PTX 互操作性编写指南
编写符合 ABI 的 PTX 的指南。
1. 简介
本文档定义了生成 PTX 时 CUDA® 架构的应用程序二进制接口 (ABI)。通过遵循 ABI,外部开发人员可以生成符合规范的 PTX 代码,该代码可以与其他代码链接。
PTX 是一种低级并行线程执行虚拟机和 ISA(指令集架构)。PTX 可以从多种工具输出,也可以由开发人员直接编写。PTX 旨在与 GPU 架构无关,以便相同的代码可以重用于不同的 GPU 架构。有关 PTX 的更多信息,请参阅最新版本的 PTX ISA 参考文档。
有多个 CUDA 架构系列,每个系列都有自己的 ISA;例如,SM 5.x 是 Maxwell 系列,SM 6.x 是 Pascal 系列。本文档描述了所有架构的高级 ABI。符合 ABI 的程序有望在适当架构的 GPU 上执行,并且可以假定该 ISA 中的指令可用。
2. 数据表示
2.1. 基本类型
下表显示了支持的本机标量 PTX 类型。任何 PTX 生成器都必须使用这些大小和对齐方式,以使其 PTX 与其他生成器生成的 PTX 兼容。PTX 还支持本机向量类型,这将在 聚合和联合 中讨论。
类型的大小由主机定义。例如,指针大小和长整型大小由主机 ABI 决定。PTX 有一个 .address_size 指令,用于指定整个 PTX 代码中使用的地址大小。在 32 位主机上,指针大小为 32 位,在 64 位主机上,指针大小为 64 位。但是,本地和共享内存空间的地址始终为 32 位大小。
在单独编译期间,我们会将有关主机平台的信息存储在每个目标文件中。链接器将无法链接为不兼容主机平台生成的目标文件。
PTX 类型 |
大小(字节) |
对齐(字节) |
硬件表示 |
|---|---|---|---|
.b8 |
1 |
1 |
无类型字节 |
.b16 |
2 |
2 |
无类型半字 |
.b32 |
4 |
4 |
无类型字 |
.b64 |
8 |
8 |
无类型双字 |
.s8 |
1 |
1 |
有符号整型字节 |
.s16 |
2 |
2 |
有符号整型半字 |
.s32 |
4 |
4 |
有符号整型字 |
.s64 |
8 |
8 |
有符号整型双字 |
.u8 |
1 |
1 |
无符号整型字节 |
.u16 |
2 |
2 |
无符号整型半字 |
.u32 |
4 |
4 |
无符号整型字 |
.u64 |
8 |
8 |
无符号整型双字 |
.f16 |
2 |
2 |
IEEE 半精度 |
.f32 |
4 |
4 |
IEEE 单精度 |
.f64 |
8 |
8 |
IEEE 双精度 |
2.2. 聚合和联合
除了标量类型之外,PTX 还支持这些标量类型的本机向量类型,包括其向量语法和字节数组语法。对于大小不超过 4 个字节的标量类型,存在具有 1、2、3 和 4 个元素的向量类型;对于所有其他类型,仅存在 1 和 2 个元素的向量类型。
所有聚合和联合都可以在 PTX 中使用其字节数组语法来支持。
以下是所有聚合和联合的大小和对齐规则。
对于非本机向量类型,整个聚合或联合与对其要求最严格的成员在同一边界上对齐。如果对齐方式由输入语言定义,则不遵循此规则。例如,在 OpenCL 中,内置向量数据类型的对齐方式设置为内置数据类型的大小(以字节为单位)。
-
对于本机向量类型(在本节开头讨论),对齐方式定义如下。(对于以下定义,本机向量具有 n 个元素,并且具有元素类型 t。)
