动态批处理 & 并发模型执行#
本系列的第 1 部分介绍了设置 Triton Inference Server 的机制。本次迭代讨论了动态批处理和并发模型执行的概念。这些是重要的功能,可用于减少延迟以及通过更高的资源利用率来提高吞吐量。
什么是动态批处理?#
动态批处理,在参考 Triton Inference Server 时,指的是将一个或多个推理请求组合成一个批次(必须动态创建)以最大化吞吐量的功能。
动态批处理可以通过在模型的 config.pbtxt 中指定选择来按模型启用和配置。可以通过将以下内容添加到 config.pbtxt 文件中,使用其默认设置启用动态批处理
dynamic_batching { }
虽然 Triton 会立即批处理这些传入的请求,但用户可以选择为调度器分配有限的延迟,以收集更多推理请求供动态批处理程序使用。
dynamic_batching {
max_queue_delay_microseconds: 100
}
让我们讨论一个示例场景(参考下图)。假设有 5 个推理请求,A、B、C、D 和 E,批次大小分别为 4、2、2、6 和 2。每个批次需要时间 X ms 才能被模型处理。模型支持的最大批次大小为 8。A 和 C 在时间 T = 0 到达,B 在时间 T = X/3 到达,D 和 E 在时间 T = 2*X/3 到达。
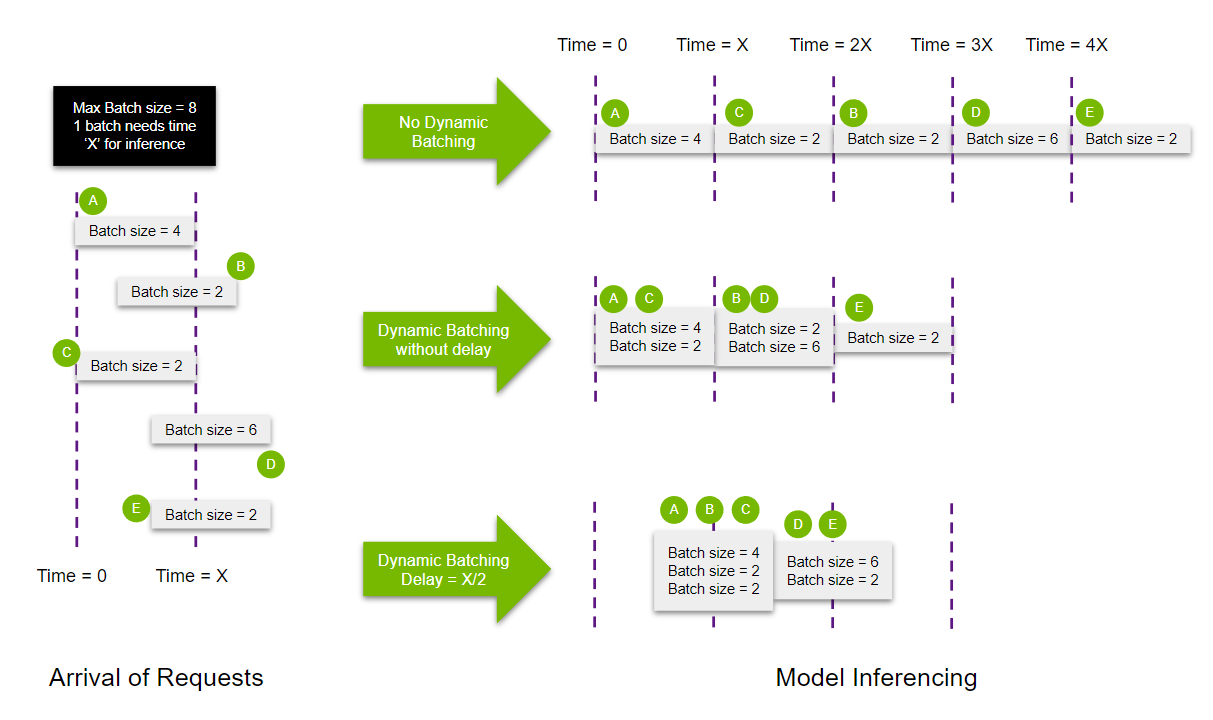
在不使用动态批处理的情况下,所有请求都按顺序处理,这意味着处理所有请求需要 5X ms。此过程非常浪费,因为每个批次处理本可以比顺序执行处理更多的批次。
在这种情况下使用动态批处理可以更有效地将请求打包到 GPU 内存中,从而显着加快速度 3X ms。它还减少了响应的延迟,因为可以在更少的周期内处理更多查询。如果考虑使用 delay,则可以将 A、B、C 和 D、E 批处理在一起,以获得更好的资源利用率。
注意: 以上是理想情况的极端版本。在实践中,并非所有执行元素都可以完美并行化,从而导致较大批次的执行时间更长。
从以上观察可以看出,使用动态批处理可以提高延迟和吞吐量,同时服务模型。此批处理功能主要侧重于为无状态模型(在执行之间不维护状态的模型,例如对象检测模型)提供解决方案。Triton 的序列批处理程序可用于管理有状态模型的多个推理请求。有关动态批处理的更多信息和配置,请参阅 Triton Inference Server 文档。
并发模型执行#
Triton Inference Server 可以启动同一模型的多个实例,这些实例可以并行处理查询。Triton 可以根据用户的规范在同一设备 (GPU) 或同一节点上的不同设备上生成实例。当考虑具有不同吞吐量的模型的集成时,这种可定制性尤其有用。可以在单独的 GPU 上生成更重的模型的多个副本,以实现更多的并行处理。这通过在模型的配置中使用 instance groups 选项启用。
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0, 1 ]
}
]
让我们以前面的示例为例,讨论添加多个模型进行并行执行的效果。在此示例中,不是让单个模型处理五个查询,而是生成两个模型。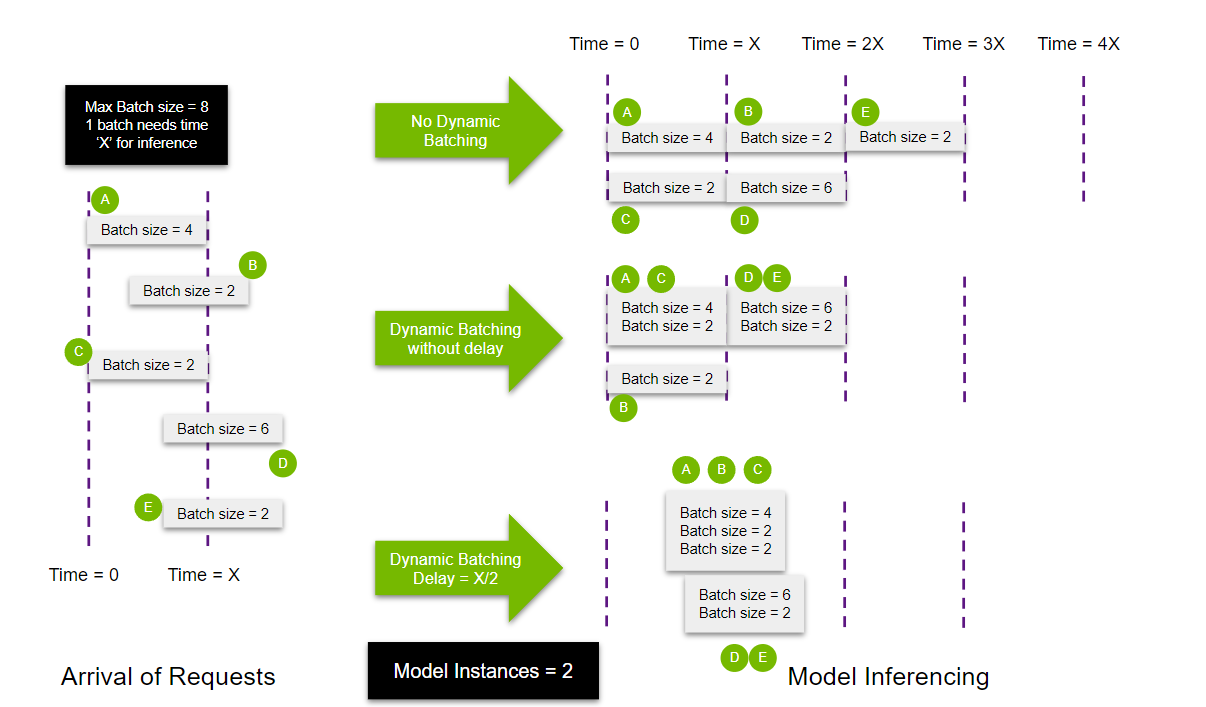
对于“无动态批处理”的情况,由于有两个模型要执行,因此查询会平均分配。用户还可以添加优先级以优先或降低任何特定实例组的优先级。
当考虑启用动态批处理的多个实例的情况时,会发生以下情况。由于另一个实例的可用性,可以使用第二个实例执行延迟到达的查询 B。在分配了一些延迟后,实例 1 在时间 T = X/2 时被填充并启动,并且由于查询 D 和 E 堆叠起来以填充到最大批次大小,因此第二个模型可以立即开始推理。
从以上示例中得出的关键结论是,Triton Inference Server 在与创建更高效的批处理相关的策略方面提供了灵活性,从而实现了更好的资源利用率,从而减少了延迟并提高了吞吐量。
演示#
