概述#
本解决方案指南概述了如何在 NVIDIA AI Enterprise 上利用自然语言处理用例示例创建 AI 管道。
NVIDIA 的 NGC 目录提供了一个预训练模型库,可与 NVIDIA AI Enterprise 软件套件一起使用;这些模型可以使用 NVIDIA AI Enterprise TensorFlow 容器在您的数据集上进行微调。在本指南中,我们将重点介绍 AI 从业者如何使用在主流 NVIDIA 认证系统上运行的虚拟机,利用预训练模型执行训练。这些虚拟机基于模板,其中包含来自 NVIDIA NGC 目录的 BERT TensorFlow 容器。使用示例 Jupyter 笔记本,模型经过训练、保存,然后转换为 TensorRT 以获得最佳性能。然后,该模型被部署到生产环境,以使用 Triton 推理服务器进行推理。
深度学习作为一种算法,需要大量数据来训练具有数百万参数的模型,以确保模型的性能和准确性适合实际用例。但并非每个客户用例都能访问大量数据。已经在大量通用数据上训练过的预训练模型可以在更小的数据集上进行微调,以在客户特定的用例中获得所需的准确性。
神经网络模型经过优化,可使用 TensorRT 进行部署,并使用 Triton 推理服务器部署在虚拟机上,为在其面向客户的应用程序中利用该服务器的不同最终用户提供服务。
Triton 推理服务器#
Triton 推理服务器是用于推理(GPU 或 CPU)的最佳部署解决方案,它简化了推理部署,同时不影响性能。Triton 推理服务器可以部署使用 TensorFlow、PyTorch、ONNX 和 TensorRT 训练的模型。建议将模型转换为 TensorRT 格式以获得最佳性能。
什么是 TensorRT?#
NVIDIA TensorRT 的核心是一个 C++ 库,它有助于在 NVIDIA GPU 上实现高性能推理。它旨在与 TensorFlow 和 PyTorch 等训练框架以互补的方式工作。它专门侧重于在 NVIDIA GPU 上快速有效地运行已训练好的网络。TensorRT 通过组合层和优化内核选择来优化网络,从而提高延迟、吞吐量、电源效率和内存消耗。如果应用程序指定,它还可以优化网络以在较低精度下运行,从而进一步提高性能并减少内存需求。
在本指南中,我们将逐步介绍如何将模型转换为 TensorRT。有关如何开始使用 TensorRT 的更多信息,请参阅 NVIDIA 开发者 页面。
Triton 推理服务器架构#
Triton 推理服务器使用存储在模型仓库中的模型,这些模型在本地可用,用于为推理请求提供服务。一旦它们在 Triton 中可用,推理请求就会从客户端应用程序发送。Python 和 C++ 库提供 API 以简化通信。客户端使用 HTTP/REST 或 gRPC 协议直接向 Triton 发送 HTTP/REST 请求。
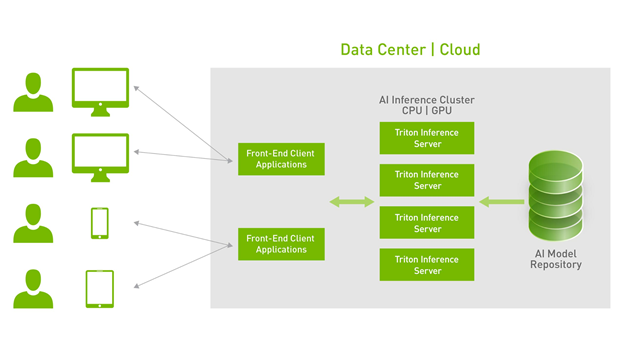
Triton 客户端 SDK 具有构建客户端的 API,该客户端序列化请求以通过网络将其发送到服务器。然后,服务器在反序列化请求后将其放入请求队列中。请求被排队在一起以获得最佳性能,然后作为一个批次进行计算(队列大小、批次大小和并发请求数是可配置的,具体取决于用例和模型)。结果被重新序列化并发送回客户端,然后由客户端反序列化并处理。
本指南以自然语言处理任务为例,说明如何使用 Triton 推理服务器进行推理,从而为读者提供企业工作流程的完整图景。