性能
目录
性能#
评估过程#
本节显示了 Riva ASR 服务在不同 GPU 上的流式和离线配置的延迟和吞吐量数据。这些数据是在部署了我们快速入门脚本中预配置的 ASR 管道后捕获的。测试了 Conformer 和 Parakeet 声学模型。
在流式模式下,客户端和服务器使用相同持续时间的音频块(100 毫秒、160 毫秒和 800 毫秒,具体取决于服务器配置)。有关要使用的块大小值,请参阅结果部分。
Riva 流式客户端 riva_streaming_asr_client(在 Riva 镜像中提供)与 --simulate_realtime 标志一起使用,以模拟来自麦克风的转录,其中每个流对 LibriSpeech dev-clean 数据集中的示例音频文件 (1272-135031-0000.wav) 执行三次迭代。LibriSpeech 数据集可以从 https://www.openslr.org/12 获取。
riva_streaming_asr_client 的源代码可以从 https://github.com/nvidia-riva/cpp-clients 获取。
用于测量性能的命令是
riva_streaming_asr_client \
--chunk_duration_ms=<chunk_duration> \
--simulate_realtime=true \
--automatic_punctuation=true \
--num_parallel_requests=<num_streams> \
--word_time_offsets=false \
--print_transcripts=false \
--interim_results=false \
--num_iterations=<3*num_streams> \
--audio_file=1272-135031-0000.wav \
--output_filename=/tmp/output.json
riva_streaming_asr_client 返回以下延迟测量值
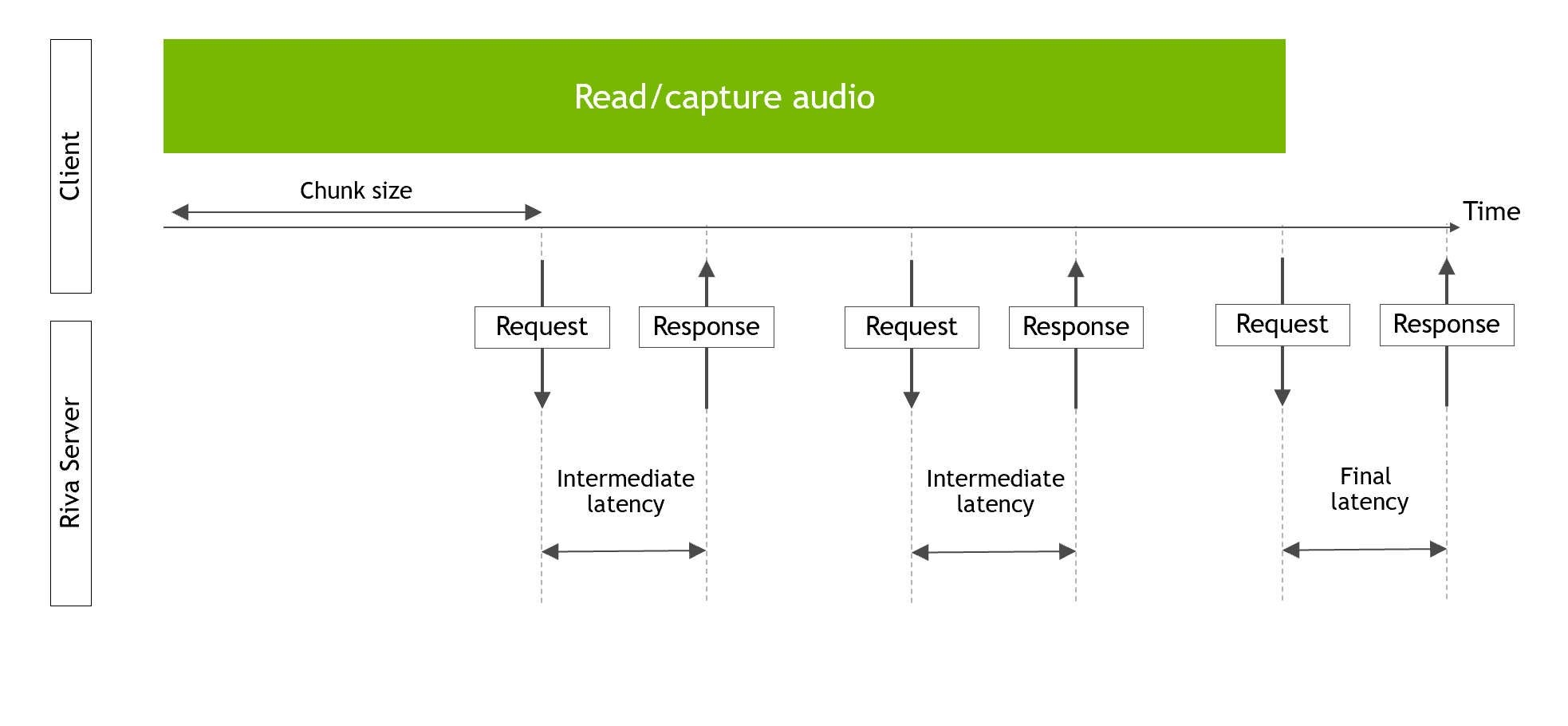
intermediate latency:使用is_final == false返回的响应的延迟final latency:使用is_final == true返回的响应的延迟latency:所有返回响应的总体延迟。这是以下表格中列出的内容。
有关 Riva 流式 ASR 客户端测量的不同延迟的示意图,请参阅下图。
在离线模式下,用于测量最大吞吐量的命令是
riva_asr_client \
--automatic_punctuation=true \
--num_parallel_requests=32 \
--word_time_offsets=false \
--print_transcripts=false \
--num_iterations=96 \
--audio_file=1272-135031-0000x5.wav \
--output_filename=/tmp/output.json
其中 1272-135031-0000x5.wav 只是 1272-135031-0000.wav 音频文件重复五次。 riva_asr_client 的源代码可以从以下网址获取: https://github.com/nvidia-riva/cpp-clients
注意
当使用 Whisper ASR 模型时,使用上述客户端命令提供输入语言代码(例如:--language_code=en-US)将产生最佳吞吐量,因为它避免了对输入音频运行语言识别的需要。
结果#
以下表格报告了流式和离线配置的延迟和吞吐量测量值。吞吐量以 RTFX(转录的音频时长/计算时间)为单位进行测量。
注意
音频文件在 Xavier AGX、Xavier NX 和 Orin AGX 上迭代 1 次,在所有其他实验中迭代 3 次。
注意
如果语言模型为 none,则推理使用贪婪解码器执行。如果语言模型为 n-gram,则使用波束解码器。
注意
表格中的值是 3 次试验的平均值。表格中的值根据 3 次试验计算的标准偏差四舍五入到最后一位有效数字。如果标准偏差小于平均值的 0.001,则将相应值四舍五入,就好像标准偏差等于该值的 0.001 一样。
有关收集这些测量值的硬件规格,请参阅硬件规格部分。请注意,
AWS 和 GCP 上的结果是使用 Riva 2.4.0 计算的
本地结果是使用 Riva 2.15.0 计算的。
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
13 |
11.9 |
12.8 |
13 |
40 |
0.999 |
n-gram |
8 |
18.8 |
17.4 |
19 |
20 |
57 |
7.99 |
n-gram |
16 |
24.8 |
22 |
30 |
32 |
80 |
15.96 |
n-gram |
32 |
34 |
30 |
43 |
46 |
110 |
31.86 |
n-gram |
48 |
44 |
41 |
60 |
66 |
160 |
47.7 |
n-gram |
64 |
50 |
50 |
67 |
75 |
200 |
63.6 |
n-gram |
128 |
86 |
67 |
100 |
220 |
360 |
126.5 |
无 |
1 |
12 |
11.3 |
12 |
12.5 |
30 |
1 |
无 |
8 |
17 |
15.8 |
16.6 |
20 |
49.6 |
7.99 |
无 |
16 |
22.1 |
19.9 |
26 |
29.5 |
70 |
15.96 |
无 |
32 |
32 |
30 |
39.7 |
44 |
100 |
31.9 |
无 |
48 |
40 |
40 |
56 |
57 |
160 |
47.7 |
无 |
64 |
46 |
45 |
60 |
65 |
170 |
63.6 |
无 |
128 |
80 |
60 |
97 |
200 |
330 |
126.5 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
16 |
13.5 |
15 |
31 |
80 |
1 |
n-gram |
64 |
65 |
69 |
80 |
160 |
210 |
63.6 |
n-gram |
128 |
90 |
80 |
120 |
240 |
330 |
126.7 |
n-gram |
256 |
140 |
110 |
180 |
390 |
600 |
251.3 |
n-gram |
384 |
188 |
165 |
246 |
460 |
850 |
374 |
n-gram |
512 |
250 |
210 |
550 |
600 |
1200 |
494 |
n-gram |
768 |
420 |
310 |
800 |
1560 |
2000 |
730 |
n-gram |
1024 |
800 |
500 |
2100 |
2900 |
3000 |
953 |
无 |
1 |
14 |
11.5 |
12 |
25 |
70 |
1 |
无 |
64 |
58 |
60 |
70 |
120 |
192 |
63.6 |
无 |
128 |
80 |
70 |
110 |
230 |
320 |
126.8 |
无 |
256 |
127 |
110 |
164 |
300 |
550 |
251.5 |
无 |
384 |
175 |
156 |
234 |
443 |
800 |
374 |
无 |
512 |
240 |
200 |
530 |
580 |
1140 |
495 |
无 |
768 |
410 |
300 |
800 |
1520 |
1900 |
731 |
无 |
1024 |
735 |
480 |
1970 |
2730 |
2900 |
955 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
2100 |
假 |
无 |
32 |
2200 |
真 |
n-gram |
32 |
84 |
真 |
无 |
32 |
135 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12 |
14 |
20 |
90 |
0.998 |
8 |
19 |
17.6 |
20 |
36.4 |
38 |
7.98 |
16 |
24.4 |
22.4 |
30 |
42 |
60 |
15.96 |
32 |
34 |
35 |
43 |
50 |
93 |
31.87 |
48 |
42 |
41 |
58 |
60 |
126 |
47.8 |
64 |
48 |
56 |
64 |
67 |
150 |
63.6 |
128 |
81 |
70 |
97 |
190 |
300 |
127 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
30 |
100 |
100 |
0.998 |
64 |
73 |
60 |
140 |
200 |
200 |
63 |
128 |
103 |
80 |
220 |
310 |
320 |
125 |
256 |
168 |
127 |
394 |
500 |
580 |
245.4 |
384 |
234 |
190 |
540 |
720 |
880 |
361 |
512 |
340 |
250 |
670 |
970 |
1320 |
472 |
768 |
650 |
410 |
1600 |
1620 |
2320 |
683 |
1024 |
1500 |
1300 |
2930 |
3300 |
3630 |
826 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
226 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
11.8 |
12.8 |
14 |
40 |
1 |
8 |
17.6 |
16.8 |
18.5 |
22 |
39 |
8 |
16 |
22.5 |
21.3 |
25 |
31 |
60.3 |
15.98 |
32 |
32.4 |
35 |
42 |
46 |
70 |
31.93 |
48 |
41 |
40 |
58 |
59 |
100 |
47.9 |
64 |
46 |
50 |
64 |
66 |
100 |
63.8 |
128 |
73 |
66 |
94 |
97 |
220 |
127.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13 |
20 |
40 |
80 |
1 |
64 |
60 |
60 |
80 |
110 |
180 |
63.8 |
128 |
90 |
80 |
110 |
230 |
300 |
127.5 |
256 |
133.3 |
120 |
174 |
340 |
530 |
254 |
384 |
183 |
166 |
245 |
430 |
800 |
380 |
512 |
260 |
223 |
510 |
600 |
1200 |
505 |
768 |
535 |
354 |
1500 |
1640 |
2150 |
739 |
1024 |
940 |
600 |
2300 |
2570 |
2930 |
960 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
460 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
11.6 |
12.4 |
20 |
80 |
0.997 |
8 |
18.4 |
16.5 |
18 |
30 |
60 |
7.96 |
16 |
24.2 |
21.2 |
29 |
31 |
83 |
15.9 |
32 |
33 |
30 |
41 |
46 |
115 |
31.63 |
48 |
42 |
40 |
57.4 |
60 |
170 |
47.3 |
64 |
48 |
50 |
63 |
66 |
185 |
62.9 |
128 |
83 |
65 |
97 |
240 |
380 |
124.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13 |
50 |
80 |
80 |
0.997 |
64 |
80 |
60 |
200 |
200 |
210 |
62.8 |
128 |
107 |
80 |
250 |
306 |
320 |
124 |
256 |
172.2 |
120 |
396 |
500 |
570 |
242 |
384 |
239 |
188 |
580 |
723 |
860 |
354.5 |
512 |
390 |
274 |
880 |
1170 |
1420 |
458 |
768 |
930 |
530 |
2070 |
2100 |
2800 |
647 |
1024 |
2040 |
2300 |
4000 |
4000 |
4360 |
716 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
168 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.8 |
14 |
15 |
40 |
1 |
8 |
18 |
17.8 |
19 |
20 |
37 |
7.99 |
16 |
23.4 |
22.7 |
27 |
31 |
42 |
15.98 |
32 |
33.8 |
37 |
44 |
47 |
52 |
31.9 |
48 |
43 |
40 |
60 |
60 |
70 |
47.85 |
64 |
46 |
55 |
64.6 |
66.6 |
76 |
63.8 |
128 |
72 |
68 |
100 |
100 |
110 |
127.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
20 |
30 |
100 |
1 |
64 |
60 |
70 |
80 |
90 |
90 |
63.8 |
128 |
80 |
80 |
110 |
120 |
140 |
127.4 |
256 |
124 |
120 |
177 |
190 |
250 |
253.4 |
384 |
171 |
170 |
251 |
300 |
406 |
378 |
512 |
217 |
210 |
326 |
420 |
554 |
501 |
768 |
316 |
307 |
490 |
640 |
860 |
742 |
1024 |
466 |
445 |
840 |
980 |
1170 |
977 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
432 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.8 |
12.5 |
12.8 |
50 |
1 |
8 |
17.6 |
16.8 |
18 |
19 |
61 |
7.99 |
16 |
23 |
21.4 |
26 |
30 |
80 |
15.96 |
32 |
33 |
30 |
43 |
45 |
90 |
31.9 |
48 |
41.4 |
41.5 |
58 |
59 |
120 |
47.8 |
64 |
46 |
45 |
63 |
65 |
140 |
63.6 |
128 |
75 |
64 |
95 |
98 |
280 |
126.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13 |
14 |
27 |
80 |
1 |
64 |
60 |
70 |
80 |
140 |
200 |
63.6 |
128 |
90 |
70 |
100 |
230 |
340 |
126.6 |
256 |
140 |
113 |
174 |
410 |
630 |
250.7 |
384 |
204 |
166 |
370 |
600 |
1000 |
372 |
512 |
277 |
210 |
750 |
800 |
1400 |
491 |
768 |
530 |
320 |
1400 |
2200 |
2600 |
720 |
1024 |
940 |
580 |
2440 |
3200 |
3400 |
940 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16.3 |
18 |
30 |
100 |
0.997 |
8 |
27 |
25 |
30 |
33 |
96 |
7.95 |
16 |
35 |
35 |
40 |
43 |
120 |
15.87 |
32 |
51 |
53 |
60 |
66 |
170 |
31.65 |
48 |
57 |
55 |
70 |
90 |
250 |
47.3 |
64 |
68 |
70 |
83 |
110 |
300 |
63 |
128 |
130 |
110 |
150 |
400 |
600 |
124 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
25.5 |
50 |
60 |
100 |
0.997 |
64 |
100 |
90 |
300 |
300 |
400 |
63 |
128 |
150 |
127 |
300 |
400 |
500 |
124.5 |
256 |
220 |
180 |
500 |
600 |
800 |
244 |
384 |
340 |
260 |
700 |
1000 |
1300 |
357 |
512 |
600 |
400 |
1500 |
1600 |
2000 |
465 |
768 |
2000 |
1000 |
4000 |
4000 |
5000 |
640 |
1024 |
4000 |
5000 |
7300 |
8000 |
8000 |
676 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
12.8 |
13 |
30 |
1 |
8 |
18 |
20 |
20 |
22 |
44 |
7.99 |
16 |
23 |
22 |
30 |
31 |
50 |
15.97 |
32 |
34 |
37 |
45 |
47 |
60 |
31.9 |
48 |
44 |
50 |
59.6 |
60.6 |
70 |
47.8 |
64 |
47 |
56 |
64.6 |
66 |
80 |
63.8 |
128 |
69.5 |
66 |
94.4 |
96 |
130 |
127.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.3 |
20 |
30 |
80 |
1 |
64 |
60 |
66 |
80 |
80 |
97 |
63.8 |
128 |
77 |
76 |
110 |
118 |
142 |
127.3 |
256 |
115 |
110 |
167 |
170 |
203 |
254 |
384 |
152 |
156 |
234 |
240 |
270 |
380 |
512 |
189 |
192 |
300 |
308 |
330 |
505 |
768 |
270 |
270 |
440 |
454 |
560 |
750 |
1024 |
370 |
370 |
590 |
650 |
860 |
989 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
446 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13 |
15.6 |
30 |
100 |
0.997 |
8 |
24 |
20 |
26 |
27 |
100 |
7.95 |
16 |
30 |
27 |
34 |
37 |
130 |
15.87 |
32 |
40 |
38 |
50 |
50 |
150 |
31.66 |
48 |
50 |
45 |
60 |
90 |
200 |
47.2 |
64 |
56 |
60 |
70 |
80 |
240 |
63.1 |
128 |
100 |
85 |
100 |
300 |
500 |
124.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
19 |
50 |
100 |
100 |
0.997 |
64 |
100 |
80 |
200 |
300 |
300 |
63 |
128 |
130 |
100 |
270 |
400 |
500 |
124.6 |
256 |
200 |
160 |
400 |
600 |
800 |
244.4 |
384 |
280 |
240 |
600 |
780 |
1000 |
358 |
512 |
400 |
300 |
900 |
1200 |
1600 |
467 |
768 |
1000 |
700 |
3000 |
3000 |
3400 |
662 |
1024 |
2800 |
3000 |
5000 |
5600 |
5800 |
720 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
300 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
12.6 |
13 |
50 |
0.999 |
8 |
18.1 |
17.3 |
18.4 |
20 |
60 |
7.98 |
16 |
23.5 |
22 |
25 |
30 |
90 |
15.95 |
32 |
33.4 |
37 |
42 |
46 |
90 |
31.86 |
48 |
42 |
40 |
57 |
58 |
160 |
47.7 |
64 |
47 |
50 |
64 |
66 |
150 |
63.6 |
128 |
75 |
65 |
95 |
98 |
270 |
126.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13 |
20 |
50 |
80 |
0.999 |
64 |
64 |
60 |
80 |
190 |
197 |
63.5 |
128 |
90 |
80 |
100 |
230 |
330 |
126.5 |
256 |
140 |
120 |
170 |
380 |
580 |
250.5 |
384 |
190 |
163 |
246 |
530 |
860 |
372 |
512 |
261 |
220 |
580 |
700 |
1260 |
491.5 |
768 |
445 |
313 |
1170 |
1560 |
2100 |
723 |
1024 |
850 |
540 |
2100 |
2850 |
3170 |
941 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
450 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
12.2 |
20 |
30 |
100 |
0.996 |
8 |
20 |
17 |
40 |
41 |
44 |
7.96 |
16 |
27 |
22 |
50 |
60 |
65 |
15.85 |
32 |
37 |
34 |
60 |
80 |
100 |
31.6 |
48 |
43 |
40 |
75 |
90 |
130 |
47.3 |
64 |
51 |
56 |
84 |
100 |
150 |
63 |
128 |
110 |
80 |
230 |
240 |
380 |
123.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
13.5 |
100 |
100 |
100 |
0.995 |
64 |
100 |
70 |
200 |
230 |
230 |
62 |
128 |
134 |
90 |
295 |
300 |
330 |
122 |
256 |
215 |
160 |
480 |
560 |
566 |
235.6 |
384 |
304 |
224 |
700 |
800 |
870 |
341 |
512 |
470 |
440 |
940 |
1130 |
1340 |
439 |
768 |
1120 |
1070 |
1870 |
2100 |
2500 |
600 |
1024 |
2250 |
2700 |
3800 |
3800 |
4400 |
643 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
110.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13 |
40 |
40 |
100 |
0.993 |
8 |
22 |
18 |
54 |
63 |
65 |
7.9 |
16 |
30 |
24 |
70 |
80 |
90 |
15.7 |
32 |
40 |
34 |
50 |
107 |
120 |
31.1 |
48 |
47 |
40 |
80 |
145 |
170 |
46.4 |
64 |
60 |
60 |
100 |
160 |
190 |
61.2 |
128 |
124 |
77 |
320 |
370 |
470 |
118.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
40 |
100 |
100 |
100 |
0.993 |
64 |
120 |
80 |
200 |
200 |
200 |
61.3 |
128 |
170 |
100 |
318 |
340 |
350 |
119 |
256 |
277 |
188 |
570 |
580 |
590 |
225 |
384 |
390 |
300 |
780 |
830 |
900 |
320 |
512 |
634 |
600 |
1100 |
1300 |
1380 |
406 |
768 |
1760 |
1870 |
2650 |
2850 |
3060 |
462 |
1024 |
2800 |
3100 |
4300 |
4500 |
4800 |
486 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
72 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12 |
14 |
20 |
80 |
0.997 |
8 |
19 |
17 |
20 |
30 |
60 |
7.96 |
16 |
25 |
22 |
29.5 |
32 |
83 |
15.9 |
32 |
35 |
34 |
45 |
50 |
120 |
31.65 |
48 |
43 |
42 |
58 |
60 |
150 |
47.3 |
64 |
50 |
50 |
65 |
70 |
179 |
63 |
128 |
83 |
68 |
98 |
240 |
350 |
124.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13.3 |
50 |
80 |
80 |
0.997 |
64 |
80 |
68 |
200 |
200 |
230 |
62.8 |
128 |
110 |
80 |
250 |
300 |
330 |
124.3 |
256 |
173 |
125 |
400 |
510 |
570 |
243 |
384 |
243.4 |
190 |
566 |
740 |
840 |
356 |
512 |
360 |
270 |
740 |
1060 |
1300 |
464 |
768 |
750 |
460 |
1700 |
1700 |
2350 |
665 |
1024 |
1800 |
2000 |
3600 |
3600 |
3950 |
756 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
180 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.7 |
12.7 |
14 |
40 |
1 |
8 |
17.7 |
16.5 |
18 |
27 |
50 |
7.99 |
16 |
23 |
21 |
25 |
30.8 |
70 |
15.96 |
32 |
33 |
34 |
42 |
47 |
100 |
31.86 |
48 |
41 |
40 |
57 |
60 |
160 |
47.7 |
64 |
48 |
53 |
64 |
68 |
170 |
63.6 |
128 |
83 |
65 |
103 |
210 |
350 |
126.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
12.3 |
20 |
40 |
80 |
1 |
64 |
70 |
60 |
170 |
170 |
200 |
63.6 |
128 |
110 |
74 |
240 |
300 |
330 |
126.6 |
256 |
175 |
140 |
410 |
500 |
570 |
251 |
384 |
245 |
190 |
600 |
740 |
834 |
373.5 |
512 |
390 |
290 |
800 |
1070 |
1300 |
494 |
768 |
860 |
760 |
1600 |
1840 |
2300 |
728 |
1024 |
3000 |
3000 |
5000 |
5000 |
5400 |
870 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12 |
13 |
20 |
80 |
0.997 |
8 |
19.5 |
17.5 |
20 |
30 |
67.3 |
7.96 |
16 |
25 |
22.5 |
30 |
34 |
90 |
15.9 |
32 |
35.2 |
36 |
44 |
45 |
120 |
31.67 |
48 |
44 |
42 |
60 |
62.5 |
170 |
47.35 |
64 |
51 |
50 |
66 |
70 |
200 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
15 |
50 |
80 |
80 |
0.997 |
64 |
80 |
60 |
196 |
200 |
220 |
62.9 |
128 |
110 |
80 |
260 |
300 |
360 |
124.7 |
256 |
173 |
130 |
420 |
500 |
570 |
244 |
384 |
239 |
190 |
580 |
710 |
830 |
358.4 |
512 |
350 |
267 |
750 |
1000 |
1300 |
468 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
193 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
12.4 |
17 |
30 |
100 |
0.997 |
8 |
21 |
17.3 |
36 |
48 |
64 |
7.96 |
16 |
28 |
24 |
50 |
70 |
80 |
15.9 |
32 |
37 |
32 |
66 |
90 |
113 |
31.7 |
48 |
45 |
39 |
80 |
117 |
140 |
47.4 |
64 |
54 |
55 |
95 |
146 |
200 |
63.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16 |
40 |
100 |
100 |
0.997 |
64 |
80 |
70 |
200 |
240 |
240 |
62.9 |
128 |
115 |
84 |
260 |
300 |
350 |
124.7 |
256 |
175 |
126 |
400 |
500 |
560 |
244 |
384 |
240 |
195 |
570 |
725 |
830 |
359 |
512 |
355 |
270 |
740 |
1000 |
1300 |
468 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
193 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
49 |
47.9 |
49 |
50 |
92 |
0.997 |
4 |
55 |
52 |
59 |
60 |
106 |
3.986 |
8 |
81.4 |
95.1 |
97.6 |
98.5 |
170.5 |
7.95 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
44 |
41.3 |
43 |
60 |
100 |
0.998 |
4 |
70 |
67 |
80 |
100 |
105 |
3.99 |
8 |
90 |
98 |
100 |
120 |
150 |
7.96 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
100 |
假 |
4 |
191 |
假 |
8 |
196 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
13.2 |
14 |
14.6 |
40 |
1 |
8 |
18.4 |
18 |
19.4 |
20.6 |
36.5 |
7.99 |
16 |
24 |
23.5 |
30 |
32 |
40 |
15.97 |
32 |
34 |
30 |
44 |
44.5 |
51 |
31.9 |
48 |
43 |
42 |
60 |
61 |
73 |
47.9 |
64 |
46 |
50 |
64 |
66 |
73 |
63.8 |
128 |
72 |
67 |
98 |
100 |
110 |
127.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
20 |
30 |
100 |
1 |
64 |
60 |
70 |
80 |
90 |
90 |
63.8 |
128 |
84 |
84 |
120 |
126 |
140 |
127.3 |
256 |
127 |
120 |
180 |
200 |
260 |
253.3 |
384 |
175 |
170 |
256 |
313 |
420 |
377.5 |
512 |
223 |
220 |
335 |
440 |
570 |
500 |
768 |
330 |
320 |
510 |
670 |
890 |
741 |
1024 |
490 |
470 |
870 |
1010 |
1180 |
976 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
203 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
14.5 |
15.6 |
16 |
40 |
1 |
8 |
23 |
22.6 |
25 |
27 |
40 |
7.99 |
16 |
29.96 |
29.4 |
33 |
37 |
47 |
15.97 |
32 |
40 |
42 |
51 |
53.2 |
60 |
31.9 |
48 |
47 |
47 |
63 |
64.7 |
70 |
47.9 |
64 |
54 |
60 |
72 |
75 |
90 |
63.8 |
128 |
90 |
90 |
120 |
120 |
140 |
127.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
15.2 |
20 |
30 |
100 |
1 |
64 |
67 |
80 |
90 |
100 |
100 |
63.8 |
128 |
97 |
96 |
130 |
140 |
160 |
127.3 |
256 |
150 |
150 |
210 |
230 |
250 |
253.7 |
384 |
190 |
200 |
290 |
300 |
320 |
379 |
512 |
245 |
248 |
380 |
395 |
500 |
502 |
768 |
360 |
367 |
560 |
620 |
830 |
743 |
1024 |
800 |
800 |
1250 |
1350 |
1520 |
960 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
13.9 |
17 |
30 |
100 |
0.996 |
8 |
24 |
21.5 |
26 |
30 |
83 |
7.96 |
16 |
30 |
28.3 |
34 |
40 |
90 |
15.9 |
32 |
41.7 |
40 |
51 |
57 |
100 |
31.7 |
48 |
50 |
47 |
64 |
90 |
200 |
47.2 |
64 |
60 |
70 |
75 |
80 |
140 |
63.3 |
128 |
100 |
90 |
120 |
200 |
300 |
125.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20 |
50 |
100 |
100 |
0.996 |
64 |
90 |
80 |
200 |
200 |
300 |
63.3 |
128 |
100 |
100 |
200 |
300 |
400 |
125.6 |
256 |
200 |
170 |
400 |
500 |
700 |
247 |
384 |
220 |
200 |
400 |
500 |
600 |
369 |
512 |
300 |
300 |
500 |
700 |
900 |
480 |
768 |
500 |
400 |
1000 |
1000 |
2000 |
700 |
1024 |
1000 |
900 |
2000 |
2000 |
2000 |
890 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2260 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
13.6 |
14.5 |
15 |
30 |
1 |
8 |
19 |
18.5 |
20 |
22 |
43 |
8 |
16 |
25 |
23.6 |
30 |
32 |
65.4 |
15.98 |
32 |
35 |
34 |
44 |
46 |
80 |
31.9 |
48 |
44 |
43 |
60.4 |
62 |
100 |
47.8 |
64 |
47.6 |
50 |
64 |
66 |
120 |
63.8 |
128 |
79 |
66 |
97 |
100 |
350 |
126.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.3 |
15.7 |
30 |
100 |
1 |
64 |
70 |
70 |
80 |
150 |
200 |
63.6 |
128 |
90 |
80 |
120 |
230 |
320 |
126.6 |
256 |
139 |
120 |
175 |
340 |
580 |
251 |
384 |
192 |
173 |
250 |
500 |
860 |
373 |
512 |
270 |
220 |
666 |
700 |
1350 |
492 |
768 |
520 |
339 |
1400 |
2100 |
2500 |
723 |
1024 |
960 |
617 |
2400 |
3200 |
3300 |
943 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
510 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.2 |
16 |
17 |
17.7 |
40 |
1 |
8 |
24 |
23.3 |
25.5 |
30 |
60 |
7.99 |
16 |
30 |
30 |
35 |
37 |
70 |
15.97 |
32 |
42 |
40 |
50 |
53.5 |
102 |
31.9 |
48 |
48 |
48 |
64 |
67 |
120 |
47.8 |
64 |
56 |
60 |
72 |
75 |
170 |
63.7 |
128 |
97 |
90 |
117 |
160 |
300 |
127.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21.5 |
23 |
40 |
100 |
0.999 |
64 |
90 |
90 |
100 |
200 |
400 |
63.6 |
128 |
130 |
110 |
200 |
300 |
700 |
126.5 |
256 |
300 |
170 |
900 |
2000 |
2000 |
248 |
384 |
500 |
230 |
1000 |
2000 |
3000 |
373 |
512 |
700 |
300 |
2000 |
3000 |
4000 |
490 |
768 |
3000 |
2000 |
6000 |
7000 |
8000 |
716 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
106 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.3 |
16.2 |
16.3 |
40 |
0.999 |
8 |
21.6 |
20.4 |
22 |
23 |
59 |
7.99 |
16 |
28 |
26.4 |
30 |
39 |
80 |
15.96 |
32 |
41.4 |
40 |
53 |
54 |
130 |
31.85 |
48 |
49 |
54 |
64 |
66 |
160 |
47.7 |
64 |
59 |
67 |
75 |
76 |
216 |
63.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.6 |
30 |
40 |
100 |
0.999 |
64 |
90 |
93 |
110 |
200 |
240 |
63.5 |
128 |
115 |
100 |
140 |
260 |
350 |
126.6 |
256 |
185 |
163 |
248 |
451 |
630 |
251 |
384 |
254 |
230 |
350 |
630 |
930 |
373 |
512 |
362 |
300 |
730 |
940 |
1550 |
491 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
2000 |
真 |
32 |
125 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
19 |
18.5 |
19.4 |
20 |
40 |
0.999 |
8 |
28 |
27.4 |
28 |
30 |
46.4 |
7.99 |
16 |
38 |
36 |
50 |
52 |
64 |
15.96 |
32 |
49.4 |
50 |
63.3 |
64 |
104 |
31.9 |
48 |
68 |
80 |
84 |
86 |
145 |
47.8 |
64 |
87 |
101 |
106 |
110 |
188 |
63.6 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.9 |
20 |
30 |
100 |
1 |
64 |
100 |
113.8 |
134 |
137 |
140 |
63.7 |
128 |
156 |
150 |
210 |
215 |
236 |
127 |
256 |
262 |
250 |
396 |
400 |
480 |
252 |
384 |
378 |
370 |
593 |
600 |
860 |
374 |
512 |
520 |
530 |
800 |
980 |
1200 |
492 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
2240 |
真 |
32 |
82 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18.8 |
19.6 |
20.6 |
52 |
0.999 |
8 |
26.84 |
25.7 |
27 |
40 |
68 |
7.98 |
16 |
33.6 |
31 |
34 |
50 |
90 |
15.96 |
32 |
50 |
50 |
64 |
66 |
140 |
31.86 |
48 |
66 |
75 |
82 |
86 |
170 |
47.7 |
64 |
77 |
86 |
94 |
97.5 |
200 |
63.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21.1 |
30 |
40 |
90 |
0.999 |
64 |
90 |
96 |
110 |
120 |
200 |
63.7 |
128 |
146 |
160 |
170 |
200 |
300 |
127 |
256 |
234 |
230 |
310 |
310 |
380 |
253 |
384 |
321 |
340 |
440 |
447 |
590 |
377 |
512 |
410 |
420 |
580 |
660 |
890 |
498 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
1800 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
22.7 |
23.7 |
25 |
50 |
0.999 |
8 |
32.7 |
31 |
33 |
51 |
72.7 |
7.98 |
16 |
44 |
40.8 |
50 |
63 |
110 |
15.94 |
32 |
59 |
60 |
73 |
75 |
180 |
31.8 |
48 |
79 |
90 |
93 |
100 |
240 |
47.6 |
64 |
100 |
109 |
114 |
160 |
310 |
63.4 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
29.1 |
40 |
50 |
100 |
0.999 |
64 |
123 |
130 |
160 |
240 |
260 |
63.5 |
128 |
185 |
165 |
240 |
360 |
430 |
126.4 |
256 |
300 |
266 |
430 |
630 |
830 |
249.4 |
384 |
460 |
445 |
770 |
1100 |
1560 |
368 |
512 |
720 |
650 |
1400 |
1550 |
2150 |
483 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1330 |
真 |
32 |
75 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
170 |
假 |
32 |
1430 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1390 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1340 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
80 |
假 |
32 |
1000 |
真 |
32 |
80 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
60 |
假 |
32 |
234 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
80 |
假 |
32 |
144.3 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
5.7 |
假 |
32 |
38.75 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
24 |
假 |
32 |
168 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
13.5 |
12.5 |
13.6 |
14.3 |
40 |
0.999 |
n-gram |
8 |
26 |
24 |
30 |
40 |
67 |
7.98 |
n-gram |
16 |
37 |
34 |
44 |
50 |
95 |
15.95 |
n-gram |
32 |
48.4 |
47 |
64 |
71 |
130 |
31.85 |
n-gram |
48 |
63 |
64 |
80 |
90 |
200 |
47.7 |
n-gram |
64 |
81 |
86 |
100 |
130 |
300 |
63.4 |
无 |
1 |
13 |
12 |
12.8 |
13.4 |
40 |
0.999 |
无 |
8 |
23 |
22 |
30 |
36 |
60 |
7.98 |
无 |
16 |
33 |
30 |
40 |
45 |
90 |
15.95 |
无 |
32 |
45 |
45 |
60 |
66 |
140 |
31.85 |
无 |
48 |
60 |
60 |
75 |
90 |
170 |
47.7 |
无 |
64 |
72 |
79 |
93 |
110 |
290 |
63.4 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
17 |
15 |
16 |
32 |
70 |
0.999 |
n-gram |
64 |
100 |
100 |
120 |
200 |
250 |
63.5 |
n-gram |
128 |
140 |
130 |
170 |
300 |
420 |
126.3 |
n-gram |
256 |
220 |
200 |
290 |
490 |
760 |
250 |
无 |
1 |
15 |
12.7 |
14 |
27.3 |
70 |
1 |
无 |
64 |
90 |
90 |
107 |
190 |
240 |
63.5 |
无 |
128 |
127 |
110 |
160 |
270 |
390 |
126.4 |
无 |
256 |
207 |
180 |
270 |
500 |
750 |
250 |
无 |
384 |
310 |
276 |
600 |
700 |
1300 |
371 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
1430 |
假 |
无 |
32 |
1460 |
真 |
n-gram |
32 |
98 |
真 |
无 |
32 |
97 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.4 |
20 |
25 |
90 |
0.998 |
8 |
25.8 |
24.3 |
30 |
40 |
50 |
7.98 |
16 |
35 |
33 |
46 |
50 |
70 |
15.93 |
32 |
48 |
50 |
65 |
74 |
108 |
31.8 |
64 |
80 |
90 |
100 |
120 |
250 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
22 |
60 |
70 |
70 |
0.997 |
64 |
107 |
100 |
224 |
240 |
250 |
62.9 |
128 |
160 |
133 |
320 |
390 |
420 |
124 |
256 |
257 |
230 |
550 |
700 |
780 |
242 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
225 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.8 |
14 |
15 |
30 |
1 |
8 |
24.5 |
23.2 |
28 |
33 |
50 |
7.99 |
16 |
34 |
33 |
41.6 |
46 |
70 |
15.97 |
32 |
44.4 |
44 |
60 |
64 |
90 |
31.9 |
64 |
70 |
84 |
95 |
100 |
200 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.9 |
20 |
30 |
70 |
1 |
64 |
100 |
102 |
120 |
200 |
250 |
63.7 |
128 |
136 |
120 |
170 |
290 |
400 |
127.2 |
256 |
218 |
200 |
290 |
520 |
754 |
253.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
450 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.6 |
13.8 |
20 |
80 |
0.997 |
8 |
26 |
23.3 |
30 |
40 |
80 |
7.95 |
16 |
34 |
30 |
42 |
48 |
90 |
15.87 |
32 |
48 |
50 |
62 |
70 |
130 |
31.6 |
64 |
