3. Nsight Compute
Nsight Compute 用户指南。
3.1. 简介
对于从 Visual Profiler 迁移到 NVIDIA Nsight Compute 的用户,请参阅 Visual Profiler 迁移指南,了解功能和工作流程的比较。
3.1.1. 概述
本文档是下一代 NVIDIA Nsight Compute 分析工具的用户指南。NVIDIA Nsight Compute 是用于 CUDA 应用程序的交互式内核分析器。它通过用户界面和命令行工具提供详细的性能指标和 API 调试。此外,其基线功能允许用户在工具内比较结果。NVIDIA Nsight Compute 提供可自定义和数据驱动的用户界面和指标收集,并且可以通过分析脚本进行扩展,以进行后处理结果。
重要功能
交互式内核分析器和 API 调试器
图形化分析报告
在工具内跨一个或多个报告进行结果比较
快速数据收集
UI 和命令行界面
完全可自定义的报告和分析规则
3.2. 快速入门
以下部分提供了关于如何设置和运行 NVIDIA Nsight Compute 以收集分析信息的简要分步指南。除非另有说明,否则所有目录均相对于 NVIDIA Nsight Compute 的基本目录。
UI 可执行文件名为 ncu-ui。基本目录的 NVIDIA Nsight Compute 安装中包含此名称的快捷方式。实际可执行文件位于 Windows 上的 host\windows-desktop-win7-x64 文件夹或 Linux 上的 host/linux-desktop-glibc_2_11_3-x64 文件夹中。默认情况下,从 Linux .run 文件安装时,NVIDIA Nsight Compute 位于 /usr/local/cuda-<cuda-version>/nsight-compute-<version> 中。从 .deb 或 .rpm 包安装时,它位于 /opt/nvidia/nsight-compute/<version> 中,以与 Nsight Systems 保持一致。在 Windows 中,默认路径为 C:\Program Files\NVIDIA Corporation\Nsight Compute <version>。
启动 NVIDIA Nsight Compute 后,默认情况下会打开欢迎页面。开始部分允许用户启动新活动、打开现有报告、创建新项目或加载现有项目。继续部分提供最近打开的报告和项目的链接。探索部分提供有关最新版本中新增功能的信息,以及其他培训的链接。请参阅 环境,了解如何更改启动操作。

欢迎页面
3.2.1. 交互式分析活动
从 NVIDIA Nsight Compute 启动目标应用程序
启动 NVIDIA Nsight Compute 时,将出现欢迎页面。单击快速启动以打开连接对话框。如果连接对话框未出现,您可以从主工具栏中使用连接按钮打开它,前提是您当前未连接。在左侧选择您的目标平台,并从连接下拉列表中选择您的连接目标(机器)。如果您选择了本地目标平台,
localhost将可用作连接。使用 + 按钮添加新的连接目标。然后,继续填写启动选项卡中的详细信息。在活动面板中,选择交互式分析活动以启动会话,该会话允许控制目标应用程序的执行并交互式选择感兴趣的内核。按启动以开始会话。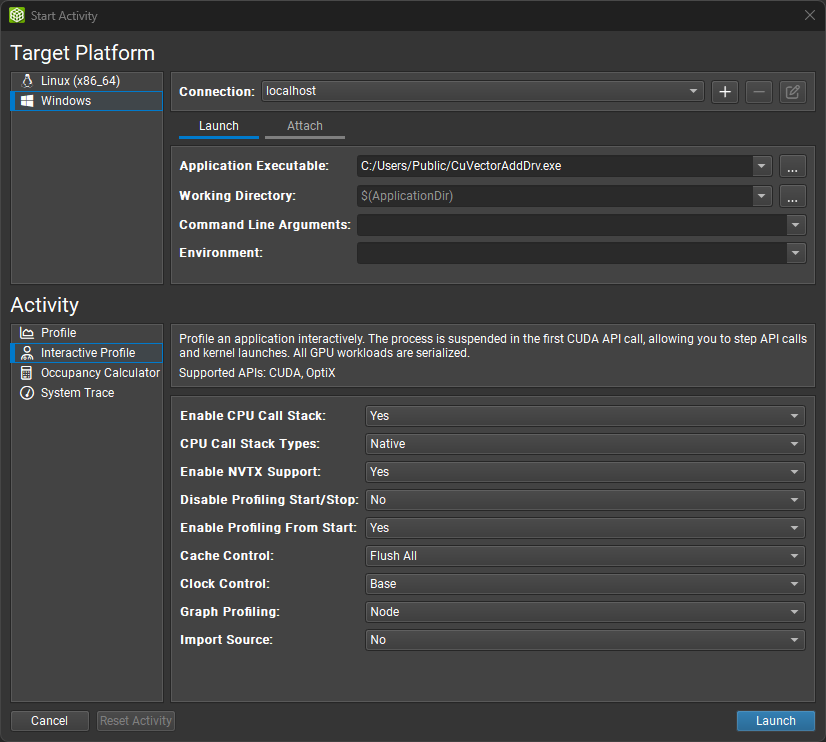
使用工具检测从命令行启动目标应用程序
ncu 可以充当简单的包装器,强制目标应用程序加载工具检测所需的库。参数
--mode=launch指定应启动目标应用程序并在第一次检测的 API 调用之前暂停。这样,应用程序将等待,直到我们使用 UI 连接。$ ncu --mode=launch CuVectorAddDrv.exe
启动 NVIDIA Nsight Compute 并连接到目标应用程序
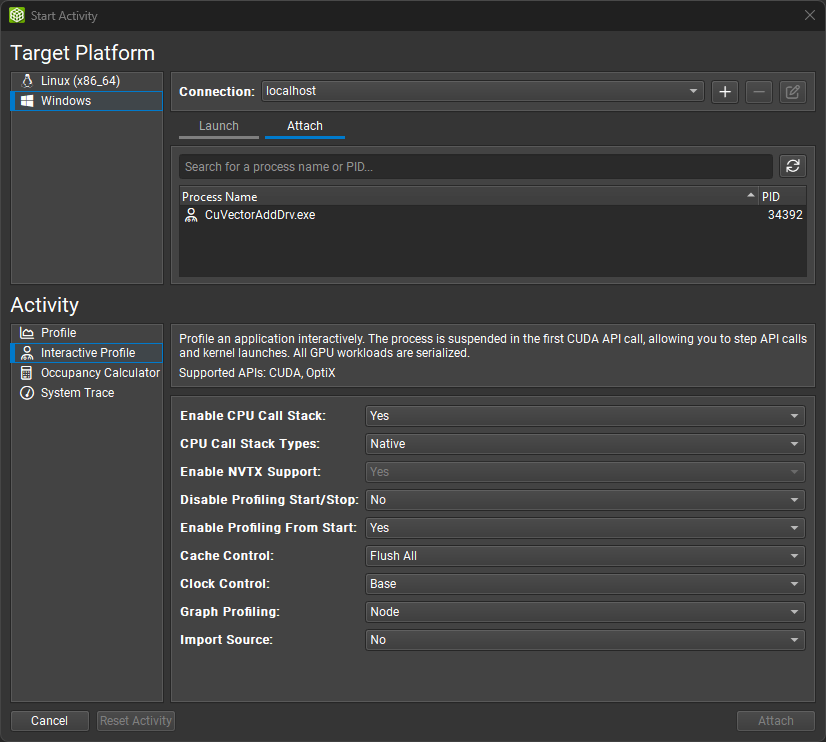
在对话框顶部选择目标机器以连接并更新可附加应用程序的列表。默认情况下,如果目标与您当前的本地平台匹配,则预先选择localhost。选择附加选项卡和感兴趣的目标应用程序,然后按附加。连接后,NVIDIA Nsight Compute 的布局将更改为步进模式,使您可以控制对检测的 API 的任何调用执行。连接后,API 流窗口指示目标应用程序在第一次 API 调用之前等待。
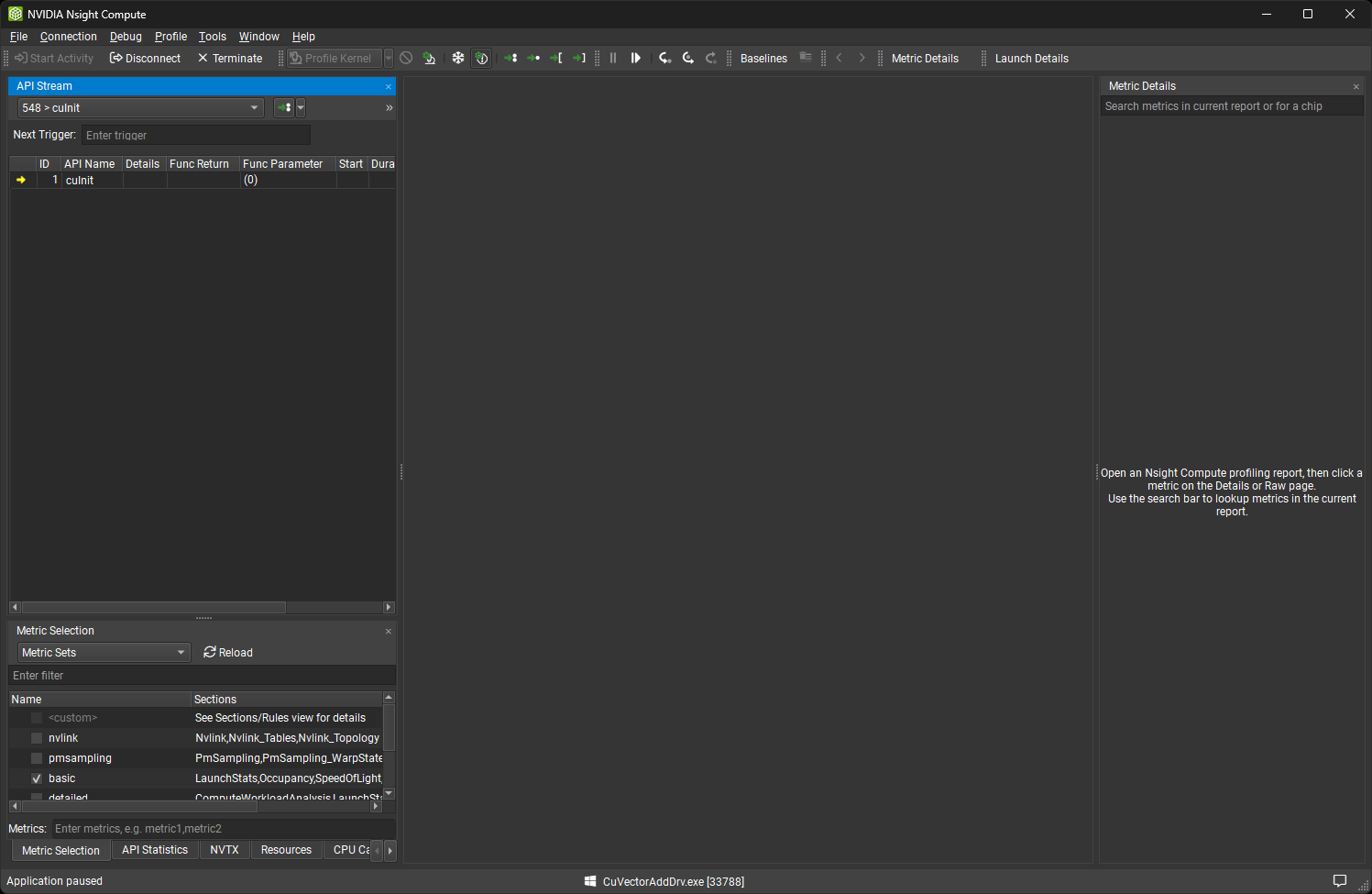
控制应用程序执行
使用API 流窗口步进对检测的 API 的调用。顶部的下拉列表允许在应用程序的不同 CPU 线程之间切换。步入 (F11)、步过 (F10) 和步出 (Shift + F11) 可从调试菜单或相应的工具栏按钮获得。步进时,会捕获函数返回值和函数参数。
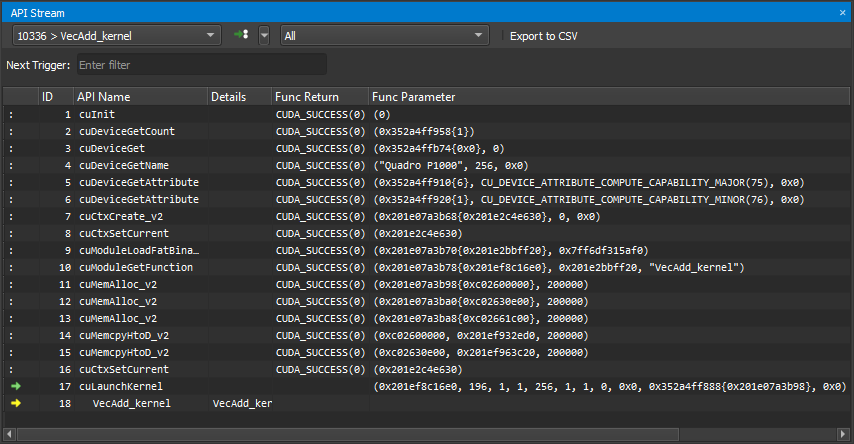
使用恢复 (F5) 和暂停以允许程序自由运行。冻结控制可用于定义当前未处于焦点状态的线程的行为,即在线程下拉列表中选择的线程。默认情况下,API 流在返回错误代码的任何 API 调用处停止。这可以在调试菜单中通过在 API 错误时中断切换。
隔离内核启动
要快速隔离内核启动以进行分析,请使用API 流窗口工具栏中的运行到下一个内核按钮跳转到下一个内核启动。执行将在内核启动执行之前停止。
分析内核启动
一旦目标应用程序的执行在内核启动处暂停,UI 中将提供其他操作。这些操作可以从菜单或工具栏获得。请注意,如果 API 流未处于合格状态(不在内核启动时或在不受支持的 GPU 上启动),则这些操作将被禁用。要分析,请按分析内核并等待结果显示在 分析器报告中。分析进度在右下角的状态栏中报告。
除了手动选择分析外,还可以从分析菜单启用自动分析。如果启用,则将使用当前节配置分析与当前内核过滤器(如果有)匹配的每个内核。如果应用程序要无人值守地进行分析,或者要分析的内核启动数量非常大,则此功能特别有用。可以使用 指标选择工具窗口启用或禁用节。
分析序列允许配置一次收集一组分析结果。该组中的每个结果都使用不同的参数进行分析。序列对于调查内核在大量参数集上的行为非常有用,而无需多次重新编译和重新运行应用程序。
有关此活动中可用选项的详细说明,请参阅 交互式分析活动。
3.2.2. 非交互式分析活动
从 NVIDIA Nsight Compute 启动目标应用程序
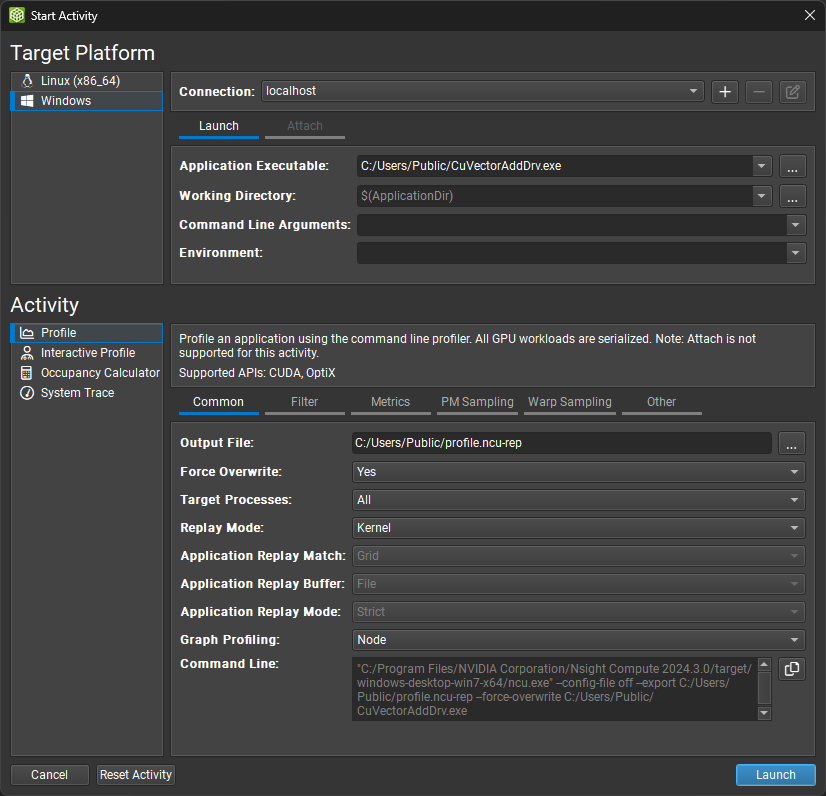
启动 NVIDIA Nsight Compute 时,将出现欢迎页面。单击开始活动以打开开始活动对话框。如果开始活动对话框未出现,您可以从主工具栏中使用开始活动按钮打开它,前提是您当前未连接。在左侧选择您的目标平台,并从连接下拉列表中选择您的 localhost。然后,填写启动详细信息。在活动面板中,选择分析活动以启动会话,该会话预先配置分析会话并启动命令行分析器以收集数据。提供输出文件名称以启用使用启动按钮启动会话。
其他启动选项
有关这些选项的更多详细信息,请参阅 命令行选项。这些选项分为选项卡:筛选器选项卡公开了用于指定应分析哪些内核的选项。选项包括内核正则表达式过滤器、要跳过的启动次数以及要分析的启动总数。节选项卡允许您选择应为每个内核启动收集哪些节。将鼠标悬停在节上以查看其描述作为工具提示。要更改默认启用的节,请使用 指标选择工具窗口。采样选项卡允许您配置每个内核启动的采样选项。其他选项卡包括通过
--metrics选项收集 NVTX 信息或自定义指标的选项。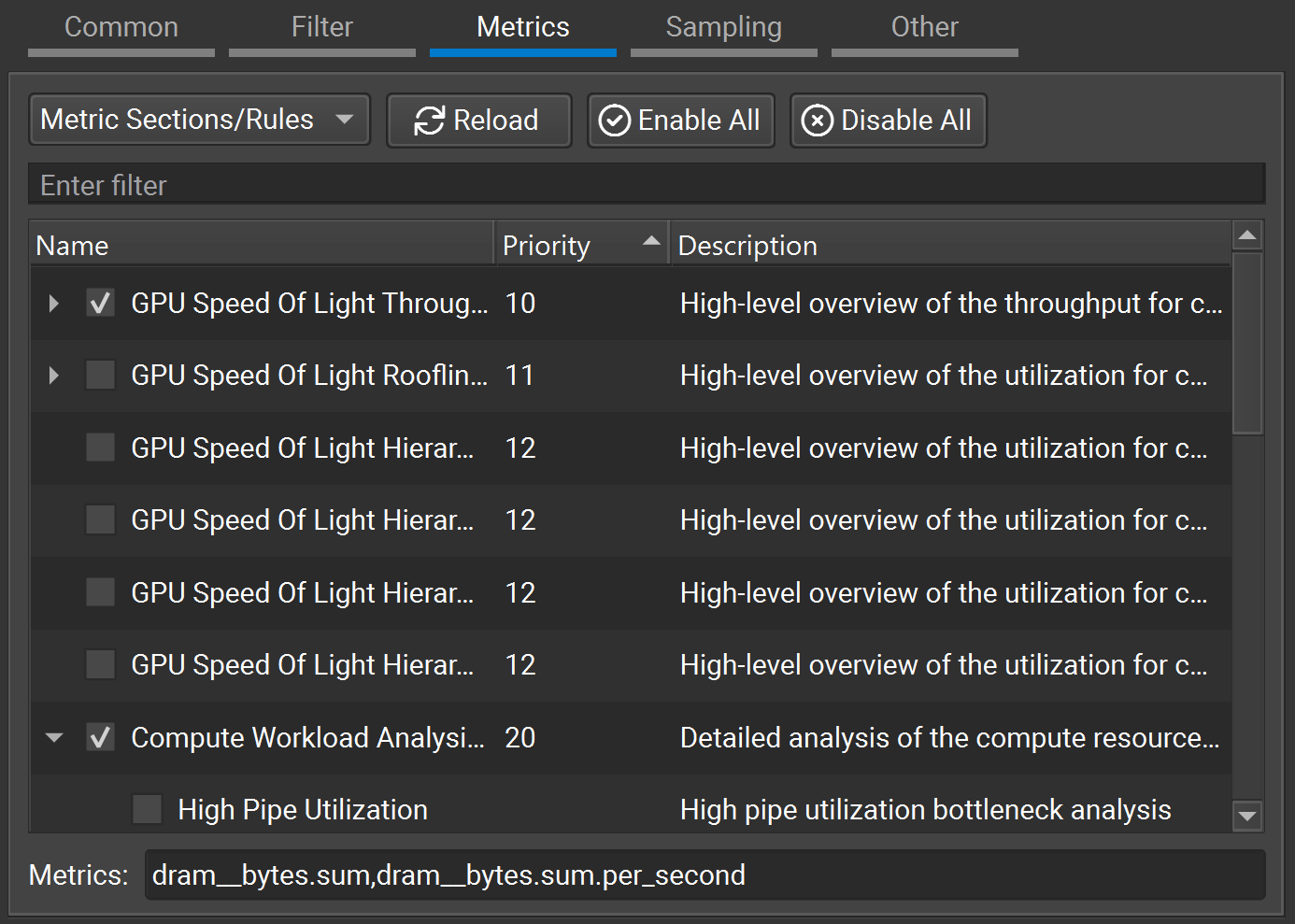
有关此活动中可用选项的详细说明,请参阅 分析活动。
3.2.3. 系统跟踪活动
从 NVIDIA Nsight Compute 启动目标应用程序
启动 NVIDIA Nsight Compute 时,将出现欢迎页面。单击开始活动以打开开始活动对话框。如果开始活动对话框未出现,您可以从主工具栏中使用开始活动按钮打开它,前提是您当前未连接。在左侧选择您的本地目标平台,并从连接下拉列表中选择您的 localhost。然后,填写启动详细信息。在活动面板中,选择系统跟踪活动以启动具有预配置设置的会话。按启动以开始会话。
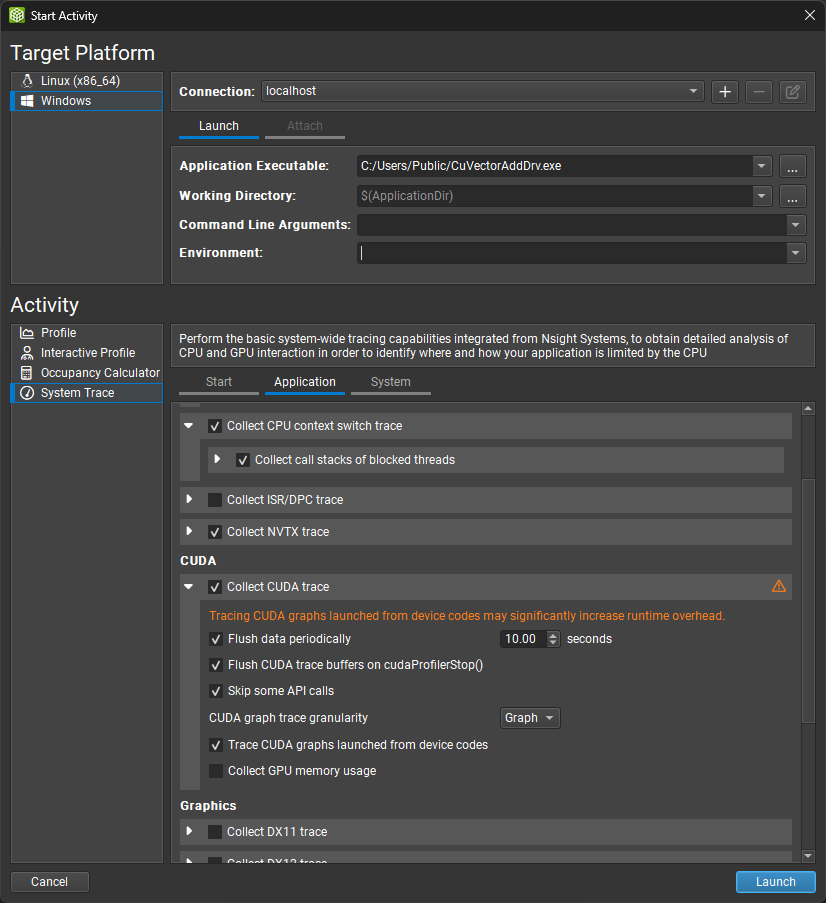
其他启动选项
有关这些选项的更多详细信息,请参阅 系统范围的分析选项。
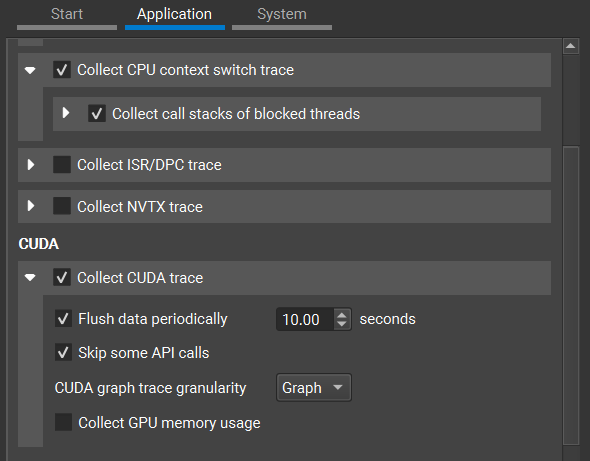
会话完成后,Nsight Systems 报告将在新文档中打开。默认情况下,显示时间线视图。它提供 CPU 和 GPU 活动的详细信息,并有助于理解应用程序的整体行为和性能。一旦确定 CUDA 内核位于关键路径上并且未达到性能预期,请右键单击时间线上的内核启动,然后从上下文菜单中选择分析内核。将打开一个新的 开始活动,该活动已预先配置为分析选定的内核启动。继续使用 非交互式分析活动优化选定的内核
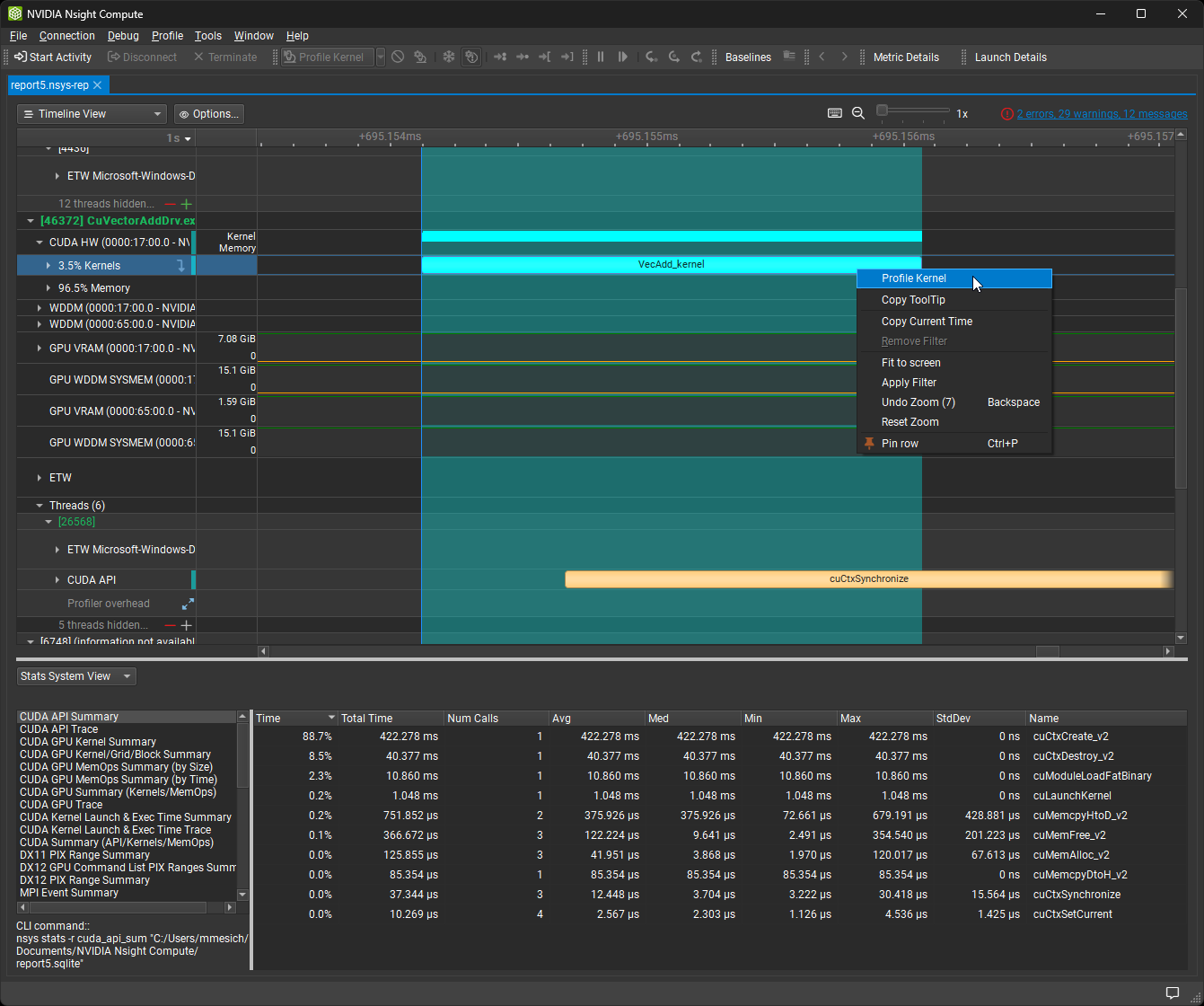
3.2.4. 导航报告
导航报告
分析报告默认在摘要页面上显示。它显示一个概述表,以总结报告中的所有结果。它还显示所选行的规则信息。
您可以使用报告左上角的选项卡栏在不同的 报告页面之间切换。您还可以使用 Ctrl + Shift + N 和 Ctrl + Shift + P 快捷键或相应的工具栏按钮分别导航到下一页和上一页。一个报告可以包含任意数量的结果。当前下拉列表允许在报告中的不同结果之间切换。
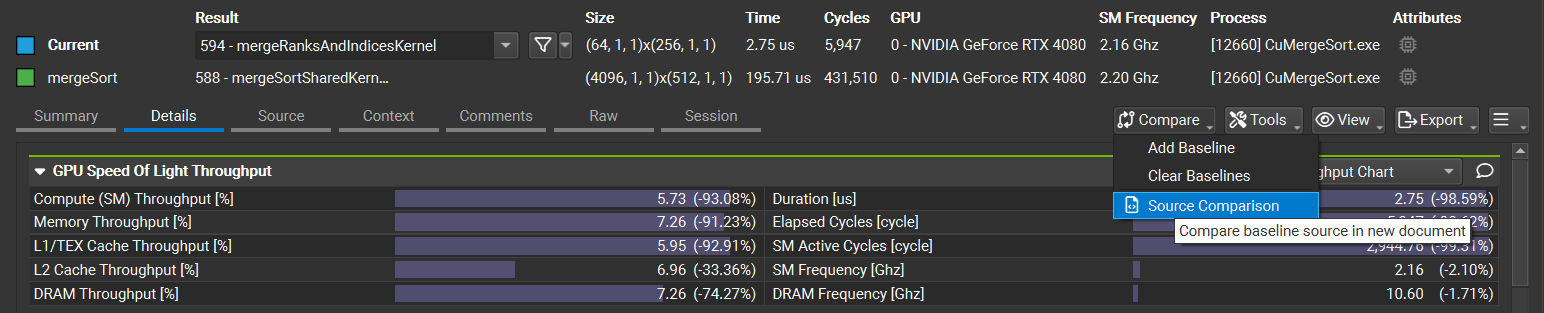
比较多个结果
在详细信息页面上,使用比较 - 添加基线按钮使当前结果成为基线,来自此报告和在 NVIDIA Nsight Compute 的同一实例中打开的任何其他报告的所有其他结果都将与之进行比较。设置基线后,详细信息页面上的每个元素都会显示两个值:焦点结果的当前值和基线的相应值或与相应基线值的更改百分比。
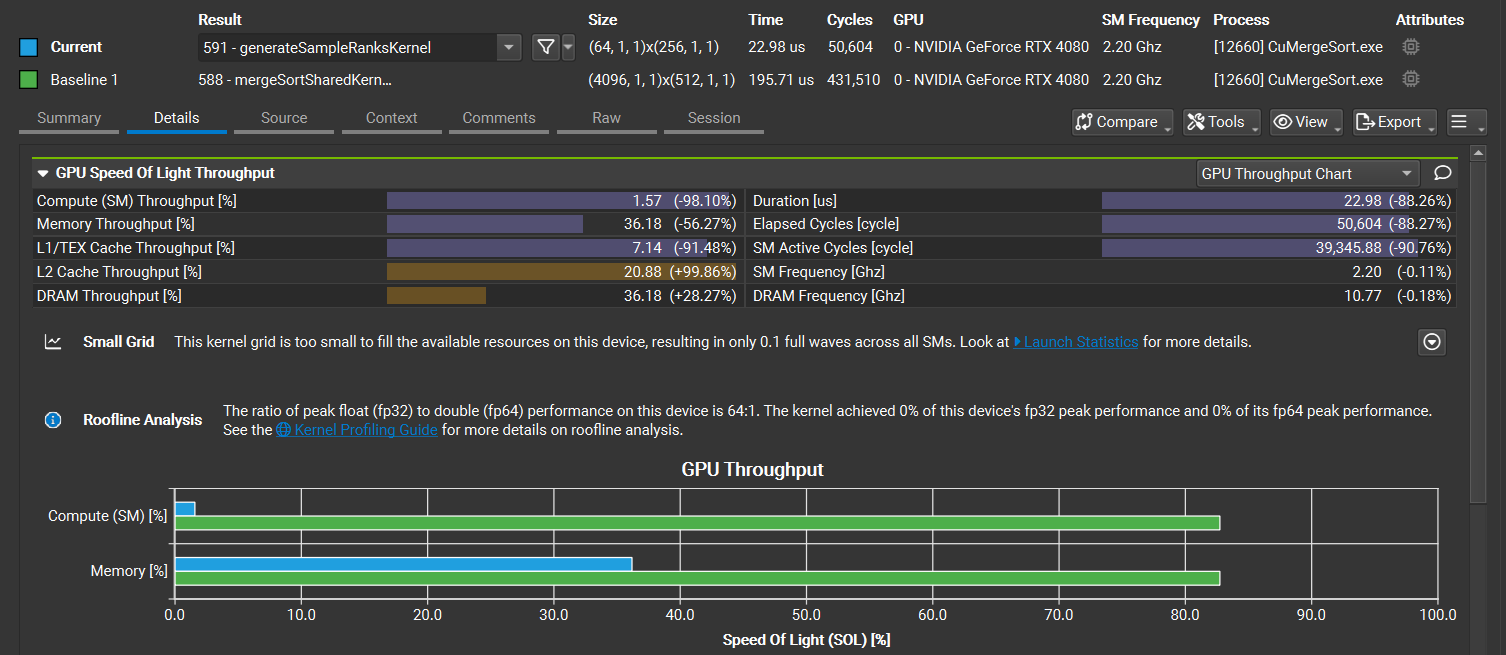
使用同一组按钮、分析菜单或相应的工具栏按钮中的清除基线条目删除所有基线。有关更多信息,请参阅 基线。
遵循规则
在详细信息页面上,许多部分提供规则,其中包含有关检测到的问题和优化建议的有价值信息。规则也可以是用户定义的。有关更多信息,请参阅 自定义指南。

