2. 内核性能分析指南
Nsight Compute 性能分析指南。
内核性能分析指南,包含指标类型和含义、数据收集模式以及常见问题解答。
2.1. 简介
本指南描述了与 NVIDIA Nsight Compute 和 NVIDIA Nsight Compute CLI 相关的各种性能分析主题。 其中大多数适用于该工具的 UI 和 CLI 版本。
为了有效使用这些工具,建议阅读本指南,以及至少阅读CUDA 编程指南的以下章节
之后,只需分别阅读 NVIDIA Nsight Compute 或 NVIDIA Nsight Compute CLI 文档的快速入门章节,即可开始使用这些工具。
2.1.1. 性能分析应用程序
在常规执行期间,CUDA 应用程序进程将由用户启动。 它直接与 CUDA 用户模式驱动程序通信,并可能与 CUDA 运行时库通信。
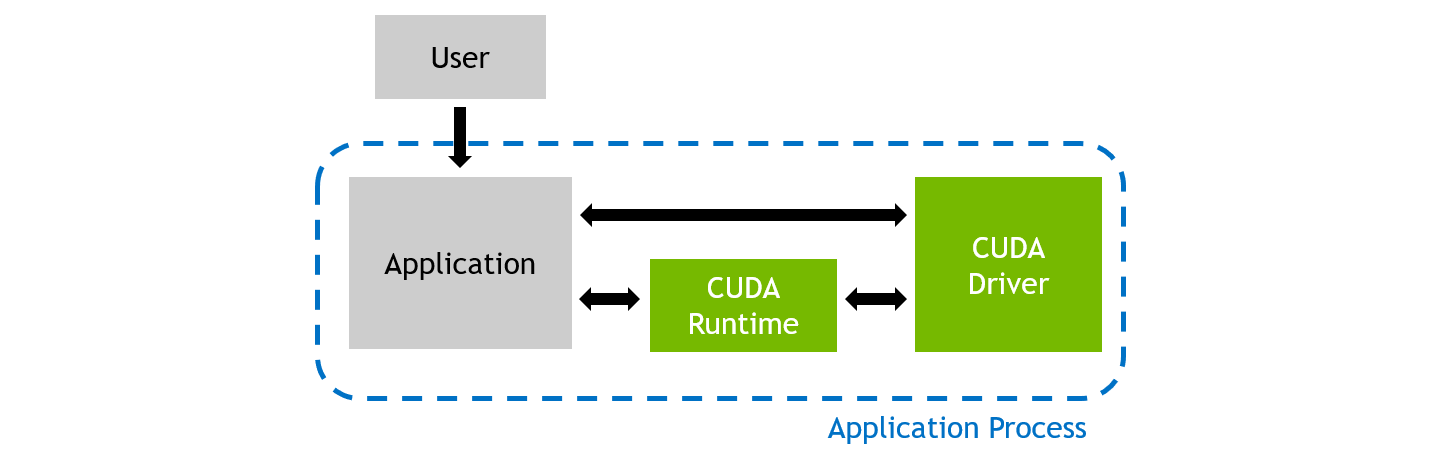
常规应用程序执行
当使用 NVIDIA Nsight Compute 分析应用程序的性能时,行为会有所不同。 用户在主机系统上启动 NVIDIA Nsight Compute 前端(UI 或 CLI),前端又在目标系统上将实际应用程序作为新进程启动。 虽然主机和目标通常是同一台机器,但目标也可能是具有潜在不同操作系统的远程系统。
该工具将其测量库插入到应用程序进程中,这允许性能分析器拦截与 CUDA 用户模式驱动程序的通信。 此外,当检测到内核启动时,库可以从 GPU 收集请求的性能指标。 然后将结果传输回前端。
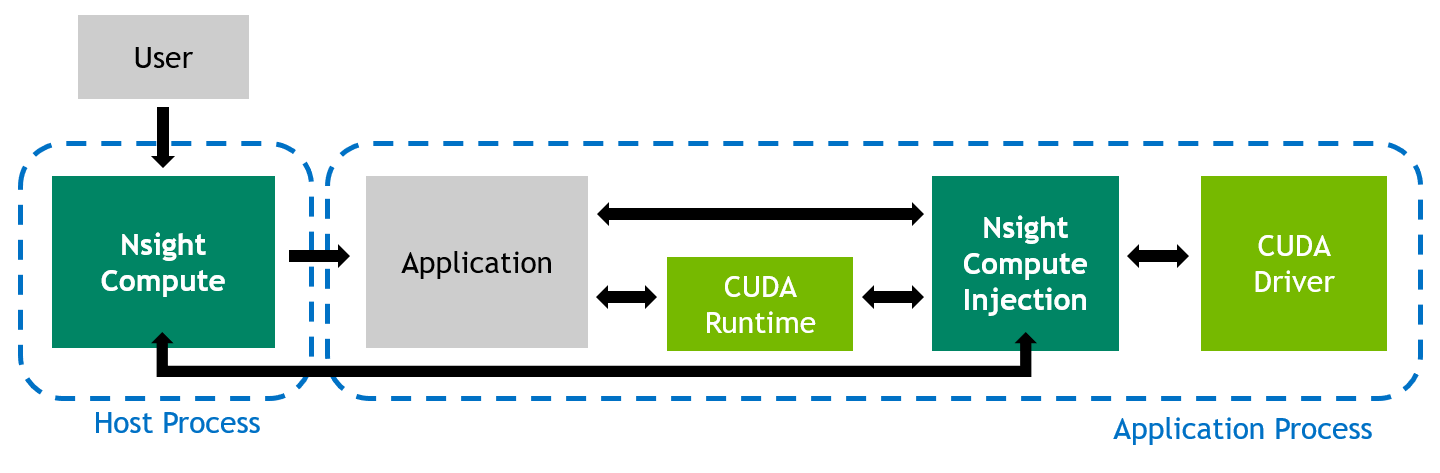
已分析性能的应用程序执行
2.2. 指标收集
性能指标的收集是 NVIDIA Nsight Compute 的关键功能。 由于有大量的指标可用,因此通常更容易使用该工具的一些预定义集合或节来收集常用的子集。 用户可以自由调整为哪些内核收集哪些指标,但重要的是要记住与数据收集相关的开销。
2.2.1. 集合和节
NVIDIA Nsight Compute 使用节集合(简称集合)来决定要收集的指标数量,从非常高的层面进行决策。 每个集合包含一个或多个节,每个节指定几个逻辑上关联的指标。 例如,一个节可能只包含高级 SM 和内存利用率指标,而另一个节可能包含与内存单元或 HW 调度器相关的指标。
节指定的指标数量和类型对性能分析期间的开销有重大影响。 为了让您能够快速在快速、不太详细的性能分析和较慢、更全面的分析之间进行选择,您可以选择相应的节集合。 有关性能分析开销的更多信息,请参阅开销。
默认情况下,会收集相对少量的指标。 这些指标主要包括高级利用率信息以及静态启动和占用率数据。 后两者通常在不重放内核启动的情况下可用。 当命令行上未传递 --set、--section 和 --metrics 选项时,会收集 basic 集合。 可以使用 --set full 收集完整的节集合。
使用 --list-sets 查看当前可用集合的列表。 使用 --list-sections 查看当前可用节的列表。 默认搜索目录和预定义节文件的位置也称为 sections/。 所有相关的命令行选项都可以在 NVIDIA Nsight Compute CLI 文档中找到。
名为 .ncu-ignore 的文件可以放置在任何目录中,以便在该工具查找节(和规则)文件时忽略其内容。 当递归添加节目录时,即使该文件存在,仍然会搜索子目录。
2.2.2. 节和规则
标识符和文件名 |
描述 |
|---|---|
ComputeWorkloadAnalysis (计算工作负载分析) |
流式多处理器 (SM) 计算资源的详细分析,包括实现的每时钟周期指令数 (IPC) 和每个可用流水线的利用率。 利用率非常高的流水线可能会限制整体性能。 |
InstructionStats (指令统计信息) |
已执行的低级汇编指令 (SASS) 的统计信息。 指令混合提供了对已执行指令类型和频率的深入了解。 指令类型的狭窄混合意味着依赖于少数指令流水线,而其他流水线仍然未使用。 使用多个流水线可以隐藏延迟并实现并行执行。 |
LaunchStats (启动统计信息) |
用于启动内核的配置摘要。 启动配置定义了内核网格的大小、网格划分为块以及执行内核所需的 GPU 资源。 选择高效的启动配置可以最大限度地提高设备利用率。 |
MemoryWorkloadAnalysis (内存工作负载分析) |
GPU 内存资源的详细分析。 当完全利用相关硬件单元(内存繁忙)、耗尽这些单元之间可用的通信带宽(最大带宽)或达到发出内存指令的最大吞吐量(内存管道繁忙)时,内存可能会成为整体内核性能的限制因素。 根据限制因素,内存图表和表格可以帮助确定内存系统中的确切瓶颈。 |
NUMA Affinity (NumaAffinity) (NUMA 亲和性) |
基于所有 GPU 的计算和内存距离的非统一内存访问 (NUMA) 亲和性。 |
Nvlink (Nvlink) |
NVLink 利用率的高级摘要。 它显示了总接收和传输(发送)的内存,以及整体链路峰值利用率。 |
Nvlink_Tables (Nvlink_Tables) |
包含每个 NVLink 属性的详细表格。 |
Nvlink_Topology (Nvlink_Topology) |
NVLink 拓扑图显示了具有传输/接收吞吐量的逻辑 NVLink 连接。 |
Occupancy (Occupancy) (占用率) |
占用率是每个多处理器活动 Warp 的数量与最大可能活动 Warp 数量的比率。 查看占用率的另一种方式是硬件处理 Warp 能力的百分比,该百分比正在积极使用中。 较高的占用率并不总是带来更高的性能,但是,较低的占用率总是会降低隐藏延迟的能力,从而导致整体性能下降。 执行期间理论占用率与实际占用率之间存在巨大差异通常表明工作负载高度不平衡。 |
PM Sampling (PmSampling) (PM 采样) |
在工作负载持续时间内定期采样的指标的时间线视图。 数据跨多个通道收集。 使用此节了解工作负载行为如何在运行时发生变化。 |
PM Sampling: Warp States (PmSampling_WarpStates) (PM 采样:Warp 状态) |
在工作负载持续时间内定期采样的 Warp 状态。 不同组中的指标来自不同的通道。 |
SchedulerStats (Scheduler Statistics) (调度器统计信息) |
调度器发布指令的活动摘要。 每个调度器维护一个 Warp 池,它可以为该池发布指令。 池中 Warp 的上限(理论 Warp)受启动配置的限制。 在每个周期,每个调度器都会检查池中已分配 Warp 的状态(活动 Warp)。 未停滞的活动 Warp(合格 Warp)已准备好发布其下一条指令。 从合格 Warp 集中,调度器选择单个 Warp 以从中发布一个或多个指令(已发布 Warp)。 在没有合格 Warp 的周期中,跳过发布槽,并且不发布指令。 有许多跳过的发布槽表明延迟隐藏效果不佳。 |
SourceCounters (Source Counters) (源计数器) |
源指标,包括分支效率和采样的 Warp 停滞原因。 Warp 停滞采样指标在内核运行时定期采样。 它们指示 Warp 何时停滞并且无法调度。 有关所有停滞原因的描述,请参阅文档。 仅当调度器未能每个周期都发布指令时,才关注停滞。 |
SpeedOfLight (GPU Speed Of Light Throughput) (光速吞吐量(GPU 光速吞吐量)) |
GPU 计算和内存资源吞吐量的高级概述。 对于每个单元,吞吐量报告相对于理论最大值的利用率百分比。 分解显示了计算和内存的每个单独子指标的吞吐量,以清楚地识别最高的贡献者。 |
WarpStateStats (Warp State Statistics) (Warp 状态统计信息) |
分析所有 Warp 在内核执行期间花费周期的状态。 Warp 状态描述了 Warp 发布其下一条指令的就绪状态或无法发布的状态。 每个指令的 Warp 周期定义了两个连续指令之间的延迟。 值越高,隐藏此延迟所需的 Warp 并行度就越高。 对于每个 Warp 状态,图表显示了每个已发布指令在该状态下花费的平均周期数。 停滞并不总是影响整体性能,也不是完全可以避免的。 仅当调度器未能每个周期都发布指令时,才关注停滞原因。 |
2.2.3. 重放
根据要收集的指标,内核可能需要重放一次或多次,因为并非所有指标都可以在单个通道中收集。 例如,GPU 可以同时收集的来自硬件 (HW) 性能计数器的指标数量有限。 此外,基于补丁的软件 (SW) 性能计数器可能对内核运行时产生很大影响,并且会使 HW 计数器的结果产生偏差。
内核重放
在内核重放中,NVIDIA Nsight Compute 中为特定内核实例请求的所有指标都分组到一个或多个通道中。 对于第一个通道,保存内核可以访问的所有 GPU 内存。 在第一个通道之后,确定内核写入的内存子集。 在每个通道(第一个通道除外)之前,此子集都将恢复到其原始位置,以使内核在每个重放通道中访问相同的内存内容。
NVIDIA Nsight Compute 尝试使用最快的可用存储位置来执行此保存和恢复策略。 例如,如果数据分配在设备内存中,并且仍有足够的设备内存可用,则直接存储在那里。 如果设备内存耗尽,则将数据传输到 CPU 主机内存。 同样,如果分配源自 CPU 主机内存,则该工具首先尝试将其保存到同一内存位置(如果可能)。
如开销中所述,访问的内存越多,尤其是内核写入的内存越多,所需的时间就越长。 如果 NVIDIA Nsight Compute 确定只需要单个重放通道即可收集请求的指标,则根本不执行保存和恢复,以减少开销。
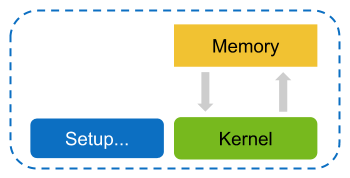
常规应用程序执行
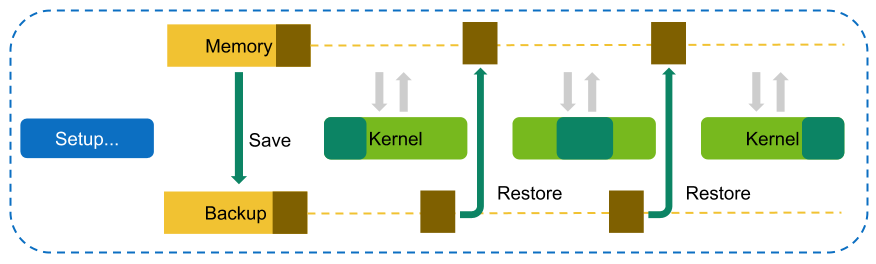
使用内核重放执行。 保存所有内存,并在重放通道之间恢复内核写入的内存。
应用程序重放
在应用程序重放中,NVIDIA Nsight Compute 中为特定内核启动请求的所有指标都分组到一个或多个通道中。 与内核重放相比,完整的应用程序运行多次,以便在每次运行时,每个内核都可以收集其中一个通道。
为了正确识别和组合从单个内核启动的多个应用程序重放通道收集的性能计数器,应用程序需要确定其内核活动的确定性以及它们到 GPU、上下文、流和可能的 NVTX 范围的分配。 通常,这也意味着应用程序需要确定其整体执行的确定性。
应用程序重放的好处是,内核访问的内存无需通过工具保存和恢复,因为在应用程序进程的生命周期内,每个内核启动仅执行一次。 除了避免内存保存和恢复开销外,应用程序重放还允许禁用缓存控制。 如果应用程序使用在特定内核启动之前的其他 GPU 活动来将缓存设置为某些预期状态,这将特别有用。
此外,应用程序重放可以支持分析在执行期间与主机具有相互依赖性的内核。 使用内核重放,此类内核在分析性能时通常会挂起,因为在除第一个通道之外的所有通道中都缺少来自主机的必要响应。 相比之下,应用程序重放确保了每个通道中程序执行的正确行为。
与内核重放相比,通过应用程序重放收集的多个通道也意味着应用程序的所有主机端活动也会重复。 如果应用程序需要大量时间进行例如设置或文件系统访问,则开销将相应增加。
常规应用程序执行

使用应用程序重放执行。 不会保存或恢复内存,但运行应用程序本身的成本会重复。
在应用程序重放通道中,NVIDIA Nsight Compute 匹配各个选定内核启动的指标数据。 可以使用 --app-replay-match 选项选择匹配策略。 对于匹配,仅考虑同一进程中且在同一设备上运行的内核。 默认情况下,使用网格策略,该策略根据内核名称和网格大小匹配启动。 当多个启动具有相同的属性(例如名称和网格大小)时,它们按执行顺序匹配。
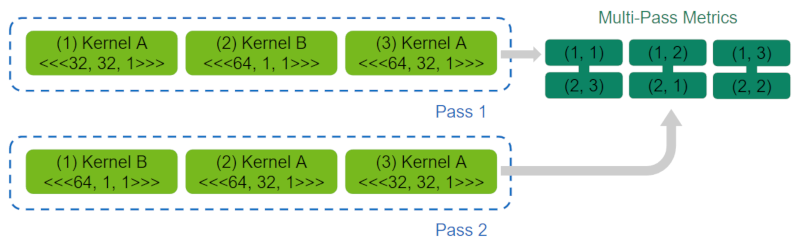
在使用网格策略的应用程序重放期间进行内核匹配。
范围重放
在范围重放中,NVIDIA Nsight Compute 中请求的所有指标都分组到一个或多个通道中。 与内核重放和应用程序重放相比,范围重放捕获并重放性能分析应用程序中 CUDA API 调用和内核启动的完整范围。 然后,指标不与单个内核关联,而是与整个范围关联。 这允许该工具在没有序列化的情况下执行内核,从而支持分析应并发运行以保证正确性或性能的内核的性能。
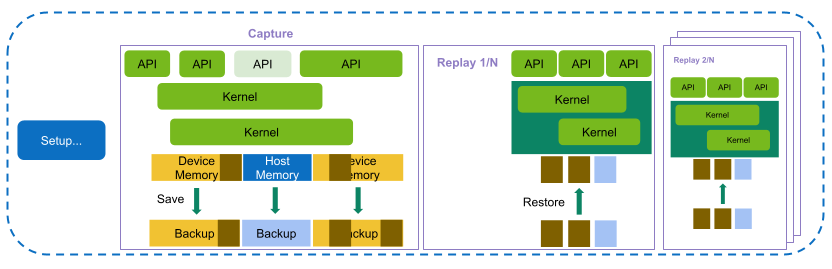
使用范围重放执行。 捕获并重放 API 调用和内核启动的整个范围。 根据需要保存和恢复主机和设备内存。
定义范围
范围重放要求您在应用程序中指定性能分析的范围。 范围由开始和结束标记定义,包括来自任何 CPU 线程的这些标记之间启动的所有 CUDA API 调用和内核。 应用程序负责在线程之间插入适当的同步,以确保捕获预期的 API 调用集。 可以使用以下选项之一设置范围标记
性能分析器启动/停止 API
使用
cu(da)ProfilerStart设置开始标记,使用cu(da)ProfilerStop设置结束标记。 注意:此 API 的 CUDA 驱动程序 API 变体需要包含cudaProfiler.h。 CUDA 运行时变体需要包含cuda_profiler_api.h。这是 NVIDIA Nsight Compute 的默认设置。
NVTX 范围
使用 NVTX Include 表达式定义范围。 范围捕获从第一个 CUDA API 调用开始,到与表达式匹配的最后一个 API 调用结束。 如果指定了多个表达式,则只要其中任何一个匹配,就会定义一个范围。 因此,可以使用多个表达式来方便地捕获和分析同一应用程序执行的多个范围的性能。
应用程序必须已使用 NVTX API 进行检测,才能使任何表达式匹配。
此模式通过将
--nvtx --nvtx-include <expression> [--nvtx-include <expression>]传递给 NVIDIA Nsight Compute CLI 来启用。
范围必须满足几个要求
必须可以在范围开始时同步所有活动的 CUDA 上下文。
范围不得包含不支持的 CUDA API 调用。 有关当前支持的 API 列表,请参阅支持的 API。
此外,还有一些建议范围应遵守,以保证正确捕获和重放
将范围设置得尽可能窄,以捕获特定的 CUDA 启动集。 包含的 API 调用越多,从捕获和重放这些 API 调用可能产生的开销就越高。
避免在范围内释放设备内存写入的主机分配。 这包括堆分配和堆栈分配。 NVIDIA Nsight Compute 不会拦截基于通用主机 (CPU) 的分配的创建或销毁。 但是,为了保证在任何范围重放后程序执行正确,该工具会尝试恢复在捕获期间从设备内存写入的主机分配。 如果这些主机地址无效或重新分配,则程序行为未定义且可能不稳定。 如果无法避免释放此类分配,则应使用
--launch-count 1将性能分析限制为一个范围,设置 disable-host-restore 范围重放选项,并可选择使用--kill yes在此范围后终止进程。在局部作用域中定义窄范围也有助于避免在范围内销毁堆栈分配。
当使用
cu(da)ProfilerStart/Stop定义范围标记时,首选 CUDA 驱动程序 API 调用cuProfilerStart/Stop。 在内部,NVIDIA Nsight Compute 仅拦截 CUDA 驱动程序 API 变体,如果调用线程上没有活动的 CUDA 上下文,则 CUDA 运行时 API 可能不会触发这些变体。
支持的 API
范围重放支持 CUDA API 的子集,用于捕获和重放。 此页面列出了支持的函数以及可能适用的任何其他 API 特定的限制。 如果在捕获的范围内检测到不支持的 API 调用,则会报告错误,并且无法分析该范围的性能。 下面列出的组与CUDA 驱动程序 API 文档中找到的组匹配。
通常,范围重放仅捕获和重放 CUDA驱动程序 API 调用。 当 CUDA运行时 API 调用在内部仅生成支持的 CUDA 驱动程序 API 调用时,可以捕获 CUDA运行时 API 调用。 不支持已弃用的 API。
错误处理
全部支持。
初始化
不支持。
版本管理
全部支持。
设备管理
全部支持,但
cuDeviceSetMemPool
主上下文管理
cuDevicePrimaryCtxGetState
上下文管理
全部支持,但
cuCtxSetCacheConfig
cuCtxSetSharedMemConfig
模块管理
cuModuleGetFunction
cuModuleGetGlobal
cuModuleGetSurfRef
cuModuleGetTexRef
cuModuleLoad
cuModuleLoadData
cuModuleLoadDataEx
cuModuleLoadFatBinary
cuModuleUnload
库管理
全部支持,但
cuKernelSetAttribute
cuKernelSetCacheConfig
内存管理
cuArray*
cuDeviceGetByPCIBusId
cuDeviceGetPCIBusId
cuMemAlloc
cuMemAllocHost
cuMemAllocPitch
