ASR 概述
目录
ASR 概述#
自动语音识别 (ASR) 接收音频流或音频缓冲区作为输入,并返回一个或多个文本转录,以及其他可选元数据。Riva 中的语音识别是一个 GPU 加速的计算流水线,具有优化的性能和准确性。Riva 支持离线/批量和流式识别模式。
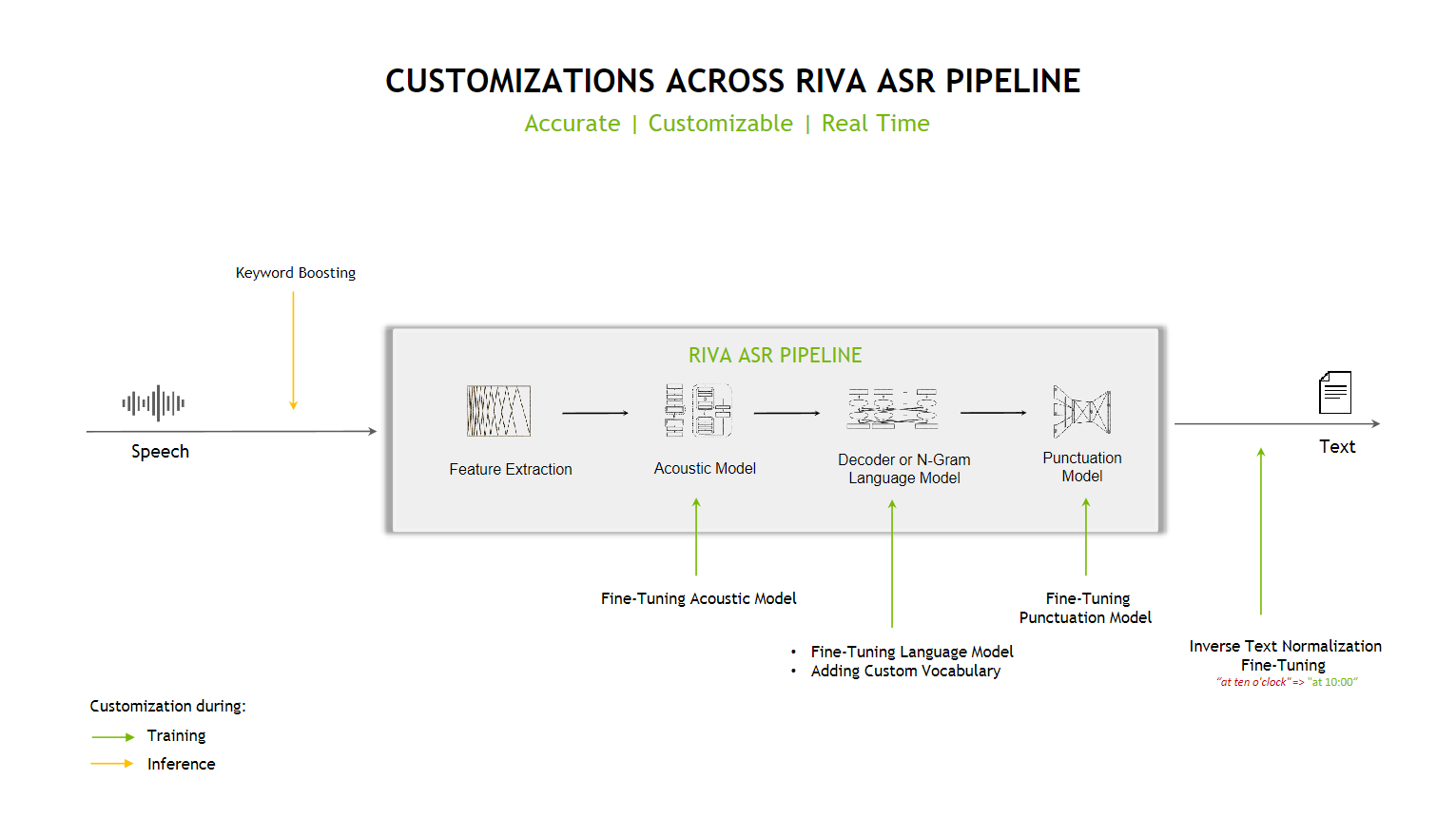
试用#
在我们的演示平台上体验 Riva ASR:https://build.nvidia.com/explore/speech
预训练 ASR 模型#
用于在快速入门脚本中生成 RMIR 的 .riva 模型、语言模型、词典词汇表和 WFST 文件可以在以下 NGC 位置找到。
语言 |
声学模型 (AM) |
语言模型 (LM) 和词典 |
标点 |
逆文本规范 (ITN) |
|---|---|---|---|---|
英语 (en-US) |
Parakeet-0.6B Parakeet-0.6B-Unified Parakeet-1.1B Parakeet-1.1B-RNNT Conformer Conformer-XL Distil-Whisper |
n-gram LM (文件 |
||
西班牙语-美国 (es-US) |
||||
西班牙语 (es-ES) |
||||
德语 (de-DE) |
||||
印地语 (hi-IN) |
不适用 |
|||
俄语 (ru-RU) |
不适用 |
|||
法语 (fr-FR) |
||||
英语 (en-GB) |
不适用 |
|||
葡萄牙语-巴西 (pt-BR) |
不适用 |
|||
韩语 (ko-KR) |
不适用 |
|||
日语 (ja-JP) |
不适用 |
|||
阿拉伯语 (ar-AR) |
||||
意大利语 (it-IT) |
不适用 |
|||
普通话 (zh-CN) |
不适用 |
|||
荷兰语 (nl-NL) |
||||
荷兰语-比利时 (nl-BE) |
||||
西班牙语-英语多语代码切换 (es-en-US) |
不适用 |
|||
日语-英语多语代码切换 (ja-en-JP) |
不适用 |
不适用 |
||
多语代码切换 (em-ea) |
不适用 |
不适用 |
||
多语 (multi) |
Parakeet-1.1B-Unified-Universal Parakeet-1.1B-Unified-Concat |
不适用 |
不适用 |
不适用 |
带有 AST 的多语 (multi) |
不适用 |
不适用 |
不适用 |
语言支持#
Riva 语音 AI 技能提供多种语言的高质量预训练模型,这些模型在上面部分列出。升级的模型和新语言会定期发布。
要选择要部署的语言,只需在快速入门脚本的 quickstart 目录中的 config.sh 文件中更改变量 asr_language_code。
目前,语音提示仅支持英语 (en-US)。
多语模型#
以下是各种多语 ASR 模型支持的语言。对于多语(通用)、多语(concat)和 多语(whisper)模型,您还可以在从客户端配置请求时在 language_code 字段中传递 multi,因为这些模型支持自动语言识别。
多语(通用)
