故障排除#
本节包含用户在 OpenShift 容器平台集群上安装 NVIDIA GPU Operator 期间执行各种检查时可能遇到的错误。
节点功能发现检查#
验证节点功能发现是否已创建
$ oc get NodeFeatureDiscovery -n openshift-nfdNAME AGE nfd-instance 4h11m
注意
如果为空,则必须创建节点功能发现自定义资源 (CR)。
确保存在带有 GPU 的节点。在此示例中,检查是针对使用 PCI ID 10de 的 NVIDIA GPU 执行的。
$ oc get nodes -l feature.node.kubernetes.io/pci-10de.presentNAME STATUS ROLES AGE VERSION ip-10-0-133-209.ec2.internal Ready worker 4h13m v1.21.1+9807387
GPU Operator 检查#
验证自定义资源定义 (CRD) 是否已部署。
$ oc get crd/clusterpolicies.nvidia.comNAME CREATED AT clusterpolicies.nvidia.com 2021-09-02T10:33:50Z
注意
如果缺失,则集群策略安装不成功。
验证集群策略是否已部署
$ oc get clusterpolicyNAME AGE gpu-cluster-policy 8m25s
注意
如果缺失,请创建自定义资源 (CR)。有关更多信息,请参阅 创建 ClusterPolicy 实例。
验证 Operator 是否正在运行
$ oc get pods -n nvidia-gpu-operator -lapp=gpu-operator
NAME READY STATUS RESTART AGE gpu-operator-6b8b8c5fd9-zcs9r 1/1 Running 0 3h55m
注意
如果报告 ImagePullBackOff,则可能是 NVIDIA 注册表已关闭。 如果报告 CrashLoopBackOff,请查看 operator 日志。
$ oc logs -f -n nvidia-gpu-operator -lapp=gpu-operator
2021-11-17T12:08:33.913Z INFO controllers.ClusterPolicy Found Resource, updating... {"ClusterRoleBinding": "nvidia-mig-manager", "Namespace": "nvidia-gpu-operator"} 2021-11-17T12:08:33.941Z INFO controllers.ClusterPolicy Found Resource, updating... {"ConfigMap": "default-mig-parted-config", "Namespace": "nvidia-gpu-operator"} 2021-11-17T12:08:33.958Z INFO controllers.ClusterPolicy Found Resource, updating... {"ConfigMap": "default-gpu-clients", "Namespace": "nvidia-gpu-operator"} 2021-11-17T12:08:33.964Z INFO controllers.ClusterPolicy Found Resource, updating... {"SecurityContextConstraints": "nvidia-mig-manager", "Namespace": "default"} 2021-11-17T12:08:33.992Z INFO controllers.ClusterPolicy DaemonSet identical, skipping update {"DaemonSet": "nvidia-mig-manager", "Namespace": "nvidia-gpu-operator", "name": "nvidia-mig-manager"} 2021-11-17T12:08:33.992Z INFO controllers.ClusterPolicy DEBUG: DaemonSet {"LabelSelector": "app=nvidia-mig-manager"} 2021-11-17T12:08:33.992Z INFO controllers.ClusterPolicy DEBUG: DaemonSet {"NumberOfDaemonSets": 1} 2021-11-17T12:08:33.992Z INFO controllers.ClusterPolicy DEBUG: DaemonSet {"NumberUnavailable": 0} 2021-11-17T12:08:33.992Z INFO controllers.ClusterPolicy INFO: ClusterPolicy step completed {"state:": "state-mig-manager", "status": "ready"} 2021-11-17T12:08:34.061Z INFO controllers.ClusterPolicy ClusterPolicy is ready.