80 |
90 |
100 |
140 |
300 |
62.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
40 |
80 |
80 |
0.997 |
64 |
113 |
105 |
230 |
235 |
250 |
62.6 |
128 |
166 |
130 |
370 |
420 |
430 |
123 |
256 |
280 |
230 |
600 |
740 |
900 |
236.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
167 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19 |
20 |
20 |
30 |
0.999 |
8 |
27 |
26 |
31.5 |
33 |
44 |
7.99 |
16 |
36 |
35 |
42 |
45 |
54 |
15.97 |
32 |
47 |
50 |
60 |
63 |
70 |
31.9 |
64 |
70 |
80 |
96 |
100 |
110 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21.4 |
30 |
37 |
90 |
0.999 |
64 |
90 |
102 |
110 |
116 |
120 |
63.7 |
128 |
130 |
136 |
167 |
183 |
210 |
127 |
256 |
210 |
205 |
290 |
340 |
450 |
251.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.8 |
13 |
13.3 |
50 |
1 |
8 |
24 |
23 |
26 |
30 |
70 |
7.98 |
16 |
34 |
32 |
40 |
40 |
90 |
15.95 |
32 |
46 |
47 |
60 |
64 |
100 |
31.86 |
48 |
60 |
60 |
80 |
80 |
150 |
47.7 |
64 |
80 |
90 |
100 |
100 |
200 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.7 |
14.6 |
30 |
70 |
1 |
64 |
100 |
100 |
120 |
230 |
260 |
63.5 |
128 |
143 |
120 |
170 |
346 |
480 |
126 |
256 |
238 |
200 |
350 |
700 |
1120 |
248.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1040 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23 |
28 |
30 |
100 |
0.996 |
8 |
40 |
38 |
46.6 |
50 |
110 |
7.94 |
16 |
50 |
48 |
58 |
62 |
140 |
15.8 |
32 |
70 |
70 |
80 |
90 |
250 |
31.54 |
48 |
90 |
90 |
100 |
150 |
400 |
47.2 |
64 |
105 |
110 |
126 |
160 |
350 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
33 |
58 |
70 |
100 |
0.996 |
64 |
150 |
130 |
300 |
300 |
400 |
62.7 |
128 |
210 |
200 |
400 |
500 |
540 |
123.6 |
256 |
360 |
300 |
700 |
1000 |
1300 |
240 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
800 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.7 |
13.6 |
13.8 |
30 |
1 |
8 |
25.4 |
24.7 |
30 |
30.8 |
50 |
7.99 |
16 |
34 |
33 |
44 |
50 |
60 |
15.96 |
32 |
50 |
50 |
60 |
70 |
80 |
31.9 |
64 |
73 |
84 |
95 |
100 |
130 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
14 |
20 |
30 |
70 |
1 |
64 |
86 |
96 |
110 |
120 |
130 |
63.7 |
128 |
121 |
114 |
160 |
165 |
190 |
127 |
256 |
190 |
190 |
277 |
284 |
300 |
253 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
19.7 |
22 |
22 |
80 |
0.996 |
8 |
33 |
30 |
38 |
40 |
100 |
7.94 |
16 |
43.2 |
40 |
50 |
56 |
130 |
15.85 |
32 |
53 |
53 |
67 |
70 |
170 |
31.6 |
48 |
80 |
80 |
90 |
140 |
300 |
47.1 |
64 |
90 |
100 |
110 |
150 |
300 |
62.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
26.7 |
70 |
90 |
90 |
0.996 |
64 |
130 |
116 |
300 |
300 |
300 |
62.6 |
128 |
200 |
160 |
400 |
500 |
600 |
123.3 |
256 |
300 |
260 |
600 |
800 |
1000 |
239.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.7 |
13.5 |
13.7 |
50 |
0.999 |
8 |
24.3 |
23.3 |
26 |
30 |
70 |
7.98 |
16 |
33 |
32 |
40 |
42 |
90 |
15.95 |
32 |
46 |
47 |
61.6 |
65 |
110 |
31.84 |
64 |
77 |
86 |
95 |
100 |
230 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
13.7 |
20 |
50 |
70 |
0.999 |
64 |
98 |
101 |
120 |
200 |
260 |
63.5 |
128 |
140 |
120 |
170 |
330 |
430 |
126 |
256 |
217 |
196 |
282 |
530 |
740 |
249 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.3 |
30 |
40 |
70 |
0.994 |
8 |
28 |
24.5 |
50 |
52 |
55 |
7.95 |
16 |
38 |
34 |
56 |
70 |
80 |
15.8 |
32 |
50 |
50 |
80 |
100 |
115 |
31.54 |
64 |
90 |
90 |
150 |
180 |
250 |
62.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20.7 |
90 |
90 |
90 |
0.994 |
64 |
130 |
100 |
240 |
240 |
250 |
61.7 |
128 |
198 |
157 |
400 |
420 |
430 |
120.3 |
256 |
330 |
260 |
700 |
750 |
800 |
229 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
110 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
40 |
40 |
90 |
0.991 |
8 |
32 |
27 |
64 |
70 |
76 |
7.88 |
16 |
41 |
34.5 |
70 |
100 |
105 |
15.6 |
32 |
55 |
50 |
90 |
140 |
150 |
30.9 |
64 |
110 |
90 |
260 |
300 |
370 |
60 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
40 |
90 |
90 |
90 |
0.99 |
64 |
155 |
110 |
260 |
260 |
260 |
60.3 |
128 |
240 |
170 |
420 |
450 |
450 |
116.7 |
256 |
400 |
300 |
770 |
800 |
840 |
215 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.6 |
14 |
20 |
70 |
0.997 |
8 |
26 |
23.3 |
30 |
33 |
70 |
7.96 |
16 |
33 |
30 |
41.5 |
50 |
95 |
15.87 |
32 |
48 |
50 |
63 |
70 |
140 |
31.6 |
64 |
80 |
84 |
100 |
200 |
300 |
62.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
50 |
70 |
70 |
0.997 |
64 |
120 |
106 |
230 |
260 |
270 |
62.5 |
128 |
164 |
140 |
340 |
386 |
420 |
123.2 |
256 |
267 |
232 |
570 |
700 |
800 |
239 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
180 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.7 |
13.7 |
16 |
40 |
1 |
8 |
25 |
23 |
30 |
40 |
66 |
7.98 |
16 |
34 |
32 |
43 |
49 |
90 |
15.95 |
32 |
45 |
45 |
60 |
67 |
130 |
31.84 |
48 |
60 |
60 |
79 |
90 |
200 |
47.7 |
64 |
78 |
82 |
98 |
122 |
300 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.2 |
20 |
40 |
70 |
1 |
64 |
110 |
100 |
226 |
235 |
250 |
63.5 |
128 |
167 |
143 |
370 |
392 |
410 |
126.3 |
256 |
268 |
230 |
600 |
680 |
770 |
249.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1080 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
13 |
14 |
20 |
70 |
0.997 |
8 |
27 |
24 |
30 |
30 |
76 |
7.95 |
16 |
36 |
32 |
43 |
50 |
106 |
15.87 |
32 |
49 |
47 |
64 |
74 |
140 |
31.6 |
48 |
65 |
70 |
83 |
90 |
220 |
47.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
50 |
70 |
70 |
0.997 |
64 |
120 |
105 |
250 |
270 |
300 |
62.5 |
128 |
170 |
140 |
370 |
420 |
430 |
123.4 |
256 |
270 |
220 |
600 |
730 |
790 |
239.6 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
192 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
19.27 |
25 |
40 |
100 |
0.997 |
8 |
30 |
26 |
50 |
66 |
80 |
7.95 |
16 |
40 |
35 |
70 |
86 |
102 |
15.86 |
32 |
54 |
50 |
85 |
116 |
145 |
31.6 |
48 |
70 |
70 |
100 |
170 |
230 |
47.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
23 |
60 |
80 |
80 |
0.997 |
64 |
120 |
108 |
250 |
260 |
270 |
62.6 |
128 |
170 |
140 |
370 |
410 |
425 |
123.4 |
256 |
275 |
235 |
600 |
760 |
800 |
239.5 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
192 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
25 |
26 |
27 |
50 |
0.998 |
4 |
56.8 |
55.3 |
61.1 |
65 |
108 |
3.99 |
8 |
84.6 |
95.5 |
103.4 |
106 |
174 |
7.95 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
26.9 |
28 |
44 |
80 |
0.999 |
4 |
60 |
58 |
64 |
84 |
100 |
3.99 |
8 |
87.6 |
97 |
110 |
116 |
146 |
7.97 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
130 |
假 |
4 |
202 |
假 |
8 |
208 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.56 |
21 |
22 |
40 |
0.999 |
8 |
27 |
26 |
31 |
33 |
49 |
7.99 |
16 |
35.5 |
35 |
44 |
47 |
60 |
15.96 |
32 |
47 |
50 |
63 |
65 |
76 |
31.9 |
48 |
57 |
60 |
77 |
80 |
90 |
47.8 |
64 |
80 |
90 |
100 |
100 |
110 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
22 |
27 |
40 |
90 |
0.999 |
64 |
92 |
104 |
120 |
120 |
130 |
63.7 |
128 |
130 |
125 |
170 |
190 |
210 |
127 |
256 |
210 |
200 |
295 |
350 |
459 |
251.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
160 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
21.7 |
21 |
23 |
27 |
40 |
0.999 |
8 |
35 |
36 |
38 |
40 |
54 |
7.99 |
16 |
44 |
44 |
50 |
52 |
60 |
15.96 |
32 |
56 |
60 |
68 |
70 |
80 |
31.9 |
48 |
67 |
70 |
85 |
90 |
100 |
47.8 |
64 |
81.5 |
96 |
107 |
110 |
130 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23 |
30 |
35 |
90 |
0.999 |
64 |
110 |
120 |
140 |
140 |
140 |
63.7 |
128 |
152 |
145 |
196 |
200 |
240 |
127 |
256 |
230 |
220 |
330 |
340 |
360 |
252.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21.3 |
24.5 |
26 |
100 |
0.996 |
8 |
36 |
36 |
40 |
46 |
90 |
7.95 |
16 |
46 |
45 |
53 |
60 |
110 |
15.86 |
32 |
57 |
56 |
70 |
80 |
160 |
31.6 |
48 |
73 |
80 |
90 |
100 |
200 |
47.3 |
64 |
85 |
95 |
110 |
118 |
200 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
26 |
60 |
80 |
80 |
0.996 |
64 |
100 |
110 |
200 |
200 |
300 |
63.1 |
128 |
170 |
150 |
300 |
400 |
500 |
125 |
256 |
250 |
240 |
400 |
500 |
600 |
246 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.5 |
21 |
23 |
40 |
1 |
8 |
27 |
26 |
31 |
33 |
50 |
7.99 |
16 |
38 |
37 |
45 |
50 |
80 |
15.98 |
32 |
49 |
50 |
60 |
64 |
120 |
31.9 |
64 |
80 |
90 |
100 |
100 |
220 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
22 |
29 |
39 |
90 |
0.999 |
64 |
98 |
102 |
114 |
190 |
250 |
63.5 |
128 |
143 |
125 |
172 |
300 |
400 |
126.3 |
256 |
220 |
200 |
300 |
500 |
800 |
249.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
23 |
26 |
30 |
50 |
1 |
8 |
36 |
34.6 |
42 |
45 |
80 |
7.98 |
16 |
44.5 |
43.6 |
52 |
56 |
100 |
15.95 |
32 |
60 |
60 |
75 |
80 |
160 |
31.9 |
64 |
90 |
100 |
110 |
120 |
200 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
32 |
29.3 |
31 |
50 |
100 |
0.998 |
64 |
130 |
120 |
200 |
200 |
400 |
63.5 |
128 |
200 |
160 |
300 |
500 |
900 |
126 |
256 |
500 |
250 |
1000 |
2000 |
3000 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
24 |
26 |
27 |
50 |
0.998 |
8 |
33 |
31 |
40 |
48 |
80 |
7.98 |
16 |
43 |
40 |
53 |
57 |
107 |
15.94 |
32 |
60 |
60 |
78 |
83 |
170 |
31.8 |
48 |
80 |
84 |
100 |
110 |
250 |
47.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
27 |
40 |
50 |
90 |
0.999 |
64 |
136 |
140 |
170 |
270 |
280 |
63.4 |
128 |
192 |
160 |
244 |
380 |
500 |
126.1 |
256 |
310 |
300 |
420 |
700 |
940 |
248.6 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1300 |
真 |
32 |
120 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28.4 |
27.6 |
28.4 |
30 |
53 |
0.998 |
8 |
40 |
38.4 |
50 |
50 |
70 |
7.98 |
16 |
55.4 |
52 |
72.4 |
76 |
90 |
15.94 |
32 |
90 |
104 |
114 |
117 |
180 |
31.8 |
48 |
122 |
138 |
150 |
155 |
260 |
47.6 |
64 |
240 |
220 |
370 |
400 |
430 |
63.3 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
29.5 |
37 |
50 |
100 |
0.999 |
64 |
188 |
203 |
214 |
218 |
220 |
63.6 |
128 |
274 |
240 |
380 |
385 |
400 |
126.4 |
256 |
480 |
500 |
710 |
780 |
1060 |
247.6 |
384 |
2500 |
2400 |
4200 |
4500 |
5000 |
330 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1470 |
真 |
32 |
116 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
28 |
30 |
33 |
60 |
0.998 |
8 |
40 |
38 |
43 |
50 |
80 |
7.98 |
16 |
56 |
60 |
70 |
71 |
130 |
15.93 |
32 |
83 |
93 |
102 |
106 |
190 |
31.8 |
48 |
114 |
126 |
137 |
144 |
257 |
47.6 |
64 |
144 |
158 |
170 |
180 |
340 |
63.3 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
36 |
33 |
40 |
60 |
100 |
0.998 |
64 |
160 |
176 |
200 |
210 |
230 |
63.6 |
128 |
280 |
307 |
330 |
350 |
400 |
126.5 |
256 |
467 |
470 |
600 |
694 |
860 |
249.3 |
384 |
700 |
720 |
1100 |
1200 |
1400 |
368 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
33.5 |
32.6 |
33.7 |
36 |
60 |
0.998 |
8 |
47 |
43 |
60 |
69 |
100 |
7.97 |
16 |
63 |
60 |
82 |
90 |
140 |
15.92 |
32 |
96 |
106 |
118 |
130 |
260 |
31.74 |
48 |
139 |
145 |
160 |
220 |
380 |
47.4 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
37 |
50 |
66 |
100 |
0.998 |
64 |
203 |
204 |
220 |
360 |
380 |
63.3 |
128 |
284 |
260 |
373 |
510 |
630 |
125.5 |
256 |
540 |
500 |
1000 |
1260 |
1900 |
244.6 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
130 |
假 |
32 |
850 |
真 |
32 |
104 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
110 |
假 |
32 |
815 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
115 |
假 |
32 |
760 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
120 |
假 |
32 |
735 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
32 |
400 |
真 |
32 |
23 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
50 |
假 |
32 |
148 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
32 |
110.7 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
5.7 |
假 |
32 |
38.6 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
26 |
假 |
32 |
166 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
17 |
15.7 |
16.7 |
17.4 |
40 |
0.999 |
n-gram |
8 |
34 |
30 |
40 |
47 |
80 |
7.98 |
n-gram |
16 |
45 |
42 |
55 |
60 |
120 |
15.94 |
n-gram |
32 |
55 |
54 |
74 |
80 |
200 |
31.8 |
n-gram |
48 |
65 |
70 |
83 |
93 |
230 |
47.65 |
n-gram |
64 |
83 |
88 |
100 |
130 |
300 |
63.4 |
无 |
1 |
16 |
15 |
15.6 |
16 |
40 |
0.999 |
无 |
8 |
30.8 |
29 |
33 |
44 |
75 |
7.98 |
无 |
16 |
42 |
39 |
53 |
57 |
110 |
15.94 |
无 |
32 |
53 |
50 |
70 |
76 |
160 |
31.8 |
无 |
48 |
59 |
60 |
77 |
86 |
200 |
47.7 |
无 |
64 |
80 |
84 |
96 |
110 |
270 |
63.4 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
20 |
17.7 |
19 |
36 |
70 |
0.999 |
n-gram |
64 |
110 |
113 |
140 |
245 |
300 |
63.5 |
n-gram |
128 |
140 |
120 |
170 |
300 |
407 |
126.3 |
n-gram |
256 |
223 |
200 |
295 |
500 |
770 |
250 |
无 |
1 |
20 |
15.6 |
16.5 |
31 |
70 |
1 |
无 |
64 |
105 |
107 |
136 |
220 |
250 |
63.5 |
无 |
128 |
133 |
110 |
165 |
290 |
400 |
126.4 |
无 |
256 |
212 |
190 |
284 |
500 |
730 |
250 |
无 |
384 |
310 |
290 |
600 |
640 |
1300 |
371.5 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
1400 |
假 |
无 |
32 |
1440 |
真 |
n-gram |
32 |
128 |
真 |
无 |
32 |
90 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
22 |
26 |
30 |
90 |
0.997 |
8 |
34.6 |
33 |
40 |
52 |
63 |
7.97 |
16 |
46 |
43 |
60 |
65 |
90 |
15.9 |
32 |
57 |
55 |
80 |
85 |
130 |
31.8 |
64 |
78 |
88 |
100 |
110 |
200 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
50 |
90 |
90 |
0.997 |
64 |
125 |
120 |
250 |
270 |
300 |
62.7 |
128 |
160 |
130 |
300 |
400 |
400 |
124.2 |
256 |
260 |
223 |
530 |
700 |
780 |
242.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
224 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.3 |
16.4 |
18 |
40 |
1 |
8 |
32 |
30.3 |
40 |
40 |
61 |
7.99 |
16 |
43 |
40 |
50 |
57 |
80 |
15.96 |
32 |
54 |
55 |
73 |
76 |
100 |
31.9 |
64 |
76 |
87 |
97 |
102 |
200 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.2 |
23 |
40 |
70 |
1 |
64 |
110 |
120 |
150 |
240 |
300 |
63.7 |
128 |
140 |
127 |
200 |
280 |
400 |
127.2 |
256 |
220 |
200 |
295 |
500 |
700 |
253.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
460 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
15.2 |
16.3 |
20 |
70 |
0.997 |
8 |
32 |
30 |
35 |
40 |
80 |
7.94 |
16 |
42 |
38.3 |
50 |
60 |
109 |
15.84 |
32 |
56 |
55 |
75 |
83 |
160 |
31.54 |
64 |
80 |
88 |
102 |
130 |
280 |
62.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
50 |
70 |
70 |
0.997 |
64 |
126 |
120 |
250 |
260 |
280 |
62.4 |
128 |
166 |
140 |
300 |
390 |
400 |
123.2 |
256 |
272 |
236 |
570 |
700 |
780 |
237.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
167 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22 |
24 |
25 |
40 |
0.999 |
8 |
33.5 |
32.6 |
38 |
40 |
55 |
7.99 |
16 |
46 |
45 |
58 |
60 |
70 |
15.96 |
32 |
56 |
60 |
75 |
78 |
87 |
31.9 |
64 |
76 |
90 |
100 |
105 |
110 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24.7 |
30 |
40 |
90 |
0.999 |
64 |
110 |
120 |
140 |
150 |
150 |
63.7 |
128 |
136 |
132 |
177 |
200 |
216 |
127 |
256 |
210 |
208 |
300 |
360 |
460 |
251.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.5 |
16.4 |
16.5 |
50 |
0.999 |
8 |
34 |
31.6 |
40 |
44 |
80 |
7.98 |
16 |
43 |
41 |
54.6 |
56 |
100 |
15.94 |
32 |
54 |
52.4 |
70.9 |
74 |
120 |
31.84 |
48 |
59 |
60 |
75 |
78 |
150 |
47.7 |
64 |
76 |
87 |
96 |
99 |
200 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.14 |
17 |
32 |
70 |
0.999 |
64 |
110 |
113 |
150 |
240 |
300 |
63.5 |
128 |
150 |
130 |
186 |
360 |
480 |
126 |
256 |
240 |
210 |
300 |
670 |
1000 |
248.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1060 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
26 |
29 |
30 |
100 |
0.996 |
8 |
45 |
42 |
50 |
60 |
120 |
7.94 |
16 |
57 |
56 |
68 |
73 |
155 |
15.83 |
32 |
68 |
70 |
85 |
100 |
250 |
31.5 |
48 |
90 |
94 |
105 |
140 |
310 |
47.2 |
64 |
110 |
113 |
130 |
160 |
370 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
35 |
60 |
72 |
100 |
0.996 |
64 |
150 |
130 |
300 |
300 |
400 |
62.7 |
128 |
200 |
194 |
400 |
500 |
500 |
124 |
256 |
300 |
290 |
700 |
800 |
1000 |
241 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.6 |
16.6 |
16.9 |
30 |
0.999 |
8 |
33 |
32 |
36 |
38 |
58 |
7.99 |
16 |
44 |
42 |
54 |
57 |
70 |
15.95 |
32 |
55 |
60 |
74 |
76 |
90 |
31.9 |
64 |
80 |
90 |
100 |
104 |
140 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.5 |
20 |
30 |
70 |
0.999 |
64 |
110 |
120 |
146 |
150 |
160 |
63.6 |
128 |
130 |
125 |
170 |
180 |
200 |
127 |
256 |
196 |
190 |
286 |
290 |
310 |
253 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
24 |
28 |
32 |
100 |
0.995 |
8 |
40.5 |
37 |
50 |
50 |
120 |
7.93 |
16 |
52 |
50 |
60 |
66 |
150 |
15.84 |
32 |
60 |
60 |
76 |
86 |
180 |
31.56 |
48 |
80 |
86 |
100 |
140 |
300 |
47.1 |
64 |
96 |
100 |
120 |
200 |
300 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
28 |
60 |
100 |
100 |
0.996 |
64 |
150 |
130 |
300 |
400 |
400 |
62.7 |
128 |
200 |
160 |
360 |
500 |
600 |
123.8 |
256 |
300 |
260 |
600 |
700 |
1000 |
241 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.6 |
16.3 |
16.5 |
50 |
0.999 |
8 |
32.4 |
31 |
35 |
36 |
80 |
7.98 |
16 |
44 |
42 |
54 |
57 |
100 |
15.93 |
32 |
56 |
60 |
73 |
77 |
130 |
31.8 |
64 |
80 |
90 |
99 |
102 |
240 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
20 |
50 |
80 |
0.999 |
64 |
120 |
130 |
150 |
250 |
300 |
63.3 |
128 |
140 |
130 |
200 |
300 |
400 |
126 |
256 |
226 |
200 |
294 |
500 |
740 |
249 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
447 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
22 |
30 |
40 |
90 |
0.994 |
8 |
35.4 |
31.2 |
56 |
60 |
64 |
7.93 |
16 |
48 |
42 |
70 |
90 |
103 |
15.83 |
32 |
58 |
60 |
90 |
120 |
150 |
31.5 |
64 |
90 |
91 |
166 |
200 |
260 |
62.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
26 |
90 |
90 |
90 |
0.994 |
64 |
150 |
110 |
300 |
300 |
300 |
61.4 |
128 |
200 |
160 |
400 |
400 |
400 |
120.5 |
256 |
320 |
260 |
660 |
720 |
750 |
230 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
110 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
22.5 |
40 |
50 |
100 |
0.99 |
8 |
40 |
33.5 |
70 |
90 |
100 |
7.86 |
16 |
50 |
43 |
90 |
110 |
120 |
15.58 |
32 |
60 |
60 |
90 |
140 |
160 |
31 |
64 |
110 |
100 |
200 |
330 |
350 |
60.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
41 |
90 |
90 |
90 |
0.99 |
64 |
160 |
130 |
260 |
260 |
260 |
60.6 |
128 |
230 |
180 |
400 |
400 |
400 |
117 |
256 |
398 |
320 |
750 |
750 |
760 |
217 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16.3 |
18 |
20 |
70 |
0.997 |
8 |
34 |
31 |
40 |
50 |
90 |
7.94 |
16 |
47 |
44 |
58 |
60 |
120 |
15.83 |
32 |
60 |
60 |
80 |
90 |
160 |
31.5 |
64 |
87 |
93 |
107 |
140 |
260 |
62.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
50 |
70 |
70 |
0.997 |
64 |
130 |
110 |
240 |
300 |
300 |
62.4 |
128 |
166 |
130 |
350 |
370 |
400 |
123 |
256 |
267 |
240 |
580 |
700 |
750 |
239 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
177 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.2 |
16.2 |
20 |
40 |
0.999 |
8 |
32 |
30 |
40 |
47 |
78 |
7.98 |
16 |
43 |
40 |
55 |
59 |
120 |
15.93 |
32 |
54 |
50 |
70 |
80 |
170 |
31.8 |
48 |
63 |
70 |
82 |
90 |
200 |
47.7 |
64 |
80 |
87 |
100 |
116 |
300 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.3 |
30 |
40 |
70 |
0.999 |
64 |
130 |
110 |
260 |
300 |
300 |
63.4 |
128 |
165 |
140 |
310 |
374 |
400 |
126.3 |
256 |
269 |
230 |
570 |
670 |
730 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16.3 |
17.6 |
20 |
80 |
0.997 |
8 |
35 |
32.5 |
38 |
40 |
90 |
7.94 |
16 |
47 |
44 |
60 |
60 |
120 |
15.84 |
32 |
57 |
57 |
80 |
84 |
150 |
31.57 |
48 |
70 |
73 |
86 |
100 |
240 |
47.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20 |
60 |
80 |
80 |
0.996 |
64 |
140 |
130 |
280 |
290 |
300 |
62.4 |
128 |
170 |
150 |
340 |
380 |
400 |
123.7 |
256 |
270 |
235 |
580 |
700 |
760 |
240 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
191 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
22.5 |
28 |
45 |
100 |
0.996 |
8 |
37 |
32 |
58 |
72 |
80 |
7.94 |
16 |
49 |
42 |
80 |
100 |
120 |
15.84 |
32 |
58 |
55 |
90 |
120 |
150 |
31.6 |
48 |
72 |
70 |
100 |
160 |
230 |
47.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
28 |
50 |
100 |
100 |
0.996 |
64 |
140 |
120 |
300 |
300 |
300 |
62.5 |
128 |
170 |
140 |
340 |
400 |
410 |
123.7 |
256 |
270 |
240 |
600 |
700 |
760 |
240.6 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
192 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
54 |
53 |
60 |
60 |
100 |
0.997 |
4 |
98 |
95 |
101 |
110 |
190 |
3.98 |
8 |
1360 |
1310 |
2440 |
2540 |
2930 |
7.37 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
70 |
68.8 |
70 |
86.7 |
100 |
0.997 |
4 |
110 |
100 |
140 |
140 |
150 |
3.984 |
8 |
153 |
170 |
185 |
200 |
230 |
7.94 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
4 |
106 |
假 |
8 |
109.3 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22.4 |
23.5 |
24 |
40 |
0.999 |
8 |
34 |
33 |
38 |
40 |
53 |
7.98 |
16 |
46 |
45 |
57 |
60 |
65 |
15.95 |
32 |
57 |
60 |
76 |
79 |
85 |
31.9 |
48 |
61 |
64 |
80 |
85 |
93 |
47.8 |
64 |
80 |
90 |
100 |
105 |
114 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
24.3 |
30 |
42 |
90 |
0.999 |
64 |
107 |
120 |
140 |
150 |
160 |
63.6 |
128 |
136 |
130 |
176 |
200 |
214 |
127 |
256 |
210 |
210 |
300 |
360 |
460 |
251.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
146 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
23 |
24.5 |
26 |
40 |
0.999 |
8 |
40 |
39.5 |
50 |
50 |
58.7 |
7.98 |
16 |
52 |
52 |
59 |
60 |
70 |
15.96 |
32 |
60 |
60 |
76 |
80 |
90 |
31.9 |
48 |
70 |
73 |
88 |
92 |
100 |
47.8 |
64 |
83 |
100 |
108 |
110 |
120 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
26 |
34 |
40 |
90 |
0.999 |
64 |
120 |
130 |
150 |
160 |
170 |
63.6 |
128 |
155 |
150 |
200 |
220 |
240 |
127 |
256 |
234 |
230 |
336 |
340 |
370 |
252.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
24.4 |
28 |
33 |
100 |
0.995 |
8 |
44 |
42 |
47 |
49 |
90 |
7.95 |
16 |
54 |
53 |
63 |
70 |
110 |
15.86 |
32 |
62 |
63 |
77 |
85 |
140 |
31.6 |
48 |
80 |
80 |
90 |
100 |
200 |
47.25 |
64 |
90 |
100 |
110 |
120 |
200 |
63.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
30 |
70 |
100 |
100 |
0.995 |
64 |
140 |
130 |
200 |
200 |
300 |
63 |
128 |
180 |
160 |
300 |
300 |
500 |
125 |
256 |
260 |
251 |
400 |
500 |
700 |
247 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22.8 |
24 |
27 |
34 |
0.999 |
8 |
35 |
34 |
39 |
40 |
65 |
7.99 |
16 |
47 |
45 |
55 |
60 |
100 |
15.97 |
32 |
60 |
60 |
80 |
80 |
120 |
31.9 |
64 |
80 |
90 |
100 |
105 |
230 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
24.6 |
30 |
44 |
90 |
0.999 |
64 |
120 |
120 |
150 |
230 |
300 |
63.4 |
128 |
146 |
130 |
180 |
300 |
410 |
126.3 |
256 |
230 |
200 |
300 |
560 |
800 |
249.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
24.6 |
30 |
30 |
47 |
0.999 |
8 |
42 |
41 |
47 |
50 |
80 |
7.98 |
16 |
54.5 |
54 |
63 |
67 |
110 |
15.95 |
32 |
64 |
67 |
81 |
86 |
150 |
31.9 |
64 |
90 |
100 |
110 |
120 |
200 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
34 |
31.7 |
35 |
50 |
100 |
0.998 |
64 |
140 |
134 |
200 |
200 |
400 |
63.5 |
128 |
200 |
160 |
300 |
400 |
1000 |
125.6 |
256 |
500 |
260 |
1000 |
2000 |
3000 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
29 |
28 |
29 |
33 |
60 |
0.998 |
8 |
43 |
40 |
50 |
60 |
95 |
7.97 |
16 |
53 |
50 |
70 |
70 |
140 |
15.93 |
32 |
60 |
60 |
76 |
80 |
160 |
31.8 |
48 |
80 |
88 |
98 |
104.4 |
250 |
47.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
34 |
31.5 |
40 |
50 |
100 |
0.998 |
64 |
140 |
144 |
170 |
260 |
300 |
63.4 |
128 |
200 |
170 |
260 |
370 |
470 |
126.1 |
256 |
325 |
300 |
440 |
722 |
950 |
248.6 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1280 |
真 |
32 |
123 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30.5 |
30 |
31 |
33 |
55 |
0.998 |
8 |
51 |
50 |
55 |
56 |
90 |
7.98 |
16 |
58 |
56 |
70 |
75 |
100 |
15.94 |
32 |
86.4 |
90 |
110 |
114 |
180 |
31.8 |
48 |
123 |
144 |
155 |
170 |
260 |
47.6 |
64 |
710 |
700 |
1160 |
1200 |
1230 |
61.4 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
36 |
33 |
40 |
53 |
100 |
0.999 |
64 |
184 |
200 |
214 |
220 |
240 |
63.5 |
128 |
280 |
250 |
386 |
390 |
420 |
126.4 |
256 |
496 |
500 |
730 |
830 |
1100 |
247.4 |
384 |
2930 |
2770 |
5020 |
5500 |
6200 |
322.6 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1450 |
真 |
32 |
