Elastic NIM#
NVIDIA Elastic NIM 是一种托管式 AI 推理服务架构,使企业能够在分布式加速云或数据中心基础设施上安全无缝地部署和扩展私有生成式 AI 模型端点。由 NVIDIA 编排和管理,专有数据永远不会离开企业混合虚拟私有云 (VPC) 的安全租户。
面向 Llama 3.x 的 NVIDIA Elastic NIM 推理服务现已面向企业开放,可在任何加速计算基础设施上安全扩展。本指南提供了在 NVIDIA 云函数 (NVCF) 上创建和部署 llama3-8b-instruct NIM 作为函数的逐步指南。
关于 NIM#
NVIDIA NIM 是一组易于使用的微服务,旨在加速在各种计算环境中部署用于生成式 AI 应用的基础模型。企业在生产环境中部署 NVIDIA NIM 时有两种选择 - 他们可以订阅由 NVIDIA 部署和管理的 Elastic NIM 服务(在其虚拟私有云或 DGX Cloud 中),或者导出、部署和自行管理 NIM。
利用 NVIDIA NIM 和 NVIDIA Elastic NIM 服务可确保大规模优化性能和托管服务的可靠性,同时兼顾数据隐私和邻近性。 主要的企业功能和优势包括:
NVIDIA Elastic NIM 部署在客户 VPC 中,使企业能够遵守公司治理并维护专有数据的安全性。
确保 NVIDIA 在任何加速基础设施上实现优化的性能,并基于 NVIDIA 在数据中心规模控制平面和集群管理方面的最佳实践。
跨混合云的统一编排确保分布式加速计算集群的高可用性和利用率。
持续的网络性能优化,实现全栈加速
按需突发至 DGX Cloud
NVIDIA 企业级支持和针对生产 AI 工作流程的服务级别协议。
先决条件#
设置#
访问具有可用 GPU 节点的 Kubernetes 集群。
使用 NVIDIA Cluster Agent 向 NVCF 注册 Kubernetes 集群并配置集群。
重要提示
请参阅集群设置与管理 以获取其他先决条件和分步说明。
访问客户端工作站或服务器。
安装 Docker 或 Podman 客户端
安装 Kubernetes 客户端 (kubectl),并能访问后端 Kubernetes API
确保客户端工作站/服务器可以从 NVIDIA NGC 下载文件。
NVIDIA NGC 账户,并有权访问企业目录和私有注册表。
注意
有关更多详细信息,请参阅 NGC 私有注册表用户指南。 私有注册表将在后续步骤中用于存储 llama3-8b-instruct NIM。
NGC 身份验证#
重要提示
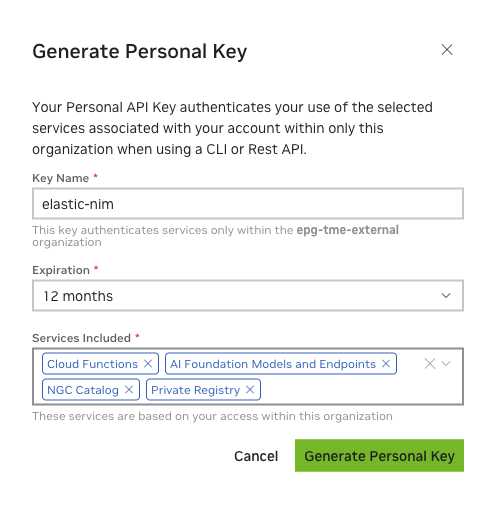
访问 NGC 资源需要 NGC 个人 API 密钥,密钥可以在此处生成。
创建 NGC 个人 API 密钥,并确保从“包含的服务”下拉列表中选择以下内容
云函数
AI 基础模型和端点
NGC 目录
私有注册表
注意
个人密钥允许您配置到期日期,使用操作按钮撤销或删除密钥,并根据需要轮换密钥。 有关密钥类型的更多信息,请参阅 NGC 用户指南。
警告
请将您的密钥保密并存放在安全的地方。 请勿共享或将其存储在其他人可以看到或复制的地方。
下载 NIM#
在客户端工作站/服务器上执行以下操作,从 NGC 中的公共注册表下载 llama3-8b-instruct NIM。
导出 NGC API 密钥#
将 API 密钥的值作为 API_KEY 环境变量传递给 docker run 命令
#NGC Organization ID. The name of the org, not the display name
export ORG_NAME=<org_name>
#NGC Personal API Key. Starts with nvapi-
export API_KEY=<your_key_here>
NGC CLI 工具#
本文档在一些步骤中使用了 NGC CLI 工具。 有关下载和配置该工具的信息,请参阅 NGC CLI 文档。
Docker 登录到 NGC#
要从 NGC 拉取 NIM 容器镜像,请首先使用以下命令向 NVIDIA 容器注册表进行身份验证
