1. 自定义指南
Nsight Compute 自定义指南。
关于自定义 NVIDIA Nsight Compute 工具或将其与自定义工作流程集成的用户手册。包含关于编写节文件、自动结果分析规则以及脚本访问报告文件的信息。
1.1. 简介
NVIDIA Nsight Compute 的目标是设计一个可以被专家用户轻松扩展和自定义的分析工具。虽然我们提供了有用的默认设置,但这允许根据特定用例调整报告,或设计调查收集数据的新方法。以下所有内容都是数据驱动的,不需要重新编译工具。
在使用节文件或规则文件时,建议从Profile菜单项中打开Metric Selection工具窗口。此工具窗口列出了已加载的所有节和规则。规则分组为其关联节的子项或分组在[独立规则]条目中。对于加载失败的文件,表格显示错误消息。使用Reload按钮从磁盘重新加载规则文件。
1.2. 指标节
详细信息页面由节组成,每个节都侧重于内核分析的特定部分。每个节都由相应的节文件定义,该文件指定要收集的数据以及在 UI 或 CLI 输出中用于此数据的可视化效果。只需修改已部署的节文件即可添加或修改要收集的内容。
1.2.1. 节文件
工具附带的节文件存储在 NVIDIA Nsight Compute 安装目录的 sections 子文件夹中。每个节都在一个单独的文件中定义,文件扩展名为 .section。在运行时,已安装的库存节(和规则)将部署到用户可写目录。可以使用环境变量禁用此功能。部署目录中的节文件在 UI 连接到目标应用程序或启动命令行分析器时自动加载。这样,对节文件的任何更改都会在下一次分析运行时立即生效。
节文件是 Google Protocol Buffer 消息的文本表示形式。节消息的所有可用字段的完整定义在节定义中给出。简而言之,每个节都包含一个唯一的标识符(不允许空格)、一个显示名称、一个可选的顺序值(用于在详细信息页面中对节进行排序)、一个可选的描述,为用户提供指导、一个可选的标题表、一个可选的要收集但不显示的指标列表、带有附加 UI 元素的可选正文以及其他元素。有关可用元素的准确列表,请参见 ProfilerSection.proto。一个非常简单的节的小例子是
Identifier: "SampleSection"
DisplayName: "Sample Section"
Description: "This sample section shows information on active warps and cycles."
Header {
Metrics {
Label: "Active Warps"
Name: "smsp__active_warps_avg"
}
Metrics {
Label: "Active Cycles"
Name: "smsp__active_cycles_avg"
}
}
在数据收集时,此节将导致收集两个 PerfWorks 指标 smsp__active_warps_avg 和 smsp__active_cycles_avg。

在“详细信息”页面上显示的节
默认情况下,当不可用时,节文件中指定的指标只会生成数据收集期间的警告,然后在 UI 或 CLI 中显示为“N/A”。这与通过 --metrics 请求的指标形成对比,后者在不可用时会导致错误。如何在指标选项和过滤器中描述指定指标作为数据收集的必需项。
更高级的元素可以在节的正文中使用。请参阅 ProfilerSection.proto 文件,了解哪些元素可用。以下示例显示了如何在稍微复杂的示例中使用这些元素。正则表达式的使用仅在节正文中的表格和图表中允许,格式为 regex:,后跟要匹配 PerfWorks 指标名称的实际正则表达式。
可以使用命令行界面和 --query-metrics 选项查询节中可以使用的受支持指标列表。这些指标中的每一个都可以在任何节中使用,并且如果它们出现在任何已启用的节中,都将自动收集。请注意,即使指标在多个节中使用,它也只会收集一次。查看所有附带的节,了解它们是如何实现的。
Identifier: "SampleSection"
DisplayName: "Sample Section"
Description: "This sample section shows various metrics."
