处理动态形状#
动态形状是指延迟指定部分或全部张量维度直到运行时的能力。动态形状可以通过 C++ 和 Python 接口使用。
以下部分提供了更详细的信息;但是,这里概述了构建具有动态形状的引擎的步骤
通过使用
-1作为维度的占位符,指定输入张量的每个运行时维度。在构建时指定一个或多个优化配置文件,这些文件指定具有运行时维度的输入的允许维度范围以及自动调谐器将优化的维度。有关更多信息,请参阅 优化配置文件 部分。
要使用引擎
从引擎创建一个执行上下文,与没有动态形状时相同。
指定步骤 2 中涵盖输入维度之一的优化配置文件。
为执行上下文指定输入维度。设置输入维度后,您可以获得 TensorRT 为给定输入维度计算的输出维度。
入队工作。
要更改运行时维度,请重复步骤 3b 和 3c,这些步骤不必重复,直到输入维度发生更改。
当预览功能 (PreviewFeature::kFASTER_DYNAMIC_SHAPES_0805) 启用时,对于动态形状网络,它可以潜在地
减少引擎构建时间,
减少运行时,以及
减少设备内存使用量和引擎大小。
最有可能从启用 kFASTER_DYNAMIC_SHAPES_0805 中受益的模型是基于 Transformer 的模型和包含动态控制流的模型。
指定运行时维度#
构建网络时,使用 -1 表示输入张量的运行时维度。例如,要创建一个名为 foo 的 3D 输入张量,其中最后两个维度在运行时指定,而第一个维度在构建时固定,请发出以下命令。
1networkDefinition.addInput("foo", DataType::kFLOAT, Dims3(3, -1, -1))
1network_definition.add_input("foo", trt.float32, (3, -1, -1))
选择优化配置文件后,您必须在运行时设置输入维度(请参阅 优化配置文件)。假设输入具有维度 [3,150,250]。为前面的示例设置优化配置文件后,您将调用
1context.setInputShape("foo", Dims{3, {3, 150, 250}})
1context.set_input_shape("foo", (3, 150, 250))
在运行时,向引擎询问绑定维度会返回用于构建网络的相同维度,这意味着对于每个运行时维度,您都会得到一个 -1。例如
1engine.getTensorShape("foo")
返回一个维度为 {3, -1, -1} 的 Dims。
1engine.get_tensor_shape("foo")
返回 (3, -1, -1)。
要获取特定于每个执行上下文的实际维度,请查询执行上下文
1context.getTensorShape("foo")
返回一个维度为 {3, 150, 250} 的 Dims。
1context.get_tensor_shape(0)
返回 (3, 150, 250)。
对于输入,setInputShape 的返回值仅指示与为该输入设置的优化配置文件的一致性。指定所有输入绑定维度后,您可以通过查询网络输出绑定的维度来检查整个网络是否与动态输入形状一致。这是一个检索名为 bar 的输出维度的示例
nvinfer1::Dims outDims = context->getTensorShape("bar"); if (outDims.nbDims == -1) { gLogError << "Invalid network output, this might be caused by inconsistent input shapes." << std::endl; // abort inference }
如果维度 k 是数据相关的,例如,它取决于 INonZeroLayer 的输入,则 outDims.d[k] 将为 -1。有关此类输出的更多信息,请参阅 动态形状输出 部分。
命名维度#
常量维度和运行时维度都可以命名。命名维度提供两个好处
对于运行时维度,错误消息使用维度的名称。例如,如果输入张量
foo的维度为[n,10,m],则获取关于m而不是(#2 (SHAPE foo))的错误消息更有帮助。具有相同名称的维度隐式相等,这可以帮助优化器生成更高效的引擎,并在运行时诊断不匹配的维度。例如,假设两个输入的维度分别为
[n,10,m]和[n,13]。在这种情况下,优化器知道引导维度始终相等,并且意外地使用 n 值不匹配的引擎将被报告为错误。
只要常量维度和运行时维度始终相等,您就可以对它们使用相同的名称。
以下语法示例将张量的第三个维度的名称设置为 m。
1tensor.setDimensionName(2, "m")
1tensor.set_dimension_name(2, "m")
有相应的方法来获取维度名称
1tensor.getDimensionName(2) // returns the name of the third dimension of the tensor, or nullptr if it does not have a name.
