培训
Nsight Compute 培训内容。
NVIDIA Nsight Compute 培训资源。
外部资源
论坛
博客
查看最新的 博客文章列表
视频
查看最新的 培训视频列表
代码示例
在 GitHub 上查看我们的代码示例
使用示例
过滤器选项
请注意,除非另有说明,否则示例将使用术语workload来指代内核、图、范围或 cmdlist。
分析前两个 workload
--launch-count 2分析在前两个 workload 在设备 ID 为 1 的设备上启动的 workload
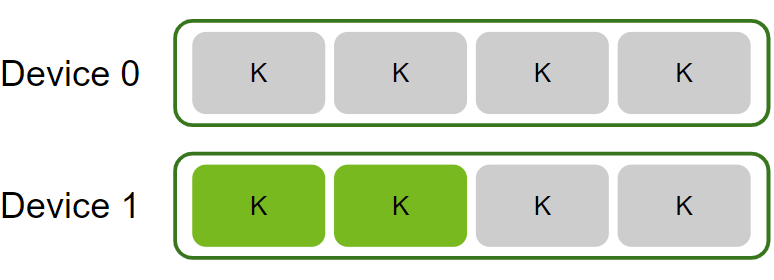
--device 1 --launch-count 2分析每个 gpu 上的第 2 个 workload
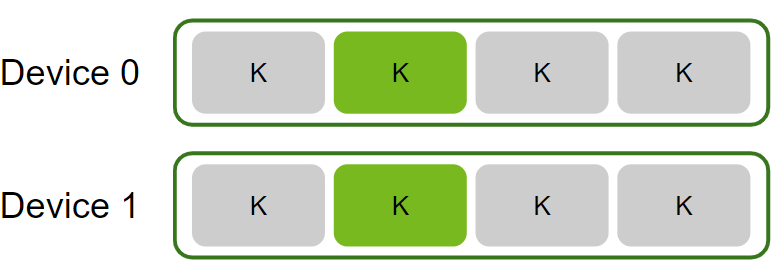
--launch-skip 1 --launch-count 1 --filter-mode per-gpu在分析之前,跳过每个启动配置的前 2 个 workload
--launch-skip 2 --filter-mode per-launch-config分析 “Bar” 内核