3.3. 启动活动对话框
使用启动活动对话框启动并附加到本地和远程平台上的应用程序。首先选择要分析的目标平台。默认情况下(如果支持),将选择您的本地平台。选择您要在其上启动目标应用程序或连接到正在运行的进程的平台。
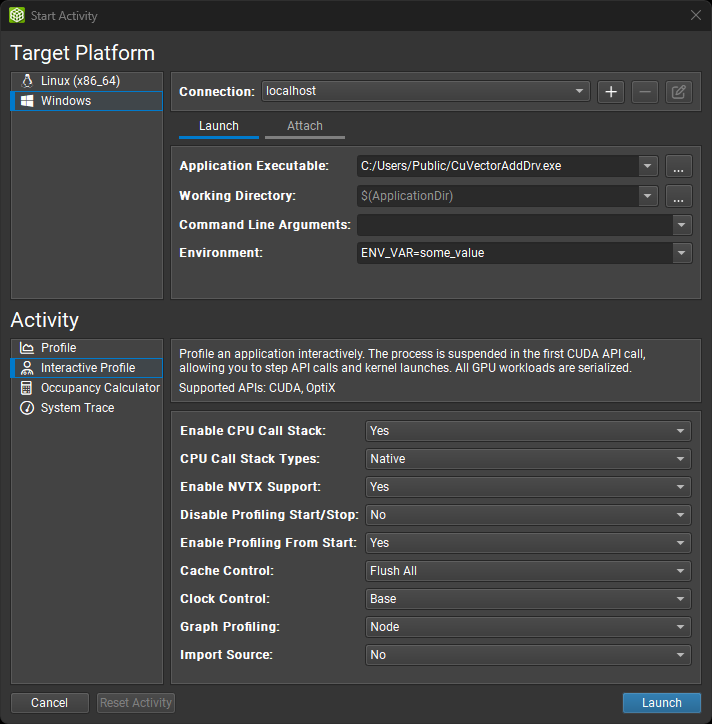
使用远程平台时,系统会要求您在顶部下拉列表中选择或创建连接。要创建新连接,请选择 + 并输入您的连接详细信息。使用本地平台时,将选择 localhost 作为默认值,并且不需要进一步的连接设置。如果分析将在同一平台的远程系统上进行,您仍然可以创建或选择远程连接。
根据您的目标平台,选择启动或远程启动以在目标平台上启动应用程序进行分析。请注意,远程启动仅在目标平台上支持时才可用。
填写应用程序的以下启动详细信息
应用程序可执行文件:指定要启动的根应用程序。请注意,这可能不是您希望分析的最终应用程序。它可以是创建其他进程的脚本或启动器。
工作目录:应用程序将在其中启动的目录。
命令行参数:指定要传递给应用程序可执行文件的参数。
环境:要为启动的应用程序设置的环境变量。
选择附加以将分析器附加到已在目标平台上运行的应用程序。此应用程序必须已使用另一个 NVIDIA Nsight Compute CLI 实例启动。列表将显示目标系统上可以附加的所有应用程序进程。选择刷新按钮以重新创建此列表。
最后,选择要在目标上为启动或附加的应用程序运行的活动。请注意,并非所有活动都必然与所有目标和连接选项兼容。目前,存在以下活动
3.3.1. 远程连接
支持 SSH 的远程设备也可以在启动活动对话框中配置为目标。要配置远程设备,请确保选择了支持 SSH 的目标平台,然后按 + 按钮。将显示以下配置对话框。
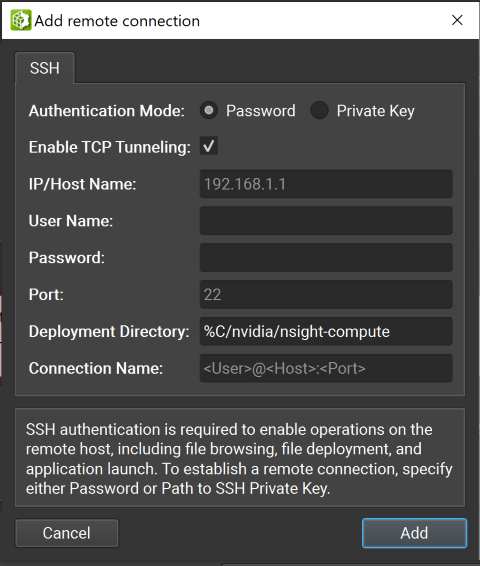
NVIDIA Nsight Compute 支持密码和私钥身份验证方法。在此对话框中,选择身份验证方法并输入以下信息
密码
IP/主机名:目标设备的 IP 地址或主机名。
用户名:用于 SSH 连接的用户名。
密码:用于 SSH 连接的用户密码。
端口:用于 SSH 连接的端口。(默认值为 22)
部署目录:在目标设备上用于部署支持文件的目录。指定的用户必须对此位置具有写入权限。
连接名称:将在启动活动对话框中显示的远程连接的名称。如果未设置,则默认为 <用户>@<主机>:<端口>。
私钥
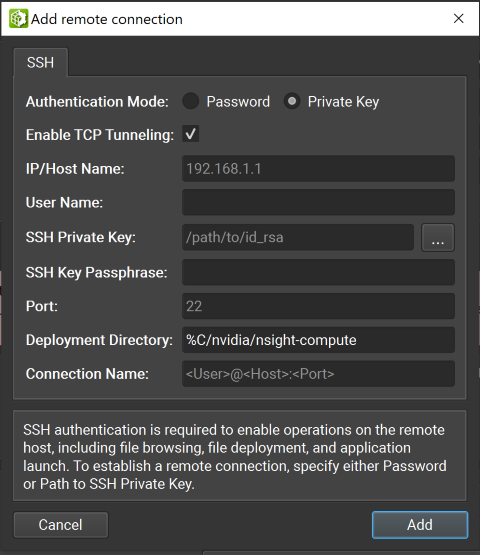
IP/主机名:目标设备的 IP 地址或主机名。
用户名:用于 SSH 连接的用户名。
SSH 私钥:用于对 SSH 服务器进行身份验证的私钥。
SSH 密钥密码:您的私钥的密码。
端口:用于 SSH 连接的端口。(默认值为 22)
部署目录:在目标设备上用于部署支持文件的目录。指定的用户必须对此位置具有写入权限。
连接名称:将在启动活动对话框中显示的远程连接的名称。如果未设置,则默认为 <用户>@<主机>:<端口>。
除了按路径指定的密钥文件和纯密码身份验证之外,NVIDIA Nsight Compute 还支持键盘交互式身份验证、标准密钥文件路径搜索和 SSH 代理。
您还可以在部署目录字段中指定占位符。使用连接时,这些占位符将被替换为实际值。支持以下占位符。
占位符 |
描述 |
|---|---|
%C |
用户缓存目录。解析为 $XDG_CACHE_HOME,如果为空则解析为 $HOME/.cache |
%E |
用户配置目录。解析为 $XDG_CONFIG_HOME,如果为空则解析为 $HOME/.config |
%h |
用户主目录。解析为 $HOME,如果为空则解析为 /root |
%H |
主机名。解析为 $HOSTNAME,如果为空则解析为主机 |
%T |
临时目录。解析为 $TMPDIR,如果为空则解析为 /tmp |
%u |
用户名。解析为 $USER,如果为空则解析为 root |
%S |
状态目录。解析为 $XDG_STATE_HOME,如果为空则解析为 $HOME/.local/state |
例如,如果您将部署目录指定为 %T/nsight-compute,则实际使用的目录将是远程设备上的 /tmp/nsight-compute。
输入所有信息后,单击添加按钮以使用此新连接。
在启动活动对话框中选择远程连接后,应用程序可执行文件文件浏览器将使用配置的 SSH 连接浏览远程文件系统,从而允许用户在远程设备上选择目标应用程序。
在远程设备上启动活动时,将执行以下步骤
命令行分析器和支持文件将复制到远程设备上的部署目录中。(仅复制不存在或过期的文件。)
通信通道已打开,以准备 UI 和应用程序可执行文件之间的流量。
对于交互式分析活动,SOCKS 代理在主机上启动。
对于非交互式分析活动,在目标机器上打开远程转发通道,以将分析信息隧道传输回主机。
应用程序可执行文件在远程设备上执行。
对于交互式分析活动,将建立与远程应用程序的连接,并且分析会话开始。
对于非交互式分析活动,远程应用程序在命令行分析器下执行,并生成指定的报告文件。
对于非交互式分析活动,生成的报告文件将复制回主机并打开。
每个步骤的进度都在进度日志中显示。
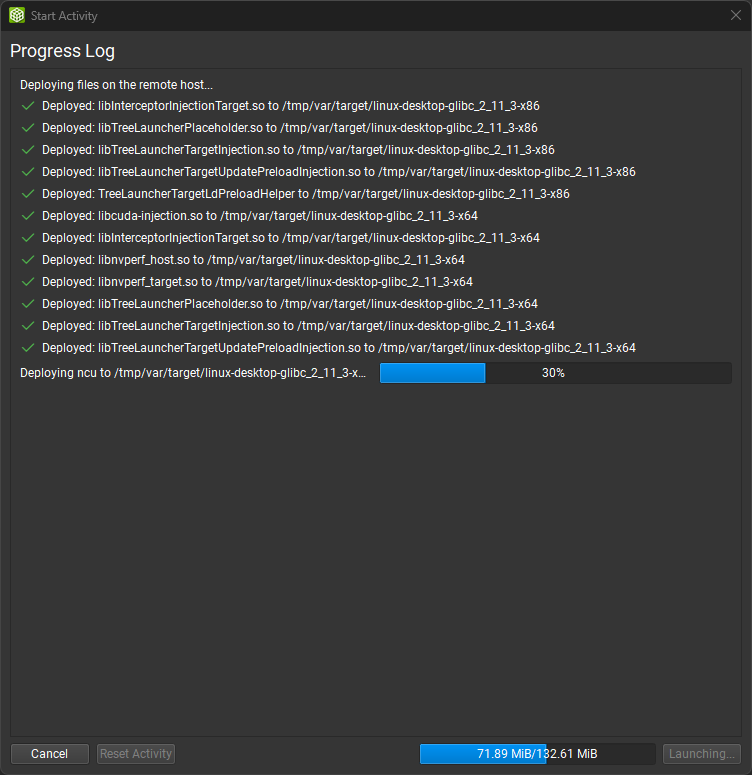
进度日志
请注意,一旦远程启动了任何活动类型,进一步分析会话所需的工具可以在远程设备上的部署目录中找到。
在 Linux 和 Mac 主机平台上,NVIDIA Nsight Compute 支持通过 ProxyJump 和 ProxyCommand SSH 选项在无法从运行 UI 的机器直接寻址的目标机器上进行 SSH 远程分析。
这些选项可用于指定要连接的中间主机或要运行的实际命令,以获取连接到目标主机上的 SSH 服务器的套接字,并且可以添加到您的 SSH 配置文件中。
请注意,对于这两个选项,NVIDIA Nsight Compute 都会运行外部命令,并且不实现任何机制来使用在 启动活动对话框中输入的凭据对中间主机进行身份验证。这些凭据将仅用于对机器链中的最终目标进行身份验证。
使用 ProxyJump 选项时,NVIDIA Nsight Compute 使用 OpenSSH 客户端来建立与中间主机的连接。这意味着为了使用 ProxyJump 或 ProxyCommand,必须在主机上安装支持这些选项的 OpenSSH 版本。
在这种情况下,对中间主机进行身份验证的常用方法是使用 SSH 代理并使其保存用于身份验证的私钥。
由于使用了 OpenSSH SSH 客户端,因此您还可以使用 SSH askpass 机制以交互方式处理这些身份验证。
在慢速网络上,通过 SSH 进行远程分析的连接可能会超时。如果是这种情况,可以使用 ConnectTimeout 选项设置所需的超时值。
通过 SSH 进行远程分析的一个已知限制是,如果 NVIDIA Nsight Compute 尝试通过 SSH 连接到其运行的同一机器来进行远程分析,则可能会出现问题。在这种情况下,解决方法是通过 localhost 进行本地分析。
有关 OpenSSH 客户端的可用选项以及可以用于身份验证的工具生态系统的更多信息,请参阅官方 手册页。
3.3.2. 交互式分析活动
交互式分析活动允许您启动一个会话,该会话控制目标应用程序的执行,类似于调试器。您可以步进 API 调用和工作负载(CUDA 内核)、暂停和恢复,并交互式选择感兴趣的内核以及要收集的指标。
此活动目前不支持分析或附加到子进程。
启用 CPU 调用堆栈
在每个分析的内核启动位置收集 CPU 端调用堆栈。
CPU 调用堆栈类型
如果“启用 CPU 调用堆栈”设置为“是”,则可以在此处选择调用堆栈的类型。
启用 NVTX 支持
收集应用程序或其库提供的 NVTX 信息。支持步进到特定 NVTX 上下文是必需的。
禁用分析启动/停止
忽略应用程序发出的
cu(da)ProfilerStart或cu(da)ProfilerStop调用。从启动启用分析
从应用程序启动启用分析。如果应用程序在第一次调用此 API 之前调用
cu(da)ProfilerStart和内核,则禁用此功能很有用,因为不应分析这些内核。请注意,禁用此功能不会阻止您手动分析内核。缓存控制
控制 GPU 缓存在分析期间的行为。允许的值:对于刷新全部,在分析期间的每次内核重放迭代之前,都会刷新所有 GPU 缓存。虽然在应用程序的执行环境中,指标值在不使缓存失效的情况下可能略有不同,但此模式提供了跨重放过程以及跨目标应用程序的多次运行的最可重现的指标结果。
对于不刷新,在分析期间不刷新任何 GPU 缓存。如果指标收集只需要单个内核重放过程,则可以提高性能并更好地复制应用程序行为。但是,某些指标结果将因先前的 GPU 工作以及重放迭代之间而异。这可能导致不一致和超出范围的指标值。
时钟控制
控制 GPU 时钟在分析期间的行为。允许的值:对于基本,GPC 和内存时钟在分析期间锁定到各自的基本频率。这对热节流没有影响。对于无,在分析期间不更改任何 GPC 或内存频率。
导入源代码
启用将可用的源文件永久导入到报告中。在 源代码查找文件夹中搜索缺少的源文件。源信息必须嵌入在可执行文件中,例如,通过
-lineinfo编译器选项。导入的文件在 源代码页面上的 CUDA-C 视图中使用。
图形分析
设置是否应将 CUDA 图形步进和分析为单个节点或完整图形。有关此模式的更多信息,请参阅 内核分析指南。
管道加速状态
控制 Tensor Core 加速状态。建议为应用程序分析设置稳定的 Tensor Core 加速,以确保可预测的运行到运行性能。默认情况下,加速状态设置为
自动,这会尝试在受支持的平台和驱动程序上设置稳定的加速状态。
3.3.3. 分析活动
分析活动提供传统的、可预配置的分析器。在配置要分析的内核、要收集的指标等之后,应用程序将在没有交互式控制的情况下在分析器下运行。一旦应用程序终止,活动就会完成。对于通常不会自行终止的应用程序,例如交互式用户界面,您可以在分析完所有预期内核后取消活动。
此活动不支持附加到以前通过 NVIDIA Nsight Compute 启动的进程。这些进程将在附加选项卡中显示为灰色。
输出文件
应存储收集的分析的报告文件的路径。如果不存在,则会自动添加报告扩展名
.ncu-rep。文件名组件支持占位符%i。它被一个顺序递增的数字替换,以创建唯一的文件名。这映射到--export命令行选项。强制覆盖
如果设置,则会覆盖现有报告文件。这映射到
--force-overwrite命令行选项。目标进程
选择要分析的进程。在仅应用程序模式下,仅分析根应用程序进程。在全部模式下,分析根应用程序进程及其所有子进程。这映射到
--target-processes命令行选项。重放模式
选择多次重放内核启动的方法。在内核模式下,单个内核启动在目标应用程序的单次执行期间透明地重放。在应用程序模式下,整个目标应用程序将多次重新启动。在每次迭代中,都会收集目标内核启动的其他数据。应用程序重放要求程序执行具有确定性。这映射到
--replay-mode命令行选项。有关重放模式的更多详细信息,请参阅 内核分析指南。
图形分析
设置是否应将 CUDA 图形分析为单个节点或完整图形。
其他选项
所有剩余选项都映射到其命令行分析器等效项。有关详细信息,请参阅 命令行选项。
3.3.4. 重置
连接对话框中的条目将作为当前 项目的一部分保存。在自定义项目中工作时,只需关闭项目即可重置对话框。
当不在自定义项目中工作时,条目将作为默认项目的一部分存储。您可以通过关闭 NVIDIA Nsight Compute,然后 从磁盘删除项目文件来删除默认项目中的所有信息。
3.4. 主菜单和工具栏
有关主菜单和工具栏的信息。

3.4.1. 主菜单
文件
打开项目 打开现有的分析项目。
最近的项目 从最近使用的项目列表中打开现有的分析项目。
保存项目 保存当前的分析项目。
项目另存为 以新文件名保存当前的分析项目。
关闭项目 关闭当前的分析项目。
新建文件 创建新文件。
打开文件 打开现有文件。
打开远程文件
从远程主机下载现有文件并在本地打开。打开的文件仅存在于内存中,除非用户显式保存,否则不会写入本地计算机的磁盘。 有关如何选择远程主机以下载文件的更多信息,请参阅关于远程连接的部分。
只有本地支持的文件类型的子集可以从远程目标打开。下表列出了可以远程打开的文件类型。
远程文件类型支持 扩展名
描述
支持
ncu-rep
Nsight Compute Profiler 报告
是
ncu-occ
占用率计算器文件
是
ncu-bvh
OptiX AS 查看器文件
是 (macOS 除外)
section
Section 描述
否
cubin
Cubin 文件
否
cuh,h,hpp
头文件
否
c,cpp,cu
源文件
否
txt
文本文件
否
nsight-cuprof-report
Nsight Compute Profiler 报告 (旧版)
是
保存 保存当前文件
另存为 使用不同的名称、类型或位置保存当前文件的副本。
保存所有文件 保存所有打开的文件。
关闭 关闭当前文件。
关闭所有文件 关闭所有打开的文件。
最近的文件 从最近使用的文件列表中打开现有文件。
退出 退出 Nsight Compute。
连接
开始活动 打开启动活动对话框以启动或附加到目标应用程序。如果已连接,则禁用。
断开连接 与当前目标应用程序断开连接,允许应用程序正常继续运行并可能重新附加。
终止 断开连接并立即终止当前目标应用程序。
调试
暂停 在下一个拦截的 API 调用或启动时暂停目标应用程序。
继续 继续目标应用程序。
步入 步入当前的 API 调用或启动以进入下一个嵌套调用(如果有),否则步入后续的 API 调用。
步过 步过当前的 API 调用或启动,并在下一个非嵌套的 API 调用或启动处暂停。
步出 步出当前嵌套的 API 调用或启动,到达上一层级的下一个非父级的 API 调用或启动。
冻结 API
禁用时,所有 CPU 线程都启用并在单步执行或继续期间继续运行,并且当至少一个线程到达下一个 API 调用或启动时,所有线程都会停止。 这也意味着在单步执行或继续期间,当前选定的线程可能会更改,因为旧的选定线程不会向前推进,并且 API 流会自动切换到具有新 API 调用或启动的线程。 启用时,仅启用当前选定的 CPU 线程。 所有其他线程均被禁用和阻止。
如果当前线程到达下一个 API 调用或启动,则单步执行完成。 选定的线程永远不会更改。 但是,如果选定的线程未调用任何进一步的 API 调用或在屏障处等待另一个线程取得进展,则单步执行可能无法完成并无限期挂起。 在这种情况下,暂停,选择另一个线程,然后继续单步执行,直到原始线程被解除阻止。 在此模式下,只有选定的线程才会向前推进。
API 错误时中断 启用后,在继续或单步执行期间,一旦 API 调用返回错误代码,执行就会暂停。
运行到下一个内核 请参阅API 流工具窗口。
运行到下一个 API 调用 请参阅API 流工具窗口。
运行到下一个范围开始 请参阅API 流工具窗口。
运行到下一个范围结束 请参阅API 流工具窗口。
API 统计信息 打开API 统计信息工具窗口
API 流 打开API 流工具窗口
资源 打开资源工具窗口
NVTX 打开NVTX工具窗口
分析
工具
窗口
保存窗口布局 允许您为当前布局指定名称。 布局将保存到文档目录中的 Layouts 文件夹中,并命名为“.nvlayout”文件。
应用窗口布局 保存布局后,可以使用“应用窗口布局”菜单项恢复它们。 只需从要应用的子菜单中选择条目。
管理窗口布局 允许您删除或重命名旧布局。
恢复默认布局 将视图恢复到其原始大小和位置。
显示欢迎页面 打开欢迎页面。
帮助
文档 在线打开 NVIDIA Nsight Compute 的最新文档。
文档 (本地) 打开 NVIDIA Nsight Compute 附带的本地 HTML 文档。
检查更新 在线检查是否有较新版本的 NVIDIA Nsight Compute 可供下载。
重置应用程序数据 重置保存在磁盘上的所有 NVIDIA Nsight Compute 配置数据,包括选项设置、默认路径、最近的项目引用等。 这不会删除已保存的报告。
发送反馈 打开一个对话框,允许您发送错误报告和功能建议。 (可选)反馈包括基本系统信息、屏幕截图或其他文件(例如分析报告)。
关于 打开“关于”对话框,其中包含有关 NVIDIA Nsight Compute 版本的信息。
3.4.2. 主工具栏
主工具栏显示主菜单中常用的操作。 有关其描述,请参阅主菜单。
3.4.3. 状态横幅
状态横幅用于显示重要消息,例如分析器错误。 可以通过单击“X”按钮来关闭消息。 同时显示的横幅数量有限,如果出现新消息,旧消息可能会自动关闭。 使用输出消息窗口查看完整的消息历史记录。

