Parallel Thread Execution ISA 版本 8.7
使用 PTX(Parallel Thread Execution)和 ISA(指令集架构)的编程指南。
1. 简介
本文档描述了 PTX,一种低级并行线程执行虚拟机和指令集架构 (ISA)。PTX 将 GPU 公开为数据并行计算设备。
1.1. 使用 GPU 的可扩展数据并行计算
在对实时、高清晰度 3D 图形的巨大市场需求的驱动下,可编程 GPU 已经发展成为高度并行、多线程、多核处理器,具有强大的计算能力和极高的内存带宽。GPU 特别适合解决可以表达为数据并行计算的问题——相同的程序并行地在多个数据元素上执行——且具有高算术强度——算术运算与内存运算的比率。由于每个数据元素都执行相同的程序,因此对复杂流程控制的需求较低;并且由于它在许多数据元素上执行并具有高算术强度,因此内存访问延迟可以通过计算而不是大数据缓存来隐藏。
数据并行处理将数据元素映射到并行处理线程。许多处理大型数据集的应用程序可以使用数据并行编程模型来加速计算。在 3D 渲染中,大量的像素和顶点被映射到并行线程。类似地,图像和媒体处理应用程序,如渲染图像的后处理、视频编码和解码、图像缩放、立体视觉和模式识别,可以将图像块和像素映射到并行处理线程。事实上,许多图像渲染和处理领域之外的算法也通过数据并行处理得到加速,从通用信号处理或物理模拟到计算金融或计算生物学。
PTX 为通用并行线程执行定义了一个虚拟机和 ISA。PTX 程序在安装时被翻译成目标硬件指令集。PTX 到 GPU 的转换器和驱动程序使 NVIDIA GPU 能够用作可编程并行计算机。
1.2. PTX 的目标
PTX 为通用并行编程提供了一个稳定的编程模型和指令集。它旨在在支持 NVIDIA Tesla 架构定义的计算特性的 NVIDIA GPU 上高效运行。CUDA 和 C/C++ 等高级语言编译器生成 PTX 指令,这些指令经过优化并转换为本机目标架构指令。
PTX 的目标包括以下内容
提供一个跨越多个 GPU 世代的稳定 ISA。
在编译后的应用程序中实现与本机 GPU 性能相当的性能。
为 C/C++ 和其他编译器提供一个与机器无关的 ISA 作为目标。
为应用程序和中间件开发人员提供代码分发 ISA。
为优化代码生成器和转换器提供一个通用的源代码级 ISA,这些生成器和转换器将 PTX 映射到特定的目标机器。
方便手动编写库、性能内核和架构测试。
提供一个可扩展的编程模型,该模型可以跨越从单个单元到多个并行单元的 GPU 尺寸。
1.3. PTX ISA 版本 8.7
PTX ISA 版本 8.7 引入了以下新功能
增加了对
sm_120目标架构的支持。增加了对支持专门加速功能的
sm_120a目标的支持。扩展了
tcgen05.mma指令,以增加对.kind::mxf4nvf4和.scale_vec::4X限定符的支持。扩展了
mma指令,以支持.f16类型累加器和形状.m16n8k16以及 FP8 类型.e4m3和.e5m2。扩展了
cvt指令,以增加对.rs舍入模式和目标类型.e2m1x4、.e4m3x4、.e5m2x4、.e3m2x4、.e2m3x4的支持。扩展了对
st.async和red.async指令的支持,以增加对.mmio、.release、.global和.scope限定符的支持。扩展了
tensormap.replace指令,以增加对.elemtype限定符的值13到15的支持。扩展了
mma和mma.sp::ordered_metadata指令,以增加对类型.e3m2/.e2m3/.e2m1和限定符.kind、.block_scale、.scale_vec_size的支持。
1.4. 文档结构
本文档中的信息组织成以下章节
编程模型 概述了编程模型。
PTX 机器模型 概述了 PTX 虚拟机模型。
语法 描述了 PTX 语言的基本语法。
状态空间、类型和变量 描述了状态空间、类型和变量声明。
指令操作数 描述了指令操作数。
抽象 ABI 描述了函数和调用语法、调用约定以及 PTX 对抽象应用程序二进制接口 (ABI) 的支持。
指令集 描述了指令集。
特殊寄存器 列出了特殊寄存器。
指令 列出了 PTX 中支持的汇编指令。
发行说明 提供了 PTX ISA 2.x 及更高版本的发行说明。
参考文献
-
754-2008 IEEE 浮点运算标准。ISBN 978-0-7381-5752-8, 2008。
-
OpenCL 规范,版本:1.1,文档修订版:44,2011 年 6 月 1 日。
-
CUDA 编程指南。
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html
-
CUDA 动态并行编程指南。
https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html#cuda-dynamic-parallelism
-
CUDA 原子性要求。
https://nvda.org.cn/cccl/libcudacxx/extended_api/memory_model.html#atomicity
-
PTX 互操作性编写指南。
https://docs.nvda.net.cn/cuda/ptx-writers-guide-to-interoperability/index.html
2. 编程模型
2.1. 高度多线程的协处理器
GPU 是一种能够并行执行大量线程的计算设备。它作为主 CPU 或主机 的协处理器运行:换句话说,主机上运行的应用程序的数据并行、计算密集型部分被卸载到设备上。
更准确地说,一个应用程序中被多次执行但独立于不同数据的部分,可以隔离到一个内核函数中,该函数在 GPU 上作为许多不同的线程执行。为此,这样的函数被编译成 PTX 指令集,并且生成的内核在安装时被翻译成目标 GPU 指令集。
2.2. 线程层次结构
执行内核的线程批次被组织成网格。网格由协作线程阵列或协作线程阵列集群组成,如本节所述并在 图 1 和 图 2 中所示。协作线程阵列 (CTA) 实现 CUDA 线程块,集群实现 CUDA 线程块集群。
2.2.1. 协作线程阵列
并行线程执行 (PTX) 编程模型是显式并行的:PTX 程序指定并行线程阵列的给定线程的执行。协作线程阵列 或 CTA 是一个线程数组,它们并发或并行地执行内核。
CTA 内的线程可以相互通信。为了协调 CTA 内线程的通信,可以指定同步点,线程在这些同步点等待直到 CTA 中的所有线程都到达。
每个线程在 CTA 中都有一个唯一的线程标识符。程序使用数据并行分解来跨 CTA 的线程划分输入、工作和结果。每个 CTA 线程使用其线程标识符来确定其分配的角色、分配特定的输入和输出位置、计算地址以及选择要执行的工作。线程标识符是一个三元素向量 tid(元素为 tid.x、tid.y 和 tid.z),它指定线程在 1D、2D 或 3D CTA 中的位置。每个线程标识符分量的范围从零到该 CTA 维度中的线程 ID 数量。
每个 CTA 都有一个 1D、2D 或 3D 形状,由一个三元素向量 ntid(元素为 ntid.x、ntid.y 和 ntid.z)指定。向量 ntid 指定每个 CTA 维度中的线程数。
CTA 内的线程以 SIMT(单指令、多线程)方式在称为warp的组中执行。warp 是来自单个 CTA 的线程的最大子集,使得线程同时执行相同的指令。warp 内的线程按顺序编号。warp 大小是机器相关的常数。通常,一个 warp 有 32 个线程。某些应用程序可能能够通过了解 warp 大小来最大化性能,因此 PTX 包括一个运行时立即常量 WARP_SZ,它可以在允许立即操作数的任何指令中使用。
2.2.2. 协作线程阵列集群
集群是一组并发或并行运行的 CTA,可以通过共享内存相互同步和通信。执行 CTA 必须确保对等 CTA 的共享内存存在,然后才能通过共享内存与其通信,并且对等 CTA 在完成共享内存操作之前尚未退出。
集群中不同 CTA 内的线程可以通过共享内存相互同步和通信。集群范围的屏障可用于同步集群内的所有线程。集群中的每个 CTA 在其集群中都有唯一的 CTA 标识符 (cluster_ctaid)。每个 CTA 集群都有由参数 cluster_nctaid 指定的 1D、2D 或 3D 形状。集群中的每个 CTA 在所有维度上也有唯一的 CTA 标识符 (cluster_ctarank)。集群中所有维度上的 CTA 总数由 cluster_nctarank 指定。线程可以通过预定义的只读特殊寄存器 %cluster_ctaid、%cluster_nctaid、%cluster_ctarank、%cluster_nctarank 读取和使用这些值。
集群级别仅适用于目标架构 sm_90 或更高版本。在启动时指定集群级别是可选的。如果用户在启动时指定集群维度,则它将被视为显式集群启动,否则它将被视为默认维度为 1x1x1 的隐式集群启动。PTX 提供了只读特殊寄存器 %is_explicit_cluster 来区分显式和隐式集群启动。
2.2.3. 集群网格
CTA 可以包含的最大线程数和集群可以包含的最大 CTA 数是有限制的。但是,执行相同内核的 CTA 集群可以批量组合成集群网格,以便可以在单个内核调用中启动的线程总数非常大。这样做会降低线程通信和同步,因为不同集群中的线程无法相互通信和同步。
每个集群在集群网格中都有唯一的集群标识符 (clusterid)。每个集群网格都有由参数 nclusterid 指定的 1D、2D 或 3D 形状。每个网格也有唯一的临时网格标识符 (gridid)。线程可以通过预定义的只读特殊寄存器 %tid、%ntid、%clusterid、%nclusterid 和 %gridid 读取和使用这些值。
每个 CTA 在网格中都有唯一的标识符 (ctaid)。每个 CTA 网格都有由参数 nctaid 指定的 1D、2D 或 3D 形状。线程可以使用和读取这些值,通过预定义的只读特殊寄存器 %ctaid 和 %nctaid。
每个内核都作为一批线程执行,这些线程组织成由 CTA 组成的集群网格,其中集群是可选级别,仅适用于目标架构 sm_90 及更高版本。图 1 显示了由 CTA 组成的网格,图 2 显示了由集群组成的网格。
网格可以在彼此之间具有依赖关系的情况下启动——一个网格可以是依赖网格和/或先决条件网格。要了解如何定义网格依赖关系,请参阅 CUDA 编程指南中关于 CUDA Graphs 的章节。
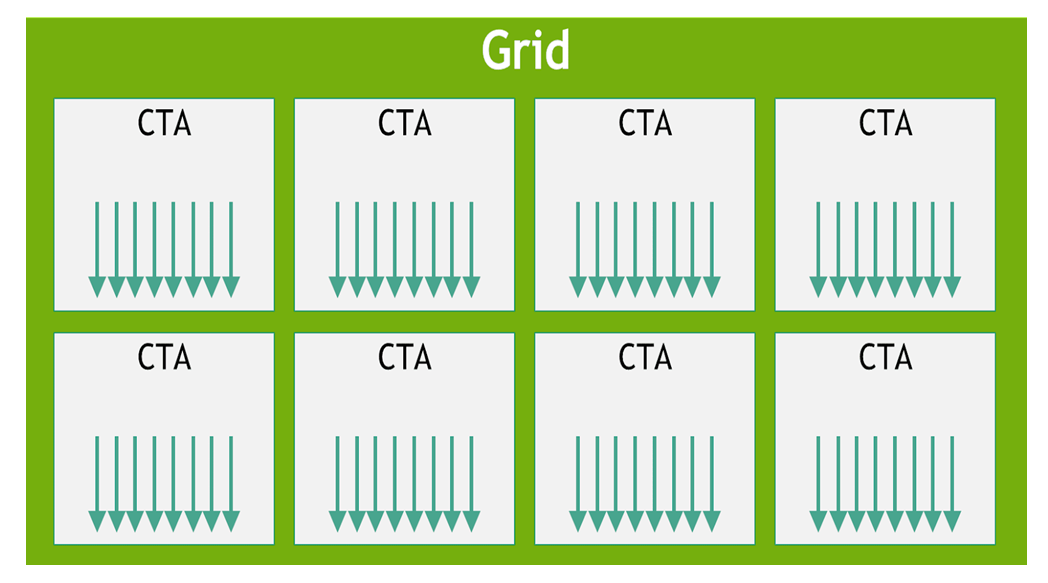
图 1 带有 CTA 的网格
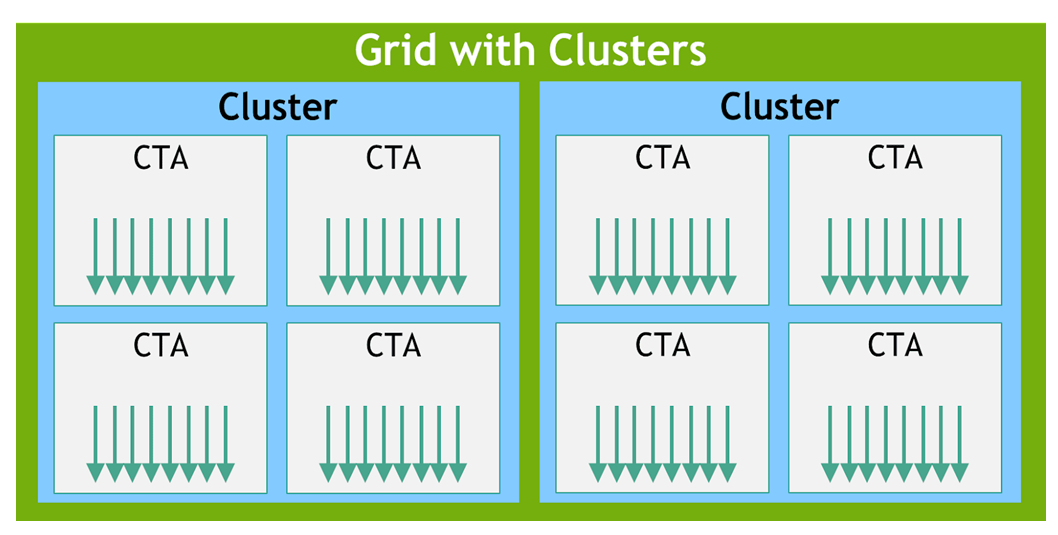
图 2 带有集群的网格
集群是一组协作线程阵列 (CTA),其中 CTA 是一组执行相同内核程序的并发线程。网格是一组由独立执行的 CTA 组成的集群。
2.3. 内存层次结构
PTX 线程在其执行期间可以访问来自多个状态空间的数据,如 图 3 所示,其中集群级别从目标架构 sm_90 开始引入。每个线程都有一个私有本地内存。每个线程块 (CTA) 都有一个共享内存,该共享内存对块的所有线程以及集群中所有活动块可见,并且具有与块相同的生命周期。最后,所有线程都可以访问相同的全局内存。
还有其他状态空间可供所有线程访问:常量、参数、纹理和表面状态空间。常量和纹理内存是只读的;表面内存是可读写的。全局、常量、参数、纹理和表面状态空间针对不同的内存用途进行了优化。例如,纹理内存为特定数据格式提供不同的寻址模式以及数据过滤。请注意,纹理和表面内存是缓存的,并且在相同的内核调用中,缓存与全局内存写入和表面内存写入不保持一致,因此在同一内核调用中,任何纹理获取或表面读取到已通过全局或表面写入写入的地址都会返回未定义的数据。换句话说,只有当内存位置已被之前的内核调用或内存复制更新时,线程才能安全地读取某些纹理或表面内存位置,但如果它已被同一线程或来自同一内核调用的另一个线程先前更新,则不能安全读取。
全局、常量和纹理状态空间在同一应用程序的内核启动之间是持久存在的。
主机和设备都维护自己的本地内存,分别称为主机内存和设备内存。设备内存可以由主机映射和读取或写入,或者,为了更有效的传输,可以通过优化的 API 调用从主机内存复制,这些 API 调用利用设备的高性能直接内存访问 (DMA) 引擎。
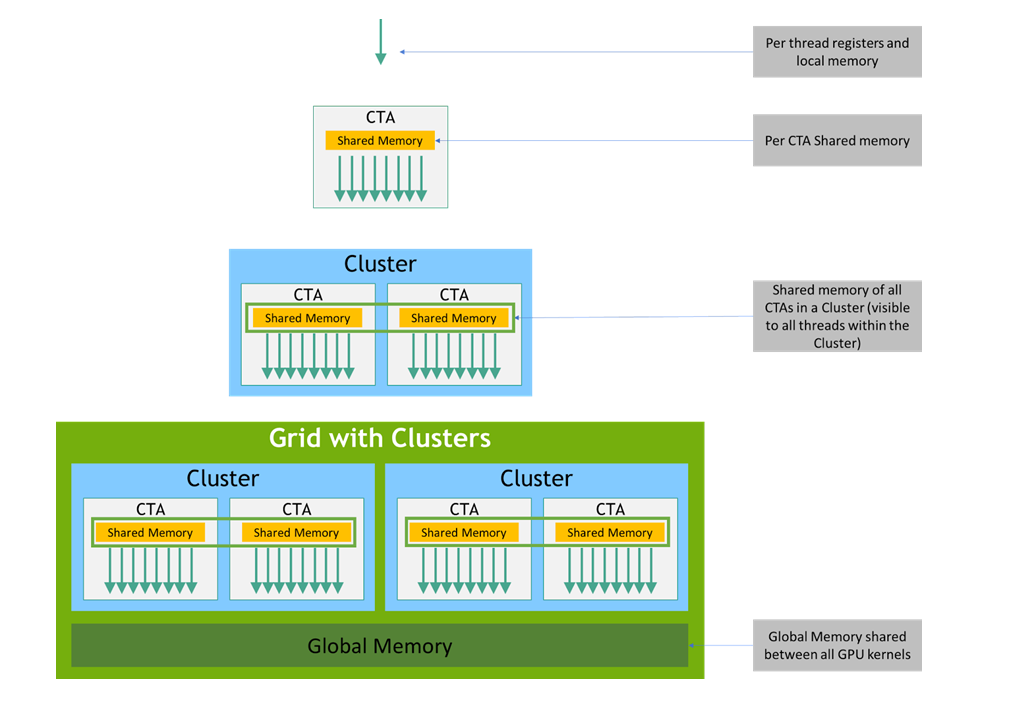
图 3 内存层次结构
3. PTX 机器模型
3.1. 一组 SIMT 多处理器
NVIDIA GPU 架构围绕可扩展的多线程流式多处理器 (SM) 阵列构建。当主机程序调用内核网格时,网格的块被枚举并分配给具有可用执行能力的多处理器。线程块的线程在一个多处理器上并发执行。当线程块终止时,新的块在空出的多处理器上启动。
一个多处理器由多个标量处理器 (SP) 核心、一个多线程指令单元和片上共享内存组成。多处理器在硬件中创建、管理和执行并发线程,零调度开销。它实现单指令屏障同步。快速屏障同步以及轻量级线程创建和零开销线程调度有效地支持非常细粒度的并行性,例如,允许通过为每个数据元素(例如图像中的像素、体中的体素、基于网格的计算中的单元)分配一个线程来低粒度分解问题。
为了管理运行多个不同程序的数百个线程,多处理器采用了一种我们称之为 SIMT(单指令、多线程) 的架构。多处理器将每个线程映射到一个标量处理器核心,并且每个标量线程都独立执行,具有自己的指令地址和寄存器状态。多处理器 SIMT 单元创建、管理、调度和执行称为 warp 的并行线程组中的线程。(这个术语起源于编织,第一种并行线程技术。)组成 SIMT warp 的各个线程从相同的程序地址一起启动,但在其他方面可以自由分支和独立执行。
当多处理器被赋予一个或多个线程块来执行时,它会将它们拆分为 warp,这些 warp 由 SIMT 单元调度。将块拆分为 warp 的方式始终相同;每个 warp 包含具有连续递增线程 ID 的线程,第一个 warp 包含线程 0。
在每个指令发出时间,SIMT 单元选择一个准备好执行的 warp,并将下一条指令发给 warp 的活动线程。一个 warp 一次执行一条公共指令,因此当 warp 的所有线程都同意它们的执行路径时,可以实现完全效率。如果 warp 的线程通过数据相关的条件分支发散,则 warp 会串行执行每个分支路径,禁用不在该路径上的线程,并且当所有路径完成时,线程会收敛回相同的执行路径。分支发散仅在 warp 内发生;不同的 warp 独立执行,无论它们是否正在执行公共或不相交的代码路径。
SIMT 架构类似于 SIMD(单指令、多数据)向量组织,因为单条指令控制多个处理元素。一个关键的区别是 SIMD 向量组织向软件公开 SIMD 宽度,而 SIMT 指令指定单个线程的执行和分支行为。与 SIMD 向量机相比,SIMT 使程序员能够为独立的标量线程编写线程级并行代码,以及为协调线程编写数据并行代码。为了正确性,程序员基本上可以忽略 SIMT 行为;但是,通过注意代码很少需要 warp 中的线程发散,可以实现显着的性能提升。实际上,这类似于传统代码中缓存行的作用:在为正确性设计时可以安全地忽略缓存行大小,但在为峰值性能设计时必须在代码结构中考虑缓存行大小。另一方面,向量架构要求软件将加载合并到向量中并手动管理发散。
一个多处理器一次可以处理多少个块取决于给定内核所需的每个线程的寄存器数量和每个块的共享内存量,因为多处理器的寄存器和共享内存在批处理块的所有线程之间分配。如果每个多处理器没有足够的寄存器或共享内存来处理至少一个块,则内核将无法启动。
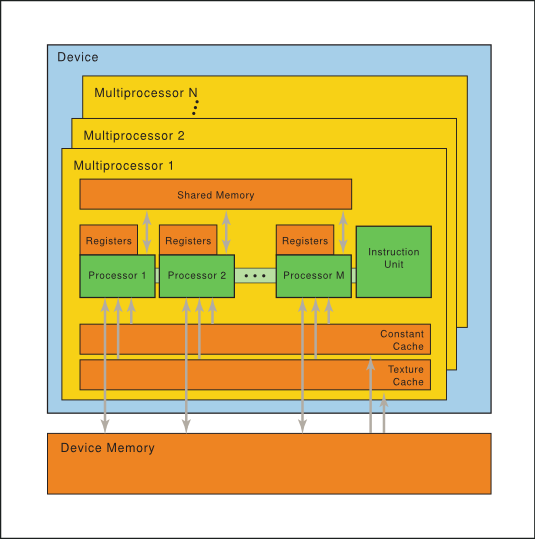
图 4 硬件模型
一组带有片上共享内存的 SIMT 多处理器。
3.2. 独立线程调度
在 Volta 之前的架构上,warp 使用一个程序计数器,该程序计数器在 warp 中的所有 32 个线程之间共享,以及一个活动掩码,用于指定 warp 的活动线程。因此,来自同一 warp 的线程在发散区域或不同的执行状态下无法相互发出信号或交换数据,并且需要细粒度数据共享的算法(受锁或互斥锁保护)很容易导致死锁,具体取决于争用线程来自哪个 warp。
从 Volta 架构开始,独立线程调度 允许线程之间完全并发,而与 warp 无关。借助独立线程调度,GPU 维护每个线程的执行状态,包括程序计数器和调用堆栈,并且可以在每个线程粒度上产生执行,以便更好地利用执行资源或允许一个线程等待另一个线程生成的数据。调度优化器确定如何将来自同一 warp 的活动线程分组到 SIMT 单元中。这保留了先前 NVIDIA GPU 中的 SIMT 执行的高吞吐量,但具有更大的灵活性:线程现在可以在子 warp 粒度上发散和重新收敛。
如果开发人员对先前硬件架构的 warp 同步性做出假设,则独立线程调度 可能导致参与执行代码的线程集与预期大相径庭。特别是,任何 warp 同步代码(例如,无同步、warp 内缩减)都应重新审视,以确保与 Volta 及更高版本的兼容性。有关更多详细信息,请参阅 Cuda 编程指南 中关于计算能力 7.x 的章节。
4. 语法
PTX 程序是文本源模块(文件)的集合。PTX 源模块具有汇编语言风格的语法,带有指令操作码和操作数。伪操作指定符号和寻址管理。ptxas 优化后端编译器优化和汇编 PTX 源模块以生成相应的二进制目标文件。
4.1. 源格式
源模块是 ASCII 文本。行由换行符 (\n) 分隔。
所有空白字符都是等效的;空白被忽略,除非它用于分隔语言中的标记。
C 预处理器 cpp 可用于处理 PTX 源模块。以 # 开头的行是预处理器指令。以下是常见的预处理器指令
#include、#define、#if、#ifdef、#else、#endif、#line、#file
Harbison 和 Steele 编写的 C: A Reference Manual 提供了对 C 预处理器的良好描述。
PTX 区分大小写,关键字使用小写。
每个 PTX 模块都必须以 .version 指令开始,指定 PTX 语言版本,然后是 .target 指令,指定假定的目标架构。有关这些指令的更多信息,请参阅 PTX 模块指令。
4.3. 语句
PTX 语句是指指令或指令。语句以可选标签开头,以分号结尾。
示例
.reg .b32 r1, r2;
.global .f32 array[N];
start: mov.b32 r1, %tid.x;
shl.b32 r1, r1, 2; // shift thread id by 2 bits
ld.global.b32 r2, array[r1]; // thread[tid] gets array[tid]
add.f32 r2, r2, 0.5; // add 1/2
4.3.1. 指令语句
指令关键字以点开头,因此不可能与用户定义的标识符冲突。PTX 中的指令在 表 1 中列出,并在 状态空间、类型和变量 和 指令 中描述。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3.2. 指令语句
指令由指令操作码后跟逗号分隔的零个或多个操作数列表组成,并以分号终止。操作数可以是寄存器变量、常量表达式、地址表达式或标签名称。指令有一个可选的保护谓词,用于控制条件执行。保护谓词位于可选标签之后和操作码之前,并写为 @p,其中 p 是谓词寄存器。保护谓词可以是可选的否定,写为 @!p。
目标操作数在前,后跟源操作数。
指令关键字在 表 2 中列出。所有指令关键字都是 PTX 中的保留标记。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.4. 标识符
用户自定义的标识符遵循扩展的 C++ 规则:它们要么以字母开头,后跟零个或多个字母、数字、下划线或美元符号;要么以一个下划线、美元符号或百分号开头,后跟一个或多个字母、数字、下划线或美元符号
followsym: [a-zA-Z0-9_$]
identifier: [a-zA-Z]{followsym}* | {[_$%]{followsym}+
PTX 没有指定标识符的最大长度,并建议所有实现都支持至少 1024 个字符的最小长度。
许多高级语言(如 C 和 C++)对于标识符名称都遵循类似的规则,只是不允许使用百分号。PTX 允许百分号作为标识符的第一个字符。百分号可用于避免名称冲突,例如,在用户定义的变量名和编译器生成的名称之间。
PTX 预定义了一个常量和少量以百分号开头的特殊寄存器,列在表 3中。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.5. 常量
PTX 支持整数和浮点常量以及常量表达式。这些常量可以用于数据初始化和作为指令的操作数。类型检查规则对于整数、浮点和位大小类型保持不变。对于谓词类型数据和指令,允许使用整数常量,并按照 C 语言中的方式解释,即零值是 False,非零值是 True。
4.5.1. 整数常量
整数常量的大小为 64 位,可以是有符号或无符号的,即,每个整数常量的类型为 .s64 或 .u64。整数常量的有符号/无符号性质是正确评估包含除法和有序比较等操作的常量表达式所必需的,其中操作的行为取决于操作数类型。当在指令或数据初始化中使用时,每个整数常量都将根据其使用时的数据或指令类型转换为适当的大小。
整数文字可以用十进制、十六进制、八进制或二进制表示法书写。语法遵循 C 语言的语法。整数文字可以紧跟字母 U,以指示该文字是无符号的。
hexadecimal literal: 0[xX]{hexdigit}+U?
octal literal: 0{octal digit}+U?
binary literal: 0[bB]{bit}+U?
decimal literal {nonzero-digit}{digit}*U?
整数文字是非负的,其类型由其大小和可选的类型后缀确定,如下所示:文字是有符号的 (.s64),除非该值无法完全用 .s64 表示,或者指定了无符号后缀,在这种情况下,文字是无符号的 (.u64)。
预定义的整数常量 WARP_SZ 指定目标平台上每个 warp 的线程数;迄今为止,所有目标架构的 WARP_SZ 值均为 32。
4.5.2. 浮点常量
浮点常量表示为 64 位双精度值,所有浮点常量表达式都使用 64 位双精度算术进行评估。唯一的例外是用于表示精确单精度浮点值的 32 位十六进制表示法;此类值保留其精确的 32 位单精度值,并且不能用于常量表达式。每个 64 位浮点常量都将根据其使用时的数据或指令类型转换为适当的浮点大小。
浮点文字可以用可选的小数点和可选的有符号指数书写。与 C 和 C++ 不同,没有后缀字母来指定大小;文字始终以 64 位双精度格式表示。
PTX 包括浮点常量的第二种表示形式,用于使用十六进制常量指定精确的机器表示。要指定 IEEE 754 双精度浮点值,常量以 0d 或 0D 开头,后跟 16 个十六进制数字。要指定 IEEE 754 单精度浮点值,常量以 0f 或 0F 开头,后跟 8 个十六进制数字。
0[fF]{hexdigit}{8} // single-precision floating point
0[dD]{hexdigit}{16} // double-precision floating point
例子
mov.f32 $f3, 0F3f800000; // 1.0
4.5.3. 谓词常量
在 PTX 中,整数常量可以用作谓词。对于谓词类型数据初始化器和指令操作数,整数常量按照 C 语言中的方式解释,即零值是 False,非零值是 True。
4.5.4. 常量表达式
在 PTX 中,常量表达式使用与 C 语言中相同的运算符形成,并使用类似于 C 语言中的规则进行评估,但通过限制类型和大小、删除大多数强制转换以及定义完整的语义来简化,以消除 C 语言中表达式评估依赖于实现的情况。
常量表达式由常量文字、一元加号和减号、基本算术运算符(加法、减法、乘法、除法)、比较运算符、条件三元运算符 (?:) 和括号组成。整数常量表达式还允许一元逻辑非 (!)、按位补码 (~)、余数 (%)、移位运算符 (<< 和 >>)、位类型运算符 (&、| 和 ^) 和逻辑运算符 (&&、||)。
PTX 中的常量表达式不支持整数和浮点之间的强制转换。
常量表达式使用与 C 语言中相同的运算符优先级进行评估。表 4 给出了运算符优先级和结合性。一元运算符的运算符优先级最高,并且在图表中每行递减。同一行上的运算符具有相同的优先级,并且对于一元运算符从右到左评估,对于二元运算符从左到右评估。
类型 |
运算符符号 |
运算符名称 |
结合性 |
|---|---|---|---|
初等 |
|
括号 |
不适用 |
一元 |
|
加号、减号、取反、补码 |
右 |
|
强制转换 |
右 |
|
二元 |
|
乘法、除法、余数 |
左 |
|
加法、减法 |
||
|
移位 |
||
|
有序比较 |
||
|
等于、不等于 |
||
|
按位与 |
||
|
按位异或 |
||
|
按位或 |
||
|
逻辑与 |
||
|
逻辑或 |
||
三元 |
|
条件 |
右 |
4.5.5. 整数常量表达式求值
整数常量表达式在编译时根据一组规则进行评估,这些规则确定每个子表达式的类型(有符号 .s64 与无符号 .u64)。这些规则基于 C 语言中的规则,但它们已简化为仅适用于 64 位整数,并且在所有情况下都完全定义了行为(特别是对于余数和移位运算符)。
-
文字是有符号的,除非需要无符号以防止溢出,或者除非文字使用
U后缀。例如42、0x1234、0123是有符号的。0xfabc123400000000、42U、0x1234U是无符号的。
-
一元加号和减号保留输入操作数的类型。例如
+123、-1、-(-42)是有符号的。-1U、-0xfabc123400000000是无符号的。
一元逻辑非 (
!) 产生一个有符号的结果,值为0或1。一元按位补码 (
~) 将源操作数解释为无符号,并产生一个无符号的结果。某些二元运算符需要对源操作数进行规范化。这种规范化称为常用算术转换,如果任一操作数是无符号的,则只需将两个操作数都转换为无符号类型。
加法、减法、乘法和除法执行常用算术转换,并产生与转换后的操作数类型相同的结果。也就是说,如果任一源操作数是无符号的,则操作数和结果是无符号的,否则是有符号的。
余数 (
%) 将操作数解释为无符号。请注意,这与 C 语言不同,C 语言允许负除数,但将行为定义为依赖于实现。左移和右移将第二个操作数解释为无符号,并产生与第一个操作数类型相同的结果。请注意,右移的行为由第一个操作数的类型决定:有符号值的右移是算术移位并保留符号,而无符号值的右移是逻辑移位并移入零位。
与 (
&)、或 (|) 和异或 (^) 执行常用算术转换,并产生与转换后的操作数类型相同的结果。逻辑与 (
&&)、逻辑或 (||)、等于 (==) 和不等于 (!=) 产生一个有符号的结果。结果值为 0 或 1。有序比较 (
<、<=、>、>=) 对源操作数执行常用算术转换,并产生一个有符号的结果。结果值为0或1。使用 (
.s64) 和 (.u64) 强制转换支持将表达式强制转换为有符号或无符号。对于条件运算符 (
? :),第一个操作数必须是整数,第二个和第三个操作数要么都是整数,要么都是浮点数。对第二个和第三个操作数执行常用算术转换,结果类型与转换后的类型相同。
4.5.6. 常量表达式求值规则摘要
表 5 包含常量表达式求值规则的摘要。
类型 |
运算符 |
操作数类型 |
操作数解释 |
结果类型 |
|---|---|---|---|---|
初等 |
|
任何类型 |
与源相同 |
与源相同 |
常量文字 |
不适用 |
不适用 |
|
|
一元 |
|
任何类型 |
与源相同 |
与源相同 |
|
整数 |
零或非零 |
|
|
|
整数 |
|
|
|
强制转换 |
|
整数 |
|
|
|
整数 |
|
|
|
二元 |
|
|
|
|
整数 |
使用常用转换 |
转换后的类型 |
||
|
|
|
|
|
整数 |
使用常用转换 |
|
||
|
|
|
|
|
整数 |
使用常用转换 |
|
||
|
整数 |
|
|
|
|
整数 |
第一个不变,第二个是 |
与第一个操作数相同 |
|
|
整数 |
|
|
|
|
整数 |
零或非零 |
|
|
三元 |
|
|
与源相同 |
|
|
使用常用转换 |
转换后的类型 |
5. 状态空间、类型和变量
虽然给定目标 GPU 中可用的特定资源会有所不同,但资源类型在不同平台之间是通用的,并且这些资源在 PTX 中通过状态空间和数据类型进行抽象。
5.1. 状态空间
状态空间是具有特定特征的存储区域。所有变量都驻留在某个状态空间中。状态空间的特征包括其大小、可寻址性、访问速度、访问权限以及线程之间的共享级别。
PTX 中定义的状态空间是并行编程和图形编程的副产品。状态空间列表如表 6所示,状态空间的属性如表 7所示。
名称 |
描述 |
|---|---|
|
寄存器,快速。 |
|
特殊寄存器。只读;预定义;平台特定。 |
|
共享,只读内存。 |
|
全局内存,由所有线程共享。 |
|
本地内存,每个线程私有。 |
|
内核参数,每个网格定义;或 函数或局部参数,每个线程定义。 |
|
可寻址内存,每个 CTA 定义,在定义它的 CTA 的整个生命周期内可供集群中的所有线程访问。 |
|
全局纹理内存(已弃用)。 |
名称 |
可寻址 |
可初始化 |
访问 |
共享 |
|---|---|---|---|---|
|
否 |
否 |
R/W |
每个线程 |
|
否 |
否 |
RO |
每个 CTA |
|
是 |
是1 |
RO |
每个网格 |
|
是 |
是1 |
R/W |
上下文 |
|
是 |
否 |
R/W |
每个线程 |
|
是2 |
否 |
RO |
每个网格 |
|
受限3 |
否 |
R/W |
每个线程 |
|
是 |
否 |
R/W |
每个集群5 |
|
否4 |
是,通过驱动程序 |
RO |
上下文 |
|
注释 1 2 仅可通过 3 可通过 4 仅可通过 5 对拥有 CTA 和集群中的其他活动 CTA 可见。 |
||||
5.1.1. 寄存器状态空间
寄存器(.reg 状态空间)是快速存储位置。寄存器的数量有限,并且会因平台而异。当超出限制时,寄存器变量将被溢出到内存中,从而导致性能变化。对于每个架构,都有建议的最大寄存器使用数量(有关详细信息,请参阅CUDA 编程指南)。
寄存器可以是类型化的(有符号整数、无符号整数、浮点数、谓词)或无类型的。寄存器大小受到限制;除了 1 位谓词寄存器外,标量寄存器的宽度为 8 位、16 位、32 位、64 位或 128 位,向量寄存器的宽度为 16 位、32 位、64 位或 128 位。8 位寄存器最常见的用途是与 ld、st 和 cvt 指令一起使用,或作为向量元组的元素。
寄存器与其他状态空间的不同之处在于它们不是完全可寻址的,即,不可能引用寄存器的地址。当编译为使用应用程序二进制接口 (ABI) 时,寄存器变量仅限于函数作用域,并且不能在模块作用域中声明。当编译包含模块作用域 .reg 变量的旧版 PTX 代码(ISA 版本早于 3.0)时,编译器会静默禁用 ABI 的使用。寄存器可能具有多字加载和存储所需的对齐边界。
5.1.2. 特殊寄存器状态空间
特殊寄存器 (.sreg) 状态空间保存预定义的、平台特定的寄存器,例如网格、集群、CTA 和线程参数、时钟计数器和性能监控寄存器。所有特殊寄存器都是预定义的。
5.1.3. 常量状态空间
常量 (.const) 状态空间是由主机初始化的只读内存。常量内存通过 ld.const 指令访问。常量内存的大小受到限制,目前限制为 64 KB,可用于保存静态大小的常量变量。还有额外的 640 KB 常量内存,组织为十个独立的 64 KB 区域。驱动程序可以在这些区域中分配和初始化常量缓冲区,并将指向缓冲区的指针作为内核函数参数传递。由于这十个区域不是连续的,因此驱动程序必须确保常量缓冲区的分配方式是每个缓冲区都完全适合 64 KB 区域内,并且不会跨越区域边界。
静态大小的常量变量具有可选的变量初始化器;没有显式初始化器的常量变量默认初始化为零。由驱动程序分配的常量缓冲区由主机初始化,指向此类缓冲区的指针作为参数传递给内核。有关将指向常量缓冲区的指针作为内核参数传递的更多详细信息,请参阅内核函数参数属性的描述。
5.1.3.1. 分块常量状态空间(已弃用)
以前版本的 PTX 将常量内存公开为一组 11 个 64 KB 块,变量声明和访问期间需要显式块号。
在 PTX ISA 2.2 版本之前,常量内存被组织成固定大小的块。有 11 个 64 KB 的块,块使用 .const[bank] 修饰符指定,其中 bank 的范围从 0 到 10。如果未给出块号,则假定为零号块。
按照惯例,零号块用于所有静态大小的常量变量。其余块用于声明不完整的常量数组(例如在 C 语言中),其中大小在编译时未知。例如,声明
.extern .const[2] .b32 const_buffer[];
导致 const_buffer 指向常量块二的开头。然后,此指针可用于访问整个 64 KB 常量块。在同一块中声明的多个不完整数组变量被别名化,每个变量都指向指定常量块的起始地址。
要访问常量块 1 到 10 中的数据,加载指令的状态空间中需要块号。例如,块 2 中的不完整数组按如下方式访问
.extern .const[2] .b32 const_buffer[];
ld.const[2].b32 %r1, [const_buffer+4]; // load second word
在 PTX ISA 2.2 版本中,我们取消了显式块,并将驱动程序分配的常量缓冲区的不完整数组表示形式替换为内核参数属性,该属性允许将指向常量缓冲区的指针作为内核参数传递。
5.1.4. 全局状态空间
全局 (.global) 状态空间是上下文中所有线程都可以访问的内存。它是不同 CTA、集群和网格中的线程可以通信的机制。使用 ld.global、st.global 和 atom.global 访问全局变量。
全局变量具有可选的变量初始化器;没有显式初始化器的全局变量默认初始化为零。
5.1.5. 本地状态空间
本地状态空间 (.local) 是每个线程用于保存其自身数据的私有内存。它通常是带有缓存的标准内存。大小受到限制,因为它必须按每个线程进行分配。使用 ld.local 和 st.local 访问本地变量。
当编译为使用应用程序二进制接口 (ABI) 时,.local 状态空间变量必须在函数作用域内声明,并在堆栈上分配。在不支持堆栈的实现中,所有本地内存变量都存储在固定地址,不支持递归函数调用,并且 .local 变量可以在模块作用域中声明。当编译包含模块作用域 .local 变量的旧版 PTX 代码(ISA 版本早于 3.0)时,编译器会静默禁用 ABI 的使用。
5.1.6. 参数状态空间
参数 (.param) 状态空间用于 (1) 将输入参数从主机传递到内核,(2a) 声明从内核执行内部调用的设备函数的形式输入和返回参数,以及 (2b) 声明本地作用域的字节数组变量,这些变量充当函数调用参数,通常用于按值将大型结构体传递给函数。内核函数参数与设备函数参数在访问和共享方面有所不同(只读与读写,每个内核与每个线程)。请注意,PTX ISA 1.x 版本仅支持 .param 空间中的内核函数参数;设备函数参数以前仅限于寄存器状态空间。在 PTX ISA 2.0 版本中引入了将参数状态空间用于设备函数参数,并且需要目标架构 sm_20 或更高版本。可以在具有 .param 状态空间的指令上指定附加的子限定符 ::entry 或 ::func,以指示地址是指内核函数参数还是设备函数参数。如果在 .param 状态空间中未指定子限定符,则默认子限定符特定于且依赖于确切的指令。例如,st.param 等效于 st.param::func,而 isspacep.param 等效于 isspacep.param::entry。有关默认子限定符假设的更多详细信息,请参阅指令描述。
注意
参数空间的位置是特定于实现的。例如,在某些实现中,内核参数驻留在全局内存中。在这种情况下,参数空间和全局空间之间不提供访问保护。尽管内核参数空间的精确定位是特定于实现的,但内核参数空间窗口始终包含在全局空间窗口内。同样,函数参数根据应用程序二进制接口 (ABI) 的函数调用约定映射到参数传递寄存器和/或堆栈位置。因此,PTX 代码不应对 .param 空间变量的相对位置或顺序做出任何假设。
5.1.6.1. 内核函数参数
每个内核函数定义都包含一个可选的参数列表。这些参数是在 .param 状态空间中声明的可寻址只读变量。从主机传递到内核的值通过使用 ld.param 指令的这些参数变量访问。内核参数变量在来自网格内所有集群的所有 CTA 之间共享。
内核参数的地址可以使用 mov 指令移动到寄存器中。结果地址位于 .param 状态空间中,并使用 ld.param 指令访问。
例子
.entry foo ( .param .b32 N, .param .align 8 .b8 buffer[64] )
{
.reg .u32 %n;
.reg .f64 %d;
ld.param.u32 %n, [N];
ld.param.f64 %d, [buffer];
...
例子
.entry bar ( .param .b32 len )
{
.reg .u32 %ptr, %n;
mov.u32 %ptr, len;
ld.param.u32 %n, [%ptr];
...
内核函数参数可以表示普通数据值,或者它们可以保存指向常量、全局、本地或共享状态空间中对象的地址。对于指针的情况,编译器和运行时系统需要知道哪些参数是指针,以及它们指向哪个状态空间。内核参数属性指令用于在 PTX 级别提供此信息。有关内核参数属性指令的描述,请参阅内核函数参数属性。
注意
当前的实现在程序中不允许创建指向常量变量的通用指针 (cvta.const),如果程序将指向常量缓冲区的指针作为内核参数传递。
5.1.6.2. 内核函数参数属性
内核函数参数可以使用可选的 .ptr 属性声明,以指示参数是指向内存的指针,并指示所指向内存的状态空间和对齐方式。内核参数属性:.ptr 描述了 .ptr 内核参数属性。
5.1.6.3. 内核参数属性:.ptr
.ptr
内核参数对齐属性。
语法
.param .type .ptr .space .align N varname
.param .type .ptr .align N varname
.space = { .const, .global, .local, .shared };
描述
用于指定指针类型内核参数指向的内存的状态空间,以及可选的对齐方式。对齐值 N(如果存在)必须是 2 的幂。如果未指定状态空间,则该指针被假定为指向常量、全局、本地或共享内存之一的通用地址。如果未指定对齐方式,则假定所指向的内存按 4 字节边界对齐。
.ptr、.space 和 .align 之间的空格可以省略以提高可读性。
PTX ISA 注释
在 PTX ISA 版本 2.2 中引入。
在 PTX ISA 版本 3.1 中添加了对 .const 空间的通用寻址的支持。
目标 ISA 注释
所有目标架构均支持。
示例
.entry foo ( .param .u32 param1,
.param .u32 .ptr.global.align 16 param2,
.param .u32 .ptr.const.align 8 param3,
.param .u32 .ptr.align 16 param4 // generic address
// pointer
) { .. }
5.1.6.4. 设备函数参数
PTX ISA 版本 2.0 将参数空间的使用扩展到设备函数参数。最常见的用途是通过值传递不适合 PTX 寄存器的对象,例如大于 8 字节的 C 结构体。在这种情况下,将使用参数空间中的字节数组。通常,调用者将声明一个局部作用域的 .param 字节数组变量,该变量表示扁平化的 C 结构体或联合。这将通过值传递给被调用者,被调用者声明一个 .param 形式参数,该参数具有与传递的参数相同的大小和对齐方式。
例子
// pass object of type struct { double d; int y; };
.func foo ( .reg .b32 N, .param .align 8 .b8 buffer[12] )
{
.reg .f64 %d;
.reg .s32 %y;
ld.param.f64 %d, [buffer];
ld.param.s32 %y, [buffer+8];
...
}
// code snippet from the caller
// struct { double d; int y; } mystruct; is flattened, passed to foo
...
.reg .f64 dbl;
.reg .s32 x;
.param .align 8 .b8 mystruct;
...
st.param.f64 [mystruct+0], dbl;
st.param.s32 [mystruct+8], x;
call foo, (4, mystruct);
...
有关更多详细信息,请参阅关于函数调用语法的章节。
函数输入参数可以通过 ld.param 读取,函数返回参数可以使用 st.param 写入;写入输入参数或从返回参数读取是非法的。
除了通过值传递结构体之外,每当在被调用函数内部获取形式参数的地址时,也需要 .param 空间。在 PTX 中,可以使用 mov 指令将函数输入参数的地址移动到寄存器中。请注意,如有必要,参数将被复制到堆栈,因此地址将位于 .local 状态空间中,并通过 ld.local 和 st.local 指令访问。无法使用 mov 获取局部作用域的 .param 空间变量的地址。从 PTX ISA 版本 6.0 开始,可以使用 mov 指令获取设备函数返回参数的地址。
例子
// pass array of up to eight floating-point values in buffer
.func foo ( .param .b32 N, .param .b32 buffer[32] )
{
.reg .u32 %n, %r;
.reg .f32 %f;
.reg .pred %p;
ld.param.u32 %n, [N];
mov.u32 %r, buffer; // forces buffer to .local state space
Loop:
setp.eq.u32 %p, %n, 0;
@%p bra Done;
ld.local.f32 %f, [%r];
...
add.u32 %r, %r, 4;
sub.u32 %n, %n, 1;
bra Loop;
Done:
...
}
5.1.8. 纹理状态空间(已弃用)
纹理 (.tex) 状态空间是通过纹理指令访问的全局内存。它由上下文中的所有线程共享。纹理内存是只读且缓存的,因此对纹理内存的访问与全局内存存储到纹理图像不一致。
GPU 硬件具有固定数量的纹理绑定,可以在单个内核中访问(通常为 128 个)。.tex 指令会将命名的纹理内存变量绑定到硬件纹理标识符,其中纹理标识符从零开始按顺序分配。可以将多个名称绑定到同一个物理纹理标识符。如果超出物理资源的最大数量,则会生成错误。纹理名称的类型必须为 .u32 或 .u64。
物理纹理资源是按内核粒度分配的,并且 .tex 变量需要在全局作用域中定义。
纹理内存是只读的。纹理的基地址假定按 16 字节边界对齐。
例子
.tex .u32 tex_a; // bound to physical texture 0
.tex .u32 tex_c, tex_d; // both bound to physical texture 1
.tex .u32 tex_d; // bound to physical texture 2
.tex .u32 tex_f; // bound to physical texture 3
注意
显式声明纹理状态空间中的变量已被弃用,程序应改为通过 .texref 类型的变量引用纹理内存。.tex 指令被保留以实现向后兼容性,并且在 .tex 状态空间中声明的变量等同于 .global 状态空间中模块作用域的 .texref 变量。
例如,传统的 PTX 定义,例如
.tex .u32 tex_a;
等同于
.global .texref tex_a;
有关 .texref 类型的描述,请参阅纹理采样器和表面类型,有关其在纹理指令中的使用,请参阅纹理指令。
5.2. 类型
5.2.1. 基本类型
在 PTX 中,基本类型反映了目标架构支持的本机数据类型。基本类型指定了基本类型和大小。寄存器变量始终是基本类型,指令对这些类型进行操作。相同的类型大小说明符用于变量定义和类型指令,因此它们的名称有意缩短。
表 8 列出了每种基本类型的基本类型说明符
基本类型 |
基本类型说明符 |
|---|---|
有符号整数 |
|
无符号整数 |
|
浮点数 |
|
位(无类型) |
|
谓词 |
|
大多数指令具有一个或多个类型说明符,需要这些说明符才能完全指定指令行为。操作数类型和大小会根据指令类型进行兼容性检查。
如果两个基本类型具有相同的基本类型并且大小相同,则它们是兼容的。如果有符号和无符号整数类型的大小相同,则它们是兼容的。位大小类型与任何大小相同的基本类型兼容。
原则上,所有变量(谓词除外)都可以仅使用位大小类型声明,但类型化变量可以提高程序的可读性,并允许更好的操作数类型检查。
5.2.2. 子字大小的限制使用
.u8、.s8 和 .b8 指令类型仅限于 ld、st 和 cvt 指令。.f16 浮点类型仅允许在与 .f32、.f64 类型之间的转换、半精度浮点指令和纹理提取指令中使用。.f16x2 浮点类型仅允许在半精度浮点算术指令和纹理提取指令中使用。
为方便起见,ld、st 和 cvt 指令允许源和目标数据操作数比指令类型大小更宽,以便可以使用常规宽度寄存器加载、存储和转换窄值。例如,在加载、存储或转换为其他类型和大小的值时,8 位或 16 位的值可以直接保存在 32 位或 64 位寄存器中。
5.2.3. 备用浮点数据格式
PTX 中支持的基本浮点类型具有隐式的位表示形式,指示用于存储指数和尾数的位数。例如,.f16 类型表示为指数保留 5 位,为尾数保留 10 位。除了基本类型假定的浮点表示形式之外,PTX 还允许以下备用浮点数据格式
-
bf16数据格式 -
此数据格式是一种 16 位浮点格式,其中指数为 8 位,尾数为 7 位。包含
bf16数据的寄存器变量必须使用.b16类型声明。 -
e4m3数据格式 -
此数据格式是一种 8 位浮点格式,其中指数为 4 位,尾数为 3 位。
e4m3编码不支持无穷大,并且NaN值限制为0x7f和0xff。包含e4m3值的寄存器变量必须使用位大小类型声明。 -
e5m2数据格式 -
此数据格式是一种 8 位浮点格式,其中指数为 5 位,尾数为 2 位。包含
e5m2值的寄存器变量必须使用位大小类型声明。 -
tf32数据格式 -
此数据格式是一种特殊的 32 位浮点格式,受矩阵乘法累加指令支持,其范围与
.f32相同,但精度降低(>=10 位)。tf32格式的内部布局是实现定义的。PTX 方便了从单精度.f32类型到tf32格式的转换。包含tf32数据的寄存器变量必须使用.b32类型声明。 -
e2m1数据格式 -
此数据格式是一种 4 位浮点格式,其中指数为 2 位,尾数为 1 位。
e2m1编码不支持无穷大和NaN。e2m1值必须以打包格式使用,指定为e2m1x2。包含两个e2m1值的寄存器变量必须使用.b8类型声明。 -
e2m3数据格式 -
此数据格式是一种 6 位浮点格式,其中指数为 2 位,尾数为 3 位。
e2m3编码不支持无穷大和NaN。e2m3值必须以打包格式使用,指定为e2m3x2。包含两个e2m3值的寄存器变量必须使用.b16类型声明,其中每个.b8元素都具有 6 位浮点值,并且 2 个 MSB 位用零填充。 -
e3m2数据格式 -
此数据格式是一种 6 位浮点格式,其中指数为 3 位,尾数为 2 位。
e3m2编码不支持无穷大和NaN。e3m2值必须以打包格式使用,指定为e3m2x2。包含两个e3m2值的寄存器变量必须使用.b16类型声明,其中每个.b8元素都具有 6 位浮点值,并且 2 个 MSB 位用零填充。 -
ue8m0数据格式 -
此数据格式是一种 8 位无符号浮点格式,其中指数为 8 位,尾数为 0 位。
ue8m0编码不支持无穷大。NaN值限制为0xff。ue8m0值必须以打包格式使用,指定为ue8m0x2。包含两个ue8m0值的寄存器变量必须使用.b16类型声明。 -
ue4m3数据格式 -
此数据格式是一种 7 位无符号浮点格式,其中指数为 4 位,尾数为 3 位。
ue4m3编码不支持无穷大。NaN值限制为0x7f。包含单个ue4m3值的寄存器变量必须使用.b8类型声明,其中 MSB 位用零填充。
备用数据格式不能用作基本类型。它们作为某些指令的源或目标格式受支持。
5.2.4. 打包数据类型
某些 PTX 指令并行地对两组或多组输入进行操作,并产生两个或多个输出。此类指令可以使用以打包格式存储的数据。PTX 支持将两个或四个相同标量数据类型的值打包成一个更大的值。打包值被视为打包数据类型的值。在本节中,我们将描述 PTX 中支持的打包数据类型。
5.2.4.1. 打包浮点数据类型
PTX 支持各种打包浮点数据类型变体。其中,只有 .f16x2 作为基本类型受支持,而其他类型不能用作基本类型 - 它们作为某些指令的指令类型受支持。当使用具有此类非基本类型的指令时,操作数数据变量必须是适当大小的位类型。例如,对于指令类型为 .bf16x2 的指令,所有操作数变量都必须是 .b32 类型。表 9 描述了 PTX 中各种打包浮点数据类型变体。
打包浮点类型 |
打包格式中包含的元素数量 |
每个元素的类型 |
声明中要使用的寄存器变量类型 |
|---|---|---|---|
|
两个 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
||
|
|
||
|
|
||
|
|
|
|
|
四个 |
|
|
|
|
||
|
|
||
|
|
||
|
|
5.2.4.2. 打包整数数据类型
PTX 支持两种打包整数数据类型变体:.u16x2 和 .s16x2。打包数据类型由两个 .u16 或 .s16 值组成。包含 .u16x2 或 .s16x2 数据的寄存器变量必须使用 .b32 类型声明。打包整数数据类型不能用作基本类型。它们作为某些指令的指令类型受支持。
5.3. 纹理采样器和表面类型
PTX 包括内置的不透明类型,用于定义纹理、采样器和表面描述符变量。这些类型具有类似于结构的命名字段,但 PTX 程序隐藏了有关布局、字段顺序、基地址和整体大小的所有信息,因此称为不透明。这些不透明类型的使用仅限于
全局(模块)作用域内和内核入口参数列表中的变量定义。
使用逗号分隔的静态赋值表达式对类型的命名成员进行模块作用域变量的静态初始化。
通过纹理和表面加载/存储指令 (
tex、suld、sust、sured) 引用纹理、采样器或表面。通过查询指令 (
txq、suq) 检索命名成员的值。使用
mov创建指向不透明变量的指针,例如,mov.u64 reg, opaque_var;。生成的指针可以存储到内存和从内存加载,作为参数传递给函数,并通过纹理和表面加载、存储和查询指令取消引用,但该指针不能以其他方式视为地址,即,使用ld和st指令访问指针,或执行指针运算将导致未定义的行为。不透明变量不能出现在初始化列表中,例如,初始化指向不透明变量的指针。
注意
从 PTX ISA 版本 3.1 开始支持使用指向不透明变量的指针间接访问纹理和表面,并且需要目标 sm_20 或更高版本。
仅在统一纹理模式下支持对纹理的间接访问(见下文)。
三个内置类型是 .texref、.samplerref 和 .surfref。为了使用纹理和采样器,PTX 有两种操作模式。在统一模式下,纹理和采样器信息通过单个 .texref 句柄访问。在独立模式下,纹理和采样器信息各自具有自己的句柄,允许它们被单独定义并在程序中的使用位置组合。在独立模式下,.texref 类型的描述采样器属性的字段将被忽略,因为这些属性由 .samplerref 变量定义。
表 10 和 表 11 列出了统一和独立纹理模式下每种类型的命名成员。这些成员及其值与纹理 HW 类中定义的方法和值以及通过 API 公开的值具有精确的映射关系。
成员 |
.texref 值 |
.surfref 值 |
|---|---|---|
|
以元素为单位 |
|
|
以元素为单位 |
|
|
以元素为单位 |
|
|
对应于源语言 API 的 |
|
|
对应于源语言 API 的 |
|
|
|
N/A |
|
|
N/A |
|
|
N/A |
|
作为纹理数组中纹理的数量 |
作为表面数组中表面的数量 |
|
作为 mipmapped 纹理中的级别数 |
N/A |
|
作为多采样纹理中的样本数 |
N/A |
|
N/A |
|
5.3.1. 纹理和表面属性
字段 width、height 和 depth 指定纹理或表面的大小,以每个维度中的元素数量为单位。
channel_data_type 和 channel_order 字段使用对应于源语言 API 的枚举类型指定纹理或表面的这些属性。例如,有关 PTX 当前支持的 OpenCL 枚举类型,请参阅通道数据类型和通道顺序字段。
5.3.2. 采样器属性
normalized_coords 字段指示纹理或表面是否使用 [0.0, 1.0) 范围内的归一化坐标,而不是 [0, N) 范围内的非归一化坐标。如果未指定值,则默认值由运行时系统根据源语言设置。
filter_mode 字段指定如何根据输入的纹理坐标计算纹理读取返回的值。
addr_mode_{0,1,2} 字段定义了每个维度中的寻址模式,该模式确定如何处理超出范围的坐标。
有关这些属性的更多详细信息,请参阅CUDA C++ 编程指南。
成员 |
.samplerref 值 |
.texref 值 |
.surfref 值 |
|---|---|---|---|
|
N/A |
以元素为单位 |
|
|
N/A |
以元素为单位 |
|
|
N/A |
以元素为单位 |
|
|
N/A |
对应于源语言 API 的 |
|
|
N/A |
对应于源语言 AP 的 |
|
|
N/A |
|
N/A |
|
|
N/A |
N/A |
|
|
已忽略 |
N/A |
|
|
N/A |
N/A |
|
N/A |
作为纹理数组中纹理的数量 |
作为表面数组中表面的数量 |
|
N/A |
作为 mipmapped 纹理中的级别数 |
N/A |
|
N/A |
作为多采样纹理中的样本数 |
N/A |
|
N/A |
N/A |
|
在独立纹理模式下,采样器属性在独立的 .samplerref 变量中携带,并且这些字段在 .texref 变量中被禁用。在独立纹理模式下,还有一个额外的采样器属性 force_unnormalized_coords 可用。
force_unnormalized_coords 字段是 .samplerref 变量的属性,允许采样器覆盖纹理头 normalized_coords 属性。此字段仅在独立纹理模式下定义。当 True 时,纹理头设置将被覆盖,并使用非归一化坐标;当 False 时,将使用纹理头设置。
force_unnormalized_coords 属性用于编译 OpenCL;在 OpenCL 中,归一化坐标的属性在采样器头中携带。为了将 OpenCL 编译为 PTX,纹理头始终使用设置为 True 的 normalized_coords 初始化,并且基于 OpenCL 采样器的 normalized_coords 标志(取反)映射到 PTX 级别的 force_unnormalized_coords 标志。
使用这些类型的变量可以在模块作用域或内核入口参数列表中声明。在模块作用域中,这些变量必须位于 .global 状态空间中。作为内核参数,这些变量在 .param 状态空间中声明。
例子
.global .texref my_texture_name;
.global .samplerref my_sampler_name;
.global .surfref my_surface_name;
当在模块作用域中声明时,可以使用静态表达式列表初始化这些类型,这些表达式将值赋给命名的成员。
例子
.global .texref tex1;
.global .samplerref tsamp1 = { addr_mode_0 = clamp_to_border,
filter_mode = nearest
};
5.3.3. 通道数据类型和通道顺序字段
channel_data_type 和 channel_order 字段具有与源语言 API 相对应的枚举类型。目前,OpenCL 是唯一定义这些字段的源语言。表 13 和 表 12 显示了 OpenCL 1.0 版本中为通道数据类型和通道顺序定义的枚举值。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.4. 变量
在 PTX 中,变量声明描述了变量的类型及其状态空间。除了基本类型之外,PTX 还支持简单聚合对象的类型,例如向量和数组。
5.4.1. 变量声明
所有数据存储都通过变量声明来指定。每个变量都必须驻留在上一节中枚举的状态空间之一中。
变量声明命名了变量驻留的空间、其类型和大小、其名称、可选的数组大小、可选的初始化器以及变量的可选固定地址。
谓词变量只能在寄存器状态空间中声明。
示例
.global .u32 loc;
.reg .s32 i;
.const .f32 bias[] = {-1.0, 1.0};
.global .u8 bg[4] = {0, 0, 0, 0};
.reg .v4 .f32 accel;
.reg .pred p, q, r;
5.4.2. 向量
支持有限长度的向量类型。长度为 2 和 4 的任何非谓词基本类型的向量可以通过在类型前加上 .v2 或 .v4 来声明。向量必须基于基本类型,并且可以驻留在寄存器空间中。向量的长度不能超过 128 位;例如,不允许使用 .v4 .f64。三元素向量可以使用 .v4 向量来处理,其中第四个元素提供填充。这对于三维网格、纹理等来说是一种常见情况。
示例
.global .v4 .f32 V; // a length-4 vector of floats
.shared .v2 .u16 uv; // a length-2 vector of unsigned ints
.global .v4 .b8 v; // a length-4 vector of bytes
默认情况下,向量变量与其总大小(向量长度乘以基本类型大小)的倍数对齐,以启用向量加载和存储指令,这些指令需要地址与访问大小的倍数对齐。
5.4.3. 数组声明
提供数组声明是为了允许程序员保留空间。要声明数组,变量名称后跟维度声明,类似于 C 中的固定大小数组声明。每个维度的大小都是常量表达式。
示例
.local .u16 kernel[19][19];
.shared .u8 mailbox[128];
数组的大小指定应保留多少个元素。对于上面数组 *kernel* 的声明,保留了 19*19 = 361 个半字,总共 722 字节。
当使用初始化器声明时,可以省略数组的第一个维度。第一个数组维度的大小由数组初始化器中元素的数量决定。
示例
.global .u32 index[] = { 0, 1, 2, 3, 4, 5, 6, 7 };
.global .s32 offset[][2] = { {-1, 0}, {0, -1}, {1, 0}, {0, 1} };
数组 *index* 有八个元素,数组 *offset* 是一个 4x2 的数组。
5.4.4. 初始化器
声明的变量可以使用类似于 C/C++ 的语法指定初始值,其中变量名称后跟等号和变量的初始值或多个值。标量采用单个值,而向量和数组采用花括号内的嵌套值列表(嵌套与声明的维度匹配)。
与 C 中一样,数组初始化器可能是不完整的,即,初始化器元素的数量可能少于相应数组维度的范围,剩余的数组位置初始化为指定数组类型的默认值。
示例
.const .f32 vals[8] = { 0.33, 0.25, 0.125 };
.global .s32 x[3][2] = { {1,2}, {3} };
等同于
.const .f32 vals[8] = { 0.33, 0.25, 0.125, 0.0, 0.0, 0.0, 0.0, 0.0 };
.global .s32 x[3][2] = { {1,2}, {3,0}, {0,0} };
目前,变量初始化仅支持常量和全局状态空间。常量和全局状态空间中没有显式初始化器的变量默认初始化为零。外部变量声明中不允许使用初始化器。
出现在初始化器中的变量名称表示变量的地址;这可以用于静态初始化指向变量的指针。初始化器还可以包含 *var+offset* 表达式,其中 *offset* 是添加到 *var* 地址的字节偏移量。只有 .global 或 .const 状态空间中的变量才能在初始化器中使用。默认情况下,结果地址是变量状态空间中的偏移量(就像使用 mov 指令获取变量地址的情况一样)。提供了一个运算符 generic(),用于为初始化器中使用的变量创建通用地址。
从 PTX ISA 版本 7.1 开始,提供了一个运算符 mask(),其中 mask 是一个整数立即数。mask() 运算符中唯一允许的表达式是整数常量表达式和表示变量地址的符号表达式。mask() 运算符从初始化器中使用的表达式中提取 n 个连续位,并将这些位插入到初始化变量的最低位置。要提取的位数 n 和起始位置由整数立即数 mask 指定。PTX ISA 版本 7.1 仅支持从变量地址提取从字节边界开始的单个字节。PTX ISA 版本 7.3 支持将整数常量表达式作为 mask() 运算符中的操作数。
支持的 mask 值包括:0xFF、0xFF00、0XFF0000、0xFF000000、0xFF00000000、0xFF0000000000、0xFF000000000000、0xFF00000000000000。
示例
.const .u32 foo = 42;
.global .u32 bar[] = { 2, 3, 5 };
.global .u32 p1 = foo; // offset of foo in .const space
.global .u32 p2 = generic(foo); // generic address of foo
// array of generic-address pointers to elements of bar
.global .u32 parr[] = { generic(bar), generic(bar)+4,
generic(bar)+8 };
// examples using mask() operator are pruned for brevity
.global .u8 addr[] = {0xff(foo), 0xff00(foo), 0xff0000(foo), ...};
.global .u8 addr2[] = {0xff(foo+4), 0xff00(foo+4), 0xff0000(foo+4),...}
.global .u8 addr3[] = {0xff(generic(foo)), 0xff00(generic(foo)),...}
.global .u8 addr4[] = {0xff(generic(foo)+4), 0xff00(generic(foo)+4),...}
// mask() operator with integer const expression
.global .u8 addr5[] = { 0xFF(1000 + 546), 0xFF00(131187), ...};
注意
PTX 3.1 重新定义了初始化器中全局变量的默认寻址方式,从通用地址到全局状态空间中的偏移量。旧版 PTX 代码被视为对初始化器中使用的每个全局变量都具有隐式 generic() 运算符。PTX 3.1 代码应在初始化器中包含显式 generic() 运算符,使用 cvta.global 在运行时形成通用地址,或使用 ld.global 从非通用地址加载。
出现在初始化器中的设备函数名称表示函数中第一条指令的地址;这可以用于初始化函数指针表,以便与间接调用一起使用。从 PTX ISA 版本 3.1 开始,内核函数名称可以用作初始化器,例如,初始化内核函数指针表,以便与 CUDA 动态并行性一起使用以从 GPU 启动内核。有关详细信息,请参阅 *CUDA 动态并行性编程指南*。
标签不能在初始化器中使用。
保存变量或函数地址的变量应为 .u8 或 .u32 或 .u64 类型。
仅当使用 mask() 运算符时,才允许使用类型 .u8。
除 .f16、.f16x2 和 .pred 外的所有类型都允许使用初始化器。
示例
.global .s32 n = 10;
.global .f32 blur_kernel[][3]
= {{.05,.1,.05},{.1,.4,.1},{.05,.1,.05}};
.global .u32 foo[] = { 2, 3, 5, 7, 9, 11 };
.global .u64 ptr = generic(foo); // generic address of foo[0]
.global .u64 ptr = generic(foo)+8; // generic address of foo[2]
5.4.5. 对齐
可以变量声明中指定所有可寻址变量的存储字节对齐方式。对齐方式使用可选的 .align*字节计数* 说明符在状态空间说明符之后立即指定。变量将对齐到字节计数的整数倍的地址。对齐值字节计数必须是 2 的幂。对于数组,对齐指定整个数组的起始地址的地址对齐,而不是单个元素的地址对齐。
标量和数组变量的默认对齐方式是基本类型大小的倍数。向量变量的默认对齐方式是整个向量大小的倍数。
示例
// allocate array at 4-byte aligned address. Elements are bytes.
.const .align 4 .b8 bar[8] = {0,0,0,0,2,0,0,0};
请注意,所有访问内存的 PTX 指令都要求地址与访问大小的倍数对齐。内存指令的访问大小是在内存中访问的总字节数。例如,ld.v4.b32 的访问大小为 16 字节,而 atom.f16x2 的访问大小为 4 字节。
5.4.6. 参数化变量名
由于 PTX 支持虚拟寄存器,因此编译器前端生成大量寄存器名称非常常见。PTX 支持一种语法,用于创建一组具有公共前缀字符串并附加整数后缀的变量,而不是要求显式声明每个名称。
例如,假设程序使用大量(例如一百个).b32 变量,命名为 %r0、%r1、…、%r99。这些 100 个寄存器变量可以声明如下
.reg .b32 %r<100>; // declare %r0, %r1, ..., %r99
此简写语法可以与任何基本类型和任何状态空间一起使用,并且可以在前面加上对齐说明符。数组变量不能以这种方式声明,也不允许使用初始化器。
5.4.7. 变量属性
可以使用可选的 .attribute 指令声明变量,该指令允许指定变量的特殊属性。关键字 .attribute 后跟括号内的属性规范。多个属性用逗号分隔。
变量和函数属性指令:.attribute 描述了 .attribute 指令。
5.4.8. 变量和函数属性指令:.attribute
.attribute
变量和函数属性
描述
用于指定变量或函数的特殊属性。
支持以下属性。
.managed-
.managed属性指定变量将分配在统一虚拟内存环境中的位置,在该环境中,主机和系统中的其他设备可以直接引用该变量。此属性只能用于 .global 状态空间中的变量。有关详细信息,请参阅 *CUDA UVM-Lite 编程指南*。 .unified-
.unified属性指定函数在主机和系统中的其他设备上具有相同的内存地址。整数常量uuid1和uuid2分别指定与函数或变量关联的唯一标识符的高 64 位和低 64 位。此属性只能用于设备函数或.global状态空间中的变量。具有.unified属性的变量是只读的,必须通过在ld指令的地址操作数上指定.unified限定符来加载,否则行为未定义。
PTX ISA 注释
在 PTX ISA 版本 4.0 中引入。
对函数属性的支持在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
.managed属性需要sm_30或更高版本。.unified属性需要sm_90或更高版本。
示例
.global .attribute(.managed) .s32 g;
.global .attribute(.managed) .u64 x;
.global .attribute(.unified(19,95)) .f32 f;
.func .attribute(.unified(0xAB, 0xCD)) bar() { ... }
5.5. 张量
张量是内存中的多维矩阵结构。张量由以下属性定义
维度
每个维度上的维度大小
单个元素类型
每个维度上的张量步幅
PTX 支持可以对张量数据进行操作的指令。PTX 张量指令包括
在全球内存和共享内存之间复制数据
使用源数据缩减目标张量数据。
张量数据可以通过各种 wmma.mma、mma 和 wgmma.mma_async 指令进行操作。
PTX 张量指令将全局内存中的张量数据视为多维结构,并将共享内存中的数据视为线性数据。
5.5.1. 张量维度、大小和格式
张量可以具有以下维度:1D、2D、3D、4D 或 5D。
每个维度都有一个大小,表示沿该维度的元素数量。元素可以具有以下类型之一
位大小类型:
.b32、.b64子字节类型:
.b4x16、.b4x16_p64、.b6x16_p32、.b6p2x16整数:
.u8、.u16、.u32、.s32、.u64、.s64浮点和备用浮点:
.f16、.bf16、.tf32、.f32、.f64(四舍五入到最接近的偶数)。
张量可以在每个维度的末尾具有填充,以便为后续维度中的数据提供对齐。张量步幅可用于指定每个维度中的填充量。
5.5.1.1. 子字节类型
5.5.1.1.1. 子字节类型的填充和对齐
子字节类型预计在全局内存中连续打包,张量复制指令将通过附加空白空间来扩展它们,如下所示
类型
.b4x16:使用此类型,不涉及填充,并且 64 位容器中打包的十六个.b4元素在共享内存和全局内存之间按原样复制。-
类型
.b4x16_p64:使用此类型,从全局内存复制十六个连续的 4 位数据到共享内存,并附加 64 位填充,如 图 5 所示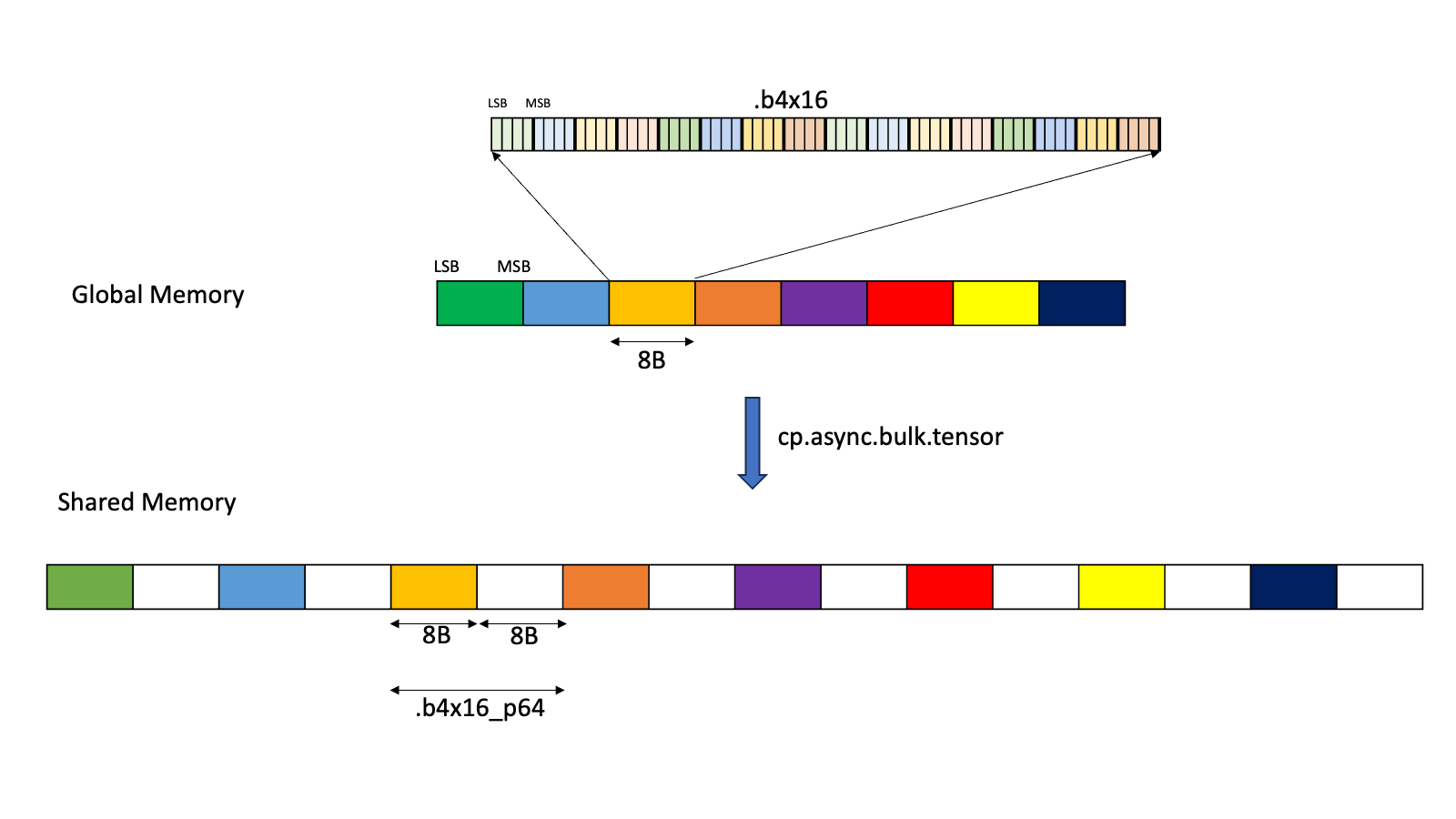
图 5 .b4x16_p64 的布局
添加的填充区域未初始化。
-
类型
.b6x16_p32:使用此类型,从全局内存复制十六个 6 位数据到共享内存,并附加 32 位填充,如 图 6 所示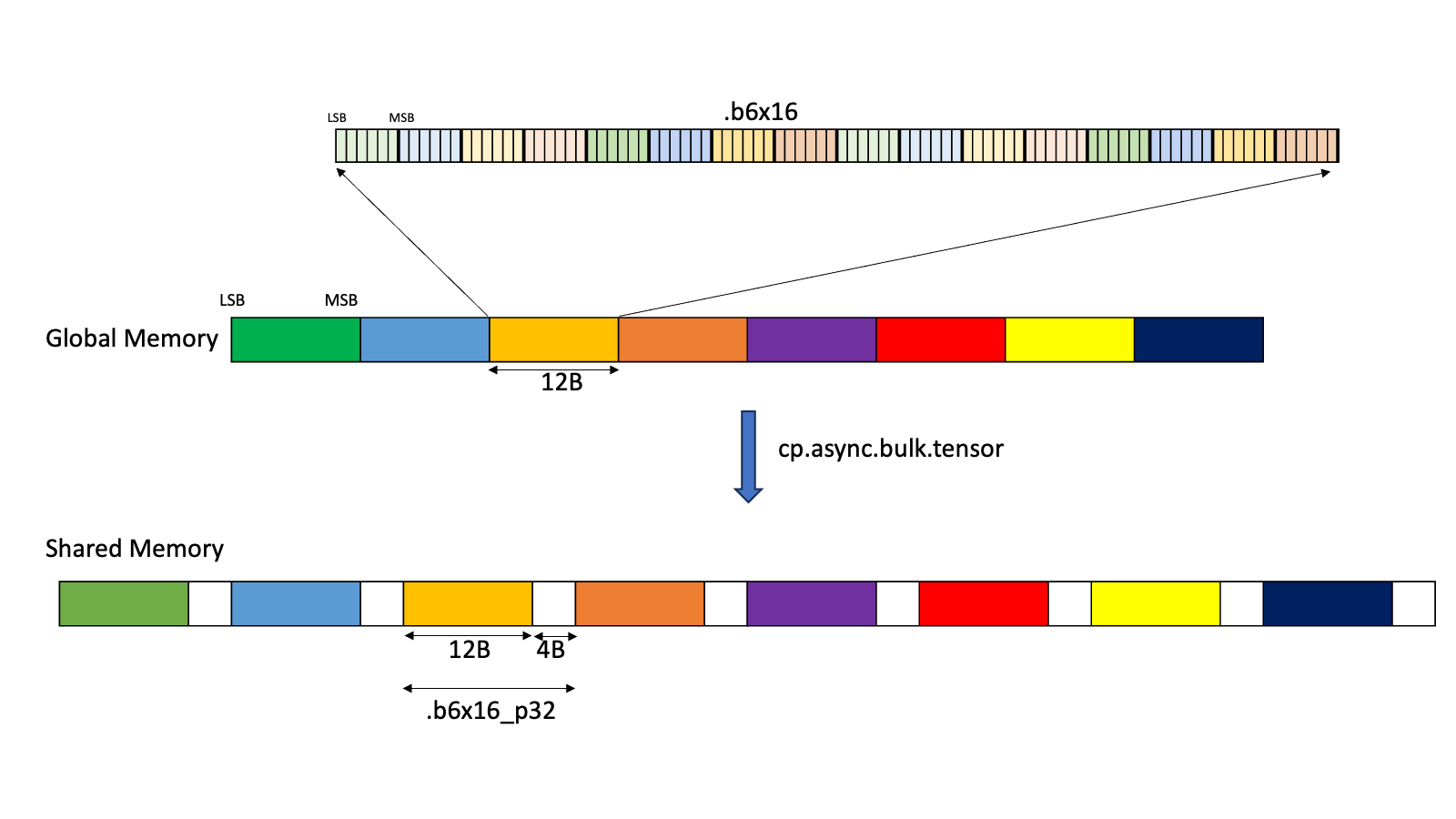
图 6 .b6x16_p32 的布局
添加的填充区域未初始化。
-
类型
.b6p2x16:使用此类型,从共享内存复制十六个元素(每个元素在 LSB 处包含 6 位数据,在 MSB 处包含 2 位填充)到全局内存,方法是丢弃 2 位填充数据并将 6 位数据连续打包,如 图 7 所示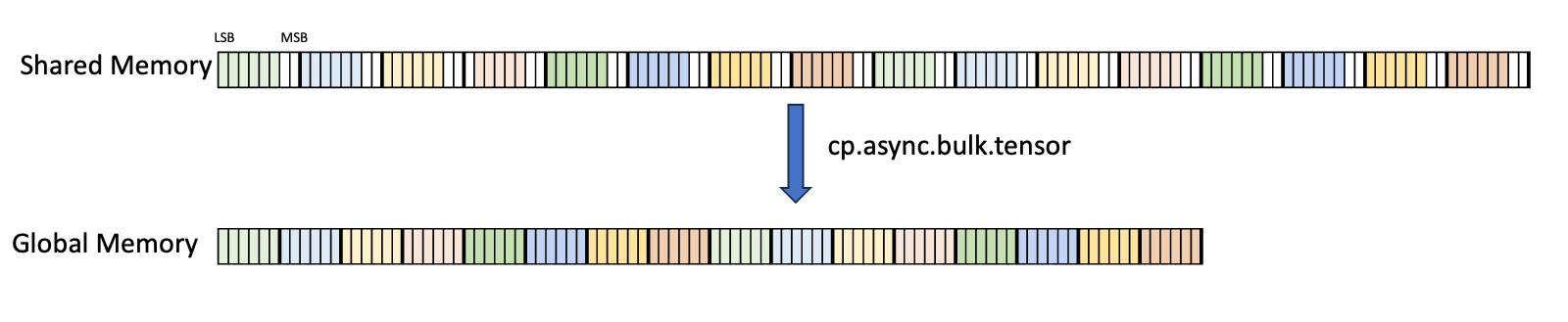
图 7 .b6p2x16 的布局
对于 .b6x16_p32 和 .b4x16_p64,添加的填充区域未初始化。
类型 .b6x16_p32 和 .b6p2x16 在描述符中共享相同的编码值(值 15),因为这两种类型适用于不同类型的张量复制操作
类型 |
有效的张量复制方向 |
|---|---|
|
|
|
|
5.5.2. 张量访问模式
张量数据可以通过两种模式访问
-
平铺模式
在平铺模式下,源多维张量布局在目标位置保留。
-
Im2col 模式
在 im2col 模式下,源张量的边界框中的元素被重新排列到目标位置的列中。有关更多详细信息,请参阅 此处。
5.5.3. 平铺模式
本节讨论张量和平铺模式下的张量访问如何工作。
5.5.3.1. 边界框
张量可以以称为 *边界框* 的块访问。边界框具有与它们访问的张量相同的维度。每个边界框的大小必须是 16 字节的倍数。边界框的地址也必须与 16 字节对齐。
边界框具有以下访问属性
边界框维度大小
超出边界访问模式
遍历步幅
PTX 张量指令中指定的张量坐标指定边界框的起始偏移量。边界框的起始偏移量以及其余边界框信息一起用于确定要访问的元素。
5.5.3.2. 遍历步幅
当边界框跨维度迭代张量时,遍历步幅指定要跳过的确切元素数。如果不需要跳过,则必须指定默认值 1。
维度 0 中的遍历步幅可用于 交错布局。对于非交错布局,维度 0 中的遍历步幅必须始终为 1。
图 8 说明了张量、张量大小、张量步幅、边界框大小和遍历步幅。
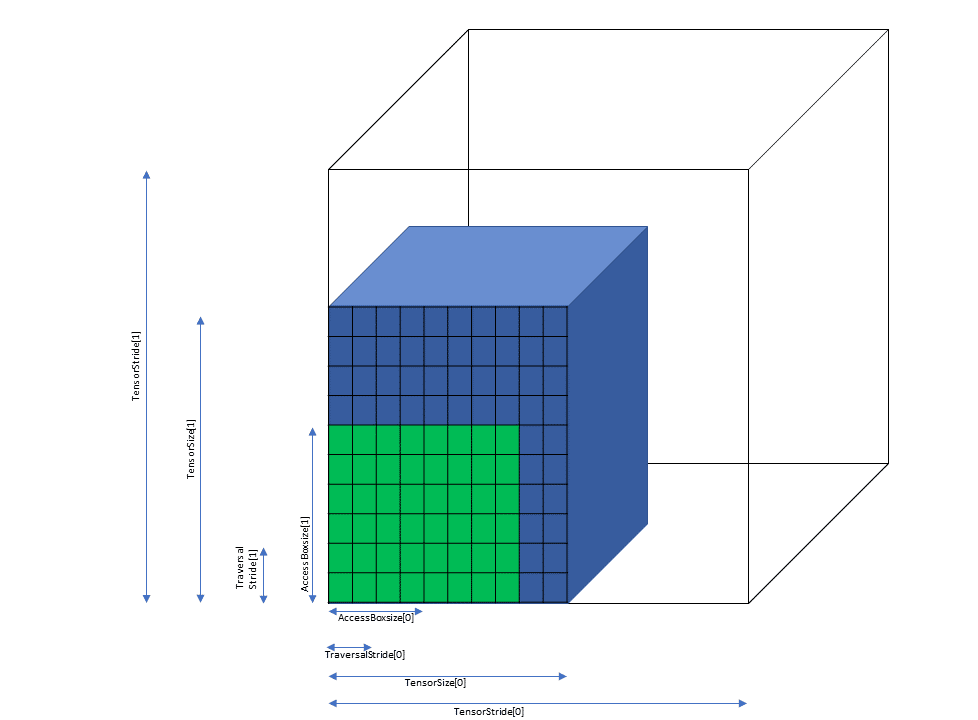
图 8 平铺模式边界框、张量大小和遍历步幅
5.5.3.3. 超出边界访问
当边界框在任何维度上跨越张量边界时,PTX 张量操作可以检测并处理这种情况。有两种模式
-
零填充模式
边界框中落在张量边界之外的元素设置为 0。
-
OOB-NaN填充模式边界框中落在张量边界之外的元素设置为特殊的 NaN,称为
OOB-NaN。
图 9 显示了超出边界访问的示例。
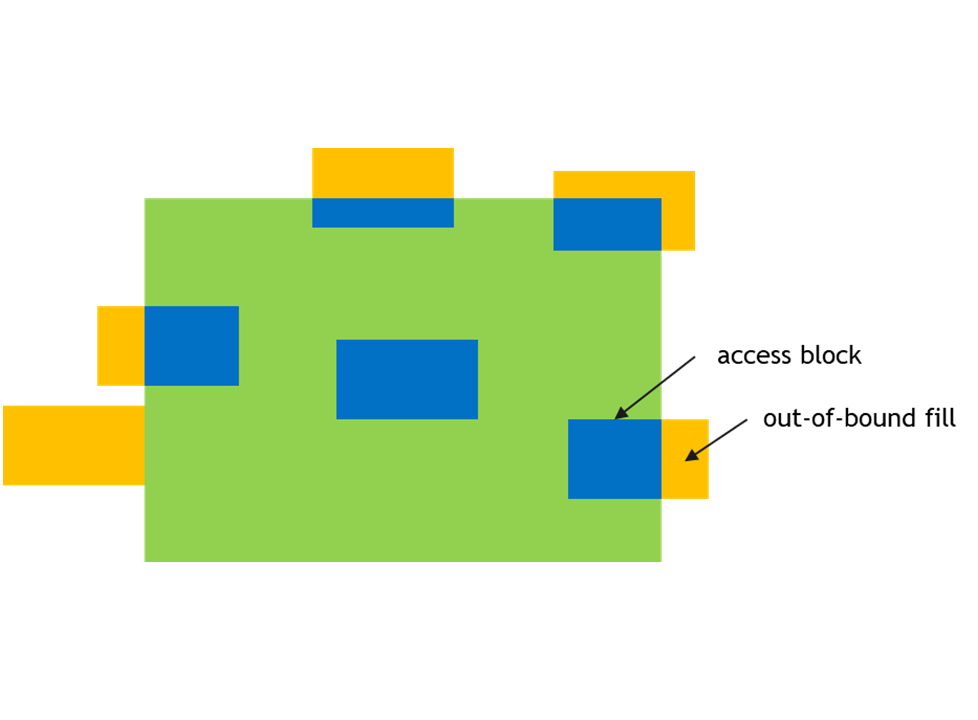
图 9 超出边界访问
5.5.3.4. Tile::scatter4 和 Tile::gather4 模式
这些模式类似于平铺模式,但限制是这些模式仅适用于 2D 张量数据。Tile::scatter4 和 Tile::gather4 模式用于访问张量数据的多个不连续行。
在 Tile::scatter4 模式下,单个 2D 源张量被分成 2D 目标张量中的四行。在 Tile::gather4 模式下,源 2D 张量中的四行被组合以形成单个 2D 目标张量。
这些模式适用于四行,因此指令将采用
维度 0 上的四个张量坐标
维度 1 上的一个张量坐标
对于 .tile::scatter4 和 .tile::gather4 模式,不支持交错布局。
平铺模式的所有其他约束和规则也适用于这些模式。
5.5.3.4.1. 边界框
对于 Tile::scatter4 和 Tile::gather4 模式,四个请求坐标将在张量空间中形成四个边界框。
图 10 显示了以起始坐标 (1, 2)、(1, 5)、(1, 0) 和 (1, 9) 为例的情况。
维度 0 中边界框的大小表示行的长度。维度 1 中边界框的大小必须为 1。
图 10 tiled::scatter4/tiled::gather4 模式边界框示例
5.5.4. Im2col 模式
Im2col 模式支持以下张量维度:3D、4D 和 5D。在此模式下,张量数据被视为一批图像,具有以下属性
N:批次中的图像数量
D、H、W:3D 图像的大小(深度、高度和宽度)
C:每个图像元素的通道数
以上属性与 3D、4D 和 5D 张量关联,如下所示
维度 |
N/D/H/W/C 适用性 |
|---|---|
3D |
NWC |
4D |
NHWC |
5D |
NDHWC |
5.5.4.1. 边界框
在 im2col 模式下,边界框在 DHW 空间中定义。沿其他维度的边界由每列像素数和每像素通道数参数指定,如下所述。
边界框的维度比张量维度小两个。
以下属性描述了如何在 im2col 模式下访问元素
边界框左下角
边界框右上角
每列像素数
每像素通道数
Bounding-box Lower-Corner 和 Bounding-box Upper-Corner 指定了 DHW 空间中边界框的两个对角。Bounding-box Lower-Corner 指定了坐标最小的角,而 Bounding-box Upper-Corner 指定了坐标最大的角。
Bounding-box Upper- 和 Lower-Corners 是 16 位有符号值,其限制因维度而异,如下所示
3D |
4D |
5D |
|
|---|---|---|---|
Upper- / Lower- Corner 尺寸 |
[-215, 215-1] |
[-27, 27-1] |
[-24, 24-1] |
图 11 和 图 12 显示了 Upper-Corners 和 Lower-Corners。
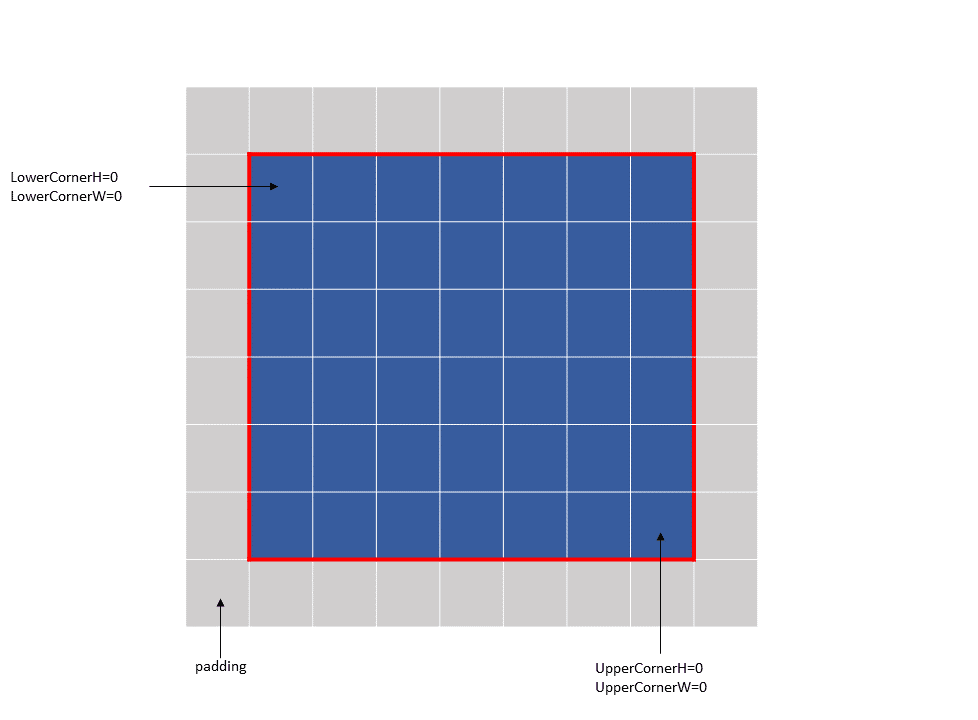
图 11 im2col 模式边界框示例 1
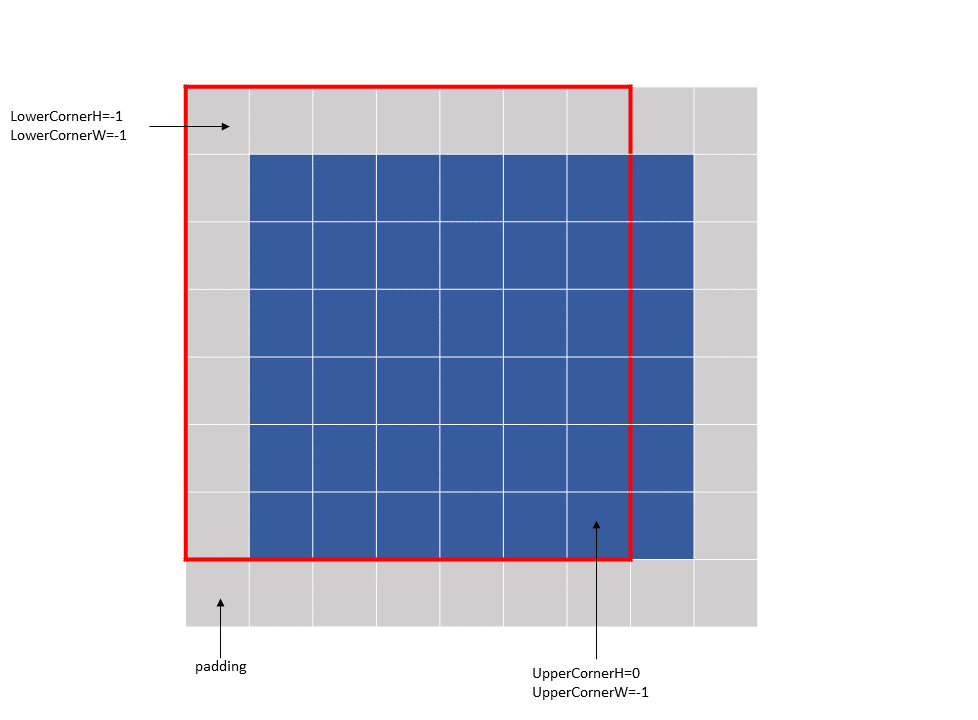
图 12 im2col 模式边界框示例 2
Bounding-box Upper- 和 Lower- Corners 仅指定边界,而不指定要访问的元素数量。Pixels-per-Column 指定了 NDHW 空间中要访问的元素数量。
Channels-per-Pixel 指定了跨 C 维度要访问的元素数量。
张量坐标在 PTX 张量指令中指定,在不同维度上的行为有所不同
跨 N 和 C 维度:指定沿维度的起始偏移量,类似于平铺模式。
跨 DHW 维度:指定卷积滤波器基在张量空间中的位置。滤波器角位置必须在边界框内。
在 im2col 模式下,PTX 张量指令中指定的 im2col 偏移量被添加到滤波器基坐标,以确定张量空间中元素访问的起始位置。
im2col 偏移量的大小因维度而异,其有效范围如下所示
3D |
4D |
5D |
|
|---|---|---|---|
im2col 偏移量范围 |
[0, 216-1] |
[0, 28-1] |
[0, 25-1] |
以下是一些 im2col 模式访问的示例
-
示例 1 (图 13)
Tensor Size[0] = 64 Tensor Size[1] = 9 Tensor Size[2] = 14 Tensor Size[3] = 64 Pixels-per-Column = 64 channels-per-pixel = 8 Bounding-Box Lower-Corner W = -1 Bounding-Box Lower-Corner H = -1 Bounding-Box Upper-Corner W = -1 Bounding-Box Upper-Corner H = -1. tensor coordinates = (7, 7, 4, 0) im2col offsets : (0, 0)
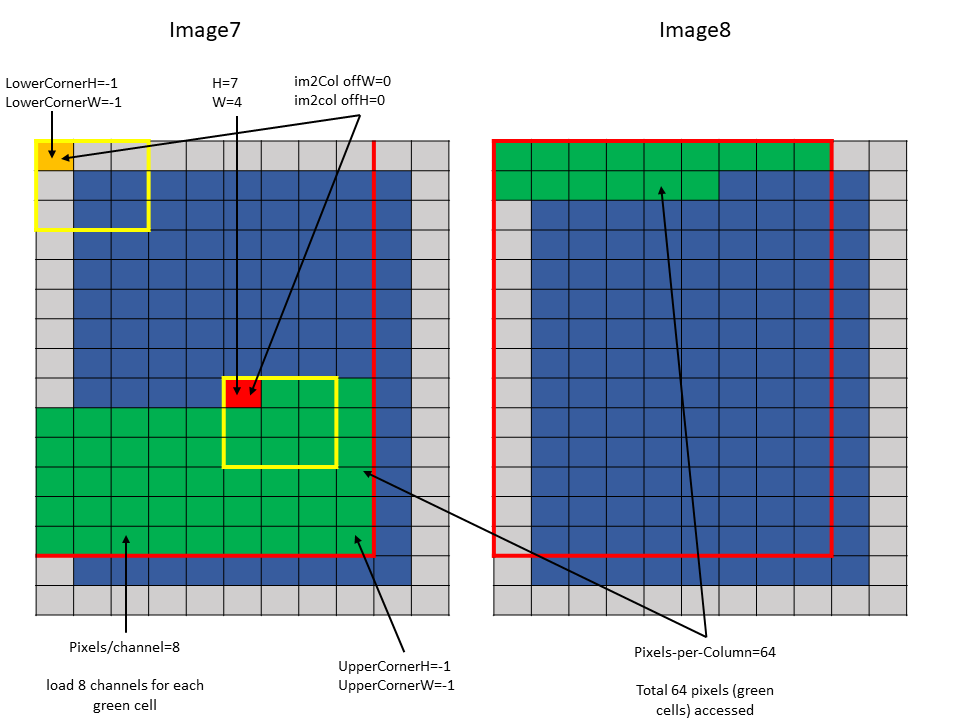
图 13 im2col 模式示例 1
-
示例 2 (图 14)
Tensor Size[0] = 64 Tensor Size[1] = 9 Tensor Size[2] = 14 Tensor Size[3] = 64 Pixels-per-Column = 64 channels-per-pixel = 8 Bounding-Box Lower-Corner W = 0 Bounding-Box Lower-Corner H = 0 Bounding-Box Upper-Corner W = -2 Bounding-Box Upper-Corner H = -2 tensor coordinates = (7, 7, 4, 0) im2col offsets: (2, 2)
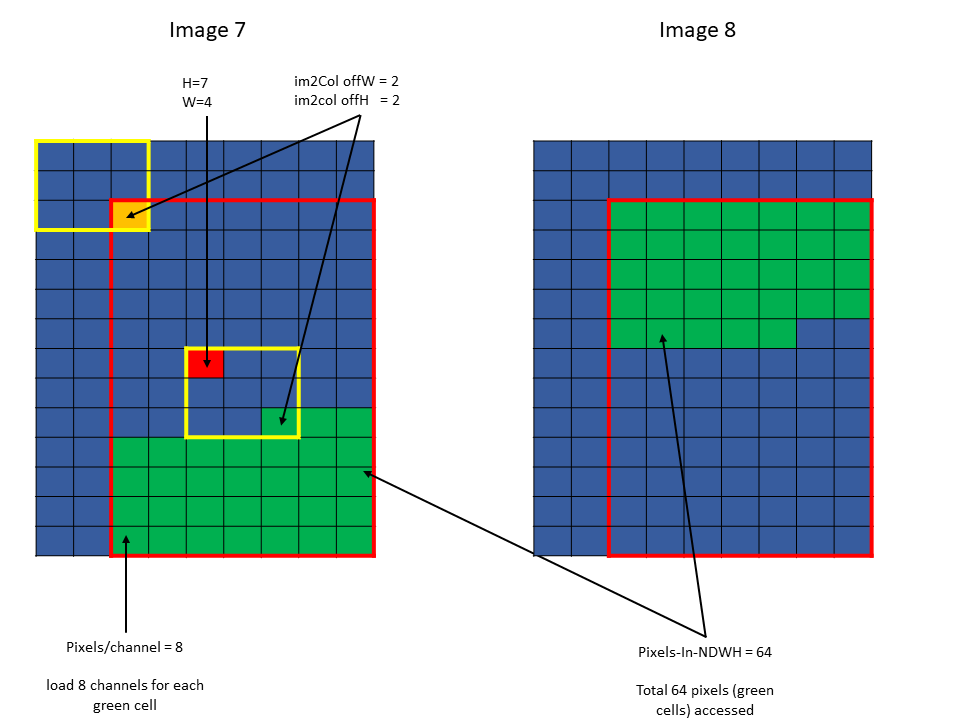
图 14 im2col 模式示例 2
5.5.4.2. 遍历步幅
在 im2col 模式下,遍历步幅不像平铺模式那样影响访问的元素(或像素)总数。在 im2col 模式下,Pixels-per-Column 决定了访问的元素总数。
沿 D、H 和 W 维度遍历的元素数量由该维度的遍历步幅进行跨步。
以下示例使用 图 15 说明了使用遍历步幅的访问
Tensor Size[0] = 64
Tensor Size[1] = 8
Tensor Size[2] = 14
Tensor Size[3] = 64
Traversal Stride = 2
Pixels-per-Column = 32
channels-per-pixel = 16
Bounding-Box Lower-Corner W = -1
Bounding-Box Lower-Corner H = -1
Bounding-Box Upper-Corner W = -1
Bounding-Box Upper-Corner H = -1.
Tensor coordinates in the instruction = (7, 7, 5, 0)
Im2col offsets in the instruction : (1, 1)
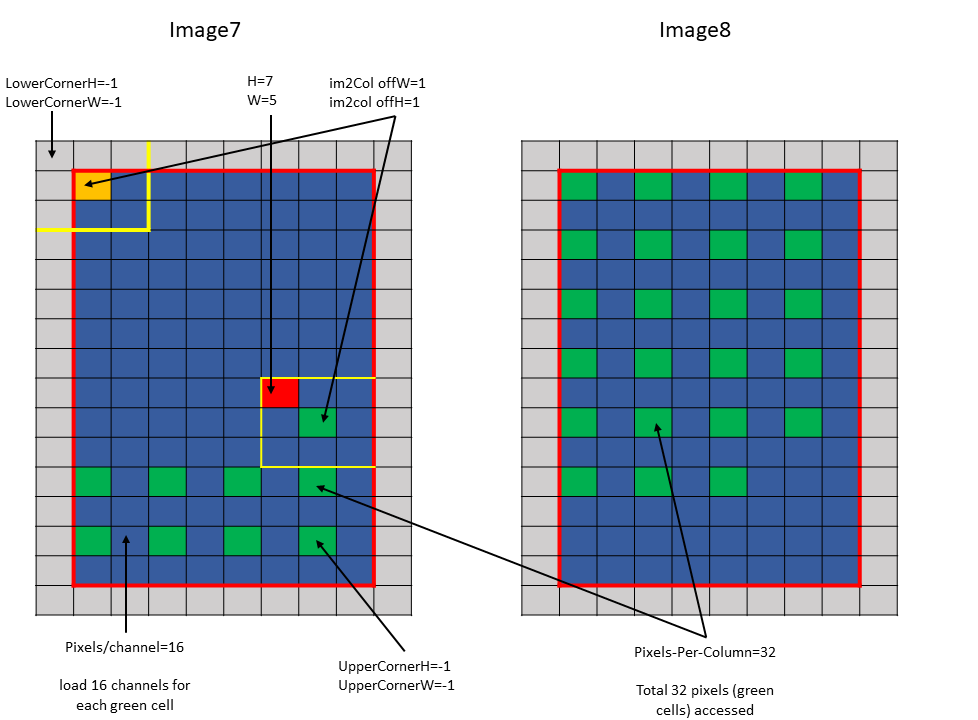
图 15 im2col 模式遍历步幅示例
5.5.4.3. 越界访问
在 im2col 模式下,当 Pixels-per-Column 指定的 NDHW 空间中请求的像素数量超过图像批次中可用的像素数量时,将执行越界访问。
与平铺模式类似,可以根据指定的填充模式执行零填充或 OOB-NaN 填充。
5.5.5. Im2col::w 和 Im2col::w::128 模式
这些模式与 im2col 模式类似,但限制是元素仅在 W 维度上访问,同时保持 H 和 D 维度恒定。
im2col 模式的所有约束和规则也适用于这些模式。
在 im2col::w::128 模式下访问的元素数量是固定的,等于 128。在 im2col::w 模式下访问的元素数量取决于 TensorMap 中的 Pixels-per-Column 字段。
5.5.5.1. 边界框
在这些模式下,D 和 H 维度中边界框的大小为 1。
PTX 指令中张量坐标参数中的 D 和 H 维度指定了边界框在张量空间中的位置。
边界框 Lower-Corner-W 和边界框 Upper-Corner-W 指定了 W 维度中边界框的两个对角。
PTX 指令中张量坐标参数中的 W 维度指定了要在边界框中访问的第一个元素的位置。
在 im2col::w 模式下加载的像素数量由 TensorMap 中的 Pixels-per-Column 指定。在 im2col::w::128 模式下加载的像素数量始终为 128。因此,在 im2col::w::128 模式下,Pixels-per-Column 被忽略。
图 16 显示了 im2col::w 和 im2col::w:128 模式的示例。
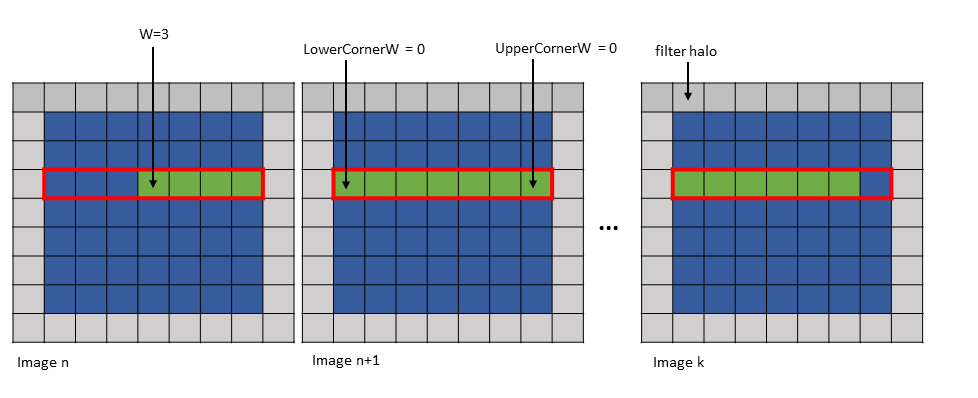
图 16 im2col::w 和 im2col::w::128 模式示例
第一个元素可以位于边界框之外,仅在 W 维度上,并且仅在边界框的左侧。图 17 显示了此示例。
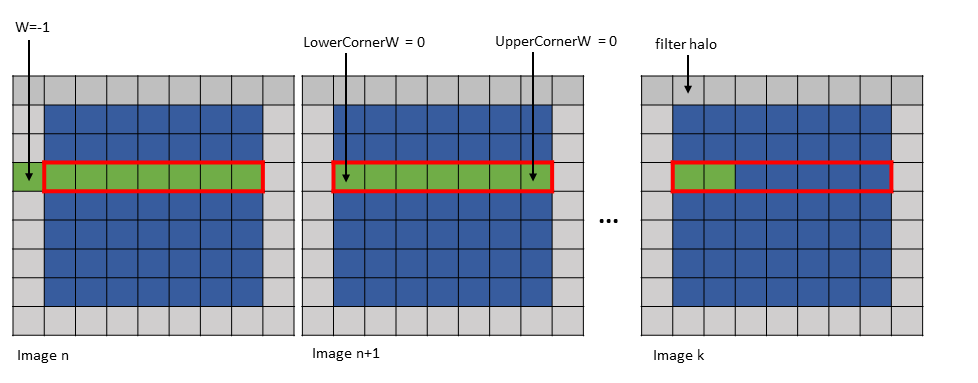
图 17 im2col::w 和 im2col::w::128 模式第一个元素位于边界框外示例
5.5.5.2. 遍历步幅
这类似于 im2col 模式,但例外是仅沿 W 维度遍历的元素数量由 TensorMap 中指定的遍历步幅进行跨步。
5.5.5.3. wHalo
在 im2col::w 模式下,PTX 指令中的 wHalo 参数指定了在图像末尾必须加载多少滤波器光环元素。
在 im2col::w::128 模式下,在沿 W 维度的边界框中每 32 个元素后加载光环元素。PTX 指令中的 wHalo 参数指定了每 32 个元素后必须加载多少光环元素。
以下是 .im2col::w 模式访问的示例
Tensor Size [0] = 128
Tensor Size [1] = 9
Tensor Size [2] = 7
Tensor Size [3] = 64
Pixels-per-column = 128
Channels-per-pixel = 64
Bounding Box Lower Corner W = 0
Bounding Box Upper Corner W = 0
Tensor Coordinates in the instruction = (7, 2, 3, 0)
wHalo in the instruction = 2 (as 3x3 convolution filter is used)
使用上述参数的张量复制操作加载 128 个像素和两个光环像素,如 图 18 所示。
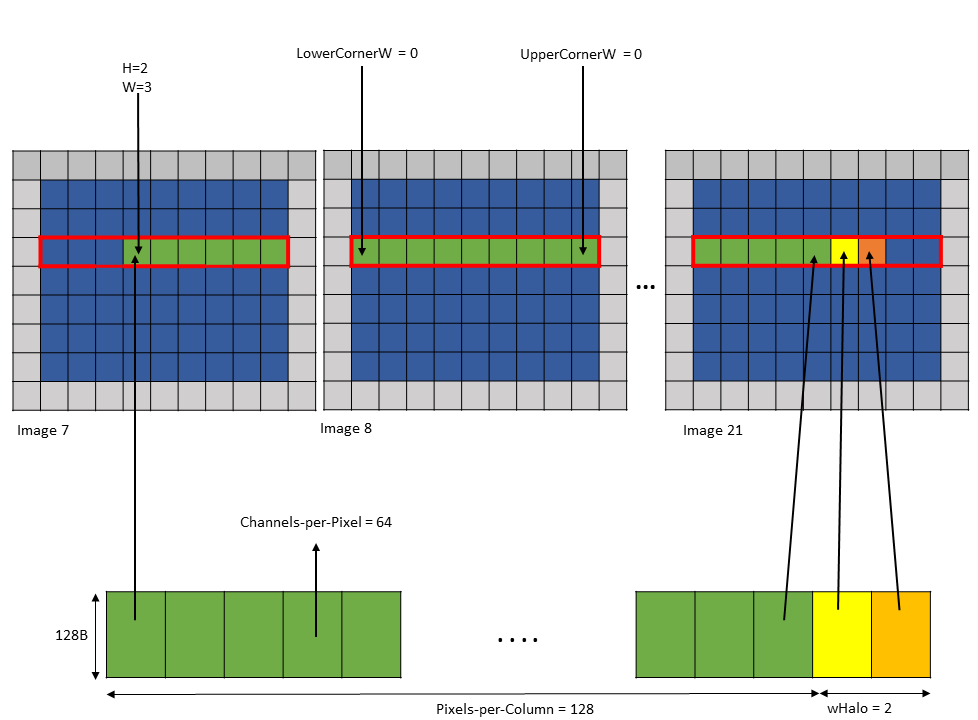
图 18 使用 im2col::w 模式示例的张量复制操作
光环像素始终加载在共享内存中,紧邻主行像素,如 图 18 所示。
以下是 .im2col::w::128 模式访问的示例
Tensor Size [0] = 128
Tensor Size [1] = 9
Tensor Size [2] = 7
Tensor Size [3] = 64
Channels-per-pixel = 64
Bounding Box Lower Corner W = 0
Bounding Box Upper Corner W = 0
Tensor Coordinates in the instruction = (7, 2, 3, 0)
wHalo in the instruction = 2 (as 3x3 convolution filter is used)
使用上述参数的张量复制操作加载 128 个元素,使得每 32 个元素后,加载 wHalo 数量的元素,如 图 19 所示。
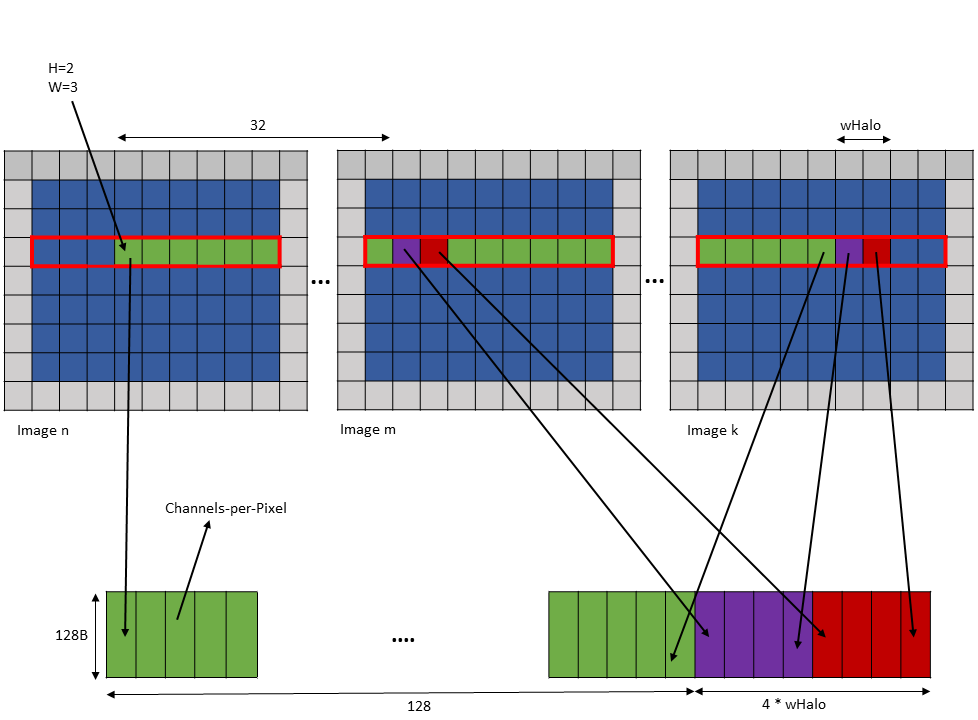
图 19 使用 im2col::w::128 模式示例的张量复制操作
5.5.5.4. wOffset
在卷积计算中,沿 W 维度的相同元素被重用于卷积滤波器足迹内的不同位置。根据像素被使用的次数,像素可以加载到不同的共享内存缓冲区中。每个缓冲区可以由单独的张量复制操作加载。
张量复制和预取指令中的 wOffset 参数调整每个缓冲区的源像素位置。缓冲区的确切位置沿 W 维度使用以下公式进行调整
Bounding Box Lower Corner W += wOffset
Bounding Box Upper Corner W += wOffset
W += wOffset
以下是使用各种 wHalo 和 wOffset 值的张量复制到多个缓冲区的示例
示例 1
Tensor Size [0] = 128
Tensor Size [1] = 9
Tensor Size [2] = 67
Tensor Size [3] = 64
Pixels-per-Column = 128
Channels-per-pixel = 64
Bounding Box Lower Corner W = -1
Bounding Box Upper Corner W = 0
Traversal Stride = 2
Tensor Coordinates in the instruction = (7, 2, -1, 0)
Shared memory buffer 1:
wHalo = 1
wOffset = 0
Shared memory buffer 2:
wHalo = 0
wOffset = 1
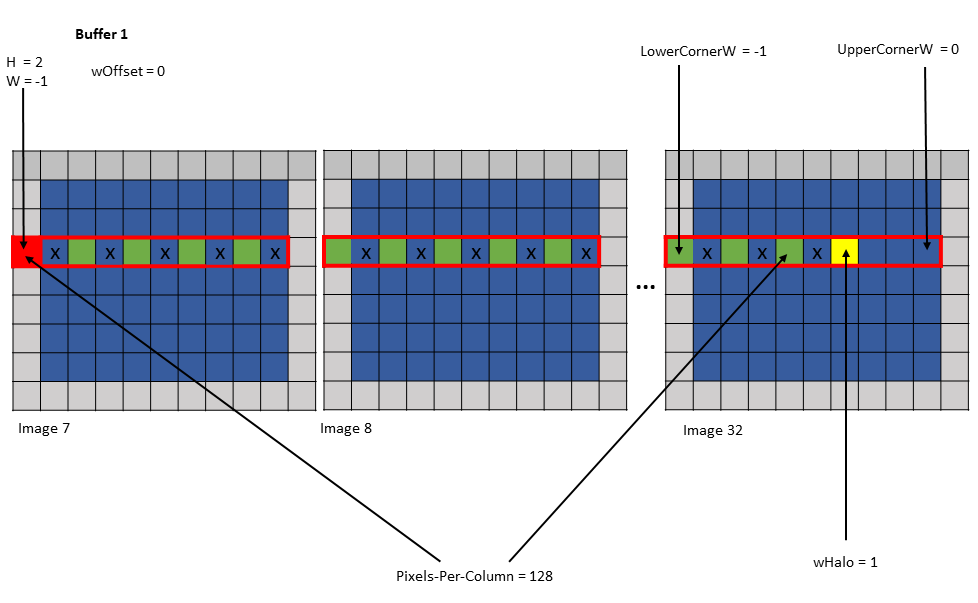
图 20 示例 1 的缓冲区 1 的张量复制操作
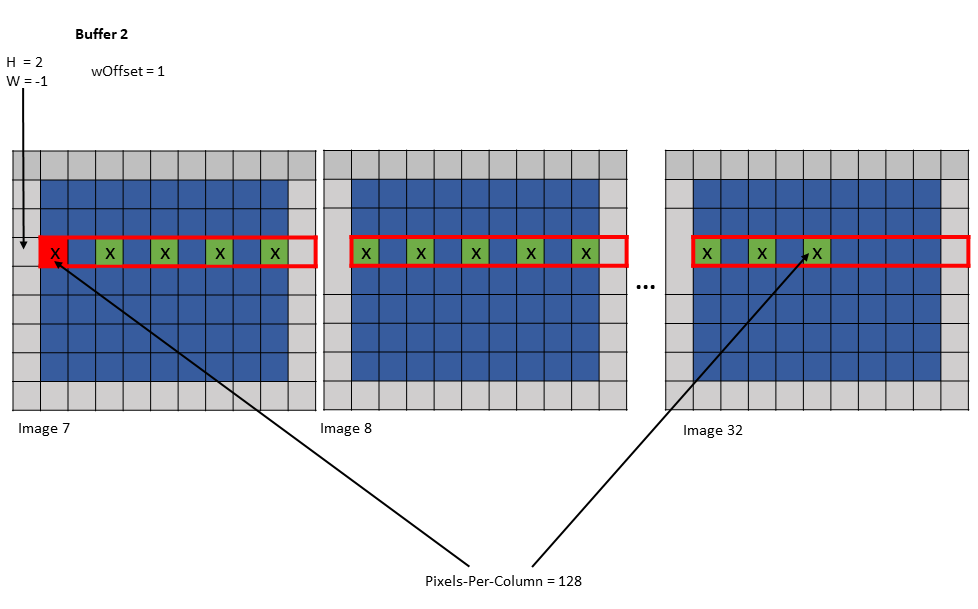
图 21 示例 1 的缓冲区 2 的张量复制操作
示例 2
Tensor Size [0] = 128
Tensor Size [1] = 7
Tensor Size [2] = 7
Tensor Size [3] = 64
Pixels-per-Column = 128
Channels-per-pixel = 64
Bounding Box Lower Corner W = -1
Bounding Box Upper Corner W = -1
Traversal Stride = 3
Tensor Coordinates in the instruction = (7, 2, -1, 0)
Shared memory buffer 1:
wHalo = 0
wOffset = 0
Shared memory buffer 2:
wHalo = 0
wOffset = 1
Shared memory buffer 3:
wHalo = 0
wOffset = 2
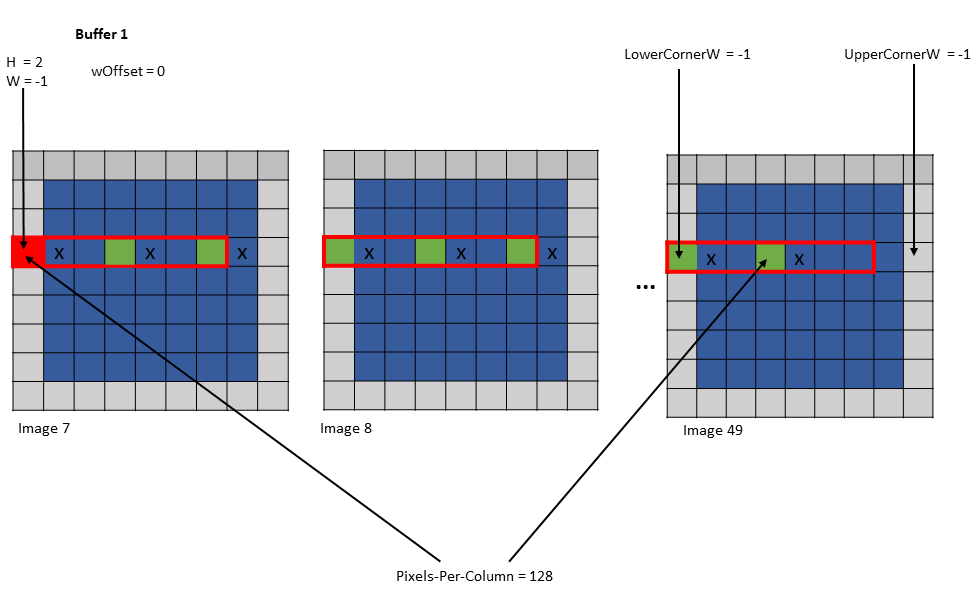
图 22 示例 2 的缓冲区 1 的张量复制操作
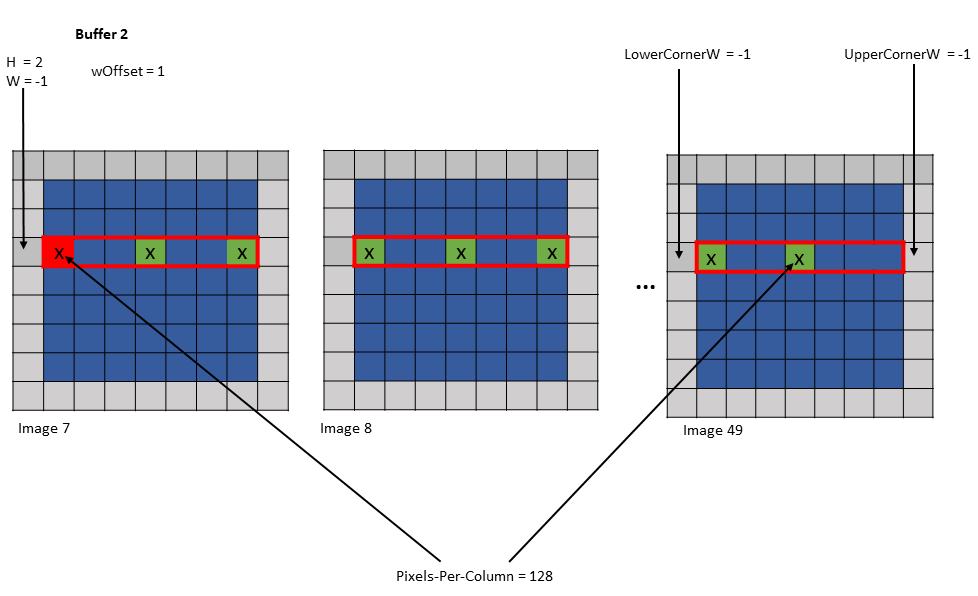
图 23 示例 2 的缓冲区 2 的张量复制操作
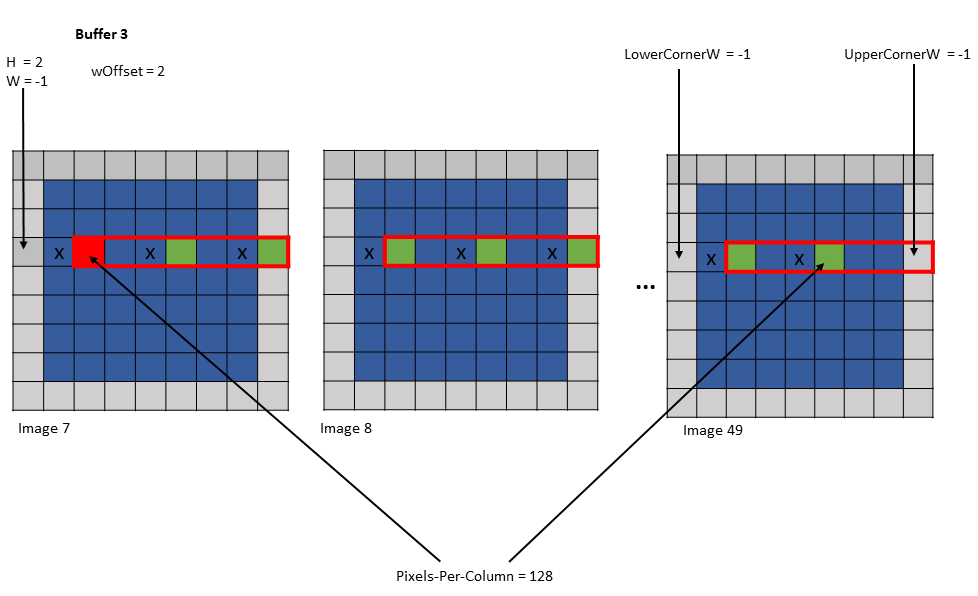
图 24 示例 2 的缓冲区 3 的张量复制操作
5.5.6. 交错布局
张量可以是交错的,并支持以下交错布局
无交错 (NDHWC)
8 字节交错 (NC/8DHWC8) : C8 在内存中利用 16 字节,假设每个通道 2B。
16 字节交错 (NC/16HWC16) : C16 在内存中利用 32 字节,假设每个通道 4B。
C 信息以切片形式组织,其中连续的 C 元素以 16 字节或 32 字节数量分组。
如果通道总数不是每个切片通道数的倍数,则最后一个切片必须用零填充,使其成为完整的 16B 或 32B 切片。
交错布局仅支持以下维度:3D、4D 和 5D。
交错布局不支持 .im2col::w 和 .im2col::w::128 模式。
5.5.7. 混合模式
出于访问性能的原因,共享内存中的数据布局可能与全局内存中的数据布局不同。以下描述了各种混合模式
-
无混合模式
在此模式下没有混合,目标数据布局与源数据布局完全相似。
0
1
2
3
4
5
6
7
0
1
2
3
4
5
6
7
… 模式重复 …
-
32 字节混合模式
下表显示了目标数据布局的模式,其中每个元素(编号单元格)为 16 字节,起始地址为 256 字节对齐
0
1
2
3
4
5
6
7
1
0
3
2
5
4
7
6
… 模式重复 …
图 25 显示了维度为 1x2x10x10xC16 的 NC/(32B)HWC(32B) 张量的 32 字节混合模式示例,其中最内层维度包含 16 个通道的切片,每个通道 2 字节。
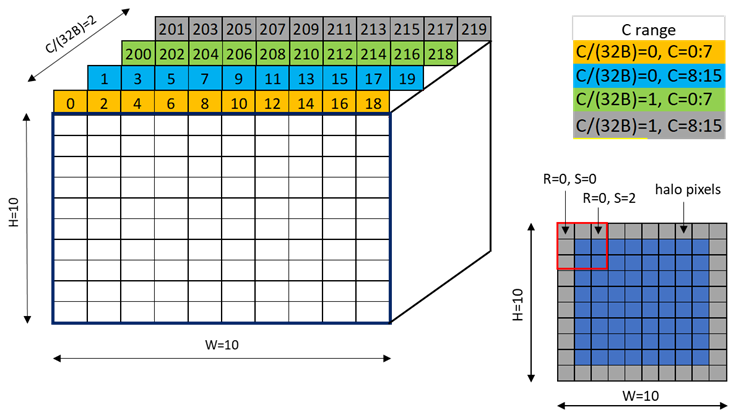
图 25 32 字节混合模式示例
图 26 显示了张量的两个片段:一个用于 C/(32B) = 0,另一个用于 C/(32B) = 1。
图 26 32 字节混合模式片段
图 27 显示了使用 32 字节混合的目标数据布局。
图 27 32 字节混合模式目标数据布局
-
64 字节混合模式
下表显示了目标数据布局的模式,其中每个元素(编号单元格)为 16 字节,起始地址为 512 字节对齐
0
1
2
3
4
5
6
7
1
0
3
2
5
4
7
6
2
3
0
1
6
7
4
5
3
2
1
0
7
6
5
4
… 模式重复 …
图 28 显示了维度为 1x10x10x64 的 NHWC 张量的 64 字节混合模式示例,每个通道 2 字节和 32 个通道。
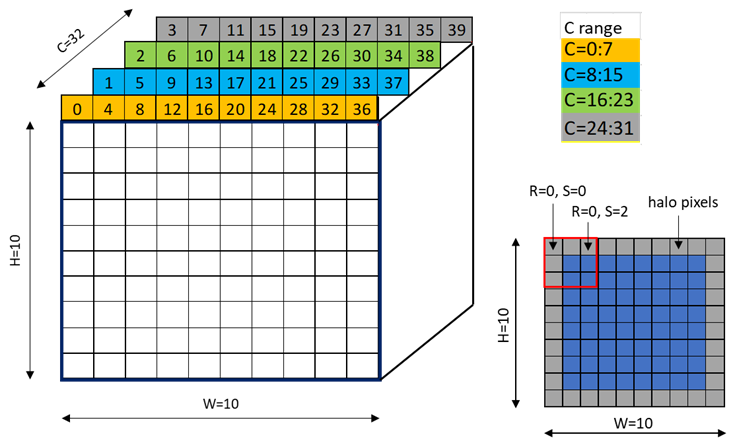
图 28 64 字节混合模式示例
每个彩色单元格代表 8 个通道。图 29 显示了源数据布局。
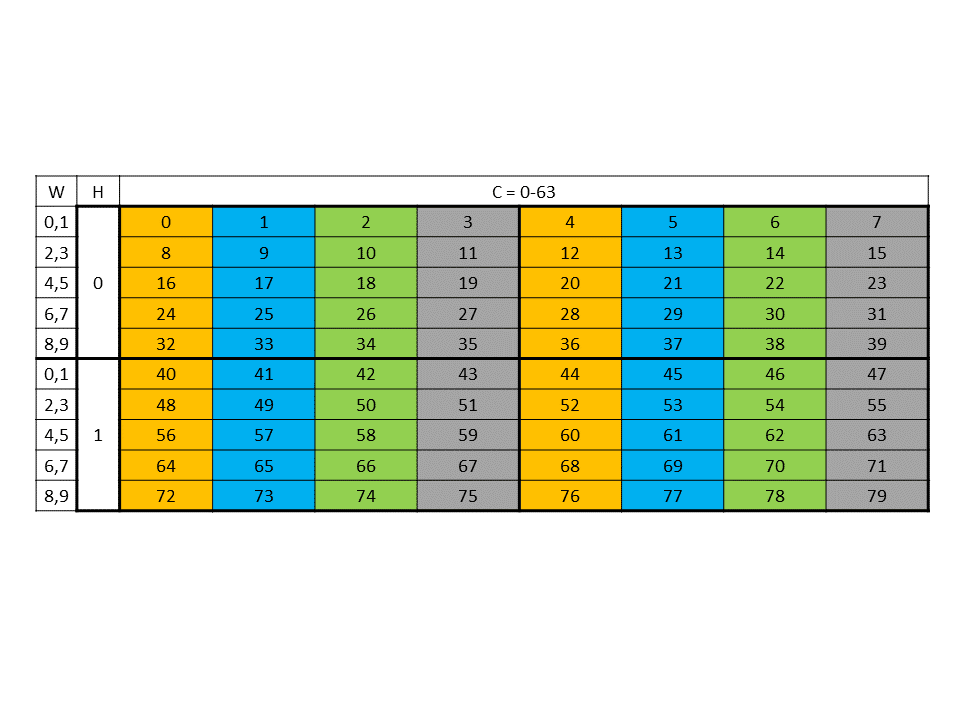
图 29 64 字节混合模式源数据布局
图 30 显示了使用 64 字节混合的目标数据布局。
图 30 64 字节混合模式目标数据布局
-
128 字节混合模式
128 字节混合模式支持以下子模式
-
16 字节原子性子模式
在此子模式下,16 字节的数据在混合时保持完整。
下表显示了目标数据布局的模式,其中每个元素(编号单元格)为 16 字节,起始地址为 1024 字节对齐
0
1
2
3
4
5
6
7
1
0
3
2
5
4
7
6
2
3
0
1
6
7
4
5
3
2
1
0
7
6
5
4
4
5
6
7
0
1
2
3
5
4
7
6
1
0
3
2
6
7
4
5
2
3
0
1
… 模式重复 …
图 31 显示了维度为 1x10x10x64 的 NHWC 张量的 128 字节混合模式示例,每个通道 2 字节和 64 个通道。
图 31 128 字节混合模式示例
每个彩色单元格代表 8 个通道。图 32 显示了源数据布局。
图 32 128 字节混合模式源数据布局
图 33 显示了使用 128 字节混合的目标数据布局。
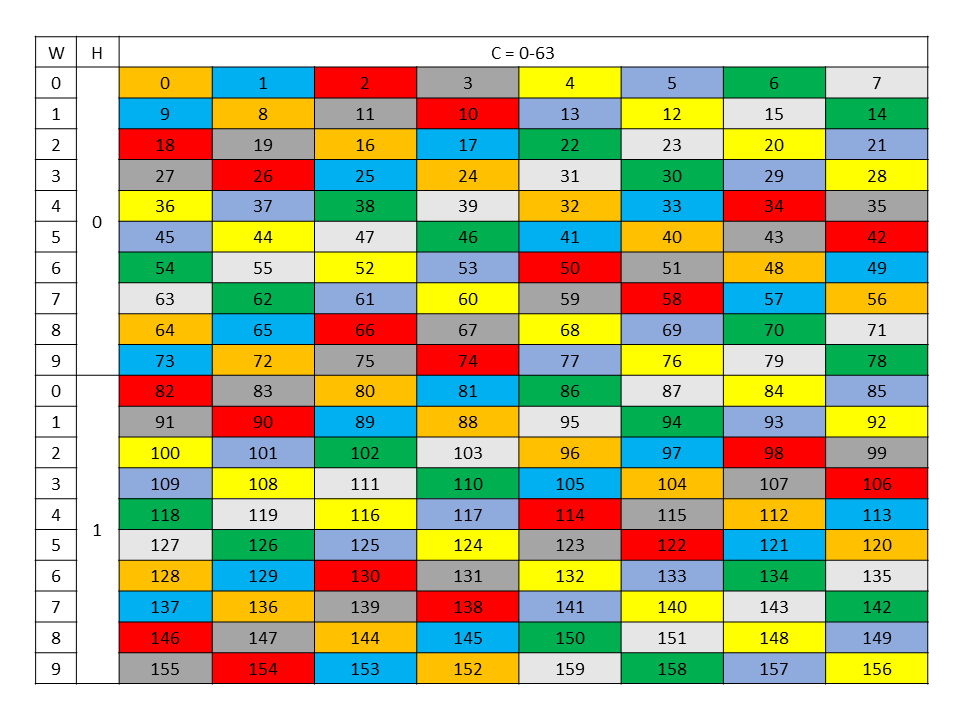
图 33 128 字节混合模式目标数据布局
-
32 字节原子性子模式
在此子模式下,32 字节的数据在混合时保持完整。
下表显示了目标数据布局中的混合模式,其中每个元素(编号单元格)为 16 字节
0 1
2 3
4 5
6 7
2 3
0 1
6 7
4 5
4 5
6 7
0 1
2 3
6 7
4 5
2 3
0 1
… 模式重复 …
此子模式需要在共享内存中进行 32 字节对齐。
图 34 显示了全局内存中的数据布局及其在共享内存中的混合数据布局的示例,其中每个元素(彩色单元格)为 16 字节
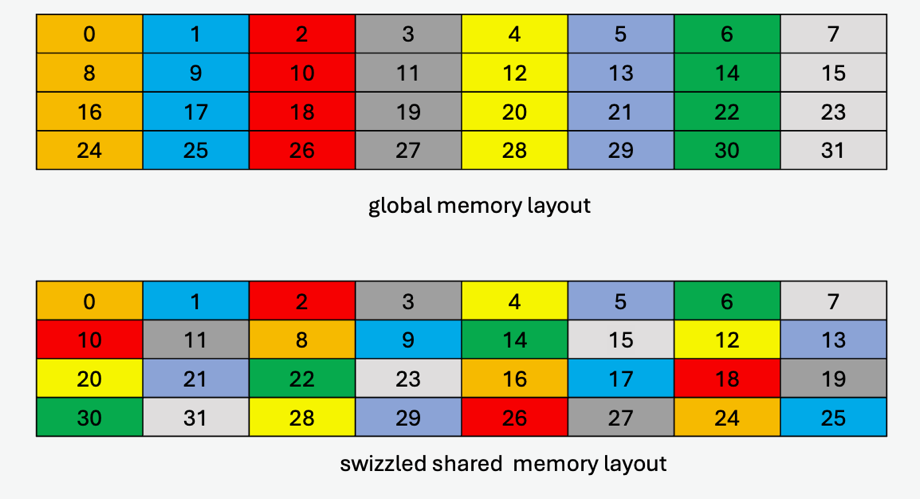
图 34 具有 32 字节原子性的 128 字节混合模式示例
-
具有 8 字节翻转的 32 字节原子性子模式
此子模式的混合模式与 32 字节原子性子模式类似,不同之处在于在每个交替的共享内存行中,16 字节数据内有相邻 8 字节的翻转。
图 35 显示了全局内存中的数据布局及其在共享内存中的混合数据布局的示例,其中每个元素(彩色单元格)为 16 字节(显示了每个 16 字节彩色单元格的两个 8 字节子元素以显示翻转)
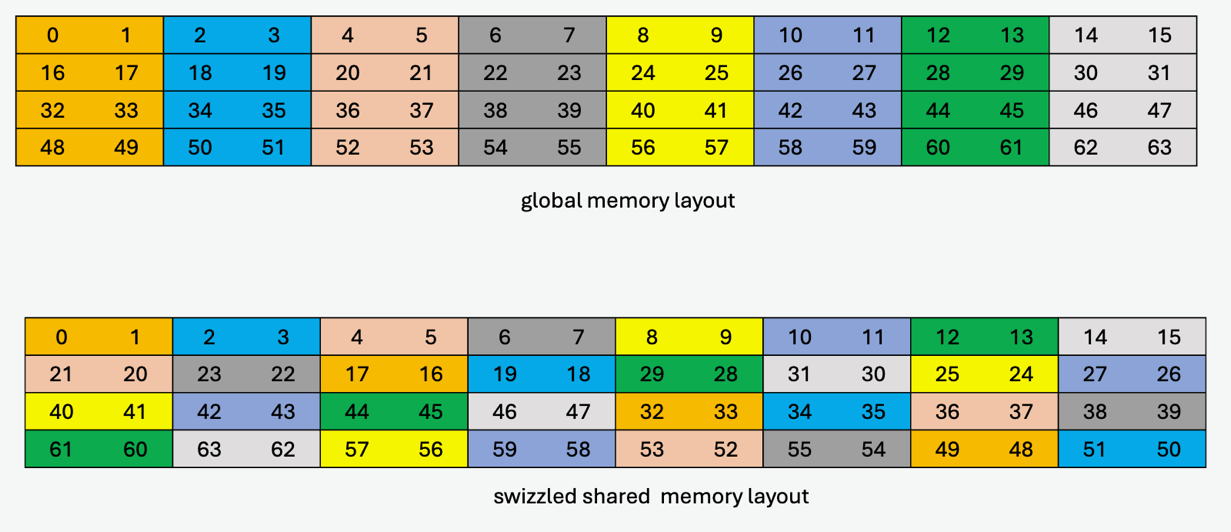
图 35 具有 8 字节翻转的 32 字节原子性的 128 字节混合模式示例
-
64 字节原子性子模式
在此子模式下,64 字节的数据在混合时保持完整。
下表显示了目标数据布局中的混合模式,其中每个元素(编号单元格)为 16 字节
0 1 2 3
4 5 6 7
4 5 6 7
0 1 2 3
… 模式重复 …
此子模式需要在共享内存中进行 64 字节对齐。
图 36 显示了全局内存中的数据布局及其在共享内存中的混合数据布局的示例,其中每个元素(彩色单元格)为 16 字节
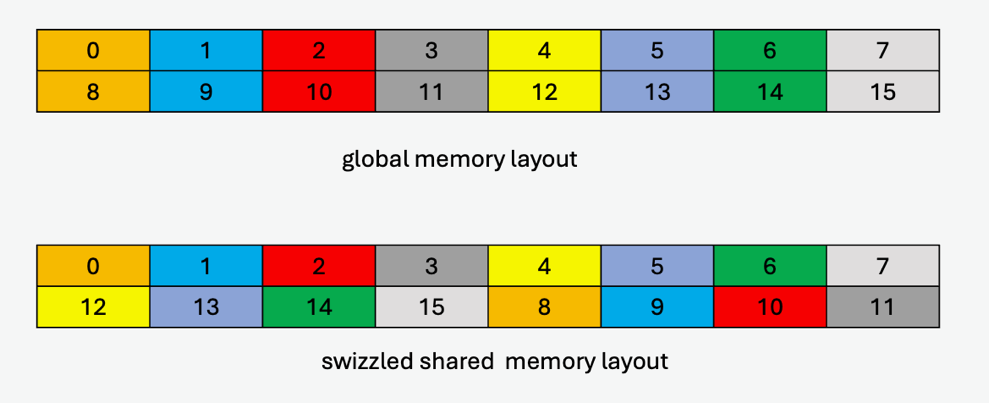
图 36 具有 64 字节原子性的 128 字节混合模式示例
-
表 14 列出了混合原子性与混合模式的有效组合。
混合模式 |
混合原子性 |
|---|---|
无混合 |
– |
32B 混合模式 |
16B |
64B 混合模式 |
16B |
128B 混合模式 |
|
当 dstMem 共享内存地址位于以下边界时,混合基偏移量的值为 0
混合模式 |
重复模式的起始地址 |
|---|---|
128 字节混合 |
1024 字节边界 |
64 字节混合 |
512 字节边界 |
32 字节混合 |
256 字节边界 |
否则,混合基偏移量为非零值,使用以下公式计算
混合模式 |
公式 |
|---|---|
128 字节混合 |
基偏移量 = (dstMem / 128) % 8 |
64 字节混合 |
基偏移量 = (dstMem / 64) % 4 |
32 字节混合 |
基偏移量 = (dstMem / 32) % 2 |
5.5.8. 张量映射
张量映射是一个 128 字节的不透明对象,位于 .const 空间、.param(内核函数参数)空间或 .global 空间中,它描述了张量属性以及前面章节中描述的张量数据的访问属性。
可以使用 CUDA API 创建张量映射。有关更多详细信息,请参阅CUDA 编程指南。
6. 指令操作数
6.1. 操作数类型信息
指令中的所有操作数都具有从其声明中已知的类型。每个操作数类型都必须与指令模板和指令类型确定的类型兼容。类型之间没有自动转换。
位大小类型与每个具有相同大小的类型兼容。公共大小的整数类型彼此兼容。类型不同但与指令类型兼容的操作数会被静默转换为指令类型。
6.2. 源操作数
源操作数在指令描述中用名称 a、b 和 c 表示。PTX 描述了一个加载-存储机器,因此 ALU 指令的操作数都必须在 .reg 寄存器状态空间中声明的变量中。对于大多数操作,操作数的大小必须一致。
cvt(转换)指令采用各种操作数类型和大小,因为它的工作是将几乎任何数据类型转换为任何其他数据类型(和大小)。
ld、st、mov 和 cvt 指令将数据从一个位置复制到另一个位置。ld 和 st 指令将数据从/到可寻址状态空间移动到/从寄存器。mov 指令在寄存器之间复制数据。
大多数指令都有一个可选的谓词保护,用于控制条件执行,少数指令还有额外的谓词源操作数。谓词操作数用名称 p、q、r、s 表示。
6.3. 目标操作数
生成单个结果的 PTX 指令将结果存储在指令描述中用 d(代表目标)表示的字段中。结果操作数是寄存器状态空间中的标量或向量变量。
6.4. 使用地址、数组和向量
使用标量变量作为操作数很简单。有趣的功能始于地址、数组和向量。
6.4.1. 地址作为操作数
所有内存指令都采用地址操作数,该操作数指定要访问的内存位置。此可寻址操作数是以下之一
[var]-
可寻址变量
var的名称。 [reg]-
包含字节地址的整数或位大小类型寄存器
reg。 [reg+immOff]-
寄存器
reg(包含字节地址)与常量整数字节偏移量(有符号,32 位)的总和。 [var+immOff]-
可寻址变量
var的地址(包含字节地址)与常量整数字节偏移量(有符号,32 位)的总和。 [immAddr]-
立即绝对字节地址(无符号,32 位)。
var[immOff]-
如数组作为操作数中所述的数组元素。
包含地址的寄存器可以声明为位大小类型或整数类型。
内存指令的访问大小是在内存中访问的总字节数。例如,ld.v4.b32 的访问大小为 16 字节,而 atom.f16x2 的访问大小为 4 字节。
地址必须自然对齐到访问大小的倍数。如果地址未正确对齐,则结果行为未定义。例如,除其他事项外,访问可能会通过静默屏蔽低位地址位以实现适当的舍入来继续,或者指令可能会出错。
地址大小可以是 32 位或 64 位。不支持 128 位地址。地址根据需要零扩展到指定的宽度,如果寄存器宽度超过目标体系结构的状态空间地址宽度,则会截断地址。
地址算术使用整数算术和逻辑指令执行。示例包括指针算术和指针比较。所有地址和地址计算都是基于字节的;不支持 C 风格的指针算术。
mov 指令可用于将变量的地址移动到指针中。该地址是变量声明所在状态空间中的偏移量。加载和存储操作在寄存器和可寻址状态空间中的位置之间移动数据。语法类似于许多汇编语言中使用的语法,其中标量变量只是简单地命名,地址通过将地址表达式括在方括号中来取消引用。地址表达式包括变量名、地址寄存器、地址寄存器加字节偏移量,以及在编译时评估为常量地址的立即地址表达式。
以下是一些示例
.shared .u16 x;
.reg .u16 r0;
.global .v4 .f32 V;
.reg .v4 .f32 W;
.const .s32 tbl[256];
.reg .b32 p;
.reg .s32 q;
ld.shared.u16 r0,[x];
ld.global.v4.f32 W, [V];
ld.const.s32 q, [tbl+12];
mov.u32 p, tbl;
6.4.1.1. 通用寻址
如果内存指令未指定状态空间,则使用通用寻址执行操作。状态空间 .const、内核函数参数 (.param)、.local 和 .shared 被建模为通用地址空间内的窗口。每个窗口由窗口基址和窗口大小定义,窗口大小等于相应状态空间的大小。除非通用地址落在 const、local 或 shared 内存的窗口内,否则通用地址将映射到 global 内存。内核函数参数 (.param) 窗口包含在 .global 窗口内。在每个窗口内,通用地址通过从通用地址中减去窗口基址来映射到基础状态空间中的地址。
6.4.2. 数组作为操作数
可以声明所有类型的数组,并且标识符成为数组声明空间中的地址常量。数组的大小是程序中的常量。
可以使用显式计算的字节地址访问数组元素,也可以使用方括号表示法索引到数组中。方括号内的表达式可以是常量整数、寄存器变量或简单的寄存器加常量偏移量表达式,其中偏移量是从寄存器变量加或减的常量表达式。如果需要更复杂的索引,则必须在使用前将其编写为地址计算。例如
ld.global.u32 s, a[0];
ld.global.u32 s, a[N-1];
mov.u32 s, a[1]; // move address of a[1] into s
6.4.3. 向量作为操作数
向量操作数受指令的有限子集支持,其中包括 mov、ld、st、atom、red 和 tex。向量也可以作为参数传递给调用的函数。
可以使用后缀 .x、.y、.z 和 .w 以及典型的颜色字段 .r、.g、.b 和 .a 从向量中提取向量元素。
花括号括起来的列表用于模式匹配以分解向量。
.reg .v4 .f32 V;
.reg .f32 a, b, c, d;
mov.v4.f32 {a,b,c,d}, V;
向量加载和存储可用于实现宽加载和存储,这可以提高内存性能。加载/存储操作中的寄存器可以是向量,也可以是花括号括起来的类似类型的标量列表。以下是一些示例
ld.global.v4.f32 {a,b,c,d}, [addr+16];
ld.global.v2.u32 V2, [addr+8];
花括号括起来的向量中的元素,例如 {Ra, Rb, Rc, Rd},对应于提取的元素,如下所示
Ra = V.x = V.r
Rb = V.y = V.g
Rc = V.z = V.b
Rd = V.w = V.a
6.4.4. 标签和函数名称作为操作数
标签和函数名称只能分别在 bra/brx.idx 和 call 指令中使用。函数名称可以在 mov 指令中使用,以获取函数地址到寄存器中,以便在间接调用中使用。
从 PTX ISA 版本 3.1 开始,mov 指令可用于获取内核函数的地址,以便传递给启动 GPU 内核调用的系统调用。此功能是 CUDA 动态并行性支持的一部分。有关详细信息,请参阅CUDA 动态并行性编程指南。
6.5. 类型转换
所有算术、逻辑和数据移动指令的所有操作数必须具有相同的类型和大小,除了更改大小和/或类型是指令定义的一部分的操作。不同大小或类型的操作数必须在操作之前进行转换。
6.5.1. 标量转换
表 15 显示了给定不同类型的操作数时,cvt 指令使用的精度和格式。例如,如果 cvt.s32.u16 指令被赋予 u16 源操作数和 s32 作为目标操作数,则 u16 将零扩展为 s32。
超出浮点数范围的浮点转换用最大浮点值表示(f32 和 f64 的 IEEE 754 Inf,以及 f16 的约 131,000)。
目标格式 |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
s8 |
s16 |
s32 |
s64 |
u8 |
u16 |
u32 |
u64 |
f16 |
f32 |
f64 |
||
源格式 |
s8 |
– |
sext |
sext |
sext |
– |
sext |
sext |
sext |
s2f |
s2f |
s2f |
s16 |
chop1 |
– |
sext |
sext |
chop1 |
– |
sext |
sext |
s2f |
s2f |
s2f |
|
s32 |
chop1 |
chop1 |
– |
sext |
chop1 |
chop1 |
– |
sext |
s2f |
s2f |
s2f |
|
s64 |
chop1 |
chop1 |
chop |
– |
chop1 |
chop1 |
chop |
– |
s2f |
s2f |
s2f |
|
u8 |
– |
zext |
zext |
zext |
– |
zext |
zext |
zext |
u2f |
u2f |
u2f |
|
u16 |
chop1 |
– |
zext |
zext |
chop1 |
– |
zext |
zext |
u2f |
u2f |
u2f |
|
u32 |
chop1 |
chop1 |
– |
zext |
chop1 |
chop1 |
– |
zext |
u2f |
u2f |
u2f |
|
u64 |
chop1 |
chop1 |
chop |
– |
chop1 |
chop1 |
chop |
– |
u2f |
u2f |
u2f |
|
f16 |
f2s |
f2s |
f2s |
f2s |
f2u |
f2u |
f2u |
f2u |
– |
f2f |
f2f |
|
f32 |
f2s |
f2s |
f2s |
f2s |
f2u |
f2u |
f2u |
f2u |
f2f |
– |
f2f |
|
f64 |
f2s |
f2s |
f2s |
f2s |
f2u |
f2u |
f2u |
f2u |
f2f |
f2f |
– |
|
注释 |
sext = 符号扩展;zext = 零扩展;chop = 仅保留低位以适应; s2f = 有符号数转浮点数;f2s = 浮点数转有符号数;u2f = 无符号数转浮点数; f2u = 浮点数转无符号数;f2f = 浮点数转浮点数。 1 如果目标寄存器比目标格式更宽,则在截断后,结果会扩展到目标寄存器宽度。扩展类型(符号或零)基于目标格式。例如,cvt.s16.u32 定向到 32 位寄存器,首先截断为 16 位,然后符号扩展为 32 位。 |
|||||||||||
6.5.2. 舍入修饰符
转换指令可以指定舍入修饰符。在 PTX 中,有四种整数舍入修饰符和四种浮点舍入修饰符。表 16 和 表 17 总结了舍入修饰符。
修饰符 |
描述 |
|---|---|
|
尾数 LSB 四舍五入到最接近的偶数 |
|
尾数 LSB 四舍五入到最接近的值,远离零 |
|
尾数 LSB 向零舍入 |
|
尾数 LSB 向负无穷大舍入 |
|
尾数 LSB 向正无穷大舍入 |
修饰符 |
描述 |
|---|---|
|
四舍五入到最接近的整数,如果源介于两个整数之间,则选择偶数整数。 |
|
向零方向舍入到最接近的整数 |
|
向负无穷大方向舍入到最接近的整数 |
|
向正无穷大方向舍入到最接近的整数 |
6.6. 操作数成本
来自不同状态空间的操作数会影响操作的速度。寄存器最快,而全局内存最慢。内存延迟的大部分可以通过多种方式隐藏。第一种方式是拥有多个执行线程,以便硬件可以发出内存操作,然后切换到其他执行。另一种隐藏延迟的方法是尽早发出加载指令,因为执行不会被阻塞,直到在后续(时间上)指令中使用所需的结果。存储操作中的寄存器可以更快地可用。表 18 给出了访问不同类型内存的成本估算。
空间 |
时间 |
注释 |
|---|---|---|
寄存器 |
0 |
|
共享 |
0 |
|
常量 |
0 |
分摊成本低,首次访问成本高 |
本地 |
> 100 个时钟周期 |
|
参数 |
0 |
|
立即数 |
0 |
|
全局 |
> 100 个时钟周期 |
|
纹理 |
> 100 个时钟周期 |
|
表面 |
> 100 个时钟周期 |
7. 抽象 ABI
PTX 没有暴露特定调用约定、堆栈布局和应用程序二进制接口 (ABI) 的细节,而是提供了一个稍高级别的抽象,并支持多种 ABI 实现。在本节中,我们将描述实现 ABI 隐藏所需的 PTX 功能。这些功能包括函数定义、函数调用、参数传递、对可变参数函数(varargs)的支持以及在堆栈上分配的内存(alloca)。
有关生成符合 CUDA® 架构的应用程序二进制接口 (ABI) 的 PTX 的详细信息,请参阅PTX Writers Guide to Interoperability。
7.1. 函数声明和定义
在 PTX 中,函数使用 .func 指令声明和定义。函数声明指定一个可选的返回参数列表、函数名称和一个可选的输入参数列表;这些共同指定了函数的接口或原型。函数定义指定了函数的接口和函数体。函数必须在被调用之前声明或定义。
最简单的函数没有参数或返回值,在 PTX 中表示如下
.func foo
{
...
ret;
}
...
call foo;
...
在这里,call 指令的执行将控制权转移到 foo,隐式保存返回地址。foo 内 ret 指令的执行将控制权转移到调用之后的指令。
标量和向量基本类型输入和返回参数可以简单地表示为寄存器变量。在调用时,参数可以是寄存器变量或常量,返回值可以直接放入寄存器变量中。调用时的参数和返回变量必须具有与被调用者的相应形式参数匹配的类型和大小。
例子
.func (.reg .u32 %res) inc_ptr ( .reg .u32 %ptr, .reg .u32 %inc )
{
add.u32 %res, %ptr, %inc;
ret;
}
...
call (%r1), inc_ptr, (%r1,4);
...
当使用 ABI 时,.reg 状态空间参数的大小必须至少为 32 位。源语言中的子字标量对象应在 PTX 中提升为 32 位寄存器,或者使用接下来描述的 .param 状态空间字节数组。
诸如 C 结构和联合之类的对象在 PTX 中被展平为寄存器或字节数组,并使用 .param 空间内存表示。例如,考虑以下 C 结构,通过值传递给函数
struct {
double dbl;
char c[4];
};
在 PTX 中,此结构将被展平为字节数组。由于内存访问需要与访问大小的倍数对齐,因此本例中的结构将是一个 12 字节的数组,具有 8 字节对齐,以便对 .f64 字段的访问是对齐的。.param 状态空间用于按值传递结构
例子
.func (.reg .s32 out) bar (.reg .s32 x, .param .align 8 .b8 y[12])
{
.reg .f64 f1;
.reg .b32 c1, c2, c3, c4;
...
ld.param.f64 f1, [y+0];
ld.param.b8 c1, [y+8];
ld.param.b8 c2, [y+9];
ld.param.b8 c3, [y+10];
ld.param.b8 c4, [y+11];
...
... // computation using x,f1,c1,c2,c3,c4;
}
{
.param .b8 .align 8 py[12];
...
st.param.b64 [py+ 0], %rd;
st.param.b8 [py+ 8], %rc1;
st.param.b8 [py+ 9], %rc2;
st.param.b8 [py+10], %rc1;
st.param.b8 [py+11], %rc2;
// scalar args in .reg space, byte array in .param space
call (%out), bar, (%x, py);
...
在本例中,请注意 .param 空间变量以两种方式使用。首先,.param 变量 y 在函数定义 bar 中用于表示形式参数。其次,.param 变量 py 在调用函数的正文中声明,并用于设置要传递给 bar 的结构。
以下是思考设备函数中 .param 状态空间使用情况的概念方式。
对于调用者,
.param状态空间用于设置将传递给被调用函数的值和/或接收来自被调用函数的返回值。通常,.param字节数组用于将按值传递的结构的字段收集在一起。
对于被调用者,
.param状态空间用于接收参数值和/或将返回值传递回调用者。
以下限制适用于参数传递。
对于调用者,
参数可以是
.param变量、.reg变量或常量。在作为字节数组的
.param空间形式参数的情况下,参数也必须是具有匹配类型、大小和对齐方式的.param空间字节数组。.param参数必须在调用者的本地作用域内声明。在作为基本类型标量或向量变量的
.param空间形式参数的情况下,相应的参数可以是具有匹配类型和大小的.param或.reg空间变量,也可以是可以用形式参数类型表示的常量。在
.reg空间形式参数的情况下,相应的参数可以是具有匹配类型和大小的.param或.reg空间变量,也可以是可以用形式参数类型表示的常量。在
.reg空间形式参数的情况下,寄存器的大小必须至少为 32 位。用于将参数传递给函数调用的所有
st.param指令都必须紧接在相应的call指令之前,并且用于收集返回值的ld.param指令必须紧接在call指令之后,且没有任何控制流更改。用于参数传递的st.param和ld.param指令不能被谓词化。这使得编译器优化成为可能,并确保.param变量不会在调用者的帧中消耗超出 ABI 所需的额外空间。.param变量仅允许在调用站点建立数据之间的映射(例如,调用者操作的结构位于寄存器和内存中),以便可以作为参数或返回值传递给被调用者。
对于被调用者,
输入和返回参数可以是
.param变量或.reg变量。.param内存中的参数必须与 1、2、4、8 或 16 字节的倍数对齐。.reg状态空间中的参数的大小必须至少为 32 位。.reg状态空间可用于接收和返回基本类型标量和向量值,包括在非 ABI 模式下编译时的子字大小对象。支持.reg状态空间提供遗留支持。
请注意,选择 .reg 或 .param 状态空间用于参数传递对参数最终是在物理寄存器还是堆栈中传递没有影响。参数到物理寄存器和堆栈位置的映射取决于 ABI 定义以及参数的顺序、大小和对齐方式。
7.1.1. PTX ISA 版本 1.x 的变更
在 PTX ISA 版本 1.x 中,形式参数被限制为 .reg 状态空间,并且不支持数组参数。诸如 C 结构之类的对象被展平并使用多个寄存器传递或返回。PTX ISA 版本 1.x 为此目的支持多个返回值。
从 PTX ISA 版本 2.0 开始,形式参数可以在 .reg 或 .param 状态空间中,并且 .param 空间参数支持数组。对于 sm_20 或更高版本的目标,PTX 将函数限制为单个返回值,并且 .param 字节数组应用于返回不适合寄存器的对象。PTX 继续为 sm_1x 目标支持多个返回寄存器。
注意
PTX 仅为 sm_20 或更高版本的目标实现基于堆栈的 ABI。
PTX ISA 3.0 之前的版本允许在模块作用域中定义 .reg 和 .local 状态空间中的变量。当编译为使用 ABI 时,PTX ISA 版本 3.0 及更高版本不允许模块作用域的 .reg 和 .local 变量,并将它们的使用限制在函数作用域内。当在不使用 ABI 的情况下编译时,模块作用域的 .reg 和 .local 变量像以前一样受到支持。当编译包含模块作用域的 .reg 或 .local 变量的旧版 PTX 代码(ISA 版本 3.0 之前)时,编译器会静默禁用 ABI 的使用。
7.2. 可变参数函数
注意
对未实现的可变参数函数的支持已从规范中删除。
PTX 版本 6.0 支持将未调整大小的数组参数传递给函数,该函数可用于实现可变参数函数。
有关详细信息,请参阅 内核和函数指令:.func
7.3. Alloca
PTX 提供了 alloca 指令,用于在运行时在每个线程的本地内存堆栈上分配存储空间。可以使用 ld.local 和 st.local 指令,使用 alloca 返回的指针访问分配的堆栈内存。
为了方便释放使用 alloca 分配的内存,PTX 提供了两个额外的指令:stacksave,它允许读取局部变量中堆栈指针的值,以及 stackrestore,它可以使用保存的值恢复堆栈指针。
alloca、stacksave 和 stackrestore 指令在 堆栈操作指令 中描述。
- 预览功能
-
堆栈操作指令
alloca、stacksave和stackrestore是 PTX ISA 版本 7.3 中的预览功能。所有详细信息如有更改,恕不另行通知,并且在未来的 PTX ISA 版本或 SM 架构上不保证向后兼容性。
8. 内存一致性模型
在多线程执行中,每个线程执行的内存操作的副作用以部分且非相同的顺序对其他线程可见。这意味着任何两个操作对于不同的线程可能看起来没有顺序,或者顺序不同。内存一致性模型引入的公理精确地指定了不同线程观察到的顺序之间禁止哪些矛盾。
在没有任何约束的情况下,每个读取操作都会返回由某个写入操作提交到同一内存位置的值,包括对该内存位置的初始写入。内存一致性模型有效地约束了读取操作可以从中返回值的一组此类候选写入。
8.1. 模型的范围和适用性
本模型下指定的约束适用于任何 PTX ISA 版本号的 PTX 程序,这些程序在 sm_70 或更高版本的架构上运行。
内存一致性模型不适用于纹理(包括 ld.global.nc)和表面访问。
8.1.1. 系统范围内原子性的限制
当与主机 CPU 通信时,某些具有系统范围的强操作在某些系统上可能无法原子地执行。有关主机内存原子性保证的更多详细信息,请参阅CUDA Atomicity Requirements。
8.2. 内存操作
PTX 内存模型中的基本存储单元是一个字节,由 8 位组成。PTX 程序可用的每个状态空间都是内存中连续字节的序列。PTX 状态空间中的每个字节都有一个相对于可以访问同一状态空间的所有线程的唯一地址。
每个 PTX 内存指令都指定一个地址操作数和一个数据类型。地址操作数包含一个虚拟地址,该虚拟地址在内存访问期间转换为物理地址。物理地址和数据类型的大小共同定义了一个物理内存位置,该位置是从物理地址开始并扩展到数据类型大小(以字节为单位)的字节范围。
内存一致性模型规范使用术语“地址”或“内存地址”来指示虚拟地址,并使用术语“内存位置”来指示物理内存位置。
每个 PTX 内存指令还指定要对相应内存位置中的所有字节执行的操作 - 读取、写入或原子读-修改-写。
8.2.1. 重叠
当一个位置的起始地址在构成另一个位置的字节范围内时,两个内存位置被称为重叠。当两个内存操作指定相同的虚拟地址并且相应的内存位置重叠时,这两个内存操作被称为重叠。当两个内存位置相同时,重叠被称为完全重叠,否则被称为部分重叠。
8.2.2. 别名
如果两个不同的虚拟地址映射到同一个内存位置,则称它们为别名。
8.2.3. 多内存地址
多内存地址是一个虚拟地址,它指向跨设备的多个不同内存位置。
只有 multimem.* 操作在多内存地址上有效。也就是说,在任何其他内存操作中访问多内存地址的行为是未定义的。
8.2.4. 向量数据类型上的内存操作
内存一致性模型将对内存位置执行的操作与标量数据类型相关联,标量数据类型的最大大小和对齐方式为 64 位。向量数据类型的内存操作被建模为一组等效的标量数据类型的内存操作,这些操作以未指定的顺序在向量中的元素上执行。
8.2.5. 打包数据类型上的内存操作
打包数据类型由两个相同标量数据类型的值组成,如 打包数据类型 中所述。这些值在相邻的内存位置中访问。打包数据类型上的内存操作被建模为一对等效的标量数据类型的内存操作,这些操作以未指定的顺序在打包数据的每个元素上执行。
8.2.6. 初始化
内存中的每个字节都由假设的写入 W0 初始化,W0 在程序中启动任何线程之前执行。如果字节包含在程序变量中,并且该变量具有初始值,则 W0 为该字节写入相应的初始值;否则,W0 被假定为已将未知但恒定的值写入该字节。
8.3. 状态空间
内存一致性模型中定义的关系独立于状态空间。特别是,因果关系闭合了所有状态空间中的所有内存操作。但是,只有一个状态空间中的内存操作的副作用才能被同样可以访问同一状态空间的操作直接观察到。这进一步约束了除了范围之外的内存操作的同步效果。例如,PTX 指令 ld.relaxed.shared.sys 的同步效果与 ld.relaxed.shared.cluster 的同步效果相同,因为同一集群之外的线程都无法执行访问同一内存位置的操作。
8.4. 操作类型
为简单起见,文档的其余部分引用以下操作类型,而不是提及产生这些操作的特定指令。
操作类型 |
指令/操作 |
|---|---|
原子操作 |
|
读取操作 |
|
写入操作 |
|
内存操作 |
读取或写入操作。 |
易失性操作 |
带有 |
获取操作 |
带有 |
释放操作 |
带有 |
mmio 操作 |
带有 |
内存屏障操作 |
|
代理屏障操作 |
|
强操作 |
内存屏障操作,或带有 |
弱操作 |
带有 |
同步操作 |
|
8.4.1. mmio 操作
mmio 操作是指定了 .mmio 限定符的内存操作。它通常在映射到对等 I/O 设备控制寄存器的内存位置上执行。它也可以用于线程之间的通信,但相对于非 mmio 操作而言,性能较差。
mmio 操作的语义含义无法精确定义,因为它是由底层 I/O 设备定义的。 从内存一致性模型的角度对 mmio 操作的语义进行形式化规范时,它等同于 strong 操作的语义。 但是,如果它在指定的范围内满足 CUDA 原子性要求,则它遵循一些特定于实现的属性。
写入操作始终执行,并且在指定的范围内永远不会合并。
-
读取操作始终执行,并且在指定的范围内不会被转发、预取、合并或允许命中任何缓存。
作为例外,在某些实现中,也可能会加载周围的位置。 在这种情况下,加载的数据量是特定于实现的,并且大小在 32 到 128 字节之间变化。
8.4.2. volatile 操作
volatile 操作是使用 .volatile 限定符指定的内存操作。 volatile 操作的语义等同于具有系统作用域的 relaxed 内存操作,但具有以下额外的特定于实现的约束
Volatile 指令 不会被 PTX 编译器拆分、合并或复制,也就是说,程序中 volatile 指令(不是操作)的数量会被保留。 硬件可能会合并和融合由多个不同的 volatile 指令发出的 volatile 操作,也就是说,程序中 volatile 操作的数量不会被保留。
Volatile 指令不会围绕其他 volatile 指令重新排序,但是这些指令的内存操作可能会彼此重新排序。
注意
PTX volatile 操作旨在供编译器将 CUDA C++ 以及其他共享 CUDA C++ volatile 语义的编程语言中的 volatile 读取和写入操作降低为 PTX。
由于 volatile 操作在系统作用域是 relaxed 的,并带有额外的约束,因此对于线程间同步,请优先使用其他 strong 读取或写入操作(例如 ld.relaxed.sys 或 st.relaxed.sys),这可能会提供更好的性能。
PTX volatile 操作不适用于 内存映射 I/O (MMIO),因为 volatile 操作不保留执行的内存操作的数量,并且可能以不确定的方式执行多于或少于请求的操作。 请改用 .mmio 操作,它严格保留执行的操作数量。
8.5. 作用域
每个 strong 操作都必须指定一个作用域,该作用域是可能与该操作直接交互并建立内存一致性模型中描述的任何关系的线程集合。 有四个作用域
作用域 |
描述 |
|---|---|
|
与当前线程在同一 CTA 中执行的所有线程的集合。 |
|
与当前线程在同一集群中执行的所有线程的集合。 |
|
当前程序中与当前线程在同一计算设备上执行的所有线程的集合。 这也包括主机程序在同一计算设备上调用的其他内核网格。 |
|
当前程序中所有线程的集合,包括主机程序在所有计算设备上调用的所有内核网格,以及构成主机程序本身的所有线程。 |
请注意,warp 不是作用域; CTA 是符合内存一致性模型中作用域条件的最小线程集合。
8.6. 代理
内存代理或代理是应用于内存访问方法的一个抽象标签。 当两个内存操作使用不同的内存访问方法时,它们被称为不同的代理。
操作类型中定义的内存操作使用通用内存访问方法,即通用代理。 其他操作(如纹理和表面)都使用不同的内存访问方法,也与通用方法不同。
需要代理栅栏来同步跨不同代理的内存操作。 尽管虚拟别名使用通用内存访问方法,但由于使用不同的虚拟地址的行为如同使用不同的代理,因此它们需要代理栅栏来建立内存排序。
8.7. Morally strong 操作
如果两个操作满足以下所有条件,则称它们相对于彼此是 morally strong 的
这些操作在程序顺序中相关(即,它们都由同一线程执行),或者每个操作都是 strong 的,并且指定了一个作用域,该作用域包括执行另一个操作的线程。
这两个操作都通过相同的代理执行。
如果两者都是内存操作,则它们完全重叠。
内存一致性模型中的大多数(但不是全部)公理都依赖于 morally strong 操作之间的关系。
8.7.1. 冲突和数据竞争
当至少其中一个操作是写入操作时,两个重叠的内存操作被称为冲突。
如果两个冲突的内存操作在因果顺序中不相关,并且它们不是 morally strong 的,则称它们处于数据竞争状态。
8.7.2. 混合尺寸数据竞争的限制
完全重叠的操作之间的数据竞争称为同尺寸数据竞争,而部分重叠的操作之间的数据竞争称为混合尺寸数据竞争。
如果 PTX 程序包含一个或多个混合尺寸数据竞争,则内存一致性模型中的公理不适用。 但是,这些公理足以描述仅具有同尺寸数据竞争的 PTX 程序的行为。
混合尺寸 RMW 操作的原子性
在任何有或没有混合尺寸数据竞争的程序中,对于每对重叠的原子操作 A1 和 A2,使得每个操作都指定了一个包含另一个操作的作用域,以下属性都成立: 由 A1 指定的读-修改-写操作要么在 A2 初始化之前完全执行,要么反之亦然。 此属性成立,而与两个操作 A1 和 A2 是部分重叠还是完全重叠无关。
8.8. 释放和获取模式
某些指令序列会产生参与内存同步的模式,如下所述。 释放模式使来自当前线程1的先前操作对来自其他线程的某些操作可见。 获取模式使来自其他线程的某些操作对来自当前线程的后续操作可见。
位置 M 上的释放模式包括以下之一
-
位置 M 上的释放操作
例如:
st.release [M];或atom.acq_rel [M];或mbarrier.arrive.release [M]; -
或位置 M 上的释放操作,后跟程序顺序中位置 M 上的 strong 写入操作
例如:
st.release [M];st.relaxed [M]; -
或内存栅栏,后跟程序顺序中位置 M 上的 strong 写入操作
例如:
fence; st.relaxed [M];
由释放模式建立的任何内存同步仅影响在该模式中第一个指令之前的程序顺序中发生的操作。
位置 M 上的获取模式包括以下之一
-
位置 M 上的获取操作
例如:
ld.acquire [M];或atom.acq_rel [M];或mbarrier.test_wait.acquire [M]; -
或位置 M 上的 strong 读取操作,后跟程序顺序中位置 M 上的获取操作
例如:
ld.relaxed [M]; ld.acquire [M]; -
或位置 M 上的 strong 读取操作,后跟程序顺序中的内存栅栏
例如:
ld.relaxed [M]; fence;
由获取模式建立的任何内存同步仅影响在该模式中最后一个指令之后的程序顺序中发生的操作。
1 对于释放和获取模式,此效果通过因果顺序的传递性进一步扩展到其他线程中的操作。
8.9. 内存操作的排序
每个线程执行的操作序列被捕获为程序顺序,而跨线程的内存同步被捕获为因果顺序。 内存操作的副作用对其他内存操作的可见性被捕获为通信顺序。 内存一致性模型定义了通信顺序与因果顺序和程序顺序之间不允许存在的矛盾。
8.9.1. 程序顺序
程序顺序将线程执行的所有操作与顺序处理器执行相应 PTX 源中指令的顺序相关联。 它是一个传递关系,在线程执行的操作上形成总顺序,但不关联来自不同线程的操作。
8.9.1.1. 异步操作
某些 PTX 指令(cp.async、cp.async.bulk、cp.reduce.async.bulk、wgmma.mma_async 的所有变体)执行的操作相对于执行该指令的线程是异步的。 这些异步操作在同一线程中的先前指令之后排序(wgmma.mma_async 的情况除外),但它们不属于该线程的程序顺序。 相反,它们提供较弱的排序保证,如指令描述中所述。
例如,作为 cp.async 一部分执行的加载和存储操作彼此之间是有序的,但与同一线程启动的任何其他 cp.async 指令的加载和存储操作无关,也与线程随后发出的任何其他指令的加载和存储操作无关,但 cp.async.commit_group 或 cp.async.mbarrier.arrive 除外。 由 cp.async.mbarrier.arrive 指令执行的异步 mbarrier arrive-on 操作相对于同一线程启动的所有先前 cp.async 操作执行的内存操作排序,但与线程发出的任何其他指令的内存操作无关。 作为 cp.async.bulk 和 cp.reduce.async.bulk 指令的所有变体一部分的隐式 mbarrier complete-tx 操作仅相对于同一异步指令执行的内存操作排序,并且特别地,它不传递性地建立与来自发出线程的先前指令的排序。
8.9.2. 观察顺序
观察顺序通过可选的原子读-修改-写操作序列将写入 W 与读取 R 相关联。
如果满足以下条件,则写入 W 在观察顺序中先于读取 R
R 和 W 是 morally strong 的,并且 R 读取由 W 写入的值,或者
对于某些原子操作 Z,W 在观察顺序中先于 Z,并且 Z 在观察顺序中先于 R。
8.9.3. Fence-SC 顺序
Fence-SC 顺序是一个运行时确定的非循环偏序,它关联每对 morally strong fence.sc 操作。
8.9.4. 内存同步
不同线程执行的同步操作在此处描述的运行时彼此同步。 这种同步的效果是在线程之间建立因果顺序。
如果 fence.sc 操作 X 在 Fence-SC 顺序中先于 fence.sc 操作 Y,则 X 与 Y 同步。
bar{.cta}.sync 或 bar{.cta}.red 或 bar{.cta}.arrive 操作与在同一栅栏上执行的 bar{.cta}.sync 或 bar{.cta}.red 操作同步。
barrier.cluster.arrive操作与barrier.cluster.wait操作同步。如果 X 中的写入操作在观察顺序中先于 Y 中的读取操作,并且 X 中的第一个操作和 Y 中的最后一个操作是 morally strong 的,则释放模式 X 与获取模式 Y 同步。
API 同步
同步关系也可以通过某些 CUDA API 建立。
在 CUDA 流中排队的任务的完成与同一流中后续任务(如果有)的开始同步。
出于上述目的,在流中记录或等待 CUDA 事件,或由于
cudaStreamLegacy而导致插入跨流栅栏,即使没有直接的副作用,也会在关联的流中排队任务。 事件记录任务与匹配的事件等待任务同步,栅栏到达任务与匹配的栅栏等待任务同步。CUDA 内核的开始与内核中所有线程的开始同步。 内核中所有线程的结束与内核的结束同步。
CUDA 图的开始与图中所有源节点的开始同步。 CUDA 图中所有 sink 节点的完成与图的完成同步。 图节点的完成与所有具有直接依赖关系的节点的开始同步。
调用 CUDA API 以排队任务的开始与任务的开始同步。
排队到流的最后一个任务(如果有)的完成与从
cudaStreamSynchronize返回同步。 最近排队的匹配事件记录任务(如果有)的完成与从cudaEventSynchronize返回同步。 同步 CUDA 设备或上下文的行为如同同步上下文中的所有流,包括已销毁的流。从 API 返回
cudaSuccess以查询 CUDA 句柄(例如流或事件)的行为与从匹配的同步 API 返回的行为相同。
除了建立同步关系外,上述 CUDA API 同步机制也参与代理保留的基本因果顺序。
8.9.5. 因果顺序
因果顺序捕获内存操作如何通过同步操作在线程之间变得可见。 “因果性”公理使用此顺序来约束读取操作可以从中读取值的写入操作集。
因果顺序中的关系主要包括基本因果顺序1 中的关系,后者是运行时确定的传递顺序。
基本因果顺序
如果满足以下条件,则操作 X 在基本因果顺序中先于操作 Y
X 在程序顺序中先于 Y,或者
X 与 Y 同步,或者
-
对于某些操作 Z,
X 在程序顺序中先于 Z,并且 Z 在基本因果顺序中先于 Y,或者
X 在基本因果顺序中先于 Z,并且 Z 在程序顺序中先于 Y,或者
X 在基本因果顺序中先于 Z,并且 Z 在基本因果顺序中先于 Y。
代理保留的基本因果顺序
如果内存操作 X 在基本因果顺序中先于内存操作 Y,并且满足以下条件,则内存操作 X 在代理保留的基本因果顺序中先于内存操作 Y
X 和 Y 使用通用代理对同一地址执行操作,或者
X 和 Y 使用相同的代理对同一地址执行操作,并且由相同的线程块执行,或者
X 和 Y 是别名,并且从 X 到 Y 的基本因果路径上存在别名代理栅栏。
因果顺序
因果顺序将基本因果顺序与一些非传递关系结合起来,如下所示
如果满足以下条件,则操作 X 在因果顺序中先于操作 Y
X 在代理保留的基本因果顺序中先于 Y,或者
对于某些操作 Z,X 在观察顺序中先于 Z,并且 Z 在代理保留的基本因果顺序中先于 Y。
1 基本因果顺序的传递性解释了同步操作的“累积性”。
8.9.6. 一致性顺序
存在一个运行时确定的关联重叠写入操作的偏序传递顺序,称为一致性顺序1。 如果两个重叠的写入操作是 morally strong 的,或者它们在因果顺序中相关,则它们在一致性顺序中相关。 如果两个重叠的写入操作处于数据竞争状态,则它们在一致性顺序中不相关,这导致了一致性顺序的偏序性质。
1 一致性顺序无法直接观察到,因为它完全由写入操作组成。 它可以间接观察到,通过其在约束读取操作可以从中读取的候选写入操作集中的使用。
8.9.7. 通信顺序
通信顺序是一个运行时确定的非传递顺序,它将写入操作与其他重叠的内存操作相关联。
如果读取 R 返回由 W 写入的任何字节的值,则写入 W 在通信顺序中先于重叠的读取 R。
如果 W 在一致性顺序中先于 W’,则写入 W 在通信顺序中先于写入 W’。
如果对于 R 和 W 都访问的任何字节,R 返回由在一致性顺序中先于 W 的写入 W’ 写入的值,则读取 R 在通信顺序中先于重叠的写入 W。
通信顺序捕获内存操作的可见性——当内存操作 X1 在通信顺序中先于内存操作 X2 时,称 X1 对 X2 可见。
8.10. 公理
8.10.1. 一致性
如果写入 W 在因果顺序中先于重叠的写入 W’,则 W 必须在一致性顺序中先于 W’。
8.10.2. Fence-SC
Fence-SC 顺序不能与因果顺序相矛盾。 对于一对 morally strong 的 fence.sc 操作 F1 和 F2,如果 F1 在因果顺序中先于 F2,则 F1 必须在 Fence-SC 顺序中先于 F2。
8.10.3. 原子性
单副本原子性
冲突的 morally strong 操作以单副本原子性执行。 当读取 R 和写入 W 是 morally strong 的时,对于 R 和 W 访问的字节集,以下两个通信不能同时存在于同一执行中
R 从 W 读取任何字节。
R 从任何在一致性顺序中先于 W 的写入 W’ 读取任何字节。
读-修改-写 (RMW) 操作的原子性
当原子操作 A 和写入 W 重叠并且是 morally strong 的时,对于 A 和 W 访问的字节集,以下两个通信不能同时存在于同一执行中
A 从在一致性顺序中先于 W 的写入 W’ 读取任何字节。
A 在一致性顺序中跟随 W。
Litmus 测试 1
.global .u32 x = 0;
|
|
T1 |
T2 |
A1: atom.sys.inc.u32 %r0, [x];
|
A2: atom.sys.inc.u32 %r0, [x];
|
FINAL STATE: x == 2
|
|
当操作是 morally strong 的时,原子性得到保证。
Litmus 测试 2
.global .u32 x = 0;
|
|
T1 |
T2(在不同的 CTA 中) |
A1: atom.cta.inc.u32 %r0, [x];
|
A2: atom.gpu.inc.u32 %r0, [x];
|
FINAL STATE: x == 1 OR x == 2
|
|
如果操作不是 morally strong 的,则原子性不能得到保证。
8.10.4. 凭空产生
值可能不会“凭空产生”:执行不能以推测方式生成值,以至于推测通过指令依赖性和线程间通信链变得自我满足。 这既符合程序员的直觉,也符合硬件的实际情况,但在执行形式化分析时必须明确说明。
Litmus 测试:加载缓冲
.global .u32 x = 0;
.global .u32 y = 0;
|
|
T1 |
T2 |
A1: ld.global.u32 %r0, [x];
B1: st.global.u32 [y], %r0;
|
A2: ld.global.u32 %r1, [y];
B2: st.global.u32 [x], %r1;
|
FINAL STATE: x == 0 AND y == 0
|
|
称为 “LB”(加载缓冲)的 litmus 测试检查可能凭空产生的此类禁止值。 两个线程 T1 和 T2 各自从第一个变量读取,并将观察到的结果复制到第二个变量中,其中第一个变量和第二个变量在线程之间交换。 如果每个变量最初都为零,则最终结果也应为零。 如果 A1 从 B2 读取,而 A2 从 B1 读取,则通过此示例中内存操作传递的值形成一个循环:A1->B1->A2->B2->A1。 只有值 x == 0 和 y == 0 才允许满足此循环。 如果此示例中的任何内存操作要推测性地将不同的值与相应的内存位置关联,则此类推测将变得自我实现,因此是被禁止的。
8.10.5. 每位置顺序一致性
在任何成对 morally strong 的重叠内存操作集合中,通信顺序不能与程序顺序相矛盾,即,重叠操作之间的程序顺序和通信顺序中 morally strong 关系的串联不能导致循环。 这确保了成对 morally strong 操作的每个程序切片都是严格顺序一致的。
Litmus 测试:CoRR
.global .u32 x = 0;
|
|
T1 |
T2 |
W1: st.global.relaxed.sys.u32 [x], 1;
|
R1: ld.global.relaxed.sys.u32 %r0, [x];
R2: ld.global.relaxed.sys.u32 %r1, [x];
|
IF %r0 == 1 THEN %r1 == 1
|
|
litmus 测试 “CoRR”(一致性读取-读取)演示了此保证的一个结果。 线程 T1 在位置 x 上执行写入 W1,线程 T2 在同一位置 x 上执行两个(或无限序列的)读取 R1 和 R2。 除了模拟初始值的写入之外,没有在 x 上执行其他写入。 操作 W1、R1 和 R2 成对是 morally strong 的。 如果 R1 从 W1 读取,则后续读取 R2 也必须观察到相同的值。 如果 R2 观察到 x 的初始值,则这将在通信顺序中形成与线程 T2 中的程序顺序 R1->R2 相矛盾的 morally-strong 关系序列 R2->W1->R1。 因此,R2 在这样的执行中不能读取 x 的初始值。
8.10.6. 因果性
通信顺序中的关系不能与因果顺序相矛盾。 这约束了读取操作可以从中读取的候选写入操作集
如果读取 R 在因果顺序中先于重叠的写入 W,则 R 不能从 W 读取。
如果写入 W 在因果顺序中先于重叠的读取 R,则对于 R 和 W 都访问的任何字节,R 不能从任何在一致性顺序中先于 W 的写入 W’ 读取。
Litmus 测试:消息传递
.global .u32 data = 0;
.global .u32 flag = 0;
|
|
T1 |
T2 |
W1: st.global.u32 [data], 1;
F1: fence.sys;
W2: st.global.relaxed.sys.u32 [flag], 1;
|
R1: ld.global.relaxed.sys.u32 %r0, [flag];
F2: fence.sys;
R2: ld.global.u32 %r1, [data];
|
IF %r0 == 1 THEN %r1 == 1
|
|
称为 “MP”(消息传递)的 litmus 测试代表了典型同步算法的本质。 绝大多数有用的程序都可以简化为此模式的顺序应用。
线程 T1 首先写入数据变量,然后写入标志变量,而第二个线程 T2 首先从标志变量读取,然后从数据变量读取。 标志上的操作是 morally strong 的,并且每个线程中的内存操作都由 fence 分隔,并且这些 fence 是 morally strong 的。
如果 R1 观察到 W2,则释放模式 “F1; W2” 与获取模式 “R1; F2” 同步。 这建立了因果顺序 W1 -> F1 -> W2 -> R1 -> F2 -> R2。 然后,因果性公理保证 R2 不能从任何在一致性顺序中先于 W1 的写入读取。 在此示例中没有任何其他写入的情况下,R2 必须从 W1 读取。
Litmus 测试:CoWR
// These addresses are aliases
.global .u32 data_alias_1;
.global .u32 data_alias_2;
|
T1 |
W1: st.global.u32 [data_alias_1], 1;
F1: fence.proxy.alias;
R1: ld.global.u32 %r1, [data_alias_2];
|
%r1 == 1
|
虚拟别名需要沿同步路径的别名代理栅栏。
Litmus 测试:存储缓冲
称为 “SB”(存储缓冲)的 litmus 测试演示了由 fence.sc 强制执行的顺序一致性。 线程 T1 写入第一个变量,然后读取第二个变量的值,而第二个线程 T2 写入第二个变量,然后读取第一个变量的值。 每个线程中的内存操作都由 fence.sc 指令分隔,并且这些 fence 是 morally strong 的。
.global .u32 x = 0;
.global .u32 y = 0;
|
|
T1 |
T2 |
W1: st.global.u32 [x], 1;
F1: fence.sc.sys;
R1: ld.global.u32 %r0, [y];
|
W2: st.global.u32 [y], 1;
F2: fence.sc.sys;
R2: ld.global.u32 %r1, [x];
|
%r0 == 1 OR %r1 == 1
|
|
在任何执行中,F1 要么在 Fence-SC 顺序中先于 F2,要么反之亦然。 如果 F1 在 Fence-SC 顺序中先于 F2,则 F1 与 F2 同步。 这在 W1 -> F1 -> F2 -> R2 中建立了因果顺序。 因果性公理确保 R2 不能从任何在一致性顺序中先于 W1 的写入读取。 在没有对该变量进行任何其他写入的情况下,R2 必须从 W1 读取。 类似地,在 F2 在 Fence-SC 顺序中先于 F1 的情况下,R1 必须从 W2 读取。 如果此示例中的每个 fence.sc 都被 fence.acq_rel 指令替换,则不能保证此结果。 可能存在执行,其中来自每个线程的写入对另一个线程保持未观察到,即,可能存在执行,其中 R1 和 R2 都分别返回变量 y 和 x 的初始值 “0”。
9. 指令集
9.1. 指令描述的格式和语义
本节介绍每个 PTX 指令。 除了指令的名称和格式外,还描述了语义,并附带一些示例,试图展示指令的几种可能的实例化。
9.2. PTX 指令
PTX 指令通常有零到四个操作数,外加一个可选的保护谓词,它出现在 opcode 左侧的 @ 符号之后
@p opcode;@p opcode a;@p opcode d, a;@p opcode d, a, b;@p opcode d, a, b, c;
对于创建结果值的指令,d 操作数是目标操作数,而 a、b 和 c 是源操作数。
setp 指令写入两个目标寄存器。我们使用 | 符号分隔多个目标寄存器。
setp.lt.s32 p|q, a, b; // p = (a < b); q = !(a < b);
对于某些指令,目标操作数是可选的。可以使用下划线 (_) 表示的位桶操作数来代替目标寄存器。
9.3. 条件执行
在 PTX 中,谓词寄存器是虚拟的,并且类型说明符为 .pred。因此,谓词寄存器可以声明为
.reg .pred p, q, r;
所有指令都有一个可选的保护谓词,用于控制指令的条件执行。指定条件执行的语法是在指令前加上 @{!}p,其中 p 是谓词变量,可以选择取反。没有保护谓词的指令会无条件执行。
谓词最常设置为 setp 指令执行比较的结果。
例如,考虑以下高级代码
if (i < n)
j = j + 1;
这可以用 PTX 写成
setp.lt.s32 p, i, n; // p = (i < n)
@p add.s32 j, j, 1; // if i < n, add 1 to j
要获得条件分支或条件函数调用,请使用谓词来控制分支或调用指令的执行。要将上述示例实现为真正的条件分支,可以使用以下 PTX 指令序列
setp.lt.s32 p, i, n; // compare i to n
@!p bra L1; // if False, branch over
add.s32 j, j, 1;
L1: ...
9.3.1. 比较
9.3.1.1. 整数和位大小比较
有符号整数比较是传统的 eq(等于)、ne(不等于)、lt(小于)、le(小于或等于)、gt(大于)和 ge(大于或等于)。无符号比较是 eq、ne、lo(更低)、ls(更低或相同)、hi(更高)和 hs(更高或相同)。位大小比较是 eq 和 ne;排序比较未为位大小类型定义。
表 21 显示了有符号整数、无符号整数和位大小类型的运算符。
含义 |
有符号运算符 |
无符号运算符 |
位大小运算符 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
不适用 |
|
|
|
不适用 |
|
|
|
不适用 |
|
|
|
不适用 |
9.3.1.2. 浮点比较
有序浮点比较是 eq、ne、lt、le、gt 和 ge。如果任一操作数是 NaN,则结果为 False。表 22 列出了浮点比较运算符。
含义 |
浮点运算符 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
为了辅助存在 NaN 值时的比较操作,提供了无序浮点比较:equ、neu、ltu、leu、gtu 和 geu。如果两个操作数都是数值(不是 NaN),则比较的结果与其有序对应项相同。如果任一操作数是 NaN,则比较的结果为 True。
表 23 列出了接受 NaN 值的浮点比较运算符。
含义 |
浮点运算符 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
为了测试 NaN 值,提供了两个运算符 num(numeric)和 nan(isNaN)。如果两个操作数都是数值(不是 NaN),则 num 返回 True,如果任一操作数是 NaN,则 nan 返回 True。表 24 列出了测试 NaN 值的浮点比较运算符。
含义 |
浮点运算符 |
|---|---|
|
|
|
|
9.3.2. 操作谓词
谓词值可以使用以下指令进行计算和操作:and、or、xor、not 和 mov。
谓词和整数值之间没有直接转换,也没有直接加载或存储谓词寄存器值的方法。但是,setp 可以用于从整数生成谓词,而基于谓词的选择 (selp) 指令可以用于基于谓词的值生成整数值;例如
selp.u32 %r1,1,0,%p; // convert predicate to 32-bit value
9.4. 指令和操作数的类型信息
类型化指令必须具有类型大小修饰符。例如,add 指令需要类型和大小信息才能正确执行加法运算(有符号、无符号、浮点、不同大小),此信息必须指定为操作码的后缀。
例子
.reg .u16 d, a, b;
add.u16 d, a, b; // perform a 16-bit unsigned add
某些指令需要多个类型大小修饰符,最值得注意的是数据转换指令 cvt。它需要为结果和源分别指定类型大小修饰符,并且这些修饰符的顺序与操作数相同。例如
.reg .u16 a;
.reg .f32 d;
cvt.f32.u16 d, a; // convert 16-bit unsigned to 32-bit float
通常,操作数的类型必须与相应的指令类型修饰符一致。操作数和指令类型一致性的规则如下
位大小类型与相同大小的任何类型一致。
有符号和无符号整数类型在具有相同大小时一致,并且如果需要,整数操作数会被静默强制转换为指令类型。例如,在有符号整数指令中使用的无符号整数操作数将被指令视为有符号整数。
浮点类型仅在具有相同大小时才一致;即,它们必须完全匹配。
表 25 总结了这些类型检查规则。
操作数类型 |
|||||
|---|---|---|---|---|---|
.bX |
.sX |
.uX |
.fX |
||
指令类型 |
.bX |
okay |
okay |
okay |
okay |
.sX |
okay |
okay |
okay |
invalid |
|
.uX |
okay |
okay |
okay |
invalid |
|
.fX |
okay |
invalid |
invalid |
okay |
|
注意
某些操作数的类型和大小独立于指令类型大小定义。例如,左移和右移指令的移位量操作数始终具有类型 .u32,而其余操作数的类型和大小由指令类型确定。
例子
// 64-bit arithmetic right shift; shift amount 'b' is .u32
shr.s64 d,a,b;
9.4.1. 操作数大小超过指令类型大小
为了方便起见,ld、st 和 cvt 指令允许源和目标数据操作数比指令类型大小更宽,以便可以使用常规宽度寄存器加载、存储和转换窄值。例如,当加载、存储或转换为其他类型和大小的值时,8 位或 16 位的值可以直接保存在 32 位或 64 位寄存器中。对于位大小和整数(有符号和无符号)指令类型,操作数类型检查规则会放宽;浮点指令类型仍然要求操作数类型大小完全匹配,除非操作数是位大小类型。
当源操作数的大小超过指令类型大小时,源数据将被截断(砍掉)到指令类型大小指定的位数。
表 26 总结了源操作数的放宽类型检查规则。请注意,某些组合对于特定指令可能仍然无效;例如,cvt 指令不支持 .bX 指令类型,因此这些行对于 cvt 无效。
源操作数类型 |
|||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
b8 |
b16 |
b32 |
b64 |
b128 |
s8 |
s16 |
s32 |
s64 |
u8 |
u16 |
u32 |
u64 |
f16 |
f32 |
f64 |
||
指令类型 |
b8 |
– |
chop |
chop |
chop |
chop |
– |
chop |
chop |
chop |
– |
chop |
chop |
chop |
chop |
chop |
chop |
b16 |
inv |
– |
chop |
chop |
chop |
inv |
– |
chop |
chop |
inv |
– |
chop |
chop |
– |
chop |
chop |
|
b32 |
inv |
inv |
– |
chop |
chop |
inv |
inv |
– |
chop |
inv |
inv |
– |
chop |
inv |
– |
chop |
|
b64 |
inv |
inv |
inv |
– |
chop |
inv |
inv |
inv |
– |
inv |
inv |
inv |
– |
inv |
inv |
– |
|
b128 |
inv |
inv |
inv |
inv |
– |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
|
s8 |
– |
chop |
chop |
chop |
chop |
– |
chop |
chop |
chop |
– |
chop |
chop |
chop |
inv |
inv |
inv |
|
s16 |
inv |
– |
chop |
chop |
chop |
inv |
– |
chop |
chop |
inv |
– |
chop |
chop |
inv |
inv |
inv |
|
s32 |
inv |
inv |
– |
chop |
chop |
inv |
inv |
– |
chop |
inv |
inv |
– |
chop |
inv |
inv |
inv |
|
s64 |
inv |
inv |
inv |
– |
chop |
inv |
inv |
inv |
– |
inv |
inv |
inv |
– |
inv |
inv |
inv |
|
u8 |
– |
chop |
chop |
chop |
chop |
– |
chop |
chop |
chop |
– |
chop |
chop |
chop |
inv |
inv |
inv |
|
u16 |
inv |
– |
chop |
chop |
chop |
inv |
– |
chop |
chop |
inv |
– |
chop |
chop |
inv |
inv |
inv |
|
u32 |
inv |
inv |
– |
chop |
chop |
inv |
inv |
– |
chop |
inv |
inv |
– |
chop |
inv |
inv |
inv |
|
u64 |
inv |
inv |
inv |
– |
chop |
inv |
inv |
inv |
– |
inv |
inv |
inv |
– |
inv |
inv |
inv |
|
f16 |
inv |
– |
chop |
chop |
chop |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
– |
inv |
inv |
|
f32 |
inv |
inv |
– |
chop |
chop |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
– |
inv |
|
f64 |
inv |
inv |
inv |
– |
chop |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
– |
|
注释 |
chop = 仅保留适合的低位;“–” = 允许,但不需要转换; inv = 无效,解析错误。
|
||||||||||||||||
当目标操作数的大小超过指令类型大小时,目标数据将被零扩展或符号扩展到目标寄存器的大小。如果相应的指令类型是有符号整数,则数据将被符号扩展;否则,数据将被零扩展。
表 27 总结了目标操作数的放宽类型检查规则。
目标操作数类型 |
|||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
b8 |
b16 |
b32 |
b64 |
b128 |
s8 |
s16 |
s32 |
s64 |
u8 |
u16 |
u32 |
u64 |
f16 |
f32 |
f64 |
||
指令类型 |
b8 |
– |
zext |
zext |
zext |
zext |
– |
zext |
zext |
zext |
– |
zext |
zext |
zext |
zext |
zext |
zext |
b16 |
inv |
– |
zext |
zext |
zext |
inv |
– |
zext |
zext |
inv |
– |
zext |
zext |
– |
zext |
zext |
|
b32 |
inv |
inv |
– |
zext |
zext |
inv |
inv |
– |
zext |
inv |
inv |
– |
zext |
inv |
– |
zext |
|
b64 |
inv |
inv |
inv |
– |
zext |
inv |
inv |
inv |
– |
inv |
inv |
inv |
– |
inv |
inv |
– |
|
b128 |
inv |
inv |
inv |
inv |
– |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
|
s8 |
– |
sext |
sext |
sext |
sext |
– |
sext |
sext |
sext |
– |
sext |
sext |
sext |
inv |
inv |
inv |
|
s16 |
inv |
– |
sext |
sext |
sext |
inv |
– |
sext |
sext |
inv |
– |
sext |
sext |
inv |
inv |
inv |
|
s32 |
inv |
inv |
– |
sext |
sext |
inv |
inv |
– |
sext |
inv |
inv |
– |
sext |
inv |
inv |
inv |
|
s64 |
inv |
inv |
inv |
– |
sext |
inv |
inv |
inv |
– |
inv |
inv |
inv |
– |
inv |
inv |
inv |
|
u8 |
– |
zext |
zext |
zext |
zext |
– |
zext |
zext |
zext |
– |
zext |
zext |
zext |
inv |
inv |
inv |
|
u16 |
inv |
– |
zext |
zext |
zext |
inv |
– |
zext |
zext |
inv |
– |
zext |
zext |
inv |
inv |
inv |
|
u32 |
inv |
inv |
– |
zext |
zext |
inv |
inv |
– |
zext |
inv |
inv |
– |
zext |
inv |
inv |
inv |
|
u64 |
inv |
inv |
inv |
– |
zext |
inv |
inv |
inv |
– |
inv |
inv |
inv |
– |
inv |
inv |
inv |
|
f16 |
inv |
– |
zext |
zext |
zext |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
– |
inv |
inv |
|
f32 |
inv |
inv |
– |
zext |
zext |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
– |
inv |
|
f64 |
inv |
inv |
inv |
– |
zext |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
inv |
– |
|
注释 |
sext = 符号扩展;zext = 零扩展;“–” = 允许,但不需要转换; inv = 无效,解析错误。
|
||||||||||||||||
9.5. 控制结构中线程的发散
CTA 中的线程至少在表面上一起执行,直到它们遇到条件控制结构,例如条件分支、条件函数调用或条件返回。如果线程执行不同的控制流路径,则这些线程称为发散。如果所有线程一致行动并遵循单个控制流路径,则这些线程称为统一。这两种情况在程序中经常发生。
具有发散线程的 CTA 可能比具有统一执行线程的 CTA 性能更低,因此尽快使发散线程重新收敛非常重要。所有控制结构都被假定为发散点,除非控制流指令被标记为统一,使用 .uni 后缀。对于发散控制流,优化代码生成器会自动确定重新收敛点。因此,以 PTX 为目标的编译器或代码作者可以忽略发散线程的问题,但是当编译器或作者可以保证分支点是非发散时,有机会通过将分支点标记为统一来提高性能。
9.6. 语义
指令语义描述的目标是以尽可能简单的语言描述所有情况下的结果。语义使用 C 语言描述,直到 C 语言不足以表达。
9.6.1. 16 位代码的机器特定语义
PTX 程序可以在具有 16 位或 32 位数据路径的 GPU 上执行。当在 32 位数据路径上执行时,PTX 中的 16 位寄存器映射到 32 位物理寄存器,并且 16 位计算被提升为 32 位计算。这可能会导致在 16 位机器上运行的代码与在 32 位机器上运行的相同代码之间存在计算差异,因为提升的计算可能在 32 位寄存器的高位半字中具有在 16 位物理寄存器中不存在的位。这些额外的精度位可能会在应用程序级别变得可见,例如,通过右移指令。
在 PTX 语言级别,一种解决方案是为 16 位代码定义与在 16 位数据路径上执行一致的语义。这种方法为在 32 位数据路径上执行的 16 位代码引入了性能损失,因为翻译后的代码将需要许多额外的掩码指令来抑制 32 位寄存器高位半字中的额外精度位。
与其为在 32 位 GPU 上运行的 16 位代码引入性能损失,不如将 PTX 中 16 位指令的语义设置为机器特定的。编译器或程序员可以选择通过在程序的适当位置添加显式转换为 16 位值的操作来强制执行可移植的、机器无关的 16 位语义,以保证代码的可移植性。但是,对于许多性能关键型应用程序,这是不可取的,并且对于许多应用程序而言,执行中的差异比限制性能更可取。
9.7. 指令
所有 PTX 指令都可以被谓词化。在以下描述中,可选的保护谓词从语法中省略。
9.7.1. 整数算术指令
整数算术指令对寄存器和常量立即数形式的整数类型进行操作。整数算术指令包括
addsubmulmadmul24mad24saddivremabsnegminmaxpopcclzbfindfnsbrevbfebfibmskszextdp4adp2a
9.7.1.1. 整数算术指令:add
add
将两个值相加。
语法
add.type d, a, b;
add{.sat}.s32 d, a, b; // .sat applies only to .s32
.type = { .u16, .u32, .u64,
.s16, .s32, .s64,
.u16x2, .s16x2 };
描述
执行加法并将结果值写入目标寄存器。
对于 .u16x2、.s16x2 指令类型,通过源操作数的半字值形成输入向量。然后并行添加半字操作数,以在目标中生成 .u16x2、.s16x2 结果。
操作数 d、a 和 b 的类型为 .type。对于指令类型 .u16x2、.s16x2,操作数 d、a 和 b 的类型为 .b32。
语义
if (type == u16x2 || type == s16x2) {
iA[0] = a[0:15];
iA[1] = a[16:31];
iB[0] = b[0:15];
iB[1] = b[16:31];
for (i = 0; i < 2; i++) {
d[i] = iA[i] + iB[i];
}
} else {
d = a + b;
}
注释
饱和修饰符
- .sat
-
将结果限制为操作大小的
MININT..MAXINT范围(无溢出)。仅适用于.s32类型。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
add.u16x2 和 add.s16x2 在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
所有目标架构均支持。
add.u16x2 和 add.s16x2 需要 sm_90 或更高版本。
示例
@p add.u32 x,y,z;
add.sat.s32 c,c,1;
add.u16x2 u,v,w;
9.7.1.2. 整数算术指令:sub
sub
从另一个值中减去一个值。
语法
sub.type d, a, b;
sub{.sat}.s32 d, a, b; // .sat applies only to .s32
.type = { .u16, .u32, .u64,
.s16, .s32, .s64 };
描述
执行减法并将结果值写入目标寄存器。
语义
d = a - b;
注释
饱和修饰符
.sat-
将结果限制为操作大小的
MININT..MAXINT范围(无溢出)。仅适用于.s32类型。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
sub.s32 c,a,b;
9.7.1.3. 整数算术指令:mul
mul
将两个值相乘。
语法
mul.mode.type d, a, b;
.mode = { .hi, .lo, .wide };
.type = { .u16, .u32, .u64,
.s16, .s32, .s64 };
描述
计算两个值的乘积。
语义
t = a * b;
n = bitwidth of type;
d = t; // for .wide
d = t<2n-1..n>; // for .hi variant
d = t<n-1..0>; // for .lo variant
注释
操作类型表示 a 和 b 操作数的类型。如果指定了 .hi 或 .lo,则 d 的大小与 a 和 b 相同,并且结果的上半部分或下半部分被写入目标寄存器。如果指定了 .wide,则 d 的宽度是 a 和 b 的两倍,以接收乘法的完整结果。
.wide 后缀仅支持 16 位和 32 位整数类型。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mul.wide.s16 fa,fxs,fys; // 16*16 bits yields 32 bits
mul.lo.s16 fa,fxs,fys; // 16*16 bits, save only the low 16 bits
mul.wide.s32 z,x,y; // 32*32 bits, creates 64 bit result
9.7.1.4. 整数算术指令:mad
mad
将两个值相乘,可选择提取中间结果的高半部分或低半部分,然后加上第三个值。
语法
mad.mode.type d, a, b, c;
mad.hi.sat.s32 d, a, b, c;
.mode = { .hi, .lo, .wide };
.type = { .u16, .u32, .u64,
.s16, .s32, .s64 };
描述
将两个值相乘,可选择提取中间结果的高半部分或低半部分,然后加上第三个值。将结果写入目标寄存器。
语义
t = a * b;
n = bitwidth of type;
d = t + c; // for .wide
d = t<2n-1..n> + c; // for .hi variant
d = t<n-1..0> + c; // for .lo variant
注释
操作类型表示 a 和 b 操作数的类型。如果指定了 .hi 或 .lo,则 d 和 c 的大小与 a 和 b 相同,并且结果的上半部分或下半部分被写入目标寄存器。如果指定了 .wide,则 d 和 c 的宽度是 a 和 b 的两倍,以接收乘法的结果。
.wide 后缀仅支持 16 位和 32 位整数类型。
饱和修饰符
.sat-
将结果限制为操作大小的
MININT..MAXINT范围(无溢出)。仅适用于
.hi模式下的.s32类型。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
@p mad.lo.s32 d,a,b,c;
mad.lo.s32 r,p,q,r;
9.7.1.5. 整数算术指令:mul24
mul24
将两个 24 位整数值相乘。
语法
mul24.mode.type d, a, b;
.mode = { .hi, .lo };
.type = { .u32, .s32 };
描述
计算两个 32 位源寄存器中保存的 24 位整数值的乘积,并返回 48 位结果的高 32 位或低 32 位。
语义
t = a * b;
d = t<47..16>; // for .hi variant
d = t<31..0>; // for .lo variant
注释
整数乘法运算产生的结果是输入操作数大小的两倍,即 48 位。
mul24.hi 执行 24x24 位乘法运算,并返回 48 位结果的高 32 位。
mul24.lo 执行 24x24 位乘法运算,并返回 48 位结果的低 32 位。
所有操作数均具有相同的类型和大小。
mul24.hi 在没有硬件支持 24 位乘法的机器上效率可能较低。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mul24.lo.s32 d,a,b; // low 32-bits of 24x24-bit signed multiply.
9.7.1.6. 整数算术指令:mad24
mad24
将两个 24 位整数值相乘,然后加上第三个值。
语法
mad24.mode.type d, a, b, c;
mad24.hi.sat.s32 d, a, b, c;
.mode = { .hi, .lo };
.type = { .u32, .s32 };
描述
计算两个 32 位源寄存器中保存的 24 位整数值的乘积,并将第三个 32 位值加到 48 位结果的高 32 位或低 32 位。返回 48 位结果的高 32 位或低 32 位。
语义
t = a * b;
d = t<47..16> + c; // for .hi variant
d = t<31..0> + c; // for .lo variant
注释
整数乘法运算产生的结果是输入操作数大小的两倍,即 48 位。
mad24.hi 执行 24x24 位乘法运算,并将 48 位结果的高 32 位加到第三个值。
mad24.lo 执行 24x24 位乘法运算,并将 48 位结果的低 32 位加到第三个值。
所有操作数均具有相同的类型和大小。
饱和修饰符
.sat-
将 32 位有符号加法的结果限制为
MININT..MAXINT(无溢出)。仅适用于 .hi 模式下的.s32类型。
mad24.hi 在没有硬件支持 24 位乘法的机器上效率可能较低。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mad24.lo.s32 d,a,b,c; // low 32-bits of 24x24-bit signed multiply.
9.7.1.7. 整数算术指令:sad
sad
绝对差之和。
语法
sad.type d, a, b, c;
.type = { .u16, .u32, .u64,
.s16, .s32, .s64 };
描述
将 a-b 的绝对值加到 c,并将结果值写入 d。
语义
d = c + ((a<b) ? b-a : a-b);
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
sad.s32 d,a,b,c;
sad.u32 d,a,b,d; // running sum
9.7.1.8. 整数算术指令:div
div
将一个值除以另一个值。
语法
div.type d, a, b;
.type = { .u16, .u32, .u64,
.s16, .s32, .s64 };
描述
将 a 除以 b,并将结果存储在 d 中。
语义
d = a / b;
注释
除以零会产生未指定的、机器特定的值。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
div.s32 b,n,i;
9.7.1.9. 整数算术指令:rem
rem
整数除法的余数。
语法
rem.type d, a, b;
.type = { .u16, .u32, .u64,
.s16, .s32, .s64 };
描述
将 a 除以 b,并将余数存储在 d 中。
语义
d = a % b;
注释
负数的行为取决于机器,并取决于除法是向零舍入还是向负无穷大舍入。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
rem.s32 x,x,8; // x = x%8;
9.7.1.10. 整数算术指令:abs
abs
绝对值。
语法
abs.type d, a;
.type = { .s16, .s32, .s64 };
描述
取 a 的绝对值并将其存储在 d 中。
语义
d = |a|;
注释
仅适用于有符号整数。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
abs.s32 r0,a;
9.7.1.11. 整数算术指令:neg
neg
算术求反。
语法
neg.type d, a;
.type = { .s16, .s32, .s64 };
描述
对 a 的符号求反,并将结果存储在 d 中。
语义
d = -a;
注释
仅适用于有符号整数。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
neg.s32 r0,a;
9.7.1.12. 整数算术指令:min
min
查找两个值中的最小值。
语法
min.atype d, a, b;
min{.relu}.btype d, a, b;
.atype = { .u16, .u32, .u64,
.u16x2, .s16, .s64 };
.btype = { .s16x2, .s32 };
描述
将 a 和 b 中的最小值存储在 d 中。
对于 .u16x2、.s16x2 指令类型,通过来自源操作数的半字值形成输入向量。然后并行处理半字操作数,以在目标中生成 .u16x2、.s16x2 结果。
操作数 d、a 和 b 具有与指令类型相同的类型。对于指令类型 .u16x2、.s16x2,操作数 d、a 和 b 具有 .b32 类型。
语义
if (type == u16x2 || type == s16x2) {
iA[0] = a[0:15];
iA[1] = a[16:31];
iB[0] = b[0:15];
iB[1] = b[16:31];
for (i = 0; i < 2; i++) {
d[i] = (iA[i] < iB[i]) ? iA[i] : iB[i];
}
} else {
d = (a < b) ? a : b; // Integer (signed and unsigned)
}
注释
有符号和无符号运算有所不同。
- 饱和修饰符
-
min.relu.{s16x2, s32}在结果为负数时将其钳位为 0。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
min.u16x2、min{.relu}.s16x2 和 min.relu.s32 在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
所有目标架构均支持。
min.u16x2、min{.relu}.s16x2 和 min.relu.s32 需要 sm_90 或更高版本。
示例
min.s32 r0,a,b;
@p min.u16 h,i,j;
min.s16x2.relu u,v,w;
9.7.1.13. 整数算术指令:max
max
查找两个值中的最大值。
语法
max.atype d, a, b;
max{.relu}.btype d, a, b;
.atype = { .u16, .u32, .u64,
.u16x2, .s16, .s64 };
.btype = { .s16x2, .s32 };
描述
将 a 和 b 中的最大值存储在 d 中。
对于 .u16x2、.s16x2 指令类型,通过来自源操作数的半字值形成输入向量。然后并行处理半字操作数,以在目标中生成 .u16x2、.s16x2 结果。
操作数 d、a 和 b 具有与指令类型相同的类型。对于指令类型 .u16x2、.s16x2,操作数 d、a 和 b 具有 .b32 类型。
语义
if (type == u16x2 || type == s16x2) {
iA[0] = a[0:15];
iA[1] = a[16:31];
iB[0] = b[0:15];
iB[1] = b[16:31];
for (i = 0; i < 2; i++) {
d[i] = (iA[i] > iB[i]) ? iA[i] : iB[i];
}
} else {
d = (a > b) ? a : b; // Integer (signed and unsigned)
}
注释
有符号和无符号运算有所不同。
- 饱和修饰符
-
max.relu.{s16x2, s32}在结果为负数时将其钳位为 0。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
max.u16x2、max{.relu}.s16x2 和 max.relu.s32 在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
所有目标架构均支持。
max.u16x2、max{.relu}.s16x2 和 max.relu.s32 需要 sm_90 或更高版本。
示例
max.u32 d,a,b;
max.s32 q,q,0;
max.relu.s16x2 t,t,u;
9.7.1.14. 整数算术指令:popc
popc
population count(人口计数/popcount)。
语法
popc.type d, a;
.type = { .b32, .b64 };
描述
计算 a 中置位位的数量,并将结果人口计数放在 32 位目标寄存器 d 中。操作数 a 具有指令类型,目标 d 具有 .u32 类型。
语义
.u32 d = 0;
while (a != 0) {
if (a & 0x1) d++;
a = a >> 1;
}
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
popc 需要 sm_20 或更高版本。
示例
popc.b32 d, a;
popc.b64 cnt, X; // cnt is .u32
9.7.1.15. 整数算术指令:clz
clz
前导零计数。
语法
clz.type d, a;
.type = { .b32, .b64 };
描述
从最高有效位开始,计算 a 中前导零的数量,并将结果放在 32 位目标寄存器 d 中。操作数 a 具有指令类型,目标 d 具有 .u32 类型。对于 .b32 类型,前导零的数量在 0 到 32 之间(含 0 和 32)。对于 .b64 类型,前导零的数量在 0 到 64 之间(含 0 和 64)。
语义
.u32 d = 0;
if (.type == .b32) { max = 32; mask = 0x80000000; }
else { max = 64; mask = 0x8000000000000000; }
while (d < max && (a&mask == 0) ) {
d++;
a = a << 1;
}
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
clz 需要 sm_20 或更高版本。
示例
clz.b32 d, a;
clz.b64 cnt, X; // cnt is .u32
9.7.1.16. 整数算术指令:bfind
bfind
查找最高有效非符号位。
语法
bfind.type d, a;
bfind.shiftamt.type d, a;
.type = { .u32, .u64,
.s32, .s64 };
描述
查找 a 中最高有效非符号位的位位置,并将结果放在 d 中。操作数 a 具有指令类型,目标 d 具有 .u32 类型。对于无符号整数,bfind 返回最高有效位 1 的位位置。对于有符号整数,bfind 对于负输入返回最高有效位 0 的位位置,对于非负输入返回最高有效位 1 的位位置。
如果指定了 .shiftamt,则 bfind 返回将找到的位左移到最高有效位位置所需的移位量。
如果没有找到非符号位,bfind 返回 0xffffffff。
语义
msb = (.type==.u32 || .type==.s32) ? 31 : 63;
// negate negative signed inputs
if ( (.type==.s32 || .type==.s64) && (a & (1<<msb)) ) {
a = ~a;
}
.u32 d = 0xffffffff;
for (.s32 i=msb; i>=0; i--) {
if (a & (1<<i)) { d = i; break; }
}
if (.shiftamt && d != 0xffffffff) { d = msb - d; }
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
bfind 需要 sm_20 或更高版本。
示例
bfind.u32 d, a;
bfind.shiftamt.s64 cnt, X; // cnt is .u32
9.7.1.17. 整数算术指令:fns
fns
查找第 n 个设置位
语法
fns.b32 d, mask, base, offset;
描述
给定一个 32 位值 mask 和一个整数值 base(介于 0 和 31 之间),从 base 位开始,在 mask 中查找第 n 个(由偏移量给出)设置位,并将位位置存储在 d 中。如果未找到,则在 d 中存储 0xffffffff。
操作数 mask 具有 32 位类型。操作数 base 具有 .b32、.u32 或 .s32 类型。操作数 offset 具有 .s32 类型。目标 d 具有 .b32. 类型。
操作数 base 必须 <= 31,否则行为未定义。
语义
d = 0xffffffff;
if (offset == 0) {
if (mask[base] == 1) {
d = base;
}
} else {
pos = base;
count = |offset| - 1;
inc = (offset > 0) ? 1 : -1;
while ((pos >= 0) && (pos < 32)) {
if (mask[pos] == 1) {
if (count == 0) {
d = pos;
break;
} else {
count = count - 1;
}
}
pos = pos + inc;
}
}
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
目标 ISA 注释
fns 需要 sm_30 或更高版本。
示例
fns.b32 d, 0xaaaaaaaa, 3, 1; // d = 3
fns.b32 d, 0xaaaaaaaa, 3, -1; // d = 3
fns.b32 d, 0xaaaaaaaa, 2, 1; // d = 3
fns.b32 d, 0xaaaaaaaa, 2, -1; // d = 1
9.7.1.18. 整数算术指令:brev
brev
位反转。
语法
brev.type d, a;
.type = { .b32, .b64 };
描述
执行输入的按位反转。
语义
msb = (.type==.b32) ? 31 : 63;
for (i=0; i<=msb; i++) {
d[i] = a[msb-i];
}
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
brev 需要 sm_20 或更高版本。
示例
brev.b32 d, a;
9.7.1.19. 整数算术指令:bfe
bfe
位字段提取。
语法
bfe.type d, a, b, c;
.type = { .u32, .u64,
.s32, .s64 };
描述
从 a 中提取位字段,并将零扩展或符号扩展的结果放在 d 中。源 b 给出位字段起始位位置,源 c 给出位字段长度(以位为单位)。
操作数 a 和 d 具有与指令类型相同的类型。操作数 b 和 c 为 .u32 类型,但限制为 8 位值范围 0..255。
提取字段的符号位定义为
-
.u32,.u64 -
零
-
.s32,.s64 -
如果提取的字段超出
a的msb,则为输入 a 的msb,否则为提取字段的msb
如果位字段长度为零,则结果为零。
目标 d 用提取字段的符号位填充。如果起始位置超出输入的 msb,则目标 d 将填充复制的提取字段的符号位。
语义
msb = (.type==.u32 || .type==.s32) ? 31 : 63;
pos = b & 0xff; // pos restricted to 0..255 range
len = c & 0xff; // len restricted to 0..255 range
if (.type==.u32 || .type==.u64 || len==0)
sbit = 0;
else
sbit = a[min(pos+len-1,msb)];
d = 0;
for (i=0; i<=msb; i++) {
d[i] = (i<len && pos+i<=msb) ? a[pos+i] : sbit;
}
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
bfe 需要 sm_20 或更高版本。
示例
bfe.b32 d,a,start,len;
9.7.1.20. 整数算术指令:bfi
bfi
位字段插入。
语法
bfi.type f, a, b, c, d;
.type = { .b32, .b64 };
描述
将 a 中的位字段对齐并插入到 b 中,并将结果放在 f 中。源 c 给出插入的起始位位置,源 d 给出位字段长度(以位为单位)。
操作数 a、b 和 f 具有与指令类型相同的类型。操作数 c 和 d 为 .u32 类型,但限制为 8 位值范围 0..255。
如果位字段长度为零,则结果为 b。
如果起始位置超出输入的 msb,则结果为 b。
语义
msb = (.type==.b32) ? 31 : 63;
pos = c & 0xff; // pos restricted to 0..255 range
len = d & 0xff; // len restricted to 0..255 range
f = b;
for (i=0; i<len && pos+i<=msb; i++) {
f[pos+i] = a[i];
}
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
bfi 需要 sm_20 或更高版本。
示例
bfi.b32 d,a,b,start,len;
9.7.1.21. 整数算术指令:szext
szext
符号扩展或零扩展。
语法
szext.mode.type d, a, b;
.mode = { .clamp, .wrap };
.type = { .u32, .s32 };
描述
从操作数 a 中符号扩展或零扩展 N 位值,其中 N 在操作数 b 中指定。结果值存储在目标操作数 d 中。
对于 .s32 指令类型,a 中的值被视为 N 位有符号值,并且此 N 位值的最高有效位被复制到第 31 位。对于 .u32 指令类型,a 中的值被视为 N 位无符号数,并零扩展为 32 位。操作数 b 是一个无符号 32 位值。
如果 N 的值为 0,则 szext 的结果为 0。如果 N 的值为 32 或更高,则 szext 的结果取决于 .mode 限定符的值,如下所示
如果
.mode为.clamp,则结果与源操作数a相同。如果
.mode为.wrap,则使用 N 的环绕值计算结果。
语义
b1 = b & 0x1f;
too_large = (b >= 32 && .mode == .clamp) ? true : false;
mask = too_large ? 0 : (~0) << b1;
sign_pos = (b1 - 1) & 0x1f;
if (b1 == 0 || too_large || .type != .s32) {
sign_bit = false;
} else {
sign_bit = (a >> sign_pos) & 1;
}
d = (a & ~mask) | (sign_bit ? mask | 0);
PTX ISA 注释
在 PTX ISA 版本 7.6 中引入。
目标 ISA 注释
szext 需要 sm_70 或更高版本。
示例
szext.clamp.s32 rd, ra, rb;
szext.wrap.u32 rd, 0xffffffff, 0; // Result is 0.
9.7.1.22. 整数算术指令:bmsk
bmsk
位字段掩码。
语法
bmsk.mode.b32 d, a, b;
.mode = { .clamp, .wrap };
描述
生成一个 32 位掩码,从操作数 a 中指定的位位置开始,宽度在操作数 b 中指定。生成的位掩码存储在目标操作数 d 中。
在以下情况下,结果位掩码为 0
当
a的值大于等于 32 且.mode为.clamp时。当指定的
b值或环绕的b值(当.mode指定为.wrap时)为 0 时。
语义
a1 = a & 0x1f;
mask0 = (~0) << a1;
b1 = b & 0x1f;
sum = a1 + b1;
mask1 = (~0) << sum;
sum-overflow = sum >= 32 ? true : false;
bit-position-overflow = false;
bit-width-overflow = false;
if (.mode == .clamp) {
if (a >= 32) {
bit-position-overflow = true;
mask0 = 0;
}
if (b >= 32) {
bit-width-overflow = true;
}
}
if (sum-overflow || bit-position-overflow || bit-width-overflow) {
mask1 = 0;
} else if (b1 == 0) {
mask1 = ~0;
}
d = mask0 & ~mask1;
注释
操作数 b 指定的位掩码宽度在 .clamp 模式下限制为范围 0..32,在 .wrap 模式下限制为范围 0..31。
PTX ISA 注释
在 PTX ISA 版本 7.6 中引入。
目标 ISA 注释
bmsk 需要 sm_70 或更高版本。
示例
bmsk.clamp.b32 rd, ra, rb;
bmsk.wrap.b32 rd, 1, 2; // Creates a bitmask of 0x00000006.
9.7.1.23. 整数算术指令:dp4a
dp4a
四路字节点积累加。
语法
dp4a.atype.btype d, a, b, c;
.atype = .btype = { .u32, .s32 };
描述
四路字节点积,在 32 位结果中累加。
操作数 a 和 b 是 32 位输入,以打包形式保存 4 个字节输入以进行点积运算。
如果 .atype 和 .btype 均为 .u32,则操作数 c 的类型为 .u32;否则操作数 c 的类型为 .s32。
语义
d = c;
// Extract 4 bytes from a 32bit input and sign or zero extend
// based on input type.
Va = extractAndSignOrZeroExt_4(a, .atype);
Vb = extractAndSignOrZeroExt_4(b, .btype);
for (i = 0; i < 4; ++i) {
d += Va[i] * Vb[i];
}
PTX ISA 注释
在 PTX ISA 版本 5.0 中引入。
目标 ISA 注释
需要 sm_61 或更高版本。
示例
dp4a.u32.u32 d0, a0, b0, c0;
dp4a.u32.s32 d1, a1, b1, c1;
9.7.1.24. 整数算术指令:dp2a
dp2a
双路点积累加。
语法
dp2a.mode.atype.btype d, a, b, c;
.atype = .btype = { .u32, .s32 };
.mode = { .lo, .hi };
描述
双路 16 位到 8 位点积,在 32 位结果中累加。
操作数 a 和 b 是 32 位输入。操作数 a 以打包形式保存两个 16 位输入,操作数 b 以打包形式保存 4 个字节输入以进行点积运算。
根据指定的 .mode,将使用操作数 b 的下半部分或上半部分进行点积运算。
如果 .atype 和 .btype 均为 .u32,则操作数 c 的类型为 .u32;否则操作数 c 的类型为 .s32。
语义
d = c;
// Extract two 16-bit values from a 32-bit input and sign or zero extend
// based on input type.
Va = extractAndSignOrZeroExt_2(a, .atype);
// Extract four 8-bit values from a 32-bit input and sign or zer extend
// based on input type.
Vb = extractAndSignOrZeroExt_4(b, .btype);
b_select = (.mode == .lo) ? 0 : 2;
for (i = 0; i < 2; ++i) {
d += Va[i] * Vb[b_select + i];
}
PTX ISA 注释
在 PTX ISA 版本 5.0 中引入。
目标 ISA 注释
需要 sm_61 或更高版本。
示例
dp2a.lo.u32.u32 d0, a0, b0, c0;
dp2a.hi.u32.s32 d1, a1, b1, c1;
9.7.2. 扩展精度整数算术指令
指令 add.cc、addc、sub.cc、subc、mad.cc 和 madc 引用隐式指定的条件代码寄存器 (CC),该寄存器具有单个进位标志位 (CC.CF),用于保存进位/借位输入/输出。这些指令支持扩展精度整数加法、减法和乘法。没有其他指令可以访问条件代码,并且不支持设置、清除或测试条件代码。条件代码寄存器在调用之间不会保留,主要用于直线代码序列中,以计算扩展精度整数加法、减法和乘法。
扩展精度算术指令为
add.cc,addcsub.cc,subcmad.cc,madc
9.7.2.1. 扩展精度算术指令:add.cc
add.cc
带进位输出的加法运算。
语法
add.cc.type d, a, b;
.type = { .u32, .s32, .u64, .s64 };
描述
执行整数加法并将进位输出值写入条件代码寄存器。
语义
d = a + b;
进位输出写入 CC.CF
注释
无整数舍入修饰符。
无饱和。
无符号整数和有符号整数的行为相同。
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入了 32 位 add.cc。
在 PTX ISA 版本 4.3 中引入了 64 位 add.cc。
目标 ISA 注释
所有目标架构都支持 32 位 add.cc。
64 位 add.cc 需要 sm_20 或更高版本。
示例
@p add.cc.u32 x1,y1,z1; // extended-precision addition of
@p addc.cc.u32 x2,y2,z2; // two 128-bit values
@p addc.cc.u32 x3,y3,z3;
@p addc.u32 x4,y4,z4;
9.7.2.2. 扩展精度算术指令:addc
addc
带进位输入和可选进位输出的加法运算。
语法
addc{.cc}.type d, a, b;
.type = { .u32, .s32, .u64, .s64 };
描述
执行带进位输入的整数加法,并可选择将进位输出值写入条件代码寄存器。
语义
d = a + b + CC.CF;
如果指定了 .cc,则进位输出写入 CC.CF
注释
无整数舍入修饰符。
无饱和。
无符号整数和有符号整数的行为相同。
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入了 32 位 addc。
在 PTX ISA 版本 4.3 中引入了 64 位 addc。
目标 ISA 注释
所有目标架构都支持 32 位 addc。
64 位 addc 需要 sm_20 或更高版本。
示例
@p add.cc.u32 x1,y1,z1; // extended-precision addition of
@p addc.cc.u32 x2,y2,z2; // two 128-bit values
@p addc.cc.u32 x3,y3,z3;
@p addc.u32 x4,y4,z4;
9.7.2.3. 扩展精度算术指令:sub.cc
sub.cc
带借位输出的减法运算。
语法
sub.cc.type d, a, b;
.type = { .u32, .s32, .u64, .s64 };
描述
执行整数减法并将借位输出值写入条件代码寄存器。
语义
d = a - b;
借位输出写入 CC.CF
注释
无整数舍入修饰符。
无饱和。
无符号整数和有符号整数的行为相同。
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入了 32 位 sub.cc。
在 PTX ISA 版本 4.3 中引入了 64 位 sub.cc。
目标 ISA 注释
所有目标架构都支持 32 位 sub.cc。
64 位 sub.cc 需要 sm_20 或更高版本。
示例
@p sub.cc.u32 x1,y1,z1; // extended-precision subtraction
@p subc.cc.u32 x2,y2,z2; // of two 128-bit values
@p subc.cc.u32 x3,y3,z3;
@p subc.u32 x4,y4,z4;
9.7.2.4. 扩展精度算术指令:subc
subc
带借位输入和可选借位输出的减法运算。
语法
subc{.cc}.type d, a, b;
.type = { .u32, .s32, .u64, .s64 };
描述
执行带借位输入的整数减法,并可选择将借位输出值写入条件代码寄存器。
语义
d = a - (b + CC.CF);
如果指定了 .cc,则借位输出写入 CC.CF
注释
无整数舍入修饰符。
无饱和。
无符号整数和有符号整数的行为相同。
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入了 32 位 subc。
在 PTX ISA 版本 4.3 中引入了 64 位 subc。
目标 ISA 注释
所有目标架构都支持 32 位 subc。
64 位 subc 需要 sm_20 或更高版本。
示例
@p sub.cc.u32 x1,y1,z1; // extended-precision subtraction
@p subc.cc.u32 x2,y2,z2; // of two 128-bit values
@p subc.cc.u32 x3,y3,z3;
@p subc.u32 x4,y4,z4;
9.7.2.5. 扩展精度算术指令:mad.cc
mad.cc
将两个值相乘,提取结果的高半部分或低半部分,并将第三个值与进位输出相加。
语法
mad{.hi,.lo}.cc.type d, a, b, c;
.type = { .u32, .s32, .u64, .s64 };
描述
将两个值相乘,提取结果的高半部分或低半部分,并加上第三个值。将结果写入目标寄存器,并将加法运算的进位输出写入条件码寄存器。
语义
t = a * b;
d = t<63..32> + c; // for .hi variant
d = t<31..0> + c; // for .lo variant
加法运算的进位输出写入 CC.CF
注释
通常与 madc 和 addc 组合使用,以实现扩展精度的多字乘法。有关示例,请参见 madc。
PTX ISA 注释
32 位 mad.cc 在 PTX ISA 版本 3.0 中引入。
64 位 mad.cc 在 PTX ISA 版本 4.3 中引入。
目标 ISA 注释
需要目标 sm_20 或更高版本。
示例
@p mad.lo.cc.u32 d,a,b,c;
mad.lo.cc.u32 r,p,q,r;
9.7.2.6. 扩展精度算术指令:madc
madc
将两个值相乘,提取结果的高半部分或低半部分,并将第三个值与进位输入和可选的进位输出相加。
语法
madc{.hi,.lo}{.cc}.type d, a, b, c;
.type = { .u32, .s32, .u64, .s64 };
描述
将两个值相乘,提取结果的高半部分或低半部分,并加上第三个值以及进位输入。将结果写入目标寄存器,并可选择将加法运算的进位输出写入条件码寄存器。
语义
t = a * b;
d = t<63..32> + c + CC.CF; // for .hi variant
d = t<31..0> + c + CC.CF; // for .lo variant
如果指定了 .cc,则加法运算的进位输出将写入 CC.CF
注释
通常与 mad.cc 和 addc 组合使用,以实现扩展精度的多字乘法。请参见下面的示例。
PTX ISA 注释
32 位 madc 在 PTX ISA 版本 3.0 中引入。
64 位 madc 在 PTX ISA 版本 4.3 中引入。
目标 ISA 注释
需要目标 sm_20 或更高版本。
示例
// extended-precision multiply: [r3,r2,r1,r0] = [r5,r4] * [r7,r6]
mul.lo.u32 r0,r4,r6; // r0=(r4*r6).[31:0], no carry-out
mul.hi.u32 r1,r4,r6; // r1=(r4*r6).[63:32], no carry-out
mad.lo.cc.u32 r1,r5,r6,r1; // r1+=(r5*r6).[31:0], may carry-out
madc.hi.u32 r2,r5,r6,0; // r2 =(r5*r6).[63:32]+carry-in,
// no carry-out
mad.lo.cc.u32 r1,r4,r7,r1; // r1+=(r4*r7).[31:0], may carry-out
madc.hi.cc.u32 r2,r4,r7,r2; // r2+=(r4*r7).[63:32]+carry-in,
// may carry-out
addc.u32 r3,0,0; // r3 = carry-in, no carry-out
mad.lo.cc.u32 r2,r5,r7,r2; // r2+=(r5*r7).[31:0], may carry-out
madc.hi.u32 r3,r5,r7,r3; // r3+=(r5*r7).[63:32]+carry-in
9.7.3. 浮点指令
浮点指令对 .f32 和 .f64 寄存器操作数和常量立即数值进行操作。浮点指令包括:
testpcopysignaddsubmulfmamaddivabsnegminmaxrcpsqrtrsqrtsincoslg2ex2tanh
支持舍入修饰符的指令符合 IEEE-754 标准。双精度指令支持次正规输入和结果。单精度指令默认情况下为 sm_20 及后续目标架构支持次正规输入和结果,对于 sm_1x 目标架构,则将次正规输入和结果刷新为符号保留零。单精度指令上的可选 .ftz 修饰符提供了与 sm_1x 目标的向后兼容性,无论目标架构如何,都将次正规输入和结果刷新为符号保留零。
单精度 add、sub、mul 和 mad 支持将结果饱和到 [0.0, 1.0] 范围,NaN 被刷新为正零。双精度指令支持 NaN 有效负载(除了 rcp.approx.ftz.f64 和 rsqrt.approx.ftz.f64,它们将输入 NaN 映射到规范 NaN)。单精度指令返回未指定的 NaN。请注意,未来的实现可能会支持单精度指令的 NaN 有效负载,因此 PTX 程序不应依赖于生成的特定单精度 NaN。
表 28 总结了 PTX 中的浮点指令。
指令 |
.rn |
.rz |
.rm |
.rp |
.ftz |
.sat |
注释 |
|---|---|---|---|---|---|---|---|
|
x |
x |
x |
x |
x |
x |
如果未指定舍入修饰符,则默认为 |
|
x |
x |
x |
x |
不适用 |
不适用 |
如果未指定舍入修饰符,则默认为 |
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
x |
无舍入修饰符。 |
|
x |
x |
x |
x |
x |
x |
|
|
x |
x |
x |
x |
不适用 |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
无舍入修饰符。 |
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
不适用 |
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
|
|
x |
x |
x |
x |
x |
不适用 |
|
|
x |
x |
x |
x |
不适用 |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
不适用 |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
不适用 |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
x |
不适用 |
|
|
不适用 |
不适用 |
不适用 |
不适用 |
不适用 |
不适用 |
|
9.7.3.1. 浮点指令:testp
testp
测试浮点属性。
语法
testp.op.type p, a; // result is .pred
.op = { .finite, .infinite,
.number, .notanumber,
.normal, .subnormal };
.type = { .f32, .f64 };
描述
testp 测试浮点数的常用属性,如果为 True 则返回谓词值 1,如果为 False 则返回 0。
testp.finite-
如果输入不是无穷大或
NaN,则为True testp.infinite-
如果输入是正无穷大或负无穷大,则为
True testp.number-
如果输入不是
NaN,则为True testp.notanumber-
如果输入是
NaN,则为True testp.normal-
如果输入是正规数(不是
NaN,不是无穷大),则为True testp.subnormal-
如果输入是次正规数(不是
NaN,不是无穷大),则为True
作为特殊情况,正零和负零被认为是正规数。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。
示例
testp.notanumber.f32 isnan, f0;
testp.infinite.f64 p, X;
9.7.3.2. 浮点指令:copysign
copysign
将一个输入的符号复制到另一个输入。
语法
copysign.type d, a, b;
.type = { .f32, .f64 };
描述
将 a 的符号位复制到 b 的值中,并将结果作为 d 返回。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。
示例
copysign.f32 x, y, z;
copysign.f64 A, B, C;
9.7.3.3. 浮点指令:add
add
将两个值相加。
语法
add{.rnd}{.ftz}{.sat}.f32 d, a, b;
add{.rnd}{.ftz}.f32x2 d, a, b;
add{.rnd}.f64 d, a, b;
.rnd = { .rn, .rz, .rm, .rp };
描述
执行加法并将结果值写入目标寄存器。
对于 .f32x2 指令类型,从源操作数形成单精度 (.f32) 值的输入向量。然后并行添加单精度 (.f32) 操作数,以在目标位置生成 .f32x2 结果。
对于 .f32x2 指令类型,操作数 d、a 和 b 具有 .b64 类型。
语义
if (type == f32 || type == f64) {
d = a + b;
} else if (type == f32x2) {
fA[0] = a[0:31];
fA[1] = a[32:63];
fB[0] = b[0:31];
fB[1] = b[32:63];
for (i = 0; i < 2; i++) {
d[i] = fA[i] + fB[i];
}
}
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
舍入修饰符的默认值为 .rn。请注意,带有显式舍入修饰符的 add 指令会被代码优化器保守处理。没有舍入修饰符的 add 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极优化。特别是,没有舍入修饰符的 mul/add 序列可能会被优化为在目标设备上使用融合乘加指令。
次正规数
sm_20+-
默认情况下,支持次正规数。
add.ftz.f32、add.ftz.f32x2将次正规输入和结果刷新为符号保留零。 sm_1x-
add.f64支持次正规数。add.f32将次正规输入和结果刷新为符号保留零。
饱和修饰符
add.sat.f32 将结果钳制到 [0.0, 1.0]。 NaN 结果被刷新为 +0.0f。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
add.f32x2 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
add.f32 在所有目标架构上均受支持。
add.f64 需要 sm_13 或更高版本。
舍入修饰符具有以下目标要求
-
.rn、.rz -
适用于所有目标
-
.rm、.rp -
对于
add.f64,需要sm_13或更高版本。对于
add.f32,需要sm_20或更高版本。
add.f32x2 需要 sm_100 或更高版本。
示例
@p add.rz.ftz.f32 f1,f2,f3;
add.rp.ftz.f32x2 d, a, b;
9.7.3.4. 浮点指令:sub
sub
从另一个值中减去一个值。
语法
sub{.rnd}{.ftz}{.sat}.f32 d, a, b;
sub{.rnd}{.ftz}.f32x2 d, a, b;
sub{.rnd}.f64 d, a, b;
.rnd = { .rn, .rz, .rm, .rp };
描述
执行减法并将结果值写入目标寄存器。
对于 .f32x2 指令类型,从源操作数形成单精度 (.f32) 值的输入向量。然后并行减去单精度 (.f32) 操作数,以在目标位置生成 .f32x2 结果。
对于 .f32x2 指令类型,操作数 d、a 和 b 具有 .b64 类型。
语义
if (type == f32 || type == f64) {
d = a - b;
} else if (type == f32x2) {
fA[0] = a[0:31];
fA[1] = a[32:63];
fB[0] = b[0:31];
fB[1] = b[32:63];
for (i = 0; i < 2; i++) {
d[i] = fA[i] - fB[i];
}
}
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
舍入修饰符的默认值为 .rn。请注意,带有显式舍入修饰符的 sub 指令会被代码优化器保守处理。没有舍入修饰符的 sub 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极优化。特别是,没有舍入修饰符的 mul/sub 序列可能会被优化为在目标设备上使用融合乘加指令。
次正规数
sm_20+-
默认情况下,支持次正规数。
sub.ftz.f32、sub.ftz.f32x2将次正规输入和结果刷新为符号保留零。 sm_1x-
sub.f64支持次正规数。sub.f32将次正规输入和结果刷新为符号保留零。
饱和修饰符
sub.sat.f32 将结果钳制到 [0.0, 1.0]。 NaN 结果被刷新为 +0.0f。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
sub.f32x2 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
sub.f32 在所有目标架构上均受支持。
sub.f64 需要 sm_13 或更高版本。
舍入修饰符具有以下目标要求
-
.rn、.rz -
适用于所有目标
-
.rm、.rp -
对于
sub.f64,需要sm_13或更高版本。对于
sub.f32,需要sm_20或更高版本。
sub.f32x2 需要 sm_100 或更高版本。
示例
sub.f32 c,a,b;
sub.rn.ftz.f32 f1,f2,f3;
9.7.3.5. 浮点指令:mul
mul
将两个值相乘。
语法
mul{.rnd}{.ftz}{.sat}.f32 d, a, b;
mul{.rnd}{.ftz}.f32x2 d, a, b;
mul{.rnd}.f64 d, a, b;
.rnd = { .rn, .rz, .rm, .rp };
描述
计算两个值的乘积。
对于 .f32x2 指令类型,从源操作数形成单精度 (.f32) 值的输入向量。然后并行乘以单精度 (.f32) 操作数,以在目标位置生成 .f32x2 结果。
对于 .f32x2 指令类型,操作数 d、a 和 b 具有 .b64 类型。
语义
if (type == f32 || type == f64) {
d = a * b;
} else if (type == f32x2) {
fA[0] = a[0:31];
fA[1] = a[32:63];
fB[0] = b[0:31];
fB[1] = b[32:63];
for (i = 0; i < 2; i++) {
d[i] = fA[i] * fB[i];
}
}
注释
对于浮点乘法,所有操作数的大小必须相同。
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
舍入修饰符的默认值为 .rn。请注意,带有显式舍入修饰符的 mul 指令会被代码优化器保守处理。没有舍入修饰符的 mul 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极优化。特别是,没有舍入修饰符的 mul/add 和 mul/sub 序列可能会被优化为在目标设备上使用融合乘加指令。
次正规数
sm_20+-
默认情况下,支持次正规数。
mul.ftz.f32、mul.ftz.f32x2将次正规输入和结果刷新为符号保留零。 sm_1x-
mul.f64支持次正规数。mul.f32将次正规输入和结果刷新为符号保留零。
饱和修饰符
mul.sat.f32 将结果钳制到 [0.0, 1.0]。 NaN 结果被刷新为 +0.0f。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
mul.f32x2 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
mul.f32 在所有目标架构上均受支持。
mul.f64 需要 sm_13 或更高版本。
舍入修饰符具有以下目标要求
-
.rn、.rz -
适用于所有目标
-
.rm、.rp -
对于
mul.f64,需要sm_13或更高版本。对于
mul.f32,需要sm_20或更高版本。
mul.f32x2 需要 sm_100 或更高版本。
示例
mul.ftz.f32 circumf,radius,pi // a single-precision multiply
9.7.3.6. 浮点指令:fma
fma
融合乘加。
语法
fma.rnd{.ftz}{.sat}.f32 d, a, b, c;
fma.rnd{.ftz}.f32x2 d, a, b, c;
fma.rnd.f64 d, a, b, c;
.rnd = { .rn, .rz, .rm, .rp };
描述
执行融合乘加运算,中间乘积和加法运算不会损失精度。
对于 .f32x2 指令类型,从源操作数形成单精度 (.f32) 值的输入向量。然后并行操作单精度 (.f32) 操作数,以在目标位置生成 .f32x2 结果。
对于 .f32x2 指令类型,操作数 d、a、b 和 c 具有 .b64 类型。
语义
if (type == f32 || type == f64) {
d = a * b + c;
} else if (type == f32x2) {
fA[0] = a[0:31];
fA[1] = a[32:63];
fB[0] = b[0:31];
fB[1] = b[32:63];
fC[0] = c[0:31];
fC[1] = c[32:63];
for (i = 0; i < 2; i++) {
d[i] = fA[i] * fB[i] + fC[i];
}
}
注释
fma.f32 计算 a 和 b 的乘积,精度为无限精度,然后将 c 加到此乘积,同样精度为无限精度。然后使用 .rnd 指定的舍入模式将结果值舍入为单精度。
fma.f64 计算 a 和 b 的乘积,精度为无限精度,然后将 c 加到此乘积,同样精度为无限精度。然后使用 .rnd 指定的舍入模式将结果值舍入为双精度。
fma.f64 与 mad.f64 相同。
舍入修饰符(无默认值)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
次正规数
sm_20+-
默认情况下,支持次正规数。
fma.ftz.f32、fma.ftz.f32x2将次正规输入和结果刷新为符号保留零。 sm_1x-
fma.f64支持次正规数。fma.f32对于sm_1x目标架构未实现。
饱和
fma.sat.f32 将结果钳制到 [0.0, 1.0]。 NaN 结果被刷新为 +0.0f。
PTX ISA 注释
fma.f64 在 PTX ISA 版本 1.4 中引入。
fma.f32 在 PTX ISA 版本 2.0 中引入。
fma.f32x2 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
fma.f32 需要 sm_20 或更高版本。
fma.f64 需要 sm_13 或更高版本。
fma.f32x2 需要 sm_100 或更高版本。
示例
fma.rn.ftz.f32 w,x,y,z;
@p fma.rn.f64 d,a,b,c;
fma.rp.ftz.f32x2 p,q,r,s;
9.7.3.7. 浮点指令:mad
mad
将两个值相乘并加上第三个值。
语法
mad{.ftz}{.sat}.f32 d, a, b, c; // .target sm_1x
mad.rnd{.ftz}{.sat}.f32 d, a, b, c; // .target sm_20
mad.rnd.f64 d, a, b, c; // .target sm_13 and higher
.rnd = { .rn, .rz, .rm, .rp };
描述
将两个值相乘并加上第三个值,然后将结果值写入目标寄存器。
语义
d = a*b + c;
注释
对于 .target sm_20 及更高版本
mad.f32计算a和b的乘积,精度为无限精度,然后将c加到此乘积,同样精度为无限精度。然后使用.rnd指定的舍入模式将结果值舍入为单精度。mad.f64计算a和b的乘积,精度为无限精度,然后将c加到此乘积,同样精度为无限精度。然后使用.rnd指定的舍入模式将结果值舍入为双精度。mad.{f32,f64}与fma.{f32,f64}相同。
对于 .target sm_1x
mad.f32以双精度计算a和b的乘积,然后将尾数截断为 23 位,但保留指数。请注意,这与使用mul计算乘积不同,在mul中,尾数可以舍入,指数将被钳制。mad.f32的例外情况是当c = +/-0.0时,mad.f32与使用单独的 mul 和 add 指令计算的结果相同。当为 SM 2.0 设备进行 JIT 编译时,mad.f32被实现为融合乘加运算(即fma.rn.ftz.f32)。在这种情况下,mad.f32可能会产生略微不同的数值结果,并且不保证向后兼容性。mad.f64计算a和b的乘积,精度为无限精度,然后将c加到此乘积,同样精度为无限精度。然后使用.rnd指定的舍入模式将结果值舍入为双精度。与mad.f32不同,次正规输入和输出的处理遵循 IEEE 754 标准。mad.f64与fma.f64相同。
舍入修饰符(无默认值)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
次正规数
sm_20+-
默认情况下,支持次正规数。
mad.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
mad.f64支持次正规数。mad.f32将次正规输入和结果刷新为符号保留零。
饱和修饰符
mad.sat.f32 将结果钳制到 [0.0, 1.0]。 NaN 结果被刷新为 +0.0f。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
在 PTX ISA 版本 1.4 及更高版本中,mad.f64 需要舍入修饰符。
没有舍入修饰符的旧版 mad.f64 指令将映射到 mad.rn.f64。
在 PTX ISA 版本 2.0 及更高版本中,对于 sm_20 及更高版本目标架构,mad.f32 需要舍入修饰符。
勘误
mad.f32 对于 sm_20 及更高版本目标架构需要舍入修饰符。但是,对于 PTX ISA 版本 3.0 及更早版本,ptxas 不强制执行此要求,并且 mad.f32 默认静默地变为 mad.rn.f32。对于 PTX ISA 版本 3.1,ptxas 生成警告并默认变为 mad.rn.f32,在后续版本中,ptxas 将强制执行 PTX ISA 版本 3.2 及更高版本的此要求。
目标 ISA 注释
mad.f32 在所有目标架构上均受支持。
mad.f64 需要 sm_13 或更高版本。
舍入修饰符具有以下目标要求
.rn、.rz、.rm、.rp对于mad.f64,需要sm_13或更高版本。.rn、.rz、.rm、.rp对于mad.f32,需要sm_20或更高版本。
示例
@p mad.f32 d,a,b,c;
9.7.3.8. 浮点指令:div
div
将一个值除以另一个值。
语法
div.approx{.ftz}.f32 d, a, b; // fast, approximate divide
div.full{.ftz}.f32 d, a, b; // full-range approximate divide
div.rnd{.ftz}.f32 d, a, b; // IEEE 754 compliant rounding
div.rnd.f64 d, a, b; // IEEE 754 compliant rounding
.rnd = { .rn, .rz, .rm, .rp };
描述
将 a 除以 b,并将结果存储在 d 中。
语义
d = a / b;
注释
快速、近似的单精度除法
div.approx.f32实现了快速近似除法,计算为d = a * (1/b)。对于 [2-126, 2126] 范围内的|b|,最大ulp误差为 2。对于 2126 <|b|< 2128,如果a是无穷大,则div.approx.f32返回NaN,否则返回 0。div.full.f32实现了相对快速、全范围的近似,它可以缩放操作数以获得更好的精度,但并非完全符合 IEEE 754 标准,并且不支持舍入修饰符。在所有输入范围内,最大ulp误差为 2。次正规输入和结果被刷新为符号保留零。快速、近似的除以零会创建一个无穷大值(符号与
a相同)。
具有 IEEE 754 兼容舍入的除法
舍入修饰符(无默认值)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
次正规数
sm_20+-
默认情况下,支持次正规数。
div.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
div.f64支持次正规数。div.f32将次正规输入和结果刷新为符号保留零。
PTX ISA 注释
div.f32 和 div.f64 在 PTX ISA 版本 1.0 中引入。
显式修饰符 .approx、.full、.ftz 和舍入在 PTX ISA 版本 1.4 中引入。
对于 PTX ISA 版本 1.4 及更高版本,需要 .approx、.full 或 .rnd 之一。
对于 PTX ISA 版本 1.0 到 1.3,div.f32 默认为 div.approx.ftz.f32,div.f64 默认为 div.rn.f64。
目标 ISA 注释
div.approx.f32 和 div.full.f32 在所有目标架构上均受支持。
div.rnd.f32 需要 sm_20 或更高版本。
div.rn.f64 需要 sm_13 或更高版本,或者 .target map_f64_to_f32。
div.{rz,rm,rp}.f64 需要 sm_20 或更高版本。
示例
div.approx.ftz.f32 diam,circum,3.14159;
div.full.ftz.f32 x, y, z;
div.rn.f64 xd, yd, zd;
9.7.3.9. 浮点指令:abs
abs
绝对值。
语法
abs{.ftz}.f32 d, a;
abs.f64 d, a;
描述
取 a 的绝对值,并将结果存储在 d 中。
语义
d = |a|;
注释
次正规数
sm_20+-
默认情况下,支持次正规数。
abs.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
abs.f64支持次正规数。abs.f32将次正规输入和结果刷新为符号保留零。
对于 abs.f32,NaN 输入产生未指定的 NaN。对于 abs.f64,NaN 输入保持不变地传递。未来的实现可能会通过保留有效载荷并仅修改符号位来符合 IEEE 754 标准。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
abs.f32 在所有目标架构上均受支持。
abs.f64 需要 sm_13 或更高版本。
示例
abs.ftz.f32 x,f0;
9.7.3.10. 浮点指令:neg
neg
算术求反。
语法
neg{.ftz}.f32 d, a;
neg.f64 d, a;
描述
取反 a 的符号,并将结果存储在 d 中。
语义
d = -a;
注释
次正规数
sm_20+-
默认情况下,支持次正规数。
neg.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
neg.f64支持次正规数。neg.f32将次正规输入和结果刷新为符号保留零。
NaN 输入产生未指定的 NaN。未来的实现可能会通过保留有效载荷并仅修改符号位来符合 IEEE 754 标准。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
neg.f32 在所有目标架构上均受支持。
neg.f64 需要 sm_13 或更高版本。
示例
neg.ftz.f32 x,f0;
9.7.3.11. 浮点指令:min
min
查找两个值中的最小值。
语法
min{.ftz}{.NaN}{.xorsign.abs}.f32 d, a, b;
min.f64 d, a, b;
描述
将 a 和 b 中的最小值存储在 d 中。
如果指定了 .NaN 修饰符,则当任一输入为 NaN 时,结果为规范 NaN。
如果指定了 .abs 修饰符,则目标操作数 d 的幅度是两个输入参数的绝对值的最小值。
如果指定了 .xorsign 修饰符,则目标 d 的符号位等于两个输入的符号位的异或。
修饰符 .abs 和 .xorsign 必须一起指定,并且 .xorsign 在应用 .abs 操作之前会考虑两个输入的符号位。
如果 min 的结果是 NaN,则 .xorsign 和 .abs 修饰符将被忽略。
语义
if (.xorsign) {
xorsign = getSignBit(a) ^ getSignBit(b);
if (.abs) {
a = |a|;
b = |b|;
}
}
if (isNaN(a) && isNaN(b)) d = NaN;
else if (.NaN && (isNaN(a) || isNaN(b))) d = NaN;
else if (isNaN(a)) d = b;
else if (isNaN(b)) d = a;
else d = (a < b) ? a : b;
if (.xorsign && !isNaN(d)) {
setSignBit(d, xorsign);
}
注释
次正规数
sm_20+-
默认情况下,支持次正规数。
min.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
min.f64支持次正规数。min.f32将次正规输入和结果刷新为符号保留零。
如果两个输入的值均为 0.0,则 +0.0 > -0.0。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
min.NaN 在 PTX ISA 版本 7.0 中引入。
min.xorsign.abs 在 PTX ISA 版本 7.2 中引入。
目标 ISA 注释
min.f32 在所有目标架构上均受支持。
min.f64 需要 sm_13 或更高版本。
min.NaN 需要 sm_80 或更高版本。
min.xorsign.abs 需要 sm_86 或更高版本。
示例
@p min.ftz.f32 z,z,x;
min.f64 a,b,c;
// fp32 min with .NaN
min.NaN.f32 f0,f1,f2;
// fp32 min with .xorsign.abs
min.xorsign.abs.f32 Rd, Ra, Rb;
9.7.3.12. 浮点指令:max
max
查找两个值中的最大值。
语法
max{.ftz}{.NaN}{.xorsign.abs}.f32 d, a, b;
max.f64 d, a, b;
描述
将 a 和 b 中的最大值存储在 d 中。
如果指定了 .NaN 修饰符,则当任一输入为 NaN 时,结果为规范 NaN。
如果指定了 .abs 修饰符,则目标操作数 d 的幅度是两个输入参数的绝对值的最大值。
如果指定了 .xorsign 修饰符,则目标 d 的符号位等于两个输入的符号位的异或。
修饰符 .abs 和 .xorsign 必须一起指定,并且 .xorsign 在应用 .abs 操作之前会考虑两个输入的符号位。
如果 max 的结果是 NaN,则 .xorsign 和 .abs 修饰符将被忽略。
语义
if (.xorsign) {
xorsign = getSignBit(a) ^ getSignBit(b);
if (.abs) {
a = |a|;
b = |b|;
}
}
if (isNaN(a) && isNaN(b)) d = NaN;
else if (.NaN && (isNaN(a) || isNaN(b))) d = NaN;
else if (isNaN(a)) d = b;
else if (isNaN(b)) d = a;
else d = (a > b) ? a : b;
if (.xorsign && !isNaN(d)) {
setSignBit(d, xorsign);
}
注释
次正规数
sm_20+-
默认情况下,支持次正规数。
max.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
max.f64支持次正规数。max.f32将次正规输入和结果刷新为符号保留零。
如果两个输入的值均为 0.0,则 +0.0 > -0.0。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
max.NaN 在 PTX ISA 版本 7.0 中引入。
max.xorsign.abs 在 PTX ISA 版本 7.2 中引入。
目标 ISA 注释
max.f32 在所有目标架构上均受支持。
max.f64 需要 sm_13 或更高版本。
max.NaN 需要 sm_80 或更高版本。
max.xorsign.abs 需要 sm_86 或更高版本。
示例
max.ftz.f32 f0,f1,f2;
max.f64 a,b,c;
// fp32 max with .NaN
max.NaN.f32 f0,f1,f2;
// fp32 max with .xorsign.abs
max.xorsign.abs.f32 Rd, Ra, Rb;
9.7.3.13. 浮点指令:rcp
rcp
取一个值的倒数。
语法
rcp.approx{.ftz}.f32 d, a; // fast, approximate reciprocal
rcp.rnd{.ftz}.f32 d, a; // IEEE 754 compliant rounding
rcp.rnd.f64 d, a; // IEEE 754 compliant rounding
.rnd = { .rn, .rz, .rm, .rp };
描述
计算 1/a,并将结果存储在 d 中。
语义
d = 1 / a;
注释
快速、近似的单精度倒数
rcp.approx.f32 实现快速近似倒数。在整个输入范围内,最大 ulp 误差为 1。
输入 |
结果 |
|---|---|
-Inf |
-0.0 |
-0.0 |
-Inf |
+0.0 |
+Inf |
+Inf |
+0.0 |
NaN |
NaN |
具有 IEEE 754 兼容舍入的倒数
舍入修饰符(无默认值)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
次正规数
sm_20+-
默认情况下,支持次正规数。
rcp.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
rcp.f64支持次正规数。rcp.f32将次正规输入和结果刷新为符号保留零。
PTX ISA 注释
rcp.f32 和 rcp.f64 在 PTX ISA 版本 1.0 中引入。rcp.rn.f64 和显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。通用舍入修饰符在 PTX ISA 版本 2.0 中添加。
对于 PTX ISA 版本 1.4 及更高版本,.approx 或 .rnd 之一是必需的。
对于 PTX ISA 版本 1.0 到 1.3,rcp.f32 默认为 rcp.approx.ftz.f32,而 rcp.f64 默认为 rcp.rn.f64。
目标 ISA 注释
rcp.approx.f32 在所有目标架构上均受支持。
rcp.rnd.f32 需要 sm_20 或更高版本。
rcp.rn.f64 需要 sm_13 或更高版本,或者 .target map_f64_to_f32.
rcp.{rz,rm,rp}.f64 需要 sm_20 或更高版本。
示例
rcp.approx.ftz.f32 ri,r;
rcp.rn.ftz.f32 xi,x;
rcp.rn.f64 xi,x;
9.7.3.14. 浮点指令:rcp.approx.ftz.f64
rcp.approx.ftz.f64
计算一个值的倒数的快速、粗略近似值。
语法
rcp.approx.ftz.f64 d, a;
描述
按如下方式计算倒数的快速、粗略近似值
提取
.f64操作数a的最高有效 32 位,采用 1.11.20 IEEE 浮点格式(即,忽略a的最低有效 32 位),使用操作数
a的尾数的最高有效 20 位,计算此值的近似.f64倒数,将生成的 32 位以 1.11.20 IEEE 浮点格式放置在目标
d的最高有效 32 位中,以及将
.f64目标d的最低有效 32 位尾数置零。
语义
tmp = a[63:32]; // upper word of a, 1.11.20 format
d[63:32] = 1.0 / tmp;
d[31:0] = 0x00000000;
注释
rcp.approx.ftz.f64 实现倒数的快速、粗略近似值。
输入 a[63:32] |
结果 d[63:32] |
|---|---|
-Inf |
-0.0 |
-次正规数 |
-Inf |
-0.0 |
-Inf |
+0.0 |
+Inf |
+次正规数 |
+Inf |
+Inf |
+0.0 |
NaN |
NaN |
输入 NaN 映射到规范 NaN,编码为 0x7fffffff00000000。
次正规输入和结果被刷新为符号保留零。
PTX ISA 注释
rcp.approx.ftz.f64 在 PTX ISA 版本 2.1 中引入。
目标 ISA 注释
rcp.approx.ftz.f64 需要 sm_20 或更高版本。
示例
rcp.approx.ftz.f64 xi,x;
9.7.3.15. 浮点指令:sqrt
sqrt
取一个值的平方根。
语法
sqrt.approx{.ftz}.f32 d, a; // fast, approximate square root
sqrt.rnd{.ftz}.f32 d, a; // IEEE 754 compliant rounding
sqrt.rnd.f64 d, a; // IEEE 754 compliant rounding
.rnd = { .rn, .rz, .rm, .rp };
描述
计算 sqrt(a) 并将结果存储在 d 中。
语义
d = sqrt(a);
注释
sqrt.approx.f32 实现平方根的快速近似值。在整个正有限浮点范围内,最大相对误差为 2-23。
对于各种边界情况输入,下表显示了 sqrt 指令的结果
输入 |
结果 |
|---|---|
-Inf |
NaN |
-正规数 |
NaN |
-0.0 |
-0.0 |
+0.0 |
+0.0 |
+Inf |
+Inf |
NaN |
NaN |
具有 IEEE 754 兼容舍入的平方根
舍入修饰符(无默认值)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
次正规数
sm_20+-
默认情况下,支持次正规数。
sqrt.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
sqrt.f64支持次正规数。sqrt.f32将次正规输入和结果刷新为符号保留零。
PTX ISA 注释
sqrt.f32 和 sqrt.f64 在 PTX ISA 版本 1.0 中引入。sqrt.rn.f64 和显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。通用舍入修饰符在 PTX ISA 版本 2.0 中添加。
对于 PTX ISA 版本 1.4 及更高版本,.approx 或 .rnd 之一是必需的。
对于 PTX ISA 版本 1.0 到 1.3,sqrt.f32 默认为 sqrt.approx.ftz.f32,而 sqrt.f64 默认为 sqrt.rn.f64。
目标 ISA 注释
sqrt.approx.f32 在所有目标架构上均受支持。
sqrt.rnd.f32 需要 sm_20 或更高版本。
sqrt.rn.f64 需要 sm_13 或更高版本,或者 .target map_f64_to_f32。
sqrt.{rz,rm,rp}.f64 需要 sm_20 或更高版本。
示例
sqrt.approx.ftz.f32 r,x;
sqrt.rn.ftz.f32 r,x;
sqrt.rn.f64 r,x;
9.7.3.16. 浮点指令:rsqrt
rsqrt
取一个值的平方根的倒数。
语法
rsqrt.approx{.ftz}.f32 d, a;
rsqrt.approx.f64 d, a;
描述
计算 1/sqrt(a) 并将结果存储在 d 中。
语义
d = 1/sqrt(a);
注释
rsqrt.approx 实现平方根倒数的近似值。
输入 |
结果 |
|---|---|
-Inf |
NaN |
-正规数 |
NaN |
-0.0 |
-Inf |
+0.0 |
+Inf |
+Inf |
+0.0 |
NaN |
NaN |
对于 rsqrt.f32,在整个正有限浮点范围内,最大相对误差为 2-22.9。
次正规数
sm_20+-
默认情况下,支持次正规数。
rsqrt.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
rsqrt.f64支持次正规数。rsqrt.f32将次正规输入和结果刷新为符号保留零。
请注意,rsqrt.approx.f64 在软件中模拟,并且相对较慢。
PTX ISA 注释
rsqrt.f32 和 rsqrt.f64 在 PTX ISA 版本 1.0 中引入。显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。
对于 PTX ISA 版本 1.4 及更高版本,.approx 修饰符是必需的。
对于 PTX ISA 版本 1.0 到 1.3,rsqrt.f32 默认为 rsqrt.approx.ftz.f32,而 rsqrt.f64 默认为 rsqrt.approx.f64。
目标 ISA 注释
rsqrt.f32 在所有目标架构上均受支持。
rsqrt.f64 需要 sm_13 或更高版本。
示例
rsqrt.approx.ftz.f32 isr, x;
rsqrt.approx.f64 ISR, X;
9.7.3.17. 浮点指令:rsqrt.approx.ftz.f64
rsqrt.approx.ftz.f64
计算一个值的平方根倒数的近似值。
语法
rsqrt.approx.ftz.f64 d, a;
描述
计算一个值的双精度 (.f64) 平方根倒数的近似值。双精度 (.f64) 目标 d 的最低有效 32 位均为零。
语义
tmp = a[63:32]; // upper word of a, 1.11.20 format
d[63:32] = 1.0 / sqrt(tmp);
d[31:0] = 0x00000000;
注释
rsqrt.approx.ftz.f64 实现一个值的平方根倒数的快速近似值。
输入 |
结果 |
|---|---|
-Inf |
NaN |
-次正规数 |
-Inf |
-0.0 |
-Inf |
+0.0 |
+Inf |
+次正规数 |
+Inf |
+Inf |
+0.0 |
NaN |
NaN |
输入 NaN 映射到规范 NaN,编码为 0x7fffffff00000000。
次正规输入和结果被刷新为符号保留零。
PTX ISA 注释
rsqrt.approx.ftz.f64 在 PTX ISA 版本 4.0 中引入。
目标 ISA 注释
rsqrt.approx.ftz.f64 需要 sm_20 或更高版本。
示例
rsqrt.approx.ftz.f64 xi,x;
9.7.3.18. 浮点指令:sin
sin
查找一个值的正弦值。
语法
sin.approx{.ftz}.f32 d, a;
描述
查找角度 a(以弧度为单位)的正弦值。
语义
d = sin(a);
注释
sin.approx.f32 实现正弦的快速近似值。
输入 |
结果 |
|---|---|
-Inf |
NaN |
-0.0 |
-0.0 |
+0.0 |
+0.0 |
+Inf |
NaN |
NaN |
NaN |
输入范围内的最大绝对误差如下
范围 |
[-2pi .. 2pi] |
[-100pi .. +100pi] |
误差 |
2-20.5 |
2-14.7 |
在范围 [-100pi .. +100pi] 之外,仅提供尽力而为的结果。没有定义的误差保证。
次正规数
sm_20+-
默认情况下,支持次正规数。
sin.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
次正规输入和结果刷新为符号保留零。
PTX ISA 注释
sin.f32 在 PTX ISA 版本 1.0 中引入。显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。
对于 PTX ISA 版本 1.4 及更高版本,.approx 修饰符是必需的。
对于 PTX ISA 版本 1.0 到 1.3,sin.f32 默认为 sin.approx.ftz.f32。
目标 ISA 注释
所有目标架构均支持。
示例
sin.approx.ftz.f32 sa, a;
9.7.3.19. 浮点指令:cos
cos
查找一个值的余弦值。
语法
cos.approx{.ftz}.f32 d, a;
描述
查找角度 a(以弧度为单位)的余弦值。
语义
d = cos(a);
注释
cos.approx.f32 实现余弦的快速近似值。
输入 |
结果 |
|---|---|
-Inf |
NaN |
-0.0 |
+1.0 |
+0.0 |
+1.0 |
+Inf |
NaN |
NaN |
NaN |
输入范围内的最大绝对误差如下
范围 |
[-2pi .. 2pi] |
[-100pi .. +100pi] |
误差 |
2-20.5 |
2-14.7 |
在范围 [-100pi .. +100pi] 之外,仅提供尽力而为的结果。没有定义的误差保证。
次正规数
sm_20+-
默认情况下,支持次正规数。
cos.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
次正规输入和结果刷新为符号保留零。
PTX ISA 注释
cos.f32 在 PTX ISA 版本 1.0 中引入。显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。
对于 PTX ISA 版本 1.4 及更高版本,.approx 修饰符是必需的。
对于 PTX ISA 版本 1.0 到 1.3,cos.f32 默认为 cos.approx.ftz.f32。
目标 ISA 注释
所有目标架构均支持。
示例
cos.approx.ftz.f32 ca, a;
9.7.3.20. 浮点指令:lg2
lg2
查找一个值的以 2 为底的对数。
语法
lg2.approx{.ftz}.f32 d, a;
描述
确定 a 的 log2。
语义
d = log(a) / log(2);
注释
lg2.approx.f32 实现 log2(a) 的快速近似值。
输入 |
结果 |
|---|---|
-Inf |
NaN |
-正规数 |
NaN |
-0.0 |
-Inf |
+0.0 |
-Inf |
+Inf |
+Inf |
NaN |
NaN |
当输入操作数在 (0.5, 2) 范围内时,最大绝对误差为 2-22。对于此区间之外的正有限输入,最大相对误差为 2-22。
次正规数
sm_20+-
默认情况下,支持次正规数。
lg2.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
次正规输入和结果刷新为符号保留零。
PTX ISA 注释
lg2.f32 在 PTX ISA 版本 1.0 中引入。显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。
对于 PTX ISA 版本 1.4 及更高版本,.approx 修饰符是必需的。
对于 PTX ISA 版本 1.0 到 1.3,lg2.f32 默认为 lg2.approx.ftz.f32。
目标 ISA 注释
所有目标架构均支持。
示例
lg2.approx.ftz.f32 la, a;
9.7.3.21. 浮点指令:ex2
ex2
查找一个值的以 2 为底的指数。
语法
ex2.approx{.ftz}.f32 d, a;
描述
将 2 提升到 a 次幂。
语义
d = 2 ^ a;
注释
ex2.approx.f32 实现 2a 的快速近似值。
输入 |
结果 |
|---|---|
-Inf |
+0.0 |
-0.0 |
+1.0 |
+0.0 |
+1.0 |
+Inf |
+Inf |
NaN |
NaN |
在整个输入范围内,最大 ulp 误差为正确舍入结果的 2 ulp。
次正规数
sm_20+-
默认情况下,支持次正规数。
ex2.ftz.f32将次正规输入和结果刷新为符号保留零。 sm_1x-
次正规输入和结果刷新为符号保留零。
PTX ISA 注释
ex2.f32 在 PTX ISA 版本 1.0 中引入。显式修饰符 .approx 和 .ftz 在 PTX ISA 版本 1.4 中引入。
对于 PTX ISA 版本 1.4 及更高版本,.approx 修饰符是必需的。
对于 PTX ISA 版本 1.0 到 1.3,ex2.f32 默认为 ex2.approx.ftz.f32。
目标 ISA 注释
所有目标架构均支持。
示例
ex2.approx.ftz.f32 xa, a;
9.7.3.22. 浮点指令:tanh
tanh
查找一个值的双曲正切值(以弧度为单位)
语法
tanh.approx.f32 d, a;
描述
取 a 的双曲正切值。
操作数 d 和 a 的类型为 .f32。
语义
d = tanh(a);
注释
tanh.approx.f32 实现 FP32 双曲正切的快速近似值。
各种边界情况输入的 tanh 结果如下
输入 |
结果 |
|---|---|
-Inf |
-1.0 |
-0.0 |
-0.0 |
+0.0 |
+0.0 |
+Inf |
1.0 |
NaN |
NaN |
在整个浮点范围内,最大相对误差为 2-11。支持次正规数。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
目标 ISA 注释
需要 sm_75 或更高版本。
示例
tanh.approx.f32 ta, a;
9.7.4. 半精度浮点指令
半精度浮点指令对 .f16 和 .f16x2 寄存器操作数进行操作。半精度浮点指令包括
addsubmulfmanegabsminmaxtanhex2
半精度 add、sub、mul 和 fma 支持将结果饱和到 [0.0, 1.0] 范围,其中 NaN 被刷新为正零。半精度指令返回未指定的 NaN。
9.7.4.1. 半精度浮点指令:add
add
将两个值相加。
语法
add{.rnd}{.ftz}{.sat}.f16 d, a, b;
add{.rnd}{.ftz}{.sat}.f16x2 d, a, b;
add{.rnd}.bf16 d, a, b;
add{.rnd}.bf16x2 d, a, b;
.rnd = { .rn };
描述
执行加法并将结果值写入目标寄存器。
对于 .f16x2 和 .bf16x2 指令类型,通过源操作数的半字值形成输入向量。然后并行添加半字操作数,以在目标中生成 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d、a 和 b 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d、a 和 b 具有 .b32 类型。对于 .bf16 指令类型,操作数 d、a、b 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d、a、b 具有 .b32 类型。
语义
if (type == f16 || type == bf16) {
d = a + b;
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
for (i = 0; i < 2; i++) {
d[i] = fA[i] + fB[i];
}
}
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
舍入修饰符的默认值为 .rn。请注意,带有显式舍入修饰符的 add 指令会被代码优化器保守处理。没有舍入修饰符的 add 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极优化。特别是,没有舍入修饰符的 mul/add 序列可能会被优化为在目标设备上使用融合乘加指令。
- 次正规数
-
默认情况下,支持次正规数。
add.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。 - 饱和修饰符
-
add.sat.{f16, f16x2}将结果钳制到 [0.0, 1.0]。NaN结果被刷新为+0.0f。
PTX ISA 注释
在 PTX ISA 版本 4.2 中引入。
add{.rnd}.bf16 和 add{.rnd}.bf16x2 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
add{.rnd}.bf16 和 add{.rnd}.bf16x2 需要 sm_90 或更高版本。
示例
// scalar f16 additions
add.f16 d0, a0, b0;
add.rn.f16 d1, a1, b1;
add.bf16 bd0, ba0, bb0;
add.rn.bf16 bd1, ba1, bb1;
// SIMD f16 addition
cvt.rn.f16.f32 h0, f0;
cvt.rn.f16.f32 h1, f1;
cvt.rn.f16.f32 h2, f2;
cvt.rn.f16.f32 h3, f3;
mov.b32 p1, {h0, h1}; // pack two f16 to 32bit f16x2
mov.b32 p2, {h2, h3}; // pack two f16 to 32bit f16x2
add.f16x2 p3, p1, p2; // SIMD f16x2 addition
// SIMD bf16 addition
cvt.rn.bf16x2.f32 p4, f4, f5; // Convert two f32 into packed bf16x2
cvt.rn.bf16x2.f32 p5, f6, f7; // Convert two f32 into packed bf16x2
add.bf16x2 p6, p4, p5; // SIMD bf16x2 addition
// SIMD fp16 addition
ld.global.b32 f0, [addr]; // load 32 bit which hold packed f16x2
ld.global.b32 f1, [addr + 4]; // load 32 bit which hold packed f16x2
add.f16x2 f2, f0, f1; // SIMD f16x2 addition
ld.global.b32 f3, [addr + 8]; // load 32 bit which hold packed bf16x2
ld.global.b32 f4, [addr + 12]; // load 32 bit which hold packed bf16x2
add.bf16x2 f5, f3, f4; // SIMD bf16x2 addition
9.7.4.2. 半精度浮点指令:sub
sub
减去两个值。
语法
sub{.rnd}{.ftz}{.sat}.f16 d, a, b;
sub{.rnd}{.ftz}{.sat}.f16x2 d, a, b;
sub{.rnd}.bf16 d, a, b;
sub{.rnd}.bf16x2 d, a, b;
.rnd = { .rn };
描述
执行减法并将结果值写入目标寄存器。
对于 .f16x2 和 .bf16x2 指令类型,通过源操作数的半字值形成输入向量。然后并行减去半字操作数,以在目标中生成 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d、a 和 b 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d、a 和 b 具有 .b32 类型。对于 .bf16 指令类型,操作数 d、a、b 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d、a、b 具有 .b32 类型。
语义
if (type == f16 || type == bf16) {
d = a - b;
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
for (i = 0; i < 2; i++) {
d[i] = fA[i] - fB[i];
}
}
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
舍入修饰符的默认值为 .rn。请注意,带有显式舍入修饰符的 sub 指令会被代码优化器保守处理。没有舍入修饰符的 sub 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极优化。特别是,没有舍入修饰符的 mul/sub 序列可能会被优化为在目标设备上使用融合乘加指令。
- 次正规数
-
默认情况下,支持次正规数。
sub.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。 - 饱和修饰符
-
sub.sat.{f16, f16x2}将结果钳制到 [0.0, 1.0]。NaN结果被刷新为+0.0f。
PTX ISA 注释
在 PTX ISA 版本 4.2 中引入。
sub{.rnd}.bf16 和 sub{.rnd}.bf16x2 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
sub{.rnd}.bf16 和 sub{.rnd}.bf16x2 需要 sm_90 或更高版本。
示例
// scalar f16 subtractions
sub.f16 d0, a0, b0;
sub.rn.f16 d1, a1, b1;
sub.bf16 bd0, ba0, bb0;
sub.rn.bf16 bd1, ba1, bb1;
// SIMD f16 subtraction
cvt.rn.f16.f32 h0, f0;
cvt.rn.f16.f32 h1, f1;
cvt.rn.f16.f32 h2, f2;
cvt.rn.f16.f32 h3, f3;
mov.b32 p1, {h0, h1}; // pack two f16 to 32bit f16x2
mov.b32 p2, {h2, h3}; // pack two f16 to 32bit f16x2
sub.f16x2 p3, p1, p2; // SIMD f16x2 subtraction
// SIMD bf16 subtraction
cvt.rn.bf16x2.f32 p4, f4, f5; // Convert two f32 into packed bf16x2
cvt.rn.bf16x2.f32 p5, f6, f7; // Convert two f32 into packed bf16x2
sub.bf16x2 p6, p4, p5; // SIMD bf16x2 subtraction
// SIMD fp16 subtraction
ld.global.b32 f0, [addr]; // load 32 bit which hold packed f16x2
ld.global.b32 f1, [addr + 4]; // load 32 bit which hold packed f16x2
sub.f16x2 f2, f0, f1; // SIMD f16x2 subtraction
// SIMD bf16 subtraction
ld.global.b32 f3, [addr + 8]; // load 32 bit which hold packed bf16x2
ld.global.b32 f4, [addr + 12]; // load 32 bit which hold packed bf16x2
sub.bf16x2 f5, f3, f4; // SIMD bf16x2 subtraction
9.7.4.3. 半精度浮点指令:mul
mul
将两个值相乘。
语法
mul{.rnd}{.ftz}{.sat}.f16 d, a, b;
mul{.rnd}{.ftz}{.sat}.f16x2 d, a, b;
mul{.rnd}.bf16 d, a, b;
mul{.rnd}.bf16x2 d, a, b;
.rnd = { .rn };
描述
执行乘法并将结果值写入目标寄存器。
对于 .f16x2 和 .bf16x2 指令类型,通过源操作数的半字值形成输入向量。然后并行乘以半字操作数,以在目标中生成 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d、a 和 b 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d、a 和 b 具有 .b32 类型。对于 .bf16 指令类型,操作数 d、a、b 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d、a、b 具有 .b32 类型。
语义
if (type == f16 || type == bf16) {
d = a * b;
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
for (i = 0; i < 2; i++) {
d[i] = fA[i] * fB[i];
}
}
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
舍入修饰符的默认值为 .rn。请注意,具有显式舍入修饰符的 mul 指令会被代码优化器保守处理。没有舍入修饰符的 mul 指令默认为舍入到最接近的偶数,并且可以由代码优化器积极优化。特别是,没有舍入修饰符的 mul/add 和 mul/sub 序列可以被优化为在目标设备上使用融合乘加指令。
- 次正规数
-
默认情况下,支持次正规数。
mul.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。 - 饱和修饰符
-
mul.sat.{f16, f16x2}将结果钳制到 [0.0, 1.0] 范围内。NaN结果被刷新为+0.0f。
PTX ISA 注释
在 PTX ISA 版本 4.2 中引入。
mul{.rnd}.bf16 和 mul{.rnd}.bf16x2 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
mul{.rnd}.bf16 和 mul{.rnd}.bf16x2 需要 sm_90 或更高架构。
示例
// scalar f16 multiplications
mul.f16 d0, a0, b0;
mul.rn.f16 d1, a1, b1;
mul.bf16 bd0, ba0, bb0;
mul.rn.bf16 bd1, ba1, bb1;
// SIMD f16 multiplication
cvt.rn.f16.f32 h0, f0;
cvt.rn.f16.f32 h1, f1;
cvt.rn.f16.f32 h2, f2;
cvt.rn.f16.f32 h3, f3;
mov.b32 p1, {h0, h1}; // pack two f16 to 32bit f16x2
mov.b32 p2, {h2, h3}; // pack two f16 to 32bit f16x2
mul.f16x2 p3, p1, p2; // SIMD f16x2 multiplication
// SIMD bf16 multiplication
cvt.rn.bf16x2.f32 p4, f4, f5; // Convert two f32 into packed bf16x2
cvt.rn.bf16x2.f32 p5, f6, f7; // Convert two f32 into packed bf16x2
mul.bf16x2 p6, p4, p5; // SIMD bf16x2 multiplication
// SIMD fp16 multiplication
ld.global.b32 f0, [addr]; // load 32 bit which hold packed f16x2
ld.global.b32 f1, [addr + 4]; // load 32 bit which hold packed f16x2
mul.f16x2 f2, f0, f1; // SIMD f16x2 multiplication
// SIMD bf16 multiplication
ld.global.b32 f3, [addr + 8]; // load 32 bit which hold packed bf16x2
ld.global.b32 f4, [addr + 12]; // load 32 bit which hold packed bf16x2
mul.bf16x2 f5, f3, f4; // SIMD bf16x2 multiplication
9.7.4.4. 半精度浮点指令:fma
fma
融合乘加
语法
fma.rnd{.ftz}{.sat}.f16 d, a, b, c;
fma.rnd{.ftz}{.sat}.f16x2 d, a, b, c;
fma.rnd{.ftz}.relu.f16 d, a, b, c;
fma.rnd{.ftz}.relu.f16x2 d, a, b, c;
fma.rnd{.relu}.bf16 d, a, b, c;
fma.rnd{.relu}.bf16x2 d, a, b, c;
fma.rnd.oob.{relu}.type d, a, b, c;
.rnd = { .rn };
描述
执行融合乘加运算,中间乘积和加法运算不会损失精度。
对于 .f16x2 和 .bf16x2 指令类型,通过源操作数中的半字值形成输入向量。然后并行操作半字操作数,以在目标中生成 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d、a、b 和 c 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d、a、b 和 c 具有 .b32 类型。对于 .bf16 指令类型,操作数 d、a、b 和 c 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d、a、b 和 c 具有 .b32 类型。
语义
if (type == f16 || type == bf16) {
d = a * b + c;
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
fC[0] = c[0:15];
fC[1] = c[16:31];
for (i = 0; i < 2; i++) {
d[i] = fA[i] * fB[i] + fC[i];
}
}
注释
舍入修饰符(默认为 .rn)
.rn-
尾数 LSB 四舍五入到最接近的偶数
- 次正规数
-
默认情况下,支持次正规数。
fma.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。 - 饱和修饰符
-
fma.sat.{f16, f16x2}将结果钳制到 [0.0, 1.0] 范围内。NaN结果被刷新为+0.0f。fma.relu.{f16, f16x2, bf16, bf16x2}如果结果为负数,则将其钳制为 0。NaN结果被转换为规范NaN。 - 越界修饰符
-
fma.oob.{f16, f16x2, bf16, bf16x2}如果任何一个操作数是OOB NaN(在张量下定义)值,则将结果钳制为 0。特殊NaN值的测试以及将结果强制为 +0.0 的操作是针对每个 SIMD 操作独立执行的。
PTX ISA 注释
在 PTX ISA 版本 4.2 中引入。
fma.relu.{f16, f16x2} 和 fma{.relu}.{bf16, bf16x2} 在 PTX ISA 版本 7.0 中引入。
对修饰符 .oob 的支持在 PTX ISA 版本 8.1 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
fma.relu.{f16, f16x2} 和 fma{.relu}.{bf16, bf16x2} 需要 sm_80 或更高架构。
fma{.oob}.{f16, f16x2, bf16, bf16x2} 需要 sm_90 或更高架构。
示例
// scalar f16 fused multiply-add
fma.rn.f16 d0, a0, b0, c0;
fma.rn.f16 d1, a1, b1, c1;
fma.rn.relu.f16 d1, a1, b1, c1;
fma.rn.oob.f16 d1, a1, b1, c1;
fma.rn.oob.relu.f16 d1, a1, b1, c1;
// scalar bf16 fused multiply-add
fma.rn.bf16 d1, a1, b1, c1;
fma.rn.relu.bf16 d1, a1, b1, c1;
fma.rn.oob.bf16 d1, a1, b1, c1;
fma.rn.oob.relu.bf16 d1, a1, b1, c1;
// SIMD f16 fused multiply-add
cvt.rn.f16.f32 h0, f0;
cvt.rn.f16.f32 h1, f1;
cvt.rn.f16.f32 h2, f2;
cvt.rn.f16.f32 h3, f3;
mov.b32 p1, {h0, h1}; // pack two f16 to 32bit f16x2
mov.b32 p2, {h2, h3}; // pack two f16 to 32bit f16x2
fma.rn.f16x2 p3, p1, p2, p2; // SIMD f16x2 fused multiply-add
fma.rn.relu.f16x2 p3, p1, p2, p2; // SIMD f16x2 fused multiply-add with relu saturation mode
fma.rn.oob.f16x2 p3, p1, p2, p2; // SIMD f16x2 fused multiply-add with oob modifier
fma.rn.oob.relu.f16x2 p3, p1, p2, p2; // SIMD f16x2 fused multiply-add with oob modifier and relu saturation mode
// SIMD fp16 fused multiply-add
ld.global.b32 f0, [addr]; // load 32 bit which hold packed f16x2
ld.global.b32 f1, [addr + 4]; // load 32 bit which hold packed f16x2
fma.rn.f16x2 f2, f0, f1, f1; // SIMD f16x2 fused multiply-add
// SIMD bf16 fused multiply-add
fma.rn.bf16x2 f2, f0, f1, f1; // SIMD bf16x2 fused multiply-add
fma.rn.relu.bf16x2 f2, f0, f1, f1; // SIMD bf16x2 fused multiply-add with relu saturation mode
fma.rn.oob.bf16x2 f2, f0, f1, f1; // SIMD bf16x2 fused multiply-add with oob modifier
fma.rn.oob.relu.bf16x2 f2, f0, f1, f1; // SIMD bf16x2 fused multiply-add with oob modifier and relu saturation mode
9.7.4.5. 半精度浮点指令:neg
neg
算术求反。
语法
neg{.ftz}.f16 d, a;
neg{.ftz}.f16x2 d, a;
neg.bf16 d, a;
neg.bf16x2 d, a;
描述
取反 a 的符号,并将结果存储在 d 中。
对于 .f16x2 和 .bf16x2 指令类型,通过从源操作数中提取半字值来形成输入向量。然后并行地对半字操作数取反,以在目标中生成 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d 和 a 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d 和 a 具有 .b32 类型。对于 .bf16 指令类型,操作数 d 和 a 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d 和 a 具有 .b32 类型。
语义
if (type == f16 || type == bf16) {
d = -a;
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
for (i = 0; i < 2; i++) {
d[i] = -fA[i];
}
}
注释
- 次正规数
-
默认情况下,支持次正规数。
neg.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。
NaN 输入产生未指定的 NaN。未来的实现可能会通过保留有效载荷并仅修改符号位来符合 IEEE 754 标准。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
neg.bf16 和 neg.bf16x2 在 PTX ISA 7.0 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
neg.bf16 和 neg.bf16x2 需要 sm_80 或更高架构。
示例
neg.ftz.f16 x,f0;
neg.bf16 x,b0;
neg.bf16x2 x1,b1;
9.7.4.6. 半精度浮点指令:abs
abs
绝对值
语法
abs{.ftz}.f16 d, a;
abs{.ftz}.f16x2 d, a;
abs.bf16 d, a;
abs.bf16x2 d, a;
描述
取 a 的绝对值并将结果存储在 d 中。
对于 .f16x2 和 .bf16x2 指令类型,通过从源操作数中提取半字值来形成输入向量。然后并行计算半字操作数的绝对值,以在目标中生成 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d 和 a 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d 和 a 具有 .f16x2 或 .b32 类型。对于 .bf16 指令类型,操作数 d 和 a 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d 和 a 具有 .b32 类型。
语义
if (type == f16 || type == bf16) {
d = |a|;
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
for (i = 0; i < 2; i++) {
d[i] = |fA[i]|;
}
}
注释
- 次正规数
-
默认情况下,支持次正规数。
abs.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。
NaN 输入产生未指定的 NaN。未来的实现可能会通过保留有效载荷并仅修改符号位来符合 IEEE 754 标准。
PTX ISA 注释
在 PTX ISA 版本 6.5 中引入。
abs.bf16 和 abs.bf16x2 在 PTX ISA 7.0 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
abs.bf16 和 abs.bf16x2 需要 sm_80 或更高架构。
示例
abs.ftz.f16 x,f0;
abs.bf16 x,b0;
abs.bf16x2 x1,b1;
9.7.4.7. 半精度浮点指令:min
min
查找两个值中的最小值。
语法
min{.ftz}{.NaN}{.xorsign.abs}.f16 d, a, b;
min{.ftz}{.NaN}{.xorsign.abs}.f16x2 d, a, b;
min{.NaN}{.xorsign.abs}.bf16 d, a, b;
min{.NaN}{.xorsign.abs}.bf16x2 d, a, b;
描述
将 a 和 b 中的最小值存储在 d 中。
对于 .f16x2 和 .bf16x2 指令类型,输入向量由源操作数中的半字值形成。然后并行处理半字操作数,以在目标中存储 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d 和 a 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d 和 a 具有 .f16x2 或 .b32 类型。对于 .bf16 指令类型,操作数 d 和 a 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d 和 a 具有 .b32 类型。
如果指定了 .NaN 修饰符,则当任一输入为 NaN 时,结果为规范 NaN。
如果指定了 .abs 修饰符,则目标操作数 d 的幅度是两个输入参数的绝对值的最小值。
如果指定了 .xorsign 修饰符,则目标 d 的符号位等于两个输入的符号位的异或。
修饰符 .abs 和 .xorsign 必须一起指定,并且 .xorsign 在应用 .abs 操作之前会考虑两个输入的符号位。
如果 min 的结果是 NaN,则 .xorsign 和 .abs 修饰符将被忽略。
语义
if (type == f16 || type == bf16) {
if (.xorsign) {
xorsign = getSignBit(a) ^ getSignBit(b);
if (.abs) {
a = |a|;
b = |b|;
}
}
if (isNaN(a) && isNaN(b)) d = NaN;
if (.NaN && (isNaN(a) || isNaN(b))) d = NaN;
else if (isNaN(a)) d = b;
else if (isNaN(b)) d = a;
else d = (a < b) ? a : b;
if (.xorsign && !isNaN(d)) {
setSignBit(d, xorsign);
}
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
for (i = 0; i < 2; i++) {
if (.xorsign) {
xorsign = getSignBit(fA[i]) ^ getSignBit(fB[i]);
if (.abs) {
fA[i] = |fA[i]|;
fB[i] = |fB[i]|;
}
}
if (isNaN(fA[i]) && isNaN(fB[i])) d[i] = NaN;
if (.NaN && (isNaN(fA[i]) || isNaN(fB[i]))) d[i] = NaN;
else if (isNaN(fA[i])) d[i] = fB[i];
else if (isNaN(fB[i])) d[i] = fA[i];
else d[i] = (fA[i] < fB[i]) ? fA[i] : fB[i];
if (.xorsign && !isNaN(d[i])) {
setSignBit(d[i], xorsign);
}
}
}
注释
- 次正规数
-
默认情况下,支持次正规数。
min.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。
如果两个输入的值均为 0.0,则 +0.0 > -0.0。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
min.xorsign 在 PTX ISA 版本 7.2 中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
对 min.xorsign.abs 的支持需要 sm_86 或更高架构。
示例
min.ftz.f16 h0,h1,h2;
min.f16x2 b0,b1,b2;
// SIMD fp16 min with .NaN
min.NaN.f16x2 b0,b1,b2;
min.bf16 h0, h1, h2;
// SIMD bf16 min with NaN
min.NaN.bf16x2 b0, b1, b2;
// scalar bf16 min with xorsign.abs
min.xorsign.abs.bf16 Rd, Ra, Rb
9.7.4.8. 半精度浮点指令:max
max
查找两个值中的最大值。
语法
max{.ftz}{.NaN}{.xorsign.abs}.f16 d, a, b;
max{.ftz}{.NaN}{.xorsign.abs}.f16x2 d, a, b;
max{.NaN}{.xorsign.abs}.bf16 d, a, b;
max{.NaN}{.xorsign.abs}.bf16x2 d, a, b;
描述
将 a 和 b 中的最大值存储在 d 中。
对于 .f16x2 和 .bf16x2 指令类型,输入向量由源操作数中的半字值形成。然后并行处理半字操作数,以在目标中存储 .f16x2 或 .bf16x2 结果。
对于 .f16 指令类型,操作数 d 和 a 具有 .f16 或 .b16 类型。对于 .f16x2 指令类型,操作数 d 和 a 具有 .f16x2 或 .b32 类型。对于 .bf16 指令类型,操作数 d 和 a 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d 和 a 具有 .b32 类型。
如果指定了 .NaN 修饰符,则当任一输入为 NaN 时,结果为规范 NaN。
如果指定了 .abs 修饰符,则目标操作数 d 的幅度是两个输入参数的绝对值的最大值。
如果指定了 .xorsign 修饰符,则目标 d 的符号位等于两个输入的符号位的异或。
修饰符 .abs 和 .xorsign 必须一起指定,并且 .xorsign 在应用 .abs 操作之前会考虑两个输入的符号位。
如果 max 的结果是 NaN,则 .xorsign 和 .abs 修饰符将被忽略。
语义
if (type == f16 || type == bf16) {
if (.xorsign) {
xorsign = getSignBit(a) ^ getSignBit(b);
if (.abs) {
a = |a|;
b = |b|;
}
}
if (isNaN(a) && isNaN(b)) d = NaN;
if (.NaN && (isNaN(a) || isNaN(b))) d = NaN;
else if (isNaN(a)) d = b;
else if (isNaN(b)) d = a;
else d = (a > b) ? a : b;
if (.xorsign && !isNaN(d)) {
setSignBit(d, xorsign);
}
} else if (type == f16x2 || type == bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
for (i = 0; i < 2; i++) {
if (.xorsign) {
xorsign = getSignBit(fA[i]) ^ getSignBit(fB[i]);
if (.abs) {
fA[i] = |fA[i]|;
fB[i] = |fB[i]|;
}
}
if (isNaN(fA[i]) && isNaN(fB[i])) d[i] = NaN;
if (.NaN && (isNaN(fA[i]) || isNaN(fB[i]))) d[i] = NaN;
else if (isNaN(fA[i])) d[i] = fB[i];
else if (isNaN(fB[i])) d[i] = fA[i];
else d[i] = (fA[i] > fB[i]) ? fA[i] : fB[i];
if (.xorsign && !isNaN(fA[i])) {
setSignBit(d[i], xorsign);
}
}
}
注释
- 次正规数
-
默认情况下,支持次正规数。
max.ftz.{f16, f16x2}将次正规输入和结果刷新为符号保留零。
如果两个输入的值均为 0.0,则 +0.0 > -0.0。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
max.xorsign.abs 在 PTX ISA 版本 7.2 中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
对 max.xorsign.abs 的支持需要 sm_86 或更高架构。
示例
max.ftz.f16 h0,h1,h2;
max.f16x2 b0,b1,b2;
// SIMD fp16 max with NaN
max.NaN.f16x2 b0,b1,b2;
// scalar f16 max with xorsign.abs
max.xorsign.abs.f16 Rd, Ra, Rb;
max.bf16 h0, h1, h2;
// scalar bf16 max and NaN
max.NaN.bf16x2 b0, b1, b2;
// SIMD bf16 max with xorsign.abs
max.xorsign.abs.bf16x2 Rd, Ra, Rb;
9.7.4.9. 半精度浮点指令:tanh
tanh
查找一个值的双曲正切值(以弧度为单位)
语法
tanh.approx.type d, a;
.type = {.f16, .f16x2, .bf16, .bf16x2}
描述
取 a 的双曲正切值。
操作数 d 和 a 的类型由 .type 指定。
对于 .f16x2 或 .bf16x2 指令类型,每个半字操作数并行操作,结果被适当地打包到 .f16x2 或 .bf16x2 中。
语义
if (.type == .f16 || .type == .bf16) {
d = tanh(a)
} else if (.type == .f16x2 || .type == .bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
d[0] = tanh(fA[0])
d[1] = tanh(fA[1])
}
注释
tanh.approx.{f16, f16x2, bf16, bf16x2} 在目标格式中实现一个近似双曲正切函数。
各种边界情况输入的 tanh 结果如下
输入 |
结果 |
|---|---|
-Inf |
-1.0 |
-0.0 |
-0.0 |
+0.0 |
+0.0 |
+Inf |
1.0 |
NaN |
NaN |
.f16 类型的最大绝对误差为 2-10.987。.bf16 类型的最大绝对误差为 2-8。
支持次正规数。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
tanh.approx.{bf16/bf16x2} 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_75 或更高版本。
tanh.approx.{bf16/bf16x2} 需要 sm_90 或更高架构。
示例
tanh.approx.f16 h1, h0;
tanh.approx.f16x2 hd1, hd0;
tanh.approx.bf16 b1, b0;
tanh.approx.bf16x2 hb1, hb0;
9.7.4.10. 半精度浮点指令:ex2
ex2
查找输入的以 2 为底的指数。
语法
ex2.approx.atype d, a;
ex2.approx.ftz.btype d, a;
.atype = { .f16, .f16x2}
.btype = { .bf16, .bf16x2}
描述
将 2 提升到 a 次幂。
操作数 d 和 a 的类型由 .type 指定。
对于 .f16x2 或 .bf16x2 指令类型,每个半字操作数并行操作,结果被适当地打包到 .f16x2 或 .bf16x2 中。
语义
if (.type == .f16 || .type == .bf16) {
d = 2 ^ a
} else if (.type == .f16x2 || .type == .bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
d[0] = 2 ^ fA[0]
d[1] = 2 ^ fA[1]
}
注释
ex2.approx.{f16, f16x2, bf16, bf16x2} 实现了对 2a 的快速近似。
对于 .f16 类型,支持次正规输入。ex2.approx.ftz.bf16 将次正规输入和结果刷新为符号保留零。
ex2.approx.ftz.bf16 对于各种极端情况输入的result如下:
输入 |
结果 |
|---|---|
-Inf |
+0.0 |
-次正规数 |
+1.0 |
-0.0 |
+1.0 |
+0.0 |
+1.0 |
+次正规数 |
+1.0 |
+Inf |
+Inf |
NaN |
NaN |
ex2.approx.f16 对于各种极端情况输入的result如下:
输入 |
结果 |
|---|---|
-Inf |
+0.0 |
-0.0 |
+1.0 |
+0.0 |
+1.0 |
+Inf |
+Inf |
NaN |
NaN |
.f16 类型的最大相对误差为 2-9.9。.bf16 类型的最大相对误差为 2-7。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
ex2.approx.ftz.{bf16/bf16x2} 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_75 或更高版本。
ex2.approx.ftz.{bf16/bf16x2} 需要 sm_90 或更高架构。
示例
ex2.approx.f16 h1, h0;
ex2.approx.f16x2 hd1, hd0;
ex2.approx.ftz.bf16 b1, b2;
ex2.approx.ftz.bf16x2 hb1, hb2;
9.7.5. 混合精度浮点指令
混合精度浮点指令对具有不同浮点精度的数据进行操作。在执行指定的操作之前,需要转换具有不同精度的操作数,以便所有指令操作数都可以用一致的浮点精度表示。用于保存特定操作数的寄存器变量取决于指令类型的组合。有关给定数据类型的确切寄存器操作数的更多详细信息,请参阅基本类型和备用浮点数据格式。
混合精度浮点指令包括:
addsubfma
混合精度 add、sub、fma 支持结果饱和到 [0.0, 1.0] 范围,其中 NaN 被刷新为正零。
9.7.5.1. 混合精度浮点指令:add
add
将两个值相加。
语法
add{.rnd}{.sat}.f32.atype d, a, c;
.atype = { .f16, .bf16};
.rnd = { .rn, .rz, .rm, .rp };
描述
将输入操作数 a 从 .atype 转换为 .f32 类型。转换后的值然后用于加法运算。结果值存储在目标操作数 d 中。
语义
d = convert(a) + c;
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
舍入修饰符的默认值为 .rn。请注意,带有显式舍入修饰符的 add 指令会被代码优化器保守处理。没有舍入修饰符的 add 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极优化。特别是,没有舍入修饰符的 mul/add 序列可能会被优化为在目标设备上使用融合乘加指令。
- 次正规数
-
默认情况下,支持次正规数。
- 饱和修饰符
-
add.sat将结果钳制到 [0.0, 1.0] 范围内。NaN结果被刷新为+0.0f。
PTX ISA 注释
add.f32.{f16/bf16} 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
add.f32.{f16/bf16} 需要 sm_100 或更高架构。
示例
.reg .f32 fc, fd;
.reg .b16 ba;
add.rz.f32.bf16.sat fd, fa, fc;
9.7.5.2. 混合精度浮点指令:sub
sub
从另一个值中减去一个值。
语法
sub{.rnd}{.sat}.f32.atype d, a, c;
.atype = { .f16, .bf16};
.rnd = { .rn, .rz, .rm, .rp };
描述
将输入操作数 a 从 .atype 转换为 .f32 类型。转换后的值然后用于减法运算。结果值存储在目标操作数 d 中。
语义
d = convert(a) - c;
注释
舍入修饰符
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
舍入修饰符的默认值为 .rn。请注意,具有显式舍入修饰符的 sub 指令会被代码优化器保守地处理。没有舍入修饰符的 sub 指令默认为舍入到最接近的偶数,并且可能被代码优化器积极地优化。特别是,没有舍入修饰符的 mul/sub 序列可能会被优化为在目标设备上使用融合乘加指令。
- 次正规数
-
默认情况下,支持次正规数。
- 饱和修饰符
-
sub.sat将结果钳制到 [0.0, 1.0] 范围内。NaN结果被刷新为+0.0f。
PTX ISA 注释
sub.f32.{f16/bf16} 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
sub.f32.{f16/bf16} 需要 sm_100 或更高架构。
示例
.reg .f32 fc, fd;
.reg .f16 ha;
sub.rz.f32.f16.sat fd, ha, fc;
9.7.5.3. 混合精度浮点指令:fma
fma
融合乘加。
语法
fma.rnd{.ftz}{.sat}.f32.abtype d, a, b, c;
.abtype = { .f16, .bf16};
.rnd = { .rn, .rz, .rm, .rp };
描述
将输入操作数 a 和 b 从 .atype 转换为 .f32 类型。转换后的值然后用于执行融合乘加运算,中间乘积和加法运算中没有精度损失。结果值存储在目标操作数 d 中。
语义
d = convert(a) * convert(b) + c;
注释
fma.f32.{f16/bf16} 计算 a 和 b 的乘积,精度为无限精度,然后将 c 加到该乘积上,同样以无限精度进行。然后使用 .rnd 指定的舍入模式将结果值舍入为单精度。
舍入修饰符(无默认值)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
- 次正规数
-
默认情况下,支持次正规数。
- 饱和修饰符
-
fma.sat将结果钳制到 [0.0, 1.0] 范围内。NaN结果被刷新为+0.0f。
PTX ISA 注释
fma.f32.{f16/bf16} 在 PTX ISA 版本 8.6 中引入。
目标 ISA 注释
fma.f32.{f16/bf16} 需要 sm_100 或更高架构。
示例
.reg .f32 fc, fd;
.reg .f16 ha, hb;
fma.rz.sat.f32.f16.sat fd, ha, hb, fc;
9.7.6. 比较和选择指令
比较选择指令包括:
setsetpselpslct
与单精度浮点指令一样,set、setp 和 slct 指令对于 sm_20 及更高目标架构支持次正规数,对于 sm_1x 目标架构,将单精度次正规输入刷新为符号保留零。可选的 .ftz 修饰符通过将次正规输入和结果刷新为符号保留零,来提供与 sm_1x 目标的向后兼容性,而无需考虑目标架构。
9.7.6.1. 比较和选择指令:set
set
使用关系运算符比较两个数值,并可以选择性地通过应用布尔运算符将此结果与谓词值组合。
语法
set.CmpOp{.ftz}.dtype.stype d, a, b;
set.CmpOp.BoolOp{.ftz}.dtype.stype d, a, b, {!}c;
.CmpOp = { eq, ne, lt, le, gt, ge, lo, ls, hi, hs,
equ, neu, ltu, leu, gtu, geu, num, nan };
.BoolOp = { and, or, xor };
.dtype = { .u32, .s32, .f32 };
.stype = { .b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64,
.f32, .f64 };
描述
比较两个数值,并可以选择性地通过应用布尔运算符将结果与另一个谓词值组合。如果此结果为 True,则对于浮点目标类型写入 1.0f,对于整数目标类型写入 0xffffffff。否则,写入 0x00000000。
操作数 d 的类型为 .dtype;操作数 a 和 b 的类型为 .stype;操作数 c 的类型为 .pred。
语义
t = (a CmpOp b) ? 1 : 0;
if (isFloat(dtype))
d = BoolOp(t, c) ? 1.0f : 0x00000000;
else
d = BoolOp(t, c) ? 0xffffffff : 0x00000000;
整数注意事项
有符号和无符号比较运算符为 eq、ne、lt、le、gt、ge。
对于无符号值,可以使用比较运算符 lo、ls、hi 和 hs 分别代替 lt、le、gt、ge,分别表示小于、小于或等于、大于和大于或等于。
无类型、位大小的比较是 eq 和 ne。
浮点注意事项
有序比较是 eq、ne、lt、le、gt、ge。如果任一操作数为 NaN,则结果为 False。
为了辅助在存在 NaN 值的情况下的比较操作,包括无序版本:equ、neu、ltu、leu、gtu、geu。如果两个操作数都是数值(不是 NaN),则这些比较的结果与其有序对应项相同。如果任一操作数为 NaN,则这些比较的结果为 True。
如果两个操作数都是数值(不是 NaN),则 num 返回 True;如果任一操作数为 NaN,则 nan 返回 True。
次正规数
sm_20+-
默认情况下,支持次正规数。
set.ftz.dtype.f32将次正规输入刷新为符号保留零。 sm_1x-
set.dtype.f64支持次正规数。set.dtype.f32将次正规输入刷新为符号保留零。
修饰符 .ftz 仅适用于 .f32 比较。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
使用 .f64 源类型的 set 需要 sm_13 或更高架构。
示例
@p set.lt.and.f32.s32 d,a,b,r;
set.eq.u32.u32 d,i,n;
9.7.6.2. 比较和选择指令:setp
setp
使用关系运算符比较两个数值,并(可选)通过应用布尔运算符将此结果与谓词值组合。
语法
setp.CmpOp{.ftz}.type p[|q], a, b;
setp.CmpOp.BoolOp{.ftz}.type p[|q], a, b, {!}c;
.CmpOp = { eq, ne, lt, le, gt, ge, lo, ls, hi, hs,
equ, neu, ltu, leu, gtu, geu, num, nan };
.BoolOp = { and, or, xor };
.type = { .b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64,
.f32, .f64 };
描述
比较两个值,并通过应用布尔运算符将结果与另一个谓词值组合。此结果被写入第一个目标操作数。使用比较结果的补码计算的相关值被写入第二个目标操作数。
适用于所有数值类型。操作数 a 和 b 的类型为 .type;操作数 p、q 和 c 的类型为 .pred。接收器符号“_”可以用来代替任何一个目标操作数。
语义
t = (a CmpOp b) ? 1 : 0;
p = BoolOp(t, c);
q = BoolOp(!t, c);
整数注意事项
有符号和无符号比较运算符为 eq、ne、lt、le、gt、ge。
对于无符号值,可以使用比较运算符 lo、ls、hi 和 hs 分别代替 lt、le、gt、ge,分别表示小于、小于或等于、大于和大于或等于。
无类型、位大小的比较是 eq 和 ne。
浮点注意事项
有序比较是 eq、ne、lt、le、gt、ge。如果任一操作数为 NaN,则结果为 False。
为了辅助在存在 NaN 值的情况下的比较操作,包括无序版本:equ、neu、ltu、leu、gtu、geu。如果两个操作数都是数值(不是 NaN),则这些比较的结果与其有序对应项相同。如果任一操作数为 NaN,则这些比较的结果为 True。
如果两个操作数都是数值(不是 NaN),则 num 返回 True;如果任一操作数为 NaN,则 nan 返回 True。
次正规数
sm_20+-
默认情况下,支持次正规数。
setp.ftz.dtype.f32将次正规输入刷新为符号保留零。 sm_1x-
setp.dtype.f64支持次正规数。setp.dtype.f32将次正规输入刷新为符号保留零。
修饰符 .ftz 仅适用于 .f32 比较。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
使用 .f64 源类型的 setp 需要 sm_13 或更高架构。
示例
setp.lt.and.s32 p|q,a,b,r;
@q setp.eq.u32 p,i,n;
9.7.6.3. 比较和选择指令:selp
selp
根据谓词源操作数的值,在源操作数之间进行选择。
语法
selp.type d, a, b, c;
.type = { .b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64,
.f32, .f64 };
描述
条件选择。如果 c 为 True,则将 a 存储在 d 中,否则存储 b。操作数 d、a 和 b 必须是相同类型。操作数 c 是一个谓词。
语义
d = (c == 1) ? a : b;
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
selp.f64 需要 sm_13 或更高架构。
示例
selp.s32 r0,r,g,p;
@q selp.f32 f0,t,x,xp;
9.7.6.4. 比较和选择指令:slct
slct
根据第三个操作数的符号选择一个源操作数。
语法
slct.dtype.s32 d, a, b, c;
slct{.ftz}.dtype.f32 d, a, b, c;
.dtype = { .b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64,
.f32, .f64 };
描述
条件选择。如果 c >= 0,则将 a 存储到 d 中,否则将 b 存储到 d 中。操作数 d、a 和 b 被视为与第一条指令类型相同宽度的位大小类型;操作数 c 必须与第二条指令类型(.s32 或 .f32)匹配。选定的输入被复制到输出,不做修改。
语义
d = (c >= 0) ? a : b;
浮点注意事项
对于 .f32 比较,负零等于零。
次正规数
sm_20+-
默认情况下,支持次正规数。
slct.ftz.dtype.f32将操作数c的次正规值刷新为符号保留零,并选择操作数a。 sm_1x-
slct.dtype.f32将操作数c的次正规值刷新为符号保留零,并选择操作数a。
修饰符 .ftz 仅适用于 .f32 比较。
如果操作数 c 是 NaN,则比较是无序的,并选择操作数 b。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
slct.f64 需要 sm_13 或更高版本。
示例
slct.u32.s32 x, y, z, val;
slct.ftz.u64.f32 A, B, C, fval;
9.7.7. 半精度比较指令
比较指令包括:
setsetp
9.7.7.1. 半精度比较指令:set
set
使用关系运算符比较两个数值,并可以选择性地通过应用布尔运算符将此结果与谓词值组合。
语法
set.CmpOp{.ftz}.f16.stype d, a, b;
set.CmpOp.BoolOp{.ftz}.f16.stype d, a, b, {!}c;
set.CmpOp.bf16.stype d, a, b;
set.CmpOp.BoolOp.bf16.stype d, a, b, {!}c;
set.CmpOp{.ftz}.dtype.f16 d, a, b;
set.CmpOp.BoolOp{.ftz}.dtype.f16 d, a, b, {!}c;
.dtype = { .u16, .s16, .u32, .s32}
set.CmpOp.dtype.bf16 d, a, b;
set.CmpOp.BoolOp.dtype.bf16 d, a, b, {!}c;
.dtype = { .u16, .s16, .u32, .s32}
set.CmpOp{.ftz}.dtype.f16x2 d, a, b;
set.CmpOp.BoolOp{.ftz}.dtype.f16x2 d, a, b, {!}c;
.dtype = { .f16x2, .u32, .s32}
set.CmpOp.dtype.bf16x2 d, a, b;
set.CmpOp.BoolOp.dtype.bf16x2 d, a, b, {!}c;
.dtype = { .bf16x2, .u32, .s32}
.CmpOp = { eq, ne, lt, le, gt, ge,
equ, neu, ltu, leu, gtu, geu, num, nan };
.BoolOp = { and, or, xor };
.stype = { .b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64,
.f16, .f32, .f64};
描述
比较两个数值,并可选择性地通过应用布尔运算符将结果与另一个谓词值组合。
此计算的结果以下列方式写入目标寄存器:
-
如果结果为
True,对于目标类型
.u32/.s32,写入0xffffffff。对于目标类型
.u16/.s16,写入0xffff。对于目标类型
.f16、.bf16,以目标精度浮点格式写入1.0。
-
如果结果为
False,对于所有整数目标类型,写入
0x0。对于目标类型
.f16、.bf16,以目标精度浮点格式写入0.0。
如果源类型是 .f16x2 或 .bf16x2,则各个操作的结果被打包到 32 位目标操作数中。
操作数 c 的类型为 .pred。
语义
if (stype == .f16x2 || stype == .bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
t[0] = (fA[0] CmpOp fB[0]) ? 1 : 0;
t[1] = (fA[1] CmpOp fB[1]) ? 1 : 0;
if (dtype == .f16x2 || stype == .bf16x2) {
for (i = 0; i < 2; i++) {
d[i] = BoolOp(t[i], c) ? 1.0 : 0.0;
}
} else {
for (i = 0; i < 2; i++) {
d[i] = BoolOp(t[i], c) ? 0xffff : 0;
}
}
} else if (dtype == .f16 || stype == .bf16) {
t = (a CmpOp b) ? 1 : 0;
d = BoolOp(t, c) ? 1.0 : 0.0;
} else { // Integer destination type
trueVal = (isU16(dtype) || isS16(dtype)) ? 0xffff : 0xffffffff;
t = (a CmpOp b) ? 1 : 0;
d = BoolOp(t, c) ? trueVal : 0;
}
浮点注意事项
有序比较是 eq、ne、lt、le、gt、ge。如果任一操作数为 NaN,则结果为 False。
为了辅助在存在 NaN 值的情况下的比较操作,包括无序版本:equ、neu、ltu、leu、gtu、geu。如果两个操作数都是数值(不是 NaN),则这些比较的结果与其有序对应项相同。如果任一操作数为 NaN,则这些比较的结果为 True。
如果两个操作数都是数值(不是 NaN),则 num 返回 True;如果任一操作数为 NaN,则 nan 返回 True。
- 次正规数
-
默认情况下,支持次正规数。
当指定
.ftz修饰符时,次正规输入和结果将被刷新为符号保留零。
PTX ISA 注释
在 PTX ISA 版本 4.2 中引入。
set.{u16, u32, s16, s32}.f16 和 set.{u32, s32}.f16x2 在 PTX ISA 版本 6.5 中引入。
set.{u16, u32, s16, s32}.bf16、set.{u32, s32, bf16x2}.bf16x2、set.bf16.{s16,u16,f16,b16,s32,u32,f32,b32,s64,u64,f64,b64} 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
set.{u16, u32, s16, s32}.bf16、set.{u32, s32, bf16x2}.bf16x2、set.bf16.{s16,u16,f16,b16,s32,u32,f32,b32,s64,u64,f64,b64} 需要 sm_90 或更高版本。
示例
set.lt.and.f16.f16 d,a,b,r;
set.eq.f16x2.f16x2 d,i,n;
set.eq.u32.f16x2 d,i,n;
set.lt.and.u16.f16 d,a,b,r;
set.ltu.or.bf16.f16 d,u,v,s;
set.equ.bf16x2.bf16x2 d,j,m;
set.geu.s32.bf16x2 d,j,m;
set.num.xor.s32.bf16 d,u,v,s;
9.7.7.2. 半精度比较指令:setp
setp
使用关系运算符比较两个数值,并可以选择性地通过应用布尔运算符将此结果与谓词值组合。
语法
setp.CmpOp{.ftz}.f16 p, a, b;
setp.CmpOp.BoolOp{.ftz}.f16 p, a, b, {!}c;
setp.CmpOp{.ftz}.f16x2 p|q, a, b;
setp.CmpOp.BoolOp{.ftz}.f16x2 p|q, a, b, {!}c;
setp.CmpOp.bf16 p, a, b;
setp.CmpOp.BoolOp.bf16 p, a, b, {!}c;
setp.CmpOp.bf16x2 p|q, a, b;
setp.CmpOp.BoolOp.bf16x2 p|q, a, b, {!}c;
.CmpOp = { eq, ne, lt, le, gt, ge,
equ, neu, ltu, leu, gtu, geu, num, nan };
.BoolOp = { and, or, xor };
描述
比较两个值,并通过应用布尔运算符将结果与另一个谓词值组合。此结果被写入目标操作数。
操作数 c、p 和 q 的类型为 .pred。
对于指令类型 .f16,操作数 a 和 b 的类型为 .b16 或 .f16。
对于指令类型 .f16x2,操作数 a 和 b 的类型为 .b32。
对于指令类型 .bf16,操作数 a 和 b 的类型为 .b16。
对于指令类型 .bf16x2,操作数 a 和 b 的类型为 .b32。
语义
if (type == .f16 || type == .bf16) {
t = (a CmpOp b) ? 1 : 0;
p = BoolOp(t, c);
} else if (type == .f16x2 || type == .bf16x2) {
fA[0] = a[0:15];
fA[1] = a[16:31];
fB[0] = b[0:15];
fB[1] = b[16:31];
t[0] = (fA[0] CmpOp fB[0]) ? 1 : 0;
t[1] = (fA[1] CmpOp fB[1]) ? 1 : 0;
p = BoolOp(t[0], c);
q = BoolOp(t[1], c);
}
浮点注意事项
有序比较是 eq、ne、lt、le、gt、ge。如果任一操作数为 NaN,则结果为 False。
为了辅助在存在 NaN 值的情况下的比较操作,包括无序版本:equ、neu、ltu、leu、gtu、geu。如果两个操作数都是数值(不是 NaN),则这些比较的结果与其有序对应项相同。如果任一操作数为 NaN,则这些比较的结果为 True。
如果两个操作数都是数值(不是 NaN),则 num 返回 True;如果任一操作数为 NaN,则 nan 返回 True。
- 次正规数
-
默认情况下,支持次正规数。
setp.ftz.{f16,f16x2}将次正规输入刷新为符号保留零。
PTX ISA 注释
在 PTX ISA 版本 4.2 中引入。
setp.{bf16/bf16x2} 在 PTX ISA 版本 7.8 中引入。
目标 ISA 注释
需要 sm_53 或更高版本。
setp.{bf16/bf16x2} 需要 sm_90 或更高版本。
示例
setp.lt.and.f16x2 p|q,a,b,r;
@q setp.eq.f16 p,i,n;
setp.gt.or.bf16x2 u|v,c,d,s;
@q setp.eq.bf16 u,j,m;
9.7.8. 逻辑和移位指令
逻辑和移位指令本质上是无类型的,对任何类型的操作数执行按位运算,前提是操作数的大小相同。这允许对浮点值进行按位运算,而无需定义联合来访问位。and、or、xor 和 not 指令也对谓词进行操作。
逻辑移位指令包括:
andorxornotcnotlop3shfshlshr
9.7.8.1. 逻辑和移位指令:and
and
按位与。
语法
and.type d, a, b;
.type = { .pred, .b16, .b32, .b64 };
描述
计算 a 和 b 中位的按位与运算。
语义
d = a & b;
注释
操作数的大小必须匹配,但不一定是类型。
允许的类型包括谓词寄存器。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
and.b32 x,q,r;
and.b32 sign,fpvalue,0x80000000;
9.7.8.2. 逻辑和移位指令:or
or
按位或。
语法
or.type d, a, b;
.type = { .pred, .b16, .b32, .b64 };
描述
计算 a 和 b 中位的按位或运算。
语义
d = a | b;
注释
操作数的大小必须匹配,但不一定是类型。
允许的类型包括谓词寄存器。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
or.b32 mask mask,0x00010001
or.pred p,q,r;
9.7.8.3. 逻辑和移位指令:xor
xor
按位异或(不等)。
语法
xor.type d, a, b;
.type = { .pred, .b16, .b32, .b64 };
描述
计算 a 和 b 中位的按位异或运算。
语义
d = a ^ b;
注释
操作数的大小必须匹配,但不一定是类型。
允许的类型包括谓词寄存器。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
xor.b32 d,q,r;
xor.b16 d,x,0x0001;
9.7.8.4. 逻辑和移位指令:not
not
按位取反;一位补码。
语法
not.type d, a;
.type = { .pred, .b16, .b32, .b64 };
描述
反转 a 中的位。
语义
d = ~a;
注释
操作数的大小必须匹配,但不一定是类型。
允许的类型包括谓词。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
not.b32 mask,mask;
not.pred p,q;
9.7.8.5. 逻辑和移位指令:cnot
cnot
C/C++ 风格的逻辑非。
语法
cnot.type d, a;
.type = { .b16, .b32, .b64 };
描述
使用 C/C++ 语义计算逻辑非。
语义
d = (a==0) ? 1 : 0;
注释
操作数的大小必须匹配,但不一定是类型。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
cnot.b32 d,a;
9.7.8.6. 逻辑和移位指令:lop3
lop3
对 3 个输入进行任意逻辑运算。
语法
lop3.b32 d, a, b, c, immLut;
lop3.BoolOp.b32 d|p, a, b, c, immLut, q;
.BoolOp = { .or , .and };
描述
计算输入 a、b、c 的按位逻辑运算,并将结果存储在目标 d 中。
可选地,可以指定 .BoolOp 以通过以下方式对目标操作数 d 和谓词 q 执行布尔运算来计算谓词结果 p:
p = (d != 0) BoolOp q;
当指定 .BoolOp 限定符时,可以使用接收器符号 ‘_’ 代替目标操作数 d。
逻辑运算由查找表定义,对于 3 个输入,可以表示为由操作数 immLut 指定的 8 位值,如下所述。immLut 是一个整数常量,可以取值从 0 到 255,从而允许对输入 a、b、c 进行多达 256 种不同的逻辑运算。
对于逻辑运算 F(a, b, c),可以通过对三个预定义的常量值应用相同的运算来计算 immLut 的值,如下所示:
ta = 0xF0;
tb = 0xCC;
tc = 0xAA;
immLut = F(ta, tb, tc);
示例
If F = (a & b & c);
immLut = 0xF0 & 0xCC & 0xAA = 0x80
If F = (a | b | c);
immLut = 0xF0 | 0xCC | 0xAA = 0xFE
If F = (a & b & ~c);
immLut = 0xF0 & 0xCC & (~0xAA) = 0x40
If F = ((a & b | c) ^ a);
immLut = (0xF0 & 0xCC | 0xAA) ^ 0xF0 = 0x1A
下表说明了各种逻辑运算的 immLut 计算
ta |
tb |
tc |
操作 0(假) |
操作 1(ta & tb & tc) |
操作 2(ta & tb & ~tc) |
… |
操作 254(ta | tb | tc) |
操作 255(真) |
|---|---|---|---|---|---|---|---|---|
0 |
0 |
0 |
0 |
0 |
0 |
… |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
|
0 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
|
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
|
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
|
1 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
|
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
|
1 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
|
immLut |
0x0 |
0x80 |
0x40 |
… |
0xFE |
0xFF |
||
语义
F = GetFunctionFromTable(immLut); // returns the function corresponding to immLut value
d = F(a, b, c);
if (BoolOp specified) {
p = (d != 0) BoolOp q;
}
PTX ISA 注释
在 PTX ISA 版本 4.3 中引入。
对 .BoolOp 限定符的支持在 PTX ISA 版本 8.2 中引入。
目标 ISA 注释
需要 sm_50 或更高版本。
限定符 .BoolOp 需要 sm_70 或更高版本。
示例
lop3.b32 d, a, b, c, 0x40;
lop3.or.b32 d|p, a, b, c, 0x3f, q;
lop3.and.b32 _|p, a, b, c, 0x3f, q;
9.7.8.7. 逻辑和移位指令:shf
shf
漏斗移位。
语法
shf.l.mode.b32 d, a, b, c; // left shift
shf.r.mode.b32 d, a, b, c; // right shift
.mode = { .clamp, .wrap };
描述
将由操作数 a 和 b 连接形成的 64 位值,按 c 中无符号 32 位值指定的量向左或向右移位。操作数 b 保存 64 位源值的位 63:32,操作数 a 保存位 31:0。源根据 c 中的钳位或环绕值向左或向右移位。对于 shf.l,结果的最高有效 32 位写入 d;对于 shf.r,结果的最低有效 32 位写入 d。
语义
u32 n = (.mode == .clamp) ? min(c, 32) : c & 0x1f;
switch (shf.dir) { // shift concatenation of [b, a]
case shf.l: // extract 32 msbs
u32 d = (b << n) | (a >> (32-n));
case shf.r: // extract 32 lsbs
u32 d = (b << (32-n)) | (a >> n);
}
注释
使用漏斗移位进行多字移位操作和旋转操作。移位量在钳位模式下限制在 0..32 范围内,在环绕模式下限制在 0..31 范围内,因此将多字值移位大于 32 的距离需要先移动 32 位字,然后使用 shf 移位剩余的 0..31 距离。
要将大于 64 位的数据大小向右移位,请使用重复的 shf.r 指令应用于相邻字,从最低有效字向最高有效字操作。在每个步骤中,计算移位结果的单个字。结果的最高有效字使用 shr.{u32,s32} 指令计算,该指令根据指令类型用零或符号填充。
要将大于 64 位的数据大小向左移位,请使用重复的 shf.l 指令应用于相邻字,从最高有效字向最低有效字操作。在每个步骤中,计算移位结果的单个字。结果的最低有效字使用 shl 指令计算。
通过为源参数 a 和 b 提供相同的值,使用漏斗移位执行 32 位左旋转或右旋转。
PTX ISA 注释
在 PTX ISA 版本 3.1 中引入。
目标 ISA 注释
需要 sm_32 或更高版本。
例子
shf.l.clamp.b32 r3,r1,r0,16;
// 128-bit left shift; n < 32
// [r7,r6,r5,r4] = [r3,r2,r1,r0] << n
shf.l.clamp.b32 r7,r2,r3,n;
shf.l.clamp.b32 r6,r1,r2,n;
shf.l.clamp.b32 r5,r0,r1,n;
shl.b32 r4,r0,n;
// 128-bit right shift, arithmetic; n < 32
// [r7,r6,r5,r4] = [r3,r2,r1,r0] >> n
shf.r.clamp.b32 r4,r0,r1,n;
shf.r.clamp.b32 r5,r1,r2,n;
shf.r.clamp.b32 r6,r2,r3,n;
shr.s32 r7,r3,n; // result is sign-extended
shf.r.clamp.b32 r1,r0,r0,n; // rotate right by n; n < 32
shf.l.clamp.b32 r1,r0,r0,n; // rotate left by n; n < 32
// extract 32-bits from [r1,r0] starting at position n < 32
shf.r.clamp.b32 r0,r0,r1,n;
9.7.8.8. 逻辑和移位指令:shl
shl
向左移位,右侧用零填充。
语法
shl.type d, a, b;
.type = { .b16, .b32, .b64 };
描述
将 a 向左移位 b 中无符号 32 位值指定的量。
语义
d = a << b;
注释
大于寄存器宽度 *N* 的移位量被钳位为 *N*。
目标和第一个源操作数的大小必须匹配,但不一定是类型。 b 操作数必须是 32 位值,与指令类型无关。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
例子
shl.b32 q,a,2;
9.7.8.9. 逻辑和移位指令:shr
shr
向右移位,左侧用符号或零填充。
语法
shr.type d, a, b;
.type = { .b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64 };
描述
将 a 向右移位 b 中无符号 32 位值指定的量。有符号移位用符号位填充,无符号和无类型移位用 0 填充。
语义
d = a >> b;
注释
大于寄存器宽度 *N* 的移位量被钳位为 *N*。
目标和第一个源操作数的大小必须匹配,但不一定是类型。 b 操作数必须是 32 位值,与指令类型无关。
位大小类型包含在内是为了与 shl 对称。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
例子
shr.u16 c,a,2;
shr.s32 i,i,1;
shr.b16 k,i,j;
9.7.9. 数据移动和转换指令
这些指令将数据从一个位置复制到另一个位置,以及从一个状态空间复制到另一个状态空间,可能会将其从一种格式转换为另一种格式。mov、ld、ldu 和 st 对标量和向量类型都进行操作。isspacep 指令用于查询通用地址是否落在特定的状态空间窗口内。cvta 指令在 generic 和 const、global、local 或 shared 状态空间之间转换地址。
ld、st、suld 和 sust 指令支持可选的缓存操作。
数据移动和转换指令包括:
movshfl.syncprmtldldustst.asyncst.bulkmultimem.ld_reduce、multimem.st、multimem.redprefetch、prefetchuisspacepcvtacvtcvt.packcp.asynccp.async.commit_groupcp.async.wait_group、cp.async.wait_allcp.async.bulkcp.reduce.async.bulkcp.async.bulk.prefetchcp.async.bulk.tensorcp.reduce.async.bulk.tensorcp.async.bulk.prefetch.tensorcp.async.bulk.commit_groupcp.async.bulk.wait_grouptensormap.replace
9.7.9.1. 缓存操作符
PTX ISA 版本 2.0 在加载和存储指令中引入了可选的缓存操作符。缓存操作符需要 sm_20 或更高版本的目标架构。
加载或存储指令上的缓存操作符仅被视为性能提示。在 ld 或 st 指令上使用缓存操作符不会更改程序的内存一致性行为。
对于 sm_20 和更高版本,缓存操作符具有以下定义和行为。
运算符 |
含义 |
|---|---|
|
在所有级别缓存,可能再次访问。 默认的加载指令缓存操作是 ld.ca,它在所有级别(L1 和 L2)分配缓存行,并采用正常的驱逐策略。全局数据在 L2 级别是一致的,但多个 L1 缓存对于全局数据不一致。如果一个线程通过一个 L1 缓存存储到全局内存,而第二个线程通过第二个 L1 缓存使用 |
|
在全球级别缓存(在 L2 及以下级别缓存,不在 L1 中)。 使用 |
|
缓存流式传输,可能只访问一次。
|
|
最后使用。 当恢复溢出的寄存器和弹出函数堆栈帧时,编译器/程序员可以使用 |
|
不缓存并再次获取(认为缓存的系统内存行已过时,再次获取)。 应用于全局系统内存地址的 ld.cv 加载操作会使匹配的 L2 行无效(丢弃),并在每次新加载时重新获取该行。 |
运算符 |
含义 |
|---|---|
|
缓存写回所有一致性级别。 默认的存储指令缓存操作是 如果一个线程存储到全局内存,绕过其 L1 缓存,并且不同 SM 中的第二个线程稍后通过不同的 L1 缓存使用 驱动程序必须在线程阵列的依赖网格之间使全局 L1 缓存行无效。然后,第一个网格程序的存储可以被第二个网格程序正确地未命中 L1 并获取,后者发出默认的 |
|
在全球级别缓存(在 L2 及以下级别缓存,不在 L1 中)。 使用 |
|
缓存流式传输,可能只访问一次。
|
|
缓存直写(到系统内存)。 应用于全局系统内存地址的 |
9.7.9.2. 缓存驱逐优先级提示
PTX ISA 版本 7.4 在加载和存储指令中添加了可选的缓存驱逐优先级提示。缓存驱逐优先级需要目标架构 sm_70 或更高版本。
加载或存储指令上的缓存驱逐优先级被视为性能提示。它支持 .global 状态空间和通用地址,其中地址指向 .global 状态空间。
缓存驱逐优先级 |
含义 |
|---|---|
|
以正常驱逐优先级缓存数据。这是默认的驱逐优先级。 |
|
以此优先级缓存的数据将在驱逐优先级顺序中排在第一位,并且在需要缓存驱逐时可能会首先被驱逐。此优先级适用于流式数据。 |
|
以此优先级缓存的数据将在驱逐优先级顺序中排在最后,并且可能仅在其他具有 |
|
不要更改作为此操作一部分的驱逐优先级顺序。 |
|
不要将数据分配到缓存。此优先级适用于流式数据。 |
9.7.9.3. 数据移动和转换指令:mov
mov
使用寄存器变量或立即值设置寄存器变量。获取全局、本地或共享状态空间中变量的非通用地址。
语法
mov.type d, a;
mov.type d, sreg;
mov.type d, avar; // get address of variable
mov.type d, avar+imm; // get address of variable with offset
mov.u32 d, fname; // get address of device function
mov.u64 d, fname; // get address of device function
mov.u32 d, kernel; // get address of entry function
mov.u64 d, kernel; // get address of entry function
.type = { .pred,
.b16, .b32, .b64,
.u16, .u32, .u64,
.s16, .s32, .s64,
.f32, .f64 };
描述
将寄存器 d 写入 a 的值。
操作数 a 可以是寄存器、特殊寄存器、可寻址内存空间中带有可选偏移量的变量或函数名。
对于在 .const、.global、.local 和 .shared 状态空间中声明的变量,mov 将变量的非通用地址(即变量在其状态空间中的地址)放入目标寄存器。可以通过首先使用 mov 获取状态空间内的地址,然后使用 cvta 指令将其转换为通用地址来生成 const、global、local 或 shared 状态空间中变量的通用地址;或者,可以使用 cvta 指令直接获取在 const、global、local 或 shared 状态空间中声明的变量的通用地址。
请注意,如果设备函数参数的地址被移动到寄存器,则参数将被复制到堆栈上,并且地址将位于本地状态空间中。
语义
d = a;
d = sreg;
d = &avar; // address is non-generic; i.e., within the variable's declared state space
d = &avar+imm;
注释
尽管只需要谓词和位大小类型,但为了程序员的方便,我们包含了算术类型:它们的使用增强了程序的可读性,并允许进行额外的类型检查。
当移动内核或设备函数的地址时,只允许
.u32或.u64指令类型。但是,如果使用有符号类型,则不会将其视为编译错误。在这种情况下,编译器会发出警告。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
获取内核入口函数的地址需要 PTX ISA 版本 3.1 或更高版本。内核函数地址应仅在 CUDA 动态并行系统调用的上下文中使用。有关详细信息,请参阅CUDA 动态并行编程指南。
目标 ISA 注释
mov.f64 需要 sm_13 或更高版本。
获取内核入口函数的地址需要 sm_35 或更高版本。
示例
mov.f32 d,a;
mov.u16 u,v;
mov.f32 k,0.1;
mov.u32 ptr, A; // move address of A into ptr
mov.u32 ptr, A[5]; // move address of A[5] into ptr
mov.u32 ptr, A+20; // move address with offset into ptr
mov.u32 addr, myFunc; // get address of device function 'myFunc'
mov.u64 kptr, main; // get address of entry function 'main'
9.7.9.4. 数据移动和转换指令:mov
mov
移动向量到标量(打包)或标量到向量(解包)。
语法
mov.type d, a;
.type = { .b16, .b32, .b64, .b128 };
描述
将标量寄存器 d 写入向量寄存器 a 的打包值,或将向量寄存器 d 写入标量寄存器 a 的解包值。
当目标操作数 d 是向量寄存器时,对于一个或多个元素可以使用接收器符号 '_',前提是至少有一个元素是标量寄存器。
对于位大小类型,mov 可以用于将向量元素打包到标量寄存器中,或将标量寄存器的子字段解包到向量中。向量的总体大小和标量的大小都必须与指令类型的大小匹配。
语义
// pack two 8-bit elements into .b16
d = a.x | (a.y << 8)
// pack four 8-bit elements into .b32
d = a.x | (a.y << 8) | (a.z << 16) | (a.w << 24)
// pack two 16-bit elements into .b32
d = a.x | (a.y << 16)
// pack four 16-bit elements into .b64
d = a.x | (a.y << 16) | (a.z << 32) | (a.w << 48)
// pack two 32-bit elements into .b64
d = a.x | (a.y << 32)
// pack four 32-bit elements into .b128
d = a.x | (a.y << 32) | (a.z << 64) | (a.w << 96)
// pack two 64-bit elements into .b128
d = a.x | (a.y << 64)
// unpack 8-bit elements from .b16
{ d.x, d.y } = { a[0..7], a[8..15] }
// unpack 8-bit elements from .b32
{ d.x, d.y, d.z, d.w }
{ a[0..7], a[8..15], a[16..23], a[24..31] }
// unpack 16-bit elements from .b32
{ d.x, d.y } = { a[0..15], a[16..31] }
// unpack 16-bit elements from .b64
{ d.x, d.y, d.z, d.w } =
{ a[0..15], a[16..31], a[32..47], a[48..63] }
// unpack 32-bit elements from .b64
{ d.x, d.y } = { a[0..31], a[32..63] }
// unpack 32-bit elements from .b128
{ d.x, d.y, d.z, d.w } =
{ a[0..31], a[32..63], a[64..95], a[96..127] }
// unpack 64-bit elements from .b128
{ d.x, d.y } = { a[0..63], a[64..127] }
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
对 .b128 类型的支持在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
所有目标架构均支持。
对 .b128 类型的支持需要 sm_70 或更高版本。
示例
mov.b32 %r1,{a,b}; // a,b have type .u16
mov.b64 {lo,hi}, %x; // %x is a double; lo,hi are .u32
mov.b32 %r1,{x,y,z,w}; // x,y,z,w have type .b8
mov.b32 {r,g,b,a},%r1; // r,g,b,a have type .u8
mov.b64 {%r1, _}, %x; // %x is.b64, %r1 is .b32
mov.b128 {%b1, %b2}, %y; // %y is.b128, %b1 and % b2 are .b64
mov.b128 %y, {%b1, %b2}; // %y is.b128, %b1 and % b2 are .b64
9.7.9.5. 数据移动和转换指令:shfl(已弃用)
shfl(已弃用)
warp 中线程之间的寄存器数据混洗。
语法
shfl.mode.b32 d[|p], a, b, c;
.mode = { .up, .down, .bfly, .idx };
弃用说明
在 PTX ISA 版本 6.0 中,不带 .sync 限定符的 shfl 指令已被弃用。
在未来的 PTX ISA 版本中,可能会删除对
.target低于sm_70的此指令的支持。
移除说明
对于 .targetsm_70 或更高版本,在 PTX ISA 版本 6.4 中移除了对不带 .sync 限定符的 shfl 指令的支持。
描述
在 warp 的线程之间交换寄存器数据。
当前执行 warp 中的每个线程将基于输入操作数 b 和 c 以及模式计算源 lane 索引 j。如果计算出的源 lane 索引 j 在范围内,则线程会将输入操作数 a 从 lane j 复制到其自身的目的寄存器 d 中;否则,线程将简单地将其自身的输入 a 复制到目的地 d。可选的目的谓词 p 在计算出的源 lane 在范围内时设置为 True,否则设置为 False。
请注意,超出范围的 b 值仍可能导致有效的计算源 lane 索引 j。在这种情况下,会发生数据传输,并且目的谓词 p 为 True。
请注意,如果活动线程从非活动线程获取寄存器,则 warp 内发散控制流中的结果是未定义的。
操作数 b 指定源 lane 或源 lane 偏移量,具体取决于模式。
操作数 c 包含两个打包值,分别指定将 warp 逻辑拆分为子段的掩码和用于钳制源 lane 索引的上限。
语义
lane[4:0] = [Thread].laneid; // position of thread in warp
bval[4:0] = b[4:0]; // source lane or lane offset (0..31)
cval[4:0] = c[4:0]; // clamp value
mask[4:0] = c[12:8];
// get value of source register a if thread is active and
// guard predicate true, else unpredictable
if (isActive(Thread) && isGuardPredicateTrue(Thread)) {
SourceA[lane] = a;
} else {
// Value of SourceA[lane] is unpredictable for
// inactive/predicated-off threads in warp
}
maxLane = (lane[4:0] & mask[4:0]) | (cval[4:0] & ~mask[4:0]);
minLane = (lane[4:0] & mask[4:0]);
switch (.mode) {
case .up: j = lane - bval; pval = (j >= maxLane); break;
case .down: j = lane + bval; pval = (j <= maxLane); break;
case .bfly: j = lane ^ bval; pval = (j <= maxLane); break;
case .idx: j = minLane | (bval[4:0] & ~mask[4:0]);
pval = (j <= maxLane); break;
}
if (!pval) j = lane; // copy from own lane
d = SourceA[j]; // copy input a from lane j
if (dest predicate selected)
p = pval;
PTX ISA 注释
在 PTX ISA 版本 3.0 中引入。
在 PTX ISA 版本 6.0 中弃用,转而使用 shfl.sync。
PTX ISA 版本 6.4 不支持用于 .target sm_70 或更高版本。
目标 ISA 注释
shfl 需要 sm_30 或更高版本。
从 PTX ISA 版本 6.4 开始,shfl 在 sm_70 或更高版本上不受支持。
示例
// Warp-level INCLUSIVE PLUS SCAN:
//
// Assumes input in following registers:
// - Rx = sequence value for this thread
//
shfl.up.b32 Ry|p, Rx, 0x1, 0x0;
@p add.f32 Rx, Ry, Rx;
shfl.up.b32 Ry|p, Rx, 0x2, 0x0;
@p add.f32 Rx, Ry, Rx;
shfl.up.b32 Ry|p, Rx, 0x4, 0x0;
@p add.f32 Rx, Ry, Rx;
shfl.up.b32 Ry|p, Rx, 0x8, 0x0;
@p add.f32 Rx, Ry, Rx;
shfl.up.b32 Ry|p, Rx, 0x10, 0x0;
@p add.f32 Rx, Ry, Rx;
// Warp-level INCLUSIVE PLUS REVERSE-SCAN:
//
// Assumes input in following registers:
// - Rx = sequence value for this thread
//
shfl.down.b32 Ry|p, Rx, 0x1, 0x1f;
@p add.f32 Rx, Ry, Rx;
shfl.down.b32 Ry|p, Rx, 0x2, 0x1f;
@p add.f32 Rx, Ry, Rx;
shfl.down.b32 Ry|p, Rx, 0x4, 0x1f;
@p add.f32 Rx, Ry, Rx;
shfl.down.b32 Ry|p, Rx, 0x8, 0x1f;
@p add.f32 Rx, Ry, Rx;
shfl.down.b32 Ry|p, Rx, 0x10, 0x1f;
@p add.f32 Rx, Ry, Rx;
// BUTTERFLY REDUCTION:
//
// Assumes input in following registers:
// - Rx = sequence value for this thread
//
shfl.bfly.b32 Ry, Rx, 0x10, 0x1f; // no predicate dest
add.f32 Rx, Ry, Rx;
shfl.bfly.b32 Ry, Rx, 0x8, 0x1f;
add.f32 Rx, Ry, Rx;
shfl.bfly.b32 Ry, Rx, 0x4, 0x1f;
add.f32 Rx, Ry, Rx;
shfl.bfly.b32 Ry, Rx, 0x2, 0x1f;
add.f32 Rx, Ry, Rx;
shfl.bfly.b32 Ry, Rx, 0x1, 0x1f;
add.f32 Rx, Ry, Rx;
//
// All threads now hold sum in Rx
9.7.9.6. 数据移动和转换指令:shfl.sync
shfl.sync
warp 中线程之间的寄存器数据混洗。
语法
shfl.sync.mode.b32 d[|p], a, b, c, membermask;
.mode = { .up, .down, .bfly, .idx };
描述
在 warp 的线程之间交换寄存器数据。
shfl.sync 将导致执行线程等待,直到与 membermask 对应的所有非退出线程都使用相同的限定符和相同的 membermask 值执行 shfl.sync 后,才恢复执行。
操作数 membermask 指定一个 32 位整数,该整数是一个掩码,指示参与屏障的线程,其中位位置对应于线程的 laneid。
shfl.sync 在 membermask 中的线程之间交换寄存器数据。
当前执行 warp 中的每个线程将基于输入操作数 b 和 c 以及模式计算源 lane 索引 j。如果计算出的源 lane 索引 j 在范围内,则线程会将输入操作数 a 从 lane j 复制到其自身的目的寄存器 d 中;否则,线程将简单地将其自身的输入 a 复制到目的地 d。可选的目的谓词 p 在计算出的源 lane 在范围内时设置为 True,否则设置为 False。
请注意,超出范围的 b 值仍可能导致有效的计算源 lane 索引 j。在这种情况下,会发生数据传输,并且目的谓词 p 为 True。
请注意,如果线程从非活动线程或不在 membermask 中的线程获取寄存器,则结果是未定义的。
操作数 b 指定源 lane 或源 lane 偏移量,具体取决于模式。
操作数 c 包含两个打包值,分别指定将 warp 逻辑拆分为子段的掩码和用于钳制源 lane 索引的上限。
如果执行线程不在 membermask 中,则 shfl.sync 的行为是未定义的。
注意
对于 .target sm_6x 或更低版本,membermask 中的所有线程必须在收敛时执行相同的 shfl.sync 指令,并且只有属于某些 membermask 的线程才能在执行 shfl.sync 指令时处于活动状态。 否则,行为是未定义的。
语义
// wait for all threads in membermask to arrive
wait_for_specified_threads(membermask);
lane[4:0] = [Thread].laneid; // position of thread in warp
bval[4:0] = b[4:0]; // source lane or lane offset (0..31)
cval[4:0] = c[4:0]; // clamp value
segmask[4:0] = c[12:8];
// get value of source register a if thread is active and
// guard predicate true, else unpredictable
if (isActive(Thread) && isGuardPredicateTrue(Thread)) {
SourceA[lane] = a;
} else {
// Value of SourceA[lane] is unpredictable for
// inactive/predicated-off threads in warp
}
maxLane = (lane[4:0] & segmask[4:0]) | (cval[4:0] & ~segmask[4:0]);
minLane = (lane[4:0] & segmask[4:0]);
switch (.mode) {
case .up: j = lane - bval; pval = (j >= maxLane); break;
case .down: j = lane + bval; pval = (j <= maxLane); break;
case .bfly: j = lane ^ bval; pval = (j <= maxLane); break;
case .idx: j = minLane | (bval[4:0] & ~segmask[4:0]);
pval = (j <= maxLane); break;
}
if (!pval) j = lane; // copy from own lane
d = SourceA[j]; // copy input a from lane j
if (dest predicate selected)
p = pval;
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
目标 ISA 注释
需要 sm_30 或更高版本。
示例
shfl.sync.up.b32 Ry|p, Rx, 0x1, 0x0, 0xffffffff;
9.7.9.7. 数据移动和转换指令:prmt
prmt
从寄存器对中置换字节。
语法
prmt.b32{.mode} d, a, b, c;
.mode = { .f4e, .b4e, .rc8, .ecl, .ecr, .rc16 };
描述
从两个 32 位寄存器中选取四个任意字节,并将它们重新组合成一个 32 位目的寄存器。
在通用形式(未指定模式)中,置换控制由四个 4 位选择值组成。两个源寄存器中的字节从 0 到 7 编号:{b, a} = {{b7, b6, b5, b4}, {b3, b2, b1, b0}}。对于目标寄存器中的每个字节,都定义了一个 4 位选择值。
选择值的 3 个最低有效位指定应将 8 个源字节中的哪个字节移动到目标位置。最高有效位定义是否应复制字节值,或者是否应将符号(字节的最高有效位)复制到目标位置的所有 8 位(字节值的符号扩展);msb=0 表示复制字面值;msb=1 表示复制符号。请注意,符号扩展仅作为通用形式的一部分执行。
因此,这四个 4 位值完全指定了任意字节置换,作为 16b 置换代码。
默认模式 |
源选择 |
源选择 |
源选择 |
源选择 |
|---|---|---|---|---|
索引 |
|
|
|
|
更专门形式的置换控制使用操作数 c 的两个最低有效位(通常是地址指针)来控制字节提取。
模式 |
选择器
|
源 |
源 |
源 |
源 |
|---|---|---|---|---|---|
|
0 |
3 |
2 |
1 |
0 |
1 |
4 |
3 |
2 |
1 |
|
2 |
5 |
4 |
3 |
2 |
|
3 |
6 |
5 |
4 |
3 |
|
|
0 |
5 |
6 |
7 |
0 |
1 |
6 |
7 |
0 |
1 |
|
2 |
7 |
0 |
1 |
2 |
|
3 |
0 |
1 |
2 |
3 |
|
|
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
|
2 |
2 |
2 |
2 |
2 |
|
3 |
3 |
3 |
3 |
3 |
|
|
0 |
3 |
2 |
1 |
0 |
1 |
3 |
2 |
1 |
1 |
|
2 |
3 |
2 |
2 |
2 |
|
3 |
3 |
3 |
3 |
3 |
|
|
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
|
2 |
2 |
2 |
1 |
0 |
|
3 |
3 |
2 |
1 |
0 |
|
|
0 |
1 |
0 |
1 |
0 |
1 |
3 |
2 |
3 |
2 |
|
2 |
1 |
0 |
1 |
0 |
|
3 |
3 |
2 |
3 |
2 |
语义
tmp64 = (b<<32) | a; // create 8 byte source
if ( ! mode ) {
ctl[0] = (c >> 0) & 0xf;
ctl[1] = (c >> 4) & 0xf;
ctl[2] = (c >> 8) & 0xf;
ctl[3] = (c >> 12) & 0xf;
} else {
ctl[0] = ctl[1] = ctl[2] = ctl[3] = (c >> 0) & 0x3;
}
tmp[07:00] = ReadByte( mode, ctl[0], tmp64 );
tmp[15:08] = ReadByte( mode, ctl[1], tmp64 );
tmp[23:16] = ReadByte( mode, ctl[2], tmp64 );
tmp[31:24] = ReadByte( mode, ctl[3], tmp64 );
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
prmt 需要 sm_20 或更高版本。
示例
prmt.b32 r1, r2, r3, r4;
prmt.b32.f4e r1, r2, r3, r4;
9.7.9.8. 数据移动和转换指令:ld
ld
从可寻址状态空间变量加载寄存器变量。
语法
ld{.weak}{.ss}{.cop}{.level::cache_hint}{.level::prefetch_size}{.vec}.type d, [a]{.unified}{, cache-policy};
ld{.weak}{.ss}{.level::eviction_priority}{.level::cache_hint}{.level::prefetch_size}{.vec}.type d, [a]{.unified}{, cache-policy};
ld.volatile{.ss}{.level::prefetch_size}{.vec}.type d, [a];
ld.relaxed.scope{.ss}{.level::eviction_priority}{.level::cache_hint}{.level::prefetch_size}{.vec}.type d, [a]{, cache-policy};
ld.acquire.scope{.ss}{.level::eviction_priority}{.level::cache_hint}{.level::prefetch_size}{.vec}.type d, [a]{, cache-policy};
ld.mmio.relaxed.sys{.global}.type d, [a];
.ss = { .const, .global, .local, .param{::entry, ::func}, .shared{::cta, ::cluster} };
.cop = { .ca, .cg, .cs, .lu, .cv };
.level::eviction_priority = { .L1::evict_normal, .L1::evict_unchanged,
.L1::evict_first, .L1::evict_last, .L1::no_allocate };
.level::cache_hint = { .L2::cache_hint };
.level::prefetch_size = { .L2::64B, .L2::128B, .L2::256B }
.scope = { .cta, .cluster, .gpu, .sys };
.vec = { .v2, .v4 };
.type = { .b8, .b16, .b32, .b64, .b128,
.u8, .u16, .u32, .u64,
.s8, .s16, .s32, .s64,
.f32, .f64 };
描述
从指定状态空间中源地址操作数 a 指定的位置加载寄存器变量 d。如果未给出状态空间,则使用通用寻址执行加载。
如果 .shared 状态空间未指定子限定符,则默认情况下假定为 ::cta。
操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
如果 .param 状态空间未指定子限定符,则
当在设备函数内部访问时,假定为
::func。当从入口函数访问内核函数参数时,假定为
::entry。否则,当从入口函数访问设备函数参数或任何其他.param变量时,默认情况下假定为::func。
对于 ld.param::entry 指令,操作数 a 必须是内核参数地址,否则行为未定义。对于 ld.param::func 指令,操作数 a 必须是设备函数参数地址,否则行为未定义。
用于读取从设备函数调用返回值的指令 ld.param{::func} 不能被谓词化。有关 ld.param 的正确用法的描述,请参阅参数状态空间和函数声明和定义。
.relaxed 和 .acquire 限定符指示内存同步,如内存一致性模型中所述。.scope 限定符指示 ld.relaxed 或 ld.acquire 指令可以直接同步1的线程集。.weak 限定符指示没有同步的内存指令。此指令的效果仅在通过其他方式建立同步时才对其他线程可见。
.mmio 限定符的语义细节在内存一致性模型中描述。只有 .sys 线程范围对 ld.mmio 操作有效。.mmio 和 .relaxed 限定符必须一起指定。
.volatile 限定符的语义细节在内存一致性模型中描述。
.weak、.volatile、.relaxed 和 .acquire 限定符是互斥的。当未指定其中任何一个时,默认情况下假定为 .weak 限定符。
.volatile、.relaxed 和 .acquire 限定符只能与 .global 和 .shared 空间以及通用寻址一起使用,其中地址指向 .global 或 .shared 空间。这些限定符不允许进行缓存操作。.mmio 限定符只能与 .global 空间以及通用寻址一起使用,其中地址指向 .global 空间。
如果 a 是使用 变量和函数属性指令:.attribute中描述的 .unified 属性声明的变量的地址,则必须在操作数 a 上指定可选的限定符 .unified。
限定符 .level::eviction_priority 指定内存访问期间将使用的驱逐策略。
限定符 .level::prefetch_size 是一个提示,用于将指定大小的额外数据提取到相应的缓存级别。子限定符 prefetch_size 可以设置为 64B、128B、256B 中的任一值,从而允许预取大小分别为 64 字节、128 字节或 256 字节。
限定符 .level::prefetch_size 只能与 .global 状态空间以及通用寻址一起使用,其中地址指向 .global 状态空间。如果通用地址不在全局内存的地址窗口内,则预取行为是未定义的。
限定符 .level::prefetch_size 仅被视为性能提示。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
限定符 .unified 和 .level::cache_hint 仅支持 .global 状态空间和通用寻址,其中地址指向 .global 状态空间。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
1 这种同步通过因果顺序的传递性进一步扩展到其他线程,如内存一致性模型中所述。
语义
d = a; // named variable a
d = *(&a+immOff) // variable-plus-offset
d = *a; // register
d = *(a+immOff); // register-plus-offset
d = *(immAddr); // immediate address
注释
目的地 d 必须在 .reg 状态空间中。
可以使用比指定类型更宽的目的寄存器。对于有符号整数,加载的值会进行符号扩展以适应目的寄存器宽度;对于无符号和位大小类型,加载的值会进行零扩展以适应目的寄存器宽度。有关这些宽松类型检查规则的描述,请参阅表 27。
.f16 数据可以使用 ld.b16 加载,然后使用 cvt 转换为 .f32 或 .f64,或者可以在半精度浮点指令中使用。
.f16x2 数据可以使用 ld.b32 加载,然后用于半精度浮点指令中。
PTX ISA 注释
ld 在 PTX ISA 版本 1.0 中引入。ld.volatile 在 PTX ISA 版本 1.1 中引入。
通用寻址和缓存操作在 PTX ISA 版本 2.0 中引入。
对范围限定符、.relaxed、.acquire、.weak 限定符的支持在 PTX ISA 版本 6.0 中引入。
在 PTX ISA 版本 3.1 中添加了对 .const 空间的通用寻址的支持。
对 .level::eviction_priority、.level::prefetch_size 和 .level::cache_hint 限定符的支持在 PTX ISA 版本 7.4 中引入。
对 .cluster 范围限定符的支持在 PTX ISA 版本 7.8 中引入。
对 ::cta 和 ::cluster 子限定符的支持在 PTX ISA 版本 7.8 中引入。
对 .unified 限定符的支持在 PTX ISA 版本 8.0 中引入。
对 .mmio 限定符的支持在 PTX ISA 版本 8.2 中引入。
对 .param 空间上的 ::entry 和 ::func 子限定符的支持在 PTX ISA 版本 8.3 中引入。
对 .b128 类型的支持在 PTX ISA 版本 8.3 中引入。
对具有 .b128 类型的 .sys 范围的支持在 PTX ISA 版本 8.4 中引入。
目标 ISA 注释
ld.f64 需要 sm_13 或更高版本。
对范围限定符、.relaxed、.acquire、.weak 限定符的支持需要 sm_70 或更高版本。
通用寻址需要 sm_20 或更高版本。
缓存操作需要 sm_20 或更高版本。
对 .level::eviction_priority 限定符的支持需要 sm_70 或更高版本。
对 .level::prefetch_size 限定符的支持需要 sm_75 或更高版本。
对 .L2::256B 和 .L2::cache_hint 限定符的支持需要 sm_80 或更高版本。
对 .cluster 范围限定符的支持需要 sm_90 或更高版本。
子限定符 ::cta 需要 sm_30 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
对 .unified 限定符的支持需要 sm_90 或更高版本。
对 .mmio 限定符的支持需要 sm_70 或更高版本。
对 .b128 类型的支持需要 sm_70 或更高版本。
示例
ld.global.f32 d,[a];
ld.shared.v4.b32 Q,[p];
ld.const.s32 d,[p+4];
ld.local.b32 x,[p+-8]; // negative offset
ld.local.b64 x,[240]; // immediate address
ld.global.b16 %r,[fs]; // load .f16 data into 32-bit reg
cvt.f32.f16 %r,%r; // up-convert f16 data to f32
ld.global.b32 %r0, [fs]; // load .f16x2 data in 32-bit reg
ld.global.b32 %r1, [fs + 4]; // load .f16x2 data in 32-bit reg
add.rn.f16x2 %d0, %r0, %r1; // addition of f16x2 data
ld.global.relaxed.gpu.u32 %r0, [gbl];
ld.shared.acquire.gpu.u32 %r1, [sh];
ld.global.relaxed.cluster.u32 %r2, [gbl];
ld.shared::cta.acquire.gpu.u32 %r2, [sh + 4];
ld.shared::cluster.u32 %r3, [sh + 8];
ld.global.mmio.relaxed.sys.u32 %r3, [gbl];
ld.global.f32 d,[ugbl].unified;
ld.b32 %r0, [%r1].unified;
ld.global.L1::evict_last.u32 d, [p];
ld.global.L2::64B.b32 %r0, [gbl]; // Prefetch 64B to L2
ld.L2::128B.f64 %r1, [gbl]; // Prefetch 128B to L2
ld.global.L2::256B.f64 %r2, [gbl]; // Prefetch 256B to L2
createpolicy.fractional.L2::evict_last.L2::evict_unchanged.b64 cache-policy, 1;
ld.global.L2::cache_hint.b64 x, [p], cache-policy;
ld.param::entry.b32 %rp1, [kparam1];
ld.global.b128 %r0, [gbl]; // 128-bit load
9.7.9.9. 数据移动和转换指令:ld.global.nc
ld.global.nc
通过非相干缓存从全局状态空间加载寄存器变量。
语法
ld.global{.cop}.nc{.level::cache_hint}{.level::prefetch_size}.type d, [a]{, cache-policy};
ld.global{.cop}.nc{.level::cache_hint}{.level::prefetch_size}.vec.type d, [a]{, cache-policy};
ld.global.nc{.level::eviction_priority}{.level::cache_hint}{.level::prefetch_size}.type d, [a]{, cache-policy};
ld.global.nc{.level::eviction_priority}{.level::cache_hint}{.level::prefetch_size}.vec.type d, [a]{, cache-policy};
.cop = { .ca, .cg, .cs }; // cache operation
.level::eviction_priority = { .L1::evict_normal, .L1::evict_unchanged,
.L1::evict_first, .L1::evict_last, .L1::no_allocate};
.level::cache_hint = { .L2::cache_hint };
.level::prefetch_size = { .L2::64B, .L2::128B, .L2::256B }
.vec = { .v2, .v4 };
.type = { .b8, .b16, .b32, .b64, .b128,
.u8, .u16, .u32, .u64,
.s8, .s16, .s32, .s64,
.f32, .f64 };
描述
从全局状态空间中源地址操作数 a 指定的位置加载寄存器变量 d,并可选择缓存在非相干只读缓存中。
注意
在某些架构上,纹理缓存比全局内存缓存更大、带宽更高且延迟更长。对于具有足够并行性以覆盖较长延迟的应用程序,在这些架构上,ld.global.nc 应提供比 ld.global 更好的性能。
地址操作数 a 可以包含指向 .global 状态空间的通用地址。操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
限定符 .level::eviction_priority 指定内存访问期间将使用的驱逐策略。
限定符 .level::prefetch_size 是一个提示,用于将指定大小的额外数据提取到相应的缓存级别。子限定符 prefetch_size 可以设置为 64B、128B、256B 中的任一值,从而允许预取大小分别为 64 字节、128 字节或 256 字节。
限定符 .level::prefetch_size 仅被视为性能提示。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
语义
d = a; // named variable a
d = *(&a+immOff) // variable-plus-offset
d = *a; // register
d = *(a+immOff); // register-plus-offset
d = *(immAddr); // immediate address
注释
目的地 d 必须在 .reg 状态空间中。
可以使用比指定类型更宽的目的寄存器。对于有符号整数,加载的值会进行符号扩展以适应目的寄存器宽度;对于无符号和位大小类型,加载的值会进行零扩展以适应目的寄存器宽度。
.f16 数据可以使用 ld.b16 加载,然后使用 cvt 转换为 .f32 或 .f64。
PTX ISA 注释
在 PTX ISA 版本 3.1 中引入。
对 .level::eviction_priority、.level::prefetch_size 和 .level::cache_hint 限定符的支持在 PTX ISA 版本 7.4 中引入。
对 .b128 类型的支持在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
需要 sm_32 或更高版本。
对 .level::eviction_priority 限定符的支持需要 sm_70 或更高版本。
对 .level::prefetch_size 限定符的支持需要 sm_75 或更高版本。
对 .level::cache_hint 限定符的支持需要 sm_80 或更高版本。
对 .b128 类型的支持需要 sm_70 或更高版本。
示例
ld.global.nc.f32 d, [a];
ld.gloal.nc.L1::evict_last.u32 d, [a];
createpolicy.fractional.L2::evict_last.b64 cache-policy, 0.5;
ld.global.nc.L2::cache_hint.f32 d, [a], cache-policy;
ld.global.nc.L2::64B.b32 d, [a]; // Prefetch 64B to L2
ld.global.nc.L2::256B.f64 d, [a]; // Prefetch 256B to L2
ld.global.nc.b128 d, [a];
9.7.9.10. 数据移动和转换指令:ldu
ldu
从 warp 中线程共用的地址加载只读数据。
语法
ldu{.ss}.type d, [a]; // load from address
ldu{.ss}.vec.type d, [a]; // vec load from address
.ss = { .global }; // state space
.vec = { .v2, .v4 };
.type = { .b8, .b16, .b32, .b64, .b128,
.u8, .u16, .u32, .u64,
.s8, .s16, .s32, .s64,
.f32, .f64 };
描述
将只读数据加载到寄存器变量 d 中,位置由全局状态空间中源地址操作数 a 指定,其中保证该地址在 warp 中的所有线程之间是相同的。如果未给出状态空间,则使用通用寻址执行加载。
操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
语义
d = a; // named variable a
d = *(&a+immOff) // variable-plus-offset
d = *a; // register
d = *(a+immOff); // register-plus-offset
d = *(immAddr); // immediate address
注释
目的地 d 必须在 .reg 状态空间中。
可以使用比指定类型更宽的目的寄存器。对于有符号整数,加载的值会进行符号扩展以适应目的寄存器宽度;对于无符号和位大小类型,加载的值会进行零扩展以适应目的寄存器宽度。有关这些宽松类型检查规则的描述,请参阅表 27。
.f16 数据可以使用 ldu.b16 加载,然后使用 cvt 转换为 .f32 或 .f64,或者可以在半精度浮点指令中使用。
.f16x2 数据可以使用 ldu.b32 加载,然后用于半精度浮点指令中。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
对 .b128 类型的支持在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
ldu.f64 需要 sm_13 或更高版本。
对 .b128 类型的支持需要 sm_70 或更高版本。
示例
ldu.global.f32 d,[a];
ldu.global.b32 d,[p+4];
ldu.global.v4.f32 Q,[p];
ldu.global.b128 d,[a];
9.7.9.11. 数据移动和转换指令:st
st
将数据存储到可寻址状态空间变量。
语法
st{.weak}{.ss}{.cop}{.level::cache_hint}{.vec}.type [a], b{, cache-policy};
st{.weak}{.ss}{.level::eviction_priority}{.level::cache_hint}{.vec}.type
[a], b{, cache-policy};
st.volatile{.ss}{.vec}.type [a], b;
st.relaxed.scope{.ss}{.level::eviction_priority}{.level::cache_hint}{.vec}.type
[a], b{, cache-policy};
st.release.scope{.ss}{.level::eviction_priority}{.level::cache_hint}{.vec}.type
[a], b{, cache-policy};
st.mmio.relaxed.sys{.global}.type [a], b;
.ss = { .global, .local, .param{::func}, .shared{::cta, ::cluster} };
.level::eviction_priority = { .L1::evict_normal, .L1::evict_unchanged,
.L1::evict_first, .L1::evict_last, .L1::no_allocate };
.level::cache_hint = { .L2::cache_hint };
.cop = { .wb, .cg, .cs, .wt };
.sem = { .relaxed, .release };
.scope = { .cta, .cluster, .gpu, .sys };
.vec = { .v2, .v4 };
.type = { .b8, .b16, .b32, .b64, .b128,
.u8, .u16, .u32, .u64,
.s8, .s16, .s32, .s64,
.f32, .f64 };
描述
将操作数 b 的值存储到指定状态空间中目的地址操作数 a 指定的位置。如果未给出状态空间,则使用通用寻址执行存储。禁止存储到 const 内存。
如果 .shared 状态空间未指定子限定符,则默认情况下假定为 ::cta。
操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
如果指定了 .param 但未指定任何子限定符,则默认设置为 .param::func。
用于将参数传递给设备函数的指令 st.param{::func} 不能被谓词化。有关 st.param 的正确用法的描述,请参阅参数状态空间和函数声明和定义。
.relaxed 和 .release 限定符指示内存同步,如内存一致性模型中所述。.scope 限定符指示 st.relaxed 或 st.release 指令可以直接同步1的线程集。.weak 限定符指示没有同步的内存指令。此指令的效果仅在通过其他方式建立同步时才对其他线程可见。
.mmio 限定符的语义细节在内存一致性模型中描述。只有 .sys 线程范围对 st.mmio 操作有效。.mmio 和 .relaxed 限定符必须一起指定。
.volatile 限定符的语义细节在内存一致性模型中描述。
.weak、.volatile、.relaxed 和 .release 限定符是互斥的。当未指定其中任何一个时,默认情况下假定为 .weak 限定符。
.volatile、.relaxed 和 .release 限定符只能与 .global 和 .shared 空间以及通用寻址一起使用,其中地址指向 .global 或 .shared 空间。这些限定符不允许进行缓存操作。.mmio 限定符只能与 .global 空间以及通用寻址一起使用,其中地址指向 .global 空间。
限定符 .level::eviction_priority 指定内存访问期间将使用的驱逐策略。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
限定符 .level::cache_hint 仅支持 .global 状态空间和通用寻址,其中地址指向 .global 状态空间。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
1 这种同步通过因果顺序的传递性进一步扩展到其他线程,如内存一致性模型中所述。
语义
d = a; // named variable d
*(&a+immOffset) = b; // variable-plus-offset
*a = b; // register
*(a+immOffset) = b; // register-plus-offset
*(immAddr) = b; // immediate address
注释
操作数 b 必须在 .reg 状态空间中。
可以使用比指定类型更宽的源寄存器。对应于指令类型宽度的较低 n 位将存储到内存中。有关这些宽松类型检查规则的描述,请参阅表 26。
由 cvt 指令产生的 .f16 数据可以使用 st.b16 存储。
.f16x2 数据可以使用 st.b32 存储。
PTX ISA 注释
st 在 PTX ISA 版本 1.0 中引入。st.volatile 在 PTX ISA 版本 1.1 中引入。
通用寻址和缓存操作在 PTX ISA 版本 2.0 中引入。
对范围限定符、.relaxed、.release、.weak 限定符的支持在 PTX ISA 版本 6.0 中引入。
PTX ISA 7.4 版本引入了对限定符 .level::eviction_priority 和 .level::cache_hint 的支持。
对 .cluster 范围限定符的支持在 PTX ISA 版本 7.8 中引入。
对 ::cta 和 ::cluster 子限定符的支持在 PTX ISA 版本 7.8 中引入。
对 .mmio 限定符的支持在 PTX ISA 版本 8.2 中引入。
PTX ISA 8.3 版本引入了对 .param 空间的 ::func 子限定符的支持。
对 .b128 类型的支持在 PTX ISA 版本 8.3 中引入。
对具有 .b128 类型的 .sys 范围的支持在 PTX ISA 版本 8.4 中引入。
目标 ISA 注释
st.f64 需要 sm_13 或更高版本。
作用域限定符 .relaxed、.release、.weak 需要 sm_70 或更高版本。
通用寻址需要 sm_20 或更高版本。
缓存操作需要 sm_20 或更高版本。
对 .level::eviction_priority 限定符的支持需要 sm_70 或更高版本。
对 .level::cache_hint 限定符的支持需要 sm_80 或更高版本。
对 .cluster 范围限定符的支持需要 sm_90 或更高版本。
子限定符 ::cta 需要 sm_30 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
对 .mmio 限定符的支持需要 sm_70 或更高版本。
对 .b128 类型的支持需要 sm_70 或更高版本。
示例
st.global.f32 [a],b;
st.local.b32 [q+4],a;
st.global.v4.s32 [p],Q;
st.local.b32 [q+-8],a; // negative offset
st.local.s32 [100],r7; // immediate address
cvt.f16.f32 %r,%r; // %r is 32-bit register
st.b16 [fs],%r; // store lower
st.global.relaxed.sys.u32 [gbl], %r0;
st.shared.release.cta.u32 [sh], %r1;
st.global.relaxed.cluster.u32 [gbl], %r2;
st.shared::cta.release.cta.u32 [sh + 4], %r1;
st.shared::cluster.u32 [sh + 8], %r1;
st.global.mmio.relaxed.sys.u32 [gbl], %r1;
st.global.L1::no_allocate.f32 [p], a;
createpolicy.fractional.L2::evict_last.b64 cache-policy, 0.25;
st.global.L2::cache_hint.b32 [a], b, cache-policy;
st.param::func.b64 [param1], %rp1;
st.global.b128 [a], b; // 128-bit store
9.7.9.12. 数据移动和转换指令:st.async
st.async
异步存储操作。
语法
st.async{.sem}{.scope}{.ss}{.completion_mechanism}{.vec}.type [a], b, [mbar];
.sem = { .weak };
.scope = { .cluster };
.ss = { .shared::cluster };
.type = { .b32, .b64,
.u32, .u64,
.s32, .s64,
.f32, .f64 };
.vec = { .v2, .v4 };
.completion_mechanism = { .mbarrier::complete_tx::bytes };
st.async{.mmio}.sem{.scope}{.ss}{.completion_mechanism}.type [a], b;
.sem = { .release };
.scope = { .gpu, .sys };
.ss = { .global };
.completion_mechanism = { };
.type = { .b8, .b16, .b32, .b64,
.u8, .u16, .u32, .u64,
.s8, .s16, .s32, .s64,
.f32, .f64 };
描述
st.async 是一条非阻塞指令,它发起一个异步存储操作,将源操作数 b 指定的值存储到操作数 a 指定的目标内存位置。
操作数
a是目标地址,必须是寄存器,或register + immOff形式,如 作为操作数的地址 中所述。b是源值,类型由限定符.type指示。mbar是 mbarrier 对象地址。
限定符
.mmio指示这是否是 mmio 操作。-
.sem指定内存排序语义,如 内存一致性模型 中所述。如果未指定
.sem,则默认为.weak。
.scope指定此指令可以直接同步的线程集。-
.ss指定目标操作数a和 mbarrier 操作数mbar的状态空间。如果未指定
.ss,则使用 通用寻址。
-
.completion_mechanism指定用于观察异步操作完成的机制。当
.completion_mechanism为.mbarrier::complete_tx::bytes时:异步操作完成后,将在操作数mbar指定的 mbarrier 对象上执行 complete-tx 操作,其中completeCount参数等于存储的数据量(以字节为单位)。当未指定
.completion_mechanism时:存储完成与 CTA 结束同步。
.type指定源操作数b的类型。
条件
当 .sem 为 .weak 时
这是对共享内存的弱存储,通过 mbarrier 对象发出完成信号。
存储操作被视为弱内存操作。
mbarrier 上的 complete-tx 操作在
.cluster作用域具有.release语义。-
要求
目标操作数
a和 *mbarrier 对象*mbar的共享内存地址属于执行线程所在的同一集群内的同一 CTA。集群内的 CTA 数量严格大于 1;
%cluster_nctarank > 1为真。
否则,行为未定义。
不得指定
.mmio。如果指定了
.scope,则必须为.cluster。如果未指定
.scope,则默认为.cluster。如果指定了
.ss,则必须为.shared::cluster。如果未指定
.ss,则对操作数a和mbar使用通用寻址。如果指定的通用地址未落在.shared::cluster状态空间的地址窗口内,则行为未定义。如果指定了
.completion_mechanism,则必须为.mbarrier::complete_tx::bytes。如果未指定
.completion_mechanism,则默认为.mbarrier::complete_tx::bytes。
当 .sem 为 .release 时
这是对全局内存的 release 存储。
存储操作是强内存操作,在
.scope指定的作用域内具有.release语义。如果指定了
.mmio,则.scope必须为.sys。如果指定了
.scope,则可以是.gpu或.sys。如果未指定
.scope,则默认为.sys。如果指定了
.ss,则必须为.global。如果未指定
.ss,则对操作数a使用通用寻址。如果指定的通用地址未落在.global状态空间的地址窗口内,则行为未定义。不得指定
.completion_mechanism。
PTX ISA 注释
在 PTX ISA 8.1 版本中引入。
PTX ISA 8.7 版本中引入了对 .mmio 限定符、.release 语义、.global 状态空间和 .scope 限定符的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
.mmio 限定符、.release 语义、.global 状态空间和 .scope 限定符需要 sm_100 或更高版本。
示例
st.async.shared::cluster.mbarrier::complete_tx::bytes.u32 [addr], b, [mbar_addr];
st.async.release.global.u32 [addr], b;
9.7.9.13. 数据移动和转换指令:st.bulk
st.bulk
初始化由状态空间指定的内存区域。
语法
st.bulk{.weak}{.shared::cta} [a], size, initval; // initval must be zero
描述
st.bulk 指令初始化从目标地址操作数 a 指定的位置开始的共享内存区域。
64 位整数操作数 size 以字节为单位指定要初始化的内存量。size 必须是 8 的倍数。如果该值不是 8 的倍数,则行为未定义。size 操作数的最大值可以是 34359738360。
整数立即操作数 initval 指定内存位置的初始化值。操作数 initval 唯一允许的数值是 0。
如果未指定状态空间,则使用 通用寻址。如果 a 指定的地址未落在 .shared 状态空间的地址窗口内,则行为未定义。
可选限定符 .weak 指定 st.bulk 指令的内存同步效果,如 内存一致性模型 中所述。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
需要 sm_100 或更高版本。
示例
st.bulk.weak.shared::cta [dst], n, 0;
st.bulk [gdst], 4096, 0;
9.7.9.14. 数据移动和转换指令:multimem.ld_reduce、multimem.st、multimem.red
multimem.* 操作作用于 multimem 地址,并访问 multimem 地址指向的所有多个内存位置。
Multimem 地址只能通过 multimem.* 操作访问。使用 ld、st 或任何其他内存操作访问 multimem 地址会导致未定义的行为。
有关 multimem 地址的创建和管理,请参阅 *CUDA 编程指南*。
multimem.ld_reduce、multimem.st、multimem.red
对 multimem 地址执行内存操作。
语法
// Integer type:
multimem.ld_reduce{.ldsem}{.scope}{.ss}.op.type d, [a];
multimem.st{.stsem}{.scope}{.ss}.type [a], b;
multimem.red{.redsem}{.scope}{.ss}.op.type [a], b;
.ss = { .global }
.ldsem = { .weak, .relaxed, .acquire }
.stsem = { .weak, .relaxed, .release }
.redsem = { .relaxed, .release }
.scope = { .cta, .cluster, .gpu, .sys }
.op = { .min, .max, .add, .and, .or, .xor }
.type = { .b32, .b64, .u32, .u64, .s32, .s64 }
// Floating point type:
multimem.ld_reduce{.ldsem}{.scope}{.ss}.op{.acc_prec}{.vec}.type d, [a];
multimem.st{.stsem}{.scope}{.ss}{.vec}.type [a], b;
multimem.red{.redsem}{.scope}{.ss}.redop{.vec}.redtype [a], b;
.ss = { .global }
.ldsem = { .weak, .relaxed, .acquire }
.stsem = { .weak, .relaxed, .release }
.redsem = { .relaxed, .release }
.scope = { .cta, .cluster, .gpu, .sys }
.op = { .min, .max, .add }
.redop = { .add }
.acc_prec = { .acc::f32, .acc::f16 }
.vec = { .v2, .v4, .v8 }
.type= { .f16, .f16x2, .bf16, .bf16x2, .f32, .f64, .e5m2, .e5m2x2, .e5m2x4, .e4m3, .e4m3x2, .e4m3x4 }
.redtype = { .f16, .f16x2, .bf16, .bf16x2, .f32, .f64 }
描述
指令 multimem.ld_reduce 执行以下操作
对 multimem 地址
a执行加载操作,这涉及从 multimem 地址a指向的所有多个内存位置加载数据,对从 multimem 地址
a加载的多个数据执行由.op指定的归约操作。
归约操作的结果在寄存器 d 中返回。
指令 multimem.st 执行将输入操作数 b 存储到 multimem 地址 a 指向的所有内存位置的存储操作。
指令 multimem.red 对 multimem 地址 a 指向的所有内存位置执行归约操作,操作数为 b。
指令 multimem.ld_reduce 对从 multimem 地址指向的所有内存位置加载的值执行归约。相比之下,multimem.red 对 multimem 地址指向的所有内存位置执行归约。
地址操作数 a 必须是 multimem 地址。否则,行为未定义。操作数 a 支持的寻址模式和对齐要求在 作为操作数的地址 中描述。
如果未指定状态空间,则使用 通用寻址。如果 a 指定的地址未落在 .global 状态空间的地址窗口内,则行为未定义。
对于浮点类型 multi- 操作,指定类型的大小以及 .vec 必须等于 32 位、64 位或 128 位。.vec 和类型的其他组合均不允许。类型 .f64 不能与 .vec 限定符一起使用。
下表描述了 .op 和基本类型的有效组合
op |
基本类型 |
|---|---|
|
.u32、.u64、.s32.f16、.f16x2、.bf16、.bf16x2.f32、.f64、.e5m2、.e5m2x2、.e5m2x4、.e4m3、.e4m3x2、.e4m3x4 |
|
|
|
.u32、.s32、.u64、.s64.f16、.f16x2、.bf16、.bf16x2.e5m2、.e5m2x2、.e5m2x4、.e4m3、.e4m3x2、.e4m3x4 |
对于 multimem.ld_reduce,中间累加的默认精度与指定的类型相同。
可选地,可以指定 .acc_prec 限定符来更改中间累加的精度,如下所示
.type |
.acc::prec |
将精度更改为 |
|---|---|---|
|
|
|
|
|
|
可选限定符 .ldsem、.stsem 和 .redsem 分别指定 multimem.ld_reduce、multimem.st 和 multimem.red 的内存同步效果,如 内存一致性模型 中所述。如果未指定显式语义限定符,则 multimem.ld_reduce 和 multimem.st 默认为 .weak,而 multimem.red 默认为 .relaxed。
可选的 .scope 限定符指定可以直接观察此操作的内存同步效果的线程集,如 内存一致性模型 中所述。如果未为 multimem.red 指定 .scope 限定符,则默认假定为 .sys 作用域。
PTX ISA 注释
在 PTX ISA 8.1 版本中引入。
PTX ISA 8.2 版本中引入了对 .acc::f32 限定符的支持。
PTX ISA 8.6 版本中引入了对类型 .e5m2、.e5m2x2、.e5m2x4、.e4m3、.e4m3x2、.e4m3x4 的支持。
PTX ISA 8.6 版本中引入了对 .acc::f16 限定符的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
以下架构支持类型 .e5m2、.e5m2x2、.e5m2x4、.e4m3、.e4m3x2、.e4m3x4
sm_100asm_101asm_120a
以下架构支持限定符 .acc::f16
sm_100asm_101asm_120a
示例
multimem.ld_reduce.and.b32 val1_b32, [addr1];
multimem.ld_reduce.acquire.gpu.global.add.u32 val2_u32, [addr2];
multimem.st.relaxed.gpu.b32 [addr3], val3_b32;
multimem.st.release.cta.global.u32 [addr4], val4_u32;
multimem.red.relaxed.gpu.max.f64 [addr5], val5_f64;
multimem.red.release.cta.global.add.v4.f32 [addr6], {val6, val7, val8, val9};
multimem.ld_reduce.add.acc::f32.v2.f16x2 {val_10, val_11}, [addr7];
multimem.ld_reduce.relaxed.cta.min.v2.e4m3x2 {val_12, val_13}, [addr8];
multimem.ld_reduce.relaxed.cta.add.v4.e4m3 {val_14, val_15, val_16, val_17}, [addr9];
multimem.ld_reduce.add.acc::f16.v4.e5m2 {val_18, val_19, val_20, val_21}, [addr10];
9.7.9.15. 数据移动和转换指令:prefetch、prefetchu
prefetch, prefetchu
在指定内存层次结构的级别和指定状态空间中,预取包含通用地址的行。
语法
prefetch{.space}.level [a]; // prefetch to data cache
prefetch.global.level::eviction_priority [a]; // prefetch to data cache
prefetchu.L1 [a]; // prefetch to uniform cache
prefetch{.tensormap_space}.tensormap [a]; // prefetch the tensormap
.space = { .global, .local };
.level = { .L1, .L2 };
.level::eviction_priority = { .L2::evict_last, .L2::evict_normal };
.tensormap_space = { .const, .param };
描述
prefetch 指令将全局或本地内存状态空间中包含指定地址的缓存行带入指定的缓存级别。
如果指定了 .tensormap 限定符,则 prefetch 指令会将 .const 或 .param 内存状态空间中包含指定地址的缓存行引入,以供 cp.async.bulk.tensor 指令后续使用。
如果未给出状态空间,则 prefetch 使用 通用寻址。
可选地,可以通过修饰符 .level::eviction_priority 指定要应用于预取缓存行的驱逐优先级。
操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
prefetchu 指令将包含指定通用地址的缓存行带入指定的统一缓存级别。
对共享内存位置的 prefetch 不执行任何操作。
预取到统一缓存需要通用地址,如果地址映射到 const、local 或 shared 内存位置,则不执行任何操作。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
PTX ISA 7.4 版本中引入了对 .level::eviction_priority 限定符的支持。
PTX ISA 8.0 版本中引入了对 .tensormap 限定符的支持。
目标 ISA 注释
prefetch 和 prefetchu 需要 sm_20 或更高版本。
对 .level::eviction_priority 限定符的支持需要 sm_80 或更高版本。
对 .tensormap 限定符的支持需要 sm_90 或更高版本。
示例
prefetch.global.L1 [ptr];
prefetch.global.L2::evict_last [ptr];
prefetchu.L1 [addr];
prefetch.const.tensormap [ptr];
9.7.9.16. 数据移动和转换指令:applypriority
applypriority
将缓存驱逐优先级应用于指定缓存级别中的指定地址。
语法
applypriority{.global}.level::eviction_priority [a], size;
.level::eviction_priority = { .L2::evict_normal };
描述
applypriority 指令将 .level::eviction_priority 限定符指定的缓存驱逐优先级应用于指定缓存级别中的地址范围 [a..a+size)。
如果未指定状态空间,则使用 通用寻址。如果指定的地址未落在 .global 状态空间的地址窗口内,则行为未定义。
操作数 size 是一个整数常量,它以字节为单位指定要在指定缓存级别中应用优先级的数据量。 size 操作数唯一支持的值是 128。
操作数 a 支持的寻址模式在 作为操作数的地址 中描述。a 必须与 128 字节对齐。
如果地址 a 指向的数据尚未存在于指定的缓存级别中,则将在应用指定的优先级之前预取数据。
PTX ISA 注释
在 PTX ISA 7.4 版本中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
applypriority.global.L2::evict_normal [ptr], 128;
9.7.9.17. 数据移动和转换指令:discard
discard
使指定地址和缓存级别中的缓存数据无效。
语法
discard{.global}.level [a], size;
.level = { .L2 };
描述
discard 指令使由 .level 限定符指定的缓存级别中地址范围 [a .. a + (size - 1)] 处的数据无效,而不会将缓存中的数据写回内存。因此,在 discard 操作之后,地址范围 [a .. a+ (size - 1)] 处的数据具有不确定的值。
操作数 size 是一个整数常量,它以字节为单位指定要丢弃的、由 .level 限定符指定的缓存级别中的数据量。 size 操作数唯一支持的值是 128。
如果未指定状态空间,则使用 通用寻址。如果指定的地址未落在 .global 状态空间的地址窗口内,则行为未定义。
地址操作数 a 支持的寻址模式在 作为操作数的地址 中描述。a 必须与 128 字节对齐。
PTX ISA 注释
在 PTX ISA 7.4 版本中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
discard.global.L2 [ptr], 128;
9.7.9.18. 数据移动和转换指令:createpolicy
createpolicy
为指定的缓存级别创建缓存驱逐策略。
语法
// Range-based policy
createpolicy.range{.global}.level::primary_priority{.level::secondary_priority}.b64
cache-policy, [a], primary-size, total-size;
// Fraction-based policy
createpolicy.fractional.level::primary_priority{.level::secondary_priority}.b64
cache-policy{, fraction};
// Converting the access property from CUDA APIs
createpolicy.cvt.L2.b64 cache-policy, access-property;
.level::primary_priority = { .L2::evict_last, .L2::evict_normal,
.L2::evict_first, .L2::evict_unchanged };
.level::secondary_priority = { .L2::evict_first, .L2::evict_unchanged };
描述
createpolicy 指令为目标操作数 cache-policy 指定的不透明 64 位寄存器中的指定缓存级别创建缓存驱逐策略。缓存驱逐策略指定如何将缓存驱逐优先级应用于带有 .level::cache_hint 限定符的内存操作中使用的全局内存地址。
有两种类型的缓存驱逐策略
-
基于范围的策略
使用
createpolicy.range创建的缓存驱逐策略指定以下三个地址范围的缓存驱逐行为[a .. a + (primary-size - 1)]称为主范围。[a + primary-size .. a + (total-size - 1)]称为尾随辅助范围。[a - (total-size - primary-size) .. (a - 1)]称为前导辅助范围。
当基于范围的缓存驱逐策略用于带有
.level::cache_hint限定符的内存操作时,驱逐优先级按如下方式应用如果内存地址落在主范围内,则应用
.L2::primary_priority指定的驱逐优先级。如果内存地址落在任何辅助范围内,则应用
.L2::secondary_priority指定的驱逐优先级。如果内存地址未落在上述任何范围内,则应用的驱逐优先级未指定。
32 位操作数
primary-size以字节为单位指定主范围的大小。32 位操作数total-size以字节为单位指定包括主范围和辅助范围在内的地址范围的总大小。primary-size的值必须小于或等于total-size的值。total-size允许的最大值为 4GB。如果未指定
.L2::secondary_priority,则默认为.L2::evict_unchanged。如果未指定状态空间,则使用 通用寻址。如果指定的地址未落在
.global状态空间的地址窗口内,则行为未定义。 -
基于分数的策略
带有
.level::cache_hint限定符的内存操作可以使用基于分数的缓存驱逐策略,请求将.L2:primary_priority指定的缓存驱逐优先级应用于由 32 位浮点操作数fraction指定的一部分缓存访问。其余缓存访问获得.L2::secondary_priority指定的驱逐优先级。这意味着在使用基于分数的缓存策略的内存操作中,内存访问有fraction操作数指定的概率获得.L2::primary_priority指定的缓存驱逐优先级。操作数
fraction的有效值范围是(0.0,.., 1.0]。如果未指定操作数fraction,则默认为 1.0。如果未指定
.L2::secondary_priority,则默认为.L2::evict_unchanged。
使用 CUDA API 创建的访问属性可以通过指令 createpolicy.cvt 转换为缓存驱逐策略。源操作数 access-property 是一个 64 位不透明寄存器。有关更多详细信息,请参阅 *CUDA 编程指南*。
PTX ISA 注释
在 PTX ISA 7.4 版本中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
createpolicy.fractional.L2::evict_last.b64 policy, 1.0;
createpolicy.fractional.L2::evict_last.L2::evict_unchanged.b64 policy, 0.5;
createpolicy.range.L2::evict_last.L2::evict_first.b64
policy, [ptr], 0x100000, 0x200000;
// access-prop is created by CUDA APIs.
createpolicy.cvt.L2.b64 policy, access-prop;
9.7.9.19. 数据移动和转换指令:isspacep
isspacep
查询通用地址是否落在指定状态空间窗口内。
语法
isspacep.space p, a; // result is .pred
.space = { const, .global, .local, .shared{::cta, ::cluster}, .param{::entry} };
描述
如果通用地址 a 落在指定的状态空间窗口内,则将谓词寄存器 p 写入 1,否则写入 0。目标 p 的类型为 .pred;源地址操作数必须是 .u32 或 .u64 类型。
如果通用地址落在 Kernel Function Parameters 的窗口内,isspacep.param{::entry} 返回 1,否则返回 0。如果 .param 在指定时没有任何子限定符,则默认为 .param::entry。
对于 Kernel Function Parameters,isspacep.global 返回 1,因为 .param 窗口包含在 .global 窗口内。
如果 .shared 状态空间未指定子限定符,则默认情况下假定为 ::cta。
注意
ispacep.shared::cluster 将为集群中线程可访问的每个共享内存地址返回 1,而仅当地址是执行 CTA 中声明的变量的地址时,ispacep.shared::cta 才会返回 1。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
isspacep.const 在 PTX ISA 版本 3.1 中引入。
isspacep.param 在 PTX ISA 版本 7.7 中引入。
对 ::cta 和 ::cluster 子限定符的支持在 PTX ISA 版本 7.8 中引入。
对 .param 空间的子限定符 ::entry 的支持在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
isspacep 需要 sm_20 或更高版本。
isspacep.param{::entry} 需要 sm_70 或更高版本。
子限定符 ::cta 需要 sm_30 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
示例
isspacep.const iscnst, cptr;
isspacep.global isglbl, gptr;
isspacep.local islcl, lptr;
isspacep.shared isshrd, sptr;
isspacep.param::entry isparam, pptr;
isspacep.shared::cta isshrdcta, sptr;
isspacep.shared::cluster ishrdany sptr;
9.7.9.20. 数据移动和转换指令:cvta
cvta
将地址从 .const、Kernel Function Parameters (.param)、.global、.local 或 .shared 状态空间转换为通用地址,反之亦然。获取在 .const、Kernel Function Parameters (.param)、.global、.local 或 .shared 状态空间中声明的变量的通用地址。
语法
// convert const, global, local, or shared address to generic address
cvta.space.size p, a; // source address in register a
cvta.space.size p, var; // get generic address of var
cvta.space.size p, var+imm; // generic address of var+offset
// convert generic address to const, global, local, or shared address
cvta.to.space.size p, a;
.space = { .const, .global, .local, .shared{::cta, ::cluster}, .param{::entry} };
.size = { .u32, .u64 };
描述
将 const、Kernel Function Parameters (.param)、global、local 或 shared 地址转换为通用地址,反之亦然。源地址和目标地址的大小必须相同。使用 cvt.u32.u64 或 cvt.u64.u32 来截断或零扩展地址。
对于在 .const、Kernel Function Parameters (.param)、.global、.local 或 .shared 状态空间中声明的变量,可以使用 cvta 获取变量的通用地址。源可以是寄存器,也可以是在 const、Kernel Function Parameters (.param)、global、local 或 shared 内存中定义的变量,并可选择添加偏移量。
当将通用地址转换为 const、Kernel Function Parameters (.param)、global、local 或 shared 地址时,如果通用地址未落在指定状态空间的地址窗口内,则结果地址是未定义的。程序可以使用 isspacep 来防止这种不正确的行为。
对于具有 .shared 状态空间的 cvta,地址必须属于 ::cta 或 ::cluster 子限定符指定的状态空间,否则行为是未定义的。如果 .shared 状态空间未指定任何子限定符,则默认假定为 ::cta。
如果 .param 在指定时没有任何子限定符,则默认为 .param::entry。对于 .param{::entry} 状态空间,操作数 a 必须是内核参数地址,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
cvta.const 和 cvta.to.const 在 PTX ISA 版本 3.1 中引入。
cvta.param 和 cvta.to.param 在 PTX ISA 版本 7.7 中引入。
注意: 当前的实现不允许在包含作为内核参数传递的常量缓冲区指针的程序中使用指向 const 空间变量的通用指针。
对 ::cta 和 ::cluster 子限定符的支持在 PTX ISA 版本 7.8 中引入。
对 .param 空间的子限定符 ::entry 的支持在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
cvta 需要 sm_20 或更高版本。
cvta.param{::entry} 和 cvta.to.param{::entry} 需要 sm_70 或更高版本。
子限定符 ::cta 需要 sm_30 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
示例
cvta.const.u32 ptr,cvar;
cvta.local.u32 ptr,lptr;
cvta.shared::cta.u32 p,As+4;
cvta.shared::cluster.u32 ptr, As;
cvta.to.global.u32 p,gptr;
cvta.param.u64 ptr,pvar;
cvta.to.param::entry.u64 epptr, ptr;
9.7.9.21. 数据移动和转换指令:cvt
cvt
将值从一种类型转换为另一种类型。
语法
cvt{.irnd}{.ftz}{.sat}.dtype.atype d, a; // integer rounding
cvt{.frnd}{.ftz}{.sat}.dtype.atype d, a; // fp rounding
cvt.frnd2{.relu}{.satfinite}.f16.f32 d, a;
cvt.frnd2{.relu}{.satfinite}.f16x2.f32 d, a, b;
cvt.rs{.relu}{.satfinite}.f16x2.f32 d, a, b, rbits;
cvt.frnd2{.relu}{.satfinite}.bf16.f32 d, a;
cvt.frnd2{.relu}{.satfinite}.bf16x2.f32 d, a, b;
cvt.rs{.relu}{.satfinite}.bf16x2.f32 d, a, b, rbits;
cvt.rna{.satfinite}.tf32.f32 d, a;
cvt.frnd2{.satfinite}{.relu}.tf32.f32 d, a;
cvt.rn.satfinite{.relu}.f8x2type.f32 d, a, b;
cvt.rn.satfinite{.relu}.f8x2type.f16x2 d, a;
cvt.rn.{.relu}.f16x2.f8x2type d, a;
cvt.rs{.relu}.satfinite.f8x4type.f32 d, {a, b, e, f}, rbits;
cvt.rn.satfinite{.relu}.f4x2type.f32 d, a, b;
cvt.rn{.relu}.f16x2.f4x2type d, a;
cvt.rs{.relu}.satfinite.f4x4type.f32 d, {a, b, e, f}, rbits;
cvt.rn.satfinite{.relu}.f6x2type.f32 d, a, b;
cvt.rn{.relu}.f16x2.f6x2type d, a;
cvt.rs{.relu}.satfinite.f6x4type.f32 d, {a, b, e, f}, rbits;
cvt.frnd3{.satfinite}.ue8m0x2.f32 d, a, b;
cvt.frnd3{.satfinite}.ue8m0x2.bf16x2 d, a;
cvt.rn.bf16x2.ue8m0x2 d, a;
.irnd = { .rni, .rzi, .rmi, .rpi };
.frnd = { .rn, .rz, .rm, .rp };
.frnd2 = { .rn, .rz };
.frnd2 = { .rn, .rz };
.frnd3 = { .rz, .rp };
.dtype = .atype = { .u8, .u16, .u32, .u64,
.s8, .s16, .s32, .s64,
.bf16, .f16, .f32, .f64 };
.f8x2type = { .e4m3x2, .e5m2x2 };
.f4x2type = { .e2m1x2 };
.f6x2type = { .e2m3x2, .e3m2x2 };
.f4x4type = { .e2m1x4 };
.f8x4type = { .e4m3x4, .e5m2x4 };
.f6x4type = { .e2m3x4, .e3m2x4 };
描述
在不同类型和大小之间进行转换。
对于 .f16x2 和 .bf16x2 指令类型,两个 .f32 类型的输入 a 和 b 被转换为 .f16 或 .bf16 类型,并且转换后的值被打包到目标寄存器 d 中,使得从输入 a 转换的值存储在 d 的上半部分,而从输入 b 转换的值存储在 d 的下半部分。
对于 .f16x2 指令类型,目标操作数 d 具有 .f16x2 或 .b32 类型。对于 .bf16 指令类型,操作数 d 具有 .b16 类型。对于 .bf16x2 指令类型,操作数 d 具有 .b32 类型。对于 .tf32 指令类型,操作数 d 具有 .b32 类型。
当转换为 .e4m3x2/.e5m2x2 数据格式时,目标操作数 d 具有 .b16 类型。当将两个 .f32 输入转换为 .e4m3x2/.e5m2x2 时,每个输入都转换为指定的格式,并且转换后的值被打包到目标操作数 d 中,使得从输入 a 转换的值存储在 d 的高 8 位中,而从输入 b 转换的值存储在 d 的低 8 位中。当将 .f16x2 输入转换为 .e4m3x2/ .e5m2x2 时,来自操作数 a 的每个 .f16 输入都转换为指定的格式。转换后的值被打包到目标操作数 d 中,使得从输入 a 的高 16 位转换的值存储在 d 的高 8 位中,而从输入 a 的低 16 位转换的值存储在 d 的低 8 位中。
当从 .e4m3x2/.e5m2x2 转换为 .f16x2 时,源操作数 a 具有 .b16 类型。操作数 a 中的每个 8 位输入值都转换为 .f16 类型。转换后的值被打包到目标操作数 d 中,使得从 a 的高 8 位转换的值存储在 d 的高 16 位中,而从 a 的低 8 位转换的值存储在 d 的低 16 位中。
当转换为 .e2m1x2 数据格式时,目标操作数 d 具有 .b8 类型。当将两个 .f32 输入转换为 .e2m1x2 时,每个输入都转换为指定的格式,并且转换后的值被打包到目标操作数 d 中,使得从输入 a 转换的值存储在 d 的高 4 位中,而从输入 b 转换的值存储在 d 的低 4 位中。
当从 .e2m1x2 转换为 .f16x2 时,源操作数 a 具有 .b8 类型。操作数 a 中的每个 4 位输入值都转换为 .f16 类型。转换后的值被打包到目标操作数 d 中,使得从 a 的高 4 位转换的值存储在 d 的高 16 位中,而从 a 的低 4 位转换的值存储在 d 的低 16 位中。
当转换为 .e2m1x4 数据格式时,目标操作数 d 具有 .b16 类型。当将四个 .f32 输入转换为 .e2m1x4 时,每个输入都转换为指定的格式,并且转换后的值被打包到目标操作数 d 中,使得从输入 a、b、e、f 转换的值存储在从 d 的高位开始的每个 4 位中。
当转换为 .e2m3x2/.e3m2x2 数据格式时,目标操作数 d 具有 .b16 类型。当将两个 .f32 输入转换为 .e2m3x2/.e3m2x2 时,每个输入都转换为指定的格式,并且转换后的值被打包到目标操作数 d 中,使得从输入 a 转换的值存储在 d 的高 8 位中,并用零填充 2 个 MSB 位,而从输入 b 转换的值存储在 d 的低 8 位中,并用零填充 2 个 MSB 位。
当从 .e2m3x2/.e3m2x2 转换为 .f16x2 时,源操作数 a 具有 .b16 类型。操作数 a 中每个高 2 位 MSB 为 0 的 8 位输入值都转换为 .f16 类型。转换后的值被打包到目标操作数 d 中,使得从 a 的高 8 位转换的值存储在 d 的高 16 位中,而从 a 的低 8 位转换的值存储在 d 的低 16 位中。
当转换为 .e5m2x4/.e4m3x4/.e3m2x4/.e2m3x4 数据格式时,目标操作数 d 具有 .b32 类型。当将四个 .f32 输入转换为 .e5m2x4/.e4m3x4/.e3m2x4/.e2m3x4 时,每个输入都转换为指定的格式,并且转换后的值被打包到目标操作数 d 中,使得从输入 a、b、e、f 转换的值存储在从 d 的高位开始的每个 8 位中。对于 .e3m2x4/.e2m3x4,每个 8 位输出都将用零填充 2 个 MSB 位。
当转换为 .ue8m0x2 数据格式时,目标操作数 d 具有 .b16 类型。当将两个 .f32 或两个打包的 .bf16 输入转换为 .ue8m0x2 时,每个输入都转换为指定的格式,并且转换后的值被打包到目标操作数 d 中,使得从输入 a 转换的值存储在 d 的高 8 位中,而从输入 b 转换的值存储在 d 的低 8 位中。
当从 .ue8m0x2 转换为 .bf16x2 时,源操作数 a 具有 .b16 类型。操作数 a 中的每个 8 位输入值都转换为 .bf16 类型。转换后的值被打包到目标操作数 d 中,使得从 a 的高 8 位转换的值存储在 d 的高 16 位中,而从 a 的低 8 位转换的值存储在 d 的低 16 位中。
rbits 是一个 .b32 类型寄存器操作数,用于为 .rs 舍入模式提供随机位。
当转换为 .f16x2 时,从 rbits 提供两个 16 位值,其中高 16 位中的 13 个 LSB 位用作操作数 a 的随机位,其中 3 个 MSB 位为 0,而低 16 位中的 13 个 LSB 位用作操作数 b 的随机位,其中 3 个 MSB 位为 0。
当转换为 .bf16x2 时,从 rbits 提供两个 16 位值,其中高 16 位用作操作数 a 的随机位,而低 16 位用作操作数 b 的随机位。
当转换为 .e4m3x4/.e5m2x4/.e2m3x4/.e3m2x4 时,从 rbits 提供两个 16 位值,其中低 16 位用于操作数 e、f,而高 16 位用于操作数 a、b。
当转换为 .e2m1x4 时,从 rbits 提供两个 16 位值,其中来自 rbits 的两个 16 位半部分中的低 8 位用于操作数 e、f,而来自 rbits 的两个 16 位半部分中的高 8 位用于操作数 a、b。
在所有以下情况下,舍入修饰符是强制性的
浮点到浮点转换,当目标类型小于源类型时
所有浮点到整数的转换
所有整数到浮点的转换
所有涉及
.f16x2、.e4m3x2,.e5m2x2,、.bf16x2、.tf32、.e2m1x2、.e2m3x2、.e3m2x2、.e4m3x4、.e5m2x4、.e2m1x4、.e2m3x4、.e3m2x4和.ue8m0x2指令类型的转换。
.satfinite 修饰符仅支持涉及以下类型的转换
.e4m3x2、.e5m2x2、.e2m1x2、.e2m3x2、.e3m2x2、.e4m3x4、.e5m2x4、.e2m1x4、.e2m3x4、.e3m2x4目标类型。对于此类转换,.satfinite修饰符是强制性的。.f16、.bf16、.f16x2、.bf16x2、.tf32、.ue8m0x2作为目标类型。
语义
if (/* inst type is .f16x2 or .bf16x2 */) {
d[31:16] = convert(a);
d[15:0] = convert(b);
} else if (/* inst destination type is .e5m2x2 or .e4m3x2 or .ue8m0x2 */) {
d[15:8] = convert(a);
d[7:0] = convert(b);
} else if (/* inst destination type is .e2m1x2 */) {
d[7:4] = convert(a);
d[3:0] = convert(b);
} else if (/* inst destination type is .e2m3x2 or .e3m2x2 */) {
d[15:14] = 0;
d[13:8] = convert(a);
d[7:6] = 0;
d[5:0] = convert(b);
} else if (/* inst destination type is .e2m1x4 */) {
d[15:12] = convert(a);
d[11:8] = convert(b);
d[7:4] = convert(e);
d[3:0] = convert(f);
} else if (/* inst destination type is .e4m3x4 or .e5m2x4 */) {
d[31:24] = convert(a);
d[23:16] = convert(b);
d[15:8] = convert(e);
d[7:0] = convert(f);
} else if (/* inst destination type is .e2m3x4 or .e3m2x4 */) {
d[31:30] = 0;
d[29:24] = convert(a);
d[23:22] = 0;
d[21:16] = convert(b);
d[15:14] = 0;
d[13:8] = convert(e);
d[7:6] = 0;
d[5:0] = convert(f);
} else {
d = convert(a);
}
// 随机位 rbits 用于 .rs 舍入的语义
-
目标类型
.f16:有关随机位布局的详细信息,请参阅 图 37。
图 37 用于
.f16目标类型的.rs舍入的随机位布局 -
目标类型
.bf16:有关随机位布局的详细信息,请参阅 图 38。
图 38 用于
.bf16目标类型的.rs舍入的随机位布局 -
目标类型
.e2m1x4:有关随机位布局的详细信息,请参阅 图 39。
图 39 用于
.e2m1x4目标类型的.rs舍入的随机位布局 -
目标类型
.e5m2x4、.e4m3x4、.e3m2x4、.e2m3x4:有关随机位布局的详细信息,请参阅 图 40。
图 40 用于
.e5m2x4/.e4m3x4/.e3m2x4/.e2m3x4目标类型的.rs舍入的随机位布局
整数注意事项
浮点到整数的转换以及将值舍入为整数的相同大小的浮点到浮点转换需要整数舍入。在所有其他情况下,整数舍入都是非法的。
整数舍入修饰符
.rni-
舍入到最接近的整数,如果源与两个整数等距,则选择偶数整数
.rzi-
向零方向舍入到最接近的整数
.rmi-
向负无穷大方向舍入到最接近的整数
.rpi-
向正无穷大方向舍入到最接近的整数
在浮点到整数的转换中,NaN 输入被转换为 0。
次正规数
sm_20+-
默认情况下,支持次正规数。
对于
cvt.ftz.dtype.f32浮点到整数的转换和cvt.ftz.f32.f32具有整数舍入的浮点到浮点转换,次正规输入被刷新为保留符号的零。仅当.dtype或.atype为.f32时,才可以指定修饰符.ftz,并且仅适用于单精度 (.f32) 输入和结果。 sm_1x-
对于
cvt.ftz.dtype.f32浮点到整数的转换和cvt.ftz.f32.f32具有整数舍入的浮点到浮点转换,次正规输入被刷新为保留符号的零。在这些情况下,可以选择指定.ftz修饰符以提高清晰度。注意: 在 PTX ISA 1.4 及更早版本中,如果目标类型大小为 64 位,则
cvt指令不会将单精度次正规输入或结果刷新为零。编译器将为旧版 PTX 代码保留此行为。
饱和修饰符
.sat-
对于整数目标类型,
.sat将结果限制为操作大小的MININT..MAXINT范围。请注意,饱和适用于有符号和无符号整数类型。仅当目标类型的值范围不是源类型的值范围的超集时,才允许使用饱和修饰符;即,如果基于源类型和目标类型不可能进行饱和,则
.sat修饰符是非法的。对于浮点到整数的转换,结果默认被钳制到目标范围;即,
.sat是冗余的。
浮点注意事项
对于导致精度损失的浮点到浮点转换以及整数到浮点的转换,需要浮点舍入。在所有其他情况下,浮点舍入都是非法的。
浮点舍入修饰符
.rn-
舍入到最接近的值,与偶数相关
.rna-
舍入到最接近的值,与零无关
.rz-
向零舍入
.rm-
向负无穷大舍入
.rp-
向正无穷大舍入
.rs-
随机舍入是通过使用提供的随机位来实现的。操作的结果根据提供的随机位 (
rbits) 与输入尾数的截断位(丢弃的位)的整数加法的进位,向零或远离零的方向舍入。
可以使用整数舍入修饰符(请参阅整数注释)将浮点值舍入为整数值。操作数的大小必须相同。结果是一个整数值,以浮点格式存储。
次正规数
sm_20+-
默认情况下,支持次正规数。可以指定修饰符
.ftz将单精度次正规输入和结果刷新为保留符号的零。修饰符.ftz只能在.dtype或.atype为.f32时指定,并且仅适用于单精度 (.f32) 输入和结果。 sm_1x-
单精度次正规输入和结果会被刷新为保留符号的零。在这些情况下,可以为了清晰起见而指定可选的
.ftz修饰符。
注意: 在 PTX ISA 1.4 及更早版本中,如果源类型或目标类型为 .f64,则 cvt 指令不会将单精度次正规输入或结果刷新为零。编译器将为旧版 PTX 代码保留此行为。具体而言,如果 PTX ISA 版本为 1.4 或更早版本,则仅对于 cvt.f32.f16、cvt.f16.f32 和 cvt.f32.f32 指令,单精度次正规输入和结果才会被刷新为保留符号的零。
饱和修饰符
-
.sat: -
对于浮点目标类型,
.sat将结果限制在 [0.0, 1.0] 范围内。NaN结果会被刷新为正零。适用于.f16、.f32和.f64类型。 -
.relu: -
对于
.f16、.f16x2、.bf16、.bf16x2、.e4m3x2、.e5m2x2、.e2m1x2、.e2m3x2、.e3m2x2、.e4m3x4、.e5m2x4、.e2m1x4、.e2m3x4、.e3m2x4和.tf32目标类型,如果结果为负数,.relu会将其钳制为 0。NaN结果会被转换为规范的NaN。 -
.satfinite: -
对于
.f16、.f16x2、.bf16、.bf16x2、.e4m3x2、.e5m2x2、.ue8m0x2、.e4m3x4、.e5m2x4和.tf32目标格式,如果输入值为NaN,则结果为指定目标格式的NaN。对于.e2m1x2、.e2m3x2、.e3m2x2、.e2m1x4、.e2m3x4、.e3m2x4目标格式,NaN结果会被转换为正 MAX_NORM。如果输入值(忽略符号)的绝对值大于指定目标格式的 MAX_NORM,则结果为保留符号的目标格式 MAX_NORM,以及.ue8m0x2中的正 MAX_NORM,对于.ue8m0x2,不支持目标符号。
注释
可以使用比指定类型更宽的源寄存器,除非源操作数具有 .bf16 或 .bf16x2 格式。转换中使用对应于指令类型宽度的较低 n 位。有关这些宽松类型检查规则的描述,请参阅 Operand Size Exceeding Instruction-Type Size。
可以使用比指定类型更宽的目标寄存器,除非目标操作数具有 .bf16、.bf16x2 或 .tf32 格式。对于有符号整数,转换结果会进行符号扩展以适应目标寄存器宽度;对于无符号、位大小和浮点类型,则会进行零扩展以适应目标寄存器宽度。有关这些宽松类型检查规则的描述,请参阅 Operand Size Exceeding Instruction-Type Size。
对于 cvt.f32.bf16,NaN 输入会产生未指定的 NaN。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
.relu 修饰符和 {.f16x2、.bf16、.bf16x2、.tf32} 目标格式在 PTX ISA 7.0 版本中引入。
cvt.bf16.{u8/s8/u16/s16/u32/s32/u64/s64/f16/f64/bf16}、cvt.{u8/s8/u16/s16/u32/s32/u64/s64/f16/f64}.bf16 和 cvt.tf32.f32.{relu}.{rn/rz} 在 PTX ISA 7.8 中引入。
用于 sm_90 或更高版本的 .e4m3x2/.e5m2x2 的 cvt 在 PTX ISA 7.8 版本中引入。
用于 sm_90 或更高版本的 cvt.satfinite.{e4m3x2, e5m2x2}.{f32, f16x2} 在 PTX ISA 7.8 版本中引入。
用于 sm_89 的 .e4m3x2/.e5m2x2 的 cvt 在 PTX ISA 8.1 版本中引入。
用于 sm_89 的 cvt.satfinite.{e4m3x2, e5m2x2}.{f32, f16x2} 在 PTX ISA 8.1 版本中引入。
在 PTX ISA 8.1 版本中引入了 cvt.satfinite.{f16, bf16, f16x2, bf16x2, tf32}.f32。
在 PTX ISA 8.6 版本中引入了 cvt.{rn/rz}.satfinite.tf32.f32。
在 PTX ISA 8.6 版本中引入了 cvt.rn.satfinite{.relu}.{e2m1x2/e2m3x2/e3m2x2/ue8m0x2}.f32。
在 PTX ISA 8.6 版本中引入了 cvt.rn{.relu}.f16x2.{e2m1x2/e2m3x2/e3m2x2}。
在 PTX ISA 8.6 版本中引入了 cvt.{rp/rz}{.satfinite}{.relu}.ue8m0x2.bf16x2。
在 PTX ISA 8.6 版本中引入了 cvt.{rz/rp}.satfinite.ue8m0x2.f32。
在 PTX ISA 8.6 版本中引入了 cvt.rn.bf16x2.ue8m0x2。
在 PTX ISA 8.7 版本中引入了 .rs 舍入模式。
在 PTX ISA 8.7 版本中引入了 cvt.rs{.e2m1x4/.e4m3x4/.e5m2x4/.e3m2x4/.e2m3x4}.f32。
目标 ISA 注释
到 .f64 或从 .f64 转换需要 sm_13 或更高版本。
.relu 修饰符和 {.f16x2、.bf16、.bf16x2、.tf32} 目标格式需要 sm_80 或更高版本。
cvt.bf16.{u8/s8/u16/s16/u32/s32/u64/s64/f16/f64/bf16}、cvt.{u8/s8/u16/s16/u32/s32/u64/s64/f16/f64}.bf16 和 cvt.tf32.f32.{relu}.{rn/rz} 需要 sm_90 或更高版本。
用于 .e4m3x2/.e5m2x2 的 cvt 需要 sm89 或更高版本。
cvt.satfinite.{e4m3x2, e5m2x2}.{f32, f16x2} 需要 sm_89 或更高版本。
cvt.{rn/rz}.satfinite.tf32.f32 需要 sm_100 或更高版本。
cvt.rn.satfinite{.relu}.{e2m1x2/e2m3x2/e3m2x2/ue8m0x2}.f32 在以下架构上受支持
sm_100asm_101asm_120a
cvt.rn{.relu}.f16x2.{e2m1x2/e2m3x2/e3m2x2} 在以下架构上受支持
sm_100asm_101asm_120a
cvt.{rz/rp}{.satfinite}{.relu}.ue8m0x2.bf16x2 在以下架构上受支持
sm_100asm_101asm_120a
cvt.{rz/rp}.satfinite.ue8m0x2.f32 在以下架构上受支持
sm_100asm_101asm_120a
cvt.rn.bf16x2.ue8m0x2 在以下架构上受支持
sm_100asm_101asm_120a
.rs 舍入模式需要 sm_100a。
cvt.rs{.e2m1x4/.e4m3x4/.e5m2x4/.e3m2x4/.e2m3x4}.f32 需要 sm_100a。
示例
cvt.f32.s32 f,i;
cvt.s32.f64 j,r; // float-to-int saturates by default
cvt.rni.f32.f32 x,y; // round to nearest int, result is fp
cvt.f32.f32 x,y; // note .ftz behavior for sm_1x targets
cvt.rn.relu.f16.f32 b, f; // result is saturated with .relu saturation mode
cvt.rz.f16x2.f32 b1, f, f1; // convert two fp32 values to packed fp16 outputs
cvt.rn.relu.satfinite.f16x2.f32 b1, f, f1; // convert two fp32 values to packed fp16 outputs with .relu saturation on each output
cvt.rn.bf16.f32 b, f; // convert fp32 to bf16
cvt.rz.relu.satfinite.bf16.f3 2 b, f; // convert fp32 to bf16 with .relu and .satfinite saturation
cvt.rz.satfinite.bf16x2.f32 b1, f, f1; // convert two fp32 values to packed bf16 outputs
cvt.rn.relu.bf16x2.f32 b1, f, f1; // convert two fp32 values to packed bf16 outputs with .relu saturation on each output
cvt.rna.satfinite.tf32.f32 b1, f; // convert fp32 to tf32 format
cvt.rn.relu.tf32.f32 d, a; // convert fp32 to tf32 format
cvt.f64.bf16.rp f, b; // convert bf16 to f64 format
cvt.bf16.f16.rz b, f // convert f16 to bf16 format
cvt.bf16.u64.rz b, u // convert u64 to bf16 format
cvt.s8.bf16.rpi s, b // convert bf16 to s8 format
cvt.bf16.bf16.rpi b1, b2 // convert bf16 to corresponding int represented in bf16 format
cvt.rn.satfinite.e4m3x2.f32 d, a, b; // convert a, b to .e4m3 and pack as .e4m3x2 output
cvt.rn.relu.satfinite.e5m2x2.f16x2 d, a; // unpack a and convert the values to .e5m2 outputs with .relu
// saturation on each output and pack as .e5m2x2
cvt.rn.f16x2.e4m3x2 d, a; // unpack a, convert two .e4m3 values to packed f16x2 output
cvt.rn.satfinite.tf32.f32 d, a; // convert fp32 to tf32 format
cvt.rn.relu.f16x2.e2m1x2 d, a; // unpack a, convert two .e2m1 values to packed f16x2 output
cvt.rn.satfinite.e2m3x2.f32 d, a, b; // convert a, b to .e2m3 and pack as .e2m3x2 output
cvt.rn.relu.f16x2.e3m2x2 d, a; // unpack a, convert two .e3m2 values to packed f16x2 output
cvt.rs.f16x2.f32 d, a, b, rbits; // convert 2 fp32 values to packed fp16 with applying .rs rounding
cvt.rs.satfinite.e2m1x4.f32 d, {a, b, e, f}, rbits; // convert 4 fp32 values to packed 4 e2m1 values with applying .rs rounding
9.7.9.22. 数据移动和转换指令:cvt.pack
cvt.pack
将两个整数值从一种整数类型转换为另一种整数类型,并将结果打包。
语法
cvt.pack.sat.convertType.abType d, a, b;
.convertType = { .u16, .s16 }
.abType = { .s32 }
cvt.pack.sat.convertType.abType.cType d, a, b, c;
.convertType = { .u2, .s2, .u4, .s4, .u8, .s8 }
.abType = { .s32 }
.cType = { .b32 }
描述
将两个 32 位整数 a 和 b 转换为指定类型,并将结果打包到 d 中。
目标 d 是一个无符号 32 位整数。源操作数 a 和 b 是 .abType 类型的整数,源操作数 c 是 .cType 类型的整数。
输入 a 和 b 被转换为 .convertType 指定类型的值,并进行饱和处理,转换后的结果被打包到 d 的低位。
如果指定了操作数 c,则 d 的剩余位将从 c 的低位复制。
语义
ta = a < MIN(convertType) ? MIN(convertType) : a;
ta = a > MAX(convertType) ? MAX(convertType) : a;
tb = b < MIN(convertType) ? MIN(convertType) : b;
tb = b > MAX(convertType) ? MAX(convertType) : b;
size = sizeInBits(convertType);
td = tb ;
for (i = size; i <= 2 * size - 1; i++) {
td[i] = ta[i - size];
}
if (isU16(convertType) || isS16(convertType)) {
d = td;
} else {
for (i = 0; i < 2 * size; i++) {
d[i] = td[i];
}
for (i = 2 * size; i <= 31; i++) {
d[i] = c[i - 2 * size];
}
}
如果对应的输入不在 .convertType 指定的数据类型范围内,则 .sat 修饰符会将转换后的值限制在 MIN(convertType)..MAX(convertedType) 范围内(无溢出)。
PTX ISA 注释
在 PTX ISA 版本 6.5 中引入。
目标 ISA 注释
需要 sm_72 或更高版本。
子字节类型(.u4/.s4 和 .u2/.s2)需要 sm_75 或更高版本。
示例
cvt.pack.sat.s16.s32 %r1, %r2, %r3; // 32-bit to 16-bit conversion
cvt.pack.sat.u8.s32.b32 %r4, %r5, %r6, 0; // 32-bit to 8-bit conversion
cvt.pack.sat.u8.s32.b32 %r7, %r8, %r9, %r4; // %r7 = { %r5, %r6, %r8, %r9 }
cvt.pack.sat.u4.s32.b32 %r10, %r12, %r13, %r14; // 32-bit to 4-bit conversion
cvt.pack.sat.s2.s32.b32 %r15, %r16, %r17, %r18; // 32-bits to 2-bit conversion
9.7.9.23. 数据移动和转换指令:mapa
mapa
映射目标 CTA 中共享变量的地址。
语法
mapa{.space}.type d, a, b;
// Maps shared memory address in register a into CTA b.
mapa.shared::cluster.type d, a, b;
// Maps shared memory variable into CTA b.
mapa.shared::cluster.type d, sh, b;
// Maps shared memory variable into CTA b.
mapa.shared::cluster.type d, sh + imm, b;
// Maps generic address in register a into CTA b.
mapa.type d, a, b;
.space = { .shared::cluster }
.type = { .u32, .u64 }
描述
获取由操作数 b 指定的 CTA 中的地址,该地址对应于由操作数 a 指定的地址。
指令类型 .type 指示目标操作数 d 和源操作数 a 的类型。
当空间为 .shared::cluster 时,源 a 要么是共享内存变量,要么是包含有效共享内存地址的寄存器,寄存器 d 包含共享内存地址。当未指定可选限定符 .space 时,a 和 d 都是包含指向共享内存的通用地址的寄存器。
b 是一个 32 位整数操作数,表示目标 CTA 的秩。
目标寄存器 d 将保存 CTA b 中的地址,该地址对应于操作数 a。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
mapa.shared::cluster.u64 d1, %reg1, cta;
mapa.shared::cluster.u32 d2, sh, 3;
mapa.u64 d3, %reg2, cta;
9.7.9.24. 数据移动和转换指令:getctarank
getctarank
生成地址的 CTA 秩。
语法
getctarank{.space}.type d, a;
// Get cta rank from source shared memory address in register a.
getctarank.shared::cluster.type d, a;
// Get cta rank from shared memory variable.
getctarank.shared::cluster.type d, var;
// Get cta rank from shared memory variable+offset.
getctarank.shared::cluster.type d, var + imm;
// Get cta rank from generic address of shared memory variable in register a.
getctarank.type d, a;
.space = { .shared::cluster }
.type = { .u32, .u64 }
描述
将目标寄存器 d 写入包含操作数 a 中指定的地址的 CTA 的秩。
指令类型 .type 指示源操作数 a 的类型。
当空间为 .shared::cluster 时,源 a 要么是共享内存变量,要么是包含有效共享内存地址的寄存器。当未指定可选限定符 .space 时,a 是一个包含指向共享内存的通用地址的寄存器。目标 d 始终是一个 32 位寄存器,用于保存 CTA 的秩。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
getctarank.shared::cluster.u32 d1, addr;
getctarank.shared::cluster.u64 d2, sh + 4;
getctarank.u64 d3, src;
9.7.9.25. 数据移动和转换指令:异步复制
异步复制操作在后台异步执行底层操作,从而允许发出线程执行后续任务。
异步复制操作可以是操作大量数据的批量操作,也可以是操作较小尺寸数据的非批量操作。批量异步操作处理的数据量必须是 16 字节的倍数。
异步复制操作通常包括以下序列
可选地,从张量映射读取。
从源位置读取数据。
将数据写入目标位置。
写入对执行线程或其他线程可见。
9.7.9.25.1. 异步复制操作的完成机制
线程必须显式等待异步复制操作完成才能访问操作结果。一旦启动异步复制操作,在异步操作完成之前修改源内存位置或张量描述符或从目标内存位置读取数据,将表现出未定义的行为。
本节介绍 PTX 中支持的两种异步复制操作完成机制:异步组机制和基于 mbarrier 的机制。
异步操作可以通过任一完成机制或两种机制进行跟踪。跟踪机制是指令/指令变体特定的。
9.7.9.25.1.1. 异步组机制
当使用异步组完成机制时,发出线程使用提交操作指定一组异步操作,称为异步组,并使用等待操作跟踪此组的完成情况。发出异步操作的线程必须为批量和非批量异步操作创建单独的异步组。
提交操作创建一个每线程异步组,其中包含所有先前由异步组完成跟踪并由执行线程启动的异步操作,但不包含提交操作之后的任何异步操作。已提交的异步操作属于单个异步组。
当异步组完成时,属于该组的所有异步操作都已完成,并且启动异步操作的执行线程可以读取异步操作的结果。执行线程提交的所有异步组始终按照提交顺序完成。异步组内的异步操作之间没有顺序。
使用异步组作为完成机制的典型模式如下
启动异步操作。
使用提交操作将异步操作分组到异步组中。
使用等待操作等待异步组完成。
一旦异步组完成,访问该异步组中所有异步操作的结果。
9.7.9.25.1.2. 基于 Mbarrier 的机制
线程可以使用 mbarrier 对象的当前阶段来跟踪一个或多个异步操作的完成情况。当 mbarrier 对象的当前阶段完成时,这意味着此阶段跟踪的所有异步操作都已完成,并且参与该 mbarrier 对象的所有线程都可以访问异步操作的结果。
用于跟踪异步操作完成情况的 mbarrier 对象可以与异步操作一起作为其语法的一部分指定,也可以作为单独的操作指定。对于批量异步操作,必须在异步操作中指定 mbarrier 对象,而对于非批量操作,可以在异步操作之后指定。
使用基于 mbarrier 的完成机制的典型模式如下
启动异步操作。
设置一个 mbarrier 对象以在其当前阶段跟踪异步操作,可以作为异步操作的一部分或作为单独的操作。
使用
mbarrier.test_wait或mbarrier.try_wait等待 mbarrier 对象完成其当前阶段。一旦
mbarrier.test_wait或mbarrier.try_wait操作返回True,访问 mbarrier 对象跟踪的异步操作的结果。
9.7.9.25.2. 异步代理
cp{.reduce}.async.bulk 操作在异步代理(或 async 代理)中执行。
跨多个代理访问相同的内存位置需要跨代理栅栏。对于异步代理,应使用 fence.proxy.async 来同步通用代理和异步代理之间的内存。
cp{.reduce}.async.bulk 操作完成后,会紧跟一个隐式的通用-异步代理栅栏。因此,一旦观察到异步操作完成,其结果就会对通用代理可见。必须使用异步组或基于 mbarrier 的完成机制来等待 cp{.reduce}.async.bulk 指令完成。
9.7.9.25.3. 数据移动和转换指令:非批量复制
9.7.9.25.3.1. 数据移动和转换指令:cp.async
cp.async
启动从一个状态空间到另一个状态空间的异步复制操作。
语法
cp.async.ca.shared{::cta}.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], cp-size{, src-size}{, cache-policy} ;
cp.async.cg.shared{::cta}.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], 16{, src-size}{, cache-policy} ;
cp.async.ca.shared{::cta}.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], cp-size{, ignore-src}{, cache-policy} ;
cp.async.cg.shared{::cta}.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], 16{, ignore-src}{, cache-policy} ;
.level::cache_hint = { .L2::cache_hint }
.level::prefetch_size = { .L2::64B, .L2::128B, .L2::256B }
cp-size = { 4, 8, 16 }
描述
cp.async 是一个非阻塞指令,它启动从源地址操作数 src 指定的位置到目标地址操作数 dst 指定的位置的数据异步复制操作。操作数 src 指定全局状态空间中的位置,dst 指定共享状态空间中的位置。
操作数 cp-size 是一个整数常量,指定要复制到目标 dst 的数据大小(以字节为单位)。cp-size 只能为 4、8 和 16。
指令 cp.async 允许可选地指定一个 32 位整数操作数 src-size。操作数 src-size 表示要从 src 复制到 dst 的数据大小(以字节为单位),并且必须小于 cp-size。在这种情况下,目标 dst 中的剩余字节将填充零。指定 src-size 大于 cp-size 会导致未定义的行为。
可选的且非立即的谓词参数 ignore-src 指定是否应完全忽略来自源位置 src 的数据。如果忽略源数据,则将零复制到目标 dst。如果未指定参数 ignore-src,则默认为 False。
操作数 src 和 dst 的支持对齐要求和寻址模式在 Addresses as Operands 中描述。
强制性的 .async 限定符指示 cp 指令将异步启动内存复制操作,并且控制将在复制操作完成之前返回到执行线程。然后,执行线程可以使用 基于异步组的完成机制 或 基于 mbarrier 的完成机制 来等待异步复制操作完成。中描述的任何其他同步机制都不能保证异步复制操作的完成。
如果两个 cp.async 操作未使用 cp.async.wait_all 或 cp.async.wait_group 或 mbarrier 指令 显式同步,则它们之间没有排序保证。
如 Cache Operators 中所述,.cg 限定符指示仅在全球级别缓存 L2 而不在 L1 缓存中缓存数据,而 .ca 限定符指示在包括 L1 缓存的所有级别缓存数据。缓存操作符仅被视为性能提示。
cp.async 在 Memory Consistency Model 中被视为弱内存操作。
限定符 .level::prefetch_size 是一个提示,用于将指定大小的额外数据提取到相应的缓存级别。子限定符 prefetch_size 可以设置为 64B、128B、256B 中的任一值,从而允许预取大小分别为 64 字节、128 字节或 256 字节。
限定符 .level::prefetch_size 只能与 .global 状态空间以及通用寻址一起使用,其中地址指向 .global 状态空间。如果通用地址不在全局内存的地址窗口内,则预取行为是未定义的。
限定符 .level::prefetch_size 仅被视为性能提示。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
限定符 .level::cache_hint 仅支持 .global 状态空间和通用寻址,其中地址指向 .global 状态空间。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 7.4 版本中引入了对 .level::cache_hint 和 .level::prefetch_size 限定符的支持。
PTX ISA 7.5 版本中引入了对 ignore-src 操作数的支持。
PTX ISA 7.8 版本中引入了对子限定符 ::cta 的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
子限定符 ::cta 需要 sm_30 或更高版本。
示例
cp.async.ca.shared.global [shrd], [gbl + 4], 4;
cp.async.ca.shared::cta.global [%r0 + 8], [%r1], 8;
cp.async.cg.shared.global [%r2], [%r3], 16;
cp.async.cg.shared.global.L2::64B [%r2], [%r3], 16;
cp.async.cg.shared.global.L2::128B [%r0 + 16], [%r1], 16;
cp.async.cg.shared.global.L2::256B [%r2 + 32], [%r3], 16;
createpolicy.fractional.L2::evict_last.L2::evict_unchanged.b64 cache-policy, 0.25;
cp.async.ca.shared.global.L2::cache_hint [%r2], [%r1], 4, cache-policy;
cp.async.ca.shared.global [shrd], [gbl], 4, p;
cp.async.cg.shared.global.L2::cache_hint [%r0], [%r2], 16, q, cache-policy;
9.7.9.25.3.2. 数据移动和转换指令:cp.async.commit_group
cp.async.commit_group
将所有先前启动但未提交的 cp.async 指令提交到 cp.async-group 中。
语法
cp.async.commit_group ;
描述
cp.async.commit_group 指令为每个线程创建一个新的 cp.async-group,并将执行线程启动但未提交到任何 cp.async-group 的所有先前 cp.async 指令批处理到新的 cp.async-group 中。如果没有未提交的 cp.async 指令,则 cp.async.commit_group 将产生一个空的 cp.async-group。
执行线程可以使用 cp.async.wait_group 等待 cp.async-group 中所有 cp.async 操作完成。
同一 cp.async-group 内的任何两个 cp.async 操作之间没有提供内存排序保证。因此,同一 cp.async-group 内的两个或多个 cp.async 操作将数据复制到同一位置会导致未定义的行为。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
// Example 1:
cp.async.ca.shared.global [shrd], [gbl], 4;
cp.async.commit_group ; // Marks the end of a cp.async group
// Example 2:
cp.async.ca.shared.global [shrd1], [gbl1], 8;
cp.async.ca.shared.global [shrd1+8], [gbl1+8], 8;
cp.async.commit_group ; // Marks the end of cp.async group 1
cp.async.ca.shared.global [shrd2], [gbl2], 16;
cp.async.cg.shared.global [shrd2+16], [gbl2+16], 16;
cp.async.commit_group ; // Marks the end of cp.async group 2
9.7.9.25.3.3. 数据移动和转换指令:cp.async.wait_group / cp.async.wait_all
cp.async.wait_group/cp.async.wait_all
等待先前异步复制操作完成。
语法
cp.async.wait_group N;
cp.async.wait_all ;
描述
cp.async.wait_group 指令将导致执行线程等待,直到只有 N 个或更少的最新 cp.async-group 处于挂起状态,并且执行线程提交的所有先前 cp.async-group 都已完成。例如,当 N 为 0 时,执行线程等待所有先前的 cp.async-group 完成。操作数 N 是一个整数常量。
cp.async.wait_all 等同于
cp.async.commit_group;
cp.async.wait_group 0;
一个空的 cp.async-group 被认为是微不足道地完成的。
仅在以下情况后,cp.async 操作执行的写入才对执行线程可见
cp.async.wait_all完成或cp.async.wait_group在cp.async所属的 cp.async-group 上完成或mbarrier.test_wait 在跟踪
cp.async操作完成情况的 mbarrier 对象上返回True。
两个 cp.async 操作之间没有排序,除非它们使用 cp.async.wait_all 或 cp.async.wait_group 或 mbarrier 对象 进行同步。
cp.async.wait_group 和 cp.async.wait_all 除了 cp.async 之外,不为任何其他内存操作提供任何排序和可见性保证。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
// Example of .wait_all:
cp.async.ca.shared.global [shrd1], [gbl1], 4;
cp.async.cg.shared.global [shrd2], [gbl2], 16;
cp.async.wait_all; // waits for all prior cp.async to complete
// Example of .wait_group :
cp.async.ca.shared.global [shrd3], [gbl3], 8;
cp.async.commit_group; // End of group 1
cp.async.cg.shared.global [shrd4], [gbl4], 16;
cp.async.commit_group; // End of group 2
cp.async.cg.shared.global [shrd5], [gbl5], 16;
cp.async.commit_group; // End of group 3
cp.async.wait_group 1; // waits for group 1 and group 2 to complete
9.7.9.25.4. 数据移动和转换指令:批量复制
9.7.9.25.4.1. 数据移动和转换指令:cp.async.bulk
cp.async.bulk
启动从一个状态空间到另一个状态空间的异步复制操作。
语法
// global -> shared::cta
cp.async.bulk.dst.src.completion_mechanism{.level::cache_hint}
[dstMem], [srcMem], size, [mbar] {, cache-policy}
.dst = { .shared::cta }
.src = { .global }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.level::cache_hint = { .L2::cache_hint }
// global -> shared::cluster
cp.async.bulk.dst.src.completion_mechanism{.multicast}{.level::cache_hint}
[dstMem], [srcMem], size, [mbar] {, ctaMask} {, cache-policy}
.dst = { .shared::cluster }
.src = { .global }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.level::cache_hint = { .L2::cache_hint }
.multicast = { .multicast::cluster }
// shared::cta -> shared::cluster
cp.async.bulk.dst.src.completion_mechanism [dstMem], [srcMem], size, [mbar]
.dst = { .shared::cluster }
.src = { .shared::cta }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
// shared::cta -> global
cp.async.bulk.dst.src.completion_mechanism{.level::cache_hint}{.cp_mask}
[dstMem], [srcMem], size {, cache-policy} {, byteMask}
.dst = { .global }
.src = { .shared::cta }
.completion_mechanism = { .bulk_group }
.level::cache_hint = { .L2::cache_hint }
描述
cp.async.bulk 是一个非阻塞指令,它启动一个异步批量复制操作,从源地址操作数 srcMem 指定的位置复制到目标地址操作数 dstMem 指定的位置。
批量复制的方向是从 .src 修饰符指定的状态空间到 .dst 修饰符指定的状态空间。
32 位操作数 size 指定要复制的内存量,以字节数为单位。size 必须是 16 的倍数。如果该值不是 16 的倍数,则行为未定义。内存范围 [dstMem, dstMem + size - 1] 不得溢出目标内存空间,内存范围 [srcMem, srcMem + size - 1] 不得溢出源内存空间。否则,行为未定义。地址 dstMem 和 srcMem 必须对齐到 16 字节。
当复制的目标是 .shared::cta 时,目标地址必须位于集群内执行 CTA 的共享内存中,否则行为未定义。
当复制的源是 .shared::cta 而目标是 .shared::cluster 时,目标必须位于集群内不同 CTA 的共享内存中。
修饰符 .completion_mechanism 指定指令变体上支持的完成机制。下表总结了不同变体支持的完成机制
.completion-mechanism |
|
|
完成机制 |
|
|---|---|---|---|---|
完成整个异步操作所需 |
可选地可用于完成 - 从源读取数据 - 从张量映射读取数据(如果适用) |
|||
|
|
|
基于 mbarrier |
基于批量异步组 |
|
|
|||
|
|
|||
|
|
|
基于批量异步组 |
|
修饰符 .mbarrier::complete_tx::bytes 指定 cp.async.bulk 变体使用基于 mbarrier 的完成机制。complete-tx 操作,其 completeCount 参数等于以字节为单位复制的数据量,将在操作数 mbar 指定的 mbarrier 对象上执行。
修饰符 .bulk_group 指定 cp.async.bulk 变体使用批量异步组完成机制。
可选修饰符 .multicast::cluster 允许将数据从全局内存复制到集群中多个 CTA 的共享内存。操作数 ctaMask 指定集群中的目标 CTA,使得 16 位 ctaMask 操作数中的每个位位置对应于目标 CTA 的 %ctaid。源数据被多播到每个目标 CTA 共享内存中与 dstMem 相同的 CTA 相对偏移量。mbarrier 信号也被多播到目标 CTA 共享内存中与 mbar 相同的 CTA 相对偏移量。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并不总是被遵守。它仅被视为性能提示,不会更改程序的内存一致性行为。仅当 .src 或 .dst 状态空间中至少有一个是 .global 状态空间时,才支持限定符 .level::cache_hint。
当指定可选限定符 .cp_mask 时,需要参数 byteMask。16 位宽 byteMask 操作数中的第 i 位指定是否将每个 16 字节宽的数据块的第 i 个字节复制到目标。如果该位被设置,则复制该字节。
cp.async.bulk 中的复制操作被视为弱内存操作,并且 mbarrier 上的 complete-tx 操作在 .cluster 范围内具有 .release 语义,如 内存一致性模型 中所述。
注释
.multicast::cluster 限定符针对目标架构 sm_90a/sm_100a/sm_101a 进行了优化,并且在其他目标上可能性能大幅降低,因此建议将 .multicast::cluster 与 .target sm_90a/sm_100a/sm_101a 一起使用。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
PTX ISA 版本 8.6 中引入了对作为目标状态空间的 .shared::cta 的支持。
PTX ISA 版本 8.6 中引入了对 .cp_mask 限定符的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
建议将 .multicast::cluster 限定符与 .target sm_90a 或 sm_100a 或 sm_101a 一起使用。
对 .cp_mask 限定符的支持需要 sm_100 或更高版本。
示例
// .global -> .shared::cta (strictly non-remote):
cp.async.bulk.shared::cta.global.mbarrier::complete_tx::bytes [dstMem], [srcMem], size, [mbar];
cp.async.bulk.shared::cta.global.mbarrier::complete_tx::bytes.L2::cache_hint
[dstMem], [srcMem], size, [mbar], cache-policy;
// .global -> .shared::cluster:
cp.async.bulk.shared::cluster.global.mbarrier::complete_tx::bytes [dstMem], [srcMem], size, [mbar];
cp.async.bulk.shared::cluster.global.mbarrier::complete_tx::bytes.multicast::cluster
[dstMem], [srcMem], size, [mbar], ctaMask;
cp.async.bulk.shared::cluster.global.mbarrier::complete_tx::bytes.L2::cache_hint
[dstMem], [srcMem], size, [mbar], cache-policy;
// .shared::cta -> .shared::cluster (strictly remote):
cp.async.bulk.shared::cluster.shared::cta.mbarrier::complete_tx::bytes [dstMem], [srcMem], size, [mbar];
// .shared::cta -> .global:
cp.async.bulk.global.shared::cta.bulk_group [dstMem], [srcMem], size;
cp.async.bulk.global.shared::cta.bulk_group.L2::cache_hint} [dstMem], [srcMem], size, cache-policy;
// .shared::cta -> .global with .cp_mask:
cp.async.bulk.global.shared::cta.bulk_group.L2::cache_hint.cp_mask [dstMem], [srcMem], size, cache-policy, byteMask;
9.7.9.25.4.2. 数据移动和转换指令:cp.reduce.async.bulk
cp.reduce.async.bulk
启动一个异步归约操作。
语法
cp.reduce.async.bulk.dst.src.completion_mechanism.redOp.type
[dstMem], [srcMem], size, [mbar]
.dst = { .shared::cluster }
.src = { .shared::cta }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.redOp= { .and, .or, .xor,
.add, .inc, .dec,
.min, .max }
.type = { .b32, .u32, .s32, .b64, .u64 }
cp.reduce.async.bulk.dst.src.completion_mechanism{.level::cache_hint}.redOp.type
[dstMem], [srcMem], size{, cache-policy}
.dst = { .global }
.src = { .shared::cta }
.completion_mechanism = { .bulk_group }
.level::cache_hint = { .L2::cache_hint }
.redOp= { .and, .or, .xor,
.add, .inc, .dec,
.min, .max }
.type = { .f16, .bf16, .b32, .u32, .s32, .b64, .u64, .s64, .f32, .f64 }
cp.reduce.async.bulk.dst.src.completion_mechanism{.level::cache_hint}.add.noftz.type
[dstMem], [srcMem], size{, cache-policy}
.dst = { .global }
.src = { .shared::cta }
.completion_mechanism = { .bulk_group }
.type = { .f16, .bf16 }
描述
cp.reduce.async.bulk 是一个非阻塞指令,它对目标地址操作数 dstMem 指定的内存位置数组启动异步归约操作,源数组的位置由源地址操作数 srcMem 指定。源数组和目标数组的大小必须相同,并由操作数 size 指定。
目标数组中的每个数据元素都与源数组中对应的数据元素进行内联归约,归约操作由修饰符 .redOp 指定。源数组和目标数组中每个数据元素的类型由修饰符 .type 指定。
源地址操作数 srcMem 位于 .src 指定的状态空间中,目标地址操作数 dstMem 位于 .dst 指定的状态中。
32 位操作数 size 指定要从源位置复制并用于归约操作的内存量,以字节数为单位。size 必须是 16 的倍数。如果该值不是 16 的倍数,则行为未定义。内存范围 [dstMem, dstMem + size - 1] 不得溢出目标内存空间,内存范围 [srcMem, srcMem + size - 1] 不得溢出源内存空间。否则,行为未定义。地址 dstMem 和 srcMem 必须对齐到 16 字节。
.redOp 支持的操作分类如下
位大小操作是
.and、.or和.xor。整数操作是
.add、.inc、.dec、.min和.max。.inc和.dec操作返回范围[0..x]内的结果,其中x是源状态空间的值。浮点运算
.add四舍五入到最接近的偶数。cp.reduce.async.bulk.add.f32的当前实现将次正规输入和结果刷新为符号保留零。cp.reduce.async.bulk.add.f16和cp.reduce.async.bulk.add.bf16操作需要.noftz限定符。它保留输入和结果次正规值,并且不会将它们刷新为零。
下表描述了 .redOp 和元素类型的有效组合
|
|
元素类型 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
修饰符 .completion_mechanism 指定指令变体上支持的完成机制。下表总结了不同变体支持的完成机制
.completion-mechanism |
|
|
完成机制 |
|
|---|---|---|---|---|
完成整个异步操作所需 |
可选地可用于完成 - 从源读取数据 - 从张量映射读取数据(如果适用) |
|||
|
|
|
基于 mbarrier |
基于批量异步组 |
|
|
|||
|
|
|
基于批量异步组 |
|
修饰符 .mbarrier::complete_tx::bytes 指定 cp.reduce.async.bulk 变体使用基于 mbarrier 的完成机制。complete-tx 操作,其 completeCount 参数等于以字节为单位复制的数据量,将在操作数 mbar 指定的 mbarrier 对象上执行。
修饰符 .bulk_group 指定 cp.reduce.async.bulk 变体使用批量异步组完成机制。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并不总是被遵守。它仅被视为性能提示,不会更改程序的内存一致性行为。仅当 .src 或 .dst 状态空间中至少有一个是 .global 状态空间时,才支持限定符 .level::cache_hint。
cp.reduce.async.bulk 执行的每个归约操作都具有单独的 .relaxed.gpu 内存排序语义。cp.reduce.async.bulk 中的加载操作被视为弱内存操作,并且 mbarrier 上的 complete-tx 操作在 .cluster 范围内具有 .release 语义,如 内存一致性模型 中所述。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
cp.reduce.async.bulk.shared::cluster.shared::cta.mbarrier::complete_tx::bytes.add.u64
[dstMem], [srcMem], size, [mbar];
cp.reduce.async.bulk.shared::cluster.shared::cta.mbarrier::complete_tx::bytes.min.s32
[dstMem], [srcMem], size, [mbar];
cp.reduce.async.bulk.global.shared::cta.bulk_group.min.f16 [dstMem], [srcMem], size;
cp.reduce.async.bulk.global.shared::cta.bulk_group.L2::cache_hint.xor.s32 [dstMem], [srcMem], size, policy;
cp.reduce.async.bulk.global.shared::cta.bulk_group.add.noftz.f16 [dstMem], [srcMem], size;
9.7.9.25.4.3. 数据移动和转换指令:cp.async.bulk.prefetch
cp.async.bulk.prefetch
向系统提供提示以启动数据到缓存的异步预取。
语法
cp.async.bulk.prefetch.L2.src{.level::cache_hint} [srcMem], size {, cache-policy}
.src = { .global }
.level::cache_hint = { .L2::cache_hint }
描述
cp.async.bulk.prefetch 是一个非阻塞指令,它可以启动从源地址操作数 srcMem 指定的位置(在 .src 状态空间中)到 L2 缓存的数据异步预取。
32 位操作数 size 指定要预取的内存量,以字节数为单位。size 必须是 16 的倍数。如果该值不是 16 的倍数,则行为未定义。地址 srcMem 必须对齐到 16 字节。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
cp.async.bulk.prefetch.L2.global [srcMem], size;
cp.async.bulk.prefetch.L2.global.L2::cache_hint [srcMem], size, policy;
9.7.9.25.5. 数据移动和转换指令:张量复制
9.7.9.25.5.1. 张量复制指令的限制
以下是关于类型 .b4x16、.b4x16_p64、.b6x16_p32 和 .b6p2x16 的限制
cp.reduce.async.bulk不支持类型.b4x16、.b4x16_p64、.b6x16_p32和.b6p2x16。方向为
.global.shared::cta的cp.async.bulk.tensor不支持类型.b4x16_p64。方向为
.shared::cluster.global的cp.async.bulk.tensor在sm_120a上不支持子字节类型。OOB-NaN 填充模式不支持类型
.b4x16、.b4x16_p64、.b6x16_p32和.b6p2x16。-
Box-Size[0] 必须完全是
对于
b6x16_p32和.b6p2x16,为 96B。对于
b4x16_p64,为 64B。
-
Tensor-Size[0] 必须是以下项的倍数
对于
b6x16_p32和.b6p2x16,为 96B。对于
b4x16_p64,为 64B。
对于
.b4x16_p64、.b6x16_p32和.b6p2x16,tensorCoords 参数向量中的第一个坐标必须是 128 的倍数。对于
.b4x16_p64、.b6x16_p32和.b6p2x16,全局内存地址必须是 32B 对齐的。-
.b4x16_p64、.b6x16_p32和.b6p2x16支持以下交换模式无。
128B
以下是关于 .global.shared::cta 方向的限制
-
沿 D、W 和 H 维度的边界框必须保持在张量边界内。这意味着
边界框的左下角必须是非负的。
边界框的右上角必须是非正的。
以下是 sm_120a 的限制
-
方向为
.shared::cluster.global的cp.async.bulk.tensor不支持子字节类型
限定符
.swizzle_atomicity
9.7.9.25.5.2. 数据移动和转换指令:cp.async.bulk.tensor
cp.async.bulk.tensor
启动张量数据从一个状态空间到另一个状态空间的异步复制操作。
语法
// global -> shared::cta
cp.async.bulk.tensor.dim.dst.src{.load_mode}.completion_mechanism{.cta_group}{.level::cache_hint}
[dstMem], [tensorMap, tensorCoords], [mbar]{, im2colInfo} {, cache-policy}
.dst = { .shared::cta }
.src = { .global }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.cta_group = { .cta_group::1, .cta_group::2 }
.load_mode = { .tile, .tile::gather4, .im2col, .im2col::w, .im2col::w::128 }
.level::cache_hint = { .L2::cache_hint }
// global -> shared::cluster
cp.async.bulk.tensor.dim.dst.src{.load_mode}.completion_mechanism{.multicast}{.cta_group}{.level::cache_hint}
[dstMem], [tensorMap, tensorCoords], [mbar]{, im2colInfo}
{, ctaMask} {, cache-policy}
.dst = { .shared::cluster }
.src = { .global }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.cta_group = { .cta_group::1, .cta_group::2 }
.load_mode = { .tile, .tile::gather4, .im2col, .im2col::w, .im2col::w::128 }
.level::cache_hint = { .L2::cache_hint }
.multicast = { .multicast::cluster }
// shared::cta -> global
cp.async.bulk.tensor.dim.dst.src{.load_mode}.completion_mechanism{.level::cache_hint}
[tensorMap, tensorCoords], [srcMem] {, cache-policy}
.dst = { .global }
.src = { .shared::cta }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .bulk_group }
.load_mode = { .tile, .tile::scatter4, .im2col_no_offs }
.level::cache_hint = { .L2::cache_hint }
描述
cp.async.bulk.tensor 是一个非阻塞指令,它启动从 .src 状态空间的位置到 .dst 状态空间的位置的张量数据异步复制操作。
操作数 dstMem 指定 .dst 状态空间中张量数据要复制到的位置,srcMem 指定 .src 状态空间中要从中复制张量数据的位置。
当 .dst 被指定为 .shared::cta 时,地址 dstMem 必须位于集群内执行 CTA 的共享内存中,否则行为未定义。
当 .dst 被指定为 .shared::cluster 时,地址 dstMem 可以位于当前集群内任何 CTA 的共享内存中。
操作数 tensorMap 是不透明张量映射对象的通用地址,该对象驻留在 .param 空间、.const 空间或 .global 空间中。操作数 tensorMap 指定张量复制操作的属性,如 张量映射 中所述。tensorMap 在张量映射代理中访问。有关在主机端创建张量映射对象的信息,请参阅CUDA 编程指南。
张量数据的维度由 .dim 修饰符指定。
向量操作数 tensorCoords 指定全局内存中张量数据的起始坐标,复制操作必须从该坐标执行或执行到该坐标。tensorCoords 中的各个张量坐标的类型为 .s32。向量参数 tensorCoords 的格式取决于指定的 .load_mode,如下所示
.load_mode |
tensorCoords |
语义 |
|---|---|---|
|
{col_idx, row_idx0, row_idx1, row_idx2, row_idx3} |
大小为 5 的固定长度向量。五个元素共同指定四行的起始坐标。 |
|
||
其余所有 |
{d0, .., dn},其中 n = .dim |
n 个元素的向量,其中 n = .dim。元素指示每个维度中的偏移量。 |
修饰符 .completion_mechanism 指定指令变体上支持的完成机制。下表总结了不同变体支持的完成机制
.completion-mechanism |
|
|
完成机制 |
|
|---|---|---|---|---|
完成整个异步操作所需 |
可选地可用于完成 - 从源读取数据 - 从张量映射读取数据(如果适用) |
|||
|
|
|
基于 mbarrier |
基于批量异步组 |
|
|
|||
|
|
|
基于批量异步组 |
|
修饰符 .mbarrier::complete_tx::bytes 指定 cp.async.bulk.tensor 变体使用基于 mbarrier 的完成机制。在异步复制操作完成时,complete-tx 操作,其 completeCount 参数等于以字节为单位复制的数据量,将在操作数 mbar 指定的 mbarrier 对象上执行。
修饰符 .cta_group 只能与基于 mbarrier 的完成机制一起指定。修饰符 .cta_group 用于指示 CTA 对中的奇数编号 CTA 或偶数编号 CTA。当指定 .cta_group::1 时,指定的 mbarrier 对象 mbar 必须与共享内存目标 dstMem 位于同一 CTA 的共享内存中。当指定 .cta_group::2 时,mbarrier 对象 mbar 可以位于与共享内存目标 dstMem 相同的 CTA 的共享内存中,也可以位于其对等 CTA 中。如果未指定 .cta_group,则默认为 .cta_group::1。
修饰符 .bulk_group 指定 cp.async.bulk.tensor 变体使用批量异步组完成机制。
限定符 .load_mode 指定源位置中的数据如何复制到目标位置。如果未指定 .load_mode,则默认为 .tile。
在 .tile 模式下,源张量的多维布局在目标位置保留。在 .tile::gather4 模式下,二维源张量中的四行组合形成单个二维目标张量。在 .tile::scatter4 模式下,单个二维源张量被分成二维目标张量中的四行。.tile::scatter4/.tile::gather4 模式的详细信息在 平铺模式 中描述。
在 .im2col 和 .im2col::* 模式下,源张量的某些维度在目标位置的单维列中展开。im2col 和 .im2col::* 模式的详细信息分别在 Im2col 模式 和 im2col::w 和 im2col::w::128 模式 中描述。在 .im2col 和 .im2col::* 模式下,张量必须至少是 3 维的。仅当 .load_mode 是 .im2col 或 .im2col::w 或 .im2col::w::128 时,才能指定向量操作数 im2colInfo。向量参数 im2colInfo 的格式取决于确切的 im2col 模式,如下所示
确切的 im2col 模式 |
im2colInfo 参数 |
语义 |
|---|---|---|
|
对于 |
im2col 偏移量的向量,其向量大小比维度数 .dim 小 2。 |
|
{ wHalo, wOffset } |
|
|
||
|
|
|
参数 wHalo 是一个 16 位无符号整数,其有效值集在不同的加载模式下有所不同,如下所示:- Im2col::w 模式:有效范围是 [0, 512)。- Im2col::w::128 模式:有效范围是 [0, 32)。
参数 wOffset 是一个 16 位无符号整数,其有效值范围是 [0, 32)。
可选修饰符 .multicast::cluster 允许将数据从全局内存复制到集群中多个 CTA 的共享内存。操作数 ctaMask 指定集群中的目标 CTA,使得 16 位 ctaMask 操作数中的每个位位置对应于目标 CTA 的 %ctaid。源数据被多播到每个目标 CTA 共享内存中与 dstMem 相同的偏移量。当 .cta_group 被指定为
.cta_group::1时:mbarrier 信号也被多播到目标 CTA 共享内存中与mbar相同的偏移量。.cta_group::2时:mbarrier 信号被多播到相应CTA 对内的所有奇数编号 CTA 或偶数编号 CTA。对于ctaMask中指定的每个目标 CTA,mbarrier 信号被发送到目标 CTA 或其对等 CTA,具体取决于 mbarrier 对象mbar所在的共享内存的 CTA%cluster_ctarank奇偶校验。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
cp.async.bulk.tensor 中的复制操作被视为弱内存操作,并且 mbarrier 上的 complete-tx 操作在 .cluster 范围内具有 .release 语义,如 内存一致性模型 中所述。
注释
.multicast::cluster 限定符针对目标架构 sm_90a/sm_100a/sm_101a 进行了优化,并且在其他目标上可能性能大幅降低,因此建议将 .multicast::cluster 与 .target sm_90a/sm_100a/sm_101a 一起使用。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
PTX ISA 版本 8.6 中引入了对作为目标状态空间的 .shared::cta 的支持。
PTX ISA 版本 8.6 中引入了对限定符 .tile::gather4 和 .tile::scatter4 的支持。
PTX ISA 版本 8.6 中引入了对限定符 .im2col::w 和 .im2col::w::128 的支持。
PTX ISA 版本 8.6 中引入了对限定符 .cta_group 的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
建议将 .multicast::cluster 限定符与 .target sm_90a 或 sm_100a 或 sm_101a 一起使用。
当目标状态空间为 .shared::cluster 时,限定符 .tile::gather4 和 .im2col::w 需要
sm_100a。当目标状态空间为
.shared::cta时,限定符.tile::gather4和.im2col::w需要sm_100或更高版本。
以下架构支持限定符 .tile::scatter4
sm_100asm_101a
以下架构支持限定符 .im2col::w::128
sm_100asm_101a
以下架构支持限定符 .cta_group
sm_100asm_101a
示例
.reg .b16 ctaMask;
.reg .u16 i2cOffW, i2cOffH, i2cOffD;
.reg .b64 l2CachePolicy;
cp.async.bulk.tensor.1d.shared::cta.global.mbarrier::complete_tx::bytes.tile [sMem0], [tensorMap0, {tc0}], [mbar0];
@p cp.async.bulk.tensor.5d.shared::cta.global.im2col.mbarrier::complete_tx::bytes
[sMem2], [tensorMap2, {tc0, tc1, tc2, tc3, tc4}], [mbar2], {i2cOffW, i2cOffH, i2cOffD};
cp.async.bulk.tensor.1d.shared::cluster.global.mbarrier::complete_tx::bytes.tile [sMem0], [tensorMap0, {tc0}], [mbar0];
@p cp.async.bulk.tensor.2d.shared::cluster.global.mbarrier::complete_tx::bytes.multicast::cluster
[sMem1], [tensorMap1, {tc0, tc1}], [mbar2], ctaMask;
@p cp.async.bulk.tensor.5d.shared::cluster.global.im2col.mbarrier::complete_tx::bytes
[sMem2], [tensorMap2, {tc0, tc1, tc2, tc3, tc4}], [mbar2], {i2cOffW, i2cOffH, i2cOffD};
@p cp.async.bulk.tensor.3d.im2col.shared::cluster.global.mbarrier::complete_tx::bytes.L2::cache_hint
[sMem3], [tensorMap3, {tc0, tc1, tc2}], [mbar3], {i2cOffW}, policy;
@p cp.async.bulk.tensor.1d.global.shared::cta.bulk_group [tensorMap3, {tc0}], [sMem3];
cp.async.bulk.tensor.2d.tile::gather4.shared::cluster.global.mbarrier::complete_tx::bytes
[sMem5], [tensorMap6, {x0, y0, y1, y2, y3}], [mbar5];
cp.async.bulk.tensor.3d.im2col::w.shared::cluster.global.mbarrier::complete_tx::bytes
[sMem4], [tensorMap5, {t0, t1, t2}], [mbar4], {im2colwHalo, im2colOff};
cp.async.bulk.tensor.1d.shared::cluster.global.tile.cta_group::2
[sMem6], [tensorMap7, {tc0}], [peerMbar];
9.7.9.25.5.3. 数据移动和转换指令:cp.reduce.async.bulk.tensor
cp.reduce.async.bulk.tensor
启动张量数据的异步归约操作。
语法
// shared::cta -> global:
cp.reduce.async.bulk.tensor.dim.dst.src.redOp{.load_mode}.completion_mechanism{.level::cache_hint}
[tensorMap, tensorCoords], [srcMem] {,cache-policy}
.dst = { .global }
.src = { .shared::cta }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .bulk_group }
.load_mode = { .tile, .im2col_no_offs }
.redOp = { .add, .min, .max, .inc, .dec, .and, .or, .xor}
描述
cp.reduce.async.bulk.tensor 是一个非阻塞指令,它启动 .dst 状态空间中张量数据与 .src 状态空间中张量数据的异步归约操作。
操作数 srcMem 指定 .src 状态空间中张量数据的位置,归约操作必须使用该位置的张量数据执行。
操作数 tensorMap 是不透明张量映射对象的通用地址,该对象驻留在 .param 空间、.const 空间或 .global 空间中。操作数 tensorMap 指定张量复制操作的属性,如 张量映射 中所述。tensorMap 在张量映射代理中访问。有关在主机端创建张量映射对象的信息,请参阅CUDA 编程指南。
.dst 状态空间中张量数据的每个元素都与 .src 状态空间中张量数据中的对应元素进行内联归约。修饰符 .redOp 指定用于内联归约的归约操作。源张量和目标张量中每个张量数据元素的类型在 张量映射 中指定。
张量的维度由 .dim 修饰符指定。
向量操作数 tensorCoords 指定了执行归约操作的张量数据在全局内存中的起始坐标。向量参数 tensorCoords 中的张量坐标数量应等于修饰符 .dim 指定的维度。各个张量坐标的类型为 .s32。
下表描述了 .redOp 和元素类型的有效组合
|
元素类型 |
|---|---|
|
|
|
|
|
|
|
|
修饰符 .completion_mechanism 指定了指令变体上支持的完成机制。修饰符 .completion_mechanism 的值 .bulk_group 指定了 cp.reduce.async.bulk.tensor 指令使用 *bulk async-group* 基于组的异步完成机制。
限定符 .load_mode 指定了源位置的数据如何复制到目标位置。如果未指定 .load_mode,则默认为 .tile。在 .tile 模式下,源张量的多维布局在目标位置被保留。在 .im2col_no_offs 模式下,源张量的某些维度在目标位置被展开为单维列。 `im2col` 模式的详细信息在 Im2col 模式 中描述。在 .im2col 模式下,张量必须至少是 3 维的。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并不总是被遵守。它仅被视为性能提示,不会更改程序的内存一致性行为。仅当 .src 或 .dst 状态空间中至少有一个是 .global 状态空间时,才支持限定符 .level::cache_hint。
cp.reduce.async.bulk.tensor 执行的每个归约操作都具有单独的 .relaxed.gpu 内存排序语义。 `cp.reduce.async.bulk.tensor` 中的加载操作被视为弱内存操作,并且 mbarrier 上的 complete-tx 操作在 `.cluster` 范围内具有 `.release` 语义,如 内存一致性模型 中所述。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
cp.reduce.async.bulk.tensor.1d.global.shared::cta.add.tile.bulk_group
[tensorMap0, {tc0}], [sMem0];
cp.reduce.async.bulk.tensor.2d.global.shared::cta.and.bulk_group.L2::cache_hint
[tensorMap1, {tc0, tc1}], [sMem1] , policy;
cp.reduce.async.bulk.tensor.3d.global.shared::cta.xor.im2col.bulk_group
[tensorMap2, {tc0, tc1, tc2}], [sMem2]
9.7.9.25.5.4. 数据移动和转换指令:cp.async.bulk.prefetch.tensor
cp.async.bulk.prefetch.tensor
向系统提供提示,以启动张量数据到缓存的异步预取。
语法
// global -> shared::cluster:
cp.async.bulk.prefetch.tensor.dim.L2.src{.load_mode}{.level::cache_hint} [tensorMap, tensorCoords]
{, im2colInfo } {, cache-policy}
.src = { .global }
.dim = { .1d, .2d, .3d, .4d, .5d }
.load_mode = { .tile, .tile::gather4, .im2col, .im2col::w, .im2col::w::128 }
.level::cache_hint = { .L2::cache_hint }
描述
cp.async.bulk.prefetch.tensor 是一个非阻塞指令,它可以启动从 .src 状态空间中的位置到 L2 缓存的张量数据的异步预取。
操作数 tensorMap 是不透明张量映射对象的通用地址,该对象驻留在 .param 空间、.const 空间或 .global 空间中。操作数 tensorMap 指定张量复制操作的属性,如 张量映射 中所述。tensorMap 在张量映射代理中访问。有关在主机端创建张量映射对象的信息,请参阅CUDA 编程指南。
张量数据的维度由 .dim 修饰符指定。
向量操作数 tensorCoords 指定全局内存中张量数据的起始坐标,复制操作必须从该坐标执行或执行到该坐标。tensorCoords 中的各个张量坐标的类型为 .s32。向量参数 tensorCoords 的格式取决于指定的 .load_mode,如下所示
.load_mode |
tensorCoords |
语义 |
|---|---|---|
|
{col_idx, row_idx0, row_idx1, row_idx2, row_idx3} |
大小为 5 的固定长度向量。五个元素共同指定四行的起始坐标。 |
其余所有 |
{d0, .., dn},其中 n = .dim |
n 个元素的向量,其中 n = .dim。元素指示每个维度中的偏移量。 |
限定符 .load_mode 指定源位置中的数据如何复制到目标位置。如果未指定 .load_mode,则默认为 .tile。
在 .tile 模式下,源张量的多维布局在目标位置被保留。在 .tile::gather4 模式下,二维源张量中的四行被提取到 L2 缓存。 `.tile::gather4` 模式的详细信息在 平铺模式 中描述。
在 .im2col 和 .im2col::* 模式下,源张量的某些维度在目标位置被展开为单维列。 `im2col` 和 `.im2col::*` 模式的详细信息分别在 Im2col 模式 和 im2col::w 和 im2col::w::128 模式 中描述。在 `.im2col` 和 `.im2col::*` 模式下,张量必须至少是 3 维的。只有当 `.load_mode` 是 `.im2col` 或 `.im2col::w` 或 .im2col::w::128` 时,才能指定向量操作数 `im2colInfo`。向量参数 `im2colInfo` 的格式取决于确切的 im2col 模式,如下所示
确切的 im2col 模式 |
im2colInfo 参数 |
语义 |
|---|---|---|
|
对于 |
im2col 偏移量的向量,其向量大小比维度数 .dim 小 2。 |
|
{ wHalo, wOffset } |
|
|
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
cp.async.bulk.prefetch.tensor 在 内存一致性模型 中被视为弱内存操作。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
PTX ISA 版本 8.6 中引入了对限定符 `.tile::gather4` 的支持。
PTX ISA 版本 8.6 中引入了对限定符 .im2col::w 和 .im2col::w::128 的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
以下架构支持限定符 `.tile::gather4`
sm_100asm_101a
以下架构支持限定符 `.im2col::w` 和 `.im2col::w::128`
sm_100asm_101a
示例
.reg .b16 ctaMask, im2colwHalo, im2colOff;
.reg .u16 i2cOffW, i2cOffH, i2cOffD;
.reg .b64 l2CachePolicy;
cp.async.bulk.prefetch.tensor.1d.L2.global.tile [tensorMap0, {tc0}];
@p cp.async.bulk.prefetch.tensor.2d.L2.global [tensorMap1, {tc0, tc1}];
@p cp.async.bulk.prefetch.tensor.5d.L2.global.im2col
[tensorMap2, {tc0, tc1, tc2, tc3, tc4}], {i2cOffW, i2cOffH, i2cOffD};
@p cp.async.bulk.prefetch.tensor.3d.L2.global.im2col.L2::cache_hint
[tensorMap3, {tc0, tc1, tc2}], {i2cOffW}, policy;
cp.async.bulk.prefetch.tensor.2d.L2.global.tile::gather4 [tensorMap5, {col_idx, row_idx0, row_idx1, row_idx2, row_idx3}];
cp.async.bulk.prefetch.tensor.4d.L2.global.im2col::w::128
[tensorMap4, {t0, t1, t2, t3}], {im2colwHalo, im2colOff};
9.7.9.25.6. 数据移动和转换指令:批量和张量复制完成指令
9.7.9.25.6.1. 数据移动和转换指令:cp.async.bulk.commit_group
cp.async.bulk.commit_group
将所有先前启动但未提交的 `cp.async.bulk` 指令提交到 *cp.async.bulk-group* 中。
语法
cp.async.bulk.commit_group;
描述
cp.async.bulk.commit_group 指令创建一个新的每线程 *bulk async-group*,并将满足以下条件的所有先前 `cp{.reduce}.async.bulk.{.prefetch}{.tensor}` 指令批处理到新的 *bulk async-group* 中
先前的 `
cp{.reduce}.async.bulk.{.prefetch}{.tensor}` 指令使用 *bulk_group* 基于组的完成机制,并且它们由执行线程启动,但未提交到任何 *bulk async-group*。
如果没有未提交的 `cp{.reduce}.async.bulk.{.prefetch}{.tensor}` 指令,则 `cp.async.bulk.commit_group` 将导致一个空的 *bulk async-group*。
执行线程可以使用 `cp.async.bulk.wait_group` 等待 *bulk async-group* 中所有 `cp{.reduce}.async.bulk.{.prefetch}{.tensor}` 操作的完成。
在同一个 *bulk async-group* 中的任何两个 `cp{.reduce}.async.bulk.{.prefetch}{.tensor}` 操作之间,不提供内存排序保证。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
cp.async.bulk.commit_group;
9.7.9.25.6.2. 数据移动和转换指令:cp.async.bulk.wait_group
cp.async.bulk.wait_group
等待 *bulk async-groups* 的完成。
语法
cp.async.bulk.wait_group{.read} N;
描述
cp.async.bulk.wait_group 指令将导致执行线程等待,直到只有 N 个或更少的最新 *bulk async-groups* 处于挂起状态,并且执行线程提交的所有先前的 *bulk async-groups* 都已完成。例如,当 N 为 0 时,执行线程等待所有先前的 *bulk async-groups* 完成。操作数 N 是一个整数常量。
默认情况下,`cp.async.bulk.wait_group` 指令将导致执行线程等待,直到指定的 *bulk async-group* 中的所有批量异步操作完成。批量异步操作包括以下内容
可选地,从张量映射读取。
从源位置读取。
写入到各自的目标位置。
使写入对执行线程可见。
可选的 `.read` 修饰符指示必须等待,直到指定的 *bulk async-group* 中的所有批量异步操作都已完成
从张量映射读取
从其源位置读取。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
cp.async.bulk.wait_group.read 0;
cp.async.bulk.wait_group 2;
9.7.9.26. 数据移动和转换指令:tensormap.replace
tensormap.replace
修改张量映射对象的字段。
语法
tensormap.replace.mode.field1{.ss}.b1024.type [addr], new_val;
tensormap.replace.mode.field2{.ss}.b1024.type [addr], ord, new_val;
tensormap.replace.mode.field3{.ss}.b1024.type [addr], new_val;
.mode = { .tile }
.field1 = { .global_address, .rank }
.field2 = { .box_dim, .global_dim, .global_stride, .element_stride }
.field3 = { .elemtype, .interleave_layout, .swizzle_mode, .swizzle_atomicity, .fill_mode }
.ss = { .global, .shared::cta }
.type = { .b32, .b64 }
描述
tensormap.replace 指令使用新值替换地址操作数 `addr` 指定的位置处的张量映射对象的字段,该字段由限定符 `.field` 指定。新值由参数 `new_val` 指定。
限定符 `.mode` 指定了位于地址操作数 `addr` 的 张量映射 对象的模式。
指令类型 `.b1024` 指示 张量映射 对象的大小为 1024 位。
操作数 `new_val` 的类型为 `.type`。当 `.field` 指定为 `.global_address` 或 `.global_stride` 时,`.type` 必须为 `.b64`。否则,`.type` 必须为 `.b32`。
立即整数操作数 `ord` 指定了张量秩中需要替换的字段的序号,该序号在 张量映射 对象中。
对于字段 `.rank`,操作数 `new_val` 必须比所需的张量秩小 1,因为此字段使用从零开始的编号。
当指定 `.field3` 时,操作数 `new_val` 必须是立即数,并且 表 32 显示了操作数 `new_val` 在各个字段之间的映射。
new_val |
.field3 |
||||
|---|---|---|---|---|---|
.elemtype |
.interleave_layout |
.swizzle_mode |
.swizzle_atomicity |
.fill_mode |
|
0 |
|
无交错 |
无混合 |
16B |
零填充 |
1 |
|
16B 交错 |
32B 混合 |
32B |
OOB-NaN 填充 |
2 |
|
32B 交错 |
64B 混合 |
32B + 8B 翻转 |
x |
3 |
|
x |
128B 混合 |
64B |
x |
4 |
|
x |
x |
x |
x |
5 |
|
x |
x |
x |
x |
6 |
|
x |
x |
x |
x |
7 |
|
x |
x |
x |
x |
8 |
|
x |
x |
x |
x |
9 |
|
x |
x |
x |
x |
10 |
|
x |
x |
x |
x |
11 |
|
x |
x |
x |
x |
12 |
|
x |
x |
x |
x |
13 |
|
x |
x |
x |
x |
14 |
|
x |
x |
x |
x |
15 |
|
x |
x |
x |
x |
如果未指定状态空间,则使用 通用寻址。如果 `addr` 指定的地址未落在 `.global` 或 `.shared::cta` 状态空间的地址窗口内,则行为未定义。
在 内存一致性模型 中,`tensormap.replace` 被视为对整个 1024 位不透明 张量映射 对象的弱内存操作。
PTX ISA 注释
在 PTX ISA 版本 8.3 中引入。
限定符 `.swizzle_atomicity` 在 PTX ISA 版本 8.6 中引入。
PTX ISA 版本 8.7 及更高版本支持值为 `13` 到 `15`(包括两者)的限定符 `.elemtype`。
目标 ISA 注释
以下架构支持
sm_90asm_100asm_101asm_120a
以下架构支持限定符 `.swizzle_atomicity`
sm_100asm_101asm_120a(有关 sm_120a 的限制,请参阅 section)
以下架构支持与 `new_val` 值 `13`、`14` 和 `15` 对应的 `.field3` 变体 `.elemtype`
sm_100asm_101asm_120a(有关 sm_120a 的限制,请参阅 section)
示例
tensormap.replace.tile.global_address.shared::cta.b1024.b64 [sMem], new_val;
9.7.10. 纹理指令
本节介绍用于访问纹理和采样器的 PTX 指令。PTX 支持对纹理和采样器描述符执行以下操作
纹理和采样器描述符的静态初始化。
模块范围和每个条目范围的纹理和采样器描述符的定义。
查询纹理和采样器描述符中字段的能力。
9.7.10.1. 纹理模式
为了使用纹理和采样器,PTX 有两种操作模式。在统一模式中,纹理和采样器信息通过单个 `.texref` 句柄访问。在独立模式中,纹理和采样器信息各有自己的句柄,允许它们分别定义并在程序中的使用位置组合。
统一模式的优点是它允许每个内核 256 个采样器(对于 `sm_3x` 之前的架构为 128 个),但限制是它们与每个内核 256 个可能的纹理(对于 `sm_3x` 之前的架构为 128 个)一一对应。独立模式的优点是可以混合和匹配纹理和采样器,但采样器的数量大大限制为每个内核 32 个(对于 `sm_3x` 之前的架构为 16 个)。
表 33 总结了不同纹理模式下可用的纹理、采样器和表面的数量。
纹理模式 |
资源 |
|
|
|---|---|---|---|
统一模式 |
纹理 |
128 |
256 |
采样器 |
128 |
256 |
|
表面 |
8 |
16 |
|
独立模式 |
纹理 |
128 |
256 |
采样器 |
16 |
32 |
|
表面 |
8 |
16 |
纹理模式是使用 `.target` 选项 `texmode_unified` 和 `texmode_independent` 选择的。一个 PTX 模块只能声明一种纹理模式。如果未声明纹理模式,则假定该模块使用统一模式。
示例:计算元素的功率贡献,即元素的功率/元素总数。
.target texmode_independent
.global .samplerref tsamp1 = { addr_mode_0 = clamp_to_border,
filter_mode = nearest
};
...
.entry compute_power
( .param .texref tex1 )
{
txq.width.b32 r6, [tex1]; // get tex1's width
txq.height.b32 r5, [tex1]; // get tex1's height
tex.2d.v4.f32.f32 {r1,r2,r3,r4}, [tex1, tsamp1, {f1,f2}];
mul.u32 r5, r5, r6;
add.f32 r1, r1, r2;
add.f32 r3, r3, r4;
add.f32 r1, r1, r3;
cvt.f32.u32 r5, r5;
div.f32 r1, r1, r5;
}
9.7.10.2. Mipmaps
mipmap 是一系列纹理,每个纹理都是同一图像的逐渐降低分辨率的表示。mipmap 中每个图像或细节级别 (LOD) 的高度和宽度都比前一个级别小 2 的幂。Mipmap 用于图形应用程序中,以提高渲染速度并减少锯齿伪影。例如,高分辨率 mipmap 图像用于靠近用户的对象;较低分辨率的图像用于看起来更远的对象。当在两个细节级别 (LOD) 之间切换时,提供 mipmap 过滤模式,以避免视觉保真度的突变。
示例: 如果纹理的基本大小为 256 x 256 像素,则关联的 mipmap 集可能包含一系列八个图像,每个图像的总面积是前一个图像的四分之一:128x128 像素、64x64、32x32、16x16、8x8、4x4、2x2、1x1(单个像素)。例如,如果场景以 40x40 像素的空间渲染此纹理,则将使用 32x32 mipmap 的放大版本(不进行三线性插值)或 64x64 和 32x32 mipmap 的插值(进行三线性插值)。
完整 mipmap 金字塔中的 LOD 总数通过以下公式计算
numLODs = 1 + floor(log2(max(w, h, d)))
最精细的 LOD 称为基本级别,是第 0 级别。下一个(较粗糙的)级别是第 1 级别,依此类推。最粗糙的级别是大小为 (1 x 1 x 1) 的级别。每个连续较小的 mipmap 级别的 {宽度、高度、深度} 是前一个级别的一半,但如果此半值是小数值,则将其向下舍入到下一个最大整数。从本质上讲,mipmap 级别的大小可以指定为
max(1, floor(w_b / 2^i)) x
max(1, floor(h_b / 2^i)) x
max(1, floor(d_b / 2^i))
其中 i 是超出第 0 级别(基本级别)的第 i 个级别。w_b、h_b 和 d_b 分别是基本级别的宽度、高度和深度。
PTX 对 mipmap 的支持
PTX `tex` 指令支持三种指定 LOD 的模式:base、level 和 gradient。在 base 模式下,指令始终选择级别 0。在 level 模式下,提供一个额外的参数来指定要从中获取 LOD 的级别。在 gradmode 中,两个浮点向量参数提供偏导数(例如,对于 2d 纹理,为 `{ds/dx, dt/dx}` 和 `{ds/dy, dt/dy}`),`tex` 指令使用这些偏导数来计算 LOD。
这些指令提供对纹理内存的访问。
textld4txq
9.7.10.3. 纹理指令:tex
tex
执行纹理内存查找。
语法
tex.geom.v4.dtype.ctype d, [a, c] {, e} {, f};
tex.geom.v4.dtype.ctype d[|p], [a, b, c] {, e} {, f}; // explicit sampler
tex.geom.v2.f16x2.ctype d[|p], [a, c] {, e} {, f};
tex.geom.v2.f16x2.ctype d[|p], [a, b, c] {, e} {, f}; // explicit sampler
// mipmaps
tex.base.geom.v4.dtype.ctype d[|p], [a, {b,} c] {, e} {, f};
tex.level.geom.v4.dtype.ctype d[|p], [a, {b,} c], lod {, e} {, f};
tex.grad.geom.v4.dtype.ctype d[|p], [a, {b,} c], dPdx, dPdy {, e} {, f};
tex.base.geom.v2.f16x2.ctype d[|p], [a, {b,} c] {, e} {, f};
tex.level.geom.v2.f16x2.ctype d[|p], [a, {b,} c], lod {, e} {, f};
tex.grad.geom.v2.f16x2.ctype d[|p], [a, {b,} c], dPdx, dPdy {, e} {, f};
.geom = { .1d, .2d, .3d, .a1d, .a2d, .cube, .acube, .2dms, .a2dms };
.dtype = { .u32, .s32, .f16, .f32 };
.ctype = { .s32, .f32 }; // .cube, .acube require .f32
// .2dms, .a2dms require .s32
描述
tex.{1d,2d,3d}
使用纹理坐标向量进行纹理查找。该指令从操作数 `a` 命名的纹理中,在操作数 `c` 给定的坐标处加载数据到目标 `d` 中。对于 1d 纹理,操作数 `c` 是标量或单例元组;对于 2d 纹理,是双元素向量;对于 3d 纹理,是四元素向量,其中第四个元素被忽略。可以指定可选的纹理采样器 `b`。如果未指定采样器,则采样器行为是命名纹理的属性。如果指定坐标处的纹理数据驻留在内存中,则可选的目标谓词 `p` 设置为 `True`,否则设置为 `False`。当可选的目标谓词 `p` 设置为 `False` 时,加载的数据将全部为零。指定坐标处纹理数据的内存驻留取决于在内核启动之前使用驱动程序 API 调用进行的执行环境设置。有关更多详细信息,包括任何系统/特定于实现的特定行为,请参阅驱动程序 API 文档。
可以为操作数 `e` 指定一个可选的操作数 `e`。操作数 `e` 是一个 `.s32` 值向量,用于指定坐标偏移量。偏移量在执行纹理查找之前应用于坐标。偏移值范围为 -8 到 +7。对于 1d 纹理,操作数 `e` 是单例元组;对于 2d 纹理,是双元素向量;对于 3d 纹理,是四元素向量,其中第四个元素被忽略。
可以为 `depth textures` 指定一个可选的操作数 `f`。深度纹理是一种特殊类型的纹理,它保存来自深度缓冲区的数据。深度缓冲区包含每个像素的深度信息。操作数 `f` 是 `.f32` 标量值,用于指定深度纹理的深度比较值。从纹理中获取的每个元素都与 `f` 操作数中给定的值进行比较。如果比较通过,则结果为 1.0;否则结果为 0.0。这些按元素比较的结果用于过滤。当使用深度比较操作数时,纹理坐标向量 `c` 中的元素具有 `.f32` 类型。
深度比较操作数不支持 `3d` 纹理。
对于目标类型 `.f16x2`,该指令返回一个双元素向量。对于所有其他目标类型,该指令返回一个四元素向量。坐标可以采用有符号 32 位整数或 32 位浮点形式给出。
假定纹理基地址与 16 字节边界对齐,并且坐标向量给出的地址必须自然对齐到访问大小的倍数。如果地址未正确对齐,则结果行为未定义;即,访问可能会通过静默屏蔽低位地址位以实现正确舍入来继续,或者指令可能会出错。
tex.{a1d,a2d}
纹理数组选择,然后进行纹理查找。该指令首先使用数组坐标向量 `c` 的第一个元素给出的索引,从操作数 `a` 命名的纹理数组中选择一个纹理。然后,该指令从选定的纹理中,在操作数 `c` 的其余元素给定的坐标处加载数据到目标 `d` 中。操作数 `c` 是位大小类型向量或元组,包含纹理数组的索引,后跟所选纹理中的坐标,如下所示
对于 1d 纹理数组,操作数 `
c` 的类型为 `.v2.b32`。第一个元素被解释为纹理数组的无符号整数索引(`.u32`),第二个元素被解释为 `.ctype` 类型的 1d 纹理坐标。对于 2d 纹理数组,操作数 `
c` 的类型为 `.v4.b32`。第一个元素被解释为纹理数组的无符号整数索引(`.u32`),接下来的两个元素被解释为 `.ctype` 类型的 2d 纹理坐标。第四个元素被忽略。
可以指定可选的纹理采样器 `b`。如果未指定采样器,则采样器行为是命名纹理的属性。
可以为操作数 `e` 指定一个可选的操作数 `e`。操作数 `e` 是一个 `.s32` 值向量,用于指定坐标偏移量。偏移量在执行纹理查找之前应用于坐标。偏移值范围为 -8 到 +7。对于 1d 纹理数组,操作数 `e` 是单例元组;对于 2d 纹理数组,是双元素向量。
可以为深度纹理数组指定一个可选的操作数 `f`。操作数 `f` 是 `.f32` 标量值,用于指定深度纹理的深度比较值。当使用深度比较操作数时,纹理坐标向量 `c` 中的坐标具有 `.f32` 类型。
对于目标类型 `.f16x2`,该指令返回一个双元素向量。对于所有其他目标类型,该指令返回一个四元素向量。纹理数组索引是一个 32 位无符号整数,纹理坐标元素是 32 位有符号整数或浮点值。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
tex.cube
立方体贴图 纹理查找。该指令从操作数 a 命名的立方体贴图纹理中,在操作数 c 给定的坐标处加载数据到目标 d 中。立方体贴图纹理是特殊的二维分层纹理,由六个层组成,代表立方体的六个面。立方体贴图中的所有层都具有相同的大小并且是正方形的(即,宽度等于高度)。
当访问立方体贴图时,纹理坐标向量 c 的类型为 .v4.f32,包含三个浮点坐标 (s、t、r) 和第四个被忽略的填充参数。坐标 (s、t、r) 投影到立方体的六个面之一上。(s、t、r) 坐标可以被认为是源自立方体中心的direction向量。在三个坐标 (s、t、r) 中,幅度最大的坐标(主轴)选择立方体面。然后,其他两个坐标(次轴)除以主轴的绝对值,以生成新的 (s、t) 坐标对,用于在选定的立方体面中进行查找。
可以指定可选的纹理采样器 `b`。如果未指定采样器,则采样器行为是命名纹理的属性。
立方体贴图纹理不支持偏移向量操作数 e。
可以为立方体贴图深度纹理指定可选的操作数 f。操作数 f 是 .f32 标量值,用于指定立方体贴图深度纹理的深度比较值。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
tex.acube
立方体贴图数组选择,然后进行立方体贴图查找。该指令首先使用数组坐标向量 c 的第一个元素给出的索引,从操作数 a 命名的立方体贴图数组中选择一个立方体贴图纹理。然后,该指令从选定的立方体贴图纹理中,在操作数 c 的其余元素给定的坐标处加载数据到目标 d 中。
立方体贴图数组 纹理由立方体贴图数组组成,即总层数是六的倍数。当访问立方体贴图数组纹理时,坐标向量 c 的类型为 .v4.b32。第一个元素被解释为立方体贴图数组的无符号整数索引 (.u32),其余三个元素被解释为浮点立方体贴图坐标 (s、t、r),用于在选定的立方体贴图中进行查找,如上所述。
可以指定可选的纹理采样器 `b`。如果未指定采样器,则采样器行为是命名纹理的属性。
立方体贴图纹理数组不支持偏移向量操作数 e。
可以为立方体贴图深度纹理数组指定可选的操作数 f。操作数 f 是 .f32 标量值,用于指定立方体贴图深度纹理的深度比较值。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
tex.2dms
使用纹理坐标向量进行多采样纹理查找。多采样纹理由每个数据元素的多个采样组成。该指令从操作数 a 命名的纹理中,从操作数 c 的第一个元素给定的采样编号,以及操作数 c 的其余元素给定的坐标处加载数据到目标 d 中。当访问多采样纹理时,纹理坐标向量 c 的类型为 .v4.b32。操作数 c 中的第一个元素被解释为无符号整数采样编号 (.u32),接下来的两个元素被解释为有符号整数 (.s32) 2d 纹理坐标。第四个元素被忽略。可以指定可选的纹理采样器 b。如果未指定采样器,则采样器行为是命名纹理的属性。
可以指定可选的操作数 e。操作数 e 是 .v2.s32 类型的向量,用于指定坐标偏移。偏移在进行纹理查找之前应用于坐标。偏移值范围为 -8 到 +7。
多采样纹理不支持深度比较操作数 f。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
tex.a2dms
多采样纹理数组选择,然后进行多采样纹理查找。该指令首先使用数组坐标向量 c 的第一个元素给出的索引,从操作数 a 命名的多采样纹理数组中选择一个多采样纹理。然后,该指令从选定的多采样纹理中,从操作数 c 的第二个元素给定的采样编号,以及操作数 c 的其余元素给定的坐标处加载数据到目标 d 中。当访问多采样纹理数组时,纹理坐标向量 c 的类型为 .v4.b32。操作数 c 中的第一个元素被解释为无符号整数采样器编号,第二个元素被解释为多采样纹理数组的无符号整数索引 (.u32),接下来的两个元素被解释为有符号整数 (.s32) 2d 纹理坐标。可以指定可选的纹理采样器 b。如果未指定采样器,则采样器行为是命名纹理的属性。
可以指定可选的操作数 e。操作数 e 是 .v2.s32 类型的值向量,用于指定坐标偏移。偏移在进行纹理查找之前应用于坐标。偏移值范围为 -8 到 +7。
多采样纹理数组不支持深度比较操作数 f。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
Mipmaps
-
.base(lod 零级) -
选择级别 0(基本级别)。如果未指定 mipmap 模式,则这是默认设置。没有额外的参数。
-
.level(lod 显式级别) -
需要额外的 32 位标量参数
lod,其中包含要从中获取的 LOD。lod的类型遵循.ctype(.s32或.f32)。此模式不支持几何类型.2dms和.a2dms。 -
.grad(lod 梯度) -
需要两个
.f32向量dPdx和dPdy,用于指定偏导数。对于 1d 和 a1d 纹理,向量是单例;对于 2d 和 a2d 纹理,向量是双元素向量;对于 3d、立方体和 acube 纹理,向量是四元素向量,其中对于 3d 和立方体几何类型,第四个元素被忽略。此模式不支持几何类型.2dms和.a2dms。
对于 mipmap 纹理查找,可以指定可选的操作数 e。操作数 e 是 .s32 类型的向量,用于指定坐标偏移。偏移在进行纹理查找之前应用于坐标。偏移值范围为 -8 到 +7。立方体和立方体贴图几何类型不支持偏移向量操作数。
可以为 mipmap 纹理指定可选的操作数 f。操作数 f 是 .f32 标量值,用于指定深度纹理的深度比较值。当使用深度比较操作数时,纹理坐标向量 c 中的坐标具有 .f32 类型。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
深度比较操作数不支持 `3d` 纹理。
间接纹理访问
从 PTX ISA 版本 3.1 开始,在统一模式下,对于目标架构 sm_20 或更高版本,支持间接纹理访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .texref 变量的地址。
注释
为了与之前的 PTX 版本兼容,不需要方括号,并且 .v4 坐标向量可以用于任何几何类型,额外的元素将被忽略。
PTX ISA 注释
PTX ISA 版本 1.0 中引入了统一模式纹理处理。PTX ISA 版本 1.5 中引入了使用不透明 .texref 和 .samplerref 类型以及独立模式纹理处理的扩展。
PTX ISA 版本 2.3 中引入了纹理数组 tex.{a1d,a2d}。
PTX ISA 版本 3.0 中引入了立方体贴图和立方体贴图数组。
PTX ISA 版本 3.1 中引入了对 mipmap 的支持。
PTX ISA 版本 3.1 中引入了间接纹理访问。
PTX ISA 版本 3.2 中引入了多采样纹理和多采样纹理数组。
PTX ISA 版本 4.2 中引入了对纹理返回 .f16 和 .f16x2 数据的支持。
PTX ISA 版本 4.3 中引入了对 tex.grad.{cube, acube} 的支持。
PTX ISA 版本 4.3 中引入了偏移向量操作数。
PTX ISA 版本 4.3 中引入了深度比较操作数。
PTX ISA 版本 7.1 中引入了对可选目标谓词的支持。
目标 ISA 注释
所有目标架构均支持。
立方体贴图数组几何类型 (.acube) 需要 sm_20 或更高版本。
Mipmaps 需要 sm_20 或更高版本。
间接纹理访问需要 sm_20 或更高版本。
多采样纹理和多采样纹理数组需要 sm_30 或更高版本。
纹理获取返回 .f16 和 .f16x2 数据需要 sm_53 或更高版本。
tex.grad.{cube, acube} 需要 sm_20 或更高版本。
偏移向量操作数需要 sm_30 或更高版本。
深度比较操作数需要 sm_30 或更高版本。
对可选目标谓词的支持需要 sm_60 或更高版本。
示例
// Example of unified mode texturing
// - f4 is required to pad four-element tuple and is ignored
tex.3d.v4.s32.s32 {r1,r2,r3,r4}, [tex_a,{f1,f2,f3,f4}];
// Example of independent mode texturing
tex.1d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a,smpl_x,{f1}];
// Example of 1D texture array, independent texturing mode
tex.a1d.v4.s32.s32 {r1,r2,r3,r4}, [tex_a,smpl_x,{idx,s1}];
// Example of 2D texture array, unified texturing mode
// - f3 is required to pad four-element tuple and is ignored
tex.a2d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a,{idx,f1,f2,f3}];
// Example of cubemap array, unified textureing mode
tex.acube.v4.f32.f32 {r0,r1,r2,r3}, [tex_cuarray,{idx,f1,f2,f3}];
// Example of multi-sample texture, unified texturing mode
tex.2dms.v4.s32.s32 {r0,r1,r2,r3}, [tex_ms,{sample,r6,r7,r8}];
// Example of multi-sample texture, independent texturing mode
tex.2dms.v4.s32.s32 {r0,r1,r2,r3}, [tex_ms, smpl_x,{sample,r6,r7,r8}];
// Example of multi-sample texture array, unified texturing mode
tex.a2dms.v4.s32.s32 {r0,r1,r2,r3}, [tex_ams,{idx,sample,r6,r7}];
// Example of texture returning .f16 data
tex.1d.v4.f16.f32 {h1,h2,h3,h4}, [tex_a,smpl_x,{f1}];
// Example of texture returning .f16x2 data
tex.1d.v2.f16x2.f32 {h1,h2}, [tex_a,smpl_x,{f1}];
// Example of 3d texture array access with tex.grad,unified texturing mode
tex.grad.3d.v4.f32.f32 {%f4,%f5,%f6,%f7},[tex_3d,{%f0,%f0,%f0,%f0}],
{fl0,fl1,fl2,fl3},{fl0,fl1,fl2,fl3};
// Example of cube texture array access with tex.grad,unified texturing mode
tex.grad.cube.v4.f32.f32{%f4,%f5,%f6,%f7},[tex_cube,{%f0,%f0,%f0,%f0}],
{fl0,fl1,fl2,fl3},{fl0,fl1,fl2,fl3};
// Example of 1d texture lookup with offset, unified texturing mode
tex.1d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a, {f1}], {r5};
// Example of 2d texture array lookup with offset, unified texturing mode
tex.a2d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a,{idx,f1,f2}], {f5,f6};
// Example of 2d mipmap texture lookup with offset, unified texturing mode
tex.level.2d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a,{f1,f2}],
flvl, {r7, r8};
// Example of 2d depth texture lookup with compare, unified texturing mode
tex.1d.v4.f32.f32 {f1,f2,f3,f4}, [tex_a, {f1}], f0;
// Example of depth 2d texture array lookup with offset, compare
tex.a2d.v4.s32.f32 {f0,f1,f2,f3}, [tex_a,{idx,f4,f5}], {r5,r6}, f6;
// Example of destination predicate use
tex.3d.v4.s32.s32 {r1,r2,r3,r4}|p, [tex_a,{f1,f2,f3,f4}];
9.7.10.4. 纹理指令: tld4
tld4
执行 4 纹素双线性插值足迹的纹理获取。
语法
tld4.comp.2d.v4.dtype.f32 d[|p], [a, c] {, e} {, f};
tld4.comp.geom.v4.dtype.f32 d[|p], [a, b, c] {, e} {, f}; // explicit sampler
.comp = { .r, .g, .b, .a };
.geom = { .2d, .a2d, .cube, .acube };
.dtype = { .u32, .s32, .f32 };
描述
使用纹理坐标向量获取 4 纹素双线性插值足迹的纹理。该指令从操作数 a 命名的纹理中,在操作数 c 给定的坐标处加载双线性插值足迹到向量目标 d 中。为每个纹素样本获取的纹理分量由 .comp 指定。四个纹素样本按逆时针顺序放置到目标向量 d 中,从左下角开始。
可以指定可选的纹理采样器 `b`。如果未指定采样器,则采样器行为是命名纹理的属性。
可选的目标谓词 p 设置为 True,如果指定坐标的纹理数据驻留在内存中;否则设置为 False。当可选的目标谓词 p 设置为 False 时,加载的数据将全部为零。指定坐标的纹理数据的内存驻留性取决于内核启动前使用驱动程序 API 调用执行的环境设置。有关更多详细信息,包括任何系统/实现特定的行为,请参阅驱动程序 API 文档。
可以为深度纹理指定可选的操作数 f。深度纹理是一种特殊类型的纹理,用于保存来自深度缓冲区的数据。深度缓冲区包含每个像素的深度信息。操作数 f 是 .f32 标量值,用于指定深度纹理的深度比较值。从纹理中获取的每个元素都与操作数 f 中给定的值进行比较。如果比较通过,则结果为 1.0;否则结果为 0.0。这些按元素比较的结果用于过滤。
假定纹理基地址与 16 字节边界对齐,并且坐标向量给出的地址必须自然对齐到访问大小的倍数。如果地址未正确对齐,则结果行为未定义;即,访问可能会通过静默屏蔽低位地址位以实现正确舍入来继续,或者指令可能会出错。
tld4.2d
对于 2D 纹理,操作数 c 将坐标指定为双元素 32 位浮点向量。
可以指定可选的操作数 e。操作数 e 是 .v2.s32 类型的向量,用于指定坐标偏移。偏移在进行纹理获取之前应用于坐标。偏移值范围为 -8 到 +7。
tld4.a2d
纹理数组选择,然后对 2d 纹理执行 tld4 纹理获取。对于 2d 纹理数组,操作数 c 是一个四元素 32 位向量。操作数 c 中的第一个元素被解释为纹理数组的无符号整数索引 (.u32),接下来的两个元素被解释为 2d 纹理的 32 位浮点坐标。第四个元素被忽略。
可以指定可选的操作数 e。操作数 e 是 .v2.s32 类型的向量,用于指定坐标偏移。偏移在进行纹理获取之前应用于坐标。偏移值范围为 -8 到 +7。
tld4.cube
对于立方体贴图纹理,操作数 c 指定一个四元素向量,该向量包含三个浮点坐标 (s, t, r) 和第四个被忽略的填充参数。
立方体贴图纹理是特殊的二维分层纹理,由六个层组成,代表立方体的六个面。立方体贴图中的所有层都具有相同的大小并且是正方形的(即,宽度等于高度)。
坐标 (s, t, r) 投影到立方体的六个面之一上。(s, t, r) 坐标可以被认为是源自立方体中心的direction向量。在三个坐标 (s, t, r) 中,幅度最大的坐标(主轴)选择立方体面。然后,其他两个坐标(次轴)除以主轴的绝对值,以生成新的 (s, t) 坐标对,用于在选定的立方体面中进行查找。
立方体贴图纹理不支持偏移向量操作数 e。
tld4.acube
立方体贴图数组选择,然后对立方体贴图纹理执行 tld4 纹理获取。操作数 c 中的第一个元素被解释为立方体贴图纹理数组的无符号整数索引 (.u32),其余三个元素被解释为浮点立方体贴图坐标 (s, t, r),用于在选定的立方体贴图中进行查找。
立方体贴图纹理数组不支持偏移向量操作数 e。
间接纹理访问
从 PTX ISA 版本 3.1 开始,在统一模式下,对于目标架构 sm_20 或更高版本,支持间接纹理访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .texref 变量的地址。
PTX ISA 注释
在 PTX ISA 版本 2.2 中引入。
PTX ISA 版本 3.1 中引入了间接纹理访问。
tld4.{a2d,cube,acube} 在 PTX ISA 版本 4.3 中引入。
PTX ISA 版本 4.3 中引入了偏移向量操作数。
PTX ISA 版本 4.3 中引入了深度比较操作数。
PTX ISA 版本 7.1 中引入了对可选目标谓词的支持。
目标 ISA 注释
tld4 需要 sm_20 或更高版本。
间接纹理访问需要 sm_20 或更高版本。
tld4.{a2d,cube,acube} 需要 sm_30 或更高版本。
偏移向量操作数需要 sm_30 或更高版本。
深度比较操作数需要 sm_30 或更高版本。
对可选目标谓词的支持需要 sm_60 或更高版本。
示例
//Example of unified mode texturing
tld4.r.2d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a,{f1,f2}];
// Example of independent mode texturing
tld4.r.2d.v4.u32.f32 {u1,u2,u3,u4}, [tex_a,smpl_x,{f1,f2}];
// Example of unified mode texturing using offset
tld4.r.2d.v4.s32.f32 {r1,r2,r3,r4}, [tex_a,{f1,f2}], {r5, r6};
// Example of unified mode texturing using compare
tld4.r.2d.v4.f32.f32 {f1,f2,f3,f4}, [tex_a,{f5,f6}], f7;
// Example of optional destination predicate
tld4.r.2d.v4.f32.f32 {f1,f2,f3,f4}|p, [tex_a,{f5,f6}], f7;
9.7.10.5. 纹理指令: txq
txq
查询纹理和采样器属性。
语法
txq.tquery.b32 d, [a]; // texture attributes
txq.level.tlquery.b32 d, [a], lod; // texture attributes
txq.squery.b32 d, [a]; // sampler attributes
.tquery = { .width, .height, .depth,
.channel_data_type, .channel_order,
.normalized_coords, .array_size,
.num_mipmap_levels, .num_samples};
.tlquery = { .width, .height, .depth };
.squery = { .force_unnormalized_coords, .filter_mode,
.addr_mode_0, addr_mode_1, addr_mode_2 };
描述
查询纹理或采样器的属性。操作数 a 可以是 .texref 或 .samplerref 变量,也可以是 .u64 寄存器。
查询 |
返回 |
|---|---|
|
|
以元素为单位的值 |
|
与源语言的通道数据类型枚举相对应的无符号整数。如果源语言将通道数据类型和通道顺序组合成一个枚举类型,则对于 |
|
与源语言的通道顺序枚举相对应的无符号整数。如果源语言将通道数据类型和通道顺序组合成一个枚举类型,则对于 |
|
|
|
|
|
来自 |
|
|
来自 |
|
对于纹理数组,数组中纹理的数量,否则为 0。 |
|
对于 mipmapped 纹理,细节级别 (LOD) 的数量,否则为 0。 |
|
对于多采样纹理,采样的数量,否则为 0。 |
纹理属性通过向 txq 提供 .texref 参数来查询。在统一模式下,采样器属性也通过 .texref 参数访问,在独立模式下,采样器属性通过单独的 .samplerref 参数访问。
txq.level
txq.level 需要额外的 32 位整数参数 lod,它指定 LOD 并查询指定 LOD 的请求属性。
间接纹理访问
从 PTX ISA 版本 3.1 开始,在统一模式下,对于目标架构 sm_20 或更高版本,支持间接纹理访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .texref 变量的地址。
PTX ISA 注释
在 PTX ISA 版本 1.5 中引入。
通道数据类型和通道顺序查询在 PTX ISA 版本 2.1 中添加。
.force_unnormalized_coords 查询在 PTX ISA 版本 2.2 中添加。
PTX ISA 版本 3.1 中引入了间接纹理访问。
.array_size、.num_mipmap_levels、.num_samples 采样查询在 PTX ISA 版本 4.1 中添加。
txq.level 在 PTX ISA 版本 4.3 中引入。
目标 ISA 注释
所有目标架构均支持。
间接纹理访问需要 sm_20 或更高版本。
查询 mipmap 级别数需要 sm_20 或更高版本。
查询采样数需要 sm_30 或更高版本。
txq.level 需要 sm_30 或更高版本。
示例
txq.width.b32 %r1, [tex_A];
txq.filter_mode.b32 %r1, [tex_A]; // unified mode
txq.addr_mode_0.b32 %r1, [smpl_B]; // independent mode
txq.level.width.b32 %r1, [tex_A], %r_lod;
9.7.10.6. 纹理指令: istypep
istypep
查询寄存器是否指向指定类型的不透明变量。
语法
istypep.type p, a; // result is .pred
.type = { .texref, .samplerref, .surfref };
描述
如果寄存器 a 指向指定类型的不透明变量,则将谓词寄存器 p 写入 1,否则写入 0。目标 p 的类型为 .pred;源地址操作数的类型必须为 .u64。
PTX ISA 注释
在 PTX ISA 版本 4.0 中引入。
目标 ISA 注释
istypep 需要 sm_30 或更高版本。
示例
istypep.texref istex, tptr;
istypep.samplerref issampler, sptr;
istypep.surfref issurface, surfptr;
9.7.11. 表面指令
本节介绍用于访问表面的 PTX 指令。PTX 支持对表面描述符执行以下操作
表面描述符的静态初始化。
模块范围和每个条目范围的表面描述符定义。
查询表面描述符内字段的能力。
这些指令提供对表面内存的访问。
suldsustsuredsuq
9.7.11.1. 表面指令: suld
suld
从表面内存加载。
语法
suld.b.geom{.cop}.vec.dtype.clamp d, [a, b]; // unformatted
.geom = { .1d, .2d, .3d, .a1d, .a2d };
.cop = { .ca, .cg, .cs, .cv }; // cache operation
.vec = { none, .v2, .v4 };
.dtype = { .b8 , .b16, .b32, .b64 };
.clamp = { .trap, .clamp, .zero };
描述
suld.b.{1d,2d,3d}
使用表面坐标向量从表面内存加载。该指令从操作数 a 命名的表面中,在操作数 b 给定的坐标处加载数据到目标 d 中。操作数 a 是 .surfref 变量或 .u64 寄存器。操作数 b 对于 1d 表面是标量或单例元组;对于 2d 表面是双元素向量;对于 3d 表面是四元素向量,其中第四个元素被忽略。坐标元素的类型为 .s32。
suld.b 执行二进制数据的未格式化加载。最低维度坐标表示表面中的字节偏移量,并且不进行缩放,数据传输的大小与目标操作数 d 的大小匹配。
suld.b.{a1d,a2d}
表面层选择,然后从选定的表面加载。该指令首先使用数组坐标向量 b 的第一个元素给出的索引,从操作数 a 命名的表面数组中选择一个表面层。然后,该指令从选定的表面中,在操作数 b 的其余元素给定的坐标处加载数据到目标 d 中。操作数 a 是 .surfref 变量或 .u64 寄存器。操作数 b 是位大小类型的向量或元组,包含表面数组的索引,后跟选定表面内的坐标,如下所示
对于 1d 表面数组,操作数 b 的类型为 .v2.b32。第一个元素被解释为表面数组的无符号整数索引 (.u32),第二个元素被解释为 .s32 类型的 1d 表面坐标。
对于 2d 表面数组,操作数 b 的类型为 .v4.b32。第一个元素被解释为表面数组的无符号整数索引 (.u32),接下来的两个元素被解释为 .s32 类型的 2d 表面坐标。第四个元素被忽略。
假定表面基址与 16 字节边界对齐,并且坐标向量给出的地址必须自然对齐到访问大小的倍数。如果地址未正确对齐,则结果行为未定义;即,访问可能会通过静默地屏蔽低位地址位以实现正确的舍入来继续,或者指令可能会出错。
.clamp 字段指定如何处理越界地址
.trap-
在越界地址上导致执行陷阱
.clamp-
加载最近的表面位置的数据(大小适当)
.zero-
为越界地址加载零
间接表面访问
从 PTX ISA 版本 3.1 开始,对于目标架构 sm_20 或更高版本,支持间接表面访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .surfref 变量的地址。
PTX ISA 注释
suld.b.trap 在 PTX ISA 版本 1.5 中引入。
其他 clamp 修饰符和缓存操作在 PTX ISA 版本 2.0 中引入。
suld.b.3d 和suld.b.{a1d,a2d} 在 PTX ISA 版本 3.0 中引入。
间接表面访问在 PTX ISA 版本 3.1 中引入。
目标 ISA 注释
suld.b 在所有目标架构上都受支持。
sm_1x 目标仅支持 .trap 钳位修饰符。
suld.3d 和suld.{a1d,a2d} 需要 sm_20 或更高版本。
间接表面访问需要 sm_20 或更高版本。
缓存操作需要 sm_20 或更高版本。
示例
suld.b.1d.v4.b32.trap {s1,s2,s3,s4}, [surf_B, {x}];
suld.b.3d.v2.b64.trap {r1,r2}, [surf_A, {x,y,z,w}];
suld.b.a1d.v2.b32 {r0,r1}, [surf_C, {idx,x}];
suld.b.a2d.b32 r0, [surf_D, {idx,x,y,z}]; // z ignored
9.7.11.2. 表面指令: sust
sust
存储到表面内存。
语法
sust.b.{1d,2d,3d}{.cop}.vec.ctype.clamp [a, b], c; // unformatted
sust.p.{1d,2d,3d}.vec.b32.clamp [a, b], c; // formatted
sust.b.{a1d,a2d}{.cop}.vec.ctype.clamp [a, b], c; // unformatted
.cop = { .wb, .cg, .cs, .wt }; // cache operation
.vec = { none, .v2, .v4 };
.ctype = { .b8 , .b16, .b32, .b64 };
.clamp = { .trap, .clamp, .zero };
描述
sust.{1d,2d,3d}
使用表面坐标向量存储到表面内存。该指令将操作数 c 中的数据存储到操作数 a 命名的表面中,位于操作数 b 给定的坐标处。操作数 a 是 .surfref 变量或 .u64 寄存器。操作数 b 对于 1d 表面是标量或单例元组;对于 2d 表面是双元素向量;对于 3d 表面是四元素向量,其中第四个元素被忽略。坐标元素的类型为 .s32。
sust.b 执行二进制数据的非格式化存储。最低维度坐标表示到表面的字节偏移量,并且不进行缩放。数据传输的大小与源操作数 c 的大小相匹配。
sust.p 执行将 32 位数据值的向量格式化存储到表面样本。源向量元素从左到右解释为 R、G、B 和 A 表面分量。这些元素被写入到相应的表面样本分量。在表面样本中未出现的源元素将被忽略。在源向量中未出现的表面样本分量将被写入一个不可预测的值。最低维度坐标表示样本偏移量而不是字节偏移量。
源数据解释基于表面样本格式,如下所示:如果表面格式包含 UNORM、SNORM 或 FLOAT 数据,则假定为 .f32;如果表面格式包含 UINT 数据,则假定为 .u32;如果表面格式包含 SINT 数据,则假定为 .s32。然后,源数据从这种类型转换为表面样本格式。
sust.b.{a1d,a2d}
表面层选择,然后对选定的表面执行非格式化存储。该指令首先使用数组坐标向量 b 的第一个元素给出的索引,从操作数 a 命名的表面数组中选择一个表面层。然后,该指令将操作数 c 中的数据存储到选定表面,坐标由操作数 b 的其余元素给出。操作数 a 是一个 .surfref 变量或 .u64 寄存器。操作数 b 是一个位大小类型向量或元组,包含表面数组的索引,后跟选定表面内的坐标,如下所示
对于 1d 表面数组,操作数
b的类型为.v2.b32。第一个元素被解释为表面数组的无符号整数索引 (.u32),第二个元素被解释为.s32类型的 1d 表面坐标。对于 2d 表面数组,操作数
b的类型为.v4.b32。第一个元素被解释为表面数组的无符号整数索引 (.u32),接下来的两个元素被解释为.s32类型的 2d 表面坐标。第四个元素被忽略。
假定表面基址与 16 字节边界对齐,并且坐标向量给出的地址必须自然对齐到访问大小的倍数。如果地址未正确对齐,则结果行为未定义;即,访问可能会通过静默地屏蔽低位地址位以实现正确的舍入来继续,或者指令可能会出错。
.clamp 字段指定如何处理越界地址
.trap-
在越界地址上导致执行陷阱
.clamp-
在最近的表面位置(大小适当)存储数据
.zero-
丢弃对越界地址的存储
间接表面访问
从 PTX ISA 版本 3.1 开始,对于目标架构 sm_20 或更高版本,支持间接表面访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .surfref 变量的地址。
PTX ISA 注释
sust.b.trap 在 PTX ISA 版本 1.5 中引入。sust.p、附加的 clamp 修饰符和缓存操作在 PTX ISA 版本 2.0 中引入。
sust.b.3d 和 sust.b.{a1d,a2d} 在 PTX ISA 版本 3.0 中引入。
间接表面访问在 PTX ISA 版本 3.1 中引入。
目标 ISA 注释
sust.b 在所有目标架构上都受支持。
sm_1x 目标仅支持 .trap 钳位修饰符。
sust.3d 和 sust.{a1d,a2d} 需要 sm_20 或更高版本。
sust.p 需要 sm_20 或更高版本。
间接表面访问需要 sm_20 或更高版本。
缓存操作需要 sm_20 或更高版本。
示例
sust.p.1d.v4.b32.trap [surf_B, {x}], {f1,f2,f3,f4};
sust.b.3d.v2.b64.trap [surf_A, {x,y,z,w}], {r1,r2};
sust.b.a1d.v2.b64 [surf_C, {idx,x}], {r1,r2};
sust.b.a2d.b32 [surf_D, {idx,x,y,z}], r0; // z ignored
9.7.11.3. 表面指令:sured
sured
减少表面内存。
语法
sured.b.op.geom.ctype.clamp [a,b],c; // byte addressing
sured.p.op.geom.ctype.clamp [a,b],c; // sample addressing
.op = { .add, .min, .max, .and, .or };
.geom = { .1d, .2d, .3d };
.ctype = { .u32, .u64, .s32, .b32, .s64 }; // for sured.b
.ctype = { .b32, .b64 }; // for sured.p
.clamp = { .trap, .clamp, .zero };
描述
使用表面坐标向量减少到表面内存。该指令使用来自操作数 c 的数据对操作数 a 命名的表面在操作数 b 给出的坐标处执行归约操作。操作数 a 是一个 .surfref 变量或 .u64 寄存器。操作数 b 对于 1d 表面是标量或单例元组;对于 2d 表面是双元素向量;对于 3d 表面是四元素向量,其中第四个元素被忽略。坐标元素的类型为 .s32。
sured.b 对 .u32、.s32、.b32、.u64 或 .s64 数据执行非格式化归约。最低维度坐标表示到表面的字节偏移量,并且不进行缩放。操作 add 适用于 .u32、.u64 和 .s32 类型;min 和 max 适用于 .u32、.s32、.u64 和 .s64 类型;操作 and 和 or 适用于 .b32 类型。
sured.p 对样本寻址的数据执行归约。最低维度坐标表示样本偏移量而不是字节偏移量。指令类型 .b64 仅限于 min 和 max 操作。对于类型 .b32,根据表面样本格式,数据被解释为 .u32 或 .s32:如果表面格式包含 UINT 数据,则假定为 .u32;如果表面格式包含 SINT 数据,则假定为 .s32。对于类型 .b64,如果表面格式包含 UINT 数据,则假定为 .u64;如果表面格式包含 SINT 数据,则假定为 .s64。
假定表面基址与 16 字节边界对齐,并且坐标向量给出的地址必须自然对齐到访问大小的倍数。如果地址未正确对齐,则结果行为未定义;即,访问可能会通过静默地屏蔽低位地址位以实现正确的舍入来继续,或者指令可能会出错。
.clamp 字段指定如何处理越界地址
.trap-
在越界地址上导致执行陷阱
.clamp-
在最近的表面位置(大小适当)存储数据
.zero-
丢弃对越界地址的存储
间接表面访问
从 PTX ISA 版本 3.1 开始,对于目标架构 sm_20 或更高版本,支持间接表面访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .surfref 变量的地址。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
间接表面访问在 PTX ISA 版本 3.1 中引入。
带有 .min/.max 操作的 .u64/.s64/.b64 类型在 PTX ISA 版本 8.1 中引入。
目标 ISA 注释
sured 需要 sm_20 或更高版本。
间接表面访问需要 sm_20 或更高版本。
带有 .min/.max 操作的 .u64/.s64/.b64 类型需要 sm_50 或更高版本。
示例
sured.b.add.2d.u32.trap [surf_A, {x,y}], r1;
sured.p.min.1d.u32.trap [surf_B, {x}], r1;
sured.b.max.1d.u64.trap [surf_C, {x}], r1;
sured.p.min.1d.b64.trap [surf_D, {x}], r1;
9.7.11.4. 表面指令:suq
suq
查询表面属性。
语法
suq.query.b32 d, [a];
.query = { .width, .height, .depth,
.channel_data_type, .channel_order,
.array_size, .memory_layout };
描述
查询表面的属性。操作数 a 是一个 .surfref 变量或一个 .u64 寄存器。
查询 |
返回 |
|---|---|
|
|
以元素为单位的值 |
|
无符号整数,对应于源语言的通道数据类型枚举。如果源语言将通道数据类型和通道顺序组合成一个单一的枚举类型,则 |
|
与源语言的通道顺序枚举相对应的无符号整数。如果源语言将通道数据类型和通道顺序组合成一个枚举类型,则对于 |
|
对于表面数组,数组中表面的数量;否则为 0。 |
|
对于具有线性内存布局的表面为 |
间接表面访问
从 PTX ISA 版本 3.1 开始,对于目标架构 sm_20 或更高版本,支持间接表面访问。在间接访问中,操作数 a 是一个 .u64 寄存器,保存 .surfref 变量的地址。
PTX ISA 注释
在 PTX ISA 版本 1.5 中引入。
通道数据类型和通道顺序查询在 PTX ISA 版本 2.1 中添加。
间接表面访问在 PTX ISA 版本 3.1 中引入。
.array_size 查询在 PTX ISA 版本 4.1 中添加。
.memory_layout 查询在 PTX ISA 版本 4.2 中添加。
目标 ISA 注释
所有目标架构均支持。
间接表面访问需要 sm_20 或更高版本。
示例
suq.width.b32 %r1, [surf_A];
9.7.12. 控制流指令
以下 PTX 指令和语法用于控制 PTX 程序中的执行
{}@bracallretexit
9.7.12.1. 控制流指令:{}
{}
指令分组。
语法
{ instructionList }
描述
花括号创建一组指令,主要用于定义函数体。花括号还提供了一种机制来确定变量的作用域:在作用域内声明的任何变量在作用域外都不可用。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
{ add.s32 a,b,c; mov.s32 d,a; }
9.7.12.2. 控制流指令:@
@
谓词执行。
语法
@{!}p instruction;
描述
为具有 guard 谓词 True 的线程执行指令或指令块。具有 False guard 谓词的线程不执行任何操作。
语义
如果 {!}p 则执行指令
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
setp.eq.f32 p,y,0; // is y zero?
@!p div.f32 ratio,x,y // avoid division by zero
@q bra L23; // conditional branch
9.7.12.3. 控制流指令:bra
bra
分支到目标并在那里继续执行。
语法
@p bra{.uni} tgt; // tgt is a label
bra{.uni} tgt; // unconditional branch
描述
在目标处继续执行。条件分支通过使用 guard 谓词来指定。分支目标必须是一个标签。
bra.uni 保证是非发散的,即 warp 中当前正在执行此指令的所有活动线程对于 guard 谓词和分支目标都具有相同的值。
语义
if (p) {
pc = tgt;
}
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
在 PTX ISA 版本 2.1 中引入的未实现的间接分支已从规范中移除。
目标 ISA 注释
所有目标架构均支持。
示例
bra.uni L_exit; // uniform unconditional jump
@q bra L23; // conditional branch
9.7.12.4. 控制流指令:brx.idx
brx.idx
分支到从潜在分支目标列表索引的标签。
语法
@p brx.idx{.uni} index, tlist;
brx.idx{.uni} index, tlist;
描述
索引到可能的目的地标签列表,并从选定的标签继续执行。条件分支通过使用 guard 谓词来指定。
brx.idx.uni 保证分支是非发散的,即 warp 中当前正在执行此指令的所有活动线程对于 guard 谓词和 index 参数都具有相同的值。
index 操作数是一个 .u32 寄存器。tlist 操作数必须是 .branchtargets 指令的标签。它使用 index 作为基于零的序列访问。如果 index 的值大于或等于 tlist 的长度,则行为未定义。
.branchtargets 指令必须在使用前在本地函数作用域中定义。它必须引用当前函数内的标签。
语义
if (p) {
if (index < length(tlist)) {
pc = tlist[index];
} else {
pc = undefined;
}
}
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
目标 ISA 注释
需要 sm_30 或更高版本。
示例
.function foo () {
.reg .u32 %r0;
...
L1:
...
L2:
...
L3:
...
ts: .branchtargets L1, L2, L3;
@p brx.idx %r0, ts;
...
}
9.7.12.5. 控制流指令:call
call
调用函数,记录返回位置。
语法
// direct call to named function, func is a symbol
call{.uni} (ret-param), func, (param-list);
call{.uni} func, (param-list);
call{.uni} func;
// indirect call via pointer, with full list of call targets
call{.uni} (ret-param), fptr, (param-list), flist;
call{.uni} fptr, (param-list), flist;
call{.uni} fptr, flist;
// indirect call via pointer, with no knowledge of call targets
call{.uni} (ret-param), fptr, (param-list), fproto;
call{.uni} fptr, (param-list), fproto;
call{.uni} fptr, fproto;
描述
call 指令存储下一条指令的地址,以便在执行 ret 指令后可以从该点恢复执行。除非存在 .uni 后缀,否则 call 被假定为发散的。.uni 后缀表示 call 保证是非发散的,即 warp 中当前正在执行此指令的所有活动线程对于 guard 谓词和 call 目标都具有相同的值。
对于直接调用,被调用位置 func 必须是符号函数名;对于间接调用,被调用位置 fptr 必须是保存在寄存器中的函数地址。输入参数和返回值是可选的。参数可以是寄存器、立即常量或 .param 空间中的变量。参数是按值传递的。
间接调用需要一个额外的操作数,flist 或 fproto,分别用于传递潜在 call 目标的列表或所有 call 目标的通用函数原型。在第一种情况下,flist 给出了潜在 call 目标的完整列表,优化后端可以自由地优化调用约定。在第二种情况下,当潜在 call 目标的完整列表可能未知时,给出通用函数原型,并且 call 必须遵守 ABI 的调用约定。
flist 操作数可以是初始化为函数名列表的数组名称;或与 .calltargets 指令关联的标签,该指令声明了潜在 call 目标的列表。在这两种情况下,fptr 寄存器都保存了调用表或 .calltargets 列表中列出的函数的地址,并且 call 操作数根据 flist 指示的函数的类型签名进行类型检查。
fproto 操作数是与 .callprototype 指令关联的标签名称。当潜在目标的完整列表未知时,使用此操作数。call 操作数根据原型进行类型检查,并且代码生成将遵循 ABI 调用约定。如果调用了与原型不匹配的函数,则行为未定义。
调用表可以在模块作用域或本地作用域中声明,可以在常量或全局状态空间中声明。.calltargets 和 .callprototype 指令必须在函数体中声明。所有函数都必须在 call 表初始化器或 .calltargets 指令中引用之前声明。
PTX ISA 注释
直接 call 在 PTX ISA 版本 1.0 中引入。间接 call 在 PTX ISA 版本 2.1 中引入。
目标 ISA 注释
直接 call 在所有目标架构上都受支持。间接 call 需要 sm_20 或更高版本。
示例
// examples of direct call
call init; // call function 'init'
call.uni g, (a); // call function 'g' with parameter 'a'
@p call (d), h, (a, b); // return value into register d
// call-via-pointer using jump table
.func (.reg .u32 rv) foo (.reg .u32 a, .reg .u32 b) ...
.func (.reg .u32 rv) bar (.reg .u32 a, .reg .u32 b) ...
.func (.reg .u32 rv) baz (.reg .u32 a, .reg .u32 b) ...
.global .u32 jmptbl[5] = { foo, bar, baz };
...
@p ld.global.u32 %r0, [jmptbl+4];
@p ld.global.u32 %r0, [jmptbl+8];
call (retval), %r0, (x, y), jmptbl;
// call-via-pointer using .calltargets directive
.func (.reg .u32 rv) foo (.reg .u32 a, .reg .u32 b) ...
.func (.reg .u32 rv) bar (.reg .u32 a, .reg .u32 b) ...
.func (.reg .u32 rv) baz (.reg .u32 a, .reg .u32 b) ...
...
@p mov.u32 %r0, foo;
@q mov.u32 %r0, baz;
Ftgt: .calltargets foo, bar, baz;
call (retval), %r0, (x, y), Ftgt;
// call-via-pointer using .callprototype directive
.func dispatch (.reg .u32 fptr, .reg .u32 idx)
{
...
Fproto: .callprototype _ (.param .u32 _, .param .u32 _);
call %fptr, (x, y), Fproto;
...
9.7.12.6. 控制流指令:ret
ret
从函数返回到调用后的指令。
语法
ret{.uni};
描述
将执行返回到调用者的环境。发散返回会暂停线程,直到所有线程都准备好返回到调用者。这允许多个发散 ret 指令。
除非存在 .uni 后缀,否则 ret 被假定为发散的,表示返回保证是非发散的。
从函数返回的任何值都应在执行 ret 指令之前移动到返回参数变量中。
在顶层入口例程中执行的返回指令将终止线程执行。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
ret;
@p ret;
9.7.12.7. 控制流指令:exit
exit
终止一个线程。
语法
exit;
描述
结束线程的执行。
当线程退出时,会检查等待所有线程的屏障,以查看退出的线程是否是唯一尚未到达 CTA 中所有线程的屏障{.cta} 或集群中所有线程的 barrier.cluster 的线程。如果退出的线程阻碍了屏障,则屏障将被释放。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
exit;
@p exit;
9.7.13. 并行同步和通信指令
这些指令是
bar{.cta},barrier{.cta}bar.warp.syncbarrier.clustermembaratomredred.asyncvotematch.syncactivemaskredux.syncgriddepcontrolelect.syncmbarrier.initmbarrier.invalmbarrier.arrivembarrier.arrive_dropmbarrier.test_waitmbarrier.try_waitmbarrier.pending_countcp.async.mbarrier.arrivetensormap.cp_fenceproxyclusterlaunchcontrol.try_cancelclusterlaunchcontrol.query_cancel
9.7.13.1. 并行同步和通信指令:bar,barrier
bar{.cta}, barrier{.cta}
屏障同步。
语法
barrier{.cta}.sync{.aligned} a{, b};
barrier{.cta}.arrive{.aligned} a, b;
barrier{.cta}.red.popc{.aligned}.u32 d, a{, b}, {!}c;
barrier{.cta}.red.op{.aligned}.pred p, a{, b}, {!}c;
bar{.cta}.sync a{, b};
bar{.cta}.arrive a, b;
bar{.cta}.red.popc.u32 d, a{, b}, {!}c;
bar{.cta}.red.op.pred p, a{, b}, {!}c;
.op = { .and, .or };
描述
在 CTA 内执行屏障同步和通信。每个 CTA 实例都有十六个屏障,编号为 0..15。
CTA 内的线程可以使用 barrier{.cta} 指令进行同步和通信。
操作数 a、b 和 d 的类型为 .u32;操作数 p 和 c 是谓词。源操作数 a 将逻辑屏障资源指定为立即常量或寄存器,其值为 0 到 15。操作数 b 指定参与屏障的线程数。如果未指定线程计数,则 CTA 中的所有线程都参与屏障。当指定线程计数时,该值必须是 warp 大小的倍数。请注意,barrier{.cta}.arrive 需要非零线程计数。
根据操作数 b,指定数量的线程(warp 大小的倍数)或 CTA 中的所有线程都参与 barrier{.cta} 指令。barrier{.cta} 指令表示执行线程到达指定的屏障。
barrier{.cta} 指令导致执行线程等待来自其 warp 的所有非退出线程,并标记 warp 到达屏障。barrier{.cta}.red 和 barrier{.cta}.sync 指令除了发出到达屏障的信号外,还导致执行线程等待参与屏障的所有其他 warp 的非退出线程到达。barrier{.cta}.arrive 不会导致执行线程等待其他参与 warp 的线程。
当屏障完成时,等待的线程将立即重新启动,并且屏障将被重新初始化,以便可以立即重用。
barrier{.cta}.sync 或 barrier{.cta}.red 或 barrier{.cta}.arrive 指令保证当屏障完成时,此线程请求的先前内存访问相对于所有参与屏障的线程都已执行。barrier{.cta}.sync 和 barrier{.cta}.red 指令进一步保证在此线程完成屏障之前不会请求新的内存访问。
当读取的值已从内存传输并且不能被参与屏障的另一个线程修改时,内存读取(例如,通过 ld 或 atom)已执行。当写入的值已对参与屏障的其他线程可见时,内存写入(例如,通过 st、red 或 atom)已执行,也就是说,当先前的值不再可读时。
barrier{.cta}.red 在线程之间执行归约操作。来自 CTA 中所有线程的 c 谓词(或其补码)使用指定的归约运算符进行组合。一旦达到屏障计数,最终值将被写入等待在屏障处的所有线程中的目标寄存器。
barrier{.cta}.red 的归约操作是 population-count (.popc)、all-threads-True (.and) 和 any-thread-True (.or)。.popc 的结果是具有 True 谓词的线程数,而 .and 和 .or 表示是否所有线程都具有 True 谓词,或者是否有任何线程具有 True 谓词。
指令 barrier{.cta} 具有可选的 .aligned 修饰符。当指定时,它表示 CTA 中的所有线程将执行相同的 barrier{.cta} 指令。在条件执行的代码中,只有当已知 CTA 中的所有线程都以相同方式评估条件时,才应使用对齐的 barrier{.cta} 指令,否则行为未定义。
不同的 warp 可以使用相同的屏障名称和线程计数来执行不同形式的 barrier{.cta} 指令。一个示例混合了 barrier{.cta}.sync 和 barrier{.cta}.arrive 来实现生产者/消费者模型。生产者线程执行 barrier{.cta}.arrive 以宣告它们到达屏障并继续执行而无需延迟以生成下一个值,而消费者线程执行 barrier{.cta}.sync 以等待资源被生产。然后角色反转,使用不同的屏障,生产者线程执行 barrier{.cta}.sync 以等待资源被消费,而消费者线程使用 barrier{.cta}.arrive 宣告资源已被消费。必须注意防止 warp 执行比预期更多的 barrier{.cta} 指令(barrier{.cta}.arrive 之后是对同一屏障的任何其他 barrier{.cta} 指令),在屏障重置之前。barrier{.cta}.red 不应与使用相同活动屏障的 barrier{.cta}.sync 或 barrier{.cta}.arrive 混合使用。在这种情况下,执行是不可预测的。
可选的 .cta 限定符仅表示屏障的 CTA 级适用性,它不会更改指令的语义。
bar{.cta}.sync 等效于 barrier{.cta}.sync.aligned。bar{.cta}.arrive 等效于 barrier{.cta}.arrive.aligned。bar{.cta}.red 等效于 barrier{.cta}.red.aligned。
注意
对于 .target sm_6x 或更低版本,
不带
.aligned修饰符的barrier{.cta}指令等同于.aligned变体,并且具有与.aligned变体相同的限制。线程束中的所有线程(已退出的线程除外)必须以收敛方式执行
barrier{.cta}指令。
PTX ISA 注释
PTX ISA 1.0 版本中引入了不带线程计数的 bar.sync。
PTX ISA 2.0 版本中引入了寄存器操作数、线程计数和 bar.{arrive,red}。
PTX ISA 6.0 版本中引入了 barrier 指令。
PTX ISA 7.8 版本中引入了 .cta 限定符。
目标 ISA 注释
寄存器操作数、线程计数和 bar{.cta}.{arrive,red} 需要 sm_20 或更高版本。
对于 sm_1x 目标,仅支持带有立即数屏障号的 bar{.cta}.sync。
barrier{.cta} 指令需要 sm_30 或更高版本。
示例
// Use bar.sync to arrive at a pre-computed barrier number and
// wait for all threads in CTA to also arrive:
st.shared [r0],r1; // write my result to shared memory
bar.cta.sync 1; // arrive, wait for others to arrive
ld.shared r2,[r3]; // use shared results from other threads
// Use bar.sync to arrive at a pre-computed barrier number and
// wait for fixed number of cooperating threads to arrive:
#define CNT1 (8*12) // Number of cooperating threads
st.shared [r0],r1; // write my result to shared memory
bar.cta.sync 1, CNT1; // arrive, wait for others to arrive
ld.shared r2,[r3]; // use shared results from other threads
// Use bar.red.and to compare results across the entire CTA:
setp.eq.u32 p,r1,r2; // p is True if r1==r2
bar.cta.red.and.pred r3,1,p; // r3=AND(p) forall threads in CTA
// Use bar.red.popc to compute the size of a group of threads
// that have a specific condition True:
setp.eq.u32 p,r1,r2; // p is True if r1==r2
bar.cta.red.popc.u32 r3,1,p; // r3=SUM(p) forall threads in CTA
// Examples of barrier.cta.sync
st.shared [r0],r1;
barrier.cta.sync 0;
ld.shared r1, [r0];
/* Producer/consumer model. The producer deposits a value in
* shared memory, signals that it is complete but does not wait
* using bar.arrive, and begins fetching more data from memory.
* Once the data returns from memory, the producer must wait
* until the consumer signals that it has read the value from
* the shared memory location. In the meantime, a consumer
* thread waits until the data is stored by the producer, reads
* it, and then signals that it is done (without waiting).
*/
// Producer code places produced value in shared memory.
st.shared [r0],r1;
bar.arrive 0,64;
ld.global r1,[r2];
bar.sync 1,64;
...
// Consumer code, reads value from shared memory
bar.sync 0,64;
ld.shared r1,[r0];
bar.arrive 1,64;
...
9.7.13.2. 并行同步和通信指令:bar.warp.sync
bar.warp.sync
线程束中线程的屏障同步。
语法
bar.warp.sync membermask;
描述
bar.warp.sync 将导致执行线程等待,直到与 membermask 对应的所有线程都执行了具有相同 membermask 值的 bar.warp.sync,然后才能恢复执行。
操作数 membermask 指定一个 32 位整数,该整数是一个掩码,指示参与屏障的线程,其中位位置对应于线程的 laneid。
如果执行线程不在 membermask 中,则 bar.warp.sync 的行为是未定义的。
bar.warp.sync 还保证参与屏障的线程之间的内存排序。因此,希望通过内存进行通信的线程束内的线程可以存储到内存,执行 bar.warp.sync,然后安全地读取线程束中其他线程存储的值。
注意
对于 .target sm_6x 或更低版本,membermask 中的所有线程必须以收敛方式执行相同的 bar.warp.sync 指令,并且当执行 bar.warp.sync 指令时,只有属于某些 membermask 的线程才能处于活动状态。否则,行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
目标 ISA 注释
需要 sm_30 或更高版本。
示例
st.shared.u32 [r0],r1; // write my result to shared memory
bar.warp.sync 0xffffffff; // arrive, wait for others to arrive
ld.shared.u32 r2,[r3]; // read results written by other threads
9.7.13.3. 并行同步和通信指令:barrier.cluster
barrier.cluster
集群内的屏障同步。
语法
barrier.cluster.arrive{.sem}{.aligned};
barrier.cluster.wait{.acquire}{.aligned};
.sem = {.release, .relaxed}
描述
在集群内执行屏障同步和通信。
集群内的线程可以使用 barrier.cluster 指令进行同步和通信。
barrier.cluster.arrive 指令标记线程束到达屏障,而不会导致执行线程等待其他参与线程束的线程。
barrier.cluster.wait 指令导致执行线程等待集群中所有未退出的线程执行 barrier.cluster.arrive。
此外,barrier.cluster 指令还会导致执行线程等待其线程束中的所有未退出的线程。
当所有已执行 barrier.cluster.arrive 的未退出线程都已执行 barrier.cluster.wait 时,屏障完成并重新初始化,以便可以立即重复使用。每个线程在屏障完成之前必须仅到达屏障一次。
barrier.cluster.wait 指令保证,当它完成执行时,在程序顺序中,在先前的 barrier.cluster.arrive 之前由集群中所有线程请求的内存访问(异步操作除外)都已完成,并且对执行线程可见。
对于执行线程在程序顺序中,在 barrier.cluster.arrive 之后和 barrier.cluster.wait 之前请求的内存访问,没有内存排序和可见性保证。
barrier.cluster.arrive 上的可选 .relaxed 限定符指定不为在 barrier.cluster.arrive 之前执行的内存访问提供内存排序和可见性保证。
指令 barrier.cluster.arrive 和 barrier.cluster.wait 上的可选 .sem 和 .acquire 限定符指定了内存一致性模型中描述的内存同步。如果 barrier.cluster.arrive 缺少可选的 .sem 限定符,则默认假定为 .release。如果 barrier.cluster.wait 缺少可选的 .acquire 限定符,则默认假定为 .acquire。
可选的 .aligned 限定符指示线程束中的所有线程都必须执行相同的 barrier.cluster 指令。在有条件执行的代码中,只有当已知线程束中的所有线程都以相同方式评估条件时,才应使用对齐的 barrier.cluster 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
PTX ISA 8.0 版本中引入了对 .acquire、.relaxed、.release 限定符的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
// use of arrive followed by wait
ld.shared::cluster.u32 r0, [addr];
barrier.cluster.arrive.aligned;
...
barrier.cluster.wait.aligned;
st.shared::cluster.u32 [addr], r1;
// use memory fence prior to arrive for relaxed barrier
@cta0 ld.shared::cluster.u32 r0, [addr];
fence.cluster.acq_rel;
barrier.cluster.arrive.relaxed.aligned;
...
barrier.cluster.wait.aligned;
@cta1 st.shared::cluster.u32 [addr], r1;
9.7.13.4. 并行同步和通信指令:membar/fence
membar/fence
强制执行内存操作的排序。
语法
// Thread fence:
fence{.sem}.scope;
// Thread fence (uni-directional):
fence.acquire.sync_restrict::shared::cluster.cluster;
fence.release.sync_restrict::shared::cta.cluster;
// Operation fence (uni-directional):
fence.op_restrict.release.cluster;
// Proxy fence (bi-directional):
fence.proxy.proxykind;
// Proxy fence (uni-directional):
fence.proxy.to_proxykind::from_proxykind.release.scope;
fence.proxy.to_proxykind::from_proxykind.acquire.scope [addr], size;
fence.proxy.async::generic.acquire.sync_restrict::shared::cluster.cluster;
fence.proxy.async::generic.release.sync_restrict::shared::cta.cluster;
// Old style membar:
membar.level;
membar.proxy.proxykind;
.sem = { .sc, .acq_rel, .acquire, .release };
.scope = { .cta, .cluster, .gpu, .sys };
.level = { .cta, .gl, .sys };
.proxykind = { .alias, .async, .async.global, .async.shared::{cta, cluster} };
.op_restrict = { .mbarrier_init };
.to_proxykind::from_proxykind = {.tensormap::generic};
描述
membar 指令保证,此线程请求的先前内存访问(ld、st、atom 和 red 指令)在指定的 level 执行,然后才执行此线程在 membar 指令之后请求的后续内存操作。level 限定符指定可以观察此操作排序效果的线程集。
当从内存传输读取的值并且不能被指示级别上的另一个线程修改时,内存读取(例如,通过 ld 或 atom)已经执行。当写入的值对指定级别的其他线程可见时,内存写入(例如,通过 st、red 或 atom)已经执行,也就是说,当不再可以读取先前的值时。
fence 指令在内存一致性模型中描述的此线程请求的内存访问(ld、st、atom 和 red 指令)之间建立排序。scope 限定符指定可以观察此操作排序效果的线程集。
fence.acq_rel 是一个轻量级 fence,足以在大多数程序中进行内存同步。fence.acq_rel 的实例在与内存一致性模型中的 acquire 和 release 模式中描述的其他内存操作结合使用时进行同步。如果缺少可选的 .sem 限定符,则默认假定为 .acq_rel。
fence.sc 是一个较慢的 fence,当在足够的位置使用时,可以恢复*顺序一致性*,但会牺牲性能。具有足够 scope 的 fence.sc 实例始终通过形成每个 scope 的总顺序(在运行时确定)来进行同步。此总顺序可以通过程序中的其他同步进一步约束。
限定符 .op_restrict 和 .sync_restrict 限制了 fence 指令提供内存排序保证的内存操作类别。当 .op_restrict 为 .mbarrier_init 时,fence 的同步效果仅适用于同一线程在 .shared::cta 状态空间中的 *mbarrier 对象* 上执行的先前 mbarrier.init 操作。当 .sync_restrict 为 .sync_restrict::shared::cta 时,.sem 必须为 .release,并且 fence 的效果仅适用于在 .shared::cta 状态空间中的对象上执行的操作。同样,当 .sync_restrict 为 .sync_restrict::shared::cluster 时,.sem 必须为 .acquire,并且 fence 的效果仅适用于在 .shared::cluster 状态空间中的对象上执行的操作。当存在 .sync_restrict::shared::cta 或 .sync_restrict::shared::cluster 时,.scope 必须指定为 .cluster。
地址操作数 addr 和操作数 size 一起指定内存范围 [addr, addr+size-1],在该范围内,将提供跨代理的内存访问的排序保证。size 操作数唯一支持的值是 128,它必须是常量整数文字。通用寻址是无条件使用的,并且操作数 addr 指定的地址必须位于 .global 状态空间内。否则,行为是未定义的。
在 sm_70 及更高版本上,membar 是 fence.sc1 的同义词,并且 membar 级别 cta、gl 和 sys 分别与 fence scope cta、gpu 和 sys 同义。
membar.proxy 和 fence.proxy 指令在可能通过不同*代理*发生的内存访问之间建立排序。
从 *from-proxykind* 到 *to-proxykind* 的*单向*代理排序在通过 *from-proxykind* 执行的先前内存访问和通过 *to-proxykind* 执行的后续内存访问之间建立排序。
两个代理类型之间的*双向*代理排序建立两个*单向*代理排序:一个从第一个代理类型到第二个代理类型,另一个从第二个代理类型到第一个代理类型。
.proxykind 限定符指示在通用代理和 .proxykind 指定的代理之间完成的内存访问之间建立的*双向*代理排序。
.proxykind 限定符的值 .alias 指的是使用虚拟别名地址对同一内存位置执行的内存访问。.proxykind 限定符的值 .async 指定在异步代理和通用代理之间建立内存排序。内存排序仅限于在指定状态空间中的对象上执行的操作。如果未指定状态空间,则内存排序适用于所有状态空间。
.release 代理 fence 可以形成一个 release 序列,该序列与包含 .acquire 代理 fence 的 acquire 序列同步。.to_proxykind 和 .from_proxykind 限定符指示建立的*单向*代理排序。
在 sm_70 及更高版本上,membar.proxy 是 fence.proxy 的同义词。
1 sm_70 引入的 fence.sc 的语义是 membar 语义的超集,并且两者是兼容的;在 sm_70 或更高版本的架构上执行时,membar 获得 fence.sc 的完整语义。
PTX ISA 注释
PTX ISA 1.4 版本中引入了 membar.{cta,gl}。
PTX ISA 2.0 版本中引入了 membar.sys。
PTX ISA 6.0 版本中引入了 fence。
PTX ISA 7.5 版本中引入了 membar.proxy 和 fence.proxy。
PTX ISA 7.8 版本中引入了 .cluster scope 限定符。
PTX ISA 8.0 版本中引入了 .op_restrict 限定符。
PTX ISA 8.0 版本中引入了 fence.proxy.async。
PTX ISA 8.3 版本中引入了 .to_proxykind::from_proxykind 限定符。
PTX ISA 8.6 版本中引入了 fence 指令的 .acquire 和 .release 限定符。
PTX ISA 8.6 版本中引入了 .sync_restrict 限定符。
目标 ISA 注释
所有目标架构都支持 membar.{cta,gl}。
membar.sys 需要 sm_20 或更高版本。
fence 需要 sm_70 或更高版本。
membar.proxy 需要 sm_60 或更高版本。
fence.proxy 需要 sm_70 或更高版本。
.cluster scope 限定符需要 sm_90 或更高版本。
.op_restrict 限定符需要 sm_90 或更高版本。
fence.proxy.async 需要 sm_90 或更高版本。
.to_proxykind::from_proxykind 限定符需要 sm_90 或更高版本。
fence 指令的 .acquire 和 .release 限定符需要 sm_90 或更高版本。
.sync_restrict 限定符需要 sm_90 或更高版本。
示例
membar.gl;
membar.cta;
membar.sys;
fence.sc.cta;
fence.sc.cluster;
fence.proxy.alias;
membar.proxy.alias;
fence.mbarrier_init.release.cluster;
fence.proxy.async;
fence.proxy.async.shared::cta;
fence.proxy.async.shared::cluster;
fence.proxy.async.global;
tensormap.replace.tile.global_address.global.b1024.b64 [gbl], new_addr;
fence.proxy.tensormap::generic.release.gpu;
cvta.global.u64 tmap, gbl;
fence.proxy.tensormap::generic.acquire.gpu [tmap], 128;
cp.async.bulk.tensor.1d.shared::cluster.global.tile [addr0], [tmap, {tc0}], [mbar0];
// Acquire remote barrier state via async proxy.
barrier.cluster.wait.acquire;
fence.proxy.async::generic.acquire.sync_restrict::shared::cluster.cluster;
// Release local barrier state via async proxy.
mbarrier.init [bar];
fence.mbarrier_init.release.cluster;
fence.proxy.async::generic.release.sync_restrict::shared::cta.cluster;
barrier.cluster.arrive.relaxed;
// Acquire local shared memory via generic proxy.
mbarrier.try_wait.relaxed.cluster.shared::cta.b64 complete, [addr], parity;
fence.acquire.sync_restrict::shared::cluster.cluster;
// Release local shared memory via generic proxy.
fence.release.sync_restrict::shared::cta.cluster;
mbarrier.arrive.relaxed.cluster.shared::cluster.b64 state, [bar];
9.7.13.5. 并行同步和通信指令:atom
atom
用于线程间通信的原子归约操作。
语法
标量类型的原子操作
atom{.sem}{.scope}{.space}.op{.level::cache_hint}.type d, [a], b{, cache-policy};
atom{.sem}{.scope}{.space}.op.type d, [a], b, c;
atom{.sem}{.scope}{.space}.cas.b16 d, [a], b, c;
atom{.sem}{.scope}{.space}.cas.b128 d, [a], b, c {, cache-policy};
atom{.sem}{.scope}{.space}.exch{.level::cache_hint}.b128 d, [a], b {, cache-policy};
atom{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.f16 d, [a], b{, cache-policy};
atom{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.f16x2 d, [a], b{, cache-policy};
atom{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.bf16 d, [a], b{, cache-policy};
atom{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.bf16x2 d, [a], b{, cache-policy};
.space = { .global, .shared{::cta, ::cluster} };
.sem = { .relaxed, .acquire, .release, .acq_rel };
.scope = { .cta, .cluster, .gpu, .sys };
.op = { .and, .or, .xor,
.cas, .exch,
.add, .inc, .dec,
.min, .max };
.level::cache_hint = { .L2::cache_hint };
.type = { .b32, .b64, .u32, .u64, .s32, .s64, .f32, .f64 };
向量类型的原子操作
atom{.sem}{.scope}{.global}.add{.level::cache_hint}.vec_32_bit.f32 d, [a], b{, cache-policy};
atom{.sem}{.scope}{.global}.op.noftz{.level::cache_hint}.vec_16_bit.half_word_type d, [a], b{, cache-policy};
atom{.sem}{.scope}{.global}.op.noftz{.level::cache_hint}.vec_32_bit.packed_type d, [a], b{, cache-policy};
.sem = { .relaxed, .acquire, .release, .acq_rel };
.scope = { .cta, .cluster, .gpu, .sys };
.op = { .add, .min, .max };
.half_word_type = { .f16, .bf16 };
.packed_type = { .f16x2, .bf16x2 };
.vec_16_bit = { .v2, .v4, .v8 }
.vec_32_bit = { .v2, .v4 };
.level::cache_hint = { .L2::cache_hint }
描述
原子地将位置 a 的原始值加载到目标寄存器 d 中,使用操作数 b 和位置 a 中的值执行归约操作,并将指定操作的结果存储在位置 a,覆盖原始值。操作数 a 指定指定状态空间中的位置。如果未给出状态空间,请使用通用寻址执行内存访问。标量类型的 atom 只能与 .global 和 .shared 空间以及通用寻址一起使用,其中地址指向 .global 或 .shared 空间。向量类型的 atom 只能与 .global 空间以及通用寻址一起使用,其中地址指向 .global 空间。
对于向量类型的 atom,操作数 d 和 b 是用花括号括起来的向量表达式,其大小等于向量限定符的大小。
如果 .shared 状态空间未指定子限定符,则默认情况下假定为 ::cta。
可选的 .sem 限定符指定了内存一致性模型中描述的内存同步效果。如果缺少 .sem 限定符,则默认假定为 .relaxed。
可选的 .scope 限定符指定可以直接观察此操作的内存同步效果的线程集,如内存一致性模型中所述。如果缺少 .scope 限定符,则默认假定为 .gpu scope。
对于向量类型的 atom,下表描述了向量限定符和类型的支持组合,以及在这些组合上支持的原子操作
向量限定符 |
类型 |
||
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不支持 |
不支持 |
只有当每个操作都指定一个包含另一个操作的 scope 时,两个原子操作(atom 或 red)才彼此原子地执行。当不满足此条件时,每个操作都观察到另一个操作的执行,就好像它被拆分为读取,然后是依赖写入一样。
打包类型或向量类型上的 atom 指令访问内存中的相邻标量元素。在这种情况下,原子性分别针对每个单独的标量元素得到保证;不保证整个 atom 作为单个访问是原子的。
对于 sm_6x 和更早版本的架构,.shared 状态空间上的 atom 操作不保证相对于同一地址的普通存储指令的原子性。程序员有责任保证使用共享内存原子指令的程序的正确性,例如,通过在普通存储和对公共地址的原子操作之间插入屏障,或者通过使用 atom.exch 存储到其他原子操作访问的位置。
操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
位大小操作是 .and、.or、.xor、.cas(比较和交换)和 .exch(交换)。
整数操作是 .add、.inc、.dec、.min、.max。.inc 和 .dec 操作返回 [0..b] 范围内的结果。
浮点运算 .add 运算舍入到最接近的偶数。atom.add.f32 在全局内存上的当前实现将次正规输入和结果刷新为保留符号的零;而共享内存上的 atom.add.f32 支持次正规输入和结果,并且不会将它们刷新为零。
atom.add.f16、atom.add.f16x2、atom.add.bf16 和 atom.add.bf16x2 操作需要 .noftz 限定符;它保留次正规输入和结果,并且不会将它们刷新为零。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
限定符 .level::cache_hint 仅支持 .global 状态空间和通用寻址,其中地址指向 .global 状态空间。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
语义
atomic {
d = *a;
*a = (operation == cas) ? operation(*a, b, c)
: operation(*a, b);
}
where
inc(r, s) = (r >= s) ? 0 : r+1;
dec(r, s) = (r==0 || r > s) ? s : r-1;
exch(r, s) = s;
cas(r,s,t) = (r == s) ? t : r;
注释
可以通过使用*位桶*目标操作数 _ 来指定简单归约。
PTX ISA 注释
PTX ISA 1.1 版本中引入了 32 位 atom.global。
PTX ISA 1.2 版本中引入了 atom.shared 和 64 位 atom.global.{add,cas,exch}。
PTX ISA 2.0 版本中引入了 atom.add.f32 和 64 位 atom.shared.{add,cas,exch}。
PTX ISA 3.1 版本中引入了 64 位 atom.{and,or,xor,min,max}。
PTX ISA 5.0 版本中引入了 atom.add.f64。
PTX ISA 5.0 版本中引入了 .scope 限定符。
PTX ISA 6.0 版本中引入了 .sem 限定符。
PTX ISA 6.2 版本中引入了 atom.add.noftz.f16x2。
PTX ISA 6.3 版本中引入了 atom.add.noftz.f16 和 atom.cas.b16。
PTX ISA 6.3 版本中澄清了 atom.f16x2 的逐元素原子性,并追溯到 PTX ISA 6.2 版本。
PTX ISA 7.4 版本中引入了对 .level::cache_hint 限定符的支持。
PTX ISA 7.8 版本中引入了 atom.add.noftz.bf16 和 atom.add.noftz.bf16x2。
对 .cluster 范围限定符的支持在 PTX ISA 版本 7.8 中引入。
对 ::cta 和 ::cluster 子限定符的支持在 PTX ISA 版本 7.8 中引入。
PTX ISA 8.1 版本中引入了对向量类型的支持。
对 .b128 类型的支持在 PTX ISA 版本 8.3 中引入。
对具有 .b128 类型的 .sys 范围的支持在 PTX ISA 版本 8.4 中引入。
目标 ISA 注释
atom.global 需要 sm_11 或更高版本。
atom.shared 需要 sm_12 或更高版本。
64 位 atom.global.{add,cas,exch} 需要 sm_12 或更高版本。
64 位 atom.shared.{add,cas,exch} 需要 sm_20 或更高版本。
64 位 atom.{and,or,xor,min,max} 需要 sm_32 或更高版本。
atom.add.f32 需要 sm_20 或更高版本。
atom.add.f64 需要 sm_60 或更高版本。
.scope 限定符需要 sm_60 或更高版本。
.sem 限定符需要 sm_70 或更高版本。
使用通用寻址需要 sm_20 或更高版本。
atom.add.noftz.f16x2 需要 sm_60 或更高版本。
atom.add.noftz.f16 和 atom.cas.b16 需要 sm_70 或更高版本。
对 .level::cache_hint 限定符的支持需要 sm_80 或更高版本。
atom.add.noftz.bf16 和 atom.add.noftz.bf16x2 需要 sm_90 或更高版本。
对 .cluster 范围限定符的支持需要 sm_90 或更高版本。
子限定符 ::cta 需要 sm_30 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
对向量类型的支持需要 sm_90 或更高版本。
对 .b128 类型的支持需要 sm_90 或更高版本。
示例
atom.global.add.s32 d,[a],1;
atom.shared::cta.max.u32 d,[x+4],0;
@p atom.global.cas.b32 d,[p],my_val,my_new_val;
atom.global.sys.add.u32 d, [a], 1;
atom.global.acquire.sys.inc.u32 ans, [gbl], %r0;
atom.add.noftz.f16x2 d, [a], b;
atom.add.noftz.f16 hd, [ha], hb;
atom.global.cas.b16 hd, [ha], hb, hc;
atom.add.noftz.bf16 hd, [a], hb;
atom.add.noftz.bf16x2 bd, [b], bb;
atom.add.shared::cluster.noftz.f16 hd, [ha], hb;
atom.shared.b128.cas d, a, b, c; // 128-bit atom
atom.global.b128.exch d, a, b; // 128-bit atom
atom.global.cluster.relaxed.add.u32 d, [a], 1;
createpolicy.fractional.L2::evict_last.b64 cache-policy, 0.25;
atom.global.add.L2::cache_hint.s32 d, [a], 1, cache-policy;
atom.global.v8.f16.max.noftz {%hd0, %hd1, %hd2, %hd3, %hd4, %hd5, %hd6, %hd7}, [gbl],
{%h0, %h1, %h2, %h3, %h4, %h5, %h6, %h7};
atom.global.v8.bf16.add.noftz {%hd0, %hd1, %hd2, %hd3, %hd4, %hd5, %hd6, %hd7}, [gbl],
{%h0, %h1, %h2, %h3, %h4, %h5, %h6, %h7};
atom.global.v2.f16.add.noftz {%hd0, %hd1}, [gbl], {%h0, %h1};
atom.global.v2.bf16.add.noftz {%hd0, %hd1}, [gbl], {%h0, %h1};
atom.global.v4.b16x2.min.noftz {%hd0, %hd1, %hd2, %hd3}, [gbl], {%h0, %h1, %h2, %h3};
atom.global.v4.f32.add {%f0, %f1, %f2, %f3}, [gbl], {%f0, %f1, %f2, %f3};
atom.global.v2.f16x2.min.noftz {%bd0, %bd1}, [g], {%b0, %b1};
atom.global.v2.bf16x2.max.noftz {%bd0, %bd1}, [g], {%b0, %b1};
atom.global.v2.f32.add {%f0, %f1}, [g], {%f0, %f1};
9.7.13.6. 并行同步和通信指令:red
red
全局和共享内存上的归约操作。
语法
标量类型的归约操作
red{.sem}{.scope}{.space}.op{.level::cache_hint}.type [a], b{, cache-policy};
red{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.f16 [a], b{, cache-policy};
red{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.f16x2 [a], b{, cache-policy};
red{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.bf16
[a], b {, cache-policy};
red{.sem}{.scope}{.space}.add.noftz{.level::cache_hint}.bf16x2
[a], b {, cache-policy};
.space = { .global, .shared{::cta, ::cluster} };
.sem = {.relaxed, .release};
.scope = {.cta, .cluster, .gpu, .sys};
.op = { .and, .or, .xor,
.add, .inc, .dec,
.min, .max };
.level::cache_hint = { .L2::cache_hint };
.type = { .b32, .b64, .u32, .u64, .s32, .s64, .f32, .f64 };
向量类型的归约操作
red{.sem}{.scope}{.global}.add{.level::cache_hint}.vec_32_bit.f32 [a], b{, cache-policy};
red{.sem}{.scope}{.global}.op.noftz{.level::cache_hint}. vec_16_bit.half_word_type [a], b{, cache-policy};
red{.sem}{.scope}{.global}.op.noftz{.level::cache_hint}.vec_32_bit.packed_type [a], b {, cache-policy};
.sem = { .relaxed, .release };
.scope = { .cta, .cluster, .gpu, .sys };
.op = { .add, .min, .max };
.half_word_type = { .f16, .bf16 };
.packed_type = { .f16x2,.bf16x2 };
.vec_16_bit = { .v2, .v4, .v8 }
.vec_32_bit = { .v2, .v4 };
.level::cache_hint = { .L2::cache_hint }
描述
执行规约操作,操作数是 b,位置 a 中的值,并将指定操作的结果存储在位置 a,覆盖原始值。操作数 a 指定指定状态空间中的一个位置。如果未给出状态空间,则使用通用寻址执行内存访问。标量类型的 red 只能与 .global 和 .shared 空间以及通用寻址一起使用,其中地址指向 .global 或 .shared 空间。向量类型的 red 只能与 .global 空间以及通用寻址一起使用,其中地址指向 .global 空间。
对于向量类型的 red,操作数 b 是用大括号括起来的向量表达式,其大小等于向量限定符的大小。
如果 .shared 状态空间未指定子限定符,则默认情况下假定为 ::cta。
可选的 .sem 限定符指定了内存一致性模型中描述的内存同步效果。如果缺少 .sem 限定符,则默认假定为 .relaxed。
可选的 .scope 限定符指定可以直接观察此操作的内存同步效果的线程集,如内存一致性模型中所述。如果缺少 .scope 限定符,则默认假定为 .gpu scope。
对于向量类型的 red,下表描述了向量限定符、类型和这些组合上支持的规约操作的支持组合
向量限定符 |
类型 |
||
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不支持 |
不支持 |
只有当每个操作都指定一个包含另一个操作的 scope 时,两个原子操作(atom 或 red)才彼此原子地执行。当不满足此条件时,每个操作都观察到另一个操作的执行,就好像它被拆分为读取,然后是依赖写入一样。
对打包类型或向量类型执行 red 指令时,会访问内存中相邻的标量元素。在这种情况下,原子性保证分别针对每个单独的标量元素;不能保证整个 red 作为单个访问是原子的。
对于 sm_6x 和更早的架构,关于 .shared 状态空间的 red 操作不保证相对于对相同地址的普通存储指令的原子性。程序员有责任保证使用共享内存规约指令的程序的正确性,例如,通过在对公共地址的普通存储和规约操作之间插入屏障,或者通过使用 atom.exch 存储到其他规约操作访问的位置。
操作数 a 的支持寻址模式和对齐要求在作为操作数的地址中描述
位大小操作是 .and、.or 和 .xor。
整数操作是 .add、.inc、.dec、.min、.max。.inc 和 .dec 操作返回 [0..b] 范围内的结果。
浮点运算 .add 操作舍入到最接近的偶数。red.add.f32 在全局内存上的当前实现将次正规输入和结果刷新为符号保留零;而共享内存上的 red.add.f32 支持次正规输入和结果,并且不会将它们刷新为零。
red.add.f16、red.add.f16x2、red.add.bf16 和 red.add.bf16x2 操作需要 .noftz 限定符;它保留次正规输入和结果,并且不会将它们刷新为零。
当指定可选参数 cache-policy 时,需要限定符 .level::cache_hint。64 位操作数 cache-policy 指定内存访问期间可能使用的缓存驱逐策略。
限定符 .level::cache_hint 仅支持 .global 状态空间和通用寻址,其中地址指向 .global 状态空间。
cache-policy 是对缓存子系统的提示,可能并非始终被遵守。它仅被视为性能提示,并且不会更改程序的内存一致性行为。
语义
*a = operation(*a, b);
where
inc(r, s) = (r >= s) ? 0 : r+1;
dec(r, s) = (r==0 || r > s) ? s : r-1;
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入。
red.add.f32 和 red.shared.add.u64 在 PTX ISA 2.0 中引入。
64 位 red.{and,or,xor,min,max} 在 PTX ISA 3.1 中引入。
red.add.f64 在 PTX ISA 5.0 中引入。
PTX ISA 5.0 版本中引入了 .scope 限定符。
PTX ISA 6.0 版本中引入了 .sem 限定符。
red.add.noftz.f16x2 在 PTX ISA 6.2 中引入。
red.add.noftz.f16 在 PTX ISA 6.3 中引入。
PTX ISA 版本 6.3 中澄清了 red.f16x2 的逐元素原子性,并具有从 PTX ISA 版本 6.2 开始的回溯效应
PTX ISA 7.4 版本中引入了对 .level::cache_hint 限定符的支持。
red.add.noftz.bf16 和 red.add.noftz.bf16x2 在 PTX ISA 7.8 中引入。
对 .cluster 范围限定符的支持在 PTX ISA 版本 7.8 中引入。
对 ::cta 和 ::cluster 子限定符的支持在 PTX ISA 版本 7.8 中引入。
PTX ISA 8.1 版本中引入了对向量类型的支持。
目标 ISA 注释
red.global 需要 sm_11 或更高版本
red.shared 需要 sm_12 或更高版本。
red.global.add.u64 需要 sm_12 或更高版本。
red.shared.add.u64 需要 sm_20 或更高版本。
64 位 red.{and,or,xor,min,max} 需要 sm_32 或更高版本。
red.add.f32 需要 sm_20 或更高版本。
red.add.f64 需要 sm_60 或更高版本。
.scope 限定符需要 sm_60 或更高版本。
.sem 限定符需要 sm_70 或更高版本。
使用通用寻址需要 sm_20 或更高版本。
red.add.noftz.f16x2 需要 sm_60 或更高版本。
red.add.noftz.f16 需要 sm_70 或更高版本。
对 .level::cache_hint 限定符的支持需要 sm_80 或更高版本。
red.add.noftz.bf16 和 red.add.noftz.bf16x2 需要 sm_90 或更高版本。
对 .cluster 范围限定符的支持需要 sm_90 或更高版本。
子限定符 ::cta 需要 sm_30 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
对向量类型的支持需要 sm_90 或更高版本。
示例
red.global.add.s32 [a],1;
red.shared::cluster.max.u32 [x+4],0;
@p red.global.and.b32 [p],my_val;
red.global.sys.add.u32 [a], 1;
red.global.acquire.sys.add.u32 [gbl], 1;
red.add.noftz.f16x2 [a], b;
red.add.noftz.bf16 [a], hb;
red.add.noftz.bf16x2 [b], bb;
red.global.cluster.relaxed.add.u32 [a], 1;
red.shared::cta.min.u32 [x+4],0;
createpolicy.fractional.L2::evict_last.b64 cache-policy, 0.25;
red.global.and.L2::cache_hint.b32 [a], 1, cache-policy;
red.global.v8.f16.add.noftz [gbl], {%h0, %h1, %h2, %h3, %h4, %h5, %h6, %h7};
red.global.v8.bf16.min.noftz [gbl], {%h0, %h1, %h2, %h3, %h4, %h5, %h6, %h7};
red.global.v2.f16.add.noftz [gbl], {%h0, %h1};
red.global.v2.bf16.add.noftz [gbl], {%h0, %h1};
red.global.v4.f16x2.max.noftz [gbl], {%h0, %h1, %h2, %h3};
red.global.v4.f32.add [gbl], {%f0, %f1, %f2, %f3};
red.global.v2.f16x2.max.noftz {%bd0, %bd1}, [g], {%b0, %b1};
red.global.v2.bf16x2.add.noftz {%bd0, %bd1}, [g], {%b0, %b1};
red.global.v2.f32.add {%f0, %f1}, [g], {%f0, %f1};
9.7.13.7. 并行同步和通信指令:red.async
red.async
异步规约操作。
语法
// Increment and Decrement reductions
red.async.sem.scope{.ss}.completion_mechanism.op.type [a], b, [mbar];
.sem = { .relaxed };
.scope = { .cluster };
.ss = { .shared::cluster };
.op = { .inc, .dec };
.type = { .u32 };
.completion_mechanism = { .mbarrier::complete_tx::bytes };
// MIN and MAX reductions
red.async.sem.scope{.ss}.completion_mechanism.op.type [a], b, [mbar];
.sem = { .relaxed };
.scope = { .cluster };
.ss = { .shared::cluster };
.op = { .min, .max };
.type = { .u32, .s32 };
.completion_mechanism = { .mbarrier::complete_tx::bytes };
// Bitwise AND, OR and XOR reductions
red.async.sem.scope{.ss}.completion_mechanism.op.type [a], b, [mbar];
.sem = { .relaxed };
.scope = { .cluster };
.ss = { .shared::cluster };
.op = { .and, .or, .xor };
.type = { .b32 };
.completion_mechanism = { .mbarrier::complete_tx::bytes };
// ADD reductions
red.async.sem.scope{.ss}.completion_mechanism.add.type [a], b, [mbar];
.sem = { .relaxed };
.scope = { .cluster };
.ss = { .shared::cluster };
.type = { .u32, .s32, .u64 };
.completion_mechanism = { .mbarrier::complete_tx::bytes };
red.async{.mmio}.sem.scope{.ss}{.completion_mechanism}.add.type [a], b;
.sem = { .release };
.scope = { .gpu, .cluster };
.ss = { .global };
.type = { .u32, .s32, .u64, .s64 };
.completion_mechanism = { };
描述
red.async 是一个非阻塞指令,它启动一个由 .op 指定的异步规约操作,操作数是 b,目标共享内存位置的值由操作数 a 指定。
操作数
a是目标地址,必须是寄存器,或register + immOff形式,如 作为操作数的地址 中所述。b是源值,类型由限定符.type指示。mbar是 mbarrier 对象地址。
限定符
.mmio指示这是否是 mmio 操作。.sem指定内存排序语义,如 内存一致性模型 中所述。.scope指定此指令可以直接同步的线程集。-
.ss指定目标操作数a和 mbarrier 操作数mbar的状态空间。如果未指定
.ss,则使用通用寻址。
-
.completion_mechanism指定用于观察异步操作完成的机制。当
.completion_mechanism为.mbarrier::complete_tx::bytes时:异步操作完成后,将在操作数mbar指定的 mbarrier 对象上执行 complete-tx 操作,其中completeCount参数等于存储的数据量(以字节为单位)。当未指定
.completion_mechanism时:存储完成与 CTA 结束同步。
-
.op指定规约操作。.inc和.dec操作返回范围[0..b]内的结果。
.type指定源操作数b的类型。
条件
当 .sem 为 .relaxed 时
规约操作是一个宽松的内存操作。
mbarrier 上的 complete-tx 操作在
.cluster作用域具有.release语义。-
目标操作数
a和 mbarrier 操作数mbar的共享内存地址必须满足以下所有条件它们属于同一个 CTA。
它们所属的 CTA 与执行线程的 CTA 不同,但必须在同一集群内。
否则,行为未定义。
不得指定
.mmio。如果指定了
.scope,则必须为.cluster。如果未指定
.scope,则默认为.cluster。如果指定了
.ss,则必须为.shared::cluster。如果未指定
.ss,则对操作数a和mbar使用通用寻址。如果指定的通用地址未落在.shared::cluster状态空间的地址窗口内,则行为未定义。如果指定了
.completion_mechanism,则必须为.mbarrier::complete_tx::bytes。如果未指定
.completion_mechanism,则默认为.mbarrier::complete_tx::bytes。
当 .sem 为 .release 时
规约操作是一个强内存操作,在
.scope指定的范围内具有.release语义。如果指定了
.mmio,则.scope必须为.sys。如果指定了
.scope,则可以是.gpu或.sys。如果未指定
.scope,则默认为.sys。如果指定了
.ss,则必须为.global。如果未指定
.ss,则对操作数a使用通用寻址。如果指定的通用地址未落在.global状态空间的地址窗口内,则行为未定义。不得指定
.completion_mechanism。
PTX ISA 注释
在 PTX ISA 8.1 版本中引入。
PTX ISA 版本 8.7 中引入了对 .mmio 限定符、.release 语义、.global 状态空间以及 .gpu 和 .sys 范围的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
.mmio 限定符、.release 语义、.global 状态空间以及 .gpu 和 .sys 范围需要 sm_100 或更高版本。
示例
red.async.relaxed.cluster.shared::cluster.mbarrier::complete_tx::bytes.min.u32 [addr], b, [mbar_addr];
red.async.release.sys.global.add.u32 [addr], b;
9.7.13.8. 并行同步和通信指令:vote(已弃用)
vote(已弃用)
跨线程组投票。
语法
vote.mode.pred d, {!}a;
vote.ballot.b32 d, {!}a; // 'ballot' form, returns bitmask
.mode = { .all, .any, .uni };
弃用说明
在 PTX ISA 版本 6.0 中,不带 .sync 限定符的 vote 指令已被弃用。
在未来的 PTX ISA 版本中,可能会删除对
.target低于sm_70的此指令的支持。
移除说明
对于 .targetsm_70 或更高版本,在 PTX ISA 版本 6.4 中移除了对不带 .sync 限定符的 vote 指令的支持。
描述
对 warp 中所有活动线程的源谓词执行规约。目标谓词值在 warp 中的所有线程中都相同。
规约模式为
.all-
如果 warp 中所有活动线程的源谓词都为
True,则为True。否定源谓词以计算.none。 .any-
如果 warp 中某些活动线程的源谓词为
True,则为True。否定源谓词以计算.not_all。 .uni-
如果 warp 中所有活动线程的源谓词都具有相同的值,则为
True。否定源谓词也会计算.uni。
在 ballot 形式中,vote.ballot.b32 只是将 warp 中每个线程的谓词复制到目标寄存器 d 的相应位位置,其中位位置对应于线程的 lane id。
当参与 vote.ballot.b32 时,warp 中的非活动线程将为其条目贡献一个 0。
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入。
在 PTX ISA 版本 6.0 中已弃用,建议使用 vote.sync。
PTX ISA 版本 6.4 不支持用于 .target sm_70 或更高版本。
目标 ISA 注释
vote 需要 sm_12 或更高版本。
vote.ballot.b32 需要 sm_20 或更高版本。
从 PTX ISA 版本 6.4 开始,vote 在 sm_70 或更高版本上不受支持。
发行说明
请注意,vote 适用于单个 warp 中的线程,而不是整个 CTA。
示例
vote.all.pred p,q;
vote.uni.pred p,q;
vote.ballot.b32 r1,p; // get 'ballot' across warp
9.7.13.9. 并行同步和通信指令:vote.sync
vote.sync
跨线程组投票。
语法
vote.sync.mode.pred d, {!}a, membermask;
vote.sync.ballot.b32 d, {!}a, membermask; // 'ballot' form, returns bitmask
.mode = { .all, .any, .uni };
描述
vote.sync 将导致执行线程等待,直到与 membermask 对应的所有非退出线程都执行了具有相同限定符和相同 membermask 值的 vote.sync,然后才能恢复执行。
操作数 membermask 指定一个 32 位整数,该整数是一个掩码,指示参与此指令的线程,其中位位置对应于线程的 laneid。操作数 a 是一个谓词寄存器。
在 mode 形式中,vote.sync 对 membermask 中所有非退出线程的源谓词执行规约。目标操作数 d 是一个谓词寄存器,其值在 membermask 中的所有线程中都相同。
规约模式为
.all-
如果
membermask中所有非退出线程的源谓词都为True,则为True。否定源谓词以计算.none。 .any-
如果
membermask中某些线程的源谓词为True,则为True。否定源谓词以计算.not_all。 .uni-
如果
membermask中所有非退出线程的源谓词都具有相同的值,则为True。否定源谓词也会计算.uni。
在 ballot 形式中,目标操作数 d 是一个 .b32 寄存器。在这种形式中,vote.sync.ballot.b32 只是将 membermask 中每个线程的谓词复制到目标寄存器 d 的相应位位置,其中位位置对应于线程的 lane id。
未在 membermask 中指定的线程将为其在 vote.sync.ballot.b32 中的条目贡献一个 0。
如果执行线程不在 membermask 中,则 vote.sync 的行为未定义。
注意
对于 .target sm_6x 或更低版本,membermask 中的所有线程必须以收敛方式执行相同的 vote.sync 指令,并且只有属于某些 membermask 的线程才能在执行 vote.sync 指令时处于活动状态。否则,行为未定义。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
目标 ISA 注释
需要 sm_30 或更高版本。
示例
vote.sync.all.pred p,q,0xffffffff;
vote.sync.ballot.b32 r1,p,0xffffffff; // get 'ballot' across warp
9.7.13.10. 并行同步和通信指令:match.sync
match.sync
跨 warp 中的线程广播和比较值。
语法
match.any.sync.type d, a, membermask;
match.all.sync.type d[|p], a, membermask;
.type = { .b32, .b64 };
描述
match.sync 将导致执行线程等待,直到来自 membermask 的所有非退出线程都执行了具有相同限定符和相同 membermask 值的 match.sync,然后才能恢复执行。
操作数 membermask 指定一个 32 位整数,该整数是一个掩码,指示参与此指令的线程,其中位位置对应于线程的 lane id。
match.sync 对 membermask 中所有非退出线程广播和比较操作数 a,并根据模式设置目标 d 和可选谓词 p。
操作数 a 具有指令类型,d 具有 .b32 类型。
目标 d 是一个 32 位掩码,其中掩码中的位位置对应于线程的 lane id。
匹配操作模式为
.all-
如果
membermask中所有非退出线程的操作数a都具有相同的值,则d设置为对应于membermask中非退出线程的掩码;否则d设置为 0。如果membermask中所有非退出线程的操作数a都具有相同的值,则可选谓词p设置为 true;否则p设置为 false。可以使用 sink 符号“_”代替任何一个目标操作数。 .any-
d设置为membermask中具有相同操作数a值的非退出线程的掩码。
如果执行线程不在 membermask 中,则 match.sync 的行为未定义。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
目标 ISA 注释
需要 sm_70 或更高版本。
发行说明
请注意,match.sync 适用于单个 warp 中的线程,而不是整个 CTA。
示例
match.any.sync.b32 d, a, 0xffffffff;
match.all.sync.b64 d|p, a, mask;
9.7.13.11. 并行同步和通信指令:activemask
activemask
查询 warp 中的活动线程。
语法
activemask.b32 d;
描述
activemask 查询执行 warp 中基于谓词的活动线程,并将目标 d 设置为 32 位整数掩码,其中掩码中的位位置对应于线程的 laneid。
目标 d 是一个 32 位目标寄存器。
活动线程将为其在结果中的条目贡献 1,而退出、非活动或基于谓词关闭的线程将为其在结果中的条目贡献 0。
PTX ISA 注释
在 PTX ISA 版本 6.2 中引入。
目标 ISA 注释
需要 sm_30 或更高版本。
示例
activemask.b32 %r1;
9.7.13.12. 并行同步和通信指令:redux.sync
redux.sync
对线程组中每个基于谓词的活动线程的数据执行规约操作。
语法
redux.sync.op.type dst, src, membermask;
.op = {.add, .min, .max}
.type = {.u32, .s32}
redux.sync.op.b32 dst, src, membermask;
.op = {.and, .or, .xor}
redux.sync.op{.abs.}{.NaN}.f32 dst, src, membermask;
.op = { .min, .max }
描述
redux.sync 将导致执行线程等待,直到与 membermask 对应的所有非退出线程都执行了具有相同限定符和相同 membermask 值的 redux.sync,然后才能恢复执行。
操作数 membermask 指定一个 32 位整数,该整数是一个掩码,指示参与此指令的线程,其中位位置对应于线程的 laneid。
redux.sync 对 membermask 中所有非退出线程的 32 位源寄存器 src 执行规约操作 .op。规约操作的结果写入 32 位目标寄存器 dst。
规约操作可以是 .and、.or、.xor 中的按位操作,也可以是 .add、.min、.max 中的算术操作。
对于 .add 操作,结果将被截断为 32 位。
对于 .f32 指令类型,如果输入值为 0.0,则 +0.0 > -0.0。
如果指定了 .abs 限定符,则在规约操作中会考虑输入的绝对值。
如果指定了 .NaN 限定符,则如果来自任何参与线程的规约操作的输入为 NaN,则规约操作的结果为规范 NaN。
在没有 .NaN 限定符的情况下,只有非 NaN 值会被考虑用于规约操作,当所有输入均为 NaN 时,结果将为规范 NaN。
如果执行线程不在 membermask 中,则 redux.sync 的行为未定义。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 8.6 中引入了对 .f32 类型的支持。
PTX ISA 版本 8.6 中引入了对 .abs 和 .NaN 限定符的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
.f32 类型需要 sm_100a。
限定符 .abs 和 .NaN 需要 sm_100a。
发行说明
请注意,redux.sync 适用于单个 warp 中的线程,而不是整个 CTA。
示例
.reg .b32 dst, src, init, mask;
redux.sync.add.s32 dst, src, 0xff;
redux.sync.xor.b32 dst, src, mask;
redux.sync.min.abs.NaN.f32 dst, src, mask;
9.7.13.13. 并行同步和通信指令:griddepcontrol
griddepcontrol
控制从属网格的执行。
语法
griddepcontrol.action;
.action = { .launch_dependents, .wait }
描述
griddepcontrol 指令允许运行时定义的从属网格和先决条件网格,以以下方式控制执行
.launch_dependents 修饰符表示,只要网格中的所有其他 CTA 发出相同的指令或已完成,运行时系统指定的对该指令做出反应的特定从属项就可以被调度。从属项可以在当前网格完成之前启动。不保证从属项会在当前网格完成之前启动。当前 CTA 中的线程重复调用此指令,除了第一次调用之外,不会产生额外的副作用。
.wait 修饰符使执行线程等待,直到所有正在运行的先决条件网格都已完成,并且先决条件网格的所有内存操作都已执行并对当前网格可见。
注意
如果先决条件网格正在使用 griddepcontrol.launch_dependents,则从属网格必须使用 griddepcontrol.wait 以确保正确的功能执行。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
griddepcontrol.launch_dependents;
griddepcontrol.wait;
9.7.13.14. 并行同步和通信指令:elect.sync
elect.sync
从一组线程中选出一个leader线程。
语法
elect.sync d|p, membermask;
描述
elect.sync 从 membermask 指定的一组线程中选出一个基于谓词的活动 leader 线程。所选线程的 laneid 在 32 位目标操作数 d 中返回。sink 符号“_”可用于目标操作数 d。谓词目标 p 对于 leader 线程设置为 True,对于所有其他线程设置为 False。
操作数 membermask 指定一个 32 位整数,指示要从中选出 leader 的线程集。如果执行线程不在 membermask 中,则行为未定义。
leader 线程的选举是确定性的,即,对于相同的 membermask,每次都会选出相同的 leader 线程。
强制性的 .sync 限定符表示 elect 会导致执行线程等待,直到 membermask 中的所有线程都执行 elect 指令,然后才能恢复执行。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
elect.sync %r0|%p0, 0xffffffff;
9.7.13.15. 并行同步和通信指令:mbarrier
mbarrier 是在共享内存中创建的屏障,它支持
同步 CTA 内的任何线程子集
集群的 CTA 之间线程的单向同步。如共享内存上的 mbarrier 支持中所述,线程只能对位于
shared::cluster空间中的 mbarrier 执行 arrive 操作,而不能执行 *_wait 操作。等待线程启动的异步内存操作完成,并使它们对其他线程可见。
mbarrier 对象 是内存中的不透明对象,可以使用以下方法进行初始化和无效化
mbarrier.initmbarrier.inval
mbarrier 对象 上支持的操作有
mbarrier.expect_txmbarrier.complete_txmbarrier.arrivembarrier.arrive_dropmbarrier.test_waitmbarrier.try_waitmbarrier.pending_countcp.async.mbarrier.arrive
对未初始化的 mbarrier 对象 执行除 mbarrier.init 之外的任何 mbarrier 操作会导致未定义的行为。对已初始化的 mbarrier 对象 执行任何 非 mbarrier 或 mbarrier.init 操作会导致未定义的行为。
与每个 CTA 只能访问有限数量屏障的 bar{.cta}/barrier{.cta} 指令不同,mbarrier 对象 是用户定义的,并且仅受可用共享内存总大小的限制。
mbarrier 操作使线程能够在到达 mbarrier 之后和等待 mbarrier 完成之前执行有用的工作。
9.7.13.15.1. mbarrier 对象的大小和对齐
mbarrier 对象是一个不透明对象,具有以下类型和对齐要求
类型 |
对齐(字节) |
内存空间 |
|---|---|---|
|
8 |
|
9.7.13.15.2. mbarrier 对象的内容
不透明的 mbarrier 对象 跟踪以下信息
mbarrier 对象 的当前阶段
mbarrier 对象 当前阶段的待处理到达计数
mbarrier 对象 下一阶段的预期到达计数
mbarrier 对象 当前阶段跟踪的待处理异步内存操作(或事务)计数。这也称为 tx-count。
mbarrier 对象 经历一系列阶段,其中每个阶段都由执行预期数量的 arrive-on 操作的线程定义。
每个计数的有效范围如下所示
计数名称 |
最小值 |
最大值 |
|---|---|---|
预期到达计数 |
1 |
220 - 1 |
待处理到达计数 |
0 |
220 - 1 |
tx-count |
-(220 - 1) |
220 - 1 |
9.7.13.15.3. mbarrier 对象的生命周期
mbarrier 对象 在使用前必须初始化。
mbarrier 对象 用于同步线程和异步内存操作。
mbarrier 对象 可用于执行一系列此类同步。
必须使 mbarrier 对象 无效,才能将其内存重新用于任何目的,包括将其重新用于另一个 mbarrier 对象。
9.7.13.15.4. mbarrier 对象的阶段
mbarrier 对象 的阶段是 mbarrier 对象 已用于同步线程和 cp.async 操作的次数。在每个阶段 {0, 1, 2, …} 中,线程按程序顺序执行
arrive-on 操作以完成当前阶段,以及
test_wait / try_wait 操作以检查当前阶段是否完成。
mbarrier 对象 在当前阶段完成后自动重新初始化,以便立即在下一阶段中使用。当前阶段未完成,并且所有先前阶段都已完成。
对于 mbarrier 对象的每个阶段,在后续阶段的 arrive-on 操作之前,必须至少执行一个 test_wait 或 try_wait 操作,该操作为 waitComplete 返回 True。
9.7.13.15.5. mbarrier 对象跟踪异步操作
从 Hopper 架构 (sm_9x) 开始,mbarrier 对象 支持一个新的计数,称为 tx-count,用于跟踪异步内存操作或事务的完成。tx-count 跟踪尚未完成的未完成异步事务的数量,单位由异步内存操作指定。
mbarrier 对象 的 tx-count 必须设置为要由当前阶段跟踪的异步内存操作的总量(单位由异步操作指定)。在每个异步操作完成时,将对 mbarrier 对象 执行 complete-tx 操作,从而推动 mbarrier 朝着当前阶段的完成前进。
9.7.13.15.5.1. expect-tx 操作
expect-tx 操作,带有一个 expectCount 参数,会将 mbarrier 对象 的 tx-count 增加 expectCount 指定的值。这使得 mbarrier 对象 的当前阶段预期并跟踪额外的异步事务的完成。
9.7.13.15.5.2. complete-tx 操作
complete-tx 操作,带有一个 completeCount 参数,在 mbarrier 对象 上包含以下内容
- mbarrier 信号发送
-
发出由当前阶段跟踪的异步事务完成的信号。因此,tx-count 会减少
completeCount。 - mbarrier 可能完成当前阶段
-
如果当前阶段已完成,则 mbarrier 转换到下一阶段。有关阶段完成要求和阶段转换过程的详细信息,请参阅 mbarrier 对象的阶段完成。
9.7.13.15.6. mbarrier 对象的阶段完成
当前阶段的完成要求如下所述。在当前阶段完成后,阶段将转换到后续阶段,如下所述。
- 当前阶段完成要求
-
当满足以下所有条件时,mbarrier 对象 完成当前阶段
待处理到达计数已达到零。
tx-count 已达到零。
- 阶段转换
-
当 mbarrier 对象完成当前阶段时,将原子地执行以下操作
mbarrier 对象 转换到下一阶段。
待处理到达计数被重新初始化为预期到达计数。
9.7.13.15.7. mbarrier 对象上的 Arrive-on 操作
mbarrier 对象 上的 arrive-on 操作,带有一个可选的 count 参数,包含以下 2 个步骤
-
mbarrier 信号发送
发出执行线程到达的信号,或者
cp.async指令完成的信号,该指令发出由执行线程在 mbarrier 对象 上启动的 arrive-on 操作的信号。因此,待处理到达计数减少 count。如果未指定 count 参数,则默认为 1。 -
mbarrier 可能完成当前阶段
如果当前阶段已完成,则 mbarrier 转换到下一阶段。有关阶段完成要求和阶段转换过程的详细信息,请参阅 mbarrier 对象的阶段完成。
9.7.13.15.9. 并行同步和通信指令:mbarrier.init
mbarrier.init
初始化 mbarrier 对象。
语法
mbarrier.init{.shared{::cta}}.b64 [addr], count;
描述
mbarrier.init 使用无符号 32 位整数 count 初始化地址操作数 addr 指定位置的 mbarrier 对象。操作数 count 的值必须在 mbarrier 对象的内容 中指定的范围内。
mbarrier 对象 的初始化包括
将当前阶段初始化为 0。
将预期到达计数初始化为
count。将待处理到达计数初始化为
count。将 tx-count 初始化为 0。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
在包含有效 mbarrier 对象 的内存位置上执行 mbarrier.init 操作的行为未定义;在使用内存位置进行任何其他用途(包括另一个 mbarrier 对象)之前,请先使用 mbarrier.inval 使 mbarrier 对象 无效。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 7.8 中引入了对 .shared 上子限定符 ::cta 的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
.shared .b64 shMem, shMem2;
.reg .b64 addr;
.reg .b32 %r1;
cvta.shared.u64 addr, shMem2;
mbarrier.init.b64 [addr], %r1;
bar.cta.sync 0;
// ... other mbarrier operations on addr
mbarrier.init.shared::cta.b64 [shMem], 12;
bar.sync 0;
// ... other mbarrier operations on shMem
9.7.13.15.10. 并行同步和通信指令:mbarrier.inval
mbarrier.inval
使 mbarrier 对象 无效。
语法
mbarrier.inval{.shared{::cta}}.b64 [addr];
描述
mbarrier.inval 使地址操作数 addr 指定位置的 mbarrier 对象 无效。
必须先使 mbarrier 对象 无效,然后才能将其内存位置用于任何其他用途。
在不包含有效 mbarrier 对象 的内存位置上执行除 mbarrier.init 之外的任何 mbarrier 操作,都会导致未定义的行为。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 7.8 中引入了对 .shared 上子限定符 ::cta 的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
.shared .b64 shmem;
.reg .b64 addr;
.reg .b32 %r1;
.reg .pred t0;
// Example 1 :
bar.sync 0;
@t0 mbarrier.init.b64 [addr], %r1;
// ... other mbarrier operations on addr
bar.sync 0;
@t0 mbarrier.inval.b64 [addr];
// Example 2 :
bar.cta.sync 0;
mbarrier.init.shared.b64 [shmem], 12;
// ... other mbarrier operations on shmem
bar.cta.sync 0;
@t0 mbarrier.inval.shared.b64 [shmem];
// shmem can be reused here for unrelated use :
bar.cta.sync 0;
st.shared.b64 [shmem], ...;
// shmem can be re-initialized as mbarrier object :
bar.cta.sync 0;
@t0 mbarrier.init.shared.b64 [shmem], 24;
// ... other mbarrier operations on shmem
bar.cta.sync 0;
@t0 mbarrier.inval.shared::cta.b64 [shmem];
9.7.13.15.11. 并行同步和通信指令:mbarrier.expect_tx
mbarrier.expect_tx
在 mbarrier 对象 上执行 expect-tx 操作。
语法
mbarrier.expect_tx{.sem}{.scope}{.space}.b64 [addr], txCount;
.sem = { .relaxed }
.scope = { .cta, .cluster }
.space = { .shared{::cta}, .shared::cluster }
描述
执行 mbarrier.expect_tx 的线程在地址操作数 addr 指定位置的 mbarrier 对象 上执行 expect-tx 操作。32 位无符号整数操作数 txCount 指定 expect-tx 操作的 expectCount 参数。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 或 .shared::cluster 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
此操作不提供任何内存排序语义,因此是宽松操作。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
mbarrier.expect_tx.b64 [addr], 32;
mbarrier.expect_tx.relaxed.cta.shared.b64 [mbarObj1], 512;
mbarrier.expect_tx.relaxed.cta.shared.b64 [mbarObj2], 512;
9.7.13.15.12. 并行同步和通信指令:mbarrier.complete_tx
mbarrier.complete_tx
在 mbarrier 对象 上执行 complete-tx 操作。
语法
mbarrier.complete_tx{.sem}{.scope}{.space}.b64 [addr], txCount;
.sem = { .relaxed }
.scope = { .cta, .cluster }
.space = { .shared{::cta}, .shared::cluster }
描述
执行 mbarrier.complete_tx 的线程在地址操作数 addr 指定位置的 mbarrier 对象 上执行 complete-tx 操作。32 位无符号整数操作数 txCount 指定 complete-tx 操作的 completeCount 参数。
mbarrier.complete_tx 不涉及任何异步内存操作,仅模拟异步内存操作的完成及其向 mbarrier 对象 发送信号的副作用。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 或 .shared::cluster 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
此操作不提供任何内存排序语义,因此是宽松操作。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
mbarrier.complete_tx.b64 [addr], 32;
mbarrier.complete_tx.shared.b64 [mbarObj1], 512;
mbarrier.complete_tx.relaxed.cta.b64 [addr2], 32;
9.7.13.15.13. 并行同步和通信指令:mbarrier.arrive
mbarrier.arrive
在 mbarrier 对象 上执行 arrive-on 操作。
语法
mbarrier.arrive{.sem}{.scope}{.shared{::cta}}.b64 state, [addr]{, count};
mbarrier.arrive{.sem}{.scope}{.shared::cluster}.b64 _, [addr] {,count}
mbarrier.arrive.expect_tx{.sem}{.scope}{.shared{::cta}}.b64 state, [addr], txCount;
mbarrier.arrive.expect_tx{.sem}{.scope}{.shared::cluster}.b64 _, [addr], txCount;
mbarrier.arrive.noComplete{.release}{.cta}{.shared{::cta}}.b64 state, [addr], count;
.sem = { .release, .relaxed }
.scope = { .cta, .cluster }
描述
执行 mbarrier.arrive 的线程在地址操作数 addr 指定位置的 mbarrier 对象 上执行 arrive-on 操作。32 位无符号整数操作数 count 指定 arrive-on 操作的 count 参数。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
可选限定符 .expect_tx 指定在 arrive-on 操作之前执行 expect-tx 操作。32 位无符号整数操作数 txCount 指定 expect-tx 操作的 expectCount 参数。当同时指定限定符 .arrive 和 .expect_tx 时,arrive-on 操作的 count 参数假定为 1。
带有 .noComplete 限定符的 mbarrier.arrive 操作不得导致 mbarrier 完成其当前阶段,否则行为未定义。
操作数 count 的值必须在 mbarrier 对象的内容 中指定的范围内。
注意:对于 sm_8x,当指定参数 count 时,需要修饰符 .noComplete。
在 .shared::cta 中的 mbarrier 对象 上执行的 mbarrier.arrive 操作会返回一个不透明的 64 位寄存器,捕获 arrive-on 操作 之前的 mbarrier 对象 的阶段,并将其存储在目标操作数 state. 中。state 操作数的内容是实现特定的。可选地,可以将接收器符号 '_' 用于 state 参数。
在 .shared::cluster 但不在 .shared::cta 中的 mbarrier 对象 上执行的 mbarrier.arrive 操作无法返回值。对于这种情况,目标操作数必须使用接收器符号 ‘_’。
可选的 .sem 限定符指定了内存同步效果,如 内存一致性模型 中所述。如果 .sem 限定符不存在,则默认假定为 .release。
.relaxed 限定符不提供任何内存排序语义和可见性保证。
可选的 .scope 限定符指示可以直接观察此操作的内存同步效果的线程集合,如 内存一致性模型 中所述。如果未指定 .scope 限定符,则默认值为 .cta。相比之下,.shared::<scope> 指示 mbarrier 所在的状态空间。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 7.1 中引入了对接收器符号 ‘_’ 作为目标操作数的支持。
PTX ISA 版本 7.8 中引入了对 .shared 上子限定符 ::cta 的支持。
PTX ISA 版本 7.8 中引入了对没有修饰符 .noComplete 的 count 参数的支持。
PTX ISA 版本 8.0 中引入了对子限定符 ::cluster 的支持。
PTX ISA 版本 8.0 中引入了对限定符 .expect_tx 的支持。
PTX ISA 版本 8.0 中引入了对 .scope 和 .sem 限定符的支持。
PTX ISA 版本 8.6 中引入了对 .relaxed 限定符的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
没有修饰符 .noComplete 的 count 参数需要 sm_90 或更高版本。
限定符 .expect_tx 需要 sm_90 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
对 .cluster 范围的支持需要 sm_90 或更高版本。
示例
.reg .b32 cnt, remoteAddr32, remoteCTAId, addr32;
.reg .b64 %r<5>, addr, remoteAddr64;
.shared .b64 shMem, shMem2;
cvta.shared.u64 addr, shMem2;
mov.b32 addr32, shMem2;
mapa.shared::cluster.u32 remoteAddr32, addr32, remoteCTAId;
mapa.u64 remoteAddr64, addr, remoteCTAId;
cvta.shared.u64 addr, shMem2;
mbarrier.arrive.shared.b64 %r0, [shMem];
mbarrier.arrive.shared::cta.b64 %r0, [shMem2];
mbarrier.arrive.release.cta.shared::cluster.b64 _, [remoteAddr32];
mbarrier.arrive.release.cluster.b64 _, [remoteAddr64], cnt;
mbarrier.arrive.expect_tx.release.cluster.b64 _, [remoteAddr64], tx_count;
mbarrier.arrive.noComplete.b64 %r1, [addr], 2;
mbarrier.arrive.relaxed.cta.b64 %r2, [addr], 4;
mbarrier.arrive.b64 %r2, [addr], cnt;
9.7.13.15.14. 并行同步和通信指令:mbarrier.arrive_drop
mbarrier.arrive_drop
减少 mbarrier 对象 的预期计数,并执行 arrive-on 操作。
语法
mbarrier.arrive_drop{.sem}{.scope}{.shared{::cta}}.b64 state, [addr]{, count};
mbarrier.arrive_drop{.sem}{.scope}{.shared::cluster}.b64 _, [addr] {,count};
mbarrier.arrive_drop.expect_tx{.shared{::cta}}{.sem}{.scope}.b64 state, [addr], tx_count;
mbarrier.arrive_drop.expect_tx{.shared::cluster}{.sem}{.scope}.b64 _, [addr], tx_count;
mbarrier.arrive_drop.noComplete{.release}{.cta}{.shared{::cta}}.b64 state, [addr], count;
.sem = { .release, .relaxed }
.scope = { .cta, .cluster }
描述
在地址操作数 addr 指定位置的 mbarrier 对象 上执行 mbarrier.arrive_drop 的线程执行以下步骤
将 mbarrier 对象 的预期到达计数减少 32 位整数操作数
count指定的值。如果未指定count操作数,则默认为 1。在 mbarrier 对象 上执行 arrive-on 操作。操作数
count指定 arrive-on 操作的 count 参数。
对 mbarrier 对象 的预期到达计数进行的减少将适用于 mbarrier 对象 的所有后续阶段。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 或 .shared::cluster 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
可选限定符 .expect_tx 指定在 arrive-on 操作之前执行 expect-tx 操作。32 位无符号整数操作数 txCount 指定 expect-tx 操作的 expectCount 参数。当同时指定限定符 .arrive 和 .expect_tx 时,arrive-on 操作的 count 参数假定为 1。
带有 .release 限定符的 mbarrier.arrive_drop 操作形成 内存一致性模型 中描述的释放模式,并与获取模式同步。
可选的 .sem 限定符指定了内存同步效果,如 内存一致性模型 中所述。如果 .sem 限定符不存在,则默认假定为 .release。.relaxed 限定符不提供任何内存排序语义和可见性保证。
可选的 .scope 限定符指示 mbarrier.arrive_drop 指令可以直接同步的线程集合。如果未指定 .scope 限定符,则默认值为 .cta。相比之下,.shared::<scope> 指示 mbarrier 所在的状态空间。
带有 .noComplete 限定符的 mbarrier.arrive_drop 不得完成 mbarrier, 否则行为未定义。
操作数 count 的值必须在 mbarrier 对象的内容 中指定的范围内。
注意:对于 sm_8x,当指定参数 count 时,需要修饰符 .noComplete。
想要退出或选择不参与 arrive-on 操作 的线程可以使用 mbarrier.arrive_drop 将自身从 mbarrier 中移除。
在 .shared::cta 中的 mbarrier 对象 上执行的 mbarrier.arrive_drop 操作会返回一个不透明的 64 位寄存器,捕获 arrive-on 操作 之前的 mbarrier 对象 的阶段,并将其存储在目标操作数 state 中。返回的状态内容是实现特定的。可选地,可以将接收器符号 '_' 用于 state 参数。
在 .shared::cluster 但不在 .shared::cta 中的 mbarrier 对象上执行的 mbarrier.arrive_drop 操作无法返回值。对于这种情况,目标操作数必须使用接收器符号 ‘_’。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 7.8 中引入了对 .shared 上子限定符 ::cta 的支持。
PTX ISA 版本 7.8 中引入了对没有修饰符 .noComplete 的 count 参数的支持。
PTX ISA 版本 8.0 中引入了对限定符 .expect_tx 的支持。
PTX ISA 版本 8.0 中引入了对子限定符 ::cluster 的支持。
PTX ISA 版本 8.0 中引入了对 .scope 和 .sem 限定符的支持。
PTX ISA 版本 8.6 中引入了对 .relaxed 限定符的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
没有修饰符 .noComplete 的 count 参数需要 sm_90 或更高版本。
限定符 .expect_tx 需要 sm_90 或更高版本。
子限定符 ::cluster 需要 sm_90 或更高版本。
对 .cluster 范围的支持需要 sm_90 或更高版本。
示例
.reg .b32 cnt;
.reg .b64 %r1;
.shared .b64 shMem;
// Example 1
@p mbarrier.arrive_drop.shared.b64 _, [shMem];
@p exit;
@p2 mbarrier.arrive_drop.noComplete.shared.b64 _, [shMem], %a;
@p2 exit;
..
@!p mbarrier.arrive.shared.b64 %r1, [shMem];
@!p mbarrier.test_wait.shared.b64 q, [shMem], %r1;
// Example 2
mbarrier.arrive_drop.shared::cluster.b64 _, [addr];
mbarrier.arrive_drop.shared::cta.release.cluster.b64 _, [addr], cnt;
// Example 3
mbarrier.arrive_drop.expect_tx.shared::cta.relaxed.cluster.b64 state, [addr], tx_count;
9.7.13.15.15. 并行同步和通信指令:cp.async.mbarrier.arrive
cp.async.mbarrier.arrive
使 mbarrier 对象 跟踪执行线程启动的所有先前的 cp.async 操作。
语法
cp.async.mbarrier.arrive{.noinc}{.shared{::cta}}.b64 [addr];
描述
导致系统在完成执行线程启动的所有先前的 cp.async 操作后,在 mbarrier 对象 上触发 arrive-on 操作。mbarrier 对象 位于操作数 addr 指定的位置。arrive-on 操作 对于 cp.async.mbarrier.arrive 的执行是异步的。
当未指定 .noinc 修饰符时,在异步 arrive-on 操作 之前,mbarrier 对象的待处理计数会递增 1。这导致当前阶段的异步 arrive-on 操作的待处理计数净变化为零。递增后,mbarrier 对象 的待处理计数不应超过 mbarrier 对象的内容 中提到的限制。否则,行为未定义。
当指定 .noinc 修饰符时,不会执行 mbarrier 对象 的待处理计数的递增。因此,异步 arrive-on 操作 完成的待处理计数减少必须在 mbarrier 对象 的初始化中考虑。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 7.8 中引入了对 .shared 上子限定符 ::cta 的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
// Example 1: no .noinc
mbarrier.init.shared.b64 [shMem], threadCount;
....
cp.async.ca.shared.global [shard1], [gbl1], 4;
cp.async.cg.shared.global [shard2], [gbl2], 16;
....
// Absence of .noinc accounts for arrive-on from completion of prior cp.async operations.
// So mbarrier.init must only account for arrive-on from mbarrier.arrive.
cp.async.mbarrier.arrive.shared.b64 [shMem];
....
mbarrier.arrive.shared.b64 state, [shMem];
waitLoop:
mbarrier.test_wait.shared.b64 p, [shMem], state;
@!p bra waitLoop;
// Example 2: with .noinc
// Tracks arrive-on from mbarrier.arrive and cp.async.mbarrier.arrive.
// All threads participating in the mbarrier perform cp.async
mov.b32 copyOperationCnt, threadCount;
// 3 arrive-on operations will be triggered per-thread
mul.lo.u32 copyArrivalCnt, copyOperationCnt, 3;
add.u32 totalCount, threadCount, copyArrivalCnt;
mbarrier.init.shared.b64 [shMem], totalCount;
....
cp.async.ca.shared.global [shard1], [gbl1], 4;
cp.async.cg.shared.global [shard2], [gbl2], 16;
...
// Presence of .noinc requires mbarrier initalization to have accounted for arrive-on from cp.async
cp.async.mbarrier.arrive.noinc.shared.b64 [shMem]; // 1st instance
....
cp.async.ca.shared.global [shard3], [gbl3], 4;
cp.async.ca.shared.global [shard4], [gbl4], 16;
cp.async.mbarrier.arrive.noinc.shared::cta.b64 [shMem]; // 2nd instance
....
cp.async.ca.shared.global [shard5], [gbl5], 4;
cp.async.cg.shared.global [shard6], [gbl6], 16;
cp.async.mbarrier.arrive.noinc.shared.b64 [shMem]; // 3rd and last instance
....
mbarrier.arrive.shared.b64 state, [shMem];
waitLoop:
mbarrier.test_wait.shared.b64 p, [shMem], state;
@!p bra waitLoop;
9.7.13.15.16. 并行同步和通信指令:mbarrier.test_wait/mbarrier.try_wait
mbarrier.test_wait/mbarrier.try_wait
检查 mbarrier 对象 是否已完成阶段。
语法
mbarrier.test_wait{.sem}{.scope}{.shared{::cta}}.b64 waitComplete, [addr], state;
mbarrier.test_wait.parity{.sem}{.scope}{.shared{::cta}}.b64 waitComplete, [addr], phaseParity;
mbarrier.try_wait{.sem}{.scope}{.shared{::cta}}.b64 waitComplete, [addr], state
{, suspendTimeHint};
mbarrier.try_wait.parity{.sem}{.scope}{.shared{::cta}}.b64 waitComplete, [addr], phaseParity
{, suspendTimeHint};
.sem = { .acquire, .relaxed }
.scope = { .cta, .cluster }
描述
test_wait 和 try_wait 操作测试地址操作数 addr 指定位置的 mbarrier 对象 的当前阶段或紧邻的前一阶段是否完成。
mbarrier.test_wait 是一个非阻塞指令,用于测试阶段是否完成。
mbarrier.try_wait 是一个潜在的阻塞指令,用于测试阶段是否完成。如果阶段未完成,则执行线程可能会被挂起。当指定阶段完成时,或者在阶段完成之前,在系统相关的时间限制之后,挂起的线程将恢复执行。可选的 32 位无符号整数操作数 suspendTimeHint 指定时间限制(以纳秒为单位),该时间限制可以代替系统相关限制使用。
mbarrier.test_wait 和 mbarrier.try_wait 测试阶段完成情况
由操作数
state指定的阶段,该操作数由同一 mbarrier 对象 在当前阶段或紧邻的前一阶段的mbarrier.arrive指令返回。或者由操作数
phaseParity指示的阶段,该操作数是 mbarrier 对象 的当前阶段或紧邻的前一阶段的整数奇偶校验位。
指令的 .parity 变体测试由操作数 phaseParity 指示的阶段的完成情况,该操作数是 mbarrier 对象 的当前阶段或紧邻的前一阶段的整数奇偶校验位。偶数阶段的整数奇偶校验位为 0,奇数阶段的整数奇偶校验位为 1。因此,phaseParity 操作数的有效值为 0 和 1。
注意:指令的 .parity 变体的使用需要跟踪 mbarrier 对象 在其整个生命周期内的阶段。
test_wait 和 try_wait 操作仅对以下阶段有效
当前未完成的阶段,对于该阶段,
waitComplete返回False。紧邻的前一阶段,对于该阶段,
waitComplete返回True。
如果未指定状态空间,则使用 通用寻址。如果 addr 指定的地址不在 .shared::cta 状态空间的地址窗口内,则行为未定义。
操作数 addr 的支持寻址模式如 作为操作数的地址 中所述。操作数 addr 的对齐方式如 mbarrier 对象的大小和对齐方式 中所述。
当带有 .acquire 限定符的 mbarrier.test_wait 和 mbarrier.try_wait 操作返回 True 时,它们形成 内存一致性模型 中描述的获取模式。
可选的 .sem 限定符指定了内存同步效果,如 内存一致性模型 中所述。如果 .sem 限定符不存在,则默认假定为 .acquire。.relaxed 限定符不提供任何内存排序语义和可见性保证。
可选的 .scope 限定符指示 mbarrier.test_wait 和 mbarrier.try_wait 指令可以直接同步的线程集合。如果未指定 .scope 限定符,则默认值为 .cta。相比之下,.shared::<scope> 指示 mbarrier 所在的状态空间。
当具有获取语义的 mbarrier.test_wait 或 mbarrier.try_wait 返回 True 时,执行线程的内存操作顺序如下
在程序顺序中,在 CTA 的参与线程的已完成阶段期间,在具有释放语义的
mbarrier.arrive之前请求的所有内存访问(异步操作 除外)都已执行,并且对执行线程可见。在程序顺序中,在 CTA 的参与线程的已完成阶段期间,在
cp.async.mbarrier.arrive之前请求的所有 cp.async 操作都已执行,并且对执行线程可见。所有使用相同 mbarrier 对象 的
cp.async.bulk异步操作,按照程序顺序,在 CTA 的参与线程完成阶段,且mbarrier.arrive具有发布语义之前被请求,都将被执行并对执行线程可见。在程序顺序中,所有在
mbarrier.test_wait或mbarrier.try_wait之后请求的内存访问,都不会被执行,并且对mbarrier.arrive具有发布语义之前,由参与mbarrier的其他线程按照程序顺序执行的内存访问不可见。对于线程在
mbarrier.arrive具有发布语义之后以及在mbarrier.test_wait之前(按照程序顺序)请求的内存访问,没有排序和可见性保证。
PTX ISA 注释
mbarrier.test_wait 在 PTX ISA 版本 7.0 中引入。
修饰符 .parity 在 PTX ISA 版本 7.1 中引入。
mbarrier.try_wait 在 PTX ISA 版本 7.8 中引入。
PTX ISA 版本 7.8 中引入了对 .shared 上子限定符 ::cta 的支持。
PTX ISA 版本 8.0 中引入了对 .scope 和 .sem 限定符的支持。
PTX ISA 版本 8.6 中引入了对 .relaxed 限定符的支持。
目标 ISA 注释
mbarrier.test_wait 需要 sm_80 或更高版本。
mbarrier.try_wait 需要 sm_90 或更高版本。
对 .cluster 范围的支持需要 sm_90 或更高版本。
示例
// Example 1a, thread synchronization with test_wait:
.reg .b64 %r1;
.shared .b64 shMem;
mbarrier.init.shared.b64 [shMem], N; // N threads participating in the mbarrier.
...
mbarrier.arrive.shared.b64 %r1, [shMem]; // N threads executing mbarrier.arrive
// computation not requiring mbarrier synchronization...
waitLoop:
mbarrier.test_wait.shared.b64 complete, [shMem], %r1;
@!complete nanosleep.u32 20;
@!complete bra waitLoop;
// Example 1b, thread synchronization with try_wait :
.reg .b64 %r1;
.shared .b64 shMem;
mbarrier.init.shared.b64 [shMem], N; // N threads participating in the mbarrier.
...
mbarrier.arrive.shared.b64 %r1, [shMem]; // N threads executing mbarrier.arrive
// computation not requiring mbarrier synchronization...
waitLoop:
mbarrier.try_wait.relaxed.cluster.shared.b64 complete, [shMem], %r1;
@!complete bra waitLoop;
// Example 2, thread synchronization using phase parity :
.reg .b32 i, parArg;
.reg .b64 %r1;
.shared .b64 shMem;
mov.b32 i, 0;
mbarrier.init.shared.b64 [shMem], N; // N threads participating in the mbarrier.
...
loopStart : // One phase per loop iteration
...
mbarrier.arrive.shared.b64 %r1, [shMem]; // N threads
...
and.b32 parArg, i, 1;
waitLoop:
mbarrier.test_wait.parity.shared.b64 complete, [shMem], parArg;
@!complete nanosleep.u32 20;
@!complete bra waitLoop;
...
add.u32 i, i, 1;
setp.lt.u32 p, i, IterMax;
@p bra loopStart;
// Example 3, Asynchronous copy completion waiting :
.reg .b64 state;
.shared .b64 shMem2;
.shared .b64 shard1, shard2;
.global .b64 gbl1, gbl2;
mbarrier.init.shared.b64 [shMem2], threadCount;
...
cp.async.ca.shared.global [shard1], [gbl1], 4;
cp.async.cg.shared.global [shard2], [gbl2], 16;
// Absence of .noinc accounts for arrive-on from prior cp.async operation
cp.async.mbarrier.arrive.shared.b64 [shMem2];
...
mbarrier.arrive.shared.b64 state, [shMem2];
waitLoop:
mbarrier.test_wait.shared::cta.b64 p, [shMem2], state;
@!p bra waitLoop;
// Example 4, Synchronizing the CTA0 threads with cluster threads
.reg .b64 %r1, addr, remAddr;
.shared .b64 shMem;
cvta.shared.u64 addr, shMem;
mapa.u64 remAddr, addr, 0; // CTA0's shMem instance
// One thread from CTA0 executing the below initialization operation
@p0 mbarrier.init.shared::cta.b64 [shMem], N; // N = no of cluster threads
barrier.cluster.arrive;
barrier.cluster.wait;
// Entire cluster executing the below arrive operation
mbarrier.arrive.release.cluster.b64 _, [remAddr];
// computation not requiring mbarrier synchronization ...
// Only CTA0 threads executing the below wait operation
waitLoop:
mbarrier.try_wait.parity.acquire.cluster.shared::cta.b64 complete, [shMem], 0;
@!complete bra waitLoop;
9.7.13.15.17. 并行同步和通信指令:mbarrier.pending_count
mbarrier.pending_count
从不透明的 mbarrier 状态查询待处理的到达计数。
语法
mbarrier.pending_count.b64 count, state;
描述
可以使用 mbarrier.pending_count 从不透明的 mbarrier 状态查询待处理计数。
state 操作数是一个 64 位寄存器,它必须是先前 mbarrier.arrive.noComplete 或 mbarrier.arrive_drop.noComplete 指令的结果。否则,行为是未定义的。
目标寄存器 count 是一个 32 位无符号整数,表示从其中获取 state 寄存器的 mbarrier 对象 在 arrive-on 操作 之前的待处理计数。
PTX ISA 注释
在 PTX ISA 版本 7.0 中引入。
目标 ISA 注释
需要 sm_80 或更高架构。
示例
.reg .b32 %r1;
.reg .b64 state;
.shared .b64 shMem;
mbarrier.arrive.noComplete.b64 state, [shMem], 1;
mbarrier.pending_count.b64 %r1, state;
9.7.13.16. 并行同步和通信指令:tensormap.cp_fenceproxy
tensormap.cp_fenceproxy
融合的复制和 fence 操作。
语法
tensormap.cp_fenceproxy.cp_qualifiers.fence_qualifiers.sync.aligned [dst], [src], size;
.cp_qualifiers = { .global.shared::cta }
.fence_qualifiers = { .to_proxy::from_proxy.release.scope }
.to_proxy::from_proxy = { .tensormap::generic }
.scope = { .cta, .cluster, .gpu , .sys }
描述
tensormap.cp_fenceproxy 指令按顺序执行以下操作:
将
size参数指定的字节大小的数据,从共享内存中地址操作数src指定的位置复制到通用代理中全局内存中地址操作数dst指定的位置。在从复制操作到 tensormap 代理上对地址
dst执行的后续访问的排序上,建立单向代理发布模式。
立即操作数 size 的有效值为 128。
操作数 src 和 dst 分别在 shared::cta 和 global 状态空间中指定非通用地址。
.scope 限定符指定可以直接观察此操作的代理同步效果的线程集,如内存一致性模型中所述。
强制性的 .sync 限定符指示 tensormap.cp_fenceproxy 会导致执行线程等待,直到 warp 中的所有线程执行相同的 tensormap.cp_fenceproxy 指令,然后才恢复执行。
强制性的 .aligned 限定符指示 warp 中的所有线程必须执行相同的 tensormap.cp_fenceproxy 指令。在条件执行的代码中,只有当已知 warp 中的所有线程对条件的评估结果相同时,才应使用对齐的 tensormap.cp_fenceproxy 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
// Example: manipulate a tensor-map object and then consume it in cp.async.bulk.tensor
.reg .b64 new_addr;
.global .align 128 .b8 gbl[128];
.shared .align 128 .b8 sMem[128];
cp.async.bulk.shared::cluster.global.mbarrier::complete_tx::bytes [sMem], [gMem], 128, [mbar];
...
try_wait_loop:
mbarrier.try_wait.shared.b64 p, [mbar], state;
@!p bra try_wait loop;
tensormap.replace.tile.global_address.shared.b1024.b64 [sMem], new_addr;
tensormap.cp_fenceproxy.global.shared::cta.tensormap::generic.release.gpu.sync.aligned
[gbl], [sMem], 128;
fence.proxy.tensormap::generic.acquire.gpu [gbl], 128;
cp.async.bulk.tensor.1d.shared::cluster.global.tile [addr0], [gbl, {tc0}], [mbar0];
9.7.13.17. 并行同步和通信指令:clusterlaunchcontrol.try_cancel
clusterlaunchcontrol.try_cancel
请求取消尚未启动的 cluster。
语法
clusterlaunchcontrol.try_cancel.async{.space}.completion_mechanism{.multicast::cluster::all}.b128 [addr], [mbar];
.completion_mechanism = { .mbarrier::complete_tx::bytes };
.space = { .shared::cta };
描述
clusterlaunchcontrol.try_cancel 指令原子地请求取消尚未开始运行的 cluster 的启动。它异步地将不透明的响应写入共享内存,指示操作是成功还是失败。异步操作的完成使用 .cluster 作用域的 mbarrier 完成机制进行跟踪。
如果成功,则不透明的响应包含已取消 cluster 的第一个 CTA 的 ctaid ;来自同一 grid 的其他 clusterlaunchcontrol.try_cancel 操作的其他成功响应将不包含该 id。
强制性的 .async 限定符指示该指令将异步启动取消操作,并且在请求的操作完成之前,控制权将返回到执行线程。
指定了 .space 限定符,则操作数 addr 和 mbar 都必须在 .shared::cta 状态空间中。否则,将假定两者都使用通用寻址。如果任何地址操作数未落在 .shared::cta 的地址窗口内,则结果是未定义的。
限定符 .completion_mechanism 指定,在异步操作完成时,将对操作数 mbar 指定的 mbarrier 对象执行 complete-tx 操作,其 completeCount 参数等于以字节为单位存储的数据量。
然后,执行线程可以使用 mbarrier 指令 等待异步操作完成。 内存一致性模型 中描述的任何其他同步机制都不能用于保证异步复制操作的完成。
.multicast::cluster::all 限定符指示使用弱异步代理写入将响应异步写入请求 cluster 中每个 CTA 的相应本地共享内存 addr 。写入特定 CTA 的 addr 的完成通过对该 CTA 的共享内存上的 mbarrier 对象的 complete-tx 操作来发出信号。
如果 cluster 中的任何 CTA 已退出,则具有 .multicast::cluster::all 限定符的指令的行为是未定义的。
操作数 addr 指定 16 字节宽的共享内存位置的自然对齐地址,请求的响应将写入到该位置。
clusterlaunchcontrol.try_cancel 指令的响应将是 16 字节的不透明值,并且将在操作数 addr 指定的位置可用。将此响应加载到 16 字节寄存器后,可以使用指令 clusterlaunchcontrol.query_cancel 检查请求是否成功并检索已取消 cluster 的第一个 CTA 的 ctaid 。
如果执行 CTA 已经观察到 clusterlaunchcontrol.try_cancel 指令的完成失败,则发出后续 clusterlaunchcontrol.try_cancel 指令的行为是未定义的。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
需要 sm_100 或更高版本。
以下架构支持限定符 .multicast::cluster::all
sm_100asm_101asm_120a
示例
// Assumption: 1D cluster (cluster_ctaid.y/.z == 1)
// with 1 thread per CTA.
// Current Cluster to be processed, initially the
// currently launched cluster:
mov.b32 xctaid, %ctaid.x;
barrier.cluster.arrive.relaxed;
processCluster:
// Wait on all cluster CTAs completing initialization or processing of previous cluster:
barrier.cluster.wait.acquire;
mov.u32 %r0, %tid.x;
setp.u32.eq p0, %r0, 0x0;
@!p0 bra asyncWork;
// All CTAs in the cluster arrive at their local
// SMEM barrier and set 16B handle tx count:
mbarrier.arrive.expect_tx.cluster.relaxed.shared::cta.b64 state, [mbar], 16;
// first CTA in Cluster attempts to cancel a
// not-yet-started cluster:
mov.u32 %r0, %cluster_ctaid.x;
setp.u32.eq p0, %r0, 0x0;
@p0 clusterlaunchcontrol.try_cancel.async.mbarrier::complete_tx::bytes.multicast::cluster::all.b128 [addr], [mbar];
asyncWork:
// ...process xctaid while cancellation request completes
// asynchronously...
// All CTAs in Cluster wait on cancellation responses on their local SMEM:
waitLoop:
// .acquire prevents the load of the handle from overtaking this read:
mbarrier.try_wait.cluster.acquire.shared::cta.b64 complete, [mbar], state;
@!complete bra waitLoop;
// Load response into 16-byte wide register after unblocking
// from mbarrier:
ld.shared.b128 handle, [addr];
// Check whether cancellation succeeded:
clusterlaunchcontrol.query_cancel.is_canceled.pred.b128 p, handle;
@!p ret; // If failed, we are don end exit:
// Otherwise, read ctaid of first CTA of cancelled Cluster for next iteration...
@p clusterlaunchcontrol.query_cancel.get_first_ctaid.v4.b32.b128 {xctaid, _, _, _}, handle;
// ...and signal CTA0 that we are done reading from handle:
// Fence generic->async
fence.proxy.async.shared::cta;
barrier.cluster.arrive.relaxed;
bra processCluster;
9.7.13.18. 并行同步和通信指令:clusterlaunchcontrol.query_cancel
clusterlaunchcontrol.query_cancel
查询 clusterlaunchcontrol.try_cancel 操作的响应。
语法
clusterlaunchcontrol.query_cancel.is_canceled.pred.b128 pred, try_cancel_response;
clusterlaunchcontrol.query_cancel.get_first_ctaid.v4.b32.b128 {xdim, ydim, zdim, _}, try_cancel_response;
clusterlaunchcontrol.query_cancel.get_first_ctaid{::dimension}.b32.b128 reg, try_cancel_response;
::dimension = { ::x, ::y, ::z };
描述
指令 clusterlaunchcontrol.query_cancel 可用于解码指令 clusterlaunchcontrol.try_cancel 写入的不透明响应。
从 clusterlaunchcontrol.try_cancel 指令加载响应到 16 字节寄存器后,可以进一步使用 clusterlaunchcontrol.query_cancel 指令进行查询,如下所示:
clusterlaunchcontrol.query_cancel.is_canceled.pred.b128:如果 cluster 已成功取消,则谓词 p 设置为 true ;否则,设置为 false 。
如果请求成功,则指令 clusterlaunchcontrol.query_cancel.get_first_ctaid 提取已取消 cluster 中第一个 CTA 的 CTA id。默认情况下,该指令返回一个 .v4 向量,其前三个元素是已取消 cluster 中第一个 CTA 的 x 、 y 和 z 坐标。第 4 个元素的内容未指定。显式的 .get_first_ctaid::x 、 .get_first_ctaid::y 或 .get_first_ctaid::z 限定符可用于将单个 x 、 y 或 z 坐标提取到 32 位寄存器中。
如果请求失败,则 clusterlaunchcontrol.query_cancel.get_first_ctaid 的行为是未定义的。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
需要 sm_100 或更高版本。
示例
clusterlaunchcontrol.query_cancel.is_canceled pred.b128 p, handle;
@p clusterlaunchcontrol.query_cancel.get_first_ctaid.v4.b32.b128 {xdim, ydim, zdim, ignr} handle;
clusterlaunchcontrol.query_cancel.get_first_ctaid::x.b32.b128 reg0, handle;
clusterlaunchcontrol.query_cancel.get_first_ctaid::y.b32.b128 reg1, handle;
clusterlaunchcontrol.query_cancel.get_first_ctaid::z.b32.b128 reg2, handle;
9.7.14. Warp 级别矩阵乘法累加指令
矩阵乘法和累加运算具有以下形式:
D = A * B + C
其中 D 和 C 称为累加器,并且可以引用相同的矩阵。
PTX 提供了两种执行矩阵乘法和累加计算的方法:
-
使用
wmma指令-
此 warp 级别计算由 warp 中的所有线程集体执行,如下所示:
使用
wmma.load操作将矩阵 A、B 和 C 从内存加载到寄存器中。当操作完成时,每个线程中的目标寄存器都保存加载矩阵的一个片段。使用
wmma.mma操作在加载的矩阵上执行矩阵乘法和累加操作。当操作完成时,每个线程中的目标寄存器都保存wmma.mma操作返回的结果矩阵的一个片段。使用
wmma.store操作将结果矩阵 D 存储回内存。或者,结果矩阵 D 也可以用作后续wmma.mma操作的参数 C。
wmma.load和wmma.store指令隐式地处理在为wmma.mma操作从内存加载输入矩阵以及在将结果存储回内存时矩阵元素的组织。
-
-
使用
mma指令与
wmma类似,mma也需要 warp 中的所有线程集体执行计算,但是,在调用mma操作之前,需要显式完成矩阵元素在 warp 中不同线程之间的分布。mma指令支持密集矩阵 A 和稀疏矩阵 A。当 A 是稀疏矩阵存储中描述的结构化稀疏矩阵时,可以使用稀疏变体。
9.7.14.1. 矩阵形状
矩阵乘法和累加运算支持操作数矩阵 A、B 和 C 的有限形状集。所有三个矩阵操作数的形状都由元组 MxNxK 统一描述,其中 A 是 MxK 矩阵,B 是 KxN 矩阵,而 C 和 D 是 MxN 矩阵。
以下矩阵形状受支持用于指定的类型:
指令 |
缩放 |
稀疏性 |
乘数数据类型 |
形状 |
PTX ISA 版本 |
|---|---|---|---|---|---|
|
NA |
密集 |
浮点 - |
|
PTX ISA 版本 6.0 |
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 7.0 |
|
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 7.0 |
|
|
密集 |
整数 - |
|
PTX ISA 版本 6.3 |
|
|
密集 |
子字节整数 - |
|
PTX ISA 版本 6.3(预览功能) |
|
|
密集 |
单比特 - |
|
PTX ISA 版本 6.3(预览功能) |
|
|
NA |
密集 |
浮点 - |
|
PTX ISA 版本 7.0 |
|
PTX ISA 版本 7.8 |
||||
|
密集 |
浮点 - |
|
PTX ISA 版本 6.4 |
|
|
PTX ISA 版本 6.5 |
||||
|
PTX ISA 版本 7.0 |
||||
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 7.0 |
|
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 7.0 |
|
|
密集 |
整数 - |
|
PTX ISA 版本 6.5 |
|
|
PTX ISA 版本 7.0 |
||||
|
密集 |
子字节整数 - |
|
PTX ISA 版本 6.5 |
|
|
PTX ISA 版本 7.0 |
||||
|
密集 |
单比特 - |
|
PTX ISA 版本 7.0 |
|
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 8.4 |
|
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
|
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
|
|
是 |
密集 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
|
密集 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
|
|
NA |
稀疏 |
浮点 - |
|
PTX ISA 版本 7.1 |
|
稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 7.1 |
|
|
稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 7.1 |
|
|
稀疏 |
整数 - |
|
PTX ISA 版本 7.1 |
|
|
稀疏 |
子字节整数 - |
|
PTX ISA 版本 7.1 |
|
|
稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.4 |
|
|
具有有序元数据的稀疏 |
浮点 - |
|
PTX ISA 版本 8.5 |
|
|
具有有序元数据的稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.5 |
|
|
具有有序元数据的稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.5 |
|
|
具有有序元数据的稀疏 |
整数 - |
|
PTX ISA 版本 8.5 |
|
|
具有有序元数据的稀疏 |
子字节整数 - |
|
PTX ISA 版本 8.5 |
|
|
具有有序元数据的稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.5 |
|
|
具有有序元数据的稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
|
|
是 |
具有有序元数据的稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
|
具有有序元数据的稀疏 |
备选浮点格式 - |
|
PTX ISA 版本 8.7 |
9.7.14.2. 矩阵数据类型
矩阵乘法和累加运算分别在整数、浮点、子字节整数和单比特数据类型上受支持。所有操作数都必须包含相同的基本类型,即整数或浮点。
对于浮点矩阵乘法和累加运算,不同的矩阵操作数可能具有不同的精度,如下所述。
数据类型 |
乘数(A 或 B) |
累加器(C 或 D) |
|---|---|---|
整数 |
|
|
浮点 |
|
|
备选浮点 |
|
|
备选浮点 |
|
|
备选浮点 |
|
|
带缩放的备选浮点 |
|
|
带缩放的备选浮点 |
|
|
浮点 |
|
|
子字节整数 |
都为 |
|
单比特整数 |
|
|
9.7.14.3. 块缩放
具有以下 .kind 限定符的 mma 指令:
.kind::mxf8f6f4.kind::mxf4.kind::mxf4nvf4
执行带块缩放的矩阵乘法。此操作具有以下形式: D = (A * scale_A) * (B * scale_B) + C 。
对于形状为 M x SFA_N 的 scale_A 矩阵,矩阵 A 的每一行被划分为 SFA_N 个块,并且行的每个块都与来自 scale_A 的同一行的相应元素(以下称为 SF_A )相乘。
类似地,对于形状为 SFB_M x N 的 scale_B 矩阵,矩阵 B 的每一列被划分为 SFB_M 个块,并且列的每个块都与来自 scale_B 的同一列的相应元素(以下称为 SF_B )相乘。
图 41 显示了带 .scale_vec::2X 块缩放的 mma 示例。
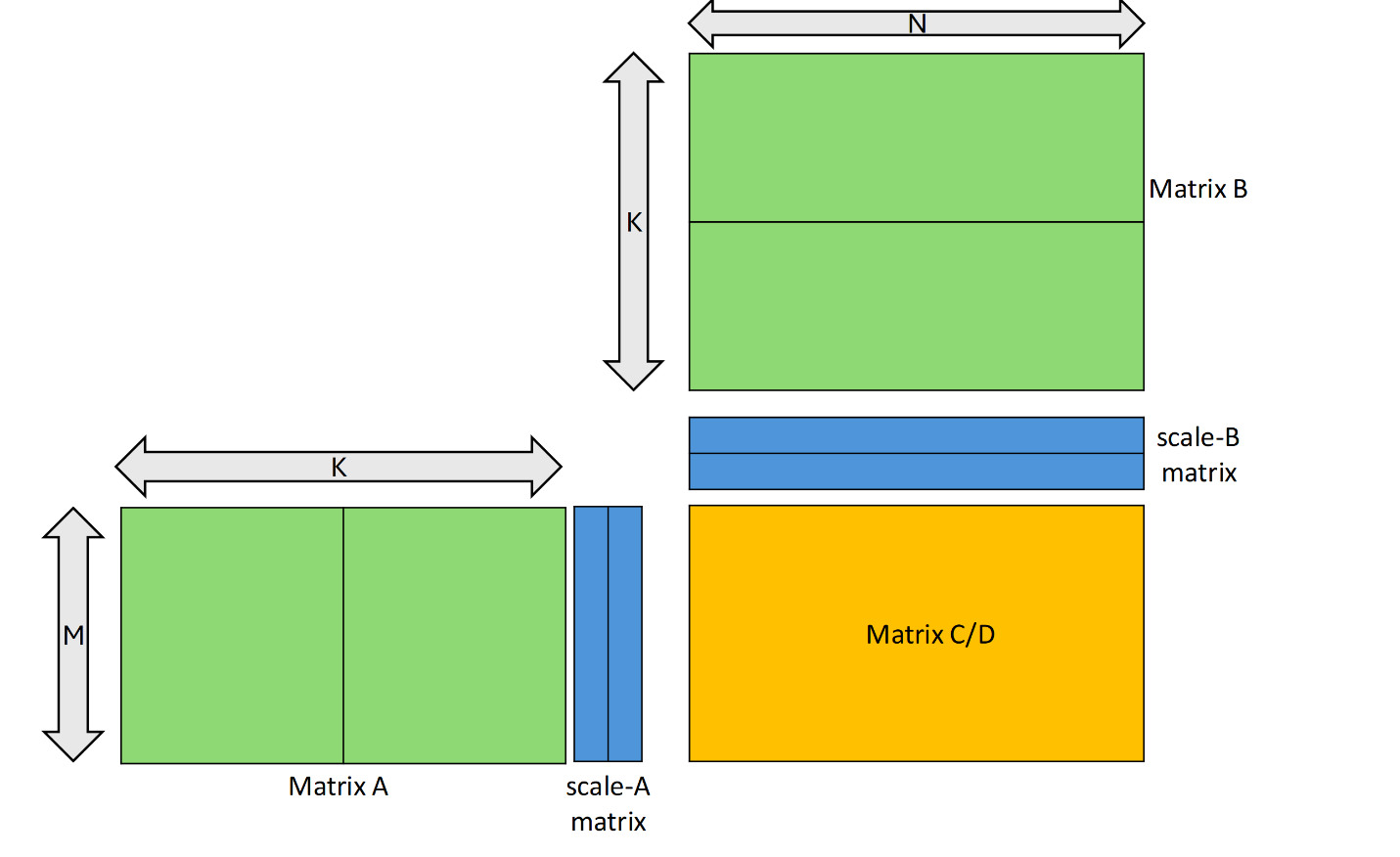
图 41 带 .scale_vec::2X 块缩放的 mma
scale_A 和 scale_B 矩阵的形状取决于限定符 .scale_vec_size ,如 表 34 所示。
.scale_vec_size |
scale_A 的形状 |
scale_B 的形状 |
|---|---|---|
|
M x 1 |
1 x N |
|
M x 2 |
2 x N |
|
M x 4 |
4 x N |
表 35 列出了确切元素类型和 .scale_vec_size 的有效组合。
.kind::* |
元素数据类型 .atype 和 .btype |
缩放数据类型 .stype |
.scale_vec_size |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
scale-a-data 和 scale-b-data 参数分别为 scale_A 和 scale_B 矩阵提供元数据。元组 {byte-id-a, thread-id-a} 和 {byte-id-b, thread-id-b} 提供选择器信息,以从相应的元数据参数 scale-a-data 和 scale-b-data 中选择元素 SF_A 和 SF_B 。元组 {byte-id-a, thread-id-a} 允许从 scale-a-data 中选择缩放矩阵元素 SF_A 。类似地,元组 {byte-id-b, thread-id-b} 允许从 scale-b-data 中选择缩放矩阵元素 SF_B 。
组件 thread-id-a , thread-id-b 决定 quad 中哪些线程贡献 SF_A 和 SF_B 值。以下列表描述了线程选择器组件 thread-id-a , thread-id-b 的影响:
-
由
thread-id-a确定的 quad 中的一个线程对提供 SF_A 值。值 0 选择较低的两个线程,而值 1 选择 quad 中较高的两个线程。换句话说,当thread-id-a设置为 0 时,满足以下条件的线程对:%laneid% 4 == 0 或 1 提供 SF_A 。相反,当thread-id-a设置为 1 时,满足以下条件的线程对:%laneid% 4 == 2 或 3 提供 SF_A 。有关更多详细信息,请参阅 图 42 。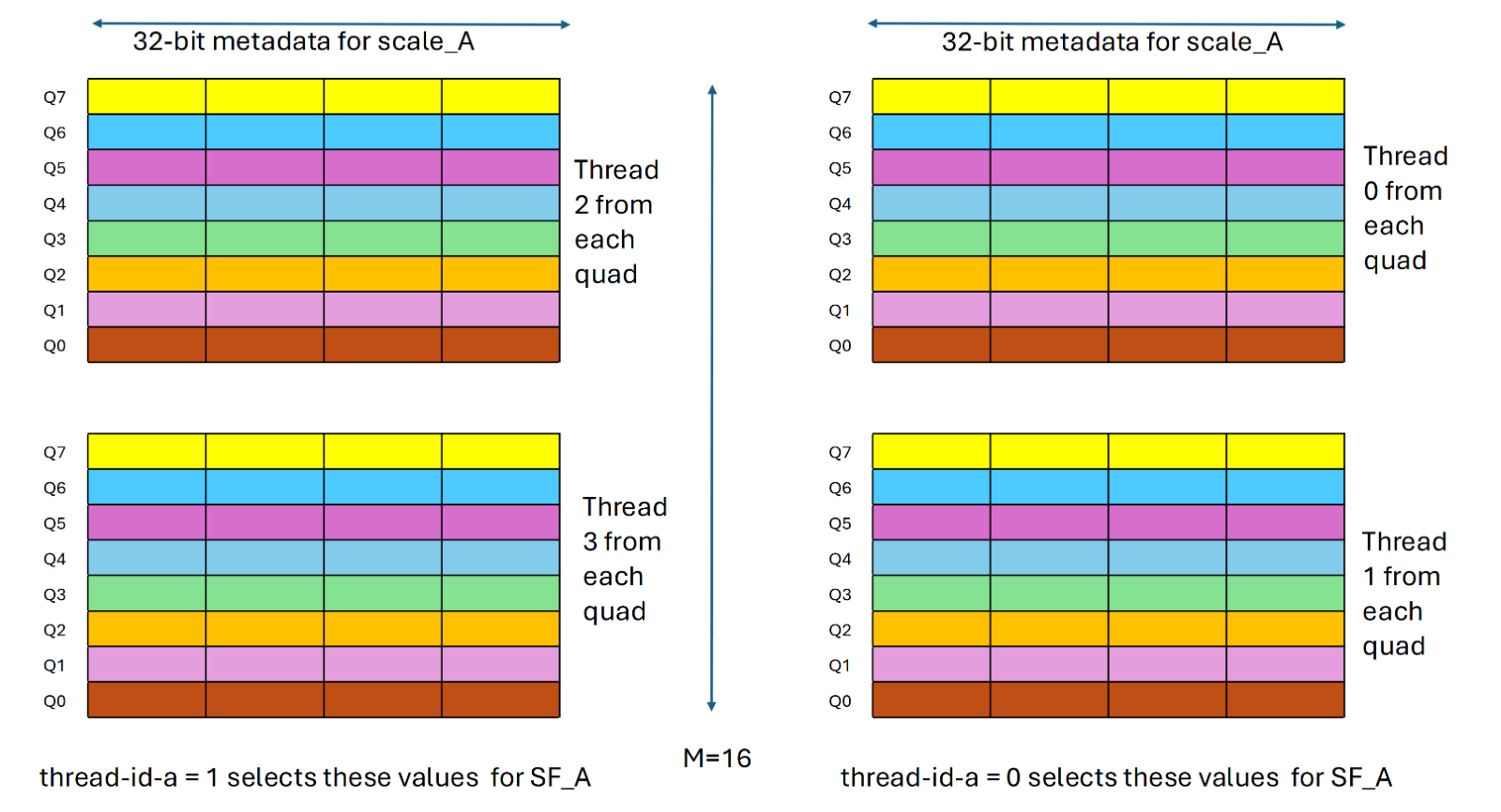
图 42 基于
thread-id-a选择 SF_A 值集 -
由
thread-id-b确定的 quad 中的一个线程提供 SF_B 值。换句话说,每个满足以下条件的线程:%laneid% 4 ==thread-id-b提供 SF_B 。有关更多详细信息,请参阅 图 43 。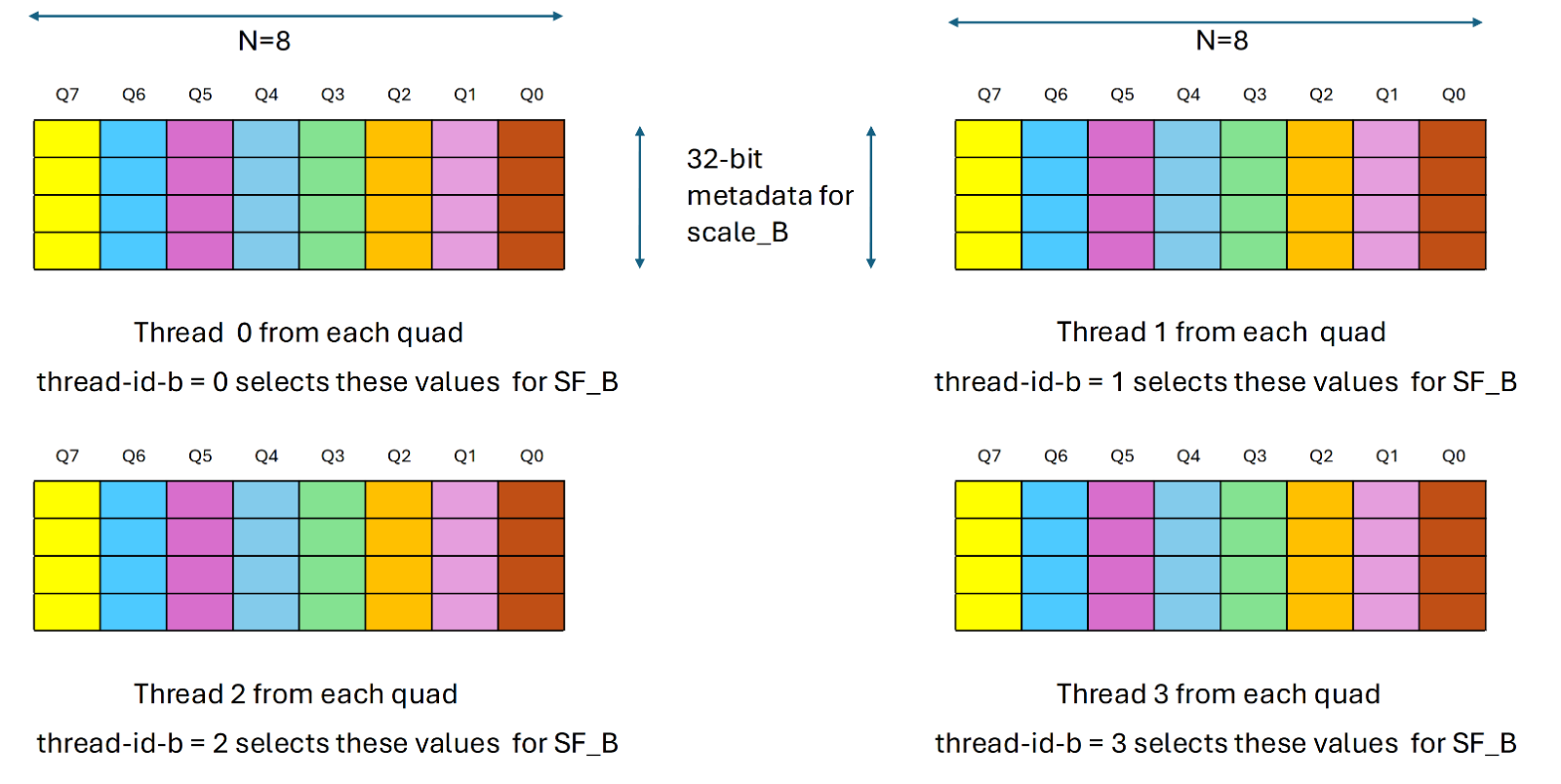
图 43 基于
thread-id-b选择 SF_B 值集
参数 byte-id-a , byte-id-b 选择来自 scale-a-data , scale-b-data 的哪些字节贡献 SF_A 和 SF_B 值。以下列表描述了 .scale_vec_size 限定符对字节选择器组件 byte-id-a , byte-id-b 的影响:
-
当
.scale_vec_size为.scale_vec::1X时:分别由
byte-id-a,byte-id-b确定的scale-a-data和scale-b-data中的每个字节提供 SF_A 和 SF_B 值。
-
当
.scale_vec_size为.scale_vec::2X时:分别由
byte-id-a和byte-id-b确定的scale-a-data和scale-b-data中的一个字节对(两个字节)提供 SF_A 和 SF_B 值。值 0 选择较低的两个字节,而值 2 选择来自相应元数据值的较高的两个字节。
-
当
.scale_vec_size为.scale_vec::4X时:scale-a-data和scale-b-data中的所有四个字节都提供这些值。因此,byte-id-a,byte-id-b必须为零。
有关更多详细信息,请参阅 图 44 。
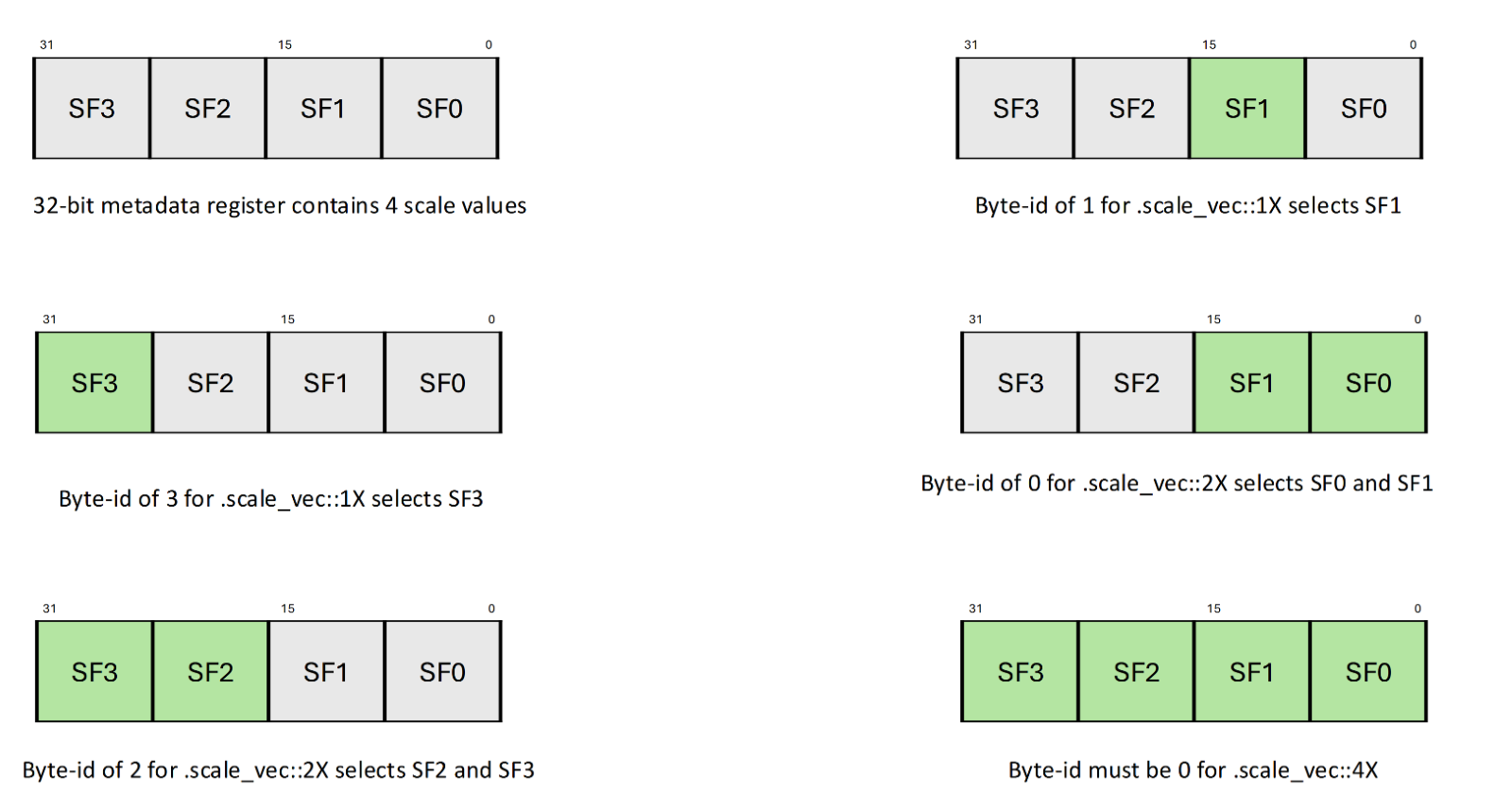
图 44 基于 byte-id-a 或 byte-id-b 选择 SF_A 或 SF_B 值集
表 36 枚举了各种选择器组件的有效值。任何其他值都会导致未定义的行为。
.scale_vec_size |
选择器组件 |
|||
|---|---|---|---|---|
byte-id-a |
thread-id-a |
byte-id-b |
thread-id-b |
|
|
[0, 1, 2, 3] |
[0, 1] |
[0, 1, 2, 3] |
[0, 1, 2, 3] |
|
[0, 2] |
[0, 2] |
||
|
0 |
0 |
||
9.7.14.4. 使用 wmma 指令的矩阵乘法累加运算
本节介绍 warp 级别 wmma.load, wmma.mma 和 wmma.store 指令以及这些指令中涉及的各种矩阵的组织。
9.7.14.4.1. WMMA 的矩阵片段
warp 中的每个线程都持有一个矩阵片段。warp 中线程加载的片段分布是未指定的,并且取决于目标架构,因此矩阵内片段的身份也是未指定的,并且取决于目标架构。如果底层矩阵的形状、布局和元素类型匹配,则 wmma 操作返回的片段可以用作另一个 wmma 操作的操作数。由于片段布局取决于架构,因此如果两个函数链接在一起,但针对不同的链接兼容 SM 架构编译,则在一个函数中使用 wmma 操作返回的片段作为另一个函数中 wmma 操作的操作数可能无法按预期工作。请注意,将 wmma 片段传递给具有 .weak 链接的函数是不安全的,因为在链接时,对此类函数的引用可能会解析为不同编译模块中的函数。
每个片段都是一个向量表达式,其内容确定如下。片段中各个矩阵元素的身份是未指定的。
- 整数片段
-
乘数(A 或 B)
数据类型
形状
矩阵
片段
.u8或.s8.m16n16k16A
一个包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的四个元素。B
一个包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的四个元素。.m8n32k16A
一个向量表达式,包含一个
.b32寄存器,其中包含来自矩阵的四个元素。B
一个包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的四个元素。.m32n8k16A
一个包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的四个元素。B
一个向量表达式,包含单个
.b32寄存器,每个寄存器包含来自矩阵的四个元素。累加器(C 或 D)
数据类型
形状
片段
.s32.m16n16k16一个包含八个
.s32寄存器的向量表达式。.m8n32k16.m32n8k16
浮点片段
数据类型
矩阵
片段
.f16A 或 B
一个包含八个
.f16x2寄存器的向量表达式。
.f16C 或 D
一个包含四个
.f16x2寄存器的向量表达式。
.f32一个包含八个
.f32寄存器的向量表达式。
.bf16 数据格式的浮点片段
乘数(A 或 B)
数据类型
形状
矩阵
片段
.bf16
.m16n16k16A
一个包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的两个元素。B
.m8n32k16A
一个向量表达式,包含两个
.b32寄存器,其中包含来自矩阵的两个元素。B
一个包含八个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的两个元素。
.m32n8k16A
一个包含八个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵的两个元素。B
一个向量表达式,包含两个
.b32寄存器,每个寄存器包含来自矩阵的两个元素。累加器(C 或 D)
数据类型
矩阵
片段
.f32C 或 D
一个包含八个
.f32寄存器的向量表达式。
.tf32 数据格式的浮点片段
乘数(A 或 B)
数据类型
形状
矩阵
片段
.tf32
.m16n16k8A
一个包含四个
.b32寄存器的向量表达式。B
一个包含四个
.b32寄存器的向量表达式。累加器(C 或 D)
数据类型
形状
矩阵
片段
.f32
.m16n16k8C 或 D
一个包含八个
.f32寄存器的向量表达式。
双精度浮点片段
乘数(A 或 B)
数据类型
形状
矩阵
片段
.f64
.m8n8k4A 或 B
一个包含单个
.f64寄存器的向量表达式。累加器(C 或 D)
数据类型
形状
矩阵
片段
.f64
.m8n8k4C 或 D
一个向量表达式,包含单个
.f64寄存器。
子字节整数和单比特片段
乘数(A 或 B)
数据类型
形状
片段
.u4或.s4
.m8n8k32一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵的八个元素。
.b1
.m8n8k128一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵的 32 个元素。累加器(C 或 D)
数据类型
形状
片段
.s32
.m8n8k32一个包含两个
.s32寄存器的向量表达式。
.m8n8k128一个包含两个
.s32寄存器的向量表达式。
操作片段内容
可以通过读取和写入片段中的单个寄存器来操作矩阵片段的内容,前提是满足以下条件
片段中的所有矩阵元素都在线程之间统一操作,使用相同的参数。
矩阵元素的顺序没有改变。
例如,如果对应于给定矩阵的每个寄存器都乘以一个统一的常数值,那么结果矩阵只是原始矩阵的缩放版本。
请注意,不支持
.f16和.f32累加器片段之间的类型转换,无论哪个方向都不支持。即使片段中元素的顺序保持不变,结果也是未定义的。
9.7.14.4.2. WMMA 的矩阵存储
每个矩阵都可以以行优先或列优先布局存储在内存中。在行优先格式中,每行的连续元素存储在连续的内存位置,并且该行称为矩阵的主导维度。在列优先格式中,每列的连续元素存储在连续的内存位置,并且该列称为矩阵的主导维度。
主导维度(行或列)的连续实例不必在内存中连续存储。wmma.load 和 wmma.store 操作接受一个可选参数 stride,该参数指定从每行(或列)的开头到下一行的偏移量,以矩阵元素(而不是字节)为单位。例如,wmma 操作访问的矩阵可能是存储在内存中的较大矩阵的子矩阵。这允许程序员在大于 wmma 操作支持的形状的矩阵上组合乘法累加操作。
地址对齐
每个主导维度实例(行或列)的起始地址必须与相应片段的大小(以字节为单位)对齐。请注意,起始地址由基指针和可选的
stride确定。
以下指令作为一个示例
wmma.load.a.sync.aligned.row.m16n16k16.f16 {x0,...,x7}, [p], s;
片段大小(字节)= 32(八个
.f16x2类型的元素)实际
stride(字节)= 2 *s(因为stride是以.f16元素而不是字节为单位指定的)-
为了使此矩阵的每行都与片段大小对齐,以下条件必须为真
p是 32 的倍数。2*s是 32 的倍数。
stride 的默认值
stride的默认值是矩阵的主导维度的大小。例如,对于一个MxK矩阵,行优先布局的stride为K,列优先布局的stride为M。特别是,支持的矩阵形状的默认 stride 如下
形状
A(行)
A(列)
B(行)
B(列)
累加器(行)
累加器(列)
16x16x16
16
16
16
16
16
16
8x32x16
16
8
32
16
32
8
32x8x16
16
32
8
16
8
32
8x8x32
32
8
8
32
8
8
8x8x128
128
8
8
128
8
8
16x16x8
8
16
16
8
16
16
8x8x4
4
8
8
4
8
8
9.7.14.4.3. Warp 级矩阵加载指令:wmma.load
wmma.load
为 WMMA 从内存中集体加载矩阵
语法
浮点格式 .f16 加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
.layout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ss = {.global, .shared{::cta}};
.atype = {.f16, .s8, .u8};
.btype = {.f16, .s8, .u8};
.ctype = {.f16, .f32, .s32};
备选浮点格式 .bf16 加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ss = {.global, .shared{::cta}};
.atype = {.bf16 };
.btype = {.bf16 };
.ctype = {.f32 };
备选浮点格式 .tf32 加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m16n16k8 };
.ss = {.global, .shared{::cta}};
.atype = {.tf32 };
.btype = {.tf32 };
.ctype = {.f32 };
双精度浮点 .f64 加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m8n8k4 };
.ss = {.global, .shared{::cta}};
.atype = {.f64 };
.btype = {.f64 };
.ctype = {.f64 };
子字节加载
wmma.load.a.sync.aligned.row.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.col.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m8n8k32};
.ss = {.global, .shared{::cta}};
.atype = {.s4, .u4};
.btype = {.s4, .u4};
.ctype = {.s32};
单比特加载
wmma.load.a.sync.aligned.row.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.col.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m8n8k128};
.ss = {.global, .shared{::cta}};
.atype = {.b1};
.btype = {.b1};
.ctype = {.s32};
描述
跨 warp 中的所有线程,从地址操作数 p 在指定状态空间中指示的位置集体加载矩阵到目标寄存器 r 中。
如果未给出状态空间,则使用通用寻址执行内存访问。wmma.load 操作只能与 .global 和 .shared 空间以及通用寻址一起使用,其中地址指向 .global 或 .shared 空间。
互斥限定符 .a、.b 和 .c 分别指示正在为 wmma 计算加载矩阵 A、B 或 C。
目标操作数 r 是一个用大括号括起来的向量表达式,可以容纳加载操作返回的片段,如WMMA 的矩阵片段中所述。
.shape 限定符指示所有矩阵参数的维度,这些矩阵参数都参与预期的 wmma 计算。
.layout 限定符指示要加载的矩阵是以行优先还是列优先格式存储。
stride 是一个可选的 32 位整数操作数,它提供主导维度(行或列)的连续实例开始之间的偏移量,以矩阵元素为单位。 stride 的默认值在WMMA 的矩阵存储中描述,如果实际值大于默认值,则必须指定。例如,如果矩阵是较大矩阵的子矩阵,则 stride 的值是较大矩阵的主导维度。指定低于默认值的值会导致未定义的行为。
地址 p 和 stride 的所需对齐方式在WMMA 的矩阵存储中描述。
强制性 .sync 限定符指示 wmma.load 导致执行线程等待,直到 warp 中的所有线程都执行相同的 wmma.load 指令,然后才恢复执行。
强制性 .aligned 限定符指示 warp 中的所有线程必须执行相同的 wmma.load 指令。在有条件执行的代码中,只有当已知 warp 中的所有线程都完全相同地评估条件时,才应使用 wmma.load 指令,否则行为未定义。
如果所有线程没有使用相同的限定符和 p 和 stride 的相同值,或者 warp 中的任何线程已退出,则 wmma.load 的行为未定义。
在内存一致性模型中,wmma.load 被视为弱内存操作。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
.m8n32k16 和 .m32n8k16 在 PTX ISA 版本 6.1 中引入。
整数、子字节整数和单比特 wmma 在 PTX ISA 版本 6.3 中引入。
wmma 上的 .m8n8k4 和 .m16n16k8 在 PTX ISA 版本 7.0 中引入。
双精度和备选浮点精度 wmma 在 PTX ISA 版本 7.0 中引入。
从 PTX ISA 版本 6.3 开始,需要修饰符 .aligned,并在低于 6.3 的 PTX ISA 版本中被认为是隐式的。
PTX ISA 版本 7.8 中引入了对 ::cta 子限定符的支持。
- 预览功能
-
子字节
wmma和单比特wmma是 PTX ISA 版本 6.3 中的预览功能。所有细节都可能会更改,并且不保证在未来的 PTX ISA 版本或 SM 架构上向后兼容。
目标 ISA 注释
浮点 wmma 需要 sm_70 或更高版本。
整数 wmma 需要 sm_72 或更高版本。
子字节和单比特 wmma 需要 sm_75 或更高版本。
双精度和备选浮点精度 wmma 需要 sm_80 或更高版本。
示例
// Load elements from f16 row-major matrix B
.reg .b32 x<8>;
wmma.load.b.sync.aligned.m16n16k16.row.f16 {x0,x1,x2,x3,x4,x5,x,x7}, [ptr];
// Now use {x0, ..., x7} for the actual wmma.mma
// Load elements from f32 column-major matrix C and scale the values:
.reg .b32 x<8>;
wmma.load.c.sync.aligned.m16n16k16.col.f32
{x0,x1,x2,x3,x4,x5,x6,x7}, [ptr];
mul.f32 x0, x0, 0.1;
// repeat for all registers x<8>;
...
mul.f32 x7, x7, 0.1;
// Now use {x0, ..., x7} for the actual wmma.mma
// Load elements from integer matrix A:
.reg .b32 x<4>
// destination registers x<4> contain four packed .u8 values each
wmma.load.a.sync.aligned.m32n8k16.row.u8 {x0,x1,x2,x3}, [ptr];
// Load elements from sub-byte integer matrix A:
.reg .b32 x0;
// destination register x0 contains eight packed .s4 values
wmma.load.a.sync.aligned.m8n8k32.row.s4 {x0}, [ptr];
// Load elements from .bf16 matrix A:
.reg .b32 x<4>;
wmma.load.a.sync.aligned.m16n16k16.row.bf16
{x0,x1,x2,x3}, [ptr];
// Load elements from .tf32 matrix A:
.reg .b32 x<4>;
wmma.load.a.sync.aligned.m16n16k8.row.tf32
{x0,x1,x2,x3}, [ptr];
// Load elements from .f64 matrix A:
.reg .b32 x<4>;
wmma.load.a.sync.aligned.m8n8k4.row.f64
{x0}, [ptr];
9.7.14.4.4. Warp 级矩阵存储指令:wmma.store
wmma.store
为 WMMA 将矩阵集体存储到内存中
语法
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
.layout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ss = {.global, .shared{::cta}};
.type = {.f16, .f32, .s32};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride}
.layout = {.row, .col};
.shape = {.m8n8k32, .m8n8k128};
.ss = {.global, .shared{::cta}};
.type = {.s32};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride}
.layout = {.row, .col};
.shape = {.m16n16k8};
.ss = {.global, .shared{::cta}};
.type = {.f32};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride}
.layout = {.row, .col};
.shape = {.m8n8k4 };
.ss = {.global, .shared{::cta}};
.type = {.f64};
描述
跨 warp 中的所有线程,从源寄存器 r 将矩阵集体存储到地址操作数 p 在指定状态空间中指示的位置。
如果未给出状态空间,则使用通用寻址执行内存访问。wmma.load 操作只能与 .global 和 .shared 空间以及通用寻址一起使用,其中地址指向 .global 或 .shared 空间。
源操作数 r 是一个用大括号括起来的向量表达式,它与存储操作期望的片段形状相匹配,如WMMA 的矩阵片段中所述。
.shape 限定符指示所有矩阵参数的维度,这些矩阵参数都参与预期的 wmma 计算。它必须与 wmma.mma 指令上指定的 .shape 限定符匹配,该指令生成要存储的 D 矩阵。
.layout 限定符指示要加载的矩阵是以行优先还是列优先格式存储。
stride 是一个可选的 32 位整数操作数,它提供主导维度(行或列)的连续实例开始之间的偏移量,以矩阵元素为单位。 stride 的默认值在WMMA 的矩阵存储中描述,如果实际值大于默认值,则必须指定。例如,如果矩阵是较大矩阵的子矩阵,则 stride 的值是较大矩阵的主导维度。指定低于默认值的值会导致未定义的行为。
地址 p 和 stride 的所需对齐方式在WMMA 的矩阵存储中描述。
强制性 .sync 限定符指示 wmma.store 导致执行线程等待,直到 warp 中的所有线程都执行相同的 wmma.store 指令,然后才恢复执行。
强制性 .aligned 限定符指示 warp 中的所有线程必须执行相同的 wmma.store 指令。在有条件执行的代码中,只有当已知 warp 中的所有线程都完全相同地评估条件时,才应使用 wmma.store 指令,否则行为未定义。
如果所有线程没有使用相同的限定符和 p 和 stride 的相同值,或者 warp 中的任何线程已退出,则 wmma.store 的行为未定义。
在内存一致性模型中,wmma.store 被视为弱内存操作。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
.m8n32k16 和 .m32n8k16 在 PTX ISA 版本 6.1 中引入。
整数、子字节整数和单比特 wmma 在 PTX ISA 版本 6.3 中引入。
.m16n16k8 在 PTX ISA 版本 7.0 中引入。
双精度 wmma 在 PTX ISA 版本 7.0 中引入。
从 PTX ISA 版本 6.3 开始,需要修饰符 .aligned,并在低于 6.3 的 PTX ISA 版本中被认为是隐式的。
PTX ISA 版本 7.8 中引入了对 ::cta 子限定符的支持。
- 预览功能
-
子字节
wmma和单比特wmma是 PTX ISA 版本 6.3 中的预览功能。所有细节都可能会更改,并且不保证在未来的 PTX ISA 版本或 SM 架构上向后兼容。
目标 ISA 注释
浮点 wmma 需要 sm_70 或更高版本。
整数 wmma 需要 sm_72 或更高版本。
子字节和单比特 wmma 需要 sm_75 或更高版本。
双精度 wmma 和形状 .m16n16k8 需要 sm_80 或更高版本。
示例
// Storing f32 elements computed by a wmma.mma
.reg .b32 x<8>;
wmma.mma.sync.m16n16k16.row.col.f32.f32
{d0, d1, d2, d3, d4, d5, d6, d7}, ...;
wmma.store.d.sync.m16n16k16.row.f32
[ptr], {d0, d1, d2, d3, d4, d5, d6, d7};
// Store s32 accumulator for m16n16k16 shape:
.reg .b32 d<8>;
wmma.store.d.sync.aligned.m16n16k16.row.s32
[ptr], {d0, d1, d2, d3, d4, d5, d6, d7};
// Store s32 accumulator for m8n8k128 shape:
.reg .b32 d<2>
wmma.store.d.sync.aligned.m8n8k128.row.s32
[ptr], {d0, d1};
// Store f64 accumulator for m8n8k4 shape:
.reg .f64 d<2>;
wmma.store.d.sync.aligned.m8n8k4.row.f64
[ptr], {d0, d1};
9.7.14.4.5. Warp 级矩阵乘法累加指令:wmma.mma
wmma.mma
在 warp 中执行单个矩阵乘法累加操作
语法
// Floating point (.f16 multiplicands) wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;
// Integer (.u8/.s8 multiplicands) wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.s32.atype.btype.s32{.satfinite} d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.dtype = {.f16, .f32};
.atype = {.s8, .u8};
.btype = {.s8, .u8};
.ctype = {.f16, .f32};
浮点格式 .bf16wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.f32.atype.btype.f32 d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.atype = {.bf16 };
.btype = {.bf16};
浮点格式 .tf32wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.f32.atype.btype.f32 d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k8 };
.atype = {.tf32 };
.btype = {.tf32};
浮点双精度 wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape{.rnd}.f64.f64.f64.f64 d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m8n8k4 };
.rnd = { .rn, .rz, .rm, .rp };
子字节(.u4/.s4 乘数)wmma.mma
wmma.mma.sync.aligned.row.col.shape.s32.atype.btype.s32{.satfinite} d, a, b, c;
.shape = {.m8n8k32};
.atype = {.s4, .u4};
.btype = {.s4, .u4};
单比特(.b1 乘数)wmma.mma
wmma.mma.op.popc.sync.aligned.row.col.shape.s32.atype.btype.s32 d, a, b, c;
.shape = {.m8n8k128};
.atype = {.b1};
.btype = {.b1};
.op = {.xor, .and}
描述
使用分别在寄存器 a、b 和 c 中加载的矩阵 A、B 和 C 执行 warp 级矩阵乘法累加计算 D = A * B + C,并将结果矩阵存储在寄存器 d 中。寄存器参数 a、b、c 和 d 保存相应矩阵的未指定片段,如WMMA 的矩阵片段中所述
限定符 .dtype、.atype、.btype 和 .ctype 分别指示矩阵 D、A、B 和 C 中元素的数据类型。
对于没有显式 .atype 和 .btype 的 wmma.mma:.atype 和 .btype 隐式设置为 .f16。
对于整数 wmma,.ctype 和 .dtype 必须指定为 .s32。此外,.atype 和 .btype 的值必须相同,即,两者都为 .s8 或两者都为 .u8。
对于子字节单比特 wmma,.ctype 和 .dtype 必须指定为 .s32。此外,.atype 和 .btype 的值必须相同;即,两者都为 .s4,两者都为 .u4,或两者都为 .b1。
对于单比特 wmma,乘法被一系列逻辑运算替换;具体来说,wmma.xor.popc 和 wmma.and.popc 分别计算 A 的 128 位行与 B 的 128 位列的异或、与,然后计算结果中设置的位数 (popc)。此结果将添加到 C 的相应元素并写入 D。
限定符 .alayout 和 .blayout 必须与生成操作数 a 和 b 内容的 wmma.load 指令上指定的布局相匹配。类似地,限定符 .atype、.btype 和 .ctype 必须与生成操作数 a、b 和 c 内容的 wmma.load 指令上的相应限定符相匹配。
.shape 限定符必须与在 wmma.load 指令上使用的 .shape 限定符相匹配,这些指令生成所有三个输入操作数 a、b 和 c 的内容。
目标操作数 d 是一个用大括号括起来的向量表达式,它与 wmma.mma 指令计算的片段的 .shape 相匹配。
- 输出时的饱和
-
可选限定符
.satfinite指示目标寄存器中的最终值按如下方式饱和输出被钳制为最小或最大 32 位有符号整数值。否则,如果累加将溢出,则值将回绕。
.f16浮点运算的精度和舍入-
矩阵 A 和 B 的元素级乘法以至少单精度执行。当
.ctype或.dtype为.f32时,中间值的累加以至少单精度执行。当.ctype和.dtype都指定为.f16时,累加以至少半精度执行。累加顺序、舍入和次正规输入的处理是未指定的。
.bf16、.tf32浮点运算的精度和舍入-
矩阵 A 和 B 的元素级乘法以指定的精度执行。中间值的累加以至少单精度执行。
累加顺序、舍入和次正规输入的处理是未指定的。
双精度 wmma.mma 上的舍入修饰符(默认为 .rn)
.rn-
尾数 LSB 四舍五入到最接近的偶数
.rz-
尾数 LSB 向零舍入
.rm-
尾数 LSB 向负无穷大舍入
.rp-
尾数 LSB 向正无穷大舍入
强制性 .sync 限定符指示 wmma.mma 导致执行线程等待,直到 warp 中的所有线程都执行相同的 wmma.mma 指令,然后才恢复执行。
强制性 .aligned 限定符指示 warp 中的所有线程必须执行相同的 wmma.mma 指令。在有条件执行的代码中,只有当已知 warp 中的所有线程都完全相同地评估条件时,才应使用 wmma.mma 指令,否则行为未定义。
如果同一 warp 中的所有线程没有使用相同的限定符,或者 warp 中的任何线程已退出,则 wmma.mma 的行为未定义。
PTX ISA 注释
在 PTX ISA 版本 6.0 中引入。
.m8n32k16 和 .m32n8k16 在 PTX ISA 版本 6.1 中引入。
整数、子字节整数和单比特 wmma 在 PTX ISA 版本 6.3 中引入。
双精度和备选浮点精度 wmma 在 PTX ISA 版本 7.0 中引入。
PTX ISA 版本 7.1 中引入了对单比特 wmma 中 .and 操作的支持。
从 PTX ISA 版本 6.3 开始,需要修饰符 .aligned,并在低于 6.3 的 PTX ISA 版本中被认为是隐式的。
PTX ISA 版本 6.4 中已弃用对浮点 wmma.mma 的 .satfinite 的支持,并已从 PTX ISA 版本 6.5 中删除。
- 预览功能
-
子字节
wmma和单比特wmma是 PTX ISA 中的预览功能。所有细节都可能会更改,并且不保证在未来的 PTX ISA 版本或 SM 架构上向后兼容。
目标 ISA 注释
浮点 wmma 需要 sm_70 或更高版本。
整数 wmma 需要 sm_72 或更高版本。
子字节和单比特 wmma 需要 sm_75 或更高版本。
双精度、备选浮点精度 wmma 需要 sm_80 或更高版本。
单比特 wmma 中的 .and 操作需要 sm_80 或更高版本。
示例
.global .align 32 .f16 A[256], B[256];
.global .align 32 .f32 C[256], D[256];
.reg .b32 a<8> b<8> c<8> d<8>;
wmma.load.a.sync.aligned.m16n16k16.global.row.f16
{a0, a1, a2, a3, a4, a5, a6, a7}, [A];
wmma.load.b.sync.aligned.m16n16k16.global.col.f16
{b0, b1, b2, b3, b4, b5, b6, b7}, [B];
wmma.load.c.sync.aligned.m16n16k16.global.row.f32
{c0, c1, c2, c3, c4, c5, c6, c7}, [C];
wmma.mma.sync.aligned.m16n16k16.row.col.f32.f32
{d0, d1, d2, d3, d4, d5, d6, d7},
{a0, a1, a2, a3, a4, a5, a6, a7},
{b0, b1, b2, b3, b4, b5, b6, b7},
{c0, c1, c2, c3, c4, c5, c6, c7};
wmma.store.d.sync.aligned.m16n16k16.global.col.f32
[D], {d0, d1, d2, d3, d4, d5, d6, d7};
// Compute an integer WMMA:
.reg .b32 a, b<4>;
.reg .b32 c<8>, d<8>;
wmma.mma.sync.aligned.m8n32k16.row.col.s32.s8.s8.s32
{d0, d1, d2, d3, d4, d5, d6, d7},
{a}, {b0, b1, b2, b3},
{c0, c1, c2, c3, c4, c5, c6, c7};
// Compute sub-byte WMMA:
.reg .b32 a, b, c<2> d<2>
wmma.mma.sync.aligned.m8n8k32.row.col.s32.s4.s4.s32
{d0, d1}, {a}, {b}, {c0, c1};
// Compute single-bit type WMMA:
.reg .b32 a, b, c<2> d<2>
wmma.mma.xor.popc.sync.aligned.m8n8k128.row.col.s32.b1.b1.s32
{d0, d1}, {a}, {b}, {c0, c1};
// Compute double precision wmma
.reg .f64 a, b, c<2>, d<2>;
wmma.mma.sync.aligned.m8n8k4.row.col.f64.f64.f64.f64
{d0, d1}, {a}, {b}, {c0, c1};
// Compute alternate floating point precision wmma
.reg .b32 a<2>, b<2>, c<8>, d<8>;
wmma.mma.sync.aligned.m16n16k8.row.col.f32.tf32.tf32.f32
{d0, d1, d2, d3, d4, d5, d6, d7},
{a0, a1, a2, a3}, {b0, b1, b2, b3},
{c0, c1, c2, c3, c4, c5, c6, c7};
9.7.14.5. 使用 mma 指令的矩阵乘法累加操作
本节介绍 warp 级 mma、ldmatrix、stmatrix 和 movmatrix 指令以及参与这些指令的各种矩阵的组织。
9.7.14.5.1. 用于 .f16 浮点类型的 mma.m8n8k4 的矩阵片段
执行 mma.m8n8k4 和 .f16 浮点类型的 warp 将计算 4 个形状为 .m8n8k4 的 MMA 操作。
4 个矩阵的元素需要在 warp 中的线程之间分布。下表显示了 MMA 操作的矩阵分布。
MMA 计算 |
参与 MMA 计算的线程 |
|---|---|
MMA 计算 1 |
laneid 为 |
MMA 计算 2 |
laneid 为 |
MMA 计算 3 |
laneid 为 |
MMA 计算 4 |
laneid 为 |
对于上面所示的每个单独的 MMA 计算,每个所需的线程都持有一个矩阵片段,用于执行 mma 操作,如下所示
-
被乘数 A
.atype
片段
元素(从低到高)
.f16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 A 的两个.f16元素。a0, a1, a2, a3
不同线程持有的片段的布局如下所示
-
行主序矩阵 A 的片段布局如图 45所示。
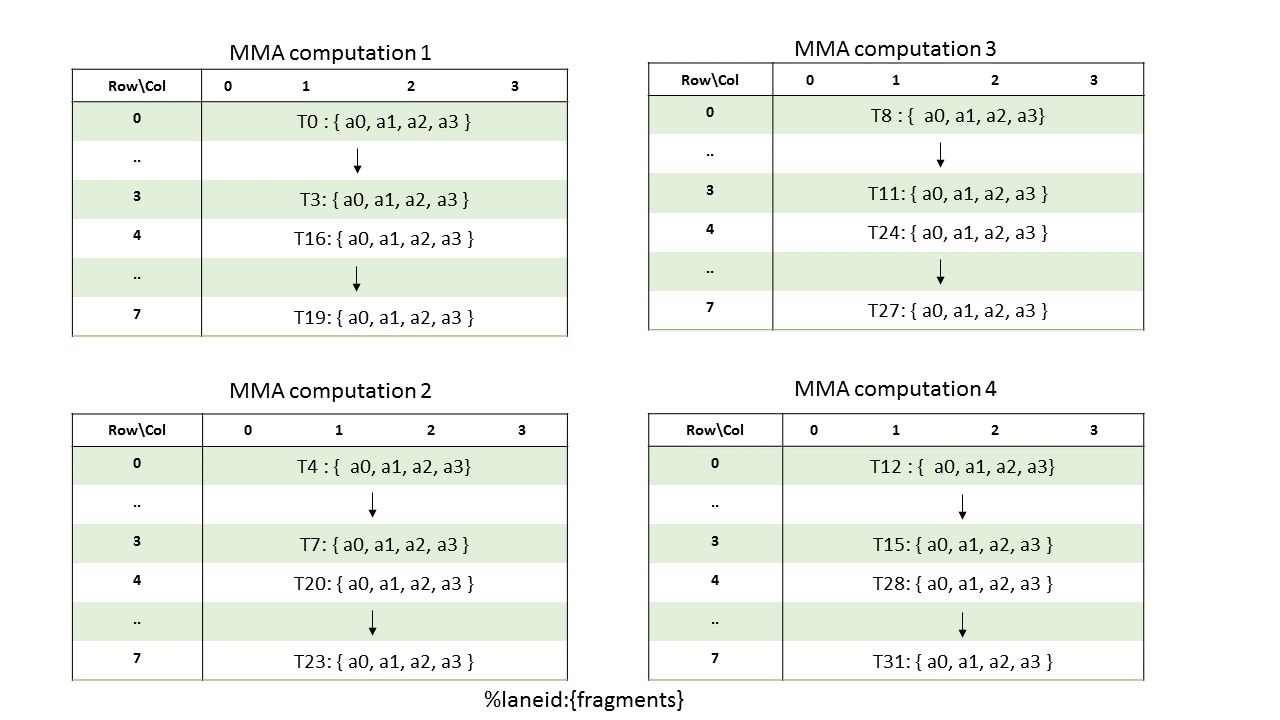
图 45 行主序矩阵 A 的 MMA .m8n8k4 分片布局,类型为
.f16矩阵片段的行和列可以计算为
row = %laneid % 4 if %laneid < 16 (%laneid % 4) + 4 otherwise col = i for ai where i = {0,..,3}
-
列主序矩阵 A 的片段布局如图 46所示。
不同线程持有的片段的布局如下所示

