NVIDIA AI Enterprise 与 OpenShift#
NVIDIA AI Enterprise 是一款端到端、云原生的人工智能和数据分析软件套件,经过 NVIDIA 优化、认证和支持,并与 NVIDIA 认证系统配合使用。更多信息请访问 NVIDIA AI Enterprise 网页。
支持以下安装方法
裸机或 VMware vSphere 上使用 GPU 直通的 OpenShift Container Platform
VMware vSphere 上使用 NVIDIA vGPU 的 OpenShift Container Platform
裸机或 VMware vSphere 上使用 GPU 直通的 OpenShift Container Platform#
对于裸机或 VMware vSphere 上使用 GPU 直通的 OpenShift Container Platform,您无需更改 ClusterPolicy。请按照 在 OpenShift 上安装 NVIDIA GPU Operator 中的指导安装 NVIDIA GPU Operator。
注意
可以选择将 vGPU 驱动程序与裸机和 VMware vSphere 虚拟机与 GPU 直通一起使用。在这种情况下,请按照“VMware vSphere 上使用 NVIDIA vGPU 的 OpenShift Container Platform”部分中的指导进行操作。
VMware vSphere 上使用 NVIDIA vGPU 的 OpenShift Container Platform#
概述#
本节深入介绍如何在 VMware vSphere 上为 RedHat OpenShift Container Platform 部署 NVIDIA AI Enterprise。
涉及的步骤包括
步骤 1:安装 Node Feature Discovery (NFD) Operator
步骤 2:安装 NVIDIA GPU Operator
步骤 3:创建 NGC secret
步骤 4:创建 ConfigMap
步骤 5:创建 Cluster Policy
简介#
当 NVIDIA AI Enterprise 在基于 VMware vSphere 的虚拟化基础设施上运行时,一个关键组件是 NVIDIA 虚拟 GPU。NVIDIA AI Enterprise Host Software vSphere 安装包 (VIB) 安装在 VMware ESXi 主机服务器上,它负责与安装在客户机 VM 上的 NVIDIA vGPU 客户机驱动程序进行通信。客户机 VM 以与物理 GPU 相同的方式使用 NVIDIA vGPU,物理 GPU 已通过虚拟机监控程序直通。在 VM 本身中,安装了 vGPU 驱动程序,这些驱动程序支持可用的不同许可级别。
注意
在 ESXi 主机上安装 NVIDIA vGPU 主机驱动程序 VIB 不在本文档的范围之内。有关详细说明,请参阅 NVIDIA AI Enterprise 部署指南。
VMware vSphere 上的 Red Hat OpenShift#
按照 RedHat OpenShift 文档中 安装 vSphere 部分 中概述的步骤,在 vSphere 上安装 OpenShift。
注意
