API#
域名: https://api.nvcf.nvidia.com
NGC 域名 (某些 API 需要): https://api.ngc.nvidia.com
OpenAPI 规范#
本页简要概述了 NVCF API 的使用方法,并未涵盖所有端点。
有关最新的 API 信息,请参阅 OpenAPI 规范。开始使用 NVCF API 最快捷的方式是通过 Postman 集合。
NVCF API 分为以下几组 API
API |
用途 |
|---|---|
函数调用 |
在工作节点上运行的函数的执行。通常是推理调用。 |
资产管理 |
用于管理大型文件,以上传请求并下载函数结果。 |
集群组和 GPU |
定义端点以列出集群组和 GPU 作为函数部署的目标。 |
队列详情 |
用于查看有关您的环境的信息,例如队列和 GPU。 |
函数管理 |
函数的创建、修改和删除 |
函数部署 |
用于创建和管理函数部署的端点。 |
API 版本控制
所有 API 端点都在路径前缀中包含版本控制。
/v2/nvcf
授权#
NVCF API 支持基于 NGC API 密钥的授权,用于直接调用 API,或通过 NGC CLI 和 NGC SDK 间接调用 API。
生成的 NGC 个人 API 密钥还将用于推送和拉取容器、模型、资源和 Helm Chart 到 NGC 私有注册表,以便在函数创建期间使用。
生成 NGC 个人 API 密钥#
API 密钥可以通过您在 个人密钥页面 中的帐户生成。
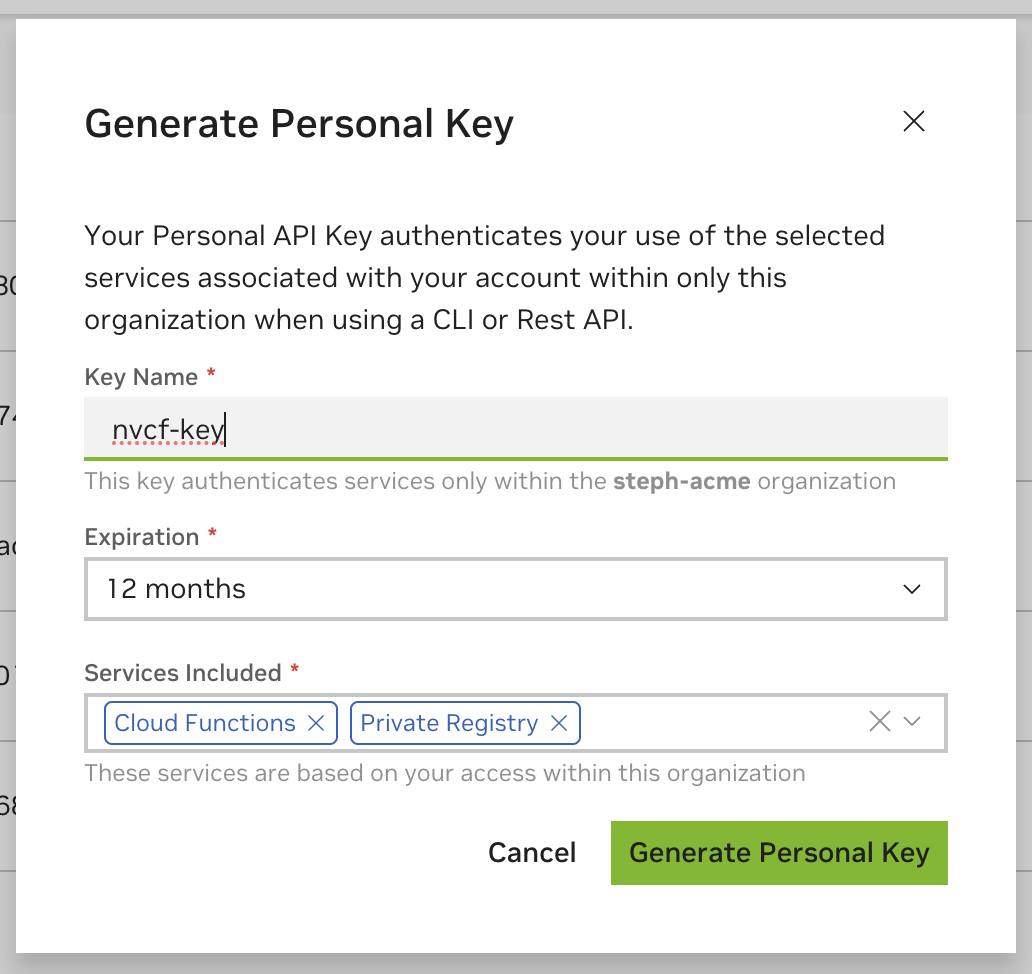
建议您生成的 API 密钥同时包含 NGC 目录 和 私有注册表 服务,以便与 NGC CLI 无缝使用。
API 密钥用法
API 密钥在 Authorization 标头中传递。
Authorization: Bearer $API_KEY
API 密钥作用域和域名#
注意
NGC 中有多种 API 密钥类型。我们强烈建议使用 NGC 个人 API 密钥以获得完整的 NVCF API 兼容性。
所需的域名在下面文档中列出,并且也预先填充在我们的 Postman 集合 中。
我们的 OpenAPI 规范 也描述了每个端点所需的作用域。
作用域名称 |
域名 |
API 类别 |
|---|---|---|
update_function |
函数管理 |
|
register_function |
函数管理 |
|
queue_details |
队列详情 |
|
list_functions |
函数管理 |
|
list_cluster_groups |
集群组和 GPU |
|
invoke_function |
函数调用和资产管理 |
|
deploy_function |
函数部署 |
|
delete_function |
函数管理 |
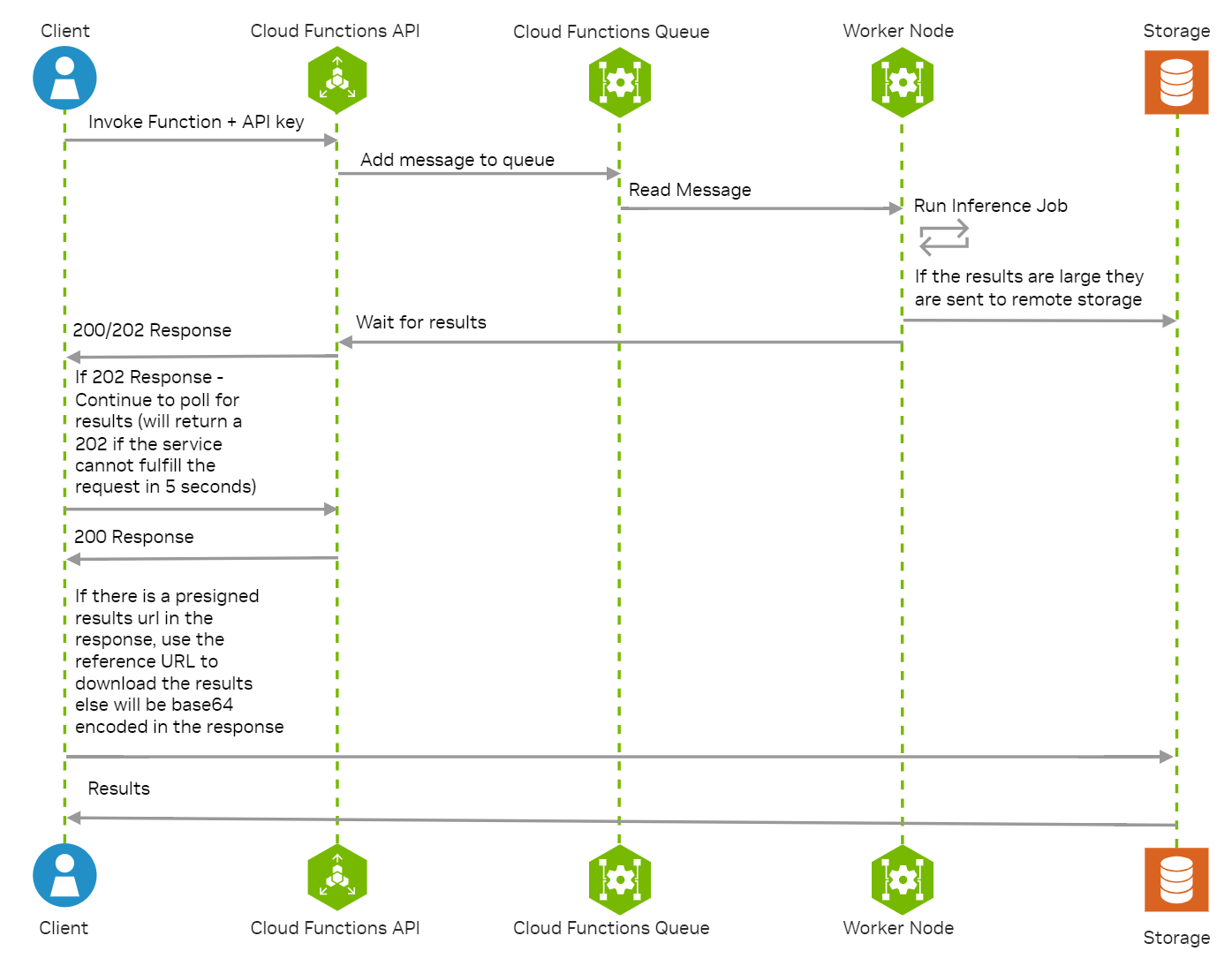
使用 NVCF 调用 API#
调用是指对部署到集群中的函数执行推理调用。
注意事项
您的请求正文必须是有效的 JSON,最大为 5MB。
如果调用调用 API 时未指定函数版本 ID,并且部署了多个函数版本 ID,则推理调用可能会转到托管任一函数版本的实例。
云函数使用 HTTP/2 持久连接。为了获得最佳性能,期望客户端在确定不再需要与服务器进行进一步通信之前不要关闭连接。
云函数调用支持以下用例
HTTP 流式传输:使用 HTTP/2 持久连接进行连续数据传输,保持打开的连接以获得最佳性能,直到不再需要与服务器进行进一步通信。
HTTP (轮询):NVCF 返回 HTTP 状态 200 表示结果已完成,或返回 HTTP 状态 202 表示响应将需要在客户端轮询结果。
gRPC:允许用户在 gRPC 元数据中通过身份验证和函数 ID 调用函数,利用基于 Protobuf 消息的通用数据。
使用函数 ID 的 HTTP 调用示例