# with docker
$ docker login nvcr.io
Username: $oauthtoken
Password: <api key>
#with podman
$ podman login nvcr.io
Username: $oauthtoken
Password: <api key>
注意
使用 $oauthtoken 作为用户名,API 密钥作为密码。$oauthtoken 用户名是一个特殊名称,表示您将使用 API 密钥而不是用户名和密码进行身份验证。
列出可用的 NIM#
NVIDIA 定期发布可作为可下载 NIM 提供给 NVIDIA AI Enterprise 客户的新模型。
注意
使用 NGC cli 查看可用 NIM 的列表。
使用以下命令以 CSV 格式列出可用的 NIM。
ngc registry image list --format_type csv nvcr.io/nim/meta/\*
这应该会产生如下内容。
Name,Repository,Latest Tag,Image Size,Updated Date,Permission,Signed Tag?,Access Type,Associated Products Llama3-70b-instruct,nim/meta/llama3-70b-instruct,1.0.0,5.96 GB,"Jun 01, 2024",unlocked,True,LISTED,"nv-ai-enterprise, nvidia-nim-da" Llama3-8b-instruct,nim/meta/llama3-8b-instruct,1.0.0,5.96 GB,"Jun 01, 2024",unlocked,True,LISTED,"nv-ai-enterprise, nvidia-nim-da"
注意
在后续步骤中调用 docker run 命令时,您将使用仓库和最新标签字段。
注意
下载 NIM 后,您需要将其上传到 NGC 私有注册表。
使用 docker 或 podman 下载 NIM 容器镜像。
# with docker docker pull nvcr.io/nim/meta/llama3-8b-instruct:1.0.0 # with podman podman pull nvcr.io/nim/meta/llama3-8b-instruct:1.0.0
注意
如果您想在上传到私有注册表之前自定义 NIM 镜像,请使用 NIM 作为基础镜像创建 Dockerfile。 有关参考,请参阅 nim-deploy 仓库中的示例。
将 NIM 上传到私有注册表#
NVCF 要求 NIM 容器镜像在创建函数之前存在于私有注册表中。
使用已启用 NVCF 的 NGC Org 名称标记镜像,并将镜像命名为 nvcf-nim,标签为 meta-llama3-8b-instruct。
#with docker docker tag nvcr.io/nim/meta/llama3-8b-instruct:1.0.0 nvcr.io/$ORG_NAME/nvcf-nim:meta-llama3-8b-instruct #with podman podman tag nvcr.io/nim/meta/llama3-8b-instruct:1.0.0 nvcr.io/$ORG_NAME/nvcf-nim:meta-llama3-8b-instruct
将镜像推送到私有注册表
# with docker docker push nvcr.io/$ORG_NAME/nvcf-nim:meta-llama3-8b-instruct #with podman podman push nvcr.io/$ORG_NAME/nvcf-nim:meta-llama3-8b-instruct
创建函数#
现在 llama3-8b-instruct NIM 已下载并上传到私有注册表,接下来,我们将添加 NVCF 函数逻辑和依赖项。
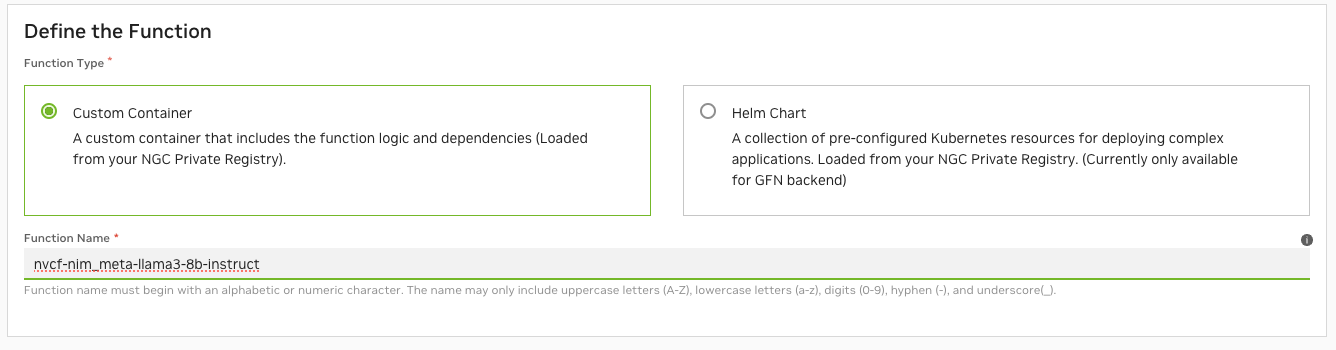
在 NGC NVCF 控制台中,从自定义容器创建函数