图 46 列主序矩阵 A 的 MMA .m8n8k4 分片布局,类型为
.f16矩阵片段的行和列可以计算为
row = i % 4 for ai where i = {0,..,3} if %laneid < 16 (i % 4) + 4 for ai where i = {0,..,3} otherwise col = %laneid % 4
-
-
被乘数 B
.btype
片段
元素(从低到高)
.f16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 B 的两个.f16元素。b0, b1, b2, b3
不同线程持有的片段的布局如下所示
-
行主序矩阵 B 的片段布局如图 47所示。
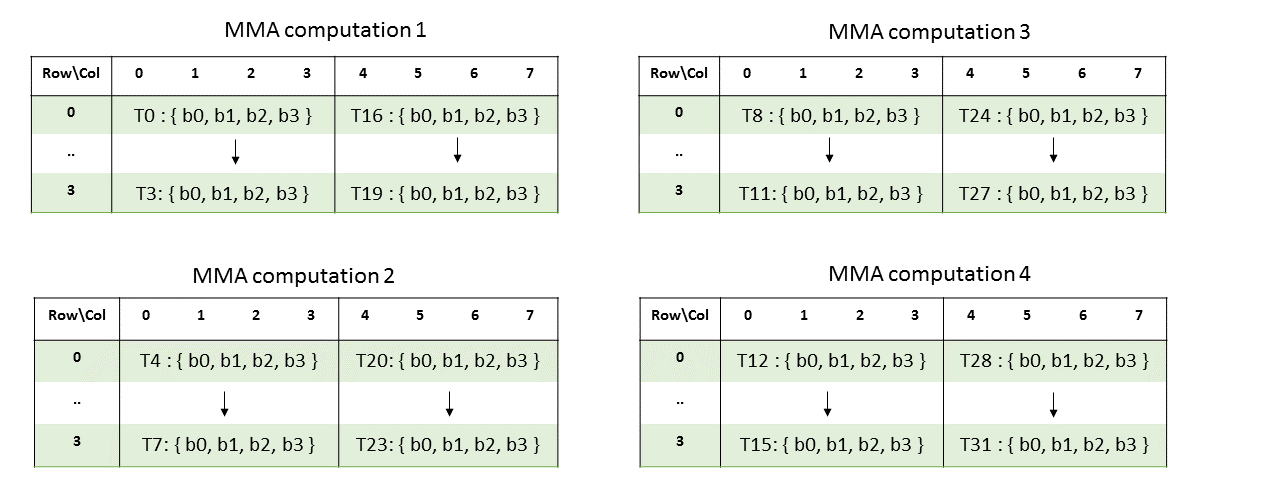
图 47 行主序矩阵 B 的 MMA .m8n8k4 分片布局,类型为
.f16矩阵片段的行和列可以计算为
row = %laneid % 4 col = i for bi where i = {0,..,3} if %laneid < 16 i+4 for bi where i = {0,..,3} otherwise
-
列主序矩阵 B 的片段布局如图 48所示。
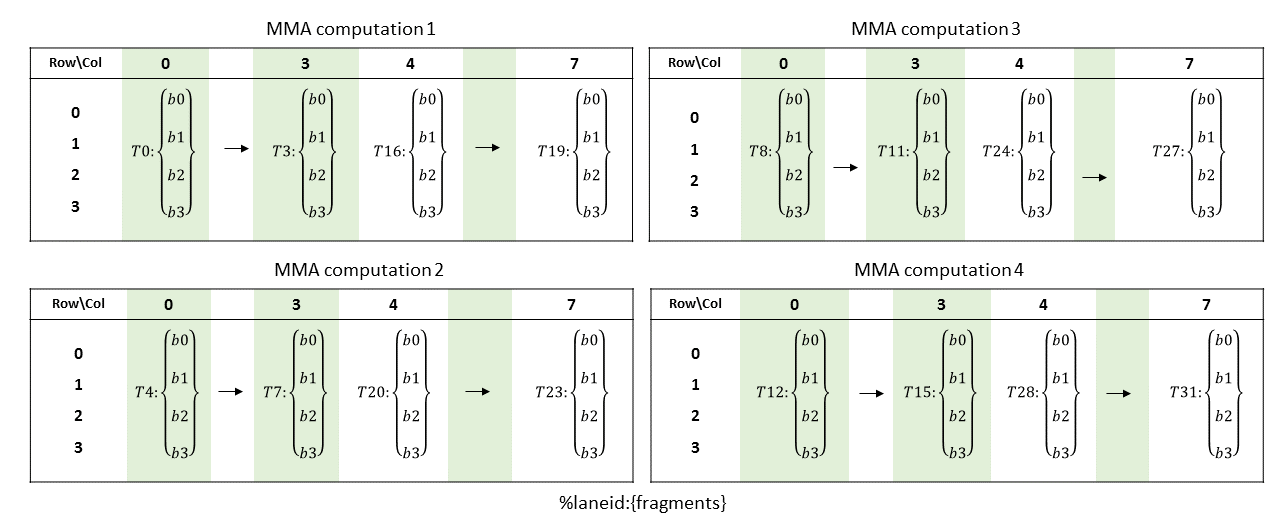
图 48 列主序矩阵 B 的 MMA .m8n8k4 分片布局,类型为
.f16矩阵片段的行和列可以计算为
row = i for bi where i = {0,..,3} col = %laneid % 4 if %laneid < 16 (%laneid % 4) + 4 otherwise
-
-
累加器 C(或 D)
.ctype / .dtype
片段
元素(从低到高)
.f16一个向量表达式,包含四个
.f16x2寄存器,每个寄存器包含来自矩阵 C(或 D)的两个.f16元素。c0, c1, c2, c3, c4, c5, c6, c7
.f32一个包含八个
.f32寄存器的向量表达式。不同线程持有的片段的布局如下所示
-
当
.ctype为.f16时,累加器矩阵的片段布局如图 49所示。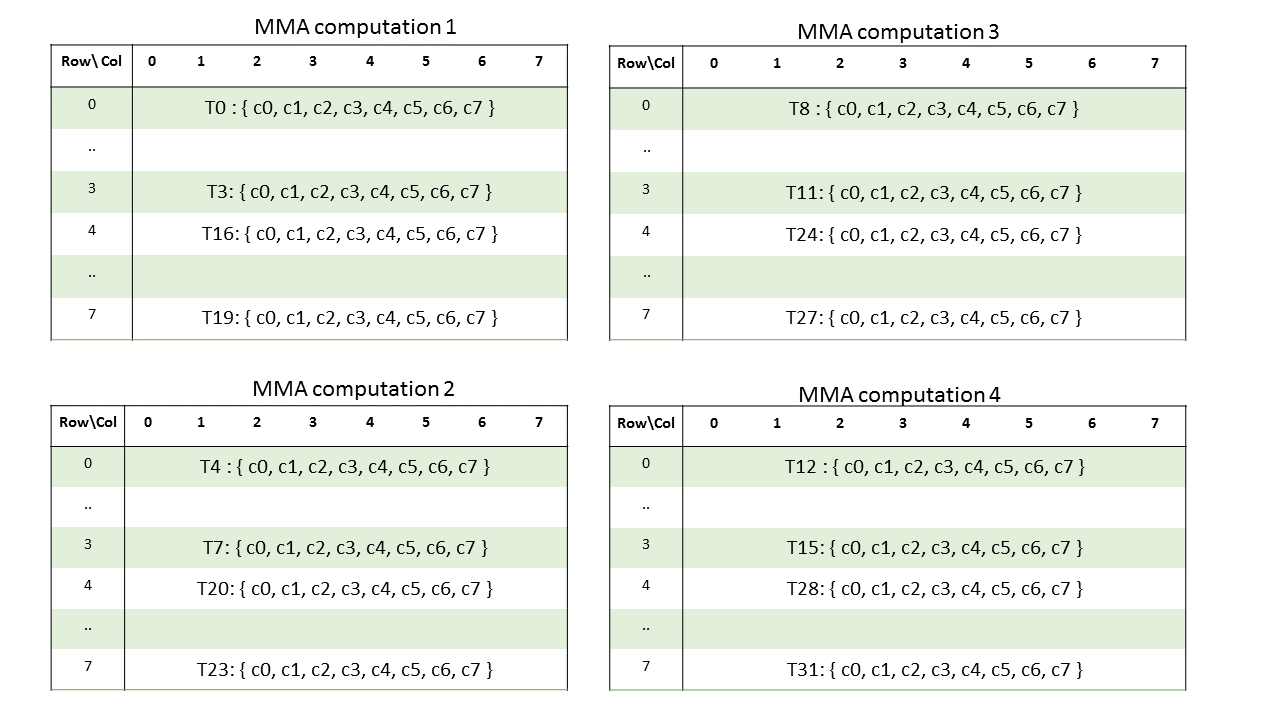
图 49 矩阵 C/D 的 MMA .m8n8k4 分片布局,
.ctype=.f16矩阵片段的行和列可以计算为
row = %laneid % 4 if %laneid < 16 (%laneid % 4) + 4 otherwise col = i for ci where i = {0,..,7}
-
当
.ctype为.f32时,累加器矩阵的片段布局如图 50和图 51所示。
图 50 矩阵 C/D 的 MMA .m8n8k4 计算 1 和 2 分片布局,
.ctype=.f32
图 51 矩阵 C/D 的 MMA .m8n8k4 计算 3 和 4 分片布局,
.ctype=.f32矩阵片段的行和列可以计算为
row = X if %laneid < 16 X + 4 otherwise where X = (%laneid & 0b1) + (i & 0b10) for ci where i = {0,..,7} col = (i & 0b100) + (%laneid & 0b10) + (i & 0b1) for ci where i = {0,..,7}
-
9.7.14.5.2. 用于 .f64 浮点类型的 mma.m8n8k4 的矩阵片段
执行 mma.m8n8k4 和 .f64 浮点类型的 warp 将计算形状为 .m8n8k4 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.f64一个向量表达式,包含单个
.f64寄存器,其中包含来自矩阵 A 的单个.f64元素。a0
不同线程持有的片段的布局如图 52所示。
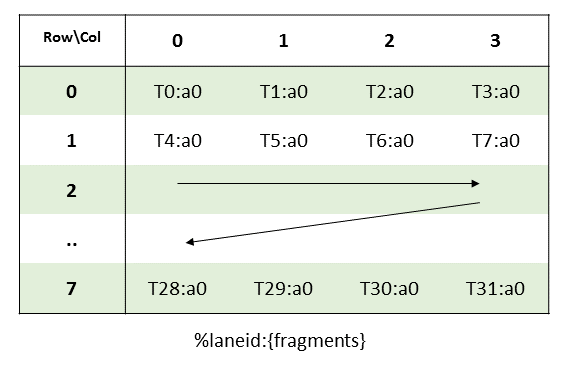
图 52 类型为
.f64的矩阵 A 的 MMA .m8n8k4 分片布局矩阵片段的行和列可以计算为
row = %laneid >> 2 col = %laneid % 4
-
被乘数 B
.btype
片段
元素(从低到高)
.f64一个向量表达式,包含单个
.f64寄存器,其中包含来自矩阵 B 的单个.f64元素。b0
不同线程持有的片段的布局如图 53所示。
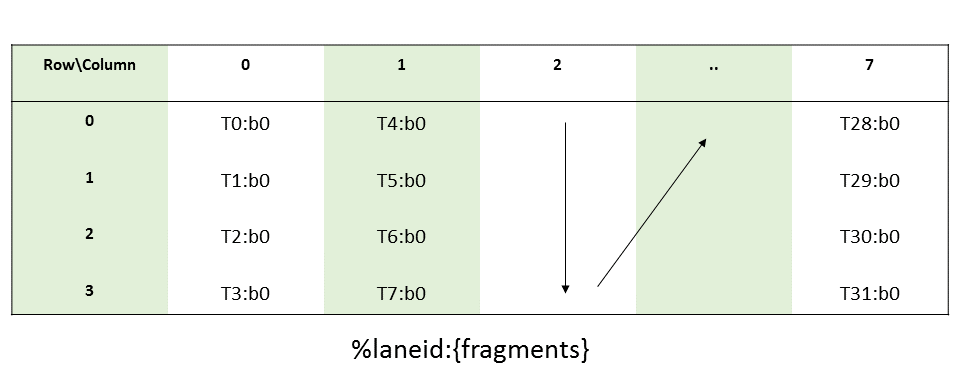
图 53 类型为
.f64的矩阵 B 的 MMA .m8n8k4 分片布局矩阵片段的行和列可以计算为
row = %laneid % 4 col = %laneid >> 2
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.f64一个向量表达式,包含两个
.f64寄存器,其中包含来自矩阵 C 的两个.f64元素。c0, c1
不同线程持有的片段的布局如图 54所示。
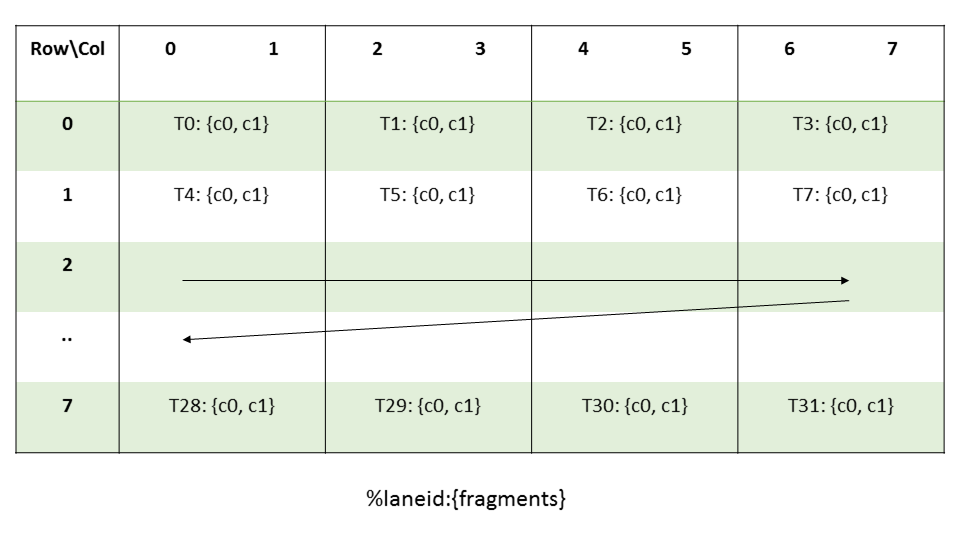
图 54 类型为
.f64的累加器矩阵 C/D 的 MMA .m8n8k4 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0, 1}
9.7.14.5.3. 用于 mma.m8n8k16 的矩阵片段
执行 mma.m8n8k16 的 warp 将计算形状为 .m8n8k16 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.s8/.u8一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 A 的四个.s8或.u8元素。a0, a1, a2, a3
不同线程持有的片段的布局如图 55所示。
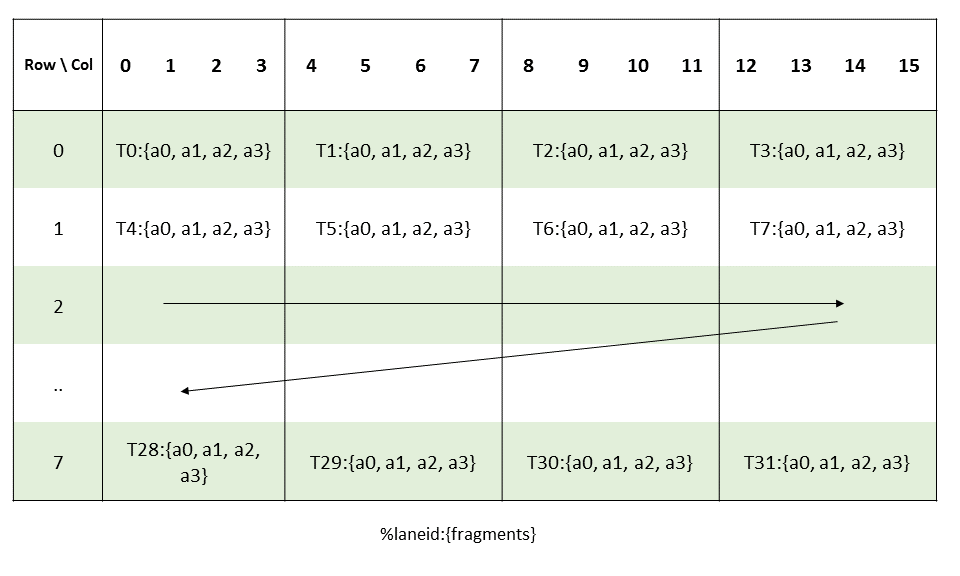
图 55 类型为
.u8/.s8的矩阵 A 的 MMA .m8n8k16 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 4) + i for ai where i = {0,..,3}
-
被乘数 B
.btype
片段
元素(从低到高)
.s8/.u8一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 B 的四个.s8或.u8元素。b0, b1, b2, b3
不同线程持有的片段的布局如图 56所示。
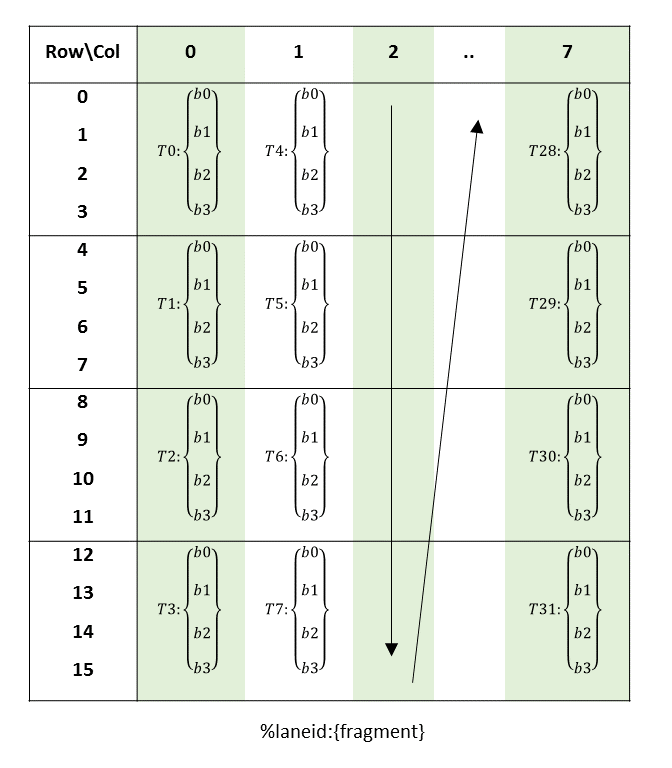
图 56 类型为
.u8/.s8的矩阵 B 的 MMA .m8n8k16 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 4) + i for bi where i = {0,..,3} col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含两个
.s32寄存器。c0, c1
不同线程持有的片段的布局如图 57所示。
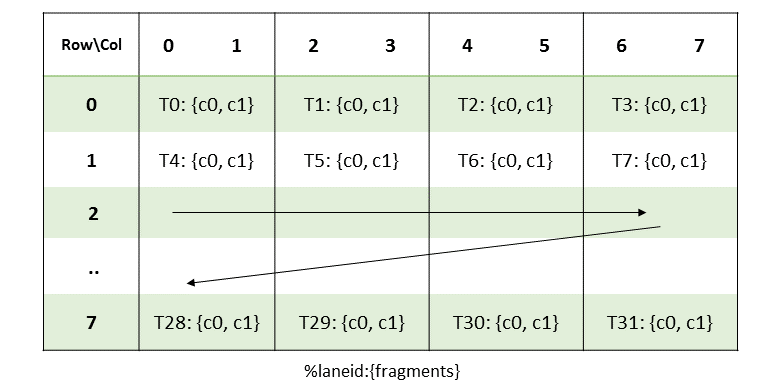
图 57 类型为
.s32的累加器矩阵 C/D 的 MMA .m8n8k16 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 2) + i for ci where i = {0, 1}
9.7.14.5.4. 用于 mma.m8n8k32 的矩阵片段
执行 mma.m8n8k32 的 warp 将计算形状为 .m8n8k32 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.s4/.u4一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 A 的八个.s4或.u4元素。a0, a1, a2, a3, a4, a5, a6, a7
不同线程持有的片段的布局如图 58所示。

