集群设置与管理#
云函数管理员可以安装 NVIDIA 集群代理,以使现有的 GPU 集群充当 NVCF 函数的部署目标。NVIDIA 集群代理是一个函数部署编排器,它与 NVCF 控制平面通信。本页介绍如何执行以下操作
使用 NVIDIA 集群代理向 NVCF 注册集群。
通过定义 GPU 实例类型、配置、区域和授权的 NCA(NVIDIA 云账户)ID 来配置集群。
验证集群设置是否成功。
在集群上安装 NVIDIA 集群代理之后
注册的集群将显示为
GET /v2/nvcf/clusterGroupsAPI 响应和云函数部署菜单中的部署选项。集群授权 NCA ID 下的任何函数现在都可以部署在该集群上。
前提条件#
访问 Kubernetes 集群,包括启用 GPU 的节点(“GPU 集群”)
集群必须具有兼容版本的 Kubernetes。
集群必须安装 NVIDIA GPU Operator。
如果您的云提供商不支持 NVIDIA GPU Operator,则可以进行手动实例配置,但由于缺乏可维护性,因此不建议这样做。
注册集群需要安装
kubectl和helm。注册集群的用户必须具有
cluster-admin角色权限才能安装 NVIDIA 集群代理 Operator (nvca-operator)。注册集群的用户必须在其 NGC 组织内拥有云函数管理员角色。
支持的 Kubernetes 版本#
最低支持的 Kubernetes 版本:
v1.25.0最高支持的 Kubernetes 版本
v1.29.x
注意事项#
NVIDIA 集群代理目前仅在集群启用
StorageClass配置的情况下支持缓存。如果启用“缓存支持”功能,代理将尽最大努力在部署期间尝试检测存储,并回退到非缓存工作流程。所有 NVIDIA 管理的集群都完全支持所有启发式方法的自动扩缩容功能。但是,通过代理注册到 NVCF 的集群仅支持通过函数队列深度启发式方法的自动扩缩容。
注册集群#
通过导航到 NGC 产品下拉菜单中的“云函数”,然后在左侧菜单中选择“设置”来访问集群注册页面。您必须是云函数管理员才能看到此页面。选择“注册集群”以开始注册过程。
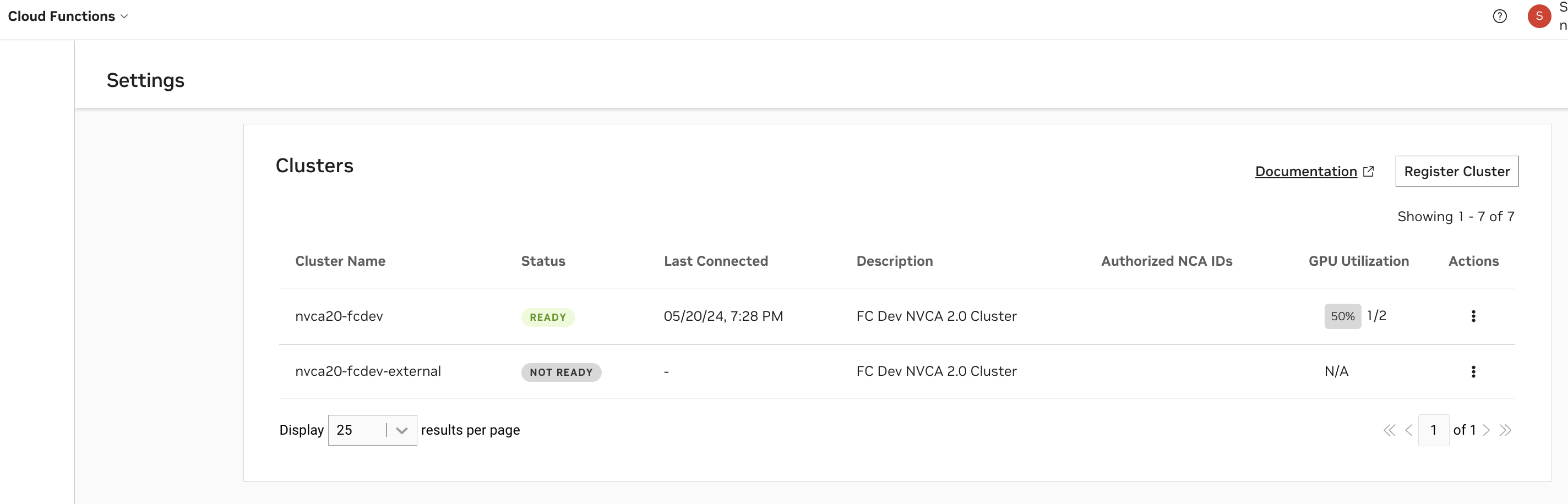
配置#
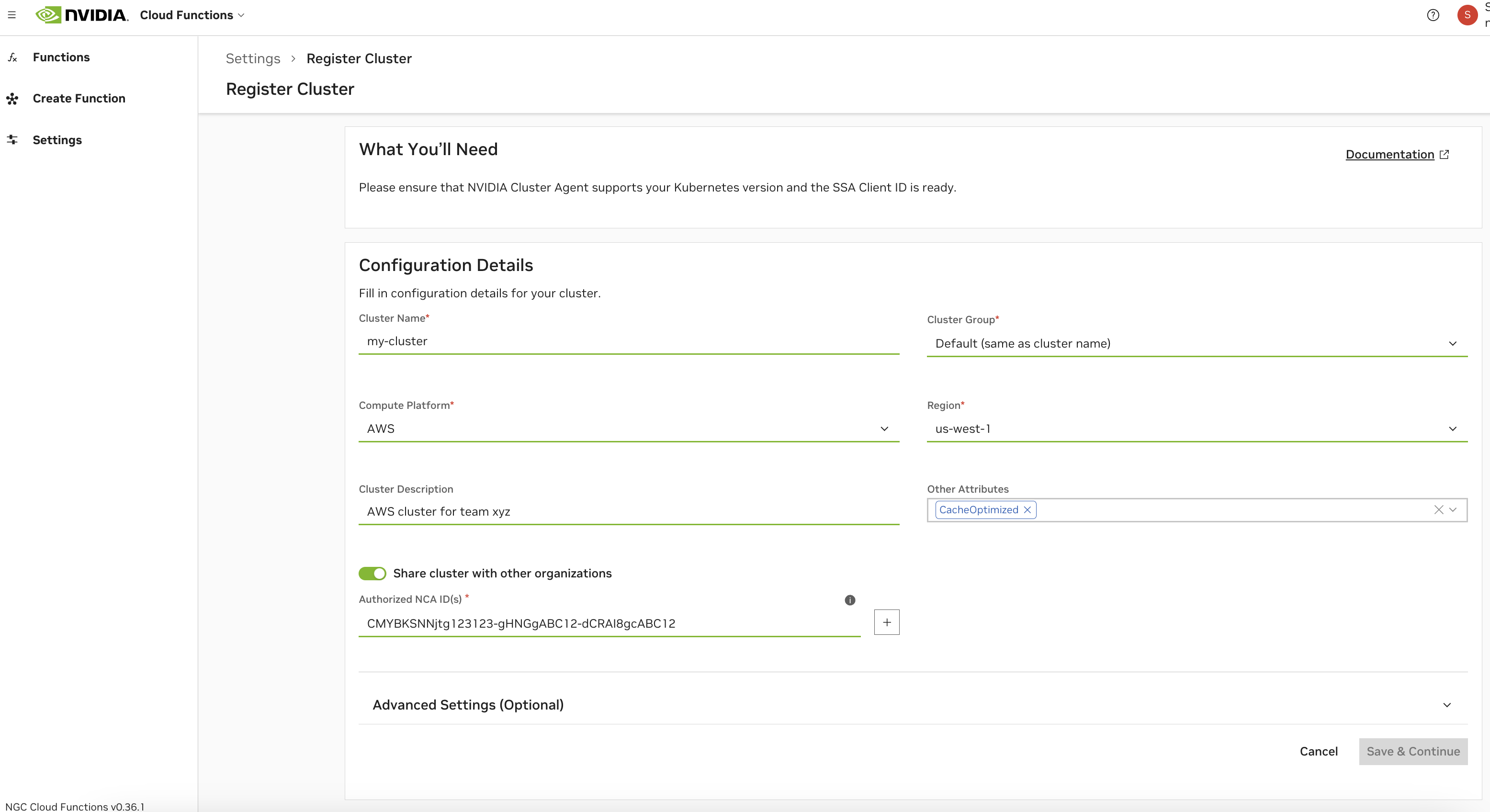
请参阅下文,了解所有集群配置选项的描述。
字段 |
描述 |
|---|---|
集群名称 |
集群的名称。此字段配置后不可更改。 |
集群组 |
集群组的名称。这通常与集群名称相同,除非在您想要对多个集群进行分组的情况下。这样做是为了使函数能够在选择组时部署在任何集群上(例如,由于相同的硬件支持)。 |