1curl --request POST \
2 --url https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/eb1100de-60bf-4e9a-8617-b7d4652e0c37 \
3 --header "Authorization: Bearer $API_KEY" \
4 --header 'Accept: application/json' \
5 --header 'Content-Type: application/json' \
6 --data '{
7 "messages": [
8 {
9 "role": "user",
10 "content": "Hello"
11 }
12 ],
13 "temperature": 0.2,
14 "top_p": 0.7,
15 "max_tokens": 512
16 }'
HTTP (轮询)#
NVCF 采用 长轮询 进行函数调用和结果检索。但是,调用 API 可以用作同步阻塞 API,最长超时时间为 20 分钟。
轮询响应超时时间默认为 1 分钟,并且可以通过在请求中设置 HTTP 标头 NVCF-POLL-SECONDS 配置为最长 20 分钟,请参阅 API 文档。
当您发出函数调用请求时,NVCF 将保持您的请求打开轮询响应周期,然后返回以下内容之一
HTTP 状态 200已完成结果HTTP 状态 202轮询响应收到轮询响应后,您的客户端应立即轮询 NVCF 以检索您的结果。
示例
以下是从 示例存储库 中的任何“echo”容器构建的“echo”函数的调用。
1curl --location 'https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/{functionId}' \
2--header 'Content-Type: application/json' \
3--header "Authorization: Bearer $API_KEY" \
4--data '{
5 "inputs": [
6 {
7 "name": "message",
8 "shape": [
9 1
10 ],
11 "datatype": "BYTES",
12 "data": [
13 "Hello"
14 ]
15 },
16 {
17 "name": "response_delay_in_seconds",
18 "shape": [
19 1
20 ],
21 "datatype": "FP32",
22 "data": [
23 0.1
24 ]
25 }
26 ],
27 "outputs": [
28 {
29 "name": "echo",
30 "datatype": "BYTES",
31 "shape": [
32 1
33 ]
34 }
35 ]
36}'
注意
如果 NVCF 错误地响应,您的客户端应该但不要求必须保护自身,确保每秒不超过一次轮询请求。
这可以通过在发出轮询请求时保留 start_time 并在从该 start_time 开始最多休眠 1 秒钟,然后再发出另一个请求来实现。
这并不意味着您的客户端应始终添加休眠。
例如,如果自上次发出轮询请求以来已过去 0.1 秒,则您的客户端应休眠 0.9 秒。
如果自上次发出轮询请求以来已过去 5 秒,则您的客户端不应休眠。
初始调用后的轮询#
当使用 pexec 端点发出函数调用请求,并且返回 HTTP 状态 202 时,响应中将包含以下标头
NVCF-REQID: 调用请求 ID,称为requestId
然后,客户端应使用 requestId 轮询响应。
示例
1curl --location 'https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/{requestId}' \
