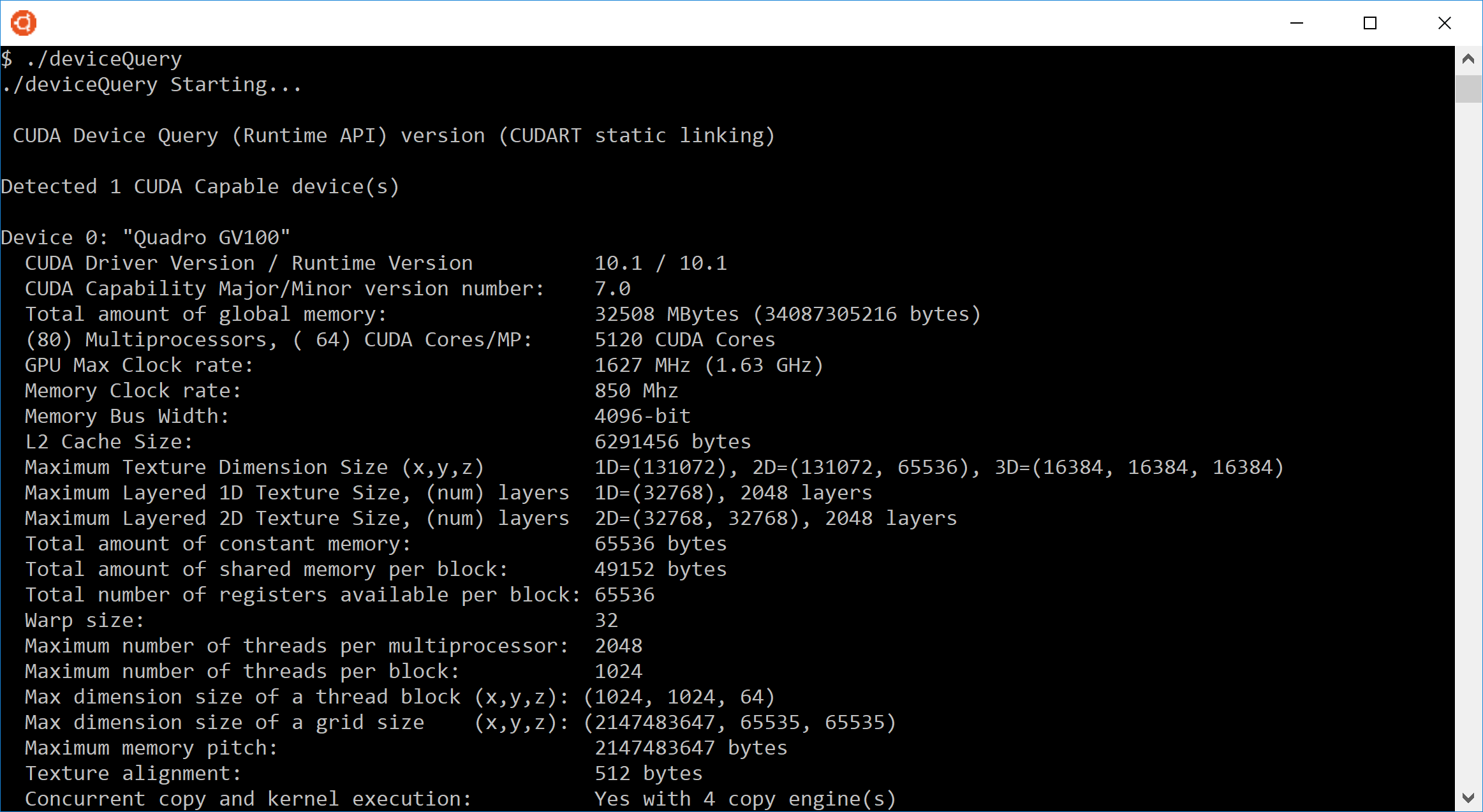
图 16 deviceQuery 报告的 CUDA 配置数据示例
计算能力 (compute capability) 的主版本号和次版本号显示在图 16的第七行。此系统的设备 0 具有计算能力 (compute capability) 7.0。
有关各种 GPU 的计算能力 (compute capabilities) 的更多详细信息,请参见《CUDA C++ Programming Guide》中的 CUDA-Enabled GPUs and Compute Capabilities。特别是,开发人员应注意设备上的多处理器数量、寄存器数量和可用内存量以及设备的任何特殊功能。
14.2. 其他硬件数据
某些硬件功能未在计算能力 (compute capability) 中描述。例如,在大多数但并非所有 GPU 上,无论计算能力 (compute capability) 如何,都可以在内核执行与主机和设备之间的异步数据传输重叠。在这种情况下,调用 cudaGetDeviceProperties() 以确定设备是否具有某种功能。例如,设备属性结构的 asyncEngineCount 字段指示是否可以重叠内核执行和数据传输(如果可以,则可以进行多少并发传输);同样,canMapHostMemory 字段指示是否可以执行零拷贝数据传输。
14.3. 选择哪个计算能力目标
要定位特定版本的 NVIDIA 硬件和 CUDA 软件,请使用 nvcc 的 -arch、-code 和 -gencode 选项。例如,使用 warp shuffle 操作的代码必须使用 -arch=sm_30(或更高的计算能力 (compute capability))编译。
有关用于同时为多个世代的 CUDA 兼容设备构建代码的标志的进一步讨论,请参阅构建以获得最大兼容性。
14.4. CUDA 运行时
CUDA 软件环境的主机运行时组件只能由主机函数使用。它提供了处理以下各项的函数:
设备管理
上下文管理
内存管理
代码模块管理
执行控制
纹理引用管理
与 OpenGL 和 Direct3D 的互操作性
与较低级别的 CUDA Driver API 相比,CUDA Runtime 通过提供隐式初始化、上下文管理和设备代码模块管理,大大简化了设备管理。nvcc 生成的 C++ 主机代码利用了 CUDA Runtime,因此链接到此代码的应用程序将依赖于 CUDA Runtime;同样,任何使用 cuBLAS、cuFFT 和其他 CUDA Toolkit 库的代码也将依赖于 CUDA Runtime,这些库在内部使用 CUDA Runtime。
构成 CUDA Runtime API 的函数在《CUDA Toolkit Reference Manual》中进行了解释。
CUDA Runtime 处理内核加载以及在内核启动之前设置内核参数和启动配置。隐式驱动程序版本检查、代码初始化、CUDA 上下文管理、CUDA 模块管理(cubin 到函数映射)、内核配置和参数传递都由 CUDA Runtime 执行。
它包含两个主要部分:
C 风格的函数接口 (
cuda_runtime_api.h)。C++ 风格的便捷封装器(
cuda_runtime.h)构建于 C 风格函数之上。
有关运行时 API 的更多信息,请参阅《CUDA C++ 编程指南》的 CUDA 运行时部分。
15. CUDA 兼容性开发者指南
CUDA 工具包以每月发布一次的频率发布,以提供新功能、性能改进和关键错误修复。CUDA 兼容性允许用户更新最新的 CUDA 工具包软件(包括编译器、库和工具),而无需更新整个驱动程序堆栈。
CUDA 软件环境由三个部分组成
CUDA 工具包(库、CUDA 运行时和开发者工具)- 供开发者构建 CUDA 应用程序的 SDK。
CUDA 驱动程序 - 用于运行 CUDA 应用程序的用户模式驱动程序组件(例如 Linux 系统上的 libcuda.so)。
NVIDIA GPU 设备驱动程序 - 用于 NVIDIA GPU 的内核模式驱动程序组件。
在 Linux 系统上,CUDA 驱动程序和内核模式组件一起在 NVIDIA 显示驱动程序包中交付。如图 1 所示。
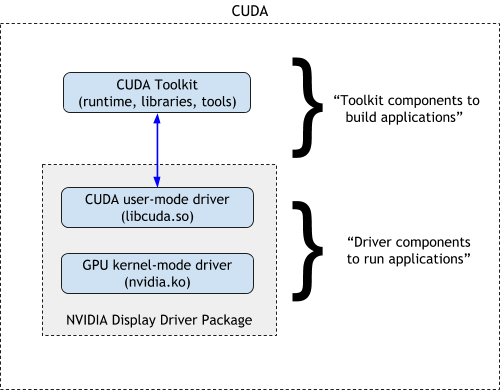
图 17 CUDA 组件
CUDA 编译器 (nvcc) 提供了一种处理 CUDA 和非 CUDA 代码的方式(通过拆分和引导编译),以及 CUDA 运行时,是 CUDA 编译器工具链的一部分。CUDA 运行时 API 为开发者提供了高级 C++ 接口,用于简化设备管理、内核执行等。而 CUDA 驱动程序 API 提供了一个低级编程接口 (CUDA 驱动程序 API),供应用程序以 NVIDIA 硬件为目标。
构建于这些技术之上的是 CUDA 库,其中一些库包含在 CUDA 工具包中,而另一些库(如 cuDNN)可能会独立于 CUDA 工具包发布。
15.1. CUDA 工具包版本控制
