扩展 Triton Inference Server#
随着服务器上请求数量的增加,需要调整并发性和批处理大小,以满足延迟需求。在生产部署中,服务级别协议 (SLA) 要求可能会规定延迟要求,并且可能有必要在多个 GPU 之间分担推理请求的负载。有两种方法可以解决这个问题。DevOps 工程师可以垂直扩展服务器(向 VM 添加更多 GPU)或水平扩展服务器(向部署添加更多带有 GPU 的 VM)。为了管理跨多个 Triton Inference Server VM 的水平扩展,IT 管理员可以使用传统的负载均衡器方法,或者使用 Kubernetes 部署和自动扩展 Triton。以下各节将更详细地描述不同的扩展选项以及部署扩展的两种方法。
vSphere VM 上的垂直扩展#
垂直扩展涉及向单个 Triton VM 添加多个完整的 vGPU 配置文件。下图说明了多 GPU 以及如何为单个 VM 分配四个共享 PCIe 设备。
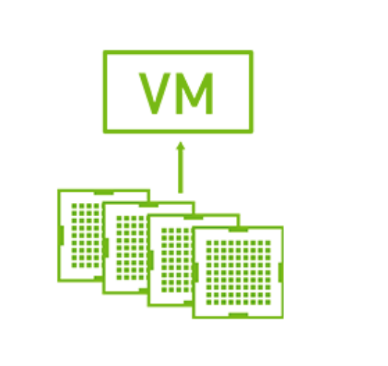
注意
VMWare 最多支持四个共享 PCIe 设备。
为了使 Triton Inference Server VM 使用额外的 GPU,DevOps 工程师可以修改 startup.sh 文件,该文件是在 IT 管理员工作流程中创建的。此文件位于 Triton Inference Server VM 上的 /home/nvidia/startup.sh。
以下文件内容显示了 docker run 命令的 --gpus=all 标志,并验证 Triton 将使用所有 GPU。
1#!/bin/bash
2docker rm -f $(docker ps -a -q)
3docker run --gpus all --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 --name triton_server_cont -v $HOME/triton_models:/models nvcr.io/nvaie/tritonserver-<NVAIE-MAJOR-VERSION>:<NVAIE-CONTAINER-TAG> tritonserver --model-store=/models --strict-model-config=false --log-verbose=1
vSphere VM 上的水平扩展(高级)#
水平扩展涉及多个 Triton Inference Server VM。由于 IT 管理员创建了 Triton Inference Server 模板,因此克隆/创建额外的 VM 非常快速。NVIDIA MiG GPU 可以添加到这些 VM 中。MiG 可以将 A100 GPU 分区为多达七个实例。可以将一个 GPU 的一个实例添加到 VM,而可以将另一个 GPU 的另一个 MiG 实例添加到另一个 VM。这为您的集群提供了灵活性和最佳资源利用率。创建完成后,DevOps 工程师将重复工作流程,将训练好的模型添加到每个 Triton Inference Server VM 的 模型目录。使用以下步骤,客户端将指向负载均衡器,该负载均衡器将充当 Triton Server VM 之间的反向代理。我们使用 HAproxy 在单独的 VM 上部署负载均衡器。NVIDIA AI Enterprise 不提供对 HAproxy 的部署支持,用户可以自由使用任何可用的负载均衡器。
为水平扩展部署负载均衡器#
在每台 Triton Server 上,编辑
/etc/hosts文件以添加负载均衡器的 IP 地址。sudo nano /etc/hosts
将以下内容添加到
/etc/host文件。hostname-of-HAproxy IP-address-of-HAproxy在负载均衡器上,将 Triton Server 的 IP 添加到
/etc/hosts并安装 HAproxy。sudo apt install haproxy
配置 HAproxy 以指向两台服务器的 gRPC 端点。
sudo nano /etc/haproxy/haproxy.cfg
1frontend triton-frontend 2 bind 10.110.16.221:80 #IP of load balancer and port 3 mode http 4 default_backend triton-backend 5 6backend triton-backend 7 balance roundrobin 8 server triton 10.110.16.186:8001 check #gRPC endpoint of Triton 9 server triton2 10.110.16.218:8001 check 10 11listen stats 12 bind 10.110.16.221:8080 #port for showing load balancer statistics 13 mode http 14 option forwardfor 15 option httpclose 16 stats enable 17 stats show-legends 18 stats refresh 5s 19 stats uri /stats 20 stats realm Haproxy\ Statistics 21 stats auth nvidia:nvidia #auth for statistics