2--header "Authorization: Bearer $API_KEY"
端点: GET /v2/nvcf/pexec/status/{requestId}
标头:
NVCF-POLL-SECONDS(可选): HTTP 轮询响应超时时间,如果不是默认值,则以秒为单位
参数:
requestId(路径,必需): 函数调用请求 ID,字符串($uuid)
响应:
200: 调用已完成。响应正文将是容器返回的响应的直通。202: 结果正在等待中。客户端应继续使用返回的请求 ID 进行轮询。302: 在这种情况下,结果位于不同的区域或是一个大型响应。客户端应使用Location响应标头中指定的完全限定端点来获取结果。客户端可以在从重定向区域检索结果时,在Authorization标头中使用相同的 API 密钥。
大型响应(302 状态代码)#
结果有效负载大小不得超过 5GB。如果您的有效负载超过 5MB,即 5MB < 结果大小 < 5GB,您将在响应中收到下载有效负载的引用。
当使用 pexec 调用 API 时,无论是在初始调用 API 调用期间还是在轮询时(GET /v2/nvcf/pexec/status/{requestId}),这将通过具有 HTTP 302 状态代码的响应来指示。Location 响应标头将包含完全限定的端点,并且没有响应正文。
您的客户端应配置为对 Location 响应标头中给出的 URL 发出新的 HTTP 请求。新的 HTTP 请求必须包含 Authorization 请求标头。
结果检索 URL 的生存时间 (TTL) 为 30 分钟。要了解有关资产的更多信息,请参阅 资产 API 和 资产流示例。
HTTP 流式传输#
此功能允许客户端接收数据作为事件流,从而无需轮询或重复请求以检查新数据。服务器通过长连接将事件发送到客户端,从而允许客户端实时接收更新。请注意,HTTP 流式传输请求使用相同的调用 API 端点。
先决条件
在 NVCF 上部署的云函数
熟悉上述基本 HTTP pexec 调用 API HTTP (轮询) 用法
客户端配置
客户端通过向 NVCF pexec 调用 API 端点发出 POST 请求来启动连接,包括标头
Accept: text/event-stream。1curl --request POST \ 2 --url https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/eb1100de-60bf-4e9a-8617-b7d4652e0c37 \ 3 --header "Authorization: Bearer $API_KEY" \ 4 --header 'Accept: text/event-stream' \ 5 --header 'Content-Type: application/json' \ 6 --data '{ 7 "messages": [ 8 { 9 "role": "user", 10 "content": "Hello" 11 } 12 ], 13 "temperature": 0.2, 14 "top_p": 0.7, 15 "max_tokens": 512 16 }'
收到带有适当标头的此请求后,NVCF 知道客户端已准备好接收流式数据。
处理服务器响应
如果来自推理容器的响应包含标头
Content-Type: text/event-stream,则客户端保持与 API 的连接打开并侦听数据。注意
NVCF 工作程序将从推理容器读取事件,最长为默认的 20 分钟,直到推理容器关闭连接为止,以较早者为准。不要创建无限事件流。即使客户端断开连接,工作程序仍将读取事件,这可能会占用您的函数,直到工作程序停止读取(如上所述)或请求超时。