函数名称:nvcf-nim_meta-llama3-8b-instruct
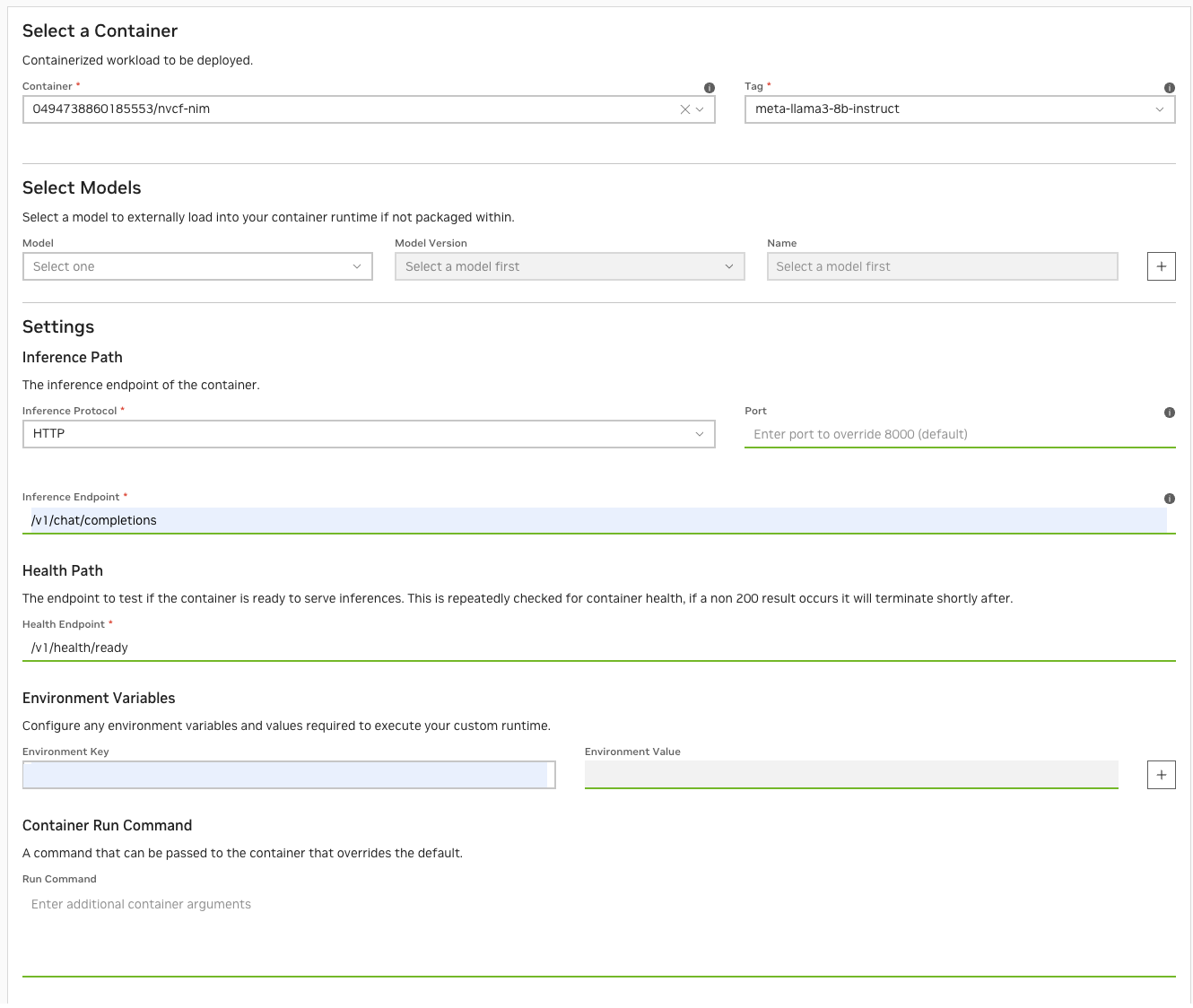
为函数定义以下设置
容器:从下拉列表中选择镜像
标签:从下拉列表中选择可用的标签
模型:留空
推理协议:
HTTP推理端点:
/v1/chat/completions健康检查路径:
/v1/health/ready使用 NVCF 密钥管理功能创建以下密钥:
NGC_API_KEY和$API_KEY
注意
NIM 将在启动期间从 NGC 下载 llama3-8b-instruct 模型到容器的临时磁盘。
点击“创建函数”
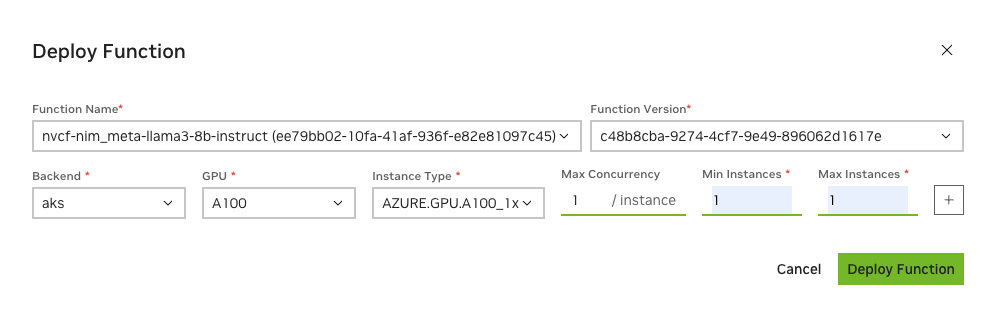
通过点击“部署版本”将函数部署到后端集群

在“部署函数”对话框中,填写以下必填字段
函数名称:预填充的函数名称
函数版本:预填充的最新函数版本
后端:一个或多个(通常为一个)集群的集合,用于部署,例如 - 诸如 Azure、OCI、GCP 之类的 CSP 或 NVIDIA 专用集群(如 GFN)。
GPU:预填充的 GPU 型号
实例类型:每种 GPU 类型可以支持一个或多个实例类型,这些类型是不同的配置,例如 CPU 核心数和每个节点的 GPU 数。
最大并发数:您的容器在任何给定时间可以处理的并发调用数
最小实例数:应在其上部署函数的最小实例数
最大实例数:允许您的函数自动扩展到的最大实例数
点击“部署函数”。
将显示以下对话框。“函数”状态将从“正在部署”更改为“活动”。
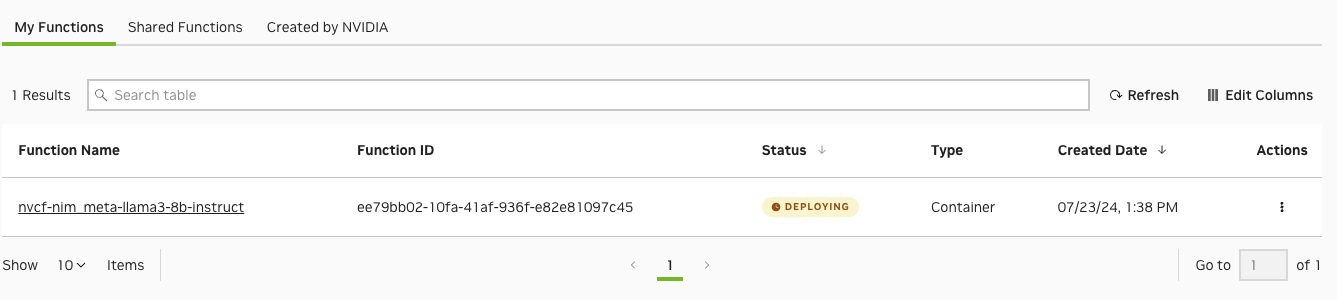
为方便起见,将函数 ID 设置为环境变量。 这将用于验证/测试函数。
$ export FUNCTION_ID=<your_function_id> $ curl -X POST "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/${FUNCTION_ID}" \ -H "Authorization: Bearer ${API_KEY}" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d '{ "model": "meta/llama3-8b-instruct", "messages": [ { "role":"user", "content":"Can you write me a happysong?" } ], "max_tokens": 32 }' #output {"id":"cmpl-3ae8dd639f74451e98c2a2e2873441ec","object":"chat.completion","created":1721774173,"model":"meta/llama3-8b-instruct","choices":[{"index":0,"message":{"role":"assistant","content":"I'd be delighted to write a happy song for you!\n\nHere's a brand new, original song, just for you:\n\n**Title:** \"Sparkle in"},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":19,"total_tokens":51,"completion_tokens":32}}%
验证函数部署#
NVCF 在 `nvcf-backend` 命名空间中为函数创建一个 pod。 pod 可能需要几分钟才能初始化,具体取决于镜像的大小和环境因素。
$ kubectl get all -n nvcf-backend
NAME READY STATUS RESTARTS AGE
pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e 2/2 Running 0 10m
在初始化期间,pod 日志不可用。 监控事件日志以获取状态
