FAQ#
通用 FAQ#
我是否需要 GPU 才能使用 cuOpt?
是的,请参考 GPU 规格。您可以获取具有受支持 GPU 的云实例并启动 cuOpt,或者,如果您的本地机器满足要求,您也可以在本地机器上启动它。
cuOpt 是否使用多个 GPU?
是的,可以配置每个 GPU 一个求解器进程来运行多个求解器。请求在轮询队列中被接受,更多详细信息请参考概述
目前不支持利用多个 GPU 来解决单个问题或为多个求解器过度订阅单个 GPU。
cuOpt 服务未启动:端口问题?
查看容器的日志(请参阅下面的 cuOpt 服务监控)。
端口 5000 是否已被占用?
如果端口 5000 不可用,日志将包含如下错误
ERROR: [Errno 98] error while attempting to bind on address ('0.0.0.0', 5000): address already in use”
尝试找到正在使用端口 5000 的进程,并尽可能停止它。像
netstat这样的工具以 root 用户身份运行可以帮助识别映射到进程的端口,而docker ps -a将显示正在运行的容器。或者,使用端口映射在不同的端口(例如 5001)上启动 cuOpt(请注意省略了
–network=host标志)docker run -d --rm --gpus all -p 5001:5000 <CUOPT_IMAGE>
为什么 Nvidia cuOpt 服务的运行时间比提供的时间限制长?
提供的时间限制将控制求解器纯粹查找解决方案的运行时间,但还存在其他开销,例如
网络延迟、etl、验证或求解器正忙于处理其他请求。因此,完整的往返求解时间可能比设置的时间长。
是否有一种方法可以使 cuOpt 服务也在提供的时间限制内考虑其他开销。
我们目前没有考虑它,因为许多此类开销是相对的,无法正确跟踪。
cuOpt 服务未运行:GPU 内存可用性问题?
如果存在与
rmm相关的错误,或者服务无法获取 GPU 内存的错误,则可能是 GPU 内存正被另一个进程消耗。可以使用命令
nvidia-smi观察到这一点。
cuOpt 服务无响应:应该检查什么?
cuOpt 主机上的 cuOpt 微服务健康检查。
在运行 cuOpt 的主机上本地执行健康检查
curl -s -o /dev/null -w '%{http_code}\\n' localhost:5000/cuopt/health 200如果此命令返回 200,则表示 cuOpt 正在运行并在指定端口上监听。
如果此命令返回 200 以外的其他内容,请检查以下内容
使用
docker -ps检查 cuOpt 容器是否正在运行。检查 cuOpt 容器日志中是否有错误。
启动 cuOpt 时,您是否在 docker 中包含了
–network=host或-p端口映射标志?如果您使用了端口映射,您是否使用正确的端口执行了健康检查?重启 cuOpt 并查看是否可以纠正问题。
从远程主机进行 cuOpt 微服务健康检查。
如果您尝试从远程主机访问 cuOpt,请从远程主机运行健康检查并指定 cuOpt 主机的 IP 地址,例如
1 curl -s -o /dev/null -w '%{http_code}\\n' <ip>::5000/cuopt/health 2 200如果此命令未返回 200,但在 cuOpt 主机上本地进行的健康检查返回 200,则问题是网络配置或防火墙问题。主机无法访问,或者 cuOpt 端口未对传入流量开放。
cuOpt 托管服务报告的常见配置错误以及如何修复它们(缺少数据、不兼容的约束)
如果托管服务的身份验证失败
确保客户端中的
sak值设置正确。sak值是在快速入门指南和客户端文档中介绍的 NVIDIA Identity Federation API 密钥。确保您没有使用过期的 API 密钥。如有必要,生成一个新的密钥。
如果您无法连接到端点
您可能有一个指向错误功能的本地缓存;删除
version_cache.json文件或运行cuopt_cli -g以解除阻止。或者,NVIDIA 云服务基础设施可能已宕机。
如果客户端停止轮询并在没有结果的情况下返回
如果使用
cuopt_cliCLI 将打印一条消息,显示如何使用 CLI 重新启动轮询
CLI 选项
-p可用于设置轮询超时时间(默认为 120 秒)。
如果使用客户端库
客户端将引发 TimeoutError 异常,其中包含具有请求 ID 和资产 ID 值的 JSON 对象。这些值可以传递给客户端的
repoll方法以重新启动轮询。轮询时间可以使用客户端中的
