概述
目录
概述#
Riva 处理完整管道的部署,这些管道可以由一个或多个受支持的 NVIDIA NeMo 模型和其他预处理/后处理组件组成。这些管道必须导出到高效的推理引擎,并针对目标平台进行优化。因此,Riva 服务器无法直接使用不受支持的 NVIDIA NeMo 模型,因为它们仅代表单个模型。
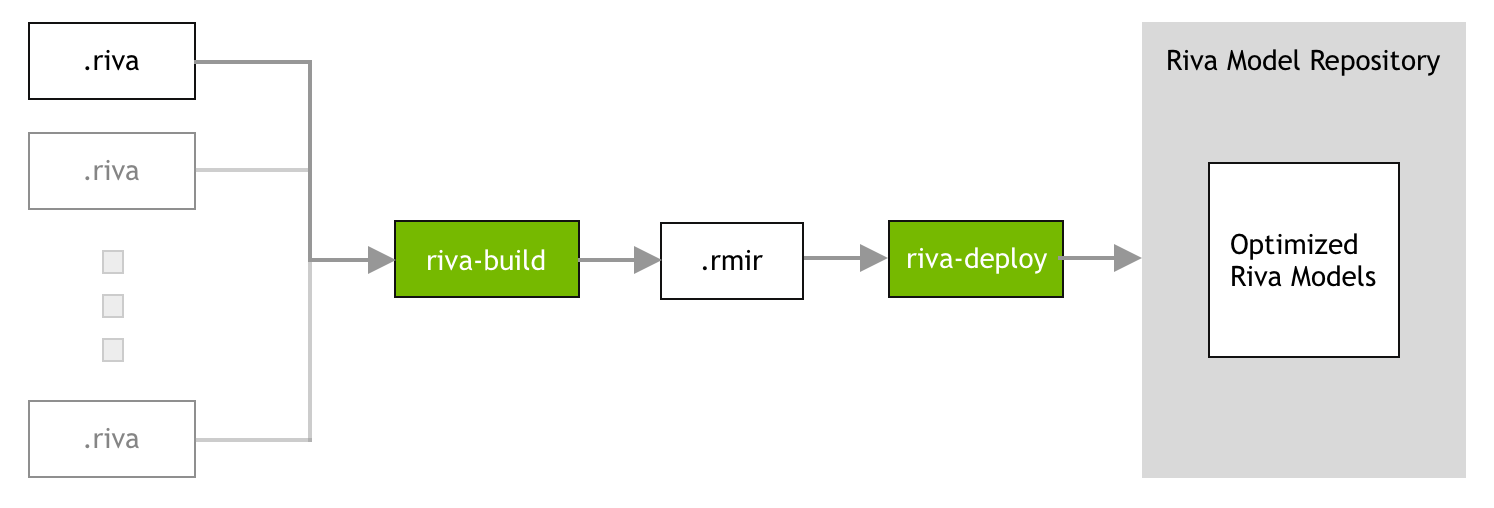
收集所有必需的工件(例如,模型、文件、配置和用户设置)并生成推理引擎的过程将称为 Riva 模型仓库生成。Riva Docker 镜像具有生成 Riva 模型仓库所需的所有工具,可以从 NGC 中拉取,如下所示
数据中心
docker pull nvcr.io/nvidia/riva/riva-speech:2.18.0
嵌入式
docker pull nvcr.io/nvidia/riva/riva-speech:2.18.0-l4t-aarch64
Riva 模型仓库生成分三个阶段完成
阶段 1: 开发阶段。要在 Riva 中创建模型,必须将模型检查点转换为 .riva 格式。您可以使用 NeMo 进一步开发这些 .riva 模型。有关更多信息,请参阅 使用 NeMo 进行模型开发 部分。
注意
对于嵌入式平台,阶段 1 必须在 Linux x86_64 工作站本身上执行,而不是在 NVIDIA Jetson 平台上执行。生成 .riva 文件后,阶段 2 和 阶段 3 必须在 Jetson 平台上执行。
阶段 2: 构建阶段。在构建阶段,部署 Riva 服务所需的所有必要工件(模型、文件、配置和用户设置)都收集到一个名为 RMIR(Riva 模型中间表示)的中间文件中。有关更多信息,请参阅 Riva Build 部分。
阶段 3: 部署阶段。在部署阶段,RMIR 文件将转换为 Riva 模型仓库,并且 NeMo 格式的神经网络将导出并优化以在目标平台上运行。部署阶段应在部署 Riva 服务器的物理集群上执行。有关更多信息,请参阅 Riva Deploy 部分。
使用您自己的数据#
许多用例需要使用新数据训练新模型或微调现有模型。在这些情况下,有一些准则需要遵循。其中许多准则也适用于推理时的输入。
如果可能,请使用无损音频格式。使用有损编解码器(如 MP3)可能会降低质量。
扩充训练数据。向音频训练数据添加背景噪声最初可能会降低准确性,但会提高鲁棒性。
如果使用抓取的文本,请限制词汇量大小。许多在线来源包含错别字或辅助代词和不常见的词语。删除这些可以改进语言模型。
如果可能,请使用至少 16kHz 的采样率,但不要重新采样。
如果使用 NeMo 微调 ASR 模型,请查阅 本教程。我们建议仅在有足够的数据(大约几百小时的语音)的情况下微调 ASR 模型。如果此类数据不可用,则更有效的方法可能是简单地在领域内文本语料库上调整 LM,而不是训练 ASR 模型。
无法保证 ASR 模型在训练后是否可流式传输。我们看到,随着更多训练(数千小时的语音,100-200 个 epoch),模型通常会获得更好的离线分数,而在线分数不会严重降低(但由于在线和离线评估之间的差异,仍然会降低到一定程度)。
使用 NeMo 进行模型开发#
NeMo 是一个基于 PyTorch 的开源工具包,用于会话 AI 研究,它公开了更多的模型和 PyTorch 内部结构。Riva 支持导入在 NeMo 中训练的受支持模型的能力。
有关更多信息,请参阅 NeMo 项目页面。
使用 NeMo2Riva 导出模型#
在 NVIDIA NeMo 中训练的模型具有 .nemo 格式。要在 Riva 中使用这些模型,请使用 nemo2riva 工具将模型检查点转换为 .riva 格式,以便使用 Riva 进行构建和部署。nemo2riva 工具当前已打包,可通过 Riva 快速入门脚本获得。
有关从 .nemo 导出到 .riva 格式的不同模型架构的详细说明,请参阅此 nemo2riva README。