cuMemBatchDecompressAsync
cuMemcpy*
cuMemFree
cuMemFreeHost
cuMemGetAddressRange
cuMemGetInfo
cuMemHostAlloc
cuMemHostGetDevicePointer
cuMemHostGetFlags
cuMemHostRegister
cuMemHostUnregister
cuMemset*
cuMipmapped*
虚拟内存管理
不支持。
流排序内存分配器
不支持。
统一寻址
不支持。
流管理
cuStreamCreate*
cuStreamDestroy
cuStreamGet*
cuStreamQuery
cuStreamSetAttribute
cuStreamSynchronize
cuStreamWaitEvent
事件管理
全部支持。
外部资源互操作性
不支持。
流内存操作
不支持。
执行控制
cuFuncGetAttribute
cuFuncGetModule
cuFuncSetAttribute
cuFuncSetCacheConfig
cuLaunchCooperativeKernel
cuLaunchHostFunc
cuLaunchKernel
图管理
不支持。
占用率
全部支持。
纹理/表面引用管理
不支持。
纹理对象管理
全部支持。
表面对象管理
全部支持。
对等上下文内存访问
不支持。
图形互操作性
不支持。
驱动程序入口点访问
全部支持。
表面对象管理
全部支持。
OpenGL 互操作性
不支持。
VDPAU 互操作性
不支持。
EGL 互操作性
不支持。
Green 上下文
cuCtxFromGreenCtx
cuGreenCtxCreate
cuGreenCtxDestroy
cuGreenCtxRecordEvent
cuGreenCtxStreamCreate
cuGreenCtxWaitEvent
cuStreamGetGreenCtx
应用程序范围重放
在应用程序范围重放中,NVIDIA Nsight Compute 中请求的所有指标都分组到一个或多个通道中。 与范围重放类似,指标不与单个内核关联,而是与整个选定范围关联。 这允许该工具在没有序列化的情况下执行工作负载(内核、CUDA 图等),从而支持分析必须并发运行以保证正确性或性能的工作负载的性能。
与范围重放相比,范围不会被显式捕获并直接为每个通道执行,而是整个应用程序会重新运行多次,每次应用程序执行的每个范围收集一个通道。 这样做的好处是不必为每个范围观察和捕获应用程序状态,并且范围内的 API 调用不需要显式支持,因为范围的正确执行由应用程序本身处理。
定义要分析性能的范围与范围重放相同。 范围应分析性能的 CUDA 上下文必须是定义范围开始的线程的当前上下文,并且必须在整个范围内处于活动状态。
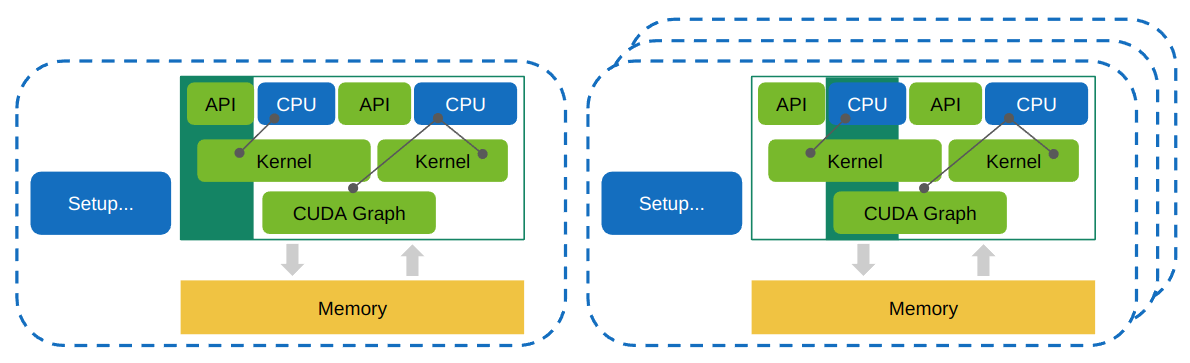
使用应用程序范围重放执行。 通过重新运行整个应用程序来重放一系列工作负载,而无需修改交互或保存和恢复内存。
图性能分析
在多种重放模式下,NVIDIA Nsight Compute 可以将 CUDA 图分析为单个工作负载实体,而不是分析单个内核节点。 可以在相应的命令行或UI选项中切换此行为。
启用此模式的主要用例是
分析包含强制并发内核节点的图。
分析包含设备端图启动的图。
更准确地分析跨多个内核节点启动的图行为,因为节点之间不会清除缓存。
请注意,当启用图性能分析时,某些指标(例如指令级源指标)不可用。 这也适用于在图外部分析性能的内核。
2.2.4. 兼容性
可用的重放模式和指标集取决于要分析性能的 GPU 工作负载类型。
工作负载类型 |
重放模式 |
指标组 |
|||||||
内核 |
应用程序 |
范围 |
应用程序-范围 |
硬件计数器 / SMSP |
单元级源 |
指令级源 3 |
启动 |
Warp/PM 采样 |
|
内核 |
是 |
是 |
是 2 |
是 2 |
是 |
是 |
是 |
是 |
是 |
范围 |
否 |
否 |
是 |
是 |
是 |
否 |
是 |
部分 |
是 |
Cmdlist |
是 |
否 |
否 |
否 |
是 |
是 |
是 |
部分 |
是 |
图 1 |
是 |
否 |
否 |
否 |
是 |
否 |
否 |
部分 |
是 |
脚注
2.2.5. 性能分析系列
内核的性能高度依赖于使用的启动参数。 启动参数的微小更改会对内核的运行时行为产生重大影响。 但是,通过手动测试大量组合来识别内核的最佳参数集可能是一个繁琐的过程。
为了使此工作流程更快、更方便,性能分析系列提供了自动使用更改的参数多次分析单个内核性能的能力。 要修改的参数和要测试的值可以独立启用和配置。 对于选定的参数值的每个组合,都会收集唯一的性能分析结果。 修改后的参数值会在系列结果的描述中进行跟踪。 通过比较性能分析系列的结果,可以看到内核在更改参数时的行为,并且可以快速识别最佳参数集。

性能分析系列操作。
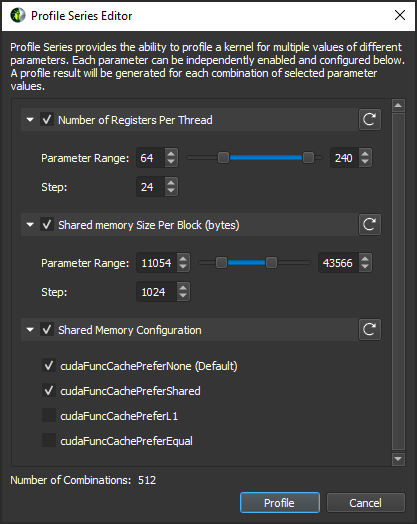
性能分析系列对话框。
2.2.6. 开销
与大多数测量一样,使用 NVIDIA Nsight Compute CLI 收集性能数据会对应用程序产生一些运行时开销。 开销取决于许多不同的因素
收集的指标的数量和类型
根据所选的指标,数据可以通过 GPU 上的硬件性能监视器、内核指令的软件补丁或通过启动或设备属性来收集。 这些机制之间的开销差异很大,启动和设备属性“静态”可用,并且不需要内核运行时开销。
此外,在内核执行的单个通道中只能收集有限数量的指标。 如果请求更多指标,则内核启动将重放多次,并在后续通道之间保存和恢复其可访问的内存,以保证确定性执行。 因此,收集更多指标可能会通过需要更多重放通道并增加重放期间需要恢复的内存总量来显着增加开销。
收集的节集合
由于每个集合都指定要收集的节组,因此选择不太全面的集合可以减少性能分析开销。 请参阅NVIDIA Nsight Compute CLI文档中的
--set命令。收集的节的数量
由于每个节都指定了要收集的指标数量,因此选择更少的节可以减少性能分析开销。 请参阅NVIDIA Nsight Compute CLI文档中的
--section命令。性能分析内核的数量
默认情况下,为所有启动的内核收集所有选定的指标。 为了减少对应用程序的影响,您可以尝试将性能数据收集限制为您分析所需的尽可能少的内核函数和实例。 请参阅NVIDIA Nsight Compute CLI文档中的筛选命令。
每个上下文中第一个分析性能的内核生成指标配置的一次性开销相对较高。 如果收集的指标列表保持不变,则同一上下文中后续内核不会发生此开销。
GPU 架构
对于某些指标,开销可能会因收集指标的确切芯片而异,例如,由于芯片上单元数量不同。 同样,在内核重放通道之间重置 L2 缓存的开销取决于该缓存的大小。
2.3. 指标指南
2.3.1. 硬件模型
计算模型
所有 NVIDIA GPU 均设计为支持通用异构并行编程模型,通常称为计算。此模型将 GPU 从传统图形管线中解耦出来,并将其作为通用并行多处理器公开。异构计算模型意味着主机和设备的存在,在本例中分别是 CPU 和 GPU。从高层次的角度来看,主机 (CPU) 管理自身和设备之间的资源,并将工作发送到设备以并行执行。
计算模型的核心是网格、块、线程层级结构,它定义了计算工作如何在 GPU 上组织。层级结构从上到下如下:
网格是线程块的 1D、2D 或 3D 阵列。
块是线程的 1D、2D 或 3D 阵列,也称为协同线程阵列 (CTA)。
线程是在 GPU 的 SM 单元之一上运行的单个线程。
网格、块、线程层级结构的目的在于公开线程组之间的局部性概念,即协同线程阵列 (CTA)。在 CUDA 中,CTA 被称为线程块。该架构可以通过在单个 CTA 内的线程之间提供快速共享内存和屏障来利用这种局部性。当启动网格时,该架构保证 CTA 内的所有线程将在同一 SM 上并发运行。有关网格和块的信息可以在 启动统计信息 部分中找到。
每个 SM 上可以容纳的 CTA 数量取决于 CTA 所需的物理资源。这些资源限制因素包括线程和寄存器的数量、共享内存利用率以及硬件屏障。每个 SM 的 CTA 数量称为 CTA 占用率,这些物理资源限制了此占用率。内核占用率的详细信息由 占用率 部分收集。
每个 CTA 都可以调度到任何可用的 SM 上,但执行顺序没有保证。因此,CTA 必须完全独立,这意味着一个 CTA 不可能等待另一个 CTA 的结果。由于 CTA 是独立的,因此主机 (CPU) 可以启动一个大型网格,该网格不会一次性全部装入硬件,但是任何 GPU 仍然能够运行它并产生正确的结果。
CTA 进一步分为 32 个线程的组,称为warp。如果 CTA 中的线程数不能被 32 整除,则最后一个 warp 将包含剩余的线程数。
可以在给定 GPU 上并发运行的 CTA 总数称为 Wave。因此,Wave 的大小随 GPU 可用 SM 的数量以及内核的占用率而扩展。
流式多处理器
流式多处理器 (SM) 是 GPU 中的核心处理单元。SM 针对各种工作负载进行了优化,包括通用计算、深度学习、光线追踪以及光照和着色。SM 旨在同时执行多个 CTA。CTA 可以来自不同的网格启动。
SM 实现了一种称为单指令多线程 (SIMT) 的执行模型,该模型允许单个线程在仍然作为 warp 的一部分执行时具有唯一的控制流。Turing SM 继承了 Volta SM 的独立线程调度模型。SM 维护每个线程的执行状态,包括程序计数器 (PC) 和调用堆栈。独立线程调度允许 GPU 暂停任何线程的执行,以便更好地利用执行资源或允许线程等待可能在同一 warp 中由另一个线程生成的数据。收集 源计数器 部分允许您在源页面上检查指令执行和谓词详细信息,以及 采样 信息。
每个 SM 分为四个处理块,称为 SM 子分区。SM 子分区是 SM 上的主要处理元件。每个子分区包含以下单元:
Warp 调度器
寄存器文件
执行单元/管线/核心
整数执行单元
浮点执行单元
内存加载/存储单元
特殊功能单元
张量核心
在四个 SM 分区之间在 SM 内共享的是:
统一 L1 数据缓存 / 共享内存
纹理单元
RT 核心(如果可用)
warp 被分配给一个子分区,并从启动到完成都驻留在该子分区上。当 warp 映射到子分区时,warp 被称为活动或驻留。子分区管理固定大小的 warp 池。在 Volta 架构上,池的大小为 16 个 warp。在 Turing 架构上,池的大小为 8 个 warp。如果 warp 已准备好发出指令,则活动 warp 可以处于合格状态。这要求 warp 具有解码后的指令,所有输入依赖项都已解决,并且功能单元可用。调度器统计信息 部分可以收集有关活动、合格和正在发出的 warp 的统计信息。
当 warp 正在等待时,warp 会停顿:
指令获取,
内存依赖性(内存指令的结果),
执行依赖性(先前指令的结果),或
同步屏障。
有关可以分析的停顿原因列表,请参阅 Warp 调度器状态,有关内核执行中发现的 warp 状态摘要,请参阅 Warp 状态统计信息 部分。
编译器控制下最重要的资源是内核使用的寄存器数量。启动统计信息 部分显示了内核的寄存器使用情况。
计算抢占
计算抢占避免了长时间运行的内核垄断 GPU,但存在上下文切换开销的风险。执行上下文(寄存器、共享内存等)在抢占时保存,并在稍后恢复。上下文切换发生在指令级粒度。独占进程计算模式可以在受支持的系统上使用,以避免上下文切换。
内存
全局内存是一个 49 位虚拟地址空间,它映射到设备上的物理内存、固定的系统内存或对等内存。全局内存对 GPU 中的所有线程都可见。全局内存通过 SM L1 和 GPU L2 访问。
本地内存是执行线程的私有存储,在线程外部不可见。它用于线程本地数据,如线程堆栈和寄存器溢出。本地内存地址由 AGU 单元转换为全局虚拟地址。本地内存的延迟与全局内存相同。全局内存和本地内存之间的一个区别是,本地内存的排列方式使得连续的 32 位字由连续的线程 ID 访问。因此,只要 warp 中的所有线程都访问相同的相对地址(例如,数组变量中的相同索引,结构变量中的相同成员等),访问就会完全合并。
共享内存位于芯片上,因此它比本地内存或全局内存具有更高的带宽和更低的延迟。共享内存可以在计算 CTA 之间共享。尝试通过共享内存跨线程共享数据的计算 CTA 必须在存储和加载之间使用同步操作(例如 __syncthreads()),以确保任何一个线程写入的数据对 CTA 中的其他线程可见。同样,需要通过全局内存共享数据的线程必须使用更重量级的全局内存屏障。
共享内存有 32 个库,这些库的组织方式使得连续的 32 位字映射到可以同时访问的连续库。因此,对 32 个不同内存库中的 32 个地址发出的任何 32 位内存读取或写入请求都可以同时得到服务,从而产生的总带宽是单个请求带宽的 32 倍。但是,如果内存请求的两个地址落在同一个内存库中,则会发生库冲突,并且访问必须串行化。
warp 的共享内存请求不会在访问同一 32 位字内任何地址的两个线程之间产生库冲突(即使这两个地址落在同一个库中)。当多个线程进行相同的读取访问时,一个线程接收数据,然后将其广播到其他线程。当多个线程写入到同一位置时,只有一个线程写入成功;哪个线程成功是未定义的。
详细的内存指标由 内存工作负载分析 部分收集。
缓存
所有 GPU 单元都通过二级缓存(也称为 L2)与主内存通信。L2 缓存位于片上内存客户端和帧缓冲区之间。L2 在物理地址空间中工作。除了提供缓存功能外,L2 还包括执行压缩和全局原子操作的硬件。
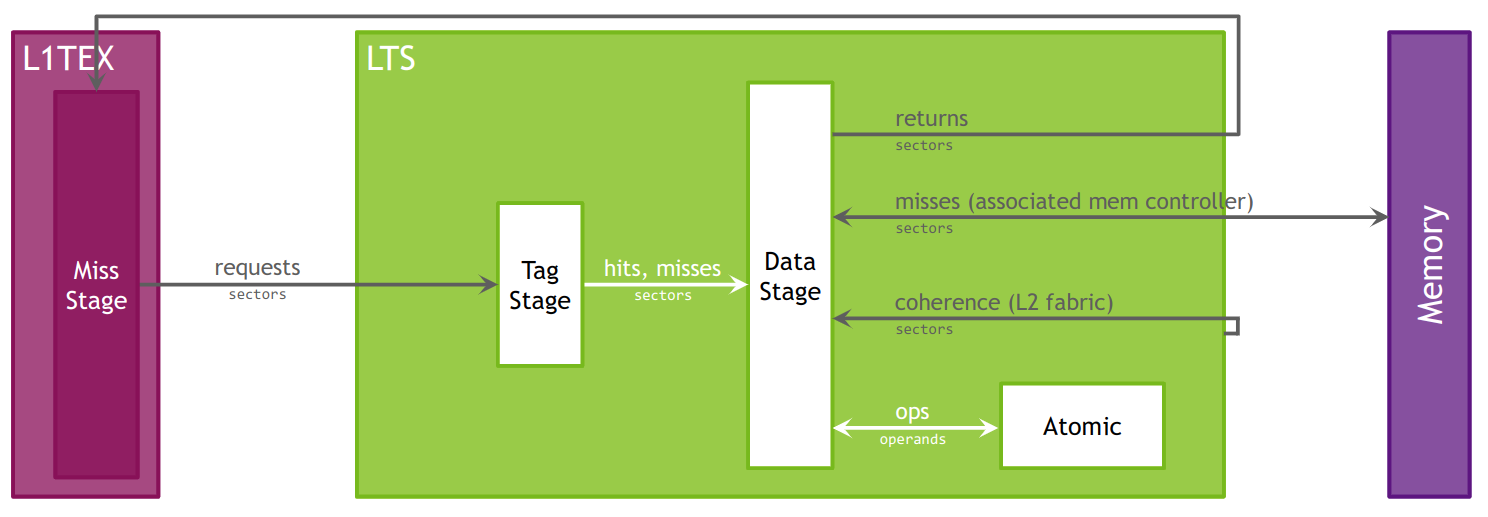
L2 缓存模型。
一级数据缓存(或 L1)在处理全局、本地、共享、纹理和表面内存的读取和写入,以及归约和原子操作中起着关键作用。在 Volta 和 Turing 架构上,每个 TPC 有两个 L1 缓存,每个 SM 一个。有关 L1 如何适应纹理管线的更多信息,请参阅 TEX 单元 描述。另请注意,虽然本节经常使用名称“L1”,但应理解 L1 数据缓存、共享数据和纹理数据缓存是同一个。
L1 接收来自两个单元的请求:SM 和 TEX。L1 接收来自 SM 的全局和本地内存请求,并接收来自 TEX 的纹理和表面请求。这些操作访问全局内存空间中的内存,L1 通过二级缓存 L2 发送这些请求。
缓存命中率和未命中率以及数据传输在 内存工作负载分析 部分中报告。
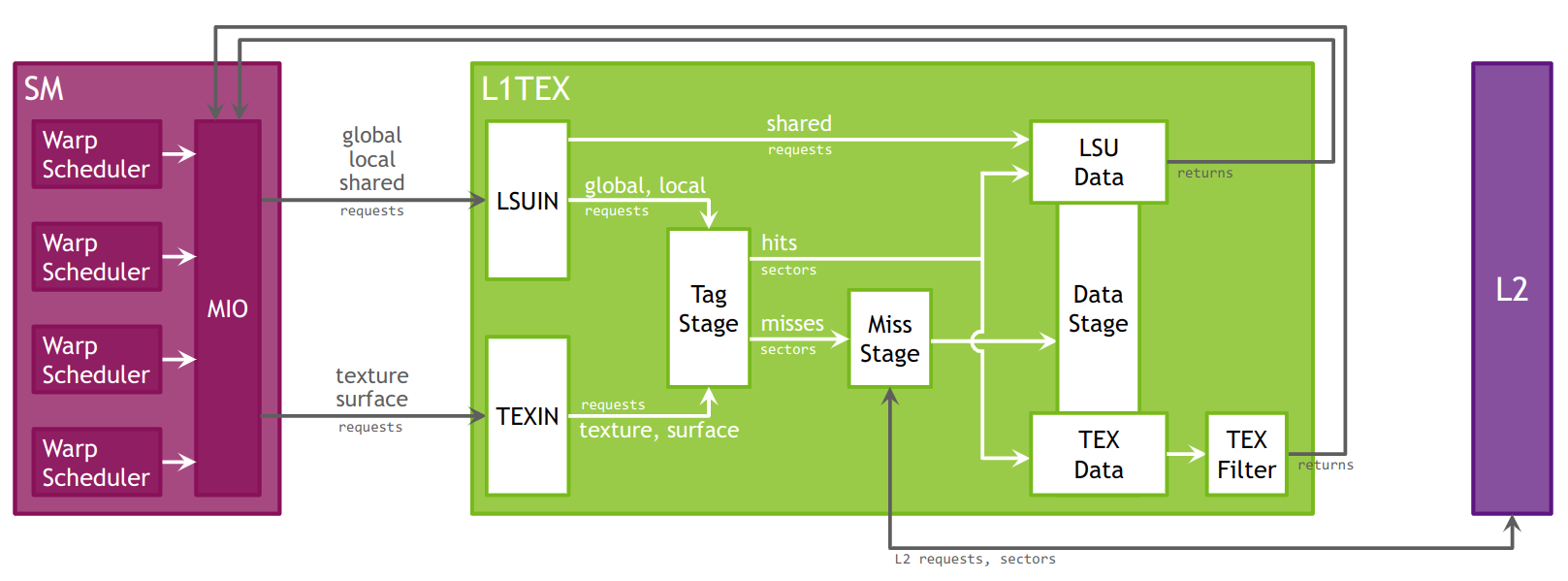
L1TEX 缓存的加载/存储和纹理管线模型。
纹理/表面
TEX 单元执行纹理获取和过滤。除了普通的纹理内存访问外,TEX 还负责将纹理读取请求转换为结果所需的寻址、LOD、wrap、filter 和格式转换操作。
TEX 通过其输入接口接收来自 SM 的两个一般类别的请求:纹理请求和表面加载/存储操作。纹理和表面内存空间驻留在设备内存中,并缓存在 L1 中。纹理和表面内存以块线性表面(例如 2D、2D 阵列、3D)分配。此类表面提供了数据的缓存友好布局,使得 2D 表面上的相邻点在内存中也彼此靠近,从而提高了访问局部性。表面访问在访问内存之前由 TEX 单元进行边界检查,这可以用于实现不同的纹理 wrap 模式。
L1 缓存针对 2D 空间局部性进行了优化,因此同一 warp 的线程读取在 2D 空间中彼此靠近的纹理或表面地址将获得最佳性能。L1 缓存也设计用于具有恒定延迟的流式获取;缓存命中减少了 DRAM 带宽需求,但不会减少获取延迟。通过纹理或表面内存读取设备内存呈现出一些优点,这些优点使其成为从全局或常量内存读取内存的有利替代方案。
有关纹理和表面内存的信息可以在 内存工作负载分析 部分中找到。
2.3.2. 指标结构
指标概述
NVIDIA Nsight Compute 使用先进的指标计算系统,旨在帮助您确定发生了什么(计数器和指标),以及程序达到 GPU 峰值性能的接近程度(通过吞吐量百分比)。每个计数器在数据库中都有关联的峰值速率,以允许计算其吞吐量百分比。
吞吐量指标返回其组成计数器的最大百分比值。这些组成部分经过精心选择,以表示控制峰值性能的 GPU 管线部分。虽然所有计数器都可以转换为峰值的百分比,但并非所有计数器都适用于峰值性能分析;不适用计数器的示例包括活动的合格子集和工作负载驻留计数器。使用吞吐量指标可确保有意义且可操作的分析。
每个计数器都有两种类型的峰值速率可用:突发速率和持续速率。突发速率是单个时钟周期内可报告的最大速率。持续速率是在无限长的测量周期内针对“典型”操作可实现的最大速率。对于许多计数器,突发速率等于持续速率。由于突发速率无法超过,因此突发速率的百分比将始终小于 100%。在极端情况下,持续速率的百分比有时可能会超过 100%。
指标实体
虽然在 NVIDIA Nsight Compute 中,所有性能计数器都称为指标,但它们可以进一步分为具有特定属性的组。对于通过 PerfWorks 测量库收集的指标,存在以下实体:
计数器可以是来自 GPU 的原始计数器,也可以是计算的计数器值。每个计数器下都有四个子指标,也称为汇总:
|
所有单元实例的计数器值的总和。 |
|
所有单元实例的计数器值的平均值。 |
|
所有单元实例的计数器值的最小值。 |
|
所有单元实例的计数器值的最大值。 |
计数器汇总具有以下计算量作为内置子指标:
|
峰值持续速率 |
|
单元活动周期内的峰值持续速率 |
|
单元活动周期内的峰值持续速率,每秒 * |
|
单元经过周期内的峰值持续速率 |
|
单元经过周期内的峰值持续速率,每秒 * |
|
每秒操作数 |
|
每个单元活动周期的操作数 |
|
每个单元经过周期的操作数 |
|
单元活动周期内达到的峰值持续速率的百分比 |
|
单元经过周期内达到的峰值持续速率的百分比 |
* NVIDIA Nsight Compute 2022.2.0 中添加的子指标。
示例:ncu --query-metrics-mode suffix --metrics sm__inst_executed --chip ga100
比率有三个子指标:
|
以百分比表示的值。 |
|
以比率表示的值。 |
|
比率的最大值。 |
示例:ncu --query-metrics-mode suffix --metrics smsp__average_warp_latency --chip ga100
吞吐量指示 GPU 的一部分达到峰值速率的接近程度。每个吞吐量都有以下子指标:
|
单元活动周期内达到的峰值持续速率的百分比 |
|
单元经过周期内达到的峰值持续速率的百分比 |
示例:ncu --query-metrics-mode suffix --metrics sm__throughput --chip ga100
吞吐量具有计算吞吐量值的底层指标的细分。您可以收集 breakdown:<throughput-metric> 以收集吞吐量的细分指标。
已弃用的计数器子指标: 以下子指标已被删除,因为它们对性能优化没有用处:
|
峰值突发速率 |
|
单元活动周期内达到的峰值突发速率的百分比 |
|
单元经过周期内达到的峰值突发速率的百分比 |
|
在用户指定的“范围”内达到的峰值突发速率的百分比 |
|
在用户指定的“帧”内达到的峰值突发速率的百分比 |
|
在用户指定的“范围”时间内达到的峰值持续速率的百分比 |
|
在用户指定的“帧”时间内达到的峰值持续速率的百分比 |
|
每个用户指定的“范围”周期的操作数 |
|
每个用户指定的“帧”周期的操作数 |
|
用户指定的“范围”内的峰值持续速率 |
|
用户指定的“范围”内的峰值持续速率,每秒 * |
|
用户指定的“帧”内的峰值持续速率 |
|
用户指定的“帧”内的峰值持续速率,每秒 * |
已弃用的吞吐量子指标: 以下子指标已被删除,因为它们对性能优化没有用处:
|
单元活动周期内达到的峰值突发速率的百分比 |
|
单元经过周期内达到的峰值突发速率的百分比 |
|
在用户指定的“范围”时间内达到的峰值突发速率的百分比 |
|
在用户指定的“帧”时间内达到的峰值突发速率的百分比 |
|
在用户指定的“范围”内达到的峰值持续速率的百分比 |
|
在用户指定的“帧”内达到的峰值持续速率的百分比 |
除了 PerfWorks 指标外,NVIDIA Nsight Compute 还使用多个其他测量提供程序,每个提供程序都生成自己的指标。这些在 指标参考 中进行了解释。
指标示例
## non-metric names -- *not* directly evaluable
sm__inst_executed # counter
smsp__average_warp_latency # ratio
sm__throughput # throughput
## a counter's four first-level sub-metrics -- all evaluable
sm__inst_executed.sum
sm__inst_executed.avg
sm__inst_executed.min
sm__inst_executed.max
## all names below are metrics -- all evaluable
l1tex__data_bank_conflicts_pipe_lsu.sum
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_sustained
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_sustained_active
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_sustained_active.per_second
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_sustained_elapsed
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_sustained_elapsed.per_second
l1tex__data_bank_conflicts_pipe_lsu.sum.per_cycle_active
l1tex__data_bank_conflicts_pipe_lsu.sum.per_cycle_elapsed
l1tex__data_bank_conflicts_pipe_lsu.sum.per_second
l1tex__data_bank_conflicts_pipe_lsu.sum.pct_of_peak_sustained_active
l1tex__data_bank_conflicts_pipe_lsu.sum.pct_of_peak_sustained_elapsed
...
指标命名约定
计数器和指标通常遵守命名方案:
单元级计数器:
unit__(subunit?)_(pipestage?)_quantity_(qualifiers?)接口计数器:
unit__(subunit?)_(pipestage?)_(interface)_quantity_(qualifiers?)单元指标:
(counter_name).(rollup_metric)子指标:
(counter_name).(rollup_metric).(submetric)
其中:
unit:GPU 的逻辑或物理单元
subunit:计数器测量的单元内的子单元。有时这也是一种管线模式。
pipestage:计数器测量的子单元内的管线阶段。
quantity:正在测量的量。通常与量纲单位匹配。
qualifiers:应用于计数器的任何其他谓词或过滤器。通常,未限定的计数器可以分解为多个限定的子组件。
interface:形式为
sender2receiver,其中sender是源单元,receiver是目标单元。rollup_metric:sum、avg、min、max 之一。
submetric:请参阅 指标实体 部分
组件并非总是存在。大多数顶级计数器没有限定符。子单元和管线阶段可能在不相关的地方不存在,或者详细的计数器可能有很多子单元说明符。
周期指标
名称中包含术语 cycles 的计数器报告单元时钟域中的周期数。单元级周期指标包括:
unit__cycles_elapsed:范围内的周期数。周期的 DimUnits 特定于单元的时钟域。unit__cycles_active:单元正在处理数据的周期数。unit__cycles_stalled:由于其输出接口被阻止,单元无法处理新数据的周期数。unit__cycles_idle:单元空闲的周期数。
接口级周期计数器通常(并非总是)在以下变体中可用:
unit__(interface)_active:数据从源单元传输到目标单元的周期。unit__(interface)_stalled:源单元有数据,但目标单元无法接受数据的周期。
实例化的指标
使用 NVIDIA Nsight Compute 收集的指标可以具有单个(聚合)值、多个实例值或两者兼而有之。实例允许指标具有多个子值,例如,表示每个指令偏移处的源指标的值。如果指标具有实例值,则它通常还具有每个实例的相关 ID。相关 ID 和值形成一个映射,该映射允许工具关联上下文中的值。对于源指标,该上下文通常是作为工作负载一部分执行的函数的地址范围。
您可以在 指标参考 中找到哪些指标具有实例值。在 UI 中,指标详细信息 工具窗口可用于方便地查看每个指标的相关 ID 和实例值。此外,UI 和命令行界面都提供了选项,除了指标聚合之外,还显示实例值(如果适用)。
2.3.3. 指标解码器
以下解释了在 指标结构 中介绍的 NVIDIA Nsight Compute 指标名称中找到的术语。
单元
单元
ctc专用、高带宽、内存一致性 NVLink 芯片到芯片 (C2C) 互连,可以访问扩展 GPU 内存 (EGM)。
有关更多信息,请参阅 https://developer.nvidia.com/blog/nvidia-grace-hopper-superchip-architecture-in-depth/。
dram设备(主)内存,GPU 全局内存和本地内存驻留的位置。
fbpa帧缓冲区分区是位于二级缓存 (LTC) 和 DRAM 之间的内存控制器。FBPA 的数量因 GPU 而异。
fe前端单元负责驱动程序发送的工作负载的整体流程。FE 还促进了许多同步操作。
gpc通用处理集群以 TPC(s) 的形式包含 SM、纹理和 L1。它在一个芯片上复制多次。
gpu整个图形处理单元。
gr图形引擎负责所有 2D 和 3D 图形、计算工作以及同步图形复制工作。
gxcGPC XBAR 压缩器尝试在将来自 GPC 的完全覆盖的 128B 写入发送到 L2 缓存之前对其进行压缩。在读取请求时,L2 缓存返回压缩数据。GXC 解压缩并返回请求的未压缩扇区。
idc索引常量缓存是 SM 的一个子单元,负责缓存使用寄存器索引的常量。
l1tex一级 (L1)/纹理缓存位于 GPC 内。它可以作为定向映射的共享内存使用,和/或在其缓存部分中存储全局、本地和纹理数据。l1tex__t 指的是其标记阶段。l1tex__m 指的是其未命中阶段。l1tex__d 指的是其数据阶段。
lrcL2 请求合并器 (LRC) 处理传入的 L2 请求,并尝试在将读取请求转发到 L2 缓存之前对其进行合并。它还为来自 SM 的程序化组播请求提供服务,并支持写入压缩。
ltc二级缓存。
ltcfabricLTC 结构是 L2 缓存分区的通信结构。
lts二级 (L2) 缓存切片是二级缓存的子分区。lts__t 指的是其标记阶段。lts__m 指的是其未命中阶段。lts__d 指的是其数据阶段。
mccMSS 的内存控制器通道。内存子系统 (MSS) 提供对本地 DRAM、SysRAM 的访问,并为处理器间信令提供 SyncPoint 接口。MCC 包括行排序器/仲裁器和 DRAM 控制器。
nvlrxNVLink 接收器。
nvltxNVLink 发射器。
pm性能监视器。
sm流式多处理器处理内核的执行,作为 32 个线程的组,称为 warp。Warp 进一步分组为协同线程阵列 (CTA),在 CUDA 中称为块。CTA 的所有 warp 都在同一 SM 上执行。CTA 在其线程之间共享各种资源,例如共享内存。
smsp每个 SM 分为四个处理块,称为 SM 子分区。SM 子分区是 SM 上的主要处理元件。子分区管理固定大小的 warp 池。
sys多个单元的逻辑分组。
syslrcLRC 的简化版本,用于 SysL2,仅为来自 SM 的程序化组播请求提供服务。
sysltsSysL2 是系统和对等内存的二级缓存。
tpc线程处理集群是 GPC 中的单元。它们包含一个或多个 SM、纹理和 L1 单元、指令缓存 (ICC) 和索引常量缓存 (IDC)。
vidlrc用于全局(视频)内存的 LRC。
xcomp交叉开关 (XBAR) 压缩器。
子单元
子单元
aperture_device到本地设备内存 (dram) 的内存接口
aperture_peer到远程设备内存的内存接口
aperture_sysmem到系统内存的内存接口
global全局内存是一个 49 位虚拟地址空间,它映射到设备上的物理内存、固定的系统内存或对等内存。全局内存对 GPU 中的所有线程都可见。全局内存通过 SM L1 和 GPU L2 访问。
ilc内联压缩器 (ILC) 是 LRC 的一部分。它在数据写入 L2 之前尽可能压缩写入,并在响应读取请求时解压缩数据。
lg本地/全局内存
local本地内存是执行线程的私有存储,在线程外部不可见。它用于线程本地数据,如线程堆栈和寄存器溢出。本地内存的延迟与全局内存相同。
lsu加载/存储单元
lsuin加载/存储输入
mio内存输入/输出
mioc内存输入/输出控制
shared共享内存位于芯片上,因此它比本地内存或全局内存具有更高的带宽和更低的延迟。共享内存可以在计算 CTA 之间共享。
surface表面内存
texinTEXIN
texture纹理内存
workid网格中工作单元的 ID。
xbar交叉开关 (XBAR) 负责将数据包从给定的源单元传输到特定的目标单元。
管线
管线
adu地址发散单元。ADU 负责处理分支/跳转的地址发散。它还为常量加载和块级屏障指令提供支持。
alu算术逻辑单元。ALU 负责执行大多数位操作和逻辑指令。它还执行整数指令,但不包括 IMAD 和 IMUL。在 NVIDIA Ampere 架构芯片上,ALU 管线执行快速 FP32 到 FP16 转换。
cbu收敛屏障单元。CBU 负责 warp 级收敛、屏障和分支指令。
fma融合乘加/累加。FMA 管线处理大多数 FP32 算术运算(FADD、FMUL、FMAD)。它还执行整数乘法运算(IMUL、IMAD)以及整数点积。在 GA10x 上,FMA 是一个逻辑管线,指示峰值 FP32 和 FP16x2 性能。它由 FMAHeavy 和 FMALite 物理管线组成。
fmaheavy融合乘加/累加重型。FMAHeavy 执行 FP32 算术运算(FADD、FMUL、FMAD)、FP16 算术运算(HADD2、HMUL2、HFMA2)、整数乘法运算(IMUL、IMAD)和整数点积。
fmalite融合乘加/累加轻型。FMALite 执行 FP32 算术运算(FADD、FMUL、FMA)和 FP16 算术运算(HADD2、HMUL2、HFMA2)。
fp16半精度浮点。在 Volta、Turing 和 NVIDIA GA100 上,FP16 管线执行配对的 FP16 指令 (FP16x2)。它还包含一个快速 FP32 到 FP16 和 FP16 到 FP32 转换器。从 GA10x 芯片开始,此功能是 FMA 管线的一部分。
fp64双精度浮点。FP64 的实现因芯片而异。
lsu加载存储单元。LSU 管线向 L1TEX 单元发出加载、存储、原子和归约指令,用于全局、本地和共享内存。它还向 L1TEX 单元发出特殊寄存器读取 (S2R)、shuffle 和 CTA 级到达/等待屏障指令。
tc张量核心。TC 管线执行 UTCBAR、UTCCP、UTC*MMA、UTCSHIFT 和 UTC*SWS 指令。它与张量管线不同。
tensor张量管线执行各种 MMA 指令。它与张量核心管线不同。
tex纹理单元。SM 纹理管线将纹理和表面指令转发到 L1TEX 单元的 TEXIN 阶段。在 FP64 或张量管线解耦的 GPU 上,纹理管线也转发这些类型的指令。
tma张量内存访问单元。提供全局内存和共享内存之间的高效数据传输机制,并能够理解和遍历多维数据布局。
tmem张量内存。TMEM 管线执行 FENCE.VIEW.ASYNC.T、LDT(M) 和 STT(M) 指令。TMEM 也指 SM 子分区 (SMSP) 内的专用张量内存。
uniform统一数据路径。此标量单元执行所有线程使用相同输入并生成相同输出的指令。
xu超越和数据类型转换单元。XU 管线负责特殊功能,如 sin、cos 和倒数平方根。它还负责 int 到 float 和 float 到 int 类型转换。
量
量
instruction汇编 (SASS) 指令。每个执行的指令可能会生成零个或多个请求。
request进入硬件单元以执行某些操作的命令,例如从某个内存位置加载数据。每个请求访问一个或多个扇区。
sector缓存行或设备内存中对齐的 32 字节块。L1 或 L2 缓存行是四个扇区,即 128 字节。如果标记存在且扇区数据存在于缓存行内,则扇区访问被归类为命中。标记未命中和标记命中数据未命中都被归类为未命中。
tag缓存行的唯一键。如果线程地址并非都落在单个缓存行对齐区域内,则请求可能会查找多个标记。L1 和 L2 都具有 128 字节的缓存行。标记访问可以归类为命中或未命中。
wavefront在请求处理阶段的末尾生成的唯一“工作包”。一个波前的所有工作项并行处理,而不同波前的工作项串行处理,并在不同的周期中处理。每个请求至少生成一个波前。
Volta 及更新架构中 L1TEX 处理的简化模型可以描述如下:当 SM 为一个 warp 执行全局或本地内存指令时,会向 L1TEX 发送单个请求。此请求传达此 warp 中所有参与线程的信息(最多 32 个)。对于本地和全局内存,基于访问模式和参与线程,该请求需要访问若干缓存行以及这些缓存行中的扇区。L1TEX 单元内部有多个流水线操作的处理阶段。