3.5. 工具窗口
3.5.1. API 统计信息
当 NVIDIA Nsight Compute 连接到目标应用程序时,API 统计信息窗口可用。 它在建立连接后默认打开。 可以使用主菜单中的调试 > API 统计信息重新打开它。
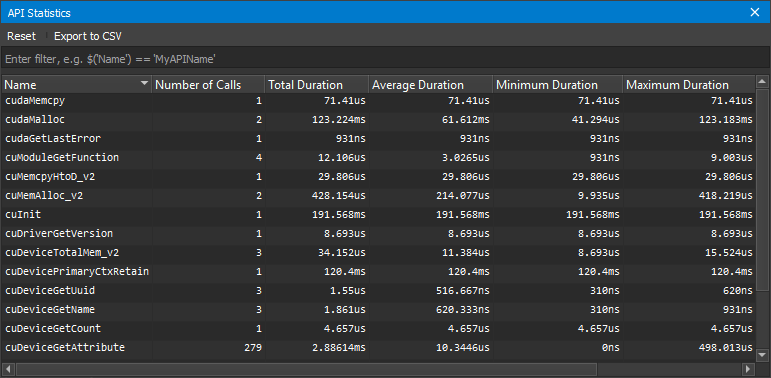
每当目标应用程序暂停时,它都会显示跟踪的 API 调用的摘要,其中包含一些统计信息,例如调用次数、总持续时间、平均持续时间、最短持续时间和最长持续时间。 请注意,当尝试优化应用程序的 CPU 性能时,此视图不能用作 Nsight Systems 的替代品。
重置按钮删除当前点之前收集的所有统计信息,并开始新的收集。 使用导出到 CSV按钮将当前统计信息导出到 CSV 文件。
3.5.2. API 流
当 NVIDIA Nsight Compute 连接到目标应用程序时,API 流窗口可用。 它在建立连接后默认打开。 可以使用主菜单中的调试 > API 流重新打开它。
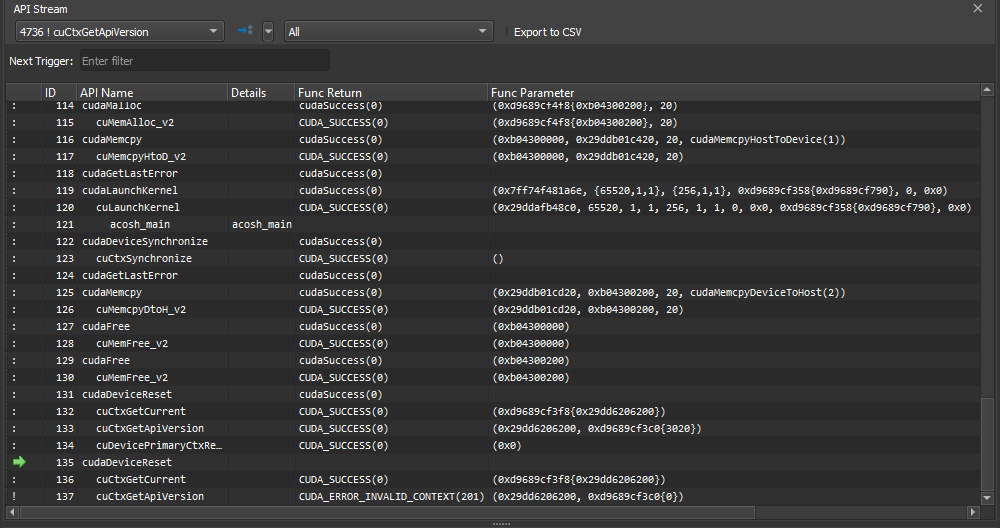
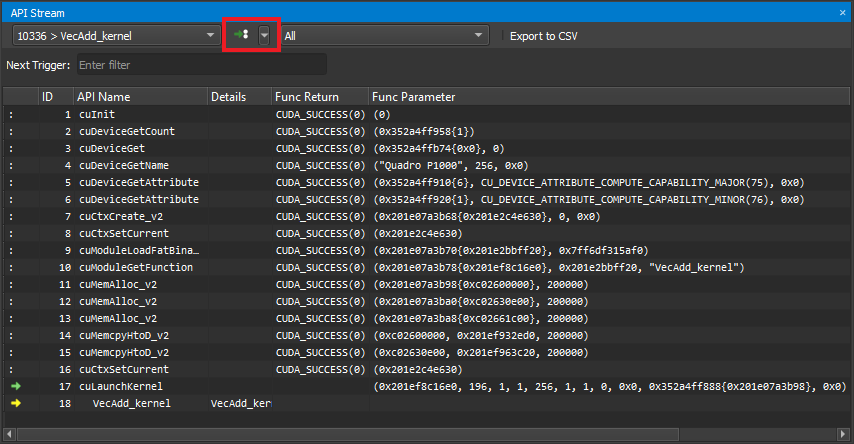
每当目标应用程序暂停时,窗口都会显示 API 调用和跟踪的内核启动的历史记录。 当前暂停的 API 调用或内核启动(活动)用黄色箭头标记。 如果暂停发生在子调用处,则父调用用绿色箭头标记。 API 调用或内核在执行之前暂停。
对于每个活动,都会显示更多信息,例如内核名称或函数参数 (函数参数) 和返回值 (函数返回值)。 请注意,函数返回值仅在您步出或步过 API 调用后才可用。
使用当前线程下拉列表在活动线程之间切换。 下拉列表显示线程 ID,后跟当前 API 名称。 可以在触发器下拉列表中选择多个选项之一,这些选项由相邻的 >> 按钮执行。 运行到下一个内核 恢复执行,直到在任何已启用线程中找到下一个内核启动。 运行到下一个 API 调用 恢复执行,直到在任何已启用线程中找到与 下一个触发器 匹配的下一个 API 调用。 运行到下一个范围开始 恢复执行,直到找到下一个活动分析器范围的开始。 分析器范围通过使用 cu(da)ProfilerStart/Stop API 调用来定义。 运行到下一个范围结束 恢复执行,直到找到下一个活动分析器范围的结束。 API 级别 下拉列表更改流中显示的 API 级别。 导出到 CSV 按钮将当前可见的流导出到 CSV 文件。
3.5.3. 基线
可以通过单击分析菜单中的基线条目来打开基线工具窗口。 它提供了一个中心位置,用于管理配置的基线。 (有关如何从分析结果创建基线的信息,请参阅基线。)

可以通过单击表格行中的复选框来控制基线可见性。 当复选框被选中时,基线将在摘要标头以及所有 section 中的所有图表中可见。 当取消选中时,基线将被隐藏,并且不会影响指标差异计算。
可以通过双击表格行中的颜色样本来更改基线颜色。 打开的颜色对话框提供了选择任意颜色的能力,并提供了与库存基线颜色轮换关联的预定义调色板。
可以通过双击表格行中的名称列来更改基线名称。 名称不能为空,并且必须小于选项对话框中指定的最大基线名称长度。
可以通过单击工具栏中的向上移动基线和向下移动基线按钮来更改选定基线的 z 顺序。 当基线向上或向下移动时,其新位置将反映在报告标头以及每个图表中。 目前,一次只能移动一个基线。
可以通过单击工具栏中的清除选定基线按钮来删除选定的基线。 可以通过单击全局工具栏或工具窗口工具栏中的清除所有基线按钮来一次删除所有基线。
可以通过单击工具栏中的保存基线按钮将配置的基线保存到文件。 默认情况下,基线文件使用 .ncu-bln 扩展名。 基线文件可以在本地打开和/或与其他用户共享。
可以通过单击工具栏中的加载基线按钮来加载基线信息。 加载基线文件后,当前配置的基线将被替换。 必要时,将向用户显示对话框以确认此操作。
当前结果与基线之间的差异可以使用 Details 页面 section 标头中指标的图形条进行可视化。 使用差异条下拉列表选择可视化模式。 条从左向右延伸,并具有固定的最大值。
3.5.4. 指标详细信息
可以使用分析菜单中的指标详细信息条目或相应的工具栏按钮打开指标详细信息工具窗口。 当报告和工具窗口打开时,可以在报告中选择一个指标,以在工具窗口中显示其他信息及其当前结果的值。 它还包含一个搜索栏,用于在焦点报告的当前结果中查找指标。
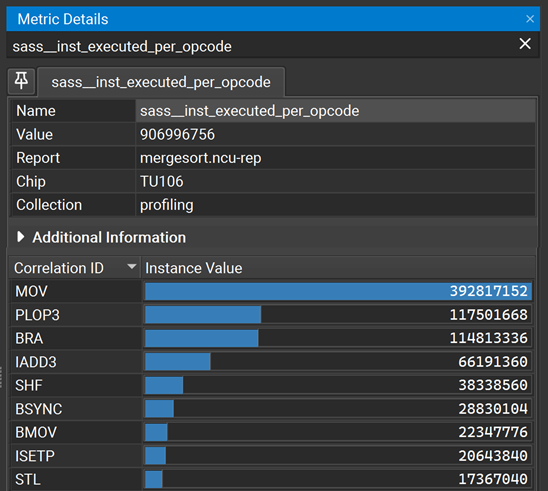
可以在Details 页面或Raw 页面上选择报告指标。 窗口将显示基本信息(指标的名称、单位和原始值)以及其他信息,例如其扩展描述。 请注意,即使在例如 Raw 页面中选择了不同的结果,所有显示的值都是当前结果中相应指标的值。
对于为 Green Contexts 应用程序收集的结果,指标详细信息工具窗口还显示一个额外的行,其中包含所选性能指标的归因级别(例如,Context 或 Green Context,如果适用)。
搜索栏可用于在焦点报告中打开指标。 它会在您键入时显示可用的匹配项。 输入的字符串必须从指标名称的开头开始匹配。
默认情况下,选择或搜索新指标会更新当前的默认选项卡。 您可以单击选项卡控件左上角的固定按钮来创建默认选项卡的副本,除非已固定相同的指标。 这使得可以保存多个选项卡并在它们之间快速切换以比较值。
某些指标包含实例值。 如果可用,它们将在工具窗口中列出。 实例值可以具有关联 ID,该 ID 允许将各个值与其关联的实体(例如,函数地址或指令名称)相关联。
对于使用 PM 采样 收集的指标,关联 ID 是纳秒级的 GPU 时间戳。 它相对于此指标的第一个时间戳显示。 请注意,即使在相应的时间线 UI 中启用了上下文切换,PM 采样指标的实例值当前也未进行上下文切换。
3.5.5. 启动详细信息
可以使用分析菜单中的启动详细信息条目或相应的工具栏按钮打开启动详细信息工具窗口。 当选择包含多个子启动的结果并且此工具窗口打开时,它将显示有关结果中包含的每个子启动的信息。
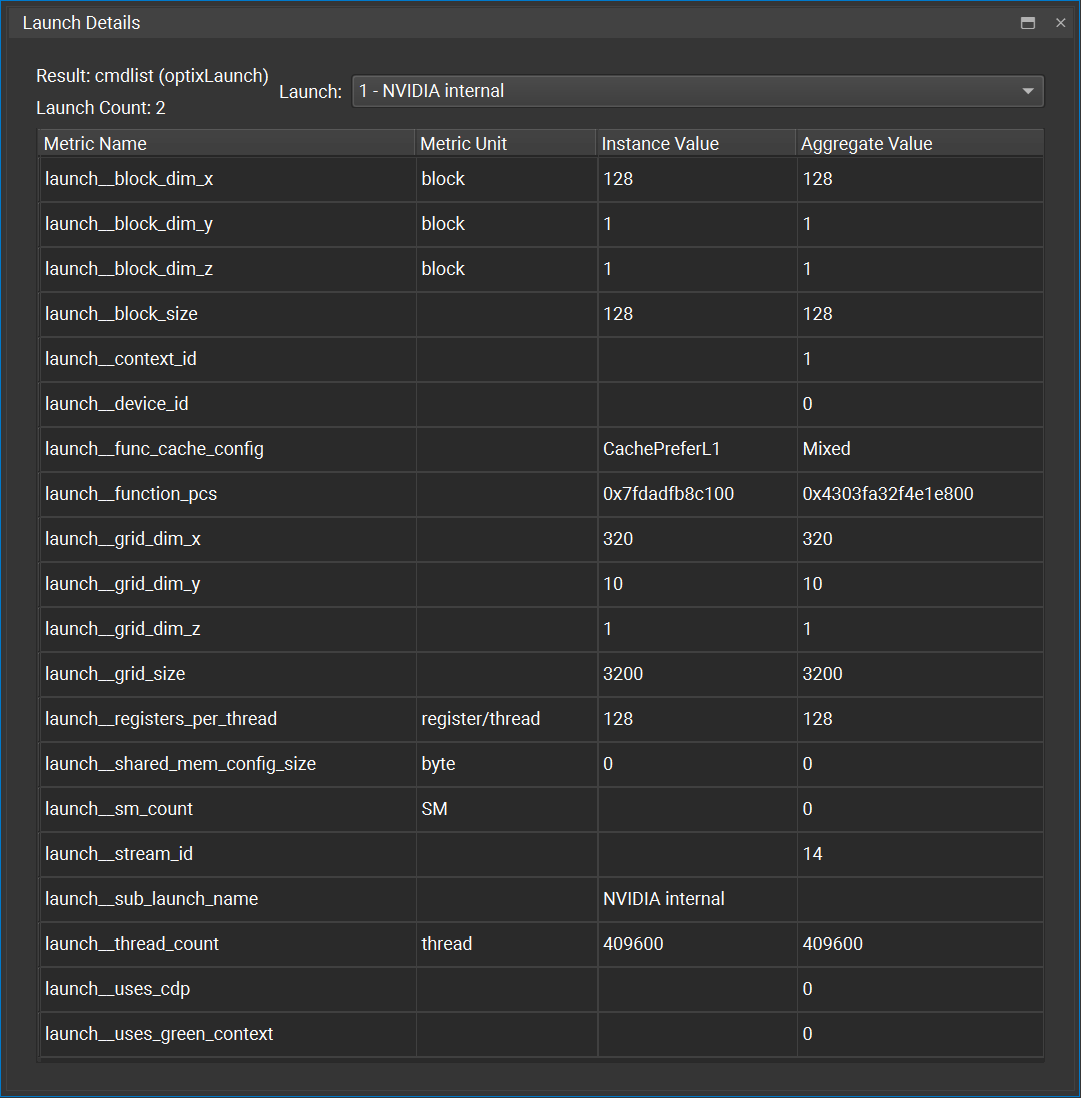
此工具窗口分为两个 section
一个标头,显示适用于整个结果的信息
一个正文,显示特定于查看的子启动的信息
标头
在其标头的左侧,此工具窗口显示选定结果的名称及其包含的子启动数量。
右侧包含一个组合框,允许选择正文应表示的子启动。 组合框的每个元素都包含子启动的索引以及它启动的函数的名称(如果可用)。
正文
此工具窗口的正文显示一个包含特定于子启动的指标的表格。 此表格有四列
指标名称:指标的名称
指标单位:指标值的单位
实例值:此指标的选定子启动的值
聚合值:此指标在选定结果中所有子启动上的聚合值
3.5.6. NVTX
当 NVIDIA Nsight Compute 连接到目标应用程序时,NVTX 窗口可用。 如果关闭,可以使用主菜单中的调试 > NVTX 重新打开它。 每当目标应用程序暂停时,窗口都会显示当前选定线程中所有活动 NVTX 域和范围的状态。 请注意,只有在启动命令行分析器实例时使用 --nvtx 启动,或者在 NVIDIA Nsight Compute 启动对话框中启用 NVTX 时,才会跟踪 NVTX 信息。
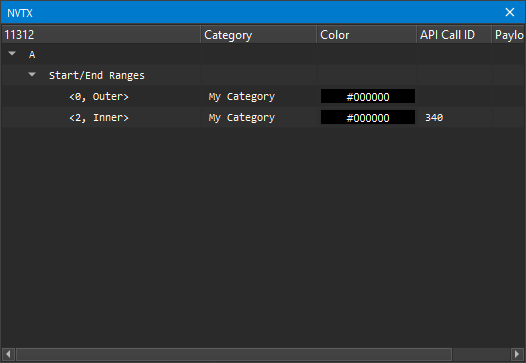
使用API 流窗口中的当前线程下拉列表来更改当前选定的线程。 NVIDIA Nsight Compute 支持 NVTX 命名资源,例如线程、CUDA 设备、CUDA 上下文等。 如果资源使用 NVTX 命名,则相应的 UI 元素将更新。
3.5.7. CPU 调用堆栈
当 NVIDIA Nsight Compute 连接到目标应用程序时,CPU 调用堆栈窗口可用。 如果关闭,可以使用主菜单中的调试 > CPU 调用堆栈重新打开它。 每当目标应用程序暂停时,窗口都会显示当前选定线程的所有已启用 CPU 调用堆栈。
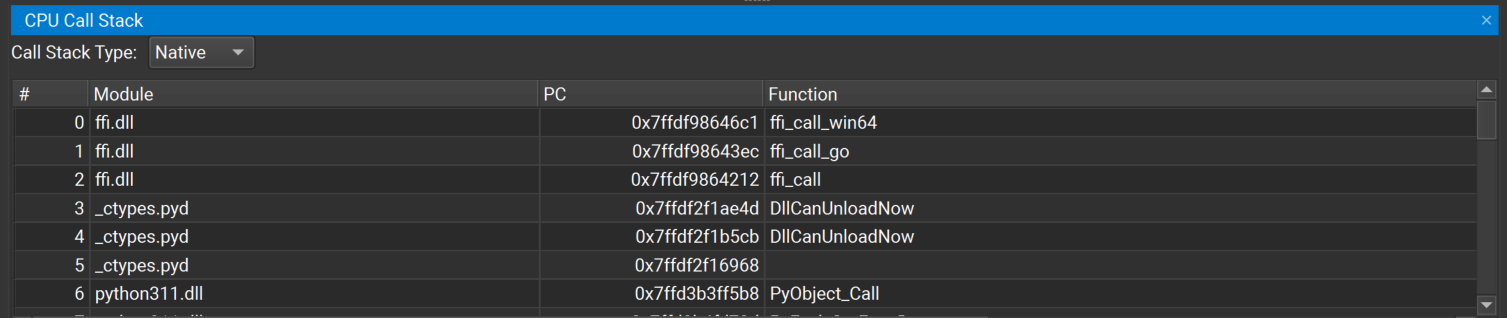
如果启用了多种堆栈类型(例如,Native、Python),请使用调用堆栈类型下拉菜单在堆栈类型之间切换。 请注意,Python 调用堆栈收集需要 CPython 版本 3.9 或更高版本。
3.5.8. 资源
当 NVIDIA Nsight Compute 连接到目标应用程序时,资源窗口可用。 它显示有关当前已知资源的信息,例如 CUDA 设备、CUDA 流或内核。 每次目标应用程序暂停时,窗口都会更新。 如果关闭,可以使用主菜单中的调试 > 资源重新打开它。
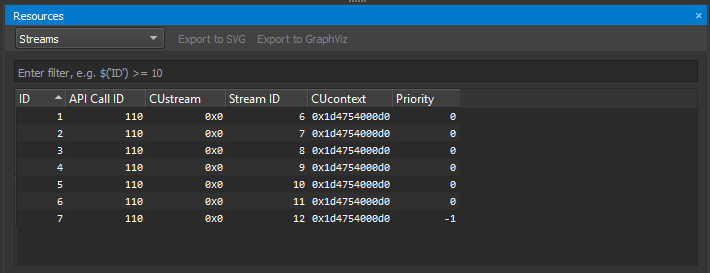
使用顶部的下拉列表,可以选择不同的视图,其中每个视图特定于一种资源类型(上下文、流、内核等)。 过滤器编辑允许您使用当前选定资源的列标题创建过滤器表达式。
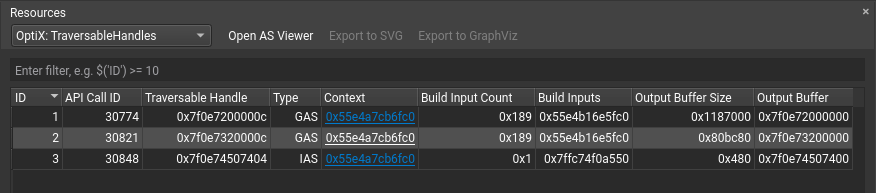
资源表显示每个资源实例的所有信息。 每个实例都有一个唯一的 ID、创建此资源时的 API 调用 ID、其句柄、关联的句柄以及其他参数。 当资源被销毁时,它将从其表中删除。
内存分配
当使用异步 malloc/free API 时,内存分配的资源视图还将包括以这种方式创建的内存对象。 这些内存对象具有非零内存池句柄。 模式列将指示在分配相应对象期间采用的代码路径。 模式有
REUSE_STREAM_SUBPOOL:内存对象在先前释放的内存中分配。 该内存由为进行分配的流设置的内存池支持。
USE_EXISTING_POOL_MEMORY:内存对象在先前释放的内存中分配。 该内存由进行分配的流的默认内存池支持。
REUSE_EVENT_DEPENDENCIES:内存对象在同一上下文的另一个流中先前释放的内存中分配。 分配流在释放操作上存在流排序依赖性。 Cuda 事件和空流交互可以创建所需的流排序依赖性。
REUSE_OPPORTUNISTIC:内存对象在同一上下文的另一个流中先前释放的内存中分配。 但是,释放和分配之间不存在依赖性。 此模式要求在请求分配时释放已提交。 执行行为的更改可能会导致应用程序的多次运行采用不同的模式。
REUSE_INTERNAL_DEPENDENCIES:内存对象在同一上下文的另一个流中先前释放的内存中分配。 可能添加了新的内部流依赖性,以便建立重用先前释放的一段内存所需的流排序。
REQUEST_NEW_ALLOCATION:必须为此内存对象分配新内存,因为未找到可行的可重用池内存。 分配性能与使用非异步 malloc/free API 相当。
Graphviz DOT 和 SVG 导出
使用 导出到 GraphViz 或 导出到 SVG 按钮,也可以将某些显示的资源导出到 GraphViz DOT 或 SVG* 文件。
导出 OptiX 可遍历句柄时,可遍历图形节点类型将使用形状和颜色进行编码,如下表所述。
节点类型 |
形状 |
颜色 |
|---|---|---|
IAS |
六边形 |
#8DD3C7 |
三角形 GAS |
方框 |
#FFFFB3 |
AABB GAS |
方框 |
#FCCDE5 |
曲线 GAS |
方框 |
#CCEBC5 |
球体 GAS |
方框 |
#BEBADA |
静态变换 |
菱形 |
#FB8072 |
SRT 变换 |
菱形 |
#FDB462 |
矩阵运动变换 |
菱形 |
#80B1D3 |
错误 |
平行四边形 |
#D9D9D9 |
3.5.9. 指标选择
可以从主菜单中使用分析 > 指标选择打开指标选择窗口。 它跟踪 NVIDIA Nsight Compute 中当前加载的所有指标集、section 和规则,独立于特定连接或报告。 可以分析选项对话框中配置从中加载这些文件的目录。 它用于检查可用的集、section 和规则,以及配置应收集哪些以及应应用哪些规则。 您还可以指定应收集的单个指标的逗号分隔列表。 窗口有两个视图,可以使用其标头中的下拉列表选择。
指标集视图显示所有可用的指标集。 每个集都与多个指标 section 相关联。 您可以选择适合您要收集性能指标的详细程度的集。 收集更详细信息的集通常会在分析期间产生更高的运行时开销。
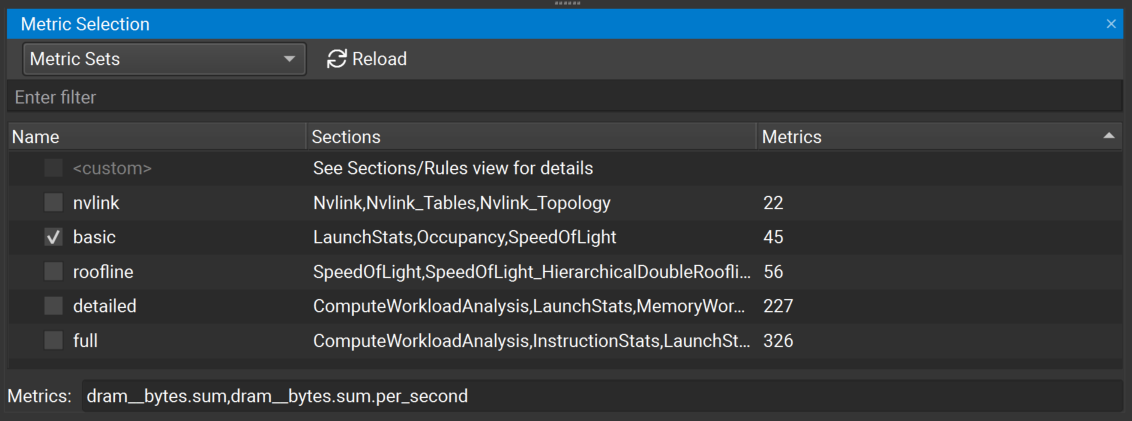
在此视图中启用集时,关联的指标 section 将在指标 Section/规则视图中启用。 在此视图中禁用集时,指标 Section/规则视图中的关联 section 将被禁用。 如果未启用任何集,或者如果在指标 Section/规则视图中手动启用/禁用 section,则 <自定义> 条目将被标记为活动,以表示当前未启用任何 section 集。 请注意,默认情况下启用基本集。
每当手动分析内核或启用自动分析时,都只会收集在指标 Section/规则视图中启用的 section 以及在输入框中指定的单个指标。 同样,每当应用规则时,只有在此视图中启用的规则才会处于活动状态。
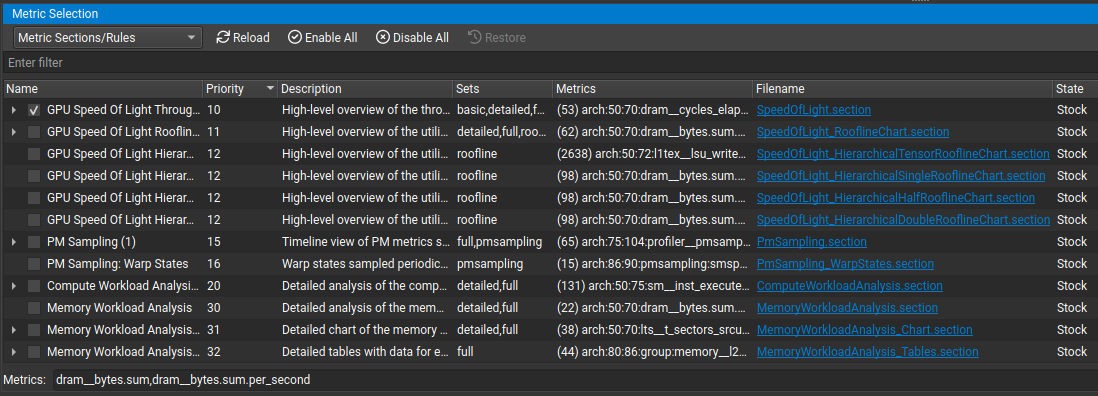
Section 和规则的启用状态在 NVIDIA Nsight Compute 启动之间持续存在。 重新加载按钮再次从磁盘重新加载所有 section 和规则。 如果找到新的 section 或规则,则会在可能的情况下启用它。 如果加载规则时发生任何错误,它们将列在带有警告图标和错误描述的额外条目中。
使用全部启用和全部禁用复选框一次启用或禁用所有 section 和规则。 过滤器文本框可用于过滤当前在视图中显示的内容。 它不会更改任何条目的激活状态。
该表显示 section 和规则及其激活状态、它们的关系以及其他参数,例如关联的指标或磁盘上的原始文件。 与 section 关联的规则显示为其 section 条目的子项。 与任何 section 无关的规则显示在额外的独立规则条目下。
单击表格文件名列中的条目将以文档形式打开此文件。 可以在 NVIDIA Nsight Compute 中直接编辑和保存 (ctrl + s)。 编辑文件后,必须选择重新加载以应用这些更改。 文档还支持文本搜索 (ctrl + f)、放大 (ctrl + 鼠标滚轮向下)、缩小 (ctrl + 鼠标滚轮向上) 功能。
当 section 或规则文件被修改时,状态列中的条目将显示用户修改,以反映它已从其默认状态修改。 当选择用户修改行时,将启用恢复按钮。 单击“恢复”按钮会将条目恢复为其默认状态,并自动重新加载 section 和规则。
同样,当从配置的Sections 目录(在分析选项对话框中指定)中删除库存 section 或规则文件时,状态列将显示用户删除。 也可以使用恢复按钮恢复用户删除的文件。
由用户创建(而不是随 NVIDIA Nsight Compute 一起提供)的 Section 和规则文件将在状态列中显示为用户创建。
有关 NVIDIA Nsight Compute 的默认 section 列表,请参阅Sections and Rules。
3.6. 分析器报告
分析器报告包含在分析期间为每个内核启动收集的所有信息。 在用户界面中,它由一个带有常规信息的标头以及用于在报告页面或各个收集的启动之间切换的控件组成。
3.6.1. 标头