Riva Build#
riva-build 工具负责部署准备。它唯一的输出是 Riva 中受支持服务的端到端管道的中间格式(称为 RMIR)。此工具可以将多种不同类型的模型作为输入。目前,支持以下管道
speech_recognition(用于 ASR)speech_synthesis(用于 TTS)punctuation(用于 NLP)translation(用于 NMT)
在 Riva 镜像中启动交互式会话。
数据中心
docker run --gpus all -it --rm \ -v <artifact_dir>:/servicemaker-dev \ -v <riva_repo_dir>:/data \ --entrypoint="/bin/bash" \ nvcr.io/nvidia/riva/riva-speech:2.18.0
嵌入式
docker run --gpus all -it --rm \ -v <artifact_dir>:/servicemaker-dev \ -v <riva_repo_dir>:/data \ --entrypoint="/bin/bash" \ nvcr.io/nvidia/riva/riva-speech:2.18.0-l4t-aarch64
其中
<artifact_dir>是包含.riva文件和准备 Riva 模型仓库所需的其他工件的文件夹或 Docker 卷。<riva_repo_dir>是生成 Riva 模型仓库的文件夹或 Docker 卷。
从容器内运行
riva-build命令。riva-build <pipeline> \ /servicemaker-dev/<rmir_filename>:<encryption_key> \ /servicemaker-dev/<riva_filename>:<encryption_key> \ <optional_args>
其中
<pipeline>必须是以下之一speech_recognitionspeech_synthesisqatoken_classificationintent_slottext_classificationpunctuationtranslation
<rmir_filename>是生成的 RMIR 文件的名称。<riva_filename>是要用作输入的riva文件的名称。<args>是用于配置 Riva 服务的可选参数。以下部分讨论了配置 ASR、NLP 和 TTS 服务的不同方法。<encryption_key>是可选的。如果生成.riva文件时没有加密密钥,则输入/输出文件将使用<riva_filename>而不是<riva_filename>:<encryption_key>指定。
默认情况下,如果名为 <rmir_filename> 的文件已存在,则不会覆盖它。要强制覆盖 <rmir_filename>,请使用 -f 或 --force 参数。例如,riva-build <pipeline> -f ...
有关可以传递给 riva-build 以自定义 Riva 管道的可选参数的详细信息,请运行
riva-build <pipeline> -h
Riva Deploy#
riva-deploy 工具将一个或多个 RMIR 文件和一个目标模型仓库目录作为输入。它负责执行以下功能
模型优化: 优化冻结的检查点,以便在目标 GPU 上进行推理。
配置生成: 为后端组件(包括模型集成)生成配置文件。
Riva 模型仓库可以从 Riva .rmir 文件中使用以下命令生成
riva-deploy /servicemaker-dev/<rmir_filename>:<encryption_key> /data/models
默认情况下,如果目标文件夹(即,上面示例中的 /data/models/)已存在,则不会覆盖它。要强制覆盖目标文件夹,请使用 -f 或 --force 参数。例如,riva-deploy -f ...
