函数创建#
本页介绍在云函数中创建函数的步骤。
注意
在创建函数之前,请确保您已安装并配置 NGC CLI 以使用 NGC 私有镜像仓库。
函数可以通过以下三种方式之一创建,这些方式在云函数 UI 中也可见。
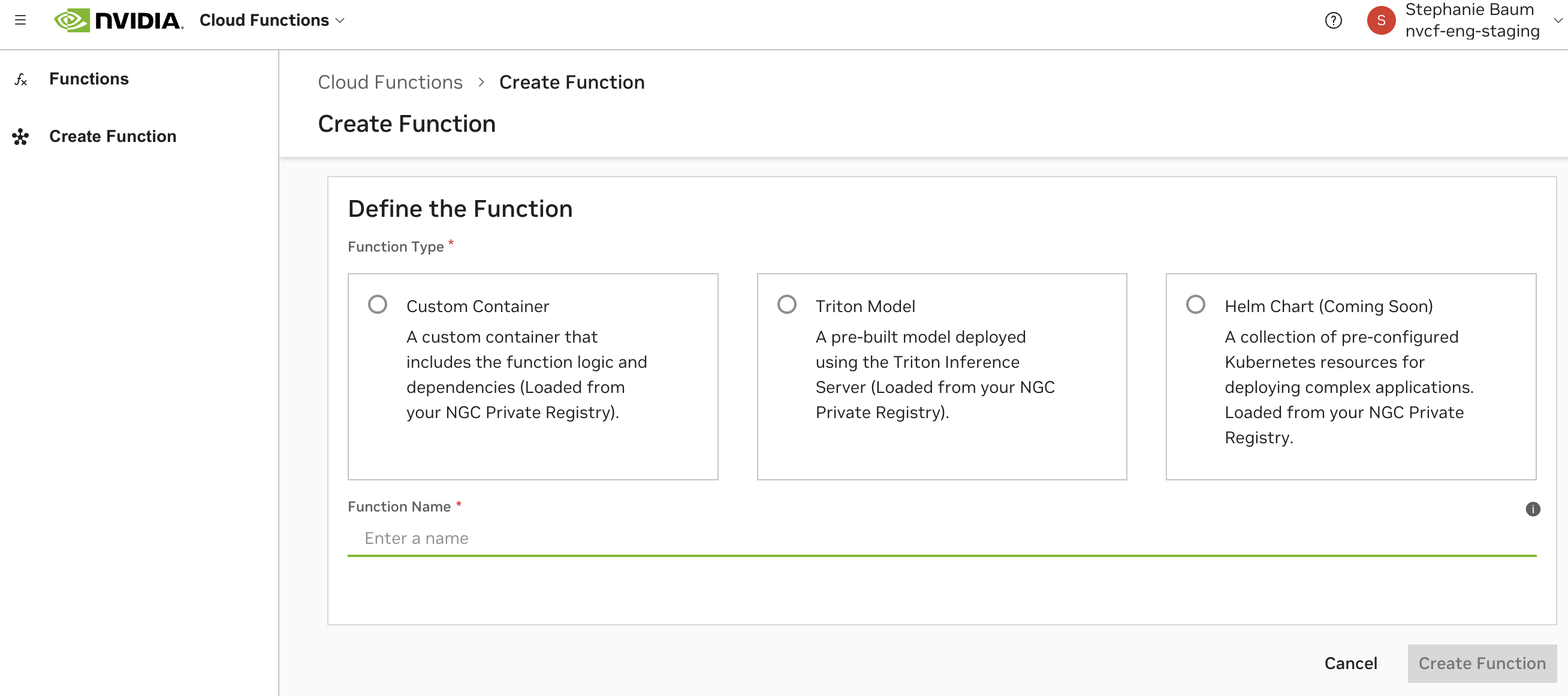
自定义容器
Helm Chart
支持跨多个容器的编排。适用于单个容器不够灵活的复杂用例。
需要将一个“迷你服务”容器定义为函数的推理入口点。
不支持部分响应报告、gRPC 或基于 HTTP 流式传输的调用。
请参阅基于 Helm 的函数创建。
使用 NGC 私有镜像仓库#
函数创建需要您的模型、容器、helm chart 和/或静态资源托管在 NGC 私有镜像仓库中,作为先决条件。请按照以下步骤优化配置 NGC CLI 以使用 NGC 私有镜像仓库和云函数。
生成 NGC 个人 API 密钥#
请导航至个人密钥页面执行此操作。有关更多详细信息,请参阅生成 NGC 个人 API 密钥。
注意
建议您生成的 API 密钥包含云函数和私有镜像仓库作用域,以实现理想的云函数工作流程。
下载并配置 NGC CLI#
导航至 NGC CLI 安装程序页面下载 CLI,并按照适用于您平台的安装说明进行操作。
在NGC 组织配置文件页面中查找您的 NGC 组织名称。这不是显示名称。例如:
qdrlnbkss123。运行
ngc config set并输入在上一步中生成的个人 API 密钥以及您的组织名称。如果出现提示,请默认选择no-team和no-ace。
1> ngc config set
2Enter API key [****bi9Z]. Choices: [<VALID_APIKEY>, 'no-apikey']: <api key>
3Enter CLI output format type [json]. Choices: ['ascii', 'csv', 'json']: json
4Enter org [ax3ysqem02xw]. Choices: ['$ORG_NAME']: <org name>
5Enter team [no-team]. Choices: ['no-team']:
6Enter ace [no-ace]. Choices: ['no-ace']:
使用 NGC Docker Registry 进行身份验证#
运行
docker login nvcr.io并输入以下内容,请注意$oauthtoken是要输入的实际字符串,而 <api key> 是在第一步中生成的个人 API 密钥。
1> docker login nvcr.io
2Username: $oauthtoken
3Password: $API_KEY
(可选)将容器推送到 NGC 私有镜像仓库#
现在您应该能够将容器推送到 NGC 私有镜像仓库。或者,通过从 示例存储库推送示例容器来验证这一点
首先克隆并构建 docker 镜像。
1> git clone https://github.com/NVIDIA/nv-cloud-function-helpers.git
2> cd nv-cloud-function-helpers/examples/fastapi_echo_sample
3> docker build . -t fastapi_echo_sample
现在标记并将 docker 镜像推送到 NGC 私有镜像仓库。
1> docker tag fastapi_echo_sample:latest nvcr.io/$ORG_NAME/fastapi_echo_sample:latest
2> docker push nvcr.io/$ORG_NAME/fastapi_echo_sample:latest
警告
请注意,在标记和推送到 nvcr.io 时,路径中的任何其他斜杠都将被私有镜像仓库检测为指定团队。这很可能不是您想要的。
完成后,您现在可以在NGC 私有镜像仓库容器页面中看到新的容器,并且它可用于函数创建。
使用 NGC Docker Registry 和云函数的最佳实践#
容器版本控制#
确保您标记为部署到生产环境的任何资源不仅仅使用“latest”,并且遵循标准的版本控制约定。
在自动扩展期间,函数扩展任何其他实例都将拉取相同的指定容器镜像和版本。如果版本设置为“latest”,并且“latest”容器镜像在实例扩展之间更新,则可能导致未定义的行为。
创建的函数版本是不可变的,这意味着在不创建函数新版本的情况下,无法更新函数的容器镜像和版本。
NGC 团队的使用#
为了更轻松地处理授权和可访问性,我们建议将您的容器、helm chart、模型和资源推送到 NGC 组织的根目录(即“无团队”),而不是组织内的团队。
请注意,在标记和推送到
nvcr.io时,路径中的任何其他斜杠都将被检测为 NGC 团队。
基于容器的函数创建#
基于容器的函数需要构建和推送与云函数兼容的 Docker 容器镜像到 NGC 私有镜像仓库。
资源#
容器端点#
可以在容器内实现任何服务器,只要它实现以下内容
对于基于 HTTP 的函数,一个健康检查端点,成功时返回 200 HTTP 状态代码。
对于基于 gRPC 的函数,一个标准的 gRPC 健康检查。请参阅这些文档以获取更多信息,另请参阅gRPC 健康检查。
一个推理端点(此端点将在函数调用期间被调用)
这些端点预计将在同一端口上提供服务,该端口定义为 inferencePort。
警告
云函数在您的容器上保留以下端口用于内部监控和指标
端口
8080端口
8010
云函数还期望容器中的以下目录保持只读状态以用于缓存目的
/config/目录在
/config/内创建的嵌套目录
编写 FastAPI 容器#