计算平台 |
集群部署所在的云平台。此字段是集群代理使用的节点名称标签格式的标准部分:<平台>.GPU.<GPU名称> |
区域 |
集群部署所在的区域。部署函数时,需要此字段来启用未来的优化和配置。 |
集群描述 |
集群的可选描述,这提供了有关集群的附加上下文,并将在“设置”页面下的集群列表和 |
其他属性 |
使用附加属性标记您的集群。 缓存优化:启用快速实例启动,需要额外的存储配置和缓存支持属性,请参阅高级设置。 KataRunTimeIsolation:集群配备了增强设置,以使用 Kata Containers 确保卓越的工作负载隔离。 |
提升快速实例启动的效率,强制要求高级集群设置中的额外存储配置和缓存支持属性。
默认情况下,集群将被授权给配置集群期间使用的当前 NGC 组织的 NCA ID。如果您选择与其他 NGC 组织共享集群,则需要检索其对应的 NCA ID。共享集群将允许其他 NVCF 账户在其上部署云函数,对他们部署在集群中的 GPU 数量没有限制。
注意
NVCF “账户”直接与 NCA ID(“NVIDIA 云账户”)相关联并由其定义。每个有权访问云函数 UI 的 NGC 组织都有一个对应的 NGC 组织名称和 NCA ID。请参阅 NGC 组织个人资料页面 以查找这些详细信息。
警告
一旦来自其他 NGC 组织的函数已部署在集群上,从授权 NCA ID 列表中删除它们,或完全从集群中删除共享,可能会导致服务中断。理想情况下,在从授权 NCA ID 列表中删除 NCA ID 之前,应先取消部署与其它 NCA ID 关联的任何函数。
高级设置#

请参阅下文,了解集群配置的“高级设置”部分中所有功能选项的描述。请注意,对于客户管理的集群(通过集群代理注册),默认启用动态 GPU 发现。对于 NVIDIA 内部集群,默认情况下也启用收集函数日志。
功能 |
描述 |
|---|---|
动态 GPU 发现 |
通过 NVIDIA GPU Operator 启用集群内可分配 GPU 容量的自动检测和管理。强烈建议使用此功能,仅在需要手动实例配置的情况下禁用。 |
收集函数日志 |
此功能启用综合集群代理日志的发送,然后将其转发给 NVIDIA 内部团队,从而有助于有效地诊断和解决问题。启用后,这些日志在 UI 中不可见,但始终可以通过运行命令以直接在集群上检索日志来获取。 |
缓存支持 |
通过将频繁访问的数据(模型、资源和容器)存储在缓存中来提高应用程序性能。请参阅缓存支持。 |
注意
删除动态 GPU 发现将需要手动实例配置。请参阅手动实例配置。
缓存支持#
建议启用模型、资源和容器的缓存以获得最佳性能。您必须在集群内创建用于缓存的 StorageClass 配置,才能使用集群代理完全启用“缓存支持”。请参阅以下示例
