语音识别和 Riva ASR 定制基础知识
目录
语音识别和 Riva ASR 定制基础知识#
即使使用最佳的 ASR 解决方案,系统在用例中的性能也可能无法满足要求。人类水平的准确率通常估计为 > 95%(即 < 5% 的词错误率 (WER))。但是,可能有些领域需要接近 99% 的准确率。此外,人类转录员还需具备领域专业知识。法律文件方面的专家在医学文件方面表现不佳,反之亦然。这同样适用于自动语音识别解决方案。
要使现有解决方案适应您的领域,需要基本了解语音识别的工作原理。如果不了解这一点,人们会发现很难理解语音识别系统的哪些组件需要定制。
自动语音识别基础知识#
语音识别是将人发出的声音单元(音素)序列转换为语言的单词序列的过程。如果没有上下文语言,音素序列就没有意义。例如,对于不懂普通话的人来说,听普通话语音毫无意义。即使有上下文语言,当文本上下文有限时,我们仍然会遇到问题。例如
我需要你识别语音
我需要你破坏一个漂亮的海滩
我需要你破坏一个漂亮的水蜜桃
那里有一个快乐的人们居住的小镇
他们有一个快乐的人们居住的小镇
人类的语音识别#
就人类而言,语音识别问题是识别在听取 \(n\) 个音素 (\(\mathbf{P}=p_1,p_2\ldots p_n\)),\(n \geq m\) 序列后产生的 \(m\) 个单词 (\(\mathbf{W}=w_1,w_2\ldots w_m\)) 序列的问题。在数学上,这可以表示为 W
也就是说,为更有可能的音素序列选择单词序列。使用贝叶斯规则,这可以扩展为
其中
\(P(\mathbf{P}|\mathbf{W})\) 是从词典/字典派生的马尔可夫模型,并且
\(P(\mathbf{W})\) 是语言模型。
机器的语音识别#
语音信号与音素没有 \(1:1\) 的对应关系。但是,语音信号与音素序列之间存在一定程度的相关性。音素指的是语音的声音的感知/心理形式。书面表示是音位。音素没有唯一的声学或时间序列表示。计算机可以利用的只是语音信号,因此,从语音信号中提取特征。现在,自动语音识别的问题是在观察到 \(t\) 个特征 (\(\mathbf{O}=o_1,o_2\ldots o_t\)) 序列后,识别 \(m\) 个单词 (\(\mathbf{W}=w_1,w_2\ldots w_m\)) 序列。在数学上,这可以表示为
其中
\(P(\mathbf{W})\) 是语言模型,
\(P(\mathbf{O})\) 假定为 \(1\)(即,所有特征序列的可能性均等)
\(P(\mathbf{O}|\mathbf{W})\) 是使用语音数据训练的声学模型。
要开发自动语音识别系统,我们需要以下内容
词典(将单词映射到音素或字母或其他单元序列的发音词典)
语言模型(给定与话语对应的可能的单词序列,这提供了最可能的单词序列)
声学模型(给定语音信号,这提供了最可能的音素/字母/其他单元序列)
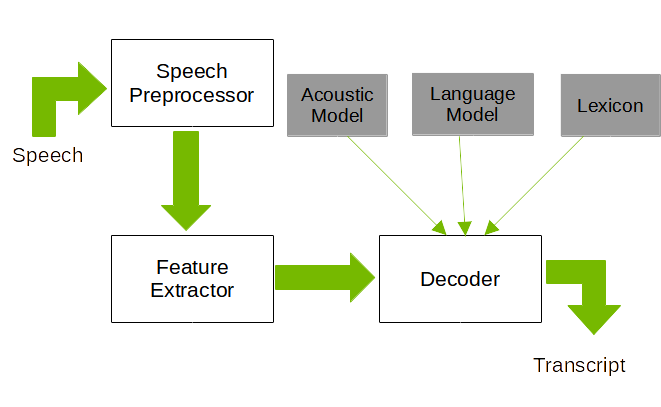 自动语音识别系统架构
自动语音识别系统架构
图 1 显示了通用语音识别系统的架构。该系统的主要组件是语音处理器、特征提取器和解码器。语音预处理器根据任务实施多种算法。一些典型的语音预处理器任务包括语音分割、语音增强、说话人分离等等。特征提取器从处理后的语音信号中提取特征序列(通常是频谱特征)。解码器使用预训练的声学模型和语言模型以及词典来查找语音信号(特征)的最佳可能单词序列。
语音数据 最好在系统将要部署的环境中录制,并尽可能保证最佳质量。
正字转录 用于语音数据。范围可以从每个录制项目的简单单词链(基于录制期间使用的脚本)到几个不同语义层的广泛标记。关于转录中包含什么内容的选择取决于语音语料库的类型和预期用途。例如,通过电话网络读取语音项目的语料库,目的是训练自动语音识别算法,则不需要对语篇事件进行任何详细的标记。包含两个或多个人之间特定于特定领域的对话语音的语料库需要付出更多努力。
词典 包含定义领域词汇表的单词列表,以及这些单词的所有可能发音。
ASR 准确性评估#
ASR 系统的评估取决于手头的任务。对于大多数简单的转录准确性问题,传统的评估指标是词错误率 (WER)。这需要为正在评估的语音数据提供实际(参考)转录(由人工验证)。预测转录和参考转录的长度可能不同,因此在计算 WER 之前需要先对齐。对齐后,可以按如下方式计算 WER
其中
\(N\) 是参考转录中存在的单词总数。
\(S\) 是替换的单词数
\(D\) 是删除的单词数
\(I\) 是错误插入的单词数
用于计算 WER 的常用工具包括 asr_evaluation 和 jiwer。
ASR 的另一种评估指标是字符错误率 (CER)。CER 的计算方式与 WER 类似,只是两个转录的对齐是在字符级别而不是单词级别。CER 对于基于字符的语言(例如,普通话)和不使用空格分隔单词的语言(例如,泰语、老挝语和高棉语)来说是更有用的指标。