报告顶部显示一个表格,其中包含有关选定分析结果(作为当前)以及可能的其他基线的信息。 对于此表中的许多值,工具提示提供其他信息或数据,例如,属性列的工具提示提供有关上下文类型和用于启动的资源的其他信息。
结果下拉列表可用于在所有收集的内核启动之间切换。 每个页面中显示的信息通常代表选定的启动实例。 在某些页面(例如原始)上,显示所有启动的信息,并突出显示选定的实例。 您可以在此下拉列表中键入内容以快速过滤和查找内核启动。
应用过滤器按钮打开过滤器对话框。您可以使用多个过滤器来缩小结果范围。在过滤器对话框中,输入您的过滤器参数并按下“确定”按钮。启动下拉菜单、摘要页表格和原始页表格将相应地进行过滤。选择箭头下拉菜单以访问清除过滤器按钮,该按钮将移除所有过滤器。
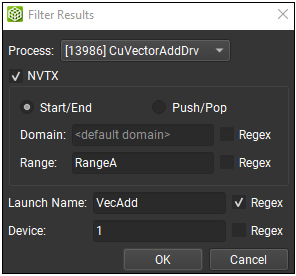
过滤器对话框
在当前结果和基线结果下方是用于在报告页面之间切换的选项卡。这些页面本身将在下一节中详细解释。
页面选项卡右侧的每个组按钮都会打开一个包含相关操作的上下文菜单。某些操作可能仅在选择相关的报告页面时才启用。
比较
工具
视图
显示/隐藏规则输出切换规则结果的可见性。
显示/隐藏节描述切换“详情”和“会话”页面上节描述的可见性。
显示/隐藏绿色上下文标记切换可归因绿色上下文指标的标记的可见性。
展开节展开所有节以显示其主体内容,而不仅仅是标题和规则输出。请注意,节可能具有多个主体,并且可以使用节标题中的下拉菜单选择可见的主体。
折叠节折叠所有节以仅显示其标题和规则输出。
导出
复制为图像 - 将页面内容作为图像复制到剪贴板。
保存为图像 - 将页面内容作为图像保存到文件。
保存为 PDF - 将页面内容作为 PDF 保存到文件。
导出到 CSV - 将页面内容导出为 CSV 格式。
更多(三条横线图标)
应用规则应用此报告可用的所有规则。如果之前已应用过规则,则这些结果将被替换。默认情况下,一旦内核启动完成性能剖析,就会立即应用规则。可以在工具 > 选项 > 性能剖析 > 报告 UI > 自动应用适用规则下的选项中更改此设置。
重置为默认通过移除任何持久化设置将页面重置为默认状态。
3.6.2. 报告页面
使用标题中的页面下拉菜单在报告页面之间切换。
默认情况下,当打开包含单个性能剖析结果的报告时,会显示详情页。当打开包含多个结果的报告时,会改为选择摘要页。您可以在性能剖析选项中更改默认报告页面。
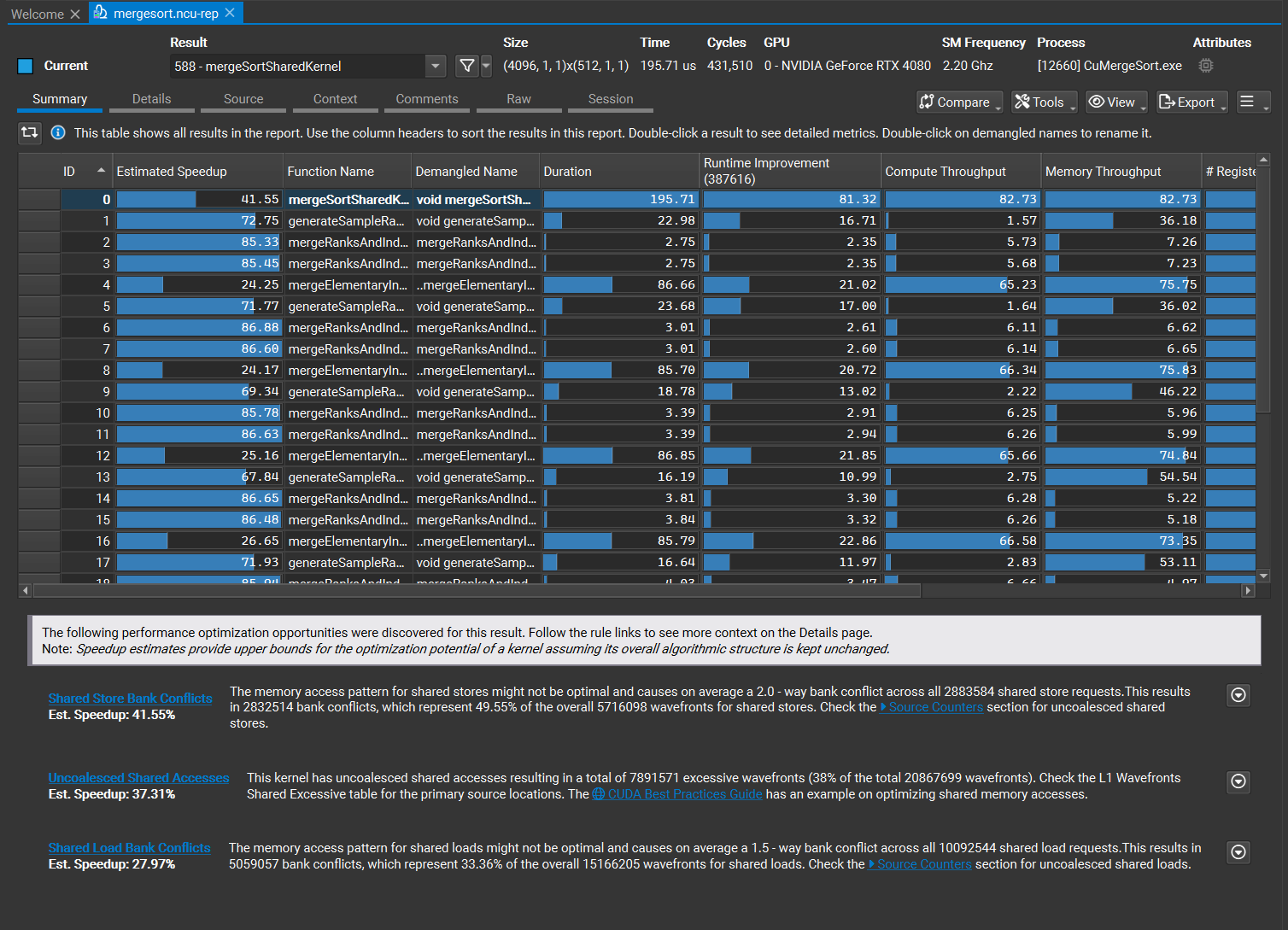
摘要页
摘要页面显示报告中所有收集结果的表格,以及最重要的规则输出列表(优先规则),这些规则输出按遵循其指导可以获得的估计加速比排序。优先规则默认显示,可以使用页面右上角的 [R] 按钮切换。
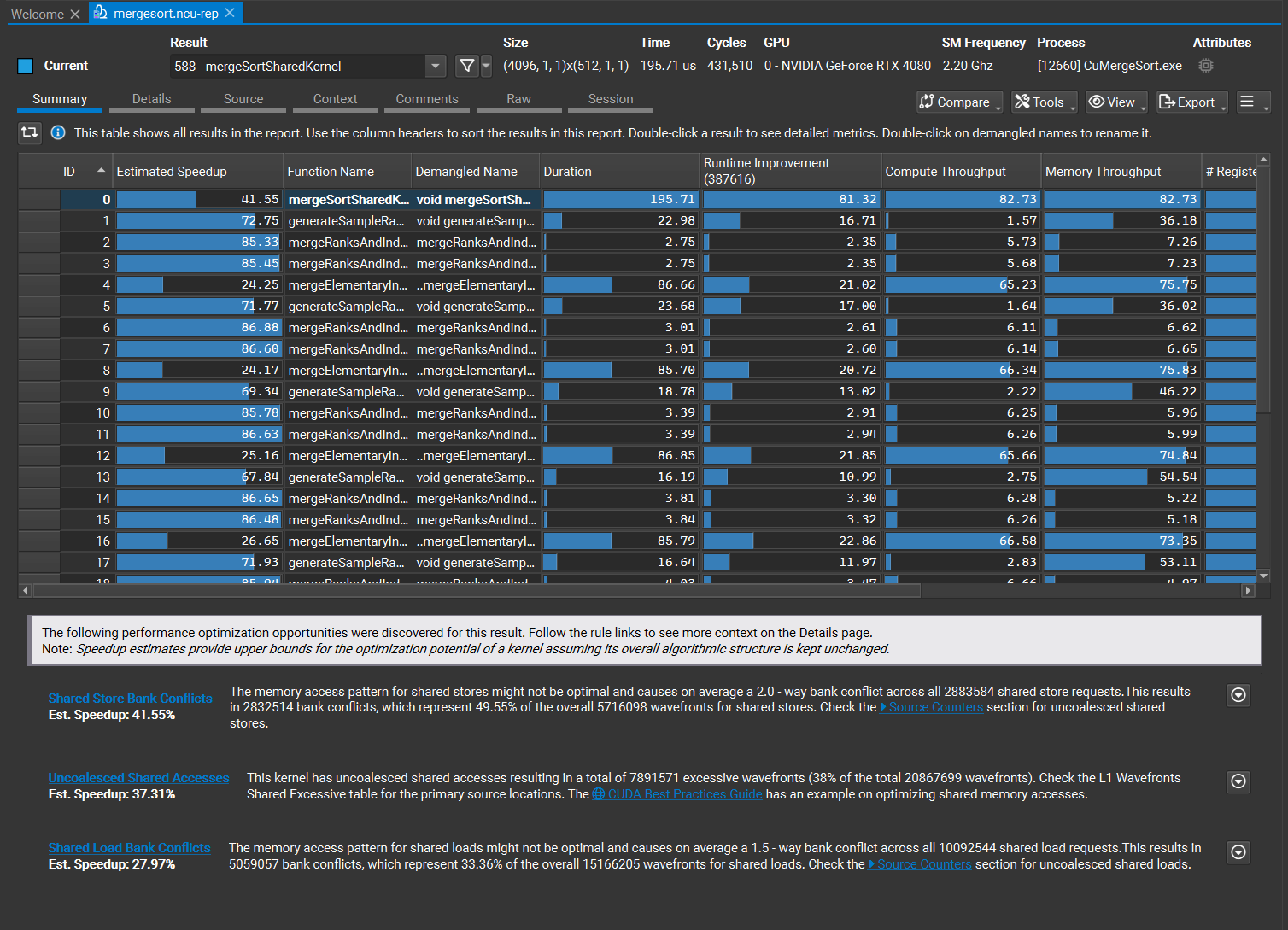
包含摘要表和优先规则的摘要页。
摘要表为您提供所有性能剖析工作负载的快速比较概览。它包含许多重要的、预选的指标,这些指标可以按照下文解释的方式进行自定义。其列可以通过单击列标题进行排序。您可以使用转置按钮转置表格。每个计数器指标的所有结果的聚合值与列名一起显示在表头中。您可以通过同时选择多个指标的所需结果来更改聚合值。当单击选择任何条目时,其优先规则列表将显示在表格下方。双击任何条目以使该结果成为当前活动结果,并切换到详情页页面以检查其性能数据。默认情况下,内核反混淆名称经过简化、重命名并以优化的方式显示。可以使用重命名反混淆名称选项更改此行为。如果自动简化的名称没有用,您可以通过配置文件重命名它。您还可以通过双击名称、重命名和保存报告来直接在报告中持久化更新的名称。使用重命名内核配置路径选项来指定在导入重命名的内核或导出具有映射的反混淆名称时应使用的配置文件,以重命名它们。要将名称导出到新文件,请单击导出按钮并使用重命名内核配置选项。有关配置文件用法的更多详细信息,请参阅内核重命名。

您可以在性能剖析选项对话框中配置此表中包含的指标列表。如果一个指标具有多个实例值,则实例的数量会显示在其标准值之后。例如,具有十个实例值的指标可能如下所示:35.48 {10}。在性能剖析选项对话框中,您可以选择应单独显示所有实例值。您还可以在指标详情工具窗口中检查指标结果的实例值。
除了指标之外,您还可以配置表格以包含以下任何属性
属性
属性
property__api_call_id与此性能剖析结果关联的 API 调用的 ID。
property__block_size块大小。如果结果包含多个启动,这将包含块的每个维度的最大值。
property__creation_time本地收集时间。
property__demangled_name内核反混淆名称,可能已重命名。
property__device_nameGPU 设备名称。
property__estimated_speedup由此引导的分析规则估计的此性能剖析结果可实现的最大相对加速比。
property__function_name内核函数名称。
property__grid_dimensions网格维度。如果结果包含多个启动,这将包含网格的每个维度的最大值。
property__grid_offset网格偏移。
property__grid_size网格大小。如果结果包含多个启动,这将包含网格的每个维度的最大值。
property__issues_detected由此引导的分析规则为此性能剖析结果检测到的问题数。
property__kernel_id内核 ID。
property__mangled_name内核混淆名称。
property__original_demangled_name没有任何重命名的原始内核反混淆名称。
property__process_name进程名称。
property__range_name范围名称。
property__runtime_improvement与估计的加速比对应的运行时改进。
property__series_id性能剖析序列的 ID。
property__series_parameters性能剖析序列参数。
property__thread_idCPU 线程 ID。
对于范围重放报告,默认情况下会显示较小的一组列,因为并非所有列都适用于此类结果。
对于当前选定的指标结果,优先规则显示了关于估计的潜在加速比的最有影响力的规则结果。单击左侧的任何规则名称可让您轻松导航到详情页上的包含节。使用右侧的向下箭头,可以切换包含相关关键性能指标的表格。此表格包含在根据规则指导优化性能时应跟踪的指标。

带有关键性能指标表格的优先规则。
详情页
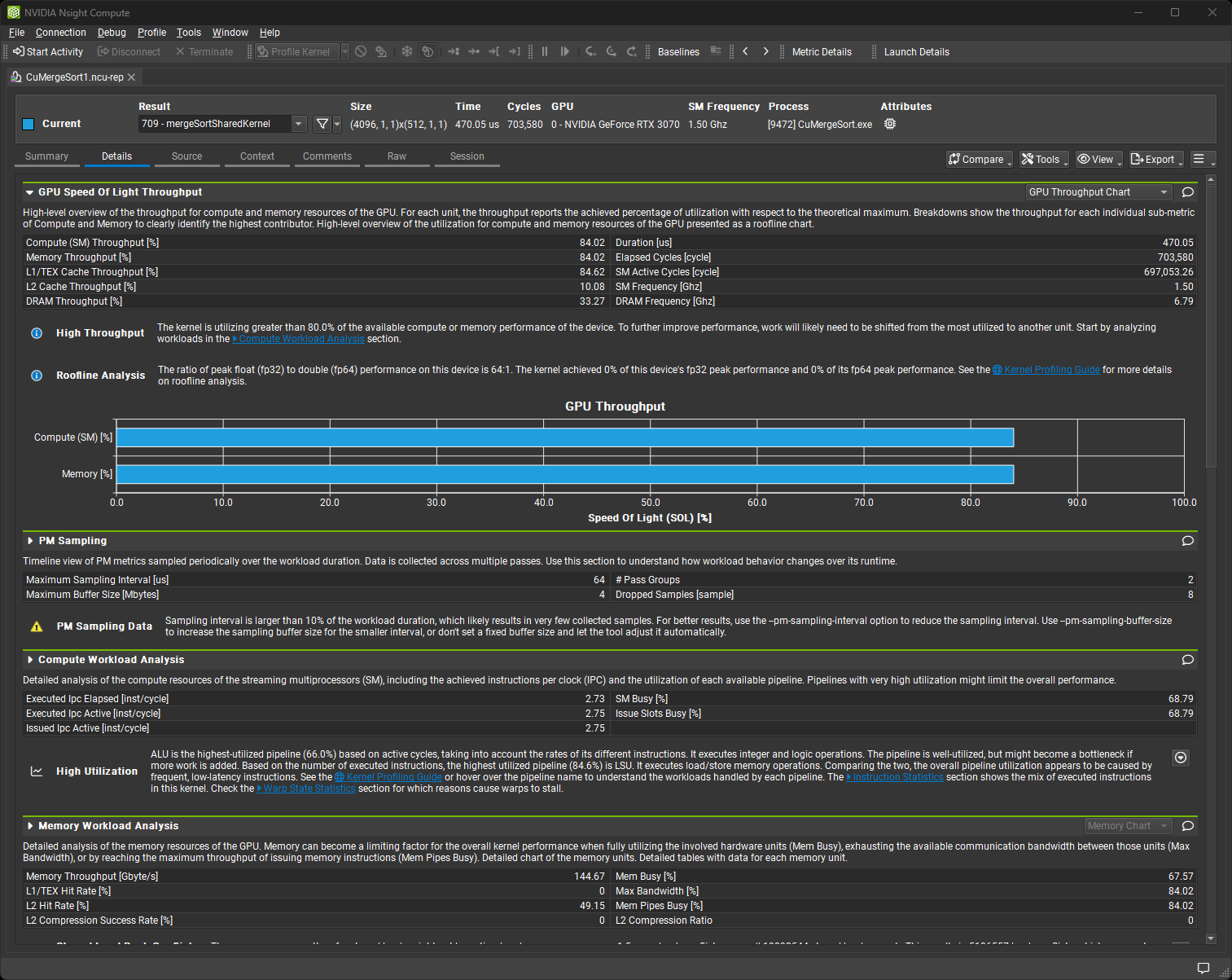
概述
详情页是内核启动期间收集的所有指标数据的主页。该页面分为各个节。每个节都由一个标题表格和一个可选的主体组成,主体可以展开。您可以通过单击每个节的标题来展开或折叠该节的主体。这些节是完全用户定义的,可以通过更新其各自的文件轻松更改。有关自定义节的更多信息,请参阅自定义指南。有关 NVIDIA Nsight Compute 附带的节列表,请参阅节和规则。
默认情况下,一旦收集到新的性能剖析结果,就会应用所有适用的规则。任何规则结果都将在此页面上显示为建议。大多数规则结果将包含优化建议以及对成功实施此建议后可以实现的改进的估计。其他规则结果将纯粹是信息性的,或者带有警告图标,指示执行期间发生的问题(例如,无法收集的可选指标)。带有错误图标的结果通常表示在应用规则时发生错误。
潜在改进的估计值显示在规则结果的名称下方,并且有两种类型。全局估计(“估计加速比”)是对工作负载运行时减少量的近似值,而局部估计(“估计局部加速比”)是对规则解决的特定性能问题的硬件利用率效率提高量的近似值。

规则结果通常指出性能问题并指导分析过程。
如果规则结果引用了另一个报告节,它将以链接形式出现在建议中。选择链接以滚动到相应的节。如果该节未在同一性能剖析结果中收集,请在指标选择工具窗口中启用它。
您可以通过单击注释按钮(语音气泡)在详情视图的每个节中添加或编辑注释。注释图标将在包含注释的节中突出显示。注释会持久保存在报告中,并在评论页中进行汇总。