从 CUDA 11 开始,工具包版本基于行业标准的语义版本控制方案:.X.Y.Z,其中
.X 代表主版本 - API 已更改,二进制兼容性已中断。
.Y 代表次要版本 - 引入了新 API,弃用了旧 API,源代码兼容性可能会中断,但二进制兼容性得以维护。
.Z 代表发布/补丁版本 - 新的更新和补丁将增加此版本号。
建议工具包中的每个组件都进行语义版本控制。从 CUDA 11.3 开始,NVRTC 也进行了语义版本控制。我们将在本文档后面注明其中一些。工具包中组件的版本在此表格中提供。
因此,CUDA 平台的兼容性旨在解决以下几种情况
对于在企业或数据中心生产环境中运行 GPU 的系统,NVIDIA 驱动程序升级可能很复杂,并且可能需要提前计划。延迟推出新的 NVIDIA 驱动程序可能意味着此类系统的用户可能无法访问 CUDA 版本中的新功能。新的 CUDA 版本不需要驱动程序更新意味着新版本的软件可以更快地提供给用户。
许多构建于 CUDA 之上的软件库和应用程序(例如数学库或深度学习框架)与 CUDA 运行时、编译器或驱动程序没有直接依赖关系。在这种情况下,用户或开发者仍然可以受益于不必升级整个 CUDA 工具包或驱动程序即可使用这些库或框架。
升级依赖项容易出错且耗时,并且在某些极端情况下,甚至会更改程序的语义。不断使用最新的 CUDA 工具包重新编译意味着强制应用程序产品的最终客户进行升级。包管理器简化了此过程,但意外问题仍然可能出现,如果发现错误,则需要重复上述升级过程。
CUDA 支持多种兼容性选择
首次在 CUDA 10 中引入的 CUDA 向前兼容升级旨在允许用户访问新的 CUDA 功能,并在安装了较旧 NVIDIA 数据中心驱动程序的系统上运行使用新 CUDA 版本构建的应用程序。
-
首次在 CUDA 11.1 中引入的 CUDA 增强兼容性提供了两个好处
通过利用 CUDA 工具包中组件的语义版本控制,应用程序可以针对一个 CUDA 次要版本(例如 11.1)构建,并在主要系列(即 11.x)中的所有未来次要版本中工作。
CUDA 运行时放宽了最低驱动程序版本检查,因此在迁移到新的次要版本时不再需要驱动程序升级。
CUDA 驱动程序确保为编译后的 CUDA 应用程序维护向后二进制兼容性。使用旧至 3.2 版本的 CUDA 工具包编译的应用程序将在较新的驱动程序上运行。
15.2. 源代码兼容性
我们将源代码兼容性定义为库提供的一组保证,其中针对特定版本的库(使用 SDK)构建的格式良好的应用程序在安装较新版本的 SDK 时将继续构建和运行而不会出错。
CUDA 驱动程序和 CUDA 运行时在不同的 SDK 版本之间都不是源代码兼容的。API 可能会被弃用和删除。因此,在旧版本的工具包上成功编译的应用程序可能需要进行更改,才能针对较新版本的工具包进行编译。
开发者会通过弃用和文档机制收到有关任何当前或即将发生的更改的通知。但这并不意味着不再支持使用旧工具包编译的应用程序二进制文件。应用程序二进制文件依赖于 CUDA 驱动程序 API 接口,即使 CUDA 驱动程序 API 本身也可能在不同的工具包版本之间发生了更改,CUDA 仍然保证 CUDA 驱动程序 API 接口的二进制兼容性。
15.3. 二进制兼容性
我们将二进制兼容性定义为库提供的一组保证,其中以所述库为目标的应用程序在动态链接到不同版本的库时将继续工作。
CUDA 驱动程序 API 具有版本化的 C 风格 ABI,这保证了针对旧驱动程序(例如 CUDA 3.2)运行的应用程序仍然可以针对现代驱动程序(例如 CUDA 11.0 附带的驱动程序)正确运行和工作。这意味着,即使应用程序源代码可能需要更改才能针对较新的 CUDA 工具包重新编译以使用较新的功能,但将系统中安装的驱动程序组件替换为较新版本将始终支持现有应用程序及其功能。
因此,CUDA 驱动程序 API 是二进制兼容的(操作系统加载程序可以获取较新版本,并且应用程序继续工作),但不是源代码兼容的(针对较新的 SDK 重新构建应用程序可能需要更改源代码)。
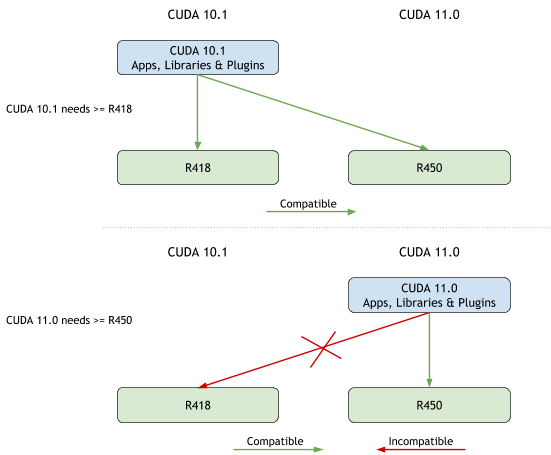
图 18 CUDA 工具包和最低驱动程序版本
在我们进一步讨论此主题之前,开发者了解最低驱动程序版本的概念以及它可能对他们产生的影响非常重要。
每个版本的 CUDA 工具包(和运行时)都需要最低版本的 NVIDIA 驱动程序。针对 CUDA 工具包版本编译的应用程序只能在具有该工具包版本指定的最低驱动程序版本的系统上运行。在 CUDA 11.0 之前,工具包的最低驱动程序版本与该版本的 CUDA 工具包附带的驱动程序相同。
因此,当使用 CUDA 11.0 构建应用程序时,它只能在安装了 R450 或更高版本驱动程序的系统上运行。如果此类应用程序在安装了 R418 驱动程序的系统上运行,则 CUDA 初始化将返回错误,如下例所示。
在此示例中,deviceQuery 示例使用 CUDA 11.1 编译,并在安装了 R418 的系统上运行。在这种情况下,由于最低驱动程序要求,CUDA 初始化返回错误。
ubuntu@:~/samples/1_Utilities/deviceQuery