GCP 中的 StorageClass 配置
1kind: StorageClass
2apiVersion: storage.k8s.io/v1
3metadata:
4 name: nvcf-sc
5provisioner: pd.csi.storage.gke.io
6allowVolumeExpansion: true
7volumeBindingMode: Immediate
8reclaimPolicy: Retain
9parameters:
10 type: pd-ssd
11 csi.storage.k8s.io/fstype: xfs
1kind: StorageClass
2apiVersion: storage.k8s.io/v1
3metadata:
4 name: nvcf-cc-sc
5provisioner: pd.csi.storage.gke.io
6allowVolumeExpansion: true
7volumeBindingMode: Immediate
8reclaimPolicy: Retain
9parameters:
10 type: pd-ssd
11 csi.storage.k8s.io/fstype: xfs
注意
GCP 目前仅允许 10 个 VM 以只读模式挂载持久卷。
Azure 中的 StorageClass 配置
1kind: StorageClass
2apiVersion: storage.k8s.io/v1
3metadata:
4 name: nvcf-sc
5provisioner: file.csi.azure.com
6allowVolumeExpansion: true
7volumeBindingMode: Immediate
8reclaimPolicy: Retain
9parameters:
10 skuName: Standard_LRS
11 csi.storage.k8s.io/fstype: xfs
1kind: StorageClass
2apiVersion: storage.k8s.io/v1
3metadata:
4 name: nvcf-cc-sc
5provisioner: file.csi.azure.com
6allowVolumeExpansion: true
7volumeBindingMode: Immediate
8reclaimPolicy: Retain
9parameters:
10 skuName: Standard_LRS
11 csi.storage.k8s.io/fstype: xfs