126 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
35 |
33.6 |
40 |
40 |
70 |
0.998 |
8 |
54 |
52 |
57 |
59 |
100 |
7.98 |
16 |
72 |
70 |
92 |
95 |
150 |
15.92 |
32 |
90 |
99 |
110 |
113 |
200 |
31.8 |
48 |
117 |
128 |
137 |
142 |
270 |
47.6 |
64 |
150 |
162 |
172 |
180 |
350 |
63.3 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
36.5 |
50 |
63 |
90 |
0.998 |
64 |
162 |
176 |
192 |
200 |
240 |
63.6 |
128 |
280 |
320 |
340 |
370 |
400 |
126.4 |
256 |
480 |
480 |
610 |
800 |
900 |
249 |
384 |
730 |
780 |
1140 |
1270 |
1500 |
367 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
230 |
假 |
32 |
1740 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
39.2 |
40 |
45 |
76 |
0.998 |
8 |
57 |
56 |
62 |
80 |
120 |
7.97 |
16 |
63 |
60 |
81 |
87 |
150 |
15.92 |
32 |
94 |
100 |
117 |
130 |
200 |
31.75 |
48 |
135 |
145 |
163 |
230 |
360 |
47.5 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
50 |
45 |
60 |
70 |
100 |
0.998 |
64 |
205 |
214 |
226 |
300 |
350 |
63.3 |
128 |
310 |
260 |
400 |
520 |
643 |
125.5 |
256 |
580 |
560 |
1030 |
1330 |
2000 |
244.6 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
150 |
假 |
32 |
825 |
真 |
32 |
84 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
730 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
170 |
假 |
32 |
714 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
160 |
假 |
32 |
700 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
32 |
400 |
真 |
32 |
23 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
50 |
假 |
32 |
142.4 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
32 |
98.4 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
5.9 |
假 |
32 |
40.5 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
26 |
假 |
32 |
173 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
14 |
13 |
13.6 |
14 |
40 |
0.999 |
n-gram |
8 |
27 |
25 |
30.6 |
37 |
70 |
7.98 |
n-gram |
16 |
39 |
37 |
47 |
51 |
100 |
15.94 |
n-gram |
32 |
52 |
50 |
70 |
74 |
150 |
31.8 |
n-gram |
48 |
70 |
70 |
90 |
100 |
250 |
47.6 |
n-gram |
64 |
100 |
100 |
120 |
200 |
350 |
63.3 |
无 |
1 |
12.6 |
12 |
12.54 |
12.7 |
40 |
0.999 |
无 |
8 |
24 |
22.9 |
26 |
29 |
60 |
7.98 |
无 |
16 |
33.6 |
31 |
40 |
44 |
90 |
15.95 |
无 |
32 |
47 |
47 |
62 |
70 |
140 |
31.8 |
无 |
48 |
63 |
70 |
83 |
90 |
230 |
47.6 |
无 |
64 |
87 |
94 |
106 |
140 |
325 |
63.4 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
17 |
14.9 |
16 |
32 |
80 |
0.999 |
n-gram |
64 |
110 |
114 |
130 |
240 |
300 |
63.4 |
n-gram |
128 |
164 |
150 |
200 |
370 |
470 |
126.1 |
n-gram |
256 |
270 |
255 |
360 |
600 |
850 |
249 |
无 |
1 |
15 |
12.6 |
13 |
26.6 |
70 |
1 |
无 |
64 |
100 |
104 |
120 |
200 |
260 |
63.5 |
无 |
128 |
152 |
130 |
192 |
300 |
450 |
126.2 |
无 |
256 |
263 |
240 |
355 |
550 |
900 |
249 |
无 |
384 |
430 |
377 |
800 |
1250 |
1800 |
369 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
1200 |
假 |
无 |
32 |
1230 |
真 |
n-gram |
32 |
93 |
真 |
无 |
32 |
90 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.4 |
22 |
26 |
60 |
0.998 |
8 |
29 |
27 |
40 |
47 |
55 |
7.97 |
16 |
39 |
38 |
48 |
58 |
80 |
15.92 |
32 |
52 |
52 |
67 |
75 |
120 |
31.8 |
64 |
90 |
100 |
116 |
150 |
310 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
21 |
60 |
70 |
70 |
0.997 |
64 |
120 |
116 |
250 |
260 |
270 |
62.8 |
128 |
190 |
160 |
370 |
440 |
466 |
123.8 |
256 |
323 |
290 |
640 |
800 |
1000 |
240 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
225 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.7 |
14 |
14.5 |
30 |
1 |
8 |
26 |
25 |
30 |
34 |
53 |
7.99 |
16 |
36 |
35 |
44 |
50 |
80 |
15.97 |
32 |
50 |
50 |
67 |
70 |
94 |
31.9 |
64 |
90 |
100 |
110 |
120 |
200 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14 |
20 |
30 |
70 |
1 |
64 |
106 |
110 |
130 |
200 |
260 |
63.7 |
128 |
160 |
140 |
200 |
340 |
470 |
127 |
256 |
270 |
253 |
367 |
613 |
900 |
252.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
457 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.8 |
13.5 |
20 |
70 |
0.997 |
8 |
27 |
24 |
30 |
30 |
80 |
7.95 |
16 |
36 |
33 |
43 |
50 |
94 |
15.86 |
32 |
51 |
50 |
70 |
80 |
140 |
31.56 |
64 |
95 |
100 |
110 |
200 |
350 |
62.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
50 |
70 |
70 |
0.997 |
64 |
120 |
112 |
240 |
250 |
260 |
62.4 |
128 |
190 |
160 |
400 |
440 |
460 |
122.4 |
256 |
366 |
300 |
800 |
940 |
1200 |
233.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
166 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.5 |
20 |
25 |
40 |
0.999 |
8 |
27 |
26.3 |
30 |
34 |
46 |
7.99 |
16 |
36 |
35.5 |
45 |
47 |
55 |
15.96 |
32 |
50 |
50 |
67 |
70 |
80 |
31.9 |
64 |
83 |
100 |
110 |
113 |
122 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21 |
30 |
30 |
90 |
0.999 |
64 |
100 |
117 |
130 |
130 |
140 |
63.7 |
128 |
158 |
150 |
207 |
220 |
280 |
126.6 |
256 |
260 |
250 |
370 |
460 |
600 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
427 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.9 |
13.6 |
13.9 |
40 |
0.999 |
8 |
27 |
25.4 |
30 |
30 |
74 |
7.98 |
16 |
35.74 |
34 |
44 |
46 |
80 |
15.95 |
32 |
50 |
50 |
70 |
70 |
111.7 |
31.85 |
48 |
70 |
79 |
90 |
94 |
200 |
47.7 |
64 |
87 |
100 |
110 |
114 |
260 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.2 |
15 |
29 |
80 |
1 |
64 |
103.4 |
110 |
120 |
200 |
270 |
63.5 |
128 |
170 |
140 |
200 |
420 |
550 |
125.8 |
256 |
310 |
250 |
630 |
800 |
1400 |
247 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
930 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
24.6 |
28 |
32 |
100 |
0.996 |
8 |
41.7 |
40 |
47 |
50 |
114 |
7.94 |
16 |
50 |
49 |
60 |
65 |
140 |
15.84 |
32 |
70 |
70 |
85 |
90 |
220 |
31.5 |
48 |
90 |
94 |
110 |
150 |
340 |
47.2 |
64 |
113 |
120 |
140 |
200 |
400 |
62.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
32 |
55 |
60 |
100 |
0.996 |
64 |
150 |
140 |
300 |
300 |
400 |
62.4 |
128 |
230 |
230 |
500 |
600 |
600 |
123.6 |
256 |
440 |
370 |
900 |
1100 |
1500 |
239 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
860 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.3 |
13 |
14 |
14 |
30 |
0.999 |
8 |
25 |
25 |
28 |
30 |
50 |
7.99 |
16 |
34.8 |
34 |
40 |
44 |
60 |
15.96 |
32 |
50 |
50 |
60 |
70 |
80 |
31.9 |
64 |
80 |
98 |
106 |
110 |
170 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
13.8 |
20 |
30 |
40 |
0.999 |
64 |
97 |
109 |
125 |
130 |
140 |
63.7 |
128 |
145 |
130 |
193 |
200 |
230 |
127 |
256 |
233.5 |
230 |
346 |
350 |
380 |
252.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
21 |
24 |
30 |
100 |
0.996 |
8 |
36 |
33 |
40 |
43 |
100 |
7.94 |
16 |
46 |
44 |
52 |
56 |
130 |
15.84 |
32 |
63 |
65 |
80 |
90 |
180 |
31.6 |
48 |
85 |
90 |
101 |
160 |
400 |
47 |
64 |
100 |
110 |
120 |
200 |
370 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
25.6 |
60 |
100 |
100 |
0.996 |
64 |
150 |
133 |
300 |
300 |
400 |
62.5 |
128 |
210 |
170 |
400 |
500 |
600 |
123 |
256 |
400 |
338 |
700 |
900 |
1300 |
239 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.9 |
13.8 |
14 |
40 |
0.999 |
8 |
27 |
26 |
30 |
32 |
74 |
7.98 |
16 |
36 |
35 |
40 |
50 |
100 |
15.94 |
32 |
51 |
54 |
70 |
73 |
120 |
31.8 |
64 |
87 |
100 |
110 |
114 |
270 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14 |
20 |
50 |
70 |
0.999 |
64 |
107 |
111 |
130 |
230 |
270 |
63.4 |
128 |
162 |
139 |
200 |
340 |
440 |
126 |
256 |
270 |
252 |
360 |
620 |
900 |
248 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
19 |
30 |
40 |
70 |
0.994 |
8 |
31 |
27 |
50 |
54 |
60 |
7.94 |
16 |
42 |
38 |
64 |
80 |
90 |
15.8 |
32 |
57 |
56 |
90 |
110 |
130 |
31.5 |
64 |
110 |
105 |
200 |
250 |
330 |
61.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
21 |
90 |
90 |
90 |
0.994 |
64 |
150 |
118 |
300 |
300 |
300 |
61.3 |
128 |
226 |
190 |
430 |
460 |
480 |
119.5 |
256 |
410 |
340 |
800 |
900 |
1000 |
226 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
109.2 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
20 |
37 |
50 |
80 |
0.991 |
8 |
35 |
30 |
60 |
73 |
80 |
7.88 |
16 |
45 |
40 |
60 |
100 |
100 |
15.64 |
32 |
60 |
60 |
90 |
160 |
170 |
30.8 |
64 |
136 |
110 |
320 |
440 |
450 |
59.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
40 |
80 |
80 |
80 |
0.99 |
64 |
170 |
130 |
270 |
270 |
270 |
60.1 |
128 |
270 |
205 |
470 |
483 |
484 |
115 |
256 |
500 |
440 |
900 |
1000 |
1060 |
212 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
13 |
15 |
20 |
70 |
0.997 |
8 |
28.5 |
26 |
33 |
40 |
73 |
7.95 |
16 |
37.4 |
34 |
46 |
53 |
100 |
15.86 |
32 |
54 |
60 |
70 |
80 |
150 |
31.55 |
64 |
90 |
98 |
110 |
170 |
330 |
62.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14.3 |
40 |
80 |
80 |
0.997 |
64 |
123 |
115 |
250 |
260 |
270 |
62.4 |
128 |
190 |
150 |
400 |
440 |
450 |
122.8 |
256 |
330 |
290 |
660 |
800 |
1000 |
236.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
178 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
13 |
15 |
40 |
0.999 |
8 |
27 |
24 |
30 |
40 |
70 |
7.98 |
16 |
35 |
33 |
40 |
50 |
90 |
15.94 |
32 |
50 |
50 |
64 |
70 |
140 |
31.8 |
48 |
70 |
70 |
87 |
110 |
250 |
47.6 |
64 |
87 |
90 |
110 |
140 |
400 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
13.8 |
20 |
40 |
70 |
0.999 |
64 |
118 |
108 |
240 |
250 |
260 |
63.5 |
128 |
188 |
170 |
370 |
430 |
450 |
126 |
256 |
344 |
290 |
700 |
800 |
1000 |
248.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
940 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
13 |
14 |
20 |
70 |
0.997 |
8 |
30 |
27 |
40 |
40 |
80 |
7.94 |
16 |
39 |
36 |
47 |
53 |
105 |
15.86 |
32 |
53 |
54 |
70 |
80 |
150 |
31.6 |
48 |
75 |
80 |
90 |
110 |
280 |
47.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16 |
40 |
80 |
80 |
0.997 |
64 |
130 |
115 |
260 |
280 |
300 |
62.5 |
128 |
194 |
160 |
400 |
450 |
460 |
123 |
256 |
335 |
290 |
670 |
800 |
1000 |
238 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
190 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
19.7 |
25 |
40 |
100 |
0.996 |
8 |
31 |
26 |
49 |
66 |
80 |
7.95 |
16 |
40.5 |
35 |
70 |
88 |
104 |
15.86 |
32 |
56 |
55 |
80 |
110 |
140 |
31.6 |
48 |
78 |
77 |
120 |
200 |
250 |
47.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
50 |
90 |
90 |
0.996 |
64 |
134 |
119 |
284 |
300 |
300 |
62.4 |
128 |
191 |
150 |
400 |
430 |
460 |
123 |
256 |
340 |
300 |
700 |
850 |
1000 |
237.7 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
191 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
36 |
35 |
36 |
36.6 |
68 |
0.998 |
4 |
71.3 |
69 |
75 |
80 |
150 |
3.98 |
8 |
118.2 |
135 |
143 |
160 |
248 |
7.93 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
35.6 |
37 |
52.7 |
100 |
0.998 |
4 |
74 |
72 |
80 |
100 |
113 |
3.99 |
8 |
115 |
130 |
143.4 |
160 |
180 |
7.96 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
100 |
假 |
4 |
135 |
假 |
8 |
137 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.4 |
21 |
24 |
36 |
0.999 |
8 |
28 |
27 |
32 |
35 |
45 |
7.99 |
16 |
37 |
37 |
45 |
48 |
53 |
15.97 |
32 |
50 |
50 |
64 |
67 |
75 |
31.9 |
48 |
65 |
67 |
87 |
90 |
100 |
47.8 |
64 |
80 |
100 |
110 |
114 |
120 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
21 |
28 |
30 |
60 |
0.999 |
64 |
97 |
113 |
128 |
130.4 |
140 |
63.7 |
128 |
160 |
150 |
210 |
230 |
300 |
126.7 |
256 |
260 |
240 |
360 |
460 |
590 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
130 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
21.3 |
23 |
26 |
40 |
0.999 |
8 |
36.2 |
36.4 |
40 |
42 |
53 |
7.99 |
16 |
45 |
45 |
50 |
53.2 |
62 |
15.96 |
32 |
58 |
63 |
71.7 |
75 |
84 |
31.9 |
48 |
73 |
80 |
93 |
98 |
108 |
47.8 |
64 |
100 |
110 |
130 |
130 |
150 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
23.5 |
30 |
40 |
90 |
0.999 |
64 |
110 |
120 |
140 |
150 |
155 |
63.6 |
128 |
180 |
160 |
230 |
240 |
300 |
127 |
256 |
280 |
265 |
400 |
420 |
500 |
251 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
21 |
24 |
30 |
100 |
0.996 |
8 |
37 |
36 |
41 |
44 |
84 |
7.95 |
16 |
46 |
45 |
54 |
60 |
100 |
15.9 |
32 |
60 |
64 |
80 |
83 |
140 |
31.64 |
48 |
77 |
80 |
100 |
100 |
200 |
47.3 |
64 |
93 |
110 |
118 |
124 |
200 |
63.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
26 |
60 |
100 |
100 |
0.996 |
64 |
130 |
127 |
200 |
200 |
200 |
63.1 |
128 |
200 |
170 |
300 |
400 |
500 |
124.8 |
256 |
300 |
280 |
400 |
500 |
600 |
246 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
21.5 |
24 |
30 |
0.999 |
8 |
28 |
27.5 |
32 |
34 |
55 |
7.99 |
16 |
38.6 |
37.7 |
45 |
49 |
80 |
15.97 |
32 |
52.6 |
54 |
68 |
73 |
110 |
31.9 |
64 |
90 |
100 |
110 |
116 |
300 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
22 |
26 |
39 |
90 |
0.999 |
64 |
106 |
110 |
130 |
200 |
270 |
63.4 |
128 |
163 |
140 |
201 |
350 |
476 |
126 |
256 |
296 |
270 |
500 |
720 |
1200 |
248 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23.9 |
22.95 |
27 |
30 |
47 |
1 |
8 |
38.5 |
38 |
43 |
46 |
80 |
7.98 |
16 |
47 |
46.5 |
53 |
56 |
100 |
15.96 |
32 |
60 |
60 |
75 |
80 |
160 |
31.9 |
64 |
100 |
117 |
127 |
130 |
210 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
32 |
29 |
35 |
50 |
100 |
0.998 |
64 |
130 |
135 |
200 |
200 |
400 |
63.4 |
128 |
220 |
180 |
300 |
400 |
1000 |
125.7 |
256 |
400 |
300 |
700 |
1000 |
2000 |
249 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23.6 |
22.7 |
24 |
27 |
50 |
0.998 |
8 |
33 |
30.6 |
40 |
45 |
80 |
7.98 |
16 |
43.9 |
42 |
56 |
60 |
120 |
15.94 |
32 |
65 |
72 |
82 |
86 |
200 |
31.8 |
48 |
96 |
105 |
120 |
140 |
306 |
47.5 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
28 |
40 |
50 |
100 |
0.999 |
64 |
160 |
167 |
190 |
300 |
340 |
63.4 |
128 |
245 |
200 |
316 |
440 |
560 |
125.8 |
256 |
446 |
420 |
780 |
1000 |
1700 |
246.3 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
170 |
假 |
32 |
1000 |
真 |
32 |
85 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
29 |
30 |
35 |
56 |
0.998 |
8 |
44.2 |
42.4 |
50 |
60 |
73 |
7.98 |
16 |
63 |
60 |
80 |
85 |
110 |
15.93 |
32 |
106 |
125 |
136 |
140 |
200 |
31.76 |
48 |
1000 |
1000 |
1700 |
1800 |
2000 |
45.2 |
64 |
6700 |
6000 |
13000 |
14400 |
16700 |
45.4 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
35 |
32.2 |
40 |
50 |
100 |
0.999 |
64 |
245 |
263 |
280 |
280 |
290 |
63.4 |
128 |
390 |
340 |
510 |
520 |
670 |
125.4 |
256 |
1700 |
1700 |
2800 |
3000 |
3500 |
230 |
384 |
10900 |
9800 |
20500 |
22000 |
25000 |
229 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
170 |
假 |
32 |
1160 |
真 |
32 |
85 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
29 |
33 |
36.5 |
62 |
0.998 |
8 |
46 |
44 |
49.3 |
50 |
86 |
7.98 |
16 |
63 |
61.8 |
78 |
80 |
136 |
15.93 |
32 |
103 |
116 |
124 |
127 |
244 |
31.76 |
48 |
147 |
163 |
170.4 |
174 |
340 |
47.5 |
64 |
194 |
209 |
218 |
240 |
430 |
63.2 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
35 |
32.5 |
40 |
60 |
90 |
0.998 |
64 |
202 |
222 |
240 |
250 |
270 |
63.5 |
128 |
400 |
428 |
450 |
600 |
700 |
125.6 |
256 |
724 |
770 |
1060 |
1200 |
1400 |
245.4 |
384 |
6300 |
5800 |
10700 |
11800 |
14000 |
282 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1360 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
31 |
30.3 |
32 |
37 |
62.7 |
0.998 |
8 |
46 |
43 |
50 |
70 |
100 |
7.97 |
16 |
63 |
59 |
80 |
84 |
155 |
15.92 |
32 |
110 |
120 |
130 |
150 |
300 |
31.7 |
48 |
400 |
400 |
700 |
700 |
900 |
46.7 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
42 |
39 |
50 |
60 |
100 |
0.998 |
64 |
260 |
273 |
285 |
350 |
430 |
63.2 |
128 |
400 |
340 |
510 |
760 |
880 |
124.7 |
256 |
1400 |
1400 |
2300 |
2400 |
3000 |
234 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
120 |
假 |
32 |
640 |
真 |
32 |
95 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
114 |
假 |
32 |
606 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
100 |
假 |
32 |
598 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
110 |
假 |
32 |
574 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
80 |
假 |
32 |
360 |
真 |
32 |
23 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
40 |
假 |
32 |
116 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
60 |
假 |
32 |
86 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
5.6 |
假 |
32 |
37.5 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
26 |
假 |
32 |
165.5 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
11 |
10.2 |
11.4 |
13 |
40 |
0.999 |
n-gram |
8 |
13.3 |
12.2 |
13.5 |
20 |
44 |
7.99 |
n-gram |
16 |
17.5 |
15 |
22 |
27 |
67 |
15.96 |
n-gram |
32 |
23.5 |
20 |
30 |
34 |
90 |
31.9 |
n-gram |
48 |
30 |
30 |
40 |
44 |
100 |
47.8 |
n-gram |
64 |
35.6 |
36 |
46 |
48.4 |
130 |
63.7 |
n-gram |
128 |
55 |
47.6 |
67 |
100 |
230 |
127 |
n-gram |
256 |
110 |
80.8 |
250 |
400 |
560 |
252 |
无 |
1 |
10 |
9.7 |
10.5 |
11 |
30 |
1 |
无 |
8 |
13 |
11.5 |
15 |
20 |
40 |
7.99 |
无 |
16 |
16 |
14 |
20 |
24 |
50 |
15.97 |
无 |
32 |
23 |
23 |
30 |
33 |
85 |
31.9 |
无 |
48 |
28 |
27 |
37 |
41 |
90 |
47.8 |
无 |
64 |
32.6 |
31.4 |
44 |
46 |
104 |
63.7 |
无 |
128 |
50 |
44 |
62 |
90 |
200 |
127 |
无 |
256 |
100.8 |
76 |
190 |
345 |
500 |
252 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
15 |
11.8 |
13 |
28 |
80 |
1 |
n-gram |
64 |
43 |
44 |
50 |
100 |
145 |
63.7 |
n-gram |
128 |
60 |
50 |
70 |
160 |
230 |
127 |
n-gram |
256 |
92 |
80 |
110 |
240 |
410 |
252.7 |
n-gram |
384 |
121 |
106 |
153 |
350 |
580 |
377 |
n-gram |
512 |
148 |
130 |
194 |
400 |
730 |
499 |
n-gram |
768 |
233 |
187 |
570 |
660 |
1200 |
740 |
n-gram |
1024 |
330 |
240 |
684 |
1240 |
1600 |
977 |
无 |
1 |
10 |
9.8 |
11 |
23 |
80 |
1 |
无 |
64 |
37 |
40 |
47 |
90 |
120 |
63.8 |
无 |
128 |
56 |
47 |
68 |
150 |
220 |
127 |
无 |
256 |
86 |
75 |
107 |
240 |
400 |
253 |
无 |
384 |
114 |
101 |
148 |
300 |
550 |
377 |
无 |
512 |
142 |
120 |
190 |
400 |
700 |
500 |
无 |
768 |
220 |
176 |
510 |
590 |
1180 |
742 |
无 |
1024 |
330 |
236 |
700 |
1200 |
1700 |
978 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
1800 |
假 |
无 |
32 |
2300 |
真 |
n-gram |
32 |
140 |
真 |
无 |
32 |
134 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
10.5 |
12 |
16 |
100 |
0.998 |
8 |
14 |
12.6 |
20 |
26 |
33 |
7.98 |
16 |
19 |
17 |
25 |
34 |
40 |
15.95 |
32 |
25 |
25 |
35 |
40 |
60 |
31.9 |
48 |
29 |
28.7 |
40 |
46 |
80 |
47.8 |
64 |
37 |
42 |
48 |
51 |
100 |
63.7 |
128 |
52 |
48 |
66.6 |
76 |
156 |
127.2 |
256 |
100 |
80 |
170 |
370 |
480 |
253 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
11.5 |
30 |
100 |
100 |
0.998 |
64 |
50 |
44 |
100 |
130 |
134 |
63.4 |
128 |
71 |
50 |
160 |
220 |
226 |
126 |
256 |
110 |
83 |
270 |
330 |
400 |
248.7 |
384 |
147.7 |
113 |
360 |
470 |
570 |
368 |
512 |
182 |
137.4 |
460 |
620 |
740 |
485 |
768 |
303 |
210 |
630 |
900 |
1280 |
710 |
1024 |
480 |
310 |
1200 |
1340 |
1900 |
924 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
227 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
9.9 |
11.3 |
12 |
40 |
1 |
8 |
12.6 |
12 |
13.4 |
17 |
31 |
8 |
16 |
17 |
15 |
22 |
25 |
40 |
15.98 |
32 |
23 |
23 |
31 |
33 |
50 |
31.94 |
48 |
29 |
28 |
40 |
41 |
70 |
47.9 |
64 |
33.6 |
38 |
45 |
47 |
70 |
63.9 |
128 |
49 |
47 |
64 |
67 |
150 |
127.6 |
256 |
84 |
75 |
107 |
126 |
391 |
255 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11 |
20 |
40 |
80 |
1 |
64 |
39 |
40 |
55 |
80 |
110 |
63.9 |
128 |
58 |
50 |
75 |
150 |
202 |
127.6 |
256 |
90 |
80 |
115 |
240 |
380 |
255 |
384 |
120 |
107 |
155 |
316 |
530 |
381.4 |
512 |
149 |
130 |
196 |
400 |
700 |
508 |
768 |
258 |
200 |
630 |
680 |
1280 |
756 |
1024 |
420 |
263 |
1280 |
1350 |
1900 |
992 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
467 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
10 |
11 |
20 |
80 |
0.997 |
8 |
14 |
12 |
15 |
20 |
48 |
7.97 |
16 |
17.6 |
14.6 |
22 |
27 |
60 |
15.9 |
32 |
24 |
23 |
32 |
36 |
87 |
31.7 |
48 |
30 |
30 |
40 |
43 |
107 |
47.5 |
64 |
35 |
40 |
45 |
48 |
123 |
63.2 |
128 |
52 |
44 |
65 |
100 |
220 |
125.3 |
256 |
116 |
79 |
270 |
430 |
600 |
245.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
12 |
50 |
80 |
80 |
0.997 |
64 |
50 |
40 |
110 |
130 |
135 |
63.2 |
128 |
73 |
50 |
170 |
200 |
220 |
125.3 |
256 |
113 |
81 |
290 |
360 |
400 |
246.3 |
384 |
155 |
110 |
400 |
520 |
590 |
362.4 |
512 |
193 |
140 |
500 |
640 |
750 |
476 |
768 |
360 |
226 |
800 |
1100 |
1350 |
680 |
1024 |
630 |
350 |
1400 |
1600 |
2100 |
880 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
169 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
10.7 |
12 |
12.8 |
50 |
1 |
8 |
14 |
12.8 |
16 |
20 |
30 |
7.99 |
16 |
16.9 |
15.2 |
22.4 |
24 |
30 |
15.98 |
32 |
23 |
25 |
32 |
34 |
40 |
31.94 |
48 |
28 |
28.3 |
38 |
40 |
50 |
47.9 |
64 |
34 |
40 |
46 |
47.7 |
55 |
63.8 |
128 |
47 |
46 |
63 |
65 |
73 |
127.6 |
256 |
71 |
73 |
103 |
105 |
110 |
254.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
12 |
20 |
20 |
100 |
1 |
64 |
37 |
40 |
50 |
55 |
62 |
63.8 |
128 |
50 |
50 |
66 |
70 |
80 |
127.6 |
256 |
74 |
76 |
105 |
110 |
124 |
254.6 |
384 |
100 |
103 |
147 |
155 |
203 |
381 |
512 |
126 |
126 |
190 |
216 |
290 |
506 |
768 |
180 |
174 |
270 |
350 |
470 |
753 |
1024 |
233 |
225 |
360 |
490 |
650 |
996 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
434 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.4 |
11.3 |
12 |
50 |
1 |
8 |
13 |
12 |
15 |
20 |
47 |
7.99 |
16 |
17 |
15 |
21 |
22 |
50 |
15.97 |
32 |
23 |
23 |
30 |
33 |
70 |
31.9 |
48 |
29 |
28 |
39 |
41 |
90 |
47.8 |
64 |
34 |
40 |
45 |
46.5 |
110 |
63.7 |
128 |
50 |
46 |
64 |
66 |
160 |
127 |
256 |
84 |
75 |
104 |
110 |
480 |
252.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.4 |
13 |
25.4 |
80 |
1 |
64 |
39.2 |
40 |
48 |
94 |
130 |
63.7 |
128 |
57.5 |
48.5 |
69 |
160 |
224 |
127 |
256 |
90 |
77 |
107 |
270 |
420 |
252.5 |
384 |
122 |
100 |
150 |
400 |
630 |
376 |
512 |
160 |
131 |
240 |
520 |
880 |
497 |
768 |
257 |
179 |
770 |
880 |
1450 |
735 |
1024 |
400 |
250 |
1050 |
1700 |
2200 |
966 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
14 |
15 |
30 |
100 |
0.997 |
8 |
18.6 |
17 |
20 |
24 |
76 |
7.96 |
16 |
25 |
23 |
32 |
35 |
100 |
15.88 |
32 |
34 |
32 |
44 |
46 |
150 |
31.67 |
48 |
43 |
42 |
57 |
58.6 |
190 |
47.4 |
64 |
60 |
60 |
70 |
75 |
200 |
63 |
128 |
90 |
80 |
106 |
200 |
400 |
125.2 |
256 |
200 |
140 |
500 |
900 |
1000 |
246 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
22.6 |
44.6 |
46 |
100 |
0.997 |
64 |
80 |
70 |
160 |
200 |
200 |
63.1 |
128 |
120 |
96 |
250 |
300 |
400 |
125.3 |
256 |
180 |
154 |
400 |
500 |
700 |
247 |
384 |
240 |
190 |
500 |
700 |
900 |
364 |
512 |
330 |
250 |
700 |
1000 |
1300 |
476 |
768 |
800 |
400 |
2000 |
2000 |
3000 |
680 |
1024 |
2000 |
2000 |
5000 |
5000 |
5000 |
840 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
320 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10 |
11 |
11.7 |
30 |
1 |
8 |
13 |
12.3 |
16 |
20 |
38 |
7.99 |
16 |
16 |
15 |
22 |
23 |
41 |
15.97 |
32 |
23 |
23.7 |
32 |
33 |
50 |
31.9 |
48 |
28 |
28 |
38 |
41 |
50 |
47.9 |
64 |
32.5 |
35 |
45 |
46.5 |
60 |
63.8 |
128 |
46 |
45 |
63 |
65 |
75 |
127.5 |
256 |
72 |
73 |
103 |
106 |
140 |
254 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11 |
20 |
30 |
80 |
1 |
64 |
38 |
43 |
50 |
60 |
80 |
63.8 |
128 |
50 |
49 |
67 |
80 |
95 |
127.6 |
256 |
75 |
78 |
106 |
110 |
135 |
254.6 |
384 |
99 |
100 |
146 |
150 |
178 |
381 |
512 |
119 |
123 |
183 |
188 |
209 |
507 |
768 |
165 |
170 |
265 |
275 |
290 |
758 |
1024 |
208 |
210 |
340 |
350 |
390 |
1006 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
447 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.36 |
14 |
20 |
100 |
0.997 |
8 |
15.6 |
13.6 |
17 |
20 |
62 |
7.97 |
16 |
20 |
18 |
24 |
28 |
80 |
15.9 |
32 |
28 |
26 |
34 |
40 |
100 |
31.7 |
48 |
36 |
34 |
45 |
50 |
150 |
47.5 |
64 |
45 |
46 |
57 |
63 |
200 |
63 |
128 |
70 |
62 |
90 |
200 |
400 |
125 |
256 |
140 |
101 |
300 |
500 |
700 |
247 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16 |
43 |
100 |
100 |
0.997 |
64 |
70 |
54 |
200 |
200 |
200 |
63 |
128 |
90 |
70 |
200 |
300 |
300 |
125.4 |
256 |
150 |
114 |
340 |
440 |
600 |
247 |
384 |
190 |
142 |
500 |
600 |
700 |
364 |
512 |
280 |
185 |
600 |
900 |
1200 |
476 |
768 |
560 |
294 |
1500 |
1600 |
2200 |
685 |
1024 |
1300 |
900 |
3000 |
3000 |
4000 |
860 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
194 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.3 |
