在 OpenShift 上安装 NVIDIA GPU Operator#
使用 Web 控制台安装 NVIDIA GPU Operator#
在 OpenShift 容器平台 Web 控制台中,从侧边菜单导航到Operators > OperatorHub,然后选择所有项目。
在 Operators > OperatorHub 中,搜索 NVIDIA GPU Operator。 有关更多信息,请参阅Red Hat OpenShift 容器平台文档。
选择 NVIDIA GPU Operator,单击安装。 在后续屏幕中,单击安装。
注意
在这里,您可以选择要部署 GPU Operator 的命名空间。 建议使用的命名空间是
nvidia-gpu-operator。 您可以选择任何现有命名空间或在选择命名空间下创建一个新命名空间。如果您安装到
nvidia-gpu-operator之外的任何其他命名空间,则 GPU Operator 将不会自动启用命名空间监控,并且 Prometheus 将不会收集指标和警报。 如果此命名空间中仅安装了受信任的 Operator,您可以手动启用命名空间监控,命令如下:$ oc label ns/$NAMESPACE_NAME openshift.io/cluster-monitoring=true
使用 CLI 安装 NVIDIA GPU Operator#
作为集群管理员,您可以使用 OpenShift CLI (oc) 安装 NVIDIA GPU Operator。
为 NVIDIA GPU Operator 创建命名空间。
创建以下
Namespace自定义资源 (CR),该资源定义了nvidia-gpu-operator命名空间,然后将 YAML 保存在nvidia-gpu-operator.yaml文件中apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator
注意
建议使用的命名空间是
nvidia-gpu-operator。 您可以选择任何现有命名空间或创建新的命名空间名称。 如果您安装到nvidia-gpu-operator之外的任何其他命名空间,则 GPU Operator 将不会自动启用命名空间监控,并且 Prometheus 将不会收集指标和警报。如果此命名空间中仅安装了受信任的 Operator,您可以手动启用命名空间监控,命令如下:
$ oc label ns/$NAMESPACE_NAME openshift.io/cluster-monitoring=true
通过运行以下命令创建命名空间
$ oc create -f nvidia-gpu-operator.yamlnamespace/nvidia-gpu-operator created
通过创建以下对象,在您在上一步中创建的命名空间中安装 NVIDIA GPU Operator
创建以下
OperatorGroupCR,并将 YAML 保存在nvidia-gpu-operatorgroup.yaml文件中apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator
通过运行以下命令创建