1tensor.get_dimension_name(2) # returns the name of the third dimension of the tensor, or None if it does not have a name.
当从 ONNX 文件导入输入网络时,ONNX 解析器会自动使用 ONNX 文件中的名称设置维度名称。因此,如果预期两个动态维度在运行时相等,请在导出 ONNX 文件时为这些维度指定相同的名称。
使用 IAssertionLayer 的维度约束#
有时,两个动态维度在静态上未知相等,但在运行时保证相等。让 TensorRT 知道它们相等可以帮助它构建更高效的引擎。有两种方法可以将相等约束传达给 TensorRT
为维度指定相同的名称,如 命名维度 部分所述。
使用
IAssertionLayer来表达约束。此技术更通用,因为它可以传达更棘手的相等性。
例如,如果张量 A 的第一个维度保证比张量 B 的第一个维度大 1,则可以通过以下方式建立约束
1// Assumes A and B are ITensor* and n is a INetworkDefinition&.
2auto shapeA = n.addShape(*A)->getOutput(0);
3auto firstDimOfA = n.addSlice(*shapeA, Dims{1, {0}}, Dims{1, {1}}, Dims{1, {1}})->getOutput(0);
4auto shapeB = n.addShape(*B)->getOutput(0);
5auto firstDimOfB = n.addSlice(*shapeB, Dims{1, {0}}, Dims{1, {1}}, Dims{1, {1}})->getOutput(0);
6static int32_t const oneStorage{1};
7auto one = n.addConstant(Dims{1, {1}}, Weights{DataType::kINT32, &oneStorage, 1})->getOutput(0);
8auto firstDimOfBPlus1 = n.addElementWise(*firstDimOfB, *one, ElementWiseOperation::kSUM)->getOutput(0);
9auto areEqual = n.addElementWise(*firstDimOfA, *firstDimOfBPlus1, ElementWiseOperation::kEQUAL)->getOutput(0);
10n.addAssertion(*areEqual, "oops");
1# Assumes `a` and `b` are ITensors and `n` is an INetworkDefinition
2shape_a = n.add_shape(a).get_output(0)
3first_dim_of_a = n.add_slice(shape_a, (0, ), (1, ), (1, )).get_output(0)
4shape_b = n.add_shape(b).get_output(0)
5first_dim_of_b = n.add_slice(shape_b, (0, ), (1, ), (1, )).get_output(0)
6one = n.add_constant((1, ), np.ones((1, ), dtype=np.int32)).get_output(0)
7first_dim_of_b_plus_1 = n.add_elementwise(first_dim_of_b, one, trt.ElementWiseOperation.SUM).get_output(0)
8are_equal = n.add_elementwise(first_dim_of_a, first_dim_of_b_plus_1, trt.ElementWiseOperation.EQUAL).get_output(0)
9n.add_assertion(are_equal, “oops”)
如果维度在运行时违反断言,TensorRT 将抛出错误。
优化配置文件#
优化配置文件描述了每个网络输入的维度范围以及自动调谐器将用于优化的维度。使用运行时维度时,您必须在构建时至少创建一个优化配置文件。两个配置文件可以指定不相交或重叠的范围。
例如,一个配置文件可能指定最小尺寸为 [3,100,200],最大尺寸为 [3,200,300],优化维度为 [3,150,250],而另一个配置文件可能指定最小、最大和优化维度为 [3,200,100]、[3,300,400] 和 [3,250,250]。
注意