现在在客户端中指向负载均衡器 IP 作为服务器 URL,如使用 Triton gRPC 客户端在 VM 上运行推理中所示。
重启 haproxy 服务器。
sudo systemctl restart haproxy.service
使用负载均衡器运行横向扩展推理#
按照使用 Triton gRPC 客户端在 VM 上运行推理中的相同步骤操作,但不要指向 localhost,而是指向负载均衡器 IP。
一个示例如下
1python triton/run_squad_triton_client.py --triton_model_name=bert --triton_model_version=1 --vocab_file=/workspace/bert/data/download/nvidia_pretrained/bert_tf_squad11_large_384/vocab.txt --predict_batch_size=1 --max_seq_length=384 --doc_stride=128 --triton_server_url=localhost:8001 --context="Good password practices fall into a few broad categories. Maintain an 8-character minimum length requirement. Don't require character composition requirements. For example, *&(^%$. Don't use a password that is the same or similar to one you use on any other websites. Don't use a single word, for example, password, or a commonly-used phrase. Most people use similar patterns, for example, a capital letter in the first position, a symbol in the last, and a number in the last 2. Cyber criminals know this, so they run their dictionary attacks using the most common substitutions for example are "@" for "a," "1" for "l". " --question="What are the common substitutions for letters in password?"
控制台输出显示预测答案为 @ 代表 a,1 代表 l。
在 Kubernetes 上部署 Triton Inference Server#
自动扩展是在 Kubernetes 上部署 Triton Inference Server 的重要优势之一,即弹性。如果没有自动扩展,DevOps 工程师每次资源利用率增加时都需要手动配置资源,然后缩减规模以确保最佳资源利用率。在本指南中,我们将讨论在 Kubernetes 上成功部署 Triton 的关键主题。使用本指南前面提到的相同用户角色,我们将主要关注 IT 管理员和 DevOps 工作流程,因为它们需要修改后的工作流程。
注意
AI 从业人员和软件工程师工作流程不会改变。
什么是 Kubernetes?#
Kubernetes 是一个开源容器编排平台,使 DevOps 工程师的工作更加轻松。应用程序可以作为逻辑单元部署在 Kubernetes 上,这些逻辑单元易于管理、升级和部署,具有零停机时间(滚动升级)和使用复制实现的高可用性。在 Kubernetes 上部署 Triton Inference Server 为企业中的 AI 提供了相同的优势。为了轻松管理 Kubernetes 集群中的 GPU 资源,利用了 NVIDIA GPU Operator。
什么是 NVIDIA GPU Operator?#
GPU Operator 允许 Kubernetes 集群的管理员像管理集群中的 CPU 节点一样管理 GPU 节点。管理员无需为 GPU 节点提供特殊的 OS 镜像,而是可以为 CPU 和 GPU 节点部署标准的 OS 镜像,然后依靠 GPU Operator 为 GPU 提供所需的软件组件。这些组件包括 NVIDIA 驱动程序、用于 GPU 的 Kubernetes 设备插件、NVIDIA 容器运行时、自动节点标记、基于 DCGM 的监控等。
IT 管理员工作流程#
下图说明了 IT 管理员工作流程,以支持 Kubernetes 上的 Triton Inference Server
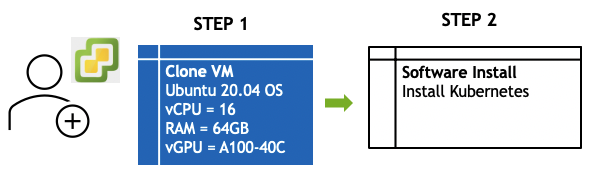
克隆 VM - 标准 OS Ubuntu 20.04#
对于本指南测试可选的自动扩展,前提条件是两个或多个带有 GPU 的 VM。使用 IT 管理员工作流程中相同的 VM 硬件配置,根据集群中需要的节点数量创建尽可能多的 VM。
注意
vGPU 配置文件应由 IT 管理员分配给 VM。NVIDIA 驱动程序和容器运行时将在 DevOps 工作流程中作为安装 GPU Operator 的一部分安装。
安装 Kubernetes#
