NVIDIA 自托管服务器概述#
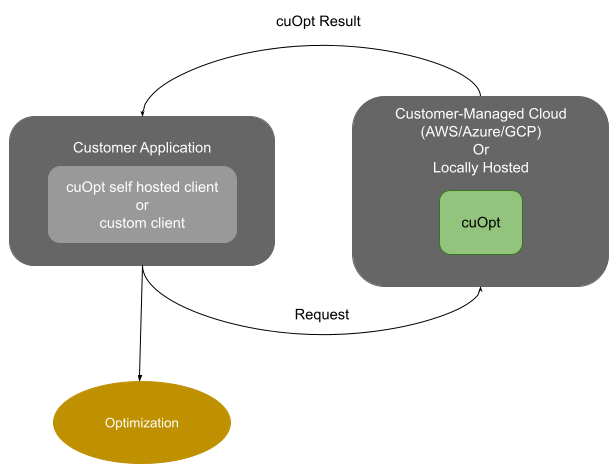
NVIDIA cuOpt 是一个容器化服务器,可以轻松地在本地和 CSP 中部署。
示例服务器使用端口 5000 上的 HTTP POST 请求来接收优化输入数据。cuOpt 根据给定的数据以及提供的选项/约束进行工作,并返回优化的结果作为响应。
快速入门指南#
步骤 1:获取 cuOpt 访问权限#
GA(仅路由):#
订阅 NVIDIA AI Enterprise (NVAIE) 以获取 cuOpt 容器并在您的云中托管。
获得访问权限后,用户可以在 NGC 目录中找到 cuOpt 容器。
EA - 提前访问 LP/MIP:#
请联系
cuopt@nvidia.com并分享您对使用路由/LP/MILP 的兴趣。获得访问权限后,用户可以在 NGC 目录中找到 EA cuOpt 容器。
步骤 2:访问 NGC#
使用邀请登录 NGC 并选择合适的 NGC 组织。
从设置中生成 NGC API 密钥。如果您尚未生成 API 密钥,可以通过转到您个人资料中的“设置”选项并选择“获取 API 密钥”来生成。存储此密钥或下次生成新密钥。更多信息请见此处。
步骤 3:拉取 cuOpt 容器#
运行容器的先决条件
请访问 自托管系统要求 以获取更多信息。
转到 cuOpt 的容器部分,并复制最新镜像的拉取标签。
在“选择标签”下拉列表中,找到您要运行的容器镜像版本。
单击“复制镜像路径”按钮以复制容器镜像路径。
在您的集群设置中登录 nvcr.io 容器注册表,使用如下所示的 NGC API 密钥。
docker login nvcr.io
Username: $oauthtoken
Password: <my-api-key>
注意
用户名是 $oauthtoken,密码是您的 API 密钥。
拉取 cuOpt 容器。
cuOpt 的容器可以在 NGC 的 容器 选项卡中找到。请从 cuOpt 容器页面复制标签,并按如下方式使用:
# Save the image tag in a variable for use below
export CUOPT_IMAGE="CONTAINER_TAG_COPIED_FROM_NGC"
docker pull $CUOPT_IMAGE
步骤 4:运行 cuOpt#
注意
以下命令以分离模式运行 cuOpt 容器。要停止分离的容器,请使用 docker stop 命令。要改为以交互模式运行容器,请删除 -d 选项。
如果您有 Docker 19.03 或更高版本,启动容器的典型命令是
docker run -it -d --gpus=1 --rm -p 5000:5000 $CUOPT_IMAGE
如果您有 Docker 19.02 或更早版本,启动容器的典型命令是
nvidia-docker run -it -d --gpus=1 --rm -p 5000:5000 $CUOPT_IMAGE
默认情况下,容器在端口
5000上运行,但这可以使用环境变量CUOPT_SERVER_PORT进行更改,
docker run -it -d --gpus=1 -e CUOPT_SERVER_PORT=8080 --rm -p 8080:8080 $CUOPT_IMAGE
此命令将启动容器,cuOpt API 端点 应可用于测试。
如果您有多个 GPU 并且想要选择特定的 GPU,请使用
--gpus device=<GPU_ID>。可以使用nvidia-smi命令找到GPU_ID。可以使用环境变量配置服务器的日志级别和其他选项,选项如下所示
CUOPT_SERVER_PORT:用于服务器端口(默认为 5000)。
CUOPT_SERVER_IP:用于服务器 IP(默认为 0.0.0.0)。
CUOPT_SERVER_LOG_LEVEL:选项为
critical、error、warning、info、debug(默认为 info)。CUOPT_DATA_DIR:一个共享挂载路径,用于选择性地将 cuOpt 问题数据文件传递到端点,而不是通过网络发送数据(默认为 None)。
CUOPT_RESULT_DIR:一个共享挂载路径,用于选择性地从端点传递 cuOpt 结果文件,而不是通过网络发送数据(默认为 None)。
CUOPT_MAX_RESULT:当设置 CUOPT_RESULT_DIR 时,通过 http 从端点返回的结果的最大大小(千字节)。设置为 0 以将所有结果写入
CUOPT_RESULT_DIR(默认为 250)。CUOPT_GPU_COUNT:配置每个 GPU 运行一个 cuOpt 求解器进程,以便 cuOpt 服务可以同时解决多个问题。问题将分配给可用的空闲求解器进程。默认为 1。此值上限为可用 GPU 的数量。使用
CUDA_VISIBLE_DEVICES选择应使用哪组 GPU,如下所示,然后在容器中设置环境变量CUOPT_GPU_COUNT以分配要使用的 GPU 数量。
export CUDA_VISIBLE_DEVICES=0,1