$ make
/usr/local/cuda-11.1/bin/nvcc -ccbin g++ -I../../common/inc -m64 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_80,code=sm_80 -gencode arch=compute_86,code=sm_86 -gencode arch=compute_86,code=compute_86 -o deviceQuery.o -c deviceQuery.cpp
/usr/local/cuda-11.1/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_80,code=sm_80 -gencode arch=compute_86,code=sm_86 -gencode arch=compute_86,code=compute_86 -o deviceQuery deviceQuery.o
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.165.02 Driver Version: 418.165.02 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 42C P0 28W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
$ samples/bin/x86_64/linux/release/deviceQuery
samples/bin/x86_64/linux/release/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
cudaGetDeviceCount returned 3
-> initialization error
Result = FAIL
有关最低驱动程序版本和工具包附带的驱动程序版本的详细信息,请参阅CUDA 工具包发行说明。
15.3.1. CUDA 二进制 (cubin) 兼容性
一个稍微相关但重要的主题是 CUDA 中跨 GPU 架构的应用程序二进制兼容性。
CUDA C++ 为熟悉 C++ 编程语言的用户提供了一条简单的路径,可以轻松编写程序以供设备执行。可以使用 CUDA 指令集架构(称为 PTX)编写内核,PTX 在 PTX 参考手册中进行了描述。但是,通常更有效地使用高级编程语言(如 C++)。在这两种情况下,内核都必须由 nvcc 编译为二进制代码(称为 cubin),才能在设备上执行。
cubin 是特定于架构的。cubin 的二进制兼容性保证从一个计算能力次要版本到下一个次要版本,但不保证从一个计算能力次要版本到上一个次要版本,也不保证跨主要计算能力版本。换句话说,为计算能力 X.y 生成的 cubin 对象将仅在计算能力为 X.z 的设备上执行,其中 z≥y。
要在特定计算能力的设备上执行代码,应用程序必须加载与此计算能力兼容的二进制代码或 PTX 代码。为了实现可移植性,即能够在具有更高计算能力的未来 GPU 架构(尚无法为其生成二进制代码)上执行代码,应用程序必须加载 PTX 代码,该代码将由 NVIDIA 驱动程序为这些未来设备进行即时编译。
有关 cubin、PTX 和应用程序兼容性的更多信息,请参见《CUDA C++ 编程指南》。
15.4. 跨次要版本的 CUDA 兼容性
通过利用语义版本控制,从 CUDA 11 开始,CUDA 工具包中的组件将在工具包的次要版本之间保持二进制兼容。为了在次要版本之间保持二进制兼容性,CUDA 运行时不再为每个次要版本都提高所需的最低驱动程序版本 - 这仅在发布主要版本时才会发生。
新工具链需要新最低驱动程序的主要原因之一是为了处理 PTX 代码的 JIT 编译和二进制代码的 JIT 链接。
在本节中,我们将回顾在使用 CUDA 平台的兼容性功能时可能需要新用户工作流程的用例。
15.4.1. CUDA 次要版本中的现有 CUDA 应用程序
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 39C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
当我们的 CUDA 11.1 应用程序(即静态链接了 cudart 11.1)在系统上运行时,我们看到即使驱动程序报告 11.0 版本,它也能成功运行 - 也就是说,无需更新系统上的驱动程序或其他工具包组件。
$ samples/bin/x86_64/linux/release/deviceQuery
samples/bin/x86_64/linux/release/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 11.0 / 11.1
CUDA Capability Major/Minor version number: 7.5
...<snip>...