图 58 类型为
.u4/.s4的矩阵 A 的 MMA .m8n8k32 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 8) + i for ai where i = {0,..,7}
-
被乘数 B
.btype
片段
元素(从低到高)
.s4/.u4一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 B 的八个.s4或.u4元素。b0, b1, b2, b3, b4, b5, b6, b7
不同线程持有的片段的布局如图 59所示。
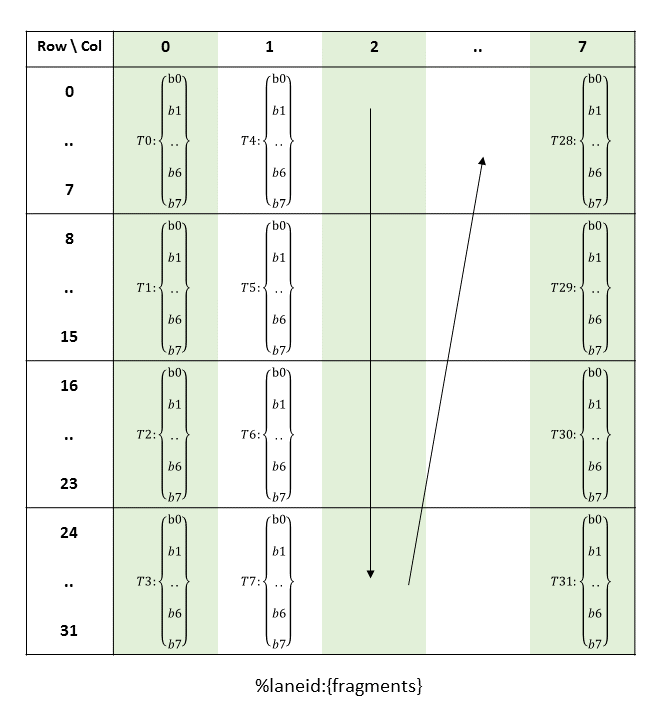
图 59 类型为
.u4/.s4的矩阵 B 的 MMA .m8n8k32 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 8) + i for bi where i = {0,..,7} col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个包含两个
.s32寄存器的向量表达式。c0, c1
不同线程持有的片段的布局如图 60所示
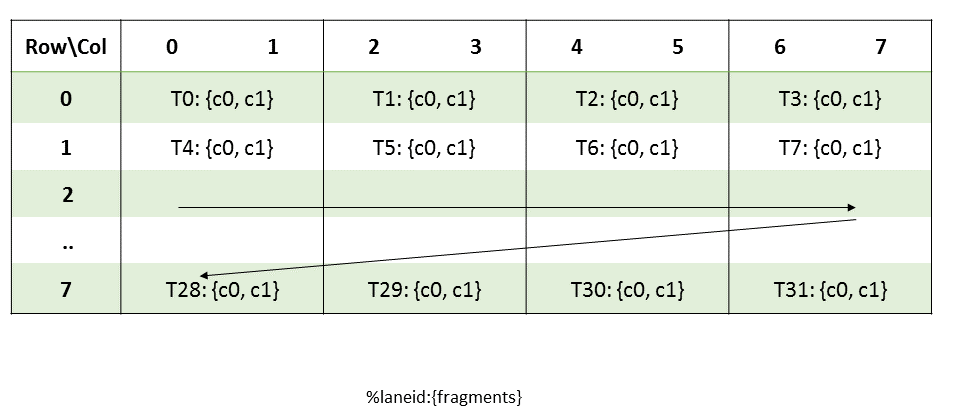
图 60 类型为
.s32的累加器矩阵 C/D 的 MMA .m8n8k32 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 2) + i for ci where i = {0, 1}
9.7.14.5.5. 用于 mma.m8n8k128 的矩阵片段
执行 mma.m8n8k128 的 warp 将计算形状为 .m8n8k128 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.b1一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 A 的三十二个.b1元素。a0, a1, … a30, a31
不同线程持有的片段的布局如图 61所示。