使用注释按钮注释节。
除了标题之外,节通常还具有一个或多个主体,其中包含其他图表或表格。单击每个节左上角的三角形展开器图标以显示或隐藏这些主体。如果一个节有多个主体,则可以使用其右上角的下拉菜单在它们之间切换。
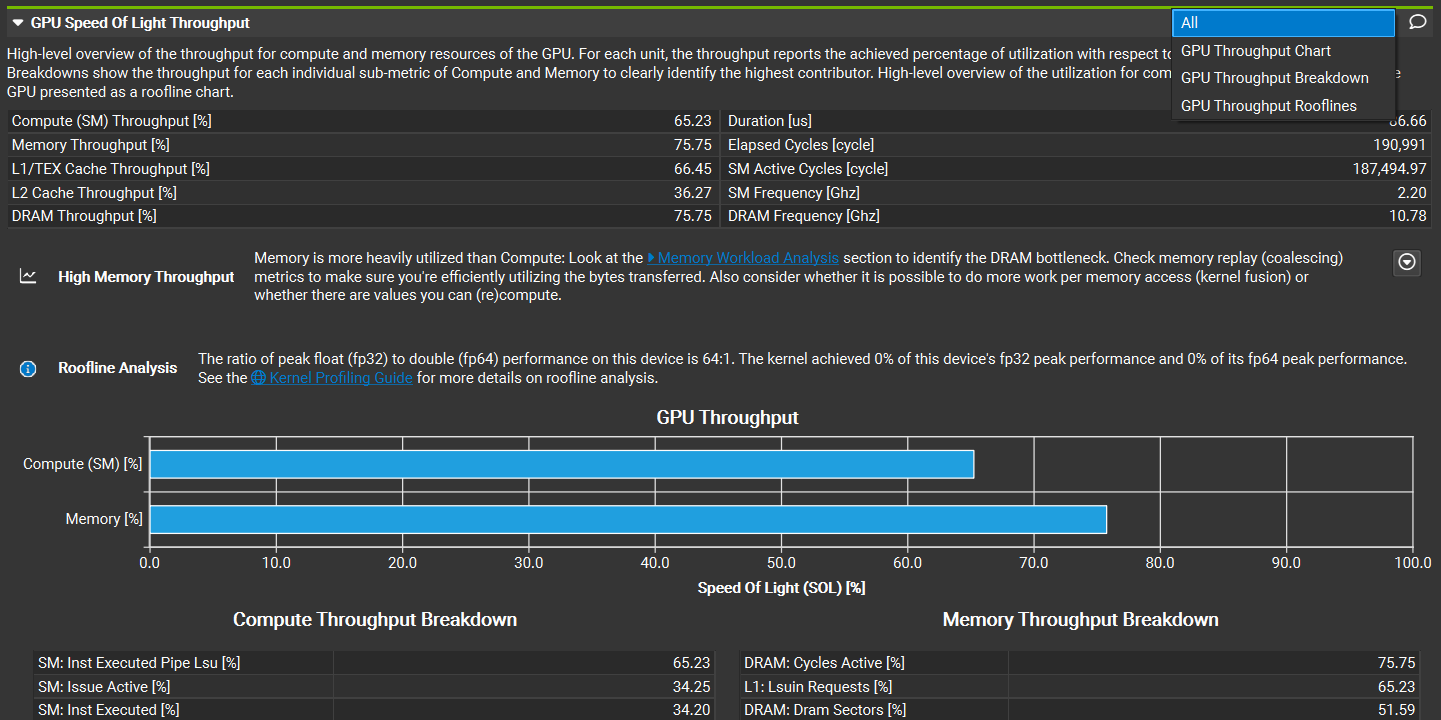
具有多个主体的节具有一个下拉菜单,可在它们之间切换。
内存
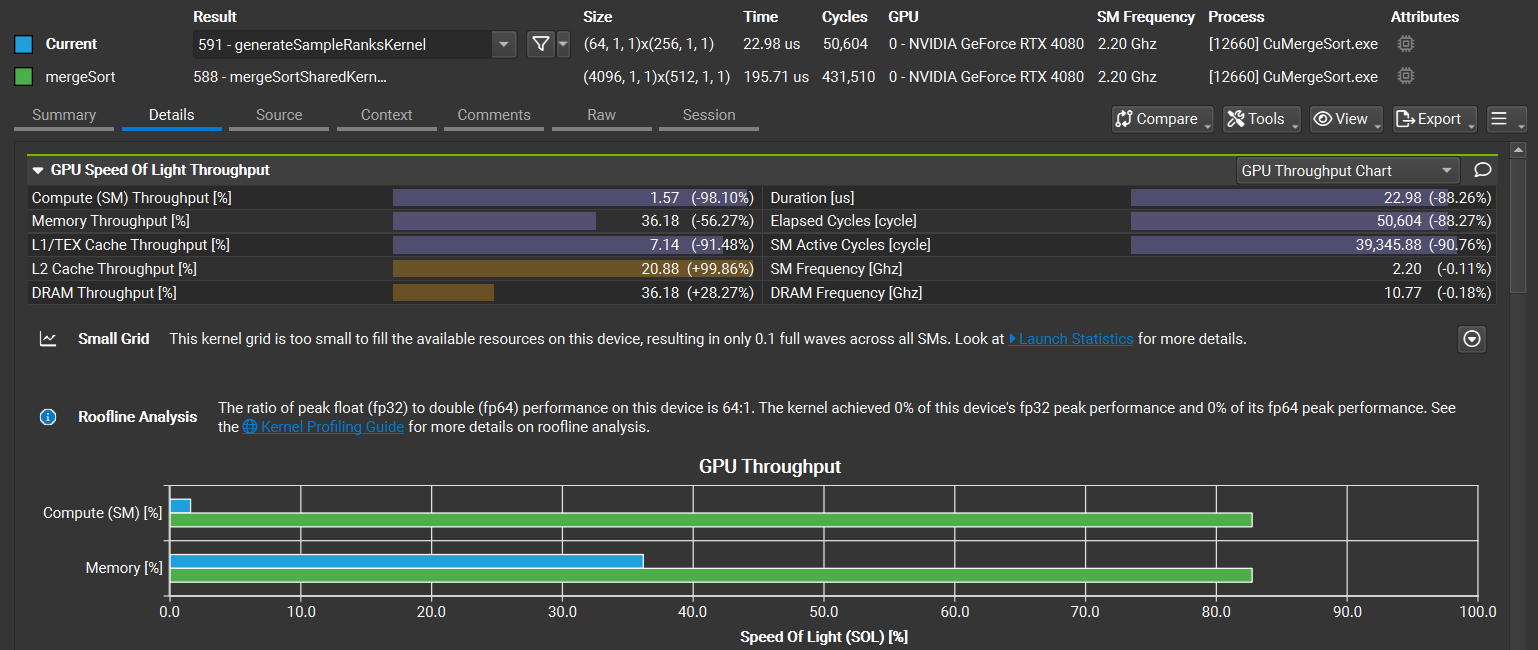
如果启用,内存工作负载分析节将包含一个内存图表,该图表可视化数据传输、缓存命中率、指令和内存请求。有关如何使用和读取此图表的更多信息,请参阅内核性能剖析指南。
占用率
您可以通过单击报告标题或占用率节标题中的计算器按钮来打开占用率计算器。
范围重放
请注意,对于范围重放结果,某些 UI 元素、分析规则、指标或节主体项(如图表或表格)可能不可用,因为它们仅适用于基于内核启动的结果。可以在相应的节文件中检查过滤器。
屋顶线
如果启用,GPU 光速屋顶线图表节包含一个屋顶线图表,该图表特别有助于一目了然地可视化内核性能。(要在报告中启用屋顶线图表,请确保在性能剖析时启用了该节。)有关如何使用和读取此图表的更多信息,请参阅屋顶线图表。NVIDIA Nsight Compute 附带了几个不同的屋顶线图表定义,包括分层屋顶线。这些额外的屋顶线在不同的节文件中定义。虽然不是完整节集的一部分,但添加了一个名为屋顶线的新节集,以在一个报告中收集和显示所有屋顶线。分层屋顶线的想法是它们定义了多个上限,这些上限代表了硬件层次结构的限制器。例如,专注于内存层次结构的分层屋顶线可以具有 L1 缓存、L2 缓存和设备内存吞吐量的上限。如果内核的已实现性能受到分层屋顶线的其中一个上限的限制,则可能表明层次结构的相应单元是潜在的瓶颈。
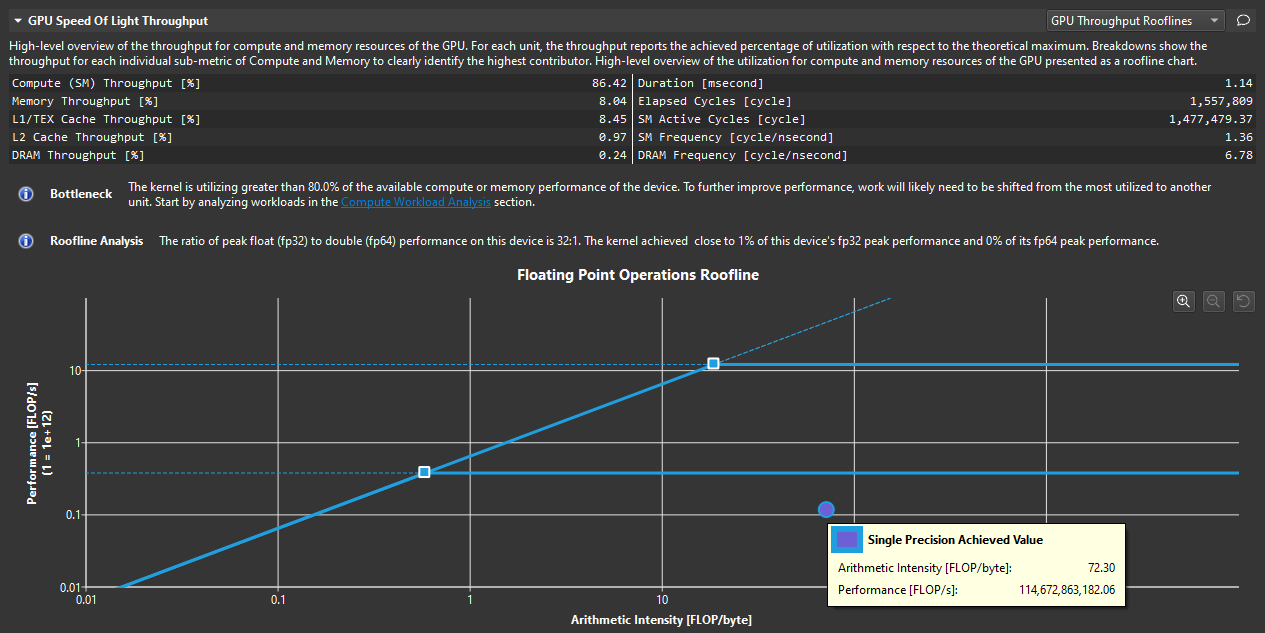
屋顶线图表示例。
可以缩放和平移屋顶线图表以进行更有效的数据分析,使用下表中的控件。当指标详情工具窗口打开时,您可以单击图表中的已实现值以在工具窗口中查看其指标公式。
放大 |
缩小 |
重置缩放 |
平移 |
|---|---|---|---|
|
|
|
|
源代码
诸如源代码计数器之类的节可以包含源代码热点表。这些表格指示内核源代码中一个或多个指标的 N 个最高或最低值。选择位置链接以直接导航到源代码页中的此位置。将鼠标悬停在值上以查看哪些指标对其有贡献。
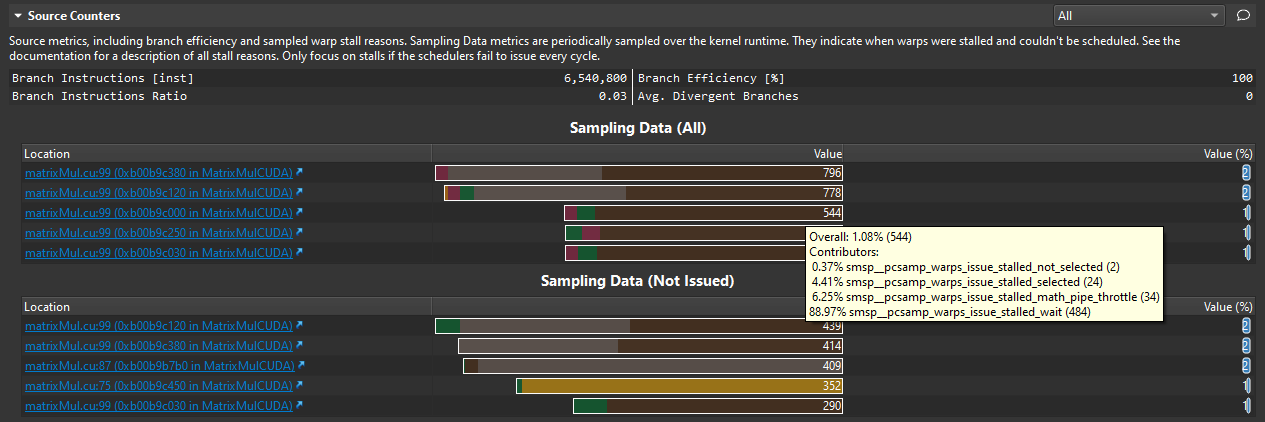
热点表指出您源代码中的性能问题。
时间线
当使用PM 采样收集指标时,可以在时间线中查看它们。时间线显示在各自的节文件中或在命令行中选择的指标,以及它们的标签/名称和它们随时间变化的值。
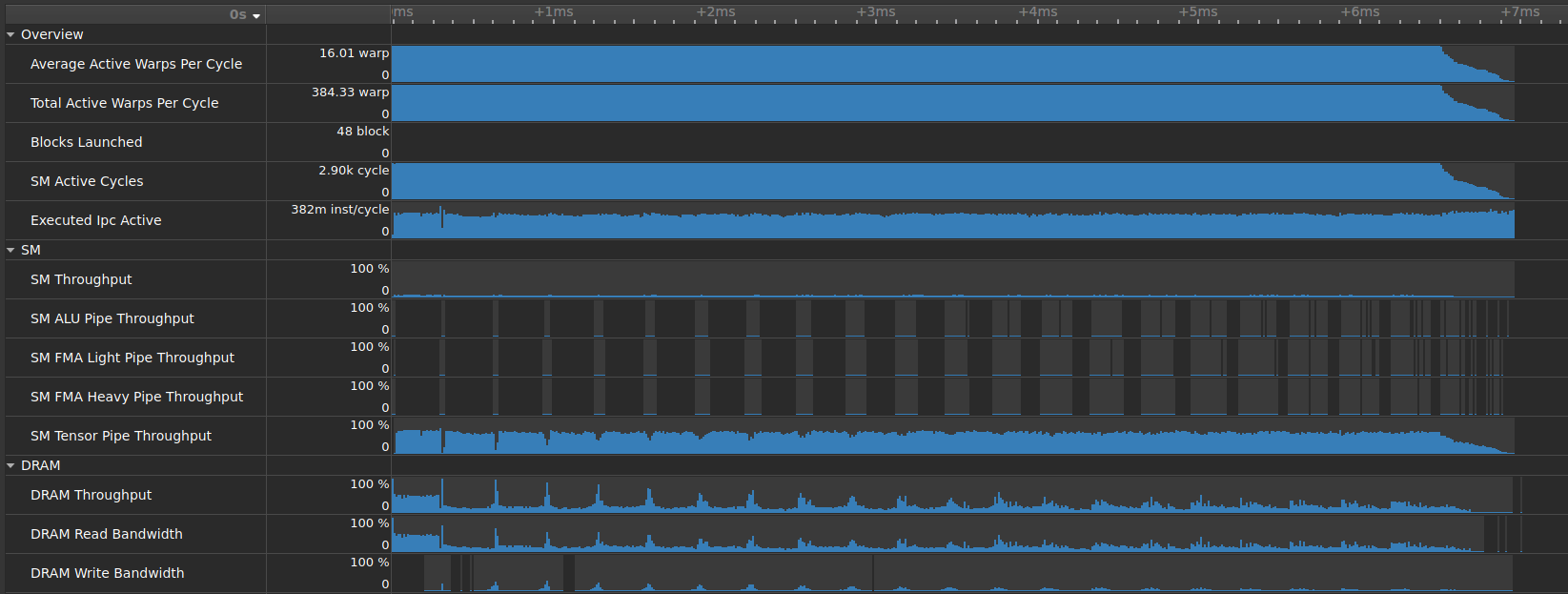
不同的指标可以在工作负载的不同遍(重放)中收集,因为在同一遍中只能采样有限数量的指标。上下文切换跟踪用于过滤收集的数据,仅包含来自性能剖析上下文的样本,并在时间线中对齐它。
您可以将鼠标悬停在指标行标签上,以查看有关该行中指标的更多信息。将鼠标悬停在时间线上的样本上会显示当前行中该时间戳的指标值。在指标详情工具窗口打开的情况下,单击以选择时间线上的值,并在工具窗口中显示指标及其所有原始时间戳(绝对和相对)相关值。
您还可以使用指标详情工具窗口来检查在 PM 采样期间生成的性能剖析器指标。这些指标提供了有关每个收集遍的已用采样间隔、缓冲区大小、丢弃的样本和其他属性的信息。详细列表可以在指标参考中找到。
时间线具有一个上下文菜单,用于执行有关复制内容和缩放的更多操作。此外,启用/禁用上下文切换过滤器选项可用于启用或禁用使用上下文切换信息过滤时间线数据(如果可用)。当上下文切换过滤器启用(默认)时,每个遍组的样本仅针对活动上下文显示。当上下文切换过滤器禁用时,原始收集的采样数据将与每个遍组的上下文切换跟踪的单独行一起显示。
当上下文菜单选项不可用时,报告不包含上下文切换跟踪数据。在这种情况下,将显示启用/禁用修剪过滤器选项,该选项在启用时,会尝试基于此遍组中任何采样指标中的第一个非零值进行对齐。但是,此后备方法不考虑实际的上下文切换。
时间线行“工作负载执行”显示每个内核的开始和结束时间戳。当上下文切换过滤器启用时,内核执行仅针对活动上下文的其中一个遍显示。当上下文切换过滤器禁用时,内核执行将针对所有遍显示。
源代码页
源代码页将汇编 (SASS) 与高级代码(如 CUDA-C、Python 或 PTX)相关联。此外,它还显示与指令相关的指标,以帮助查明代码中的性能问题。
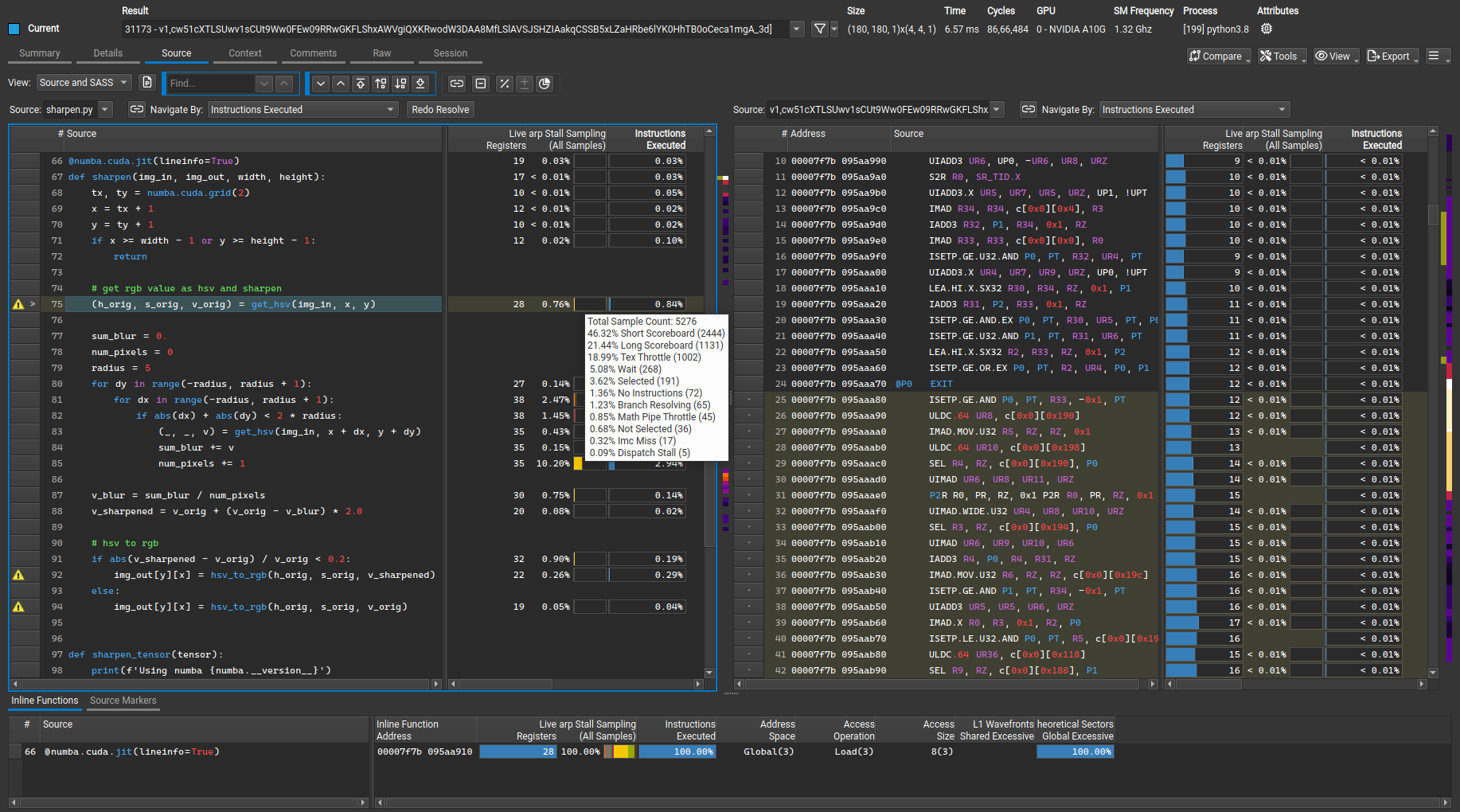
源代码关联
页面可以在不同的视图之间切换,以专注于特定的源代码层或并排查看两个层。这包括 SASS、PTX 和源代码(CUDA-C、Fortran、Python 等)以及它们的组合。可用的选项取决于嵌入到可执行文件中的源代码信息。
如果应用程序是使用 -lineinfo 或 --generate-line-info nvcc 标志构建的,则高级源代码 (CUDA-C) 视图可用,以关联 SASS 和源代码。当在 ELF 级别使用单独链接时,ELF 中没有与最终 SASS 对应的 PTX。因此,即使 PTX 在可执行文件中静态可用,并且可以使用 cuobjdump -all -lptx 显示,NVIDIA Nsight Compute 也不显示任何 PTX。但是,这是 PTX 的预链接版本,不能可靠地用于关联。
导航
视图下拉菜单可用于选择不同的代码(关联)选项:SASS、PTX 和源代码(CUDA-C、Fortran、Python 等)。
在并排视图中,当在左侧或右侧选择一行时,相对视图中的任何相关行都会突出显示。但是,当为多文件源代码显示单个文件选项设置为是时,必须已在相应视图中选择目标文件或源代码对象,才能显示这些相关行。
在并排视图中,带有蓝色边框的视图称为聚焦视图。可以通过单击另一个视图中的任何位置来更改聚焦视图。带有蓝色边框的控件组仅适用于聚焦视图。
源代码下拉菜单允许您在提供视图内容的文件或函数之间切换。当选择不同的源代码条目时,视图会滚动到此文件或函数的开头。
如果视图包含多个源代码文件或函数,则会显示 [+] 和 [-] 按钮。这些按钮可用于展开或折叠视图,从而显示或隐藏文件或函数内容,但标题除外。如果该组处于链接状态,则这些按钮将适用于两个视图,否则,如果处于未链接状态,则这些按钮将适用于聚焦视图。如果折叠,则所有指标都会聚合显示,以提供快速概览。

折叠的源代码视图
您可以使用搜索功能来有效地查找数据中的信息。此功能允许用户通过单击列中的任何位置来选择列,从而在特定列中搜索。如果未选择任何列,则搜索默认设置为源代码列。该功能支持高级搜索表达式,例如正则表达式 (regex) 和值比较(例如,“>= 5”)。可以使用通用控件工具栏上的搜索按钮或按 Ctrl+F 键打开搜索控件。可以使用叉号按钮或按 Esc 键关闭它。
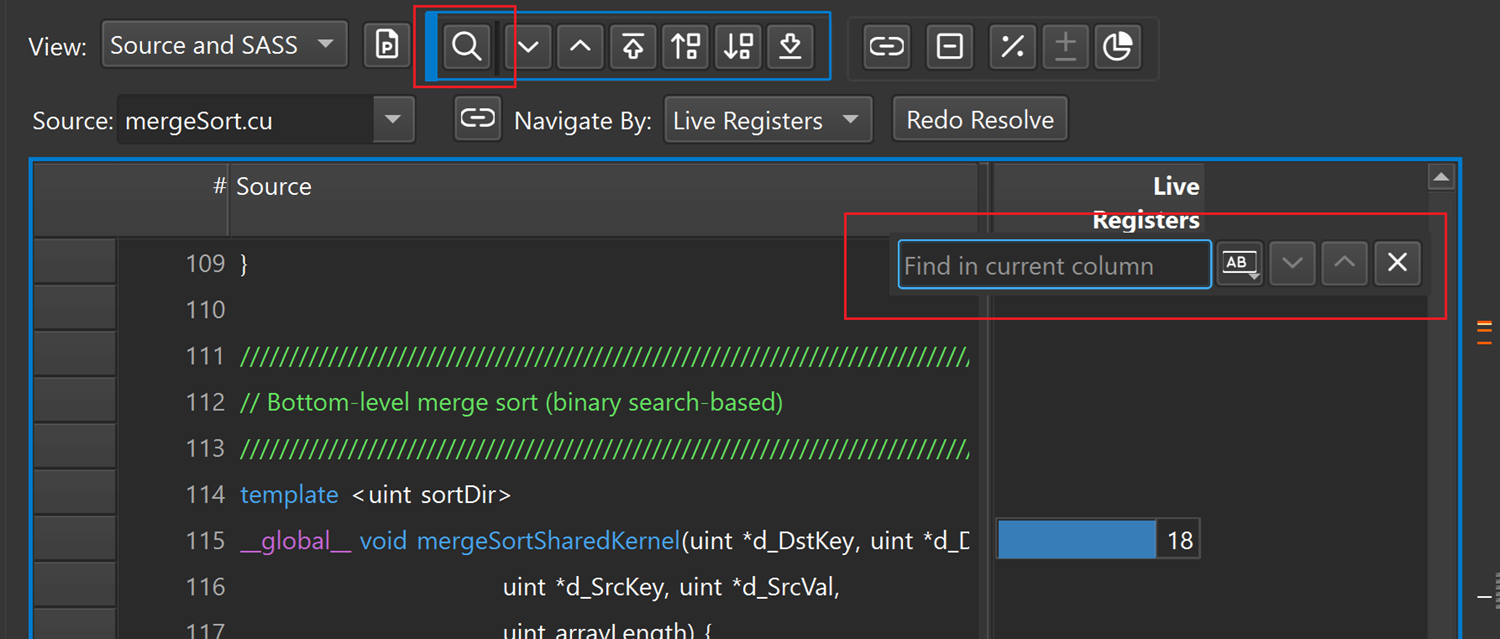
搜索控件
SASS 视图经过过滤,仅显示在启动中执行的函数。您可以切换仅显示已执行函数选项来更改此设置,但对于大型二进制文件,此页面的性能可能会受到负面影响。某些 SASS 指令可能显示为N/A。这些指令目前未公开。
在并排视图中,按...导航下拉菜单默认情况下彼此链接,因此,仅当列可用时,从一个下拉菜单更改列名才会更改另一个视图中的列名。这些下拉菜单可以使用其前面的链接-取消链接按钮取消链接。

“按...导航”下拉菜单的链接状态
仅文件名显示在视图中,如果找不到源文件在其原始位置,则会显示未找到文件错误。例如,如果报告已移动到不同的系统,则可能会发生这种情况。选择文件名并单击上方的解析按钮以指定可以在本地文件系统上的哪个位置找到此源代码。但是,如果在性能剖析期间选择了导入源代码选项,并且文件在当时可用,则视图始终显示源文件。如果在其原始位置或任何源代码查找位置找到了文件,但其属性不匹配,则会显示文件不匹配错误。有关更改文件查找行为的信息,请参阅源代码查找选项。

解析源代码
如果报告是使用远程性能剖析收集的,并且在性能剖析选项中启用了远程文件的自动解析,则 NVIDIA Nsight Compute 将尝试从远程目标加载源代码。如果当前 NVIDIA Nsight Compute 实例中尚不可用连接凭据,则会在对话框中提示它们。从远程目标加载目前仅适用于 Linux x86_64 目标以及 Linux 和 Windows 主机。
指标
指标关联
当检查与您的代码相关的性能信息和指标时,该页面最有用。指标显示在列中,可以使用列选择器启用或禁用列,列选择器可以使用列标题右键单击菜单访问。
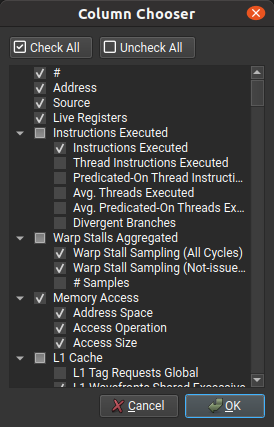
列选择器
为了在水平滚动时不会移出视图,可以冻结列。默认情况下,源代码列固定在左侧,从而可以轻松检查与源代码行相关的所有指标。要更改列的冻结,请右键单击列标题并分别选择冻结或取消冻结。
列冻结/取消冻结
每个视图右侧的热图可用于快速识别下拉菜单中当前选定指标的高指标值的位置。热图使用黑体辐射颜色标度,其中黑色表示最低映射值,白色表示最高映射值。单击并按住鼠标右键单击热图时,会显示当前标度。

热图颜色标度
默认情况下,适用的指标显示为占启动总和的百分比值。条形图从左向右填充,以指示特定源位置的值相对于该指标在启动中的最大值。[%] 和 [+-] 按钮可用于将显示从相对值切换到绝对值,以及从简写绝对值切换到全精度绝对值。对于相对值和条形图,[圆形/饼图] 按钮可用于在相对于全局(启动)范围和相对于局部(函数/文件)范围之间切换显示。当视图折叠时,此按钮将被禁用,因为在这种情况下,百分比始终相对于全局启动范围。
相对和绝对指标值。
预定义的源指标
活动寄存器
编译器需要保持有效的寄存器数量。高值表示在此代码位置需要许多寄存器,可能会增加寄存器压力和内核所需的最大寄存器数量。
报告为
launch__registers_per_thread的寄存器总数可能远高于最大活动寄存器数。编译器可能需要分配特定的寄存器,这可能会在分配中产生空洞,从而影响launch__registers_per_thread,即使最大活动寄存器数较小。这可能是由于 ABI 限制或特定硬件指令强制执行的限制而发生的。编译器可能无法完全了解在被调用者或调用者中可能使用哪些寄存器,并且必须遵守 ABI 约定,因此即使某些寄存器在理论上可以重复使用,也必须分配不同的寄存器。Warp 停顿采样(所有样本)1
来自 统计采样器 在此程序位置的样本数。
Warp 停顿采样(未发布样本)2
来自 统计采样器 在 warp 调度器未发布指令的周期内,在此程序位置的样本数。请注意,(未发布) 样本可能在与上面提到的 (所有) 样本不同的分析过程中采集,因此它们的值并不严格相关。
此指标仅在计算能力为 7.0 或更高的设备上可用。
执行的指令数
每个 warp 执行源(指令)的次数,与每个 warp 内参与线程的数量无关。
线程执行的指令数
任何线程执行源(指令)的次数,无论谓词是否存在或评估结果如何。
基于谓词的线程执行的指令数
任何活动的、基于谓词的线程执行源(指令)的次数。对于无条件执行的指令(即没有谓词),这是 warp 中活动线程的数量乘以相应的执行的指令数值。
平均线程执行数
每个 warp 中线程级执行指令的平均数量,无论其谓词如何。
平均基于谓词的线程执行数
每个 warp 中基于谓词的线程级执行指令的平均数量。
发散分支
发散分支目标的数量,包括 fallthrough。仅当有两个或多个具有发散目标的活动线程时才会递增。发散分支可能会因解决分支或指令缓存未命中而导致 warp 停顿。
内存操作信息
标签
名称
描述
地址空间
memory_type
访问的地址空间(全局/本地/共享)。
访问操作
memory_access_type
内存访问的类型(例如,加载或存储)。
访问大小
memory_access_size_type
内存访问的大小,以位为单位。
L1 标记请求 全局
memory_l1_tag_requests_global
全局内存指令生成的 L1 标记请求数。
L1 冲突 共享 N 路
derived__memory_l1_conflicts_shared_nway
每个共享内存指令的 L1 平均 N 路冲突。1 路访问没有冲突,并在一次传递中解决。注意:这是一个派生指标,无法直接收集。
L1 波前 共享 过多
derived__memory_l1_wavefronts_shared_excessive
来自共享内存指令的 L1 中的过多波前,因为并非所有未基于谓词关闭的线程都执行了操作。注意:这是一个派生指标,无法直接收集。
L1 波前 共享
memory_l1_wavefronts_shared
来自共享内存指令的 L1 中的波前数。
L1 波前 共享 理想
memory_l1_wavefronts_shared_ideal
来自共享内存指令的 L1 中的理想波前数,假设每个未基于谓词关闭的线程都执行了操作。
L2 理论扇区 全局 过多
derived__memory_l2_theoretical_sectors_global_excessive
来自全局内存指令的 L2 中请求的过多理论扇区数,因为并非所有未基于谓词关闭的线程都执行了操作。注意:这是一个派生指标,无法直接收集。
L2 理论扇区 全局
memory_l2_theoretical_sectors_global
来自全局内存指令的 L2 中请求的理论扇区数。
L2 理论扇区 全局 理想
memory_l2_theoretical_sectors_global_ideal
来自全局内存指令的 L2 中请求的理想扇区数,假设每个未基于谓词关闭的线程都执行了操作。
L2 理论扇区 本地
memory_l2_theoretical_sectors_local
来自本地内存指令的 L2 中请求的理论扇区数。
所有 L1/L2 扇区/波前/请求 指标都给出了已实现(实际需要)、理想和过多(已实现 - 理想)的扇区/波前/请求数。理想 指标指示在给定每个未基于谓词关闭的线程都执行了给定宽度的操作的情况下,所需的数量。过多 指标指示超过理想情况所需的盈余。减少线程之间的发散可以减少过多的数量,并减少相应硬件单元的工作量。
在 2021.2 版本中,以上几个关于内存操作的指标已重命名,如下所示
旧名称 |
新名称 |
memory_l2_sectors_global |
memory_l2_theoretical_sectors_global |
memory_l2_sectors_global_ideal |
memory_l2_theoretical_sectors_global_ideal |
memory_l2_sectors_local |
memory_l2_theoretical_sectors_local |
memory_l1_sectors_global |
memory_l1_tag_requests_global |
memory_l1_sectors_shared |
memory_l1_wavefronts_shared |
memory_l1_sectors_shared_ideal |
memory_l1_wavefronts_shared_ideal |
L2 显式驱逐策略指标
从 NVIDIA Ampere 架构开始,可以调整 L2 缓存的驱逐策略以匹配内核的访问模式。驱逐策略可以为内存窗口隐式设置(有关更多详细信息,请参阅 CUaccessProperty),也可以为每个执行的内存指令显式设置。如果显式设置,则 L2 缓存命中或未命中情况所需的驱逐行为将作为指令的输入传递。有关更多详细信息,请参阅 CUDA 的 缓存驱逐优先级提示。
标签
名称
描述
L2 显式驱逐策略
smsp__inst_executed_memdesc_explicit_evict_type
配置的显式驱逐策略的逗号分隔列表。由于策略可以在运行时动态设置,因此此列表包括作为任何执行指令一部分的所有策略。
L2 显式命中策略 优先驱逐
smsp__inst_executed_memdesc_explicit_hitprop_evict_first
任何 warp 执行内存指令的次数,如果访问导致 L2 中的缓存命中,则该 warp 设置了
evict_first策略。使用此策略缓存的数据将在驱逐优先级顺序中排在首位,并且在需要缓存驱逐时很可能会被驱逐。此策略适用于流式数据。L2 显式命中策略 最后驱逐
smsp__inst_executed_memdesc_explicit_hitprop_evict_last
任何 warp 执行内存指令的次数,如果访问导致 L2 中的缓存命中,则该 warp 设置了
evict_last策略。使用此策略缓存的数据将在驱逐优先级顺序中排在最后,并且很可能仅在其他具有evict_normal或evict_first驱逐策略的数据已被驱逐后才会被驱逐。此策略适用于应在缓存中保持持久性的数据。L2 显式命中策略 正常驱逐
smsp__inst_executed_memdesc_explicit_hitprop_evict_normal
任何 warp 执行内存指令的次数,如果访问导致 L2 中的缓存命中,则该 warp 设置了
evict_normal(默认)策略。L2 显式命中策略 正常驱逐 降级
smsp__inst_executed_memdesc_explicit_hitprop_evict_normal_demote
任何 warp 执行内存指令的次数,如果访问导致 L2 中的缓存命中,则该 warp 设置了
evict_normal_demote策略。L2 显式未命中策略 优先驱逐
smsp__inst_executed_memdesc_explicit_missprop_evict_first
任何 warp 执行内存指令的次数,如果访问导致 L2 中的缓存未命中,则该 warp 设置了
evict_first策略。使用此策略缓存的数据将在驱逐优先级顺序中排在首位,并且在需要缓存驱逐时很可能会被驱逐。此策略适用于流式数据。L2 显式未命中策略 正常驱逐
smsp__inst_executed_memdesc_explicit_missprop_evict_normal
任何 warp 执行内存指令的次数,如果访问导致 L2 中的缓存未命中,则该 warp 设置了
evict_normal(默认)策略。单个 Warp 停顿采样指标
所有 stall_* 指标都单独显示 Warp 停顿采样 中组合的信息。有关其描述,请参阅 统计采样器。
寄存器依赖关系
寄存器之间的依赖关系显示在 SASS 视图中。当读取寄存器时,会找到所有可能写入该寄存器的地址。这些行之间的链接绘制在视图中。寄存器、谓词、统一寄存器和统一谓词的所有依赖关系都显示在各自的列中。
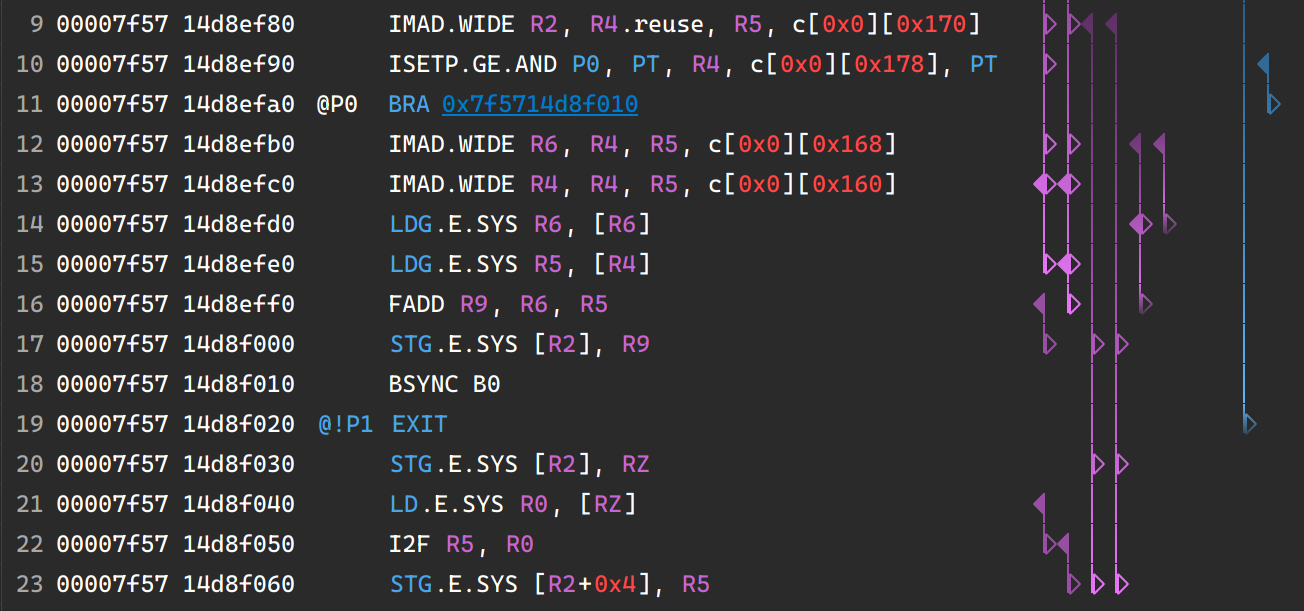
寄存器依赖关系
上图显示了一个简单的 CUDA 内核的一些依赖关系。在第一行,即 SASS 代码的第 9 行,我们可以看到寄存器 R2 和 R3 的写入,由指向左侧的填充三角形表示。这些寄存器然后在第 17、20 和 23 行被读取,这由指向右侧的规则三角形表示。还有一些行在同一行上同时具有两种类型的三角形,这意味着同一寄存器发生了读取和写入。
这些线条用渐变色着色,有助于可视化依赖关系的持续时间。
不跟踪跨源文件和函数的依赖关系。
寄存器依赖关系跟踪功能默认启用,但可以在工具 > 选项 > 分析 > 报告源页面 > 启用寄存器依赖关系中完全禁用。
配置文件
视图下拉菜单旁边的图标可用于管理源视图配置文件。