$ kubectl get events -n nvcf-backend
LAST SEEN TYPE REASON OBJECT MESSAGE
12m Normal Scheduled pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Successfully assigned nvcf-backend/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e to aks-ncvfgpu-13288136-vmss000000
12m Normal Pulled pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Container image "nvcr.io/qtfpt1h0bieu/nvcf-core/nvcf_worker_init:0.24.10" already present on machine
12m Normal Created pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Created container init
12m Normal Started pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Started container init
12m Normal Pulled pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Container image "nvcr.io/0494738860185553/nvcf-nim:meta-llama3-8b-instruct" already present on machine
12m Normal Created pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Created container inference
12m Normal Started pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Started container inference
12m Normal Pulled pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Container image "nvcr.io/qtfpt1h0bieu/nvcf-core/nvcf_worker_utils:2.24.2" already present on machine
12m Normal Created pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Created container utils
12m Normal Started pod/0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Started container utils
25m Normal Killing pod/0-sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d Stopping container inference
25m Normal Killing pod/0-sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d Stopping container utils
12m Normal InstanceStatusUpdate spotrequest/sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Request accepted for processing
12m Normal InstanceCreation spotrequest/sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Creating 1 requested instances
12m Normal InstanceCreation spotrequest/sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e Created Pod Instance 0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e
12m Normal InstanceStatusUpdate spotrequest/sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e 0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e is running
25m Normal InstanceTermination spotrequest/sr-d4c0d756-1a30-41bd-afdb-b8f440ac5ce4 Stopped instance nvcf-backend/0-sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d
25m Normal InstanceStatusUpdate spotrequest/sr-d4c0d756-1a30-41bd-afdb-b8f440ac5ce4 0-sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d is terminated
23m Normal InstanceTermination spotrequest/sr-d4c0d756-1a30-41bd-afdb-b8f440ac5ce4 All instances terminated, request will be cleaned-up
23m Normal InstanceStatusUpdate spotrequest/sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d 0-sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d is terminated
23m Normal InstanceTermination spotrequest/sr-dca52008-f0ae-43ca-9f5a-ff9c4ca8c00d All instances terminated, request will be cleaned-up
一旦运行,如果磁盘上不存在模型,NIM 将在启动期间下载模型。 对于大型模型,这可能需要几分钟时间。
llama3-8b-instruct 的启动日志示例
$ kubectl logs 0-sr-60f3f280-10a3-42bd-945a-97dd9fc1e67e -n nvcf-backend
Defaulted container "inference" out of: inference, utils, init (init)
===========================================
== NVIDIA Inference Microservice LLM NIM ==
===========================================
NVIDIA Inference Microservice LLM NIM Version 1.0.0
Model: nim/meta/llama3-8b-instruct
Container image Copyright (c) 2016-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This NIM container is governed by the NVIDIA AI Product Agreement here:
https://www.nvidia.com/en-us/data-center/products/nvidia-ai-enterprise/eula/.