图 61 类型为
.b1的矩阵 A 的 MMA .m8n8k128 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 32) + i for ai where i = {0,..,31}
-
被乘数 B
.btype
片段
元素(从低到高)
.b1一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 B 的三十二个.b1元素。b0, b1, …, b30, b31
不同线程持有的片段的布局如图 62所示。
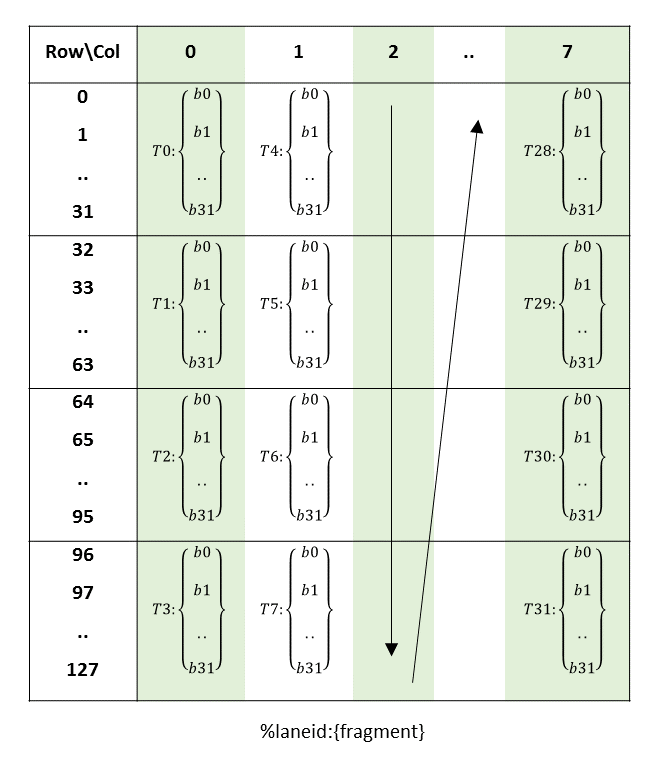
图 62 类型为
.b1的矩阵 B 的 MMA .m8n8k128 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 32) + i for bi where i = {0,..,31} col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含两个
.s32寄存器,其中包含来自矩阵 C(或 D)的两个.s32元素。c0, c1
不同线程持有的片段的布局如图 63所示。
图 63 类型为
.s32的累加器矩阵 C/D 的 MMA .m8n8k128 分片布局矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 2) + i for ci where i = {0, 1}
9.7.14.5.6. 用于 mma.m16n8k4 的矩阵片段
执行 mma.m16n8k4 的 warp 将计算形状为 .m16n8k4 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
-
被乘数 B
-
.tf32: -
.f64:
-
-
累加器(C 或 D)
-
.tf32:.ctype / .dtype
片段
元素(从低到高)
.f32一个向量表达式,包含四个
.f32寄存器,其中包含来自矩阵 C(或 D)的四个.f32元素。c0, c1, c2, c3
不同线程持有的片段的布局如图 68所示。
图 68 类型为
.f32的累加器矩阵 C/D 的 MMA .m16n8k4 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for c0 and c1 groupID + 8 for c2 and c3 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
-
.f64:.ctype / .dtype
片段
元素(从低到高)
.f64一个向量表达式,包含四个
.f64寄存器,其中包含来自矩阵 C(或 D)的四个.f64元素。c0, c1, c2, c3
不同线程持有的片段的布局如图 69所示。
图 69 类型为
.f64的累加器矩阵 C/D 的 MMA .m16n8k4 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for c0 and c1 groupID + 8 for c2 and c3 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
-
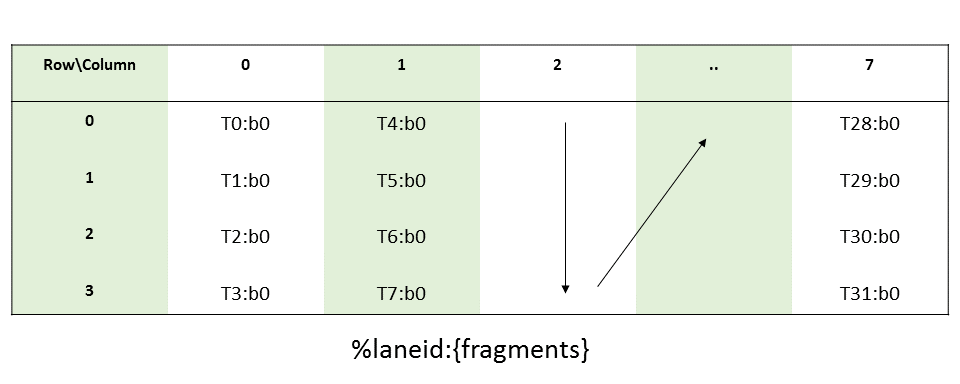
9.7.14.5.7. 用于 mma.m16n8k8 的矩阵片段
执行 mma.m16n8k8 的 warp 将计算形状为 .m16n8k8 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
-
.f16和.bf16.atype
片段
元素(从低到高)
.f16/.bf16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 A 的两个.f16/.bf16元素。a0, a1, a2, a3
不同线程持有的片段的布局如图 70所示。