本节展示了如何使用本系列第 1 部分的示例使用动态批处理和并发模型执行。
获取模型访问权限#
让我们使用第 1 部分中使用的 text recognition。我们确实需要在模型中进行一些小的更改,即使模型的第 0 轴具有动态形状以启用批处理。步骤 1,下载文本识别模型权重。将 NGC PyTorch 容器用作以下环境。
docker run -it --gpus all -v ${PWD}:/scratch nvcr.io/nvidia/pytorch:<yy.mm>-py3
cd /scratch
wget https://www.dropbox.com/sh/j3xmli4di1zuv3s/AABzCC1KGbIRe2wRwa3diWKwa/None-ResNet-None-CTC.pth
使用 utils 文件夹中的文件将模型导出为 .onnx。此文件改编自 Baek et. al. 2019。
import torch
from utils.model import STRModel
# Create PyTorch Model Object
model = STRModel(input_channels=1, output_channels=512, num_classes=37)
# Load model weights from external file
state = torch.load("None-ResNet-None-CTC.pth")
state = {key.replace("module.", ""): value for key, value in state.items()}
model.load_state_dict(state)
# Create ONNX file by tracing model
trace_input = torch.randn(1, 1, 32, 100)
torch.onnx.export(model, trace_input, "str.onnx", verbose=True, dynamic_axes={'input.1':[0],'308':[0]})
启动服务器#
正如在 Part 1 中讨论的那样,模型仓库是 Triton Inference Server 使用的基于文件系统的模型和配置模式仓库(有关模型仓库的更详细说明,请参阅 Part 1)。对于此示例,模型仓库结构需要按以下方式设置
model_repository
|
|-- text_recognition
|
|-- config.pbtxt
|-- 1
|
|-- model.onnx
此仓库是上一个示例的子集。此设置中的主要区别在于在模型配置中使用了 instance_group 和 dynamic_batching。添加内容如下
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching { }
使用 instance_group,用户主要可以调整两件事。首先,每个 GPU 上部署的该模型的实例数。上面的示例将 per GPU 部署 2 个模型实例。其次,可以使用 gpus: [ <device number>, ... <device number> ] 指定此组的目标 GPU。
添加 dynamic_batching {} 将启用动态批处理的使用。用户还可以在动态批处理的主体中添加 preferred_batch_size 和 max_queue_delay_microseconds,以根据其用例管理更高效的批处理。有关更多信息,请浏览模型配置文档。
设置模型仓库后,即可启动 Triton Inference Server。
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}:/workspace/ -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:yy.mm-py3 bash
tritonserver --model-repository=/models