Header {
Metrics {
Label: "Active Warps"
Name: "smsp__active_warps_avg"
}
Metrics {
Label: "Active Cycles"
Name: "smsp__active_cycles_avg"
}
}
Body {
Items {
Table {
Label: "Example Table"
Rows: 2
Columns: 1
Metrics {
Label: "Avg. Issued Instructions Per Scheduler"
Name: "smsp__inst_issued_avg"
}
Metrics {
Label: "Avg. Executed Instructions Per Scheduler"
Name: "smsp__inst_executed_avg"
}
}
}
Items {
Table {
Label: "Metrics Table"
Columns: 2
Order: ColumnMajor
Metrics {
Name: "regex:.*__elapsed_cycles_sum"
}
}
}
Items {
BarChart {
Label: "Metrics Chart"
CategoryAxis {
Label: "Units"
}
ValueAxis {
Label: "Cycles"
}
Metrics {
Name: "regex:.*__elapsed_cycles_sum"
}
}
}
}
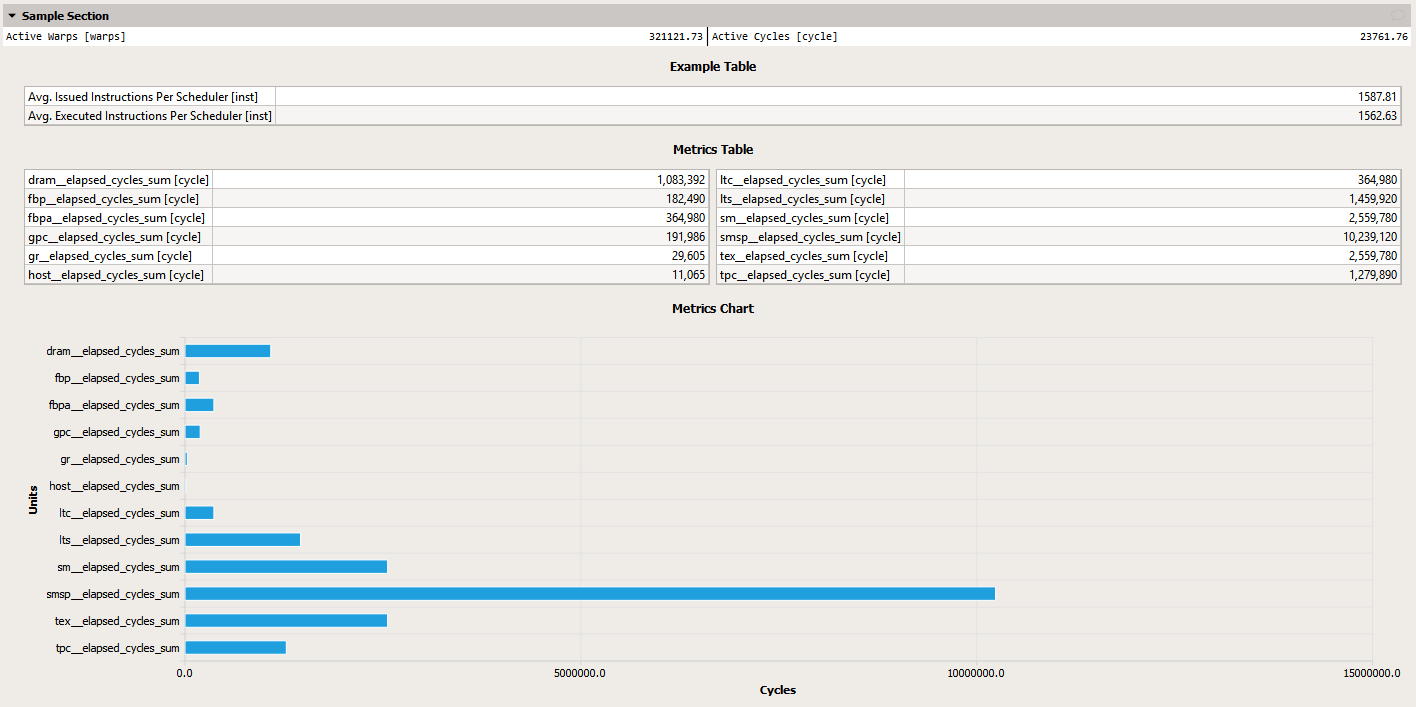
此节的输出在 UI 中看起来类似于此屏幕截图
1.2.2. 节定义
协议缓冲区定义位于 NVIDIA Nsight Compute 安装目录下的 extras/FileFormat 中。要理解节文件,请从 ProfilerSection.proto 中的定义和文档开始。
要查看任何设备或芯片的可用 PerfWorks 指标列表,请使用命令行的 --query-metrics 选项。
1.2.3. 指标选项和过滤器
节允许用户为在不同 GPU 架构上具有不同指标名称的指标指定替代选项。指标选项使用最小架构/最大架构范围过滤器,将基本指标替换为当前 GPU 架构与之匹配的第一个指标选项。虽然不是严格强制执行,但基本指标的选项应与基本指标共享相同的含义和随后的单位等。
除了其选项外,基本指标还可以通过相同的标准进行过滤。这对于仅在某些架构或有限的收集范围内可用的指标非常有用。有关哪些过滤器选项可用,请参阅 ProfilerMetricOptions.proto。
在下面的示例中,指标 dram__cycles_elapsed.avg.per_second 在 SM 7.0 和 SM 7.5-8.6 上收集,但在两者之间的任何架构上都不收集。它在这些架构上使用相同的指标名称。
Metrics {
Label: "DRAM Frequency"
Name: "dram__cycles_elapsed.avg.per_second"
Filter {
MaxArch: CC_70
}
Options {
Name: "dram__cycles_elapsed.avg.per_second"
Filter {
MinArch: CC_75
MaxArch: CC_86
}
}
}
在下一个示例中,节标题中的指标仅针对基于启动的收集范围(即 CUDA 内核或 CUDA 图节点的内核和应用程序重放)收集,而不是针对基于范围的范围。
Header {
Metrics {
Label: "Theoretical Occupancy"
Name: "sm__maximum_warps_per_active_cycle_pct"
Filter {
CollectionFilter {
CollectionScopes: CollectionScope_Launch
}
}
}
}
同样,CollectionFilter 可以用于设置指标的 Importance,它指定了在数据收集期间其可用性的预期。Required 指标(例如)应可收集,如果不可用,则会生成错误,而 Optional 指标只会生成警告。这是一个最小的示例,说明了该功能
Metrics {
Label: "Compute (SM) Throughput"
Name: "sm__throughput.avg.pct_of_peak_sustained_elapsed"
Filter {
CollectionFilter {
Importance: Required
}
}
}
过滤器可以应用于整个节,而不是或除了为单个指标设置过滤器之外。如果指定了两种类型的过滤器,则它们会组合在一起,以便 Metrics-范围过滤器优先于节范围过滤器。
1.2.4. 自定义描述
节文件支持在可以使用指标的许多位置指定自定义描述。只有在创建派生指标或通过规则系统添加新指标时,才需要指定自定义描述。当为原本具有描述的指标设置此项时,现有描述将被自定义值覆盖。
Metrics {
Label: "Custom Metric"
Name: "custom_metric"
Description: "Metric added when the rule associated with this section file is triggered."