按照 Kubernetes 网站上的步骤使用 kubeadm 安装和 配置 集群。
DevOps 工程师工作流程#
现在 Kubernetes VM 已配置,DevOps 工程师需要在 Kubernetes VM 内执行特定的应用程序级配置。
安装 GPU Operator。
在 Kubernetes 上部署 Triton Inference Server。
可选 - 添加水平 Pod 自动扩展器以自动扩展部署。
安装 GPU Operator#
先决条件
NVIDIA vGPU 驱动程序
访问私有容器注册表或 NVIDIA 的 NGC 注册表
在 Kubernetes 上部署 Triton Inference Server#
为了在 Kubernetes 上快速部署 Triton Inference Server,DevOps 工程师需要访问 NFS 共享,该共享将用作 Triton 模型存储库,然后管理存储。然后为 Triton Inference Server 设计 Kubernetes Deployment,并为 Deployment 设计 Kubernetes Service。以下详细介绍了这些步骤。
管理存储#
容器是不可变的,这意味着容器在其生命周期内创建的所有数据在容器关闭时都会丢失。因此,容器需要一个持久存储信息的位置,Kubernetes 为容器提供了一种持久存储机制,它基于 Persistent Volume。
PersistentVolume (PV) 是集群中的一块存储,由管理员配置或使用 Storage Classes 动态配置。持久卷将底层存储资源从 Kubernetes 中抽象出来。这意味着底层存储可以是任何东西(S3、GCFS、NFS 等)。
对于像 pod 这样的计算资源要开始使用这些卷,它必须通过发出 Persistent Volume Claim (PVC) 来请求卷。PVC 将自身绑定到 Persistent Volume,其资源与 PVC 发出的声明相匹配。
创建 Persistent Volume (PV) 以供 Kubernetes 访问 NFS 服务器#
在本指南中,我们将使用 YAML 文件创建 NFS 类型的 Persistent Volume (PV)。
需要注意的一些事项
YAML 文件中的存储容量设置为 500GiB。将其更改为您集群中的存储容量。
将 server IP 地址更改为您自己的 NFS 服务器 IP。
将 path 更改为您复制 BERT Triton 模型的路径。
以下是 YAML 文件的内容;在本指南中,该文件名为 nfs-pv.yaml。
1apiVersion: v1
2kind: PersistentVolume
3metadata:
4name: nfs-pv
5spec:
6capacity:
7 storage: 500Gi
8accessModes:
9 - ReadWriteMany
10persistentVolumeReclaimPolicy: Retain
11nfs:
12 path: /Datasets/triton/triton_models
13 server: 10.136.144.98
14 readOnly: false
使用上面的 YAML 并运行以下命令以在集群上创建 PV。
kubectl apply -f nfs-pv.yaml
创建 Persistent Volume Claim (PVC)#
在本指南中,我们将使用 YAML 文件来创建 PVC。以下是该文件的内容,名为 nfs-pvc.yaml。
1apiVersion: v1
2kind: PersistentVolumeClaim
3metadata:
4 name: nfs-pvc
5spec:
6 accessModes:
7 - ReadWriteMany
8resources:
9 requests:
10 storage: 500Gi
使用上面的 YAML 并运行以下命令以在集群上创建 PVC。
kubectl apply -f nfs-pvc.yaml
创建 PVC 后,PVC 应锁定到 PV。要确认这一点,请运行以下命令。
kubectl get pvc
以下输出表明 NFS PVC 已绑定到 NFS PV。
1nvidia@node1:~$ kubectl get pvc
2NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
3nfs-pvc Bound nfs-pv 500Gi RWX 3d1h
创建 Triton Inference Server Kubernetes Deployment#
由于 Kubernetes 不直接运行容器,它将一个或多个容器包装到一个称为 Pods 的更高级别。Kubernetes Pod 是一组一个或多个容器,它们具有共享存储和网络资源以及用于运行容器的规范。Pod 通常也由一个抽象层 Deployment 管理。使用 Deployment,您不必手动处理 pod;它可以动态地创建和销毁 Pods。Kubernetes Deployment 将一组 pod 管理为副本集。
同一 pod 的多个副本可用于提供高可用性。使用 Kubernetes 部署 Triton Inference Server 为企业中的 AI 提供了相同的优势。由于 deployment 具有复制功能,如果其中一个 Triton Inference Server pod 失败,则作为 deployment 一部分的另一个副本 pod 仍然可以为最终用户提供服务。滚动更新允许进行 Deployment 更新,例如升级应用程序,而不会造成停机。