CUOPT_SSL_CERTFILE:容器中 SSL 证书的文件路径,可能需要挂载一个目录以供此文件进行读写访问。
CUOPT_SSL_KEYFILE:容器中密钥文件的文件路径,可能需要挂载一个目录以供此文件进行读写访问。
您可以轻松生成自签名证书,如下所示
openssl genrsa -out ca.key 2048
openssl req -new -x509 -days 365 -key ca.key -subj "/C=CN/ST=GD/L=SZ/O=Acme, Inc./CN=Acme Root CA" -out ca.crt
openssl req -newkey rsa:2048 -nodes -keyout server.key -subj "/C=CN/ST=GD/L=SZ/O=Acme, Inc./CN=*.example.com" -out server.csr
openssl x509 -req -extfile <(printf "subjectAltName=DNS:example.com,DNS:www.example.com") -days 365 -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt
server.crt 和 server.key 用于服务器,ca.crt 用于客户端。
可以使用共享挂载路径共享输入数据和累积结果,而不是使用
CUOPT_DATA_DIR和CUOPT_RESULT_DIR选项通过网络发送,如下所示创建要与容器共享的目录并运行容器。
注意
挂载在 cuOpt 容器上的数据和结果目录需要可供容器用户读取和写入,并且还必须设置执行权限。如果不是,容器将打印错误消息并退出。在运行 cuOpt 服务器之前,请注意正确设置这些目录的权限。
mkdir data mkdir result CID=$(docker run --rm --gpus=1 \ -v `pwd`/data:/cuopt_data \ -v `pwd`/results:/cuopt_results \ -e CUOPT_DATA_DIR=/cuopt_data \ -e CUOPT_RESULT_DIR=/cuopt_results \ -e CUOPT_MAX_RESULT=0 \ -e CUOPT_SERVER_PORT=8081 \ -p 8081:8081 \ -it -d $CUOPT_IMAGE)
使用以下健康检查来检查容器是否已启动并正在运行,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/health'
在数据目录中创建一个数据文件,并向 cuOpt 发送一个 POST 请求,其中包含数据文件的名称。
echo "{ \"cost_matrix_data\": {\"data\": {\"0\": [[0, 1], [1, 0]]}}, \"task_data\": {\"task_locations\": [1], \"demand\": [[1]], \"task_time_windows\": [[0, 10]], \"service_times\": [1]}, \"fleet_data\": {\"vehicle_locations\":[[0, 0]], \"capacities\": [[2]], \"vehicle_time_windows\":[[0, 20]] }, \"solver_config\": {\"time_limit\": 2} }" >> data/data.json curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request' \ --header 'Content-Type: application/json' \ --header "CLIENT-VERSION: custom" \ --header "CUOPT-DATA-FILE: data.json" \ -d {}
结果将如下所示在 result 目录中可用
cat results/*
注意
完成测试后,杀死正在运行的 Docker 容器。
docker kill $CID
步骤 5:测试容器#
curl和jq可以代替瘦客户端用于与服务器通信。为了确保它们已安装在 Ubuntu 上sudo apt install jq curl
注意
示例使用 HTTP,因为未启用 SSL,请参阅 容器设置 以了解如何启用 SSL,然后您可以使用 HTTPS。
注意
不要在 curl 命令中添加任何注释,它可能会将其视为输入并报错。
健康检查
使用以下健康检查来检查容器是否已启动并正在运行,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/health' | jq
路由示例
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request' \
--header 'Content-Type: application/json' \