只要容器实现了具有上述端点的服务器,就可以将任何容器与云函数一起使用。以下是与云函数兼容的基于 FastAPI 的容器示例。克隆完整示例。
创建 “requirements.txt” 文件#
1fastapi==0.110.0
2uvicorn==0.29.0
实现服务器#
1import os
2import time
3import uvicorn
4from pydantic import BaseModel
5from fastapi import FastAPI, status
6from fastapi.responses import StreamingResponse
7
8
9app = FastAPI()
10
11class HealthCheck(BaseModel):
12 status: str = "OK"
13
14# Implement the health check endpoint
15@app.get("/health", tags=["healthcheck"], summary="Perform a Health Check", response_description="Return HTTP Status Code 200 (OK)", status_code=status.HTTP_200_OK, response_model=HealthCheck)
16def get_health() -> HealthCheck:
17 return HealthCheck(status="OK")
18
19class Echo(BaseModel):
20 message: str
21 delay: float = 0.000001
22 repeats: int = 1
23 stream: bool = False
24
25
26# Implement the inference endpoint
27@app.post("/echo")
28async def echo(echo: Echo):
29 if echo.stream:
30 def stream_text():
31 for _ in range(echo.repeats):
32 time.sleep(echo.delay)
33 yield f"data: {echo.message}\n\n"
34 return StreamingResponse(stream_text(), media_type="text/event-stream")
35 else:
36 time.sleep(echo.delay)
37 return echo.message*echo.repeats
38
39# Serve the endpoints on a port
40if __name__ == "__main__":
41 uvicorn.run(app, host="0.0.0.0", port=8000, workers=int(os.getenv('WORKER_COUNT', 500)))
请注意,在上面的示例中,函数在创建期间的配置将是
推理协议:HTTP
推理端点:
/echo健康端点:
/health推理端口(也用于健康检查):
8000
创建 Dockerfile#
1FROM python:3.10.13-bookworm
2
3ENV WORKER_COUNT=10
4
5WORKDIR /app
6
7COPY requirements.txt ./
8
9RUN python -m pip install --no-cache-dir -U pip && \
10 python -m pip install --no-cache-dir -r requirements.txt
11
12COPY http_echo_server.py /app/
13
14CMD uvicorn http_echo_server:app --host=0.0.0.0 --workers=$WORKER_COUNT
构建容器并创建函数#
请参阅快速入门以了解剩余步骤。
编写 PyTriton 容器#
NVIDIA 的 PyTriton 是 Triton 推理服务器的 Python 原生解决方案。最低版本要求为 0.3.0。
创建 “requirements.txt” 文件#
此文件应列出您的模型所需的 Python 依赖项。
将 nvidia-pytriton 添加到您的
requirements.txt文件。
以下是 requirements.txt 文件的示例
1--extra-index-url https://pypi.ngc.nvidia.com
2opencv-python-headless
3pycocotools
4matplotlib
5torch==2.1.0
6nvidia-pytriton==0.3.0
7numpy
创建 “run.py” 文件#
您的
run.py文件(或类似的 Python 文件)需要定义一个 PyTriton 模型。这包括导入您的模型依赖项,使用
__init__函数、_infer_fn函数和一个run函数创建 PyTritonServer 类,该函数提供 inference_function,定义模型名称、输入和输出以及可选配置。
以下是 run.py 文件的示例
1import numpy as np
2from pytriton.model_config import ModelConfig, Tensor
3from pytriton.triton import Triton, TritonConfig
4import time
5....