对于特定用例,WER 评估可能过于简单。例如,考虑一个记录临床信息的听写系统。如果患者的姓名、地址以及特定的医学术语被错误转录,则这些单词的错误率明显更高,并且比动词/形容词或其他短语被错误转录更重要。在这种情况下更好地评估的一种技术是在评估 WER 时忽略最常用单词的列表。或者,可以为某些单词提供更多权重,以更好地估计任务的 ASR 准确性。执行此操作的一种机制是使用术语频率-逆文档频率 (TF-IDF) 来确定单词的重要性。
对于像语音助手这样的槽填充应用程序,WER 是一个不太有用的指标。槽填充的目标是识别意图以及与该意图相关的任何相关实体。与通用词汇表不同,槽填充使用与各种意图相关联的特定语法/短语集以及数据库中可能存在的实体的详尽列表。与这些应用程序相关的评估指标主要使用意图分类错误率 (ICER) 和实体错误率 (EER)。ICER 和 EER 通常使用 精确率/召回率 或 F1/F2 分数 来衡量。
Riva ASR#
Riva ASR 支持使用 Connectionist Temporal Classification 算法 (CTC) 的模型。了解 CTC 解码器的工作原理对根本原因分析准确性问题有很大帮助。
对齐问题#
ASR 是一项序列判别任务。判别任务是指需要为给定数据分配标签的任务。然而,由于语音是声学声音的序列,这需要为语音信号的各个部分分配标签,并且语音信号与标签之间没有 1:1 的映射。即使对于训练有素的人类专家来说,标记语音信号也很困难,因为没有人能够就边界达成一致。传统上,语音识别系统依赖于一种称为强制对齐的技术来对齐两个序列,在本例中是文本和语音。
CTC 解码器通过计算输入序列标签的所有可能对齐上的输出分布来克服此问题。例如,给定一个观察序列 (\(\mathbf{O}=o_1,o_2\ldots o_7\)) 并说出语音信号的转录“heart”,一些可能的对齐方式是
h,e,e,a,a,r,t
h,e,a,a,a,r,t
h,e,a,a,r,t,t
h,h,e,a,r,t,t
折叠文本会得到字符串“heart”。但是,这可能会导致单词中包含重复字母的问题,例如单词“harry”。此外,发声中也可能存在静音。为了解决这个问题,使用了一个额外的标记,称为空白标记 (\(\epsilon\))。该算法经过修改,使其仅重复空白标记之间的字符。例如,“harry”的一种对齐方式将是“h,a,a,r,\(\epsilon\),r,y”。
CTC 对齐给出了每个时间步的输出标签的分布。存在各种技术来提取与语音信号对应的文本序列。最常用的两种技术是
贪婪解码器
波束搜索解码器
词典搜索解码器(使用单词语言模型和词典)
无词典解码器(使用字符语言模型)
贪婪搜索解码器#
贪婪(搜索)解码器是获得文本序列的最简单且计算强度最低的算法。该算法假定通过将每个时间步中具有最高值(logit)的字符与先前选择的字符序列连接而获得的最佳路径是最可能的文本序列。
波束搜索解码器#
波束搜索解码器是一种计算强度更高的算法,更有可能生成最可能的文本序列。这尤其有用,因为 CTC 算法在估计当前时间戳的 logits 时不考虑先前时间步的输出。这里的想法是可以从与文本序列对应的字首路径迭代计算与最可能的文本序列对应的路径总和。由于这可能会导致每个时间步路径数量呈指数增长,因此通过忽略概率小于特定值的所有路径来修剪其中一些路径。或者,可以对可能的路径数量施加额外的限制。可以简单地从多个路径中选择最可能的序列,或者使用语言模型重新评估波束。
Riva 语音识别管道#
以下流程图显示了 Riva 语音识别管道以及可能的定制。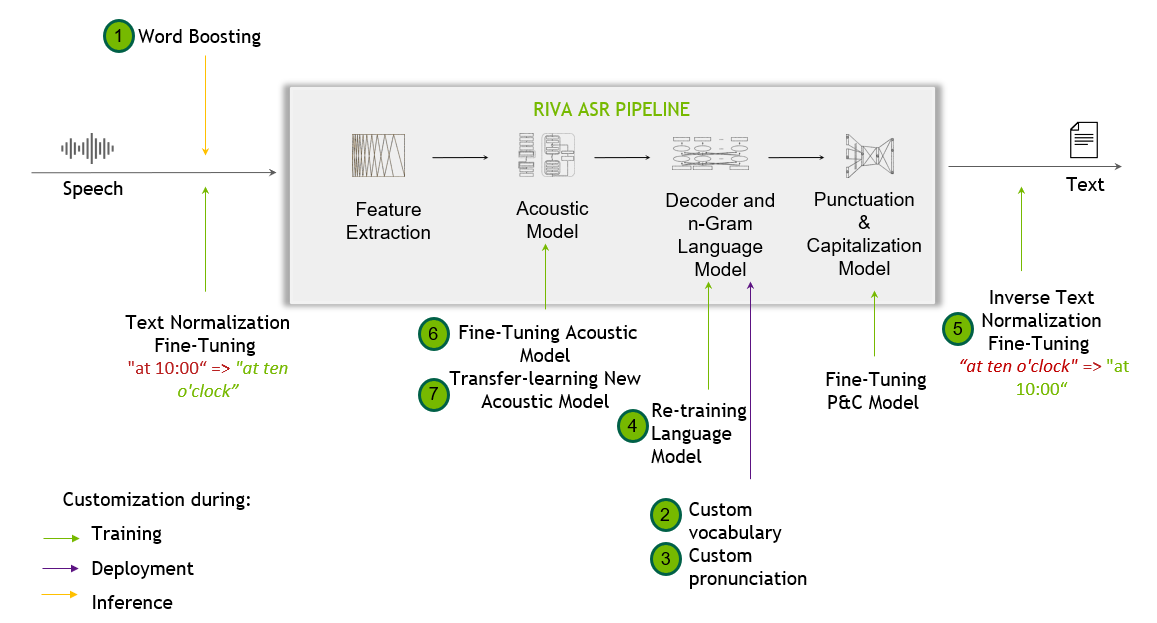
Riva ASR 定制摘要#
在下表中,相应的定制按难度和工作量递增的顺序列出
技术 |
难度 |
功能 |
何时使用 |
如何使用 |
|---|---|---|---|---|
|
快速简便 |
扩展词汇表,同时增加识别所提供关键字列表的机会。此策略使您能够轻松提高请求时特定单词的识别率。 |
当某些单词或短语在特定上下文中很重要时。例如,会议中的与会者姓名。 |
|
|
简单 |
扩展默认词汇表以涵盖新的感兴趣的单词。 |
当默认模型词汇表没有充分涵盖感兴趣的领域时。 |
|
|
简单 |
显式指导解码器将发音(即,标记序列)映射到特定单词。词典解码器发出解码器词典中存在的单词。可以修改解码器使用的词典以提高识别率。 |
当一个单词可以有一个或多个可能的发音时。 |
|
|
中等 |
为应用程序域训练新的语言模型,以提高领域特定术语的识别率。Riva ASR 管道支持使用 n-gram 语言模型。使用针对您的用例量身定制的语言模型可以极大地帮助提高转录的准确性。 |
当领域文本数据可用时。 |
|
|
中等偏难 |
将转录的口语单词序列映射到所需的书写格式。 |
当需要特定的书写格式时。 |
|
|