衡量性能#
通过启用 dynamic batching 和使用 multiple model instances 对模型的服务能力进行了一些改进后,下一步是衡量这些功能的影响。为此,Triton Inference Server 打包了 性能分析器,该工具专门用于衡量 Triton Inference Server 的性能。为了便于使用,建议用户在用于运行本系列第 1 部分中客户端代码的同一容器内运行此工具。
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:yy.mm-py3-sdk bash
在第三个终端上,建议监控 GPU 利用率,以查看部署是否使 GPU 资源饱和。
watch -n0.1 nvidia-smi
为了衡量性能提升,让我们在以下配置上运行性能分析器
无动态批处理,单模型实例:此配置将作为基线测量。要在此配置中设置 Triton Server,请勿在
config.pbtxt中添加instance_group或dynamic_batching,并确保在docker run命令中包含--gpus=1以设置服务器。
# perf_analyzer -m <model name> -b <batch size> --shape <input layer>:<input shape> --concurrency-range <lower number of request>:<higher number of request>:<step>
# Query
perf_analyzer -m text_recognition -b 2 --shape input.1:1,32,100 --concurrency-range 2:16:2 --percentile=95
# Summarized Inference Result
Inferences/Second vs. Client p95 Batch Latency
Concurrency: 2, throughput: 955.708 infer/sec, latency 4311 usec
Concurrency: 4, throughput: 977.314 infer/sec, latency 8497 usec
Concurrency: 6, throughput: 973.367 infer/sec, latency 12799 usec
Concurrency: 8, throughput: 974.623 infer/sec, latency 16977 usec
Concurrency: 10, throughput: 975.859 infer/sec, latency 21199 usec
Concurrency: 12, throughput: 976.191 infer/sec, latency 25519 usec
Concurrency: 14, throughput: 966.07 infer/sec, latency 29913 usec
Concurrency: 16, throughput: 975.048 infer/sec, latency 34035 usec
# Perf for 16 concurrent requests
Request concurrency: 16
Client:
Request count: 8777
Throughput: 975.048 infer/sec
p50 latency: 32566 usec
p90 latency: 33897 usec
p95 latency: 34035 usec
p99 latency: 34241 usec
Avg HTTP time: 32805 usec (send/recv 43 usec + response wait 32762 usec)
Server:
Inference count: 143606
Execution count: 71803