不同配置文件的内存使用量可能会根据 min、max 和 opt 参数指定的维度而发生巨大变化。某些操作的策略仅适用于
MIN=OPT=MAX,因此当这些值不同时,该策略将被禁用。
要创建优化配置文件,首先构造一个 IOptimizationProfile。然后,设置最小、优化和最大维度,并将它们添加到网络配置中。优化配置文件定义的形状必须为网络定义有效的输入形状。以下是先前针对输入 foo 提到的第一个配置文件的调用
1IOptimizationProfile* profile = builder.createOptimizationProfile();
2profile->setDimensions("foo", OptProfileSelector::kMIN, Dims3(3,100,200);
3profile->setDimensions("foo", OptProfileSelector::kOPT, Dims3(3,150,250);
4profile->setDimensions("foo", OptProfileSelector::kMAX, Dims3(3,200,300);
5
6config->addOptimizationProfile(profile)
1profile = builder.create_optimization_profile();
2profile.set_shape("foo", (3, 100, 200), (3, 150, 250), (3, 200, 300))
3config.add_optimization_profile(profile)
在运行时,您必须在设置输入维度之前设置优化配置文件。配置文件按添加顺序编号,从 0 开始。请注意,每个执行上下文必须使用单独的优化配置文件。
要选择示例中的第一个优化配置文件,请使用
1context.setOptimizationProfileAsync(0, stream)
1context.set_optimization_profile_async(0, stream)
提供的 stream 参数应与将用于后续 ``enqueue()``、enqueueV2() 或 enqueueV3() 调用的同一 CUDA 流相同。这确保了上下文执行发生在优化配置文件设置之后。
假设关联的 CUDA 引擎具有动态输入。在这种情况下,必须至少设置一次优化配置文件,使用未被其他执行上下文使用且未被销毁的唯一配置文件索引。对于为引擎创建的第一个执行上下文,隐式选择配置文件 0。
可以调用 setOptimizationProfileAsync() 以在配置文件之间切换。它必须在当前上下文中任何 enqueue()、enqueueV2() 或 enqueueV3() 操作完成后调用。当多个执行上下文并发运行时,它可以切换到先前使用的配置文件,该配置文件已被另一个具有不同动态输入维度的执行上下文释放。
setOptimizationProfileAsync() 函数取代了现已弃用的 API 版本 setOptimizationProfile()。使用 setOptimizationProfile() 在优化配置文件之间切换可能会在随后的 enqueue() 或 enqueueV2() 操作中导致 GPU 内存复制操作。为了避免在入队期间进行这些调用,请改用 setOptimizationProfileAsync() API。
动态形状输出#
如果网络的输出具有动态形状,则可以使用多种策略来分配输出内存。
如果输出的维度可以从输入的维度计算出来,请使用 IExecutionContext::getTensorShape() 在提供输入张量的维度和 输入形状张量 后获取输出的维度。使用 IExecutionContext::inferShapes() 方法检查您是否忘记提供必要的信息。
否则,如果输出的维度无法提前计算或调用 enqueueV3,请将 IOutputAllocator 与输出关联。更具体地说
从
IOutputAllocator派生您的分配器类。覆盖
reallocateOutput和notifyShape方法。当 TensorRT 需要分配输出内存时调用第一个方法,当它知道输出维度时调用第二个方法。例如,INonZeroLayer的输出内存是在层运行之前分配的。
这是一个派生类的示例