从推理容器的响应中读取的数据会由事件缓冲,并作为正在进行的响应发送到 NVCF API。较小的事件更具交互性,但不应太小。如果太小,事件流包装器的大小可能会超过实际数据,从而导致客户端的数据传输量增加。允许的最大事件大小为 4MB。
此过程持续进行,直到流完成。
示例
请参阅我们的示例容器存储库中的 流式容器和客户端。
关闭行为
在正常关闭期间,NVCF API 会等待所有正在进行的事件流请求完成。
这些事件流请求有一个 5 分钟的全局请求超时时间。
HTTP 流式传输的优势#
减少延迟:客户端在数据可用时立即接收数据。
降低开销:无需重复的轮询请求。
灵活性:推理容器控制响应是否将流式传输,从而允许客户端实现保持一致,而无需考虑服务器端更改。
警告
此功能引入了长时间“阻塞”客户端请求的可能性,系统必须有效地管理这些请求,尤其是在关闭序列期间。
gRPC#
用户可以通过在 gRPC 元数据中包含其身份验证信息和特定函数 ID 来调用函数。
正在传输的数据是通用的,并且基于 Protobuf 消息。
每个模型或容器都将具有其自己唯一的 API,由其实现的 Protobuf 消息定义。
gRPC 连接在空闲时将保持活动状态 30 秒,这是不可配置的。
gRPC 函数没有输入请求大小限制。
代理主机和端点
gRPC 代理主机是
grpc.nvcf.nvidia.com:443。在调用您的 gRPC 端点时使用此主机。
云函数 gRPC 代理将尝试打开与您的函数实例的连接 30 秒,然后超时。
API 密钥和元数据密钥
将您的 API 密钥设置为调用凭据。可以使用 gRPC 对 调用凭据(有时称为每个 RPC 凭据)的支持来传递 API 密钥,或者手动将
authorization元数据设置为Bearer $API_Key。设置
function-id元数据密钥。可选地,设置
function-version-id元数据密钥。当客户端完成 gRPC 调用后,关闭 gRPC 客户端连接,这样您就不会占用函数的工作程序超过所需时间。
示例
请参阅我们的示例容器存储库中的完整 gRPC 服务器和客户端示例。
1 def call_grpc( 2 create_grpc_function: CreateFunctionResponse, # function def info 3 ) -> None: 4 channel = grpc.secure_channel("grpc.nvcf.nvidia.com:443", 5 grpc.ssl_channel_credentials()) 6 # proto generated grpc client 7 grpc_client = grpc_service_pb2_grpc.GRPCInferenceServiceStub(channel) 8 9 function_id = create_grpc_function.function.id 10 function_version_id = create_grpc_function.function.version_id 11 12 apiKey = "$API_KEY" 13 metadata = [("function-id", function_id), # required 14 ("function-version-id", function_version_id), # optional 15 ("authorization", "Bearer " + apiKey)] # required 16 17 # make 100 unary inferences in a row 18 for i in range(ITERATIONS): 19 # this would be your client, request, and body. 20 # it does not have any proto def restriction. 21 infer = grpc_client.ModelInfer(MODEL_INFER_REQUEST, 22 metadata=metadata) 23 _ = infer 24 logging.info(f"finished invoking {ITERATIONS} times")