OperatorGroupCR$ oc create -f nvidia-gpu-operatorgroup.yamloperatorgroup.operators.coreos.com/nvidia-gpu-operator-group created
运行以下命令以获取步骤 5 所需的
channel值。$ oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}'
示例输出
v22.9运行以下命令以获取步骤 5 所需的
startingCSV值。$ CHANNEL=v22.9
$ oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV'
示例输出
gpu-operator-certified.v22.9.0创建以下
SubscriptionCR,并将 YAML 保存在nvidia-gpu-sub.yaml文件中apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "v22.9" installPlanApproval: Manual name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "gpu-operator-certified.v22.9.0"
注意
使用步骤 3 和 4 中返回的信息更新
channel和startingCSV字段。通过运行以下命令创建订阅对象
$ oc create -f nvidia-gpu-sub.yamlsubscription.operators.coreos.com/gpu-operator-certified created可选:登录到 Web 控制台并导航到 Operators > Installed Operators 页面。 在
Project: nvidia-gpu-operator中,将显示以下内容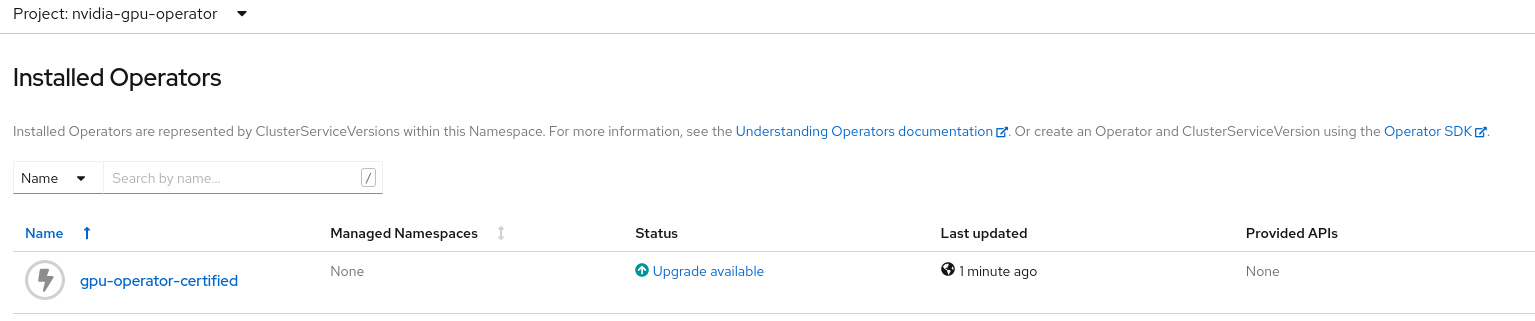
验证是否已创建安装计划
$ oc get installplan -n nvidia-gpu-operator示例输出
NAME CSV APPROVAL APPROVED install-wwhfj gpu-operator-certified.v22.9.0 Manual false
使用 CLI 命令批准安装计划
$ INSTALL_PLAN=$(oc get installplan -n nvidia-gpu-operator -oname)
$ oc patch $INSTALL_PLAN -n nvidia-gpu-operator --type merge --patch '{"spec":{"approved":true }}'
示例输出
installplan.operators.coreos.com/install-wwhfj patched或者,单击
Upgrade available并使用 Web 控制台批准计划
可选:在 Web 控制台中验证安装是否成功。 显示更改为
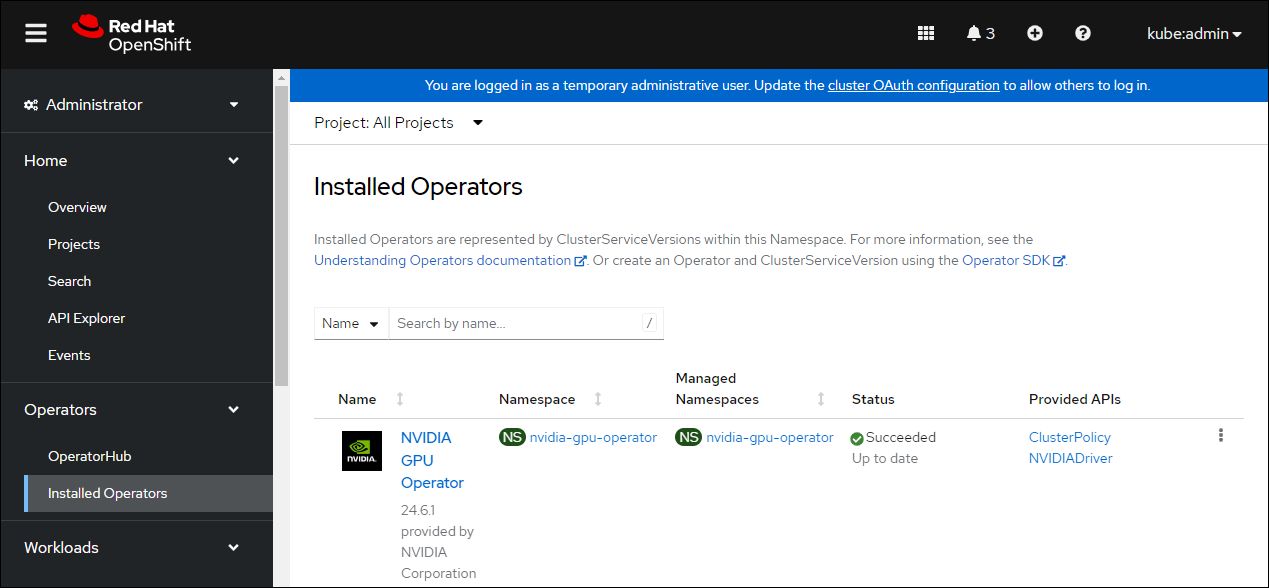