中等偏难 |
使用少量领域数据微调现有声学模型,以更好地适应领域。 |
当转录的领域音频数据(10 小时-100 小时)可用,其他更简单的方法都失败时。 |
|
|
难 |
从头开始或使用跨语言迁移学习训练全新的声学模型,使用数千小时的音频数据。 |
仅当将 Riva 适配到新语言或方言时才推荐。 |
Riva ASR 的基本定制#
单词增强#
单词增强为模型提供了一种快速且临时的适配,以应对新的场景,例如识别专有名词、产品以及新的或特定领域的术语。对于 OOV(词汇表外)单词,单词增强功能在推理时扩展词汇表。您必须在每次请求时显式指定增强单词的列表。其他适配方法(例如自定义词汇表和词典映射)提供了更持久的解决方案,这将影响每个后续请求。
在所有适配技术中,单词增强是最容易且最快实施的。单词增强允许您偏置 ASR 引擎以识别请求时感兴趣的特定单词,方法是在解码声学模型的输出时为它们提供更高的分数。您需要做的只是将重要单词列表以及权重作为额外的上下文传递给 API 调用,如下例所示。
# Word Boosting
boosted_lm_words = ["BMW", "Ashgard"]
boosted_lm_score = 20.0
speech_context = rasr.SpeechContext()
speech_context.phrases.extend(boosted_lm_words)
speech_context.boost = boosted_lm_score
config.speech_contexts.append(speech_context)
# Creating StreamingRecognitionConfig instance with config
streaming_config = rasr.StreamingRecognitionConfig(config=config, interim_results=True)
在实施单词增强时,请注意以下事项
可以增强的单词数量没有限制。您应该看到所有请求的延迟影响最小,即使对于数十个增强单词也是如此,除了第一个请求,这是预期的。
默认情况下,服务器端不增强任何单词。仅增强客户端传递的单词。
支持词汇表外单词增强。
短语或单词组合增强尚未完全支持(但确实有效)。我们将在即将发布的版本中重新审视最终的此项支持。
单词增强可以提高识别所需单词的机会,但同时,也可能增加误报。因此,从小的正权重开始,逐渐增加,直到看到积极效果。从 20 的增强分数开始,如果需要,最多增加到 100。
单词增强最适合作为临时修复。为了获得最佳输出,您可以尝试对增强权重进行二分查找,同时监控测试集上的准确性指标。准确性指标应包括词错误率 (WER) 和可能的术语错误率 (TER) 形式,重点关注感兴趣的术语。
单词增强示例 - 演示如何使用单词增强的示例可以在 Riva 客户端镜像的 /opt/riva/examples/transcribe_file_offline.py 和 /opt/riva/examples/transcribe_file.py Python 脚本中找到。以下示例命令显示了如何从 Riva 客户端容器中运行这些脚本(以及它们生成的输出)
/opt/riva/examples# python3 transcribe_file.py --server <Riva API endpoint hostname>:<Riva API endpoint port number> --input-file <audio file path>/audiofile.wav
Final transcript: I had a meeting today with Muhammad Oscar and Katherine Rutherford about the future of Riva at NVIDIA.
/opt/riva/examples# python3 transcribe_file.py --server <Riva API endpoint hostname>:<Riva API endpoint port number> --input-file <audio file path>/audiofile.wav --boosted-lm-words "asghar"
Final transcript: I had a meeting today with Muhammad Asghar and Katherine Rutherford about the future of Riva at NVIDIA.
这些脚本显示了如何将增强单词添加到 RecognitionConfig,以及 SpeechContext(查找 "# Append boosted words/score" 注释)。有关 SpeechContext 的更多信息,请参阅 riva/proto/riva_asr.proto 描述。