}
请注意,Description 字段目前仅支持节 Metrics 字段,但不支持单个选项。
1.2.5. PM 采样时间线
节文件中的 PM 采样指标应在时间线字段中指定。时间线是节正文字段的项目。时间线由任意数量的MetricGroups和任意数量的MetricRows组成。MetricGroups 可以在时间线 UI 中展开或折叠。每个 MetricRow 可以包含任意数量的 Metrics。如果一行包含多个指标,则会聚合它们的值。
每个时间线指标都应与 Groups 字段关联。同一组中的所有指标都在同一重放通道中收集。指标可以具有可选的 Multiplier 字段。指标的值在记录在报告中之前会与其相乘。
Timeline {
MetricGroups {
Label: "Overview"
Expanded: true
MetricRows {
Metrics {
Label: "Average Active Warps Per Cycle"
Name: "TriageAC.tpc__warps_active_realtime.avg.per_cycle_active"
Groups: "sampling_0"
Multiplier: 0.5
}
}
MetricRows {
Metrics {
Label: "Total Active Warps Per Cycle"
Name: "TriageAC.tpc__warps_active_realtime.sum.per_cycle_active"
Groups: "sampling_0"
}
}
}
MetricGroups {
Label: "SM"
Expanded: true
MetricRows {
Metrics {
Label: "SM Throughput"
Name: "TriageSCG.sm__throughput.avg.pct_of_peak_sustained_elapsed"
Groups: "sampling_1"
}
}
1.2.6. 计数器域
PM 采样指标在内部由一个或多个原始计数器依赖项组成。每个计数器都与一个计数器域关联,该域描述了计数器在硬件中收集的方式和位置。对于在节文件中指定的指标,可以在需要时覆盖自动域选择,以形成更优化的 PM 采样指标组。
Metrics {
Label: "Short Scoreboard"
Name: "pmsampling:smsp__warps_issue_stalled_short_scoreboard.avg"
Groups: "sampling_ws4"
CtrDomains: "gpu_sm_c"
}
请注意,CtrDomains 字段目前仅支持节 Metrics 字段,但不支持单个选项。
1.2.7. 缺失节
如果 NVIDIA Nsight Compute 未使用新的或更新的节文件,则最常见的原因是以下两种之一
未找到文件: 节文件必须具有 .section 扩展名。它们还必须位于节搜索路径中。默认搜索路径是安装目录中的 sections 目录。在 NVIDIA Nsight Compute CLI 中,可以使用 --section-folder 和 --section-folder-recursive 选项覆盖搜索路径。在 NVIDIA Nsight Compute 中,可以在Profile选项中配置搜索路径。
语法错误: 如果找到文件但存在语法错误,则该文件将不可用于指标收集。但是,会报告错误消息以方便调试。在 NVIDIA Nsight Compute CLI 中,使用 --list-sections 选项获取错误消息列表(如果有)。在 NVIDIA Nsight Compute 中,错误消息在Metric Selection工具窗口中报告。
1.2.8. 派生指标
派生指标允许您直接在节文件中定义由常量或现有指标组成的新指标。新指标在收集时计算,并永久添加到报告中的分析结果中。然后,它们可以随后用于任何表格、图表、规则等。
NVIDIA Nsight Compute 当前支持以下语法,用于在节文件中定义派生指标
MetricDefinitions {
MetricDefinitions {
Name: "derived_metric_name"
Expression: "derived_metric_expr"
}
MetricDefinitions {
...
}
...
}
实际指标表达式定义如下
derived_metric_expr ::= operand operator operand
operator ::= + | - | * | /
operand ::= metric | constant
metric ::= (an existing metric name)
constant ::= double | uint64
double ::= (double-precision number of the form "N.(M)?", e.g. "5." or "0.3109")
uint64 ::= (64-bit unsigned integer number of the form "N", e.g. "2029")
运算符定义如下
For op in (+ | - | *): For each element in a metric it is applied to, the expression left-hand side op-combined with expression right-hand side.
For op in (/): For each element in a metric it is applied to, the expression left-hand side op-combined with expression right-hand side. If the right-hand side operand is of integer-type, and 0, the result is the left-hand side value.