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.0, CUDA Runtime Version = 11.1, NumDevs = 1
Result = PASS
通过使用新的 CUDA 版本,用户可以受益于新的 CUDA 编程模型 API、编译器优化和数学库功能。
以下各节讨论了一些注意事项和考虑因素。
15.4.1.1. 处理新的 CUDA 功能和驱动程序 API
一部分 CUDA API 不需要新的驱动程序,它们都可以在没有任何驱动程序依赖项的情况下使用。例如,cuMemMap API 或在 CUDA 11.0 之前引入的任何 API,例如 cudaDeviceSynchronize,都不需要驱动程序升级。要使用在次要版本中引入的其他 CUDA API(需要新的驱动程序),则必须实现回退或优雅地失败。这种情况与今天的情况没有什么不同,开发者今天也使用宏来根据 CUDA 版本编译掉功能。用户应参考 CUDA 头文件和文档,了解版本中引入的新 CUDA API。
当使用工具包的次要版本中公开的功能时,如果应用程序针对较旧的 CUDA 驱动程序运行,则该功能可能在运行时不可用。希望利用此类功能的用户应在代码中使用动态检查来查询其可用性
static bool hostRegisterFeatureSupported = false;
static bool hostRegisterIsDeviceAddress = false;
static error_t cuFooFunction(int *ptr)
{
int *dptr = null;
if (hostRegisterFeatureSupported) {
cudaHostRegister(ptr, size, flags);
if (hostRegisterIsDeviceAddress) {
qptr = ptr;
}
else {
cudaHostGetDevicePointer(&qptr, ptr, 0);
}
}
else {
// cudaMalloc();
// cudaMemcpy();
}
gemm<<<1,1>>>(dptr);
cudaDeviceSynchronize();
}
int main()
{
// rest of code here
cudaDeviceGetAttribute(
&hostRegisterFeatureSupported,
cudaDevAttrHostRegisterSupported,
0);
cudaDeviceGetAttribute(
&hostRegisterIsDeviceAddress,
cudaDevAttrCanUseHostPointerForRegisteredMem,
0);
cuFooFunction(/* malloced pointer */);
}
或者,应用程序的接口可能在没有新的 CUDA 驱动程序的情况下根本无法工作,那么最好立即返回错误
#define MIN_VERSION 11010
cudaError_t foo()
{
int version = 0;
cudaGetDriverVersion(&version);
if (version < MIN_VERSION) {
return CUDA_ERROR_INSUFFICIENT_DRIVER;
}
// proceed as normal
}
添加了一个新的错误代码,以指示您正在运行的驱动程序缺少该功能:cudaErrorCallRequiresNewerDriver。
15.4.1.2. 使用 PTX
PTX 为通用并行线程执行定义了一个虚拟机和 ISA。PTX 程序在加载时通过 JIT 编译器(它是 CUDA 驱动程序的一部分)转换为目标硬件指令集。由于 PTX 由 CUDA 驱动程序编译,因此新的工具链将生成与旧 CUDA 驱动程序不兼容的 PTX。当 PTX 用于未来设备兼容性(最常见的情况)时,这不是问题,但当用于运行时编译时,可能会导致问题。
对于继续使用 PTX 的代码,为了支持在旧驱动程序上编译,您的代码必须首先通过静态 ptxjitcompiler 库或 NVRTC 转换为设备代码,并选择为特定架构(例如 sm_80)而不是虚拟架构(例如 compute_80)生成代码。对于此工作流程,新的 nvptxcompiler_static 库随 CUDA 工具包一起提供。
我们可以在以下示例中看到这种用法
char* compilePTXToNVElf()
{
nvPTXCompilerHandle compiler = NULL;
nvPTXCompileResult status;
size_t elfSize, infoSize, errorSize;
char *elf, *infoLog, *errorLog;
int minorVer, majorVer;
const char* compile_options[] = { "--gpu-name=sm_80",
"--device-debug"
};
nvPTXCompilerGetVersion(&majorVer, &minorVer);
nvPTXCompilerCreate(&compiler, (size_t)strlen(ptxCode), ptxCode);
status = nvPTXCompilerCompile(compiler, 2, compile_options);
if (status != NVPTXCOMPILE_SUCCESS) {
nvPTXCompilerGetErrorLogSize(compiler, (void*)&errorSize);
if (errorSize != 0) {
errorLog = (char*)malloc(errorSize+1);
nvPTXCompilerGetErrorLog(compiler, (void*)errorLog);
printf("Error log: %s\n", errorLog);
free(errorLog);
}
exit(1);
}
nvPTXCompilerGetCompiledProgramSize(compiler, &elfSize));
elf = (char*)malloc(elfSize);
nvPTXCompilerGetCompiledProgram(compiler, (void*)elf);
nvPTXCompilerGetInfoLogSize(compiler, (void*)&infoSize);
if (infoSize != 0) {
infoLog = (char*)malloc(infoSize+1);
nvPTXCompilerGetInfoLog(compiler, (void*)infoLog);
printf("Info log: %s\n", infoLog);
free(infoLog);
}
nvPTXCompilerDestroy(&compiler);
return elf;
}
15.4.1.3. 动态代码生成
NVRTC 是 CUDA C++ 的运行时编译库。它接受字符字符串形式的 CUDA C++ 源代码,并创建可用于获取 PTX 的句柄。NVRTC 生成的 PTX 字符串可以由 cuModuleLoadData 和 cuModuleLoadDataEx 加载。
尚不支持处理可重定位对象,因此 CUDA 驱动程序中的 cuLink* API 集不适用于增强兼容性。当前这些 API 需要与 CUDA 运行时版本匹配的升级驱动程序。
如 PTX 部分所述,PTX 到设备代码的编译与 CUDA 驱动程序一起存在,因此生成的 PTX 可能比部署系统上的驱动程序支持的更新。使用 NVRTC 时,建议首先通过 PTX 用户工作流程概述的步骤将生成的 PTX 代码转换为最终设备代码。这可确保您的代码兼容。或者,NVRTC 可以直接从 CUDA 11.1 开始直接生成 cubin。使用新 API 的应用程序可以使用驱动程序 API cuModuleLoadData 和 cuModuleLoadDataEx 直接加载最终设备代码。