Successful request count: 71803
Avg request latency: 17937 usec (overhead 14 usec + queue 15854 usec + compute input 20 usec + compute infer 2040 usec + compute output 7 usec)
仅动态批处理:要在此配置中设置 Triton Server,请在
config.pbtxt中添加dynamic_batching。
# Query
perf_analyzer -m text_recognition -b 2 --shape input.1:1,32,100 --concurrency-range 2:16:2 --percentile=95
# Inference Result
Inferences/Second vs. Client p95 Batch Latency
Concurrency: 2, throughput: 998.141 infer/sec, latency 4140 usec
Concurrency: 4, throughput: 1765.66 infer/sec, latency 4750 usec
Concurrency: 6, throughput: 2518.48 infer/sec, latency 5148 usec
Concurrency: 8, throughput: 3095.85 infer/sec, latency 5565 usec
Concurrency: 10, throughput: 3182.83 infer/sec, latency 7632 usec
Concurrency: 12, throughput: 3181.3 infer/sec, latency 7956 usec
Concurrency: 14, throughput: 3184.54 infer/sec, latency 10357 usec
Concurrency: 16, throughput: 3187.76 infer/sec, latency 10567 usec
# Perf for 16 concurrent requests
Request concurrency: 16
Client:
Request count: 28696
Throughput: 3187.76 infer/sec
p50 latency: 10030 usec
p90 latency: 10418 usec
p95 latency: 10567 usec
p99 latency: 10713 usec
Avg HTTP time: 10030 usec (send/recv 54 usec + response wait 9976 usec)
Server:
Inference count: 393140
Execution count: 64217
Successful request count: 196570
Avg request latency: 6231 usec (overhead 31 usec + queue 3758 usec + compute input 35 usec + compute infer 2396 usec + compute output 11 usec)
由于每个请求都有一个批次大小(为 2),而模型的最大批次大小为 8,因此动态批处理这些请求显着提高了吞吐量。另一个结果是延迟的减少。这种减少主要归因于队列等待时间的减少。由于请求被批处理在一起,因此可以并行处理多个请求。
具有多个模型实例的动态批处理:要在此配置中设置 Triton Server,请在
config.pbtxt中添加instance_group,并确保在docker run命令中包含--gpus=1和--gpus=1以设置服务器。按照上一节的说明在模型配置中包含dynamic_batching。需要注意的一点是,仅使用具有动态批处理的单个模型实例时,GPU 的峰值利用率飙升至 74%(在本例中为 A100)。添加一个或多个实例肯定会提高性能,但在这种情况下不会实现线性性能扩展。