创建 ClusterPolicy 实例#
当您在 OpenShift 容器平台中安装 NVIDIA GPU Operator 时,将创建一个 ClusterPolicy 的自定义资源定义。 ClusterPolicy 配置 GPU 堆栈,配置镜像名称和仓库、Pod 限制/凭据等。
注意
如果您创建一个包含空规范的 ClusterPolicy,例如 spec{},则 ClusterPolicy 部署将失败。
作为集群管理员,您可以使用 OpenShift 容器平台 CLI 或 Web 控制台创建 ClusterPolicy。 此外,当使用 NVIDIA vGPU 时,这些步骤有所不同。 请参阅下面的相应部分。
使用 Web 控制台创建集群策略#
在 OpenShift 容器平台 Web 控制台中,从侧边菜单中选择 Operators > Installed Operators,然后单击 NVIDIA GPU Operator。
选择 ClusterPolicy 选项卡,然后单击创建 ClusterPolicy。 平台分配默认名称 *gpu-cluster-policy*。
注意
您可以使用此屏幕自定义 ClusterPolicy,但是默认设置足以配置和运行 GPU。
单击创建。
此时,GPU Operator 继续并安装所有必需的组件,以在 OpenShift 4 集群中设置 NVIDIA GPU。 至少等待 10-20 分钟,然后再深入研究任何形式的故障排除,因为这可能需要一段时间才能完成。
当安装成功时,新部署的 ClusterPolicy *gpu-cluster-policy* 的状态更改为
State:ready。
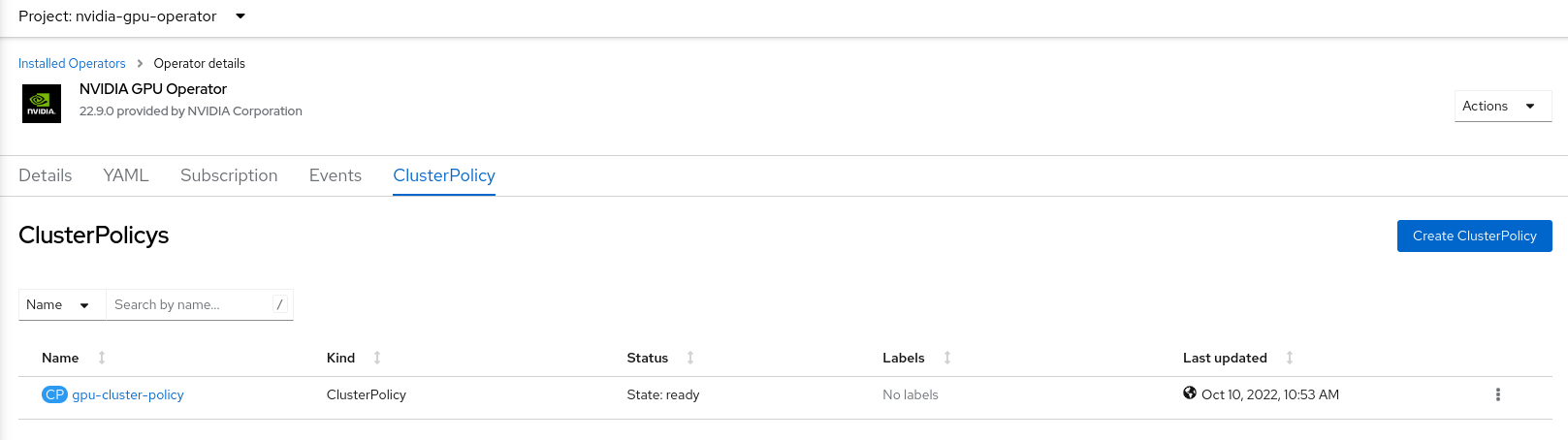
使用 CLI 创建集群策略#
创建 ClusterPolicy
$ oc get csv -n nvidia-gpu-operator gpu-operator-certified.v22.9.0 -ojsonpath={.metadata.annotations.alm-examples} | jq .[0] > clusterpolicy.json
$ oc apply -f clusterpolicy.jsonclusterpolicy.nvidia.com/gpu-cluster-policy created
使用 NVIDIA vGPU 创建 ClusterPolicy 实例#
先决条件#
请参阅 使用 NVIDIA vGPU 部分,了解有关在 RedHat OpenShift 上使用 NVIDIA vGPU 的先决条件步骤。
使用 Web 控制台创建集群策略#
在 OpenShift 容器平台 Web 控制台中,从侧边菜单中选择 Operators > Installed Operators,然后单击 NVIDIA GPU Operator。
选择 ClusterPolicy 选项卡,然后单击创建 ClusterPolicy。 平台分配默认名称 *gpu-cluster-policy*。
在驱动程序部分下提供许可
ConfigMap的名称,这应在上面 NVIDIA vGPU 的先决条件步骤中创建。 有关示例,请参阅以下屏幕截图,并相应地修改值。