应用 StorageClass 配置
将 StorageClass 模板保存到文件 nvcf-sc.yaml 和 nvcf-cc-sc.yaml,并按如下方式应用它们
1kubectl create -f nvcf-sc.yaml
2kubectl create -f nvcf-cc-sc.yaml
安装集群代理#
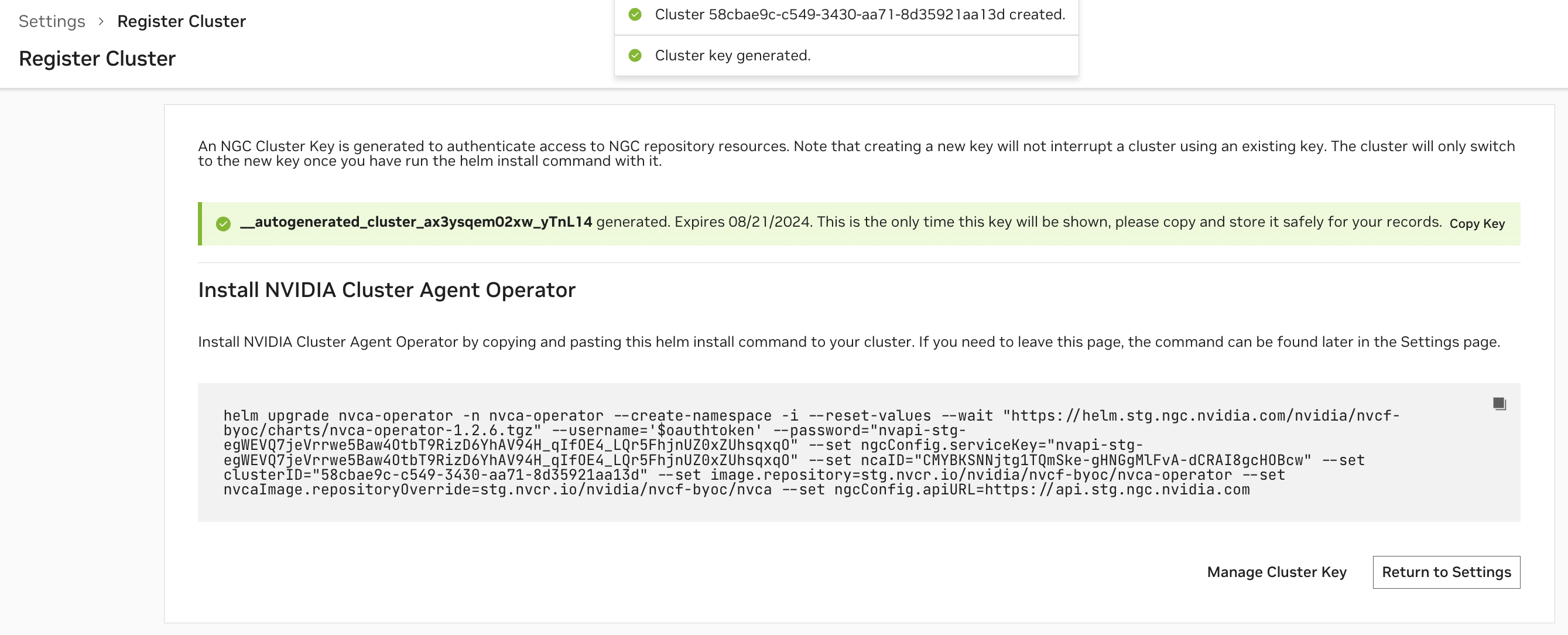
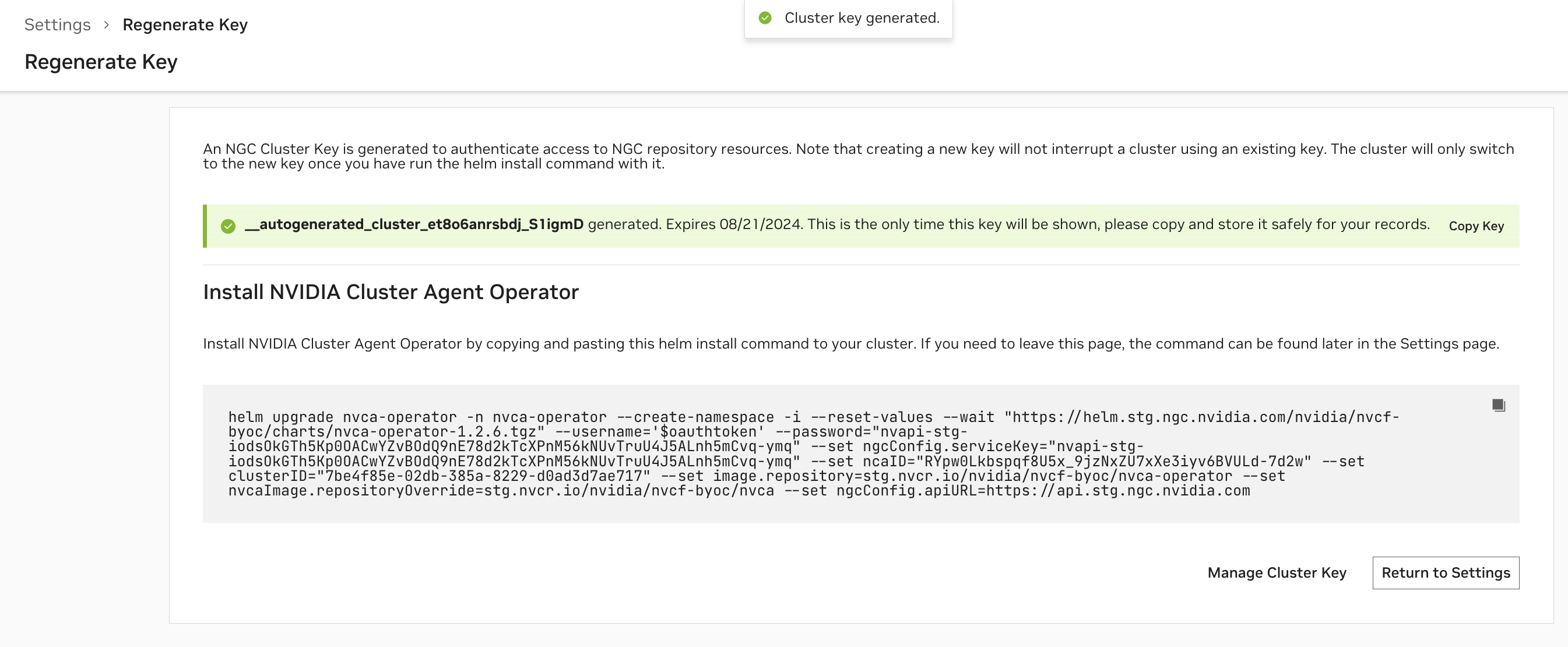
配置集群后,将生成用于向 NGC 验证身份的 NGC 集群密钥,并且您将看到用于安装 NVIDIA 集群代理 Operator 的命令片段。请参考此命令片段以获取最新的安装说明。
注意
NGC 集群密钥的默认有效期为 90 天。定期或接近到期时,您必须轮换您的 NGC 集群密钥。
集群代理 Operator 安装完成后,Operator 将自动安装所需的 NVIDIA 集群代理版本,并且集群页面中集群的状态将变为“就绪”。
之后,您可以随时修改配置。集群名称和 SSA 客户端 ID(仅适用于 NVIDIA 内部集群)不可重新配置。请参考 UI 中用于重新配置的任何附加安装说明。配置更新后,每 15 分钟轮询更改的集群代理 Operator 将应用新配置。
查看和验证集群设置#
通过 UI 验证集群代理安装#
您可以随时在“设置”页面上查看您已开始注册或已注册的集群及其状态。
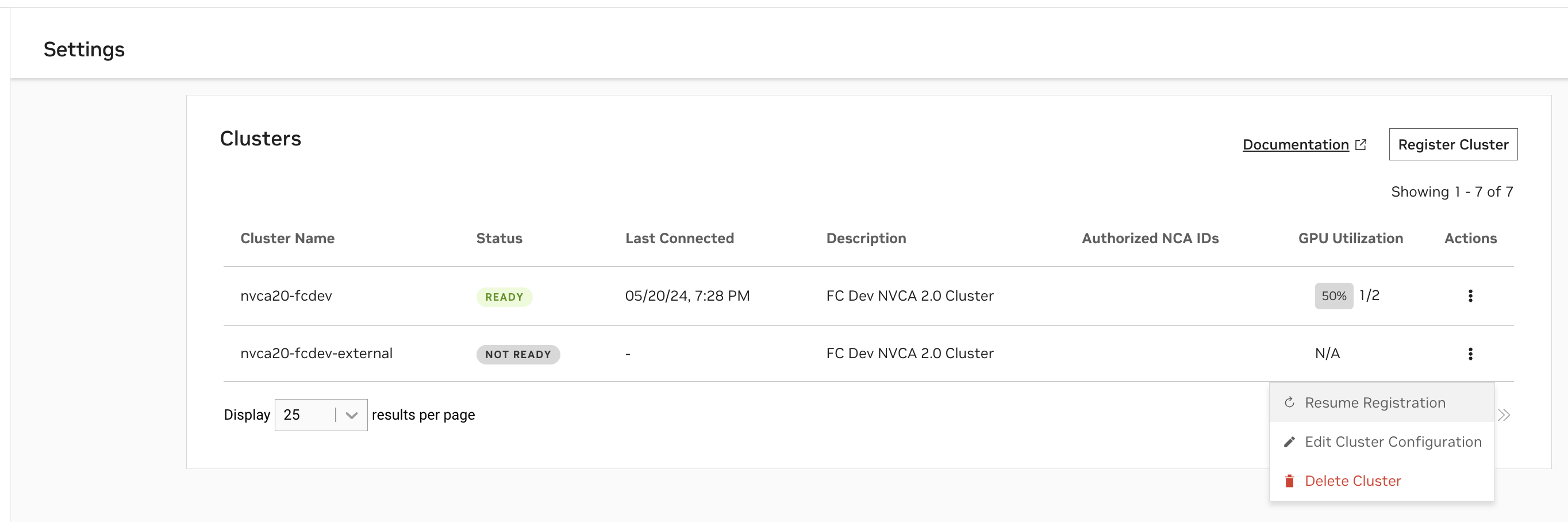
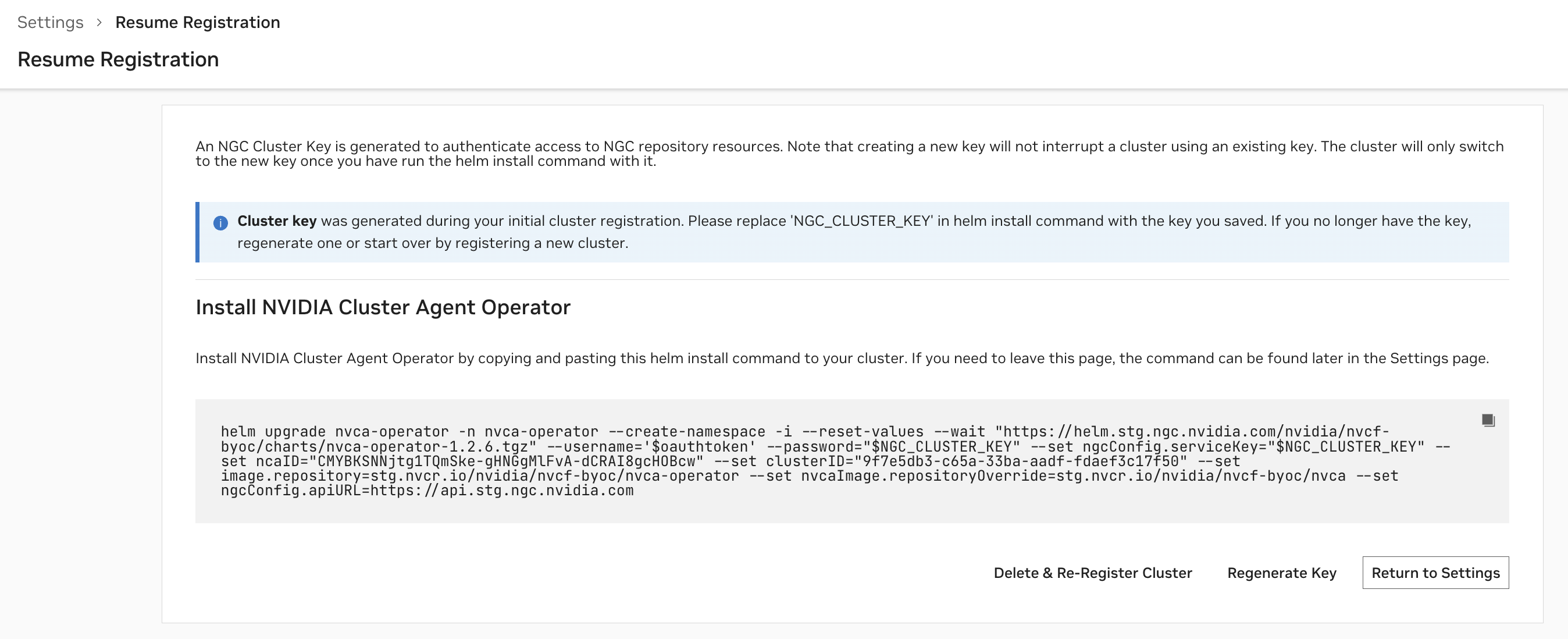
“
就绪”状态表示集群代理已成功向 NVCF 注册集群。“
未就绪”状态表示注册命令刚刚应用且正在进行中,或者注册正在失败。
如果注册失败,请使用以下命令检索更多详细信息
1kubectl get nvcfbackend -n nvca-operator
当集群处于“未就绪”状态时,您可以随时恢复注册以完成安装。
“GPU 利用率”列基于集群内已占用 GPU 数量与可用 GPU 数量之比。“上次连接时间”列指示上次从集群代理收到状态更新到 NVCF 控制平面的时间。
通过终端验证集群代理安装#
通过以下命令验证安装是否成功,您应该看到“healthy”响应,如本例所示
1> kubectl get nvcfbackend -n nvca-operator
2NAME AGE VERSION HEALTH
3nvcf-trt-mgpu-cluster 3d16h 2.30.4 healthy
注销集群#
删除配置为 NVCF 函数部署目标的集群是一个两步过程。它包括从 NGC 中删除集群,然后在集群上执行一系列命令以删除已安装的集群代理和 NVCA operator。