当使用虚拟化 GPU 时,您必须将部署为工作节点的每个 VM 以及 VM 模板的启动方法更改为 EFI。这需要关闭正在运行的工作节点 VM。模板必须转换为 VM,然后将启动方法更改为 EFI,然后再转换回模板。
还需要禁用安全启动,如下所示
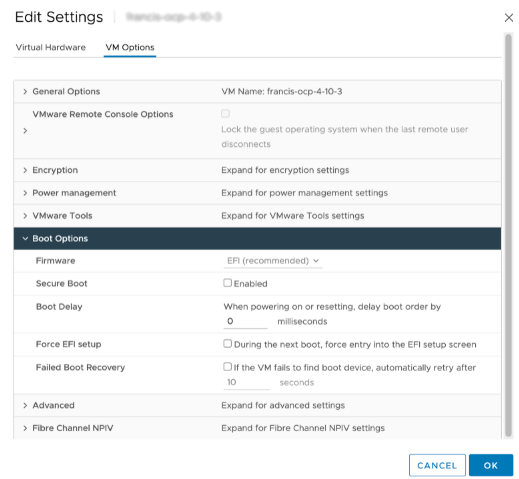
当使用 UPI 安装方法 时,在“安装 RHCOS 并启动 OpenShift Container Platform 引导过程”的步骤 8 之后,在继续步骤 9 之前,将启动方法更改为 EFI。
当使用 IPI 方法时,可以在 VM 部署后将每个 VM 的启动方法更改为 EFI。
除了 EFI 启动设置之外,还要确保 VM 设置了以下配置参数
虚拟机设置 > 虚拟机选项 > 高级 > 配置参数 > 编辑配置
pciPassthru.use64bitMMIO TRUE
pciPassthru.64bitMMIOSizeGB 512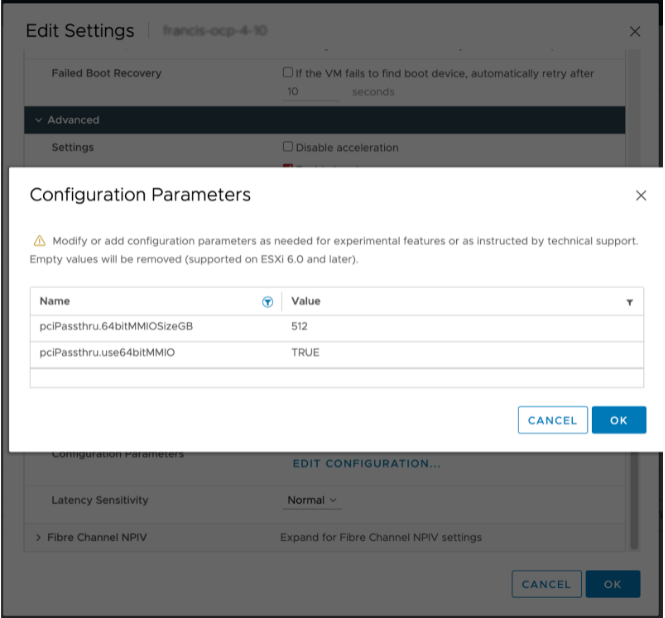
为了支持 GPUDirect RDMA,请确保 VM 设置了以下配置参数
虚拟机设置 > 虚拟机选项 > 高级 > 配置参数 > 编辑配置
pciPassthru.allowP2P = true
pciPassthru.RelaxACSforP2P = true
还建议您参考 在 VMware Cloud Foundation 上运行 Red Hat OpenShift Container Platform 文档,了解部署最佳实践、系统配置和参考架构。
安装 Node Feature Discovery Operator#