6class PyTritonServer:
7 """triton server for timed_sleeper"""
8
9 def __init__(self):
10 # basically need to accept image, mask(PIL Images), prompt, negative_prompt(str), seed(int)
11 self.model_name = "timed_sleeper"
12
13 def _infer_fn(self, requests):
14 responses = []
15 for req in requests:
16 req_data = req.data
17 sleep_duration = numpy_array_to_variable(req_data.get("sleep_duration"))
18 # deal with header dict keys being lowerscale
19 request_parameters_dict = uppercase_keys(req.parameters)
20 time.sleep(sleep_duration)
21 responses.append({"sleep_duration": np.array([sleep_duration])})
22
23 return responses
24
25 def run(self):
26 """run triton server"""
27 with Triton(
28 config=TritonConfig(
29 http_header_forward_pattern="NVCF-*", # this is required
30 http_port=8000,
31 grpc_port=8001,
32 metrics_port=8002,
33 )
34 ) as triton:
35 triton.bind(
36 model_name="timed_sleeper",
37 infer_func=self._infer_fn,
38 inputs=[
39 Tensor(name="sleep_duration", dtype=np.uint32, shape=(1,)),
40 ],
41 outputs=[Tensor(name="sleep_duration", dtype=np.uint32, shape=(1,))],
42 config=ModelConfig(batching=False),
43 )
44 triton.serve()
45if __name__ == "__main__":
46 server = PyTritonServer()
47 server.run()
创建 “Dockerfile”#
在您的模型目录中创建一个名为
Dockerfile的文件。强烈建议使用 NVIDIA 优化的容器(如 CUDA、Pytorch 或 TensorRT)作为您的基础容器。它们可以从 NGC Catalog 下载。
确保在您的
Dockerfile中安装您的 Python requirements。复制您的模型源代码和模型权重,除非您计划将它们托管在 NGC 私有镜像仓库中。
以下是 Dockerfile 的示例
1FROM nvcr.io/nvidia/cuda:12.1.1-devel-ubuntu22.04
2RUN apt-get update && apt-get install -y \
3 git \
4 python3 \
5 python3-pip \
6 python-is-python3 \
7 libsm6 \
8 libxext6 \
9 libxrender-dev \
10 curl \
11 && rm -rf /var/lib/apt/lists/*
12WORKDIR /workspace/
13
14# Install requirements file
15COPY requirements.txt requirements.txt
16RUN pip install --no-cache-dir --upgrade pip
17RUN pip install --no-cache-dir -r requirements.txt
18ENV DEBIAN_FRONTEND=noninteractive
19
20# Copy model source code and weights
21COPY model_weights /models
22COPY model_source .
23COPY run.py .
24
25# Set run command to start PyTriton to serve the model
26CMD python3 run.py
构建 Docker 镜像#
打开终端或命令提示符。
导航到
my_model目录。运行以下命令以构建 docker 镜像
docker build -t my_model_image .