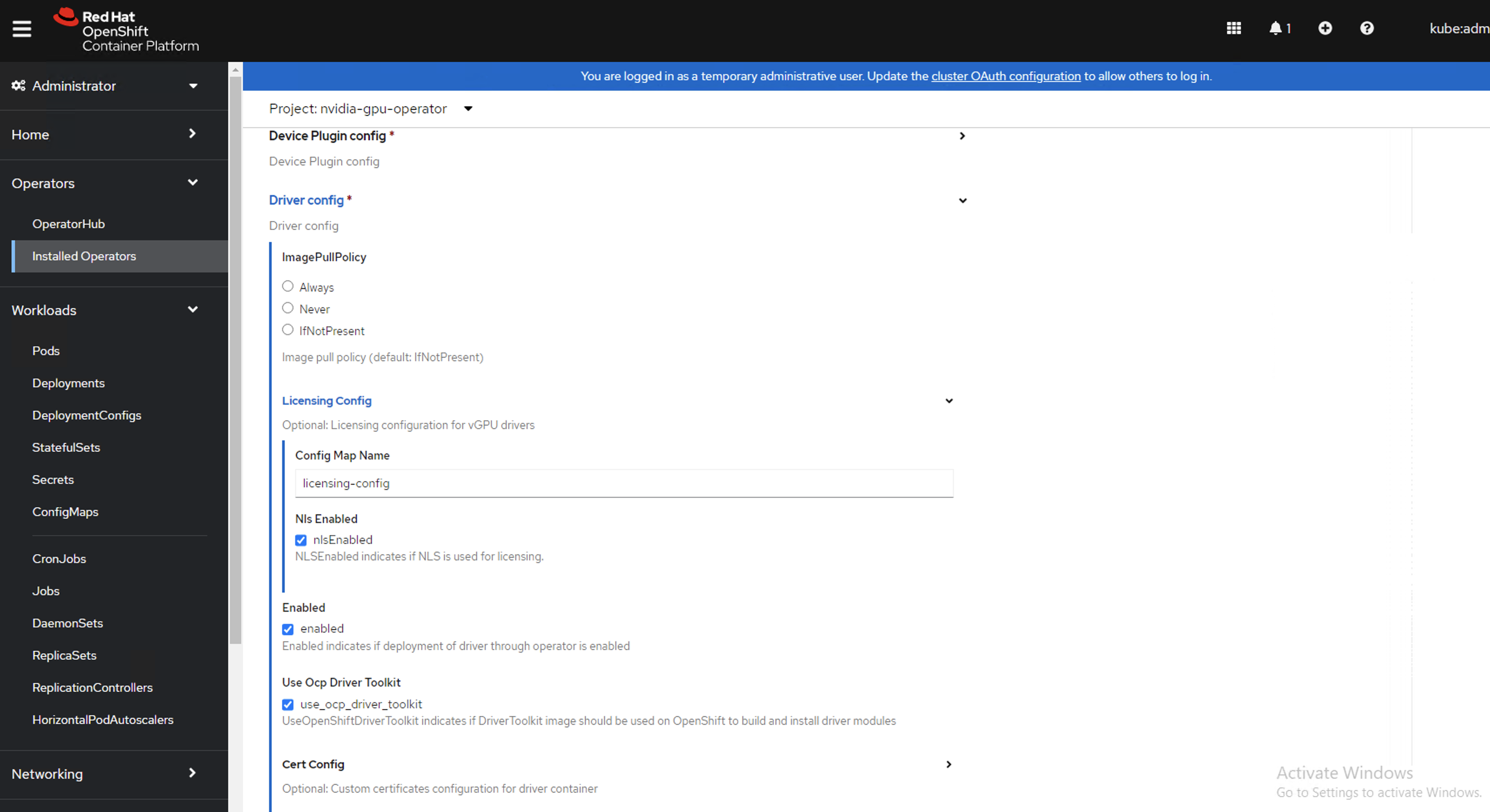
在驱动程序部分下指定
repository路径、image名称和捆绑的 NVIDIA vGPU 驱动程序version。 如果注册表不是公共的,请在驱动程序高级配置部分下指定先决条件步骤中创建的imagePullSecret。
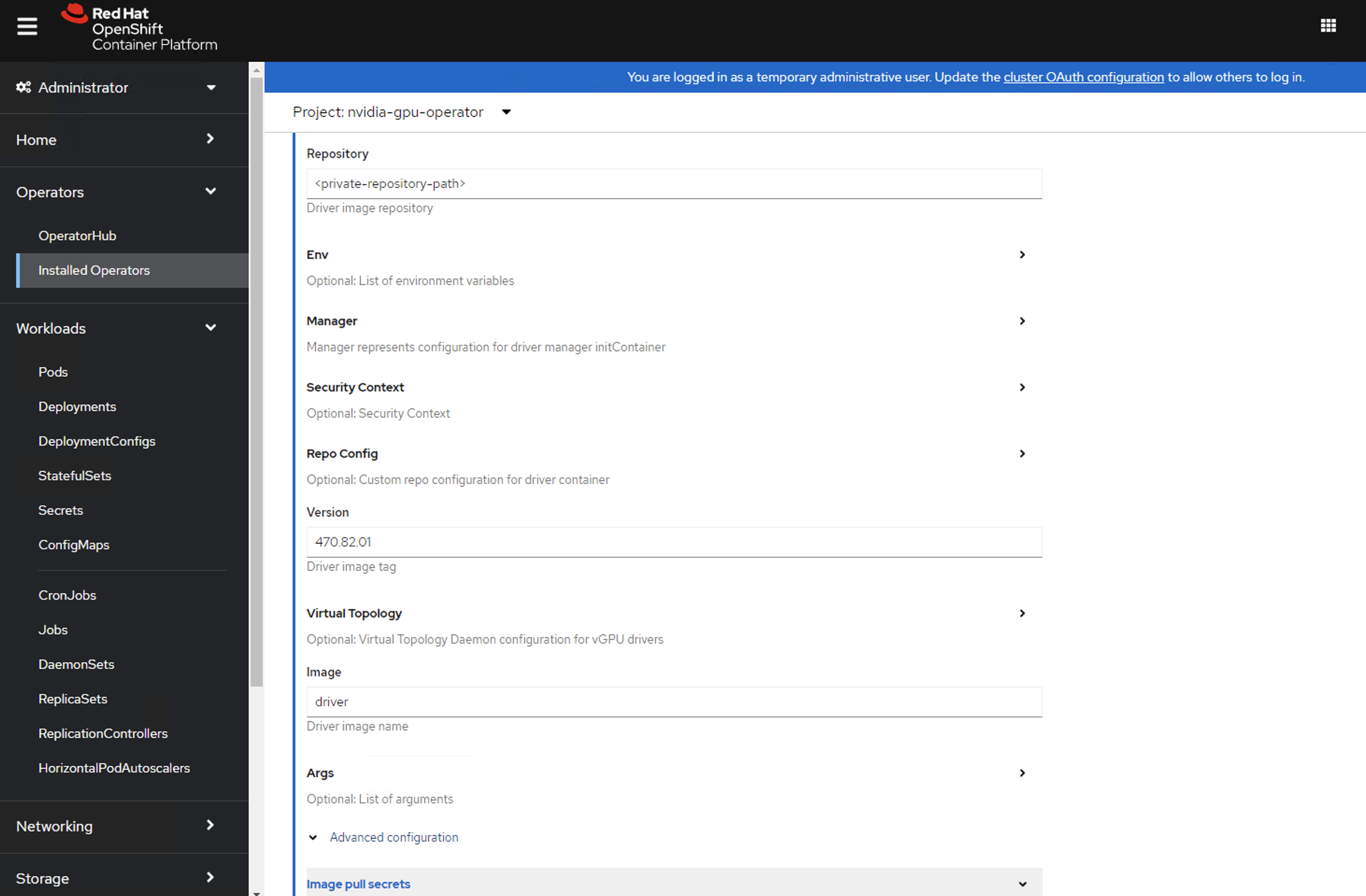
单击创建。
此时,GPU Operator 继续并安装所有必需的组件,以在 OpenShift 4 集群中设置 NVIDIA GPU。 至少等待 10-20 分钟,然后再深入研究任何形式的故障排除,因为这可能需要一段时间才能完成。
当安装成功时,新部署的 ClusterPolicy *gpu-cluster-policy* 的状态更改为
State:ready。
使用 CLI 创建集群策略#
创建 ClusterPolicy
$ oc get csv -n nvidia-gpu-operator gpu-operator-certified.v22.9.0 -ojsonpath={.metadata.annotations.alm-examples} | jq .[0] > clusterpolicy.json
修改 clusterpolicy.json 文件以指定在先决条件步骤中创建的
driver.licensingConfig、driver.repository、driver.image、driver.version和driver.imagePullSecrets。 下面的代码段显示了一个示例,请根据需要更改值。"driver": { "repository": "<repository-path>" "image": "driver", "imagePullSecrets": [], "licensingConfig": { "configMapName": "licensing-config", "nlsEnabled": true } "version": "470.82.01" }
$ oc apply -f clusterpolicy.jsonclusterpolicy.nvidia.com/gpu-cluster-policy created
验证 NVIDIA GPU Operator 是否成功安装#
验证 NVIDIA GPU Operator 是否成功安装,如此处所示
运行以下命令以查看这些新的 Pod 和 DaemonSet
$ oc get pods,daemonset -n nvidia-gpu-operatorNAME READY STATUS RESTARTS AGE pod/gpu-feature-discovery-c2rfm 1/1 Running 0 6m28s pod/gpu-operator-84b7f5bcb9-vqds7 1/1 Running 0 39m pod/nvidia-container-toolkit-daemonset-pgcrf 1/1 Running 0 6m28s pod/nvidia-cuda-validator-p8gv2 0/1 Completed 