按照 在 OpenShift 上安装 Node Feature Discovery Operator 中的指导安装 Node Feature Discovery Operator。
安装 NVIDIA GPU Operator#
按照 在 OpenShift 上安装 NVIDIA GPU Operator 中的指导安装 NVIDIA GPU Operator。
注意
跳过与创建集群策略相关的指导,而是遵循后续部分中的指导。
创建 NGC secret#
OpenShift 具有 secret 对象类型,它提供了一种机制来保存敏感信息,例如密码和私有源存储库凭据。接下来,您将创建一个 secret 对象,用于存储我们的 NGC API 密钥(用于验证您对 NGC 容器注册表的访问权限的机制)。
注意
在开始之前,请拥有或生成 NGC API 密钥。有关更多信息,请参阅NVIDIA NGC Private Registry Guide 中的 生成 NGC API 密钥。
导航到 主页 > 项目 并确保选择了
nvidia-gpu-operator。在 OpenShift Container Platform Web 控制台中,从“工作负载”下拉菜单中单击 Secrets。
单击 创建 下拉菜单。
选择 镜像拉取 Secret。
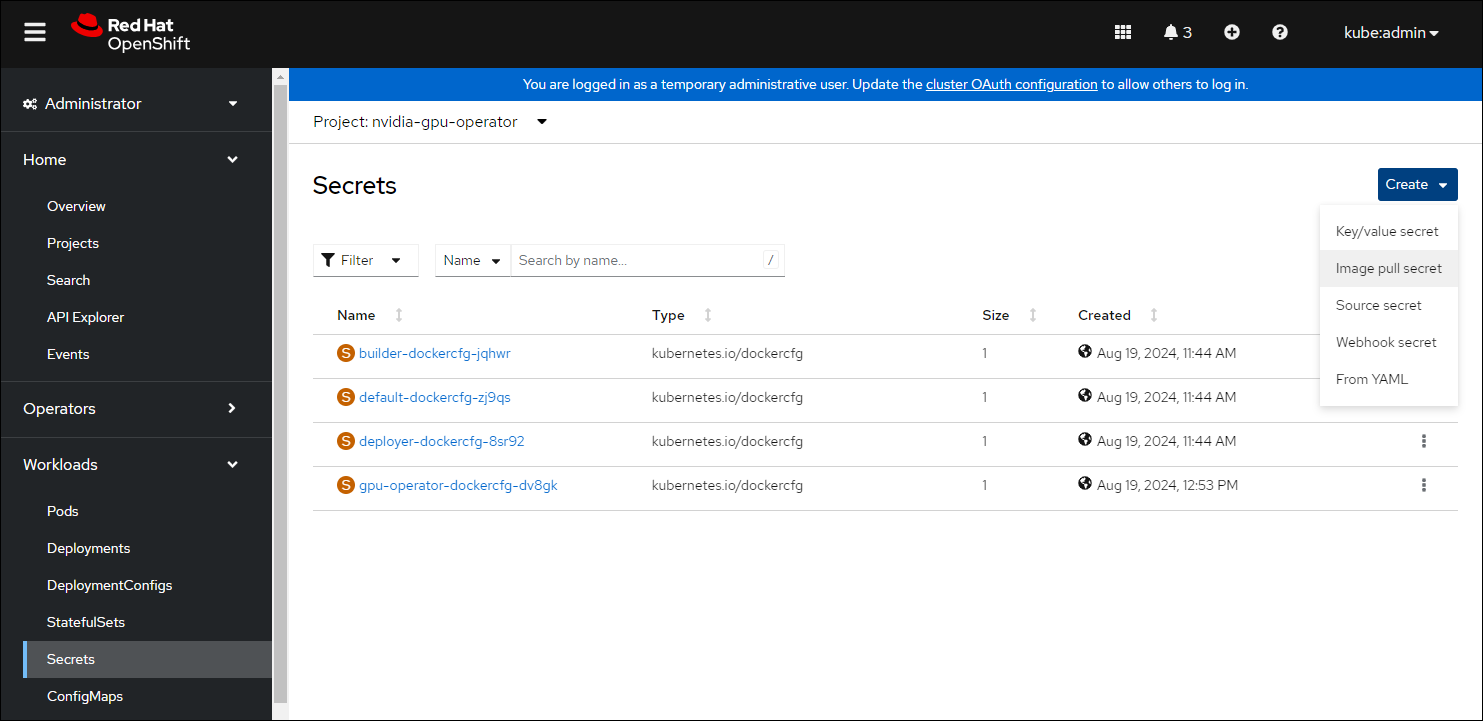
在每个字段中输入以下内容
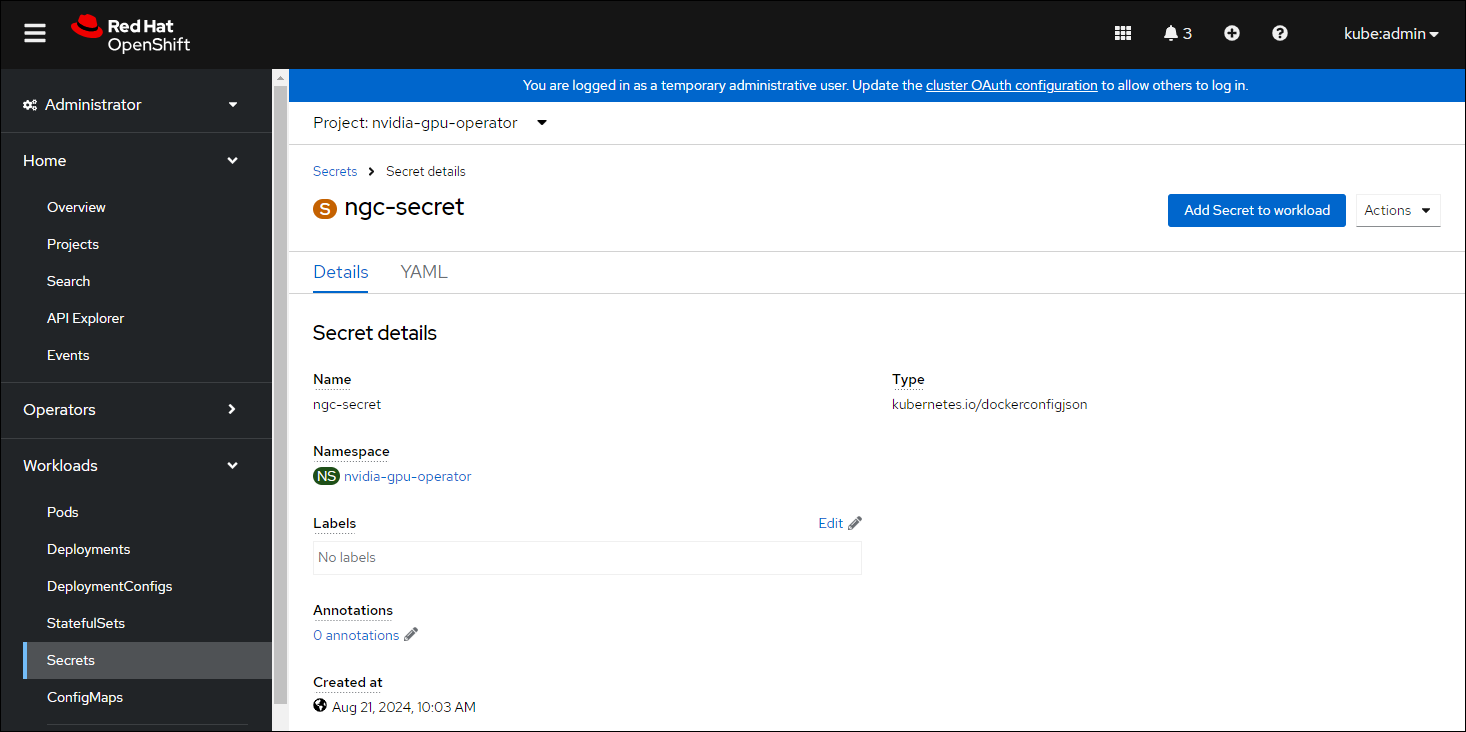
Secret 名称: ngc-secret
身份验证类型: 镜像注册表凭据
注册表服务器地址:
nvcr.io/nvidia/vgpu用户名:
$oauthtoken密码:
<NGC-API-KEY>电子邮件:
<YOUR-EMAIL>
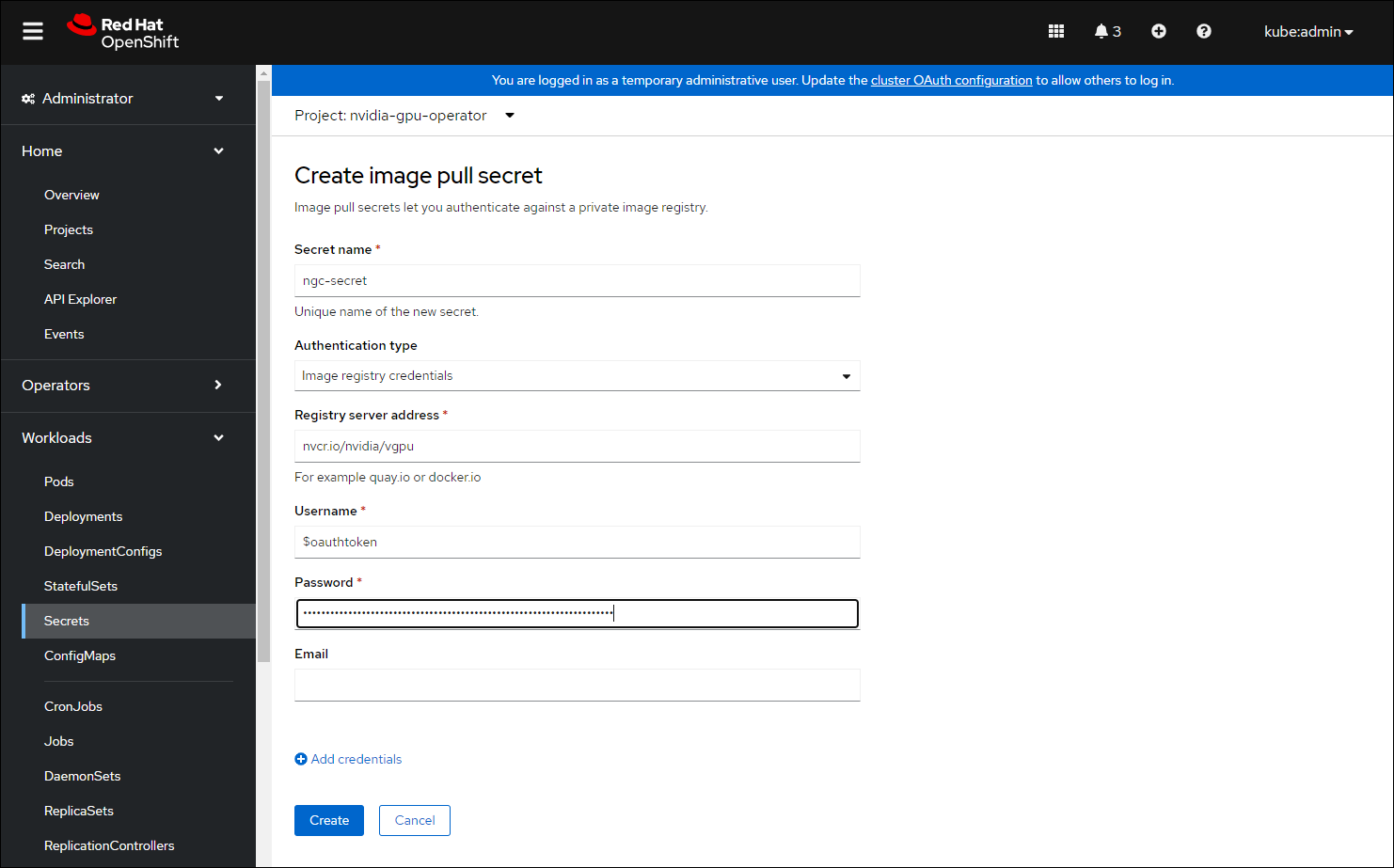
单击 创建。
已创建拉取 secret。
为 NLS 令牌创建 ConfigMap#
先决条件#
生成并下载 NLS 客户端许可证令牌。有关说明,请参阅 NVIDIA 许可证系统用户指南 的第 4.6 节。
步骤#
导航到 主页 > 项目 并确保选择了
nvidia-gpu-operator。选择 工作负载 下拉菜单。
选择 ConfigMaps,然后单击 创建 ConfigMap。
在 创建 ConfigMap 窗口中,单击 YAML 视图。
输入您的 config map 的详细信息。
name必须为licensing-config。将 NLS 客户端令牌的信息复制并粘贴到
client_configuration_token.tok参数中。
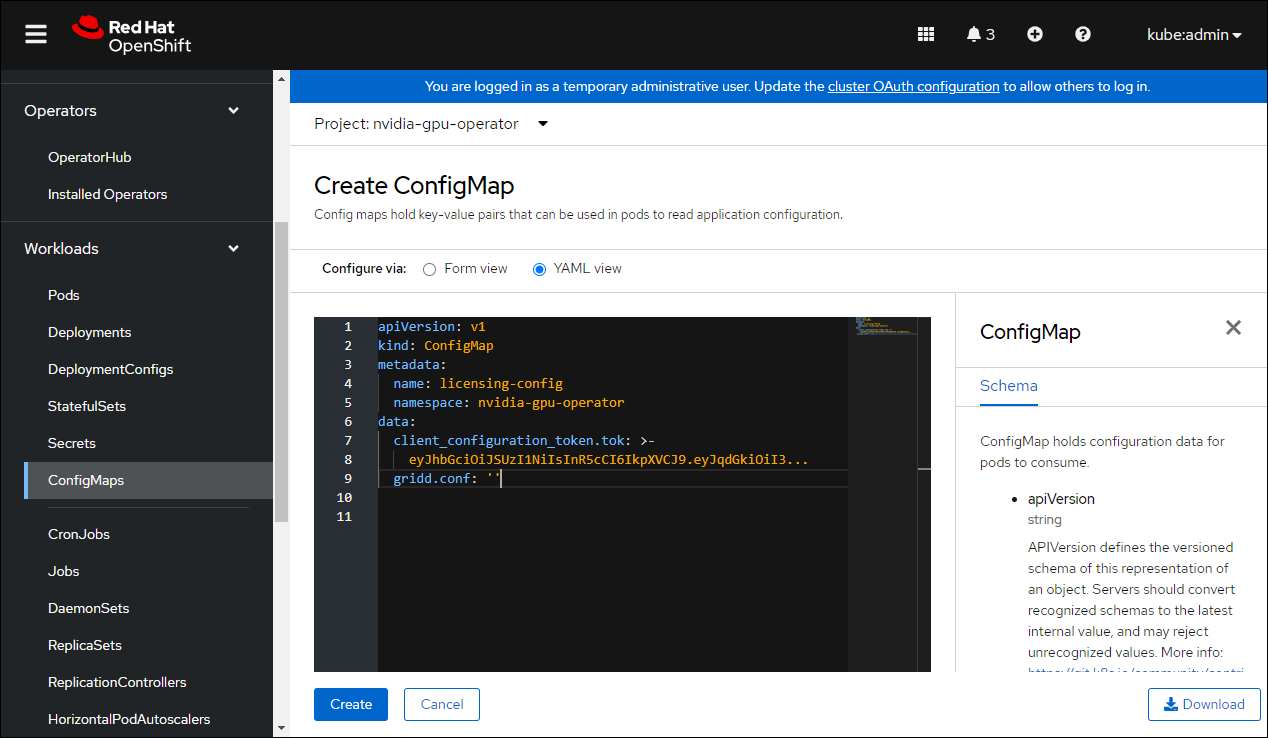
单击 创建。
创建集群策略实例#
现在创建集群策略,该策略负责维护策略资源以在集群中创建 Pod。
在 OpenShift Container Platform Web 控制台中,从侧边菜单中选择 Operators > Installed Operators,然后单击 NVIDIA GPU Operator。
选择 ClusterPolicy 选项卡,然后单击 创建 ClusterPolicy。
控制台会分配默认名称