此按钮打开一个对话框,其中显示已保存的源视图配置文件列表。可以使用对话框中的 + 按钮创建此类配置文件。配置文件允许您将报告中所有视图的列属性存储到文件中。此类属性包括列可见性、冻结状态、宽度、顺序和选定的导航指标。双击已保存的配置文件以将其应用于任何打开的报告。这将使用所选配置文件中的列属性更新所有视图中提到的上述属性。
配置文件对于根据您的偏好或特定用例配置视图非常有用。首先从列选择器中选择指标列。接下来,配置其他属性,例如冻结列、更改宽度或顺序以及在创建配置文件之前在导航下拉菜单中设置热图指标。创建配置文件后,您可以始终在任何打开的报告中使用此配置文件来隐藏所有不需要的列或恢复您配置的属性。只需从源视图配置文件对话框中选择配置文件并应用它即可。您也可以通过单击星形按钮将配置文件设置为默认值,以便在打开报告时自动应用它。
请注意,列属性是为配置文件中的每个视图单独存储的,并且在应用时,只会更新所选配置文件中存在的那些视图。即使您已配置为在您应用的源配置文件中可见,您也不会看到报告中不可用的指标列。
其他表格
内联函数表
此表显示源视图中选定函数内联的所有调用站点。
在源视图中,每个内联函数源代码行的相关指标值是来自所有调用站点的相关 SASS 行的指标值的聚合。该表为每个调用站点单独提供此类 SASS 行信息,以帮助识别哪个调用站点对总体指标值贡献了多少。
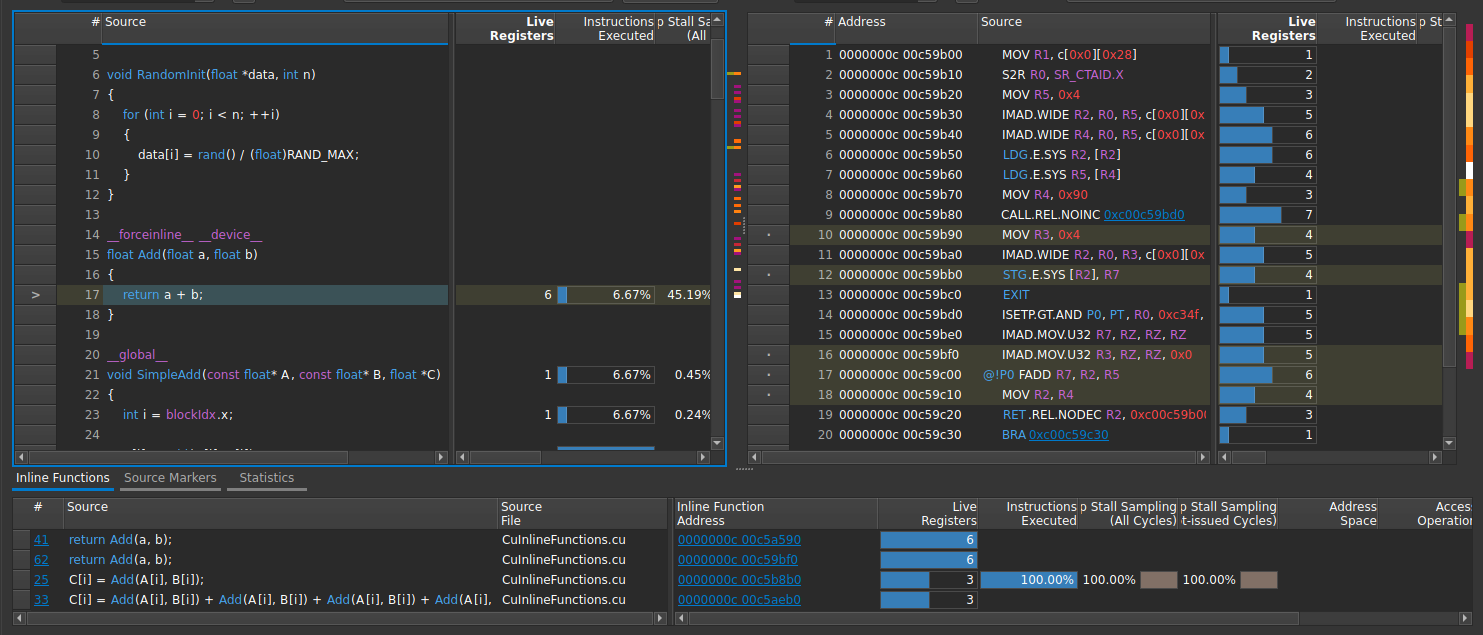
内联函数表
源标记表
不同视图中的代码还可以包含警告、错误或仅是通知,这些警告、错误或通知在左侧标题中显示为源标记,如下所示。这些可以从多个来源生成,但到目前为止仅支持 NvRules。
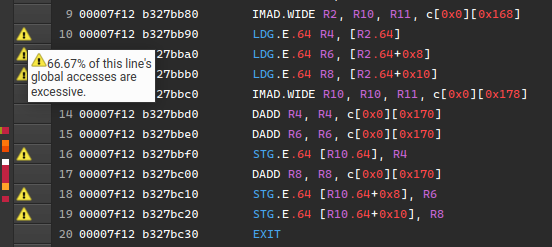
源标记
此表显示打开的视图中包含源标记的所有行。用户可以单击行号以导航到视图中的相应行。
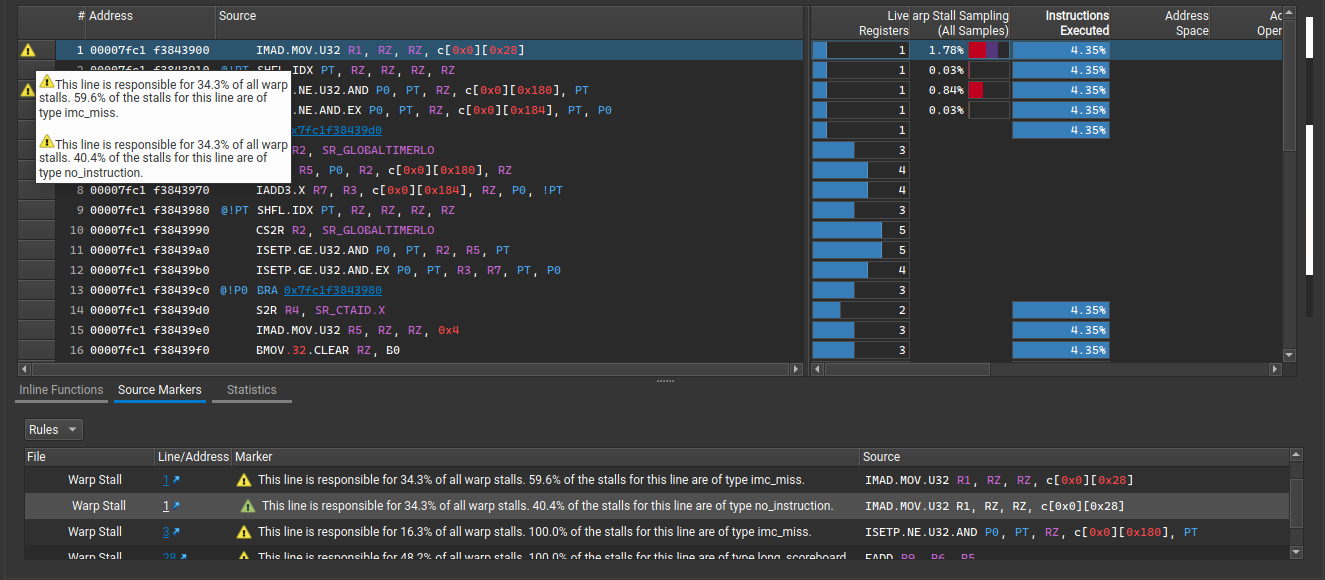
源标记表
统计信息表
此表允许用户在上面的源代码中选择多行并计算各种统计信息。它们可用于检查是否有任何异常情况,例如最小值和最大值之间是否存在意外差距。
如果指标尚未收集或其统计值在计算上下文中没有意义,则单元格将为空。例如,内存访问或任何其他非数字指标不能有最小值或最大值,因为没有定义的顺序。
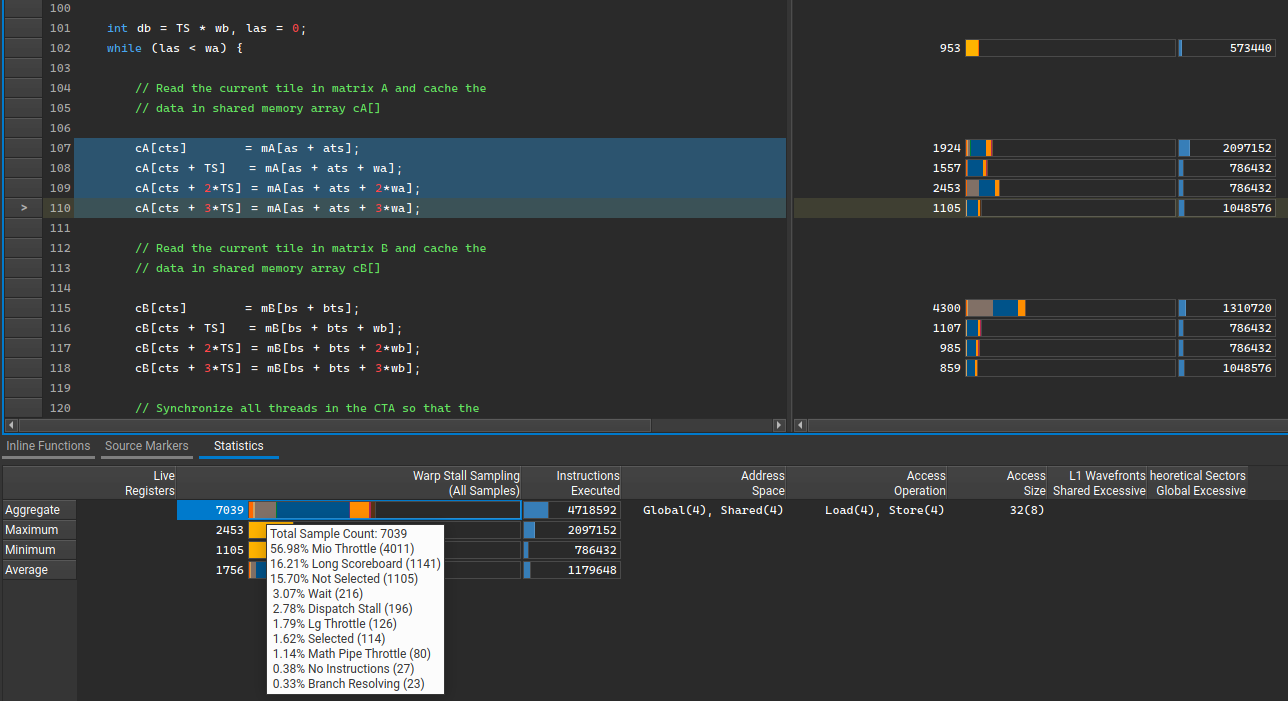
统计信息表
局限性
图形分析
当分析完整的 CUDA 图形时,指令级源指标不可用。
上下文页面
此报告页面的CPU 调用堆栈部分显示内核启动时执行 CPU 线程的 CPU 调用堆栈。为了使此信息显示在分析器报告中,必须在 连接对话框 中或使用相应的 NVIDIA Nsight Compute CLI 命令行参数启用收集 CPU 调用堆栈的选项。
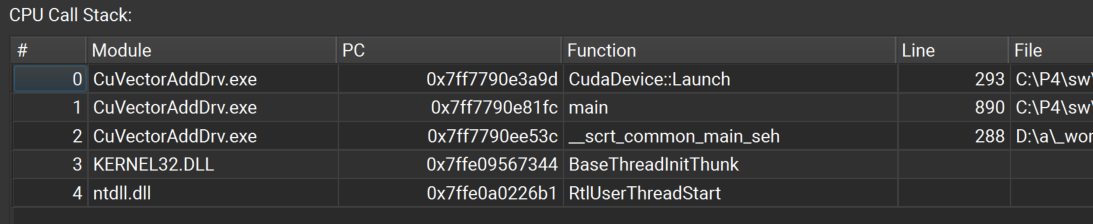
NVIDIA Nsight Compute 支持收集原生 CPU 调用堆栈以及 Python 应用程序的调用堆栈。可以在 连接对话框 的活动菜单中(通过“CPU 调用堆栈类型”选项)或使用 NVIDIA Nsight Compute CLI 命令行参数 –call-stack-type 选择一种或两种类型。如果同时启用两种类型,将出现一个下拉菜单以选择所需的调用堆栈类型。
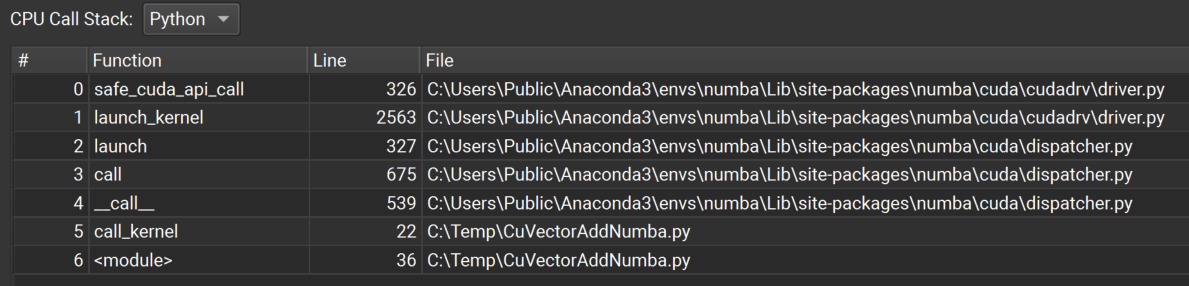
请注意,Python 调用堆栈收集需要 CPython 版本 3.9 或更高版本。
此报告页面的 NVTX 状态 部分显示内核启动时的 NVTX 上下文。所有线程特定信息都与内核启动 API 调用的线程相关。请注意,仅当分析器在启用 NVTX 支持的情况下启动时,才会收集 NVTX 信息,无论是在 连接对话框 中还是使用 NVIDIA Nsight Compute CLI 命令行参数。
此页面已从“调用堆栈 / NVTX 页面”重命名。
原始页面
原始页面显示所有收集的指标列表,其中包含每个分析内核启动的单位。它可以导出,例如,以 CSV 格式进行进一步分析。该页面具有过滤器编辑功能,可快速查找特定指标。您可以使用转置按钮转置内核和指标表。
如果指标具有多个实例值,则实例数显示在标准值之后。例如,此指标有十个实例值:35.48 {10}。您可以在 配置文件 选项对话框中选择应单独显示所有实例值,或在 指标详细信息 工具窗口中检查指标结果。
会话页面
此会话页面包含有关报告和机器的基本信息,以及启动分析的所有设备的设备属性。在启动实例之间切换时,相应的设备属性将突出显示。
3.6.3. 指标和单位
数值指标值显示在报告中的多个位置,包括标题以及大多数页面上的表格和图表。NVIDIA Nsight Compute 支持多种显示这些指标及其值的方式。
当可用且适用于 UI 组件时,指标与其单位一起显示。这是为了清楚地表明指标是否表示周期、线程、字节/秒等。单位通常会显示在方括号中,例如 指标 名称 [字节] 128。
默认情况下,单位会自动缩放,以便以合理的数量级显示指标值。单位使用其 SI 系数缩放,即基于字节的单位使用 1000 的因子和前缀 K、M、G 等缩放。基于时间的单位也使用 1000 的因子缩放,前缀为 n、u 和 m。可以在 配置文件 选项中禁用此缩放。
无法收集的指标显示为 n/a 并分配一个警告图标。如果指标浮点值超出常规范围(即 nan (非数字) 或 inf (无穷大)),它们也会被分配一个警告图标。例外情况是这些值是预期值且在内部允许列表中的指标。
3.6.4. 过滤后的分析器报告
过滤后的分析器报告是完整分析器报告的子集。您可以将完整分析器报告中过滤或选择的结果保存到新文件中。要保存过滤后的结果,您可以使用文件 > 另存为过滤结果菜单选项,这将把过滤结果保存到新文件中。或者,您可以在摘要页面或原始页面上选择一个或多个结果,并使用文件 > 另存为所选结果菜单选项或右键单击保存结果菜单选项将它们保存到新文件中。
3.7. 基线
NVIDIA Nsight Compute 支持使用基线跨一个或多个报告对比收集的结果。任何报告中的每个结果都可以提升为基线。这会导致所有报告中所有结果的指标值显示与基线的差异。如果同时选择多个基线,则指标值将与所有当前基线的平均值进行比较。基线不随报告存储,并且仅在相同的 NVIDIA Nsight Compute 实例打开时可用,除非它们从 基线工具窗口 保存到 ncu-bln 文件中。
具有一个基线的分析器报告
选择添加基线以将当前焦点结果提升为基线。如果设置了基线,则详细信息页面、原始页面和摘要页面上的大多数指标都显示两个值:焦点结果的当前值,以及基线的相应值或与相应基线值的变化百分比。(请注意,当指标的基线值为零,而焦点值不为零时,可能会显示无限百分比增益 inf%。)
如果选择了多个基线,则每个指标将显示以下符号
<focus value> (<difference to baselines average [%]>, z=<standard score>@<number of values>)
标准分数是当前值与所有基线的平均值之间的差异,并按标准偏差进行归一化。如果构成标准分数的指标值数量等于结果数量(当前和所有基线),则省略 @<值数量> 符号。
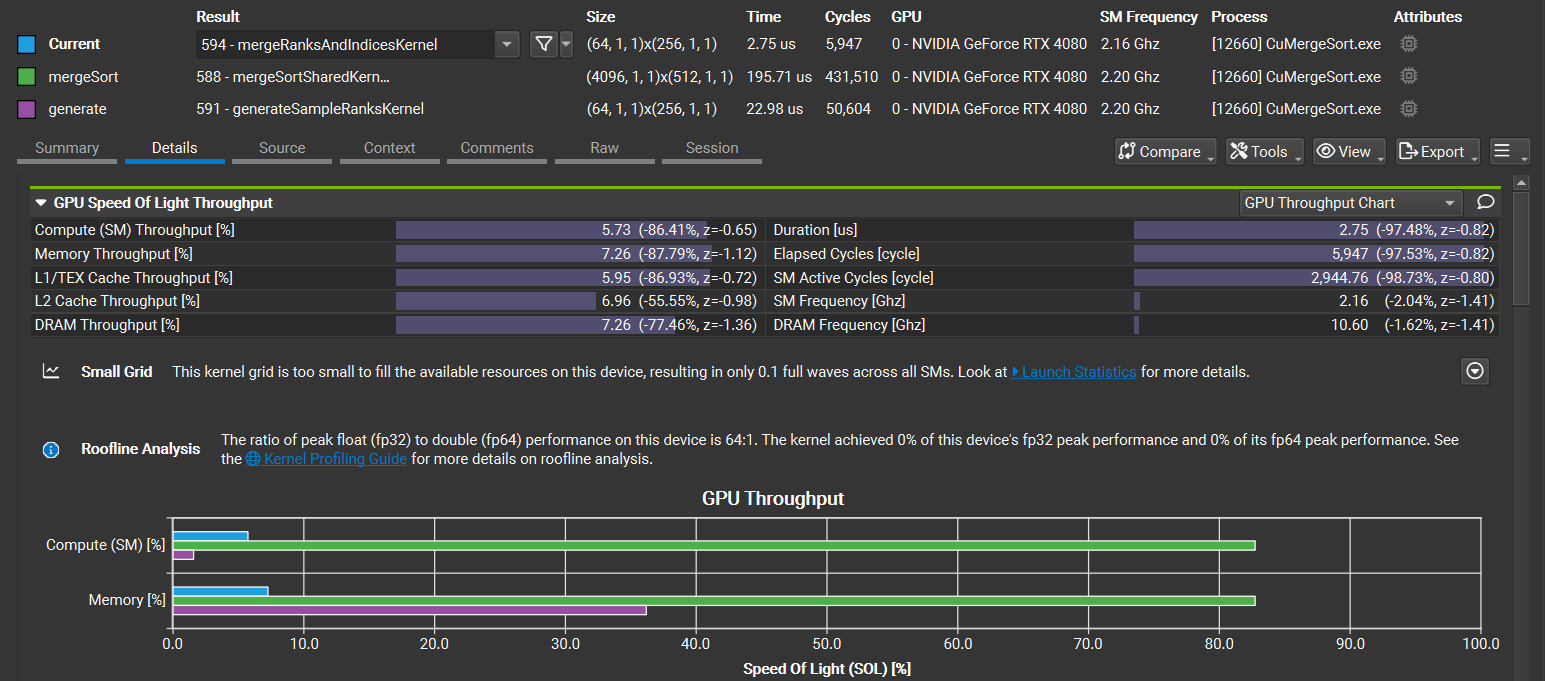
具有多个基线的分析器报告
为当前焦点结果添加的基线始终显示在顶部。但是,添加基线的实际顺序显示在基线工具窗口中。
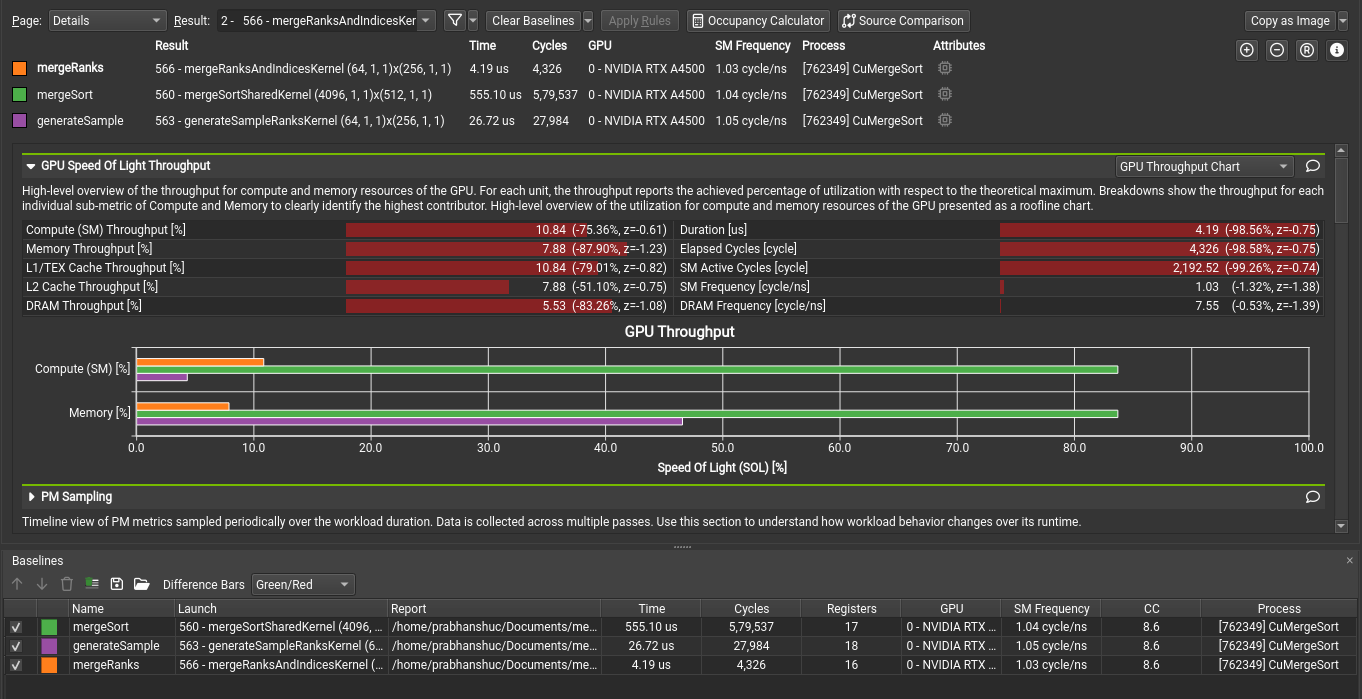
具有多个基线的基线工具窗口
双击基线名称允许用户编辑显示的名称。通过按 Enter/Return 或在失去焦点时提交编辑,并通过按 Esc 放弃编辑。将鼠标悬停在基线颜色图标上允许用户从列表中删除此特定基线。
使用下拉按钮、配置文件菜单或相应的工具栏按钮中的清除基线条目来删除所有基线。
基线更改也可以在基线工具窗口中进行。
3.8. 独立源查看器
NVIDIA Nsight Compute 包括一个用于 cubin 文件的独立源查看器。此视图与 源页面 相同,只是它不包含任何性能指标。
可以从文件 > 打开主菜单命令打开 Cubin 文件。在打开独立源视图之前,将显示 SM 选择对话框。如果可用,文件名中存在的 SM 版本将被预先选择。例如,如果您的文件名是 mergeSort.sm_80.cubin,则 SM 8.0 将在对话框中预先选择。如果文件名中未包含 SM 版本,请从下拉菜单中选择适当的 SM 版本。
SM 选择对话框
单击“确定”按钮以打开 独立源查看器。
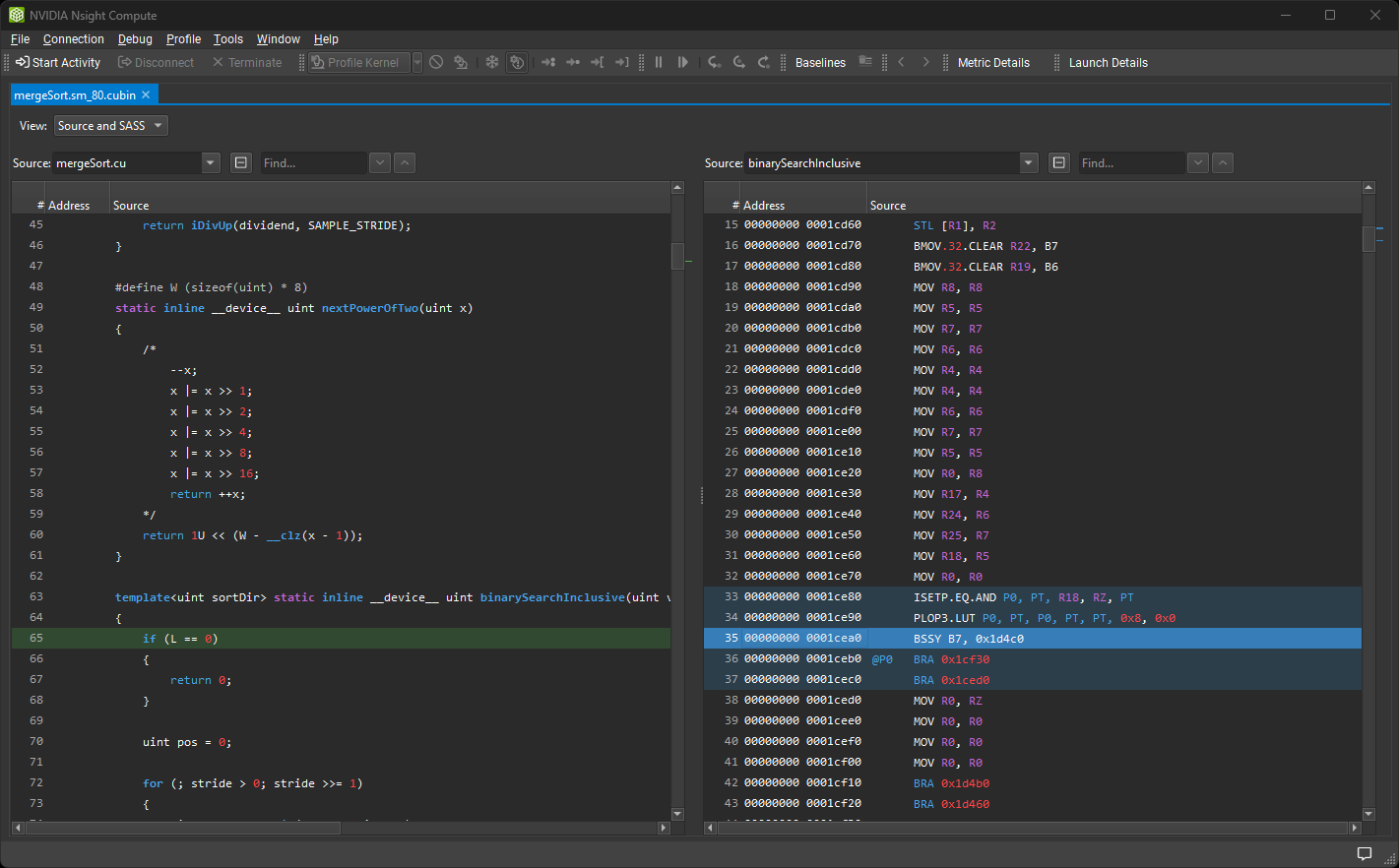
独立源查看器
3.9. 源比较
源比较提供了一种并排查看两个分析结果的源文件的方法。它使您能够快速识别源差异并了解指标值的变化。
要并排比较两个结果,请添加一个结果作为基线,导航到另一个结果,然后单击报告标题中的源比较按钮。
例如,如果要比较报告 R1 中的内核 XYZ 与报告 R2 中的内核 XYZ,请首先打开报告 R1,将内核 XYZ 的分析结果添加为基线,打开报告 R2,选择内核 XYZ,然后单击“源比较”按钮。
源比较将仅与第一个添加的基线结果一起显示。
源比较按钮
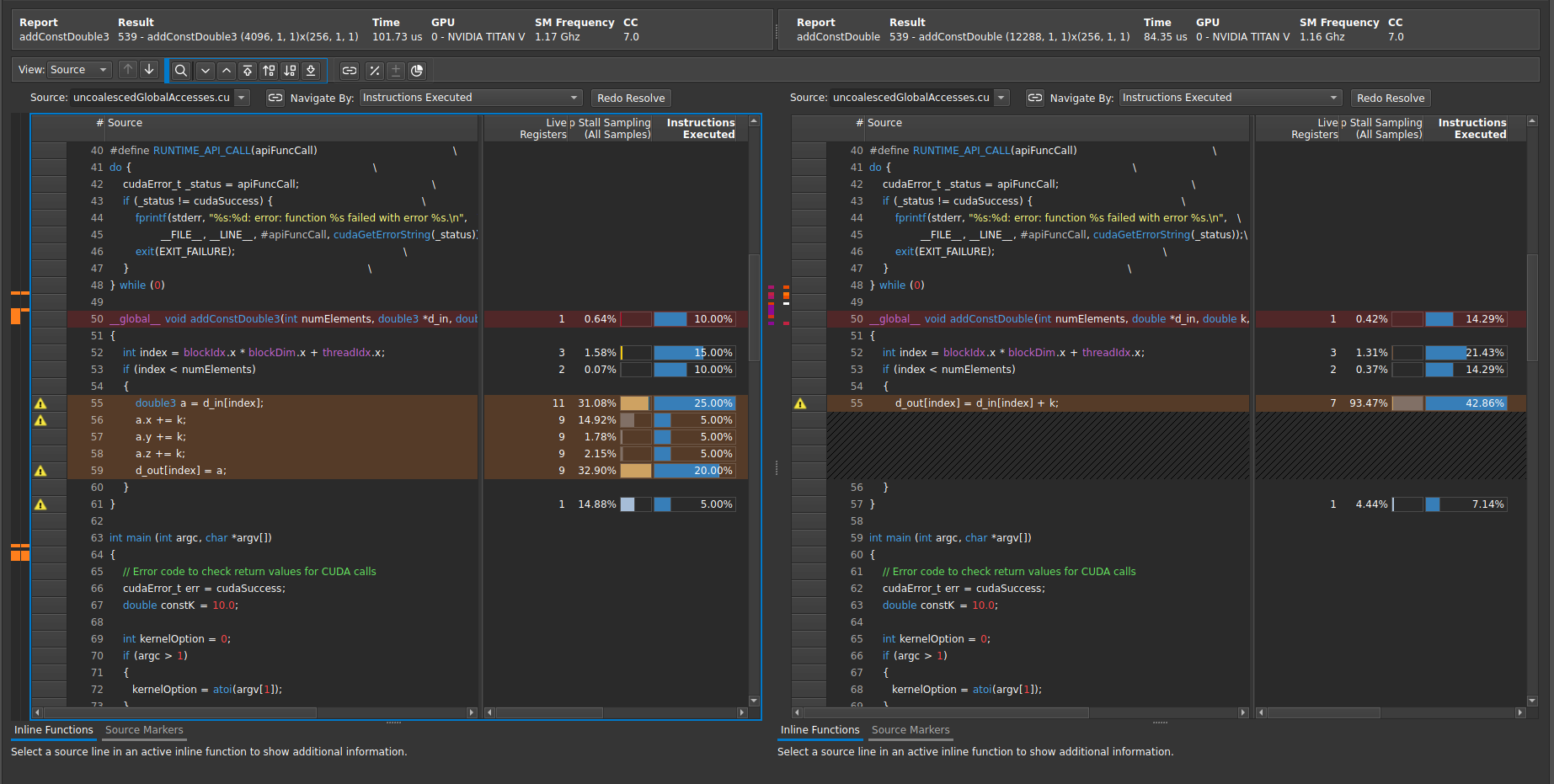
源比较
目前,比较仅支持高级源 (CUDA-C) 视图和 SASS 视图。源差异热图位于最左侧。它的每个分区代表源差异的一侧。单击热图将滚动到相应的源代码行。
使用导航按钮或键盘快捷键 Ctrl + 1 和 Ctrl + 2 支持导航到上一个或下一个差异。
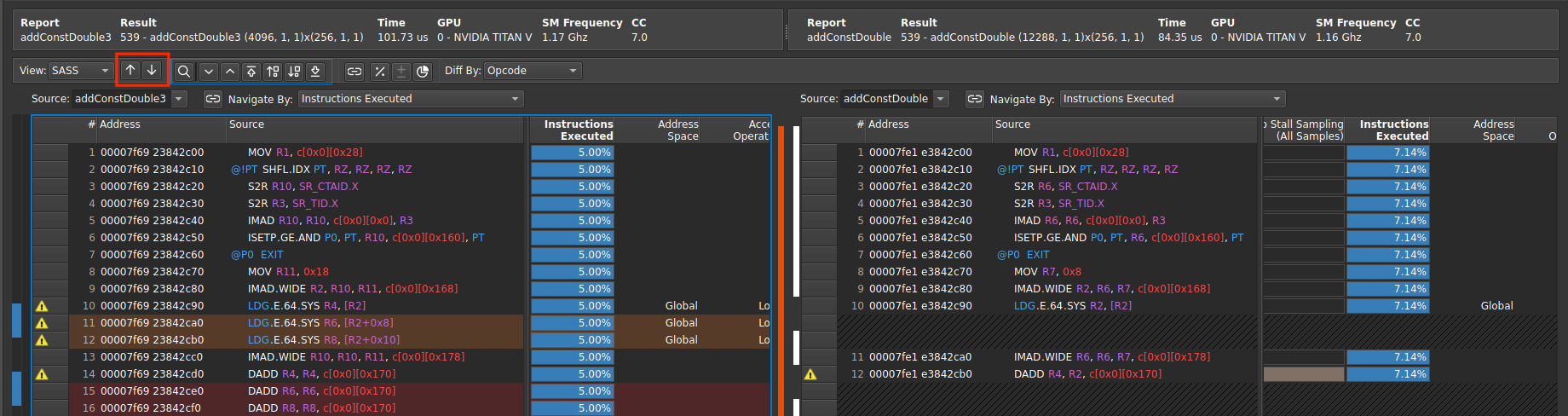
源比较导航按钮
在 SASS 视图中,Diff By 下拉菜单允许您基于 Opcode 或 Full Instruction 选择差异比较的基准。对于后者,除了操作码之外,所有指令修饰符和参数都将用于比较。
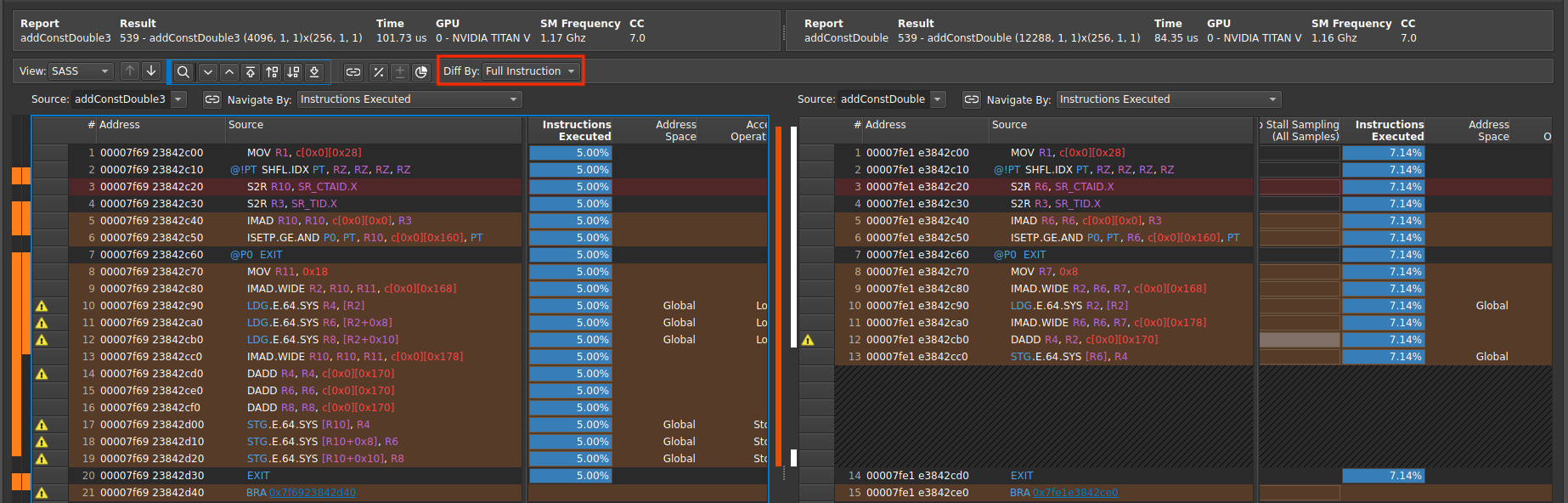
源比较差异依据菜单
3.10. 占用率计算器
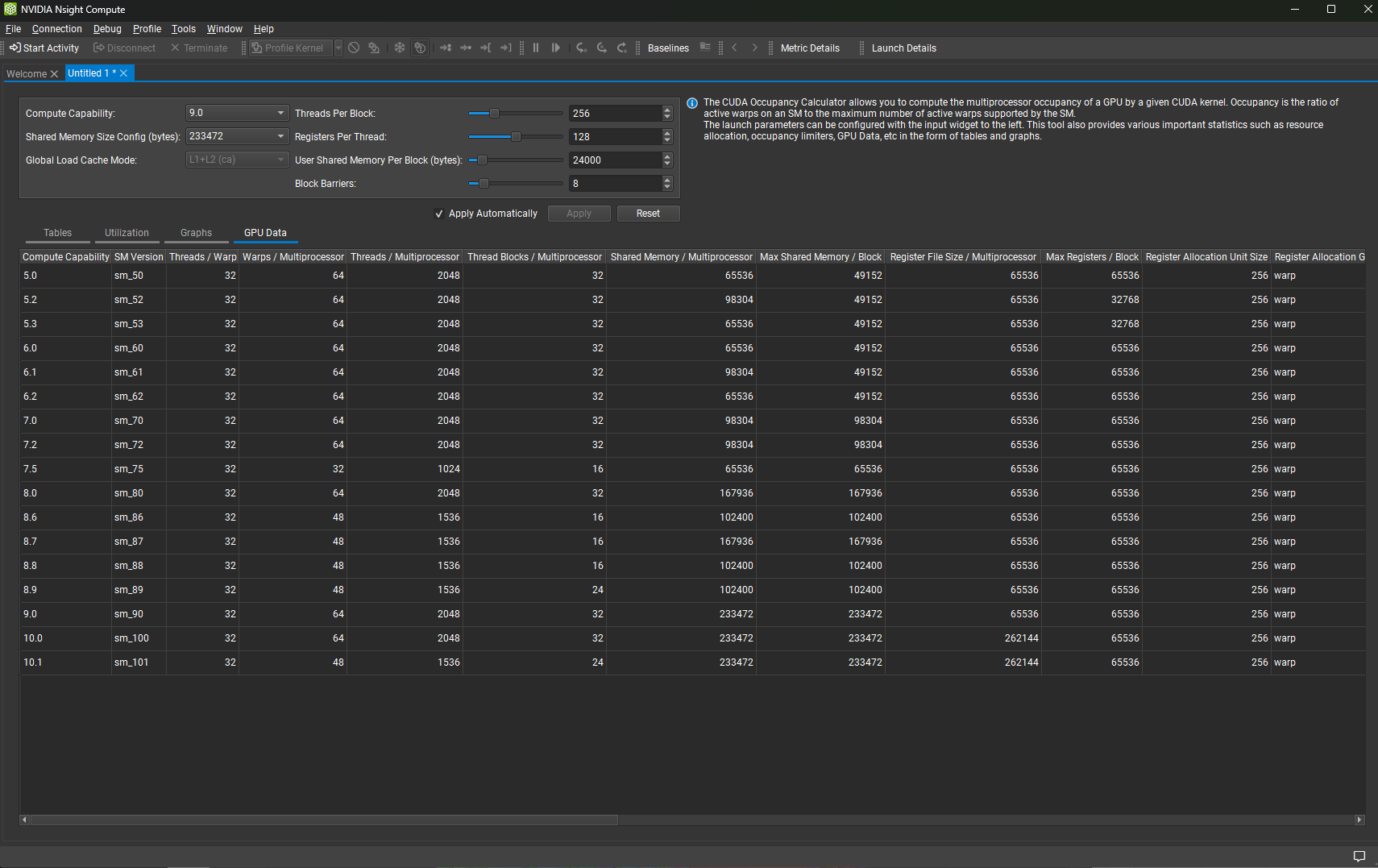
NVIDIA Nsight Compute 提供了一个占用率计算器,允许您计算给定 CUDA 内核的 GPU 多处理器占用率。它取代了之前提供的 CUDA 占用率计算器电子表格。
占用率计算器可以直接从性能剖析报告或作为新活动打开。占用率计算器数据可以使用文件 > 保存 保存到文件。默认情况下,该文件使用 .ncu-occ 扩展名。占用率计算器文件可以使用文件 > 打开文件 打开
从连接对话框启动
从连接对话框中选择占用率计算器活动。您可以选择性地指定一个占用率计算器数据文件,该文件用于使用已保存文件中的数据初始化计算器。单击启动按钮以打开占用率计算器。
从性能剖析器报告启动
占用率计算器可以从性能剖析器报告中打开,使用报告标题或详细信息页上的占用率部分标题中的计算器按钮。