11.3 |
11.4 |
50 |
0.999 |
8 |
13 |
12.4 |
14 |
20 |
49 |
7.99 |
16 |
17.4 |
16 |
22 |
24.3 |
60 |
15.96 |
32 |
23 |
22 |
31 |
33 |
80 |
31.9 |
48 |
30 |
29 |
40 |
41.5 |
100 |
47.8 |
64 |
34 |
40 |
44 |
46 |
110 |
63.7 |
128 |
49.2 |
45 |
64 |
66 |
170 |
127 |
256 |
85 |
76 |
106 |
130 |
460 |
252 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.1 |
20 |
50 |
80 |
1 |
64 |
40 |
40 |
50 |
126 |
140 |
63.7 |
128 |
60 |
48 |
70 |
160 |
220 |
127 |
256 |
90 |
78 |
108 |
270 |
400 |
252 |
384 |
120 |
105 |
150 |
350 |
550 |
376 |
512 |
148 |
126 |
190 |
450 |
700 |
498 |
768 |
230 |
182 |
560 |
640 |
1200 |
738 |
1024 |
330 |
243 |
900 |
1160 |
1550 |
970 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
451 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
10.4 |
20 |
30 |
100 |
0.995 |
8 |
15 |
12.4 |
29 |
30 |
39 |
7.97 |
16 |
20 |
16 |
40 |
42 |
50 |
15.92 |
32 |
25.7 |
23 |
46 |
58 |
64 |
31.7 |
48 |
31.2 |
29 |
53 |
68 |
79 |
47.5 |
64 |
37 |
36.6 |
60 |
75 |
100 |
63.2 |
128 |
60 |
50 |
110 |
134 |
210 |
125.5 |
256 |
150 |
97 |
380 |
400 |
505 |
242.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
11 |
100 |
100 |
100 |
0.996 |
64 |
60 |
46 |
130 |
140 |
140 |
62.8 |
128 |
90 |
60 |
200 |
207 |
211 |
124 |
256 |
142 |
100 |
330 |
377 |
386 |
241.7 |
384 |
190 |
130 |
450 |
510 |
560 |
354 |
512 |
242 |
160 |
600 |
680 |
730 |
460 |
768 |
430 |
370 |
900 |
1060 |
1300 |
660 |
1024 |
690 |
500 |
1260 |
1500 |
1800 |
840 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
110.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
10.5 |
30 |
60 |
100 |
0.993 |
8 |
20 |
20 |
40 |
50 |
50 |
7.9 |
16 |
20.5 |
16 |
40 |
60 |
60 |
15.8 |
32 |
28 |
26 |
50 |
78 |
90 |
31.4 |
48 |
35 |
30 |
44 |
100 |
120 |
46.7 |
64 |
40 |
34 |
60 |
120 |
140 |
62 |
128 |
70 |
50 |
130 |
200 |
270 |
121.3 |
256 |
180 |
107 |
500 |
600 |
700 |
231.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
34 |
100 |
100 |
100 |
0.992 |
64 |
90 |
60 |
150 |
150 |
160 |
61.8 |
128 |
120 |
75 |
223 |
225 |
230 |
121.5 |
256 |
190 |
110 |
380 |
400 |
412 |
233 |
384 |
254 |
159 |
530 |
570 |
590 |
338 |
512 |
320 |
200 |
700 |
750 |
780 |
432 |
768 |
630 |
600 |
1100 |
1300 |
1400 |
605 |
1024 |
1370 |
1440 |
2140 |
2300 |
2500 |
672 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
72.2 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
10 |
12 |
20 |
80 |
0.998 |
8 |
14 |
12.2 |
20 |
20 |
47 |
7.97 |
16 |
19 |
15.6 |
24 |
28 |
60 |
15.9 |
32 |
24.7 |
24 |
33 |
37 |
86 |
31.75 |
48 |
32 |
30 |
42 |
44 |
110 |
47.5 |
64 |
35.6 |
37 |
45 |
50 |
124 |
63.3 |
128 |
53 |
46 |
66 |
100 |
230 |
125.5 |
256 |
102 |
79 |
180 |
340 |
460 |
246.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
11.3 |
50 |
80 |
80 |
0.998 |
64 |
50 |
43 |
120 |
130 |
137 |
63.2 |
128 |
74 |
52 |
170 |
210 |
220 |
125.5 |
256 |
115 |
84 |
300 |
360 |
390 |
247 |
384 |
150 |
112 |
400 |
500 |
550 |
365 |
512 |
190 |
140 |
500 |
630 |
730 |
479 |
768 |
320 |
220 |
700 |
950 |
1250 |
697 |
1024 |
500 |
300 |
1100 |
1360 |
1750 |
900 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
180 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10 |
11.3 |
13 |
40 |
1 |
8 |
13 |
12 |
16 |
20 |
40 |
7.99 |
16 |
17.3 |
14.7 |
22 |
27 |
60 |
15.96 |
32 |
25 |
25 |
33 |
37 |
80 |
31.9 |
48 |
29 |
28 |
38 |
42 |
90 |
47.8 |
64 |
34 |
34 |
45 |
47.6 |
110 |
63.7 |
128 |
53 |
45.5 |
66 |
120 |
220 |
127 |
256 |
110 |
80 |
228 |
380 |
540 |
252 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
10.6 |
20 |
40 |
80 |
1 |
64 |
45 |
40 |
100 |
104 |
126 |
63.7 |
128 |
70 |
49 |
160 |
188 |
220 |
127 |
256 |
115 |
82 |
280 |
343 |
386 |
252.7 |
384 |
156 |
110 |
400 |
500 |
560 |
376.5 |
512 |
193 |
134 |
510 |
620 |
700 |
499 |
768 |
360 |
240 |
740 |
1000 |
1300 |
740 |
1024 |
580 |
350 |
1200 |
1443 |
1740 |
976 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2200 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
10.8 |
12 |
20 |
80 |
0.997 |
8 |
14 |
12.3 |
14 |
20.4 |
52 |
7.97 |
16 |
18 |
15.2 |
22 |
26 |
65 |
15.92 |
32 |
26 |
25 |
34 |
37.4 |
80 |
31.76 |
48 |
30 |
30 |
40 |
44 |
110 |
47.5 |
64 |
37 |
40 |
47 |
50 |
132 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
50 |
80 |
80 |
0.997 |
64 |
53 |
45 |
130 |
134 |
140 |
63.3 |
128 |
77 |
55 |
200 |
220 |
230 |
125.6 |
256 |
118 |
86 |
300 |
370 |
400 |
247.4 |
384 |
158 |
116 |
410 |
500 |
580 |
365.4 |
512 |
195 |
140 |
520 |
650 |
740 |
480 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
193.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
10.4 |
14 |
30 |
100 |
0.997 |
8 |
16 |
13 |
25 |
36.5 |
53 |
7.97 |
16 |
20 |
15.6 |
35 |
50 |
64 |
15.92 |
32 |
27 |
25 |
40 |
64 |
90 |
31.77 |
48 |
34 |
30 |
52 |
80 |
100 |
47.5 |
64 |
40 |
40 |
60 |
103 |
126 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
15 |
35 |
100 |
100 |
0.997 |
64 |
53 |
45 |
120 |
134 |
140 |
63.3 |
128 |
78 |
55 |
170 |
220 |
226 |
125.5 |
256 |
116 |
85 |
300 |
360 |
390 |
247.4 |
384 |
157 |
116 |
386 |
500 |
570 |
366 |
512 |
195 |
142 |
500 |
632 |
740 |
481 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
194 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
22.6 |
23.6 |
24 |
50 |
0.999 |
4 |
30.6 |
29.8 |
31 |
34 |
60 |
3.99 |
8 |
44.6 |
52 |
54 |
54.7 |
92.4 |
7.97 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24.4 |
26 |
41 |
90 |
0.999 |
4 |
34.3 |
32.4 |
34 |
55 |
64 |
3.99 |
8 |
48.2 |
54 |
60 |
73 |
91 |
7.98 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
140 |
假 |
4 |
367 |
假 |
8 |
391 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11 |
11.6 |
12 |
50 |
1 |
8 |
14 |
13 |
16 |
20 |
32.5 |
7.99 |
16 |
18 |
16 |
23 |
25 |
35 |
15.97 |
32 |
23 |
24 |
32 |
33 |
40 |
31.93 |
48 |
28 |
29 |
38 |
41 |
50 |
47.9 |
64 |
33 |
36 |
46 |
47.7 |
50 |
63.8 |
128 |
47 |
47 |
64 |
66 |
70 |
127.6 |
256 |
73 |
75 |
104 |
107 |
112 |
254.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
11.7 |
20 |
20 |
100 |
1 |
64 |
37 |
42 |
50 |
54 |
64 |
63.8 |
128 |
50.6 |
50 |
68 |
73 |
85 |
127.6 |
256 |
76 |
76 |
107 |
112 |
128 |
254.6 |
384 |
100 |
102 |
148 |
158 |
206 |
380.6 |
512 |
127 |
126 |
190 |
220 |
290 |
506 |
768 |
180 |
170 |
270 |
350 |
460 |
753 |
1024 |
230 |
220 |
360 |
485 |
640 |
996 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
200 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
13 |
14 |
40 |
1 |
8 |
15 |
14.3 |
20 |
20 |
33.4 |
7.99 |
16 |
20 |
20 |
27 |
30 |
37 |
15.97 |
32 |
27 |
27 |
36 |
40 |
44 |
31.93 |
48 |
34 |
36 |
47 |
50 |
56 |
47.9 |
64 |
41 |
44 |
56 |
58 |
65 |
63.8 |
128 |
64 |
67 |
83 |
87 |
100 |
127.5 |
256 |
91.4 |
95 |
126 |
130 |
143 |
254.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.5 |
20 |
23 |
100 |
1 |
64 |
45 |
50 |
60 |
70 |
73 |
63.8 |
128 |
70 |
70 |
90 |
100 |
110 |
127.5 |
256 |
100 |
100 |
150 |
160 |
200 |
254.4 |
384 |
128 |
130 |
191 |
200 |
230 |
380.6 |
512 |
160 |
160 |
240 |
250 |
300 |
506 |
768 |
220 |
220 |
350 |
370 |
460 |
753 |
1024 |
280 |
280 |
450 |
500 |
640 |
995 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
12 |
15 |
20 |
100 |
0.997 |
8 |
16.4 |
14.3 |
20 |
20 |
61 |
7.96 |
16 |
21 |
20 |
27 |
30 |
70 |
15.9 |
32 |
29 |
27 |
37 |
42 |
100 |
31.76 |
48 |
36 |
35 |
48 |
53 |
130 |
47.5 |
64 |
45 |
50 |
59 |
63 |
160 |
63.2 |
128 |
80 |
70 |
100 |
200 |
300 |
126 |
256 |
120 |
100 |
200 |
300 |
500 |
248.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
50 |
100 |
100 |
0.997 |
64 |
60 |
54 |
100 |
200 |
200 |
63 |
128 |
90 |
76 |
200 |
200 |
300 |
126 |
256 |
130 |
110 |
300 |
350 |
500 |
248 |
384 |
170 |
146 |
360 |
500 |
600 |
367 |
512 |
200 |
180 |
400 |
600 |
800 |
485 |
768 |
400 |
280 |
800 |
1000 |
1000 |
710 |
1024 |
500 |
400 |
1000 |
2000 |
2000 |
924 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2300 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.4 |
12.2 |
12.5 |
20 |
1 |
8 |
15 |
15 |
20 |
20 |
30 |
7.99 |
16 |
18 |
16 |
23 |
25 |
40 |
15.98 |
32 |
24 |
24 |
32 |
34 |
52.4 |
31.95 |
48 |
30 |
30 |
40 |
43 |
60 |
47.9 |
64 |
35 |
40 |
47 |
48 |
70 |
63.9 |
128 |
51 |
47 |
65 |
67 |
180 |
127.3 |
256 |
87 |
78 |
105 |
133 |
500 |
253 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
12.1 |
13.6 |
27 |
100 |
1 |
64 |
42 |
44 |
52 |
90 |
128 |
63.7 |
128 |
60 |
50 |
72 |
150 |
220 |
127 |
256 |
90 |
80 |
110 |
240 |
380 |
252.7 |
384 |
120 |
106 |
153 |
320 |
570 |
377 |
512 |
147.7 |
130 |
195 |
410 |
710 |
500 |
768 |
230 |
183 |
600 |
630 |
1230 |
740 |
1024 |
356 |
243 |
840 |
1410 |
1800 |
972 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
470 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
13.7 |
14.8 |
15 |
33 |
1 |
8 |
17 |
16 |
20 |
20 |
46 |
7.99 |
16 |
21 |
19.6 |
26 |
30 |
60 |
15.97 |
32 |
30 |
29.5 |
40 |
40 |
90 |
31.9 |
48 |
35 |
35 |
47 |
50 |
110 |
47.9 |
64 |
45 |
50 |
60 |
60 |
130 |
63.8 |
128 |
72 |
70 |
90 |
120 |
220 |
127.4 |
256 |
140 |
110 |
200 |
400 |
700 |
253.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
20.6 |
22 |
40 |
100 |
0.999 |
64 |
70 |
60 |
100 |
100 |
300 |
63.7 |
128 |
100 |
80 |
200 |
300 |
600 |
126.6 |
256 |
200 |
120 |
400 |
700 |
1000 |
250 |
384 |
300 |
150 |
800 |
2000 |
2000 |
373 |
512 |
400 |
200 |
1000 |
2000 |
3000 |
490 |
768 |
1000 |
600 |
4000 |
5000 |
6000 |
730 |
1024 |
2000 |
2000 |
5000 |
6000 |
7000 |
960 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
110 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.7 |
13.4 |
13.7 |
40 |
0.999 |
8 |
15.3 |
14.3 |
15.5 |
20 |
45.5 |
7.99 |
16 |
21 |
18 |
26 |
28 |
60 |
15.97 |
32 |
28 |
28 |
37 |
40 |
90 |
31.9 |
48 |
35 |
35 |
46 |
47.4 |
100 |
47.8 |
64 |
42 |
40 |
54 |
55 |
130 |
63.7 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13.7 |
20 |
30 |
100 |
1 |
64 |
53 |
50 |
64 |
120 |
150 |
63.7 |
128 |
77 |
65 |
96 |
200 |
245 |
127 |
256 |
120 |
107 |
156 |
300 |
440 |
252.5 |
384 |
162 |
145 |
220 |
440 |
640 |
376 |
512 |
200 |
180 |
276 |
530 |
800 |
499 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
2200 |
真 |
32 |
170 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
13.5 |
14 |
14.6 |
30 |
1 |
8 |
17.5 |
17 |
18 |
19 |
35 |
7.99 |
16 |
24 |
22 |
32.3 |
33 |
50 |
15.97 |
32 |
33.6 |
38 |
43 |
46 |
66 |
31.9 |
48 |
43 |
46 |
60 |
60.3 |
90 |
47.85 |
64 |
53 |
63 |
71 |
72 |
113 |
63.8 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13.5 |
20 |
30 |
100 |
1 |
64 |
60 |
70 |
77 |
80 |
90 |
63.8 |
128 |
87.2 |
82 |
122 |
123.7 |
140 |
127.4 |
256 |
140 |
140 |
215 |
217 |
230 |
254 |
384 |
192 |
194 |
310 |
314 |
330 |
380 |
512 |
250 |
250 |
400 |
410 |
510 |
503 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
400 |
假 |
32 |
2270 |
真 |
32 |
130 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
13.2 |
14.2 |
15 |
46 |
0.999 |
8 |
17 |
15.4 |
18 |
27 |
50 |
7.99 |
16 |
21 |
18 |
29.6 |
30.4 |
64 |
15.96 |
32 |
27 |
30 |
36 |
40 |
80 |
31.9 |
48 |
34 |
33 |
44.9 |
46 |
100 |
47.8 |
64 |
38.6 |
40 |
50.4 |
52 |
100 |
63.8 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14.6 |
20 |
40 |
100 |
0.999 |
64 |
47 |
50 |
60 |
90 |
100 |
63.8 |
128 |
72 |
69 |
86 |
120 |
170 |
127.4 |
256 |
117 |
100 |
149 |
200 |
200 |
254 |
384 |
148 |
160 |
200 |
204 |
300 |
380.6 |
512 |
180 |
190 |
257 |
260 |
330 |
506 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
1660 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16.7 |
17.4 |
20 |
40 |
0.999 |
8 |
21 |
19.8 |
21 |
30 |
50.4 |
7.99 |
16 |
29 |
26 |
40 |
41 |
70 |
15.96 |
32 |
41 |
45 |
51 |
55 |
110 |
31.9 |
48 |
53 |
58 |
71 |
73 |
160 |
47.75 |
64 |
65.5 |
72 |
83 |
85 |
210 |
63.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18.4 |
20 |
36 |
100 |
0.999 |
64 |
80 |
83 |
95 |
140 |
200 |
63.7 |
128 |
119 |
100 |
155 |
230 |
296 |
126.8 |
256 |
190 |
170 |
270 |
400 |
530 |
252 |
384 |
260 |
245 |
378 |
580 |
800 |
374.5 |
512 |
346 |
330 |
496 |
850 |
1200 |
494 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
2000 |
真 |
32 |
120 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
2050 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
2000 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
1860 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
100 |
假 |
32 |
1500 |
真 |
32 |
120 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
370 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
100 |
假 |
32 |
231 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
11 |
假 |
32 |
77 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
40 |
假 |
32 |
300 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
17 |
16 |
17 |
17.7 |
40 |
0.999 |
n-gram |
8 |
24.5 |
22.6 |
24.4 |
34 |
71 |
7.98 |
n-gram |
16 |
33 |
30 |
40 |
42.4 |
110 |
15.94 |
n-gram |
32 |
45 |
44 |
56 |
60 |
160 |
31.8 |
n-gram |
48 |
62 |
66.6 |
74 |
100 |
260 |
47.6 |
n-gram |
64 |
84 |
84 |
93 |
150 |
350 |
63.3 |
无 |
1 |
15.6 |
15 |
15.7 |
16 |
40 |
0.999 |
无 |
8 |
22.4 |
20.8 |
21.8 |
32 |
60 |
7.98 |
无 |
16 |
29 |
26 |
35 |
38 |
90 |
15.95 |
无 |
32 |
41.5 |
44 |
50 |
55 |
140 |
31.84 |
无 |
48 |
58.6 |
64 |
70 |
86 |
240 |
47.6 |
无 |
64 |
80 |
80.4 |
88 |
130 |
310 |
63.4 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
20 |
17.7 |
18.7 |
36.6 |
60 |
0.999 |
n-gram |
64 |
87 |
90 |
100 |
200 |
270 |
63.5 |
n-gram |
128 |
140 |
123 |
164 |
350 |
500 |
126 |
n-gram |
256 |
236 |
209 |
300 |
500 |
1000 |
249 |
无 |
1 |
17 |
14.8 |
15.7 |
30 |
60 |
1 |
无 |
64 |
78.4 |
83 |
90 |
170 |
256 |
63.5 |
无 |
128 |
130 |
111 |
155 |
340 |
480 |
126 |
无 |
256 |
226 |
200 |
290 |
470 |
900 |
249 |
无 |
384 |
357 |
300 |
750 |
1070 |
1600 |
368 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
1300 |
假 |
无 |
32 |
1300 |
真 |
n-gram |
32 |
104 |
真 |
无 |
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
16 |
17.4 |
23 |
60 |
0.998 |
8 |
24.1 |
22.6 |
30 |
41.4 |
50 |
7.98 |
16 |
32.7 |
30.3 |
40 |
50 |
82 |
15.95 |
32 |
44 |
48 |
55 |
63 |
130 |
31.84 |
64 |
79 |
86 |
93 |
130 |
290 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
40 |
70 |
70 |
0.998 |
64 |
100 |
92 |
200 |
270 |
270 |
62.8 |
128 |
165 |
126 |
360 |
450 |
490 |
123.6 |
256 |
290 |
260 |
640 |
800 |
1100 |
240 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
224 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.7 |
17 |
18 |
40 |
1 |
8 |
23.7 |
22 |
30 |
33 |
50 |
7.99 |
16 |
31.1 |
29.5 |
40 |
40 |
80 |
15.98 |
32 |
42 |
40 |
55 |
57 |
100 |
31.9 |
64 |
74 |
83.8 |
90 |
93 |
280 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.7 |
24 |
40 |
60 |
1 |
64 |
85 |
87 |
104 |
240 |
260 |
63.8 |
128 |
137 |
120 |
170 |
340 |
470 |
127.2 |
256 |
234 |
210 |
310 |
600 |
1000 |
253 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
455 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
15.5 |
16.4 |
20 |
60 |
0.997 |
8 |
24.4 |
21.97 |
24 |
33 |
74 |
7.95 |
16 |
33 |
29.4 |
40 |
42 |
105 |
15.84 |
32 |
45 |
47 |
53 |
60 |
150 |
31.5 |
64 |
80 |
84 |
91 |
160 |
310 |
62.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
50 |
60 |
60 |
0.997 |
64 |
104 |
88 |
260 |
263 |
270 |
62.4 |
128 |
172 |
120 |
360 |
470 |
500 |
122 |
256 |
330 |
256 |
800 |
970 |
1170 |
233.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
167 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.6 |
16.2 |
17.4 |
18 |
30 |
0.999 |
8 |
23.3 |
22.8 |
26 |
31 |
40 |
7.99 |
16 |
31.6 |
30.6 |
40 |
41 |
50 |
15.97 |
32 |
45 |
50 |
58 |
59 |
65.8 |
31.9 |
64 |
72 |
86 |
92 |
93 |
104 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.8 |
20 |
30 |
70 |
0.999 |
64 |
79.5 |
92 |
105 |
109 |
114 |
63.7 |
128 |
126 |
124 |
165 |
200 |
220 |
127 |
256 |
215 |
210 |
301 |
380 |
500 |
251 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
424 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.6 |
16.3 |
16.5 |
50 |
0.999 |
8 |
24 |
22.8 |
24 |
30 |
75 |
7.98 |
16 |
32 |
30.2 |
30 |
40 |
109 |
15.95 |
32 |
43 |
40 |
54 |
55 |
140 |
31.83 |
48 |
57 |
66.8 |
70 |
74 |
150 |
47.7 |
64 |
74 |
84 |
90 |
92 |
200 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.7 |
17.7 |
33 |
60 |
0.999 |
64 |
85 |
88 |
100 |
200 |
265 |
63.5 |
128 |
140 |
121 |
160 |
380 |
550 |
125.8 |
256 |
262 |
209 |
550 |
720 |
1270 |
247 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
990 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
20.4 |
22.1 |
23 |
90 |
0.996 |
8 |
32.5 |
30 |
33.5 |
40 |
120 |
7.94 |
16 |
44 |
43 |
51 |
54 |
170 |
15.83 |
32 |
70 |
70 |
80 |
100 |
250 |
31.5 |
48 |
82 |
80 |
95 |
160 |
330 |
47.1 |
64 |
106 |
110 |
120 |
200 |
460 |
62.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
35 |
32 |
60 |
60 |
90 |
0.996 |
64 |
140 |
120 |
300 |
350 |
400 |
62.5 |
128 |
220 |
200 |
470 |
600 |
700 |
123 |
256 |
400 |
330 |
800 |
1100 |
1500 |
238 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
875 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.9 |
16.6 |
17 |
30 |
0.999 |
8 |
24 |
22.6 |
30 |
32 |
50 |
7.98 |
16 |
30.7 |
29.8 |
36 |
40.6 |
57.6 |
15.97 |
32 |
42 |
48 |
55 |
56 |
70 |
31.9 |
64 |
70 |
82 |
88 |
90 |
140 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.2 |
20 |
30 |
60 |
0.999 |
64 |
75 |
88 |
100 |
100 |
120 |
63.7 |
128 |
120 |
120 |
160 |
165 |
188 |
127 |
256 |
194 |
200 |
288 |
292 |
320 |
253 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
437 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18.8 |
17 |
20 |
20.6 |
90 |
0.996 |
8 |
28 |
25.2 |
30 |
36 |
100 |
7.94 |
16 |
39 |
34.8 |
40 |
50 |
150 |
15.84 |
32 |
53 |
50 |
63 |
78 |
210 |
31.53 |
48 |
71 |
80 |
86 |
130 |
280 |
47.1 |
64 |
96.5 |
99 |
112 |
230 |
400 |
62.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
23 |
60 |
90 |
90 |
0.996 |
64 |
120 |
108 |
200 |
300 |
300 |
62.6 |
128 |
200 |
160 |
440 |
500 |
600 |
123 |
256 |
360 |
300 |
700 |
1000 |
1300 |
238 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
250 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
16.2 |
17 |
17.2 |
50 |
0.999 |
8 |
23.5 |
22.5 |
23.5 |
24 |
70 |
7.98 |
16 |
32 |
30 |
39 |
40 |
100 |
15.94 |
32 |
43 |
40 |
55 |
57 |
130 |
31.8 |
64 |
74 |
84.3 |
90 |
92 |
200 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.1 |
20 |
50 |
60 |
0.999 |
64 |
86 |
88 |
100 |
200 |
270 |
63.4 |
128 |
142 |
120 |
160 |
360 |
520 |
125.7 |
256 |
240 |
205 |
350 |
650 |
1000 |
247.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16 |
26 |
40 |
70 |
0.995 |
8 |
26 |
22.6 |
40 |
52 |
53 |
7.95 |
16 |
36 |
30.34 |
56 |
82 |
84 |
15.87 |
32 |
48 |
49 |
80 |
93.6 |
130 |
31.54 |
64 |
100 |
88 |
200 |
216 |
330 |
62 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
17 |
70 |
70 |
70 |
0.995 |
64 |
123 |
92 |
260 |
260 |
262 |
61.6 |
128 |
205 |
140 |
460 |
480 |
480 |
119.3 |
256 |
380 |
300 |
770 |
900 |
1000 |
225.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
109.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.2 |
36 |
40 |
80 |
0.992 |
8 |
28 |
23.4 |
60 |
70 |
76 |
7.88 |
16 |
38 |
31 |
90 |
100 |
105 |
15.66 |
32 |
52 |
50 |
60 |
153 |
160 |
30.8 |
64 |
125 |
93 |
300 |
400 |
440 |
59.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
35 |
70 |
70 |
70 |
0.992 |
64 |
160 |
140 |
276 |
280 |
280 |
60.2 |
128 |
264 |
176 |
490 |
500 |
500 |
114.8 |
256 |
484 |
390 |
870 |
1000 |
1100 |
211.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16 |
18 |
20 |
60 |
0.997 |
8 |
24.7 |
22.4 |
27 |
32 |
74 |
7.95 |
16 |
33.3 |
29.9 |
39 |
40 |
105 |
15.86 |
32 |
46 |
40 |
55 |
60 |
150 |
31.55 |
64 |
80 |
84.5 |
92.5 |
150 |
305 |
62.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
50 |
60 |
60 |
0.997 |
64 |
105 |
90 |
254 |
270 |
300 |
62.5 |
128 |
170 |
125 |
360 |
470 |
500 |
122.6 |
256 |
302 |
250 |
640 |
810 |
1030 |
236 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
178 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.3 |
16.4 |
20 |
40 |
0.999 |
8 |
23.3 |
21.7 |
24 |
33 |
70 |
7.98 |
16 |
30 |
28 |
37 |
40 |
95 |
15.95 |
32 |
43 |
40 |
52 |
57 |
140 |
31.8 |
48 |
59 |
64.5 |
70 |
105 |
240 |
47.6 |
64 |
81 |
81.7 |
91 |
140 |
400 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16.3 |
30 |
40 |
60 |
0.999 |
64 |
103 |
86.3 |
243 |
250 |
265 |
63.5 |
128 |
174 |
130 |
400 |
460 |
490 |
126 |
256 |
312 |
250 |
650 |
800 |
1040 |
248.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
960 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
16 |
17.3 |
20 |
70 |
0.997 |
8 |
24.7 |
22.5 |
24.7 |
35 |
79 |
7.95 |
16 |
33.7 |
30 |
40 |
42 |
114 |
15.86 |
32 |
45 |
40 |
56 |
58 |
160 |
31.56 |
48 |
60.4 |
66.4 |
71 |
95 |
230 |
47.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20 |
60 |
70 |
70 |
0.996 |
64 |
110 |
94 |
263 |
280 |
300 |
62.6 |
128 |
180 |
130 |
400 |
500 |
510 |
122.6 |
256 |
320 |
260 |
680 |
900 |
1100 |
236.8 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
190 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16 |
21.5 |
35 |
80 |
0.997 |
8 |
28 |
23 |
50.3 |
68 |
81 |
7.95 |
16 |
38 |
30.3 |
77 |
96 |
110 |
15.86 |
32 |
50.6 |
48 |
90 |
130 |
160 |
31.6 |
48 |
72 |
67.6 |
130 |
190 |
260 |
47.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
21 |
50 |
80 |
80 |
0.996 |
64 |
110 |
93 |
270 |
280 |
280 |
62.5 |
128 |
175 |
126.5 |
400 |
500 |
500 |
123 |
256 |
310 |
260 |
700 |
800 |
1100 |
237.3 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
170 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
38.5 |
37.7 |
38.6 |
39.3 |
73 |
0.998 |
4 |
69 |
67 |
70 |
80 |
140 |
3.98 |
8 |
109.8 |
126 |
131 |
150 |
240 |
7.93 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
41 |
40 |
40 |
57 |
80 |
0.998 |
4 |
72 |
69.6 |
80 |
100 |
108 |
3.99 |
8 |
109 |
126 |
132 |
140 |
178 |
7.96 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
84 |
假 |
4 |
146 |
假 |
8 |
148 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
17 |
18 |
18.3 |
30 |
0.999 |
8 |
23.44 |
23.2 |
24.56 |
29 |
40 |
7.99 |
16 |
31.8 |
31 |
40 |
41 |
50 |
15.97 |
32 |
44 |
40 |
58 |
59 |
66 |
31.9 |
48 |
56 |
67 |
71.5 |
73 |
83 |
47.8 |
64 |
74 |
87 |
93 |
95 |
107 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
23 |
30 |
80 |
0.999 |
64 |
79 |
90 |
105 |
110 |
115 |
63.7 |
128 |
128 |
124 |
167 |
184 |
224 |
127 |
256 |
218 |
214 |
310 |
380 |
500 |
251 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
140 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
17.8 |
19 |
19.3 |
30 |
0.999 |
8 |
26.7 |
26.4 |
28 |
30 |
45 |
7.99 |
16 |
38 |
37 |
40 |
46.3 |
55.7 |
15.97 |
32 |
50 |
50 |
64 |
66 |
75 |
31.9 |
48 |
67 |
79 |
85 |
87 |
98 |
47.8 |
64 |
87.4 |
103.7 |
110 |
110 |
130 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
25 |
30 |
70 |
0.999 |
64 |
94 |
110 |
120 |
130 |
140 |
63.7 |
128 |
147 |
147 |
190 |
200 |
220 |
127 |
256 |
240 |
245 |
350 |
360 |
420 |
252 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1450 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
21 |
22 |
80 |
0.996 |
8 |
29 |
26 |
30 |
38 |
100 |
7.95 |
16 |
39.5 |
37 |
43 |
47 |
114 |
15.88 |
32 |
56.6 |
60 |
70 |
75 |
170 |
31.6 |
48 |
70 |
78 |
87 |
90 |
200 |
47.3 |
64 |
90 |
103 |
114 |
120 |
220 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
26 |
65 |
90 |
90 |
0.995 |
64 |
120 |
110 |
200 |
300 |
300 |
63 |
128 |
180 |
160 |
300 |
380 |
500 |
124 |
256 |
280 |
270 |
400 |
600 |
700 |
244 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1450 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
17.14 |
18 |
18.24 |
27 |
1 |
8 |
24.1 |
23.6 |
25 |
30 |
54 |
7.99 |
16 |
32 |
31 |
40 |
42 |
90 |
15.98 |
32 |
44 |
47 |
60 |
60 |
100 |
31.9 |
64 |
77.7 |
86 |
92 |
95 |
280 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18.7 |
20 |
35 |
70 |
0.999 |
64 |
87 |
92 |
100 |
181 |
264 |
63.5 |
128 |
142 |
125 |
170 |
340 |
504 |
126 |
256 |
250 |
200 |
400 |
660 |
1180 |
248 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
21.2 |
21.6 |
49.2 |
0.999 |
8 |
29.5 |
29 |
31 |
38 |
70 |
7.99 |
16 |
41.1 |
40.3 |
46 |
50 |
96 |
15.97 |
32 |
54 |
53 |
66 |
70 |
158 |
31.9 |
64 |
93 |
106 |
114 |
120 |
220 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
28 |
30 |