对于具有奇数个元素的向量,其对齐方式与其成员相同:alignof(t)。
对于具有偶数个元素的向量,其对齐方式设置为元素数量乘以其成员的对齐方式:n*alignof(t)。
每个成员都分配到具有适当对齐方式的最低可用偏移量。这可能需要内部填充,具体取决于上一个成员。
聚合或联合的大小(如果需要)会增加,使其成为聚合或联合对齐方式的倍数。这可能需要尾部填充,具体取决于最后一个成员。
2.3. 位域
C 结构和联合定义可能具有位域,这些位域定义了具有指定位数的整型对象。
位域类型 |
宽度 w |
范围 |
|---|---|---|
有符号字符 |
1 到 8 |
-2w-1 到 2w-1 - 1 |
无符号字符 |
1 到 8 |
0 到 2w - 1 |
有符号短整型 |
1 到 16 |
-2w-1 到 2w-1 - 1 |
无符号短整型 |
1 到 16 |
0 到 2w - 1 |
有符号整型 |
1 到 32 |
-2w-1 到 2w-1 - 1 |
无符号整型 |
1 到 32 |
0 到 2w - 1 |
有符号长长整型 |
1 到 64 |
-2w-1 到 2w-1 - 1 |
无符号长长整型 |
1 到 64 |
0 到 2w - 1 |
当前 GPU 仅支持小端内存,因此以下内容假定为小端布局。
以下是适用于位域的规则。
普通位域(既未指定有符号也未指定无符号)被视为有符号。
当未提供类型时(例如,指定了 signed : 6),类型默认为 int。
位域遵循与其他结构和联合成员相同的大小和对齐规则,但有以下修改。
对于小端,位域在内存中从右到左(从最低有效位到最高有效位)分配。
位域必须完全驻留在适合其声明类型的存储单元中。位域绝不应跨越其单元边界。
位域可以与其他结构和联合成员共享存储单元,包括非位域的成员,只要存储单元中有足够的空间。
未命名的位域不影响结构或联合的对齐方式。
零长度位域强制结构的以下成员与位域类型对应的下一个对齐边界对齐。未命名的零长度位域不会强制结构的外部对齐方式达到该边界。如果未命名的零长度位域具有比外部对齐方式更严格的对齐方式,则无法保证在将结构或联合分配到内存时会保持更严格的对齐方式。
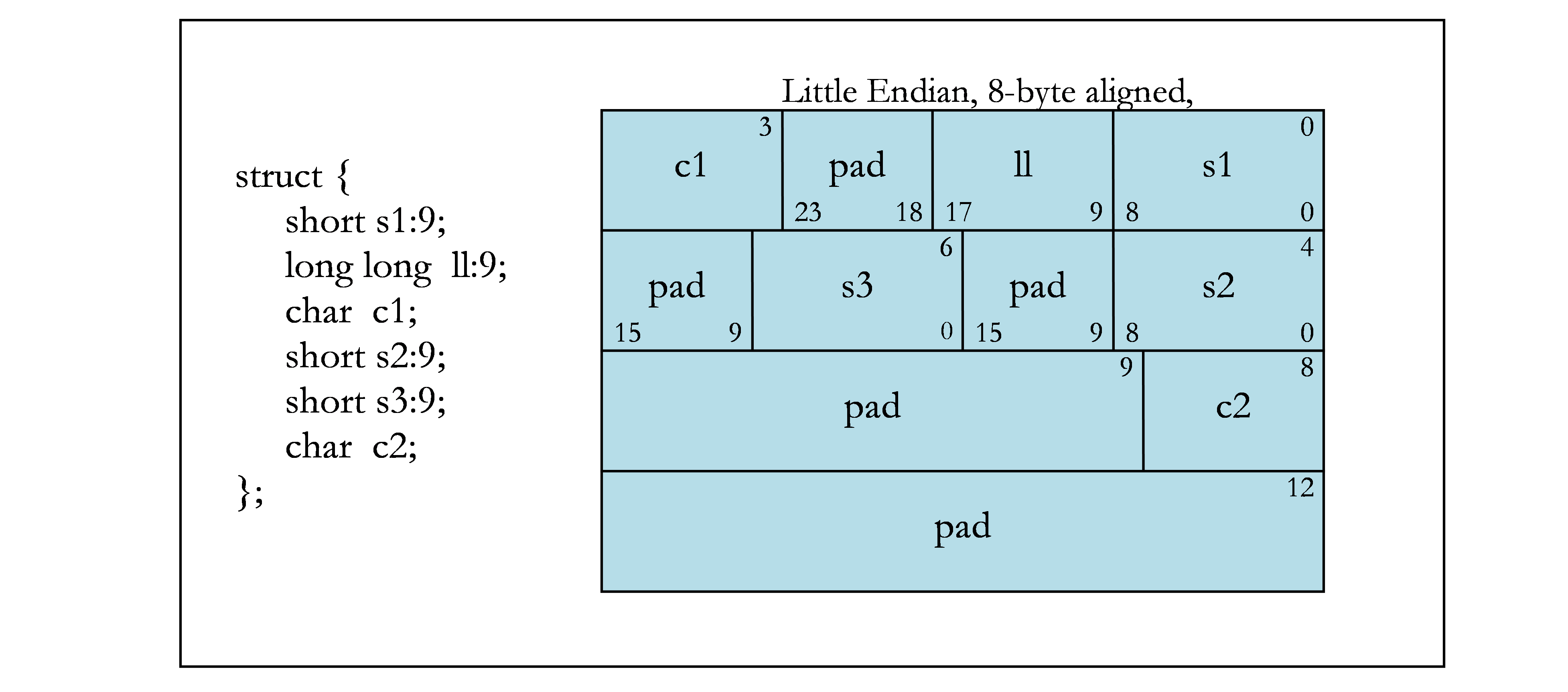
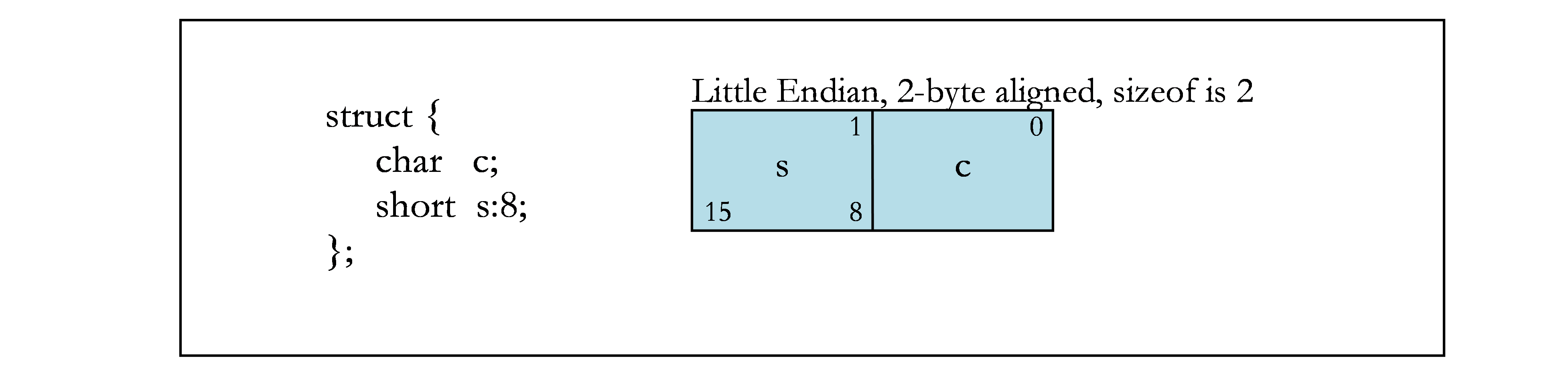
下图包含位域的示例。图 1 显示了示例中使用的字节偏移量(上角)和位号(下角)。其余各图显示了不同的位域示例。
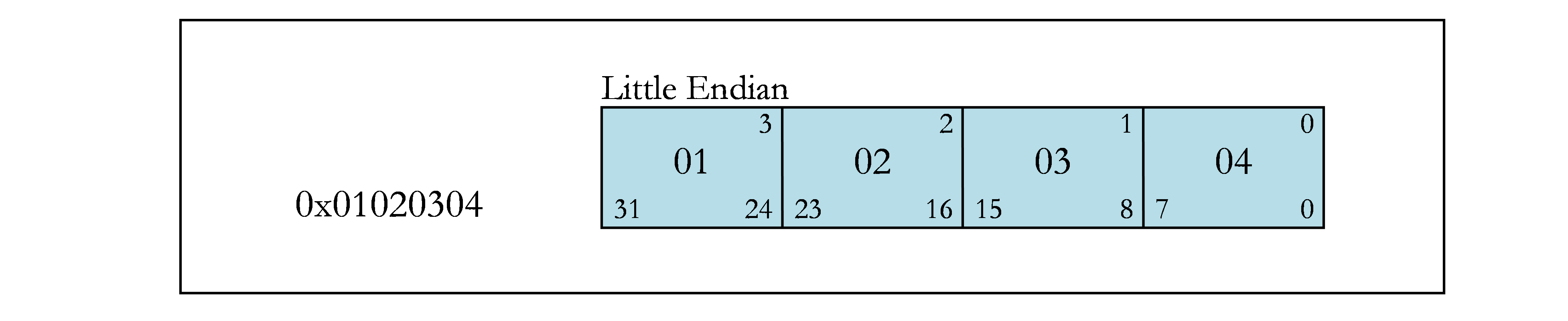
位编号
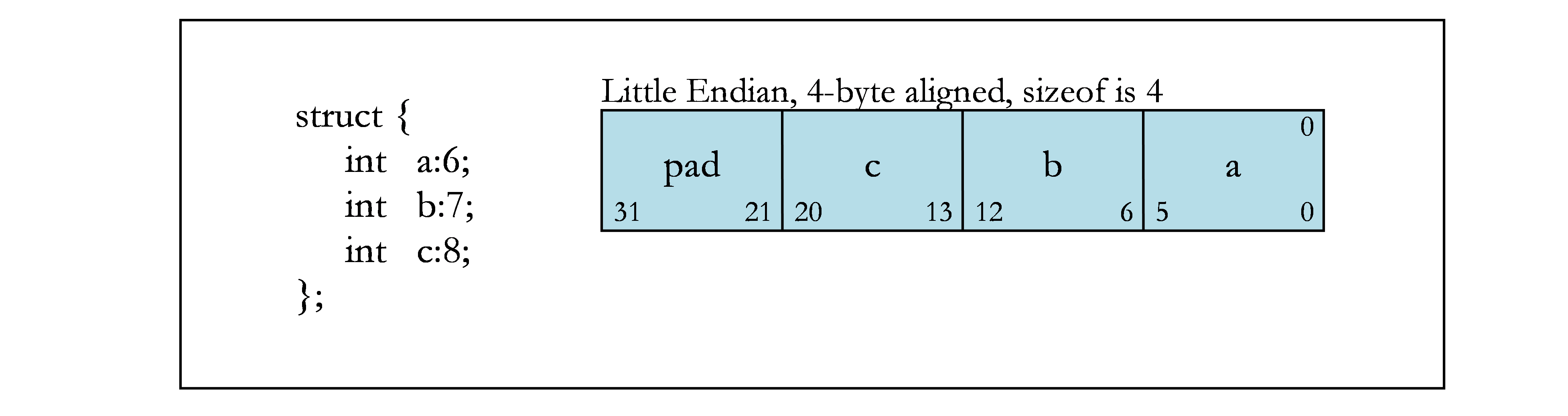
位域分配
边界对齐
存储单元共享
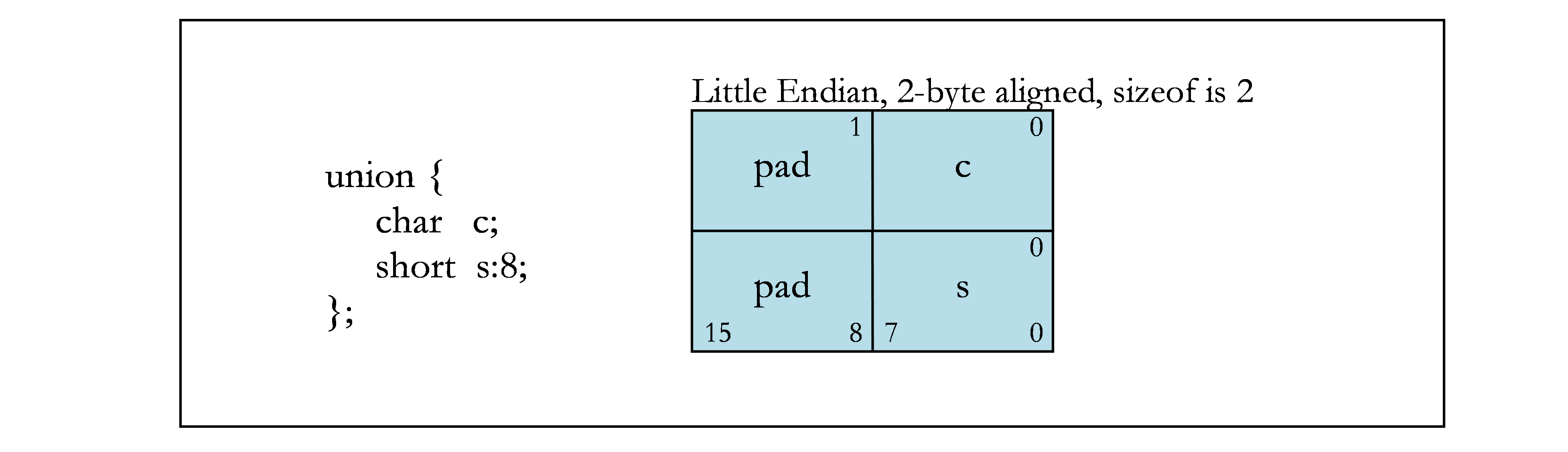
联合分配
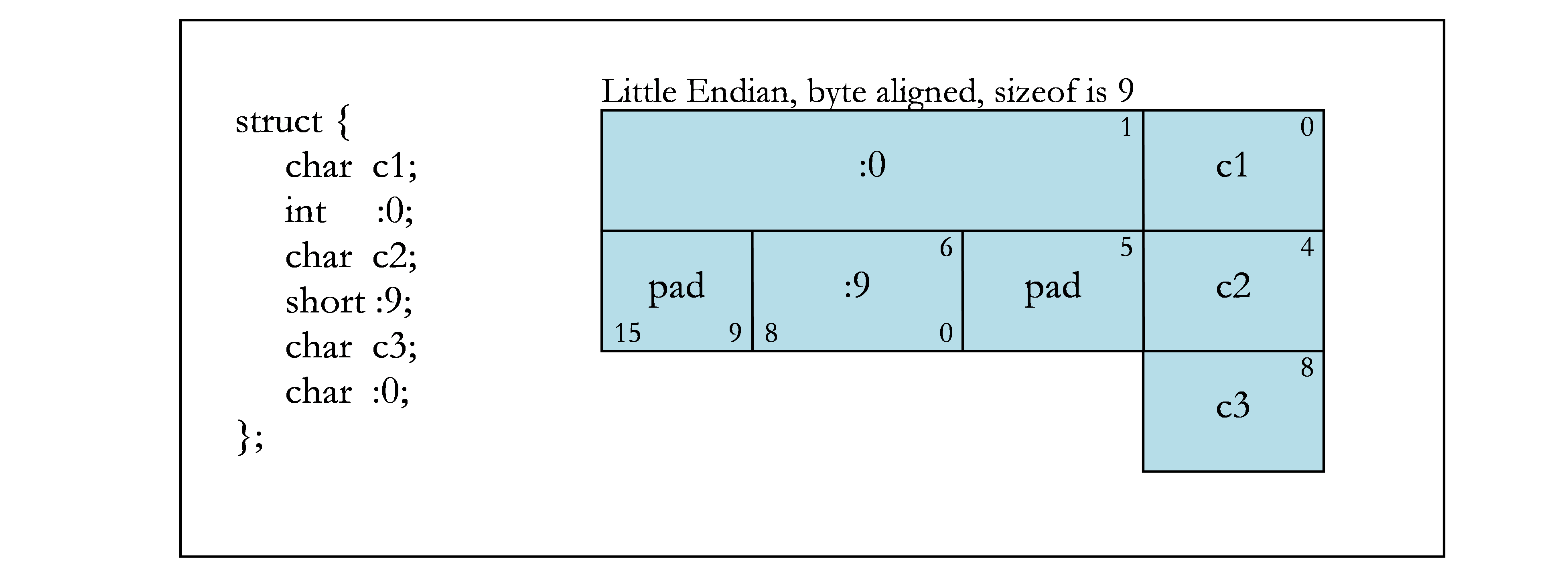
未命名的位域
2.4. 纹理、采样器和表面类型
纹理、采样器和表面类型用于定义对纹理和表面内存的引用。CUDA 架构提供硬件和指令,以便有效地从纹理或表面内存而不是全局内存中读取数据。
在内核可以使用纹理引用之前,纹理引用通过运行时函数绑定到设备的只读内存区域(称为纹理内存)。纹理引用具有多个属性,例如归一化模式、寻址模式和纹理过滤等。采样器引用可用于在内核中读取纹理时对其进行采样。表面引用用于从表面内存读取数据以及向表面内存写入数据。它还具有与纹理类似的各种属性。