图 70 类型为
.f16/.bf16的矩阵 A 的 MMA .m16n8k8 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for a0 and a1 groupID + 8 for a2 and a3 col = threadID_in_group * 2 + (i & 0x1) for ai where i = {0,..,3}
-
.tf32:.atype
片段
元素(从低到高)
.tf32一个向量表达式,包含四个
.b32寄存器,其中包含来自矩阵 A 的四个.tf32元素。a0, a1, a2, a3
不同线程持有的片段的布局如图 71所示。
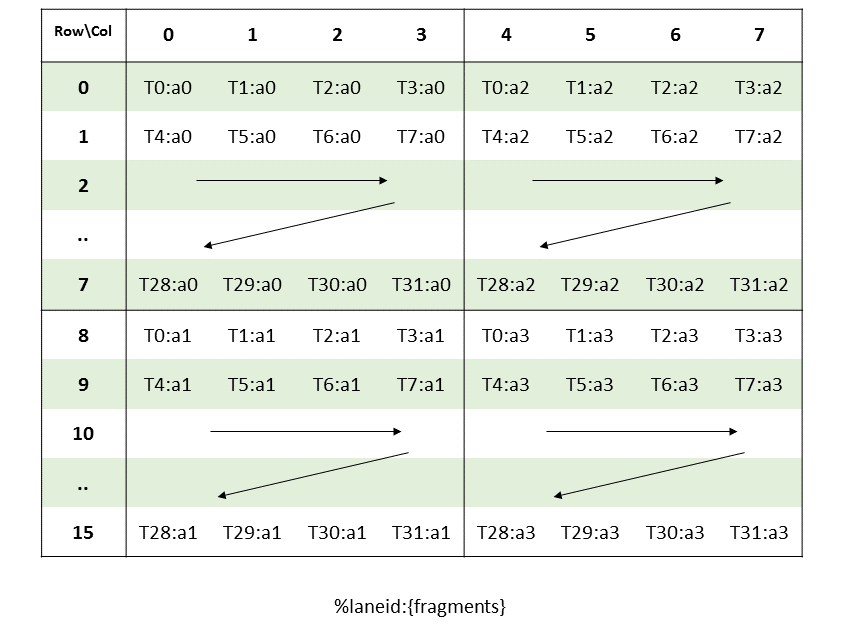
图 71 类型为
.tf32的矩阵 A 的 MMA .m16n8k8 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for a0 and a2 groupID + 8 for a1 and a3 col = threadID_in_group for a0 and a1 threadID_in_group + 4 for a2 and a3
-
.f64:.atype
片段
元素(从低到高)
.f64一个向量表达式,包含四个
.f64寄存器,其中包含来自矩阵 A 的四个.f64元素。a0, a1, a2, a3
不同线程持有的片段的布局如图 72所示。
图 72 类型为
.f64的矩阵 A 的 MMA .m16n8k8 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for a0 and a2 groupID + 8 for a1 and a3 col = threadID_in_group for a0 and a1 threadID_in_group + 4 for a2 and a3
-
-
被乘数 B
-
.f16和.bf16.btype
片段
元素(从低到高)
.f16/.bf16一个向量表达式,包含单个
.f16x2寄存器,其中包含来自矩阵 B 的两个.f16/.bf16元素。b0, b1
不同线程持有的片段的布局如图 73所示。
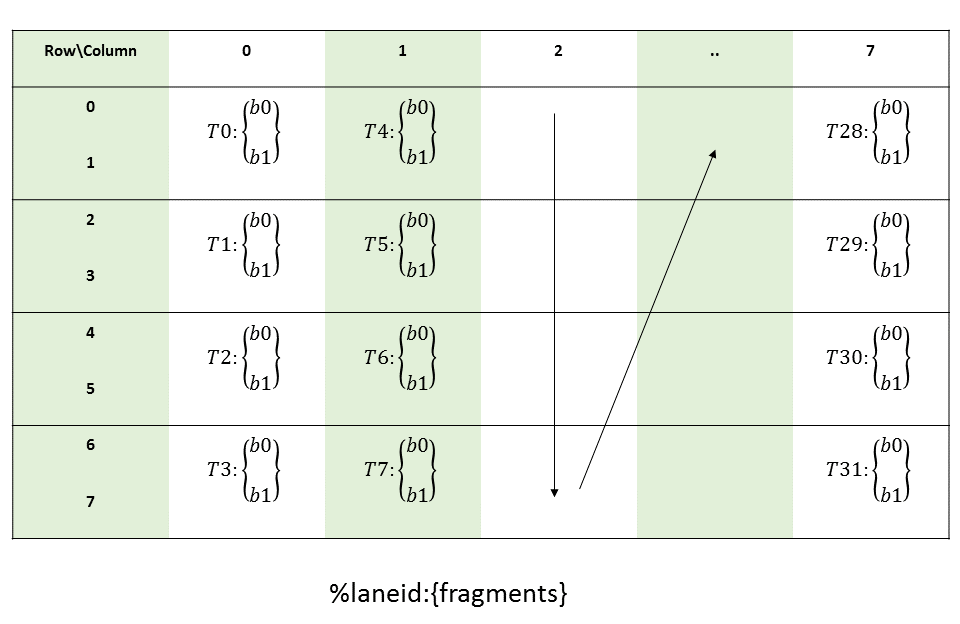
图 73 类型为
.f16/.bf16的矩阵 B 的 MMA .m16n8k8 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 2) + i for bi where i = {0, 1} col = groupID
-
.tf32: -
.f64:
-
-
累加器(C 或 D)
-
.f16,.bf16和.tf32.ctype / .dtype
片段
元素(从低到高)
.f16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 C(或 D)的两个.f16元素。c0, c1, c2, c3
.f32一个向量表达式,包含四个
.f32寄存器。不同线程持有的片段的布局如图 76所示。
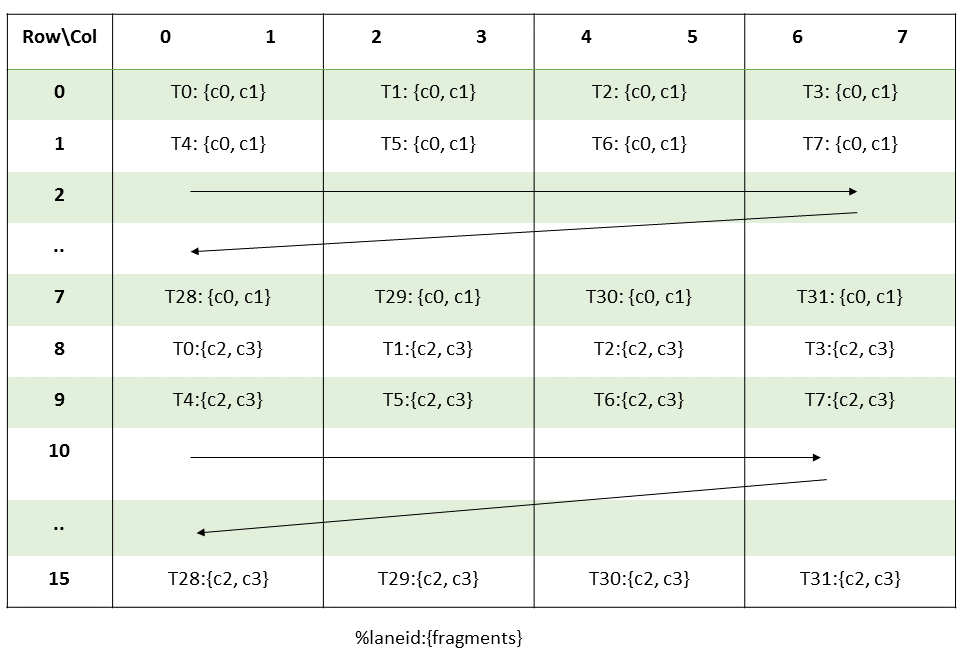
图 76 类型为
.f16x2/.f32的累加器矩阵 C/D 的 MMA .m16n8k8 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for c0 and c1 groupID + 8 for c2 and c3 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
-
.f64:.ctype / .dtype
片段
元素(从低到高)
.f64一个向量表达式,包含四个
.f64寄存器,其中包含来自矩阵 C(或 D)的四个.f64元素。c0, c1, c2, c3
不同线程持有的片段的布局如图 77所示。
图 77 类型为
.f64的累加器矩阵 C/D 的 MMA .m16n8k8 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for c0 and c1 groupID + 8 for c2 and c3 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
-
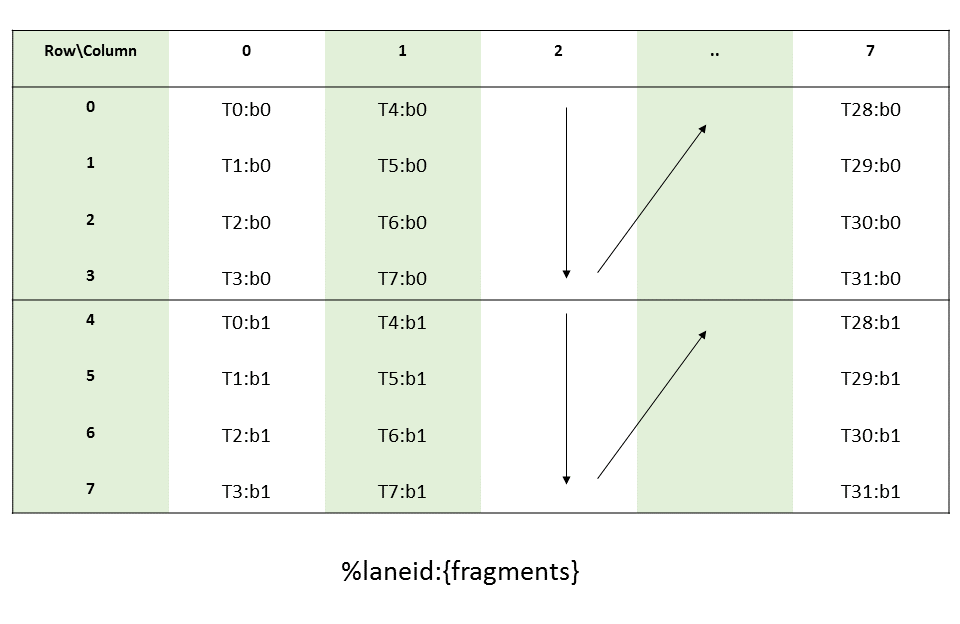
9.7.14.5.8. 用于浮点类型的 mma.m16n8k16 的矩阵片段
执行 mma.m16n8k16 浮点类型的 warp 将计算形状为 .m16n8k16 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
-
.f16和.bf16.atype
片段
元素(从低到高)
.f16/.bf16一个向量表达式,包含四个
.f16x2寄存器,每个寄存器包含来自矩阵 A 的两个.f16/.bf16元素。a0, a1, a2, a3, a4, a5, a6, a7
不同线程持有的片段的布局如图 78所示。

图 78 类型为
.f16/.bf16的矩阵 A 的 MMA .m16n8k16 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 2 || 4 <= i < 6 groupID + 8 Otherwise col = (threadID_in_group * 2) + (i & 0x1) for ai where i < 4 (threadID_in_group * 2) + (i & 0x1) + 8 for ai where i >= 4
-
.f64:.atype
片段
元素(从低到高)
.f64一个向量表达式,包含八个
.f64寄存器,每个寄存器包含来自矩阵 A 的一个.f64元素。a0, a1, a2, a3, a4, a5, a6, a7
不同线程持有的片段的布局如图 79所示。
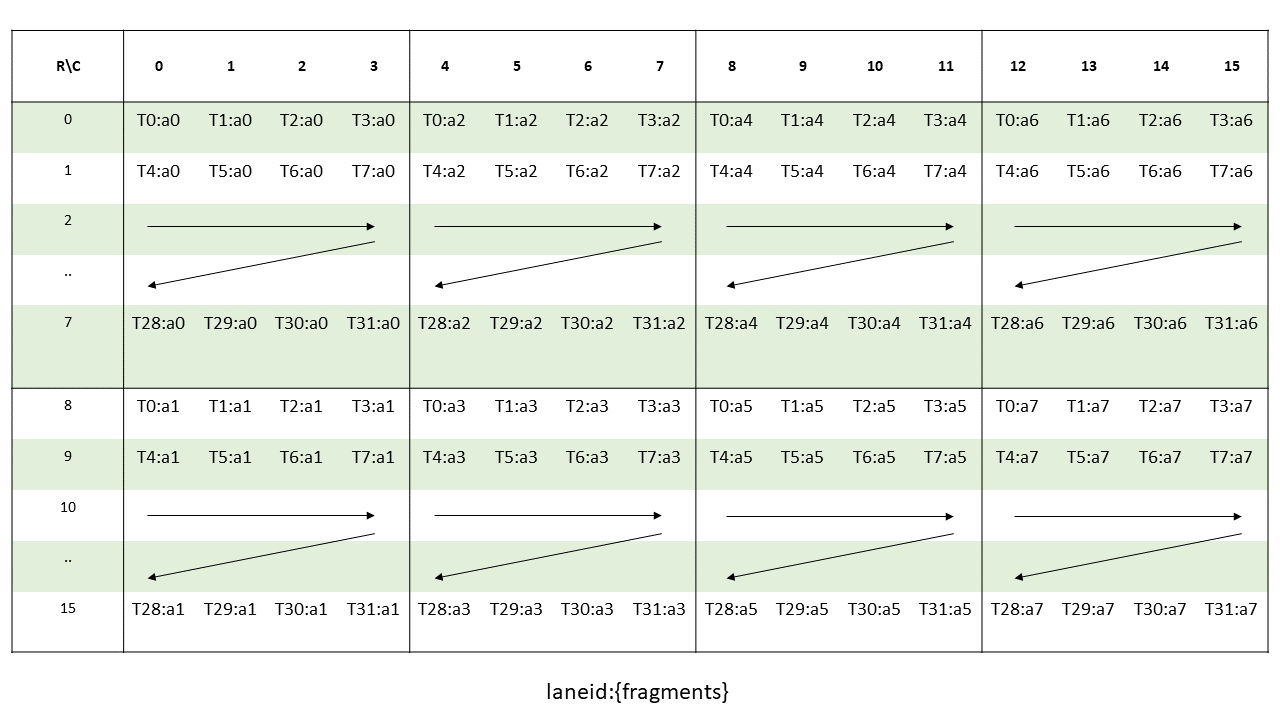
图 79 类型为
.f64的矩阵 A 的 MMA .m16n8k16 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where i % 2 = 0 groupID + 8 Otherwise col = (i * 2) + threadID_in_group for ai where i % 2 = 0 (i * 2) - 2 + (threadID_in_group Otherwise
-
-
被乘数 B
-
.f16和.bf16.btype
片段
元素(从低到高)
.f16/.bf16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 B 的两个.f16/.bf16元素。b0, b1, b2, b3
不同线程持有的片段的布局如图 80所示。
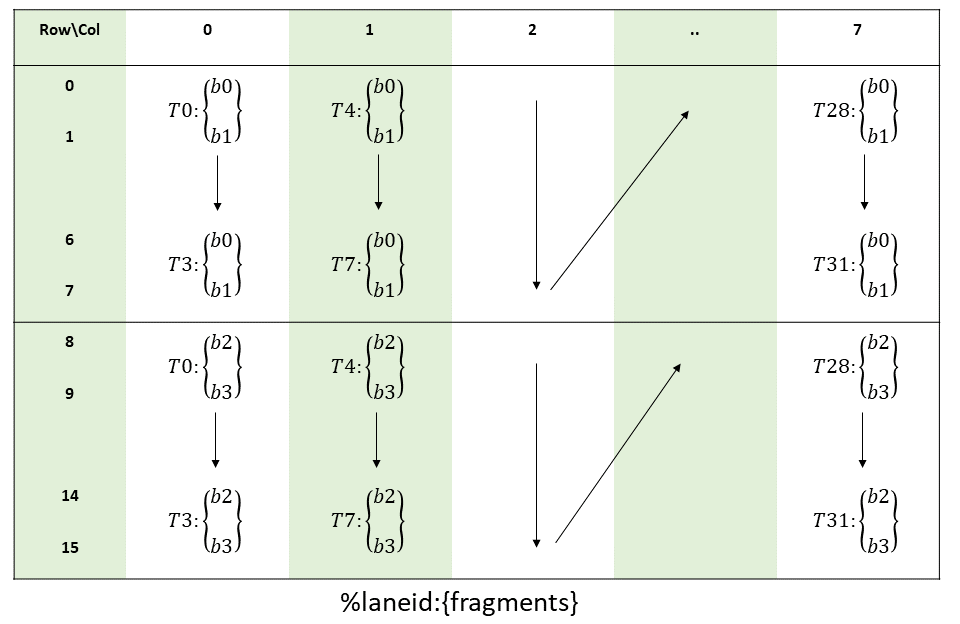
图 80 类型为
.f16/.bf16的矩阵 B 的 MMA .m16n8k16 分片布局。其中矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 2) + (i & 0x1) for bi where i < 2 (threadID_in_group * 2) + (i & 0x1) + 8 for bi where i >= 2 col = groupID
-
.f64:
-
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.f64一个向量表达式,包含四个
.f64寄存器,其中包含来自矩阵 C(或 D)的.f64元素。c0, c1, c2, c3
.f32一个向量表达式,包含四个
.f32寄存器,其中包含来自矩阵 C(或 D)的四个.f32元素。.f16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 C(或 D)的两个.f16元素。不同线程持有的片段的布局如图 82所示。
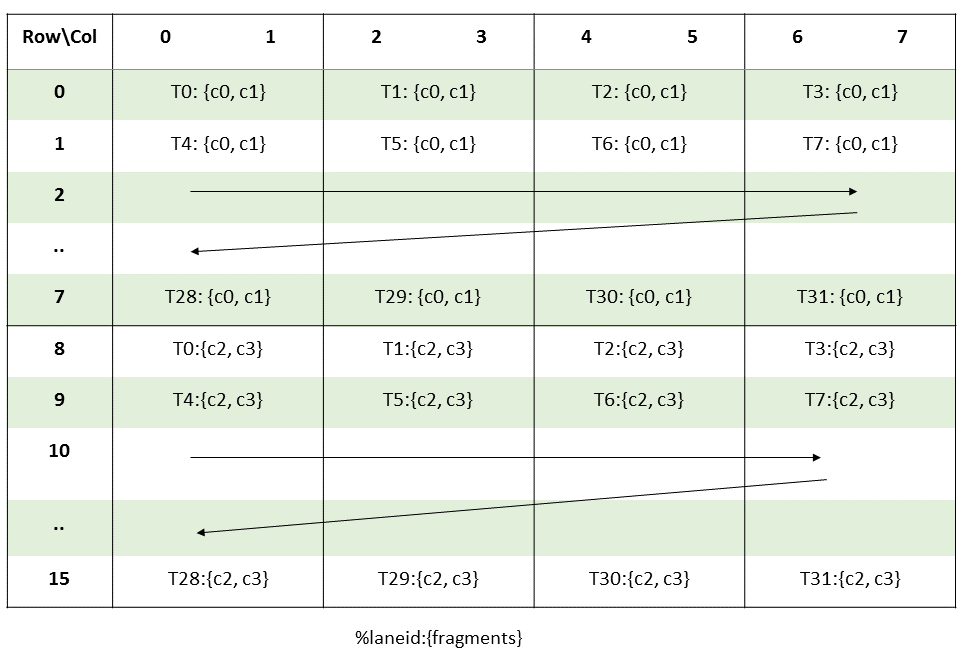
图 82 累加器矩阵 C/D 的 MMA .m16n8k16 分片布局。
矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ci where i < 2 groupID + 8 for ci where i >= 2 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
9.7.14.5.9. 用于 mma.m16n8k16 的矩阵片段
执行 mma.m16n8k16 的 warp 将计算形状为 .m16n8k16 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.u8/.s8一个向量表达式,包含两个
.b32寄存器,每个寄存器包含来自矩阵 A 的四个.u8/.s8元素。a0, a1, a2, a3, a4, a5, a6, a7
.e4m3/.e5m2一个向量表达式,包含两个
.b32寄存器,每个寄存器包含来自矩阵 A 的四个.e4m3/.e5m2元素。a0, a1, a2, a3, a4, a5, a6, a7
不同线程持有的片段的布局如图 83所示。
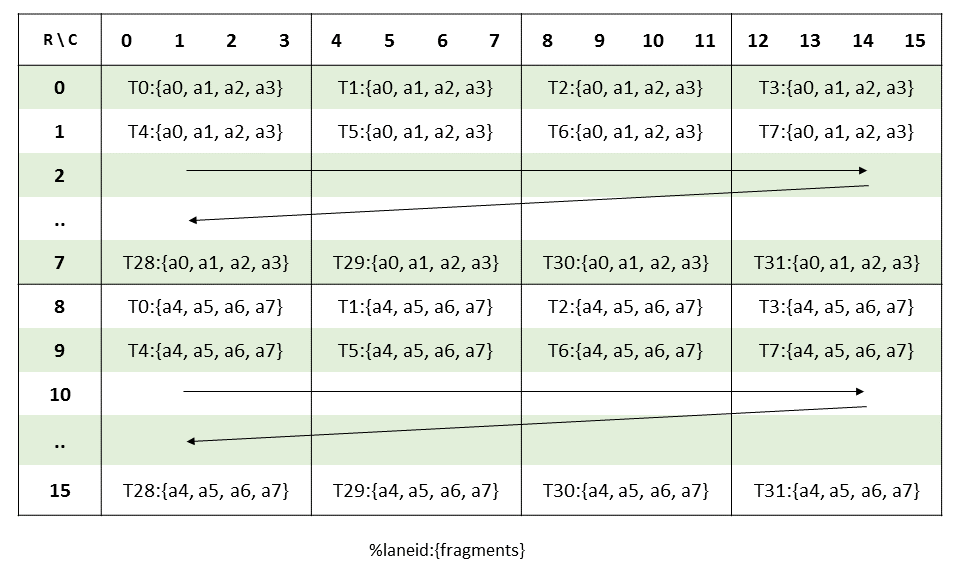
图 83 类型为
.u8/.s8的矩阵 A 的 MMA .m16n8k16 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where i < 4 groupID + 8 for ai where i >= 4 col = (threadID_in_group * 4) + (i & 0x3) for ai where i = {0,..,7}
-
被乘数 B
.btype
片段
元素(从低到高)
.u8/.s8一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 B 的四个.u8/.s8元素。b0, b1, b2, b3
.e4m3/.e5m2一个向量表达式,包含单个
.b32寄存器,其中包含来自矩阵 B 的四个.e4m3/.e5m2元素。b0, b1. b2. b3
不同线程持有的片段的布局如图 84所示。
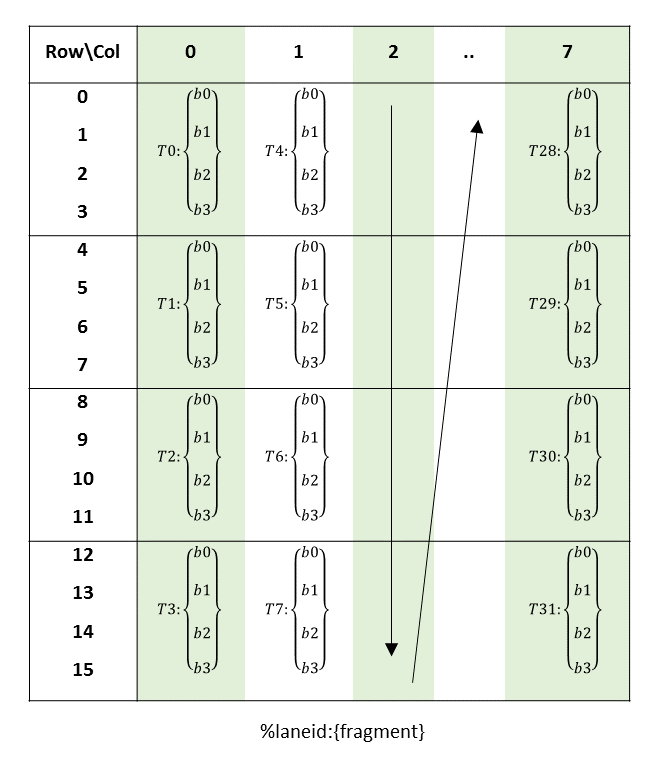
图 84 类型为
.u8/.s8的矩阵 B 的 MMA .m16n8k16 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 4) + i for bi where i = {0,..,3} col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含四个
.s32寄存器,其中包含来自矩阵 C(或 D)的四个.s32元素。c0, c1, c2, c3
.f32一个向量表达式,包含四个
.f32寄存器,其中包含来自矩阵 C(或 D)的四个.f32元素。c0, c1, c2, c3
.f16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 C(或 D)的两个.f16元素。c0, c1, c1, c2
不同线程持有的片段的布局如图 85所示。
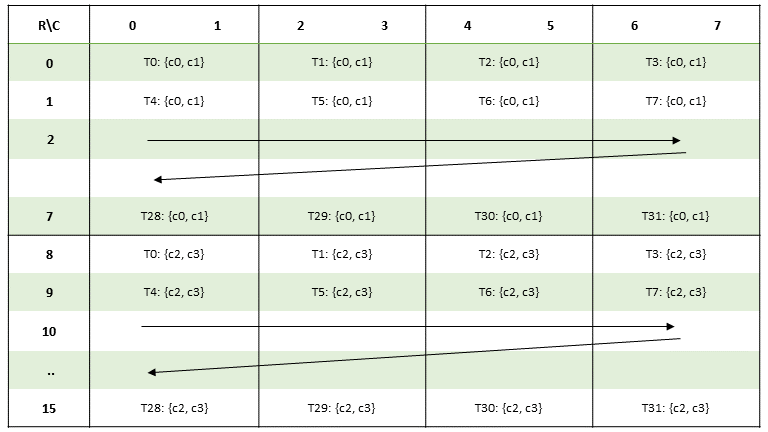
图 85 类型为
.s32的累加器矩阵 C/D 的 MMA .m16n8k16 分片布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ci where i < 2 groupID + 8 for ci where i >= 2 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
9.7.14.5.10. 用于 mma.m16n8k32 的矩阵片段
执行 mma.m16n8k32 的 warp 将计算形状为 .m16n8k32 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
-
.s4或.u4.atype
片段
元素(从低到高)
.s4/.u4一个向量表达式,包含两个
.b32寄存器,每个寄存器包含来自矩阵 A 的八个.u4/.s4元素。a0, a1, …, a14, a15
不同线程所持有的分片的布局如图 86所示。
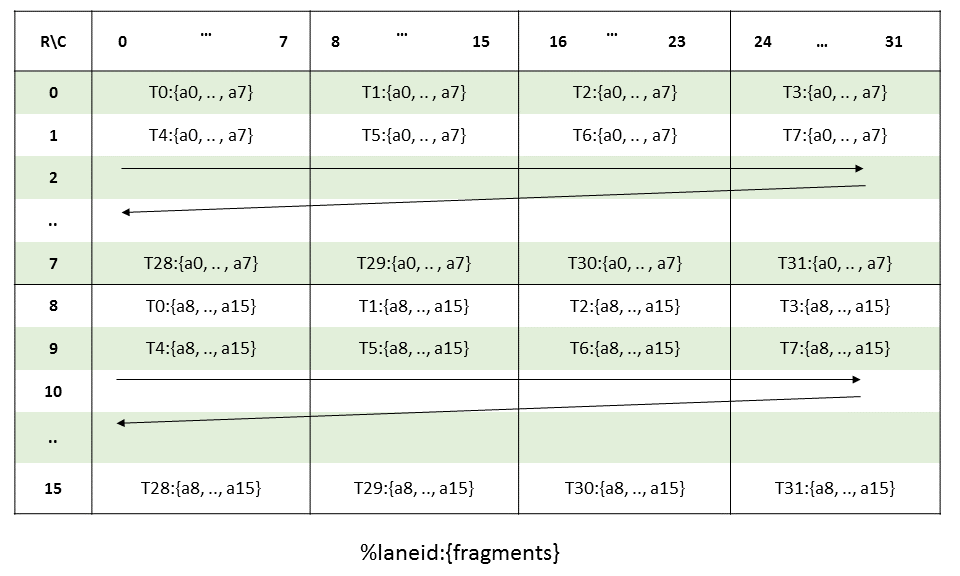
图 86 矩阵 A 的 MMA .m16n8k32 分片布局,类型为
.u4/.s4。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where i < 8 groupID + 8 for ai where i >= 8 col = (threadID_in_group * 8) + (i & 0x7) for ai where i = {0,..,15}
-
.s8或.u8或.e4m3或.e5m2或.e3m2或.e2m3或.e2m1.atype
片段
元素(从低到高)
.s8/.u8包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的四个.s8/.u8元素。a0, a1, .., a14, a15
.e4m3/.e5m2/.e3m2/.e2m3/.e2m1包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的四个.e4m3/.e5m2/.e3m2/.e2m3/.e2m1元素。a0, a1, …, a14, a15
不同线程所持有的分片的布局如图 87所示。
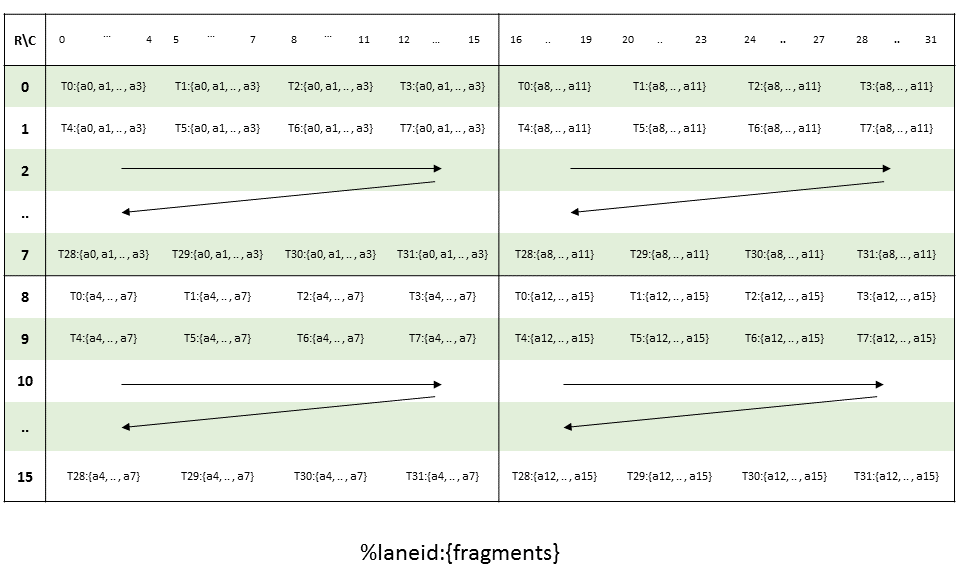
图 87 矩阵 A 的 MMA .m16n8k32 分片布局,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 4 || 8 <= i < 12 groupID + 8 otherwise col = (threadID_in_group * 4) + (i & 0x3) for ai where i < 8 (threadID_in_group * 4) + (i & 0x3) + 16 for ai where i >= 8
-
-
被乘数 B
-
.s4或.u4
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 8) + (i & 0x7) for bi where i = {0,..,7} col = groupID
-
.s8或.u8或.e4m3或.e5m2或.e3m2或.e2m3或.e2m1.btype
片段
元素(从低到高)
.s8/.u8包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的四个.s8/.u8元素。b0, b1, b2, b3, b4, b5, b6, b7
.e4m3/.e5m2/.e3m2/.e2m3/.e2m1包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的四个.e4m3/.e5m2/.e3m2/.e2m3/.e2m1元素。b0, b1, b2, b3, b4, b5, b6, b7
图 89 矩阵 B 第 0-15 行的 MMA .m16n8k32 分片布局,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。
图 90 矩阵 B 第 16-31 行的 MMA .m16n8k32 分片布局,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 4) + (i & 0x3) for bi where i < 4 (threadID_in_group * 4) + (i & 0x3) + 16 for bi where i >= 4 col = groupID
-
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含四个
.s32寄存器,其中包含来自矩阵 C(或 D)的四个.s32元素。c0, c1, c2, c3
.f32一个向量表达式,包含四个
.f32寄存器,其中包含来自矩阵 C(或 D)的四个.f32元素。c0, c1, c2, c3
.f16一个向量表达式,包含两个
.f16x2寄存器,每个寄存器包含来自矩阵 C(或 D)的两个.f16元素。c0, c1, c2, c3
不同线程所持有的分片的布局如图 91所示。
图 91 累加器矩阵 C/D 的 MMA .m16n8k32 分片布局,类型为
.s32/.f32/.f16。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ci where i < 2 groupID + 8 for ci where i >= 2 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
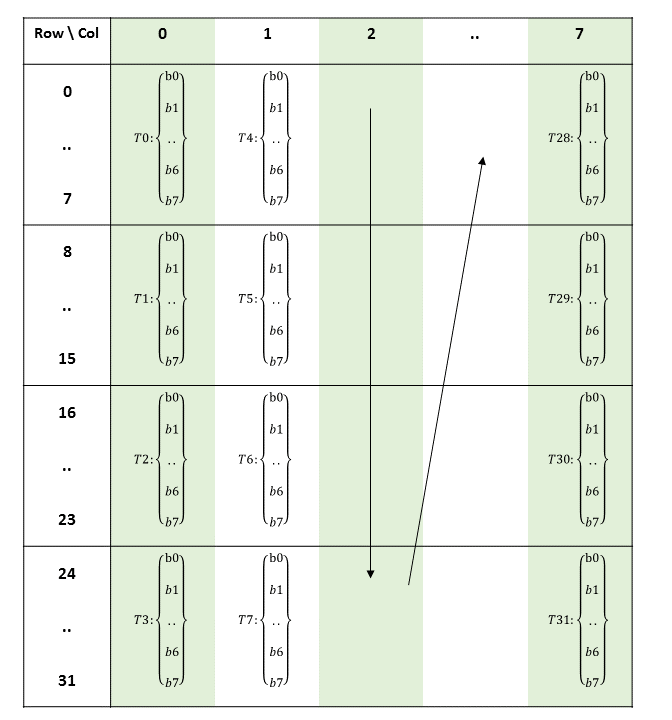
9.7.14.5.11. mma.m16n8k64 的矩阵分片
执行 mma.m16n8k64 的 warp 将计算形状为 .m16n8k64 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.s4/.u4包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的八个.s4/.u4元素。a0, a1, …, a30, a31
.e2m1包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的八个.e2m1元素。a0, a1, …, a30, a31
不同线程所持有的分片的布局如图 92所示。