--kernel-name Bar分析函数名中包含 “Bar” 的内核

--kernel-name regex:Bar仅分析内核 “Foo” 的第 2 次调用

--kernel-id ::Foo:2仅分析名称中包含 “Bar” 的所有内核的第 2 次调用

--kernel-id ::regex:Bar:2在匹配内核名称中的 “Foo” 或 “Bar” 之前,跳过前 2 个 workload

--launch-skip-before-match 2 --kernel-name regex:“Foo|Bar”分析在 CUDA 上下文 ID 1 和流 ID 2 上,所有 mangled 名称为 “_FooBar” 的第 7 次内核调用
--kernel-id 1:2:_Foobar:7 --kernel-name-base mangled仅分析内核 “Foo” 的第 7 次调用,与上下文 ID 和流 ID 无关
--kernel-id ::Foo:7分析在流 ID 1 和 NVTX 流名称 “cuda_stream” 上启动的内核 “Foo” 的每第 7 次调用,与上下文 ID 无关
--kernel-id :1|cuda_stream:Foo:7 --nvtx分析在前 3 个 cu(da)ProfilerStart/Stop API 创建的范围内启动的所有 workload
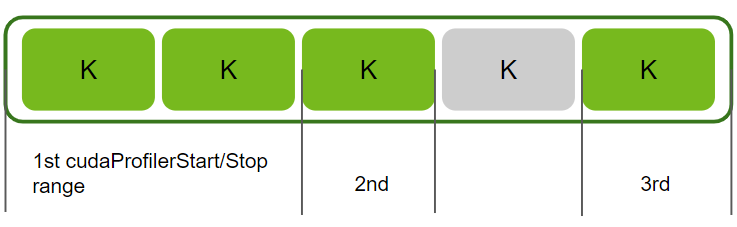
--range-filter :[1-3]:分析在第 2 个 NVTX Push/Pop 范围 A 中启动的所有 workload
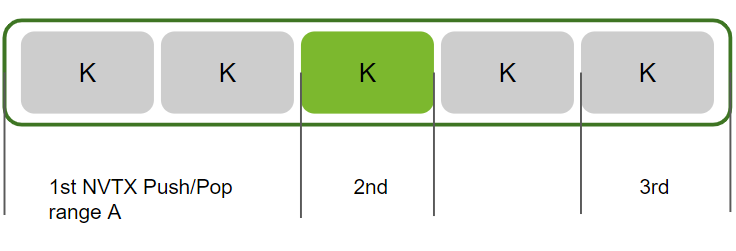
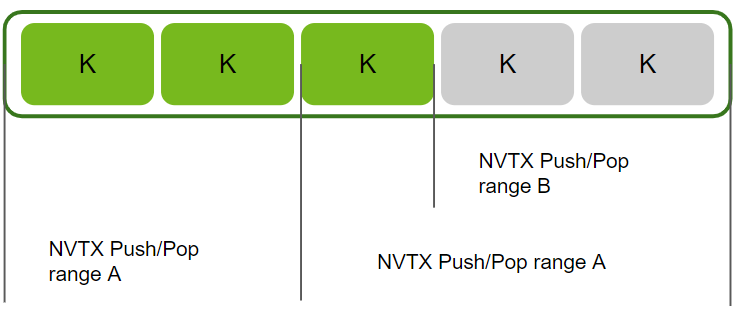
--range-filters ::2 --nvtx --nvtx-include A/分析在 NVTX Push/Pop 范围 A 中启动的所有 workload,但 NVTX Push/Pop 范围 B 中的 workload 除外
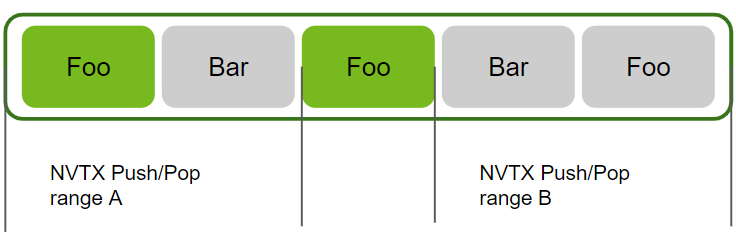
--nvtx --nvtx-include A/ --nvtx-exclude B/分析所有 “Foo” 内核,但在 NVTX Push/Pop 范围 B 中启动的内核除外
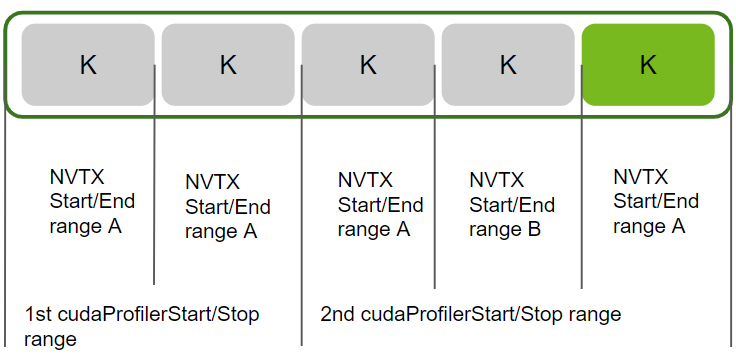
--nvtx --nvtx-exclude B/ --kernel-name Foo分析在第 2 个 NVTX Start/End 范围 A 内启动的所有 workload,该范围在第 2 个 cu(da)ProfilerStart/Stop API 创建的范围内
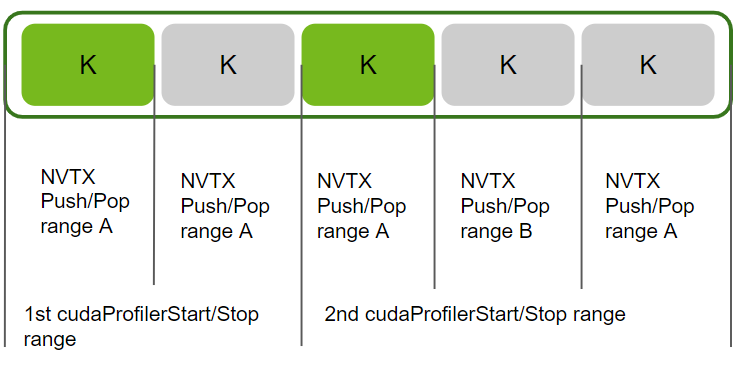
--range-filter yes:2:2 --nvtx --nvtx-include A分析在第 1 个 NVTX Push/Pop 范围 A 内启动的所有 workload,该范围在第 1 个和第 2 个 cu(da)ProfilerStart/Stop API 创建的范围内
--range-filter yes:[1-2]:1 --nvtx --nvtx-include A/分析在第 1 个 cu(da)ProfilerStart/Stop API 创建的范围内启动的所有 workload,该范围具有第 2 个 NVTX push/pop 范围 A 和域 D
--range-filter no:1:2 --nvtx --nvtx-include D@A/
注意事项
注意事项
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独或一起)均“按原样”提供。 NVIDIA 不对这些材料做出任何明示、暗示、法定或其他方面的保证,并且明确否认所有关于不侵权、适销性和特定用途适用性的暗示保证。
提供的信息被认为是准确和可靠的。 但是,NVIDIA 公司对使用此类信息造成的后果或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。 NVIDIA 公司未以暗示或其他方式授予任何专利权许可。 本出版物中提及的规格如有更改,恕不另行通知。 本出版物取代并替换之前提供的所有其他信息。 未经 NVIDIA 公司的明确书面批准,NVIDIA 公司产品不得用作生命支持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标或注册商标。 其他公司和产品名称可能是与其相关的各自公司的商标。