request_excess_timeout参数设置(默认为 120 秒)。设置为None将导致客户端永远轮询。
在任何一种情况下,如果对于一个简单的问题来说时间过长,并且无法通过重新轮询检索到结果,请联系 cuOpt 支持。
如果您收到 HTTP 错误 500 或 409 或您不理解的验证错误
捕获程序中的任何输出,并通过错误或事件报告将其发送给 NVIDIA。使用的数据集将有助于添加,但请确保它不包含任何专有详细信息。
收到 401 或 404 http 错误
这可能是版本缓存不匹配;需要清除缓存。rm -rf version_cache.json 或 cuopt_cli -g (如果使用 CLI)
来自 Python 客户端的证书验证错误
这主要可能发生在云实例中运行的 cuOpt 上。
可能是您位于生成证书链的代理之后,并且您需要在您的机器上安装额外的证书颁发机构。
您可以使用以下命令或类似命令检查连接上返回的证书链。如果看起来链中有由您自己的组织颁发的证书,请联系您当地的 IT 部门,并向他们索取要在您的机器上安装的正确证书。
在此示例中,我们将检查从连接到 NVIDIA 的 NVCF 返回的证书链,但如果您尝试连接到部署在云中的 cuOpt 实例,则可以替换为不同的地址
1export MY_SERVER_ADDRESS=”api.nvcf.nvidia.com:443”
2openssl s_client -showcerts -connect $MY_SERVER_ADDRESS </dev/null 2>/dev/null | sed -n -e '/BEGIN\ CERTIFICATE/,/END CERTIFICATE/ p' > test.pem
3
4while openssl x509 -noout -text; do :; done < test.pem.txt
路径规划 FAQ#
什么是航点图?
航点图是一个加权有向图,其中权重表示成本。与成本矩阵不同,此图通常表示的不仅仅是目标位置,还包括沿途的中间决策点(仅通过的位置)。此方法通常用于自定义环境和室内空间,例如仓库和工厂,其中目标位置之间的成本是动态的或不易量化的。下面说明了一个具有四个节点的基本航点图
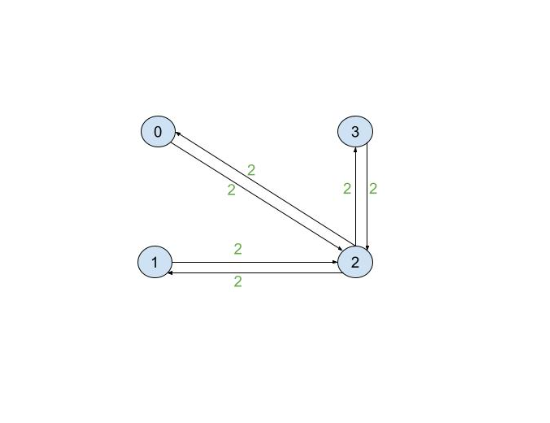
1{
2"cost_waypoint_graph_data":{
3 "waypoint_graph": {
4 "0": {
5 "offsets": [0, 1, 2, 5, 6],
6 "edges": [2, 2, 0, 1, 3, 2],
7 "weights": [2, 2, 2, 2, 2, 2]
8 }
9 }
10}
旨在输入到 cuOpt 中的图以 **压缩稀疏行 (CSR)** 格式显示,以提高效率。从更传统的(且人类可读的)图格式(例如加权边列表)到 CSR 的转换可以快速完成,如下所示
1graph = { 2 0:{ 3 "edges":[2], 4 "weights":[2]}, 5 1:{ 6 "edges":[2], 7 "weights":[2]}, 8 2:{ 9 "edges":[0, 1, 3], 10 "weights":[2, 2, 2]}, 11 3:{ 12 "edges":[2], 13 "weights":[2]} 14 } 15 16def convert_to_csr(graph): 17 num_nodes = len(graph) 18 19 offsets = [] 20 edges = [] 21 weights = [] 22 23 cur_offset = 0 24 for node in range(num_nodes): 25 offsets.append(cur_offset) 26 cur_offset += len(graph[node]["edges"]) 27 28 edges = edges + graph[node]["edges"] 29 weights = weights + graph[node]["weights"] 30 31 offsets.append(cur_offset) 32 33 return offsets, edges, weights 34 35offsets, edges, weights = convert_to_csr(graph) 36print(f"offsets = {offsets}") 37print(f"edges = {edges}") 38print(f"weights = {weights}")
什么是混合车队?