在 PTX 级别,访问纹理或表面内存的对象称为不透明对象。纹理由 .texref 或 .samplerref 类型表示,表面由 .surfref 类型表示。可以通过特定指令(.texref/.samplerref 的 TEX 和 .surfref 的 SULD/SUST)访问不透明对象的数据。不透明对象的属性通过在内存中分配由驱动程序填充的描述符来实现。PTX TXQ/SUQ 指令转换为描述符字段的内存读取。描述符的内部格式随每个架构而异,用户不应依赖它。如果纹理或表面引用在编译时已知或间接已知,则可以直接访问不透明对象的数据和属性。如果引用在编译期间未知,则读取数据和属性所需的所有信息都包含在称为句柄的 .b64 值中。句柄可用于将不透明对象引用传递和返回到函数以及从函数传递和返回,以及引用外部纹理、采样器和表面。
3. 函数调用序列
本节介绍 PTX 级别的函数调用序列,包括寄存器使用、堆栈帧布局和参数传递。PTX 级别的函数调用序列描述了在 PTX 中表示什么以启用函数调用。此级别存在抽象。与函数调用序列相关的大多数细节都在 SASS 级别处理。
早于 2.0 的 PTX 版本不符合本文档中定义的 ABI,并且无法执行 ABI 兼容的函数调用。为了使调用约定起作用,必须使用 PTX 版本 2.0 或更高版本。
3.1. 寄存器
在 PTX 级别,指定的寄存器是虚拟的。寄存器分配发生在 PTX 到 SASS 的转换期间。PTX 到 SASS 的转换还会将参数和返回值转换为物理寄存器或堆栈位置。
3.2. 堆栈帧
PTX 级别没有软件堆栈的概念。堆栈的操作完全在 SASS 级别定义,并在 PTX 到 SASS 的转换过程中分配。
3.3. 参数传递
在 PTX 级别,设备函数中存在的所有参数和返回值都使用参数状态空间 (.param)。下表包含用于处理在源级别定义的参数和返回值的规则。对于每种源级别类型,都提供了应使用的相应 PTX 级别类型。
源类型 |
大小(位) |
PTX 类型 |
|---|---|---|
整型 |
8 到 32 (A) |
.u32(如果无符号)或 .s32(如果有符号) |
整型 |
64 |
.u64(如果无符号)或 .s64(如果有符号) |
指针 (B) |
32 |
.u32 |
指针 (B) |
64 |
.u64 |
浮点类型 (C) |
32 |
.f32 |
浮点类型 (C) |
64 |
.f64 |
聚合或联合 |
任何大小 |
.align 其中 |
句柄 (E) |
64 |
.b64(从 .texref、.sampleref、.surfref 分配) |
注释
小于 32 位的数值会根据它们是有符号类型还是无符号类型进行符号扩展或零扩展。
除非在函数声明中指定了内存类型,否则在 PTX 级别传递的所有指针都必须使用通用地址。
16 位浮点类型仅用于存储。因此,它们不能用于参数或返回值。
对齐方式必须为 1、2、4、8、16、32、64 或 128 字节。
PTX 内置不透明类型(如纹理、采样器和表面类型)可以通过 64 位句柄作为参数传递到函数中,并由函数返回。句柄包含从纹理或表面内存访问实际数据以及存储在其类型描述符中的对象属性的必要信息。有关句柄的更多信息,请参见 纹理、采样器和表面类型 部分。
4. 系统调用
系统调用是对驱动程序操作系统代码的调用。在 PTX 中,它们看起来像常规调用,但未给出函数定义。必须在 PTX 文件中提供原型,但函数的实现由驱动程序提供。