详细信息页标题

占用率部分标题
用户界面由输入部分以及显示有关 GPU 占用率信息的表格和图表组成。要使用计算器,请更改输入部分中的输入值,单击应用按钮并检查表格和图表。
3.10.1. 表格
表格显示了占用率,以及每个多处理器的活动线程、warp 和线程块的数量,以及 GPU 上的最大活动块数。
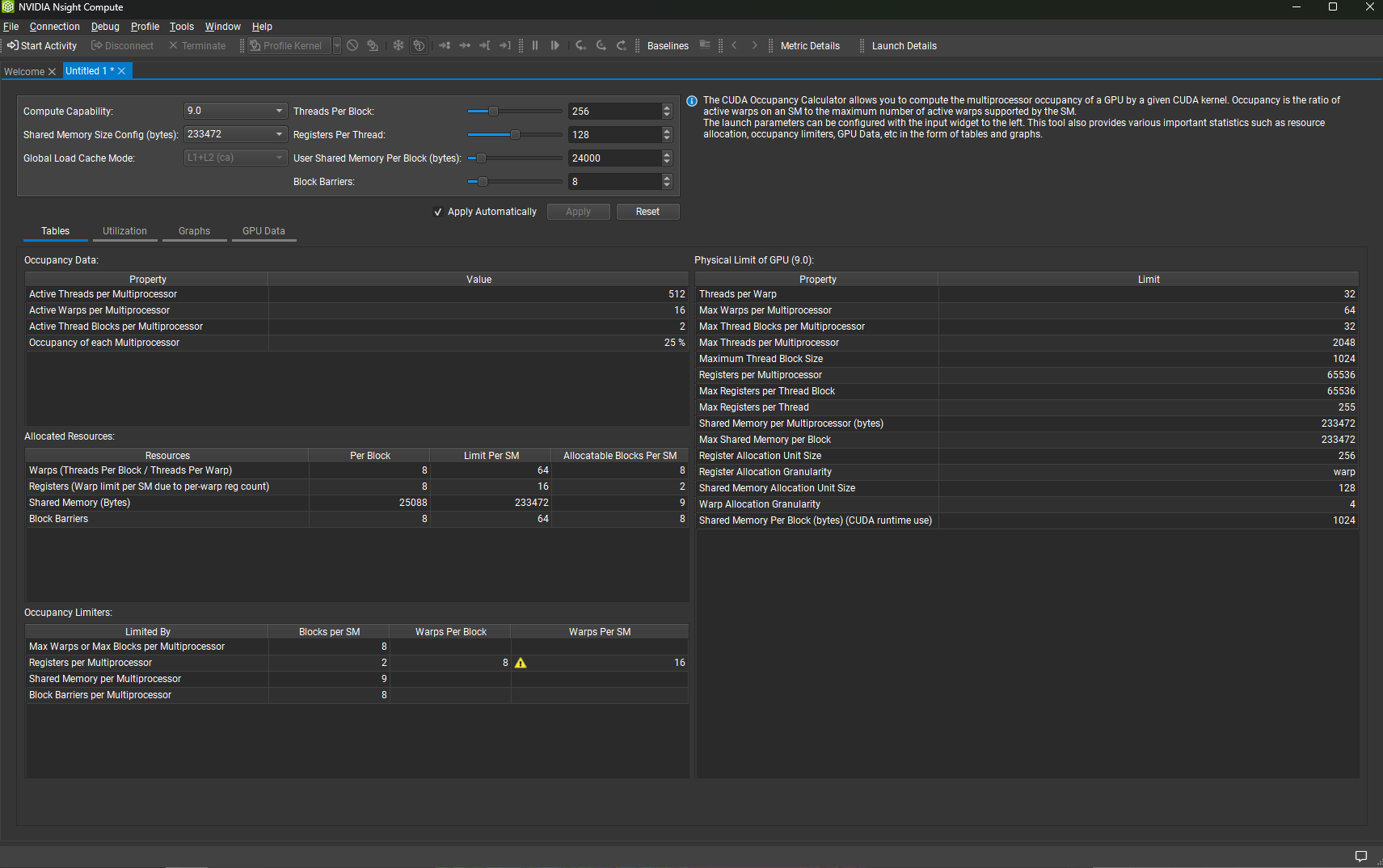
表格
3.10.2. 利用率
这些堆积条形图显示了分配给块的资源部分、由于其他资源成为限制因素而未分配的部分,以及最后小于块所需的最小量的未使用部分。
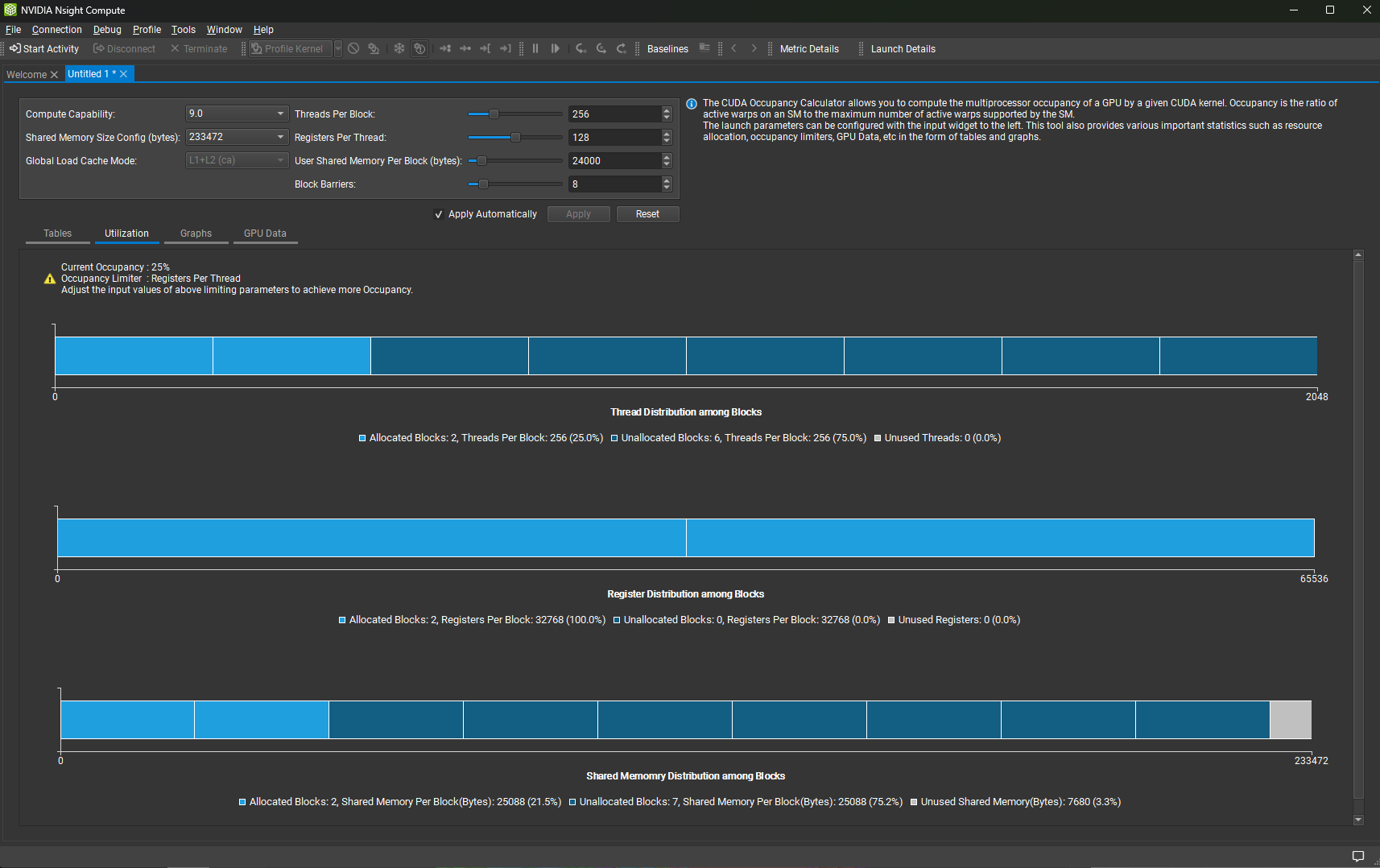
利用率
3.10.3. 图表
图表以蓝色圆圈显示您选择的块大小的占用率,并以折线图显示所有其他可能的块大小的占用率。“显示为”选项允许您在 Y 轴上以百分比和 warp 绝对数量之间切换占用率。当您将鼠标悬停在图表上时,最近的数据点将突出显示,其 X 轴和 Y 轴值将显示在工具提示中。
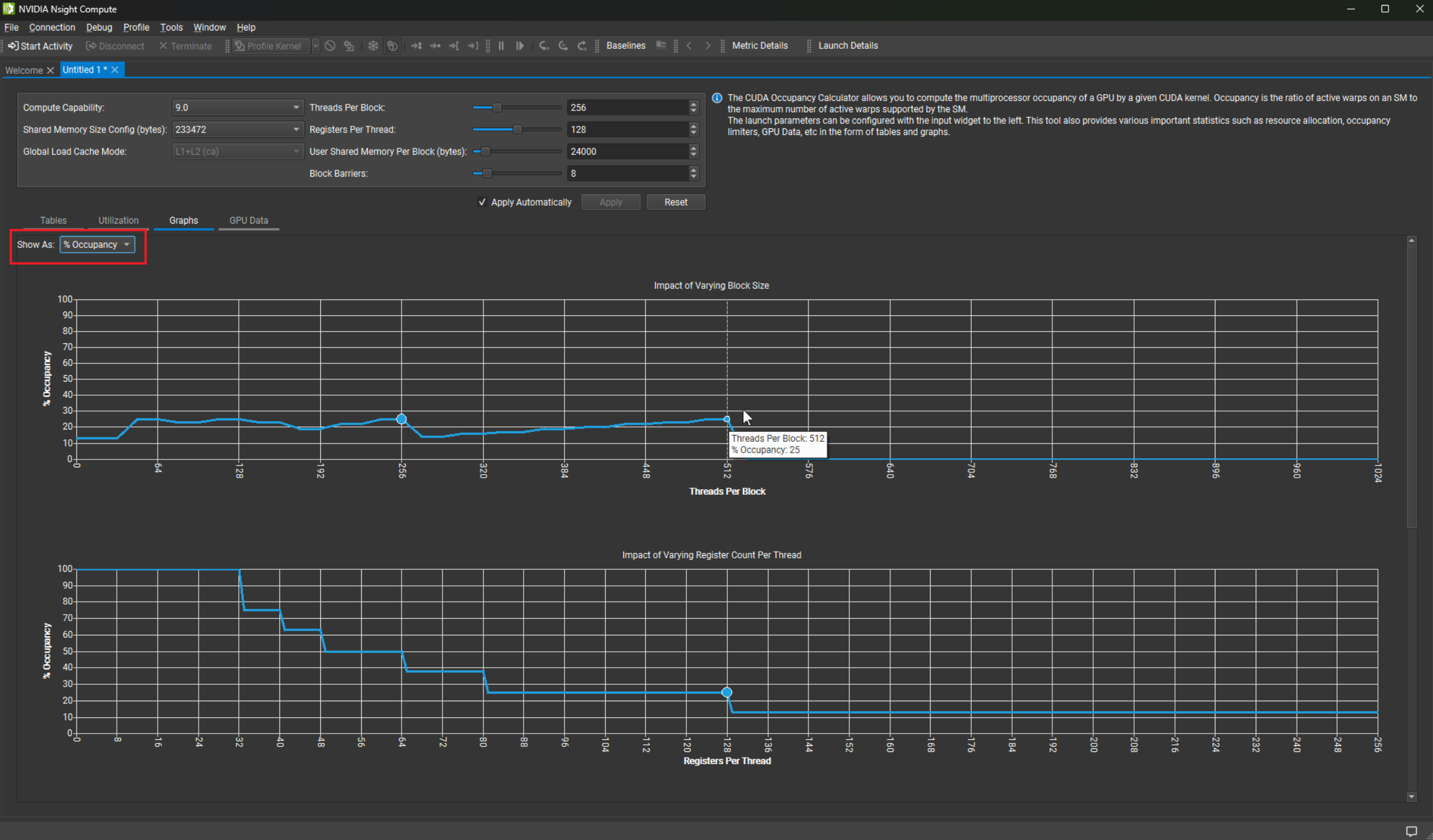
图表
3.10.4. GPU 数据
GPU 数据显示所有支持的设备的属性。
GPU 数据
3.11. 绿色上下文支持
NVIDIA Nsight Compute 提供了许多功能,以简化使用 CUDA 绿色上下文 的应用程序的分析,有关分析此类应用程序的概述,请参阅 内核性能剖析指南。
为了快速识别绿色上下文结果,性能剖析器报告标题中属性按钮的图标对于绿色上下文结果会变为叶子。单击此按钮会导航到结果的启动统计信息部分(如果可用),其中包含与绿色上下文相关的 其他指标(例如,其 ID 和使用的 SM 数量)。当鼠标悬停在属性按钮上时,工具提示中也会提供此信息中的一些内容。
为了在导航 详细信息页 时区分绿色上下文可归因和不可归因指标,可以使用绿色上下文标记。这些标记可以通过 报告标题 的视图菜单切换,并在所有部分标题中的可归因指标后添加叶子图标。当鼠标悬停在可归因指标上时,工具提示还会显示有关此类指标缩放的提示。此外,指标详细信息工具窗口为绿色上下文结果的指标显示归因行。