# Query
perf_analyzer -m text_recognition -b 2 --shape input.1:1,32,100 --concurrency-range 2:16:2 --percentile=95
# Inference Result
Inferences/Second vs. Client p95 Batch Latency
Concurrency: 2, throughput: 1446.26 infer/sec, latency 3108 usec
Concurrency: 4, throughput: 1926.1 infer/sec, latency 5491 usec
Concurrency: 6, throughput: 2695.12 infer/sec, latency 5710 usec
Concurrency: 8, throughput: 3224.69 infer/sec, latency 6268 usec
Concurrency: 10, throughput: 3380.49 infer/sec, latency 6932 usec
Concurrency: 12, throughput: 3982.13 infer/sec, latency 7233 usec
Concurrency: 14, throughput: 4027.74 infer/sec, latency 7879 usec
Concurrency: 16, throughput: 4134.09 infer/sec, latency 8244 usec
# Perf for 16 concurrent requests
Request concurrency: 16
Client:
Request count: 37218
Throughput: 4134.09 infer/sec
p50 latency: 7742 usec
p90 latency: 8022 usec
p95 latency: 8244 usec
p99 latency: 8563 usec
Avg HTTP time: 7734 usec (send/recv 54 usec + response wait 7680 usec)
Server:
Inference count: 490626
Execution count: 101509
Successful request count: 245313
Avg request latency: 5287 usec (overhead 29 usec + queue 1878 usec + compute input 36 usec + compute infer 3332 usec + compute output 11 usec)
这是一个完美的例子,说明“简单地启用所有功能”并非万能解决方案。需要注意的一点是,此实验是通过将模型的最大批次大小限制为 8,同时设置单个 GPU 来进行的。每个生产环境都不同。模型、硬件、业务级别 SLA、成本都是在选择合适的部署配置时需要考虑的变量。为每个部署运行网格搜索并非可行的策略。为了解决这一挑战,Triton 用户可以利用本教程第 3 部分中介绍的模型分析器!查看文档的此部分以获取动态批处理和多模型实例的另一个示例。
下一步是什么?#
在本教程中,我们介绍了两个关键概念,dynamic batching 和 concurrent model execution,它们可用于提高资源利用率。这是由 6 部分组成的教程系列的第 2 部分,该系列涵盖了将深度学习模型部署到生产环境时面临的挑战。您可能已经发现,可以使用本教程中讨论的功能进行多种可能的组合,尤其是在具有多个 GPU 的节点上。第 3 部分介绍了 Model Analyzer,该工具可帮助找到最佳的部署配置。