由于指标可以包含常规值和/或实例值,因此元素组合如下。常量被视为仅具有常规值的指标。
1. Regular values are operator-combined.
a + b
2. If both metrics have no correlation ids, the first N values are operator-combined, where N is the minimum of the number of elements in both metrics.
a1 + b1
a2 + b2
a3
a4
3. Else if both metrics have correlation ids, the sets of correlation ids from both metrics are joined and then operator-combined as applicable.
a1 + b1
a2
b3
a4 + b4
b5
4. Else if only the left-hand side metric has correlation ids, the right-hand side regular metric value is operator-combined with every element of the left-hand side metric.
a1 + b
a2 + b
a3 + b
5. Else if only the right-hand side metric has correlation ids, the right-hand side element values are operator-combined with the regular metric value of the left-hand side metric.
a + b1 + b2 + b3
在所有运算中,都使用左侧操作数的值类型。如果右侧操作数具有不同的值类型,则会进行转换。如果左侧操作数是字符串类型,则返回不变。
派生指标的示例包括 derived__avg_thread_executed,它提供了关于每个指令平均执行的线程数的提示,以及 derived__uncoalesced_l2_transactions_global,它指示在每个适用指令处实际 L2 事务与理想 L2 事务的比率。
MetricDefinitions {
MetricDefinitions {
Name: "derived__avg_thread_executed"
Expression: "thread_inst_executed_true / inst_executed"
}
MetricDefinitions {
Name: "derived__uncoalesced_l2_transactions_global"
Expression: "memory_l2_transactions_global / memory_ideal_l2_transactions_global"
}
MetricDefinitions {
Name: "sm__sass_thread_inst_executed_op_ffma_pred_on_x2"
Expression: "sm__sass_thread_inst_executed_op_ffma_pred_on.sum.peak_sustained * 2"
}
}
1.3. 规则系统
NVIDIA Nsight Compute 具有新的基于 Python 的规则系统。它被设计为 NVIDIA Visual Profiler 中专家系统(非)引导式分析的继任者,但旨在更灵活,更易于扩展到不同的用例和 API。
1.3.1. 编写规则
要创建新规则,您需要创建一个新的文本文件,扩展名为 .py,并将其放置在工具可检测到的某个位置(请参阅 Nsight Compute 集成,了解如何指定规则的搜索路径)。至少,规则文件必须实现两个函数,get_identifier 和 apply。有关规则文件中支持的所有函数的描述,请参阅规则文件 API。有关规则的 apply 函数中可用接口的详细信息,请参阅 NvRules。
1.3.2. 集成
规则系统作为分析报告视图的一部分集成到 NVIDIA Nsight Compute 中。当您分析内核时,可用规则将显示在报告的详细信息页面中。您可以选择通过单击页面顶部的应用规则一次应用所有可用规则,也可以单独应用规则。应用后,规则结果将添加到当前报告中。默认情况下,所有规则都会自动应用。
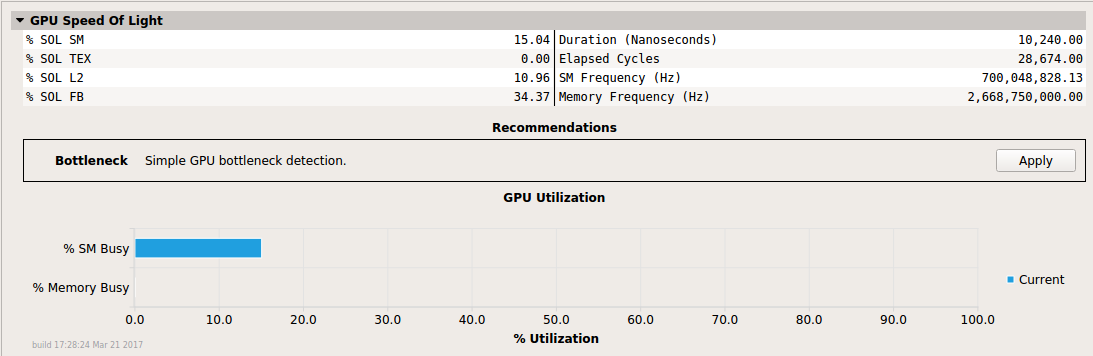
具有单个可用 Bottleneck 规则的节。

应用 Bottleneck 规则的同一节。它向报告添加了一条消息。
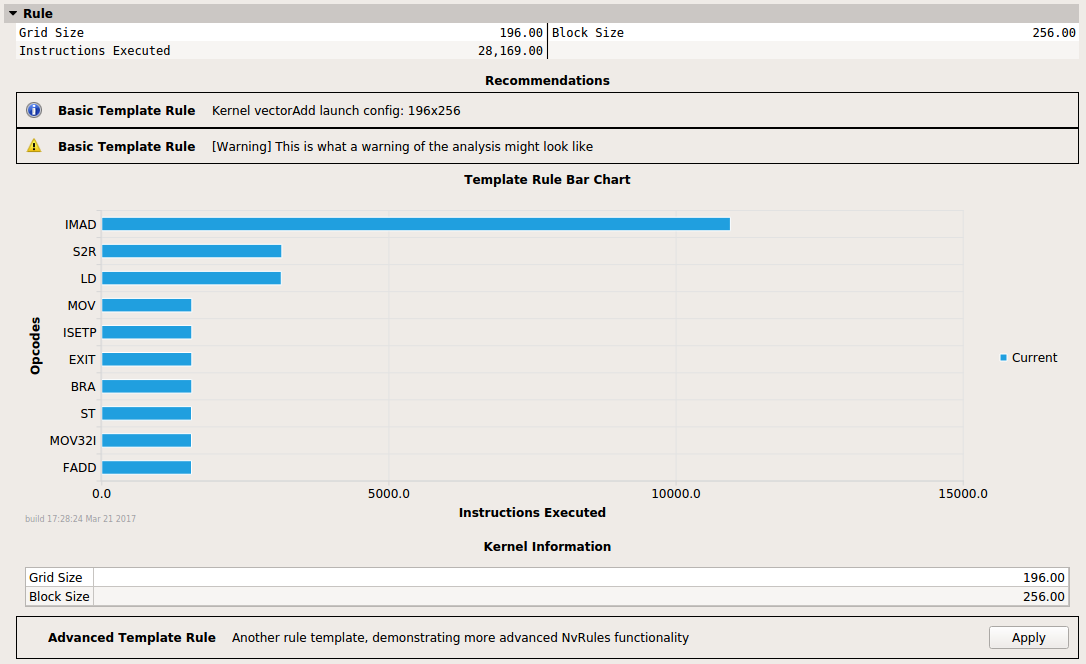
节规则有两个关联的规则,基本模板规则和高级模板规则。后者尚未应用。规则可以添加各种 UI 元素,包括警告和错误消息以及图表和表格。

某些规则独立于节应用。它们显示在“独立规则”下。
1.3.3. 规则系统架构
规则系统由 Python 解释器、NvRules C++ 接口、NvRules Python 接口 (NvRules.py) 和一组规则文件组成。每个规则文件都是有效的 Python 代码,它导入 NvRules.py 模块,遵守规则文件 API定义的某些标准,并从工具中调用。