在本指南中,我们将使用 triton_deployment.yaml(如下所示)部署相同的自然语言处理 BERT 用例示例,我们已将其用作 Kubernetes deployment。关于 deployment 对象,有几个令人兴奋的注意事项。
replica 字段用于指定我们希望在 deployment 中拥有的 Triton Inference Server pod 的数量。这些 pod 在它们之间共享传入负载,从而在它们之间服务多个并行请求。在我们的示例中,每个副本将以轮询方式接收请求,如果其中一个副本出现故障,则另一个副本仍然可以服务请求。
nfs-pvc 作为卷挂载到 pod 的 /models 目录中,并且 pod 运行指向 command 字段内部该目录的 Triton Inference Server。
容器/pod 内的端口 8000、8001 和 8002 被暴露,因为 gRPC 服务器、HTTP 服务器和指标服务器是 Triton Inference Server 在这些端口上运行的一部分。
我们在 resources 字段中为每个 pod 连接一个 GPU。
以下是 triton_deployment.yaml 文件的内容。
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: bert-qa
5 labels:
6 app: triton-server
7spec:
8 selector:
9 matchLabels:
10 app: triton-server
11 replicas: 2
12 template:
13 metadata:
14 labels:
15 app: triton-server
16 spec:
17 volumes:
18 - name: model-repo
19 persistentVolumeClaim:
20 claimName: nfs-pvc
21 containers:
22 - name: serving
23 image: docker pull nvcr.io/nvaie/tritonserver-<NVAIE-MAJOR-VERSION>:<NVAIE-CONTAINER-TAG>
24 ports:
25 - name: grpc
26 containerPort: 8001
27 - name: http
28 containerPort: 8000
29 - name: metrics
30 containerPort: 8002
31 volumeMounts:
32 - name: model-repo
33 mountPath: "/models"
34 resources:
35 limits:
36 nvidia.com/gpu: 1
37 command: ["tritonserver", "--model-store=/models"]
38 volumes:
39 - name: model-repo
40 persistentVolumeClaim:
41 claimName: nfs-pvc
使用上面的 YAML 并运行以下命令以在集群上创建 Triton Kubernetes Deployment。
kubectl apply -f triton_service.yaml
运行以下命令以验证服务是否已添加。
kubectl get svc
以下输出描述了新添加的服务
1nvidia@node1:~/yaml$ kubectl get svc
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3bert-qa ClusterIP 10.111.115.59 <none> 8001/TCP,8000/TCP,8002/TCP 4h29m
检查 Kubernetes deployment 的健康状况#
部署 Service 后,您可以通过创建一个客户端 pod 并 ping 服务的健康状况来检查 Triton Service 是否可在集群内部访问并且健康。
在本指南中,我们将使用 client.yaml(如下所示)作为 Triton 客户端。
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4name: client
5labels:
6 app: client
7spec:
8replicas: 1
9selector:
10 matchLabels:
11 app: client
12template:
13 metadata:
14 labels:
15 app: client
16 spec:
17 containers:
18 - name: serving
19 image: docker pull nvcr.io/nvaie/tritonserver-<NVAIE-MAJOR-VERSION>:<NVAIE-CONTAINER-TAG>
20 command: [ "curl -m 1 -L -s -o /dev/null -w %{http_code} http://$SERVICE_CLUSTER_IP:8000/v2/health/ready" ]
注意