在某些情况下,并非车队中的所有车辆都相同。有些可能行驶速度更快,而另一些在某些区域行驶时可能会产生难以承受的成本。例如,我们可能有一个由飞机和卡车组成的车队。
vehicle_types可以与每种车辆的成本/时间矩阵等数据一起使用。鉴于上面的示例,飞机将具有一个成本/时间矩阵,而卡车将具有不同的成本/时间矩阵。
如何获得不可行问题的部分可行解?
使用奖金收集,它将每个任务与奖金相关联,求解器将最大化收集的奖金。这允许 cuOpt 优先考虑某些任务而不是其他任务。
什么是维度不匹配错误?
某些指标的大小需要相等,例如任务数量及其需求。如果它们不匹配,则意味着问题部分定义或数据存在问题。
cuOpt 资源估算;在给定一组约束的情况下,我可以运行多大的问题?
对于具有真实世界约束的标准 CVRPTW(带时间窗的车辆路径问题),cuOpt 可以轻松解决 NVIDIA GPU A100/H100 的 15K 个位置。
每次运行都无法获得相同的解决方案:确定性?
cuOpt 路径规划求解器不是确定性的,因此结果可能在多次运行中有所不同。增加为求解器设置的时间限制将增加在多次运行中获得相同结果的可能性。
此外,可能存在多个具有相同成本的不同解决方案。
我们如何处理动态变化的约束?
cuOpt 是无状态的,无法直接处理动态约束,但这可以通过建模来解决。
当操作条件发生变化时,例如车辆发生故障、司机请病假、道路封闭、交通或紧急高优先级订单进入时,会使用动态重新优化。
问题的准备方式使得已在途的包裹仅分配给这些车辆,并且新的和旧的交付将被添加到此问题中。请参考 cuOpt 资源中的示例笔记本,以了解有关如何解决此问题的更多信息。
cuOpt 是否接受初始解决方案?
目前 cuOpt 不接受初始解决方案。
在创建时间窗口矩阵时,我们需要对数据进行归一化处理吗?
单位可以是客户想要的任何单位:分钟、秒、毫秒、小时等等。用户有责任对整个问题的数据进行归一化处理,以便所有与时间相关的约束都使用相同的单位。例如,如果出行时间矩阵以分钟为单位给出,我们希望确保时间窗口和服务时间也以分钟为单位给出。
是否有一种方法可以阻止车辆在航点图中沿同一路径行驶,或者是否有一种方法可以阻止多辆车访问某个位置,甚至某个位置仅被单辆车访问一次?
目前,我们没有此类限制,cuOpt 尝试优化最少数量的车辆作为主要默认目标。
出行时间偏差:当使用相同的数据集时,不同运行中的出行时间变化几秒钟,但距离保持不变。在相同数据和距离保持不变的情况下,出行时间如何会在多次运行中发生偏差?