应用规则时,会向其 apply 函数提供规则上下文的句柄。此上下文捕获了作为 NvRules API 一部分可供规则使用的大部分功能。此外,某些功能由 NvRules 模块直接提供,例如用于全局错误报告。最后,由于规则是有效的 Python 代码,它们也可以使用 Python 附带的常规库和语言功能。
从规则上下文中,可以访问多个其他对象,例如 Frontend、Ranges 和 Actions。应该注意的是,这些只是接口,即实际实现可能因决定实现此功能的工具而异。
这些接口的命名选择尽可能独立于 API,即不暗示 CUDA 特定的语义。但是,由于许多计算和图形 API 映射到相似的概念,因此也可以轻松地映射到 CUDA 术语。Range 指的是 CUDA 流,Action 指的是单个 CUDA 内核实例。每个操作引用在分析期间收集的多个指标(例如,instructions executed)或静态可用的指标(例如,启动配置)。指标通过它们的名称从 Action 访问。
每个 CUDA 流可以包含任意数量的内核(或其他设备活动)实例,因此每个 Range 可以引用一个或多个 Actions。但是,目前每个 Range 只有一个 Action 可用,因为一次只能分析一个 CUDA 内核。
Frontend 提供了一个接口来操作工具 UI,通过添加消息、图形元素(如图表和表格)以及加速估计、焦点指标和源标记。最常见的用例是规则至少显示一条消息,向用户说明结果,如 extras/RuleTemplates/BasicRuleTemplate.py 中所示。这可以简单到“未检测到问题”,或者包含关于用户如何改进代码的直接提示,例如“内存利用率高于计算。考虑内核是否可以执行更多计算工作。” 对于更高级的用例,例如添加加速估计、关键绩效指标(又名焦点指标)或源标记以注释规则的代码的各个行,请参阅 extras/RuleTemplates 中的模板。
1.3.4. NvRules API
NvRules API 定义为 C/C++ 风格的接口,它被转换为 NvRules.py Python 模块,以便规则可以使用。因此,C++ 类接口直接转换为 Python 类和函数。有关此接口中可用的类和函数,请参阅 NvRules API 文档。
1.3.5. 规则文件 API
规则文件 API 是规则 Python 文件和工具之间的隐式约定。它定义了 Python 文件必须提供哪些函数(语法和语义)才能作为规则正常工作。
强制函数
get_identifier():返回唯一的规则标识符字符串。apply(handle):将此规则应用于句柄提供的规则上下文。使用NvRules.get_context(handle)从句柄获取Context接口。get_name():返回此规则的用户可读显示名称。get_description():返回此规则的用户可读描述。
可选函数
get_section_identifier():返回将此规则映射到节的唯一节标识符。仅当收集了相应的节时,节映射规则才可用。它们隐式地假设在应用规则时收集了节请求的指标。evaluate(handle):声明应用此规则所需的指标和规则。使用
NvRules.require_metrics(handle, [...])声明在应用此规则之前必须收集的指标列表。例如,使用
NvRules.require_rules(handle, [...])声明在应用此规则之前必须可用的其他规则的列表。这些是唯一可以由 Controller 接口安全提出的规则。
1.3.6. 规则示例
以下示例规则确定内核在哪个主要 GPU 架构上运行。
import NvRules
def get_identifier():
return "GpuArch"
def apply(handle):
ctx = NvRules.get_context(handle)
action = ctx.range_by_idx(0).action_by_idx(0)
ccMajor = action.metric_by_name("device__attribute_compute_capability_major").as_uint64()
ctx.frontend().message("Running on major compute capability " + str(ccMajor))
1.4. Python 报告接口
NVIDIA Nsight Compute 具有基于 Python 的接口,用于与导出的报告文件进行交互。
该模块称为 ncu_report,可在 3.4 1 及更高版本的任何 Python 版本上运行。它可以在您的 NVIDIA Nsight Compute 包的 extras/python 目录中找到。
为了使用 Python 模块,您需要 NVIDIA Nsight Compute 生成的报告文件。您可以通过从图形界面保存文件或使用命令行工具的 --export 标志来获取此类文件。
ncu_report 模块中的类型和函数是 NvRules API 中可用类型和函数的子集。本节中的文档用作教程。有关公开 API 的更正式描述,请参阅 NvRules API 文档。
- 1
在 Linux 机器上,您还需要与 GNU 兼容的 libc 和
libgcc_s.so。
1.4.1. 基本用法