注意
使用 gRPC 进行授权处理的官方术语是“调用凭据”。更多详细信息可以在 grpc.io 凭据类型文档中找到。提供的 Python 示例未展示这一点。相反,它演示了手动使用 API 密钥设置“authorization”。使用调用凭据将隐式地处理这一点。
状态和错误#
以下是 API 可以生成的状态和错误代码列表。
函数调用响应状态
如果客户端从 pexec 调用 API 调用收到 HTTP 状态代码 202,则客户端应轮询或使用标头中定义的 NVCF-REQID 发出 GET 请求。
NVCF-STATUS 标头可以具有以下值
pending-evaluation- 工作程序尚未接受请求。fulfilled- 进程已完成并带有结果。rejected- 请求被服务拒绝。errored- 工作程序处理期间发生错误。in-progress- 工作程序正在处理请求。
状态 fulfilled、rejected 和 errored 是已完成状态,您不应继续轮询。
推理容器状态代码和响应#
在您的推理端点响应中生成的错误消息从您的推理容器传播。这是一个示例
1{ 2 "type": "urn:inference-service:problem-details:bad-request", 3 "title": "Bad Request", 4 "status": 400, 5 "detail": "invalid datatype for input message", 6 "instance": "/v2/nvcf/pexec/functions/{functionId}", 7 "requestId": "{requestId}" 8}
错误响应的格式如下
如果错误源自您的推理容器,则错误响应中的
type字段将始终包含inference-service。响应状态代码将设置为您的推理容器返回的状态代码。这就是在
status和title字段中返回的内容。instance和requestId字段由工作程序自动填充。detail字段包含您的推理容器返回的错误消息正文。
设置错误详情字段
您的推理容器错误响应格式必须返回 JSON 并且必须设置 error 字段
1{ 2 "error": "put your error here" 3}
如果未设置此字段,则任何错误响应中的 detail 字段都将设置为通用的 Inference error 字符串。
警告
强烈建议从您的推理容器发出日志。有关在云函数 UI 中设置和查看日志的信息,请参阅 日志记录和指标。
NVCF API 状态代码#
有关并非从您的推理容器生成的其他可能的状态代码失败原因,请参阅 OpenAPI 文档。
有关函数状态,请参阅 函数生命周期。
注意
为了轻松区分源自 NVCF 的 API 或控制平面的错误,以及您自己的推理容器的错误,请确定 type 字段是否包含 inference-service(指示错误来自您的推理容器)
常见函数调用错误#
失败类型 |
描述 |
|---|---|
调用响应返回 4xx 或 5xx 状态代码 |
检查错误消息响应的“type”,如果 |
调用请求需要很长时间才能获得结果 |
使用函数指标 UI 或 API 检查函数的容量,以查看您的函数是否正在排队。考虑使用其他指标来检测您的容器,以便进行进一步调试 - NVCF 容器允许公共出口。将 |
调用响应返回 401 或 403 |
这表示调用者未获得授权,请确保 |
容器 OOM |
如果不使用其他指标来检测您的容器,则很难检测到这一点,除非您的容器发出指示内存不足的日志。我们建议在本地分析内存使用情况。对于本地和函数中的测试,您可以查看使用 本指南 的内存分配配置文件。 |