--header "CLIENT-VERSION: custom" \
-d '{
"cost_matrix_data": {"data": {"0": [[0, 1], [1, 0]]}},
"task_data": {"task_locations": [1], "demand": [[1]], "task_time_windows": [[0, 10]], "service_times": [1]},
"fleet_data": {"vehicle_locations":[[0, 0]], "capacities": [[2]], "vehicle_time_windows":[[0, 20]] },
"solver_config": {"time_limit": 2}
}' | jq
在成功的情况下,这将为您提供一个请求 ID,格式为 {reqId:<REQUEST_ID>}。这是用户用来跟踪请求状态的 ID。使用此请求 ID 轮询服务器以获取响应,响应可能是 201(表示仍在等待中)或 200(表示已返回结果)。您可以使用以下命令进行轮询,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request/<REQUEST_ID>' --header 'Content-Type: application/json' --header "CLIENT-VERSION: custom" | jq
响应将如下所示,有关响应的更多详细信息可以在 open-api 规范的响应架构下找到,或者也可以在 redoc 中找到
{
"response": {
"solver_response": {
"status": 0,
"num_vehicles": 1,
"solution_cost": 2.0,
"objective_values": {
"cost": 2.0
},
"vehicle_data": {
"0": {
"task_id": [
"Depot",
"0",
"Depot"
],
"arrival_stamp": [
0.0,
1.0,
3.0
],
"type": [
"Depot",
"Delivery",
"Depot"
],
"route": [
0,
1,
0
]
}
},
"dropped_tasks": {
"task_id": [],
"task_index": []
}
}
},
"reqId": "0eabe835-a7e0-4d84-9410-1602eaa254c0"
}
LP 示例
注意
线性规划 (LP) 和混合整数线性规划 (MILP) 是早期访问功能,目前仅对部分客户开放。
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request' \
--header 'Content-Type: application/json' \
--header "CLIENT-VERSION: custom" \
-d '{
"csr_constraint_matrix": {
"offsets": [0, 2, 4],
"indices": [0, 1, 0, 1],
"values": [3.0, 4.0, 2.7, 10.1]
},
"constraint_bounds": {
"upper_bounds": [5.4, 4.9],
"lower_bounds": ["ninf", "ninf"]
},
"objective_data": {
"coefficients": [0.2, 0.1],
"scalability_factor": 1.0,
"offset": 0.0
},
"variable_bounds": {
"upper_bounds": ["inf", "inf"],
"lower_bounds": [0.0, 0.0]
},
"maximize": false,
"solver_config": {
"tolerances": {
"optimality": 0.0001
}}
}' | jq
在成功的情况下,这将为您提供一个请求 ID,格式为 {reqId:<REQUEST_ID>}。这是用户用来跟踪请求状态的 ID。使用此请求 ID 轮询服务器以获取响应,响应可能是 201(表示仍在等待中)或 200(表示已返回结果)。您可以使用以下命令进行轮询,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request/<REQUEST_ID>' --header 'Content-Type: application/json' --header "CLIENT-VERSION: custom" | jq
响应将如下所示,有关响应的更多详细信息可以在 open-api 规范的响应架构下找到,或者也可以在 redoc 中找到
{
"response": {
"solver_response": {
"status": 1,
"solution": {
"primal_solution": [
0.0,
0.0