通过 UI 删除集群#
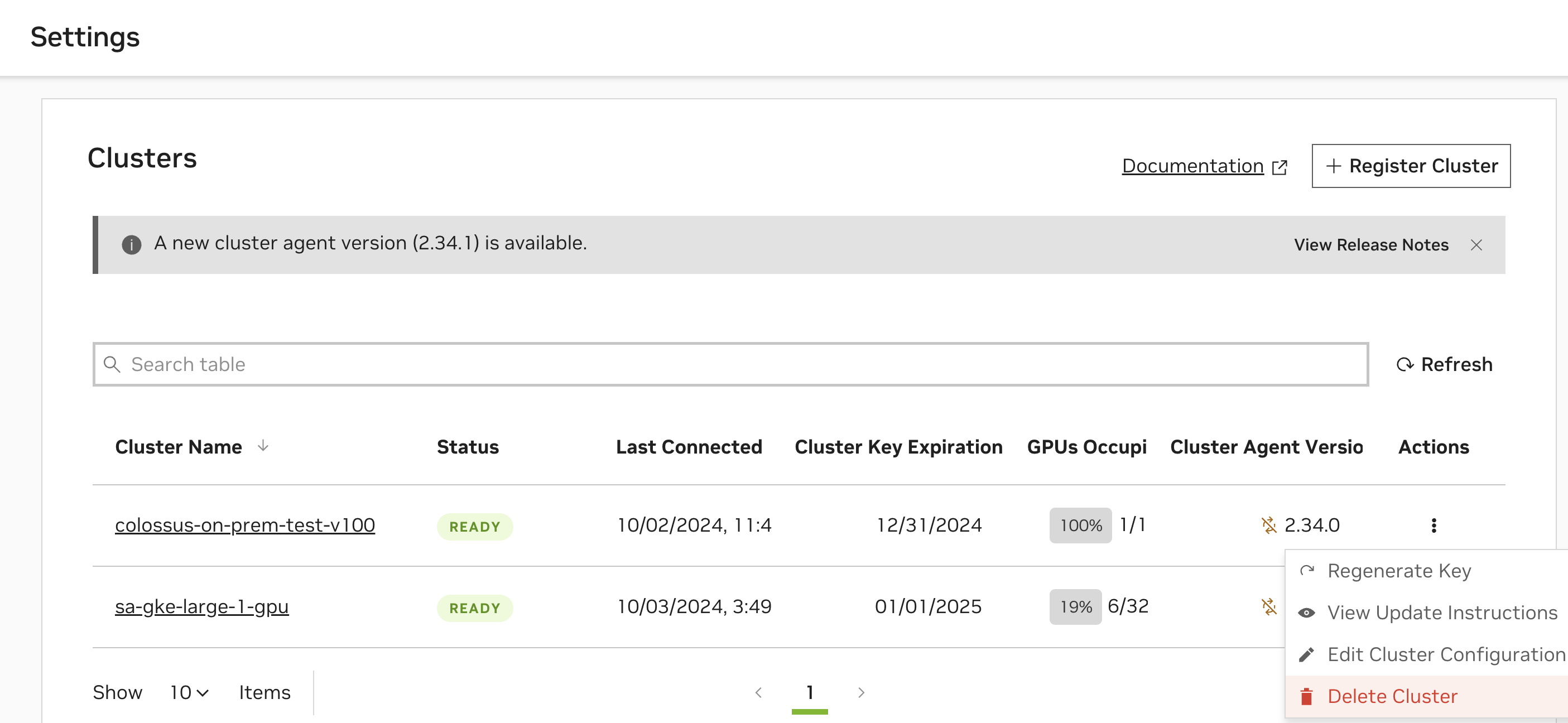
通过导航到 NGC 产品下拉菜单中的“云函数”,然后在左侧菜单中选择“设置”来访问集群注册页面。您必须是云函数管理员才能看到此页面。
从要删除的集群的“操作”下拉菜单中选择“删除集群”。
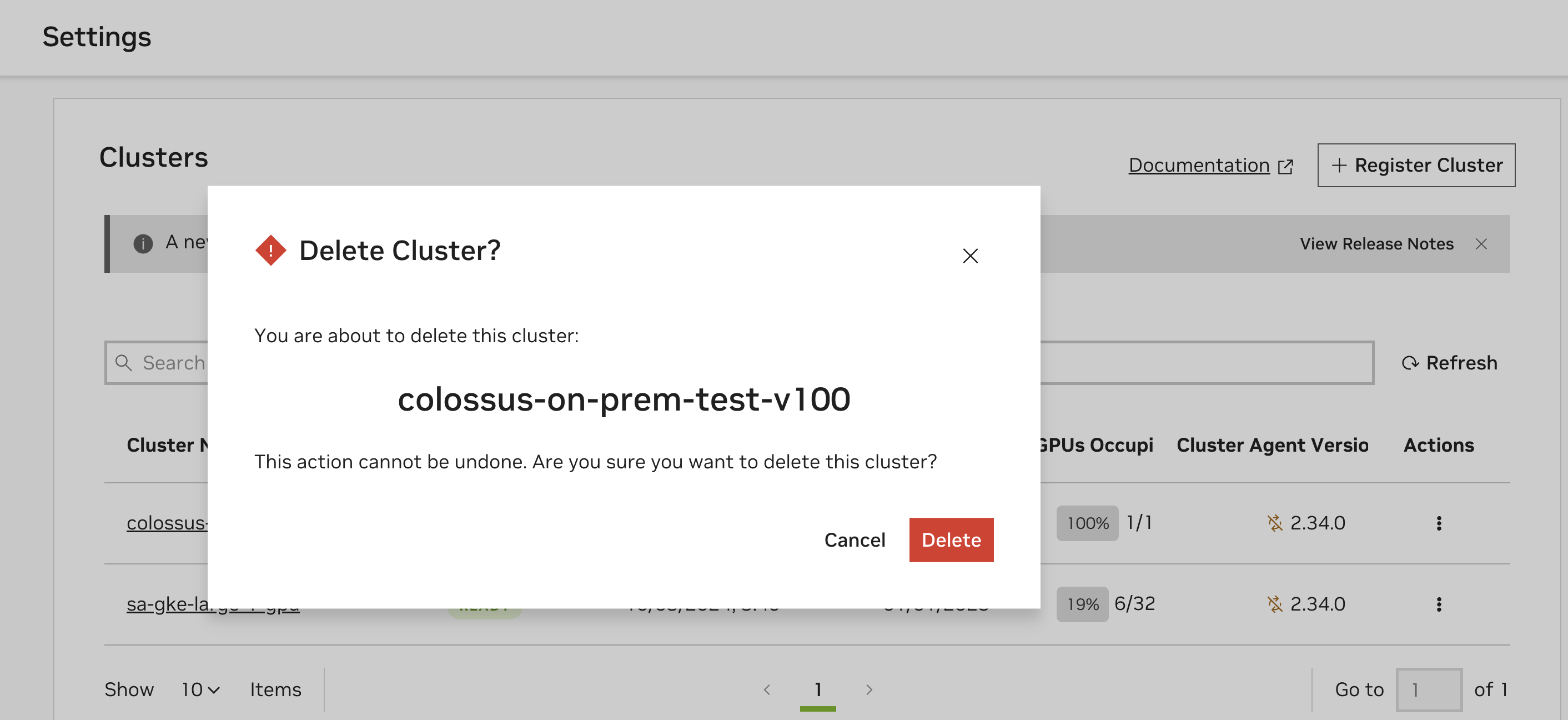
在此之后,将出现一个对话框,询问您是否确认删除集群。单击“删除”以删除作为部署目标的集群。
删除集群代理和 NVCA Operator#
在注册的集群上,执行以下命令以完成注销过程。
1kubectl delete nvcfbackends -A --all
2kubectl delete ns nvca-system
3helm uninstall -n nvca-operator nvca-operator
4kubectl delete ns nvca-operator
注意
如果 Kubernetes CRD nvcfbackend 的删除被阻止,则需要使用以下命令手动删除终结器 (nvca-operator.finalizers.nvidia.io)
kubectl edit nvcfbackend -n nvca-operator
集群代理监控和可靠性#
监控数据#
指标#
集群代理和 operator 发出 Prometheus 风格的指标。以下指标和标签默认可用。
指标名称 |
指标描述 |
|---|---|
nvca_event_queue_length |
命名事件队列的长度 |
nvca_event_process_latency |
在 NVCA 中处理事件所花费的时间 |
指标标签 |
指标标签描述 |
|---|---|
nvca_event_name |
事件的名称 |
nvca_nca_id |
此 NVCA 实例的 NCA ID |
nvca_cluster_name |
NVCA 集群名称 |
nvca_cluster_group |
NVCA 集群组 |
nvca_version |
NVCA 版本 |
集群维护人员可以使用以下 NVCA Operator 的 PodMonitor 和 NVCA 的 ServiceMonitor 示例来抓取可用的指标以供参考
NVCA Operator PodMonitor 示例
1apiVersion: monitoring.coreos.com/v1
2kind: PodMonitor
3metadata:
4 labels:
5 app.kubernetes.io/component: metrics