0 99s pod/nvidia-dcgm-exporter-kv6k8 1/1 Running 0 6m28s pod/nvidia-dcgm-tpsps 1/1 Running 0 6m28s pod/nvidia-device-plugin-daemonset-gbn55 1/1 Running 0 6m28s pod/nvidia-device-plugin-validator-z7ltr 0/1 Completed 0 82s pod/nvidia-driver-daemonset-410.84.202203290245-0-xxgdv 2/2 Running 0 6m28s pod/nvidia-node-status-exporter-snmsm 1/1 Running 0 6m28s pod/nvidia-operator-validator-6pfk6 1/1 Running 0 6m28s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/gpu-feature-discovery 1 1 1 1 1 nvidia.com/gpu.deploy.gpu-feature-discovery=true 6m28s daemonset.apps/nvidia-container-toolkit-daemonset 1 1 1 1 1 nvidia.com/gpu.deploy.container-toolkit=true 6m28s daemonset.apps/nvidia-dcgm 1 1 1 1 1 nvidia.com/gpu.deploy.dcgm=true 6m28s daemonset.apps/nvidia-dcgm-exporter 1 1 1 1 1 nvidia.com/gpu.deploy.dcgm-exporter=true 6m28s daemonset.apps/nvidia-device-plugin-daemonset 1 1 1 1 1 nvidia.com/gpu.deploy.device-plugin=true 6m28s daemonset.apps/nvidia-driver-daemonset-410.84.202203290245-0 1 1 1 1 1 feature.node.kubernetes.io/system-os_release.OSTREE_VERSION=410.84.202203290245-0,nvidia.com/gpu.deploy.driver=true 6m28s daemonset.apps/nvidia-mig-manager 0 0 0 0 0 nvidia.com/gpu.deploy.mig-manager=true 6m28s daemonset.apps/nvidia-node-status-exporter 1 1 1 1 1 nvidia.com/gpu.deploy.node-status-exporter=true 6m29s daemonset.apps/nvidia-operator-validator 1 1 1 1 1 nvidia.com/gpu.deploy.operator-validator=true 6m28s