class MyOutputAllocator : nvinfer1::IOutputAllocator { public: void* reallocateOutput( char const* tensorName, void* currentMemory, uint64_t size, uint64_t alignment) override { // Allocate the output. Remember it for later use. outputPtr = /* depends on strategy, as discussed later …*/ return outputPtr; } void notifyShape(char const* tensorName, Dims const& dims) { // Remember output dimensions for later use. outputDims = dims; } // Saved dimensions of the output Dims outputDims{}; // nullptr if memory could not be allocated void* outputPtr{nullptr}; };
这是一个如何使用它的示例
std::unordered_map<std::string, MyOutputAllocator> allocatorMap; for (const char* name : /* names of outputs */) { Dims extent = context->getTensorShape(name); void* ptr; if (engine->getTensorLocation(name) == TensorLocation::kDEVICE) { if (/* extent.d contains -1 */) { auto allocator = std::make_unique<MyOutputAllocator>(); context->setOutputAllocator(name, allocator.get()); allocatorMap.emplace(name, std::move(allocator)); } else { ptr = /* allocate device memory per extent and format */ } } else { ptr = /* allocate cpu memory per extent and format */ } context->setTensorAddress(name, ptr); }
可以使用多种策略来实现 reallocateOutput
- A
延迟分配直到大小已知。不要调用
IExecution::setTensorAddress,或者使用nullptr调用它作为张量地址。- B
根据
IExecutionTensor::getMaxOutputSize报告的上限预先分配足够的内存。这保证了引擎不会因输出内存不足而失败,但上限可能太高以至于无用。- C
如果您根据经验预先分配了足够的内存,请使用
IExecution::setTensorAddress告知 TensorRT。如果张量不适合,请使reallocateOutput返回nullptr,这将导致引擎正常失败。- D
像
C中一样预先分配内存,但如果有适合问题,则让reallocateOutput返回指向更大缓冲区的指针。这会根据需要增加输出缓冲区。- E
延迟分配直到大小已知,如
A。然后,尝试在后续调用中回收该分配,直到请求更大的缓冲区,然后像D中一样增加它。这是一个实现
E的派生类示例class FancyOutputAllocator : nvinfer1::IOutputAllocator { public: void reallocateOutput( char const* tensorName, void* currentMemory, uint64_t size, uint64_t alignment) override { if (size > outputSize) { // Need to reallocate cudaFree(outputPtr); outputPtr = nullptr; outputSize = 0; if (cudaMalloc(&outputPtr, size) == cudaSuccess) { outputSize = size; } } // If the cudaMalloc fails, outputPtr=nullptr, and engine // gracefully fails. return outputPtr; } void notifyShape(char const* tensorName, Dims const& dims) { // Remember output dimensions for later use. outputDims = dims; } // Saved dimensions of the output tensor Dims outputDims{}; // nullptr if memory could not be allocated void* outputPtr{nullptr}; // Size of allocation pointed to by output uint64_t outputSize{0}; ~FancyOutputAllocator() override { cudaFree(outputPtr); } };