NVRTC 过去只通过 -arch 选项支持虚拟架构,因为它只发出 PTX。现在它还将支持实际架构以发出 SASS。该接口已得到增强,如果指定了实际架构,则可以检索 PTX 或 cubin。
以下示例显示了如何调整现有示例以使用新功能,在本例中由 USE_CUBIN 宏保护
#include <nvrtc.h>
#include <cuda.h>
#include <iostream>
void NVRTC_SAFE_CALL(nvrtcResult result) {
if (result != NVRTC_SUCCESS) {
std::cerr << "\nnvrtc error: " << nvrtcGetErrorString(result) << '\n';
std::exit(1);
}
}
void CUDA_SAFE_CALL(CUresult result) {
if (result != CUDA_SUCCESS) {
const char *msg;
cuGetErrorName(result, &msg);
std::cerr << "\ncuda error: " << msg << '\n';
std::exit(1);
}
}
const char *hello = " \n\
extern \"C\" __global__ void hello() { \n\
printf(\"hello world\\n\"); \n\
} \n";
int main()
{
nvrtcProgram prog;
NVRTC_SAFE_CALL(nvrtcCreateProgram(&prog, hello, "hello.cu", 0, NULL, NULL));
#ifdef USE_CUBIN
const char *opts[] = {"-arch=sm_70"};
#else
const char *opts[] = {"-arch=compute_70"};
#endif
nvrtcResult compileResult = nvrtcCompileProgram(prog, 1, opts);
size_t logSize;
NVRTC_SAFE_CALL(nvrtcGetProgramLogSize(prog, &logSize));
char *log = new char[logSize];
NVRTC_SAFE_CALL(nvrtcGetProgramLog(prog, log));
std::cout << log << '\n';
delete[] log;
if (compileResult != NVRTC_SUCCESS)
exit(1);
size_t codeSize;
#ifdef USE_CUBIN
NVRTC_SAFE_CALL(nvrtcGetCUBINSize(prog, &codeSize));
char *code = new char[codeSize];
NVRTC_SAFE_CALL(nvrtcGetCUBIN(prog, code));
#else
NVRTC_SAFE_CALL(nvrtcGetPTXSize(prog, &codeSize));
char *code = new char[codeSize];
NVRTC_SAFE_CALL(nvrtcGetPTX(prog, code));
#endif
NVRTC_SAFE_CALL(nvrtcDestroyProgram(&prog));
CUdevice cuDevice;
CUcontext context;
CUmodule module;
CUfunction kernel;
CUDA_SAFE_CALL(cuInit(0));
CUDA_SAFE_CALL(cuDeviceGet(&cuDevice, 0));
CUDA_SAFE_CALL(cuCtxCreate(&context, 0, cuDevice));
CUDA_SAFE_CALL(cuModuleLoadDataEx(&module, code, 0, 0, 0));
CUDA_SAFE_CALL(cuModuleGetFunction(&kernel, module, "hello"));
CUDA_SAFE_CALL(cuLaunchKernel(kernel, 1, 1, 1, 1, 1, 1, 0, NULL, NULL, 0));
CUDA_SAFE_CALL(cuCtxSynchronize());
CUDA_SAFE_CALL(cuModuleUnload(module));
CUDA_SAFE_CALL(cuCtxDestroy(context));
delete[] code;
}
15.4.1.4. 构建次要版本兼容库的建议
我们建议静态链接 CUDA 运行时以最大限度地减少依赖项。验证您的库不会泄漏依赖项、中断、命名空间等,超出您已建立的 ABI 约定。
为库的 soname 遵循语义版本控制。拥有语义版本化的 ABI 意味着需要维护和版本化接口。库应遵循语义规则,并在进行影响此 ABI 约定的更改时增加版本号。缺少依赖项也是二进制兼容性中断,因此您应该为依赖于这些接口的功能提供回退或保护。当存在 ABI 中断更改(例如 API 弃用和修改)时,增加主版本。可以在次要版本中添加新 API。
有条件地使用功能以保持与旧驱动程序的兼容性。如果不使用新功能(或者如果有条件地使用并提供回退),您将能够保持兼容性。
不要公开可能更改的 ABI 结构。指向嵌入大小的结构的指针是更好的解决方案。
当与工具包中的动态库链接时,该库必须等于或新于应用程序链接中涉及的任何一个组件所需的库。例如,如果您链接到 CUDA 11.1 动态运行时,并使用 11.1 的功能,以及链接到 CUDA 11.2 动态运行时且需要 11.2 功能的单独共享库,则最终链接步骤必须包含 CUDA 11.2 或更新的动态运行时。
15.4.1.5. 在应用程序中利用次要版本兼容性的建议
某些功能可能不可用,因此您应在适用的情况下进行查询。这对于构建与 GPU 架构、平台和编译器无关的应用程序很常见。但是,我们现在将“底层驱动程序”添加到该组合中。
与上一节关于库构建建议一样,如果使用 CUDA 运行时,我们建议在构建应用程序时静态链接到 CUDA 运行时。当直接使用驱动程序 API 时,我们建议使用新的驱动程序入口点访问 API (cuGetProcAddress),其文档在此处:CUDA 驱动程序 API :: CUDA 工具包文档。
当使用共享库或静态库时,请遵循所述库的发行说明,以确定该库是否支持次要版本兼容性。
16. 准备部署
16.1. 测试 CUDA 可用性
在部署 CUDA 应用程序时,通常希望确保即使目标计算机没有支持 CUDA 的 GPU 和/或安装了足够版本的 NVIDIA 驱动程序,应用程序也能继续正常运行。(针对配置已知的单台计算机的开发者可以选择跳过本节。)
检测支持 CUDA 的 GPU
当应用程序将部署到任意/未知配置的目标计算机时,应用程序应显式测试是否存在支持 CUDA 的 GPU,以便在没有此类设备可用时采取适当的措施。cudaGetDeviceCount() 函数可用于查询可用设备的数量。与所有 CUDA 运行时 API 函数一样,如果不存在支持 CUDA 的 GPU,则此函数将正常失败并向应用程序返回 cudaErrorNoDevice;如果未安装适当版本的 NVIDIA 驱动程序,则返回 cudaErrorInsufficientDriver。如果 cudaGetDeviceCount() 报告错误,则应用程序应回退到备用代码路径。
具有多个 GPU 的系统可能包含不同硬件版本和功能的 GPU。当从同一应用程序使用多个 GPU 时,建议使用相同类型的 GPU,而不是混合硬件世代。cudaChooseDevice() 函数可用于选择最符合所需功能集的设备。
检测硬件和软件配置