6 app.kubernetes.io/instance: prometheus-agent
7 app.kubernetes.io/name: metrics-nvca-operator
8 jobLabel: metrics-nvca-operator
9 release: prometheus-agent
10 prometheus.agent/podmonitor-discover: "true"
11 name: metrics-nvca-operator
12 namespace: monitoring
13spec:
14 podMetricsEndpoints:
15 - port: http
16 scheme: http
17 path: /metrics
18 jobLabel: jobLabel
19 selector:
20 matchLabels:
21 app.kubernetes.io/name: nvca-operator
22 namespaceSelector:
23 matchNames:
24 - nvca-operator
NVCA ServiceMonitor 示例
1apiVersion: monitoring.coreos.com/v1
2kind: ServiceMonitor
3metadata:
4 labels:
5 app.kubernetes.io/component: metrics
6 app.kubernetes.io/instance: prometheus-agent
7 app.kubernetes.io/name: metrics-nvca
8 jobLabel: metrics-nvca
9 release: prometheus-agent
10 prometheus.agent/servicemonitor-discover: "true"
11 name: prometheus-agent-nvca
12 namespace: monitoring
13spec:
14 endpoints:
15 - port: nvca
16 jobLabel: jobLabel
17 selector:
18 matchLabels:
19 app.kubernetes.io/name: nvca
20 namespaceSelector:
21 matchNames:
22 - nvca-system
日志#
默认情况下,集群代理和集群代理 Operator 都在本地发出日志。
NVIDIA 集群代理 Operator 的本地日志可以通过 kubectl 获取