nvidia-driver-daemonsetPod 在每个包含受支持 NVIDIA GPU 的工作节点上运行。注意
当驱动程序工具包处于活动状态时,
DaemonSet被命名为nvidia-driver-daemonset-<RHCOS-version>。 其中RHCOS-version等于<OCP XY>.<RHEL XY>.<related date YYYYMMDDHHSS-0。DaemonSet的 Pod 被命名为nvidia-driver-daemonset-<RHCOS-version>-<UUID>。
集群监控#
GPU Operator 生成 GPU 性能指标 (DCGM-export)、状态指标 (node-status-exporter) 和节点状态警报。 为了使 OpenShift Prometheus 收集这些指标,托管 GPU Operator 的命名空间必须具有标签 openshift.io/cluster-monitoring=true。
当 GPU Operator 安装在建议的 nvidia-gpu-operator 命名空间中时,如果未定义 openshift.io/cluster-monitoring 标签,则 GPU Operator 会自动启用监控。 如果定义了标签,则 GPU Operator 将不会更改其值。
通过设置 openshift.io/cluster-monitoring=false 来禁用 nvidia-gpu-operator 命名空间中的集群监控,如下所示
$ oc label ns/nvidia-gpu-operator openshift.io/cluster-monitoring=false
如果 GPU Operator 未安装在建议的命名空间中,则 GPU Operator 将不会自动启用监控。 如下所示手动设置标签
$ oc label ns/$NAMESPACE openshift.io/cluster-monitoring=true注意
仅当在此命名空间中安装了受信任的 Operator 时才执行此操作。
日志记录#
nvidia-driver-daemonset Pod 有两个容器。
运行以下命令以检查与
nvidia-driver-ctr关联的日志注意
此日志显示主容器正在等待驱动程序二进制文件,并将其加载到内存中。
$ oc logs -f nvidia-driver-daemonset-410.84.202203290245-0-xxgdv -n nvidia-gpu-operator -c nvidia-driver-ctr运行以下命令以检查与
openshift-driver-toolkit-ctr关联的日志注意
此日志显示正在构建驱动程序。
$ oc logs -f nvidia-driver-daemonset-410.84.202203290245-0-xxgdv -n nvidia-gpu-operator -c openshift-driver-toolkit-ctr
运行示例 GPU 应用程序#
