函数部署#
本页介绍使用 Cloud Functions 部署函数的部署概念和步骤。
函数部署是指在一个集群上运行的一个或多个函数实例。
有关更多关键术语和图表,请参阅 函数生命周期。
部署验证#
如果您的函数是基于容器的,在部署之前,强烈建议运行本地 部署验证器,以捕捉常见的配置问题并加快开发周期。
克隆 helper 存储库并安装验证器
1> git clone https://github.com/NVIDIA/nv-cloud-function-helpers.git
2> cd nv-cloud-function-helpers/local_deployment_test/
3> pip install -r requirements.txt
在您的容器上运行验证器。 支持的验证参数
--protocol--health-endpoint--inference-endpoint--container-port
1> python3 test_container.py --image-name $CONTAINER_IMAGE_NAME --protocol http --health-endpoint v2/health/live --inference-endpoint /v2/models/echo/infer --container-port 8000
一旦检查通过,系统将提示您测试容器的推理端点。 将您函数期望的推理端点 JSON 请求主体粘贴到生成的临时文件中。 如果一切顺利,请继续部署您的函数。
部署函数#
在部署函数之前,您必须先创建它。 创建后,它将显示为 INACTIVE。 请参阅 函数创建。
您的 Cloud Functions 帐户将有权访问各种 GPU 集群、实例类型、区域和配置,直至达到设定的数量。 这由您的 NVIDIA 客户经理决定。
每个函数版本都可以有不同的部署配置,从而允许在单个函数端点上使用异构计算基础设施。 一旦创建了部署,就可以随时更新它,例如,更改最小或最大实例计数。
关键概念#
术语 |
描述 |
|---|---|
集群组(后端) |
一个或多个(通常是一个)集群的集合,用于部署,例如 - CSP(如 Azure、OCI、GCP)或 NVIDIA 专用集群(如 GFN)。 |
实例类型 |
每个 GPU 类型可以支持一个或多个实例类型,这些实例类型是不同的配置,例如 CPU 核心数和每个节点的 GPU 数。 |
属性 |
集群的特定能力或合规性,例如 HIPAA、SOC2、图形优化等。 |
区域 |
集群所在的地理位置,例如 |
最小实例数 |
您的函数应部署的最小实例数。 |
最大实例数 |
您的函数允许自动扩展到的最大实例数。 |
最大并发数 |
您的容器在任何给定时间可以处理的并发调用数。 |
函数请求队列 |
在函数版本部署期间创建的先进先出队列,它根据函数“worker”实例的可用性缓冲传入的请求。 |
自动伸缩 |
基于利用率启发式和队列深度,将实例从最小实例计数自动向上或向下扩展到最大实例计数。 |
函数排队#
以下描述了触发函数排队的情况。 Cloud Functions 为每个函数版本 ID 维护一个队列。
对于同步 HTTP 请求 - 当函数达到当前正在进行的请求的最大并发限制时,会触发排队。
示例
单个函数实例部署,最大并发设置为 2,最小和最大实例计数为 1。
3 个调用请求通过函数的 /pexec 端点访问 Cloud Functions API。
Cloud Functions API 将转发 2 个函数调用请求。
剩余的请求将排队,返回 202,并且必须由 HTTP 轮询 处理。
对于流式请求(如 gRPC)- 当函数达到当前连接的最大并发限制时,会触发排队。
示例
gRPC 函数部署,最大并发设置为 2,最小和最大实例计数为 1。
3 个连接请求访问函数的 gRPC 端点。
将为该函数创建 2 个连接。
剩余的连接请求将等待连接,直到当前 2 个连接之一关闭。
自动伸缩和实例计数#
只有当最大实例计数高于最小实例计数时,才会发生函数实例的自动伸缩。 向上或向下扩展取决于专有的利用率启发式和函数的队列深度。