这是因为出行时间不是目标的一部分,因此我们可能有两个等效的解决方案,并在选择最佳解决方案时出现偏差。您可以将总出行时间(包括等待时间)作为目标的一部分。
两个位置之间没有路径,如何将此信息输入到求解器?
设置与其他实际值相比更高的值,而不是浮点类型的最大值。
这将确保不会遍历此路径,因为它会产生巨大的成本。
用于指定任务位置的浮点数与整数。
文档说 task_locations 应该是整数。但在现实世界中,纬度和经度坐标是浮点值。为了解释这一点,请阅读以下部分。
cuOpt 期望用户提供以下任一项
成本矩阵和相应的地点索引。
航点图和与航点对应的位置(整数)。
因此,在任何一种情况下,任务位置实际上都是另一个结构的整数索引。
如果您有(纬度、经度)值,则可以使用地图 API 生成成本矩阵。cuOpt 不直接连接到第三方地图引擎,但这可以在 cuOpt 外部完成,如此处所示。
是否可以定义诸如某些订单需要冷藏车之类的约束?
是的,您可以使用 vehicle_order_match 定义约束以将车辆与订单类型匹配。冷冻货物就是一个很好的例子。
我们如何建模以下场景:从多个不同地点取货并交付给单个客户?
这可以看作是一个取货和交付问题。
我知道该问题有一个可行解,但 cuOpt 返回一个不可行解。如何避免这种情况?
时间限制可能太短。
不可行解始终提供有关导致它的约束以及可以放宽哪些约束的信息,这可能会提供更多提示。
如何设置奖金收集以交付尽可能多的订单?
将所有奖金值设置为 1,并设置非常高的奖金目标(如 10^6),然后将成本、travel_time 和 route_variance 的其他目标值设置为彼此成比例,以便 cuOpt 始终返回最佳解决方案。
线性规划 FAQ#
使用批量模式时,我可以给出多小和多少个问题?
批量模式允许并行求解许多 LP,以便在 LP 问题太小时尝试充分利用 GPU。使用 H100 SXM,问题应至少有 1K 个元素,并且给出超过 100 个 LP 通常不会提高性能。
求解器可以在密集问题上运行吗?
是的,但我们通常在非常大且稀疏的问题上看到很好的结果。
问题可以有多大?
如果在 H100 SXM 80GB 上运行(使用 NVIDIA Cloud Functions 时使用的硬件),您可以运行以下大小的问题
450 万行/约束;450 万列/变量;以及约束矩阵中 9 亿个非零元素
3600 万行/约束;3600 万列/变量;以及约束矩阵中 7.2 亿个非零元素
如何获得最佳性能?
有几种方法可以调整求解器以获得最佳性能
硬件:如果使用自托管,您应该使用最新的服务器级 GPU。我们推荐 H100 SXM(而不是 PCIE 版本)。
容差:设置容差通常对性能有巨大影响。尝试使用
set_optimality_tolerance直到您达到最低可接受的精度。求解器模式:求解器模式将更改求解器内部优化问题的方式。使用
set_solver_mode进行模式选择会极大地影响特定问题的求解速度。您应该测试不同的模式,以查看哪种模式最适合您的问题。不可行性检测:默认情况下,求解器将尝试检测不可行问题,这需要时间。如果您知道您的问题是可行的,请使用
set_infeasibility_detection以加快求解速度。批量模式:如果您预先知道您需要解决多个 LP 问题,则应使用批量模式并行解决多个 LP,而不是按顺序解决它们。
我应该选择哪种求解器模式?
我们无法预先预测哪种求解器模式最适合特定问题。唯一的了解方法是进行测试。一旦您知道某种求解器模式在一类问题上表现良好,它也应该在其他类似问题上表现良好。
我应该使用什么阈值?
选择完全取决于您的问题所需的精度水平。较高的阈值通常会产生更快的结果。一般来说,1e-2 是低精度,1e-4 是普通精度,1e-6 是高精度,1e-8 是非常高精度。