对于具有数据相关形状的网络,TensorRT 在设备当前内存池中异步分配内存。假设当前设备内存池没有设置释放阈值。在这种情况下,由于内存会在流同步时返回到操作系统,因此运行之间的性能可能会下降。在这些情况下,建议您为 TensorRT 运行时提供具有自定义内存池的自定义 IGpuAllocator,或者尝试设置释放阈值。有关设置释放阈值的更多信息,请参见 在池中保留内存 和 代码迁移指南。
查找多个优化配置文件的绑定索引#
如果您使用 enqueueV3 而不是已弃用的 enqueueV2,则可以跳过此部分,因为基于名称的方法(例如 IExecutionContext::setTensorAddress)不需要配置文件后缀。
每个配置文件在从多个配置文件构建的引擎中都有单独的绑定索引。第 K 个配置文件的 I/O 张量的名称附加了 [profile K],其中 K 以十进制形式书写。例如,如果 INetworkDefinition 的名称为 foo,并且 bindingIndex 指的是索引为 3 的优化配置文件中的该张量,则 engine.getBindingName(bindingIndex) 返回 foo [profile 3]。
同样,如果使用 ICudaEngine::getBindingIndex(name) 获取超出第一个配置文件 (K=0) 的配置文件 K 的索引,请将 [profile K] 附加到 INetworkDefinition 中使用的名称。例如,如果张量在 INetworkDefinition 中称为 foo,则 engine.getBindingIndex(foo [profile 3]) 返回优化配置文件 3 中张量 foo 的绑定索引。
始终省略 K=0 的后缀。
多个优化配置文件的绑定#
本节介绍已弃用的接口 enqueueV2 及其绑定索引。较新的接口 enqueueV3 取消了绑定索引。
考虑一个网络,它在 IBuilderConfig 中具有四个输入、一个输出和三个优化配置文件。引擎有 15 个绑定,每个优化配置文件有 5 个,概念上组织成一个表
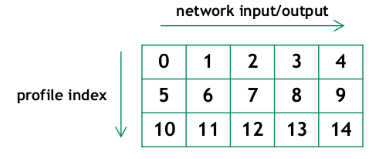
每一行都是一个配置文件。表中的数字表示绑定索引。第一个配置文件的绑定索引为 0..4,第二个配置文件的绑定索引为 5..9,第三个配置文件的绑定索引为 10..14。
当绑定属于第一个配置文件,但指定了另一个配置文件时,接口具有“自动更正”功能。在这种情况下,TensorRT 会警告该错误,然后从同一列中选择正确的绑定索引。
动态形状的层扩展#
某些层具有允许指定动态形状信息的可选输入;IShapeLayer 可以在运行时访问张量的形状。此外,某些层允许计算新形状。下一节将介绍语义细节和限制。以下是您可能会发现与动态形状结合使用的有用功能的摘要。
IShapeLayer 输出一个 1D 张量,其中包含输入张量的维度。例如,如果输入张量的维度为 [2,3,5,7],则输出张量是一个包含 {2,3,5,7} 的四元素 1D 张量。如果输入张量是标量,则其维度为 [],并且输出张量是一个包含 {} 的零元素 1D 张量。
IResizeLayer 接受一个可选的第二个输入,其中包含所需的输出维度。
IShuffleLayer 接受一个可选的第二个输入,其中包含在应用第二个转置之前的重塑维度。例如,以下网络将张量 Y 重塑为与 X 具有相同的维度
1auto* reshape = networkDefinition.addShuffle(Y);
2reshape.setInput(1, networkDefintion.addShape(X)->getOutput(0));
1reshape = network_definition.add_shuffle(y)
2reshape.set_input(1, network_definition.add_shape(X).get_output(0))
ISliceLayer 接受可选的第二、第三和第四个输入,其中包含起始位置、大小和步幅。
IConcatenationLayer、IElementWiseLayer、IGatherLayer、IIdentityLayer 和 IReduceLayer 可以计算形状并创建新的形状张量。
动态形状的限制#
以下层限制的出现是因为层的权重具有固定大小
IConvolutionLayer和IDeconvolutionLayer要求通道维度是构建时常量。Int8要求通道维度是构建时常量。接受附加形状输入的层 (