1kubectl logs -l app.kubernetes.io/instance=nvca-operator -n nvca-operator --tail 20
同样,NVIDIA 集群代理日志可以通过以下 kubectl 命令获取
1kubectl logs -l app.kubernetes.io/instance=nvca -n nvca-system --tail 20
警告
当前不支持在非 NVIDIA 管理的集群上部署的函数的功能级推理容器日志。鼓励客户直接从其在自己的集群上运行的推理容器向任何第三方工具发送日志,容器没有公共出口限制。
追踪#
NVIDIA 集群代理提供 OpenTelemetry 集成,用于将跟踪和事件导出到兼容的收集器。从代理版本 2.0 开始,唯一支持的收集器是 Lightstep。请参阅高级:NVCA Operator 配置选项。
集群密钥轮换#
要重新生成或轮换集群的密钥,请从“设置”页面上的“集群”表中选择“重新生成密钥”选项。请参考此命令片段以获取最新的升级说明。
警告
更新您的服务密钥可能会中断对现有函数的任何正在进行的更新或部署,因此在升级之前暂停部署非常重要。
高级:NVCA Operator 配置选项#
以下是供参考的附加配置选项。
节点亲和性#
集群代理使用 节点亲和性 确定哪些 GPU 节点可用于云函数工作负载。
例如,要将集群中所有节点标记为可调度
1kubectl label nodes -l 'nvidia.com/gpu.present=true' nvca.nvcf.nvidia.io/schedule=true
要将单个节点标记为不可调度/隔离
1kubectl label node <node-name> nvca.nvcf.nvidia.io/schedule-
NVCA Operator 参数#
名称 |
描述 |
值 |
|---|---|---|
image.repository |
NVCA Operator 容器注册表路径,不带标签 |
nvcr.io/nvidia/nvcf-byoc/nvca-operator |
image.tag |
NVCA Operator 容器镜像标签。默认值为 chart 版本 |
“” |
image.pullPolicy |
K8s |
IfNotPresent |
nvcaImage.repositoryOverride |
(可选)完整的 NVCA 容器注册表路径,不带标签。仅当需要覆盖默认值时才设置此项,例如“nvcr.io/nvidia/nvcf-byoc/nvca”。标签在集群配置中设置 |
“” |
nvcaImage.pullPolicy |
K8s |
IfNotPresent |