gpu-cluster-policy。展开 NVIDIA GPU/vGPU 驱动程序配置 的下拉菜单,然后展开 licensingConfig。在 configMapName 字段中,输入您之前创建的许可 config map 的名称
licensing-config。选中 nlsEnabled 复选框。请参考屏幕截图以获取参数示例,并相应地修改值。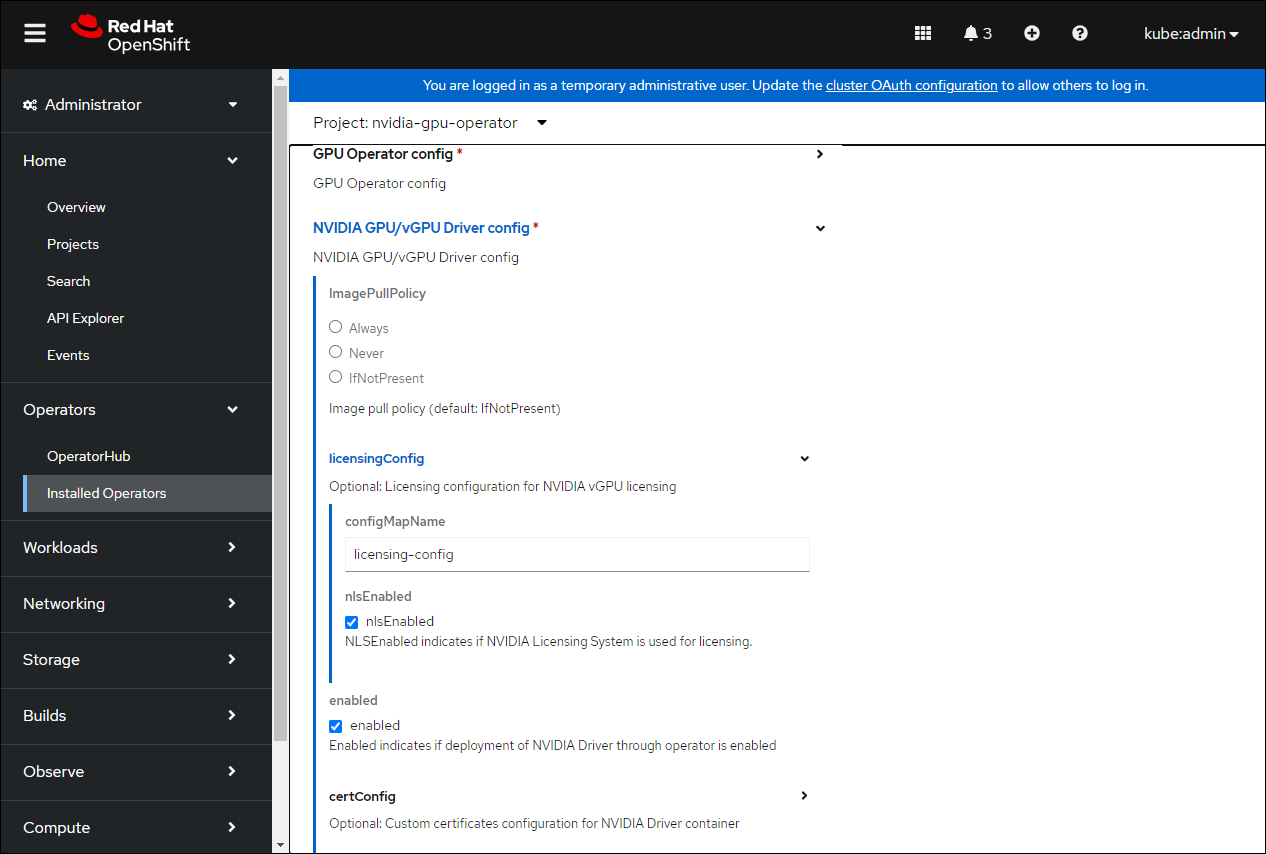
configMapName: licensing-config
nlsEnabled: nlsEnabled
enabled: enabled
如果您要部署 GPUDirect RDMA,请展开 rdma 菜单并选择 enabled
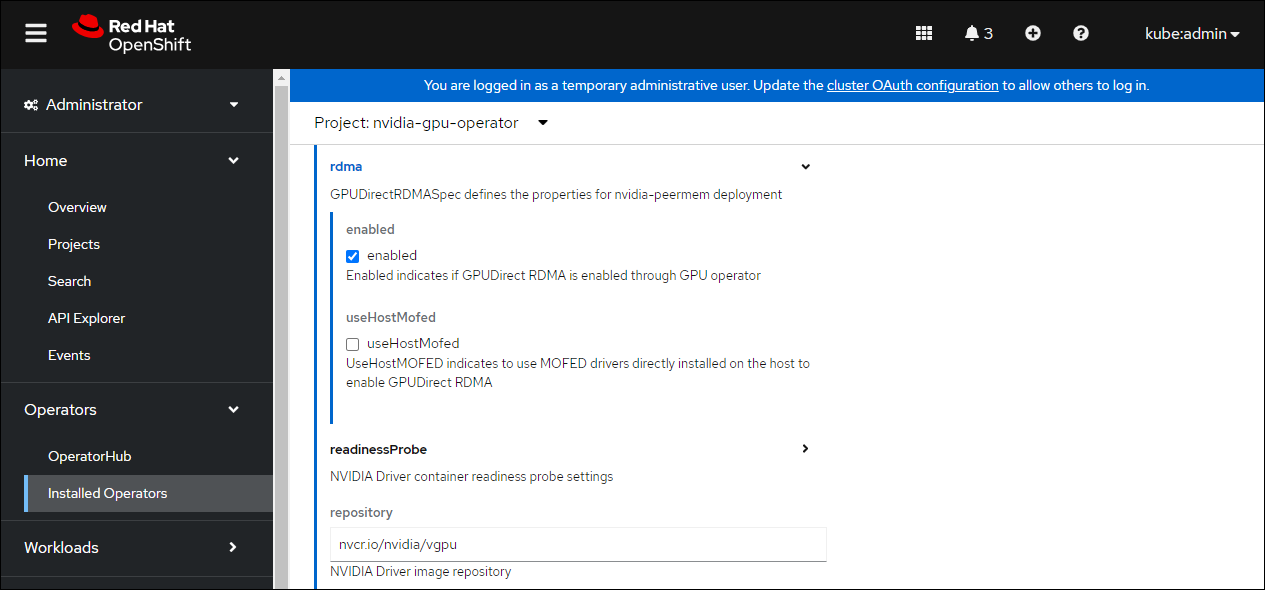
向下滚动以在 NVIDIA GPU/vGPU 驱动程序配置 部分下指定存储库路径。请参阅下面的屏幕截图以获取参数示例,并相应地修改值。
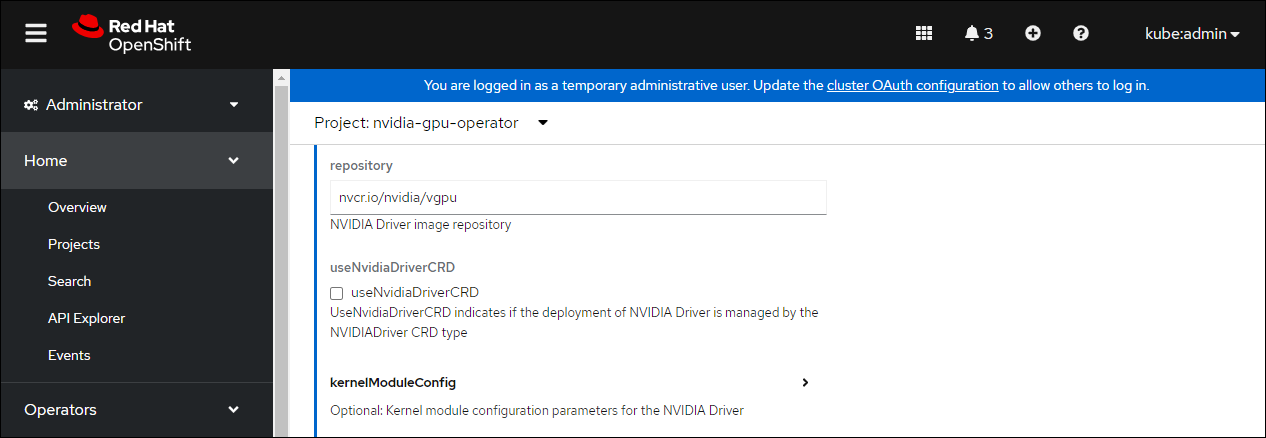
repository:
nvcr.io/nvidia/vgpu
进一步向下滚动到镜像名称,并在 NVIDIA GPU/vGPU 驱动程序配置 部分下指定 NVIDIA vGPU 驱动程序版本。
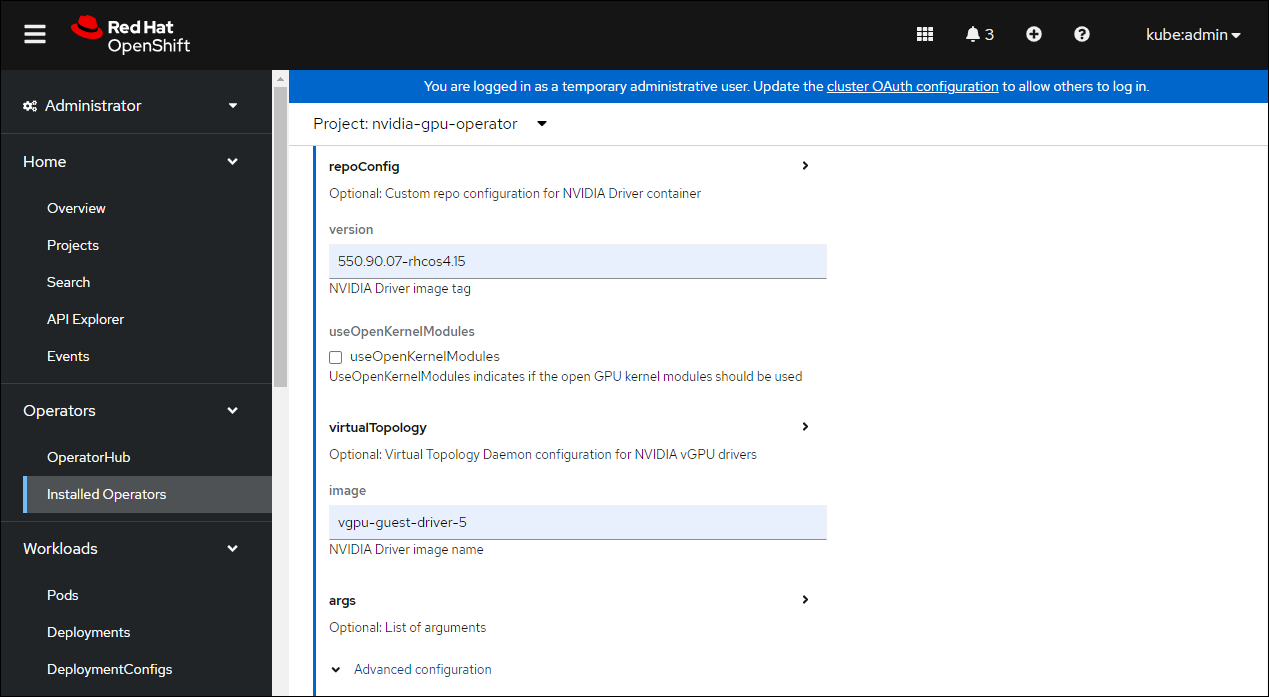
version: 550.90.07-rhcos4.15
image: vgpu-guest-driver-5
上述版本和镜像是 NVIDIA AI Enterprise 5 的示例。请为相应的 OpenShift Container Platform 版本指定 vGPU 驱动程序版本和镜像。
4.9 是