为了能够导入 ncu_report,您要么需要导航到 extras/python 目录,要么将其绝对路径添加到 PYTHONPATH 环境变量。然后,可以像导入任何 Python 模块一样导入该模块
>>> import ncu_report
导入报告
导入模块后,您可以通过使用文件路径调用 load_report 函数来加载报告文件。此函数返回 IContext 类型的对象,该对象保存有关该报告的所有信息。
>>> my_context = ncu_report.load_report("my_report.ncu-rep")
查询范围
在使用 Python 模块时,分析结果分组为由 IRange 对象表示的范围。您可以通过调用 IContext 对象的 num_ranges() 成员函数来检查加载的报告中包含的范围数量,并使用 range_by_idx(index) 按索引检索范围。
>>> my_context.num_ranges()
1
>>> my_range = my_context.range_by_idx(0)
查询操作
在范围内,分析结果称为操作。您可以使用 IRange 对象的 num_actions 方法查询给定范围中包含的操作数量。
>>> my_range.num_actions()
2
与可以使用 range_by_idx(index) 方法从 IContext 对象获取范围的方式相同,可以使用 action_by_idx(index) 方法从 IRange 对象获取单个操作。生成的操作由 IAction 类表示。
>>> my_action = my_range.action_by_idx(0)
如前所述,操作表示单个分析结果。要查询工作负载的名称,可以使用 IAction 类的 name() 成员函数。
>>> my_action.name()
MyKernel
要查询工作负载类型,可以使用 IAction 类的 workload_type() 成员函数,它将返回 enum class WorkloadType 的整数。对于 CUDA 内核,您将获得以下结果
>>> my_action.workload_type()
0
workload_type() 的所有返回值都在此处记录。
查询指标
要获取 action 中包含的所有指标名称的元组,可以使用 metric_names() 方法。它旨在与返回 IMetric 对象的 metric_by_name() 方法结合使用。但是,对于相同的任务,您也可以使用 [] 运算符,如下面的高级接口部分中所述。
此处显示的指标名称与您可以与 NVIDIA Nsight Compute 的 --metrics 标志一起使用的指标名称相同。从 action 中提取 metric 后,您可以使用以下三种方法之一获取其值
as_string()以字符串形式获取其值 Pythonstras_uint64()以无符号 64 位整数形式获取其值 Pythonintas_double()以双精度浮点数形式获取其值 Pythonfloat
例如,要打印分析工作负载的 GPU 的显示名称,您可以查询 device__attribute_display_name 指标。
>>> display_name_metric = my_action.metric_by_name('device__attribute_display_name')
>>> display_name_metric.as_string()
'NVIDIA GeForce RTX 3060 Ti'
请注意,使用错误的类型访问指标可能会导致意外(转换)结果。
>>> display_name_metric.as_double()
0.0
因此,建议直接使用高级函数 value(),如下所述。
1.4.2. 高级接口
在低级 NvRules API 之上,Python 报告接口还实现了Python 对象模型的一部分。通过实现特殊方法,Python 报告接口的公开类可以与内置的 Python 机制一起使用,例如迭代、字符串格式化和长度查询。
这允许您通过 IAction 类的 self[key] 实例方法访问指标对象
>>> display_name_metric = my_action["device__attribute_display_name"]
还有一个方便的方法 IMetric.value(),允许您查询 metric 对象的值,而无需了解其类型
>>> display_name_metric.value()
'NVIDIA GeForce RTX 3060 Ti'
可以通过交互方式查找类的所有可用方法及其关联的 Python 文档字符串
>>> help(ncu_report.IMetric)
或类似地用于其他类和方法。在您的代码中,您可以通过 __doc__ 属性访问文档字符串,即 ncu_report.IMetric.value.__doc__。
1.4.3. 指标属性
除了可以查询 IMetric 对象的 name() 和 value() 之外,您还可以查询以下其他指标属性
metric_type()metric_subtype()rollup_operation()unit()description()
如果指标是硬件指标,则第一种方法 metric_type() 返回三个 enum 值之一(IMetric.MetricType_COUNTER、IMetric.MetricType_RATIO、IMetric.MetricType_THROUGHPUT),否则返回 IMetric.MetricType_OTHER(例如,对于启动或设备属性)。