波前是每个周期可以通过该流水线阶段的最大单元。如果并非所有缓存行或扇区都可以在单个波前中访问,则会创建多个波前并逐个发送以进行处理,即以串行方式处理。波前内工作的限制可能包括需要一致的内存空间、可以访问的最大缓存行数以及各种其他原因。然后,每个波前流经 L1TEX 流水线,并获取在该波前中处理的扇区。此模型中三个关键值的给定关系是请求:扇区为 1:N,波前:扇区为 1:N,以及请求:波前为 1:N。
波前被描述为一个可以一次处理的(工作)包,即在 L1TEX 中存在每个周期处理一个波前的概念。因此,波前代表处理请求所需的周期数,而每个请求的扇区数是所有参与线程的内存指令的访问模式的属性。例如,可能存在一个内存指令,每个请求需要 4 个扇区,并且在 1 个波前中完成。但是,您也可能有一个内存指令,每个请求有 4 个扇区,但需要 2 个或更多波前。
2.3.4. 范围和精度
概述
通常,超出指标预期逻辑范围的测量值可归因于以下一个或多个根本原因。如果值超出此范围,工具不会出于故意将其钳制在其预期值,以确保分析器报告的其余部分保持自身一致性。
异步 GPU 活动
指标测量的 GPU 引擎以外的其他 GPU 引擎(显示、复制引擎、视频编码器、视频解码器等)可能在分析期间访问共享资源。此类芯片全局共享资源包括 L2、DRAM、PCIe 和 NVLINK。如果内核启动较小,则其他引擎可能会在 DRAM 结果中引起明显的混淆,因为它无法隔离 SM 的 DRAM 流量。为了减少此类异步单元的影响,请考虑在没有活动显示且没有其他进程可以在此时访问 GPU 的 GPU 上进行分析。
多趟数据收集
当分析器重放内核启动以收集指标,并且工作分配在重放趟次之间显着不同时,通常会发生超出范围的指标。如果命中和查询在不同的趟次中收集,并且内核未饱和 GPU 以达到稳态(通常 > 20 µs),则诸如命中率(命中数 / 查询数)之类的指标可能会出现显着误差。同样,当工作负载本质上是可变的(例如,在自旋循环的情况下)时,它可能会显示意外的值。
为了缓解此问题,在适用时,尝试增加测量的工作负载,以允许 GPU 在每次启动时达到稳态。减少同时收集的指标数量也可以通过增加在单趟次中收集有助于一个指标的计数器的可能性来提高精度。
工具问题
如果在遵循上述指南后仍然观察到指标问题,请联系我们并描述您的问题。
2.4. 指标参考
概述
可以使用 ncu 命令行界面的 –query-metrics 选项查询 NVIDIA Nsight Compute 中的大多数指标。
以下指标可以显式收集,但不遵循 指标结构 中解释的命名方案。它们应按原样使用。可以使用 --query-metrics 按照 –query-metrics-collection 选项列出这些指标。
launch__* 指标是按内核启动收集的,不需要额外的重放趟次。它们作为内核启动参数(例如网格大小、块大小等)的一部分提供,或者使用 CUDA 占用率计算器 计算得出。对于基于范围的结果,launch__* 指标针对每次启动进行实例化,但 launch__uses_*、launch__graph_* 和 launch__occupancy_per_* 除外。
启动指标
启动指标
launch__barrier_count内核启动中的屏障数量。
launch__block_dim_x内核启动在 X 维度中的最大线程数。
launch__block_dim_y内核启动在 Y 维度中的最大线程数。
launch__block_dim_z内核启动在 Z 维度中的最大线程数。
launch__block_size内核启动的每个块的最大总线程数。
launch__cluster_dim_x内核启动在 X 维度中的集群数。
launch__cluster_dim_y内核启动在 Y 维度中的集群数。
launch__cluster_dim_z内核启动在 Z 维度中的集群数。
launch__cluster_max_active目标设备上可以共存的最大集群数。运行时环境可能会影响硬件调度集群的方式,因此无法保证计算出的占用率是可实现的。
launch__cluster_max_potential_size内核函数和启动配置的最大有效集群大小。
launch__cluster_scheduling_policy集群调度策略。
launch__context_id内核启动的 CUDA 上下文 ID(如果启动在绿色上下文中,则为主上下文的 ID)。
launch__device_id内核启动的 CUDA 设备 ID。
launch__func_cache_config在 L1 缓存和共享内存使用相同硬件资源的设备上,这是 CUDA 函数的首选缓存配置。运行时将在可能的情况下使用请求的配置,但如果需要,运行时可以自由选择不同的配置。
launch__function_pcs内核函数入口 PC。
launch__graph_contains_device_launch如果分析图中的任何节点可以启动 CUDA 设备图,则设置为 1。
launch__graph_is_device_launchable如果分析图是可设备启动的,则设置为 1。
launch__green_context_id内核启动的绿色上下文的 CUDA 上下文 ID(如果适用)。
launch__grid_dim_x内核启动在 X 维度中的最大块数。
launch__grid_dim_y内核启动在 Y 维度中的最大块数。
launch__grid_dim_z内核启动在 Z 维度中的最大块数。
launch__grid_size内核启动的最大总块数。
launch__kernel_name内核启动中内核的名称。
launch__occupancy_cluster_gpu_pct集群导致的总体 GPU 占用率。
launch__occupancy_cluster_pct由于集群,活动块与最大可能活动块的比率。
launch__occupancy_limit_barriers由于使用的屏障数量而导致的占用率限制。
launch__occupancy_limit_blocks由于每个 SM 可管理的最大块数而导致的占用率限制。
launch__occupancy_limit_registers由于寄存器使用而导致的占用率限制。
launch__occupancy_limit_shared_mem由于共享内存使用而导致的占用率限制。
launch__occupancy_limit_warps由于块大小而导致的占用率限制。
launch__occupancy_per_barrier_count给定屏障计数的活动 warp 数。
实例值从 warp 数 (uint64) 映射到值 (uint64)。
launch__occupancy_per_block_size给定块大小的活动 warp 数。
实例值从 warp 数 (uint64) 映射到值 (uint64)。
launch__occupancy_per_cluster_size给定集群大小的活动集群数。
实例值从集群数 (uint64) 映射到值 (uint64)。
launch__occupancy_per_register_count给定寄存器计数的活动 warp 数。
实例值从 warp 数 (uint64) 映射到值 (uint64)。
launch__occupancy_per_shared_mem_size给定共享内存大小的活动 warp 数。
实例值从 warp 数 (uint64) 映射到值 (uint64)。
launch__registers_per_thread每个线程分配的寄存器数。
launch__registers_per_thread_allocated每个线程分配的寄存器数。
launch__shared_mem_config_size为内核启动配置的共享内存大小。该大小取决于静态、动态和驱动程序共享内存需求以及指定的或平台确定的配置大小。
launch__shared_mem_per_block每个块的共享内存大小。
launch__shared_mem_per_block_allocated每个块分配的共享内存大小。
launch__shared_mem_per_block_driver每个块的共享内存大小,为 CUDA 驱动程序分配。
launch__shared_mem_per_block_dynamic每个块的动态共享内存大小,为内核分配。
launch__shared_mem_per_block_static每个块的静态共享内存大小,为内核分配。
launch__sm_count启动中使用的 SM 数量。
launch__stack_size启动期间的堆栈大小。
launch__stream_id内核启动的 CUDA 流 ID。
launch__sub_launch_name用于类似范围结果的每个子启动的名称。
launch__thread_count内核启动的所有块中的线程总数。
launch__tpc_count启动中使用的 TPC 数量。
launch__tpc_enabled已启用的 TPC 的 ID 的逗号分隔列表。
launch__uses_cdp如果启动的工作负载中的任何函数对象可以使用 CUDA 动态并行性,则设置为 1。
launch__uses_green_context如果启动在绿色上下文中,则设置为 1。
launch__uses_vgpu如果启动在 vGPU 设备上,则设置为 1。
launch__waves_per_multiprocessor每个 SM 的波front数。部分波front可能导致尾部效应,其中一些 SM 变为空闲,而其他 SM 仍有待完成的工作。
NVLink 拓扑指标
NVLink 拓扑指标
nvlink__bandwidth链路带宽,单位为字节/秒。
实例值从逻辑 NVLink ID (uint64) 映射到值 (double)。
nvlink__count_logical逻辑 NVLink 的总数。
nvlink__count_physical物理链路的总数。
实例值从物理 NVLink 设备 ID (uint64) 映射到值 (uint64)。
nvlink__destination_ports目标端口号(作为字符串)。
实例值从逻辑 NVLink ID (uint64) 映射到端口号的逗号分隔列表(字符串)。
nvlink__dev0Id第一个连接设备的 ID。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
nvlink__dev0type第一个连接设备的类型。
实例值从逻辑 NVLink ID (uint64) 映射到值 [1=GPU, 2=CPU] (uint64)。
nvlink__dev1Id第二个连接设备的 ID。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
nvlink__dev1type第二个连接设备的类型。
实例值从逻辑 NVLink ID (uint64) 映射到值 [1=GPU, 2=CPU] (uint64)。
nvlink__dev_display_name_all设备显示名称。
实例值从逻辑 NVLink 设备 ID (uint64) 映射到值 (string)。
nvlink__enabled_mask每个设备的 NVLink 启用掩码。
实例值从物理 NVLink 设备 ID (uint64) 映射到值 (uint64)。
nvlink__is_direct_link指示每个 NVLink 链路是否为直接链路。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
nvlink__is_nvswitch_connected指示是否连接了 NVSwitch。
nvlink__max_countNVLink 的最大数量。
实例值从物理 NVLink 设备 ID (uint64) 映射到值 (uint64)。
nvlink__peer_access指示是否支持对等访问。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
nvlink__peer_atomic指示是否支持对等原子操作。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
nvlink__source_ports源端口号(作为字符串)。
实例值从逻辑 NVLink ID (uint64) 映射到端口号的逗号分隔列表(字符串)。
nvlink__system_access指示是否支持系统访问。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
nvlink__system_atomic指示是否支持系统原子操作。
实例值从逻辑 NVLink ID (uint64) 映射到值 (uint64)。
NUMA 拓扑指标
NUMA 拓扑指标
numa__cpu_affinity每个设备的 CPU 亲和性。
实例值从设备 ID (uint64) 映射到逗号分隔值(字符串)。
numa__dev_display_name_all所有设备的设备显示名称。
实例值从设备 ID (uint64) 映射到逗号分隔值(字符串)。
numa__id_cpu每个设备最近 CPU 的 NUMA ID。
实例值从设备 ID (uint64) 映射到逗号分隔值(字符串)。
numa__id_memory每个设备最近内存的 NUMA ID。
实例值从设备 ID (uint64) 映射到逗号分隔值(字符串)。
设备属性
device__attribute_* 指标表示 CUDA 设备属性。收集它们不需要额外的内核重放趟次,因为它们的值可以从每个 CUDA 设备的 CUDA 驱动程序获得。
请参阅下文了解自定义 device__attribute_* 指标。
device__attribute_architectureCUDA 设备的芯片架构。
device__attribute_confidential_computing_mode机密计算模式。
device__attribute_device_index设备索引。
device__attribute_display_nameCUDA 设备的产品名称。
device__attribute_fb_bus_width帧缓冲区总线宽度。
device__attribute_fbp_count帧缓冲区分区的总数。
device__attribute_implementationCUDA 设备的芯片实现。
device__attribute_l2s_count二级缓存切片的总数。
device__attribute_limits_max_cta_per_sm每个 SM 的最大 CTA 数。
device__attribute_max_gpu_frequency_khz最大 GPU 频率,单位为千赫兹。
device__attribute_max_ipc_per_multiprocessor每个多处理器每时钟的最大指令数。
device__attribute_max_ipc_per_scheduler每个调度器每时钟的最大指令数。
device__attribute_max_mem_frequency_khz峰值内存频率,单位为千赫兹。
device__attribute_max_registers_per_thread每个线程可用的最大寄存器数。
device__attribute_max_warps_per_multiprocessor每个多处理器的最大 warp 数。
device__attribute_max_warps_per_scheduler每个调度器的最大 warp 数。
device__attribute_num_l2s_per_fbp每个帧缓冲区分区的二级缓存切片数。
device__attribute_num_schedulers_per_multiprocessor每个多处理器的调度器数。
device__attribute_num_tex_per_multiprocessor每个多处理器的 TEX 单元数。
device__attribute_sass_levelSASS 级别。
Warp 停顿原因
使用 warp 调度器状态采样收集。无论调度器是否在同一周期发出指令,它们都会递增。这些指标的实例值从函数地址 (uint64) 映射到样本数 (uint64)。
Warp 停顿原因
smsp__pcsamp_warps_issue_stalled_barrierWarp 因等待 CTA 屏障处的同级 warp 而停顿。大量 warp 在屏障处等待通常是由屏障之前的代码路径发散引起的。这会导致一些 warp 等待很长时间,直到其他 warp 到达同步点。在可能的情况下,尝试将工作划分为统一工作负载的块。如果块大小为 512 个线程或更大,请考虑将其拆分为更小的组。这可以增加符合条件的 warp,而不会影响占用率,除非共享内存成为新的占用率限制因素。此外,尝试确定哪个屏障指令导致最多的停顿,并首先优化在该同步点之前执行的代码。
smsp__pcsamp_warps_issue_stalled_branch_resolvingWarp 因等待分支目标被计算且 warp 程序计数器被更新而停顿。为了减少停顿周期数,请考虑使用更少的跳转/分支操作并减少控制流发散,例如,通过减少或合并代码中的条件语句。另请参阅相关的“无指令”状态。