$SERVICE_CLUSTER_IP 是集群中 Triton 服务的 IP,可以通过运行以下命令获得。在我们的示例中,它是 10.111.115.59,如下所示。
1nvidia@node1:~$ kubectl get svc
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3bert-qa ClusterIP 10.111.115.59 <none> 8001/TCP,8000/TCP,8002/TCP 4h39m
使用上面的 YAML 并运行以下命令以创建客户端 deployment。
kubectl apply -f client.yaml
运行以下命令以检查 Pod 日志。
kubectl logs -f <name of the triton client pod>
200 OK HTTP 代码表示健康状况良好。
使用 Kubernetes 自动扩展 Triton Inference Server deployment#
水平 Pod 自动扩展器#
Kubernetes 水平 Pod 自动扩展器根据资源的 CPU 利用率自动扩展 Deployment、复制控制器或副本集中 Pod 的数量。自定义指标(如 GPU 利用率)不易用于水平 pod 自动扩展器。通过提供 GPU 指标,Triton Inference Server deployment 对象可以根据自定义指标(如平均 GPU 利用率和 GPU 占空比等)自动扩展。
需要在集群上安装以下组件,以方便水平 pod 自动扩展器使用 GPU 指标。
自定义指标服务器
NVIDIA Data Center GPU Manager (DCGM) 导出器服务
Prometheus 服务器
Prometheus 适配器
自定义指标服务器#
自定义指标服务器向 API 服务器公开用于水平 Pod 自动扩展器的自定义指标。运行以下命令以在 Kubernetes 集群上安装自定义指标服务器。
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.4.1/components.yaml
NVIDIA DCGM 导出器服务#
为了在 Kubernetes 中收集 GPU 遥测数据,使用了 Nvidia Data Center GPU Manager (DCGM)。这套数据中心管理工具允许您管理和监控加速数据中心中的 GPU 资源。由于 DevOps 工程师已经安装了 GPU Operator,因此 NVIDIA DCGM 导出器服务已安装到集群中。
要验证,请运行以下命令
kubectl get svc -A | grep dcgm
以下输出验证 NVIDIA DCGM 已安装。
1nvidia@node1:~$ kubectl get svc -A | grep dcgm
2gpu-operator-resources nvidia-dcgm-exporter ClusterIP 10.102.108.202 <none> 9400/TCP 4d6h
Prometheus 服务器#
为了公开集群级和节点级指标,使用了 Prometheus。Prometheus 是一个 Cloud Native Computing Foundation 项目,是一个系统和服务监控系统。它以给定的间隔从配置的目标收集指标,评估规则表达式,显示结果,并在观察到特定条件时触发警报。请参阅 GPU Operator 网站上的 指南,在您的集群上设置 Prometheus。要验证安装,请检查 Prometheus 服务器是否作为 NodePort 服务安装,并且您可以从集群的任何节点访问服务器。从浏览器访问服务器,地址为 http://$node_IP:30090。
安装 Prometheus 适配器#
Prometheus 适配器将来自 DCGM 导出器的 Prometheus 指标公开给已部署的自定义指标服务器。因此,此适配器适用于 Kubernetes 1.16+ 中的 autoscaling/v2 水平 Pod 自动扩展器。它还可以替换已运行 Prometheus 并收集适当指标的集群上的 指标服务器。
要安装 Prometheus 适配器,请运行以下命令
helm install --name-template prometheus-adapter --set rbac.create=true,prometheus.url=http://$PROMETHEUS_SERVICE_IP.prometheus.svc.cluster.local,prometheus.port=9090 prometheus-community/prometheus-adapter
通过运行以下命令获取上述 Prometheus 服务器 IP
kubectl get svc -n prometheus -lapp=kube-prometheus-stack-prometheus
验证自定义指标是否可用于指标服务器#
来自 NVIDIA DGCM 导出器的 GPU 指标现在应该可用于指标服务器。您可以通过运行以下命令来验证这一点。
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
以下输出验证指标可用。
1nvidia@node1:~/yaml$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq -r . | grep DCGM_FI_DEV_MEM_COPY_UTIL