我们建议使用介于 20 和 100 之间的增强分数。更高的分数会增加增强单词出现在转录中的可能性(如果这些单词出现在音频中)。但是,它也可能增加增强单词出现在转录中的可能性,即使它们没有出现在音频中。尝试试验增强分数,直到获得准确的转录结果。此外,如果切换到不同的声学模型,请重新访问增强分数。
以下 word boosting 代码片段包含在这些示例 脚本 和 教程 中
import riva.client
uri = "localhost:50051" # Default value
auth = riva.client.Auth(uri=uri)
asr_service = riva.client.ASRService(auth)
config = riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
max_alternatives=1,
profanity_filter=False,
enable_automatic_punctuation=True,
verbatim_transcripts=False,
)
my_wav_file=PATH_TO_YOUR_WAV_FILE
boosted_lm_words = ["first", "second", "third"]
boosted_lm_score = 10.0
riva.client.add_audio_file_specs_to_config(config, my_wav_file)
riva.client.add_word_boosting_to_config(config, boosted_lm_words, boosted_lm_score)
您还可以为不同的单词设置不同的增强值。例如,这里 first 的增强值为 10,second 的增强值为 20
riva.client.add_word_boosting_to_config(config, ['first'], 10.)
riva.client.add_word_boosting_to_config(config, ['second'], 20.)
自定义词汇表#
Riva 中默认部署的 Flashlight 解码器是基于词典的解码器,仅发出提供的词汇表文件中存在的单词。这意味着,词汇表文件中不存在的特定领域单词不可能生成。
有两种方法可以扩展解码器词汇表
在 Riva 构建时 - 在构建自定义模型时,将扩展的词汇表文件传递给构建命令的
--decoding_vocab=<vocabulary_file>参数。Riva 语言的开箱即用词汇表文件可以在 NGC 上找到,例如,对于英语,名为flashlight_decoder_vocab.txt的词汇表文件可以在 Riva ASR English(en-US) LM 模型中找到。部署后 - 对于生产 Riva 系统,可以修改、扩展词典文件,并在服务器重启后生效。请参阅下一节。
请注意,贪婪解码器(在标志 --decoder_type=greedy 下的 riva-build 过程中可用)不是基于词汇表的,因此,可以生成任何字符序列。
自定义发音(词典映射)#
当使用 Flashlight 解码器时,词典文件提供词汇表词典单词与其标记化形式之间的映射,例如,许多 Riva 模型的 sentence piece 标记。
修改词典文件有两个目的
扩展词汇表。
为特定单词提供一个或多个显式自定义发音。例如
manu ▁ma n u manu ▁man n n ew manu ▁man n ew
训练语言模型#
在 ASR 管道中引入语言模型是提高自然语言准确性的简便方法,并且可以针对小众设置进行微调。简而言之,n-gram 语言模型估计 n 个或更少连续单词组的概率分布,P (word-1, …, word-n)。通过更改或偏置训练语言模型的数据,从而改变它正在估计的分布,它可以用于预测不同的转录更可能,从而在不更改声学模型的情况下更改预测。Riva 支持从 KenLM 训练和导出的 n-gram 模型。
自定义语言模型可以为提高领域特定术语和短语的识别率提供持久的解决方案。领域特定的自定义 LM 可以通过称为插值的过程与通用领域 LM 混合。
KenLM 设置#
KenLM 是构建语言模型的推荐工具。此工具包支持估计、过滤和查询 n-gram 语言模型。首先,请确保您已安装 Boost 和 zlib。根据您的要求,您可能需要其他依赖项。通过参考依赖项列表仔细检查。
满足所有依赖项后,创建一个单独的目录来构建 KenLM。
wget -O - https://kheafield.com/code/kenlm.tar.gz | tar xz
mkdir kenlm/build
cd kenlm/build
cmake ..