vgpu-guest-driver-3-0:525.60.13-rhcos4.94.10 是
vgpu-guest-driver-3-0:525.60.13-rhcos4.104.11 是
vgpu-guest-driver-3-0:525.60.13-rhcos4.11
展开 高级配置 菜单,并指定您之前创建的镜像拉取 secret。
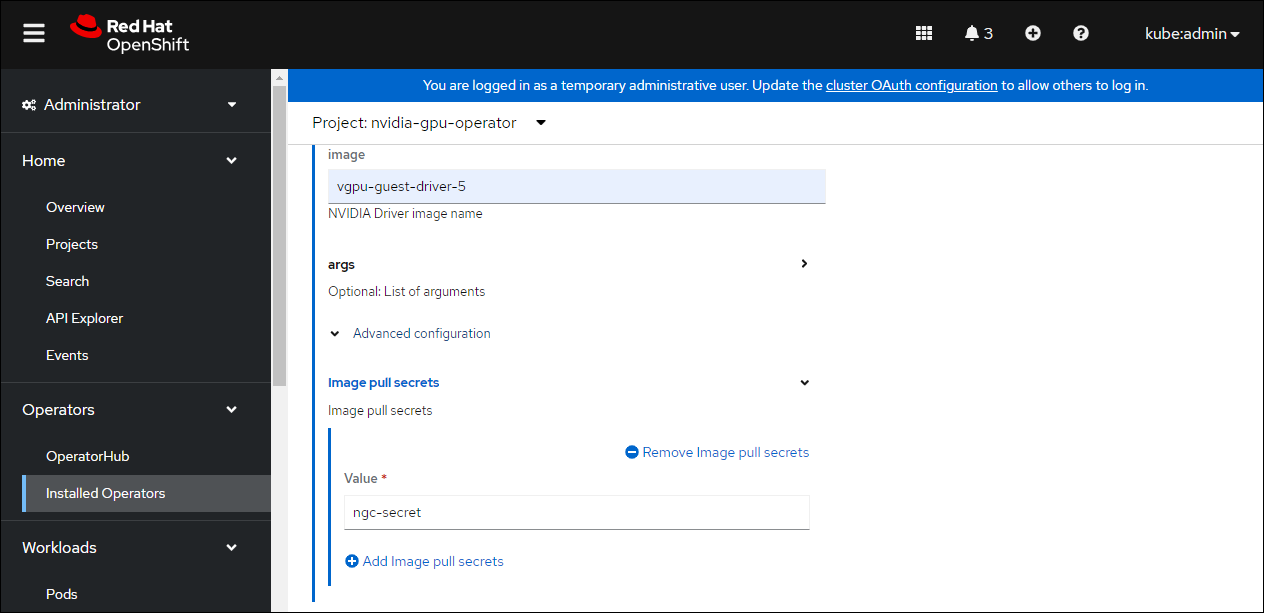
单击 创建。
GPU Operator 安装所有必需的组件,以在 OpenShift Container Platform 集群中设置 NVIDIA GPU。
注意
在执行故障排除之前,请至少等待 10 到 20 分钟,因为安装需要几分钟才能完成。
新部署的 NVIDIA GPU Operator 的 ClusterPolicy gpu-cluster-policy 的状态在安装成功时会变为 State:ready。
通过运行以下命令验证 ClusterPolicy 安装,该命令显示节点名称和 GPU 计数
$ oc get nodes -o=custom-columns='Node:metadata.name,GPUs:status.capacity.nvidia\.com/gpu'示例输出
Node GPUs nvaie-ocp-7rfr8-master-0 <none> nvaie-ocp-7rfr8-master-1 <none> nvaie-ocp-7rfr8-master-2 <none> nvaie-ocp-7rfr8-worker-7x5km 1 nvaie-ocp-7rfr8-worker-9jgmk <none> nvaie-ocp-7rfr8-worker-jntsp 1 nvaie-ocp-7rfr8-worker-zkggt <none>
验证 NVIDIA GPU Operator 是否成功安装#
执行以下步骤以验证 NVIDIA GPU Operator 是否成功安装。
在 OpenShift Container Platform Web 控制台中,从侧边菜单中选择 工作负载 > Pod。
在 项目 下拉菜单中,选择 nvidia-gpu-operator 项目。
验证 Pod 是否已成功部署。
或者,从命令行运行以下命令
$ oc get pods -n nvidia-gpu-operatorNAME READY STATUS RESTARTS AGE pod/gpu-feature-discovery-hlpgs 1/1 Running 0 91m pod/gpu-operator-8dc8d6648-jzhnr 1/1 Running 0 94m pod/nvidia-dcgm-exporter-ds9xd 1/1 Running 0 91m pod/nvidia-dcgm-k7tz6 1/1 Running 0 91m pod/nvidia-device-plugin-daemonset-nqxmc 1/1 Running 0 91m pod/nvidia-driver-daemonset-49.84.202202081504-0-9df9j 2/2 Running 0 91m pod/nvidia-node-status-exporter-7bhdk 1/1 Running 0 91m