验证 GPU 堆栈#
GPU Operator 使用 nvidia-device-plugin-validator 和 nvidia-cuda-validator pod 验证堆栈。 如果它们报告状态 Completed,则堆栈按预期工作。
$ oc get po -n nvidia-gpu-operatorNAME READY STATUS RESTARTS AGE bb0dd90f1b757a8c7b338785a4a65140732d30447093bc2c4f6ae8e75844gfv 0/1 Completed 0 125m gpu-feature-discovery-hlpgs 1/1 Running 0 122m gpu-operator-8dc8d6648-jzhnr 1/1 Running 0 125m nvidia-container-toolkit-daemonset-z2wh7 1/1 Running 0 122m nvidia-cuda-validator-8fx22 0/1 Completed 0 117m nvidia-dcgm-exporter-ds9xd 1/1 Running 0 122m nvidia-dcgm-k7tz6 1/1 Running 0 122m nvidia-device-plugin-daemonset-nqxmc 1/1 Running 0 122m nvidia-device-plugin-validator-87zdl 0/1 Completed 0 117m nvidia-driver-daemonset-48.84.202110270303-0-9df9j 2/2 Running 0 122m nvidia-node-status-exporter-7bhdk 1/1 Running 0 122m nvidia-operator-validator-kjznr 1/1 Running 0 122m
验证 cuda validator 日志
$ oc logs -f nvidia-cuda-validator-8fx22 -n nvidia-gpu-operatorcuda workload validation is successful验证 nvidia-device-plugin-validator 日志
$ oc logs nvidia-device-plugin-validator-87zdl -n nvidia-gpu-operatordevice-plugin workload validation is successful
验证 NVIDIA 驱动程序部署#
这是一个说明性示例,说明 Operator 的部署未按预期进行的情况。
列出部署到 nvidia-gpu-operator 命名空间的 pod
$ oc get pods -n nvidia-gpu-operatorNAME READY STATUS RESTARTS AGE gpu-feature-discovery-hlpgs 0/1 Init:0/1 0 53m gpu-operator-8dc8d6648-jzhnr 0/1 Init:0/1 0 53m nvidia-container-toolkit-daemonset-z2wh7 0/1 Init:0/1 0 53m nvidia-cuda-validator-8fx22 0/1 Init:0/1 0 53m nvidia-dcgm-exporter-ds9xd 0/1 Init:0/2 0 53m nvidia-dcgm-k7tz6 0/1 Init:0/1 0 53m nvidia-device-plugin-daemonset-nqxmc 0/1 Init:0/1 0 53m nvidia-device-plugin-validator-87zd 0/1 Init:0/1 0 53m nvidia-driver-daemonset-48.84.202110270303-0-9df9j 0/1 CrashLoopBackOff 13 53m nvidia-node-status-exporter-7bhdk 1/1 Init: 0/1 0 53m nvidia-operator-validator-kjznr 0/1 Init:0/4 0 53m