如果部署的最小实例数设置为 0,则函数状态将为 ACTIVE,但实例仅在首次调用函数时部署。 在长时间空闲且没有请求后,函数将缩减回 0。 因此,将最小实例计数设置为 0 通常是节省硬件成本的最佳实践,但需要权衡函数部署时间。 当不常用函数可以接受更长的响应时间时,这尤其有用。
在实例启动期间进行的调用将排队,直到实例准备就绪。 有关理解每个状态的含义,请参阅 函数状态。
通过 UI 部署#
创建函数后,单击右侧的 kebab 菜单,然后选择
Deploy Function Version。首先,选择您要使用的 GPU 类型。
您可以选择性地选择
Instance Type Settings以筛选您想要的部署的Regions或Attributes。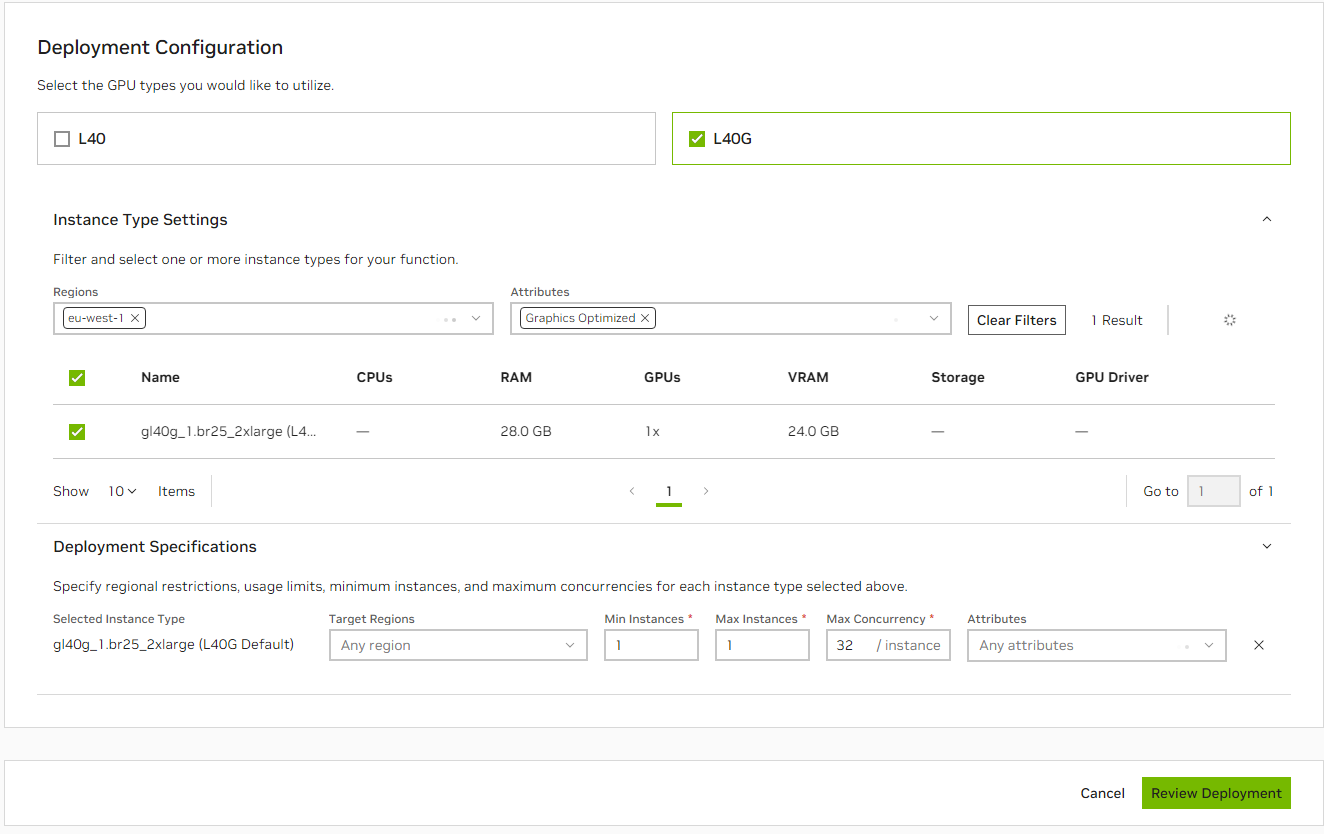
注意
实例类型:选择与您的函数需求匹配的所需实例类型。
区域(可选):指定您要部署函数的地理区域。
属性(可选):选择任何特定的属性或合规性要求,例如
HIPAA、SOC2。
显示的实例类型将与您指定的 requirements 匹配。 从您要部署到的结果中选择实例类型。
在
Deployment Specifications下,设置您要部署到的区域,或者将其保留为Any Region并指定您想要的attributes。如果您有权访问非 GFN 集群,您将需要选择
Cluster作为Deployment Specifications的一部分。
# 单击 Review Deployment 和 #。
注意
当您筛选区域或属性时,它将在
Deployment Specifications下自动选择这些项。即使您的函数不一定在执行工作,它也将占用 GPU,直到达到最小实例计数。
默认情况下,所有函数都启用自动伸缩。 因此,最经济高效的做法是将最小实例数设置为尽可能低,并允许 Cloud Functions 根据需要自动伸缩。
选择“Review Deployment”。 它将向您显示部署摘要以及任何指定的区域或属性,以及实例计数和最大并发数。 您还将看到有关实例类型的技术详细信息。 部署时间将因所做的选择和可用容量而异。
通过 API 部署#
确保您已创建 API 密钥,请参阅 生成 NGC 个人 API 密钥。
首先,列出可用的 GPU 集群、类型和配置。
1 curl --location 'https://api.ngc.nvidia.com/v2/nvcf/clusterGroups' \
2 --header 'Accept: application/json' \
3 --header "Authorization: Bearer $API_KEY"
请参阅下面的示例响应
1 {
2 "clusterGroups": [
3 {
4 "id": "...",
5 "name": "GCP-ASIASE1-A",
6 "ncaId": "...",
7 "authorizedNcaIds": [
8 "*"
9 ],
10 "gpus": [
11 {
12 "name": "H100",
13 "instanceTypes": [
14 {
15 "name": "a3-highgpu-8g_1x",
16 "description": "Single H100 GPU",
17 "default": true
18 },
19 {
20 "name": "a3-highgpu-8g_4x",
21 "description": "Four 80 GB H100 GPU",
22 "default": false
23 },
24 {
25 "name": "a3-highgpu-8g_2x",
26 "description": "Two 80 GB H100 GPU",
27 "default": false
28 },
29 {
30 "name": "a3-highgpu-8g_8x",
31 "description": "Eight 80 GB H100 GPU",
32 "default": false
33 }
34 ]
35 }
36 ],
37 "clusters": [
38 {
39 "k8sVersion": "v1.29.2-gke.1060000",
40 "id": "...",
41 "name": "nvcf-gcp-prod-asiase1-a"
42 }
43 ]
44 }
45 ...