vprintf 系统调用的原型是
.extern .func (.param .s32 status) vprintf (.param t1 format, .param t2 valist)
以下是 vprintf 参数和返回值的定义。
status:vprintf 返回的状态值。
format:指向格式说明符输入的指针。对于 32 位地址,类型 t1 为 .b32。对于 64 位地址,类型 t1 为 .b64。
valist:指向 valist 输入的指针。对于 32 位地址,类型 t2 为 .b32。对于 64 位地址,类型 t2 为 .b64。
使用 32 位地址调用 vprintf 如下所示
cvta.global.b32 %r2, _fmt;
st.param.b32 [param0], %r2;
cvta.local.b32 %r3, _valist_array;
st.param.b32 [param1], %r3;
call.uni (_), vprintf, (param0, param1);
对于此代码,_fmt 是全局内存中的格式字符串,_valist_array 是参数的 valist。请注意,任何指针都必须转换为通用空间。vprintf 系统调用作为 “stdio.h” 中定义的 printf 函数的一部分发出。
malloc 系统调用的原型是
.extern .func (.param t1 ptr) malloc (.param t2 size)
以下是 malloc 参数和返回值的定义。
ptr:指向 malloc 分配的内存的指针。对于 32 位地址,类型 t1 为 .b32。对于 64 位地址,类型 t1 为 .b64。
size:malloc 需要的内存大小。此大小由 size_t 类型定义。当 size_t 为 32 位时,类型 t2 为 .b32。当 size_t 为 64 位时,类型 t2 为 .b64。
free 系统调用的原型是
.extern .func free (.param t1 ptr)
以下是 free 参数的定义。
ptr:指向应释放的内存的指针。对于 32 位地址,类型 t1 为 .b32。对于 64 位地址,类型 t1 为 .b64。
malloc 和 free 系统调用作为 “malloc.h” 中定义的 malloc 和 free 函数的一部分发出。
为了支持 assert,当 assert 表达式生成 false 值时,使用 PTX 函数调用 __assertfail。__assertfail 系统调用的原型是
.extern .func __assertfail (.param t1 message, .param t1 file, .param .b32 line, .param t1 function, .param t2 charSize)
以下是 __assertfail 参数的定义。
message:指向应输出的字符串的指针。对于 32 位地址,类型 t1 为 .b32。对于 64 位地址,类型 t1 为 .b64。
file:指向与 assert 关联的文件名字符串的指针。对于 32 位地址,类型 t1 为 .b32。对于 64 位地址,类型 t1 为 .b64。
line:与 assert 关联的行号。
function:指向与 assert 关联的函数名称字符串的指针。对于 32 位地址,类型 t1 为 .b32。对于 64 位地址,类型 t1 为 .b64。