当应用程序依赖于某些硬件或软件功能的可用性来启用某些功能时,可以查询 CUDA API 以获取有关可用设备的配置和已安装软件版本的详细信息。
cudaGetDeviceProperties() 函数报告可用设备的各种功能,包括设备的 CUDA 计算能力(另请参见《CUDA C++ 编程指南》的计算能力部分)。请参阅版本管理,了解有关如何查询可用 CUDA 软件 API 版本的详细信息。
16.2. 错误处理
所有 CUDA 运行时 API 调用都返回 cudaError_t 类型的错误代码;如果没有发生错误,则返回值将等于 cudaSuccess。(此规则的例外是内核启动,它返回 void,以及 cudaGetErrorString(),它返回一个描述传入的 cudaError_t 代码的字符串。)CUDA 工具包库(cuBLAS、cuFFT 等)同样返回它们自己的一组错误代码。
由于某些 CUDA API 调用和所有内核启动相对于主机代码是异步的,因此错误也可能异步地报告给主机;通常,这发生在主机和设备彼此同步的下一次,例如在调用 cudaMemcpy() 或 cudaDeviceSynchronize() 期间。
始终检查所有 CUDA API 函数的错误返回值,即使对于预期不会失败的函数也是如此,因为这将使应用程序能够在错误发生时尽快检测并从中恢复。要检查在使用 <<<...>>> 语法启动内核期间发生的错误(该语法不返回任何错误代码),应在内核启动后立即检查 cudaGetLastError() 的返回值。不检查 CUDA API 错误的应用程序有时可能会运行完成,而没有注意到 GPU 计算的数据不完整、无效或未初始化。
注意
CUDA 工具包示例为使用各种 CUDA API 进行错误检查提供了几个辅助函数;这些辅助函数位于 CUDA 工具包的 samples/common/inc/helper_cuda.h 文件中。
16.3. 构建以实现最大兼容性
每一代支持 CUDA 的设备都有一个关联的计算能力版本,该版本指示设备支持的功能集(请参阅 CUDA 计算能力)。可以在构建文件时为 nvcc 编译器指定一个或多个计算能力版本;为应用程序的目标 GPU 的本机计算能力进行编译对于确保应用程序内核获得最佳性能并能够使用给定 GPU 世代可用的功能非常重要。
当应用程序同时为多种计算能力构建时(使用 -gencode 标志的多个实例传递给 nvcc),指定计算能力的二进制文件将合并到可执行文件中,并且 CUDA 驱动程序会根据当前设备的计算能力在运行时选择最合适的二进制文件。如果合适的本机二进制文件 (cubin) 不可用,但中间 PTX 代码(以抽象虚拟指令集为目标并用于向前兼容性)可用,则内核将从 PTX 即时 (JIT) 编译(请参阅 编译器 JIT 缓存管理工具)为设备的本机 cubin。如果 PTX 也不可用,则内核启动将失败。
Windows
nvcc.exe -ccbin "C:\vs2008\VC\bin"
-Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT"
-gencode=arch=compute_30,code=sm_30
-gencode=arch=compute_35,code=sm_35
-gencode=arch=compute_50,code=sm_50
-gencode=arch=compute_60,code=sm_60
-gencode=arch=compute_70,code=sm_70
-gencode=arch=compute_75,code=sm_75
-gencode=arch=compute_75,code=compute_75
--compile -o "Release\mykernel.cu.obj" "mykernel.cu"
Mac/Linux
/usr/local/cuda/bin/nvcc
-gencode=arch=compute_30,code=sm_30
-gencode=arch=compute_35,code=sm_35
-gencode=arch=compute_50,code=sm_50
-gencode=arch=compute_60,code=sm_60
-gencode=arch=compute_70,code=sm_70
-gencode=arch=compute_75,code=sm_75
-gencode=arch=compute_75,code=compute_75
-O2 -o mykernel.o -c mykernel.cu
或者,可以使用 nvcc 命令行选项 -arch=sm_XX 作为以下更明确的 -gencode= 命令行选项的简写等效项,如上所述
-gencode=arch=compute_XX,code=sm_XX
-gencode=arch=compute_XX,code=compute_XX
但是,虽然 -arch=sm_XX 命令行选项确实默认包含 PTX 后端目标(由于它隐含的 code=compute_XX 目标),但它一次只能指定单个目标 cubin 架构,并且不可能在同一 nvcc 命令行上使用多个 -arch= 选项,这就是为什么上面的示例显式使用 -gencode= 的原因。
16.4. 分发 CUDA 运行时和库
CUDA 应用程序是针对 CUDA 运行时库构建的,该库处理设备、内存和内核管理。与 CUDA 驱动程序不同,CUDA 运行时不保证跨版本的前向或后向二进制兼容性。因此,最好在使用动态链接时重新分发 CUDA 运行时库,或者静态链接到 CUDA 运行时。这将确保即使最终用户未安装应用程序构建时所用的 CUDA 工具包,可执行文件也能够运行。
注意
当静态链接到 CUDA 运行时时,运行时的多个版本可以同时在同一应用程序进程中和平共处;例如,如果应用程序使用一个版本的 CUDA 运行时,并且该应用程序的插件静态链接到不同的版本,那是完全可以接受的,只要安装的 NVIDIA 驱动程序对于两者都足够即可。
静态链接的 CUDA 运行时
最简单的选择是静态链接到 CUDA 运行时。如果使用 nvcc 在 CUDA 5.5 及更高版本中进行链接,则这是默认设置。静态链接会使可执行文件略微增大,但它可以确保正确的运行时库函数版本包含在应用程序二进制文件中,而无需单独重新分发 CUDA 运行时库。
动态链接的 CUDA 运行时
如果由于某些原因静态链接到 CUDA 运行时不切实际,那么也可以使用动态链接版本的 CUDA 运行时库。(这是 CUDA 5.0 及更早版本中提供的默认且唯一的选项。)
当从 CUDA 5.5 或更高版本使用 nvcc 链接应用程序时,要将动态链接与 CUDA 运行时一起使用,请将 --cudart=shared 标志添加到链接命令行;否则,默认使用静态链接的 CUDA 运行时库。
在应用程序针对 CUDA 运行时进行动态链接后,此版本的运行时库应与应用程序捆绑在一起。它可以复制到与应用程序可执行文件相同的目录中,或复制到该安装路径的子目录中。
其他 CUDA 库
尽管 CUDA 运行时提供了静态链接的选项,但 CUDA 工具包中包含的某些库仅以动态链接形式提供。与动态链接版本的 CUDA 运行时库一样,在分发应用程序时,这些库也应与应用程序可执行文件捆绑在一起。
16.4.1. CUDA 工具包库再分发
CUDA 工具包的最终用户许可协议 (EULA) 允许在某些条款和条件下再分发许多 CUDA 库。这允许依赖这些库的应用程序再分发与其构建和测试时所用的完全相同的库版本,从而避免最终用户可能在其机器上安装了不同版本的 CUDA 工具包(或根本没有安装)而导致任何问题。请参阅 EULA 了解详细信息。
注意
这不适用于 NVIDIA 驱动程序;最终用户仍然必须下载并安装适合其 GPU 和操作系统的 NVIDIA 驱动程序。
16.4.1.1. 要再分发哪些文件
在再分发一个或多个 CUDA 库的动态链接版本时,务必确定需要再分发的准确文件。以下示例使用 CUDA 工具包 5.5 中的 cuBLAS 库作为说明
Linux