A copy of this license can be found under /opt/nim/LICENSE.
The use of this model is governed by the AI Foundation Models Community License
here: https://docs.nvda.net.cn/ai-foundation-models-community-license.pdf.
ADDITIONAL INFORMATION: Meta Llama 3 Community License, Built with Meta Llama 3.
A copy of the Llama 3 license can be found under /opt/nim/MODEL_LICENSE.
2024-07-23 22:27:23,428 [INFO] PyTorch version 2.2.2 available.
2024-07-23 22:27:24,016 [WARNING] [TRT-LLM] [W] Logger level already set from environment. Discard new verbosity: error
2024-07-23 22:27:24,016 [INFO] [TRT-LLM] [I] Starting TensorRT-LLM init.
2024-07-23 22:27:24,202 [INFO] [TRT-LLM] [I] TensorRT-LLM inited.
[TensorRT-LLM] TensorRT-LLM version: 0.10.1.dev2024053000
INFO 07-23 22:27:24.927 api_server.py:489] NIM LLM API version 1.0.0
INFO 07-23 22:27:24.929 ngc_profile.py:217] Running NIM without LoRA. Only looking for compatible profiles that do not support LoRA.
INFO 07-23 22:27:24.929 ngc_profile.py:219] Detected 1 compatible profile(s).
INFO 07-23 22:27:24.929 ngc_injector.py:106] Valid profile: 8835c31752fbc67ef658b20a9f78e056914fdef0660206d82f252d62fd96064d (vllm-fp16-tp1) on GPUs [0]
INFO 07-23 22:27:24.929 ngc_injector.py:141] Selected profile: 8835c31752fbc67ef658b20a9f78e056914fdef0660206d82f252d62fd96064d (vllm-fp16-tp1)
INFO 07-23 22:27:25.388 ngc_injector.py:146] Profile metadata: llm_engine: vllm
INFO 07-23 22:27:25.388 ngc_injector.py:146] Profile metadata: precision: fp16
INFO 07-23 22:27:25.388 ngc_injector.py:146] Profile metadata: feat_lora: false
INFO 07-23 22:27:25.388 ngc_injector.py:146] Profile metadata: tp: 1
INFO 07-23 22:27:25.389 ngc_injector.py:166] Preparing model workspace. This step might download additional files to run the model.