构建过程#
对于您的自定义训练模型,请参阅您模型类型的 riva-build 阶段(ASR、NLP、NMT、TTS)。在此阶段结束时,您将拥有自定义模型的 RMIR 存档。
部署过程#
此时,您已经拥有了 RMIR 存档。现在,您有两种部署此 RMIR 的选项。
选项 1: 使用快速入门脚本 (riva_init.sh 和 riva_start.sh) 以及 config.sh 中的相应参数。
选项 2: 手动运行 riva-deploy,然后使用目标模型仓库启动 riva-server。
使用快速入门脚本进行部署(推荐)#
快速入门脚本 (riva_init.sh 和 riva_start.sh) 使用特定目录进行操作。此目录由 config.sh 中指定的变量 $riva_model_loc 定义。
对于数据中心,默认情况下,这设置为使用 Docker 卷,但是,您可以将任何本地目录指定给此变量。
对于嵌入式平台,这设置为名为 model_repository 的本地目录,该目录在快速入门脚本所在的同一位置创建。
默认情况下,riva_init.sh 快速入门脚本执行以下操作
将
config.sh中定义和启用的 RMIR 从 NGC 下载到$riva_model_loc中的子目录,特别是$riva_model_loc/rmir。为
$riva_model_loc/rmir中的每个 RMIR 执行riva-deploy,以在$riva_model_loc/models中生成其对应的 Riva 模型仓库。
当您执行 riva_start.sh 时,它通过将此 $riva_model_loc 目录挂载到容器内的 /data 来启动 riva-speech 容器。
要部署您自己的自定义 RMIR 或 RMIR 集,请将它们放置在 $riva_model_loc/rmir 目录中。确保您已在 config.sh 中的 $riva_model_loc 变量中定义了一个目录(您有权访问),因为您需要将您的 RMIR 复制到其子目录中。如果子目录 $riva_model_loc/rmir 不存在,请创建它,然后将您的自定义 RMIR 复制到那里。
如果您想跳过从 NGC 下载默认 RMIR,请将 $use_existing_rmirs 变量设置为 true。在您的自定义 RMIR 位于此 $riva_model_loc/rmir 目录中之后,运行 riva_init.sh 以对您的自定义 RMIR 以及该目录中存在的任何其他 RMIR 执行 riva-deploy,并在 $riva_model_loc/models 中生成 Riva 模型仓库。
接下来,运行 riva_start.sh 以启动 riva-speech 容器并加载您的自定义模型以及 $riva_model_loc/models 中存在的任何其他模型。如果您只想加载您的特定模型,请确保 $riva_model_loc/models 为空,或者在运行 riva_init.sh 之前不存在 /models 目录。riva_init.sh 脚本会创建 /rmir 和 /models 子目录(如果它们尚不存在)。
有关查看日志和使用客户端容器测试模型的更多信息,请参阅 本地 (Docker) 部分。
使用 riva-deploy 和 Riva Speech Container(高级)#
执行
riva-deploy。有关riva-deploy的简要概述,请参阅 Riva Deploy 部分。riva-deploy -f <rmir_filename>:<encryption_key> /data/models
如果您的
.rmir存档已加密,则需要在 RMIR 文件名的末尾包含:<encryption_key>。否则,这是不必要的。上面的命令在
/data/models中创建 Riva 模型仓库。如果您想写入/data/models以外的任何其他位置,则需要在某些模型仓库内的配置文件中嵌入式工件目录中进行其他手动更改,这些模型仓库具有模型特定的工件(例如类标签)。因此,除非您熟悉 Triton Inference Server 模型仓库配置,否则请坚持使用/data/models。使用
docker run手动启动riva-serverDocker 容器。在为您的自定义模型生成 Riva 模型仓库后,在该目标仓库上启动 Riva 服务器。以下命令假定您在/data/models中生成了模型仓库。docker run -d --gpus 1 --init --shm-size=1G --ulimit memlock=-1 --ulimit stack=67108864 \ -v /data:/data \ -p 50051:50051 \ -e "CUDA_VISIBLE_DEVICES=0" \ --name riva-speech \ nvcr.io/nvidia/riva/riva-speech:2.18.0 \ start-riva --riva-uri=0.0.0.0:50051 --nlp_service=true --asr_service=true --tts_service=true
此命令启动 Riva Speech Service API 服务器,类似于快速入门脚本
riva_start.sh。例如Starting Riva Speech Services > Waiting for Riva server to load all models...retrying in 10 seconds > Waiting for Riva server to load all models...retrying in 10 seconds > Waiting for Riva server to load all models...retrying in 10 seconds > Riva server is ready…
验证服务器是否已正确启动,并检查
docker logs riva-speech的输出是否显示I0428 03:14:50.440955 1 riva_server.cc:71] Riva Conversational AI Server listening on 0.0.0.0:50051