在 Linux 上的共享库中,有一个名为 SONAME 的字符串字段,指示库的二进制兼容性级别。应用程序构建时所用的库的 SONAME 必须与随应用程序再分发的库的文件名匹配。
例如,在标准 CUDA 工具包安装中,文件 libcublas.so 和 libcublas.so.5.5 都是指向 cuBLAS 特定版本的符号链接,该版本的名称类似于 libcublas.so.5.5.x,其中 x 是构建编号(例如,libcublas.so.5.5.17)。但是,此库的 SONAME 给定为 “libcublas.so.5.5”
$ objdump -p /usr/local/cuda/lib64/libcublas.so | grep SONAME
SONAME libcublas.so.5.5
因此,即使在链接应用程序时使用了 -lcublas(未指定版本号),在链接时找到的 SONAME 也意味着 “libcublas.so.5.5” 是动态加载器在加载应用程序时将查找的文件名,因此必须是随应用程序再分发的文件(或指向同一文件的符号链接)的名称。
ldd 工具可用于识别应用程序在运行时期望找到的库的准确文件名,以及在给定当前库搜索路径的情况下,动态加载器在加载应用程序时将选择的该库副本的路径(如果有)。
$ ldd a.out | grep libcublas
libcublas.so.5.5 => /usr/local/cuda/lib64/libcublas.so.5.5
Mac
在 Mac OS X 上的共享库中,有一个名为 install name 的字段,指示库的预期安装路径和文件名;CUDA 库也使用此文件名来指示二进制兼容性。此字段的值会传播到针对该库构建的应用程序中,并在运行时用于查找正确版本的库。
例如,如果 cuBLAS 库的安装名称给定为 @rpath/libcublas.5.5.dylib,则该库为 5.5 版本,并且随应用程序再分发的此库副本必须命名为 libcublas.5.5.dylib,即使在链接时仅使用了 -lcublas(未指定版本号)。此外,此文件应安装到应用程序的 @rpath 中;请参阅在何处安装再分发的 CUDA 库。
要查看库的安装名称,请使用 otool -L 命令
$ otool -L a.out
a.out:
@rpath/libcublas.5.5.dylib (...)
Windows
Windows 上 CUDA 库的二进制兼容性版本在文件名中指示。
例如,链接到 cuBLAS 5.5 的 64 位应用程序将在运行时查找 cublas64_55.dll,因此这是应随该应用程序再分发的文件,即使 cublas.lib 是应用程序链接的文件。对于 32 位应用程序,该文件将为 cublas32_55.dll。
要验证应用程序在运行时期望找到的准确 DLL 文件名,请使用 Visual Studio 命令提示符中的 dumpbin 工具
$ dumpbin /IMPORTS a.exe
Microsoft (R) COFF/PE Dumper Version 10.00.40219.01
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file a.exe
File Type: EXECUTABLE IMAGE
Section contains the following imports:
...
cublas64_55.dll
...
16.4.1.2. 在何处安装再分发的 CUDA 库
一旦确定了用于再分发的正确库文件,就必须配置它们以安装到应用程序能够找到它们的位置。
在 Windows 上,如果将 CUDA 运行时或其他动态链接的 CUDA 工具包库放置在与可执行文件相同的目录中,Windows 将自动找到它。在 Linux 和 Mac 上,应使用 -rpath 链接器选项来指示可执行文件在其本地路径中搜索这些库,然后再搜索系统路径。
Linux/Mac
nvcc -I $(CUDA_HOME)/include
-Xlinker "-rpath '$ORIGIN'" --cudart=shared
-o myprogram myprogram.cu
Windows
nvcc.exe -ccbin "C:\vs2008\VC\bin"
-Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT" --cudart=shared
-o "Release\myprogram.exe" "myprogram.cu"
注意
可能需要调整 -ccbin 的值以反映您的 Visual Studio 安装位置。
要指定将分发库的备用路径,请使用类似于以下内容的链接器选项
Linux/Mac
nvcc -I $(CUDA_HOME)/include
-Xlinker "-rpath '$ORIGIN/lib'" --cudart=shared
-o myprogram myprogram.cu
Windows
nvcc.exe -ccbin "C:\vs2008\VC\bin"
-Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT /DELAY" --cudart=shared
-o "Release\myprogram.exe" "myprogram.cu"
对于 Linux 和 Mac,-rpath 选项像以前一样使用。对于 Windows,使用 /DELAY 选项;这要求应用程序在首次调用任何 CUDA API 函数之前调用 SetDllDirectory(),以便指定包含 CUDA DLL 的目录。
注意
对于 Windows 8,应使用 SetDefaultDLLDirectories() 和 AddDllDirectory() 而不是 SetDllDirectory()。有关这些例程的更多信息,请参阅 MSDN 文档。
17. 部署基础设施工具
17.1. Nvidia-SMI
NVIDIA 系统管理界面 (nvidia-smi) 是一种命令行实用程序,有助于管理和监控 NVIDIA GPU 设备。此实用程序允许管理员查询 GPU 设备状态,并在具有适当权限的情况下,允许管理员修改 GPU 设备状态。nvidia-smi 针对 Tesla 和某些 Quadro GPU,尽管在其他 NVIDIA GPU 上也提供有限的支持。nvidia-smi 随附于 Linux 上的 NVIDIA GPU 显示驱动程序,以及 64 位 Windows Server 2008 R2 和 Windows 7。nvidia-smi 可以将查询的信息输出为 XML 或人类可读的纯文本,输出到标准输出或文件。有关详细信息,请参阅 nvidia-smi 文档。请注意,不保证新版本的 nvidia-smi 与以前的版本向后兼容。
17.1.1. 可查询状态
- ECC 错误计数
-
报告可纠正的单位错误和可检测的双位错误。错误计数提供 GPU 当前启动周期和生命周期的计数。
- GPU 利用率
-
报告 GPU 计算资源和内存接口的当前利用率。
- 活动计算进程
-
报告 GPU 上运行的活动进程列表,以及相应的进程名称/ID 和分配的 GPU 内存。
- 时钟和性能状态
-
报告几个重要时钟域的最大和当前时钟频率,以及当前的 GPU 性能状态(pstate)。
- 温度和风扇速度
-
报告当前的 GPU 核心温度,以及具有主动散热产品的风扇速度。
- 电源管理
-
报告报告这些测量的产品的当前板卡功耗和功率限制。
- 识别
-
报告各种动态和静态信息,包括板卡序列号、PCI 设备 ID、VBIOS/Inforom 版本号和产品名称。
17.1.2. 可修改状态
- ECC 模式
-
启用和禁用 ECC 报告。
- ECC 重置
-
清除单位和双位 ECC 错误计数。
- 计算模式
-
指示计算进程是否可以在 GPU 上运行,以及它们是独占运行还是与其他计算进程并发运行。
- 持久模式
-
指示当没有应用程序连接到 GPU 时,NVIDIA 驱动程序是否保持加载状态。在大多数情况下,最好启用此选项。