],
"dual_solution": [
0.0,
0.0
],
"primal_objective": 0.0,
"dual_objective": 0.0,
"solver_time": 72.0,
"vars": {},
"lp_statistics": {
"primal_residual": 0.0,
"dual_residual": 0.0,
"gap": 0.0,
"reduced_cost": [
0.2,
0.1
]
}
}
}
},
"reqId": "3b16c9cb-fbe0-4f11-9d9f-c77f260a0745",
"notes": [
"Optimal"
]
}
步骤 6:使用 Pip 索引安装瘦客户端#
注意
自托管瘦客户端需要 Python 3.10。
瘦客户端使用户能够快速测试,但用户可以使用此链接设计自己的客户端。
每当需要更新或安装瘦客户端时,您可以直接使用 NVIDIA pip 索引进行安装。
要求
请访问 自托管瘦客户端的系统要求 以获取更多信息。
pip install --upgrade --extra-index-url https://pypi.nvidia.com cuopt-sh-client
有关更多信息,请导航至 自托管瘦客户端。
步骤 7:使用 Helm Chart 在 Kubernetes 上安装 cuOpt#
有关 Kubernetes 集群要求和 Kubernetes 资源链接的信息,请参阅 Kubernetes 上自托管容器的系统要求。
在 Helm 中创建一个命名空间。
1kubectl create namespace <some name> 2export NAMESPACE="<some name>"
使用以下示例测试集群是否具有 GPU 访问权限(如果
kubectl不可用,请使用 Kubernetes 安装的类似命令来运行此 Pod)kubectl apply -f - <<EOF apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 EOF kubectl logs cuda-vector-add
应获得如下响应,
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
将 NGC API 密钥配置为 secret。
请参阅 步骤 2 以获取 NGC API 密钥。
kubectl create secret docker-registry ngc-docker-reg-secret \ -n $NAMESPACE --docker-server=nvcr.io --docker-username='$oauthtoken' \ --docker-password=$NGC_CLI_API_KEY
获取 Helm Chart。
cuOpt 的 Helm chart 可以在 NGC 的
Helm Charts选项卡中找到。请从 cuOpt Helm 页面复制提取标签,并按如下方式使用helm fetch <FETCH-TAG-COPIED-FROM-NGC> --username='$oauthtoken' --password=$NGC_CLI_API_KEY --untar
运行 cuOpt 服务器。
对于 GA
helm install --namespace $NAMESPACE nvidia-cuopt-chart cuopt --values cuopt/values.yaml
对于 EA
helm install --namespace $NAMESPACE nvidia-cuopt-chart cuopt-ea --values cuopt-ea/values.yaml
下载容器可能需要一些时间,状态显示为 PodInitializing;否则将为 Running。使用以下命令进行验证
kubectl -n $NAMESPACE get all
NAME READY STATUS RESTARTS AGE pod/cuopt-cuopt-deployment-595656b9d6-dbqcb 1/1 Running 0 21s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/cuopt-cuopt-deployment-cuopt-service ClusterIP X.X.X.X <none> 5000/TCP,8888/TCP 21s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/cuopt-cuopt-deployment 1/1 1 1 21s NAME DESIRED CURRENT READY AGE replicaset.apps/cuopt-cuopt-deployment-595656b9d6 1 1 1 21s
使用容器测试下列出的示例测试部署
卸载 NVIDIA cuOpt 服务器
helm uninstall -n $NAMESPACE nvidia-cuopt-chart