将 my_model_image 替换为您 docker 镜像的所需名称。
推送 Docker 镜像#
在开始之前,请确保您已通过 NGC Docker Registry 进行了身份验证。
标记并将 docker 镜像推送到 NGC 私有镜像仓库。
1> docker tag my_model_image:latest nvcr.io/$ORG_NAME/my_model_image:latest
2> docker push nvcr.io/$ORG_NAME/my_model_image:latest
创建函数#
通过运行以下 curl 命令并使用
$API_KEY和您的$ORG_NAME,通过 API 创建函数。在此示例中,我们将推理端点定义为8000,并使用默认的推理和健康端点路径。
1API_KEY=<your api key>
2ORG_NAME=<your organization name>
3
4 curl --location 'https://api.ngc.nvidia.com/v2/nvcf/functions' \
5 --header 'Content-Type: application/json' \
6 --header 'Accept: application/json' \
7 --header "Authorization: Bearer $API_KEY" \
8 --data '{
9 "name": "my-model-function",
10 "inferenceUrl": "/v2/models/my_model_image/infer",
11 "inferencePort": 8000,
12 "containerImage": "nvcr.io/'$ORG_NAME'/my_model_image:latest",
13 "health": {
14 "protocol": "HTTP",
15 "uri": "/v2/health/ready",
16 "port": 8000,
17 "timeout": "PT10S",
18 "expectedStatusCode": 200
19 }
20 }'
更多示例#
请在此处查看更多与云函数兼容的 PyTriton 容器示例:此处。
基于 Triton 的容器配置#
NVIDIA 云函数旨在与基于 Triton Inference Server 的容器原生配合使用,包括利用服务器的指标和健康检查。
预构建的 Triton docker 镜像可以在 NGC 的容器目录中找到。最低版本要求为 23.04 (2.33.0)。
配置#
默认的健康检查 /v2/health/ready、端口 8000 和推理端点 (v2/models/$MODEL_NAME/infer) 可以自动与基于 Triton 的容器一起使用。
注意
docker 镜像的运行命令必须配置为以下内容
CMD tritonserver --model-repository=${MODEL_PATH} --http-header-forward-pattern NVCF-.*
以下是 Dockerfile 的示例
1FROM nvcr.io/nvidia/tritonserver:24.01-py3
2
3# install requirements file
4COPY requirements.txt requirements.txt
5RUN pip install --no-cache-dir --upgrade pip
6RUN pip install --no-cache-dir -r requirements.txt
7
8COPY model_repository /model_repository
9
10ENV CUDA_MODULE_LOADING LAZY
11ENV LOG_VERBOSE 0
12
13CMD tritonserver --log-verbose ${LOG_VERBOSE} --http-header-forward-pattern (nvcf-.*|NVCF-.*) \
14 --model-repository /model_repository/ --model-control-mode=none --strict-readiness 1
请参阅 Triton 容器的完整示例。
使用 NGC 模型和资源创建函数#
创建函数时,可以将模型和资源挂载到函数实例。模型将在 /config/models/{modelName} 和 /config/resources/{resourceName} 下可用,其中 modelName 和 resourceName 在 API 请求中指定。
以下示例说明如何将模型和资源添加到函数创建 API 调用中,以用于 echo 示例函数
1curl -X 'POST' \
2 'https://api.ngc.nvidia.com/v2/nvcf/functions' \
3 -H "Authorization: Bearer $API_KEY" \
4 -H 'accept: application/json' \
5 -H 'Content-Type: application/json' \
6 -d '{