make -j2
估计#
下一步是收集和处理数据。在大多数情况下,KenLM 期望数据是自然语言(适合您的用例)。常见的预处理步骤包括替换数字和删除变音符号、标点符号或特殊字符。但是,最重要的是您的预处理步骤在语言模型和声学模型之间保持一致。
假设您当前的工作目录是 KenLM 的 build 子目录,bin/lmplz 对通过 stdin 提供的语料库执行估计,并将 ARPA(语言模型的人类可读形式)写入 stdout。运行 bin/lmplz 会记录命令行参数,但是,以下是一些重要的参数
-o:必需。语言模型的阶数。取决于用例,但通常为 3-8。-S:要使用的内存。数字后跟%表示百分比,b表示字节,K表示千字节,依此类推。默认为80%。-T: 临时文件位置--text arg: 从文件读取文本,而不是从stdin读取。--arpa arg: 将 ARPA 写入文件,而不是写入stdout。--prune arg: 剪枝计数小于或等于给定阈值的 n-gram,每个阶数指定一个值。例如,要剪枝单例三元组,使用--prune 0 0 1。值的序列必须是非递减的,最后一个值适用于所有剩余的阶数。默认情况下不进行剪枝。不支持一元组剪枝,因此第一个数字必须为0。--limit_vocab_file arg: 从参数文件读取以空格分隔的允许词汇表,并剪枝所有包含不在列表中的词汇项的 n-gram。可以与剪枝结合使用。
剪枝和限制词汇表有助于去除数据集中的拼写错误、非常用词和一般异常值,从而使生成的 ARPA 文件更小,通常更不容易过拟合,但可能会以丢失一些行话或口语为代价。
使用适当的选项,可以估计语言模型。
bin/lmplz -o 4 < text > text.arpa
查询和评估#
为了加快加载速度,请将 arpa 文件转换为二进制格式。
bin/build_binary text.arpa text.binary
可以通过命令行查询二进制或 ARPA 文件。
bin/query text.binary < data
>>>>>>> release/22.06
从零开始训练#
当有大量的原始文本可用时,可以从零开始训练自定义 LM。Riva 支持从 KenLM 训练和导出的 n-gram 模型。
对于生产环境中的 Riva ASR 模型,我们聚合训练数据中所有转录的文本,用于训练语言模型。
如果使用抓取的文本,请限制词汇表大小。许多在线资源包含拼写错误或辅助代词和非常用词。删除这些可以改进语言模型。
当文本属于狭窄的、小众的领域时,在识别通用领域语言方面可能会对整体 ASR 流程产生影响,这是一种权衡。因此,请尝试将领域文本与通用文本混合,以获得平衡的表示。
LM 插值#
混合数据的另一种方法是混合两个或多个预训练的 .ARPA 格式的 n-gram 语言模型。这可以使用第三方工具来完成,例如 SRI ngram 工具。例如
./ngram -order 4 -lm <lm1.arpa> -mix-lm <lm2.arpa> -lambda 0.4 -write-lm <output_lm.arpa>
此命令使用权重 [0.6, 0.4] 插值 lm1.arpa 和 lm2.arpa,同时写入 output_lm.arpa。
部署自定义语言模型#
可以通过将二进制语言模型文件传递给 riva-build 并使用标志 --decoding_language_model_binary=<lm_binary>,将二进制格式的自定义 n-gram 语言模型文件部署为 ASR 流程的一部分。
Riva ASR 的高级自定义#
逆文本规范化#
Riva 为 ASR 请求实现逆文本规范化 (ITN)。它使用基于权重有限状态转换器 (WFST) 的模型,将 ASR 模型的口语领域输出转换为书写领域文本,以提高 ASR 系统输出的可读性。
文本规范化将文本从书写形式转换为口语形式。它用作 TTS 之前的预处理步骤。它也可以用于预处理 ASR 训练脚本。
ITN 是 ASR 后处理流程的一部分。ITN 的任务是将 ASR 模型的原始口语输出转换为书写形式,以提高文本可读性。
Riva 实现了 NeMo ITN,它基于 WFST 语法。该工具使用 Pynini 构建 WFST。创建的语法可以导出并集成到 Sparrowhawk(Kestrel TTS 文本规范化系统的开源版本)中以用于生产环境。
在 NeMo 功能安装的情况下,例如,可以使用 pynini_export.py 工具 导出德语 ITN 语法,如下所示
python3 pynini_export.py --output_dir . --grammars itn_grammars --input_case cased --language de
这将导出 tokenizer_and_classify 和 verbalize FST 作为 OpenFst 有限状态归档 (FAR) 文件,准备好与 Riva 一起部署。
[NeMo I 2022-04-12 14:43:17 tokenize_and_classify:80] Creating ClassifyFst grammars.