INFO 07-23 22:28:14.764 ngc_injector.py:172] Model workspace is now ready. It took 49.375 seconds
INFO 07-23 22:28:14.767 llm_engine.py:98] Initializing an LLM engine (v0.4.1) with config: model='/tmp/meta--llama3-8b-instruct-k3_wpocb', speculative_config=None, tokenizer='/tmp/meta--llama3-8b-instruct-k3_wpocb', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=8192, download_dir=None, load_format=auto, tensor_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), seed=0)
WARNING 07-23 22:28:15.0 logging.py:314] Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO 07-23 22:28:15.16 utils.py:609] Found nccl from library /usr/local/lib/python3.10/dist-packages/nvidia/nccl/lib/libnccl.so.2
INFO 07-23 22:28:16 selector.py:28] Using FlashAttention backend.
INFO 07-23 22:28:19 model_runner.py:173] Loading model weights took 14.9595 GB
INFO 07-23 22:28:20.644 gpu_executor.py:119] # GPU blocks: 27793, # CPU blocks: 2048
INFO 07-23 22:28:22 model_runner.py:973] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 07-23 22:28:22 model_runner.py:977] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
INFO 07-23 22:28:27 model_runner.py:1054] Graph capturing finished in 5 secs.
WARNING 07-23 22:28:28.194 logging.py:314] Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO 07-23 22:28:28.205 serving_chat.py:347] Using default chat template:
{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>
'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>
' }}{% endif %}
WARNING 07-23 22:28:28.420 logging.py:314] Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO 07-23 22:28:28.431 api_server.py:456] Serving endpoints:
0.0.0.0:8000/openapi.json
0.0.0.0:8000/docs
0.0.0.0:8000/docs/oauth2-redirect
0.0.0.0:8000/metrics
0.0.0.0:8000/v1/health/ready
0.0.0.0:8000/v1/health/live
0.0.0.0:8000/v1/models
0.0.0.0:8000/v1/version
0.0.0.0:8000/v1/chat/completions
0.0.0.0:8000/v1/completions
INFO 07-23 22:28:28.431 api_server.py:460] An example cURL request:
curl -X 'POST' \
'http://0.0.0.0:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-8b-instruct",
"messages": [
{
"role":"user",
"content":"Hello! How are you?"
},
{
"role":"assistant",
"content":"Hi! I am quite well, how can I help you today?"
},
{
"role":"user",
"content":"Can you write me a song?"
}
],
"top_p": 1,
"n": 1,
"max_tokens": 15,
"stream": true,
"frequency_penalty": 1.0,
"stop": ["hello"]
}'
INFO 07-23 22:28:28.476 server.py:82] Started server process [32]
INFO 07-23 22:28:28.477 on.py:48] Waiting for application startup.
INFO 07-23 22:28:28.478 on.py:62] Application startup complete.
INFO 07-23 22:28:28.480 server.py:214] Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
INFO 07-23 22:28:28.574 httptools_impl.py:481] 127.0.0.1:40948 - "GET /v1/health/ready HTTP/1.1" 503
INFO 07-23 22:28:29.75 httptools_impl.py:481] 127.0.0.1:40962 - "GET /v1/health/ready HTTP/1.1" 200
INFO 07-23 22:28:38.478 metrics.py:334] Avg prompt throughput: 0.3 tokens/s, Avg generation throughput: 1.5 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%
INFO 07-23 22:28:48.478 metrics.py:334] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%
故障排除#
问题:Pod 卡在“正在初始化”状态
此过程可能需要几分钟。 如果时间过长,请确保 API 个人密钥有效,并且事件日志中没有问题。
问题:Pod 卡在“Pending”状态
确保可以在集群中调度启用 GPU 的 pod。 检查 GPU 是否可用,并且不存在会阻止调度程序的污点。 有关更多信息,请参阅 GPU Operator 故障排除
问题:发送到 API 端点的推理请求未返回任何输出
确保 Authorization 标头中的 NGC 个人 API 密钥正确且具有适当的访问权限。 有关更多提示,请参阅 状态和错误。