charSize:__assertfail 参数字符串中包含的字符的大小(以字节为单位)。唯一支持的字符大小为 1。字符大小由 size_t 类型定义。当 size_t 为 32 位时,类型 t2 为 .b32。当 size_t 为 64 位时,类型 t2 为 .b64。
__assertfail 系统调用作为 “assert.h” 中定义的 assert 宏的一部分发出。
5. 原子操作应用程序二进制接口
编程语言的原子操作到 PTX ISA 的映射需要在可能同时访问共享内存的所有编程语言中以一致的方式实现。CUDA 架构的 C++11 原子操作的映射在 NVIDIA PTX 内存一致性模型的形式化分析 中得到证实。PTX ISA 为 acquire、release、acquire-release 和 relaxed C++ 内存排序语义提供原子内存操作和 fences。C++ 顺序一致原子操作的 PTX ABI 如下
C 或 C++ 或 CUDA C++ API |
PTX ABI ISA 映射 |
|---|---|
|
|
|
|
|
|
|
|
6. 调试信息
调试信息以 DWARF(任意记录格式调试信息)编码。
6.1. 调试信息的生成
调试信息的生成责任在 PTX 生成器和 PTX 到 SASS 后端之间分配。PTX 生成器负责使用 PTX 中的 .section 和 .b8-.b16-.b32-and-.b64 指令将二进制 DWARF 发射到 PTX 文件中。这应包含 .debug_info 和 .debug_abbrev 节,以及可能的可选节 .debug_pubnames 和 .debug_aranges。这些节是标准 DWARF2 节,它们引用 PTX 中的标签和寄存器。
PTX 到 SASS 后端负责从 PTX 文件中的 .file 和 .loc 指令生成 .debug_line 节。此节将源行映射到 SASS 地址。后端还生成 .debug_frame 节。
6.2. CUDA 特定的 DWARF 定义
为了支持调试多个内存段,定义了地址类别代码以反映变量的内存空间。地址类别值作为所有变量和参数调试信息条目的 DW_AT_address_class 属性发出。地址类别代码在下表中定义。
代码 |
值 |
描述 |
|---|---|---|
ADDR_code_space |
1 |
代码存储 |
ADDR_reg_space |
2 |
寄存器存储 |
ADDR_sreg_space |
3 |
特殊寄存器存储 |
ADDR_const_space |
4 |
常量存储 |
ADDR_global_space |
5 |
全局存储 |
ADDR_local_space |
6 |
本地存储 |
ADDR_param_space |
7 |
参数存储 |
ADDR_shared_space |
8 |
共享存储 |
ADDR_surf_space |
9 |
表面存储 |
ADDR_tex_space |
10 |
纹理存储 |
ADDR_tex_sampler_space |
11 |
纹理采样器存储 |
ADDR_generic_space |
12 |
通用地址存储 |
7. 示例
以下是示例 PTX,其中包含用于实现以下程序的调试信息,该程序进行调用
__device__ __noinline__ int foo (int i, int j)
{