replicaCount |
operator 部署的副本数 |
1 |
systemNamespace |
在其中创建 NVCFBackend 对象的命名空间。 |
nvca-operator |
logLevel |
模块的日志级别 |
info |
ncaID |
主账户的 NVIDIA 云账户 ID |
“” |
clusterID |
此 NVCA 实例要管理的集群的 ID |
“” |
clusterName |
用于指标和遥测 |
“” |
k8sVersionOverride |
覆盖 NVCA 注册的 K8s 版本 |
“” |
priorityClassName |
用于 pod 在驱逐期间的优先级的 K8s PriorityClassName |
“” |
skipFluxInit |
如果管理员已安装 Flux,则跳过 Flux 安装 |
false |
NGC 配置#
名称 |
描述 |
值 |
|---|---|---|
ngcConfig.username |
用于注册表身份验证的用户名 |
$oauthtoken |
ngcConfig.serviceKey |
用于身份验证的 ServiceKey(密码) |
“” |
ngcConfig.apiURL |
用于请求身份验证令牌的 NGC API URL |
节点选择器配置#
名称 |
描述 |
值 |
|---|---|---|
nodeSelector.key |
节点选择器标签键 |
node.kubernetes.io/instance-type |
nodeSelector.value |
节点选择器标签值 |
“” |
OpenTelemetry 配置#
名称 |
描述 |
值 |
|---|---|---|
otel.enabled |
启用 OpenTelemetry。 |
false |
otel.lightstep.serviceName |
用于推送遥测数据的 Lightstep 服务的名称 |
“” |
otel.lightstep.accessToken |
用于访问 Lightstep API 的访问令牌 |
“” |
高级:手动实例配置#
警告
强烈建议依赖动态 GPU 发现,因此依赖 NVIDIA GPU Operator,因为手动实例配置容易出错。
仅当集群云提供商不支持 NVIDIA GPU Operator 时,才需要这种类型的配置。
启用手动实例配置,删除“动态 GPU 发现”功能。
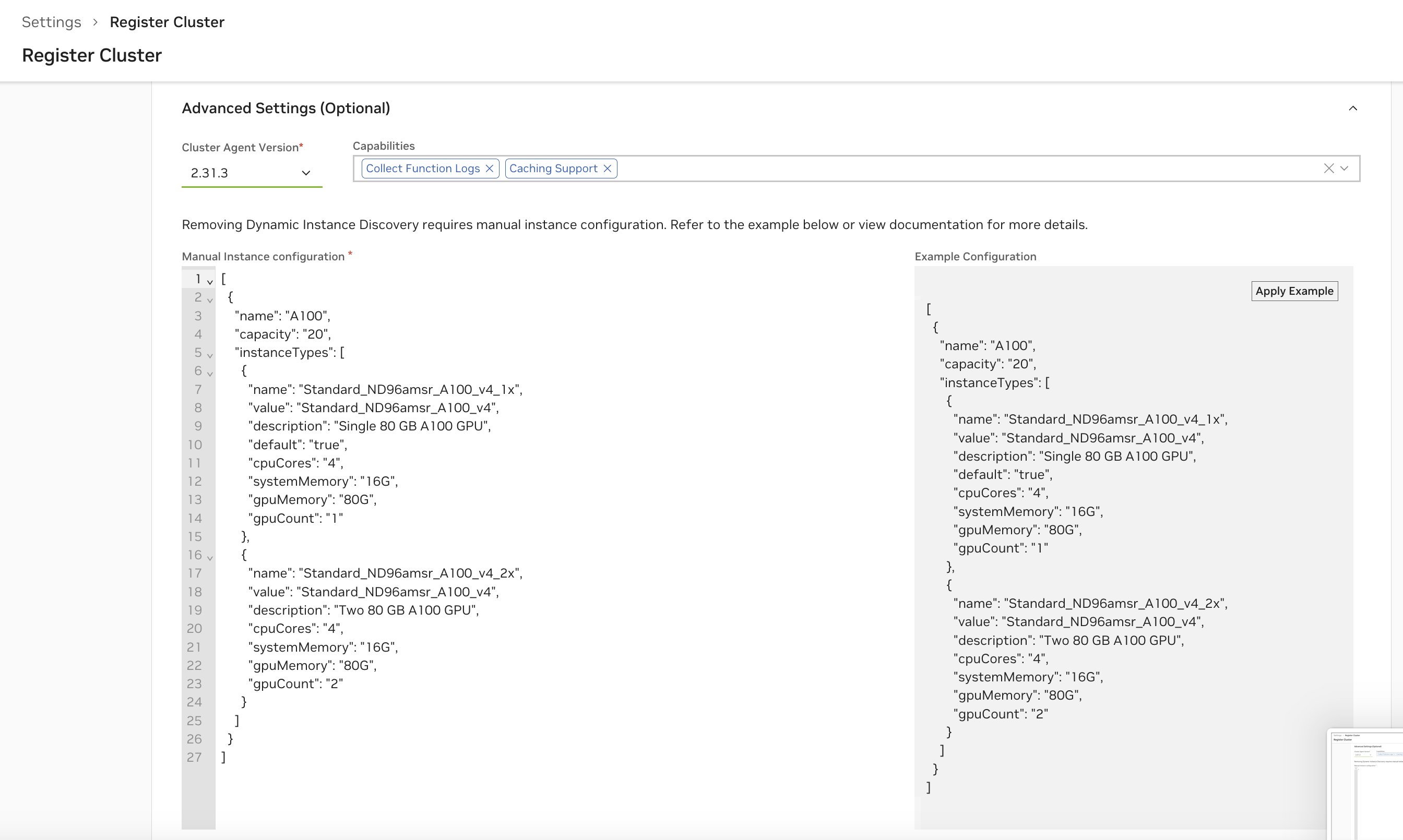
UI 中生成的示例配置中的所有字段都是必需的。首先选择“应用示例”以复制示例配置,然后根据集群的实例规范对其进行修改。