50 |
100 |
0.998 |
64 |
130 |
123.5 |
200 |
200 |
500 |
63.4 |
128 |
200 |
170 |
300 |
400 |
1000 |
125 |
256 |
500 |
300 |
1000 |
2000 |
3000 |
248 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
82 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22 |
23 |
24 |
50 |
0.999 |
8 |
30 |
29 |
30 |
46 |
80 |
7.98 |
16 |
39.6 |
37 |
50 |
54 |
110 |
15.94 |
32 |
57.3 |
65 |
70.4 |
73 |
210 |
31.8 |
48 |
80 |
90 |
93 |
106 |
300 |
47.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
28 |
40 |
50 |
80 |
0.999 |
64 |
126 |
133 |
150 |
230 |
295 |
63.4 |
128 |
204 |
180 |
250 |
420 |
570 |
125.8 |
256 |
360 |
364 |
510 |
840 |
1300 |
247 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1140 |
真 |
32 |
95 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22.6 |
23.24 |
23.3 |
40 |
0.999 |
8 |
41 |
40.3 |
41.5 |
45 |
71 |
7.98 |
16 |
56 |
55 |
66 |
70 |
100 |
15.94 |
32 |
86 |
105 |
109 |
110 |
200 |
31.8 |
48 |
132 |
150 |
158 |
195 |
300 |
47.6 |
64 |
2670 |
2520 |
4890 |
5090 |
6130 |
55.1 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23.2 |
30 |
40 |
70 |
0.999 |
64 |
180 |
213 |
220 |
230 |
237 |
63.5 |
128 |
306 |
280 |
410 |
415 |
485 |
126 |
256 |
574 |
640 |
900 |
1090 |
1280 |
246 |
384 |
5700 |
5280 |
10300 |
10950 |
12600 |
282.3 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1400 |
真 |
32 |
93 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27.7 |
27 |
28 |
28 |
62 |
0.998 |
8 |
43 |
41.5 |
44 |
58 |
85.8 |
7.98 |
16 |
60 |
55 |
70 |
75 |
120 |
15.94 |
32 |
90 |
100 |
107 |
109.5 |
200 |
31.8 |
48 |
121 |
141 |
147 |
150 |
290 |
47.6 |
64 |
160 |
181.3 |
190 |
200 |
390 |
63.2 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25 |
30 |
50 |
70 |
0.999 |
64 |
174 |
198 |
210 |
260 |
280 |
63.5 |
128 |
350 |
378 |
390 |
500 |
500 |
126 |
256 |
616 |
650 |
830 |
1000 |
1200 |
247 |
384 |
3700 |
3500 |
6000 |
6400 |
8000 |
316.3 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
190 |
假 |
32 |
1410 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
36 |
35.5 |
37 |
40 |
68 |
0.998 |
8 |
46 |
44 |
50 |
70 |
100 |
7.97 |
16 |
63.4 |
58.5 |
85 |
88 |
155 |
15.92 |
32 |
97 |
110 |
123 |
140 |
230 |
31.7 |
48 |
146 |
150 |
200 |
260 |
400 |
47.4 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
39 |
50 |
60 |
90 |
0.998 |
64 |
200 |
220 |
240 |
400 |
420 |
63.2 |
128 |
330 |
280 |
416 |
610 |
770 |
125 |
256 |
690 |
640 |
1350 |
1500 |
2300 |
242.7 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
140 |
假 |
32 |
730 |
真 |
32 |
80 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
669 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
652 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
635 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
50 |
假 |
32 |
500 |
真 |
32 |
90 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
50 |
假 |
32 |
154.7 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
60 |
假 |
32 |
97 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
3.2 |
假 |
32 |
21.97 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
15 |
假 |
32 |
85 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
25.5 |
24.55 |
25.7 |
26 |
50 |
0.998 |
n-gram |
8 |
49.2 |
48 |
50.7 |
64 |
140 |
7.97 |
n-gram |
16 |
54 |
50 |
60 |
70 |
160 |
15.9 |
n-gram |
32 |
88 |
80 |
101 |
160 |
280 |
31.7 |
n-gram |
64 |
5000 |
4700 |
9600 |
10300 |
12300 |
48.7 |
无 |
1 |
23.4 |
22.7 |
23.3 |
24 |
50 |
0.999 |
无 |
8 |
47 |
46.6 |
48.5 |
60 |
130 |
7.97 |
无 |
16 |
51 |
49 |
56 |
60 |
150 |
15.92 |
无 |
32 |
87 |
80 |
100 |
164 |
292 |
31.7 |
无 |
64 |
5400 |
5000 |
10200 |
11000 |
13000 |
48 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
28 |
25.5 |
26.4 |
46.6 |
70 |
0.999 |
n-gram |
64 |
170 |
193 |
200 |
340 |
420 |
63.2 |
n-gram |
128 |
310 |
303 |
395.5 |
600 |
800 |
125 |
n-gram |
256 |
2000 |
1800 |
3300 |
4000 |
4500 |
227 |
无 |
1 |
26 |
23.66 |
24 |
40 |
60 |
0.999 |
无 |
64 |
162 |
188 |
194 |
320 |
410 |
63.2 |
无 |
128 |
306 |
290 |
390 |
610 |
800 |
125 |
无 |
256 |
2000 |
1900 |
3400 |
4000 |
5000 |
226 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
600 |
假 |
无 |
32 |
600 |
真 |
n-gram |
32 |
90 |
真 |
无 |
32 |
90 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
23.53 |
24.3 |
33 |
60 |
0.998 |
8 |
50 |
49.5 |
53 |
60 |
101 |
7.97 |
16 |
55 |
52 |
60 |
70 |
130 |
15.93 |
32 |
84 |
80 |
100 |
120 |
210 |
31.7 |
64 |
2200 |
2000 |
4000 |
4700 |
5100 |
49 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
25 |
44 |
70 |
70 |
0.997 |
64 |
185 |
190 |
330 |
396 |
400 |
62.2 |
128 |
340 |
300 |
630 |
770 |
790 |
121 |
256 |
1860 |
2000 |
3200 |
3800 |
4500 |
207 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
223.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23.5 |
23 |
24 |
25.3 |
40 |
0.999 |
8 |
50 |
49.1 |
51 |
60 |
103 |
7.99 |
16 |
53 |
53 |
60 |
64 |
120 |
15.97 |
32 |
86 |
85 |
99 |
102 |
200 |
31.9 |
64 |
4400 |
4000 |
8600 |
9000 |
11000 |
49.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25.36 |
34 |
40 |
60 |
0.999 |
64 |
170 |
190 |
210 |
300 |
400 |
63.5 |
128 |
310 |
300 |
396 |
640 |
777 |
126.3 |
256 |
2200 |
2000 |
4084 |
4500 |
5200 |
224 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
410 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23.5 |
24.6 |
30 |
60 |
0.996 |
8 |
49 |
48 |
51 |
60 |
125 |
7.91 |
16 |
52 |
50 |
60 |
70 |
150 |
15.8 |
32 |
90 |
90 |
98 |
160 |
300 |
31.3 |
64 |
1600 |
1500 |
2800 |
3000 |
4400 |
49 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24.5 |
60 |
60 |
60 |
0.996 |
64 |
200 |
190 |
400 |
400 |
420 |
61.5 |
128 |
430 |
380 |
900 |
1000 |
1200 |
117 |
256 |
2500 |
2700 |
4700 |
4700 |
6300 |
177 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
166.8 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.5 |
24 |
25 |
26 |
40 |
0.999 |
8 |
50 |
49.9 |
51.5 |
60 |
69 |
7.98 |
16 |
54 |
54.4 |
60 |
64 |
75 |
15.96 |
32 |
80 |
80 |
99 |
100 |
110 |
31.85 |
64 |
3900 |
3600 |
7300 |
7700 |
9400 |
49.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25.4 |
30 |
40 |
70 |
0.999 |
64 |
163 |
190 |
200 |
290 |
300 |
63.3 |
128 |
306 |
300 |
396 |
520 |
680 |
124.8 |
256 |
1300 |
1300 |
2100 |
2100 |
2700 |
231 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
422 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.6 |
24 |
25 |
25 |
50 |
0.999 |
8 |
49 |
49.4 |
50.7 |
51 |
120 |
7.97 |
16 |
54 |
52.5 |
60 |
63 |
130 |
15.93 |
32 |
84 |
80 |
98.7 |
100.8 |
200 |
31.8 |
64 |
4400 |
4000 |
8300 |
9000 |
11000 |
50 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
24.1 |
25 |
43 |
60 |
0.999 |
64 |
176 |
190 |
197 |
520 |
540 |
63 |
128 |
356 |
300 |
630 |
1000 |
1430 |
123.7 |
256 |
2100 |
1900 |
3900 |
4600 |
5500 |
222 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
498 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
30 |
32 |
32 |
90 |
0.996 |
8 |
57 |
56 |
63 |
70 |
114 |
7.95 |
16 |
56 |
58 |
68 |
70 |
120 |
15.88 |
32 |
97 |
112 |
119 |
123 |
200 |
31.6 |
64 |
2300 |
2100 |
4300 |
4600 |
5600 |
49.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
38 |
60 |
60 |
90 |
0.996 |
64 |
200 |
230 |
260 |
300 |
310 |
62.7 |
128 |
350 |
370 |
500 |
630 |
660 |
122.8 |
256 |
1470 |
1500 |
2400 |
2500 |
3100 |
213 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
84 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.3 |
23.8 |
24.7 |
25 |
40 |
0.999 |
8 |
50 |
49.7 |
53 |
60 |
77 |
7.98 |
16 |
53 |
53 |
60 |
60 |
78.6 |
15.96 |
32 |
80 |
80 |
98 |
99.5 |
160 |
31.8 |
64 |
3500 |
3300 |
6700 |
7000 |
8700 |
51 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25.3 |
30 |
40 |
60 |
0.999 |
64 |
154 |
190 |
198 |
210 |
250 |
63.5 |
128 |
284 |
290 |
390 |
392 |
440 |
126 |
256 |
1100 |
1100 |
1800 |
2000 |
2200 |
235 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
437 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
24.5 |
27.6 |
28.2 |
80 |
0.996 |
8 |
53 |
52 |
55 |
60 |
100 |
7.95 |
16 |
59 |
58 |
66 |
70 |
110 |
15.88 |
32 |
90 |
90 |
106 |
110 |
180 |
31.6 |
64 |
2100 |
2000 |
4000 |
4100 |
5000 |
49 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
34 |
31 |
55 |
80 |
80 |
0.996 |
64 |
180 |
205 |
260 |
300 |
300 |
62.6 |
128 |
314 |
330 |
413 |
450 |
500 |
123.5 |
256 |
1000 |
1000 |
1600 |
1600 |
2000 |
222 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
140 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
23.5 |
24.3 |
24.5 |
60 |
0.998 |
8 |
51 |
49.9 |
51 |
52 |
124 |
7.97 |
16 |
54 |
53 |
60 |
60 |
140 |
15.92 |
32 |
84 |
84 |
98.5 |
101 |
240 |
31.73 |
64 |
3800 |
3500 |
7000 |
7700 |
9000 |
50 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25 |
30 |
60 |
70 |
0.998 |
64 |
170 |
190 |
198 |
360 |
410 |
63 |
128 |
308 |
300 |
388 |
630 |
790 |
124.4 |
256 |
1700 |
1700 |
3200 |
3700 |
4000 |
226 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
24 |
36 |
40 |
80 |
0.994 |
8 |
47 |
40 |
80 |
100 |
104 |
7.91 |
16 |
55 |
45.5 |
90 |
115 |
126 |
15.8 |
32 |
100 |
90 |
200 |
220 |
300 |
31 |
64 |
1470 |
1300 |
2900 |
3200 |
3300 |
45 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
70 |
70 |
70 |
0.993 |
64 |
220 |
190 |
397 |
400 |
400 |
60.4 |
128 |
404 |
360 |
760 |
780 |
780 |
114.7 |
256 |
2440 |
2960 |
3850 |
4000 |
4630 |
173.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
108.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
33 |
29.4 |
53 |
60 |
80 |
0.988 |
8 |
50 |
40 |
83 |
100 |
120 |
7.85 |
16 |
56 |
47 |
90 |
140 |
140 |
15.52 |
32 |
120 |
90 |
260 |
300 |
370 |
30.1 |
64 |
1180 |
1130 |
2240 |
2270 |
3040 |
42.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
50 |
50 |
80 |
80 |
80 |
0.988 |
64 |
270 |
300 |
420 |
420 |
420 |
58.4 |
128 |
480 |
500 |
800 |
800 |
800 |
108.2 |
256 |
2650 |
3000 |
3800 |
3840 |
4000 |
145 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.2 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23.8 |
26 |
30 |
60 |
0.996 |
8 |
50 |
48 |
51 |
60 |
122 |
7.92 |
16 |
55 |
52 |
60 |
70 |
150 |
15.8 |
32 |
93 |
90 |
101 |
140 |
300 |
31.35 |
64 |
1800 |
1650 |
3300 |
3500 |
5000 |
48.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24.5 |
60 |
60 |
60 |
0.996 |
64 |
190 |
190.5 |
380 |
400 |
410 |
61.7 |
128 |
360 |
310 |
630 |
770 |
800 |
119.3 |
256 |
2200 |
2400 |
4100 |
4100 |
5000 |
190 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
178 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23.4 |
23 |
23.9 |
24.7 |
38 |
0.999 |
8 |
49 |
48.8 |
51 |
53 |
87 |
7.98 |
16 |
53.5 |
53 |
60 |
62 |
100 |
15.94 |
32 |
80 |
80 |
98 |
100 |
170 |
31.8 |
64 |
4100 |
3700 |
7800 |
8300 |
10000 |
50.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
24.3 |
30 |
40 |
60 |
0.999 |
64 |
153 |
190 |
200 |
210 |
240 |
63.5 |
128 |
284 |
300 |
391 |
395 |
420 |
126.2 |
256 |
900 |
900 |
1400 |
1500 |
1600 |
242 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
470 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23.6 |
25 |
30 |
70 |
0.996 |
8 |
49 |
49 |
51 |
52 |
128 |
7.92 |
16 |
55 |
52 |
60 |
70 |
150 |
15.8 |
32 |
90 |
80 |
100 |
150 |
300 |
31.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
27 |
60 |
60 |
60 |
0.996 |
64 |
200 |
190 |
350 |
401 |
406 |
61.9 |
128 |
356 |
310 |
600 |
760 |
800 |
120 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
191.3 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
24.3 |
33 |
46 |
90 |
0.996 |
8 |
50 |
45 |
95 |
100 |
128 |
7.93 |
16 |
56 |
46 |
113 |
120 |
140 |
15.83 |
32 |
100 |
86 |
200 |
260 |
300 |
31.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
34 |
28.7 |
52 |
80 |
80 |
0.996 |
64 |
196 |
194 |
360 |
402 |
410 |
61.9 |
128 |
356 |
300 |
700 |
770 |
800 |
120 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
191 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
58 |
56 |
62.1 |
63.4 |
120 |
0.996 |
4 |
4000 |
3600 |
7500 |
8000 |
9500 |
3.2 |
8 |
24500 |
24700 |
46700 |
48600 |
52600 |
3.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
100 |
100 |
112 |
112 |
150 |
0.997 |
4 |
187 |
185 |
190 |
225 |
240 |
3.97 |
8 |
307 |
340 |
380.5 |
382 |
435 |
7.9 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
40 |
假 |
4 |
48 |
假 |
8 |
47.7 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.5 |
24 |
25.2 |
26 |
40 |
0.999 |
8 |
50 |
50 |
51.4 |
53 |
67 |
7.98 |
16 |
54.6 |
55 |
60.8 |
64 |
75 |
15.96 |
32 |
80 |
80 |
99 |
100.4 |
106 |
31.85 |
64 |
3500 |
3300 |
6700 |
7000 |
8600 |
50.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25.2 |
30 |
35 |
70 |
0.999 |
64 |
167 |
195 |
200 |
307 |
310 |
63.2 |
128 |
316 |
310 |
408 |
545 |
710 |
124.6 |
256 |
1700 |
1700 |
3000 |
3000 |
3700 |
224 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
423 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
25.7 |
27 |
27.4 |
40 |
0.999 |
8 |
53 |
53.3 |
55.5 |
60 |
73 |
7.98 |
16 |
59 |
59 |
66 |
68 |
84 |
15.96 |
32 |
90 |
100 |
108 |
110 |
120 |
31.85 |
64 |
4000 |
3700 |
7500 |
8000 |
9700 |
49.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
28.3 |
33 |
40 |
70 |
0.999 |
64 |
170 |
206 |
220 |
230 |
250 |
63.5 |
128 |
317 |
320 |
416 |
430 |
547 |
125.4 |
256 |
1500 |
1500 |
2600 |
2700 |
3000 |
228 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
430 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
27 |
25.2 |
29 |
30 |
90 |
0.995 |
8 |
54.3 |
52 |
57 |
60 |
114 |
7.94 |
16 |
62 |
60 |
67 |
80 |
122 |
15.87 |
32 |
95 |
100 |
110 |
115 |
180 |
31.5 |
64 |
2100 |
2000 |
3900 |
4200 |
5160 |
49 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
32 |
70 |
80 |
80 |
0.995 |
64 |
190 |
208 |
300 |
300 |
400 |
62.5 |
128 |
330 |
330 |
450 |
500 |
600 |
123 |
256 |
1160 |
1200 |
1800 |
1900 |
2300 |
218 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.5 |
24 |
25 |
25 |
36 |
0.999 |
8 |
50.5 |
51 |
52.5 |
60 |
111 |
7.98 |
16 |
55 |
55 |
60 |
70 |
130 |
15.96 |
32 |
87 |
90 |
101 |
103 |
270 |
31.8 |
64 |
4800 |
4400 |
9000 |
10000 |
11700 |
49 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
27 |
29 |
46 |
80 |
0.999 |
64 |
169 |
195 |
204 |
340 |
400 |
63.2 |
128 |
340 |
307 |
450 |
750 |
1240 |
124.3 |
256 |
2300 |
2200 |
4000 |
5000 |
5600 |
220 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
450 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
28 |
29.5 |
30 |
52 |
0.999 |
8 |
50 |
50 |
60 |
66 |
90 |
7.98 |
16 |
60 |
60 |
66 |
70 |
106 |
15.96 |
32 |
100 |
106 |
113.7 |
116 |
180 |
31.85 |
64 |
7900 |
7200 |
15000 |
16500 |
19600 |
48.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
36 |
35.3 |
36.4 |
50 |
100 |
0.998 |
64 |
200 |
222 |
250 |
300 |
700 |
63.2 |
128 |
360 |
350 |
500 |
500 |
1250 |
124.9 |
256 |
2800 |
2700 |
5000 |
5000 |
7000 |
226 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
39 |
38.6 |
39.5 |
40 |
76 |
0.998 |
8 |
54 |
53 |
59 |
60 |
130 |
7.97 |
16 |
67.8 |
64.9 |
70 |
80 |
194 |
15.9 |
32 |
140 |
126 |
206 |
290 |
380 |
31.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
64 |
61 |
70 |
84 |
100 |
0.997 |
64 |
270 |
306 |
340 |
500 |
520 |
63 |
128 |
557 |
470 |
930 |
1430 |
1900 |
123 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
470 |
真 |
32 |
82 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
46 |
45.2 |
46.4 |
46.7 |
80 |
0.997 |
8 |
63 |
61.7 |
64.6 |
65.5 |
124 |
7.97 |
16 |
128 |
125 |
129 |
140 |
249 |
15.88 |
32 |
11000 |
10300 |
21400 |
23400 |
26400 |
19.1 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
50 |
47.7 |
50 |
59 |
90 |
0.998 |
64 |
470 |
550 |
600 |
820 |
830 |
62.4 |
128 |
5000 |
5000 |
9300 |
10000 |
12000 |
97 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
550 |
真 |
32 |
90 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
43 |
41.7 |
42.7 |
43 |
81.6 |
0.997 |
8 |
85 |
86.8 |
93 |
100 |
170 |
7.96 |
16 |
120 |
118 |
121 |
136 |
255 |
15.87 |
32 |
240 |
230 |
270 |
440 |
531 |
31.5 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
48 |
46 |
50 |
70 |
90 |
0.998 |
64 |
470 |
540 |
600 |
840 |
880 |
62.4 |
128 |
6000 |
5500 |
10000 |
11000 |
14000 |
95 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
570 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
53 |
53 |
56.5 |
58 |
110 |
0.997 |
8 |
63.3 |
60.6 |
64 |
85 |
154 |
7.96 |
16 |
115 |
110 |
122 |
170 |
280 |
15.86 |
32 |
8500 |
7700 |
16500 |
18800 |
21300 |
21 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
97 |
96 |
100 |
112 |
100 |
0.997 |
64 |
457 |
513 |
550 |
950 |
970 |
62.2 |
128 |
3500 |
3300 |
6000 |
7000 |
8300 |
105 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
120 |
假 |
32 |
300 |
真 |
32 |
72 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
230 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
230 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
90 |
假 |
32 |
220 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
32 |
202 |
真 |
32 |
60 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
25 |
假 |
32 |
52.4 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
30 |
假 |
32 |
37 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
6 |
假 |
32 |
26 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
25 |
假 |
32 |
103 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
14 |
12.8 |
13.7 |
14.3 |
40 |
0.999 |
n-gram |
8 |
27 |
25 |
30 |
34 |
70 |
7.98 |
n-gram |
16 |
36 |
34 |
43 |
48 |
100 |
15.95 |
n-gram |
32 |
50 |
49 |
64 |
70 |
150 |
31.84 |
n-gram |
48 |
66 |
70 |
83 |
95 |
240 |
47.6 |
n-gram |
64 |
90 |
94 |
110 |
150 |
330 |
63.3 |
无 |
1 |
12.4 |
11.7 |
12.5 |
13 |
40 |
1 |
无 |
8 |
25 |
23.3 |
30 |
35 |
60 |
7.98 |
无 |
16 |
33 |
29 |
41.5 |
47 |
87 |
15.95 |
无 |
32 |
47 |
45 |
60 |
70 |
130 |
31.84 |
无 |
48 |
63 |
70 |
80 |
92 |
240 |
47.6 |
无 |
64 |
85 |
90 |
104 |
137 |
320 |
63.4 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
17 |
15 |
16 |
32.4 |
70 |
0.999 |
n-gram |
64 |
110 |
113 |
130 |
260 |
300 |
63.4 |
n-gram |
128 |
164 |
140 |
200 |
360 |
470 |
126.1 |
n-gram |
256 |
270 |
260 |
370 |
600 |
900 |
249 |
无 |
1 |
14 |
12.2 |
13 |
26 |
60 |
1 |
无 |
64 |
97 |
100 |
116 |
200 |
240 |
63.5 |
无 |
128 |
153 |
130 |
190 |
330 |
450 |
126.2 |
无 |
256 |
263 |
240 |
357 |
550 |
900 |
249 |
无 |
384 |
430 |
380 |
800 |
1300 |
1760 |
369 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
1180 |
假 |
无 |
32 |
1200 |
真 |
n-gram |
32 |
90 |
真 |
无 |
32 |
94 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19 |
22 |
26 |
80 |
0.998 |
8 |
29 |
28 |
34 |
48 |
53 |
7.97 |
16 |
38 |
36 |
46 |
57 |
76 |
15.92 |
32 |
50 |
50 |
67 |
74 |
120 |
31.8 |
64 |
83 |
91.5 |
110 |
140 |
280 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20.7 |
40 |
90 |
90 |
0.997 |
64 |
117 |
114 |
240 |
240 |
260 |
62.8 |
128 |
187 |
150 |
350 |
420 |
460 |
123.8 |
256 |
320 |
290 |
640 |
800 |
1000 |
240.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
225 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.29 |
13.29 |
15 |
30 |
1 |
8 |
26.4 |
25 |
30 |
34 |
53 |
7.99 |
16 |
35 |
34 |
44 |
47 |
76 |
15.97 |
32 |
48 |
50 |
66 |
70 |
100 |
31.9 |
64 |
80 |
92 |
104 |
110 |
170 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.8 |
20 |
40 |
60 |
1 |
64 |
103 |
108 |
120 |
240 |
253 |
63.7 |
128 |
158 |
137 |
200 |
325 |
430 |
127 |
256 |
270 |
250 |
370 |
604 |
860 |
252.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
460 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.4 |
13.3 |
20 |
70 |
0.997 |
8 |
26.5 |
24 |
30 |
32 |
71 |
7.95 |
16 |
35 |
31 |
50 |
50 |
92 |
15.86 |
32 |
50 |
50 |
70 |
80 |
140 |
31.54 |
64 |
85 |
92 |
100 |
170 |
330 |
62.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13.6 |
40 |
70 |
70 |
0.997 |
64 |
116 |
110 |
250 |
260 |
260 |
62.4 |
128 |
190 |
150 |
400 |
440 |
460 |
122.4 |
256 |
380 |
310 |
840 |
960 |
1250 |
233.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
167 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
19 |
18.6 |
19.55 |
20 |
30 |
0.999 |
8 |
28 |
26.7 |
34 |
36 |
47 |
7.99 |
16 |
37 |
37 |
45 |
50 |
56 |
15.96 |
32 |
48 |
50 |
60 |
64 |
70 |
31.9 |
64 |
80 |
100 |
110 |
110 |
120 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
27 |
40 |
90 |
0.999 |
64 |
100 |
110 |
123 |
127 |
130 |
63.7 |
128 |
160 |
146 |
210 |
240 |
283 |
126.6 |
256 |
266 |
250 |
375 |
460 |
610 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
420 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.4 |
13 |
13.2 |
50 |
1 |
8 |
25 |
24 |
26 |
28 |
60 |
7.98 |
16 |
34 |
32 |
40 |
44 |
90 |
15.95 |
32 |
46 |
46 |
60 |
64 |
100 |
31.85 |
48 |
63 |
73 |
80 |
84 |
200 |
47.7 |
64 |
77 |
90 |
100 |
104 |
230 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.63 |
15 |
29 |
70 |
1 |
64 |
105 |
110 |
124 |
200 |
270 |
63.5 |
128 |
168 |
140 |
205 |
430 |
530 |
125.8 |
256 |
310 |
260 |
600 |
810 |
1340 |
247 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
920 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
24 |
27 |
30 |
100 |
0.996 |
8 |
42 |
41 |
47 |
50 |
110 |
7.95 |
16 |
50 |
49 |
58 |
60 |
150 |
15.84 |
32 |
70 |
70 |
85 |
100 |
200 |
31.56 |
48 |
90 |
90 |
110 |
160 |
330 |
47.1 |
64 |
116 |
123 |
140 |
200 |
400 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
32.7 |
58 |
70 |
100 |
0.996 |
64 |
150 |
140 |
300 |
400 |
400 |
62.5 |
128 |
220 |
220 |
400 |
500 |
600 |
123.5 |
256 |
440 |
360 |
900 |
1100 |
1600 |
239 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
900 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.5 |
13.2 |
13.6 |
30 |
1 |
8 |
26 |
25 |
28 |
30.6 |
52 |
7.99 |
16 |
34 |
33 |
40 |
44 |
50 |
15.97 |
32 |
48 |
50 |
64 |
68 |
76 |
31.9 |
64 |
80 |
95 |
103 |
106 |
160 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.7 |
20 |
30 |
70 |
1 |
64 |
95 |
107 |
124 |
130 |
140 |
63.7 |
128 |
143 |
132 |
190 |
200 |
220 |
127 |
256 |
234 |
230 |
350 |
356 |
370 |
252.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
20 |
25 |
26 |
100 |
0.996 |
8 |
35.2 |
33 |
38.4 |
40 |
100 |
7.95 |
16 |
45 |
43 |
50 |
55 |
130 |
15.85 |
32 |
58 |
60 |
70 |
77 |
170 |
31.6 |
48 |
80 |
80 |
92 |
150 |
300 |
47.2 |
64 |
100 |
100 |
120 |
200 |
400 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
50 |
100 |
100 |
0.996 |
64 |
130 |
122 |
250 |
300 |
300 |
62.7 |
128 |
210 |
180 |
400 |
500 |
500 |
123.3 |
256 |
400 |
340 |
700 |
900 |
1300 |
238.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
700 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.6 |
13.2 |
13.25 |
50 |
0.999 |
8 |
26 |
25 |
30 |
33 |
70 |
7.98 |
16 |
34 |
32 |
42 |
44 |
90 |
15.94 |
32 |
50 |
50 |
60 |
66 |
130 |
31.8 |
64 |
80 |
90 |
102 |
105 |
240 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
13.7 |
20 |
50 |
70 |
0.999 |
64 |
106 |
111 |
130 |
240 |
270 |
63.3 |
128 |
164 |
140 |
198 |
370 |
460 |
125.8 |
256 |
280 |
250 |
370 |
640 |
900 |
248 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
444 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
19 |
27 |
38 |
90 |
0.995 |
8 |
30 |
27 |
50 |
53 |
60 |
7.93 |
16 |
42.4 |
39.4 |
62 |
80 |
86 |
15.8 |
32 |
54 |
52 |
90 |
100 |
130 |
31.5 |
64 |
100 |
100 |
200 |
240 |
300 |
61.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20 |
90 |
90 |
90 |
0.994 |
64 |
140 |
114 |
300 |
300 |
300 |
61.4 |
128 |
224 |
186 |
440 |
450 |
460 |
119.6 |
256 |
400 |
340 |
800 |
860 |
1000 |
226 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
110 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.6 |
40 |
40 |
100 |
0.991 |
8 |
32 |
27 |
60 |
70 |
76 |
7.88 |
16 |
44 |
40 |
60 |
100 |
100 |
15.6 |
32 |
60 |
50 |
100 |
150 |
170 |
30.9 |
64 |
131.6 |
101 |
310 |
440 |
460 |
59.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
37 |
90 |
90 |
90 |
0.992 |
64 |
160 |
120 |
260 |
260 |
260 |
60.3 |
128 |
270 |
210 |
450 |
466 |
470 |
115.6 |
256 |
490 |
420 |
800 |
1000 |
1000 |
213 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.35 |
14 |
20 |
70 |
0.997 |
8 |
26 |
24 |
30 |
35 |
68 |
7.96 |
16 |
37 |
33.3 |
46 |
55 |
100 |
15.86 |
32 |
52 |
50 |
70 |
77 |
150 |
31.6 |
64 |
86 |
94 |
110 |
170 |
300 |
62.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
13.6 |
40 |
70 |
70 |
0.997 |
64 |
120 |
110 |