ASR:en-US、en-GB、es-ES、ar-AR、es-US、pt-BR、fr-FR、de-DE、it-IT、ja-JP、ko-KR、ru-RU、hi-IN、he-IL、nb-NO、nl-NL、cs-CZ、da-DK、fr-CA、pl-PL、sv-SE、th-TH、tr-TR、pt-PT、nn-NO
推荐语言:en-US、en-GB、es-ES、ar-AR、es-US、pt-BR、fr-FR、de-DE、hi-IN多语 (concat)
ASR:en-US、en-GB、es-ES、ar-AR、es-US、pt-BR、fr-FR、de-DE、it-IT、ja-JP、ko-KR、ru-RU、hi-IN、he-IL、nb-NO、nl-NL、cs-CZ、da-DK、fr-CA、pl-PL、sv-SE、th-TH、tr-TR、pt-PT、nn-NO
推荐语言:en-US、ar-AR、de-DE、it-IT、ja-JP、ko-KR、ru-RU、hi-IN多语 (whisper)
ASR:en、zh、de、es、ru、ko、fr、ja、pt、tr、pl、ca、nl、ar、sv、it、id、hi、fi、vi、he、uk、el、ms、cs、ro、da、hu、ta、no、th、ur、hr、bg、lt、la、mi、ml、cy、sk、te、fa、lv、bn、sr、az、sl、kn、et、mk、br、eu、is、hy、ne、mn、bs、kk、sq、sw、gl、mr、pa、si、km、sn、yo、so、af、oc、ka、be、tg、sd、gu、am、yi、lo、uz、fo、ht、ps、tk、nn、mt、sa、lb、my、bo、tl、mg、as、tt、haw、ln、ha、ba、jw、su、yue
AST:支持从上面列表中所有 ASR 语言翻译成en。多语 (canary-1b 和 canary-0.6b-turbo)
ASR:en-US、en-GB、es-ES、ar-AR、es-US、pt-BR、fr-FR、de-DE、it-IT、ja-JP、ko-KR、ru-RU、hi-IN
AST:支持上面列表中所有非英语和英语 ASR 语言之间的双向翻译。此外,还支持从英语到普通话zh-CN的翻译,以及ar-AR、es-ES、fr-FR、de-DE之间任意两种语言的翻译。从ja-JP、ko-KR、es-ES、es-US到en-US的翻译质量为 Beta 版。多语代码切换 (em-ea)
ASR:en-GB、es-ES、fr-FR、it-IT、de-DE、ar-AR
功能特性#
Riva ASR 的功能特性包括
支持离线和流式用例
一种流式模式,以低延迟返回中间转录
GPU 加速的特征提取
多种(且不断增长的)声学模型架构选项,由 NVIDIA TensorRT 加速
基于 n-gram 语言模型的波束搜索解码器
语音活动检测算法(基于 CTC)
自动标点
能够从波束解码器返回前 N 个转录
词级时间戳
词级置信度
逆文本规范 (ITN)
离线非重叠说话人分离
语音提示
支持 Opus 编码的流
两遍式语句结束
自动语音翻译 (AST)
离线识别#
在离线或批量模式下,首先从文件读取或从麦克风捕获完整音频信号。在捕获整个信号后,客户端向 Riva 语音 AI 服务器发出请求以转录它。然后,客户端等待来自服务器的响应。
提示
此方法可能具有较长延迟,因为音频信号的处理仅在捕获完整音频信号或从文件读取后才开始。
流式识别#
在流式识别模式下,一旦捕获或读取指定长度的音频段,就会向服务器发出请求以处理该段。在服务器端,一旦中间转录可用,就会返回响应。