图 92 矩阵 A 的 MMA .m16n8k64 分片布局,类型为
.u4/.s4/.e2m1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 8 || 16 <= i < 24 groupID + 8 otherwise col = (threadID_in_group * 8) + (i & 0x7) for ai where i < 16 (threadID_in_group * 8) + (i & 0x7) + 32 for ai where i >= 16
-
被乘数 B
.btype
片段
元素(从低到高)
.s4/.u4包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的八个.s4/.u4元素。b0, b1, …, b14, b15
.e2m1包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的八个.e2m1元素。b0, b1, …, b14, b15
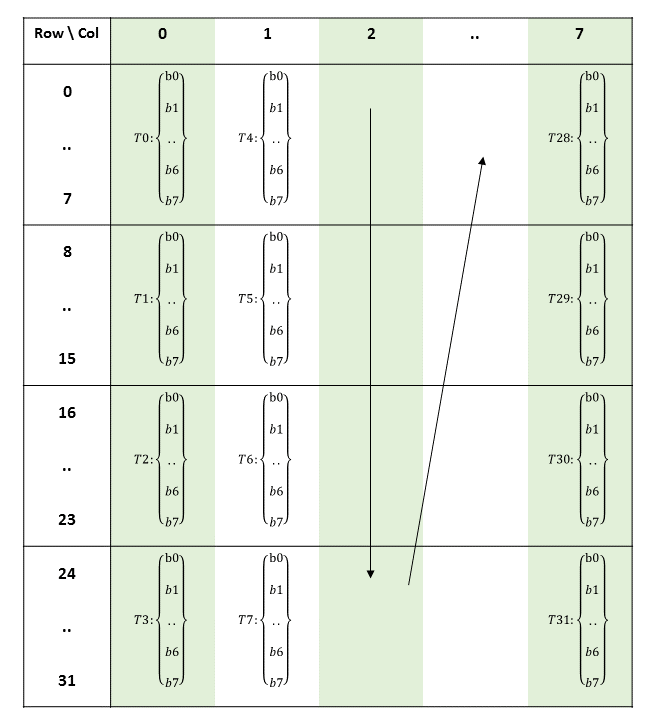
图 93 矩阵 B 第 0-31 行的 MMA .m16n8k64 分片布局,类型为
.u4/.s4/.e2m1。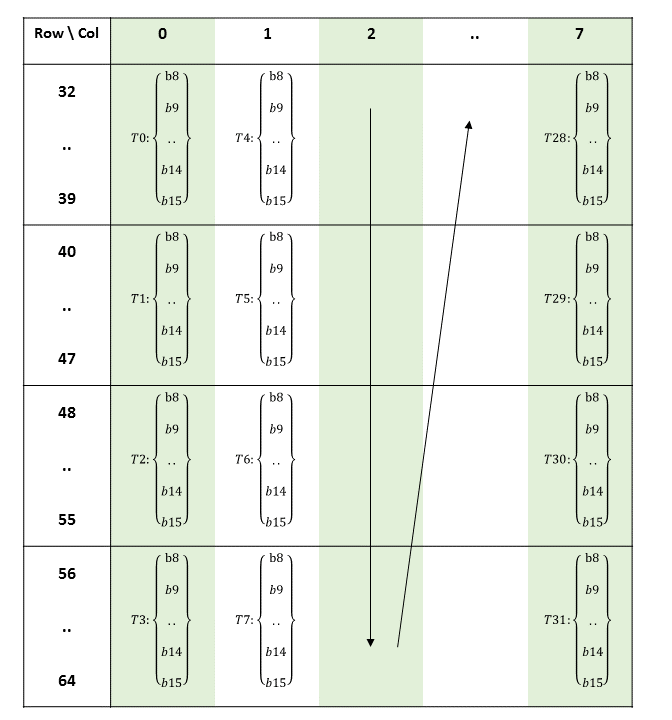
图 94 矩阵 B 第 32-63 行的 MMA .m16n8k64 分片布局,类型为
.u4/.s4/.e2m1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 8) + (i & 0x7) for bi where i < 8 (threadID_in_group * 8) + (i & 0x7) + 32 for bi where i >= 8 col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含四个
.s32寄存器,其中包含来自矩阵 C(或 D)的四个.s32元素。c0, c1, c2, c3
.f32一个向量表达式,包含四个
.f32寄存器,其中包含来自矩阵 C(或 D)的四个.f32元素。c0, c1, c2, c3
不同线程所持有的分片的布局如图 95所示。
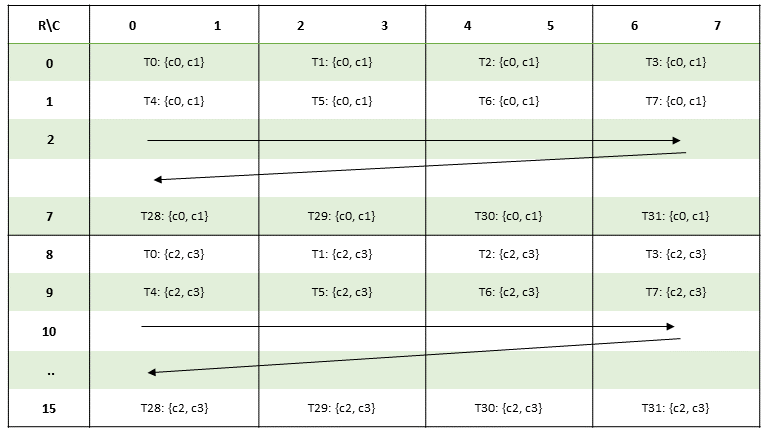
图 95 累加器矩阵 C/D 的 MMA .m16n8k64 分片布局,类型为
.s32/.f32。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ci where i < 2 groupID + 8 for ci where i >= 2 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
9.7.14.5.12. mma.m16n8k128 的矩阵分片
执行 mma.m16n8k128 的 warp 将计算形状为 .m16n8k128 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.b1包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的三十二个.b1元素。a0, a1, …, a62, a63
不同线程所持有的分片的布局如图 96所示。
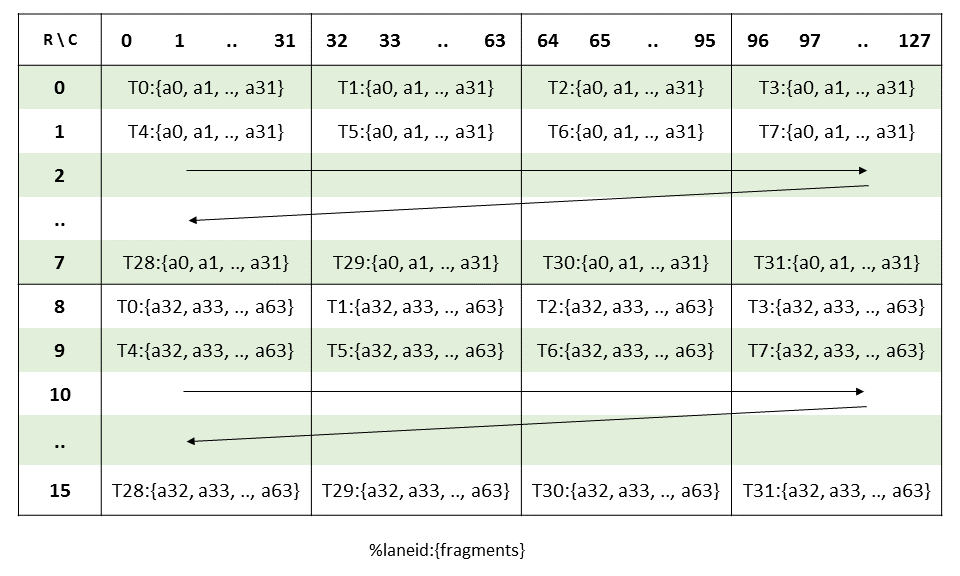
图 96 矩阵 A 的 MMA .m16n8k128 分片布局,类型为
.b1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where i < 32 groupID + 8 for ai where i >= 32 col = (threadID_in_group * 32) + (i & 0x1F) for ai where i = {0, ...,63}
-
被乘数 B
.btype
片段
元素(从低到高)
.b1包含单个
.b32寄存器的向量表达式,包含来自矩阵 B 的三十二个.b1元素。b0, b1, … , b30, b31
不同线程所持有的分片的布局如图 97所示。
图 97 矩阵 B 的 MMA .m16n8k128 分片布局,类型为
.b1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 32) + i for bi where i = {0,...,31} col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含四个
.s32寄存器,其中包含来自矩阵 C(或 D)的四个.s32元素。c0, c1, c2, c3
不同线程所持有的分片的布局如图 98所示。
图 98 累加器矩阵 C/D 的 MMA .m16n8k128 分片布局,类型为
.s32。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ci where i < 2 groupID + 8 for ci where i >= 2 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0, 1, 2, 3}
9.7.14.5.13. mma.m16n8k256 的矩阵分片
执行 mma.m16n8k256 的 warp 将计算形状为 .m16n8k256 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素(从低到高)
.b1包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的三十二个.b1元素。a0, a1, …, a126, a127
不同线程所持有的分片的布局如图 99所示。
图 99 矩阵 A 的 MMA .m16n8k256 分片布局,类型为
.b1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 32 || 64 <= i < 96 groupID + 8 otherwise col = (threadID_in_group * 32) + i for ai where i < 64 (threadID_in_group * 32) + (i & 0x1F) + 128 for ai where i >= 64
-
被乘数 B
.btype
片段
元素(从低到高)
.b1包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的三十二个.b1元素。b0, b1, …, b62, b63
不同线程所持有的分片的布局如图 100 和 图 101所示。
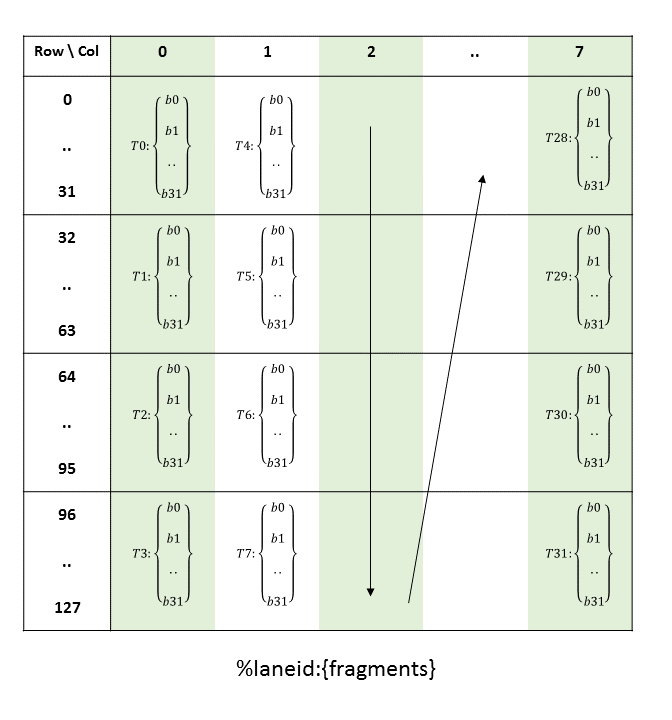
图 100 矩阵 B 第 0-127 行的 MMA .m16n8k256 分片布局,类型为
.b1。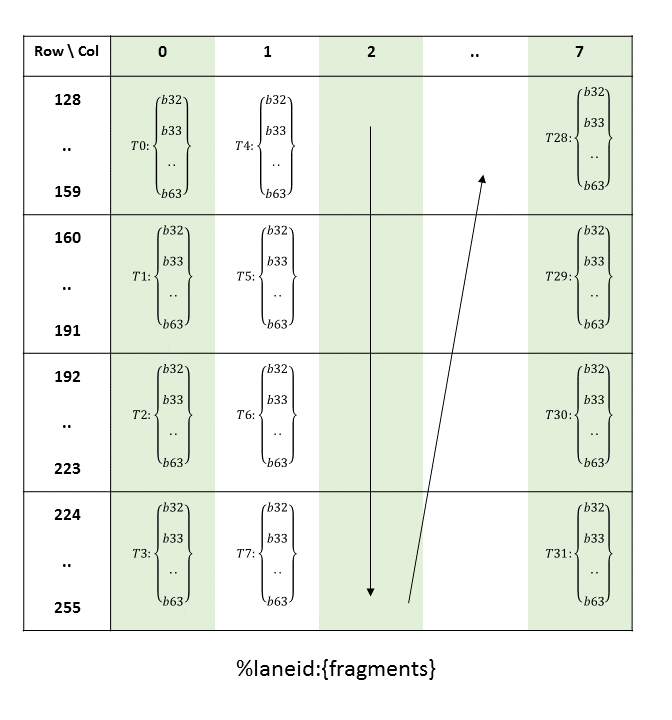
图 101 矩阵 B 第 128-255 行的 MMA .m16n8k256 分片布局,类型为
.b1。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = (threadID_in_group * 32) + (i & 0x1F) for bi where i < 32 (threadID_in_group * 32) + (i & 0x1F) + 128 for bi where i >= 32 col = groupID
-
累加器(C 或 D)
.ctype / .dtype
片段
元素(从低到高)
.s32一个向量表达式,包含四个
.s32寄存器,其中包含来自矩阵 C(或 D)的四个.s32元素。c0, c1, c2, c3
不同线程所持有的分片的布局如图 102所示。
图 102 累加器矩阵 C/D 的 MMA .m16n8k256 分片布局,类型为
.s32。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ci where i < 2 groupID + 8 for ci where i >= 2 col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0, 1, 2, 3}
9.7.14.5.14. 乘-加指令:mma
mma
执行矩阵乘-加运算
语法
半精度浮点类型
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
备选浮点类型
mma.sync.aligned.m16n8k4.row.col.f32.tf32.tf32.f32 d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.f32.atype.btype.f32 d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 d, a, b, c;
mma.sync.aligned.shape.row.col.dtype.f8type.f8type.ctype d, a, b, c;
mma.sync.aligned.m16n8k32.row.col.kind.dtype.f8f6f4type.f8f6f4type.ctype d, a, b, c;
.atype = {.bf16, .tf32};
.btype = {.bf16, .tf32};
.f8type = {.e4m3, .e5m2};
.f8f6f4type = {.e4m3, .e5m2, .e3m2, .e2m3, .e2m1};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
.shape = {.m16n8k16, .m16n8k32};
.kind = {.kind::f8f6f4};
带块缩放的备选浮点类型
mma.sync.aligned.m16n8k64.row.col.kind.block_scale{.scale_vec_size}.f32.e2m1.e2m1.f32.stype d, a, b, c, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.kind = {.kind::mxf4};
.scale_vec_size = {.scale_vec::2X};
.stype = {.ue8m0};
mma.sync.aligned.m16n8k64.row.col.kind.block_scale.scale_vec_size.f32.e2m1.e2m1.f32.stype d, a, b, c, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.kind = {.kind::mxf4nvf4};
.scale_vec_size = {.scale_vec::2X, .scale_vec::4X};
.stype = {.ue8m0, .ue4m3};
mma.sync.aligned.m16n8k32.row.col.kind.block_scale{.scale_vec_size}.f32.f8f6f4type.f8f6f4type.f32.stype d, a, b, c, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.kind = {.kind::mxf8f6f4};
.scale_vec_size = {.scale_vec::1X};
.f8f6f4type = {.e4m3, .e5m2, .e3m2, .e2m3, .e2m1};
.stype = {.ue8m0};
双精度浮点类型
mma.sync.aligned.shape.row.col.f64.f64.f64.f64 d, a, b, c;
.shape = {.m8n84, .m16n8k4, .m16n8k8, .m16n8k16};
整数类型
mma.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c;
.shape = {.m8n8k16, .m16n8k16, .m16n8k32}
.atype = {.u8, .s8};
.btype = {.u8, .s8};
mma.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c;
.shape = {.m8n8k32, .m16n8k32, .m16n8k64}
.atype = {.u4, .s4};
.btype = {.u4, .s4};
单比特
mma.sync.aligned.shape.row.col.s32.b1.b1.s32.bitOp.popc d, a, b, c;
.bitOp = {.xor, .and}
.shape = {.m8n8k128, .m16n8k128, .m16n8k256}
描述
执行 MxNxK 矩阵乘法和累加运算,D = A*B+C,其中 A 矩阵为 MxK,B 矩阵为 KxN,C 和 D 矩阵为 MxN。
限定符 .block_scale 指定在执行矩阵乘法和累加运算之前,分别使用 scale_A 和 scale_B 矩阵对矩阵 A 和 B 进行缩放,如块缩放部分所述。 scale_A 和 Scale_B 矩阵中每个元素对应的数据类型由 .stype 指定。限定符 .scale_vec_size 指定 scale_A 矩阵的列数和矩阵 scale_B 中的行数。
.kind、.stype 和 .scale_vec_size 的有效组合在表 35中描述。对于 mma 和 .kind::mxf4,当未指定限定符 .scale_vec_size 时,则默认为 2X。相反,当 .kind 指定为 .kind::mxf8f6f4 时,限定符 .scale_vec_size 默认为 1X。但是,对于 .kind::mxf4nvf4,必须提供有效的 .scale_vec_size。
执行 mma.sync.m8n8k4 指令的 warp 计算 4 个矩阵乘法和累加运算。mma.sync 的其余操作每个 warp 计算单个矩阵乘法和累加运算。
对于单比特 mma.sync,乘法被一系列逻辑运算所取代;具体而言,mma.xor.popc 和 mma.and.popc 分别计算 A 的 k 比特行与 B 的 k 比特列的 XOR、AND,然后计算结果中设置比特的数量 (popc)。此结果将添加到 C 的相应元素中,并写入 D。
操作数 a 和 b 表示两个乘数矩阵 A 和 B,而 c 和 d 表示累加器矩阵和目标矩阵,它们分布在 warp 中的线程之间。当指定 .block_scale 限定符时,操作数 scale-a-data、scale-b-data 分别表示与 scale_A 和 scale_B 矩阵对应的缩放矩阵元数据。元组 {byte-id-a, thread-id-a} 和 {byte-id-b, thread-id-b} 分别表示从其对应的元数据参数 scale-a-data、scale-b-data 中选择矩阵 scale_A 和 scale_B 的选择器。操作数 scale-a-data、scale-b-data 的类型为 .b32。操作数 byte-id-a、thread-id-a、byte-id-b、thread-id-b 是无符号 16 位整数值。有关选择器参数的更多详细信息,请参阅块缩放部分。
每个线程中的寄存器保存矩阵的分片,如使用 mma 指令的矩阵乘法累加运算中所述。
限定符 .dtype、.atype、.btype 和 .ctype 分别指示矩阵 D、A、B 和 C 中元素的数据类型。限定符 .stype 指示矩阵 scale_A 和 scale_B 中元素的数据类型。特定形状具有类型限制
.m8n8k4:当.ctype为.f32时,.dtype也必须为.f32。-
.m16n8k8:.dtype必须与.ctype相同。.atype必须与.btype相同。
限定符 .alayout 和 .blayout 分别指示矩阵 A 和 B 的行优先或列优先布局。
当 .kind 是 .kind::mxf8f6f4 或 .kind::f8f6f4 之一时,各个 4 比特和 6 比特浮点类型元素必须打包在 8 比特容器中。 .e2m1 类型的矩阵元素位于 8 比特容器的中心 4 比特中,并在容器的上 2 比特和下 2 比特中填充。当矩阵元素为 .e3m2 或 .e2m3 类型时,矩阵元素位于 8 比特容器的下 6 比特中,并在容器的上 2 比特中填充。 相比之下,请注意,当将 mma 与 .kind::mxf4 或 .kind::mxf4nvf4 一起使用时,即使矩阵元素为 .e2m1 类型,也不需要显式填充。
- 精度和舍入
-
-
.f16浮点运算矩阵 A 和 B 的元素级乘法以至少单精度执行。当
.ctype或.dtype为.f32时,中间值的累加以至少单精度执行。当.ctype和.dtype都指定为.f16时,累加以至少半精度执行。累加顺序、舍入和次正规输入的处理方式未指定。
-
.e4m3、.e5m2、.e3m2、.e2m3、.e2m1浮点运算矩阵 A 和 B 的元素级乘法以指定的精度执行。中间值的累加以至少单精度执行。
累加顺序、舍入和次正规输入的处理方式未指定。
-
.bf16和.tf32浮点运算矩阵 A 和 B 的元素级乘法以指定的精度执行。中间值的累加以至少单精度执行。
累加顺序、舍入和次正规输入的处理方式未指定。
-
.f64浮点运算逐元素乘法和加法运算的精度与
.f64精度融合乘加运算的精度相同。 支持的舍入修饰符包括.rn:尾数 LSB 四舍五入到最接近的偶数。 这是默认值。.rz:尾数 LSB 向零舍入。.rm:尾数 LSB 向负无穷大舍入。.rp:尾数 LSB 向正无穷大舍入。
-
整数运算
整数
mma运算使用.s32累加器执行。.satfinite限定符指示,发生溢出时,累加值将限制在 MIN_INT32..MAX_INT32 范围内(其中边界定义为最小负有符号 32 位整数和最大正有符号 32 位整数)。如果未指定
.satfinite,则累加值将改为回绕。
-
强制性 .sync 限定符指示 mma 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 mma 指令,然后才恢复执行。
强制性 .aligned 限定符指示 warp 中的所有线程必须执行相同的 mma 指令。 在有条件执行的代码中,仅当已知 warp 中的所有线程对条件的评估结果相同时,才应使用 mma 指令,否则行为未定义。
如果同一 warp 中的所有线程未使用相同的限定符,或者 warp 中的任何线程已退出,则 mma 指令的行为未定义。
注释
使用双精度浮点 mma 指令且形状为 .m16n8k4、.m16n8k8 和 .m16n8k16 的程序需要至少 64 个寄存器才能进行编译。
PTX ISA 注释
在 PTX ISA 版本 6.4 中引入。
在 PTX ISA 版本 6.4 中引入了形状为 .m8n8k4 的 .f16 浮点类型 mma 运算。
在 PTX ISA 版本 6.5 中引入了形状为 .m16n8k8 的 .f16 浮点类型 mma 运算。
在 PTX ISA 版本 6.5 中引入了形状为 .m8n8k16 的 .u8/.s8 整数类型 mma 运算。
在 PTX ISA 版本 6.5 中引入了形状为 .m8n8k32 的 .u4/.s4 整数类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m8n8k4 的 .f64 浮点类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m16n8k16 的 .f16 浮点类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m16n8k8 和 .m16n8k16 的 .bf16 备选浮点类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m16n8k4 和 .m16n8k8 的 .tf32 备选浮点类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m16n8k16 和 .m16n8k32 的 .u8/.s8 整数类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m16n8k32 和 .m16n8k64 的 .u4/.s4 整数类型 mma 运算。
在 PTX ISA 版本 7.0 中引入了形状为 .m8n8k128、.m16n8k128 和 .m16n8k256 的 .b1 单比特整数类型 mma 运算。
在 PTX ISA 版本 7.1 中引入了单比特 mma 中对 .and 运算的支持。
在 PTX ISA 版本 7.8 中引入了形状为 .m16n8k4、.m16n8k8 和 .m16n8k16 的 .f64 浮点类型 mma 运算。
在 PTX ISA 版本 8.4 中引入了对 .e4m3 和 .e5m2 备选浮点类型 mma 运算的支持。
在 PTX ISA 版本 8.7 中引入了对形状 .m16n8k16 和 .f16 dtype/.ctype 以及 .e4m3/.e5m2 备选浮点类型 mma 运算的支持。
在 PTX ISA 版本 8.7 中引入了对 .e3m2、.e2m3、.e2m1 备选浮点类型 mma 运算的支持。
在 PTX ISA 版本 8.7 中引入了对 .kind、.block_scale、.scale_vec_size 限定符的支持。
目标 ISA 注释
需要 sm_70 或更高版本。
形状为 .m8n8k4 的 .f16 浮点类型 mma 运算需要 sm_70 或更高版本。
注意
mma.sync.m8n8k4 针对目标架构 sm_70 进行了优化,并且在其他目标架构上性能可能会大幅降低。
形状为 .m16n8k8 的 .f16 浮点类型 mma 运算需要 sm_75 或更高版本。
形状为 .m8n8k16 的 .u8/.s8 整数类型 mma 运算需要 sm_75 或更高版本。
.u4/.s4 整数类型 mma 操作,形状为 .m8n8k32,需要 sm_75 或更高架构。
.b1 单比特整数类型 mma 操作,形状为 .m8n8k128,需要 sm_75 或更高架构。
.f64 浮点类型 mma 操作,形状为 .m8n8k4,需要 sm_80 或更高架构。
.f16 浮点类型 mma 操作,形状为 .m16n8k16,需要 sm_80 或更高架构。
.bf16 备选浮点类型 mma 操作,形状为 .m16n8k8 和 .m16n8k16,需要 sm_80 或更高架构。
.tf32 备选浮点类型 mma 操作,形状为 .m16n8k4 和 .m16n8k8,需要 sm_80 或更高架构。
.u8/.s8 整数类型 mma 操作,形状为 .m16n8k16 和 .m16n8k32,需要 sm_80 或更高架构。
.u4/.s4 整数类型 mma 操作,形状为 .m16n8k32 和 .m16n8k64,需要 sm_80 或更高架构。
.b1 单比特整数类型 mma 操作,形状为 .m16n8k128 和 .m16n8k256,需要 sm_80 或更高架构。
.and 操作在单比特 mma 中需要 sm_80 或更高架构。
.f64 浮点类型 mma 操作,形状为 .m16n8k4、.m16n8k8 和 .m16n8k16,需要 sm_90 或更高架构。
.e4m3 和 .e5m2 备选浮点类型 mma 操作需要 sm_89 或更高架构。
.e3m2、.e2m3 和 .e2m1 备选浮点类型 mma 操作需要 sm_120a。
对 .kind、.block_scale、.scale_vec_size 限定符的支持需要 sm_120a。
半精度浮点类型示例
// f16 elements in C and D matrix
.reg .f16x2 %Ra<2> %Rb<2> %Rc<4> %Rd<4>
mma.sync.aligned.m8n8k4.row.col.f16.f16.f16.f16
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
// f16 elements in C and f32 elements in D
.reg .f16x2 %Ra<2> %Rb<2> %Rc<4>
.reg .f32 %Rd<8>
mma.sync.aligned.m8n8k4.row.col.f32.f16.f16.f16
{%Rd0, %Rd1, %Rd2, %Rd3, %Rd4, %Rd5, %Rd6, %Rd7},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
// f32 elements in C and D
.reg .f16x2 %Ra<2>, %Rb<1>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k8.row.col.f32.f16.f16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .f16x2 %Ra<4>, %Rb<2>, %Rc<2>, %Rd<2>;
mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1};
.reg .f16 %Ra<4>, %Rb<2>;
.reg .f32 %Rc<2>, %Rd<2>;
mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
备选浮点类型示例
.reg .b32 %Ra<2>, %Rb<1>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k4.row.col.f32.tf32.tf32.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .f16x2 %Ra<2>, %Rb<1>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k8.row.col.f32.bf16.bf16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<2>, %Rb<1>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Rb2, %Rb3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .f16x2 %Ra<2>, %Rb<1>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k32.row.col.f32.e4m3.e5m2.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k16.row.col.f32.e5m2.e4m3.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .b32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k32.row.col.f16.e4m3.e5m2.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .b32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k16.row.col.f16.e5m2.e5m2.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1},
{%Rb0},
{%Rc0, %Rc1};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k32.row.col.kind::f8f6f4.f32.e3m2.e2m3.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .b32 %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k32.row.col.kind::f8f6f4.f16.e2m3.e2m1.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1};
整数类型示例
.reg .b32 %Ra, %Rb, %Rc<2>, %Rd<2>;
// s8 elements in A and u8 elements in B
mma.sync.aligned.m8n8k16.row.col.satfinite.s32.s8.u8.s32
{%Rd0, %Rd1},
{%Ra},
{%Rb},
{%Rc0, %Rc1};
// u4 elements in A and B matrix
mma.sync.aligned.m8n8k32.row.col.satfinite.s32.u4.u4.s32
{%Rd0, %Rd1},
{%Ra},
{%Rb},
{%Rc0, %Rc1};
// s8 elements in A and u8 elements in B
.reg .b32 %Ra<2>, %Rb, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k16.row.col.satfinite.s32.s8.u8.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb},
{%Rc0, %Rc1, %Rc2, %Rc3};
// u4 elements in A and s4 elements in B
.reg .b32 %Ra<2>, %Rb, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k32.row.col.satfinite.s32.u4.s4.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb},
{%Rc0, %Rc1, %Rc2, %Rc3};
// s8 elements in A and s8 elements in B
.reg .b32 %Ra<4>, %Rb<2>, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k32.row.col.satfinite.s32.s8.s8.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
// u8 elements in A and u8 elements in B
.reg .b32 %Ra<4>, %Rb<2>, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k64.row.col.satfinite.s32.u4.u4.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1 },
{%Rc0, %Rc1, %Rc2, %Rc3};
单比特类型示例
// b1 elements in A and B
.reg .b32 %Ra, %Rb, %Rc<2>, %Rd<2>;
mma.sync.aligned.m8n8k128.row.col.s32.b1.b1.s32.and.popc
{%Rd0, %Rd1},
{%Ra},
{%Rb},
{%Rc0, %Rc1};
// b1 elements in A and B
.reg .b32 %Ra, %Rb, %Rc<2>, %Rd<2>;
mma.sync.aligned.m8n8k128.row.col.s32.b1.b1.s32.xor.popc
{%Rd0, %Rd1},
{%Ra},
{%Rb},
{%Rc0, %Rc1};
.reg .b32 %Ra<2>, %Rb, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k128.row.col.s32.b1.b1.s32.xor.popc
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<2>, %Rb, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k128.row.col.s32.b1.b1.s32.and.popc
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<4>, %Rb<2>, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k256.row.col.s32.b1.b1.s32.xor.popc
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
.reg .b32 %Ra<4>, %Rb<2>, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k256.row.col.s32.b1.b1.s32.and.popc
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
.f64 浮点类型示例
.reg .f64 %Ra, %Rb, %Rc<2>, %Rd<2>;
mma.sync.aligned.m8n8k4.row.col.f64.f64.f64.f64
{%Rd0, %Rd1},
{%Ra},
{%Rb},
{%Rc0, %Rc1};
.reg .f64 %Ra<8>, %Rb<4>, %Rc<4>, %Rd<4>;
mma.sync.aligned.m16n8k4.row.col.f64.f64.f64.f64.rn
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0},
{%Rc0, %Rc1, %Rc2, %Rc3};
mma.sync.aligned.m16n8k8.row.col.f64.f64.f64.f64.rn
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3};
mma.sync.aligned.m16n8k16.row.col.f64.f64.f64.f64.rn
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3, %Ra4, %Ra5, %Ra6, %Ra7},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3};
带块缩放的 mma 示例
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
mma.sync.aligned.m16n8k64.row.col kind::mxf4.block_scale.f32.e2m1.e2m1.f32.ue8m0
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3},
scaleAData, {2, 1}, scaleBData, {2, 3};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
.reg .u16 bidA, bidB, tidA, tidB;
mma.sync.aligned.m16n8k64.row.col.kind::mxf4nvf4.block_scale.scale_vec::4X.f32.e2m1.e2m1.f32.ue4m3
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3},
scaleAData, {bidA, tidA}, scaleBData, {bidB, tidB};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
mma.sync.aligned.m16n8k32.row.col.kind::mxf8f6f4.block_scale.scale_vec::1X.f32.e3m2.e2m1.f32.ue8m0
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3},
scaleAData, {0, 1}, scaleBData, {0, 1};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
mma.sync.aligned.m16n8k32.row.col.kind::mxf8f6f4.block_scale.scale_vec::1X.f32.e4m3.e5m2.f32.ue8m0
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3},
scaleAData, {0, 1}, scaleBData, {0, 0};
9.7.14.5.15. Warp 级矩阵加载指令:ldmatrix
ldmatrix
从共享内存中集体加载一个或多个矩阵,用于 mma 指令
语法
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
ldmatrix.sync.aligned.m8n16.num{.ss}.dst_fmt.src_fmt r, [p];
ldmatrix.sync.aligned.m16n16.num.trans{.ss}.dst_fmt.src_fmt r, [p];
.shape = {.m8n8, .m16n16};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};
.dst_fmt = { .b8x16 };
.src_fmt = { .b6x16_p32, .b4x16_p64 };
描述
跨 Warp 中的所有线程从地址操作数 p 指示的位置,从 .shared 状态空间集体加载一个或多个矩阵到目标寄存器 r 中。如果未提供状态空间,则使用通用寻址,使得 p 中的地址指向 .shared 空间。如果通用地址不在 .shared 状态空间内,则行为未定义。
.shape 限定符指示正在加载的矩阵的维度。每个矩阵元素保存 16 位、8 位、6 位或 4 位数据。
下表显示了每个 .shape 的矩阵加载情况。
.shape |
矩阵形状 |
元素大小 |
|---|---|---|
|
8x8 |
16 位 |
|
16x16 |
8 位、6 位或 4 位 |
|
8x16 |
6 位或 4 位 |
下表显示了 6 位或 4 位数据加载的有效用法。
.src_fmt |
.shape |
源数据 |
填充 |
.dst_fmt |
|---|---|---|---|---|
|
|
16 个 6 位元素 |
32 位 |
|
|
||||
|
|
16 个 4 位元素 |
64 位 |
|
|
对于 .b6x16_p32 格式,源数据为 16 个无符号 6 位元素,带有 32 位填充。对于 .b4x16_p64 格式,源数据为 16 个无符号 4 位元素,带有 64 位填充。
对于 .num,值 .x1、.x2 和 .x4 分别表示一个、两个或四个矩阵。当 .shape 为 .m16n16 时,只有 .x1 和 .x2 是 .num 的有效值。
强制性 .sync 限定符指示 ldmatrix 会导致执行线程等待,直到 Warp 中的所有线程执行相同的 ldmatrix 指令,然后才能恢复执行。
强制性 .aligned 限定符指示 Warp 中的所有线程必须执行相同的 ldmatrix 指令。在条件执行的代码中,只有当已知 Warp 中的所有线程对条件的评估结果相同时,才应使用 ldmatrix 指令,否则行为未定义。
如果所有线程未使用相同的限定符,或者 Warp 中的任何线程已退出,则 ldmatrix 的行为未定义。
目标操作数 r 是一个用花括号括起来的向量表达式,根据 .num 的值,由 1、2 或 4 个 32 位寄存器组成。向量表达式的每个组件都保存来自相应矩阵的片段。
对 p 支持的寻址模式在 作为操作数的地址 中进行了描述。
行的连续实例不必在内存中连续存储。每个矩阵所需的八个地址由八个线程提供,具体取决于 .num 的值,如下表所示。每个地址对应于矩阵行的开始。地址 addr0–addr7 对应于第一个矩阵的行,地址 addr8–addr15 对应于第二个矩阵的行,依此类推。
|
线程 0–7 |
线程 8–15 |
线程 16–23 |
线程 24–31 |
|---|---|---|---|---|
|
addr0–addr7 |
– |
– |
– |
|
addr0–addr7 |
addr8–addr15 |
– |
– |
|
addr0–addr7 |
addr8–addr15 |
addr16–addr23 |
addr24–addr31 |
注意
对于目标架构 sm_75 或更低版本,所有线程必须包含有效地址。否则,行为未定义。对于 .num = .x1 和 .num = .x2,可以将较低线程中包含的地址复制到较高线程以实现预期的行为。
读取 8x8 矩阵时,四个连续线程的组加载 16 字节。矩阵地址必须相应地自然对齐。
Warp 中的每个线程加载矩阵行的片段,线程 0 在其寄存器 r 中接收第一个片段,依此类推。如图 图 103 所示,四个线程的组加载矩阵的整行。
图 103 具有 16 位元素的 8x8 矩阵的 ldmatrix 片段布局
当 .num = .x2 时,第二个矩阵的元素按照上表中的布局加载到每个线程的下一个目标寄存器中。类似地,当 .num = .x4 时,第三个和第四个矩阵的元素加载到每个线程的后续目标寄存器中。
对于矩阵形状 16x16,必须指定两个 .b32 类型的目标寄存器 r0 和 r1,并且每个寄存器中加载四个 8 位元素。对于 4 位或 6 位数据,8 位元素将分别具有 4 位或 2 位填充。有关这些格式的更多详细信息,请参阅 可选解压缩。
矩阵的整行可以由四个连续且对齐的线程组加载。如图 图 104 所示,Warp 中的每个线程加载跨越 2 行的 4 个连续列。
图 104 具有 8 位元素的 16x16 矩阵的 ldmatrix 片段布局
对于矩阵形状 8x16,必须指定一个 .b32 类型的目标寄存器 r0,其中寄存器中加载了四个 8 位元素。对于 4 位或 6 位数据,8 位元素将分别具有 4 位或 2 位填充。
矩阵的整行可以由四个连续且对齐的线程组加载。如图 图 105 所示,Warp 中的每个线程加载 4 个连续列。
图 105 具有包含 4 位/6 位数据的 8 位元素的 8x16 矩阵的 ldmatrix 片段布局
可选限定符 .trans 指示矩阵以列优先格式加载。但是,对于 16x16 矩阵,.trans 是强制性的。
在 内存一致性模型 中,ldmatrix 指令被视为弱内存操作。
PTX ISA 注释
在 PTX ISA 版本 6.5 中引入。
PTX ISA 版本 7.8 中引入了对 ::cta 子限定符的支持。
PTX ISA 版本 8.6 中引入了对 .m16n16、.m8n16 形状的支持。
PTX ISA 版本 8.6 中引入了对 ldmatrix 的 .b8 类型的支持。
PTX ISA 版本 8.6 中引入了对 .src_fmt、.dst_fmt 限定符的支持。
目标 ISA 注释
需要 sm_75 或更高版本。
以下架构支持形状 .m16n16、.m8n16
sm_100asm_101asm_120a
以下架构支持带有 ldmatrix 的类型 .b8
sm_100asm_101asm_120a
以下架构支持限定符 .src_fmt、.dst_fmt
sm_100asm_101asm_120a
示例
// Load a single 8x8 matrix using 64-bit addressing
.reg .b64 addr;
.reg .b32 d;
ldmatrix.sync.aligned.m8n8.x1.shared::cta.b16 {d}, [addr];
// Load two 8x8 matrices in column-major format
.reg .b64 addr;
.reg .b32 d<2>;
ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {d0, d1}, [addr];
// Load four 8x8 matrices
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m8n8.x4.b16 {d0, d1, d2, d3}, [addr];
// Load one 16x16 matrices of 64-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<2>;
ldmatrix.sync.aligned.m16n16.x1.trans.shared.b8 {d0, d1}, [addr];
// Load two 16x16 matrices of 64-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m16n16.x2.trans.shared::cta.b8 {d0, d1, d2, d3}, [addr];
// Load two 16x16 matrices of 6-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m16n16.x2.trans.shared::cta.b8x16.b6x16_p32 {d0, d1, d2, d3}, [addr];
9.7.14.5.16. Warp 级矩阵存储指令:stmatrix
stmatrix
将一个或多个矩阵集体存储到共享内存。
语法
stmatrix.sync.aligned.shape.num{.trans}{.ss}.type [p], r;
.shape = {.m8n8, .m16n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};
描述
跨 Warp 中的所有线程将一个或多个矩阵集体存储到地址操作数 p 指示的位置,在 .shared 状态空间中。如果未提供状态空间,则使用通用寻址,使得 p 中的地址指向 .shared 空间。如果通用地址不在 .shared 状态空间内,则行为未定义。
.shape 限定符指示正在加载的矩阵的维度。每个矩阵元素保存 16 位或 8 位数据,如 .type 限定符所示。
.m16n8 形状仅对 .b8 类型有效。
对于 .num,值 .x1、.x2 和 .x4 分别表示一个、两个或四个矩阵。
强制性 .sync 限定符指示 stmatrix 会导致执行线程等待,直到 Warp 中的所有线程执行相同的 stmatrix 指令,然后才能恢复执行。
强制性 .aligned 限定符指示 Warp 中的所有线程必须执行相同的 stmatrix 指令。在条件执行的代码中,只有当已知 Warp 中的所有线程对条件的评估结果相同时,才应使用 stmatrix 指令,否则行为未定义。
如果所有线程未使用相同的限定符,或者 Warp 中的任何线程已退出,则 stmatrix 的行为未定义。
源操作数 r 是一个用花括号括起来的向量表达式,根据 .num 的值,由 1、2 或 4 个 32 位寄存器组成。向量表达式的每个组件都保存来自相应矩阵的片段。
对 p 支持的寻址模式在 作为操作数的地址 中进行了描述。
行的连续实例不必在内存中连续存储。每个矩阵所需的八个地址由八个线程提供,具体取决于 .num 的值,如下表所示。每个地址对应于矩阵行的开始。地址 addr0–addr7 对应于第一个矩阵的行,地址 addr8–addr15 对应于第二个矩阵的行,依此类推。
|
线程 0–7 |
线程 8–15 |
线程 16–23 |
线程 24–31 |
|---|---|---|---|---|
|
addr0–addr7 |
– |
– |
– |
|
addr0–addr7 |
addr8–addr15 |
– |
– |
|
addr0–addr7 |
addr8–addr15 |
addr16–addr23 |
addr24–addr31 |
存储 8x8 矩阵时,四个连续线程的组存储 16 字节。矩阵地址必须相应地自然对齐。
Warp 中的每个线程存储矩阵行的片段,线程 0 从其寄存器 r 存储第一个片段,依此类推。如图 图 106 所示,四个线程的组存储矩阵的整行。
图 106 具有 16 位元素的 8x8 矩阵的 stmatrix 片段布局
当 .num = .x2 时,第二个矩阵的元素按照上表中的布局从每个线程的下一个源寄存器存储。类似地,当 .num = .x4 时,第三个和第四个矩阵的元素从每个线程的后续源寄存器存储。
对于 16x8 矩阵形状,Warp 中的每个 32 个线程为每个矩阵提供四个数据元素。
源操作数 r 中的每个元素都是 .b32 类型,包含四个 8 位元素 e0、e1、e2、e3,其中 e0 和 e3 分别包含寄存器 r 的 LSB 和 MSB。
图 107 具有 8 位元素的 16x8 矩阵的 stmatrix 片段布局
可选限定符 .trans 指示矩阵以列优先格式存储。但是,对于 16x8 矩阵,.trans 是强制性的。
在 内存一致性模型 中,stmatrix 指令被视为弱内存操作。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
PTX ISA 版本 8.6 中引入了对 .m16n8 形状的支持。
PTX ISA 版本 8.6 中引入了对带有 stmatrix 的 .b8 类型的支持。
目标 ISA 注释
需要 sm_90 或更高版本。
以下架构支持形状 .m16n8
sm_100asm_101asm_120a
以下架构支持带有 stmatrix 的类型 .b8
sm_100asm_101asm_120a
示例
// Store a single 8x8 matrix using 64-bit addressing
.reg .b64 addr;
.reg .b32 r;
stmatrix.sync.aligned.m8n8.x1.shared.b16 [addr], {r};
// Store two 8x8 matrices in column-major format
.reg .b64 addr;
.reg .b32 r<2>;
stmatrix.sync.aligned.m8n8.x2.trans.shared::cta.b16 [addr], {r0, r1};
// Store four 8x8 matrices
.reg .b64 addr;
.reg .b32 r<4>;
stmatrix.sync.aligned.m8n8.x4.b16 [addr], {r0, r1, r2, r3};
// Store a single 16x8 matrix using generic addressing
.reg .b64 addr;
.reg .b32 r;
stmatrix.sync.aligned.m16n8.x1.trans.shared.b8 [addr], {r};
// Store two 16x8 matrices
.reg .b64 addr;
.reg .b32 r<2>;
stmatrix.sync.aligned.m16n8.x2.trans.shared::cta.b8 [addr],{r0, r1};
// Store four 16x8 matrices
.reg .b64 addr;
.reg .b32 r<4>;
stmatrix.sync.aligned.m16n8.x4.b8 [addr], {r0, r1, r2, r3};
9.7.14.5.17. Warp 级矩阵转置指令:movmatrix
movmatrix
在 Warp 中的寄存器之间转置矩阵。
语法
movmatrix.sync.aligned.shape.trans.type d, a;
.shape = {.m8n8};
.type = {.b16};
描述
跨 Warp 中的所有线程移动行优先矩阵,从源 a 读取元素,并将转置后的元素写入目标 d。
.shape 限定符指示正在转置的矩阵的维度。每个矩阵元素保存 16 位数据,如 .type 限定符所示。
强制性 .sync 限定符指示 movmatrix 会导致执行线程等待,直到 Warp 中的所有线程执行相同的 movmatrix 指令,然后才能恢复执行。
强制性 .aligned 限定符指示 Warp 中的所有线程必须执行相同的 movmatrix 指令。在条件执行的代码中,只有当已知 Warp 中的所有线程对条件的评估结果相同时,才应使用 movmatrix 指令,否则行为未定义。
操作数 a 和 d 是 32 位寄存器,分别包含输入矩阵和结果矩阵的片段。强制性限定符 .trans 指示 d 中的结果矩阵是由 a 指定的输入矩阵的转置。
Warp 中的每个线程都保存输入矩阵行的片段,线程 0 在寄存器 a 中保存第一个片段,依此类推。如图 图 108 所示,四个线程的组保存输入矩阵的整行。
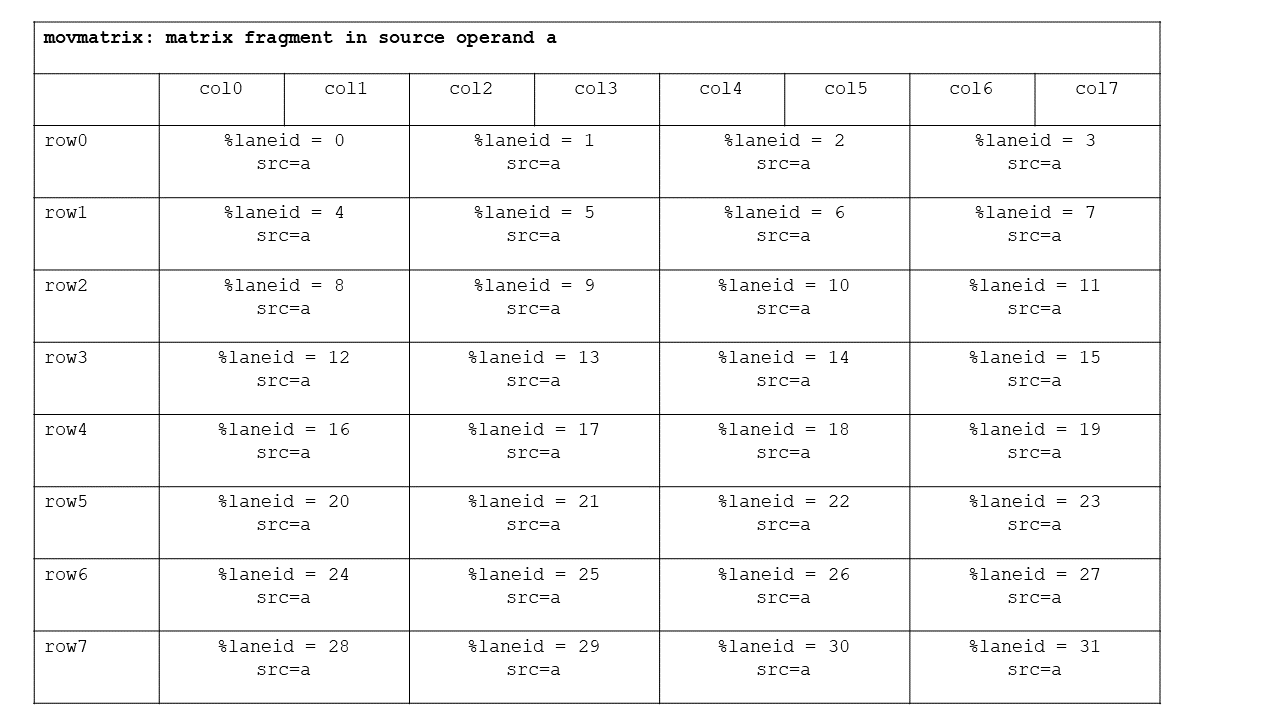
图 108 movmatrix 源矩阵片段布局
Warp 中的每个线程都保存结果矩阵列的片段,线程 0 在寄存器 d 中保存第一个片段,依此类推。如图 图 109 所示,四个线程的组保存结果矩阵的整列。
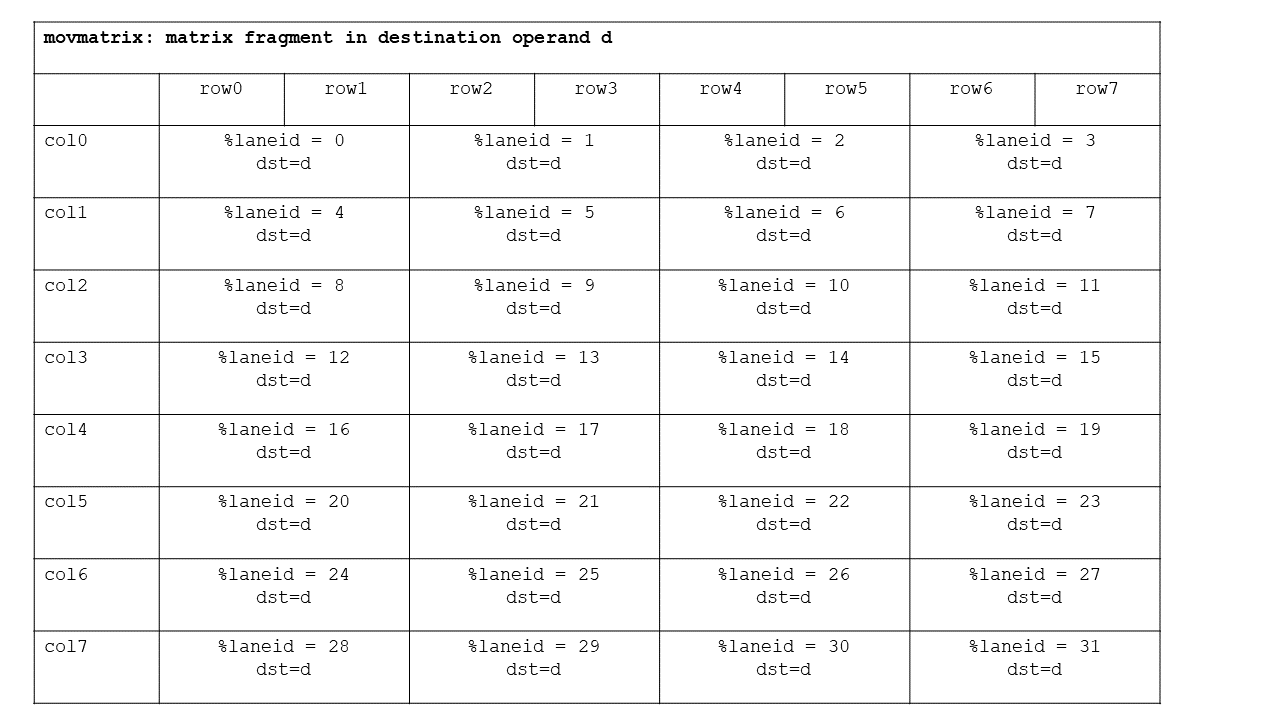
图 109 movmatrix 结果矩阵片段布局
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_75 或更高版本。
示例
.reg .b32 d, a;
movmatrix.sync.aligned.m8n8.trans.b16 d, a;
9.7.14.6. 使用稀疏矩阵 A 的 mma.sp 指令进行矩阵乘法累加运算
本节介绍 Warp 级 mma.sp{::ordered_metadata} 指令与稀疏矩阵 A 的使用。当 A 是结构化稀疏矩阵,每行中有 50% 的零元素以形状特定的粒度分布时,可以使用 mma 操作的这种变体。对于 MxNxK 稀疏 mma.sp{::ordered_metadata} 操作,MxK 矩阵 A 被打包到 MxK/2 个元素中。对于矩阵 A 的每个 K 宽行,50% 的元素为零,其余 K/2 个非零元素打包在表示矩阵 A 的操作数中。这些 K/2 个元素到相应 K 宽行的映射以元数据的形式显式提供。
9.7.14.6.1. 稀疏矩阵存储
稀疏矩阵 A 的粒度定义为矩阵行子块中非零元素的数量与该子块中元素总数的比率,其中子块的大小是形状特定的。例如,在 16x16 矩阵 A 中,稀疏性预计为 2:4 粒度,即矩阵行的每个 4 元素向量(即 4 个连续元素的子块)包含 2 个零。子块中每个非零元素的索引存储在元数据操作数中。值 0b0000、0b0101、0b1010、0b1111 是元数据的无效值,将导致未定义的行为。在一组四个连续的线程中,一个或多个线程根据矩阵形状存储整个组的元数据。这些线程使用额外的稀疏性选择器操作数指定。
图 110 显示了以稀疏格式表示的 16x16 矩阵 A 的示例,以及指示四个连续线程组中哪个线程存储元数据的稀疏性选择器。
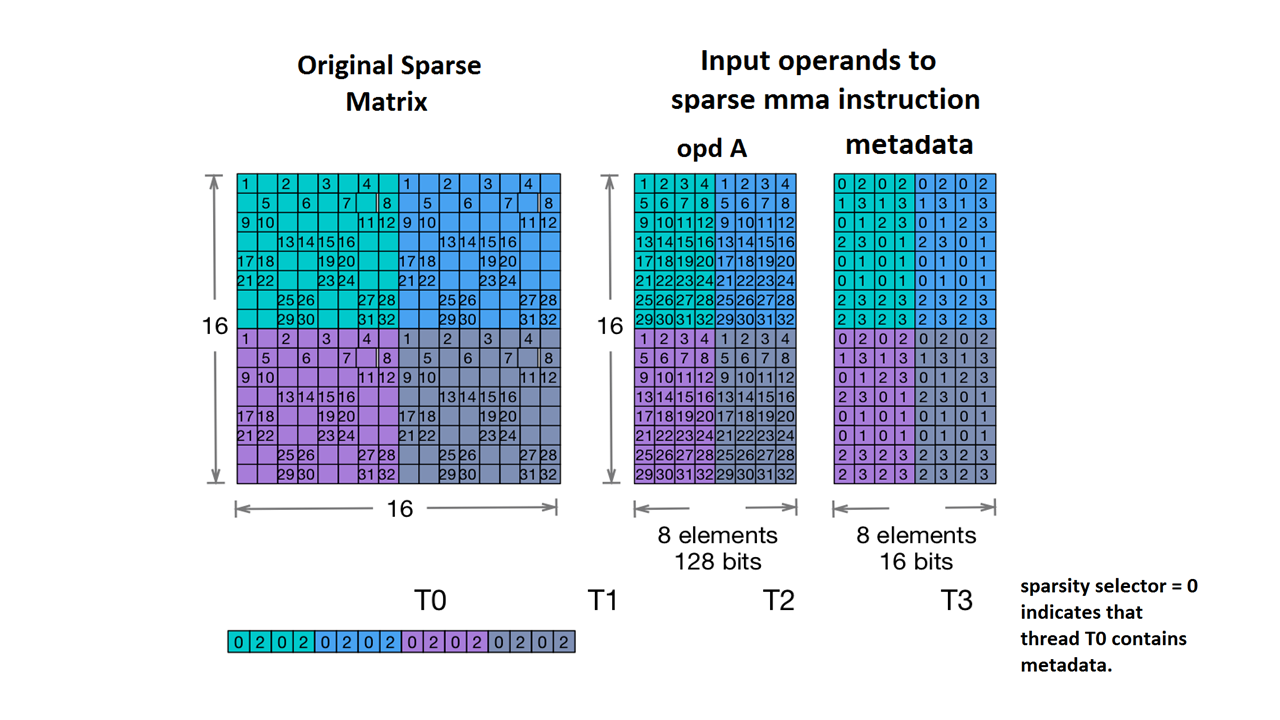
图 110 稀疏 MMA 存储示例
不同矩阵形状和数据类型的粒度如下所述。
稀疏 mma.sp{::ordered_metadata} ,具有半精度和 .bf16 类型
对于 .m16n8k16 和 .m16n8k32 mma.sp{::ordered_metadata} 操作,矩阵 A 是结构化稀疏的,粒度为 2:4。换句话说,矩阵 A 的一行中每四个相邻元素的块有两个零和两个非零元素。只有两个非零元素存储在表示矩阵 A 的操作数中,并且它们在矩阵 A 的四宽块中的位置由元数据操作数中的两个 2 位索引指示。对于 mma.sp::ordered_metadata,0b0100、0b1000、0b1001、0b1100、0b1101、0b1110 是索引的有意义的值;任何其他值都会导致未定义的行为。
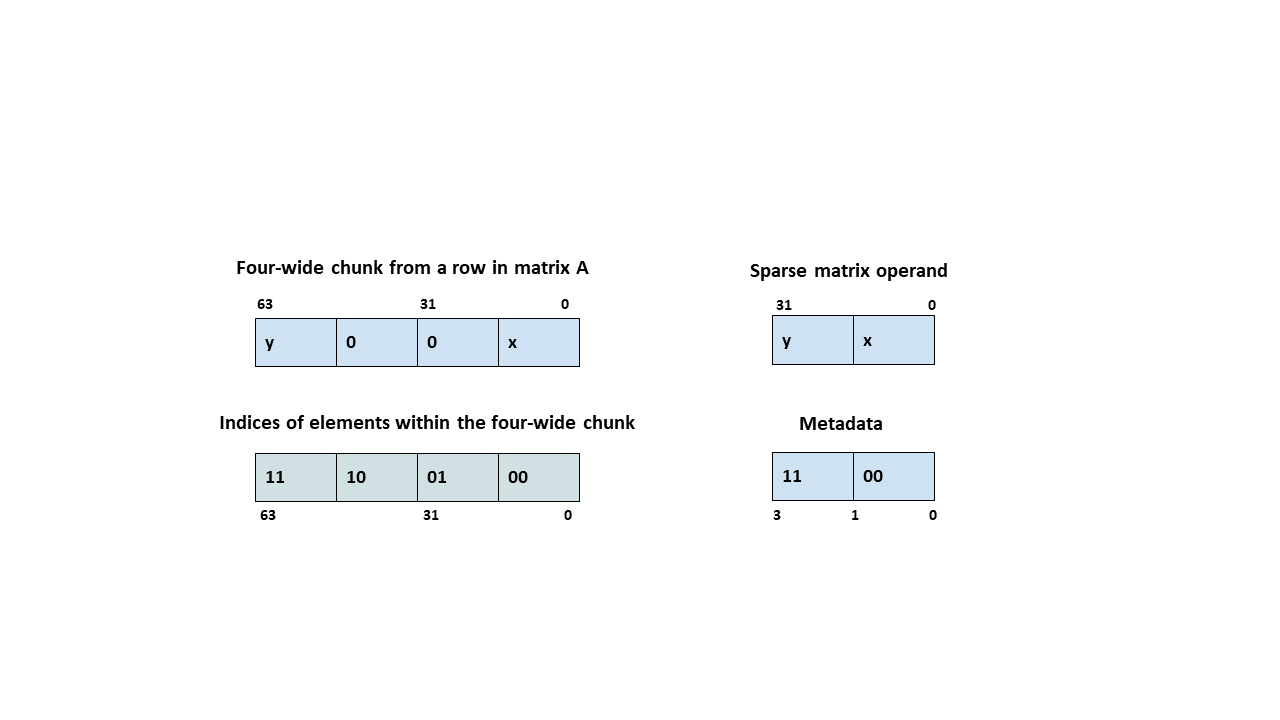
图 111 .f16/.bf16 类型的稀疏 MMA 元数据示例。
稀疏性选择器指示贡献元数据的线程,如下所示
m16n8k16:四个连续线程组中的一个线程为整个组贡献元数据。此线程由 {0, 1, 2, 3} 中的值指示。m16n8k32:四个连续线程组中的一个线程对组贡献稀疏性元数据。因此,稀疏性选择器必须是 0(线程 T0、T1)或 1(线程 T2、T3);任何其他值都会导致未定义的行为。
稀疏 mma.sp{::ordered_metadata} ,具有 .tf32 类型
当矩阵 A 具有 .tf32 元素时,矩阵 A 在 1:2 的粒度上是结构化稀疏的。换句话说,矩阵 A 的一行中每两个相邻元素的块中,有一个零元素和一个非零元素。只有非零元素存储在矩阵 A 的操作数中,它们在矩阵 A 的两个元素宽的块中的位置由元数据中的 4 位索引指示。0b1110 和 0b0100 是仅有的有意义的索引值;任何其他值都会导致未定义的行为。
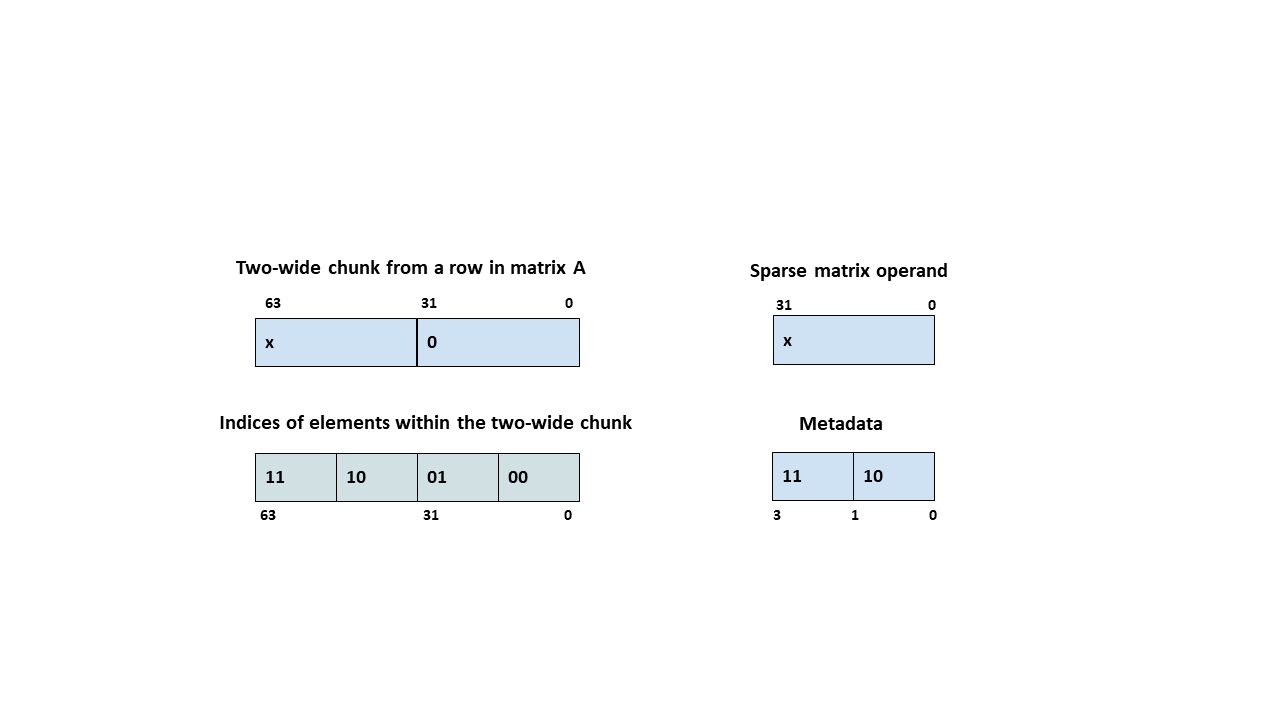
图 112 .tf32 类型的稀疏 MMA 元数据示例。
稀疏性选择器指示贡献元数据的线程,如下所示
m16n8k8:四个连续线程组中的一个线程为整个组贡献元数据。此线程由 {0, 1, 2, 3} 中的一个值指示。m16n8k16:四个连续线程组中的一个线程对组贡献稀疏性元数据。因此,稀疏性选择器必须是 0(线程 T0、T1)或 1(线程 T2、T3);任何其他值都会导致未定义的行为。
稀疏 mma.sp{::ordered_metadata} 与整数类型
当矩阵 A 和 B 具有 .u8/.s8 元素时,矩阵 A 在 2:4 的粒度上是结构化稀疏的。换句话说,矩阵 A 的一行中每四个相邻元素的块中,有两个零元素和两个非零元素。只有两个非零元素存储在稀疏矩阵中,它们在四个元素宽的块中的位置由元数据中的两个 2 位索引指示。对于 mma.sp::ordered_metadata,0b0100、0b1000、0b1001、0b1100、0b1101、0b1110 是索引的有意义的值;任何其他值都会导致未定义的行为。
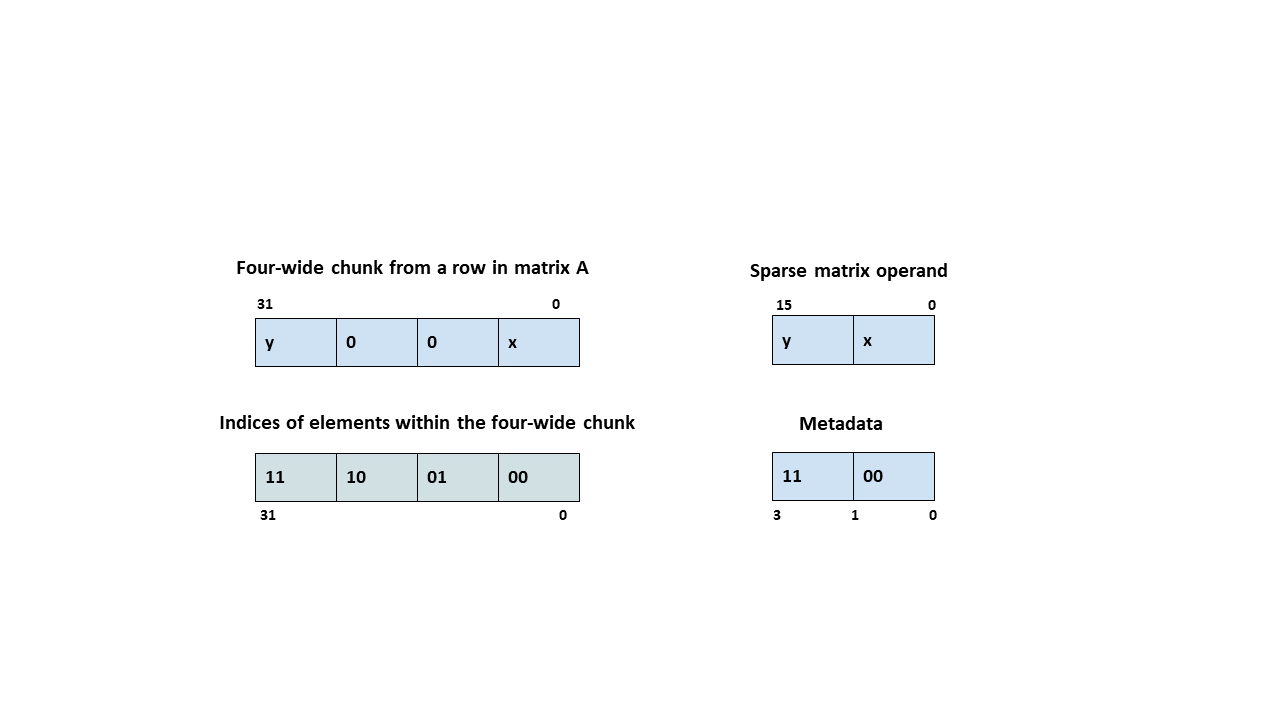
图 113 .u8/.s8 类型的稀疏 MMA 元数据示例。
当矩阵 A 和 B 具有 .u4/.s4 元素时,矩阵 A 在 4:8 的粒度上是成对结构化稀疏的。换句话说,矩阵 A 的一行中每八个相邻元素的块中,有四个零值和四个非零值。此外,零值和非零值在八元素宽的块内的每个两个元素的子块中聚集。即,八元素宽的块内的每个两个元素宽的子块必须全部为零或全部为非零。只有四个非零值存储在稀疏矩阵中,并且矩阵 A 的一行中的八元素宽的块中具有非零值的两个两个元素宽的子块的位置由元数据中的两个 2 位索引指示。对于 mma.sp::ordered_metadata,0b0100、0b1000、0b1001、0b1100、0b1101、0b1110 是索引的有意义的值;任何其他值都会导致未定义的行为。
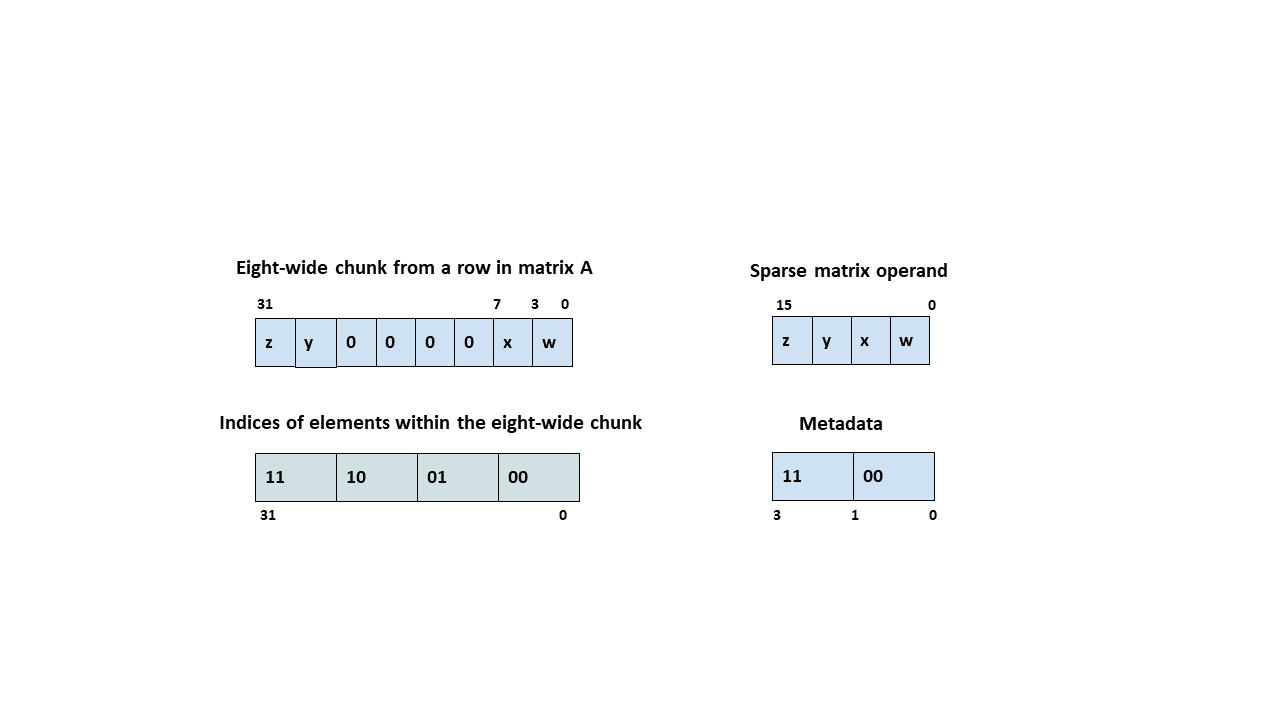
图 114 .u4/.s4 类型的稀疏 MMA 元数据示例。
稀疏性选择器指示贡献元数据的线程,如下所示
m16n8k32与.u8/.s8类型和m16n8k64与.u4/.s4类型:四个连续线程组中的一个线程对组贡献稀疏性元数据。因此,稀疏性选择器必须是 0(线程 T0、T1)或 1(线程 T2、T3);任何其他值都会导致未定义的行为。m16n8k64与.u8/.s8类型和m16n8k128与.u4/.s4类型:四个连续线程组中的所有线程都贡献稀疏性元数据。因此,在这种情况下,稀疏性选择器必须为 0。稀疏性选择器的任何其他值都会导致未定义的行为。
稀疏 mma.sp{::ordered_metadata} 在 .e4m3/.e5m2/.e3m2/.e2m3/.e2m1 类型上使用,类型为 .kind::f8f6f4 或 .kind::mxf8f6f4
当矩阵 A 和 B 具有 .e4m3/.e5m2/.e3m2/.e2m3/.e2m1 元素时,矩阵 A 在 2:4 的粒度上是结构化稀疏的。换句话说,矩阵 A 的一行中每四个相邻元素的块中,有两个零元素和两个非零元素。只有两个非零元素存储在稀疏矩阵中,它们在四个元素宽的块中的位置由元数据中的两个 2 位索引指示。0b0100、0b1000、0b1001、0b1100、0b1101、0b1110 是索引的有意义的值;任何其他值都会导致未定义的行为。
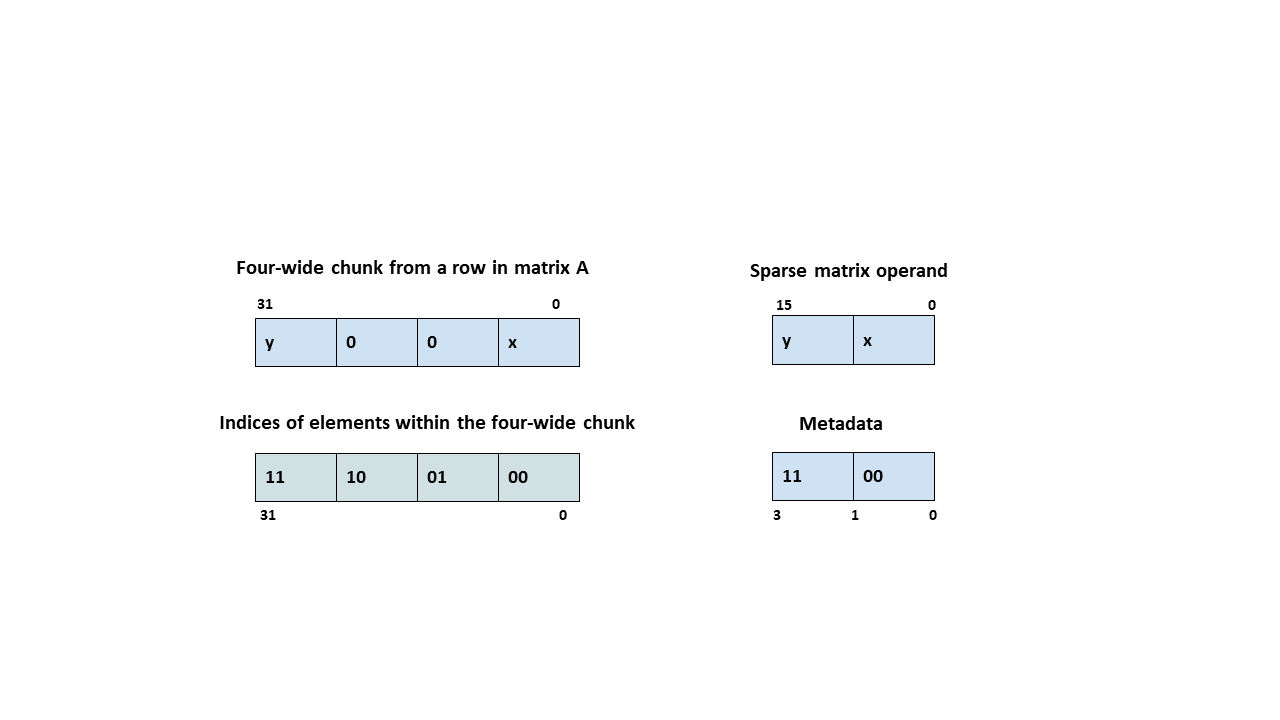
图 115 .e4m3/.e5m2/.e3m2/.e2m3/.e2m1 类型的稀疏 MMA 元数据示例。
稀疏性选择器指示贡献元数据的线程,如下所示
m16n8k64:四个连续线程组中的所有线程都贡献稀疏性元数据。因此,在这种情况下,稀疏性选择器必须为 0。稀疏性选择器的任何其他值都会导致未定义的行为。
稀疏 mma.sp::ordered_metadata 在 .e2m1 类型上使用,类型为 .kind::mxf4 或 .kind::mxf4nvf4
当矩阵 A 和 B 具有 .e2m1 元素时,矩阵 A 在 4:8 的粒度上是成对结构化稀疏的。换句话说,矩阵 A 的一行中每八个相邻元素的块中,有四个零值和四个非零值。此外,零值和非零值在八元素宽的块内的每个两个元素的子块中聚集。即,八元素宽的块内的每个两个元素宽的子块必须全部为零或全部为非零。只有四个非零值存储在稀疏矩阵中,并且矩阵 A 的一行中的八元素宽的块中具有非零值的两个两个元素宽的子块的位置由元数据中的两个 2 位索引指示。0b0100、0b1000、0b1001、0b1100、0b1101、0b1110 是索引的有意义的值;任何其他值都会导致未定义的行为。
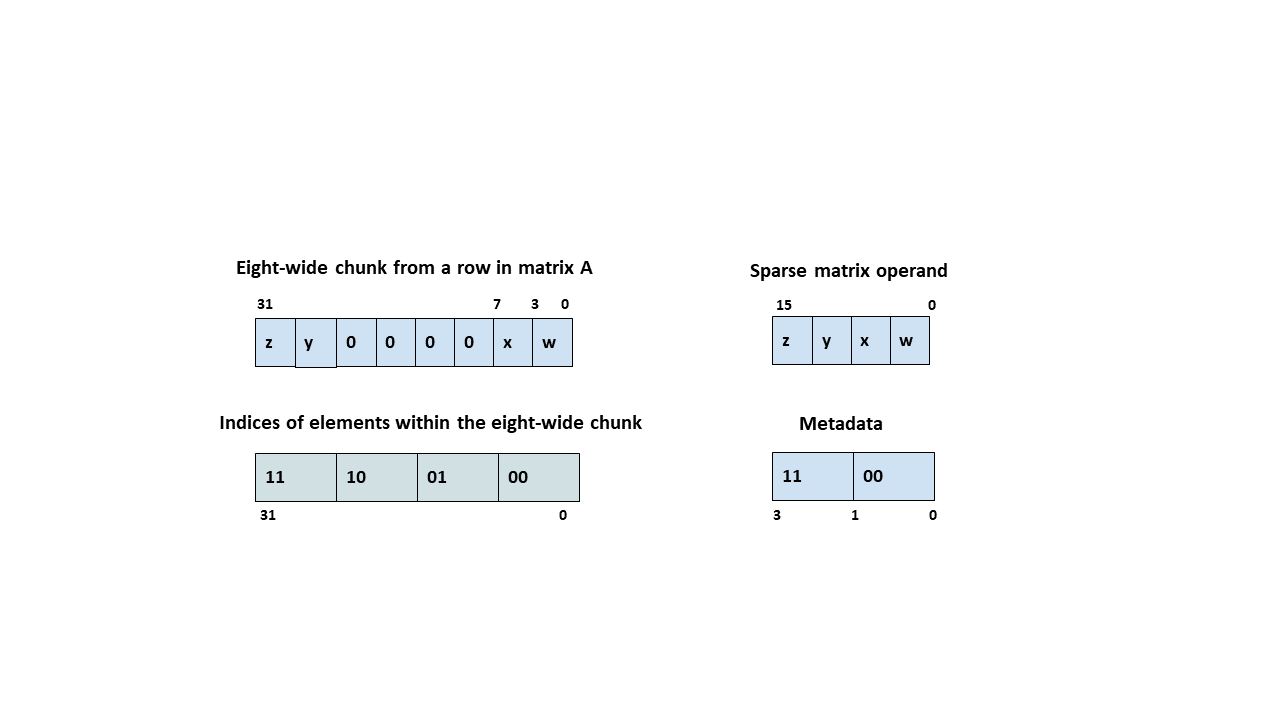
图 116 .e2m1 类型(类型为 .kind::mxf4 或 .kind::mxf4nvf4)的稀疏 MMA 元数据示例
稀疏性选择器指示贡献元数据的线程,如下所示
m16n8k128:四个连续线程组中的所有线程都贡献稀疏性元数据。因此,在这种情况下,稀疏性选择器必须为 0。稀疏性选择器的任何其他值都会导致未定义的行为。
9.7.14.6.2. 用于稀疏矩阵 A 的乘-累加运算的矩阵片段
在本节中,我们将描述线程寄存器的内容如何与各种矩阵的片段和稀疏性元数据相关联。本节通篇使用以下约定
对于矩阵 A,仅根据寄存器向量大小及其与矩阵数据的关联来描述片段的布局。
对于矩阵 B,当矩阵维度和支持的数据类型的组合未在使用 mma 指令的矩阵乘-累加运算中涵盖时,将提供矩阵片段的图形表示。
对于矩阵 C 和 D,由于矩阵维度 - 数据类型组合对于所有支持的形状都相同,并且已在使用 mma 指令的矩阵乘-累加运算中涵盖,因此本节未包含矩阵片段的图形表示。
对于元数据操作数,包括矩阵 A 元素索引与元数据操作数内容之间关联的图形表示。
Tk: [m..n]出现在单元格[x][y..z]中表示%laneid=k的线程的元数据操作数中从位m到n(其中m是高位)包含来自矩阵 A 的块[x][y]..[x][z]的非零元素的索引。
9.7.14.6.2.1. 用于具有 .f16 和 .bf16 类型的稀疏 mma.m16n8k16 的矩阵片段
执行稀疏 mma.m16n8k16 与 .f16 / .bf16 浮点类型的 warp 将计算形状为 .m16n8k16 的 MMA 运算。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.f16/.bf16包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 4 个连续元素中的两个非零.f16/.bf16元素。非零元素的映射如稀疏矩阵存储中所述。
不同线程持有的片段的布局显示在图 117中。
图 117 矩阵 A 的
.f16/.bf16类型的稀疏 MMA .m16n8k16 片段布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for a0 and a1 groupID + 8 for a2 and a3 col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 4 lastcol = firstcol + 3
乘数 B 和累加器 C 和 D 的矩阵片段与用于具有浮点类型的 mma.m16n8k16 的矩阵片段中
.f16/.b16格式的情况相同。-
元数据:一个
.b32寄存器,包含 16 个 2 位向量,每个向量存储矩阵 A 的 4 元素宽的块的非零元素的索引,如图 118所示。
图 118
.f16/.bf16类型的稀疏 MMA .m16n8k16 元数据布局。
9.7.14.6.2.2. 用于具有 .f16 和 .bf16 类型的稀疏 mma.m16n8k32 的矩阵片段
执行稀疏 mma.m16n8k32 与 .f16 / .bf16 浮点类型的 warp 将计算形状为 .m16n8k32 的 MMA 运算。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.f16/.bf16包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 4 个连续元素中的两个非零.f16/.bf16元素。非零元素的映射如稀疏矩阵存储中所述。
不同线程持有的片段的布局显示在图 119中。
图 119 矩阵 A 的
.f16/.bf16类型的稀疏 MMA .m16n8k32 片段布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 2 || 4 <= i < 6 groupID + 8 Otherwise col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 4 For ai where i < 4 (threadID_in_group * 4) + 16 for ai where i >= 4 lastcol = firstcol + 3
-
被乘数 B
.atype
片段
元素(从低到高)
.f16/.bf16包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的两个.f16/.bf16元素。b0, b1, b2, b3
不同线程持有的片段的布局显示在图 120中。
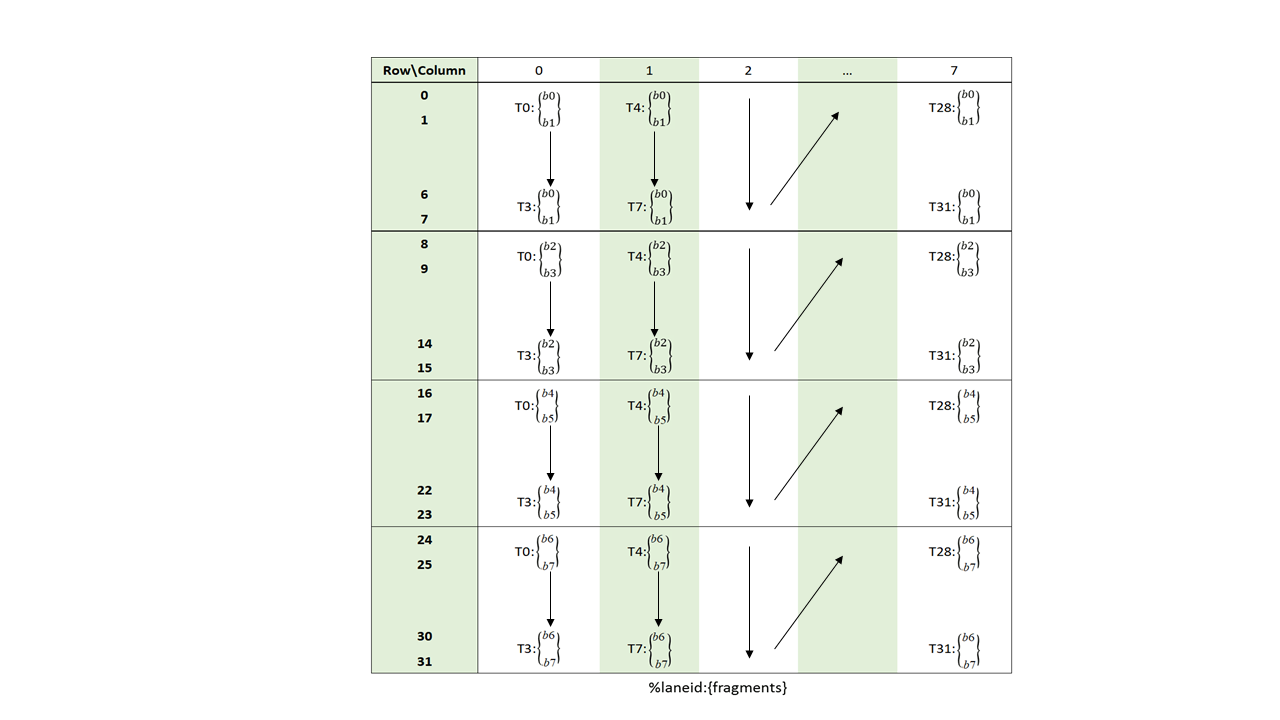
图 120 矩阵 B 的
.f16/.bf16类型的稀疏 MMA .m16n8k32 片段布局。 累加器 C 和 D 的矩阵片段与用于具有浮点类型的 mma.m16n8k16 的矩阵片段中
.f16/.b16格式的情况相同。-
元数据:一个
.b32寄存器,包含 16 个 2 位向量,每对 2 位向量存储来自矩阵 A 的 4 元素宽的块的两个非零元素的索引,如图 121所示。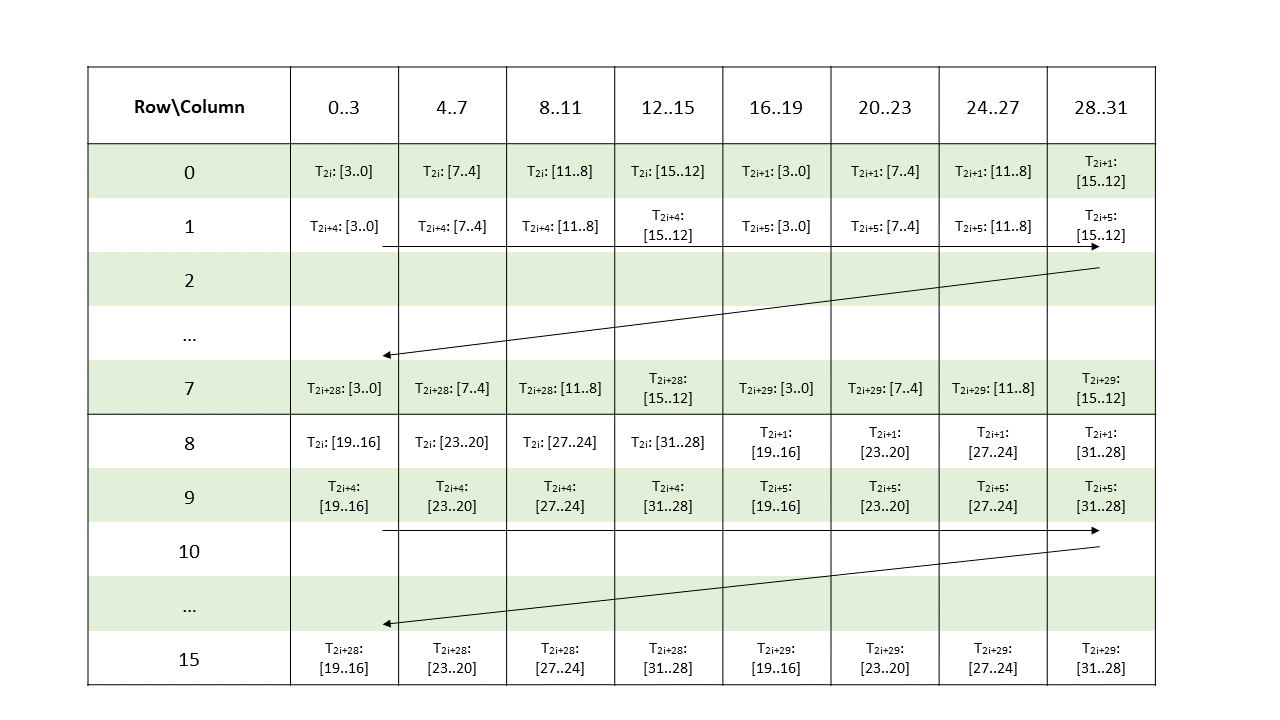
图 121
.f16/.bf16类型的稀疏 MMA .m16n8k32 元数据布局。
9.7.14.6.2.3. 用于具有 .tf32 浮点类型的稀疏 mma.m16n8k16 的矩阵片段
执行稀疏 mma.m16n8k16 与 .tf32 浮点类型的 warp 将计算形状为 .m16n8k16 的 MMA 运算。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.tf32包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 2 个连续元素中的一个非零.tf32元素。非零元素的映射如稀疏矩阵存储中所述。
不同线程持有的片段的布局显示在图 122中。
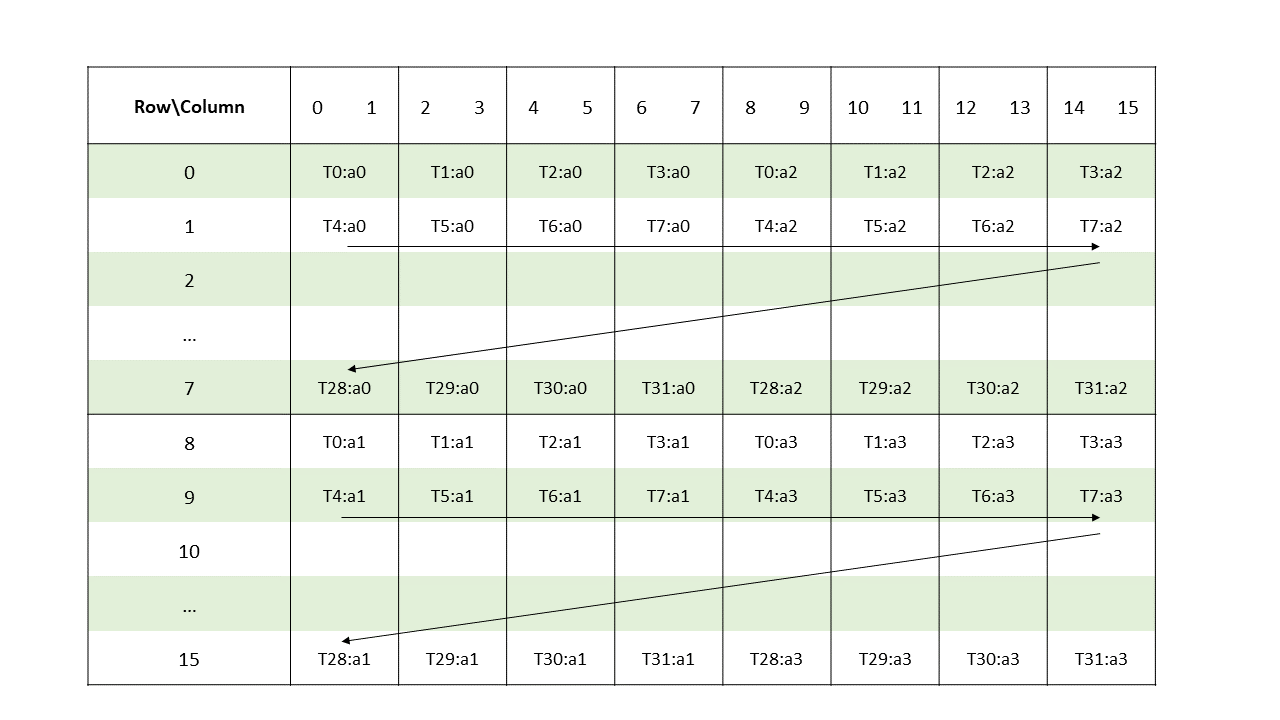
图 122 矩阵 A 的
.tf32类型的稀疏 MMA .m16n8k16 片段布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for a0 and a2 groupID + 8 for a1 and a3 col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 2 for a0 and a1 (threadID_in_group * 2) + 8 for a2 and a3 lastcol = firstcol + 1
-
被乘数 B
.atype
片段
元素(从低到高)
.tf32包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的四个.tf32元素。b0, b1, b2, b3
不同线程持有的片段的布局显示在图 123中。
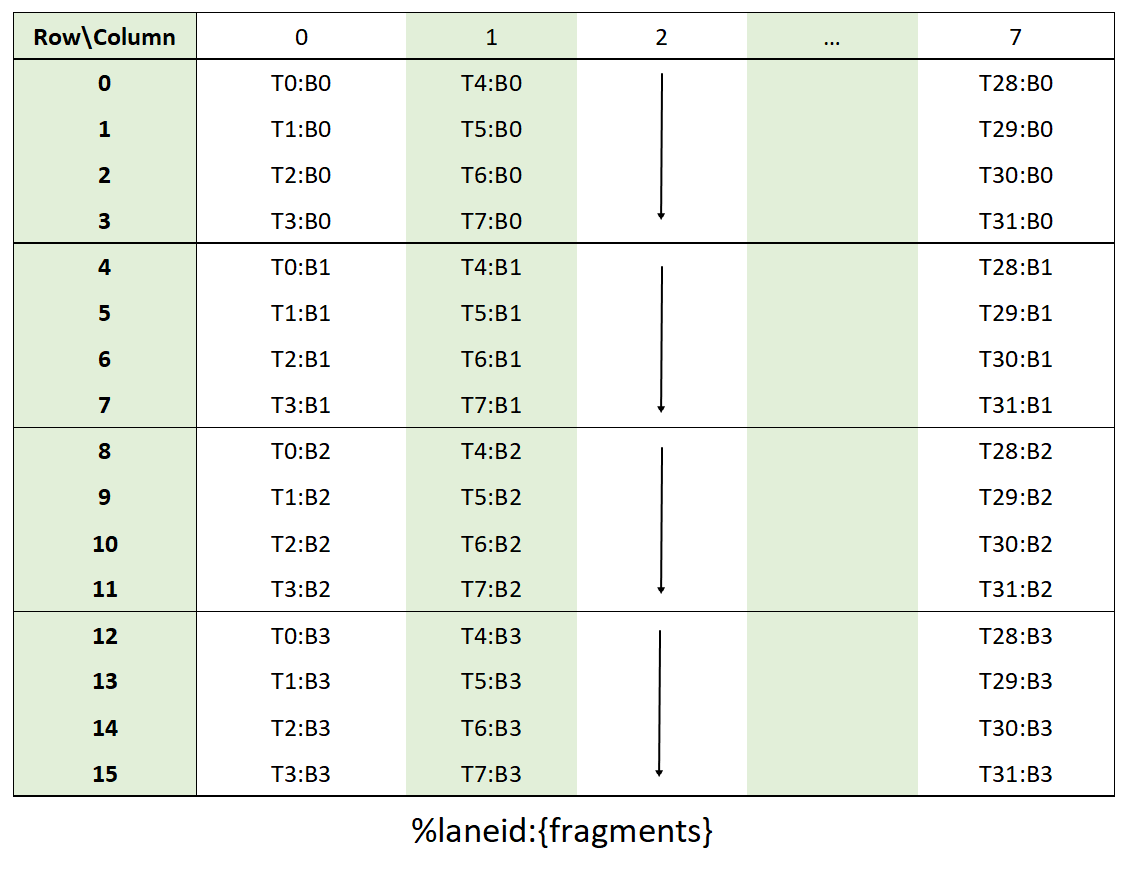
图 123 矩阵 B 的
.tf32类型的稀疏 MMA .m16n8k16 片段布局。 累加器 C 和 D 的矩阵片段与用于具有浮点类型的 mma.m16n8k16 的矩阵片段中的情况相同。
-
元数据:一个
.b32寄存器,包含 8 个 4 位向量,每个向量存储矩阵 A 的 2 元素宽的块的非零元素的索引,如图 124所示。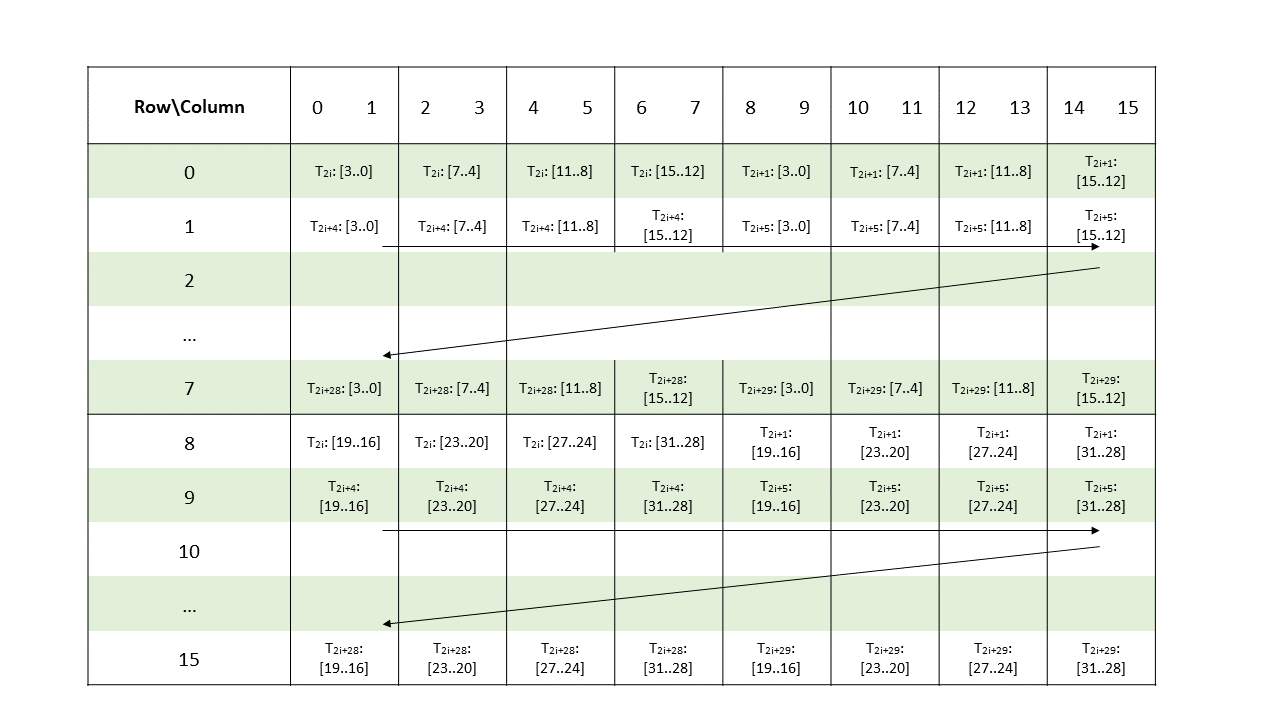
图 124
.tf32类型的稀疏 MMA .m16n8k16 元数据布局。
9.7.14.6.2.4. 用于具有 .tf32 浮点类型的稀疏 mma.m16n8k8 的矩阵片段
执行稀疏 mma.m16n8k8 与 .tf32 浮点类型的 warp 将计算形状为 .m16n8k8 的 MMA 运算。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.tf32包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 2 个连续元素中的一个非零.tf32元素。非零元素的映射如稀疏矩阵存储中所述。
不同线程持有的片段的布局显示在图 125中。
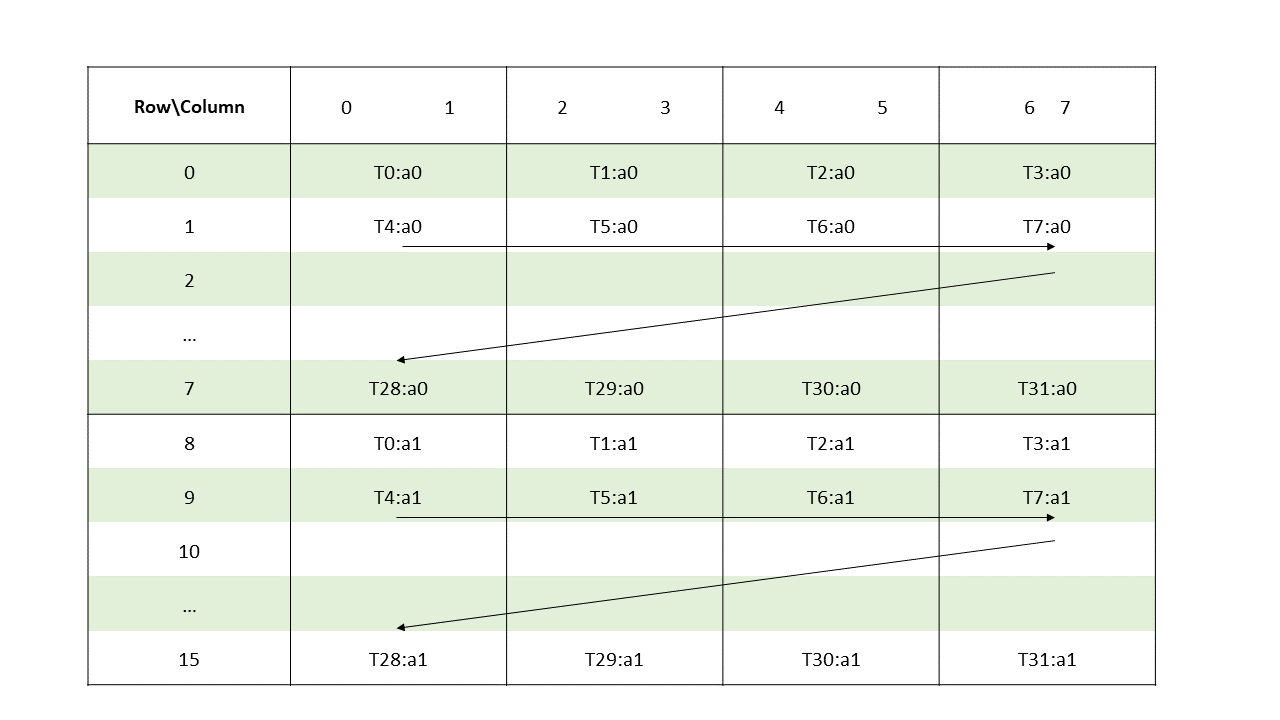
图 125 矩阵 A 的
.tf32类型的稀疏 MMA .m16n8k8 片段布局。矩阵片段的行和列可以计算为
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for a0 groupID + 8 for a1 col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 2 lastcol = firstcol + 1
乘数 B 和累加器 C 和 D 的矩阵片段与用于 mma.m16n8k8 的矩阵片段中
.tf32格式的情况相同。-
元数据:一个
.b32寄存器,包含 8 个 4 位向量,每个向量存储矩阵 A 的 2 元素宽的块的非零元素的索引,如图 126所示。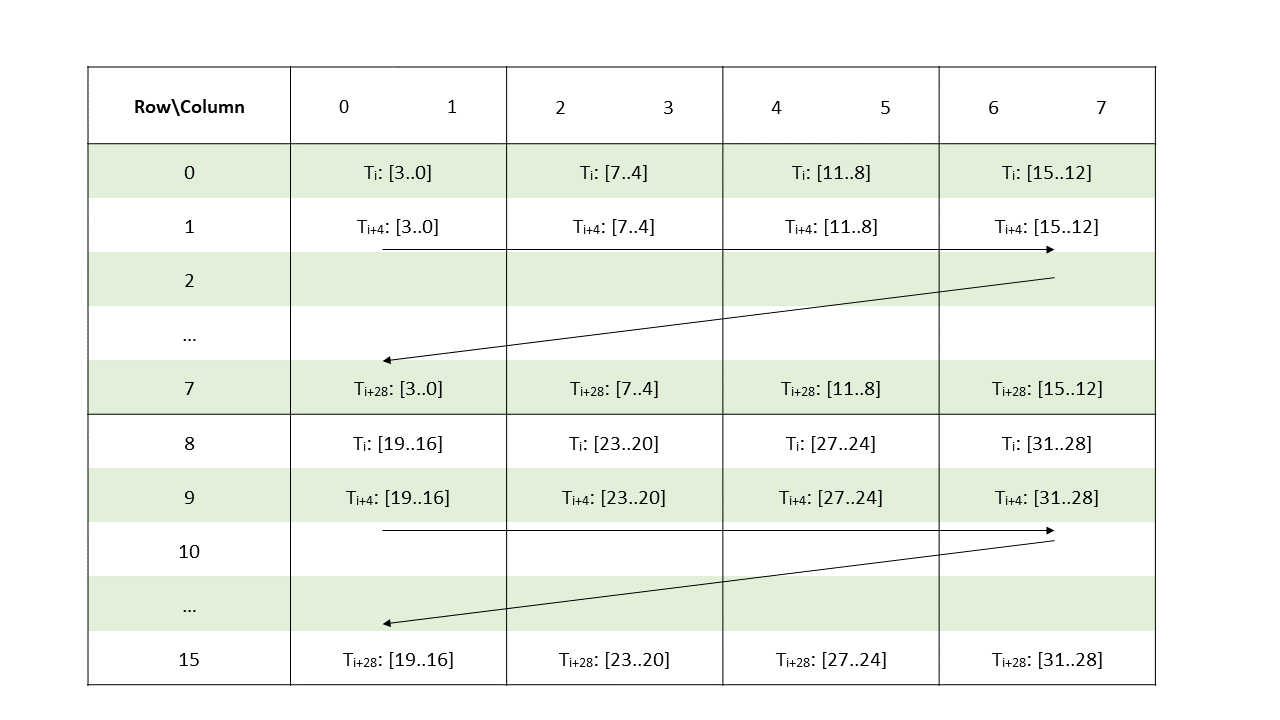
图 126
.tf32类型的稀疏 MMA .m16n8k8 元数据布局。
9.7.14.6.2.5. 用于具有 .u8/.s8 整数类型的稀疏 mma.m16n8k32 的矩阵片段
执行稀疏 mma.m16n8k32 与 .u8 / .s8 整数类型的 warp 将计算形状为 .m16n8k32 的 MMA 运算。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.u8/.s8包含两个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 8 个连续元素中的四个非零.u8/.s8元素。非零元素的映射如稀疏矩阵存储中所述。
不同线程持有的片段的布局显示在图 127中。
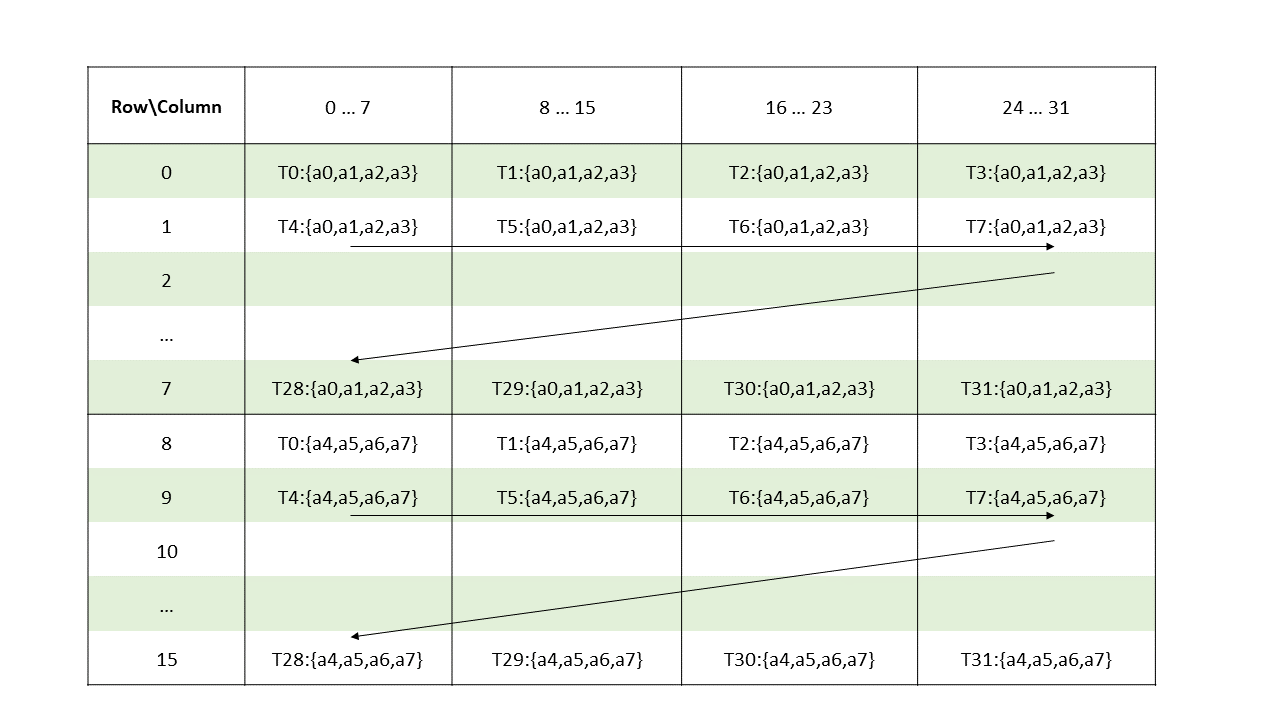
图 127 矩阵 A 的
.u8/.s8类型的稀疏 MMA .m16n8k32 片段布局。groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 4 groupID + 8 Otherwise col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 8 lastcol = firstcol + 7
乘数 B 和累加器 C 和 D 的矩阵片段与用于 mma.m16n8k32 的矩阵片段中的情况相同。
-
元数据:一个
.b32寄存器,包含 16 个 2 位向量,每对 2 位向量存储来自矩阵 A 的 4 元素宽的块的两个非零元素的索引,如图 128所示。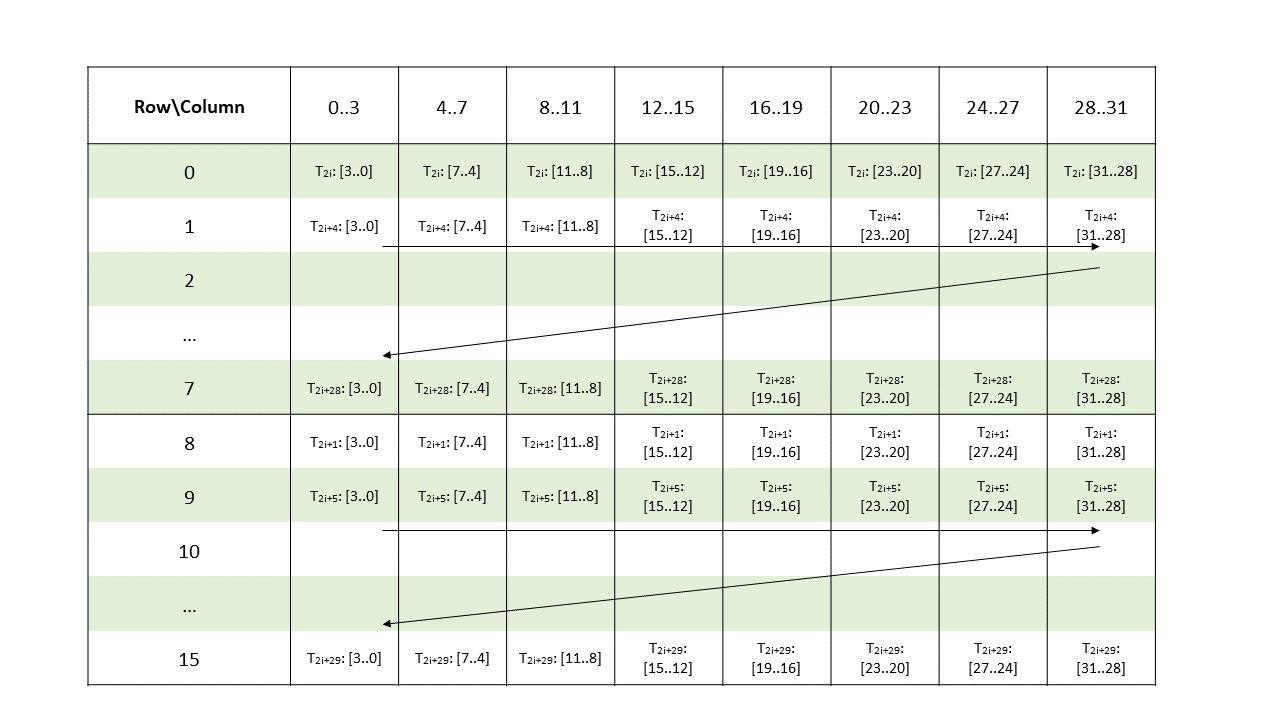
图 128
.u8/.s8类型的稀疏 MMA .m16n8k32 元数据布局。
9.7.14.6.2.6. 用于具有 .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 类型的稀疏 mma.m16n8k64 的矩阵片段
执行稀疏 mma.m16n8k64 与 .u8 / .s8/ .e4m3/ .e5m2 / .e3m2 / .e2m3 / .e2m1 类型的 warp 将计算形状为 .m16n8k64 的 MMA 运算。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.u8/.s8包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 8 个连续元素中的四个非零.u8/.s8元素。非零元素的映射如稀疏矩阵存储中所述。
.e4m3/.e5m2/.e3m2/.e2m3/.e2m1包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的 8 个连续元素中的四个非零.e4m3/.e5m2/.e3m2/.e2m3/.e2m1元素。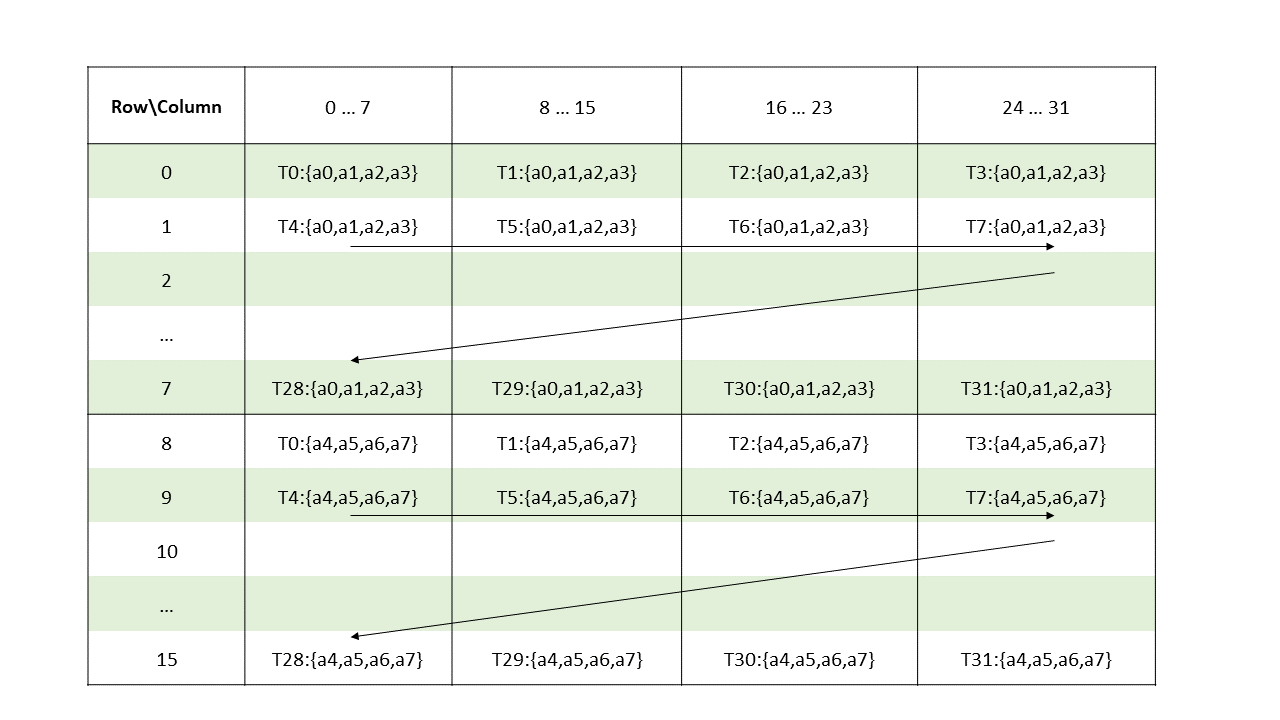
图 129 矩阵 A 的
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1类型的矩阵 A 的 0–31 列的稀疏 MMA .m16n8k64 片段布局。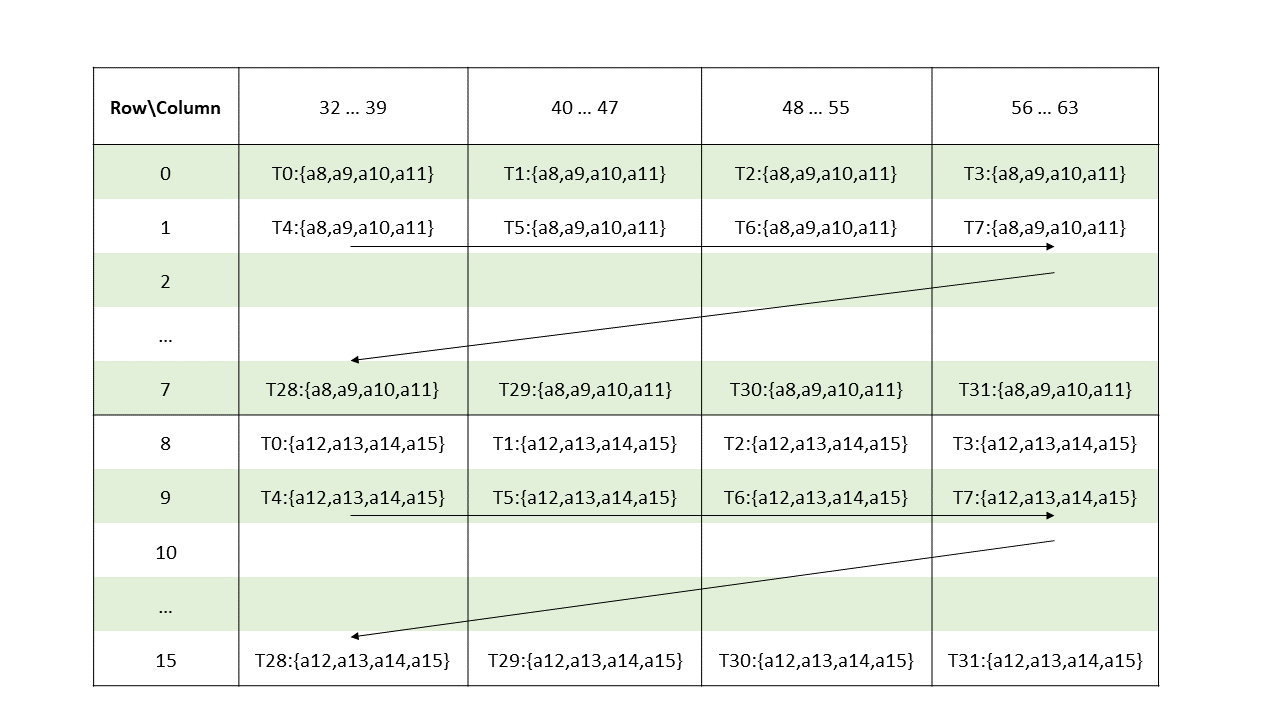
图 130 矩阵 A 的
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1类型的矩阵 A 的 32–63 列的稀疏 MMA .m16n8k64 片段布局。groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 4 || 8 <= i < 12 groupID + 8 Otherwise col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 8 For ai where i < 8 (threadID_in_group * 8) + 32 For ai where i >= 8 lastcol = firstcol + 7
-
被乘数 B
.btype
片段
元素(从低到高)
.u8/.s8包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的四个.u8/.s8元素。b0, b1, b2, b3, …, b15
.e4m3/.e5m2/.e3m2/.e2m3/.e2m1包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 B 的四个.e4m3/.e5m2/.e3m2/.e2m3/.e2m1元素。不同线程持有的片段布局如 Figure 131、Figure 132、Figure 133 和 Figure 134 所示。
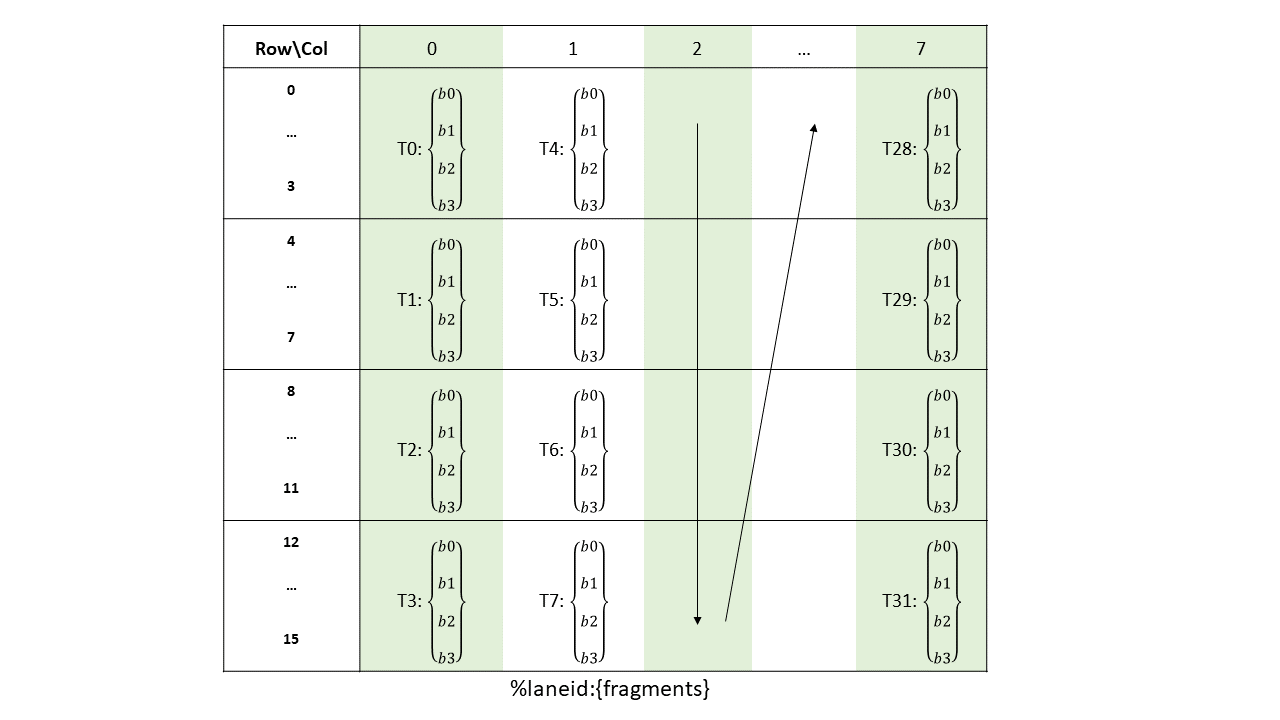
Figure 131 稀疏 MMA .m16n8k64 片段布局,针对矩阵 B 的第 0–15 行,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。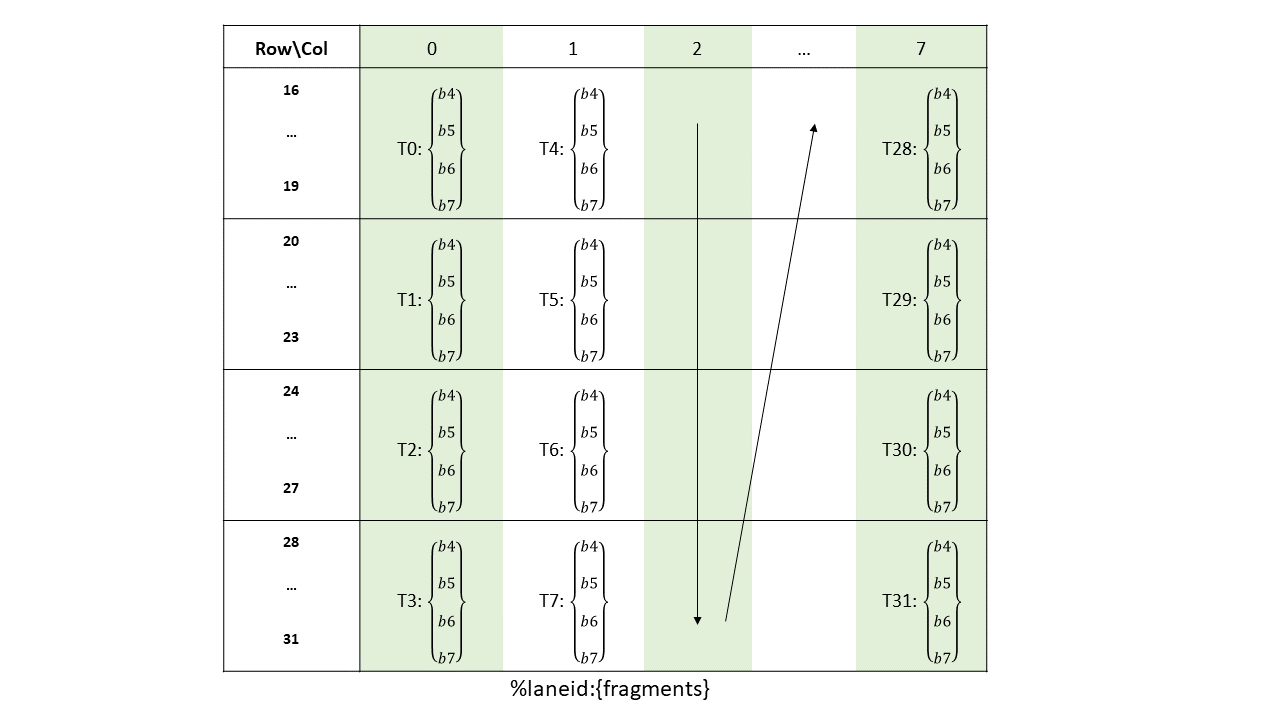
Figure 132 稀疏 MMA .m16n8k64 片段布局,针对矩阵 B 的第 16–31 行,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。
Figure 133 稀疏 MMA .m16n8k64 片段布局,针对矩阵 B 的第 32–47 行,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。
Figure 134 稀疏 MMA .m16n8k64 片段布局,针对矩阵 B 的第 48–63 行,类型为
.u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1。 累加器 C 和 D 的矩阵片段与 mma.m16n8k16 的矩阵片段相同。
-
元数据:一个
.b32寄存器,包含 16 个 2 位向量,每对 2 位向量存储来自矩阵 A 的 4 宽块中两个非零元素的索引,如图 Figure 135 和 Figure 136 所示。
9.7.14.6.2.7. 稀疏 mma.m16n8k64 的矩阵片段,针对 .u4/.s4 整数类型
一个 warp 执行稀疏 mma.m16n8k64 和 .u4 / .s4 整数类型将计算形状为 .m16n8k64 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.u4/.s4一个向量表达式,包含两个
.b32寄存器,每个寄存器包含来自矩阵 A 的 16 个连续元素中的八个非零.u4/.s4元素。非零元素的映射如稀疏矩阵存储中所述。
不同线程持有的片段布局如 Figure 137 所示。
Figure 137 稀疏 MMA .m16n8k64 片段布局,针对矩阵 A,类型为
.u4/.s4。groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 8 groupID + 8 Otherwise col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 16 lastcol = firstcol + 15
乘数 B 和累加器 C 和 D 的矩阵片段与 mma.m16n8k64 的矩阵片段相同。
-
元数据:一个
.b32寄存器,包含 16 个 2 位向量,每对 2 位向量存储来自矩阵 A 的 8 宽块中四个非零元素的索引,如图 Figure 138 所示。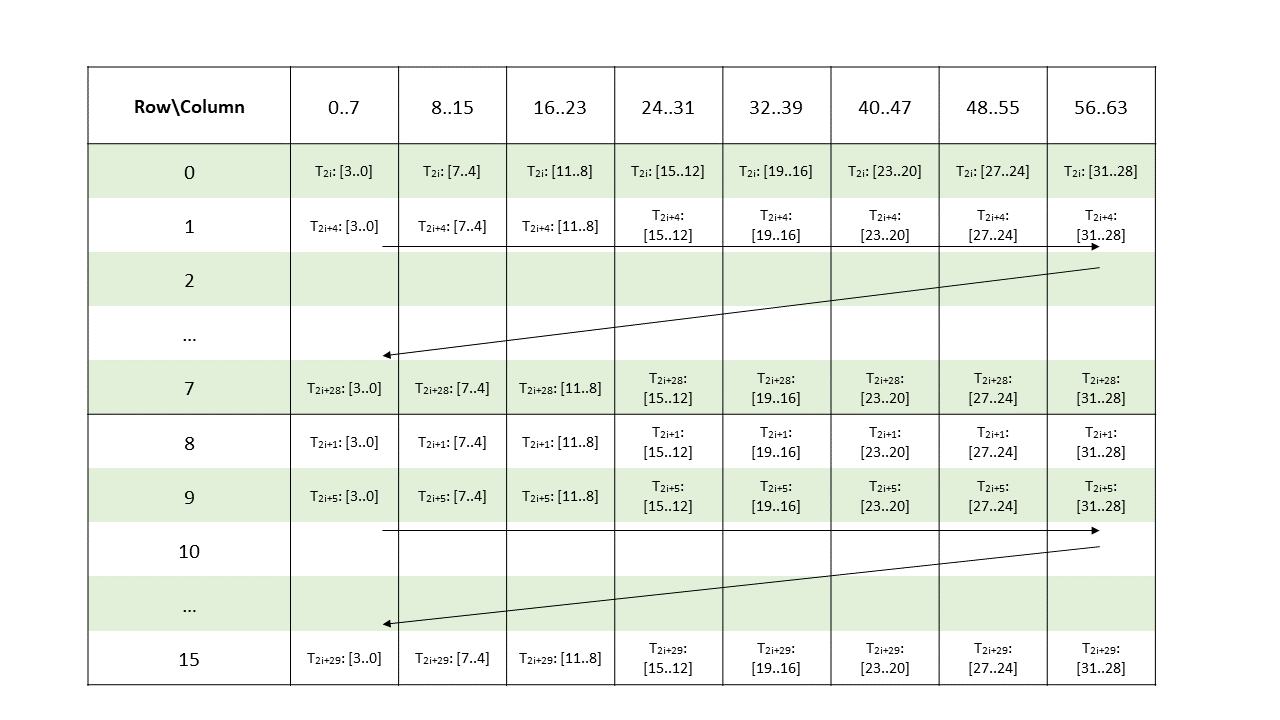
Figure 138 稀疏 MMA .m16n8k64 元数据布局,针对
.u4/.s4类型。
9.7.14.6.2.8. 稀疏 mma.m16n8k128 的矩阵片段,针对 .u4/.s4/.e2m1 类型
一个 warp 执行稀疏 mma.m16n8k128 和 .u4 / .s4 / .e2m1 整数类型将计算形状为 .m16n8k128 的 MMA 操作。
矩阵元素分布在 warp 中的线程之间,因此 warp 的每个线程都持有一个矩阵片段。
-
被乘数 A
.atype
片段
元素
.u4/.s4一个向量表达式,包含四个
.b32寄存器,每个寄存器包含来自矩阵 A 的 16 个连续元素中的八个非零.u4/.s4元素。非零元素的映射如稀疏矩阵存储中所述。
.e2m1一个向量表达式,包含四个
.b32寄存器,每个寄存器包含来自矩阵 A 的 16 个连续元素中的八个非零.e2m1元素。不同线程持有的片段布局如 Figure 139 和 Figure 140 所示。
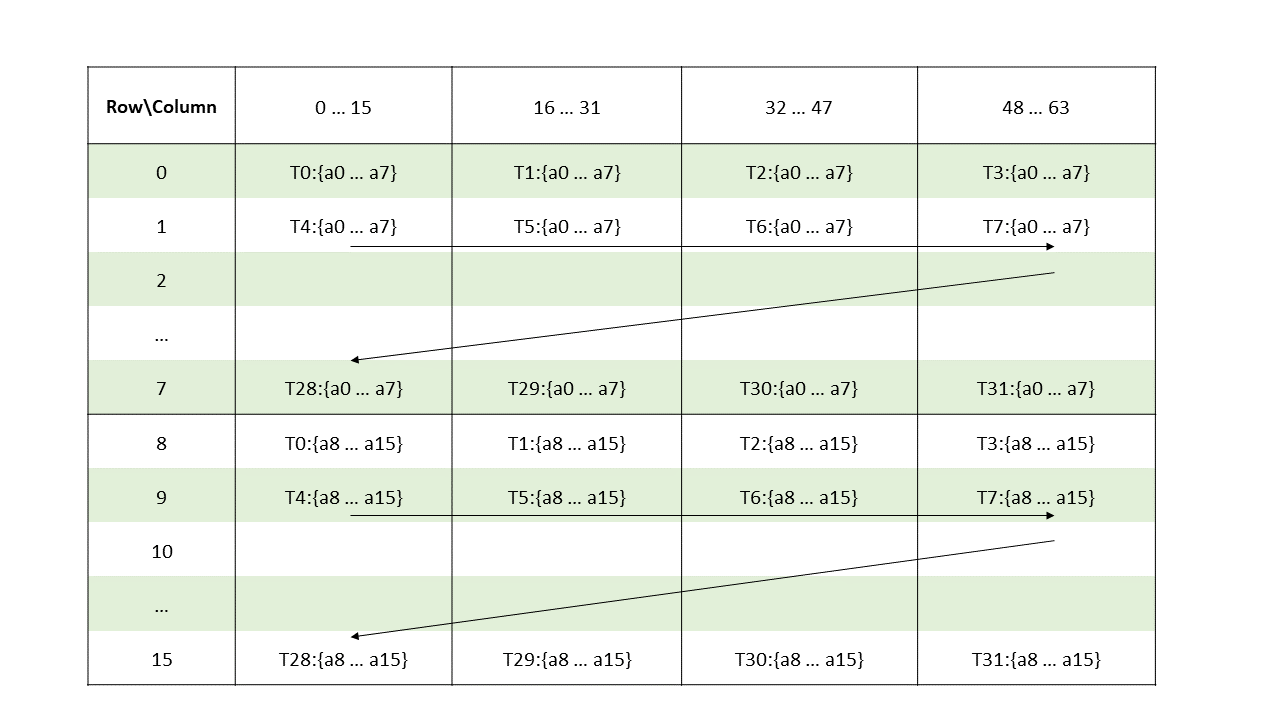
Figure 139 稀疏 MMA .m16n8k128 片段布局,针对矩阵 A 的第 0–63 列,类型为
.u4/.s4/.e2m1。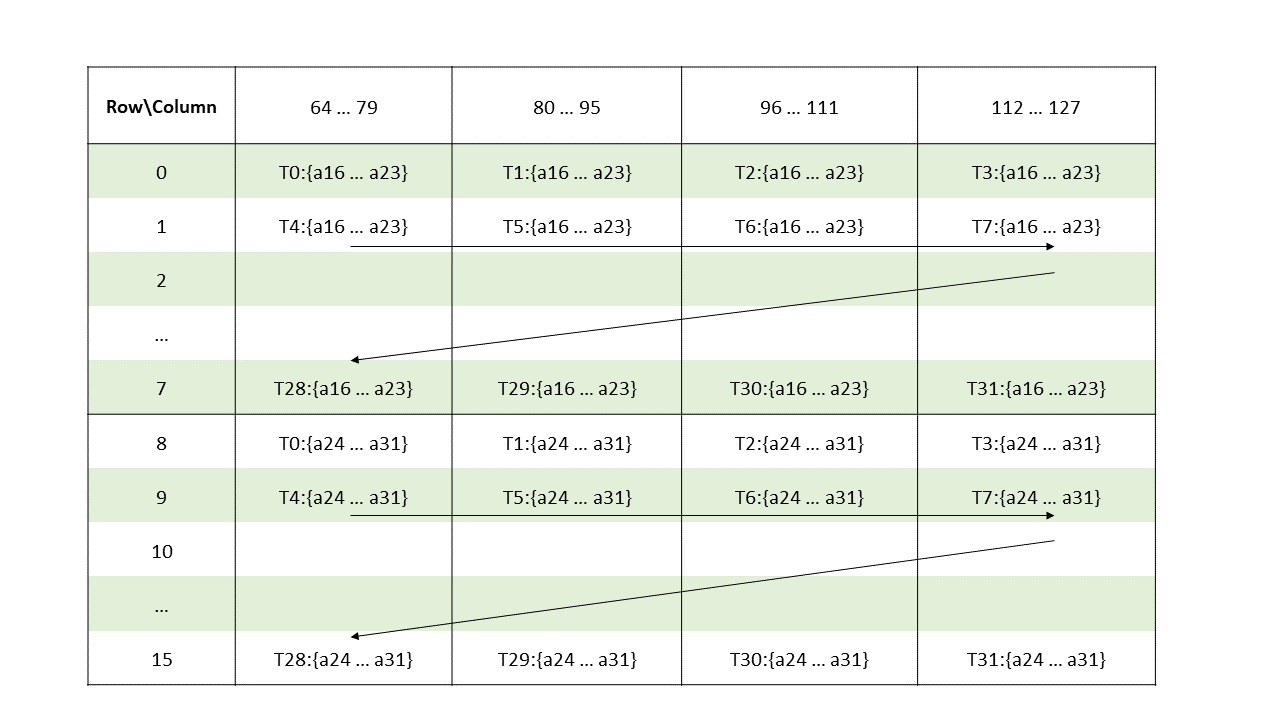
Figure 140 稀疏 MMA .m16n8k128 片段布局,针对矩阵 A 的第 64–127 列,类型为
.u4/.s4/.e2m1。groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID for ai where 0 <= i < 8 || 16 <= i < 24 groupID + 8 Otherwise col = [firstcol ... lastcol] // As per the mapping of non-zero elements // as described in Sparse matrix storage Where firstcol = threadID_in_group * 16 For ai where i < 16 (threadID_in_group * 16) + 64 For ai where i >= 16 lastcol = firstcol + 15
-
被乘数 B
.atype
片段
元素(从低到高)
.u4/.s4一个向量表达式,包含四个
.b32寄存器,每个寄存器包含来自矩阵 B 的八个.u4/.s4元素。b0, b1, b2, b3, …, b31
.e2m1一个向量表达式,包含四个
.b32寄存器,每个寄存器包含来自矩阵 B 的八个.e2m1元素。不同线程持有的片段布局如 Figure 141、Figure 142、Figure 143、Figure 144 所示。
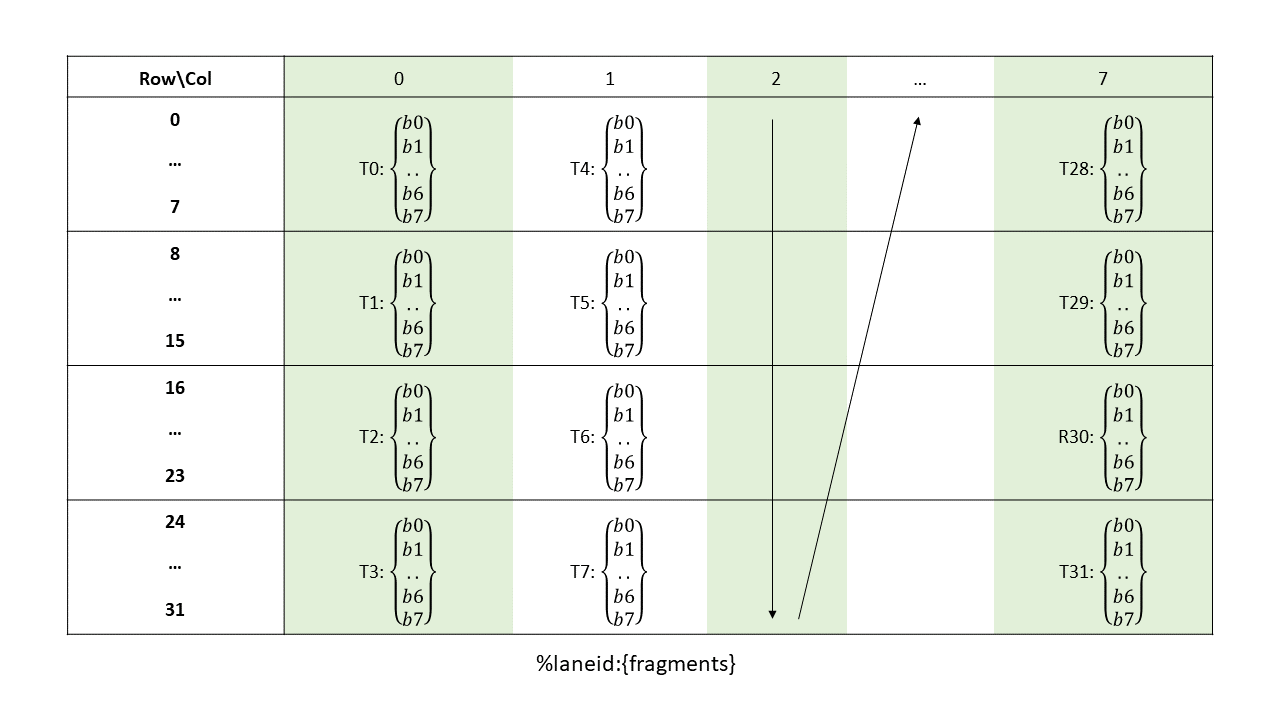
Figure 141 稀疏 MMA .m16n8k128 片段布局,针对矩阵 B 的第 0–31 行,类型为
.u4/.s4/.e2m1。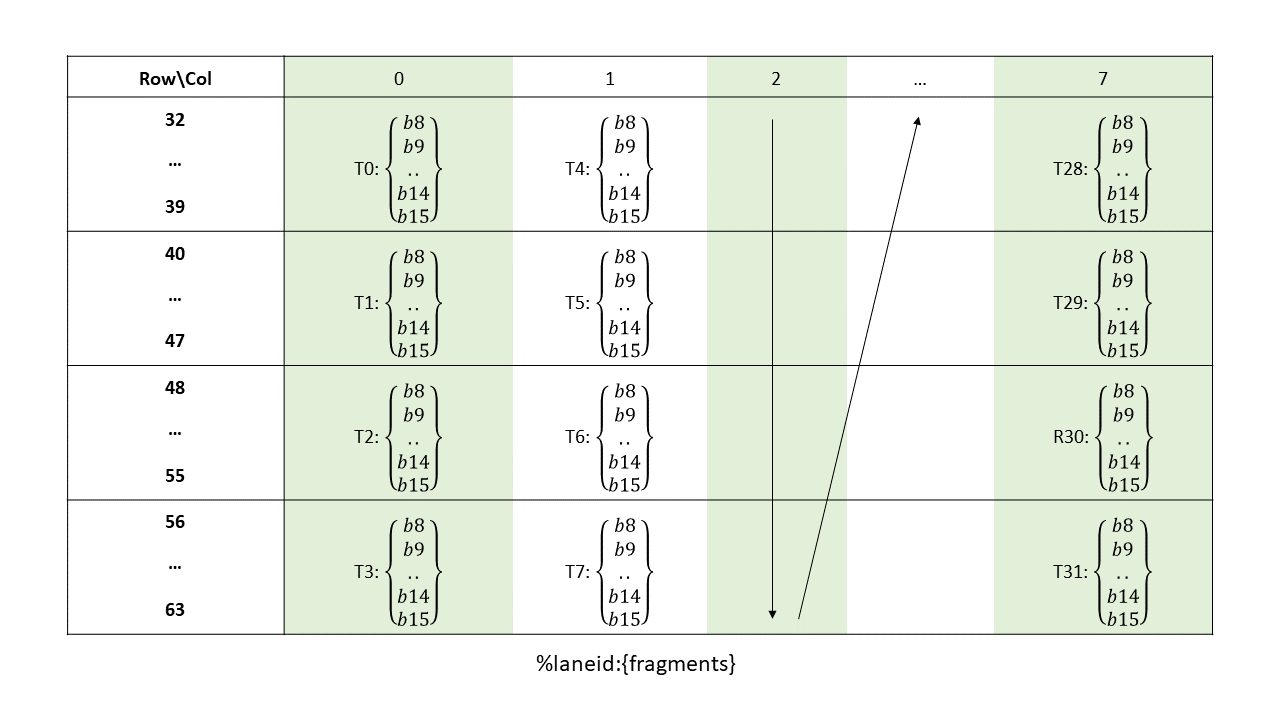
Figure 142 稀疏 MMA .m16n8k128 片段布局,针对矩阵 B 的第 32–63 行,类型为
.u4/.s4/.e2m1。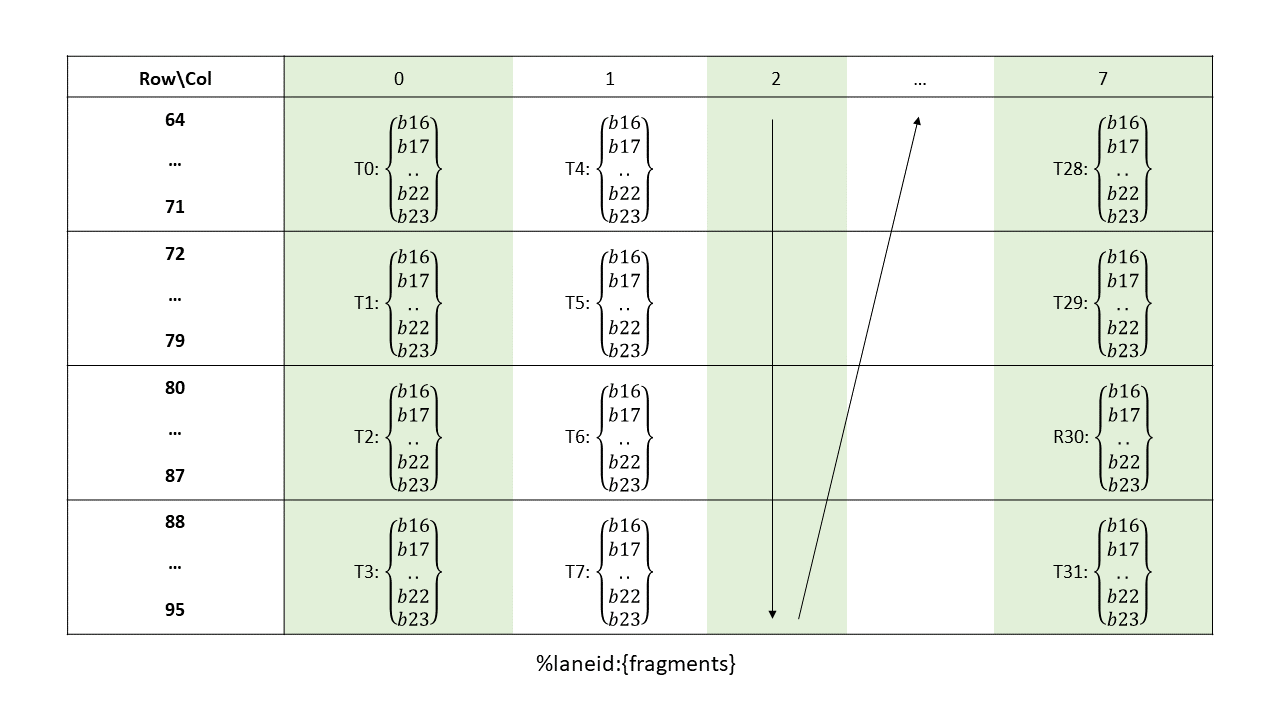
Figure 143 稀疏 MMA .m16n8k128 片段布局,针对矩阵 B 的第 64–95 行,类型为
.u4/.s4/.e2m1。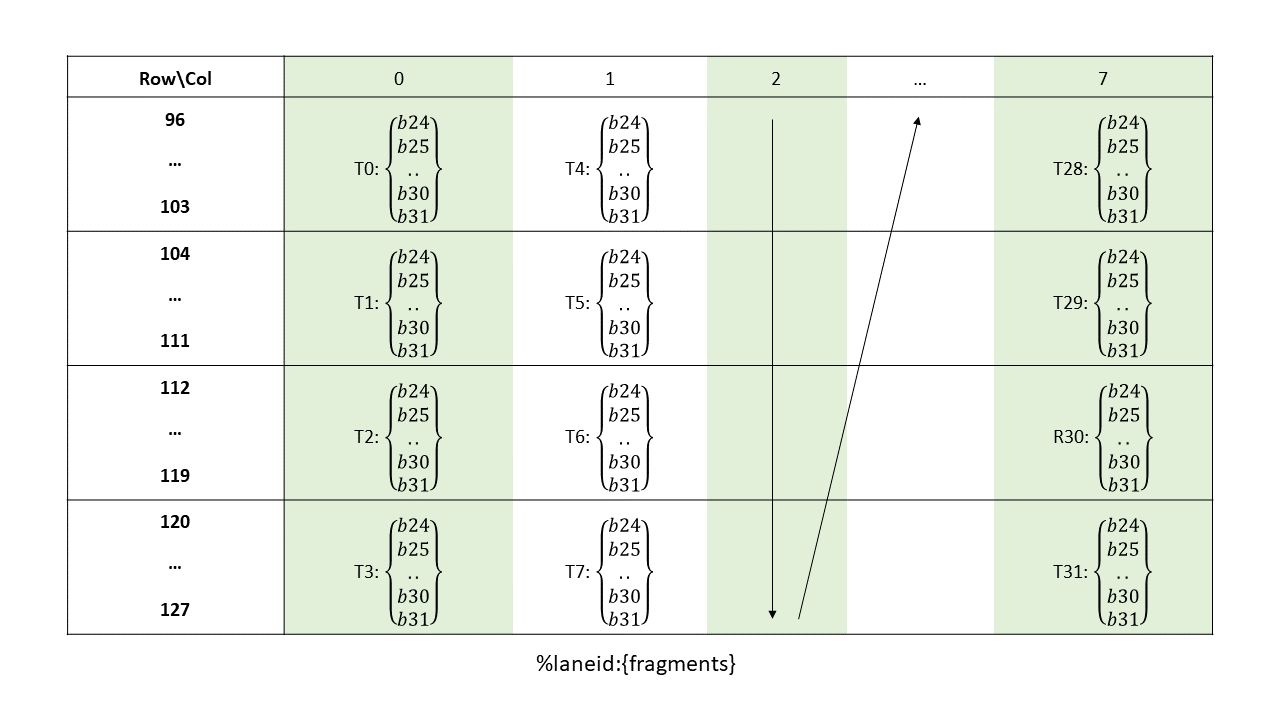
Figure 144 稀疏 MMA .m16n8k128 片段布局,针对矩阵 B 的第 96–127 行,类型为
.u4/.s4/.e2m1。 累加器 C 和 D 的矩阵片段与 mma.m16n8k64 的矩阵片段相同。
-
元数据:一个
.b32寄存器,包含 16 个 2 位向量,每对 2 位向量存储来自矩阵 A 的 8 宽块中四个非零元素的索引,如图 Figure 145 和 Figure 146 所示。
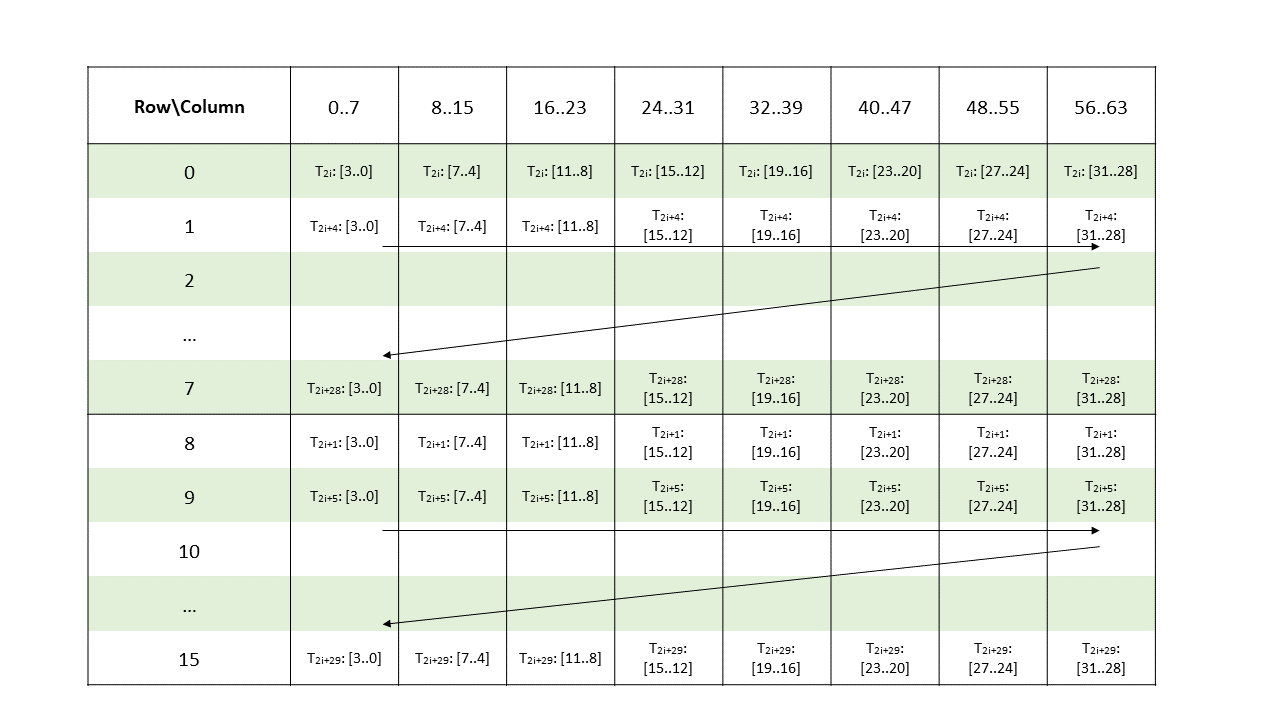
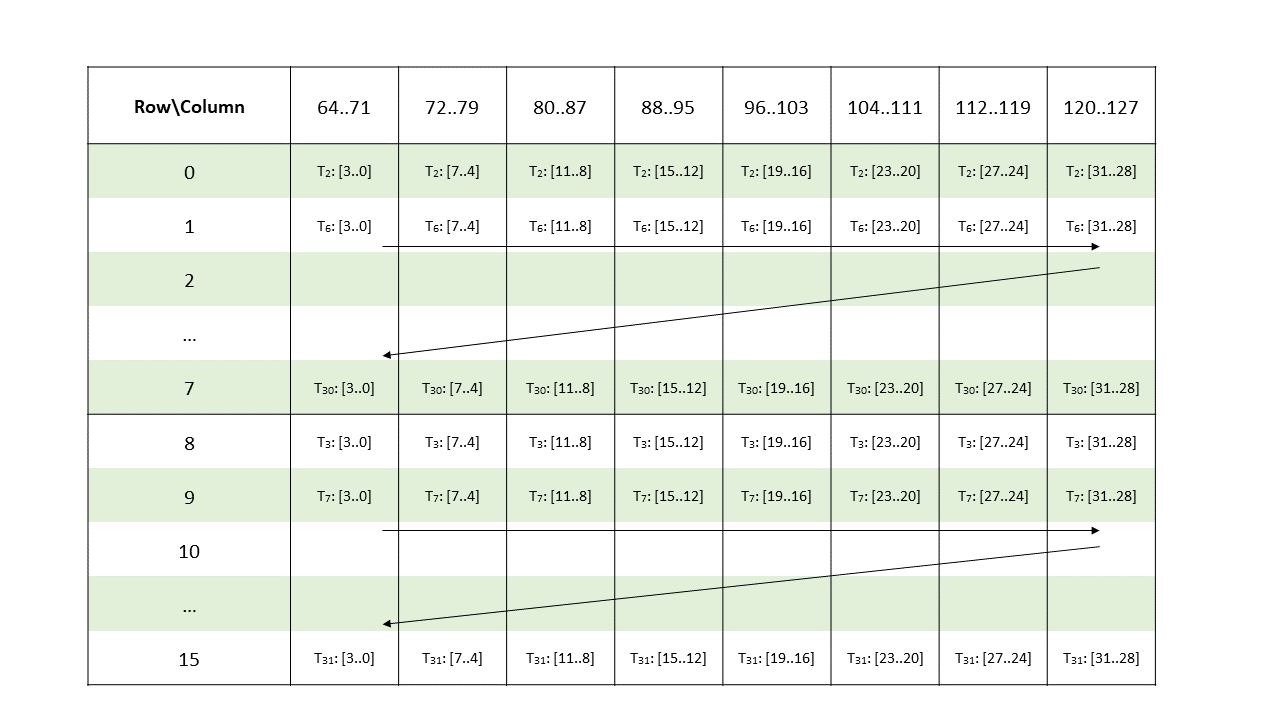
9.7.14.6.3. 乘法累加指令:mma.sp/mma.sp::ordered_metadata
mma.sp/mma.sp::ordered_metadata
使用稀疏矩阵 A 执行矩阵乘法累加运算
语法
半精度浮点类型
mma.spvariant.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c, e, f;
mma.spvariant.sync.aligned.m16n8k32.row.col.dtype.f16.f16.ctype d, a, b, c, e, f;
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
.spvariant = {.sp, .sp::ordered_metadata};
备选浮点类型
mma.spvariant.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 d, a, b, c, e, f;
mma.spvariant.sync.aligned.m16n8k32.row.col.f32.bf16.bf16.f32 d, a, b, c, e, f;
mma.spvariant.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32 d, a, b, c, e, f;
mma.spvariant.sync.aligned.m16n8k16.row.col.f32.tf32.tf32.f32 d, a, b, c, e, f;
mma.spvariant.sync.aligned.m16n8k64.row.col.f32.f8type.f8type.f32 d, a, b, c, e, f;
mma.sp::ordered_metadata.sync.aligned.m16n8k64.row.col.kind.dtype.f8f6f4type.f8f6f4type.ctype d, a, b, c, e, f;
.f8type = {.e4m3, .e5m2};
.spvariant = {.sp, .sp::ordered_metadata};
.f8f6f4type = {.e4m3, .e5m2, .e3m2, .e2m3, .e2m1};
.kind = {kind::f8f6f4};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
带块缩放的备选浮点类型
mma.spvariant.sync.aligned.m16n8k128.row.col.kind.block_scale{.scale_vec_size}.f32.e2m1.e2m1.f32.stype d, a, b, c, e, f, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.spvariant = {.sp::ordered_metadata};
.kind = {.kind::mxf4};
.scale_vec_size = {.scale_vec::2X};
.stype = {.ue8m0};
mma.spvariant.sync.aligned.m16n8k128.row.col.kind.block_scale.scale_vec_size.f32.e2m1.e2m1.f32.stype d, a, b, c, e, f, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.spvariant = {.sp::ordered_metadata};
.kind = {.kind::mxf4nvf4};
.scale_vec_size = {.scale_vec::2X, .scale_vec::4X};
.stype = {.ue8m0, .ue4m3};
mma.spvariant.sync.aligned.m16n8k64.row.col.kind.block_scale{.scale_vec_size}.f32.f8f6f4type.f8f6f4type.f32.stype d, a, b, c, e, f, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.spvariant = {.sp::ordered_metadata};
.kind = {.kind::mxf8f6f4};
.scale_vec_size = {.scale_vec::1X};
.f8f6f4type = {.e4m3, .e5m2, .e3m2, .e2m3, .e2m1};
.stype = {.ue8m0};
整数类型
mma.spvariant.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c, e, f;
.shape = {.m16n8k32, .m16n8k64}
.atype = {.u8, .s8};
.btype = {.u8, .s8};
.spvariant = {.sp, .sp::ordered_metadata};
mma.spvariant.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c, e, f;
.shape = {.m16n8k64, .m16n8k128}
.atype = {.u4, .s4};
.btype = {.u4, .s4};
.spvariant = {.sp, .sp::ordered_metadata};
描述
执行 MxNxK 矩阵乘法和累加运算,D = A*B+C,其中 A 矩阵为 MxK,B 矩阵为 KxN,C 和 D 矩阵为 MxN。
一个 warp 执行 mma.sp.sync/mma.sp::ordered_metadata.sync 指令计算单个矩阵乘法和累加运算。
限定符 .block_scale 指定矩阵 A 和 B 在执行矩阵乘法和累加运算之前分别使用 scale_A 和 scale_B 矩阵进行缩放,如 Block Scaling 章节中所述。scale_A 和 scale_B 矩阵中每个元素对应的数据类型由 .stype 指定。限定符 .scale_vec_size 指定 scale_A 矩阵的列数和矩阵 scale_B 的行数。
.kind、.stype 和 .scale_vec_size 的有效组合在表 35中描述。对于 mma 和 .kind::mxf4,当未指定限定符 .scale_vec_size 时,则默认为 2X。相反,当 .kind 指定为 .kind::mxf8f6f4 时,限定符 .scale_vec_size 默认为 1X。但是,对于 .kind::mxf4nvf4,必须提供有效的 .scale_vec_size。
操作数 a 和 b 表示两个乘数矩阵 A 和 B,而 c 和 d 表示累加器和目标矩阵,它们分布在 warp 中的线程之间。矩阵 A 是结构化稀疏矩阵,如 Sparse matrix storage 中所述。操作数 e 和 f 分别表示稀疏元数据和稀疏选择器。操作数 e 是一个 32 位整数,操作数 f 是一个 32 位整数常量,其值范围为 0..3。当指定 .block_scale 限定符时,操作数 scale-a-data、scale-b-data 分别表示与 scale_A 和 scale_B 矩阵对应的缩放矩阵元数据。元组 {byte-id-a, thread-id-a} 和 {byte-id-b, thread-id-b} 分别表示从其对应的元数据参数 scale-a-data、scale-b-data 中选择矩阵 scale_A 和 scale_B 的选择器。操作数 scale-a-data、scale-b-data 的类型为 .b32。操作数 byte-id-a、thread-id-a、byte-id-b、thread-id-b 是无符号 16 位整数值。有关选择器参数的更多详细信息,请参阅 Block Scaling 章节。
指令 mma.sp::ordered_metadata 要求稀疏元数据中的索引从 LSB 开始按升序排序,否则行为未定义。
每个线程中的寄存器都保存矩阵的一个片段,如 Matrix fragments for multiply-accumulate operation with sparse matrix A 中所述。
限定符 .dtype、.atype、.btype 和 .ctype 分别指示矩阵 D、A、B 和 C 中元素的数据类型。限定符 .stype 指示矩阵 scale_A 和 scale_B 中元素的数据类型。对于形状 .m16n8k16 和 .m16n8k32,.dtype 必须与 .ctype 相同。
当 .kind 是 .kind::mxf8f6f4 或 .kind::f8f6f4 之一时,各个 4 比特和 6 比特浮点类型元素必须打包在 8 比特容器中。 .e2m1 类型的矩阵元素位于 8 比特容器的中心 4 比特中,并在容器的上 2 比特和下 2 比特中填充。当矩阵元素为 .e3m2 或 .e2m3 类型时,矩阵元素位于 8 比特容器的下 6 比特中,并在容器的上 2 比特中填充。 相比之下,请注意,当将 mma 与 .kind::mxf4 或 .kind::mxf4nvf4 一起使用时,即使矩阵元素为 .e2m1 类型,也不需要显式填充。
- 精度和舍入
-
-
.f16浮点运算矩阵 A 和 B 的元素级乘法以至少单精度执行。当
.ctype或.dtype为.f32时,中间值的累加以至少单精度执行。当.ctype和.dtype都指定为.f16时,累加以至少半精度执行。累加顺序、舍入和次正规输入的处理方式未指定。
-
.e4m3、.e5m2、.e3m2、.e2m3、.e2m1浮点运算矩阵 A 和 B 的元素级乘法以指定的精度执行。中间值的累加以至少单精度执行。
累加顺序、舍入和次正规输入的处理方式未指定。
-
.bf16和.tf32浮点运算矩阵 A 和 B 的元素级乘法以指定的精度执行。中间值的累加以至少单精度执行。
累加顺序、舍入和次正规输入的处理方式未指定。
-
整数运算
整数
mma.sp/mma.sp::ordered_metadata操作使用.s32累加器执行。.satfinite限定符指示,当发生溢出时,累加值被限制在 MIN_INT32..MAX_INT32 范围内(其中边界定义为最小负 signed 32 位整数和最大正 signed 32 位整数)。如果未指定
.satfinite,则累加值将改为回绕。
-
强制性 .sync 限定符指示,mma.sp/mma.sp::ordered_metadata 指令导致执行线程等待,直到 warp 中的所有线程都执行相同的 mma.sp/mma.sp::ordered_metadata 指令,然后才能继续执行。
强制性 .aligned 限定符指示,warp 中的所有线程必须执行相同的 mma.sp/mma.sp::ordered_metadata 指令。在条件执行的代码中,只有当已知 warp 中的所有线程对条件的评估结果相同时,才应使用 mma.sp/mma.sp::ordered_metadata 指令,否则行为未定义。
如果同一 warp 中的所有线程未使用相同的限定符,或者 warp 中的任何线程已退出,则 mma.sp/mma.sp::ordered_metadata 指令的行为未定义。
注释
在某些目标架构上,mma.sp 指令的性能可能会大幅降低。因此,建议使用 mma.sp::ordered_metadata 指令。
PTX ISA 注释
在 PTX ISA 版本 7.1 中引入。
在 PTX ISA 版本 8.4 中引入了对 .e4m3 和 .e5m2 备选浮点类型 mma 运算的支持。
mma.sp::ordered_metadata 在 PTX ISA 版本 8.5 中引入。
在 PTX ISA 版本 8.7 中引入了对形状 .m16n8k32 和 .f16 dtype/ctype 以及 .e4m3/.e5m2 备用浮点类型的 mma 运算的支持。
在 PTX ISA 版本 8.7 中引入了对 .e3m2、.e2m3、.e2m1 备选浮点类型 mma 运算的支持。
在 PTX ISA 版本 8.7 中引入了对 .kind、.block_scale、.scale_vec_size 限定符的支持。
目标 ISA 注释
需要 sm_80 或更高架构。
.e4m3 和 .e5m2 备选浮点类型 mma 操作需要 sm_89 或更高架构。
mma.sp::ordered_metadata 需要 sm_80 或更高版本。
对形状 .m16n8k32 和 .f16 dtype/ctype 以及 .e4m3/.e5m2 备用浮点类型的 mma 运算的支持需要 sm_120a。
.e3m2、.e2m3 和 .e2m1 备选浮点类型 mma 操作需要 sm_120a。
对 .kind、.block_scale、.scale_vec_size 限定符的支持需要 sm_120a。
半精度浮点类型示例
// f16 elements in C and D matrix
.reg .f16x2 %Ra<2> %Rb<2> %Rc<2> %Rd<2>
.reg .b32 %Re;
mma.sp.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1}, %Re, 0x1;
.reg .f16x2 %Ra<2> %Rb<2> %Rc<2> %Rd<2>
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1}, %Re, 0x1;
备选浮点类型示例
.reg .b32 %Ra<2>, %Rb<2>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x1;
.reg .b32 %Ra<2>, %Rb<2>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x1;
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp.sync.aligned.m16n8k32.row.col.f32.bf16.bf16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x1;
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp.sync.aligned.m16n8k64.row.col.f32.e5m2.e4m3.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0;
.reg .b32 %Ra<2>, %Rb<2>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x1;
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k64.row.col.kind::f8f6f4.f32.e3m2.e2m3.f32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0;
.reg .b32 %Ra<4>, %Rb<4>;
.reg .b32 %Rc<4>, %Rd<4>;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k64.row.col.kind::f8f6f4.f16.e2m3.e2m1.f16
{%Rd0, %Rd1},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1}, %Re, 0;
整数类型示例
.reg .b32 %Ra<4>, %Rb<4>, %Rc<4>, %Rd<4>;
.reg .u32 %Re;
// u8 elements in A and B matrix
mma.sp.sync.aligned.m16n8k32.row.col.satfinite.s32.u8.u8.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x1;
// s8 elements in A and B matrix
mma.sp.sync.aligned.m16n8k64.row.col.satfinite.s32.s8.s8.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x0;
// s8 elements in A and B matrix with ordered metadata
mma.sp::ordered_metadata.sync.aligned.m16n8k64.row.col.satfinite.s32.s8.s8.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x0;
// u4 elements in A and B matrix
mma.sp.sync.aligned.m16n8k64.row.col.s32.s4.s4.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1},
{%Rb0, %Rb1},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x1;
// u4 elements in A and B matrix
mma.sp.sync.aligned.m16n8k128.row.col.satfinite.s32.u4.u4.s32
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3}, %Re, 0x0;
带块缩放的 mma 示例
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k128.row.col.kind::mxf4.block_scale.f32.e2m1.e2m1.f32.ue8m0
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3},
%Re, 0,
scaleAData, {2, 1}, scaleBData, {2, 3};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
.reg .u16 bidA, bidB, tidA, tidB;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k128.row.col.kind::mxf4nvf4.block_scale.scale_vec::4X.f32.e2m1.e2m1.f32.ue4m3
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3},
%Re, 0,
scaleAData, {bidA, tidA}, scaleBData, {bidB, tidB};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k64.row.col.kind::mxf8f6f4.block_scale.scale_vec::1X.f32.e3m2.e2m1.f32.ue8m0
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3},
%Re, 0,
scaleAData, {0, 1}, scaleBData, {0, 1};
.reg .b32 %Ra<4>, %Rb<4>;
.reg .f32 %Rc<4>, %Rd<4>;
.reg .b32 scaleAData, scaleBData;
.reg .b32 %Re;
mma.sp::ordered_metadata.sync.aligned.m16n8k64.row.col.kind::mxf8f6f4.block_scale.scale_vec::1X.f32.e4m3.e5m2.f32.ue8m0
{%Rd0, %Rd1, %Rd2, %Rd3},
{%Ra0, %Ra1, %Ra2, %Ra3},
{%Rb0, %Rb1, %Rb2, %Rb3},
{%Rc0, %Rc1, %Rc2, %Rc3},
%Re, 0,
scaleAData, {0, 1}, scaleBData, {0, 0};
9.7.15. 异步 Warpgroup 级别矩阵乘法累加指令
warpgroup 级别矩阵乘法和累加运算具有以下形式之一,其中矩阵 D 称为累加器
D = A * B + DD = A * B,其中禁用了来自累加器 D 的输入。
wgmma 指令通过让 warpgroup 中的所有线程共同执行以下操作来执行 warpgroup 级别矩阵乘法累加运算
将矩阵 A、B 和 D 加载到寄存器或共享内存中。
-
执行以下 fence 操作
wgmma.fence操作,用于指示 warpgroup 之间的寄存器/共享内存已被写入。fence.proxy.async操作,使通用代理操作对异步代理可见。
使用输入矩阵上的
wgmma.mma_async操作发出异步矩阵乘法和累加运算。wgmma.mma_async操作在异步代理中执行。创建一个 wgmma-group 并使用
wgmma.commit_group操作将所有先前的未完成wgmma.mma_async操作提交到该组。等待所需的 wgmma-group 完成。
一旦 wgmma-group 完成,所有
wgmma.mma_async操作都已执行并完成。
9.7.15.1. Warpgroup
Warpgroup 是一组四个连续的 warp,其中第一个 warp 的 warp-rank 是 4 的倍数。
warp 的 warp-rank 定义为
(%tid.x + %tid.y * %ntid.x + %tid.z * %ntid.x * %ntid.y) / 32
9.7.15.2. 矩阵形状
矩阵乘法和累加运算支持操作数矩阵 A、B 和 D 的一组有限形状。所有三个矩阵操作数的形状都由元组 MxNxK 共同描述,其中 A 是 MxK 矩阵,B 是 KxN 矩阵,而 D 是 MxN 矩阵。
以下矩阵形状受 wgmma.mma_async 操作的指定类型支持
乘数数据类型 |
稀疏性 |
形状 |
|---|---|---|
浮点 - |
密集 |
|
备选浮点格式 - |
||
备选浮点格式 - |
稀疏 |
|
备选浮点格式 - |
密集 |
|
备用浮点格式 - |
密集 |
|
浮点 - |
稀疏 |
|
备用浮点格式 - |
||
整数 - |
密集 |
|
备用浮点格式 - |
稀疏 |
|
整数 - |
稀疏 |
|
单比特 - |
密集 |
|
9.7.15.3. 矩阵数据类型
矩阵乘法和累加运算分别在整数、浮点、子字节整数和单比特数据类型上受支持。所有操作数都必须包含相同的基本类型,即整数或浮点。
对于浮点矩阵乘法和累加运算,不同的矩阵操作数可能具有不同的精度,如下所述。
对于整数矩阵乘法和累加运算,两个被乘数矩阵(A 和 B)必须具有相同的数据类型元素,例如,都是有符号整数或都是无符号整数。
数据类型 |
乘数(A 或 B) |
累加器 (D) |
|---|---|---|
整数 |
都是 |
|
浮点 |
|
|
备选浮点 |
|
|
备选浮点 |
|
|
备选浮点 |
|
|
单比特整数 |
|
|
9.7.15.4. 异步代理
wgmma.mma_async 操作在异步代理(或 async proxy)中执行。
跨多个代理访问相同的内存位置需要跨代理栅栏。对于异步代理,应使用 fence.proxy.async 来同步通用代理和异步代理之间的内存。
wgmma.mma_async 操作的完成之后会跟随一个隐式的通用-异步代理栅栏。因此,一旦观察到异步操作的完成,异步操作的结果就会对通用代理可见。wgmma.commit_group 和 wgmma.wait_group 操作必须用于等待 wgmma.mma_async 指令的完成。
9.7.15.5. 使用 wgmma.mma_async 指令的异步 Warpgroup 级别矩阵乘法-累加运算
本节介绍 warpgroup 级别 wgmma.mma_async 指令以及此指令中涉及的各种矩阵的组织方式。
9.7.15.5.1. 寄存器片段和共享内存矩阵布局
warpgroup 宽 MMA 操作的输入矩阵 A 可以位于寄存器或共享内存中。warpgroup 宽 MMA 操作的输入矩阵 B 必须位于共享内存中。本节介绍 warpgroup MMA 指令期望的寄存器片段和共享内存的布局。
当矩阵位于共享内存中时,它们的起始地址必须与 16 字节对齐。
9.7.15.5.1.1. 寄存器片段
本节介绍 wgmma.mma_async 指令的寄存器操作数中各种矩阵的组织方式。
执行 wgmma.mma_async.m64nNk16 的 warpgroup 将计算形状为 .m64nNk16 的 MMA 操作,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
-
寄存器中的被乘数 A
.atype
片段
元素(从低到高)
.f16/.bf16包含四个
.f16x2寄存器的向量表达式,每个寄存器包含来自矩阵 A 的两个.f16/.bf16元素。a0, a1, a2, a3, a4, a5, a6, a7
不同线程持有的片段布局如 图 147 所示。
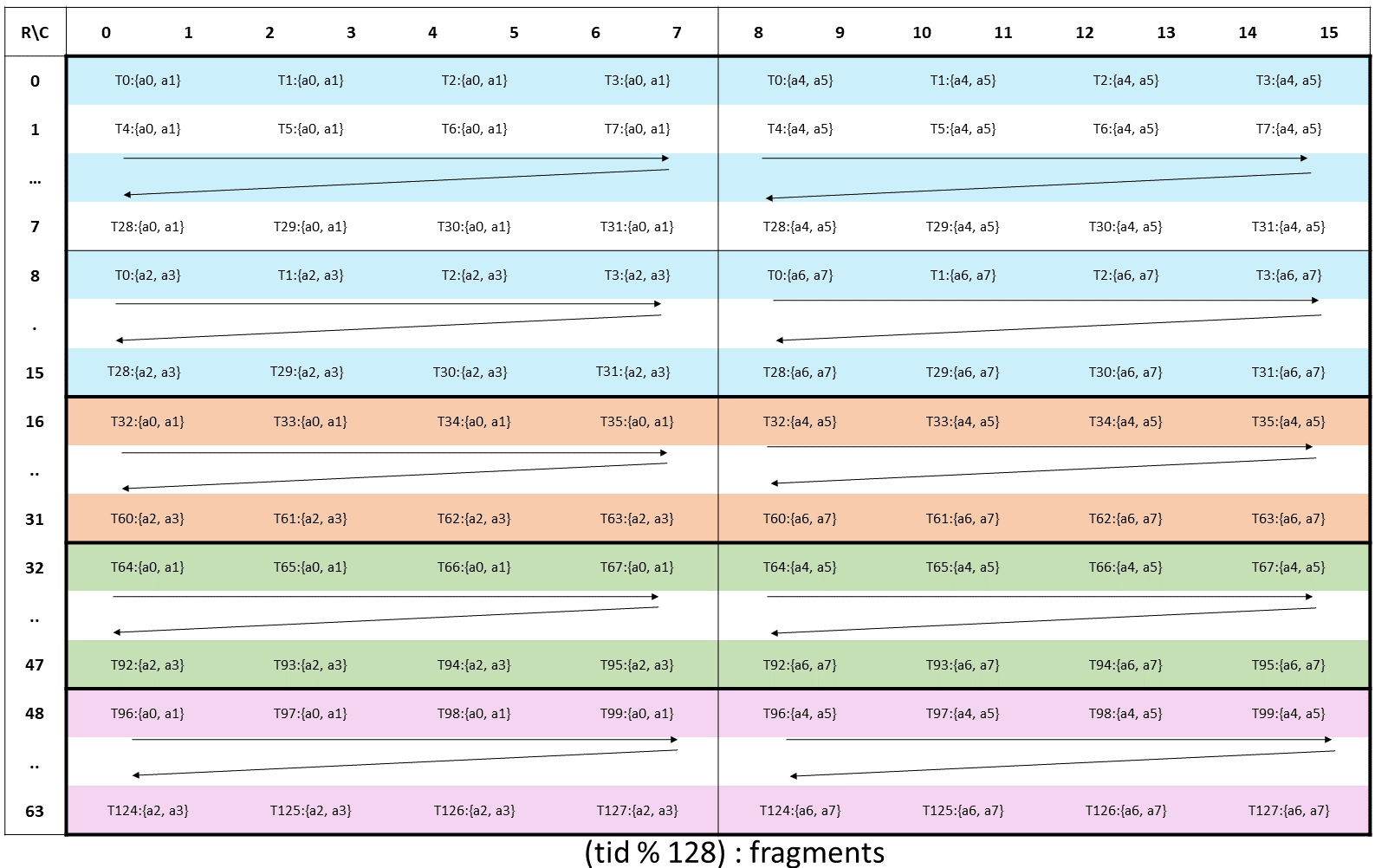
图 147 矩阵 A 的 WGMMA .m64nNk16 寄存器片段布局。
-
累加器 D
.dtype
片段
元素(从低到高)
.f16包含 N/4 个
.f16x2寄存器的向量表达式,每个寄存器包含来自矩阵 D 的两个.f16元素。d0, d1, d2, d3, …, dX, dY, dZ, dW
其中
X = N/2 - 4Y = N/2 - 3Z = N/2 - 2W = N/2 - 1N = 8*i 其中 i = {1, 2, ... , 32}.f32包含 N/2 个
.f32寄存器的向量表达式。不同线程持有的片段布局如 图 148 所示。
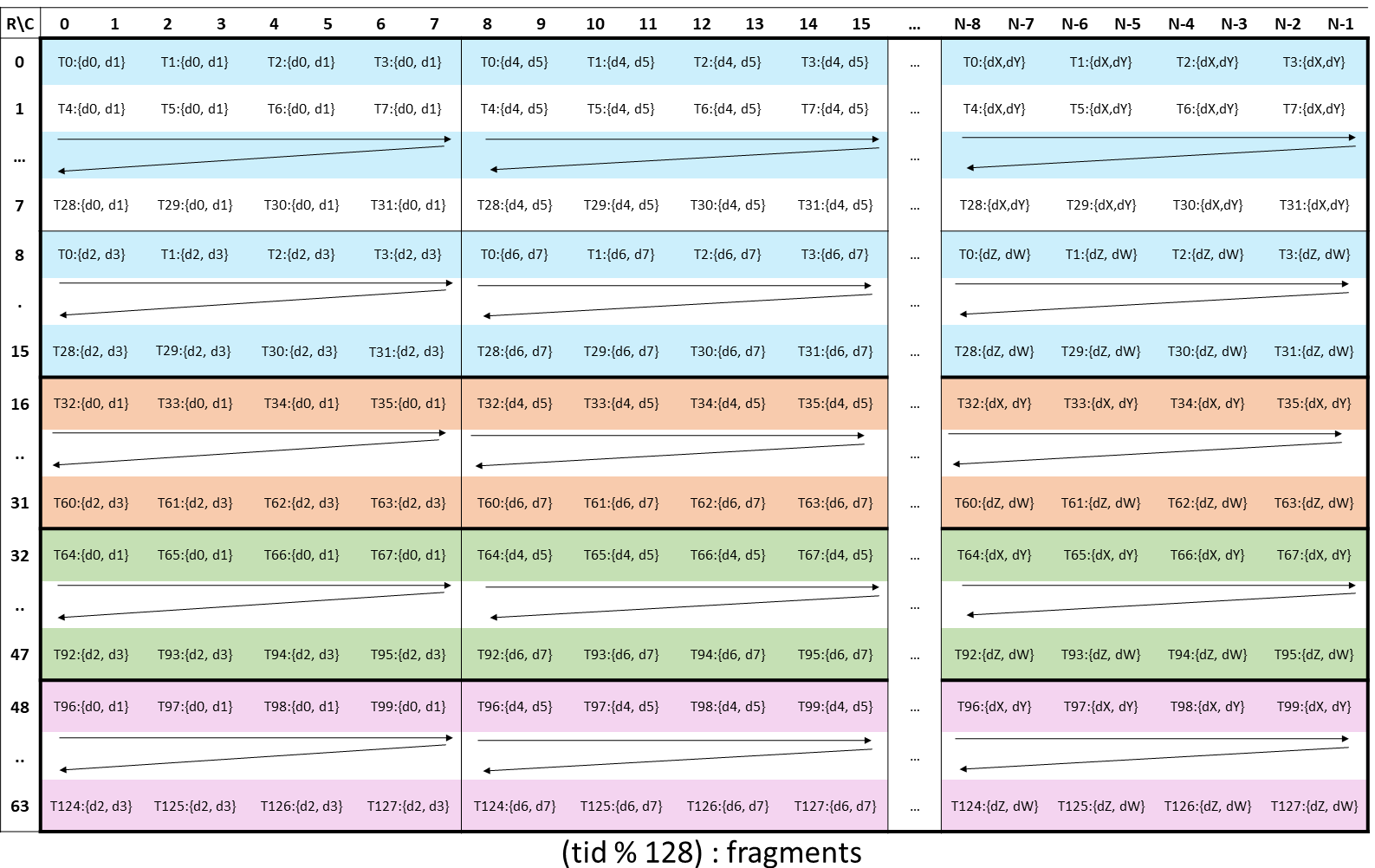
图 148 累加器矩阵 D 的 WGMMA .m64nNk16 寄存器片段布局。
执行 wgmma.mma_async.m64nNk8 的 warpgroup 将计算形状为 .m64nNk8 的 MMA 操作,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
-
寄存器中的被乘数 A
.atype
片段
元素(从低到高)
.tf32包含四个
.b32寄存器的向量表达式,这些寄存器包含来自矩阵 A 的四个.tf32元素。a0, a1, a2, a3
不同线程持有的片段布局如 图 149 所示。

图 149 矩阵 A 的 WGMMA .m64nNk8 寄存器片段布局。
-
累加器 D
.dtype
片段
元素(从低到高)
.f32包含 N/2 个
.f32寄存器的向量表达式。d0, d1, d2, d3, …, dX, dY, dZ, dW
其中
X = N/2 - 4Y = N/2 - 3Z = N/2 - 2W = N/2 - 1N = 8*i 其中 i = {1, 2, ... , 32}不同线程持有的片段布局如 图 150 所示。
图 150 累加器矩阵 D 的 WGMMA .m64nNk8 寄存器片段布局。
执行 wgmma.mma_async.m64nNk32 的 warpgroup 将计算形状为 .m64nNk32 的 MMA 操作,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
-
寄存器中的被乘数 A
.atype
片段
元素(从低到高)
.s8/.u8包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的四个.u8/.s8元素。a0, a1, a2, a3, … , a14, a15
.e4m3/.e5m2包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的四个.e4m3/.e5m2元素。不同线程持有的片段布局如 图 151 所示。
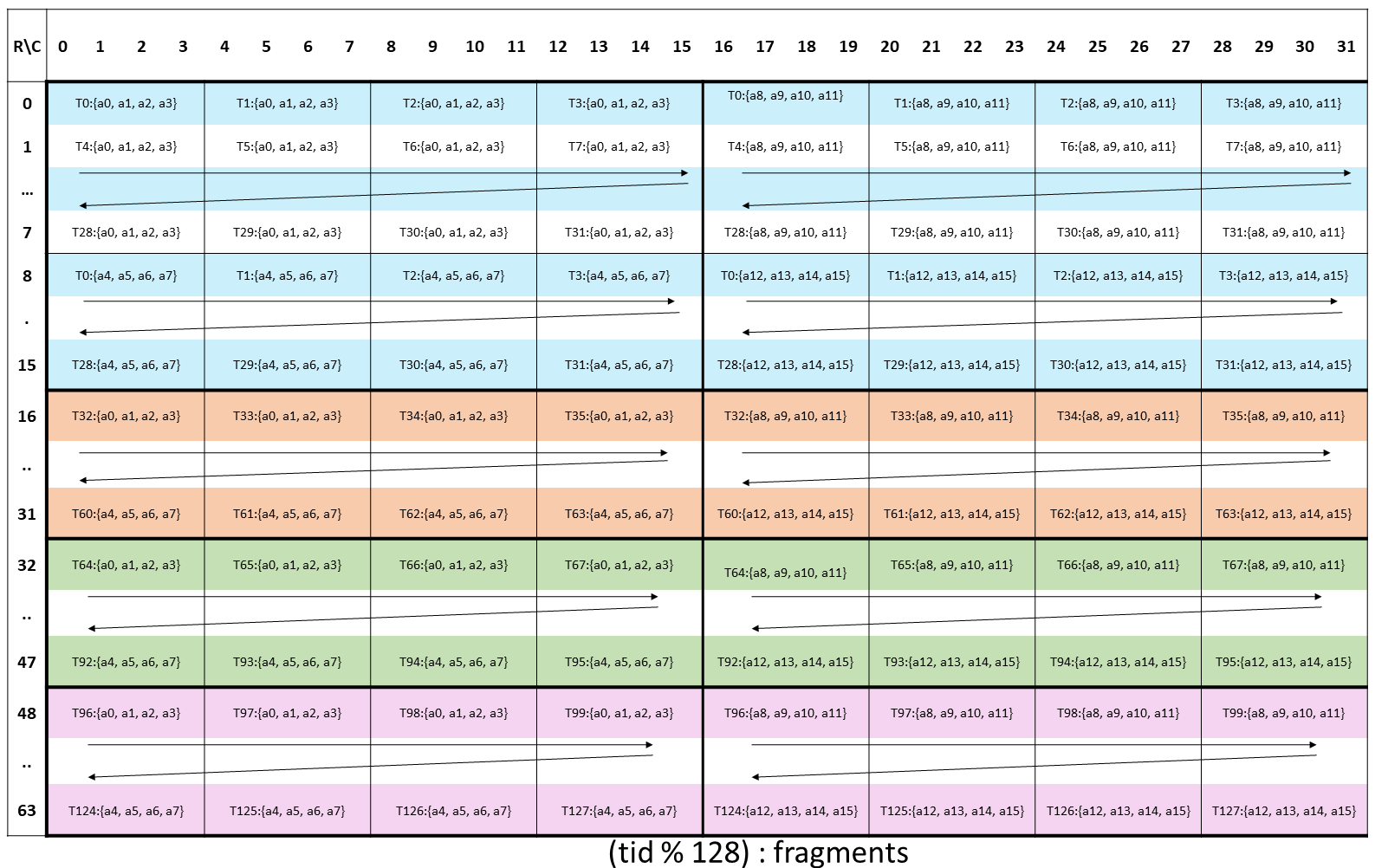
图 151 矩阵 A 的 WGMMA .m64nNk32 寄存器片段布局。
-
累加器 D
.dtype
片段
元素(从低到高)
杂项信息
.s32包含 N/2 个
.s32寄存器的向量表达式。d0, d1, d2, d3, …, dX, dY, dZ, dW
其中
X = N/2 - 4Y = N/2 - 3Z = N/2 - 2W = N/2 - 1N取决于 .dtype,如下一列所述。N = 8*i 其中 i = {1, 2, 3, 4}= 16*i 其中 i = {3, 4, ..., 15, 16}.f32包含 N/2 个
.f32寄存器的向量表达式。N = 8*i 其中 i = {1, 2, ... , 32}.f16包含 N/4 个
.f16x2寄存器的向量表达式,每个寄存器包含来自矩阵 D 的两个.f16元素。不同线程持有的片段布局如 图 152 所示。
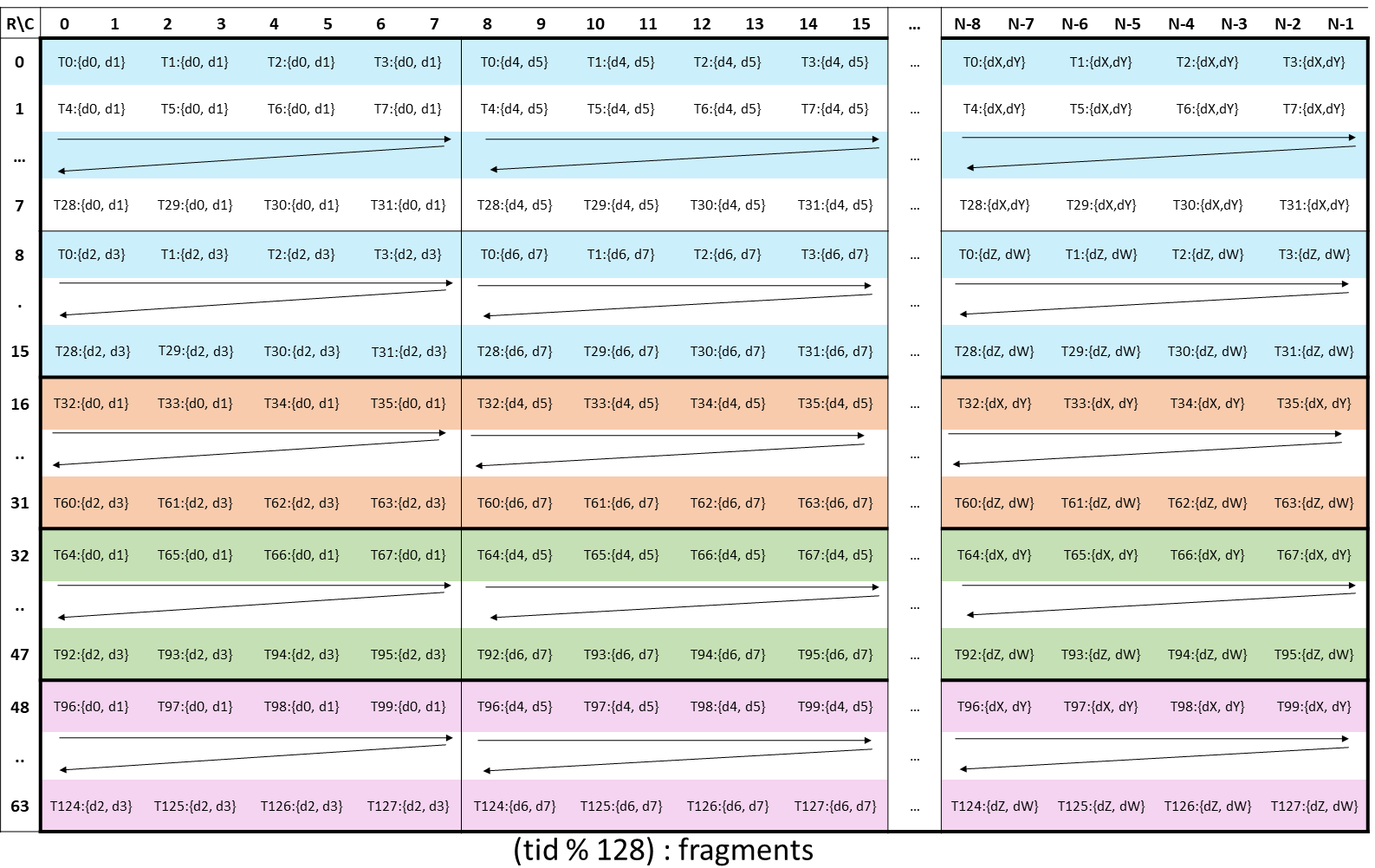
图 152 累加器矩阵 D 的 WGMMA .m64nNk32 寄存器片段布局。
执行 wgmma.mma_async.m64nNk256 的 warpgroup 将计算形状为 .m64nNk256 的 MMA 操作,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
-
寄存器中的被乘数 A
.atype
片段
元素(从低到高)
.b1包含四个
.b32寄存器的向量表达式,每个寄存器包含来自矩阵 A 的三十二个.b1元素。a0, a1, a2, …, a127
不同线程持有的片段布局如 图 153 所示。

图 153 矩阵 A 的 WGMMA .m64nNk256 寄存器片段布局。
-
累加器 D
.dtype
片段
元素(从低到高)
.s32包含 N/2 个
.s32寄存器的向量表达式。d0, d1, d2, d3, …, dX, dY, dZ, dW
其中
X = N/2 - 4Y = N/2 - 3Z = N/2 - 2W = N/2 - 1N = 8*i 其中 i = {1, 2, 3, 4}= 16*i 其中 i = {3, 4, ..., 15, 16}不同线程持有的片段布局如 图 154 所示。

图 154 累加器矩阵 D 的 WGMMA .m64nNk256 寄存器片段布局。
9.7.15.5.1.2. 共享内存矩阵布局
如果指令 wgmma.mma_async{.sp} 的参数 imm-trans-a / imm-trans-b 为 0,则矩阵 A / B 分别使用K-major 布局。如果参数 imm-trans-a 的值为 1,则矩阵 A 使用 M-major 布局。如果参数 imm-trans-b 的值为 1,则矩阵 B 使用 N-major 布局。
在列优先默认 BLAS 库(如 cuBLAS)中,带或不带转置的矩阵 A 和 B 可以分为 K-Major 或 M-or-N-Major,如下表所示
非转置 |
转置 |
|
|---|---|---|
A |
K-major |
M-major |
B |
K-major |
N-major |
为了避免与 A、B、row-major、col-major、transpose 和 non-transpose 混淆,我们在本节中将使用 MN-Major 和 K-Major。
共享内存中的矩阵由一个或多个“swizzle 布局原子”组成。这些 swizzle 原子的确切布局取决于 swizzling 模式、swizzle 原子性和前导维度。swizzle 的布局如 表 37 所示。
Swizzling 模式 |
前导维度 / Major-ness |
Swizzle 原子布局(128b 元素) |
|---|---|---|
128B 混合模式 |
M/N |
8x8 |
K |
8x8 |
|
64B 混合模式 |
M/N |
4x8 |
K |
8x4 |
|
32B 混合模式 |
M/N |
2x8 |
K |
8x2 |
|
无 |
M/N |
1x8 |
K |
8x1 |
以上形状适用于大小为 128 位的元素。对于较小的元素大小,相同的形状将沿前导维度乘以 128/sizeof_bits(Element) 的因子。例如,对于 tf32 tensor core 输入,128B MN major swizzle 原子将具有 (8*(128/32))x8 = 32x8 的形状。
示例
以下是一些 MxK 或 KxN 矩阵在各种 swizzling 模式下的示例布局,单位为 128b 元素,如每个彩色单元所示,如 图 155、图 156、图 157、图 158、图 159、图 160、图 161、图 162 所示。
图 155 MN major 128B swizzling
图 156 K major 128B swizzling
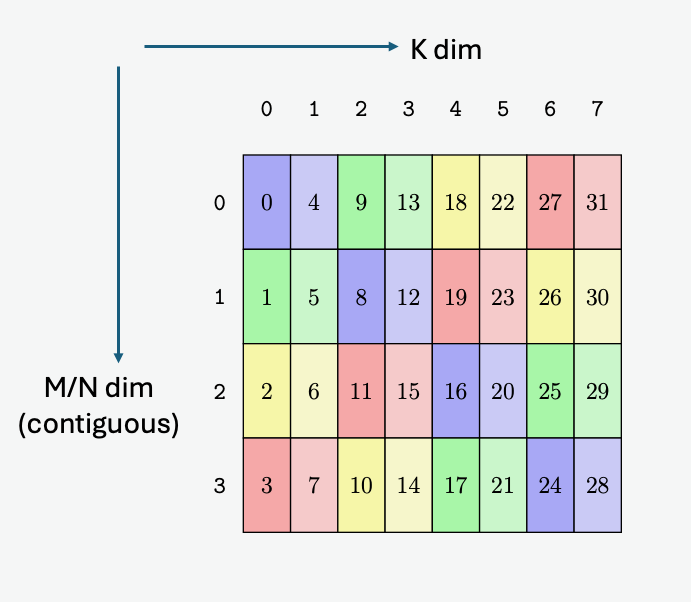
图 157 MN major 64B swizzling
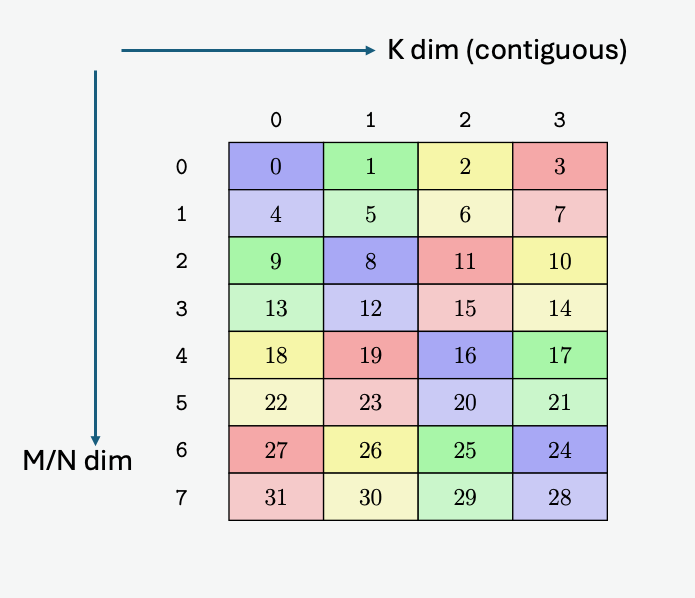
图 158 K major 64B swizzling
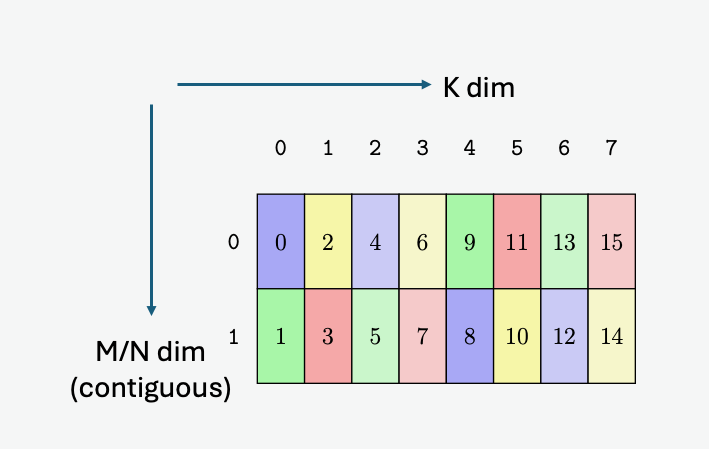
图 159 MN major 32B swizzling
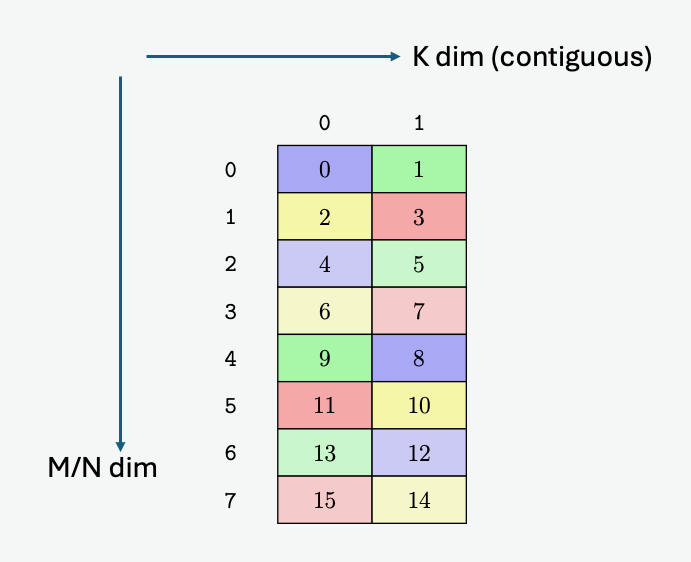
图 160 K major 32B swizzling
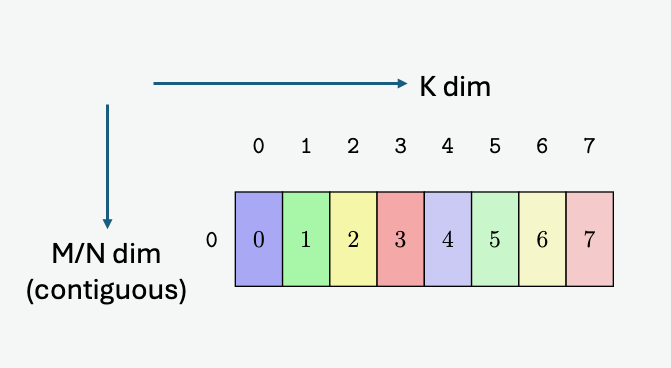
图 161 MN major 交错
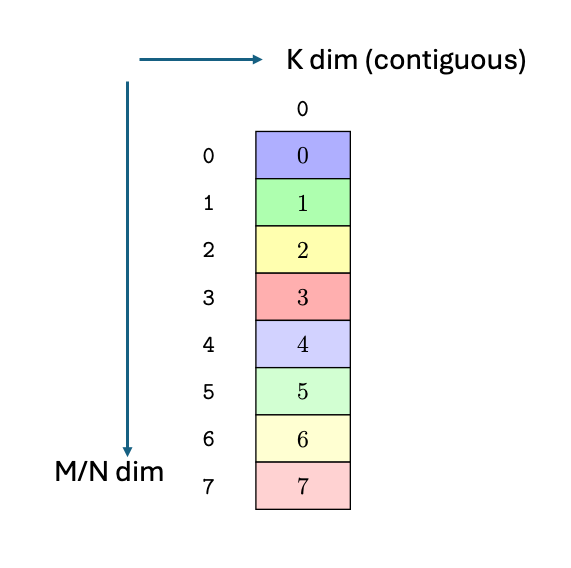
图 162 K major 交错
以下是 tf32 元素类型的 128B swizzling 布局的一些示例。
从共享内存访问矩阵时,涉及两个步幅
前导维度字节偏移
步幅维度字节偏移
对于转置和非转置矩阵,前导维度字节偏移的定义不同。对于元素类型归一化为 128 位的矩阵,前导字节偏移定义如下
Major-ness |
定义 |
|---|---|
K-Major |
|
MN-Major |
|
对于转置和非转置矩阵,步幅维度字节偏移的定义不同。对于元素类型归一化为 128 位的矩阵,步幅维度字节偏移定义如下
Major-ness |
定义 |
|---|---|
K-Major |
从前 8 行到后 8 行的偏移量。 |
MN-Major |
|
根据 CuTe 布局,规范布局可以表示如下
Major- ness |
Swizzling 模式 |
无 swizzling 的规范布局 |
前一列的Swizzling |
|---|---|---|---|
MN- major |
无 swizzling 或交错 |
((T,1,m),(8,k)):((1,T,SBO),(1T,LBO)) |
Swizzle<0, 4, 3> |
32B Swizzling |
((T,2,m),(8,k)):((1,T,LBO),(2T,SBO)) |
Swizzle<1, 4, 3> |
|
64B Swizzling |
((T,4,m),(8,k)):((1,T,LBO),(4T,SBO)) |
Swizzle<2, 4, 3> |
|
128B Swizzling |
((T,8,m),(8,k)):((1,T,LBO),(8T,SBO)) |
Swizzle<3, 4, 3> |
|
K- major |
无 swizzling 或交错 |
((8,m),(T,2k)):((1T,SBO),(1,LBO)) |
Swizzle<0, 4, 3> |
32B Swizzling |
((8,m),(T,2k)):((2T,SBO),(1,T)) |
Swizzle<1, 4, 3> |
|
64B Swizzling |
((8,m),(T,2k)):((4T,SBO),(1,T)) |
Swizzle<2, 4, 3> |
|
128B Swizzling |
((8,m),(T,2k)):((8T,SBO),(1,T)) |
Swizzle<3, 4, 3> |
其中
T = 128 / sizeof-elements-in-bits T 表示将矩阵元素类型归一化为 128 位的比例因子。
m 表示跨行的重复模式数。
k 表示跨列的重复模式数。
示例
-
K-Major,无 swizzling 和 tf32 类型:图 165
图 165 K major,无 swizzling 和 tf32 类型
步幅和相关详细信息如下
确切布局:Swizzle<0,4,3> o ((8,2),(4,4)):((4,32),(1,64))
规范布局:Swizzle<0,4,3> o ((8,m),(T,2k)):((1T,SBO),(1,LBO))
参数
值
T
4
m
2
k
2
LBO
32*sizeof(tf32)
SBO
64*sizeof(tf32)
描述符中 LBO 的编码
(LBO) >> 4 = 16
描述符中 SBO 的编码
(SBO) >> 4 = 8
-
K-Major,32B swizzling 和 tf32 类型:图 166
图 166 K major,32B swizzling 和 tf32 类型
步幅和相关详细信息如下
确切布局:Swizzle<1,4,3> o ((8,2),(4,4)):((8,64),(1,4))
规范布局:Swizzle<1,4,3> o ((8,m),(T,2k)):((2T,SBO),(1,T))
参数
值
T
4
m
2
k
2
LBO
NA
SBO
64*sizeof(tf32)
描述符中 LBO 的编码
1 (假定)
描述符中 SBO 的编码
(SBO) >> 4 = 16
-
MN-Major,无 swizzling 和 bf16 类型:图 167
图 167 MN major,无 swizzling 和 bf16 类型
步幅和相关详细信息如下
确切布局:Swizzle<0,4,3> o ((8,1,2),(8,2)):((1,8,64),(8,128))
规范布局:Swizzle<0,4,3> o ((T,1,m),(8,k)):((1,T,SBO),(1T,LBO))
参数
值
T
8
m
2
k
2
LBO
128*sizeof(bf16)
SBO
64*sizeof(bf16)
描述符中 LBO 的编码
(LBO) >> 4 = 16
描述符中 SBO 的编码
(SBO) >> 4 = 8
-
MN-Major,32B swizzling 和 bf16 类型:图 168
图 168 MN major,32B swizzling 和 bf16 类型
步幅和相关详细信息如下
确切布局:Swizzle<1,4,3> o ((8,2,2),(8,2)):((1,8,128),(16,256))
规范布局:Swizzle<1,4,3> o ((T,2,m),(8,k)):((1,T,LBO),(2T,SBO))
参数
值
T
8
m
2
k
2
LBO
128*sizeof(bf16)
SBO
256*sizeof(bf16)
描述符中 LBO 的编码
(LBO) >> 4 = 16
描述符中 SBO 的编码
(SBO) >> 4 = 32
-
MN-Major,64B swizzling 和 bf16 类型:图 169
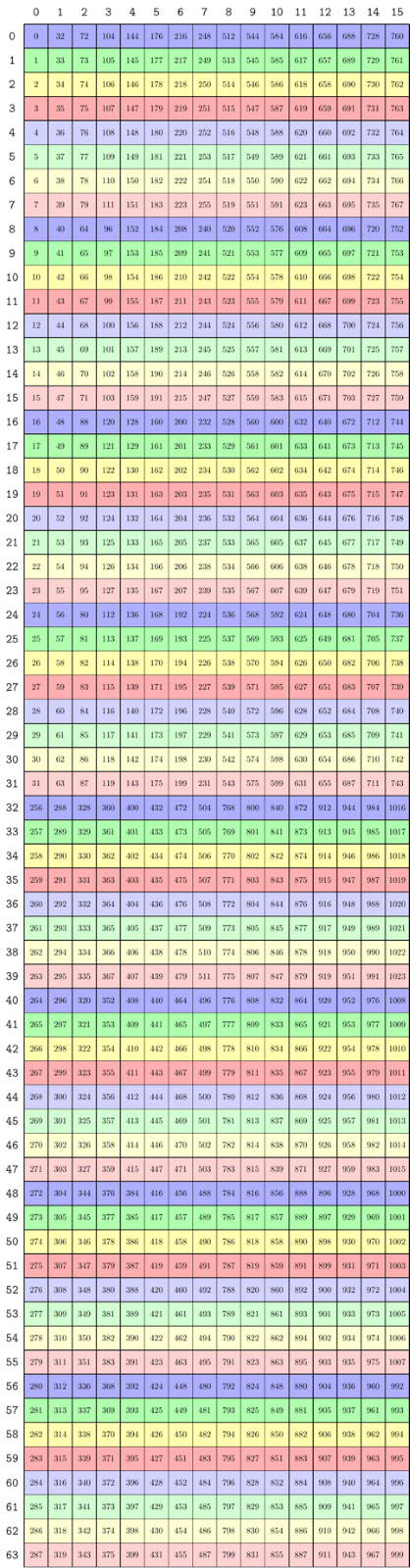
图 169 MN major,64B swizzling 和 bf16 类型
步幅和相关详细信息如下
确切布局:Swizzle<2,4,3> o ((8,4,2),(8,2)):((1,8,256),(32,512))
规范布局:Swizzle<2,4,3> o ((T,4,m),(8,k)):((1,T,LBO),(4T,SBO))
参数
值
T
8
m
2
k
2
LBO
256*sizeof(bf16)
SBO
512*sizeof(bf16)
描述符中 LBO 的编码
(LBO) >> 4 = 32
描述符中 SBO 的编码
(SBO) >> 4 = 64
矩阵描述符指定共享内存中矩阵的属性,该矩阵是矩阵乘法和累加运算中的被乘数。它是一个 64 位值,包含在具有以下布局的寄存器中
位字段 |
位大小 |
描述 |
|---|---|---|
13–0 |
14 |
matrix-descriptor-encode(矩阵起始地址) |
29–16 |
14 |
matrix-descriptor-encode (前导维度字节偏移) |
45–32 |
14 |
matrix-descriptor-encode (步幅维度字节偏移) |
51–49 |
3 |
矩阵基址偏移。这对于除无 swizzle 模式外的所有 swizzling 模式都有效。 |
63–62 |
2 |
指定要使用的 swizzling 模式
|
其中
matrix-descriptor-encode(x) = (x & 0x3FFFF) >> 4
当指定 swizzling 模式的重复模式按照下表开始时,基址偏移的值为 0
Swizzling 模式
重复模式的起始地址
128 字节混合
1024 字节边界
64 字节混合
512 字节边界
32 字节混合
256 字节边界
否则,基址偏移必须为非零值,使用以下公式计算
base offset = (pattern start addr >> 0x7) & 0x7
9.7.15.5.2. 异步乘法和累加指令:wgmma.mma_async
wgmma.mma_async
在 warpgroup 之间执行矩阵乘法和累加运算
语法
半精度浮点类型
wgmma.mma_async.sync.aligned.shape.dtype.f16.f16 d, a-desc, b-desc, scale-d, imm-scale-a, imm-scale-b, imm-trans-a, imm-trans-b;
wgmma.mma_async.sync.aligned.shape.dtype.f16.f16 d, a, b-desc, scale-d, imm-scale-a, imm-scale-b, imm-trans-b;
.shape = {.m64n8k16, .m64n16k16, .m64n24k16, .m64n32k16,
.m64n40k16, .m64n48k16, .m64n56k16, .m64n64k16,
.m64n72k16, .m64n80k16, .m64n88k16, .m64n96k16,
.m64n104k16, .m64n112k16, .m64n120k16, .m64n128k16,
.m64n136k16, .m64n144k16, .m64n152k16, .m64n160k16,
.m64n168k16, .m648176k16, .m64n184k16, .m64n192k16,
.m64n200k16, .m64n208k16, .m64n216k16, .m64n224k16,
.m64n232k16, .m64n240k16, .m64n248k16, .m64n256k16};
.dtype = {.f16, .f32};
备选浮点类型
.bf16 floating point type:
wgmma.mma_async.sync.aligned.shape.dtype.bf16.bf16 d, a-desc, b-desc, scale-d, imm-scale-a, imm-scale-b, imm-trans-a, imm-trans-b;
wgmma.mma_async.sync.aligned.shape.dtype.bf16.bf16 d, a, b-desc, scale-d, imm-scale-a, imm-scale-b, imm-trans-b;
.shape = {.m64n8k16, .m64n16k16, .m64n24k16, .m64n32k16,
.m64n40k16, .m64n48k16, .m64n56k16, .m64n64k16,
.m64n72k16, .m64n80k16, .m64n88k16, .m64n96k16,
.m64n104k16, .m64n112k16, .m64n120k16, .m64n128k16,
.m64n136k16, .m64n144k16, .m64n152k16, .m64n160k16,
.m64n168k16, .m648176k16, .m64n184k16, .m64n192k16,
.m64n200k16, .m64n208k16, .m64n216k16, .m64n224k16,
.m64n232k16, .m64n240k16, .m64n248k16, .m64n256k16};
.dtype = {.f32};
.tf32 floating point type:
wgmma.mma_async.sync.aligned.shape.dtype.tf32.tf32 d, a-desc, b-desc, scale-d, imm-scale-a, imm-scale-b;
wgmma.mma_async.sync.aligned.shape.dtype.tf32.tf32 d, a, b-desc, scale-d, imm-scale-a, imm-scale-b;
.shape = {.m64n8k8, .m64n16k8, .m64n24k8, .m64n32k8,
.m64n40k8, .m64n48k8, .m64n56k8, .m64n64k8,
.m64n72k8, .m64n80k8, .m64n88k8, .m64n96k8,
.m64n104k8, .m64n112k8, .m64n120k8, .m64n128k8,
.m64n136k8, .m64n144k8, .m64n152k8, .m64n160k8,
.m64n168k8, .m648176k8, .m64n184k8, .m64n192k8,
.m64n200k8, .m64n208k8, .m64n216k8, .m64n224k8,
.m64n232k8, .m64n240k8, .m64n248k8, .m64n256k8};
.dtype = {.f32};
FP8 floating point type
wgmma.mma_async.sync.aligned.shape.dtype.atype.btype d, a-desc, b-desc, scale-d, imm-scale-a, imm-scale-b;
wgmma.mma_async.sync.aligned.shape.dtype.atype.btype d, a, b-desc, scale-d, imm-scale-a, imm-scale-b;
.shape = {.m64n8k32, .m64n16k32, .m64n24k32, .m64n32k32,
.m64n40k32, .m64n48k32, .m64n56k32, .m64n64k32,
.m64n72k32, .m64n80k32, .m64n88k32, .m64n96k32,
.m64n104k32, .m64n112k32, .m64n120k32, .m64n128k32,
.m64n136k32, .m64n144k32, .m64n152k32, .m64n160k32,
.m64n168k32, .m648176k32, .m64n184k32, .m64n192k32,
.m64n200k32, .m64n208k32, .m64n216k32, .m64n224k32,
.m64n232k32, .m64n240k32, .m64n248k32, .m64n256k32};
.atype = {.e4m3, .e5m2};
.btype = {.e4m3, .e5m2};
.dtype = {.f16, .f32};
整数类型
wgmma.mma_async.sync.aligned.shape{.satfinite}.s32.atype.btype d, a-desc, b-desc, scale-d;
wgmma.mma_async.sync.aligned.shape{.satfinite}.s32.atype.btype d, a, b-desc, scale-d;
.shape = {.m64n8k32, .m64n16k32, .m64n24k32, .m64n32k32,
.m64n48k32, .m64n64k32, .m64n80k32, .m64n96k32,
.m64n112k32, .m64n128k32, .m64n144k32, .m64n160k32,
.m648176k32, .m64n192k32, .m64n208k32, .m64n224k32};
.atype = {.s8, .u8};
.btype = {.s8, .u8};
单比特
wgmma.mma_async.sync.aligned.shape.s32.b1.b1.op.popc d, a-desc, b-desc, scale-d;
wgmma.mma_async.sync.aligned.shape.s32.b1.b1.op.popc d, a, b-desc, scale-d;
.shape = {.m64n8k256, .m64n16k256, .m64n24k256, .m64n32k256,
.m64n48k256, .m64n64k256, .m64n80k256, .m64n96k256,
.m64n112k256, .m64n128k256, .m64n144k256, .m64n160k256,
.m64n176k256, .m64n192k256, .m64n208k256, .m64n224k256,
.m64n240k256, .m64n256k256};
.op = {.and};
描述
指令 wgmma.mma_async 发出 MxNxK 矩阵乘法和累加运算,D = A*B+D,其中 A 矩阵为 MxK,B 矩阵为 KxN,D 矩阵为 MxN。
当输入谓词参数 scale-d 为 false 时,发出 D = A*B 形式的操作。
必须使用 wgmma.fence 指令来隔离 wgmma.mma_async 指令的寄存器访问与其先前的访问。否则,行为是未定义的。
必须使用 wgmma.commit_group 和 wgmma.wait_group 操作来等待异步矩阵乘法和累加操作完成,然后才能访问结果。
寄存器操作数 d 表示累加器矩阵以及目标矩阵,分布在参与线程中。寄存器操作数 a 表示乘数矩阵 A,在参与线程中分布在寄存器中。64 位寄存器操作数 a-desc 和 b-desc 是矩阵描述符,分别表示共享内存中的乘数矩阵 A 和 B。矩阵描述符的内容在 warp group 中的所有 warp 中必须相同。矩阵描述符的格式在 矩阵描述符格式 中描述。
矩阵 A 和 B 分别以行优先和列优先格式存储。对于某些浮点变体,可以通过为立即整数参数 imm-trans-a 和 imm-trans-b 分别指定值 1 来转置输入矩阵 A 和 B。可以使用值 0 来避免转置操作。imm-trans-a 和 imm-trans-b 的有效值为 0 和 1。转置操作仅支持 wgmma.mma_async 变体,其类型为 .f16/ .bf16,且矩阵从共享内存中使用矩阵描述符访问。
对于 wgmma.mma_async 操作的浮点变体,可以通过为操作数 imm-scale-a 和 imm-scale-b 分别指定值 -1 来对输入矩阵 A 和 B 的每个元素取反。可以使用值 1 来避免取反操作。imm-scale-a 和 imm-scale-b 的有效值为 -1 和 1。
限定符 .dtype、.atype 和 .btype 分别指示矩阵 D、A 和 B 中元素的数据类型。对于所有浮点 wgmma.mma_async 变体,除了 FP8 浮点变体之外,.atype 和 .btype 必须相同。wgmma.mma_async 操作的备选浮点变体中矩阵 A 和 B 的各个数据元素的大小如下
当
.atype/.btype为.e4m3/.e5m2时,矩阵 A 和 B 具有 8 位数据元素。当
.atype/.btype为.bf16时,矩阵 A 和 B 具有 16 位数据元素。当
.atype/.btype为.tf32时,矩阵 A 和 B 具有 32 位数据元素。
精度和舍入
-
浮点运算
矩阵 A 和 B 的逐元素乘法以至少单精度执行。当
.dtype为.f32时,中间值的累加以至少单精度执行。当.dtype为.f16时,累加以至少半精度执行。累加顺序、舍入和次正规输入的处理方式未指定。
-
.bf16和.tf32浮点运算矩阵 A 和 B 的逐元素乘法以指定的精度执行。涉及
.tf32类型的wgmma.mma_async操作将在发出乘法之前截断 32 位输入数据的低 13 位。中间值的累加以至少单精度执行。累加顺序、舍入和次正规输入的处理方式未指定。
-
整数运算
整数
wgmma.mma_async操作使用.s32累加器执行。.satfinite限定符指示,当溢出时,累加值被限制在 MIN_INT32..MAX_INT32 范围内(其中边界定义为最小负有符号 32 位整数和最大正有符号 32 位整数)。如果未指定
.satfinite,则累加值将改为回绕。
强制性的 .sync 限定符指示 wgmma.mma_async 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 wgmma.mma_async 指令,然后才恢复执行。
强制性的 .aligned 限定符指示 warpgroup 中的所有线程必须执行相同的 wgmma.mma_async 指令。在条件执行的代码中,只有当已知 warpgroup 中的所有线程对条件的评估结果相同时,才应使用 wgmma.mma_async 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
PTX ISA 版本 8.4 中引入了对 .u8.s8 和 .s8.u8 作为 .atype.btype 的支持。
目标 ISA 注释
需要 sm_90a。
半精度浮点类型示例
.reg .f16x2 f16a<40>, f16d<40>;
.reg .f32 f32d<40>;
.reg .b64 descA, descB;
.reg .pred scaleD;
wgmma.mma_async.sync.aligned.m64n8k16.f32.f16.f16
{f32d0, f32d1, f32d2, f32d3},
{f16a0, f16a1, f16a2, f16a3},
descB,
1, -1, -1, 1;
wgmma.mma_async.sync.aligned.m64n72k16.f16.f16.f16
{f16d0, f16d1, f16d2, f16d3, f16d4, f16d5, f16d6, f16d7, f16d8,
f16d9, f16d10, f16d11, f16d12, f16d13, f16d14, f16d15, f16d16, f16d17},
descA,
descB,
scaleD, -1, 1, 1, 0;
备选浮点类型示例
.reg .f32 f32d<40>;
.reg .b32 bf16a<40>
.reg .b64 descA, descB;
wgmma.mma_async.sync.aligned.m64n120k16.f32.bf16.bf16
{f32d0, f32d1, f32d2, f32d3, f32d4, f32d5, f32d6, f32d7, f32d8, f32d9,
f32d10, f32d11, f32d12, f32d13, f32d14, f32d15, f32d16, f32d17, f32d18, f32d19,
f32d20, f32d21, f32d22, f32d23, f32d24, f32d25, f32d26, f32d27, f32d28, f32d29,
f32d30, f32d31, f32d32, f32d33, f32d34, f32d35, f32d36, f32d37, f32d38, f32d39,
f32d40, f32d41, f32d42, f32d43, f32d44, f32d45, f32d46, f32d47, f32d48, f32d49,
f32d50, f32d51, f32d52, f32d53, f32d54, f32d55, f32d56, f32d57, f32d58, f32d59},
{bf16a0, bf16a1, bf16a2, bf16a3},
descB,
scaleD, -1, -1, 0;
.reg .f32 f32d<40>;
.reg .b64 descA, descB;
wgmma.mma_async.sync.aligned.m64n16k8.f32.tf32.tf32
{f32d0, f32d1, f32d2, f32d3, f32d4, f32d5, f32d6, f32d7},
descA,
descB,
0, -1, -1;
.reg .b32 f16d<8>, f16a<8>;
.reg .f32 f32d<8>;
.reg .b64 descA, descB;
wgmma.mma_async.sync.aligned.m64n8k32.f16.e4m3.e5m2
{f16d0, f16d1},
descA,
descB,
scaleD, -1, 1;
wgmma.mma_async.sync.aligned.m64n8k32.f32.e5m2.e4m3
{f32d0, f32d1, f32d2, f32d3},
{f16a0, f16a1, f16a2, f16a3},
descB,
1, -1, -1;
整数类型示例
.reg .s32 s32d<8>, s32a<8>;
.reg .u32 u32a<8>;
.reg .pred scaleD;
.reg .b64 descA, descB;
wgmma.mma_async.sync.aligned.m64n8k32.s32.s8.s8.satfinite
{s32d0, s32d1, s32d2, s32d3},
{s32a0, s32a1, s32a2, s32a3},
descB,
1;
wgmma.mma_async.sync.aligned.m64n8k32.s32.u8.u8
{s32d0, s32d1, s32d2, s32d3},
descA,
descB,
scaleD;
wgmma.mma_async.sync.aligned.m64n8k32.s32.s8.u8.satfinite
{s32d0, s32d1, s32d2, s32d3},
{s32a0, s32a1, s32a2, s32a3},
descB,
scaleD;
wgmma.mma_async.sync.aligned.m64n8k32.s32.u8.s8
{s32d0, s32d1, s32d2, s32d3},
descA,
descB,
scaleD;
单比特类型示例
.reg .s32 s32d<4>;
.reg .b32 b32a<4>;
.reg .pred scaleD;
.reg .b64 descA, descB;
wgmma.mma_async.sync.aligned.m64n8k256.s32.b1.b1.and.popc
{s32d0, s32d1, s32d2, s32d3},
{b32a0, b32a1, b32a2, b32a3},
descB,
scaleD;
9.7.15.6. 使用 wgmma.mma_async.sp 指令的异步 Warpgroup 级别乘加运算
本节介绍使用稀疏矩阵 A 的 warp 级别 wgmma.mma_async.sp 指令。wgmma.mma_async 操作的此变体可用于当 A 是结构化稀疏矩阵,且每行有 50% 的零元素,并以特定于形状的粒度分布时。对于 MxNxK 稀疏 wgmma.mma_async.sp 操作,MxK 矩阵 A 被打包成 MxK/2 个元素。对于矩阵 A 的每个 K 宽行,50% 的元素为零,其余 K/2 个非零元素打包在表示矩阵 A 的操作数中。这些 K/2 个元素到相应 K 宽行的映射以元数据的形式显式提供。
9.7.15.6.1. 稀疏矩阵存储
稀疏矩阵 A 的粒度定义为矩阵行子块中非零元素的数量与该子块中元素总数的比率,其中子块的大小是特定于形状的。例如,在浮点 wgmma.mma_async 操作中使用的 64x32 矩阵 A 中,稀疏度预计为 2:4 粒度,即矩阵行的每个 4 元素向量(即 4 个连续元素的子块)包含 2 个零。子块中每个非零元素的索引存储在元数据操作数中。值 0b0000、0b0101、0b1010、0b1111 对于元数据是无效值,并将导致未定义的行为。在一组四个连续的线程中,一个或多个线程根据矩阵形状存储整个组的元数据。这些线程使用额外的稀疏选择器操作数指定。
矩阵 A 及其对应的稀疏 wgmma 的输入操作数类似于 图 110 中所示的图,具有适当的矩阵大小。
不同矩阵形状和数据类型的粒度如下所述。
稀疏 wgmma.mma_async.sp ,具有半精度和 .bf16 类型
对于 .f16 和 .bf16 类型,对于所有支持的 64xNx32 形状,矩阵 A 是结构化稀疏的,粒度为 2:4。换句话说,矩阵 A 的一行中每四个相邻元素的块中有两个零和两个非零元素。只有两个非零元素存储在矩阵 A 中,并且它们在矩阵 A 中四个宽度块中的位置由元数据操作数中的两个 2 位索引指示。
图 170 .f16/.bf16 类型的稀疏 WGMMA 元数据示例。
稀疏选择器指示四个连续线程组中的一个线程对,该线程对贡献稀疏元数据。因此,稀疏选择器必须是 0(线程 T0、T1)或 1(线程 T2、T3);任何其他值都会导致未定义的行为。
稀疏 wgmma.mma_async.sp ,具有 .tf32 类型
对于 .tf32 类型,对于所有支持的 64xNx16 形状,矩阵 A 是结构化稀疏的,粒度为 1:2。换句话说,矩阵 A 的一行中每两个相邻元素的块中有一个零和一个非零元素。只有非零元素存储在矩阵 A 的操作数中,并且元数据中的 4 位索引指示非零元素在两个宽度块中的位置。0b1110 和 0b0100 是索引的唯一有意义的值,其余值会导致未定义的行为。
图 171 .tf32 类型的稀疏 WGMMA 元数据示例。
稀疏选择器指示四个连续线程组中的一个线程对,该线程对贡献稀疏元数据。因此,稀疏选择器必须是 0(线程 T0、T1)或 1(线程 T2、T3);任何其他值都会导致未定义的行为。
稀疏 wgmma.mma_async.sp ,具有 .e4m3 和 .e5m2 浮点类型
对于 .e4m3 和 .e5m2 类型,对于所有支持的 64xNx64 形状,矩阵 A 是结构化稀疏的,粒度为 2:4。换句话说,矩阵 A 的一行中每四个相邻元素的块中有两个零和两个非零元素。只有两个非零元素存储在矩阵 A 中,并且它们在矩阵 A 中四个宽度块中的位置由元数据操作数中的两个 2 位索引指示。
图 172 .e4m3/.e5m2 类型的稀疏 WGMMA 元数据示例。
所有线程都贡献稀疏元数据,并且稀疏选择器必须为 0;任何其他值都会导致未定义的行为。
稀疏 wgmma.mma_async.sp ,具有整数类型
对于整数类型,对于所有支持的 64xNx64 形状,矩阵 A 是结构化稀疏的,粒度为 2:4。换句话说,矩阵 A 的一行中每四个相邻元素的块中有两个零和两个非零元素。只有两个非零元素存储在矩阵 A 中,并且元数据中的两个 2 位索引指示这两个非零元素在四个宽度块中的位置。
图 173 .u8/.s8 类型的稀疏 WGMMA 元数据示例。
所有线程都贡献稀疏元数据,并且稀疏选择器必须为 0;任何其他值都会导致未定义的行为。
9.7.15.6.2. 用于稀疏 WGMMA 的 Warpgroup 级别矩阵片段
在本节中,我们描述线程寄存器的内容如何与矩阵 A 的片段和稀疏元数据关联。
warpgroup 中的每个 warp 为矩阵 A 的 16 行提供稀疏信息。下表显示了 warp 到矩阵 A 行的分配
Warp |
矩阵 A 行的稀疏信息 |
|---|---|
|
48-63 |
|
32-47 |
|
16-31 |
|
0-15 |
本节通篇使用以下约定
对于矩阵 A,仅根据寄存器向量大小及其与矩阵数据的关联来描述片段的布局。
对于矩阵 D,由于矩阵维度 - 数据类型组合对于所有支持的形状都相同,并且已在 使用 wgmma 指令的矩阵乘加运算 中涵盖,因此本节中未包含矩阵片段的图形表示。
对于元数据操作数,包括矩阵 A 元素索引与元数据操作数内容之间关联的图形表示。
Tk: [m..n]出现在单元格[x][y..z]中表示%laneid=k的线程的元数据操作数中从位m到n(其中m是高位)包含来自矩阵 A 的块[x][y]..[x][z]的非零元素的索引。
9.7.15.6.2.1. 用于稀疏 wgmma.mma_async.m64nNk32 的矩阵片段
执行稀疏 wgmma.mma_async.m64nNk32 的 warpgroup 将计算形状为 .m64nNk32 的 MMA 运算,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
来自共享内存的乘数 A 在 wgmma.mma_async.m64nNk32 的共享内存布局 中记录。
-
来自寄存器的乘数 A
-
累加器 D
累加器 D 的矩阵片段与相同
.dtype格式的 用于浮点类型的 wgmma.m64nNk32 的矩阵片段 中的情况相同。 -
被乘数 B
矩阵 B 的共享内存布局在 wgmma.mma_async.m64nNk32 的共享内存布局 中记录。
-
元数据操作数是一个
.b32寄存器,其中包含 16 个 2 位向量,每个向量存储矩阵 A 的 4 宽块的非零元素的索引。图 175 显示了 warp 的元数据位到矩阵 A 元素的映射。在此图中,变量
i表示稀疏选择器操作数的值。
图 175 用于
.f16/.bf16类型的稀疏 WGMMA .m64nNk32 元数据布局。