绿色上下文结果的详细信息页显示属性工具提示、指标详细信息工具窗口和绿色上下文标记。
如果报告包含绿色上下文结果,则 会话页 包含一个额外的绿色上下文资源部分。它包含一个表格,其中包含有关每个绿色上下文使用的资源的信息,例如分配给它的 TPC。结果 ID 列允许您导航到使用相应绿色上下文的每个性能剖析结果。
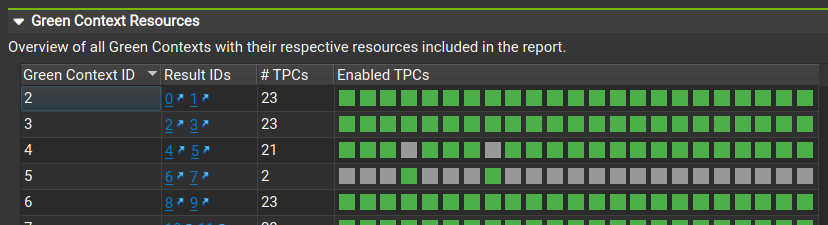
当交互式地分析绿色上下文应用程序时,资源工具窗口还允许跟踪所有绿色上下文的状态、它们的资源以及它们关联的流。

3.12. 加速结构查看器
加速结构查看器允许检查使用 OptiX API 构建的加速结构。在像 OptiX 这样的现代光线追踪 API 中,加速结构是描述渲染场景几何体的数据结构,这些几何体将在执行光线追踪操作时被相交。有关加速结构的更多信息,请参阅 OptiX 编程指南。
用户有责任设置这些结构并将它们传递给 OptiX API,OptiX API 将它们转换为在现代 GPU 上表现良好的内部数据结构。用户创建的描述可能非常容易出错,有时很难理解为什么渲染结果不如预期。加速结构查看器是一个组件,允许 OptiX 用户在启动光线追踪管线之前检查他们构建的加速结构。
加速结构查看器通过 资源 窗口中的按钮打开。该按钮仅在当前查看的资源为 OptiX: TraversableHandles 时可用。它打开当前选定的句柄。
查看器是多窗格的:它在左侧显示加速结构的分层视图,在中间显示加速结构的图形视图,并在右侧显示控件和选项。在查看器左侧的分层树视图中,显示了实例加速结构 (IAS)、几何加速结构 (GAS)、子实例和子几何体。除此之外,还显示了每个结构的一些常规属性,例如它们的图元计数、表面积和设备上的大小。
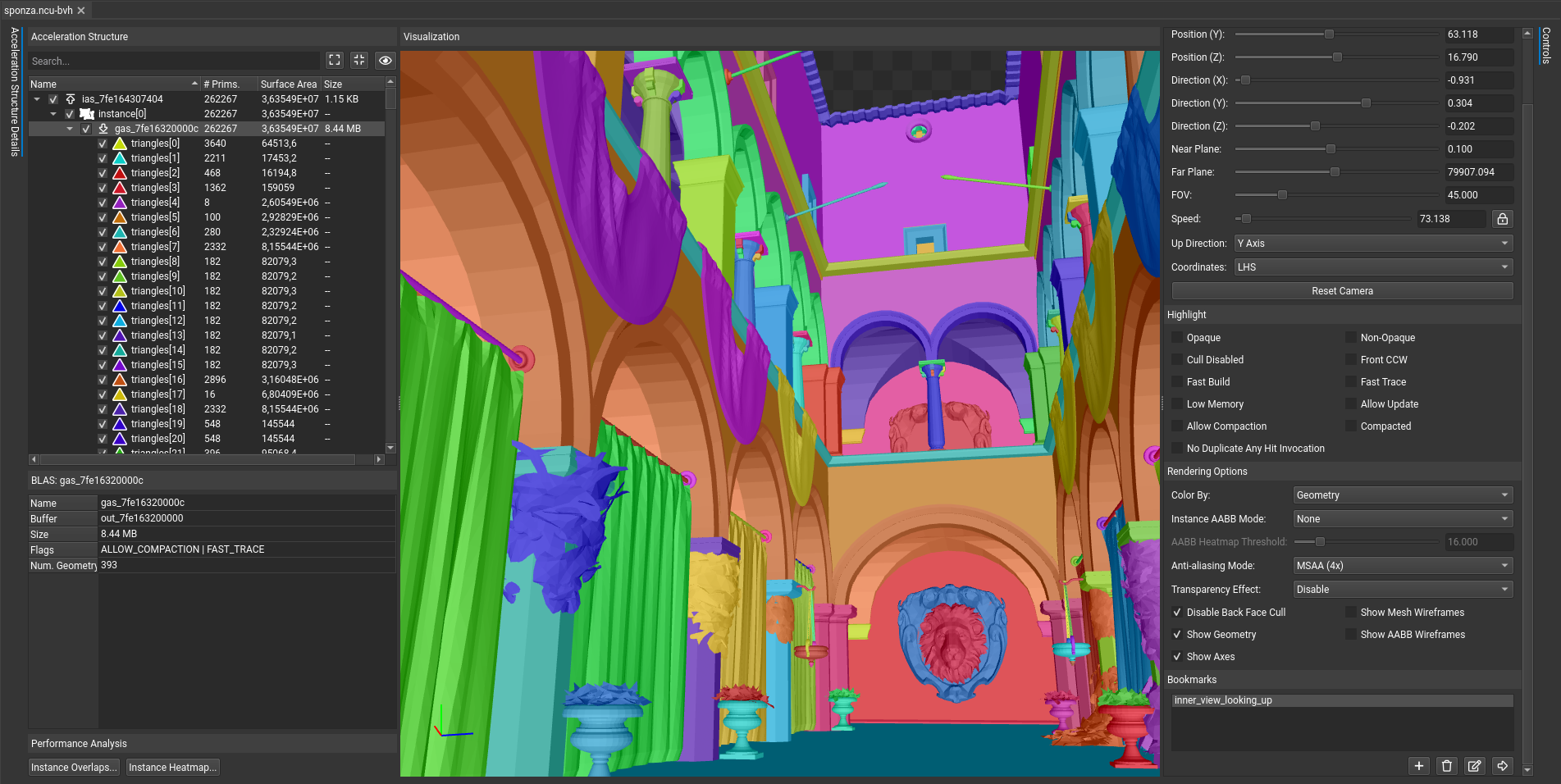
在加速结构查看器左侧的分层视图中,适用时会显示以下信息。
列 |
描述 |
|---|---|
名称 |
层次结构中每一行的标识符。单击名称旁边的复选框以显示或隐藏选定的几何体或层次结构。双击此条目可跳转到渲染视图中的项目。 |
# 图元 |
构成此加速结构的图元数量。 |
表面积 |
对边界特定条目的 AABB 的总表面积的计算。 |
大小 |
设备上保存此加速结构的输出缓冲区的大小。 |
性能分析工具可以在主视图的左下角访问。这些工具可以帮助识别 RTX 光线追踪最佳实践指南 中概述的潜在性能问题。这些分析工具旨在提供可能表现出次优性能的加速结构的概况。为了找到最佳解决方案,建议进行性能剖析和实验,但这些工具可以更好地说明为什么一个结构比另一个结构性能差。
操作 |
描述 |
|---|---|
实例重叠 |
识别与其他实例在 3D 中重叠的实例 AABB。当实例世界空间 AABB 显着重叠时,考虑合并 GAS 以潜在地提高性能。 |
实例热图 |
这允许您设置可视化工具中渲染的 AABB 热图使用的阈值。 |
3.12.1. 导航
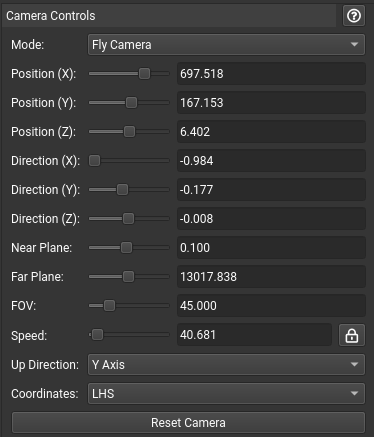
加速结构查看器支持多种导航模式。导航模式可以使用相机控件窗格中的组合框更改,该窗格位于渲染窗格的右侧。每种模式的键盘和鼠标绑定如下
绑定 |
飞行相机 |
推拉相机 |
轨道相机 |
|---|---|---|---|
WASD/方向键 |
向前、向后、向左、向右移动 |
向前、向后、向左、向右移动 |
跟踪(向上、向下、向左、向右移动) |
E/Q |
向上/向下移动 |
向上/向下移动 |
不适用 |
Z/C |
增加/减小视野 |
增加/减小视野 |
增加/减小视野 |
Shift/Ctrl |
更快/更慢地移动 |
更快/更慢地移动 |
更快/更慢地移动 |
鼠标滚轮 |
放大/缩小 |
放大/缩小 |
放大/缩小 |
LMB + 拖动 |
原地旋转 |
向左/向右旋转,向前/向后移动 |
围绕几何体旋转 |
RMB + 拖动 |
放大/缩小 |
原地旋转 |
放大/缩小 |
MMB + 拖动 |
跟踪(向上、向下、向左、向右移动) |
跟踪(向上、向下、向左、向右移动) |
跟踪(向上、向下、向左、向右移动) |
Alt |
临时切换到轨道相机 |
临时切换到轨道相机 |
不适用 |
F/双击 |
聚焦于选定的几何体 |
聚焦于选定的几何体 |
聚焦于选定的几何体 |
根据输入几何体的坐标系,您可能需要将向上方向设置更改为 Z 轴,或将坐标设置更改为 RHS。要将相机重置到其原始位置,请单击重置相机。
还有一系列相机控件用于快速而精确的导航。要保存位置,请使用书签控件。加速结构层次结构中的每个节点也可以双击以快速导航到该位置。
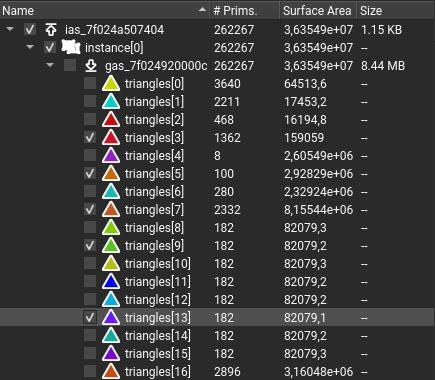
3.12.2. 过滤和高亮显示
加速结构视图支持加速结构过滤以及匹配特定特征的数据的高亮显示。每个几何体旁边的复选框允许用户切换每个可遍历对象的渲染。
几何体实例也可以通过在主图形视图中单击它们来选择。此外,在主图形视图中单击鼠标右键会提供隐藏或显示所有几何体、隐藏选定几何体或隐藏除选定几何体之外的所有几何体的选项。
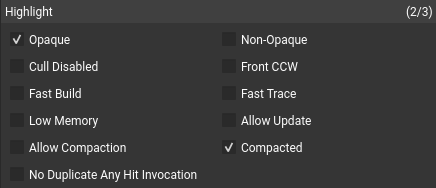
除了过滤之外,视图还支持基于高亮显示的几何体标识,该几何体使用特定标志指定。选中每个高亮显示选项将识别与该标志匹配的资源,并对其进行着色以便于识别。单击此部分中的条目将使所有不满足过滤器条件的几何体变暗,从而使与过滤器匹配的项目突出显示。选择多个过滤器需要传递几何体以满足所有选定的过滤器(例如,与逻辑)。此外,标题文本将更新以反映满足此过滤器条件的项目数。
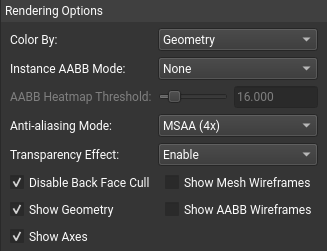
3.12.3. 渲染选项
在高亮显示控件下,提供了其他渲染选项。这些选项包括控制几何体颜色的方法以及切换网格和 AABB 的线框绘制的能力。
3.12.4. 导出
加速结构查看器文档中显示的数据可以保存到文件。导出加速结构查看器文档允许持久保存您收集的数据,超出即时分析会话。此功能对于比较几何体的不同修订版本或与他人共享尤其有价值。书签也会被持久保存。
3.13. 选项
可以通过主菜单在工具 > 选项下访问 NVIDIA Nsight Compute 选项。所有选项都持久保存在磁盘上,并在下次启动 NVIDIA Nsight Compute 时可用。当选项从其默认设置更改时,其标签将变为粗体。您可以使用恢复默认值按钮将所有选项恢复为其默认值。
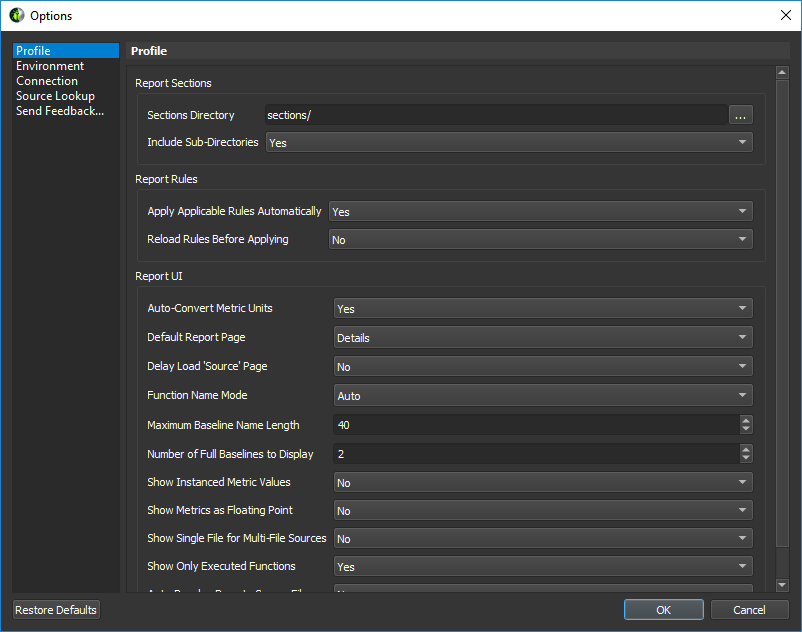
性能剖析选项
3.13.1. 性能剖析
名称 |
描述 |
值 |
|---|---|---|
节目录 |
从中导入节文件和规则的目录。相对路径相对于 NVIDIA Nsight Compute 安装目录。 |
|
包含子目录 |
从子目录递归包含节文件和规则。 |
是(默认)/否 |
自动应用适用规则 |
自动应用活动和适用的规则。 |
是(默认)/否 |
在应用前重新加载规则 |
在应用规则之前强制重新加载规则,以确保规则脚本中的更改被识别。 |
是/否(默认) |
默认报告页 |
生成或打开报告时显示的报告页。自动让工具决定打开报告时显示的最佳页面。 |
|
函数名称模式 |
确定如何显示函数/内核名称。 |
|
NVTX 重命名模式 |
确定如何使用 NVTX 信息进行重命名。范围重放结果在可能的情况下始终重命名。 |
|
显示指标聚合 |
在表头中显示每个计数器指标的所有结果的聚合。此外,在右下角的标签中显示摘要或原始页面表中所有随机选择的指标的聚合值。 |
是(默认)/否 |
重命名解构名称 |
对内核解构名称执行自动简化,或从配置文件导入重命名的名称。在展开列时,首先查看内核解构名称中更多唯一的关键字。 |
是(默认)/否 |
重命名内核配置路径 |
使用配置文件重命名多个解构名称。此外,将报告中的解构名称导出到指定的文件,并带有用于重命名的映射。 |
ncu-kernel-renames.yaml |
最大基线名称长度 |
基线名称的最大长度。 |
1..N(默认值:40) |
要显示的完整基线数量 |
除了当前结果或为当前结果添加的基线之外,要在报告标题中显示的所有详细信息的基线数量 |
0..N(默认值:2) |
自动转换指标单位 |
自动调整显示的指标单位和值(例如,字节到千字节)。 |
是(默认)/否 |
显示实例化的指标值 |
在表格中显示实例化指标的各个值。 |
是/否(默认) |
将指标显示为浮点数 |
将所有数字指标显示为浮点数。 |
是/否(默认) |
显示知识库信息 |
在(指标)工具提示中显示来自知识库的信息,以解释术语。注意:需要重新启动 Nsight Compute 才能使此选项生效。 |
是(默认)/否 |
指标/属性 |
要在摘要页面上显示的指标和属性列表。以逗号分隔的指标条目列表。每个条目的格式为 {Label:MetricName}。 |
|
延迟加载“源”页面 |
延迟加载报告页面的内容,直到页面变为可见。避免在打开报告页面之前产生处理成本和内存开销。 |
是/否(默认) |
为多文件源显示单个文件 |
即使对于多文件源,也在每个源页面视图中显示单个文件。 |
是/否(默认) |
仅显示已执行的函数 |
仅在源页面视图中显示已执行的函数。禁用此选项可能会影响性能。 |
是(默认)/否 |
自动解析远程源文件 |
如果连接仍然注册,则自动尝试在源页面上解析远程源文件(例如,通过 SSH)。 |
是/否(默认) |
启用寄存器依赖项 |
跟踪 SASS 寄存器/谓词之间的依赖关系,并在 SASS 视图中显示它们。 |
是(默认)/否 |
内核分析大小阈值 (KB) |
为低于此阈值的函数启用 SASS 流图分析。实时寄存器和寄存器依赖项信息需要 SASS 分析。设置为 -1 以对所有函数启用分析。 |
-1..N(默认值:1024) |
启用 ELF 验证 |
启用 ELF (cubin) 验证,以便在每次 SASS 分析之前运行。仅当使用 CUDA 11.0 之前编译的应用程序或遇到源页面问题时,才应启用此功能。 |
是/否(默认) |
API 调用历史记录 |
API 流视图中显示的最近 API 调用的数量。 |
1..N(默认值:100) |
3.13.2. 环境
名称 |
描述 |
值 |
|---|---|---|
颜色主题 |
当前选定的 UI 颜色主题。 |
|
混合 DPI 缩放 |
如果在使用具有不同 DPI 的显示器时检测到不需要的人工痕迹,则禁用混合 DPI 缩放。 |
|
默认文档文件夹 |
将保存与项目无关的文档的目录。 |
|
启动时 |
启动 NVIDIA Nsight Compute 时要执行的操作。 |
|
显示版本更新通知 |
当此产品的新版本可用时显示通知。 |
|
3.13.3. 连接
连接属性分为目标连接选项和主机连接属性。
目标连接属性
目标连接属性确定主机如何在交互式性能剖析活动期间连接到目标应用程序。此连接用于在性能剖析会话期间将性能剖析信息传输到主机。
名称 |
描述 |
值 |
|---|---|---|
基本端口 |
用于在交互式性能剖析活动(本地和远程)期间建立从主机到目标应用程序的连接的基本端口。 |
1-65535(默认值:49152) |
最大端口数 |
尝试连接到目标应用程序时要尝试的最大端口数(从基本端口开始)。 |
2-65534(默认值:64) |
主机连接属性
主机连接属性确定命令行性能剖析器如何在性能剖析活动期间连接到主机应用程序。此连接用于在性能剖析会话期间将性能剖析信息传输到主机。
名称 |
描述 |
值 |
|---|---|---|
基本端口 |
用于在性能剖析活动(本地和远程)期间建立从命令行性能剖析器到主机应用程序的连接的基本端口。 |
1-65535(默认值:50152) |
最大端口数 |
尝试连接到主机应用程序时要尝试的最大端口数(从基本端口开始)。 |
1-100(默认值:10) |
3.13.4. 源查找
名称 |
描述 |
值 |
|---|---|---|
程序源位置 |
设置程序源搜索路径。如果在原始位置找不到相应的 CUDA-C 源文件,则这些路径用于在“源”页面上解析这些文件。找不到的文件标记有文件未找到错误。有关已找到但不匹配的文件,请参阅忽略文件属性选项。 |
|
忽略文件属性 |
忽略源解析的文件属性(例如,时间戳、大小)。如果禁用此选项,则所有文件属性(如修改时间戳和文件大小)都将针对编译器在编译期间存储在应用程序中的信息进行检查。如果源查找路径上存在同名文件,但并非所有属性都匹配,则不会将其用于解析(并且将显示文件不匹配错误)。 |
是/否(默认) |
3.13.5. 发送反馈
名称 |
描述 |
值 |
|---|---|---|
收集使用情况和平台数据 |
选择您是否希望允许 NVIDIA Nsight Compute 收集使用情况和平台数据。 |
|
3.14. 项目
NVIDIA Nsight Compute 使用项目文件来分组和组织性能剖析报告。在任何给定时间,NVIDIA Nsight Compute 中只能打开一个项目。收集的报告会自动分配给当前项目。存储在磁盘上的报告可以随时分配给项目。除了性能剖析报告外,相关文件(如注释或源代码)也可以与项目关联以供将来参考。
请注意,项目文件中仅保存对报告或其他文件的引用。这些引用可能会失效,例如,当关联的文件被删除、移除或在当前系统上不可用时,如果项目文件本身被移动。
NVIDIA Nsight Compute 对项目文件使用 ncu-proj 文件扩展名。
当没有自定义项目处于活动状态时,将使用默认项目来存储,例如当前的 启动活动对话框 条目。要从默认项目中删除所有信息,您必须关闭 NVIDIA Nsight Compute,然后从磁盘中删除该文件。
在 Windows 上,该文件位于
<USER>\AppData\Local\NVIDIA Corporation\NVIDIA Nsight Compute\在 Linux 上,该文件位于
<USER>/.local/share/NVIDIA Corporation/NVIDIA Nsight Compute/在 macOS 上,该文件位于
<USER>/Library/Application Support/NVIDIA Corporation/NVIDIA Nsight Compute/
3.14.1. 项目对话框
新建项目
创建一个新项目。必须为项目命名,该名称也将用于项目文件。您可以选择项目文件应保存在磁盘上的位置。选择是否应在该位置创建具有项目名称的新目录。
3.14.2. 项目资源管理器
项目资源管理器窗口允许您检查和管理当前项目。它显示项目名称以及与之关联的所有项目(性能剖析报告和其他文件)。右键单击任何条目以查看更多操作,例如添加、删除或分组项目。在顶部的搜索项目工具栏中键入以过滤当前显示的条目。
项目资源管理器
3.15. Visual Profiler 过渡指南
本指南提供从 Visual Profiler 迁移到 NVIDIA Nsight Compute 的技巧。NVIDIA Nsight Compute 尝试尽可能提供与 Visual Profiler 的内核性能剖析功能相同的奇偶校验,但某些功能现在由不同的工具涵盖。
3.15.1. 跟踪
NVIDIA Nsight Compute 不支持在准确的时间线上跟踪 GPU 或 API 活动。此功能由 NVIDIA Nsight Systems 涵盖。在 交互式性能剖析活动 中,API 流工具窗口提供了每个线程上最近 API 调用的流。但是,由于默认情况下所有跟踪的 API 调用都已序列化,因此它不收集准确的时间戳。
3.15.2. 会话
NVIDIA Nsight Compute 使用 项目 而不是会话来启动和收集连接详细信息和收集的报告。
3.15.3. 时间线
由于跟踪分析现在由 Nsight Systems 涵盖,因此 NVIDIA Nsight Compute 不提供应用程序时间线的视图。API 流工具窗口确实显示了每个线程的最后一个捕获的 CUDA API 调用的流。但是,这些调用已序列化,并且不维护运行时并发性或提供准确的计时信息。
3.15.4. 分析
引导式分析
所有基于跟踪的分析现在都由 NVIDIA Nsight Systems 涵盖。这意味着 NVIDIA Nsight Compute 不包括有关并发 CUDA 流或(例如)UVM 事件的分析。对于每个内核的分析,NVIDIA Nsight Compute 基于在 详细信息页 上收集的性能数据提供建议。这些规则当前要求您预先通过其节收集所需的指标,并且不支持部分按需性能剖析。
要使用基于规则的建议,请在 指标选择中启用相应的规则。在性能剖析之前,在 性能剖析选项中启用应用规则,或之后单击报告中的应用规则按钮。
非引导式分析
所有基于跟踪的分析现在都由 Nsight Systems 涵盖。对于每个内核的分析,基于 Python 的规则提供分析和建议。有关更多详细信息,请参阅上面的引导式分析。
PC 采样视图
源相关的 PC 采样信息现在可以在 源页面 中查看。聚合的 warp 状态显示在 详细信息页 的Warp 状态统计信息部分中。
内存统计信息
内存统计信息位于 详细信息页 上。启用内存工作负载分析节以收集各自的信息。
NVLink 视图
NVLink 拓扑图和 NVLink 属性表位于 详细信息页 上。启用NVLink 拓扑和NVLink 表节以收集各自的信息。
有关与 NVLink 相关的限制,请参阅 已知问题 部分。
源-反汇编视图
源与 PTX 和 SASS 反汇编相关联地显示在 源页面 上。哪些信息可用取决于您的应用程序的编译/JIT 标志。
GPU 详细信息视图
NVIDIA Nsight Compute 不会自动收集每个执行内核的数据,并且不收集设备端内存副本的任何数据。所有性能剖析的内核启动的摘要信息显示在 摘要页 上。所有性能剖析的内核启动的所有收集指标的全面信息显示在 原始页 上。
CPU 详细信息视图
CPU 调用堆栈采样现在由 NVIDIA Nsight Systems 涵盖。
OpenACC 详细信息视图
NVIDIA Nsight Compute 对 OpenACC 性能分析的支持有限。OpenACC 并行区域未显式识别,但由 OpenACC 编译器生成的 CUDA 内核可以作为常规 CUDA 内核进行性能剖析。请参阅 NVIDIA Nsight Systems 发行说明以检查其最新的支持状态。
OpenMP 详细信息视图
NVIDIA Nsight Compute 不支持 OpenMP 性能分析。请参阅 NVIDIA Nsight Systems 发行说明以检查其最新的支持状态。
属性视图
NVIDIA Nsight Compute 不收集 CUDA API 和 GPU 活动及其属性。性能剖析的内核启动的性能数据在(例如)详细信息页 上报告。
控制台视图
NVIDIA Nsight Compute 当前不收集 stdout/stderr 应用程序输出。
设置视图
CPU 源视图
CPU-only API 的源代码不可用。性能剖析的 GPU 内核启动的源代码显示在 源页面 上。
3.15.5. 命令行参数
请在 shell 窗口中使用 -h 参数执行 ncu-ui,以查看 NVIDIA Nsight Compute UI 当前支持的命令行参数。
要使用 ncu-ui 打开收集的性能剖析报告,只需将报告文件的路径作为参数传递给 shell 命令即可。
3.16. Visual Studio 集成指南
本指南提供有关在 Microsoft Visual Studio 中使用 NVIDIA Nsight Compute 的信息,通过使用 NVIDIA Nsight Integration Visual Studio 扩展,实现无缝的开发工作流程。
3.16.1. Visual Studio 集成概述
NVIDIA Nsight Integration 是一款 Visual Studio 扩展,让您可以从 Visual Studio 内部访问 NVIDIA Nsight Compute 的强大功能。
当 NVIDIA Nsight Compute 与 NVIDIA Nsight Integration 一起安装时,NVIDIA Nsight Compute 的活动将出现在 Visual Studio 菜单栏的 NVIDIA ‘Nsight’ 菜单下。这些活动会使用当前项目设置和可执行文件启动 NVIDIA Nsight Compute。
有关从 Visual Studio 内部使用 NVIDIA Nsight Compute 的更多信息,请访问
声明
声明
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“资料”,单独或合并)均“按原样”提供。NVIDIA 对这些资料不作任何明示、暗示、法定或其他方面的保证,并且明确声明不承担任何关于不侵权、适销性和适用于特定用途的暗示保证。
所提供的信息据信是准确可靠的。但是,NVIDIA 公司对使用此类信息造成的后果或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。未通过暗示或其他方式授予 NVIDIA 公司专利权下的任何许可。本出版物中提及的规格如有更改,恕不另行通知。本出版物取代并替换以前提供的所有其他信息。未经 NVIDIA 公司明确书面批准,NVIDIA 公司产品不得用作生命维持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。
注释页面
注释页面在单个视图中聚合所有节注释,并允许用户编辑任何启动实例或节以及整个报告上的这些注释。注释随报告一起持久保存。如果添加了节注释,则 详细信息页面 中相应节的注释图标将突出显示。