return i+j;
}
__global__ void test (int *p)
{
*p = foo(1, 2);
}
生成的 PTX 将类似于
.version 4.2
.target sm_20, debug
.address_size 64
.file 1 "call_example.cu"
.visible .func (.param .b32 func_retval0) // return value
_Z3fooii(
.param .b32 _Z3fooii_param_0, // parameter "i"
.param .b32 _Z3fooii_param_1) // parameter "j"
{
.reg .s32 %r<4>;
.loc 1 1 1 // following instructions are for line 1
func_begin0:
ld.param.u32 %r1, [_Z3fooii_param_0]; // load 1st param
ld.param.u32 %r2, [_Z3fooii_param_1]; // load 2nd param
.loc 1 3 1 // following instructions are for line 3
add.s32 %r3, %r1, %r2;
st.param.b32 [func_retval0+0], %r3; // store return value
ret;
func_end0:
}
.visible .entry _Z4testPi(
.param .u64 _Z4testPi_param_0) // parameter *p
{
.reg .s32 %r<4>;
.reg .s64 %rd<2>;
.loc 1 6 1
func_begin1:
ld.param.u64 %rd1, [_Z4testPi_param_0]; // load *p
mov.u32 %r1, 1;
mov.u32 %r2, 2;
.loc 1 8 9
.param .b32 param0;
st.param.b32 [param0+0], %r1; // store 1
.param .b32 param1;
st.param.b32 [param1+0], %r2; // store 2
.param .b32 retval0;
call.uni (retval0), _Z3fooii, ( param0, param1); // call foo
ld.param.b32 %r3, [retval0+0]; // get return value
st.u32 [%rd1], %r3; // *p = return value
.loc 1 9 2
ret;
func_end1:
}
.section .debug_info {
.b32 262
.b8 2, 0
.b32 .debug_abbrev
.b8 8, 1, 108, 103, 101, 110, 102, 101, 58, 32, 69, 68, 71, 32, 52, 46, 57
.b8 0, 4, 99, 97, 108, 108, 49, 46, 99, 117, 0
.b64 0
.b32 .debug_line // the .debug_line section will be created by ptxas from the .loc