9.7.15.6.2.2. 用于稀疏 wgmma.mma_async.m64nNk16 的矩阵片段
执行稀疏 wgmma.mma_async.m64nNk16 的 warpgroup 将计算形状为 .m64nNk16 的 MMA 运算,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
来自共享内存的乘数 A 在 wgmma.mma_async.m64nNk16 的共享内存布局 中记录。
-
来自寄存器的乘数 A
-
累加器 D
累加器 D 的矩阵片段与相同
.dtype格式的 用于浮点类型的 wgmma.m64nNk8 的矩阵片段 中的情况相同。 -
被乘数 B
矩阵 B 的共享内存布局在 wgmma.mma_async.m64nNk16 的共享内存布局 中记录。
-
元数据操作数是一个
.b32寄存器,其中包含八个 4 位向量,每个向量存储矩阵 A 的 2 宽块的非零元素的索引。图 177 显示了 warp 的元数据位到矩阵 A 元素的映射。在此图中,变量
i表示稀疏选择器操作数的值。
图 177 用于
.tf32类型的稀疏 WGMMA .m64nNk16 元数据布局。
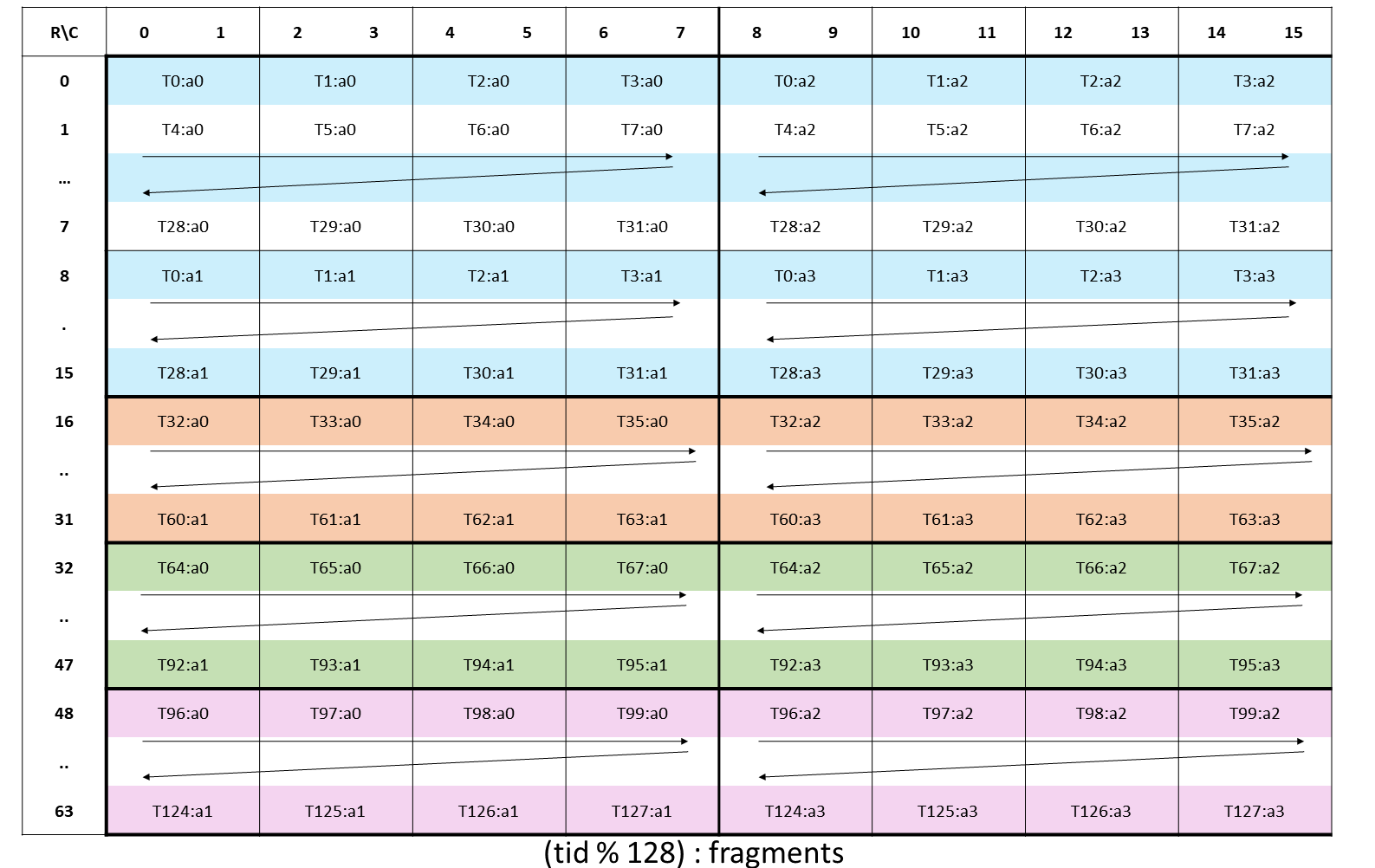
9.7.15.6.2.3. 用于稀疏 wgmma.mma_async.m64nNk64 的矩阵片段
执行稀疏 wgmma.mma_async.m64nNk64 的 warpgroup 将计算形状为 .m64nNk64 的 MMA 运算,其中 N 是 矩阵形状 中列出的有效 n 维度。
矩阵的元素分布在 warpgroup 中的线程之间,因此 warpgroup 的每个线程都持有一个矩阵片段。
来自共享内存的乘数 A 在 wgmma.mma_async.m64nNk64 的共享内存布局 中记录。
-
来自寄存器的乘数 A
-
累加器 D
累加器 D 的矩阵片段与相同
.dtype格式的 用于浮点类型的 wgmma.m64nNk32 的矩阵片段 中的情况相同。 -
被乘数 B
矩阵 B 的共享内存布局在 wgmma.mma_async.m64nNk64 的共享内存布局 中记录。
-
元数据操作数是一个
.b32寄存器,其中包含 16 个 4 位向量,每个向量存储矩阵 A 的 4 宽块的两个非零元素的索引。图 179 显示了元数据位到矩阵 A 的 0-31 列元素的映射。
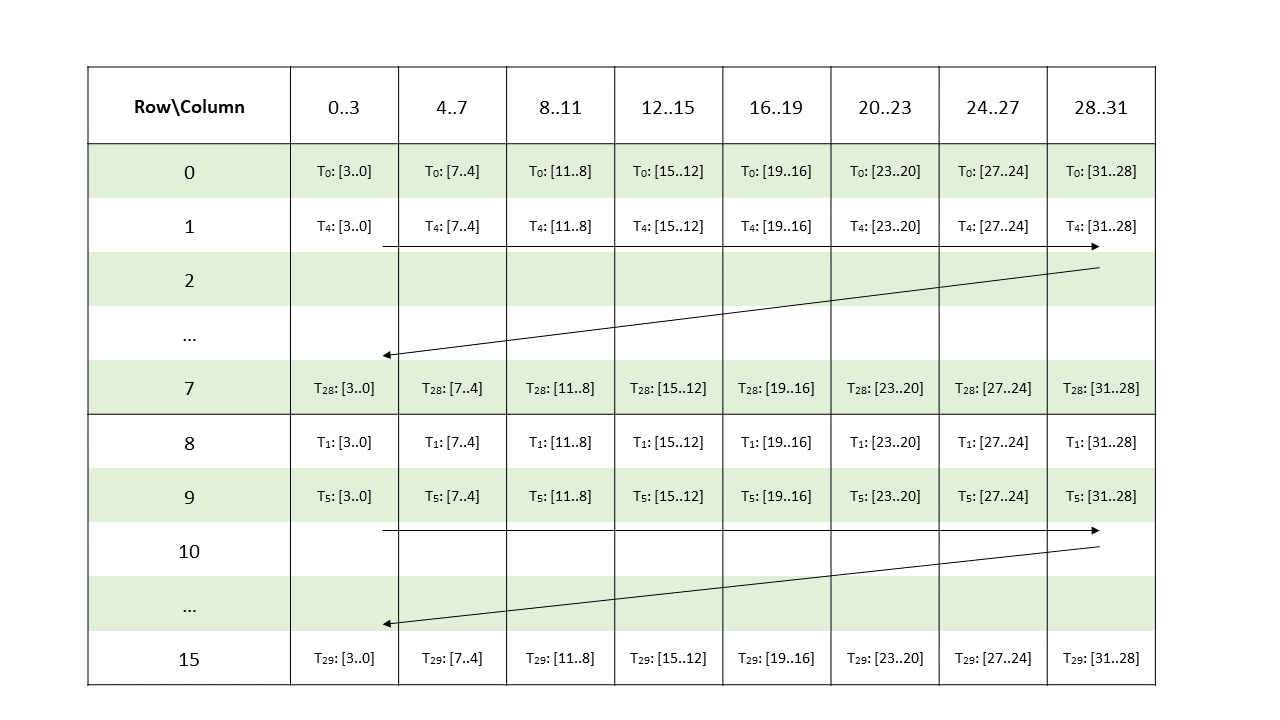
图 179 用于
.e4m3/.e5m2/.s8/.u8类型的稀疏 WGMMA .m64nNk64 元数据布局,适用于 0-31 列图 180 显示了元数据位到矩阵 A 的 32-63 列元素的映射。
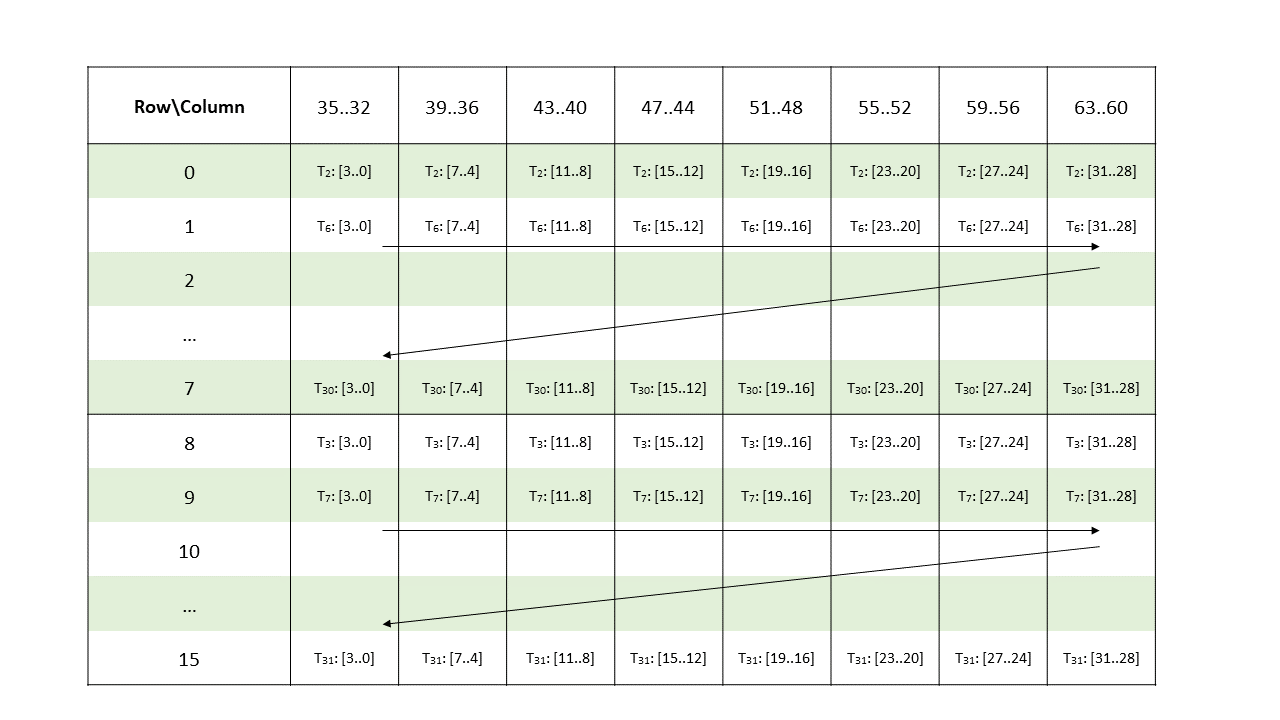
图 180 用于
.e4m3/.e5m2/.s8/.u8类型的稀疏 WGMMA .m64nNk64 元数据布局,适用于 32-63 列
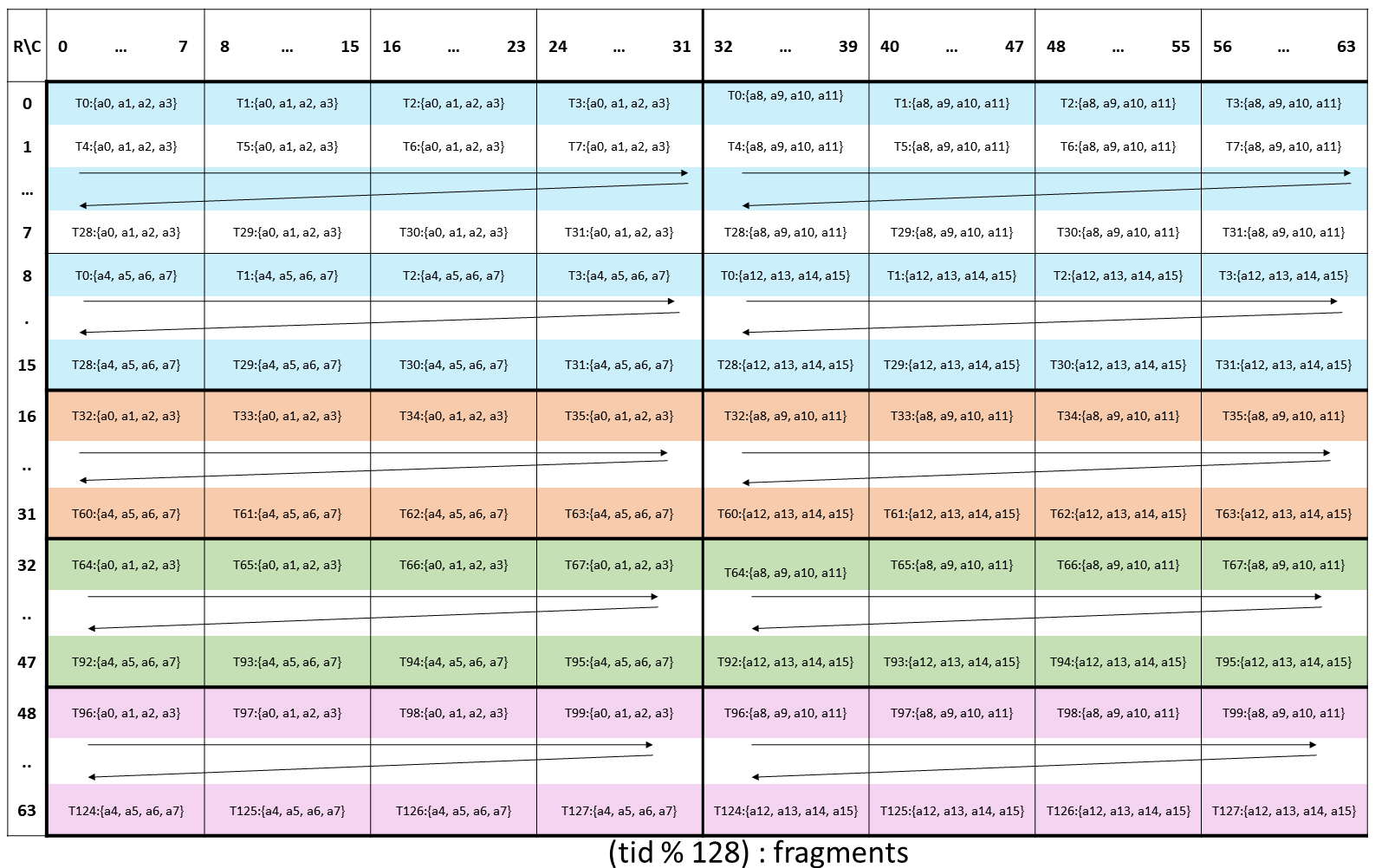
9.7.15.6.3. 异步乘加指令:wgmma.mma_async.sp
wgmma.mma_async.sp
跨 warpgroup 执行使用稀疏矩阵 A 的矩阵乘加运算
语法
半精度浮点类型
wgmma.mma_async.sp.sync.aligned.shape.dtype.f16.f16 d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-a, imm-trans-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.f16.f16 d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-b;
.shape = {.m64n8k32, .m64n16k32, .m64n24k32, .m64n32k32,
.m64n40k32, .m64n48k32, .m64n56k32, .m64n64k32,
.m64n72k32, .m64n80k32, .m64n88k32, .m64n96k32,
.m64n104k32, .m64n112k32, .m64n120k32, .m64n128k32,
.m64n136k32, .m64n144k32, .m64n152k32, .m64n160k32,
.m64n168k32, .m648176k32, .m64n184k32, .m64n192k32,
.m64n200k32, .m64n208k32, .m64n216k32, .m64n224k32,
.m64n232k32, .m64n240k32, .m64n248k32, .m64n256k32};
.dtype = {.f16, .f32};
备选浮点类型
.bf16 floating point type:
wgmma.mma_async.sp.sync.aligned.shape.dtype.bf16.bf16 d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-a, imm-trans-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.bf16.bf16 d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-b;
.shape = {.m64n8k32, .m64n16k32, .m64n24k32, .m64n32k32,
.m64n40k32, .m64n48k32, .m64n56k32, .m64n64k32,
.m64n72k32, .m64n80k32, .m64n88k32, .m64n96k32,
.m64n104k32, .m64n112k32, .m64n120k32, .m64n128k32,
.m64n136k32, .m64n144k32, .m64n152k32, .m64n160k32,
.m64n168k32, .m648176k32, .m64n184k32, .m64n192k32,
.m64n200k32, .m64n208k32, .m64n216k32, .m64n224k32,
.m64n232k32, .m64n240k32, .m64n248k32, .m64n256k32};
.dtype = {.f32};
.tf32 floating point type:
wgmma.mma_async.sp.sync.aligned.shape.dtype.tf32.tf32 d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.tf32.tf32 d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;
.shape = {.m64n8k16, .m64n16k16, .m64n24k16, .m64n32k16,
.m64n40k16, .m64n48k16, .m64n56k16, .m64n64k16,
.m64n72k16, .m64n80k16, .m64n88k16, .m64n96k16,
.m64n104k16, .m64n112k16, .m64n120k16, .m64n128k16,
.m64n136k16, .m64n144k16, .m64n152k16, .m64n160k16,
.m64n168k16, .m648176k16, .m64n184k16, .m64n192k16,
.m64n200k16, .m64n208k16, .m64n216k16, .m64n224k16,
.m64n232k16, .m64n240k16, .m64n248k16, .m64n256k16};
.dtype = {.f32};
FP8 floating point type
wgmma.mma_async.sp.sync.aligned.shape.dtype.atype.btype d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.atype.btype d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;
.shape = {.m64n8k64, .m64n16k64, .m64n24k64, .m64n32k64,
.m64n40k64, .m64n48k64, .m64n56k64, .m64n64k64,
.m64n72k64, .m64n80k64, .m64n88k64, .m64n96k64,
.m64n104k64, .m64n112k64, .m64n120k64, .m64n128k64,
.m64n136k64, .m64n144k64, .m64n152k64, .m64n160k64,
.m64n168k64, .m648176k64, .m64n184k64, .m64n192k64,
.m64n200k64, .m64n208k64, .m64n216k64, .m64n224k64,
.m64n232k64, .m64n240k64, .m64n248k64, .m64n256k64};
.atype = {.e4m3, .e5m2};
.btype = {.e4m3, .e5m2};
.dtype = {.f16, .f32};
整数类型
wgmma.mma_async.sp.sync.aligned.shape{.satfinite}.s32.atype.btype d, a-desc, b-desc, sp-meta, sp-sel, scale-d;
wgmma.mma_async.sp.sync.aligned.shape{.satfinite}.s32.atype.btype d, a, b-desc, sp-meta, sp-sel, scale-d;
.shape = {.m64n8k64, .m64n16k64, .m64n24k64, .m64n32k64,
.m64n48k64, .m64n64k64, .m64n80k64, .m64n96k64,
.m64n112k64, .m64n128k64, .m64n144k64, .m64n160k64,
.m648176k64, .m64n192k64, .m64n208k64, .m64n224k64,
.m64n240k64, .m64n256k64};
.atype = {.s8, .u8};
.btype = {.s8, .u8};
描述
指令 wgmma.mma_async 发出 MxNxK 矩阵乘法和累加运算,D = A*B+D,其中 A 矩阵为 MxK,B 矩阵为 KxN,D 矩阵为 MxN。
矩阵 A 以打包格式 Mx(K/2) 存储,如 使用稀疏矩阵 A 的 wgmma.mma_async.sp 指令的矩阵乘加运算 中所述。
当输入谓词参数 scale-d 为 false 时,发出 D = A*B 形式的操作。
必须使用 wgmma.fence 指令来隔离 wgmma.mma_async 指令的寄存器访问与其先前的访问。否则,行为是未定义的。
必须使用 wgmma.commit_group 和 wgmma.wait_group 操作来等待异步矩阵乘法和累加操作完成,然后才能访问结果。
寄存器操作数 d 表示累加器矩阵以及目标矩阵,分布在参与线程中。寄存器操作数 a 表示乘数矩阵 A,在参与线程中分布在寄存器中。64 位寄存器操作数 a-desc 和 b-desc 是矩阵描述符,分别表示共享内存中的乘数矩阵 A 和 B。矩阵描述符的内容在 warpgroup 中的所有 warp 中必须相同。矩阵描述符的格式在 矩阵描述符格式 中描述。矩阵 A 是结构化稀疏的,如 稀疏矩阵存储 中所述。操作数 sp-meta 和 sp-sel 分别表示稀疏元数据和稀疏选择器。sp-meta 操作数是 32 位整数,sp-sel 操作数是 32 位整数常量,其值范围为 0..3。
每个形状的 sp-meta 和 sp-sel 的有效值在 使用稀疏矩阵 A 的 wgmma.mma_async.sp 指令的矩阵乘加运算 中指定,并在此处总结
矩阵形状 |
|
|
|
|---|---|---|---|
|
|
0b1110 , 0b0100 |
0(线程 T0、T1)或 1(线程 T2、T3) |
|
|
0b00, 0b01, 0b10, 0b11 |
0(线程 T0、T1)或 1(线程 T2、T3) |
|
|
0b00, 0b01, 0b10, 0b11 |
0(所有线程贡献) |
矩阵 A 和 B 分别以行优先和列优先格式存储。对于某些浮点变体,可以通过为立即整数参数 imm-trans-a 和 imm-trans-b 分别指定值 1 来转置输入矩阵 A 和 B。可以使用值 0 来避免转置操作。imm-trans-a 和 imm-trans-b 的有效值为 0 和 1。转置操作仅支持 wgmma.mma_async 变体,其类型为 .f16/ .bf16,且矩阵从共享内存中使用矩阵描述符访问。
对于 wgmma.mma_async 操作的浮点变体,可以通过为操作数 imm-scale-a 和 imm-scale-b 分别指定值 -1 来对输入矩阵 A 和 B 的每个元素取反。可以使用值 1 来避免取反操作。imm-scale-a 和 imm-scale-b 的有效值为 -1 和 1。
限定符 .dtype、.atype 和 .btype 分别指示矩阵 D、A 和 B 中元素的数据类型。对于所有浮点 wgmma.mma_async 变体,除了 FP8 浮点变体之外,.atype 和 .btype 必须相同。wgmma.mma_async 操作的备选浮点变体中矩阵 A 和 B 的各个数据元素的大小如下
当
.atype/.btype为.e4m3/.e5m2时,矩阵 A 和 B 具有 8 位数据元素。当
.atype/.btype为.bf16时,矩阵 A 和 B 具有 16 位数据元素。当
.atype/.btype为.tf32时,矩阵 A 和 B 具有 32 位数据元素。
精度和舍入
-
浮点运算
矩阵 A 和 B 的逐元素乘法以至少单精度执行。当
.dtype为.f32时,中间值的累加以至少单精度执行。当.dtype为.f16时,累加以至少半精度执行。累加顺序、舍入和次正规输入的处理方式未指定。
-
.bf16和.tf32浮点运算矩阵 A 和 B 的逐元素乘法以指定的精度执行。涉及
.tf32类型的wgmma.mma_async操作将在发出乘法之前截断 32 位输入数据的低 13 位。中间值的累加以至少单精度执行。累加顺序、舍入和次正规输入的处理方式未指定。
-
整数运算
整数
wgmma.mma_async操作使用.s32累加器执行。.satfinite限定符指示,当溢出时,累加值被限制在 MIN_INT32..MAX_INT32 范围内(其中边界定义为最小负有符号 32 位整数和最大正有符号 32 位整数)。如果未指定
.satfinite,则累加值将改为回绕。
强制性的 .sync 限定符指示 wgmma.mma_async 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 wgmma.mma_async 指令,然后才恢复执行。
强制性的 .aligned 限定符指示 warpgroup 中的所有线程必须执行相同的 wgmma.mma_async 指令。在条件执行的代码中,只有当已知 warpgroup 中的所有线程对条件的评估结果相同时,才应使用 wgmma.mma_async 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 8.2 中引入。
PTX ISA 版本 8.4 中引入了对 .u8.s8 和 .s8.u8 作为 .atype.btype 的支持。
目标 ISA 注释
需要 sm_90a。
整数类型示例
wgmma.fence.sync.aligned;
wgmma.mma_async.sp.sync.aligned.m64n8k64.s32.u8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, spMeta, 0, scaleD;
wgmma.mma_async.sp.sync.aligned.m64n8k64.s32.s8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, spMeta, 0, scaleD;
wgmma.commit_group.sync.aligned;
wgmma.wait_group.sync.aligned 0;
9.7.15.7. 异步 wgmma 代理操作
本节介绍 warpgroup 级别 wgmma.fence、wgmma.commit_group 和 wgmma.wait_group 指令。
9.7.15.7.1. 异步乘加指令:wgmma.fence
wgmma.fence
强制 wgmma.mma_async 和其他操作之间的寄存器访问顺序。
语法
wgmma.fence.sync.aligned;
描述
wgmma.fence 指令在任何 warpgroup 寄存器的先前访问和 wgmma.mma_async 指令对相同寄存器的后续访问之间建立顺序。只有累加器寄存器和包含矩阵 A 片段的输入寄存器才需要此顺序。
wgmma.fence 指令必须由 warpgroup 的所有 warp 在以下位置发出
在 warpgroup 中的第一个
wgmma.mma_async操作之前。在 warpgroup 中的线程的寄存器访问与任何访问相同寄存器的
wgmma.mma_async指令之间,无论是作为累加器还是包含矩阵 A 片段的输入寄存器,除非这些是跨多个相同形状的wgmma.mma_async指令的累加器寄存器访问。在后一种情况下,默认提供排序保证。
否则,行为未定义。
必须使用异步代理 fence 来建立先前写入共享内存矩阵和后续在 wgmma.mma_async 指令中读取相同矩阵之间的顺序。
强制性的 .sync 限定符指示 wgmma.fence 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 wgmma.fence 指令,然后才恢复执行。
强制性的 .aligned 限定符指示 warpgroup 中的所有线程必须执行相同的 wgmma.fence 指令。在条件执行的代码中,只有当已知 warpgroup 中的所有线程对条件的评估结果相同时,才应使用 wgmma.fence 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90a。
示例
// Example 1, first use example:
wgmma.fence.sync.aligned; // Establishes an ordering w.r.t. prior accesses to the registers s32d<0-3>
wgmma.mma_async.sync.aligned.m64n8k32.s32.u8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, scaleD;
wgmma.commit_group.sync.aligned;
wgmma.wait_group.sync.aligned 0;
// Example 2, use-case with the input value updated in between:
wgmma.fence.sync.aligned;
wgmma.mma_async.sync.aligned.m64n8k32.s32.u8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, scaleD;
...
mov.b32 s32d0, new_val;
wgmma.fence.sync.aligned;
wgmma.mma_async.sync.aligned.m64n8k32.s32.u8.u8 {s32d4, s32d5, s32d6, s32d7},
{s32d0, s32d1, s32d2, s32d3},
descB, scaleD;
wgmma.commit_group.sync.aligned;
wgmma.wait_group.sync.aligned 0;
9.7.15.7.2. 异步乘加指令:wgmma.commit_group
wgmma.commit_group
将所有先前的未提交的 wgmma.mma_async 操作提交到 wgmma-group 中。
语法
wgmma.commit_group.sync.aligned;
描述
wgmma.commit_group 指令为每个 warpgroup 创建一个新的 wgmma-group,并将执行 warp 启动但未提交到任何 wgmma-group 的所有先前的 wgmma.mma_async 指令批处理到新的 wgmma-group 中。如果没有未提交的 wgmma.mma_async 指令,则 wgmma.commit_group 会生成一个空的 wgmma-group。
执行线程可以使用 wgmma.wait_group 等待 wgmma-group 中所有 wgmma.mma_async 操作的完成。
强制性的 .sync 限定符指示 wgmma.commit_group 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 wgmma.commit_group 指令,然后才恢复执行。
强制性的 .aligned 限定符指示 warpgroup 中的所有线程必须执行相同的 wgmma.commit_group 指令。在条件执行的代码中,只有当已知 warpgroup 中的所有线程对条件的评估结果相同时,才应使用 wgmma.commit_group 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90a。
示例
wgmma.commit_group.sync.aligned;
9.7.15.7.3. 异步乘加指令:wgmma.wait_group
wgmma.wait_group
发出先前 warpgroup 操作完成的信号。
语法
wgmma.wait_group.sync.aligned N;
描述
wgmma.wait_group 指令将导致执行线程等待,直到只有 N 个或更少的最新 wgmma-group 处于挂起状态,并且执行线程提交的所有先前的 wgmma-group 都已完成。例如,当 N 为 0 时,执行线程等待所有先前的 wgmma-group 完成。操作数 N 是一个整数常量。
访问 wgmma.mma_async 指令的累加器寄存器或包含矩阵 A 片段的输入寄存器,而没有首先执行等待包含该 wgmma.mma_async 指令的 wgmma-group 的 wgmma.wait_group 指令是未定义的行为。
强制性的 .sync 限定符指示 wgmma.wait_group 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 wgmma.wait_group 指令,然后才恢复执行。
强制性的 .aligned 限定符指示 warpgroup 中的所有线程必须执行相同的 wgmma.wait_group 指令。在条件执行的代码中,只有当已知 warpgroup 中的所有线程对条件的评估结果相同时,才应使用 wgmma.wait_group 指令,否则行为是未定义的。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_90a。
示例
wgmma.fence.sync.aligned;
wgmma.mma_async.sync.aligned.m64n8k32.s32.u8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, scaleD;
wgmma.commit_group.sync.aligned;
wgmma.mma_async.sync.aligned.m64n8k16.f32.f16.f16 {f32d0, f32d1, f32d2, f32d3},
{f16a0, f16a1, f16a2, f16a3},
descB, 1, -1, -1, 1;
wgmma.commit_group.sync.aligned;
wgmma.wait_group.sync.aligned 0;
9.7.16. TensorCore 第五代系列指令
9.7.16.1. 张量内存
第五代 TensorCore 拥有专用的片上内存,专门供 TensorCore 操作使用。此张量内存被组织成一个二维矩阵,其中水平行称为通道 (lanes),垂直列称为列 (columns)。
在 sm_100a 架构上,第五代 TensorCore 的张量内存具有二维结构,每个 CTA 有 512 列和 128 行,每个单元格大小为 32 位。
通过加载和存储操作访问张量内存的线程的限制在加载/存储访问限制中指定。
9.7.16.1.1. 张量内存寻址
张量内存地址为 32 位宽,并指定两个组成部分。
通道索引
列索引
布局如下
31 16
15 0
通道索引
列索引
图 181 显示了 CTA 内张量内存布局的视图。
图 181 张量内存布局和寻址
9.7.16.1.2. 张量内存分配
张量内存是动态分配的。张量内存必须由 CTA 中的单个 warp 使用 张量内存分配管理指令 进行分配。
张量内存的分配和释放以列为单位执行。分配单位为 32 列,并且要分配的列数必须是 2 的幂。当分配一列时,该列的所有 128 个通道都会被分配。
9.7.16.2. 矩阵和数据移动形状
涉及两种形状。
数据移动操作中的形状
MMA 操作中的形状
9.7.16.2.1. 矩阵形状
矩阵乘法和累加运算支持操作数矩阵 A、B 和 D 的一组有限的形状。所有三个矩阵操作数的形状都由元组 *MxNxK* 共同描述,其中 A 是 *MxK* 矩阵,B 是 *KxN* 矩阵,而 D 是 *MxN* 矩阵。
表 38 显示了 tcgen05.mma 操作的指定类型支持的矩阵形状。
各种组合 |
支持的形状 |
|||||||
|---|---|---|---|---|---|---|---|---|
.kind::* |
具有 .ws |
CTA 组 |
稀疏性 |
dtype |
atype/btype |
|||
|
无 |
1 |
密集 |
|
|
64xN1xK 128xN2xK |
N1 = {8, 16, 24, … 256},步长为 8 N2 = {16, 32, … 256},步长为 16 |
K = 16 |
|
|
|||||||
稀疏 |
|
|
K = 32 |
|||||
|
|
|||||||
2 |
密集 |
|
|
128xNxK 256xNxK |
N = {32, 64, … 256},步长为 32 |
K = 16 |
||
|
|
|||||||
稀疏 |
|
|
K = 32 |
|||||
|
|
|||||||
|
1 |
密集 |
|
|
32xNxK 64xNxK 128xNxK |
N = {64, 128, 256} |
K = 16 |
|
|
|
|||||||
稀疏 |
|
|
N = {64, 128} |
K = 32 |
||||
|
|
|||||||
2 |
两者都可 |
|
|
无效 |
||||
|
|
|||||||
|
无 |
1 |
密集 |
|
|
64xN1xK 128xN2xK |
N1 = {8, 16, 24, … 256},步长为 8 N2 = {16, 32, … 256},步长为 16 |
K = 8 |
稀疏 |
K = 16 |
|||||||
2 |
密集 |
128xNxK 256xNxK |
N = {32, 64, … 256},步长为 32 |
K = 8 |
||||
稀疏 |
K = 16 |
|||||||
|
1 |
密集 |
32xNxK 64xNxK 128xNxK |
N= {64, 128, 256} |
K = 8 |
|||
稀疏 |
N= {64, 128} |
K = 16 |
||||||
2 |
密集 |
无效 |
||||||
稀疏 |
||||||||
|
无 |
1 |
密集 |
|
|
64xN1xK 128xN2xK |
N1 = {8, 16, … 256},步长为 8 N2 = {16, 32, … 256},步长为 16 |
K = 32 |
稀疏 |
K = 64 |
|||||||
2 |
密集 |
128xNxK 256xNxK |
N = {32, 64, … 256},步长为 32 |
K = 32 |
||||
稀疏 |
K = 64 |
|||||||
|
1 |
密集 |
32xNxK 64xNxK 128xNxK |
N= {64, 128, 256} |
K = 32 |
|||
稀疏 |
N= {64, 128} |
K = 64 |
||||||
2 |
密集 |
无效 |
||||||
稀疏 |
||||||||
|
无 |
1 |
密集 |
|
X (缩放)
|
128xNxK |
N = {8, 16, … 256},步长为 8 |
K = 32 |
稀疏 |
K = 64 |
|||||||
2 |
密集 |
128xNxK 256xNxK |
N = {16, 32, … 256},步长为 16 |
K = 32 |
||||
稀疏 |
256xNxK |
K = 64 |
||||||
|
1 |
密集 |
无效 |
|||||
稀疏 |
||||||||
2 |
密集 |
|||||||
稀疏 |
||||||||
|
无 |
1 |
密集 |
|
|
64xNxK 128xNxK |
N = {8, 16, 24, 32, 48, … 256} N > 32 后,步长为 16 |
K = 32 |
稀疏 |
K = 64 |
|||||||
2 |
密集 |
128xNxK 256xNxK |
N = {32, 64, … 256},步长为 32 |
K = 32 |
||||
稀疏 |
K = 64 |
|||||||
|
1 |
密集 |
32xNxK 64xNxK 128xNxK |
N= {64, 128, 256} |
K = 32 |
|||
稀疏 |
N= {64, 128} |
K = 64 |
||||||
2 |
密集 |
无效 |
||||||
稀疏 |
||||||||
|
无 |
1 |
密集 |
|
X (缩放)
|
128xNxK |
N = {8, 16, … 256},步长为 8 |
K = 64 |
稀疏 |
K = 128 |
|||||||
2 |
密集 |
128xNxK 256xNxK |
N = {16, 32, … 256},步长为 16 |
K = 64 |
||||
稀疏 |
256xNxK |
K = 128 |
||||||
|
1 / 2 |
两者都可 |
无效 |
|||||
|
无 |
1 |
密集 |
|
X (缩放)
|
128xNxK |
N = {8, 16, … 256},步长为 8 |
K = 64 |
稀疏 |
K = 128 |
|||||||
2 |
密集 |
128xNxK 256xNxK |
N = {16, 32, … 256},步长为 16 |
K = 64 |
||||
稀疏 |
256xNxK |
K = 128 |
||||||
|
1 / 2 |
两者都可 |
无效 |
|||||
9.7.16.2.2. 指定矩阵形状
*M* 和 *N* 可以在指令描述符中指定。
*K* 无法显式指定,但由 MMA-kind 和稀疏性隐式确定,如表 38所示。
9.7.16.2.3. 数据移动形状
数据移动形状指示要移动到张量内存或从张量内存移动的数据的维度。这些形状被描述为元组 lane x size,其中
以下形状受各种 tcgen05 操作支持
形状 |
tcgen05.<op> |
|---|---|
|
|
|
|
|
|
9.7.16.2.3.1. 内存布局
下面显示了 warp 的线程之间矩阵片段的布局。
tcgen05{.ld,.st}.32x32b 指令具有以下数据向量寄存器。
片段 |
元素(从低到高) |
|---|---|
包含 |
r0, r1, … |
执行 tcgen05{.ld,.st}.32x32b 的 warp 将访问张量内存的 32 个通道。它从每个通道加载或存储(32 * .num)位的数据,如图 182所示。
图 182 形状为 .32x32b 的矩阵片段
tcgen05{.ld,.st}.16x64b 指令具有以下数据向量寄存器。
片段 |
元素(从低到高) |
|---|---|
包含 |
r0, r1, … |
执行 tcgen05{.ld,.st}.16x64b 的 warp 将访问张量内存的 16 个通道。它从每个通道加载或存储(64 * .num)位的数据,如图 183所示。
图 183 形状为 .16x64b 的矩阵片段
tcgen05{.ld,.st}.16x128b 指令具有以下数据向量寄存器。
片段 |
元素(从低到高) |
|---|---|
包含 |
r0, r1, … |
执行 tcgen05{.ld,.st}.16x128b 的 warp 将访问张量内存的 16 个通道。它从每个通道加载或存储(128 * .num)位的数据,如图 184所示。
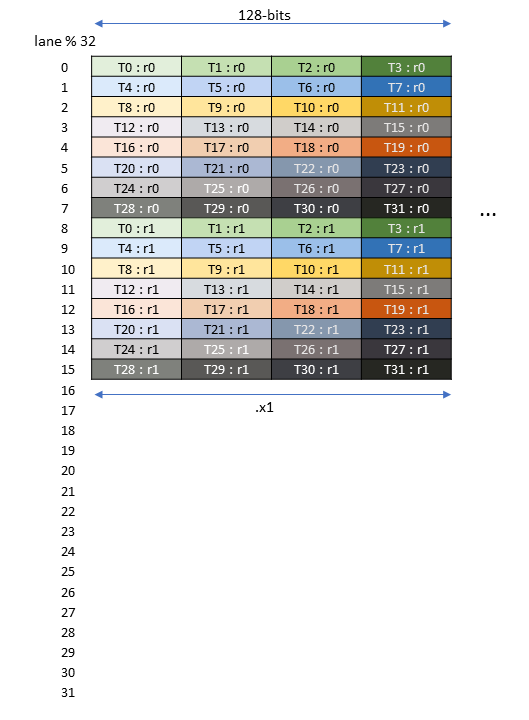
图 184 形状为 .16x128b 的矩阵片段
tcgen05{.ld,.st}.16x256b 指令具有以下数据向量寄存器。
片段 |
元素(从低到高) |
|---|---|
包含 |
r0, r1, r2, r3, … |
执行 tcgen05{.ld,.st}.16x256b 的 warp 将访问张量内存的 16 个通道。它从每个通道加载或存储(256 * .num)位的数据,如图 185所示。
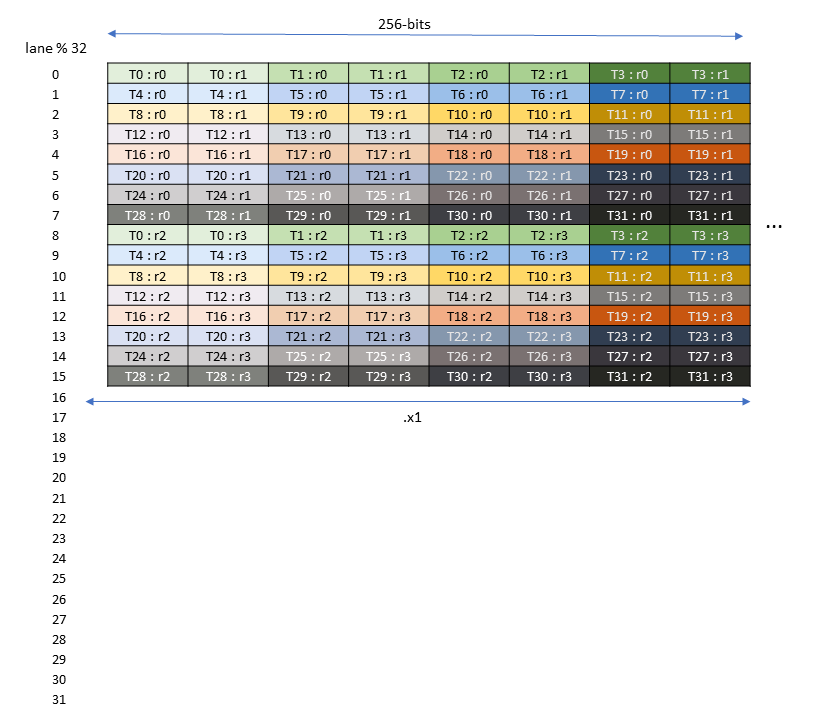
图 185 形状为 .16x256b 的矩阵片段
tcgen05{.ld,.st}.16x32bx2 指令具有以下数据向量寄存器。
片段 |
元素(从低到高) |
|---|---|
包含 |
r0, r1, … |
执行 tcgen05{.ld,.st}.16x32bx2 的 warp 将访问张量内存的 16 个通道。它从每个通道加载或存储(32 * .num)位的数据,如图 186所示。

图 186 形状为 .16x32bx2 的矩阵片段
9.7.16.3. 矩阵描述符
tcgen05 指令系列使用三种矩阵描述符。
9.7.16.3.2. 指令描述符
指令描述符描述了所有矩阵以及矩阵乘法和累加运算的形状、类型和其他详细信息。它是一个 32 位值,位于寄存器中,确切的布局取决于 MMA-Kind
位 |
大小 (位) |
描述 |
值 |
|||
|---|---|---|---|---|---|---|
.kind::tf32 |
.kind::f16 |
.kind::f8f6f4 |
.kind::i8 |
|||
0-1 |
2 |
稀疏选择器,如果启用稀疏性 |
0-3 |
|||
2 |
1 |
稀疏性 |
稠密 = 0 稀疏 = 1 |
|||
3 |
1 |
整数类型的饱和 |
0 (NA) |
无饱和 = 0 饱和 = 1 |
||
4-5 |
2 |
dtype (矩阵 D 类型) |
F32 = 1 |
F16 = 0 F32 = 1 |
S32 = 2 |
|
6 |
1 |
保留 |
0 |
|||
7-9 |
3 |
atype (矩阵 A 类型) |
TF32 = 2 |
F16 = 0 BF16 = 1 |
E4M3 = 0 E5M2 = 1 E2M3 = 3 E3M2 = 4 E2M1 = 5 |
无符号 8b = 0 有符号 8b = 1 |
10-12 |
3 |
btype (矩阵 B 类型) |
||||
13 |
1 |
矩阵 A 取反 |
不取反 = 0 取反 = 1 |
不取反 = 0 |
||
14 |
1 |
矩阵 B 取反 |
||||
15 |
1 |
矩阵 A 转置 |
不转置 = 0 转置 = 1 |
|||
16 |
1 |
矩阵 B 转置 |
||||
17-22 |
6 |
N,矩阵 B 的维度(不包括 3 个 LSB) |
N >> 3 |
|||
23 |
1 |
保留 |
0 |
|||
24-28 |
5 |
M,矩阵 A 的维度(不包括 4 个 LSB) |
M >> 4 |
|||
29 |
1 |
保留 |
0 |
|||
30-31 |
2 |
在 |
无偏移 = 0 最大偏移 8 = 1 最大偏移 16 = 2 最大偏移 32 = 3 |
|||
位 |
大小 (位) |
描述 |
值 |
|---|---|---|---|
.kind::mxf8f6f4 |
|||
0-1 |
2 |
保留 |
0 |
2 |
1 |
稀疏性 |
稠密 = 0 稀疏 = 1 |
3 |
1 |
保留 |
0 |
4-5 |
2 |
0-3 |
|
6 |
1 |
保留 |
0 |
7-9 |
3 |
atype (矩阵 A 类型) |
E4M3 = 0 E5M2 = 1 E2M3 = 3 E3M2 = 4 E2M1 = 5 |
10-12 |
3 |
btype (矩阵 B 类型) |
|
13 |
1 |
矩阵 A 取反 |
不取反 = 0 取反 = 1 |
14 |
1 |
矩阵 B 取反 |
|
15 |
1 |
矩阵 A 转置 |
不转置 = 0 转置 = 1 |
16 |
1 |
矩阵 B 转置 |
|
17-22 |
6 |
N,矩阵 B 的维度(不包括 3 个 LSB) |
N >> 3 |
23 |
1 |
缩放矩阵类型,用于 scale_A / scale_B |
UE8M0 = 1 |
24-26 |
3 |
保留 |
0 |
27-28 |
5 |
M,矩阵 A 的维度(不包括 7 个 LSB) |
M >> 7 |
29-30 |
2 |
0-3 |
|
31 |
1 |
保留 |
0 |
位 |
大小 (位) |
描述 |
值 |
|
|---|---|---|---|---|
.kind::mxf4 |
.kind::mxf4nvf4 |
|||
0-1 |
2 |
保留 |
0 |
|
2 |
1 |
稀疏性 |
稠密 = 0 稀疏 = 1 |
|
3 |
1 |
保留 |
0 |
|
4-5 |
2 |
0 或 2 |
||
6 |
1 |
保留 |
0 |
|
7-9 |
3 |
atype (矩阵 A 类型) |
E2M1 = 1 |
|
10-11 |
2 |
btype (矩阵 B 类型) |
||
12 |
1 |
保留 |
0 |
|
13 |
1 |
矩阵 A 取反 |
不取反 = 0 取反 = 1 |
|
14 |
1 |
矩阵 B 取反 |
||
15 |
1 |
矩阵 A 转置 |
不转置 = 0 |
|
16 |
1 |
矩阵 B 转置 |
||
17-22 |
6 |
N,矩阵 B 的维度(不包括 3 个 LSB) |
N >> 3 |
|
23 |
1 |
缩放矩阵类型,用于 scale_A / scale_B |
UE8M0 = 1 |
UE4M3 = 0 UE8M0 = 1 |
24-26 |
3 |
保留 |
0 |
|
27-28 |
5 |
M,矩阵 A 的维度(不包括 7 个 LSB) |
M >> 7 |
|
29-30 |
2 |
0 或 2 |
||
31 |
1 |
保留 |
0 |
|
9.7.16.3.3. 零列掩码描述符
零列掩码描述符用于生成一个掩码,该掩码指定矩阵 B 的哪些列对于 MMA 操作将具有零值,而不管共享内存中存在的值如何。生成的掩码的总大小为 N 位。
掩码中的 0 位指定矩阵 B 中相应列的值应用于 MMA 操作。掩码中的 1 位指定必须为 MMA 操作的整个列使用 0。
零列掩码描述符是一个 64 位值,位于具有以下布局的寄存器中
位 |
大小(位) |
字段名称 |
描述 |
|---|---|---|---|
0-7 |
8 |
起始计数 0 (sc0) |
指定必须跳过的 LSB 用于子掩码 mask-i |
8-15 |
8 |
起始计数 1 (sc1) |
|
16-23 |
8 |
起始计数 2 (sc2) |
|
24-31 |
8 |
起始计数 3 (sc3) |
|
32 |
1 |
第一个跨度 0 (fs0) |
指定 子掩码 mask-i 的起始值 |
33 |
1 |
第一个跨度 1 (fs1) |
|
34 |
1 |
第一个跨度 2 (fs2) |
|
35 |
1 |
第一个跨度 3 (fs3) |
|
36-38 |
3 |
保留 |
|
39 |
1 |
非零掩码 |
值 0 表示生成的掩码将全部为 0 值 1 表示必须生成掩码 |
40-47 |
8 |
跳过跨度 |
(使用 B 矩阵的连续列的计数)- 1 |
48-55 |
8 |
使用跨度 |
(使用 0 的连续列的计数)- 1 |
56-61 |
6 |
列偏移 |
按指定量偏移列。因此允许对非 0 起始列进行 MMA。 M=32 时最大偏移量 = 16 否则最大偏移量 = 32 |
零列掩码由一个或多个子掩码组成,具体取决于 M,如下表所示
M |
零列掩码分解 |
子掩码 |
使用的第一个跨度 |
使用的起始列 |
|---|---|---|---|---|
128 |
大小为 N 位的单个子掩码 |
mask0 |
fs0 |
sc0 |
64 |
两个子掩码,每个子掩码的大小为 N/2 位 |
mask0, mask1 |
fs0, fs1 |
sc0, sc1 |
32 |
四个子掩码,每个子掩码的大小为 N/4 位 |
mask0, mask1 mask2, mask3 |
fs0, fs1, fs2, fs3 |
sc0, sc1, sc2, sc3 |
下表显示了子掩码在 N 维度上的覆盖范围
子掩码 |
M |
||
|---|---|---|---|
128 |
64 |
32 |
|
mask0 |
列 [0, N-1] |
列 [0, N/2-1] |
列 [0, N/4-1] |
mask1 |
– |
列 [N/2, N-1] |
列 [N/4, N/2-1] |
mask2 |
– |
– |
列 [N/2, (N/4*3)-1] |
mask3 |
– |
– |
列 [(N/4*3), N-1] |
以下示例显示了零列掩码描述符及其对应的生成的掩码
-
示例 1:M = 128
输入零列掩码描述符
起始计数
第一个跨度
非零掩码
跳过跨度
使用跨度
偏移
{0, 0, 0, 0}
{0, 0, 0, 0}
0
4
3
0
输出零列掩码:0x0。
由于非零掩码字段为 0,因此掩码为 0x0。矩阵
B的所有列将用于 MMA 操作。 -
示例 2:M = 128
输入零列掩码描述符
起始计数
第一个跨度
非零掩码
跳过跨度
使用跨度
偏移
{-, -, -, 0}
{-, -, -, 0}
1
2
3
0
输出 mask0: 0b … 111 0000 111 0000 (大小 = N)
-
示例 3:M = 64
输入零列掩码描述符
起始计数 {.., sc1, sc0}
第一个跨度 {.., fs1, fs0}
非零掩码
跳过跨度
使用跨度
偏移
{-, -, 0, 0}
{-, -, 0, 1}
1
2
3
0
输出 mask0: 0b … 111 0000 111 0000 111
输出 masl1: 0b … 0000 111 0000 111 0000
-
示例 4:M = 32
输入零列掩码描述符
起始计数 {sc3, sc2, sc1, sc0}
第一个跨度 {fs3, fs2, fs1, fs0}
非零掩码
跳过跨度
使用跨度
偏移
{1, 2, 1, 0}
{0, 0, 1, 1}
1
2
3
2
输出 mask0: 0b … 0000 111 0000 111
输出 mask1: 0b … 0000 111 0000 11
输出 mask2: 0b … 111 0000 111 00
输出 mask3: 0b … 111 0000 111 000
如果 N = 128,则由于偏移量为 2,因此将使用列从 2 到 129 的
B矩阵进行 MMA 操作。
9.7.16.4. 发布粒度
每个 tcgen05 操作对需要发布它们线程/warp 的数量有不同的要求。
下表列出了每个 tcgen05 操作的执行粒度要求
tcgen05 操作 |
.cta_group |
发布粒度 |
|---|---|---|
.mma,
.cp,
.shift,
.commit
|
::1 |
从当前 CTA 中的单个线程发布将启动基本操作。 |
::2 |
从 CTA 对中的单个线程发布将启动基本操作。 |
|
.alloc,
.dealloc,
.relinquish_alloc_permit
|
::1 |
从当前 CTA 中的单个 warp 发布将启动分配管理指令。 |
::2 |
从两个 warp 发布,每个 warp 分别位于当前 CTA 及其对等 CTA中,需要共同执行操作。 |
|
.ld,
.st,
.wait::{ld, st}
|
N/A |
当前 CTA 中的 warp 只能访问当前 CTA 的张量内存的 1/4。因此,需要一个 warpgroup 才能访问当前 CTA 的整个张量内存。 |
.fence::*
|
N/A |
线程需要 fence 其所有对张量内存的访问,以便将其与其他线程对张量内存的访问进行排序。 |
9.7.16.4.1. CTA 对
集群中任何 2 个 CTA,其 %cluster_ctarank 仅在最后一位上有所不同,都称为形成 CTA 对。
在 CTA 对中,%cluster_ctarank 的最后一位为
0 的 CTA 在 CTA 对中称为偶数 CTA。
1 的 CTA 在 CTA 对中称为奇数 CTA。
大多数 tcgen05 操作可以在单个 CTA 级别粒度或 CTA 对级别粒度执行。tcgen05 操作在 CTA 对粒度执行时,将访问 CTA 对中两个 CTA 的张量内存。需要发布 tcgen05 操作的线程集在发布粒度中列出。
9.7.16.4.2. 对等 CTA
CTA 对中奇数 CTA 的对等 CTA 是同一对中的偶数 CTA。 同样,CTA 对中偶数 CTA 的对等 CTA 是同一对中的奇数 CTA。
9.7.16.5. 第五代 TensorCore 操作的内存一致性模型
tcgen05 指令的排序根据两个关键概念进行描述
流水线化的 tcgen05 指令
专门的 tcgen05 特定线程间同步机制。
这些概念结合起来形成了四种规范的同步模式,如下所述。
9.7.16.5.1. 异步操作
tcgen05 指令系列分为 2 类
-
异步指令
这些
tcgen05操作相对于同一线程中的其他tcgen05操作没有固有的顺序(除非如下所述进行流水线化)。 -
同步指令
这些
tcgen05操作相对于同一顺序中的其他tcgen05操作具有固有的顺序。访问共享内存的张量内存分配相关指令相对于非
tcgen05指令保持同地址排序。
下表列出了每个 tcgen05 指令的类别
tcgen05.* 操作 |
类别 |
|---|---|
|
同步 指令 |
|
|
|
|
|
|
|
|
|
|
|
异步 指令 |
|
|
|
|
|
|
|
9.7.16.5.2. 流水线化的 tcgen05 指令
异步 tcgen05 操作可能会以与它们发布顺序不同的顺序执行和完成。但是,一些特定的异步 tcgen05 指令对形成 tcgen05 流水线,其中两个异步操作保证以与发布它们的指令相同的顺序执行。具体配对如下:
tcgen05.mma.cta_group::N->tcgen05.mma.cta_group::N(相同的 N 以及累加器和形状)tcgen05.copy.cta_group::N->tcgen05.mma.cta_group::N(相同的 N)tcgen05.shift.cta_group::N->tcgen05.mma.cta_group::N(相同的 N)tcgen05.shift.cta_group::N->tcgen05.cp.4x256b.cta_group::N(相同的 N)tcgen05.mma.cta_group::N->tcgen05.shift.cta_group::N(相同的 N)
9.7.16.5.2.1. 隐式流水线化的 tcgen05 指令
指令 tcgen05.commit 和 tcgen05.wait 分别相对于先前发布的 tcgen05.{mma,cp,shift} 和 tcgen05.{ld,st} 指令隐式地进行流水线化,它们从同一线程跟踪这些指令。
以下指令的异步操作的完成通过基于 mbarrier 的等待机制观察到
tcgen05.mmatcgen05.cptcgen05.shift
tcgen05.commit 用于跟踪上述异步指令的完成。
以下是使用基于 mbarrier 的完成机制的隐式流水线化的 tcgen05 指令配对
tcgen05.mma.cta_group::N->tcgen05.commit.cta_group::N(相同的 N)tcgen05.cp.cta_group::N->tcgen05.commit.cta_group::N(相同的 N)tcgen05.shift.cta_group::N->tcgen05.commit.cta_group::N(相同的 N)
以下指令的异步操作的完成通过基于 tcgen05.wait 的等待机制观察到
tcgen05.ldtcgen05.st
tcgen05.wait::ld 和 tcgen05.wait::st 用于跟踪 tcgen05.ld 和 tcgen05.st 异步指令的完成。
以下是使用基于 tcgen05.wait 的完成机制的隐式流水线化的 tcgen05 指令配对
tcgen05.ld->tcgen05.wait::ldtcgen05.st->tcgen05.wait::st
9.7.16.5.3. tcgen05 指令的专用线程间同步
tcgen05 指令支持专用的线程间同步,这些同步针对 tcgen05 指令系列进行了优化。标准内存一致性模型同步机制也适用于 tcgen05 指令系列。
章节包含 tcgen05 指令的专用线程间同步。
tcgen05.fence::before_thread_synctcgen05.fence::after_thread_syncldstatommbarrierbarriertcgen05tcgen05tcgen05
在 tcgen05.fence::before_thread_synctcgen05tcgen05
在 tcgen05.fence::after_thread_synctcgen05tcgen05
9.7.16.5.4. 规范同步模式
使用上述规则,以下是五种规范同步模式
9.7.16.5.4.1. 流水线指令,同一线程
在这种模式中,不需要显式的排序机制,排序保证由流水线指令配对提供。
例子
tcgen05.mma
tcgen05.mma (same shape and accumulator)
这两条指令将按照程序顺序执行。
9.7.16.5.4.2. 非流水线指令,同一线程
在这种模式中,使用显式等待机制来等待异步 tcgen05
示例 1
tcgen05.st
tcgen05.wait::st
tcgen05.ld
tcgen05.wait::sttcgen05.st
示例 2
tcgen05.mma [d], ...
tcgen05.commit.mbarrier::arrive::one
mbarrier.try_wait.relaxed.cluster (loop until successful)
tcgen05.fence::after_thread_sync
tcgen05.ld [d], ...
对于异步 tcgen05.mmatcgen05.commit
由于 tcgen05.ldtcgen05.fence::after_thread_sync
不需要显式的 tcgen05.fence::before_thread_synctcgen05.committcgen05.mmatcgen05.commit
tcgen05.mma [d], ...
tcgen05.fence::before_thread_sync
mbarrier::arrive
9.7.16.5.4.3. 流水线指令,不同线程
在这种模式中,不需要显式的等待机制,但需要线程之间进行适当的同步。
例子
线程 0 |
线程 1 |
|---|---|
tcgen05.cp
tcgen05.fence::before_thread_sync
mbarrier.arrive.relaxed.cluster
|
|
mbarrier.try_wait.relaxed.cluster // loop til success
tcgen05.fence::after_thread_sync
tcgen05.mma
|
9.7.16.5.4.4. 非流水线指令,不同线程
在这种模式中,发出异步 tcgen05
示例 1
线程 0 |
线程 1 |
|---|---|
tcgen05.ld
tcgen05.wait::ld
tcgen05.fence::before_thread_sync
mbarrier.arrive.relaxed.cluster
|
|
mbarrier.try_wait.relaxed.cluster // loop til success
tcgen05.fence::after_thread_sync
tcgen05.mma
|
示例 1
线程 0 |
线程 1 |
|---|---|
tcgen05.mma
tcgen05.commit.mbarrier::arrive::one [mbar]
|
|
mbarrier.try_wait.relaxed.cluster [mbar] // loop till success
tcgen05.fence::after_thread_sync
tcgen05.ld
|
同步机制也可以相互组合。例如
线程 0 |
线程 1 |
|---|---|
tcgen05.mma
tcgen05.commit.mbarrier::arrive::one [bar1]
mbarrier.try_wait.relaxed.cluster [bar1] // loop
...
tcgen05.fence::after_thread_sync
...// completion is guaranteed
tcgen05.fence::before_thread_sync
mbarrier.arrive.relaxed.cluster [bar2] // loop
...
|
|
mbarrier.try_wait.relaxed.cluster [bar2] // loop
...
tcgen05.fence::after_thread_sync
tcgen05.ld
|
9.7.16.5.4.5. 寄存器依赖性,同一线程
对于 tcgen05.ldtcgen05.ldtcgen05.wait::ld
例子
tcgen05.ld %r1, ...;
tcgen05.mma ..., %r1, ...;
9.7.16.6. 张量内存分配和管理指令
9.7.16.6.1. 第五代 Tensorcore 指令:tcgen05.alloc, tcgen05.dealloc, tcgen05.relinquish_alloc_permit
tcgen05.alloc, tcgen05.dealloc, tcgen05.relinquish_alloc_permit
动态 张量内存 分配管理指令
语法
tcgen05.alloc.cta_group.sync.aligned{.shared::cta}.b32 [dst], nCols;
tcgen05.dealloc.cta_group.sync.aligned.b32 taddr, nCols;
tcgen05.relinquish_alloc_permit.cta_group.sync.aligned;
.cta_group = { .cta_group::1, .cta_group::2 }
描述
tcgen05.alloctcgen05.alloc
指令 tcgen05.dealloctaddrtaddr
无符号 32 位操作数 nColsnColsnCols
指令 tcgen05.relinquish_alloc_permittcgen05.relinquish_alloc_permittcgen05.alloc
如果未指定状态空间,则使用 通用寻址。如果 dst.shared::cta
限定符 .cta_group.cta_group::1.cta_group::2.cta_group::2
强制性 .sync
强制性 .aligned
如果 Warp (线程束) 中的所有线程未使用相同的 nCols
tcgen05.alloc
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
// Example 1:
tcgen05.alloc.cta_group::1.sync.aligned.shared::cta.b32 [sMemAddr1], 32;
ld.shared.b32 taddr, [sMemAddr1];
// use taddr ...
// more allocations and its usages ...
tcgen05.dealloc.cta_group::1.sync.aligned.b32 taddr, 32;
// more deallocations ...
tcgen05.relinquish_alloc_permit.cta_group::1.sync.aligned;
// Example 2:
// Following instructions are performed by current warp and the warp in the peer-CTA:
tcgen05.alloc.cta_group::2.sync.aligned.shared::cta.b32 [sMemAddr2], 32;
ld.shared.b32 taddr, [sMemAddr2];
// use taddr ...
// more allocations and its usages ...
tcgen05.dealloc.cta_group::2.sync.aligned.b32 taddr, 32;
// more deallocations ...
tcgen05.relinquish_alloc_permit.cta_group::2.sync.aligned;
9.7.16.7. 张量内存和寄存器加载/存储指令
CTA 的线程可以对 CTA 的 张量内存 执行加载和存储,并在寄存器和张量内存之间移动数据。数据加载和存储可以以 矩阵和数据移动形状 部分中指定的某些形状执行。
9.7.16.7.1. 访问限制
并非 CTA 的所有线程都可以通过 tcgen05.ldtcgen05.st
CTA 的张量内存被分为 4 个相等的分块,以便 CTA 中 Warpgroup (线程束组) 的每个 Warp (线程束) 都可以访问张量内存的一个分块。张量内存的所有列都可以由 Warpgroup (线程束组) 的所有四个 Warp (线程束) 访问。张量内存的一个通道可以由 Warpgroup (线程束组) 中的单个 Warp (线程束) 访问。下表描述了访问限制。
Warpgroup (线程束组) 内 Warp (线程束) 的 ID |
可访问的通道 |
|---|---|
0 |
0-31 |
1 |
32-63 |
2 |
64-95 |
3 |
96-127 |
9.7.16.7.2. 打包和解包
可选地,可以在加载和存储期间执行以下打包和解包操作
打包:在
tcgen05.ld解包:在
tcgen05.st
如 图 187 所示。
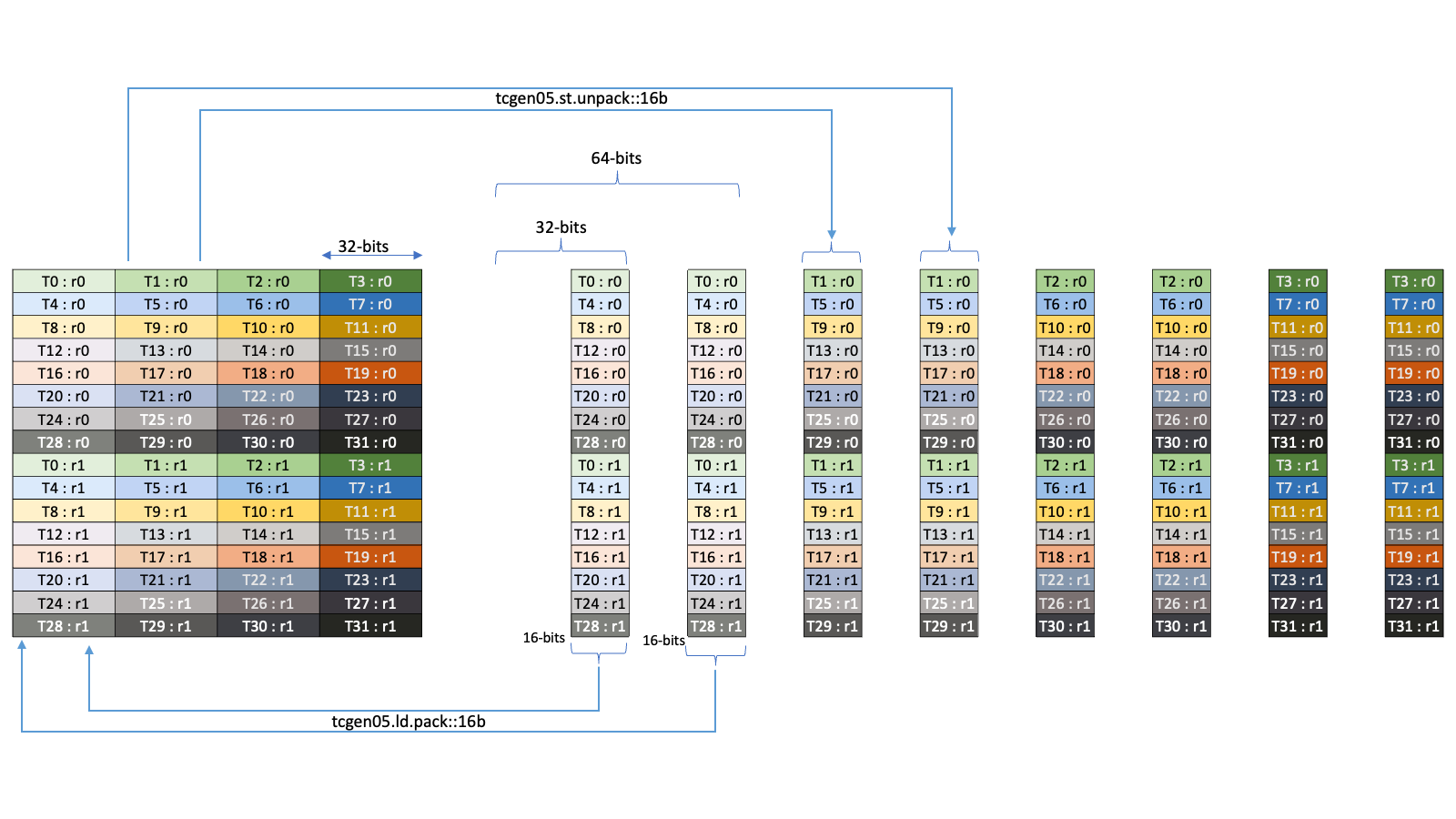
图 187 tcgen05 ld/st 的打包/解包操作
9.7.16.7.3. 第五代 Tensorcore 指令:tcgen05.ld
tcgen05.ld
从张量内存异步集体加载到寄存器。
语法
// Base load instruction:
tcgen05.ld.sync.aligned.shape1.num{.pack}.b32 r, [taddr];
tcgen05.ld.sync.aligned.shape2.num{.pack}.b32 r, [taddr], immHalfSplitoff;
.shape1 = { .16x64b, .16x128b, .16x256b, .32x32b }
.shape2 = { .16x32bx2 }
.num = { .x1, .x2, .x4, .x8, .x16, .x32, .x64, .x128 }
.pack = { .pack::16b }
描述
指令 tcgen05.ldtaddrr
Warp (线程束) 中的所有线程必须指定相同的 taddr
.shape.num.shape.num
形状 .16x32bx2.16x32btaddr+immHalfSplitoffimmHalfSplitoff
目标操作数 r.shape.num.num.shape
.num |
.shape |
||
|---|---|---|---|
.16x32bx2 / .16x64b / .32x32b |
.16x128b |
.16x256b |
|
|
1 |
2 |
4 |
|
2 |
4 |
8 |
|
4 |
8 |
16 |
|
8 |
16 |
32 |
|
16 |
32 |
64 |
|
32 |
64 |
128 |
|
64 |
128 |
NA |
|
128 |
NA |
NA |
可选限定符 .pack::16b
强制性 .synctcgen05.ldtcgen05.ld
强制性 .alignedtcgen05.ldtcgen05.ld
如果所有线程未使用相同的 taddrtcgen05.ld
指令 tcgen05.ld
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
tcgen05.ld.sync.aligned.32x32b.x2.b32 {r0, r1}, [taddr1];
tcgen05.ld.sync.aligned.16x128b.x4.b32 {r0, r1, r2, r3, r4, r5, r6, r7}, [taddr2];
9.7.16.7.4. 第五代 Tensorcore 指令:tcgen05.st
tcgen05.st
从寄存器异步集体存储到张量内存。
语法
tcgen05.st.sync.aligned.shape1.num{.unpack}.b32 [taddr], r;
tcgen05.st.sync.aligned.shape2.num{.unpack}.b32 [taddr], immHalfSplitoff, r;
.shape1 = { .16x64b, .16x128b, .16x256b, .32x32b }
.shape2 = { .16x32bx2 }
.num = { .x1, .x2, .x4, .x8, .x16, .x32, .x64, .x128 }
.unpack = { .unpack::16b }
描述
指令 tcgen05.strtaddr
Warp (线程束) 中的所有线程必须指定相同的 taddr
.shape.num.shape.num
形状 .16x32bx2.16x32btaddrtaddr+immHalfSplitoffimmHalfSplitoff
源操作数 r.shape.num.num.shape
.num |
.shape |
||
|---|---|---|---|
.16x32bx2 / .16x64b / .32x32b |
.16x128b |
.16x256b |
|
|
1 |
2 |
4 |
|
2 |
4 |
8 |
|
4 |
8 |
16 |
|
8 |
16 |
32 |
|
16 |
32 |
64 |
|
32 |
64 |
128 |
|
64 |
128 |
NA |
|
128 |
NA |
NA |
可选限定符 .unpack::16b
强制性 .synctcgen05.sttcgen05.st
强制性 .alignedtcgen05.sttcgen05.st
如果所有线程未使用相同的 taddrtcgen05.st
指令 tcgen05.st
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
tcgen05.st.sync.aligned.16x64b.x4.b32 [taddr0], {r0, r1, r2, r3};
tcgen05.st.sync.aligned.16x128b.x1.unpack::16b.b32 [taddr1], {r0, r1};
9.7.16.7.5. 第五代 Tensorcore 指令:tcgen05.wait
tcgen05.wait
等待所有先前的异步 tcgen05.ldtcgen05.st
语法
tcgen05.wait_operation.sync.aligned;
.wait_operation = { .wait::ld, .wait::st }
描述
指令 tcgen05.wait::sttcgen05.st
指令 tcgen05.wait::ldtcgen05.ld
强制性 .synctcgen05.wait_operationtcgen05.wait_operation
强制性 .alignedtcgen05.wait_operation
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
Example 1:
tcgen05.ld.sync.aligned.32x32b.x2.b32 {r0, r1}, [taddr0];
// Prevents subsequent tcgen05.mma from racing ahead of the tcgen05.ld
tcgen05.wait::ld.sync.aligned;
tcgen05.mma.cta_group::1.kind::f16 [taddr0], a-desc, b-desc, idesc, p;
Example 2:
tcgen05.st.sync.aligned.32x32b.x2.b32 [taddr0], {r0, r1};
// Prevents the write to taddr0 in tcgen05.mma from racing ahead of the tcgen05.st
tcgen05.wait::st.sync.aligned;
tcgen05.mma.cta_group::1.kind::f16 [taddr0], a-desc, b-desc, idesc, p;
9.7.16.8. 张量内存数据移动指令
可以使用 tcgen05.cp 操作将共享内存中的数据异步复制到 张量内存。
9.7.16.8.1. 可选的解压缩
可选地,在复制期间,可以将 4 位和 6 位自定义浮点类型的向量解压缩为 8 位类型。
9.7.16.8.1.1. 将 4 位浮点解压缩为 8 位类型
可以将 16 个连续的 4 位元素集合,后跟 8 字节的填充,转换为 16 个 8 位元素,如 图 188 所示。
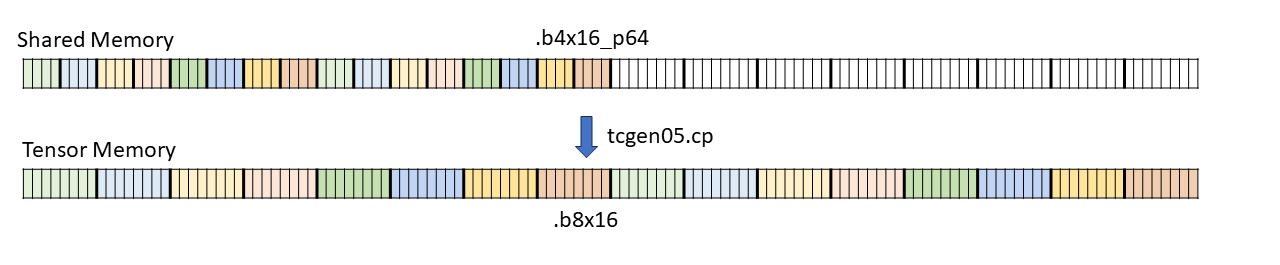
图 188 从 4 位到 8 位的解压缩
单个 4 位到 8 位的解压缩看起来像 图 189 所示。
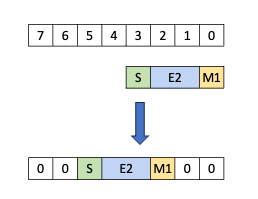
图 189 从 4 位到 8 位的单个解压缩
9.7.16.8.1.2. 将 6 位浮点解压缩为 8 位类型
可以将 16 个连续的 6 位元素集合,后跟 4 字节的填充,解压缩为 16 个 8 位元素,如 图 190 所示。

图 190 从 6 位到 8 位的解压缩
类型 E3M2E2M3
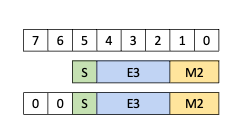
图 191 E3M2 类型的从 6 位到 8 位的单个解压缩
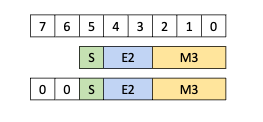
图 192 E2M3 类型的从 6 位到 8 位的单个解压缩
9.7.16.8.2. 第五代 Tensorcore 指令:tcgen05.cp
tcgen05.cp
启动从共享内存到 张量内存 的异步复制操作。
语法
tcgen05.cp.cta_group.shape{.multicast}{.dst_fmt.src_fmt} [taddr], s-desc;
.cta_group = { .cta_group::1, .cta_group::2 }
.src_fmt = { .b6x16_p32 , .b4x16_p64 }
.dst_fmt = { .b8x16 }
.shape = { .128x256b, .4x256b, .128x128b, .64x128b**, .32x128b*** }
.multicast = { .warpx2::02_13** , .warpx2::01_23**, .warpx4*** }
描述
指令 tcgen05.cptaddr
64 位寄存器操作数 s-desc
.shape
限定符 .cta_grouptcgen05.cp.cta_group::1.cta_group::2
当指定限定符 .dst_fmt 和 .src_fmt 时,数据通过复制操作,从共享内存中的源格式 .src_fmt 解压缩到 Tensor Memory 中的目标格式 .dst_fmt。源格式和目标格式的详细信息在 可选解压缩 部分中指定。
一些 .shape 限定符需要特定的 .multicast 限定符。
.64x128b需要.warpx2::02_13或.warpx2::01_23.32x128b需要.warpx4
当 .multicast 限定符被指定为 .warpx2::02_13 或 .warpx2::01_23 时,被复制的数据将被多播到 warp 对中,并且 warp 对中的每个 warp 接收一半数据。Warp 对的形成方式如下
.warpx2::02_13:warp 0 和 2 形成一对;warp 1 和 3 形成一对。.warpx2::01_23:warp 0 和 1 形成一对;warp 2 和 3 形成一对。
当 .multicast 修饰符被指定为 .warpx4 时,被复制的数据将被多播到所有 4 个 warp。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
tcgen05.cp.cta_group::1.128x256b [taddr0], sdesc0;
tcgen05.cp.cta_group::2.128x128b.b8x16.b6x16_p32 [taddr1], sdesc1;
tcgen05.cp.cta_group::1.64x128b.warpx2::02_13 [taddr2], sdesc2;
9.7.16.8.3. Tensorcore 第五代指令:tcgen05.shift
tcgen05.shift
异步向下移动 warp 的 Tensor Memory 中的矩阵行。
语法
tcgen05.shift.cta_group.down [taddr];
.cta_group = { .cta_group::1, .cta_group::2 }
描述
指令 tcgen05.shift 是一个异步指令,它启动跨所有行(最后一行除外)向下移动 32 字节元素一个行的操作。taddr 地址操作数指定了 Tensor Memory 中矩阵的基地址,该矩阵的行必须向下移动。
地址操作数 taddr 的 lane 必须与 32 对齐。
限定符 .cta_group 指定了当单个 CTA 的单个线程执行 tcgen05.shift 指令时,触及的 CTA 数量。.cta_group::1 被指定时,移位操作在当前 CTA 的 Tensor Memory 中执行。.cta_group::2 被指定时,移位操作在当前 CTA 和 对等 CTA 的 Tensor Memory 中执行。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
tcgen05.shift.down.cta_group::1 [taddr0];
tcgen05.shift.down.cta_group::2 [taddr1];
9.7.16.9. TensorCore 第五代矩阵乘法和累加运算
第五代 TensorCore 运算,形状为 MxNxK,执行矩阵乘法和累加,形式如下
D = A*B+D
其中
A矩阵的形状为 MxK,位于 Tensor Memory 或共享内存中B矩阵的形状为 KxN,位于当前 CTA 的共享内存中,并且可以选择性地位于对等 CTA 中D矩阵的形状为 MxN,位于 Tensor Memory 中
可选地,可以使用输入谓词来禁用来自累加器矩阵的输入,并且可以执行以下操作:
D = A*B
矩阵乘法和累加运算根据输入类型和乘法运算的吞吐量分为各种类型。以下显示了支持的不同类型的 MMA 运算
f16:支持f16和bf16输入类型。tf32:支持tf32输入类型。f8f6f4:支持f8、f6和f4类型的所有输入组合。i8:支持有符号和无符号 8 位整数输入类型。mxf8f6f4/mxf4:支持 mx-浮点输入类型。mxf4nvf4:支持mxf4类型和自定义 NVIDIA 浮点类型,用于向量元素类型为 4 位且需要公共缩放因子以形成完整浮点类型的输入,类似于其他 mx 类型。
可选地,第五代 TensorCore MMA 支持稠密和稀疏矩阵 A。稀疏矩阵 描述了稀疏矩阵的详细信息。
一些 MMA 类型需要从内存中缩放输入矩阵,以在执行 MMA 运算之前形成矩阵 A 和矩阵 B。块缩放 描述了矩阵缩放的详细信息。
下表显示了 MMA 运算中涉及的各种矩阵以及它们可以驻留的内存
矩阵类型 |
内存 |
|---|---|
|
Tensor Memory 或共享内存 |
|
共享内存 |
|
Tensor Memory |
|
|
|
一系列 MMA 指令可以重用相同的 A 矩阵和一系列 B 矩阵,或者可以重用相同的 B 矩阵和一系列 A 矩阵。在这些模式中,TensorCore 可能能够加载一次不变的矩阵,并在整个序列中重用它,而无需多次重新加载。A 或 B 矩阵被加载到 TensorCore 收集器缓冲区(即,特殊缓存)中。
MMA 指令有一个可选的 collector 限定符,用于指定何时 A 或 B 矩阵是序列中的新矩阵并应加载,在序列中保持不变并应重用,或者是在序列中的最后一次使用并应丢弃。collector 限定符用于授予 TensorCore 权限以重用先前加载的 A 或 B 矩阵;但是,重用是机会性的,因为即使 TensorCore 有权重用矩阵,它也可能重新加载矩阵。因此,在使用这些矩阵的 MMA 指令完成之前,不得修改 A 或 B 矩阵的源内存 - 无论 collector 限定符权限如何。
第五代 TensorCore MMA 可用于通用矩阵乘法或卷积运算。在卷积的情况下,激活可以存储在矩阵 A 或矩阵 B 中,而权重将存储在另一个矩阵中。
激活矩阵 |
权重矩阵 |
运算名称 |
指令名称 |
收集器缓冲区适用性 |
|---|---|---|---|---|
|
|
激活 Stationary |
(默认 |
收集器缓冲区适用于矩阵 |
|
|
权重 Stationary |
|
收集器缓冲区适用于矩阵 |
9.7.16.9.1. 转置和求反运算
矩阵 A 和 B 可以通过分别在指令描述符中指定“转置 A 矩阵”和“转置 B 矩阵”位来转置。
矩阵 A 和 B 的元素可以通过分别在指令描述符中指定“求反 A 矩阵”和“求反 B 矩阵”位来求反。
各种 MMA 类型的转置和求反运算的支持在 表 48 中显示。
MMA 类型 |
是否支持转置 A/B |
是否支持求反 A/B |
|---|---|---|
|
是 |
是 |
|
是 |
是 |
|
是 |
是 |
|
是 |
是 |
|
是 |
否 |
|
否 |
是 |
|
否 |
是 |
对于 .kind::tf32,矩阵 A 和 B 上的转置运算仅在使用 128B 交换模式和 32B 交换原子性时才受支持。
对于所有其他 MMA 类型,矩阵 A 和 B 上的转置运算在具有 32B 交换原子性的 128B 交换模式下不受支持。
9.7.16.9.2. 矩阵布局组织
表 49 描述了不同矩阵使用的主序。
矩阵 |
驻留在内存中 |
默认主序 |
|---|---|---|
D |
Tensor Memory |
行主序 |
A |
Tensor Memory |
|
共享内存 |
取决于交换模式。请参考 共享内存布局和交换 |
|
B |
共享内存 |
9.7.16.9.3. 类型大小、主序和交换的有效组合
类型大小 |
Major-ness |
矩阵 |
支持的交换 |
|---|---|---|---|
4 位、6 位、8 位、16 位、32 位 |
行 |
A |
所有交换模式 |
列 |
B |
||
|
8 位 16 位 |
列(转置) |
A |
除具有 32B 原子性的 128B 交换外,所有模式 |
行(转置) |
B |
||
32 位 |
列(转置) |
A |
仅具有 32B 原子性的 128B 交换 |
行(转置) |
B |
9.7.16.9.4. Tensor 和共享内存中元素的打包格式
9.7.16.9.4.1. Tensor Memory 中矩阵 D 的打包格式
矩阵 D 的子字元素预计不会在 32 位 Tensor Memory 字中打包。例如,如果矩阵 D 的元素类型为 16 位,则 Tensor Memory 字将在其较低的 16 位中包含单个 16 位元素。
9.7.16.9.4.2. 矩阵 A 和 B 的打包格式
对于 Tensor memory 和共享内存中的不同 MMA 类型,6 位和 4 位浮点类型具有不同的打包格式要求。要求如下。
9.7.16.9.4.3. Tensor Memory 中 .kind::mxf8f6f4 使用的矩阵 A 的打包格式
单个 4 位和 6 位浮点类型元素必须在 Tensor memory 中以 8 位容器打包,如下所示。8 位容器必须连续地打包在 32 位 Tensor Memory 字中。例如,如果矩阵 A 的元素类型为 6 位,则 4 个连续的 A 元素应打包在一个 32 位 Tensor Memory 字中。
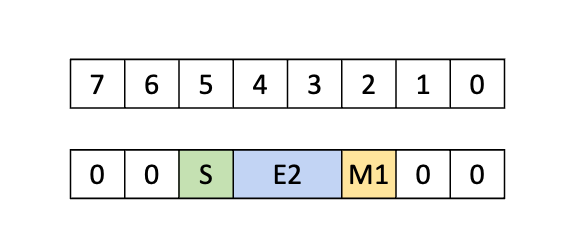
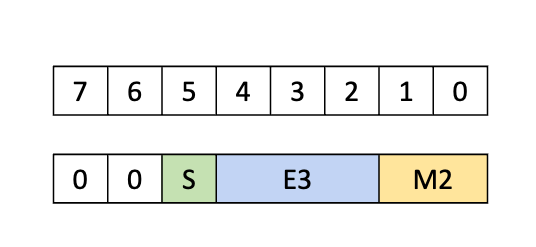
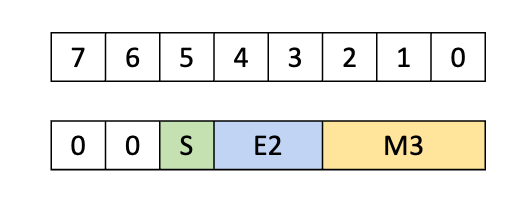
9.7.16.9.4.4. 共享内存中 .kind::mxf8f6f4 使用的矩阵 A 和 B 的打包格式
共享内存中的 4 位和 6 位浮点元素必须与填充一起连续打包,如下所示。
图 197 6 位打包格式
9.7.16.9.4.5. Tensor Memory 中 .kind::mxf4 和 .kind::mxf4nvf4 使用的矩阵 A 的打包格式
两个 4 位浮点类型元素必须在 Tensor memory 中以 8 位容器打包,如 图 198 中针对 mxf4 所示。
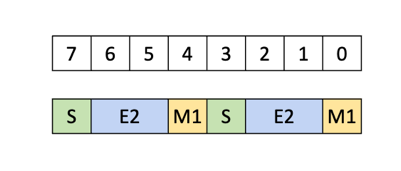
图 198 类型为 E2M1 的 4 位打包格式
9.7.16.9.5. 数据路径布局组织
不同的 MMA 变体以不同的布局组织访问 tensor memory。下表列出了各种布局
M |
cta_group |
A-稀疏性 |
是否为 .ws 模式 |
数据路径组织 |
布局 ID |
Tensor Memory 数据路径 Lane 对齐 |
|---|---|---|---|---|---|---|
32 |
::1 |
两者都可 |
是 |
1x4 |
0 |
|
64 |
::1 |
两者都可 |
是 |
2x3 |
0 |
|
64 |
::1 |
两者都可 |
否 |
4x1(1/2 数据路径被利用) |
0 或 16 |
|
128 |
::1 |
两者都可 |
两者都可 |
4x1 |
0 |
|
128 |
::2 |
密集 |
N/A |
2x2 |
0 |
|
128 |
::2 |
稀疏 |
N/A |
4x1(1/2 数据路径被利用) |
0 或 16 |
|
256 |
::2 |
两者都可 |
N/A |
4x1 |
0 |
仅利用一半数据路径 lane 的布局,即 布局 F 和 布局 C,必须在矩阵 A、D 和稀疏元数据矩阵中使用相同的 Tensor Memory lane 对齐方式。
以下显示了可以通过 tcgen05.ld / tcgen05.st 访问 Tensor Memory 区域的 warp,以及各种 Tensor Memory 布局的地址。
9.7.16.9.5.1. 布局 A (M = 256)
M = 256 的布局组织如 图 199 所示。
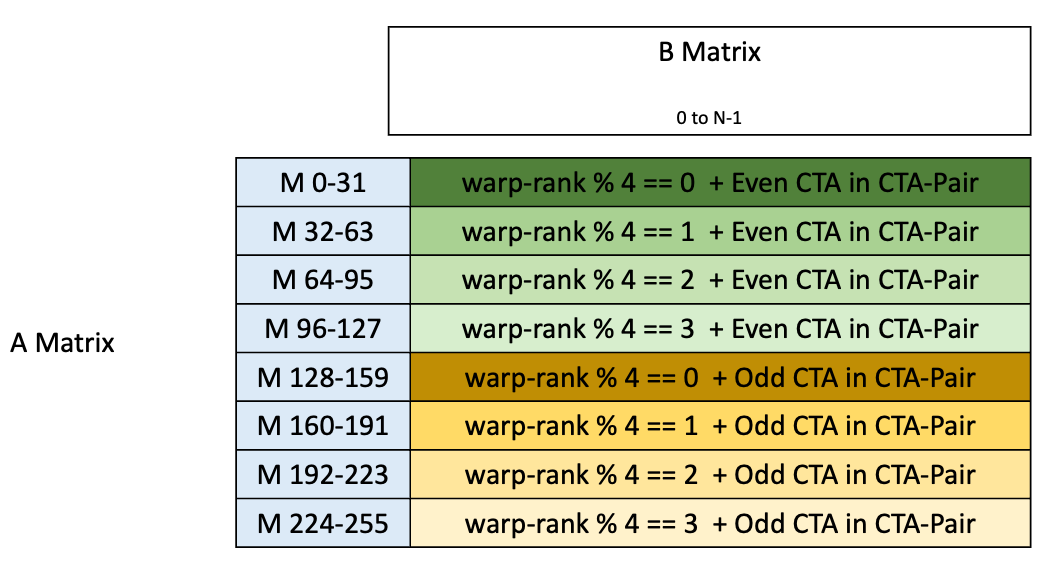
图 199 M = 256 的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 200 所示
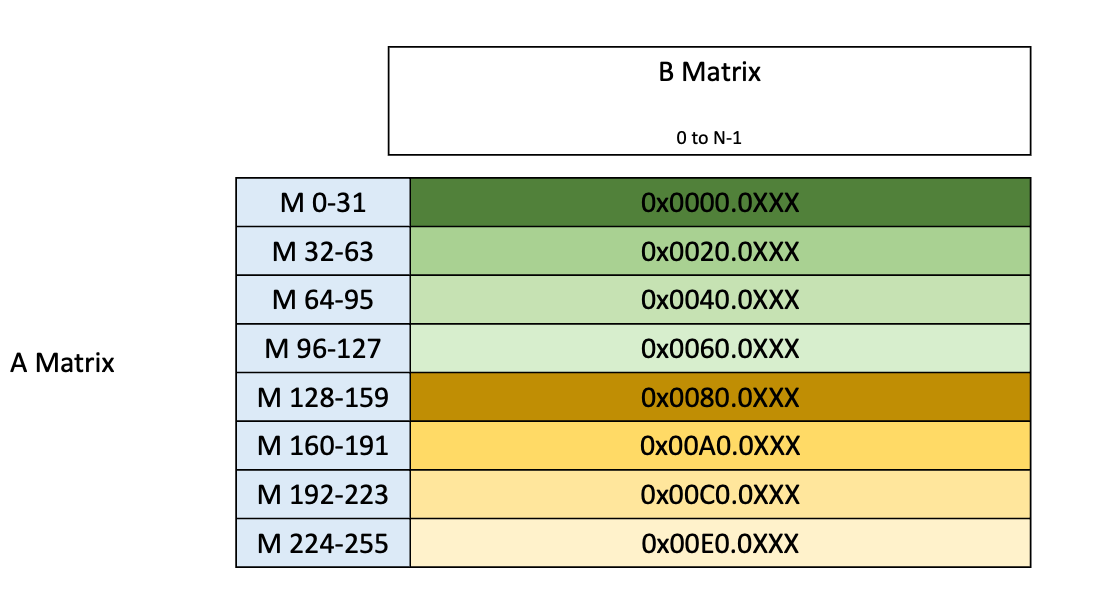
图 200 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.5.2. 布局 B (M = 128 + cta-group::2 + 稠密 A 矩阵)
M = 128 + .cta_group::2 + 稠密 A 矩阵的布局组织如 图 201 所示。
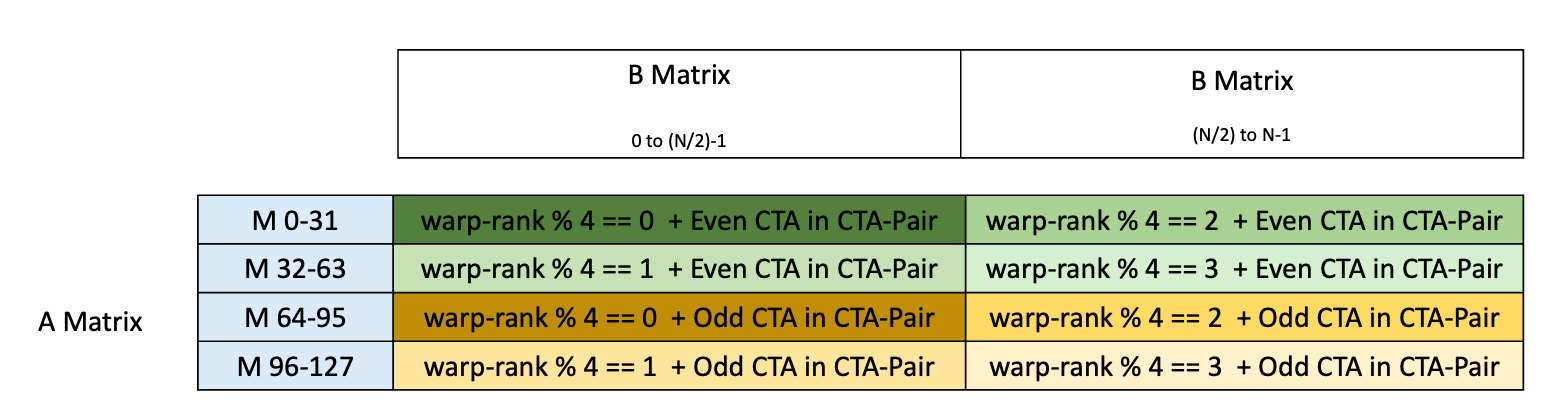
图 201 M = 128 + .cta_group::2 + 稠密 A 矩阵的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 202 所示
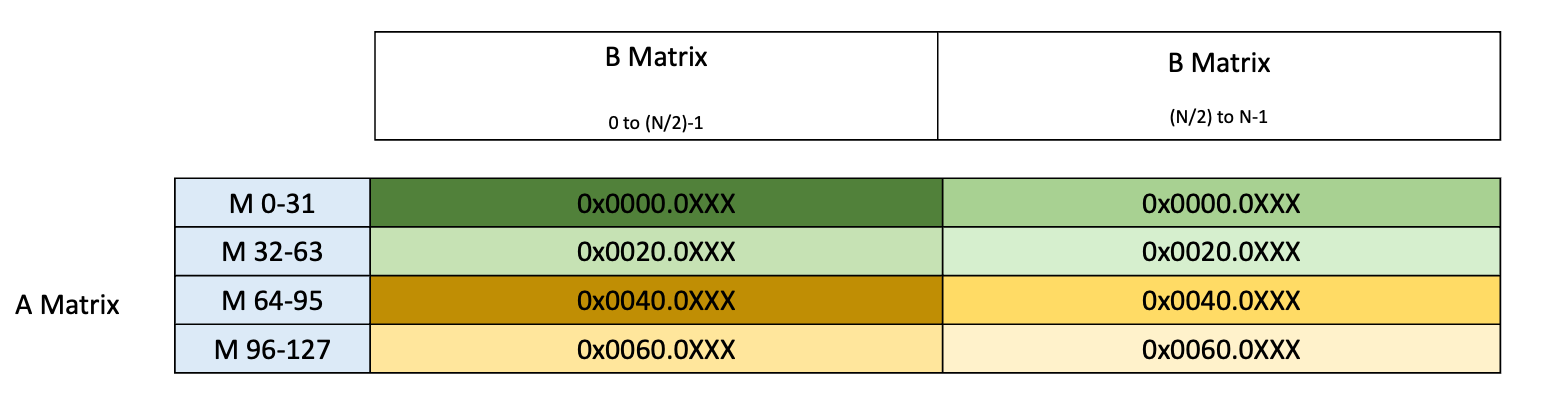
图 202 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.5.3. 布局 C (M = 128 + cta-group::2 + 稀疏 A 矩阵)
M = 128 + .cta_group::2 + 稀疏 A 矩阵的布局组织如 图 203 所示。
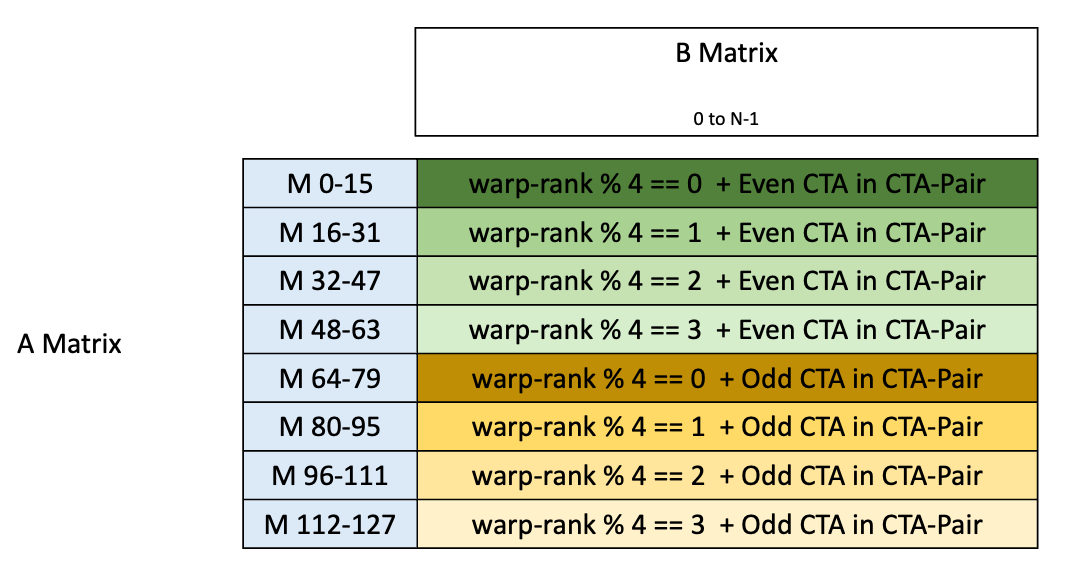
图 203 M = 128 + .cta_group::2 + 稀疏 A 矩阵的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 204 所示
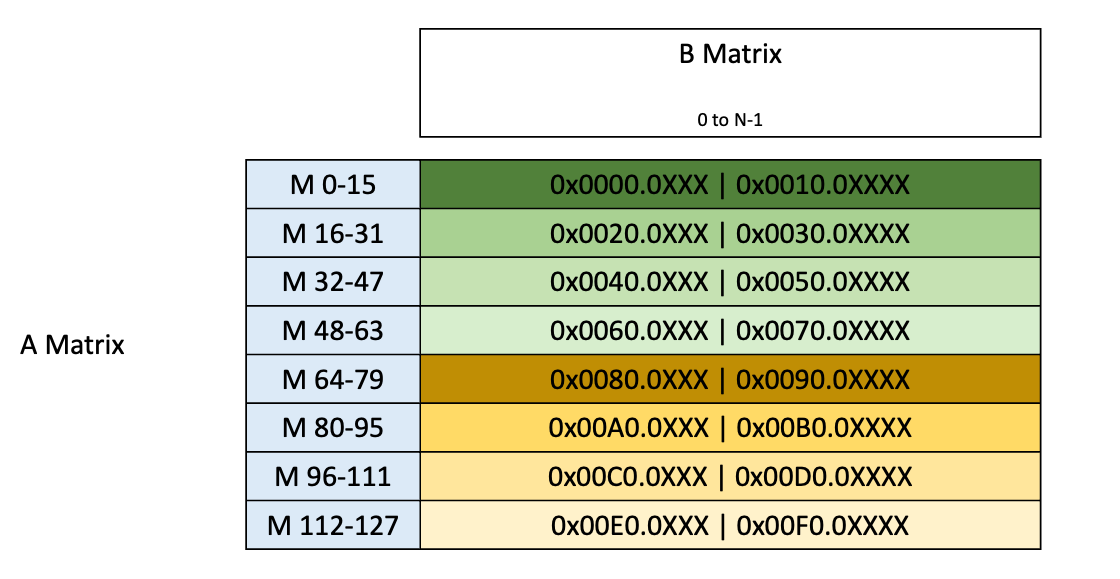
图 204 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.5.4. 布局 D (M = 128 + cta-group::1)
M = 128 + .cta_group::1 的布局组织如 图 205 所示。
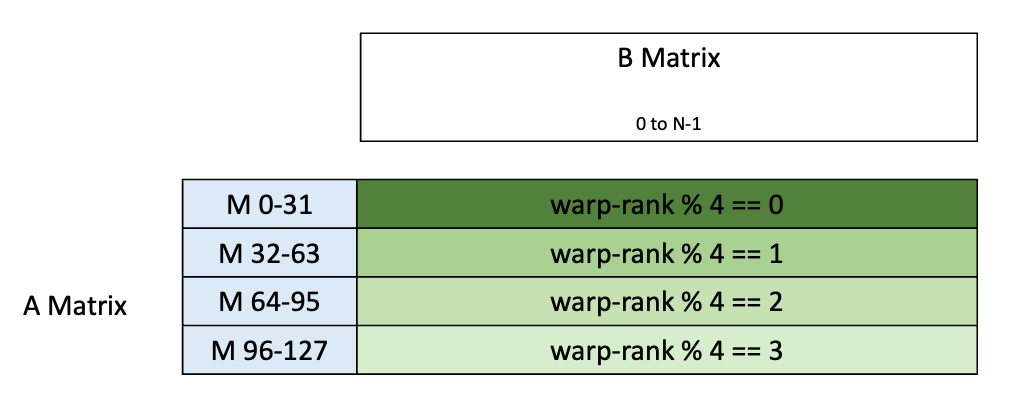
图 205 M = 128 + .cta_group::1 的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 206 所示
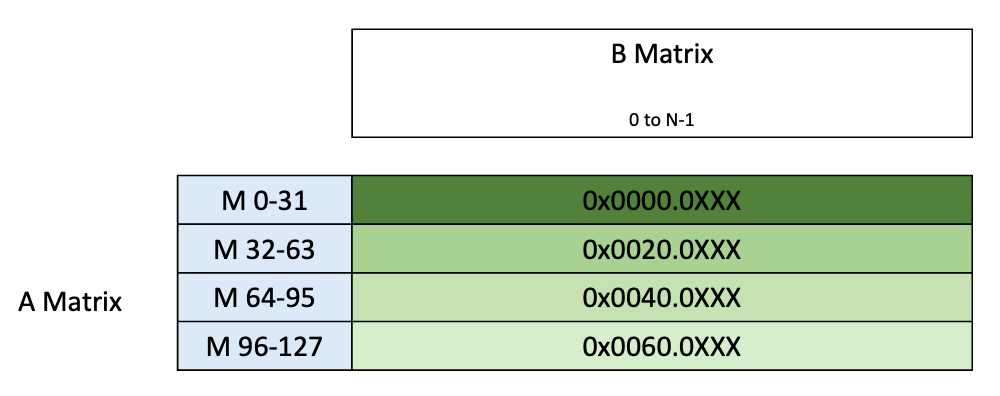
图 206 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.5.5. 布局 E (M = 64 + .ws 模式)
M = 64 + .ws 模式的布局组织如 图 207 所示。

图 207 M = 64 + .ws 模式的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 208 所示

图 208 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.5.6. 布局 F (M = 64 + 非 .ws 模式)
M = 64 + 非 .ws 模式的布局组织如 图 209 所示。
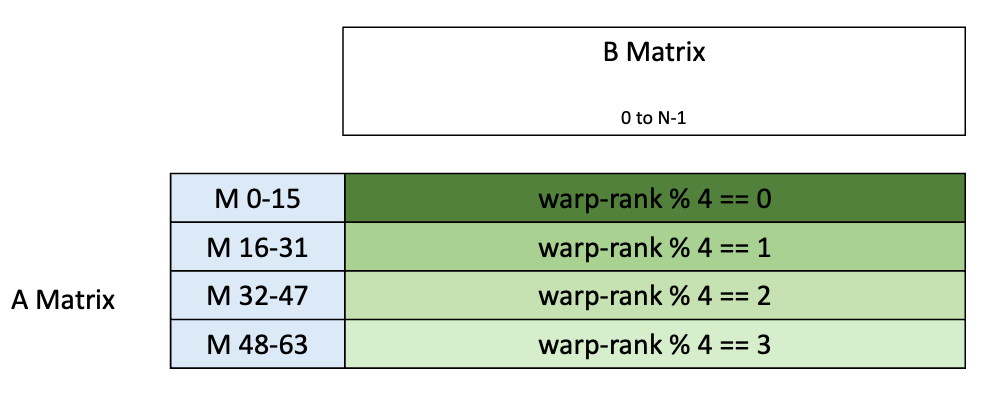
图 209 M = 64 + 非 .ws 模式的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 210 所示
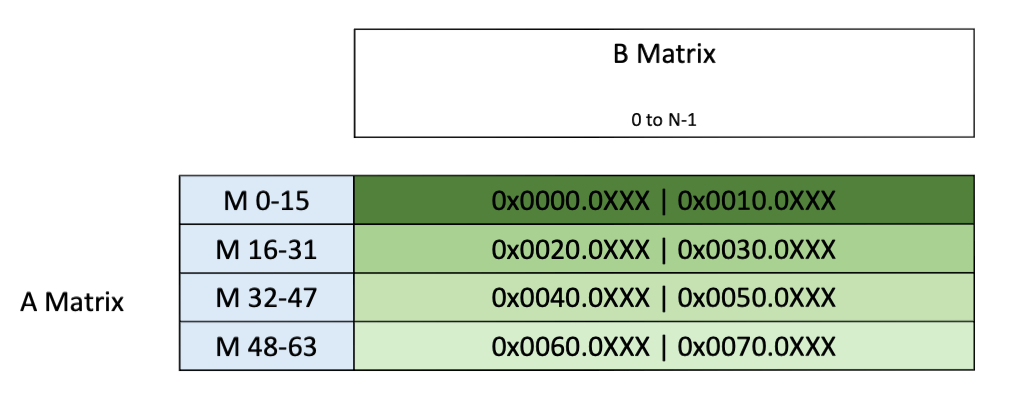
图 210 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.5.7. 布局 G (M = 32)
M = 32 的布局组织如 图 211 所示。

图 211 M = 32 的布局组织
在 tcgen05.ld / tcgen05.st 中使用的上述区域的地址如 图 212 所示

图 212 在 tcgen05.ld / tcgen05.st 中使用的地址
9.7.16.9.6. 共享内存布局和交换
如果在 指令描述符 中的位 Transpose A Matrix / Transpose B Matrix 为 0,则矩阵 A / B 分别使用 K-major。如果在 指令描述符 中的位 Transpose A Matrix 为 1,则矩阵 A 使用 M-major。如果在 指令描述符 中的位 Transpose B Matrix 为 1,则矩阵 B 使用 N-major。
在列优先默认 BLAS 库(如 cuBLAS)中,带或不带转置的矩阵 A 和 B 可以分为 K-Major 或 M-or-N-Major,如下表所示
非转置 |
转置 |
|
|---|---|---|
A |
K-major |
M-major |
B |
K-major |
N-major |
为了避免与 A、B、row-major、col-major、transpose 和 non-transpose 混淆,我们在本节中将使用 MN-Major 和 K-Major。
共享内存中的矩阵由一个或多个“扭曲布局原子”组成。这些扭曲原子的确切布局取决于扭曲模式、扭曲原子性和前导维度。扭曲的布局如表 51所示
扭曲模式和扭曲原子性 |
前导维度 |
Swizzle 原子布局(128b 元素) |
|---|---|---|
128B 扭曲,具有 32B 原子性 |
M/N |
8x4 |
– |
– |
|
128B 扭曲,具有 16B 原子性 |
M/N |
8x8 |
K |
8x8 |
|
64B 混合模式 |
M/N |
4x8 |
K |
8x4 |
|
32B 混合模式 |
M/N |
2x8 |
K |
8x2 |
|
无 |
M/N |
1x8 |
K |
8x1 |
以上形状适用于 128 位大小的元素。对于较小的元素大小,相同的形状将沿前导维度乘以 128 / sizeof_bits(Element) 的因子。例如,对于 tf32 张量核心输入,128B MN 主序扭曲原子将具有 (8*(128/32))x8 = 32x8 的形状。
MxK 或 KxN 矩阵在各种扭曲模式下的一些布局示例,以 128b 元素为单位,如每个彩色单元格所示,如图 213、 图 214、 图 215、 图 216、 图 217、 图 218、 图 219、 图 220、 图 221中所示。
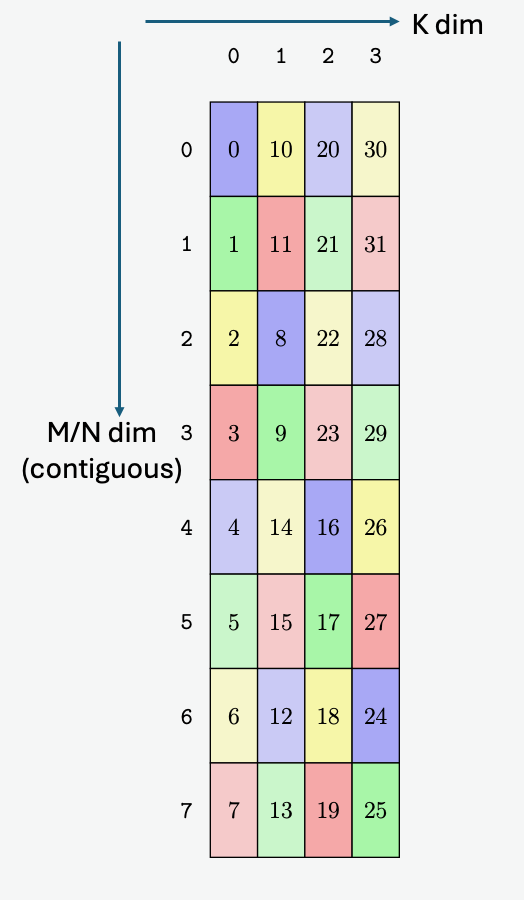
图 213 MN 主序 128B 扭曲,具有 32B 原子性
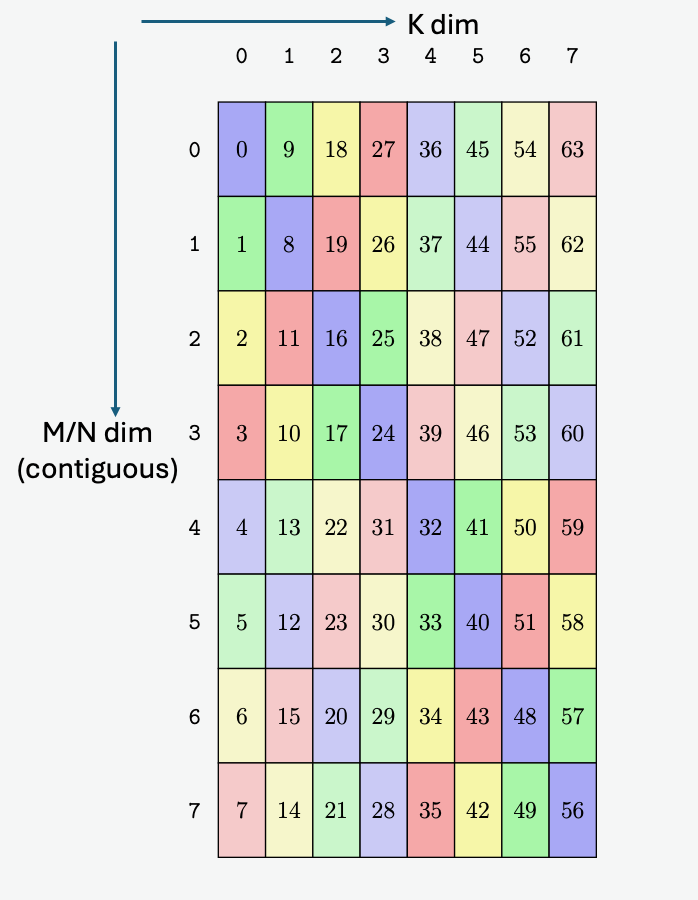
图 214 MN 主序 128B 扭曲
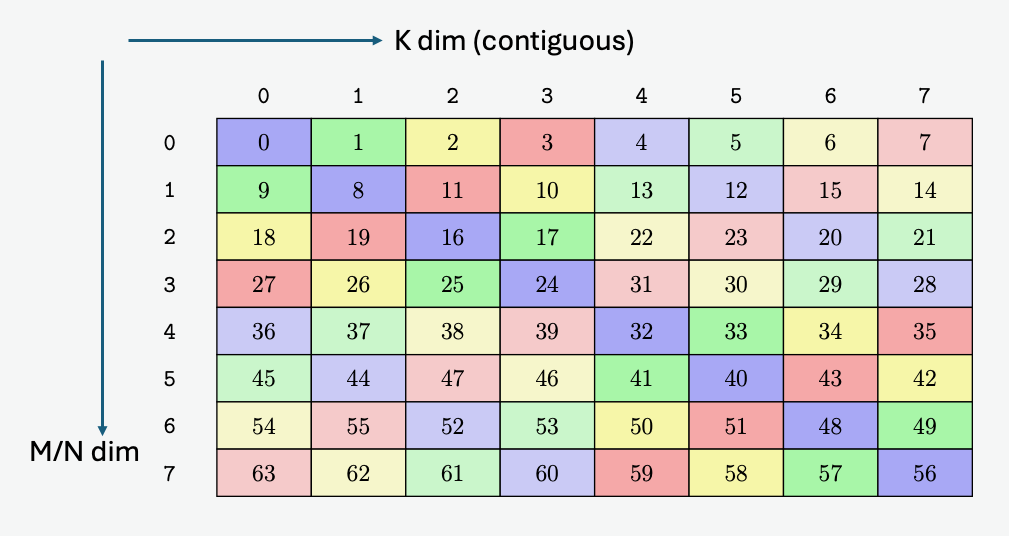
图 215 K 主序 128B 扭曲
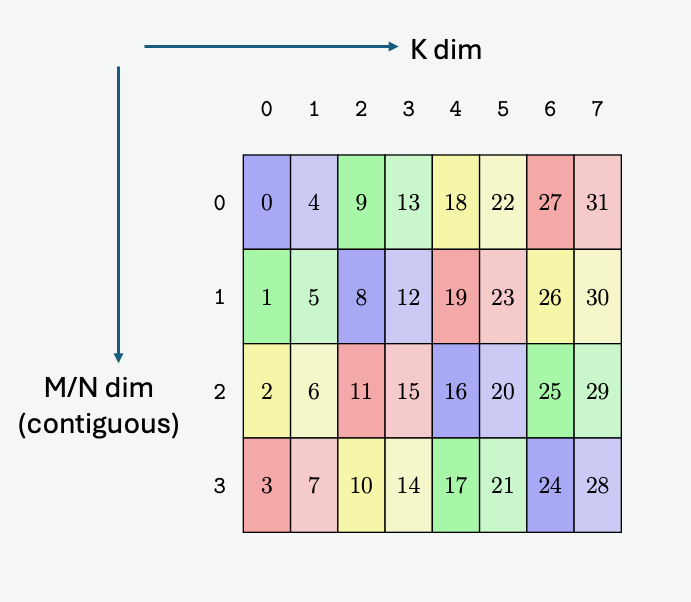
图 216 MN 主序 64B 扭曲
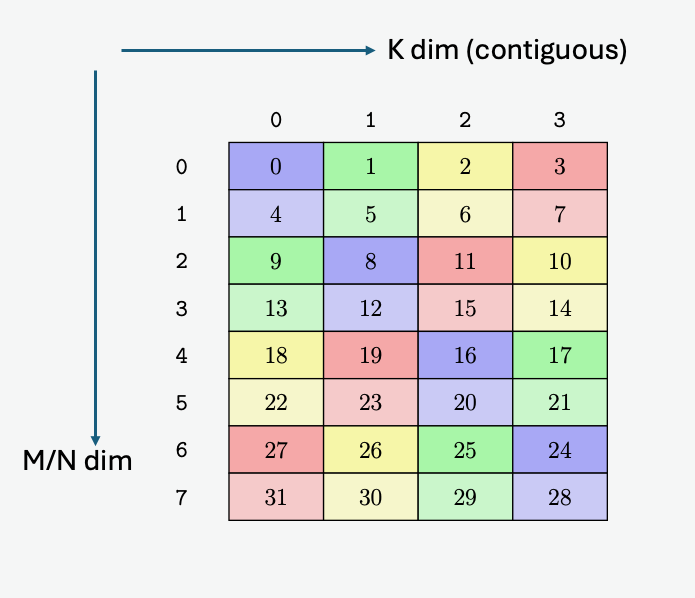
图 217 K 主序 64B 扭曲
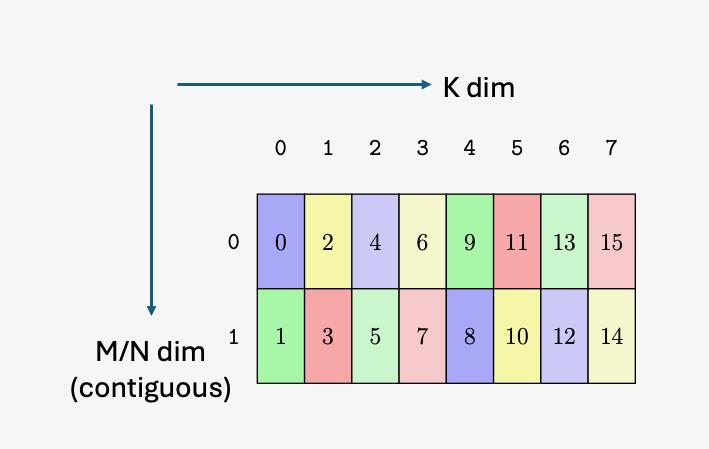
图 218 MN 主序 32B 扭曲
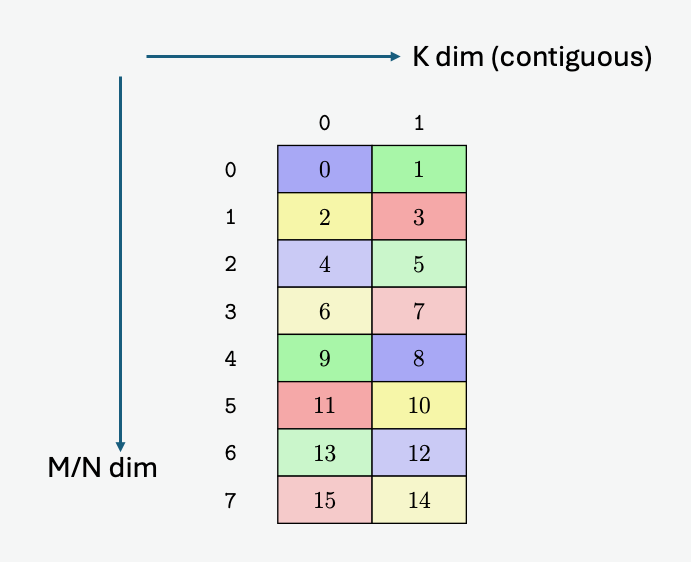
图 219 K 主序 32B 扭曲
图 220 MN 主序无扭曲模式
图 221 K 主序无扭曲模式
以下是 tf32 元素类型的 128B swizzling 布局的一些示例。