IResizeLayer、IShuffleLayer、ISliceLayer) 要求附加形状输入与最小和最大优化配置文件的维度以及运行时数据输入的维度兼容;否则,可能会导致构建时或运行时错误。
并非所有必需的构建时常量都需要手动设置。TensorRT 将通过网络层推断形状,只有那些无法推断为构建时常量的形状才必须手动设置。
有关层的更多信息,请参阅 TensorRT 运算符文档。
执行张量与形状张量#
TensorRT 8.5 在很大程度上消除了执行张量和形状张量之间的区别。但是,设计网络或分析性能可能有助于理解内部结构以及发生内部同步的位置。
使用动态形状的引擎采用乒乓执行策略。
在 CPU 上计算张量的形状,直到达到需要 GPU 结果的形状。
将工作流式传输到 GPU,直到您用完工作或达到未知形状。如果是后者,则同步并返回步骤 1。
执行张量是传统的 TensorRT 张量。形状张量是与形状计算相关的张量。它必须具有 Int32、Int64、Float 或 Bool 类型,其形状必须在构建时可确定,并且它必须不超过 64 个元素。有关网络 I/O 边界处形状张量的其他限制,请参阅 形状张量 I/O(高级)。例如,有一个 IShapeLayer,其输出是一个 1D 张量,其中包含输入张量的维度。输出是形状张量。IShuffleLayer 接受一个可选的第二个输入,该输入可以指定重塑维度。第二个输入必须是形状张量。
当 TensorRT 需要形状张量,但该张量已被分类为执行张量时,运行时会将张量从 GPU 复制到 CPU,这会产生同步开销。
某些层在它们处理的张量类型方面是多态的。例如,IElementWiseLayer 可以将两个 INT32 执行张量或两个 INT32 形状张量相加。张量的类型取决于其最终用途。如果总和用于重塑另一个张量,则它是形状张量。
形式推理规则#
TensorRT 用于对张量进行分类的形式推理规则基于类型推理代数。设 E 表示执行张量,S 表示形状张量。
IActivationLayer 具有签名
IActivationLayer: E → E
因为它将执行张量作为输入,并将执行张量作为输出。IElementWiseLayer 在这方面是多态的,具有两个签名
IElementWiseLayer: S × S → S, E × E → E
为了简洁起见,让我们采用约定,即 t 是一个变量,表示张量的任一类,并且签名中的所有 t 都指同一类张量。然后,可以将之前的两个签名写成单个多态签名
IElementWiseLayer: t × t → t
双输入 IShuffleLayer 具有形状张量作为第二个输入,并且关于第一个输入是多态的
IShuffleLayer (two inputs): t × S → t
IConstantLayer 没有输入,但可以生成任一种张量,因此其签名是
IConstantLayer: → t
IShapeLayer 的签名允许所有四种可能的组合 E→E、E→S、S→E 和 S→S,因此可以用两个独立变量编写
IShapeLayer: t1 → t2
这是完整的规则集,它也可以作为哪些层可以用于操作形状张量的参考
IAssertionLayer: S → IConcatenationLayer: t × t × ...→ t ICumulativeLayer: t × t → t IIfConditionalInputLayer: t → t IIfConditionalOutputLayer: t → t IConstantLayer: → t IActivationLayer: t → t IElementWiseLayer: t × t → t IFillLayer: S → t IFillLayer: S × t × t → t IGatherLayer: t × t → t IIdentityLayer: t → t IReduceLayer: t → t IResizeLayer (one input): E → E IResizeLayer (two inputs): E × S → E ISelectLayer: t × t × t → t IShapeLayer: t1 → t2 IShuffleLayer (one input): t → t IShuffleLayer (two inputs): t × S → t ISliceLayer (one input): t → t ISliceLayer (two inputs): t × S → t ISliceLayer (three inputs): t × S × S → t ISliceLayer (four inputs): t × S × S × S → t IUnaryLayer: t → t all other layers: E × ... → E × ...