7 "name": "echo_function",
8 "inferenceUrl": "/echo",
9 "containerImage": "nvcr.io/$ORG_NAME/echo:latest",
10 "apiBodyFormat": "CUSTOM",
11 "models": [
12 {
13 "name": "simple_int8",
14 "version": "1",
15 "uri": "v2/org/'$ORG_NAME'/models/simple_int8/1/files"
16 }
17 ],
18 "resources": [
19 {
20 "name": "simple_resource",
21 "version": "1",
22 "uri": "v2/org/'$ORG_NAME'/resources/simple_resource/1/files"
23 }
24 ]
25 }'
在容器内部,一旦函数实例部署,模型将挂载在 /config/models/simple_int8,资源将挂载在 /config/resources/simple_int8
创建基于 gRPC 的函数#
云函数支持通过 gRPC 调用函数。在函数创建期间,通过将“推理协议”或 inferenceUrl 字段设置为 /grpc,指定该函数为 gRPC 函数。
先决条件#
函数容器必须实现 gRPC 端口、端点和健康检查。健康检查预计由 gRPC 推理端口提供服务,无需定义单独的健康端点路径。
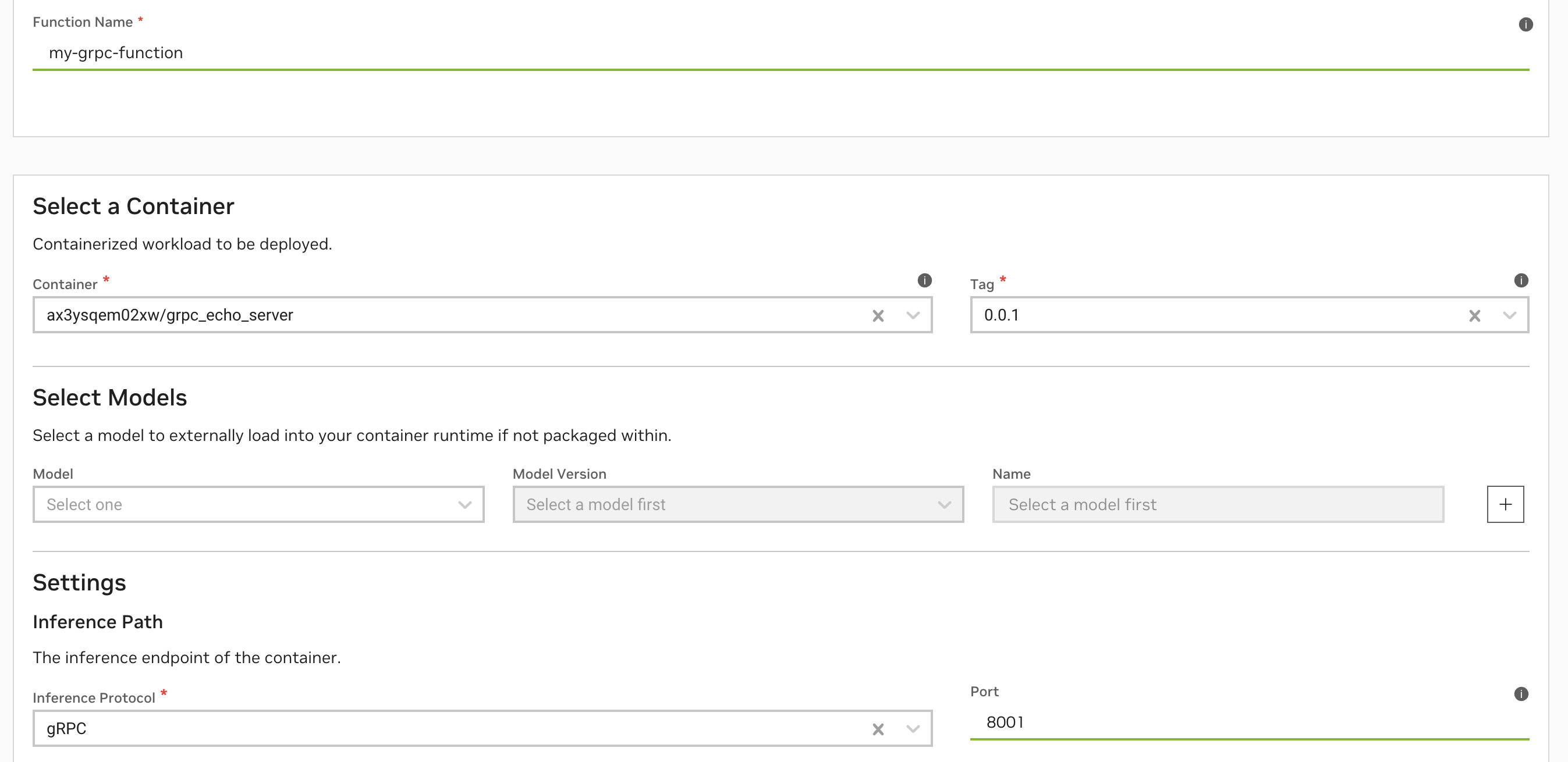
通过 UI 创建 gRPC 函数#
在函数创建页面中,将“推理协议”设置为 gRPC,并将端口设置为您的 gRPC 服务器已实现的端口。
通过 CLI 创建 gRPC 函数#
创建 gRPC 函数时,将 --inference-url 参数设置为 /grpc
1 ngc cf function create --inference-port 8001 --container-image nvcr.io/$ORG_NAME/grpc_echo_sample:latest --name my-grpc-function --inference-url /grpc
通过 API 创建 gRPC 函数#
创建 gRPC 函数时,将 inferenceURl 字段设置为 /grpc
1 curl --location 'https://api.ngc.nvidia.com/v2/nvcf/functions' \
2 --header 'Content-Type: application/json' \
3 --header 'Accept: application/json' \
4 --header "Authorization: Bearer $API_KEY" \
5 --data '{
6 "name": "my-grpc-function",
7 "inferenceUrl": "/grpc",
8 "inferencePort": 8001,
9 "containerImage": "nvcr.io/'$ORG_NAME'/grpc_echo_sample:latest"
10 }'
gRPC 函数调用#
有关如何验证和调用您的 gRPC 函数的详细信息,请参阅gRPC 调用。
创建低延迟流式传输(LLS 又名 GameStreamSDK/WebRTC)函数#
云函数支持使用 WebRTC 流式传输视频、音频和其他数据的功能。
以下是整体设置的详细图表。
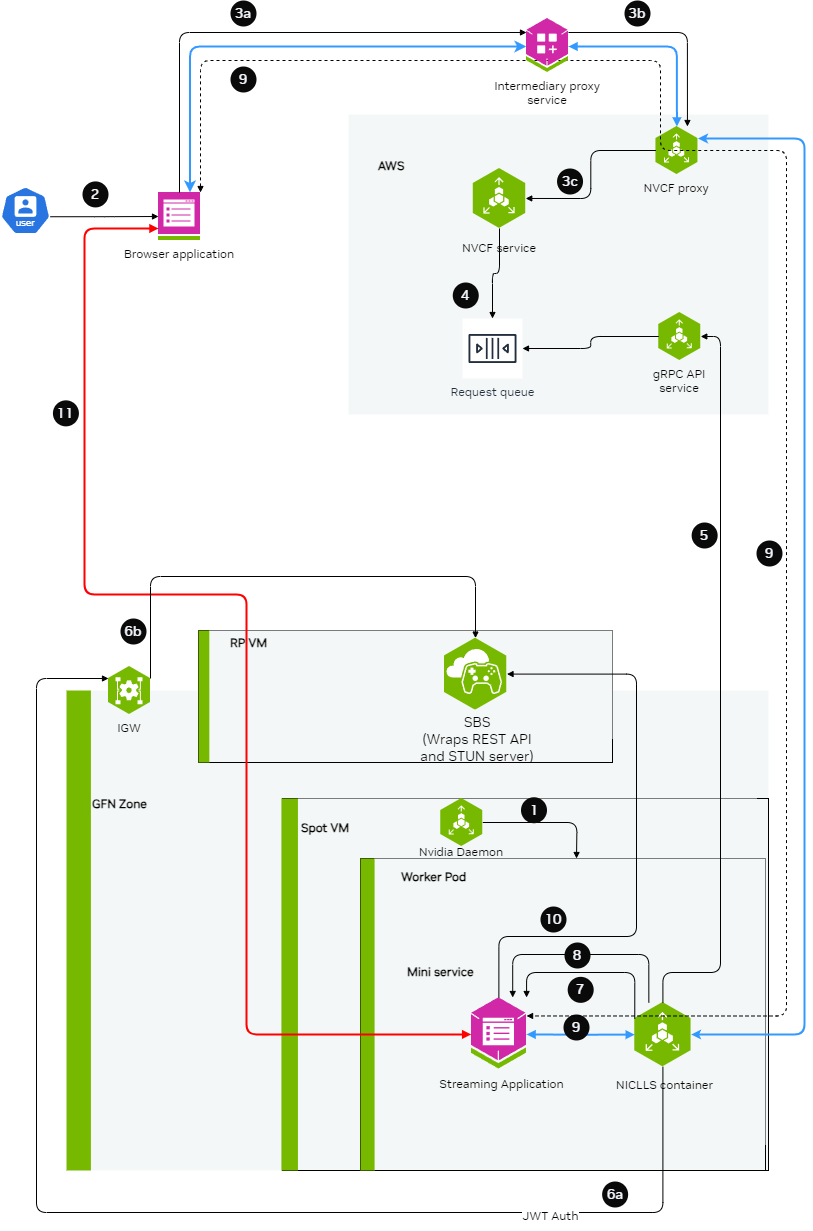
有关 LLS 流式传输函数的完整示例,请参阅NVCF LLS 函数示例。
目前,LLS 流式传输仅支持基于 GFN 的实例。可以使用单个容器或 helm chart。
构建流式传输服务器应用程序#
流式传输应用程序需要打包在容器内,并且应利用 StreamSDK。流式传输应用程序需要遵循以下准则:1. 在端口 CONTROL_SERVER_PORT 上公开一个 HTTP 服务器,其中包含以下 2 个端点
1. 健康端点: 仅当流式传输应用程序容器准备好开始流式传输会话时,此端点才应返回 200 HTTP 状态代码。如果流式传输应用程序容器不想为当前容器部署提供更多流式传输会话,则此端点应返回 HTTP 状态代码 500。.. code-block:: yaml
- 请求
- 端点
GET /v1/streaming/ready
- 响应
- 状态代码
200 OK 500 内部服务器错误
2. STUN creds 端点:此端点应接受 STUN 服务器的访问详细信息和凭据,并将其缓存在流式传输应用程序的内存中。当流式传输请求到达时,流式传输应用程序可以使用这些访问详细信息和凭据与 STUN 服务器通信,并请求打开用于流式传输的端口。.. code-block:: yaml
- 请求
- 端点
POST /v1/streaming/creds
- 标头
Content-Type: application/json
- 请求正文
- {
“stunIp”: “<string>”, “stunPort”: <int>, “username”: “<string>”, “password”: “<string>”