260 |
260 |
270 |
62.5 |
128 |
190 |
150 |
400 |
430 |
450 |
123 |
256 |
327 |
300 |
660 |
780 |
920 |
237.3 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
177 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.2 |
13 |
15 |
40 |
1 |
8 |
26 |
24.4 |
30 |
40 |
70 |
7.98 |
16 |
34 |
31.2 |
42 |
47 |
90 |
15.95 |
32 |
48 |
48 |
60 |
68 |
140 |
31.83 |
48 |
65 |
70.4 |
82 |
100 |
240 |
47.6 |
64 |
88 |
93 |
110 |
150 |
400 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
13.6 |
20 |
40 |
70 |
0.999 |
64 |
120 |
106 |
240 |
245 |
260 |
63.4 |
128 |
190 |
170 |
370 |
420 |
440 |
126.2 |
256 |
330 |
297 |
700 |
770 |
900 |
249 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
930 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
13 |
14 |
20 |
70 |
0.997 |
8 |
28 |
26 |
30 |
36 |
80 |
7.95 |
16 |
36 |
33 |
46 |
50 |
100 |
15.87 |
32 |
52 |
55 |
65 |
70 |
150 |
31.6 |
48 |
70 |
73 |
88 |
100 |
250 |
47.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
16 |
50 |
70 |
70 |
0.997 |
64 |
120 |
120 |
250 |
300 |
300 |
62.5 |
128 |
193 |
170 |
380 |
450 |
461 |
123.2 |
256 |
340 |
300 |
700 |
800 |
900 |
238 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
192 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.3 |
25 |
38 |
100 |
0.997 |
8 |
30 |
26 |
48 |
64 |
78 |
7.95 |
16 |
40 |
35 |
71 |
84 |
100 |
15.87 |
32 |
55 |
50 |
90 |
114 |
140 |
31.6 |
48 |
78 |
77 |
120 |
180 |
250 |
47.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
25 |
50 |
90 |
90 |
0.996 |
64 |
130 |
115 |
270 |
300 |
300 |
62.5 |
128 |
192 |
150 |
400 |
440 |
460 |
123.2 |
256 |
340 |
300 |
670 |
800 |
1000 |
238 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
190 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
39 |
38.6 |
39.4 |
39.6 |
75 |
0.998 |
4 |
72 |
70.5 |
76 |
80 |
153 |
3.98 |
8 |
131 |
144 |
165 |
210 |
280 |
7.92 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
42 |
39.4 |
41 |
57 |
90 |
0.998 |
4 |
78 |
75 |
90 |
110 |
130 |
3.986 |
8 |
122 |
135 |
160 |
178 |
196 |
7.95 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
72 |
假 |
4 |
128.6 |
假 |
8 |
132 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.3 |
20.7 |
22 |
40 |
0.999 |
8 |
29 |
28 |
33 |
35 |
50 |
7.99 |
16 |
38 |
38 |
46 |
50 |
55 |
15.96 |
32 |
49 |
51 |
62 |
65 |
70 |
31.9 |
48 |
62 |
70 |
81 |
84 |
96 |
47.8 |
64 |
80.7 |
98 |
107 |
110 |
120 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21 |
28 |
35 |
90 |
0.999 |
64 |
100 |
110 |
130 |
130 |
140 |
63.7 |
128 |
160 |
150 |
210 |
240 |
290 |
126.6 |
256 |
264 |
250 |
380 |
470 |
610 |
250 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
126 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20.2 |
21.4 |
23 |
30 |
0.999 |
8 |
35 |
35.6 |
39 |
40 |
50 |
7.99 |
16 |
44.4 |
44.4 |
50 |
53 |
64 |
15.96 |
32 |
57 |
60 |
70 |
73 |
81 |
31.9 |
48 |
70 |
72 |
90 |
93 |
105 |
47.8 |
64 |
90 |
100 |
120 |
120 |
140 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
26 |
23 |
31.3 |
40 |
90 |
0.999 |
64 |
107 |
121.5 |
140 |
140 |
160 |
63.7 |
128 |
176 |
170 |
233 |
240 |
300 |
127 |
256 |
290 |
280 |
410 |
438 |
524 |
251 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1300 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
21 |
24 |
26 |
100 |
0.996 |
8 |
37 |
36 |
41 |
45 |
100 |
7.96 |
16 |
47 |
45 |
54 |
57 |
100 |
15.88 |
32 |
60 |
60 |
75 |
80 |
150 |
31.6 |
48 |
80 |
84 |
97 |
100 |
200 |
47.3 |
64 |
100 |
110 |
120 |
130 |
180 |
63.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
27 |
60 |
100 |
100 |
0.996 |
64 |
130 |
130 |
200 |
300 |
300 |
63.1 |
128 |
200 |
200 |
300 |
400 |
400 |
125 |
256 |
300 |
280 |
400 |
500 |
600 |
246 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1340 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.4 |
20.7 |
22 |
30 |
1 |
8 |
29 |
28 |
33.6 |
34.9 |
54 |
7.99 |
16 |
39 |
38 |
46 |
50 |
80 |
15.97 |
32 |
52 |
52 |
62 |
66 |
110 |
31.9 |
64 |
83 |
95 |
105 |
110 |
280 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
21 |
27 |
37 |
90 |
0.999 |
64 |
108 |
113 |
130 |
200 |
270 |
63.5 |
128 |
166 |
140 |
204 |
340 |
460 |
126.2 |
256 |
296 |
260 |
470 |
700 |
1240 |
248 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22.6 |
26 |
27 |
46 |
1 |
8 |
39 |
38.5 |
42 |
44 |
76 |
7.99 |
16 |
47 |
47 |
54 |
57 |
100 |
15.95 |
32 |
60 |
60 |
75 |
80 |
144 |
31.9 |
64 |
100 |
114 |
126 |
130 |
220 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
32 |
29 |
35 |
50 |
100 |
0.998 |
64 |
130 |
130 |
200 |
200 |
500 |
63.5 |
128 |
200 |
175 |
300 |
500 |
1000 |
125.4 |
256 |
400 |
300 |
700 |
1000 |
2000 |
249 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
24.4 |
25.5 |
30 |
53 |
0.998 |
8 |
34 |
32 |
37.6 |
44 |
80 |
7.98 |
16 |
44 |
41 |
56 |
60 |
110 |
15.94 |
32 |
66 |
70 |
90 |
90 |
200 |
31.8 |
48 |
90 |
98 |
110 |
123 |
290 |
47.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
25.4 |
30 |
50 |
90 |
0.999 |
64 |
168 |
180 |
200 |
300 |
340 |
63.3 |
128 |
266 |
220 |
346 |
500 |
600 |
125.6 |
256 |
540 |
470 |
1200 |
1300 |
2000 |
245 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
938 |
真 |
32 |
115 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
27.4 |
28 |
30 |
52 |
0.998 |
8 |
46 |
45 |
49.5 |
50 |
74 |
7.98 |
16 |
65 |
60 |
82 |
85 |
120 |
15.93 |
32 |
110 |
135 |
140 |
150 |
240 |
31.74 |
48 |
3680 |
3440 |
6890 |
7250 |
8830 |
39.2 |
64 |
10700 |
9700 |
20800 |
22740 |
25600 |
38.7 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
33 |
30.2 |
40 |
50 |
100 |
0.999 |
64 |
260 |
289 |
300 |
300 |
310 |
63.4 |
128 |
420 |
350 |
560 |
600 |
780 |
125 |
256 |
3800 |
3600 |
6600 |
7000 |
8560 |
206.5 |
384 |
13700 |
13000 |
25600 |
26800 |
29200 |
208 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1063 |
真 |
32 |
114 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
29 |
34 |
36 |
60 |
0.998 |
8 |
48 |
46 |
50 |
60 |
85 |
7.98 |
16 |
66 |
63 |
83.6 |
88 |
140 |
15.93 |
32 |
110 |
126 |
136 |
143 |
260 |
31.7 |
48 |
167 |
186 |
195 |
200 |
387 |
47.4 |
64 |
220 |
240 |
255 |
320 |
510 |
63 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
33 |
30.5 |
40 |
57 |
90 |
0.998 |
64 |
240 |
254 |
270 |
280 |
300 |
63.4 |
128 |
450 |
470 |
500 |
700 |
770 |
125.2 |
256 |
1100 |
1100 |
1550 |
1700 |
1940 |
241 |
384 |
9900 |
9200 |
18000 |
20000 |
23500 |
246 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1230 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
34 |
33 |
34 |
39.2 |
70 |
0.998 |
8 |
50 |
46 |
60 |
71 |
103 |
7.97 |
16 |
65 |
57 |
85 |
90 |
149.4 |
15.9 |
32 |
110 |
122 |
130 |
150 |
300 |
31.7 |
48 |
215 |
196 |
330 |
370 |
450 |
47.3 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
37 |
34 |
40 |
60 |
100 |
0.998 |
64 |
280 |
294 |
320 |
434 |
460 |
63.1 |
128 |
455 |
377 |
600 |
890 |
1060 |
124 |
256 |
4100 |
3800 |
7100 |
8000 |
9800 |
202 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
120 |
假 |
32 |
596 |
真 |
32 |
90 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
160 |
假 |
32 |
508 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
150 |
假 |
32 |
508 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
160 |
假 |
32 |
486 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
80 |
假 |
32 |
300 |
真 |
32 |
23 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
30 |
假 |
32 |
77 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
50 |
假 |
32 |
61.4 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
5.8 |
假 |
32 |
38.4 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
26 |
假 |
32 |
159 |
160语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
11 |
10.4 |
11.4 |
12 |
40 |
0.999 |
n-gram |
8 |
23 |
22 |
27 |
30 |
60 |
7.98 |
n-gram |
16 |
29 |
27 |
34 |
40 |
80 |
15.96 |
n-gram |
32 |
37 |
34.4 |
47 |
50 |
100 |
31.9 |
n-gram |
48 |
44 |
44 |
58 |
64 |
120 |
47.8 |
n-gram |
64 |
50 |
50 |
63 |
69 |
150 |
63.6 |
无 |
1 |
10 |
9.5 |
10.3 |
11 |
30 |
1 |
无 |
8 |
19.3 |
18.2 |
24 |
26 |
50 |
7.99 |
无 |
16 |
24 |
21.6 |
31 |
37.5 |
64 |
15.97 |
无 |
32 |
34 |
32 |
44 |
50 |
100 |
31.9 |
无 |
48 |
40 |
40 |
55 |
63 |
120 |
47.8 |
无 |
64 |
47 |
50 |
62 |
68 |
140 |
63.7 |
800语言模型 |
流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
|||
n-gram |
1 |
15 |
12.3 |
13.4 |
28.8 |
70 |
1 |
n-gram |
64 |
70 |
70 |
90 |
160 |
200 |
63.6 |
n-gram |
128 |
90 |
80 |
100 |
200 |
300 |
126.8 |
n-gram |
256 |
130 |
119 |
170 |
300 |
500 |
252 |
无 |
1 |
12 |
10 |
10.7 |
23.5 |
60 |
1 |
无 |
64 |
64 |
65 |
77 |
140 |
170 |
63.7 |
无 |
128 |
81 |
74 |
98 |
190 |
260 |
126.8 |
无 |
256 |
120 |
110 |
150 |
300 |
500 |
252 |
无 |
384 |
160 |
143 |
212 |
400 |
700 |
375 |
说话人分离 |
语言模型 |
流数 |
吞吐量 (RTFX) |
|---|---|---|---|
假 |
n-gram |
32 |
2000 |
假 |
无 |
32 |
2200 |
真 |
n-gram |
32 |
110 |
真 |
无 |
32 |
150 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
16.8 |
20 |
23 |
80 |
0.998 |
8 |
23.7 |
22 |
30 |
40 |
45.4 |
7.97 |
16 |
31 |
29 |
40 |
50 |
60 |
15.93 |
32 |
40 |
40 |
50 |
60 |
86 |
31.84 |
64 |
52 |
54 |
66 |
72 |
140 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
35 |
90 |
90 |
0.998 |
64 |
80 |
70 |
170 |
180 |
180 |
63.1 |
128 |
105 |
90 |
230 |
260 |
280 |
125.4 |
256 |
159 |
132 |
350 |
450 |
510 |
246.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
223 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.3 |
11.2 |
12.4 |
30 |
1 |
8 |
20 |
19 |
26 |
30 |
42 |
7.99 |
16 |
28 |
26 |
35 |
40 |
56 |
15.97 |
32 |
35 |
35 |
48 |
52 |
73 |
31.9 |
64 |
50 |
55 |
66 |
70 |
100 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.5 |
20 |
30 |
60 |
1 |
64 |
70 |
70 |
90 |
100 |
170 |
63.8 |
128 |
88 |
84 |
110 |
190 |
250 |
127.4 |
256 |
128 |
117 |
164 |
300 |
460 |
254.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
440 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
10 |
12 |
20 |
60 |
0.997 |
8 |
23 |
21 |
27 |
30 |
65 |
7.96 |
16 |
30 |
27 |
40 |
45 |
80 |
15.88 |
32 |
37 |
35 |
49 |
60 |
100 |
31.7 |
64 |
51 |
50 |
66 |
74 |
150 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
12 |
40 |
60 |
60 |
0.997 |
64 |
80 |
73 |
160 |
180 |
180 |
63 |
128 |
105 |
85 |
240 |
260 |
270 |
124.6 |
256 |
165 |
130 |
400 |
470 |
500 |
243.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
167 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17.3 |
17 |
20 |
22 |
30 |
0.999 |
8 |
23 |
22 |
28 |
30 |
40 |
7.99 |
16 |
30.5 |
29.5 |
37.5 |
40 |
50 |
15.97 |
32 |
38 |
39 |
49 |
52 |
60 |
31.9 |
64 |
50.6 |
53.4 |
67 |
70 |
78 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.9 |
20 |
30 |
60 |
0.999 |
64 |
70 |
73 |
90 |
90 |
100 |
63.8 |
128 |
80 |
82 |
110 |
100 |
200 |
127.4 |
256 |
120 |
120 |
160 |
200 |
200 |
254 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
420 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.4 |
11 |
11.5 |
40 |
1 |
8 |
20 |
20 |
23 |
25 |
60 |
7.99 |
16 |
27 |
25 |
33 |
35 |
70 |
15.96 |
32 |
35 |
33 |
45 |
49 |
90 |
31.9 |
48 |
40 |
40 |
54 |
57 |
120 |
47.8 |
64 |
50 |
53 |
62 |
66 |
140 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.5 |
12.6 |
30 |
60 |
1 |
64 |
70 |
73 |
90 |
130 |
180 |
63.6 |
128 |
88 |
80 |
100 |
200 |
274 |
126.8 |
256 |
130 |
115 |
160 |
370 |
540 |
251.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
20.5 |
24 |
29 |
90 |
0.996 |
8 |
35 |
34 |
41 |
45.7 |
100 |
7.95 |
16 |
45 |
42 |
54 |
60 |
130 |
15.84 |
32 |
60 |
60 |
75 |
90 |
230 |
31.6 |
48 |
80 |
77 |
90 |
110 |
300 |
47 |
64 |
90 |
90 |
100 |
120 |
280 |
62.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
30 |
53 |
70 |
90 |
0.997 |
64 |
120 |
100 |
200 |
300 |
300 |
62.9 |
128 |
160 |
140 |
300 |
400 |
500 |
124.8 |
256 |
300 |
200 |
500 |
700 |
1000 |
245 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10.4 |
10 |
10.8 |
11.3 |
30 |
1 |
8 |
21.45 |
20.7 |
25 |
27 |
49.5 |
7.99 |
16 |
27 |
26 |
34 |
36 |
52 |
15.96 |
32 |
35.4 |
35 |
47 |
50 |
70 |
31.9 |
64 |
50 |
50 |
60 |
66 |
90 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
11.6 |
20 |
30 |
40 |
1 |
64 |
64 |
69 |
80 |
90 |
100 |
63.7 |
128 |
80 |
80.5 |
100 |
120 |
140 |
127.3 |
256 |
114 |
120 |
157 |
164 |
200 |
254 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
443 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
22 |
24 |
90 |
0.996 |
8 |
30 |
30 |
35 |
40 |
90 |
7.96 |
16 |
38 |
36 |
44 |
50 |
120 |
15.86 |
32 |
48 |
45 |
60 |
64 |
160 |
31.6 |
48 |
60 |
57 |
72 |
100 |
300 |
47.1 |
64 |
66 |
67 |
80 |
90 |
230 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
70 |
80 |
80 |
0.996 |
64 |
100 |
90 |
200 |
300 |
300 |
63 |
128 |
140 |
108 |
300 |
400 |
500 |
124.7 |
256 |
200 |
155 |
500 |
600 |
800 |
244 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
300 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.02 |
11.4 |
12 |
40 |
0.999 |
8 |
21 |
20.5 |
24 |
27 |
63 |
7.98 |
16 |
27.7 |
26 |
34 |
37 |
80 |
15.95 |
32 |
36 |
34.8 |
47 |
50 |
100 |
31.86 |
64 |
51 |
55 |
66 |
69 |
170 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
11.7 |
20 |
50 |
70 |
0.999 |
64 |
70 |
70 |
90 |
150 |
180 |
63.6 |
128 |
90 |
80 |
100 |
230 |
300 |
126.7 |
256 |
129 |
118 |
159 |
330 |
480 |
251.4 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
447 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
30 |
40 |
60 |
0.994 |
8 |
26 |
24 |
40 |
46 |
50 |
7.94 |
16 |
32 |
28 |
50 |
55 |
70 |
15.86 |
32 |
40 |
40 |
60 |
80 |
90 |
31.6 |
64 |
60 |
60 |
88 |
100 |
160 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
20 |
80 |
80 |
80 |
0.995 |
64 |
100 |
80 |
200 |
200 |
200 |
62.1 |
128 |
130 |
93 |
260 |
280 |
285 |
122.7 |
256 |
210 |
150 |
450 |
500 |
530 |
238 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
109 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
35 |
60 |
80 |
0.992 |
8 |
29 |
26 |
50 |
50 |
65 |
7.9 |
16 |
36 |
33 |
60 |
75 |
90 |
15.72 |
32 |
50 |
45 |
64 |
100 |
120 |
31.1 |
64 |
66 |
60 |
90 |
160 |
200 |
61.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
40 |
35 |
90 |
90 |
90 |
0.992 |
64 |
110 |
90 |
180 |
200 |
200 |
61.4 |
128 |
160 |
110 |
270 |
280 |
300 |
120 |
256 |
250 |
180 |
480 |
500 |
500 |
229 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
71.7 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
10.3 |
12 |
20 |
60 |
0.997 |
8 |
24 |
21 |
30 |
30 |
60 |
7.96 |
16 |
29 |
26 |
35 |
44 |
80 |
15.9 |
32 |
39 |
40 |
52.5 |
58 |
110 |
31.7 |
64 |
55 |
57 |
70 |
79 |
170 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
11.7 |
40 |
60 |
60 |
0.997 |
64 |
80 |
70 |
160 |
200 |
200 |
63 |
128 |
105 |
86 |
230 |
250 |
280 |
124.8 |
256 |
160 |
130 |
380 |
470 |
500 |
244 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
178 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
9.7 |
10.7 |
12 |
27 |
1 |
8 |
22 |
20 |
30 |
30 |
70 |
7.98 |
16 |
26 |
24 |
32 |
40 |
70 |
15.96 |
32 |
35 |
35 |
48 |
54 |
100 |
31.87 |
48 |
40.4 |
39 |
54 |
60 |
130 |
47.8 |
64 |
48 |
50 |
60 |
67 |
160 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.3 |
20 |
30 |
60 |
1 |
64 |
75 |
67 |
150 |
155 |
170 |
63.6 |
128 |
103 |
82 |
220 |
240 |
270 |
126.8 |
256 |
162 |
126 |
370 |
450 |
480 |
252 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
10.4 |
11.5 |
20 |
70 |
0.997 |
8 |
23 |
21 |
30 |
30 |
70 |
7.96 |
16 |
29.4 |
26 |
35 |
40 |
85 |
15.9 |
32 |
39 |
36 |
51 |
58 |
130 |
31.6 |
48 |
50 |
50 |
62 |
67 |
160 |
47.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
50 |
70 |
70 |
0.997 |
64 |
90 |
80 |
180 |
200 |
200 |
63 |
128 |
110 |
90 |
240 |
270 |
300 |
125 |
256 |
169 |
130 |
400 |
490 |
520 |
245 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
190 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
24 |
37 |
100 |
0.997 |
8 |
24.4 |
20.7 |
37 |
54 |
64 |
7.96 |
16 |
32 |
27 |
50 |
70 |
83 |
15.9 |
32 |
43 |
40 |
70 |
93 |
110 |
31.7 |
48 |
50 |
50 |
84 |
120 |
160 |
47.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
22 |
60 |
80 |
80 |
0.996 |
64 |
90 |
80 |
180 |
200 |
200 |
63 |
128 |
110 |
90 |
240 |
260 |
300 |
125 |
256 |
170 |
130 |
400 |
500 |
500 |
245 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
192 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
19 |
18.53 |
19.2 |
19.7 |
40 |
0.999 |
4 |
37 |
35.3 |
40 |
45 |
67 |
3.99 |
8 |
53 |
57 |
65 |
67 |
110 |
7.97 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
22.4 |
23 |
38 |
80 |
0.999 |
4 |
41 |
39 |
45 |
70 |
80 |
3.99 |
8 |
56 |
57 |
70 |
80 |
104 |
7.98 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
4 |
292 |
假 |
8 |
294 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18 |
17.5 |
20 |
22 |
40 |
0.999 |
8 |
22 |
21 |
26.5 |
29 |
40 |
7.99 |
16 |
29 |
28 |
35 |
38 |
46 |
15.97 |
32 |
37 |
38 |
47.5 |
51 |
60 |
31.9 |
48 |
43 |
44 |
60 |
60 |
70 |
47.9 |
64 |
51 |
55 |
68 |
72.3 |
80 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18 |
27 |
40 |
60 |
0.999 |
64 |
67 |
73 |
85 |
90 |
90 |
63.8 |
128 |
86 |
85 |
110 |
120 |
140 |
127.4 |
256 |
120 |
123 |
170 |
180 |
200 |
254 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
206 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
19 |
18.2 |
19.6 |
24.3 |
40 |
0.999 |
8 |
30 |
31 |
36 |
38 |
47 |
7.99 |
16 |
37 |
37 |
43 |
47 |
54 |
15.96 |
32 |
46 |
47 |
56 |
59 |
70 |
31.9 |
48 |
54 |
55 |
68 |
71.6 |
78 |
47.8 |
64 |
62 |
67 |
80 |
83 |
93 |
63.8 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
20.4 |
25 |
30 |
60 |
0.999 |
64 |
77 |
83 |
100 |
100 |
120 |
63.8 |
128 |
100 |
100 |
140 |
160 |
200 |
127.3 |
256 |
150 |
146 |
210 |
230 |
260 |
253.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
21 |
18.7 |
24 |
28 |
80 |
0.996 |
8 |
32 |
31 |
36 |
40 |
80 |
7.95 |
16 |
39 |
37 |
46 |
50 |
100 |
15.9 |
32 |
50 |
50 |
64 |
70 |
160 |
31.6 |
48 |
65 |
65 |
77 |
90 |
300 |
47.3 |
64 |
70 |
70 |
90 |
100 |
200 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
60 |
70 |
70 |
0.996 |
64 |
100 |
89 |
200 |
200 |
200 |
63.2 |
128 |
130 |
110 |
200 |
300 |
400 |
125 |
256 |
200 |
160 |
300 |
400 |
600 |
247 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2310 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
16.7 |
18.4 |
20 |
30 |
1 |
8 |
23 |
22.6 |
28 |
30 |
45 |
7.99 |
16 |
30.6 |
29.7 |
36 |
38 |
65 |
15.98 |
32 |
40 |
40 |
50 |
60 |
80 |
31.9 |
64 |
60 |
60 |
70 |
76 |
150 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.8 |
25 |
40 |
90 |
0.999 |
64 |
72 |
74 |
90 |
150 |
170 |
63.6 |
128 |
90 |
80 |
110 |
200 |
280 |
126.8 |
256 |
136 |
125 |
170 |
320 |
520 |
251.6 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
450 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
21 |
24 |
27 |
46 |
1 |
8 |
34 |
34 |
37 |
40 |
70 |
7.99 |
16 |
41 |
39.2 |
50 |
54 |
110 |
15.95 |
32 |
50 |
50 |
63 |
67 |
140 |
31.9 |
64 |
72 |
76 |
88 |
100 |
200 |
63.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
29 |
27 |
30 |
40 |
100 |
0.999 |
64 |
100 |
93 |
200 |
200 |
500 |
63.5 |
128 |
200 |
120 |
300 |
500 |
1000 |
125.6 |
256 |
400 |
180 |
900 |
2000 |
2000 |
249 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
19 |
18.3 |
19.3 |
20 |
43.5 |
0.999 |
8 |
24 |
23 |
30 |
30 |
65 |
7.98 |
16 |
31.4 |
29 |
38.3 |
42 |
80 |
15.96 |
32 |
42 |
42 |
57 |
60 |
100 |
31.9 |
48 |
52 |
53 |
69.6 |
75 |
130 |
47.8 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
22 |
30 |
50 |
90 |
0.999 |
64 |
90 |
90 |
110 |
160 |
200 |
63.6 |
128 |
120 |
100 |
150 |
240 |
330 |
126.8 |
256 |
180 |
160 |
240 |
400 |
560 |
251.5 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
240 |
假 |
32 |
2030 |
真 |
32 |
101.5 |
160none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
19.4 |
20.3 |
21 |
43 |
0.999 |
8 |
27 |
27 |
33 |
34 |
50 |
7.99 |
16 |
38.6 |
36.6 |
46 |
50 |
64 |
15.96 |
32 |
52 |
55 |
70 |
70 |
90 |
31.9 |
48 |
67 |
76.5 |
85 |
90 |
150 |
47.8 |
64 |
87 |
100 |
110 |
110 |
188 |
63.6 |
960none流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
21 |
26 |
40 |
90 |
1 |
64 |
110 |
126 |
140 |
145 |
150 |
63.7 |
128 |
170 |
150 |
230 |
235 |
244 |
127 |
256 |
287 |
265 |
430 |
440 |
540 |
251.6 |
384 |
420 |
410 |
650 |
680 |
980 |
372.4 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
300 |
假 |
32 |
2300 |
真 |
32 |
150 |
320n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
21.7 |
26 |
28 |
53 |
0.998 |
8 |
30 |
28 |
36 |
40 |
70 |
7.98 |
16 |
40 |
37 |
50 |
52 |
90 |
15.96 |
32 |
54 |
55 |
70 |
74 |
130 |
31.9 |
48 |
67 |
70 |
86 |
90 |
160 |
47.8 |
64 |
80 |
90 |
103 |
110 |
200 |
63.6 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
24 |
30 |
50 |
90 |
0.999 |
64 |
93 |
101 |
120 |
138 |
150 |
63.7 |
128 |
157 |
160 |
194 |
250 |
300 |
127 |
256 |
270 |
290 |
354 |
370 |
440 |
252.5 |
384 |
380 |
400 |
520 |
600 |
760 |
375 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
260 |
假 |
32 |
1500 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
23 |
29 |
30 |
50 |
0.999 |
8 |
31 |
29 |
35.5 |
46 |
70 |
7.98 |
16 |
44 |
40 |
56 |
60 |
100 |
15.95 |
32 |
60 |
62 |
76 |
80 |
150 |
31.84 |
48 |
80 |
86 |
100 |
112 |
227 |
47.7 |
960n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
30 |
27 |
40 |
50 |
100 |
0.999 |
64 |
120 |
130 |
150 |
200 |
240 |
63.5 |
128 |
170 |
150 |
220 |
310 |
380 |
126.5 |
256 |
270 |
250 |
390 |
540 |
700 |
250.5 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1440 |
真 |
32 |
94 |
160n-gram960n-gramn-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1270 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
200 |
假 |
32 |
1220 |
160none960nonenone说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
180 |
假 |
32 |
1200 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
80 |
假 |
32 |
405 |
真 |
32 |
24 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
70 |
假 |
32 |
193.5 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
100 |
假 |
32 |
152 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
6.2 |
假 |
32 |
43.3 |
none说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
1 |
28 |
假 |
32 |
192 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
14.2 |
14.87 |
14.96 |
99 |
15.45 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
14.4 |
15.97 |
17 |
99.8 |
17.36 |
0.997 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.48 |
14.38 |
14.8 |
102.8 |
14.8 |
0.999 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.65 |
15.34 |
17.65 |
99.3 |
17.64 |
0.995 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
14.16 |
14.8 |
15 |
93.2 |
15.52 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
14.1 |
14.55 |
14.83 |
93.7 |
15.23 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
15.3 |
16.17 |
16.66 |
96.4 |
16.78 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.97 |
15.1 |
17.28 |
98.8 |
15.5 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
24.3 |
25.75 |
62 |
219 |
32.7 |
0.994 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.26 |
14.38 |
14.97 |
192.7 |
16.73 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
16.1 |
20.7 |
98 |
98 |
21.95 |
0.99 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
14.43 |
97 |
97 |
97 |
23.05 |
0.987 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.23 |
14.88 |
17.96 |
155.8 |
19.73 |
0.995 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.46 |
14.33 |
16.06 |
102 |
14.92 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
11.15 |
12.1 |
12.56 |
187 |
14.06 |
0.999 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
11.15 |
11.96 |
12.31 |
103 |
12.6 |
0.999 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.2 |
14.22 |
14.44 |
94 |
16.82 |
0.995 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
11.35 |
12.02 |
12.66 |
91.2 |
12.73 |
0.999 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.26 |
14.07 |
14.28 |
107.1 |
15.36 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.16 |
20.66 |
36.24 |
96.5 |
16.22 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
12.77 |
13.44 |
14.02 |
100.8 |
14.3 |
0.998 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.03 |
93.8 |
93.8 |
93.8 |
20.98 |
0.99 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
13.63 |
14.98 |
17.28 |
93.8 |
17.24 |