2 "name": "pods/DCGM_FI_DEV_MEM_COPY_UTIL",
3 "name": "jobs.batch/DCGM_FI_DEV_MEM_COPY_UTIL",
4 "name": "namespaces/DCGM_FI_DEV_MEM_COPY_UTIL",
创建水平 Pod 自动扩展器对象#
在本指南中,我们将使用 hps_gpu.yaml(如下所示)来创建 Kubernetes 水平 Pod 自动扩展器。
需要注意的几个有趣的点
minReplicas 是 pod 自动扩展器 deployment 中要缩减到的 pod 数量的下限,maxReplicas 是上限。要自动扩展 pod 的自定义指标是
DCGM_FI_DEV_GPU_UTIL(即平均 GPU 利用率)。如果超过 40% 的平均目标值,则会调度一个新的 pod。我们正在定位之前创建的 deployment 的 pod。
1kind: HorizontalPodAutoscaler
2apiVersion: autoscaling/v2beta1
3metadata:
4name: gpu-hpa
5spec:
6scaleTargetRef:
7 apiVersion: apps/v1
8 kind: Deployment
9 name: bert-qa
10minReplicas: 1
11maxReplicas: 3
12metrics:
13- type: Pods
14 pods:
15 metricName: DCGM_FI_DEV_GPU_UTIL # Average GPU usage of the pod.
16 targetAverageValue: 40
使用上面的 YAML 文件,运行以下命令以创建 HPA 对象。
kubectl apply -f hpa_gpu.yaml
检查 HPA deployment 是否成功。
1nvidia@node1:~/yaml$ kubectl get hpa
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3gpu-hpa Deployment/bert-qa 0/40 1 2 1 4h18m
生成负载以显示自动扩展#
最后一步是测试我们刚刚部署的自动扩展功能。我们将创建一个 perf 客户端 deployment,通过生成人工负载来显示集群上的自动扩展,并验证 pod 是否自行添加。
在本指南中,我们将使用 gpu_load.yaml(如下所示)来创建 perf 客户端 deployment。
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: perf-client
5 labels:
6 app: perf-client
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 app: perf-client
12 template:
13 metadata:
14 labels:
15 app: perf-client
16 spec:
17 containers:
18 - name: serving
19 image: vbagade/bert
20 command: [ "/workspace/install/bin/perf_client --max-threads 10 -m bert -x 1 -p 200000 -d -v -z -i gRPC -u $TRITON_SERVICE_IP:8001 -b 1 -l 100 -c 50 "]
注意
Triton 服务 IP 是我们作为创建 Kubernetes Service 以指向您的 deployment 一部分创建的服务。运行以下命令以获取 IP kubectl get svc。
1nvidia@node1:~$ kubectl get svc
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3bert-qa ClusterIP 10.111.115.59 <none> 8001/TCP,8000/TCP,8002/TCP 4h39m
这里的集群 IP 是 10.111.115.59。
在运行客户端之前,执行以下命令以输出 pod 的数量。
kubectl get pods
此输出显示只有一个 pod。
1nvidia@node1:~/yaml$ kubectl get pods
2NAME READY STATUS RESTARTS AGE
3bert-qa-74469c8b8-62472 1/1 Running 0 5h56m
使用上面的 YAML 文件,运行以下命令,该命令将运行客户端。
kubectl apply -f gpu_load.yaml
再次执行以下命令以输出 pod 的数量。
kubectl get pods
启动客户端后,Kubernetes 自动扩展器开始工作,我们现在有一个正在创建的新 pod 和现有 pod。
1nvidia@node1:~$ kubectl get pods
2NAME READY STATUS RESTARTS AGE
3bert-qa-74469c8b8-62472 1/1 Running 0 97m
4bert-qa-74469c8b8-h4zls 0/1 ContainerCreating 0 1s