.b8 47, 104, 111, 109, 101, 47, 109, 109, 117, 114, 112, 104, 121, 47, 116
.b8 101, 115, 116, 0, 2, 95, 90, 51, 102, 111, 111, 105, 105, 0, 95, 90
.b8 51, 102, 111, 111, 105, 105, 0
.b32 1, 1, 164
.b8 1
.b64 func_begin0 // start and end location of foo
.b64 func_end0
.b8 1, 156, 3, 105, 0
.b32 1, 1, 164
.b8 5, 144, 177, 228, 149, 1, 2, 3, 106, 0
.b32 1, 1, 164
.b8 5, 144, 178, 228, 149, 1, 2, 0, 4, 105, 110, 116, 0, 5
.b32 4
.b8 2, 95, 90, 52, 116, 101, 115, 116, 80, 105, 0, 95, 90, 52, 116, 101
.b8 115, 116, 80, 105, 0
.b32 1, 6, 253
.b8 1
.b64 func_begin1 // start and end location of test
.b64 func_end1
.b8 1, 156, 3, 112, 0
.b32 1, 6, 259
.b8 9, 3
.b64 _Z4testPi_param_0
.b8 7, 0, 5, 118, 111, 105, 100, 0, 6
.b32 164
.b8 12, 0
}
.section .debug_abbrev {
.b8 1, 17, 1, 37, 8, 19, 11, 3, 8, 17, 1, 16, 6, 27, 8, 0, 0, 2, 46, 1, 135
.b8 64, 8, 3, 8, 58, 6, 59, 6, 73, 19, 63, 12, 17, 1, 18, 1, 64, 10, 0, 0
.b8 3, 5, 0, 3, 8, 58, 6, 59, 6, 73, 19, 2, 10, 51, 11, 0, 0, 4, 36, 0, 3
.b8 8, 62, 11, 11, 6, 0, 0, 5, 59, 0, 3, 8, 0, 0, 6, 15, 0, 73, 19, 51, 11
.b8 0, 0, 0
}
.section .debug_pubnames {
.b32 41
.b8 2, 0
.b32 .debug_info
.b32 262, 69
.b8 95, 90, 51, 102, 111, 111, 105, 105, 0
.b32 174
.b8 95, 90, 52, 116, 101, 115, 116, 80, 105, 0
.b32 0
}
8. C++
设备函数的 C++ 实现遵循 Itanium C++ ABI。但是,并非 C++ 中的所有内容都受支持。特别是,设备代码中不支持以下内容。
异常和 try/catch 块
RTTI
STL 库
全局构造函数和析构函数
跨主机和设备的虚函数和类(即,vtables 不能跨主机和设备使用)
还有一些 C 功能当前不受支持
除 printf 之外的 stdio
9. 声明
9.1. 声明