Created ./de/classify/tokenize_and_classify.far
Created ./de/verbalize/verbalize.far
要使用 Riva 部署这些 ITN 规则,请在以下选项下将 FAR 文件传递给 riva-build 命令
riva-build speech_recognition
[--wfst_tokenizer_model WFST_TOKENIZER_MODEL]
[--wfst_verbalizer_model WFST_VERBALIZER_MODEL]
此外,riva-build 还支持 --wfst_pre_process_model 和 --wfst_post_process_model 参数,用于传递逆文本规范化的预处理和后处理 FAR 文件。
要了解有关如何从头开始构建语法的更多信息,请查阅 NeMo 加权有限状态转换器 (WSFT) 教程。
有关模型架构的详细信息,请参见论文 NeMo 逆文本规范化:从开发到生产。
语音提示#
语音提示将超出词汇表 (OOV) 类作为 ASR 后处理流程的一部分应用。它使用有限状态转换器 (FST) 根据应用于规范化输出的预期 OOV 类来提高可读性,使其格式更易于阅读。
语音提示应用于 ASR 的口语领域输出,然后再将生成的文本传递到 ITN。需要应用的短语使用 SpeechContext 添加到 RecognitionConfig。
import riva.client
uri = "localhost:50051" # Default value
auth = riva.client.Auth(uri=uri)
asr_service = riva.client.ASRService(auth)
config = riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
max_alternatives=1,
profanity_filter=False,
enable_automatic_punctuation=True,
verbatim_transcripts=False,
)
my_wav_file=PATH_TO_YOUR_WAV_FILE
speech_hints = ["$OOV_ALPHA_SEQUENCE", "i worked at the $OOV_ALPHA_SEQUENCE"]
boost_lm_score = 4.0
riva.client.add_audio_file_specs_to_config(config, my_wav_file)
riva.client.add_word_boosting_to_config(config, speech_hints, boost_lm_score)
支持以下类和短语
$OOV_NUMERIC_SEQUENCE$OOV_ALPHA_SEQUENCE$OOV_ALPHA_NUMERIC_SEQUENCE$ADDRESSNUM$FULLPHONENUM$POSTALCODE$OOV_CLASS_ORDINAL$MONTH
训练或微调声学模型#
模型微调是一组技术,它使用新数据对预先存在的模型进行微小调整,使其适应新情况,同时保留其原始功能。
模型训练指的是从零开始(即从随机权重开始)或使用从现有模型初始化的权重训练新模型,但目标是让模型获得全新的技能,而不一定保留原始功能(例如在跨语言迁移学习中)。
许多用例需要使用新数据训练新模型或微调现有模型。在这些情况下,有一些最佳实践需要遵循。其中许多最佳实践也适用于推理时的输入。
如果可能,请使用无损音频格式。使用有损编解码器(如 MP3)可能会降低质量。
扩充训练数据。向音频训练数据添加背景噪声最初可能会降低准确率,但会提高鲁棒性。
如果使用抓取的文本,请限制词汇表大小。许多在线资源包含拼写错误或辅助代词和非常用词。删除这些可以改进语言模型。
如果可能,请使用至少 16kHz 的采样率,但不要重新采样。
如果使用 NeMo 微调 ASR 模型,请参阅 在其他语言上微调 CTC 模型 教程。我们建议仅在有足够数据(大约数百小时的语音)的情况下才微调 ASR 模型。如果此类数据不可用,则在领域内文本语料库上简单地调整 LM 可能比训练 ASR 模型更有用。
没有正式保证 ASR 模型在训练后是否可以流式传输。如果进行流式识别,我们建议微调 Conformer 声学模型。根据我们的经验,与 Citrinet 相比,微调后它提供更好的流式 WER。
训练新模型#
从零开始训练模型 - ASR 模型的端到端训练需要大型数据集和大量的计算资源。世界各地有 5,000 多种语言,但只有极少数语言拥有足够大的数据集来训练高质量的 ASR 模型。因此,我们只建议在有数千小时的转录语音数据可用的情况下从零开始训练模型。
跨语言迁移学习 - 当为低资源语言训练新模型时,跨语言迁移学习尤其有用。但即使有大量数据可用,跨语言迁移学习也可以帮助进一步提高性能。
它基于音素表示可以在不同语言之间共享的想法。NeMo 团队的实验表明,即使只有 16 小时的目标语言音频数据,迁移学习也比从零开始训练效果好得多。在 GTC 2020 演讲 中,NVIDIA 数据科学家演示了对语音数据少于 30 小时的低资源语言进行跨语言迁移学习。
微调现有模型#
当其他更简单的方法未能解决由显着的声学因素(例如不同的口音、嘈杂的环境或较差的音频质量)带来的具有挑战性的情况下的准确性问题时,应尝试微调声学模型。