}
- 响应
- 状态代码
200 OK
在端口
STREAMING_SERVER_PORT上公开一个服务器,以接受 WebSocket 连接此服务器应公开一个端点
STREAMING_START_ENDPOINT
WebSocket 连接建立后准则
当浏览器客户端请求打开特定协议(例如 WebRTC)的端口时,流式传输应用程序需要请求 STUN 服务器打开端口。此端口应在 47998 到 48020 的范围内,在本文档中称为
STREAMING_PORT_BINDING_RANGE。
容器化准则
容器应确保
CONTROL_SERVER_PORT、STREAMING_SERVER_PORT和STREAMING_PORT_BINDING_RANGE由容器公开,并且可以从容器外部访问。如果需要连续支持多个会话,并在容器重新启动后开始,则在流式传输会话结束后退出容器。
创建 LLS 流式传输函数#
创建函数时,我们需要确保 functionType 设置为 STREAMING
1curl -X 'POST' \
2 'https://api.ngc.nvidia.com/v2/nvcf/functions' \
3 -H "Authorization: Bearer $API_KEY" \
4 -H 'accept: application/json' \
5 -H 'Content-Type: application/json' \
6 -d '{
7 "name": "'$STREAMING_FUNCTION_NAME'",
8 "inferenceUrl": "/sign_in",
9 "inferencePort": '$STREAMING_SERVER_PORT',
10 "health": {
11 "protocol": "HTTP",
12 "uri": "/v1/streaming/ready",
13 "port": '$CONTROL_SERVER_PORT',
14 "timeout": "PT10S",
15 "expectedStatusCode": 200
16 },
17 "containerImage": "'$STREAMING_CONTAINER_IMAGE'",
18 "apiBodyFormat": "CUSTOM",
19 "description": "'$STREAMING_FUNCTION_NAME'",
20 "functionType": "STREAMING"
21 }
22 }'
使用客户端连接到流式传输函数#
中介代理#
需要部署中介代理服务,以方便连接到流式传输函数。此中介代理执行以下功能
验证来自浏览器的用户令牌到中介代理
授权用户访问特定的流式传输函数
一旦用户通过身份验证和授权,修改传入的 websocket 连接,以在标头中附加 NVCF_API_KEY 和 STREAMING_FUNCTION_ID。
将 websocket 连接请求转发到 NVCF
Web 浏览器客户端#
使用代理,可以使用浏览器客户端连接到流。浏览器客户端需要由客户使用 raganrok 开发分支 0.0.1503 版本进行开发。请确保设置了以下标志: .. code-block:: javascript
const configData: RagnarokConfigData = {
overrideData: “disableworkerws=true”
}
ConfigureRagnarokSettings(configData);
可用的容器变量#
以下是通过调用消息的标头(由云函数自动填充)提供的可用变量的参考,可在容器内访问。
有关如何提取和使用其中一些变量的示例,请参阅NVCF 容器辅助函数。
名称 |
描述 |
|---|---|
NVCF-REQID |
此请求的请求 ID。 |
NVCF-SUB |
消息主题。 |
NVCF-NCAID |
函数的组织的 NCA ID。 |
NVCF-FUNCTION-NAME |
函数名称。 |
NVCF-FUNCTION-ID |
函数 ID。 |
NVCF-FUNCTION-VERSION-ID |
函数版本 ID。 |
NVCF-ASSET-DIR |
资产目录路径。不适用于 helm 部署。 |
NVCF-LARGE-OUTPUT-DIR |
大型输出目录路径。 |
NVCF-MAX-RESPONSE-SIZE-BYTES |
函数的最大响应大小(以字节为单位)。 |
NVCF-NSPECTID |
NVIDIA 保留变量。 |
NVCF-BACKEND |
函数部署所在的后端或“集群组”。 |
NVCF-INSTANCETYPE |
函数部署所在的实例类型。 |
NVCF-REGION |
函数部署所在的区域或区域。 |
NVCF-ENV |
如果部署在竞价型实例上,则为竞价型环境。 |
添加部分响应(进度)#
以下是在云函数中使用设置输出目录并有效跟踪和传达推理进度的说明。此功能仅支持基于容器的函数。
云函数会自动为您配置输出目录。要访问路径,只需读取
NVCF-LARGE-OUTPUT-DIR标头。NVCF-LARGE-OUTPUT-DIR指向特定requestId的目录。要启用部分进度报告,您需要存储部分和完整输出,并在输出目录中创建一个