- GPU 重置
-
通过辅助总线重置重新初始化 GPU 硬件和软件状态。
17.2. NVML
NVIDIA 管理库 (NVML) 是一个基于 C 的接口,可直接访问通过 nvidia-smi 公开的查询和命令,旨在作为构建第三方系统管理应用程序的平台。NVML API 随附于 CUDA 工具包(自 8.0 版本起),也可在 NVIDIA 开发者网站上作为 GPU 部署工具包的一部分独立提供,通过单个头文件以及 PDF 文档、存根库和示例应用程序提供;请参阅 https://developer.nvidia.com/gpu-deployment-kit。每个新版本的 NVML 都是向后兼容的。
为 NVML API 提供了额外的 Perl 和 Python 绑定。这些绑定公开了与基于 C 的接口相同的功能,并且还提供向后兼容性。Perl 绑定通过 CPAN 提供,Python 绑定通过 PyPI 提供。
所有这些产品(nvidia-smi、NVML 和 NVML 语言绑定)都会随着每个新的 CUDA 版本更新,并提供大致相同的功能。
有关更多信息,请参阅 https://developer.nvidia.com/nvidia-management-library-nvml。
17.3. 集群管理工具
管理您的 GPU 集群将有助于实现最大的 GPU 利用率,并帮助您和您的用户获得最佳性能。许多行业最流行的集群管理工具都通过 NVML 支持 CUDA GPU。有关其中一些工具的列表,请参阅 https://developer.nvidia.com/cluster-management。
17.4. 编译器 JIT 缓存管理工具
应用程序在运行时加载的任何 PTX 设备代码都会由设备驱动程序进一步编译为二进制代码。这称为即时编译 (JIT)。即时编译会增加应用程序加载时间,但允许应用程序从最新的编译器改进中受益。这也是应用程序在应用程序编译时不存在的设备上运行的唯一方法。
当使用 PTX 设备代码的 JIT 编译时,NVIDIA 驱动程序会将生成的二进制代码缓存在磁盘上。可以通过使用环境变量来控制此行为的某些方面,例如缓存位置和最大缓存大小;请参阅 CUDA C++ 编程指南的即时编译。
17.5. CUDA_VISIBLE_DEVICES
可以通过 CUDA_VISIBLE_DEVICES 环境变量在启动 CUDA 应用程序之前,重新排列 CUDA 应用程序可见和枚举的已安装 CUDA 设备集合。
要使应用程序可见的设备应以逗号分隔列表的形式包含在系统范围的可枚举设备列表中。例如,要仅使用系统范围设备列表中的设备 0 和 2,请在启动应用程序之前设置 CUDA_VISIBLE_DEVICES=0,2。然后,应用程序将这些设备分别枚举为设备 0 和设备 1。
18. 建议和最佳实践
本章包含本文档中解释的优化建议摘要。
18.1. 总体性能优化策略
性能优化围绕三个基本策略展开
最大化并行执行
优化内存使用以实现最大内存带宽
优化指令使用以实现最大指令吞吐量
最大化并行执行首先要以尽可能暴露并行性的方式构建算法。一旦算法的并行性被暴露出来,就需要尽可能高效地将其映射到硬件。这通过仔细选择每个内核启动的执行配置来完成。应用程序还应通过流显式地暴露设备上的并发执行,以及最大化主机和设备之间的并发执行,从而在更高级别上最大化并行执行。
优化内存使用首先要最大限度地减少主机和设备之间的数据传输,因为这些传输的带宽远低于内部设备数据传输。还应通过最大限度地利用设备上的共享内存来最大限度地减少内核对全局内存的访问。有时,最好的优化甚至可能是在需要数据时简单地重新计算数据,从而避免任何数据传输。
有效带宽可能会因每种类型的内存的访问模式而异,差异可达一个数量级。因此,优化内存使用的下一步是根据最佳内存访问模式组织内存访问。这种优化对于全局内存访问尤为重要,因为访问延迟成本数百个时钟周期。相反,仅当存在高度的 bank 冲突时,共享内存访问通常才值得优化。
至于优化指令使用,应避免使用吞吐量低的算术指令。这表明在不影响最终结果的情况下,可以牺牲精度来换取速度,例如使用内部函数而不是常规函数,或使用单精度而不是双精度。最后,由于设备的 SIMT(单指令多线程)性质,必须特别注意控制流指令。
19. nvcc 编译器开关
19.1. nvcc
NVIDIA nvcc 编译器驱动程序将 .cu 文件转换为用于主机的 C++ 和用于设备的 CUDA 汇编或二进制指令。它支持许多命令行参数,其中以下参数对于优化和相关最佳实践特别有用
-maxrregcount=N指定内核在每个文件级别可以使用的最大寄存器数。请参阅寄存器压力。(另请参阅 CUDA C++ 编程指南的执行配置中讨论的__launch_bounds__限定符,以控制每个内核使用的寄存器数量。)--ptxas-options=-v或-Xptxas=-v列出每个内核的寄存器、共享内存和常量内存使用情况。-ftz=true(反常数被刷新为零)-prec-div=false(精度较低的除法)-prec-sqrt=false(精度较低的平方根)-use_fast_mathnvcc的编译器选项强制将每个functionName()调用转换为等效的__functionName()调用。这使得代码运行得更快,但代价是降低了精度和准确性。请参阅数学库。
20. 声明
20.1. 声明
本文档仅供参考,不应视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果或使用概不负责。本文档不构成对开发、发布或交付任何材料(下文定义)、代码或功能的承诺。
NVIDIA 保留随时修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应确认此类信息是最新且完整的。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户一般条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命维持设备,也不适用于 NVIDIA 产品的故障或故障可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用风险由客户自行承担。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品适用于任何特定用途。NVIDIA 不一定对每种产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合且符合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认、损坏、成本或问题不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或本文档项下的其他 NVIDIA 知识产权的任何明示或暗示许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权下的第三方许可,或获得 NVIDIA 的专利或其他知识产权下的 NVIDIA 许可。
仅在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并应完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独或合并)均“按原样”提供。NVIDIA 不对材料作出任何明示、暗示、法定或其他方面的保证,并明确声明不承担所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论何种原因造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计责任应根据产品的销售条款进行限制。
20.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
20.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的相应公司的商标。