0.995 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
p50 |
p90 |
p95 |
p99 |
平均值 |
||
1 |
12.98 |
13.47 |
13.72 |
98 |
14.2 |
0.999 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
50 |
49.6 |
50.1 |
50.4 |
100 |
0.997 |
8 |
70 |
70 |
80 |
80 |
130 |
7.96 |
16 |
100 |
100 |
111 |
114 |
230 |
15.87 |
32 |
300 |
280 |
450 |
500 |
660 |
31.4 |
48 |
12100 |
13000 |
23200 |
24000 |
24700 |
34.2 |
64 |
22000 |
24500 |
38400 |
39100 |
39700 |
34 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
52.6 |
52 |
53 |
64.3 |
67 |
0.998 |
64 |
300 |
320 |
340 |
550 |
700 |
62.7 |
128 |
580 |
570 |
680 |
900 |
2000 |
123.2 |
256 |
17000 |
19000 |
30000 |
30000 |
38000 |
154 |
384 |
31000 |
32600 |
50000 |
53000 |
62600 |
155.5 |
512 |
45500 |
47000 |
71000 |
73000 |
86800 |
159 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
423 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22.3 |
21.76 |
22 |
22 |
42.6 |
0.999 |
8 |
50 |
48 |
50 |
60 |
100 |
7.97 |
16 |
57 |
56 |
60 |
63 |
125 |
15.9 |
32 |
100 |
95 |
100 |
100 |
280 |
31.7 |
48 |
170 |
145 |
200 |
330 |
500 |
47.3 |
64 |
10000 |
10000 |
19000 |
20000 |
20400 |
52.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
23.4 |
23.8 |
32 |
34 |
0.999 |
64 |
185 |
180 |
190 |
300 |
370 |
63.2 |
128 |
360 |
370 |
386 |
510 |
740 |
124.8 |
256 |
1300 |
800 |
1800 |
2200 |
12000 |
240 |
384 |
17000 |
18000 |
27400 |
27800 |
34700 |
246 |
512 |
28000 |
32000 |
40500 |
41000 |
50000 |
250 |
768 |
45000 |
50000 |
68000 |
70000 |
80000 |
256 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
49 |
48.6 |
49 |
49 |
100 |
0.997 |
8 |
70 |
80 |
85 |
85 |
120 |
7.97 |
16 |
90 |
100 |
100 |
102 |
200 |
15.9 |
32 |
300 |
286 |
400 |
485 |
780 |
31.5 |
48 |
10000 |
11000 |
21000 |
22000 |
23000 |
36.6 |
64 |
20300 |
23600 |
35400 |
36400 |
37000 |
37 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
52 |
51.2 |
52 |
63.3 |
65 |
0.998 |
64 |
300 |
300 |
310 |
400 |
500 |
63 |
128 |
520 |
550 |
600 |
790 |
1500 |
124 |
256 |
14000 |
15000 |
25000 |
26000 |
35000 |
172 |
384 |
27000 |
27000 |
44000 |
48000 |
58000 |
174 |
512 |
39000 |
38000 |
61900 |
63000 |
80500 |
175 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
460 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22.3 |
21.7 |
21.8 |
21.9 |
42 |
0.999 |
8 |
50 |
50 |
55 |
56 |
100 |
7.97 |
16 |
55 |
53.5 |
60 |
62 |
110 |
15.93 |
32 |
92 |
90 |
94 |
97 |
264 |
31.7 |
48 |
150 |
134 |
145 |
230 |
500 |
47.4 |
64 |
8000 |
7200 |
16000 |
17000 |
17700 |
57 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
21.4 |
20.9 |
21 |
28.25 |
30 |
1 |
64 |
174 |
171 |
177 |
240 |
334 |
63.3 |
128 |
350 |
340 |
350 |
460 |
663 |
125.2 |
256 |
860 |
700 |
1000 |
1500 |
6000 |
243.5 |
384 |
14400 |
14500 |
24000 |
24800 |
32800 |
267 |
512 |
24000 |
27000 |
37000 |
37500 |
47000 |
269 |
768 |
40000 |
44000 |
61000 |
64000 |
75000 |
272 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1200 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
49 |
48.9 |
49.3 |
49.4 |
100 |
0.997 |
8 |
70 |
70 |
80 |
80 |
130 |
7.96 |
16 |
90 |
90 |
100 |
100 |
200 |
15.9 |
32 |
200 |
200 |
400 |
500 |
800 |
31.5 |
48 |
13000 |
14000 |
25000 |
26000 |
26000 |
33.3 |
64 |
24000 |
27000 |
42000 |
43000 |
44000 |
33 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
52 |
51.4 |
52.4 |
63.3 |
65 |
0.998 |
64 |
300 |
300 |
320 |
400 |
500 |
63 |
128 |
530 |
560 |
610 |
810 |
1550 |
123.9 |
256 |
16000 |
17000 |
30000 |
30000 |
40000 |
160 |
384 |
30000 |
30000 |
50000 |
56000 |
66000 |
157 |
512 |
46000 |
42000 |
74000 |
75000 |
93000 |
155 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
460 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22.5 |
22 |
22.2 |
22.3 |
44.4 |
0.999 |
8 |
50 |
50 |
50 |
60 |
97 |
7.97 |
16 |
55 |
53 |
60 |
60 |
110 |
15.93 |
32 |
96 |
91 |
98 |
103 |
260 |
31.7 |
48 |
160 |
140 |
160 |
260 |
460 |
47.4 |
64 |
9000 |
9000 |
18000 |
20000 |
20000 |
53 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22.7 |
22 |
23 |
30.3 |
30 |
1 |
64 |
180 |
173 |
183 |
250 |
350 |
63.2 |
128 |
353 |
345 |
360 |
470 |
690 |
125 |
256 |
1000 |
700 |
1200 |
1700 |
9000 |
242 |
384 |
19000 |
20000 |
30000 |
30000 |
37000 |
240 |
512 |
30000 |
35000 |
45000 |
46000 |
55000 |
236 |
768 |
49000 |
55000 |
73700 |
76200 |
88800 |
236.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1200 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14.4 |
14.1 |
14.6 |
14.78 |
27 |
1 |
8 |
33 |
34 |
36 |
36 |
60 |
7.98 |
16 |
42 |
45 |
48 |
50 |
110 |
15.92 |
32 |
77 |
80 |
84 |
87 |
270 |
31.7 |
48 |
115 |
116 |
120 |
134 |
360 |
47.3 |
64 |
150 |
140 |
160 |
280 |
500 |
62.9 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.8 |
17 |
22.6 |
25 |
1 |
64 |
150 |
150 |
200 |
300 |
380 |
63.2 |
128 |
240 |
240 |
300 |
410 |
650 |
125.3 |
256 |
480 |
470 |
600 |
1000 |
2200 |
244 |
384 |
2000 |
1300 |
3000 |
4000 |
13100 |
344 |
512 |
13000 |
14400 |
23000 |
24000 |
30740 |
320 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
870 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10.6 |
10.5 |
10.9 |
11.05 |
16 |
1 |
8 |
22 |
20 |
24 |
24 |
39 |
7.99 |
16 |
30 |
30 |
32 |
33 |
70 |
15.95 |
32 |
51 |
50 |
53.6 |
55 |
130 |
31.8 |
48 |
65 |
65 |
70 |
73 |
200 |
47.6 |
64 |
83.3 |
82.5 |
90 |
95 |
300 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11.4 |
11.1 |
12 |
15 |
17 |
1 |
64 |
89 |
86 |
100 |
150 |
245 |
63.4 |
128 |
158 |
156 |
175 |
280 |
464 |
126 |
256 |
303 |
295 |
330 |
550 |
1200 |
248 |
384 |
450 |
420 |
500 |
930 |
2260 |
366 |
512 |
770 |
580 |
1300 |
1800 |
6200 |
477 |
768 |
11000 |
11500 |
17000 |
17000 |
27000 |
555 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.3 |
15 |
15.7 |
16 |
29 |
1 |
8 |
33 |
30 |
35 |
35 |
66 |
7.98 |
16 |
42 |
45 |
47 |
47 |
105 |
15.93 |
32 |
73 |
77 |
80 |
83 |
200 |
31.76 |
48 |
110 |
110 |
118 |
120 |
290 |
47.5 |
64 |
140 |
135 |
150 |
190 |
400 |
63.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.7 |
16.4 |
17.5 |
23.8 |
27 |
1 |
64 |
140 |
140 |
160 |
200 |
300 |
63.4 |
128 |
240 |
250 |
300 |
370 |
540 |
125.6 |
256 |
420 |
430 |
500 |
720 |
1500 |
247 |
384 |
1040 |
730 |
1030 |
2200 |
12000 |
357 |
512 |
9000 |
9000 |
14500 |
17500 |
30200 |
373 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1020 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11.5 |
11.3 |
12 |
12 |
17 |
1 |
8 |
18.6 |
18.3 |
21 |
21 |
37 |
7.99 |
16 |
30.5 |
29.47 |
32.7 |
34 |
60 |
15.95 |
32 |
48.7 |
48.3 |
51.6 |
53 |
107 |
31.8 |
48 |
66 |
65 |
70 |
72 |
160 |
47.6 |
64 |
80 |
81 |
86 |
90 |
240 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12.05 |
11.7 |
12.5 |
16 |
20 |
1 |
64 |
86 |
83 |
90 |
133 |
219 |
63.5 |
128 |
150 |
153 |
170 |
252 |
420 |
126 |
256 |
280 |
280 |
300 |
492 |
1100 |
248.7 |
384 |
404 |
410 |
450 |
730 |
2060 |
368 |
512 |
600 |
540 |
660 |
1480 |
4600 |
482 |
768 |
8000 |
8000 |
12000 |
13000 |
26000 |
590 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.4 |
15 |
16 |
16 |
30 |
1 |
8 |
35 |
34 |
36 |
36 |
70 |
7.98 |
16 |
42.2 |
45 |
47 |
47 |
100 |
15.93 |
32 |
70 |
75 |
80 |
80 |
180 |
31.8 |
48 |
100 |
110 |
115 |
120 |
280 |
47.5 |
64 |
140 |
137 |
148 |
190 |
390 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
17 |
17.7 |
24 |
27 |
1 |
64 |
130 |
140 |
160 |
200 |
280 |
63.4 |
128 |
250 |
250 |
300 |
360 |
530 |
125.7 |
256 |
420 |
440 |
500 |
705 |
1490 |
247 |
384 |
980 |
713 |
1000 |
2000 |
10400 |
359 |
512 |
8300 |
8500 |
13000 |
16000 |
30400 |
373 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1040 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11.8 |
11.6 |
12 |
13 |
18 |
1 |
8 |
19 |
18.8 |
20.5 |
21 |
38 |
7.99 |
16 |
33 |
32 |
34 |
35 |
67 |
15.95 |
32 |
49 |
48 |
50 |
52 |
110 |
31.84 |
48 |
67 |
66 |
70 |
71 |
157 |
47.6 |
64 |
80 |
82 |
88 |
90 |
250 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.7 |
12 |
16.4 |
20 |
1 |
64 |
90 |
84 |
100 |
135 |
220 |
63.5 |
128 |
147 |
150 |
170 |
250 |
420 |
126 |
256 |
280 |
280 |
300 |
490 |
1000 |
248.7 |
384 |
406 |
410 |
450 |
727 |
2040 |
368 |
512 |
590 |
540 |
630 |
1450 |
4300 |
482 |
768 |
7500 |
7000 |
12000 |
13000 |
26000 |
590 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20.5 |
20 |
20.6 |
20.8 |
43 |
0.999 |
8 |
60 |
60 |
60 |
62 |
110 |
7.97 |
16 |
67 |
70 |
80 |
80 |
160 |
15.9 |
32 |
93 |
95 |
104 |
110 |
280 |
31.65 |
48 |
130 |
130 |
150 |
160 |
400 |
47.3 |
64 |
180 |
174 |
200 |
300 |
630 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
22 |
23 |
33 |
34.3 |
0.999 |
64 |
180 |
170 |
194 |
400 |
500 |
62.9 |
128 |
270 |
240 |
300 |
600 |
1100 |
124 |
256 |
510 |
450 |
800 |
1000 |
2870 |
240 |
384 |
2000 |
1900 |
3000 |
4000 |
10800 |
336 |
512 |
11400 |
12500 |
20000 |
22000 |
25000 |
320 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
740 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.8 |
13.3 |
13.5 |
23 |
1 |
8 |
28 |
27 |
29.9 |
30.6 |
50 |
7.98 |
16 |
37 |
36 |
40 |
40 |
90 |
15.93 |
32 |
50 |
50 |
60 |
60 |
134 |
31.8 |
48 |
67 |
66 |
76 |
80 |
240 |
47.5 |
64 |
86 |
83 |
94 |
100 |
294 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14.5 |
14.1 |
14.4 |
20 |
22 |
1 |
64 |
94 |
90 |
100 |
180 |
300 |
63.3 |
128 |
166 |
160 |
190 |
340 |
600 |
125.4 |
256 |
310 |
290 |
335 |
640 |
1400 |
246 |
384 |
480 |
420 |
600 |
1180 |
3030 |
361.5 |
512 |
1000 |
660 |
1600 |
2300 |
7800 |
467 |
768 |
11000 |
13000 |
18000 |
18000 |
26000 |
530 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
20 |
20.6 |
42 |
0.999 |
8 |
50 |
54 |
60 |
60 |
100 |
7.97 |
16 |
66 |
70 |
70 |
75 |
140 |
15.9 |
32 |
90 |
100 |
100 |
110 |
230 |
31.7 |
48 |
120 |
127 |
143 |
146 |
316 |
47.4 |
64 |
150 |
149 |
170 |
180 |
425 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
21 |
22 |
31 |
33 |
0.999 |
64 |
150 |
153 |
172 |
230 |
350 |
63.2 |
128 |
240 |
250 |
270 |
394 |
630 |
125.3 |
256 |
400 |
400 |
470 |
730 |
1570 |
245.7 |
384 |
710 |
630 |
750 |
1670 |
5700 |
360 |
512 |
5000 |
5400 |
8000 |
9000 |
21000 |
415 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
950 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12.5 |
12 |
12.4 |
12.5 |
23 |
1 |
8 |
24 |
23 |
27.46 |
28 |
50 |
7.98 |
16 |
36 |
35 |
37 |
37.8 |
77 |
15.94 |
32 |
50 |
50 |
53 |
54 |
130 |
31.8 |
48 |
68 |
65.5 |
69 |
72 |
190 |
47.5 |
64 |
85 |
80.4 |
85 |
90 |
280 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.4 |
13 |
13.6 |
19 |
20 |
1 |
64 |
90 |
80 |
90 |
150 |
280 |
63.4 |
128 |
145 |
142 |
160 |
281 |
530 |
125.6 |
256 |
270 |
260 |
287 |
550 |
1250 |
246.7 |
384 |
398 |
374.4 |
420 |
870 |
2260 |
363.6 |
512 |
590 |
500 |
600 |
1530 |
4700 |
475 |
768 |
5400 |
5000 |
10000 |
11000 |
22000 |
600 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
20 |
21 |
43 |
0.999 |
8 |
50 |
50 |
60 |
60 |
100 |
7.97 |
16 |
67 |
70 |
74 |
76 |
140 |
15.9 |
32 |
90 |
90 |
100 |
102 |
240 |
31.7 |
48 |
120 |
130 |
140 |
150 |
320 |
47.4 |
64 |
160 |
152 |
176 |
200 |
430 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
23 |
24 |
33 |
35 |
0.999 |
64 |
160 |
160 |
180 |
250 |
400 |
63.1 |
128 |
250 |
257 |
300 |
400 |
690 |
125 |
256 |
430 |
420 |
500 |
770 |
2060 |
244.6 |
384 |
730 |
643 |
760 |
1700 |
5900 |
358 |
512 |
4000 |
4000 |
7000 |
7000 |
23000 |
413 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
940 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.5 |
13 |
13.4 |
13.6 |
24 |
1 |
8 |
20.8 |
20.05 |
20.8 |
21.3 |
46 |
7.98 |
16 |
33 |
33 |
37 |
38 |
70 |
15.94 |
32 |
52 |
50 |
54 |
57 |
130 |
31.8 |
48 |
70 |
68 |
74 |
76 |
180 |
47.6 |
64 |
90 |
86 |
92 |
96 |
280 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14.6 |
14 |
14.8 |
20 |
22 |
1 |
64 |
90 |
85 |
95 |
160 |
300 |
63.3 |
128 |
170 |
150 |
170 |
296 |
570 |
125.5 |
256 |
290 |
268 |
304 |
580 |
1320 |
246 |
384 |
420 |
384 |
450 |
930 |
2340 |
362.5 |
512 |
610 |
510 |
630 |
1540 |
4720 |
473 |
768 |
6000 |
6000 |
10000 |
13000 |
23000 |
590 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.7 |
16.3 |
17 |
17 |
33 |
0.999 |
8 |
40 |
30 |
40 |
40 |
70 |
7.98 |
16 |
47.3 |
52 |
54 |
54 |
100 |
15.93 |
32 |
60 |
60 |
70 |
70 |
140 |
31.8 |
48 |
76 |
78 |
81 |
83 |
160 |
47.6 |
64 |
90 |
90 |
96 |
100 |
250 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18.3 |
18 |
19 |
25.3 |
30 |
1 |
64 |
110 |
105 |
128 |
170 |
270 |
63.4 |
128 |
146 |
140 |
190 |
240 |
420 |
126.2 |
256 |
233 |
240 |
290 |
450 |
850 |
249 |
384 |
345 |
360 |
410 |
658 |
1470 |
367.5 |
512 |
480 |
480 |
540 |
1000 |
2700 |
484 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.8 |
12.2 |
12.4 |
19 |
1 |
8 |
24 |
23 |
26 |
26.5 |
40 |
7.99 |
16 |
28 |
27.4 |
28.7 |
30 |
56 |
15.95 |
32 |
39 |
38 |
40 |
42 |
93 |
31.84 |
48 |
48 |
47 |
52 |
54 |
130 |
47.7 |
64 |
57 |
55 |
64 |
68 |
160 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.9 |
13.6 |
17 |
20 |
1 |
64 |
65 |
60 |
70 |
114 |
220 |
63.5 |
128 |
110 |
100 |
120 |
200 |
390 |
126.3 |
256 |
180 |
166 |
200 |
360 |
720 |
250 |
384 |
250 |
230.6 |
276 |
524 |
1240 |
369 |
512 |
323 |
298 |
358 |
700 |
1900 |
487 |
768 |
510 |
453 |
580 |
1400 |
3800 |
710 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
4000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.8 |
15.45 |
16 |
16.5 |
33.6 |
0.999 |
8 |
39 |
39 |
40 |
40 |
76 |
7.98 |
16 |
44 |
47 |
50 |
50 |
100 |
15.93 |
32 |
60 |
61 |
67.4 |
69 |
225 |
31.7 |
48 |
74 |
76 |
81 |
84 |
230 |
47.5 |
64 |
90 |
90.7 |
97 |
100 |
290 |
63.1 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18.7 |
18.2 |
19.6 |
27.9 |
30 |
1 |
64 |
120 |
116 |
140 |
280 |
370 |
63.2 |
128 |
160 |
144.7 |
200 |
370 |
560 |
125.6 |
256 |
270 |
250 |
300 |
600 |
1200 |
247 |
384 |
420 |
380 |
700 |
1000 |
2200 |
363 |
512 |
700 |
550 |
1380 |
2000 |
4000 |
472.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1240 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11.2 |
10.92 |
11.4 |
12 |
19.3 |
1 |
8 |
20 |
20 |
24 |
25 |
37.3 |
7.99 |
16 |
27 |
26.5 |
29 |
30.5 |
57 |
15.96 |
32 |
40 |
40 |
43 |
44 |
115 |
31.8 |
48 |
47 |
47 |
52.4 |
53.6 |
140 |
47.65 |
64 |
57 |
56 |
64 |
67 |
190 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12.5 |
12 |
14 |
17 |
20 |
1 |
64 |
70 |
66 |
80 |
130 |
220 |
63.5 |
128 |
112 |
106 |
130 |
222 |
390 |
126.3 |
256 |
180 |
170 |
200 |
400 |
730 |
249.3 |
384 |
259 |
237 |
291 |
580 |
1300 |
369.5 |
512 |
340 |
300 |
380 |
780 |
2090 |
487 |
768 |
700 |
508 |
1200 |
1800 |
6000 |
708 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
3000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.5 |
15.18 |
15.6 |
15.8 |
33 |
0.999 |
8 |
40 |
40 |
40 |
40 |
70 |
7.98 |
16 |
47 |
49 |
51 |
52 |
100 |
15.94 |
32 |
57 |
60 |
66.4 |
68 |
144 |
31.8 |
48 |
70 |
74 |
78 |
80 |
160 |
47.6 |
64 |
85 |
86.6 |
90.8 |
94 |
210 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18.2 |
17.8 |
18.8 |
27 |
30 |
1 |
64 |
107 |
110 |
120 |
170 |
250 |
63.4 |
128 |
140 |
130 |
160 |
240 |
410 |
126.2 |
256 |
220 |
230 |
300 |
450 |
780 |
249 |
384 |
339 |
350 |
400 |
670 |
1450 |
369 |
512 |
480 |
480 |
600 |
1080 |
2800 |
485 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.74 |
11 |
11.2 |
18.8 |
1 |
8 |
20 |
20 |
22 |
23 |
40 |
7.99 |
16 |
26 |
25 |
27 |
28 |
50 |
15.96 |
32 |
39 |
39 |
42.2 |
43 |
90 |
31.85 |
48 |
50 |
50 |
53 |
55 |
125 |
47.7 |
64 |
55 |
54 |
62 |
64 |
144 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.6 |
12.3 |
16.9 |
20 |
1 |
64 |
65 |
60 |
70 |
116 |
210 |
63.5 |
128 |
103 |
95 |
110 |
200 |
366 |
126.4 |
256 |
170 |
160 |
200 |
360 |
690 |
250 |
384 |
240 |
226 |
270 |
525 |
1200 |
370.6 |
512 |
320 |
290 |
360 |
700 |
1880 |
488 |
768 |
510 |
450 |
560 |
1400 |
3880 |
716 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
3000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.5 |
15.17 |
15.6 |
16 |
33 |
0.999 |
8 |
38.2 |
39 |
39.9 |
40.2 |
67 |
7.98 |
16 |
42 |
47 |
50 |
50 |
100 |
15.93 |
32 |
55 |
57 |
65 |
67 |
140 |
31.8 |
48 |
70 |
72 |
75 |
77.8 |
150 |
47.7 |
64 |
84 |
87 |
90 |
95 |
230 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
18.5 |
18 |
19.5 |
26.9 |
30 |
1 |
64 |
110 |
106 |
130 |
175 |
260 |
63.4 |
128 |
145 |
140 |
180 |
255 |
420 |
126.2 |
256 |
230 |
230 |
300 |
470 |
800 |
249 |
384 |
350 |
350 |
400 |
700 |
1500 |
369 |
512 |
500 |
480 |
600 |
1200 |
3000 |
485 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1600 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11.1 |
10.9 |
11.3 |
11.63 |
19 |
1 |
8 |
20 |
20 |
20 |
20 |
35 |
7.99 |
16 |
28 |
27 |
30 |
30.4 |
50 |
15.96 |
32 |
40 |
39 |
43 |
44 |
90 |
31.85 |
48 |
50 |
50 |
50 |
54 |
124 |
47.7 |
64 |
57 |
56 |
62 |
65 |
150 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12.4 |
12 |
12.4 |
17 |
20 |
1 |
64 |
64 |
60 |
70 |
113 |
210 |
63.5 |
128 |
110 |
104 |
130 |
205 |
370 |
126.3 |
256 |
180 |
170 |
200 |
350 |
680 |
250 |
384 |
240 |
230 |
270 |
510 |
1166 |
371 |
512 |
314 |
293 |
350 |
690 |
1600 |
489 |
768 |
506 |
450 |
570 |
1370 |
3800 |
716 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
4000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
50.6 |
50.1 |
50.7 |
50.9 |
100 |
0.997 |
8 |
70 |
60 |
104 |
106 |
150 |
7.96 |
16 |
106 |
112 |
117 |
120 |
260 |
15.85 |
32 |
640 |
630 |
900 |
1000 |
1200 |
31.2 |
48 |
14400 |
16000 |
27000 |
27000 |
28000 |
32 |
64 |
24000 |
26000 |
42000 |
43000 |
43000 |
32.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
53.3 |
52.6 |
53.5 |
66 |
68 |
0.998 |
64 |
350 |
350 |
370 |
600 |
700 |
62.6 |
128 |
660 |
600 |
800 |
1300 |
2600 |
122 |
256 |
19000 |
20000 |
32000 |
33000 |
40500 |
146 |
384 |
34300 |
36000 |
57000 |
58000 |
65600 |
148 |
512 |
48000 |
50000 |
77000 |
79000 |
90400 |
151 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
400 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
21.5 |
21.9 |
22.1 |
43 |
0.999 |
8 |
50 |
50 |
60 |
60 |
110 |
7.97 |
16 |
58 |
56 |
62 |
70 |
130 |
15.9 |
32 |
100 |
100 |
100 |
110 |
305 |
31.67 |
48 |
180 |
150 |
300 |
400 |
570 |
47.3 |
64 |
12400 |
12200 |
22000 |
22700 |
27000 |
49.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.6 |
24 |
25 |
32.7 |
35 |
0.999 |
64 |
200 |
194 |
206 |
290 |
410 |
63.1 |
128 |
370 |
375 |
403 |
520 |
800 |
124.7 |
256 |
3000 |
2000 |
4000 |
5000 |
13000 |
233 |
384 |
20000 |
21000 |
30000 |
30000 |
37000 |
233 |
512 |
31000 |
37000 |
44000 |
45000 |
52500 |
237 |
768 |
50000 |
56000 |
73000 |
74000 |
83400 |
246 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
51.4 |
51.2 |
51.8 |
52.1 |
105 |
0.997 |
8 |
70 |
70 |
90 |
100 |
136 |
7.96 |
16 |
100 |
100 |
120 |
120 |
220 |
15.88 |
32 |
480 |
470 |
660 |
730 |
900 |
31.4 |
48 |
12300 |
13000 |
24300 |
25000 |
25700 |
33.8 |
64 |
22700 |
26000 |
39500 |
40400 |
41000 |
34 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
54.3 |
53.8 |
54.6 |
66.6 |
70 |
0.998 |
64 |
300 |
320 |
340 |
400 |
520 |
62.9 |
128 |
570 |
560 |
654 |
900 |
1800 |
123.5 |
256 |
17000 |
20000 |
30000 |
30000 |
38400 |
160 |
384 |
31000 |
33000 |
52000 |
54000 |
62500 |
160 |
512 |
43000 |
42000 |
68000 |
69000 |
86700 |
163.7 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
430 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25.1 |
24.5 |
24.9 |
25.1 |
48 |
0.998 |
8 |
50 |
52 |
60 |
60 |
100 |
7.97 |
16 |
58 |
56 |
62 |
64 |
120 |
15.92 |
32 |
100 |
95 |
100 |
105 |
280 |
31.7 |
48 |
157 |
140 |
170 |
260 |
430 |
47.3 |
64 |
9200 |
8600 |
17900 |
18800 |
19500 |
54.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.3 |
23.6 |
24 |
33 |
35 |
0.999 |
64 |
183 |
180 |
190 |
260 |
380 |
63.2 |
128 |
360 |
360 |
387 |
510 |
760 |
124.8 |
256 |
1100 |
730 |
1600 |
2000 |
10000 |
240 |
384 |
17000 |
17700 |
27000 |
28000 |
35000 |
250 |
512 |
28000 |
31500 |
41000 |
41600 |
50000 |
253 |
768 |
46000 |
50000 |
67800 |
69500 |
79700 |
256.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
52 |
51.3 |
52 |
52.4 |
106 |
0.997 |
8 |
70 |
80 |
90 |
90 |
130 |
7.96 |
16 |
90 |
90 |
114 |
120 |
220 |
15.87 |
32 |
450 |
400 |
700 |
700 |
900 |
31.4 |
48 |
12000 |
12000 |
23400 |
25000 |
25900 |
33.4 |
64 |
22300 |
24000 |
40000 |
41000 |
41800 |
33.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
55 |
54.4 |
56 |
67.7 |
70 |
0.998 |
64 |
330 |
335 |
360 |
430 |
550 |
62.9 |
128 |
600 |
600 |
680 |
1000 |
2300 |
123.3 |
256 |
16000 |
17000 |
30000 |
30000 |
39400 |
156 |
384 |
32000 |
33000 |
55000 |
55000 |
64000 |
160 |
512 |
45000 |
46000 |
72000 |
76000 |
88500 |
160 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
430 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25.4 |
24.7 |
25.2 |
25.4 |
49 |
0.998 |
8 |
50 |
50 |
50 |
60 |
110 |
7.96 |
16 |
56 |
54 |
60 |
65 |
120 |
15.9 |
32 |
100 |
96 |
100 |
100 |
284 |
31.7 |
48 |
156 |
139 |
180 |
270 |
420 |
47.3 |
64 |
9800 |
9200 |
18600 |
19400 |
20100 |
54 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.5 |
23.7 |
24.4 |
33 |
36 |
0.999 |
64 |
190 |
187 |
200 |
270 |
390 |
63.2 |
128 |
360 |
360 |
400 |
510 |
766 |
124.7 |
256 |
1500 |
900 |
2000 |
2500 |
12400 |
236 |
384 |
18000 |
19000 |
28000 |
29000 |
36000 |
240 |
512 |
29000 |
33000 |
42400 |
43200 |
51700 |
247 |
768 |
47000 |
50000 |
70000 |
72000 |
81700 |
250.5 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
1100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
20 |
20 |
21 |
40 |
0.999 |
8 |
64 |
64 |
66 |
67 |
115 |
7.97 |
16 |
69 |
73 |
80 |
80 |
160 |
15.9 |
32 |
100 |
102 |
110 |
120 |
300 |
31.6 |
48 |
134 |
130 |
150 |
160 |
400 |
47.2 |
64 |
172 |
163 |
190 |
260 |
600 |
62.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
23 |
23 |
24 |
33 |
34 |
0.999 |
64 |
180 |
170 |
204 |
400 |
500 |
63 |
128 |
290 |
270 |
330 |
600 |
1000 |
124.3 |
256 |
520 |
470 |
700 |
1000 |
2500 |
242 |
384 |
1260 |
910 |
2200 |
3000 |
9600 |
350 |
512 |
9600 |
10500 |
16800 |
18000 |
25000 |
340 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
770 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.5 |
13.2 |
13.7 |
14 |
23.6 |
1 |
8 |
28 |
28 |
31 |
31 |
53 |
7.98 |
16 |
38 |
37 |
40 |
40 |
90 |
15.93 |
32 |
50 |
50 |
60 |
60 |
145 |
31.8 |
48 |
63.8 |
64 |
70 |
75 |
220 |
47.5 |
64 |
84 |
82 |
90 |
100 |
295 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
14.4 |
15 |
20.6 |
21 |
1 |
64 |
94 |
89 |
100 |
180 |
310 |
63.3 |
128 |
162 |
156 |
180 |
310 |
570 |
125.5 |
256 |
310 |
290 |
340 |
600 |
1400 |
246.3 |
384 |
477 |
422 |
540 |
1100 |
2960 |
362 |
512 |
860 |
610 |
1400 |
2000 |
7000 |
470 |
768 |
10000 |
11000 |
16000 |
16600 |
25000 |
550 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
21 |
22 |
22 |
43 |
0.999 |
8 |
60 |
60 |
60 |
60 |
100 |
7.97 |
16 |
70 |
73 |
77 |
80 |
150 |
15.9 |
32 |
90 |
99 |
102 |
106 |
240 |
31.7 |
48 |
128 |
130 |
146 |
149 |
330 |
47.4 |
64 |
154 |
150.8 |
177 |
190 |
430 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24 |
24 |
25 |
34 |
35.4 |
0.999 |
64 |
160 |
160 |
200 |
247 |
371 |
63.2 |
128 |
250 |
260 |
300 |
390 |
640 |
125.2 |
256 |
420 |
420 |
500 |
740 |
1800 |
245.4 |
384 |
720 |
640 |
800 |
1730 |
6300 |
359 |
512 |
6000 |
6000 |
10000 |
12000 |
24300 |
414 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
920 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14.7 |
14.46 |
14.8 |
15 |
25 |
1 |
8 |
30 |
30 |
30 |
30 |
52 |
7.98 |
16 |
36 |
35 |
37 |
40 |
80 |
15.94 |
32 |
53 |
52 |
57 |
60 |
130 |
31.8 |
48 |
66.6 |
64.9 |
68.7 |
70.3 |
180 |
47.6 |
64 |
83 |
81.4 |
86 |
92 |
270 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.7 |
15.2 |
15.7 |
22.1 |
23 |
1 |
64 |
90 |
83 |
90 |
161 |
300 |
63.3 |
128 |
150 |
144 |
160 |
300 |
575 |
125.4 |
256 |
280 |
268 |
300 |
580 |
1320 |
246 |
384 |
420 |
386 |
440 |
970 |
2500 |
362 |
512 |
620 |
510 |
620 |
1600 |
5400 |
473 |
768 |
6500 |
6000 |
12000 |
13000 |
24000 |
580 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
22 |
21 |
22 |
22 |
44 |
0.999 |
8 |
60 |
50 |
60 |
65 |
110 |
7.97 |
16 |
70 |
71 |
76 |
78 |
150 |
15.9 |
32 |
90 |
100 |
110 |
110 |
250 |
31.7 |
48 |
125 |
125 |
145 |