progress文件。一旦输出文件和进度文件在正确的请求 ID 下正确设置在输出目录中,云函数将自动检测到它们。
当使用调用 API 来轮询响应时,
progress将作为标头NVCF-PERCENT-COMPLETE以及任何部分响应数据返回。
存储部分和完整输出#
当您的自定义 BLS 生成大型输出时,请使用 “*.partial” 扩展名将其临时保存在
NVCF-LARGE-OUTPUT-DIR目录中。例如,如果您要写入图像,请将其命名为image1.partial。一旦输出文件写入完成,请将其从 “*.partial” 重命名为其适当的扩展名。继续我们的示例,将
image1.partial重命名为image1.jpg。
创建进度文件#
云函数会主动监视输出目录中名为 progress 的文件。此文件用于将进度和部分响应传达回调用方。
此文件应包含格式正确的 JSON 数据。按如下方式构建 JSON 内容
1{
2 "id": "{requestId}",
3 "progress": 50,
4 "partialResponse": {
5 "exampleKey": "Insert any well-formed JSON here, but ensure its size is less than 250K"
6 }
7}
如果存在,请将 requestId 替换为实际的请求 ID。根据需要修改进度整数,范围从 0(刚开始)到 100(完全完成)。在 partialResponse 中,插入您要作为部分响应发送的任何 JSON 内容,确保其小于 250KB。
最佳实践#
始终使用 “.partial” 扩展名以避免发送部分或不完整的数据。
仅当写入过程完全完成时才重命名为最终扩展名。
确保您的进度文件保持在 250KB 以下,以保持效率并避免错误。
基于 Helm 的函数创建#
云函数支持基于 helm 的函数,用于跨多个容器进行编排。
先决条件#
警告
确保您的 helm chart 版本不包含 -。例如,v1 可以,但 v1-test 会导致问题。
helm chart 必须定义一个“迷你服务”容器,该容器将用作推理入口点。
您应该在函数定义期间设置
helmChartServiceName来提供 helm chart 中此服务的名称。这允许云函数与“迷你服务”端点进行通信并发出推理请求。
注意
helm chart 中定义的 servicePort 应用作函数创建期间提供的 inferencePort。否则,云函数将无法访问“迷你服务”。
确保您已配置了 NGC CLI,并将您的 helm chart 推送到了 NGC 私有镜像仓库。请参阅使用 NGC CLI 管理 Helm Charts。
密钥管理#
为了从 NGC 私有镜像仓库拉取定义为 helm chart 一部分的容器,请在 values.yaml 中定义 ngcImagePullSecretName。此值将在部署规范中用作 pod 的 spec.imagePullSecrets.name。
对于嵌套的 Helm chart,请在 values.yaml 中定义 global.ngcImagePullSecretName,它将在部署规范中 pod 的 spec.imagePullSecrets.name 下被引用。
警告
helm chart 中定义的容器应与 helm chart 本身从中拉取的 NGC 组织和团队相同。
创建基于 Helm 的函数#
确保您的 helm chart 已上传到 NGC 私有镜像仓库并符合上面列出的先决条件。
创建函数
在函数定义中包含以下附加参数
helmCharthelmChartServiceName
helmChart属性应设置为 NGC 模型注册表托管的 URL,该 URL 指向将部署“迷你服务”的 helm chart。请注意,此 helm chart URL 应该可以被最终部署函数的 NGC 组织访问。helm chart URL 应遵循以下格式:https://helm.ngc.nvidia.com/$ORG_ID/$TEAM_NAME/charts/$NAME-X.Y.Z.tgz例如,https://helm.ngc.nvidia.com/abc123/teamA/charts/nginx-0.1.5.tgz将是有效的 chart URL,但https://helm.ngc.nvidia.com/abc123/teamA/charts/nginx-0.1.5-hello.tgz将无效。helmChartServiceName用于检查 “mini-service” 是否已准备好进行推理,并被抓取以获取函数指标。目前,不支持模板化服务名称。这必须与您的 “mini-service” 的服务名称以及暴露的入口点端口相匹配。重要提示:Helm chart 名称不应包含下划线或其他特殊符号,因为这可能会在部署期间导致问题。
通过 API 创建示例
请参阅我们在本示例中使用的 示例 helm chart 以供参考。
以下是创建基于 helm 的函数的示例函数创建 API 调用
1curl -X 'POST' \
2 'https://api.ngc.nvidia.com/v2/nvcf/functions' \
