RHCOS 的 NVIDIA GPU Operator 预编译驱动程序#
注意
技术预览版功能在生产环境中不受支持,并且功能不完整。技术预览版功能提供对即将推出的产品功能的早期访问,使客户能够在开发过程中测试功能并提供反馈。这些版本可能没有任何文档,并且测试受到限制。
关于预编译驱动程序容器#
默认情况下,当您部署 GPU Operator 时,NVIDIA GPU 驱动程序会在集群节点上构建。驱动程序的编译和打包在每个 Kubernetes 节点上完成,这会导致计算需求的突增、资源浪费和较长的配置时间。相比之下,使用包含预编译驱动程序的容器镜像使驱动程序在所有节点上立即可用,从而加快配置速度并节省公有云部署中的成本。
限制和约束#
NVIDIA 不为 Red Hat OpenShift 提供预编译的驱动程序镜像。此类镜像必须自定义构建并托管在公共或私有镜像注册表中。
NVIDIA 为自定义驱动程序容器镜像提供有限的支持。
预编译驱动程序容器不支持 NVIDIA vGPU 或 GPUDirect Storage (GDS)。
Red Hat OpenShift Container Platform 的预编译驱动程序容器镜像已通过以下版本测试
4.12 (RHEL 8.6)
4.13 (RHEL 9.2)
构建预编译驱动程序镜像#
执行以下步骤来构建自定义驱动程序镜像,以便与 Red Hat OpenShift Container Platform 一起使用。
先决条件
您可以访问容器注册表,例如 NVIDIA NGC Private Registry、Red Hat Quay 或 OpenShift 内部容器注册表,并且可以将容器镜像推送到该注册表。
您拥有有效的 Red Hat 订阅以及激活密钥。
您拥有 Red Hat OpenShift 拉取密钥。
您的构建机器可以访问互联网以下载操作系统软件包。
您知道要使用的 CUDA 版本,例如
12.1.0。查找操作系统支持的 CUDA 版本的一种方法是访问 NVIDIA GPU Cloud 注册表:CUDA | NVIDIA NGC 并查看标签。使用搜索字段过滤标签,例如 RHEL 8 的
base-ubi8和 RHEL 9 的base-ubi9。过滤后的结果显示 CUDA 版本,例如12.1.0、12.0.1、12.0.0等。您知道要使用的 GPU 驱动程序版本,例如
525.105.17。
步骤
克隆驱动程序容器存储库
$ git clone https://gitlab.com/nvidia/container-images/driver将目录更改为克隆存储库下的
rhel8/precompiled。您可以从此目录为 RHEL 版本 8 和 9 构建预编译驱动程序镜像$ cd driver/rhel8/precompiled
创建 Red Hat 客户门户激活密钥,并记下您的 Red Hat 订阅管理 (RHSM) 组织 ID。这些用于在构建期间安装软件包。将这些值保存到文件中,例如
$HOME/rhsm_org和$HOME/rhsm_activationkeyexport RHSM_ORG_FILE=$HOME/rhsm_org export RHSM_ACTIVATIONKEY_FILE=$HOME/rhsm_activationkey
下载您的 Red Hat OpenShift 拉取密钥并将其存储在文件中,例如
${HOME}/pull-secretexport PULL_SECRET_FILE=$HOME/pull-secret.txt设置 Red Hat OpenShift 版本和集群的目标架构,例如
x86_64export OPENSHIFT_VERSION="4.12.13" export TARGET_ARCH="x86_64"