Init 状态指示驱动程序 pod 未就绪。 在此示例中,驱动程序 Pod 处于 CrashLoopBackOff 状态。 这与 RESTARTS 等于 13 相结合表明存在问题。
验证主控制台页面
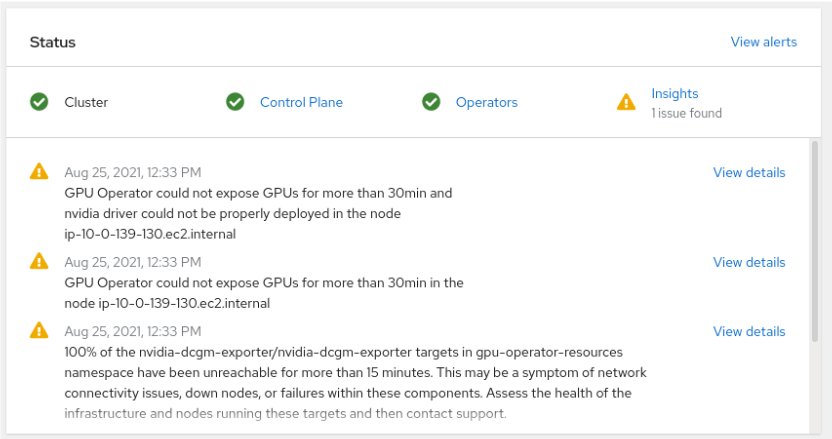
第一个警报显示“nvidia 驱动程序无法正确部署”。
检查 NVIDIA 驱动程序主容器日志
$ oc logs -f nvidia-driver-daemonset-48.84.202110270303-0-9df9j -n nvidia-gpu-operator -c nvidia-driver-ctr在日志中,此行指示权利问题
FATAL: failed to install elfutils packages. RHEL entitlement may be improperly deployed此消息可能与驱动程序工具包部署不成功有关。 要确认驱动程序工具包已成功部署,请遵循 验证 OpenShift Driver Toolkit 中的指南。 如果您看到此消息,一种解决方法是在 OpenShift 容器平台控制台中编辑创建的
gpu-cluster-policyYAML 文件,并将use_ocp_driver_toolkit设置为false。设置权利。 有关更多信息,请参阅 启用集群范围的权利。
验证 OpenShift Driver Toolkit#
验证 OpenShift Driver Toolkit 是否已成功部署。
检查日志以确保驱动程序工具包已成功部署
oc logs $(oc get pods -l app=gpu-operator -oname -n nvidia-gpu-operator) -n nvidia-gpu-operator以下输出指示
dependencies missing存在问题。2021-11-15T11:43:51.626Z INFO controllers.ClusterPolicy ocpHasDriverToolkitImageStream: driver-toolkit imagestream not found {"Name": "driver-toolkit", "Namespace": "openshift"} 2021-11-15T11:43:51.626Z INFO controllers.ClusterPolicy WARNING OpenShift Driver Toolkit requested {"hasCompatibleNFD": true, "hasDriverToolkitImageStream": false} 2021-11-15T11:43:51.626Z INFO controllers.ClusterPolicy WARNING OpenShift Driver Toolkit {"enabled": false} ... 2021-11-15T11:43:52.048Z INFO controllers.ClusterPolicy WARNING: OpenShift DriverToolkit was requested but could not be enabled (dependencies missing)
检查 OpenShift 容器平台 Web 控制台上的警报会显示以下 GPUOperatorOpenshiftDriverToolkitEnabledImageStreamMissing。 此屏幕截图提供了额外的证据,表明 Openshift 版本需要升级。
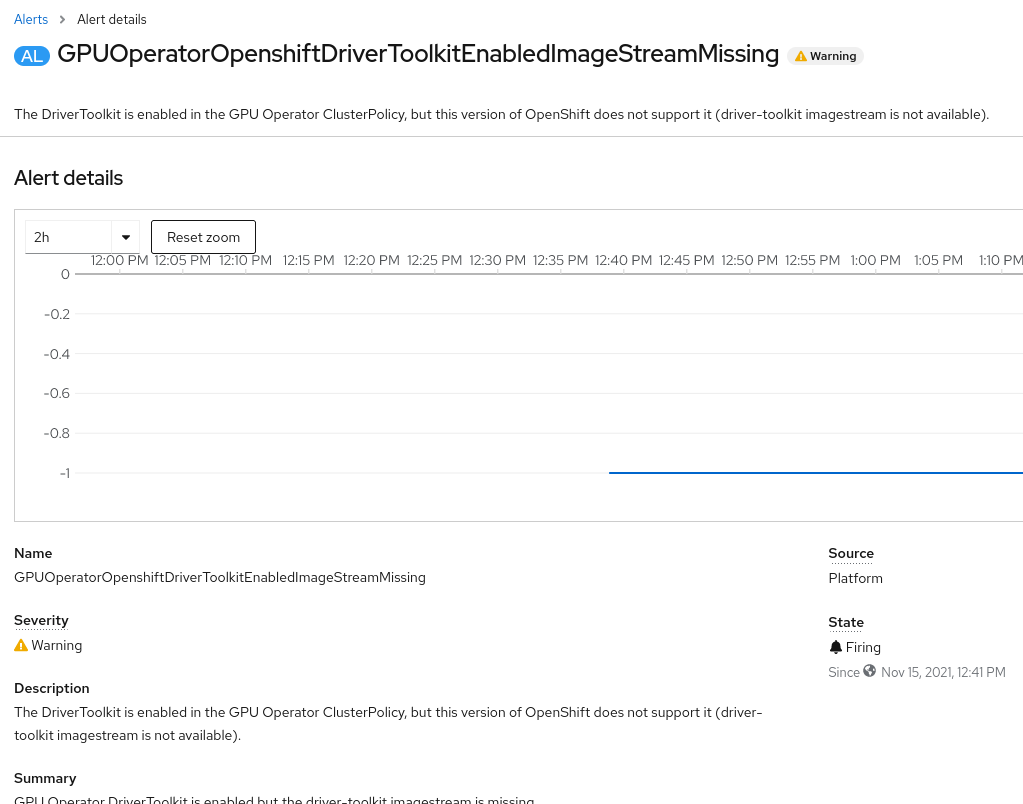
日志条目和来自警报的信息表明此版本的 OpenShift 不支持成功部署 OpenShift Driver Toolkit。 有关 OpenShift 容器平台版本和 OpenShift Driver Toolkit 之间依赖关系的更多详细信息,请参阅 OpenShift 上的安装和升级概述。