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)不对本文档中包含的信息的准确性或完整性做出任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为的后果或使用不承担任何责任。本文档不承诺开发、发布或交付任何材料(下文定义)、代码或功能。
NVIDIA 保留在不另行通知的情况下随时对本文档进行更正、修改、增强、改进和任何其他更改的权利。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件销售,除非 NVIDIA 和客户的授权代表签署的单独销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户一般条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、飞机、航天或生命维持设备,也不适用于 NVIDIA 产品的故障或故障可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对 NVIDIA 产品包含和/或用于此类设备或应用不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不做任何基于本文档的产品适用于任何特定用途的陈述或保证。NVIDIA 不一定执行每个产品的所有参数的测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并符合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。对于可能基于以下原因或归因于以下原因的任何默认设置、损坏、成本或问题,NVIDIA 不承担任何责任:(i)以违反本文档的方式使用 NVIDIA 产品,或(ii)客户产品设计。
本文档未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息并不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在 NVIDIA 的专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并且必须完全遵守所有适用的出口法律和法规,并且必须附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独称为“材料”)均按“原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并且明确声明不承担任何关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带性、惩罚性或后果性损害)负责,无论其由何种原因引起,也无论责任理论如何,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因而遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计总责任应根据产品的销售条款进行限制。
9.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
9.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。