确定目标 Red Hat OpenShift 版本和架构的 Driver Toolkit (DTK) 镜像
export DRIVER_TOOLKIT_IMAGE=$(oc adm release info -a $HOME/pull-secret.txt --image-for=driver-toolkit quay.io/openshift-release-dev/ocp-release:${OPENSHIFT_VERSION}-${TARGET_ARCH})确定目标 OpenShift 集群的 RHEL 和内核版本
export RHEL_VERSION=$(podman run --authfile $HOME/pull-secret.txt --rm -ti ${DRIVER_TOOLKIT_IMAGE} cat /etc/driver-toolkit-release.json | jq -r '.RHEL_VERSION')export RHEL_MAJOR=$(echo "${RHEL_VERSION}" | cut -d '.' -f 1)export KERNEL_VERSION=$(podman run --authfile $HOME/pull-secret.txt --rm -ti ${DRIVER_TOOLKIT_IMAGE} cat /etc/driver-toolkit-release.json | jq -r '.KERNEL_VERSION')设置驱动程序和 CUDA 版本以及镜像的环境变量
export CUDA_VERSION=12.1.0 export CUDA_DIST=ubi${RHEL_MAJOR} export DRIVER_EPOCH=1 export DRIVER_VERSION=525.105.17 export OS_TAG=rhcos4.12
构建并推送镜像
make image image-push
(可选)覆盖 IMAGE_REGISTRY、IMAGE_NAME 和 CONTAINER_TOOL。如果您愿意,还可以覆盖 BUILDER_USER 和 BUILDER_EMAIL,否则将使用您的 Git 用户名和电子邮件。有关所有可用变量,请参阅 Makefile。
注意
不要设置 DRIVER_TYPE。passthrough 是当前唯一支持的值,默认情况下已设置。
启用预编译驱动程序容器支持#
先决条件
您已安装 NVIDIA GPU Operator。请参阅 在 OpenShift 上安装 NVIDIA GPU Operator。
使用 Web 控制台#
在 OpenShift Container Platform Web 控制台中,从侧边菜单中选择Operators > Installed Operators,然后单击 NVIDIA GPU Operator。
选择 ClusterPolicy 选项卡,然后单击 Create ClusterPolicy。平台分配默认名称gpu-cluster-policy。
打开 Driver 部分。
选中 usePrecompiled 复选框。
为 repository、version 和 image 指定值。
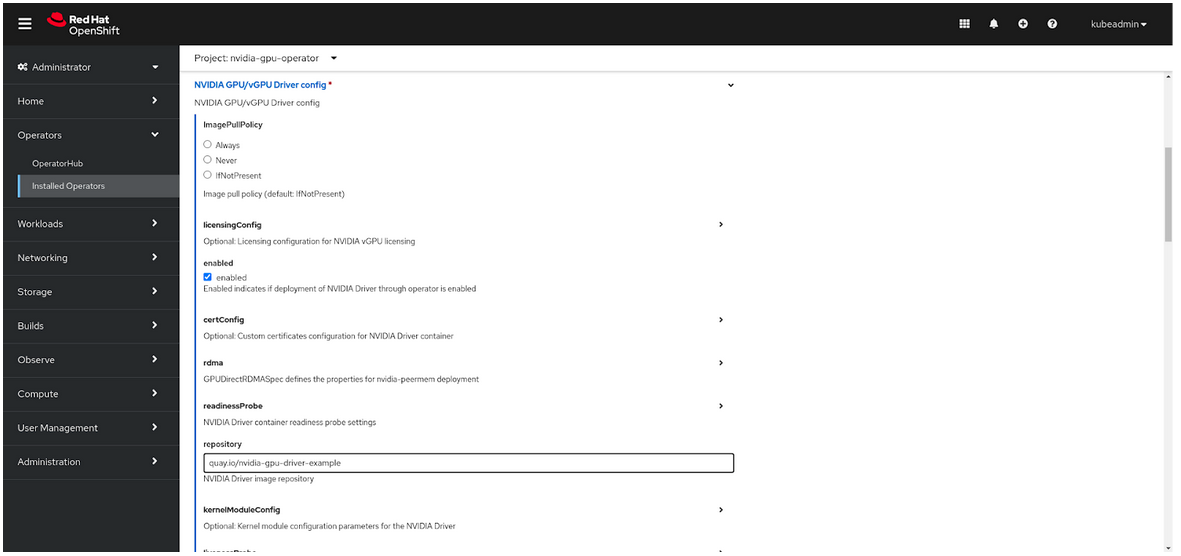
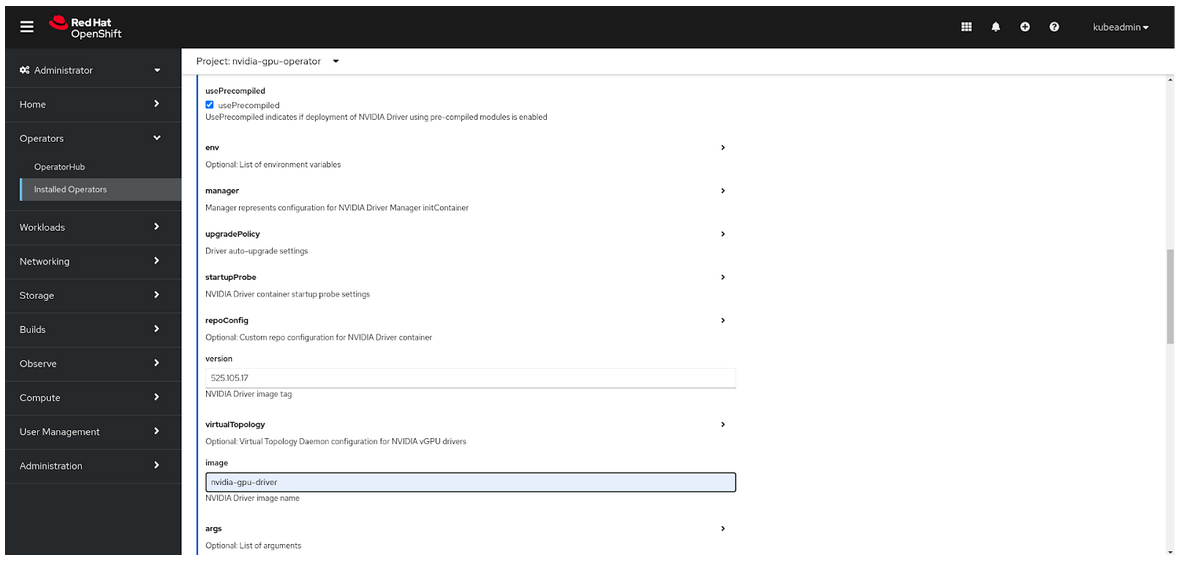
选择 Create。
使用 YAML 文件#
使用 使用 Web 控制台创建集群策略 中的步骤来创建集群策略。在创建
ClusterPolicy资源时切换到 YAML 视图。添加预编译驱动程序镜像属性
spec: driver: usePrecompiled: true image: <image_name> repository: <image_registry> version: <driver_version>