注意
您可以根据速度和内存要求选择音频段的长度。
有关使用文件或麦克风输入运行语音识别的更多详细信息,请参阅 riva/proto/riva_asr.proto 文档和 ASR 示例命令行客户端。
离线识别与非重叠说话人分离#
当启用说话人分离运行 ASR 离线客户端时,音频数据将作为输入发送到 Riva 语音 AI 服务器。然后,服务器将 ASR 转录作为输出返回给客户端,以及转录中每个词语的说话人标签。
下表包含用于在快速入门脚本中生成说话人分离 RMIR 的神经 VAD 和嵌入提取器 .riva 模型的 NGC 位置。
流水线 |
神经 VAD |
嵌入提取器 |
|---|---|---|
离线说话人分离器 |
基于神经的语音活动检测#
可以在 Riva ASR 中使用基于神经的语音活动检测 (VAD) 算法。这可以帮助过滤掉音频中的噪声,并可以帮助减少 ASR 转录中出现的虚假词语。
以下是 Riva ASR 支持的基于神经的语音活动检测 (VAD) 模型,以及其 .riva 模型的 NGC 位置。
有关如何构建和部署启用基于神经的 VAD 的 ASR 模型的详细信息,请参阅流水线配置部分。
两遍式语句结束#
这是 ASR 的可选配置,用于接收具有更高准确率和更低延迟的中间输出。当使用在 stop_history_eou 和 stop_threshold_eou 参数中设置的正值运行 ASR 客户端时,ASR 会根据这些值检测第一遍语句结束。ASR 会保留当前语句状态,直到收到最终输出,如在 stop_history 参数中配置的值所示。使用此配置观察到的延迟改进相当于第一遍和最终语句结束检测之间的时间差。有关更多详细信息,请参阅 ASR gRPC 文档中的此参考。
自动语音翻译 (AST)#
自动语音翻译 (AST) 将源语言的音频信号直接翻译成目标语言的文本。在 Riva 中,这通过 riva/proto/riva_asr.proto 文档中提到的 custom_configuration 字段使用 Whisper 模型来支持。例如,您可以在 language_code 字段中传递 fr-FR,并在 custom_configuration 字段中传递 target_language:en-US,task:translate,同时配置来自客户端的请求以执行从法语到英语的 AST。
多个已部署模型#
Riva 服务器支持同时部署多个语音识别模型,最多达到 GPU 内存的限制。因此,单个服务器进程可以托管针对流式或批量、各种语言、口音或通道特征定制的模型。
当接收来自客户端应用程序的请求时,Riva 服务器根据客户端请求的 RecognitionConfig 选择要使用的已部署 ASR 模型。如果没有模型可用于满足请求,则返回错误。如果多个模型可能能够满足客户端请求,则随机选择一个模型。您还可以通过将 RecognitionConfig protobuf 对象的 model 字段设置为与 riva-build 命令一起使用的 <流水线名称> 值来显式选择要使用的 ASR 模型。这使您能够并发部署多个 ASR 流水线,并在运行时选择要使用哪个流水线。
检查已部署模型#
一旦服务器正在运行,就可以通过 GetRivaSpeechRecognitionConfig rpc 检索可用模型。对于每个可用于发出推理请求的模型,rpc 返回模型部署时使用的参数。