smsp__pcsamp_warps_issue_stalled_dispatch_stallWarp 因等待调度停顿而停顿。在调度期间停顿的 warp 有一个准备好发出的指令,但调度器由于其他冲突或事件而阻止发出 warp。
smsp__pcsamp_warps_issue_stalled_drainWarp 在 EXIT 后停顿,等待所有未完成的内存操作完成,以便可以释放 warp 的资源。当在内核结束时向内存写入大量数据时,通常会发生因耗尽 warp 导致的停顿。确保这些存储操作的内存访问模式对于目标架构是最佳的,并在适用时考虑并行数据缩减。
smsp__pcsamp_warps_issue_stalled_imc_missWarp 因等待立即常量缓存 (IMC) 未命中而停顿。从常量内存读取仅在缓存未命中时才花费一次从设备内存读取的内存读取;否则,它只花费一次从常量缓存读取的读取。立即常量被编码到 SASS 指令中,形式为“c[bank][offset]”。warp 内线程对不同地址的访问是串行的,因此成本与 warp 内所有线程读取的唯一地址数成线性关系。因此,当同一 warp 中的线程仅访问几个不同的位置时,常量缓存是最佳的。如果 warp 的所有线程都访问相同的位置,则常量内存可以像寄存器访问一样快。
smsp__pcsamp_warps_issue_stalled_lg_throttleWarp 因等待本地和全局 (LG) 内存操作的 L1 指令队列未满而停顿。通常,只有在极其频繁地执行本地或全局内存指令时才会发生此停顿。避免冗余的全局内存访问。尝试避免使用线程本地内存,方法是检查动态索引数组是否在本地范围内声明,或者内核是否由于溢出而导致过多的寄存器压力。如果适用,请考虑将多个较低宽度的内存操作组合为较少的较宽内存操作,并尝试交错内存操作和数学指令。
smsp__pcsamp_warps_issue_stalled_long_scoreboardWarp 因等待 L1TEX(本地、全局、表面、纹理)操作的记分牌依赖关系而停顿。查找生成正在等待的数据的指令以识别原因。为了减少等待 L1TEX 数据访问的周期数,请验证内存访问模式对于目标架构是否最佳,尝试通过增加数据局部性(合并)或更改缓存配置来提高缓存命中率。考虑将常用数据移动到共享内存。
smsp__pcsamp_warps_issue_stalled_math_pipe_throttleWarp 因等待执行管道可用而停顿。当所有活动 warp 在特定的、过载的数学管道上执行其下一条指令时,会发生此停顿。尝试增加活动 warp 的数量以隐藏存在的延迟,或尝试更改指令组合以更平衡地利用所有可用的管道。
smsp__pcsamp_warps_issue_stalled_membarWarp 因等待内存屏障而停顿。避免执行任何不必要的内存屏障,并确保针对目标架构充分优化任何未完成的内存操作。
smsp__pcsamp_warps_issue_stalled_mio_throttleWarp 因等待 MIO(内存输入/输出)指令队列未满而停顿。在 MIO 管道的极端利用率的情况下,此停顿原因很高,其中包括特殊数学指令、动态分支以及共享内存指令。当由共享内存访问引起时,尝试使用更少但更宽的加载可以减少管道压力。
smsp__pcsamp_warps_issue_stalled_miscWarp 因各种硬件原因而停顿。
smsp__pcsamp_warps_issue_stalled_no_instructionsWarp 因等待被选中以获取指令或等待指令缓存未命中而停顿。大量 warp 没有获取指令是网格中工作量少于一个完整波front的非常短的内核的典型情况。如果过度跳转跨越大量的汇编代码块,也可能导致更多 warp 因指令缓存未命中而停顿。另请参阅相关的“分支解析”状态。
smsp__pcsamp_warps_issue_stalled_not_selectedWarp 因等待微调度器选择要发出的 warp 而停顿。未选择的 warp 是符合条件的 warp,但调度器未选择在该周期发出,因为选择了另一个 warp。大量未选择的 warp 通常意味着您有足够的 warp 来覆盖 warp 延迟,您可以考虑减少活动 warp 的数量,以可能增加缓存一致性和数据局部性。
smsp__pcsamp_warps_issue_stalled_selectedWarp 已被微调度器选中并发出了一条指令。
smsp__pcsamp_warps_issue_stalled_short_scoreboardWarp 因等待 MIO(内存输入/输出)操作(非 L1TEX)的记分牌依赖关系而停顿。由于短记分牌导致大量停顿的主要原因是共享内存的内存操作。其他原因包括频繁执行特殊数学指令(例如 MUFU)或动态分支(例如 BRX、JMX)。查阅“内存工作负载分析”部分,以验证是否存在共享内存操作,并在报告时减少bank冲突。将频繁访问的值分配给变量可以帮助编译器使用低延迟寄存器而不是直接内存访问。
smsp__pcsamp_warps_issue_stalled_sleepingWarp 因 warp 中的所有线程都处于阻塞、让步或睡眠状态而停顿。减少执行的 NANOSLEEP 指令的数量,降低指定的延迟时间,并尝试以一种方式对线程进行分组,以便 warp 中的多个线程同时睡眠。
smsp__pcsamp_warps_issue_stalled_tex_throttleWarp 因等待纹理操作的 L1 指令队列未满而停顿。在 L1TEX 管道的极端利用率的情况下,此停顿原因很高。尝试发出更少的纹理提取、表面加载、表面存储或解耦的数学运算。如果适用,请考虑将多个较低宽度的内存操作组合为较少的较宽内存操作,并尝试交错内存操作和数学指令。考虑将纹理查找或表面加载转换为全局内存查找。纹理可以接受每个周期四个线程的请求,而全局内存接受 32 个线程。
smsp__pcsamp_warps_issue_stalled_waitWarp 因等待固定延迟执行依赖关系而停顿。通常,此停顿原因应该非常低,并且仅在已经高度优化的内核中显示为主要贡献因素。尝试通过增加活动 warp 的数量、重构代码或展开循环来隐藏相应的指令延迟。此外,考虑切换到更低延迟的指令,例如,通过利用快速数学编译器选项。
smsp__pcsamp_warps_issue_stalled_warpgroup_arriveWarp 因等待 WARPGROUP.ARRIVES 或 WARPGROUP.WAIT 指令而停顿。
Warp 停顿原因(未发出)
使用 warp 调度器状态采样收集。它们仅在 warp 调度器未发出指令的周期中递增。这些指标的实例值从函数地址 (uint64) 映射到样本数 (uint64)。
Warp 停顿原因(未发出)
smsp__pcsamp_warps_issue_stalled_barrier_not_issuedWarp 因等待 CTA 屏障处的同级 warp 而停顿。大量 warp 在屏障处等待通常是由屏障之前的代码路径发散引起的。这会导致一些 warp 等待很长时间,直到其他 warp 到达同步点。在可能的情况下,尝试将工作划分为统一工作负载的块。如果块大小为 512 个线程或更大,请考虑将其拆分为更小的组。这可以增加符合条件的 warp,而不会影响占用率,除非共享内存成为新的占用率限制因素。此外,尝试确定哪个屏障指令导致最多的停顿,并首先优化在该同步点之前执行的代码。
smsp__pcsamp_warps_issue_stalled_branch_resolving_not_issuedWarp 因等待分支目标被计算且 warp 程序计数器被更新而停顿。为了减少停顿周期数,请考虑使用更少的跳转/分支操作并减少控制流发散,例如,通过减少或合并代码中的条件语句。另请参阅相关的“无指令”状态。
smsp__pcsamp_warps_issue_stalled_dispatch_stall_not_issuedWarp 因等待调度停顿而停顿。在调度期间停顿的 warp 有一个准备好发出的指令,但调度器由于其他冲突或事件而阻止发出 warp。
smsp__pcsamp_warps_issue_stalled_drain_not_issuedWarp 在 EXIT 后停顿,等待所有内存操作完成,以便可以释放 warp 资源。当在内核结束时向内存写入大量数据时,通常会发生因耗尽 warp 导致的停顿。确保这些存储操作的内存访问模式对于目标架构是最佳的,并在适用时考虑并行数据缩减。
smsp__pcsamp_warps_issue_stalled_imc_miss_not_issuedWarp 因等待立即常量缓存 (IMC) 未命中而停顿。从常量内存读取仅在缓存未命中时才花费一次从设备内存读取的内存读取;否则,它只花费一次从常量缓存读取的读取。warp 内线程对不同地址的访问是串行的,因此成本与 warp 内所有线程读取的唯一地址数成线性关系。因此,当同一 warp 中的线程仅访问几个不同的位置时,常量缓存是最佳的。如果 warp 的所有线程都访问相同的位置,则常量内存可以像寄存器访问一样快。
smsp__pcsamp_warps_issue_stalled_lg_throttle_not_issuedWarp 因等待本地和全局 (LG) 内存操作的 L1 指令队列未满而停顿。通常,只有在极其频繁地执行本地或全局内存指令时才会发生此停顿。避免冗余的全局内存访问。尝试避免使用线程本地内存,方法是检查动态索引数组是否在本地范围内声明,或者内核是否由于溢出而导致过多的寄存器压力。如果适用,请考虑将多个较低宽度的内存操作组合为较少的较宽内存操作,并尝试交错内存操作和数学指令。
smsp__pcsamp_warps_issue_stalled_long_scoreboard_not_issuedWarp 因等待 L1TEX(本地、全局、表面、纹理)操作的记分牌依赖关系而停顿。查找生成正在等待的数据的指令以识别原因。为了减少等待 L1TEX 数据访问的周期数,请验证内存访问模式对于目标架构是否最佳,尝试通过增加数据局部性(合并)或更改缓存配置来提高缓存命中率。考虑将常用数据移动到共享内存。
smsp__pcsamp_warps_issue_stalled_math_pipe_throttle_not_issuedWarp 因等待执行管道可用而停顿。当所有活动 warp 在特定的、过载的数学管道上执行其下一条指令时,会发生此停顿。尝试增加活动 warp 的数量以隐藏存在的延迟,或尝试更改指令组合以更平衡地利用所有可用的管道。
smsp__pcsamp_warps_issue_stalled_membar_not_issuedWarp 因等待内存屏障而停顿。避免执行任何不必要的内存屏障,并确保针对目标架构充分优化任何未完成的内存操作。
smsp__pcsamp_warps_issue_stalled_mio_throttle_not_issuedWarp 因等待 MIO(内存输入/输出)指令队列未满而停顿。在 MIO 管道的极端利用率的情况下,此停顿原因很高,其中包括特殊数学指令、动态分支以及共享内存指令。当由共享内存访问引起时,尝试使用更少但更宽的加载可以减少管道压力。
smsp__pcsamp_warps_issue_stalled_misc_not_issuedWarp 因各种硬件原因而停顿。
smsp__pcsamp_warps_issue_stalled_no_instructions_not_issuedWarp 因等待被选中以获取指令或等待指令缓存未命中而停顿。大量 warp 没有获取指令是网格中工作量少于一个完整波front的非常短的内核的典型情况。如果过度跳转跨越大量的汇编代码块,也可能导致更多 warp 因指令缓存未命中而停顿。另请参阅相关的“分支解析”状态。
smsp__pcsamp_warps_issue_stalled_not_selected_not_issuedWarp 因等待微调度器选择要发出的 warp 而停顿。未选择的 warp 是符合条件的 warp,但调度器未选择在该周期发出,因为选择了另一个 warp。大量未选择的 warp 通常意味着您有足够的 warp 来覆盖 warp 延迟,您可以考虑减少活动 warp 的数量,以可能增加缓存一致性和数据局部性。
smsp__pcsamp_warps_issue_stalled_selected_not_issuedWarp 已被微调度器选中并发出了一条指令。
smsp__pcsamp_warps_issue_stalled_short_scoreboard_not_issuedWarp 因等待 MIO(内存输入/输出)操作(非 L1TEX)的记分牌依赖关系而停顿。由于短记分牌导致大量停顿的主要原因是共享内存的内存操作。其他原因包括频繁执行特殊数学指令(例如 MUFU)或动态分支(例如 BRX、JMX)。查阅“内存工作负载分析”部分,以验证是否存在共享内存操作,并在报告时减少bank冲突。将频繁访问的值分配给变量可以帮助编译器使用低延迟寄存器而不是直接内存访问。
smsp__pcsamp_warps_issue_stalled_sleeping_not_issuedWarp 因 warp 中的所有线程都处于阻塞、让步或睡眠状态而停顿。减少执行的 NANOSLEEP 指令的数量,降低指定的延迟时间,并尝试以一种方式对线程进行分组,以便 warp 中的多个线程同时睡眠。
smsp__pcsamp_warps_issue_stalled_tex_throttle_not_issuedWarp 因等待纹理操作的 L1 指令队列未满而停顿。在 L1TEX 管道的极端利用率的情况下,此停顿原因很高。尝试发出更少的纹理提取、表面加载、表面存储或解耦的数学运算。如果适用,请考虑将多个较低宽度的内存操作组合为较少的较宽内存操作,并尝试交错内存操作和数学指令。考虑将纹理查找或表面加载转换为全局内存查找。纹理可以接受每个周期四个线程的请求,而全局内存接受 32 个线程。
smsp__pcsamp_warps_issue_stalled_wait_not_issuedWarp 因等待固定延迟执行依赖关系而停顿。通常,此停顿原因应该非常低,并且仅在已经高度优化的内核中显示为主要贡献因素。尝试通过增加活动 warp 的数量、重构代码或展开循环来隐藏相应的指令延迟。此外,考虑切换到更低延迟的指令,例如,通过利用快速数学编译器选项。
smsp__pcsamp_warps_issue_stalled_warpgroup_arrive_not_issuedWarp 因等待 WARPGROUP.ARRIVES 或 WARPGROUP.WAIT 指令而停顿。
源指标
大多数是使用 SASS-patching 4 收集的。这些指标的实例值从函数地址 (uint64) 映射到关联值 (uint64)。指标 memory_[access_]type 映射到字符串值。
源指标
branch_inst_executed分配给指令的唯一分支目标数,包括发散分支和统一分支。
derived__avg_thread_executed每个 warp 的线程级执行指令的平均数(与其谓词无关)。计算公式为:thread_inst_executed / inst_executed
derived__avg_thread_executed_true每个 warp 的基于谓词的线程级执行指令的平均数。计算公式为:thread_inst_executed_true / inst_executed
derived__memory_l1_conflicts_shared_nway每个共享内存指令在 L1 中的平均 N 路冲突。1 路访问没有冲突,并在单趟次中解决。计算公式为:memory_l1_wavefronts_shared / inst_executed
derived__memory_l1_wavefronts_shared_excessive来自共享内存指令的 L1 中的波前数过多,因为并非所有未被谓词关闭的线程都执行了该操作。
derived__memory_l2_theoretical_sectors_global_excessive来自全局内存指令的 L2 中请求的理论扇区数过多,因为并非所有未被谓词关闭的线程都执行了该操作。
inst_executedWarp 级别已执行指令数,忽略指令谓词。Warp 级别意味着每个执行指令的独立 Warp 增加的值,与每个 Warp 内参与线程的数量无关。
memory_access_size_type内存访问的大小,以位为单位。
memory_access_type内存访问的类型(例如,加载或存储)。
memory_l1_tag_requests_global全局内存指令生成的 L1 标签请求数。
memory_l1_wavefronts_shared来自共享内存指令的 L1 中的波前数。
memory_l1_wavefronts_shared_ideal来自共享内存指令的 L1 中的理想波前数,假设每个未被谓词关闭的线程都执行了该操作。
memory_l2_theoretical_sectors_global从全局内存指令请求的 L2 中的理论扇区数。
memory_l2_theoretical_sectors_global_ideal从全局内存指令请求的 L2 中的理想扇区数,假设每个未被谓词关闭的线程都执行了该操作。