为
image、repository和version提供值。例如spec: driver: usePrecompiled: true image: nvidia-gpu-driver repository: quay.io/nvidia-gpu-driver-example version: 525.105.17
使用 CLI#
为
ClusterPolicy资源创建模板。将 NVIDIA GPU operator 版本替换为您的值$ oc get csv -n nvidia-gpu-operator gpu-operator-certified.v23.6.1 -ojsonpath={.metadata.annotations.alm-examples} | jq '.[0]' > clusterpolicy.json
修改
clusterpolicy.json文件,为driver.usePrecompiled、driver.repository、driver.image和driver.version指定值。例如"driver": { "usePrecompiled": true, "repository": "quay.io/nvidia-gpu-driver-example", "image": "nvidia-gpu-driver", "version": "525.105.17" }
从修改后的
clusterpolicy.json文件创建ClusterPolicy资源$ oc apply -f clusterpolicy.json示例输出
clusterpolicy.nvidia.com/gpu-cluster-policy created确认驱动程序容器 Pod 正在运行
$ oc get pods -l app=nvidia-driver-daemonset -n nvidia-gpu-operator
示例输出
NAME READY STATUS RESTARTS AGE nvidia-driver-daemonset-4.18.0-372.51.1.el8_6-rhcos4.12-mlpd4 1/1 Running 0 44s
确保 Pod 名称包含 Linux 内核版本号,例如
4.18.0-372.51.1.el8_6。
禁用预编译驱动程序容器支持#
执行以下步骤来禁用对预编译驱动程序容器的支持。
通过修改集群策略禁用预编译驱动程序支持
$ oc patch clusterpolicy/gpu-cluster-policy --type='json' \ -p='[{"op": "replace", "path": "/spec/driver/usePrecompiled", "value":false},{"op": "remove", "path": "/spec/driver/version"},{"op": "remove", "path": "/spec/driver/image"},{"op": "remove", "path": "/spec/driver/repository"}]'
示例输出
clusterpolicy.nvidia.com/gpu-cluster-policy patched确认传统的驱动程序容器 Pod 正在运行
$ oc get pods -l openshift.driver-toolkit=true -n nvidia-gpu-operator
示例输出
NAME READY STATUS RESTARTS AGE nvidia-driver-daemonset-412.86.202303241612-0-f7v4t 2/2 Running 0 4m20s
确保 Pod 名称不包含 Linux 内核语义版本号。