我们建议使用大约 100 小时或更长时间的语音数据来微调 ASR 模型。正如 跨语言迁移学习、持续学习和端到端自动语音识别的领域自适应 论文所示,我们用于 NeMo 迁移学习的最小时数为 CORAAL 数据集的约 100 小时。我们的实验表明,在跨语言迁移学习、持续学习和领域自适应这三种情况下,从良好的基础模型进行迁移学习比从零开始训练的模型具有更高的准确性。即使微调的数据集很小,也最好微调大型模型,而不是从零开始训练小型模型。
低资源领域自适应 - 如果数据集较小(例如约 10 小时),应采取适当的预防措施,以避免对领域过度拟合,从而牺牲通用领域中的显着准确性,这也称为灾难性遗忘。如果将在此小型数据集上进行微调,请与其他更大的数据集(“基础”)混合。例如,对于英语,NeMo 有一个 公共数据集列表,可以与之混合使用。
在迁移学习中,持续学习是一个子问题,其中使用新领域数据训练的模型应仍保持在原始源领域上的良好性能。
如果使用 NeMo 微调 ASR 模型,请参阅 在其他语言上微调 CTC 模型 教程。
数据质量和增强 - 如果可能,请使用无损音频格式。使用有损编解码器(如 MP3)可能会降低质量。作为常规做法,请使用至少 16kHz 的采样率。您还可以使用采样率为 8K、16K、24K 或 48K 的 Opus 编码源。
用噪声扩充训练数据可以提高模型应对嘈杂环境的能力。向音频训练数据添加背景噪声最初可能会降低准确率,但会提高鲁棒性。
标点符号和大小写模型#
ASR 系统通常生成没有标点符号和单词大小写的文本。在 Riva 中,标点符号和大小写模型负责格式化文本,并增强了标点符号和大小写。
当开箱即用的模型在应用上下文中表现不佳时,例如当应用于新的语言变体时,应自定义标点符号和大小写模型。
要训练或微调,然后部署自定义标点符号和大小写模型,请参阅 RIVA 标点符号 和 NeMo 标点符号和大小写。
部署自定义声学模型#
如果使用 NVIDIA NeMo,则必须首先使用 Riva 发行版中提供的 nemo2riva 工具将模型从 .nemo 格式导出为 .riva 格式。接下来,使用 Riva 容器和工具(riva-build 和 riva-deploy)进行部署。有关更多信息,请参阅 将您的自定义模型部署到 Riva 中 部分。
WFST 解码#
语言模型用于语音识别任务,以帮助消除歧义,确定在给定单词序列之前最有可能出现的单词。传统的 n-gram 模型对给定单词序列 (n-1) 之前的单词出现的概率进行建模。
但是,在许多领域中,可能存在一系列本质上相似的单词序列。
例如,考虑短语“我想从纽约飞往西雅图”和“我想从伦敦飞往巴黎”,这两个句子的概率通常仅取决于人们在这两个地方之间飞行的频率。否则,在涉及预订航班的领域中,这两个句子出现的概率是相同的。
这需要支持构建考虑词类的 ngram 模型。词类也可以被视为实体或实体类型(如在 NER 中),但本质上更通用。
使用 n-gram 支持词类并非易事。一种替代方法可能是使用 BNF 语法生成所有可能的此类序列。但是,这可能会很容易地增加 LM 的大小,并且仍然可能导致多词词类出现问题。
另一种方法是使用加权有限状态转换器 (WFST)。用于语音识别的 WFST 由三个主要组件组成
语法 WFST (
G.fst) - 语法 WFST 编码语言/领域中的单词序列。一般来说,这基本上是一个表示为加权有限状态接受器的语言模型。词典 WFST (
L.fst) - 词典 WFST 编码令牌序列(音素/BPE/WPE 或其他 CTC 单元)与相应单词之间的映射。令牌 WFST (
T.fst) - 令牌 WFST 将帧级 CTC 标签序列映射到单个词典单元(音素/BPE/WPE 或其他 CTC 单元)。
这三个 WFST 与其他操作组合在一起以形成 TLG.fst。操作顺序为 T ◦ min ( det ( L ◦ G ) ),其中
◦指的是组合操作min指的是最小化det指的是确定化
有关更多信息,请参阅 Mohri、Pereira 和 Riley 的“使用加权有限状态转换器进行语音识别”(载于 Springer Handbook on SpeechProcessing and Speech Communication,2008 年)。
在 WFST 框架中支持类语言模型#
在 WFST 框架中支持类语言模型可以概括为修改 G.fst 以支持接受器中引用词类的路径。这要求
词典包含来自语言模型的所有条目以及每个词类中的条目。这很重要,因为否则词类中的单词将无法被识别。
n-gram 模型应具有从词类语法构建的相关短语。例如,在上面的示例中,词类语法将是“我想从 #entity:city 飞往 #entity:city”,其中 #entity:city 是对应于有机场的城市的词类的标签。这可以通过以下两种方式实现
从包含标准文本以及词类标签的文本构建语言模型
两个 LM 的 n-gram LM 插值/混合,一个来自标准文本,另一个来自特定领域的语法。
后一种选项可以在领域内和领域外 LM 之间提供更好的权重分配。有关使用 kenlm 进行 LM 模型插值,请参阅教程 “如何训练、评估和微调 n-gram 语言模型”。或者,SRILM(需要许可证)也可以在此处使用