方法 metric_subtype() 返回表示指标子类型的 enum 值(例如,IMetric.MetricSubtype_PEAK_SUSTAINED、IMetric.MetricSubtype_PER_CYCLE_ACTIVE)。如果指标没有子类型,则返回 None。所有可用值(不带必需的 IMetric.MetricSubtype_ 前缀)都可以在NvRules API 文档中找到,或者可以通过执行 help(ncu_report.IMetric) 以交互方式查找。
IMetric.rollup_operation() 返回用于累积同一指标的不同值的操作,可以是 IMetric.RollupOperation_AVG、IMetric.RollupOperation_MAX、IMetric.RollupOperation_MIN 或 IMetric.RollupOperation_SUM,分别对应平均值、最大值、最小值或总和。如果所讨论的指标未指定汇总操作,则将返回 None。
最后,unit() 和 description() 分别返回指标单位的(可能为空的)字符串和硬件指标的简短文本描述。
上述方法可以结合使用,以筛选报告中的所有指标,并给定某些标准
for metric in metrics:
if metric.metric_type() == IMetric.MetricType_COUNTER and \
metric.metric_subtype() == IMetric.MetricSubtype_PER_SECOND and \
metric.rollup_operation() == IMetric.RollupOperation_AVG:
print(f"{metric.name()}: {metric.value()} {metric.unit()}")
1.4.4. NVTX 支持
ncu_report 支持 NVIDIA Tools Extension (NVTX)。这通过 INvtxState 对象实现,该对象表示已分析内核的 NVTX 状态。
可以通过使用 action 的 nvtx_state() 方法从 action 获取 INvtxState 对象。它公开了 domains() 方法,该方法返回表示此内核具有状态的域的整数元组。这些整数可以与 domain_by_id(id) 方法一起使用,以获取表示域状态的 INvtxDomainInfo 对象。
INvtxDomainInfo 可以使用 push_pop_ranges() 和 start_end_ranges() 方法来获取 Push-Pop 或 Start-End 范围的元组。
在 IRange 类中还有一个 actions_by_nvtx 成员函数,您可以使用它来获取与参数中描述的 NVTX 状态匹配的 action 元组。
actions_by_nvtx 函数的参数是两个字符串列表,分别表示我们要查询 action 的状态。第一个参数描述要包含的 NVTX 状态,而第二个参数描述要排除的 NVTX 状态。这些字符串的格式与 --nvtx-include 和 --nvtx-exclude 选项使用的格式相同。
1.4.5. 示例脚本
NVTX Push-Pop 范围过滤
这是一个示例脚本,它加载报告并打印所有被包装在默认 NVTX 域的 BottomRange 和 TopRange Push-Pop 范围内的已分析内核的名称。
#!/usr/bin/env python3
import sys
import ncu_report
if len(sys.argv) != 2:
print("usage: {} report_file".format(sys.argv[0]), file=sys.stderr)
sys.exit(1)
report = ncu_report.load_report(sys.argv[1])
for range_idx in range(report.num_ranges()):
current_range = report.range_by_idx(range_idx)
for action_idx in current_range.actions_by_nvtx(["BottomRange/*/TopRange"], []):
action = current_range.action_by_idx(action_idx)
print(action.name())
1.5. 源计数器
Source 页面根据可用性提供各种指标与应用程序的 CUDA-C、PTX 和 SASS 源代码的关联。
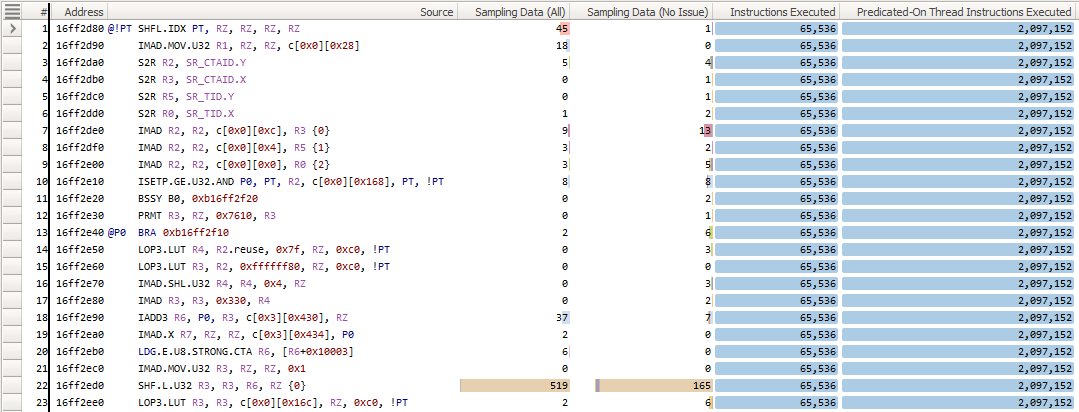
哪些源指标被收集以及它们在此页面中显示的顺序由 section 文件控制,特别是使用 SourceMetrics 条目。每个 SourceMetrics 条目定义一组有序的指标,并且可以分配一个可选的 Order 值。此值定义 Source 页面中这些组之间的顺序。这允许您在一个 section 文件中定义一组与内存相关的源计数器,并在另一个 section 文件中定义一组与指令相关的计数器。
Identifier: "CustomSourceMetrics"
DisplayName: "Custom Source Metrics"
SourceMetrics {