46 ]
47 }
在此示例(省略了一些数据)中,该帐户被授权在 GCP-ASIASE1-A 集群上部署,该集群具有 H100 GPU 类型,具有四种不同的实例类型配置。
通过创建部署规范,通过 API 部署函数。
1 curl --location "https://api.ngc.nvidia.com/v2/nvcf/deployments/functions/$FUNCTION_ID/versions/$FUNCTION_VERSION_ID" \
2 --header 'Content-Type: application/json' \
3 --header 'Accept: application/json' \
4 --header "Authorization: Bearer $API_KEY" \
5 --data '{
6 "deploymentSpecifications": [
7 {
8 "instanceType": "AZURE.GPU.H100_4x",
9 "gpu": "H100",
10 "minInstances": "1",
11 "maxInstances": "2",
12 "maxRequestConcurrency": 1,
13 "regions": ["us-west-2", "us-east-1"],
14 "clusters": ["byoc-cluster-1"],
15 "attributes": ["HIPAA", "SOC2"]
16
17 }
18
19 ]
20
21 }'
有关更多 API 文档,请参阅 OpenAPI 规范。
通过 CLI 部署#
确保您已创建 API 密钥,请参阅 生成 NGC 个人 API 密钥。
确保您已配置 NGC CLI。
首先,列出可用的 GPU 集群、类型和配置。
1 ngc cloud-function available-gpus
通过创建部署规范,通过 CLI 部署函数。
1 ngc cf function deploy create --deployment-specification $CLUSTER_BACKEND:$GPU_TYPE:$INSTANCE_TYPE:$MIN_INSTANCES:$MAX_INSTANCES $FUNCTION_ID:$FUNCTION_VERSION_ID:minInstances=$MIN_INSTANCES:maxInstances=$MAX_INSTANCES:maxRequestConcurrency=$MAX_CONCURRENCY:regions=$REGIONS,clusters=$CLUSTERS:attributes=$ATTRIBUTES \
有关更多命令,请参阅 NGC CLI 文档。
删除部署#
要删除函数版本部署,请提供函数 ID 和版本 ID。
通过 UI,在任何已部署函数和版本的函数列表页面中选择“禁用函数版本”。
通过 API
1curl -X 'DELETE' \
2 "https://api.nvcf.nvidia.com/v2/nvcf/functions/$FUNCTION_ID"
通过 CLI
1 ngc cloud-function function deploy remove $FUNCTION_ID:$FUNCTION_VERSION_ID
提示
指定 graceful 参数为 true,以要求活动的函数实例完成任何正在进行的推理请求,并在终止之前耗尽队列中的所有请求。
删除部署后,函数的状态将立即变为 INACTIVE,表示它不再可以提供调用。
部署失败#
根据您的容器和模型的大小,您的函数部署可能需要 2 分钟到 30 分钟不等,尽管允许的最长持续时间为 2 小时。 这也取决于您的函数是从冷启动部署,还是正在向上或向下扩展(由于缓存到位,通常速度更快)。 通过 函数指标页面 监控函数的实例计数和伸缩。
如果您认为您的函数应该已经部署,或者如果它已进入错误状态,请查看日志以了解发生了什么,或联系您的 NVCF 支持团队。
以下是一些常见的部署失败
失败类型 |
描述 |
|---|---|
函数配置问题 |
这是由于定义了不正确的推理或健康端点和端口而发生的,导致容器被标记为不健康。 尝试在本地容器上运行 部署验证,以排除配置问题。 |
所选集群的容量不足 |
这通常会在 UI 中的部署失败错误消息中指示。 尝试减少您请求的实例数量或更改函数使用的 GPU/实例类型。 |
容器处于重启循环 |
这将在推理容器日志中指示(如果您的容器配置为发出日志),并且可以通过调试和更新您的推理容器代码来修复。 |
未找到模型文件 |
当推理容器期望在指定位置找到模型文件,但该文件不存在时,通常会发生此错误。 确保您的模型文件的路径正确,并且必要的文件(如 |