运行一个简单的 CUDA VectorAdd 示例,该示例将两个向量相加在一起,以确保 GPU 已正确引导。
运行以下命令
$ cat << EOF | oc create -f - apiVersion: v1 kind: Pod metadata: name: cuda-vectoradd spec: restartPolicy: OnFailure containers: - name: cuda-vectoradd image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0-ubi8" resources: limits: nvidia.com/gpu: 1 EOF
pod/cuda-vectoradd created检查容器的日志
$ oc logs cuda-vectoradd[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
获取有关 GPU 的信息#
nvidia-smi 显示内存使用情况、GPU 利用率和 GPU 的温度。 通过在 Pod 中运行流行的 nvidia-smi 命令来测试 GPU 访问。
要查看 GPU 利用率,请从 GPU Operator DaemonSet 中的 Pod 运行 nvidia-smi。
切换到 nvidia-gpu-operator 项目
$ oc project nvidia-gpu-operator运行以下命令以查看这些新的 Pod
$ oc get pod -owide -lopenshift.driver-toolkit=true
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nvidia-driver-daemonset-410.84.202203290245-0-xxgdv 2/2 Running 0 23m 10.130.2.18 ip-10-0-143-147.ec2.internal <none> <none>
注意
使用 Pod 和节点名称,在正确的节点上运行
nvidia-smi。在 Pod 中运行
nvidia-smi命令$ oc exec -it nvidia-driver-daemonset-410.84.202203290245-0-xxgdv -- nvidia-smi
Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, openshift-driver-toolkit-ctr, k8s-driver-manager (init) Mon Apr 11 15:02:23 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 | | N/A 33C P8 15W / 70W | 0MiB / 15360MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
生成两个表。 第一个表反映了有关所有可用 GPU 的信息(示例显示了一个 GPU)。 第二个表提供了有关使用 GPU 的进程的详细信息。
有关描述表内容的更多信息,请参阅
nvidia-smi的手册页。