memory_l2_theoretical_sectors_local从本地内存指令请求的 L2 中的理论扇区数。
memory_type访问的地址空间(全局/本地/共享)。
smsp__branch_targets_threads_divergent发散分支目标数,包括 fallthrough。仅当有两个或更多具有发散目标的活动线程时才会递增。
smsp__branch_targets_threads_uniform统一分支执行数,包括 fallthrough,其中所有活动线程都选择了相同的分支目标。
smsp__pcsamp_sample_count每个程序计数器收集的 Warp 状态样本数。此指标使用 Warp 采样收集。
thread_inst_executed线程级别已执行指令数,与谓词是否存在或评估无关。
thread_inst_executed_true线程级别已执行指令数,其中指令谓词评估为 true,或者未给出谓词。
L2 缓存驱逐指标
L2 缓存驱逐指标
smsp__sass_inst_executed_memdesc_explicit_evict_typeL2 缓存驱逐策略类型。
smsp__sass_inst_executed_memdesc_explicit_hitprop_evict_firstL2 缓存驱逐命中属性为 “first” 的 Warp 级别已执行指令数。
smsp__sass_inst_executed_memdesc_explicit_hitprop_evict_lastL2 缓存驱逐命中属性为 “last” 的 Warp 级别已执行指令数。
smsp__sass_inst_executed_memdesc_explicit_hitprop_evict_normalL2 缓存驱逐命中属性为 “normal” 的 Warp 级别已执行指令数。
smsp__sass_inst_executed_memdesc_explicit_hitprop_evict_normal_demoteL2 缓存驱逐命中属性为 “normal demote” 的 Warp 级别已执行指令数。
smsp__sass_inst_executed_memdesc_explicit_missprop_evict_firstL2 缓存驱逐未命中属性为 “first” 的 Warp 级别已执行指令数。
smsp__sass_inst_executed_memdesc_explicit_missprop_evict_normalL2 缓存驱逐未命中属性为 “normal” 的 Warp 级别已执行指令数。
每操作码指令指标
使用 SASS 补丁收集。这些指标具有从 SASS 操作码(字符串)到执行次数(uint64)的实例值映射。
每操作码指令指标
sass__inst_executed_per_opcodeWarp 级别已执行指令数,按基本 SASS 操作码实例化。
sass__inst_executed_per_opcode_with_modifier_allWarp 级别已执行指令数,按所有 SASS 操作码修饰符实例化。
sass__inst_executed_per_opcode_with_modifier_selectiveWarp 级别已执行指令数,按选择性 SASS 操作码修饰符实例化。
sass__thread_inst_executed_true_per_opcode线程级别已执行指令数,按基本 SASS 操作码实例化。
sass__thread_inst_executed_true_per_opcode_with_modifier_all线程级别已执行指令数,按所有 SASS 操作码修饰符实例化。
sass__thread_inst_executed_true_per_opcode_with_modifier_selective线程级别已执行指令数,按选择性 SASS 操作码修饰符实例化。
SASS 单元级别已执行指令指标
单元级别 Warp 指令的执行次数。
SASS 单元级别已执行指令指标
sass__inst_executed_global_loads全局内存加载指令的执行次数。
sass__inst_executed_global_stores全局内存存储指令的执行次数。
sass__inst_executed_local_loads本地内存加载指令的执行次数。
sass__inst_executed_local_stores本地内存存储指令的执行次数。
sass__inst_executed_register_spilling由于寄存器溢出而生成的本地存储和加载指令数。
sass__inst_executed_shared_loads共享内存加载指令的执行次数。
sass__inst_executed_shared_stores共享内存存储指令的执行次数。
指标组
指标组
group:memory__chart工作负载分析图表的指标组。
group:memory__dram_table设备内存工作负载分析表的指标组。
group:memory__first_level_cache_tableL1/TEX 缓存工作负载分析表的指标组。
group:memory__l2_cache_evict_policy_tableL2 缓存驱逐策略表的指标组。
group:memory__l2_cache_tableL2 缓存工作负载分析表的指标组。
group:memory__shared_table共享内存工作负载分析表的指标组。
group:smsp__pcsamp_warp_stall_reasons每个程序位置的 Warp 采样器样本数的指标组。
group:smsp__pcsamp_warp_stall_reasons_not_issued在 Warp 调度器未发出指令的周期内,每个程序位置的 Warp 采样器样本数的指标组。
Profiler 指标
由工具本身生成的指标,用于告知分析期间的统计信息或问题。
Profiler 指标
profiler__perfworks_session_reuse指示 PerfWorks 会话是否在结果之间重用。
profiler__pmsampler_buffer_size_bytes每个用于 PM 采样的 pass group 的缓冲区大小(以字节为单位)。
实例值从 pass group 映射到字节。
profiler__pmsampler_ctxsw_*特定 pass group 的 PM 采样期间,GPU 上下文切换状态随时间变化的情况。
实例值从时间戳映射到上下文状态(1 - 启用,0 - 禁用)。
profiler__pmsampler_dropped_samples由于缓冲区大小不足,在 PM 采样期间每个 pass group 丢弃的样本数。
实例值从 pass group 映射到样本。
profiler__pmsampler_interval_cycles每个用于 PM 采样的 pass group 的采样间隔(以周期为单位),如果使用基于时间的间隔,则为零。
实例值从 pass group 映射到周期。
profiler__pmsampler_interval_time每个用于 PM 采样的 pass group 的采样间隔(以纳秒为单位),如果使用基于周期的间隔,则为零。
实例值从 pass group 映射到纳秒。
profiler__pmsampler_merged_samples由于在流式传输结果时 HW 反压,在 PM 采样期间每个 pass group 合并的样本数。
实例值从 pass group 映射到样本。
profiler__pmsampler_pass_groups用于 PM 采样的 pass group 的数量。
实例值从 pass group 映射到在此 pass 中收集的指标的逗号分隔列表。
profiler__replayer_bytes_mem_accessible.avg重放期间工作负载可访问的内存字节数的平均值。
profiler__replayer_bytes_mem_accessible.max重放期间工作负载可访问的内存字节数的最大值。
profiler__replayer_bytes_mem_accessible.min重放期间工作负载可访问的内存字节数的最小值。
profiler__replayer_bytes_mem_accessible.sum重放期间工作负载可访问的内存字节数的总和。
profiler__replayer_bytes_mem_backed_up.avg重放期间备份的内存字节数的平均值。
profiler__replayer_bytes_mem_backed_up.max重放期间备份的内存字节数的最大值。
profiler__replayer_bytes_mem_backed_up.min重放期间备份的内存字节数的最小值。
profiler__replayer_bytes_mem_backed_up.sum重放期间备份的内存字节数的总和。
profiler__replayer_passes跨所有实验重放结果以进行分析的 pass 数。
profiler__replayer_passes_type_warmup为预热 GPU 以进行分析而重放结果的 pass 数。
smsp__pcsamp_aggregated_passes统计 Warp 停顿采样所需的 pass 数。
smsp__pcsamp_buffer_size_bytes用于统计 Warp 停顿采样的缓冲区大小(以字节为单位)。
smsp__pcsamp_dropped_bytes由于缓冲区大小不足,在统计 Warp 停顿采样期间丢弃的字节数。
smsp__pcsamp_intervalWarp 停顿采样的间隔数。
smsp__pcsamp_interval_cycles统计 Warp 停顿采样的间隔周期。
脚注
- 4
当通过命令行界面收集指令级源指标时,指令级源指标不需要目标设备上的性能分析权限。
2.5. 采样
NVIDIA Nsight Compute 可以通过以固定间隔进行采样来收集某些性能数据。
2.5.1. PM 采样
NVIDIA Nsight Compute 支持通过以固定间隔定期采样 GPU 的性能监视器 (PM) 来收集许多指标。生成的指标是实例化的,每个样本都由其值和收集时的(GPU)时间戳组成。这使该工具能够在时间线上可视化数据,这有助于您了解分析的工作负载的行为在其运行时如何变化。
使用 PM 采样收集的指标具有从其样本时间戳(以纳秒为单位)到其样本值的实例值映射。在逻辑上可行的情况下,指标的非实例值表示所有实例的聚合。聚合操作(例如,总和、平均值)取决于指标结构。
在以下情况下,使用 PM 采样收集指标
指标名称具有
pmsampling:前缀。指标名称包含有效的
Triage组。指标在节的
Timeline字段中请求。在这种情况下,仍然建议使用pmsampling:前缀指标,以避免与例如由其他节收集的同名分析器指标冲突。
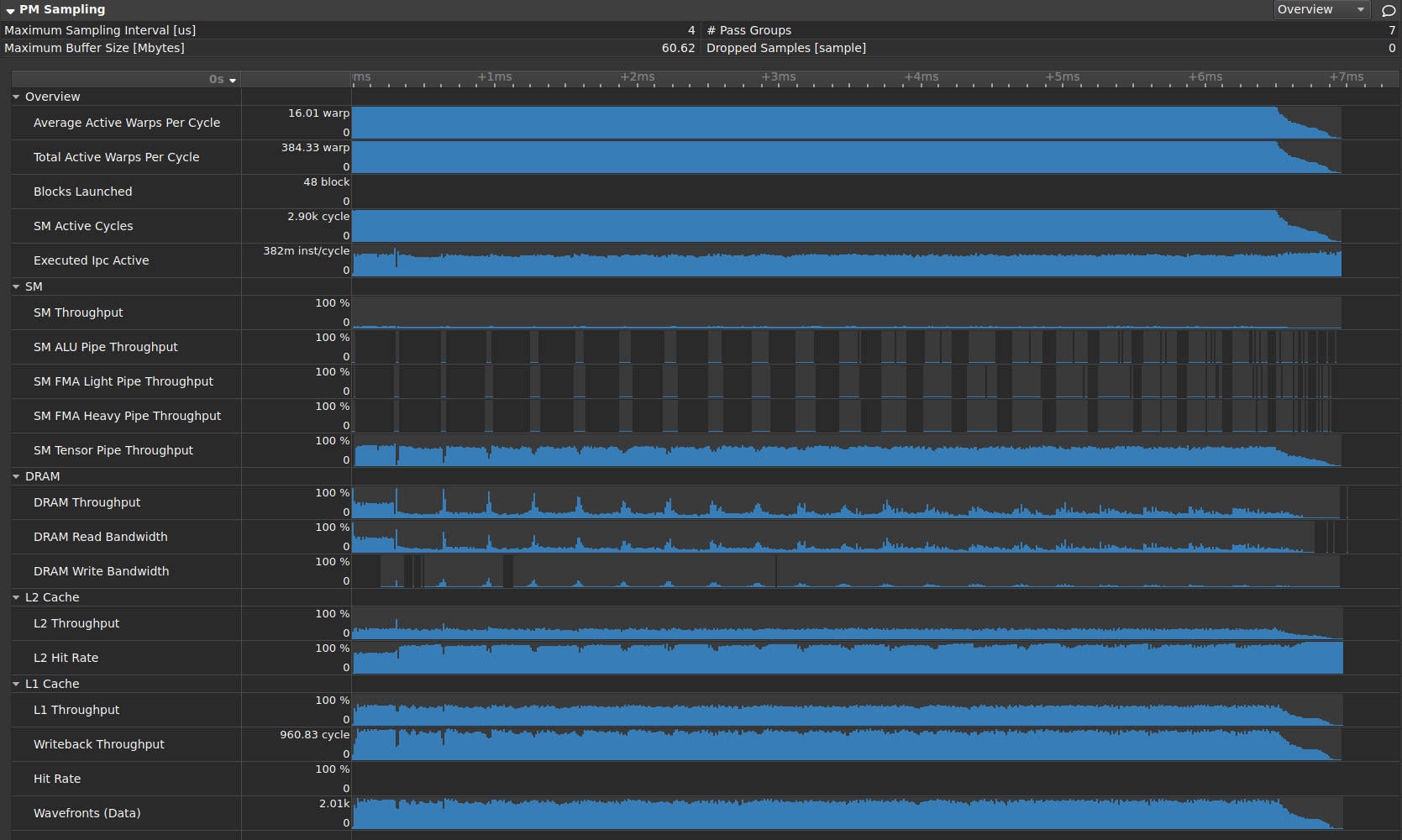
使用 Tensor Core 的应用程序的 PM 采样时间线示例。该时间线显示了典型的尾部效应,从约 6.5 毫秒开始,此时没有足够的工作来填充所有 SM。它还允许您查看计算(SM Tensor Pipe Throughput)和数据加载(DRAM Throughput 和 L2 命中率)之间的关系。每当 L2 缓存不再容易获得所需数据时,其命中率就会降低,DRAM Throughput 会随着需要从全局内存加载数据而增加,并且 SM Tensor Pipe Throughput 会随着 SM 等待数据到达而降低。
支持
架构 |
支持 |
采样间隔 |
|---|---|---|
Volta 及更早版本 |
不支持 |
不适用 |
TU10x-GA100 |
支持 |
>= 20000 个周期 |
GA10x 及更高版本 |
支持 |
>= 1000 纳秒 5 |
PM 采样在除 vGPU 之外的所有平台上均受支持。有关适用于上下文切换跟踪的进一步限制,请参见下文。您可以使用 --query-metrics-collection pmsampling 选项查询 PM 采样可用的指标列表。但请注意,虽然 PM 采样器可以使用所有列出的指标,但只能收集需要单次 pass 的指标。
上下文切换跟踪
由于此数据收集跨整个 GPU 设备进行采样,因此该工具同时收集上下文切换跟踪。该跟踪存储为单独的、实例化的指标。它跟踪感兴趣的上下文何时处于活动状态,可用于过滤采样指标,使其仅包含相关实例,并更好地对齐时间线上的多次 pass 的指标。虽然通常最好收集此跟踪,但可以使用环境变量禁用它。
请注意,Windows Linux 子系统 (WSL)、多实例 GPU (MIG) 或移动平台不支持上下文切换跟踪。容器中的上下文切换跟踪在 CUDA 12.7 驱动程序或更高版本中受支持。
计数器域
PM 采样指标在内部由一个或多个原始计数器依赖项组成。如果同一 pass 中的指标共享此类依赖项,则仅收集一次。每个计数器都与一个计数器域相关联,该域描述了计数器在硬件中如何以及在何处收集。每个域中可以在同一 pass 中并发收集的计数器数量有限,并且数量可能会因所选计数器而异。
从不同域中选择计数器有可能使更多指标依赖项适合同一 pass。此外,可以通过不同的域收集某些计数器,并且域可以由工具或用户选择。
当查询 PM 采样指标集合时,将显示指标的计数器依赖项的必需域和可选域。例如,对于 l1tex__throughput gpu_sm_a,[gpu_sm_b,gpu_sm_c],域 gpu_sm_a 是必需的,并且必须选择可选域 [gpu_sm_b,gpu_sm_c] 之一才能收集此指标。只能在节文件中使用 PM 采样指标的一个或多个 CtrDomains: "<domain>" 字段实例显式选择计数器域。
请注意,大多数用户应该能够依赖工具自动选择计数器域,或节文件中预配置的域。
已知问题
使用 PM 采样时,您应该注意以下潜在问题
从不同 pass 收集的数据可能无法完全对齐。在下面的示例中,每组 Warp 停顿原因都在单独的 pass 中收集。Warp 总数在工作负载执行期间不会改变,即,在一个时间戳,来自所有 pass 的数据应总计为相同的 Warp 总数。但是,由于轻微的未对齐,聚合行显示了几个峰值,这些峰值在实际执行中可能更平坦。
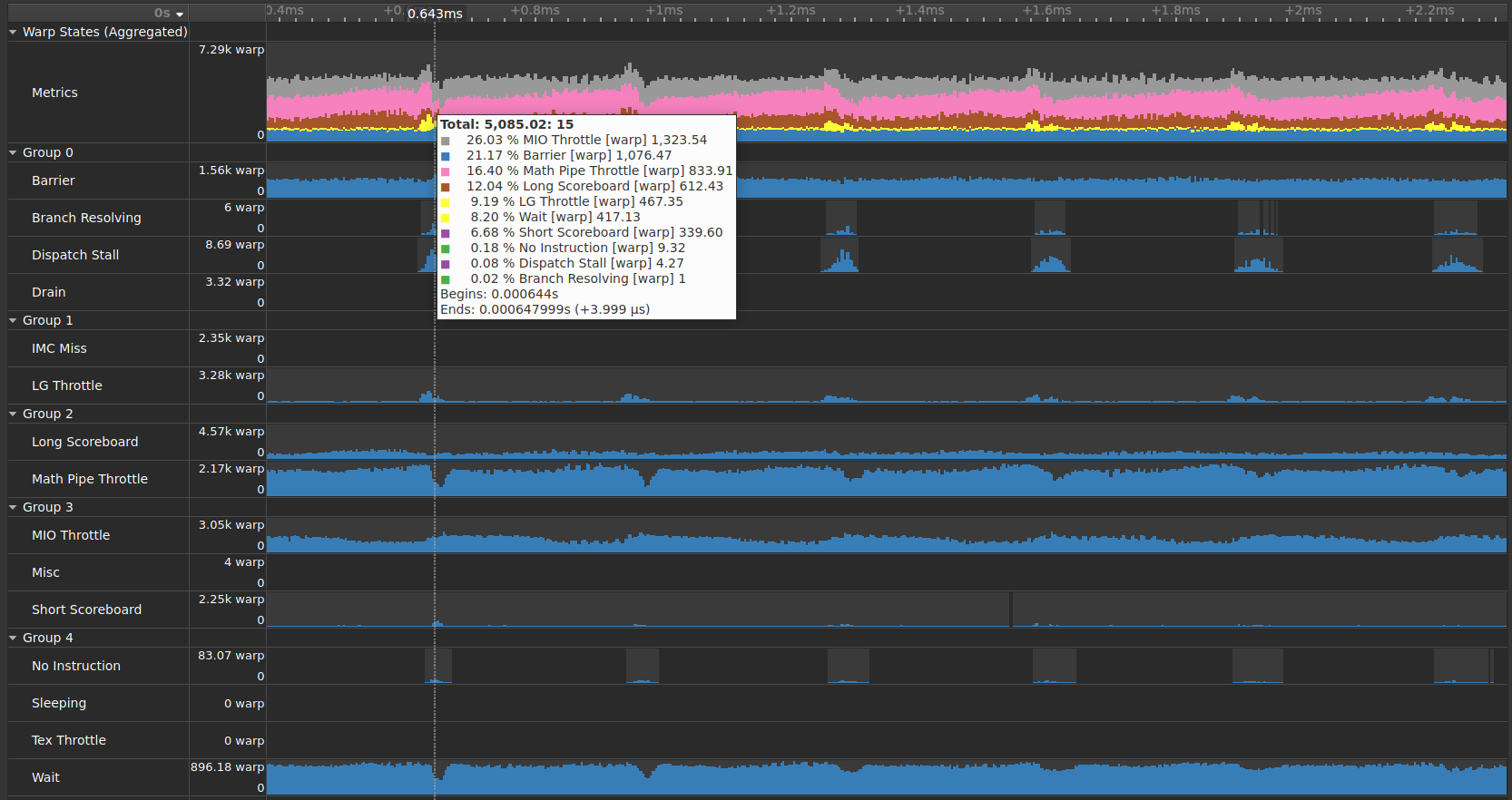
脚注
- 5
对于某些芯片或配置,最小采样间隔可能更高。
2.5.2. Warp 采样
NVIDIA Nsight Compute 支持定期采样 Warp 程序计数器和 Warp 调度器状态。在固定的周期间隔内,每个流式多处理器中的采样器选择一个活动的 Warp,并输出程序计数器和 Warp 调度器状态。该工具为设备选择最小间隔。在小型设备上,这可以是每 32 个周期。在具有更多多处理器的大型芯片上,这可能是 2048 个周期。采样器选择一个随机的活动 Warp。在同一周期内,调度器可能会选择不同的 Warp 来发出。
生成的指标与各个已执行的指令相关,但不具有任何时间分辨率。
有关各个 Warp 调度器状态的描述,请参阅指标参考中的Warp 停顿原因表。
2.6. 可重现性
为了在应用程序运行中提供可操作且确定性的结果,NVIDIA Nsight Compute 应用了各种方法来调整指标的收集方式。这包括序列化内核启动、在每次内核重放之前清除 GPU 缓存或调整 GPU 时钟。
2.6.1. 序列化
NVIDIA Nsight Compute 在分析的应用程序中序列化内核启动,可能会跨由一个或多个工具实例同时分析的多个进程。
跨进程序列化是必要的,因为对于 HW 性能指标的收集,某些 GPU 和驱动程序对象一次只能由单个进程获取。为了实现这一点,使用了锁定文件 TMPDIR/nsight-compute-lock。在 Windows 上,TMPDIR 是 Windows GetTempPath API 函数返回的路径。在其他平台上,它是列表 TMPDIR、 TMP、 TEMP、 TEMPDIR 中第一个环境变量提供的路径。如果找不到这些环境变量,则在 QNX 上为 /var/nvidia,否则为 /tmp。
进程内序列化是必需的,以便将大多数指标映射到正确的内核。此外,如果没有序列化,如果内核在同一设备上并发执行,性能指标值可能会差异很大。
目前无法禁用此工具行为。请参阅有关可能的解决方法FAQ条目。
2.6.2. 时钟控制
对于许多指标,它们的值直接受当前 GPU SM 和内存时钟频率的影响。例如,如果分析的内核实例在应用程序中具有先前的内核执行,则 GPU 可能已处于更高的时钟状态,并且测量的内核持续时间以及其他指标将受到影响。同样,如果内核实例是应用程序中要启动的第一个内核,则 GPU 时钟通常会较低。此外,由于内核重放,指标值可能取决于在哪个重放 pass 中收集,因为后面的 pass 会导致更高的时钟状态。
为了缓解这种不确定性,NVIDIA Nsight Compute 尝试将 GPU 时钟频率限制为其基本值。因此,指标值受内核在应用程序中的位置或特定重放 pass 的次数影响较小。
但是,对于内核分析,此行为可能不受欢迎,例如,在使用外部工具来固定时钟频率,或者分析应用程序中内核行为的情况下。为了解决这个问题,用户可以调整 --clock-control 选项来指定是否应由工具固定任何时钟频率。