3 -H "Authorization: Bearer $API_KEY" \
4 -H 'accept: application/json' \
5 -H 'Content-Type: application/json' \
6 -d '{
7 "name": "function_name",
8 "inferenceUrl": "v2/models/model_name/versions/model_version/infer",
9 "inferencePort": 8001,
10 "helmChart": "https://helm.ngc.nvidia.com/'$ORG_ID'/'$TEAM_NAME'/charts/inference-test-1.0.tgz",
11 "helmChartServiceName": "service_name",
12 "apiBodyFormat": "CUSTOM"
13}'
注意
对于基于 gRPC 的函数,请设置 "inferenceURL" : "/gRPC"。这向 Cloud Functions 发出信号,表明该函数正在使用 gRPC 协议,并且不希望暴露 /gRPC 端点以用于推理请求。
照常进行函数部署和调用。
限制#
- 当使用 helm charts 时,需要考虑以下限制
不支持自动挂载 NGC 模型和资源到您的容器。
对于函数容器内发生的任何下载(例如资产或模型),下载大小受 VM 上的磁盘空间限制 - 对于 GFN,这大约为 100GB,对于其他集群,此限制会有所不同。
不支持进度/部分响应报告,包括推理期间生成的任何其他工件。请考虑选择 HTTP 流式传输或 gRPC 双向支持。
此外,helm charts 必须符合某些安全标准才能部署为函数。这意味着某些 helm 和 Kubernetes 功能在 NVCF 后端受到限制。NVCF 将在函数创建时处理您的 helm chart,然后在部署时使用您的 Helm 值和其他部署元数据,以确保标准得到执行。
NVCF 可能会自动修改您的 chart 中的某些对象,使其符合这些标准;只有在修改不会破坏您的 chart 在目标后端安装时,才会这样做。可进行修改的可能区域将在下面的限制部分中注明。任何无法通过修改强制执行的标准都将在函数创建期间导致错误。
- 限制
Helm Chart 及其指定的所有容器必须托管在 NGC Private Registry 中。请按照这些步骤 将您的 helm chart 和容器上传到 NGC。
下面列出了 Helm Chart 命名空间下支持的 k8s 工件。其他工件将被拒绝
ConfigMaps
Secrets
Services - 仅限
type: ClusterIP或无PersistentVolumeClaims
Deployments
ReplicaSets
StatefulSets
Jobs
CronJobs
Pods
ServiceAccounts
Roles
Rolebindings
PersistentVolumeClaims(仅限 GFN 后端)
所有 Pod 及其定义 Pod 模板的资源都必须符合 Kubernetes Pod 安全标准 Baseline 和 Restricted 策略。许多这些限制会自动应用于您的 Pod 或 Pod 模板。除了这些限制之外
- 唯一允许的 Pod 或 Pod 模板卷类型是
configMapsecretpersistentVolumeClaim
不允许使用chart hooks;如果在 chart 中指定了它们,则不会执行。
Helm Chart 覆盖#
要覆盖您的 helm chart values.yml 中的键,您可以提供 configuration 参数,并以 JSON 格式提供相应的键值对,您希望在部署函数时覆盖这些键值对。
1curl -X 'POST' \
2 'https://api.ngc.nvidia.com/v2/nvcf/deployments/functions/fe6e6589-12bb-423a-9bf6-8b9d028b8bf4/versions/fe6e6589-12bb-423a-9bf6-8b9d028b8bf4' \
3 -H "Authorization: Bearer $API_KEY" \
4 -H 'accept: application/json' \
5 -H 'Content-Type: application/json' \
6 -d '{
7 "deploymentSpecifications": [{
8 "gpu": "L40",
9 "backend": "OCI",
10 "maxInstances": 2,
11 "minInstances": 1,
12 "configuration": {
13 "key_one": "<value>",
14 "key_two": { "key_two_subkey_one": "<value>", "key_two_subkey_two": "<value>" }
15 ...
16 },
17 {
18 "gpu": "T10",
19 "backend": "GFN",
20 "maxInstances": 2,
21 "minInstances": 1
22 }]
23 }'