推断类型不是排他的,因为输出可以是多个后续层的输入。例如,IConstantLayer 可能会馈送到一个需要执行张量的用途,以及另一个需要形状张量的用途。IConstantLayer 的输出被分类为两者,并且可以在两阶段执行的阶段 1 和阶段 2 中使用。
形状张量的大小必须在构建时已知的要求限制了 ISliceLayer 可以如何用于操作形状张量。具体来说,假设第三个参数指定结果的大小,并且不是构建时常量。在这种情况下,生成的张量的长度在构建时是未知的,这打破了形状张量具有常量形状的限制。切片仍然有效,但会在运行时产生同步开销,因为张量被视为必须复制回 CPU 以进行进一步形状计算的执行张量。
任何张量的秩都必须在构建时已知。例如,如果 ISliceLayer 的输出是一个长度未知的 1D 张量,该张量用作 IShuffleLayer 的重塑维度,则 shuffle 的输出在构建时将具有未知的秩,因此禁止这种组合。
可以使用方法 ITensor::isShapeTensor()(对于形状张量返回 true)和 ITensor::isExecutionTensor()(对于执行张量返回 true)来检查 TensorRT 的推断。首先构建整个网络,然后再调用这些方法,因为它们的答案可能会根据已添加的张量的用途而更改。
例如,如果部分构建的网络将两个张量 T1 和 T2 相加来创建张量 T3,并且尚未使用任何一个作为形状张量,则 isShapeTensor() 对所有三个张量都返回 false。将 IShuffleLayer 的第二个输入设置为 T3 将导致所有三个张量都成为形状张量,因为 IShuffleLayer 要求其第二个可选输入是形状张量。如果 IElementWiseLayer 的输出是形状张量,则其输入也是。
形状张量 I/O(高级)#
有时,需要使用形状张量作为网络 I/O 张量。例如,考虑一个仅由 IShuffleLayer 组成的网络。TensorRT 推断第二个输入是形状张量。ITensor::isShapeTensor 对其返回 true。因为它是一个输入形状张量,所以 TensorRT 对它有两个要求
在构建时:形状张量的优化配置文件值。
在运行时:形状张量的值。
输入形状张量的形状在构建时始终已知。必须描述这些值,因为它们可用于指定执行张量的维度。
可以使用 IOptimizationProfile::setShapeValues 设置优化配置文件值。与必须为具有运行时维度的执行张量提供最小、最大和优化维度类似,必须在构建时为形状张量提供最小、最大和优化值。
相应的运行时方法是 IExecutionContext::setTensorAddress,它告诉 TensorRT 在哪里查找形状张量值。
由于执行张量与形状张量的推断是基于最终用途的,因此 TensorRT 无法推断网络输出是否为形状张量。您必须使用方法 INetworkDefinition::markOutputForShapes 告诉它。
除了让您输出形状信息以进行调试外,此功能对于组合引擎非常有用。例如,考虑构建三个引擎,每个引擎分别用于子网络 A、B 和 C,其中从 A 到 B 或从 B 到 C 的连接可能涉及形状张量。按相反的顺序构建网络:C、B 和 A。构建网络 C 后,您可以使用 ITensor::isShapeTensor 来确定输入是否为形状张量,并使用 INetworkDefinition::markOutputForShapes 来标记网络 B 中的相应输出张量。然后检查 B 的哪些输入是形状张量,并标记网络 A 中的相应输出张量。
网络边界的形状张量必须是 Int32 或 Int64 类型。它们不能是 Float 或 Bool 类型。对于 Bool 类型,一种解决方法是为 I/O 张量使用 Int32 类型(用零和一表示),并使用 IIdentityLayer 在 Bool 类型之间进行转换。
在运行时,可以通过 ICudaEngine::isShapeInferenceIO() 来确定张量是否为 I/O 形状张量。
动态形状的 INT8 校准#
必须设置校准优化配置文件才能为具有动态形状的网络运行 INT8 校准。校准使用配置文件的 kOPT 值执行,并且校准输入数据大小必须与此配置文件匹配。
首先,像创建常规 optimization profile 一样构建一个 IOptimizationProfile 来创建校准优化配置文件。然后,将该配置文件设置为配置
1config->setCalibrationProfile(profile)
1config.set_calibration_profile(profile)
校准配置文件必须有效或为 nullptr。kMIN 和 kMAX 值会被 kOPT 覆盖。要检查当前的校准配置文件,请使用 IBuilderConfig::getCalibrationProfile。
如果校准配置文件未设置,此方法返回指向当前校准配置文件的指针,否则返回 nullptr。当为动态形状网络运行校准时,getBatchSize() 校准器方法必须返回 1。
注意
如果未设置校准优化配置文件,则第一个网络优化配置文件将用作校准优化配置文件。