影响时钟控制的因素
请注意,驱动程序指示的热节流无法由工具控制,并且始终会覆盖任何选定的选项。
在移动目标(例如 L4T 或 QNX)上,由于工具无法锁定时钟,因此分析结果可能会有所不同。在 GPU 分区上进行分析时,使用 Nsight Compute 的
--clock-control设置 GPU 时钟将失败或被静默忽略。在 L4T 上,您可以使用 jetson_clocks 脚本在分析期间将时钟锁定在其最大值。
有关 MIG 和 vGPU 时钟控制,请参阅特殊配置部分。
2.6.3. 缓存控制
如内核重放中所述,可能需要多次重放内核才能收集所有请求的指标。虽然 NVIDIA Nsight Compute 可以为每个 pass 保存和恢复内核访问的 GPU 设备内存的内容,但它无法对 HW 缓存(例如 L1 和 L2 缓存)的内容执行相同的操作。
这可能会导致后续的重放 pass 可能比例如第一个 pass 具有更好或更差的性能,因为缓存可能已经使用内核上次访问的数据进行了预热。同样,第一个 pass 收集的 HW 性能计数器的值可能取决于在测量的内核启动之前执行了哪些内核(如果有)。
为了使 HW 性能计数器值更具确定性,默认情况下,NVIDIA Nsight Compute 会在每个重放 pass 之前刷新所有 GPU 缓存。因此,在每个 pass 中,内核将访问干净的缓存,并且行为将如同内核完全隔离执行一样。
对于性能分析,此行为可能不受欢迎,特别是当测量侧重于较大应用程序执行中的内核,并且收集的数据针对以缓存为中心的指标时。在这种情况下,您可以使用 --cache-control none 禁用工具对任何 HW 缓存的刷新。
2.6.4. 持久模式
在任何用户与目标 GPU 设备进行交互之前,NVIDIA 内核模式驱动程序必须正在运行并连接到该设备。驱动程序的行为因操作系统而异。通常,在 Linux 上,如果内核模式驱动程序尚未运行或连接到目标 GPU,则任何尝试与该 GPU 交互的程序的调用都将透明地导致驱动程序加载和/或初始化 GPU。当所有 GPU 客户端终止时,驱动程序将取消初始化 GPU。
如果未启用持久模式(作为操作系统的一部分,或由用户启用),则触发 GPU 初始化的应用程序可能会产生较短的启动成本。此外,在某些配置中,当应用程序结束时 GPU 被取消初始化时,也可能存在关闭成本。
建议在适用操作系统上启用持久模式,然后再使用 NVIDIA Nsight Compute 进行分析,以获得更一致的应用程序行为。
2.7. 特殊配置
2.7.1. 多实例 GPU
多实例 GPU (MIG) 是一项功能,允许将 GPU 分区为多个 CUDA 设备。分区在两个级别上进行:首先,可以将 GPU 拆分为一个或多个 GPU 实例。每个 GPU 实例声明拥有一个或多个流式多处理器 (SM)、GPU 总内存的子集,以及可能的其他 GPU 资源,例如视频编码器/解码器。其次,每个 GPU 实例可以进一步分区为一个或多个计算实例。每个计算实例独占拥有其分配的 GPU 实例的 SM。但是,GPU 实例内的所有计算实例共享 GPU 实例的内存和内存带宽。每个计算实例都充当 CUDA 设备并以唯一设备 ID 运行。有关如何配置 MIG 实例的更多信息,请参阅驱动程序发行说明以及 nvidia-smi CLI 工具的文档。
对于分析,计算实例可以是两种类型之一:隔离或共享。
隔离计算实例拥有其所有分配的资源,并且不与另一个计算实例共享任何 GPU 单元。换句话说,计算实例的大小与其父 GPU 实例相同,因此没有任何其他同级计算实例。分析对于隔离的计算实例照常工作。
共享计算实例使用 GPU 资源,这些资源也可能由同一 GPU 实例中的其他计算实例访问。由于这种资源共享,不允许从这些共享单元收集分析数据。尝试从共享单元收集指标会失败,并显示错误消息 ==ERROR== Failed to access the following metrics. When profiling on a MIG instance, it is not possible to collect metrics from GPU units that are shared with other MIG instances,后跟失败指标的列表。仍然可以仅从共享计算实例独占拥有的 GPU 单元收集指标。
锁定时钟
NVIDIA Nsight Compute 无法为分析设置任何计算实例上的时钟频率。您可以继续分析内核,而无需固定时钟频率(使用 --clock-control none;有关更多详细信息,请参阅此处)。如果您具有足够的权限,则可以使用 nvidia-smi 通过调用 nvidia-smi --lock-gpu-clocks=tdp,tdp 为整个 GPU 配置固定频率。这会将 GPU 时钟设置为基本 TDP 频率,直到您通过调用 nvidia-smi --reset-gpu-clocks 重置时钟为止。
裸机上的 MIG (非 vGPU)
GPU 上的所有计算实例共享相同的时钟频率。
NVIDIA vGPU 上的 MIG
为 VM 启用分析使 VM 可以访问 GPU 的全局性能计数器,其中可能包括在同一 GPU 上执行的其他 VM 的活动。为 VM 启用分析还允许 VM 锁定 GPU 上的时钟,这会影响在同一 GPU 上执行的所有其他 VM,包括 MIG 计算实例。
2.7.2. CUDA Green Contexts
CUDA Green Contexts 是 CUDA 驱动程序 API 的一项功能,它允许通过将一组资源分配给 CUDA 上下文(上下文应在其上运行)来对 GPU 进行空间分区。NVIDIA Nsight Compute 支持通过启用收集指标参考中描述的相同指标来分析使用 CUDA Green Contexts 的应用程序。特别是,兼容性矩阵中的工作负载类型和重放模式的任何组合也受 Green Context 应用程序支持。有关基于范围的重放模式中支持的 API 函数的列表,请参阅支持的 API 中的Green Contexts 部分。
与常规 CUDA 上下文不同,当使用 Green Contexts 时,指标细分为两类:可以直接归因于 Green Context 的指标和不能直接归因于 Green Context 的指标。前者包括在直接分配给 Green Context 的硬件单元(例如 SM 或 L1 缓存)上收集的指标,而后者由不提供对 Green Context 独占访问权限的指标组成,例如 L2 缓存。前者将称为 Green-Context 可归因指标,后者将称为不可归因指标。
由于分析 Green Context 应用程序相对于其分配的资源(而不是整个 GPU)的性能通常更有见地,因此可归因指标会缩放到 Green Context 的 SM 数量。6不可归因指标并非如此。有关此功能所需的最低驱动程序版本的更多信息,请参阅下面的支持的驱动程序版本。
要概述 UI 中如何支持 Green Contexts,包括区分可归因和不可归因指标的方法,请参阅Green Contexts 支持部分。在 CLI 上,可以使用 –print-metric-attribution 显示归因级别,请参阅命令行选项。
支持的驱动程序版本
从 NVIDIA Nsight Compute 2024.1 开始,完全支持分析使用 CUDA Green Contexts 的应用程序。这需要最低驱动程序版本 550。但请注意,使用此版本,指标始终使用 GPU 上可用的所有 SM 的数量进行缩放。
从 NVIDIA Nsight Compute 2024.3 开始,可归因指标会缩放到 Green Context 使用的 SM 数量。这需要最低驱动程序版本 560。
脚注
- 6
虽然不打算作为主要用例,但可以使用重叠资源初始化不同的 Green Contexts。当并发执行和分析此类 Green Contexts 时,可归因指标可能包含来自多个 Green Contexts 的贡献,尽管本节中描述的相同指标缩放行为仍然适用。
2.8. Roofline 图表
Roofline 图表提供了一种非常有用的方法,可以可视化复杂处理单元(如 GPU)上实现的性能。本节介绍在性能分析报告中呈现的 Roofline 图表。
注意
从此 NVIDIA 开发者工具站点计算的值以及使用数据中心监控工具生成的操作/秒值,与用于出口管制目的的操作/秒值的计算方式不同,不应依赖这些值来评估是否符合出口管制限制。
2.8.1. 概述
内核性能不仅取决于 GPU 的运算速度。由于内核需要数据才能工作,因此性能还取决于 GPU 向内核馈送数据的速率。典型的 roofline 图表将 GPU 的峰值性能和内存带宽与称为算术强度(工作量和内存流量之间的比率)的指标结合在一个图表中,以更真实地表示所分析内核的实现性能。一个简单的 roofline 图表可能如下所示
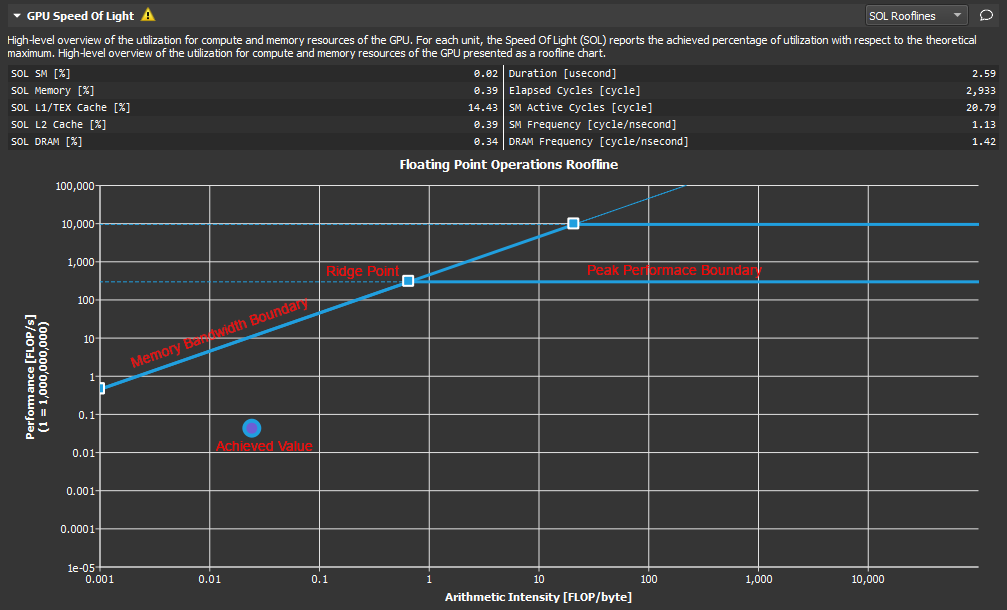
Roofline 概述。
此图表实际上显示了两个不同的 roofline。但是,可以为每个 roofline 识别以下组成部分
垂直轴 - 垂直轴表示每秒浮点运算次数 (FLOPS)。对于 GPU,这个数字可能非常大,因此可以缩放此轴上的数字以便于阅读(如此处所示)。为了更好地适应范围,此轴使用对数刻度渲染。
水平轴 - 水平轴表示算术强度,它是工作量(以每秒浮点运算次数表示)和内存流量(以每秒字节数表示)之间的比率。结果单位为每字节浮点运算次数。此轴也使用对数刻度显示。
内存带宽边界 - 内存带宽边界是 roofline 的倾斜部分。默认情况下,此斜率完全由 GPU 的内存传输速率决定,但如果需要,可以在 SpeedOfLight_RooflineChart.section 文件中自定义。
峰值性能边界 - 峰值性能边界是 roofline 的平坦部分。默认情况下,此值完全由 GPU 的峰值性能决定,但如果需要,可以在 SpeedOfLight_RooflineChart.section 文件中自定义。
山脊点 - 山脊点是内存带宽边界与峰值性能边界相交的点。此点是在分析内核性能时非常有用的参考。
已实现值 - 已实现值表示所分析内核的性能。如果正在使用基线,则 roofline 图表还将包含每个基线的已实现值。绘制的已实现值点的轮廓颜色可用于确定该点来自哪个基线。
2.8.2. 分析
Roofline 图表对于指导特定内核的性能优化工作非常有帮助。
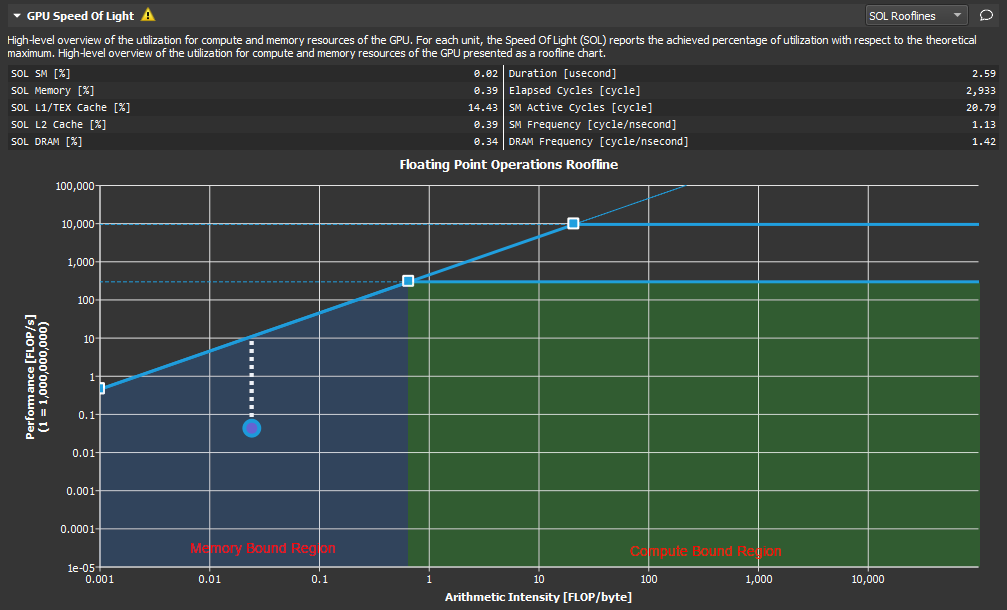
Roofline 分析。
如此处所示,山脊点将 roofline 图表划分为两个区域。倾斜的内存带宽边界下方蓝色阴影区域是内存受限区域,而峰值性能边界下方绿色阴影区域是计算受限区域。已实现值所在的区域决定了内核性能当前的限制因素。
从已实现值到各自 roofline 边界的距离(在此图中显示为白色虚线)表示性能改进的机会。已实现值越接近 roofline 边界,其性能就越佳。位于内存带宽边界上但尚未达到山脊点高度的已实现值表示,只有同时提高算术强度,才有可能进一步提高总 FLOPS。
将基线功能与 roofline 图表结合使用,是跟踪多次内核执行的优化进度的好方法。
2.9. 内存图表
内存图表显示了 GPU 上和 GPU 外内存子单元的性能数据的图形化逻辑表示。性能数据包括传输大小、命中率、指令或请求数等。
2.9.1. 概述
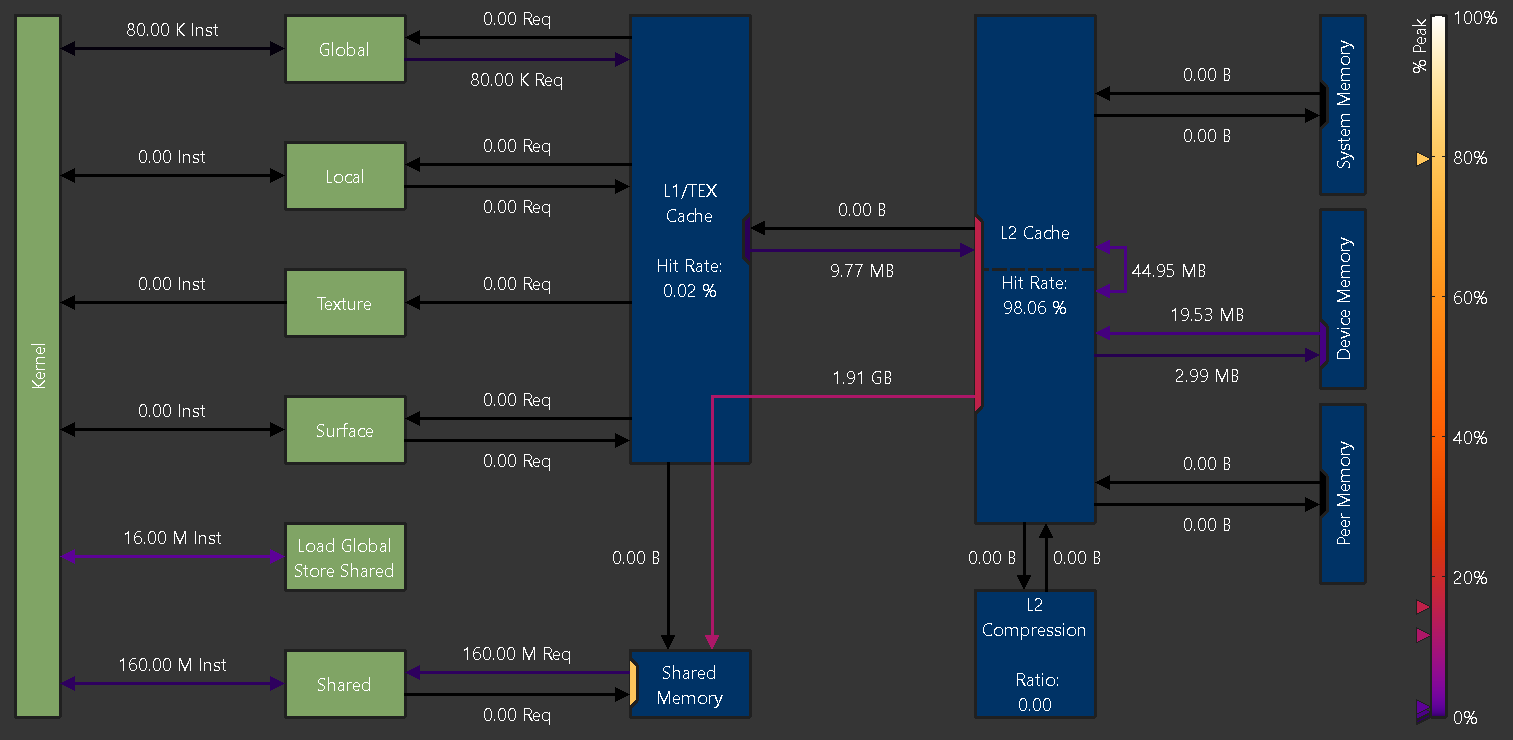
NVIDIA A100 GPU 的内存图表
逻辑单元(绿色)
逻辑单元以绿色(活动)或灰色(非活动)显示。
内核:在 GPU 的流式多处理器上执行的 CUDA 内核
全局:CUDA 全局内存
局部:CUDA 局部内存
纹理:CUDA 纹理内存
表面:CUDA 表面内存
共享:CUDA 共享内存
加载全局存储共享:直接从全局内存加载到共享内存而无需中间寄存器文件访问的指令
物理单元(蓝色)
物理单元以蓝色(活动)或灰色(非活动)显示。
L1/TEX 缓存:L1/纹理缓存。底层物理内存在此缓存和用户管理的共享内存之间分配。
共享内存:CUDA 的用户管理 共享内存。底层物理内存在此内存和 L1/TEX 缓存之间分配。
L2 缓存:L2 缓存
L2 压缩:L2 缓存的内存压缩单元
系统内存:片外 系统(CPU)内存
设备内存:片上 设备(GPU)内存,即执行内核的 CUDA 设备的内存
对等内存:片上 设备(GPU)内存,即其他 CUDA 设备的内存
根据具体的 GPU 架构,显示的单元的确切集合可能会有所不同,因为并非所有 GPU 都具有所有单元。
链接
内核和其他逻辑单元之间的链接表示针对相应单元执行的指令数(Inst)。例如,内核和全局之间的链接表示从全局内存空间加载或存储到全局内存空间的指令。使用 NVIDIA A100 的加载全局存储共享范例的指令是单独显示的,因为它们的寄存器或缓存访问行为可能与常规全局加载或共享存储不同。
逻辑单元和蓝色物理单元之间的链接表示由于其各自的指令而发出的请求数(Req)。例如,从 L1/TEX 缓存到全局的链接显示了由于全局加载指令而生成的请求数。
每个链接的颜色表示相应通信路径的峰值利用率百分比。图表右侧的颜色图例显示了从未使用(0%)到以峰值性能运行(100%)的应用颜色渐变。如果链接处于非活动状态,则以灰色显示。图例左侧的三角形标记对应于图表中的链接。与仅颜色渐变相比,标记为实现的峰值性能提供了更准确的值估计。
端口
一个单元通常为传入和传出流量共享一个公共数据端口。虽然共享端口的链接可能远低于其各自的峰值性能运行,但单元的数据端口可能已经达到其峰值。端口利用率在图表中通过位于传入和传出链接的单元内的彩色矩形显示。端口使用与数据链接相同的颜色渐变,并且在图例左侧也有相应的标记。非活动端口以灰色显示。
指标
可以使用命令行 --set full、--section MemoryWorkloadAnalysis_Chart 或 --metrics group:memory__chart 从此图表中收集指标。下面显示了内存表和内存图表中报告的峰值之间的相关性示例。
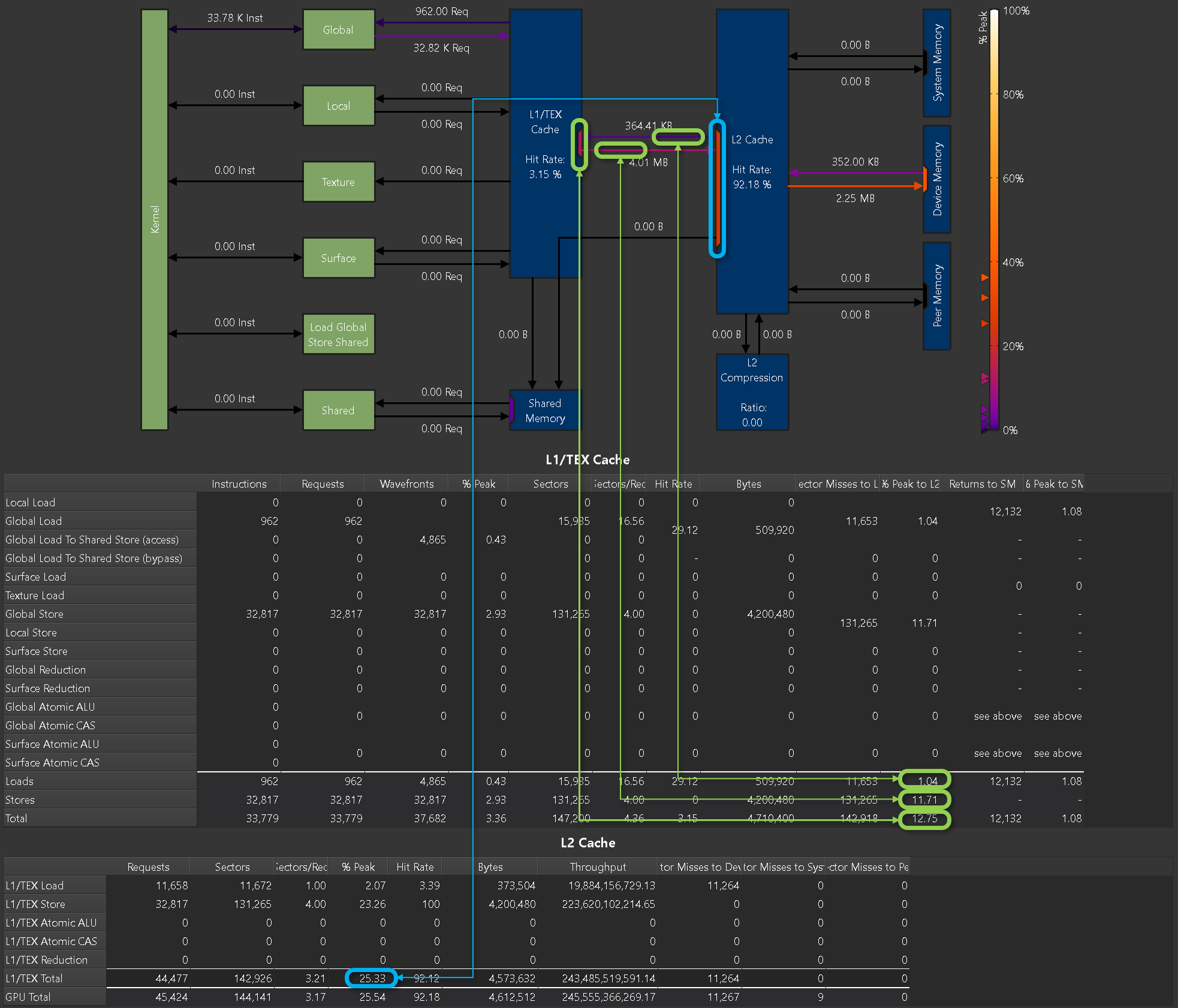
内存表和内存图表之间峰值映射
2.10. 内存表
内存表显示了各种内存硬件单元(例如共享内存、缓存和设备内存)的详细指标。对于大多数表格条目,您可以将鼠标悬停在其上方以查看底层指标名称和描述。某些条目是从其他单元格派生生成的,并且它们本身不显示指标名称,而是显示各自的计算。如果某个指标不影响通用派生计算,则在工具提示中显示为未使用。您可以将鼠标悬停在行或列标题上以查看表格此部分的描述。
2.10.1. 共享内存
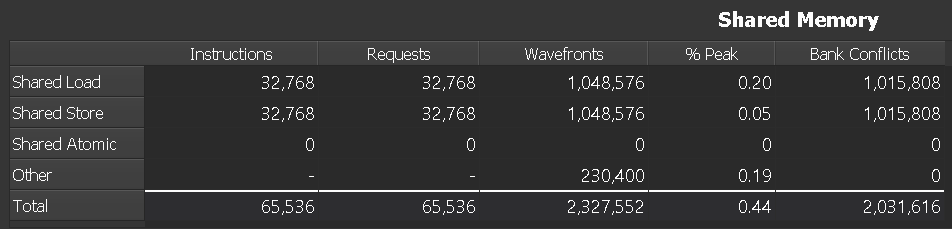
在 RTX 2080 Ti 上收集的共享内存表示例
列
|
对于每种访问类型,每个 Warp 实际执行的所有汇编 (SASS) 指令总数。不包括谓词关闭的指令。 例如,指令 STS 将计入共享存储。 |
|
对共享内存的所有 请求 总数。在 SM 7.0 (Volta) 和更新的架构上,每个共享内存指令正好生成一个请求。 |
|
服务请求的共享内存数据所需的 波阵面 数量。波阵面被串行化并在不同的周期内处理。 |
|
峰值利用率百分比。较高的值表示单元的利用率较高,并可能显示潜在的瓶颈,因为它不一定表示高效的使用。 |
|
如果多个线程请求的地址映射到同一内存 Bank 中的不同偏移量,则访问将被串行化。硬件会将冲突的内存请求拆分为尽可能多的单独的无冲突请求,从而将有效带宽降低等于冲突内存请求数的倍数。 |
行
|
共享内存访问操作。 |
|
同一列中所有访问类型的聚合。 |
指标
可以使用命令行 --set full、--section MemoryWorkloadAnalysis_Tables 或 --metrics group:memory__shared_table 从此表中收集指标。
2.10.2. L1/TEX 缓存
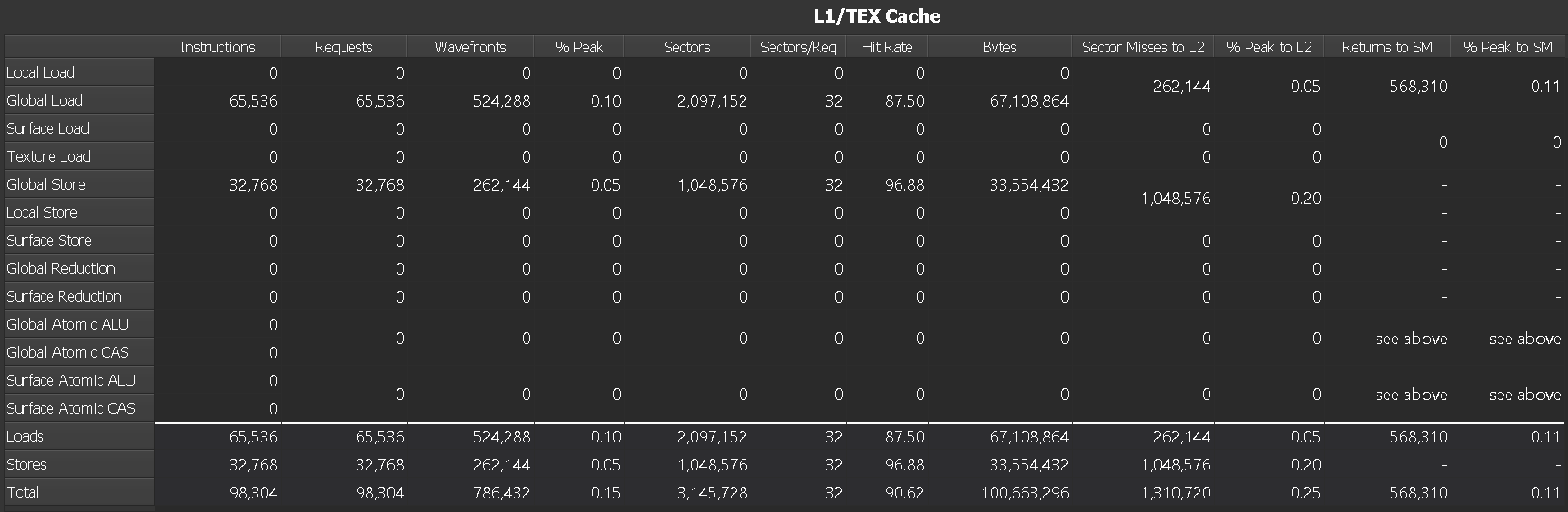
在 RTX 2080 Ti 上收集的 L1/TEX 缓存内存表示例
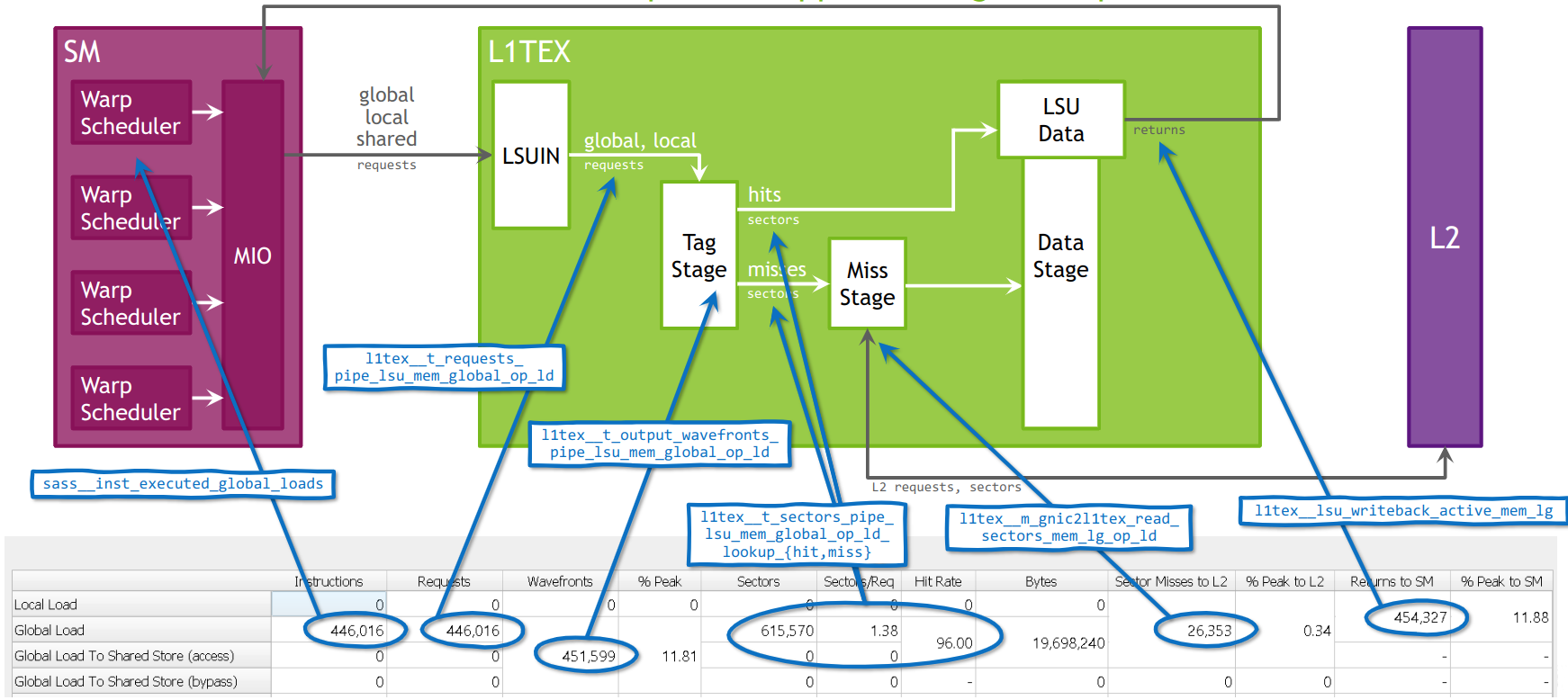
GA100 上 L1TEX 缓存的全局加载流水线模型,映射到内存表。
列
|
对于每种访问类型,每个 Warp 实际执行的所有汇编 (SASS) 指令总数。不包括谓词关闭的指令。 例如,指令 LDG 将计入全局加载。 |
|
为每种指令类型生成的对 L1 的所有 请求 总数。在 SM 7.0 (Volta) 和更新的架构上,每个指令为 LSU 流量(全局、局部等)生成正好一个请求。对于纹理 (TEX) 流量,可能会生成多个请求。 在示例中,65536 个全局加载指令中的每个指令正好生成一个请求。 |
|
服务请求的内存操作所需的 波阵面 数量。波阵面被串行化并在不同的周期内处理。 |
|
处理 波阵面 的单元的峰值利用率百分比。较高的数字可能表示处理流水线已饱和,并可能成为瓶颈。 |
|
发送到 L1 的所有 L1 扇区 访问总数。每个加载或存储请求访问 L1 缓存中的一个或多个扇区。原子操作和归约操作将传递到 L2 缓存。 |
|