Order: 2
Metrics {
Label: "Instructions Executed"
Name: "inst_executed"
}
Metrics {
Label: "Float-value metric"
Name: "float_value_metric"
Description: "Custom, optional metric description"
DisplayProperties {
SourceView {
DefaultVisible: false
}
}
}
Metrics {
Label: ""
Name: "collected_but_not_shown"
}
}
Metrics {
Order: 3
Metrics {
Label: "Uint64-value metric"
Name: "uint64_value_metric"
}
如果为 Source Counter 指标在 section 文件中给定一个空的标签属性,则将收集该指标,但不会显示在该页面上。默认可见性也可以通过 DisplayProperties 字段设置,如上面的示例所示。Metrics 组已被弃用,不能用于定义应在 Source 页面上显示的指标,而应使用 SourceMetrics 组,因为前者仅支持具有 uint64 类型实例值的指标。
1.6. 报告文件格式
本节介绍 NVIDIA Nsight Compute 创建的分析器报告文件(以下简称报告)的内部结构。
注意
文件格式可能会在未来的版本中更改,恕不另行通知。
1.6.1. 版本 7 格式
版本 7 的报告是原始二进制数据和序列化的 Google Protocol Buffer 版本 2 消息 (proto) 的组合。所有二进制条目都以小端字节序存储。协议缓冲区定义位于 NVIDIA Nsight Compute 安装目录下的 extras/FileFormat 中。
偏移量 [字节] |
条目 |
类型 |
值 |
|---|---|---|---|
0 |
魔数 |
二进制 |
NVR\0 |
4 |
整数 |
二进制 |
sizeof(文件头) |
8 |
文件头 |
Proto |
报告版本 |
8 + sizeof(文件头) |
块 0 |
混合 |
CUDA CUBIN 源代码、分析结果、会话信息 |
8 + sizeof(文件头) + sizeof(块 0) |
块 1 |
混合 |
CUDA CUBIN 源代码、分析结果、会话信息 |
… |
… |
… |
… |
偏移量 [字节] |
条目 |
类型 |
值 |
|---|---|---|---|
0 |
整数 |
二进制 |
sizeof(块头) |
4 |
块头 |
Proto |
每种有效负载类型的条目数、有效负载大小 |
4 + sizeof(块头) |
块有效负载 |
混合 |
有效负载(CUDA CUBIN 源代码、分析结果、会话信息、字符串表) |
偏移量 [字节] |
条目 |
类型 |
值 |
|---|---|---|---|
0 |
整数 |
二进制 |
sizeof(有效负载类型 1,条目 1) |
4 |
有效负载类型 1,条目 1 |
Proto |
|
4 + sizeof(有效负载类型 1,条目 1) |
整数 |
二进制 |
sizeof(有效负载类型 1,条目 2) |
8 + sizeof(有效负载类型 1,条目 1) |
有效负载类型 1,条目 2 |
Proto |
|
… |
… |
… |
… |
… |
整数 |
二进制 |
sizeof(有效负载类型 2,条目 1) |
… |
有效负载类型 2,条目 1 |
Proto |
|
… |
… |
… |
… |
- Proto 文件当前部署在扁平目录中,但可能需要在编译期间按以下目录结构排列,以使其
import指令正常工作 CpuStacktrace/CpuStacktrace.proto
Nvtx/Nvtx.proto
Nvtx/NvtxCategories.proto
Profiler/ProfilerMetricOptions.proto
Profiler/ProfilerResultsCommon.proto
Profiler/ProfilerStringTable.proto
ProfilerReport.proto
ProfilerReport/ProfilerReportCommon.proto
ProfilerSection/ProfilerSection.proto
RuleSystem/RuleResults.proto
声明
声明
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他方面的保证,并且明确声明不承担任何关于不侵权、适销性和针对特定用途适用性的暗示保证。
所提供的信息据信是准确可靠的。但是,NVIDIA 公司对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果不承担任何责任。未通过暗示或其他方式授予 NVIDIA 公司专利权下的任何许可。本出版物中提及的规范如有更改,恕不另行通知。本出版物取代并替换以前提供的所有其他信息。未经 NVIDIA 公司的明确书面批准,NVIDIA 公司产品未被授权用作生命支持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。