在 WFST 框架中支持词类的过程基本上涉及用从词类中存在的实体创建的 FST 替换表示类标签的弧。给定一个包含词类标签 (#entity:<class>) 的 G.fst,以及包含该类的实体列表的文件(文件名 <class>.txt)。实体列表不限于单词,也可以是短语
例如,在上面的示例中,cities.txt 至少应包含以下内容
$> cat city.txt
london
new york
paris
seattle
创建支持词类的 TLG.fst#
从 https://github.com/anand-nv/riva-asrlib-decoder/tree/class_lm 检出 class_lm 分支。以下所有脚本都可以在 src/riva/decoder/scripts/prepare_TLG_fst 路径中找到。
从 arpa 文件生成词典、令牌/单元列表和实体列表。这是使用
lexicon_from_arpa.py脚本完成的。命令的语法如下
lexicon_from_arpa.py --asr_model <path_to_nemo_model> --lm_path <path_to_arpa_file> --grammars <path_to_folder_containing_grammars> <units_txt_path:output> <lexicon_path:output> <classlabels_path:output>
这将生成单元(令牌)列表、词典和词类列表(用作消歧符号)
生成 FST,
T.fst、L.fst和G.fst,扩展并组合以形成TLG.fst
mkgraph_ctc_classlm.sh --units <units_txt_path> --extra_word_disamb <classlabels_path> <lexicon_path> <path_to_arpa_file> <lang_folder_path:output>
成功运行后,上述命令将在 <lang_folder_path> 中生成一个名为 graph_CTC_<lm_name> 的 graph 文件夹,其中包含使用 WFST 解码的所有相关文件
评估#
evaluate_nemo_wfst.py 脚本可以帮助评估 WFST 解码器,然后再在 Riva 服务生成器构建中使用。这对于调试 TLG.fst 的任何问题非常有用
该脚本可以按如下方式运行
./evaluate_nemo_wfst.py <model_path> <graph_path> <path_containing_audio_files:input> <results_txt_file:output>
在 Riva 中部署#
生成的 TLG.fst 可以与 riva 中的 kaldi 解码器一起使用。要使用生成的 TLG.fst 构建 riva ASR 服务,可以使用以下命令
# Syntax: riva-build <task-name> output-dir-for-rmir/model.rmir:key dir-for-riva/model.riva:key
! docker run --rm --gpus 0 -v $MODEL_LOC:/data $RIVA_SM_CONTAINER -- \
riva-build speech_recognition \
/data/rmir/asr_offline_conformer_ctc.rmir:$KEY \
/data/$MODEL_NAME:$KEY \
--offline \
--name=asr_offline_conformer_wfst_pipeline \
--ms_per_timestep=40 \
--chunk_size=4.8 \
--left_padding_size=1.6 \
--right_padding_size=1.6 \
--nn.fp16_needs_obey_precision_pass \
--featurizer.use_utterance_norm_params=False \
--featurizer.precalc_norm_time_steps=0 \
--featurizer.precalc_norm_params=False \
--featurizer.max_batch_size=512 \
--featurizer.max_execution_batch_size=512 \
--decoder_type=kaldi \
--decoding_language_model_fst=/data/graph/TLG.fst \
--decoding_language_model_words=/data/graph/words.txt \
--kaldi_decoder.asr_model_delay=5 \
--kaldi_decoder.default_beam=17.0 \
--kaldi_decoder.max_active=7000 \
--kaldi_decoder.determinize_lattice=true \
--kaldi_decoder.max_batch_size=1 \
--language_code=en-US \
--wfst_tokenizer_model=<far_tokenizer_file> \
--wfst_verbalizer_model=<far_verbalizer_file> \
--speech_hints_model=<far_speech_hints_file>