L1 缓存的扇区与请求的平均比率。对于 Warp 中相同数量的活动线程,较小的数字表示更高效的内存访问模式。对于具有 32 个活动线程的 Warp,每个访问大小的最佳比率为:32 位:4,64 位:8,128 位:16。较小的比率表示缓存行内存在一定程度的均匀性或重叠加载。较高的数字可能表示 非合并内存访问,并将导致内存流量增加。 在示例中,全局加载的平均比率为每个请求 32 个扇区,这意味着每个线程都需要访问不同的扇区。理想情况下,对于具有 32 个活动线程的 Warp,每个线程访问单个对齐的 32 位值,则比率应为 4,因为每 8 个连续线程访问同一扇区。 |
|
L1 缓存中的 扇区 命中率(未命中的请求扇区的百分比)。未命中的扇区需要从 L2 请求,从而导致发送到 L2 的扇区未命中。较高的命中率意味着更好的性能,因为访问延迟更低,因为请求可以由 L1 而不是后续阶段提供服务。不要与标记命中率(未显示)混淆。 |
|
从 L1 请求的总字节数。这与扇区数乘以 32 字节相同,因为 L1 中的最小访问大小为一个扇区。 |
|
在 L1 中未命中并在 L2 缓存中生成后续请求的扇区总数。 在此示例中,全局和局部加载的 262144 个扇区未命中可以计算为未命中率 12.5% 乘以 2097152 个扇区数。 |
|
L1 到 XBAR 接口的峰值利用率百分比,用于发送 L2 缓存请求。如果此数字较高,则工作负载可能主要由分散的 {写入、原子操作、归约操作} 组成,这会增加延迟并导致 Warp 停顿。 |
|
从 L1 缓存发送回 SM 的返回数据包数。较大的请求访问大小会导致返回的数据包数更多。 |
|
XBAR 到 L1 返回路径的峰值利用率百分比(比较返回到 SM)。如果此数字较高,则工作负载可能主要由分散的读取组成,从而导致 Warp 停顿。提高读取合并或 L1 命中率可以降低此利用率。 |
行
|
各种访问类型,例如从全局内存加载或对表面内存执行归约操作。 |
|
同一列中所有加载访问类型的聚合。 |
|
同一列中所有存储访问类型的聚合。 |
|
同一列中所有加载和存储访问类型的聚合。 |
指标
可以使用命令行 --set full、--section MemoryWorkloadAnalysis_Tables 或 --metrics group:memory__first_level_cache_table 从此表中收集指标。
2.10.3. L2 缓存

在 RTX 2080 Ti 上收集的 L2 缓存内存表示例
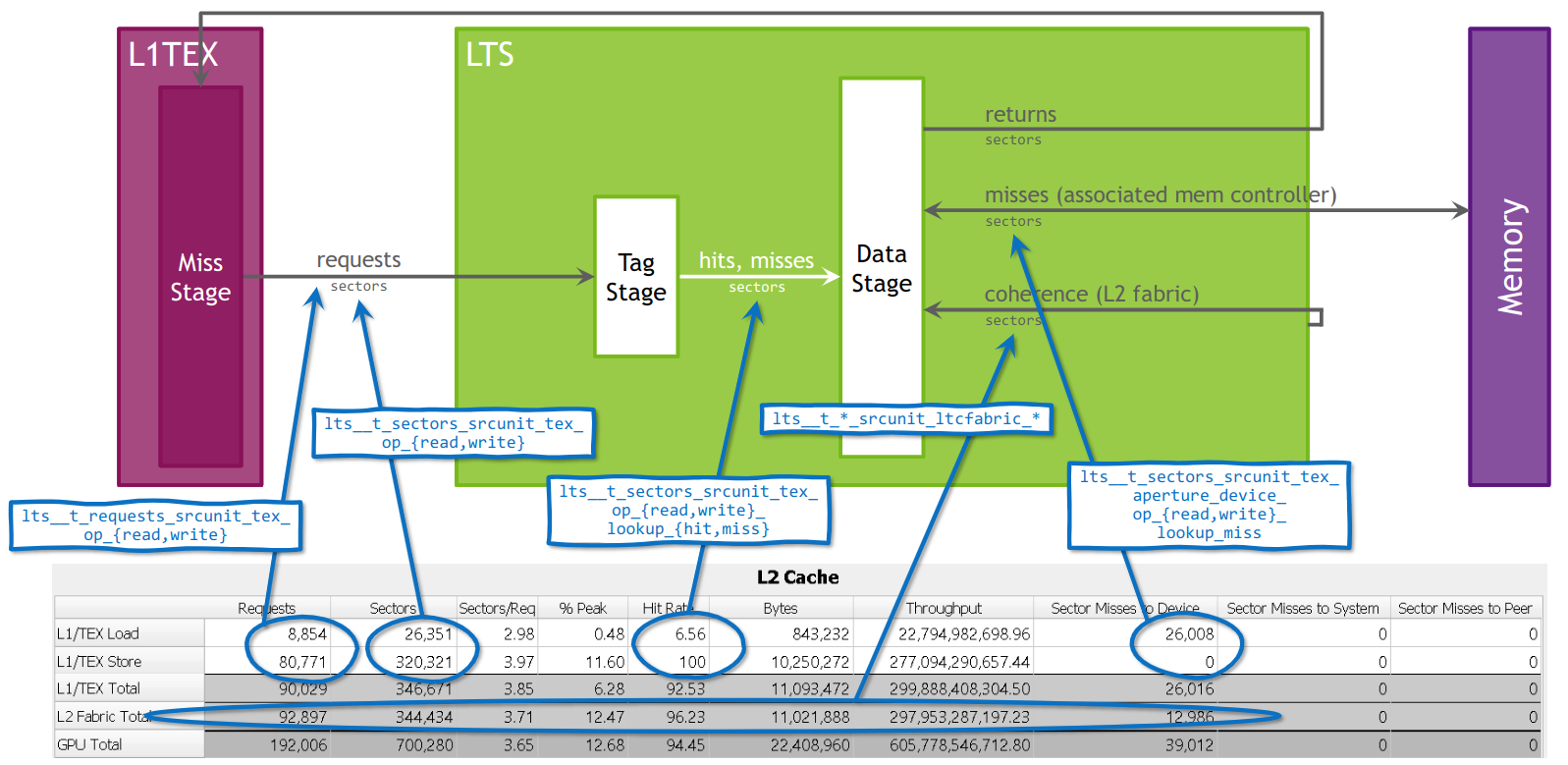
GA100 上 L2 缓存的模型,映射到内存表。
列
|
对于每种访问类型,对 L2 缓存发出的 请求 总数。这与 L1 缓存的发送到 L2 的扇区未命中相关。每个请求从单个 128 字节缓存行访问最多四个扇区。 |
|
对于每种访问类型,从 L2 缓存请求的 扇区 总数。每个请求访问一到四个扇区。 |
|
L2 缓存的扇区与请求的平均比率。对于 Warp 中相同数量的活动线程,较小的数字表示更高效的内存访问模式。较小的比率表示缓存行内存在一定程度的均匀性或重叠加载。较高的数字可能表示 非合并内存访问,并将导致内存流量增加。 |
|
峰值持续扇区数百分比。“工作包”在 L2 缓存中是一个扇区。较高的值表示单元的利用率较高,并可能显示潜在的瓶颈,因为它不一定表示高效的使用。 |
|
L2 缓存中的命中率(未命中的请求扇区的百分比)。未命中的扇区需要从后续阶段请求,从而导致发送到设备的扇区未命中、发送到系统的扇区未命中或发送到对等设备的扇区未命中之一。较高的命中率意味着更好的性能,因为访问延迟更低,因为请求可以由 L2 而不是后续阶段提供服务。 |
|
从 L2 请求的总字节数。这与扇区数乘以 32 字节相同,因为 L2 中的最小访问大小为一个扇区。 |
|
实现的 L2 缓存吞吐量,单位为字节/秒。较高的值表示单元的利用率较高。 |
|
|
|
在 L2 中未命中并在 系统内存中生成后续请求的扇区总数。 |
|
在 L2 中未命中并在 对等内存中生成后续请求的扇区总数。 |
行
|
各种访问类型,例如源自 L1 缓存的加载或归约操作。 |
|
源自 L1 缓存的所有操作的总计。 |
|
由 ECC(纠错码)引起的所有操作的总计。如果启用了 ECC,则部分修改扇区的 L2 写入请求会导致从 DRAM 加载相应的扇区。这些额外的加载操作会增加 L2 的扇区未命中数。 |
|
跨连接两个 L2 分区的 L2 Fabric 的所有操作的总计。此行仅针对在具有 L2 Fabric 的 CUDA 设备上启动的内核显示。 |
|
跨 L2 缓存的所有客户端的所有操作的总计。与是否在此表中单独拆分它们无关。 |
指标
可以使用命令行 --set full、--section MemoryWorkloadAnalysis_Tables 或 --metrics group:memory__l2_cache_table 从此表中收集指标。
2.10.4. L2 缓存驱逐策略
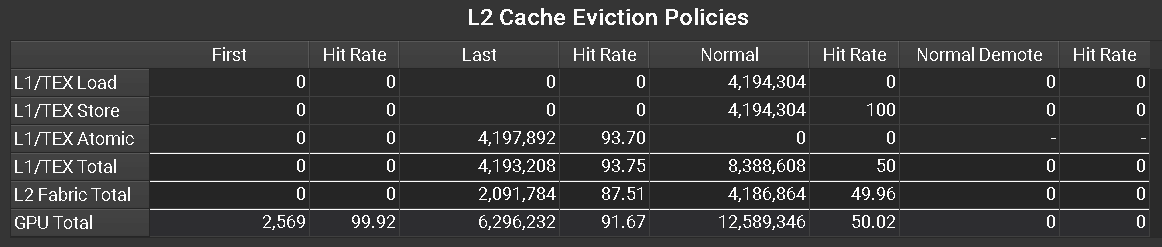
在 A100 GPU 上收集的 L2 缓存驱逐策略内存表示例
列
|
使用 |
|
使用 |
|
使用 |
|
使用 |
|
使用 |
|
使用 |
|
使用 |
|
使用 |
行
|
各种访问类型,例如源自 L1 缓存的加载或归约操作。 |
|
源自 L1 缓存的所有操作的总计。 |
|
跨连接两个 L2 分区的 L2 Fabric 的所有操作的总计。此行仅针对在具有 L2 Fabric 的 CUDA 设备上启动的内核显示。 |
|
跨 L2 缓存的所有客户端的所有操作的总计。与是否在此表中单独拆分它们无关。 |
指标
可以使用命令行 --set full、--section MemoryWorkloadAnalysis_Tables 或 --metrics group:memory__l2_cache_evict_policy_table 从此表中收集指标。请注意,此表仅在具有 GA100 或更高版本的 GPU 上可用。
2.10.5. 设备内存

在 RTX 2080 Ti 上收集的设备内存表示例
列
|
对于每种访问类型,从设备内存请求的 扇区 总数。 |
|
设备内存峰值利用率百分比。较高的值表示单元的利用率较高,并可能显示潜在的瓶颈,因为它不一定表示高效的使用。 |
|
在 L2 缓存和设备内存之间传输的总字节数。 |
|
实现的设备内存吞吐量,单位为字节/秒。较高的值表示单元的利用率较高。 |
行
|
设备内存加载和存储。 |
|
同一列中所有访问类型的聚合。 |
指标
可以使用命令行 --set full、--section MemoryWorkloadAnalysis_Tables 或 --metrics group:memory__dram_table 从此表中收集指标。
2.11. 常见问题解答
n/a 指标值
n/a 表示指标值“不可用”。最常见的原因是请求的指标不存在。这可能是拼写错误或缺少 后缀 的结果。对照
--query-metricsNVIDIA Nsight Compute CLI 选项的输出验证指标名称。如果指标名称是复制的(例如从本文档的旧版本复制),请确保它不包含零宽度 Unicode 字符。
最后,该指标可能只是在目标 GPU 架构上不存在。例如,IMMA 流水线指标
sm__inst_executed_pipe_tensor_op_imma.avg.pct_of_peak_sustained_active在 GV100 芯片上不可用。指标值超出预期的逻辑范围
这包括例如超过 100% 的百分比或报告负值的指标。有关更多详细信息,请参阅 范围和精度。
ERR_NVGPUCTRPERM - 用户没有访问目标设备上 NVIDIA GPU 性能计数器的权限。
默认情况下,NVIDIA 驱动程序需要提升的权限才能访问 GPU 性能计数器。在移动平台上,以 root 身份或使用 sudo 进行性能分析。在其他平台上,您可以 root 身份或使用 sudo 启动性能分析,或者启用非管理员性能分析。有关更多详细信息,请参阅 https://developer.nvidia.com/ERR_NVGPUCTRPERM。
在适用于 Linux 的 Windows 子系统 (WSL) 上,必须在 Windows 主机的 NVIDIA 控制面板中启用对 NVIDIA GPU 性能计数器的访问。
不支持的 GPU
这表示当前内核在其上启动的 GPU 不受支持。有关 NVIDIA Nsight Compute 版本支持的设备列表,请参阅发行说明。这也可能表示当前的GPU 配置不受支持。例如,NVIDIA Nsight Compute 可能无法分析 SLI 配置中的 GPU。
检测到与目标应用程序通信的连接错误。
与性能分析应用程序的进程间连接意外断开。如果应用程序被终止或发出异常信号(例如段错误),则会发生这种情况。
连接失败。目标进程可能已退出。
如果发生以下情况,则会发生这种情况
应用程序在退出之前未调用任何 CUDA API 调用。
应用程序过早终止,因为它从错误的工作目录启动,或使用了错误的参数。在这种情况下,请检查启动活动对话框中的详细信息。
应用程序在调用任何 CUDA API 调用之前崩溃。
应用程序启动使用 CUDA 的子进程。在这种情况下,请使用
--target-processes all选项启动。
分析器返回错误代码:(数字)
对于非交互式性能分析活动,将启动 NVIDIA Nsight Compute CLI 以生成报告。如果应用程序以非零返回代码退出,或者 NVIDIA Nsight Compute CLI 本身遇到错误,则结果返回代码将在此消息中显示。
例如,如果应用程序在 Linux 上遇到段错误 (SIGSEGV),则可能会返回错误代码 11。所有非零返回代码都被视为错误,因此即使应用程序在正常执行期间以返回代码 1 退出,也会显示此消息。
为了调试此问题,直接从命令行使用
ncu运行数据收集可能会有所帮助,以便观察应用程序和分析器的命令行输出,例如==ERROR== The application returned an error code (11)无法打开/创建锁定文件 (路径)。请检查此进程是否对此文件具有写入权限。
NVIDIA Nsight Compute 无法创建或打开具有写入权限的文件
(path)。此文件用于进程间 序列化。根据设计,NVIDIA Nsight Compute 在分析后不会删除此文件。如果文件是由具有阻止当前进程写入此文件权限的分析进程创建的,或者如果当前用户由于其他原因(例如某些 Linux 内核安全设置)无法获取此文件,则会发生此错误。该文件位于当前临时目录中,即
TMPDIR/nsight-compute-lock。在 Windows 上,TMPDIR 是 WindowsGetTempPathAPI 函数返回的路径。在其他平台上,它是列表TMPDIR, TMP, TEMP, TEMPDIR中第一个环境变量提供的路径。如果未找到任何一个,则在 QNX 上为/var/nvidia,否则为/tmp。较旧版本的 NVIDIA Nsight Compute 默认情况下未对所有用户设置此文件的写入权限。因此,在同一系统上以不同的用户身份运行该工具可能会导致此错误。自 2020.2.1 版本起,此问题已得到解决。
可以使用以下解决方法来解决此问题
如果可以确保同一系统上没有并发的 NVIDIA Nsight Compute 实例处于活动状态,请将
TMPDIR设置为当前用户具有写入权限的其他目录。请拥有该文件的用户或系统管理员删除该文件,或为所有潜在用户添加写入权限。
在 Linux 系统上设置
fs.protected_regular=1后,即使所有者可以访问,root 用户或其他用户也可能无法访问此文件(如果临时目录上设置了粘滞位)。可以使用sudo sysctl fs.protected_regular=0禁用此设置,使用其他临时目录(见上文),或者为非 root 用户启用对硬件性能计数器的访问,并以拥有该文件的同一用户身份进行分析(有关如何更改此设置,请参阅 https://developer.nvidia.com/ERR_NVGPUCTRPERM)。
分析失败,因为驱动程序资源不可用。
此错误表明在分析期间所需的 CUDA 驱动程序资源不可用。最常见的情况是,这意味着 NVIDIA Nsight Compute 无法保留驱动程序的性能监视器,这对于收集大多数指标是必需的。
如果另一个应用程序对此资源有并发预留,则可能会发生这种情况。此类应用程序可以是例如 DCGM、CUPTI 的 Profiling API 的客户端、Nsight Graphics,或另一个无法访问同一文件系统的 NVIDIA Nsight Compute 实例(有关如何在同一文件系统中防止这种情况,请参阅 序列化)。
如果您认为问题是由 DCGM 引起的,请考虑在使用 NVIDIA Nsight Compute 进行分析时使用
dcgmi profile --pause停止其监视。无法部署库存 * 文件到 *
无法确定用于 section 部署的用户主目录。
尝试部署库存 section 或规则文件时发生错误。默认情况下,NVIDIA Nsight Compute 尝试将这些文件部署到用户主目录中的版本化目录(由 Linux 上的
HOME环境变量标识),例如/home/user/Documents/NVIDIA Nsight Compute/<version>/Sections。如果无法确定目录(例如,因为此环境变量未指向有效目录),或者在部署文件时发生错误(例如,因为当前进程对其没有写入权限),则会显示警告消息,并且 NVIDIA Nsight Compute 将回退到使用安装目录中的库存 section 和规则。
如果您所处的环境始终没有对用户主目录的写入权限,请考虑使用
ncu --section-folder-restore预先填充此目录,或将/home/user/Documents/NVIDIA Nsight Compute/<version>创建为指向可写目录的符号链接。ProxyJump SSH 选项不起作用
当使用
ProxyJump选项时启动 OpenSSH 客户端时,NVIDIA Nsight Compute 不管理身份验证或交互式提示。因此,首次通过中间主机进行连接时,您将无法接受中间主机的密钥。在这种情况下,查明故障原因的简单方法是打开终端并使用 OpenSSH 客户端连接到远程目标。一旦连接成功,NVIDIA Nsight Compute 也应该能够连接到目标。SSH 连接失败,未尝试连接
如果连接失败,且未尝试连接,则可能是您在“启动活动对话框”中输入的设置有问题。请确保
IP/主机名、用户名和端口字段已正确设置。SSH 连接仍然无法工作
问题可能来自 NVIDIA Nsight Compute 的 SSH 客户端未找到远程服务器支持的合适主机密钥算法来使用。您可以通过在 SSH 配置文件中为有问题的主机设置
HostKeyAlgorithms选项,强制 NVIDIA Nsight Compute 使用一组特定的主机密钥算法。要列出远程目标支持的主机密钥算法,您可以使用 OpenSSH 客户端附带的ssh-keyscan实用程序。从已知主机文件中删除主机密钥
连接到目标机器时,NVIDIA Nsight Compute 尝试根据与 OpenSSH 客户端相同的本地数据库验证目标的主机密钥。如果 NVIDIA Nsight Compute 发现主机密钥不正确,它将通过失败对话框通知您。如果您信任对话框中显示的密钥哈希值,则可以通过手动编辑已知主机数据库或使用
ssh-keygen -R <host>命令删除先前为该主机保存的密钥。Qt 初始化失败
无法加载 Qt 平台插件
有关 Linux 的信息,请参阅 系统要求。
ImportError: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.xx' not found**在导入**ncu_report**时**如果系统的
libstdc++版本对于ncu_report来说太旧,您可以使用 NVIDIA Nsight Compute 附带的版本。为此,请将相应的目录添加到 *LD_LIBRARY_PATH*,例如,export LD_LIBRARY_PATH=<ncu_install_dir>/host/<arch>/:$LD_LIBRARY_PATH。
通知
通知
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他方面的保证,并明确声明不承担任何关于不侵权、适销性和特定用途适用性的暗示保证。
所提供的信息被认为是准确和可靠的。但是,NVIDIA 公司对使用此类信息造成的后果或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。在 NVIDIA 公司的任何专利权项下,无论是暗示的还是其他的,均未授予任何许可。本出版物中提及的规格如有更改,恕不另行通知。本出版物取代并替换以前提供的所有其他信息。未经 NVIDIA 公司明确书面批准,NVIDIA 公司产品不得用作生命支持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。