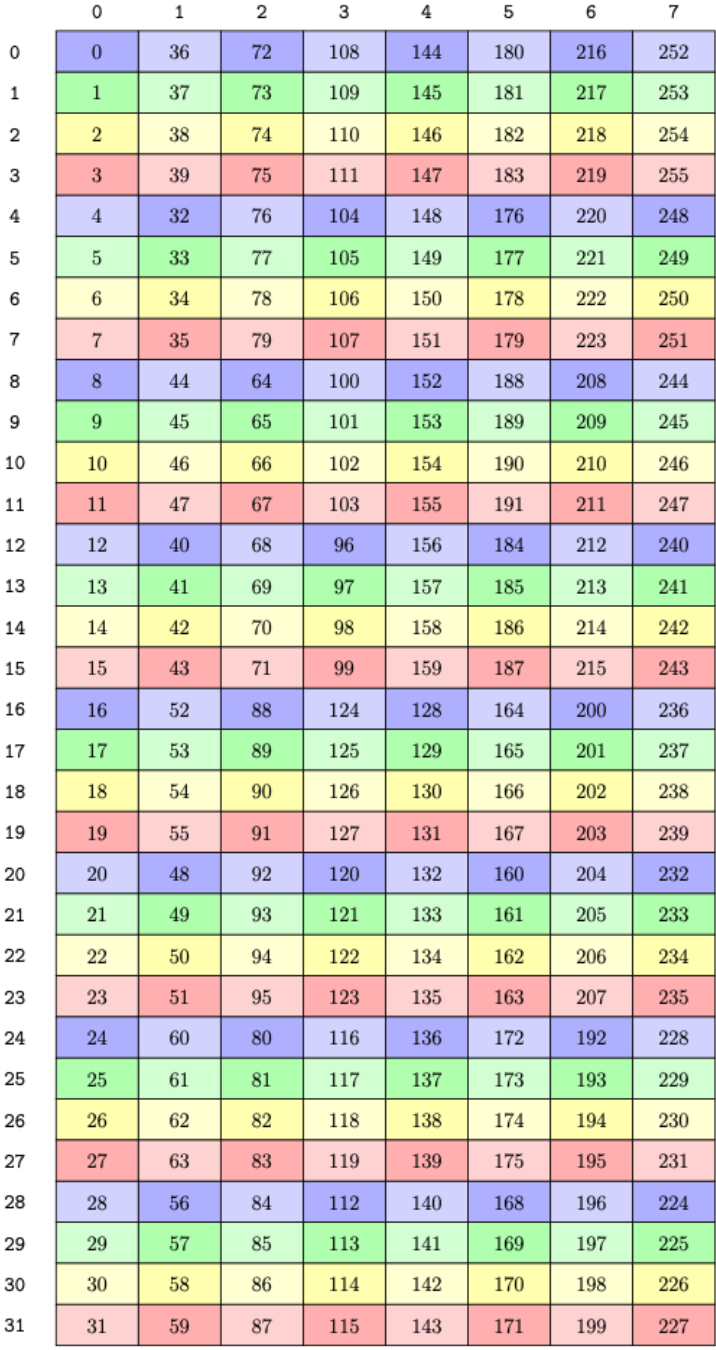
9.7.16.9.7. 块缩放
带有以下 .kind 限定符的 tcgen05.mma 指令
.kind::mxf8f6f4.kind::mxf4.kind::mxf4nvf4
执行带块缩放的矩阵乘法。此操作具有以下形式
(A * scale_A) * (B * scale_B) + D
其中 scale_A 和 scale_B 是驻留在 张量内存中的矩阵。
对于形状为 M x SFA_N 的 scale_A 矩阵,矩阵 A 的每一行被分成 SFA_N 个块,并且每一行的每个块都与同一行的 SF_A 中的对应元素相乘。
类似地,对于形状为 SFB_M x N 的 scale_B 矩阵,矩阵 B 的每一列被分成 SFB_M 个块,并且每一列的每个块都与同一列的 SF_B 中的对应元素相乘。
图 224 显示了 tcgen05.mma 使用 scale_vec::2X 块缩放的示例。
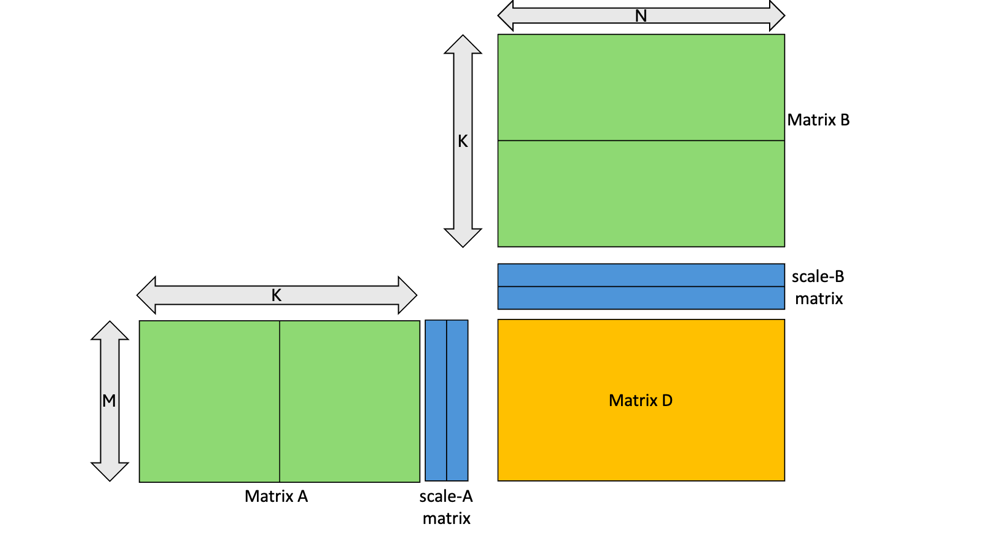
图 224 tcgen05.mma 使用 scale_vec::2X 块缩放
9.7.16.9.7.1. scale_vec_size 与类型和 MMA-Kind 的有效组合
scale_A 和 scale_B 矩阵的形状取决于 .scale_vec_size,如表 52所示。
.scale_vec_size |
scale_A 的形状 |
scale_B 的形状 |
|---|---|---|
|
M x 1 |
1 x N |
|
M x 2 |
2 x N |
|
M x 4 |
4 x N |
精确元素类型和 .scale_vec_size 的有效组合在表 53中列出。
.kind::* |
元素数据类型 |
缩放数据类型 |
.scale_vec_size |
|---|---|---|---|
|
E4M3, E5M2, E2M3 E3M2, E2M1 |
UE8M0 |
|
|
E2M1 |
UE8M0 |
|
|
E2M1 |
UE8M0 |
|
E2M1 |
UE4M3 |
|
9.7.16.9.7.2. 缩放因子 A ID
缩放因子 A ID 的值选择张量内存中的子列以形成缩放因子 A 矩阵,该矩阵用于缩放矩阵 A。
以下显示了各种缩放向量大小的缩放因子矩阵布局
矩阵 A 的每一行都有一个缩放因子,并且缩放因子必须在张量内存的 1 字节对齐的子列中提供。SFA_ID 指定必须用于缩放因子矩阵的张量内存字中的字节偏移量。图 225 显示了对于不同的 SFA_ID 值,哪些子列会被选中。
图 225 scale_vec::1X 的缩放因子 A 矩阵的布局
例如,如果 SFA_ID 为 0,则所有绿色列都被选中以形成缩放因子矩阵。类似地,SFA_ID 值为 1、2 和 3 将分别选择蓝色、黄色和红色列。
矩阵 A 的每一行有两个缩放因子,并且缩放因子必须在张量内存的 2 字节对齐的子列中提供。SFA_ID 指定必须用于缩放因子矩阵的张量内存字中的半字偏移量。图 226 显示了对于不同的 SFA_ID 值,哪些子列会被选中。
图 226 scale_vec::2X 的缩放因子 A 矩阵的布局
例如,如果 SFA_ID 为 0,则所有绿色列都被选中以形成缩放因子矩阵。类似地,如果 SFA_ID 为 2,则所有蓝色列都被选中以形成缩放因子矩阵。
矩阵 A 的每一行有四个缩放因子,并且缩放因子必须在张量内存的 4 字节对齐的子列中提供。SFA_ID 值必须为 0,这指定所有列(绿色)将用于缩放因子矩阵。图 227 显示了对于不同的 SFA_ID 值,哪些子列会被选中。
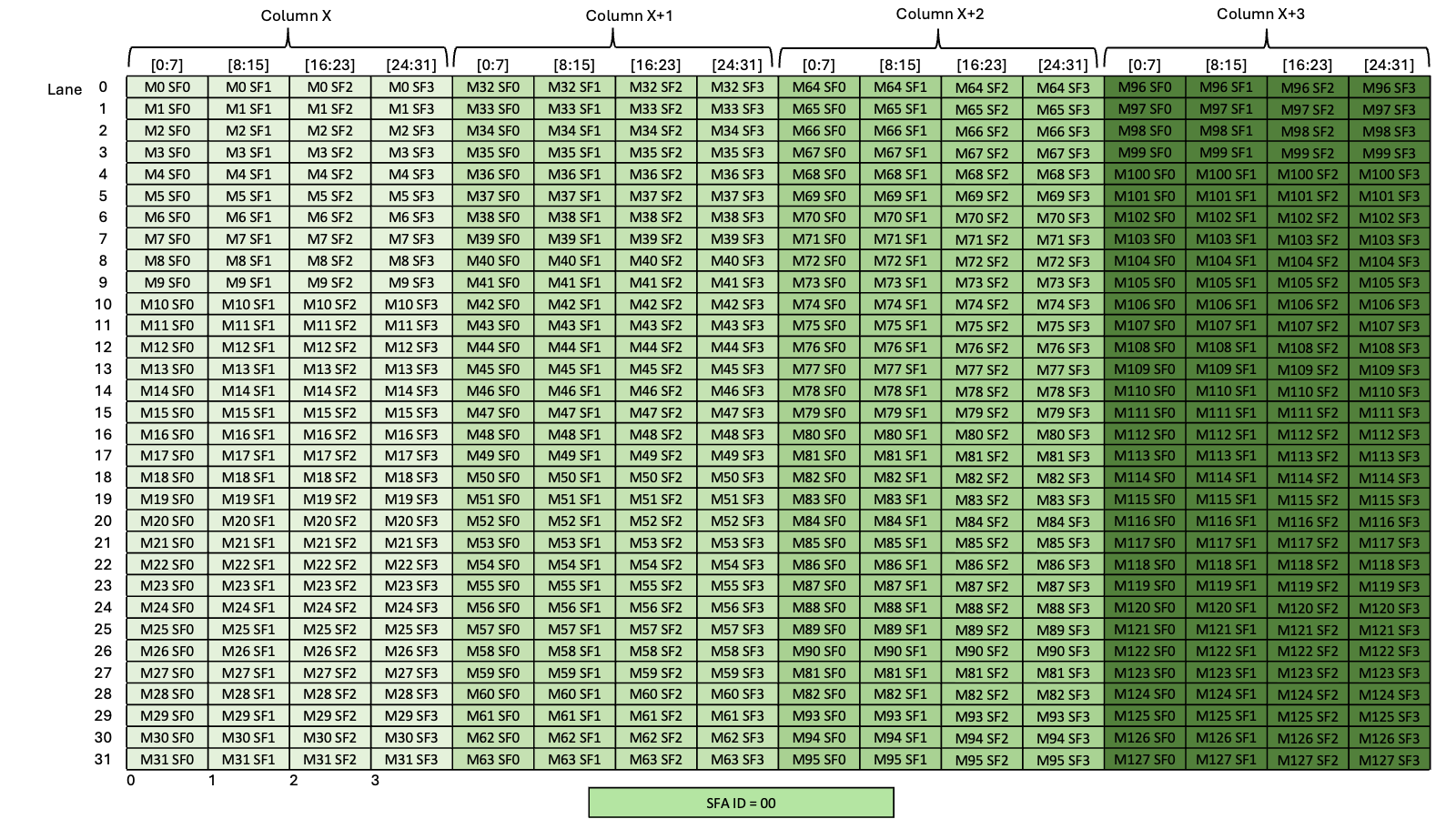
图 227 scale_vec::4X 的缩放因子 A 矩阵的布局
9.7.16.9.7.3. 缩放因子 B ID
缩放因子 B ID 的值选择张量内存中的子列以形成缩放因子 B 矩阵,该矩阵用于缩放矩阵 B。
以下显示了各种缩放向量大小的缩放因子矩阵布局
矩阵 B 的每一行都有一个缩放因子,并且缩放因子必须在张量内存的 1 字节对齐的子列中提供。SFB_ID 指定必须用于缩放因子矩阵的张量内存字中的字节偏移量。图 228 显示了对于不同的 SFB_ID 值,哪些子列会被选中。
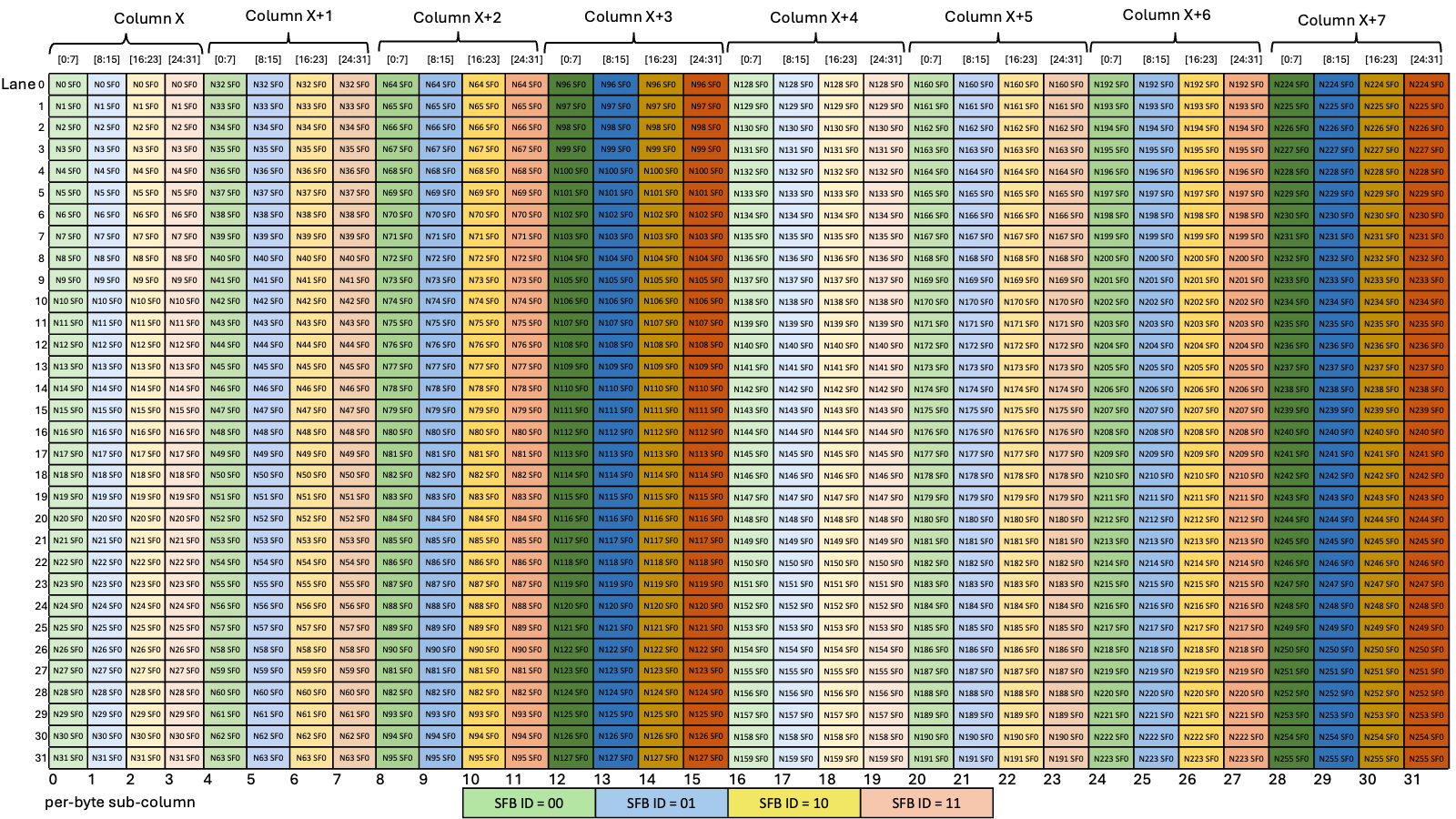
图 228 scale_vec::1X 的缩放因子 B 矩阵的布局
例如,如果 SFB_ID 为 0,则所有绿色列都被选中以形成缩放因子矩阵。类似地,SFB_ID 值为 1、2 和 3 将分别选择蓝色、黄色和红色列。
矩阵 B 的每一行有两个缩放因子,并且缩放因子必须在张量内存的 2 字节对齐的子列中提供。SFB_ID 指定必须用于缩放因子矩阵的张量内存字中的半字偏移量。图 229 显示了对于不同的 SFB_ID 值,哪些子列会被选中。
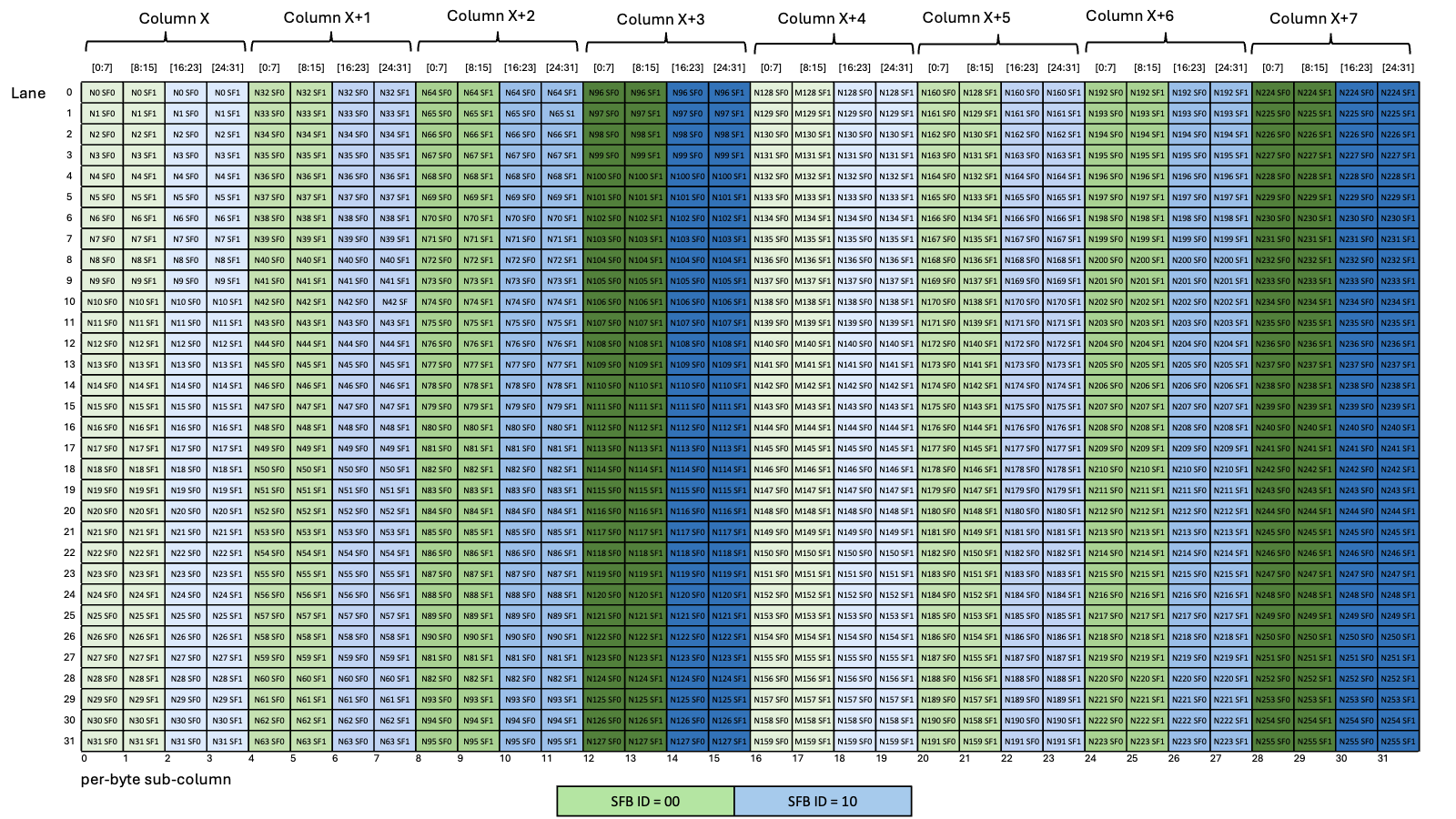
图 229 scale_vec::2X 的缩放因子 B 矩阵的布局
例如,如果 SFB_ID 为 0,则所有绿色列都被选中以形成缩放因子矩阵。类似地,如果 SFB_ID 为 2,则所有蓝色列都被选中以形成缩放因子矩阵。
矩阵 B 的每一行有四个缩放因子,并且缩放因子必须在张量内存的 4 字节对齐的子列中提供。SFB_ID 值必须为 0,这指定所有列(绿色)将用于缩放因子矩阵。图 230 显示了对于不同的 SFB_ID 值,哪些子列会被选中。
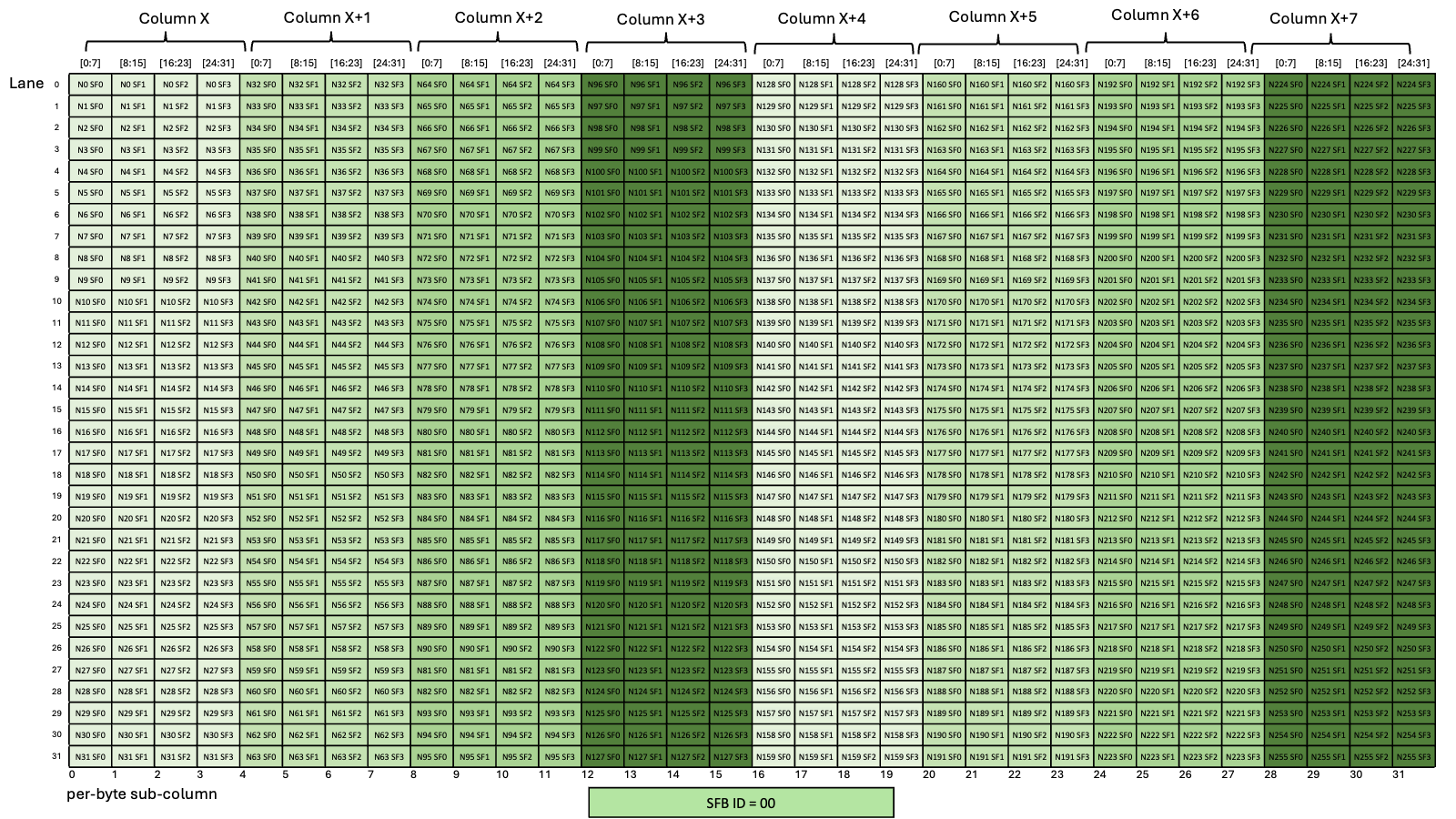
图 230 scale_vec::4X 的缩放因子 B 矩阵的布局
9.7.16.9.8. 稀疏矩阵
当矩阵 A 是结构化稀疏矩阵,并且每行中有 50% 的零元素按照其稀疏粒度分布时,可以使用此指令 tcgen05.mma.sp。
在 MxNxK 稀疏 tcgen05.mma.sp 操作中,形状为 MxK 的矩阵 A 以 Mx(K/2) 的压缩形式存储在内存中。对于矩阵 A 的每一行 K-宽 行,50% 的元素为零,其余 K/2 个非零元素存储在内存中。元数据指定 K/2 个非零元素到 K 个元素的映射,然后再执行 MMA 操作。
稀疏矩阵 A 的粒度定义为矩阵行子块中非零元素数量与该子块中元素总数的比率,其中子块的大小是特定于形状的。下表列出了不同 tcgen05.mma.sp 变体的粒度
tcgen05.mma 的 .kind |
稀疏粒度 |
|---|---|
|
1:2 |
|
2:4 |
|
|
|
|
|
|
|
4:8(成对) |
9.7.16.9.8.1. 具有 .kind::tf32 的稀疏 tcgen05.mma.sp
对于 .kind::tf32,矩阵 A 在 1:2 的粒度上是结构化稀疏的。换句话说,矩阵 A 的一行中每两个相邻元素的块有一个零元素和一个非零元素。只有非零元素存储在内存中,并且元数据中的 4 位索引指示两个宽块中非零元素的位置。索引的唯一有意义的值是
0b11100b0100
其余值会导致未定义的行为。
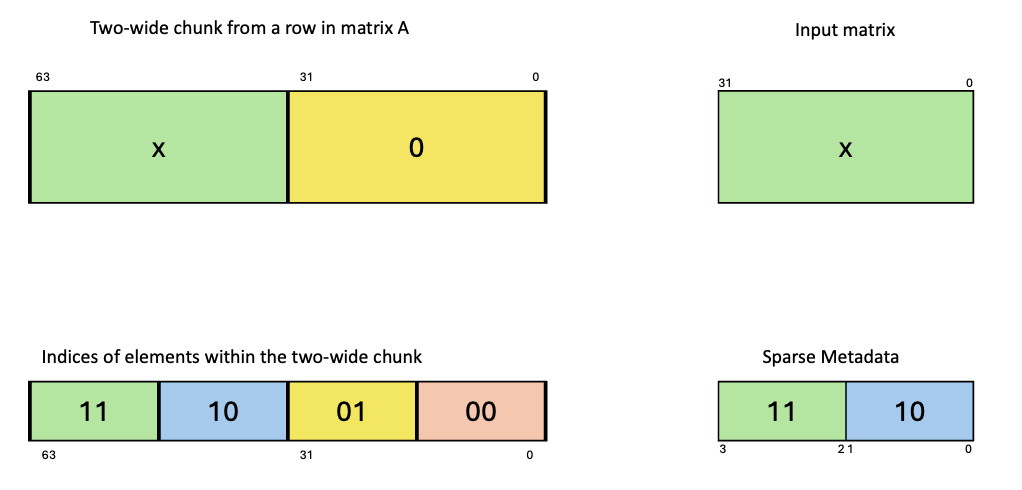
图 231 tf32 类型的稀疏 tcgen05.mma 元数据示例
9.7.16.9.8.2. 具有 .kind::f16、.kind::f8f6f4、.kind::mxf8f6f4、.kind::i8 的稀疏 tcgen05.mma.sp
对于以下 tcgen05.mma 的 .kind 变体
.kind::f16.kind::f8f8f4.kind::mxf8f6f4.kind::i8
矩阵 A 在 2:4 的粒度上是结构化稀疏的。换句话说,矩阵 A 的一行中每四个相邻元素的块有两个零元素和两个非零元素。只有非零元素存储在内存中,并且元数据中的两个 2 位索引指示四个宽块中两个非零元素的位置。索引的唯一有意义的值是
0b01000b10000b11000b10010b11010b01100b1110
图 232 f16/f8f6f4/mxf8f6f4 类型的稀疏 tcgen05.mma 元数据示例
9.7.16.9.8.3. 具有 .kind::mxf4 和 .kind::mxf4nvf4 的稀疏 tcgen05.mma.sp
对于 .kind::mxf4 和 .kind::mxf4nvf4,矩阵 A 在 4:8 的粒度上是成对结构化稀疏的。换句话说,矩阵 A 的一行中每八个相邻元素的块有四个零元素和四个非零元素。零元素和非零元素聚集在八个宽块内的每个两个元素的子块中,因此八个宽块内的每个两个宽子块必须全部为零或全部为非零。只有四个非零元素存储在内存中,并且元数据中的两个 2 位索引指示矩阵 A 的一行中八个宽块中具有非零值的两个两个宽子块的位置。索引的唯一有意义的值是
0b01000b10000b11000b10010b11010b01100b1110
其余值会导致未定义的行为。
图 233 mxf4 类型的稀疏 tcgen05.mma 元数据示例
9.7.16.9.8.4. 稀疏选择器
稀疏选择器的值选择张量内存中的子列以形成稀疏元数据矩阵,该矩阵与矩阵 A 一起用于形成被乘数矩阵。
以下显示了张量内存中各种 MMA 变体的稀疏元数据矩阵布局
图 234 显示了对于不同的稀疏选择器值,哪些子列会被选中。
图 234 M = 64 时 .kind::f16 的稀疏元数据布局
图 235 显示了对于不同的稀疏选择器值,哪些子列会被选中。
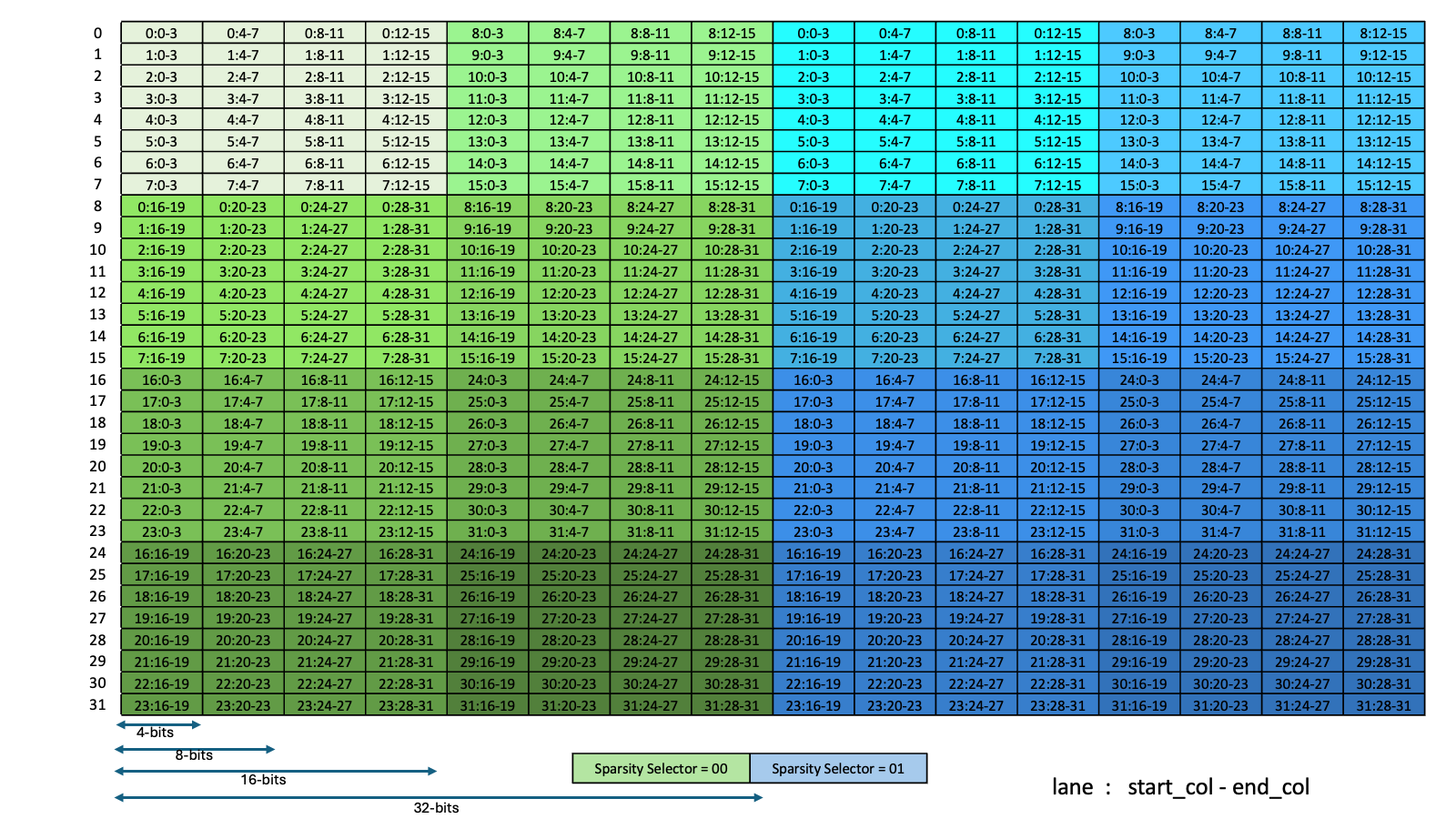
图 235 M = 128 / M = 256 时 .kind::f16 的稀疏元数据布局
图 236 显示了对于不同的稀疏选择器值,哪些子列会被选中。
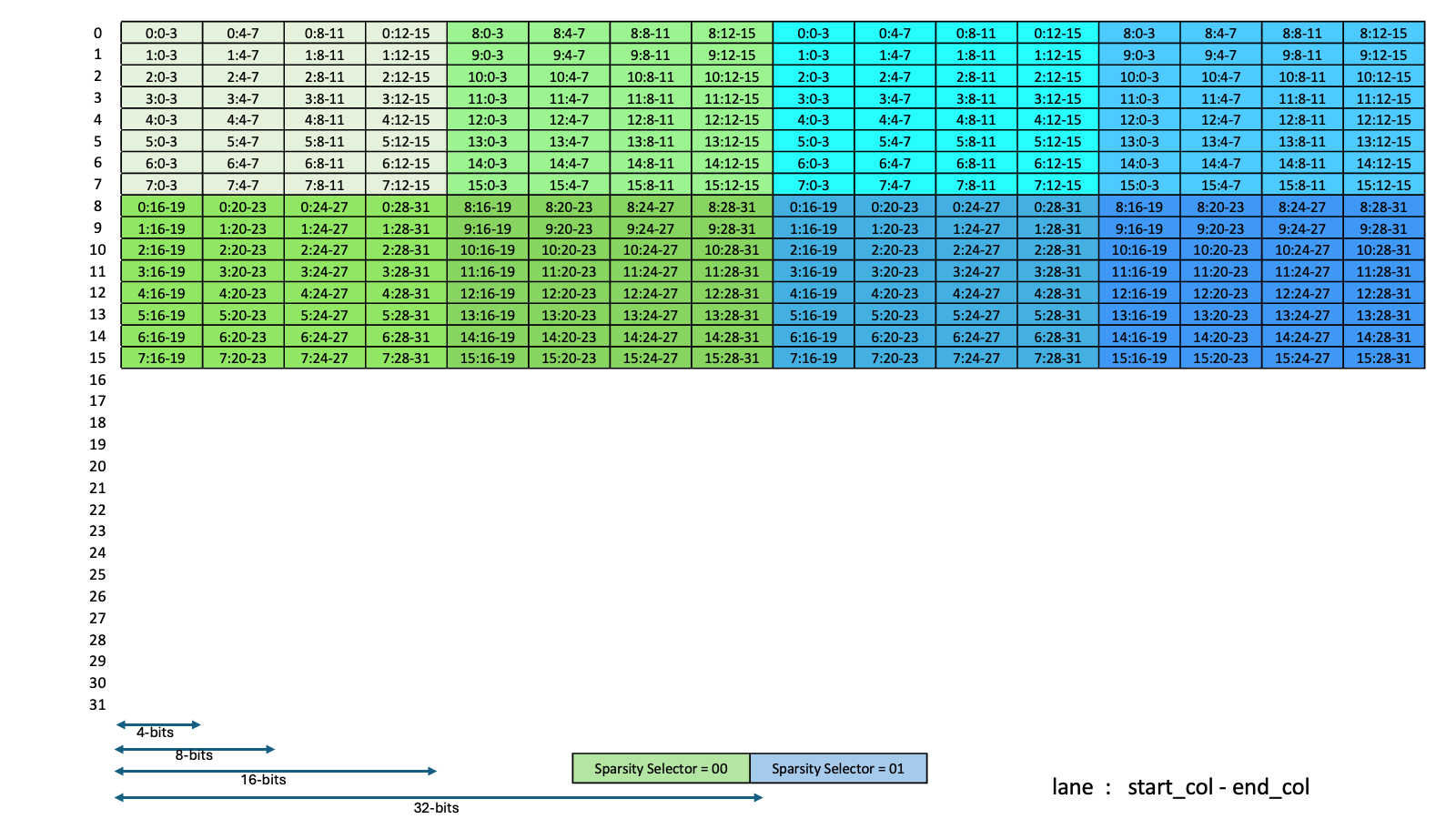
图 236 M = 64 时 .kind::tf32 的稀疏元数据布局
图 237 显示了对于不同的稀疏选择器值,哪些子列会被选中。
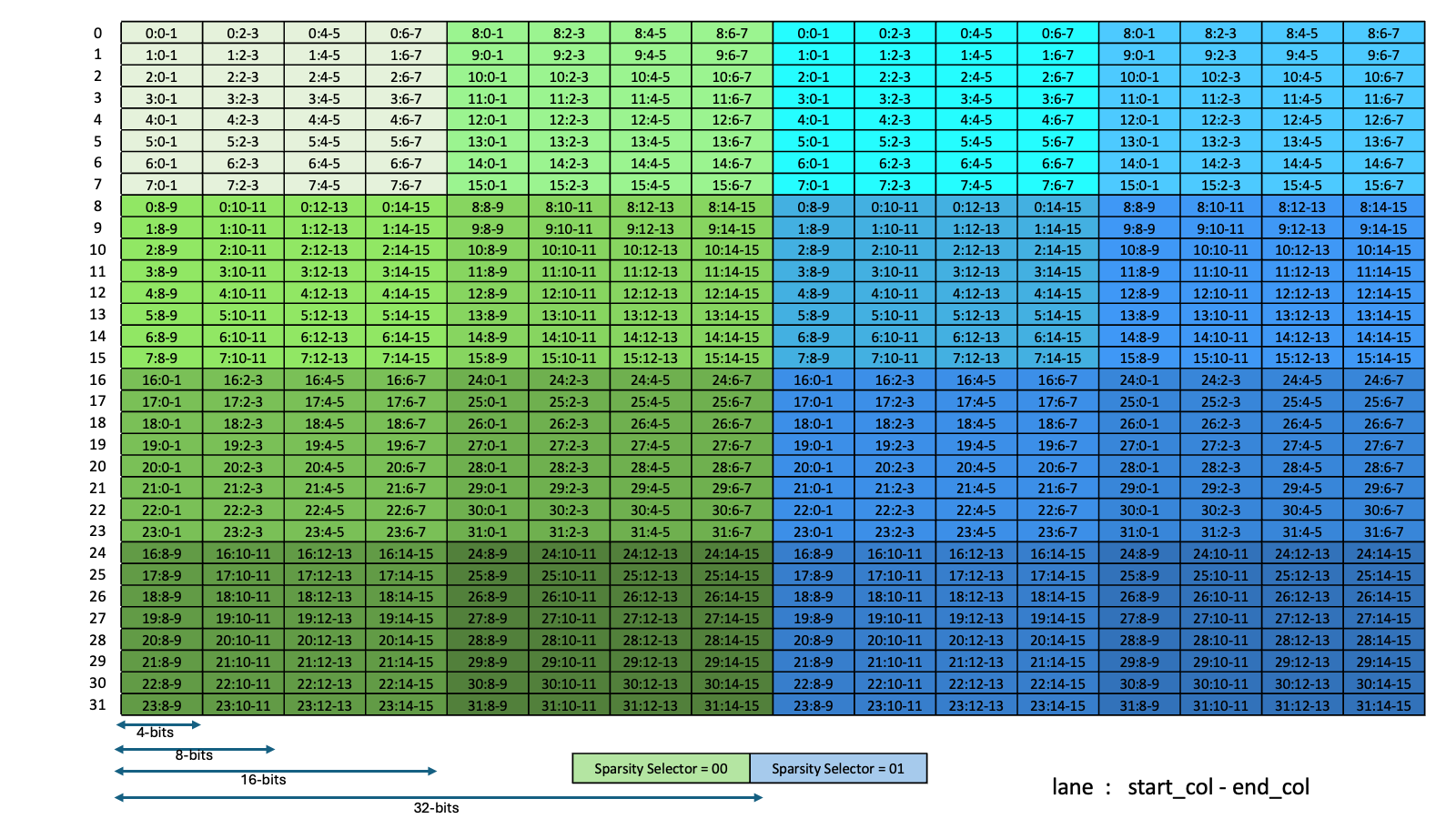
图 237 M = 128 / M = 256 时 .kind::tf32 的稀疏元数据布局
稀疏选择器的值
对于
.kind::i8和.kind::f8f6f4必须为 0对于
.kind::mxf8f6f4、.kind::mxf4和.kind::mxf4nvf4假定为 0
并且所有列都被选中,如图 238所示
图 238 M = 64 时 .kind::f8f6f4、.kind::mxf8f6f4、.kind::i8、.kind::mxf4、.kind::mxf4nvf4 的稀疏元数据布局
稀疏选择器的值
对于
.kind::i8和.kind::f8f6f4必须为 0对于
.kind::mxf8f6f4、.kind::mxf4和.kind::mxf4nvf4假定为 0
并且所有列都被选中,如图 239所示
图 239 M = 128 / M = 256 时 .kind::f8f6f4、.kind::mxf8f6f4、.kind::i8、.kind::mxf4、.kind::mxf4nvf4 的稀疏元数据布局
9.7.16.9.8.5. 对齐限制
如数据路径布局组织中指定的,仅使用一半数据路径通道的布局,即 布局 F 和 布局 C,必须在矩阵 A、D 和稀疏元数据矩阵之间使用相同的对齐方式。
9.7.16.9.9. TensorCore 第五代 MMA 指令
9.7.16.9.9.1. TensorCore 第五代指令:tcgen05.mma
tcgen05.mma
执行第五代矩阵乘法和累加运算。
语法
// 1. Floating-point type without block scaling:
tcgen05.mma.cta_group.kind [d-tmem], a-desc, b-desc, idesc,
{ disable-output-lane }, enable-input-d {, scale-input-d};
tcgen05.mma.cta_group.kind [d-tmem], [a-tmem], b-desc, idesc,
{ disable-output-lane }, enable-input-d {, scale-input-d};
.kind = { .kind::f16, .kind::tf32, .kind::f8f6f4 }
.cta_group = { .cta_group::1, .cta_group::2 }
----------------------------------------------------------------------------------
// 2. Floating-point type with block scaling:
tcgen05.mma.cta_group.kind.block_scale{.scale_vec_size}
[d-tmem], a-desc, b-desc, idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
tcgen05.mma.cta_group.kind.block_scale{.scale_vec_size}
[d-tmem], [a-tmem], b-desc, idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
.kind = { .kind::mxf8f6f4, .kind::mxf4, .kind::mxf4nvf4 }
.cta_group = { .cta_group::1, .cta_group::2 }
.scale_vec_size = { .scale_vec::1X, .scale_vec::2X, .scale_vec::4X }
----------------------------------------------------------------------------------
// 3. Convolution MMA for floating-point type without block scaling:
tcgen05.mma.cta_group.kind.collector_usage [d-tmem], a-desc, b-desc, idesc,
{ disable-output-lane }, enable-input-d {, scale-input-d};
tcgen05.mma.cta_group.kind{.ashift}.collector_usage [d-tmem], [a-tmem], b-desc, idesc,
{ disable-output-lane }, enable-input-d {, scale-input-d};
tcgen05.mma.cta_group.kind.ashift{.collector_usage} [d-tmem], [a-tmem], b-desc, idesc,
{ disable-output-lane }, enable-input-d {, scale-input-d};
.kind = { .kind::f16, .kind::tf32, .kind::f8f6f4 }
.cta_group = { .cta_group::1, .cta_group::2 }
.collector_usage = { .collector::buffer::op }
::buffer = { ::a }
::op = { ::fill, ::use, ::lastuse, ::discard* }
----------------------------------------------------------------------------------
// 4. Activation Stationary MMA for floating-point type with block scaling:
tcgen05.mma.cta_group.kind.block_scale{.scale_vec_size}.collector_usage
[d-tmem], a-desc, b-desc, idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
tcgen05.mma.cta_group.kind.block_scale{.scale_vec_size}.collector_usage
[d-tmem], [a-tmem], b-desc, idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
.cta_group = { .cta_group::1, .cta_group::2 }
.scale_vec_size = { .scale_vec::1X, .scale_vec::2X, .scale_vec::4X }
.kind = { .kind::mxf8f6f4, .kind::mxf4, .kind::mxf4nvf4 }
.collector_usage = { .collector::buffer::op }
::buffer = { ::a }
::op = { ::fill, ::use, ::lastuse, ::discard* }
----------------------------------------------------------------------------------
// 5. Integer type:
tcgen05.mma.cta_group.kind::i8 [d-tmem], a-desc, b-desc, idesc,
{ disable-output-lane }, enable-input-d;
tcgen05.mma.cta_group.kind::i8 [d-tmem], [a-tmem], b-desc, idesc,
{ disable-output-lane }, enable-input-d;
.cta_group = { .cta_group::1, .cta_group::2 }
----------------------------------------------------------------------------------
// 6. Convolution MMA for integer type:
tcgen05.mma.cta_group.kind::i8.collector_usage [d-tmem], a-desc, b-desc, idesc,
{ disable-output-lane }, enable-input-d;
tcgen05.mma.cta_group.kind::i8.ashift{.collector_usage} [d-tmem], [a-tmem], b-desc, idesc,
{ disable-output-lane }, enable-input-d;
tcgen05.mma.cta_group.kind::i8{.ashift}.collector_usage [d-tmem], [a-tmem], b-desc, idesc,
{ disable-output-lane }, enable-input-d;
.cta_group = { .cta_group::1, .cta_group::2 }
.collector_usage = { .collector::buffer::op }
::buffer = { ::a }
::op = { ::fill, ::use, ::lastuse, ::discard* }
描述
指令 tcgen05.mma 是一条异步指令,它启动 MxNxK 矩阵乘法和累加运算,D = A*B+D,其中 A 矩阵为 MxK,B 矩阵为 KxN,D 矩阵为 MxN。
当输入谓词参数 enable-input-d 为 false 时,发出 D = A*B 形式的操作。
可选的立即数参数 scale-input-d 可以指定用于缩放输入矩阵 D,如下所示:D = A*B+D * (2 ^ - scale-input-d)
参数 scale-input-d 的有效值范围为 [0, 15]。参数 scale-input-d 仅对 .kind::tf32 和 .kind::f16 有效。
32 位寄存器操作数 idesc 是指令描述符,如指令描述符中所述,指定输入矩阵、输出矩阵以及矩阵乘法和累加运算的形状、精确类型、稀疏性和其他详细信息。
限定符 .cta_group::1 指定矩阵乘法和累加运算仅在执行线程的 CTA 的 张量内存上执行。限定符 .cta_group::2 指定矩阵乘法和累加运算在执行线程的 CTA 及其 对等 CTA 的 张量内存上执行。
与集合指令 mma.sync 或 wgmma.mma_async 不同,指令 tcgen05.mma 具有单线程语义。因此,单个线程发出 tcgen05.mma 将导致整个矩阵乘法和累加操作的启动。请参阅 Issue granularity 部分。
限定符 .kind 指定了乘数矩阵元素类型的大致种类。每种 MMA 类型的输入和输出矩阵元素的具体类型在 Instruction descriptor 中指定。
地址操作数 d-tmem 指定了 Tensor Memory 中目标矩阵和累加矩阵 D 的地址。地址操作数 a-tmem 指定了 Tensor Memory 中矩阵 A 的地址。64 位寄存器操作数 a-desc 和 b-desc 是矩阵描述符,分别代表共享内存中的矩阵 A 和 B。矩阵描述符的格式在 Matrix Descriptor Format 中描述。
向量操作数 disable-output-lane 指定了 Tensor Memory 中不应使用结果矩阵 D 更新的通道。向量操作数 disable-output-lane 的元素构成一个掩码,其中每个位对应于 Tensor Memory 的一个通道,向量的第一个元素(语法中最左侧)的最低有效位对应于 Tensor Memory 的通道 0。如果掩码中的位为 1,则结果矩阵 D 的 Tensor Memory 中的相应通道将不会被更新。向量的大小如下:
.cta_group |
向量 disable-output-lane 的大小 |
|---|---|
::1 |
4 |
::2 |
8 |
限定符 .block_scale 指定矩阵 A 和 B 在执行矩阵乘法和累加操作之前,分别使用 scale_A 和 scale_B 矩阵进行缩放,如 Block Scaling 部分所述。地址操作数 scale-A-tmem 和 scale-B-tmem 分别指定了 Tensor Memory 中矩阵 scale_A 和 scale_B 的基地址。
限定符 .scale_vec_size 指定了 scale_A 矩阵的列数和 scale_B 中的行数。表 52 中描述了 MMA 类型和 .scale_vec_size 的有效组合。对于 .kind::mxf4,当未指定限定符 .scale_vec_size 时,则默认为 2X。对于 .kind::mxf4nvf4,必须显式指定限定符 .scale_vec_size。
限定符 .ashift 将矩阵 A 的行向下移动一行,但 Tensor Memory 中的最后一行除外。限定符 .ashift 仅允许与 M = 128 或 M = 256 一起使用。
限定符 .collector_usage 指定了矩阵 A 的收集器缓冲区的用法。可以指定以下收集器缓冲区操作:
.collector_usage |
语义 |
|---|---|
|
指定从内存读取的 |
|
指定可以从收集器缓冲区读取 |
|
指定可以从收集器缓冲区读取 |
|
指定可以丢弃 |
如果未指定 .collector_usage 限定符,则默认为 .collector::a::discard。将 .collector::a::use 或 .collector::a::fill 与 .ashift 一起指定是非法的。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
PTX ISA 版本 8.7 中引入了限定符 .kind::mxf4nvf4。
目标 ISA 注释
以下架构支持
sm_100asm_101a
参数 scale-input-d 需要 sm_100a。
示例
tcgen05.mma.cta_group::1.kind::tf32 [taddr0], adesc, bdesc, idesc, {m0, m1, m2, m3}, p;
tcgen05.mma.cta_group::1.kind::mxf8f6f4 [taddr2], [taddr1], bdesc, idesc,
[tmem_scaleA], [tmem_scaleB], p;
tcgen05.commit.cta_group::1.mbarrier::arrive::one.b64 [mbarObj0];
loop:
mbarrier.try_wait.parity.b64 p, [mbarObj0], 0;
@!p bra loop;
9.7.16.9.9.2. TensorCore 第五代指令:tcgen05.mma.sp
tcgen05.mma.sp
使用稀疏 A 矩阵执行第五代矩阵乘法和累加运算。
语法
// 1. Floating-point type without block scaling:
tcgen05.mma.sp.cta_group.kind [d-tmem], a-desc, b-desc, [sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d{, scale-input-d};
tcgen05.mma.sp.cta_group.kind [d-tmem], [a-tmem], b-desc, [sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d{, scale-input-d};
.kind = { .kind::f16, , .kind::tf32, .kind::f8f6f4 }
.cta_group = { .cta_group::1, .cta_group::2 }
----------------------------------------------------------------------------------
// 2. Floating-point type with block scaling:
tcgen05.mma.sp.cta_group.kind.block_scale{.scale_vec_size}
[d-tmem], a-desc, b-desc , [sp-meta-tmem] , idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
tcgen05.mma.sp.cta_group.kind.block_scale{.scale_vec_size}
[d-tmem], [a-tmem], b-desc , [sp-meta-tmem] , idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
.scale_vec_size = { .scale_vec::1X, .scale_vec::2X, .scale_vec::4X }
.cta_group = { .cta_group::1, .cta_group::2 }
.kind = { .kind::mxf8f6f4, .kind::mxf4, .kind::mxf4nvf4 }
----------------------------------------------------------------------------------
// 3. Convolution MMA with floating-point type without block scaling:
tcgen05.mma.sp.cta_group.kind.collector_usage [d-tmem], a-desc, b-desc,
[sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d
{, scale-input-d};
tcgen05.mma.sp.cta_group.kind.ashift{.collector_usage} [d-tmem], [a-tmem], b-desc,
[sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d
{, scale-input-d};
tcgen05.mma.sp.cta_group.kind{.ashift}.collector_usage [d-tmem], [a-tmem], b-desc,
[sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d
{, scale-input-d};
.kind = { .kind::f16, .kind::tf32, .kind::f8f6f4 }
.collector_usage = { .collector::buffer::op }
::buffer = { ::a }
::op = { ::fill, ::use, ::lastuse, ::discard* }
----------------------------------------------------------------------------------
// 4. Activation Stationary MMA with floating-point type with block scaling:
tcgen05.mma.sp.cta_group.kind.block_scale{.scale_vec_size}.collector_usage
[d-tmem], a-desc, b-desc , [sp-meta-tmem] , idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
tcgen05.mma.sp.cta_group.kind.block_scale{.scale_vec_size}.collector_usage
[d-tmem], [a-tmem], b-desc , [sp-meta-tmem] , idesc,
[scale-A-tmem], [scale-B-tmem], enable-input-d;
.kind = { .kind::mxf8f6f4, .kind::mxf4, .kind::mxf4nvf4 }
.scale_vec_size = { .scale_vec::1X, .scale_vec::2X, .scale_vec::4X }
.collector_usage = { .collector::buffer::op }
::buffer = { ::a }
::op = { ::fill, ::use, ::lastuse, ::discard* }
----------------------------------------------------------------------------------
// 5. Integer type:
tcgen05.mma.sp.cta_group.kind::i8 [d-tmem], a-desc, b-desc, [sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d;
tcgen05.mma.sp.cta_group.kind::i8 [d-tmem], [a-tmem], b-desc, [sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d;
.cta_group = { .cta_group::1, .cta_group::2 }
----------------------------------------------------------------------------------
// 6. Convolution MMA with Integer type:
tcgen05.mma.sp.cta_group.kind::i8.collector_usage [d-tmem], a-desc, b-desc,
[sp-meta-tmem] , idesc,
{ disable-output-lane }, enable-input-d;
tcgen05.mma.sp.cta_group.kind::i8.ashift{.collector_usage} [d-tmem], [a-tmem], b-desc,
[sp-meta-tmem], idesc ,
{ disable-output-lane }, enable-input-d;
tcgen05.mma.sp.cta_group.kind::i8{.ashift}.collector_usage [d-tmem], [a-tmem], b-desc,
[sp-meta-tmem], idesc ,
{ disable-output-lane }, enable-input-d;
.collector_usage = { .collector::buffer::op }
::buffer = { ::a }
::op = { ::fill, ::use, ::lastuse, ::discard* }
描述
指令 tcgen05.mma.sp 是一条异步指令,它启动 MxNxK 矩阵乘法和累加运算,形式为 D = A*B+D,其中 A 矩阵为 Mx(K/2),B 矩阵为 KxN,D 矩阵为 MxN。Sparse Matrices 描述了稀疏性的详细信息。
当输入谓词参数 enable-input-d 为 false 时,发出 D = A*B 形式的操作。
可选的立即数参数 scale-input-d 可以指定用于缩放输入矩阵 D,如下所示:D = A*B+D * (2 ^ - scale-input-d)
参数 scale-input-d 的有效值范围为 [0, 15]。参数 scale-input-d 仅对 .kind::tf32 和 .kind::f16 有效。
32 位寄存器操作数 idesc 是指令描述符,如指令描述符中所述,指定输入矩阵、输出矩阵以及矩阵乘法和累加运算的形状、精确类型、稀疏性和其他详细信息。
限定符 .cta_group::1 指定矩阵乘法和累加运算仅在执行线程的 CTA 的 张量内存上执行。限定符 .cta_group::2 指定矩阵乘法和累加运算在执行线程的 CTA 及其 对等 CTA 的 张量内存上执行。
与集合指令 mma.sync 或 wgmma.mma_async 不同,指令 tcgen05.mma.sp 具有单线程语义。因此,单个线程发出 tcgen05.mma.sp 将导致整个矩阵乘法和累加操作的启动。请参阅 Issue granularity 部分。
限定符 .kind 指定了乘数矩阵元素类型的大致种类。每种 MMA 类型的输入和输出矩阵元素的具体类型在 Instruction descriptor 中指定。
地址操作数 d-tmem 指定了 Tensor Memory 中目标矩阵和累加矩阵 D 的地址。地址操作数 a-tmem 指定了 Tensor Memory 中矩阵 A 的地址。64 位寄存器操作数 a-desc 和 b-desc 是矩阵描述符,分别代表共享内存中的矩阵 A 和 B。矩阵描述符的格式在 Matrix Descriptor Format 中描述。
向量操作数 disable-output-lane 指定了 Tensor Memory 中不应使用结果矩阵 D 更新的通道。向量操作数 disable-output-lane 的元素构成一个掩码,其中每个位对应于 Tensor Memory 的一个通道。向量的第一个元素(语法中最左侧)的最低有效位对应于 Tensor Memory 的通道 0。如果掩码中的位为 1,则结果矩阵 D 的 Tensor Memory 中的相应通道将不会被更新。向量的大小如下:
.cta_group |
向量 disable-output-lane 的大小 |
|---|---|
::1 |
4 |
::2 |
8 |
限定符 .block_scale 指定矩阵 A 和 B 在执行矩阵乘法和累加操作之前,分别使用 scale_A 和 scale_B 矩阵进行缩放,如 Block Scaling 部分所述。地址操作数 scale-A-tmem 和 scale-B-tmem 分别指定了 Tensor Memory 中矩阵 scale_A 和 scale_B 的基地址。
限定符 .scale_vec_size 指定了 scale_A 矩阵的列数和 scale_B 中的行数。表 52 中描述了 MMA 类型和 .scale_vec_size 的有效组合。对于 .kind::mxf4,当未指定限定符 .scale_vec_size 时,则默认为 2X。对于 .kind::mxf4nvf4,必须显式指定限定符 .scale_vec_size。
限定符 .ashift 将矩阵 A 的行向下移动一行,但 Tensor Memory 中的最后一行除外。限定符 .ashift 仅允许与 M = 128 或 M = 256 一起使用。
限定符 .collector_usage 指定了矩阵 A 的收集器缓冲区的用法。可以指定以下收集器缓冲区操作:
.collector_usage |
语义 |
|---|---|
|
指定从内存读取的 |
|
指定可以从收集器缓冲区读取 |
|
指定可以从收集器缓冲区读取 |
|
指定可以丢弃 |
如果未指定 .collector_usage 限定符,则默认为 .collector::a::discard。将 .collector::a::use 或 .collector::a::fill 与 .ashift 一起指定是非法的。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
PTX ISA 版本 8.7 中引入了限定符 .kind::mxf4nvf4。
目标 ISA 注释
以下架构支持
sm_100asm_101a
参数 scale-input-d 需要 sm_100a。
示例
tcgen05.mma.sp.cta_group::1.kind::f16 [taddr0], adesc, bdesc, [tmem_spmeta0], idesc, p;
tcgen05.mma.sp.cta_group::1.kind::mxf8f6f4.collector::a:fill
[taddr2], [taddr1], bdesc, [tmem_spmeta1], idesc,
[tmem_scaleA], [tmem_scaleB], p;
tcgen05.commit.cta_group::1.mbarrier::arrive::one.b64 [mbarObj0];
loop:
mbarrier.try_wait.parity.b64 p, [mbarObj0], 0;
@!p bra loop;
9.7.16.9.9.3. TensorCore 第五代指令:tcgen05.mma.ws
tcgen05.mma.ws
执行第五代权重静止卷积矩阵乘法和累加运算。
语法
// 1. Floating-point type without block scaling:
tcgen05.mma.ws.cta_group::1.kind{.collector_usage} [d-tmem], a-desc, b-desc, idesc,
enable-input-d {, zero-column-mask-desc };
tcgen05.mma.ws.cta_group::1.kind{.collector_usage} [d-tmem], [a-tmem], b-desc, idesc,
enable-input-d {, zero-column-mask-desc };
.kind = { .kind::f16, .kind::tf32, .kind::f8f6f4 }
----------------------------------------------------------------------------------
// 2. Integer type:
tcgen05.mma.ws.cta_group::1.kind::i8{.collector_usage} [d-tmem], a-desc, b-desc, idesc,
enable-input-d {, zero-column-mask-desc};
tcgen05.mma.ws.cta_group::1.kind::i8{.collector_usage} [d-tmem], [a-tmem], b-desc, idesc,
enable-input-d {, zero-column-mask-desc};
.collector_usage = { .collector::buffer::op }
::buffer = { ::b0, ::b1, ::b2, ::b3 }
::op = { ::fill, ::use, ::lastuse, ::discard}
描述
指令 tcgen05.mma.ws 是一条异步指令,它启动 MxNxK 矩阵乘法和累加运算 D = A*B+D,其中 A 矩阵为 MxK,B 矩阵为 KxN,D 矩阵为 MxN。
当输入谓词参数 enable-input-d 为 false 时,发出 D = A*B 形式的操作。
32 位寄存器操作数 idesc 是指令描述符,如指令描述符中所述,指定输入矩阵、输出矩阵以及矩阵乘法和累加运算的形状、精确类型、稀疏性和其他详细信息。
限定符 .cta_group::1 指定矩阵乘法和累加运算仅在执行线程的 CTA 的 Tensor Memory 上执行。
与集合指令 mma.sync 或 wgmma.mma_async 不同,指令 tcgen05.mma.ws 具有单线程语义。因此,单个线程发出 tcgen05.mma.ws 将导致整个矩阵乘法和累加操作的启动。请参阅 Issue granularity 部分。
限定符 .kind 指定了乘数矩阵元素类型的大致种类。每种 MMA 类型的输入和输出矩阵元素的具体类型在 Instruction descriptor 中指定。
地址操作数 d-tmem 指定了 Tensor Memory 中目标矩阵和累加矩阵 D 的地址。地址操作数 a-tmem 指定了 Tensor Memory 中矩阵 A 的地址。64 位寄存器操作数 a-desc 和 b-desc 是矩阵描述符,分别代表共享内存中的矩阵 A 和 B。矩阵描述符的格式在 Matrix Descriptor Format 中描述。
可选操作数 zero-column-mask-desc 是一个 64 位寄存器,它指定了 zero-column mask descriptor。zero-column mask descriptor 用于生成一个掩码,该掩码指定 B 矩阵的哪些列在矩阵乘法和累加运算中将具有零值,而与共享内存中存在的值无关。
限定符 .collector_usage 指定了矩阵 B 的收集器缓冲区的用法。可以指定以下收集器缓冲区操作:
.collector_usage |
语义 |
|---|---|
|
指定从内存读取的 |
|
指定可以从收集器缓冲区 #N 读取 |
|
指定可以从收集器缓冲区 #N 读取 |
|
指定可以丢弃收集器缓冲区 #N 的内容。 |
如果未指定 .collector_usage 限定符,则默认为 .collector::b0::discard。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
tcgen05.mma.ws.cta_group::1.kind::i8.collector::b2:use [taddr2], [taddr1], bdesc, idesc, p;
tcgen05.commit.cta_group::1.mbarrier::arrive::one.b64 [mbarObj0];
loop:
mbarrier.try_wait.parity.b64 p, [mbarObj0], 0;
@!p bra loop;
9.7.16.9.9.4. TensorCore 第五代指令:tcgen05.mma.ws.sp
tcgen05.mma.ws.sp
使用稀疏 A 矩阵执行第五代权重静止卷积矩阵乘法和累加运算。
语法
// 1. Floating-point type without block scaling:
tcgen05.mma.ws.sp.cta_group::1.kind{.collector_usage} [d-tmem], a-desc, b-desc,
[sp-meta-tmem] , idesc,
enable-input-d {, zero-column-mask-desc};
tcgen05.mma.ws.sp.cta_group::1.kind{.collector_usage} [d-tmem], [a-tmem], b-desc,
[sp-meta-tmem] , idesc,
enable-input-d {, zero-column-mask-desc};
.kind = { .kind::f16, .kind::tf32, .kind::f8f6f4 }
----------------------------------------------------------------------------------
// 2. Integer type:
tcgen05.mma.ws.sp.cta_group::1.kind::i8{.collector_usage} [d-tmem], a-desc, b-desc,
[sp-meta-tmem] , idesc,
enable-input-d {, zero-column-mask-desc};
tcgen05.mma.ws.sp.cta_group::1.kind::i8{.collector_usage} [d-tmem], [a-tmem], b-desc,
[sp-meta-tmem] , idesc,
enable-input-d {, zero-column-mask-desc};
.collector_usage = { .collector::buffer::op }
::buffer = { ::b0, ::b1, ::b2, ::b3 }
::op = { ::fill, ::use, ::lastuse, ::discard}
描述
指令 tcgen05.mma.ws.sp 是一条异步指令,它启动 MxNxK 矩阵乘法和累加运算 D = A*B+D,其中 A 矩阵为 Mx(K/2),B 矩阵为 KxN,D 矩阵为 MxN。Sparse Matrices 描述了稀疏性的详细信息。
当输入谓词参数 enable-input-d 为 false 时,发出 D = A*B 形式的操作。
32 位寄存器操作数 idesc 是指令描述符,如指令描述符中所述,指定输入矩阵、输出矩阵以及矩阵乘法和累加运算的形状、精确类型、稀疏性和其他详细信息。
限定符 .cta_group::1 指定矩阵乘法和累加运算仅在执行线程的 CTA 的 Tensor Memory 上执行。
与集合指令 mma.sync 或 wgmma.mma_async 不同,指令 tcgen05.mma.ws.sp 具有单线程语义。因此,单个线程发出 tcgen05.mma.ws.sp 将导致整个矩阵乘法和累加操作的启动。请参阅 Issue granularity 部分。
限定符 .kind 指定了乘数矩阵元素类型的大致种类。每种 MMA 类型的输入和输出矩阵元素的具体类型在 Instruction descriptor 中指定。
地址操作数 d-tmem 指定了 Tensor Memory 中目标矩阵和累加矩阵 D 的地址。地址操作数 a-tmem 指定了 Tensor Memory 中矩阵 A 的地址。64 位寄存器操作数 a-desc 和 b-desc 是矩阵描述符,分别代表共享内存中的矩阵 A 和 B。矩阵描述符的格式在 Matrix Descriptor Format 中描述。
可选操作数 zero-column-mask-desc 是一个 64 位寄存器,它指定了 zero-column mask descriptor。zero-column mask descriptor 用于生成一个掩码,该掩码指定 B 矩阵的哪些列在矩阵乘法和累加运算中将具有零值,而与共享内存中存在的值无关。
限定符 .collector_usage 指定了矩阵 B 的收集器缓冲区的用法。可以指定以下收集器缓冲区操作:
.collector_usage |
语义 |
|---|---|
|
指定从内存读取的 |
|
指定可以从收集器缓冲区 #N 读取 |
|
指定可以从收集器缓冲区 #N 读取 |
|
指定可以丢弃收集器缓冲区 #N 的内容。 |
如果未指定 .collector_usage 限定符,则默认为 .collector::b0::discard。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
tcgen05.mma.ws.sp.cta_group::1.kind::tf32.collector::b1::fill [taddr1], [taddr0], bdesc,
[tmem_spmeta0], idesc, p;
tcgen05.commit.cta_group::1.mbarrier::arrive::one.b64 [mbarObj0];
loop:
mbarrier.try_wait.parity.b64 p, [mbarObj0], 0;
@!p bra loop;
9.7.16.10. TensorCore 第五代专用同步操作
9.7.16.10.1. TensorCore 第五代指令:tcgen05.fence
tcgen05.fence
用于异步 tcgen05 操作的专用栅栏。
语法
tcgen05.fence::before_thread_sync ;
tcgen05.fence::after_thread_sync ;
描述
指令 tcgen05.fence::before_thread_sync 相对于后续的 tcgen05 操作和执行排序操作,对所有先前的异步 tcgen05 操作进行排序。
指令 tcgen05.fence::after_thread_sync 相对于先前的 tcgen05 操作和执行排序操作,对所有后续的异步 tcgen05 操作进行排序。
tcgen05.fence::* 指令与线程范围内的执行排序指令组合,并在同一范围内的 tcgen05 指令之间提供排序。
tcgen05.fence::before_thread_sync 指令充当先前 tcgen05 指令的代码移动栅栏,因为它们不能被提升。 tcgen05.fence::after_thread_sync 指令充当后续 tcgen05 指令的代码移动栅栏,因为它们不能被提升。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
// Producer thread:
tcgen05.cp.cta_group::1.128x256b [taddr0], sdesc0;
tcgen05.fence::before_thread_sync;
st.relaxed.b32 [flag], 1;
// Consumer thread:
loop:
ld.relaxed.b32 r, [flag];
setp.eq.u32 p, r, 1;
@!p bra loop;
tcgen05.fence::after_thread_sync;
tcgen05.mma.cta_group.kind [taddr0], adesc, bdesc, idesc, p;
9.7.16.11. TensorCore 第五代异步同步操作
9.7.16.11.1. TensorCore 第五代指令:tcgen05.commit
tcgen05.commit
使 mbarrier 对象跟踪执行线程启动的所有先前 async-tcgen05 操作的完成情况。
语法
tcgen05.commit.cta_group.completion_mechanism{.shared::cluster}{.multicast}.b64
[mbar] {, ctaMask};
.completion_mechanism = { .mbarrier::arrive::one }
.cta_group = { .cta_group::1, .cta_group::2 }
.multicast = { .multicast::cluster }
描述
指令 tcgen05.commit 是一条异步指令,它使地址操作数 mbar 指定的 mbarrier 对象跟踪执行线程启动的所有先前异步 tcgen05 操作的完成情况,如 基于 mbarrier 的完成机制 中所列。在跟踪的异步 tcgen05 操作完成时,系统会在 mbarrier 对象上触发 .completion_mechanism 指定的信号。
指令 tcgen05.commit.cta_group::1 跟踪当前线程发出的所有先前带有 .cta_group::1 的异步 tcgen05 操作的完成情况。同样,指令 tcgen05.commit.cta_group::2 跟踪当前线程发出的所有先前带有 .cta_group::2 的异步 tcgen05 操作的完成情况。
限定符 .mbarrier::arrive::one 指示在当前线程发出的先前异步 tcgen05 操作完成时,将在 mbarrier 对象上发出到达信号,计数参数为 1。到达信号的作用域是集群作用域。
可选限定符 .multicast::cluster 允许在集群中多个 CTA 的 mbarrier 对象上发出信号。操作数 ctaMask 指定集群中的 CTA,使得 16 位 ctaMask 操作数中的每个位位置对应于目标 CTA 的 %cluster_ctarank。mbarrier 信号被多播到每个目标 CTA 的共享内存中与 mbar 相同的偏移量。
如果未指定状态空间,则使用 Generic Addressing。如果 mbar 指定的地址未落在 .shared::cluster 状态空间的地址窗口内,则行为未定义。
PTX ISA 注释
在 PTX ISA 8.6 版本中引入。
目标 ISA 注释
以下架构支持
sm_100asm_101a
示例
Example 1:
tcgen05.cp.cta_group::1.128x256b [taddr0], sdesc0;
tcgen05.commit.cta_group::1.mbarrier::arrive::one.b64 [mbarObj1];
loop:
mbarrier.try_wait.parity.b64 p, [mbarObj1], 0;
@!p bra loop;
Example 2:
tcgen05.mma.cta_group::2.kind::tf32 [taddr0], adesc, bdesc, idesc, p;
tcgen05.commit.cta_group::2.mbarrier::arrive::one.b64 [mbarObj2];
loop:
mbarrier.try_wait.parity.b64 p, [mbarObj2], 0;
@!p bra loop;
9.7.17. 堆栈操作指令
堆栈操作指令可用于动态分配和释放当前函数堆栈帧上的内存。
堆栈操作指令包括:
stacksavestackrestorealloca
9.7.17.1. 堆栈操作指令:stacksave
stacksave
将堆栈指针的值保存到寄存器中。
语法
stacksave.type d;
.type = { .u32, .u64 };
描述
将堆栈指针的当前值复制到目标寄存器 d 中。stacksave 返回的指针可以在后续的 stackrestore 指令中使用,以恢复堆栈指针。如果在 stackrestore 指令中使用之前修改了 d,则可能会损坏堆栈中的数据。
目标操作数 d 的类型与指令类型相同。
语义
d = stackptr;
PTX ISA 注释
在 PTX ISA 版本 7.3 中引入。
- 预览功能
-
stacksave是 PTX ISA 版本 7.3 中的预览功能。所有细节都可能更改,并且不保证未来 PTX ISA 版本或 SM 架构的向后兼容性。
目标 ISA 注释
stacksave 需要 sm_52 或更高版本。
示例
.reg .u32 rd;
stacksave.u32 rd;
.reg .u64 rd1;
stacksave.u64 rd1;
9.7.17.2. 堆栈操作指令:stackrestore
stackrestore
使用新值更新堆栈指针。
语法
stackrestore.type a;
.type = { .u32, .u64 };
描述
将当前堆栈指针设置为源寄存器 a。
当 stackrestore 与由先前的 stacksave 指令写入的操作数 a 一起使用时,它将有效地恢复堆栈状态,使其与执行 stacksave 之前相同。请注意,如果 stackrestore 与任意值 a 一起使用,则可能会导致堆栈指针损坏。这意味着此功能的正确使用要求在 stacksave.type a 之后使用 stackrestore.type a,而无需在它们之间重新定义 a 的值。
操作数 a 的类型与指令类型相同。
语义
stackptr = a;
PTX ISA 注释
在 PTX ISA 版本 7.3 中引入。
- 预览功能
-
stackrestore是 PTX ISA 版本 7.3 中的预览功能。所有细节都可能更改,并且不保证未来 PTX ISA 版本或 SM 架构的向后兼容性。
目标 ISA 注释
stackrestore 需要 sm_52 或更高版本。
示例
.reg .u32 ra;
stacksave.u32 ra;
// Code that may modify stack pointer
...
stackrestore.u32 ra;
9.7.17.3. 堆栈操作指令:alloca
alloca
在堆栈上动态分配内存。
语法
alloca.type ptr, size{, immAlign};
.type = { .u32, .u64 };
描述
alloca 指令在当前函数的堆栈帧上动态分配内存,并相应地更新堆栈指针。返回的指针 ptr 指向本地内存,并且可以在 ld.local 和 st.local 指令的地址操作数中使用。
如果堆栈上没有足够的内存用于分配,则执行 alloca 可能会导致堆栈溢出。在这种情况下,尝试使用 ptr 访问已分配的内存将导致未定义的程序行为。
alloca 分配的内存通过以下方式释放:
当函数退出时,它会自动释放。
可以使用
stacksave和stackrestore指令显式释放:stacksave可用于在执行alloca之前保存堆栈指针的值,stackrestore可在alloca之后使用,以将堆栈指针恢复为先前使用stacksave保存的原始值。请注意,在执行stackrestore后访问已释放的内存会导致未定义的行为。
size 是一个无符号值,它指定要在堆栈上分配的内存量(以字节为单位)。 size = 0 可能不会导致有效的内存分配。
ptr 和 size 都具有与指令类型相同的类型。
immAlign 是一个 32 位值,它指定 alloca 分配的内存的对齐要求(以字节为单位)。它是一个整数常量,必须是 2 的幂,并且不得超过 2^23。 immAlign 是一个可选参数,默认值为 8,这是保证的最小对齐方式。
语义
alloca.type ptr, size, immAlign:
a = max(immAlign, frame_align); // frame_align is the minimum guaranteed alignment
// Allocate size bytes of stack memory with alignment a and update the stack pointer.
// Since the stack grows down, the updated stack pointer contains a lower address.
stackptr = alloc_stack_mem(size, a);
// Return the new value of stack pointer as ptr. Since ptr is the lowest address of the memory
// allocated by alloca, the memory can be accessed using ptr up to (ptr + size of allocated memory).
stacksave ptr;
PTX ISA 注释
在 PTX ISA 版本 7.3 中引入。
- 预览功能
-
alloca是 PTX ISA 版本 7.3 中的预览功能。所有细节都可能更改,并且不保证未来 PTX ISA 版本或 SM 架构的向后兼容性。
目标 ISA 注释
alloca 需要 sm_52 或更高版本。
示例
.reg .u32 ra, stackptr, ptr, size;
stacksave.u32 stackptr; // Save the current stack pointer
alloca ptr, size, 8; // Allocate stack memory
st.local.u32 [ptr], ra; // Use the allocated stack memory
stackrestore.u32 stackptr; // Deallocate memory by restoring the stack pointer
9.7.18. 视频指令
所有视频指令都在 32 位寄存器操作数上运行。但是,视频指令可以根据其核心操作是应用于一个值还是多个值而分为标量或 SIMD。
视频指令包括:
vadd、vadd2、vadd4vsub、vsub2、vsub4vmadvavrg2、vavrg4vabsdiff、vabsdiff2、vabsdiff4vmin、vmin2、vmin4vmax、vmax2、vmax4vshlvshrvset、vset2、vset4
9.7.18.1. 标量视频指令
所有标量视频指令都在 32 位寄存器操作数上运行。标量视频指令包括:
vaddvsubvabsdiffvminvmaxvshlvshrvmadvset
标量视频指令执行以下阶段:
从其源操作数中提取并进行符号扩展或零扩展字节、半字或字值,以生成带符号的 33 位输入值。
执行标量算术运算以生成带符号的 34 位结果。
可选地将结果钳制到目标类型的范围。
-
可选地执行以下操作之一:
将二次运算应用于中间结果和第三个操作数,或
将中间结果截断为字节或半字值,并合并到第三个操作数中的指定位置以生成最终结果。
标量视频指令的一般格式如下:
// 32-bit scalar operation, with optional secondary operation
vop.dtype.atype.btype{.sat} d, a{.asel}, b{.bsel};
vop.dtype.atype.btype{.sat}.secop d, a{.asel}, b{.bsel}, c;
// 32-bit scalar operation, with optional data merge
vop.dtype.atype.btype{.sat} d.dsel, a{.asel}, b{.bsel}, c;
.dtype = .atype = .btype = { .u32, .s32 };
.dsel = .asel = .bsel = { .b0, .b1, .b2, .b3, .h0, .h1 };
.secop = { .add, .min, .max };
源操作数和目标操作数均为 32 位寄存器。每个操作数的类型(.u32 或 .s32)在指令类型中指定;dtype、atype 和 btype 的所有组合均有效。使用 atype/btype 和 asel/bsel 说明符,输入值被提取并在内部进行符号扩展或零扩展为 .s33 值。然后执行主运算以生成 .s34 中间结果。中间结果的符号取决于 dtype。
中间结果可选地钳制到目标类型的范围(有符号或无符号),在可选数据合并的情况下,需要考虑子字目标大小。
.s33 optSaturate( .s34 tmp, Bool sat, Bool sign, Modifier dsel ) {
if ( !sat ) return tmp;
switch ( dsel ) {
case .b0, .b1, .b2, .b3:
if ( sign ) return CLAMP( tmp, S8_MAX, S8_MIN );
else return CLAMP( tmp, U8_MAX, U8_MIN );
case .h0, .h1:
if ( sign ) return CLAMP( tmp, S16_MAX, S16_MIN );
else return CLAMP( tmp, U16_MAX, U16_MIN );
default:
if ( sign ) return CLAMP( tmp, S32_MAX, S32_MIN );
else return CLAMP( tmp, U32_MAX, U32_MIN );
}
}
然后,此中间结果可选地与第三个源操作数结合使用,使用二次算术运算或子字数据合并,如下面的伪代码所示。第三个操作数的符号基于 dtype。
.s33 optSecOp(Modifier secop, .s33 tmp, .s33 c) {
switch ( secop ) {
.add: return tmp + c;
.min: return MIN(tmp, c);
.max return MAX(tmp, c);
default: return tmp;
}
}
.s33 optMerge( Modifier dsel, .s33 tmp, .s33 c ) {
switch ( dsel ) {
case .h0: return ((tmp & 0xffff) | (0xffff0000 & c);
case .h1: return ((tmp & 0xffff) << 16) | (0x0000ffff & c);
case .b0: return ((tmp & 0xff) | (0xffffff00 & c);
case .b1: return ((tmp & 0xff) << 8) | (0xffff00ff & c);
case .b2: return ((tmp & 0xff) << 16) | (0xff00ffff & c);
case .b3: return ((tmp & 0xff) << 24) | (0x00ffffff & c);
default: return tmp;
}
}
然后将低 32 位写入目标操作数。
9.7.18.1.1. 标量视频指令:vadd、vsub、vabsdiff、vmin、vmax
vadd、vsub
整数字节/半字/字加法/减法。
vabsdiff
整数字节/半字/字差值的绝对值。
vmin、vmax
整数字节/半字/字最小值/最大值。
语法
// 32-bit scalar operation, with optional secondary operation
vop.dtype.atype.btype{.sat} d, a{.asel}, b{.bsel};
vop.dtype.atype.btype{.sat}.op2 d, a{.asel}, b{.bsel}, c;
// 32-bit scalar operation, with optional data merge
vop.dtype.atype.btype{.sat} d.dsel, a{.asel}, b{.bsel}, c;
vop = { vadd, vsub, vabsdiff, vmin, vmax };
.dtype = .atype = .btype = { .u32, .s32 };
.dsel = .asel = .bsel = { .b0, .b1, .b2, .b3, .h0, .h1 };
.op2 = { .add, .min, .max };
描述
执行标量算术运算,可选择饱和,以及可选的二次算术运算或子字数据合并。
语义
// extract byte/half-word/word and sign- or zero-extend
// based on source operand type
ta = partSelectSignExtend( a, atype, asel );
tb = partSelectSignExtend( b, btype, bsel );
switch ( vop ) {
case vadd: tmp = ta + tb;
case vsub: tmp = ta - tb;
case vabsdiff: tmp = | ta - tb |;
case vmin: tmp = MIN( ta, tb );
case vmax: tmp = MAX( ta, tb );
}
// saturate, taking into account destination type and merge operations
tmp = optSaturate( tmp, sat, isSigned(dtype), dsel );
d = optSecondaryOp( op2, tmp, c ); // optional secondary operation
d = optMerge( dsel, tmp, c ); // optional merge with c operand
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
vadd、vsub、vabsdiff、vmin、vmax 需要 sm_20 或更高版本。
示例
vadd.s32.u32.s32.sat r1, r2.b0, r3.h0;
vsub.s32.s32.u32.sat r1, r2.h1, r3.h1;
vabsdiff.s32.s32.s32.sat r1.h0, r2.b0, r3.b2, c;
vmin.s32.s32.s32.sat.add r1, r2, r3, c;
9.7.18.1.2. 标量视频指令:vshl、vshr
vshl、vshr
整数字节/半字/字左移/右移。
语法
// 32-bit scalar operation, with optional secondary operation
vop.dtype.atype.u32{.sat}.mode d, a{.asel}, b{.bsel};
vop.dtype.atype.u32{.sat}.mode.op2 d, a{.asel}, b{.bsel}, c;
// 32-bit scalar operation, with optional data merge
vop.dtype.atype.u32{.sat}.mode d.dsel, a{.asel}, b{.bsel}, c;
vop = { vshl, vshr };
.dtype = .atype = { .u32, .s32 };
.mode = { .clamp, .wrap };
.dsel = .asel = .bsel = { .b0, .b1, .b2, .b3, .h0, .h1 };
.op2 = { .add, .min, .max };
描述
vshl-
将
a左移b中的无符号量,可选择饱和,以及可选的二次算术运算或子字数据合并。左移用零填充。 vshr-
将
a右移b中的无符号量,可选择饱和,以及可选的二次算术运算或子字数据合并。有符号移位用符号位填充,无符号移位用零填充。
语义
// extract byte/half-word/word and sign- or zero-extend
// based on source operand type
ta = partSelectSignExtend( a,atype, asel );
tb = partSelectSignExtend( b, .u32, bsel );
if ( mode == .clamp && tb > 32 ) tb = 32;
if ( mode == .wrap ) tb = tb & 0x1f;
switch ( vop ){
case vshl: tmp = ta << tb;
case vshr: tmp = ta >> tb;
}
// saturate, taking into account destination type and merge operations
tmp = optSaturate( tmp, sat, isSigned(dtype), dsel );
d = optSecondaryOp( op2, tmp, c ); // optional secondary operation
d = optMerge( dsel, tmp, c ); // optional merge with c operand
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
vshl、vshr 需要 sm_20 或更高版本。
示例
vshl.s32.u32.u32.clamp r1, r2, r3;
vshr.u32.u32.u32.wrap r1, r2, r3.h1;
9.7.18.1.3. 标量视频指令:vmad
vmad
整数字节/半字/字乘法累加。
语法
// 32-bit scalar operation
vmad.dtype.atype.btype{.sat}{.scale} d, {-}a{.asel}, {-}b{.bsel},
{-}c;
vmad.dtype.atype.btype.po{.sat}{.scale} d, a{.asel}, b{.bsel}, c;
.dtype = .atype = .btype = { .u32, .s32 };
.asel = .bsel = { .b0, .b1, .b2, .b3, .h0, .h1 };
.scale = { .shr7, .shr15 };
描述
计算 (a*b) + c,带有可选的操作数取反、加一 模式和缩放。
源操作数支持可选的取反,但有一些限制。尽管 PTX 语法允许单独取反 a 和 b 操作数,但在内部,这表示为乘积 (a*b) 的取反。也就是说,当且仅当 a 或 b 中恰好有一个被取反时,(a*b) 才会被取反。PTX 允许取反 (a*b) 或 c。
加一模式 (.po) 计算 (a*b) + c + 1,这用于计算平均值。源操作数在 .po 模式下可能不会被取反。
如果 atype 和 btype 是无符号的,并且乘积 (a*b) 未被取反,则 (a*b) 的中间结果是无符号的;否则,中间结果是有符号的。输入 c 与中间结果具有相同的符号。
如果中间结果是无符号的,并且 c 未被取反,则最终结果是无符号的。
根据 a 和 b 操作数的符号以及操作数取反,VMAD 支持以下操作数组合
(u32 * u32) + u32 // intermediate unsigned; final unsigned
-(u32 * u32) + s32 // intermediate signed; final signed
(u32 * u32) - u32 // intermediate unsigned; final signed
(u32 * s32) + s32 // intermediate signed; final signed
-(u32 * s32) + s32 // intermediate signed; final signed
(u32 * s32) - s32 // intermediate signed; final signed
(s32 * u32) + s32 // intermediate signed; final signed
-(s32 * u32) + s32 // intermediate signed; final signed
(s32 * u32) - s32 // intermediate signed; final signed
(s32 * s32) + s32 // intermediate signed; final signed
-(s32 * s32) + s32 // intermediate signed; final signed
(s32 * s32) - s32 // intermediate signed; final signed
中间结果可以选择通过右移进行缩放;如果最终结果是有符号的,则此结果进行符号扩展,否则进行零扩展。
最终结果可以选择根据最终结果的类型(有符号或无符号)饱和到适当的 32 位范围。
语义
// extract byte/half-word/word and sign- or zero-extend
// based on source operand type
ta = partSelectSignExtend( a, atype, asel );
tb = partSelectSignExtend( b, btype, bsel );
signedFinal = isSigned(atype) || isSigned(btype) ||
(a.negate ^ b.negate) || c.negate;
tmp[127:0] = ta * tb;
lsb = 0;
if ( .po ) { lsb = 1; } else
if ( a.negate ^ b.negate ) { tmp = ~tmp; lsb = 1; } else
if ( c.negate ) { c = ~c; lsb = 1; }
c128[127:0] = (signedFinal) sext32( c ) : zext ( c );
tmp = tmp + c128 + lsb;
switch( scale ) {
case .shr7: result = (tmp >> 7) & 0xffffffffffffffff;
case .shr15: result = (tmp >> 15) & 0xffffffffffffffff;
}
if ( .sat ) {
if (signedFinal) result = CLAMP(result, S32_MAX, S32_MIN);
else result = CLAMP(result, U32_MAX, U32_MIN);
}
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
vmad 需要 sm_20 或更高版本。
示例
vmad.s32.s32.u32.sat r0, r1, r2, -r3;
vmad.u32.u32.u32.shr15 r0, r1.h0, r2.h0, r3;
9.7.18.1.4. 标量视频指令:vset
vset
整数字节/半字/字比较。
语法
// 32-bit scalar operation, with optional secondary operation
vset.atype.btype.cmp d, a{.asel}, b{.bsel};
vset.atype.btype.cmp.op2 d, a{.asel}, b{.bsel}, c;
// 32-bit scalar operation, with optional data merge
vset.atype.btype.cmp d.dsel, a{.asel}, b{.bsel}, c;
.atype = .btype = { .u32, .s32 };
.cmp = { .eq, .ne, .lt, .le, .gt, .ge };
.dsel = .asel = .bsel = { .b0, .b1, .b2, .b3, .h0, .h1 };
.op2 = { .add, .min, .max };
描述
使用指定的比较来比较输入值,带有可选的辅助算术运算或子字数据合并。
比较的中间结果始终是无符号的,因此目标 d 和操作数 c 也是无符号的。
语义
// extract byte/half-word/word and sign- or zero-extend
// based on source operand type
ta = partSelectSignExtend( a, atype, asel );
tb = partSelectSignExtend( b, btype, bsel );
tmp = compare( ta, tb, cmp ) ? 1 : 0;
d = optSecondaryOp( op2, tmp, c ); // optional secondary operation
d = optMerge( dsel, tmp, c ); // optional merge with c operand
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
vset 需要 sm_20 或更高版本。
示例
vset.s32.u32.lt r1, r2, r3;
vset.u32.u32.ne r1, r2, r3.h1;
9.7.18.2. SIMD 视频指令
SIMD 视频指令对成对的 16 位值和四元组的 8 位值进行操作。
SIMD 视频指令包括
vadd2,vadd4vsub2,vsub4vavrg2、vavrg4vabsdiff2,vabsdiff4vmin2,vmin4vmax2,vmax4vset2,vset4
PTX 包括 SIMD 视频指令,用于对成对的 16 位值和四元组的 8 位值进行操作。SIMD 视频指令执行以下阶段
通过从源操作数中提取字节或半字值并进行符号或零扩展来形成输入向量,以形成成对的有符号 17 位值。
对输入对执行 SIMD 算术运算。
可选地将结果钳位到由目标类型确定的适当有符号或无符号范围。
-
可选地执行以下操作之一:
执行第二次 SIMD 合并操作,或者
应用标量累加操作以将中间 SIMD 结果缩减为单个标量。
双半字 SIMD 视频指令的一般格式如下
// 2-way SIMD operation, with second SIMD merge or accumulate
vop2.dtype.atype.btype{.sat}{.add} d{.mask}, a{.asel}, b{.bsel}, c;
.dtype = .atype = .btype = { .u32, .s32 };
.mask = { .h0, .h1, .h10 };
.asel = .bsel = { .hxy, where x,y are from { 0, 1, 2, 3 } };
四字节 SIMD 视频指令的一般格式如下
// 4-way SIMD operation, with second SIMD merge or accumulate
vop4.dtype.atype.btype{.sat}{.add} d{.mask}, a{.asel}, b{.bsel}, c;
.dtype = .atype = .btype = { .u32, .s32 };
.mask = { .b0,
.b1, .b10
.b2, .b20, .b21, .b210,
.b3, .b30, .b31, .b310, .b32, .b320, .b321, .b3210 };
.asel = .bsel = .bxyzw, where x,y,z,w are from { 0, ..., 7 };
源操作数和目标操作数都是 32 位寄存器。每个操作数的类型(.u32 或 .s32)在指令类型中指定;dtype、atype 和 btype 的所有组合都是有效的。使用 atype/btype 和 asel/bsel 说明符,输入值被提取并在内部进行符号或零扩展为 .s33 值。然后执行主运算以产生 .s34 中间结果。中间结果的符号取决于 dtype。
中间结果可选地钳制到目标类型的范围(有符号或无符号),在可选数据合并的情况下,需要考虑子字目标大小。
9.7.18.2.1. SIMD 视频指令:vadd2、vsub2、vavrg2、vabsdiff2、vmin2、vmax2
vadd2, vsub2
整数双半字 SIMD 加法/减法。
vavrg2
整数双半字 SIMD 平均值。
vabsdiff2
整数双半字 SIMD 差的绝对值。
vmin2, vmax2
整数双半字 SIMD 最小值/最大值。
语法
// SIMD instruction with secondary SIMD merge operation
vop2.dtype.atype.btype{.sat} d{.mask}, a{.asel}, b{.bsel}, c;
// SIMD instruction with secondary accumulate operation
vop2.dtype.atype.btype.add d{.mask}, a{.asel}, b{.bsel}, c;
vop2 = { vadd2, vsub2, vavrg2, vabsdiff2, vmin2, vmax2 };
.dtype = .atype = .btype = { .u32, .s32 };
.mask = { .h0, .h1, .h10 }; // defaults to .h10
.asel = .bsel = { .hxy, where x,y are from { 0, 1, 2, 3 } };
.asel defaults to .h10
.bsel defaults to .h32
描述
带有辅助运算的双向 SIMD 并行算术运算。
每个双半字源操作的元素都从两个源操作数 a 和 b 中的四个半字中的任何一个中选择,使用 asel 和 bsel 修饰符。
然后对选定的半字并行执行操作。
结果可以选择钳位到由目标类型(有符号或无符号)确定的适当范围。饱和不能与辅助累加运算一起使用。
对于具有辅助 SIMD 合并操作的指令
对于掩码中指示的半字位置,选定的半字结果被复制到目标
d中。对于所有其他位置,源操作数c中的相应半字被复制到d。
对于具有辅助累加操作的指令
对于掩码中指示的半字位置,选定的半字结果被添加到操作数
c,在d中产生结果。
语义
// extract pairs of half-words and sign- or zero-extend
// based on operand type
Va = extractAndSignExt_2( a, b, .asel, .atype );
Vb = extractAndSignExt_2( a, b, .bsel, .btype );
Vc = extractAndSignExt_2( c );
for (i=0; i<2; i++) {
switch ( vop2 ) {
case vadd2: t[i] = Va[i] + Vb[i];
case vsub2: t[i] = Va[i] - Vb[i];
case vavrg2: if ( ( Va[i] + Vb[i] ) >= 0 ) {
t[i] = ( Va[i] + Vb[i] + 1 ) >> 1;
} else {
t[i] = ( Va[i] + Vb[i] ) >> 1;
}
case vabsdiff2: t[i] = | Va[i] - Vb[i] |;
case vmin2: t[i] = MIN( Va[i], Vb[i] );
case vmax2: t[i] = MAX( Va[i], Vb[i] );
}
if (.sat) {
if ( .dtype == .s32 ) t[i] = CLAMP( t[i], S16_MAX, S16_MIN );
else t[i] = CLAMP( t[i], U16_MAX, U16_MIN );
}
}
// secondary accumulate or SIMD merge
mask = extractMaskBits( .mask );
if (.add) {
d = c;
for (i=0; i<2; i++) { d += mask[i] ? t[i] : 0; }
} else {
d = 0;
for (i=0; i<2; i++) { d |= mask[i] ? t[i] : Vc[i]; }
}
PTX ISA 注释
在 PTX ISA 版本 3.0 中引入。
目标 ISA 注释
vadd2、vsub2、varvg2、vabsdiff2、vmin2、vmax2 需要 sm_30 或更高版本。
示例
vadd2.s32.s32.u32.sat r1, r2, r3, r1;
vsub2.s32.s32.s32.sat r1.h0, r2.h10, r3.h32, r1;
vmin2.s32.u32.u32.add r1.h10, r2.h00, r3.h22, r1;
9.7.18.2.2. SIMD 视频指令:vset2
vset2
整数双半字 SIMD 比较。
语法
// SIMD instruction with secondary SIMD merge operation
vset2.atype.btype.cmp d{.mask}, a{.asel}, b{.bsel}, c;
// SIMD instruction with secondary accumulate operation
vset2.atype.btype.cmp.add d{.mask}, a{.asel}, b{.bsel}, c;
.atype = .btype = { .u32, .s32 };
.cmp = { .eq, .ne, .lt, .le, .gt, .ge };
.mask = { .h0, .h1, .h10 }; // defaults to .h10
.asel = .bsel = { .hxy, where x,y are from { 0, 1, 2, 3 } };
.asel defaults to .h10
.bsel defaults to .h32
描述
带有辅助运算的双向 SIMD 并行比较。
每个双半字源操作的元素都从两个源操作数 a 和 b 中的四个半字中的任何一个中选择,使用 asel 和 bsel 修饰符。
然后对选定的半字并行进行比较。
比较的中间结果始终是无符号的,因此目标 d 和操作数 c 的半字也是无符号的。
对于具有辅助 SIMD 合并操作的指令
对于掩码中指示的半字位置,选定的半字结果被复制到目标
d中。对于所有其他位置,源操作数b中的相应半字被复制到d。
对于具有辅助累加操作的指令
对于掩码中指示的半字位置,选定的半字结果被添加到操作数
c,在d中产生a结果。
语义
// extract pairs of half-words and sign- or zero-extend
// based on operand type
Va = extractAndSignExt_2( a, b, .asel, .atype );
Vb = extractAndSignExt_2( a, b, .bsel, .btype );
Vc = extractAndSignExt_2( c );
for (i=0; i<2; i++) {
t[i] = compare( Va[i], Vb[i], .cmp ) ? 1 : 0;
}
// secondary accumulate or SIMD merge
mask = extractMaskBits( .mask );
if (.add) {
d = c;
for (i=0; i<2; i++) { d += mask[i] ? t[i] : 0; }
} else {
d = 0;
for (i=0; i<2; i++) { d |= mask[i] ? t[i] : Vc[i]; }
}
PTX ISA 注释
在 PTX ISA 版本 3.0 中引入。
目标 ISA 注释
vset2 需要 sm_30 或更高版本。
示例
vset2.s32.u32.lt r1, r2, r3, r0;
vset2.u32.u32.ne.add r1, r2, r3, r0;
9.7.18.2.3. SIMD 视频指令:vadd4、vsub4、vavrg4、vabsdiff4、vmin4、vmax4
vadd4, vsub4
整数四字节 SIMD 加法/减法。
vavrg4
整数四字节 SIMD 平均值。
vabsdiff4
整数四字节 SIMD 差的绝对值。
vmin4, vmax4
整数四字节 SIMD 最小值/最大值。
语法
// SIMD instruction with secondary SIMD merge operation
vop4.dtype.atype.btype{.sat} d{.mask}, a{.asel}, b{.bsel}, c;
// SIMD instruction with secondary accumulate operation
vop4.dtype.atype.btype.add d{.mask}, a{.asel}, b{.bsel}, c;
vop4 = { vadd4, vsub4, vavrg4, vabsdiff4, vmin4, vmax4 };
.dtype = .atype = .btype = { .u32, .s32 };
.mask = { .b0,
.b1, .b10
.b2, .b20, .b21, .b210,
.b3, .b30, .b31, .b310, .b32, .b320, .b321, .b3210 };
defaults to .b3210
.asel = .bsel = .bxyzw, where x,y,z,w are from { 0, ..., 7 };
.asel defaults to .b3210
.bsel defaults to .b7654
描述
带有辅助运算的四向 SIMD 并行算术运算。
每个四字节源操作的元素都从两个源操作数 a 和 b 中的八个字节中的任何一个中选择,使用 asel 和 bsel 修饰符。
然后对选定的字节并行执行操作。
结果可以选择钳位到由目标类型(有符号或无符号)确定的适当范围。饱和不能与辅助累加运算一起使用。
对于具有辅助 SIMD 合并操作的指令
对于掩码中指示的字节位置,选定的字节结果被复制到目标
d中。对于所有其他位置,源操作数c中的相应字节被复制到d。
对于具有辅助累加操作的指令
对于掩码中指示的字节位置,选定的字节结果被添加到操作数
c,在d中产生结果。
语义
// extract quads of bytes and sign- or zero-extend
// based on operand type
Va = extractAndSignExt_4( a, b, .asel, .atype );
Vb = extractAndSignExt_4( a, b, .bsel, .btype );
Vc = extractAndSignExt_4( c );
for (i=0; i<4; i++) {
switch ( vop4 ) {
case vadd4: t[i] = Va[i] + Vb[i];
case vsub4: t[i] = Va[i] - Vb[i];
case vavrg4: if ( ( Va[i] + Vb[i] ) >= 0 ) {
t[i] = ( Va[i] + Vb[i] + 1 ) >> 1;
} else {
t[i] = ( Va[i] + Vb[i] ) >> 1;
}
case vabsdiff4: t[i] = | Va[i] - Vb[i] |;
case vmin4: t[i] = MIN( Va[i], Vb[i] );
case vmax4: t[i] = MAX( Va[i], Vb[i] );
}
if (.sat) {
if ( .dtype == .s32 ) t[i] = CLAMP( t[i], S8_MAX, S8_MIN );
else t[i] = CLAMP( t[i], U8_MAX, U8_MIN );
}
}
// secondary accumulate or SIMD merge
mask = extractMaskBits( .mask );
if (.add) {
d = c;
for (i=0; i<4; i++) { d += mask[i] ? t[i] : 0; }
} else {
d = 0;
for (i=0; i<4; i++) { d |= mask[i] ? t[i] : Vc[i]; }
}
PTX ISA 注释
在 PTX ISA 版本 3.0 中引入。
目标 ISA 注释
vadd4、vsub4、varvg4、vabsdiff4、vmin4、vmax4 需要 sm_30 或更高版本。
示例
vadd4.s32.s32.u32.sat r1, r2, r3, r1;
vsub4.s32.s32.s32.sat r1.b0, r2.b3210, r3.b7654, r1;
vmin4.s32.u32.u32.add r1.b00, r2.b0000, r3.b2222, r1;
9.7.18.2.4. SIMD 视频指令:vset4
vset4
整数四字节 SIMD 比较。
语法
// SIMD instruction with secondary SIMD merge operation
vset4.atype.btype.cmp d{.mask}, a{.asel}, b{.bsel}, c;
// SIMD instruction with secondary accumulate operation
vset4.atype.btype.cmp.add d{.mask}, a{.asel}, b{.bsel}, c;
.atype = .btype = { .u32, .s32 };
.cmp = { .eq, .ne, .lt, .le, .gt, .ge };
.mask = { .b0,
.b1, .b10
.b2, .b20, .b21, .b210,
.b3, .b30, .b31, .b310, .b32, .b320, .b321, .b3210 };
defaults to .b3210
.asel = .bsel = .bxyzw, where x,y,z,w are from { 0, ..., 7 };
.asel defaults to .b3210
.bsel defaults to .b7654
描述
带有辅助运算的四向 SIMD 并行比较。
每个四字节源操作的元素都从两个源操作数 a 和 b 中的八个字节中的任何一个中选择,使用 asel 和 bsel 修饰符。
然后对选定的字节并行进行比较。
比较的中间结果始终是无符号的,因此目标 d 和操作数 c 的字节也是无符号的。
对于具有辅助 SIMD 合并操作的指令
对于掩码中指示的字节位置,选定的字节结果被复制到目标
d中。对于所有其他位置,源操作数b中的相应字节被复制到d。
对于具有辅助累加操作的指令
对于掩码中指示的字节位置,选定的字节结果被添加到操作数
c,在d中产生结果。
语义
// extract quads of bytes and sign- or zero-extend
// based on operand type
Va = extractAndSignExt_4( a, b, .asel, .atype );
Vb = extractAndSignExt_4( a, b, .bsel, .btype );
Vc = extractAndSignExt_4( c );
for (i=0; i<4; i++) {
t[i] = compare( Va[i], Vb[i], cmp ) ? 1 : 0;
}
// secondary accumulate or SIMD merge
mask = extractMaskBits( .mask );
if (.add) {
d = c;
for (i=0; i<4; i++) { d += mask[i] ? t[i] : 0; }
} else {
d = 0;
for (i=0; i<4; i++) { d |= mask[i] ? t[i] : Vc[i]; }
}
PTX ISA 注释
在 PTX ISA 版本 3.0 中引入。
目标 ISA 注释
vset4 需要 sm_30 或更高版本。
示例
vset4.s32.u32.lt r1, r2, r3, r0;
vset4.u32.u32.ne.max r1, r2, r3, r0;
9.7.19. 杂项指令
杂项指令包括
brkptnanosleeppmeventtrapsetmaxnreg
9.7.19.1. 杂项指令:brkpt
brkpt
断点。
语法
brkpt;
描述
暂停执行。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
brkpt 需要 sm_11 或更高版本。
示例
brkpt;
@p brkpt;
9.7.19.2. 杂项指令:nanosleep
nanosleep
挂起线程,延迟时间近似以纳秒为单位给出。
语法
nanosleep.u32 t;
描述
挂起线程,睡眠持续时间近似接近延迟时间 t,以纳秒为单位指定。t 可以是寄存器或立即数。
睡眠持续时间是近似的,但保证在区间 [0, 2*t] 内。最大睡眠持续时间为 1 毫秒。实现可能会减少 warp 中各个线程的睡眠持续时间,以便 warp 中所有休眠的线程一起唤醒。
PTX ISA 注释
nanosleep 在 PTX ISA 6.3 中引入。
目标 ISA 注释
nanosleep 需要 sm_70 或更高版本。
示例
.reg .b32 r;
.reg .pred p;
nanosleep.u32 r;
nanosleep.u32 42;
@p nanosleep.u32 r;
9.7.19.3. 杂项指令:pmevent
pmevent
触发一个或多个性能监视器事件。
语法
pmevent a; // trigger a single performance monitor event
pmevent.mask a; // trigger one or more performance monitor events
描述
触发固定数量的性能监视器事件中的一个或多个,事件索引或掩码由立即操作数 a 指定。
pmevent(不带修饰符 .mask)触发由立即操作数 a 索引的单个性能监视器事件,范围为 0..15。
pmevent.mask 触发一个或多个性能监视器事件。16 位立即操作数 a 中的每一位控制一个事件。
程序化性能监视器事件可以与使用布尔函数的其他硬件事件组合,以递增四个性能计数器之一。事件和计数器之间的关系通过来自主机的 API 调用进行编程。
注释
目前,有 16 个性能监视器事件,编号为 0 到 15。
PTX ISA 注释
pmevent 在 PTX ISA 版本 1.4 中引入。
pmevent.mask 在 PTX ISA 版本 3.0 中引入。
目标 ISA 注释
所有目标架构都支持 pmevent。
pmevent.mask 需要 sm_20 或更高版本。
示例
pmevent 1;
@p pmevent 7;
@q pmevent.mask 0xff;
9.7.19.4. 杂项指令:trap
trap
执行陷阱操作。
语法
trap;
描述
中止执行并向主机 CPU 生成中断。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
trap;
@p trap;
9.7.19.5. 杂项指令:setmaxnreg
setmaxnreg
提示更改 warp 拥有的寄存器数量。
语法
setmaxnreg.action.sync.aligned.u32 imm-reg-count;
.action = { .inc, .dec };
描述
setmaxnreg 向系统提供一个提示,以将执行 warp 拥有的每个线程的最大寄存器数量更新为 imm-reg-count 操作数指定的值。
限定符 .dec 用于释放额外的寄存器,以便将每个线程的绝对最大寄存器计数从其当前值减少到 imm-reg-count。限定符 .inc 用于请求额外的寄存器,以便将每个线程的绝对最大寄存器计数从其当前值增加到 imm-reg-count。
每个 CTA 维护一个可用寄存器池。setmaxnreg 指令请求的寄存器调整通过根据 .action 限定符的值,从该池向请求 warp 提供额外的寄存器,或者从请求 warp 向该池释放额外的寄存器来处理。
setmaxnreg.inc 指令会阻止执行,直到 CTA 的寄存器池中有足够的寄存器可用。在指令 setmaxnreg.inc 从 CTA 池中获取新寄存器后,新寄存器的初始内容是未定义的。新寄存器在使用前必须初始化。
相同的 setmaxnreg 指令必须由 warpgroup 中的所有 warp 执行。执行 setmaxnreg 指令后,warpgroup 中的所有 warp 必须显式同步,然后才能执行后续的 setmaxnreg 指令。如果 warpgroup 中的所有 warp 未执行 setmaxnreg 指令,则行为未定义。
操作数 imm-reg-count 是一个整数常量。imm-reg-count 的值必须在 24 到 256(包括两者)的范围内,并且必须是 8 的倍数。
对 warp 寄存器文件的更改始终发生在寄存器文件的尾端。
setmaxnreg 指令要求内核已使用通过适当的编译时选项或适当的性能调优指令进行的适当编译指定的每个线程的最大寄存器数的有效值启动。否则,setmaxnreg 指令可能无效。
当指定限定符 .dec 时,在执行 setmaxnreg 指令之前,warp 拥有的每个线程的最大寄存器数应大于或等于 imm-reg-count。否则,行为未定义。
当指定限定符 .inc 时,在执行 setmaxnreg 指令之前,warp 拥有的每个线程的最大寄存器数应小于或等于 imm-reg-count。否则,行为未定义。
强制性限定符 .sync 指示 setmaxnreg 指令导致执行线程等待,直到 warp 中的所有线程执行相同的 setmaxnreg 指令,然后才能恢复执行。
强制性限定符 .aligned 指示 warpgroup 中的所有线程必须执行相同的 setmaxnreg 指令。在有条件执行的代码中,只有当已知 warpgroup 中的所有线程都相同地评估条件时,才应使用 setmaxnreg 指令,否则行为未定义。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
以下架构支持
sm_90asm_100asm_101asm_120a
示例
setmaxnreg.dec.sync.aligned.u32 64;
setmaxnreg.inc.sync.aligned.u32 192;
10. 特殊寄存器
PTX 包括许多预定义的只读变量,这些变量作为特殊寄存器可见,并通过 mov 或 cvt 指令访问。
特殊寄存器包括
%tid%ntid%laneid%warpid%nwarpid%ctaid%nctaid%smid%nsmid%gridid%is_explicit_cluster%clusterid%nclusterid%cluster_ctaid%cluster_nctaid%cluster_ctarank%cluster_nctarank%lanemask_eq,%lanemask_le,%lanemask_lt,%lanemask_ge,%lanemask_gt%clock,%clock_hi,%clock64%pm0, ..., %pm7%pm0_64, ..., %pm7_64%envreg0, ..., %envreg31%globaltimer,%globaltimer_lo,%globaltimer_hi%reserved_smem_offset_begin,%reserved_smem_offset_end,%reserved_smem_offset_cap,%reserved_smem_offset<2>%total_smem_size%aggr_smem_size%dynamic_smem_size%current_graph_exec
10.1. 特殊寄存器:%tid
%tid
CTA 内的线程标识符。
语法(预定义)
.sreg .v4 .u32 %tid; // thread id vector
.sreg .u32 %tid.x, %tid.y, %tid.z; // thread id components
描述
一个预定义的、只读的、每个线程的特殊寄存器,使用 CTA 内的线程标识符初始化。%tid 特殊寄存器包含与 CTA 形状匹配的 1D、2D 或 3D 向量;未使用的维度中的 %tid 值为 0。第四个元素未使用,并且始终返回零。每个维度中的线程数由预定义的特殊寄存器 %ntid 指定。
CTA 中的每个线程都有一个唯一的 %tid。
%tid 组件值在每个 CTA 维度中从 0 到 %ntid-1 范围内。
%tid.y == %tid.z == 0 在 1D CTA 中。%tid.z == 0 在 2D CTA 中。
保证
0 <= %tid.x < %ntid.x
0 <= %tid.y < %ntid.y
0 <= %tid.z < %ntid.z
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入,类型为 .v4.u16。
在 PTX ISA 版本 2.0 中重新定义为类型 .v4.u32。为了与旧版 PTX 代码兼容,可以使用 16 位 mov 和 cvt 指令来读取 %tid 的每个组件的低 16 位。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u32 %r1,%tid.x; // move tid.x to %rh
// legacy code accessing 16-bit components of %tid
mov.u16 %rh,%tid.x;
cvt.u32.u16 %r2,%tid.z; // zero-extend tid.z to %r2
10.2. 特殊寄存器:%ntid
%ntid
每个 CTA 的线程 ID 数量。
语法(预定义)
.sreg .v4 .u32 %ntid; // CTA shape vector
.sreg .u32 %ntid.x, %ntid.y, %ntid.z; // CTA dimensions
描述
一个预定义的只读特殊寄存器,使用每个 CTA 维度中的线程 ID 数量初始化。%ntid 特殊寄存器包含一个 3D CTA 形状向量,其中包含 CTA 维度。CTA 维度是非零的;第四个元素未使用,并且始终返回零。CTA 中的线程总数为 (%ntid.x * %ntid.y * %ntid.z)。
%ntid.y == %ntid.z == 1 in 1D CTAs.
%ntid.z ==1 in 2D CTAs.
%ntid.{x,y,z} 的最大值如下
.target 架构 |
%ntid.x |
%ntid.y |
%ntid.z |
|---|---|---|---|
|
512 |
512 |
64 |
|
1024 |
1024 |
64 |
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入,类型为 .v4.u16。
在 PTX ISA 版本 2.0 中重新定义为类型 .v4.u32。为了与旧版 PTX 代码兼容,可以使用 16 位 mov 和 cvt 指令来读取 %ntid 的每个组件的低 16 位。
目标 ISA 注释
所有目标架构均支持。
示例
// compute unified thread id for 2D CTA
mov.u32 %r0,%tid.x;
mov.u32 %h1,%tid.y;
mov.u32 %h2,%ntid.x;
mad.u32 %r0,%h1,%h2,%r0;
mov.u16 %rh,%ntid.x; // legacy code
10.3. 特殊寄存器:%laneid
%laneid
Lane 标识符。
语法(预定义)
.sreg .u32 %laneid;
描述
一个预定义的只读特殊寄存器,返回线程在 warp 中的 lane。Lane 标识符的范围从零到 WARP_SZ-1。
PTX ISA 注释
在 PTX ISA 版本 1.3 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u32 %r, %laneid;
10.4. 特殊寄存器:%warpid
%warpid
Warp 标识符。
语法(预定义)
.sreg .u32 %warpid;
描述
一个预定义的只读特殊寄存器,返回线程的 warp 标识符。warp 标识符提供 CTA 内的唯一 warp 编号,但不跨网格内的 CTA。对于单个 warp 中的所有线程,warp 标识符将是相同的。
请注意,%warpid 返回读取时线程的位置,但其值可能会在执行期间更改,例如,由于抢占后线程的重新调度。因此,如果内核代码中需要这样的值,则应使用 %ctaid 和 %tid 来计算虚拟 warp 索引;%warpid 主要用于使分析和诊断代码能够采样和记录诸如工作场所映射和负载分配之类的信息。
PTX ISA 注释
在 PTX ISA 版本 1.3 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u32 %r, %warpid;
10.5. 特殊寄存器:%nwarpid
%nwarpid
Warp 标识符的数量。
语法(预定义)
.sreg .u32 %nwarpid;
描述
一个预定义的只读特殊寄存器,返回最大 warp 标识符数量。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%nwarpid 需要 sm_20 或更高版本。
示例
mov.u32 %r, %nwarpid;
10.6. 特殊寄存器:%ctaid
%ctaid
网格内的 CTA 标识符。
语法(预定义)
.sreg .v4 .u32 %ctaid; // CTA id vector
.sreg .u32 %ctaid.x, %ctaid.y, %ctaid.z; // CTA id components
描述
一个预定义的只读特殊寄存器,使用 CTA 网格内的 CTA 标识符初始化。%ctaid 特殊寄存器包含 1D、2D 或 3D 向量,具体取决于 CTA 网格的形状和秩。第四个元素未使用,并且始终返回零。
保证
0 <= %ctaid.x < %nctaid.x
0 <= %ctaid.y < %nctaid.y
0 <= %ctaid.z < %nctaid.z
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入,类型为 .v4.u16。
在 PTX ISA 版本 2.0 中重新定义为类型 .v4.u32。为了与旧版 PTX 代码兼容,可以使用 16 位 mov 和 cvt 指令来读取 %ctaid 的每个组件的低 16 位。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u32 %r0,%ctaid.x;
mov.u16 %rh,%ctaid.y; // legacy code
10.7. 特殊寄存器: %nctaid
%nctaid
每个网格的 CTA ID 数量。
语法(预定义)
.sreg .v4 .u32 %nctaid // Grid shape vector
.sreg .u32 %nctaid.x,%nctaid.y,%nctaid.z; // Grid dimensions
描述
一个预定义的、只读的特殊寄存器,用每个网格维度中 CTA 的数量初始化。 %nctaid 特殊寄存器包含一个 3D 网格形状向量,每个元素的值至少为 1。 第四个元素未使用,始终返回零。
%nctaid.{x,y,z} 的最大值如下
.target 架构 |
%nctaid.x |
%nctaid.y |
%nctaid.z |
|---|---|---|---|
|
65535 |
65535 |
65535 |
|
231 -1 |
65535 |
65535 |
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入,类型为 .v4.u16。
在 PTX ISA 版本 2.0 中重新定义为类型 .v4.u32。 为了与旧版 PTX 代码兼容,可以使用 16 位 mov 和 cvt 指令来读取 %nctaid 的每个组件的低 16 位。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u32 %r0,%nctaid.x;
mov.u16 %rh,%nctaid.x; // legacy code
10.8. 特殊寄存器: %smid
%smid
SM 标识符。
语法(预定义)
.sreg .u32 %smid;
描述
一个预定义的、只读的特殊寄存器,返回特定线程正在执行的处理器 (SM) 标识符。 SM 标识符的范围从 0 到 %nsmid-1。 不保证 SM 标识符编号是连续的。
注释
请注意,%smid 返回读取时线程的位置,但其值可能会在执行期间更改,例如,由于抢占后重新调度线程。 %smid 主要用于使性能分析和诊断代码能够采样和记录诸如工作场所映射和负载分配等信息。
PTX ISA 注释
在 PTX ISA 版本 1.3 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u32 %r, %smid;
10.9. 特殊寄存器: %nsmid
%nsmid
SM 标识符的数量。
语法(预定义)
.sreg .u32 %nsmid;
描述
一个预定义的、只读的特殊寄存器,返回 SM 标识符的最大数量。 不保证 SM 标识符编号是连续的,因此 %nsmid 可能大于设备中 SM 的物理数量。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%nsmid 需要 sm_20 或更高版本。
示例
mov.u32 %r, %nsmid;
10.10. 特殊寄存器: %gridid
%gridid
网格标识符。
语法(预定义)
.sreg .u64 %gridid;
描述
一个预定义的、只读的特殊寄存器,用每个网格的时间网格标识符初始化。 %gridid 供调试器用于区分并发(小)网格中的 CTA 和集群。
在执行期间,可能会发生程序的重复启动,每次启动都会启动一个 CTA 网格。 此变量为此上下文提供时间网格启动编号。
对于 sm_1x 目标,%gridid 的范围限制为 [0..216-1]。 对于 sm_20,%gridid 的范围限制为 [0..232-1]。 sm_30 支持整个 64 位范围。
PTX ISA 注释
在 PTX ISA 版本 1.0 中作为类型 .u16 引入。
在 PTX ISA 版本 1.3 中重新定义为类型 .u32。
在 PTX ISA 版本 3.0 中重新定义为类型 .u64。
为了与旧版 PTX 代码兼容,可以使用 16 位和 32 位 mov 和 cvt 指令来读取 %gridid 的每个组件的低 16 位或 32 位。
目标 ISA 注释
所有目标架构均支持。
示例
mov.u64 %s, %gridid; // 64-bit read of %gridid
mov.u32 %r, %gridid; // legacy code with 32-bit %gridid
10.11. 特殊寄存器: %is_explicit_cluster
%is_explicit_cluster
检查用户是否显式指定了集群启动。
语法(预定义)
.sreg .pred %is_explicit_cluster;
描述
一个预定义的、只读的特殊寄存器,用谓词值初始化,指示集群启动是否由用户显式指定。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .pred p;
mov.pred p, %is_explicit_cluster;
10.12. 特殊寄存器: %clusterid
%clusterid
网格内的集群标识符。
语法(预定义)
.sreg .v4 .u32 %clusterid;
.sreg .u32 %clusterid.x, %clusterid.y, %clusterid.z;
描述
一个预定义的、只读的特殊寄存器,用每个维度中网格内的集群标识符初始化。 网格中的每个集群都有一个唯一的标识符。
%clusterid 特殊寄存器包含一个 1D、2D 或 3D 向量,具体取决于集群的形状和秩。 第四个元素未使用,始终返回零。
保证
0 <= %clusterid.x < %nclusterid.x
0 <= %clusterid.y < %nclusterid.y
0 <= %clusterid.z < %nclusterid.z
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .b32 %r<2>;
.reg .v4 .b32 %rx;
mov.u32 %r0, %clusterid.x;
mov.u32 %r1, %clusterid.z;
mov.v4.u32 %rx, %clusterid;
10.13. 特殊寄存器: %nclusterid
%nclusterid
每个网格的集群标识符数量。
语法(预定义)
.sreg .v4 .u32 %nclusterid;
.sreg .u32 %nclusterid.x, %nclusterid.y, %nclusterid.z;
描述
一个预定义的、只读的特殊寄存器,用每个网格维度中集群的数量初始化。
%nclusterid 特殊寄存器包含一个 3D 网格形状向量,其中包含集群方面的网格维度。 第四个元素未使用,始终返回零。
有关 %nclusterid.{x,y,z} 最大值的详细信息,请参阅 *Cuda Programming Guide*。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .b32 %r<2>;
.reg .v4 .b32 %rx;
mov.u32 %r0, %nclusterid.x;
mov.u32 %r1, %nclusterid.z;
mov.v4.u32 %rx, %nclusterid;
10.14. 特殊寄存器: %cluster_ctaid
%cluster_ctaid
集群内的 CTA 标识符。
语法(预定义)
.sreg .v4 .u32 %cluster_ctaid;
.sreg .u32 %cluster_ctaid.x, %cluster_ctaid.y, %cluster_ctaid.z;
描述
一个预定义的、只读的特殊寄存器,用每个维度中集群内的 CTA 标识符初始化。 集群中的每个 CTA 都有一个唯一的 CTA 标识符。
%cluster_ctaid 特殊寄存器包含一个 1D、2D 或 3D 向量,具体取决于集群的形状。 第四个元素未使用,始终返回零。
保证
0 <= %cluster_ctaid.x < %cluster_nctaid.x
0 <= %cluster_ctaid.y < %cluster_nctaid.y
0 <= %cluster_ctaid.z < %cluster_nctaid.z
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .b32 %r<2>;
.reg .v4 .b32 %rx;
mov.u32 %r0, %cluster_ctaid.x;
mov.u32 %r1, %cluster_ctaid.z;
mov.v4.u32 %rx, %cluster_ctaid;
10.15. 特殊寄存器: %cluster_nctaid
%cluster_nctaid
每个集群的 CTA 标识符数量。
语法(预定义)
.sreg .v4 .u32 %cluster_nctaid;
.sreg .u32 %cluster_nctaid.x, %cluster_nctaid.y, %cluster_nctaid.z;
描述
一个预定义的、只读的特殊寄存器,用每个维度中集群内的 CTA 数量初始化。
%cluster_nctaid 特殊寄存器包含一个 3D 网格形状向量,其中包含 CTA 方面的集群维度。 第四个元素未使用,始终返回零。
有关 %cluster_nctaid.{x,y,z} 最大值的详细信息,请参阅 *Cuda Programming Guide*。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .b32 %r<2>;
.reg .v4 .b32 %rx;
mov.u32 %r0, %cluster_nctaid.x;
mov.u32 %r1, %cluster_nctaid.z;
mov.v4.u32 %rx, %cluster_nctaid;
10.16. 特殊寄存器: %cluster_ctarank
%cluster_ctarank
集群中跨所有维度的 CTA 标识符。
语法(预定义)
.sreg .u32 %cluster_ctarank;
描述
一个预定义的、只读的特殊寄存器,用集群中跨所有维度的 CTA 秩初始化。
保证
0 <= %cluster_ctarank < %cluster_nctarank
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .b32 %r;
mov.u32 %r, %cluster_ctarank;
10.17. 特殊寄存器: %cluster_nctarank
%cluster_nctarank
集群中跨所有维度的 CTA 标识符数量。
语法(预定义)
.sreg .u32 %cluster_nctarank;
描述
一个预定义的、只读的特殊寄存器,用集群中跨所有维度的 CTA 数量初始化。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.reg .b32 %r;
mov.u32 %r, %cluster_nctarank;
10.18. 特殊寄存器: %lanemask_eq
%lanemask_eq
32 位掩码,其中位设置在等于 Warp 中线程 Lane 号的位置。
语法(预定义)
.sreg .u32 %lanemask_eq;
描述
一个预定义的、只读的特殊寄存器,用一个 32 位掩码初始化,其中位设置在等于 Warp 中线程 Lane 号的位置。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%lanemask_eq 需要 sm_20 或更高版本。
示例
mov.u32 %r, %lanemask_eq;
10.19. 特殊寄存器: %lanemask_le
%lanemask_le
32 位掩码,其中位设置在小于或等于 Warp 中线程 Lane 号的位置。
语法(预定义)
.sreg .u32 %lanemask_le;
描述
一个预定义的、只读的特殊寄存器,用一个 32 位掩码初始化,其中位设置在小于或等于 Warp 中线程 Lane 号的位置。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%lanemask_le 需要 sm_20 或更高版本。
示例
mov.u32 %r, %lanemask_le
10.20. 特殊寄存器: %lanemask_lt
%lanemask_lt
32 位掩码,其中位设置在小于 Warp 中线程 Lane 号的位置。
语法(预定义)
.sreg .u32 %lanemask_lt;
描述
一个预定义的、只读的特殊寄存器,用一个 32 位掩码初始化,其中位设置在小于 Warp 中线程 Lane 号的位置。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%lanemask_lt 需要 sm_20 或更高版本。
示例
mov.u32 %r, %lanemask_lt;
10.21. 特殊寄存器: %lanemask_ge
%lanemask_ge
32 位掩码,其中位设置在大于或等于 Warp 中线程 Lane 号的位置。
语法(预定义)
.sreg .u32 %lanemask_ge;
描述
一个预定义的、只读的特殊寄存器,用一个 32 位掩码初始化,其中位设置在大于或等于 Warp 中线程 Lane 号的位置。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%lanemask_ge 需要 sm_20 或更高版本。
示例
mov.u32 %r, %lanemask_ge;
10.22. 特殊寄存器: %lanemask_gt
%lanemask_gt
32 位掩码,其中位设置在大于 Warp 中线程 Lane 号的位置。
语法(预定义)
.sreg .u32 %lanemask_gt;
描述
一个预定义的、只读的特殊寄存器,用一个 32 位掩码初始化,其中位设置在大于 Warp 中线程 Lane 号的位置。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%lanemask_gt 需要 sm_20 或更高版本。
示例
mov.u32 %r, %lanemask_gt;
10.23. 特殊寄存器: %clock, %clock_hi
%clock, %clock_hi
%clock-
一个预定义的、只读的 32 位无符号周期计数器。
%clock_hi-
%clock64特殊寄存器的高 32 位。
语法(预定义)
.sreg .u32 %clock;
.sreg .u32 %clock_hi;
描述
特殊寄存器 %clock 和 %clock_hi 是无符号 32 位只读周期计数器,它们会静默回绕。
PTX ISA 注释
%clock 在 PTX ISA 版本 1.0 中引入。
%clock_hi 在 PTX ISA 版本 5.0 中引入。
目标 ISA 注释
%clock 在所有目标架构上均受支持。
%clock_hi 需要 sm_20 或更高版本。
示例
mov.u32 r1,%clock;
mov.u32 r2, %clock_hi;
10.24. 特殊寄存器: %clock64
%clock64
一个预定义的、只读的 64 位无符号周期计数器。
语法(预定义)
.sreg .u64 %clock64;
描述
特殊寄存器 %clock64 是一个无符号 64 位只读周期计数器,它会静默回绕。
注释
%clock64 的低 32 位与 %clock 相同。
%clock64 的高 32 位与 %clock_hi 相同。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
%clock64 需要 sm_20 或更高版本。
示例
mov.u64 r1,%clock64;
10.25. 特殊寄存器: %pm0..%pm7
%pm0..%pm7
性能监控计数器。
语法(预定义)
.sreg .u32 %pm<8>;
描述
特殊寄存器 %pm0..%pm7 是无符号 32 位只读性能监控计数器。 它们的行为目前未定义。
PTX ISA 注释
%pm0..%pm3 在 PTX ISA 版本 1.3 中引入。
%pm4..%pm7 在 PTX ISA 版本 3.0 中引入。
目标 ISA 注释
%pm0..%pm3 在所有目标架构上均受支持。
%pm4..%pm7 需要 sm_20 或更高版本。
示例
mov.u32 r1,%pm0;
mov.u32 r1,%pm7;
10.26. 特殊寄存器: %pm0_64..%pm7_64
%pm0_64..%pm7_64
64 位性能监控计数器。
语法(预定义)
.sreg .u64 %pm0_64;
.sreg .u64 %pm1_64;
.sreg .u64 %pm2_64;
.sreg .u64 %pm3_64;
.sreg .u64 %pm4_64;
.sreg .u64 %pm5_64;
.sreg .u64 %pm6_64;
.sreg .u64 %pm7_64;
描述
特殊寄存器 %pm0_64..%pm7_64 是无符号 64 位只读性能监控计数器。 它们的行为目前未定义。
注释
%pm0_64..%pm7_64 的低 32 位与 %pm0..%pm7 相同。
PTX ISA 注释
%pm0_64..%pm7_64 在 PTX ISA 版本 4.0 中引入。
目标 ISA 注释
%pm0_64..%pm7_64 需要 sm_50 或更高版本。
示例
mov.u32 r1,%pm0_64;
mov.u32 r1,%pm7_64;
10.27. 特殊寄存器: %envreg<32>
%envreg<32>
驱动程序定义的只读寄存器。
语法(预定义)
.sreg .b32 %envreg<32>;
描述
一组 32 个预定义的只读寄存器,用于捕获 PTX 虚拟机外部 PTX 程序的执行环境。 这些寄存器由驱动程序在内核启动之前初始化,并且可以包含 CTA 范围或网格范围的值。
这些寄存器的精确语义在驱动程序文档中定义。
PTX ISA 注释
在 PTX ISA 版本 2.1 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
mov.b32 %r1,%envreg0; // move envreg0 to %r1
10.28. 特殊寄存器: %globaltimer, %globaltimer_lo, %globaltimer_hi
%globaltimer, %globaltimer_lo, %globaltimer_hi
%globaltimer-
一个预定义的 64 位全局纳秒计时器。
%globaltimer_lo-
%globaltimer 的低 32 位。
%globaltimer_hi-
%globaltimer 的高 32 位。
语法(预定义)
.sreg .u64 %globaltimer;
.sreg .u32 %globaltimer_lo, %globaltimer_hi;
描述
旨在供 NVIDIA 工具使用的特殊寄存器。 其行为是特定于目标的,并且可能会在未来的 GPU 中更改或删除。 当 JIT 编译到其他目标时,这些寄存器的值是未指定的。
PTX ISA 注释
在 PTX ISA 版本 3.1 中引入。
目标 ISA 注释
需要目标 sm_30 或更高版本。
示例
mov.u64 r1,%globaltimer;
10.29. 特殊寄存器: %reserved_smem_offset_begin, %reserved_smem_offset_end, %reserved_smem_offset_cap, %reserved_smem_offset_<2>
%reserved_smem_offset_begin, %reserved_smem_offset_end, %reserved_smem_offset_cap, %reserved_smem_offset_<2>
%reserved_smem_offset_begin-
保留共享内存区域的起始位置。
%reserved_smem_offset_end-
保留共享内存区域的结束位置。
%reserved_smem_offset_cap-
保留共享内存区域的总大小。
%reserved_smem_offset_<2>-
保留共享内存区域中的偏移量。
语法(预定义)
.sreg .b32 %reserved_smem_offset_begin;
.sreg .b32 %reserved_smem_offset_end;
.sreg .b32 %reserved_smem_offset_cap;
.sreg .b32 %reserved_smem_offset_<2>;
描述
这些是预定义的、只读的特殊寄存器,其中包含有关为 NVIDIA 系统软件使用而保留的共享内存区域的信息。 用户无法使用此共享内存区域,并且从用户代码访问此区域会导致未定义的行为。 有关详细信息,请参阅 *CUDA Programming Guide*。
PTX ISA 注释
在 PTX ISA 版本 7.6 中引入。
目标 ISA 注释
需要 sm_80 或更高版本。
示例
.reg .b32 %reg_begin, %reg_end, %reg_cap, %reg_offset0, %reg_offset1;
mov.b32 %reg_begin, %reserved_smem_offset_begin;
mov.b32 %reg_end, %reserved_smem_offset_end;
mov.b32 %reg_cap, %reserved_smem_offset_cap;
mov.b32 %reg_offset0, %reserved_smem_offset_0;
mov.b32 %reg_offset1, %reserved_smem_offset_1;
10.30. 特殊寄存器: %total_smem_size
%total_smem_size
内核的 CTA 使用的共享内存总大小。
语法(预定义)
.sreg .u32 %total_smem_size;
描述
一个预定义的、只读的特殊寄存器,用在启动时为内核的 CTA 分配的共享内存总大小(静态和动态分配,不包括为 NVIDIA 系统软件使用而保留的共享内存)初始化。
大小以目标架构支持的共享内存分配单元大小的倍数返回。
分配单元值如下
目标架构 |
共享内存分配单元大小 |
|---|---|
|
128 字节 |
|
256 字节 |
|
128 字节 |
PTX ISA 注释
在 PTX ISA 版本 4.1 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。
示例
mov.u32 %r, %total_smem_size;
10.31. 特殊寄存器: %aggr_smem_size
%aggr_smem_size
内核的 CTA 使用的共享内存总大小。
语法(预定义)
.sreg .u32 %aggr_smem_size;
描述
一个预定义的、只读的特殊寄存器,用共享内存的总聚合大小初始化,该大小包括启动时分配的用户共享内存大小(静态和动态)和为 NVIDIA 系统软件使用而保留的共享内存区域的大小。
PTX ISA 注释
在 PTX ISA 8.1 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
mov.u32 %r, %aggr_smem_size;
10.32. 特殊寄存器: %dynamic_smem_size
%dynamic_smem_size
在内核启动时动态分配的共享内存大小。
语法(预定义)
.sreg .u32 %dynamic_smem_size;
描述
在内核启动时动态分配的共享内存大小。
一个预定义的、只读的特殊寄存器,用在启动时为内核的 CTA 动态分配的共享内存大小初始化。
PTX ISA 注释
在 PTX ISA 版本 4.1 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。
示例
mov.u32 %r, %dynamic_smem_size;
10.33. 特殊寄存器: %current_graph_exec
%current_graph_exec
当前正在执行的 CUDA 设备图的标识符。
语法(预定义)
.sreg .u64 %current_graph_exec;
描述
一个预定义的、只读的特殊寄存器,用引用当前正在执行的 CUDA 设备图的标识符初始化。 如果正在执行的内核不是 CUDA 设备图的一部分,则此寄存器为 0。
有关 CUDA 设备图的更多详细信息,请参阅 *CUDA Programming Guide*。
PTX ISA 注释
在 PTX ISA 版本 8.0 中引入。
目标 ISA 注释
需要 sm_50 或更高版本。
示例
mov.u64 r1, %current_graph_exec;
11. 指示符
11.1. PTX 模块指示符
以下指示符声明模块中代码的 PTX ISA 版本、为其生成代码的目标架构以及 PTX 模块中地址的大小。
.version.target.address_size
11.1.1. PTX 模块指示符: .version
.version
PTX ISA 版本号。
语法
.version major.minor // major, minor are integers
描述
指定 PTX 语言版本号。
当 PTX 语言发生不兼容的更改时,例如语法或语义的更改,*主*版本号会递增。 PTX 编译器使用版本主版本号来确保旧版 PTX 代码的正确执行。
当向 PTX 添加新功能时,*次*版本号会递增。
语义
指示此模块必须使用支持相等或更高版本号的工具进行编译。
每个 PTX 模块都必须以 .version 指示符开头,并且模块内的任何其他位置都不允许使用其他 .version 指示符。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.version 3.1
.version 3.0
.version 2.3
11.1.2. PTX 模块指示符: .target
.target
架构和平台目标。
语法
.target stringlist // comma separated list of target specifiers
string = { sm_120a, sm_120 // sm_12x target architectures
sm_100a, sm_100, sm_101a, sm_101 // sm_10x target architectures
sm_90a, sm_90, // sm_9x target architectures
sm_80, sm_86, sm_87, sm_89, // sm_8x target architectures
sm_70, sm_72, sm_75, // sm_7x target architectures
sm_60, sm_61, sm_62, // sm_6x target architectures
sm_50, sm_52, sm_53, // sm_5x target architectures
sm_30, sm_32, sm_35, sm_37, // sm_3x target architectures
sm_20, // sm_2x target architectures
sm_10, sm_11, sm_12, sm_13, // sm_1x target architectures
texmode_unified, texmode_independent, // texturing mode
debug, // platform option
map_f64_to_f32 }; // platform option
描述
指定为其生成当前 PTX 代码的目标架构中的功能集。 通常,SM 架构的世代遵循*洋葱层*模型,其中每一代都添加新功能并保留前几代的所有功能。 洋葱层模型允许为给定目标生成的 PTX 代码在后代设备上运行。
带有后缀“a”的目标架构,例如 sm_90a,包括仅在指定的架构上支持的架构加速功能,因此此类目标不遵循洋葱层模型。 因此,为此类目标生成的 PTX 代码无法在后代设备上运行。 架构加速功能只能与支持这些功能的目标一起使用。
语义
每个 PTX 模块都必须以 .version 指示符开头,紧随其后是一个 .target 指示符,其中包含目标架构和可选平台选项。 一个 .target 指示符指定一个单一目标架构,但后续的 .target 指示符可用于更改解析期间允许的目标功能集。 具有多个 .target 指示符的程序将仅在支持程序中列出的编号最高的架构的所有功能的设备上编译和运行。
PTX 功能根据指定的目标架构进行检查,如果使用了不支持的功能,则会生成错误。 下表总结了 PTX 中根据目标架构而异的功能。
目标 |
描述 |
|---|---|
|
|
|
增加对 |
目标 |
描述 |
|---|---|
|
|
|
增加对 |
|
|
|
增加对 |
目标 |
描述 |
|---|---|
|
|
|
增加对 |
目标 |
描述 |
|---|---|
|
|
|
在 |
|
|
|
|
目标 |
描述 |
|---|---|
|
|
|
在 增加对 |
|
在 增加对 增加对 增加对 |
目标 |
描述 |
|---|---|
|
|
|
增加对 |
|
|
目标 |
描述 |
|---|---|
|
|
|
|
|
增加对 |
目标 |
描述 |
|---|---|
|
|
|
增加 64 位 增加 增加 |
|
增加对 CUDA 动态并行性的支持。 |
|
|
目标 |
描述 |
|---|---|
|
|
目标 |
描述 |
|---|---|
|
如果使用任何 |
|
增加 64 位 如果使用任何 |
|
增加 如果使用任何 |
|
增加双精度支持,包括扩展的舍入修饰符。 禁止使用 |
纹理模式是为整个模块指定的,并且无法在模块内更改。
.target debug
map_f64_to_f32.f64.f64.f32
注释
compute_xxsm_xx
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标字符串 sm_10sm_11
目标字符串 sm_12sm_13
纹理模式在 PTX ISA 版本 1.5 中引入。
目标字符串 sm_20
目标字符串 sm_30
平台选项 debug
目标字符串 sm_35
目标字符串 sm_32sm_50
目标字符串 sm_37sm_52
目标字符串 sm_53
目标字符串 sm_60sm_61sm_62
目标字符串 sm_70
目标字符串 sm_72
目标字符串 sm_75
目标字符串 sm_80
目标字符串 sm_86
目标字符串 sm_87
目标字符串 sm_89
目标字符串 sm_90
目标字符串 sm_90a
目标字符串 sm_100
目标字符串 sm_100a
目标字符串 sm_101
目标字符串 sm_101a
目标字符串 sm_120
目标字符串 sm_120a
目标 ISA 注释
.target
示例
.target sm_10 // baseline target architecture
.target sm_13 // supports double-precision
.target sm_20, texmode_independent
.target sm_90 // baseline target architecture
.target sm_90a // PTX using arch accelerated features
11.1.3. PTX 模块指令:.address_size
.address_size
在整个 PTX 模块中使用的地址大小。
语法
.address_size address-size
address-size = { 32, 64 };
描述
指定 PTX 代码和 PTX 中的二进制 DWARF 信息在整个模块中假定的地址大小。
不允许在模块内重新定义此指令。在存在单独编译的情况下,所有模块都必须指定(或默认为)相同的地址大小。
.address_size.target
语义
如果省略 .address_size
PTX ISA 注释
在 PTX ISA 版本 2.3 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
// example directives
.address_size 32 // addresses are 32 bit
.address_size 64 // addresses are 64 bit
// example of directive placement within a module
.version 2.3
.target sm_20
.address_size 64
...
.entry foo () {
...
}
11.2. 指定内核入口点和函数
以下指令指定内核入口点和函数。
.entry.func
11.2.1. 内核和函数指令:.entry
.entry
内核入口点和主体,带有可选参数。
语法
.entry kernel-name ( param-list ) kernel-body
.entry kernel-name kernel-body
描述
为内核函数定义内核入口点名称、参数和主体。
参数通过 .paramld.param{::entry}
除了普通参数外,不透明的 .texref.samplerref.surfrefld.param
执行内核的 CTA 的形状和大小在特殊寄存器中可用。
语义
为内核程序指定入口点。
在内核启动时,内核维度和属性被建立,并通过特殊寄存器(例如,%ntid%nctaid
PTX ISA 注释
对于 PTX ISA 版本 1.4 及更高版本,参数变量在内核参数列表中声明。对于 PTX ISA 版本 1.0 到 1.3,参数变量在内核主体中声明。
PTX 支持的普通(非不透明类型)参数的最大内存大小为 32764 字节。根据 PTX ISA 版本,参数大小限制有所不同。下表显示了 PTX ISA 版本允许的参数大小
PTX ISA 版本 |
最大参数大小(字节) |
|---|---|
PTX ISA 版本 8.1 及更高版本 |
32764 |
PTX ISA 版本 1.5 及更高版本 |
4352 |
PTX ISA 版本 1.4 及更高版本 |
256 |
CUDA 和 OpenCL 驱动程序支持以下参数内存限制
驱动程序 |
参数内存大小 |
|---|---|
CUDA |
对于 |
OpenCL |
对于 |
目标 ISA 注释
所有目标架构均支持。
示例
.entry cta_fft
.entry filter ( .param .b32 x, .param .b32 y, .param .b32 z )
{
.reg .b32 %r<99>;
ld.param.b32 %r1, [x];
ld.param.b32 %r2, [y];
ld.param.b32 %r3, [z];
...
}
.entry prefix_sum ( .param .align 4 .s32 pitch[8000] )
{
.reg .s32 %t;
ld.param::entry.s32 %t, [pitch];
...
}
11.2.2. 内核和函数指令:.func
.func
函数定义。
语法
.func {.attribute(attr-list)} fname {.noreturn} function-body
.func {.attribute(attr-list)} fname (param-list) {.noreturn} function-body
.func {.attribute(attr-list)} (ret-param) fname (param-list) function-body
描述
定义函数,包括输入和返回参数以及可选的函数主体。
可选的 .noreturn.noreturn.noreturn
可选的 .attribute
没有主体的 .func
参数列表在函数主体中定义了局部作用域变量。参数必须是寄存器或参数状态空间中的基本类型。寄存器状态空间中的参数可以在函数主体中的指令中直接引用。.paramld.param{::func}st.param{::func}
参数列表中的最后一个参数可以是类型为 .b8.param
当调用具有此类未调整大小的最后一个参数的函数时,如果没有通过它传递任何参数,则可以从 call
语义
PTX 语法隐藏了底层调用约定和 ABI 的所有细节。
参数传递的实现留给优化翻译器,它可以使用寄存器和堆栈位置的组合来传递参数。
发行说明
对于 PTX ISA 版本 1.x 代码,参数必须在寄存器状态空间中,没有堆栈,并且递归是非法的。
PTX ISA 版本 2.0 及更高版本,目标为 sm_20.param
PTX ISA 版本 2.0 及更高版本,目标为 sm_20
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
对未调整大小的数组参数的支持在 PTX ISA 版本 6.0 中引入。
对 .noreturn
对 .attribute
目标 ISA 注释
所有目标架构都支持没有未调整大小的数组参数的函数。
未调整大小的数组参数需要 sm_30
.noreturnsm_30
.attributesm_90
示例
.func (.reg .b32 rval) foo (.reg .b32 N, .reg .f64 dbl)
{
.reg .b32 localVar;
... use N, dbl;
other code;
mov.b32 rval,result;
ret;
}
...
call (fooval), foo, (val0, val1); // return value in fooval
...
.func foo (.reg .b32 N, .reg .f64 dbl) .noreturn
{
.reg .b32 localVar;
... use N, dbl;
other code;
mov.b32 rval, result;
ret;
}
...
call foo, (val0, val1);
...
.func (.param .u32 rval) bar(.param .u32 N, .param .align 4 .b8 numbers[])
{
.reg .b32 input0, input1;
ld.param.b32 input0, [numbers + 0];
ld.param.b32 input1, [numbers + 4];
...
other code;
ret;
}
...
.param .u32 N;
.param .align 4 .b8 numbers[8];
st.param.u32 [N], 2;
st.param.b32 [numbers + 0], 5;
st.param.b32 [numbers + 4], 10;
call (rval), bar, (N, numbers);
...
11.2.3. 内核和函数指令:.alias
.alias
为现有函数符号定义别名。
语法
.alias fAlias, fAliasee;
描述
.aliasfAliasfAliasee
fAliasfAliasee
标识符 fAlias
标识符 fAliasee.aliasfAliasee.weak
fAliasfAliasee
程序可以使用 fAliasfAliseefAliasee
PTX ISA 注释
.alias
目标 ISA 注释
.aliassm_30
示例
.visible .func foo(.param .u32 p) {
...
}
.visible .func bar(.param .u32 p);
.alias bar, foo;
.entry test()
{
.param .u32 p;
...
call foo, (p); // call foo directly
...
.param .u32 p;
call bar, (p); // call foo through alias
}
.entry filter ( .param .b32 x, .param .b32 y, .param .b32 z )
{
.reg .b32 %r1, %r2, %r3;
ld.param.b32 %r1, [x];
ld.param.b32 %r2, [y];
ld.param.b32 %r3, [z];
...
}
11.3. 控制流指令
PTX 提供了用于指定 brx.idxcallbrx.idxcall
.branchtargets.calltargets.callprototype
11.3.1. 控制流指令:.branchtargets
.branchtargets
声明潜在的分支目标列表。
语法
Label: .branchtargets list-of-labels ;
描述
为后续的 brx.idx
列表中的所有控制流标签都必须与声明位于同一函数内。
标签列表可以使用紧凑的速记语法来枚举具有公共前缀的标签范围,类似于 参数化变量名 中描述的语法。
PTX ISA 注释
在 PTX ISA 版本 2.1 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。
示例
.function foo () {
.reg .u32 %r0;
...
L1:
...
L2:
...
L3:
...
ts: .branchtargets L1, L2, L3;
@p brx.idx %r0, ts;
...
.function bar() {
.reg .u32 %r0;
...
N0:
...
N1:
...
N2:
...
N3:
...
N4:
...
ts: .branchtargets N<5>;
@p brx.idx %r0, ts;
...
11.3.2. 控制流指令:.calltargets
.calltargets
声明潜在的调用目标列表。
语法
Label: .calltargets list-of-functions ;
描述
为后续的间接调用声明潜在的调用目标列表,并将该列表与行首的标签关联。
列表中命名的所有函数都必须在 .calltargets
PTX ISA 注释
在 PTX ISA 版本 2.1 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。
示例
calltgt: .calltargets fastsin, fastcos;
...
@p call (%f1), %r0, (%x), calltgt;
...
11.3.3. 控制流指令:.callprototype
.callprototype
声明用于间接调用的原型。
语法
// no input or return parameters
label: .callprototype _ .noreturn;
// input params, no return params
label: .callprototype _ (param-list) .noreturn;
// no input params, // return params
label: .callprototype (ret-param) _ ;
// input, return parameters
label: .callprototype (ret-param) _ (param-list);
描述
定义一个没有特定函数名称的原型,并将该原型与一个标签关联。然后,该原型可以用于对可能的调用目标了解不完整的间接调用指令中。
参数可以具有寄存器或参数状态空间中的基本类型,也可以具有参数状态空间中的数组类型。sink 符号 '_'
可选的 .noreturn.noreturn
PTX ISA 注释
在 PTX ISA 版本 2.1 中引入。
对 .noreturn
目标 ISA 注释
需要 sm_20 或更高版本。
.noreturnsm_30
示例
Fproto1: .callprototype _ ;
Fproto2: .callprototype _ (.param .f32 _);
Fproto3: .callprototype (.param .u32 _) _ ;
Fproto4: .callprototype (.param .u32 _) _ (.param .f32 _);
...
@p call (%val), %r0, (%f1), Fproto4;
...
// example of array parameter
Fproto5: .callprototype _ (.param .b8 _[12]);
Fproto6: .callprototype _ (.param .f32 _) .noreturn;
...
@p call %r0, (%f1), Fproto6;
...
11.4. 性能调优指令
为了提供低级性能调优的机制,PTX 支持以下指令,这些指令将信息传递给后端优化编译器。
.maxnreg.maxntid.reqntid.minnctapersm.maxnctapersm.pragma
.maxnreg.maxntid.reqntid.minnctapersm.minnctapersm.maxntid.reqntid
目前,.maxnreg.maxntid.reqntid.minnctapersm.entry
通用的 .pragma.pragma.pragma
11.4.1. 性能调优指令:.maxnreg
.maxnreg
每个线程可以分配的最大寄存器数。
语法
.maxnreg n
描述
声明 CTA 中每个线程的最大寄存器数。
语义
编译器保证不会超过此限制。实际使用的寄存器数可能会更少;例如,后端可能能够编译到更少的寄存器,或者最大寄存器数可能受到 .maxntid.maxctapersm
PTX ISA 注释
在 PTX ISA 版本 1.3 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.entry foo .maxnreg 16 { ... } // max regs per thread = 16
11.4.2. 性能调优指令:.maxntid
.maxntid
线程块 (CTA) 中的最大线程数。
语法
.maxntid nx
.maxntid nx, ny
.maxntid nx, ny, nz
描述
声明线程块 (CTA) 中的最大线程数。此最大值通过给出 1D、2D 或 3D CTA 的每个维度的最大范围来指定。最大线程数是每个维度最大范围的乘积。
语义
线程块中的最大线程数(计算为每个维度指定的最大范围的乘积)保证在出现此指令的内核的任何调用中都不会超过。超过最大线程数将导致运行时错误或内核启动失败。
请注意,此指令保证总线程数不超过最大值,但不保证任何特定维度的限制都不会超过。
PTX ISA 注释
在 PTX ISA 版本 1.3 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.entry foo .maxntid 256 { ... } // max threads = 256
.entry bar .maxntid 16,16,4 { ... } // max threads = 1024
11.4.3. 性能调优指令:.reqntid
.reqntid
线程块 (CTA) 中的线程数。
语法
.reqntid nx
.reqntid nx, ny
.reqntid nx, ny, nz
描述
通过指定 1D、2D 或 3D CTA 的每个维度的范围来声明线程块 (CTA) 中的线程数。线程总数是每个维度中线程数的乘积。
语义
在内核的任何调用中指定的每个 CTA 维度的大小都必须等于此指令中指定的大小。在启动时指定不同的 CTA 维度将导致运行时错误或内核启动失败。
注释
.reqntid.maxntid
PTX ISA 注释
在 PTX ISA 版本 2.1 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.entry foo .reqntid 256 { ... } // num threads = 256
.entry bar .reqntid 16,16,4 { ... } // num threads = 1024
11.4.4. 性能调优指令:.minnctapersm
.minnctapersm
每个 SM 的最小 CTA 数。
语法
.minnctapersm ncta
描述
声明要从内核网格映射到单个多处理器 (SM) 的最小 CTA 数。
注释
基于 .minnctapersm.maxntid.reqntid
如果由 .minnctapersm.maxntid.reqntid.minnctapersm
在 PTX ISA 版本 2.1 或更高版本中,如果在未指定 .maxntid.reqntid.minnctapersm
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入,作为 .maxnctapersm
目标 ISA 注释
所有目标架构均支持。
示例
.entry foo .maxntid 256 .minnctapersm 4 { ... }
11.4.5. 性能调优指令:.maxnctapersm(已弃用)
.maxnctapersm
每个 SM 的最大 CTA 数。
语法
.maxnctapersm ncta
描述
声明可能映射到单个多处理器 (SM) 的内核网格中的最大 CTA 数。
注释
基于 .maxnctapersm 的优化通常还需要指定 .maxntid.maxntid.maxnctapersm.maxnctapersm
PTX ISA 注释
在 PTX ISA 版本 1.3 中引入。在 PTX ISA 版本 2.0 中已弃用。
目标 ISA 注释
所有目标架构均支持。
示例
.entry foo .maxntid 256 .maxnctapersm 4 { ... }
11.4.6. 性能调优指令:.noreturn
.noreturn
指示函数不返回到其调用函数。
语法
.noreturn
描述
指示函数不返回到其调用函数。
语义
可选的 .noreturn.noreturn.func
该指令不能在具有返回参数的函数上指定。
如果在运行时具有 .noreturn
PTX ISA 注释
在 PTX ISA 版本 6.4 中引入。
目标 ISA 注释
需要 sm_30 或更高版本。
示例
.func foo .noreturn { ... }
11.4.7. 性能调优指令:.pragma
.pragma
将指令传递给 PTX 后端编译器。
语法
.pragma list-of-strings ;
描述
将模块作用域、入口作用域或语句级指令传递给 PTX 后端编译器。
.pragma
语义
.pragmaptxas
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.pragma "nounroll"; // disable unrolling in backend
// disable unrolling for current kernel
.entry foo .pragma "nounroll"; { ... }
11.5. 调试指令
DWARF 格式的调试信息通过使用以下指令的 PTX 模块传递
@@DWARF.section.file.loc
.section@@DWARF@@DWARF
从 PTX ISA 版本 3.0 开始,包含 DWARF 调试信息的 PTX 文件应包含 .target debug
11.5.1. 调试指令:@@dwarf
@@dwarf
DWARF 格式的信息。
语法
@@DWARF dwarf-string
dwarf-string may have one of the
.byte byte-list // comma-separated hexadecimal byte values
.4byte int32-list // comma-separated hexadecimal integers in range [0..2^32-1]
.quad int64-list // comma-separated hexadecimal integers in range [0..2^64-1]
.4byte label
.quad label
PTX ISA 注释
在 PTX ISA 版本 1.2 中引入。自 PTX ISA 版本 2.0 起已弃用,并由 .section
目标 ISA 注释
所有目标架构均支持。
示例
@@DWARF .section .debug_pubnames, "", @progbits
@@DWARF .byte 0x2b, 0x00, 0x00, 0x00, 0x02, 0x00
@@DWARF .4byte .debug_info
@@DWARF .4byte 0x000006b5, 0x00000364, 0x61395a5f, 0x5f736f63
@@DWARF .4byte 0x6e69616d, 0x63613031, 0x6150736f, 0x736d6172
@@DWARF .byte 0x00, 0x00, 0x00, 0x00, 0x00
11.5.2. 调试指令:.section
.section
PTX section 定义。
语法
.section section_name { dwarf-lines }
dwarf-lines have the following formats:
.b8 byte-list // comma-separated list of integers
// in range [-128..255]
.b16 int16-list // comma-separated list of integers
// in range [-2^15..2^16-1]
.b32 int32-list // comma-separated list of integers
// in range [-2^31..2^32-1]
label: // Define label inside the debug section
.b64 int64-list // comma-separated list of integers
// in range [-2^63..2^64-1]
.b32 label
.b64 label
.b32 label+imm // a sum of label address plus a constant integer byte
// offset(signed, 32bit)
.b64 label+imm // a sum of label address plus a constant integer byte
// offset(signed, 64bit)
.b32 label1-label2 // a difference in label addresses between labels in
// the same dwarf section (32bit)
.b64 label3-label4 // a difference in label addresses between labels in
// the same dwarf section (64bit)
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入,取代了 @@DWARF
label+imm 表达式在 PTX ISA 版本 3.2 中引入。
对 dwarf-lines 中的 .b16
在 DWARF section 中定义 label
label1-label2
dwarf lines 中的负数在 PTX ISA 版本 7.5 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.section .debug_pubnames
{
.b32 LpubNames_end0-LpubNames_begin0
LpubNames_begin0:
.b8 0x2b, 0x00, 0x00, 0x00, 0x02, 0x00
.b32 .debug_info
info_label1:
.b32 0x000006b5, 0x00000364, 0x61395a5f, 0x5f736f63
.b32 0x6e69616d, 0x63613031, 0x6150736f, 0x736d6172
.b8 0x00, 0x00, 0x00, 0x00, 0x00
LpubNames_end0:
}
.section .debug_info
{
.b32 11430
.b8 2, 0
.b32 .debug_abbrev
.b8 8, 1, 108, 103, 101, 110, 102, 101, 58, 32, 69, 68, 71, 32, 52, 46, 49
.b8 0
.b32 3, 37, 176, -99
.b32 info_label1
.b32 .debug_loc+0x4
.b8 -11, 11, 112, 97
.b32 info_label1+12
.b64 -1
.b16 -5, -65535
}
11.5.3. 调试指令:.file
.file
源文件名。
语法
.file file_index "filename" {, timestamp, file_size}
描述
将源文件名与整数索引关联。 .loc
.filetimestampfile_size
timestamptime_t
file_size
.file
语义
如果未指定 timestamp 和 file size,则它们默认为 0。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
Timestamp 和 file size 在 PTX ISA 版本 3.2 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.file 1 "example.cu"
.file 2 "kernel.cu"
.file 1 "kernel.cu", 1339013327, 64118
11.5.4. 调试指令:.loc
.loc
源文件位置。
语法
.loc file_index line_number column_position
.loc file_index line_number column_position,function_name label {+ immediate }, inlined_at file_index2 line_number2 column_position2
描述
声明要与词法后续 PTX 指令关联的源文件位置(源文件、行号和列位置)。.loc.filefile_index
为了指示从内联函数生成的 PTX 指令,可以指定额外的属性 .inlined_at 作为 .loc 指令的一部分。.inlined_at 属性指定内联指定函数的源位置。file_index2、line_number2 和 column_position2 指定函数被内联的位置。作为 .inlined_at 指令一部分指定的源位置必须在词法上先于 .loc 指令中的源位置。
function_name 属性指定 DWARF section 中名为 .debug_str 的偏移量。偏移量被指定为 label 表达式或 label + immediate 表达式,其中 label 在 .debug_str section 中定义。DWARF section .debug_str 包含 ASCII 空字符结尾的字符串,这些字符串指定了被内联的函数的名称。
请注意,PTX 指令可能有一个与其关联的源位置(由最近的词法上靠前的 .loc 指令确定),或者如果没有靠前的 .loc 指令,则没有关联的源位置。PTX 中的标签继承最近的词法上靠后的指令的位置。没有后续 PTX 指令的标签没有关联的源位置。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
function_name 和 inlined_at 属性在 PTX ISA 版本 7.2 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.loc 2 4237 0
L1: // line 4237, col 0 of file #2,
// inherited from mov
mov.u32 %r1,%r2; // line 4237, col 0 of file #2
add.u32 %r2,%r1,%r3; // line 4237, col 0 of file #2
...
L2: // line 4239, col 5 of file #2,
// inherited from sub
.loc 2 4239 5
sub.u32 %r2,%r1,%r3; // line 4239, col 5 of file #2
.loc 1 21 3
.loc 1 9 3, function_name info_string0, inlined_at 1 21 3
ld.global.u32 %r1, [gg]; // Function at line 9
setp.lt.s32 %p1, %r1, 8; // inlined at line 21
.loc 1 27 3
.loc 1 10 5, function_name info_string1, inlined_at 1 27 3
.loc 1 15 3, function_name .debug_str+16, inlined_at 1 10 5
setp.ne.s32 %p2, %r1, 18;
@%p2 bra BB2_3;
.section .debug_str {
info_string0:
.b8 95 // _
.b8 90 // z
.b8 51 // 3
.b8 102 // f
.b8 111 // o
.b8 111 // o
.b8 118 // v
.b8 0
info_string1:
.b8 95 // _
.b8 90 // z
.b8 51 // 3
.b8 98 // b
.b8 97 // a
.b8 114 // r
.b8 118 // v
.b8 0
.b8 95 // _
.b8 90 // z
.b8 51 // 3
.b8 99 // c
.b8 97 // a
.b8 114 // r
.b8 118 // v
.b8 0
}
11.6. 链接指令
.extern.visible.weak
11.6.1. 链接指令:.extern
.extern
外部符号声明。
语法
.extern identifier
描述
声明标识符在当前模块外部定义。定义此类标识符的模块必须在单个目标文件中仅定义一次,且定义为 .weak 或 .visible。符号的 Extern 声明可以出现多次,并且对该符号的引用将针对该符号的单个定义进行解析。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.extern .global .b32 foo; // foo is defined in another module
11.6.2. 链接指令:.visible
.visible
可见(外部)符号声明。
语法
.visible identifier
描述
声明标识符为全局可见。与 C 不同,在 C 中,标识符是全局可见的,除非声明为静态,否则 PTX 标识符仅在当前模块中可见,除非在当前模块外部声明为 .visible。
PTX ISA 注释
在 PTX ISA 版本 1.0 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.visible .global .b32 foo; // foo will be externally visible
11.6.3. 链接指令:.weak
.weak
可见(外部)符号声明。
语法
.weak identifier
描述
声明标识符为全局可见但弱。弱符号类似于全局可见符号,但在链接期间,仅在符号解析期间全局可见符号之后才选择弱符号。与全局可见符号不同,多个目标文件可以声明相同的弱符号,并且仅当没有全局符号具有相同名称时,对符号的引用才会针对弱符号进行解析。
PTX ISA 注释
在 PTX ISA 版本 3.1 中引入。
目标 ISA 注释
所有目标架构均支持。
示例
.weak .func (.reg .b32 val) foo; // foo will be externally visible
11.6.4. 链接指令:.common
.common
可见(外部)符号声明。
语法
.common identifier
描述
声明标识符为全局可见但 “common”。
Common 符号类似于全局可见符号。但是,多个目标文件可以声明相同的 common 符号,并且它们可能具有不同的类型和大小,并且对符号的引用将针对具有最大大小的 common 符号进行解析。
只有一个目标文件可以初始化 common 符号,并且该目标文件必须在来自不同目标文件的该 common 符号的所有其他定义中具有最大大小。
.common 链接指令只能用于具有 .global 存储的变量。它不能用于函数符号或具有不透明类型的符号。
PTX ISA 注释
在 PTX ISA 版本 5.0 中引入。
目标 ISA 注释
.common 指令需要 sm_20 或更高版本。
示例
.common .global .u32 gbl;
11.7. 集群维度指令
以下指令指定有关集群的信息
.reqnctapercluster.explicitcluster.maxclusterrank
.reqnctapercluster 指令指定集群中 CTA 的数量。.explicitcluster 指令指定内核应使用显式集群详细信息启动。.maxclusterrank 指令指定集群中 CTA 的最大数量。
集群维度指令只能应用于内核函数。
11.7.1. 集群维度指令:.reqnctapercluster
.reqnctapercluster
声明集群中 CTA 的数量。
语法
.reqnctapercluster nx
.reqnctapercluster nx, ny
.reqnctapercluster nx, ny, nz
描述
通过指定 1D、2D 或 3D 集群的每个维度的范围来设置集群中线程块 (CTA) 的数量。CTA 的总数为每个维度中 CTA 数量的乘积。对于指定了 .reqnctapercluster 指令的内核,如果在启动时未指定相同的值,则运行时将使用指定的值来配置启动。
语义
如果在启动时显式指定了集群维度,则它应等于此指令中指定的值。在启动时指定不同的集群维度将导致运行时错误或内核启动失败。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.entry foo .reqnctapercluster 2 { . . . }
.entry bar .reqnctapercluster 2, 2, 1 { . . . }
.entry ker .reqnctapercluster 3, 2 { . . . }
11.7.2. 集群维度指令:.explicitcluster
.explicitcluster
声明内核必须使用显式指定的集群维度启动。
语法
.explicitcluster
描述
声明此内核应使用显式指定的集群维度启动。
语义
具有 .explicitcluster 指令的内核必须使用显式指定的集群维度启动(在启动时或通过 .reqnctapercluster),否则程序将因运行时错误或内核启动失败而失败。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.entry foo .explicitcluster { . . . }
11.7.3. 集群维度指令:.maxclusterrank
.maxclusterrank
声明可以成为集群一部分的 CTA 的最大数量。
语法
.maxclusterrank n
描述
声明允许成为集群一部分的线程块 (CTA) 的最大数量。
语义
任何内核调用中指定的每个集群维度中 CTA 数量的乘积都必须小于或等于此指令中指定的数量。否则,调用将导致运行时错误或内核启动失败。
.maxclusterrank 指令不能与 .reqnctapercluster 指令结合使用。
PTX ISA 注释
在 PTX ISA 7.8 版本中引入。
目标 ISA 注释
需要 sm_90 或更高版本。
示例
.entry foo ..maxclusterrank 8 { . . . }
12. 发行说明
本节描述了 PTX ISA 和实现的更改历史。第一节描述了当前 PTX ISA 版本 8.7 的 ISA 和实现更改,其余各节提供了 PTX ISA 早期版本(追溯到 PTX ISA 版本 2.0)的更改记录。
表 54 显示了 PTX 发行历史。
PTX ISA 版本 |
CUDA 版本 |
支持的目标 |
|---|---|---|
PTX ISA 1.0 |
CUDA 1.0 |
|
PTX ISA 1.1 |
CUDA 1.1 |
|
PTX ISA 1.2 |
CUDA 2.0 |
|
PTX ISA 1.3 |
CUDA 2.1 |
|
PTX ISA 1.4 |
CUDA 2.2 |
|
PTX ISA 1.5 |
driver r190 |
|
PTX ISA 2.0 |
CUDA 3.0, driver r195 |
|
PTX ISA 2.1 |
CUDA 3.1, driver r256 |
|
PTX ISA 2.2 |
CUDA 3.2, driver r260 |
|
PTX ISA 2.3 |
CUDA 4.0, driver r270 |
|
PTX ISA 3.0 |
CUDA 4.1, driver r285 |
|
CUDA 4.2, driver r295 |
|
|
PTX ISA 3.1 |
CUDA 5.0, driver r302 |
|
PTX ISA 3.2 |
CUDA 5.5, driver r319 |
|
PTX ISA 4.0 |
CUDA 6.0, driver r331 |
|
PTX ISA 4.1 |
CUDA 6.5, driver r340 |
|
PTX ISA 4.2 |
CUDA 7.0, driver r346 |
|
PTX ISA 4.3 |
CUDA 7.5, driver r352 |
|
PTX ISA 5.0 |
CUDA 8.0, driver r361 |
|
PTX ISA 6.0 |
CUDA 9.0, driver r384 |
|
PTX ISA 6.1 |
CUDA 9.1, driver r387 |
|
PTX ISA 6.2 |
CUDA 9.2, driver r396 |
|
PTX ISA 6.3 |
CUDA 10.0, driver r400 |
|
PTX ISA 6.4 |
CUDA 10.1, driver r418 |
|
PTX ISA 6.5 |
CUDA 10.2, driver r440 |
|
PTX ISA 7.0 |
CUDA 11.0, driver r445 |
|
PTX ISA 7.1 |
CUDA 11.1, driver r455 |
|
PTX ISA 7.2 |
CUDA 11.2, driver r460 |
|
PTX ISA 7.3 |
CUDA 11.3, driver r465 |
|
PTX ISA 7.4 |
CUDA 11.4, driver r470 |
|
PTX ISA 7.5 |
CUDA 11.5, driver r495 |
|
PTX ISA 7.6 |
CUDA 11.6, driver r510 |
|
PTX ISA 7.7 |
CUDA 11.7, driver r515 |
|
PTX ISA 7.8 |
CUDA 11.8, driver r520 |
|
PTX ISA 8.0 |
CUDA 12.0, driver r525 |
|
PTX ISA 8.1 |
CUDA 12.1, driver r530 |
|
PTX ISA 8.2 |
CUDA 12.2, driver r535 |
|
PTX ISA 8.3 |
CUDA 12.3, driver r545 |
|
PTX ISA 8.4 |
CUDA 12.4, driver r550 |
|
PTX ISA 8.5 |
CUDA 12.5, driver r555 |
|
CUDA 12.6, driver r560 |
||
PTX ISA 8.6 |
CUDA 12.7, driver r565 |
|
PTX ISA 8.7 |
CUDA 12.8, driver r570 |
|
12.1. PTX ISA 版本 8.7 中的更改
新功能
PTX ISA 版本 8.7 引入了以下新功能
增加了对
sm_120目标架构的支持。增加了对支持专门加速功能的
sm_120a目标的支持。扩展了
tcgen05.mma指令,以增加对.kind::mxf4nvf4和.scale_vec::4X限定符的支持。扩展了
mma指令,以支持.f16类型累加器和形状.m16n8k16以及 FP8 类型.e4m3和.e5m2。扩展了
cvt指令,以增加对.rs舍入模式和目标类型.e2m1x4、.e4m3x4、.e5m2x4、.e3m2x4、.e2m3x4的支持。扩展了对
st.async和red.async指令的支持,以增加对.mmio、.release、.global和.scope限定符的支持。扩展了
tensormap.replace指令,以增加对.elemtype限定符的值13到15的支持。扩展了
mma和mma.sp::ordered_metadata指令,以增加对类型.e3m2/.e2m3/.e2m1和限定符.kind、.block_scale、.scale_vec_size的支持。
语义更改和澄清
澄清了在
.tile::gather4、.tile::scatter4模式中,张量坐标需要指定为 {col_idx, row_idx0, row_idx1, row_idx2, row_idx3},即 {x, y0, y1, y2, y3},而不是 {x0, x1, x2, x3, y}。更新了
tcgen05.mma指令的 指令描述符,以澄清为将来使用而保留的位。
12.2. PTX ISA 版本 8.6 中的更改
新功能
PTX ISA 版本 8.6 引入了以下新功能
增加了对
sm_100目标架构的支持。增加了对支持专门加速功能的
sm_100a目标的支持。增加了对
sm_101目标架构的支持。增加了对支持专门加速功能的
sm_101a目标的支持。扩展了
cp.async.bulk和cp.async.bulk.tensor指令,以添加.shared::cta作为目标状态空间。扩展了
fence指令,以添加对.acquire和.release限定符的支持。扩展了
fence和fence.proxy指令,以添加对.sync_restrict限定符的支持。扩展了
ldmatrix指令,以支持.m16n16、.m8n16形状和.b8类型。扩展了
ldmatrix指令,以支持.src_fmt、.dst_fmt限定符。扩展了
stmatrix指令,以支持.m16n8形状和.b8类型。增加了对
clusterlaunchcontrol指令的支持。扩展了
add、sub和fma指令,以支持混合精度浮点运算,其中.f32作为目标操作数类型,.f16/.bf16作为源操作数类型。扩展了
add、sub、mul和fma指令,以支持.f32x2类型。扩展了具有
.tf32类型的cvt指令,以支持用于.rn/.rz舍入模式的.satfinite限定符。扩展了
cp.async.bulk指令,以支持.cp_mask限定符和byteMask操作数。扩展了
multimem.ld_reduce和multimem.st指令,以支持.e5m2、.e5m2x2、.e5m2x4、.e4m3、.e4m3x2和.e4m3x4类型。扩展了
cvt指令,以支持与.e2m1x2、.e3m2x2、.e2m3x2和.ue8m0x2类型之间的转换。扩展了
cp.async.bulk.tensor和cp.async.bulk.prefetch.tensor指令,以支持新的 load_mode 限定符.tile::scatter4和.tile::gather4。扩展了
tensormap.replace指令,以添加对新限定符.swizzle_atomicity的支持,以支持新的 swizzle 模式。扩展了
mbarrier.arrive、mbarrier.arrive_drop、.mbarrier.test_wait和.mbarrier.try_wait指令,以支持.relaxed限定符。扩展了
cp.async.bulk.tensor和cp.async.bulk.prefetch.tensor指令,以支持新的 load_mode 限定符.im2col::w和.im2col::w::128。扩展了
cp.async.bulk.tensor指令,以支持新的限定符.cta_group。增加了对
st.bulk指令的支持。增加了对 tcgen05 功能和相关指令的支持:
tcgen05.alloc、tcgen05.dealloc、tcgen05.relinquish_alloc_permit、tcgen05.ld、tcgen05.st、tcgen05.wait、tcgen05.cp、tcgen05.shift、tcgen05.mma、tcgen05.mma.sp、tcgen05.mma.ws、tcgen05.mma.ws.sp、tcgen05.fence和tcgen05.commit。扩展了
redux.sync指令,以添加对.f32类型和限定符.abs和.NaN的支持。
语义更改和澄清
无。
12.3. PTX ISA 版本 8.5 中的更改
新功能
PTX ISA 版本 8.5 引入了以下新功能
增加了对
mma.sp::ordered_metadata指令的支持。
语义更改和澄清
指令
mma.sp的稀疏元数据(操作数e)的值0b0000、0b0101、0b1010、0b1111无效,并且它们的使用会导致未定义的行为。
12.4. PTX ISA 版本 8.4 中的更改
新功能
PTX ISA 版本 8.4 引入了以下新功能
使用
.b128类型扩展了ld、st和atom指令,以支持.sys范围。扩展了整数
wgmma.mma_async指令,以分别支持.u8.s8和.s8.u8作为.atype和.btype。扩展了
mma、mma.sp指令,以支持 FP8 类型.e4m3和.e5m2。
语义更改和澄清
无。
12.5. PTX ISA 版本 8.3 中的更改
新功能
PTX ISA 版本 8.3 引入了以下新功能
增加了对 pragma
used_bytes_mask的支持,该 pragma 用于为加载操作指定已用字节的掩码。扩展了
isspacep、cvta.to、ld和st指令,以接受带有.param状态空间限定符的::entry和::func子限定符。在指令
ld、ld.global.nc、ldu、st、mov和atom上增加了对.b128类型的支持。增加了对指令
tensormap.replace、tensormap.cp_fenceproxy的支持,以及对指令fence.proxy上的限定符.to_proxykind::from_proxykind的支持,以支持修改tensor-map。
语义更改和澄清
无。
12.6. PTX ISA 版本 8.2 中的更改
新功能
PTX ISA 版本 8.2 引入了以下新功能
在
ld和st指令上添加了对.mmio限定符的支持。扩展了
lop3指令以允许谓词目标。扩展了
multimem.ld_reduce指令以支持.acc::f32限定符,从而允许中间累加使用.f32精度。扩展了异步线程束组级别的矩阵乘法累加操作
wgmma.mma_async,以支持.sp修饰符,该修饰符允许在输入矩阵 A 为稀疏矩阵时执行矩阵乘法累加操作。
语义更改和澄清
在 cp.async.bulk 和 cp.async.bulk.tensor 指令上的 .multicast::cluster 限定符针对目标架构 sm_90a 进行了优化,并且在其他目标架构上可能性能大幅降低,因此建议 .multicast::cluster 与 sm_90a 一起使用。
12.7. PTX ISA 版本 8.1 中的更改
新功能
PTX ISA 版本 8.1 引入了以下新功能
添加了对
st.async和red.async指令的支持,分别用于共享内存上的异步存储和异步归约操作。在半精度
fma指令上添加了对.oob修饰符的支持。在
cvt指令上为.f16、.bf16和.tf32格式添加了对.satfinite饱和修饰符的支持。扩展了对
cvt指令对.e4m3/.e5m2格式的支持,使其适用于sm_89。扩展了
atom和red指令以支持向量类型。添加了对特殊寄存器
%aggr_smem_size的支持。使用 64 位
min/max操作扩展了sured指令。添加了对增加内核参数大小至 32764 字节的支持。
在内存一致性模型中添加了对多内存地址的支持。
添加了对
multimem.ld_reduce、multimem.st和multimem.red指令的支持,以对多内存地址执行内存操作。
语义更改和澄清
无。
12.8. PTX ISA 版本 8.0 中的更改
新功能
PTX ISA 版本 8.0 引入了以下新功能
添加了对支持专用加速功能的目标
sm_90a的支持。添加了对异步线程束组级别矩阵乘法累加操作
wgmma的支持。使用对大数据(包括张量数据)进行操作的批量操作扩展了异步复制操作。
引入了打包整数类型
.u16x2和.s16x2。扩展了整数算术指令
add以允许打包整数类型.u16x2和.s16x2。扩展了整数算术指令
min和max以允许打包整数类型.u16x2和.s16x2,以及.s16x2和.s32类型上的饱和修饰符.relu。添加了对特殊寄存器
%current_graph_exec的支持,该寄存器标识当前正在执行的 CUDA 设备图。添加了对
elect.sync指令的支持。在函数和变量上添加了对
.unified属性的支持。添加了对
setmaxnreg指令的支持。在
barrier.cluster指令上添加了对.sem限定符的支持。扩展了
fence指令,以允许使用op_restrict限定符进行特定于操作码的同步。在
mbarrier.arrive、mbarrier.arrive_drop、mbarrier.test_wait和mbarrier.try_wait操作上添加了对.cluster范围的支持。添加了对
mbarrier对象上的事务计数操作的支持,使用.expect_tx和.complete_tx限定符指定。
语义更改和澄清
无。
12.9. PTX ISA 版本 7.8 中的更改
新功能
PTX ISA 版本 7.8 引入了以下新功能
添加了对
sm_89目标架构的支持。添加了对
sm_90目标架构的支持。扩展了
bar和barrier指令以接受可选的范围限定符.cta。使用可选的子限定符
::cta扩展了.shared状态空间限定符。添加了对
movmatrix指令的支持,该指令在线程束之间转置寄存器中的矩阵。添加了对
stmatrix指令的支持,该指令将一个或多个矩阵存储到共享内存。使用形状
.m16n8k4、.m16n8k8和.m16n8k16扩展了.f64浮点类型mma操作。使用
bf16备用浮点数据格式扩展了add、sub、mul、set、setp、cvt、tanh、ex2、atom和red指令。添加了对新的备用浮点数据格式
.e4m3和.e5m2的支持。扩展了
cvt指令以转换.e4m3和.e5m2备用浮点数据格式。添加了对
griddepcontrol指令的支持,作为控制从属网格执行的通信机制。扩展了
mbarrier指令以允许新的阶段完成检查操作 *try_wait*。添加了对新的线程范围
.cluster的支持,该范围是一组协同线程阵列 (CTA)。扩展了
fence/membar、ld、st、atom和red指令以接受.cluster范围。添加了对共享状态空间在集群内所有线程中扩展可见性的支持。
使用
::cluster子限定符扩展了.shared状态空间限定符,以实现共享内存的集群级可见性。扩展了
isspacep、cvta、ld、st、atom和red指令以接受带有.shared状态空间限定符的::cluster子限定符。添加了对
mapa指令的支持,以将共享内存地址映射到集群内不同 CTA 中的相应地址。添加了对
getctarank指令的支持,以查询包含给定地址的 CTA 的等级。添加了对新的屏障同步指令
barrier.cluster的支持。扩展了内存一致性模型以包含新的集群范围。
添加了对与集群信息相关的特殊寄存器的支持:
%is_explicit_cluster、%clusterid、%nclusterid、%cluster_ctaid、%cluster_nctaid、%cluster_ctarank、%cluster_nctarank。添加了对集群维度指令
.reqnctapercluster、.explicitcluster和.maxclusterrank的支持。
语义更改和澄清
无。
12.10. PTX ISA 版本 7.7 中的更改
新功能
PTX ISA 版本 7.7 引入了以下新功能
扩展了
isspacep和cvta指令,以包含内核函数参数的.param状态空间。
语义更改和澄清
无。
12.11. PTX ISA 版本 7.6 中的更改
新功能
PTX ISA 版本 7.6 引入了以下新功能
支持
szext指令,该指令对指定值执行符号扩展或零扩展。支持
bmsk指令,该指令创建从指定位位置开始的指定宽度的位掩码。支持特殊寄存器
%reserved_smem_offset_begin、%reserved_smem_offset_end、%reserved_smem_offset_cap、%reserved_smem_offset<2>。
语义更改和澄清
无。
12.12. PTX ISA 版本 7.5 中的更改
新功能
PTX ISA 版本 7.5 引入了以下新功能
调试信息增强功能,以支持
.section调试指令中的标签差异和负值。支持
cp.async指令上的ignore-src操作数。-
对内存一致性模型的扩展,以引入以下新概念
内存代理,作为不同内存访问方法的抽象标签。
虚拟别名,作为访问相同物理内存位置的不同内存地址。
支持新的
fence.proxy和membar.proxy指令,以允许同步通过虚拟别名执行的内存访问。
语义更改和澄清
无。
12.13. PTX ISA 版本 7.4 中的更改
新功能
PTX ISA 版本 7.4 引入了以下新功能
支持
sm_87目标架构。支持
.level::eviction_priority限定符,该限定符允许在ld、ld.global.nc、st和prefetch指令上指定缓存驱逐优先级提示。支持
.level::prefetch_size限定符,该限定符允许在ld和cp.async指令上指定数据预取提示。支持
createpolicy指令,该指令允许构造不同类型的缓存驱逐策略。支持
.level::cache_hint限定符,该限定符允许将缓存驱逐策略与ld、ld.global.nc、st、atom、red和cp.async指令一起使用。支持对缓存数据执行
applypriority和discard操作。
语义更改和澄清
无。
12.14. PTX ISA 版本 7.3 中的更改
新功能
PTX ISA 版本 7.3 引入了以下新功能
扩展了初始化程序中使用的
mask()运算符,以同时支持整数常量表达式。添加了对堆栈操作指令的支持,这些指令允许使用
stacksave和stackrestore指令操作堆栈,并使用alloca指令分配每线程堆栈。
语义更改和澄清
旧版 PTX ISA 规范中未实现的 alloca 版本已在 PTX ISA 版本 7.3 中被新的堆栈操作指令替换。
12.15. PTX ISA 版本 7.2 中的更改
新功能
PTX ISA 版本 7.2 引入了以下新功能
增强了
.loc指令以表示内联函数信息。添加了在调试节内部定义标签的支持。
扩展了
min和max指令以支持.xorsign和.abs修饰符。
语义更改和澄清
无。
12.16. PTX ISA 版本 7.1 中的更改
新功能
PTX ISA 版本 7.1 引入了以下新功能
支持
sm_86目标架构。添加了一个新的运算符
mask(),用于从初始化程序中使用的变量地址中提取特定字节。扩展了
tex和tld4指令以返回一个可选的谓词,指示指定坐标处的数据是否驻留在内存中。扩展了单比特
wmma和mma指令以支持.and操作。扩展了
mma指令以支持.sp修饰符,该修饰符允许在输入矩阵 A 为稀疏矩阵时执行矩阵乘法累加操作。扩展了
mbarrier.test_wait指令以测试特定阶段奇偶校验的完成情况。
语义更改和澄清
无。
12.17. PTX ISA 版本 7.0 中的更改
新功能
PTX ISA 版本 7.0 引入了以下新功能
支持
sm_80目标架构。添加了对异步复制指令的支持,这些指令允许将数据从一个状态空间异步复制到另一个状态空间。
添加了对
mbarrier指令的支持,这些指令允许在内存中创建 *mbarrier 对象*,并使用这些对象来同步线程和线程启动的异步复制操作。添加了对
redux.sync指令的支持,该指令允许跨线程束中的线程执行归约操作。添加了对新的备用浮点数据格式
.bf16和.tf32的支持。扩展了
wmma指令以支持形状为.m8n8k4的.f64类型。扩展了
wmma指令以支持.bf16数据格式。扩展了
wmma指令以支持形状为.m16n16k8的.tf32数据格式。扩展了
mma指令以支持形状为.m8n8k4的.f64类型。扩展了
mma指令以支持形状为.m16n8k8的.bf16和.tf32数据格式。扩展了
mma指令以支持新的形状.m8n8k128、.m16n8k4、.m16n8k16、.m16n8k32、.m16n8k64、.m16n8k128和.m16n8k256。扩展了
abs和neg指令以支持.bf16和.bf16x2数据格式。扩展了
min和max指令以支持.NaN修饰符和.f16、.f16x2、.bf16和.bf16x2数据格式。扩展了
fma指令以支持.relu饱和模式以及.bf16和.bf16x2数据格式。扩展了
cvt指令以支持.relu饱和模式以及.f16、.f16x2、.bf16、.bf16x2和.tf32目标格式。添加了对计算双曲正切的
tanh指令的支持。扩展了
ex2指令以支持.f16和.f16x2类型。
语义更改和澄清
无。
12.18. PTX ISA 版本 6.5 中的更改
新功能
PTX ISA 版本 6.5 引入了以下新功能
为半精度比较指令
set添加了对整数目标类型的支持。扩展了
abs指令以支持.f16和.f16x2类型。添加了对
cvt.pack指令的支持,该指令允许转换两个整数值并将结果打包在一起。在
mma指令上添加了新的形状.m16n8k8、.m8n8k16和.m8n8k32。添加了对
ldmatrix指令的支持,该指令为mma指令从共享内存加载一个或多个矩阵。
移除的功能
PTX ISA 版本 6.5 移除以下功能
已移除对浮点
wmma.mma指令上的.satfinite限定符的支持。此支持自 PTX ISA 版本 6.4 起已弃用。
语义更改和澄清
无。
12.19. PTX ISA 版本 6.4 中的更改
新功能
PTX ISA 版本 6.4 引入了以下新功能
添加了对
.noreturn指令的支持,该指令可用于指示函数不返回到其调用函数。添加了对
mma指令的支持,该指令允许执行矩阵乘法累加操作。
已弃用的功能
PTX ISA 版本 6.4 弃用以下功能
对浮点
wmma.mma指令上的.satfinite限定符的支持。
移除的功能
PTX ISA 版本 6.4 移除以下功能
对于
.targetsm_70及更高版本,已移除不带.sync限定符的shfl和vote指令的支持。此支持自 PTX ISA 版本 6.0 起已弃用,如 PTX ISA 版本 6.2 中所述。
语义更改和澄清
澄清了解析
.weak符号的引用仅考虑具有相同名称的.weak或.visible符号,而不考虑具有相同名称的本地符号。澄清了在
cvt指令中,只有当.atype或.dtype为.f32时,才能指定修饰符.ftz。
12.20. PTX ISA 版本 6.3 中的更改
新功能
PTX ISA 版本 6.3 引入了以下新特性
支持
sm_75目标架构。新增对新指令
nanosleep的支持,该指令可使线程暂停指定的持续时间。新增对
.alias指令的支持,该指令允许为函数符号定义别名。扩展了
atom指令,以执行.f16加法运算和.cas.b16运算。扩展了
red指令,以执行.f16加法运算。wmma指令扩展为支持类型为.s8、.u8、.s4、.u4、.b1的被乘数矩阵和类型为.s32的累加器矩阵。
语义更改和澄清
为所有
wmma指令引入了强制性的.aligned限定符。指定了传递给
wmma.load和wmma.store的基地址和步幅参数所需的对齐方式。阐明了
wmma运算返回的片段布局取决于架构,并且为不同的链接兼容 SM 架构编译的函数之间传递wmma片段可能无法按预期工作。阐明了
{atom/red}.f16x2}运算的原子性保证分别针对两个.f16元素,但不保证作为单个 32 位访问是原子的。
12.21. PTX ISA 版本 6.2 的变更
新功能
PTX ISA 版本 6.2 引入了以下新特性
用于查询 warp 中活动线程的新指令
activemask。扩展了原子和归约指令,以执行带有强制性
.noftz限定符的.f16x2加法运算。
已弃用的功能
PTX ISA 版本 6.2 弃用了以下特性
追溯自 PTX ISA 版本 6.0(引入了实现独立线程调度的
sm_70架构)起,不带.sync的shfl和vote指令的使用已被弃用。
语义更改和澄清
阐明了仅当已知 warp 中的所有线程都以相同方式评估条件时,才能在有条件执行的代码中使用
wmma指令,否则行为未定义。在内存一致性模型中,道德上强操作的定义已更新,以将栅栏从完全重叠的要求中排除,因为栅栏不访问内存。
12.22. PTX ISA 版本 6.1 的变更
新功能
PTX ISA 版本 6.1 引入了以下新特性
支持
sm_72目标架构。在
wmma指令中支持新的矩阵形状32x8x16和8x32x16。
语义更改和澄清
无。
12.23. PTX ISA 版本 6.0 的变更
新功能
PTX ISA 版本 6.0 引入了以下新特性
支持
sm_70目标架构。指定了在
sm_70及更高版本架构上运行的程序的内存一致性模型。对内存指令的各种扩展,以指定内存同步语义和可以观察到此类同步的范围。
用于矩阵运算的新指令
wmma,允许从内存加载矩阵,对其执行乘法累加运算,并将结果存储在内存中。支持新的
barrier指令。扩展了
neg指令,以支持.f16和.f16x2类型。一种新的指令
fns,允许查找整数中的第 n 个设置位。一种新的指令
bar.warp.sync,允许同步 warp 中的线程。使用
.sync修饰符扩展了vote和shfl指令,该修饰符在分别执行vote和shfl运算之前等待指定的线程。一种新的指令
match.sync,允许在 warp 中的线程之间广播和比较值。一种新的指令
brx.idx,允许分支到从潜在目标列表索引的标签。支持
.func的无大小数组参数,可用于实现可变参数函数。在 dwarf-lines 中支持
.b16整数类型。支持使用
mov指令获取设备函数返回参数的地址。
语义更改和澄清
更新了
bar指令的语义,以指示执行线程等待来自其 warp 的其他非退出线程。PTX 2.1 中引入的间接分支支持(未实现)已从规范中删除。
标签地址的支持以及在初始化程序中使用标签的支持(未实现)已从规范中删除。
对未实现的可变参数函数的支持已从规范中删除。
12.24. PTX ISA 版本 5.0 的变更
新功能
PTX ISA 版本 5.0 引入了以下新特性
支持
sm_60、sm_61、sm_62目标架构。扩展了原子和归约指令,以执行双精度加法运算。
扩展了原子和归约指令,以指定
scope修饰符。一个新的
.common指令,允许链接包含相同符号但大小不同的声明的多个目标文件。一个新的
dp4a指令,允许 4 路点积与累加运算。一个新的
dp2a指令,允许 2 路点积与累加运算。支持特殊寄存器
%clock_hi。
语义更改和澄清
阐明了 ld 和 st 指令上缓存修饰符的语义,以反映缓存操作仅被视为性能提示,并且不更改程序的内存一致性行为。
阐明了 ld 和 st 指令上 volatile 操作的语义,以反映优化编译器如何处理 volatile 操作。
12.25. PTX ISA 版本 4.3 的变更
新功能
PTX ISA 版本 4.3 引入了以下新特性
一个新的
lop3指令,允许对 3 个输入执行任意逻辑运算。在扩展精度算术指令中增加了对 64 位计算的支持。
扩展了
tex.grad指令,以支持cube和acube几何形状。扩展了
tld4指令,以支持a2d、cube和acube几何形状。扩展了
tex和tld4指令,以支持用于偏移向量和深度比较的可选操作数。扩展了
txq指令,以支持从特定 LOD 查询纹理字段。
语义更改和澄清
无。
12.26. PTX ISA 版本 4.2 的变更
新功能
PTX ISA 版本 4.2 引入了以下新特性
支持
sm_53目标架构。支持
.f16和.f16x2类型的算术、比较和纹理指令。支持表面的
memory_layout字段,以及suq指令对查询此字段的支持。
语义更改和澄清
更新了 ABI 下参数传递的语义,以指示用于参数传递的 ld.param 和 st.param 指令不能被谓词化。
更新了 {atom/red}.add.f32 的语义,以指示全局内存上的原子操作的次正规输入和结果将被刷新为符号保留零;而共享内存上的原子操作则保留次正规输入和结果,并且不会将其刷新为零。
12.27. PTX ISA 版本 4.1 的变更
新功能
PTX ISA 版本 4.1 引入了以下新特性
支持
sm_37和sm_52目标架构。支持纹理的新字段
array_size、num_mipmap_levels和num_samples,以及txq指令对查询这些字段的支持。支持表面的新字段
array_size,以及suq指令对查询此字段的支持。支持特殊寄存器
%total_smem_size和%dynamic_smem_size。
语义更改和澄清
无。
12.28. PTX ISA 版本 4.0 的变更
新功能
PTX ISA 版本 4.0 引入了以下新特性
支持
sm_32和sm_50目标架构。支持 64 位性能计数器特殊寄存器
%pm0_64,..,%pm7_64。一个新的
istypep指令。添加了一个新的指令
rsqrt.approx.ftz.f64,用于计算值的平方根倒数的快速近似值。支持新的指令
.attribute,用于指定变量的特殊属性。支持
.managed变量属性。
语义更改和澄清
更新了 vote 指令的语义,以明确指示 warp 中的非活动线程在参与 vote.ballot.b32 时为其条目贡献 0。
12.29. PTX ISA 版本 3.2 的变更
新功能
PTX ISA 版本 3.2 引入了以下新特性
纹理指令支持从多采样和多采样数组纹理读取。
扩展了
.section调试指令,以包括标签 + 立即表达式。扩展了
.file指令,以包括时间戳和文件大小信息。
语义更改和澄清
更新了 vavrg2 和 vavrg4 指令的语义,以指示仅当 Va[i] + Vb[i] 为非负数时,指令才加 1,并且加法结果移位 1 位(而不是除以 2)。
12.30. PTX ISA 版本 3.1 的变更
新功能
PTX ISA 版本 3.1 引入了以下新特性
支持
sm_35目标架构。支持 CUDA 动态并行性,这使内核能够创建和同步新的工作。
ld.global.nc用于通过非相干纹理缓存加载只读全局数据。一个新的漏斗移位指令
shf。扩展了原子和归约指令,以执行 64 位
{and, or, xor}运算和 64 位整数{min, max}运算。增加了对
mipmaps的支持。增加了对纹理和表面的间接访问的支持。
扩展了对通用寻址的支持,以包括
.const状态空间,并添加了一个新的运算符generic(),以形成用于初始化程序的.global或.const变量的通用地址。一个新的
.weak指令,允许链接包含相同符号声明的多个目标文件。
语义更改和澄清
PTX 3.1 重新定义了初始化器中全局变量的默认寻址方式,从通用地址到全局状态空间中的偏移量。旧版 PTX 代码被视为对初始化器中使用的每个全局变量都具有隐式 generic() 运算符。PTX 3.1 代码应在初始化器中包含显式 generic() 运算符,使用 cvta.global 在运行时形成通用地址,或使用 ld.global 从非通用地址加载。
指令 mad.f32 需要用于 sm_20 及更高版本目标的舍入修饰符。但是,对于 PTX ISA 版本 3.0 及更早版本,ptxas 不强制执行此要求,并且 mad.f32 默认静默为 mad.rn.f32。对于 PTX ISA 版本 3.1,ptxas 生成警告并默认设置为 mad.rn.f32,在后续版本中,ptxas 将对 PTX ISA 版本 3.2 及更高版本强制执行此要求。
12.31. PTX ISA 版本 3.0 的变更
新功能
PTX ISA 版本 3.0 引入了以下新特性
支持
sm_30目标架构。SIMD 视频指令。
一个新的 warp shuffle 指令。
用于高效、扩展精度整数乘法的指令
mad.cc和madc。具有 3D 和数组几何形状的表面指令。
纹理指令支持从立方体贴图和立方体贴图数组纹理读取。
平台选项
.targetdebug 用于声明 PTX 模块包含DWARF调试信息。pmevent.mask,用于触发多个性能监视器事件。性能监视器计数器特殊寄存器
%pm4..%pm7。
语义更改和澄清
特殊寄存器 %gridid 已从 32 位扩展到 64 位。
当编译到应用程序二进制接口 (ABI) 时,PTX ISA 版本 3.0 弃用了模块作用域的 .reg 和 .local 变量。在不使用 ABI 进行编译时,模块作用域的 .reg 和 .local 变量与以前一样受到支持。当编译包含模块作用域的 .reg 或 .local 变量的旧版 PTX 代码(ISA 版本早于 3.0)时,编译器会静默禁用 ABI 的使用。
更新了 shfl 指令的语义,以明确指示 warp 内非活动和谓词关闭线程的源操作数 a 的值是不可预测的。
PTX 模块不再允许重复的 .version 指令。此功能未实现,因此没有语义更改。
已删除未实现的指令 suld.p 和 sust.p.{u32,s32,f32}。
12.32. PTX ISA 版本 2.3 的变更
新功能
PTX 2.3 增加了对纹理数组的支持。纹理数组功能支持访问 1D 或 2D 纹理数组,其中整数索引到纹理数组中,然后使用一个或两个单精度浮点坐标来寻址所选的 1D 或 2D 纹理。
PTX 2.3 添加了一个新的指令 .address_size,用于指定地址的大小。
.const 和 .global 状态空间中的变量默认初始化为零。
语义更改和澄清
已更新 .maxntid 指令的语义以匹配当前实现。具体而言,.maxntid 仅保证线程块中的线程总数不超过最大值。以前,语义表明最大值在每个维度中分别强制执行,但事实并非如此。
位字段提取和插入指令 BFE 和 BFI 现在指示 len 和 pos 操作数被限制为值范围 0..255。
已删除未实现的指令 {atom,red}.{min,max}.f32}。
12.33. PTX ISA 版本 2.2 的变更
新功能
PTX 2.2 添加了一个新的指令,用于指定内核参数属性;具体而言,有一个新的指令用于指定内核参数是指针,用于指定参数指向的状态空间,以及可选地指定参数指向的内存的对齐方式。
PTX 2.2 向 .samplerref 不透明类型添加了一个名为 force_unnormalized_coords 的新字段。此字段用于独立纹理模式,以覆盖纹理标头中的 normalized_coords 字段。需要此字段来支持 OpenCL 等语言,这些语言在采样器标头而不是纹理标头中表示归一化/未归一化坐标的属性。
PTX 2.2 弃用了显式常量存储体,并支持 .const 状态空间的大型平面地址空间。仍然支持使用显式常量存储体的旧版 PTX。
PTX 2.2 添加了一个新的 tld4 指令,用于从构成给定纹理位置的双线性插值足迹的四个纹素中加载组件(r、g、b 或 a)。此指令可用于在软件中计算更高精度的双线性插值结果,或用于执行更高带宽的纹理加载。
语义更改和澄清
无。
12.34. PTX ISA 版本 2.1 的变更
新功能
PTX ISA 版本 2.1 在 sm_2x 目标中支持基于堆栈的底层 ABI。
已为 sm_2x 目标实现了对间接调用的支持。
添加了新的指令 .branchtargets 和 .calltargets,用于指定间接分支和间接函数调用的潜在目标。添加了 .callprototype 指令,用于声明间接函数调用的类型签名。
现在可以在变量初始化程序中指定 .global 和 .const 变量的名称,以表示它们的地址。
添加了一组 32 个驱动程序特定的执行环境特殊寄存器。这些寄存器被命名为 %envreg0..%envreg31。
纹理和表面具有新的通道数据类型和通道顺序字段,并且 txq 和 suq 指令支持查询这些字段。
指令 .minnctapersm 已替换 .maxnctapersm 指令。
已添加指令 .reqntid,以允许指定确切的 CTA 维度。
添加了一个新的指令 rcp.approx.ftz.f64,用于计算快速、粗略的近似倒数。
语义更改和澄清
如果指定了 .minnctapersm 但未同时指定 .maxntid,则会发出警告。
12.35. PTX ISA 版本 2.0 的变更
新功能
浮点扩展
本节介绍了 PTX ISA 版本 2.0 中针对 sm_20 目标的浮点更改。目标是在尽可能实现 IEEE 754 兼容性的同时,最大限度地提高与旧版 PTX ISA 版本 1.x 代码和 sm_1x 目标的向后兼容性。
PTX ISA 版本 1.x 的更改如下
单精度指令默认支持
sm_20目标的次正规数。.ftz修饰符可用于强制与sm_1x的向后兼容性。单精度
add、sub和mul现在支持sm_20目标的.rm和.rp舍入修饰符。添加了单精度融合乘加 (fma) 指令,支持 IEEE 754 兼容的舍入修饰符和对次正规数的支持。
fma.f32指令还支持.ftz和.sat修饰符。fma.f32需要sm_20。mad.f32指令已使用舍入修饰符进行了扩展,因此对于sm_20目标,它与fma.f32同义。fma.f32和mad.f32都需要sm_20目标的舍入修饰符。不带舍入的
mad.f32指令被保留,以便编译器可以为sm_1x目标生成代码。当为sm_1x编译的代码在sm_20设备上执行时,mad.f32映射到fma.rn.f32。添加了具有 IEEE 754 兼容舍入的单精度和双精度
div、rcp和sqrt。这些通过使用舍入修饰符来指示,并且需要sm_20。添加了指令
testp和copysign。
新指令
添加了一个加载 uniform 指令 ldu。
表面指令支持其他 .clamp 修饰符,.clamp 和 .zero。
指令 sust 现在支持格式化表面存储。
添加了一个前导零计数指令 clz。
添加了一个查找前导非符号位指令 bfind。
添加了一个位反转指令 brev。
添加了位字段提取和插入指令 bfe 和 bfi。
添加了一个人口计数指令 popc。
添加了一个投票表决指令 vote.ballot.b32。
指令 {atom,red}.add.f32 已被实现。
指令 {atom,red}.shared 已被扩展,以处理 sm_20 目标的 64 位数据类型。
已添加系统级内存屏障指令 membar.sys。
bar 指令已按如下方式扩展:
已添加
bar.arrive指令。已添加指令
bar.red.popc.u32和bar.red.{and,or}.pred。bar现在支持可选的线程计数和寄存器操作数。
已添加标量视频指令(包括 prmt)。
已添加指令 isspacep,用于查询通用地址是否在指定的状态空间窗口内。
已添加指令 cvta,用于将全局、本地和共享地址转换为通用地址,反之亦然。
其他新功能
指令 ld、ldu、st、prefetch、prefetchu、isspacep、cvta、atom 和 red 现在支持通用寻址。
已添加新的特殊寄存器 %nwarpid、%nsmid、%clock64、%lanemask_{eq,le,lt,ge,gt}。
缓存操作已添加到指令 ld、st、suld 和 sust,例如,用于 prefetching 到指定级别的内存层次结构。还添加了指令 prefetch 和 prefetchu。
.maxnctapersm 指令已被弃用,并替换为 .minnctapersm,以更好地匹配其行为和用法。
已添加新的指令 .section,以替换用于通过 PTX 传递 DWARF 格式调试信息的 @@DWARF 语法。
已添加新的指令 .pragma nounroll,以允许用户禁用循环展开。
语义更改和澄清
PTX ISA 1.4 及更早版本中 cvt.ftz 的勘误表已得到修复。在这些版本中,如果源类型或目标类型大小为 64 位,则单精度次正规输入和结果不会刷新为零。在 PTX ISA 1.5 及更高版本中,对于所有浮点指令类型,cvt.ftz(以及 .target sm_1x 的 cvt,其中隐含 .ftz)指令都会将单精度次正规输入和结果刷新为符号保留零。为了保持与旧版 PTX 代码的兼容性,如果 .version 为 1.4 或更早版本,则仅当源类型和目标类型大小都不是 64 位时,单精度次正规输入和结果才会刷新为符号保留零。
特殊寄存器 %tid、%ntid、%ctaid 和 %nctaid 的组件已从 16 位扩展到 32 位。这些寄存器现在具有 .v4.u32 类型。
在 PTX ISA 1.5 版本中,独立纹理模式下可用的采样器数量被错误地列为 32 个;正确的数量是 16 个。
14. .pragma 字符串的描述
本节介绍 ptxas 定义的 .pragma 字符串。
14.1. Pragma 字符串:“nounroll”
“nounroll”
禁用优化后端编译器中的循环展开。
语法
.pragma "nounroll";
描述
"nounroll" pragma 是一个指令,用于禁用优化后端编译器中的循环展开。
"nounroll" pragma 允许在模块、入口函数和语句级别使用,含义如下:
- 模块作用域
-
禁用模块中所有循环的展开,包括
.pragma之前的循环。 - 入口函数作用域
-
禁用入口函数体中所有循环的展开。
- 语句级 pragma
-
禁用当前块作为循环头的循环的展开。
请注意,为了在语句级别获得预期的效果,"nounroll" 指令必须出现在所需循环的循环头基本块中的任何指令语句之前。循环头块定义为支配循环体中所有块并且是循环回边的目标的块。出现在循环头块之外的语句级 "nounroll" 指令将被静默忽略。
PTX ISA 注释
在 PTX ISA 版本 2.0 中引入。
目标 ISA 注释
需要 sm_20 或更高版本。对于 sm_1x 目标将被忽略。
示例
.entry foo (...)
.pragma "nounroll"; // do not unroll any loop in this function
{
...
}
.func bar (...)
{
...
L1_head:
.pragma "nounroll"; // do not unroll this loop
...
@p bra L1_end;
L1_body:
...
L1_continue:
bra L1_head;
L1_end:
...
}
14.2. Pragma 字符串:“used_bytes_mask”
“used_bytes_mask”
用于指示 ld 操作数据中已使用字节的掩码。
语法
.pragma "used_bytes_mask mask";
描述
"used_bytes_mask" pragma 是一个指令,用于根据提供的掩码指定加载操作中已使用的字节。
"used_bytes_mask" pragma 需要在加载指令之前指定,以便获得有关加载操作中使用的字节的信息。如果其后的指令不是加载指令,则 pragma 将被忽略。
对于没有此 pragma 的加载指令,假定使用了加载操作中的所有字节。
操作数 mask 是一个 32 位整数,设置位表示加载操作数据中已使用的字节。
语义
Each bit in mask operand corresponds to a byte data where each set bit represents the used byte.
Most-significant bit corresponds to most-significant byte of data.
// For 4 bytes load with only lower 3 bytes used
.pragma "used_bytes_mask 0x7";
ld.global.u32 %r0, [gbl]; // Higher 1 byte from %r0 is unused
// For vector load of 16 bytes with lower 12 bytes used
.pragma "used_bytes_mask 0xfff";
ld.global.v4.u32 {%r0, %r1, %r2, %r3}, [gbl]; // %r3 unused
PTX ISA 注释
在 PTX ISA 版本 8.3 中引入。
目标 ISA 注释
需要 sm_50 或更高版本。
示例
.pragma "used_bytes_mask 0xfff";
ld.global.v4.u32 {%r0, %r1, %r2, %r3}, [gbl]; // Only lower 12 bytes used
15. 声明
15.1. 声明
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息或因其使用可能导致的侵犯第三方专利或其他权利的后果或使用不承担任何责任。本文档不构成开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留在任何时候对本文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或 malfunction 可以合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每种产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并符合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品;或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对此类产品或服务的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在 NVIDIA 的专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,并且复制时不得进行更改,必须完全符合所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文件和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独称为“材料”)均按“原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他方面的保证,并明确声明不承担所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文件而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论何种原因造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的累计责任应根据产品的销售条款的规定进行限制。
15.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
15.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。
4.2. 注释
PTX 中的注释遵循 C/C++ 语法,使用非嵌套的
/*和*/用于可能跨越多行的注释,并使用//开始一个注释,该注释扩展到下一个换行符,该换行符终止当前行。注释不能出现在字符常量、字符串文字或其他注释中。PTX 中的注释被视为空白。