148 |
340 |
47.4 |
64 |
160 |
153 |
187 |
200 |
400 |
63 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
24 |
26 |
35 |
36.2 |
0.999 |
64 |
160 |
160 |
200 |
240 |
380 |
63.2 |
128 |
254 |
257 |
300 |
410 |
690 |
125 |
256 |
440 |
430 |
500 |
764 |
2110 |
245 |
384 |
730 |
630 |
800 |
1800 |
6400 |
357.6 |
512 |
5600 |
6000 |
10000 |
12000 |
24300 |
410 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
900 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14.8 |
14.5 |
15 |
15.2 |
26.4 |
1 |
8 |
25 |
20 |
30 |
30 |
52 |
7.98 |
16 |
34 |
33 |
36 |
40 |
80 |
15.94 |
32 |
53 |
51 |
55 |
57 |
133 |
31.8 |
48 |
67 |
66 |
70 |
72 |
200 |
47.5 |
64 |
83.9 |
82.4 |
90 |
93 |
280 |
63.2 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15.93 |
15.5 |
16 |
22 |
24 |
1 |
64 |
90 |
83 |
100 |
160 |
300 |
63.3 |
128 |
152 |
145 |
170 |
300 |
580 |
125.4 |
256 |
286 |
270 |
300 |
580 |
1330 |
246 |
384 |
424 |
390 |
440 |
983 |
2600 |
362 |
512 |
630 |
520 |
640 |
1600 |
5410 |
472 |
768 |
7000 |
6000 |
13000 |
14000 |
24000 |
580 |
n-gram流数 |
吞吐量 (RTFX) |
|---|---|
32 |
2000 |
以下表格展示了 CPU 数量对延迟和吞吐量的影响。测量是在本地使用英语 Conformer 模型进行的。
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
13 |
13.3 |
40 |
0.999 |
8 |
21 |
19 |
26 |
30 |
60 |
7.98 |
16 |
28.6 |
25.2 |
35 |
44 |
90 |
15.95 |
32 |
40 |
40 |
53 |
60 |
135 |
31.84 |
48 |
50 |
48 |
69 |
80 |
200 |
47.7 |
64 |
64 |
60 |
81 |
110 |
250 |
63.5 |
128 |
116 |
85 |
200 |
363 |
510 |
126.3 |
256 |
3600 |
3500 |
7000 |
7200 |
8300 |
206 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
12.8 |
15 |
40 |
0.999 |
8 |
20.5 |
18.7 |
23.5 |
28 |
59 |
7.99 |
16 |
27 |
24 |
31 |
40 |
90 |
15.96 |
32 |
38 |
36 |
49 |
54 |
122 |
31.86 |
48 |
50 |
50 |
66 |
77 |
180 |
47.7 |
64 |
56 |
55 |
73 |
95 |
230 |
63.5 |
128 |
104 |
80 |
140 |
300 |
440 |
126.4 |
256 |
2600 |
2500 |
5000 |
5000 |
6000 |
218 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
13 |
14 |
40 |
0.999 |
8 |
26 |
24.5 |
29 |
34 |
67 |
7.98 |
16 |
32 |
29.5 |
35 |
45 |
90 |
15.95 |
32 |
44 |
38 |
56 |
60 |
130 |
31.85 |
48 |
50 |
50 |
70 |
80 |
180 |
47.7 |
64 |
62 |
64 |
82 |
98 |
240 |
63.5 |
128 |
102 |
80 |
140 |
280 |
400 |
126.4 |
256 |
2300 |
2300 |
4400 |
4500 |
5000 |
221 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
12.6 |
13.2 |
40 |
0.999 |
8 |
22 |
20 |
25 |
30 |
60 |
7.98 |
16 |
30 |
30 |
35 |
40 |
90 |
15.95 |
32 |
40 |
37 |
53 |
60 |
130 |
31.85 |
48 |
51 |
48.4 |
70 |
80 |
190 |
47.7 |
64 |
59 |
58 |
77 |
90 |
230 |
63.5 |
128 |
100 |
80 |
130 |
260 |
400 |
126.4 |
256 |
1800 |
1700 |
3400 |
3500 |
3900 |
227.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
14 |
15 |
31 |
80 |
1 |
64 |
80 |
80 |
100 |
200 |
270 |
63.5 |
128 |
123.5 |
109 |
153.4 |
340 |
440 |
126.3 |
256 |
190 |
160 |
240 |
570 |
790 |
249.7 |
384 |
280 |
225 |
640 |
800 |
1340 |
370 |
512 |
410 |
294 |
1200 |
1440 |
2000 |
488 |
768 |
940 |
530 |
2700 |
3500 |
3700 |
711 |
1024 |
3900 |
3700 |
6900 |
8200 |
9000 |
791 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.6 |
15 |
31 |
80 |
1 |
64 |
73 |
74 |
93 |
160 |
224 |
63.6 |
128 |
107 |
90 |
130 |
270 |
366 |
126.5 |
256 |
164 |
140 |
206 |
450 |
680 |
250.5 |
384 |
238 |
200 |
450 |
640 |
1200 |
372 |
512 |
320 |
250 |
800 |
940 |
1500 |
491 |
768 |
670 |
400 |
2000 |
2700 |
3000 |
722 |
1024 |
1700 |
1600 |
3600 |
4240 |
5000 |
900 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.8 |
15 |
30 |
80 |
1 |
64 |
75 |
78 |
90 |
160 |
230 |
63.6 |
128 |
100 |
90 |
130 |
270 |
350 |
126.6 |
256 |
154 |
130 |
200 |
400 |
600 |
251 |
384 |
217 |
190 |
330 |
550 |
900 |
373 |
512 |
284.5 |
230 |
650 |
730 |
1350 |
493 |
768 |
540 |
350 |
1500 |
2200 |
2500 |
727 |
1024 |
1080 |
660 |
2800 |
3500 |
3700 |
948 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
13.7 |
14.6 |
30 |
80 |
1 |
64 |
74 |
75 |
96 |
150 |
210 |
63.6 |
128 |
106 |
90 |
136 |
250 |
350 |
126.7 |
256 |
150 |
130 |
194 |
400 |
600 |
251 |
384 |
205 |
180 |
270 |
500 |
900 |
373.5 |
512 |
277 |
228 |
600 |
700 |
1350 |
494 |
768 |
500 |
340 |
1200 |
2000 |
2300 |
728 |
1024 |
960 |
600 |
2600 |
3400 |
3500 |
950 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1500 |
真 |
32 |
126 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1740 |
真 |
32 |
110 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1800 |
真 |
32 |
110 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.4 |
12.6 |
13.4 |
14 |
40 |
0.999 |
8 |
20 |
18 |
24 |
28.5 |
60 |
7.98 |
16 |
27 |
25 |
32 |
37 |
80 |
15.96 |
32 |
41 |
41 |
49.5 |
56 |
150 |
31.85 |
48 |
53 |
52 |
67 |
80 |
223 |
47.7 |
64 |
70 |
73 |
87 |
120 |
280 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.5 |
13.6 |
14 |
40 |
0.999 |
8 |
21 |
19 |
25 |
28 |
60 |
7.98 |
16 |
29.5 |
27 |
34 |
40 |
90 |
15.95 |
32 |
42 |
43 |
54 |
60 |
140 |
31.85 |
48 |
57 |
56 |
73 |
90 |
200 |
47.7 |
64 |
70 |
73 |
90 |
110 |
290 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.8 |
14 |
15 |
40 |
0.999 |
8 |
25 |
23 |
30 |
40 |
70 |
7.98 |
16 |
35 |
33 |
44 |
49 |
100 |
15.95 |
32 |
50 |
50 |
65 |
70 |
150 |
31.84 |
48 |
64 |
70 |
83 |
93 |
200 |
47.7 |
64 |
80 |
85 |
102 |
130 |
290 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.4 |
15.4 |
31 |
70 |
1 |
64 |
80 |
87 |
100 |
200 |
260 |
63.5 |
128 |
135 |
120 |
160 |
340 |
440 |
126.3 |
256 |
225 |
190 |
290 |
600 |
860 |
249.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.5 |
15.5 |
32 |
70 |
0.999 |
64 |
79 |
85 |
100 |
170 |
230 |
63.5 |
128 |
130.2 |
119 |
158 |
306 |
420 |
126.4 |
256 |
210 |
180 |
280 |
500 |
760 |
250 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
15 |
15.8 |
32 |
70 |
0.999 |
64 |
100 |
96 |
120 |
200 |
250 |
63.5 |
128 |
140 |
130 |
180 |
300 |
400 |
126.4 |
256 |
220 |
200 |
286 |
490 |
740 |
250 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1350 |
真 |
32 |
140 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1430 |
真 |
32 |
150 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1430 |
真 |
32 |
103 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.2 |
16 |
17 |
40 |
0.999 |
8 |
28 |
26 |
32 |
37 |
80 |
7.98 |
16 |
38 |
40 |
46 |
50 |
110 |
15.94 |
32 |
50 |
48 |
63 |
69 |
170 |
31.8 |
48 |
56 |
56 |
70 |
90 |
210 |
47.7 |
64 |
73 |
77 |
88 |
117 |
270 |
63.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.3 |
15.4 |
16.4 |
17.2 |
40 |
0.999 |
8 |
30 |
27 |
33 |
40 |
80 |
7.98 |
16 |
39 |
36 |
48 |
53 |
117 |
15.94 |
32 |
52 |
50 |
70 |
73 |
170 |
31.8 |
48 |
56 |
56 |
70 |
88 |
200 |
47.7 |
64 |
73 |
77 |
93 |
113 |
280 |
63.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
15.8 |
17 |
18 |
40 |
0.999 |
8 |
33 |
31 |
38 |
46 |
84 |
7.98 |
16 |
46 |
44 |
58 |
65 |
120 |
15.94 |
32 |
56 |
55 |
77 |
84 |
170 |
31.8 |
48 |
65 |
67 |
86 |
94 |
200 |
47.7 |
64 |
80 |
90 |
103 |
125 |
270 |
63.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.4 |
18.4 |
35 |
70 |
0.999 |
64 |
100 |
110 |
130 |
200 |
300 |
63.4 |
128 |
137 |
122 |
170 |
320 |
430 |
126.3 |
256 |
227 |
200 |
300 |
550 |
800 |
249.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.6 |
19 |
40 |
70 |
0.999 |
64 |
100 |
104 |
133 |
200 |
260 |
63.5 |
128 |
136 |
120 |
170 |
305 |
400 |
126.3 |
256 |
220 |
194 |
290 |
540 |
770 |
250 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
18.7 |
19.7 |
40 |
100 |
0.999 |
64 |
120 |
120 |
160 |
260 |
300 |
63.4 |
128 |
150 |
130 |
180 |
315 |
430 |
126.3 |
256 |
230 |
206 |
300 |
500 |
770 |
249.7 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1340 |
真 |
32 |
140 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1400 |
真 |
32 |
124 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1400 |
真 |
32 |
100 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.6 |
13.4 |
14.3 |
40 |
0.999 |
8 |
22 |
20 |
26.6 |
30 |
70 |
7.98 |
16 |
29.2 |
26.5 |
35 |
40 |
100 |
15.95 |
32 |
43 |
40 |
55 |
60 |
150 |
31.84 |
48 |
62 |
68 |
77 |
100 |
250 |
47.6 |
64 |
86 |
89.1 |
103 |
150 |
330 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.5 |
12.6 |
14 |
14 |
40 |
0.999 |
8 |
23 |
21 |
27 |
33 |
65 |
7.98 |
16 |
30.7 |
28 |
38 |
45 |
90 |
15.95 |
32 |
47 |
47 |
60 |
65 |
170 |
31.8 |
48 |
63 |
65 |
80 |
110 |
240 |
47.6 |
64 |
87 |
90 |
110 |
148 |
330 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
13.6 |
14.6 |
20 |
40 |
0.999 |
8 |
27 |
25 |
30 |
40 |
70 |
7.98 |
16 |
37 |
34 |
44 |
50 |
100 |
15.95 |
32 |
53 |
50 |
70 |
77 |
150 |
31.8 |
48 |
70 |
70 |
90 |
100 |
260 |
47.6 |
64 |
93 |
98 |
113 |
150 |
330 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.3 |
15 |
31 |
70 |
1 |
64 |
90 |
100 |
110 |
200 |
280 |
63.4 |
128 |
160 |
140 |
194 |
370 |
480 |
126 |
256 |
277 |
244 |
400 |
650 |
1100 |
249 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
14 |
15 |
31 |
70 |
0.999 |
64 |
95 |
100 |
114 |
200 |
270 |
63.5 |
128 |
155 |
130 |
190 |
357 |
470 |
126.1 |
256 |
264 |
230 |
350 |
640 |
900 |
249 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.5 |
15.5 |
30 |
70 |
1 |
64 |
116 |
120 |
130 |
240 |
300 |
63.4 |
128 |
170 |
140 |
210 |
360 |
490 |
126 |
256 |
280 |
265 |
370 |
600 |
900 |
249 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1170 |
真 |
32 |
130 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1200 |
真 |
32 |
122 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1200 |
真 |
32 |
140 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
10 |
9.6 |
10.6 |
12 |
30 |
1 |
8 |
15 |
14 |
17 |
23 |
46 |
7.99 |
16 |
20 |
18 |
26 |
30 |
70 |
15.96 |
32 |
28 |
26 |
35 |
40 |
100 |
31.9 |
48 |
34 |
32 |
45 |
50 |
110 |
47.8 |
64 |
41 |
40 |
53 |
57 |
150 |
63.7 |
128 |
67 |
57 |
78 |
160 |
290 |
126.8 |
256 |
150 |
95 |
400 |
600 |
700 |
251.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10 |
11 |
13 |
40 |
0.999 |
8 |
15 |
13.7 |
17 |
20 |
50 |
7.99 |
16 |
20.4 |
18.3 |
27 |
31 |
70 |
15.96 |
32 |
27 |
26 |
34 |
38.4 |
100 |
31.9 |
48 |
33 |
32.5 |
44 |
50 |
100 |
47.8 |
64 |
40 |
38 |
52 |
57 |
130 |
63.7 |
128 |
63 |
55 |
76.4 |
140 |
270 |
127 |
256 |
136 |
90.5 |
350 |
500 |
670 |
252 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.3 |
11.6 |
13 |
40 |
0.999 |
8 |
16 |
15 |
19.8 |
23 |
52 |
7.99 |
16 |
22.6 |
20.5 |
30 |
35 |
70 |
15.96 |
32 |
30.8 |
28 |
39 |
46 |
100 |
31.9 |
48 |
36 |
35 |
50 |
57 |
110 |
47.8 |
64 |
42 |
40 |
55 |
60 |
140 |
63.7 |
128 |
65 |
57 |
79 |
140 |
270 |
127 |
256 |
137 |
93 |
350 |
500 |
660 |
252 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.2 |
11.5 |
14 |
40 |
0.999 |
8 |
13.1 |
12 |
13.3 |
17 |
44.7 |
7.99 |
16 |
17 |
14.9 |
22 |
26 |
60 |
15.97 |
32 |
23 |
22 |
30.6 |
32.5 |
80 |
31.9 |
48 |
28.4 |
28 |
38 |
41.5 |
90 |
47.8 |
64 |
34 |
35 |
45 |
47 |
110 |
63.7 |
128 |
52 |
45 |
64 |
100 |
230 |
127 |
256 |
110 |
80 |
260 |
400 |
560 |
252 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11 |
12 |
27 |
80 |
1 |
64 |
50 |
50 |
65 |
140 |
170 |
63.7 |
128 |
80 |
70 |
90 |
240 |
340 |
126.8 |
256 |
120 |
100 |
150 |
400 |
560 |
251.7 |
384 |
160 |
130 |
200 |
500 |
760 |
375 |
512 |
210 |
164 |
400 |
650 |
1150 |
495 |
768 |
350 |
230 |
1000 |
1300 |
1800 |
733 |
1024 |
600 |
310 |
2000 |
2300 |
3000 |
962 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
11.5 |
12.6 |
28 |
80 |
1 |
64 |
47 |
40 |
60 |
120 |
160 |
63.7 |
128 |
73 |
63 |
86 |
200 |
270 |
127 |
256 |
106 |
94 |
130 |
300 |
447 |
252.3 |
384 |
136 |
120 |
170 |
400 |
620 |
376 |
512 |
170 |
146 |
220 |
500 |
850 |
498 |
768 |
270 |
200 |
700 |
800 |
1400 |
739 |
1024 |
430 |
270 |
1120 |
1700 |
2230 |
972 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12 |
12.8 |
28 |
80 |
1 |
64 |
50 |
50 |
65 |
120 |
150 |
63.7 |
128 |
73 |
65 |
85 |
190 |
260 |
127 |
256 |
106 |
94 |
130 |
280 |
430 |
252.5 |
384 |
135 |
120 |
170 |
380 |
620 |
376 |
512 |
170 |
144 |
215 |
480 |
800 |
499 |
768 |
260 |
200 |
640 |
800 |
1400 |
739 |
1024 |
390 |
260 |
900 |
1500 |
2000 |
970 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
12 |
13 |
28 |
80 |
1 |
64 |
42 |
43 |
52 |
100 |
140 |
63.7 |
128 |
60 |
50 |
72 |
157 |
228 |
127 |
256 |
93 |
84 |
110 |
240 |
410 |
252.7 |
384 |
124 |
110 |
154 |
340 |
600 |
376.6 |
512 |
154 |
134 |
200 |
430 |
760 |
499 |
768 |
240 |
188 |
600 |
700 |
1300 |
740 |
1024 |
350 |
246.4 |
760 |
1350 |
1720 |
974 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
150 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
150 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
140 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1900 |
真 |
32 |
130 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16 |
15.2 |
16.3 |
17 |
40 |
0.999 |
8 |
25.5 |
23.6 |
26 |
34.6 |
70 |
7.98 |
16 |
35.3 |
32 |
40 |
45 |
114 |
15.94 |
32 |
49 |
50 |
60 |
66 |
160 |
31.8 |
48 |
70 |
70 |
82 |
130 |
300 |
47.5 |
64 |
99.5 |
93 |
120 |
250 |
410 |
63.2 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.2 |
15.3 |
16.5 |
16.8 |
40 |
0.999 |
8 |
25.5 |
24 |
26 |
35 |
73 |
7.98 |
16 |
34.3 |
31 |
40 |
44 |
111 |
15.94 |
32 |
46.9 |
40 |
58 |
60 |
160 |
31.8 |
48 |
67 |
69 |
78 |
120 |
260 |
47.6 |
64 |
94 |
90 |
105 |
200 |
377 |
63.3 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.3 |
15.5 |
16.6 |
17 |
40 |
0.999 |
8 |
26 |
24.5 |
27 |
36 |
73 |
7.98 |
16 |
33 |
30 |
40 |
43 |
110 |
15.95 |
32 |
46.5 |
49 |
58 |
63 |
160 |
31.8 |
48 |
64.3 |
68 |
75 |
118 |
270 |
47.6 |
64 |
88 |
86 |
97 |
170 |
360 |
63.3 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
16.6 |
16 |
17 |
17.3 |
40 |
0.999 |
8 |
25.6 |
23.7 |
27 |
35 |
73 |
7.98 |
16 |
33 |
30 |
33 |
44 |
104 |
15.95 |
32 |
46 |
40 |
55 |
60 |
150 |
31.8 |
48 |
63 |
67.4 |
73.7 |
110 |
270 |
47.6 |
64 |
85 |
86 |
96 |
150 |
350 |
63.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
18 |
36 |
60 |
0.999 |
64 |
110 |
110 |
130 |
300 |
360 |
63.3 |
128 |
182 |
154 |
210 |
550 |
690 |
125.3 |
256 |
340 |
270 |
730 |
1000 |
1460 |
246 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17 |
18.3 |
36 |
60 |
0.999 |
64 |
103 |
106 |
120 |
300 |
340 |
63.4 |
128 |
164 |
143 |
190 |
470 |
600 |
125.8 |
256 |
293 |
250 |
600 |
740 |
1300 |
247 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.5 |
18.6 |
37 |
60 |
0.999 |
64 |
94 |
97 |
100 |
190 |
290 |
63.4 |
128 |
150 |
130 |
170 |
400 |
540 |
125.9 |
256 |
263 |
226 |
460 |
600 |
1100 |
248 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
17.5 |
20 |
36 |
60 |
0.999 |
64 |
90 |
94 |
100 |
170 |
270 |
63.5 |
128 |
140 |
130 |
165 |
360 |
500 |
126 |
256 |
250 |
220 |
400 |
600 |
1000 |
248.5 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
970 |
真 |
32 |
105 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1130 |
真 |
32 |
103 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1260 |
真 |
32 |
104 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1270 |
真 |
32 |
103 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
24.7 |
23.8 |
25 |
25.4 |
50 |
0.998 |
8 |
50 |
50 |
56 |
64 |
145 |
7.96 |
16 |
50 |
50 |
64 |
70 |
170 |
15.9 |
32 |
100 |
90 |
107 |
220 |
310 |
31.7 |
64 |
5200 |
4800 |
10000 |
10500 |
12600 |
48.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25 |
24.3 |
25.2 |
26 |
50 |
0.998 |
8 |
51 |
50 |
53.7 |
60 |
143 |
7.96 |
16 |
56 |
53 |
62 |
70 |
162 |
15.9 |
32 |
90 |
80 |
106 |
200 |
300 |
31.7 |
64 |
5100 |
4800 |
10000 |
10400 |
12500 |
48.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25.3 |
24.3 |
25.4 |
26 |
60 |
0.998 |
8 |
51 |
50 |
54 |
65 |
140 |
7.96 |
16 |
56 |
53 |
62 |
70 |
165 |
15.92 |
32 |
100 |
90 |
106 |
180 |
300 |
31.7 |
64 |
5100 |
4800 |
9800 |
10400 |
12500 |
48.5 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
25.6 |
24.7 |
25.7 |
26.5 |
60 |
0.998 |
8 |
48.9 |
48 |
50.7 |
60 |
130 |
7.97 |
16 |
54 |
50 |
60 |
65 |
160 |
15.92 |
32 |
95 |
90 |
103 |
190 |
300 |
31.7 |
64 |
5100 |
4700 |
9800 |
10400 |
12400 |
48.5 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
25.5 |
26.7 |
46.7 |
60 |
0.999 |
64 |
190 |
207 |
230 |
400 |
500 |
63 |
128 |
350 |
300 |
440 |
730 |
1000 |
124.5 |
256 |
2400 |
2200 |
4200 |
5000 |
6000 |
220 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
25.7 |
27 |
47 |
70 |
0.999 |
64 |
173 |
198 |
210 |
350 |
430 |
63.2 |
128 |
320 |
326 |
410 |
627 |
830 |
124.8 |
256 |
2000 |
2000 |
3600 |
4000 |
5000 |
226 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
26 |
27 |
48 |
70 |
0.999 |
64 |
173 |
195 |
210 |
360 |
420 |
63.2 |
128 |
316 |
300 |
400 |
620 |
800 |
125 |
256 |
2000 |
1800 |
3400 |
4000 |
5000 |
226 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
28 |
26 |
27 |
48 |
70 |
0.998 |
64 |
170 |
195 |
200 |
320 |
420 |
63.2 |
128 |
310 |
310 |
395 |
600 |
785 |
125 |
256 |
2000 |
1800 |
3400 |
4000 |
5000 |
227 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
560 |
真 |
32 |
103 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
590 |
真 |
32 |
100 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
592 |
真 |
32 |
97 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
590 |
真 |
32 |
94 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12 |
13 |
14 |
40 |
0.999 |
8 |
23 |
20 |
26 |
31 |
70 |
7.98 |
16 |
29 |
26 |
34 |
40 |
90 |
15.95 |
32 |
44 |
43 |
52 |
57 |
150 |
31.84 |
48 |
60 |
60 |
74 |
90 |
234 |
47.65 |
64 |
80 |
84 |
98 |
140 |
320 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13 |
12.5 |
13.5 |
14 |
40 |
0.999 |
8 |
23 |
21 |
27 |
31 |
70 |
7.98 |
16 |
30 |
30 |
40 |
46 |
90 |
15.95 |
32 |
46 |
46 |
57 |
63 |
158 |
31.84 |
48 |
61 |
62 |
78 |
100 |
238 |
47.6 |
64 |
83 |
86 |
100 |
150 |
320 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
13.5 |
12.7 |
13.7 |
14 |
40 |
0.999 |
8 |
23.4 |
21 |
28 |
32 |
66 |
7.98 |
16 |
32 |
29 |
40 |
48 |
90 |
15.96 |
32 |
48 |
45.5 |
60 |
65 |
160 |
31.84 |
48 |
62.4 |
60 |
80 |
100 |
230 |
47.65 |
64 |
83 |
87 |
104 |
140 |
300 |
63.4 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
13.2 |
14.4 |
20 |
40 |
0.999 |
8 |
27.5 |
26 |
31 |
35 |
70 |
7.98 |
16 |
37 |
34 |
45 |
50 |
100 |
15.95 |
32 |
50 |
50 |
64 |
71 |
150 |
31.83 |
48 |
67 |
70 |
85 |
100 |
240 |
47.6 |
64 |
90 |
95 |
109 |
150 |
320 |
63.4 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14 |
15 |
31 |
70 |
1 |
64 |
90 |
94 |
110 |
200 |
270 |
63.5 |
128 |
155 |
134 |
190 |
380 |
500 |
126.1 |
256 |
273 |
240 |
363 |
620 |
1000 |
249 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.5 |
15.5 |
30 |
70 |
0.999 |
64 |
90 |
100 |
110 |
200 |
250 |
63.5 |
128 |
153 |
130 |
190 |
330 |
455 |
126.2 |
256 |
265 |
236 |
355 |
600 |
900 |
249.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
17 |
14.7 |
15.7 |
31 |
70 |
1 |
64 |
90 |
100 |
120 |
200 |
250 |
63.5 |
128 |
152 |
130 |
190 |
338 |
450 |
126.2 |
256 |
263 |
250 |
350 |
590 |
900 |
249.3 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
15 |
16 |
34.5 |
100 |
0.999 |
64 |
110 |
110 |
130 |
230 |
270 |
63.5 |
128 |
163 |
140 |
198 |
350 |
450 |
126.2 |
256 |
270 |
250 |
360 |
600 |
900 |
249 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1170 |
真 |
32 |
140 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1200 |
真 |
32 |
120 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1200 |
真 |
32 |
114 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
1200 |
真 |
32 |
90 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.1 |
11.1 |
11.5 |
40 |
0.999 |
8 |
16 |
14 |
20 |
24 |
50 |
7.99 |
16 |
19.9 |
17 |
26 |
30 |
70 |
15.96 |
32 |
29 |
28 |
36 |
40 |
100 |
31.9 |
48 |
36 |
34 |
47 |
52 |
130 |
47.8 |
64 |
42 |
40 |
55.5 |
70 |
160 |
63.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.1 |
11.1 |
12 |
40 |
0.999 |
8 |
16.2 |
14.5 |
20 |
24 |
50 |
7.99 |
16 |
22 |
20 |
30 |
34 |
72.6 |
15.96 |
32 |
30 |
28 |
40 |
46 |
100 |
31.9 |
48 |
36 |
34 |
50 |
60 |
120 |
47.8 |
64 |
43 |
44 |
60 |
65 |
150 |
63.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
11 |
10.6 |
11.4 |
12 |
40 |
0.999 |
8 |
17 |
15 |
20 |
25 |
56 |
7.99 |
16 |
24 |
22 |
33 |
38 |
70 |
15.96 |
32 |
32 |
30 |
43 |
48 |
100 |
31.9 |
48 |
37.6 |
36 |
50 |
57 |
130 |
47.8 |
64 |
46 |
45 |
63 |
71 |
160 |
63.6 |
160n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
12 |
11.1 |
12 |
14 |
40 |
0.999 |
8 |
23 |
21 |
30 |
30 |
60 |
7.98 |
16 |
30 |
28 |
37 |
43 |
80 |
15.96 |
32 |
40 |
40 |
50 |
60 |
104 |
31.9 |
48 |
46 |
46 |
60 |
65 |
130 |
47.8 |
64 |
53 |
55 |
68 |
74 |
160 |
63.6 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
14 |
12.3 |
13 |
30 |
70 |
1 |
64 |
60 |
60 |
70 |
140 |
200 |
63.6 |
128 |
92 |
79 |
110 |
270 |
350 |
126.6 |
256 |
140 |
120 |
170 |
400 |
600 |
251 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
12.3 |
13.5 |
29 |
70 |
1 |
64 |
57 |
56 |
74 |
110 |
170 |
63.7 |
128 |
85.6 |
77 |
100 |
220 |
300 |
126.8 |
256 |
130 |
110 |
160 |
360 |
530 |
251.7 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
15 |
12.6 |
13.5 |
29 |
70 |
1 |
64 |
58 |
57 |
73 |
130 |
170 |
63.7 |
128 |
84 |
76 |
100 |
200 |
300 |
127 |
256 |
126 |
110 |
156 |
340 |
500 |
252 |
800n-gram流数 |
延迟 (毫秒) |
吞吐量 (RTFX) |
||||
|---|---|---|---|---|---|---|
平均值 |
p50 |
p90 |
p95 |
p99 |
||
1 |
20 |
14 |
15 |
40 |
100 |
0.999 |
64 |
72 |
70 |
90 |
160 |
190 |
63.6 |
128 |
90 |
80 |
110 |
230 |
300 |
126.8 |
256 |
130 |
120 |
160 |
320 |
510 |
252 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
180 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
146 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
132 |
n-gram说话人分离 |
流数 |
吞吐量 (RTFX) |
|---|---|---|
假 |
32 |
2000 |
真 |
32 |
150 |
本地硬件规格#
GPU |
|
|---|---|
NVIDIA DGX A100 40 GB |
|
CPU |
|
型号 |
AMD EPYC 7742 64-Core Processor |
每核线程数 |
2 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
2250 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Micron DDR4 36ASF8G72PZ-3G2B2 3200MHz |
配置内存速度 |
2933 MT/s |
内存大小 |
32x64GB (2048GB Total) |
GPU |
|
|---|---|
NVIDIA A40 |
|
CPU |
|
型号 |
AMD EPYC 7763 64-Core Processor |
每核线程数 |
1 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
3529 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
配置内存速度 |
3200 MT/s |
内存大小 |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA A30 |
|
CPU |
|
型号 |
AMD EPYC 7742 64-Core Processor |
每核线程数 |
1 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
2 |
频率加速 |
已禁用 |
CPU 最大 MHz |
2250.0000 |
CPU 最小 MHz |
1500.0000 |
内存 |
|
型号 |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
配置内存速度 |
3200 MT/s |
内存大小 |
32x64GB (2048GB Total) |
GPU |
|
|---|---|
NVIDIA A10 |
|
CPU |
|
型号 |
AMD EPYC 7763 64-Core Processor |
每核线程数 |
1 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
2450 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Samsung DDR4 M393A4K40DB3-CWE 3200 MHz |
配置内存速度 |
3200 MT/s |
内存大小 |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA H100 80GB HBM3 |
|
CPU |
|
型号 |
Intel(R) Xeon(R) Platinum 8480CL |
每核线程数 |
2 |
插槽数 |
2 |
每插槽核心数 |
56 |
NUMA 节点数 |
2 |
CPU 最大 MHz |
3800 |
CPU 最小 MHz |
800 |
内存 |
|
型号 |
Micron DDR5 MTC40F2046S1RC48BA1 4800MHz |
配置内存速度 |
4400 MT/s |
内存大小 |
32x64GB (2048GB Total) |
GPU |
|
|---|---|
NVIDIA V100 SXM2 16 GB |
|
CPU |
|
型号 |
Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz |
每核线程数 |
2 |
插槽数 |
2 |
每插槽核心数 |
20 |
NUMA 节点数 |
2 |
CPU 最大 MHz |
3600 |
CPU 最小 MHz |
1200 |
内存 |
|
型号 |
Micron DDR4 36ASF4G72PZ-2G6D1 2667MHz |
配置内存速度 |
2133 MT/s |
内存大小 |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA T4 |
|
CPU |
|
型号 |
Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz |
每核线程数 |
2 |
插槽数 |
2 |
每插槽核心数 |
18 |
NUMA 节点数 |
2 |
CPU 最大 MHz |
3900 |
CPU 最小 MHz |
1000 |
内存 |
|
型号 |
Samsung DDR4 M393A2K43BB1-CTD 2666MHz |
配置内存速度 |
2666 MT/s |
内存大小 |
24x16GB (384GB Total) |
GPU |
|
|---|---|
NVIDIA L4 |
|
CPU |
|
型号 |
AMD EPYC 7763 64-Core Processor |
每核线程数 |
1 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
3529 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
配置内存速度 |
3200 MT/s |
内存大小 |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA L40 |
|
CPU |
|
型号 |
AMD EPYC 7763 64-Core Processor |
每核线程数 |
1 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
3529 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
配置内存速度 |
3200 MT/s |
内存大小 |
16x32GB (512GB Total) |